
02 Compression
32
1 Multimedia Communications Chapter 2 Compression Basics 아주대학교 정보및컴퓨터공학부 모바일 멀티미디어통신 연구실 (http://mmcn.ajou.ac.kr) 노병희 ([email protected]) 목차 압축 (compression) 개요 기본적인 압축 방법들 Entropy 압축방법 • Huffman Coding • Arithmetic Coding • Run Length Coding Predictive Coding Transform Coding Subband Coding Rate-Distortion Curve
-
Upload
jhcloudnine -
Category
Technology
-
view
296 -
download
4
Transcript of 02 Compression

1
Multimedia Communications
Chapter 2Compression Basics
아주대학교 정보및컴퓨터공학부
모바일 멀티미디어통신 연구실 (http://mmcn.ajou.ac.kr)
노병희 ([email protected])
목차
압축 (compression) 개요
기본적인 압축 방법들Entropy 압축방법
• Huffman Coding• Arithmetic Coding• Run Length Coding
Predictive CodingTransform CodingSubband Coding
Rate-Distortion Curve

2
2.1 압축 (compression) 개요
데이터 압축 개요
데이터 압축 (data compression)사용되지 않거나 표현의 중복된 부분을 적절히 제거함으로써데이터의 크기를 줄이기 위한 수단
• 사용되지 않는 부분 : 전화 에서의 침묵 기간 (silent period)• 표현의 중복성
– 공간 중복성 (spatial redundancy)– 시간 중복성 (temporal redundancy)
시간중복성
공간중복성

3
데이터 압축 개요
음성신호의 상관성
voice의 정보형태
부분 확장한 모습
침묵기간
대화기간
시간상관성
데이터 압축 개요
Video의 상관성 - AKIYO

4
데이터 압축 개요
Video의 상관성 -STEPHAN
데이터 압축 개요
무손실 압축과 손실 압축 방식Lossless compression (무손실 압축)
• 압축된 데이터를 복원시 원래의 데이터와 동일한 형태가 복원됨(Original Data = Recovered Data)
– 예: Arithmatic coding, Huffman coding, Run-length coding등
Lossy compression(손실 압축)• 압축시 원래 데이터의 손실이 발생하고, 복원된 데이터는 원래
데이터와 유사하나 완전히 일치하지는 않음 (Original Data ≈Recovered Data)
– 예: DPCM, DCT, FFT, vector quantization 등• Lossy라고 해서 품질저하를 의미하는 것은 아니며, 오히려 품질이
향상될 수도 있음.– Drop random noise in images (dust on lens)– Drop background in music– Fix spelling errors in text. Put into better form.– Writing is the art of lossy text compression

5
데이터 압축 개요
복합 방식 (Hybrid compression)무손실 압축 방식과 손실 압축 방식을 혼합 적용
• source 자체에 대하여는 손실 압축
• 전송 데이터에는 무손실 압축 방식 적용
– H.261, H.263, JPEG, MPEG audio/video, …
데이터 압축 개요
압축 형태에 따른 품질과 요구 대역폭간의 관계
low high
low
high
bandwidth
quality
lossycompression
losslesscompression
lossy의 정도가커질수록, bit량은작아지지만, 품질저하정도가 커짐
lossless에가까워질수록품질은 향상되지만, 비트량은 커짐

6
데이터 압축 개요
데이터 압축의 경향데이터 압축률에 관심 : JPEG, H.26x, MPEG-1/2데이터의 형태에 관심 : MPEG-4데이터의 표현 방법에 관심 : MPEG-7
time
데이터형태의 예: 비디오 프레임을구성하는 각 object 단위로, 이들을사용자의 요구에 따라 배열하고조작하는 것이 가능해 짐
데이터 압축의 목적
압축 방식들의 목적소스로 부터 생성된 심볼들을 binary code로 변환하는 과정에서평균코드길이를 최소화함
평균코드길이
• 소스로 부터는 n개의 symbol a1, a2, a3,..., an 만 발생하고
• 이들 심볼들이 발생하는 빈도는 각각 p1, p2, p3,..., pn 이고,• 이들 각 심볼에 부여된 binary code의 길이가 l1, l2, l3, ..., ln 이라고 할때
– 이 binary code를 codeword라고 함.• 평균코드길이는 다음과 같음
∑=
×=n
iii lpl
1
)(
symbol (prob.)source a1
a2a3.. an
(p1)(p2)(p3).. (pn)
coder
c1c2c3.. cn
codeword (length)
(l1)(l2)(l3).. (ln)

7
데이터 압축 - 유일 디코딩의 조건
유일 디코딩(Unique Decoding) 조건어떤 codeword도 다른 codeword의 prefix가 되지 않도록 하여야 함
binary tree representation
0
10
110
111
a1
a2
a3
a4
codewordsymbol
서로간에 prefix 가 되는 codeword들이없음 (uniquely decodable)
unique decoding의 조건을만족하는 압축코드들은binary tree로서 표현가능하게 됨
데이터 압축 - 유일 디코딩의 조건
압축 방식들의 Unique Decoding 조건 (cont'd)unique code의 조건에 위배되는 경우
0
10
101
0101
a1
a2
a3
a4
codewordsymbol
a2의 prefix 가 됨
a0 의 prefix 가 됨
received bit sequence
0 1 0 1 1 0 1 0 1 0 ....
0a
3a
2a 2a 0a
2a
1a
0a 1a
이와 같이, unique decoding의 조건이만족되지 않을 경우에는 수신측에서수신한 정보를 여러가지로 해석하게 되어완전한 정보 교환이 불가능하게 됨

8
2.2 기본적인 압축방법2.2.1 Entropy 압축방법
1) Huffman Coding2) Arithmetic Coding3) Run Length Coding
Entropy Encoding
Entropy Encoding무손실 압축 방식
압축되는 정보의 형태와 상관없는 압축 처리
Entropy Encoding 방법들
• Run Length Encoding• Huffman Encoding
Entropy Encoding의 목적
• 유일디코딩(unique decoding)의 조건을 만족시키면서, 각 심볼에 대한평균 비트수를 최소화하는 것임
Entropy• 이론적으로 심볼들의 최대 압축 가능한 최소 평균 비트수
– entropy 이하가 되는 압축 방법은 존재하지 않음
∑=
=n
iipipH
1
)/1(2log*
pi : i-번째 심볼이 발생할 확률n : 총 심볼의 수

