
水分1日め 2日め 3日め 4日め 5日め 6日め 感染症に 負けない!本日の ミッション ひざのばし 水分補給 あーんー体操 日付の確認 ...

3 - 正しい SQL
(方言を排除した SQL 文の記述方法)

2
このドキュメントに記載されている情報 (URL 等のインターネット Web サイトに関する情報を含む) は、将来予告なしに変更するこ
とがあります。このドキュメントに記載された内容は情報提供のみを目的としており、明示または黙示に関わらず、これらの情報につ
いてマイクロソフトはいかなる責任も負わないものとします。 お客様が本製品を運用した結果の影響については、お客様が負うものとします。お客様ご自身の責任において、適用されるすべての著
作権関連法規に従ったご使用を願います。このドキュメントのいかなる部分も、米国 Microsoft Corporation の書面による許諾を受け
ることなく、その目的を問わず、どのような形態であっても、複製または譲渡することは禁じられています。ここでいう形態とは、複写や記録など、電子的な、または物理的なすべての手段を含みます。
マイクロソフトは、このドキュメントに記載されている内容に関し、特許、特許申請、商標、著作権、またはその他の無体財産権を有
する場合があります。別途マイクロソフトのライセンス契約上に明示の規定のない限り、このドキュメントはこれらの特許、商標、著作権、またはその他の無体財産権に関する権利をお客様に許諾するものではありません。
別途記載されていない場合、このソフトウェアおよび関連するドキュメントで使用している会社、組織、製品、ドメイン名、電子メー
ル アドレス、ロゴ、人物、出来事などの名称は架空のものです。実在する会社名、組織名、商品名、個人名などとは一切関係ありません。
© 2010 Microsoft Corporation. All rights reserved.
Microsoft、SQL Server は、米国 Microsoft Corporation の米国およびその他の国における登録商標または商標です。
記載されている会社名、製品名には、各社の商標のものもあります。

3
目次
1. はじめに .................................................................................................. 4
2. 説明に必要な環境について ........................................................................... 4 (1) 本書で使用するテーブルの構造 ........................................................................... 4 (2) 各テーブルのデータ .......................................................................................... 4
3. SELECT 文.............................................................................................. 5 (1) 内部結合......................................................................................................... 5 (2) 外部結合......................................................................................................... 6 (3) オブジェクト名の書き方 .................................................................................... 7 (4) 列の別名......................................................................................................... 8 (5) リテラル文字 ................................................................................................... 9 (6) 集合演算子 .................................................................................................... 10 (7) 副次問い合わせ .............................................................................................. 10 (8) 共通テーブル式 .............................................................................................. 13
4. NULL 値の扱い ....................................................................................... 15 (1) 「NULL = NULL」と「1 = 1」の違い................................................................ 15 (2) 「NULL = ‘’」 じゃない .................................................................................. 16 (3) NULL 値とソート ........................................................................................... 16
5. 更新系................................................................................................... 17 (1) INSERT 文 ................................................................................................... 17 (2) UPDATE 文と DELETE 文............................................................................... 18
6. 最後に................................................................................................... 19

4
1. はじめに
SQL は、リレーショナルデータベース管理システム (RDBMS) において、データの操作や定義を行うため
のデータベース言語です。SQL は、ISO によて標準規格として定められており、近年では、SQL 2003、SQL
2009 などの規格があります。一方、各社の RDBMS では、これら ISO の規格に対する実装度合いがばら
ばらで、古くから独自の拡張を行ってきた関係から、互換性の保証の必要もあり、SQL に独自の差異が生じ
ています。
この独自の拡張による差異を、SQL の方言と呼びます。本書では、特に SQL Server® 2008 と Oracle 11g
に的を絞り、方言を排除した SQL を記述する方法を説明します。もう何度も SQL Server で SQL を組ん
だことがあるけど、Oracle は使ったことが無いとか、Oracle は得意なので、これから SQL Server を勉強
されるという方には、どちらの RDBMS でもほぼ同じ SQL で操作することが出来るようになり、お勧めの
内容です。
2. 説明に必要な環境について
(1) 本書で使用するテーブルの構造
本書では、以下の環境を前提に説明します。
(2) 各テーブルのデータ
各テーブルには以下のデータが格納されていることとします。
①社員表:EMPLOYEE
社員番号 氏名 給料 部署番号
1 山田 一郎 500,000 10
2 鈴木 太郎 300,000 10
3 浅田 あさみ NULL 20
4 松田 裕太 700,000 10
5 田中 次郎 500,000 10
6 中村 五郎 500,000 10
本書で使用する環境
社員表:EMPLOYEE
項目名
(日本語)
項目名 属性 制約
社員番号 ID INT 主キー
氏名 NAME CHAR(50) NOT NULL
給料 SALARY INT
部署番号 BU_ID INT
部署表:BUSINESS_UNIT
項目名
(日本語)
項目名 属性 制約
部署番号 BU_ID INT 主キー
部署名 BU_NAME CHAR(20)

