
NG D NG TIN H C TRONG CÔNG NGH SINH H C · Measure, Analyze,… chuy n i gi !a 2 h th ˛ng Menu ch...
94
1 BỘ GIÁO DỤC VÀ ĐÀO TẠO TRƯỜNG ĐẠI HỌC KỸ THUẬT CÔNG NGHỆ TP.HCM KHOA MÔI TRƯỜNG & CÔNG NGHỆ SINH HỌC ---------- ---------- BÀI GIẢNG: ỨNG DỤNG TIN HỌC TRONG CÔNG NGHỆ SINH HỌC GVGD: BÙI VĂN THẾ VINH Tài liệu lưu hành nội bộ TP.HCM, Tháng 01/2008
-
Upload
duongnguyet -
Category
Documents
-
view
214 -
download
0
Transcript of NG D NG TIN H C TRONG CÔNG NGH SINH H C · Measure, Analyze,… chuy n i gi !a 2 h th ˛ng Menu ch...

1
BỘ GIÁO DỤC VÀ ĐÀO TẠO TRƯỜNG ĐẠI HỌC KỸ THUẬT CÔNG NGHỆ TP.HCM
KHOA MÔI TRƯỜNG & CÔNG NGHỆ SINH HỌC
---------- ���� ���� ���� ----------
BÀI GIẢNG:
ỨNG DỤNG TIN HỌC TRONG CÔNG NGHỆ SINH HỌC
GVGD: BÙI VĂN THẾ VINH
Tài liệu lưu hành nội bộ TP.HCM, Tháng 01/2008

2
I. GIỚI THIỆU CHUNG VỀ STATGRAPHICS CENTURION (HOẶC STATGRAPHICS PLUS) 1. Hướng dẫn cài đặt Statgraphics Centurion XVI và đăng ký bản quyền Chạy file “setup.exe” trong đĩa chương trình Một loạt hộp thoại hiện ra, nhấp chọn “Next” đến khi xuất hiện hộp thoại:
Nhấp chọn “I accept the terms in the license agreement” � Chọn “Next” � Điền thông tin vào hộp thoại:
Chạy file “KeyGen.exe” trong đĩa chương trình xuất hiện hộp thoại:

3
Nhấp chọn “Generate Serial” sẽ xuất hiện một dãy ký tự trong box “Serial Number” � Nhấp chọn “(1) Copy” � Paste “Serial Number” vào hộp thoại:
Tiếp tục chọn “Next” liên tục và chọn “Install” để bắt đầu cài đặt, chờ đợi cài đặt xong và chọn “Finish” để hoàn tất. Khởi động Statgraphics, xuất hiện hộp thoại:
Click bỏ chọn mục “Show the StatWizard at Startup” ở góc dưới bên trái rồi Chọn “Cancel” � “Yes” để bỏ hộp thoại trở về màn hình chính Chọn menu “Help” � Chọn “License Manager”

4
Copy “Product key” và Paste vào hộp thoại của keygen:
Nhấp chọn “Generate Activation Code” � Copy “Activation code” và paste vào hộp thoại của License Manager:
Nhấp chọn “UPGRADE” để hoàn tất đăng ký bản quyền. * Đối với Statgraphics Plus, chỉ cần chạy file “SGWIN.EXE”.

5
2. Thiết lập các thông số hệ thống ban đầu Phần mềm Statgraphics Centurion có 2 hệ thống Menu có thể được sử dụng là “Classic menu” với các heading lần lượt là File, Edit, Plot, Describe, Compare,… và “Six sigma menu” với các heading lần lượt là File, Edit, Define, Measure, Analyze,… Để chuyển đổi giữa 2 hệ thống Menu chọn Edit � Preferences xuất hiện hộp thoại:
Chọn tab “General”, trong box “System Options” click chọn hoặc bỏ chọn mục “Use Six Sigma Menu”. Thông thường, để dễ sử dụng nên chọn hệ thống “Classic menu” (tương tự như hệ thống menu được sử dụng trong Statgraphics Plus). 3. Nhập dữ liệu và quản lý dữ liệu: Dữ liệu phải được nhập vào “DataBook”, một “DataBook” chuNn gồm 10 “datasheet” được ký hiệu bằng các chữ cái từ A đến J. Trong mỗi “datasheet” có các cột và hàng: mỗi hàng chứa thông tin về một mẫu, một trường hợp hay một quan sát đơn lẻ còn mỗi cột đại diện cho một biến. Có 2 cách để nhập dữ liệu vào “DataBook”:
- Cách 1: Nhập trực tiếp vào “DataBook” - Cách 2: Nhập dữ liệu vào một phần mềm khác như Excel, sau đó copy hay
load vào phần mềm Statgraphics. Trước khi nhập dữ liệu vào “DataBook”, cần phải định nghĩa biến trong mỗi cột bằng cách click phải chuột vào cột muốn định nghĩa biến � Chọn “Modify column” xuất hiện hộp thoại:
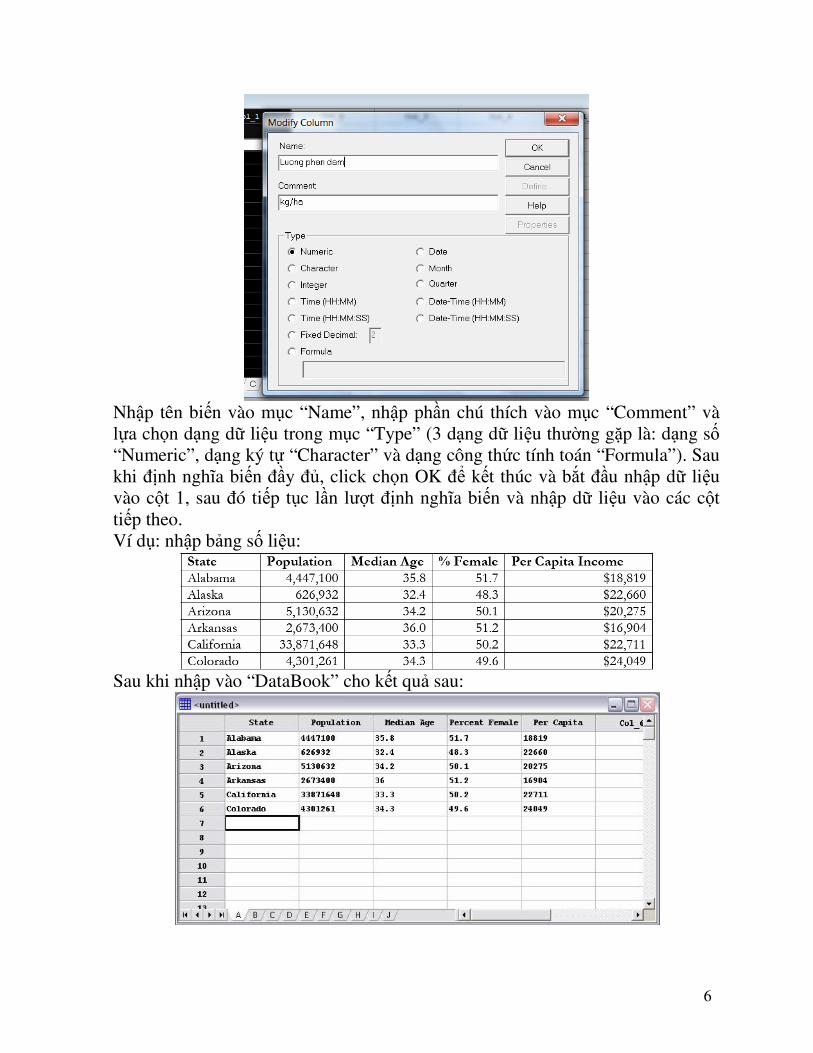
6
Nhập tên biến vào mục “Name”, nhập phần chú thích vào mục “Comment” và lựa chọn dạng dữ liệu trong mục “Type” (3 dạng dữ liệu thường gặp là: dạng số “Numeric”, dạng ký tự “Character” và dạng công thức tính toán “Formula”). Sau khi định nghĩa biến đầy đủ, click chọn OK để kết thúc và bắt đầu nhập dữ liệu vào cột 1, sau đó tiếp tục lần lượt định nghĩa biến và nhập dữ liệu vào các cột tiếp theo. Ví dụ: nhập bảng số liệu:
Sau khi nhập vào “DataBook” cho kết quả sau:

7
Để lưu bảng số liệu: chọn File � Save � Save Data File (file dữ liệu được lưu dưới dạng .sf6 và chỉ được đọc bằng phần mềm Statgraphics). Để mở một file dữ liệu đã lưu: chọn File � Open � Open Data Source. Một khi dữ liệu đã được nhập vào Datasheet, có một số thao tác quan trọng có thể được thực hiện như:
- Cut, Copy, Paste, Insert và Delete dữ liệu: khi tiến hành các lệnh trên cần lưu ý rằng mỗi cột có một kiểu định dạng khác nhau, nếu copy cột có định dạng Character và paste và cột có định dạng Numeric thì sẽ không thực hiện được � Cần phải định dạng lại cột dữ liệu.
- Tạo thêm một biến mới từ các cột dữ liệu có sẵn: Click phải chuột vào một cột mới, chọn “Modify Column” � Chọn định dạng “Formula” và nhập công thức tính toán giữa các cột dữ liệu có sẵn.
- Sort dữ liệu: Chọn cột dữ liệu được xác định để làm cơ sở sắp xếp � Menu Edit � Sort data.
Khi một phép phân tích được thực hiện, chỉ có một vài bảng kết quả hay đồ thị được trình bày. Để hiển thị thêm những output khác, cần phải chọn button thích hợp trên thanh công cụ “Analysis Toolbar” xuất hiện ngay trên tiêu đề của phép phân tích.
Các button trên thanh công cụ phân tích rất quan trọng và được tổng kết trong bảng sau: Cen Plus Tên Chức năng
Input dialog Hiển thị một hộp thoại nhập dữ liệu
để thay đổi cột dữ liệu
Tables Hiển thị danh sách các bảng khác có
thể được tạo lập
Graphs Hiển thị danh sách các dạng đồ thị
khác có thể được tạo lập
Save results Cho phép các phân tích đã tính toán
được lưu vào các cột của datasheet

8
Analysis options Chọn những options khác nhau áp
dụng cho phép phân tích đang tiến hành
Pane options Chọn những options khác nhau áp
dụng cho bảng biểu hay đồ thị đang sử dụng
Graphics options Cho phép thay đổi tiêu đề, thang trục
và các đặc tính khác trên đồ thị đang sử dụng
4. Xuất kết quả: Khi một phép phân tích được tiến hành, các kết quả được xuất ra theo nhiều cách khác nhau: Copy output sang một ứng dụng khác
Click chọn một bảng biểu hay đồ thị và chọn menu Edit � Copy sau đó khởi động một ứng dụng khác (Ví dụ như MS Word) để paste vào.
Lưu kết quả phân tích vào một report
Click phải chuột và chọn “Copy Analysis to StatReporter”, sau đó vào File � Save � Save StatReporter để lưu thành file .rtf (có thể import vào các ứng dụng khác như MS Word).
Lưu đồ thị dưới dạng file ảnh
Phóng cực đại cửa sổ đồ thị muốn lưu, click phải chuột và chọn Save Graph.
5. Lưu công việc đang tiến hành: Phép phân tích đang tiến hành có thể được lưu tại bất kỳ thời điểm nào bằng cách chọn menu File � Save StatFolio (dạng file .sgp). Sau khi mở file đã lưu thì những dữ liệu và phép phân tích đang tiến hành sẽ được tự động khôi phục (Lưu ý: file data và file StatFolio phải được lưu trữ dưới nhiều file khác nhau, nếu muốn chuyển file StatFolio từ máy này sang máy khác để tiếp tục phân tích thì phải chuyển kèm file data).

9
II. TIẾN HÀNH MỘT PHÉP PHÂN TÍCH THỐNG KÊ Có hơn 150 phép phân tích thống kê trên Menu chính của chương trình Statgraphics Centurion tuy nhiên các phép phân tích khác nhau đều có cùng một cách tiến hành:
1. Khi một phép phân tích được lựa chọn từ menu chính, một hộp hội thoại nhập dữ liệu (data input dialog box) được hiển thị, hộp thoại này cho phép lựa chọn biến cần phân tích.
2. Dữ liệu sau đó được đọc và phân tích, một cửa sổ phân tích (analysis
window) mới được tạo ra với các bảng biểu và đồ thị kết quả mặc định. 3. Các kết quả xuất hiện lần đầu tiên được tính toán dựa trên những thông
số chuNn, các thông số mặc định này có thể được thay đổi bằng cách chọn phím “Analysis Options” trên thanh công cụ analysis; các thông số mới được thay đổi sẽ làm thay đổi kết quả trên các bảng biểu và đồ thị.
4. Các bảng kết quả và đồ thị mới có thể được thêm vào hoặc bỏ bớt bằng cách chọn phím “Tables” hay “Graphs” trên thanh công cụ phân tích.
5. Các bảng kết quả và đồ thị có thể được thay đổi bằng cách phóng đại cửa sổ tương ứng và chọn “Pane options” trên thanh công cụ phân tích.
6. Đối với các đồ thị, có thể thay đổi phần tiêu đề, trục số, điểm số, font chữ,… bằng cách phóng đại cửa sổ tương ứng và chọn “Graphics
options” trên thanh công cụ phân tích. 7. Các bảng kết quả và đồ thị có thể được in, chuyển thành file HTML
hay copy sang các chương trình ứng dụng khác như MS Word, Power Point,…
8. Các kết quả dạng số có thể được lưu thành các cột kết quả trong một data sheet bất kỳ bằng cách chọn “Save results” trên thanh công cụ phân tích.
9. Toàn bộ phép phân tích có thể được lưu lại thành file StatFolio để tiện sử dụng những lần sau.

10
1. Hộp thoại nhập dữ liệu:
Hộp thoại nhập dữ liệu thường gồm 2 phần: phần bên trái liệt kê tất cả các cột dữ liệu trong datasheet, phần bên phải là nơi nhập dữ liệu cần phân tích. Muốn phân tích cột dữ liệu nào thì lựa chọn ở phần bên trái rồi click vào biểu tượng để chuyển dữ liệu sang vùng phân tích. Có thể chọn lọc lại dữ liệu cần phân tích bằng các toán tử như FIRST(k), LAST(k), ROWS(start,end), RANDOM(k), >, <, =, & (and), / (or),… trong mục “Select”. Khi điều kiện chọn lọc không phải là dạng số thì giá trị điều kiện phải được đặt trong dấu ngoặc kép. 2. Cửa sổ phân tích: Khi phép phân tích được tiến hành, một cửa sổ phân tích được hiển thị:
Đối với phần mềm Statgraphics Centurion, kết quả phân tích sẽ được hiển thị gồm 4 pane (cửa sổ): 2 pane bên trái là output dạng bảng và 2 pane bên phải là output dạng đồ thị. Đối với phần mềm Statgraphics Plus, kết quả được hiển thị chỉ gồm 2 pane: pane bên trái là output dạng bảng và pane bên phải là output dạng đồ thị. Nếu click đôi vào một pane bất kỳ thì pane sẽ được phóng lớn ở kích thước cực đại để dễ dàng quan sát và đọc kết quả, click đôi tiếp tục vào pane để trở về màn hình ban đầu.

