
Midterm Reviewvision.stanford.edu/.../slides/2020/section_5_midterm.pdf · 2020-05-08 · Midterm...
77
Fei-Fei Li & Ranjay Krishna & Danfei Xu Midterm Review May 8, 2020 Midterm Review 1
Transcript of Midterm Reviewvision.stanford.edu/.../slides/2020/section_5_midterm.pdf · 2020-05-08 · Midterm...

Fei-Fei Li & Ranjay Krishna & Danfei Xu Midterm Review May 8, 2020
Midterm Review
1

Fei-Fei Li & Ranjay Krishna & Danfei Xu Midterm Review May 3, 2019
Logistics
● The midterm is scheduled on May 12th (Tuesday). ● Choose an 1hr40min contiguous slot yourself. ● Open book and web (although you won’t need it).
● You will take the test entirely online in gradescope:○ The format will be the same as practice midterm. Do try it in advance.○ A 1hr40min timer will start as soon as you open the test page, and won’t stop in between.
● Questions during midterm:○ Raise all questions privately on piazza.○ We will make a pinned thread to update all necessary exam clarifications. So pay
attention to that.
2
May 8, 2020

Fei-Fei Li & Ranjay Krishna & Danfei Xu Midterm Review May 3, 2019
Logistics
● Question types:○ True / False:
■ 10 questions. 2 points each. ■ Correct answer is worth 2 points. To discourage guessing, incorrect answers are
worth -1 points. Leaving a question blank will give 0 points.)○ Multiple Choice:
■ 10 questions. 4 points each. ■ Selecting all of the correct options and none of the incorrect options will get full
credits. For each incorrect selection, you’ll get 2 points off from the 4. The minimum score is 0.
■ I know this is confusing, so examples:● Correct answer is A. You select A -> 4 points; AB -> 2 points; ABC -> 0
points; ABCD -> 0 points.● Correct answer is AB. You select AB -> 4 points; A -> 2 points; ABC -> 2
points; AC -> 0 points; CD -> 0 points.
3
May 8, 2020

Fei-Fei Li & Ranjay Krishna & Danfei Xu Midterm Review May 3, 2019
Logistics
● Question types:○ Short Answers:
■ 40 points. ? questions.■ You could either type in your answers (math in latex is available by $$$$💰) or write,
scan (or photo) and upload. Please make it visually clear if you are writing. We may take points off if we can’t easily understand your handwritten work.
■ Note: certain questions might be easier done with the write option. So do prepare a pen, paper, and camera.
4
May 8, 2020

Fei-Fei Li & Ranjay Krishna & Danfei Xu
50 minutes is short!
This is just to help you get going with your studies.
Midterm Review May 3, 2019
Session Objectives
● You should understand all we’ve learned so far● We won’t cover everything that the midterm has and we might cover things
not on the midterm● Want to synthesize concepts of the course to give intuition/high level picture. ● Try to clarify things we’ve seen people have more difficulties with● Would highly recommend really understand the fundamental concepts, details,
and reasoning behind the many topics covered in lectures
5
May 8, 2020

Fei-Fei Li & Ranjay Krishna & Danfei Xu
Overview of today’s sessionSummary of Course Material:
● Basics of neural networks:○ Loss function & Regularization○ Optimization○ Activation Functions
● How we build complex network models○ Convolutional Layers○ Recurrent Neural Networks
Practice Midterm ProblemsQ&A, time permitting
Midterm Review May 3, 2019
6
May 8, 2020

Fei-Fei Li & Ranjay Krishna & Danfei Xu
Overview of today’s sessionSummary of Course Material:
● Basics of neural networks:○ Loss function & Regularization○ Optimization○ Activation Functions
● How we build complex network models○ Convolutional Layers○ Recurrent Neural Networks
Practice Midterm ProblemsQ&A, time permitting
Midterm Review May 3, 2019
7
May 8, 2020
Fei-Fei Li & Ranjay Krishna & Danfei Xu
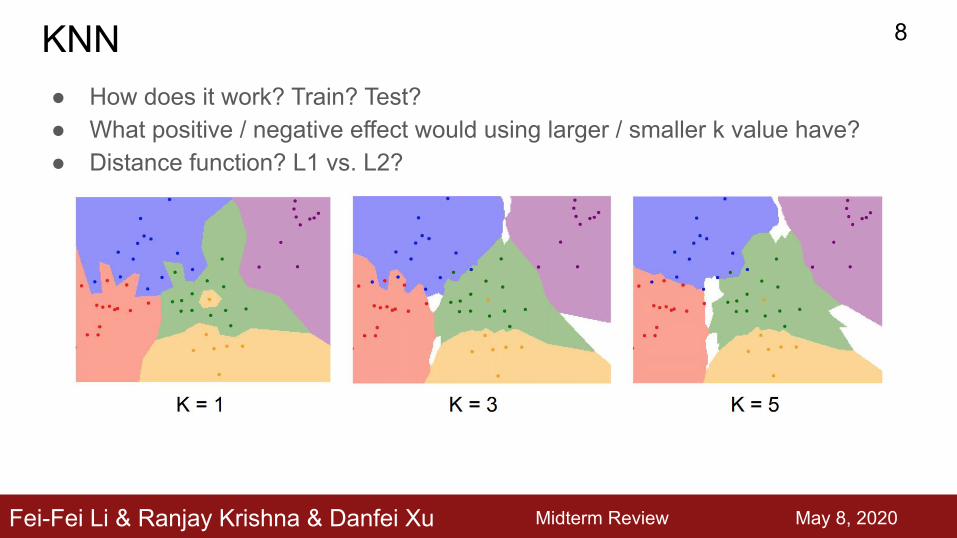
KNN● How does it work? Train? Test?● What positive / negative effect would using larger / smaller k value have?● Distance function? L1 vs. L2?
Midterm Review May 3, 2019
8
May 8, 2020
Fei-Fei Li & Ranjay Krishna & Danfei Xu Midterm Review April 9, 2019
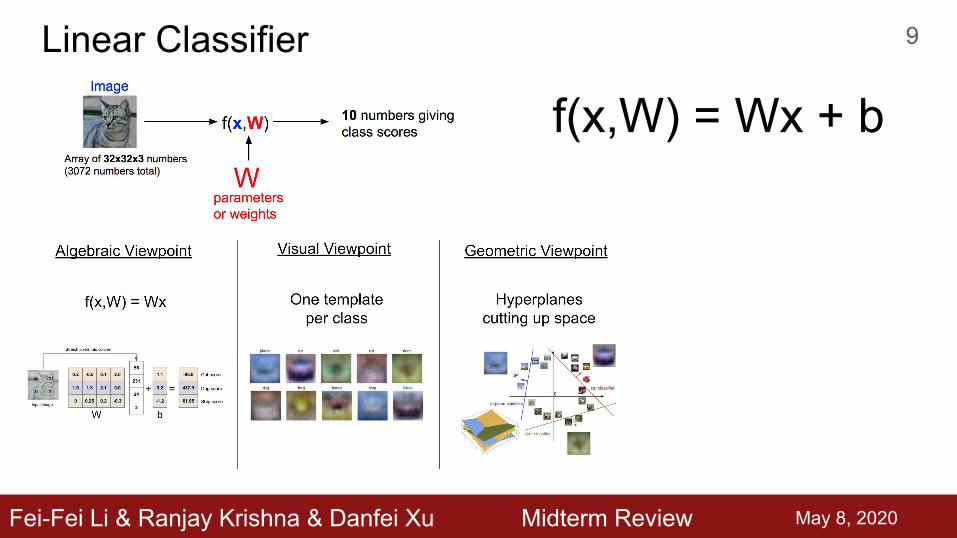
Linear Classifier
f(x,W) = Wx + b
9
May 8, 2020

Fei-Fei Li & Ranjay Krishna & Danfei Xu Midterm Review April 9, 2019
cat
frog
car
3.25.1-1.7
4.91.3
2.0 -3.12.52.2
Suppose: 3 training examples, 3 classes.With some W the scores are:
A loss function tells how good our current classifier is
Given a dataset of examples
Where is image and is (integer) label
Loss over the dataset is a average of loss over examples:
10
May 8, 2020

Fei-Fei Li & Ranjay Krishna & Danfei Xu Midterm Review April 9, 2019
“Hinge loss”
Loss Function: Multiclass SVM Loss 11
May 8, 2020

Fei-Fei Li & Ranjay Krishna & Danfei Xu Midterm Review April 9, 2019
“Hinge loss”
Loss Function: Multiclass SVM Loss
= max(0, 5.1 - 3.2 + 1) +max(0, -1.7 - 3.2 + 1)
= max(0, 2.9) + max(0, -3.9)
= 2.9 + 0
= 2.9
12
May 8, 2020

