
キャパシア 手洗器一体人大カウンター - LIXILPSU-1399(14091) セミオーダー手洗 (奥行280タイプ、奥行160タイプ) 【奥行160タイプ:フルキャビネット
Upload
jun-okumuraCategory
view
19.657download
0
Copyright©DeNACo.,Ltd.AllRightsReserved.
Stochas(cNeuralNetworksforHierarchicalReinforcementLearningCarlosFlorensa,YanDuan,PieterAbbeel
June17,2017ICLR読み会@DeNA
JunErnestoOkumuraAISystemDept.DeNACo.,Ltd.
論⽂紹介
h;ps://openreview.net/pdf?id=B1oK8aoxe

Copyright©DeNACo.,Ltd.AllRightsReserved.
⾃⼰紹介
名前 奥村 エルネスト 純(@pacocat)経歴 宇宙物理学 Ph.D → DeNA⼊社(2014年) → データアナリスト@分析部(〜2016年) → 機械学習エンジニア@AIシステム部(2017年〜)業務領域 ゲームデータ分析、ゲームパラメータデザイン 機械学習、強化学習を使ったゲームAI研究開発
2

Copyright©DeNACo.,Ltd.AllRightsReserved.
TL;DR
n 報酬がsparse(疎)で学習が進みにくいタスクについて有効な、階層的学習法を提案1. Proxy rewardを⽤いたスキルの学習フェーズ2. スキルの組み合わせによってタスクを解くフェーズ
n スキルの学習を効率化するために、以下の⼯夫を⾏っている1. Stochastic Neural Networkの利⽤2. Mutual Information (MI) bonusによる探索の動機づけ
n 実際にlocomotion(⾏動⽅法)+Maze/Gatherタスクにおいて、本⼿法が学習を促進することを確認した
3
ICLRcommi;eefinaldecision

Copyright©DeNACo.,Ltd.AllRightsReserved.
論⽂の選択理由
n Atari2600のようなベンチマークとなっている多くのゲームと異なり、実際のゲームでは中⻑期的な戦略が重要&報酬がsparseとなるものも多い
n そうした戦略を効率的に学習するための⼿法に興味がある⁃ 階層的な報酬設計・学習による⻑期戦略の学習⁃ pseudo-count等、効率化な探索アルゴリズム etc…
4

Copyright©DeNACo.,Ltd.AllRightsReserved.
強化学習の問題設定
n エージェントは、環境の状態 を観測した上で、ある⽅策 に従って⾏動を選択し、次状態と報酬を観測する
n ある環境において期待報酬(累積割引報酬和など)を最⼤化するように状況の価値や⽅策を学習していく
5
Environment
①状態の観測
②⾏動の選択
③結果の観測
最⼤化したい、、
*iconfrom:h;p://free-illustraRons.gatag.net/2014/09/12/160000.html

Copyright©DeNACo.,Ltd.AllRightsReserved.
強化学習の学習⽅法
1. 価値ベースの学習⁃ エージェントは⾏動によってサンプリングされた(状態, ⾏動, 報酬)の対を
使って、ある状態における⾏動の価値(⾏動価値関数Q)を更新する※ベルマン作⽤素Tの不動点を求める問題に帰着
2. ⽅策ベースの学習⁃ パラメトライズされた⽅策を直接更新(⽅策勾配定理)
6

Copyright©DeNACo.,Ltd.AllRightsReserved.
本論⽂のモチベーション
n 報酬がsparseとなるタスクにおいて、有効な学習法を⾒つけたい⁃ 過去に提案されてきたアプローチは主に以下
1. 学習を階層的に⾏う⼿法⁃ ⼈⼿で中間的な報酬設計にドメイン知識を⼊れていく必要がある ⇒ 極⼒hand-engineeringに頼らない⽅法が好ましい
2. Intrinsic rewardsを⽤いて、探索を効率化する⼿法⁃ ドメイン知識に頼らなくて済むが、複数のタスクを解く場合に、
転移可能かどうかはっきりしない⇒ ⼀度覚えたことは他のタスクでも汎⽤的に使いまわしたい
7

