







Languages
Pages
Legal


Analisis Regresi Linier ( Lanjutan )

Outline- Regresi Berganda
- Pemeriksaan Regresi : Koef. Determinasi Standar ErrorInterval KepercayaanUji Hipotesis :t test, F test,
- Pelanggaran Asumsi : MulticollinearityHeteroscedasticityOtokorelasi

Regresi Berganda
Apakah Konsumsi hanya dipengaruhi oleh Pendapatan saja?
Ada beberapa variabel lain yang berpengaruh, seperti jumlah anggota keluarga, umur anggota keluarga, selera pribadi, dan sebagainya.
Bila dianggap variabel lain perlu diakomodasikan dalam menganalisis konsumsi, maka Regresi Sederhana dikembangkan menjadi Regresi Berganda.

MODEL
Yi = β 0 + β 1X1i + β 2X2i + β 3X3i + ........+ β kXki + ui
i = 1,2,3,......., N (banyaknya observasi)
Contoh Aplikasi:Yi = β 0 + β 1X1 + β 2X2 + β 3X3 + ui
Y : KonsumsiX1 : PendapatanX2 : Umur X3 : Jumlah tanggungan

Pemeriksaan Regresi
Koefisien Determinasi Standard Error Koefisien Interval Kepercayaan
Uji Hipotesis: Uji t Uji F

Pemeriksaan Regresi
Standard Error Prinsip OLS: meminimalkan error. Oleh karena itu, ketepatan dari nilai dugaan sangat ditentukan oleh standard error dari masingmasing penduga. Adapun standard error dirumuskan sebagai berikut:
Se=∑ Υ− Υ 2
n−2= SST−SSR
n−2=∑ Υ2
−b∑ ΧΥn−2
=MSE

Pemeriksaan Regresi
Oleh karena σ merupakan penyimpangan yang terjadi dalam populasi, yang nilainya tidak diketahui, maka σ biasanya diduga berdasarkan data sampel. Adapun penduganya adalah sebagai berikut : s
u N
i = −
∑ 2 1/2
2
ui2 =
2)ˆ( ii YY −ui2 =
Berdasar formula: error yang minimal akanmengakibatkan standar error koefisien yang minimal pula. Berapa batasannya standar error disebut besar atau kecil?

Pemeriksaan Regresi Sulit ditentukan secara absolut. Data jutaan
rupiah tentunya akan memiliki standar error yang lebih besar dibanding ratusan rupiah.
Digunakan dengan membuat rasio dengan koefisien regresi.
Rasio inilah yang menjadi acuan pada Ujit.

Interval Kepercayaan β j
Apa yang dimaksud Interval kepercayaan? Untuk apa? Formulasi:
bj ± tα /2 s.e(bj)
atauP(bj tα /2 s.e(bj) ≤ βj ≤ bj + tα /2 s.e(bj))= 1 α

Interval Kepercayaan β j
b1 = 0,1022 dan s.e (b1) = 0,0092. Banyaknya observasi (n) = 10; Banyaknya parameter yang diestimasi (k) = 2; Dengan demikian derajat bebas = 10 – 2 = 8; dan tingkat signifikansi 1α = 95 %. Dari tabel t0,025 dengan derajat bebas = 8, diperoleh nilai t = 2,306.
Maka interval kepercayaan untuk β1 adalah : ( 0,1022 ± 2,306 (0,0092) ) atau (0,0810 ; 0,1234)
Artinya: Nilai β1 terletak antara 0,0810 dan 0,1234 dengan peluang sebesar 95%.

Uji Hipotesis
Pengujian koefisien regresi secara individu. H0 : β j = 0H1 : β j ≠ 0; j = 0, 1, 2........, k k adalah koefisien slop.
Untuk regresi sederhana: (1) H0 : β 0 = 0 (2) H0 : β 1 = 0 H1 : β 0 ≠ 0 H1 : β 1 ≠ 0;
Ujit didefinisikan sebagai berikut:
t =b j−β j
s . e b j
β j akan diuji apakah sama dengan 0
t =b j
s . e b j
Uji t

Ujit
Nilai t dibandingkan dengan nilai t tabel. Bila ternyata, setelah dihitung t > tα /2,df, maka nilai t berada dalam daerah penolakan, sehingga hipotesis nol (β j = 0) ditolak pada tingkat kepercayaan (1α ) x100%. Dalam hal ini dapat dikatakan bahwa β j statistically significance.

Uji Hipotesis
UjiF
Diperuntukkan guna melakukan uji hipotesis koefisien (slop) regresi secara bersamaan. H0 : β 2 = β 3 = β 4 =............= β k = 0H1 : Tidak demikian (paling tidak ada satu slop yang ≠ 0)
Dimana: k adalah banyaknya variabel bebas.
Regresi sederhana: H0 : β 1 = β 2 = β 3 = 0 H1 : Tidak demikian (paling tidak ada satu slop yang ≠ 0)
Pengujian: ANOVA (Analysis of Variance).