5
②部署表:BUSINESS_UNIT
部署番号 部署名
10 総務部
20 業務部
30 情報システム部
3. SELECT 文
(1) 内部結合
まず、下記の SQL を見てください。
SELECT * FROM EMPLOYEE
上記の SQL は、社員表 (EMPLOYEE) のリストを表示します。この SQL は、SQL Server と Oracle で
はそれぞれ以下のように記述します。特に違いはありません。
SQL Server SELECT * FROM EMPLOYEE
Oracle SELECT * FROM EMPLOYEE
では、次の SQL はどうでしょうか?
SELECT BU_NAME, ID, NAME
FROM EMPLOYEE INNER JOIN BUSINESS_UNIT
ON EMPLOYEE.BU_ID = BUSINESS_UNIT.BU_ID

6
上記 SQL は、社員表 (EMPLOYEE) と部署表 (BUSINESS_UNIT) を内部結合して、社員が所属している
部署の部署名と社員名の一覧を作成し、表示します。この SQL には以下のように SQL Server と Oracle
では FROM 句以降の記述の仕方に違いがあります。
SQL Server select BU_NAME, ID, NAME from EMPLOYEE INNER JOIN BUSINESS_UNIT on EMPLOYEE.BU_ID = BUSSINESS_UNIT.BU_ID
Oracle select BU_NAME, ID, NAME from EMPLOYEE, BUSINESS_UNIT where EMPLOYEE.BU_ID = BUSSINESS_UNIT.BU_ID
(2) 外部結合
次は、外部結合です。以下の SQL を見てみましょう。
SELECT BUSINESS_UNIT.BU_ID, BU_NAME, ID, NAME
FROM BUSINESS_UNIT LEFT JOIN EMPLOYEE
ON BUSINESS_UNIT.BU_ID = EMPLOYEE.BU_ID

7
上記 SQL は、社員表 (EMPLOYEE) と部署表 (BUSINESS_UNIT) を外部結合して、まだだれも配属して
いない部署 (‘情報システム部’) も含めて一覧表示します。この SQL にも先ほどと同じように、記述に違い
があります。
SQL Server SELECT BUSINESS_UNIT.BU_ID, BU_NAME, ID, NAME FROM BUSINESS_UNIT LEFT JOIN EMPLOYEE ON BUSINESS_UNIT.BU_ID = EMPLOYEE.BU_ID
Oracle SELECT BUSINESS_UNIT.BU_ID, BU_NAME, ID, NAME FROM BUSINESS_UNIT, EMPLOYEE WHERE BUSINESS_UNIT.BU_ID = EMPLOYEE.BU_ID(+)
SQL Server と Oracle では、上記のようにテーブル結合の記述方法に違いがあります。ですが、実は Oracle
は SQL Server と同様の記述でも処理することができるのです。よって、テーブル結合の場合は、「INNER
JOIN」、「LEFT JOIN」、「RIGHT JOIN」を使用することで、どちらの RDBMS でもおなじ SQL が実行で
きます。
(3) オブジェクト名の書き方
SQL Server ではオブジェクト名であることを明確に判断し、また通常許可されない文字をオブジェクト名
に使用するために、角カッコ (「 [ 」, 「 ] 」) を利用することができます。以下のように、テーブル名に
空白を含めることや、項目名に「\n\t」といった制御文字チックな名称を付与することも出来ます。
CREATE TABLE [あいう] (
COL01 INT,
[a¥n¥t] char(10)
)
ところが、Oracle では角カッコを使用することができません。特殊文字を使用したオブジェクト名定義する
まとめ
テーブルの結合は、「INNER JOIN」、「LEFT JOIN」、「RIGHT JOIN」を使用すること。