11
III. PHÂN TÍCH CÁC ĐẶC TRƯNG CỦA MỘT MẪU
Một vấn đề thường gặp trong thống kê là phân tích một mẫu với n giá trị quan sát từ một tổng thể. Ví dụ: đo thân nhiệt của n=130 người được kết quả sau:
Dữ liệu thân nhiệt trong ví dụ trên được lưu trong file bodytemp.sf3 trong thư mục Data.
1. Chọn menu File � Open � Open Data Source 2. Trong hộp thoại “Data Source” chọn “STATGRAPHICS Data File” 3. Chọn file bodytemp.sf3 trong thư mục Data (C:\Program
Files\Statgraphics\STATGRAPHICS Centurion XV.I\Data) 4. Dữ liệu xuất hiện như bảng sau:
Thân nhiệt được trình bày trong cột bên trái với đơn vị đo là độ F. Phép phân tích một biến được tiến hành bằng cách:
1. chọn Menu Describe � Numeric Data � One-Variable Analysis 2. Trong hộp thoại nhập dữ liệu, chọn cột dữ liệu cần phân tích

12
3. Kết quả phân tích sẽ được trình bày trong 4 cửa sổ:
Cửa sổ trên cùng bên trái cho biết dung lượng mẫu n=130 giá trị nằm trong khoảng từ 96,3 đến 100,8 độ F. Cửa sổ trên cùng bên phải biểu diễn đồ thị phân tán của số liệu với các điểm phân bố ngẫu nhiên theo hướng thẳng đứng. Các điểm số liệu tập trung trong khoảng từ 98 đến 99 độ F và thưa dần ra 2 đầu. Hai cửa sổ bên dưới biểu diễn các đặc trưng thống kê và đồ thị “box-and-whisker”. 1. Các đặc trưng thống kê: Bảng kết quả được trình bày trong cửa sổ dưới cùng bên trái biểu diễn nhiều kết quả thống kê của mẫu. Các kết quả thống kê khác có thể được thêm

13
vào bằng cách nhấp đúp chuột vào cửa sổ kết quả để phóng đại cửa sổ tương ứng và chọn “Pane Options”
Một giả định thường gặp đối với dữ liệu ghi nhận được là mẫu có phân bố chuNn hay phân bố Gaussian (đồ thị có dạng hình chuông). Dữ liệu từ một mẫu có phân bố chuNn được mô tả đầy đủ bằng 2 giá trị thống kê:
1. Trung bình mẫu (Mean hay Average - X): ước lượng giá trị trung tâm của phân bố.
2. Độ lệch chuNn của mẫu (Standard deviation - SD): liên quan đến sự phân tán của số liệu.
Đối với một phân bố chuNn, khoảng 68% số liệu nằm trong khoảng X ± SD, 95% số liệu nằm trong khoảng X ± 2SD và 99,73% số liệu nằm trong khoảng X ± 3SD. Hai giá trị trung bình mẫu và độ lệch chuNn chỉ có giá trị đại diện cho mẫu khi mẫu có phân bố chuNn. Hai kết quả thống kê khác có thể được sử dụng để kiểm tra lại giả định mẫu có phân bố chuNn hay không là độ lệch (Standardized skewness) và độ nhọn (Standardized kurtosis):
1. Độ lệch (Skewness): là tiêu chuNn để đánh giá tính đối xứng của số liệu. Kiểu phân bố đối xứng như phân bố chuNn có độ lệch bằng 0. Phân bố với các giá trị có xu hướng tập trung về phía bên phải của đồ thị có giá trị độ lệch > 0. Phân bố với các giá trị có xu hướng tập trung về phía bên trái của đồ thị có giá trị độ lệch < 0.
2. Độ nhọn (Kurtosis): là tiêu chuNn để xác định hình dạng của phân bố đối xứng. Phân bố chuNn có độ nhọn bằng 0. Phân bố có đồ thị nhọn hơn phân bố chuNn có giá trị độ nhọn > 0. Phân bố có đồ thị bẹt hơn phân bố chuNn có giá trị độ nhọn < 0.
Nếu mẫu có phân bố chuNn, cả 2 giá trị độ lệch và độ nhọn phải nằm trong khoảng [-2;2].

14
Một số đặc trưng thống kê khác thường được sử dụng: - Giá trị cực tiểu (Minimum) = 96,3 - Điểm tứ phân vị ¼ (25th percentile) = 97,8 - Trung vị (Median, 50th percentile) = 98,3 - Điểm tứ phân vị ¾ (75th percentile) = 98,7 - Giá trị cực đại (Maximum) = 100,8
Các giá trị này chia dãy số liệu thành 4 phần bằng nhau và là cơ sở để xây dựng đồ thị “box-and-whisker”. 2. Đồ thị “box-and-whisker” Đồ thị “box-and-whisker” được đề xuất bởi John Tukey và được xây dựng bằng cách:
1. Dựng một khối hộp “box” kéo dài từ giá trị phân vị ¼ đến giá trị phân vị ¾. Vì vậy 50% số liệu sẽ nằm trong hộp này.
2. Kẻ một đường thẳng đứng ở vị trí trung vị mẫu, chia dãy số liệu thành 2 phần bằng nhau. Nếu mẫu có phân bố đối xứng thì đường thẳng này nằm gần với trung tâm của khối hộp.
3. Đánh một dấu + vào vị trí trung bình mẫu. Một sự khác biệt đáng kể giữa 2 giá trị trung bình và trung vị cho thấy có sự hiện diện của một hay vài số liệu có khả năng gây ra sai số (các số liệu này không có chung luật phân phối so với các số liệu còn lại) làm cho phân bố của mẫu bị lệch.

15
4. Hai đầu đoạn thẳng được gọi là “whisker” nối từ giá trị cực tiểu đến điểm phân vị ¼ và từ điểm phân vị ¾ đến giá trị cực đại trừ phi có một số giá trị nằm quá xa so với khối hộp được xác định là “những điểm gây ra sai số” (outside points), trong trường hợp đó, whisker được kéo dài đến những điểm giá trị xa nhất không được xác định là điểm gây ra sai số.
- Điểm “far outsides”: là những điểm có giá trị gấp 3 lần khoảng tứ phân vị (Khoảng tứ phân vị - interquartile range – là khoảng cách giữa các điểm tứ phân vị và bằng với chiều rộng của hộp “box”). Những điểm “far outsides” được biểu thị bằng một hình vuông nhỏ có một dấu + ở giữa. Nếu mẫu có phân bố chuNn thì khả năng để một số liệu nào đó được xác định là điểm “far outside” chỉ khoảng 1/300 (với mẫu có n=300). Trừ khi có hàng trăm giá trị quan sát của mẫu nếu không thì các điểm “far outside” luôn là những điểm gây ra sai số.
- Điểm “outside”: là những điểm có giá trị gấp 1,5 lần khoảng tứ phân vị và được biểu diễn bằng những hình vuông nhỏ không có dấu + ở giữa. Khi mẫu có phân bố chuNn, khả năng có 1 hay 2 giá trị “outside” trong một mẫu có n=100 là khoảng 50% và không cần thiết phải chỉ ra sự hiện diện của các điểm gây ra sai số thật sự (true outlier). Những điểm này được xem là số liệu nghi ngờ, đáng quan tâm và nghiên cứu kỹ hơn.
Đồ thị “box-and-whisker” trong ví dụ trên khá đối xứng. Các đoạn “whisker” có độ dài khá bằng nhau và hai giá trị trung bình và trung vị của mẫu nằm gần với trung tâm của “box”. Có 3 điểm gây ra sai số (outliers) được xác định nhưng không có điểm “far outside”. Click chuột vào điểm outlier ngoài cùng bên phải chỉ ra số liệu gây ra sai số tương ứng nằm ở hàng 15 của file dữ liệu. Nếu chọn “Pane Options” từ thanh công cụ phân tích, có thể thêm khoảng ước lượng khoảng tin cậy của trung vị được ký hiệu bằng vết lõm hình chữ V

16
3. Kiểm tra xác định điểm Outlier Trước khi tiến hành đánh giá một kết quả thống kê nào, cần phải xác định các điểm outlier có thật sự gây ra sai số và cần phải loại bỏ khỏi dữ liệu gốc hay không. STATGRAPHICS cung cấp một công cụ để tiến hành một phép kiểm tra cơ bản nhằm xác định liệu một giá trị quan sát nào đó có cùng luật phân bố với các số liệu còn lại hay không (thường là phân bố chuNn) bằng cách chọn Menu Describe � Numeric Data � Outlier Identification. Trong ví dụ về kết quả đo thân nhiệt ở trên, sau khi tiến hành xác định điểm outlier, bảng kết quả được trình bày trong phần dưới của cửa sổ bên trái biểu diễn 5 giá trị nhỏ nhất và 5 giá trị lớn nhất của dữ liệu:
Giá trị “bất thường” nằm ở hàng 15 và được tô màu đỏ. Giá trị “Studentized Value Without Deletion” là 3,479 được tính bằng công thức (Xi – X)/S khi dùng cả giá trị outlier để tính giá trị trung bình và độ lệch chuNn. Nếu giá trị “Studentized Value Without Deletion” lớn hơn 3 thì số liệu này là nguyên nhân gây ra sai số trừ khi mẫu có kích thước n vô cùng lớn hay mẫu không có phân bố chuNn. Phương pháp thường được sử dụng để xác định điểm outlier là phương pháp Grubbs’ test. STATGRAPHICS sẽ tiến hành kiểm tra theo phương pháp này và biểu diễn kết quả “P-value”. Nếu giá trị P-value < 0,05 thì điểm outlier thật sự gây ra sai số. Trong ví dụ này, Giá trị P-value = 0,0484 (<0,05) � Số liệu ở hàng 15 là số liệu gây ra sai số. Có thể loại bỏ giá trị ở hàng 15 bằng cách lựa chọn lại dữ liệu nhập

17
Vì số liệu ở hàng 15 là số liệu duy nhất lớn hơn 100 độ F nên phần dữ liệu phân tích sẽ chỉ còn n = 129 giá trị. Kết quả xác định điểm outlier như sau:
Vì giá trị P-value = 0,676 lớn hơn rất nhiều so với 0,05 nên các số liệu còn lại (129 số liệu) có chung một dạng phân bố. Từ kết quả kiểm tra này, có thể quay trở lại từ nghiên cứu ban đầu để xác định xem nguyên nhân nào có thể gây ra giá trị “bất thường” ở hàng 15 và có thể làm lại thí nghiệm để ghi nhận lại kết quả ở hàng 15.

18
4. Biểu đồ Một dạng hiển thị biểu đồ thường gặp để đánh giá dữ liệu là biểu đồ tần số. Trong các cửa sổ hiển thị kết quả phân tích “One-Variable Analysis”, chọn phím “Graphs” trên thanh công cụ phân tích và click chọn “Frequency Histogram”
Đồ thị tần số (sau khi đã bỏ giá trị ở hàng 15) được hiển thị như sau:
Chiều cao của mỗi thanh bar trong biểu đồ cho thấy số kết quả quan sát được rơi vào khoảng nhiệt độ bằng bề rộng của mỗi thanh bar. Số thanh bar và độ lớn của chúng được thiết lập dựa trên kích thước mẫu n. Các giá trị này có thể được thay đổi bằng cách phóng đại cửa sổ đồ thị tương ứng và chọn “Pane Options”. Trong cửa sổ “Frequency Plot Options”, thiết lập lại các thông số như: Số lớp (Number of Classes), Giới hạn dưới (Lower Limit) và giới hạn trên (Upper Limit).

19
Số lớp càng nhiều thì càng có nhiều chi tiết rõ ràng. Hình dạng chung của phân bố là dạng đường cong giống hình cái chuông.
Các dữ liệu để xây dựng nên biểu đồ tần số có thể được hiển thị bằng cách chọn phím “Tables” trên thanh công cụ phân tích và click chọn “Frequency Tabulation”

20
5. Ước lượng khoảng: Sau khi đã loại bỏ số liệu có khả năng gây ra sai số ra khỏi mẫu, có thể tiến hành ước lượng các thông số đặc trưng phân bố. Click chọn mục “Confidence Intervals” từ hộp thoại “Tables”
Kết quả ước lượng trung bình và ước lượng độ lệch chuNn
Kết quả trên cho thấy từ dữ liệu thân nhiệt của 129 người có thể suy ra thân nhiệt trung bình nằm trong khoảng [98,11-98,35] độ F. Kết luận đó có độ chính xác là 95% (mức ý nghĩa α=0,05). Có thể thay đổi mức ý nghĩa cho phép ước lượng bằng cách chọn “Pane Options” và thay đổi thông số trong mục “Confidence Level”

21
IV. SO SÁNH 2 MẪU Trong ví dụ trước, thân nhiệt được đo từ 130 người, trong đó có 65 nam và 65 nữ. Trong phần này, thân nhiệt của nam và nữ sẽ được so sánh xem có sự khác biệt đáng kể giữa 2 mẫu hay không. 1. So sánh trung bình 2 mẫu: Vào Menu Compare � Two Samples � Two-Sample Comparison Hộp thoại nhập dữ liệu xuất hiện như sau:
Trong phần “Input”, có 2 cách lựa chọn nhập dữ liệu: “Two Data Columns” được sử dụng khi dữ liệu 2 mẫu được trình bày trên 2 cột khác nhau; “Data and Code Columns” được sử dụng khi 2 mẫu khác nhau được mã hóa trong cùng một cột.

22
Trong ví dụ trên, dữ liệu thân nhiệt được trình bày chung trong một cột “Temperature”, thân nhiệt riêng của Nam và Nữ được mã hóa và trình bày trong cột “Gender” nên lựa chọn kiểu nhập dữ liệu là “Data and Code Columns”. Trong mục “Select” cần phải loại bỏ số liệu gây ra sai số đã trình bày trong phần trên (số liệu ở hàng 15 có giá trị 100,8 là số liệu duy nhất lớn hơn 100 nên có thể loại bỏ số này bằng cách chỉ lấy những số liệu <100 để phân tích mà không cần xóa giá trị ở hàng 15 trong bảng dữ liệu ban đầu). Bảng kết quả phân tích gồm 4 cửa sổ:
Kết quả các giá trị đặc trưng thống kê, đồ thị “Box-and-Whisker” và đồ thị tần số tương tự như phần phân tích một biến. 2. So sánh độ lệch chu-n: Trên thanh công cụ phân tích, chọn phím “Tables” và click chọn “Comparison of Standard Deviations”:
- Giả thiết H0: σ1 = σ2 - Đối thiết H1: σ1 ≠ σ2

23
Kết quả quan trọng nhất được tô đỏ. Giá trị P-value là một tiêu chuNn của F-test để kiểm định giả thiết H0 ở trên. Nếu P-value < 0,05 thì cho thấy có sự khác biệt đáng kể giữa 2 phương sai ở mức ý nghĩa 5%. Trong ví dụ trên, giá trị P-value = 0,868 (>0,05) � Không bác bỏ giả thiết H0 (“Do not reject the null hypothesis for alpha = 0.05”) hay có thể kết luận phương sai của hai mẫu không có sự khác biệt về mặt thống kê. 3. So sánh 2 giá trị trung bình:
- Giả thiết H0: µ1 = µ2 - Đối thiết H1: µ1 ≠ µ2
Để tiến hành so sánh 2 giá trị trung bình, chọn phím “Tables” từ thanh công cụ phân tích và click chọn “Comparision of Means”:
Giá trị P-value cũng được sử dụng trong t-test để so sánh 2 giá trị trung bình tương tự như trong so sánh phương sai. Vì P-value = 0,0408 (<0,05) nên bác bỏ giả thiết H0 (Reject the null hypothesis for alpha = 0,05) hay có thể kết luận thân nhiệt trung bình của phụ nữ và nam giới có sự khác biệt đáng kể ở mức ý nghĩa

24
5%. (Chú ý: phương pháp t-test được sử dụng trong trường hợp này dựa trên cơ sở 2 phương sai bằng nhau theo kết quả so sánh phương sai bằng phương pháp F-test ở trên. Nếu kết quả F-test cho kết quả 2 phương sai có sự khác biệt đáng kể thì trong bảng kết quả t-test phải chọn “Pane Options” và click bỏ chọn mục “Assume Equal Sigmas”).