Copyright©DeNACo.,Ltd.AllRightsReserved.
本研究で扱うタスク
n Maze(迷路を解く問題)⁃ エージェントは図の例では蛇のような形をしており、複数の関節を
⾃由に動かすことでゴールを⽬指す(ゴールに辿り着いたら報酬)⁃ ランダムに動いても⼀向に進まないので、報酬を獲得出来ずに
学習が進まない ⇒ 報酬がsparse⁃ ⾃⾝の動作⽅法(locomotion)とタスクの解き⽅を学ぶ必要がある
8h;ps://youtu.be/gr6KvOq2eYc

Copyright©DeNACo.,Ltd.AllRightsReserved.
本研究で扱うタスク
n Gather(ボール集め)⁃ 緑のボールを取ると+1、⾚のボールを取ると-1の報酬• ⾚いボールを避けながら、なるべく多くの緑のボールを集めるタスク
⁃ Locomotionを覚える必要があり報酬はsparse
9h;ps://youtu.be/CdV_XvM3S9Y

Copyright©DeNACo.,Ltd.AllRightsReserved.
課題へのアプローチと考え⽅
n タスクを階層的に分解する⁃ まずは動き⽅(locomotion skills)を学習し、その後タスクを解く
ためのskillの組み合わせを学習する ⇒ §5.1, §5.4 • Skillのイメージ:前進、後退、右折、等• Skillの習得は、極⼒シンプルな報酬を設計する
n 様々なタスクを解くため、skillsが汎⽤的になるよう学習する⁃ ⽅策のネットワークを、独⽴な形(distinct)で効率的に学習したい
⇒ §5.3, §5.2 • 似たようなskillばかり学習してしまうと⾮効率
10