8
場合は、ダブルコーテーション「"」を使用します。
SQL Server CREATE TABLE [あ い う] ( COL01 INT, [a¥n¥t] CHAR(10) )
Oracle CREATE TABLE "あ い う" ( COL01 INT, "a¥n¥t" CHAR(10) )
どちらの RDBMS でも、極力特殊な文字は使用しないことが望ましいと言えます。ただし、どうしても使用
したい場合には、下記のように SQL Server でもオブジェクト名をダブルコーテーション「"」でくくるこ
とで、どちらの RDBMS でも同じ SQL を使用することができます。
(4) 列の別名
列の別名を指定する場合、SQL Server では以下のような 2 種類の方法が使用できます。
SELECT "部署名" = BU_NAME, "部署コード" = BU_ID
FROM BUSINESS_UNIT
SELECT BU_NAME as "部署名", BU_ID as "部署コード"
FROM BUSINESS_UNIT

9
Oracle では、列の別名の定義は「項目名 as 別名」の記述方法のみで、「別名 = 項目名」のような記述方
法は使用できません。
SQL Server SELECT “部署名” = BU_NAME,
“部署コード” = BU_ID FROM BUSINESS_UNIT
Oracle SELECT BU_NAME AS “部署名”,
BU_ID AS “部署コード” FROM BUSINESS_UNIT
よって、どちらの RDBMS でも「項目名 AS 別名」の書き方に統一すべきです。
(5) リテラル文字
SQL Server ではリテラル文字を表す際に、ダブル コーテーション「“」とシングル コーテーション「‘」が
使用できます。Oracle では、リテラル文字は、「‘」のみですので、どちらの RDBMS でも、「‘」で統一しま
しょう。
SELECT * FROM EMPLOYEE
WHERE NAME = '鈴木太郎'
まとめ
オブジェクト名には特殊文字を極力使用しないように心がけること。また、列の別名は、「項目名 AS 別名」とすること。 リテラル文字は、シングルコーテーション「‘’」を使用すること。

10
(6) 集合演算子
集合関数には、最大 (MAX)、最小 (MIN)、平均 (AVG)、合計 (SUM)、件数 (COUNT) があります。これ
らの記述は、どちらの RDBMS でも同じです。
SELECT MAX(SALARY) AS 最大値, MIN(SALARY) AS 最小値,
AVG(SALARY) AS 平均, SUM(SALARY) AS 合計,
COUNT(*) AS 件数
FROM EMPLOYEE
集合関数では、NULL 値は集計されません。前述した (1) の結果にもありますが、「浅田 あさみ」さんの
SALARY が NULL 値となっており、社員表の件数は 6 件ですが、上記の COUNT (SALARY) の結果が 5
件となっています。また、平均 (AVG) では合計値 (2,500,000) を 5 で割った結果 (500,000) となって
います。ただし、COUNT(*) は特例で、行数の集計という意味で、6 件という結果となります。これらの結
果も、どちらの RDBMS でも同じです。
(7) 副次問い合わせ
次は、副次問い合せです。副次問い合せは便利な反面、SQL が複雑になりやすく、処理性能の面でも問題を
起こしやすい記述方法です。
① 下は、会社全体の平均給与より、給与の多い社員の一覧を表示する SQL です。
まとめ
集合関数は、NULL値は集計されない。ただし、COUNT(*)は件数を集計するため、全ての行を集計するので、結果が異なる場合がある。