UjiF
Observasi: Yi = β 0 + β 1 Xi + ei
Regresi: Ŷi = b1 + b2 Xi (catatan: Ŷi merupakan estimasi dari Yi).
Bila kedua sisi dikurangi maka:
Selanjutnya kedua sisi dikomulatifkan:
SST SSR SSE SST : Sum of Squared Total SSR: Sum of Squared Regression SSE : Sum of Squared Error/Residual
Y Y Y Y ei i− = − +
( ) ( )Y Y Y Y ei i i− = − +∑∑ 2 2
( ) ( )Y Y Y Y ei i i− = − + ∑∑∑ 2 2 2
Y

Uji F
Tabel ANOVASumber Sum of Square df Mean Squares F HitungRegresi SSR k MSR = SSR/k F = MSRError SSE nk1 MSE= SSE/(nk1) MSETotal SST n1
Dimana df adalah degree of freedom, k adalah jumlah variabel bebas (koefisien slop), dan n jumlah observasi (sampel).
Bandingkan F Hit dengan F (k,nk1)α

Asumsiasumsi dasar OLS
Pendugaan OLS akan bersifat BLUE (Best Linier Unbiased Estimate) jika memenuhi 3 asumsi utama, yaitu: Tidak ada multikolinieritas Tidak mengandung Heteroskedastisitas Bebas dari otokorelasi

BLUE jika:
Penduga bersifat linear
Dan efisien ( tak bias dan varians minimum)

Multikolinieritas Multikolinieritas: adanya hubungan
linier antara regressor. Misalkan terdapat dua buah regressor, X1 dan X2. Jika X1 dapat dinyatakan sebagai fungsi linier dari X2, misal : X1 = γ X2, maka ada kolinieritas antara X1 dan X2. Akan tetapi, bila hubungan antara X1 dan X2 tidak linier, misalnya X1 = X22 atau X1 = log X2, maka X1 dan X2 tidak kolinier.

Ilustrasi
Yi = β 0 + β 1X1 + β 2X2 + β 3X3 + ui
Y : KonsumsiX1 : Total PendapatanX2 : Pendapatan dari upahX3 : Pendapatan bukan dari upah
Secara substansi: total pendapatan (X1) = pendapatan dari upah (X2) + pendapatan bukan dari upah (X3). Bila model ini ditaksir menggunakan Ordinary Least Square (OLS), maka β i tidak dapat diperoleh, karena terjadi perfect multicollinearity. Tidak dapatnya β diperoleh karena ( XT X )1, tidak bisa dicari.

Data Perfect Multikolinieritas
11811629969223827619656416514812X3X2X1
Nilainilai yang tertera dalam tabel menunjukan bahwa Antara X1 dan X2 mempunyai hubungan: X2 = 4X1. Hubungan seperti inilah yang disebut dengan perfect multicollinearity.

Akibat Multikolinieritas
Varians besar (dari taksiran OLS) Interval kepercayaan lebar (variansi besar ⇒
Standar Error besar ⇒ Interval kepercayaan lebar) R2 tinggi tetapi tidak banyak variabel yang
signifikan dari uji t. Terkadang taksiran koefisien yang didapat akan
mempunyai nilai yang tidak sesuai dengan substansi, sehingga dapat menyesatkan interpretasi.