Copyright©DeNACo.,Ltd.AllRightsReserved.
Methodology①:pre-training
n locomotion skills習得のため、適当な空間を⽤意n proxy rewardを設定
⁃ 今回の場合はエージェントの重⼼速度• どこかしらの⽅向に動くような⾏動が学習される
n 事前学習の結果、特定⽅向に移動する⽅策群(skills)が獲得されている
11
Copyright©DeNACo.,Ltd.AllRightsReserved.
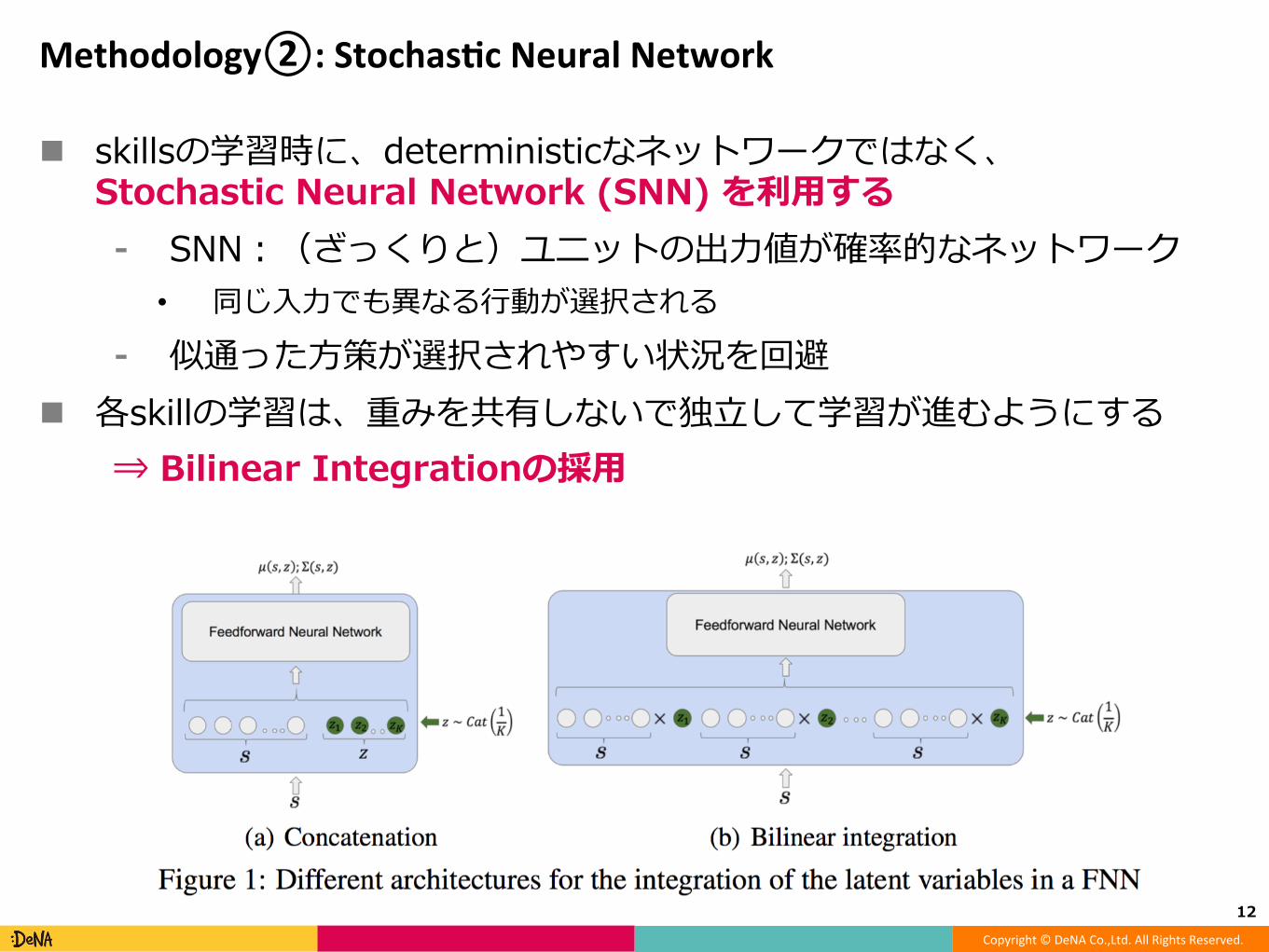
Methodology②:Stochas(cNeuralNetwork
n skillsの学習時に、deterministicなネットワークではなく、Stochastic Neural Network (SNN) を利⽤する⁃ SNN:(ざっくりと)ユニットの出⼒値が確率的なネットワーク• 同じ⼊⼒でも異なる⾏動が選択される