9
Huffman Coding
Huffman coding1952년, Huffman에 의하여 개발
심볼(Symbol)들의 발생 확률을 이용하여 부호화
• 빈번히 발생하는 심볼의 코드는 적은 수의 비트로 표현
• 빈번하지 않은 심볼은 상대적으로 많은 수의 비트로 표현
– 심볼의 부호화된 비트열의 평균길이를 감소 시킴.
Basic Algorithm1. symbol을 발생확률에 대하여 내림차순으로 정리
2. 가장 작은 확률을 가진 두 symbol을 합하여 하나로 합침
3. 합쳐지게 된 두 symbol에 대하여 하나는 0를 다른 하나는 1를 부여함
4. 새로 합쳐진 symbol과 남은 symbol들에 대하여 step1을 계속함. (남은 symbol들이 없는 경우에는 step4로)
5. 구성된 binary tree를 root에서 leaf에 도달할때까지의 binary 값들을symbol의 codeword로 할당
Huffman Coding
Example (1/5)5개의 symbol a1, a2, a3, a4, a5 의 발생확률이 다음과 같다.p1=0.4, p2=0.2, p3=0.2, p4=0.1, p5=0.1
1) Entropy를 구하라.2) Huffman Code를 구하시오.
i) 구한 code 길이에 대한 평균과 분산을 구하시오.
3) 디코딩트리를 그리시오.
Solution1) Entropy
H= 0.4 x log2(1/0.4) + 0.2 x log2(1/0.2) +
0.2 x log2(1/0.2) + 0.1 x log2(1/0.1) + 0.1 x log2(1/0.1)= 0.4 x 1.32 + 0.2 x 2.32 + 0.2 x 2.32 + 0.1 x 3.32 + 0.1 x 3.32= 2.12 비트/심볼

10
Huffman Coding
Example (2/5)2) Solution 1 - 결합된 확률을 가능한 최상위에 위치 시킴
a1
a2
a3
a4
심볼 확률
0.40
0.20
0.20
0.10
0.20
0.20
0.40
확률을 내림차순으로 정리
가장 낮은 두개의 확률을 합한 것과나머지들을 다시 내림 차순 정리. 동일한 값이 나올때는 합해서 생긴값을 위로 위치 시킴.
0
a5 0.10
0.20
0.40
0.20
0.40
0.40
0.601.00
1
1
00
0110
11
01
0000
010
011
11
10
00
010
011
11
10
평균코드길이 = 0.4x2 + 0.2x2 + 0.2x2 + 0.1x3 + 0.1x3 = 2.2분산=(2-2.2)2x0.4 + (2-2.2)2x0.2 + (2-2.2)2x0.2 +(3-2.2)2x0.1 +(3-2.2)2x0.1 = 0.16
Huffman Coding
Example (3/5)2) Solution 2 - 결합된 확률을 가능한 최하위에 위치 시킴
평균코드길이 = 0.4x2 + 0.2x2 + 0.2x2 + 0.1x3 + 0.1x3 = 2.2분산=(1-2.2)2x0.4 + (2-2.2)2x0.2 + (3-2.2)2x0.2 +(4-2.2)2x0.1 +(4-2.2)2x0.1 = 1.36
a1
a2
a3
a4
심볼 확률
0.40
0.20
0.20
0.10
0.20
0.20
0.40
확률을 내림차순으로 정리
가장 낮은 두개의 확률을 합한 것과나머지들을 다시 내림 차순 정리. 동일한 값이 나올때는 합해서 생긴값을 아래로 위치 시킴.
0
a5 0.10
0.20
0.40
0.20
0.40
0.40
0.601.00
1
1
00
01000
01
11
0010
0011
000
01
1
0010
0011
000
01
001

11
Huffman Coding
Example (4/5)Solution1 과 Solution2의 비교
• Solution 1: 결합된 확률을 가능한 최상위에 위치 시킴
• Solution 2: 결합된 확률을 가능한 최하위에 위치 시킴
– 평균코드길이는 두 방법 모두 동일함
– 분산은 solution 1이 0.16이고, solution 2가 1.36 으로 다름
코드길이의 분산이 적은 경우
• 코드의 길이가 크게 변하지 않음
• 수신측의 동기(synchronization) 획득에 유리함
따라서, Huffman Coding 과정에서 결합된 확률을 가능한 최상위에위치시키는 것이 더 유리함.
Huffman Coding
Example (5/5)3) solution 1에 대한 decoding tree
• example– 수신된 bit 시퀀스가 다음과 같을때, 위의 decoding tree에 의하여
쉽게 디코딩됨
0
1
1
11
00
0
a1=00
a4=010
a5=011
a2=10
a3=11
a1 a5a3a3a2a2a5a5
0 1 1 0 1 1 1 0 1 0 1 1 1 1 0 0 0 1 1

12
2.2 기본적인 압축방법2.2.1 Entropy 압축방법
1) Huffman Coding2) Arithmetic Coding3) Run Length Coding
Arithmetic Coding
Huffman Coding의 문제점심볼의 확률이 1/2의 배수인 경우에 entropy에 근접하는 부호화를이룰수 있음
대부분의 경우 심볼의 확률은 1/2의 배수가 아님
Arithmetic Coding일반적인 확률에 대하여 entropy에 근접하는 성능을 얻을수 있음
하나의 심볼이 아니라, 심볼의 스트림에 대하여 하나의 실수값을부여함
• 이에따라, 입력 스트림의 길이가 길수록 출력비트의 수가 증가함

13
Arithmetic Coding
Arithmetic Coding - 인코딩인코딩 과정
step0) 심볼들의 발생 빈도를 0~1사이에 구분된 구간으로 나타냄
step1) 스트림의 첫번째 심볼에 해당하는 구간을 선택
step2) 선택된 구간을 심볼들의 발생 빈도에 맞추어 다시 구분함
step3) 구분된 구간에서 다음 심볼에 해당하는 구간을 선택하고, step 2부터 반복함
step4) 모든 스트림의 심볼이 완료되어 선택된 구간내의 한 값을
스트림에 대한 인코딩된 값으로 부여함
Arithmetic Coding
Example다섯개의 symbol: "e", "n", "t", "w", "."의 발생빈도가 각각 0.3, 0.3, 0.2, 0.1, 0.1 일때, 스트림 "went."을 arithmetic encoding 하시오.