Fei-Fei Li & Ranjay Krishna & Danfei Xu Midterm Review April 9, 2019
E.g. Suppose that we found a W such that L = 0. Is this W unique?
No! 2W also has L = 0! How do we choose between W and 2W?Regularization
Aside: Regularization 13
May 8, 2020
Fei-Fei Li & Ranjay Krishna & Danfei Xu Midterm Review April 9, 2019
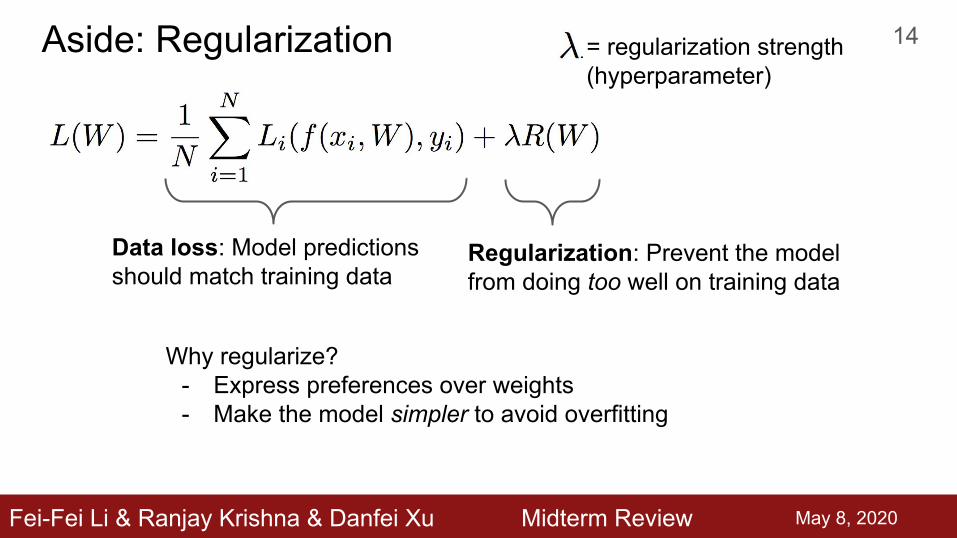
Aside: Regularization
Data loss: Model predictions should match training data
Regularization: Prevent the model from doing too well on training data
= regularization strength(hyperparameter)
Why regularize?- Express preferences over weights- Make the model simpler to avoid overfitting
14
May 8, 2020

Fei-Fei Li & Ranjay Krishna & Danfei Xu Midterm Review April 9, 2019
Want to interpret raw classifier scores as probabilitiesSoftmax Function
Loss Function: Softmax Classifier 15
May 8, 2020

Fei-Fei Li & Ranjay Krishna & Danfei Xu Midterm Review April 9, 2019
cat
frog
car
3.25.1-1.7
Want to interpret raw classifier scores as probabilitiesSoftmax Function
24.5164.00.18
0.130.870.00
exp normalize
unnormalized probabilities
Probabilities must be >= 0
Probabilities must sum to 1
probabilitiesUnnormalized log-probabilities / logits
Li = -log(0.13) = 2.04
Loss Intuition:● Maximizing Likelihood ● Comparing Probabilities
Loss Function: Softmax Classifier 16
May 8, 2020

Fei-Fei Li & Ranjay Krishna & Danfei Xu
Optimization Motivation
- We have some dataset of (x,y)- We have a score function: - We have a loss function:
How do we find the best W?
17
May 8, 2020

Fei-Fei Li & Ranjay Krishna & Danfei Xu
Gradient DescentFull sum expensive when N is large!
Approximate sum using a minibatch of examples32 / 64 / 128 common
Midterm Review May 3, 2019
18
May 8, 2020
Fei-Fei Li & Ranjay Krishna & Danfei Xu
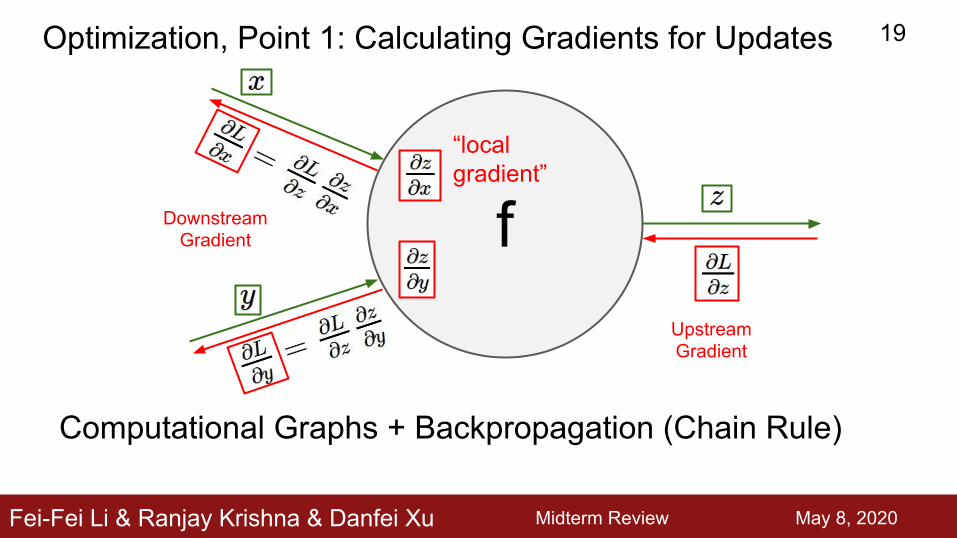
f“local gradient”
Upstream Gradient
DownstreamGradient
Optimization, Point 1: Calculating Gradients for Updates
Computational Graphs + Backpropagation (Chain Rule)
19
Midterm Review May 8, 2020
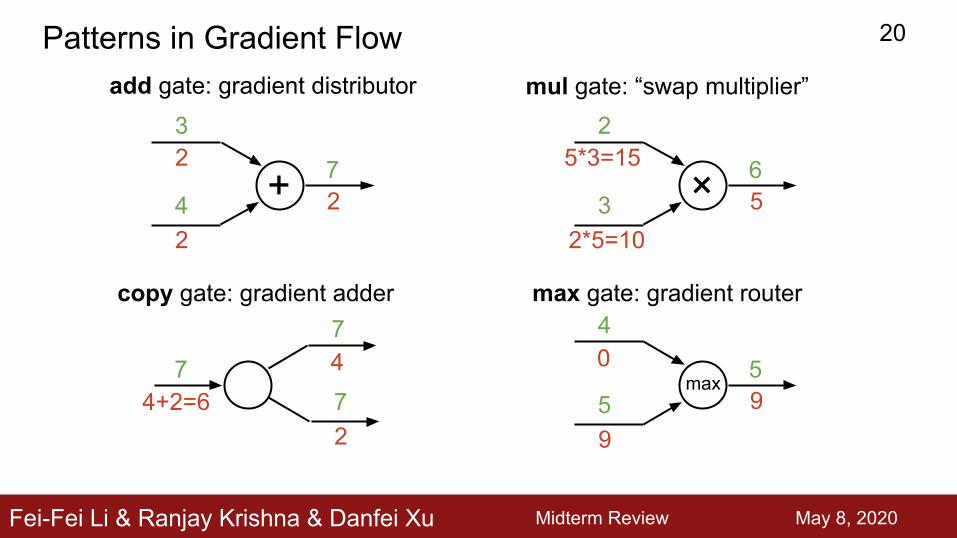
Fei-Fei Li & Ranjay Krishna & Danfei Xu
add gate: gradient distributor
+3
472
2
2
mul gate: “swap multiplier”
max gate: gradient router
max
copy gate: gradient adder
×2
365
5*3=15
2*5=10
4
559
0
9
7
77
4+2=6
4
2
Patterns in Gradient Flow 20
May 8, 2020Midterm Review
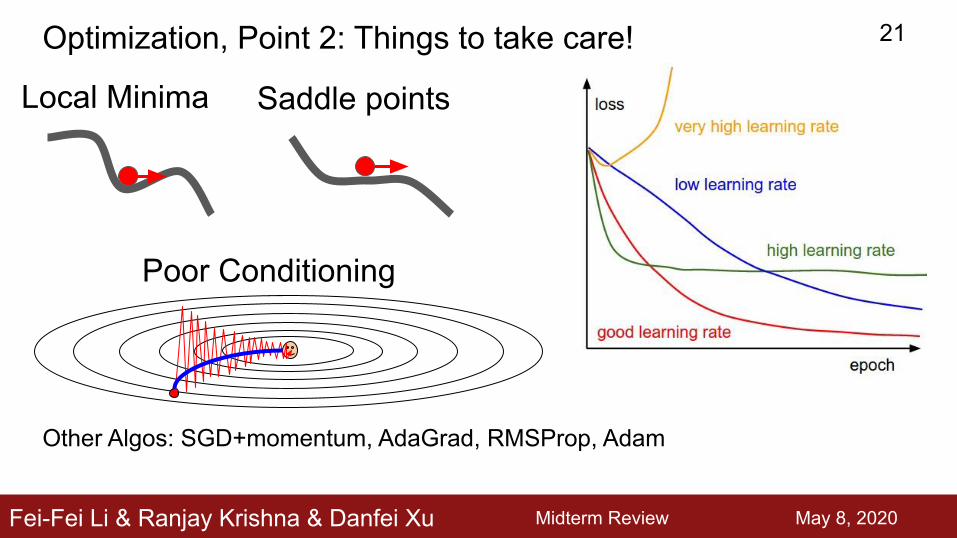
Fei-Fei Li & Ranjay Krishna & Danfei Xu
Local Minima Saddle points
Poor Conditioning
Optimization, Point 2: Things to take care!
Other Algos: SGD+momentum, AdaGrad, RMSProp, Adam
21
May 8, 2020Midterm Review

