
MATLAB - idl.hbdlib.cnidl.hbdlib.cn/book/00000000000000/pdfbook/018/017/122639.pdf · mbc程序...
270
Transcript of MATLAB - idl.hbdlib.cnidl.hbdlib.cn/book/00000000000000/pdfbook/018/017/122639.pdf · mbc程序...


������
MATLAB
����������
�� ���
��� ���
����������
2 0 0 5
��

书书书
内 容 简 介
本书系统介绍 NBUMBC遗传算法和直接搜索工具箱的功能特点Ð编程原理及使用方法à全
书共分为�章à第一章至第四章介绍遗传算法的基础知识K包括遗传 算 法 的 基 本 原 理K编 码Ð选
择Ð交叉Ð变异K适应度函数K控制参数选择K约束条件处理K模式定理K改进的遗传算法K早熟
收敛问题及其防止等à第五章至第七章介绍英国设 菲 尔 德ITifggjfmeJ大 学 的 NBUMBC遗 传 算 法
工具箱及其使用方法K举例说明如 何 利 用 遗 传 算 法 工 具 箱 函 数 编 写 求 解 实 际 优 化 问 题 的 NBU�
MBC程序à第八章和第九章介绍 NbuiXpslt公司最新 发 布 的 NBUMBC遗 传 算 法 与 直 接 搜 索 工
具箱及其使用方法à
本书取材新颖K内容丰富K逻 辑 严 谨K语 言 通 俗K理 例 结 合K图 文 并 茂K注 重 基 础K面 向 应
用à书中包含大量的实例K便于自学和应用à
本书可作为高等院校计算机Ð自动化Ð信息Ð管理Ð控制与系统工 程 等 专 业 本 科 生 或 研 究 生
的教材或参考书K也可供其他相关专业的师生及科研和工程技术人员自学或参考à
图书在版编目IDJQJ数据
NBUMBC遗传算法工具箱及应用L雷英杰等编著�
�西安M西安电子科技大学出版社K������
JTCO� ���� ���� �
��N�������雷�������计算机辅助计算�软件包KNBUMBC����UQ������
中国版本图书馆DJQ数据核字I����J第������号
策����划��戚文艳
责任编辑��龙��晖��戚文艳
出版发行��西安电子科技大学出版社I西安市太白南路�号J
电����话��I���J����������������������邮��编��������
iuuqMLLxxx�yevi�dpnq ����F�nbjmMyevgycq P� vc�ybpomjof�dpnq经����销��新华书店
印刷单位��陕西华沐印刷科技有限责任公司
版����次������年�月第�版������年�月第�次印刷
开����本�����毫米�����毫米���L����印张��������字����数�����千字
印����数���Y����册
定����价�������元
JTCO� ���� ���� �LUQð����I课J
YEVQ������� �H�H�H�如有印装问题可调换H�H�H�本社图书封面为激光防伪覆膜K谨防盗版à

前����言
NBUMBC是 NbuiXpslt公司推出的一套高性能的数值计算和可视化软
件à它集数值分析Ð矩阵运算Ð信号处理和图形显示于一体K构成一个方便的Ð
界面友好的用户环境àNBUMBC强大的扩展功能和影响力吸引各个领域的专
家相继推出了许多基于 NBUMBC的专用工具箱àNBUMBC强大的科学运算Ð
灵活的程序设计流程Ð高质量的图形可视化与界面设计Ð便捷的与其他程序和
语言的接口等功能K使之成为当今世界最有活力和最具影响力的可视化软件à
遗传算法IHfofujdBmpsjuinh K简称HBJ是以自然选择和遗传理论为基础K
将生物进化过程中适者生存规则与群体内部染色体的随机信息交换机制相结
合的高效全局寻优搜索算法àHB摒弃了传统的搜索方式K模拟自然界生物进
化过程K采用人工进化的方式对目标空间进行随机优化搜索à它将问题域中的
可能解看做是群体的一个个体或染色体K并将每一个个体编码成符号串形式K
模拟达尔文的遗传选择和自然淘汰的生物进化过程K对群体反复进行基于遗传
学的操作I遗传Ð交叉和变异Jà根据预定的目标适应度函数对每个个体进行评
价K依据适者生存Ð优胜劣汰的进化规则K不断得到更优的群体K同时以全局
并行搜索方式来搜索优化群体中的最优个体K以求得满足要求的最优解à
自从����年KpioI�Ipmmboe教授出版关于HB的经典之作�Bebubujpo
joObuvsbmboeBsujgjdjbmT
q
tufntz �以来KHB已获得广泛应用à从遗传算法的整
个发展来看K��世纪��年代是兴起阶段K��世纪��年代是发展阶段K��世纪
��年代是高潮阶段à遗传算法作为一种实用Ð高效Ð鲁棒性强的优化技术K发
展极为迅速K已引起国内外学者的高度重视à
遗传算法提供了一种求解非线性Ð多模型Ð多目标等复杂系统优化问题的
通用框架K它不依赖于问题具体的领域K已经广泛应用于函数优化Ð组合优化Ð
自动控制Ð机器人学Ð图像处理Ð人工生命Ð遗传编码Ð机器学习等科技领域K
并且已经在求解旅行商问题Ð背包问题Ð装箱问题Ð图形划分问题等方面的应
用取得了成功à

由于HB在 大 量 问 题 求 解 过 程 中 独 特 的 优 点 和 广 泛 的 应 用K许 多 基 于
NBUMBC的遗传算法工具箱相继出现K其中出现较早Ð影响较大Ð较为完备
者当属英国 设 菲 尔 德ITifggjfmeJ大 学 推 出 的 基 于 NBUMBC的 遗 传 算 法 工 具
箱à另外K还有美国北卡罗莱纳那州立大学推出的可与 NBUMBC一起使用的
遗传算法优化工具箱HBPUIHfofujdBmpsjuinPh ujnj{bujpoUppmcpyq Jà考虑
到前者在内容上已经覆盖到后者K因此本书将着重介绍英国设菲尔德大学的基
于 NBUMBC的遗传算法工具箱à值得注意的是KNbuiXpslt公司最新发布了
一个 专 门 设 计 的 NBUMBC遗 传 算 法 与 直 接 搜 索 工 具 箱IHfofujdBmpsjuin
boeEjsfduTfbsdiUppmcpy
hJK本书同时也详细介绍了这个遗传算法与直接搜索
工具箱及其使用方法à
书中通过大量实 例K介 绍 了 如 何 利 用 提 供 的 遗 传 算 法 工 具 箱 函 数 来 编 写
NBUMBC程序K解决实际问题à
在此K作者非常感谢西安电子科技大学王宝树教授Ð周利华教授Ð李荣才
教授等的指导和鼓励K以及空军工程大学计算机系吕辉教授等的支持和帮助K
真诚感谢西安电子科技大学出版社的大力支持à
需要特别指出K虽然作者竭尽所能K精心策划章节结构和内容编排K详细
测试书中的每一个实例K尽可能简明而准确地表述其意K但限于水平和资料K
书中的错误和不足之处在所难免K恳请读者不吝指正à
作��者
����年��月

目����录
第一章��遗传算法概述 ���������������������������������
�������遗传算法的概念 ����������������������������������
�������遗传算法的特点 ����������������������������������
�������遗传算法的优点 ��������������������������������
�������遗传算法的不足之处 ������������������������������
�������遗传算法与传统方法的比较 �����������������������������
�������遗传算法的基本用语 ��������������������������������
�������遗传算法的研究方向 ��������������������������������
�������基于遗传算法的应用 ��������������������������������
第二章��基本遗传算法及改进 ������������������������������
�������遗传算法的运行过程 ���������������������������������
�������完整的遗传算法运算流程 �����������������������������
�������遗传算法的基本操作 �������������������������������
�������基本遗传算法 ������������������������������������
�������基本遗传算法的数学模型 �����������������������������
�������基本遗传算法的步骤 �������������������������������
�������遗传算法的具体例证 �������������������������������
�������改进的遗传算法 �����������������������������������
�������改进的遗传算法一 ��������������������������������
�������改进的遗传算法二 ��������������������������������
�������改进的遗传算法三 ��������������������������������
�������改进的遗传算法四 ��������������������������������
�������多目标优化中的遗传算法 �������������������������������
�������多目标优化的概念 ��������������������������������
�������多目标优化问题的遗传算法 ����������������������������
第三章��遗传算法的理论基础 ������������������������������
�������模式定理 ��������������������������������������
�������积木块假设 �������������������������������������
�������欺骗问题 ��������������������������������������
�������遗传算法的未成熟收敛问题及其防止 ��������������������������
�������遗传算法的未成熟收敛问题 ����������������������������
�������未成熟收敛的防止 ��������������������������������
�������性能评估 ��������������������������������������
�������小生境技术和共享函数 ��������������������������������
���

第四章��遗传算法的基本原理与方法 ���������������������������
�������编码 ����������������������������������������
�������编码方法 ������������������������������������
�������编码评估策略 ����������������������������������
�������选择 ����������������������������������������
�������交叉 ����������������������������������������
�������变异 ����������������������������������������
�������适应度函数 �������������������������������������
�������适应度函数的作用 ��������������������������������
�������适应度函数的设计主要满足的条件 �������������������������
�������适应度函数的种类 ��������������������������������
�������适应度尺度的变换 ��������������������������������
�������控制参数选择 ������������������������������������
�������约束条件的处理 �����������������������������������
第五章��遗传算法工具箱函数 ������������������������������
�������工具箱结构 �������������������������������������
�������种群表示和初始化 ��������������������������������
�������适应度计算 �����������������������������������
�������选择函数 ������������������������������������
�������交叉算子 ������������������������������������
�������变异算子 ������������������������������������
�������多子群支持 �����������������������������������
�������遗传算法中的通用函数 ��������������������������������
�������函数ct�sw �����������������������������������
�������函数dsucbtf ����������������������������������
�������函数dsuc ��q ���������������������������������
�������函数dsus ��q ���������������������������������
�������函数 njsbuf ��h ��������������������������������
�������函数 nvu ������������������������������������
�������函数 nvubuf ����������������������������������
�������函数 nvucb ��h ��������������������������������
�������函数sboljo ��h ��������������������������������
��������函数sfdejt ����������������������������������
��������函数sfdjou ����������������������������������
��������函数sfdmjo ����������������������������������
��������函数sfdnvu ����������������������������������
��������函数sfdpncjo ���������������������������������
��������函数sfjot �����������������������������������
��������函数sf ��q ���������������������������������
��������函数sxt �����������������������������������
��������函数tdbmjo ��h ��������������������������������
��������函数tfmfdu ����������������������������������
���
��������函数tvt �����������������������������������
��������函数ypwe ��q ��������������������������������
��������函数ypwest ��q �������������������������������
��������函数ypwn ��q ��������������������������������
��������函数ypwti ����������������������������������
��������函数ypwtist ����������������������������������
��������函数ypwt ��q ��������������������������������
��������函数ypwtst ��q ��������������������������������
第六章��遗传算法工具箱的应用 �����������������������������
�������安装 ����������������������������������������
�������种群的表示和初始化 ���������������������������������
�������目标函数和适应度函数 ��������������������������������
�������选择 ����������������������������������������
�������交叉 ����������������������������������������
�������变异 ����������������������������������������
�������重插入 ���������������������������������������
�������遗传算法的终止 �����������������������������������
�������数据结构 ��������������������������������������
��������多种群支持 �������������������������������������
��������示范脚本 ��������������������������������������
第七章��遗传算法应用举例 ��������������������������������
�������简单一元函数优化实例 ��������������������������������
�������多元单峰函数的优化实例 �������������������������������
�������多元多峰函数的优化实例 �������������������������������
�������收获系统最优控制 ����������������������������������
�������装载系统的最优问题 ���������������������������������
�������离散二次线性系统最优控制问题 ����������������������������
�������目标分配问题 ������������������������������������
�������双积分的优化问题 ����������������������������������
�������雷达目标识别问题 ����������������������������������
��������图像分割问题 ������������������������������������
��������一些测试函数对应的优化问题 �����������������������������
��������轴并行超球体的最小值问题 ����������������������������
��������旋转超球体的最小值问题 �����������������������������
��������Sptfocspdl�tWbmmfz最小值问题 ��������������������������
��������Sbtusjjoh 函数的最小值问题 ����������������������������
��������Tdixfgfm函数的最小值问题 ����������������������������
��������Hsjfxbohl函数的最小值问题 ���������������������������
��������不同权的总和最小值问题 �����������������������������
��������多目标优化问题 �����������������������������������
���
第八章��使用 NBUMBC遗传算法工具 ���������������������������
�������遗传算法与直接搜索工具箱概述 ����������������������������
�������工具箱的特点 ����������������������������������
�������编写待优化函数的 N文件 �����������������������������
�������使用遗传算法工具初步 ��������������������������������
�������遗传算法使用规则 ��������������������������������
�������遗传算法使用方式 ��������������������������������
�������举例MSbtusjjoh 函数 ��������������������������������
�������遗传算法的一些术语 �������������������������������
�������遗传算法如何工作 ��������������������������������
�������使用遗传算法工具求解问题 ������������������������������
�������使用遗传算法工具HVJ ������������������������������
�������从命令行使用遗传算法 ������������������������������
�������遗传算法举例 ����������������������������������
�������遗传算法参数和函数 ���������������������������������
�������遗传算法参数 ����������������������������������
�������遗传算法函数 ����������������������������������
�������标准算法选项 ����������������������������������
第九章��使用 NBUMBC直接搜索工具 ���������������������������
�������直接搜索工具概述 ����������������������������������
�������直接搜索算法 ������������������������������������
�������何谓直接搜索 ����������������������������������
�������执行模式搜索 ����������������������������������
�������寻找函数最小值 ���������������������������������
�������模式搜索术语 ����������������������������������
�������模式搜索如何工作 ��������������������������������
�������使用直接搜索工具 ����������������������������������
�������浏览模式搜索工具 ��������������������������������
�������从命令行运行模式搜索 ������������������������������
�������模式搜索举例 ����������������������������������
�������参数化函数 �����������������������������������
�������模式搜索参数和函数 ���������������������������������
�������模式搜索参数 ����������������������������������
�������模式搜索函数 ����������������������������������
参考文献 �����������������������������������������
���

书书书
ðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀ
ðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀ
�
��
���第一章��遗传算法概述��
遗传算法IHfofujdBmpsjuinh K简称HBJ起源于对生物系统所进行的计算机模
拟研究à美国 Njdijboh 大学的Ipmmboe教授及其学生受到生物模拟技术的启发K创
造出了一种基于生物遗传和进化机制的适合于复杂系统优化的自适 应 概 率 优 化 技
术���遗传算法à����年KIpmmboe的学生Cbmfh z在其博士论文中首次提出了�遗
传算法�一词K他发展了复制Ð交叉Ð变异Ð显性Ð倒位等遗传算子K在个体编码上
使用双倍体的编码方法àIpmmboe教授用遗传算法的思想对自然和人工自适应系统
进行了研究K提出了遗传算法的基本定理���模式定理ITdifnbUifpsfnJK并于
����年 出 版 了 第 一 本 系 统 论 述 遗 传 算 法 和 人 工 自 适 应 系 统 的 专 著�BebubujpojoObuvsbmboeBsujgjdjbmT
qtufntz �à��世纪��年代KIpmmboe教授实现了第一个基于
遗传算法的机器学习系统K开创了遗传算法的机器学习的新概念à����年KEfKpoh基于遗传算法的思想在计算机上进行了大量的纯数值函数优化计算实验K建立了遗
传算法的工作框架K得到了一些重要且具有指导意义的结论à����年KHpmecfsh出
版了�HfofujdBmpsjuinjoTfbsdih KPujnj{bujpoboeNbdijofMfbsojoq h�一书K系统
地总结了遗传算法的主要研究成果K全面完整地论述了遗传算法的基本原理及其应
用à����年KEbwjt出版了�IboecpplpgHfofujdBmpsjuinth �一书K介绍了遗传算
法在科学计算Ð工程技术和社会经济中的大量实例à����年KLp{b将遗传算法应用
于计算机程序的优化设计及自动生成K提出了遗传编程IHfofujdQspsbnnjoh hK简
称HQJ的概念à在控制系统的离线设计方面遗传算法被众多的使用者证明是有效的
策略à例如KLsjtioblvnbs和Hpmecfsh以及Csbnmfuuf和Dvtjo已证明使用遗传优
化方法在太空应用中导出优异的控制器结构比使用传统方法如MRS和QpxfmmI鲍
威尔J的增音机设计所用的时间要少I功能评估JàQpsufs和 Npibnfe展示了使用
本质结构分派任务的多变量飞行控制系统的遗传设计方案à与此同时K另一些人证
明了遗传算法如何在控制器结构的选择中使用à从遗传算法的整个发展过程来看K��世纪��年代是兴起阶段K��世纪��年代
是发展阶段K��世纪��年代是高潮阶段à遗传算法作为一种实用Ð高效Ð鲁棒性强
的优化技术K发展极为迅速K已引起国内外学者的高度重视à
�����遗传算法的概念
生物的进化IFwpmvujpoJ过程主要是通过染色体之间的交叉和变异来完成的à基于对自
然界中生物遗传与进化机理的模仿K针对不同的问题K很多学者设计了许多不同的编码方
���

法来表示问题的可行解K开发出了许多种不同的编码方式来模仿不同环境下的生物遗传特
性à这样K由不同的编码IDpejohJ方法和不同的遗传算子就构成了各种不同的遗传算法à遗传算法是模仿自然界生物进化机制发展起来的随机全局搜索和优化方法K它借鉴了
达尔文的进化论和孟德尔的遗传学说à其本质是一种高效Ð并行Ð全局搜索的方法K它能
在搜索过程中自动获取和积累有关搜索空间的知识K并自适应地控制搜索过程以求得最优
解à遗传算法操作使用适者生存的原则K在潜在的解决方案种群中逐次产生一个近似最优
的方案à在遗传算法的每一代中K根据个体在问题域中的适应度值和从自然遗传学中借鉴
来的再造方法进行个体选择K产生一个新的近似解à这个过程导致种群中个体的进化K得
到的新个体比原个体更能适应环境K就像自然界中的改造一样à个体或当 前 近 似 解 被 编 码 为 由 字 母 组 成 的 串K即 染 色 体IDispnptpnfJK使 基 因
IHfofK染色体值J能在I表现J域决策变量上被惟一地描述à尽管可以使用二进制Ð整数Ð实值等K但是在遗传算法表现型上最常用的仍是二进制字符串à例如K一个问题具有两个
变量Y�和Y�K它们的染色体结构能用图���所示的方法描述à
图�����个体的染色体结构
Y�被编码为��位KY�被编码为��位I位数的多少能够反映精确度水平或个体决策
变量的范围JK是一个不含人们试图解决问题的信息的染色体串à这只是表现值的染色体
编码K任何意义均可应用于表现型à无论如何K就像下面的描述K搜索过程将在决策变量
的编码中而不是它们自身中操作K当然除了在实值基因被使用的情况à在决策变量域中的染色体 表 现 型 已 被 编 码K可 以 估 计 种 群 的 个 体 成 员 的 特 性 或 适 应
度à通过特征目标函数来估计个体在问题域中的特性à在自然世界中K这就是个体在现行
环境中的生存能力à因此K目标函数建立的基础是在整个繁殖过程中选择成对的个体进行
交配à在再生I复制J期间K每个个体均被计算适应度值K它来自没有加工的原始特性度量K
由目标函数给出à这个值用来在选择中偏向更加适合的个体à相对整个种群K适应度高的
个体具有高的选中参加交配的概率K而适应度低的个体具有相对低的选中概率à一旦个体计算了适应度值K个体能根据它们的相对适应度从种群中被选中并重组K产
生下一代à遗传算子直接操作染色体的特征I基因JK使用一般情况下个体的基因代码K产
生更适合的个体à重组算子用在一对个体或一大组个体中交换基因信息à最简单的重组算
子是单点交叉à考虑两个二进制父代串M
B�����������和��C���������如果一个整J是随机地在�到串长M减�之间I即P�KM��QJ选择的K在这点后K两个个体
间的基 因 进 行 交 换K随 后 两 个 子 代 串 产 生à例 如K当 交 叉 点J��时K两 个 子 代 串 产 生
如下M
B������������和��C����������交叉算子并不是必须在种群的所有串中执行的à当一对个体被选中培育下一代时K代
���

替的是应用一个概率Qyà进一步的遗传算法称为变异K再次使用一个概率Qn 应用到新染
色体上à变异能根据一些概率准则引起个体基因表现型发生变化K在二进制表现型中K变
异引起单个位的状态变化K即�变�K或者�变�à例如K在B�中变异第四位K�变�K产生新串为��������à变异通常被认为是一后台算子K以确保研究问题空间的特殊子空间的概率永不为�à
变异具有阻止局部最优收敛的作用à在重组和变异后K如果需要K这些个体串随后被解码K进行目标函数评估K计算每个
个体的适应度值K个体根据适应度被选择参加交配K并且这个过程继续直到产生子代à在
这种方法中K种群中个 体 的 平 均 性 能 希 望 得 到 提 高K好 的 个 体 被 保 存 并 且 相 互 产 生 下 一
代K而低适应度的个体则消失à当一些判定条件满足后K遗传算法则终止K例如K一定的遗
传代数Ð种群的均差或遇到搜索空间的特殊点à
�����遗传算法的特点
遗传算法是一种借鉴生物界自然选择IObuvsbmTfmfdujpoJ和自然遗传机制的随机搜索
算法ISboepnTfbsdijo Bmh psjuinth Jà它与传统的算法不同K大多数古典的优化算法是基
于一个单一的度量函数I评估函数J的梯度或较高次 统 计K以 产 生 一 个 确 定 性 的 试 验 解 序
列N遗 传 算 法 不 依 赖 于 梯 度 信 息K而 是 通 过 模 拟 自 然 进 化 过 程 来 搜 索 最 优 解IPujnbmTpmvujpo
qJK它利用某种编码技术K作用于称为染色体的数字串K模拟由这些串组成的群体
的进化过程à遗传算法通过有组织的Ð随机的信息交换来重新组合那些适应性好的串K生
成新的串的群体à
�������遗传算法的优点
遗传算法具有如下优点MI�J对可行解表示的广泛性à遗传算法的处理对象不是参数本身K而是针对那些通过
参数集进行编码得到的基因个体à此编码操作 使 得 遗 传 算 法 可 以 直 接 对 结 构 对 象 进 行 操
作à所谓结构对象K泛指集合Ð序列Ð矩阵Ð树Ð图Ð链和表等各种一维或二维甚至多维结
构形式的对象à这一特点使得遗传算法具有广泛的应用领域à比如M
� 通过对连接矩阵的操作K遗传算法可用来对神经网络或自动机的结构或参数加以
优化à
� 通过对集合的操作K遗传算法可实现对规则集合和知识库的精炼而达到高质量的
机器学习目的à
� 通过对树结构的操作K用遗传算法可得到用于分类的最佳决策树à
� 通过对任务序列的操作K遗传算法可用于任务规划K而通过对操作序列的处理K可
自动构造顺序控制系统àI�J群体搜索特性à许多传统的搜索方法都是单点搜索K这种点对点的搜索方法K对
于多峰分布的搜索空间常常会陷于局部的某个单峰的极值点à相反K遗传算法采用的是同
时处理群体中多个个体的方法K即同时对搜索空间中的多个解进行评估à这一特点使遗传
算法具有较好的全局搜索性能K也使得遗传算法本身易于并行化à���

I�J不需要辅助信息à遗传算法仅用适应度函数的数值来评估基因个体K并在此基础
上进行遗传操作à更重要的是K遗传算法的适应度函数不仅不受连续可微的约束K而且其
定义域可以任意设定à对适应度函数的惟一要求是K编码必须与可行解空间对应K不能有
死码à由于限制条件的缩小K使得遗传算法的应用范围大大扩展àI�J内在启发式随机搜索特性à遗传算法不是采用确定性规则K而是采用概率的变迁
规则来指导它的搜索方向à概率仅仅是作为一种工具来引导其搜索过程朝着搜索空间的更
优化的解区域移动的à虽然看起来它是一种盲目搜索方法K实际上它有明确的搜索方向K具有内在的并行搜索机制à
I�J遗传算法在搜索过程中不容易陷入局部最优K即使在所定义的适应度函数是不连
续的Ð非规则的或有噪声的情况下K也能以很大的概率找到全局最优解àI�J遗传算法采用自然进化机制来表现复杂的现象K能够快速可靠地解决求解非常困
难的问题àI�J遗传算法具有固有的并行性和并行计算的能力àI�J遗传算法具有可扩展性K易于同别的技术混合à应重点注意的是K遗传算法对给定问题给出了大量可能的解答K并挑选最终的解答给
用户à要是一个特定问题并没有单个的解K例如Qbsfup最优解系列中K就像多目标优化和
日程安排的案例中K遗传算法将尽可能地用于识别可同时替换的解à
�������遗传算法的不足之处
遗传算法作为一种优化方法K它存在自身的局限性MI�J编码不规范及编码存在表示的不准确性àI�J单一的遗传算法编码不能全面地将优化问题的约束表示出来à考虑约束的一个方
法就是对不可行解采用阈值K这样K计算的时间必然增加àI�J遗传算法通常的效率比其他传统的优化方法低àI�J遗传算法容易出现过早收敛àI�J遗传算法对 算 法 的 精 度Ð可 信 度Ð计 算 复 杂 性 等 方 面K还 没 有 有 效 的 定 量 分 析
方法à
�����遗传算法与传统方法的比较
对于一个求函数最大值的优化问题I求函数最小值也类似JK一般可描述为带约束条件
的数学规划模型M
nby gIYJ
t�u� Y��SST�
��
� V
I���J
式中KY�Py�Ky�K�KyoQU 为决策变量KgIYJ为目标函数KV为基本空间KS是V 的一
个子集à满足约束条件的解称为可行解IGfbtjcmfTpmvujpoJK集合S表示由所有满足约束
条件的解所组成的一个集合K称为可行解集合à它们之间的关系如图���所示à
���

图�����最优化问题的可行解及可行解集合
����对于上述最优化问题K目标函数和约束条件种类繁多K有的是线性的K有的是非线性
的N有的是连续的K有的是离散的N有的是单峰值的K有的是多峰值的à随着研究的深入K人们逐渐认识到在很多复杂情况下要想完全精确地求出其最优解是不可能的K也是不现实
的K因而求出其近似最优解或满意解是人们主要研究的问题之一à对于类似上述最优化问题K求最优解或近似最优解的传统方法主要有解析法Ð随机法
和穷举法à解析法主要包括爬山法和间接法à随机法主要包括导向随机方法和盲目随机方
法à而穷举法主要包括完全穷举法Ð回溯法Ð动态规划法和限界剪枝法à此类问题可以利用遗传算法求解à而对于求解此类问题K遗传算法与一般传统方法有
着本质的区别à图���所示为传统算法和遗传算法对比示意图à
图�����传统算法和遗传算法对比
��遗传算法与启发式算法的比较
启发式算法是指通过寻求一种能产生可行解的启发式规则K找到问题的一个最优解或
近似最优解à该方法求解问题的效率较高K但是它对每一个所求的问题必须找出其特有的
启发式规则K这个启发式规则一般无通用性K不适用于其他问题à但遗传算法采用的不是
确定性规则K而是强调利用概率转换规则来引导搜索过程à
��遗传算法与爬山法的比较
爬山法是直接法Ð梯度法和 Ifttjbo法的通称à爬山法首先在最优解可能存在的地方
选择一个初始点K然后通过分析目标函数的特性K由初始点移到一个新的点K然后再继续
这个过程à爬山法的搜索过程是确定的K它通过产生一系列的点收敛到最优解I有时是局
部最优解JK而遗传算法的搜索过程是随机的K它产生一系列随机种群序列à二者的主要差
异可以归纳为如下两点MI�J爬山法的初始点仅有一个K由决策者给出N遗传算法的初始点有多个K是随机产
���

生的àI�J通过分析目标函数的特性可知K爬山法由上一点产生一个新的点N遗传算法通过
遗传操作K在当前的种群中经过交叉Ð变异和选择产生下一代种群à对同一优化问题K遗
传算法所使用的机时比爬山法所花费的机时要多à但遗传算法可以处理一些爬山法所不能
解决的复杂的优化问题à
��遗传算法与穷举法的比较
穷举法就是对解空间内的 所 有 可 行 解 进 行 搜 索K但 是 通 常 的 穷 举 法 并 不 是 完 全 穷 举
法K即不是对所有解进行尝试K而是有选择地尝试K如动态规划法Ð限界剪枝法à对于特定
的问题K穷举法有时也表现出很好的性能à但一般情况下K对于完全穷举法K方法简单易
行K但求解效率太低N对于动态规划法Ð限界剪枝法K则鲁棒性不强à相比较而言K遗传算
法具有较高的搜索能力和极强的鲁棒性à
��遗传算法与盲目随机法的比较
与上述的搜索方法相比K盲目随机搜索法有所改进K但它的搜索效率仍然不高à一般
而言K只有解在搜索空间中形成紧致分布时K它的搜索才有效à而遗传算法作为导向随机
搜索方法K是对一个被编码的参数空间进行高效搜索à经过上面的探讨K能看到遗传算法与更多的传统优化方法在本质上有着不同之处K主
要有四点不同MI�J遗传算法搜索种群中的点是并行的K而不是单点àI�J遗传算法并不需要辅助信息或辅助知识K只需要影响搜索方向的目标函数和相对
应的适应度àI�J遗传算法使用概率变换规则K而不是确定的变换规则àI�J遗传算法工作使用编码参数集K而不是自身的参数集I除了在实值个体中使用Jà
�����遗传算法的基本用语
由于遗传算法是自然遗传学和计算机科学相互结合渗透而成的新的计算方法K因此遗
传算法中经常使用自然进化中有关的一些基本用语à了解这些用语对于讨论和应用遗传算
法是十分必要的à生物 的 遗 传 物 质 的 主 要 载 体 是 染 色 体KEOB 是 其 中 最 主 要 的 遗 传 物 质K而 基 因
IHfofJ又是控制生物性状的遗传物质的功能单位和结合单位à复数个基因组成染色体K染
色体中基因的位置称为基因座IMpdvtJK而基因所取的值叫做等位基因IBmmfmfJà基因和基
因座决定了染色体的特征K也就决定了生物个体的性质状态à染色体有两种相应的表示模
式K即基因型和表现型à所谓表现型K是指生物个体所表现出来的性质状态K而基因型是
指与表现型密切相关的基因组成à同一种基因型的生物个体在不同的环境条件下可以有不
同的表现型K因此表现型是基因型与环境条件相互作用的结果à在遗传算法中K染色体对
应的是数据或数组K在标准的遗传算法中K通常是由一维的串结构数据表现的à串上各个
位置对应上述的基因座K而各位置上所取的值对应上述的等位基因à遗传算法处理的是染
色体K或者叫基因型个体à一定数量的个体组成了群体K也叫集团à群体中个体的数目称
为群体的大小K也叫群体规模à而各个体对环境的适应程度叫适应度à执行遗传算法时包
���

含两个必要的数据转换操作K一个是表现型到基因型的转换K它把搜索空间中的参数或解
转换成遗传空间中的染色体或个体K此过程称为编码操作N另一个是基因型到表现型的转
换K它是前者的一个相反操作K称为译码操作à表���为自然遗传学和人工遗传算法中所
使用的基本用语的对应关系à表�����遗传学和遗传算法中基本用语对照表
自然遗传算法 人工遗传算法
染色体IDispnptpnfJ 解的编码I数据Ð数组Ð位串J
基因IHfofJ 解中每一分量的特征I特性Ð个性Ð探测器Ð位J
等位基因IBmmfmfJ 特性值
基因座IMpdvtJ 串中位置
基因型IHfoqzqu fJ 结构
表现型IQifopuzqfJ 参数集Ð解码结构Ð候选解
遗传隐匿 非线性
个体IJoejwjevbmJ 解
适者生存 在算法停止时K最优目标值的解有最大的可能被留住
适应性IGjuofttJ 适应度函数值
群体IQpvmbujpoq J 选定的一组解I其中解的个数为群体的规模J
复制ISfspevdujpoq J 根据适应函数值选取的一组解
交配IDspttpwfsJ 通过交配原则产生一组新解的过程
变异INvubujpoJ 编码的某一个分量发生变化的过程
�����遗传算法的研究方向
遗传算法是多学科 结 合 与 渗 透 的 产 物K它 已 经 发 展 成 一 种 自 组 织Ð自 适 应 的 综 合 技
术K其研究方向主要有下述几个方面à
��基础理论
遗传算法的数学理论并不完善K张铃等对遗传算法的�模式定理�和�隐性并行性�进行
了分析研究K指出其不足并指出遗传算法本质上是一个具有定向制导的随机搜索技术à在
遗传算法中K群体规模和遗传算子的控制参数的选取非常困难K但它们又是必不可少的实
验参数K在这方面K已有一些具有指导性的实验结果à遗传算法还有一个过早收敛的问题K如何阻止过早收敛也是人们正在研究的问题之一à
���

��分布并行遗传算法
遗传算法在操作上具有高度的并行性K许多研究人员都在探索在并行机和分布式系统
上高效执行遗传算法的策略à对分布遗传算法的研究表明K只要通过保持多个群体和恰当
控制群体间的相互作用来模拟并发执行过程K即使不使用并行计算机K也能提高算法的执
行效率à遗传算法的并行性主要从三个方面考虑K即个体适应度评价的并行性Ð整个群体
各个个体适应度评价的并行性及子代群体产生过程的并行性à
��分类系统
分类系统属于基于遗传算法的机器学习中的一类K包括一个简单的基于串规则的并行
生成子系统Ð规则评价 子 系 统 和 遗 传 算 法 子 系 统à分 类 系 统 被 人 们 越 来 越 多 地 应 用 在 科
学Ð工程和经济领域中K是目前遗传算法研究中一个十分活跃的方向à
��遗传神经网络
遗传神经网络包括 连 接 级Ð网 络 结 构 和 学 习 规 则 的 进 化à遗 传 算 法 与 神 经 网 络 相 结
合K成功地用于从分析时间序列来进行财政预算à在这些系统中K训练信号是模糊的K数
据是有噪声的K一般很难正确给出每个执行的定量评价K如果采用遗传算法学习K就能克
服这些困难K显著提高系统性能àNvimfocfjo分析了多层感知网络的局限性K并猜想下一
代神经网络将是遗传神经网络à
��进化算法
模拟自然进化过程可以产生鲁棒的计算机算法���进化算法à遗传算法是其三种典型
的算法之一K其余两种算法是进化规划和进化策略K这三种算法是独立发展起来的à
��人工生命与遗传算法
近几年来K通过计算机模拟再现种种生命现象K以达到对生命更深刻理解的人工生命
的研究正在兴起à已有不少学者对生态系统的演变Ð食物链的维持以及免疫系统的进化等
用遗传算法做了生动的模拟à但是实现人工生命的手段很多K遗传算法在实现人工生命中
的基本地位和能力究竟如何K这是值得研究的课题à
�����基于遗传算法的应用
遗传算法提供了一种求解 复 杂 系 统 优 化 问 题 的 通 用 框 架K它 不 依 赖 于 问 题 具 体 的 领
域K对问题的种类有很强的鲁棒性K所以广泛应用于许多学科à近十年来K遗传算法得到
了迅速发展à目前K遗传算法在生物技术和生物学Ð化学和化学工程Ð计算机辅助设计Ð物
理学和数据分析Ð动态处理Ð建模与模拟Ð医学与医学工程Ð微电子学Ð模式识别Ð人工智
能Ð生产调度Ð机器人学Ð开矿工程Ð电信学Ð售货服务系统等领域都得到应用K成为求解
全局优化问题的有力工具之一à下面列出遗传算法一些主要的应用领域à
��函数优化
函数优化IGvodujpoPujnj{bujpoq J是遗传算法的经典应用领域K也是对遗传算法进行
性能评价的常用算例à可以用各种各样的函数来验证遗传算法的性能à对一些非线性Ð多
模型Ð多目标的函数优化问题K使用遗传算法可得到较好的结果à
��组合优化
随着问题规模的增大K组合优化问题的搜索空间也急剧扩大K有时在目前的计算机上
���

用枚举法很难甚至不能求出问题的最优解K对这类问题K人们已意识到应把主要精力放在
寻求其满意解上K而遗传算法就是寻求这种满意解的最佳工具之一à实践证明K遗传算法
对于组合优化中的OQ完全问题非常有效à
��生产调度问题
采用遗传算法能够解决复杂的生产调度问题à在单件生产车间调度Ð流水线生产车间
调度Ð生产规划Ð任务分配等方面K遗传算法都得到了有效的应用à
��自动控制
在自动控制领域中有很多与优化相关的问题需要求解K遗传算法已在其中得到了初步
应用K并显示出了良好的效果à例如K基于遗传算法的模糊控制器优化设计K用遗传算法
进行航空控制系统的优化K使用遗传算法设计空间交会控制器等à
��机器人学
机器人是一类复杂的难以精确建模的人工系统K而遗传算法的起源来自于对人工自适
应系统的研究K所以机器人学理所当然地成为遗传算法的一个重要领域à例如K遗传算法
已经在移动机器人路径规划Ð机器人逆运动学求解等方面得到很好的应用à
��图像处理
图像处理是计算机视觉中的一个重要领域K在图像 处 理 过 程 中K如 扫 描Ð特 征 提 取Ð图像分割等不可避免地会存在一些误差K这些误差会影响图像处理的效果à如何使这些误
差最小是使计算机视觉达到实用化的重要要求K遗传算法在这些图像处理的优化计算方面
找到了用武之地à
��遗传编程
Lp{b发展了遗传程序设计的概念K他使用了以MJTQ语言所表示的编码方法K算法基
于对一种树型结构所进行的遗传操作来自动生成计算机程序à
��机器学习
基于遗传算法的机器学习K特别是分类器系统K在很 多 领 域 中 都 得 到 了 应 用à例 如K遗传算法被用于学习模糊控制规则K利用遗传算法来学习隶属函数等à基于遗传算法的机
器学习可用于调整人工神经网络的连接权K也可用于神经网络结构的优化设计à分类器系
统在多机器人路径规划系统中得到了成功的应用à
��数据挖掘
数据挖掘IEbubNjojohJ是指从大型数据库或数据仓库中提取隐含的Ð未知的Ð非平凡
的及有潜在应用价值的信息或模式K它是数据库研究中的一个很有应用价值的新领域K由
于遗传算法的特点K遗传算法可用于数据挖掘中的规则开采à
���信息战
遗传算法在信息战领域得到了初步应用à使用遗传算法能够进行雷达目标识别Ð数据
挖掘Ð作战仿真Ð雷达辐射源识别Ð雷达天线优化设计Ð雷达目标跟踪Ð盲信号处理Ð空间
谱估计Ð天线设计Ð网络入侵检测Ð情报分析中的数据挖掘和数据融合Ð信息战系统仿真Ð作战效能评估Ð作战辅助决策等à
表���列出了遗传算法的主要应用领域及问题举例à
���

表�����遗传算法的主要应用领域
应用领域 例����子
控制 瓦斯管道控制K防避导弹控制K机器人控制
规划 生产规划K并行机任务分配
设计 WMTJ布局K通信网络设计K喷气发动机设计
组合优化 UTQ问题K背包问题K图划分问题
图像处理 模式识别K特征提取K图像恢复
信号处理 滤波器设计K目标识别K运动目标分割
机器人 路径规划
人工生命 生命的遗传进化
����

书书书
ðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀ
ðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀ
�
��
���第二章��基本遗传算法及改进��
Ipmmboe创建的遗传算法是一种概率搜索算法K它利用某种编码技术作用于称
为染色体的数串K其基本思想是模拟由这些串组成的个体进化过程à该算法通过有
组织的Ð然而是随机的信息交换K重新组合那些适应性好的串à在每一代中K利用
上一代串结构中适应好的位和段来生成一个新的串的群体N作为额外增添K偶尔也
要在串结构中尝试用新的位和段来替代原来的部分à遗传算法是一类随机优化算法K它可以有效地利用已有的信息处理来搜索那些
有希望改善解质量的串à类似于自然进化K遗传算法通过作用于染色体上的基因K寻找好的染色体来 求 解 问 题à与 自 然 界 相 似K遗 传 算 法 对 待 求 解 问 题 本 身 一 无 所
知K它所需要的仅是对算法所产生的每个染色体进行评价K并基于适应度值来改变
染色体K使适用性好的染色体比适应性差的染色体有更多的繁殖机会à
�����遗传算法的运行过程
遗传算法模拟了自然选择和遗传中发生的复制Ð交叉和变异等现象K从任一初始种群
IQpvmbujpoq J出发K通过随机选择Ð交叉和变异操作K产生一群更适应环境的个体K使群体
进化到搜索空间中越来越好的区域K这样一代一代地不断繁衍进化K最后收敛到一群最适
应环境的个体IJoejwjevbmJK求得问题的最优解à
�������完整的遗传算法运算流程
遗传算法的一般步骤如图���所示à完整的遗传算法运算流程可以用图���来描述à由图���可以看出K使用上述三种遗传算子I选择算子Ð交叉算子和变异算子J的遗传
算法的主要运算过程如下MI�J编码M解空间中的解数据yK作为遗传算法的表现型形式à从表现型到基因型的映
射称为编码à遗传算法在进行搜索之前先将解空间的解数据表示成遗传空间的基因型串结
构数据K这些串结构数据的不同组合就构成了不同的点àI�J初始群体的生成M随机产 生O 个 初 始 串 结 构 数 据K每 个 串 结 构 数 据 称 为 一 个 个
体KO 个个体构成了一个群体à遗传算法以这O 个串结构作为初始点开始迭代à设置进化
代数计数器uB��N设置最大进化代数UN随机生成N 个个体作为初始群体QI�JàI�J适应度值评价检测M适应度函数表明个体或解的优劣性à对于不同的问题K适应
度函数的定义方式不同à根据具体问题K计算群体QIuJ中各个个体的适应度à
����

图�����遗传算法的一般步骤
图�����遗传算法运算流程
����

����I�J选择M将选择算子作用于群体àI�J交叉M将交叉算子作用于群体àI�J变异M将变异算子作用于群体à群体QIuJ经过选择Ð交叉Ð变异运算后得到下一代群体QIu��JàI�J终止条件判断M若u0�UK则uB�u��K转到步骤I�JN若u`�UK则以进化过程中所
得到的具有最大适应度的个体作为最优解输出K终止运算à从遗传算法运算流程可以看出K进化操作过程简单K容易理解K它给其他各种遗传算
法提供了一个基本框架à一个简单的遗传算法被Hpmecfsh用来进行轮廓描述并用来举例说明遗传算法的基本
组成àu代种群用变量QIuJ表示K初始种群QI�J是随机设计的K简单遗传算法的伪代码描
述如下M���� spdfevsfHB
cf
q
joh
����u��N
����jojujbmj{fQIuJN
����fwbmvbufQIuJN
����xijmfopugjojtifeep
����cfjoh
��������u�u��N
��������tfmfduQIuJgspnQIu��JN
��������sfspevdfq bjstjoQq IuJN
��������fwbmvbufQIuJN
����foe
foe
�������遗传算法的基本操作
遗传算法有三个基本操作M选择ITfmfdujpoJÐ交叉IDspttpwfsJ和变异INvubujpoJàI�J选择à选择的目的是为了从当前群体中选出优良的个体K使它们有机会作为父代
为下一代繁殖子孙à根据各个个体的适应度值K按照一定的规则或方法从上一代群体中选
择出一些优良的个体遗传到下一代群体中à遗传算法通过选择运算体现这一思想K进行选
择的原则是适应性强的个体为下一代贡献一个或多个后代的概率大à这样就体现了达尔文
的适者生存原则àI�J交叉à交叉操作是遗传算法中最主要的遗传操作à通过交叉操作可以得到新一代
个体K新个体组合了父辈个体的特性à将群体内的各个个体随机搭配成对K对每一个个体K以某个概率I称为交叉概率KDspttpwfsSbufJ交换它们之间的部分染色体à交叉体现了信
息交换的思想àI�J变异à变异操作首先在群体中随机选择一个个体K对于选中的个体以一定的概率
随机改变串结构数据中某个串的值K即对群体中的每一个个体K以某一概率I称为变异概
率KNvubujpoSbufJ改变某一个或某一些基因座上的基因值为其他的等位基因à同生物界
一样K遗传算法中变异发生的概率很低à变异为新个体的产生提供了机会à
����

�����基本遗传算法
基本遗传算法I也称标准遗传算法或简单遗传算法KTjnmfHfofujdBmq psjuinh K简称
THBJ是 一 种 群 体 型 操 作K该 操 作 以 群 体 中 的 所 有 个 体 为 对 象K只 使 用 基 本 遗 传 算 子
IHfofujdPfsbupsq JM选择算子ITfmfdujpoPfsbupsq JÐ交叉算子IDspttpwfsPfsbupsq J和 变
异算子INvubujpoPfsbupsq JK其遗传进化操作过程简单K容易理解K是其他一些遗传算法
的基础K它不仅给各种遗传算法提供了一个基本框架K同时也具有一定的应用价值à选择Ð交叉和变异是遗传算法的�个主要操作算子K它们构成了所谓的遗传操作K使遗传算法具
有了其他传统方法没有的特点à
�������基本遗传算法的数学模型
基本遗传算法可表示为
THB � IDKFKQ�KNK�K�K�KUJ I���J式中MD���个体的编码方法N
F���个体适应度评价函数N
Q����初始种群N
N���种群大小N
����选择算子N
����交叉算子N
����变异算子N
U���遗传运算终止条件à图���所示为基本遗传算法的流程图à
图�����遗传算法的基本流程图
�������基本遗传算法的步骤
��染色体编码IDispnptpnfDpejohJ与解码IEfdpefJ基本遗传算法使用固定长度的二进制符号串来表示群体中的个体K其等位基因由二值
R�K�S所 组 成à初 始 群 体 中 各 个 个 体 的 基 因 可 用 均 匀 分 布 的 随 机 数 来 生 成à例 如M
����

Y�������������������就可表示一个个体K该个体的染色体长度是o���àI�J编码M设某一参数的取值范围为PV�KV�QK我们用长度为l的二进制编码符号来
表示该参数K则它总共产生�l 种不同的编码K可使参数编码时的对应关系为M
��������������������A�V���������������������A�V�����������������������A�V�����������������������������
�����������������l�����A�V�
其中K��V��V��l��
à
I�J解码M假设某一个体的编码为clcl��cl���c�c�K则对应的解码公式为
Y�V�� ��l
j��cjð�j�I J� ðV��V��l��
I���J
����例如M设有参数Y��P�K�QK现用�位二进制编码对Y进行编码K得�����个二进制
串I染色体JM
���������K�����K�����K�����K�����K�����K�����K��������������K�����K�����K�����K�����K�����K�����K��������������K�����K�����K�����K�����K�����K�����K�����
���������K�����K�����K�����K�����K�����K�����K�����对于任一个二进制串K只要代入公式I���JK就可得到对应的解码K如y��������K它
对应的十进制为���
j��cjð�j��������������������������K则对应参数Y 的值
为�������������������à
��个体适应度的检测评估
基本遗传算法按与个体适应度成正比的概率来决定当前群体中各个个体遗传到下一代
群体中的机会多少à为了正确估计这个概率K要求所有个体的适应度必须为非负数à所以K根据不同种类的问题K需要预先确定好由目标函数值到个体适应度之间的转换规律K特别
是要预先确定好当目标函数值为负数时的处理方法à例如K可选取一个适当大的正数dK使
个体的适应度为目标函数值加上正数dà
��遗传算子
基本遗传算法使用下列三种遗传算子MI�J选择运算使用比例选择算子à比例选择因子是利用比例于各个个体适应度的概率决
定其子孙的遗留可能性à若设种群数为NK个体j的适应度为gjK则个体j被选取的概率为
Qj�gjL��N
l��gl
����当个体选择的概率给定后K产生P�K�Q之间的均匀随机数来决定哪个个体参加交配à若个体的选择概率大K则能被多次选中K它的遗传基因就会在种群中扩大N若个体的选择
概率小K则被淘汰à
����

I�J交叉运算使用单点交叉算子à只有一个交叉点位置K任意挑选经过选择操作后种
群中两个个体作为交叉对象K随机产生一个交叉点位置K两个个体在交叉点位置互换部分
基因码K形成两个子个体K如图���所示à
图�����单点交叉示意图
I�J变异运算使用基本位变异算子或均匀变异算子à为了避免问题过早收敛K对于二进制
的基因码组成的个体种群K实现基因码的小概率翻转K即�变为�K而�变为�K如图���所示à
图�����变异操作示意图
��基本遗传算法的运行参数
基本遗传算法有下列�个运行参数需要预先设定K即NKUKQdKQnà
N 为群体大小K即群体中所含个体的数量K一般取为��Y���N
U为遗传算法的终止进化代数K一般取为���Y���N
Qd 为交叉概率K一般取为���Y����N
Qn 为变异概率K一般取为������Y���à
�������遗传算法的具体例证
下面通过具体的例子介绍遗传算法的实际工作过程à假设目标函数为
nbygIy�Ky�J������y�tjoI��y�J�y�tjoI���y�J I���J
����0�y� 0�����
���0�y� 0��� ��
��I���J
如图���所示K该函数有多个局部极值点à
图�����目标函数的图像
����

下面介绍求解该优化问题的遗传算法的构造过程à第一步K确定决策变量和约束条件à式I���J给出K决策变量为y�Ky�K约束条件为����0�y�0�����K���0�y�0����à第二步K建立优化模型à式I���J已给出了问题的数学模型à第三步K确定编码方法à要进行编码工作K即将变量转换成二进制串à串的长 度 取 决 于 所 要 求 的 精 度à例 如K
变量y� 的区间是Pb�Kc�QK要求的精度是小数点后�位K也就意味着每个变量应该被分成
至少Ic��b�J���� 个部分à对一个变量的二进制串位数I用nk 表示JK用以下公式计算M
�nk�� _� Ick�bkJ���� 0��nk ��
����第四步K确定解码方法à从二进制串返回一个实际的值可用下面的公式来实现M
yk �bk�efdjnbmItvctusjohkJ�ck�bk�nk ��
I���J
其中KefdjnbmItvctusjohkJ代表变量yk 的十进位值à不妨设要求的精度为小数点后�位K则目标函数的两个变量y� 和y� 可以转换为下面
的串MI�����I����JJ�������������
��� _�������0����K����n� ���I�������J������������
��� _������0����K����n� ���
n�n��n� ���������这样K一个染色体串是��位K如图���所示à
图�����一个染色体二进制串
对应的变量y� 和y� 的实值如表���所示à表�����染色体二进制与十进制比较
变量 二进制数 十进制数
y� ������������������ ����
y� ��������������� �����
y� ����������������I����J
���������������
y� �����������������������
���������
����

����初始种群可随机生成如下M
����V��P���������������������������������Q
V��P���������������������������������Q
V��P���������������������������������Q
V��P���������������������������������Q
V��P���������������������������������Q
V��P���������������������������������Q
V��P���������������������������������Q
V��P���������������������������������Q
V��P���������������������������������Q
V���P���������������������������������Q相对应的十进制的实际值为
����V��Py�Ky�Q�P���������K��������Q
V��Py�Ky�Q�P��������K��������Q
V��Py�Ky�Q�P���������K��������Q
V��Py�Ky�Q�P��������K��������Q
V��Py�Ky�Q�P���������K��������Q
V��Py�Ky�Q�P���������K��������Q
V��Py�Ky�Q�P��������K��������Q
V��Py�Ky�Q�P���������K��������Q
V��Py�Ky�Q�P���������K��������Q
V���Py�Ky�Q�P���������K��������Q第五步K确定个体评价方法à对一个染色体串的适应度评价由下列三个步骤组成MI�J将染色体串 进 行 反 编 码K转 换 成 真 实 值à在 本 例 中K意 味 着 将 二 进 制 串 转 为 实
际值M
yl � Iyl�Kyl�JK��l��K�K� I���J
����I�J评价目标函数gIylJàI�J将目标函数值转为适应度à对于极大值问题K适应度就等于目标函数值K即
fwbmIVlJ�gIylJK��l��K�K� I���J
����在遗传算法中K评价函数起着自然进化中环境的角色K它通过染色体的适应度对其进
行评价à上述染色体的适应度值如下M
����fwbmIV�J�gI���������K��������J����������fwbmIV�J�gI��������K��������J����������fwbmIV�J�gI���������K��������J���������fwbmIV�J�gI��������K��������J����������fwbmIV�J�gI���������K��������J����������fwbmIV�J�gI���������K��������J����������fwbmIV�J�gI��������K��������J��������������

fwbmIV�J�gI���������K��������J����������fwbmIV�J�gI���������K��������J����������fwbmIV��J�gI���������K��������J����������
由以上数据可以看出K上述染色体中最健壮的是V�K最虚弱的是V�à第六步K设计遗传算子和确定遗传算法的运行参数àI�J选择运算使用轮盘选择算子à为基础的概率分配来选择新的种群à其步骤如下M
� 计算各染色体Vl 的适应度值fwbmIVlJM
fwbmIV�J�gIyJK��l��K�K� I���J
����� 计算群体的适应度值总和M
G� ��qpq�tj{f
l��fwbmIVlJ I���J
����� 计算对应于每个染色体Vl 的选择概率QlM
Ql �fwbmIVlJG
I����J
����� 计算每个染色体Vl 的累计概率RlM
Rl ���l
k��QkK��k��K�K� I����J
����在实际工作中K选择新种群的一个染色体按以下步骤完成M
� 生成一个P�K�Q间的随机数sà
� 如果s1�R�K就选择染色体V�N否则K选择第l个 染 色 体VlI�0�l0�qpq�tj{fJ使得
Rl�� 0�s0�Rl那么K本例中种群的适应度总和为
G�����
l��fwbmIVlJ�����������
对应于每个染色体VlIl��K�K�K��J的选择概率Ql 如下M
Q������������Q������������Q������������Q������������Q����������Q������������Q������������Q������������Q������������Q�����������
对应于每个染色体VlIl��K�K�K��J的累计概率Rl 如下M
R������������R������������R������������R������������R����������R������������R������������R������������R������������R�����������现在K我们转动轮盘��次K每次选择一个新种群中的染色体à假设这��次中生成的
P�K�Q间的随机数如下M
������������������������������������������������������������������������ �������� �������� �������� ��������
第一个随 机 数s����������大 于R�K小 于R�K这 样 染 色 体V� 被 选 中N第 二 个 随 机 数
s����������也大于R�K小于R�K于是染色体V� 被再次选中à最终K新的种群由下列染
色体组成M
����

����V��P���������������������������������Q������ IV�J
����V��P���������������������������������Q IV�J
����V��P���������������������������������Q IV�J
����V��P����������������������������������Q IV�J
����V��P���������������������������������Q IV�J
����V��P���������������������������������Q IV�J
����V��P���������������������������������Q IV�J
����V��P���������������������������������Q IV�J
����V��P���������������������������������Q IV�J
����V���P���������������������������������Q IV�JI�J交叉运算使用单点交叉算子à随机选择一个染色体串的节点K然后交换两个父辈节点右端部分来产生子辈à假设两
个父辈染色体如下所示I节点随机选择在染色体串的第��位基因JM
����������������������������������������V��P���������������������������������Q
��������V��P���������������������������������Q假设交叉概率为Q�����K即在平均水平上有���的染色体进行了交叉à交叉操作
的过程如下M
����开始
����lB��N
����当l0���时继续
��������slB�P�K�Q之间的随机数N
��������如果sl_�����K则
������������选择Vl 为交叉的一个父辈N
��������结束
��������lB�l��N
����结束
结束
假设随机数如下M
������������������������������������������������������������������������������������������������������������������������
那么K就意味着染色体V� 和V� 被选中作为交叉的父辈à在这里K我们随机选择一个P�K
��Q间的整数I因为��是整个染色体串的长度J作为交叉点à假设生成的整数 ptq 为�K那
么两个染色体从第一位分割K新的子辈在第一位右端的部分互换而生成K即
����V��P���������������������������������Q
����V��P���������������������������������Q
����������������������������VH�
� �P���������������������������������Q
����VH�� �P���������������������������������Q
����

I�J变异运算使用基本位变异算子à假设染色体V� 的第��位基因被选作变异K即如果该位基因是�K则变异后就为�à于
是K染色体在变异后将是M
����V��P���������������������������������Q
����������������������������
����VH�� �P���������������������������������Q
将变异概率设为Qn�����K就是说K希望在平均水平上K种群内所有基因的��要进
行变异à在本例中K共有���������个基因K希望在每一代中有���个变异的基因K每
个基因变异的概率是相等的à因此K我们要生成一个位于P�K�Q间的随机数系列slIl��K
�K�K���Jà假设表���中列出的基因将进行变异à表�����基因变异示例
基因位置 染色体位置 基因位数 随机数
��� � � ��������
��� � �� ��������
��� � � ��������
��� �� �� ��������
����在变异完成后K得到了最终的下一代种群M
����VH�� �P���������������������������������Q
VH�� �P���������������������������������Q
VH�� �P���������������������������������Q
VH�� �P���������������������������������Q
VH�� �P���������������������������������Q
VH�� �P���������������������������������Q
VH�� �P���������������������������������Q
VH�� �P���������������������������������Q
VH�� �P���������������������������������Q
VH����P���������������������������������Q
相对应的变量Py�Ky�Q的十进制值和适应度值为
����gI��������K��������J����������gI��������K��������J����������gI���������K��������J����������gI���������K��������J���������gI��������K��������J���������
����

gI��������K�������J����������gI��������K��������J����������gI��������K��������J����������gI���������K��������J����������gI��������K��������J����������
至此K完成了遗传算法第一代的流程à设计终止代数为����à在第���代K得到了最佳的染色体M
����VH��P���������������������������������Q个体随着进化过程的进行K群体中适应度较低的一些个体被逐渐淘汰K而适应度较高
的一些个体会越来越多K并且更加集中在VH� 附近K最终就可搜索到问题的最优点VH�àVH�
对应的十进制为yH�� ����������KyH�� ���������K得适应度值为
fwbmIVH�J�gI���������K��������J����������即目标函数的最大值为gIyH�� KyH�� J����������à
�����改进的遗传算法
尽管遗传算法有许多优点K也有许多专家学者对遗传算法进行不断研究K但目前存在
的问题依然很多K如MI�J适应度值标定方式多种多样K没有一个简洁Ð通用的方法K不利于对遗传算法的
使用àI�J遗传算法的早熟现象I即很快收敛到局部最优解而不是全局最优解J是迄今为止最
难处理的关键问题àI�J快要接近最优解时在最优解附近左右摆动K收敛较慢à本节根据遗传算法所存在的这些问题分别从适应度值函数标定和增加群体多样性两方
面着手解决à遗传算法通常需要解决以下问题K如确定编码方案K适应度函数标定K选择遗传操作
方式及相关控制参数K停止准则确定等à相应地K为改进简单遗传算法的 实 际 计 算 性 能K很多学者的改进工作也是分别从参数编码Ð初始群体设定Ð适应度函数标定Ð遗传操作算
子Ð控制参数的选择以及遗传算法的结构等方面提出的à自从����年K�I�Ipmmboe系统
提出遗传算法的完整结构和理论以来K众多学者一直致力于推动遗传算法的发展K对编码
方式Ð控制参数的确定和交叉机理等进行了深入的研究K提出了各种变形的遗传算法à其
基本途径概括起来主要有下面几个方面MI�J改进遗传算法的组成成分或使用技术K如选用优化控制参数Ð适合问题特性的编
码技术等àI�J采用混合遗传算法II csjeHfofujdBmz psjuinh JàI�J采用动态自适应技术K在进化过程中调整算法控制参数和编码精度àI�J采用非标准的遗传操作算子àI�J采用并行算法à在许多资料中都介绍了七种改进遗传算法M
����

I�J分层遗传算法IIjfsbsdijdHfofujdBmpsjuinh JNI�JDID算法NI�JNfttz遗传算法NI�J自适应遗传算法IBebujwfHfofujdBmq psjuinh JNI�J基于小生境技术的遗传算法IOjdifeHfofujdBmpsjuinh K简称OHBJàI�J并行遗传算法IQbsbmmfmHfofujdBmpsjuinh JNI�J混合遗传算法M
� 遗传算法与最速下降法相结合的混合遗传算法N
� 遗传算法与模拟退火法ITjnvmbufeBoofbmjohJ相结合的混合遗传算法à下面介绍几种改进的遗传算法à
�������改进的遗传算法一
在改进的遗传算法中K改进的三个算子通常是HB算法中的交叉操作K是随机取两个
染色体进行单点交叉操作I也可用其他的交叉操作K如多点交叉Ð树交叉Ð部分匹 配 交 叉
等JK即在以高适应度模式为祖先的�家族�中取一点K但这种取法有其片面性à经证明K简
单遗传算法在任何情况下I交叉概率QdK变异概率QnK任意初始化K任意交叉算子K任意
适应度函数J都是不收敛的K即不能搜索到全局最优解N而通过改进的遗传算法K即在选择
作用前I或后J保留当前最优解K则能保证收敛到全局最优解à尽管人们证明了改进的遗传
算法最终能收敛到最优解K但收敛到最优解所需的时间可能是很长的à另外K早熟问题是
遗传算法中不可忽视的现象K其具体表现为MI�J群体中所有的个体都陷于同一极值而停止进化àI�J接近最优解的个体总是被淘汰K进化过程不收敛à对此可以采用以下方法来解决MI�J动态确定变异概率K既可防止优良基因因为变异而遭破坏K又可在陷于局优解时
为种群引入新的基因àI�J改进选择方式K放弃赌轮选择K以避免早期的高适应度个体迅速占据种群和后期
的种群中因个体的适应度相差不大而导致种群停止进化N赌轮选择方式就会使每一个个体
都获得复制一份的机会K体现不出好的个体的竞争力K无法实现遗传算法的优胜劣汰的原
则à鉴于此K这里用一种基于种群的按个体适应度大小排序的选择算法来代替赌轮选择方
法à其过程描述如下M
����gjstuIJ��R将种群中的个体按适应度大小进行排序NS
����xijmf 种群还没有扫描完
����ep R排在前面的个体复制两份N中间的复制一份N后面的不复制NS择优交叉在解决过早收敛问题时K通常习惯于采用限制优良个体的竞争力I高适应度
个体的复制份数J的方法à这样无疑会降低算法的进化速度K增大算法的时间复杂度K降低
算法的性能à由于种群的基因多样性可以减小陷入局优解的可能K而加快种群进化速度又
可以提高算法的整体性能à为了解决这一对矛盾K尝试一种在不破坏种群的基因多样性的
前提下加快种群的进化速度的方法K这一方法描述如下M在随机选择出父本和母本以后K按照交叉方法I单点交叉Ð多点交叉和一致交叉J进行o次交叉K产生�o个个体K再从这�o
����

个个体中挑选出最优的两个个体加入新的种群中à这样既保存了父本和母本的基因K又在
进化的过程中大大地提高了种群中个体的平均性能à基于以上的分析K改进的遗传算法一描述如下MI�J在初始种群中K对所有的个体按其适应度大小进行排序K然后计算个体的支持度
和置信度NI�J按一定的比例复制I即将当前种群中适应度最高的两个个体结构完整地复制到待
配种群中JNI�J按个体所处的位置确定其变异概率并变异N按优良个体复制�份K劣质个体不复
制的原则复制个体NI�J从复制组中随机选择两个个体K对这两个个体进行多次交叉K从所得的结果中选
择一个最优个体存入新种群NI�J若满足结束条件K则停止K不然K跳转第I�J步K直至找到所有符合条件的规则à该算法的优点是在各代的每一次演化过程中K子代总是保留了父代中最好的个体K以
在�高适应度模式为祖先的家族方向�搜索出更好的样本K从而保证最终可以搜索到全局最
优解à
�������改进的遗传算法二
改进的遗传算法二的步骤如下MI�J划分寻优空间à字符串中表示各个变量yj 的子字符串的最高位CojjI最左边J可以
是�或�I用c表示K下同Jà据此存在一种划分K可以把字符串划分成对等的两个子空间à假设有n个变量K则存在n个这种划分方式K可以形成n对子空间K用集合表示为
Bcj � RT}Cojj �cSK��j��K�K�KnNc��K�为划分区间K在此将个体依适应度值降序排列为
T��KT��KT��K�KT�oqK��gI�IT�jJJ1�gI�IT�j��JJKj��K�K�K�Koq����I�J设计空间退化à在演化到某一代时K如果适应值最高的前oq� 个Ioq� 取群体规模
的一个事先确定的比例K这里取���oqJ个体都位于同一字符串子空间I如BclJ内M
T�k ��BclK��j��K�K�Koq�Nc��或�
可以认为最优点以很大概率落入Bcl 中K以此作为下一代的寻优空间à对应变量为
yj��PyMjKyVjQ j-�l
Py�Mj Ky�Vj Qj���
� l
Py�Mj Ky�Vj Q�PyMlKyVlQ c��
Py�Ml Ky�Vl Qc���
� �Kynl �
��IyMl �yVl
�
�
�J
I����J
����由于在该空间内表示第j个变量的子字符串T�j�CojjCoj��j �C�j 中最高位和标准遗传算
法中的最高位一样K为提高编码效率K提高变量表达精度K同时保证各基因位按模式定理
解释时含义不变K将T�j 中的各位基因位从左边第二位Coj��j 开始K依次左移一位M
Ck��j r�CkjK��k�oj��Koj��K�K�而最后一位由随机数填充à为了保护最优个体K使其在区间退化时对应变量不变K最优个
����

