Tanulás az idegrendszerben - KFKIcneuro.rmki.kfki.hu/sites/default/files/tanulas14_0.pdf ·...
49
Tanulás az idegrendszerben Structure – Dynamics – Implementation – Algorithm – Computation - Function
Transcript of Tanulás az idegrendszerben - KFKIcneuro.rmki.kfki.hu/sites/default/files/tanulas14_0.pdf ·...

Tanulás az idegrendszerben
Structure – Dynamics – Implementation – Algorithm – Computation - Function
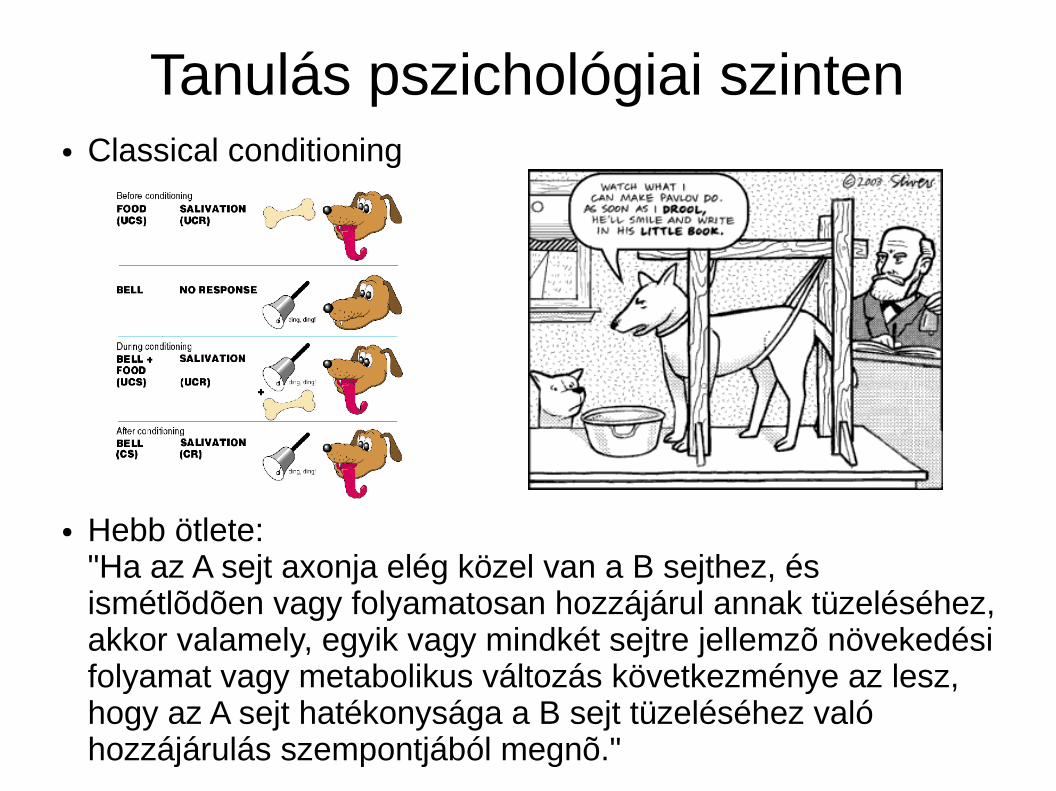
Tanulás pszichológiai szinten● Classical conditioning
● Hebb ötlete:"Ha az A sejt axonja elég közel van a B sejthez, és ismétlõdõen vagy folyamatosan hozzájárul annak tüzeléséhez, akkor valamely, egyik vagy mindkét sejtre jellemzõ növekedési folyamat vagy metabolikus változás következménye az lesz, hogy az A sejt hatékonysága a B sejt tüzeléséhez való hozzájárulás szempontjából megnõ."

A tanulás problémája matematikailag
● Modell paramétereinek hangolása adatok alapján
● Kettős dinamika● Változók (bemenet-kimenet leképezés) - gyors● Paraméterek - lassú
● Memória és tanulás különbsége● Memória használatánál a bemenetre egy konkrét kimenetet
szeretnék kapni a reprezentáció megváltoztatása nélkül● Tanulásnál minden bemenetet felhasználok arra, hogy finomítsam
a reprezentációt, miközben kimenetet is generálok
● Alapvető cél: predikciót adni a jövőbeli történésekre a múlt alapján

A tanulás alapvető típusai
● Felügyelt● Az adat: bemenet-kimenet párok halmaza● A cél: függvényapproximáció, klasszifikáció
● Megerősítéses● Az adat: állapotmegfigyelések és jutalmak● A cél: optimális stratégia a jutalom
maximalizálására
● Nem felügyelt, reprezentációs● Az adat: bemenetek halmaza● A cél: az adat optimális reprezentációjának
megtalálása / magyarázó modell felírása
● Egymásba ágyazások

Perceptron
● Bináris neuron: lineáris szeparáció● Két dimenzióban a szeparációs egyenes:
● Logikai függvények
= x1 w1 x2 w2 x2=−w1
w2
x1
w2

Tanulásra alkalmas neurális rendszerek
● Egyetlen sejt● Előrecsatolt hálózat● Rekurrens hálózat● Ezen az órán: rátamodell
● Paraméterek: súlyok, küszöbök● Különböző kimeneti nemlinearitások
– Lépcső: H (Heavyside)– Szigmoid: – Lineáris neuron
y=f (xw−θ)
Tanulásra alkalmas neurális rendszerek

Error-correcting tanulási szabályok
● Felhasználjuk azt az információt, hogy milyen messze van a céltól a rendszer
● Rosenblatt-algoritmus – bináris neuron
● Delta-szabály● Folytonos kimenetű neuron – gradiens-módszer
lineáris neuronra, egy pontpárra vonatkozó közelítéssel:
● Minsky-paper 1969: a neurális rendszerek csak lineáris problémákat tudnak megoldani
w(t+1)=w(t )+ϵ(tm− y (xm
))xm
wb(t+1)=wb(t )−ϵ∂ E∂ wb
E=12 ∑m
Ns
( tm− y (xm))2 ∂ E∂wb
=−∑m
N s
(tm− y (xm)) xm
w(t+1)=w+ϵ( tm− y (xm
))xm

