二、公司簡介與治理 - chengfwa.com.t · 22.3產品介紹 ((1) 產品介產品介紹 紹紹紹 振發公司係電腦、電信、網路及電子工業所需之精密沖壓件的製造加工商。
description
TFIDF 方法之介紹
指導教授 : 王宗一 老師 報告者 : 林群貿
Outline
1. 前言 2.TFIDF 演算法介紹 3. 應用 TFIDF 觀念於自動摘要實作評估 4. 結論

前言 詞頻 (Term Frequency, TF) 的觀念起源於 (Lu
hn,1958) 從進行自動索引的實驗中,為統計詞彙的出現頻率,發現除卻高頻與低頻者,所留下的中頻( middle-frequency )字詞,多半是比較有意義的,因而提出「關鍵字詞適度詞頻論」 (resolving power of significant words) 。

前言 而後引發日後諸多學者如: Sparck Jones(197
2), Salton & McGill (1983) 等人投入自動文件處理的興趣。

一般自動索引的主題分析主要可以歸納成三種不同的方式 : 1. 語意( semantic ) 2. 語法( syntactic ) 3. 統計( statistical )

統計學派可以說是三種方式中的主流,多數的自動摘要與自動分類也遵循 Sparck Jones與 Salton 所建構,以文件詞彙頻率為主的統計學派。 其中 TFIDF 方法就是計算文件詞彙頻率 , 常用的方法。

Term frequency and Document Frequency
Term frequency tfij: the number of occurrences of Tj in Di
Document Frequency dfj :(document frequency of term Tj) is number of documents in which Tj occurs

Inverse Document Frequency
Inverse Document Frequency (IDF) for term Tj
idf Ndfj
j
log

應用 TFIDF 觀念於自動摘要實作評估 嘗試以文句中重要關鍵詞出現的頻率及其與逆向文件的關係,推估句子的重要性,採 TF
IDF 觀念用以計算句子權重,並擷取權重值排行在前的句子用以組合成摘要。
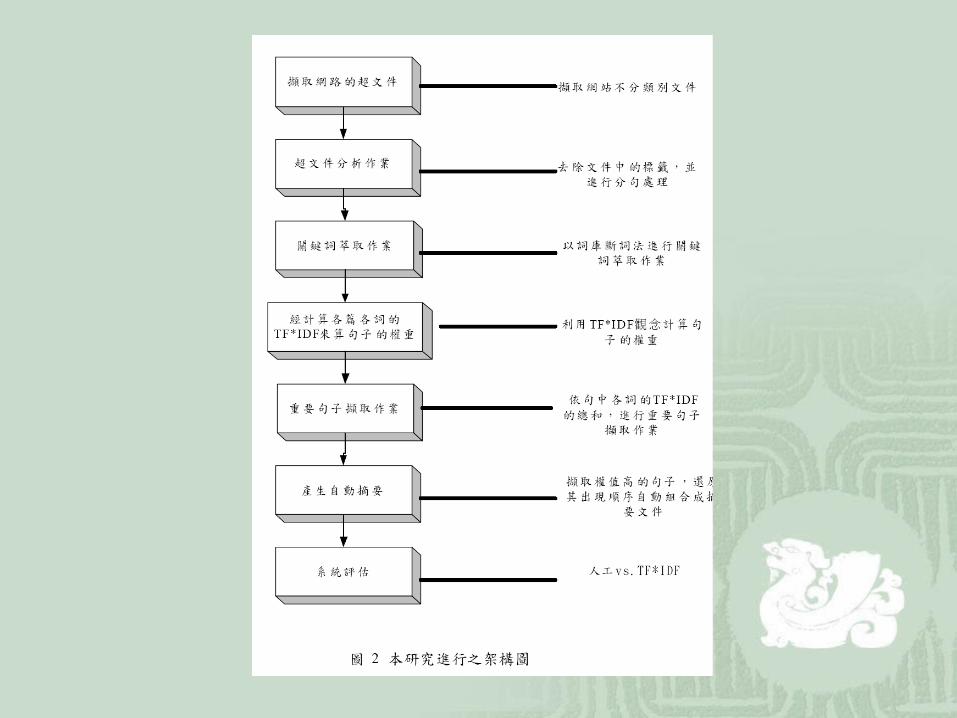