⁃ 似通った⽅策が選択されやすい状況を回避n 各skillの学習は、重みを共有しないで独⽴して学習が進むようにする
⇒ Bilinear Integrationの採⽤
12
Copyright©DeNACo.,Ltd.AllRightsReserved.
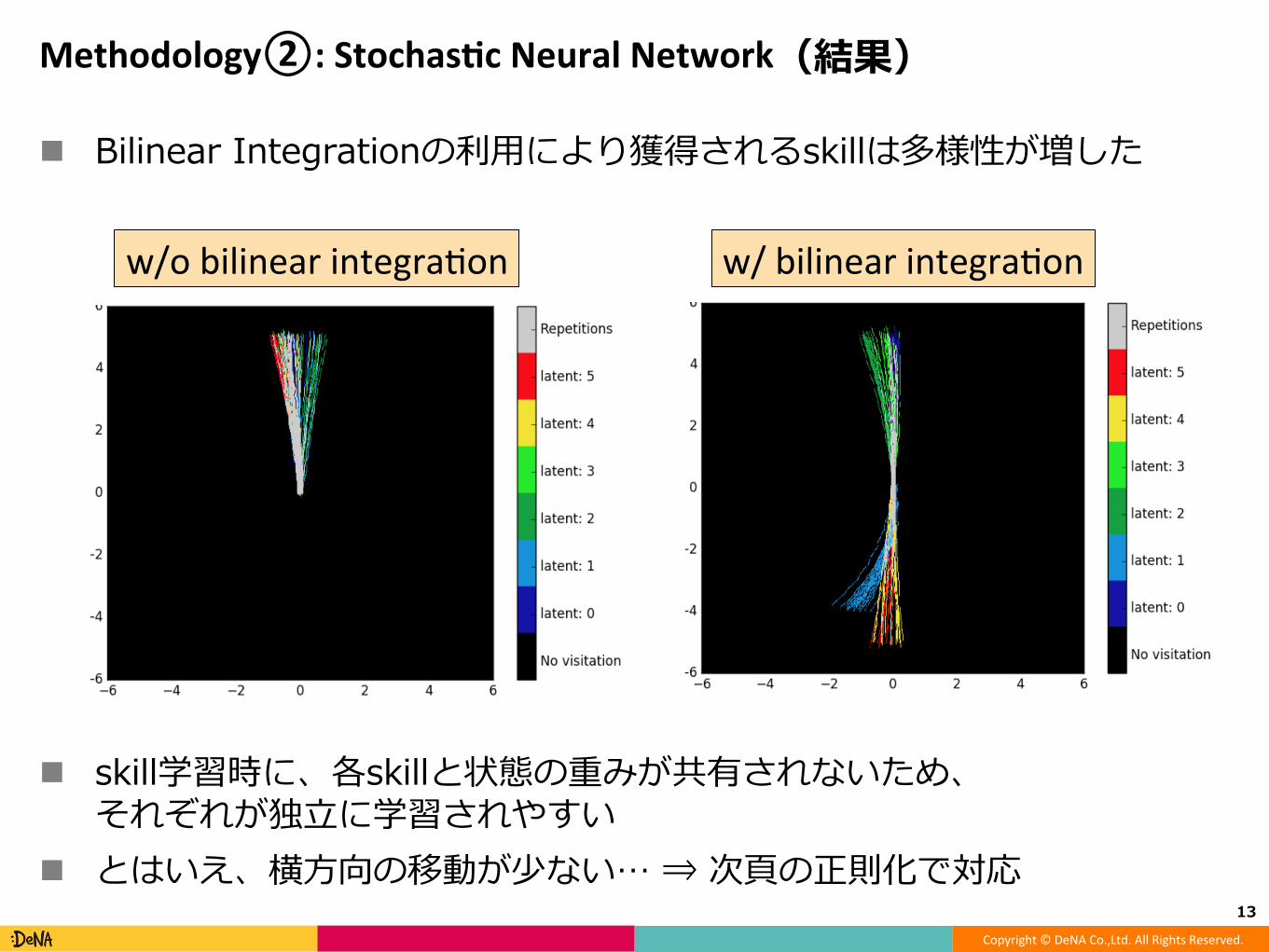
Methodology②:Stochas(cNeuralNetwork(結果)
n Bilinear Integrationの利⽤により獲得されるskillは多様性が増した
n skill学習時に、各skillと状態の重みが共有されないため、それぞれが独⽴に学習されやすい
n とはいえ、横⽅向の移動が少ない… ⇒ 次⾴の正則化で対応13
w/obilinearintegraRon w/bilinearintegraRon