Kesalahan Interpretasi“Interpretasi dari persamaan regresi ganda secara implisit bergantung pada asumsi bahwa variabel-variabel bebas dalam persamaan tersebut tidak saling berkorelasi. Koefisien-koefisien regresi biasanya diinterpretasikan sebagai ukuran perubahan variabel terikat jika salah satu variabel bebasnya naik sebesar satu unit dan seluruh variabel bebas lainnya dianggap tetap. Namun, interpretasi ini menjadi tidak benar apabila terdapat hubungan linier antara variabel bebas”
(Chatterjee and Price, 1977).
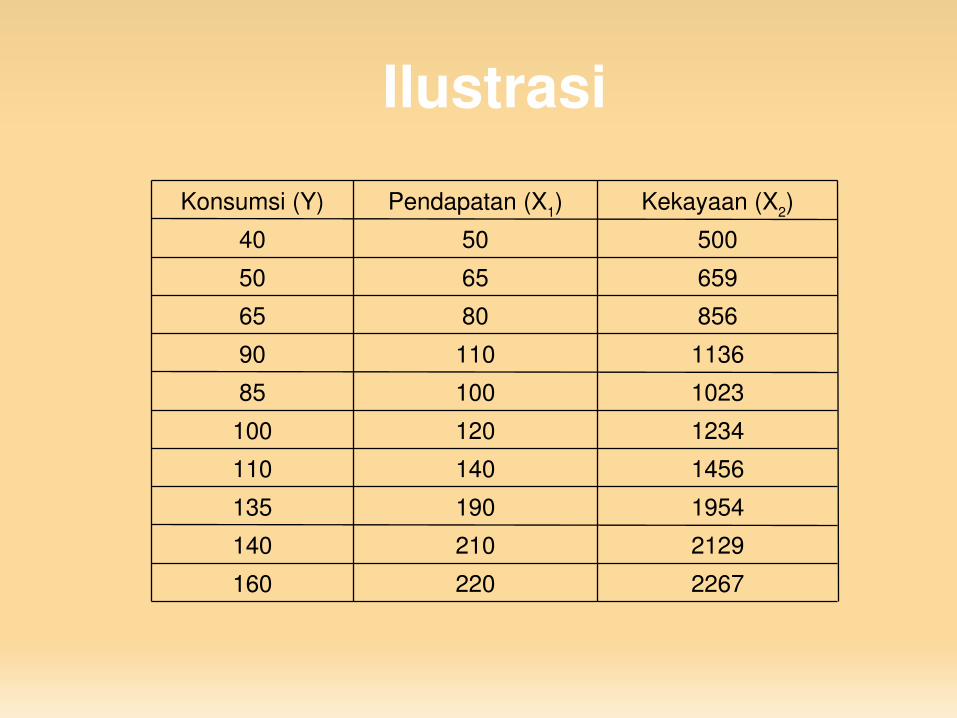
Ilustrasi
2267220160
2129210140
1954190135
1456140110
1234120100
102310085
113611090
8568065
6596550
5005040
Kekayaan (X2)Pendapatan (X1)Konsumsi (Y)

Ilustrasi
Model:Y = 12,8 – 1,414X1 + 0,202 X2
SE (4,696) (1,199) (0,117)t (2,726) (1,179) (1,721)
R2 = 0,982
R2 relatif tinggi, yaitu 98,2%. Artinya? Uji t tidak signifikan. Artinya? Koefisien X1 bertanda negatif. Artinya?

Ilustrasi: Model dipecah
Dampak Pendapatan pada Konsumsi Y = 14,148 + 0,649X1
SE (5,166) (0,037) t (2,739) (17,659)
R2 = 0,975R2 tinggi, Uji t signifikan, dan tanda X1 positif.
Dampak Kekayaan pada Konsumsi Y = 13,587 + 0,0635X2
SE (4,760) (0,003) t (2,854) (19,280)
R2 = 0,979 R2 tinggi, Uji t signifikan, dan tanda X2 positif.
X1 dan X2 menerangkan variasi yang sama. Bila 1 variabel saja cukup, kenapa harus dua?

Mendeteksi Multikolinieritas
1. Membandingkan R2 dan nilai tstat R2 cukup tinggi (0,7 – 1,0) tetapi ujitnya
untuk masing masing koefisien regresinya menunjukkan tidak signifikan.
Tingginya nilai R2 merupakan syarat yang cukup (sufficient) akan tetapi bukan merupakan syarat yang penting untuk terjadinya multikorelineartitas, sebab pada R2 yang rendah (<5%) bisa juga terjadi multikolinearitas.

2. Menggunakan Matriks Korelasi antara variabel independent.
Jika korelasi antara variable independent kuat ( > 0.70 ) menjadi dugaan adanya multikolinearitas

3. VIF (Variance Inflation Factor) dan Tolerance Value (TOL)
VIF j=1
1 −R j2
; j = 1,2,……,k
k adalah banyaknya variabel bebas
adalah koefisien determinasi antara variabel bebas kej dengan variabel bebas lainnya.
R j2
Batas nilai VIF adalah 10. Oleh karena itu, dapat disimpulkan bahwa kolinieritas tidak ada jika nilai VIF dibawah batas nilai tersebut

VIF ini mempunyai hubungan dengan Tolerance (TOL), dimana hubungannya adalah sebagai berikut:
TOL j=1
VIF=1−R j
2
Variabel bebas dinyatakan tidak multikolinieritas jika TOL tidak melebihi 0.10

4. Meregresikan variabel independent X dengan variabel independent variabelvariabel lain, kemudian dihitung R2 nya yaitu dengan uji F (uji signifikansi).
Jika F* adalah F hitung maka :
Jika F* > F tabel, artinya Ho ditolak; H1 diterima ada multikolinearitas
Jika F* < F tabel, artinya Ho diterima; H1 diterima tidak ada multikolinearitas

Mengatasi multikolinieritas
Melihat informasi sejenis yang ada ( teori ekonomi atau penelitian sebelumnya)
Kombinasi crosssection dan time series Tidak mengikutsertakan salah satu variabel yang
kolinier – Banyak dilakukan.– Hatihati, karena dapat menimbulkan specification bias
yaitu salah spesifikasi kalau variabel yang dibuang merupakan variabel yang sangat penting.
Mentransformasikan variabel : first difference method
Mencari data tambahan