Fei-Fei Li & Ranjay Krishna & Danfei Xu
Problem 2.1
Midterm Review May 3th, 2019
22
May 8, 2020

Fei-Fei Li & Ranjay Krishna & Danfei Xu
Problem 2.1: Solution
Midterm Review May 3th, 2019
23
May 8, 2020

Fei-Fei Li & Ranjay Krishna & Danfei Xu
Problem 2.1: Solution
Midterm Review May 3th, 2019
24
May 8, 2020

Fei-Fei Li & Ranjay Krishna & Danfei Xu
Problem 2.1: Solution
Midterm Review May 3th, 2019
25
May 8, 2020

Fei-Fei Li & Ranjay Krishna & Danfei Xu
Problem 2.1: Solution
Midterm Review May 3th, 2019
26
May 8, 2020
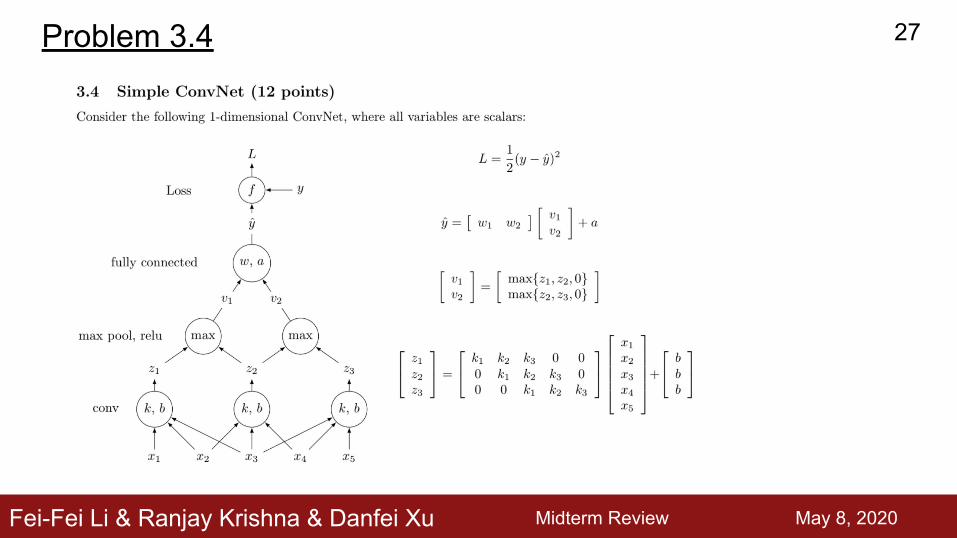
Fei-Fei Li & Ranjay Krishna & Danfei Xu
Problem 3.4
Midterm Review May 3th, 2019
27
May 8, 2020
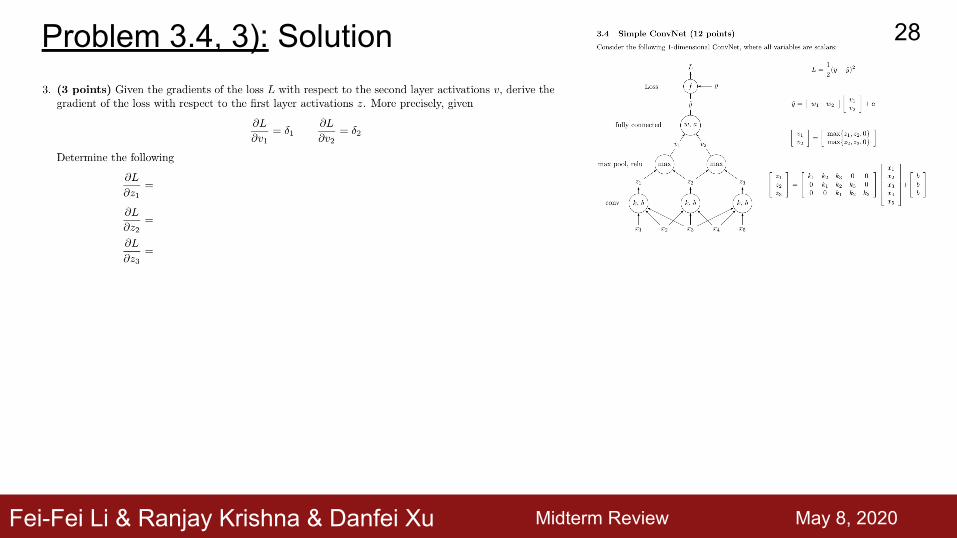
Fei-Fei Li & Ranjay Krishna & Danfei Xu
Problem 3.4, 3): Solution
Midterm Review May 3th, 2019
28
May 8, 2020
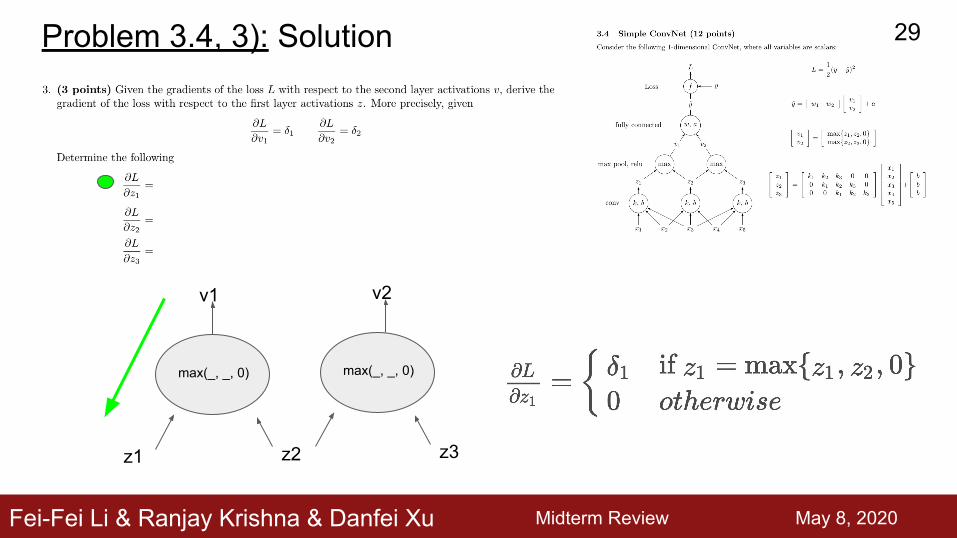
Fei-Fei Li & Ranjay Krishna & Danfei Xu
Problem 3.4, 3): Solution
max(_, _, 0)
z1 z2
v1
max(_, _, 0)
z3
v2
Midterm Review May 3th, 2019
29
May 8, 2020
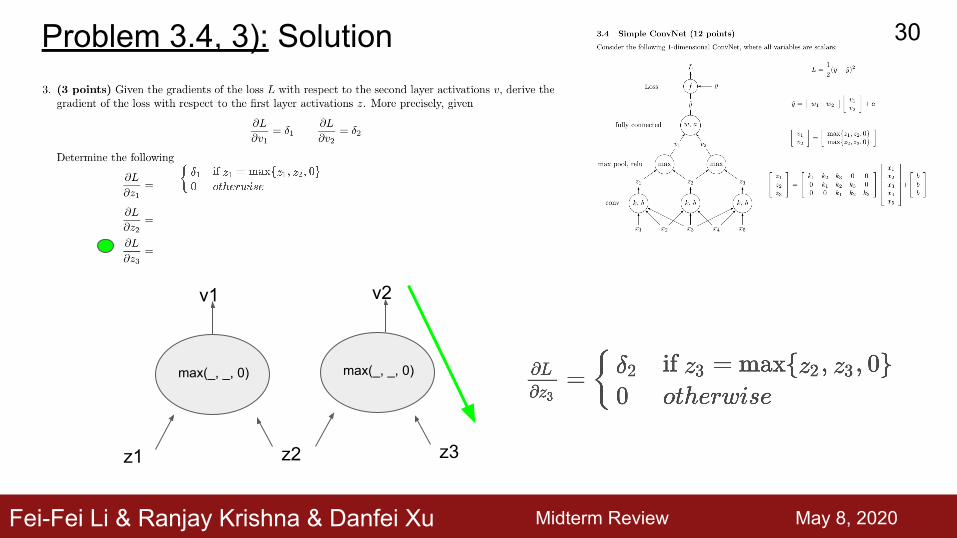
Fei-Fei Li & Ranjay Krishna & Danfei Xu
Problem 3.4, 3): Solution
max(_, _, 0)
z1 z2
v1
max(_, _, 0)
z3
v2
Midterm Review May 3th, 2019
30
May 8, 2020
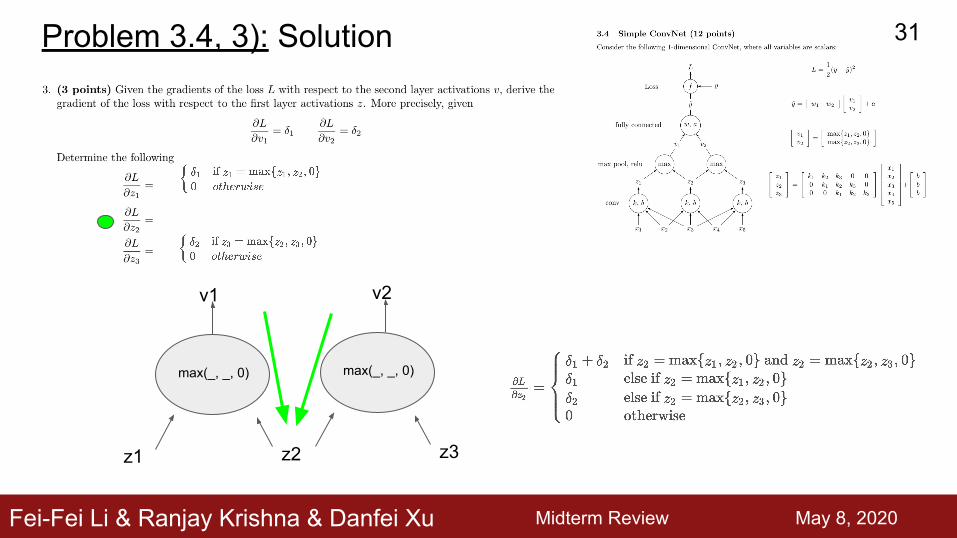
Fei-Fei Li & Ranjay Krishna & Danfei Xu
Problem 3.4, 3): Solution
max(_, _, 0)
z1 z2
v1
max(_, _, 0)
z3
v2
Midterm Review May 3th, 2019
31
May 8, 2020