14
Arithmetic Coding
"went."의 encdoing 과정
첫번째 심볼 "w"에해당하는 구간을선택
선택된 구간을 다시심볼들의 빈도로구분함
구분된 구간내에서두번째 심볼인 "e"에해당하는 구간을선택
최종적으로 마지막심볼인 "."은 구간[0.81602,0.8162)에지정됨
최종 선택구간인[0.81602,0.8162)중의한값을 "went."에 대한인코딩된 값으로부여함
Arithmetic Coding
Huffman coding과의 비교“went.”이라는 신호를 보내려고 할때,
• Huff. coding– “w”, “e”, “n”, “t”, “.” 각각에 대한 codeword를 보내야 함
– 5개의 Huffman codeword 필요
• Arithmetic coding– "went." 에 대하여 [0.81602, 0.8162)의 범위에 있는 하나의 숫자
(예를들어, 0.81602)만 필요

15
Arithmetic Coding
Arithmetic Coding - 디코딩디코딩 과정
step0) 심볼들의 발생 빈도를 0~1사이에 구분된 구간으로 나타내고, 인코딩된 값을 X로 부여함
step1) X가 속하는 심볼의 구간을 선택
step2) 선택된 구간에 대한 심볼값을 디코딩 결과로 출력함
step3) 선택된 구간을 0~1의 크기로 rescale (nomarlize) 함step4) X값을 다음과 같이 계산함
X = (X - XL)/(XR)XL : 선택된 구간을 0~1값으로 rescale 했을때, 해당 구간의 하한값
XR : 선택된 구간을 0~1값으로 rescale 했을때, 해당 구간의 크기
step5) X=0이면 디코딩을 종료하고, 아니면 step1 부터 다시 시작함
Example)• 다섯개의 symbol: "e", "n", "t", "w", "."의 발생빈도가 각각 0.3, 0.3,
0.2, 0.1, 0.1 일때, 인코딩된 값 0.81602값을 arithmetic decoding 하시오.
Arithmetic Coding
encoding된 값 0.81602의 decoding 과정
"0.81602"이속하는 구간을선택
첫번째 decoded symbol = "w"
X=(0.81602-0.8)/0.1=0.1602
구간을 noramlize 하고 새로 계산된X값인 "0.1602"가속하는 구간을 선택
두번째 decoded symbol = "e"
X=0.81602 X=(0.1602-0)/0.3=0.534
1.0
0.9
0.8
0.6
0.3
0
1.0
0.9
0.8
0.6
0.3
0
1.0
0.9
0.8
0.6
0.3
0
1.0
0.9
0.8
0.6
0.3
0
새로 계산된X값인 "0.534"가속하는 구간을선택
새로 계산된X값인 "0.78"가속하는 구간을선택
새로 계산된X값인 "0.9"가속하는 구간을선택
세번째 decoded symbol = "n"
네번째 decoded symbol = "t"
다섯번째 decoded symbol = "."
X=(0.534-0.3)/0.3=0.78
X=(0.78-0.6)/0.2=0.9
X=(0.9-0.9)/0.1=0
종료

16
Arithmetic Coding
Psuedo Code – encodingcum_freq[i] : i-번째 symbol의 확률범위의 상한값
• 즉, i-번째 심볼에 대한 확률 또는 빈도 범위는 cum_freq[i]에서cum_freq[i-1]까지임
• i가 감소함에 따라 cum_ freq[i]는 증가하고 cum_freq[0]=1로 된다.
/* Arithmetic Encoding Algorithm */encode_symbol(symbol, cum_freq)
range = high - lowhigh = low +
range*cum_freq[symbol-1]low = low +
range*cum_freq[symbol]
Arithmetic Coding
Pseudo Code – Decoding pseudo code
/* Arithmetic Decoding Algorithm *//* "Value" is the number that has been received. Continue calling *//* decode_symbol until the terminator symbol is returned. */
decode_symbol(cum_freq)find symbol such that
cum_freq[symbol] <= (value-low)/(high-low) < cum_freq[symbol-1]/* This ensures that value lies within the new *//* [low, high) range that will be calculated *//* by the following lines of code. */
range = high - lowhigh = low + range*cum_freq[symbol-1]low = low + range*cum_freq[symbol]return symbol