Heteroskedastisitas
Variasi Error tidak konstan. Umumnya terjadi pada data cross section. Misal
data konsumsi dan pendapatan, atau data keuntungan dan asset perusahaan
Pelanggaran homoskedastis membuat penduga OLS tetap tak bias dan konsisten , tetapi tidak lagi efisien
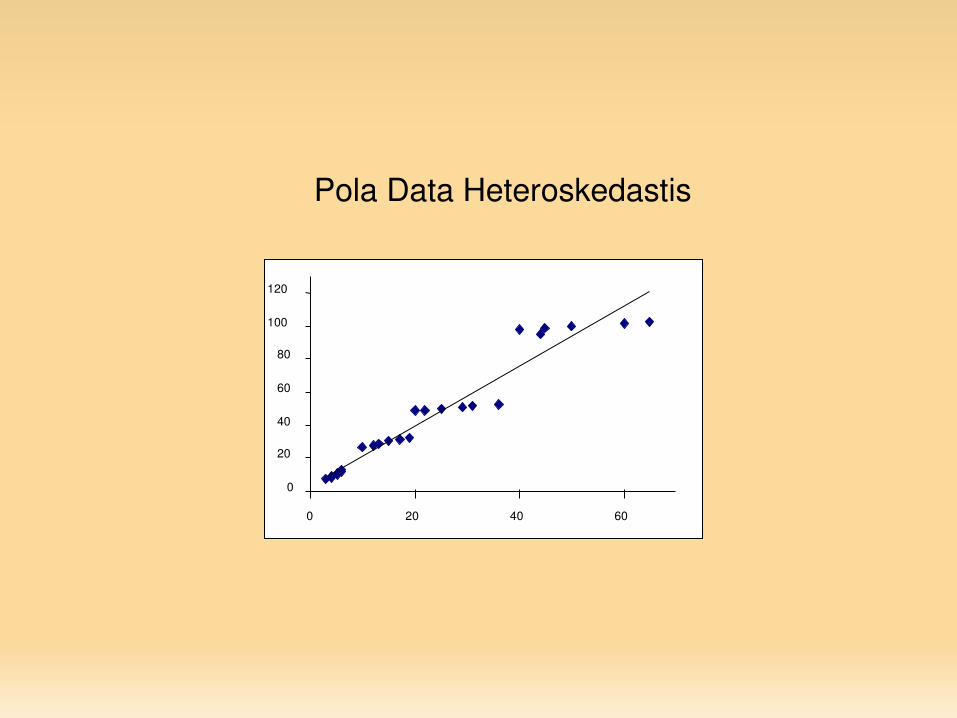
0
20
40
60
80
100
120
0 20 40 60
Pola Data Heteroskedastis

Penyebab
Adanya errorlearning model ( kesalahanjam praktek)
Discretionary yang lebih besar untuk kasus income yang besar (konsumsi pendapatan)
Teknik pendataan yang semakin baik ( kesalahan – kemajuan teknik )

Data Heteroskedastisitas
Fakta: hubungan positif antara X dan Y, dimana
nilai Y meningkat searah dengan nilai X. semakin besar nilai variabel bebas (X)
dan variabel bebas (Y), semakin jauh koordinat (x,y) dari garis regresi (Error/residual makin membesar)
besarnya variasi seiring dengan membesarnya nilai X dan Y. Atau dengan kata lain, variasi data yang digunakan untuk membuat model tidak konstan.

Pemeriksaan Heteroskedastisitas
1. Metode Grafik Prinsip: memeriksa pola residual (ui
2) terhadap taksiran Yi.
Langkahlangkah: Run suatu model regresi Dari persamaan regresi, hitung ui
2 Buat plot antara ui
2 dan taksiran Yi

