AI・機械学習を用いた異常検知...AI・機械学習を用いた異常検知...
2
18 ビジネスコミュニケーション 2019 Vol.56 No.7 知 今 連載 ビッグデータが流行語となって久し いが、いざデータが手元に集まってく ると必ず含まれているのが異常値であ る。 異常値とは、「予想していた正常 な振る舞い」 から大きく外れたデータ である。異常値は、データの入力ミス 等で偶然に生じることもあれば、シス テムの故障や第三者による攻撃といっ た深刻な原因で生じることもある。 発生の原因が何であれ、大量の データの中から異常値を見つけ出す 「異常検知」を素早く・正確に実行 することは、異常値を放置した場合 に生じる可能性がある将来の損害を 未然に防ぐ上で極めて重要である。 異常検知を行う最も単純な方法 は、データをグラフとして可視化し て、人手で異常なデータを発見する というものだ。また、「5 を超える値 は異常値」といったルールを用いて、 コンピュータに自動で異常値を抽出 させることも過去には行われた。 これらの可視化やルールに基づく 異常検知は、データの種類や量が増 えるに伴って必要な人手やルールの 数が爆発的に増加するため、大量の データが収集される現代では必ずし も有効な手段ではない。 最近の AI ブームの中で脚光を浴 びているのが、機械学習を用いた異 常検知だ。機械学習では、データの 振る舞いを上手く要約した数学的表 現(数理モデル)を用いて異常検知 を行う。機械学習の手法は、大量の データに対しても効率的に異常検知 が行えるという強みがある。また、 人間の直感や経験が働きづらい複雑 なデータに関しても有効であること が確かめられている。 近年の AI・機械学習ブームによ り、手軽に機械学習の数理モデルを 作成できる様々なライブラリやサー ビスが公開され、AI・機械学習への 参入障壁は大きく下がった。異常検 知に関しても、既存のライブラリを 用いてとりあえず数理モデルを作成 してみることはできるだろう。 しかし、ライブラリを使いこなし て結果に繋げるのは簡単ではない。 例えば機械学習の有名なライブラリ である scikit-learn には、異常検知 の手法として Elliptic Envelope, Isolation Forest, Local Outlier Factor, one-class SVM が実装されて いるが、これらはそれぞれ検出しや すい異常値のタイプが異なる。 加えて、新しい手法も次々に提案 されている。例えば、2016 年に提 AI・機械学習を用いた異常検知 大量のデータから異常な値を発見する異常検知には長い歴史があるが、近年のデータの増大・多様化に伴って、AI・機械学習を用 いた異常検知が注目されている。AI・機械学習はデータをうまく表現する数理モデルを用いて異常検知を行う。数理モデルを現場 で使える高品質なものにしていくには、数理モデルへの深い理解・高い実装力・現場の実務家との密接な協力が鍵になる。 清水レポート : データサイエンスの現場から (3) 株式会社 NTT データ数理システム 数理工学部 研究員 清水 浩之 図 1 Random Cut Forest と Isolation Forest の比較。 黒い点が正常値の場合、濃い青の領域を異常値と判定する。 異常検知は可視化・ルール任せ から AI・機械学習へ ビッグデータから素早く・ 正確に異常値を発見したい 数理モデルが多すぎる
Transcript of AI・機械学習を用いた異常検知...AI・機械学習を用いた異常検知...

18 ビジネスコミュニケーション 2019 Vol.56 No.7
知 今連載
知 今連載
ビッグデータが流行語となって久しいが、いざデータが手元に集まってくると必ず含まれているのが異常値である。異常値とは、「予想していた正常な振る舞い」から大きく外れたデータである。異常値は、データの入力ミス等で偶然に生じることもあれば、システムの故障や第三者による攻撃といった深刻な原因で生じることもある。発生の原因が何であれ、大量のデータの中から異常値を見つけ出す「異常検知」を素早く・正確に実行することは、異常値を放置した場合に生じる可能性がある将来の損害を未然に防ぐ上で極めて重要である。
異常検知を行う最も単純な方法は、データをグラフとして可視化して、人手で異常なデータを発見するというものだ。また、「5を超える値は異常値」といったルールを用いて、コンピュータに自動で異常値を抽出させることも過去には行われた。これらの可視化やルールに基づく異常検知は、データの種類や量が増
えるに伴って必要な人手やルールの数が爆発的に増加するため、大量のデータが収集される現代では必ずしも有効な手段ではない。最近の AIブームの中で脚光を浴
びているのが、機械学習を用いた異常検知だ。機械学習では、データの振る舞いを上手く要約した数学的表現(数理モデル)を用いて異常検知を行う。機械学習の手法は、大量のデータに対しても効率的に異常検知が行えるという強みがある。また、人間の直感や経験が働きづらい複雑なデータに関しても有効であることが確かめられている。
近年の AI・機械学習ブームによ
り、手軽に機械学習の数理モデルを作成できる様々なライブラリやサービスが公開され、AI・機械学習への参入障壁は大きく下がった。異常検知に関しても、既存のライブラリを用いてとりあえず数理モデルを作成してみることはできるだろう。しかし、ライブラリを使いこなして結果に繋げるのは簡単ではない。例えば機械学習の有名なライブラリである scikit-learnには、異常検知の手法として Elliptic Envelope,
Isolat ion Forest , Local Outl ier
Factor, one-class SVMが実装されているが、これらはそれぞれ検出しやすい異常値のタイプが異なる。加えて、新しい手法も次々に提案されている。例えば、2016年に提
AI・機械学習を用いた異常検知
大量のデータから異常な値を発見する異常検知には長い歴史があるが、近年のデータの増大・多様化に伴って、AI・機械学習を用いた異常検知が注目されている。AI・機械学習はデータをうまく表現する数理モデルを用いて異常検知を行う。数理モデルを現場で使える高品質なものにしていくには、数理モデルへの深い理解・高い実装力・現場の実務家との密接な協力が鍵になる。
清水レポート : データサイエンスの現場から (3)
株式会社NTTデータ数理システム
数理工学部 研究員 清水 浩之
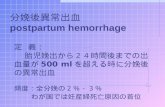
図 1 Random Cut Forest と Isolation Forest の比較。 黒い点が正常値の場合、濃い青の領域を異常値と判定する。
異常検知は可視化・ルール任せからAI・機械学習へ
ビッグデータから素早く・正確に異常値を発見したい
数理モデルが多すぎる