17
2.2 기본적인 압축방법2.2.1 Entropy 압축방법
1) Huffman Coding2) Arithmetic Coding3) Run Length Coding
Run Length Coding (RLC)
Huffman & Arithmetic Coding연속된 symbol 각각을 독립적으로 다룸
각 symbol의 발생 확률을 기준으로 가변길이 codeword를생성함으로써 평균 코드 길이를 최소화함
Multimedia Datasymbol들은 1차원 또는 2차원적으로 주위 symbol들과 상관성을갖고 있음
• ex. binary image (e.g. fax)
87 4 3
18
Run Length Coding (RLC)
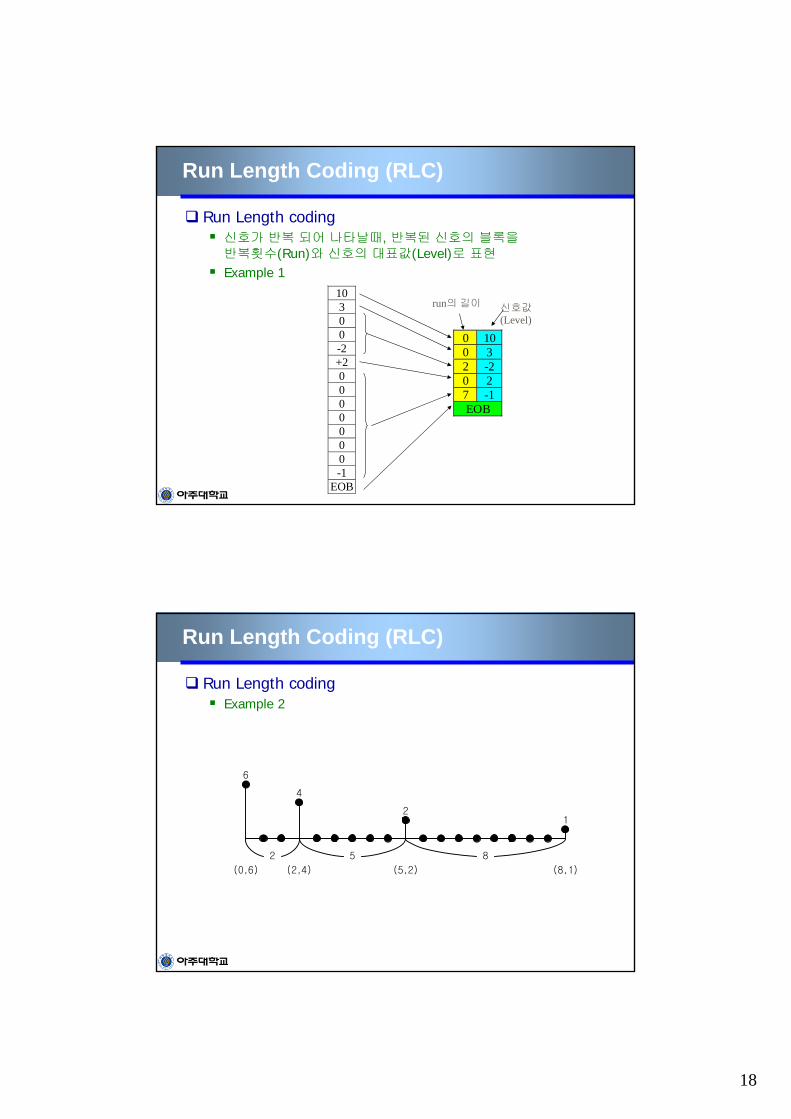
Run Length coding신호가 반복 되어 나타날때, 반복된 신호의 블록을반복횟수(Run)와 신호의 대표값(Level)로 표현
Example 110300-2+20000000-1
EOB
0 100 32 -20 27 -1EOB
run의 길이 신호값(Level)
Run Length Coding (RLC)
Run Length codingExample 2
2 5 8
6
4
21
(0,6) (2,4) (5,2) (8,1)