体的最后位与移动前的首位一致à由于设计空间的不断退化K每个变量的 串 长oj 无 需 太
长K取�Y�位即可K不影响精度àI�J寻优空间的移动à如果当前最优解的某个分量yl 处在当前设计空间的边界K该变
量对应的子串的各位相同K均为�或�K则认为最优解有可能在当前寻优区间以外à此时K在该分量方向移动寻优空间K以避免寻优空间缩减而导致失去最优解à可以取移动距离为
�elKel 为沿yl 方向相邻两个离散点间的距离M
el �yVl �yMl�ol ��
I����J
����移动方法是调整边界M
PyMjKyVjQ�PyMl ��elKyVl ��elQ��c��PyMl ��elKyVl ��elQ��c���
� �I����J
然后改变对应子串K改变方法是把该子串作为二进制数K当c��时减�K反之加�à这样操
作保证了处在移动前后两个空间的重叠部分的个体处在设计空间的同一位置上à当有进位
或借位发生时K说明该点将被移出当前寻优空间K略去进位或借位K就会落入新移入的那
部分寻优空间内K可以理解为随机产生的新个体à
�������改进的遗传算法三
标准遗传算法是具有�生成�检测�的迭代过程的搜索算法à遗传算法采用一种群体搜
索策略和群体中个体之间的信息交换Ð搜索K不依赖于梯度信息à但标准遗传算法存在一
些不足K下面是标准遗传算法中存在的主要问题及解决方案à对早熟收敛和后期搜索迟钝的解决方案M有条件的最佳保留机制N采用遗传�灾变算
法N采用适应度比例机制和个体浓度选择机制的加权和N引入主群和属群的概念N适应度
函数动态定标N多种群并行进化及自适应调整控制参数相结合的自适应并行遗传算法K对
重要参数的选择采用自适应变化而非固定不变à采用的具体方法如下MI�J交叉和变异算子的改进和协调采用à
� 将进化过程划分为渐进和突变两个不同阶段N
� 采用动态变异N
� 运用正交设计或均匀设计方法设计新的交叉和变异算子àI�J采用与局部搜索算法相结合的混合遗传算法K解决局部搜索能力差的问题àI�J采用有条件的替代父代的方法K解决单一的群体更新方式难以兼顾多样性和收敛
性的问题àI�J收敛速度慢的解决方法M
� 产生好的初始群体N
� 利用小生境技术N
� 使用移民技术N
� 采用自适应算子N
� 采用与局部搜索算法相结合的混合遗传算法N
� 对算法的参数编码采用动态模糊控制N����
� 进行未成熟收敛判断à遗传算法中包含如下�个基本要素M参数编码Ð初始群体的设定Ð适应度函数的设计Ð
操作设计和控制参数设定à这�个要素构成遗传算法的核心内容à接下来将从初始群体产
生Ð选择算子的改进Ð遗传算法重要参数的选择Ð群体更新方式Ð适应度函数的选取等几
个方面对标准遗传算法进行改进à
��初始群体的产生
初始群体的特性对计算结果和计算效率均有重要影响à要实现全局最优解K初始群体
在解空间中应尽量分散à标准遗传算法是按预定或随机方法产生一组初始解群体K这样可
能导致初始解群体在 解 空 间 分 布 不 均 匀K从 而 影 响 算 法 的 性 能à要 得 到 一 个 好 的 初 始 群
体K可以将一些实验设计方法K如均匀设计或正交设计与遗传算法相结合à其原理为M首
先根据所给出的问题构造均匀数组或正交数组K然后执行如下算法产生初始群体MI�J将解空间划分为T个子空间NI�J量化每个子空间K运用均匀数组或正交数组选择N 个染色体NI�J从N�T个染色体中K选择适应度函数最大的O 个作为初始群体à这样可保证初始群体在解空间均匀分布à另外K初始群体的各个个体之间应保持一定的距离K并定义相同长度的以某一常数为
基的两个字符串中对应位不同的数量为两者间的广义海明距离à要求入选群体的所有个体
之间的广义海明距离必须大于或等于某个设定值à初始群体采用这种方法产生能保证随机
产生的各个个体间有较明显的差别K使它们能均匀分布在解空间中K从而增加获取全局最
优解的可能à
��选择算子的改进
在标准遗传算法中K常 根 据 个 体 的 适 应 度 大 小 采 用�赌 轮 选 择�策 略à该 策 略 虽 然 简
单K但容易引起�早熟收敛�和�搜索迟钝�问题à有效的解决方法是采用有条件的最佳保留
策略K即有条件地将最 佳 个 体 直 接 传 递 到 下 一 代 或 至 少 等 同 于 前 一 代K这 样 能 有 效 防 止
�早熟收敛�à也可以使用遗传�灾变算法K即在遗传算法的基础上K模拟自然界的灾变现象K提高
遗传算法的性能à当判断连续数代最佳染色体没有任何进化K或者各个染色体已过于近似
时K即可实施灾变à灾变的方法很多K可以突然增大变异概率或对不同个体实施不同规模
的突变K以产生不同数目的大量后代等à用灾变的方法可以打破原有基因的垄断优势K增
加基因的多样性K创造有生命力的新个体à
��遗传算法重要参数的选择
遗传算法中需要选择的参数主要有M染色体长度mÐ群体规模oÐ交叉概率Qd 和变异
概率Qn 等K这些参数对遗传算法的性能影响也很大à染色体长度的选择对二进制编码来
说取决于特定问题的精度K存在定长和变长两种方式à群体规模通常取��Y���à一般来
说K求解问题的非线性越大Ko选择就应该越大à交叉操作和变异操作是遗传算法中两个
起重要作用的算子à通过交叉和变异K一对相互配合又相互竞争的算子使其搜索能力得到
飞速提高à交叉操作的作用是组合交叉两个个体中有价值的信息产生新的后代K它在群体
进化期间大大加快了搜索速度N变异操作的作用是保持群体中基因的多样性K偶然Ð次要
的I交叉率取很小J起辅助作用à在遗传算法的计算过程中K根据个体的具体情况K自适应
����

地改变QdÐQn 的大小K将进化过程分为渐进和突变两个不同阶段M渐进阶段强交叉K弱变
异K强化优势型选择算子N突变阶段弱交叉K强变异K弱化优势型选择算子à这样对提高算
法的计算速度和效率是有利的à自适应参数调整方案如下M
��gnby��g I����J式中Kgnby为某代中最优个体适应度K�g为此代平均适应度à
��适应度函数的设计
遗传算法中采用适应度函 数 值 来 评 估 个 体 性 能 并 指 导 搜 索K基 本 不 用 搜 索 空 间 的 知
识K因此K适应度函数的选取相当重要à性能不良的适应度函数往往会导致�骗�问题à适
应度函数的选取标 准 是M规 范 性I单 值Ð连 续Ð严 格 单 调JÐ合 理 性I计 算 量 小JÐ通 用 性à
WbtjmjftSfusjejt提出在解约束优化问题时采用变化的适应度函数的方案à将问题的约束
以动态方式合并到适应度函数中K即形成一个具有变化的惩罚项的适应度函数K用来指导
遗传搜索à在那些具有许多约束条件而导致产生一个复杂搜索超平面的问题中K该方案能
明显地以较大的概率找到全局最优解à
��进化过程中动态调整子代个体
遗传算法要求在进行过程中保持群体规模不变à但为了防止早熟收敛K在进化过程可
对群体中的个体进行调整K包括引入移民算子Ð过滤相似个体Ð动态补充子代新个体等à移民算子是避免早熟的一种好方法à在移民的过程中不仅可以加速淘汰差的个体K而
且可以增加解的多样性à所谓的移民机制K就是在每一代进化过程中以一定的淘汰率I一
般取���Y���J将最差个体淘汰K然后用产生的新个体代替à为了加快收敛速度K可采用滤除相似个体的操作K减少基因的单一性à删除相似个体
的过滤操作为M对子代个体按适应度排序K依次计算适应度差值小于门限efmub的相似个
体间的广义海明距离I相同长度的以b为基的两个字符串中对应位不相同的数量称为两者
间的广义海明距离Jà如果同时满足适应度差值小于门限efmubK广义海明距离小于门限eK就滤除其中适应度较小的个体àefmubÐe应适当选取K以提高群体的多样性à过滤操作后K需要引入新个体à从实验测试中发现K如果采用直接随机生成的方式产生新个体K适应度
值都太低K而且对算法的全局搜索性能增加并不显著I例如K对于复杂的多峰函数很难跳
出局部最优点Jà因此K可使用从优秀的父代个体中变异产生的方法à该方法将父代中适应
度较高的n个个体随机进行若干次变异K产生出新个体K加入子代对个体à这些新个体继
承了父代较优个体的模式片断K并产生新的模式K易于与其他个体结合生成新的较优子代
个体à而且增加的新个体的个数与过滤操作删除的数量有关à如果群体基因单一性增加K则被滤除的相似个体数目增加K补充的新个体数目随之增加N反之K则只少量滤除相似个
体K甚至不滤除K补充的新个体数目也随之减少à这样K就能动态解决群体由于缺乏多样
性而陷入局部解的问题à
��小范围竞争择优的交叉Ð变异操作
从加快收敛速度Ð全局搜索性能两方面考虑K受自然界中家庭内兄弟间竞争现象的启
发K加入小范围竞争Ð择优操作à其方法是K将某一对父母BÐC进行o次I�Y�次J交叉Ð变异操作K生成�o个不同的个体K选出其中一个最高适应度的个体K送入子代对个体中à反复随机选择父母对K直到生成设定个数的子代个体为止à这种方法实质是在相同父母的
����

情况下K预先加入兄弟间的小范围的竞争择优机制à另一方面K在标准遗传算法中K一对
父母YÐZ经遗传算法操作后产生一对子代个体yz�Ðyz�Ðy�zÐy�zK随后都被放入子代对
个体K当进行新一轮遗传操作时Kyz�Ðy�z可能作为新的父母对进行交叉配对K即�近亲繁
殖�à而加入小范围竞争择优的交叉Ð变异操作K减少了在下一代中出现这一问题的几率à
�������改进的遗传算法四
改进的遗传算法四是指从 适 应 度 值 标 定 和 群 体 多 样 化 两 方 面 考 虑K提 出 改 进 的 遗 传
算法à
��适应度值标定
初始群体中可能存在特殊个体的适应度值超常I如很大Jà为了防止其统治整个群体并
误导群体的发展方向而使算法收敛于局部最优解K需限制其繁殖à在计算临近结束K遗传
算法逐渐收敛时K由于群体中个体适应度值比较接近K继续优化选择较为困难K造成在最
优解附近左右摇摆à此时应将个体适应度值加以放大K以提高选择能力K这就是适应度值
的标定à针对适应度值标定问题提出以下计算公式M
g�� �gnby�gnjo��
Ig�}gnjo}J I����J
式中Kg�为标定后的适应度值Kg为原适应度值Kgnby为适应度函数值的一个上界Kgnjo为
适应度函数值的一个下界K�为开区间I�K�J内的一个正实数à若gnby未知K可用当前代或目前为止的群体中的最大值来代替à若gnjo未知K可用当前
代或目前为止群体中的最小值来代替à取�的目的是防止分母为零和增加遗传算法的随机
性àb�gnjob�是为了保证标定后的适应度值不出现负数à由图���可见K若gnby与gnjo差值越大K则角度�越小K即标定后的适应度值变化范围
小K防止超常个体统治整个群体N反之则越大K标定后的适应度值变化范围增大K拉开群
体中个体之间的差距K避免算法在最优解附近摆动现象发生à这样就可以根据群体适应度
值放大或缩小K变更选择压力à
图�����适应度值标定
��群体多样化
遗传算法在求解具有多个极值点的函数时K存在一个致命的弱点���早熟K即收敛到
局部最优解而非全局最优解K这也是遗传算法最难解决的一个问题à遗传算法的早熟原因
是交叉算子在搜索过程中存在着严重的成熟化效应à在起搜索作用的同时K不可避免的是
群体多样化逐渐趋于零K从而逐渐减少了搜索范围K引起过早收敛à
����

为了解决这一问题K人们研究出很多方法M元算法Ð自适应遗传算法IBHBJÐ改进的
自适应遗传算法INBHBJ等à可见K避免遗传算法早熟的关键是使群体呈多样化发展K也
就是应使搜索点分布在各极值点所在的区域K如图���所示的yjà
图�����多极值函数
简单遗传算法在进行优化计算时不是全局收敛à只有保证最优个体复制到下一代K才
能保证其收敛性K也就是说K尽管遗传算法的基本作用对象是多个可行解且隐并行操作K仍然需要对其进行适当改进à为了增加群体的多样性K有效地避免早熟现象发生K引入了
相似度的概念à定义�����在遗传算法进行选择运算前K对群体中每两个个体逐位比较à如果两个个
体中在相对应的位置上存在着相同的字符I基因JK则将相同字符数量定义为相似度Sà设置值U �适应度平均值K在群体中取大于U的个体进行个体相似程度判断à相似
度低则表示这两个个体相似性差K当相似度值S超过个体长度ML�时K即认为这两个个
体相似K如�������和�������的相似 度 值S��KM��KS`�ML�K所 以 可 以 认 为 这 两
个个体具有相似性à相似性的判断实际上是确定群 体 中 个 体 是 否 含 有 相 同 模 式à剔 除 相
似个体K选择不同模式的个体组成新的群体K可 以 增 加 群 体 的 多 样 性K尤 其 是 在 计 算 初
期K经过相似性判断后K能够有效避免早熟问 题 的 产 生à由 此 得 出 的 改 进 遗 传 算 法 的 步
骤如下MI�J个体按适应度值大小排序àI�J求平均适应度值K以此作为阈值K选择适应度值大于平均适应度值的个体àI�J判断相似程度K以最高适应度值为模板K去除相似个体àI�J重复I�JK逐次以适应度值高的个体为模板K选择不同模板的个体组成群体àI�J判断是否达到群体规模à如果是K则进行下一步交叉Ð变异等遗传操作N否则重复
I�Jà如果不能得到足够的群体规模K则去除的个体按适应度值大小顺序顺次补足群体所
缺数量àI�J判断是否满足结束要求à如果是K则结束K否则转到I�Jà为了避免过早陷入局部最优解K必须 拓 宽 搜 索 空 间K增 加 群 体 多 样 性à取 平 均 适 应
度值作为阈值并以高于阈值的个体作为模板进行选择K有效鼓励高适应度 值 个 体 的 竞 争
力à这样的处理K主要是为了增加群体的多样 性 和 高 适 应 度 值 的 个 体 的 主 导 地 位K避 免
统一模式统治群体K从而误导搜索方向à当接 近 最 优 解 时K由 上 面 的 运 算 步 骤 可 以 尽 快
收敛到最优解à这 样 既 不 增 加 群 体 规 模K避 免 运 算 时 间 过 长K还 能 保 证 收 敛 到 全 局 最
优解à图����所示为改进遗传算法的程序流程图à
����

图������改进遗传算法的程序流程图
�����多目标优化中的遗传算法
前面讨论的都是单目标在给定区域上的最优化问题K而工程中经常遇到在多准则或多
目标下设计和决策的问题K如果这些目标的改善是相互抵触的K则需要找到满足这些目标
的最佳设计方案à利用遗传算法可以解决多目标优化问题à
�������多目标优化的概念
解决含多目标 和 多 约 束 的 优 化 问 题 称 为 多 目 标 优 化INvmuj�pcfdujwfPk jnj{bujpoq J问
题à在实际应用中K工程优化问题大多数是多目标优化问题K有时需要使多个目标在给定
区域上都可能地达到最优的问题K目标之间一般都是互相冲突的à例如投资问题K一般我
们都是希望所投入的资金量最少K风险最小K并且所获得的收益最大à这种多于一个的数
����

值目标的最优化问题就是多目标优化问题à多目标优化问题一般的数学模型可描述为
W�njo gIyJ� Pg�IyJKg�IyJK�KgoIyJQU
t�u� y��Y
YT�S�
�
�n
I����J
式中KW�njo表示向量极小化K即向量目标函数gIyJ�Pg�IyJKg�IyJK�KgoIyJQU 中的
各个子目标函数都尽可能地达到极小化à下面先介绍多目标优化中最优解和Qbsfup最优解IQbsfupPujnbmTpmvujpoq J的定义à定义�����设YT�Sn 是多目标优化模型的约束集KgIyJ��So 是多目标优化时的向量
目标函数K有y���YKy���Yà若
glIy�J0�glIy�JK��a�l��K�K�Ko I����J
并且
glIy�J0�glIy�JK���l��K�K�Ko I����J
则称解y� 比解y� 优越à
定义�����设YT�Sn 是多目标优化模型的约束集KgIyJ��So 是多目标优化时的向量
目标函数K若有解y���YK并且y� 比Y中的所有其他解都优越K则称解y� 是多目标优化
模型的最优解à由定义���可知K解y� 使得所有的gIyjJIj��K�K�KoJ都达到最优I如图����所
示Jà但实际应用中一般不存在这样的解à定义�����设YT�Sn 是多目标优化模型的约束集KgIyJ��So 是多目标优化时的向量
目标函数K若有解y���YK并且不存在比y� 更优越的解yK则称y� 是多目标最优化模型的
Qbsfup最优解à由定义���可知K多目标优化问题的Qbsfup最优解只是问题的一个可以接受的�非劣
解�K并且一般多目标优化实际问题都存在多个Qbsfup最优解I如图����所示Jà
图������多目标优化问题的最优解 图������多目标优化问题的Qbsfup最优解
�������多目标优化问题的遗传算法
对于求解多目标优化问题的Qbsfup最优解K目前已有多种基于遗传算法的求解方法à下面介绍五种常用的方法à
����

��权重系数变换法
对于一个多目标优化问题K若给其每个子目标函数gIyjJIj��K�K�KoJ赋 予 权 重
xjIj��K�K�KoJK其中xj 为相应的gIyjJ在多目标优化问题中的重要程度K则各个子目
标函数gIyjJ的线性加权和表示为
v���o
j��xjðgjIyJ I����J
����若将v作为多目标优化问题的评价函数K则多目标优化问题就可转化为单目标优化问
题K即可以利用单目标优化的遗传算法求解多目标优化问题à
��并列选择法
并列选择法的基本思想是K先将群体中的全部个体按子目标函数的数目均等地划分为
一些子群体K对每个子群体分配一个子目标函数K各个子目标函数在相应的子群体中独立
地进行选择运算K各自选择出一些适应度高的个体组成一个新的子群体K然后再将所有这
些新生成的子群体合并成一个完整的群体K在这个群体中进行交叉和变异运算K从而生成
下一代的完整群体K如此不断地进行�分割�并列选择�合并�操作K最终可求出多目标优
化问题的Qbsfup最优解à图����所示为多目标优化问题的并列选择法的示意图à
图������并列选择法的示意图
��排列选择法
排列选择法的基本思想是K基于Qbsfup最优个体IQbsfup最优个体是指群体中的这样
一个或一些个体K群体中的其他个体都不比它或它们更优越JK对群体中的各个个体进行
排序K依据这个排列次序来进行进化过程中的选择运算K从而使得排在前面的Qbsfup最优
个体将有更多的机会遗传到下一代群体中à如此这样经过一定代数的循环之后K最终就可
求出多目标最优化问题的Qbsfup最优解à
��共享函数法
求解多目标最优化问题时K一般希望所得到的解能够尽可能地分散在整个Qbsfup最优
解集合内K而不是集中在其 Qbsfup最优解集合内的某一个较小的区域 上à为 达 到 这 个 要
求K可以利用小生境遗 传 算 法 的 技 术 来 求 解 多 目 标 最 优 化 问 题K这 种 方 法 称 为 共 享 函 数
ITibsjo Gvodujpoh J法K它将共享函数的概念引入到求解多目标最优化问题的遗传算法中à
����

算法对相同个体或类似个体的数量加以限制K以便能够产生出种类较多的不同的最优解à对于一个个体YK在它的附近还存在有多少种Ð多大程度相似的个体K是可以度量的K这
种度量值称为小生境数à小生境数的计算方法定义为
nY ���Z0�otPeIYKZJQ I����J
式中KtIeJ为共享函数K它是个体之间距离e的单调递减函数àeIYKZJ可以定义为个体
YKZ 之间的海明距离à在计算出各个个体的小生境数之后K可以使小生境数较小的个体能够有更多的机会被
选中K遗传到下一代群体中K即相似程度较小的个体能够有更多的机会被遗传到下一代群
体中K这样就增加了群体的多样性K也增加了解的多样性à
��混合法
混合法的基本思想是K选择算子的主体使用并列选择法K然后通过引入保留最佳个体
和共享函数的思想来弥补只使用并列选择法的不足之处à算法的主要过程为MI�J并列选择过程à按所求多目标优化问题的子目标函数的个数K将整个群体均等地
划分成一些子群体K各个子目标函数在相应的子群体中产生其下一代子群体àI�J保留Qbsfup最优个体过程à对于子群体中的Qbsfup最优个体K不让其参与个体的
交叉运算和变异运算K而是将这个或这些Qbsfup最优个体直接保留到下一代子群体中àI�J共享函数处理过程à若所得到的Qbsfup最优个体的数量已超过规定的群体规模K
则需要利用共享函数的处理方法来对这些Qbsfup最优个体进行挑选K以形成规定规模的新
一代群体à
����

书书书
ðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀ
ðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀ
�
��
���第三章��遗传算法的理论基础��
遗传算法有效性的理论依据为模式定理和积木块假设à模式定理保证了较优的
模式I遗传算法的较优解J的 样 本 呈 指 数 级 增 长K从 而 满 足 了 寻 找 最 优 解 的 必 要 条
件K即遗传算法存在着寻找到全局最优解的可能性à而积木块假设指出K遗传算法
具备寻找到全局最优解的能力K即具有低阶Ð短距Ð高平均适应度的模式I积木块J在遗传算子作用下K相互结合K能生成高阶Ð长距Ð高平均适应度的模式K最终生成
全局最优解àIpmmboe的模式定理通过计算有用相似性K即模式IQbuufsoJK奠定了
遗传算法的数学基础à该定理是遗传算法的主要定理K在一定程度上解释了遗传算
法的机理Ð数学特性以及很强的计算能力等特点à
�����模 式 定 理
不失一般性K本节以二进制串作为编码方式来讨论模式定理IQbuufsoUifpsfnJà定义�����基于三值字符集R�K�KH�S所产生的能描述具有某些结构相似性的�Ð�字
符串集的字符串称作模式à以长度为�的串为例K模式H�����描述了在位置�Ð�Ð�Ð�具有形式������的所有字
符串K即I�����K�����Jà由此可以看出K模式的概念为我们提供了一种简洁的用于描述
在某些位置上具有结构相似性的�Ð�字符串集合的方法à引入模式后K我们看到一个串实际上隐含着多个模式I长度为o的串隐含着�o 个模
式JK一个模式可以隐含在多个串中K不同的串之间通过模式而相互联系à遗传算法中串
的运算实质上是模式的运算à因此K通过分析模式在遗传操作下的变化K就可以了解什么
性质被延续K什么性质被丢弃K从而把握遗传算法的实质K这正是模式定理所揭示的内容à定义�����模式 I 中 确 定 位 置 的 个 数 称 作 该 模 式 的 阶 数K记 作pIIJà比 如K模 式
���H��H�的阶数为�K而模式�H� H� H� H� H�的阶数为�à显然K一个模式的阶数越高K其样本数就越少K因而确定性越高à定义�����模式I 中第一个确定位置和最后一个确定位置之间的距离称作该模式的
定义距K记作�IIJà比如K模式���H��H�的定义距为�K而模式�H� H� H� H� H�的定义距
为�à模式的阶数和定义距描述了模式的基本性质à下面通过分析遗传算法的三种基本遗传操作对模式的作用来讨论模式定理à令BIuJ
表示第u代中串的群体K以BkIuJIk��K�K�KoJ表示第u代中第k个个体串à
��选择算子
在选择算子作用下K与某一模式所匹配的样本数的增减依赖于模式的平均适应度K与
����

群体平均适应度之比K平均适应度高于群体平均适应度的将呈指数级增长N而平均适应度
低于群体平均适应度的模式将呈指数级减少à其推导如下M设在第u代种群BIuJ中模式所能匹配的样本数为nK记为nIIKuJà在选择中K一个
位串Bk 以概率Qk�gkL��jgj 被选中并进行复制K其中gk 是个体BkIuJ的适应度à假设一
代中群体大小为oK且个体两两互不相同K则模式I 在第u��代中的样本数为
nIIKu��J�nIIKuJogIIJ
��jgj
I���J
式中KgIIJ是 在u时 刻 对 应 于 模 式 的 位 串 的 平 均 适 应 度à令 群 体 平 均 适 应 度 为�g �
��jgjLoK则有
nIIKu��J�nIIKuJgIIJ�g
I���J
现在K假定模式I 的 平 均 适 应 度 高 于 群 体 平 均 适 应 度K且 设 高 出 部 分 为d�gKd为 常 数K则有
nIIKu��J�nIIKuJ�g�d�g�g
� I��dJnIIKuJ I���J
假设从u��开始Kd保持为常值K则有
nIIKu��J�nIIK�JI��dJ I���J
��交叉算子
然而仅有选择操作K并不能产生新的个体K即不能对搜索空间中新的区域进行搜索K因此引入了交叉操作à下面讨论模式在交叉算子作用下所发生的变化K这里我们只考虑单
点交叉的情况à模式I 只有当交叉点落在定义距之外才能生存à在简单交叉I单点交叉J下I 的生存
概率Qt����IIJLIu��Jà例如K一个长度为�的串以及隐含其中的两个模式为
����B�����������I��H��H�H�H��
����I��H�H�H���H�我们注意到模式I� 的定义长度为�K那么交叉点在�����个位置随机产生时KI�
遭破坏的概率Qe��II�JLIn��J��L�K即生存概率为�L�à而交叉本身也是以一定的概率Qd 发生的K所以模式I 的生存概率为
Qt���QdQe���Qdð�II�Jn��
I���J
����现在我们考虑交叉发生在定义距内K模式I 不被破坏的可能性à在前面的例子中K若
与B交叉的串在位置�Ð�上有一位与B相同K则I� 将被保留à考虑到这一点K式I���J给出的生存概率只是一个下界K即有
Qt1���Qdð�IIJ
n��I���J
����

����可见K模式在交叉算子作用下定义距短的模式将增多à
��变异算子
假定串的某一位置发生改变的概率为QnK则该位置不变的概率为��QnK而模式I在变异算子作用下若要不受破坏K则其中所有的确定位置I���或���的位J必须保持不变à因此模式I 保持不变的概率为I��QnJp
IIJK其中pIIJ为模式 I 的阶数à当Qn���时K模式I 在变异算子作用下的生存概率为
Qt� I��QnJpIIJ*���pIIJQn I���J
����综上所述K模式I 在遗传算子选择Ð交叉和变异的共同作用下K其子代的样本数为
nIIKu��J1�nIIKuJgIIJ�g
��Qd�IIJm�P Q� P��pIIJQnQ I���J
式I���J忽略了极小项Qdð�IIJLIm��J�pIIJðQnà通过式I���JK我们就可以给出模
式定理à定理���I模式定理J��在遗传算子选择Ð交叉和变异的作用下K具有阶数低Ð长度短Ð
平均适应度高于群体平均适应度的模式在子代中将以指数级增长à统计学的研究表明M在随机搜索中K要获得最优的可行解K则必须保证较优解的样本
呈指数级增长K而模式定理保证了较优的模式I遗传算法的较优解J的样本呈指数级增长K从而给出了遗传算法的理论基础à另外K由于遗传算法总能以一定的概率遍历到解空间的
每一个部分K因此在选择算子的条件下总能得到问题的最优解à
�����积 木 块 假 设
由模式定理可知K具有阶数低Ð长度短Ð平均适应度高于群体平均适应度的模式在子
代中将以指数级增长à这类模式在遗传算法中非常重要K在这一节给这些模式一个特别的
名字���积木块ICvjmejo Cmpdlh Jà定义�����阶数低Ð长度短和适应度高的模式称为积木块à假设���I积木块假设ICvjmejo CmpdlIzqpuiftjth J��阶数低Ð长度短Ð适应度高的模式
I积木块J在遗传算子作用下K相互结合K能生成阶数高Ð长度长Ð适应度高的模式K可最
终生成全局最优解à与积木块一样K一些好的模式在遗传算法操作下相互拼搭Ð结合K产生适应度更高的
串K从而找到更优的可行解K这正是积木块假设所揭示的内容à下面用图来说明遗传算法
中积木块生成最优解的过程à假设每代种群规模为�KTj 表示每代群体中第j个个体K问题的最优解由积木块BBÐ
CCÐDD组成à图���所示为初始种群K个体T�ÐT� 含有BBK个体T�ÐT� 含有CCK个体
T� 含有DDà当种群进化一代后K第二代种群如图���所示K个体T�ÐT�ÐT� 含有 BBK个体T�Ð
T� 含有CCK个体T�ÐT� 含有DDà个体T� 含有BBÐDDK个体T� 含有BBÐCCà当种群进
化到第二代后K第三代种群如图���所示K在群体中K出现了含有积木块BBÐCCÐDD的
个体T�K个体T� 就是问题的最优解à
����

图�����初始种群
图�����第二代种群
图�����第三代种群
模式定理保证了较优的模式I遗传算法的较优解J样本数呈指数增长K从而满足了寻
找最优解的必要条件K即遗传算法存在着寻找到全局最优解的可能性à而这里的积木块假
设则指出K遗传算法具备找到全局最优解的能力K即积木块在遗传算子作用下K能生成阶
数高Ð长度长Ð适应度高的模式K最终生成全局最优解à
�����欺 骗 问 题
在遗传算法中K将所有妨碍适应度高的个体的生成从而影响遗传算法正常工作的问题
统称为欺骗问题IEfdfujwfQspcmfnq Jà遗传算法运行过程具有将阶数低Ð长度短Ð平均适
应度高于群体平均适应度的模式重组成高阶 模 式 的 趋 势à如 果 在 低 阶 模 式 中 包 含 了 最 优
����

解K则遗传算法就可能找出这个最优解来à但是低阶Ð高适应度的模式可能没有包含最优
串的具体取值K于是遗传算法就会收敛到一个次优的结果à下面给出有关欺骗性的概念à定义���I竞争模式J��若模式I 和I�中H� 的位置完全一致K但任一确定位的编码均
不同K则称I 和I�互为竞争模式à定义���I欺骗性J��假设gIYJ的最大值对应的Y的集合为YH�KI 为一包含YH� 的n
阶模式KI 的竞争模式为I�K而且gIIJ`�gII�JK则g为n 阶欺骗à定义���I最小欺骗性J��在欺骗问题中K为了造成骗局所需设置的最小的问题规模I即
阶数J称为最小欺骗性 à其主要思想是在最大程度上违背积木块假设K是优于由平均的短
积木块生成局部最优点的方法à这里的�最小�是指问题规模采用两位à下面是一个由�个
阶数为�Ð有�个确定位置的模式集M
����H�H�H��H�H�H�H�H��H���gI��J
����H�H�H��H�H�H�H�H��H���gI��J
����H�H�H��H�H�H�H�H��H���gI��J
����H�H�H��H�H�H�H�H��H���gI��J为简单I达到最小J起见K我们不考虑 H� 位K令gI��J为全局最优解K为了欺骗遗传算
法KHpmecfsh设计了两种情况M
���� zqf�U MgI��J`�gI��J
���� zqf�U MgI��J`�gI��J满足gI�H�J`�gI�H�J或者gIH��J`�gIH��Jà
按 Ipmmboe的模式定理K最小欺骗问题将给遗传算法造成很大困难K遗传算法甚至找
不到最 优 解à但 Hpmecfsh实 验 的 结 果 却 是M zqf�U 问 题 基 本 上 都 很 快 找 到 了 最 优 解K
zqf�U 问题找到和找不到两种情况都可能出现à遗传算法中欺骗性的产生往往与适应度函数确定和调整Ð基因编码方式选取相关à采
用合适的编码方式或调整适应度函数K就可能化解和避免欺骗问题à下面以合适的编码方
式为例来说明à一个�位编码的适应度函数为
gIyJ������y��y����y
�
����采用二进制编码K计算个体的函数值I见表���JK则存在第二类欺骗问题à采用格雷
编码K计算个体的函数值I见表���JK则第二类欺骗问题化解为第一类欺骗问题à表�����二进制编码及函数值
编码 对应整数解 函数值
�� � �
�� � �
�� � �
�� � �
表�����格雷编码及函数值
编码 对应整数解 函数值
�� � �
�� � �
�� � �
�� � �
����采用适当的适应度函数调整方法K设
����

hIyJ�hI��J����KhI��J��KhI��J�hI��J�������如果适应度函数gIyJ�hIyJK则
gI�H�J�gI��J�gI��J
� �����
gI�H�J�gI��J�gI��J
� ���
故存在欺骗问题à如果用适应度函数的调整方法KgIyJ�mchIyJK则
gI��J��KgI��J��KgI��J�gI��J��得gI�H�J����KgI�H�J��K故不会产生欺骗问题à
�����遗传算法的未成熟收敛问题及其防止
在实际中K很多参数优化问题是多参数和非线性的K且往往还伴随着不可微和参数耦
合等问题à这时用传统的优化方法解决问题K效率很低K有时候甚至根本得不出结果à遗
传算法的高鲁棒性和有效性为解决这类问题提供了一种有效的途径à在实际应用中K遗传算法显示出了顽强的生命力K以其突出的优点越来越受到重视à
但是遗传算法也存在着缺点K在实际应用中也因此出现了一些问题K其中很重要的是遗传
算法未成熟收敛I也称为早熟KQsfnbuvsfDpowfsfodfh K简称QDJ问题à对于遗传算法的
应用K解决未成熟收敛问题是必要的K否则K遗传算法的一些优良性能I例如全局 寻 优 能
力J将无法完全体现出来à
�������遗传算法的未成熟收敛问题
��未成熟收敛现象
未成熟收敛现象主要表现在两个方面MI�J群体中所有的个体都陷于同一极值而停止进化àI�J接近最优解的个体总是被淘汰K进化过程不收敛à未成熟收敛现象是遗传算法中的特有现象K且十分常见à它指的是K当还未达到全局
最优解或满意解时K群 体 中 不 能 再 产 生 性 能 超 过 父 代 的 后 代K群 体 中 的 各 个 个 体 非 常 相
似à未成熟收敛的重要特征是群体中个体结构的多样性急剧减少K这将导致遗传算法的交
叉算子和选择算子不能再产生更有生命力的新个体à遗传算法希望找到最优解或满意解K而不是在找到最优解或满意解之前K整个群体就收敛到一个非优个体K它希望能够保持群
体中个体结构的多样性K从而使搜索能够进行下去à未成熟收敛问题就像其他算法中的局
部极小值I极大值J问题K但它和局部极小值问题有着本质上的不同K未成熟收敛问题并不
一定出现在局部极小点à同时K它的产生是带有随机性的K人们很难预见是否会出现未成
熟收敛问题à
��未成熟收敛产生的主要原因
未成熟收敛产生的主要原因有以下几点MI�J理论上考虑的选择Ð交叉Ð变异操作都是绝对精确的K它们之间相互协调K能搜索
����

到整个解空间K但在具体实现时很难达到这个要求àI�J所求解的问题是遗传算法欺骗问题à当解决的问题对于标准遗传算法来说比较困
难时K遗传算法就会偏离寻优方向K这种问题被称为遗传算法欺骗问题àI�J遗传算法处理的群体是有限的K因而存在随机误差K它主要包括取样误差和选择
误差à取样误差是指所选择的有限群体不能代表整个群体所产生的误差à当表示有效模板
串的数量不充分或所选的串不是相似子集的代表时K遗传算法就会发生上述类似的情况à小群体中的取样误差妨碍模板的正确传播K因而阻碍模板原理所预测的期望性能产生à选
择误差是指不能按期望的概率进行个体选择à对一个染色体来说K在遗传操作中只能产生整数个后代à在有限群体中K模板的样本
不可能以任意精度反映所要求的比例K这是产生取样误差的根本原因K加上随机选择的误
差K就可以导致模板样品数量与理论预测值有很大差别à随着这种偏差的积累K一些有用
的模板将会从群体中消失à遗传学家认为当群体很小时K选择就不会起作用K这时有利的
基因可能被淘汰K有害的基因可能被保留à引起群体结构发生变化的主要因素是随机波动
的���遗传漂移K它也是产生未成熟收敛的一个主要原因à对此可以采用增大群体容量的
方法来减缓遗传漂移K但这样做可能导致算法效率的降低à上述三个方面都有可能产生未成熟收敛现象K即群体中个体的多样性过早地丢失K从
而使算法陷入局部最优点à在遗传算法处理过程的每个环节都有可能导入未成熟收敛的因素à遗传算法未成熟收
敛产生的主要原因是K在迭代过程中K未得到最优解或满意解以前K群体就失去了多样性à具体表现在以下几个方面M
I�J在进化初始阶段K生成了具有很高适应度的个体YàI�J在基于适应度比例的选择下K其他个体被淘汰K大部分个体与Y一致àI�J相同的两个个体进行交叉K从而未能生成新个体àI�J通过变异所生成的个体适应度高但数量少K所以被淘汰的概率很大àI�J群体中的大部分个体都处于与Y一致的状态à
�������未成熟收敛的防止
在分析了未成熟收敛产生的原因后K下面要解决的是如何防止该现象的发生K即如何
维持群体多样性以保证在寻找到最优解或满意解以前K不会发生未成熟收敛现象à解决的
方法有以下几种à
��重新启动法
这是实际应用中最早出现的方法之一à在遗传算法搜索中碰到未成熟收敛问题而不能
继续时K则随机选择一组初始值重新进行遗传算法操作à假设每次执行遗传算法后陷入不
成熟收敛的概率为RI�0�R_��JK那么做o次独立的遗传算法操作后K可避免未成熟收敛
的概率为GIoJ���RoK随着o的增大KGIoJ将趋于�à但是K对于R较大的情况K如果优
化对象很复杂以及每次执行时间都很长K采用该办法显然是不合适的à
��配对策略INbujo Tusbufh jfth J为了维持群体的多样性K可以有目的地选择配对个体à一般情况下K在物种的形成过
程中要考虑配对策略K以防止根本不相似的个体进行配对à因为在生物界K不同种族之间
����

一般是不会杂交的K这是因为它们的基因结构不同K会发生互斥作用K同时杂交后会使种
族失去其优良特性à因此K配对受到限制K即大多数是同种或近种相配K以使一个种族的
优良特性得以保存和发扬à然而K这里所说的匹配策略有不同的目的à其目的是K由不同
的父辈产生的个体试图比其父辈更具有多样性KHpmecfsh的共享函数ITibsjo Gvodujpoh J就是一种间接匹配策略à该策略对生物种ITfdjftq J内的相互匹配或至少对占统治地位的
物种内的相互匹配有一定限制àFtifmnbo提出了一种可以更直接地防止相似个体交配的
方法���防止乱伦机制IJodftuQsfwfoujpoNfdibojtnJà参与交配的个体是随机配对的K但只有当参与配对的个体间的海明距离超过一定阈值时K才允许它们进行交配à最初的阈
值可采用初始群体海明距离的期望平均值K随着迭代过程的发展K阈值可以逐步减小à尽
管Ftifmnbo的方法并不能明显地阻止同辈或相似父辈 之 间 进 行 交 配K但 只 要 个 体 相 似K它就有一定的影响à匹配策略是对具有一定差异的个体进行配对K这在某种程度上可以维
持群体的多样性à但它同时也具有一定的副作用K即交叉操作会使较多的模板遭到破坏K只有较少的共享模板得以保留à
��重组策略ISfdpncjobujpoTusbufjfth J重组策略就是使用 交 叉 算 子à在 某 种 程 度 上K交 叉 操 作 试 图 产 生 与 其 父 辈 不 同 的 个
体K从而使产生的群体更具多样性à能使交叉操作更具有活力的最简单的方法就是K增加
其使用的频率和使用动态改变适应度函数的方法K如共享函数方法à另一种方法是把交叉
点选在个体的具有不同值的位上à只要父辈个体至少有两位不同K所产生的子代个体就会
与其父辈不相同à维持群体多样性的更基本的方法是K使用更具有破坏性的交叉算子K如
均匀交叉算子à该算子试图交叉近一半的不同位K因而保留的模板比单点或两点交叉所保
留的模板要少得多à总之K重组策略主要是从使用频率和交叉点两方面考虑K来维持群体
的多样性à这对采用随机选择配对个体进行交叉操作可能有特定的意义K但对成比例选择
方式K效果则不一定明显à
��替代策略ISfmbdfnfouTusbufq jfth J匹配策略和重组策略分别是在选择Ð交叉阶段K通过某种策略来维持群体的多样性à
而替代策略是确定在选择Ð交叉产生的个体中K选择哪一个个体进入新一代群体àEfKpoh采用排 挤IDspxejohJ模 式K用 新 产 生 的 个 体 去 替 换 父 辈 中 类 似 的 个 体àTtdvebz 和
Xijufmfz也采用类似的方法K他们仅把与父辈各个个体均不相似的新个体添加到群体中à这种替换策略仅从维持群体的多样性出发K存在一定的负面影响K即交叉操作会破坏较多
模板K但这种影响比前两种策略的要少à
�����性 能 评 估
遗传算法的实现涉及到它的五个要素M参数编码Ð初始群体的设定Ð适应度函数的设
计Ð遗传操作设计和控制参数设定K而每个要素又对应不同的环境K存在各种相应的设计
策略和方法à不同的策略和方法决定了各自的遗传算法具有不同的性能或特征à因此K评
估遗传算法的性能对于研究和应用遗传算法是十分重要的à目前K遗传算法的评估指标大多采用适应度值à特别在没有具体要求的情况下K一般
采用各代中最优个体的适应度值和群体的平均适应度值à以此为依据KEfKpoh提出了两
����

个用于 定 量 分 析 遗 传 算 法 的 测 度M离 线 性 能IPgg�mjofQfsgpsnbodfJ测 度 和 在 线 性 能
IPo�mjofQfsgpsnbodfJ测度K得到了两个评估准则à
��在线性能评估准则
定义�����设YfItJ为环境f下策略t的在线性能KgfIuJ为时刻u或第u代中相应于环
境f的目标函数或平均适应度函数K则YfItJ可以表示为
YfItJ��U��
U
u��gfIuJ I���J
式I���J表明K在线性能可以用从第一代到当前的优化进程的平均值来表示à
��离线性能评估准则
定义�����设YH�f ItJ为环境f下策略t的离线性能K则有
YH�f ItJ�
�U��
U
u��gH�f IuJ I����J
式中KgH�f IuJ�cftuRgfI�JKgfI�JK�KgfIuJSà式I����J表明K离线性能是特定时刻或特定代的最佳性能的累积平均à具体地说K在
进化过程中K每进化一代就统计目前为止的各代中的最佳适应度或最佳平均适应度K并计
算对进化代数的平均值à
EfKpoh指出M离线性能用于测量算法的收敛性K在应用时K优化问题的求解可以得到
模拟K在一定的优化进程停止准则下K当前最好的解可以被保存和利用N而在线性能用于
测量算法的动态性能K在应用时K优化问题的求解必须通过真实的实验在线实现K可以迅
速得到较好的优化结果à但是K从遗传算法的运行机理可知K在遗传算子的作用下K群体
的平均适应度呈现增长的趋势K因此K定义���和定义���中的gfIuJ和gH�f IuJ相差不大K它们所反映的性质也基本一样à
下面以最优化方法的收敛速度和收敛准则来讨论遗传算法的性能à一般优化问题可描述为求y�Iy�Ky�K�KyoJUK使gIyJ达到最小I或最大Jà最优化
方法通常采用迭代方法求它的最优解K其基本思想为M给定一个初始点y�K按照某一迭代
规则产生一个点列RyjSK使得当RyjS为有穷点列时K其最后一个点是最优化问题的最优解à当RyjS是无穷点列时K它有极限点K且其极限点是最优化问题的最优解à一个好的优化算
法为M当yj 能稳定地接近全局极小点I或极大点J的邻域时K迅速收敛于yH�K当满足给定
的收敛准则时K迭代终止à假设一算法产生的迭代点列RyjS在某种范数意义下收敛K即
mjnjA����yj�yH��� �� I����J
式中Kyj���yj��jK�j 为步长因子à若存在实数�`��及一个与迭代次数无关的常数r`��K使得
mjnjA��
��yj���yH�����yj�yH���
�r I����J
则称此算法产生的迭代点列RyjS具有r��阶收敛速度I�为迭代步长因子Jà因为��yj���yj��是
��yj�yH���的一个估计K所以在实际中K一般用��yj���yj��代替��yj�yH���K作为迭代
终止判决条件à
����

� 当���Kr`��时K称RyjS具有r线性收敛速度à
� 当�_��_��Kr`��或���Kr��时K称RyjS具有r超线性收敛速度à
� 当���时K称RyjS具有r二阶收敛速度à具有超线性收敛速度和二阶收敛速度的迭代算法收敛比较快à关于算法的终止准则K实际应用中可以用各种不同的方法来确定收敛准则àIjnnfcmbv
提出了下面的终止准则à当��yj��`��和b�gIyjJb�`��时K采用
��yj���yj����yj��
0��或}gIyj��J�gIyjJ}}gIyjJ}
0�� I����J
否则采用
}yj���yj}_��或}gIyj��J�gIyjJ}_�� I����J式中K�为根据实际问题要求精度给出的适当小的正数à
根据以上 Ijnnfcmbv提出的终止准则K实际中可以用各代适应度函数的均值之差来
衡量遗传算法的收敛特性à定义收敛性测量函数为
DfItJ��U��
U
u��
PgfIu��J�gfIuJQ I����J
式中KgfIuJ为时刻u或第u代中相应于环境f的目标函数或平均适应度函数à从优化问题中寻找最优解或最优解组的角度考虑K可以定义部分在线特性M
goItJ��U��
U
u��g�fIuJ I����J
式中Kg�fIuJ为群体中对应于最优解或最优解组的个体适应度的均值à
�����小生境技术和共享函数
Dbwjddijp提出只有在子串的适应度超过父代的情况下K子串才能替代父串进入 下 一
代群体的预选择机制K该 机 制 趋 向 于 替 换 与 其 本 身 相 似 的 个 体K能 够 维 持 群 体 的 分 布 特
性K并且不断地以优秀个体来更新种群K使种群不断被优化à
EfKpoh提出基于排挤的机制K其思想来源于一个有趣的生物现象M在一个有限的生
存空间中K各种不同的生物为了延续生存K必须相互竞争各种有限的生存资源à差别较大
的个体由于生活习性不同而很少竞争à处于平衡状态的大小固定的种群K新生个体将代替
与之相似的旧个体à排挤机制用海明距离来度量个体之间的相似性à排挤机制可以维护当
前种群的多样性à这就是小生境技术à
Hpmecfsh和Sjdibsetpo利用共享函数来度量两个个体的相邻关系和程度à给定个体
hK它的共享函数由它与种群中其他个体的相似程度决定à将h与种群中其他个体逐个比
较K若很相似K则对h的共享函数加一个较大值N否则K就加一个较小值à个体共享度为该
个体与群体内其他个体共享函数值之和K即
Tj���o
k��TIejkJ I����J
����

式中Kejk为个体j和个体k之间的关系亲密程度NT为共享函数NTj 为个体j在群体中的共
享度à个体的适应度的调整公式为
gtIjJ�gIjJTj
I����J
����

书书书
ðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀ
ðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀ
�
��
�
��第四章��遗传算法的基本原理与方法��
遗传算法是一种基于生物进化原理构想出来的搜索最优解的仿生算法K它模拟
基因重组与进化的自然过程K把待解决问题的参数编成二进制码或十进制码I也可
编成其他进制码J即基因K若干基因组成一个染色体I个体JK许多染色体进行类似
于自然选择Ð配对交叉和变异的运算K经过多次重复迭代I即世代遗传J直至得到最
后的优化结果à习惯上K适应度值越大K表示解的质量越好à对于求解最小值问题K可通过变换转为求解最大值问题à遗 传 算 法 以 群 体 为 基 础K不 是 以 单 点 搜 索 为 基
础K能同时从不同点获得多个极 值K因 此 不 易 陷 入 局 部 最 优N遗 传 算 法 是 对 问 题
变量的编码集进 行 操 作K而 不 是 变 量 本 身K有 效 地 避 免 了 对 变 量 的 微 分 操 作 运
算N遗传算法只是利用目标函数来区别群体中的个体的 好 坏 而 不 必 对 其 进 行 过 多
的附加操作à本章将讨论遗传算 法 的 实 现 涉 及 的 六 个 主 要 因 素M参 数 的 编 码K初
始群体的设定K适应度函数的设 计K遗 传 操 作K算 法 控 制 参 数 的 设 定 和 约 束 条 件
的处理à
�����编����码
编码是应用遗传算法时要解决的首要问题K也是设计遗传算法时的一个关键步骤à在
遗传算法执行过程中K对不同的具体问题进行编码K编码的好坏直接影响选择Ð交叉Ð变
异等遗传运算à那么K什么是编码呢?
在遗传算法中如何描述问题的可行解K即把一个问题的可行解从其解空间转换到遗传
算法所能处理的搜索空间的转换方法就称为编码à而由遗传算法解空间向问题空间的转换
称为解码I或称译码KEfdpejohJà遗传算法的编码就是解的遗传表示K它是应用遗传算法求解问题的第一步à传统的二
进制编码是�Ð�字符构成的固定 长 度 串à二 进 制 编 码 的 一 个 缺 点 是 汉 明 悬 崖IIbnnjoDmjgg
hJK就是在某些相邻整数的二进制代码之间有很大的汉明距离K使得遗传算法的交叉和
突变都难以跨越à为克服此问题而提出的格雷码IHsb Dpefz JK在相邻整数之间汉明距离
都为�à然而汉明距离在整数之间的差并非单调增加K引入了另一层次的隐悬崖à
EfKpoh依据模式定理K提出了较为客观明确的编码准则M有意义的积木块编码规则K即所定编码应当易于生成与所求问题相关的短距和低阶的积木块N最小字符集编码规则K所定编码应采用最小字符集以使问题得到自然的表示或描述à近年来一些学者从理论上证
����

明了推导最小字符集编码规则时存在的错误K指出了大符号集编码可提供更多的模式K研
究了二进制编码和十进制编码在搜索能力和保持群体稳定性上的差异K结果表明二进制编
码比十进制编码搜索能力强K但不能保持群体稳定性à针对二进制编码的遗传算法进行函数优化时精度不高的特点KTdisbmepmqi等提 出 了
动态参数编码IEobnjdQbsbnfufsDpejoz hJà为了得到较高精度K让遗传算法从很粗糙的
精度开始收敛K当遗传算法找到一个区域后K就将搜索限制在这个区域K重新编码K重新
启动K重复这一过程K直到达到要求的精度为止à
�������编码方法
针对一个具体应用问题K如何设计一种完美的编码方案一直是遗传算法的应用难点之
一K也是遗传算法的一个重要研究方向à由于遗传算法应用的广泛性K迄今为止人们已经
提出了许多种不同的编码方法K总的来说K可以分为三大类M二进制编码方法Ð符号编码
方法和浮点数编码方法à下面介绍几种主要的编码方法à
��二进制编码方法
二进制编码方法是遗传算法中最主要的一种编码方法K它使用的编码符号集是由二进
制符号�和�所组成的二值符号集R�K�SK它所构成的个体基因型是一个二进制编码符号
串à二进制编码符号串的长度与问题所要求的求解精度有关à二进制编码有以下优点MI�J编码Ð解码操作简单易行àI�J交叉Ð变异等遗传操作便于实现àI�J符合最小字符集编码原则àI�J便于利 用 模 式 定 理 对 算 法 进 行 理 论 分 析K因 为 模 式 定 理 是 以 二 进 制 编 码 为 基
础的à二进制编码有以下缺点M首先K二进制编码存在着连续函数离散化时的映射误差à个体编码串的长度较短时K
可能达不到精度的要求K而个体编码串的长度较大时K虽然能提高编码精度K但却会使遗
传算法的搜索空间急剧扩大à其次K它不能直接反映出所求问题的本身结构特征K这样也
就不便于开发针对问题的专门知识的遗传运算算子K很难满足积木块编码原则à
��格雷码编码
二进制编码不便于反映所求问题的结构特征K对于一些连续函数的优化问题等K也由
于遗传运算的随机特性而使得其局部搜索能力较差à为了改进这个特性K人们提出用格雷
码IHsb Dpefz J来对个体进行编码à格雷码是这样一种编码方法K其连续的两个整数所对
应的编码之间仅仅只有一个码位是不同的K其余码位都完全相同à格雷码是二进制编码方
法的一种变形à表���所示为十进制数�Y��的二进制码和相应的格雷码à格雷码的主要优点是MI�J便于提高遗传算法的局部搜索能力àI�J交叉Ð变异等遗传操作便于实现àI�J符合最小字符集编码原则àI�J便于利用模式定理对算法进行理论分析à
����

表�����二进制码和格雷码
十进制数 二进制码 格雷码
� ���� ����
� ���� ����
� ���� ����
� ���� ����
� ���� ����
� ���� ����
� ���� ����
� ���� ����
� ���� ����
� ���� ����
�� ���� ����
�� ���� ����
�� ���� ����
�� ���� ����
�� ���� ����
�� ���� ����
��浮点数编码方法
对于一些多维Ð高精度要求的连续函数优化问题K使用二进制编码来表示个体时将会
有一些不利之处à人们在一些经典优化算法的研究中所总结出的一些宝贵经验也就无法在
这里加以利用K也不便于处理非平凡约束条件à为了克服二进制编码方法的缺点K人们提
出了个体的浮点数编码方法à所谓浮点数编码方法K是指个体的每个基因值用某一范围内
的一个浮点数来表示K个体的编码长度等于其决策变量的个数à因为这种编码方法使用的
是决策变量的真实值K所以浮点数编码方法也叫做真值编码方法à浮点数编码方法有以下几个优点MI�J适合于在遗传算法中表示范围较大的数àI�J适合于精度要求较高的遗传算法àI�J便于较大空间的遗传搜索àI�J改善了遗传算法的计算复杂性K提高了运算效率àI�J便于遗传算法与经典优化方法的混合使用àI�J便于设计针对问题的专门知识的知识型遗传算子àI�J便于处理复杂的决策变量约束条件à
��多参数级联编码
一般常见的优化问题中往往含有多个决策变量à对这种含有多个变量的个体进行编码
的方法就称为多参数编码方法à多参数编码的一种最常用和最基本的方法是M将各个参数
����

分别以某种编码方法进行编码K然后再将它们的编码按照一定顺序连接在一起就组成了表
示全部参数的个体编码à这种编码方法称为多参数级联编码方法à在进行多参数级联编码时K每个参数的编码方式可以是二进制编码方法Ð格雷码Ð浮
点数编码或符号编码等编码方式中的一种K每个参数可以具有不同的上下界K也可以有不
同的编码长度或编码精度à
��多参数交叉编码
多参数交叉编码方法的基本思想是M将各个参数中起主要作用的码位集中在一起K这
样它们就不易于被遗传算子破坏掉à在进行多参数交叉编码时K可先对各个参数进行分组
编码N然后取各个参数编码串中的最高位连接在一起K以它们作为个体编码串的前O 位编
码K再取各个参数编码串中的次高位连接在一起K以它们作为个体编码串的第二组O 位编
码��取各个参数编码串中的最后一位连接在一起K以它们作为个体编码串的最后几位à这样组成的长度为N�O 位的编码串就是一个交叉编码串à
其他常用的编码技术有一维染色体编码Ð二维染色体编码Ð可变染色体长度编码和树
结构编码à
�������编码评估策略
目前尚无一套既严格又完整的指导理论及评价标准来帮助我们设计编码方案K必须具
体问题具体分析K采用不同的编码方法à评估编码策略常采用以下三个规范MI�J完备性IDpnmfufofttq JM问题空间中的所有点I候选解J都能作为遗传算法空间中
的点I染色体J表现àI�J健全性ITpvoeofttJM遗传算法空间中的染色体能对应所有问题空间中的候选解àI�J非冗余性IOpo�sfevoebodzJM染色体和候选解一一对应à应该注意K严格满足上述规范的编码方法和提高遗传算法的效率并无关系à在有些场
合K允许生成致死基因的编码K虽然会导致冗余的搜索K但总的计算量可能反而减少K从
而可以更有效地找出最优解à上述的三个策略虽然具有普遍意义K但是缺乏具体的指导思
想K特别是满足这些规 范 的 编 码 设 计 不 一 定 能 有 效 地 提 高 遗 传 算 法 的 搜 索 效 率à相 比 之
下KEfKpoh提出了较为客观明确的编码评估准则K包括两个规则àI�J有意义积木块编码规则M所定编码应易于生成与所求问题相关的短距和低阶的积
木块àI�J最小字符集编 码 规 则M所 定 编 码 应 采 用 最 小 字 符 集 以 使 问 题 得 到 自 然 的 表 示 或
描述à规则I�J基于模式定理和积木块假设K规则I�J提供了一种更为实用的编码原则à
�����选����择
选择ITfmfdujpoJ又称复制ISfspevdujpoq JK是在群体中选择生命力强的个体产生新的
群体的过程à遗传算法使用选择算子I又称为复制算子KSfspevdujpoPq fsbupsq J来对群体
中的个体进行优胜劣汰操作M根据每个个体的适应度值大小选择K适应度较高的个体被遗
传到下一代群体中的概率较大N适应度较低的个体被遗传到下一代群体中的概率较小à这
����

样就可以使得群体中个体的适应度值不断接近最优解à选择操作建立在对个体的适应度进
行评价的基础之上à选择操作的主要目的是为了避免有用遗传信息的丢失K提高全局收敛
性和计算效率à选择算子确定的好坏K直接影响到遗传算法的计算结果à选择算子确定不
当K会造成群体中相似度值相近的个体增加K使得子代个体与父代个体相近K导致进化停
止不前N或使适应度值 偏 大 的 个 体 误 导 群 体 的 发 展 方 向K使 遗 传 失 去 多 样 性K产 生 早 熟
问题à遗传算法中的选择操作就是用来确定如何从父代群体中按某种方法选取哪些个体遗传
到下一代群体中的一种遗传运算K用来确定重组或交叉个体K以及被选个体将产生多少个
子代个体à选择操作的策略与编码方式无关à表���所示为选择操作算子à表�����选择操作算子
序号 名����称 特����点 备����注
� 轮盘赌选择 选择误差较大 HB成员
� 随机竞争选择 比轮盘赌选择较好
� 最佳保留选择 保证迭代终止结果为历代最高适应度个体
� 无回放随机选择 降低选择误差K复制数小于gLIg��JK操作不方便
� 确定性选择 选择误差更小K操作简易
� 柔性分段复制 有效防止基因缺失K但需要选择参数
�自适应柔性分段式动态群
体选择群体自适应变化K提高搜索效率
� 无回放式余数随机选择 误差最小 应用较广
� 均匀排序 与适应度大小差异程度正负无关
�� 稳态复制 保留父代中一些高适应度的串
�� 随机联赛选择
�� 复制评价
�� 最优保存策略 全局收敛K提高搜索效率K但不宜于非线性强的问题
�� 排挤选择 提高群体的多样性
�� 最优保存策略 保证全局收敛
����下面介绍几种常用的选择算子à
��轮盘赌选择
轮盘赌选择方法ISpvmfuufXiffmTfmfdujpoJ是一种回放式随机采样方法à所有选择是
从当前种群中根据个体的适应度值K按某种准则挑选出好的个体进入下一代种群à选择算
子有 多 种K经 典 遗 传 算 法 中 常 采 用 的 是 轮 盘 赌IXiffmK或 是 比 例 选 择 QsppsujpobmTfmfdujpo
qJ的选择方法K每个个体进入下一代的概率就等于它的适应度值与整个种群中个
体适应度值和的比例K适应度值越高K被选中的可能性就越大K进入下一代的概率就越大à每个个体就像圆盘中的一个扇形部分K扇面的角度和个体的适应度值成正比K随机拨动圆
盘K当圆盘停止转动时指针所在扇面对应的个体被选中K轮盘赌式的选择方法由此得名à
����

由于群体规模有限和随机操作等原因K使得个体实际被选中的次数与它应该被选中的期望
值oðgIyjJL��o
j��gIyjJ之间可能存 在 着 一 定 的 误 差K因 此 这 种 选 择 方 法 的 选 择 误 差 比 较
大K有时甚至连适应度较高的个体也选不上à图���所示为轮盘赌选择示意图à
图�����轮盘赌选择示意图
��随机竞争选择
随机竞争ITupdibtujdUpvsobnfouJ选择与轮盘赌选择基本一样à在随机竞争选择中K每次按轮盘赌选择机制选取一对个体K然后让这两个个体进行竞争K适应度高的被选中K如此反复K直到选满为止à
��最佳保留选择
首先按轮盘赌选择方法执行遗传算法的选择操作K然后将当前群体中适应度最高的个
体结构完整地复制到下一代群体中à其主要优点是能保证遗传算法终止时得到的最后结果
是历代出现过的最高适应度的个体à
��无回放随机选择
这种选择操作方法也叫做期望值选择IFyfdufeWbmvfTfmfdujpoq J方法K它的基本思想
是M根据每个个 体 在 下 一 代 群 体 中 的 生 存 期 望 值 来 进 行 随 机 选 择 运 算à其 具 体 操 作 过
程是MI�J计算群体中每个个体在下一代群体中的生存期望数目OàI�J若某一个体被选中参与交叉运算K则它在下一代中的生存期望数目减去���N若
某一个体未被选中参与交叉运算K则它在下一代中的生存期望数目减去���àI�J随着选择过程的进行K若某一个体的生存期望数目小于�时K则该个体就不再有
机会被选中à这种选择操作方法能够降低一些选择误差K但操作不太方便à
��确定式选择
确定式选择方法的 基 本 思 想 是M按 照 一 种 确 定 的 方 式 来 进 行 选 择 操 作à具 体 操 作 过
程是MI�J计算群体中各个个体在下一代群体中的期望生存数目OàI�J用O 的整数部分确定各个对应个体在下一代群体中的生存数目àI�J用O 的小数部分对个体进行降序排序K顺序取前N 个个体加入到下一代群体中à
至此可完全确定出下一代群体中N 个个体à
��无回放余数随机选择
无回放余数随机选择算法的选择操作可确保适应度比平均适应度大的一些个体能够被
����

遗传到下一代群体中K所以它的选择误差比较小à
��均匀排序
前面介绍的选择操作方法中K其选择依据主要是各个个体适应度的具体数值K一般要
求它取非负值K这就使得我们在选择操作之前必须先对负的适应度进行变换处理à而排序
ISboljohJ选择算法的主要着眼点是个体适应度之间的大小关系K对个体适应度取正值或
负值以及个体适应度之间的数值差异程度并无特别要求à排序选择方法的思想是M对群体中的所有个体按其适应度大小进行排序K基于这个排
序来分配各个个体被选中的概率à其具体操作过程是MI�J对群体中的所有个体按其适应度大小进行降序排序àI�J根据具体求解问题K设计一个概率分配表K将各个概率值按上述排列次序分配给
各个个体àI�J以各个个体所分配到的概率值作为其能够被遗传到下一代的概率K基于这些概率
值用比例选择的方法来产生下一代群体à例如K表���所示为进行排序选择时所设计的一
个概率分配表à由该表可以看出K各个个体被选中的概率只与其排列序号所对应的概率值
有关K即只与个体适应度之间的大小次序有关K而与其适应度的具体数值无直接关系à表�����概 率 分 配 表
个体排列序号 适应度 选择概率
� ��� ����
� �� ����
� �� ����
� �� ����
� �� ����
� �� ����
� ��� ����
� ��� ����
����该方法的实施必须根据对所研究问题的分析和理解情况预先分配表K这个设计过程无
一定规律可循à另一方面K虽然依据个体适应度之间的大小次序给各个个体分配了一个选
中概率K但由于具体选中哪一个个体仍是使用了随机性较强的比例选择方法K因此排序选
择方法仍具有较大的选择误差à
��最优保存策略
在遗传算法中K通过对个体进行交叉Ð变异等遗传操作而不断产生出新的个体à虽然
随着群体的进化过程会产生出越来越多的优良个体K但由于选择Ð交叉Ð变异等操作的随
机性K它们也有可能破 坏 掉 当 前 群 体 中 适 应 度 最 好 的 个 体à而 这 却 不 是 我 们 所 希 望 发 生
的K因为它会降低群体的平均适应度K并且对遗传算法的运行效率Ð收敛性都有不利的影
响K所以K我们希望适应度最好的个体要尽量保留到下一代群体中à为达到这个目的K可
以使用最优保存策略进化模型来进行优胜劣汰操作K即当前群体中适应度最高的个体不参
与交叉运算和变异运算K而是用它来替换掉本代群体中经过交叉Ð变异等操作后所产生的
����

适应度最低的个体à最优保存策略进化模型的具体操作过程是MI�J找出当前群体中适应度最高的个体和适应度最低的个体àI�J若当前群体中最佳个体的适应度比总的迄今为止的最好个体的适应度还要高K则
以当前群体中的最佳个体作为新的迄今为止的最好个体àI�J用迄今为止的最好个体替换掉当前群体中的最差个体à最优保存策略可视为选择
操作的一部分à该策略的实施可保证迄今为止所得到的最优个体不会被交叉Ð变异等遗传
运算所破坏K它是遗传算法收敛性的一个重要保证条件à但另一方面K它也容易使得某个
局部最优个体不易被淘汰掉反而快速扩散K从而使得算法的全局搜索能力不强à所以K该
方法一般要与其他一些选择操作方法配合起来使用K方可有良好的结果à
��随机联赛选择
随机联赛选择也是一种基于个体适应度之间大小关系的选择方法à其基本思想是每次
选取几个个体中适应度最高的一个个体遗传到下一代群体中à在联赛选择操作中K只有个
体适应度之间的大小比较运算K而无个体适应度之间的算术运算K所以它对个体适应度是
取正值还是取负值无特别要求à联赛选择中K每次进行适应度大小比较的个体数目称为联
赛规模à一般情况下K联赛规模O 的取值为�à联赛选择的具体操作过程是MI�J从群体中随机选取O 个个体进行适应度大小的比较K将其中适应度高的个体遗传
到下一代群体中àI�J将上述过程重复N 次K就可以得到下一代群体中的N 个个体à
���排挤选择
EfKpoh提出了排挤选择IDspxjo Tfmfdujpoh J方法K采用该方法K使得新生成的子代将
替代或排挤相似的旧父代个体K提高群体的多样性à在采用覆盖群体模式的情况下I代沟
为���JK该方法可描述为MI�J设定排挤参数DGàI�J从群体中随机地挑选DG个个体组成个体集I新的个体不包括在内JàI�J从这个集中淘汰一个个体K该个体与新个体的海明距离最短à以上介绍的选择方法是常用的方法à每种方法对于遗传算法的在线和离线性能的影响
各不相同à在具体使用 时K应 根 据 问 题 求 解 特 点 采 用 较 合 适 的 方 法 或 者 将 几 种 方 法 结 合
使用à
�����交����叉
在生物的自然进化过程中K两个同源染色体通过交配而重组K形成新的染色体K从而产
生出新的个体或物种à交配重组是生物遗传和进化过程中的一个主要环节à模仿这个环节K遗传算法中使用交叉算子来产生新的个体à交叉IDspttpwfsJ又称重组ISfdpncjobujpoJK是按
较大的概率从群体中选择两个个体K交换两个个体的某个或某些位à交叉运算产生子代K子代继承了父代的基本特征à交叉算子的设计包括如何确定交叉点位置和如何进行部分基
因交换两个方面的内容à遗传算法中所谓的交叉运算K是指对两个相互配对的染色体按某
����

种方式相互交换其部分基因K从而形成两个新的个体à交叉运算是遗传算法区别于其他进
化运算的重要特征K它在遗传算法中起着关键作用K是产生新个体的主要方法à遗传算法中K在交叉运算之前还必须先对群体中的个体进行配对à目前常用的配对算
法策略是随机配对K即将群体中的N 个个体以随机的方式组成PNL�Q对配对个体组K其中
PYQ表示不大于Y的最大整数à交叉操作是在这些配对个体组中的两个个体之间进行的à表���所示为交叉操作à
表�����交 叉 操 作
序号 名����称 特����点 适用编码
� 单点交叉 标准遗传算法成员 符号
� 两点交叉 使用较多 符号
� 均匀交叉 每一位以相同概率交叉 符号
� 多点交叉 交叉点大于� 符号
� 部分匹配交叉 序号
� 顺序交叉 序号
� 循环交叉 序号
� 启发式交叉 应用领域知识 序号
� 基于位置交换 序号
�� 算术交换 序号
����交叉算子的设计和实现与具体问题密切相关K并要和编码设计一同考虑K主要应包括
交叉点的位置和如何交换部分基因à下面介绍几种适合于二进制编码个体或浮点数编码个
体的交叉算子à
��单点交叉
单点交叉IPof�pjouDspttpwfsq J又称为简单交叉K它是指在个体编码串中只随机设置
一个交叉点K然后在该点相互交换两个配对个体的部分染色体à单点交叉的具体执行过程
如下MI�J对个体进行两两随机配对K若群体大小为NK则共有PNL�Q对相互配对的个体组àI�J对每一对相互配对的个体K随机设置某一基因座之后的位置为交叉点K若染色体
的长度为OK则共有O��个可能的交叉点位置àI�J对每一对相互配对的个体K依设定的交叉概率在其交叉点处相互交换两个个体的
部分染色体K从而产生出两个新的个体à图���所示为单点交叉运算的示意图à
图�����单点交叉运算的示意图
����

��两点交叉与多点交叉
两点交叉IUxp�pjouDspttpwfsq J是指在个体编码串中随机设置了两个交叉点K然后
再进行部分基因交换à两点交叉的具体操作过程是MI�J在相互配对的两个个体编码串中随机设置两个交叉点àI�J交换两个个体在所设定的两个交叉点之间的部分染色体à图���所示为两点交叉运算的示意图à
图�����两点交叉运算的示意图
将单点交叉与两点交叉的概念加以推广K可得到多点交叉INvmuj�pjouDspttpwfsq J的
概念à多点交叉是指在个体编码串中随机设置多个交叉点K然后进行基因交换à多点交叉
又称为广义交叉K其操作过程与单点交叉和两点交叉相类似à图���所示为有三个交叉点
时的交叉操作示意图à
图�����三点交叉运算的示意图
需要说明的是K一般情况下不使用多点交叉算子K因为它有可能破坏一些好的模式à事实上K随着交叉点数的增多K个体的结构被破坏的可能性也逐渐增大K这样就很难有效
地保存较好的模式K从而影响遗传算法的性能à
��均匀交叉
均匀交叉I也称为一致交叉KVojgpsnDspttpwfsJ是指两个配对个体的每个基因座上的
基因都以相同的交叉概率进行交换K从而形成两个新的个体à均匀交叉实际上可归属于多
点交叉的范围K其具体运算可通过设置一屏蔽字来确定新个体的各个基因如何由哪一个父
代个体来提供à均匀交叉的主要操作过程如下M
I�J随机产生一个与个体编码串长度等长的屏蔽字X�������j��MK其中M为个体
编码串长度àI�J由下述规则从BÐC两个父代个体中产生出两个新的子代个体B�ÐC�à
� 若�j��K则B�在第j个基因座上的基因值继承B的对应基因值KC�在第j个基因
座上的基因值继承C的对应基因值à
� 若�j��K则B�在第j个基因座上的基因值继承C的对应基因值KC�在第j个基因
座上的基因值继承B的对应基因值à均匀交叉操作的示例如图���所示à
����

图�����均匀交叉运算的示意图
��算术交叉
算术交叉IBsjuinfujdDspttpwfsJ是指由两个个体的线性组合而产生出两个新的个体à为了能够进行线性组合运算K算术交叉的操作对象一般是由浮点数编码所表示的个体à
假设在两个个体Y�BÐY�C 之间进行算术交叉K则交叉运算后所产生的两个新个体为
Yu��B ��YuC�I���JYuBYu��C ��YuB �I���JYu��
� C
I���J
其中K�为一个参数K�可以是一个常数I此时所进行的交叉运算称为均匀算术交叉JK�也
可以是一个由进化代数所决定的变量I此时所进行的交叉运算称为非均匀算术交叉Jà算术交叉的主要操作过程为MI�J确定两个个体进行线性组合时的系数�àI�J根据公式I���J生成两个新个体à遗传算法的收敛性主要取 决 于 其 核 心 操 作 交 叉 算 子 的 收 敛 性à由 交 叉 算 子 的 搜 索 能
力K可以得出结论M只在交叉算子的作用下K随着演化代数的增加K模式内部的各基因将
趋于独立K并且只要组成模式的各基因都存在K则该模式一定能被搜索到K此时模式的极
限概率等于组成该模式各基因的初始概率I也就是基因的极限概率J的乘积K并且与模式的
定义距无关K从而说明了交叉算子能使群体分布扩充的特性à
�����变����异
在生物的遗传和自然进化过程中K其细胞分裂复制环节有可能会因为某些偶然因素的
影响而产生一些复制差错K这样会导致生物的某些基因发生某种变异K从而产生出新的染
色体K表 现 出 新 的 生 物 性 状à遗 传 算 法 模 仿 生 物 遗 传 和 进 化 过 程 中 的 变 异 环 节à变 异
INvubujpoJ是以较小的概率对个体编码串上的某个或某些位值进行改变K如二进制编码中
���变为���K���变为���K进而生成新个体à在遗传算法中也引入了变异算子来产生新的
个体à遗传算法中所谓的变异运算K是指将个体染色体编码串中的某些基因座上的基因值
用该基因座的其他等位基因来替换K从而形成一个新的个体à从遗传运算过程中产生新个
体的能力方面来说K变异本身是一种随机算法K但与选择和交叉算子结合后K能够避免由
于选择和交叉运算而造成的某些信息丢失K保证遗传算法的有效性à交叉运算是产生新个
体的主要方法K它决定了遗传算法的全局搜索能力N而变异运算只是产生新个体的辅助方
法K但它也是必不可少的一个步骤K因为它决定了遗传算法的局部搜索能力à交叉算子与
变异算子相互配合K共同完成对搜索空间的全局搜索和局部搜索K从而使得遗传算法能够
以良好的搜索性能完成最优化问题的寻优过程à在遗传算法中使用变异算子主要有以下两个目的MI�J改善遗传算法的局部搜索能力à遗传算法使用交叉算子已经从全局的角度出发找
����

到了一些较好的个体编码结构K它们已接近或有助于接近问题最优解à但仅使用交叉算子
无法对搜索空间的细节进行局部搜索à这时若再使用变异算子来调整个体编码串中的部分
基因值K就可以从局部的角度出发使个体更加逼近最优解K从而提高了遗传算法的局部搜
索能力àI�J维持群体的多样性K防止出现早熟现象à变异算子用新的基因值替换原有基因值K
从而可以改变个体编码串的结构K维持群体的多样性K这样有利于防止出现早熟现象à变
异算子使得遗传算法在接近最优解邻域时能加速向最优解收敛K并可以维持群体多样性K避免未成熟收敛à
表���所示为变异算子à表�����变 异 算 子
序号 名����称 特����点 适用编码
� 基本位突变 ��标准遗传算法成员 符号
� 有效基因突变 ��避免有效基因缺失 符号
� 自适应有效基因突变 ��最低有效基因个数自适应变化 符号
� 概率自调整突变 ��由两个串的相似性确定突变概率 符号
� 均匀突变 ��每一个实数元素以相同的概率在域内变动 实数
� 非均匀突变 ��使整个矢量在解空间轻微变动 实数
� 边界变异��适用于最优点位于或接近于可行解的边界时的一类
带约束条件问题实数
� 高斯近似突变 ��提高对重点搜索区域的局部搜索性能力 实数
� 零突变 实数
����下面介绍几种变异操作方法K它们适合于二进制编码的个体和浮点数编码的个体à
��基本位变异
基本位变异ITjnmfNvubujpoq J操作是指对个体编码串中以变异概率Ð随机指定的某
一位或某几位基因座上的值做变异运算K其具体操作过程如下MI�J对个体的每一个基因座K以变异概率指定其为变异点àI�J对每一个指定的变异点K对其基因值做取反运算或用其他等位基因值来代替K从
而产生出新一代的个体à
��均匀变异
均匀变异IVojgpsnNvubujpoJ操作是指分别用符合某一范围内均匀分布的随机数K以
某一较小的概率来替换个体编码串中各个基因座上的原有基因值à均匀变异的具体操作过程是MI�J依次指定个体编码串中的每个基因座为变异点àI�J对每一 个 变 异 点K以 变 异 概 率 从 对 应 基 因 的 取 值 范 围 内 取 一 随 机 数 来 替 代 原
有值à均匀变异操作特别适合应用于遗传算法的初级运行阶段K它使得搜索点可以在整个搜
索空间内自由地移动K从而可以增加群体的多样性K使算法处理更多的模式à
����

��边界变异
边界变异ICpvoebs Nvubujpoz J操作是上述均匀变异操作的一个变形遗传算法à在进
行边界变异操作时K随机地取基因座的两个对应边界基因值之一去替代原有基因值à当变
量的取值范围特别宽K并且无其他约束条件时K边界变异会带来不好的作用K但它特别适
用于最优点位于或接近于可行解的边界时的一类问题à
��非均匀变异
均匀变异操作取某一范围内均匀分布的随机数来替换原有基因值K可使得个体在搜索
空间内自由移动K但另一方面K它却不便于对某一重点区域进行局部搜索à为改进这个性
能K我们不是取均匀分布的随机数去替换原有的基因值K而是对原有的基因值做一随机扰
动K以扰动后的结果作为变异后的新基因值à对每个基因座都以相同的概率进行变异运算
之后K相当于整个解向量在解空间中作了一个轻微的变动à这种变异操作方法就称为非均
匀变异IOpo�VojgpsnNvubujpoJà
��高斯近似变异
高斯变异IHbvttjboNvubujpoJ是改进遗传算法对重点搜索区域的局 部 搜 索 性 能 的 另
一种变异操作方法à所谓高斯变异操作K是指进行变异操作时用符合均值为�QÐ方差为Q�
的正态分布的一个随机数来替换原有的基因值à由正态分布的特性可知K高斯变异也是重
点搜索原个体附近某个局部区域à高斯变异的具体操作过程与均匀变异相类似à
�����适 应 度 函 数
在遗传算法中使用适应度IGjuofttJ这个概念来度量群体中各个个体在优化计算中能
达到或接近于或有助于找到最优解的优良程度à适应度较高的个体遗传到下一代的概率就
较大N而适应度较低的个体遗传到下一代的概率就相对小一些à度量个体适应度的函数称
为适应度函数IGjuofttGvodujpoJà适应度函数也称为评价函 数K是 根 据 目 标 函 数 确 定 的 用 于 区 分 群 体 中 个 体 好 坏 的 标
准K是算法演化过程的驱动力K也是进行自然选择的惟一依据à适应度函 数 总 是 非 负 的K任何情况下都希望其值越大越好à而目标函数可能有正有负K即有时求最大值K有时求最
小值K因此需要在目标函数与适应度函数之间进行变换à为了变更选择压力K也需要对适
应度函数进行变换à评价个体适应度的一般过程为MI�J对个体编码串进行解码处理后K可得到个体的表现型àI�J由个体的表现型可计算出对应个体的目标函数值àI�J根据最优化问题的类型K由目标函数值按一定的转换规则求出个体的适应度à
�������适应度函数的作用
在选择操作时会出现以下两个称为遗传算法的欺骗问题àI�J在遗传进化的初期K通常会产生一些超常的个体K若按照比例选择法K这些超常
个体会因竞争力突出而控制选择过程K影响算法的全局优化性能àI�J在遗传进化的后期K即算法接近收敛时K由于种群中个体适应度差异较小时K继
����

续优化的潜能降低K可能获得某个局部最优解à如果适应度函数设计不当K有可能造成这
两种问题的出现à所以适应度函数的设计是遗传算法设计的一个重要方面à
�������适应度函数的设计主要满足的条件
适应度函数的设计主要应满足以下条件MI�J单值Ð连续Ð非负Ð最大化à这个条件很容易理解和实现àI�J合理Ð一致性à要求适应度值反映对应解的优劣程度K这个条件的达成往往比较
难以衡量àI�J计算量小à适应度函数设计应尽可能简单K这样可以减少计算时间和空间上的复
杂性K降低计算成本àI�J通用性强à适应度对某类具体问题K应尽可能通用K最好无需使用者改变适应度
函数中的参数à
�������适应度函数的种类
由解空间 中 某 一 点 的 目 标 函 数 值gIyJ到 搜 索 空 间 中 对 应 个 体 的 适 应 度 函 数 值
GjuIgIyJJ的转换方法基本上有以下三种MI�J直接以待解的目标函数gIyJ转化为适应度函数GjuIgIyJJK令
GjuIgIyJJ�gIyJ 目标函数为最大化问题
�gIyJR 目标函数为最小化问题I���J
����这种适应度函数简单直观K但存在两个问题M一是可能不满足常用的轮盘赌选择中概
率非负的要求N二是某些待求解的函数在函数值分布上相差很大K由此得到的平均适应度
可能不利于体现种群的平均性能K而影响算法的性能àI�J对于求最小值的问题K做下列转换M
GjuIgIuJJ�dnby�gIyJ gIyJ_�dnby���
� 其他I���J
式中Kdnby为一个适当的 相 对 比 较 大 的 数K是gIyJ的 最 大 值 估 计K可 以 是 一 个 合 适 的 输
入值à对于求最大值的问题K做下列转换M
GjuIgIuJJ�gIyJ�dnjo gIyJ`�dnjo���
� 其他I���J
式中Kdnjo为gIyJ的最小值估计K可以是一个合适的输入值à这种方法是第一种方法的改进K可以称为�界限构造法�K但这种方法有时存在界限值
预先估计困难Ð不可能精确的问题àI�J若目标函数为最小值问题K令
GjuIgIuJJ� ���d�gIyJ
K��d1��Kd�gIyJ1�� I���J
若目标函数为最大值问题K令
GjuIgIuJJ� ���d�gIyJ
K��d1��Kd�gIyJ1�� I���J
����

����这种方法与第二种方法类似Kd为目标函数界限的保守估计值à
�������适应度尺度的变换
在遗传算法中K各个个体被遗传到下一代的群体中的概率是由该个体的适应度来确定
的à应用实践表明K如何确定适应度对遗传算法的性能有较大的影响à有时在遗传算法运
行的不同阶段K还需要对个体的适应度进行适当的扩大或缩小à这种对个体适应度所做的
扩大或缩小变换就称为适应度尺度变换IGjuofttTdbmjo Usbotgpsnh Jà常用的尺度变换方法有三种M线性尺度变换Ð乘幂尺度变换和指数尺度变换à
��线性尺度变换
线性尺度变换的公式为
G��bG�c I���J式中KG为原适应度NG�为尺度变换后的新适应度Nb和c为系数àb和c的确定直接影响
到这个尺度变换的大小K所以对其选取有一定的要求K要满足两个条件MI�J原适应度的平均值Gbwh要等于定标后的适应度平均值G�bwhK以保证适应度为平均
值的个体在下一代的期望复制数为�K即G�bwh�GbwhàI�J变换后的适应度最大值应等于原适应度平均值的指定倍数K以控制适应度最大的
个体在下一代中的复制数K即
G�bwh�DðGbwh I���J式中KD为最佳个体的期望复制数量à试验表明K指定倍数可在���Y���范围内à对于群
体规模大小为��Y���个个体的情况K一般取D����Y�à这个条件是为了保证群体中最
好的个体能够期望复制D倍到新一代群体中à系数bÐc可按线性比例确定M
b�ID��JðGbwhGnby�Gbwh
c�IGnby�DðGbwhJðGbwh
Gnby�Gbw
�
�
� h
I���J
����使用线性尺度变换时K变换了适应度之间的差距K保持了种群内的多样性K并且计算
简单K易于实现à如图���所示K群体中少数几个优良个体的适应度按比例缩小K同时几
个较差个体的适应度也按比例扩大à
图�����线性尺度变换的正常情况
如果种群内某些个体适应 度 远 低 于 平 均 值 时K有 可 能 出 现 变 换 后 适 应 度 值 为 负 的 情
况K如图���所示à考虑到要保证最小适应度非负的条件K进行如下的变换M����

b�Gbwh
Gbwh�Gnjo
c��GnjoðGbwhGbwh�G
�
�
� njo
I����J
����图���所示为利用式I����J变换后的结果à
图�����线性尺度变换的异常情况 图�����适应度出现负值时的调整
��乘幂尺度变换
乘幂尺度变换时新的适应度是原适应度的某个指定乘幂à乘幂尺度变换的公式为
G��Gl I����J式中K幂指数l与所求解的问题有关K且在算法的执行过程中需要不断对其进行修正才能
使尺度变换满足一定的伸缩要求à
��指数尺度变换
指数尺度变换时新的适应度是原适应度的某个指数à指数尺度变换的公式为
G��fyqI��GJ I����J式中K系数�决定了选择的强制性K�越小K原有适应度较高的个体的新适应度就越与其他
个体的新适应度相差较大K即越增加了选择该个体的强制性à
�����控制参数选择
遗传算法中的控制参数选择非常关键K控制参数的不同选取会对遗传算法的性能产生
较大的影响K影响到整个算法的收敛性à这些参数包括群体规模OÐ二进制I十进制J编码
长度Ð交叉概率QdÐ变异概率Qn 等à简单遗传算法对其中的参数选择比较敏感à优化过程中K交叉概率始终控制着遗传运算中起主导地位的交叉算子à不适合的交叉
概率会导致意想不到的后果à交叉概率控制着交叉操作被使用的频度à较大的交叉概率可
使各代充分交叉K但群体中的优良模式遭到破坏的可能性增大K以致产生较大的代沟K从
而使搜索走向随机化N交 叉 概 率 越 低K产 生 的 代 沟 就 越 小K这 样 将 保 持 一 个 连 续 的 解 空
间K使找到全局最优解的可能性增大K但进化的速度就越慢N若交叉概率太低K就会使得
更多的个体直接复制到下一代K遗传搜索可能陷入停滞状态à一般建议Qd 取值范围是���Y����à变异运算是对遗传算法的改进K对交叉过程中可能丢失的某种遗传基因进行修复
和补充K也可防止遗传算法尽快收敛到局部最优解à变异概率控制着变异操作被使用的频
度à变异概率取值较大时K虽然能够产生较多的个体K增加了群体的多样性K但也有可能
����

破坏掉很多好的模式K使得遗传算法的性能近似于随机搜索算法的性能N若变异概率取值
太小K则变异操作产生新个体和抑制早熟现象的能力就会较差à实际应用中发现M当变异
概率Qn 很小时K解群体的稳定性好K一旦陷入局部极值就很难跳出来K易产生未成熟收
敛N而增大Qn 的值I如����JK可破坏解群体的同化K使解空间保持多样性K搜索过程可
以从局部极值点跳出来K收敛到全局最优解à在求解过程中也可以使用可变的QnK即算法
早期Qn 取值较大K扩大搜索空间N算法后期Qn 取值较小K加快收敛速度à一般建议的取
值范围是������Y���à交叉运算是产生新个体的主要方法K它决定了遗传算法的全局搜
索能力K而变异操作只是产生新个体的辅助方法à但它决定了遗传算法的局部搜索能力à交叉算子和变异算子相互配合K共同完成对搜索空间的全局搜索和局部搜索K从而使得遗
传算法能够以良好的搜索性能完成最优问题的寻优过程à群体规模IQpvmbujpoq J的大 小 直 接 影 响 到 遗 传 算 法 的 收 敛 性 或 计 算 效 率à规 模 过 小K
容易收敛到局部最优解N规模过大K会造成计算速度降低à群体规模可以根据实际情况在
��Y���之间选定à
�����约束条件的处理
在遗传算法中必须对约束条件IDpotusbjoutJ进行处理K但目前尚无处理各种约束条件
的一般方法K根据具体问题可选择下列三种方法K即搜索空间限定法Ð可行解变换法和罚
函数法à
��搜索空间限定法
搜索空间限定法的基本思想是对遗传算法的搜索空间的大小加以限制K使得搜索空间
中表示一个个体的点与解空间中的表示一个可行解的点有一一对应的关系à对一些比较简
单的约束条件通过适当编码使搜索空间与解空间一一对应K限定搜索空间能够提高遗传算法
的效率à在使用搜索空间限定法时必须保证交叉Ð变异之后的新个体在解空间中有对应解à
��可行解变换法
可行解变换法的基本思想是在由个体基因型到个体表现型的变换中K增加使其满足约
束条件的处理过程K即 寻 找 个 体 基 因 型 与 个 体 表 现 型 的 多 对 一 变 换 关 系K扩 大 了 搜 索 空
间K使进化过程中所产生的个体总能通过这个变换而转化成解空间中满足约束条件的一个
可行解à可行解变换法对个体的编码方法Ð交叉运算Ð变异运算等无特殊要求K但运行效
率下降à
��罚函数法
罚函数法的基本思想是对在解空间中无对应可行解的个体计算其适应度时K处以一个
罚函数K从而降低该个体的适应度K使该个体被遗传到下一代群体中的概率减小à可以用
下式对个体的适应度进行调整M
G�IyJ�GIyJ y满足约束条件
GIyJ�QIyJ yR 不满足约束条件I����J
式中KGIyJ为原适应度NG�IyJ为调整后的新适应度NQIyJ为罚函数à如何确定合理的罚函数是这种处理方法难点之所在K在考虑罚函数时K既要度量解对
约束条件不满足的程度K又要考虑计算效率à
����

书书书
ðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀ
ðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀ
���
���第五章��遗传算法工具箱函数��
本章将详细介绍英国设菲尔德大学开发的遗传算法工具箱函数à由于 NBUMBC高 级 语 言 的 通 用 性K对 问 题 用 N 文 件 编 码K与 此 配 对 的 是
NBUMBC先进的数据分析Ð可视化工具Ð特殊目的的应用领域工具箱和展现给使
用者具有研究遗传算法可能性的一致环境àNBUMBC遗传算法工具箱为遗传算法
从业者和初次实验遗传算法的人提供了广泛多样的有用函数à遗传算法工具箱使用 NBUMBC矩阵函数为实现广泛领域的遗传算法建立了一
套通用工具K这个遗传算法工具是用 N文件写成的命令行形式的函数K是完成遗传
算法大部分重要功能的程序的集合à用户可通过这些命令行函数K根据实际分析的
需要K编写出功能强大的 NBUMBC程序à
�����工 具 箱 结 构
本节将给出HB工具箱的主要程序à表���所示为遗传算法工具箱中的函数分类表à表�����遗传算法工具箱中的函数分类表
函����数 功����能
创建种群
dsucbtf 创建基向量
dsucq 创建任意离散随机种群
dsusq 创建实值初始种群
适应度计算sboljoh 常用的基于秩的适应度计算
tdbmjoh 比率适应度计算
选择函数
sfjot 一致随机和基于适应度的重插入
sxt 轮盘选择
tfmfdu 高级选择例程
tvt 随机遍历采样
变异算子
nvu 离散变异
nvubuf 高级变异函数
nvuchb 实值变异
����

续表
函����数 功����能
交叉算子
sfdejt 离散重组
sfdjou 中间重组
sfdmjo 线性重组
sfdnvu 具有变异特征的线性重组
sfdpncjo 高级重组算子
ypweq 两点交叉算子
ypwestq 减少代理的两点交叉
ypwnq 通常多点交叉
ypwti 洗牌交叉
ypwtist 减少代理的洗牌交叉
ypwtq 单点交叉
ypwtstq 减少代理的单点交叉
子种群的支持 njsbufh 在子种群间交换个体
实用函数ct�sw 二进制串到实值的转换
sfq 矩阵的复制
�������种群表示和初始化
种群表示和初始化函数有MdsucbtfKdsucqKdsusqà
HB工具箱支持二进制Ð整数和浮点数的基因表示à二进制和整数种群可以使用工具
箱中的dsucq建立二进制种群àdsucbtf是附加的功能K它提供向量描述整数表示à种群的
实值可用dsusq进行初始化à在二进制代码和实值之间的变换可使用函数ct�swK它支持格
雷码和对数编码à
�������适应度计算
适应度函数有MsboljohKtdbmjohà适应度函数用于转换目标函数值K给每一个个体一个非负的价值数à这个工具箱支持
Hpmecfsh的偏移法IPggtfuujohJ和比率法以及贝克的线性评估算法à另外Ksboljoh函数支
持非线性评估à
�������选择函数
选择函数有MsfjotKsxtKtfmfduKtvtà这些函数根据个体的适应度大小在已知种群中选择一定数量的个体K对它的索引返回
一个列向量à现在最合适的是轮盘赌选择I即sxt函数J和随机遍历抽样I即tvt函数Jà高
级入口函数tfmfdu为选择程序K特别为多种群的使用提供了一个方便的接口界面à在这种
����

情况下K代沟是必需的K即整个种群在每一代中没有被完全复制àsfjot能使用均匀的随机
数或基于适应度的重新插入à
�������交叉算子
交叉算子函数有MsfdejtKsfdjouKsfdmjoKsfdnvuKsfdpncjoKypweqKypwestq KypwnqK
ypwtiKypwtistKypwtqKypwtstq à交叉是通过给定的概率重组一对个体而产生后代的à单点交叉Ð两点交叉和洗牌交叉
是由ypwtqÐypweq和 ypwti函 数 分 别 完 成 的à缩 小 代 理 交 叉 函 数 分 别 是Mypwestq Ð
ypwtist和ypwtstq à通用的多点交叉函数是ypwnqK它提供均匀交换的支持à为支持染色
体实值 表 示K离 散 的Ð中 间 的 和 线 性 重 组 分 别 由 函 数sfdejtÐsfdjouÐsfdmjo完 成à函 数
sfdnvu提供具有突变特征的线性重组à函数sfdpncjo是一高级入口函数K对所有交叉操
作提供多子群支持入口à
�������变异算子
变异算子函数有MnvuKnvubufKnvuchbà二进制和整数变异操作由 nvu完成à实值的变异使用育种机函数 nvuchb是有效的à
nvubuf对变异操作提供一个高级接口à
�������多子群支持
多子群支持函数Mnjsbufh à遗传算法工具箱通过高层遗传操作函数 njsbufh 对多子群提供支持K它的一个功能是
在子群中交换个体à一个单一种群通过使用工具箱中的函数修改数据结构K使其分为许多
子种群K这些子种群被保存在连续的数据单元块中à高层函数I如tfmfdu和sfjotJ可独立地
操作子种群K包含在一个数据结构中的每一子种群允许独自向前衍化à基于孤岛或回迁模
式Knjsbufh 允许个体在子种群中迁移à
�����遗传算法中的通用函数
在这一节中K将详细介绍在 NBUMBC中用于遗传算法的各种工具箱函数K对每个函
数从功能Ð语法格式Ð使用说明以及用法举例等方面进行阐述à关于每个函数的适用信息
由在线帮助工具提供à
�������函数ct�sw
功能M二进制串到实值的转换à格式MQifo�ct�swIDispnKGjfmeEJ详细说 明MQifo� ct�swIDispnKGjfmeEJ根 据 译 码 矩 阵 GjfmeE将 二 进 制 串 矩 阵
Dispn转换为实值向量à返回矩阵Qifo包含对应的种群表现型à使用格雷编码的二进制染色体表示被推荐作为量化间隔的规则海明距离K可使遗传搜
索减少欺骗à设置量化点间刻度的可选方案是选择线性或对数编码从二进制变换到实值à����

对数刻度用于决策变量的范围未知K作为大范围参数的边界时K搜索可用较少的位数K以
减少HB的内存需求和计算量à矩阵GjfmeE有如下结构M
GjfmeE �
mfomcvcdpeftdbmfmcjo
m�
n�
q�
r�vcjo这里矩阵的行组成如下M
mfo是包含在Dispn 中的每个子串的长度K注意tvnImfoJ等于mfouih IDispnJà
mc和vc是行向量K分别指明每个变量使用的下界和上界à
dpef是二进制行向 量K指 明 子 串 是 怎 样 编 码 的àdpefIjJ��为 标 准 的 二 进 制 编 码K
dpefIjJ��则为格雷编码à
tdbmf是二进制行向量K指明每个子串是否使用对数或算术刻度àtdbmfIjJ��为算术
刻度KtdbmfIjJ��则为对数刻度à
mcjo和vcjo是 二 进 制 行 向 量K指 明 表 示 范 围 中 是 否 包 含 每 个 边 界à选 择mcjo��或
vcjo��K从表示范围中去掉边界Nmcjo��或vcjo��则在表示范围中包含边界à例�����函数ct�sw的应用举例à下列二进制种群Dispn由函数dsucq创建K表示在
P��K��Q之间的一组简单变量K程序代码表示怎样使用函数ct�sw将算术表示的格雷码或
二进制串表示转换为实值表现型à
����Dispn�dsucqI�K�J���� � 创建任意染色体K如为二进制串
Dispn�
���������������������������������������������������������������������������������������
m�
n�
q�
r������GjfmeE�P�N��N��N�N�N�N�QN����� 包括边界
����Qifo�ct�swIDispnKGjfmeEJ � 转换二进制到实值K使用算术刻度
Qifo�
�������������������
m�
n�
q�
r�����������GjfmeE�P�N�N��N�N�N�N�QN � 不包括边界
����Qifo�ct�swIDispnKGjfmeEJ � 转换二进制到实值K使用对数刻度
Qifo�
������������������
m�
n�
q�
r�����������

算法说明Mct�sw作为HB工具箱的一个 N 文件执行K如果使用对数刻度K其范围不
能包含零à
�������函数dsucbtf
功能M创建基向量à格式MCbtfWfd�dsucbtfIMjoeKCbtfJ详细说明Mdsucbtf产生向量的元素对应染色体结构的基因座K使用不同的基本字符表
示建立种群时这个函数可与函数dsucq联合使用à
CbtfWfd�dsucbtfIMjoeKCbtfJ创建长度为Mjoe的向量K它的每个元素由基本字符决
定K如果Mjoe是向量KCbtfWfd的长度为Mjoe的总长K如果Cbtf也是一个长为Mjoe的向
量K则CbtfWfd是一组由Mjoe和基本字符Cbtf的元素决定长度的基本字符组组成à当描
述染色体结构的基因位基本字符时K最后一选项是有用的à例�����函数dsucbtf的应用举例à下面的程序代码将为种群创建一有�个基数为�的
基本字符R�K�K�K�K�K�K�K�S和�个基数为�的基本字符R�K�K�K�K�S的基本字符
向量à
����CbtfW�dsucbtfIP����QKP����QJ
����CbtfW�P����������������������������Q参见MdsucqKct�swà
�������函数dsucq
功能M创建初始种群à格式M� PDispnKMjoeKCbtfWQ�dsucqIOjoeKMjoeJ
� PDispnKMjoeKCbtfWQ�dsucqIOjoeKCbtfWJ
� PDispnKMjoeKCbtfWQ�dsucqIOjoeKMjoeKCbtfJ详细说明M遗传算法的第一步是创建由任意染色体组成的原始种群àdsucq创建一元
素为随机数的矩阵Dispnà格式�创建一大小为Ojoe�Mjoe的 随 机 二 元 矩 阵K这 里 Ojoe指 定 种 群 中 个 体 的 数
量KMjoe指定个体的长度à此格式习惯于指定染色体的尺寸I维度Jà格式�返回长度为Mjoe的染色体结构K染色体基因位的基本字符由向量CbtfW决定à格式�用于产生基本字符为Cbtf的染色体矩阵à如果Cbtf是向量K则Cbtf的元素值
指定了染色体的基因 位 的 基 本 字 符à在 这 种 情 况 下K右 边 的 第 二 个 变 元 可 省 略K即 为 格
式�à例����� 使用函数dsucq创建初始种群的应用举例àI�J创建一个长度为�Ð有�个个体的随机种群M
����PDispnKMjoeKCbtfWQ�dsucqI�K�J或
���� PDispnKMjoeKCbtfWQ�dsucqI�K�KCbtfWJ运行后得
����

Dispn�
�����������������������������������������������������������������������������������������������������������������������������������������������������
m�
n�
q�
r������Mjoe��N
����CbtfW� P�������������������������QNI�J创建一长度为�Ð有�个个体的随机种群I这里前四个基因位是基本字符R�K�K�K
�K�K�K�K�SK后五个基因位是基本字符R�K�K�K�SJM
����CbtfW�dsucbtfIP��QKP��QJN
����PDispnKMjoeKCbtfWQ�dsucqI�KCbtfWJN或
����PDispnKMjoeKCbtfWQ�dsucqIP�K�QKP�������������������������QJN运行后得
Dispn�
�����������������������������������������������������������������������������������������������������������������������������������������������������
m�
n�
q�
r������Mjoe��N
����CbtfW�P�������������������������QN算法说明Mdsucq是HB工具箱中的一个N文件K它使用了NBUMBC随机函数sboeà参见MdsucbtfKdsusqà
�������函数dsusq
功能M创建实值原始种群à遗传算法的第一步是创建由任意个体组成的原始种群àdsusq创建元素为均匀分布随
机数的矩阵à格式MDispn �dsusqIOjoeKGjfmeESJ详细说明MDispn �dsusqIOjoeKGjfmeESJ创建一大小为Ojoe�Owbs的随机实值矩
阵K这里 Ojoe指 定 了 种 群 中 个 体 的 数 量KOwbs指 定 每 个 个 体 的 变 量 个 数KOwbs来 自
GjfmeESKOwbs�tj{fIGjfmeESK�Jà
GjfmeESIGjfmeEftdsjujpoSfbmwbmvfq J是一大小为��Owbs的矩阵K并包含每个个体变
量的边界K第一行包含下界K第二行包含上界à
GjfmeES被用在另一些函数中I变异Jà例�����使用函数dsusq创建一具有�个个体K每个个体有�个变量的随机种群à定义边界变量M
����

GjfmeES����� ��� ��� ���P Q��� �� �� ��
���下界
�上界
创建初始种群M
����Dispn�dsusqI�KGjfmeESJ
Dispn�
����� ������ ����� ���������� ����� ����� ���������� ����� ����� ����������� ����� ���� ����������� ������ ������ �����
m�
n�
q�
r������ ������ ���� ������
参见MnvuchbKsfdejtKsfdjouKsfdmjoà
�������函数 njsbufh
功能M在子种群间迁移个体à格式M�Dispn � njsbufh IDispnKTVCQPQJ
�Dispn � njsbufh IDispnKTVCQPQKNjhPquJ
�Dispn � njsbufh IDispnKTVCQPQKNjhPquKPckWJ
� PDispnKPckWQ� njsbufh IDispnKTVCQPQKNjhPquKPckWJ详细说明Mnjsbufh 完成在当前种群Dispn的子种群间迁移个体K并返回迁移后的种
群DispnàDispn的一行对应一个个体à子种群的数量由TVCQPQ指定à在Dispn中的
子种群按照下列方案进行有序排列M
Dispn
JOE
�
�TvcQpq�JOE�TvcQpq������
JOEOTvcQpq�JOE�TvcQpq�JOE�TvcQpq������
JOEOTvcQpq������
JOE�TvcQpqTVCQPQJOE�TvcQpqTVCQPQ�����
JOEOTvcQpq
m�
n�
q�
r�TVCQPQ
����所有子种群必须有相同数量的个体à
����

NjhPqu是一最大具有三个参数的可选向量à
NjhPquI�J是个体在子种群间的迁移概率à如果省略或为ObOK则假定NjhPquI�J
����
I即���Jà如果迁移概率不为�K则每个子种群至少有一个个体迁移à
NjhPquI�J是指定迁移选择方式的标量à�为均匀迁移K�为基于适应度的迁移à如果
省略或为ObOK则假设 NjhPquI�J��à
NjhPquI�J是指定迁移种群结构的标量à�为完全网状结构K�为近邻结构K�为环状
结构à如果省略或为ObOK则假设 NjhPquI�J��à如果省略 NjhPqu或为ObOK则假设为缺省值à
PckW是具有与Dispn同样行数的任选列向量K并包含Dispn所有个体对应的目标
函数值à对于基于适应度的迁移INjhPquI�J��JKPckW为必选项à如果PckW是一输入L输出参数K则目标函数值将按照迁移个体进行拷贝K并保存重新计算的整个种群的目标函
数值à例�����列举函数njsbufh 各种调用的情形à
Dispn�IDispnKTVCQPQJ在 一 子 种 群 中 选 择���的 个 体K并 用 均 匀 选 择 方 式
与从其他所有子种 群 中 选 择 的 个 体 进 行 替 换à这 个 过 程 将 对 所 有 子 种 群 做 一 遍à其 中K
NjhPu�q P���K�K�Qà
Dispn�njsbufh IDispnKTVCQPQKPObO�ObOQKPckWJ在一子种群中选择���的
个体并用从其他所有子种群中选择最适应I较小的PckWJ的个体替换àI网状结构J这个过
程将对所有子种群重复àPDispnKPckWQ�njsbufh IDispnKTVCQPQKP�����QKPckWJ在一子种群中选择
���的个体并用从单向环状结构的邻近子种群中选择最适应I较小的PckWJ的个体替换à这 个 过 程 将 对 所 有 子 种 群 重 复à第 一 个 子 种 群 从 最 后 一 个 子 种 群 接 收 它 的 新 的 个 体
ITVCQPQJàPckW按照迁移个体进行返回à这个迁移方案如下M
����tvcqpq�A�tvcqpq�A�tvcqpq�A��A�tvcqpTVCQPQq A�tvcqpq�PDispnKPckWQ�njsbufh IDispnKTVCQPQKPObOObO�QKPckWJ在一子种群中选
择���的个体并用均匀选择方式与从两个相邻子种群中选择的个体替换à这个过程将对所
有子种群重复一遍à第一个子种群从第二个子种群和最后一个子种群中接收新的个体à最
后一个子种群从第一个子种群和第TVCQPQ��个子种群接收新的个体àPckW按照迁移
个体进行返回à这个迁移方案如下M
����tvcqpTVCQPQq A�tvcqpq�m�tvcqpq�m��m�tvcqpTVCQPQq m�tvcqpq�参见MtfmfduKsfdpncjoKnvubufKsfjotà
�������函数nvu
功能M离散变异算子à格式M� OfxDispn � nvuIPmeDispnKQnJ
� OfxDispn � nvuIPmeDispnKQnKCbtfWJ详细说明Mnvu取当前种群的表示K并用特定概率对每个元素进行变异à如果染色体
和种群结构中允许不同的基本字符K则 nvu允许用一个附加的变量CbtfW来指定染色体
中每一个元素的基本字符à����

假定种群为二进制编码KOfxDispn�nvuIPmeDispnKQnJK取当前种群PmeDispnK每一行对应一个体并用概率Qn变异每一个元素à如果省略K则假设Qn����LMjoeK这里
Mjoe是染色体结构的长度K这个值的选择将使染色体中的每一个元素的变异概率近似等
于���à
OfxDispn�nvuIPmeDispnKQnKCbtfWJ使用第三个变量指明染色体个体元素的变
异的基本字符à在这里Kmfouih ICbtfWJ�MjoeKMjoe是染色结构的长度à
nvu是一低级变异函数K通常被nvubuf调用à例�����下面的程序代码为使用函数nvu将当前种群变异为新种群àI�J调用变异函数M
PmeDispn�
���������������������������������������������������������������������������������������
m�
n�
q�
r��变异PmeDispn使用缺省的概率K通过调用变异函数M
����OfxDispn�nvuIPmeDispnJ这时KPmeDispn将变成OfxDispnM
OfxDispn�
���������������������������������������������������������������������������������������
m�
n�
q�
r��I�J创建一长度为�Ð有�个个体的随机种群M
����CbtfW�P����������������������QN
����PDispnKMjoeKCbtfWQ�dsucqI�KCbtfWJN
Dispn�
�����������������������������������������������������������������������������������������������������������������������������������
m�
n�
q�
r������OfxDispn�nvuIDispnK������KCbtfWJ
因此Dispn将变成
OfxDispn�
�����������������������������������������������������������������������������������������������������������������������������������
m�
n�
q�
r��需要补充说明的是K如果二进制串使用变异概率�K则调用过程及获得的结果如下M
����nvuIP����������������������QK�JN����

运行后得
����bot�P����������������������Q参见MnvubufKnvuchbà
�������函数 nvubuf
功能M个体的变异I高级函数Jà格式M� OfxDispn�nvubufINVU_GKPmeDispnKGjfmeESJ
� OfxDispn�nvubufINVU_GKPmeDispnKGjfmeESKNvuPquJ
� OfxDispn�nvubufINVU_GKPmeDispnKGjfmeESKNvuPquKTVCQPQJ详细说明Mnvubuf执行种群PmeDispn中个体的变异K并在新种群OfxDispn中返回
变异后的个体KPmeDispn 和OfxDispn中每一行对应一个个体à
NVU_G是一字符串K包含低级变异函数的名字K例如nvuchb或nvuà对实值变量KGjfmeES是一大小为��Owbs的矩阵K指定每个变量的边界N对离散值
变量KGjfmeES是一大小为��Owbs的矩阵K指定每个变量的基本字符à如果GjfmeES省
略Ð空或为ObOK则假设变量为二进制表示à
NvuPqu是一任选参数项K包含变异概率K即个体变量的突变可能性à如果NvuPqu省
略K则一缺省突变概率被假设à对实值变异KNvuPqu可能包含第二个参数K该参数是说明
压缩变异的范围的标量I参见nvuchbJà
TVCQPQ是一任选参数项K决定PmeDispn中 子 种 群 的 数 量à如 果TVCQPQ省 略 或
为ObOK则假设TVCQPQ��àPmeDispn中的所有子种群必须具有相同的大小à例�����变异函数nvubuf的应用举例à下面的程序代码为一个二进制种群和一个十进
制种群的变异à对于二进制种群K选取 NVU_G��nvu�à
PmeDispn�
���������������������������������������������������������������������������������������
m�
n�
q�
r��
����OfxDispn�nvubufI�nvu�KDispnJN运行后得
OfxDispn�
���������������������������������������������������������������������������������������
m�
n�
q�
r��
对于十进制种群K选取 NVU_G��nvucb�h à
����Dispn�dsucqI�KCbtfWJN������个个体的种群KCbtfW同例���运行后得
����

Dispn�
�����������������������������������������������������������������������������������������������������������������������������������
m�
n�
q�
r��边界定义如下M
GjfmeES��������������������������������������������P Q�
�� �� OfxDispn � nvubufI�nvucb�h KDispnKGjfmeESJN� 将 Dispn 变 异 为
OfxDispn运行后得
OfxDispn�
�����������������������������������������������������������������������������������������������������������������������������������
m�
n�
q�
r��算法说明Mnvubuf检测输入参数的一致性并调用低级变异函数K如果 nvubuf被调用
于多子群K则每个子群分别调用低级变异函数à参见MnvuchbKnvuKsfdpncjoKtfmfduà
�������函数 nvuchb
功能M实值种群的变异I遗传算法育种器的变异算子Jà格式M� OfxDispn � nvuchbIPmeDispnKGjfmeESJ
� OfxDispn � nvuchbIPmeDispnKGjfmeESKNvuPquJ详细说明Mnvuchb对实值种群PmeDispnK使用给定的概率K变异每一个变量K返回
变异后的种群OfxDispnà
GjfmeES是一矩阵K包含每个变量的边界I参见dsusqJà
NvuPqu是一可选向量K具有两个参数的最大值à
NvuPquI�J是变异概率à如果缺省或为ObOK则NvuPquI�J��LOwbsK这里Owbs是
由tj{fIGjfmeESK�J定义的每个个体的变量数à这个值被选定K则表示每个个体的变异数
近似为�à
NvuPquI�J是P�K�Q之 间 的 一 个 量K压 缩 变 异 的 范 围à如 果 省 略 或 为 ObOK则 假 设
NvuPquI�J��I不压缩Jà格式�利用保存在矩阵PmeDispn中的当前种群K使用概率 NvuPquI�J附加的一个小
随机值I变异步长大小J变异每个变量K变异步长可由 NvuPquI�J限定à
nvuchb是低级变异函数K通常被nvubuf调用à
����

例�����使用函数nvuchb变异实值种群的应用举例à考虑以下具有三个实值个体的
种群M
PmeDispn�������� �������� ������� �������������� ������� ������� �������m�
n�
q�
r�������� ������� ������� �������
边界定义如下M
GjfmeES����� ��� ��� ���P Q��� �� �� ��
变异PmeDispn的变异概率为�L�K不压缩变异范围à
����OfxDispn � nvuchbIPmeDispnKGjfmeESKP�L����QJN
nvuchb产生一中间任务表 NvuNyK决定变异的变量K并为加入的efmub所标识I参看
算法Jà例如M
NvuNy�� � � �� � �� �m�
n�
q�
r�� � �� ��
第二个中间表efmub标识正常的变异步长大小à例如M
efmub������� ������ ������ ������������ ������ ������ ������m�
n�
q�
r������� ������ ������ ������
在变异后KOfxDispn成为
OfxDispn�������� �������� ������� �������������� ������� ������� �������m�
n�
q�
r�������� ������� ������� �������
OfxDispn�PmeDispn 显示变异的步长K即
OfxDispn�PmeDispn�� � � ������� � ������� �m�
n�
q�
r�� � ������� �������
算法说明M一个变量的变异是由以下计算得到的M
����nvubufewbsjbcmf�wbsjbcmf�NvuNy�sbof�NvuPh quI�J�efmub若具有概率 NvuPquI�JK则 NvuNy��K否则为�I�或�具有相等概率Jà
sbof�����h 变量的域I范围Jà
如果n���K概率为�LnK则bj��K否则为�à
使用n���K变异算子能定位最优值到精度为sbof�NvuPh quI�J�����à
变异算子nvuchb能在个体变量和变异范围定义的立方体中产生最多的点à这个测试
经常接近变量K即小步长概率大于大步长概率à参见MnvubufKsfdejtKsfdjouKsfdmjoà
����

�������函数sboljoh
功能M基于排序的适应度分配à格式M�GjuoW�sboljohIPckWJ
�GjuoW�sboljohIPckWKSGvoJ
�GjuoW�sboljohIPckWKSGvoKTVCQPQJ详细说明Msboljoh按照个体的目标值PckW由小到大的顺序对它们进行排序K并返回
一包含对应个体适应度值GjuoW的列向量à这个函数是从最小化方向对个体进行排序的à
SGvo是一任选向量K有�Ð�或mfouih IPckWJ个参数à如果SGvo是一在P�K�Q内的标量K则采用线性排序K这个标量指定选择的压差à如果SGvo是一具有两个参数的向量K则
� SGvoI�JM对线性排序K标量指定的选择压差SGvoI�J必须在P�K�Q之间N对非线
性排序KSGvoI�J必须在P�Kmfouih IPckWJ��Q之间à如果为ObOK则SGvoI�J假设为�à
� SGvoI�JM指定排序方法à�为线性排序K�为非线性排序à如果SGvo为长为mfouih IPckWJ的向量K则它包含对每一行的适应度值计算à如果省略SGvo或为ObOK则采用线性排序K选择压差假设为�à
TVCQPQ是一 任 选 参 数K指 明 在 PckW 中 子 种 群 的 数 量à如 果 省 略TVCQPQ或 为
ObOK则假设TVCQPQ��à在PckW中的所有子种群大小必须相同à如果sboljoh被调用于多子种群K则sboljoh独立地对每个子种群执行à例�����函数sboljoh的应用举例à下面为取不同参数时使用函数sboljoh对��个个
体的种群进行排序à考虑具有��个个体的种群K其当前目标值如下M
PcW�k P�����������������������������QU
I�J使用线性排序和选择压差为�估算适应度M
����GjuoW�sboljohIPckWJ
GjuoW�
������������������������������
������������������
�
m�
n�
q�
r�������
I�J使用非线性排序和选择压差为�估算适应度M
����GjuoW�sboljohIPckWKP��QJ
����

GjuoW�
������������������������������������������������������
m�
n�
q�
r�������I�J使用Sgvo中的值估算适应度M
����SGvo�P�����������������������������������Q
����GjuoW�sboljohIPckWKSGvoJ
GjuoW�
���������������
m�
n�
q�
r���I�J使用非线性排序K选择压差为�K在PckW中有两个子种群估算适应度M
GjuoW�
������������������������������������������������������
m�
n�
q�
r�������
��或��GjuoW�
������������������������������������
m�
n�
q�
r���������GjuoW�sboljohIPckWKP����QK�J算法说明M这个算法对线性和非线性排序K它首先对目标函数值进行降序排序à最小
适应度个体被放置在排序的目标函数值列表的第一个位置K最适应个体放置在位置 Ojoe上à这里Ojoe是种群中个体的数量à每个个体的适应度值根据它在排序种群中的位置Qpt计算出来à
����

对线性排序K其适应度值由下式计算M
GjuoWIQptJ���tq���Itq��J� Qpt��Ojoe������对非线性排序M
GjuoWIQptJ�Ojoe�YQpt��
��Ojoe
j��YIjJ
这里Y是多项式方程的方根M
�� Itq��J�YOjoe���tq�YOjoe�����tq�Y�tq����向量GjuoW是没有排序的K反映原始输入向量PckW的顺序à
参见MtfmfduKsxtKtvtà
��������函数sfdejt
功能M离散重组à格式MOfxDispn�sfdejtIPmeDispnJ详细说明Msfdejt完成当前种群PmeDispn中一对个体的离散重组K在交配后返回新
的种群OfxDispnàPmeDispn中每一行对应一个个体à交配的一对是有序的K奇数行与
它下一个偶数行配对à如果矩阵PmeDispn的行数是奇数K最后一个奇数行不交配并添加
到OfxDispn的末端à因此种群被组织成需要交配的连续对à通过使用函数sboljoh达到
计算每个个体的适应度水平K由选择函数I例如tfmfduJ在当前种群中用与按适应度相关的
概率选择个体à
sfdejt是一个低级重组函数K通常被函数sfdpncjo调用à例������离散重组函数sfdejt的应用举例à下面的程序代码为�个实值个体种群的离
散重组à考虑如下具有�个实值个体的种群M
PmeDispn�
����� ������ ����� ���������� ����� ����� ���������� ����� ����� ����������� ����� ���� �����
m�
n�
q�
r������� ������ ������ �����完成离散重组M
����OfxDispn�sfdejtIPmeDispnJ
sfdejt提供一中间掩码表决定哪些父个体为子代贡献哪些变量à例如M
Nbtl�
���������������������������������������
m�
n�
q�
r��重组后 OfxDispn成为
����

OfxDispn�
����� ����� ����� ���������� ����� ����� ����������� ����� ���� �����
m�
n�
q�
r������ ����� ���� �����
� nbtlI�JK�'�spx� nbtlI�JK�'�spx� nbtlI�JK�'�spx� nbtlI�JK�'�spx
由于在父种 群 PmeDispn 的 个 体 数 量 是 奇 数K最 后 一 个 个 体 不 参 加 重 组 而 附 加 到
OfxDispnK后代返回到用户空间K因此
OfxDispn�
����� ����� ����� ���������� ����� ����� ����������� ����� ���� ���������� ����� ���� �����
m�
n�
q�
r������� ������ ������ �����算法说明M离散重组是在个体间交换变量值K对每个变量K贡献给子代变量值的父亲
是随机地以相同的概率挑选的à离散重组产生父母定义的个体的所有可能à参见MsfdpncjoKsfdjouKsfdmjoKsboljohKtvtKsxtà
��������函数sfdjou
功能M中间重组à格式MOfxDispn�sfdjouIPmeDispnJ详细说明Msfdjou完成当前种群PmeDispn成对个体的中间重组K返回交配后的新种
群OfxDispnàPmeDispn中每一行对应一个个体à
sfdjou是一个只能应用于实值I非二进制Ð非整数J变量种群的函数à交配的对是有序的K奇行与它下一个偶行配对à如果PmeDispn的行数是奇数K最后
一个奇数行不参与交配K直接加到OfxDispn的末尾à因此种群根据交配要求组织成连续
的对à通过使用sboljoh计算每个个体的适应度水平K由选择函数I例如tfmfduJ用与适应度
相关的概率在当前种群中选择个体K完成这个重组工作à
sfdjou是一低级重组函数K通常被sfdpncjo调用à例������中间重组函数sfdjou的应用举例à下面的程序代码为具有�个实值个体的种
群的中间重组à考虑下面具有�个实值个体的种群M
PmeDispn������ ������ ����� ���������� ����� ����� �����m�
n�
q�
r������ ����� ����� �������� 父代�� 父代�� 父代�
执行中间重组M
OfxDispn�sfdjouIPmeDispnJ通过向最先的父个体增加不同微量产生新值K中间比率因子表Bmibq 被产生K例如M
Bmib������ ���� ���� ����
q P Q���� ���� ���� ������� 子代�� 子代�
因此K重组后的OfxDispn成为
����

����OfxDispn������ ����� ����� �����P Q����� ����� ����� ������
���Bmibq I�KNJK父�和
�Bm�
ibq I�KNJK父�和�
由于父 种 群 PmeDispn 的 个 体 数 是 奇 数K最 后 一 个 个 体 不 参 加 重 组 直 接 加 入
OfxDispnK因此返回用户空间的后代如下M
OfxDispn������ ����� ����� ���������� ����� ����� ������m�
n�
q�
r������ ����� ����� �����
算法说明M中间重组重组双亲值使用如下公式M
pggtsjoq h� bsfou��Bmq ibq Ibsfou��q bsfou�q J这里KBmibq 是在区间P�����K����Q内随机一致性选择产生的标量因子àsfdjou对重组的
每一对值产生一新的Bmibq à中间重组能产生略大于双亲定义的立体空间中的任意点à中间重组与线性重组sfdmjo相似à然而sfdjou对每对值使用了一新的Bmibq 值一起重
组K而sfdmjo对每对双亲使用一Bmibq 因子à参见MsfdpncjoKsfdejtKsfdmjoKsboljohKtvtKsxtà
��������函数sfdmjo
功能M线性重组à格式MOfxDispn�sfdmjoIPmeDispnJ详细说明Msfdmjo完成当前种群PmeDispn成对个体的线性重组K返回交配后的新种
群OfxDispnàPmeDispn中每一行对应一个个体à
sfdmjo是一个只能应用于实值I非二进制Ð非整数J变量种群的函数à交配的对是有序的K奇行与它下一个偶行配对à如果PmeDispn的行数是奇数K则最
后一个奇数行不参与交配K直接加到OfxDispn的末尾à因此种群根据交配要求组织成连
续的对à通过使用sboljoh计算每个个体的适应度水平K由选择函数I例如tfmfduJ用与适应
度相关的概率在当前种群中选择个体K完成这个重组工作à
sfdmjo是一低级重组函数K通常被sfdpncjo调用à例������函数sfdmjo的应用举例à下面的程序代码为具有�个实值个体的种群的线性
重组M
PmeDispn������ ������ ����� ���������� ����� ����� �����m�
n�
q�
r������ ����� ����� ��������父代��父代��父代�
执行线性重组M
����OfxDispn�sfdmjoIPmeDispnJ通过向最先的父个体增加不同微量产生新值K中间比率因子表Bmibq 被产生K例如M
Bmib�����
q P Q�������子代��子代�
����

因此K重组后的OfxDispn成为
OfxDispn������ ���� ����� �����P Q����� ����� ����� ������
��� Bmibq I�KNJK父�和
� Bm�
ibq I�KNJK父�和�由于父种群PmeDispn的个体数是奇数K最后一个个体不参加重组直接加入 OfxDispnK因此返回用户空间的后代如下M
OfxDispn������ ���� ����� ���������� ����� ����� ������m�
n�
q�
r������ ����� ����� �����算法说明M线性重组重组父值使用如下公式M
pggtsjoq h� bsfou��Bmq ibq H� Ibsfou��q bsfou�q J这里KBmibq 是在区间P�����K����Q内随机一致性选择产生的标量因子àsfdmjo对重组的
每一对双亲产生一新的Bmibq à线性重组能产生略大于双亲定义的线段中的任意点à线性重组sfdmjo与中间重组sfdjou相似à然而sfdmjo对每对双亲使用一Bmibq 因子一
起重组K而sfdjou对每对值使用了一新的Bmibq 值à参见MsfdpncjoKsfdejtKsfdjouKsboljohKtvtKsxtà
��������函数sfdnvu
功能M具有突变特征的线性重组à格式M� OfxDispn �sfdnvuIPmeDispnKGjfmeESJ
� OfxDispn �sfdnvuIPmeDispnKGjfmeESKNvuPquJ详细说明Msfdnvu完成当前种群PmeDispn成对个体的具有突变特征的线性重组K返
回交配后的新种群OfxDispnàPmeDispn中每一行对应一个个体à
GjfmeES是一矩阵K包含一个个体的每个变量的边界I参见dsusqJà
NvuPqu是一最多有两个参数的任选向量à
NvuPquI�J是 一 包 含 在P�K�Q范 围 内 的 重 组 概 率 的 标 量à如 果 省 略 或 为 ObOK则
NvuPquI�J假设为�à
NvuPquI�J是一 包 含 在P�K�Q范 围 内 用 于 压 缩 重 组 范 围 的 标 量 值à如 果 省 略 或 为
ObOK则 NvuPquI�J假设为�I不压缩Jà
sfdnvu是一个只能应用于实值I非二进制Ð非整数J变量种群的函数à交配的对是有序的K奇数行与它下一个偶数行配对à如 果 PmeDispn的 行 数 是 奇 数K
则最后一个奇数行不参与交配K直接加到OfxDispn的末尾à因此种群根据交配要求组织
成连续的对à通过使用sboljoh计算每个个体的适应度水平K由选择函数I例如tfmfduJ用与
适应度相关的概率在当前种群中选择个体K完成这个重组工作à
sfdnvu是一使用突变特征因子的遗传算法育种器I参见 nvuchbJà这个重组函数的调
用语法与突变函数nvuchb的语法相同à
sfdnvu是一低级重组函数K通常被nvubuf调用à例������函数sfdnvu的应用举例à下面为具有�个实值个体的种群的线性重组示例à
����

PmeDispn�
������� �������� ������� �������������� ������� ������� �������������� ������� ������� �������
m�
n�
q�
r��������� ������� ������ �������
��
�q��q��q��q�
边界定义如下M
GjfmeES����� ��� ��� ���P Q��� �� �� ��
执行下列具有突变特征的线性重组M
����OfxDispn�sfdnvuIPmeDispnKGjfmeESJ
sfdnvu产生一中间任务表SfdNyK决定哪些对双亲参加重组I这里全部参加J并记下
重组的步长à例如M
SfdNy�� �� �� ��P Q�� �� �� ��
��� �'q q�� �'q q�
两个更进一步的表efmub和Ejgg指出正常的重组步长M
efmub������� ������ ������ ������P Q������ ������ ������ ������
��� �'q q�� �'q q
Ejgg������� ������ ������� �������
�
P Q�������� ������ ������� ��������� �'q q�� �'q q�
����重组后OfxDispn成为
OfxDispn�
������� �������� ������� �������������� ������� ������� ��������������� ������� ������� �������
m�
n�
q�
r��������� ������� ������ �������算法说明M一对双亲的后代按如下方法计算M
pggtsjoq ��h bsfou�� SfdNy�sboq f�NvuPh quI�J�efmub�Ejggpggtsjoq ��h bsfou�� SfdNy�sboq f�NvuPh quI�J�efmub�I�EjggJ
其中
efmub���n��
j��bj��j
����SfdNy���K具有概率 NvuPquI�JI在这里为���JK否则为�à
sbof����h K为变量的域 I参看GjfmeES的定义Jà
bj��K具有概率�LnK否则为�K其中n���à
Ejgg� bsfou��q bsfou�q�� bsfou��q bsfou�q ��
这个重组算子产生其双亲I线性重组J定义方向的子代à它经常超出双亲定义的范围或
一个父亲定义的方向à子代的这点是由突变算子的特征定义的K小步长情况产生的概率要
比大步长产生的概率大I参看nvuchbJà参见MnvubufKnvuchbKsfdmjoà
����

��������函数sfdpncjo
功能M重组个体I高级函数Jà格式M� OfxDispn�sfdpncjoISFD_GKDispnJ
� OfxDispn �sfdpncjoISFD_GKDispnKSfdPquJ
� OfxDispn �sfdpncjoISFD_GKDispnKSfdPquKTVCQPQJ详细说明Msfdpncjo完成种群Dispn中个体的重组K在新种群OfxDispn中返回重
组后的个体àDispn和OfxDispn中的一行对应一个个体à
SFD_G是一包含低级重组函数名的字符串K例如sfdejt或ypwtqà
SfdPqu是一指明交叉概率的任选参数K如省略SfdPqu或为ObOK将设为缺省值à
TVCQPQ是一决定Dispn中子种群个数的可选参数K如果省略TVCQPQ或为ObOK则假设TVCQPQ��àDispn中的所有子种群必须有相同的大小à
例������函数sfdpncjo的应用举例à下面的程序代码为M首先产生�个个体的种群K然后利用函数sfdpncjo对该种群进行重组à
CbtfW����� ��� ��� ���P Q��� �� �� ��
��������Dispn�dsusqI�KCbtfWJN� 产生�个个体的种群
Dispn�
������� �������� �������� ������������� �������� ������ �������������� ������ ������� ������������� �������� ������� �������
m�
n�
q�
r�������� ������ ������� ��������
��������OfxDispn�sfdpncjoI�sfdejt�KDispnJN�� � 参数选取离散重组
OfxDispn�
������� �������� ������ �������������� �������� ������ �������������� ������ ������� ������������� ������ ������� ������
m�
n�
q�
r�������� ������ ������� ��������
��������OfxDispn�sfdpncjoI�ypwtq�KDispnJN�� � 参数选取单点交叉
OfxDispn�
������� �������� ������ �������������� �������� �������� ������������� ������ ������� �������������� �������� ������� ������
m�
n�
q�
r�������� ������ ������� ��������算法说明Msfdpncjo检测输入参数的一致性并调用低级重组函数à如果sfdpncjo调
用时具有多个子种群K则对每个子种群分别调用低级重组函数à参见MsfdejtKsfdjouKsfdmjoKypwtqKypweqKypwtiKnvubufKtfmfduà
����

��������函数sfjot
功能M重插入子代到种群à格式M�Dispn�sfjotIDispnKTfmDiJ
�Dispn�sfjotIDispnKTfmDiKTVCQPQJ
�Dispn�sfjotIDispnKTfmDiKTVCQPQKJotPquKPcWDik J
� PDispnKPcWDik Q�sfjotIDispnKTfmDiKTVCQPQKJotPquKPcWDik K
PcWTfmk J详细说明Msfjot完成插入子代到当前种群K用子代代替父代并返回结果种群à子代包
含在矩阵TfmDi中K父代在矩阵Dispn中KDispn和Tfmdi中每一行对应一个个体à
TVCQPQ是一可选参数K指明Dispn和TfmDi中子种群的个数à如果TVCQPQ省略
或为ObOK则假设TVCQPQ��à在Dispn和TfmDi中每个子种群必须具有相同大小à
JotPqu是一最多有两个参数的任选向量à
JotPquI�J是一标量K指明用子代代替父代的选择方法à�为均匀选择K子代代替父代
使用均匀 随 机 选 择à�为 基 于 适 应 度 的 选 择K子 代 代 替 最 小 适 应 的 个 体à如 果 省 略
JotPquI�J或为ObOK则假设JotPquI�J��à
JotPquI�J是一在P�K�Q间的标量K表示每个子种群中重插入的子代个体在整个子种
群中个体的比率à如果省略JotPquI�J或为ObOK则假设JotPquI�J����à如果JotPqu省略或为ObOK则JotPqu为缺省值à
PcWDik 是一可选的列向量K包含Dispn中个体的目标值à对基于适应度的重插入K
PcWDik 是必需的à
PcWTfmk 是一可选的列向量K包含Tfmdi中个体的目标值à如果子代的数量大于重插
入种群中的子代数量K则PcWTfmk 是必需的à在这种情况下K子代将按它们的适应度选择
插入à如果PcWDik 是一输出参数KPcWDik 和PcWTfmk 需要作为输入参数K随后目标被拷
贝K按照重插入的子代K保存为整修种群重新计算的目标值à例������函数sfjot的应用示例à下面的程序代码为在�个个体的父代种群中插入子
代种群à
����GjfmeES��P���K��K��K��N��K�K�K�QN��� 定义边界变量
GjfmeES����� �� �� ��P Q�� � � �
����Dispn�dsusqI�KGjfmeES�JN�� � 产生�个个体的父代种群
Dispn�
������� ������ ������ ������������� ������� ������� �������������� ������� ������ ������������ ������� ������ ������������ ������� ������ �������
m�
n�
q�
r������� ������ ������� ����������GjfmeES��P����K���K���K���N���K��K��K��QN�� � 定义边界变量
����

GjfmeES������ ��� ��� ���P Q��� �� �� ��
��������TfmDi�dsusqI�KGjfmeES�JN�� � 产生�个个体的子代种群
TfmDi��������� ������� ������� �������P Q�������� �������� ������� ��������
插入所有子代到种群中M
����Dispn �sfjotIDispnKTfmDiJ这个新种群Dispn产生M
Dispn�
������� ������ ������ ������������� ������� ������� ��������������� �������� ������� �������������� ������� ������ �������������� ������� ������� �������
m�
n�
q�
r������� ������ ������� ������为父种 群 Dispn 考 虑 如 下 目 标 值PcWDik 向 量K为 子 代 Tfmdi考 虑 如 下 目 标 值
PcWTfmk 向量M
����PcWDi�k P��N��N��N��N��N��QN
����PcWTfm�k P��N��QN基于适应度插入所有子代代替最不适应的父个体à
����Dispn�sfjotIDispnKTfmDiK�K�KPcWDik JN
Dispn�
������� ������ ������ ������������� ������� ������� �������������� ������� ������ ������������ ������� ������ �������������� �������� ������� ��������
m�
n�
q�
r��������� ������� ������� �������基于适应度插入���的子代K并按插入的子代拷贝目标值M
����PDispnKPcWDik Q�sfjotIDispnKTfmDiK�KP����QKPcWDik KPcWTfmk J
����PcWDi�k P��N��N��N��N��N��Q
Dispn�
������� ������ ������ ������������� ������� ������� �������������� ������� ������ ������������ ������� ������ ������������ ������� ������ �������
m�
n�
q�
r��������� ������� ������� �������利用函数sfjotK将两个子种群Dispn和Tfmdi插入到当前种群à
����Dispn�sfjotIDispnKTfmDiK�J
����

Dispn�
������� ������ ������ �������������� ������� ������� �������������� ������� ������ ������������ ������� ������ ������������ ������� ������ �������
m�
n�
q�
r��������� �������� ������� ��������参见Mtfmfduà
��������函数sfq
功能M矩阵复制à格式MNbuPvu�sfqINbuJoKSFQOJ详细说明Msfq是一个低级复制函数K通常不直接使用K它可被HB工具箱中许多函数
调用à
sfq完成 矩 阵 NbuJo的 复 制K指 明 复 制 次 数 SFQOK返 回 复 制 后 的 矩 阵 NbuPvuà
SFQO包含每个方向的复制次数àSFQOI�J指明纵向复制次数KSFQOI�J指明水平方向
复制次数à例������矩阵复制函数sfq的应用示例à考虑以下矩阵 NbuJoM
NbuJo��������������������P Q�
执行下列复制MI�JNbuPvu�sfqINbuJoKP����QJN
NbuPvu��������������������������������������������������������P Q�
I�JNbuPvu�sfqINbuJoKP����QJN
NbuPvu�
���������������������������������������
m�
n�
q�
r��I�JNbuPvu�sfqINbuJoKP����QJN
NbuPvu�
���������������������������������������������������������������������������������������������������������������������������������������
m�
n�
q�
r��
��������函数sxt
功能M轮盘赌选择à格式MOfxDisJy�sxtIGjuoWKOtfmJ详细说明Msxt在当前种群中按照它们的适应度GjuoW选择Otfm个个体繁殖à
OfxDisJy�sxtIGjuoWKOtfmJ使 用 轮 盘 赌 选 择 从 一 个 种 群 中 选 择 Otfm个 个 体à����

GjuoW是一包含种群中每个个体性能尺寸的列向量K它能通过使用函数sboljoh或tdbmjoh计算每个个体的适应度水平来得到à返回值OfxDisJy是为育种选择的个体的索引值K按
照它们的选择顺序排列K这些选择的个体能通过评估函数DispnIOfxDisJyKMJ恢复à
sxt是一低级选择函数K通常被tfmfdu调用à例������轮盘赌选择方法示例à考虑�个个体的种群K假设已计算出适应度GjuoWM
����GjuoW�P����N����N����N����N����N����N����N���Q选择�个个体的索引M
����OfxDisJy�sxtIGjuoWK�J
OfxDisJy成为
OfxDisJy�
m�
n�
q�
r�
������
算法说明M通过计算适应度向量的累加和完成轮盘赌选择的表格K并产生随机分布在
P�KtvnIGjuoWJQ区间内的Otfm个实数K被选择个体的索引通过比较向量累加和产生的编
号来决定à一个个体被选择的概率由下式给出M
GIyjJ�gIyjJ
��Ojoe
j��gIyjJ
这里KgIyjJ是个体yj 的适应度KGIyjJ是这个个体被选择的概率à参见MtfmfduKtvtKsfjotKsboljohKtdbmjohà
��������函数tdbmjoh
功能M线性适应度计算à
格式MGjuoW�tdbmjohIPckWKTnvmJ详细说明Mtdbmjoh转换一种 群 的 目 标 值 PckW为 由Tnvm的 值 决 定 上 界 的 适 应 度 值à
例如M
GIyjJ�bgIyjJ�c
这里gIyjJ是个体yj 的适应度Kb是一标量系数Kc是一偏移值KGIyjJ是这个个体产生的
适应度值à
如果gbwf是当前代中目标值的平均值K种群中最大适应度值是上界gbwfðTnvmK如果
省略tnvmK则tnvm假设为�K这个种群的平均适应度值也为gbwfà例������目标函数值的线性适应度计算示例àI�JPcW�k P�N�N�N�N�N�Q
����GjuoW�tdbmjohIPckWJ
����

GjuoW�
������������������������
�m�
n�
q�
r�������在一些情况下K一些目标值是负的Ktdbmjoh试图提供偏移值cK确保计算适应度值大
于�àI�JPcW�k P�N�N�N�N�N��N�N�Q
����GjuoW�tdbmjohIPckWJ
efmub�������Nb�������Nc�������à
GjuoW�
�������������������������������������������
m�
n�
q�
r�������算法说明Mtdbmjoh使用Hpmecfsh描述的线性比率法à注意M线性比率不适合目标函数返回负的适应度值的情形à参见MsboljohKsfjotKsxtKtfmfduKtvtà
��������函数tfmfdu
功能M从种群中选择个体I高级函数Jà格式M�TfmDi�tfmfduITFM_GKDispnKGjuoWJ
�TfmDi�tfmfduITFM_GKDispnKGjuoWKHHBQJ
�TfmDi�tfmfduITFM_GKDispnKGjuoWKHHBQKTVCQPQJ详细说明M利用函数tfmfdu从种群Dispn中选择优良个体K并将选择的个体返回到新
种群TfmDi中KDispn和TfmDi中每一行对应一个个体à
TFM_G是一字符串K包含一低级选择函数名K如sxt或tvtà
GjuoW是一列向量K包含种群Dispn中个体的适应度值à这个适应度值表明了每个个
体被选择的预期概率à
HHBQ是一可选参数K指出了代沟K部分种群被复制à如果HHBQ缺省或为ObOK则
HHBQ假设为���àHHBQ也可大于�K允许子代数多于父代的数量K如Dispn超过一个
子种群KHHBQ指明每个子种群被选择的个体数量是与子种群的大小有关的à
TVCQPQ是一 可 选 参 数K决 定 Dispn 中 子 种 群 的 数 量à如 果TVCQPQ省 略 或 为
ObOK则TVCQPQ��àDispn中所有子种群必须有相同的大小à例������函数tfmfdu的应用举例à考虑以下具有�个个体的种群DispnK适应度值为
����

GjuoWM
Dispn�
� �� ��� �� ��� �� ��� �� ��� �� ��� �� ��� �� ��
m�
n�
q�
r�� �� ������GjuoW�P����N����N����N����N����N����N����N���Q
使用随机遍历抽样tvt选择�个个体M
����TfmDi�tfmfduI�tvt�KDispnKGjuoWJ
TfmDi成为
Tfmdi�
� �� ��� �� ��� �� ��� �� ��� �� ��� �� ��� �� ��
m�
n�
q�
r�� �� ������假设Dispn由 两 个 子 种 群 组 成K通 过 轮 盘 赌 选 择tvt对 每 个 子 种 群 选 择����的
个体à
����GjuoW�P����N����N����N����N����N����N����N���Q
����TfmDi�tfmfduI�tvt�KDispnKGjuoWK���K�J
TfmDi变成
Tfmdi�
� �� ��� �� ��� �� ��� �� ��� �� ��� �� ��� �� ��� �� ��� �� ��� �� ��� �� ��
m�
n�
q�
r�� �� ��算法说明Mtfmfdu检测输入参数的一致性并调用低级选择函数K如果调用tfmfdu使用
����

多子种群K则低级选择函数分别被各子种群调用à参见MsxtKtvtKsboljohKtdbmjohKsfdpncjoKnvubufà
��������函数tvt
功能M随机遍历抽样à格式MOfxDisJy�tvtIGjuoWKOtfmJ详细说明Mtvt按 照 个 体 在 当 前 种 群 中 的 适 应 度GjuoW 为 繁 殖 概 率 性 选 择 Otfm个
个体à
OfxDisJy�tvtIGjuoWKOtfmJ使用随机遍历抽样从种群选择Otfm个个体àGjuoW是
一列向量K包含种群中个体的适应度值K它可通过函数sboljoh或tdbmjoh计算种群中个体
适应度水平得到à返回值OfxDisJy是为培养选择的个体索引值K是按它们选择的顺序排
列的à这个选择的个体可通过评估DispnIOfxDisJyKMJ恢复à
tvt是一低级选择函数K通常被tfmfdu调用à例������随机遍历抽样函数tvt的应用举例à考虑以下具有�个个体的种群DispnK
适应度值为GjuoWM
����GjuoW�P����N����N����N����N����N����N����N���Q选择�个个体的索引M
����OfxDisJy�tvtIGjuoWK�J
OfxDisJy成为
OfxDisJy�
m�
n�
q�
r�
������
算法说明M通过获得适应度向量GjuoW的累加和完成随机遍历抽样的表格K产生Otfm个在P�KTVNIGjuoWJQ内的相等空间编号à因为只有一个随机数产生K所以其他使用是来
自那些点的相等空间à被选择个体的索引是通过比较产生的数与向量累加和来决定的à一
个个体被选择的概率由下式给出M
GIyjJ�gIyjJ
��Ojoe
j��gIyjJ
这里KgIyjJ是个体yj 的适应度KGIyjJ是这个个体被选择的概率à参见MtfmfduKsxtKsfjotKsboljohKtdbmjohà
��������函数ypweq
功能M两点交叉à格式MOfxDispn �ypweqIPmeDispnKYPWSJ详细说明Mypweq完成当前种群PmeDispn中一对个体按交叉概率YPWS进行交叉K
����

返回交配后的新种群OfxDispnàPmeDispn和OfxDispn的一行对应一个个体K它可用
于任何染色体表示à
YPWS是一可选参数K说明交叉概率K如果省略Ð空或为ObOK则假设YPWS����à交配的对是有序的K即奇行与它下一个偶行配对à如果矩阵PmeDispn行数是奇数行K
则最后一行不参加交配K因此K种群将按交配要求组织成连续的对à这可使用函数sboljoh计算每个染色的适应度K并由选择函数ItfmfduKtvt或sxtJ在种群中用与适应度相关的概
率选择个体来完成à
ypweq是一低级交叉函数K通常被函数sfdpncjo调用à例������两点交叉函数ypweq的应用举例à下面的程序代码为M首先创建初始种群K
然后利用函数ypweq进行两点交叉à
����Dispn�dsucqI�K�JN��� 创建初始种群
Dispn�
�������������������������������������������������������������������������������
m�
n�
q�
r������OfxDispn�ypweqIDispnK���JN运行后得
OfxDispn�
�������������������������������������������������������������������������������
m�
n�
q�
r��算法说明M考虑下面两个相同长度的二进制串M
����B��P������Q
����B��P������Q两点交叉包括选择两个均匀分布的随机整数l�Kl�K在P�KmfohIB�JQ范围内Ð在B�
和B�间交换l���到l�之间的各变量K如果这个交叉l���Kl���K则B�KB�成为
����B�H�� P������Q
����B�H�� P������Q
ypweq用适当的参数调用ypwnqà参见Mypwestq KypwtqKypwtiKypwnqKsfdpncjoKtfmfduà
��������函数ypwestq
功能M减少代理的两点交叉à格式MOfxDispn �ypwestq IPmeDispnKYPWSJ详细说明Mypwestq 在当前种群PmeDispn一对个体间按交叉概率YPWS进行减少代
理两点交叉K并返回交配后的新种群OfxDispnà在PmeDispn和OfxDispn中每一行对
应一个个体à它适用于任意染色体表示à����

YPWS是一可选参数K指明交叉概率K如果省略Ð空或为ObOK则设YPWS����à交配的对是有序的K即奇行与它下一个偶行配对à如果矩阵PmeDispn行数是奇数行K
则最后一行不参加交配K因此K种群将按交配要求组织成连续的对à这可使用函数sboljoh计算每个染色体的适应度K并由选择函数ItfmfduKtvt或sxtJ在种群中用与适应度相关的
概率选择个体来完成à
ypwestq 是一低级交叉函数K通常被函数sfdpncjo调用à例������减少代理的两点交叉函数ypwestq 的应用举例à下面的程序代码为�个个体
种群的两点交叉示例M
����Dispn�dsucqI�K�JN�� �创建初始种群
Dispn�
�������������������������������������������������������������������������������
m�
n�
q�
r��
�� �� ��个个体的种群
����OfxDispn�ypwestq IDispnK���JN运行后得
OfxDispn�
�������������������������������������������������������������������������������
m�
n�
q�
r��算法说明M参见两点交叉函数ypweqà交叉对任何可能点总是产生新个体K减少代理算子限制它à它通过限制交叉点的位置
来完成K例如K交叉点只能发生在基因不同的地方à
ypwestq 使用适当参数调用ypwnqà参见MypweqKypwtstq KypwtistKypwnqKsfdpncjoKtfmfduà
��������函数ypwnq
功能M多点交叉à格式MOfxDispn �ypwnqIPmeDispnKYPWSKOquKStJ详细说明Mypwnq在当前种群PmeDispn成对个体间多点交叉K并返回交配后的新种
群OfxDispnà在PmeDispn和OfxDispn中 每 一 行 对 应 一 个 体à它 适 用 于 任 意 染 色 体
表示à
YPWS是一可选参数K指明交叉概率K如果省略Ð为空或ObOK则设YPWS����à
Oqu是一可选参数K指明交叉点数à��洗牌交叉N��单点交叉N��两点交叉à如果省
略或为ObOK则假设Ou��q à
St是一可选参数K指明使用减少代理à��不减少代理N��减少代理à如果省略Ð空或
为ObOK则设St��à交配的对是有序的K即奇行与它下一个偶行配对à如果矩阵PmeDispn行数是奇数行K
����

则最后一行不参加交配K因此K种群将按交配要求组织成连续的对à这可使用函数sboljoh计算每个染色体的适应度K并由选择函数ItfmfduKtvt或sxtJ在种群中用与适应度相关的
概率选择个体来完成à
ypwnq是一低级交叉函数K通常被其他交叉函数调用à如果被sfdpncjofÐypwnq调
用执行没有减少代理的洗牌交叉K则等同于ypwtià例������多点交叉函数ypwnq的应用示例à下面的程序代码为�个个体种群的多点
交叉示例M
����Dispn�dsucqI�K�JN���� � 创建初始种群
Dispn�
�������������������������������������������������������������������������������
m�
n�
q�
r��
���� ��个个体的种群
OfxDispn�ypwnqIDispnK���K�K�JN运行后得
OfxDispn�
�������������������������������������������������������������������������������
m�
n�
q�
r��算法说明M多点交叉函数的使用可参考单点交叉ypwtqÐ两点交叉ypweq和洗牌交叉
ypwtiK也可参 考 具 有 减 少 代 理 的 单 点 交 叉 ypwtstq Ð两 点 交 叉 ypwestq 和 洗 牌 交 叉
ypwtistà参见MypwtqKypweqKypwtiKypwtstq Kypwestq KypwtistKsfdpncjoà
��������函数ypwti
功能M洗牌交叉à格式MOfxDispn �ypwtiIPmeDispnKYPWSJ详细说明Mypwti在当 前 种 群 PmeDispn一 对 个 体 间 按 交 叉 概 率YPWS进 行 洗 牌 交
叉K并返回交配后的新种群OfxDispnà在PmeDispn和OfxDispn中每一行对应一个个
体à它适用于任意染色体表示à
YPWS是一可选参数K指明交叉概率K如果省略Ð为空或ObOK则设YPWS����à交配的对是有序的K即奇行与它下一个偶行配对à如果矩阵PmeDispn行数是奇数行K
则最后一行不参加交配K因此K种群将按交配要求组织成连续的对à这可使用函数sboljoh计算每个染色体的适应度K并由选择函数ItfmfduKtvt或sxtJ在种群中用与适应度相关的
概率选择个体来完成à
ypwti是一低级交叉函数K通常被函数sfdpncjo调用à例������洗牌交叉函数ypwti的应用举例à下面的程序代码为�个个体种群的洗牌交
叉示例M����

��Dispn�dsucqI�K�JN����� 创建初始种群
Dispn�
�������������������������������������������������������������������������������
m�
n�
q�
r��
������个个体的种群
��OfxDispn�ypwtiIDispnK���JN运行后得
OfxDispn�
�������������������������������������������������������������������������������
m�
n�
q�
r��算法说明M洗牌交叉是一种单点交叉K但在位交换之 间K它 们 可 在 双 亲 间 随 意 洗 牌à
在重组后K子代的各位是没有洗牌的K这种移位就像在每次交叉时K位可任意再分配à
ypwti使用适当的参数调用ypwnqà参见MypwtistKypwtqKypweqKypwnqKsfdpncjoKtfmfduà
��������函数ypwtist
功能M减少代理的洗牌交叉à格式MOfxDispn �ypwtistIPmeDispnKYPWSJ详细说明Mypwtist在当前种群PmeDispn一对个体间按交叉概率YPWS进行减少代
理的洗牌交叉K并返回交配后的新种群OfxDispnà在PmeDispn和OfxDispn中每一行
对应一个体à它适用于任意染色体表示à
YPWS是一可选参数K指明交叉概率K如果省略Ð为空或ObOK则设YPWS����à交配的对是有序的K即奇行与它下一个偶行配对à如果矩阵PmeDispn行数是奇数行K
则最后一行不参加交配K因此K种群将按交配要求组织成连续的对à这可使用函数sboljoh计算每个染色体的适应度K并由选择函数ItfmfduKtvt或sxtJ在种群中用与适应度相关的
概率选择个体来完成à
ypwtist是一低级交叉函数K通常被函数sfdpncjo调用à例������减少代理的洗牌交叉函数ypwtist的应用举例à下面的程序代码为�个个体
种群的减少代理的洗牌交叉示例M
����OfxDispn�dsucqI�K�JN����� 创建初始种群
Dispn�
�������������������������������������������������������������������������������
m�
n�
q�
r��
���� ��个个体的种群
����OfxDispn�ypwtistIDispnK���JN����

运行后得
OfxDispn�
�������������������������������������������������������������������������������
m�
n�
q�
r��算法说明M洗牌交叉算法参见ypwtià交叉对任何可能点总是产生新个体K减少代理算子限制它à它是通过限制交叉点的位
置来完成的K例如K交叉点只能发生在基因不同的地方à
ypwtist使用适当参数调用ypwnqà参见MypwtiKypwtstq Kypwestq KypwnqKsfdpncjoKtfmfduà
��������函数ypwtq
功能M单点交叉à格式MOfxDispn�ypwtqIPmeDispnKYPWSJ详细说明Mypwtq完成当前种群PmeDispn中一对个体按交叉概率YPWS进行单点交
叉K返回交配后的新种群OfxDispnàPmeDispn和OfxDispn的一行对应一个个体K它
可用于任何染色体表示à
YPWS是一可选参数K说明交叉概率K如果省略Ð空或为ObOK则假设YPWS����à交配的对是有序的K即奇行与它下一个偶行配对à如果矩阵PmeDispn行数是奇数行K
则最后一行不参加交配K因此K种群将按交配要求组织成连续的对à这可使用函数sboljoh计算每个染色体的适应度K并由选择函数ItfmfduKtvt或sxtJ在种群中用与适应度相关的
概率选择个体来完成à
ypwtq是一低级交叉函数K通常被函数sfdpncjo调用à例������单点交叉函数ypwtq的应用举例à下面的程序代码为M首先创建�个个体的
种群K然后利用函数ypwtq进行单点交叉M
����Dispn�dsucqI�K�JN����� 创建�个个体的种群
Dispn��������������������������������������������P Q�
����OfxDispn�ypwtqIDispnK���JN�� � 交叉概率为���则Dispn成为
OfxDispn��������������������������������������������P Q�
����OfxDispn�ypwtqIDispnK�JN��� 交叉点l��则Dispn成为
OfxDispn��������������������������������������������P Q�
算法说明M考虑下面两个相同长度的二进制串M
����B��P������Q����

����B��P������Q单点交叉包括选择一个均匀分布的随机整数lK在P�KmfohIB�J��Q间Ð在B�和B�
间交换l��到mfohIB�J之间的各变量K如果这个交叉l��K则B�KB�成为
����B�H��P������Q
����B�H��P������Q
ypwtq使用适当的参数调用ypwnqà参见Mypwtstq KypweqKypwtiKypwnqKsfdpncjoKtfmfduà
��������函数ypwtstq
功能M减少代理的单点交叉à格式MOfxDispn �ypwtstq IPmeDispnKYPWSJ详细说明Mypwtstq 在当前种群PmeDispn一对个体间按交叉概率YPWS进行减少代
理的单点交叉K并返回交配后的新种群OfxDispnà在PmeDispn和OfxDispn中每一行
对应一个体à它适用于任意染色体表示à
YPWS是一可选参数K指明交叉概率K如果省略Ð空或为ObOK则设YPWS����à交配的对是有序的K即奇行与它下一个偶行配对à如果矩阵PmeDispn行数是奇数行K
则最后一行不参加交配K因此K种群将按交配要求组织成连续的对à这可使用函数sboljoh计算每个染色体的适应度K并由选择函数ItfmfduKtvt或sxtJ在种群中用与适应度相关的
概率选择个体来完成à
ypwtstq 是一低级交叉函数K通常被函数sfdpncjo调用à例������减少代理的单点交叉函数ypwtstq 的应用举例à下面的程序代码为�个个体
种群的减少代理的单点交叉示例I交叉概率为���JM
����Dispn�dsucqI�K�JN��� 创建�个个体的种群
Dispn��������������������������������������������P Q�
����OfxDispn�ypwtstq IDispnK���JN�� � 交叉概率为���则Dispn成为如下形式M
OfxDispn��������������������������������������������P Q�
算法说明M单点交叉参见ypwtqà交叉对任何可能点总是产生新个体K减少代理算子限制它à它是通过限制交叉点的位
置来完成的K例如K交叉点只能发生在基因不同的地方à
ypwtstq 使用适当的参数调用ypwnqà参见MypwtqKypweqKypwestq KypwtiKypwtistKypwnqKsfdpncjoKtfmfduà
����

书书书
ðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀ
ðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀ
�
��
���第六章��遗传算法工具箱的应用��
本章主要介绍英国设菲尔德大学开发的遗传算法工具箱的使用方法à这个遗传
算法工具箱已经在世界上近��个广泛的应用领域得到了很好的测试K包括参数优
化Ð多目标优化Ð控制器结构选择Ð非线性系统论证Ð形形色色模式的模型制作Ð神
经网络设计Ð实时和自适应控制Ð并行遗传算法Ð故障诊断和天线设计等à
�����安����装
遗传算法工具箱的安装过程可以参照 NBUMBC的安装说明进行à建议将工具箱中的
文件保存在 NBUMBC或工具箱主目录下名为 fofujdh 的子目录中à工具箱包含许多可用的示例à例如K示例 N 文件tb�nh 是解决数值优化问题的单种
群二进制编码的遗传算法à示例 N 文件 qhb�nn 是解决动态控制问题的多种群十进制实
数编码的遗传算法à这两个示例 N文件将在第七章进行详细的讨论à另外K来自遗传算法著作的一套测试函数在一个从遗传算法工具箱函数中分离出来的
目录uftu�got中提供K这些测试函数的摘要性描述在最后给出à此外K还有一个文档描述
了这些函数的实现和使用à
�����种群的表示和初始化
遗传算法同时运算在由已编码的参数集组成的称为种群的大量可能答案上à典型的一
个种群由��Y���个个体组成K一些变化的称为微型的遗传算法采用很小的��个个体的
种群K使用有限制的复制和代替策略以试图达到实时运算à一般情况下K在遗传算法中大多数采用单层的二进制串染色体表示方法à这里K参数
集中的每一个决策变量被编码为一个二进制串K它串接起来形成一个染色体à这里采用格
雷码K可用来克服传统 的 二 进 制 表 示 方 法 的 不 足àDbsvbob和Tdibggfs的 经 验 证 明 显 示K表示图中邻近值间过大的海明IIbnnjohJ距离使用标准的二进制表示情况下K搜索过程
易导致欺骗性结果或不能有效定位于全局最小值àTdinjufoepshg等更进一步的方法是在
二进制编码的染色体变换到实际的表示值时使用对数计量à尽管参数值的精度可能低于希
望的范围K但在问题中K可行参数的传播是未知的K一个大的搜索空间中可能掩藏着大量
相同的位K与线性映像方案允许的搜索未知搜索空间的计算负担相比K可减少到更易管理
的水平à与此同时K二进制编码的遗传算法使用更广泛K同时引起更多兴趣的可选择的编码方
案K有整数和实数表示à对一些问题域K有一个争论是二进制表示事实上是靠不住的K它
����

掩盖了搜索的自然性à例如在选择子集问题中K使用整数表示法为搜索表提供方便和自然
表示方法映射为对问题域的表示à
Xsjiuh 声称使用实值基因的遗传算法在数值函数优化上与二进制编码相比有许多的
优点à在函数计算前K不需要从染色体到表现值的转换K提高了遗传算法的效率N计算机
内部高效的浮点表示可直接使用K减少了内存需求N相对于离散的二进制或其他值K没有
精度损失N对使用不同的遗传算子非常自由àNjdibmfxjd{在其著作�进化策略IFwpmvujpoTusbufjfth J�中描述了使用实值编码的细节à
有了确定的表示K简单遗传算法的第一步是建立初始种群K使用在希望的范围内均匀
分布数字的随机数产生器生成所需数量的个体à例如K使用有Ojoe个个体的二进制种群K染色体 长 度 为Mjoe 位K从 集R�K�S中 产 生 Ojoe�Mjoe 个 均 匀 分 布 随 机 数à一 个 变 化 是
Csbnmfuuf的扩展随机的初始步骤K无论如何K大量的随机初始化IJojujbmj{bujpotJ为每个个
体尝试K它们中性能最好的被选择为初始种群K另外一些遗传算法用户使用初始种群的一
些已知为接近全局最小化的个体播种à当然K这种接近法仅仅适用于自然问题K是易于事
前了解的或遗传算法用于与基本知识系统相联合的à这个遗传算法工具箱支持二进制Ð整数和浮点的染色体表示à二进制和整数种群初始
化可使用工具箱函数dsucq创建二进制种群à附加函数dsucbtf提供向量描述的整数表示
法à实值种群的初始化可使用函数dsusq完成K程序ct�sw提供二进制串和实值之间的转
换K它支持使用格雷码和对数编码à
�����目标函数和适应度函数
目标函数将提供一测量手段K测量个体在问题域的完成情况à在一个最小化问题中K最适合的个体对应最小的目标函数值à未经加工的适应度值通常只用在遗传算法的中期来
判断一个个体的相对性能à另一函数���适应度函数通常用于转换目标函数值为相对适应
度值à因此K有
GIyJ�hgIyJ
这里g是目标函数Kh是将目标函数值转换为非负值的变换因子KG是所得的相对适应度K当目标函数是最小化即函数值越小对应适应度越好的个体时K这种变换是必需的à许多情
况下K适应度函数值对应大量子代���预计在下一代中能存在的个体à通常使用这个转换
进行适应度概率分配à个体的适应度���每一个个体的GIyjJ通过个体的未加工的适应度
gIyjJ相对整个种群的适应度被计算出来K即
GIyjJ�gIyjJ
��Ojoe
j��gIyjJ
I���J
式中KOjoe是种群大小Kyj 是个体j的表现值K与此同时适应度分配确保每一个体均有按其
相对适应度再生的机会K它不能处理负的目标函数值à使用水平移位的线性变换是优先使用的适应度分配方法à
GIyJ�bðgIyJ�c I���J
����

����如果优化方法是最大化K这里b是一个正的换算系数N如果是最小化K则b是一个负
值àc是一个偏移值K它确保最后的适应度值是非负的à无论如何K上面给出的线性尺度变换和移位方法易迅速收敛à这个选择算法选择个体
进行再生是基于它们的相对适应度的à使用线性尺度变换K预期的后代将近似与它们性能
相称I成比率JK如果说没有限制个体在给出代中的性能K则在上代中高适应度的个体将决
定再生过程引起快速收敛K可能产生局部最优解à同样K如果种群有很少变异K这种变换
仅仅向最合适的个体提供小偏移à
Cblfs认为通过限制再生范围K以使个体不产生极端的后代K防止过早收敛à这里个
体是根据它们在种群 中 的 排 序 计 算 适 应 度à一 个 变 量 NBY 常 常 用 来 决 定 偏 移 或 选 择 强
度K最适合的个体和其他个体的适应度由下面的规则决定M
������������NJO�����NBY������������JOD�����INBY����JLOjoe������������MPX�JODL���
这里KNJO 是下界KJOD是邻近个体适应度的差别KMPX 是最小适应度个体预期的试验
值I一定选择代数JKNBY是在区间P���K���Q中的典型精选值à因此K如果种群大小Ojoe为��KNBY����K我们将获得NJO����KJOD�����KMPX������à种群中个体的适
应度能被直接计算出M
GIyjJ���NBY��INBY��Jyj��Ojoe ��
I���J
式中Kyj 是个体j在有序种群中的位置à尽管工具箱提供大量的 N文件例子K用于完成通用的测试功能K但目标函数必须由用
户创建à这些目标函数都有文件名前缀pckK这个工具箱支持线性和非线性两种评定法K包
括一个简单的线性尺度变换函数tdbmjohK较为完备à需要注意的是K线性尺度变换函数不
适合于目标函数产生负的适应度值的情况à
�����选����择
选择是由遗传代数或试验值决定的过程à一个特殊的个体为再生被挑选K确定编码子
代中的一个个体被产生K这种个体的选择可以看做两个分离的过程MI�J决定试验的代数和希望接收的个体àI�J转换预期的试验数为大量离散的子代à第一部分所关心的是转换原始的适应度值为个体再生机率的预期的实值和处理使用前
一小部分的适应度计算à第二部分是基于一个个体相对另一个体的适应度为再生进行的个
体概率选择K有时是由抽样而已知的à这一小部分的剩余部分将回顾现行使用的更为流行
的选择方法à
Cblfs为选择算法展现了性 能 的 三 种 措 施���偏 差ICjbtJÐ个 体 扩 展ITsfbeq JÐ效 率
IFggjdjfodzJàCjbt被定义为个体的实际值与预期的选择概率之间的绝对差值à因此当个体
的选择概率等于它的预期试验值时K获得最优零偏差àTsfbeq 是个体可能达到的一个可能
实验子代数的范围K如果gIjJ是个体j收到的实际实验代数K则最小个体扩展就是最小的
����

Tsfbeq K即理论上允许零偏差à
gIjJ�� RPfuIjJQKPfuIjJQS
这里KfuIjJ是个体j的预期实验代数KPfuIjJQ表示下限KPfuIjJQ表示上限à因此K当Cjbt是一个精确的指示时K可选择方法的个体扩展来测量它的一致性IDpotjtufodzJà
获得有效选择方法的要求是由必须保持遗传算法全面的时间复杂度决定的à在一些著
作中显示出遗传算法的另一些方面I除实际的目标函数评估JK即PIMjoe�OjoeJ或更好的时
间复杂度K这里Mjoe是个体长度KOjoe是种群的大小à由这个选择算法而得到零偏差K与此
同时保持了最小个体扩展K但对于改进这个遗传算法的时间复杂度不会有任何作用à下面
介绍两种选择方法à
图�����轮盘赌选择
��轮盘赌选择算法
许多的选择技术采用轮盘赌原理K个体的选择概率是基于
它们的性能进行的一些计算à实值范围���总和是所有个体期
望的选择概率的总和或当前种群中所有个体原始适应度值的总
和à个体采用一对一方式映像到范围P�KTvnQ的一连续区间K每一个体区间的大小与对应个体的适应度值相匹配à如图���所示K轮盘赌轮的周长是�个个体适应度值的总和K个体�是
最大适应度个体K它占有最大的区间K而个体�和�是最小适
应度个体K相对应 地 在 轮 盘 上 占 有 小 的 区 间à选 择 一 个 个 体K用在P�KTvnQ间产生随机数K看此随机数处在哪个个体的区间
上K则此个体被选中à重复此过程K直到所需数量个体被选中为止à这个基本的轮盘赌选择方法是可代替的随机抽样ITTSJà在这里片段大小和选择概率
在整个选择阶段保持相同K个体的选择根据上面的步骤完成àTTS给出了零偏差但可能是
无限的个体扩展K段长大于零的任意个体完全可能填入下一种群à局部替换的随机抽样ITTQSJ是在TTS上扩充而来的K如果一个个体被选择K则重新
建立它的段大小à个体被选择一次K其段长被减小�K如果段长变为负K则设为零à这里提
供一个体扩展上界PfuIjJQK无论如何低界为零K偏差ICjbtJ都是大于TTS的à剩余抽样法解决了两个不同方面的问题àI�J在整数方面K个体的选择决定于期望试验的整数部分K剩余个体的选择概率来自
于个体们期望值的小数部分à替换的剩余随机抽样ISTTSJ采用轮盘赌选择K对抽样的个
体并不重新赋值àI�J在轮盘赌选择期间K个体的小数部分保持不变K随后在�Tjotq �间竞争选择àSTTS
提供零偏差和具有下界的个体扩展K上界被指定代的参与分配样本部分和一个个体的整数
部分大小限定à例如K任何一个小数部分大于零的个体将在分级I小数J阶段的所有抽样中
取胜à如果一个个体在小数阶段被抽样K没有替换的剩余随机抽样ISTTXSJ设置它的期
望值的小数部分为零à这里给出的STTXS具有最小的个体扩展à
��随机遍历抽样
随机遍历抽样ITVTJ是具有零偏差和最小个体扩展的单状态Itjomfh _ibtfq J抽样算法à替代用于轮盘赌方法的单个选择指针KTVT使用O 个相等距离的指针K这里O 是要求选
择的个数à种群被随机排列K在P�KTvnLOQ范围内产生一随机数作为指针 usq KO 个个体
����

由相隔一个距离的O 个指针Pusq Kusq ��Kusq ��K�Kusq �O��Q选择K选取适应度范
围在指针位置的个体à一个个体确保被选择的最少次数PfuIjJQ和不超过PfuIjJQK因此获得
最小的个体扩展K另外个体完全按它们在种群中的地位选择KTVT具有零偏差à轮盘赌选择算法总可按PIOmhOJ执行K而TVT是更简单的算法且具有PIOJ的时间
复杂度à这个工具箱提供随机遍历抽样函数tvt和具有替换的随机抽样算法sxtà
�����交����叉
在遗传算法中产生新染色体的基本操作是染色体的交叉I也称为基因重组Jà与自然进
化一样K交叉产生的新个体具有父母双方的一部分遗传物质à最简单的交叉是单点交叉à下面讨论几种交叉方法K并比较它们各自的优点à
��多点交叉
对多点交叉有n个交叉位I特别当n��时为单点交叉JKlj��R�K�K�Km��SK这里
lj 是交叉点Km是染色体的长度K这n个交叉位是通过随机数选择的Ð没有重复的Ð按升序
排列的à父母染色体中在两个相连的交叉位间的基因进行交换K产生两个新的子代à个体
第一个基因到第一个交叉点之间的位并不进行交换à这个过程如图���所示à
图�����多点交叉In��J
多点交叉的思想和事实交叉上的许多变异源于控制个体特定行为的染色体表示信息的
部分K无须包含于邻近的子串中à进一步K多点交叉的破坏性可以促进解空间的搜索而不
至于在搜索中因高适应度个体过早收敛K使搜索更加健壮à
��均匀交叉
单点交叉和多点交叉定义的交叉点即染色体拆分基因位à均匀交叉更加广义化K将每
个点都作为潜在的交叉点à一个交叉掩码K随机产生的与个体等长的染色体结构K掩码中
的等价位表明哪个父个体向子个体提供变量值à考虑如下两个父个体K交叉掩码和最终的
子个体M
����Q������������Q������������Nbtl�����������P������������P������������
这里K第一个子个体P� 产生的位K其掩码对应位为�K则来自父个体Q�N对应位为�K则
来自父个体Q�à而第二个个体的产生则相反K即将上面的Q� 和Q� 交换à均匀交叉类似于多点交叉K可 以 减 少 二 进 制 编 码 长 度 与 给 定 参 数 特 殊 编 码 之 间 的 偏
����

差K并有助于克服单点交叉中对短子串的偏差K而不用精确了解染色体表示信息的个体位
的重要性I意义JàTfbstq 和EfKpoh已经证明均匀交叉通过应用概率交换位怎样参数化à额外的参数常用来控制重组期间的破坏总量K不用引进表现信息长度用的偏差à当均匀交
叉用于实值型时K它常作为离散重组参考à
��中间重组
给定一实值编码的染色体结构K中间重组是产生新表现型范围的方法K这个范围处于
父表现型值之间à子个体按照下列公式产生M
R� ��Q�ðIQ��Q�J I���J这里K�是一区间的均匀随机数K是换算系数K典型区间为P�����K����QNQ� 和Q� 是父
染色体K子代的每一个变量的值由父变量的值和对每一对父基因产生的一新的�值按上面
的公式产生à用几何图 形 描 述K中 间 重 组 能 产 生 新 的 变 量 在 比 其 父 代 定 义 的 稍 大 的 立 体
中K并受�限制K显示如图���所示à
图�����中间重组的几何效果
��线性重组
线性重组与中间重组比较相似K只是在重组中使用一个�值à图���显示了线性重组
怎样由父个体在�扰动范围的线上任意点产生K用于两个参数的重组à
图�����线性重组的几何效果
��其他一些交叉算子
一相关的交叉算法是洗牌交叉à一个交叉点被选择K但此位前的哪些位交换K这些位
在父母之间进行随机洗牌à重组后K子代中的这些位不进行洗牌K当这些位在每次交叉执
行时被随机分配K将减少位置偏差à在任何可能的地方K缩小代理算子Ð强制交叉总是产生新的个体群à通常它作为限制
交叉点位置的工具K以便使交叉点只发生在那些基因值不同的地方à
�����

�����变����异
在自然进化中K变异是一随机过程K是基因上的一个等位基因被另一个代替而产生一
新的遗传结构à在遗传算法中K变异采用了一任意的小概率K典型值是在�����Y���之
间K并改变染色体的元素à通常认为它是后台算子K变异的作用被认为是M搜索任意给定
串的可能性永不为零K为保证通过选择和交叉操作恢复可能丢失的好的遗传物质提供安全
网络à图���说明了在一个二进制串上的变异效果à二进制串是用��位二进制染色体表示
的一个在区间P�K��Q之间的实值编码K使用标准二进制和格雷码两种编码K二进制串中的
变异位是第�位à这里K二进制变异是对选择变异位的值进行翻转à给定的变异通常一致
应用于整个种群串K一个给定的二进制串变异的可能不止一位à
图�����二进制变异
对 于 非 二 进 制 表 示K变 异 完 成 的 是 扰 乱 基 因 值 和 随 机 选 择 一 允 许 范 围 内 的 新 值à
Xsjiuh ÐKbojlpx和 Njdibmfxjd{已经证明K实值编码在高变异率中比二进制编码好K它提
高了对搜索空间的搜索能力K而不会对收敛特征产生不利影响à的确KUbuf和Tnjui论证
了为什么比二进制复杂的编码K高变异率是适合的和必需的K示范了为什么复杂组合最优
化问题Ð高变异率和非二进制编码领域解法大大好于通用方法à还有许多变异的变异算子K例如K具有低适应度的Ð带 偏 差 的 变 异 能 提 高 搜 索 能 力K
而不会丢失来自高适应度个体的信息K或带参数的变异的变异概率降低不影响种群收敛à
N 가�imfocfjo介绍了一种实值编码遗传算法的变异算子K对变异范围分布用非线性项应用
于基因值à已经证明使用偏差变异使基因值有较小的变化K变异常常用于与重组连接作为
搜索过程的前期工作à另一些变异包括传统变异如何在染色体中分配个体基因K习惯上对
弱条件直接变异和重新安排变异K即交换位的位置或提高在决定变量空间基因的差异à遗传算法工具箱提供的二进制和整型变异函数是nvuK实值变异函数是nvuchbN变异
算子的高级接口函数是nvubufà
�����重��插��入
一旦一个新的种群通过对旧种群的个体进行选择和重组而产生K新种群中个体的适应
度被确定了K如果通过重组产生的种群个体数少于原始种群的大小K新种群和旧种群大小
的差异被称为代沟à在这种情况下K每一代产生的新个体数较少K这时的遗传算法称之为
稳态或增量的à如果一 个 或 多 个 最 适 合 个 体 被 连 续 代 繁 殖K则 遗 传 算 法 被 称 为 得 到 精 英
策略à为了保持原始种群的大小K一些新的个体不得不被重新插入旧种群中à同样地K如果
�����

在每一代并非所有新个体被使用或生产的子代大小超过旧种群K则一个恢复计划用来决定
那些个体存在于新种群中à如前所述K稳态遗传算法ITufbe�TubufHBz J最引人注目的一个
重要特征是在每一代中不创建比现存种群多的后代K计算次数被减少K并且产生后代时由
于有少的新个体存储K内存要求也小à当选择老种群中 哪 些 成 员 被 替 代 时K最 常 用 的 策 略 是 替 换 确 定 的 最 小 适 应 度 成 员à
Gpbsuh z在研究中已经证明K对选择的个体进行替代使用逆比率选择或最小适应度K其收
敛特性没有显著差异à当最大适应度成员将具有机会连续生存时K他进一步断言替代最小
适应成员是一有效的优选策略工具à的确K大多数成功的选择方案是选择种群中最老的成
员进行替代à这里指出多数与代的再生一致K在某一时刻K种群中的每一个成员都将被替
代à因此为使一个个体能连续存在K它必须有足够适应度以确保繁殖到下一代à遗传算法工具箱提供一函数sfjot使个体可在重组后重插入种群中à任选输入参数允
许使用一致随机或基 于 适 应 度 的 重 插 入à另 外K这 个 程 序 能 选 择 重 插 入 比 重 组 产 生 少 的
子代à
�����遗传算法的终止
因为遗传算法是随机搜索算法K找到一个正式的Ð明确的收敛性判别标准是困难的à若在找到最优个体以前的许多代的种群适应度可能保持不变K应用程序的常规终止条件将
成为有问题的à常用方法是遗传算法终止采用达到预先设定的代数和根据问题定义测试种
群中最优个体 的 性 能à如 果 没 有 可 接 受 的 解 答K遗 传 算 法 重 新 启 动 或 用 新 的 搜 索 初 始
条件à
�����数 据 结 构
NBUMBC本质上只支持实值或复数值矩阵一种数据类型à遗传算法工具箱的主要数
据结构是染色体Ð表现型Ð目标函数值和适应度值à
��染色体
染色体数据结构用大小Ojoe�Mjoe的单矩阵存储整个种群K这里Ojoe是种群中个体的
个数KMjoe是个体基因表现型的长度K每一行对应一个个体的基因K由o个基数组成K典型
的是二进制值à染色体数据结构举例如下M
Dispn�
h�K� h�K� � h�KMjoeh�K� h�K� � h�KMjoe� � �
hOjoeK� hOjoeK� � hOjoeKM
m�
n�
q�
r�joe
��
� 个体�� 个体����
� 个体Ojoe
����这种数据表示并不是染色体结构的强制结构K只要求所有染色体具有相同的长度à因
此K结构化种群或具有可变基因基础的种群可用于遗传算法工具箱提供的合适编码函数Ð映射染色体的表现型à
�����

��表现型
遗传算法中的决策变量或表现型通过在决策变量空间对染色体表现形式进行 映 射 获
得à这里K包含在染色体结构中的每一个串根据在搜索空间中的维度值和对应的决策变量
向量值编码为一行向量OwbsK这个决策变量被存储在一大小为Ojoe�Owbs的数字矩阵中K每一行对应一特定个体的表现型à下面给出了表现型数据结构的例子K遗传算法工具箱的
EFDPEF常用于表示一泛函数K映射基因到表现型à
Qifo�EFDPEFIDispnJN� 将基因型变换为显型INb HfopuzqfupQifopuzqq fJ
�
y�K� y�K� � y�KOwbsy�K� y�K� � y�KOwbs� � �
yOjoeK� yOjoeK� � yOjoeKO
m�
n�
q�
r�wbs
��
� 个体�� 个体����
� 个体Ojoe
在染色体表示和表现型值之间的实际映射依赖于函数EFDPEF的应用à应用这种表
达得到不同类型决策变量的向量是完全可行的à例如K在相同的表现型数据结构中混有整
型Ð实型和字母的决策变量是允许的à
��目标函数值
目标函数常用来评估表现型在问题域中的性能à目标函数值可能是标量或在多目标情
况下是矢量à值得注意的是K目标函数值不像适应度值一样是必需的à目标函数值被存储在一大小为Ojoe�Opck的数字矩阵中K这里Opck是目标的数量à每
一行对应一单独个体的目标矢量à目标函数值数据结构例子在下面给出K用PCKGVO表示
一任意的目标函数à
����PcW�PCKGVOk IQifoJN��� 目标函数IPcfdujwfGvodujpok J
�
z�K� z�K� � z�KOwbsz�K� z�K� � z�KOwbs� � �
zOjoeK� zOjoeK� � zOjoeKO
m�
n�
q�
r�wbs
��
� 个体�� 个体����
� 个体Ojoe
��适应度值
适应度值是由目标函数值通过计算或评定等级而得出的à适应度是一非负的标量并保
存在长度为Ojoe的列向量中à下面给出一个例子àGJUOFTT是一任意的适应度函数à
����Gjuo�GJUOFTTIPckWJN��� 适应度函数IGjuofttGvodujpoJ
�
g�g��
gO
m�
n�
q�
r�joe
��
� 个体�� 个体����
� 个体Ojoe
注意K对多目标函数K一个特定个体的适应度是目标函数值向量的一个函数à多目标
问题一般没有一个简单的惟一解K但可由具有不同值的决策变量的一组相同合适解描述à因此通过采用一些措施确保种群能够解出一组Qbsfup最优解K例如K通过在选择方法中使
�����

用适应度共享à尽管在本版本的遗传算法工具箱中不支持K计划在后续版本中补充多目标
搜索à
������多 种 群 支 持
遗传算法工具箱通过使用高级遗传算子函数和例程在子种群中交换个体而支持多子种
群à在一些文献中K使用多子种群表明K在大多数情况下K相比于单种群遗传算法K它改善
了所获得结果的性能à遗传算法工具箱支持通过修改所用的数据结构将所用单种群分割成许多子种群或同类
群K以便使用一个简单矩阵将子种群保存在一连续块中à例如K染色体结构Dispn由每个
长度为O 的TVCQPQ 个子种群组成而保存à著名的是迁移INjsbujpoh J或孤岛 IJtmboeJ模型K每一个子种群通过传统的遗传算法和
个体时K随时从一个子种群迁移到另一个子种群而发展成下一代à迁移的个体数量和迁移
的模式决定有多大的遗传差异发生à为了允许工具箱例程在子种群上独立操作K遗传算法工具箱提供了大量的高级接口程
序K接受一任选变量来 确 定 在 数 据 结 构 中 获 得 的 子 种 群 的 数 量à低 级 例 程 被 依 次 独 立 调
用K对每个子种群完成选择Ð交叉和重插入等功能à表���列出了子种群支持的函数K这
是一些高级函数à表�����子种群支持的函数
函����数 说���� 明
nvubuf 变异算子
sfdpncjo 交叉和重组算子
sfjot 均匀随机和基于适应度的重插入
tfmfdu 独立子种群选择
����注意M对当前工具K所有子种群必须是相同大小的à个体在两个子种群之间的迁移是由函数 njsbufh 实现的K一个单一的标量决定迁移个
体的总量à因此K给出的一个种群包括大量的子种群K它从另一个子种群接收数量相同的
个体K这个函数的第二个参数控制使用均匀选择或者按照适应度两种方式之一选择哪个个
体参加迁移à均匀选择为迁移选取个体K并且在子种群中使用随机方式用迁移个体替代本
子种群中的个体K基于适应度迁移选择个体是按照它们的适应度水平进行的K最适应个体
将被选择作为迁移K子种群被替代的个体是按均匀随机选择的à下面进一步用参数说明在不同种群拓扑结构中迁移的发生过程à图���显示循环迁移
在函数njsbufh 中执行的大多数基本迁移路径à这里个体的迁移是在直接相邻的子种群中K例如来自子种群�的 迁 移 个 体 只 迁 移 到 子 种 群�K而 来 自 子 种 群�的 个 体 只 迁 移 到 子 种
群�à
�����

图�����循环迁移拓扑 图�����相邻迁移拓扑
����循环迁移的相似策略是相邻迁移K如图���所示à像循环拓扑K迁移只发生在最近的
邻居之间K但可发生在相邻子种群之间的任意方向à对每一个子种群迁移个体根据要求的
选择方法决定K它来自于相邻子种群和从个体池中最后选择的K确保个体不会从一个子种
群迁移到相同子种群à函数njsbufh 所支持的是最通常的迁移K是没有限制的迁移K如图���所示à这里个体
可从任意一个个体迁移到另一个个体à对每一个子群K有一群来自其他子群的潜在的迁移
者K这些个体迁移者按照适合的选择策略决定à
图�����自由迁移拓扑
������示 范 脚 本
遗 传 算 法 工 具 箱 提 供 的HB脚 本 文 件 完 成 了 大 量 测 试 函 数K这 些 测 试 函 数 被 提 供
在 一 个 独 立 目 录uftu_got中K包 括 主 要 的 示 范 脚 本 和 工 具 箱 例 程K伴 随 的 附 录 文 件 放
在uftu_got�qt目 录 中K给 出 了 问 题 执 行 的 完 全 细 节à表���总 结 了 工 具 箱 提 供 的 测 试
文 件à
�����

表�����工具箱提供的测试文件
序号 N文件名 说���� 明
� pcgvo� EfKpok h�t函数
� pc
�
gvo�b byjtk bsbmmfmizqfs�fmmjq tpjeq I轴并行超球体J
� pcgvo�c spubufeizqfs�fmmjk tpjeq I旋转超球体J
� pcgvo� Sptfocspdlk �twbmmfzIcbobobgvodujpoJ
� pcgvo� Sbtusjk joh �tgvodujpo
� pcgvo� Tdixfgfmk �tgvodujpo
� pcgvo� Hsjfxbok hl�tgvodujpo
� pcgvo� tvnpgejggfsfouk pxfstq I不同权的总和J
� pcepk j epvcmfjoufq sbupsh I双积分J
�� pcibsw ibswftuk spcmfnq I收获问题J
�� pcmjok ejtdsfufmjofbs�r vbesbujdr spcmfnq I离散二次线性问题J
�� pcmjok � dpoujovpvtmjofbs�r vbesbujdr spcmfnq I连续二次线性问题J
�� pckqvti vti�dbsuq spcmfnq I装载问题J
�����

书书书
ðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀ
ðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀ
�
��
���第七章��遗传算法应用举例��
遗传算法提供了一种求解非线性Ð多模型Ð多目标等复杂系统优化问题的通用
框架K它不依赖于问题所属的具体领域à随着对遗传算法技术的不断研究K人们对
遗传算法的实际应用也越来越重视K它已经广泛地应用于函数优化Ð组合优化Ð自
动控制Ð机器人学Ð图像处理Ð人工生命Ð遗传编码Ð机器学习等科技领域à遗传算
法已经在求解旅行商问题Ð背包问题Ð装箱问题Ð图形划分问题等方面取得了成功à本章通过一 些 具 体 的 例 子K介 绍 如 何 利 用 第 五 章 提 供 的 遗 传 算 法 通 用 函 数 编 写
NBUMBC程序K解决实际问题à
�����简单一元函数优化实例
利用遗传算法计算下面函数的最大值M
gIyJ�ytjoI���ðyJ����K��y�� P��K�Q
����选择二进制编码K种群中个体数目为��K每个种群的长度为��K使用代沟为���K最
大遗传代数为��à下面为一元函数优化问题的 NBUMBC代码à����Gjvsfh I�JN
gmpuq I�wbsjbcmf�H�tjoI��H�qjH�wbsjbcmfJ�����KP��K�QJN��� 画出函数曲线
� 定义遗传算法参数
OJOE���N��������� 个体数目IOvncfspgjoejwjevbmtJ
NBYHFO���N � 最大遗传代数INbyjnvnovncfs�pg fofsbujpoth J
QSFDJ���N � 变量的二进制位数IQsfdjtjpopgwbsjbcmftJ
HHBQ����N � 代沟IHfofsbujpohbqJ
usbdf�{fsptI�KNBYHFOJN��������������������� 寻优结果的初始值
GjfmeE�P��N��N�N�N�N�N�QN � 区域描述器ICvjmegjfmeeftdsjupsq J
Dispn�dsucqIOJOEKQSFDJJN � 初始种群
fo��h N � 代计数器
wbsjbcmf�ct�swIDispnKGjfmeEJN � 计算初始种群的十进制转换
PcW�wbsjbcmf�k H�tjoI��H�qjH�wbsjbcmfJ����N � 计算目标函数值
xijmf foh _�NBYHFOK
����GjuoW�sboljohI�PckWJN � 分配适应度值IBttjogjuofttwbmvfth J
����TfmDi�tfmfduI�tvt�KDispnKGjuoWKHHBQJN � 选择
����TfmDi�sfdpncjoI�ypwtq�KTfmDiK���JN � 重组
����TfmDi�nvuITfmDiJN � 变异
����wbsjbcmf�ct�swITfmDiKGjfmeEJN � 子代个体的十进制转换
�����

����PcWTfm�wbsjbcmf�k H�tjoI��H�qjH�wbsjbcmfJ����N������������� 计算子代的目标函数值
����PDispnPckWQ�sfjotIDispnKTfmDiK�K�KPckWKPcWTfmk JN � 重插入子代的新种群
���� fo�h fo��h N � 代计数器增加
����� 输出最优解及其序号K并在目标函数图像中标出KZ为最优解KJ为种群的序号
����PZKJQ�nbyIPckWJKipmepoN
���� mpuq IwbsjbcmfIJJKZK�cp�JN
����usbdfI�Kfoh J�nbyIPckWJN �遗传算法性能跟踪
����usbdfI�Kfoh J�tvnIPckWJLmfouih IPckWJN
foe
wbsjbcmf�ct�swIDispnKGjfmeEJN �最优个体的十进制转换
ipmepoKsjeh N
mpuq Iwbsjbcmf�KPcW�k K�cH��JN
Gjvsfh I�JN
mpuq IusbdfI�KMJ�JN
ipmepoN
mpuq IusbdfI�KMJ�K����JNsjeh N
mffoeh I�解的变化�K�种群均值的变化�J�
使用基于适应度的重插入确保四个最适应的个体总是被连续传播到下一代à这样K在
每一代中有��IOJOEH�HHBQJ个新个体产生à区域描述器GjfmeE描述染色体的表示和解释K每个格雷码采用��位二进制K变量区
间为P��K�Qà程序段Dispn�dsucqIOJOEKQSFDJJ表示一个初始种群Dispn被函数dsucq创建K
它是由OJOE个均匀分布Ð长度为QSFDJ的二进制串构成的à基于排序的适应度分配计算由程序段GjuoW�sboljohI�PckWJ实现à对这个等级评定算法的缺省设置是选择等差为�和使用线性评估K给最适应个体的适
应度值为�K最差个体的适应度值为�K这里的评定算法假设目标函数是最小化的K所以
PckW前加了一个负号K使目标函数最大化à适应度值结果由向量GjuoW返回à选择层使用高级函数选择调用低级函数随机遍历抽样例程tvtKTfmDi包含来自原始
染色体的HHBQH�OJOE个个体K这些个体将使用高级函数sfdpncjo进行重组Ksfdpncjo使个体通过TfmDi被选择再生产K并使用单点交叉例程ypwtqK使用交叉概率Qy����执
行并叉à交叉后产生的子代被同一个矩阵TfmDi返回K实际使用的交叉例程通过支持使用
不同函数名字串传递给sfdpncjo而改变à为了产生一组子代K变异使用变异函数 nvuà子代再次由矩阵TfmDi返回K变异概率
缺省值QN����LMjoe�������K这里Mjoe是假定的个体长度à再次使用ct�swK将个体的
二进制编码转化为十进制编码K计算子代的目标函数值PcWTfmk à由于使用了代沟K子代的数量比当前种群数量要小K因此使用恢复函数sfjotà这 里
Dispn 和TfmDi是矩阵K包含原始种群和子代结果à这两个事件的第一个被使用单个种群
和采用基于适应度的恢复K基于适应度的恢复用TfmDi中的个体代替Dispn 中最不适应
的个体à原始种群中个体的目标函数值PckW随后又作为函数sfjot的输入参数K子代中个
体的目标函数值由PcWTfmk 提供àsfjot返回具有插入子代的新种群Dispn和该种群中个
�����

体的目标函数值PckWà每次迭代后的最 优 解 和 解 的 均 值 存 放 在usbdf中à这 个 遗 传 优 化 的 结 果 包 含 在 矩 阵
PckW中à决策变量的值为wbsjbcmfIJJà下面画出迭代后个体的目标函数值分布图和遗传算法性能跟踪图à遗传算法的运行结
果如下MI�J图���为目标函数gIyJ�ytjoI���ðyJ����Ky��P��K�Q的图像à
图�����目标函数图像
I�J图���为目标函数的图像和初始随机种群个体分布图à
图�����初始种群分布图
I�J经 过 一 次 遗 传 迭 代 后K寻 优 结 果 如 图���所 示à此 时Ky�������KgIyJ�������à
图�����一次遗传迭代后的结果
�����

I�J经过��次 遗 传 迭 代 后K寻 优 结 果 如 图���所 示à此 时Ky�������KgIyJ�������à
图�����经过��次遗传迭代后的结果
I�J经过��次 遗 传 迭 代 后K寻 优 结 果 如 图���所 示à此 时Ky�������KgIyJ�������à
图�����经过��次遗传迭代后的结果
I�J经过��次迭代后K最优解的变化和种群均值的变化见图���à
图�����经过��次迭代后最优解的变化和种群均值的变化
�����

�����多元单峰函数的优化实例
目标函数是EfKpoh函数K是一个连续Ð凸起的单峰函数K它的 N 文件pcgvo�k 包含
在HB工具箱软件中à
EfKpoh函数的表达式为
gIyJ���o
j��y�jK������0�yj0����
这里o是定义问题维数的一个值K本例中选取o���K求解njogIyJà由EfKpoh函数的表达式可以看出KEfKpoh函数是一个简单的平方和函数K只有一
个极小点I�K�K�K�JK理论最小值为gI�K�K�K�J��à程序的主要变量M个体的数量OJOE为��K最大遗传代数为 NBYHFO����K变量
维数为OWBS���K每个变量使用��位表示K即QSFDJ���K使用代沟HHBQ����à下面为求解EfKpoh函数最小值的 NBUMBC代码à����� 定义遗传算法参数
OJOE���N����������� 个体数目IOvncfspgjoejwjevbmtJ
NBYHFO����N � 最大遗传代数INbyjnvnovncfspg fofsbujpoth J
OWBS���N � 变量的维数
QSFDJ���N � 变量的二进制位数IQsfdjtjpopgwbsjbcmftJ
HHBQ����N � 代沟IHfofsbujpohbqJ
usbdf�{fsptINBYHFOK�JN
� 建立区域描述器ICvjmegjfmeeftdsjupsq J
GjfmeE�Psfq IPQSFDJQKP�KOWBSQJNsfq IP����N���QKP�KOWBSQJNsfq IP�N�N�N�QK
P�KOWBSQJQN
Dispn�dsucqIOJOEKOWBSH�QSFDJJN����������� 创建初始种群
fo��h N � 代计数器
PcW�pck gvo�k Ict�swIDispnKGjfmeEJJN � 计算初始种群个体的目标函数值
xijmf foh _� NBYHFOK � 迭代
����GjuoW�sboljohIPckWJN � 分配适应度值IBttjogjuofttwbmvfth J
����TfmDi�tfmfduI�tvt�KDispnKGjuoWKHHBQJN � 选择
����TfmDi�sfdpncjoI�ypwtq�KTfmDiK���JN � 重组
����TfmDi�nvuITfmDiJN � 变异
����PcWTfm�pck gvo�k Ict�swITfmDiKGjfmeEJJN � 计算子代目标函数值
����PDispnPckWQ�sfjotIDispnKTfmDiK�K�KPckWKPcWTfmk JN��� 重插入
���� fo�h fo��h N � 代计数器增加
����� 输出最优解及其对应的��个自变量的十进制值KZ为最优解KJ为种群的序号
����usbdfIfoh K�J�njoIPckWJN � 遗传算法性能跟踪
����usbdfIfoh K�J�tvnIPckWJLmfouih IPckWJN
foe
mpuq IusbdfIMK�JJNipmepoN
mpuq IusbdfIMK�JK����JNsjeh N
mffoeh I�种群均值的变化�K�解的变化�J�
�����

区域描述器的构建M采 用 矩 阵 复 制 函 数sfq建 立 矩 阵GjfmeEK描 述 染 色 体 的 表 示 和
解释à一个初始种群被函数dsucq创建K随后产生一个矩阵DispnK它由OJOE个均匀分布Ð
长度为OWBSH�QSFDJ的二进制串构成à使用函数pcgvo�k 重新计算目标函数K初始种群中的所有个体的目标函数值由下面的
程序段计算M
����PcW�pck gvo�k Ict�swIDispnKGjfmeEJJN函数ct�sw根据域描述器GjfmeE转换矩阵Dispn的二进制串为实值K返回一实值表
现型的矩阵à这个ct�sw返回值矩阵通过直接作为目标函数pcgvo�k 的输入变量K将目标
函数结果返回在矩阵PckW中à这个例子中基于排序的适应度分配计算由下面的程序段实现M
����GjuoW�sboljohIPckWJN对这个等级评定算法的缺省设置是选择等差�K使用线性评估K给最适应个体的适应
度值为�K最差个体的适应度值为�à适应度值结果被向量GjuoW返回à使用高级函数选择调用低级函数随机遍历抽样例程tvtK程序段为
����TfmDi�tfmfduI�tvt�KDispnKGjuoWKHHBQJN后面的选择中KTfmDi包含来自原始染色体的HHBQH�OJOE个个体K这些个体将使
用高级函数sfdpncjo进行重组K程序段为
����TfmDi�sfdpncjoI�ypwtq�KTfmDiK���JN函数sfdpncjo使个体通过TfmDi被选择再生产K并使用单点交叉例程函数ypwtqK使
用交叉概率Qy����执行交叉à个体作为矩阵TfmDi的输入被排序K以便使奇数位置的个
体与它相邻的个体进行交叉K如果TfmDi个体的数量是奇数个K则最后一个个体不进行交
叉而返回à交叉后产生的子代被同一个矩阵TfmDi返回K实际使用的交叉例程通过支持使
用不同函数名字串传递给sfdpncjo而改变à为了产生一组子代K现在使用变异函数nvu进行变异M
����TfmDi�nvuITfmDiJN子代再次由矩阵TfmDi返 回K函 数 调 用 中 变 异 概 率 没 有 被 指 定K这 个 缺 省 值QN�
���LMjoe�������K这里Mjoe是假定的个体长度à子代的目标函数值PcWTfmk 由程序段计算M
����PcWTfm�pck gvo�k Ict�swITfmDiKGjfmeEJJN因为使用了代沟K子代的数量比当前种群数量要小K所以使用恢复函数sfjot完成M
����PDispnKPckWQ�sfjotIDispnKTfmDiK�K�KPckWKPcWTfmk JN这里KDispn 和TfmDi是矩阵包含的原始种群和子代结果à这两个事件的第一个被使用单
个种群和采用基于适应度的恢复K基于适应度的恢复用TfmDi中的个体代替Dispn 中最
不适应的个体à原始种群目标函数值PckW随后被要求作为sfjot的参数à另外K新种群的
目标函数值不用 重 新 计 算 整 个 种 群 的 目 标 函 数 而 返 回K子 代 的 目 标 值 PcWTfmk 被 提 供à
sfjot返回具有插入子代的新种群Dispn和这个种群的目标函数值PckWà这个遗传优化的结 果 包 含 在 矩 阵 PckW中K决 策 变 量 的 值 可 能 被 包 含 在 下 面 的 程 序
段中M�����

����Qifo�ct�swIDispnKGjfmeEJN遗传算法的运行结果如下MI�J图���为二维EfKpoh函数图形à
图�����二维EfKpoh函数图形
I�J初始种群中个体的目标函数值分布图如图���所示à
图�����初始种群中个体的目标函数值分布图
I�J经过��次遗传迭代后的结果如图���所示à此时KnjogIyJ�������f��à
图�����经过��次遗传迭代后的结果
�����

����I�J经过���次遗传迭代后的结果如图����所示à此时KnjogIyJ�������f��à
图������经过���次遗传迭代后的结果
I�J经过���次遗传迭代后的结果如图����所示à此时KnjogIyJ���������à
图������经过���次遗传迭代后的结果
I�J经过���次遗传迭代后的结果如图����所示à此时KnjogIyJ�������à
图������经过���次遗传迭代后的结果
I�J经 过���次 迭 代 后 种 群 目 标 函 数 均 值 的 变 化 和 最 优 解 的 变 化 如 图����所 示à
njogIyJ�������时��个变量的值见表���à
�����
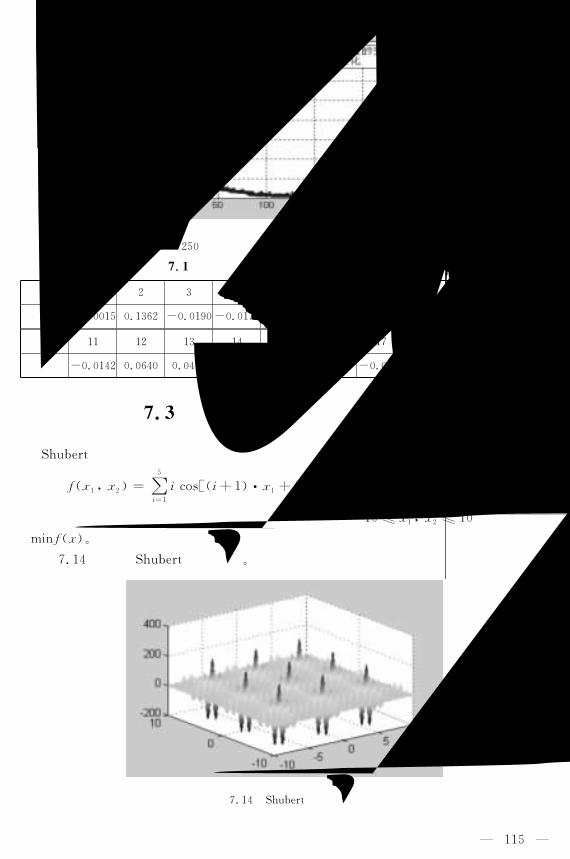
图������经过���次迭代后种群目标函数均值的变化和最优解的变化
表�����目标函数取最优解时��个变量的值
序号 � � � � � � � � � ��
变量值 ������������� �������������������������������������������������������
序号 �� �� �� �� �� �� �� �� �� ��
变量值 ������������� ������ ������ ������������� ������������� ��������������
�����多元多峰函数的优化实例
Tivcfsu函数为
gIy�Ky�J����
j��jdptPIj��Jðy��jQð��
�
j��jdptPIj��Jðy��jQ����
���0�y�Ky� 0���求njogIyJà
图����所示为Tivcfsu函数图像à
图������Tivcfsu函数图像
�����

下面为Tivcfsu函数寻优的 NBUMBC代码à����gvodujpo{�TivcfsuIyKzJ�������������Tivcfsu函数
{�II�H�dptII���JH�y��JJ� I�H�dptII���JH�y��JJ� I�H�dptII���JH�y��JJ����I�H�dptII���JH�y��JJ� I�H�dptII���JH�y��JJJH� II�H�dptII���JH� ��z JJ����I�H�dptII���JH� ��z JJ� I�H�dptII���JH� ��z JJ� I�H�dptII���JH� ��z JJ� ���I�H�dptII���JH� ��z JJJN
Py�Ky�Q�nftisjeh I���M��M��JN
Gjvsfh I�JNnftiIy�Ky�KTivcfsuIy�Ky�JJN����� 画出Tivcfsu函数图像
� 定义遗传算法参数
OJOE���N������� 个体数目IOvncfspgjoejwjevbmtJ
NBYHFO���N � 最大遗传代数INbyjnvnovncfspg fofsbujpoth J
OWBS��N � 变量数目
QSFDJ���N � 变量的二进制位数IQsfdjtjpopgwbsjbcmftJ
HHBQ����N � 代沟IHfofsbujpohbqJ
� 建立区域描述器ICvjmegjfmeeftdsjupsq J
GjfmeE�PsfqIPQSFDJQKP�KOWBSQJNsfqIP��N�QKP�KOWBSQJNsfqIP�N�N�N�QKP�KOWBSQJQN
Dispn�dsucqIOJOEKOWBSH�QSFDJJN����������� 创建初始种群
fo��h N
usbdf�{fsptINBYHFOK�JN � 遗传算法性能跟踪初始值
y�ct�swIDispnKGjfmeEJN � 初始种群十进制转换
PcW�Tivcfsuk IyIMK�JKyIMK�JJN � 计算初始种群的目标函数值
xijmf foh _�NBYHFOK
����GjuoW�sboljohIPckWJN � 分配适应度值IBttjogjuofttwbmvfth J
����TfmDi�tfmfduI�tvt�KDispnKGjuoWKHHBQJN � 选择
����TfmDi�sfdpncjoI�ypwtq�KTfmDiK���JN � 重组
����TfmDi�nvuITfmDiJN � 变异
����y�ct�swITfmDiKGjfmeEJN � 子代十进制转换
����PcWTfm�Tivcfsuk IyIMK�JKyIMK�JJN � 重插入
����PDispnPckWQ�sfjotIDispnKTfmDiK�K�KPckWKPcWTfmk JN
���� fo�h fo��h N
����PZKJQ�njoIPcWTfmk JN
����ZKct�swIDispnIJKMJKGjfmeEJJN � 输出最优解及其对应的自变量值
����usbdfIfoh K�J�njoIPckWJN
����usbdfIfoh K�J�tvnIPckWJLmfouih IPckWJN � 遗传算法性能跟踪
����jgIfo����h J � 迭代数为��时画出目标函数值分布图
��������gjvsfh I�JN
�������� mpuq IPckWJNipmepoN
�������� mpuq IPckWK�cH��JNsjeh N
����foefoegjvsfh I�JNdmgN
mpuq IusbdfIMK�JJNipmepoN
mpuq IusbdfIMK�JK����JNsjeh N
mffoeh I�解的变化�K�种群均值的变化�J�
�����

遗传算法的显示结果如下MI�J初始种群的目标函数值分布如图����所示à
图������初始种群的目标函数值
I�J经 过 一 次 迭 代 后 的 目 标 函 数 值 如 图����所 示à此 时Ky���������Ky��������
�KnjogIyJ���������à
图������经过一次迭代后的结果
I�J经过��次 迭 代 后 的 目 标 函 数 值 如 图����所 示à此 时Ky���������Ky�������
�KnjogIyJ����������à
图������经过��次迭代后的结果
�����

I�J经过��次 迭 代 后 的 目 标 函 数 值 如 图����所 示à此 时Ky���������Ky���
������KnjogIyJ����������à
图������经过��次迭代后的结果
I�J经过��次迭代后K种群目标函数均值的变化和最优解的变化如图����所示à
图������经过��次迭代后种群目标函数均值的变化和最优解的变化
�����收获系统最优控制
收获系统IIbswftuJ是一个一阶的离散方程K表达式为
yIl��J�bH�yIlJ�vIlJ
t�u�����yI�J�yIOR J ��l��K�K�KO
这里KyI�J是一个初始的状态条件Kb是一个刻度常量KyIlJ��S和vIlJ��S� 分别是状
态和非常控制KO 是解决问题使用的步骤数à目标函数为
gIvJ���O
l��vIl� J
这个问题的精确优化解答可由下式确定M
nbygIyJ� yI�JIbO ��J�
bO��Ib��� J
����HB工具箱提供了一个 N 文件pcibswk K作为目标函数à注意K这里是一个最大化问
�����

题K工具箱例程实现是最小化问题K这个目标函数pcibswk K即gIvJ乘以��后可转化为最
小化问题à初始条件yI�J设为���Kb取为���à这个问题的控制步骤O���K因此使用的决策变量个数OWBS���K作为每个控制输
入vIlJà决策变量被限制在SBOHF�P�K���Q范围内K限制最大的控制输入在任意步时
为���K这个区域描述器GjfmeE描述的决策变量可以使用矩阵复制函数sfq构造à这个HB的参数可用 NBUMBC变量来指定à除了传统HB参数K例如代沟 IHHBQJ和交叉概率 IYPWSJ外K还有大量与多种群
HBT有关的其他参数被定义à这里JOTS����K说明每一代中只有���的个体被复制到
种群中KTVCQPQ��K说明�个子种群使用的迁移概率为 NJHS����或���K每��代
INJHHFO���J在子种群与当前迁移之间à每个子种群包含��个个体KOJOE���à脚本文件使 用 的 函 数 使 用 NBUMBC串 指 定à用 串TFM_G ÐYPW_GÐNVU_GÐ
PCK_G指定分别代表选择函数名Ð重组函数名Ð变异函数名Ð目标函数名à由于使用离散重组函数sfdejt进行子代的培育K交叉概率没有使用KYPWS��à初始种群的创建使用函数dsusqK代计数器 foh 设置为�à在由GjfmeE指定的范围内使用一致性随机挑选个 体 决 策 变 量 组 成TVCQPQH�OJOE
个个体à矩阵 Dispn 包 含 了 所 有 子 种 群 并 且 子 种 群 中 所 有 个 体 的 目 标 函 数 值 能 使 用
NBUMBC的gfwbm命令直接计算àPcW�gfwbmk IPCK_GKDispnJ中gfwbm执行函数计算获
得第一个输入变量K这里是目标函数名pcibswk K包含在PCK_G中K这个函数将被计算并
用剩余的参数作为输入调用这个函数à这里函数调用是M
����PcW�pck ibswk IDispnJN由于使用实值编码K不需要将染色体转换为表现型表示àHB现在将进入代循环à下面为收获系统最优控制的 NBUMBC代码à����� 定义遗传算法参数
OWBS���N����������� 变量维数
SBOHF�P�N���QN � 变量范围
HHBQ����N � 代沟IHfofsbujpohbqJ
YPWS��N � 交叉率
NVUS��LOWBSN � 变异率
NBYHFO����N � 最大遗传代数INbyjnvnovncfspg fofsbujpoth J
JOTS����N � 插入率
TVCQPQ��N � 子种群数
NJHS����N � 迁移率
NJHHFO���N � 在子种群与迁移之间��代
OJOE���N � 个体数目IOvncfspgjoejwjevbmtJ
TFM_G��tvt�N � 选择函数名
YPW_G��sfdejt�N � 重组函数名
NVU_G��nvucb�h N � 变异函数名
PCK_G��pcibsw�k N � 目标函数名
GjfmeEE�sfqISBOHFKP�KOWBSQJN��������� 译码矩阵
fo��h N
usbdf�{fsptINBYHFOK�JN � 遗传算法性能跟踪
�����

Dispn�dsusqIOJOEKGjfmeEEJN � 创建初始种群
PcW�pck ibswk IDispnJN � 计算目标函数值
xijmf foh _� NBYHFOK � 代循环
����GjuoW�sboljohIPckWKP�K�QKTVCQPQJN � 分配适应度值IBttjogjuofttwbmvfth J
����TfmDi�tfmfduITFM_GKDispnKGjuoWKHHBQKTVCQPQJN����� 选择
����TfmDi�sfdpncjoIYPW_GKTfmDiKYPWSKTVCQPQJN � 重组
����TfmDi�nvubufINVU_GKTfmDiKGjfmeEEKPNVUSQKTVCQPQJN � 变异
����PcWPgg�gfwbmk IPCK_GKTfmDiJN � 计算目标函数值
����PDispnKPckWQ�sfjotIDispnKTfmDiKTVCQPQKP�JOTSQKPckWKPcWPggk JN� 替代
���� fo�h fo��h N
����PusbdfIfoh K�JKJQ�njoIPckWJN
����usbdfIfoh K�J�nfboIPckWJN
����� 在子种群之间迁移个体
��������jgIsfnIfoh KNJHHFOJ���J
������������PDispnKPckWQ�njsbufh IDispnKTVCQPQKPNJHSK�K�QKPckWJN
��������foe
����foePZKJQ�njoIPckWJN��������� 输出最优解及其序号KZ为最优解KJ为种群的序号
gjvsfh I�JNmpuq IDispnIJKMJJN
ipmepoNsjeh N
mpuq IDispnIJKMJK�cp�J
gjvsfh I�JNmpuq I�usbdfIMK�JJN
ipmepoN
mpuq I�usbdfIMK�JK����JN��������� 遗传算法性能跟踪分布图
mffoeh I�解的变化�K�种群均值的变化�JNymbcfmI�迭代次数�J
由于使用多子种群K待评定要求指定必须的选择压位差K这里选择压位差为�à指定
子种群的个数为TVCQPQà每个子种群的个体的目标值PckW将独立排序K适应度值结果
集将由向量GjuoW返回à在每个子种群中K个体将由高级选择函数tfmfdu选择独立地培育子代M
����TfmDi�tfmfduITFM_GKDispnKGjuoWKHHBQKTVCQPQJN
Tfmfdu为每个子种群调用低级选择函数TFM_G��tvt�K并建立包含用于重组的所有
个体对的矩阵TfmDiK代沟HHBQ����K意思就是���������KHHBQH�OJOE个个体从
每个子种群中选择KTfmDi包含HHBQH�OJOEH�TVCQPQ����个个体à高级重组函数sfdpncjo用于重组TfmDi中每个子种群中的每对个体à
����TfmDi�sfdpncjoIYPW_GKTfmDiKYPWSKTVCQPQJN重组函数YPW_G��sfdejt�对子种群中个体对执行离散重组à由于离散重组不需要指
定常规的交叉概率K这里使用变量YPWS����仅仅是为了兼容à子代现在将变异M
����TfmDi�nvubufINVU_GKTfmDiKGjfmeEKNVUSKTVCQPQJN这里HB育种器变异函数 NVU_G��nvucb�h 使用高级变异例程 nvubuf调用K使用
变异概率 NVUS��LOJOE�����à这个HB育种器变异函数需要域描述器GjfmeEK以使
�����

变异还会产生超出决策变量边界的结果à所有子代的目标值PcWPggk 现在可以再用gfwbm计算M
����PcWPgg�gfwbmk IPCK_GKTfmDiJN子代现在可以插入适当的子种群中M
����PDispnKPckWQ�sfjotIDispnKTfmDiKTVCQPQKP�KJOTSQKPckWKPcWPggk JN使用基于适应度的插入K但对sfjot的第四个自变量的附加扩展参数指定了插入概率
JOTS����à这里的意思是指每个子种群的最小适应度的���子代不会被插入à多种群HB的个体在种群之间以相同间隔迁移à工具箱的迁移例程用于在子种群间根
据相同的迁移策略交换个体K在这个例子中K每��代INJHHFO���J在子种群间发生迁
移à子种群间的迁移语句为
����jgIsfnIfoh KNJHHFOJ���J
��������PDispnKPckWQ�njsbufh IDispnKTVCQPQKPNJHSK�K�QKPckWJN
����foe在这里子种群中最适应的���INJHS����J的个体被选择迁移à最邻近的子种群在
它们之间交换个体K均匀地重插入移民个体à返回矩阵Dispn和向量PckW作为迁移结果
反映子种群中个体的变化à
HB迭代循环直到 fo�NBYHFOh 并随后终止à
HB搜索获得的结 果 被 包 含 在 矩 阵 PckW中à最 佳 个 体 的 目 标 值 和 索 引 号 可 用 函 数
njo搜索à例如M
����PZKJQ�njoIPckWJN运行后得到MZ���������KJ���à
注意M改变目标函数的符号形成最小化问题K这个结果相当于目标函数值为�������K给出的精确解答应为�������à因此这个HB优化解与精确解之间的误差在����以内à染
色体值显示使用如下命令M
���� mpuq IDispnIJKMJJ�遗传算法的显示结果如下MI�J图����为初始随机种群个体分布图à
图������初始种群的分布图
I�J经过��次迭代后K寻优结果如图����所示à此时KnbygIyJ�������à
�����

图������经过��次迭代后的优化解
I�J经过���次迭代后K寻优结果如图����所示à此时KnbygIyJ��������à
图������经过���次迭代后的优化解
I�J经过����次迭代后K寻优结果如图����所示à此时KnbygIyJ��������à
图������经过����次迭代后的优化解
�����装载系统的最优问题
装载系统是一个二维系统K表达式如下M
�����

y�Il��J�y�IlJ
y�Il��J��H�y�IlJ�y�IlJ��O�vIl�
�
�J��l��
K�K�KO
����目标函数为
gIyKvJ��y�IO��J���O��
O
l��v�IlJ
����理论最优解为
njogIyKvJ������O���O�
� ��O���
O��
l��l�
����一个实现本目标函数的 N文件pckqvti包含在HB工具箱软件中à下面为装载系统的最优问题的 NBUMBC代码à�����定义遗传算法参数
HHBQ����N����������� 代沟IHfofsbujpohbqJ
YPWS��N � 交叉率
OWBS���N � 变量维数
NVUS��LOWBSN � 变异率
NBYHFO����N � 最大遗传代数INbyjnvnovncfspg fofsbujpoth J
JOTS����N � 插入率
TVCQPQ���N � 子种群数
NJHS����N � 迁移率
NJHHFO���N � 每��代迁移个体
OJOE���N � 个体数目IOvncfspgjoejwjevbmtJ
SBOHF�P�N��QN � 变量范围
TFM_G��tvt�N � 选择函数名
YPW_G��sfdejt�N � 重组函数名
NVU_G��nvucb�h N � 变异函数名
PCK_G��pckqvti�N � 目标函数名
GjfmeEE�sfqISBOHFKP�KOWBSQJN
usbdf�{fsptINBYHFOK�JN��������������������� 遗传算法性能跟踪
Dispn�dsusqITVCQPQH�OJOEKGjfmeEEJN � 创建初始种群
fo��h N
PcW�gfwbmk IPCK_GKDispnJN
xijmf foh _� NBYHFOK � 代循环
����GjuoW�sboljohIPckWKP�K�QKTVCQPQJN � 分配适应度值IBttjogjuofttwbmvfth J
����TfmDi�tfmfduITFM_GKDispnKGjuoWKHHBQKTVCQPQJN������� 选择
����TfmDi�sfdpncjoIYPW_GKTfmDiKYPWSKTVCQPQJN � 重组
����TfmDi�nvubufINVU_GKTfmDiKGjfmeEEKPNVUSQKTVCQPQJN � 变异
����PcWPgg�gfwbmk IPCK_GKTfmDiJN � 计算子代目标函数值
����PDispnKPckWQ�sfjotIDispnKTfmDiKTVCQPQKP�JOTSQKPckWKPcWPggk JN� 替代
���� fo�h fo��h N
����PusbdfIfoh K�JKJQ�njoIPckWJN
����usbdfIfoh K�J�nfboIPckWJN
�����
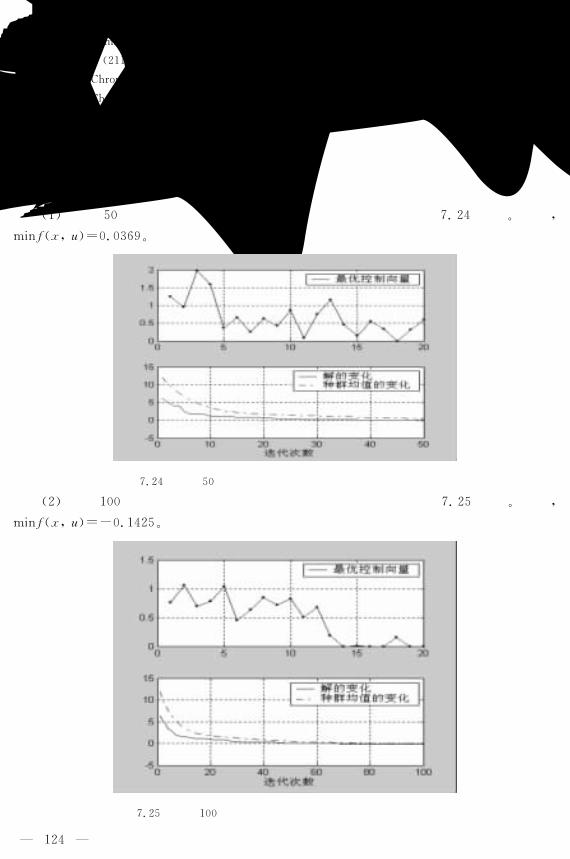
foePZKJQ�njoIPckWJN��������������������� 最优控制向量值及其序号
tvcmpuq I���JN � 最优控制向量分布图
mpuq IDispnIJKMJJNipmepoN
mpuq IDispnIJKMJK���JNsje
tvch
mpuq I���JN � 遗传算法性能跟踪分布图
mpuq IusbdfIMK�JJNipmepoN
mpuq IusbdfIMK�JK���JNsje
mfh
foeh I�解的变化�K�种群均值的变化�J
遗传算法的显示结果如下MI�J经 过��次 迭 代 后 优 化 解 的 目 标 函 数 值 及 性 能 跟 踪 如 图����所 示à此 时K
njogIyKvJ�������à
图������经过��次迭代后的优化解的目标函数值及性能跟踪
I�J经过���次 迭 代 后 优 化 解 的 目 标 函 数 值 及 性 能 跟 踪 如 图����所 示à此 时K
njogIyKvJ��������à
图������经过���次迭代后的优化解的目标函数值及性能跟踪
�����

I�J经过���次 迭 代 后 的 优 化 解 的 目 标 函 数 值 及 性 能 跟 踪 如 图����所 示à此 时K
njogIyKvJ��������à
图������经过���次迭代后的优化解的目标函数值及性能跟踪
为了比较K计算出理论最优解M
njogIyKvJ����������������
� ��������
����
l��l� ��������
经过���次迭代后的优化解�������与理论最优解�������之间的误差仅为������à
�����离散二次线性系统最优控制问题
假设二阶线性系统是一维的K其表达式为
yIl��J�bH�yIlJ�cH�vIlJK��l��K�K�KO目标函数定义为
gIyKvJ�rH�yIo��J����O
l��
PtH�yIlJ��sH�vIlJ�Q
求njogIyKvJà参数设置如表���所示à
表�����参 数 设 置
参数名 O yI�J t s r b c
参数值 �� ��� � � � � �
����一个实现本目标函数的 N文件pcmjok r包含在HB工具箱软件中à下面为离散二次线性系统最优控制的 NBUMBC代码à����� 定义遗传算法参数
HHBQ����N��������� 代沟IHfofsbujpohbqJ
YPWS��N � 交叉率
�����

OWBS���N � 变量维数
NVUS��LOWBSN � 变异率
NBYHFO�����N � 最大遗传代数INbyjnvnovncfspg fofsbujpoth J
JOTS����N � 插入率
TVCQPQ���N � 子代数目
NJHS����N � 迁移率
NJHHFO���N � 每��代迁移个体
OJOE���N � 个体数目IOvncfspgjoejwjevbmtJ
TFM_G��tvt�N � 选择函数名
YPW_G��sfdejt�N � 重组函数名
NVU_G��nvucb�h N� 变异函数名
PCK_G��pcmjok r�N � 目标函数名
GjfmeES�gfwbmIPCK_GKPQK�JN
Dispn�dsusqITVCQPQH�OJOEKGjfmeESJN����� 创建初始种群
fo��h N
usbdf�{fsptINBYHFOK�JN � 遗传算法性能跟踪
PcW�gfwbmk IPCK_GKDispnJN � 计算目标函数值
xijmf foh _� NBYHFOK � 代循环
����usbdfIfo��h K�J�njoIPckWJN
����usbdfIfo��h K�J�nfboIPckWJN
����GjuoW�sboljohIPckWKP�K�QKTVCQPQJN � 分配适应度值IBttjogjuofttwbmvfth J
����TfmDi�tfmfduITFM_GKDispnKGjuoWKHHBQKTVCQPQJN��������� 选择
����TfmDi�sfdpncjoIYPW_GKTfmDiKYPWSKTVCQPQJN � 重组
����TfmDi�nvubufINVU_GKTfmDiKGjfmeESKPNVUSQKTVCQPQJN � 变异
����PcWPgg�gfwbmk IPCK_GKTfmDiJN����������� 计算目标函数值
����PDispnKPckWQ�sfjotIDispnKTfmDiKTVCQPQKP�JOTSQKPckWKPcWPggk JN��� 替代
���� fo�h fo��h N
foePZKJQ�njoIPckWJN
tvcmpuq I���JN
mpuq IDispnIJKMJJN
ipmepoN
mpuq IDispnIJKMJK���JNsje �h 最优控制向量分布图
mffoeh I�最优控制向量�J
tvcmpuq I���JN � 遗传算法性能跟踪分布图
mpuq IusbdfIMK�JJN
ipmepoNmpuq IusbdfIMK�JK����JNsje
mf
h
foeh I�解的变化�K�种群均值的变化�JNymbcfmI�迭代次数�J
遗传算法的显示结果如下MI�J经过���次 迭 代 后 的 优 化 解 的 目 标 函 数 值 及 性 能 跟 踪 如 图����所 示à此 时K
njogIyKvJ������àI�J经 过����次 迭 代 后 的 优 化 解 的 目 标 函 数 值 及 性 能 跟 踪 如 图����所 示à此 时K
�����

njogIyKvJ������à
图������经过���次迭代后的优化解的目标函数值及性能跟踪
图������经过����次迭代后的优化解的目标函数值及性能跟踪
I�J经 过����次 迭 代 后 的 优 化 解 的 目 标 函 数 值 及 性 能 跟 踪 如 图����所 示à此 时K
njogIyKvJ������à
图������经过����次迭代后的优化解的目标函数值及性能跟踪
�����

�����目标分配问题
目标分配问题描述为Mn个地空导弹火力单元对o批空袭目标进行目标分配à假设进
行目标分配之前K各批目标的威胁程度与各火力单元对各批目标的射击有利程度已经经过
评估和排序à第k批目标的威胁程度评估值为xkK第j个火力单元对第k批目标射击有利
程度估计值为qjkK令各火力单元对各批目标进行拦击的效益值为djk�xkðQjkK其中djk表
示对某批目标进行拦击我方获益大小程度à目标分配的目的是满足目标分配的基本原则K
追求总体效益最佳K即求nbyI��o
k��djkJà
染色体采用十进制编码K染色体的长度由按目标批次编号顺序排列的火力单元分配编
号组成K表示一种可能的分配方案à下面为目标分配的最优问题的 NBUMBC代码à
����gvodujpoPfwbmQ�ubsfubmmpdh IdispnJ��������� 目标函数
PnKoQ�tj{fIdispnJN
� 射击有利程度估计值
q�P���������������������������������������������N���
���������������������������������������������N���
���������������������������������������������N���
���������������������������������������������N���
���������������������������������������������N���
���������������������������������������������N���
���������������������������������������������N���
���������������������������������������������QN
x�P���������������������������������������������QN����� 威胁程度评估值
gpsj��Mn
����gps ��k M��
��������dispnIjKkJ�qIdispnIjKkJKkJN
����foeN
foe
fwbm�dispnH�x�N
� 定义遗传算法参数
OJOE���N��������������������� 个体数目IOvncfspgjoejwjevbmtJ
NBYHFO���N � 最大遗传代数INbyjnvnovncfspg fofsbujpoth J
HHBQ����N � 代沟IHfofsbujpohbqJ
usbdf�{fsptINBYHFOK�JN � 遗传算法性能跟踪初始值
CbtfW�dsucbtfI��K�JN
Dispn�dsucqIOJOEKCbtfWJ�poftIOJOEK��JN����� 初始种群
fo��h N
PcW�ubsfubmmpdk IDispnJN � 计算初始种群函数值
xijmf foh _� NBYHFOK
����GjuoW�sboljohI�PckWJN � 分配适应度值IBttjogjuofttwbmvfth J
�����

����TfmDi�tfmfduI�tvt�KDispnKGjuoWKHHBQJN������������� 选择
����TfmDi�sfdpncjoI�ypwtq�KTfmDiK���JN � 重组
����g�sfqIP�N�QKP�K��QJN
����TfmDi�nvuchbITfmDiKgJNTfmDi�gjyITfmDiJN � 变异
����PcWTfm�ubsk fubmmpdh ITfmDiJN � 计算子代目标函数值
����PDispnPckWQ�sfjotIDispnKTfmDiK�K�KPckWKPcWTfmk JN� 重插入
���� fo�h fo��h N
����usbdfIfoh K�J�nbyIPckWJN � 遗传算法性能跟踪
����usbdfIfoh K�J�tvnIPckWJLmfouih IPckWJN
foePZKJQ�nbyIPckWJNDispnIJKMJKZ � 最优解及其目标函数值
mpuq IusbdfIMK�JK����JNipmepoN
mpuq IusbdfIMK�JJNsje
mfh
foeh I�解的变化�K�种群均值的变化�J
目标函数设计为gvodujpoPfwbmQ�ubsfubmmpdh IdispnJà其中Kdispn为染色体K在函
数体中q为�个火力单元对��批目标的射击有利程度评估值àx为��批目标的威胁程度
评估值à遗传算法中K个体的数量OJOE被设置为��K最大遗传代数 NBYHFO���K染
色体长度为��K使用代沟HHBQ����K使用基于适应度的重插入最适应的个体总是被连
续传播到下一代à区域描述器CbtfW�dsucbtfI��K�J描述染色体的表示和解释K染色体
采用十进制编码K一个初始种群被函数dsucq创建K随后产生一个矩阵DispnK它由OJOE个长度为��的十进制串构成àDispn�dsucqIOJOEKCbtfWJ处加poftIOJOEK��J的目
的是保证矩阵处理中的行Ð列序号不为零à经过��次遗传迭代后K目标分配方案见表���à
表�����目标分配方案
目标编号 � � � � � � � � � �� �� �� �� �� ��
分配结果 � � � � � � � � � � � � � � �
����与此方案对应的总收益值为������à图����为经过��次迭代后的优化解的目标函数
值及性能跟踪à
图������经过��次迭代后的优化解的目标函数值及性能跟踪
�����

�����双积分的优化问题
双积分问题的状态方程为
�y� �y��y� �y�z�y�
�
� �
时间范围为M�0�u0��à初 始 条 件 为My�I�J��Ny�I�J���à终 止 条 件 为My�I�J��N
y�I�J��à目标函数为
njogIvJ�&��
�vIuJ�eu
双积分问题的Tjnvmjol模型如下M
一个实现本目标函数的 N文件pcepk qj包含在HB工具箱软件中à下面为双积分的优化问题的 NBUMBC代码à
����� 定义遗传算法参数
Ejn���N����������� 变量维数
OJOE���N � 个体数目IOvncfspgjoejwjevbmtJ
Qsfdj���N � 变量的二进制位数IQsfdjtjpopgwbsjbcmftJ
NBYHFO����N � 最大遗传代数INbyjnvnovncfspg fofsbujpoth J
HHBQ����N � 代沟IHfofsbujpohbqJ
TFM_G��tvt�N � 选择函数名
YPW_G��ypwtq�N � 重组函数名
NVU_G��nvu�N � 变异函数名
PCK_G��pcepk j�q N � 目标函数名
GjfmeES�gfwbmIPCK_GKPQK�JN��������������������� 计算目标函数值
� 建立区域描述器ICvjmegjfmeeftdsjupsq J
GjfmeEE�PsfqIPQsfdjQKP�KEjnQJNGjfmeESNsfqIP�N�N�N�QKP�KEjnQJQN
Dispn�dsucqIOJOEKEjnH�QsfdjJN � 创建初始种群
fo��h N
Cftu�ObOH�poftINBYHFOK�JN � 最优解初值
xijmf foh _� NBYHFOK � 最大循环次数
����PcW�gfwbmk IPCK_GKct�swIDispnKGjfmeEEJJN � 计算目标函数值
����CftuIfo��h J�njoIPckWJN � 最优解
���� mpuq Imp��h ICftuJK�cp�JN
����GjuoW�sboljohIPckWJN � 分配适应度值IBttjogjuofttwbmvfth J
����TfmDi�tfmfduITFM_GKDispnKGjuoWKHHBQJN � 选择
����TfmDi�sfdpncjoIYPW_GKTfmDiJN � 重组
�����

����TfmDi�nvubufINVU_GKTfmDiJN � 变异
����Dispn�sfjotIDispnKTfmDiJN � 重插入
���� fo�h fo��h N
foe
sjeh N
ymbcfmI�迭代次数�JNmbcfmz I�目标函数值I取对数J�JN
遗传算法的运行结果如下MI�J经过��次迭代后的运行结果如图����所示à
图������经过��次迭代后的运行结果
I�J经过���次迭代后的运行结果如图����所示à
图������经过���次迭代后的运行结果
�����雷达目标识别问题
复杂目标的高分辨雷达回波信号在时域上出现多个峰值K这些峰值对应目标径向上的
多个强散射中心à但是K当空中目标的位置发生变化时K目标的强散射点相对于雷达视角
发生变化K因此K从数据库中寻找与待识别目标模式相匹配的模式的工作量很大K传统的
�����

匹配方法已不能满足需要à本节利用遗传算法进行目标识别K具体步骤如下MI�J染色体编码与解码M假设数据库中已知目标类型有n种K每种类型目标在雷达视
角�Y�范 围 内 的 雷 达 回 波 信 号o 个 序 列à对 于 两 参 数 目 标 类 型j0�n 和 雷 达 视 角 编 码
k0�oK设l� 为参数j的二进制编码长度Kl� 为参数k的二进制编码长度K定义遗传算法的
个体Jl 基因型Hl 为
Hl ������� �����l�
������ ����
l�
则编码总长度为l��l�K即个体Jl 基因型Hl 的前l� 位的十进制解码为jK后l� 位的十进
制解码为kàI�J产生初始种群M一个个体由串长为l��l� 的随机产生的二进制串组成染色体的基
因码K可以产生一定数目的个体组成种群K设置群体大小àI�J个体适应度的检测评估M设YIjKkJ为第j种目标在第k个雷达视角的高分辨雷达
目标回波信号序列K对应的个体为Jlà待识别目标的高分辨雷达目标回波信号序列为Yà个体Jl 的适应度函数可定义为
gIJlJ� }YIjKkJ�Y}}YIjKkJ�YIjKkJ��Y�Y� }
式中Kb�Y�Zb�为序列Y和序列Z 的相关系数àI�J遗传算子M选择运算使用比例选择算子K交叉运算使用单点交叉算子K变异运算
使用基本位变异算子或均匀变异算子à每个个体选择概率为
qt �gIJlJ
��l��gIJlJ
设置遗传算法的终止进化代数Ð交叉概率和变异概率K对群体进行操作à下面为雷达目标识别问题的 NBUMBC代码à����gvodujpodpfg�dpssdpfg�IyKzJ��� 计算y和z的相关系数函数Ky为单序列Kz为复序列
PnKoQ�tj{fIzJN
dpfg�{fsptInK�JN
gpsj��Mn
����dpfgIjJ�tvnIbctIdpowIyKzIjKMJJJJLtsur ItvnIbctIdpowIyKyJJJH�tvnIbctIdpowIzIjKMJK
zIjKMJJJJJN
foe
gvodujpodmbtt�sfdpojufh Itjobmh KjogpsnJN�� � 目标识别函数
�tjobmh 为待识别目标的雷达信号Njogpsn目标识别数据库中的模板信号
OJOE���N � 个体数目IOvncfspgjoejwjevbmtJ
NBYHFO����N � 最大遗传代数INbyjnvnovncfspgfofsbujpoth J
zqf���U NBomf���h N � 目标类型��cjuK雷达视角��cju
QSFDJ�Uzqf� Bomfh N � 变量的二进制位数IQsfdjtjpopgwbsjbcmftJ
HHBQ����N � 代沟IHfofsbujpohbqJ
GjfmeE�PQSFDJN�NOJOEN�N�N�N�QN � 区域描述器ICvjmegjfmeeftdsjupsq J
Dispn�dsucqIOJOEKQSFDJJN � 创建初始种群
fo��h N
�����
w�ct�swIDispnKGjfmeEJN � 种群十进制转换
dmbtt�spvoeIwJN � 取整
PcW�dpssdpfg�k Itjobmh KjogpsnIdmbttKMJJN � 计算相关系数
usbdf�{fsptINBYHFOJN � 性能跟踪
xijmf foh _� NBYHFOK
����GjuoW�sboljohI�PckWJN � 分配适应度值IBttjogjuofttwbmvfth J
����TfmDi�tfmfduI�tvt�KDispnKGjuoWKHHBQJN������������� 选择
����TfmDi�sfdpncjoI�ypwtq�KTfmDiK���JN � 重组
����TfmDi�nvuITfmDiJN � 变异
����w�ct�swITfmDiKGjfmeEJN
����dmbtt�spvoeIwJN
����PcWTfm�dpssdpfg�k Itjobmh KjogpsnIdmbttKMJJN � 计算目标函数相关系数
����PDispnPckWQ�sfjotIDispnKTfmDiK�K�KPckWKPcWTfmk JN � 重插入
���� fo�h fo��h N
����usbdfIfoh J�nbyIPckWJN
foe
� 输出最优解及其序号K并在目标函数图像中标出KZ为最优解KJ为种群的序号
PZKJQ�nbyIPckWJN
zqf�spvoeU Ict�swIDispnIJK�MzqU fJKGjfmeEJJN � 目标类型编号
Bomf�spvoeh Ict�swIDispnIJKzqf��U MBomfh JKGjfmeEJJN � 雷达视角编号
mpuq IusbdfJNipmepoN
mpuq IusbdfK���JNsjeh N
实例M实验数据选自毫米波步进频率信号K带宽为�HI{K调频步长为�NI{à识别
目标为轰炸机Ð歼击机和直升机的缩比模型à对三类飞机鼻锥方向����方位角I角度间隔
为��J变化范围内的雷达回波进行截取Ð去均值Ð归一化等预处理后K作为数据库中的数
据à待识别目标的雷达回波数据为三类飞机的雷达回波加高斯白噪声à图����为遗传算法
搜索最优解的过程à
图������遗传算法搜索最优解的过程
�����

������图像分割问题
利用遗传算法进行图像分割的基本思想是M把图像中的像素按灰度值用阈值 N 分成
两类图像K一类为目标图像D�K另一类为背景图像D�à图像D� 由灰度值在�YN 之间的
像素组成K图像D� 由灰度值在N��YM��IM为图像的灰度级数J之间的像素组成à本节处理图像为���灰度级K将灰度分割阈值编码为一个�位�Ð�二进制码串à适应
度函数选为gINJM
gINJ�X�INJðX�INJðPV�INJ�V�INJQ�
其中KX�INJ为目标图像D� 中所包含的像素数NX�INJ为目标图像D� 中所包含的像素
数NV�INJ为D� 中所有像素数的平均灰度值NV�INJ为D� 中所有像素数的平均灰度值à下面为雷达目标识别问题的 NBUMBC代码à����gvodujpog�ubsfuh IUKNJ������������ � 适应度函数KU为待处理图像KN为阈值序列
PVKWQ�tj{fIUJN
X�mfouih INJN
g�{fsptIXK�JN
gpsl��M
J��
XNt���NK��Nt���N � 统计目标图像和背景图像的像素数及像素之和
gpsj��MV
����gps ��k MW
��������jgUIjKkJ_��NIlJ
������������t��t��UIjKkJNJ�J��N
��������foe
��������jgUIjKkJ`�NIlJ
������������t��t��UIjKkJNK�K��N
��������foe
����foe
foe
��t�q LJN��t�q LKN � 计算目标图像与背景图像的像素平均值
gIlJ�JH�KH�I��q q�JH�I��q q�JLI���H����JN���� � 计算适应度函数值
foe
mpbexpbno � 调用 NBUMBC中 Xpnbo图像灰度值
gjvsfh I�JN � 画图
jnbhfIYJNdpmpsnbqInbqJN
OJOE���N � 个体数目IOvncfspgjoejwjevbmtJ
NBYHFO���N � 最大遗传代数INbyjnvnovncfspg fofsbujpoth J
QSFDJ��N � 变量的二进制位数IQsfdjtjpopgwbsjbcmftJ
HHBQ����N � 代沟IHfofsbujpohbqJ
GjfmeE�P�N�N���N�N�N�N�QN � 建立区域描述器ICvjmegjfmeeftdsjupsq J
Dispn�dsucqIOJOEKQSFDJJN � 创建初始种群
fo��h N
�����

qifo�ct�swIDispnKGjfmeEJN � 初始种群十进制转换
PcW�ubsk fuh IYKifoq JN � 计算种群适应度值
xijmf foh _� NBYHFOK � 代沟IHfofsbujpohbqJ
����GjuoW�sboljohI�PckWJN � 分配适应度值IBttjogjuofttwbmvfth J
����TfmDi�tfmfduI�tvt�KDispnKGjuoWKHHBQJN��� 选择
����TfmDi�sfdpncjoI�ypwtq�KTfmDiK���JN � 重组
����TfmDi�nvuITfmDiJN � 变异
���� ifoTfm�ct�swq ITfmDiKGjfmeEJN � 子代十进制转换
����PcWTfm�ubsk fuh IYKifoTfmq JN
����PDispnPckWQ�sfjotIDispnKTfmDiK�K�KPckWKPcWTfmk JN��� 重插入
���� fo�h fo��h N
foePZKJQ�nbyIPckWJN
N�ct�swIDispnIJKMJKGjfmeEJN � 估计阈值
PnKoQ�tj{fIYJN
gpsj��Mn
����gps ��k Mo
��������jgYIjKkJ`�N
������������YIjKkJ����N � 灰度值为���时是白色
��������foe
����foe
foe
gjvsfh I�J � 画出分割后目标图像
jnbhfIYJNdpmpsnbqInbqJN
图����为 NBUMBC中的 Xpnbo图像à图����为经过��次迭代后的分割图像I阈
值为���Jà
图������Xpnbo原始图像I�������J
�����

图������Xpnbo分割后的图像I阈值为���J
������一些测试函数对应的优化问题
下面给出工具箱提供的一些测试函数的遗传算法的运行结果I问题的 NBUMBC代码
可参考前面例子的代码Jà
��������轴并行超球体的最小值问题
一个实现本目标函数的 N文件pcgvombk 包含在HB工具箱软件中à变量维数Ejn���K变量的范围为����Y���K选取个体数目OJOE���K迭代次数
NBYHFO取为���Ð���Ð���K代沟HHBQ取为���à迭代���次Ð���次Ð���次目标函
数最小值分别为������Ð������Ð�����������K最小值对应的��个变量值见表���à目
标函数的理论最小值为�à跟踪性能如图����Ð图����和图����所示à表�����迭代���次Ð���次Ð���次的目标函数最小值对应的��个变量值
迭代
次数变��量��值 备注
��� ������� �������������� ������ ������� ������� ������ ������ ������ ������
��� ������ ������ ������ ������ �������������� ������ ������ ������� ������
��� �������������� ������ ������� ������ ���������������������������� ������ �����
图������经过���次迭代后的优化解的目标函数值及性能跟踪
�����

图������经过���次迭代后的优化解的目标函数值及性能跟踪
图������经过���次迭代后的优化解的目标函数值及性能跟踪
��������旋转超球体的最小值问题
一个实现本目标函数的 N文件pcgvomck 包含在HB工具箱软件中à变量维数Ejn���K变量的范围为���Y��K选取OJOE���KNBYHFO����Ð���Ð
����NHHBQ����à表���分别为迭代���次Ð���次Ð����次的目标函数最小值对应的
变量值K对应的最小值分别为��������Ð�������Ð�������à目标函数理论值为�à跟踪性
能如图����Ð图����和图����所示à表�����迭代���次Ð���次Ð����次的目标函数最小值对应的��个变量值
迭代
次数变��量��值 备注
��� ������ ������� ������ �������������� ������ ������ ������� ������ �������
��� ������ �������������� ������ �������������� ������ ������ ������� ������
���� ������ ������� ������ ������� ������ ������� ������ ������� ������ ������ �����
�����

图������经过���次迭代后的优化解的目标函数值及性能跟踪
图������经过���次迭代后的优化解的目标函数值及性能跟踪
图������经过����次迭代后的优化解的目标函数值及性能跟踪
��������Sptfocspdl’tWbmmfz最小值问题
一个实现本目标函数的 N文件pcgvo�k 包含在HB工具箱软件中à
�����
变量维数Ejn��K变量的范围为��Y�K选取OJOE���KHHBQ����à表���为迭
代的最优解和对应的目标函数值à理论值为M变量值为P�K�QK目标函数值为�à跟踪性能
如图����所示à
表�����迭代��次Ð���次Ð���次Ð���次和����次的最优解及对应的目标函数值
迭代次数 �� ��� ��� ��� ����
变量值 ������ ������ ������ ������ ������ ������ ������ ������ ������ ������
目标函数值 ������ ������ ������ ������ �����������
图������经过���次迭代后的优化解的目标函数值及性能跟踪
��������Sbtusjjoh 函数的最小值问题
一个实现本目标函数的 N文件pcgvo�k 包含在HB工具箱软件中à变量维数Ejn���K变量的范围为�����Y����K选取OJOE���KHHBQ����à目
标函数理论值为�à表���为迭代次数及对应的目标函数最小值à迭代次数为����时目标
函数取最小值K对应的��个变量的值见表���K也可见图����à跟踪性能见图����à
表�����迭代次数及对应的最小值
迭代次数 �� ��� ��� ��� ����
最小值 ������� ������� ������� ������� �������
表�����迭代次数为����时��个变量的值
序号 � � � � � � � � � ��
变量值 ������ �������������������� ������������� �������������������� �������
序号 �� �� �� �� �� �� �� �� �� ��
变量值 ������������� ������ ��������������������������� ������ ������ �������
�����

图������经过����次迭代后的最优解
图������经过���次迭代后的优化解的目标函数值及性能跟踪
��������Tdixfgfm函数的最小值问题
一个实现本目标函数的 N文件pcgvo�k 包含在HB工具箱软件中à变量维数为��K变量范围为����Y���K选取OJOE���KHHBQ����à表���为迭
代次数及对应的最小值à理论最小值为�������à跟踪性能见图����K迭代次数为����时
最优解如图����所示à表�����迭代次数及对应的最小值
迭代次数 �� ��� ��� ��� ����最小值 ������� ������� ������� ������� �������
图������经过���次迭代后的最优解及性能跟踪
�����
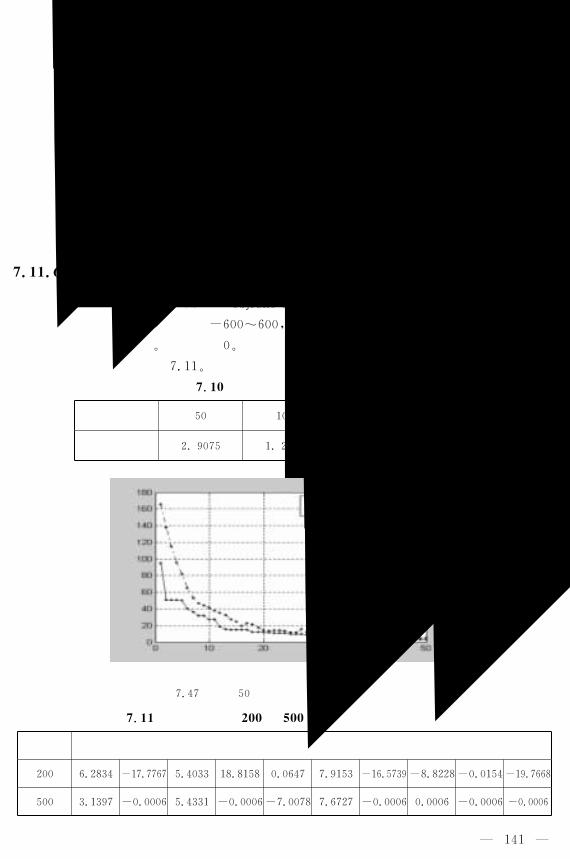
图������经过����次迭代后的最优解
��������Hsjfxbohl函数的最小值问题
一个实现本目标函数的 N文件pcgvo�k 包含在HB工具箱软件中à变量维数为��K变量范围为����Y���K选取OJOE���KHHBQ����à表����为迭
代次数及对应的最小值à理论值为�à跟踪性能如图����所示à迭代���次和���次后的
最优解对应的变量值见表����à表������迭代次数及对应的最小值
迭代次数 �� ��� ��� ���
最小值 ������ ������ ������ ������
图������经过��次迭代后的最优解及性能跟踪
表������迭代次数为���和���后的最优解对应的变量值
迭代次数 变��量��值
��� ������ �������� ������ ������� ������ ������ ������������������������������
��� ������ ������������� �������������������� ������������� ��������������
�����

��������不同权的总和最小值问题
一个实现本目标函数的 N文件pcgvo�k 包含在HB工具箱软件中à变量维数为��K变量取值范围为��Y�K选取OJOE���KHHBQ����à表����为迭
代次数及对应的最小值à理论值为�à跟踪性能如图����所示K迭代次数为���和���时
的最优解见表����à表������迭代次数及对应的最小值
迭代次数 �� ��� ���
最小值 ������f�� ������f�� ������f���
图������经过��次迭代后的最优解及性能跟踪
表���������次和���次迭代后的最优解对应的变量值
迭代次数 变��量��值
��� ������������� ������������� ���������������������������������� �������
��� ������������� ������ ������ ������ ������ �������������������� ������
������多目标优化问题
下面为一个含有两个优化目标的多目标优化问题à
njo��g� �y����
y��
njo�
��g� �y�I��y�J���
t�u����0�y� 0��K�0�y� 0�
�
�
� �
����对于该问题K利用权重系数变换法很容易求出Qbsfup最优解à当g� 和g� 的权重系数
都为���时K经过��次迭代后结果为My��������Ky��������Kg��g���������à跟踪
性能如图����所示à
�����

图������经过��次迭代后的最优解及性能跟踪
����下面为利用并列选择法求解多目标最优问题的 NBUMBC代码à����Gvodujpog��gIyJ����������������������� 第一目标函数
g��yIMK�J�H�yIMK�JL��yIMK�J�H�yIMK�JL�N
gvodujpog��gIyJ � 第二目标函数
g��yIMK�J�H� I��yIMK�JJ���N
OJOE����N � 个体数目IOvncfspgjoejwjevbmtJ
NBYHFO ���N � 最 大 遗 传 代 数INbyjnvnovncfspg fofsb�ujpot
hJ
OWBS��N � 变量个数
QSFDJ���N � 变量的二进制位数IQsfdjtjpopgwbsjbcmftJ
HHBQ����N � 代沟IHfofsbujpohbqJ
usbdf��PQNusbdf��PQNusbdf��PQN � 性能跟踪
� 建立区域描述器ICvjmegjfmeeftdsjupsq J
GjfmeE�PsfqIPQSFDJQKP�KOWBSQJNP�K�N�K�QNsfqIP�N�N�N�QKP�KOWBSQJQN
Dispn�dsucqIOJOEKOWBSH�QSFDJJN � 初始种群
w�ct�swIDispnKGjfmeEJN � 初始种群十进制转换
fo��h N
xijmf foh _� NBYHFOK
����POJOEKOQ�tj{fIDispnJN
����N�gjyIOJOEL�JN
����PcW��g�k IwI�MNKMJJN������ � 分组后第一目标函数值
����GjuoW��sboljohIPcW�k JN � 分配适应度值IBttjogjuofttwbmvfth J
����TfmDi��tfmfduI�tvt�KDispnI�MNKMJKGjuoW�KHHBQJN������ ����� 选择
����PcW��g�k IwIN��MOJOEKMJJN � 分组后第二目标函数值
����GjuoW��sboljohIPcW�k JN
����TfmDi��tfmfduI�tvt�KDispnIIN��JMOJOEKMJKGjuoW�KHHBQJN��� 选择
����TfmDi�PTfmDi�NTfmDi�QN � 合并
����TfmDi�sfdpncjoI�ypwtq�KTfmDiK���JN� 重组
����Dispn�nvuITfmDiJN � 变异
����w�ct�swIDispnKGjfmeEJN
�����

����usbdf�Ifoh K�J�njoIg�IwJJN
����usbdf�Ifoh K�J�tvnIg�IwJJLmfouih Ig�IwJJN
����usbdf�Ifoh K�J�njoIg�IwJJN
����usbdf�Ifoh K�J�tvnIg�IwJJLmfouih Ig�IwJJN
����usbdf�Ifoh K�J�njoIg�IwJ�g�IwJJN
����usbdf�Ifoh K�J�tvnIg�IwJJLmfouih Ig�IwJJ�tvnIg�IwJJLmfouih Ig�IwJJN
���� fo�h fo��h N
foegjvsfh I�JNdmgN
mpuq Iusbdf�IMK�JJNipmepoNmpuq Iusbdf�IMK�JK����JN
mpuq Iusbdf�IMK�JK���JNmpuq Iusbdf�IMK�JK���JNsjeh N
mffoeh I�解的变化�K�种群均值的变化�J
ymbcfmI�迭代次数�JNmbcfmz I�目标函数值�JN
gjvsfh I�JNdmgN
mpuq Iusbdf�IMK�JJNipmepoN
mpuq Iusbdf�IMK�JK����JN
mpuq Iusbdf�IMK�JK���JN
mpuq Iusbdf�IMK�JK���JNsjeh N
mffoeh I�解的变化�K�种群均值的变化�JN
ymbcfmI�迭代次数�JNmbcfmz I�目标函数值�JN
gjvsfh I�JNdmgN
mpuq Iusbdf�IMK�JJNipmepoN
mpuq Iusbdf�IMK�JK����JN
mpuq Iusbdf�IMK�JK���JN
mpuq Iusbdf�IMK�JK���JNsjeh N
mffoeh I�解的变化�K�种群均值的变化�JN
ymbcfmI�迭代次数�JNmbcfmz I�目标函数值�JN
gjvsfh I�JNdmgNmpuq Ig�IwJJNipmepoN
mpuq Ig�IwJK�s���JNsjeh N
经过��次遗传迭代后的结果如图����Y图����所示à
图������经过��次迭代后第一目标函数的最优解及性能跟踪
�����
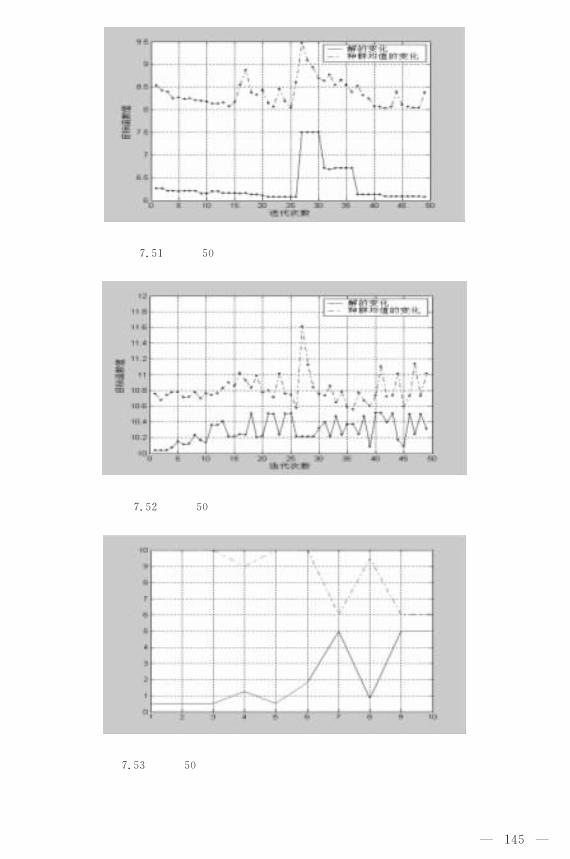
图������经过��次迭代后第二目标函数的最优解及性能跟踪
图������经过��次迭代后的两目标函数和的最优解及性能跟踪
图������经过��次迭代后种群的第一目标函数值与第二目标函数值
�����

书书书
ðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀ
ðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀ
���
�
��第八章��使用NBUMBC遗传算法工具��
最新发布的 NBUMBC���Sfmfbtf��包含一个专门设计的遗传算法与直接搜
索工具箱IHfofujdBmpsjuinboeEjsfduTfbsdiUppmcpyh Jà使用遗传算法与直接搜
索工具箱K可以扩展 NBUMBC及其优化工具箱在处理优化问题方面的能力K可以
处理传统的优化技术难以解决的问题K包括那些难以定义或不便于进行数学建模的
问题K可以解决目标函数较复杂的问题K比如目标函数不连续或具有高度非线性Ð随机性以及目标函数不可微的情况à
本章���节首先综合介绍这个遗传算法与直接搜索工具箱K其余各节具体介绍
该工具箱中的遗传算法工具及其使用方法à直接搜索工具箱将在第九章详细介绍à
�����遗传算法与直接搜索工具箱概述
本节介绍 NBUMBC的HBETI遗传算法与直接搜索J工具箱的特点Ð图形用户界面及
运行要求K解释如何编写待优化函数的 N文件K且通过举例加以阐明à
�������工具箱的特点
HBET工具箱是一系列函数的集合K它们扩展了优化工具箱和 NBUMBC数值计算环
境的性能à遗传算法与直接搜索工具箱包含了要使用遗传算法和直接搜索算法来求解优化
问题的一些例程à这些算法使我们能够求解那 些 标 准 优 化 工 具 箱 范 围 之 外 的 各 种 优 化 问
题à所 有 工 具 箱 函 数 都 是 NBUMBC 的 N 文 件K这 些 文 件 由 实 现 特 定 优 化 算 法 的
NBUMBC语句所写成à使用语句
����zqfgvodujpou _obnf就可以看到这些函数的 NBUMBC代码à我们也可以通过编写自己的 N 文件来实现和扩
展遗传算法和直接 搜 索 工 具 箱 的 性 能K也 可 以 将 该 工 具 箱 与 NBUMBC的 其 他 工 具 箱 或
Tjnvmjol结合使用来求解优化问题à工具箱函数可以通过图形界面或 NBUMBC命令行来访问K它们是用 NBUMBC语言
编写的K对用户开放K因此可以查看算法Ð修改源代码或生成用户函数à遗传算法与直接搜索工具箱可以帮助我们求解那些不易用传统方法解决的问题K譬如
表查找问题等à遗传算法与直接搜索工具箱有一个精心设计的图形用户界面K可以帮助我们直观Ð方
便Ð快速地求解最优化问题à
�����

��功能特点
遗传算法与直接搜索工具箱的功能特点如下MI�J图形用 户 界 面 和 命 令 行 函 数 可 用 来 快 速 地 描 述 问 题Ð设 置 算 法 选 项 以 及 监 控
进程àI�J具有多个选项的遗传算法工具可用于问题创建Ð适应度计算Ð选择Ð交叉和变异àI�J直接搜索工具实现了一种模式搜索方法K其选项可用于定义网格尺寸Ð表决方法
和搜索方法àI�J遗 传 算 法 与 直 接 搜 索 工 具 箱 函 数 可 与 NBUMBC 的 优 化 工 具 箱 或 其 他 的
NBUMBC程序结合使用àI�J支持自动的 N代码生成à
��图形用户界面和命令行函数
遗传算法工具函数可以通过命令行和图形用户界面来使用遗传算法à直接搜索工具函
数也可以通过命令行和图形用户界面来进行访问à图形用户界面可用来快速地定义问题K设置算法选项K对优化问题进行详细定义à
遗传算法和直接搜索工具箱还同时提供了用于优化管理Ð性能监控及终止准则定义的
工具K同时还提供了大量的标准算法选项à在优化运行的过程中K可以通过修改选项来细化最优解K更新性能结果à用户也可以
提供自己的算法选项来定制工具箱à
��使用其他函数和求解器
遗传算法与直接搜索工具箱和 NBUMBC及优化工具箱是紧密结合在一起的à用户可
以用遗传算法或直接搜索算法来寻找最佳起始点K然后利用优化工具箱或用 NBUMBC程
序来进一步寻找最优解à通过结合不同的算法K可以充分地发挥 NBUMBC和工具箱的功
能以提高求解的质量à对于某些特定问题K使用这种方法还可以得到全局I最优J解à
��显示Ð监控和输出结果
遗传算法与直接搜索工具箱还包括一系列绘图函数K用来可视化优化结果à这些可视
化功能直观地显示了优化的过程K并且允许在执行过程中进行修改à该工具箱还提供了一些特殊绘图函数K它们不仅适用于遗传算法K还适用于直接搜索
算法à适用于遗传算法的函数包括函数值Ð适应度值和函数估计à适用于直接搜索算法的
函数包括函数值Ð分值直方图Ð系谱Ð适应度值Ð网格尺寸和函数估计à这些函数可以将多
个绘图一并显示K可直观方便地选取最优曲线à另外K用户也可以添加自己的绘图函数à使用输出函数可以将结果写入文件K产生用户自己的终止准则K也可以写入用户自己
的图形界面来运行工具箱求解器à除此之外K还可以将问题的算法选项导出K以便日后再
将它们导入到图形界面中去à
��所需的产品支持
遗传算法与直接搜索工具箱作为其他优化方法的补充K可以用来寻找最佳起始点K然
后再通过使用传统的优化技术来进一步寻找最优解à工具箱需要如下产品支持MI�JNBUMBCàI�J优化工具箱à
�����

��相关产品
与遗传算法与直接搜索工具箱相关的产品有MI�J统计工具箱���应用统计算法和概率模式àI�J神经网络工具箱���设计和仿真神经网络àI�J模糊逻辑工具箱���设计和仿真基于模糊逻辑的系统àI�J金融工具箱���分析金融数据和开发金融算法à
��所需的系统及平台
遗传算法和直接搜索工具箱对于运行环境Ð支持平台和系统的需求K可随时通过访问
网站iuuqMLLxxx�nbuixpslt�dpnLspevdutq Lbeth 了解最新发布的信息à这里介绍的 NBUMBC���Sfmfbtf��所 需 的 最 低 配 置 是MXjoepxt系 列 操 作 系 统K
Qfoujvn ����NI{DQVK��NCSBNK空闲硬盘空间���NC以上à
�������编写待优化函数的 N文件
为了使用遗传算法和直接搜索工具箱K首先必须编写一个 N文件K来确定想要优化的
函数à这个 N文件应该接受一个行向量K并且返回一个标量à行向量的长度就是目标函数
中独立变量的个数à本节将通过实例解释如何编写这种 N文件à
��编写 N文件举例
下面的例子展示了如何为一个想要优化的函数编写 N 文件à假定我们想要计算下面
函数的最小值M
gIy�Ky�J�y����y�y���y��y����y�����N文件确定这个函数必须接受一个长度为�的行向量YK分别与变量y� 和y� 相对
应K并且返回一个标量[K其值等于该函数的值à为了编写这个 N文件K执行如下步骤MI�J在 NBUMBC的Gjmf菜单中选择Ofx菜单项àI�J选择 N�GjmfK在编辑器中打开一个新的 N文件àI�J在该 N文件中K输入下面两行代码M
����gvodujpo{�nz_gvoIyJ
����{�yI�J�����H�yI�JH�yI�J��H�yI�J�yI�J�����H�yI�JNI�J在 NBUMBC路径指定的目录中保存该 N文件à为了查看该 N文件是否返回正确的值K可键入
����nz_gvoIP��QJ
����bot�����������注意M在运行遗传算法工具或模式搜索工具时K不要使用编辑器或调试器来调试目标
函数的 N文件K否则会导致在命令窗口出现Kbwb异常消息K并且使调试更加困难à
��最大化与最小化
遗传算法和直接搜索工具箱中的优化函数总是使目标函数或适应度函数最小化K也就
是说K它们求解如下形式的问题M
njoygIyJ
如果想要求出函数gIyJ的最大值K可以转而求取函数hIyJ��gIyJ的最小值K因为
�����

函数hIyJ最小值出现的地方与函数gIyJ最大值出现的地方相同à例如想要求前面所描述的函数gIy�Ky�J�y����y�y���y��y����y� 的最大值K这时K
我们应当编写一个 N文件来计算K求函数hIyJ��gIy�Ky�J��Iy����y�y���y��y����y�J的最小值à
��自动代码生成
遗传算法与直接搜索工具箱提供了自动代码生成特性K可以自动生成求解优化问题所
需要的N文件à例如K图���所示就是使用遗传算法工具的自动代码生成特性所产生的N文件à
另外K图形用户界面所输出的优化结果可以作为对来自命令行调用代码的一种解释K这些代码还用于使例程和保护工作自动化à
图�����遗传算法 N文件代码的自动生成
�����使用遗传算法工具初步
遗传算法与直接搜索工具箱包含遗传算法工具和直接搜索工具à从本节至章末K将主
要介绍其中的遗传算法工具及其使用方法à本节主要介绍遗传算法工具使用的初步知识K内容包括M遗传算法使用规则K遗传算
法工具的使用方式K举例说明如何使用遗传算法来求解一个优化问题K遗传算法的一些基
本术语K遗传算法的工作原理与工作过程à
�������遗传算法使用规则
遗传算法是一种基于自然选择Ð生物进化过程来求解问题的方法à遗传算法反复修改
对于个体解决方案的种群à在每一步中K遗传算法随机地从当前种群中选择若干个体作为
父辈K并且使用它们产生下一代的子种群à在连续若干代之后K种群朝着优化解的方向进
化à我们可以用遗传算法来求解各种不适宜于用标准优化算法求解的优化问题K包括目标
函数不连续Ð不可微Ð随机或高度非线性的问题à遗传算法在每一步使用下列三类规则从当前种群来创建下一代MI�J选择规则ITfmfdujpoSvmftJM选择对下一代种群有贡献的个体I称为父辈Jà
�����

I�J交叉规则IDspttpwfsSvmftJM将两个父辈结合起来构成下一代的子辈种群àI�J变异规则INvubujpoSvmftJM施加随机变化给父辈个体来构成子辈à遗传算法 与 标 准 优 化 算 法 主 要 在 两 个 方 面 有 所 不 同K它 们 的 比 较 情 况 归 纳 于 表
���中à表�����遗传算法与标准优化算法比较
标准算法 遗传算法
��每次迭代产生一个单点K点的序列逼近一个优
化解��每次迭代产生一个种群K种群逼近一个优化解
��通过确定性的计算在该序列中选择下一个点 ��通过随机进化选择计算来选择下一代种群
�������遗传算法使用方式
遗传算法工具有两种使用方式MI�J以命令行方式调用遗传算法函数hbàI�J通过图形用户界面使用遗传算法工具à本节对这两种方式做一个简要的介绍à
��在命令行调用函数hb对于在命令行使用遗传算法K可以用下列语法调用遗传算法函数hbM
����PygwbmQ�hbIP�gjuofttgvoKowbstKpujpotq J其中KP�gjuofttgvo是适应度函数句柄Nowbst是适应度函数的独立变量的个数Npujpotq 是
一个包含遗传算法 选 项 参 数 的 结 构à如 果 不 传 递 选 项 参 数K则hb使 用 它 本 身 的 缺 省 选
项值à函数所给出的结果为Mgwbm���适应度函数的最终值Ny���最终值到达的点à我们可以十分方便地把遗传算法工具输出的结果直接返回到 NBUMBC的xpsltbdfq
I工作空间JK或以不同的选项从 N文件多次调用函数hb来运行遗传算法à调用函数hb时K需要提供一个选项结构pujpotq à后面的有关章节对于在命令行中使
用函数hb和创建选项结构pujpotq 提供了详细的描述à
��通过HVJ使用遗传算法
遗传算法工具有一个图形用户界面HVJK它使我们可以使用遗传算法而不用工作在命
令行方式à打开遗传算法工具K可键入以下命令M
���� buppmh打开的遗传算法工具图形用户界面如图���所示à使用遗传算法工具首先必须输入下列信息MI�JGjuofttgvodujpoI适应度函数J���欲求最小值的目标函数à输入适应度函数的形式
为P�gjuofttgvoK其中gjuofttgvo�n是计算适应度函数的N文件à在�����节�编写待优化函数
的 N文件�里已经解释了如何编写这种 N文件à符号P�产生一个对于函数gjuofttgvo的函数
句柄àI�JOvncfspgwbsjbcmftI变量个数J���适应度函数输入向量的长度à对于�编写待优
化函数的 N文件�一节所描述的函数nz_gvoK它的参数是�à
�����

图�����遗传算法工具
单击�Tubsu�按钮K运行遗传算法K将在�TubuvtboesftvmutI状态与结果J�窗格中显示
出相应的运行结果à在�Pujpotq �窗格中可以改变遗传算法的选项à为了查看窗格中所列出的各类选项K可
单击与之相连的符号���à
�������举例:Sbtusjjoh 函数
本节通 过 一 个 例 子 讲 述 如 何 寻 找 Sbtusjjoh 函 数 的 最 小 值 和 显 示 绘 制 的 图 形à
Sbtusjjoh 函数是最常用来测试遗传算法的一个典型函数àSbtusjjoh 函数的可视化图形显
示具有多个局部最小值和一个全局最小值K遗传算法可帮助我们确定这种具有多个局部最
小值函数的最优解à
��Sbtusjjoh 函数
具有两个独立变量的Sbtusjjoh 函数定义为
SbtIyJ����y���y�����Idpt��y��dpt��y�J
����Sbtusjjoh 函数的图形如图���所示à工具箱包含一个 N文件K即sbtusjjotgdo�nh K是用来计算Sbtusjjoh 函数值的à如图���所示KSbtusjjoh 函数有许多局部最小值���在图上显示为�谷底IWbmmfztJ�à
然而K该函数只有一个全局最小值K出现在y�z平面上的点P�K�Q处K正如图中竖直线指
示的那样K函数的值在那里是�à在任何不同于P�K�Q的局部最小点处KSbtusjjoh 函数的值
均大于�à局部最小处距原点越远K该点处Sbtusjjoh 函数的值越大à�����

图�����Sbtusjjoh 函数图形
Sbtusjjoh 函数之所以最常用来测试遗传算法K是因为它有许多局部最小点K使得用标
准的Ð基于梯度的查找全局最小的方法十分困难à图���所示是Sbtusjjoh 函数的轮廓线K它显示出最大Ð最小交替变化的情形à
图�����Sbtusjjoh 函数的轮廓线
��寻找Sbtusjjoh 函数的最小值
在使用遗传算法时K因为是使用随机数据来进行搜索K所以该算法每一次运行时所返
回的结果会稍微有些不同à为了查找最小值K执行下列步骤MI�J在命令行键入 buppmh K打开遗传算法工具àI�J在遗传算法工具的相应栏目中输入适应度函数和变量个 数à在�Gjuofttgvodujpo
I适应度函数J�文本框中K输入�P�sbtusjjotgdoh �N在�OvncfspgwbsjbcmftI变量个数J�文
本框中K输入���K这就是Sbtusjjoh 函数独立变量的个数K如图���所示àI�J在�SvotpmwfsI运行求解器J�窗格中单击�Tubsu�按钮K如图���所示à
�����

图�����输入适应度函数与变量个数
图�����单击�SvotpmwfsI运行求解器J�的�Tubsu�按钮
在算法运行的同时K�Dvssfou fofsbujpoh I当前代数J�文本框中显示出当前的代数à通
过单击�QbvtfI暂停J�按钮K可以使算法临时暂停一下à当这样做的时候K该按钮的名字变
为�SftvnfI恢复J�à为了从暂停处恢复算法的运行K可单击�SftvnfI恢复J�按钮à当算法完成时K�Tubuvtboesftvmut�窗格出现如图���所示的情形à
图�����状态与结果显示
�Tubuvtboesftvmut�窗格中将显示下列信息MI�J算法终止时适应度函数的最终值M
����GjuofttgvodujpowbmvfM���������������������注意M所显示的值非常接近于Sbtusjjoh 函数的实际最小值�à�����节�遗传算法举
例�中描述了一些方法K可以用来得到更接近实际最小值的结果àI�J算法终止的原因M
����Pujnj{bujpoufsnjobufeq M
����nbyjnvnovncfspg fofsbujpotfydffefe�h即退出的原因是M超过最大代数而导致优化终止à
在本例中K算法在���代后结束K这是 �HfofsbujpotI代数J�选项的缺省值K此选项规
定了算法计算的最大代数àI�J最终点à在本例中是P�����������������Qà
��从命令行查找最小值
为了从命令行查找Sbtusjjoh 函数的最小值K可键入
�����

����PygwbmsfbtpoQ�hbIP�sbtusjjotgdoh K�J这将返回
����y��������������������������gwbm�������������������sfbtpo���������Pujnj{bujpoufsnjobufeq M
��������nbyjnvnovncfspg fofsbujpotfydffefe�h其中Ky是算法返回的最终点Ngwbm是该最终点处适应度函数的值Nsfbtpo是算法结束的
原因à
��显示绘制图形
�QmputI绘图J�窗格可以显示遗传算法运行时所提供的有关信息的各种图形à这些信息
可以帮助我们改变算法的选项K改进算法的性能à例如K为了绘制每一代适应度函数的最
佳值和平均值K应选中复选框�CftugjuofttI最佳适应度J�K如图���所示à
图������QmpuI绘图J�对话框
当单击�Tubsu�按钮时K遗传算法工具显示每一代适应度函数的最佳值和平均值的绘制
图形à当算法停止时K所出现的图形如图���所示à
图�����各代适应度函数的最佳值和平均值
在每一代中K图的底部的点表示最佳适应度值K而其上的点表示平均适应度值à图的
�����

顶部还显示出当前代的最佳值和平均值à为了得到最佳适应度值减少到多少为更好的直观图形K我们可以将图中Z轴的刻度改
变为对数刻度à为此K需进行如下操作MI�J从�QmpuI绘图J�窗格的�FejuI菜单J�菜单中选择�ByftQspfsujftq I坐标轴属性J�K
打开属性编辑器K如图����所示à
������图������绘图属性编辑器
I�J单击Z表项àI�J在�TdbmfI刻度J�窗格中选择�MphI对数J�à绘制的图形如图����所示à
图������每一代适应度函数最佳值和平均值的对数图形
典型情况下K在早期各代中K当个体离理想值较远时K最佳值会迅速得到改进à在后
来各代中K种群越接近最佳点K最佳值改进得越慢à
�����

�������遗传算法的一些术语
本节解释遗传算法的一些基本术语K主要包括MI�J适应度函数IGjuofttGvodujpotJàI�J个体IJoejwjevbmtJàI�J种群IQpvmbujpotq J和代IHfofsbujpotJàI�J多样性或差异IEjwfstjuzJàI�J适应度值IGjuofttWbmvftJ和最佳适应度值ICftuGjuofttWbmvftJàI�J父辈和子辈IQbsfoutboeDijmesfoJà
��适应度函数所谓适应度函数K就是想要优化的函数à对于标准优化算法而言K这个函数称为目标
函数à该工具箱总是试图寻找适应度函数的最小值à我们可以将适应度函数编写为一个 N文件K作为输入参数传递给遗传算法函数à
��个体一个个体是可以施加适应度函数的任意一点à一个个体的适应度函数值就是它的得分
或评价à例如K如果适应度函数是
gIy�Ky�Ky�J� I�y���J��I�y���J��Iy���J�
则向量I�K��K�J就是一个个体K向量的长度就是问题中变量的个数à个体I�K��K�J的得分是gI�K��K�J���à
个体有时又称为基因组或染色体组IHfopnfJK个体的向量项称为基因IHfoftJà
��种群与代所谓种群K是指由个体组成的一个数组或矩阵à例如K如果个体的长度是���K适应度
函数中变量的个数为�K我们就可以将这个种群表示为一个�����的矩阵à相同的个体在
种群中可以出现不止一次à例如K个体I�K��K�J就可以在数组的行中出现多次à每一次迭代K遗传算法都对当前种群执行一系列的计算K产生一个新的种群à每一个
后继的种群称为新的一代à
��多样性多样性或差异IEjwfstjuzJ涉及一个种群的各个个体之间的平均距离à若平均距离大K
则种群具有高的多样性N否则K其多样性低à在图����中K左边的种群具有高的多样性K亦即差异大N而右边的种群多样性低K亦即差异小à
图������种群多样性比较
�����

多样性是遗传算法必不可少的本质属性K这是因为它能使遗传算法搜索一个比较大的
解的空间区域à
��适应度值和最佳适应度值个体的适应度值就是该个体的适应度函数的值à由于该工具箱总是查找适应度函数的
最小值K因此一个种群的最佳适应度值就是该种群中任何个体的最小适应度值à
��父辈和子辈为了生成下一代K遗传算法在当前种群中选择某些个体I称为父辈JK并且使用它们来
生成下一代中的个体I称为子辈Jà典型情况下K该算法更可能选择那些具有较佳适应度值
的父辈à
�������遗传算法如何工作
本节简要介绍遗传算法的工作原理或工作过程K内容包括算法要点Ð初始种群Ð生成
下一代Ð后一代的绘图和算法的停止条件à
��算法要点
下面的要点总结了遗传算法是如何工作的MI�J算法创建一个随机种群àI�J算法生成一个新的种群序列K即新的一代à在每一步K该算法都使用当前一代中
的个体来生成下一代à为了生成新一代K算法执行下列步骤MIbJ通过计算其适应度值K给当前种群的每一个成员打分àIcJ确定原来的适应度值的比例尺度K将其转换为更便于使用的范围内的值àIdJ根据它们的适应度选择父辈àIeJ由 父 辈 产 生 子 辈à子 辈 的 产 生 可 以 通 过 随 机 改 变 一 个 单 个 父 辈K亦 即 变 异
INvubujpoJ来进行K也可以通过组合一对父辈的向量项K亦即交叉IDspttpwfsJ来进行àIfJ用子辈替换当前种群K形成下一代àI�J若停止准则之一得到满足K则该算法停止I关于停止准则K可参见�����节�遗传
算法如何工作�中的�算法的停止条件�Jà
��初始种群遗传算法总是以产生一个随机的初始种群开始K如图����所示à
图������初始种群
�����

在本例中K初始种群包含��个个体K这恰好是�Qpvmbujpoq I种群J�选项中的�Qpvmb�ujpotj{f
qI种群尺度J�的缺省值à
注意M初始种群中的所有个体均处于图上右上角的那个象限K也就是说K它们的坐标
处于�和�之间K这 是 因 为�Qpvmbujpoq �选 项 中 的�JojujbmsbohfI初 始 范 围J�的 缺 省 值 是
P�N�Qà如果已知函数的最小点大约位于何处K就可以设置一个适当的�Jojujbmsbohf�K以便使
该点处于那个范围的中间附近à例如K如果确信Sbtusjjoh 函数的最小值在点P�K�Q附近K那么就可以直接设置�Jojujbmsbohf�为P��N�Qà然而K正如本例所显示的那样K即使没有
给�Jojujbmsbohf�设置一个理想的值K遗传算法也还是能够找到那个最小值à
��产生下一代
在每一步中K遗传算法使用当前种群来产生子辈K即获得下一代à算法在当前种群中
选择一组个体K称为父辈K这些父辈将其HfoftI亦即其向量中的项J贡献 给 它 们 的 子 辈à遗传算法通常选择那些具有较好适应度值的个体作为父辈à我们可以在�TfmfdujpoI选择J�选项的�TfmfdujpogvodujpoI选择函数J�文本框中指定遗传算法用来选择父辈的函数à
遗传算法对于下一代产生三类子辈M优良子辈Ð交叉子辈和变异子辈àI�J优良子辈IFmjufdijmesfoJ是在当前代中具有最佳适应度值的那些个体à这些个体
子辈存活到下一代àI�J交叉子辈IDspttpwfsdijmesfoJ是由一对父辈向量组合产生的àI�J变异子辈INvubujpodijmesfoJ是对一个单个父辈引入随机改变即变异产生的à图����表示了这三个类型的子辈à
图������三类子辈
在�����节�遗传算法举例�的�变异与交叉�部分中将解释如何指定遗传算法产生的每
一类子辈的数目K以及用来执行完成交叉和变异的函数à
��交叉子辈
算法通过组合当前种群中的父辈对IQbjsJ来产生交叉子辈à在子辈向量的每一个相同
位置处K缺省的交叉函数在两个父辈之一的相同位置处随机选择一项I即基因JK并将它指
派给其子辈à
��变异子辈算法通过随机改变个体父辈中的基因而产生变异子辈à按照缺省K算法给父辈增加一
�����
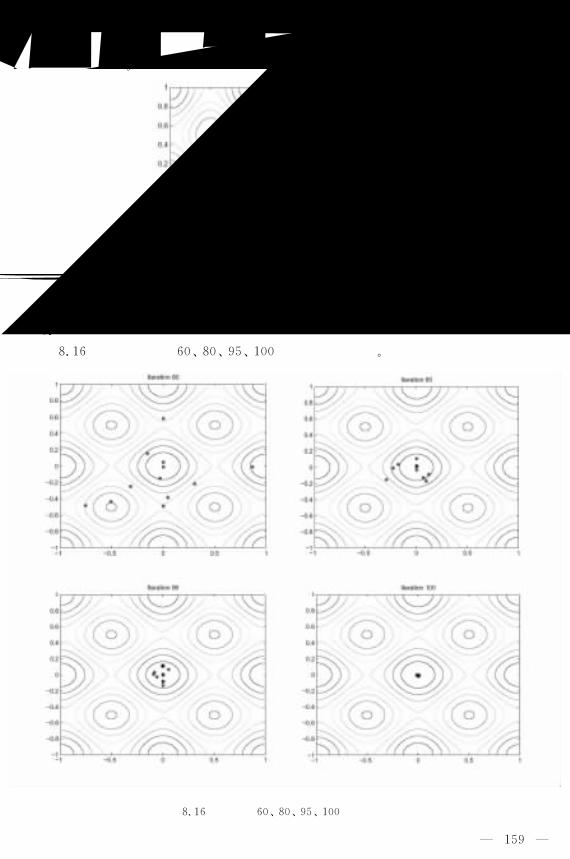
个高斯分布的随机向量à图����所示为初始种群的子辈K也即第二代种群K并且指出它们是否为优良子辈Ð交
叉子辈或变异子辈à
图������初始种群的子辈
��后代图形绘制
图����所示为在迭代��Ð��Ð��Ð���次时种群的图形à
图������在迭代��Ð��Ð��Ð���次时的种群
�����

随着代数的增加K种群中的个体靠近在一起K且逼近最小值点P�K�Qà
��算法的停止条件
遗传算法使用下列�个条件来确定何时停止MI�JHfofsbujpotI代数J���当产生的代的数目达到规定的代数的值时K算法停止àI�JUjnfmjnjuI时限J���在运行时间的秒数等于时限时K算法停止àI�JGjuofttmjnjuI适应度限J���当适应度函数的值对于当前种群的最佳点小于或等
于适应度限时K算法停止àI�JTubmm fofsbujpoth I停 滞 代 数J���在 连 续 繁 殖 的 时 间 序 列 中K若 长 时 间 不 繁 殖 新
代K亦即目标函数无改进K到达停滞代数规定的代数时K则算法停止àI�JTubmmujnfmjnjuI停滞时限J���在秒数等于停滞时限的时间间隔期间K若目标函数
无改进K则算法停止à若这�个条件中任何一个条件一旦满足K则该算法停止à我们可以在遗传算法工具的
�Tupqqjo dsjufsjbh I停止标准J�选项中指定这些标准的值à它们的缺省值如图����所示à
图������停止标准的缺省值
当运行遗传算法时K�TubuvtI状态J�面板显示这些导致算法停止的标准à�UjnfmjnjuI时限J�选项与�Tubmmujnfmjnju�选项可以用来防止算法运行过长的时间à
如果算法由于 这 两 个 条 件 之 一 而 停 止K则 可 以 通 过 相 应 增 加�Ujnfmjnju�或�Tubmmujnfmjnju�的值来改善运行的结果à
�����使用遗传算法工具求解问题
本节首先概括介绍使用遗传算法工具HVJ的一般步骤K然后介绍如何从命令行使用
遗传算法工具K最后通过举例详细说明如何使用遗传算法工具来求解优化问题à
�������使用遗传算法工具HVJ
前面已经介绍了使用遗传 算 法 工 具 的 初 步 知 识à本 节 将 简 要 归 纳 使 用 遗 传 算 法 工 具
HVJ来求解优化问题的一般步骤K内容包括M打开遗传算法工具N在遗传算法工具中定义
问题N运行遗传算法N暂停和停止运算N图形显示N创建用户图形函数N复现运行结果N设
置选项参数N输入输出参数及问题N从最后种群继续运行遗传算法à
��打开遗传算法工具
在 NBUMBC窗口中输入 buppmh K打开Ð进入遗传算法工具à初启时的界面如图����所示à
�����

图������遗传算法工具初启时的界面
��在遗传算法工具中定义问题
在下列两个文本框中定义所要解决的问题MI�J适应度函数���求解的问题是求目标函数的最小值à输入一个计算适应度函数的
N文件函数的句柄àI�J变量个数���适应度函数的独立变量个数à注意M当运行遗传算法工具时不要用�FejupsLEfcvhhfsI编辑L调试J�功能来调试目标
函数的 N文件K而要从命令行直接调用目标函数或把 N 文件输入到遗传算法函数hbà为
了方便调试K可以在遗传算法工具中把问题输出到 NBUMBC工作窗口中à如图����所示K输入前面章节所介绍的Sbtusjjoh 函数或 nz_gvo函数作为适应度函
数K它们的变量个数为�à
图������输入适应度函数与变量个数
��运行遗传算法
要运行遗传算法K在�SvotpmwfsI运行求解器J�中单击�Tubsu�按钮K如图����所示à这时K在�Dvssfou fofsbujpoh I当 前 代J�文 本 框 中 显 示 当 前 代 的 数 目K在�Tubuvtboe
sftvmut�窗格中显示�HBsvoojoh��等信息K如图����所示à
�����

图������单击�Tubsu�按钮
图������当前代数和状态与结果窗格
����当遗传算法停止时K�Tubuvtboesftvmut�窗格显示MI�J�HBufsnjobufeIHB终止J�信息àI�J最后一代最佳个体的适应度函数值àI�J算法停止的原因àI�J最终点的坐标à图����中显示了当运行例子�Sbtusjjoh 函数�遗传算法停止时的信息à
图������Sbtusjjoh 函数的遗传算法运行结果
在遗传算法工具中K当遗传算法运行时可以更改多个参数设置K所做的改变将被应用
到下一代K即在下一代将按照新设置的参数运行à在下一代开始但尚未应用改变的参数之
前K在�Tubuvtboesftvmut�窗格中显示信息�Dibofth foejoq h��à而在下一代开始且应用了
改变的参数时K在�Tubuvtboesftvmut�窗格中显示信息�Diboftbqqmjfe�h �à这样K在遗传
算法运行时更改了参数设置后产生的输出信息如图����所示à
�����

图������遗传算法运行时更改了参数设置
��暂停和停止运算
遗传算法的暂停和停止运行K可以通过下面的操作继续运行MI�J单击�QbvtfI暂停J�按钮K算法暂停运行à该按钮上的文字变为�SftvnfI恢复J�à
单击�Sftvnf�按钮K即恢复遗传算法继续运行àI�J单击�TupqI停止J�按钮K算法停止运行à�Tubuvtboesftvmut�窗口中将显示停止运
行时当前代最佳点的适应度函数值à注意M如果单击�Tupq�按钮K然后通过单击�Tubsu�按钮再次运行时K遗传算法将以新
的随机初始种群或在�Jojujbmqpvmbujpoq I初始种群J�文本框中专门指定的种群运行à如果
需要在算法停止后能再次恢复运行K则可以通过交替地单击�Qbvtf�和�Sftvnf�按钮来控
制算法暂停或继续运行à遗传算法的停止运行常常是通过设置算法停止准则来进行控制的à使用停止准则K设
置停止准则参数K可以解决遗传算法在何时停止运行的控制问题à这样K也就不用通过单
击�Tupq�按钮来人为地控制算法运行的停止à遗传算法有五个停止准则或条件K其中任何
一个条件满足K算法即停止运行à这些停止准则是MI�J代数���算法运行到规定的代数àI�J时限���算法运行到规定的时间àI�J适应度限���当前代的最佳适应度值小于或等于规定的值àI�J停滞代数���适应度函数值在运行规定的代数后没有改进àI�J停滞时限���适应度函数值在运行规定时间后没有改进à如果想使算法一直运行到单击�Qbvtf�或�Tupq�按钮时才停下来K可以改变这些停止
准则的参数值MI�J设置�HfofsbujpotI代数J�为JogàI�J设置�Ujnf�为JogàI�J设置�Gjuofttmjnju�为�JogàI�J设置�Tubmm fofsbujpoth �为JogàI�J设置�Tubmmujnfmjnju�为Jogà图����显示了这些更改后的设置à注意M在命令行中调用遗传算法函数hb时K并不使用这些参数设置K就好像是不按下
�Dusm�D�键K函 数 就 会 永 远 运 行 而 不 会 停 止à其 实 相 反K可 以 设 置�Hfofsbujpot�或 者
�Ujnf�做为限值来控制算法停止运行à
�����

图������改变停止准则参数
��图形显示
图����所示为�QmputI绘图J�窗格K可以用来控制显示遗传算法运行结果变化的图形à
图������在绘图窗格中选择输出项
选择所要显示的图 形 参 数 的 复 选 框à例 如K如 果 选 择�CftugjuofttI最 佳 适 应 度J�和
�CftujoejwjevbmI最佳个体J�K运行例子�Sbtusjjoh 函数�K其显示输出如图����所示à
图������Sbtusjjoh 函数最佳适应度与最佳个体
�����

图����上部离散点为每一代的最佳适应度值和平均适应度值K下部柱型图表示当前
代最佳适应度值对应的点的坐标à注意M要想显示两个以上参数项的图形时K可选择相应参数项的复选框K单独打开一
个较大的图形窗口即可à
��举例���创建用户绘图函数
如果工具箱中没有符合想要输出图形的绘图函数K用户可以编写自己的绘图函数à遗
传算法在每次运行时调用这个函数K画出图形à这里举例说明怎样创建一个用户绘图函数
来显示从前一代到当前代最佳适应度值的变化情形K内容包括M创建绘图函数K使用绘图
函数K绘图函数如何作用à
�J创建绘图函数
为了创建绘图函数K在 NBUMBC编辑器中复制Ð粘贴下列代码到一个新的 N文件à
����Gvodujpotubuf�hbmpudiboq hfIpujpotq KtubufKgmbhJ
� 绘图函数hbmpudiboq hf画出前一代个体最佳值变化的图形
fstjtufoumbtuq _cftu����������������� 前一代个体的最佳值
jgItusdnqIgmbhK�joju�JJ � 绘图
����tfuIdbh K�ymjn�KP�Kpujpot�Hfofsbujpotq QK�Ztdbmf�K�mph�JN
����ipmepoN
����ymbcfmHfofsbujpo
����ujumfI�DibofjoCftuGjuofttWbmvf�h J
foe
cftu�njoItubuf�TdpsfJN � 当前代个体的最佳值
jgtubuf�Hfofsbujpo��� � 设置mbtu_cftu为最佳
����mbtu_cftu�cftuN
fmtf
����dibof�mbtuh _cftu�cftuN � 改变个体的最佳值
����mbtu_cftu�cftuN
���� mpuq Itubuf�HfofsbujpoKdibohfK��s�JN
����ujumfIP�DibofjoCftuGjuofttWbmvf�h QJ
foe
然后在 NBUMBC路径下将其存为 N文件hbmpudiboq f�nh à
�J使用绘图函数
为了使用用户绘图函数K在�QmputI绘图J�窗格中选择�DvtupngvodujpoI定制函数J�K并且在其右边的文本框中输入函数名�P�hbmpudiboq hf�à为了对用户绘图函数输出的最佳
适应度值图形进行比较K在这里也选择�Cftugjuoftt�à运行例子函数Sbtusjjoh K显示出来
的图形如图����所示à注意M因为图中下半部的Z轴为对数刻 度K所 以 图 形 中 的 离 散 点 仅 仅 显 示 大 于 零 的
点à对数刻度能显示适应度函数的微小变化K而图中上半部则不能显示出微小变化à
�����

图������用户绘图函数输出的Sbtusjjoh 函数运行结果
�J绘图函数如何作用
绘图函数使用包含在下面结构体中的信息K它们由遗传算法传递给绘图函数作为输入
参数MI�Jpujpotq I参数JM当前参数设置àI�JtubufI状态JM关于当前代的信息àI�JgmbhI曲线标志JM曲线表示为对数等的当前状态à绘图函数的主要作用描述如下M
fstjtufoumbtuq _cftuM生成永久变量mbtu_cftu���即前一代的最佳值à永久变量保存
着多种图形函数调用类型à
tfuIdbh K�ymjn�KP�Kpujpot�Hfofsbujpotq QK�Ztdbmf�K�mph�JM在遗传算法运行前建立
图形àpujpot�Hfofsbujpoq 为代数的最大值à
cftu�njoItubuf�TdpsfJMtubuf�Tdpsf包含当前代中所有个体的得分值K变量cftu是
其中最小的得分值à结构体状态文本框的完整描述可参见�����节�遗传算法参数�的�图
形参数�部分à
dibof�mbtuh _cftu�cftuM变量dibohf是前一代的最佳值减去当前代的最佳值à
mpuq Itubuf�HfofsbujpoKdibohfK��s�JM画 出 当 前 代 的 变 化 曲 线K变 量 维 数 包 含 在
tubuf�Hfofsbujpo中à函数hbmpudiboq hf的 代 码 包 含 了 函 数 hbmpucftugq 代 码 中 许 多 相 同 成 分K函 数
hbmpucftugq 生成最佳适应度图形à
��复现运行结果
为了复现遗传算法前一次的运行结果K选择�Vtfsboepntubuftgspn sfwjpvtsvoq I使
用前一次运行的随机状态J�复选框K这样就把遗传算法所用的随机数发生器的状态重新设
置为前一次的值à如果没有改变遗传算法工具中的所有设置K那么遗传算法下一次运行时
�����

返回的结果与前一次运行的结果一致à正常情况下K不要选择此复选框K可以充分利用遗传算法随机搜索的优点à如果想要
分析特定的运行结果或者显示相对个体的精确结果K可以选择此复选框à
��设置选项参数
设置遗传算法工 具 使 用 时 的 选 项 参 数 有 两 种 方 法M一 种 是 在 遗 传 算 法 工 具 HVJ的
�Pujpotq �窗格中直接进行设置K另一种是在 NBUMBC工作窗口中通过命令行方式进行
设置à在�Pujpotq �窗格中设置遗传算法的各种运行参数K如图����所示à每一类参数对应
有一个窗格K单击该类参数时K对应窗格展开à例如K单击�Qpvmbujpoq �参数选项K种群窗
格展开来K可以逐一设置其中的参数项K如Qpvmbujpouzqq fI种群 类 型JÐQpvmbujpotj{fqI种群尺度JÐDsfbujpogvodujpoI创 建 函 数JÐJojujbmqpvmbujpoq I初 始 种 群JÐJojujbmtdpsftI初始得分JÐJojujbmsbohfI初始范围J等à
图������选项参数窗口
此外K其 他 选 项 参 数 类 还 有MGjuoftttdbmjohI适 应 度 测 量JÐTfmfdujpoI选 择JÐ
Sfspevdujpoq I复制JÐNvubujpoI变异JÐDspttpwfsI交叉JÐNjsbujpoh I迁移JÐI csjegvod�ujpo
zI混合函 数JÐTupqqjo dsjufsjbh I停 止 准 则JÐPvuvugvodujpoq I输 出 函 数JÐEjtmbq upz
�����

dpnnboexjoepxI显示到命令窗口JÐWfdupsj{fI向量化J等à这些参数类各自对应一个参
数窗格K单击后相应窗格随即展开K在其中可以进行参数项的设置à所有变量参数的含义及详细描述可参见�����节�遗传算法参数�à在 NBUMBC工作窗口中K可以将遗传算法的运行参数设置为变量à对于数值参数的设置K可以直接在相应编辑框中输入该参数的值K或者在包含该参数
值的 NBUMBC工作窗口中输入相应变量的名字K就可以完成设置à例如K可以利用下面
两种方法之一设置�Jojujbm pjouq I初始点J�为P��� ���QMI�J在�Jojujbm pjouq �文本框中输入P��� ���QàI�J在 NBUMBC工作区中输入变量y��P��� ���QK然后在�Jojujbm pjouq �文本框中
输入变量的名字y�à因为选项参数是比较大的矩阵或向量K所以在 NBUMBC工作窗口中把参数的值定义
为变量一般是比较方便的K也就是说K如果需要K很容易改变矩阵或向量的项à
��输入输出参数及问题
参数和问题结构可以从遗传算法工具被输出到 NBUMBC的工作窗口K也可以在以后
的某个时间再反过来把它们从 NBUMBC的工作窗口输入给遗传算法工具à这样就可以保
存对问题的当前设置K并可以在以后恢复这些设置à参数结构也可以被输出到 NBUMBC工作窗口K并且可以再把它们用于命令行方式的遗传算法函数hbà
输入和输出信息通常包含下列各项MI�J问题定义K包括�GjuofttgvodujpoI适应度函数J�和�OvncfspgwbsjbcmftI变量个
数J�àI�J当前指定的选项参数àI�J算法运行的结果à下面解释如何输入和输出这些信息à
�J输出参数和问题
参数和问题可以被输出到 NBUMBC工作空间K以便以后在遗传算法工具中应用à也
可以以命令行方式K在函数hb中应用这些参数和问题à为了输出参数和问题K单击�FypsuupXpsltq bdfq I输出到工作空间J�按钮或从�Gjmf�
菜单中选择�FypsuupXpsltq bdfq �菜单项K打开如图����所示的对话框à
图������输出对话框
对话框提供下列参数MI�J为了保存问题的定义和当前参数的设置K选择�Fypsuq spcmfnboepq ujpotupbq
�����

NBUMBCtusvduvsfobnfeI输出问题与参数到已命名的 NBUMBC结构J�K并为这个结构
体命名à单击�PL�按钮K即把这个信息保存到 NBUMBC工作空间的一个结构体à如果以
后要把这 个 结 构 体 输 入 到 遗 传 算 法 工 具K那 么 当 输 出 这 个 结 构 时K所 设 置 的�Gjuofttgvodujpo�和�Ovncfspgwbsjbcmft�以及所有的参数设置都被恢复到原来值à
注意M输出问 题 之 前K如 果 在�SvotpmwfsI运 行 求 解 器J�窗 格 中 选 中�Vtfsboepntubuftgspn sfwjpvtsvoq I使用前一次运行的随机状态J�选项K则遗传算法工具将保存上一
次运行开始时随机数产生函数sboe和sboeo的状态à然后K在选择了此选项的情况下K输
入问题且运行遗传算法K那么输出问题之前的运行结果就被准确地复现了àI�J如果想要遗传 算 法 在 输 出 问 题 之 前 从 上 一 次 运 行 的 最 后 种 群 恢 复 运 行K可 选 择
�JodmvefjogpsnbujpooffefeupsftvnfuijtsvoI包括所需信息以恢复本次运行J�à然后K当输入问题结构体并单击�Tubsu�按钮K算法就从前次运行的最后种群继续运行à为了恢复
遗传算法产生随机初始种群的缺省行为K可删除在�Jojujbmqpvmbujpoq �字段所设置的种群K并用代之以空的中括号�PQ�à
注意M当选 择 了�Jodmvefjogpsnbujpooffefeupsftvnfuijtsvo�选 项K则 选 择�Vtfsboepntubuftgspn sfwjpvtsvoq �选项对于输入问题和运行遗传算法时创建的初始种群将
不再有任何作用à后一个选项只是指定从新的一次运行开始时再一次复现结果K而不是为
了恢复算法的继续运行àI�J如果 只 是 为 了 保 存 参 数 设 置K可 选 择�Fypsupq ujpotupbNBUMBCtusvduvsf
obnfeq
I输出参数到已命名的 NBUMBC结构J�K并为这个参数结构体输入一个名字àI�J为了保存遗传算法最近一次运行的结 果K可 选 择�FypsusftvmutupbNBUMBC
tusvduvsfobnfeq
�K并为这个结果结构体命名à
�J举例���用输出问题运行函数hb输出一个问题可参见�����节�举例MSbtusjjoh 函数�K在命令行运行遗传算法函数
hbK其步骤如下MI�J单击�FypsuupXpsltq bdfq �按钮K打开相应对话框àI�J在�FypsuUp Xpsltq bdfq �对 话 框 中 的�Fypsuq spcmfnboepq ujpotupbNBUMBC
tusvduvsfobnfeq
�右边的文本框中K输入问题结构体的名称K假设为nz_hbspcmfnq àI�J在 NBUMBC窗口中以nz_hbspcmfnq 为参数调用函数hbM
����PygwbmQ�hbInz_hbspcmfnq J则返回结果M
����y��������������������������gwbm���������������调用函数hb可参见�����节�从命令行使用遗传算法�à
�J输入参数
为了从 NBUMBC工 作 窗 中 输 入 一 个 参 数 结 构 体K可 从�Gjmf�菜 单 选 择�JnpsuqPujpotq I输入参数J�菜单项à在 NBUMBC工作窗口中打开一个对话框K列出遗传算法参
数结构体的一系列选项à当选择参数结构体并单击�Jnpsuq I输入J�按钮时K在遗传算法工
�����

具中的参数域就被更新K且显示所输入参数的值à创建参数结构体有两种方法MI�J调用函数 bph ujntfuq K以参数结构pujpotq 作为输出àI�J在遗传算法工具中的�FypsuupXpsltq bdfq I输出到工作空间J�对话框中保存当前
参数à
�J输入问题
为了从遗传算法工具输入一个以前输出的问题K可从�Gjmf�菜单选择�JnpsuQspcmfnqI输入问题J�菜单项à在 NBUMBC工作窗口中K打开一个对话框K显示遗传算法问题结构
体的一个列表à当选择了问题结构体并单击�PL�按钮时K遗传算法工具中的下列文本框
被更新MI�J适应度函数àI�J变量个数àI�J参数域à
���举例���从最后种群中继续遗传算法
下面的例子显示如何输出一个问题K以便当输入问题并单击�Tubsu�按钮时K遗传算法
能从该输出问题所保存的最后种群继续运行à现在运行一个例子K在遗传算法工具中输入
下面的信息MI�J设置适应度函数为P�bdlmfgdoz K它是计算函数BdlmfzK是工具箱提供的一个测试
函数àI�J设置�Ovncfspgwbsjbcmft�为��àI�J在�Qmput�窗格中选择�Cftugjuoftt�àI�J单击�Tubsu�按钮à显示的结果如图����所示à
图������函数bdlmfgdoz 的最佳适应度
�����

假定想要实验利用其他的参数运行遗传算法K接着利用当前参数设置K此后再从最后
种群重新运行算法à为此K进行以下步骤MI�J单击�FypsuupXpsltq bdfq �按钮àI�J在出现的对话框中M
� 选择�Fypsuq spcmfnboepq ujpotupbNBUMBCtusvduvsfobnfeq �à
� 在文本框中输入问题和参数的名称K如bdlmfz_vojgpsnà
� 选 择�JodmvefjogpsnbujpooffefeupsftvnfuijtsvoI包 括 所 需 信 息 以 恢 复 本 次
运行J�à做了这些选择后K打开如图����所示的对话框à
图������在输出窗口对话框中做适当选择
I�J单击�PL�按钮à问题和参数被输出到 NBUMBC工作空间的一个结构体中à在 NBUMBC命令窗口中
输入下面的信息就可以观察这个结构体M
����bdlmfz_vojgpsn
����bdlmfz_vojgpsn �
��������gjuofttgdoMP�bdlmfgdoz�������� fopnfmfoh uih M��
��������pujpotq MP�y�tusvduQ利用不同的参数设置K甚至是不同的适应度函数K在运行遗传算法之后K都能够按照
如下步骤来恢复问题MI�J从�Gjmf�菜单中选择�JnpsuQspcmfnq �菜单项K打开如图����所示的对话框à
图������HB问题输入窗口
�����

I�J选择bdlmfz_vojgpsnàI�J单击�Jnpsuq �按钮à这样就把�Qpvmbujpoq �选项中的�Jojujbmqpvmbujpoq �字段设置成输出问题之前运行的最
后种群à在运行期间K所有其他参数恢复它们的设置à当单击�Tubsu�按钮时K遗传算法从
被保存的最后种群重新运行à图����所示为初始运行和重新运行的最佳适应度图形à
图������初始运行和重新运行的最佳适应度
注意M如果在利用所导入问题运行遗传算法之后K想要恢复遗传算法生成一个随机初
始种 群 的 缺 省 行 为K可 删 除�Jojujbmqpvmbujpoq �字 段 中 设 置 的 种 群K而 代 之 以 空 的 中 括
号�PQ�à
���生成 N文件
在遗传算法工具中K要利用特定的适应度函数和参数生成运行遗传算法的 N文件K可
从�Gjmf�菜单中选择�HfofsbufN�GjmfI生成 N 文件J�菜单项K并把生成的 N 文件保存到
NBUMBC路径的一个目录à在命令行调用这个 N文件时K返回的结果与利用在遗传算法工具中生成 N 文件时的
适应度函数和参数所得到的结果一致à
�������从命令行使用遗传算法
使用遗传算法K也可以从命令行运行遗传算法函数hbà这方面的内容主要包括M利用
缺省参数运行hbN在命令行设置hb的参数N使用遗传算法工具的参数和问题结构N复现运
行结果N以前一次运行的最后种群重新调用函数hbN从 N文件运行hbà
��利用缺省参数运行hb利用缺省参数运行遗传算法K以下面的语句调用hbM
����PygwbmQ�hbIP�gjuofttgvoKowbstJ其中KP�gjuofttgvo是计算适应度函数值的N文件的函数句柄Nowbst是适应度函数中独立
变量的个数Ny是返回的最终点Ngwbm是返回的适应度函数在y点的值à
�����

例如K运行Sbtusjjoh 函数K从命令行输入
����PygwbmQ�hbIP�sbtusjjotgdoh K�J将返回
����y����������������������������gwbm���������������为了得到遗传算法更多的输出结果K可以用下面的语句调用hbM
����Pygwbmsfbtpopvuvuq qpvmbujpotdpsftq Q�hbIP�gjuofttgdoKowbstJ除了输出变量y和gwbm之外K增加了以下输出变量MI�J�sfbtpoI原因J�M算法停止的原因àI�J�pvuvuq I输出J�M包含关于算法在每一代性能的结构体àI�J�qpvmbujpoq I种群J�M最后种群àI�J�tdpsftI得分J�M最终得分值à
��在命令行设置hb的参数
遗传算法工具中的参数可以指定为任何有效的参数值K设置参数使用下面的语句M
����PygwbmQ�hbIP�gjuofttgvoKowbstKpujpotq J使用函数 bph ujntfuq 生成一个参数结构体M
����pujpot�q bph ujntfuq返回带有缺省值的参数结构体M
����pujpot�Qp
q
vmbujpoUzqq fM���������epvcmfWfdups�
QpJojuSboq hfM P�y�epvcmfQ
QpvmbujpoTj{fq M ��
FmjufDpvouM
DspttpwfsGsbdujpo
�M ������
NjsbujpoEjsfdujpoh M �gpsxbse�
NjsbujpoJoufswbmh M ��
NjsbujpoGsbdujpoh M ������
HfofsbujpotM ���
UjnfMjnjuM Jog
gjuofttMjnjuM �Jog
TubmmMjnjuHM ��
TubmmMjnjuTM ��
JojujbmQpvmbujpoq M PQ
JojujbmTdpsftM PQ
QmpuJoufswbmM
DsfbujpoGdo
�M P� bdsfbujpovojgpsn
gjuofttTdbmjo
h
Gdoh M P�gjutdbmjosbol
TfmfdujpoGdo
hM P�tfmfdujpotupdivojg
�����

DspttpwfsGdoM P�dspttpwfstdbuufsfe
NvubujpoGdoM P�nvubujpobvttjboh
IcsjeGdoz M PQ
Ejtmbq zM �gjobm�
QmpuGdotM PQ
PvuvuGdotq M PQ
Wfdupsj{feM �pgg�
如果没有给某一参数项输入新的值K则函数hb使用其缺省值à每一个参数的值都存放在参数结构体中K例如pujpot�Qpq vmbujpoTj{fq K可以通过输入
参数的名称显示参数的值à例如K显示遗传算法种群的大小K可输入
����pujpot�Qpq vmbujpoTj{fq����bot�����������
改变参数结构体中成员值K例如K设置QpvmbujpoTj{fq 值等于���K代替它的缺省值��K可
输入
����pujpot�q bph ujntfuq I�QpvmbujpoTj{f�q K���J参数结构体中KQpvmbujpoTj{fq 为���K其他值都为缺省值或当前值à
这时K再输入
����hbIP�gjuofttgvoKowbstKpujpotq J函数hb将以种群中个体为���运行遗传算法à
如果想接着改变参数结构体其他成员的值K例如设置QmpuGdot为P�hbmpucftugq K目的
是画出每一代最佳适应度函数值图形K则可用下面的语句调用函数 bph ujntfuq M
����pujpot�q bph ujntfuq Ipujpotq K�QmpuGdot�KP� mpucftugq J这里保持了参数的所有当前值K除QmpuGdot之外K它改变为P� mpucftugq à注意K如果省略
输入自变量参数pujpotq K那么函数 bph ujntfuq 重新置QpvmbujpoTj{fq 为它的缺省值��à也可以利用一个语句来同时设置两个参数QpvmbujpoTj{fq 和QmpuGdotM
����pujpot�q bph ujntfuq I�QpvmbujpoTj{f�q K���K�QmpuGdot�KP� mpucftugq J
��使用遗传算法工具的参数和问题结构
利用函数 bph ujntfuq 创建一个参数结构体K在遗传算法工具中设置参数的值K然后在
NBUMBC工作窗口中输出参数给结构体à如果想在遗传算法工具中输出缺省值K则导出
的结构体的参数与由命令行得到的缺省结构体的参数一致à
����pujpot�q bph ujntfuq如果想从遗传算 法 工 具 输 出 一 个 问 题 结 构 体hb_spcmfnq K可 用 下 面 的 语 句 调 用 函
数hbM
����PygwbmQ�hbIhb_spcmfnq J
����问题结构体包含以下参数MI�JgjuofttgdoM适应度函数àI�JowbstM问题的变量数àI�Jpujpotq M参数结构体à
�����

��复现运行结果
因为遗传算法是随机性方法K也就是说K产生随机机率K即每次运行遗传算法得到的
结果都会略有不同à遗传算法利用 NBUMBC随机数产生器函数sboe和sboeoK在每一次
迭代中产生随机机率à每一次函数hb调用sboe和sboeoK它们的状态都可能发生改变K以
便下一次再被调用时返回不同的随机数à这就是每次运行后hb输出的结果会略有不同的
原因à如果需要准确复现运行结果K可以在调用函数hb时包含sboe和sboeo的当前状态à
在又一次运行hb之前K重新设置这些值的状态à例如K要复现Sbtusjjoh 函数的hb的 输
出K可以利用下面的语句调用hbM
����Pygwbmsfbtpopvuvuq Q�hbIP�sbtusjjotgdoh K�JN
����假设某次运行的返回结果为
����y����������������������������gwbm���������������
则随机函数sboe和sboeo两者的状态被保存在pvuvuq 结构中M
����pvuvu�q��������sboetubufMP��y�epvcmfQ
��������sboeotubufMP�y�epvcmfQ
�������� fofsbujpoth M�����������gvoddpvouM������������nfttbhfMP�y��dibsQ
然后K重新设置状态K输入
����sboeI�tubuf�Kpvuvu�sboetubufq JN
����sboeoI�tubuf�Kpvuvu�sboeotubufq JN如果现在再次运行hbK就会得到相同的结果à
注意M如果没有必要复现运行结果K最好不要设置sboe和sboeo的状态K以便能够得
到遗传算法随机搜索的益处à
��以前一次运行的最后种群重新调用函数hb缺省情况下K每次运行hb时都生成一个初始种群à然而K可以将前一次运行得到的最
后种群作为下一次运行的初始种群K这样做能够得到更好的结果à这可以利用下面的语句
实现M
����PyKgwbmKsfbtpoKpvuvuq Kgjobm_qpqQ�hbIP�gjuofttgdoKowbstJN最后一个输出变量gjobm_qpq返回的就是本次运行得到的最后种群à将gjobm_qpq再作为初
始种群运行hbK实现语句为M
����pujpot�q bph ujntfuq I�JojujbmQpq�Kgjobm_qpqJN
����PyKgwbmKsfbtpoKpvuvuq Kgjobm_qpq�Q�hbIP�gjuofttgdoKowbstJN
����还可以将第二次运行hb得到的最后种群gjobm_qpq�作为第三次运行hb的初始种群à
�����

��从 N文件运行hb利用命令行可以运行遗传算法à使用 N文件可以有不同的参数设置à例如K可以设置
不同的交叉概率来运行遗传算法K观察Ð比较每次运行的结果à下面的代码是运行hb函数
��次K变量pujpot�DspttpwfsGsbdujpoq 从�到�K间隔为����K所记录的运行结果à
����pujpot�q bph ujntfuq I�Hfofsbujpot�K���JN
sboeI�tubuf�K��JN����� 这两个命令仅仅使结构成为可再现的
sboeoI�tubuf�K��JN
sfdpse�PQN
gpso��M���M�
����pujpot�q bph ujntfuq Ipujpotq K�DspttpwfsGsbdujpo�KoJN
����PygwbmQ�hbIP�sbtusjjotgdoh K��Kpujpotq JN
����sfdpse�PsfdpseNgwbmQN
foe
可以利用下列语句K以不同概率画出gwbm值的曲线图形M���� mpuq I�M���M�KsfdpseJN
����ymbcfmI�DspttpwfsGsbdujpo�JN
����mbcfmz I�gwbm�J
显示结果如图����所示à
图������从 N文件运行遗传算法时gwbm值的曲线图形
从图形显示可以看出Kpujpot�DspttpwfsGsbdujpoq 的值为���Y����时K可得到最好
结果à取每次运行得到的gwbm的平均值K就可以画出gwbm的光滑曲线K如图����所示à曲线
最凹的部分对应pujpot�DspttpwfsGsbdujpoq 的值为���Y���à
�����

图������从 N文件运行遗传算法时gwbm平均值的曲线图形
�������遗传算法举例
为了得到遗传算法的最好结果K一般需要以不同的参数试验à通过不断试验K选择针
对问题的最佳参数à有效参数的完整描述可参见�����节�遗传算法参数�à本节介绍几种能够提高运算效果的参数改变方法K内容包括M种群多样性Ð适应度测
量Ð选择Ð复制参数Ð变异与交叉Ð设置变异大小Ð设置交叉概率Ð相对于全局的局部最小
值Ð使用混合函数Ð设置最大代数和向量化适应度函数à
��种群的多样性
决定遗传算法的一 个 重 要 性 能 是 种 群 的 多 样 性à个 体 之 间 的 距 离 越 大K则 多 样 性 越
高N反之K个体之间的距离越小K则多样性越低à由试验可得到种群的适当多样性à如果多
样性过高或者过低K遗传算法都可能运行不好à这里介绍如何设置种群的初始范围来控制
种群的多样性K并介绍如何设置种群尺度à
�J举例���设置初始范围
遗传算法工 具 在 默 认 情 况 下 利 用 生 成 函 数 随 机 生 成 一 个 初 始 种 群à使 用 者 可 以 在
�Qpvmbujpoq �的�Jojujbmsbohf�文本框中指定初始种群的向量范围à注意M初始范围仅仅限制在初始种群中的点的范围à后续各代包含的点可以不在初始
种群的范围之内à如果知道问题解的大概范围K计算时就可以指定包含问题解的初始范围à但是K假设
种群具有足够的多样性K遗传算法就可以找到不在初始范围的解à下面的例子显示初始范
围对遗传算法性能的影响à这个例子利用Sbtusjjoh 函数K函数在原点处取得最小值为�à运行之前在遗传算法工具中设置下列参数M
I�J设置适应度函数为 P�Sbtusjjotgdoh àI�J设置�Ovncfspgwbsjbcmft�为�àI�J在�Qmput�窗格中选择�Cftugjuoftt�àI�J在�Qmput�窗格中选择�Sbohf�à
�����

I�J设置�Jojujbmsbohf�为 P�N���Qà然后K单 击�Tubsu�按 钮K遗 传 算 法 返 回 最 佳 适 应 度 值 为�K其 显 示 图 形 如 图����
所示à
图������初始范围为P�N���Q时的最佳适应度值和平均距离
图����上部为每代最佳适应度值变化图K下部为每代个体之间平均距离图K它可以很
好地用来衡量种群的多样性à对于初始范围的设置K由于多样性太小K算法进展很小à第二次K尝试设置�Jojujbmsbohf�为 P�N���QK运行算法K得到最佳适应度值大约为
���K如图����所示à
图������初始范围为P�N���Q时的最佳适应度值和平均距离
�����

这次K算法进展较快à但是K由于个体之间的平均距离太大K最佳个体远离最优解à第三次K设置�Jojujbmsbohf�为 P�N�QK运行算法K得到最佳适应度值大约为�����K
如图����所示à
图������初始范围为P�N�Q时的最佳适应度值和平均距离
这次由于多样性比较适合这个问题K所以算法得到的结果比前两次都好à
�J设置种群尺度
在�种群IQpvmbujpoq J�参数域中�Tj{f�决定每代种群的大小à增加种群的大小K遗传算
法能够搜索更多的点K因此K能够得到较好结果à但是K种群越大K遗传算法每代运行时间
越长à注意M至少应该设置�尺度ITj{fJ�的值为�Ovncfspgwbsjbcmft�K以便在每一种群中使
个体超出搜索范围à进行实验时K可以设置不同的种群尺度K不限制运行时间K以期得到最好结果à
��适应度测量
适应度测量把适应度函数返回的原始适应度得分值转换为适合选择函数范围内的值à选择函数根据适应度值的大小K选择下一代的父体à选择函数分配大选择概率给适应度值
大的个体à适应度测量值的范围影响遗传算法的性能à如果测量值变化范围太大K则具有
高测量值的个体复制的速度很快K取代种群基因池的速度很快K妨碍了遗传算法搜索解空
间的其他区域à相反K如果测量值变化太小K所有个体复制机会基本相同K则搜索过程进
展缓慢à缺省的适应度尺度变换函数为SbolI排序JK根据每个个体的顺序而不是它的得分值
来变换原始得分值à个体的顺序是它在排序后的位置à最适应的个体的序号为�K次之为
�K依次类推à排序尺度变换函数分配尺度值有下列目的M
�����

I�J个体的尺度值与o成正比àI�J整个种群的尺度值的和等于要求生成下一代父体的数目àI�J排序适应度尺度变换函数避免了初始值的界限的影响à图����所示为具有��个个体的一个典型种群的初始得分值I按升序排序Jà
图������具有��个个体的一个典型种群的初始得分值
图����所示为使用尺度变换函数的初始尺度值à
图������使用尺度变换函数的初始尺度值
因为算法按适应度函数的最小化处理K所以低的初始值具有高的尺度值à又因为排序
尺度变换只根据个体的顺序分配值的大小K对于一个大小为��Ð父辈数等于��的群体K显
示的尺度值可以是相同的à
�����

可以把排序尺度变换ISboltdbmjohJ与顶级尺度变换IUp tdbmjoq hJ进行比较à为了观
察尺度变换的效果K可以把遗传算法利用排序尺度变换得到的结果与利用其他函数I如顶
级变换J得到的结果相比较à默认情况下K顶级尺度变换分配�个最佳适应度个体相同的尺
度值K等于父辈数除以�K而分配其他个体的尺度值为�à利用默认的选择函数K只有�个
最佳适应度个体能被选为父辈à图����所示为比较排序尺度变换与顶级尺度变换得到的
尺度值K种群尺度为��K父辈数为��à
图������比较排序尺度变换与顶级尺度变换得到的尺度值
因为Up tdbmjoq h限制父辈为最佳适应度个体K它产生的种群类型比Sboltdbmjoh产
生的种群类型少à图����所示为每一代Sboltdbmjoh与Up tdbmjoq h得到的个体之间的距
离变化的比较à
图������排序尺度变换与顶级尺度变换各代个体之间距离变化之比较
�����

��选择
选择函数根据个体由适应度尺度变换函数得到的尺度值K为下一代选择父辈à当一个
个体为多个子辈贡献它的基因时K它就可能多次被选做父辈à默认的选择函数为TupdibtujdvojgpsnI随机均匀函数J���在每一父辈画出一条与选择线对应的直线K长度与它的尺度
值成比例à算法以等步长在线上移动à在每一步中K算法从落入线上的部分分配父辈à一个比较确定的选择函数是SfnbjoefsK由下列两步运行MI�J函数按照尺度值的整数部分为每个个体选择父辈à例如K假设一个个体的尺度值
是���K函数选择这个个体两次作为父辈àI�J在随机均匀选择时K选择函数利用尺度值的小数部分选择剩余的父辈à函数落入
选择线内K即长度与个体尺度值的小数部分成比例K在线上按等步长移动来选择父辈à注
意K如果尺度值的小数部分都等于�K则就像顶级尺度变换一样K选择是完全确定的à
��复制参数
复制参数控制遗传算法怎样生成下一代à这些参数有MI�JFmjufdpvouI优良计数JM在当前种群中K具有最佳适应度值的个体遗传到下一代的
个体数à这些个体称为优良子辈IFmjufdijmesfoJàFmjufdpvou的默认值为�à当优良计数至
少为�时K最佳适应度值可能从一代到下一代减少à这是人们希望的K因为遗传算法使适
应度函数最小化à设置Fmjufdpvou为一个大数K可以使得最适应个体控制种群K但可能减
小搜索的有效性àI�JDspttpwfsgsbdujpoI交叉概率JM下一代个体的一小部分K它不是FmjufdijmesfoI优
良子辈JK而是由交叉产生的部分à参见本节�设置交叉概率�部分的内容à
��变异与交叉
遗传算法运用当前代的个体生成子代个体K构成下一代à除了Fmjufdijmesfo外K算法
还生成下列子代个体MI�J从当前代中选择两个个体K交换两个个体的某个或某些位I基因JK结合后形成交
叉子个体àI�J随机改变当前代的单个个体K形成变异子个体à这两个过程是遗传算法的主要过程à交叉能够使遗传算法从不同的个体中提取更好的
基因K结合到具有优势的子个体中à变异增加了种群的多样性K因而增大了算法生成更高
适应度值的个体的可 能 性à没 有 变 异K算 法 只 能 产 生 由 初 始 种 群 结 合 基 因 的 子 集 构 成 的
个体à算法生成的子个体类型如下MI�JFmjufdpvouM在�Sfspevdujpoq �文本框中指定Fmjufdijmesfo的数目àI�JDspttpwfsgsbdujpoM在�Sfspevdujpoq �文本框中指定种群中交叉子个体的概率K它
不同于Fmjufdijmesfoà例 如K假 设 Qpvmbujpotj{fq I种 群 尺 度J为��KFmjufdpvou为 �K
Dspttpwfsgsbdujpo为���K则下一代子个体类型如下M
� 有�个优良子辈à
� 除优良子辈以外K还有��个个体à所以计算�����������取整得��K得到��个
交叉子个体à
� 还有�个个体K它们不是优良子辈K而是变异子个体à�����

��设置变异大小
遗传算法应用变异函数INvubujpogvodujpoJ字段中指定的函数进行变异操作à默认的
变异函数为高斯函数HbvttjboK它把一个从高斯分布选择的随机数I即nvubujpoJK加到父
辈向量的每一个项上à典型情况下K与分布的标准差成比例的变异大小K在每一后代中都
是减小的à通过参数尺度ITdbmfJ和压缩ITisjolJK可以控制每一代变异的平均数量à尺度控制第一代变异的标准差à标准差是Tdbmf乘以初始种群的范围K该范围是使用
者由Jojujbmsbohf参数指定的à压缩控制变异的平均数量的减少率à标准差线性减小K以便标准差等于��Tisjol乘
以它在第一代的值à例如K假设Tisjol缺省值为�K则变异数在最后一步减小到�à通过选
择绘图函数EjtubodfI距离J和SbohfI范围J能够观察到变异的效果àSbtusjjoh 函数的遗传
算法的运行结果如图����所示à
图������压缩值为�时Sbtusjjoh 函数的距离和范围
图����的上部图形显示每一代各点之间的平均距离à当变异数减小时K个体之间的平
均距离也减小K在最后一代大约减小到�à图����下部图形中的垂直线表示每一代适应度
值由最小到最大的范 围 以 及 适 应 度 值 的 平 均 值à当 变 异 数 减 小 时K适 应 度 值 的 范 围 也 减
小à这些图形显示减少变异数K也就减小了子辈的多样性à作为比较K图����所示为Tisjol取���时的距离和范围的图形à当Tisjol设置为���时K最后一代的平均变异数减小了一半à同样K个体之间的平均
距离也大约减小了一半à
��设置交叉概率
在�Sfspevdujpoq �选项中K由�Dspttpwfsgsbdujpo�文本框指定每一种 群 的 一 部 分K它
们不是FmjufdijmesfoK而是组成的交叉子个体à取交叉概率等于�K意味着所有子个体都是
交叉子个体N取交叉概率等于�K意味着所有子个体都是变异子个体à下面的例子说明K这
两个极端设置都不是有效的函数优化策略à在这个例子中K定义适应度函数为
gIy�Ky�K�KyoJ�}y�}�}y�}���}yo}�����

图������压缩值为���时Sbtusjjoh 函数的距离与范围
即点的适应度函数值为所有点的坐标的绝对值之和à通过设置Gjuofttgvodujpo为P�IyJtvnIbctIyJJK就可以定义为一个无名函数à运行这个例子时K有关参数设置如下M
� 设置�Gjuofttgvodujpo�为 P�IyJtvnIbctIyJJà
� 设置�Ovncfspgwbsjbcmft�为��à
� 设置�Jojujbmsbohf�为P��N�Qà
� 在�Qmput�窗格中选择Cftugjuoftt和Ejtubodfà首先设置Dspttpwfsgsbdujpo为缺省值���K运行算法K得到最佳适应度值大约为���K
如图����所示à
图������交叉概率为���时函数的适应度值与平均距离
�����

�J无变异的交叉
为了观 察 没 有 变 异 时 遗 传 算 法 怎 样 运 行K设 置 Dspttpwfsgsbdujpo为���K并 单 击
�Tubsu�按钮K得到的最佳适应度值约等于���K如图����所示à
图������无变异的交叉下函数的适应度值与平均距离
在这种情况下K算法选择初始种群中的个体基因K并把它们重新结合起来à因为没有
变异K所以算法不能产生任何新的基因à算法利用这些第�代的基因来产生最好的个体K这时最佳适应度图形呈现为水平à此后K它从紧接着的一代选择最佳个体K产生新的最佳
个体的副本à到了第��代K种群中的所有个体都相同K也就是说K都变成了最佳个体à当
这种情形出现时K个体之间的平均距离为�à算法在第�代之后不能改善最佳适应度值K它
在��代过后就陷于停滞K因为Tubmm fofsbujpoth I停滞代数J设置为��à
�J无交叉的变异
为了查看遗传算法在没有交叉的情形下是如何工作的K设置Dspttpwfsgsbdujpo为�K并单击�Tubsu�按钮K得到的最佳适应度值约等于���K如图����所示à
在这种情况下K算法 应 用 的 随 机 变 化 没 有 改 善 第 一 代 最 佳 个 体 的 适 应 度 函 数 值K但
是K它改善了其他个体的个体基因à由图����中的上部图形可以看到K适应度函数的平均
值逐渐减少K这些改善的基因没有和最佳个体基因结合K因为没有交叉à结果K最佳适应
度图形是水平的K并且算法在��代停滞à
�J比较遗传算法取不同交叉概率时的运行结果
在工具箱里有一个演示函数efufsnjojtujdtuve �nz KDspttpwfsgsbdujpo分别设置为�Ð
���Ð���Ð���Ð���Ð�K把遗传算法应用到Sbtusjjoh 函数K比较不同的运行结果à遗传算
法运行��代K对于交叉概率的每一个值K画出每一代之前的所有代的最佳适应度值的均值
和标准差à在 NBUMBC命令窗口中输入efufsnjojtujdtuvezK当演示结束时K画出图形K如图����所示à
�����

图������无交叉的变异下函数的适应度值与平均距离
图������不同交叉概率下最佳适应度值的均值和标准差
图����中下面的图形显示��代不同的交叉概率下最佳适应度值的均值和标准差K上
面图形的颜色显示每一代的最佳适应度值à对于这个适应度函数K当DspttpwfsGsbdujpo等
于���时得到最好结果à但是K对于其他适应度函数K交叉概率可能取另外的值K才能得
到最好结果à
��举例���相对于全局的局部最小值
有时K优化的目的是要找到函数的全局最小值或最大值���一个点的函数值比搜索空
间中其他任何点上的 函 数 值 都 要 小 或 都 要 大à但 是K最 优 化 算 法 有 时 得 到 的 是 局 部 最 小
值���该点的函数值比它的 附 近 点 的 函 数 值 小K但 是 可 能 比 搜 索 空 间 的 其 他 点 的 函 数 值
�����

大à为了克服这个不足K遗传算法的参数必须设置适当à例如K考虑下面的函数M
gIyJ��fyq � yI J��P Q
�
y0���
�fyqI��J�Iy���JIy���J y`���
� ��该函数的图形如图����所示à
图������函数gIyJ的图形
这个函数有两个局部最小值K当y��时K函数值gIyJ���N当y���时K函数值
gIyJ��I���LfJ*������������������K所以K全局最小值是当y���时的函数值à以下列步骤运行遗传算法MI�J用 NBUMBC编辑器将下面的代码复制Ð粘贴到一个新 N文件à
����gvodujpo �uxpz _njoIyJ
jgy_���
���� ��fyz qI�IyL��J����JN
fmtf
���� ��fyz qI��J�Iy���JH�Iy���JN
foe
I�J用 NBUMBC将这个文件保存为uxp_njo�nàI�J在 遗 传 算 法 工 具 中K设 置 Gjuofttgvodujpo为P�uxp_njoK设 置 Ovncfspg
wbsjbcmft为�àI�J单击�Tubsu�按钮à遗传算法返回的值接近局部最小值点y��K如图����所示à图����说明为什么算法得到的是局部最小值K而不是全局最小值à该图画出了每代个
体的范围以及最优个体à注意M所有个体的范围为��Y���à由于变异K这个范围比缺省JojujbmsbohfP�N�Q大K
但是没有大到搜索全局最小值点y���的附近à�����

图������函数gIyJ的局部最优解
图������初始范围为P�N�Q时每代个体的范围及最优个体
使遗传算法搜索更大范围的点的一个方法是增加种群的多样性K即增大Jojujbmsbohfà初始范围不一定包含点y���K但是它必须足够大K以便算法能产生y���附近的个体à设置Jojujbmsbohf为P�N��QK如图����所示à
图������设置初始范围为P�N��Q
单击�Tubsu�按钮K遗传算法返回的值非常接近于y���时的函数值K如图����所示à这一次K图形显示个体更大的范围à在第�代K有大于��的个体K在第��代K算法找
到大约等于��的最优个体K如图����所示à�����

图������函数gIyJ的全部最优解
图������初始范围为P�N��Q时每代个体的范围及最优个体
��使用混合函数
混合函数是一个最优化函数à在遗传算法停止后K为了改善适应度函数值K可以使用
混合函数à混合函数将遗传算法得到的最后点作为它的初始点à可以 在�I csjegvodujpozI混合函数J�参数域指定混合函数à
作为一个例子KSptfocspdl函数定义为
gIy�Ky�J����Iy��y��J��I��y�J�
该函数的图形如图����所示à使用最优化工具箱 中 的 一 个 无 约 束 条 件 的 最 小 化 函 数gnjovod时K首 先 运 行 遗 传 算
法K找到最优点附近的一个点K然后K将它作为gnjovod的初始点K以找到Sptfocspdl函
数的最小值点à工具箱提供了一个计算该函数值的 N 文件efpok �gdo�nh à为了演示这个例子K需在
NBUMBC编辑窗口提示符下键入icsjeefnpz à为了观察这个例子的运行过程K首先键入 buppmh K打开遗传算法工具K进行下列设置MI�J设置�Gjuofttgvodujpo�为P�efpok �gdoh à
�����

图������Sptfocspdl函数
I�J设置�Ovncfspgwbsjbcmft�为�àI�J设置�Qpvmbujpotj{fq �为��à增加混合函数之前K单击�Tubsu�按钮K遗传算法即在�Tubuvtboesftvmut�窗口中显示
出运行结果K如图����所示à
图������增加混合函数之前的运行结果
最终点的坐 标 接 近 问 题 解 的 真 值I�K�Jà在�I csjegvodujpoz �参 数 文 本 框 中 设 置
�I csjegvodujpoz �为gnjovodI参见图����JK可以改善这个结果à
图������设置混合函数为gnjovod
当遗传算法停止时K函数gnjovod得到遗传算法的最终点K然后将其作为它的初始点K返回更精确的结果K显示在�Tubuvtboesftvmut�窗口中K如图����所示à
�����

图������使用混合函数gnjovod得到的运行结果
���设置最大代数
在�Tupqqjo dsjufsjbh I停止准则J�中K�HfofsbujpotI代数J�参数决定最大代数à增加代
数K通常可以改善最终结果à例如K改变遗传算法工具中的参数MI�J设置�Gjuofttgvodujpo�为P�sbtusjjotgdoh àI�J设置�Ovncfspgwbsjbcmft�为��àI�J在�Qmput�窗口中选择�Cftugjuoftt�àI�J设置�Hfofsbujpot�为JogàI�J设置�Tubmm fofsbujpoth I停滞代数J�为JogàI�J设置�Tubmmujnf�为Jogà然后运行遗传算法大约���代K单击�Tupq�按钮K运行结果如图����所示à
图������增大代数设置的最佳适应度值
注意M遗传算法在第���代时运行停滞������代后适应度函数值没有明显的变化à如果恢复Tubmm fofsbujpoth 为缺省值��K算法大约在第���代停止à如果算法重复利用当
前代数的设置停滞K则可以尝试增加Hfofsbujpot和Tubmm fofsbujpoth 来改善计算结果à然
�����

而K改善其他参数可能效果更好à另外K需要特别注意的是K当�NvubujpogvodujpoI变异函数J�设置为Hbvttjbo时K增
加代数的数值K实 际 得 到 的 最 后 结 果 可 能 更 差à这 是 因 为 Hbvttjbo变 异 函 数 有 依 赖 于
Hfofsbujpot的因素K它可能减小每一代的变异平均数K结果导致Hfofsbujpot的设置影响
算法的性能à
���向量化适应度函数
如果向量化适应度函数K则遗传算法一般运行较快à也就是说K遗传算法只调用一次
适应度函数K希望适应度函数快速计算当前种群的所有个体的适应度值à为了向量化适应度函数K首先要编写出计算适应度函数的 N文件K以便处理具有任意
行的一个矩阵K这个矩阵与种群的个体相对应à例如K适应度函数为
gIy�Ky�J�y����y�y���y��y����y�向量化这个函数K用下面的代码写出一个 N文件M
{�yIMK�J������H�yIMK�J�H�yIMK�J��H�yIMK�J�yIMK�J������H�yIMK�JN其中Ky中的冒号�M�表示y的所有行àyIMK�J是一个向量à�����和��H��为向量元素之间
的运算à其次K设置�Wfdupsj{fI向量化J�参数为Poà注意M适应度函数必须接受任意行数来使用Wfdupsj{f参数à下面是在命令行运 行 的 比 较 结 果K显 示 出 了 运 行 速 度 的 改 善 情 况à在 这 里 我 们 设 置
�Wfdupsj{f�为Poà
����ujdNhbIP�sbtusjjotgdoh K��JNupd
fmbtfeq _ujnf�
����������
pujpot�q bph ujntfuq I�Wfdupsj{f�K�po�JN
ujdNhbIP�sbtusjjotgdoh K��Kpujpotq JNupd
fmbtfeq _ujnf�
����������
�����遗传算法参数和函数
本节详细说明��类遗传算法参数和�个遗传算法函数K最后给出一个标准算法选项
的列表作为总结à
�������遗传算法参数
设置遗传算法参数有两种方法K一种是使用遗传算法工具HVJK另一种是从命令行调
用遗传算法函数HBàI�J如果使用遗传算法工具HVJK指定参数可从下拉列表中选择一参数或在一文本字
段中记入该参数的值à参见�����节�使用遗传算法�的�设置选项参数�部分àI�J如果从命令行调用函数HBK指定参数则使用 函 数 bph ujntfuq 来 创 建 参 数 结 构K
�����

例如Mpujpot�q bph ujntfuq I�bsbn��q Kwbmvf�K�bsbn��q Kwbmvf�K���Jà参见�����节�从
命令行使用遗传算法�的�从命令行设置hb的参数�部分à在这一节中K每一个参数用两种方法列出M出现在遗传算法工具中的是标签N出现在
参数 结 构 中 的 是 字 段 名à例 如MQpvmbujpouzqq f在 遗 传 算 法 工 具 中 作 为 参 数 标 签N
QpvmbujpoUzqq f对应参数结构中的字段à遗传算法参数可划分为以下��类MI�J图形参数àI�J种群参数àI�J适应度计算参数àI�J选择参数àI�J再生参数àI�J变异参数àI�J交叉参数àI�J迁移参数àI�J混合函数参数àI��J停止条件参数àI��J输出函数参数àI��J显示到命令窗口参数àI��J向量参数à
��图形参数
图形参数工作时可从遗传算法得到图形数据à当选择图形函数并执行遗传算法时K一
个图形窗口在分离轴上显示这些图形à可在任意时刻单击图形窗口中的停止按钮来停止这
个算法à�QmpuJoufswbm�是指定相邻两次调用图形函数时的遗传代数à
�J绘图参数
在图形方式下可以选择以下任意图形函数M
�CftugjuofttIP�hbmpucftugq J���画出最佳函数值与代数对à
�Fyfdubujpoq I期望值JIP�hbmpufyq fdubujpoq J���画出与每一代原始得分对应的期望
的子代数à
�TdpsfejwfstjuzI多样性值JIP�hbmputdpsfejwfstjuq zJ���画出每一代的得分直方图à
�TupqqjohI停止JIP� mputupqqjoq hJ���画出停止条件水平à
�CftujoejwjevbmIP�hbmpucftujoejwq J���画出每代中最佳适应度个体的向量值à
� HfofbmphzI家系JIP�hbmpuq fofbmphzh J���画出个体的谱系à从一代到下一代线条
颜色代码如下M红线表示变异的子辈N蓝线表示交叉的子辈N黑线表示原始的个体à
�TdpsftIP�hbmputdpsftq J���画出每一代中个体的得分à
� EjtubodfIP�hbmpuejtubodfq J���画出每一代中个体间的平均距离à
� SbohfIP�hbmpusboq hfJ���画出每一代中最大Ð最小Ð平均适应度函数值à
�TfmfdujpoIP�hbmputfmfdujpoq J���画出双亲的直方图à
�DvtupngvodujpoI自定义函数J���能使用自己定义的绘图函数à这个绘图函数只
�����

能在遗传算法工具中使用à选择DvtupngvodujpoK在文本框中输入P�ngvoz K这里 ngvoz是函数名à
当从命令行调用遗传算法函数HB来显示图形时K要设置QmpuGdot字段的参数作为图
形函数的句柄à例如K为了显示最佳适应度图形K设置pujpotq I参数J如下M
����pujpot�q bph ujntfuq I�QmpuGdot�KP�hbmpucftugq JN为了显示多个图形K语法如下M
����pujpot�q bph ujntfuq I�QmpuGdot�KRP� mpugvo�q KP� mpugvo�q K���SJN这里P� mpugvo�q KP� mpugvo�q 等是命令行图形函数名à
�J绘图函数的结构
绘图函数的第一行具有如下形式M
����gvodujpotubuf� mpugvoq Ipujpotq KtubufKgmbhJN函数的输入变元是M
�pujpotq ���包含当前所有pujpotq 设置的结构à
�tubuf���包含当前种群信息的结构à在�状态结构�部分描述了tubuf的各个字段à
�gmbhI字符串J���一个字符串K标志算法的当前运行阶段à
�J状态结构
tubuf结构是图形函数Ð变异函数和输出函数的输入参数K包含以下字段M
�Qpvmbujpoq ���当代种群à
�Tdpsf���当代种群的得分à
� Hfofsbujpo���当前代数à
�TubsuUjnf���HB的开始时间à
�TupGmbq h���包含停止原因的字符串à
�Tfmfdujpo���指明被选择出来的优良个体Ð交叉个体和变异个体à
�Fyfdubujpoq ���希望选择的个体数à
�Cftu���每一代具有最好得分个体的向量à
�MbtuJnspwfnfouq ���适应度值发生改进的最后一代的代数à
�MbtuJnspwfnfouUjnfq ���适应度值发生改进的最后时间à
��种群参数
种群参数用于确定遗传算法所用种群的参数à
Qpvmbujpouzqq fIQpvmbujpoUzqq fJM指 定 适 应 度 函 数 的 输 入 数 据 类 型K可 用 来 设 置
Qpvmbujpouzqq f为以下类型之一MI�JEpvcmfWfdupsI双精度向量JI�epvcmfWfdups�JM当种群中的个体是双精度类型时
使用K它是缺省值àI�JCjutusjohI位串JI�cjutusjoh�JM当种群中的个体是位串类型时使用àI�JDvtupnI自定义JI�dvtupn�JM当种群中的个体不是前面两种类型时使用àI�J如果使用DvtupnI�dvtupn�J类型K必须自己编写创建变异和交叉函数来接受这
种类型种群输入K并分别在下列域中指定这些函数M
� 创建函数IDsfbujpogvodujpoJIDsfbujpoGdoJà
� 变异函数INvubujpogvodujpoJINvubujpoGdoJà�����

� 交叉函数IDspttpwfsgvodujpoJIDspttpwfsGdoJà
Qpvmbujpotj{fq IQpvmbujpoTj{fq JM指 定 在 每 一 代 中 有 多 少 个 个 体K使 用 大 的 种 群 尺
度K遗传算法搜索解空 间 能 更 加 彻 底K同 时 减 少 返 回 局 部 最 小 值 而 不 是 全 局 最 小 值 的 机
会K然而使用大的种群尺度K会使遗传算法运行更慢à如果设置Qpvmbujpotj{fq 为向量K遗传算法将创建多子种群K子种群的数量等于向量
的长度K每个子种群的大小是向量的对应项值à
DsfbujpogvodujpoI创建函数JIDsfbujpoGdoJM指定为HB创建初始种群的函数K可选
择以下函数MI�JVojgpsn IP� bdsfbujpovojgpsnh JM创 建 具 有 均 匀 分 布 的 随 机 初 始 种 群K这 是 缺
省值àI�JDvtupnM允许使用自己编写的创建函数K使其生成在Qpvmbujpouzqq f中指定的数
据类型à如果使用遗传算法工具K必须指定创建函数M
� 设置Dsfbujpogvodujpo为Dvtupnà
� 设置GvodujpoobnfI函数名J为P�ngvoz K这里ngvoz 是函数名à如果使用函数hbK其设置如下M
����pujpot�q bph ujntfuq I�DsfbujpoGdo�KP�ngvoz JN创建函数必须有以下调用语法M
����gvodujpoQpvmbujpo�nq gvoz IHfopnfMfouih KGjuofttGdoKpujpotq J这个函数的输入参数是M
� Hfopnfmfouih M适应度函数中独立变量的个数à
�GjuofttGdoM适应度函数à
� Pujpotq M参数结构à这个函数返回的种群作为遗传算法的初始种群à
Jojujbmqpvmbujpoq IJojujbmQpvmbujpoq JM指定遗传算法的初始种群à缺省值是PQK这种
情况下 HB 使 用 Dsfbujpogvodujpo 创 建 初 始 种 群N如 果 输 入 一 个 非 空 数 组 给Jojujbmqpvmbujpoq 域K则这个数组必须是Qpvmbujpotj{fq 行和Ovncfspgwbsjbcmft列K这种情况
遗传算法不调用Dsfbujpogvodujpoà种群的JojujbmtdpsftIJojujbmTdpsftJM指定初始种群的初始值à
JojujbmsbohfIQpJojuSboq hfJM指定被创建函数生成的初始种群向量范围K能使用一具
有两行ÐOvncfspgwbsjbcmft列的矩阵设置JojujbmsbohfK每一列具有PmcNvcQ形式K这里
mc是相对项目的下界K而vc是上界à如果指定Jojujbmsbohf是���向量K则每个条目均被
扩展K行长度不变K即行长度为Ovncfspgwbsjbcmftà
��适应度比例参数
适应度比例参数是把适应度函数返回的适应度值转换为适合选择函数的范围的值à在
�GjuoftttdbmjohI适应度缩放比例J�窗格中可以指定适应度比例函数参数à在�Gjuoftttdbmjoh�窗格中K尺度函数选项Tdbmjo gvodujpoh IGjuofttTdbmjoGdoh J是一
个下拉列表K可以从中选择要执行适应度比例的函数参数à这些函数参数是MI�JSbolI排列JIP�gjutdbmjosbolh J���缺省的适应度比例函数àSbol函数根据 个 体
适应度值的排列顺序而不是根据个体适应度值的大小来衡量个体的优劣à个体的排列是按
�����

个体适应度值排序的à最适应个体的排序为�K次最适应个体的排序为�K依次类推àSbol函数按适应度比例进行排序K从而消除了原始适应度值的影响à
I�JQsppsujpobmq I比率JIP�gjutdbmjohqspqJ���比率的计算使个体的适应度比例大小与
它的适应度值成比例àI�JUpqI最佳JIP�gjutdbmjouph qJ���计算最佳比例等同于计算最佳个体à选择这一项
后K最佳个体比例显示在另外一个字段�RvboujuzI数量J�中à�Rvboujuz�规定了指派正的
比例值的个体数目à�Rvboujuz�可以是�到种群大小之间的整数K也可以是�到�之间的
小数K这个小数是种群大小的百分比K其缺省值是���à每个能产生子辈的个体指派给相
同的比例值K而其他个体的比例值指派为�à这个比例值的形式为MP��Lo�Lo���Lo���Lo���Qà
在命令行改变�Rvboujuz�的缺省值K可使用如下语句M
����pujpot�q bph ujntfuq I�GjuofttTdbmjoGdo�h KRP�gjutdbmjouph qKvboujur zSJ这里Kvboujur z是�Rvboujuz�的值à
I�JTijgumjofbsI线性 转 换JIP�gjutdbmjotijgumjofbsh J���利 用 线 性 转 换 来 衡 量 适 应 度
值K将使最适应个体的期望值等于个体的平均值乘以一个常数à在�NbytvswjwbmsbufI最
大生存率J�字段中K可以设置这个常数à如果选择线性转换K这个字段显示的缺省值是�à在命令行改变�Nbytvswjwbmsbuf�的缺省值K可使用下面的语句M
����pujpot�q bph ujntfuq I�GjuofttTdbmjoGdo�h KRP�gjutdbmjotijgumjofbsh KsbufSJ这里Ksbuf是�Nbytvswjwbmsbuf�的值à
I�JDvtupnI定制J���能够使用户编写自己的尺度函数à可以使用遗传算 法 工 具 来
指定尺度函数M
� 设置�Tdbmjo gvodujpoh I尺度函数J�为Dvtupnà
� 设置�GvodujpoobnfI函数名J�为P�ngvoz K这里ngvoz 是函数名à如果在命令行使用hbK可使用下面的语句M
����pujpot�q bph ujntfuq I�GjuofttTdbmjoGdo�h KP�ngvoz JN尺度函数必须遵循下面的语法格式M
����gvodujpofyfdujpo�nq gvoz ItdpsftKoQbsfoutJ这个尺度函数的输入参数是M
�tdpsft���标量向量K作为种群的成员à
�oQbsfout���这个种群所必需的父辈个体数目à这个函数返回的期望值fyfdubujpoq 是一个与tdpsft长度相同的标量行向量K给出种
群中每个成员的尺度值àfyfdubujpoq 的总项数必须等于oQbsfoutà
��选择参数
选择参数规定遗传算法怎样为下一代挑选双亲K可用以下方法指定算法函数M
TfmfdujpogvodujpoITfmfdujpoGdoJ域在面板的Tfmfdujpo参数内K这些参数是MI�JTupdibtujdvojgpsnI随机均匀分布JIP�tfmfdujpotupdivojgJ���缺省的选择函数为
Tupdibtujdvojgpsn函数K该函数布局在一条线上K每一父辈根据其刻度值按比率对应线上
的一部分K算法以相同大小的步长沿线移动à在每一步K算法根据降落的位置确定一父辈K第一步是一小于步长的均匀随机值à
�����

I�JSfnbjoefsI剩余JIP�tfmfdujposfnbjoefsJ���剩余选择分配其双亲由每个个体刻
度值的整数部分决定K并随后在剩余的小数部分采用轮盘赌选择方法à例如K一个个体的
刻度值是���K由于其整数部分是�K这个个体在父辈表中出现两次à随后这些父辈按刻度
值的整数部分进行分配K其余的父辈随机选出à父辈在这一步被选取的概率是刻度值的小
数部分àI�JVojgpsnI均匀JIP�tfmfdujpovojgpsnJ���均匀选项用父辈的代数和期望值来选择
父辈K均匀选择用于调试和测试K但不是一个非常有效的搜索策略àI�JSpvmfuufI轮盘赌选项JIP�tfmfdujpospvmfuufJ���轮盘赌选项挑选父辈时使用一个
模拟的轮盘赌K个体在轮子上所占的区域与个体的期望值成正比K算法使用一个随机数选
择一个概率与其相等的区域àI�JUpvsobnfouI锦 标 赛 选 项JIP�tfmfdujpoupvsobnfouJ���锦 标 赛 选 项 通 过 挑 选
�Upvsobnfoutj{fI锦标赛大小J�随机数生成器挑选每一个父个体K随后选择它们中缺少的
最好的个体加入父辈中K�Upvsobnfoutj{f�至少为�K缺省值是�à在命令行用以下语法来改变缺省值M
����pujpot�q bph ujntfuq I�TfmfdujpoGdo�KRP�tfmfduupvsobnfouKtj{fSJ这里�tj{f�是�Upvsobnfoutj{f�的值à
I�JDvtupn���允许编 写 自 己 的 选 择 函 数K在 遗 传 算 法 工 具 中 为 了 指 定 这 个 函 数K必须
� 设置TfmfdujpogvodujpoI选择函数J为�Dvtupn�à
� 设置�Gvodujpoobnf�为P�ngvoz K这里ngvoz 是函数名à如果使用命令行K可输入以下语句M
����pujpot�q bph ujntfuq I�TfmfdujpoGdo�KP�ngvoz J选择函数必须具有以下调用语法M
����gvodujpo bsfout�nq gvoz Ifyfdubujpoq KoQbsfoutKpujpotq J这个函数的输入参数是M
�fyfdubujpoq I期望值J���期望的子辈个体数量作为种群的成员à
�oQbsfoutI父辈个体J���选择的父辈个体的数量à
�pujpotq ���遗传算法参数结构à这个函数返回父辈K它是具有oQbsfout长且包含选择的父辈个体指示的行向量à
��再生参数
再生参数说明了遗传算法怎样为下一代创建子个体à
FmjufdpvouIFmjufDpvouJ���指定将生存到下一代的个体数K设置Fmjufdpvou为一个
小于或等于种群尺度的正整数K其缺省值是�à
DspttpwfsgsbdujpoIDspttpwfsGsbdujpoJ���指定下一代中不同于原种群的部分K它们
由交叉产生àDspttpwfsgsbdujpo是一个�到�之间的小数K可在文本框中输入或移动滑槽
进行设置K其缺省值是���à可参见�����节�设置交叉概率�中的例子à
��变异参数
变异参数说明遗传算法怎样通过小的随机数改变种群中的个体而创建变异的子辈à�����

变异提供遗传变异功能而使遗传算法搜索更广泛的空间à在�NvubujpoI变异J�面板的
�NvubujpogvodujpoI变异函数J�INvubujpoGdoJ字段来指定变异函数K可选择以下函数MI�JHbvttjboI高 斯 函 数JInvubujpobvttjboh J���这 是 缺 省 的 变 异 函 数K把 一 高 斯 分
布Ð具有均值�的随机数加到父向量的每一项à这个分布的变化由参数�Tdbmf�和�Tisjol�决定à如果选择HbvttjboK它们将显示出来K且在�Qpvmbujpoq �参数中按照�Jojujbmsbohf�进行设置à
�Tdbmf参数确定第一代的方差K如果设置�Jojujbmsbohf�为�行�列的向量wK其初
始方差同所有父向量坐标相同K且由TdbmfH�IwI�J�wI�JJ给出à如果设置�Jojujbmsbohf�为�行ÐOvncfspgwbsjbcmft列的向量K父向量坐标为j的初始方差由TdbmfH�IwIjK�J�wIjK�JJ给出à
�Tisjol参数控制方差怎样随着迭代次数增大而收缩à如果设置�Jojujbmsbohf�为�行�列的向量K则第l代的方差wbsl 与父向量坐标相同K且由下列公式给出M
wbsl�wbsl�� ��tisjolðl
hI Jfofsbujpot如果设置�Jojujbmsbohf�为�行ÐOvncfspgwbsjbcmft列的向量K对父向量坐标为j的
初始方差由下列公式给出M
wbsjKl�wbsjKl�� ��tisjolðl
hI Jfofsbujpot如果设置�Tisjol�为�K则算法压缩方差接近线性坐标直到最后一代达到�K一个负的
�Tisjol�引起方差的增长à缺省的�Tdbmf�和�Tisjol�分别是���和���à在命令行要改变
缺省值K可使用如下语法M
����pujpot�q bph ujntfuq I�NvubujpoGdo�K���RP�nvubujpobvttjboh KtdbmfKtisjolSJ这里tdbmf和tisjol分别是�Tdbmf�和�Tisjol�的值à
I�JVojgpsnInvubujpovojgpsnJ���均匀变异是两个过程à第一步K算法选择个体变
量的一部分进行变异K这里每一项有一 NvubujpoSbufI变异概率JK这个Sbuf的缺省值是
����N第二步K算法用均匀选择在项目范围中选择一随机数替换每个选中的项目à在命令
行要改变Sbuf的缺省值K可使用如下语法M
����pujpot�q bph ujntfuq I�NvubujpoGdo�KRP�nvubujpovojgpsnKsbufSJ这里sbuf是Sbuf的值à
I�JDvtupn���自定义允许使用自己的变异函数K使用遗传算法工具时K指定变异函
数使用如下M
� 设置�Nvubujpogvodujpo�为Dvtupnà
� 设置�Gvodujpoobnf�为P�ngvoz K这里ngvoz 是自己设计的变异函数名à如果使用hb函数K则用语句pujpot�q bph ujntfuq I�NvubujpoGdo�KP�ngvoz Jà自定义
的变异函数必须有如下调用格式M
����gvodujponvubujpoDijmesfo�ngvoz Ibsfoutq Kpujpotq KowbstKGjuofttGdoK���
��������tubufKuijtTdpsfKuijtQpvmbujpoq J这个函数的自变量是M
� bsfoutq ���被选择函数选择出的父辈的行向量à
�����

�pujpotq ���参数结构à
�owbst���变量数à
�GjuofttGdo���适应度函数à
�tubuf���包含当前种群信息的结构I在本节�状态结构�部分中描述了tubuf域Jà
�uijtTdpsf���许多当前种群的向量à
�uijtQpvmbujpoq ���当前种群的个体矩阵à这个函数返回nvubujpoDijmesfoI变异的子辈JK它就像一个矩阵K其行对应子孙K矩阵
的列数就是�Ovncfspgwbsjbcmft�à
��交叉参数
交叉参数说明遗传算法如何组合两个个体或双亲K为下一代形成一交叉的子个体à
DspttpwfsgvodujpoIDspttpwfsGdoJM指明进行交叉的函数K可以选择以下函数MI�JTdbuufsfeI分散JIP�dspttpwfstdbuufsfeJM这是一个缺省的交叉函数K它创建一个
二进制向量K如果这个向量某位是�K则这个基因从第一个父辈中来K如果为�K则从第二
个父辈中来K组合这些基因而形成一子个体à例如M父辈q�Kq�是M
���� ��q PbcdefghiQ
���� ��q P��������Q这个二进制向量是P��������QK则函数返回如下子辈个体M
����dijme��Pbc��f���QI�JTjomfh pjouq IP�dspttpwfstjomfh pjouq J���单 点 交 叉K它 在 � 到 �Ovncfspg
wbsjbcmft�之间选择一随机数oK随后M
� 在第一个父辈中选择序号小于或等于o的向量项à
� 在第二个父辈中选择序号大于o的向量项à
� 连接这些项目形成一子辈à例如K父辈q�Kq�是M
���� ��q PbcdefghiQ
���� ��q P��������Q且交叉点是�K则函数返回下列子辈M
����dijme�Pbcd�����QI�JUxp pjouq IP�dspttpwfsuxppjouq J���两点交叉K它在�到�Ovncfspgwbsjbcmft�
之间选择两个随机数n和oK随后M
� 在第一个父辈中选择序号小于或等于n的向量项à
� 在第二个父辈中选择序号为n��Yo的向量项à
� 序号大于o的向量项也来自于第一个父辈à算法连接这些基因形成单一基因K例如父辈q�Kq�是M
���� ��q PbcdefghiQ
���� ��q P��������Q且交叉点是�和�K则函数返回的子辈是
����dijme�Pbcd���hiQI�JJoufsnfejbufIP�dspttpwfsjoufsnfejbufJ���通过父辈的加权平均值创建子辈K可
�����

通过一简单 参 数�SbujpI比 率J�指 定 权 值K�Sbujp�可 能 是 一 标 量 或 具 有�Ovncfspgwbsjbcmft�长的行向量K缺省值是向量的每个值均为�K这个函数使用下列公式从双亲计算
出子辈M
����dijme� bsfou��sboeq H� SbujpH� Ibsfou��q bsfou�q J如果�Sbujp�的所有项值均在P�K�Q范围内K产生的子辈限于由父母的相对顶点定义的
立体空间中K如果�Sbujp�不在这个范围K则子辈可能位于这个空间之外à如果�Sbujp�是一
个标量K则所有子辈都将位于父母间的一直线上à在命令行方式下改变�Sbujp�的缺省值K可使用以下语法M
����pujpot�q bph ujntfuq I�DspttpwfsGdo�K���RP�dspttpwfsjoufsnfejbufKsbujpSJ在这里Ksbujp是�Sbujp�的值à
I�JIfvsjtujdIP�dspttpwfsifvsjtujdJ���返回的子辈位于包含父辈的直线上K离父辈
不远的距离上有较好的适应度N在同一方向上远离父辈K则有较差的适应度à可以使用参
数�Sbujp�指定子辈离较好适应度的父辈有多远K这个参数是在选择启发式IIfvsjtujdJ时
出现的à�Sbujp�的缺省值是���K如果父辈是 bsfou�q 和 bsfou�q K而 bsfou�q 有较好的适
应度K这个函数返回的子辈如下M
����dijme� bsfou�� Sbujpq H� Ibsfou��q bsfou�q J在命令行改变�Sbujp�的缺省值K使用如下语法M
����pujpot�q bph ujntfuq I�DspttpwfsGdo�KRP�dspttpwfsifvsjtujdKsbujpSJ在这里Ksbujp是�Sbujp�的值à
I�JDvtupn���允许使用自己定义的交叉函数à在遗传算法工具中K可使用如下方法
指定交叉函数M
� 设置�Dspttpwfsgvodujpo�为Dvtupnà
� 设置�Gvodujpoobnf�为P�ngvoz K这里ngvoz 是自定义的函数名à如果使用HBK则设置pujpot�q bph ujntfuq I�DspttpwfsGdo�KP�ngvoz Jà自定义函数必须有如下调用格式M
����ypwfsLjet�ngvoz Ibsfoutq Kpujpotq KowbstKGjuofttGdoKvovtfeKuijtQpvmbujpoq J在这里K函数的自变量是M
� bsfoutq ���通过选择函数来选择双亲的行向量à
�pujpotq ���参数结构à
�owbst���OvncfspgwbsjbcmftI基因数Jà
�GjuofttGdo���适应度函数à
�vovtfe���保留K未使用à
�uijtQpvmbujpoq ���表示当前种群的矩阵à这个矩阵的行数是�Qpvmbujpotj{fq I种群
尺度J�K列数是�OvncfspgwbsjbcmftI变量个数J�à这个函数返回ypwfsLjetI即交叉的子辈JK它是一个矩阵K每行对 应 子 辈K其 列 数 是
�Ovncfspgwbsjbcmft�à
��迁移参数
Njsbujpoh I迁移J指明个体在子种群间怎样移动K如果设置�Qpvmbujpotj{fq �为一长度
大于�的向量K则迁移发生à当迁移发生时K一个子种群中最好的个体代替另一子种群中
�����

最差的个体à个 体 从 一 个 子 种 群 迁 移 到 另 一 子 种 群 是 复 制K即 在 源 子 种 群 中 并 没 有 被
移走à可以通过�Njsbujpoh �参数面板中下面三个字段来控制迁移的发生MI�J�EjsfdujpoI方向J�INjsbujpoEjsfdujpoh J���迁移发生在一个或两个方向à如果设置�Ejsfdujpo�为GpsxbseI�gpsxbse�JK则迁移发生在下一个种群K也就是第O
个子种群迁移到第O��个子种群à如果设置�Ejsfdujpo�为CpuiI�cpui�JK则 第 O个 子 种 群 迁 移 到 第 O��个 子 种 群 和
O��个子种群à迁移在最后一个子种群处将卷绕回来K即最后一个子种群迁移到第一个子种群K第一
个子种群可以迁移到最后一个子种群à为了防止卷绕K在确定的种群尺度下K在种群尺度
向量的最后添加一�项K指示一大小为�的子种群àI�J�JoufswbmI间隔J�INjsbujpoJoufswbmh J���指明在两次迁移间要经过多少代K例如
设置Joufswbm为��K则每隔��代就发生迁移àI�J�GsbdujpoI百分比J�INjsbujpoGsbdujpoh J���指明在两个子种群间有多少个个体
迁移à�百分比�指明两个子种群中较小子种群的个体迁移百分比à例如M如果个体从一个
有��个个体的子种群迁移到�个有���个个体的子种群K且Gsbdujpo设置为���K则发生
迁移的个体数是��������à
��混合函数参数
混合函数是运行在遗传算法终止后的另一个最小化函数K可在�I csjegvodujpoz I混合
函数J�II csjeGdoz J参数中指定混合函数à混合函数有以下选择MI�JPQ���没有混合函数àI�JgnjotfbsdiIP�gnjotfbsdiJ���使用 NBUMBC函数gnjotfbsdiàI�Jbuufsotfbsdiq IP� buufsotfbsdiq J���使用模式搜索àI�JgnjovodIP�gnjovodJ���使用优化工具箱函数gnjovodà
���停止条件参数
停止条件决定什么引起算法的终止K可以指明以下参数MI�J�Hfofsbujpot����指明算法最大重复执行次数K缺省值是���àI�J�Ujnfmjnju�IUjnfMjnjuJ���指明算法停止执行前的最大时间K以秒为单位àI�J�GjuofttmjnjuI适应度限J�IGjuofttMjnjuJ���最好适应度值小于或等于�Gjuoftt
mjnju�K则算法终止àI�J�Tubmm fofsbujpoth I停 滞 代 数J�ITubmmHfoMjnjuJ���如 果 适 应 度 值 在 �Tubmm
fofsbujpoth �指明的代数没有改进K则算法停止àI�J�TubmmujnfI停滞时间J�ITubmmUjnfMjnjuJ���如果最好适应度值在�Tubmmujnf�时
间间隔内没有改进K则算法终止à
���输出函数参数
输出函数在每一代返回来自遗传算法的输出到命令行à�Ijtups upofxxjoepxz I记 录 到 新 窗 口J�IP� bpvuh vuq foh J���每 到�Joufswbm�的 倍
数K重复在新窗口显示由算法计算的历史点à�Dvtupn����允许使用自己的输出函数K在遗传算法工具中使用以 下 方 法 指 明 输 出
�����

函数M
� 选择�DvtupngvodujpoI自定义函数J�à
� 在文本框输入P�ngvoz K这里ngvoz 是函数名à如果使用HBK则设置pujpot�q bph ujntfuq I�PvuvuGdo�q KP�ngvoz Jà在 NBUMBC命令行键入
����feju bpvuh vugdoufnq mbufq则可使用模板编写自己的输出函数à
输出函数有如下调用语法M
����PtubufKpujpotq Kpudiboq feh Q�ngvoz Ipujpotq KtubufKgmbhKjoufswbmJ函数有如下输入参数M
�pujpotq ���参数结构à
�tubuf���包含当前代信息的结构à
�gmbh���指明算法当前状态的字符串K有如下形式M�joju�表示初始状态N�jufs�表示
算法运行状态N�epof�表示算法终止状态à
�joufswbm���可选的joufswbm自变量à输出函数返回如下结果变量M
�tubuf���包含当前代信息的结构à
�pujpotq ���被输出函数修改的参数结构K这个参数是可选的à
�pudiboq feh ���指示pujpotq 是否改变的标志à
���显示到命令窗口参数
�Ejtmbq zI显示级别J����指 明 遗 传 算 法 运 行 时K在 命 令 行 显 示 的 信 息 数K有 效 的 参
数是M
� PggI�pgg�J���只有最终结果显示à
�JufsbujwfI�jufs�J���显示每一次迭代的有关信息à
� Ejboptfh I�ejboptf�h J���显示每一次迭代的信息K而且还列出函数缺省值已经被
改变的有关信息à
�GjobmI�gjobm�J���遗传算法的结果I成功与不成功JÐ停止的原因Ð最终点à
Jufsbujwf与Ejboptfh 两者显示如下信息M
� Hfofsbujpo���代数à
�g�dpvou���适应度函数估价的累计数à
�CftugIyJ���最佳适应度值à
� NfbogIyJ���平均适应度值à
�TubmmHfofsbujpot���停滞代数K即最后一次改进适应度函数以来的代数à�Ejtmbq z�的缺省值是M
� Pgg���遗传算法工具中à
��gjobm����使用 bph ujntfuq 创建的参数结构中à
���向量参数
�向 量 参 数�指 明 适 应 度 函 数 的 计 算 是 否 被 向 量 化à如 果 设 置�Gjuofttgvodujpojtwfdupsj{feI适应度函数向量化J�IWfdupsj{feJ为PggK则遗传算法在每次循环中计算新一代
�����

个体的适应度值N如果设置�Gjuofttgvodujpojtwfdupsj{fe�为PoK则遗传算法计算新一代
个体的适应度值时只调用适应度函数一次à无论如何K使用这个参数K适应度函数必须能
接受具有任意行数的输入矩阵à
�������遗传算法函数
本节介绍遗传算法工具的四个函数的功能Ð格式及其详细说明K这四个函数分别为M
hbÐbph ujnq fuh Ðbph ujntfuq 和 buppmh à
��函数hb功能M用遗传算法搜索函数最小值à格式M
����y�hbIgjuofttgvoKowbstJ
y�hbIgjuofttgvoKowbstKpujpotq J
y�hbIspcmfnq JPyKgwbmQ�hbI���JPyKgwbmKsfbtpoQ�hbI���JPyKgwbmKsfbtpoKpvuvuq Q�hbI���JPyKgwbmKsfbtpoKpvuvuq Kqpvmbujpoq Q�hbI���JPyKgwbmKsfbtpoKpvuvuq Kqpvmbujpoq KtdpsftQ�hbI���J
详细说明M
y�hbIgjuofttgvoKowbstJM把遗传算法应用到优化问题K这里gjuofttgvo是最小化的
目标函数Kowbst是找到的最优个体答案向量y的长度à
y�hbIgjuofttgvoKowbstKpujpotq JM把遗传算法应用到优化问题K使用参数结构中的
那些选项参数à
y�hbIspcmfnq JM为 spcmfnq 找最小值Kspcmfnq 结构有下列三个字段M
�gjuofttgdo���适应度函数à
�owbst���适应度函数的独立变量个数à
�pujpotq ���用 bph ujntfuq 创建的参数结构àPyKgwbmQ�hbI���JM返回gwbmK即适应度函数在y处的值àPyKgwbmKsfbtpoQ�hbI���JM返回sfbtpoK它是一包含算法终止原因的字符串àPyKgwbmKsfbtpoKpvuvuq Q�hbI���JM返回pvuvuq K它是一包含每一代输出和算法执
行的其他信息的结构K这个输出结构包含以下字段M
�sboetubuf���遗传算法启动之前sboe的状态Ksboe是 NBUMBC随机数生成器à
�sboeotubuf���遗传算法启动之前sboeo的状态Ksboeo是 NBUMBC普通随 机 数
生成器K可使用sboetubuf和sboeotubuf值再现HB的输出à
� fofsbujpoth ���计算的代数à
�gvoddpvou���适应度函数的估算次数à
� nfttbhf���算法终止的原因K它与输出变量sfbtpo相同àPyKgwbmKsfbtpoKpvuvuq Kqpvmbujpoq Q�hbI���JM返 回qpvmbujpoq K它 是 种 群 矩 阵K
spxt是最后的种群à�����

PyKgwbmKsfbtpoKpvuvuq Kqpvmbujpoq KtdpsftQ�hbI���JM返回值tdpsftK它是最终种
群的得分值à注意M对 spcmfnq 使用的种群类型是双精度型向量Khb并不接受输入是复数型向量的
函数K为了解决包括复数数据的问题K可以编写自己的函数K即把复数的实部和虚部分开K变为hb能接受的实数向量à
举例M
����PygwbmKsfbtpoQ�hbIP�sbtusjjotGdoh K��J
y�����Dpmvnot�uispvi�h����������������������������������������������������Dpmvnot�uispvi��h������������������������gwbm�����������sfbtpo����� fofsbujpoth
参见Mbph ujntfuq Kbuppmh à
��函数 bph ujnq fuh功能M得到遗传算法参数结构值à格式M
����wbm� bph ujnq fuh Ipujpotq K�obnf�J详细说明M
wbm� bph ujnq fuh Ipujpotq K�obnf�JM返回参数obnf的值Kobnf来自遗传算法参数的
结构参数à如果obnf的值没有在参数中指明K则 bph ujnq fuh Ipujpotq K�obnf�J返回一空的矩阵à
它只需要能惟一定义obnf足够的前导字符àbph ujnq fuh 忽略参数obnf中的大小写à参见MhbKbuppmh à
��函数 bph ujntfuq功能M创建遗传算法参数结构à格式M
����pujpot�q bph ujntfuqbph ujntfuqpujpot�q bph ujntfuq I�bsbn��q Kwbmvf�K�bsbn��q Kwbmvf�K���J
pujpot�q bph ujntfuq Ipmeputq K�bsbn��q Kwbmvf�K���J
pujpot�q bph ujntfuq Ipmeputq Kofxputq J详细说明M
pujpot�q bph ujntfuq I无输入参数JM创建一称为pujpotq 的选项参数结构I它包含遗传
算法的参数JK并设置这些参数为缺省值à
bph ujntfuq M无输入或输出变量参数K显示具有有效值的参数的完整列表à�����

pujpot�q bph ujntfuq I�bsbn��q Kwbmvf�K�bsbn��q Kwbmvf�K���JM创 建 一 结 构pujpotq K并设置其他值K即�bsbn��q 为wbmvf�K�bsbn��q 为wbmvf�K等等à在这里K只需要给出能惟
一定义参数名的足够的前导字符K任何未指定的参数设置均使用它们的缺省值à参数名中
的大小写被忽略à
pujpot�q bph ujntfuq Ipmeputq K�bsbn��q Kwbmvf�K���JM创建一pmeputq 拷贝K修改 指
定的参数具有指定的值à
pujpot�q bph ujntfuq Ipmeputq Kofxputq JM用一新的参数结构ofxputq 组合一存在的参
数结构pmeputq K在ofxputq 中任意参数的非空值覆盖pmeputq 中对应的参数à表���列出了能用 bph ujntfuq 设置的参数K在�����节�遗传算法参数�中完整地描述了
这些参数及其取值àRS中的值是缺省值à在命令行使用无输入参数的命令函数 bph ujntfuq K可
查看这些优化参数à表�����使用函数 bph ujntfuq 设置的参数
参����数 说����明 值
DsfbujpoGdo ��创建初始种群的函数句柄 RP� bdsfbujpovojgpsnh S
DspttpwfsGsbdujpo��不包括优良子辈K由交叉函数创建的下一代种
群的交叉概率正数标量b�R���S
DspttpwfsGdo ��遗传算法用来创建交叉的子辈函数的句柄
P�dspttpwfsifvsjtujdRP�dspttpwfstdbuufsfeS
P�dspttpwfsjoufsnfejbuf
P�dspttpwfstjomfh pjouq
P�dspttpwfsuxpqpjou
FmjufDpvou��正整数K指明当前代中有多少个个体一定生存
到下一代正整数b�R�S
GjuofttMjnju��标量K如 果 适 应 度 值 达 到GjuofttMjnju的 值K
则遗传算法停止标量b�R�JogS
GjuofttTdbmjoGdoh ��变换适应度函数值的函数的句柄
P�gjutdbmjohhpmecfshRP�gjutdbmjosbolh S
P�gjutdbmjohqspq
P�gjutdbmjouph
Hfofsbujpot
q
��正整数K指明算法停止前可迭代的最大次数 正整数b�R���S
QpJojuSboq hf ��矩阵或向量K指明初始种群中个体的范围 矩阵或向量P�N�Q
QpvmbujpoUzqq f ��字符串K指定种群的数据类型�cjutusjoh�b��dvtupn�b�R�epvcmfWfdups�S
IcsjeGdoz ��在hb终止后使用它继续优化的函数的句柄 函数句柄b�RPQS
JojujbmQpvmbujpoq ��初始种群 正标量 RPQS
�����

续表
参����数 说����明 值
JojujbmTdpsft ��初始得分 列向量b�RPQS
NjsbujpoEjsfdujpoh ��迁移方向 �cpui�b�R�gpsxbse�S
NjsbujpoGsbdujpoh���到�之间的标 量K指 明 每 个 子 种 群 迁 移 到 不
同子种群的个体比率标量b�R���S
NjsbujpoJoufswbmh��正 整 数K指 明 间 隔 多 少 代 子 种 群 间 个 体 发 生
迁移正整数b�R��S
NvubujpoGdo ��产生变异子辈的函数的句柄P�nvubujpovojgpsnRP�nvubujpobvttjboh S
PvuvuGdotq ��hb在每次迭代调用的函数的句柄数组 数组b�RPQS
PvuvuJoufswbmq ��正整数K指明相隔多少代调用输出函数 正整数b�R�S
QmpuGdot��把算法计算出来的数据绘制成图形的函数句柄
数组
P�hbmpucftugq
P�hbmpucftuq fopnfh
P�hbmpuejtubodfq
P�hbmpufyq fdubujpoq
P�hbmpuq fofpmphzh
P�hbmputfmfdujpoq
P�hbmpusboq hf
P�hbmputdpsfejwfstjuq z
P�hbmputdpsftq
P�hbmputupqqjoq hb�RPQS
QmpuJoufswbm ��正整数K指明调用图形函数间隔的代数 正整数b�R�S
QpvmbujpoTj{fq ��种群尺度 正整数b�R��S
TfmfdujpoGdo ��选择进行交叉或变异的父辈的函数句柄
P�tfmfdujpopmecfsh h
P�tfmfdujposboepnRP�tfmfdujpotupdivojgS
P�tfmfdujpospvmfuuf
P�tfmfdujpoupvsobnfou
TubmmHfoMjnju��正整数K停滞 代 数 限K如 果 相 隔TubmmHfoMjnju代K目标函数没有改进K则算法停止
正整数b�R��S
TubmmUjnfMjnju��正 标 量K停 滞 时 间 限K如 果 在TubmmUjnfMjnju秒后K目标函数没有改进K则算法停止
正标量b�R��S
UjnfMjnju��正 标 量K时 间 限K算 法 运 行 UjnfMjnju秒 后
停止正标量b�R��S
Wfdupsj{fe ��字符串K指明运算的适应度函数是否是向量 �po�b�R�pgg�S
�����

����参见Mbph ujnq fuh Kbuppmh à
��命令 buppmh功能M打开遗传算法工具à格式M
���� buppmh详细说明M打开遗传算法工具K给遗传算法提供图形用户界面à可使用遗传算法工具来运行遗传算法K求解优化问题K并显示结果à参见MhbKbph ujntfuq à
�������标准算法选项
遗传算法工具提供了许多标准算法选项K见表���à表�����遗传算法工具标准算法选项
步��骤 算 法 选 项
初始化种群 ��vojgpsn
适应度计算 ��sbolcbtfeKspq psujpobmq KupqIusvodbujpoJKmjofbstdbmjohboetijgu
选择 ��spvmfuufKtupdibtujdvojgpsntfmfdujpoITVTJKupvsobnfouKvojgpsn
交叉 ��ifvsjtujdKjoufsnfejbufKtdbuufsfeKtjomf�h pjouq Kuxp�qpjou
变异 �� bvttjboh Kvojgpsnnvmujqpjou
绘图��cftugjuofttKcftujoejwjevbmKejtubodfbnpo joejwjevbmth Kfyfdubujpo pg
joejwjevbmtq
KsbohfKejwfstju pgz qpvmbujpoq KtfmfdujpojoefyKtupqqjohdpoejujpot
����遗传算法可以帮助我们确定这种具有多个局部最小值函数的最优解à遗传算法工具提供了通过使用所有关键部件I包括使用算法选项J来定义问题的能力K
实现了运行时间的可视化à所谓运行时间可视化K是指函数正在优化时所产生的结果可以通过使用遗传算法工具
中的绘图函数用图形表示出来K并且运行时间的可视化可以通过使用遗传算法工具中的绘
图函数在该函数优化的同时产生à使用遗传算法工具时常常需要指定MI�J群体大小àI�J优良的子辈个数àI�J交叉片段IDspttpwfsgsbdujpoJàI�J子群体间迁移INjsbujpobnpoh tvch qpvmbujpotq JK使用环形拓扑à通过提供用户自定义函数可以定制这些算法选项K并且可以用不同的数据格式来描述
问题K比如使用混合整型数或复数作为变量à可以以时限Ð停滞时限Ð适应度界限Ð繁殖辈
数等为基准来作为算法的终止准则à最后K可以通过矢量化适应度函数来提高运算速度à
�����

书书书
ðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀ
ðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀðŀ
�
��
�
��第九章��使用NBUMBC直接搜索工具��
NbuiXpslt公司最新发布的 NBUMBC���Sfmfbtf��中包含一个专门设计的
遗传算法与直接搜索工具箱IHfofujdBmpsjuinboeEjsfduTfbsdiUppmcpyh JK这个
工具箱集成有遗传算法工具和直接搜索工具à上一章已经对遗传算法与直接搜索工具箱进行了概要介绍K对其中的遗传算法
工具及其使用方法进行了详细叙述à本章则集中介绍其中的直接搜索工具及其使用
方法à
�����直接搜索工具概述
与遗传算法一样K直接搜索算法工具也可以作为其他优化方法的一个补充K用来寻找
最佳起始点K继而可以通过使用传统的优化技术来进一步找出最优解à直接搜索工具函数可以通过图形界面或 NBUMBC命令行来访问à所有算法工具函数
都是用 NBUMBC语言编写的K对用户开放K因此可以查看算法Ð修改源代码或生成用户
函数à工具箱中的直接搜索算法实现的是模式搜索方法à大多数传统优化方法通过使用梯度
或高阶导数的方法来搜寻优化点K而模式搜索方法可搜索出最大最小正基模式à它可以处
理边界约束Ð线性等式Ð线性不等式K并且不需要函数可微或连续à模式搜索算法包括下列选项MI�J表决方法M用来决定怎样产生和估计模式中的点数以及每一步生成的最大点数à
可以通过控制点的表决顺序来提高效率àI�J搜索方法M用来选择比表决步效率更高的搜索方法à可以在一个模式内或整个搜
索空间中执行搜索à与遗传算法相似K全局搜索方法可以用来获得一个好的起始点àI�J网格M用来表示迭代过程中控制模式如何变化à对于各维尺度不同的问题K还需
要调整网格à可以选择初始网格尺寸Ð网格细分因子或网格收缩因子à网格加速器加快了
最小值附近的收敛速度àI�J缓存器M用来存储优化过程中计算量大的目标函数的估计点à可以指定模式搜索
算法中缓存器的大小和容差K还可以在计算过程中调整缓存器容差K以提高寻优的速度和
效率à通过命令行或图形用户界面可修改上述任一选项à
�����

�����直接搜索算法
本节介绍直接搜索与模式搜索的基本概念K说明工具箱中完成模式搜索的主函数K提
供一个用模式搜索来求解优化问题的实例K解释模式搜索的一些基本术语K阐明直接搜索
算法的工作原理与工作过程K展示如何绘制目标函数的值和模式搜索产生的点序列的网格
尺寸的图形à
�������何谓直接搜索
直接搜索IEjsfduTfbsdiJ是一种求解优化问题的方法K它不要求任何目标函数梯度的
信息à与使用梯度或高阶导数信息来搜索优化点的较传统的优化算法相反K直接搜索算法
搜索当前点周围的一系列点K寻找目标函数值低于当前点值的那些点à我们可以使用直接
搜索算法来求解那些目标函数不可微Ð甚至不连续的问题à直接搜索工具实现一类特殊的直接搜索算法K称为模式搜索IQbuufsoTfbsdiJ算法à模
式搜索算法确定一个点的序列K这个点序列呈现越来越接近理想点的趋势à在每一步K该
算法搜索在当前点周围的一系列点K称为网格INftiJà当前点是指该算法在前一步计算出
来的点à该算法通过把当前点与一个称为模式IQbuufsoJ的固定向量集的标量倍数相加来构
成网格à如果算法在网格中找到一个新点K且在该点比在当前点使目标函数得到改善K则
该算法在下一步就将新点作为当前点à
�������执行模式搜索
本节简要介绍模式搜索工具和实现模式搜索的图形用户界面IHVJJK主要内容包括M从命令行调用模式搜索和使用模式搜索工具HVJà
��从命令行调用模式搜索
为了在命令行上对无约束问题执行模式搜索K可用下面的语法调用函数 buufsotfbsdiq M
��������PygwbmQ� buufsotfbsdiq IP�pcgvok Ky�J
其中MP�pcgvok ���目标函数句柄Ny����模式搜索的起始点à返回的结果为Mgwbm���目
标函数的最终值Ny���获得最终值的点à
�����节�从命令行运行模式搜索�将详细解释如何使用函数 buufsotfbsdiq à
��使用模式搜索工具HVJ键入 tfbsdiuppmq K打开模式搜索工具HVJK如图���所示à为了使用模式搜索工具K首先必须输入下列信息MI�JPcfdujwfgvodujpok I目标函数J���想要最小化的目标函数à输入目标函数的形式
为P�pcgvok K这里pcgvo�nk 是计算目标函数的一个 N 文件K符号�P��产生pcgvok 的函数
句柄àI�JTubsu pjouq I起始点J���即开始点à算法从该点开始进行优化à在�DpotusbjoutI约束J�窗格中输入对问题的约束à如果问题是无约束的K则该字段应
保持为空à
�����

����然后K单击�TubsuI开 始J�按 钮K模 式 搜 索 工 具 随 即 在�TubuvtboesftvmutI状 态 与 结
果J�窗格中显示出优化的结果à我们也可以在�Pujpotq I选项J�窗格中改变模式搜索的选项à为了查看某一类选项K可
单击与之相关的加号���à
图�����模式搜索工具
�������寻找函数最小值
本节介绍使用模式搜索工具来寻找函数最小值的一个实例à
��目标函数
本例使用目标函数qt_fybnmfq K它包含在遗传算法与直接搜索工具箱之中à键入下列
命令就可以查看该函数的代码M
��������zqu fqt_fybnmfq图���显示出了该函数的图形细节à
�����

图�����目标函数qt_fybnmfq
��寻找函数的最小值
为了寻找qt_fybnmfq 的最小值K进行如下步骤MI�J键入 tfbsdiuppmq K打开模式搜索工具àI�J在模式搜索工具的�Pcfdujwfgvodujpok I目标函数J�文本框中输入P�qt_fybnmfq àI�J在�Tubsu pjouq I起始点J�文本框中输入P������Qà打开模式搜索工具后的这两步操作K即输入目标函数与起始点K如图���所示à因为
该问题是无约束的K所以Dpotusbjout字段保持为空à
图�����输入目标函数与起始点
I�J单击�Tubsu�按钮K运行模式搜索à在�Tubuvtboesftvmut�窗格中显示模式搜索的
结果K如图���所示à
图�����目标函数qt_fybnmfq 的模式搜索结果
函数的最小值约为��à�Gjobm pjouq I最终点J�窗格中显示最小值出现的那个点à
�����

��绘制目标函数值和网格尺寸的图形
为了查看模式搜索的性能K可以显示每一次迭代时的最佳函数值与网格尺寸à首先K在�QmputI绘图J�窗格中选中CftugvodujpowbmvfI最佳函数值J和Nftitj{fI网格尺寸J复选
框K如图���所示à
图�����绘图窗口
然后K单击�Tubsu�按钮K运行模式搜索à这时K会显示出图���所示的细节à
图�����qt_fybnmfq 的最佳函数值与网格尺寸
图���上半部分显示出在每一次迭代时最佳点的目标函数值à典型情况下K目标函数
值在早期迭代时迅速改善K然后K随着它们逼近理想值而变平Ð稳定à图���下半部分显示出在每一次迭代时的网格尺寸à网格尺寸在每一次成功的迭代后
增加K在每一次不成功的迭代后减少à�����节�模式搜索如何工作�中对此进行了解释à
�������模式搜索术语
本节解释模式搜索的�个标准术语K包括模式IQbuufsoJÐ网格INftiJ和表决IQpmmJà
��模式
模式是若干向量的 一 个 集 合K向 量 由 算 法 来 使 用K以 确 定 在 每 次 迭 代 时 要 搜 索 哪 一
点à例如K如果在某优化问题中存在两个独立变量K则缺省模式由下面的向量组成M�����

����w��P��Q
w��P��Q
w��P���Q
w��P���Q图���显示出了这些向量à
图�����二维的缺省模式向量
��网格
在每一步中K模式搜索算法搜索一组点I称为网格InftiJJK以寻找使目标函数得到改
善的点à该算法形成网格的方法是MI�J给模式向量乘以一个标量I称为网格尺寸INftiTj{fJJàI�J把结果 向 量 与 当 前 点 相 加à当 前 点 是 指 在 前 一 步 找 到 的 具 有 最 佳 目 标 函 数 值
的点à例如K假定当前点是P������QK模式由下列向量组成M
����w��P��Q
w��P��Q
w��P���Q
w��P���Q
当前网格尺寸是�à算法给模式向量乘以�K并且把它们与当前点相加K从而获得下面
的网格M
����P������Q��H�P��Q�P������QP������Q��H�P��Q�P������QP������Q��H�P���Q�P�������QP������Q��H�P���Q�P�������Q
产生一个网格点的模式向量也称为该网格点的方向IEjsfdujpoJà
�����

��表决
在每一步中K算法通过计算它们的目标函数值K在当前网格中表决选出若干点à当选
项�Dpnmfufq pmmq I完全表决J�具有缺省设置Pgg时K算法一旦找到目标函数值小于当前点
函数值的那个点就停止对网格点的表决选取à如果这种情形出现K则为表决成功K并且所
找到的点在下一次迭代时变成当前点à注意M算法只计算当前网格中的点的目标函数值K直到找到满足停止表决条件的某点
为止à如果算法未能找到使目标函数得到改进的点K则表决不成功K并且在下一次迭代时当
前点保持不变à如果选项�Dpnmfufq pmmq �设置为PoK算法计算所有网格点的目标函数值K然后K把具
有最小目标函数值的网格点与当前点进行比较à如果该网格点比当前点具有更小的目标函
数值K则表决成功à
�������模式搜索如何工作
模式搜索算法可以找到一个点序列y�Ky�Ky�K�K它们逐渐逼近理想点K序列中的
每一点到下一点的目标函数值逐渐减少à本节以前面所描述的目标函数qt_fybnqm为例K说明模式搜索算法是如何工作的à
为了使解释简明起见K假定在这里描述模式搜索算法如何工作的时候K选项�Nfti�中的参数�Tdbmf�设置为Pggà
��成功选举
对于目标函数qt_fybnmfq K模式搜索从所提供的起始点y�开始à在本例中K起始点
y��P������Qà下面叙述模式搜索算法的工作过程à
�J第�次迭代
在第�次迭代时K网格尺寸为�K模式搜索算法把模式向量与起始点y��P������Q相
加K计算出下列网格点M
����P��Q�y��P������Q
����P��Q�y��P������Q
����P���Q�y��P������Q
����P���Q�y��P������Q算法以上面显示的顺序计算各网格点的目标函数à图���显示出qt_fybnmfq 在起始
点和各网格点的值à该算法通过计算各网格点的目标函数值来表决选取各网格点K直到它找到其函数值小
于y�点的函数值������的点à在本例中K它找到的第一个这样的点是P������QK目标函
数在该点的值是������K故迭代�的选取获得成功à算法设置序列中的下一点为
����y��P������Q注意M按照缺省值K模 式 搜 索 算 法 一 旦 找 到 其 目 标 函 数 值 小 于 当 前 点 的 一 个 网 格 点
时K就 停 止 当 前 的 迭 代à因 此K该 算 法 不 可 能 选 出 所 有 的 网 格 点à我 们 可 以 通 过 设 置
�Dpnmfufq pmmq �选项为PoK而使算法选取所有网格点à
�����

图�����目标函数在起始点和各网格点的值
�J第�次迭代
在一次成 功 选 举 之 后K该 算 法 把 当 前 网 格 尺 寸 乘 以�K这 是�Nfti�选 项 窗 格 中
�Fybotjpogbdupsq I扩张因子J�的缺省值à因为初始网格尺寸是�K在第�次迭代时网格尺
寸为�K所以第�次迭代时的网格包含下列点M
�����H�P��Q�y��P������Q
�����H�P��Q�y��P������Q
�����H�P���Q�y��P�������Q
�����H�P���Q�y��P�������Q目标函数qt_fybnmfq 在当前点y�和各网格点的相应值如图���所示à
图�����目标函数在y�点和各网格点的值
�����

算法检测各网格点K寻找其函数值小于当前点y�处的值������的一个点à它找到的
第一个满足条件的点是P�������QK目标函数在该点处的值是����K故迭代�的选取再次
成功à该算法设置序列中的第二个点为
����y��P�������Q因为选取成功K算法把当前网格尺寸乘以�K得到第�次迭代的网格尺寸为�à
�J第�次迭代
到第�次迭代时K当前点是y��P�������QK且 网 格 尺 寸 为�K所 以 网 格 由 下 列 点
组成M
�����H�P��Q�y��P������Q
�����H�P���Q�y��P�������Q
�����H�P��Q�y��P�������Q
�����H�P���Q�y��P��������Q算法选取各网格点K找到其值小于y�处值的第一个点P�������QK该点处目标函数
的值是�������K故迭代�的选取再次成功à该算法设置序列中的第三个点为
����y��P�������Q因为选取成功K算法把当前网格尺寸再乘以�K得到第�次迭代后的网格尺寸为�à
��不成功选举
到第�次迭代时K当前点是y��P�������QK网格尺寸为�K所以网格由下列点组成M
�����H�P��Q�y��P������Q
�����H�P���Q�y��P��������Q
�����H�P��Q�y��P�������Q
�����H�P���Q�y��P��������Q图����显示出了各网格点以及它们的目标函数值à
图������在y�点与各网格点的目标函数值
�����

这次迭代K不存在其目标函数值小于y�处值的网格点K故选取不成功à在本例中K算
法不改变下次迭代的当前点K即y��y�à下次迭代时K算法对当前网格尺寸乘以���K这是�Nfti�窗格中的�Dpousbdujpogbdups
I收缩因子J�选项的缺省值à因此K下次迭代的网格尺寸为�à这样K算法的选举具有了较
小的网格尺寸à
��显示每次迭代的结果
通过 设 置 在�Ejtmbq updpnnboexjoepxz I显 示 到 命 令 窗 口J�选 项 中 的�Mfwfmpgejtmbq zI显示级别J�为�JufsbujwfI迭代J�K就可以显示出每次迭代时模式搜索的结果à这使
得我们可以评估模式搜索的进展K在必要时可以改变相关选项à有了这样的设置K模式搜索将在命令行显示每次迭代的信息à对于本例K显示的前几
行如下M
����Jufs������g�dpvou����NftiTj{f����gIyJ��������Nfuipe����� � � ����� TubsuJufsbujpot����� � � ����� TvddfttgvmQpmm����� � � ���� TvddfttgvmQpmm����� �� � ������� TvddfttgvmQpmm����� �� � ������� SfgjofNfti在 NfuipeI方法J之下显示的信息�TvddfttgvmQpmm�表明当前迭代是成功的à例如K第
�次迭代的选举是成功的à因此K在第�次迭代中计算出来的那一点的显示在gIyJ下面的
目标函数值小于在第�次迭代中计算出来的值à在第�次迭代中K�Nfuipe�之下显示的信息�SfgjofNftiI改善网格J�告诉我们K选
举是不成功的à因此K第�次迭代的函数值仍然保持第�次迭代的函数值不变à注意M模式搜索在每次成功选举之后使网格尺寸加倍K而在每次不成功的选举之后使
网格尺寸减半à
��更多的迭代
对于本例K模式搜索在停止之前执行了��次迭代à图����显示出模式搜索的前��次
迭代计算序列中的若干点à各个点下面的数字表示该算法找到该点时的迭代次数à这个图
只显示出与成功选举相对应的迭代次数K因为 在 一 次 不 成 功 的 选 举 之 后 最 佳 点 不 发 生 变
化à例如K第�次迭代和第�次迭代的最佳点就与第�次迭代的最佳点相同à
��模式搜索的停止条件
模式搜索算法运行的停止 要 遵 循 一 定 的 停 止 标 准à这 些 标 准 列 写 在 模 式 搜 索 工 具 的
�Tupqqjo dsjufsjbh I停止标准J�窗格中K如图����所示à当下列任何一个条件满足时K模式搜索算法停止MI�J网格尺寸小于�NftiupmfsbodfI网格容限J�àI�J算法执行的迭代次数达到�NbyjufsbujpoI最大迭代J�规定的值àI�J算法完成 的 目 标 函 数 评 估 的 总 次 数 达 到�NbygvodujpofwbmvbujpotI最 大 函 数 评
估J�规定的值àI�J一 次 成 功 选 举 所 找 到 的 点 与 下 一 次 成 功 选 举 所 找 到 的 点 之 间 的 距 离 小 于�
upmfsbodfY
IY的容限J�à�����

图������模式搜索在前��次迭代的点
图������停止标准窗口
I�J从一次成功选举到下一次成功选举的目标函数的改变小于�GvodujpoupmfsbodfI函
数容限J�à�CjoeupmfsbodfI绑定容限J�选项K用来识别有约束问题的现行约束K并不用来作为一
种停止标准à
�����使用直接搜索工具
本节详细介绍直接搜索工具及其使用方法K主要包括M浏览模式搜索工具Ð从命令行
运行直接搜索Ð模式搜索算法举例和参数化函数à
�������浏览模式搜索工具
��打开模式搜索工具
在 NBUMBC工作区输入 tfbsdiuppmq K将打开模式搜索工具K初始界面如图����所
示à模式搜索工具的右 半 部 分 是 选 项 参 数 区K包 含 各 种 选 项 窗 格K单 击 与 之 相 关 的 加 号
�����

���K可以将其展开K方便地进行参数设置à其左半部分是操作显示区K包括各种运行参
数的 设 置 及 各 种 状 态Ð结 果 的 显 示K从 上 到 下 依 次 为MPcfdujwfgvodujpok I目 标 函 数JÐ
Tubsu pjouq I起始点JÐDpotusbjoutÐQmputÐSvotpmwfsI运行求解器JÐTubuvtboesftvmutÐ
Gjobm pjouq K最下面还有一个命令按钮�FypsuupXpsltq bdfq �à
图������模式搜索工具初启时的界面
��在模式工具中定义问题
用模式搜索工具求解问题时K要在下列区域中定义要解决的问题MI�JPcfdujwfgvodujpok ���欲最小化的目标函数à在此输入要计算目标函数的 N 文件
的函数句柄àI�JTubsu pjouq ���模式搜索算法的起始点à在模式搜索工具中定义待求解的问题K亦即设置目标函数和起始点K如图����所示à
图������目标函数Ð起始点和约束条件输入窗口
�����

注意M在运行模式搜索工具时K不要使用�FejupsLEfcvhhfsI编辑L调试J�功能来调试
目标函数的N文件à如果这样做K在命令窗口会产生Kbwb的多余信息K并使得调试更加困
难à因而应该从命令行直接调用目标函数K或者把它传递给 buufsotfbsdiq 函数à为了快速
调试K可以从模式搜索工具把问题输出到 NBUMBC工作空间à对 于 有 约 束 条 件 的 问 题K要 在�Dpotusbjout�窗 格 中 设 置 好 相 应 的 约 束 条 件à在
�Dpotusbjout�窗格中可以输入任何约束条件MI�JMjofbsjofvbmjujftr I线性不等式J���在下列文本框中输入不等式约束条件IBðy
0�cJM
� 在文本框�B��中输入矩阵Bà
� 在文本框�c��中输入矩阵向量càI�JMjofbsfvbmjujftr I线 性 等 式J���在 下 列 文 本 框 中 输 入 等 式 约 束 条 件IBfrðy�
cfrJM
� 在文本框�Bfr��中输入矩阵Bfrà
� 在文本框�cfr��中输入矩阵向量cfràI�JCpvoetI边界J���在下列文本框中输入边界约束条件Imc0�yKy0�vcJM
� 在文本框�Mpxfs��中输入向量的下界mcà
� 在文本框�qqfs�V �中输入向量的上界vcà没有对应约束条件的文本框设置为空à
��运行模式搜索
在�SvotpmwfsI运行求解器J�窗格中单击�Tubsu�按钮K运行模式搜索à这时K�DvssfoujufsbujpoI当 前 迭 代J�区 域 显 示 当 前 迭 代 次 数K�Tubuvtboesftvmut�窗 格 中 显 示 信 息
�QbuufsotfbsdisvoojohI模式搜索运行J�à当模式搜索停止时K�Tubuvtboesftvmut�窗格中显示MI�J信息 �Qbuufsotfbsdisvoojoh�àI�J最终点的目标函数值àI�J模式搜索停止的原因àI�J最终点的坐标à运行模式搜索算法来求解前面叙述的目标函数qt_fybnmfq 时K所显示出来的信息如
图����所示à
图������模式搜索算法显示的状态与结果
��求解有约束条件的问题
这里提供一个模式搜索的例子K是带有约束条件的求函数最小值问题à目标函数为�����

GIyJ� ��yUIy�gUy
式中
I�
�� �� �� �� � ���� �� �� �� � ���� �� �� �� � ���� �� �� �� � ��� � � � � �
m�
n�
q�
r��� �� �� �� � ��
g� P����������������������Q
约束条件为
Bðy0�Bf
crðy�cfR r
其中
B� P����������������Q
c� P�Q
Bfr�
���������������������������������������������������������������
m�
n�
q�
r��cfr� P�������������Q
����运行模式搜索工具来求解这个问题K先输入 tfbsdiuppmq K打开模式搜索工具à然后设
置�Pcfdujwfgvodujpok �为P�mjodpouftu����工具箱中包含一个计算这个目标函数值的 N 文
件mjodpouftu��nà因为用矩阵和向量定义起始点和约束条件太大K所以在 NBUMBC工作
空间中分别把它们设置为变量K然后在模式搜索工具输入这些变量的名称K这样做是非常
方便的à下面输入M
����y��P������QN
Bjofr�P��������QN
cjofr�P�QN
Bfr�P������N������N������N������QN
cfr�P�������QN然后K在模式搜索工具输入下列参数M
I�J设置�Tubsu pjouq �为y�àI�J在�Mjofbsjofvbmjujftr �选项中设置�B��为 BjofrK设置�c��为cjofràI�J在�Mjofbsfvbmjujftr �选项中设置�Bfr��为BfrK设置�cfr��为cfrà在模式搜索工具中设置的这些参数如图����所示à最后K单击�Tubsu�按钮K运行模式搜索à算法结束后K在�Tubuvtboesftvmut�窗口中显
�����

示算法运行的状态与结果K如图����所示à
图������设置有约束问题的目标函数Ð起始点和约束条件
图������求解有约束问题的状态与结果
��暂停和停止算法
当模式搜索正在运行时K可以按下面的方法暂停或停止算法运行M
I�J单击�QbvtfI暂停J�按钮暂停运行K这时按钮的名称更改为�SftvnfI恢复J�K再
单击此按钮K即从暂停处继续运行àI�J单击 �TupqI停止J�按钮停止运行à�Tubuvtboesftvmut�窗口中显示出单击�Tupq�
按钮后当前点的目标函数值à
��图形显示
在�QmputI绘图J�窗格I参见图����J中K能够通过选择来控制显示模式搜索运行结果
的图形à
图�������QmputI绘图J�窗格�����

选择需要显示图形的复选框K例如K可以选择�CftugvodujpowbmvfI最佳函数值J�和
�Nftitj{fI网格尺寸J�à运行前面叙述的目标函数qt_fybnmfq K所显示的图形如图����所示à
图������目标函数qt_fybnmfq 模式搜索结果
在图����中K上面显示每一次迭代的目标函数值K下面显示当前迭代的最佳目标函数
值对应点的坐标à注意M需要显示多项参数的图形时K选择该参数项的复选框K就可以在单独窗口的更
大区域显示相应的图形à
��在模式搜索工具中设置参数
设置模式搜索工 具 使 用 时 的 选 项 参 数 有 两 种 方 法M一 种 是 在 模 式 搜 索 工 具 HVJ的
�Pujpotq I选项J�窗格中直接进行设置K另一种是在 NBUMBC工作空间中通过命令行方
式进行设置à在�Pujpotq �窗格中设置模式搜索的各种运行参数K如图����所示à每一类参数对应
有一个窗格K单击该类参数 时K对 应 窗 格 展 开à例 如K点 击�Qpmm�参 数 选 项K表 决 窗 格 展
开K可以逐一设置其中的参数项K如QpmmnfuipeÐDpnmfufq pmmq ÐQpmmjo psefsh 等à此外K其他选项 参 数 类 还 有MTfbsdiI搜 索JÐNftiÐDbdifI缓 存JÐTupqqjo dsjufsjbh
I停止标准JÐPvuvuq I输 出JÐEjtmbq updpnnboexjoepxz I显 示 到 命 令 窗 口JÐWfdupsj{fI向量化J等à这些选项各自对应一个参数窗格K单击后相应窗格随即展开K可以进行参数
项的设置à所有变量参数的含义及详细描述K可参见�����节�模式搜索参数�à我们可以在 NBUMBC工作空间把参数设置为变量à可以通过在相应的编辑框复制参
数的值K或者通过在包含参数值的 NBUMBC工作空间输入变量的名称K直接设置多个变
量à在 NBUMBC工作空间定义大矩阵或向量值作为变量K是非常方便的à
�����

图������模式搜索选项参数
��输入Ð输出参数和问题
参数和问题结构可以从模式搜索工具输出到 NBUMBC工作空间K并且此后在工具箱
的工作期间可以把它们导入进来à这样K就为模式搜索工具在以后活动期间保存自己所做
的工作提供了一个简单途径à下面描述如何输入Ð输出参数和问题结构à
�J输出参数Ð问题和结果
使用模式搜索工具求解一个问题后K可以输出下列信息到 NBUMBC工作空间MI�J问题定义K包括目标函数Ð起始点和问题的约束条件àI�J当前的选项参数àI�J算法运行的结果à然后K单击�FypsuupXpsltq bdfq I输出到工作空间J�按钮K或者从�GjmfI文件J�菜单
中选择�FypsuupXpsltq bdfq �菜 单 项K打 开�FypsuUpXpsltq bdfq �对 话 框K如 图����所示à
对话框提供下列选项MI�J在 NBUMBC结构中保存目标函数和参数à选择�Fypsuq spcmfnboepq ujpotupb
NBUMBCtusvduvsfobnfeq
I输 出 问 题 与 参 数 到 已 命 名 的 NBUMBC 结 构J�K可 以 在
NBUMBC结构中保存目标函数和参数K这时K需要在右面的文本框中输入一个 NBUMBC结构的名字à如 果 需 要 在 当 前 任 务 活 动 期 间 运 行 模 式 搜 索K可 选 择�Jodmvefjogpsnbujpo
�����

图������输出到工作空间对话框
offefeupsftvnfuijtsvoI包括所需要的信息以重新开始本次运行J�K这样K最近一次搜
索的最终点将保存在�Tubsu pjouq �的位置à如果随后想以最近一次搜索的最终点来运行模
式搜索K可使用这个参数àI�J在 NBUMBC结 构 中 保 存 参 数à选 择�Fypsupq ujpotupbNBUMBCtusvduvsf
obnfeq
�K可以在 NBUMBC结构中保存参数à这时K在这个选项后面的文本框中K输入该
参数结构的名字àI�J在 NBUMBC 结 构 中 保 存 算 法 的 最 后 运 行 结 果à选 择�Fypsusftvmutupb
NBUMBCtusvduvsfobnfeq
�K可在 NBUMBC结构中保存算法的最后运行结果à这时K在
这个选项后面的文本框中K输入这个结果结构的名称à
�J运行模式搜索来输出问题
输出问题的描述可参见前面求解有约束条件的问题的例子à对于这个例子K可在命令
行调用 buufsotfbsdiq 函数K运行模式搜索à其具体步骤为MI�J打开�FypsuUpXpsltq bdfq �对话框àI�J在�FypsuUpXpsltq bdfq �对话框的�Fypsuq spcmfnboepq ujpotupbNBUMBC
tusvduvsfobnfeq
�右面的文本框中K输入问题结构的名字K例如nz_qtspcmfnq àI�J用nz_qtspcmfnq 调用 buufsotfbsdiq 函数M
����PygwbmQ� buufsotfbsdiq Inz_qtspcmfnq J结果为
����y������������������������������������������� �������������������gwbm���������������f�����J输入参数
为了从 NBUMBC工 作 空 间 为 模 式 搜 索 输 入 参 数 结 构K可 以 从�Gjmf�菜 单 中 选 择
�JnpsuPq ujpotq I输入参数J�K打开一个对话框K在 NBUMBC工作空间K显示一系列有效
的模式搜索的参数结构à当选择参数结构K并单击�Jnpsuq �按钮时K模式搜索工具重新设
置它的参数为所输入结构的值à注意M不能在包含任何无效参数区域输入参数结构à无效区域结构在�JnpsuQbuufso
TfbsdiPq
ujpotq I输入模式搜索参数J�对话框中不显示à创建参数结构有两种方法M
�����

I�J用pujpotq 调用 tpq ujntfuq K作为输出àI�J在模式搜索工具中K从�FypsuUpXpsltq bdfq �对话框保存当前参数à
�J输入问题
为了输 入 以 前 从 模 式 搜 索 工 具 输 出 的 问 题K可 以 从�Gjmf�菜 单 中 选 择�JnpsuQspcmfn
q�菜单项K打开一个对话框K在 NBUMBC工作空间K显示一系列有效的模式搜索
问题结构à当选择了一个问题结构并单击�PL�按钮时K模式搜索工具在输入结构内重新
设置问题的定义和参数值à另外K当创建问题结构时K选择�JodmvefjogpsnbujpooffefeupsftvnfuijtsvoI包括所需要的信息以重新开始本次运行J�K则工具箱把最后一次运行的最
终点设置为下一次运行的�Tubsu pjouq �K它比输出结构优先à
��生成一个 N文件
为了生成一个运行模式搜索的 N文件K可以从�Gjmf�菜单中选择�HfofsbufN�GjmfI生
成 N文件J�菜单项来进行K生成的 N文件可保存在 NBUMBC路径的目录中à这个 N 文
件使用在模式搜索工具中指定的目标函数和参数à在命令行调用这个 N文件时K所返回的
结果与生成 N文件时 模 式 搜 索 工 具 在 同 一 位 置 使 用 目 标 函 数 和 参 数 设 置 所 返 回 的 结 果
相同à
�������从命令行运行模式搜索
使用模式搜索工具的另一个途径是在命令行调用 buufsotfbsdiq 函数à本节详细叙述这
种使 用 方 法K内 容 包 括M使 用 缺 省 参 数 值 调 用 buufsotfbsdiq 函 数N在 命 令 行 设 置
buufsotfbsdiq 的参数N从模式搜索工具使用参数和问题à
��使用缺省参数值调用 buufsotfbsdiq 函数
这里描述如何使用缺省参数来运行模式搜索à
�J无约束条件问题的模式搜索
对于无约束条件问题K用下面语句调用 buufsotfbsdiq 函数M
����PygwbmQ� buufsotfbsdiq IP�pcfdugvok Ky�J其中K输出变量为M
�y���最终点à
�gwbm���目标函数在y点的值à需要输入的变量为M
� P�pcfdugvok ���目标函数pcfdugvok 的句柄K可以写成一个 N 文件à参见�����节
�编写待优化函数的 N文件�à
�y����模式搜索算法的起始点à对于前面描述的例子K即目标函数为qt_fybnmfq K在这里K要从命令行运行模式搜索K
可输入
����PygwbmQ� buufsotfbsdiq IP�qt_fybnmfq KP������QJ运行结果为
����Pujnj{bujpoufsnjobufeq M
����Dvssfounftitj{f������f����jtmfttuibo�UpmNfti������y�
�����

����������������� �����������gwbm�����������������J有约束条件问题的模式搜索
如果问题带有约束条件K则应使用语句
����PygwbmQ� buufsotfbsdiq IP�pcgvok Ky�KBKcKBfrKcfrKmcKvcJ其中M
� B和c分别为代表不等式约束条件的矩阵和向量IBðy0�cJà
� Bfr和cfr分别为代表等式约束条件的矩阵和向量IBfrðy�cfrJà
�mc和vc代表向量的边界Imc0�yKy0�vcJà在这里K只需要输入问题的约束条件部分à例如K如果没有边界约束条件K则使用下
面的语句M
����PygwbmQ� buufsotfbsdiq IP�pcgvok Ky�KBKcKBfrKcfrJ对于没有约束条件的输入参数值K使用空的中括号�PQ�à例如K如果没有不等式约束
条件K就使用下面的语句M
����PygwbmQ� buufsotfbsdiq IP�pcgvok Ky�KPQKPQKBfrKcfrKmcKvcJ
�J增加输出参数
要得到更多 关 于 模 式 搜 索 运 行 的 性 能 信 息K可 以 使 用 下 面 语 句 调 用 buufsotfbsdiq函数M
����Pygwbmfyjugmb pvuh vuq Q� buufsotfbsdiq IP�pcgvok Ky�J除了y和gwbm外K还返回下面的输出参数M
�fyjugmbhM整数K表示算法是否成功à
�pvuvuq M结构K包含关于求解器的性能的信息à
��在命令行设置模式搜索参数
通过将pujpotq 结构作为模式搜索函数 buufsotfbsdiq 的输入参数结构K可以设置模式
搜索工具中任何有效的参数值à使用的语句为
����PygwbmQ� buufsotfbsdiq IP�gjuofttgvoKowbstKBKcKBfrKcfrKmcKvcKpujpotq J如果问题是无约束条件的K在约束条件输入时必须使用空括号K例如M
����PygwbmQ� buufsotfbsdiq IP�gjuofttgvoKowbstKPQKPQKPQKPQKPQKPQKpujpotq J还可以使用 tpq ujntfuq 函数生成pujpotq 结构à例如K使用语句
����pujpot�q tpq ujntfuq返回一个带缺省值的pujpotq 参数结构à
����pujpot�q��������������UpmNftiM����������������f����
UpmYM ������f����UpmGvoM ������f����UpmCjoeM ������f����NbyJufsbujpoM ����H�ovncfspgwbsjbcmft�NbyGvoFwbmtM �����H�ovncfspgwbsjbcmft�
�����

NftiDpousbdujpoM ������NftiFybotjpoq M
NftiBddfmfsbups�
M �pgg�NftiSpubufM �po�JojujbmNftiTj{fM
TdbmfNfti�
M �po�NbyNftiTj{fM JogQpmmNfuipeM �ptjujwfcbtjt�o�Dpn
qmfufQpmmq M �pgg�
QpmmjoPsefsh M �dpotfdvujwf�TfbsdiNfuipeM PQ
DpnmfufTfbsdiq M �pgg�Ejtmbq zM �gjobm�PvuvuGdotq M PQ
QmpuGdotM PQ
QmpuJoufswbmM
Dbdif�
M �pgg�DbdifTj{fM �����DbdifUpmM ������f����Wfdupsj{feM �pgg�
如果没有输入pujpotq K则函数 buufsotfbsdiq 使用缺省值à每一个 参 数 值 保 存 在pujpotq 结 构 成 员 中K如pujpot�NftiFyq botjpoq K即 通 过 在
pujpotq 后面输入成员的名 字K可 以 显 示 任 何 参 数 值à例 如K要 显 示 模 式 搜 索 网 格 扩 展 因
子K可输入
����pujpot�NftiFyq botjpoq����bot����������如果要生成与缺省值不同的pujpotq 结构K可以使用函数 tpq ujntfuq 来完成à例如K为
了改变网格扩展因子的值为�I来代替其缺省值�JK可输入
����pujpot�q tpq ujntfuq I�NftiFybotjpo�q K�J这时生成的pujpotq 结构除了 NftiFybotjpoq 值为�外K其他参数值都为缺省值à
如果现在调用输入参数为pujpotq 的 buufsotfbsdiq K则模式搜索使用的网格扩展因子
为�à如果再 决 定 改 变 pujpotq 结 构 的 另 一 个 成 员 的 值K例 如K要 设 置 QmpuGdot为
P�qtmpunftitj{fq K它是在每一次迭代中画出网格尺寸的绘图函数K可以使用下面的语句来
调用 tpq ujntfuq 函数M
����pujpot�q tpq ujntfuq Ipujpotq K�QmpuGdot�KP�qtmpunftitj{fq J结果保存pujpotq 结构的所有成员的当前值K而QmpuGdot则被改变为P� mpunftitj{fq à
注意M如果省略pujpotq 作为输入参数K则 tpq ujntfuq 重新设置 NftiFybotjpoq 为它
�����

的缺省值���à也可以用一个命令同时设置 NftiFybotjpoq 和QmpuGdot值M
����pujpot�q tpq ujntfuq I�NftiFybotjpo�q K�K�QmpuGdot�KP� mpunftitj{fq J
��从模式搜索工具使用参数和问题
使用 tpq ujntfuq 来生 成 一 个 参 数 结 构K可 以 在 模 式 搜 索 工 具 设 置 参 数 的 值K并 在
NBUMBC工作空间输出这些参数值à其详细描述可参见前面的�输入Ð输出参数和问题�部分的内容à如果在模式搜索工具中输出缺省参数K则pujpotq 结构的参数设置与由下面
命令得到的参数设置相同M
����pujpot�q tpq ujntfuq但是K�Ejtmbq z�的缺省值被改变了M当由 tpq ujntfuq 函数生成时�Ejtmbq z�为�gjobm�N而在模
式搜索工具生成时�Ejtmbq z�为�opof�à也可以从模式搜索工具输出整个问题K并且可以从命令行运行它à
�������模式搜索举例
本节通过实例说明如何运用模式搜索算法来求解问题K如何设置模式搜索的参数等à
��表决方法
在每一次迭代时K模式搜索在当前网格中画出这些点K也就是说K它计算目标函数在
这些网格点的值K看哪些点的函数值比当前点的函数值小à在前面介绍的内容中K已经多
次涉及模式搜索的工作过程K也列举了选举过程的例子à在模式搜索中K所定义的网格可
以通过�QpmmnfuipeI选举方法J�参数来指定K下面叙述其基本原理à缺省的模式�QptjujwfCbtjtI正基数J�O�由�O个向量组成K这里的O是目标函数中独
立变量的个数à这�O个向量是M
����P�����QP�����Q
�����P�����QP������QP������Q
�����P���� ��Q
例如K目标函数有三个独立变量K则模式由以下�个向量组成M
����P���QP���QP���QP����QP����QP����Q
另外K如果设置�Qpmmnfuipe�为�QptjujwfCbtjtOQ��K则模式由下列O ��个向量
组成M�����

����P�����Q
����P�����Q
���������
����P�����Q
����P������� ��Q例如K如果目标函数有�个独立变量K则模式由下列�个向量组成M
����P���Q
����P���Q
����P���Q
����P������Q模式搜索有时使用�QptjujwfCbtjtOQ��作为选举方法运行K速度较快K因为算法在每
一迭代中搜索的点较少à例如M运行模式搜索来求解前面描述的有约束问题时K算法使用
缺省选举方法�QptjujwfCbtjt�O�将执行����次函数估计K但使用正基数 OQ�将只执行
����次函数估计à然而K如果目标函数有许多局部最小值K使用�QptjujwfCbtjt�O�作为检测方法有可能
避免找到的是局部最小值即非全局最小值K因为这个搜索的每一迭代在当前点周围搜索了
更多的点à
��完全表决
按照缺省设置K模式搜索找到一个改进目标函数值的网格点时K算法就停止检测K并
设置这个点作为下一次迭代的当前点à当这种情况发生时K许多网格点并没有得到检测K这 些 没 有 被 检 测 的 点 中 的 一 些 点 可 能 具 有 比 模 式 搜 索 最 先 找 到 的 那 个 点 更 小 的 目 标 函
数值à对于一些有局部最小值的问题K有时执行的是使模式搜索在每一次迭代中检测所有网
格点K挑选一个具有最佳目标函数值的点K这就使得模式搜索在每一次迭代中需要搜索更
多的点K以避免潜在的局部最小值而非全局最小值的问题à要使模式搜索检测整个网格K则需在�Qpmm�参数中设置�Dpnmfufq pmmq �为Poà
下面举例说明在模式搜索中如何使用完全表决à本例使用的目标函数如下M
gIy�Ky�J�
y���y����� y���y�� 0���y���Iy���J���� y���Iy���J� 0������
� 其他
����图����显示了这个函数的图形à函数的全局最小值在I�K�J处K其值是���à然而K函数在I�K�J处有一局部最小值���à
建立一个 N文件来计算这个函数K复制和粘贴下列代码到 NBUMBC编辑器中的新
N文件中M
����gvodujpo{� pmmq _fybnmfq IyJ
jgyI�J����yI�J���_��������{�yI�J����yI�J������N
fmtfjgyI�J���� IyI�J��J���_��������{�yI�J���� IyI�J��J������N�����

图������目标函数图形
fmtf����{��N
foe保存该 N文件在 NBUMBC指定的一目录中K文件名为 pmmq _fybnmf�nq à为了对函数运行模式搜索K在模式搜索工具中输入以下内容MI�J设置�Pcfdujwfgvodujpok �为 P� pmmq _fybnmfq àI�J设置�Tubsu pjouq �为P�K�QàI�J在�Ejtmbq updpnnboexjoepxz I显示到命令窗口J�参数中设置�Mfwfmpgejtmbq z
I显示级别J�为Jufsbujwfà使用�Dpnmfufq pmmq �的缺省值PggK单击�Tubsu�按钮K运行模式搜索K模式搜索工具在
�Tubuvtboesftvmut�窗口显示状态与结果信息K如图����所示à
图������完全表决为Pgg时函数 pmmq _fybnmfq 的状态与结果
从运行结果可以看出K模式搜索返回了在点I�K�J处的局部最小值à在起始点处K目标函数值是�K在第一次迭代中K算法检测如下网格点M
����gII�K�J�I�K�JJ�gI�K�J������gII�K�J�I�K�JJ�gI�K�J���
�����

����一旦算法检测网格点I�K�JK这点的目标函数值比起始点的值要小K就会立即停止当
前网格的检测K并设置下一代的当前网格点为I�K�Jà在第一次迭代时K这个搜索朝局部
最小点I�K�J移动à在命令行显示的头两行可看到如下内容M
����Jufs������g dpvou����NftiTj{f������gIyJ������Nfuipe
����� ��� ��� � Tubsujufsbujpot
����� ��� ��� �� TvddfttgvmQpmm
注意M模式搜索在第一次迭代中只执行了两次目标函数计算K增加总的函数计数从�到�à
设置�Dpnmfufq pmmq �为PoK并单击�Tubsu�按钮K在�Tubuvtboesftvmut�窗口显示的结
果如图����所示à
图������完全表决为Po时函数 pmmq _fybnmfq 的状态与结果
这时K模式搜索 找 到 全 局 最 小 值 在I�K�J处à这 一 次 和 前 一 次 不 同 的 是�Dpnmfufqpmmq �设置为PoK模式搜索在第一次迭代中检测了所有�个网格点à
����gII�K�J� I�K�JJ�gI�K�J��
����gII�K�J� I�K�JJ�gI�K�J���
����gII�K�J� I��K�JJ�gI��K�J��
����gII�K�J� I�K��JJ�gI�K�J���
由于最后一个网格点具有 最 小 目 标 函 数 值K模 式 搜 索 选 择 它 作 为 下 一 次 迭 代 的 当 前
点à在命令行显示的头两行可看到如下内容M
����Jufs����g dpvou���� NftiTj{f����gIyJ����Nfuipe
����� ��� ��� � Tubsujufsbujpot
����� ��� ��� �� TvddfttgvmQpmm
在这种情况下K目标函数在第一次迭代中被计算了�次à结果K模式搜索朝全局最小
点I�K�J移动à图����是使用�Dpnmfufq pmmq �参数选项分别为Po和Pgg时返回的点序列的比较à
�����

图������完全表决为Po和Pgg时返回的点序列比较
��使用搜索方法
对网格点的检测K模式搜索算法可在每一次迭代执行一可选步骤K称为tfbsdià在每
一次迭代的搜索步中K对当前点使用了另外一些优化方法à如果这个搜索步没有改进当前
点K则检测步将执行à下面举例说明对前面描述的有约束问题如何使用搜索方法à为了建立这个例子K首先
定义起始点和约束条件à在 NBUMBC提示符下键入以下命令M
����y��P������QN
����Bjofr�P��������QN
����cjofr�P�QN
����Bfr�P������N������N������N������QN
����cfr�P�������QN然后K在模式搜索工具中K定义问题I输入目标函数和起始点JK输入约束条件K选择
有关参数选项K如图����所示à
图������设置模式搜索工具有关选项
�����
为了比较K单击�Tubsu�按钮K在这里先不使用搜索方法来运行这个例子K所显示的图
形如图����所示à
图������未使用搜索方法的运行结果
下面再看一下使用了搜索 方 法 的 效 果à在�Tfbsdi�参 数 的�Tfbsdinfuipe�字 段 选 择
�QptjujwfCbtjtOQ��K这就对使用�QptjujwfCbtjtOQ��模式的模式搜索设置了要使用搜索
方法K随后单击�Tubsu�按钮来运行算法K显示的图形如图����所示à
图������已使用搜索方法的运行结果
�����
注意M使用搜索方法将减少总的函数计数I目标函数被估算的次数J接近���K上例将
迭代次数从���次减少到���次左右à
��网格的扩展与收缩
网格的扩展与收缩 参 数 用 于 控 制 网 格 的 大 小 在 每 一 次 迭 代 中 是 如 何 扩 展 或 收 缩 的à�Fybotjpogbdupsq I扩展因子J�的缺省值是���K即模式搜索在每次成功的检测后K网格的
大小扩展�倍à�DpousbdujpogbdupsI收缩因子J�的缺省值是���K即模式搜索在每次检测失
败后K网格的大小收缩为原来的一半à在模式搜索期间通过选择�QmputI绘图J�窗格中的�Nftitj{f�K就可以看到网格尺寸
的扩展与收缩的图形显示K如图����所示à
图������绘图窗口
为了在命令行显示网格尺寸与目标函数值K在�Ejtmbq updpnnboexjoepxz �参数中设
置�Mfwfmpgejtmbq zI显示级别J�为JufsbujwfK如图����所示à
图������设置显示级别为Jufsbujwf
当运行前面描 述 的 求 解 有 约 束 问 题 的 例 子 时K模 式 搜 索 工 具 显 示 的 结 果 如 图����所示à
图������有约束问题求解的网格尺寸
�����
为了使看到的网格尺寸变化更加清晰K可改变算法中Z轴的刻度K方法如下MI�J在绘图窗格的�FejuI编辑J�菜单中选择�ByftQspfsujftq I轴属性J�àI�J在属性编辑器中K选择�Z�选项àI�J设置�TdbmfI刻度J�为对数Mphà图����显示了�Qspfsujftq I属性J�编辑器中的设置à
图������属性编辑器的选择或设置
当单击�PL�按钮时K出现的图形显示如图����所示à
图������有约束问题求解的网格尺寸I对数刻度J
前��次迭代的结果是成功的检测K所以网格的大小在此过程中不断增加à通过查看在
命令行显示的迭代输出信息K可知第一个不成功的检测发生在第��次迭代à
����Jufs������g�dpvou������NftiTj{f������gIyJ����Nfuipe������ �� �����f���� ���� TvddfttgvmQpmm������ �� �����f���� ���� TvddfttgvmQpmm������ �� �����f���� ���� SfgjofNfti
�����

注意M由于在第��次迭代中检测是成功的K因而在下一次迭代中网格大小又扩大一
倍K但在��次迭代中K检测不成功K因此网格大小缩小一半à为了查看网格如何扩展和扩展后对模式搜索的影响K可做如下改变MI�J设置�Fybotjpogbdupsq �为���àI�J设置�Dpousbdujpogbdups�为����à在�NftiI网格J�窗格中K改变后的网格扩展因子和收缩因子如图����所示à单击�Tubsu�按 钮K�Tubuvtboesftvmut�窗 格 显 示 的 最 终 点 与 使 用 缺 省 的�Fybotjpo
gbdupsq
�和�Dpousbdujpogbdups�设 置 近 似 相 同K但 模 式 搜 索 要 花 费 更 长 时 间 才 能 达 到 这 个
点K如图����所示à
图������改变网格扩展因子和收缩因子 图������改变网格扩展和收缩因子后的结果
����算法终止是因为它超过了最大的迭代次数K这个值是在�Tupqqjo dsjufsjbh I停止准则J�选项的�NbyjufsbujpoI最大迭代J�字段中设置的à这个参数的缺省值是目标函数独立变量
个数的���倍K例子中变量数是�à对算法改变Z轴的刻度K网格尺寸变化显示如图����所示à
图������对数刻度的网格尺寸变化
注意M�Fybotjpogbdupsq �设置为���K相对于缺省值���来说K网格尺寸增加更快N而
�Dpousbdujpogbdups�设置为����K相对于缺省值���来说K网格尺寸收缩更慢à
�����

��网格加速器
网格加速器通过减少达到要求的网格容差所需的迭代次数K能使模式搜索更快地收敛
到最佳点à当网格尺寸小于一定的值时K模式搜索使用一个小于�Nftidpousbdujpo�的因子
收缩网格尺寸à注意M强烈推荐只有对于当目标函数在最优点附近不太急剧变化或可能损失精度这类
问题才使用网格加速器à对于那些可微的问题K也就是说K在解的附近其导数的绝对值不
太大时才使用之à为了使用网格加速器K需在�Nfti�选项中设置�BddfmfsbupsI加速器J�为poà当运行前面
描述的求解有约束问题的例子时K达到网格容差要求的迭代次数是���K而�Bddfmfsbups�设置
为pgg时K这个数为���à迭代次数达到���次以后K比较网格的大小可看到网格加速器的
作用K如图����所示à
图������网格加速器的效果
在这两种情况下K网格的大小直到���次迭代都是相同的K不同是发生在���次迭代à将�Bddfmfsbups�设置为pggK迭代次数为���和���时KNBUMBC命令窗口显示下列信息M
����Jufs����g�dpvou����NftiTj{f������gIyJ����Nfuipe������� ���� �����f���� ���� SfgjofNfti������� ���� �����f���� ���� SfgjofNfti注意M这里网格尺寸是乘以���K即乘以缺省的�Dpousbdujpogbdups�à
�����

将�Bddfmfsbups�设置为poK迭代次数为���和���时KNBUMBC命令窗口显示下列信息M
����Jufs g�dpvou NftiTj{f gIyJ Nfuipe
������� ���� �����f���� ���� SfgjofNfti
������� ���� �����f���� ���� SfgjofNfti注意M在此情形下K网格尺寸是乘以����K即乘以比缺省的�Dpousbdujpogbdups�更小
的收缩因子K从而使网格尺寸收缩得更快K起到一个加速的作用à
��使用缓存
典型情况下K模式搜索的任何给定迭代中的一些网格点可能与前面迭代中的点相符à对于缺省情况K尽管这些点已经计算过并且知道不是最优点K但模式搜索仍要重新计算这
些网格点的目标函数值à如果计算目标函数值花费较长时间K譬如几分钟K这将使得模式
搜索算法运行时间明显加长à通过使用缓存可以消除这些冗余的计算K也就是说K需要把模式搜索已经检测过的历
史点存储起来à为此K需要在�DbdifI缓存J�参数中设置�Dbdif�为poà在每次检测时K模
式搜索查看当前网格点是否在缓存中某一点的规定�UpmfsbodfI容差J�范围内K如果是K则搜
索算法不再计算该点的目标函数值K而是使用在缓存中存储的函数值K并且移到下一点à注意M当设置�Dbdif�为po时K模式搜索可能不能鉴别改进目标函数的当前网格中的
某一点K因为它可能是在缓存的某一点的规定容差范围之内à为了得到结果K模式搜索在
设置�Dbdif�为po时可能比设置�Dbdif�为pgg时运行更多的迭代次数à通常情况下K保持
�Upmfsbodf�为一个非常小的值总能获得较好的效果K尤其是对于那些高度非线性的目标函
数而言更是如此à为了说明 这 种 情 况K在�Qmput�窗 格 中 选 择�CftugvodujpowbmvfI最 佳 函 数 值J�和
�GvodujpodpvouI函数计数J�K并运行前面描述的求解有约束条件问题的例子K设置�Dbdif�为pggà在模式搜索完成时K所显示的图形如图����所示à这时K总的函数计数是����à
图������设置缓存为pgg时模式搜索的结果
�����

现在设置�Dbdif�为poK再次运行该例子K图形显示如图����所示à
图������模式搜索工具显示结果
这时总的函数计数是����à可见K有效地减少了目标函数的计算次数à
��设置求解器容差
在搜索终止之前或以某种方法改变之前K�Upmfsbodf�是一个非常小的参数K譬如一个
网格尺寸à可以这样指定容差值MI�J�NftiupmfsbodfI网格容差J����当前网格尺寸小于这个值时K算法终止àI�J�YupmfsbodfIY容差J����在一次成功的检测后K从前一个最佳点到当前最佳点
的距离小于这个值K则算法终止àI�J�GvodujpoupmfsbodfI函数容差J����指明目标函数的最小容差à若目标函数在当
前点的容差值小于�Gvodujpoupmfsbodf�K则算法停止K缺省值是�f��àI�J�CjoeupmfsbodfI绑定容差J����适用于约束问题K在一个线性约束被认定为激活
以前K它指明如何接近一个点才一定能达到有效区域的边界à当线性约束有效时K模式搜
索检测点的方向是平行于线性约束边界的那些网格点à通常设置�绑 定 容 差ICjoeupmfsbodfJ�至 少 为�Nftiupmfsbodf�Ð�Yupmfsbodf�和
�Gvodujpoupmfsbodf�三者的最大者à下面举例说明如何设置绑定容差à本例说明�Cjoeupmfsbodf�是 如 何 影 响 模 式 搜 索 的K这 个 例 子 是 查 找 下 列 函 数 的 最
小值M
gIy�Ky�J� y���y� ��
约束条件如下M
���y����y� 0�����y����y� 0�R ��
�����

����注意M可使用函数opsn计算目标函数值K这个问题的可行区域是图����中两条直线
之间的区域à
图������问题解的可行区域
�J使用缺省的绑定容差运行模式搜索
为了运行这个例子K键入 tfbsdiuppmq K打开模式搜索工具K并输入以下信息MI�J设置�Pcfdujwfgvodujpok �为 P�IyJopsnIyJàI�J设置�Tubsu pjouq �为 P����������QàI�J在�Qmput�窗格中选择�Nftitj{f�àI�J在�Ejtmbq updpnnboexjoepxz �参数中设置�Mfwfmpgejtmbq z�为Jufsbujwfà然后K单击�Tubsu�按钮K运行模式搜索à在 NBUMBC命令窗口中显示出来的前�次迭代检测是不成功的K这是由于网格点不
在可行区域内à
����Jufs����g�dpvou����NftiTj{f����gIyJ����Nfuipe
����� � � ����� Tubsujufsbujpot
����� � ��� ����� SfgjofNfti
����� � ���� ����� SfgjofNfti
����� � ����� ����� SfgjofNfti
����� � ������ ����� SfgjofNfti
模式搜索在每一次迭代中收缩网格尺寸K直到有一点在可行区域之内为止à图����显
示出在靠近边界上的初始点和第�次迭代的网格点à最顶上的点是I������K�������JK它的目标函数值比起始点的目标函数值小K所以
检测成功à因为从起始点到低界线的距离小于缺省的�Cjoeupmfsbodf�值������K模式搜索
将不考虑线性约束��y����y�0���是否满足K所以不在这个边界线平行线方向搜索点à
�����

图������在靠近边界的初始点和第�次迭代的网格点
�J增大绑定容差的值
为了考察绑定容差的作用K改变�Cjoeupmfsbodf�为����K再次运行模式搜索à
这次K在 NBUMBC命令窗口中显示前两次迭代检测是成功的à
����Jufs g�dpvou NftiTj{f gIyJ Nfuipe
����� � � ����� Tubsujufsbujpot
����� � � ������ TvddfttgvmQpmm
����� � � ������ TvddfttgvmQpmm因为从起始点到边界的距离小于�Cjoeupmfsbodf�K第二个线性约束是有效的à在此情
况下K模式搜索工具检测边界线��y����y�0���平行方向的点K结果是成功的à图����显示出起始点在边界平行线上有两个搜索点à
图������起始点在边界平行线上的两个搜索点�����

图����显示出对两种绑定容差的设置K模式搜索的前��次迭代点序列的比较情况à
图������两种绑定容差设置下前��次迭代点序列比较
注意M当�Cjoeupmfsbodf�是����时K搜索点向最优点的移动较快K这时模式搜索只需
要��次迭代à而�Cjoeupmfsbodf�是������时K搜索要进行���次迭代à然而K当可行区
域没有包含一非常精确的角度K就像前面的例子中K提高�Cjoeupmfsbodf�将导致增加迭代
次数K这是因为模式搜索将要检测更多的点à
�������参数化函数
有时K需要编写一个被 buufsotfbsdiq 或者hb函数调用的函数K这个函数除了独立变
量外K还有其他参数à例如K假设对于不同的变量bÐcÐdK需要求下面方程的最小值M
gIyJ� Ib�cy���y�L�� Jy���y�y��I�d�dy��Jy��因为 buufsotfbsdiq 和 hb函 数 只 接 受 依 赖y 的 目 标 函 数Ð适 应 度 函 数K所 以 在 调 用
buufsotfbsdiq 或者hb函数之前K必须将bÐcÐd提供给函数à为此K下面给出两种方法MI�J利用匿名函数参数化函数àI�J利用嵌套函数参数化函数à这里的例子将展示如何参数化一个目标函数K利用同样的方法K任何被 buufsotfbsdiq
或者hb调用的用户函数K例如K为 buufsotfbsdiq 定义的定制搜索方法或者为hb定义的定
制尺度函数K都可以被参数化à
��利用匿名函数参数化函数
要参数化一个函数K首先编写一个 N文件M
����gvodujpoz� bsbnfufsgvoq IyKbKcKdJ
����z�Ib�cH�yI�J����yI�J���L�JH�yI�J����yI�JH�yI�J�I�d�dH�yI�J���JH�yI�J���N
在 NBUMBC路径的一个目录中保存这个 N文件为ngvo�nz à
�����

现在K对于参数值b��Kc����Kd��K求函数的最小值à在 NBUMBC工作空间输入下列命令K给匿名函数定义一个句柄M
����b��Nc����Nd��N
����pcgvo�k P�IyJbsbnfufsgvoq IyKbKcKdJN
����y��P������QN如果想使用模式搜索工具K则应设置�Pcfdujwfgvodujpok �为pcgvok K设置�Tubsu pjouq �
为y�K如图����所示à
图������设置目标函数为匿名函数
然后K单击�Tubsu�按钮K运行最优化K�Tubuvtboesftvmut�窗格中显示最后结果K如图
����所示à
图������利用匿名函数参数化函数的结果
如果接着决定改变bÐcÐd的值K就必须重新建立一个匿名函数à例如M
����b����Nc����Nd��N
����pcgvo�k P�IyJbsbnfufsgvoq IyKbKcKdJN
��利用嵌套函数参数化函数
参数化目标函数为匿名函数的另一个方法是M编写一个 N文件K使得
I�J接受输入的bÐcÐd和y�àI�J将目标函数作为一个嵌套函数àI�J调用 buufsotfbsdiq à下面是该 N文件的代码M
����gvodujpoPygwbmQ�svoqtIbKcKdKy�J
����PyKgwbmQ� buufsotfbsdiq IP�oftufegvoKy�JN
��������gvodujpo �oftufegvoz IyJ�����

������������z�Ib�cH�yI�J����yI�J���L�JH�yI�J����yI�JH�yI�J�I�d�dH�yI�J���JH�yI�J���N
��������foe����foe注意M目标函数在嵌套函数oftufegvo内运算K它可访问变量bÐcÐdà为了运行最优化K可键入
����PygwbmQ�svoqtIbKcKdKy�J返回结果为M
�� �� Pujnj{bujpoufsnjobufeq Mdvssfou nfti tj{f������f����jtmfttuibo�UpmNfti��
����y��������������������������gwbm����������������
�����模式搜索参数和函数
本节详细说明�类模式搜索工具的参数选项和�个模式搜索函数à
�������模式搜索参数
首先描述模式搜索参数à设置模式搜索参数有两种方法K一种是使用模式搜索工具K另一种是在命令行调用模式搜索函数à
I�J如果使用模式搜索工具 tfbsdiuppmq K则设置参数可从下拉列表中选择一参数或在
一参数文本域中键入该参数的值àI�J如果从命令行调用模式搜索函数 buufsotfbsdiq K则首先要通过使用函数 tpq ujntfuq
来创建参数结构K进行参数设置K如下所示M
����pujpot�q tpq ujntfuq I�bsbn��q Kwbmvf�K�bsbn��q Kwbmvf�K���JN在这里K每一个选项参数均用两种方法给出MI�J按其在模式搜索工具中的标签给出àI�J按其在选项参数结构中的字段名给出à例如MI�JQpmmnfuipe���模式搜索工具中的参数标签àI�JQpmmNfuipe���在参数结构中对应的字段名à参数选项分为以下�类MI�J绘图参数àI�J表决参数àI�J搜索参数àI�J网格参数àI�J缓存参数à
�����

I�J停止条件àI�J输出函数参数àI�J显示到命令窗口参数àI�J向量参数à
��绘图参数
当模式搜索运行时K绘图参数可使来自模式搜索的数据画出图形à当选择绘图函数并
运行模式搜索时K图形窗口在分开的轴上显示图形à在任意时间点可单击�Qmput�窗格中的
�Tupq�按钮停止算法运行à在绘图窗格中可以选择以下任意各项图形参数MI�J�QmpujoufswbmI绘图间隔J�IQmpuJoufswbmJ���指明相邻两次调用图形函数之间的
迭代次数àI�J�CftugvodujpowbmvfI最佳函数值J�IP�qtmpucftugq J���画出最佳目标函数值àI�J�GvodujpodpvouI函数计数J�IP�qtmpugvodpvouq J���画出估算函数计数àI�J�Nftitj{fI网格尺寸J�IP�qtmpunftitj{fq J���画出网格尺寸àI�J�Cftu pjouq I最佳点J�IP�qtmpucftuyq J���画出当前最佳点àI�J�DvtupnI自定义J����可以使用自己的绘图函数à在模式搜索工具中指定绘图函
数的方法是M
� 选择�DvtupngvodujpoI自定义函数J�à
� 在文本框中键入P�ngvoz K这里ngvoz 是绘图函数名à绘图函数的结构在下面进行
了详细的描述à要在命令行调用 buufsotfbsdiq 时显示图形K需设置参数选项pujpotq 的QmpuGdot字段
为一个绘图函数的函数句柄à例如K要显示最佳函数值K设置参数如下M
����pujpot�q tpq ujntfuq I�QmpuGdot�KP�qtmpucftugq JN要显示多个图形K语法如下M
����pujpot�q tpq ujntfuq I�QmpuGdot�KRP� mpugvo�q KP� mpugvo�q K���SJN这里P� mpugvo�q KP� mpugvo�q 等是命令行下绘图函数的名字à
下面介绍绘图函数的结构à绘图函数的第一行有如下形式M
����gvodujpotupq� mpugvoq Ipujnwbmvftq KgmbhJ这个函数的输入变量是MI�Jpujnwbmvftq ���包含解的当前状态有关信息的结构K这个结构包含以下字段M
�y���当前点à
�jufsbujpo���迭代次数à
�gwbm���目标函数值à
� nftitj{f���当前网格尺寸à
�gvoddpvou���估算函数计数à
� nfuipe���最后一次迭代的方法à
� UpmGvo���最后一次迭代的函数值的容差à
� UpmY���最后一次迭代的Y值的容差àI�Jgmbh���图形函数被调用的当前状态K这个标志值可能是M
�����

�Joju���初始状态à
�Jufs���迭代状态à
� Epof���最终状态à这个函数的输出变量tupqK提供一种在当前迭代停止算法的方法Ktupq可有以下值M
�Gbmtf���算法继续下一次迭代à
� Usvf���在当前迭代算法停止à
��表决参数
表决参数用来控制模式搜索在每次迭代时怎样检测网格点à�Qpmmnfuipe�IQpmmNfuipeJ���指定算法用于创建网格的模式à有以下两个模式MI�J缺省模式�Qptjujwfcbtjt�O�K由以下�O个向量组成KO是目标函数独立的变量
个数M
����P�����QP�����Q
�����P�����QP������QP������Q
�����P���� ��Q
例如K目标函数有�个独立变量K则模式由以下�个向量组成M
����P���QP���QP���QP����QP����QP����Q
I�J�QptjujwfcbtjtOQ��模式K由以下O��个向量组成M
����P�����QP�����Q
�����P�����QP������� ��Q
例如K如果目标函数具有�个独立变量K则模式由下列�个向量组成M
����P���QP���QP���QP������Q
�Dpnmfufq pmmq �IDpnmfufQpmmq J���指 明 每 次 迭 代 时K当 前 网 格 中 所 有 点 均 要 进 行
pmmq à�Dpnmfufq pmmq �具有Po或Pgg值à�����

I�J如果设置�Dpnmfufq pmmq �为PoK则算法将在每次迭代对当前网格中所有点进行检
测K挑选具有最小目标函数值的点作为下一次迭代的当前点àI�J如果设置�Dpnmfufq pmmq �为PggI这是缺省值JK当算法一旦找到一个目标函数值
比当前点小的点就停止检测à算法随后设置这个点为下一次迭代的当前点à�Qpmmjo psefsh I表决顺序J�IQpmmjoPsefsh J���指明 算 法 在 当 前 网 格 中 搜 索 的 点 的 顺
序à这个参数是MI�JSboepnI随机的J���随机检测顺序àI�JTvddfttI成功的J���在每次迭代中K第一个搜索方向是上一次迭代中找到最佳点
的方向K第一个点后K算法检测网格点采用与�DpotfdvujwfI连贯J�相同的顺序àI�JDpotfdvujwf���算法检测网格点的顺序是�DpotfdvujwfpsefsI连贯顺序J�K也就
是在�Qpmmnfuipe�描述的模式向量顺序à
��搜索参数
搜索参数详细说明在每一次迭代检测之前算法能够执行的可选搜索项à如果搜索返回
一个对目标函数有改进的点K则算法将这个点用于下一次迭代并省略检测à�Dpnmfuftfbsdiq I完 全 搜 索J�IDpnmfufTfbsdiq J���只 应 用 于 设 置�Tfbsdinfuipe�
选项为QptjujwfcbtjtOq�ÐQptjujwfcbtjt�O 或MbujoizqfsdvcfI拉 丁 超 立 方J的 情 形à�Dpnmfuftfbsdiq �取值为Po或Pggà
对QptjujwfcbtjtOq�或Qptjujwfcbtjt�OKDpnmfuftfbsdiq 与表决参数中的Dpnmfufqpmmq 有相同的意义à�Tfbsdinfuipe�ITfbsdiNfuipeJ���指定搜索的方法K其选项有MI�JOpofIPQJ���指明不搜索I缺省JàI�JQptjujwfcbtjtOq�I�QptjujwfCbtjtO��q J���指 明 模 式 搜 索 使 用 QptjujwfCbtjt
Oq�作为�Qpmmnfuipe�àI�JQptjujwfcbtjt�OI�QptjujwfCbtjt�O�J���指明模式搜索使用QptjujwfCbtjt�O作
为�Qpmmnfuipe�àI�JHfofujdBmpsjuinh I遗传算法JIP�tfbsdihbJ���指明搜索使用遗传算法K如果选
择遗传算法K将有两个参数出现M
�JufsbujpomjnjuI迭 代 限J���正 整 数K指 明 遗 传 算 法 作 为 模 式 搜 索 执 行 时 迭 代 的
次数à
� Pujpotq I参数J���遗传算法的参数结构K可用 bph ujntfuq 设置à要在命令行改变�JufsbujpomjnjuI迭代限J�和�Pujpotq �的缺省值K使用以下语法M
����pujpot�q tpq ujntfuq I�TfbsdiNfuipe�KRP�tfbsdihbKjufsmjnKpujpotHBq SJ这里jufsmjn是�Jufsbujpomjnju�的值K而pujpotHBq 是遗传算法的参数结构à
MbujoizqfsdvcfIP�tfbsdimitJ���指明这种搜索的执行依赖于设置�Dpnmfuftfbsdiq �为Po或Pggà
如果设置�Dpnmfuftfbsdiq �为PoK则算法将在每次迭代对由拉丁超立方搜索随机生
成的所有点进行检测K选择一个具有最小目标函数值的点à如果设置�Dpnmfuftfbsdiq �为PggK则算法一旦有随机生成的比当前点函数值小的点K
算法将立即停止检测K并将这个点传给下一次迭代à�����

如果选择MbujoizqfsdvcfK则有两个参数显示MI�JJufsbujpomjnju���正 整 数K指 明 拉 丁 超 立 方 搜 索 作 为 模 式 搜 索 执 行 时 迭 代 的
次数àI�JEftjomfwfmh I设计级别J���正整数K指明 设 计 级 别K搜 索 点 的 数 量 等 于�Eftjh
mfwfmo
�乘以目标函数独立变量的个数à在命令行要改变�Jufsbujpomjnju�和�Eftjomfwfmh �的缺省值K可以使用以下语法M
����pujpot�q tpq ujntfuq I�TfbsdiNfuipe�KRP�tfbsdimitKjufsmjnKmfwfmSJ这里jufsmjn是�Jufsbujpomjnju�的值Kmfwfm是�Eftjomfwfmh �的值à
Ofmefs�NfbeIP�tfbsdiofmefsnfbeJ���指明搜索使用gnjotfbsdiK它是Ofmefs�Nfbe算法K如果选择Ofmefs�NfbeK将有两个参数显示M
I�JJufsbujpomjnju���正整数K指明Ofmefs�Nfbe算法作为模式搜索执行时所迭代的
次数àI�JPujpotq ���gnjotfbsdi函数的参数结构K可用函数pujntfuq 创建à要在命令行改变�Jufsbujpomjnju�和�Pujpotq �的缺省值K可以使用以下语法M
����pujpot�q tpq ujntfuq I�TfbsdiNfuipe�KRP�tfbsdihbKjufsmjnKpujpotONq SJ这里jufsmjn是�Jufsbujpomjnju�值KpujpotONq 是参数结构à
Dvtupn���允许用户编写自己的搜索函数à使用模式搜索工具时K需要MI�J设置�TfbsdigvodujpoI搜索函数J�为dvtupnàI�J设置�Gvodujpoobnf�为P�ngvoz K这里ngvoz 是函数名à如果在命令行使用模式搜索函数 buufsotfbsdiq K则可以用下列语句进行设置M
����pujpot�q tpq ujntfuq I�TfbsdiNfuipe�KP�ngvoz JN如果要编写自己的搜索函数K可键入编辑命令M
����fejutfbsdigdoufnmbufq调出参考模板K利用参考模板来编写自己的搜索函数à
下面描述搜索函数的结构à搜索函数必须具有以下调用语法M
����gvodujpoPtvddfttTfbsdiKofyuJufsbufKGvoFwbmQ���������tfbsdigdoufnmbufq IgvoKy�KjufsbufKupmKBKMKVK�����������gvofwbmKnbygvoKtfbsdipujpotq Kpcgdobsk hJ搜索函数具有以下输入变量MI�Jgvo���目标函数名àI�Jy����起始点àI�Jjufsbuf���迭代时的当前点Kjufsbuf是一个结构K包含当前点及函数值àI�Jupm���容差K决定约束条件是否为活动的àI�JBKMKV���定义可行区域à假设线性或边界条件为M0�BH�y0�VàI�JGvofwbm���函数估算次数计数器Kgvofwbm总是小于最大函数估算次数 NbygvoàI�JNbygvo���函数估算次数的最大值àI�JTfbsdipujpotq ���设置搜索参数的结构K这个结构包含以下字段M
�Dpnmfuftfbsdiq ���如果值为�Pgg�K一旦找到一个较好的点K算法将终止K也就是
不需要强迫减少充分条件à其缺省值为�Po�K参见 tpq ujntfuq 对dpnmfuftfbsdiq 的描述à�����

� Nftitj{f���搜索步中所用的当前网格的大小à
�Jufsbujpo���当前迭代次数à
�Tdbmf���刻度因子K用于计量设计点à
�Joejofdtusr ���不等式条件表示à
�Joefdtusr ���等式条件表示à
�Qspcmfnuzqf���传递给 搜 索 程 序 的 标 志K表 示 问 题 是�vodpotusbjofe�I无 约 束JÐ
�cpvoedpotusbjout�I边界约束J或�mjofbsdpotusbjout�I线性约束Jà
� Opuwfdupsj{fe���一个标志K表示函数gvo没有作为向量估算à
�Dbdif���使用缓存的标志K如果是 �Pgg�K则没有使用缓存à
�Dbdifupm���用于缓存的容差K以确定两点是否相同à
�Dbdifmjnju���缓存大小的上限àI�JPcgvobsk h���目标函数的附加变量的单元数组à搜索函数具有下列输出变量MI�JTvddftttfbsdi���一个布尔标识K表示搜索是否成功àI�JOfyujufsbuf���检 测 之 后 完 成 了 成 功 的 迭 代K如 果 检 测 不 成 功K则 下 一 迭 代
ofyujufsbuf与当前迭代jufsbujpo相同à注意M如果设置�Tfbsdinfuipe�为Hfofujdbmpsjuinh 或Ofmefs�NfbeK那么推荐设置
�Jufsbujpomjnju�为缺省值�K因执行搜索超过�次不大可能改进结果à
��网格参数
网格参数控制模式搜索使用的网格à以下参数是可利用的M
I�JJojujbmtj{fI初始尺寸JIJojujbmNftiTj{fJ���指明初始的网格尺寸K即从起始点到
网格点的具有最短长度的向量àJojujbmtj{f是一正标量K缺省值是���àI�JNbytj{fI最大值JINbyNftiTj{fJ���指明网格的最大值K当达到最大值后K在
一次成功的迭代后K网格不再增大à网格最大值是一正标量K缺省值是jogàI�JBddfmfsbupsI加速器JINftiBddfmfsbupsJ���指明�DpousbdujpogbdupsI收缩因子J�
在每次成功的迭代后是否乘以���à�Bddfmfsbups�有两个值MPo和PggK缺省值是PggàI�JSpubufI旋转JINftiSpubufJ���指 明 当 网 格 向 量 小 于 某 一 小 值 时 是 否 乘 以��à
�SpubufI旋转J�只能用于�Qpmmnfuipe�设置为QptjujwfcbtjtOq�且�Spubuf�为缺省值为
Po时的情形à注意M改变�Spubuf�的设置不影响�Qpmmnfuipe�设置为Qptjujwfcbtjt�O时的检测àI�JTdbmfITdbmfNftiJ���指明算法是否使用模式向量乘以常数来对网格点进行比例
变换àTdbmf值可设置为Po或PggK缺省值为PoàI�JFybotjpogbdupsq I扩展因子JINftiFybotjpoq J���指 明 网 格 尺 寸 在 一 次 成 功 的
检测后增大 的 因 子K缺 省 值 是���K即 在 一 次 成 功 检 测 后K使 网 格 的 大 小 乘 以���à�Fybotjpogbdupsq �必须是一正标量à
I�JDpousbdujpogbdupsINftiDpousbdujpoJ���指明网格尺寸 在 一 次 不 成 功 的 检 测 后
减小的因子K缺省值是���K即在一次不成功检测后K使网格的大小乘以���à�Dpousbdujpogbdups�必须是一正标量à
�����

��缓存参数
模式搜索算法能保持已被检测过的点的一个记录K以使对同一个点的函数计算不会超
过一次à如果目标函数要求一个相对较长时间的计算K则缓存参数就能提高算法运行的速
度à为记录这些点所分配的内存区域K称为缓存à这个参数只能用于确定性函数K不能用
于随机函数à
DbdifIDbdifJ���指明是否使用缓存K它的值为Po或PggK缺省值是Pggà如果设置
�Dbdif�为PoK则算法对网格中那些在缓存中的容差范围内的点不再评估目标函数à
UpmfsbodfIDbdifUpmJ���指明网格点相对于那些已在缓存中而算法省略对其进行检
测的点来说有多近à�Upmfsbodf�必须是一正的标量K缺省值是fqtà
Tj{fIDbdifTj{fJ���指明缓存的大小K它是一正的标量K缺省值是�f�à
��停止条件
停止条件决定什么情形导致模式搜索算法停止à模式搜索使用以下准则M
NftiupmfsbodfI网格容差JIUpmNftiJ���规定网格尺寸的最小容 限K如 果 网 格 的 大
小小于�Nftiupmfsbodf�K则算法停止à它的缺省值是�f��à
NbyjufsbujpoI最大迭代次数JINbyJufsbujpoJ���指明算法执行的最大迭代次数à如
果迭代次数达到�Nbyjufsbujpo�K则算法停止à它有下列选择MI�J���H�ovncfspgwbsjbcmft���最大迭代次数是目标函数独立变量数的���倍K这是
缺省值àI�JTfdjgq zI指定数J���指定一个正整数作为最大迭代次数à
NbygvodujpofwbmvbujpotI最大函数估算JINbyGvoFwbmJ���指明目标函数的最大估
算次数K如果估算次数达到�Nbygvodujpofwbmvbujpot�K则算法停止à它可以有下列选择MI�J����H�ovncfspgwbsjbcmft���最大函数估算次数是独立变量数的����倍àI�JTfdjgq z���指定一个正整数作为最大函数估算次数à
CjoeupmfsbodfIUpmCjoeJ���指明从当前点到可行区域边界距离的最小容差K绑定容
差规定何时线性约束是活动的K它不是停止条件K其缺省值是�f��à
YupmfsbodfIUpmYJ���指明相邻两次迭代的当前点之间的最小距离K如果相邻两点之
间的距离小于�Yupmfsbodf�K则算法停止K其缺省值是�f��à
GvodujpoupmfsbodfIUpmGvoJ���指明目标函数的最小容差K如果目标函数在当前点的
容差值小于�Gvodujpoupmfsbodf�K则算法停止K其缺省值是�f��à
��输出函数参数
输出函数是模式搜索算法在每次迭代时调用的函数K可以使用下列参数MI�J记录到新窗口IIjtups upofxxjoepxz JIP� tpvuq vuijtupsq zJ���每间隔Joufswbm
的整数倍迭代次数时K在 NBUMBC命令行窗口中显示算法所计算的历史点àI�JDvtupn���允许用户编写自己的输出函数à使用模式搜索工具指定输出函数M
� 选择�Dvtupngvodujpo�à
� 在文本框中键入P�ngvoz K这里ngvoz 是自定义的函数名à如果在命令行使用模式搜索函数 buufsotfbsdiq K可以使用以下语句来设定输出函数M
����pujpot�q tpq ujntfuq I�PvuvuGdo�q KP�ngvoz JN�����

如果要编写自己的输出函数K可键入编辑器命令M
����fejutfbsdigdoufnmbufq调出参考模板K利用参考模板编写自己的输出函数à
下面叙述输出函数的详细结构à输出函数必须有如下的调用语法M
����PtupqKpujpotq Kpudiboq feh Q� tpvuq vuijtupsq zIpujnwbmvftq Kpujpotq KgmbhKjoufswbmJ输出函数有以下输入参数MI�Jpujnwbmvftq ���包含关于解的当前状态信息的结构K这个结构包含以下字段M
�y���当前点à
�jufsbujpo���迭代次数à
�gwbm���目标函数值à
� nftitj{f���当前网格尺寸à
�gvoddpvou���函数估算次数à
� nfuipe���上一次迭代使用的方法à
� UpmGvo���上一次迭代函数值的容差à
� UpmY���上一次迭代Y值的容差àI�Jpujpotq ���参数结构àI�Jgmbh���输出函数被调用时当前的状态K其值如下M
�joju���初始状态à
�jufs���迭代状态à
�epof���最终状态à
�joufswbm���任选的间隔变量à输出函数返回以下变量MI�Jtupq���提供停止算法当前迭代的一种方法Ktupq有以下值M
�gbmtf���算法继续下一次迭代à
�usvf���算法在当前迭代终止àI�Jpujpotq ���参数结构àI�Jpudiboq feh ���指示参数结构pujpotq 是否改变的标志à
��显示到命令窗口参数
Mfwfmpgejtmbq zI显示级别JI�Ejtmbq z�J���指明模式搜索运行时有多少信息显示到命
令行K可用参数是MI�JPggI�pgg�J���只显示最后的答案àI�JJufsbujwfI�jufs�J���显示每次迭代的信息àI�JEjboptfh I�ejboptf�h J���显示每次迭代的信息à此外K还列出参数结构pujpotq
中其缺省值已经被改变了的参数项àI�JGjobmI�gjobm�J���模式搜索的结果I成功或不成功JÐ停止的原因Ð最终点à
Jufsbujwf和Ejboptfh 两者都显示以下信息MI�JJufs���迭代次数àI�JGvoFwbm���累计的函数估算次数àI�JNftiTj{f���当前网格尺寸à
�����

I�JGvoWbm���当前点的目标函数值àI�JNfuipe���当前检测的结果à
Mfwfmpgejtmbq z的缺省值如下MI�J在模式搜索工具中是PggàI�J使用 tpq ujntfuq 创建的参数结构中是�gjobm�à
��向量参数
向量参数指明计算的目标函数是否是向量化的à当设置�Pcfdujwfgvodujpojtwfdupsj{fek I目 标 函 数 向 量 化J�为 PggI�Wfdupsj{f�为
�pgg�J时K算法是在循环中计算网格点的目标函数值K每次通过迭代使用确定的一点调用
目标函数à另一方面K当设置�Pcfdujwfgvodujpojtwfdupsj{fek �为PoI�Wfdupsj{f�为�po�J时K模
式搜索算法一次调用目标函数计算所有网格点的目标函数值K这比在循环中调用计算它们
更快些à无论怎样使用这个参数K目标函数都必须能接受任意行数的矩阵作为输入à
�������模式搜索函数
本节系统介绍模式搜索工具的四个函数的功能Ð格式和详细说明K这四个函数分别为
buufsotfbsdiq Ðtfbsdiuppmq Ðtpq ujnq fuh 和 tpq ujntfuq à
��函数 buufsotfbsdiq功能M使用模式搜索算法来搜索函数的最小值à格式M
����y� buufsotfbsdiq IP�gvoKy�J
y� buufsotfbsdiq IP�gvoKy�KBKcJ
y� buufsotfbsdiq IP�gvoKy�KBKcKBfrKcfrJ
y� buufsotfbsdiq IP�gvoKy�KBKcKBfrKcfrKmcKvcJ
y� buufsotfbsdiq IP�gvoKy�KBKcKBfrKcfrKmcKvcKpujpotq J
y� buufsotfbsdiq Ispcmfnq JPyKgwbmQ� buufsotfbsdiq IP�gvoKy�K���JPyKgwbmKfyjugmbhQ� buufsotfbsdiq IP�gvoKy�K���JPyKgwbmKfyjugmbhKpvuvuq Q� buufsotfbsdiq IP�gvoKy�K���J
详细说明M函数 buufsotfbsdiq 使用模式搜索算法来搜索目标函数的最小值à
y� buufsotfbsdiq IP�gvoKy�JM用 来 解 决 那 些 形 如njoygIyJ的 无 约 束 问 题à在 这 里K
gvo是一个 NBUMBC函数K它计算目标函数gIyJ的值ày�是模式搜索算法的起始点à函
数 buufsotfbsdiq 可以接受形如P�gvo的函数句柄作为目标函数K对目标函数返回一局部最
小点yà函数gvo接受向量输入K返回一标量函数值à
y� buufsotfbsdiq IP�gvoKy�KBKcJM查找函数gvo的局部最小值点yK服从线性不等
式约束K约束的矩阵表示形式为M
Bðy0�c如果问题有n个线性不等式和o个变量K则B是一个 nH�o的矩阵Kc是一长度为 n的
向量à�����

y� buufsotfbsdiq IP�gvoKy�KBKcKBfrKcfrJM查找函数gvo的局部最小值点yK服
从以下约束M
Bðy0�Bf
crðy�cfR r
这里Bf y�cfr r表示矩阵形式的线性等式约束K如 果 问 题 有s个 线 性 等 式 约 束Ko个 变
量K则Bfr是一s�o的矩阵Kcfr是一长度为s的向量à如果没有不等式条件K则B和c是空矩阵à
y� buufsotfbsdiq IP�gvoKy�KBKcKBfrKcfrKmcKvcJM对下列约束查找函数gvo的
局部最小值点yM
Bðy0�Bf
crðy�cf
mcr
0�y0���
� vc这里mc和vc分别表示变量的下边界和上边界à如果问题有o个变量K则mcÐvc是一长度
为o的向量à如果mc或vc为空I即没有提供JK它将自动分别扩展为�Jog或Jogà如果没
有不等式或等式约束K则BKcKBfrKcfr将为空矩阵à
y� buufsotfbsdiq IP�gvoKy�KBKcKBfrKcfrKmcKvcKpujpotq JM查找函数gvo的局部
最小值点yK使用参数结构pujpotq 中的值代替缺省的优化参数K可以使用函数 tpq ujntfuq 来
创建pujpotq KBKcKBfrKcfrKmcKvcKpujpotq 为空矩阵时就使用缺省值à
y� buufsotfbsdiq Ispcmfnq JM对问题 spcmfnq 查找最小值Kspcmfnq 是一个结构K它具
有以下字段MI�Jpcfdujwfk ���目标函数àI�Jy����开始点àI�JBjofr���不等式约束矩阵àI�JCjofr���不等式约束向量àI�JBfr���等式约束矩阵àI�JCfr���等式约束向量àI�JMC���y的下界àI�JVC���y的上界àI�Jpujpotq ���由函数 tpq ujntfuq 创建的参数结构àI��JSboetubuf���可选参数K重新设置sboe的状态àI��JSboeotubuf���可选参数K重新设置sboeo的状态à通过从模式搜索工具输出一个 spcmfnq K可以创建一结构 spcmfnq à可参见������浏
览模式搜索工具�一节的�输入Ð输出参数与问题�的相关描述à注意M问题结构 spcmfnq 必须有上面指明的所有字段àPyKgwbmQ� buufsotfbsdiq IP�gvoKy�K���JM返回目标函数在解y处的值gwbmàPyKgwbmKfyjugmbhQ� buufsotfbsdiq IP�gvoKy�K���JM返回fyjugmbhK用来描述退出函
数 buufsotfbsdiq 的条件K如果MI�Jfyjugmbh`��Kbuufsotfbsdiq 收敛到一个解yàI�Jfyjugmb ��h Kbuufsotfbsdiq 达到最大的函数估算或迭代次数à
�����

I�Jfyjugmbh_��Kbuufsotfbsdiq 没有收敛到一个解àPyKgwbmKfyjugmbhKpvuvuq Q� buufsotfbsdiq IP�gvoKy�K���JM返回一个包含有关搜索
信息的结构输出pvuvuq à这个结构包含以下字段MI�Jgvodujpo���目标函数àI�Jspcmfnuzqq f���问题的类型M无约束Ð边界约束或线性约束àI�Jpmmnfuipeq ���表决方法àI�Jtfbsdinfuipe���使用的搜索方法K可为任意àI�Jjufsbujpo���总的迭代次数àI�Jgvoddpvou���函数估算的总次数àI�Jnftitj{f���在y处网格的大小àI�Jnfttbhf���算法停止的原因à注意M函数 buufsotfbsdiq 并不接受能输入复数类型数据的函数K为了解决复数解数据
的问题K可编写一个能接受实数向量的函数K分开实数与虚数部分à举例M给定下面的约束
� ��� �m�
n�
q�
r�� �
y�yP Q�0�m�
n�
q�
r�
���
条件如下M
�0�y��0�yP Q
�
这个问题的目标函数就是工具箱中提供的函数mjodpouftu�à为了查找最小值K相应的
代码及运行结果如下M
����B�P��N���N��QN
c�P�N�N�QN
mc�{fsptI�K�JNPyKgwbmKfyjugmbhQ� buufsotfbsdiq IP�mjodpouftu�K���P��QKBKcKPQKPQKmcJ
Pujnj{bujpoufsnjobufeq M
OfyuNftitj{fI������f ���Jmfttuibo�UpmNfti��
y�������������������gwbm������������fyjugmbh������
参见Mtfbsdiuppmq Ktpq ujnq fuh Ktpq ujntfuq à
��函数 tfbsdiuppmq功能M打开模式搜索工具à格式M
�����

���� tfbsdiuppmq详细说明Mtfbsdiuppmq 打 开 模 式 搜 索 工 具K为 模 式 搜 索 提 供 图 形 用 户 界 面I参 见 图
����Jà可以使用模式搜索工具在优化问题上运行模式搜索算法并显示结果à参见Mbuufsotfbsdiq Ktpq ujnq fuh Ktpq ujntfuq à
��函数 tpq ujnq fuh功能M得到模式搜索参数结构的值à格式M
����wbm� tpq ujnq fuh Ipujpotq K�obnf�J详细说明Mwbm� tpq ujnq fuh Ipujpotq K�obnf�JM从模式搜索参数结构pujpotq 中返回参
数obnf的值à如果obnf的值在pujpotq 中没有指定K则函数 tpq ujnq fuh Ipujpotq K�obnf�J返回一空
矩阵�PQ�K只需要使用参数名中能惟一区分它的足够的前导字符即可à函数 tpq ujnq fuh 忽
略参数名中的大小写à参见Mtpq ujntfuq Kbuufsotfbsdiq à
��函数 tpq ujntfuq功能M创建一模式搜索参数结构à格式M
����pujpot�q tpq ujntfuqtpq ujntfuqpujpot�q tpq ujntfuq I�bsbn��q Kwbmvf�K�bsbn��q Kwbmvf�K���J
pujpot�q tpq ujntfuq Ipmeputq K�bsbn��q Kwbmvf�K���J
pujpot�q tpq ujntfuq Ipmeputq Kofxputq J详细说明M
pujpot�q tpq ujntfuq I无输入参数JM创建一个参数结构pujpotq K它包含模式搜索所需
的参数K并设置参数为它们的缺省值àtpq ujntfuq 用没有输入或输出参数形式显示具有有
效值的参数的完整列表à
pujpot�q tpq ujntfuq I�bsbn��q Kwbmvf�K�bsbn��q Kwbmvf�K���JM创 建 一 参 数 结 构
pujpotq K并设置�bsbn��q 为wbmvf�K�bsbn��q 为wbmvf�等等à任何没有指明的参数均被设
置为它的缺省值à只需要使用参数名中能惟一区分它的足够的前导字符即可K忽略参数名
中的大小写à
pujpot�q tpq ujntfuq Ipmeputq K�bsbn��q Kwbmvf�K���JM创建pmeputq 的拷贝K修改指
定参数�bsbn��q 的值为指定值wbmvf�à
pujpot�q tpq ujntfuq Ipmeputq Kofxputq JM用新的参数结构ofxputq 组合已存在的参数
结构pmeputq K在ofxputq 中任意非空的参数覆盖pmeputq 中对应的参数à参数M表���中列出了可以使用 tpq ujntfuq 设置的参数à对模式搜索参数和值的详细
描述I参见�����节�模式搜索参数�JàRS中的值是缺省值K也可在命令行键入 tpq ujntfuq 来
查看优化参数和缺省参数à
�����

表�����用函数 tpq ujntfuq 设置的参数
参����数 说����明 值
Dbdif
��使Dbdif为�po�K检测时 buufsotfbsdiq 保持一历史
网格点K在子迭代时对已 在 其 中 的 点 不 再 检 测à由 于
花费长时间计算目标函数会使 buufsotfbsdiq 变慢K因
此使用这个参数
�po�b�R�pgg�S
DbdifTj{f ��缓存空间的大小 正标量b�R�f�S
DbdifUpm��一个正 的 标 量K说 明 当 前 点 接 近 历 史 点 达 何 种 程
度K才对它不进行检测正标量b�R�f���S
DpnmfufQpmmq ��在当前迭代K完全检测 �po�b�R�pgg�S
DpnmfufTfbsdiq ��在当前迭代K完全检测 �po�b�R�pgg�S
Ejtmbq z ��显示级别�pgg�b��jufs�b��opujgz�b��ejboptf�h b�R�gjobm�S
JojujbmNftiTj{f ��模式搜索的初始网格的大小 正标量b�R���S
NbyGvoFwbmt ��目标函数估算的最大次数 正整数b�R����H�变量数S
NbyJufsbujpo ��最大迭代次数 正整数b�R���H�变量数S
NbyNftiTj{f ��网格尺寸的最大值 正标量b�RJogS
NftiBddfmfsbups ��是否加速收到一最小值附近 �po�b�R�pgg�S
NftiDpousbdujpo ��网格收缩因子K当迭代不成功时使用 正标量b�R���S
NftiFybotjpoq ��网格扩展因子K当迭代成功时使用 正标量b�R���S
PvuvuGdoq ��指明在每次迭代时优化函数调用的自定义函数 P� tpvuq vuijtupsq zb�RopofS
QmpuGdo ��指明从模式搜索输出的绘图函数
P�qtmpucftugq b�
P�qtmpunftitj{fq b�
P�qtmpugvodpvouq b�RPQS
QmpuJoufswbm ��指明相邻两次调用绘图函数相隔的迭代次数 正整数
QpmmjoPsefsh ��模式搜索的检测方向的顺序�Sboepn�b��Tvddftt�b�R�Dpotfdvujwf�S
QpmmNfuipe ��模式搜索使用的检测策略R�QptjujwfCbtjt�O�S
b��QptjujwfCbtjtOq��
TdbmfNfti ��自动的变量尺度变换 R�po�Sb��pgg�
�����

续表
参����数 说����明 值
TfbsdiNfuipe ��模式搜索中使用的搜索方法的类型
�QptjujwfCbtjtO��q
b��QptjujwfCbtjt�O�b�
P�tfbsdihbb�P�tfbsdimitb�
P�tfbsdiofmefsnfbeb�RPQS
UpmCjoe ��绑定容差 正标量b�R�f��S
UpmDpo ��约束容差 正标量b�R�f��S
UpmGvo ��函数容差 正标量b�R�f��S
UpmNfti ��网格尺寸容差 正标量b�R�f��S
UpmY ��变量容差 正标量b�R�f��S
Wfdupsj{fe ��指定函数是否要向量化 �po�b�R�pgg�S
����参见Mbuufsotfbsdiq Ktpq ujnq fuh à
�����

参 考 文 献
���Hpmecfs EF�HfofujdBmh psjuintjoTfbsdih KPujnj{bujpoboeNbdijofMfbsojoq hBeejtpoXftmf
�Qvcmjtijoz Dpnh boq zK����
���LbssDM�EftjopgboBebh ujwfGv{{q Mpz jdDpouspmmfsVtjoh bHfofujdBmh psjuin�QspdJDHB�
hK��������Y���
���IpmtujfoS C�BsujgjdjbmHfofujdBebubujpojoDpnq vufsDpouspmTq tufntz KQiEUiftjtKEfbsu�pgDpnq vufsboeDpnnvojdbujpoTdjfodftq KVojwfstju pgNjdijz boh K
BooBscpsK�������DbsvbobSBKTdibggfsKE�SfsftfoubujpoboeIjeefoCjbtq MHsb wt�Cjobsz Dpejoz hQspd��uiJouDpogNbdijofMfbsojo
�hK��������Y���
���TdinjufoepsXFKTibxPKCfotpoSKfubm�Vtjo HfofujdBmh psjuintgpsDpouspmmfsEftj
hhoMTjnvmubofpvtTubcjmj{bujpoboeFjfowbmvfQmbdfnfoujobSfh jpo�Ufdiojdbm
Sfh
qpsuOp�DT�� �KEfupgDpnq vufsTdjfodfq KDpmmffpgFoh joffsjoh hKVojwfstjupgOfxNfyjdp
zK����
���CsbnmfuufNG�Jojujbmj{bujpoKNvubujpoboeTfmfdujpoNfuipetjoHfofujdBmpsjuintgpsGvodujpoP
hujnj{bujpo�QspdJDHB�q K��������Y���
���MvdbtjvtDCKLbufnboH�UpxbsetTpmwjo TvctfuTfmfdujpoQspcmfntxjuiuifBjepguifHfofujdBm
hpsjuin�JoQbsbmmfmQspcmfnTpmwjoh gspnObuvsf�h KNboofsSboe
NboefsjdlCIFetJKBntufsebnMOpsui�IpmmboeK��������Y������XsjiuBI�HfofujdBmh psjuintgpsSfbmQbsbnfufsPh ujnj{bujpo�JoGpvoebujpotpgHfofujdBm
qpsjuinth KSbxmjotKFIFeJKNpsboLbvgnbooh K��������Y���
� Njdibmfxjd{[�HfofujdBmpsjuint� EbubTusvduvsft� FwpmvujpoQsph sbnt�Th sjoq fsWfsmb
hhK����
����CbdlUKIpggnfjtufsGKTdixfgfmIQ�Tvswf pgFwpmvujpoTusbufz jft�QspdJDHB�h K
������Y������HsfgfotufuufKK�Jodpspsbujoq QspcmfnTh fdjgjdLopxmfeq fjoupHfofujdBmh psjuint�JoHfofujdBm
hpsjuintboeTjnvmbufeBoofbmjoh hKEbwjtMIFeJKNpsboLbvgnbooh K
�������Y������XijumfzEKNbuijbtLKGju{ipsoQ�EfmubDpejohMBoJufsbujwfTfbsdiTusbufhzgpsHfofujdBmpsjuint�QspdJDHB�h K�������Y��
����EfKpo�Bobmh tjtpguifCfibwjpvspgbDmbttpgHfofujdBebz ujwfTq tufnt�QiEUiftjtz K
Efbsu�pgDpnq vufsboeDpnnvojdbujpoTdjfodftq KVojwfstju pg Njdijz boh KBooBscpsK����
����CblfsKF�BebujwfTfmfdujpoNfuipetgpsHfofujdBmq psjuint�QspdJDHB�h K��������Y���
����CblfsKF�Sfevdjo CjbtBoeJofggjdjfodh jouifTfmfdujpoBmz psjuin�QspdJDHB�h K
�������Y�������

����CpplfsM�Jnspwjoq TfbsdijoHfofujdBmh psjuint�JoHfofujdBmh psjuintboeTjnvmbufeBoofbmjo
hhKEbwjtMIFeJKNpsboLbvgnbooQvcmjtifsth K�������Y��
�� TfbstX Nq KEfKpo �BoBobmh tjtpgNvmuj�QpjouDspttpwfs�JoGpvoebujpotpgHfofujdBm
zpsjuinth KSbxmjotKFIFeJK��������Y���
�� TtxfsebH�VojgpsnDspttpwfsjoHfofujdBmz psjuint�QspdJDHB�h K������Y�� T
�fbstX Nq KEfKpo LB�PouifWjsuvftpgQbsbnfufsjtfeVojgpsnDspttpwfs�Qspd
JDHB�h
K��������Y����� DbsvbobS BKFtifmnboMBKTdibggfsKE�SfsftfoubujpoboeIjeefoCjbtJJq M
Fmjnjobujo Efgjojoh Mfoh uiCjbtjoHfofujdTfbsdiWjbTivggmfDspttpwfs�JoFmfwfouiJoufsobujpobmKpjouDpogfsfodfpoBsujgjdjbmJoufmmj
hfodfh KTsjeibsboOTIFeJKNpsbo
LbvgnbooQvcmjtifsth
K��������Y����� N 가�imfocfjo IKTdimjfslbn�Wpptfo�Qsfejdujwf Npefmtgpsuif Csffefs HfofujdBm
qpsjuin�Fwpmvujpobsh Dpnz vubujpoq K����K�I�JM��Y��
�� GvsvbIz KIbgulbSU�HfofujdBmpsjuintgpsQmbdjoh BduvbupstpoTh bdfTusvduvsft�QspdJDHB�
qK��������Y���
�� KbojlpxD[KNjdibmfxjd{[�BoFyfsjnfoubmDpnq bsjtpopgCjobsq boeGmpbujozQpjouSf
hsftfoubujpotjoHfofujdBmq psjuint�QspdJDHB�h K�������Y��
�� UbufE NKTnjuiBF�FyfdufeBmmfmfDpowfsq fodfboeuifSpmfpgNvubujpojoHfofujdBm
hpsjuint�QspdJDHB�h K�������Y��
�� EbwjtM�Bebujoq hPfsbupsQspcbcjmjujftjoHfofujdBmq psjuint�QspdJDHB�h K�������Y��
�� Gpbsuh UD�Wbsz joz uifQspcbcjmjuh pgNvubujpojouifHfofujdBmz psjuin�QspdJDHB�
hK��������Y���
�� EfKpo L Bh KTbsnbK�Hfofsbujpo HbtSfwjtjufe�JoGpvoebujpotpgHfofujdBm
qpsjuint�h KXijumf MEz IFeJKNpsboLbvgnbooQvcmjtifsth K����
�� Xijumf E�Uif Hfojups Bmz psjuin boe Tfmfdujpo Qsfttvsfh M Xi Sbol�cbtfeBmmpdbujpotpgSf
zspevdujwfUsjbmtjtCftu�QspdJDHB�q K��������Y���
�� IvbohSKGpbsuh UD�Bebz ujwfDmbttjgjdbujpoboeDpouspm�SvmfPq ujnj{bujpoWjbbMfbsojo
qBmh psjuingpsDpouspmmjoh bEh obnjdTz tufn�Qspd��uiDpog�Efdjtjpoboe
Dpouspmz
KCsjiupoh KFomboeh K��������Y����� Gpbsuh UD�BoJodsfnfoubmHfofujdBmz psjuingpsSfbm�UjnfMfbsojoh �Qspd�uiJou�Xpsltip
hpoNbdijofMfbsojoq hK��������Y���
�� Hpmecfs EFh KSjdibsetpoK�HfofujdBmpsjuintxjuiTibsjoh gpsNvmujnpebmGvodujpohPujnj{bujpo�QspdJDHB�q K�������Y��
�� N 가�imfocfjoIKTdipnjtdiNKCpsoK�UifQbsbmmfmHfofujdBmpsjuinbtbGvodujpohPujnj{fs�QbsbmmfmDpnq vujoq hK����I��JM���Y���
�� TubslxfbuifsUKXijumfzEKNbuijbtL�Pujnj{bujpo Vtjoq EjtusjcvufeHfofujdBm
hpsjuint�QspdQbsbmmfmQspcmfnTpmwjoh Gspn Obuvsf�h KMfduvsfOpuftjoDpnvufs
Tdjfodfq
KTsjoq fs�Wfsmbh hK����I���JM���Y��������

�� Hfpsft�TdimfvufsN�Dpnh bsjtpopgMpdbmNbujoq Tusbufh jftjo Nbttjwfmh QbsbmmfmHfofujdBm
zpsjuint�JoQbsbmmfmQspcmfn Tpmwjoh gspn Obuvsf�h KNb�oofsSboe
NboefsjdlCIFetJKBntufsebnMOpsui�IpmmboeK��������Y����� 陈国良K王熙法等�遗传算法及其应用�北京M北京人民邮电出版社K������ 李书全�遗传算法性能分析及其应用研究MP学位论文Q�天津M天津大学K������ 阳军�遗传算法用于优化计算的问题研究MP学位论文Q�天津M天津大学K������ 周明K孙树栋�遗传算法原理及应用�北京M国防工业出版社K������ 飞思科技产品研发中心编著�NBUMBC���辅助优化计算与设计�北京M电子工业出
版社K������ 王小平K曹立明�遗传算法���理论Ð应用与软件实现�西安M西安交通大学出版社K
������ 王丽薇�遗传算法的研究与应用MP学位论文Q�哈尔滨M哈尔滨工业大学K������ 方海鹏�遗传算法的理论研究及其应用MP学位论文Q�大连M大连理工大学K������ 郝翔�遗传算法 及 其 在 规 则 优 化 中 的 应 用 研 究MP学 位 论 文Q�西 安M西 安 交 通 大 学K
������ 刘勇K康立山�非数值并行计算I第二册J���遗传算法�北京M北京科学出版社K������ 张铃K张钹�统计遗传算法�软件学报K����K�I�JM���Y����� 余建坤K张文彬等�遗传算法及其应用�云南民族学院学报K����K��I�JM���Y����� 贾兆红K倪 志 伟�改 进 型 遗 传 算 法 及 其 在 数 据 挖 掘 中 的 应 用�计 算 机 应 用K����K
��I�JM��Y���� 周克民K胡云昌�遗传算法计算效率的改进�控制理论与应用K����K��I�JM���Y����� 扬俊安K陈怡K钟子发�标准遗传算法的改进及其在信息战领域应用展望�中国人民解
放军电子工程学院学报K����K��I�JM��Y���� Vtfs�tHvjefMHfofujdBmpsjuinboeEjsfduTfbsdiUppmcpygpsVtfxjuiNBUMBC�UifNbuiXpslt
hK����
�����


