11
SELECT BU.BU_NAME AS 部署名, EMP.NAME AS 氏名,
EMP.SALARY AS 給料
FROM EMPLOYEE EMP INNER JOIN BUSINESS_UNIT BU
ON EMP.BU_ID = BU.BU_ID
AND EMP.SALARY >= (SELECT AVG(SALARY)
FROM EMPLOYEE SALALY_AVG )
上記の SQL では、単一結果を返す(平均値を 1 件だけ返す)副次問い合せの例です。
この場合、SQL Server と Oracle での違いは特にありません。
SQL Server SELECT BU.BU_NAME AS 部署名, EMP.NAME AS 氏名, EMP.SALARY AS 給料 FROM EMPLOYEE EMP INNER JOIN BUSINESS_UNIT BU ON EMP.BU_ID = BU.BU_ID AND EMP.SALARY >= (SELECT AVG(SALARY) FROM EMPLOYEE SALALY_AVG )
Oracle SELECT BU.BU_NAME AS 部署名, EMP.NAME AS 氏名, EMP.SALARY AS 給料 FROM EMPLOYEE EMP INNER JOIN BUSINESS_UNIT BU ON EMP.BU_ID = BU.BU_ID AND EMP.SALARY >= (SELECT AVG(SALARY) FROM EMPLOYEE SALALY_AVG )
②次は、各部署毎の給料の平均より給料が多い社員の一覧を部署毎に表示する SQL です。
SELECT BU.BU_NAME AS 部署名, EMP.NAME AS 氏名,
EMP.SALARY AS 給料, BSA.SALARY AS 平均給料
FROM EMPLOYEE EMP RIGHT JOIN BUSINESS_UNIT BU
ON EMP.BU_ID = BU.BU_ID
INNER JOIN ( SELECT BU.BU_ID AS BU_ID, AVG(EMP.SALARY) AS SALARY
FROM EMPLOYEE EMP RIGHT JOIN BUSINESS_UNIT BU
ON EMP.BU_ID = BU.BU_ID
GROUP BY BU.BU_ID ) BSA
ON BU.BU_ID = BSA.BU_ID
AND EMP.SALARY >= BSA.SALARY

12
上記の SQL は、各部署の給料の平均を求める部分に副次問い合せを使用しています。
その問い合せ結果と別の表を結合するパターンです。
Oracle では、「INNER JOIN」、「LEFT JOIN」、「RIGHT JOIN」を使用しない記述方法が通例で、SQL Server
の記述の仕方と比較すると、以下のように FROM 句以降が違います。
SQL Server SELECT BU.BU_NAME AS 部署名, EMP.NAME AS 氏名,
EMP.SALARY AS 給料, BSA.SALARY AS 平均給料 FROM EMPLOYEE EMP RIGHT JOIN BUSINESS_UNIT BU ON EMP.BU_ID = BU.BU_ID INNER JOIN ( SELECT BU.BU_ID AS BU_ID, AVG(EMP.SALARY) AS SALARY FROM EMPLOYEE EMP RIGHT JOIN BUSINESS_UNIT BU ON EMP.BU_ID = BU.BU_ID GROUP BY BU.BU_ID ) BSA ON BU.BU_ID = BSA.BU_ID AND EMP.SALARY >= BSA.SALARY
Oracle SELECT BU1.BU_NAME AS 部署名, EMP.NAME AS 氏名,
EMP.SALARY AS 給料, BSA.SALARY AS 平均給料 FROM EMPLOYEE EMP, BUSINESS_UNIT BU1, ( SELECT BU2.BU_ID AS BU_ID, AVG(EMP1.SALARY) AS SALARY FROM EMPLOYEE EMP1, BUSINESS_UNIT BU2 WHERE EMP1.BU_ID = BU2.BU_ID GROUP BY BU2.BU_ID) BSA WHERE EMP.BU_ID(+) = BU1.BU_ID AND BU1.BU_ID = BSA.BU_ID AND EMP.SALARY >= BSA.SALARY
副次問い合せ結果の結合の場合も、前述した「(1)内部結合」や、「(2)外部結合」と同様に、「INNER JOIN」、
「LEFT JOIN」、「RIGHT JOIN」を使用して結合するようにします。よって、SQL Server の記述方法に合
わせる必要があります。