19
2.2 기본적인 압축방법2.2.1 Entropy 압축방법2.2.2 Predictive Coding2.2.3 Transform Coding2.2.4 Subband Coding
Predictive Coding
기본 원리 (1/3)현재 전송하려는 신호에 대한 예측을 통해서, 연속되는 신호들사이의 중복성을 제거하고 새로운 정보만을 encoding함으로써데이터량을 감소시킴
Predictive Coding System Model
nX̂
nXnnn XXe ~
−=
$ ( )e Q en n=nX~n-번째 입력신호값
Xn 의 과거값에 근거한 Xn의 예측값
n-번째 신호의 재생신호값
Xn 의 예측오차신호
en 의 양자화값
nX~
nenX ne
nX~
nX
20
Predictive Coding
기본 원리 (2/3)
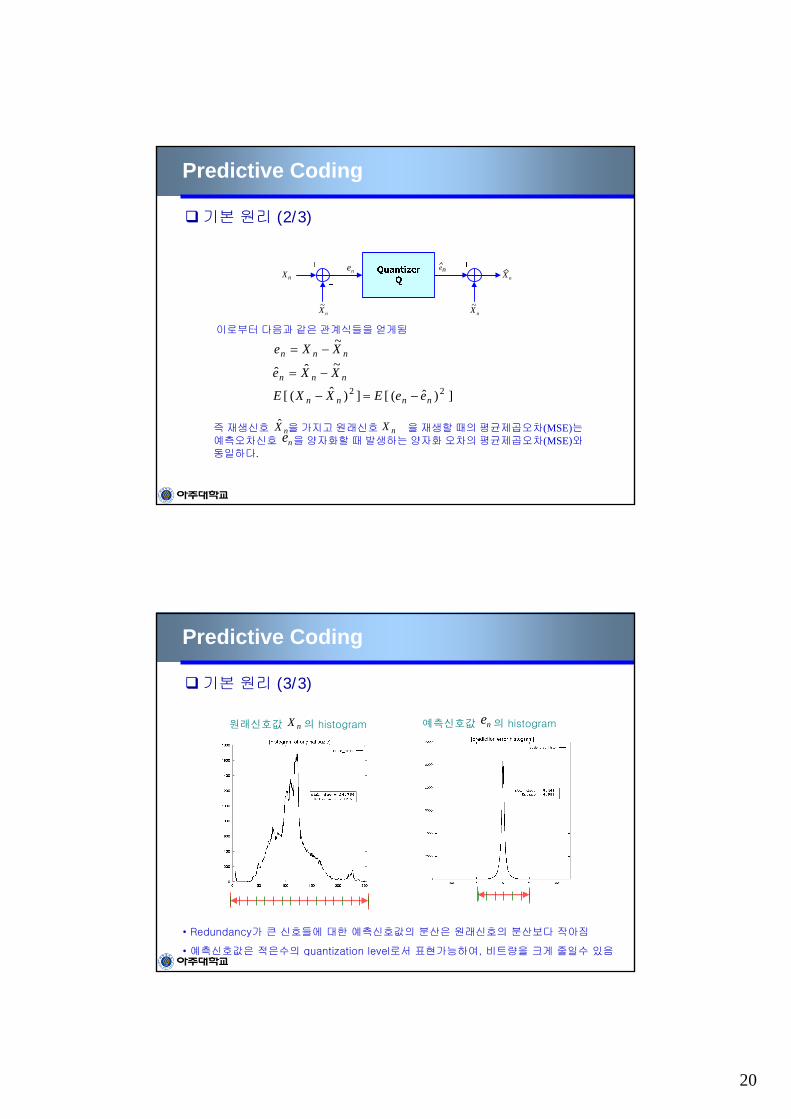
nnn XXe ~−=
nnn XXe ~ˆˆ −=
])ˆ([])ˆ([ 22nnnn eeEXXE −=−
이로부터 다음과 같은 관계식들을 얻게됨
nX~
nenX ne
nX~
nX
즉 재생신호 을 가지고 원래신호 을 재생할 때의 평균제곱오차(MSE)는예측오차신호 을 양자화할 때 발생하는 양자화 오차의 평균제곱오차(MSE)와동일하다.
nX̂ nXne
Predictive Coding
기본 원리 (3/3)
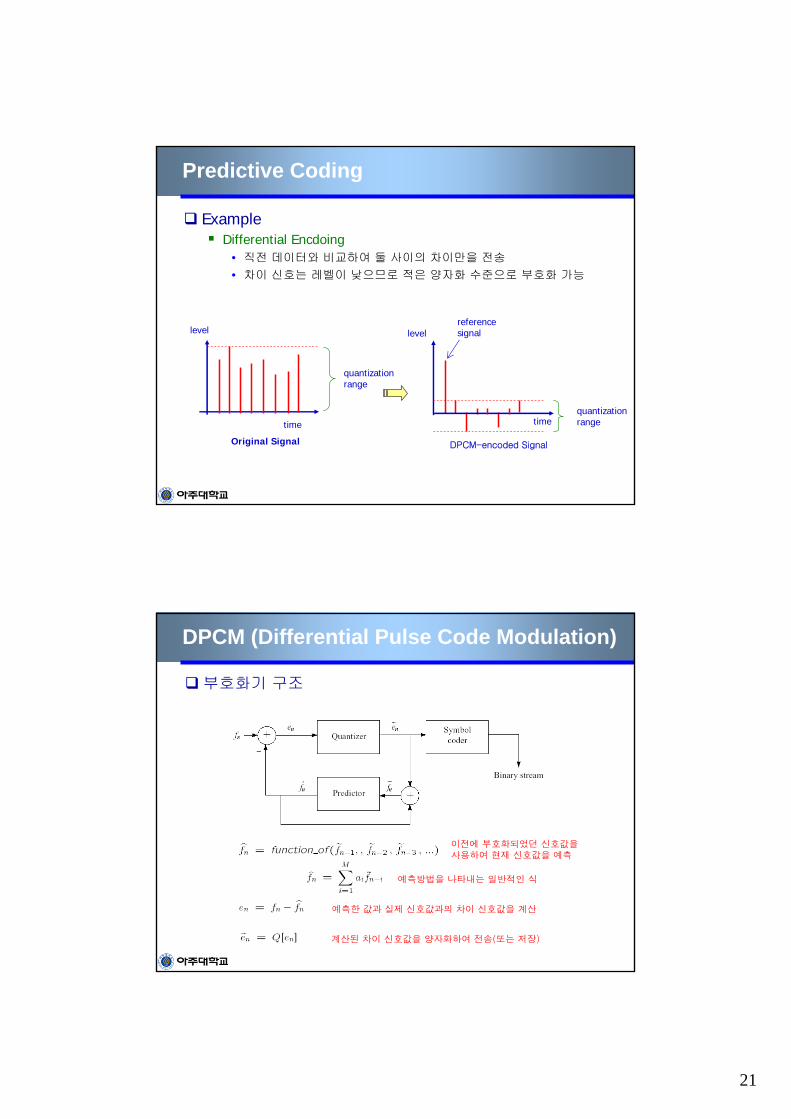
• Redundancy가 큰 신호들에 대한 예측신호값의 분산은 원래신호의 분산보다 작아짐
• 예측신호값은 적은수의 quantization level로서 표현가능하여, 비트량을 크게 줄일수 있음
nX원래신호값 의 histogram ne예측신호값 의 histogram
21
Predictive Coding
ExampleDifferential Encdoing
• 직전 데이터와 비교하여 둘 사이의 차이만을 전송
• 차이 신호는 레벨이 낮으므로 적은 양자화 수준으로 부호화 가능
level
time
quantization range
Original Signal
time
level
DPCM-encoded Signal
quantization range
reference signal
DPCM (Differential Pulse Code Modulation)
부호화기 구조
이전에 부호화되었던 신호값을사용하여 현재 신호값을 예측
예측한 값과 실제 신호값과의 차이 신호값을 계산
계산된 차이 신호값을 양자화하여 전송(또는 저장)
예측방법을 나타내는 일반적인 식

22
DPCM
복호화기 구조
복호화기로 입력되는 DPCM 부호화된 오차신호 값
심볼 디코더로 부터 역양자화된 오차신호 값
복원된 신호값
부호기와 동일한 예측방법이 적용됨
2.2 기본적인 압축방법2.2.1 Entropy 압축방법2.2.2 Predictive Coding2.2.3 Transform Coding2.2.4 Subband Coding

23
Transform
Transform의 개념멀티미디어 신호의 상관성
• 멀티미디어 데이터들은 큰 상관성을 갖고 있어서, 이들을개별적으로 압축하거나 양자화하는 것은 비효율적임
• 멀티미디어 신호의 효율적 압축을 위하여 신호간의 상관성을활용하기 위한 transform 방법들이 사용됨
Transform• 정보를 바라보는 관점을 바꿈
• Transform Examples– 시간 영역의 데이터를 다른 영역(예. 주파수 영역)으로 변환
• 예) DFT (Discrete Fourier Transform)– 공간 영역 (spatial domain)의 데이터를 주파수 영역으로 변환
• 예) 영상 데이터의 경우, DCT (discrete cosine transform)을 주로 사용
Transform
Transform의 개념Transform의 잇점
• 원래의 신호값들보다 훨씬 낮은 correlation을 갖는 변환값(transform coefficient)들로 구성된 vector를 얻을수 있음
• 신호의 에너지가 단지 몇개의 transform coefficient 로 집중되는energy compaction 효과를 얻음
신호값
시간
시/공간적 도메인 주파수 도메인
신호값
주파수
중요한 정보
덜 중요한 정보
Transform