Fei-Fei Li & Ranjay Krishna & Danfei Xu
Overview of today’s sessionSummary of Course Material:
● Basics of neural networks:○ Loss function $ Regularization○ Optimization○ Activation Functions
● How we build complex network models○ Convolutional Layers○ Recurrent Neural Networks
Practice Midterm ProblemsQ&A, time permitting
Midterm Review May 3th, 2019
32
May 8, 2020

Fei-Fei Li & Ranjay Krishna & Danfei Xu
Activation FunctionsSigmoid
tanh
ReLU
Leaky ReLU
Maxout
ELU
May 3th, 2019
33
May 8, 2020Midterm Review

Fei-Fei Li & Ranjay Krishna & Danfei Xu
Problem 2.4:
Midterm Review May 3th, 2019
34
May 8, 2020

Fei-Fei Li & Ranjay Krishna & Danfei Xu
Problem 2.4: Solution
Midterm Review May 3th, 2019
35
May 8, 2020

Fei-Fei Li & Ranjay Krishna & Danfei Xu
Problem 2.4: Solution
Midterm Review May 3th, 2019
36
May 8, 2020

Fei-Fei Li & Ranjay Krishna & Danfei Xu
Problem 2.4: Solution
Midterm Review May 3th, 2019
37
May 8, 2020

Fei-Fei Li & Ranjay Krishna & Danfei Xu
Problem 2.4: Solution
Midterm Review May 3th, 2019
38
May 8, 2020