Error-correcting tanulási szabályok
Rosenblatt-algoritmus – bináris neuron
W1
W2 Θ
W1
W2
b1
Egy konstans 1 bemenet és a b=-Θ (bias) bevezetésével kitranszformáljuka küszöböt. A bias tanulása így ekvivalens egy kapcsolatsúly tanulásával.
y=H(w1+w
2Θ) y=H(w
1+w
2+b)
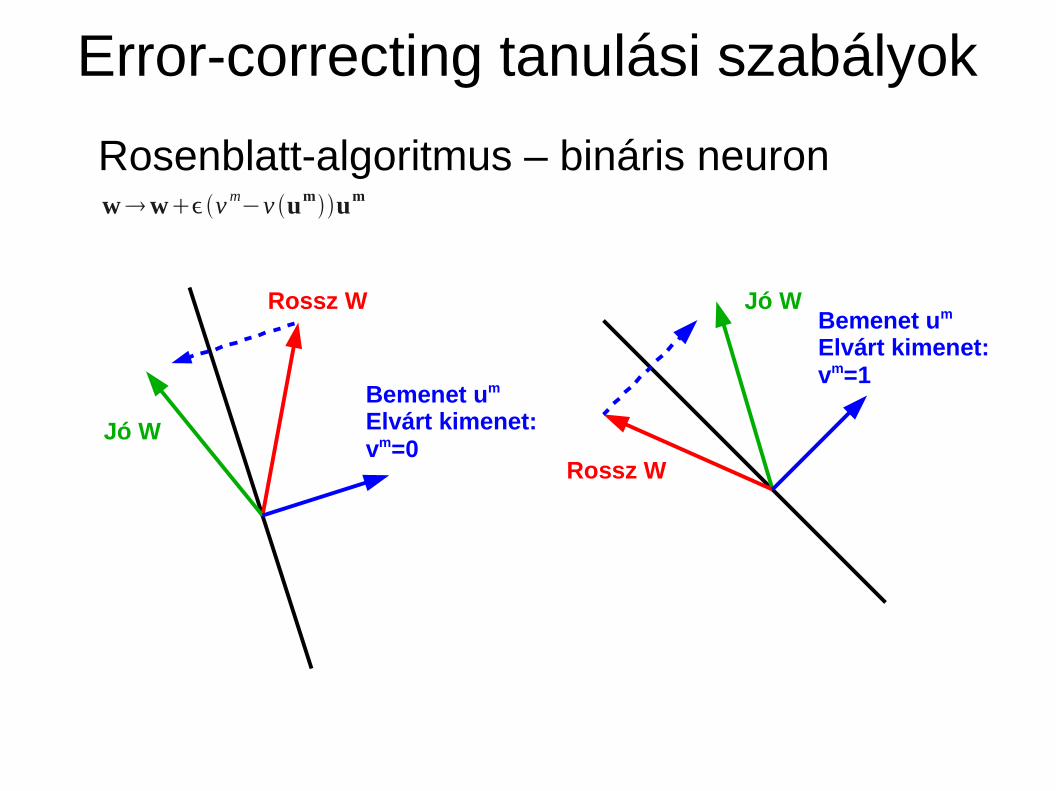
Error-correcting tanulási szabályok
Rosenblatt-algoritmus – bináris neuronwwv m−v umum
Bemenet um
Elvárt kimenet:vm=1
Jó W
Rossz W
Bemenet um
Elvárt kimenet:vm=0
Rossz W
Jó W
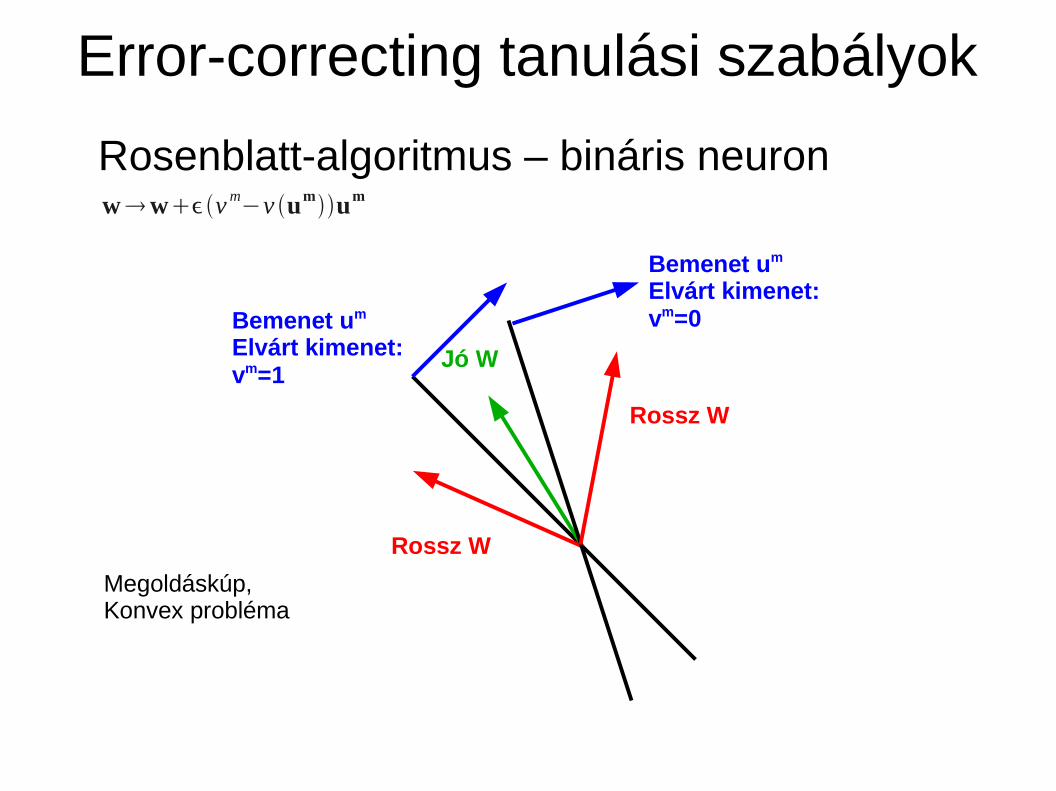
Error-correcting tanulási szabályok
Rosenblatt-algoritmus – bináris neuronwwv m−v umum
Bemenet um
Elvárt kimenet:vm=1
Jó W
Rossz W
Bemenet um
Elvárt kimenet:vm=0
Rossz W
Megoldáskúp,Konvex probléma
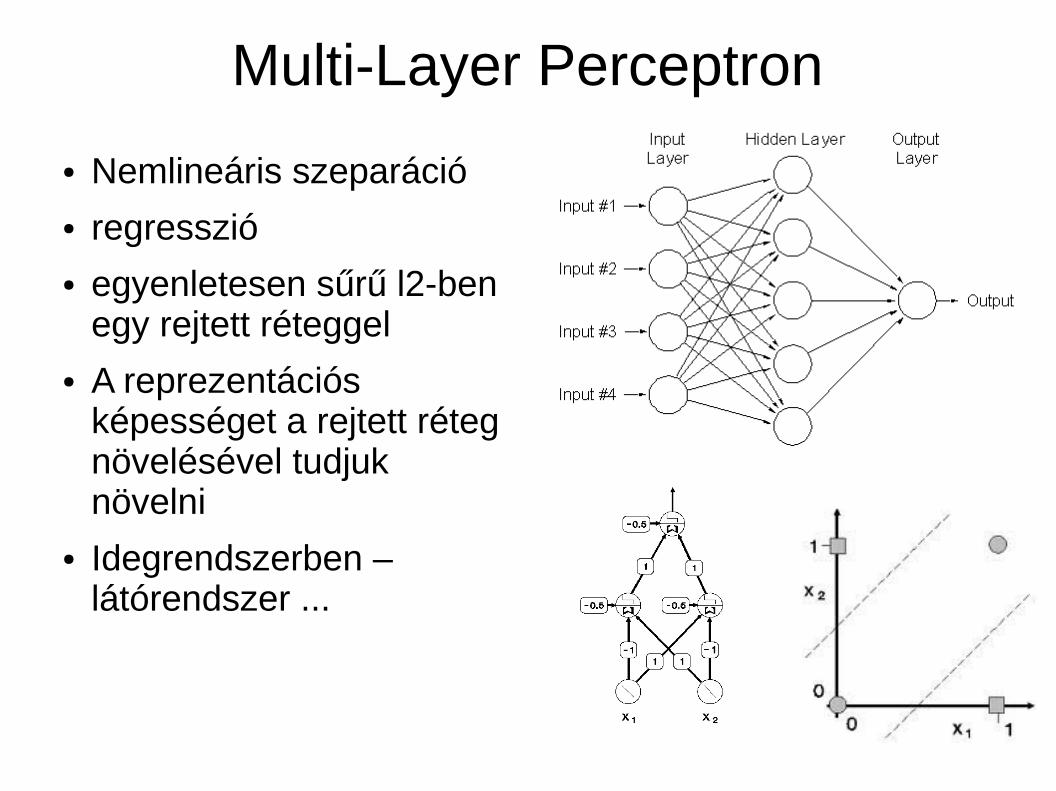
Multi-Layer Perceptron
● Nemlineáris szeparáció ● regresszió ● egyenletesen sűrű l2-ben
egy rejtett réteggel● A reprezentációs
képességet a rejtett réteg növelésével tudjuk növelni