Pola Grafik
ui2
i
Pengamatan:1.Tidak adanya pola yang sistematis.2.Berapapun nilai Y prediksi, residual kuadratnya relatif sama. 3.Variansi konstan, dan data homoskedastis.
,
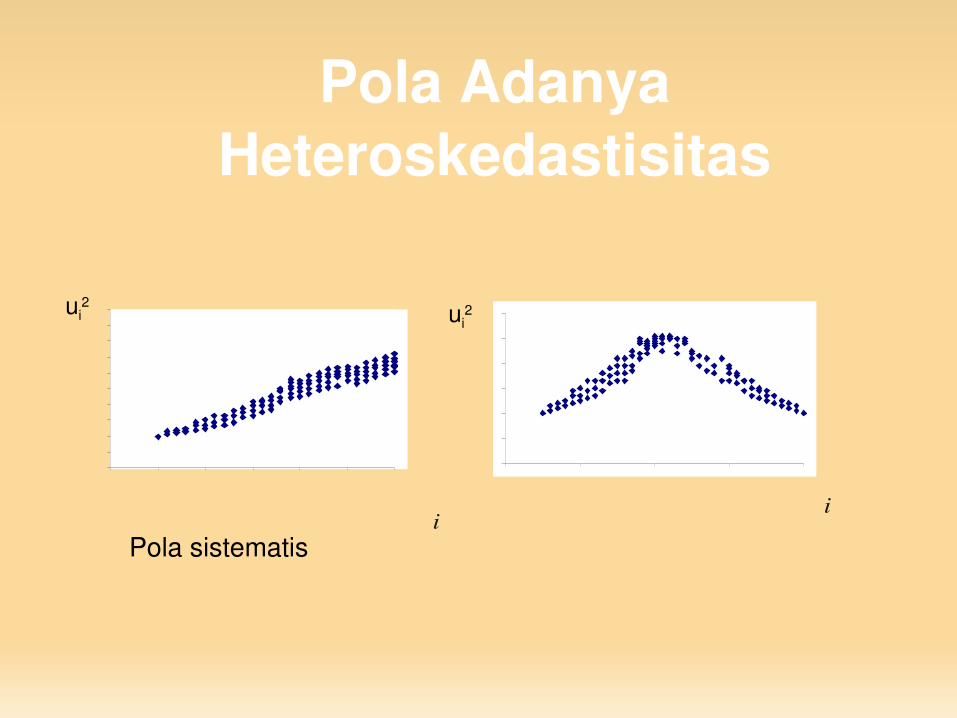
Pola Adanya Heteroskedastisitas
Pola sistematis
ui2 ui
2
ii

2. Uji Park
Prinsip: memanfaatkan bentuk regresi untuk melihat adanya heteroskedastisitas dimana ui
2
adalah suatu fungsi yang menjelaskan Xi
Langkahlangkah yang dikenalkan Park: 1. Run regresi Yi = α 0 + β 0Xi + ui
2. Hitung ln ui2
3. Run regresi ln ui2 = α + β ln Xi + vi
4. Lakukan ujit. Bila β signifikan, maka ada
heteroskedastisitas dalam data.
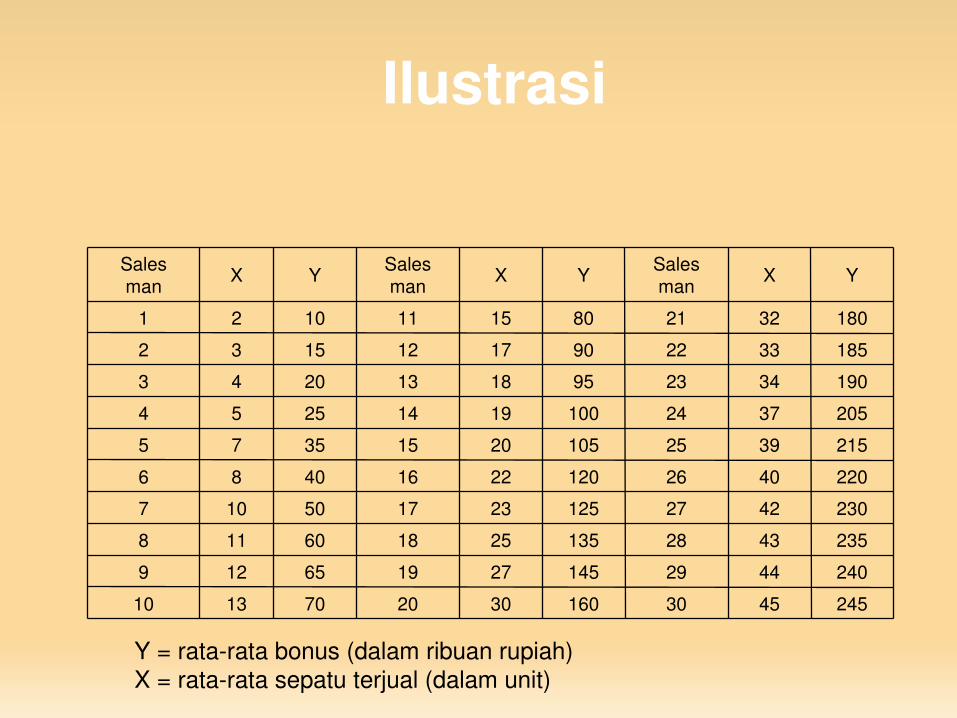
Ilustrasi
24545301603020701310
2404429145271965129
2354328135251860118
2304227125231750107
220402612022164086
215392510520153575
205372410019142554
19034239518132043
18533229017121532
18032218015111021
YXSalesmanYXSales
manYXSalesman
Y = ratarata bonus (dalam ribuan rupiah)X = ratarata sepatu terjual (dalam unit)

Ilustrasi
Y = 3,1470 + 5,5653 XSE (0,0305) R2 = 0,9992
slope signifikan: Bila sepatu terjual naik 1 unit, maka bonus akan naik Rp.5.563.
Apakah ada heteroskedastisitas ?
Run regresi, didapat:ln ui
2 = 6,0393 – 2,1116 ln Xi
SE (0,0090) R2 = 0,9995
Menurut uji t, β signifikan sehingga dalam model penjualan sepatu vs bonus di atas ada heteroskedastisitas.