Fei-Fei Li & Ranjay Krishna & Danfei Xu
Overview of today’s sessionSummary of Course Material:
● Basics of neural networks:○ Loss function & Regularization○ Optimization○ Activation Functions
● How we build complex network models○ Convolutional Layers○ Batch/Layer Normalization○ Recurrent Neural Networks
Practice Midterm ProblemsQ&A, time permitting
Midterm Review May 3th, 2019
39
May 8, 2020
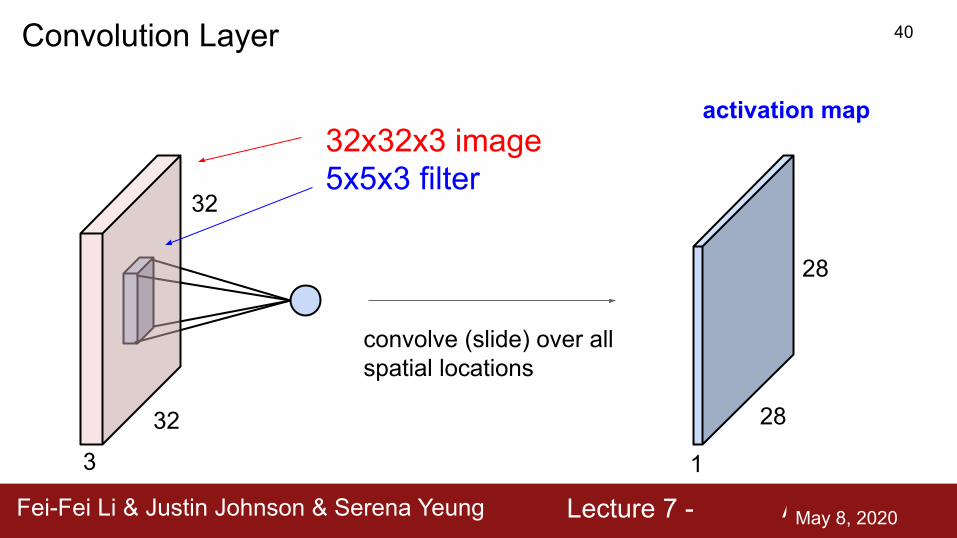
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 7 - April 22, 2019
32
32
3
32x32x3 image5x5x3 filter
convolve (slide) over all spatial locations
activation map
1
28
28
Convolution Layer 40
May 8, 2020
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 7 - April 22, 2019
32
32
3
Convolution Layer
activation maps
6
28
28
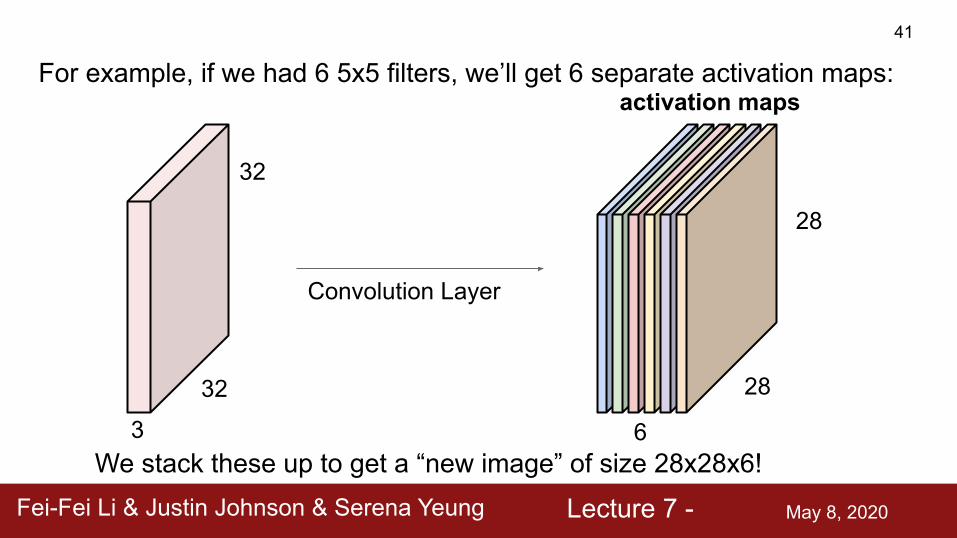
We stack these up to get a “new image” of size 28x28x6!
For example, if we had 6 5x5 filters, we’ll get 6 separate activation maps:41
May 8, 2020
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 7 - April 22, 2019Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 7 - April 22, 2019
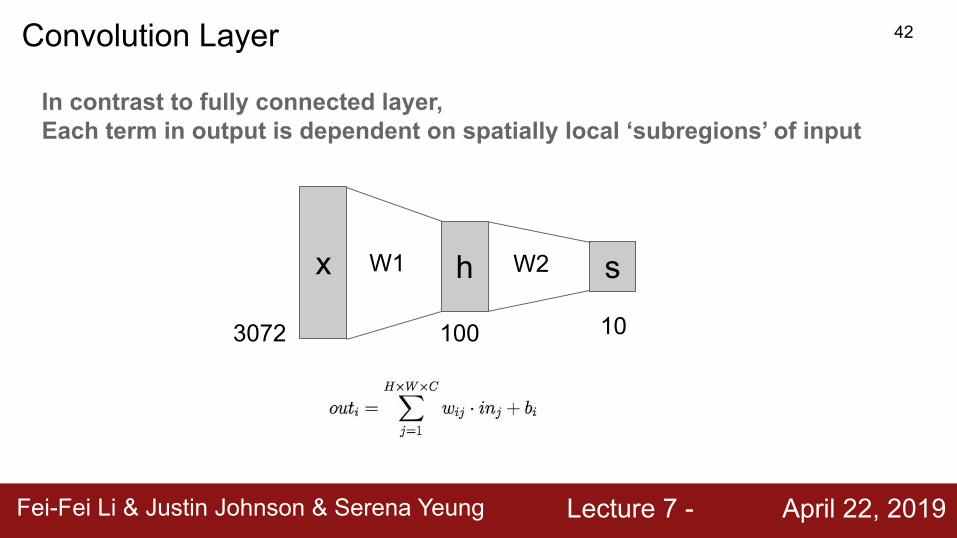
x hW1 sW2
3072 100 10
In contrast to fully connected layer, Each term in output is dependent on spatially local ‘subregions’ of input
Convolution Layer 42
Fei-Fei Li & Ranjay Krishna & Danfei Xu Midterm Review May 3, 2019
43
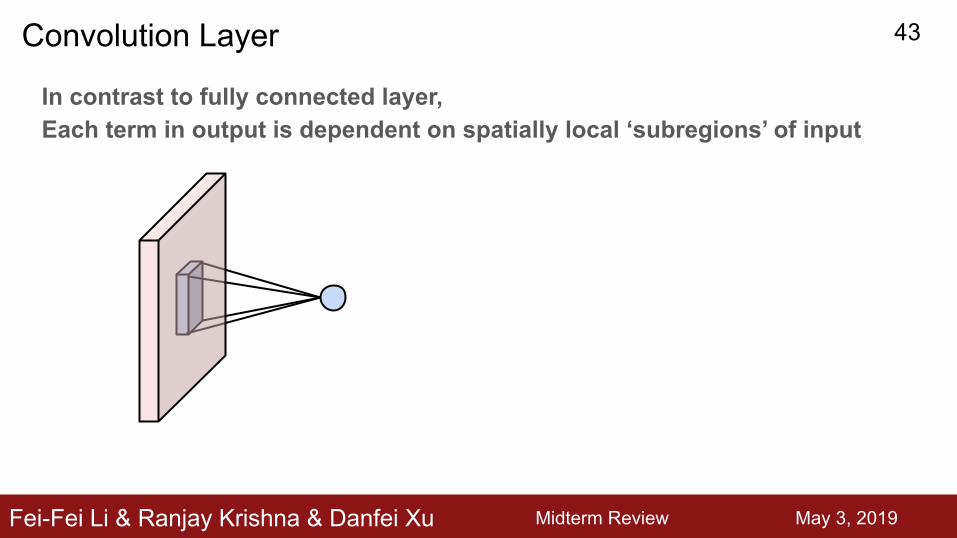
In contrast to fully connected layer, Each term in output is dependent on spatially local ‘subregions’ of input
Convolution Layer
Fei-Fei Li & Ranjay Krishna & Danfei Xu Midterm Review May 3, 2019
44
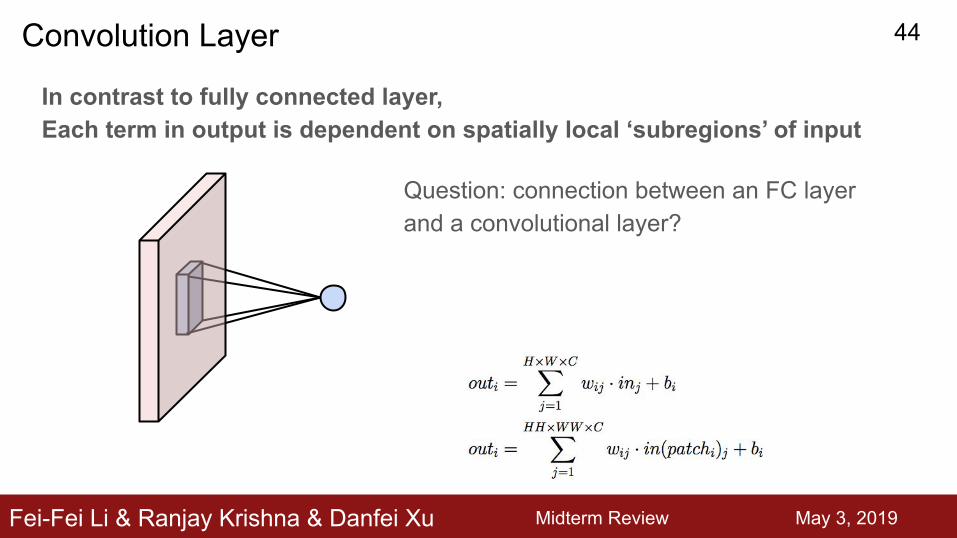
In contrast to fully connected layer, Each term in output is dependent on spatially local ‘subregions’ of input
Convolution Layer
Question: connection between an FC layer and a convolutional layer?
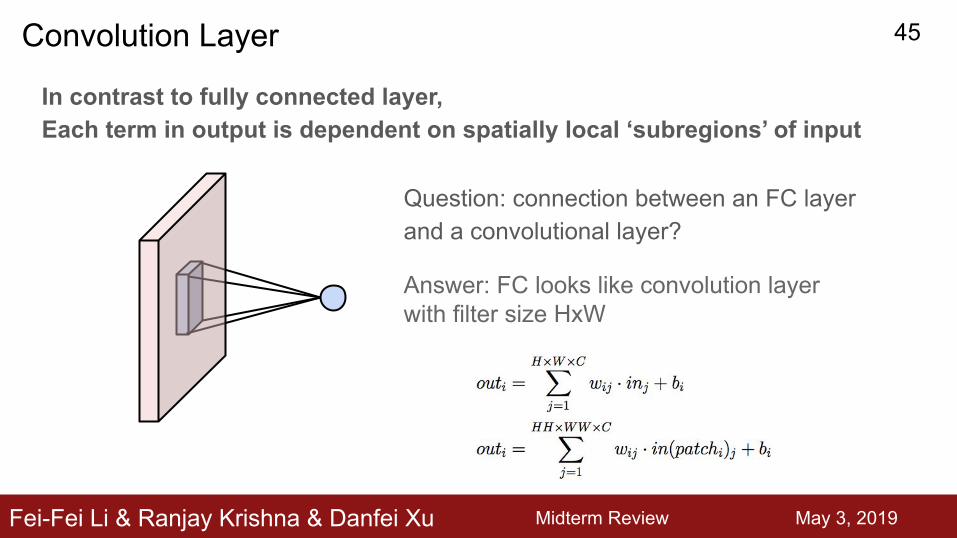
Fei-Fei Li & Ranjay Krishna & Danfei Xu Midterm Review May 3, 2019
45
In contrast to fully connected layer, Each term in output is dependent on spatially local ‘subregions’ of input
Convolution Layer
Question: connection between an FC layer and a convolutional layer?
Answer: FC looks like convolution layer with filter size HxW
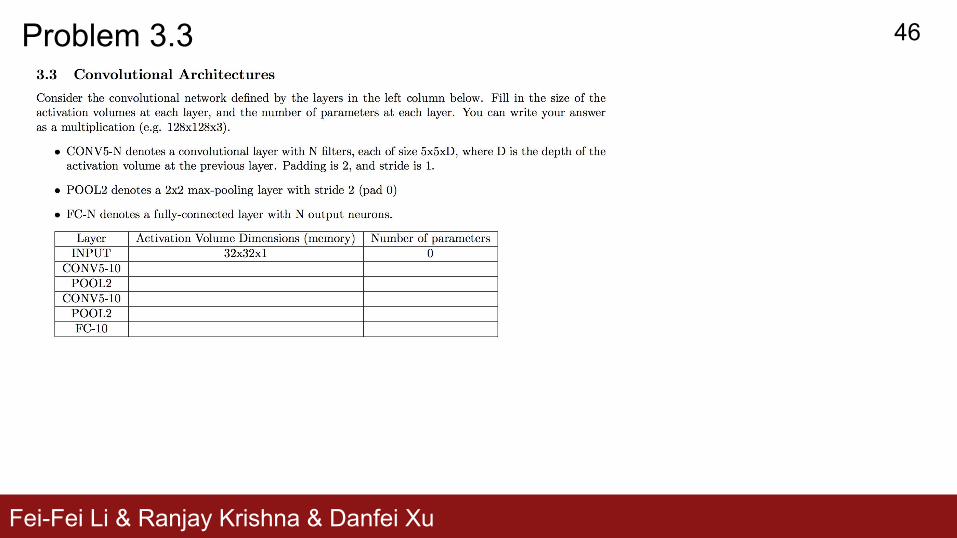
Fei-Fei Li & Ranjay Krishna & Danfei Xu
Problem 3.3 46