● Idegrendszerben – látórendszer ...
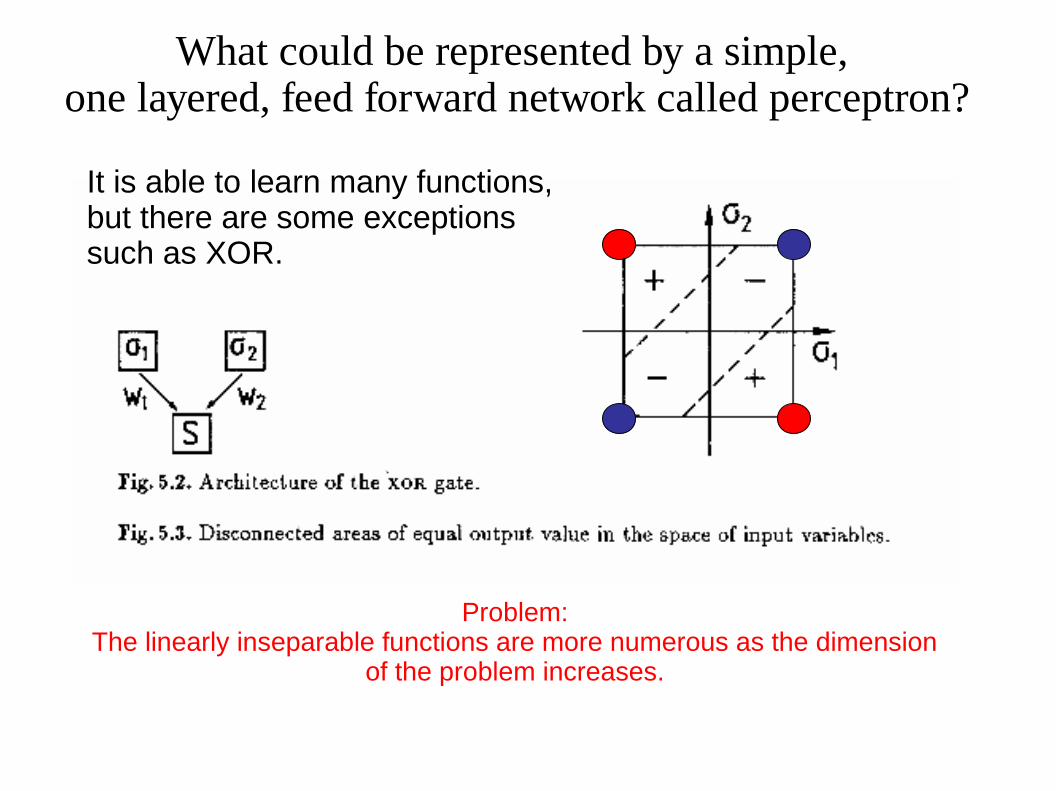
What could be represented by a simple, one layered, feed forward network called perceptron?
Problem:The linearly inseparable functions are more numerous as the dimension
of the problem increases.
It is able to learn many functions,but there are some exceptionssuch as XOR.
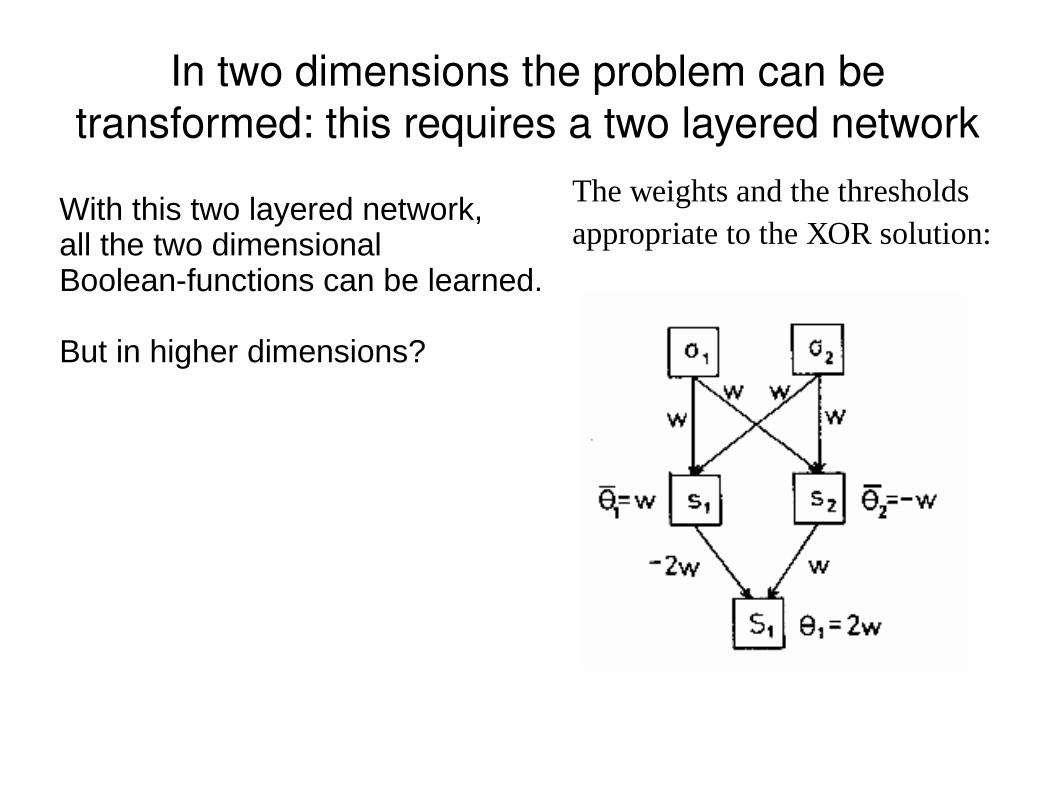
In two dimensions the problem can be transformed: this requires a two layered network
The weights and the thresholds appropriate to the XOR solution:
With this two layered network,all the two dimensionalBoolean-functions can be learned.
But in higher dimensions?
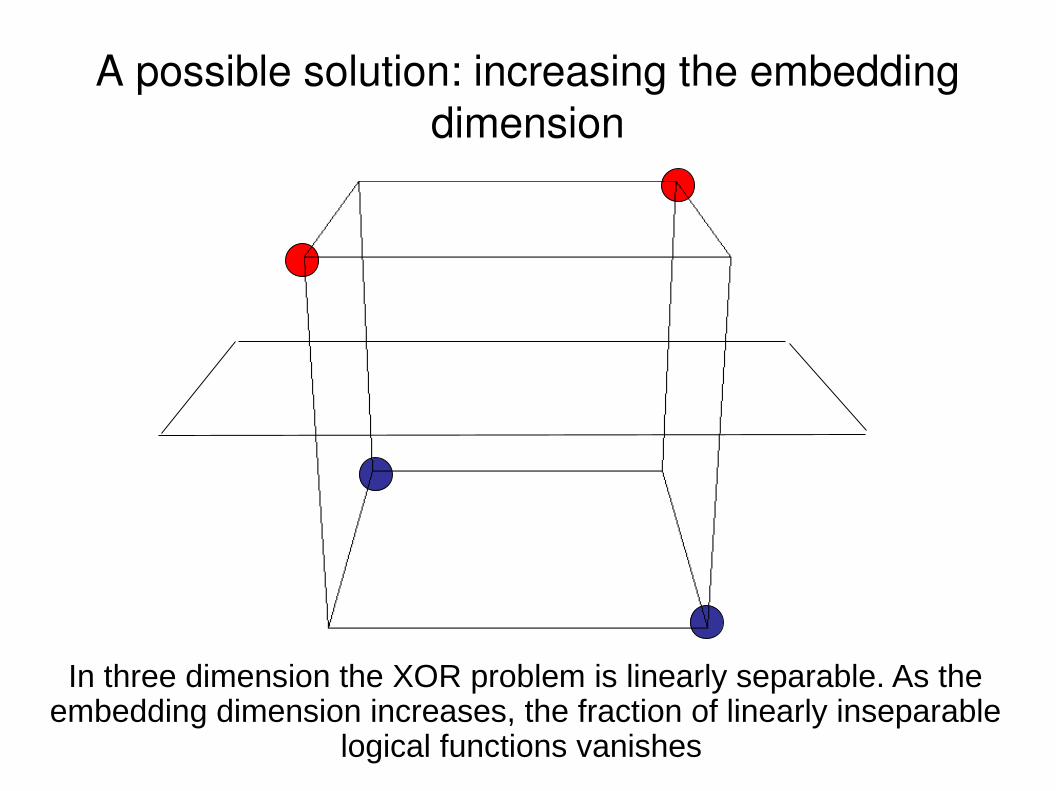
A possible solution: increasing the embedding dimension
In three dimension the XOR problem is linearly separable. As the embedding dimension increases, the fraction of linearly inseparable
logical functions vanishes