3. Uji Goldfeld – Quandt Metode Goldfeld – Quandt sangat populer untuk digunakan,
namun agak merepotkan, terutama untuk data yang besar. Langkahlangkah pada metode ini:
Urutkan nilai X dari kecil ke besar Abaikan beberapa pengamatan sekitar median, katakanlah
sebanyak c pengamatan. Sisanya, masih ada (N – c) pengamatan
Lakukan regresi pada pengamatan 1, dan hitung SSE 1 Lakukan regresi pada pengamatan 2 dan hitung SSE 2. Hitung df Lakukan uji F > F hit = SSE2 / SSE1
BilaF hit > F tabel, kita tolak hipotesis yang mengatakan data mempunyai variasi yang homoskedastis > terjadi hetero

Ilustrasi
Ada 30 pengamatan penjualan sepatu dan bonus. Sebanyak 4 pengamatan yang di tengah diabaikan sehingga tinggal 13 pengamatan pertama (Kelompok I) dan 13 pengamatan kedua (Kelompok II).
Regresi berdasarkan pengamatan pada kelompok I:Y = 1,7298 + 5,4199 X R2 = 0,9979 RSS1 = 28192,66 df1 = 11
Regresi berdasarkan pengamatan pada kelompok II:Y = 0,8233 + 5,5110 X R2 = 0,9941RSS2 = 354397,6 df2 = 11

Ilustrasi
=λRSS 2/df 2
RSS1/df 1
= 354397,6/11 28192,66/11
= 12,5706
Dari tabel F, didapat F = 2,82 sehingga λ > F
Kesimpukan: ada heteroskedastisitas dalam data

Mengatasi heteroskedastisitas
1. Transformasi dengan Logaritma Transformasi ini ditujukan untuk memperkecil skala
antar variabel bebas. Dengan semakin ‘sempitnya’ range nilai observasi, diharapkan variasi error juga tidak akan berbeda besar antar kelompok observasi.
Keuntungan tambahan berupa interpretasi elastisita
Adapun model yang digunakan adalah:Ln Yj = β0 + β1 Ln Xj + uj

2. Metode Generalized Least Squares (GLS)
(
Perhatikan model berikut :Yj = β 1 + β 2 Xj + uj dengan Var (uj) = σ j
2
Masingmasing dikalikan 1s j
Y j
s j
=β1 1s j +β2 X j
s j u j
s j Maka diperoleh transformed model sebagai berikut :
Yi* = β 1* + β 2Xi* + ui*

GLS
Kita periksa dulu apakah ui* homoskedastis ?
E ui 2
σi 2 = 1
σi 2
E u i 2 =1σ
i 2
σ i2 =1E(ui*2) = konstan

Transformasi
Oleh karena mencari σ j2 hampir tidak pernah diketahui, maka
biasanya digunakan asumsi untuk mendapat nilai σ j2. Asumsi
ini dapat dilakukan dengan mentransformasikan variabel. Ada beberapa jenis, yaitu:
1X j
1. Transformasi dengan
Asumsi: σ j2 = E u j
2 =σ2 X j2
Akibat transformasi, model menjadi: Y j
X j
=β0 1X j +β1 u j
X j atau dapat ditulis dengan: Yi* = β 0 X* + β 1 + vi

Transformasi
Apakah sudah homoskedastis? Perhatikan bukti berikut:
E uj 2
Xj 2 = 1
Xj 2
E u j 2 =1
Xj2σ2 X j 2 =σ2E(vi
2) = konstan
2. Transformasi dengan 1
X iAsumsi: σ j
2 = E u j2 =σ2 X j
3. Transformasi dengan E(Yi), dimana E(Yi) = β 1 + β 2 X2
E u j2 =σ2
[E Y j ]2Asumsi: σ j
2 =

Otokorelasi Otokorelasi: korelasi antara variabel itu
sendiri, pada pengamatan yang berbeda waktu atau individu. Umumnya kasus otokorelasi banyak terjadi pada data time series Kondisi sekarang dipengaruhi waktu lalu. Tapi pada data cross section juga mungkin terjadi
E (ui uj) menjadi tidak = 0 Akibat yang ditimbulkan penaksir
menjadi tidak efisien

Penyebab
Inersia Bias Spesifikasi : ada variabel penting
yang diexclude Fenomena cobweb Adanya lag

Mendeteksi Otokorelasi
Pola Autokorelasi
ui ui * * ** * * * * * * * * * ** * * * Waktu/X * ** Waktu/X * * *
Gambar nomor (1) menunjukan adanya siklus, sedang nomor (2) menunjukan garis linier. Kedua pola ini menunjukan adanya otokorelasi.
1. Grafik