13
(8) 共通テーブル式
上記「(7) 副次問い合せ」のような、副次的な検索を行う SQL は、非常に便利ですが、SQL が複雑にな
り、同じような副次問い合せが何度も出てくる場合に、非常にわかりづらい事があります。
共通テーブル式 (WITH 句)を用いると、同じ SQL の副次問い合せが複数回登場する場合に、その副次問い
合せを構造化し、一時的にビュー表のような機能によって簡略化することができます。
WITH BU_SALARY_AVG(BU_ID, SALARY) AS (
SELECT BU.BU_ID, AVG(EMP.SALARY)
FROM EMPLOYEE EMP RIGHT JOIN BUSINESS_UNIT BU
ON EMP.BU_ID = BU.BU_ID
GROUP BY BU.BU_ID
)
SELECT BU.BU_NAME, EMP.NAME, EMP.SALARY, BSA.SALARY
FROM EMPLOYEE EMP RIGHT JOIN BUSINESS_UNIT BU
ON EMP.BU_ID = BU.BU_ID
INNER JOIN BU_SALARY_AVG BSA
ON BU.BU_ID = BSA.BU_ID
AND EMP.SALARY >= BSA.SALARY

14
共通テーブル式の記述の違いは、1 行目の識別子の後の括弧で括った別名の定義部分にあります。Oracle で
は、識別子のあとに括弧で括って、別名の定義を記述することができません。具体的には、以下のように共
通テーブル式 (WITH 句) の結果の別名の定義方法に差異があります。
SQL Server WITH BU_SALARY_AVG(BU_ID, SALARY) AS ( SELECT BU.BU_ID, AVG(EMP.SALARY) FROM EMPLOYEE EMP RIGHT JOIN BUSINESS_UNIT BU ON EMP.BU_ID = BU.BU_ID GROUP BY BU.BU_ID ) SELECT BU.BU_NAME, EMP.NAME, EMP.SALARY, BSA.SALARY FROM EMPLOYEE EMP RIGHT JOIN BUSINESS_UNIT BU ON EMP.BU_ID = BU.BU_ID INNER JOIN BU_SALARY_AVG BSA ON BU.BU_ID = BSA.BU_ID AND EMP.SALARY >= BSA.SALARY
Oracle WITH BU_SALARY_AVG AS ( SELECT BU.BU_ID AS BU_ID, AVG(EMP.SALARY) AS SALARY FROM EMPLOYEE EMP RIGHT JOIN BUSINESS_UNIT BU ON EMP.BU_ID = BU.BU_ID GROUP BY BU.BU_ID ) SELECT BU.BU_NAME, EMP.NAME, EMP.SALARY, BSA.SALARY FROM EMPLOYEE EMP RIGHT JOIN BUSINESS_UNIT BU ON EMP.BU_ID = BU.BU_ID INNER JOIN BU_SALARY_AVG BSA ON BU.BU_ID = BSA.BU_ID AND EMP.SALARY >= BSA.SALARY FROM EMPLOYEE EMP RIGHT JOIN BUSINESS_UNIT BU ON EMP.BU_ID = BU.BU_ID INNER JOIN BU_SALARY_AVG BSA ON BU.BU_ID = BSA.BU_ID AND EMP.SALARY >= BSA.SALARY
上記のように、別名の定義方法に違いがありますが、前述した「(4)列の別名」と同様に、SQL Server で
も Oracle のような別名の定義方法が使用できます。よって、共通テーブル式を使用する場合は、列の別名
の定義方法を Oracle の記述方法に合わせる必要があります。
まとめ
副次問い合せでは、単一結果の結合方法に差異はない。副次問い合せの結果を結合する場合は、「INNER JOIN」、「LEFT JOIN」、「RIGHT JOIN」を使用すること。 共通テーブル式を使用する場合は、別名の記述に識別子の後の括弧を使用せず、検索結果の別名定義「項目名 AS 別名」を使用すること。 副次問い合せは、性能面で問題になりやすいので、使用する場合は、結合結果を少しでも多く絞り込める条件を副次化することが重要。