25
V. SO SÁNH NHIỀU GIÁ TRN TRUNG BÌNH Ví dụ: so sánh độ bền của sản phNm được sản xuất từ 4 loại vật liệu khác nhau, người ta tiến hành đo 12 mẫu đối với mỗi loại vật liệu và trình bày trong bảng sau:
(Dữ liệu đã được lưu sẵn ở file “widgets.sf6”)
Mục đích của thí nghiệm là để xác định xem loại vật liệu nào có độ bền tốt nhất. Có 2 cách nhập số liệu để so sánh:
- Cách 1: Các mẫu khác nhau được trình bày trên mỗi cột khác nhau - Cách 2: Tất cả các kết quả được nhập trên cùng một cột, tạo một cột thứ
hai để nhập vào các mã (codes) để xác định xem các số liệu ở cột thứ nhất thuộc mẫu nào (Tương tự như ví dụ về thân nhiệt ở trên, có 1 cột để nhập thân nhiệt cho 130 người và 1 cột thứ hai để nhập các mã xác định là “Male” hay “Female”).
Trong ví dụ này, dữ liệu được nhập vào theo cách thứ nhất ở trên. 1. Tiến trình so sánh nhiều mẫu: Chọn Menu Compare � Multiple Sample � Multiple-Sample Comparison Hộp thoại đầu tiên xuất hiện để xác định kiểu nhập dữ liệu ban đầu :
- Chọn “Multiple Data Columns” nếu nhập theo cách 1 ở trên - Chọn “Data and Code Columns” nếu nhập theo cách 2 ở trên
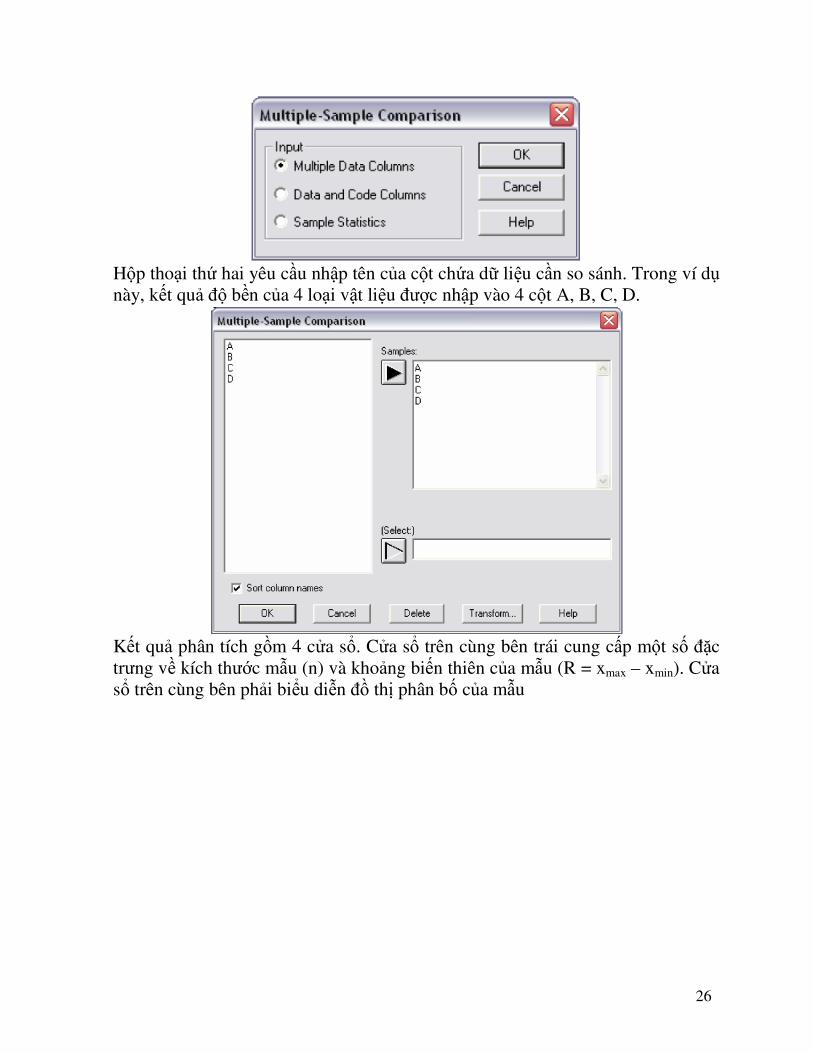
26
Hộp thoại thứ hai yêu cầu nhập tên của cột chứa dữ liệu cần so sánh. Trong ví dụ này, kết quả độ bền của 4 loại vật liệu được nhập vào 4 cột A, B, C, D.
Kết quả phân tích gồm 4 cửa sổ. Cửa sổ trên cùng bên trái cung cấp một số đặc trưng về kích thước mẫu (n) và khoảng biến thiên của mẫu (R = xmax – xmin). Cửa sổ trên cùng bên phải biểu diễn đồ thị phân bố của mẫu

27
2. Phân tích phương sai 1 dấu hiệu (One-way ANOVA):
- Giả thiết H0: µ1 = µ2 = µ3 = µ4
- Đối thiết H1: Độ bền của các loại vật liệu có sự khác biệt về mặt thống kê. Bước đầu tiên khi tiến hành so sánh nhiều mẫu là phân tích phương sai (ANOVA). Bảng phân tích ANOVA được trình bày ở cửa sổ dưới cùng bên trái.
Phương sai của thí nghiệm bao gồm 2 phần: phương sai giữa các nhóm (Between groups) và phương sai trong cùng nhóm (within groups). Giá trị quan trọng nhất trong bảng ANOVA là P-value. Nếu P-value <0,05 � Bác bỏ giả thiết H0 (Reject the null hypothesis) hay có thể kết luận độ bền của 4 loại vật liệu là khác nhau. Để biết loại vật liệu nào tốt nhất cần phải tiến hành so sánh các giá trị trung bình 3. So sánh các giá trị trung bình: Chọn phím “Tables” trên thanh công cụ phân tích và click chọn “Multiple Range Test”
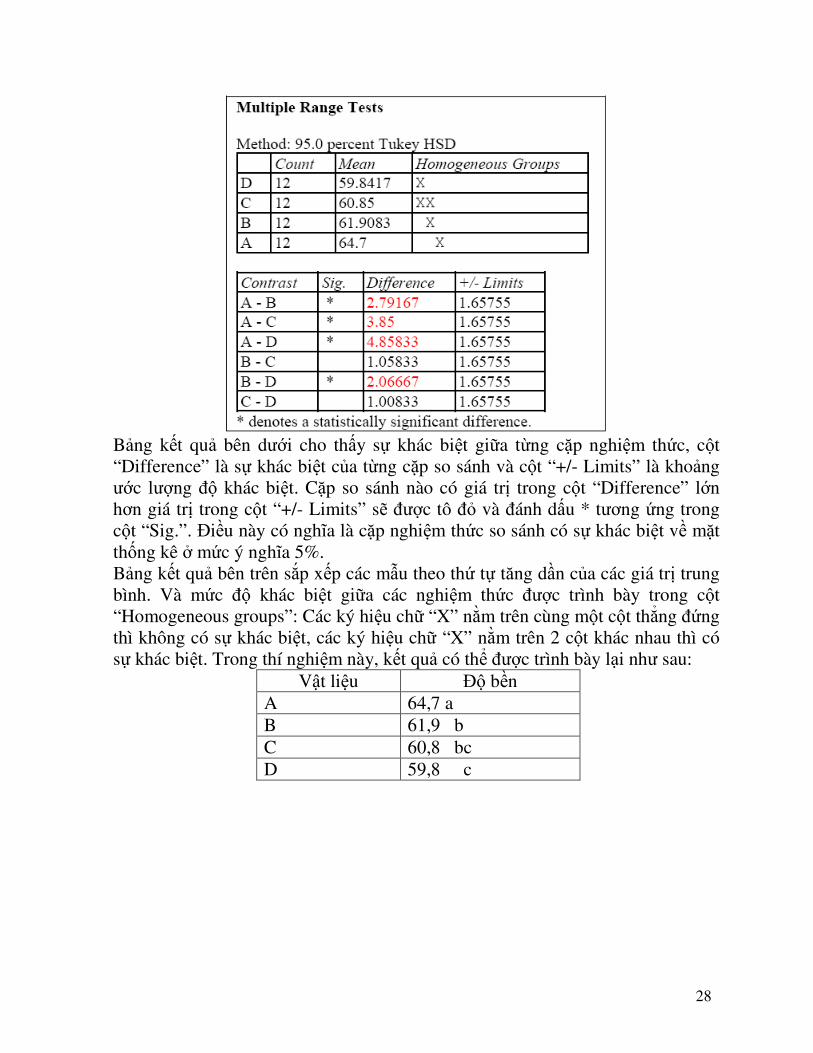
28
Bảng kết quả bên dưới cho thấy sự khác biệt giữa từng cặp nghiệm thức, cột “Difference” là sự khác biệt của từng cặp so sánh và cột “+/- Limits” là khoảng ước lượng độ khác biệt. Cặp so sánh nào có giá trị trong cột “Difference” lớn hơn giá trị trong cột “+/- Limits” sẽ được tô đỏ và đánh dấu * tương ứng trong cột “Sig.”. Điều này có nghĩa là cặp nghiệm thức so sánh có sự khác biệt về mặt thống kê ở mức ý nghĩa 5%. Bảng kết quả bên trên sắp xếp các mẫu theo thứ tự tăng dần của các giá trị trung bình. Và mức độ khác biệt giữa các nghiệm thức được trình bày trong cột “Homogeneous groups”: Các ký hiệu chữ “X” nằm trên cùng một cột thẳng đứng thì không có sự khác biệt, các ký hiệu chữ “X” nằm trên 2 cột khác nhau thì có sự khác biệt. Trong thí nghiệm này, kết quả có thể được trình bày lại như sau:
Vật liệu Độ bền A 64,7 a B 61,9 b C 60,8 bc D 59,8 c

29
VI. PHÂN TÍCH TƯƠNG QUAN – HỒI QUY 1. Hồi quy đơn giản Các bảng đánh giá mô hình hồi quy
1) Analysis Summary
Tính: các hệ số a (intercept), b (slope), t-test (đánh giá tính có nghĩa của các hệ số hồi
quy), F-test (đánh giá tính có nghĩa của mô hình)…
2) Lack -of-Fit test
Đánh giá mô hình đang dùng có hoàn toàn phù hợp với các số liệu hay không (đánh giá
qua giá trị p-value). Chú ý cần phải lặp lại sự quan sát ở một hay nhiều giá trị X
3) Forecasts
Dự đoán giá trị của Y sử dụng mô hình phù hợp. Bảng này cho biết các giá trị giới hạn
dự đoán và giới hạn tin cậy.
4) Comparison of Alternative Models
Bảng này cho biết các giá trị hằng số tương quan và R-squared của một số mô hình
(simple regression)phù hợp với các số liệu đã cho.
5) Unusual Residuals
Bảng này cho phép loại các giá trị bất thường (có giá trị tuyệt đối của phần dư lớn hơn
3) của số liệu quan sát được.
6) Influential Points
Bảng này liệt kê tất cả các quan sát có những giá trị đòn bNy (leverage) lớn hơn 3 lần
giá trị đó ở điểm trung bình nhằmđánh giá mức độ ảnh hưởng của một số liệu đến giá
trị của các hệ số hồi quy
Ví dụ: Người ta dùng ba mức nhiệt độ gồm 105,120,1350C kết hợp với ba khoảng thời
gian là 15, 30 và 60 phút để thực hiện một phản ứng tổng hợp. Các hiệu suất của phản
ứng (%) được trình bày trong bảng sau:
Thời gian (ph) X1 Nhiệt độ (oC) X2 Hiệu suất (%) Y 15 105 1.87 30 105 2.02 60 105 3.28 15 120 3.05 30 120 4.07 60 120 5.54 15 135 5.03

30
30 135 6.45 60 135 7.26
Hãy cho biết yếu tố nhiệt độ và/hoặc thời gian có liên quan tuyến tính với hiệu suất của phản ứng tổng hợp? Nếu có thì ở nhiệt độ 1150C trong 50 phút thì hiệu suất phản ứng là bao nhiêu.
Cách làm
Bước 1. Nhập số liệu:
Bước 2. Chọn Relate….Simple Regression để ấn định các giá trị của biến số Y và X
3.Nhấn OK để hiển thị bảng Analysis Summary
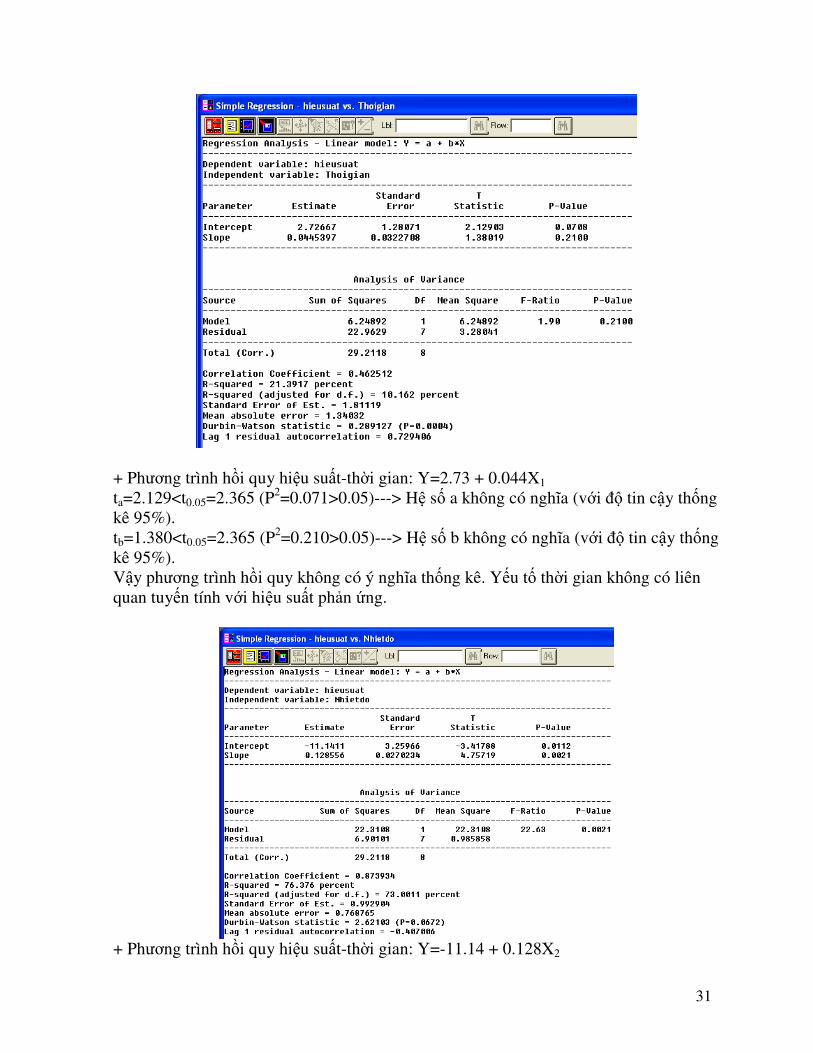
31
+ Phương trình hồi quy hiệu suất-thời gian: Y=2.73 + 0.044X1
ta=2.129<t0.05=2.365 (P2=0.071>0.05)---> Hệ số a không có nghĩa (với độ tin cậy thống kê 95%). tb=1.380<t0.05=2.365 (P2=0.210>0.05)---> Hệ số b không có nghĩa (với độ tin cậy thống kê 95%). Vậy phương trình hồi quy không có ý nghĩa thống kê. Yếu tố thời gian không có liên quan tuyến tính với hiệu suất phản ứng.
+ Phương trình hồi quy hiệu suất-thời gian: Y=-11.14 + 0.128X2