Fei-Fei Li & Ranjay Krishna & Danfei Xu
Prob 3.3 - Solution 47
Fei-Fei Li & Ranjay Krishna & Danfei Xu
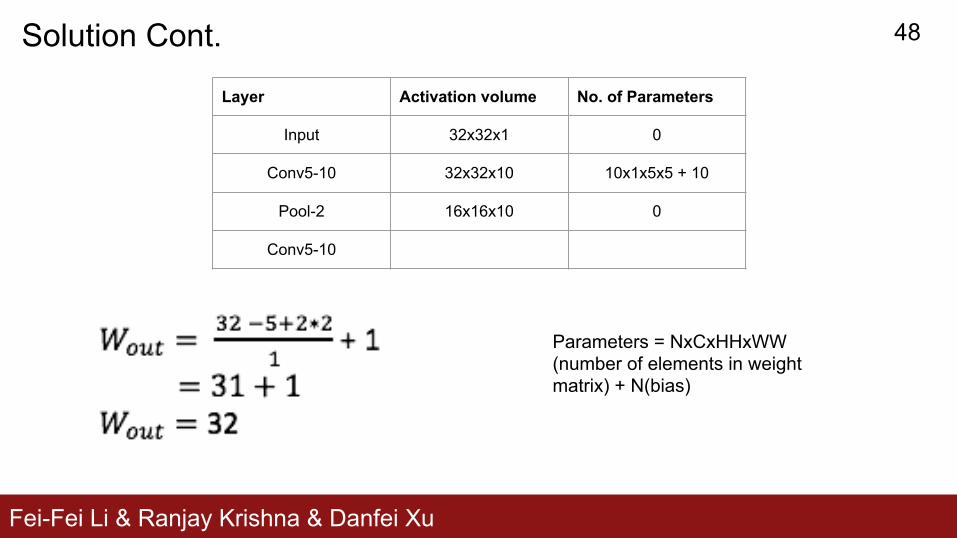
Layer Activation volume No. of Parameters
Input 32x32x1 0
Conv5-10 32x32x10 10x1x5x5 + 10
Pool-2 16x16x10 0
Conv5-10
Parameters = NxCxHHxWW (number of elements in weight matrix) + N(bias)
Solution Cont. 48
Fei-Fei Li & Ranjay Krishna & Danfei Xu
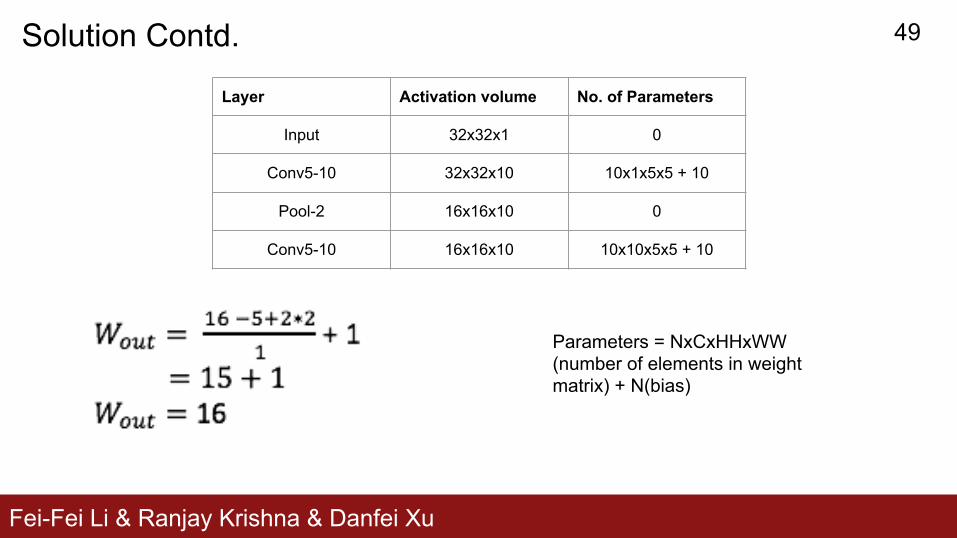
Layer Activation volume No. of Parameters
Input 32x32x1 0
Conv5-10 32x32x10 10x1x5x5 + 10
Pool-2 16x16x10 0
Conv5-10 16x16x10 10x10x5x5 + 10
Parameters = NxCxHHxWW (number of elements in weight matrix) + N(bias)
Solution Contd. 49
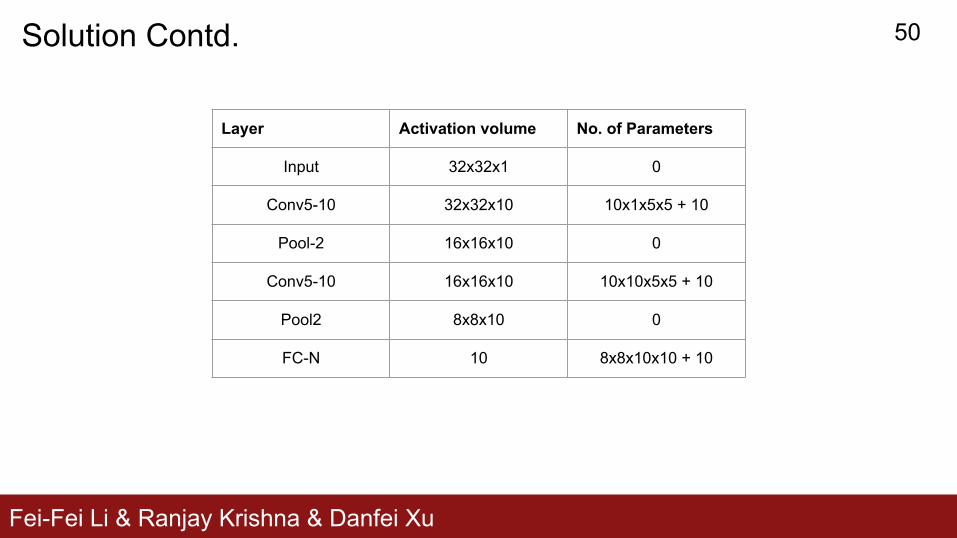
Fei-Fei Li & Ranjay Krishna & Danfei Xu
Layer Activation volume No. of Parameters
Input 32x32x1 0
Conv5-10 32x32x10 10x1x5x5 + 10
Pool-2 16x16x10 0
Conv5-10 16x16x10 10x10x5x5 + 10
Pool2 8x8x10 0
FC-N 10 8x8x10x10 + 10
Solution Contd. 50