Soft-max kimeneti réteg,valószínűségi eloszlások reprezentációjára
pi= y i=e
zi
T
∑ ezi
T
A softmax réteg a logisztikus függvény általánosítása több változóra:
A logisztikus függvény 0 és 1 közé képzi le az aktivációt:
y=f (z)=1
(1+e− z)
Nem lokális, a kimenet a softmax rétegMinden neuronjának bemenetétől függ,nem csak az adott neuronétól.
T: hőmérséklet paraméterT->inf: egyenletes eloszlást adT->0: konvergál a Max függvényhez
A deriváltja szépen viselkedik és lokális,Mint a logisztikus függvény esetében
∂ y i
∂ zi
= y i(1− y i)

Error backpropagation● Bemenet/aktiváció: z
● Elvárt kimenet: tn
● Aktuális kimenet: y
● A hibafüggvény parciális deriváltjai:
● Mivel gradiens-módszer, a hibafüggvény lokális minimumába fog konvergálni.
dydz
= y (1− y )
∂ E∂wbi
=∂ E∂ y
∂ y∂ z
∂ z∂ wbi
w i(t+1)=wi(t )+( y−t n) y (1− y ) xi
δ j= y j (1− y j)∑ w jq δq
z=xw+b
y=f (z)=1
(1+e− z)
∂ E∂ y
=t n− y (x)
∂ z∂w i
=x i

Lassú konvergencia a korrelált változók mentén
Probléma: Erősen korrelált változók esetén a gradiens gyakran/általábanmajdnem merőleges a minimum valódi irányára.
Lehetséges megoldások:
Momentum módszer,
Hessian mátrix
Hessian mentes optimalizátor
Konjugált Grádiensek
Adaptív lépésköz
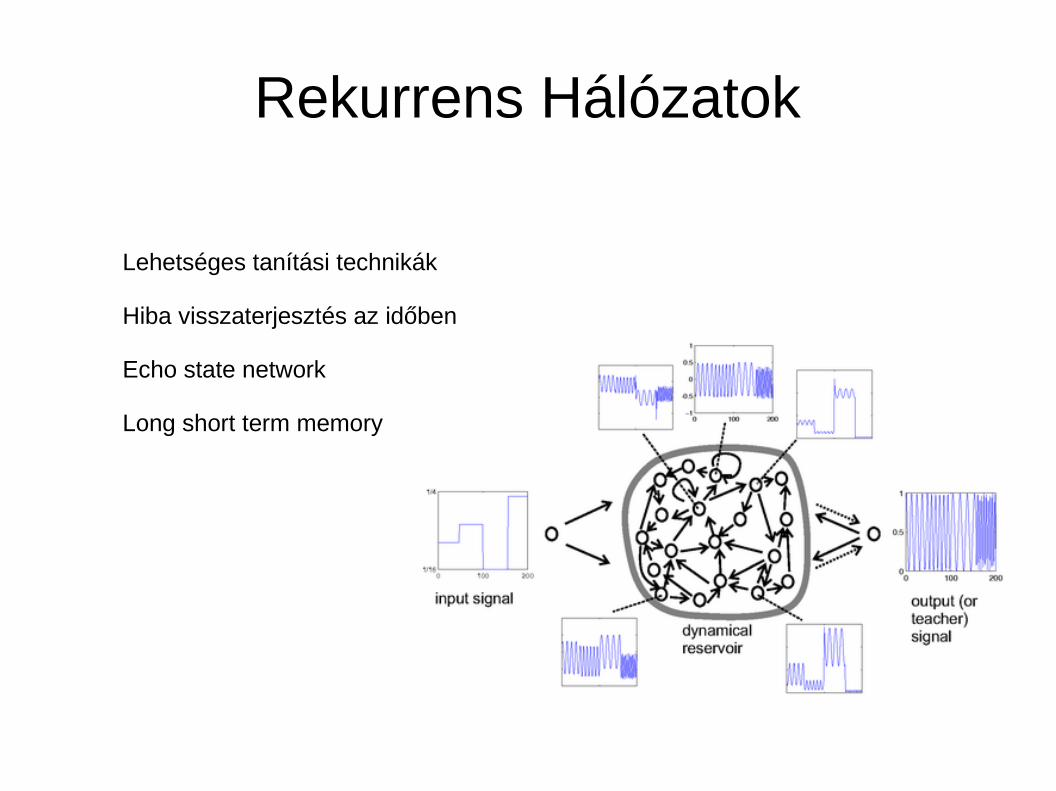
Rekurrens Hálózatok
Lehetséges tanítási technikák
Hiba visszaterjesztés az időben
Echo state network
Long short term memory

Hebb's rule
When an axon of cell A is near enough to excite cellB, and repeatedly or consistently takes part in firingit, some growth process or metabolic change takespart in one or both cells such that A's efficiency, asone of cell firing B, is increased"(Hebb, The Organization of Behavior, 1949)

Hebb's rule in an experiment at population level
LTP – long term potentation LTD – long term depression
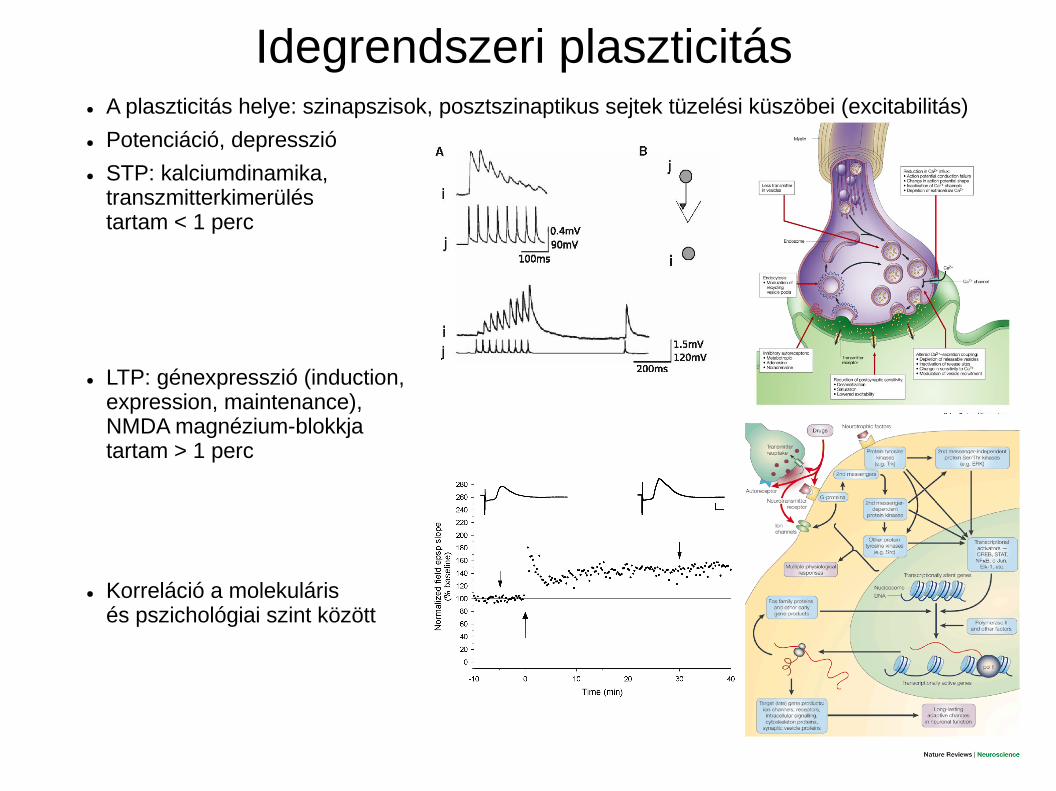
Idegrendszeri plaszticitás● A plaszticitás helye: szinapszisok, posztszinaptikus sejtek tüzelési küszöbei (excitabilitás)
● Potenciáció, depresszió
● STP: kalciumdinamika, transzmitterkimerüléstartam < 1 perc
● LTP: génexpresszió (induction, expression, maintenance), NMDA magnézium-blokkjatartam > 1 perc
● Korreláció a molekuláris és pszichológiai szint között
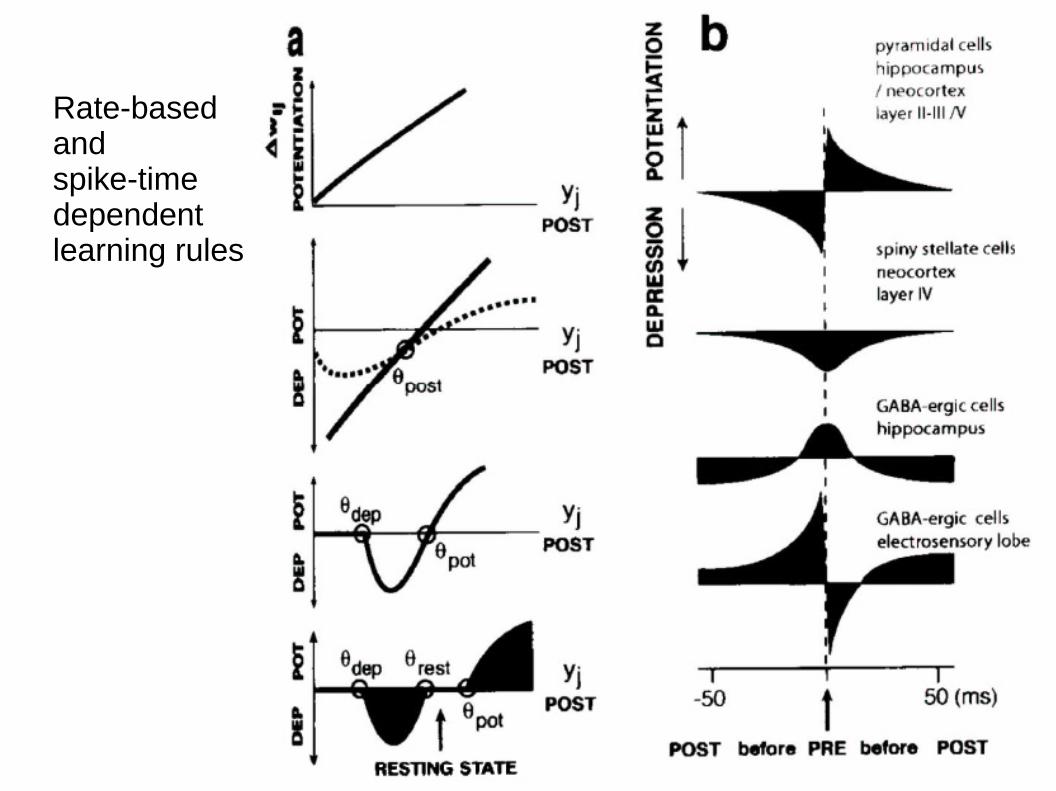
Rate-basedandspike-timedependentlearning rules