32
ta=3.417>t0.05=2.365 (P2=0.011<0.05)---> Hệ số a có nghĩa (với độ tin cậy thống kê 95%). tb=4.757>t0.05=2.365 (P2=0.021<0.05)---> Hệ số b có nghĩa (với độ tin cậy thống kê 95%). F=22.63>F0.05=5.590 Vậy phương trình hồi quy có ý nghĩa thống kê. Yếu tố nhiệt độ có liên quan tuyến tính với hiệu suất phản ứng. Trong mục này ta cũng có thể kích chuột phảI vào màn hình nền của bảng Analysis
Summary để hiện bảng Analysis Options cho phép chọn các mô hình hồi quy đơn giản
khác.
* Một số đánh giá khác
Kích chuột vào nút Tabular Option để hiển thị bảng lựa chọn một số các đánh giá khác
+Lack of Fit Test:

33
Giá trị p-value của Lack-of-fit Test là 0.9 >0.1, tức là mô hình này hoàn toàn phù hợp với các số liệu nhiệt độ và hiệu suất quan sát đựoc. +Forecast
Bảng này dự đoán các giá trị Y (hiệu suất) ở những giá trị X2( nhiệt độ) cho trước cùng với khoảng giới hạn dự đoán và khoảng giới hạn tin cậy. Nhấp chuột phảI vào màn hình nền của bảng Forecast, chọn Panel Option để hiển thị hộp thoại cho phép nhập các giá trị X và độ tin cậy để tính Y.
+Comparision of alternative model

34
Bảng này hiển thị kết quả của một số mô hình phù hợp (fitted models) với mối tương quan giữa hiệu suất (Y) và nhiệt độ (X2), nhằm đánh giá mô hình nào mô tả tốt nhất mối tương quan này. Ta thấy giá trị R-squared của mô hình tuyến tính Square root-Y (Y=(a+b*X2)^1/2) có giá trị lớn nhất, như vậy mô hình này phù hợp hơn mô hình tuyến tính để mô tả mối tương quan giữa hiệu suất và nhiệt độ. +Unusual Residual
Nếu giá trị Studentized Residual >2 thì cặp số liệu (X-Y) tương ứng là bất thường, trong thí nghiệm này thì không có những giá trị bất thường của cặp số liệu hiệu suất-nhiệt độ. +Influential Points

35
Giá trị leverage của điểm trung bình là 0.222 và trong thí nghiệm này không quan sát được các điểm có giá trị leverage lớn hơn ba lần giá trị này.
* Các lựa chọn đồ hoạ Nhấn nút Graphic Options trên cửa sổ Simple Regression để hiênt thị hộp thoại cho phép lựa chọn các kiểu đồ thị
+Plot of Fitted model

36
Nhấp chuột phảI vào màn hình nền của cửa sổ này, chọn Panel Option để hiển thị hộp thoại cho phép nhập các giá trị độ tin cậy và khoảng đơn vị của trục X
+Observed versus Predicted
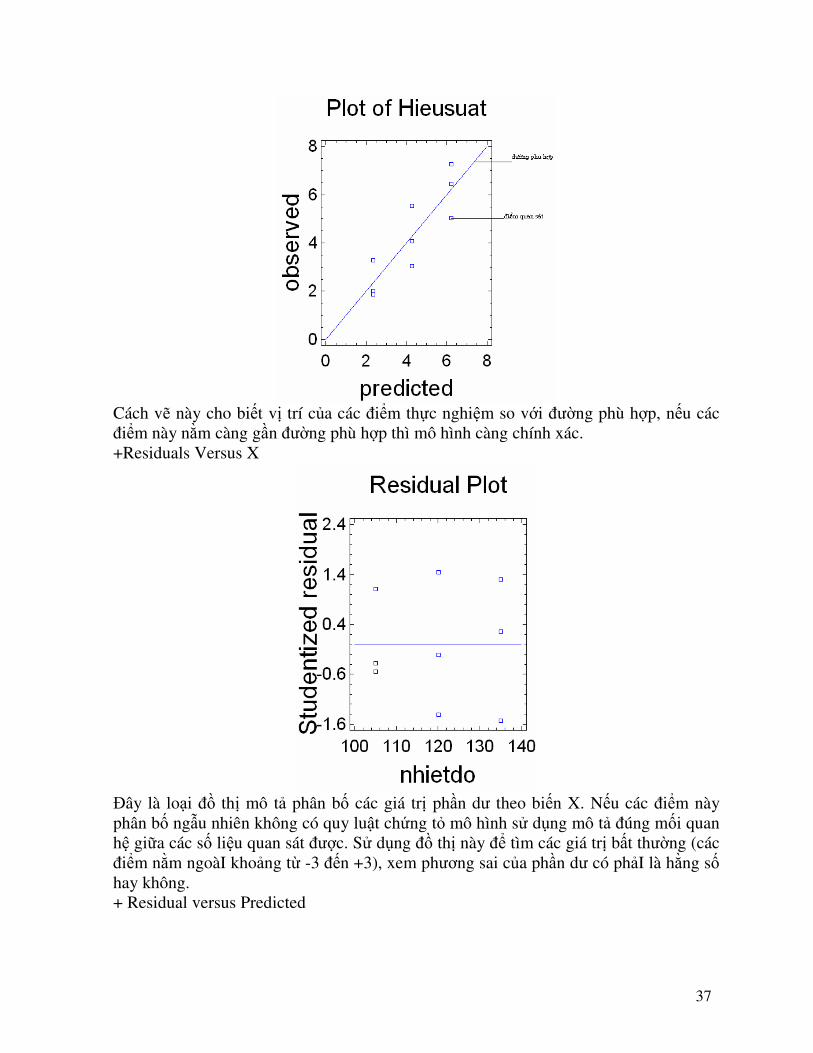
37
Cách vẽ này cho biết vị trí của các điểm thực nghiệm so với đường phù hợp, nếu các điểm này nằm càng gần đường phù hợp thì mô hình càng chính xác. +Residuals Versus X
Đây là loại đồ thị mô tả phân bố các giá trị phần dư theo biến X. Nếu các điểm này phân bố ngẫu nhiên không có quy luật chứng tỏ mô hình sử dụng mô tả đúng mối quan hệ giữa các số liệu quan sát được. Sử dụng đồ thị này để tìm các giá trị bất thường (các điểm nằm ngoàI khoảng từ -3 đến +3), xem phương sai của phần dư có phảI là hằng số hay không. + Residual versus Predicted

38
Đồ thị này mô tả sự biến thiên của phần dư theo biến phụ thuộc Y. Nếu mô hình sử dụng là phù hợp thì các điểm biểu diễn giá trị của phần dư phân bố ngẫu nhiên quanh trục biểu diễn Y. 2. Hồi quy đa thức (Polinominal Regression) Ví dụ: Sự phụ thuộc của nhân tố Y vào nhân tố X được cho trong bảng sau Cách làm
Bước 1. Nhập số liệu

39
Bước 2. Khởi động chương trình RELATE….Polinominal Regression để ấn định
các giá trị Y và X
Bước 3. Nhấn OK để hiển thị hộp thoại Polinominal Regression Analysis

40
Phương trình liên hệ giữa X và Y (hồi quy đa thức bậc hai) Y=80.0751-0.978865*X + 0.00387125*X^2 Các giá trị P ứng với các hệ số hồi quy <0.01 � các hệ số này đều có nghĩa với độ tin cậy 99% Giá trị P ứng với mô hình <0.01� Mô hình phù hợp để mô tả mối liên hệ giữa X và Y. Để chọn bậc của đa thức hồi quy, kích chuột phảI vào màn hình nền, chọn Analysis Option (nếu không chọn bậc của đa thứcc được ấn định là 2)
* Một số đánh giá khác về mô hình Chọn nút Tabular Options tren cửa sổ Polinominal Analysis để hiển thị hộp thoại để chọn các đánh giá khác cho mô hình.

41
+Conditional Sum of Square
Bảng này được sử dụng để xác định liệu một đa thức có bậc nhỏ hơn có thể mô tả được mối quan hệ giữa các biến hay không, bằng cách phân tích phương sai và đánh giá tính có nghĩa của các hệ số hồi quy ứng với bậc khác nhau. Giá trị P ứng với hệ số bậc hai =0.0007 <0.01, chứng tỏ mô hình bậc hai phù hợp để mô tả mối quan hệ giữa X và Y. +Lack of fit test
Giá trị P của Lack-of-fit Test <0.05� mô hình này hoàn toàn phù hợp để mô tả mối liên hệ giữa X và Y.

42
+Confidential Interval
Bảng này cho biết khoảng tin cậy xác định các hệ số hồi quy. Kích chuột phảI vào màn hình nền, chọn Panel Option để hiển thị hộp thoại cho phép nhập độ tin cậy
+Forecast
Bảng này có ý nghĩa tương tự như trong phần hồi quy đơn giản. Kích chuột phảI vào màn hình nền, chọn Panel Options để hiển thị hộp thoại cho phép nhập giá trị của X và độ tin cậy.

43
+Unusual Residuals
ý nghĩa của bảng này có thể xem trong phần hồi quy đơn giản +Influentia Points
*Các lựa chọn đồ hoạ Các dạng đồ hoạ tương tự như trong mục hồi quy đơn giản

44
3. Phép phân tích Box-Cox Transformation
Phép phân tích Box-cox transformation cho phép tìm kiếm tham số chuyên hóa nhằm tối thiểu hoá tổng bình phương trung bình của một mô hình phù hợp (Lambdal 1).
Để làm phù hợp hoá một mô hình hồi qui đơn giản người ta giả thiết rằng sai khác phương sai trong những nhóm khác nhau là đồng nhất và không liên hệ với các giá trị trung bình. Người ta cũng giả thiết rằng tất cả các loại sai số đều tuân theo phân phối chuNn. Nếu có sự sai lệch khỏi mô hình hồi qui đơn giản, sẽ là tiện lợi nếu ta có thể chuyển đổi sốliệu nhằm ổn định sai khác phương sai và đơn giản các loại sai số. Chuyển đổi số liệu có thể tuyến tính hoá các mối quan hệ không tuyến tính.
Ví dụ: Nghiên cứu mối quan hệ giữa hàm lượng chất béo và khối lượng cơ đùi của một số bệnh nhân bị mắc bệnh máu nhiễm mỡ cho số liệu sau: Cách làm: * nhập số liệu: Nhập số liệu như trong excel.

45
* Khởi động chương trình: chọn relate…..Box – cox transformation
Khi đó sẽ hiển thị hộp thoại cho phép bạn ấn định các giá trị của Y và X
Nhấn nút ok để hiển thị hộp thoại analysis summary

46
Mối liên hệ giữu hàm lượng chất béo và khối lưọng cơ đùi được biểu diễn theo phương trình: Boxcox (ham luong chat beo) = -26.9212 + 0.848399*khoi luong co dui Trong đó: Boxcox (ham luong chat beo) = 1 + (ham luong chat beo^1.30854 - 1) / (1.30854 * 19.5084^0.308537)
- Giá trị P nhỏ hơn 0.01 suy ra có mối liên hệ giữa các giá trị đã được chuyển đổi của hàm lượng chất béo và khối lượng cơ đùi có độ tin cậy 99%.
- R-square = 76.9367% nghĩa là mô hình có thể giảI thích 76.9367% của lượng biến thiên trong hàm lượng chất béo.
- Hệ số tương quan = 0.877135 chứng tỏ mối quan hệ giữa hai biến là rất tương quan.
Kích chuột phảI vào màn hình nền của hộp thoại analysis summary chọn analysis option để hiển thị hộp thoại Box-cox transformation option.
Sử dụng hộp thoại này để đưa vào giá trị của power(lambda1) và độ dịch chuyển shift(lambda2) và để chứng tỏ giá trị lambda1 đã được tối ưu hoá.

47
* Một số đánh giá khác: Kích vào nút tabular option trên cửa sổ analysis summary để hiển thị hộp thoại cho phép chon các đánh giá khác về mô hình
- Lựa chọn lack of fit test: Để xem mô hình lựa chọn có hoàn toàn phù hợp với các số liệu quan sat được hay không người ta đã tiến hành xác định hàm lượng chất béo của cùng một khối lượng cơ đùi của một loàI động vật. Số liệu cho ở bảng sau
Kết quả cho thấy

48
P = 0.1891 > 0.1 chứng tỏ mô hình hoàn toàn phù hợp để mô tả các số liệu quan sát được - Forecasts :
Lựa chọn Forecats cho phép dự đoán khoảng giá trị của Hàm lượng chất béo của một khối lượng cơ đùi cho trước tại một khoảng tin cậy xác định. Ngoài giá trị dự đoán tốt nhất nó còn cho ta biết khoảng giá trị của một thí nghiệm mới và giá trị trung bình của rất nhiều thí nghiệm lặp lại tại điểm đó.
Kích chuột phảI vào màn hình forecasts chọn Pane option để gọi hộp thoại
Forecasts options. Hộp thoại Forecasts options cho phép ta đưa vào giá trị khối lượng cơ(X) để tính ra khoảng giá trị của hàm lượng chất béo ngoàI ra ta có thể thay đổi khoảng tin cậy

49
- MSE comparison table: Lựa chon MSE comparison table tạo ra bảng hiển thị trung bình bình phương nhỏ nhất của rất nhiều giá trị tham biến chuyển đổi (Lambda1) trong khoảng {-2 ; 2}. Theo qui ước thì phép phân tích sẽ chọn giá trị lambda1 tối ưu, bằng cách sử dụng lựa chọn này chúng ta có thể xác định nhiều giá trị tổng trung bình bình phương nhỏ nhất (MSE) ứng với mỗi giá trị lambda1 khác nhau. Kết quả MSE ứng với Lambda1 = 1.30854 và giá trị này nhỏ hơn 0.960467% so với MSE cho các giá trị chưa đựoc chuyển đổi của hàm lượng chất béo.

50
Kích chuột phải vào cửa sổ MSE comparison table chọn Pane option để gọi hộp thoại MSE comparison table option. Hộp thoại này cho phép ta ấn định giá trị min, max của lambda1 và số khoảng chia giưa hai giá trị min và max đó.
- Unusual residuals Lựa chọn Unusual residuals cho ta một bảng liệt kê tất cả các thí nghiệm có sự khác biệt ( studentize residual) lớn hơn 2 ( về giá trị tuyệt đối). studentize residual đo số thí nghiệm có sự sai khác độ lệch chuNn lớn hơn 2.Với mỗi giá trị quan sát được

51
của biến số phụ thuộc sai khác với giá trị được dự đoán trước theo một mô hình hồi qui phù hợp, người ta tiến hành tính độ lệch chuNn của các cặp giá trị còn lại trừ cặp số liệu nghi vấnânso sánh với kết quả tính toán mà có sử dụng cặp số liệu nghi vấn. Nếu sự khác biệt là lớn hơn 3 thì giá trị đó phải bị loại bỏ khởi phép phân tích.
ở đây không có giá trị nào cho studentized residual lớn hơn 2 nên không có giá trị nào bị loại khỏi phép phân tích. - Influent point Lựa chọn Influent point cho ta một bảng liệt kê tất cả các thí nghiệm có ảnh hưởng lớn hơn 3 lần ảnh hưởng trung bình của tất cả các thí nghiệm. Dữ kiện này rất quan trọng và nó ảnh hưởng mạnh đến hệ số tương quan của mô hình
ở đây không có điểm nào gây ảnh hưởng lớn gấp 3 lần ảnh hưởng trung bình.
* Graphic option ( các tuỳ chọn đồ thị) Từ của sổ Box-cox transformation ta chon Graphic option.

52
Từ cửa sổ này ta có thể gọi ra các lựa chọn về đồ thị
- Plot of fitted model:
Đường màu tím là đường giới hạn của giá trị hàm lượng chất béo được dự đoán từ một giá trị khối lượng cơ cho trước, hai đường màu đỏ là đường giới hạn giá trị hàm lượng chất béo dự đoán của rất nhiều thí nghiệm lặp lại tại một giá trị khối lượng cơ cho trước. Tương tự như phần trên ta co thể gọi ra một loạt các ứng dụng trong phần graphic option.