19ビジネスコミュニケーション 2019 Vol.56 No.7
知 今連載
知 今連載
唱された Random Cut Forestは、定番手法の 1つである Isolation Forest
を改良した新手法だが、その異常値の検出の様子は、Isolation Forestとはかなり異なっている(図 1)。このように特性の違う複数の手法があるため、実際のデータにうまくフィットする手法を見つけるには、地道な試行錯誤が欠かせない。場合によっては、複数の手法を組み合わせる必要もあるだろう。こうした探索的プロセスの道しるべになるのはそれぞれの手法に対する深い理解である。
実運用を考えると、既存のライブラリの実装を「ユーザー」として使っているだけでは不十分である。このことを、センサーデータの異常検知を例にして説明する。まず、センサーから取得できるデータにはノイズが載っており、シグナルを抽出するには何等かの信号処理は欠かせない。さらに、センサーからは高頻度かつ持続的にデータがやってくるため、数理モデルの実行の際に必要な計算機資源にも配慮が必要である。実運用においてはCPUやメモリに制限がかからないことの方が珍しい。ライブラリとして手軽に試せる手法であっても、その実装は上記のような厳しい条件下に最適化されたものではない。実際にあったケースでは既存ライブラリの利用を放棄し、性能要件を満たすために手法を自力で実装しなおす必要に迫られた。実運用の現場での性能要求を満たすには、高い実装力が要求される。
イントを述べた。AI・機械学習を実務で役立てるために、その周辺のプロセスが大きな役割を果たしている。
NTTデータ数理システムは、機械学習・データ分析を用いたソリューションを 10年以上にわたって提供している。特に、数理工学部はセンサーデータや異常検知に関するノウハウを多く蓄積している。これまでに手掛けた案件としては、ウェアラブルデバイスから得られる生体データの信号処理・分析、組み込み機器向けの省メモリ・高速な異常検知アルゴリズムの開発、センサーデータから工業製品の異常検知を行うシステムの開発、等が挙げられる。我々の持つ数理科学とコンピュータサイエンスに関する知見が、異常検知に AI・機械学習を導入しようと検討している方々の助けになれば幸いである。〈NTTデータ数理システムの機械学習ソリューションのことなら下記へ〉http://www.msi.co.jp/technology/machinelearning.html
数理モデルをより良いものにしてゆくには、現場の実務家の知見が欠かせない。実務家は、異常値の発生メカニズムを理解していて、異常値が偶然の産物なのか、注意すべき振る舞いなのかを柔軟に判断できる。また、数理モデル作成者が見落としがちな説明変数も広く考慮することができる。実務家の有益な知見を取り込む方法論そのものが機械学習プロジェクト成功の鍵の一つと言える。1つの方法は、使いやすいユー
ザーインターフェースを備えたプロトタイプを素早く開発し、実際に現場で使用してもらうことである(図2)。 事前に必要な機能を定義して、それに従って開発を進めていくやり方は、機械学習を用いたシステム開発には必ずしも適していない。最初の段階で作られるモデルでは、しばしば異常値の見逃しや誤検知が発生するため、適宜実務家からのフィードバックを受けながら、モデルを継続的に改善するのである。以上、数理モデルの探索、実装、現場との協力という観点から、機械学習による異常検知を成功させる上のポ
図 2 異常検知システムのプロトタイプのイメージ図
実運用の性能要求は厳しい
現場の実務家と協力しよう
NTTデータ数理システムの異常検知ソリューション




![《不良反應》 以下列出的不良反應是根據身體系統及發生機率 常 … · [免疫系統異常] 不常見 [代謝異常] 不常見 [精神異常] 不常見 [神經系統異常]](https://static.fdocument.pub/doc/165x107/5f02143c7e708231d4027797/e-ceeeccccc.jpg)