A Hebb-szabály
● Timing-dependent plasticity:● Ha a posztszinaptikus neuron nagy frekvenciával közvetlenül
a preszinaptikus után tüzel, akkor erősödik a kapcsolat
● Az alacsony frekvenciájú tüzelés gyengíti a kapcsolatot
● Sok más lehetőség
● A Hebb-szabály formalizációja:
lineáris ráta-modellben
wd wdt
=v u

Stabilizált Hebb-szabályok
● Problémák a Hebb szabállyal: ● csak nőni tudnak a súlyok
● Nincs kompetíció a szinapszisok között – inputszelektivitás nem megvalósítható
● Egyszerű megoldás: felső korlát a súlyokra
● BCM: a posztszinaptikus excitabilitás felhasználása a stabilizásra
● Szinaptikus normalizáció● Szubsztraktív normalizáció
Globális szabály, de generál egyes megfigyelt mintázatokat (Ocular dominance)
● Oja-szabály
Lokális szabály, de nem generálja a megfigyelt mintázatokat
wd wdt
=v u v−u
d u
dt=v2
−u
wd wdt
=v u−v 1⋅u1
N u
wd wdt
=v u− v2u

Principal component analysis

Principal component network,derivation of Oja's rule:

y=wTx=xTw
Δw=α(xy−y2w)
Δw=α(xxTw−wTxxTww)
Cw−wTCww=0
The Oja-rule and the pricipal component analysis
y outputx inputw weight matrix
Oja's rule
Substituting y:
Assuming mean(x)=0 & averaging over the input => xxT = C
The convergence point: Δw=0
wTCw is scalar!This is an eigenvector equation!
Δw=α(xy3−w)E modification for IndenpendentComponent analysis
If C=1
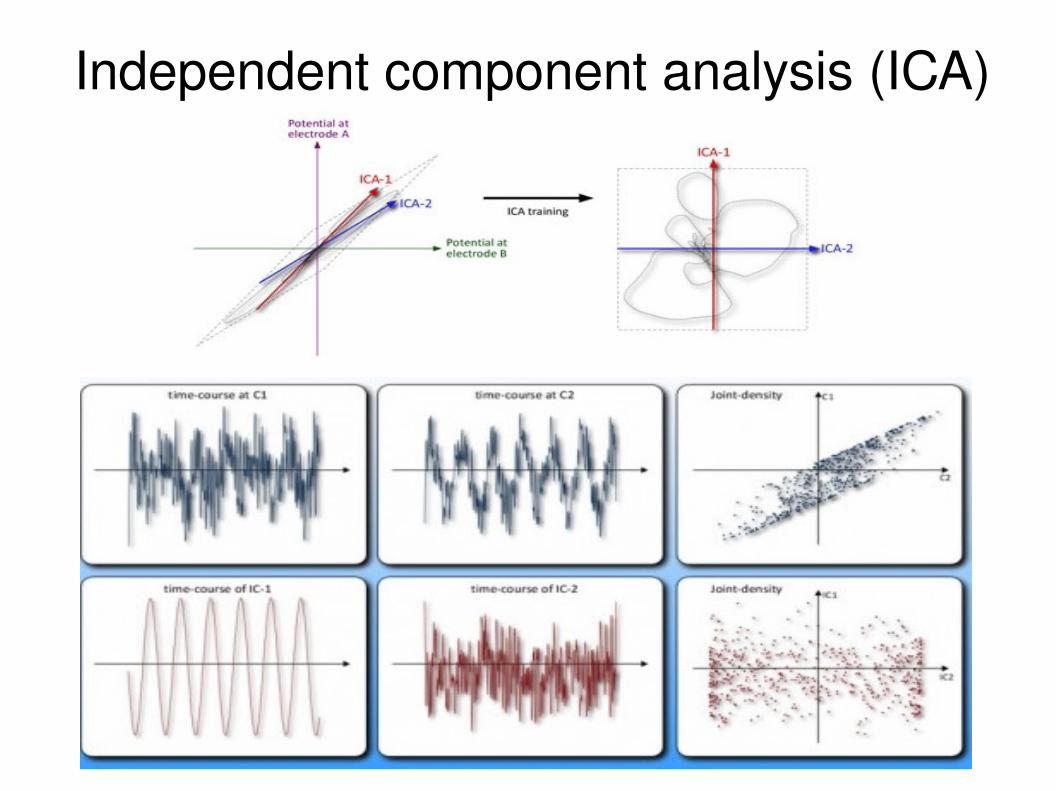
Independent component analysis (ICA)

Independent component analysis (ICA)

The somatosensory map

Kohonen's selforganizing map
Winner take all

Kohonen's selforganizing mapGenerates feature maps Captures the structure in the inputs
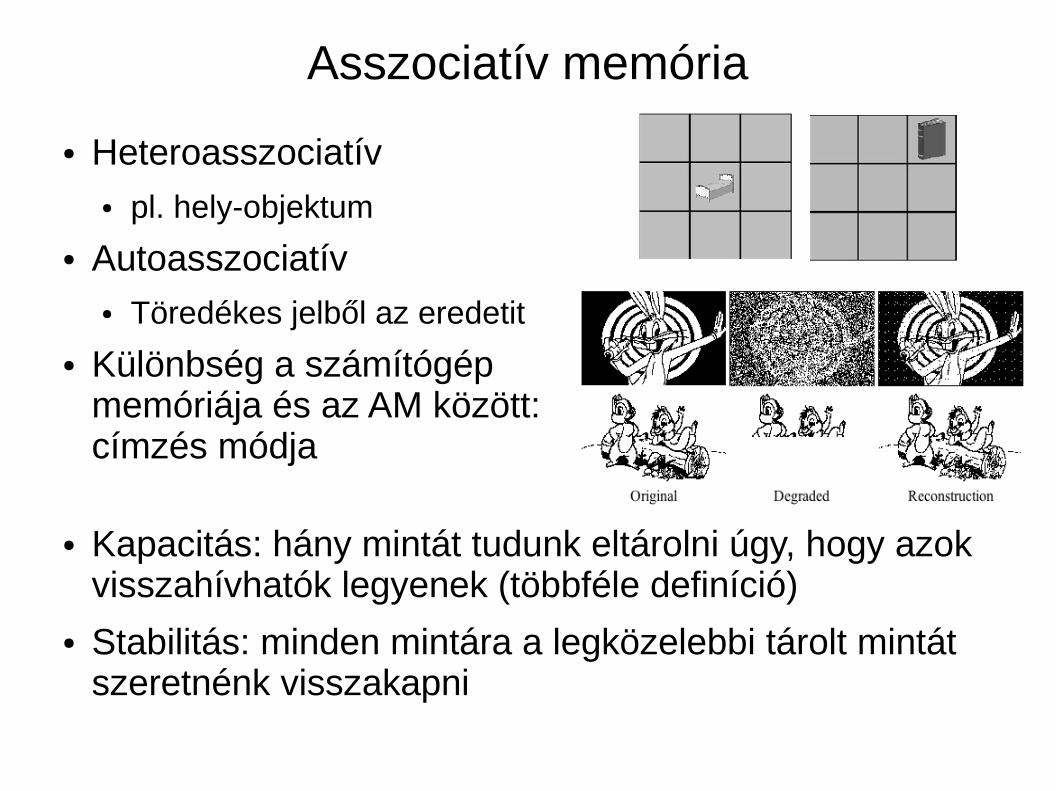
Asszociatív memória
● Heteroasszociatív● pl. hely-objektum
● Autoasszociatív● Töredékes jelből az eredetit
● Különbség a számítógép memóriája és az AM között: címzés módja
● Kapacitás: hány mintát tudunk eltárolni úgy, hogy azok visszahívhatók legyenek (többféle definíció)
● Stabilitás: minden mintára a legközelebbi tárolt mintát szeretnénk visszakapni