24
DCT (Discrete Cosine Transform)
DCT (Discrete Cosine Transform)영상 정보는 공간영역에서 매우 큰 상관성을 갖고 있음
DCT의 특징
• Forward와 Inverse에서의 fast implementation 가능
• 반복적인 구조를 갖으므로, 다양한 크기에 대하여 쉽게 적용 가능
• 수학적으로 최적인 KLT (Karhunen-Loeve Transform)에 근접한성능을 나타냄
• 다양한 차원 (multiple dimension)에 쉽게 확장 가능
• 변환후 계수들간의 상관성 (correlation)이 최소화 됨.
일반적으로 영상은인접한 픽셀들끼리매우 비슷한 값을 갖음
DCT
x(j,k) : 원래 데이터 블럭에서 (j,k)에 위치한 데이터 값
y(u,v) : DCT 변환된 블록의 (u,v)에 위치한 데이터 값
C(u)=C(v)= if u,v=0
C(u)=C(v)= 1 if u,v=1,2,…,7
⎟⎠⎞
⎜⎝⎛ +
⎟⎠⎞
⎜⎝⎛ +
= ∑∑= = 16
)12(cos16
)12(cos),(4
)()(),(7
0
7
0
ππ vkujkjxvCuCvuyj k
21
u
v
0 1 2 3 4 5 6 701234567
직류(DC) 성분
교류(AC) 성분
고주파 영역 저주파
영역
y(u=4,v=2) j
k
x(j=4,k=3)
0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7
8x8 DCT equation
FDCT
⎟⎠⎞
⎜⎝⎛ +
⎟⎠⎞
⎜⎝⎛ +
= ∑∑= = 16
)12(cos16
)12(cos),()()(41),(*
7
0
7
0
ππ vkujvuyvCuCkjxu v
forward DCT:
inverse DCT:
IDCT

25
DCT
시간영역에서의 분포 : x(j,k)591 106 -18 28 -34 14 18 335 0 0 0 0 0 0 0-1 0 0 0 0 0 0 03 0 0 0 0 0 0 0-1 0 0 0 0 0 0 00 0 0 0 0 0 0 0-1 0 0 0 0 0 0 00 0 0 0 0 0 0 0
98 92 95 80 75 82 68 5097 91 94 79 74 81 67 4995 89 92 77 72 79 65 4793 87 90 75 70 77 63 4591 85 88 73 68 75 61 4389 83 86 71 66 73 59 4187 81 84 69 64 71 57 3985 79 82 67 62 69 55 37
DCT 영역에서의 분포 : y(u,v)
1 2 3 4 5 6 7 8S1
S4
S7
-100
0
100
200
300
400
500
600
1 2 3 4 5 6 7 8S1
S3
S5
S7
0
10
20
30
40
50
60
70
80
90
100
FDCT
Example
픽셀의 값들이 모두 비슷하게 큰값들로 이루어져 있음
픽셀의 변환된 값들이 한 곳에집중되어 있음
DCT
Zig-zag scan8x8 블록 데이터를 직렬로 처리하기 위하여 값들을 읽는 순서
40 10 -2 2 -1 0 0 0
3 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
Zig-zag scanned values: 40, 10, 3, 0, 0, 2 , 2, 0, 0, 0, 0, 0, 0, 0, -1, 0, ..., 0
RLC encoded values: (0,40), (0,10), (0,3), (2,2) , (0,2), (7,-1), EOB
주파수 분포
zig-zag scan 번호
1 2 3 4 5 … … 61 62 63 64
low freq. high freq.
DC AC