Copyright©DeNACo.,Ltd.AllRightsReserved.
Methodology③:Informa(on-theore(cRegulariza(on
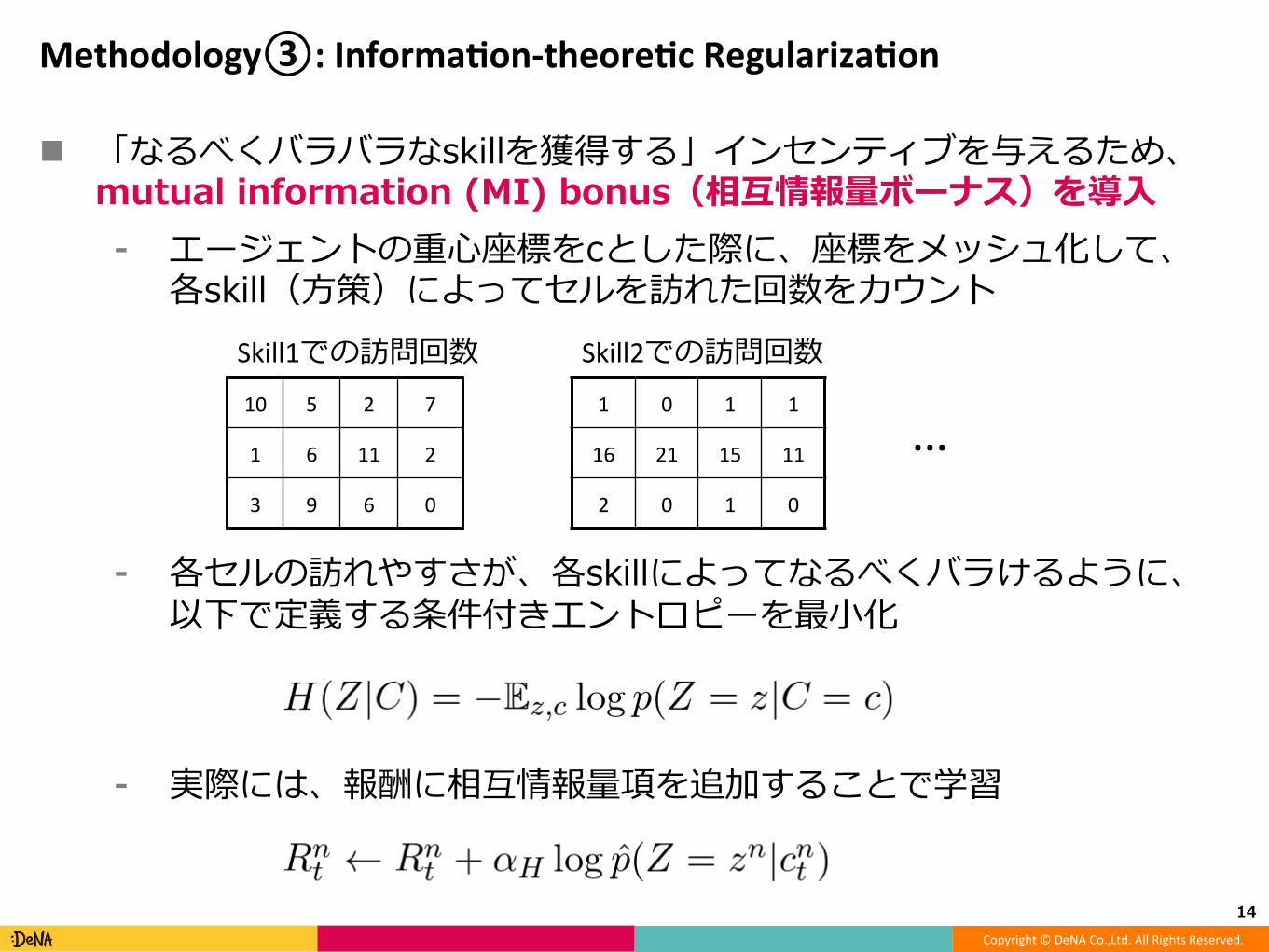
n 「なるべくバラバラなskillを獲得する」インセンティブを与えるため、mutual information (MI) bonus(相互情報量ボーナス)を導⼊⁃ エージェントの重⼼座標をcとした際に、座標をメッシュ化して、
各skill(⽅策)によってセルを訪れた回数をカウント
⁃ 各セルの訪れやすさが、各skillによってなるべくバラけるように、以下で定義する条件付きエントロピーを最⼩化
⁃ 実際には、報酬に相互情報量項を追加することで学習
14
10 5 2 7
1 6 11 2
3 9 6 0
1 0 1 1
16 21 15 11
2 0 1 0
Skill1での訪問回数 Skill2での訪問回数
…