Attraktorhálózatok
● Attraktorok típusai● Pont● Periodikus● Kaotikus
● Vonzási tartományok
● Realizáció: rekurrens neurális hálózatok
● Attraktorok tárolása: szinaptikus súlyokon● Offline tanulás● Online tanulás● One-shot learning
● Előhívás: konvergencia tetszőleges pontból egy fix pontba

W. J. Freeman
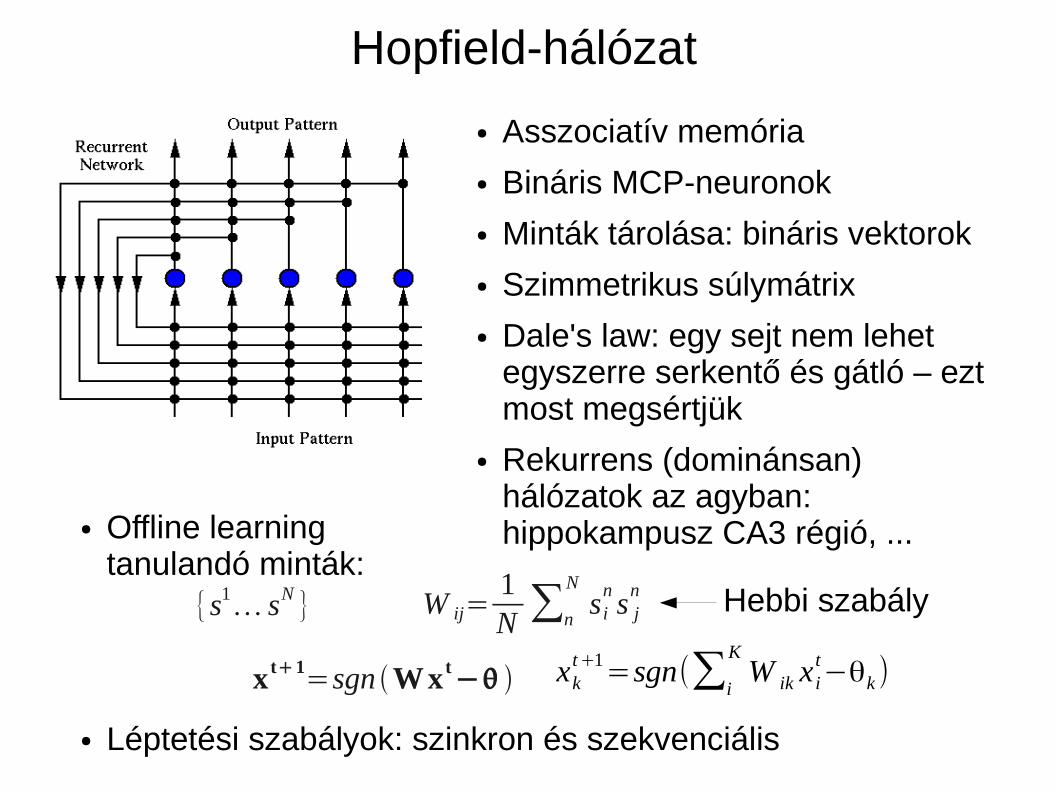
Hopfield-hálózat
● Asszociatív memória
● Bináris MCP-neuronok
● Minták tárolása: bináris vektorok
● Szimmetrikus súlymátrix
● Dale's law: egy sejt nem lehet egyszerre serkentő és gátló – ezt most megsértjük
● Rekurrens (dominánsan) hálózatok az agyban: hippokampusz CA3 régió, ...● Offline learning
tanulandó minták: Hebbi szabály
● Léptetési szabályok: szinkron és szekvenciális
x t1=sgn Wx t− xkt+1
=sgn(∑i
KW ik x i
t−θk )
W ij=1N ∑n
Nsi
ns j
n{s1 sN }

A HN dinamikája
● Nemlineáris rendszerek stabilitás-analízise: Lyapunov-függvény segítségével definiáljuk az állapotokhoz rendelhető energiát. Ha a függvény:
● Korlátos● Belátható, hogy a léptetési dinamika mindig csökkenti (növeli)
Akkor a rendszer minden bemenetre stabil fix pontba konvergál.
● Hopfield-hálózat Lyapunov-függvénye:
● Attraktorok az eltárolt mintáknál, de más helyeken is
● A HN használható kvadratikus alakra hozható problémák optimalizációjára is
E=−12
xTW x− x

A HN kapacitása
● Információelméleti kapacitás● A tárolandó mintákat tekintsük Bernoulli-eloszlású változók halmazának
● Követeljük meg az egy valószínűségű konvergenciát
● Ekkor (sok közelítő lépéssel) megmutatható, hogy
● Összehasonlítás a CA3-mal● Kb. 200000 sejt, kb. 6000 minta tárolható
● Más becslések● figyelembevéve a minták ritkaságát
P sin=1=P s i
n=0 =0.5
lim n∞ P sa=sgn Wsa
=1 ∀ a=1 M
M ≈N
2 log 2 N
M ≈N1
log21P s i
n=1=
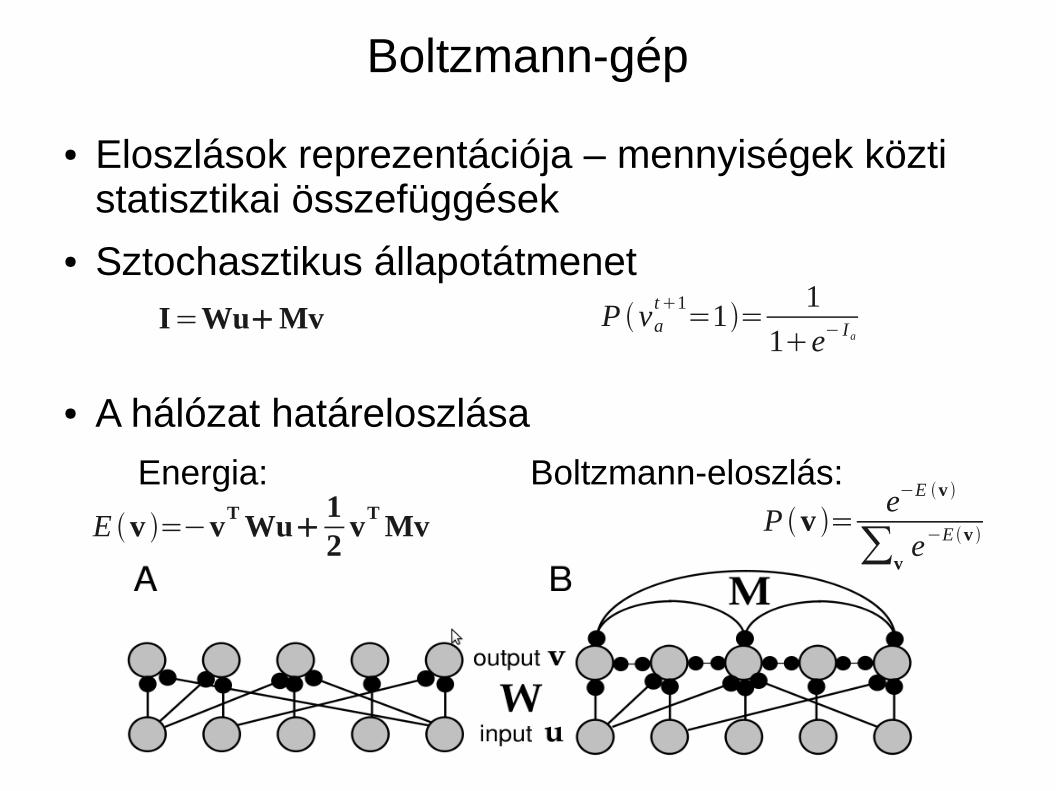
Boltzmann-gép
● Eloszlások reprezentációja – mennyiségek közti statisztikai összefüggések
● Sztochasztikus állapotátmenet
● A hálózat határeloszlása
Energia: Boltzmann-eloszlás:
I=WuMv P vat1
=1=1
1e− I a
E v =−vTWu
12
vTMv P v =
e−E v
∑ve−E v