15
4. NULL 値の扱い
(1) 「NULL = NULL」と「1 = 1」の違い
あまりこのような SQL は記述しないと思いますが、以下のような SQL では、WHERE 句の評価結果が
TRUE (真) となるため、全ての行が選択されます。
SELECT * FROM EMPLOYEE WHERE 1=1
では、以下の SQL の場合はどうでしょうか? WHERE 句にある、「=」の右辺と左辺は同じ値に見えます
が、「NULL = NULL」の評価結果は、FALSE (偽) で、「1 = 1」の評価結果とは違う結果になります。
SELECT * FROM EMPLOYEE WHERE NULL = NULL
これは、NULL 値の扱いによるもので、NULL 値とは、「値が無い」事を意味します。よって、「1 = 1」は同
じ値を比較しているので等価ですが、「NULL」は値が無いので比較できず、等価ではない為、FALSE となる
のです。

16
(2) 「NULL = ‘’」 じゃない
「NULL = NULL」 や「NULL = ‘’(0文字のリテラル)」等の扱いは、SQL Server と Oracle で異なる評
価結果となるものがあります。下記の表に実行結果をまとめてみました。
SQL 文 SQL Server での
評価結果
Oracle での評価結果
SELECT * FROM EMPLOYEE WHERE NULL IS NULL TRUE
TRUE
SELECT * FROM EMPLOYEE WHERE '' IS NULL FALSE
TRUE
SELECT * FROM EMPLOYEE WHERE '' = NULL FALSE
FALSE
SELECT * FROM EMPLOYEE WHERE '' = '' TRUE
FALSE
SELECT * FROM EMPLOYEE WHERE NULL = NULL FALSE
FALSE
上記の結果より、おそらく SQL Server は、「NULL」と「‘’」を違うものとして扱い、「= NULL」と「IS NULL」
は、同じ評価方法であるのに対し、Oracle では、「NULL」と「‘’」を同じものとして扱い、「= NULL」と「IS
NULL」が違う評価方法となっているのではないでしょうか。これにより、プログラム等を利用し、両方の
RDBS で同じ SQL を実行したとしても、思わぬトラブルに遭遇することになります。
例えば、ある変数 ([変数 X]) の値と NULL 値を比較する SQL (「・・・ WHERE [変数 X] IS NULL」や、
「・・・ WHERE [変数 X] = NULL」) で考えて見ましょう。SQL Server では、変数 ([変数 X]) の値が
「‘’」でも「NULL」でも結果は FALSE となりますが、Oracle では、異なる結果となる場合があります。実
際に同じデータで同じ SQL を実行しても違う結果を返すので、間違いなく混乱するでしょう。極力「‘’」を
使用せず、「NULL」に統一することが混乱を防ぐポイントとなります。
(3) NULL 値とソート
以下の SQL を見てください。NULL 値を含む項目でソートを行っています。下記の結果では、NULL 値の
項目は、先頭にきていますが、Oracle の場合は、NULL 値の項目は最後になります。結果として、NULL 値
を含む値のソート結果は同じにはなりません。
SELECT * FROM EMPLOYEE ORDER BY SALARY

17
Oracle では、ORDER BY 句で、「NULLS FIRST」 オプションを使用することで、SQL Server と同じ結果
が得られます。ただし、同様の SQL を SQL Server で実行した場合、エラーとなってしまいますので、同
じ SQL で同じ結果とすることはできません。
SQL Server SELECT * FROM EMPLOYEE ORDER BY SALARY
Oracle SELECT * FROM EMPLOYEE ORDER BY SALARY NULLS FIRST
5. 更新系
(1) INSERT 文
次は、挿入 (INSERT) 文です。以下の挿入文は、SQL Server では実行できますが、Oracle では、実行で
きません。Oracle では、INTO 句が必須だからです。
INSERT EMPLOYEE VALUES (7, '斉藤武', 250000, 30)
SQL Server INSERT EMPLOYEE VALUES (7, '斉藤 武', 250000, 30)
Oracle INSERT INTO EMPLOYEE VALUES (7, '斉藤 武', 250000, 30)
どちらの RDBMS でも同じ SQL を実行するために、挿入文では INTO 句を必ずつけましょう。そうする
ことで、特に問題なく同じ SQL を実行できます。
まとめ
NULL 値の取り扱いは、「NULL」 と、「‘’」の値の扱いや、「= NULL」 や 「IS NULL」 の評価方法が SQL Server と Oracle で違う。「‘’」を使用せず、「NULL」に NULL 値を統一することが、評価の違いを避ける方法である。また、ソート データに NULL 値が含まれる場合の順序が違う為、十分注意すること。