53
4. Hồi quy đa nhân tố Trong phương pháp phân tích hồi qui có nhiều trường hợp để rút ra kết luận về mối liên hệ giữa các biến số và mô tả các số liệu quan sát được người ta phải dùng hồi qui đa nhân tố đặc biệt khi số liệu chứa hai hay nhiều biến số độc lập và một biến số phụ thuộc. Hồi qui đa nhân tố giúp chúng ta đánh giá được ảnh hưởng của một biến số độc lập lên biến số phụ thuộc và cùng một lúc điều khiển ảnh hưởng của các nhân tố khác. Từ màn hình chính của phần mềm ta chon File…open….open data file…..cardata.
Sau khi phần mềm đã mở dữ kiện cho bài toán của chúng ta. Chọn tiếp Relate….multiple regression để khởi động chương trình hồi qui đa nhân tố.

54
Cửa sổ này cho phép ta ấn định các biến: ở đây biến số phụ thuộc được chọn là mpg và hai biến độc lập là horsepower và weight. Nhấn ok để hiển thị cửa sổ analysis summary.
Kết quả: phương trình hồi qui thể hiện mối liên hệ giữa biến số phụ thuộc mpg và hai biến số độc lập horsepower và weight là:

55
mpg = 55.7694 - 0.104891*horsepower - 0.00661426*weight - P – value = 0.000 < 0.01 có mối liên hệ rõ rệt giữa các biến số ở mức độ tin cậy 99%. - R-square = 72.3401% chứng tỏ mô hình giải thích đúng cho 72.3401% của sự biến thiên đối với mpg. - R-square hiệu chỉnh = 71.9368% ( giá trị này thường được dùng đẻ so sánh các mô hình hồi qui với số biến số độc lập khác nhau. - Standard Error of Est. = 3.9008 : độ lệch chuNn của phần sai khác là 3.9008 giá trị này được dùng để dự đoán giá trị giới hạn cho các thí nghiệm tiếp theo. - Mean absolute error = 3.03489 giá trị trung bình của phần sai khác. - Phân tích Durbin- watson kiểm tra phàn sai khác để xác định xem liệu có mối tương quan nào dựa trên thứ tự nhập vào của biến số trong tập số liệu. P = 0.0018 < 0.05 chứng tỏ có thể có mối liên hệ. Conditional sums of square
Phân tích conditional sums of square cho ta bảng phân tích tầm quan trọng của mỗi tham biến đóng góp vào mô hình, điều này giúp ta có thể xác định liệu mô hình này có thể được đon giản hoá. Ta thấy răng giá trị cao nhất của P – value là 0.000 của horsepower vì P – value < 0.01 nên mô hình có độ tin cậy thống kê là 99% nghĩa là ta không thể đơn giản hoá bất kì biến số nào trong hai biến số độc lập đó. Confidence intervals Bảng thể hiện khoảng tin cậy là 95% cho các hệ số trong phương trình. Ta có thể sử dụng hộp thoại confidênc interval option để thay đổi khoảng tin cây thống kê
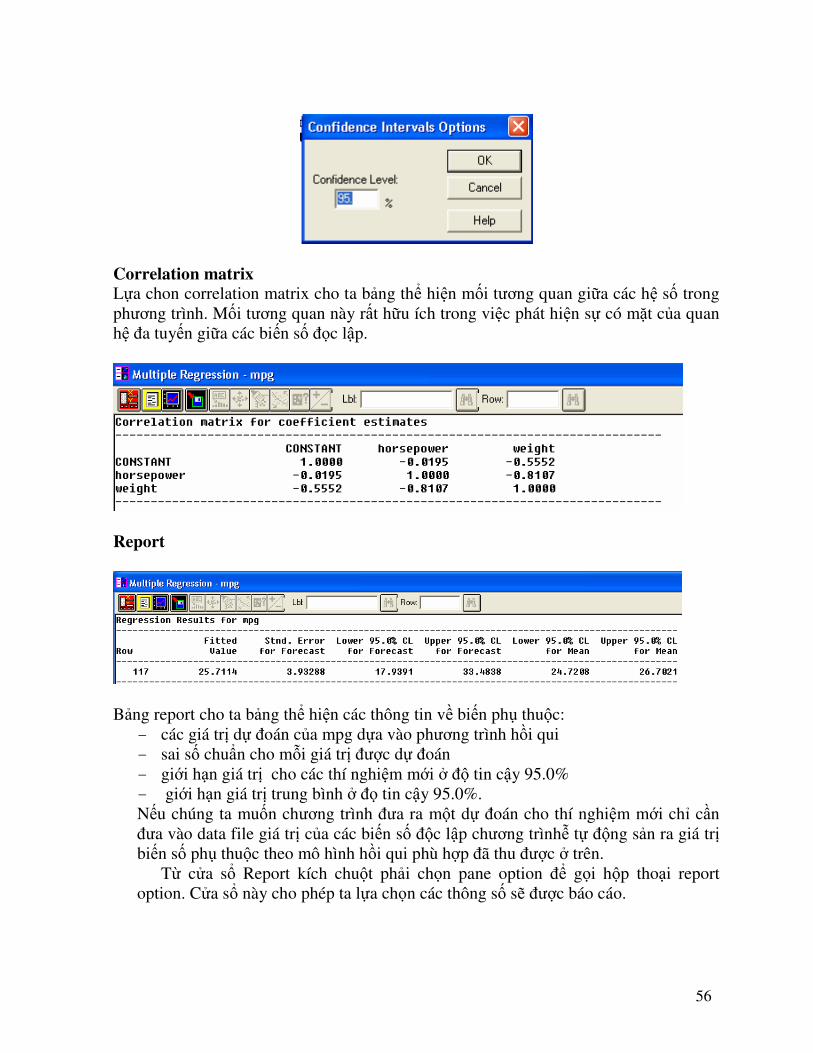
56
Correlation matrix Lựa chon correlation matrix cho ta bảng thể hiện mối tương quan giữa các hệ số trong phương trình. Mối tương quan này rất hữu ích trong việc phát hiện sự có mặt của quan hệ đa tuyến giữa các biến số đọc lập.
Report
Bảng report cho ta bảng thể hiện các thông tin về biến phụ thuộc:
- các giá trị dự đoán của mpg dựa vào phương trình hồi qui - sai số chuNn cho mỗi giá trị được dự đoán - giới hạn giá trị cho các thí nghiệm mới ở độ tin cậy 95.0% - giới hạn giá trị trung bình ở đọ tin cậy 95.0%. Nếu chúng ta muốn chương trình đưa ra một dự đoán cho thí nghiệm mới chỉ cần đưa vào data file giá trị của các biến số độc lập chương trìnhễ tự động sản ra giá trị biến số phụ thuộc theo mô hình hồi qui phù hợp đã thu được ở trên. Từ cửa sổ Report kích chuột phải chọn pane option để gọi hộp thoại report option. Cửa sổ này cho phép ta lựa chọn các thông số sẽ được báo cáo.
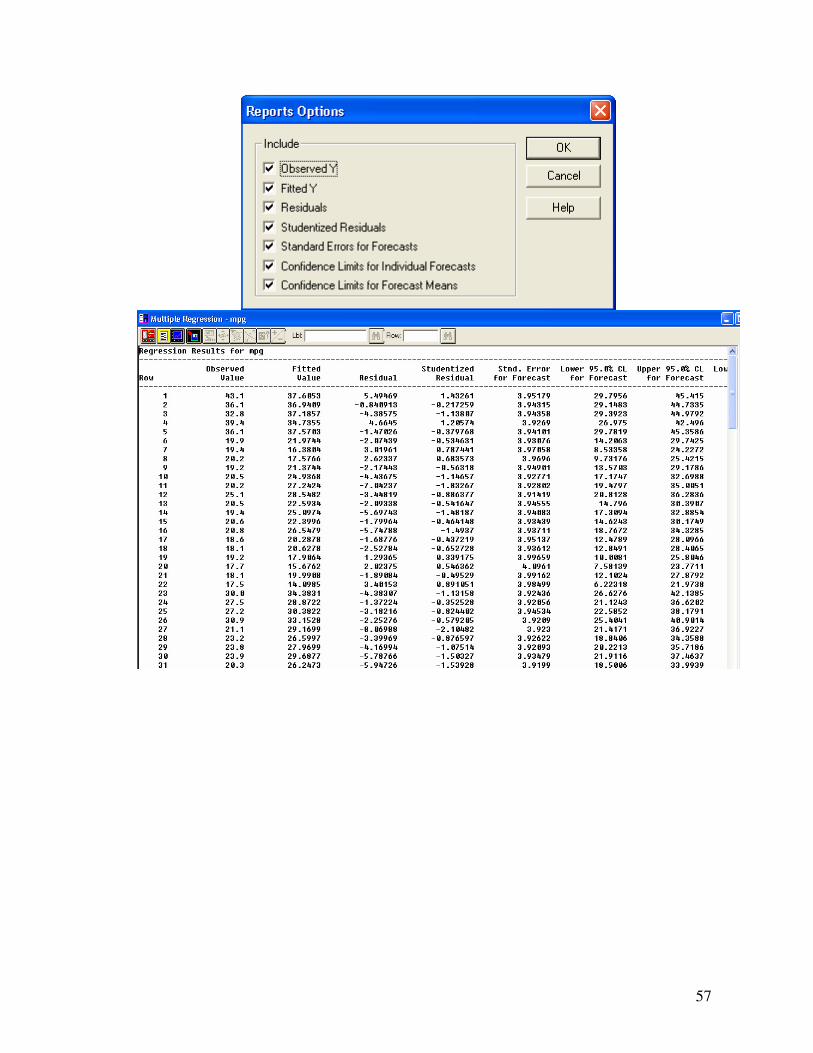
57

58
Unusual residuals Tương tự như trong phương pháp Box-cox transformation tuỳ chọn unusual residual cho ta bảng liệt kê tất cả các thí nghiệm có độ sai biệt lớn hơn 2. Ta cần tìm xem thí nghiệm nào có đọ sai biệt lơn hơn 3 để loại ra khỏi tập số liệu.
ở đây có 8 thí nghiệm có stuđentize residual > 2 và 1 thí nghiệm có stuđentize residual >3. thí nghiệm đó nếu nằm ngoài khoảng dự đoán cần phải loại ra khỏi tập số liệu. Influential points
Trong trường hợp này ảnh hưởng trung bình của mỗi số liệu là 0.02. Có 4 số liệu ảnh hưởng của chúng gấp 3 lần ảnh hưởng trung bình, và 1 số liệu ảnh hưởng gấp 5 lần ảnh hưởng trung bình. Chúng ta phải xem xét kĩ số liệu này xét xem kết quả sẽ thay đổi
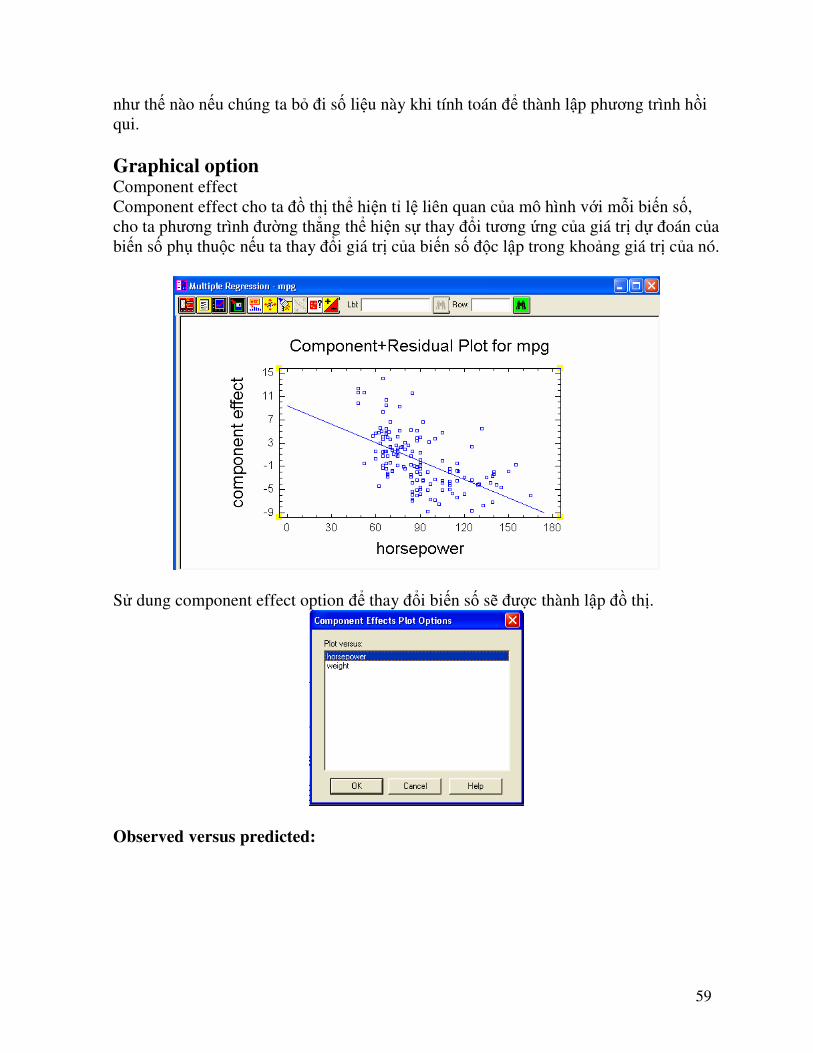
59
như thế nào nếu chúng ta bỏ đi số liệu này khi tính toán để thành lập phương trình hồi qui. Graphical option Component effect Component effect cho ta đồ thị thể hiện tỉ lệ liên quan của mô hình với mỗi biến số, cho ta phương trình đường thẳng thể hiện sự thay đổi tương ứng của giá trị dự đoán của biến số phụ thuộc nếu ta thay đổi giá trị của biến số độc lập trong khoảng giá trị của nó.
Sử dung component effect option để thay đổi biến số sẽ được thành lập đồ thị.
Observed versus predicted:

60
Residual versus X

61
VII. THIẾT KẾ THÍ NGHIỆM
Thông thường trong nghiên cứu, việc thiết kế được một thí nghiệm nhỏ nhưng hợp lý mang lại nhiều kết quả hơn so với một thí nghiệm lớn nhưng được bố trí rườm rà. STATGRAPHICS cung cấp thêm một công cụ để thiết kế và phân tích thí nghiệm. Ví dụ một người kỹ sư muốn xác định trong các yếu tố: nhiệt độ đầu vào, lưu lượng dòng chảy, nồng độ cơ chất, tốc độ chảy rối và phần trăm chất xúc tác, yếu tố nào ảnh hưởng nhiều nhất đến sản phNm cuối cùng. Trong thực tế, vấn đề này có thể được giải quyết bằng nhiều phương pháp:
1. Phương pháp thử và sai: Mỗi lần tiến hành thí nghiệm chọn bất kỳ một sự kết hợp giữa các yếu tố khác nhau � Tốn thời gian nhưng không ghi nhận được nhiều kết quả
2. Phương pháp bố trí thí nghiệm trên từng yếu tố riêng biệt: tiến hành tất cả các nghiệm thức trên từng yếu tố thí nghiệm để xác định ảnh hưởng của từng yếu tố � Không đánh giá được sự tương tác giữa các yếu tố thí nghiệm
3. Phương pháp thiết kế thí nghiệm có phân tích thống kê: đưa ra một trình tự tiến hành thí nghiệm để thu nhận được nhiều kết quả nhất về ảnh hưởng riêng lẻ và ảnh hưởng tương tác của các yếu tố thí nghiệm với số nghiệm thức ít nhất có thể.
1. Chọn kiểu thí nghiệm thử nghiệm: Mục đích của việc chọn kiểu thí nghiệm là để tìm cách bố trí thí nghiệm như thế nào để với số nghiệm thức nhỏ nhất nhưng vẫn xác định được yếu tố chính tác động đến sản phNm cuối cùng của thí nghiệm. Với phần mềm STATGRAPHICS, việc đầu tiên là phải xác định kiểu bố trí thí nghiệm phải tiến hành và cần bao nhiêu nghiệm thức thí nghiệm. Từ Menu, chọn DOE � Design Creation � Screening Design Selection. Hộp thoại đầu tiên hiện ra để lựa chọn những thông tin cơ bản về thí nghiệm:

62
Các thông số nhập dữ liệu: • Number of factors: Số yếu tố thí nghiệm. Trong ví dụ trên, người kỹ sư
muốn nghiên cứu 5 yếu tố. • Designs to Consider: kiểu thiết kế được đánh giá. STATGRAPHICS đưa ra
những kiểu thiết kế tốt nhất đáp ứng được những yêu cầu đặc biệt: 1. Factorials (thí nghiệm thừa số): các nghiệm thức được thiết kế kết hợp tất
cả mức cao và thấp của mỗi yếu tố. 2. Fractional factorials (thí nghiệm thừa số phân đoạn): các nghiệm thức
trong thí nghiệm thừa số đầy đủ (full factorials) được chia thành các tập hợp con để thí nghiệm (ví dụ chia thành ½, ¼,…)
3. Irregular fractions (thí nghiệm phân đoạn bất quy tắc): các nghiệm thức trong thí nghiệm thừa số đầy đủ được chia thành các tập hợp con để thí nghiệm nhưng các tập hợp con này không tuân theo quy tắc (ví dụ chia thành 3/8).