Tanulás Boltzmann-géppel● Felügyelt tanulás, csak W-re, M analóg
● Hiba: Kullback-Leibler-divergencia a közelítendő és a megvalósított eloszlás között nem függ W-től
a -val súlyozott kimeneti összegzés helyett bemeneteke vett átlag:
● Gradient descent – egyetlen bemenetre
a Boltzmann-eloszlásból
● Delta-szabály – az összes lehetséges kimenetre való átlagot az aktuális értékkel közelítjük
Két fázis: hebbi anti-hebbi
● Nem felügyelt
DKL [ P v∣u , P v∣u , W ]=∑vP v∣u ln
P v∣u
P v∣u ,W
P v∣u
⟨ DKL⟩=−1
N s∑ ln P v
m∣um
, W−K
∂ ln P vm∣um ,W
∂W ij
=v im u j
m−∑vP v∣um , W v i u j
m
W ij W ijw v im u j
m−v i um u j
m
DKL[ P u , P u ,W ]

Tanulás Boltzmann-géppel● Felügyelt tanulás, csak W-re, M analóg
● Hiba: Kullback-Leibler-divergencia a közelítendő és a megvalósított eloszlás között nem függ W-től
a -val súlyozott kimeneti összegzés helyett bemeneteke vett átlag:
● Gradient descent – egyetlen bemenetre
a Boltzmann-eloszlásból
● Delta-szabály – az összes lehetséges kimenetre való átlagot az aktuális értékkel közelítjük
Két fázis: hebbi anti-hebbi
● Nem felügyelt
DKL [ P v∣u , P v∣u , W ]=∑vP v∣u ln
P v∣u
P v∣u ,W
P v∣u
⟨ DKL⟩=−1
N s∑ ln P v
m∣um
, W−K
∂ ln P vm∣um ,W
∂W ij
=v im u j
m−∑vP v∣um , W v i u j
m
W ij W ijw v im u j
m−v i um u j
m
DKL[ P u , P u ,W ]

Tanulás Boltzmann-géppel● Felügyelt tanulás, csak W-re, M analóg
● Hiba: Kullback-Leibler-divergencia a közelítendő és a megvalósított eloszlás között nem függ W-től
a -val súlyozott kimeneti összegzés helyett bemeneteke vett átlag:
● Gradient descent – egyetlen bemenetre
a Boltzmann-eloszlásból
● Delta-szabály – az összes lehetséges kimenetre való átlagot az aktuális értékkel közelítjük
Két fázis: hebbi anti-hebbi
● Nem felügyelt
DKL [ P v∣u , P v∣u , W ]=∑vP v∣u ln
P v∣u
P v∣u ,W
P v∣u
⟨ DKL⟩=−1
N s∑ ln P v
m∣um
, W−K
∂ ln P vm∣um ,W
∂W ij
=v im u j
m−∑vP v∣um , W v i u j
m
W ij W ijw v im u j
m−v i um u j
m
DKL[ P u , P u ,W ]

Tanulás Boltzmann-géppel● Felügyelt tanulás, csak W-re, M analóg
● Hiba: Kullback-Leibler-divergencia a közelítendő és a megvalósított eloszlás között nem függ W-től
a -val súlyozott kimeneti összegzés helyett bemeneteke vett átlag:
● Gradient descent – egyetlen bemenetre
a Boltzmann-eloszlásból
● Delta-szabály – az összes lehetséges kimenetre való átlagot az aktuális értékkel közelítjük
Két fázis: hebbi anti-hebbi
DKL [ P v∣u , P v∣u , W ]=∑vP v∣u ln
P v∣u
P v∣u ,W
P v∣u
⟨ DKL⟩=−1
N s∑ ln P v
m∣um
, W−K
∂ ln P vm∣um ,W
∂W ij
=v im u j
m−∑vP v∣um , W v i u j
m
W ij W ijw v im u j
m−v i um u j
m

Tanulás Boltzmann-géppel● Felügyelt tanulás, csak W-re, M analóg
● Hiba: Kullback-Leibler-divergencia a közelítendő és a megvalósított eloszlás között nem függ W-től
a -val súlyozott kimeneti összegzés helyett bemeneteke vett átlag:
● Gradient descent – egyetlen bemenetre
a Boltzmann-eloszlásból
● Delta-szabály – az összes lehetséges kimenetre való átlagot az aktuális értékkel közelítjük
Két fázis: hebbi anti-hebbi
● Nem felügyelt
DKL [ P v∣u , P v∣u , W ]=∑vP v∣u ln
P v∣u
P v∣u ,W
P v∣u
⟨ DKL⟩=−1
N s∑ ln P v
m∣um
, W−K
∂ ln P vm∣um ,W
∂W ij
=v im u j
m−∑vP v∣um , W v i u j
m
W ij W ijw v im u j
m−v i um u j
m
DKL[ P u , P u ,W ]
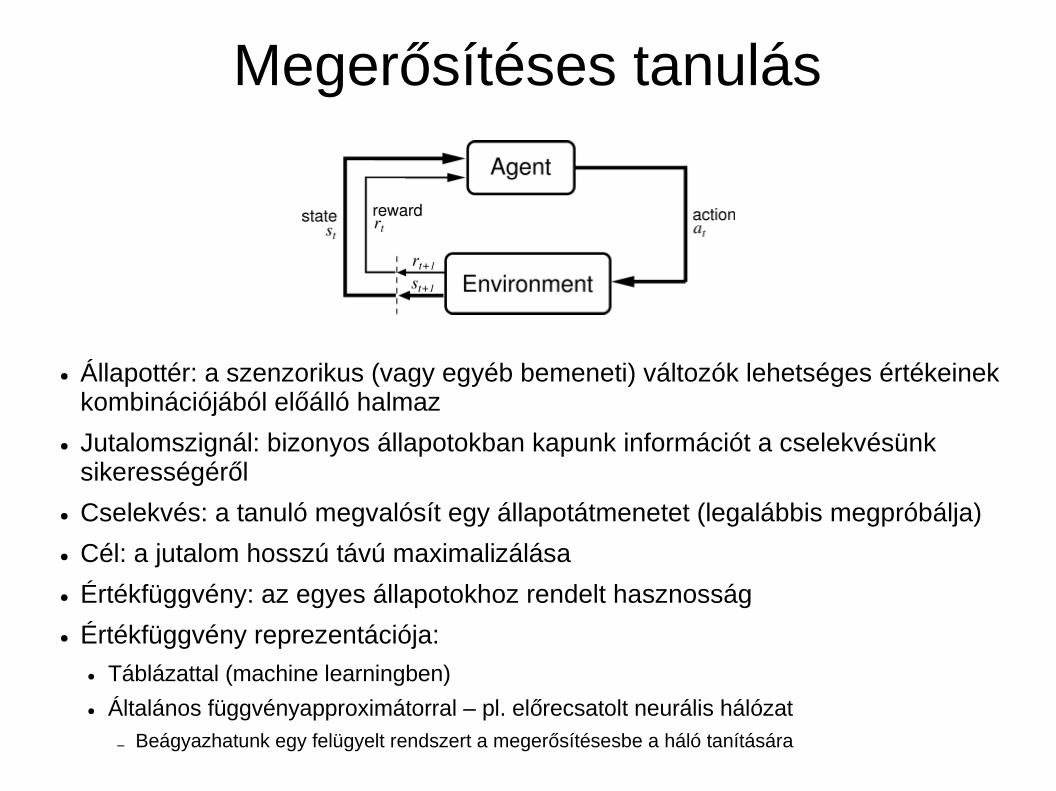
Megerősítéses tanulás
● Állapottér: a szenzorikus (vagy egyéb bemeneti) változók lehetséges értékeinek kombinációjából előálló halmaz
● Jutalomszignál: bizonyos állapotokban kapunk információt a cselekvésünk sikerességéről
● Cselekvés: a tanuló megvalósít egy állapotátmenetet (legalábbis megpróbálja)
● Cél: a jutalom hosszú távú maximalizálása
● Értékfüggvény: az egyes állapotokhoz rendelt hasznosság
● Értékfüggvény reprezentációja:● Táblázattal (machine learningben)
● Általános függvényapproximátorral – pl. előrecsatolt neurális hálózat
– Beágyazhatunk egy felügyelt rendszert a megerősítésesbe a háló tanítására