26
DCT
Quantization for DCT CoefficientsTransform Coefficients
• 서로간에 통계적 상관성이 낮아짐
• 에너지가 몇개의 coefficients로 집중
– 모든 coefficients에 동일한 bit를 할당하는 것보다 중요한 coeff.에더 많은 bit를 할당하고, 덜 중요한 곳에는 적게 할당함으로써 압축효율을 높일 수 있음
0000000000000001000001110001111100011122001112330011234501112358
8x8 DCT coefficients에 대한quantization bit allocation 예(한 모의 영상에서 평균비트율이 1 bit/pixel 인 경우)
DCT
Transform Coder Example (JPEG)
• 입력 영상을 크기가 8x8인 영상 블록으로 나눔• 각 블록은 DCT를 사용하여 독립적으로 변환• 실수값인 모든 변환계수들을 양자화• 양자화된 8x8 블록의 coeff.들을 zig-zag scan하여 1차원 데이터열로 만듬• DCT coeff. (첫번째 coeff.)는 영상 블록의 평균 밝기에 비례하고 값이 매우 크므로,
무손실 DPCM 방식으로 부호화 함• AC coeff.는 양자화하면 ‘0’이 많이 나오며, 특히 고주파수 영역에서 많이 나오므로,
이러한 ‘0’의 값들을 활용하기 위해, RLC등의 entropy coding 방법을 사용
27
2.2 기본적인 압축방법2.2.1 Entropy 압축방법2.2.2 Predictive Coding2.2.3 Transform Coding2.2.4 Subband Coding
Subband Coding
Subbnad Coding 개요신호는 주파수영역에서 분산되지 않고 특정 주파수 부근에 집중되는형태를 보여줌
입력신호를 주파수 스펙트럼 상에서 각기 다른 subband를 나타내는협대역 신호들로 구분
• 각 subband 신호들간에는 상관성(correlation)이 없게 됨.• 신호의 에너지가 집중된 주파수 대역에는 많은 비트를 할당하고, 약한
부분에는 적은 비트를 할당함으로써, 비트율을 줄일수 있음
28
Subband Coding
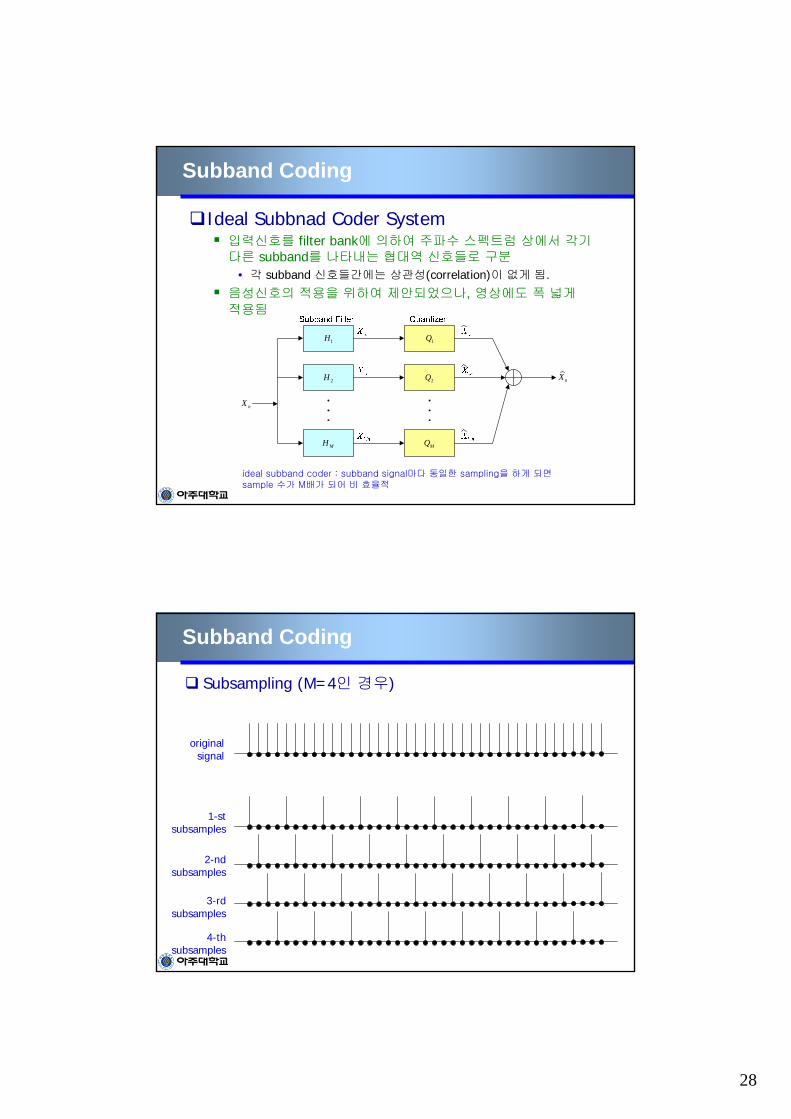
Ideal Subbnad Coder System입력신호를 filter bank에 의하여 주파수 스펙트럼 상에서 각기다른 subband를 나타내는 협대역 신호들로 구분
• 각 subband 신호들간에는 상관성(correlation)이 없게 됨.
음성신호의 적용을 위하여 제안되었으나, 영상에도 폭 넓게적용됨
1H
2H
MH
2Q
MQ
nX
nX
1Q
ideal subband coder : subband signal마다 동일한 sampling을 하게 되면sample 수가 M배가 되어 비 효율적
Subband Coding
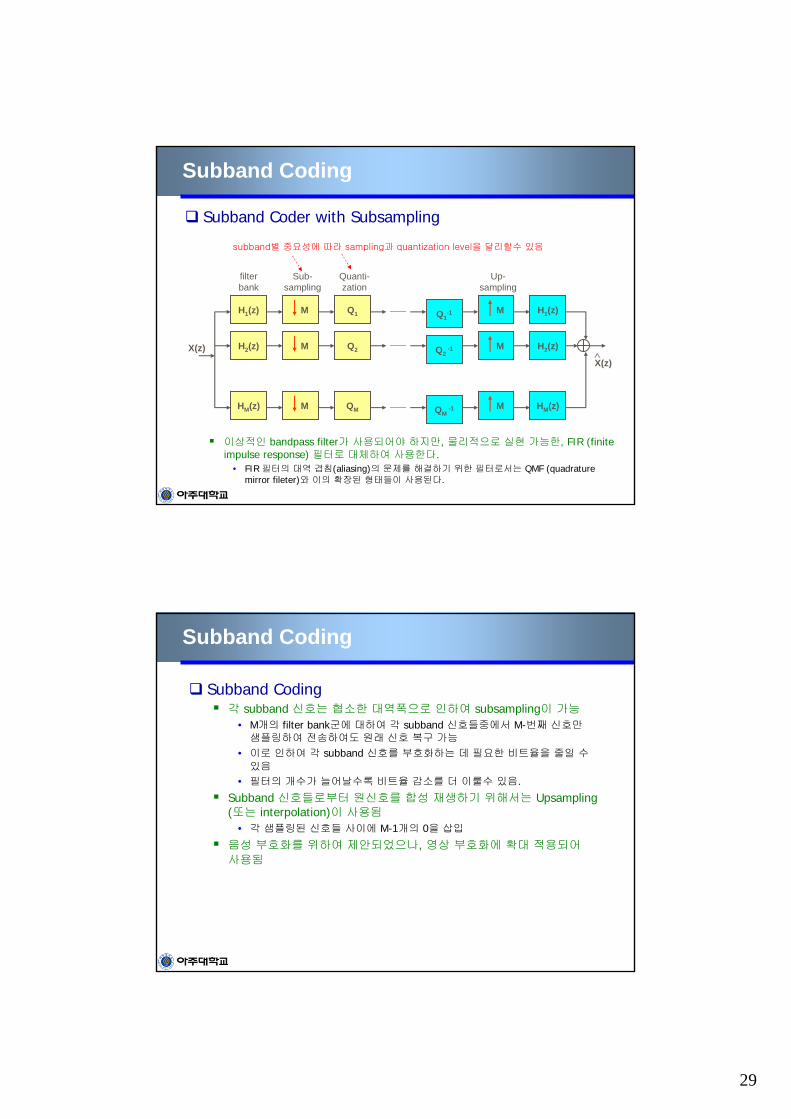
Subsampling (M=4인 경우)
original signal
1-st subsamples
2-ndsubsamples
3-rd subsamples
4-th subsamples
29
Subband Coding
Subband Coder with Subsampling
이상적인 bandpass filter가 사용되어야 하지만, 물리적으로 실현 가능한, FIR (finite impulse response) 필터로 대체하여 사용한다.
• FIR 필터의 대역 겹침(aliasing)의 문제를 해결하기 위한 필터로서는 QMF (quadrature mirror fileter)와 이의 확장된 형태들이 사용된다.
H1(z)
HM(z)
H2(z)
M Q1
M
M
Q2
QM
filter bank
Sub-sampling
Quanti-zation
X(z)
H1(z)
HM(z)
H2(z)
MQ1-1
M
M
Q2 -1
QM -1
Up-sampling
∧X(z)
subband별 중요성에 따라 sampling과 quantization level을 달리할수 있음
Subband Coding
Subband Coding각 subband 신호는 협소한 대역폭으로 인하여 subsampling이 가능
• M개의 filter bank군에 대하여 각 subband 신호들중에서 M-번째 신호만샘플링하여 전송하여도 원래 신호 복구 가능
• 이로 인하여 각 subband 신호를 부호화하는 데 필요한 비트율을 줄일 수있음
• 필터의 개수가 늘어날수록 비트율 감소를 더 이룰수 있음.
Subband 신호들로부터 원신호를 합성 재생하기 위해서는 Upsampling (또는 interpolation)이 사용됨
• 각 샘플링된 신호들 사이에 M-1개의 0을 삽입
음성 부호화를 위하여 제안되었으나, 영상 부호화에 확대 적용되어사용됨