63
4. Mixed level factorials (thí nghiệm thừa số nhiều mức độ hỗn hợp): một yếu tố được nghiên cứu ở 3 mức trong khi các yếu tố khác được nghiên cứu ở 2 mức.
5. Plackett-Burman designs (thí nghiệm thiết kế kiểu Plackett-Burman): các thiết kế trên 2 mức thí nghiệm mà số nghiệm thức không phải là lũy thừa 2.
Các thiết kế được phân loại dựa vào cách giải quyết bài toán (resolution) của chúng:
- Resolution V designs: có thể đánh giá tất cả các tác động chính và sự tương tác giữa các yếu tố.
- Resolution IV designs: có thể đánh giá tất cả các tác động chính nhưng một số hay tất cả các tương tác giữa hai yếu tố có thể bị rối, lẫn với những tương tác khác hay có tác động nghịch.
- Resolution III designs: chỉ có thể đánh giá các tác động chính, không có sự tương tác giữa các yếu tố.
• Maximum Runs per Block: khi chuNn bị làm thí nghiệm, người kỹ sư nhận thấy rằng cô ta không thể tiến hành nhiều hơn 10 nghiệm thức trong một lần làm thí nghiệm. Vì mỗi lần làm thí nghiệm có thể khác nhau nên các nghiệm thức thí nghiệm cần phải được nhóm lại thành từng block nhỏ hơn 10 nghiệm thức.
• Minimum Centerpoints per Block: xác định rõ số điểm trung tâm (centerpoints) nhỏ nhất muốn có trong mỗi block. Điểm trung tâm là một nghiệm thức thí nghiệm ở trung tâm của vùng thí nghiệm và thường được sử dụng để tạo sự lặp lại từ đó đánh giá sai số của thí nghiệm. Trong trường hợp này, người kỹ sư quyết định để chương trình STATGRAPHICS xác định số điểm trung tâm cần thiết.
• Experimental Error Sigma: độ lệch chuNn của quá trình thí nghiệm. Đây là độ lệch chuNn sẽ được ghi nhận từ những nghiệm thức được lặp lại trong cùng điều kiện thí nghiệm. Từ nghiên cứu trước cho thấy giá trị này khoảng 0,5 đối với năng suất.
Khi nhấn OK, một hộp thoại thứ hai xuất hiện:

64
This box is used to specify the required power of experiment. “Power” là xác suất để một yếu tố tác động ở một cường độ xác định sẽ có ý nghĩa thống kê sau khi thí nghiệm hoàn tất và dữ liệu kết quả được phân tích thống kê. Nói một cách chính xác hơn, đây là xác suất để đạt được giá trị P-value có ý nghĩa trong bảng phân tích. Trong ví dụ này, người kỹ sư mong muốn có 90% cơ hội để tìm ra một tác động bằng 3 lần độ lệch sai số của thí nghiệm. Những tác động nhỏ hơn được xem như là không đáng quan tâm. Vì mức ý nghĩa được thiết lập là 95% nên giá trị P-value có ý nghĩa sẽ nhỏ hơn 0,05. Khi nhấn OK, một cửa sổ xuất hiện liệt kê số nghiệm thức thí nghiệm ít nhất đáp ứng được yêu cầu đề ra ứng với mỗi kiểu bố trí thí nghiệm:

65
Có 2 kiểu bố trí thí nghiệm được đề xuất:
1. Thí nghiệm thừa số đầy đủ 25 (Factorial in 4 blocks 2^5): gồm tất cả các nghiệm thức kết hợp 2 mức của 5 yếu tố thí nghiệm. Kiểu thiết kế thí nghiệm này khá lớn với 8 nghiệm thức trong mỗi 4 block (giá trị “power” cao hơn yêu cầu)
2. Thí nghiệm phân đoạn một nửa (A half fraction in 2 blocks): 2 block với 10 nghiệm thức mỗi block. Mỗi block gồm 8 thừa số hay điểm góc và 2 điểm trung tâm. Thiết kế kiểu resolution IV nên có thể ước lượng tất cả các yếu tố chính và một số tương tác giữa 2 yếu tố. Với 5 yếu tố thí nghiệm, các tác động có thể có là:
a. 1 tác động trung bình rất quan trọng b. 5 tác động chính c. 10 tác động tương tác giữa 2 yếu tố d. 1 tác động block
Nếu không có tác động block, thiết kế thuộc resolution V, vì 16 yếu tố

66
Trong hộp thoại đầu tiên, cần phải chỉ ra kiểu thí nghiệm muốn xem xét và những thông tin quan trọng khác. Trong trường hợp này, chúng ta muốn chương trình chỉ xét kiểu thí nghiệm thừa số 2 mức độ và kiểu thí nghiệm thừa số phân đoạn vì chúng ta cho rằng có thể cần phải bổ sung thiết kế sau khi tiến hành. Những thiết kế này bao gồm một tập hợp các loạt thí nghiệm ở 2 mức của mỗi yếu tố thí nghiệm với tổng số loạt thí nghiệm là lũy thừa 2. Một hộp thoại rất quan trọng là Experimental error sigma. Thông số này liên quan đến khả năng lặp lại của bất kỳ loạt thí nghiệm nào. Nó bao gồm sự nhiễu trong điều chỉnh loạt thí nghiệm, sự biến động của các yếu tố bên ngoài, sai số đo lường và những nguyên nhân gây ra sự sai khác khi cố gắng lặp lại cùng một thí nghiệm nhiều hơn một lần dưới cùng một điều kiện. Từ những thí nghiệm khác, chúng ta hi vọng sai số cho phép σ sẽ là khoảng 0,5%. Chúng ta cũng có thể thêm yếu tố giới hạn kích cỡ block hay số điểm centerpoint tối thiểu nếu muốn. Trong hộp thoại thứ hai, cần chỉ ra độ chính xác mà chúng ta muốn đạt được trong thí nghiệm này. Bằng cách chọn Power và chỉ rõ mục Effect to detect chúng ta yêu cầu thí nghiệm phải có 90% cơ hội để phát hiện bất kỳ một yếu tố nào hay một sự tương tác nào có thể tạo ra sự khác biệt 1,0% hoặc hơn ở mức sai số cho phép. Centerpoint để ước lượng sai số thí nghiệm VII. TIẾN HÀNH THÍ NGHIỆM TỐI ƯU HÓA
Mục đích của phần này là hướng dẫn một công cụ đặc biệt của Statgraphics, bắt đầu với việc thiết kế thí nghiệm sàng lọc để xác định những yếu tố quan trọng nhất ảnh hưởng đến toàn bộ tiến trình và kết thúc với việc xác định những điều kiện thí nghiệm tối ưu. Xem xét trường hợp các nhà nghiên cứu quan tâm đến việc nghiên cứu ảnh hưởng của các yếu tố có thể kiểm soát khác nhau lên các biến đáp ứng khác nhau bao gồm shrinkage (mức độ hao hụt cho phép) và warpage (trạng thái vênh của vật liệu). Các yếu tố ảnh hưởng bao gồm:
- Yếu tố A: mold temperature (nhiệt độ khuôn) - Yếu tố B: moisture content (độ Nm) - Yếu tố C: holding presure (áp suất chân không) - Yếu tố D: cavity thickness (độ dày ổ khoang) - Yếu tố E: booster presure (áp suất nâng) - Yếu tố F: cycle time (thời gian lặp chu trình) - Yếu tố G: gate size (kích thước cổng) - Yếu tố H: screw speed (tốc độ quay)

67
Mục đích cuối cùng là tìm ra các mức độ của mỗi yếu tố để giảm thấp nhất trạng thái vênh và mức độ hao hụt vật liệu. Bước 1. Thiết kế thí nghiệm sàng lọc Việc tối ưu những tiến trình đòi hỏi một phương pháp đa biến. Ngoại trừ trong những trường hợp mà các yếu tố thí nghiệm không bao giờ tương tác với nhau nếu không thì người ta không thể hy vọng tìm được những điều kiện tiến trình tối ưu bằng cách tối ưu hóa quá trình đối với chỉ một yếu tố ở một thời điểm. Nói cách khác, việc nỗ lực để tối ưu nhiều hơn 3 hay 4 yếu tố cùng một lúc có thể vừa đắt vừa rối. Trong hầu hết các trường hợp, một vài yếu tố sẽ chịu trách nhiệm cho hầu hết các biến được quan sát trong một sản phNm. Việc xác định những yếu tố ảnh hưởng chính từ những yếu tố ban đầu luôn là một điều kiện tiên quyết cần thiết để tối ưu hóa tiến trình. Phần thiết kế thí nghiệm của Statgraphics có chứa một công cụ được xây dựng để giúp thiết lập một thí nghiệm sàng lọc. Từ menu chính chọn: DOE � Design Creation � Screening Design Selection. Tiến trình sẽ bắt đầu bằng cách hiển thị hộp thoại:

68
Trong hộp thoại này, bạn có thể chỉ ra kiểu bố trí thí nghiệm mà bạn muốn xem xét và những thông tin quan trọng khác. Trong trường hợp này, chúng ta muốn chương trình chỉ xem xét những kiểu thí nghiệm thừa số 2 mức độ thuần túy và thí nghiệm thừa số phân đoạn, vì chúng ta mong muốn rằng có thể chúng ra cần phải bổ sung thêm thiết kế sau khi tiến hành thí nghiệm. Những kiểu thiết kế này bao gồm một tập hợp các lượt thí nghiệm ở 2 mức độ của mỗi yếu tố thí nghiệm với tổng số loạt thí nghiệm là lũy thừa của 2. Một dữ liệu nhập quan trọng vào hộp thoại này là “Experimental error sigma”. Nó đề cập đến khả năng lặp lại bất kỳ một lượt thí nghiệm nào. Nó bao gồm sự nhiễu trong việc điều chỉnh lượt thí nghiệm, những sự thay đổi đối với những yếu tố bên ngoài, sai số đo lường và bất cứ thứ gì gây ra sự khác biệt khi chúng ta lặp lại cùng một thí nghiệm hơn một lần dưới cùng một điều kiện. Từ những thí nghiệm khác, chúng ta tin rằng σ cho mức độ hao hụt (được xem như là biến phụ thuộc quan trọng hơn trong 2 biến phụ thuộc) sẽ khoảng 0,5%. Chúng ta cũng có thể bổ sung giới hạn về kích thước block hay số điểm centerpoints thấp nhất nếu muốn. Tiến trình sẽ tiếp tục với sự xuất hiện hộp thoại thứ hai:
Trong hộp thoại này, chúng tôi chỉ ra độ chính xác mong muốn cho thí nghiệm này. Bằng cách chọn mục “Power” và chỉ rõ mục “Effect to Detect”, chúng ta muốn các thiết kế phải có 90% cơ hội (biểu thị như mức ý nghĩa thống kê) để tìm được các yếu tố hay tương tác tạo ra được sự khác biệt về mức độ hao hụt 1% hoặc hơn.
Sau đó tiến trình sẽ mở ra một cửa sổ phân tích và chỉ ra cho chúng ta những thiết kế nhỏ nhất của mỗi kiểu đáp ứng được các tiêu chuNn đặt ra.

69
Có 3 kiểu thiết kế với số lượt thí nghiệm nằm trong khoảng từ 22 đến 128 lượt. Kiểu thiết kế với resolution V nhỏ nhất là kiểu thiết kế có thể đánh giá những yếu tố chính trong 8 yếu tố và những tương tác giữa 2 yếu tố đòi hỏi chúng ta phải tiến hành 64 lượt thí nghiệm. Nếu chúng ta có chọn kiểu thiết kế với resolution IV thì chỉ có thể đánh giá những yếu tố chính nhưng lại bỏ qua những tương tác giữa 2 yếu tố và chúng ta chỉ phải tiến hành 22 lượt thí nghiệm. Kiểu thiết kế với 22 lượt thí nghiệm bao gồm 16 sự kết hợp khác nhau giữa các mức cao và thấp của 8 yếu tố thí nghiệm (các điểm góc) cộng với 6 lần lặp lại ở trung tâm của vùng thí nghiệm. 6 lần lặp lại cần để đánh giá đúng sai số σ của thí nghiệm. Nếu chúng ta không muốn tiến hành nhiều điểm trung tâm như vậy thì có thể nhấn phím “Analysis Options” trên thanh công cụ phân tích và thay đổi thông số để giảm xuống còn 19 lượt thí nghiệm.
Kết quả phân tích sau đó sẽ được biểu diễn chỉ với một lựa chọn

70
Với chỉ 19 lượt thí nghiệm, kiểu thiết kế resolution IV cho thấy dung sai
(Tolerance) bằng 0,8. Tolerance được xác định là rìa của sai số kết hợp với việc đánh giá tác động của mỗi yếu tố, dựa trên khoảng tin cậy 95% của dạng: tác động được đánh giá ± dung sai.
Đối với kiểu thiết kế 19 lượt thí nghiệm, chúng ta có thể trông chờ khả năng đánh giá mọi tác động nằm trong khoảng ± 0,8% với độ tin cậy 95%.
Tiến trình “Screening Design Selection” cũng biểu diễn một đường cong lũy thừa đối với thí nghiệm:
Đường cong lũy thừa (Power Curve) biểu thị khả năng đạt được một mức
ý nghĩa thống kê nếu một yếu tố thí nghiệm bị thay đổi từ một mức này sang một mức khác, là hàm số cường độ hay tác động thực của nó. Chú ý rằng đường cong khoảng 80% tác động thực nằm trong khoảng [-1;1]. Mặc dù ban đầu chúng ta hi vọng 90% khả năng nhưng vẫn có 4/5 khả năng bất kỳ một yếu tố nào tạo ra được 1% khác biệt về mức độ hao hụt cho phép. Bước 2. Xây dựng thí nghiệm sàng lọc