擷取網路的超文件 以聯合新聞網、中央日報網和台灣新生報網三個網站的文件為擷取對象。其中聯合新聞網的文章篇數計擷取 18758 筆、中央日報的新聞 11864 篇,台灣新聞報則是摘取近三年來的社論資料 544 筆。總計類別包括了社論、經貿、政治、科技、藝文專欄、國際新聞、休閒等七類。

關鍵詞萃取作業 英文:對於英文的處理,我們透過多重判斷處理 ( 包括半形字元、全形字元、全形符號字元及注音符號處理 ) 之後,利用停用字詞 表去除停用字 (Stopword) ,再將英文關鍵字載入表格。

關鍵詞萃取作業 中文 : 在字詞處理方面,本研究以詞庫斷詞法進行斷詞作業,為顧及辭彙的有效及新穎性,採中研院八萬詞目,加上最近教育部國語推行委員會所公佈的新詞語料庫,進行關鍵詞的篩選。

關鍵詞萃取作業 以 2 字詞到 9 字詞為主,並以長詞為優先選取對象。基於字數越長的詞出現的機率越少,實質代表的意義卻越重要,因此對於字詞長度均以加乘本身字數的方式,進行加權 如:〔知識〕出現 10 次,轉換後〔 10次 *2 字詞 =20 次〕,〔知識管理〕原出現 5次,轉換後〔 5 次 *4 字詞 =20 次〕,藉由加權方式,以提高長詞的詞頻權重。

重要句子擷取作業 字詞選取原則須符合詞頻要夠、類別集中 (conformity) 、本類分佈廣 (Uniformity) 的原則。因此關鍵詞彙的權重多以詞頻與逆向文件頻率的內積 (TF * IDF) 計算出,句子的權重則包括所有出現在該句子的重要詞彙權重總合。

計算公式如下 :
(1) TFij =代表單字 j 在文件 I 的出現頻率 (2)
N :代表所有文件的總數 dfj :代表單字 j 有出現過的文章總數
idf Ndfj
j
log

這兩者相乘之後,即代表修正過後的關鍵詞TFij 在文件 D 的加權 (weight) ,如下式所述:
句子中各個詞彙的 TF*IDF 值經算出後, 進行加總所得出的值,即象徵該句子的權重。

例若有一個關鍵詞 ”大學“ 在一篇文章出現 1
0 次 , 而此篇文章共有 100 個關鍵詞 , 所有文件集合共有 10000 篇文章 , 而 ”大學”一詞在 10000 篇文章內 ,曾出現在 5 篇文章 TF=10/100=0.1 IDF=log(10000/5) 11≒ 加權值 =0.1*11=1.1

產生自動摘要 摘要的目的在於產生一個言簡意垓的文件描述,它應比文件標題更具敘述性,但又短的可讓人一眼就明瞭內文意旨。利用 TFIDF 方法用以計算句子權重,並擷取權重值排行在前的句子用以組合成摘要。

摘要的評估一般認為是一件困難且主觀的工作,所以以人工評選句子的交集率作為比對依據。文件樣本乃隨機抽取自實驗資料庫中,字數在 1000 字以上的文件 60 篇 ,每篇文件由三位受測者進行評選,每位受測者最多評選 5 篇。

評量準則

評量準則 (1) 回現率 (recall ratio) :將人工評估值認為重要的句子,作為文件相關句子總數的基 數,將系統所擷取到的重要句子,作為分 子,可計算出系統選句的正確率。