Fei-Fei Li & Ranjay Krishna & Danfei Xu
Summary 51
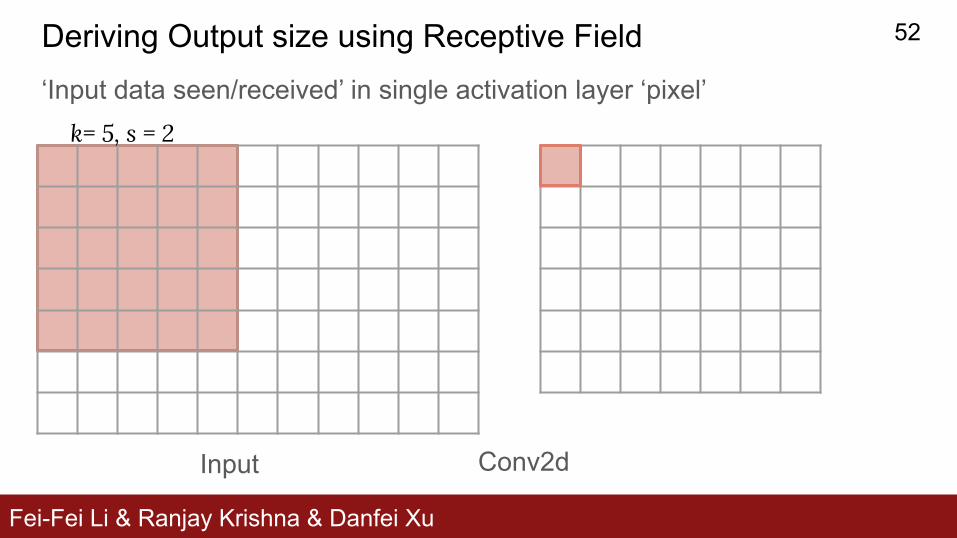
Fei-Fei Li & Ranjay Krishna & Danfei Xu
Deriving Output size using Receptive Field‘Input data seen/received’ in single activation layer ‘pixel’
Input Conv2d
k= 5, s = 2
52
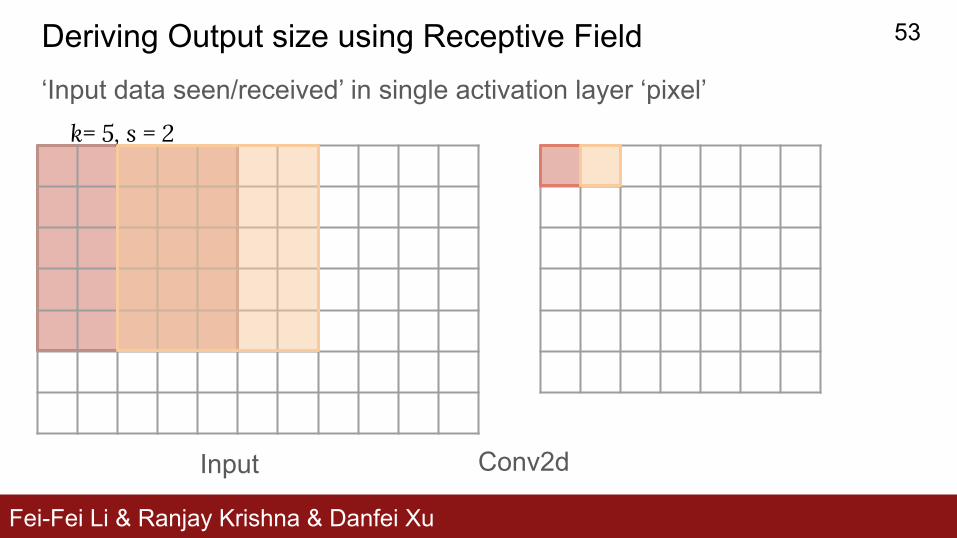
Fei-Fei Li & Ranjay Krishna & Danfei Xu
Input Conv2d
k= 5, s = 2
Deriving Output size using Receptive Field‘Input data seen/received’ in single activation layer ‘pixel’
53
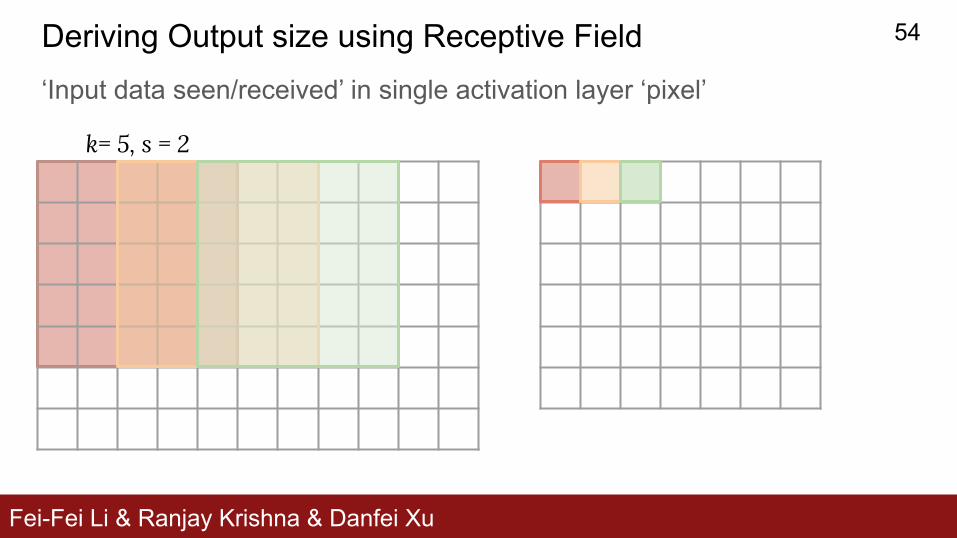
Fei-Fei Li & Ranjay Krishna & Danfei Xu
k= 5, s = 2
Deriving Output size using Receptive Field‘Input data seen/received’ in single activation layer ‘pixel’
54
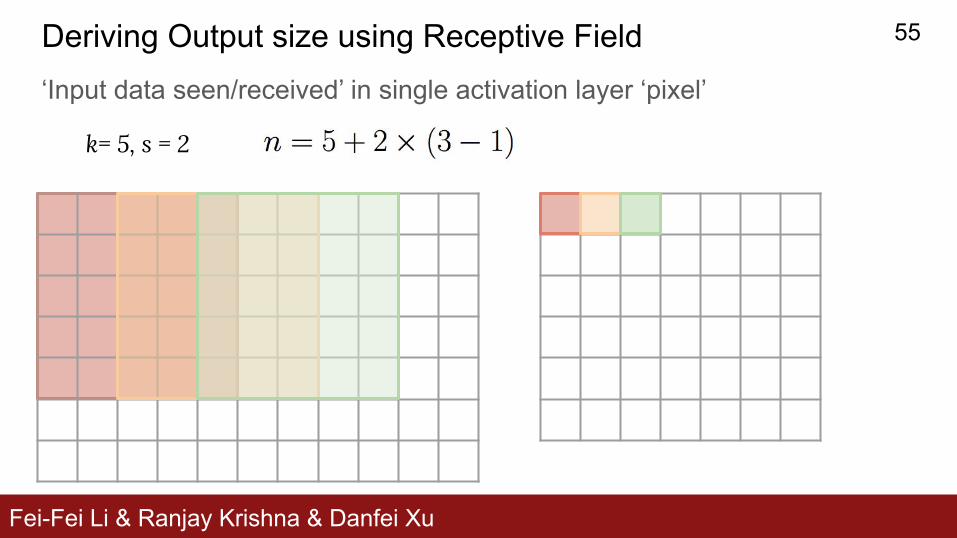
Fei-Fei Li & Ranjay Krishna & Danfei Xu
k= 5, s = 2
Deriving Output size using Receptive Field‘Input data seen/received’ in single activation layer ‘pixel’
55
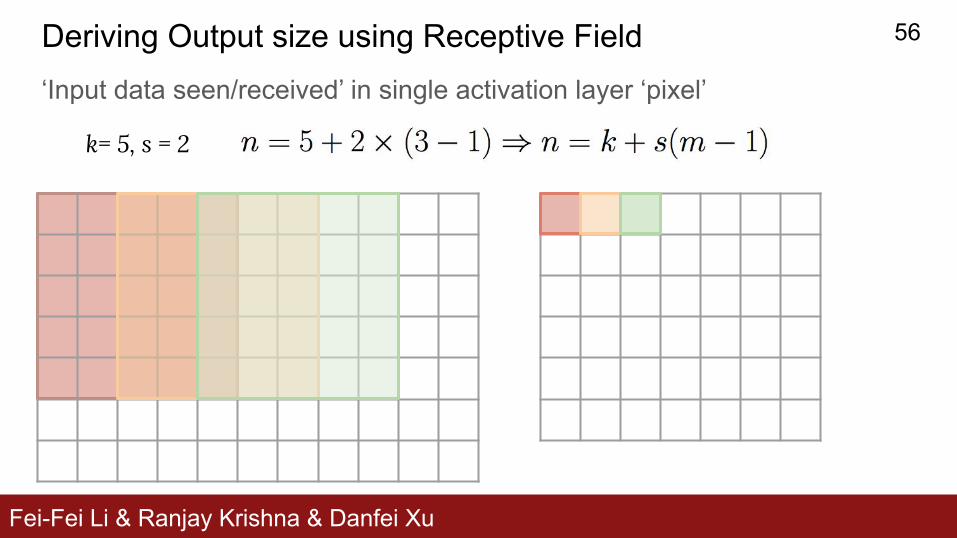
Fei-Fei Li & Ranjay Krishna & Danfei Xu
k= 5, s = 2
Deriving Output size using Receptive Field‘Input data seen/received’ in single activation layer ‘pixel’
56

Fei-Fei Li & Ranjay Krishna & Danfei Xu
Summary 57

Fei-Fei Li & Ranjay Krishna & Danfei Xu
Receptive field size
Note: Generally when we refer to ‘ effective receptive field’, we mean with respect to input data/layer 0/original image,
not with respect to direct input to the layer
58

Fei-Fei Li & Ranjay Krishna & Danfei Xu
Receptive field size
Note: Need to be computed recursively
59