18
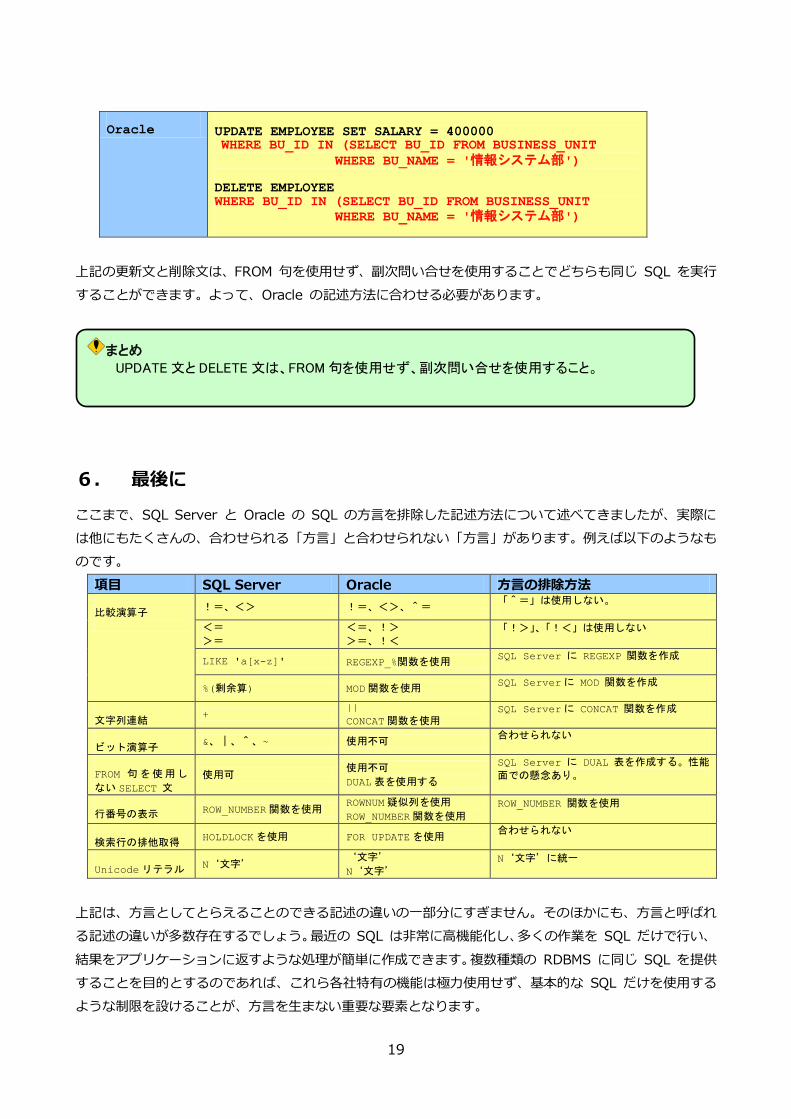
(2) UPDATE 文と DELETE 文
最後は、更新文 (UPDATE) と削除 (DELETE) 文です。以下の更新文を見てください。
UPDATE EMPLOYEE SET SALARY = 400000
FROM BUSINESS_UNIT
WHERE EMPLOYEE.BU_ID = BUSINESS_UNIT.BU_ID
AND BUSINESS_UNIT.BU_NAME = '情報システム部'
SQL Server では、FROM 句を使用して、他のテーブルとの結合した結果を更新することが可能ですが、
Oracle では FROM 句が使用できないため、同じように記述することができません。
また、以下の削除文も同様です。
DELETE EMPLOYEE
FROM BUSINESS_UNIT
WHERE EMPLOYEE.BU_ID = BUSINESS_UNIT.BU_ID
AND BUSINESS_UNIT.BU_NAME = '情報システム部'
Oracle では、UPDATE 文も DELETE 文も、副次問い合せを使用します。
SQL Server UPDATE EMPLOYEE SET SALARY = 400000 FROM BUSINESS_UNIT WHERE EMPLOYEE.BU_ID = BUSINESS_UNIT.BU_ID
AND BUSINESS_UNIT.BU_NAME = '情報システム部' DELETE EMPLOYEE FROM BUSINESS_UNIT WHERE EMPLOYEE.BU_ID = BUSINESS_UNIT.BU_ID
AND BUSINESS_UNIT.BU_NAME = '情報システム部’
19
Oracle UPDATE EMPLOYEE SET SALARY = 400000 WHERE BU_ID IN (SELECT BU_ID FROM BUSINESS_UNIT
WHERE BU_NAME = '情報システム部') DELETE EMPLOYEE WHERE BU_ID IN (SELECT BU_ID FROM BUSINESS_UNIT
WHERE BU_NAME = '情報システム部')
上記の更新文と削除文は、FROM 句を使用せず、副次問い合せを使用することでどちらも同じ SQL を実行
することができます。よって、Oracle の記述方法に合わせる必要があります。
6. 最後に
ここまで、SQL Server と Oracle の SQL の方言を排除した記述方法について述べてきましたが、実際に
は他にもたくさんの、合わせられる「方言」と合わせられない「方言」があります。例えば以下のようなも
のです。
項目 SQL Server Oracle 方言の排除方法
比較演算子
!=、<> !=、<>、^= 「^=」は使用しない。
<=
>=