(2).精確率 (precision ratio) :將系統評估值,作為文件相關句子總數的基數,原則上,做法與回現率差不多

(3).樂觀率 (optimistic ratio) :將 3 位評量者所 評選的同一篇文章重要句子評分與 TF*IDF 的結果比較,取其中重疊率最多者,計算兩者的重疊比率稱之為樂觀率。 (4).悲觀率 (Pessimistic ratio) :作法類似樂觀評估,但是選取其中一組重疊率最低者,則此最低重疊率者就稱之為悲觀率。
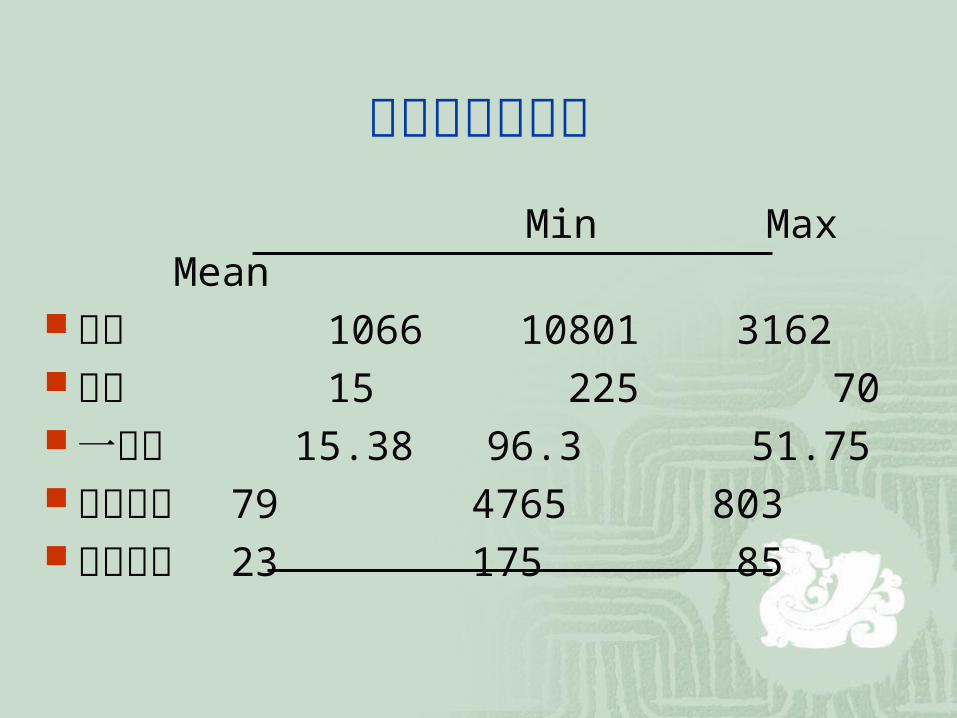
基本資料統計表 Min Max Mean 字數 1066 10801 3162 句數 15 225 70 一致性 15.38 96.3 51.75 人工時間 79 4765 803系統時間 23 175 85

實驗結果樂觀率的平均高達 93.17% ,表示自動機制所擷取的重要句子,與評量者的重疊率最高平均可超過九成﹔悲觀率的平均為 65.09% ,也說明了系統所擷取的句子與評量者的重疊率最低平均可達到六成五的水準。

就評量時間而言,評量者真正花在評量一篇的時間最短 79 秒,最長 4765 秒﹔系統運作的時間受到分句數的影響大於字數,時間最短 23 秒,最長 175 秒。可見人工作業即使未包括閱讀時間,仍需要 27 倍於自動機制的時間。

結論這次實驗中,我們利用了辭庫比對法來做斷詞、使用句子來做為我們選取摘要的單位、以及利用 TFIDF 和相似度的算法來算出句子 的權重,進而產生摘要。

自動摘要可有效的幫助使用者在有效的時間內,了解該篇文章,減少閱讀所花費的時間,又可避免不必要的全文鏈結,進而降低 網路的下載,所以這對整體的網路傳輸速度將會有極大的影響,也是本研究最主要的目的。