Copyright©DeNACo.,Ltd.AllRightsReserved.
Methodology③:Informa(on-theore(cRegulariza(on(結果)
n 正則化の度合いが強い(αが⼤きい)ほど、他のskill(⽅策)が訪れない⽅向を積極的に探索しようとしている
15

Copyright©DeNACo.,Ltd.AllRightsReserved.
Methodology④:LearningHigh-LevelPolicies
n これまでに学習した独⽴で汎⽤的なスキル群を使って、さらに上位のタスク(迷路・ボール集め)を学習⁃ エージェントは、タスクの⽬標に従って、skillの使い⽅を学習する
(Manager Neural Network)⁃ (⼤雑把に)状態空間は、⾃⾝の運動に関わるS_agentと、
タスクの環境に関連するS_restに分解される
16

Copyright©DeNACo.,Ltd.AllRightsReserved.
ここまでの実験結果
a) ランダムなエージェント⁃ ほとんど初期状態から動かず、探索が出来ていない
b) 階層的強化学習を利⽤⁃ 探索範囲は広がるが、skillが多様でないため上下にしか伸びない
c) SNNの⼊⼒にBilinear Integrationを導⼊⁃ Skillが独⽴に学習されやすくなり、横にも探索が広がってくる
d) さらに報酬に相互情報量項を加える⁃ Skillの多様性を増すインセンティブが働き、探索範囲がさらに広がる
17

Copyright©DeNACo.,Ltd.AllRightsReserved.
Experiments
n 以下のパラメータによって、上記4タスクを解いた⁃ ⽅策の学習:TRPOを利⽤、step size 0.01、割引率 0.99⁃ ネットワーク:2層、隠れ層のユニット数 32⁃ 学習スキルの数:6⁃ 事前学習:バッチサイズ 50,000、最⼤パス⻑ 500⁃ 下流タスクのパラメータ:
18

Copyright©DeNACo.,Ltd.AllRightsReserved.
Experiments(結果)
n SNN+MI bonusモデル(⾚)が概ね好成績n タスクによっては、他のモデルでも⼗分な成績が出ている
⁃ 例えばMaze2/3では⼀⽅向に進めばいいのでMI bonusを⼊れなくても⼗分
19
ゴー
ルに
到達
する
確率

Copyright©DeNACo.,Ltd.AllRightsReserved.
今後のスコープ
n SnakeのようなエージェントでMaze/Gatherタスクを解くことは出来たが、まだ以下のようなチャレンジ余地はある1. Antのように不安定なエージェントでは学習が上⼿くいかない
• Skillの学習は成功しているようにみえるが、skillをスイッチする際に不安定になり、起き上がれなくなる
• ⽅策の切り替え⾃体を学習するエージェントで解決出来るかもしれない
2. ⽅策の数やスイッチ時間が固定されており、柔軟ではない3. 直近観測される状態からのみ⾏動が判断されるため、過去のセンサー情報を
活⽤できない• RNN的なアーキテクチャの導⼊で解決するかもしれない
20









![A4 縦 [更新済み]パンフ表(20170617)SOY MY LIFE シリーズ その他のラインナップ Title A4_縦 [更新済み]パンフ表(20170617) Created Date 6/17/2017](https://static.fdocument.pub/doc/165x107/5fdee5790c410212ee0aaeaa/a4-c-fffei20170617i-soy-my-life-ff-ffffff.jpg)




![[电子书]奥莉薇1.29 MB](https://static.fdocument.pub/doc/165x107/5695d2b11a28ab9b029b5ea0/129-mb.jpg)



![arXiv:1411.7610v3 [stat.ML] 5 Mar 2015 · Under review as a conference paper at ICLR 2015 LEARNING STOCHASTIC RECURRENT NETWORKS Justin Bayer Lehrstuhl fur Echtzeitsysteme und Robotik¨](https://static.fdocument.pub/doc/165x107/5aca63d07f8b9a51678ddb9d/arxiv14117610v3-statml-5-mar-2015-review-as-a-conference-paper-at-iclr-2015.jpg)