2. Uji DurbinWatson ( Uji d)
d=∑t= 2
N
ut−u t−1 2
∑t=1
N
u t 2
Statistik Uji
Dalam Paket Program SPSS/EViews Sudah dihitungkan

Aturan main menggunakan uji DurbinWatson :
Bandingkan nilai d yang dihitung dengan nilai dL dan dU dari tabel ( melihat jumlah observasi dan variabel bebas) dengan aturan berikut :
Bila d < dL ⇒ tolak H0; Berarti ada korelasi yang positif atau kecenderungannya ρ = 1
Bila dL ≤ d ≤ dU ⇒ kita tidak dapat mengambil kesimpulan apaapa
Bila dU < d < 4 – dU ⇒ jangan tolak H0; Artinya tidak ada korelasi positif maupun negatif
Bila 4 – dU ≤ d ≤ 4 – dL ⇒ kita tidak dapat mengambil kesimpulan apaapa
Bila d > 4 – dL ⇒ tolak H0; Berarti ada korelasi negatif

Gambar aturan main menggunakan uji DurbinWatson
Tidak tahu Tidak tahu
Korelasi positif Tidak ada korelasi Korelasi negatif
0 dL dU 4dU 4dL 4

Mengatasi Otokorelasi: Metode Pembedaan Umum (Generalized Differences)
Yt = β0 + β1Xt + ut dan ut = uρ t1 + vt
Untuk waktu ke t1: Yt1 = β0 + β1Xt1 + ut1
Bila kedua sisi persamaan dikali dengan , maka:ρ Yρ t1 = ρ β0 + ρ β1Xt1 + uρ t1
Sekarang kita kurangkan dengan persamaan Model Yt Yρ t1 = (β0 ρ β0) + β1(Xt Xρ t1) + (ut uρ t1)
Persamaan tersebut dapat dituliskan sebagai:Yt* = β0 (1 ) + ρ β1Xt* + vt
Dimana: Yt* = Yt Yρ t1 dan Xt* = Xt Xρ t1
Idealnya kita harus dapat mencari nilai . ρTapi dalam banyak kasus, diasumsikan
= 1, ρsehingga:Yt* = Yt Yt1Xt* = Xt Xt1

Pemilihan Model 1. R2 Adjusted
Perhatikan Model:(i) LABA = 5053,712 + 0,049 KREDIT; R2 = 80,6%(ii) LABA = 45748,484 + 0,0106 ASET + 0,0081 KREDIT; R2= 87,4%.
Model manakah yang lebih baik ditinjau dari koefisien determinasinya?.
Sekarang kita perhatikan kembali formula untuk menghitung R2
R2=
SSRSST
=1−SSESST
=1−∑ ui
2
∑ Y i−Y 2

R2 Adjusted SST sama sekali tidak dipengaruhi oleh jumlah variabel bebas,
karena formulasinya hanya memperhitungkan variabel terikat SSE dipengaruhi oleh variabel bebas, dimana semakin banyak
variabel bebas, maka nilai SSE cenderung semakin kecil, atau paling tidak tetap. SSE kecil, maka nilai SSR akan besar.
Akibat kedua hal tersebut, maka semakin banyak variabel bebas yang dimasukkan dalam model, maka nilai R2 akan semakin besar.
R2=1−∑ ui
2/ n−k
∑ Y i−Y / n−1
Pemilihan Model
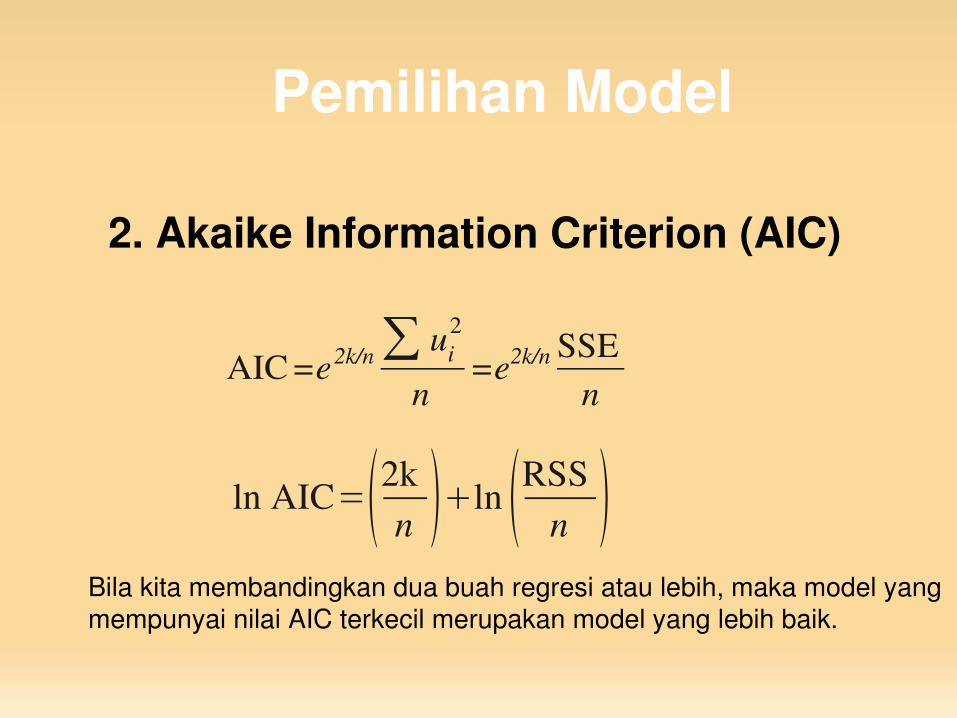
2. Akaike Information Criterion (AIC)
AIC=e2k/n∑ ui2
n=e2k/n SSE
n
ln AIC=2kn ln RSS
n Bila kita membandingkan dua buah regresi atau lebih, maka model yang mempunyai nilai AIC terkecil merupakan model yang lebih baik.