Fei-Fei Li & Ranjay Krishna & Danfei Xu
Receptive field size computation
Conv2dk=3, s=1
Conv2dk=5, s=1
k=3, s=1, m=1
60
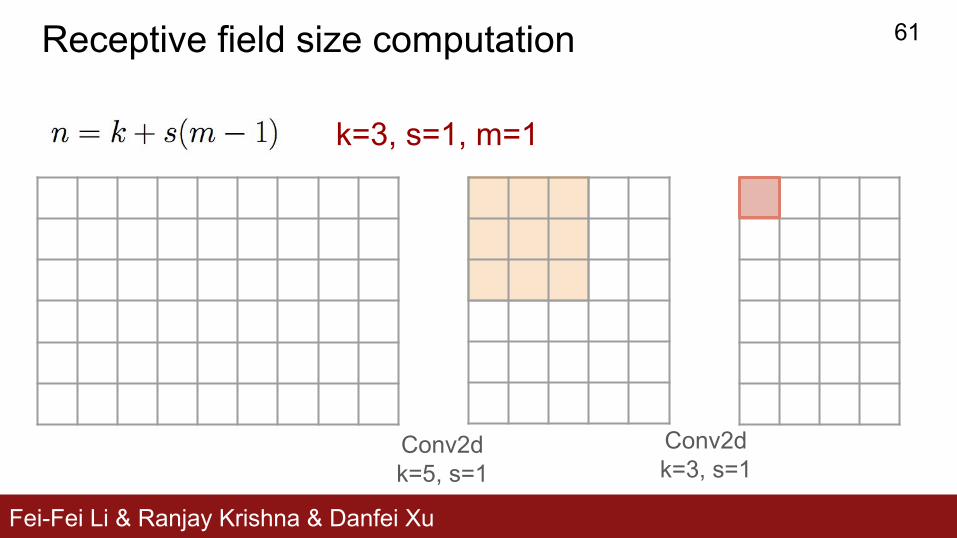
Fei-Fei Li & Ranjay Krishna & Danfei Xu
Receptive field size computation
k=3, s=1, m=1
Conv2dk=3, s=1
Conv2dk=5, s=1
61
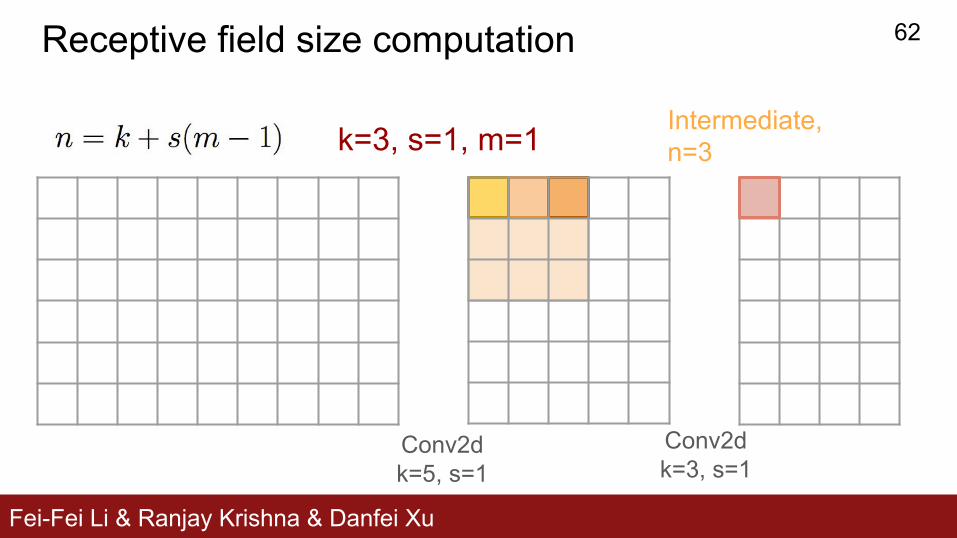
Fei-Fei Li & Ranjay Krishna & Danfei Xu
Receptive field size computation
Conv2dk=3, s=1
Conv2dk=5, s=1
k=3, s=1, m=1 Intermediate,n=3
62
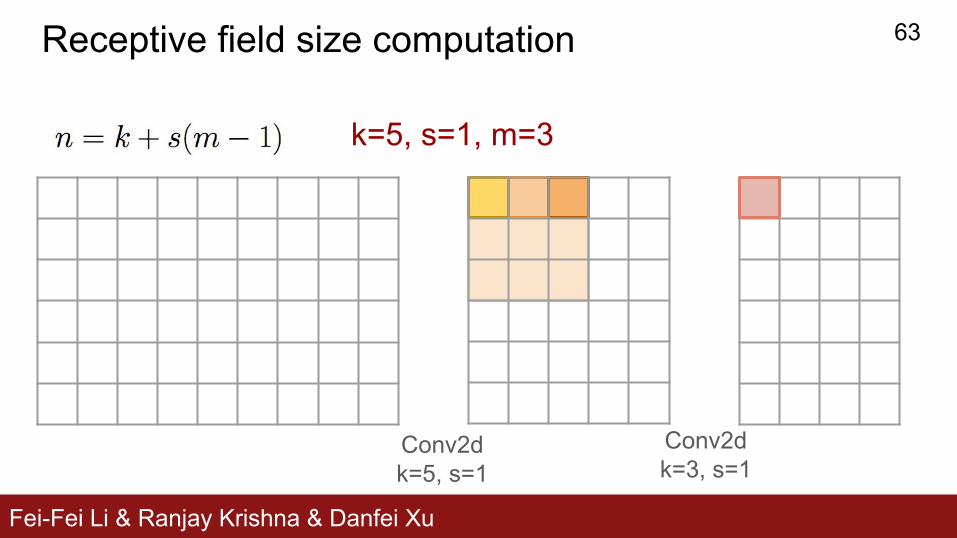
Fei-Fei Li & Ranjay Krishna & Danfei Xu
Receptive field size computation
Conv2dk=3, s=1
Conv2dk=5, s=1
k=5, s=1, m=3
63
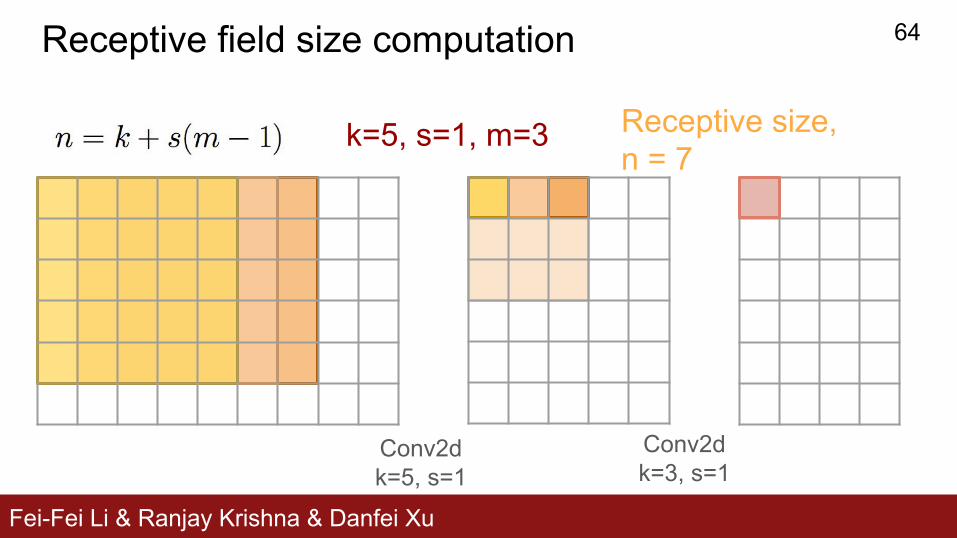
Fei-Fei Li & Ranjay Krishna & Danfei Xu
Receptive field size computation
k=5, s=1, m=3 Receptive size, n = 7
Conv2dk=3, s=1
Conv2dk=5, s=1
64

Fei-Fei Li & Ranjay Krishna & Danfei XuFei-Fei Li & Justin Johnson & Serena Yeung Lecture 7 - April 24, 201865
Batch Normalization for ConvNets
x: N × D
𝞵,𝝈: 1 × Dɣ,β: 1 × Dy = ɣ(x-𝞵)/𝝈+β
x: N×C×H×W
𝞵,𝝈: 1×C×1×1ɣ,β: 1×C×1×1y = ɣ(x-𝞵)/𝝈+β
Normalize Normalize
Batch Normalization for fully-connected networks
Batch Normalization for convolutional networks(Spatial Batchnorm, BatchNorm2D)

Fei-Fei Li & Ranjay Krishna & Danfei XuFei-Fei Li & Justin Johnson & Serena Yeung Lecture 7 - April 24, 201866
Layer Normalization
x: N × D
𝞵,𝝈: 1 × Dɣ,β: 1 × Dy = ɣ(x-𝞵)/𝝈+β
x: N × D
𝞵,𝝈: N × 1ɣ,β: 1 × Dy = ɣ(x-𝞵)/𝝈+β
Normalize Normalize
Layer Normalization for fully-connected networksSame behavior at train and test!Can be used in recurrent networks
Batch Normalization for fully-connected networks
Ba, Kiros, and Hinton, “Layer Normalization”, arXiv 2016
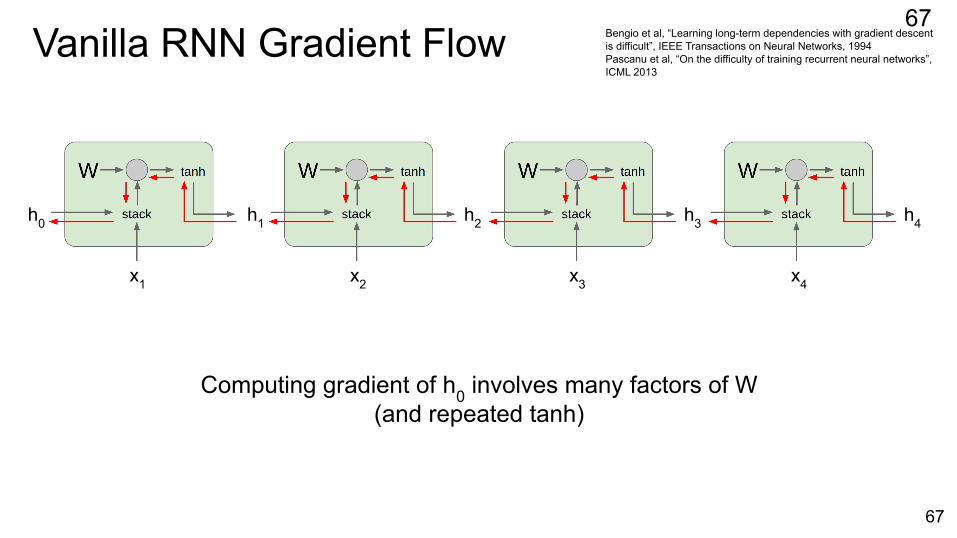
Vanilla RNN Gradient Flow
h0 h1 h2 h3 h4
x1 x2 x3 x4
Computing gradient of h0 involves many factors of W(and repeated tanh)
Bengio et al, “Learning long-term dependencies with gradient descent is difficult”, IEEE Transactions on Neural Networks, 1994Pascanu et al, “On the difficulty of training recurrent neural networks”, ICML 2013
67
67

Vanishing/Exploding Gradient
Vanishing Gradient:- Gradient becomes too small
68
68

Vanishing/Exploding Gradient
Vanishing Gradient:- Gradient becomes too small- Some causes:
- Choice of activation function- Multiplying many small numbers
together
69
69

Vanishing/Exploding Gradient
Vanishing Gradient:- Gradient becomes too small- Some causes:
- Choice of activation function- Multiplying many small numbers
together
Exploding Gradient:- Gradient becomes too large- Gradient clipping: Scale gradient if its
norm is too big 70
70

Solution
Modified versions of the RNN cells like,
● LSTM● GRU
Vanishing gradient problem is controlled by computing some intermediate values also called as gates, that give greater control over the values you want to write, pass to next time step and reveal as hidden state.
For exploding gradients, gradient clipping is a standard technique.
71
71

Fei-Fei Li & Ranjay Krishna & Danfei Xu
All the best for your midterm!
Midterm Review May 3, 2019
72

Fei-Fei Li & Ranjay Krishna & Danfei Xu
Sample Problem 73

Fei-Fei Li & Ranjay Krishna & Danfei Xu
74

Fei-Fei Li & Ranjay Krishna & Danfei Xu
75

Fei-Fei Li & Ranjay Krishna & Danfei Xu
76

Fei-Fei Li & Ranjay Krishna & Danfei Xu
77


