71
Khi đã quyết định tiến hành, chúng ta có thể sử dụng Statgraphics để xây dựng kiểu bố trí thí nghiệm và đặt trong datasheet. Tiến trình: chọn menu DOE � Design Creation � Create New Design Một loạt hộp thoại sẽ xuất hiện để khai báo các thuộc tính thiết kế thí nghiệm. Hộp thoại đầu tiên xác định kiểu bố trí thí nghiệm, số biến phụ thuộc (kết quả) và số yếu tố thí nghiệm.
Hộp thoại thứ hai yêu cầu chỉ ra tên của mỗi yếu tố và các giới hạn thí nghiệm đối với mỗi yếu tố.
Vì tất cả các yếu tố trong thí nghiệm này có thể thay đổi tiên tục giữa các mức giới hạn dưới và giới hạn trên nên cần phải check vào mục “Continuous”. Hộp thoại thứ ba chỉ ra tên và đơn vị của biến phụ thuộc (đáp ứng kết quả)

72
Hộp thoại thứ tư chứa một danh sách tất cả các kiểu thí nghiệm sàng lọc có thể thực hiện đối với thí nghiệm gồm 8 yếu tố.
Kiểu thiết kế đã được chọn ở phần trước là kiểu “Sixteenth fraction” với 16 lượt thí nghiệm là những sự kết hợp được chọn lọc cNn thận của các yếu tố thí nghiệm ở các mức giới hạn dưới và trên. Chú ý rằng bậc tự do sai số bằng 0 để ước lượng sai số thí nghiệm. Thông số này sẽ được hiệu chỉnh trong hộp thoại tiếp theo khi các điểm centerpoints được thêm vào trong phần bố trí thí nghiệm. Hộp thoại thứ tư và hộp thoại cuối cùng chỉ ra các thông số lựa chọn đối với kiểu bố trí thí nghiệm đã được chọn:

73
Để ước lượng sai số thí nghiệm cần phải có 3 điểm centerpoints nên tổng số nghiệm thức thí nghiệm là 19. Các nghiệm thức này cần phải được tiến hành theo một trật tự ngẫu nhiên. Sau khi hoàn tất hộp thoại cuối cùng, một cửa sổ phân tích có tên là “Screening Design Attributes” sẽ xuất hiện. Bảng này đưa ra những tổng kết về kiểu thiết kế thí nghiệm:
Để có thêm thông tin, có thể nhấn phím “Tables” trên thanh công cụ phân tích và chọn mục “Alias Structure”

74
Mỗi dòng trên bảng biểu diễn một yếu tố tác động hay một sự kết hợp giữa các yếu tố có thể được đánh giá. Một ký tự chữ cái đại diện cho một tác động hay một yếu tố chính. Vì mỗi tác động chính xuất hiện riêng lẻ trên một hàng riêng biệt nên có thể đánh giá rõ bất kỳ một tác động khác nhau nào trong thí nghiệm. Những ký hiệu gồm 2 ký tự chữ cái như “AB” đại diện cho sự tương tác giữa 2 yếu tố thí nghiệm A và B. Trong trường hợp này, mỗi tương tác giữa 2 yếu tố thí nghiệm kết hợp với 3 cặp tương tác khác. Điều đó làm cho chúng ta không thể đánh giá riêng từng cặp tương tác vì không đủ số nghiệm thức để đánh giá hết các tác động này. Thí nghiệm bố trí cuối cùng với 19 nghiệm thức sẽ được cập nhật vào datasheet A:

75
Datasheet bao gồm:
1. Mỗi hàng là một nghiệm thức thí nghiệm 2. Cột “Block” xác định lô thí nghiệm mà mỗi nghiệm thức được gán
vào. Cột này chỉ xuất hiện khi các nghiệm thức được chia thành từng lô theo yếu tố gây rắc rối. Trong trường hợp này, tất cả các nghiệm thức đều nằm trong một lô thí nghiệm.
3. Một cột dành cho mỗi yếu tố thí nghiệm 4. Một cột dành cho biến đáp ứng phụ thuộc
Bước 3: Tiến hành thí nghiệm sàng lọc 19 nghiệm thức trong thí nghiệm sau đó sẽ được tiến hành và các giá trị kết quả ghi nhận được sẽ được nhập vào cột tương ứng trong datasheet. Các kết quả đáp ứng khác cũng có thể được thêm vào các cột phía sau của datasheet nếu người làm thí nghiệm muốn phân tích thêm độ lệch chuNn hay các phân tích thống kê khác của mẫu. Dữ liệu kết quả được lưu trong file howto9.sfx. Chú ý là file thí nghiệm trong Statgraphics có một phần mở rộng đặc biệt, vì chúng không chỉ chứa dữ liệu mà còn chứa thêm những thông tin bổ trợ về kiểu thiết kế thí nghiệm được lập. Bước 4: Phân tích kết quả sàng lọc Để phân tích kết quả thí nghiệm chọn menu DOE � Design Analysis �
Analyze Design. Một hộp thoại nhập dữ liệu sẽ xuất hiện, liệt kê mỗi biến kết quả phụ thuộc
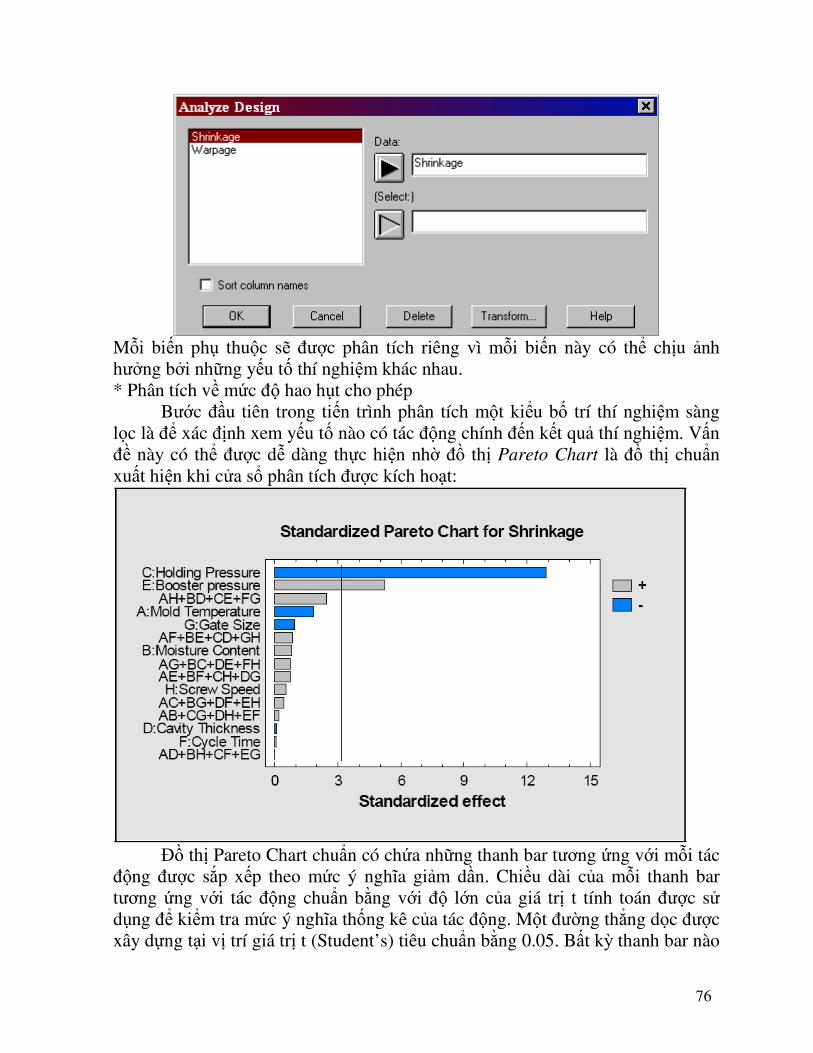
76
Mỗi biến phụ thuộc sẽ được phân tích riêng vì mỗi biến này có thể chịu ảnh hưởng bởi những yếu tố thí nghiệm khác nhau. * Phân tích về mức độ hao hụt cho phép Bước đầu tiên trong tiến trình phân tích một kiểu bố trí thí nghiệm sàng lọc là để xác định xem yếu tố nào có tác động chính đến kết quả thí nghiệm. Vấn đề này có thể được dễ dàng thực hiện nhờ đồ thị Pareto Chart là đồ thị chuNn xuất hiện khi cửa sổ phân tích được kích hoạt:
Đồ thị Pareto Chart chuNn có chứa những thanh bar tương ứng với mỗi tác động được sắp xếp theo mức ý nghĩa giảm dần. Chiều dài của mỗi thanh bar tương ứng với tác động chuNn bằng với độ lớn của giá trị t tính toán được sử dụng để kiểm tra mức ý nghĩa thống kê của tác động. Một đường thẳng dọc được xây dựng tại vị trí giá trị t (Student’s) tiêu chuNn bằng 0.05. Bất kỳ thanh bar nào

77
kéo dài sang phía bên phải của đường thẳng trên cho thấy tác động đó có ý nghĩa thống kê ở mức α = 0,05. Để biết được giá trị P-values có thể xem thêm ở bảng ANOVA
Chú ý rằng có 2 tác động có giá trị P-value nhỏ hơn 0,05: tác động chính của áp suất chân không và áp suất nâng. Một tác động khác là tổng của 4 tương tác AH + BD + CE + FG có giá trị P-value khoảng 0,09. Vì chúng ta quyết định tiến hành một thí nghiệm chỉ với 3 bậc tự do đối với sai số nên giá trị P-value bằng 0,1 bên cạnh có thể đủ lớn để quan tâm. Với tất cả các kiểu thiết kế có resolution IV, không thể xác định được yếu tố nào trong 4 tương tác có ảnh hưởng lớn nhất đến kết quả. Tuy nhiên, với tác động có chứa sự tương tác của 2 yếu tố ảnh hưởng chính (C và E) thì tương tác CE có thể đóng vai trò quan trọng. Nếu chúng ta sử dụng công cụ Analysis Options để loại trừ tất cả những tác động khác ngoài C, E và CE thì đồ thị Interaction Plot có thể thu nhận được như sau:

78
Kết quả cho thấy khi gia tăng áp suất chân không làm giảm độ hao hụt cho phép. Hơn nữa, tác động dễ nhận thấy hơn ở mức áp suất nâng thấp. Tác động của 2 yếu tố cũng có thể được biểu diễn bằng đồ thị Contour
plot
Vùng màu xanh đậm ở góc phải bên dưới chỉ sự kết hợp của áp suất làm giảm khá thấp mức độ hao hụt cho phép. Phân tích mức độ cong vênh

79
Khi tiến hành phân tích tương tự đối với mức độ cong vênh, có 2 yếu tố chính tác động được biểu diễn trong đồ thị Pareto Chart là áp suất chân không và thời gian lặp chu kỳ.
Sau khi loại trừ các yếu tố không gây ảnh hưởng lên kết quả được đồ thị Contour Plot sau:

80
Kết quả cho thấy mức độ cong vênh thấp khi áp suất chân không cao và thời gian lặp chu kỳ thấp. Bước 5: Theo phương pháp lên hoặc xuống đường dốc nhất Dường như cả 2 kết quả mức độ hao hụt cho phép và mức độ cong vênh có thể được giảm xuống bằng cách tăng áp suất chân không. Cùng lúc đó, nếu giảm áp suất nâng sẽ làm giảm mức độ hao hụt cho phép còn nếu tăng thời gian lặp chu kỳ thì sẽ làm giảm mức độ cong vênh. Để khẳng định lại những kết quả này, người nghiên cứu phải quyết định tiến hành một số thí nghiệm dọc theo đường dốc nhất. Đây là đường được dự đoán sẽ làm giảm các đáp ứng kết quả nhânh chóng khi thay đổi các yếu tố thí nghiệm ban đầu. Chúng ta sẽ phải tiến hành theo 2 con đường tương ứng với 2 đáp ứng kết quả. Đối với kết quả mức độ hao hụt cho phép, trước tiên chúng ta sẽ phải giảm bớt yếu tố thí nghiệm ban đầu chỉ để lại 2 yếu tố áp suất chân không và áp suất nâng bằng cách:
1. Đóng file Howto9.sgp StatFolio
2. Mở lại file thí nghiệm trong datasheet A của Howto9.sfx
3. Chọn menu DOE � Design Creation � Augment Existing Design
Khi hộp thoại đầu tiên xuất hiện, chọn “Collapse Design” để giảm bớt yếu tố thí nghiệm
Trong hộp thoại thứ hai, click chọn vào những yếu tố muốn loại bỏ, giả sử trong trường hợp này muốn loại bỏ yếu tố Nhiệt độ khuôn

81
Sau khi nhấn OK, cột “Mold Temperature” sẽ bị xóa khỏi datasheet A. Bây giờ lặp lại bước trên cho đến khi chỉ còn lại 2 yếu tố là áp suất chân không và áp suất nâng còn lại trong thí nghiệm. Sau đó vào menu File � Save as để lưu lại phần bố trí thí nghiệm với tên mới.
4. Chọn Menu Analyze Design và sửa lại mô hình đối với Shrinkage. Chắc chắn sẽ còn lại 3 tác động có ý nghĩa được ký hiệu là A, B và AB như được trình bày trong đồ thị Pareto bên dưới:

82
5. Cuối cùng, chọn “Path oh Steepest Ascent” từ danh sách bảng có sẵn trong cửa sổ Analyze Design. Trước khi kiểm tra lại kết quả, nhấn “Pane Options” và thiết lập các thông số như bên dưới:
Hộp thoại trên yêu cầu 5 bước dọc theo đường dốc nhất giảm dần hoặc tăng dần mỗi mức 5 Mpa đối với áp suất chân không. Sau đó chương trình sẽ tính và hiển thị giá trị của yếu tố còn lại để chúng ta có thể loại bỏ khỏi đường dốc nhất:
Khi áp suất chân không tăng thì áp suất nâng giảm. Chú ý là giá trị Shrinkage được dự đoán giảm nhanh chóng khi di chuyển dọc theo đường dốc nhất. Cuối cùng, phép ngoại suy của mô hình dẫn đến những kết quả dự đoán

83
mang giá trị âm không có thật. Mặc dù những mô hình này không thể dự đoán tốt đối với những giá trị nằm quá xa vùng thí nghiệm nhưng chúng lại có thể gợi lên được hướng tiếp cận để tìm ra được giá trị kết quả tốt hơn. Để tạo ra đường dốc nhất giảm dần đối với Warpage, bạn phải khởi động lại kiểu bố trí thí nghiệm ban đầu. Bây giờ mới bắt đầu tiến hành loại bỏ các yếu tố thí nghiệm không liên quan ngoại trừ áp suất chân không và thời gian vòng lặp. Sau đó chọn Analyze Design để sửa lại mô hình chỉ với 2 yếu tố còn lại. Đồ thị Pareto chuNn sẽ xuất hiện như hình bên dưới:
Sau đó tạo đường dốc nhất giảm dần đối với Warpage
Kết quả đáp ứng được dự đoán ở những điểm dọc theo đường dốc nhất giảm dần đưa ra hướng nghiên cứu tiếp tục để có kết quả tốt hơn. Người nghiên cứu hoàn toàn có thể quyết định phải tiếp tục làm gì tiếp theo dựa trên những gợi

84
ý đó để kiểm tra lại những dự đoán. Bảng bên dưới chỉ ra 5 nghiệm thức thí nghiệm dọc theo đường dốc nhất:
Chú ý rằng một vài bước đầu tiên dọc theo đường dốc nhất làm giảm cả Shrinkage và Warpage mặc dù không đáng kể như mô hình đã dự đoán. Cuối cùng, cả 2 đáp ứng kết quả bắt đầu tăng trở lại. Đây là bằng chứng cho thấy những mô hình bậc 1 được đề nghị bởi thiết kế sàng lọc (Screening designs) ban đầu không đạt được độ cong trên bề mặt đáp ứng. Điều này không có gì đáng ngạc nhiên, vì nhiệm vụ ban đầu của thí nghiệm sàng lọc (screening experiment) là để lựa chọn những yếu tố quan trọng nhất trong số 8 yếu tố. Và thực tế là thí nghiệm sàng lọc đã đưa ra được những chỉ dẫn về hướng nghiên cứu tiếp tục để đạt được kết quả tốt hơn. Bước 6: Xây dựng thí nghiệm tối ưu Bây giờ số yếu tố thí nghiệm đã giảm xuống đáng kể và có thể quản lý được nên có thể xây dựng một thí nghiệm tối ưu. Dựa trên những kết quả của thí nghiệm dọc theo đường dốc nhất, có thể quyết định xây dựng một thí nghiệm thứ hai bao phủ lên toàn bộ vùng nghiệm thức sau: Áp suất chân không: 65 – 80 Mpa Áp suất nâng: 60 – 65 Mpa Thời gian lặp chu kỳ: 40 – 45 s Để xây dựng thí nghiệm này, StatFolio sẽ được xóa và sau đó chọn mục Create Design từ menu chính:

85
Trong 2 hộp thoại tiếp theo, các yếu tố và vùng thí nghiệm sẽ được xác định như bên dưới. Trong hộp thoại chọn kiểu bố trí thí nghiệm, kiểu bố trí hỗn hợp trung tâm (central composite design) được lựa chọn:

86
Kiểu bố trí thí nghiệm này gồm có 16 nghiệm thức:
1. 8 nghiệm thức ở tất cả các sự kết hợp ở 2 mức cao và thấp của 3 yếu tố thí nghiệm. Khi xây dựng đồ thị 3 chiều thì những điểm này tạo thành một khối lập phương.
2. 6 nghiệm thức ở các điểm star point định vị ở đầu cuối của các đường thẳng xuyên tâm kéo dài qua 6 mặt của khối lập phương
3. 2 nghiệm thức ở trung tâm Trong hộp thoại nhập thông số của kiểu bố trí thí nghiệm, tất cả các thông
số chuNn vẫn giữ nguyên:

87
Kết quả bố trí thí nghiệm thu được như sau:
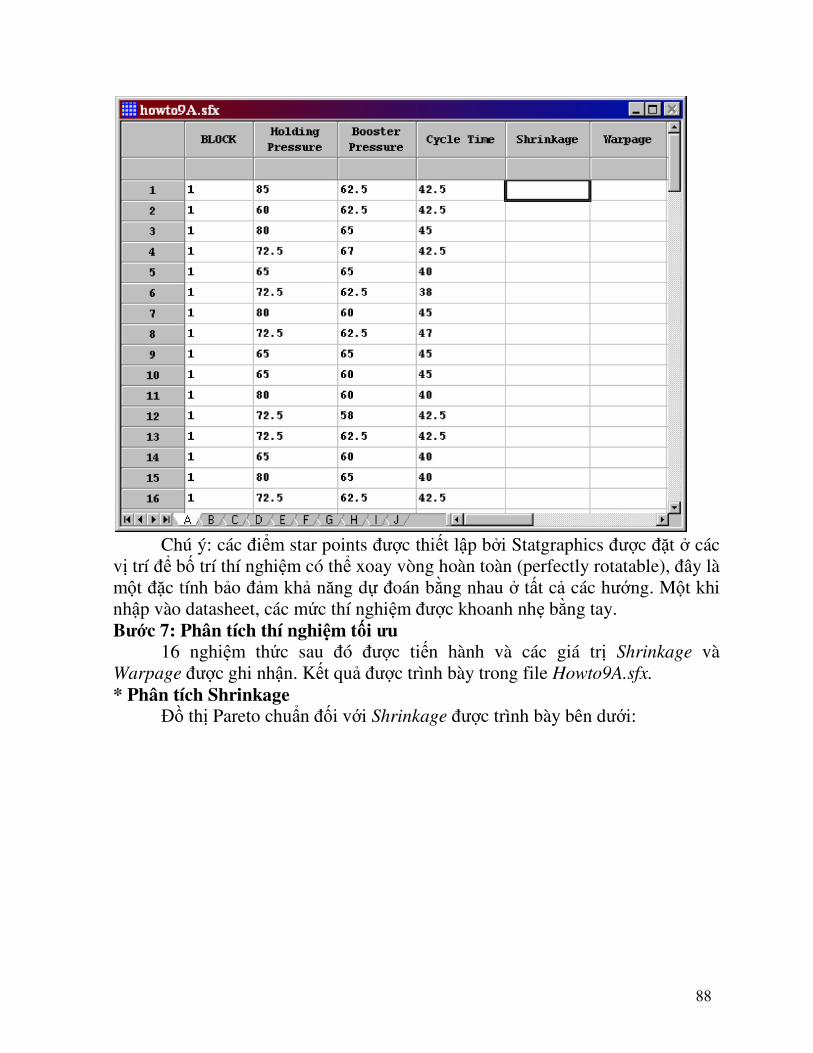
88
Chú ý: các điểm star points được thiết lập bởi Statgraphics được đặt ở các vị trí để bố trí thí nghiệm có thể xoay vòng hoàn toàn (perfectly rotatable), đây là một đặc tính bảo đảm khả năng dự đoán bằng nhau ở tất cả các hướng. Một khi nhập vào datasheet, các mức thí nghiệm được khoanh nhẹ bằng tay. Bước 7: Phân tích thí nghiệm tối ưu 16 nghiệm thức sau đó được tiến hành và các giá trị Shrinkage và Warpage được ghi nhận. Kết quả được trình bày trong file Howto9A.sfx.
* Phân tích Shrinkage Đồ thị Pareto chuNn đối với Shrinkage được trình bày bên dưới:

89
Không có tác động nào có liên quan tới yếu tố C (thời gian lặp chu kỳ) gây ảnh hưởng có ý nghĩa thống kê đối với Shrinkage vì vậy yếu tố thời gian lặp chu kỳ bị loại khỏi mô hình. Đồ thị contour plot thu được như sau:
Giá trị Shrinkage đạt được thấp nhất ở áp suất nâng thấp và áp suất chân không khoảng 71 Mpa. Khi giảm dần áp suất nâng xuống dưới 58 có thể làm giảm Shrinkage nhiều hơn. * Phân tích Warpage
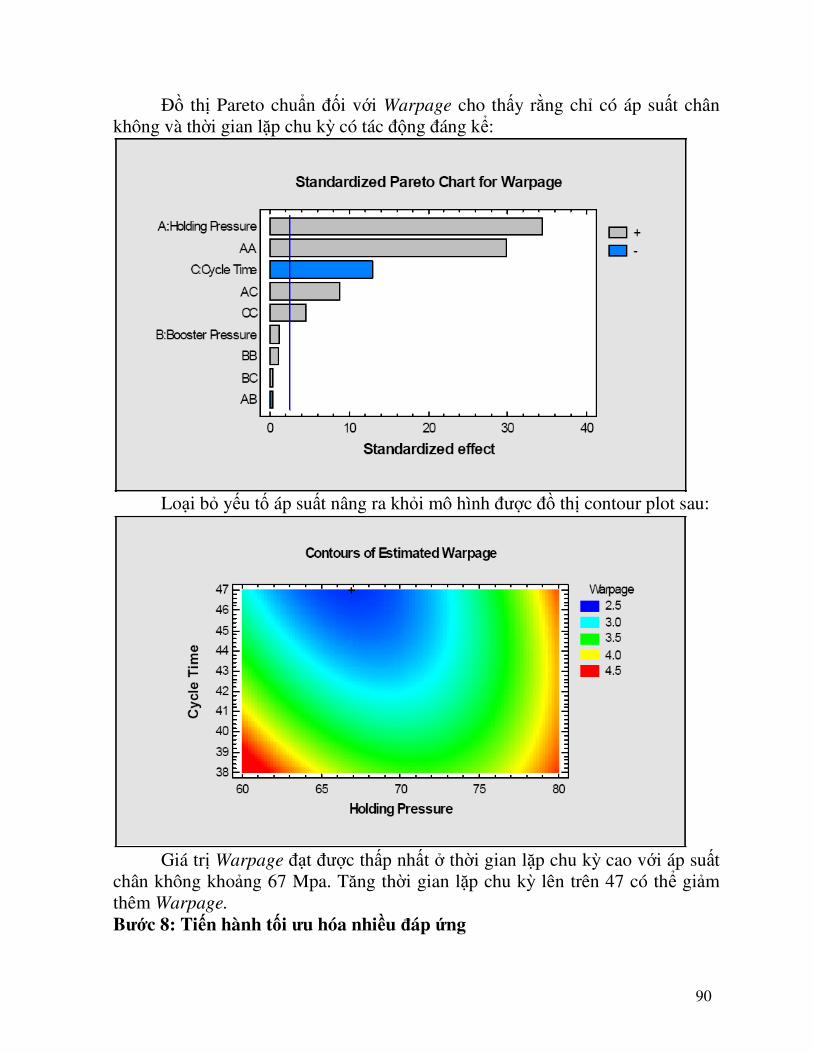
90
Đồ thị Pareto chuNn đối với Warpage cho thấy rằng chỉ có áp suất chân không và thời gian lặp chu kỳ có tác động đáng kể:
Loại bỏ yếu tố áp suất nâng ra khỏi mô hình được đồ thị contour plot sau:
Giá trị Warpage đạt được thấp nhất ở thời gian lặp chu kỳ cao với áp suất chân không khoảng 67 Mpa. Tăng thời gian lặp chu kỳ lên trên 47 có thể giảm thêm Warpage.
Bước 8: Tiến hành tối ưu hóa nhiều đáp ứng

91
Các thông số tối ưu hóa đối với mỗi biến đáp ứng kết quả thu được từ cửa sổ Optimization trong mỗi cửa sổ phân tích riêng biệt được tóm tắt lại như sau:
Vì áp suất nâng và thời gian lặp chu kỳ chỉ tác động đến một đáp ứng nên không cần phải thay đổi các yếu tố này. Tuy nhiên, áp suất chân không có ảnh hưởng đến cả 2 đáp ứng và thông số tối ưu đối với mỗi đáp ứng lại khác nhau nên để tìm ra một mức áp suất chân không để tạo ra kết quả tốt đối với cả 2 đáp ứng thì có thể tiến hành thêm phần Multiple Response Optimization. Phải chắc chắn là bạn đang mở cửa sổ phân tích Analyze Design đối với cả 2 đáp ứng vì tiến trình Multiple Response Optimization sẽ tra thông tin trên những cửa sổ này để tìm mô hình phù hợp nhất cho mỗi đáp ứng. Sau đó chọn Menu DOE �
Design Analysis � Multiple Response Optimization
Trong hộp thoại nhập dữ liệu, chỉ ra tên của cả 2 biến đáp ứng phụ thuộc:
Sau đó chương trình sẽ tìm các thông số của các yếu tố thí nghiệm để đạt được một hàm số tốt nhất.

92
Người sử dụng phải xác định rõ các giá trị ở mức thấp và cao, cũng như thông số hình dạng (shape parameter) s, thông số này có thể nằm trong khoảng từ 0,1 đến 10. Đồ thị bên dưới minh họa cho hình dạng của hàm mong muốn đối với các giá trị s khác nhau:
Đối với s = 1, một đường thẳng giảm dần từ 1 ở giá trị thấp (low) đến 0 ở giá trị cao (high). Đối với s < 1, đồ thị giảm chậm sau đó giảm rất nhanh. Người phân tích có thể thiết lập thông số s lớn nếu tầm quan trọng nằm gần với mức thấp nhất (minimum level). Khi cửa sổ Multiple Response Optimization mở ra, chọn Analysis Options để được hộp thoại sau:
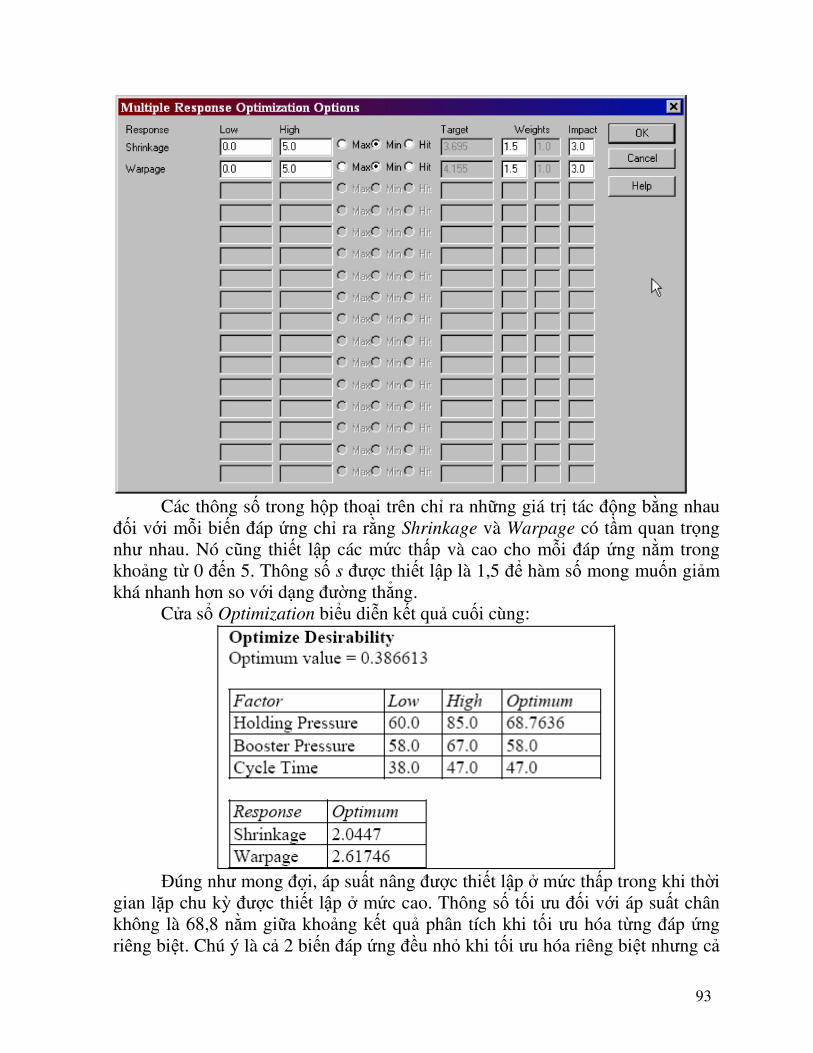
93
Các thông số trong hộp thoại trên chỉ ra những giá trị tác động bằng nhau đối với mỗi biến đáp ứng chỉ ra rằng Shrinkage và Warpage có tầm quan trọng như nhau. Nó cũng thiết lập các mức thấp và cao cho mỗi đáp ứng nằm trong khoảng từ 0 đến 5. Thông số s được thiết lập là 1,5 để hàm số mong muốn giảm khá nhanh hơn so với dạng đường thẳng. Cửa sổ Optimization biểu diễn kết quả cuối cùng:
Đúng như mong đợi, áp suất nâng được thiết lập ở mức thấp trong khi thời gian lặp chu kỳ được thiết lập ở mức cao. Thông số tối ưu đối với áp suất chân không là 68,8 nằm giữa khoảng kết quả phân tích khi tối ưu hóa từng đáp ứng riêng biệt. Chú ý là cả 2 biến đáp ứng đều nhỏ khi tối ưu hóa riêng biệt nhưng cả

94
2 đáp ứng đều có giá trị trung bình so với sự biến động ghi nhận được trong vùng thí nghiệm.






![Đi m nh n th tr ng] 26/12/2019 [H ng T [C phi n th ng] PC1, HBC · 2019-12-26 · - S£ n lÇÄ ng tiêu thÅ thép b© t ¥ u h» i phÅ c tr l ¢ i - Giá thép xây dÌ ng có](https://static.fdocument.pub/doc/165x107/5e2a8144bad5182d3212c220/i-m-nh-n-th-tr-ng-26122019-h-ng-t-c-phi-n-th-ng-pc1-hbc-2019-12-26-.jpg)