Ilustrasi
LABA = 5053,712 + 0,049 KREDIT; SSE = 3,28E+12 LABA = 58260,461 + 0,013 ASET; SSE = 2,1E+12 LABA = 45748,484 + 0,0106 ASET + 0,0081 KREDIT; SSE =
2,17E+12
ln AICi =2kn ln RSS
n =2x250 ln 3,28E12
50 =24 , 9868
ln AIC ii =2kn ln RSS
n =2x250 ln 2,1E12
50 =24 , 5409
ln AIC iii =2kn ln RSS
n =2x350 ln 2,17E12
50 =24 , 6137
Pemilihan Model
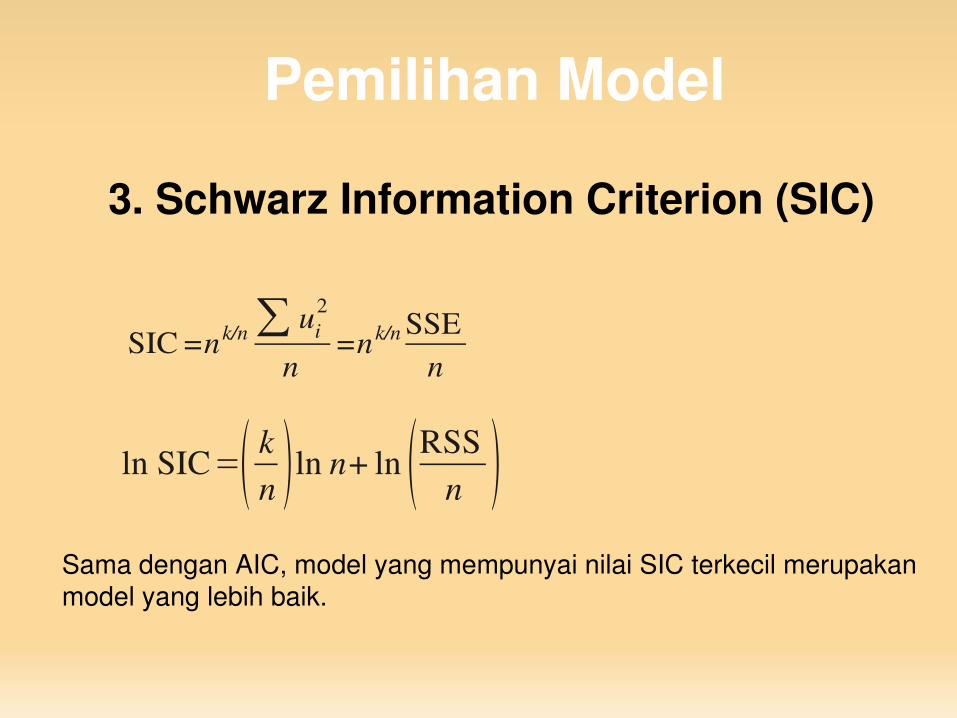
3. Schwarz Information Criterion (SIC)
SIC =nk/n∑ ui2
n=nk/n SSE
n
ln SIC= kn ln n+ ln RSS
n Sama dengan AIC, model yang mempunyai nilai SIC terkecil merupakan model yang lebih baik.

Ilustrasi
ln SIC i = kn ln n+ ln RSS
n = 250 ln50ln 3,28 E+12
50 =25 ,06
ln SIC ii = kn ln n+ ln RSS
n = 250 ln50ln 2,1E12
50 =24 , 62
ln SIC iii = kn ln n+ ln RSS
n = 350 ln50ln 2,17 E+ 12
50 =24 ,73
Top Related