<=、!>
>=、!<
「!>」、「!<」は使用しない
LIKE 'a[x-z]' REGEXP_%関数を使用 SQL Server に REGEXP 関数を作成
%(剰余算) MOD関数を使用 SQL Serverに MOD 関数を作成
文字列連結 +
||
CONCAT関数を使用
SQL Serverに CONCAT 関数を作成
ビット演算子 &、|、^、~ 使用不可
合わせられない
FROM 句を使用し
ない SELECT 文
使用可 使用不可
DUAL表を使用する
SQL Server に DUAL 表を作成する。性能
面での懸念あり。
行番号の表示 ROW_NUMBER関数を使用
ROWNUM疑似列を使用
ROW_NUMBER関数を使用
ROW_NUMBER 関数を使用
検索行の排他取得 HOLDLOCKを使用 FOR UPDATEを使用
合わせられない
Unicodeリテラル N‘文字’
‘文字’
N‘文字’
N‘文字’に統一
上記は、方言としてとらえることのできる記述の違いの一部分にすぎません。そのほかにも、方言と呼ばれ
る記述の違いが多数存在するでしょう。最近の SQL は非常に高機能化し、多くの作業を SQL だけで行い、
結果をアプリケーションに返すような処理が簡単に作成できます。複数種類の RDBMS に同じ SQL を提供
することを目的とするのであれば、これら各社特有の機能は極力使用せず、基本的な SQL だけを使用する
ような制限を設けることが、方言を生まない重要な要素となります。
まとめ
UPDATE文と DELETE文は、FROM句を使用せず、副次問い合せを使用すること。

20
ただし、機能制限するだけでは、せっかくの高機能な RDBMS も宝の持ち腐れとなってしまいます。特に性
能を求める部分に関しては、方言を使用することもやむを得ない場合もあるでしょう。どうしても差異が生
まれてしまう部分については、上記の表のような差異の一覧を作成して管理することで、RDBMS 間の SQL
の移植をスムーズに行えるようになります。ですが、基本的には本書に書いたように、極力 SQL の方言を
排除していれば、いつでも RDBMS を問わずに、データベースアクセス機能をツール (部品) 化し、簡単に
再利用することが可能となったり、システムを別の RDBMS に移植する際も、非常に簡単になります。みな
さんも、ぜひ実践し開発コストの削減に役立ててください。











![データベース - Oshita Lab · 2019-09-24 · 教科書 •「リレーショナルデータベース入門 [第3版]」 増永良文著、サイエンス社(3,200円) –3章(3.1~3.5節)](https://static.fdocument.pub/doc/165x107/5f440bfccbd07c7deb6ef92e/ffff-oshita-2019-09-24-c-aoeffffffffffe.jpg)