Temporal difference learning● Prediction error felhasználása a tanuláshoz
● Az állapotérték frissítése neurális reprezentációban:
● A prediction error kiszámítása● A teljes jövőbeli jutalom kellene hozzá ● Egylépéses lokális közelítést alkalmazunk
● Ha a környezet megfigyelhető, akkor az optimális stratégiához konvergál
● A hibát visszaterjeszthetjük a korábbi állapotokra is (hasonlóan a backpropagation algoritmushoz)
● Akciókiválasztás: exploration vs. exploitation
w w tu t− t =∑r t−v t
∑r t−v t ≈r t v t1

TD tanulás neurális hálózattal
● Gerald Tesauro: TD-Gammon● Előrecsatolt hálózat● Bemenet: a lehetséges lépések
nyomán elért állapotok● Kimenet: állapotérték (nyerési valószínűség)
● Minden lépésben meg kell határozni a hálózat kimeneti hibáját
● Reward signal alapján
● Eredmény: a legjobb emberi játékosokkal összemérhető
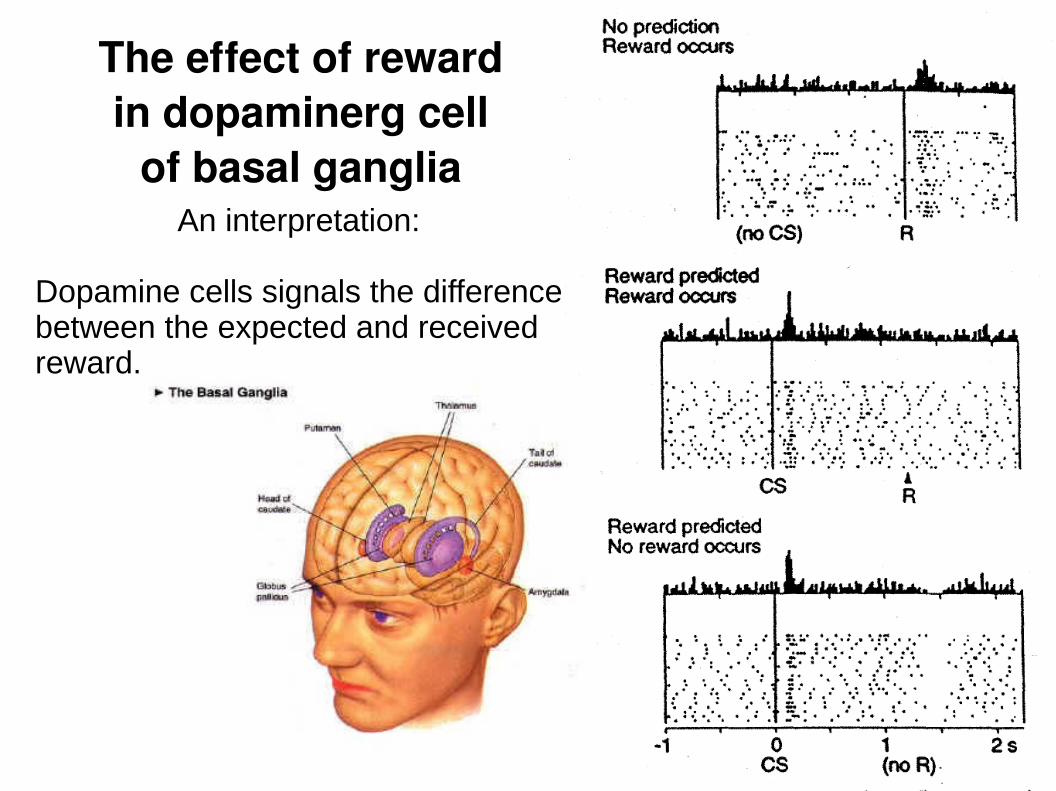
The effect of rewardin dopaminerg cell
of basal gangliaAn interpretation:
Dopamine cells signals the differencebetween the expected and receivedreward.
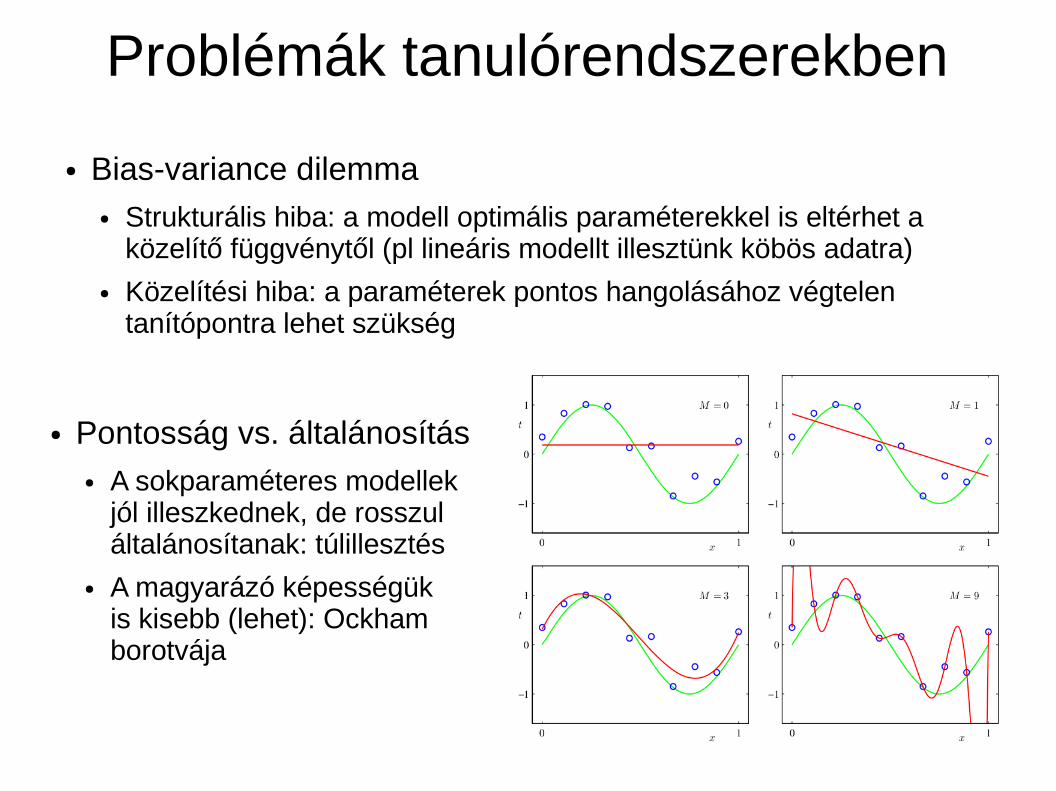
Problémák tanulórendszerekben
● Bias-variance dilemma● Strukturális hiba: a modell optimális paraméterekkel is eltérhet a
közelítő függvénytől (pl lineáris modellt illesztünk köbös adatra)● Közelítési hiba: a paraméterek pontos hangolásához végtelen
tanítópontra lehet szükség
● Pontosság vs. általánosítás● A sokparaméteres modellek
jól illeszkednek, de rosszul általánosítanak: túlillesztés
● A magyarázó képességük is kisebb (lehet): Ockham borotvája