30
Subband Coding
2차원 신호에 대한 Subband coding1차원 QMF필터들을 수평 및 수직 방향으로 분리 적용
2차원 신호의 7 대역(subband) 부호화 예(example)
HPH (High Pass Horizontal) HPV (High Pass Vertical)
HPH
X(z)
LPH
HPV
LPV
HPV
LPV
HPV
LPV
HPV
LPV
HPV
LPV 1 LL-LL
2 LL-LH
3 LL-HL
4 LL-HH
5 LH
6 HL
7 HH
HH(z) 2
LPH (Low Pass Horizontal) LPV (Low Pass Vertical)
HL(z) 2
Subband Coding
2차원 신호의 7 대역(subband) 부호화 예 (cont’d)
LL-LL LL-HL
LL-LH LL-HH
LH
HL
HH
fh
fv
LL-LLlow resolution representation of the original image, and has similar historgram characteristics, but with much smoother spatial distribution
spatial high-frequency components including edges and impulses corresponding to different directions and resolution levels
31
2.3 Rate-Distortion Curve
Rate-Distortion Curve
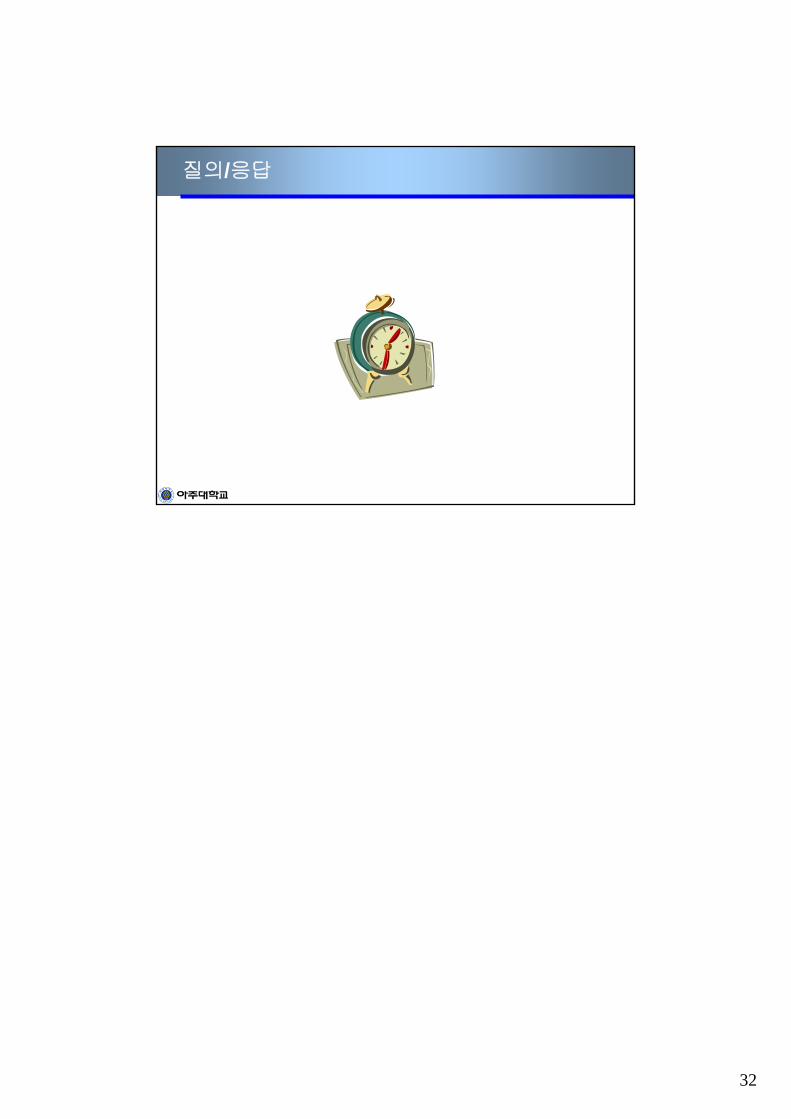
압축정도와 distortion간의 상관 관계동일한 압축 방식에 대하여
• 압축률 higher -> 부호율 lower -> 평균왜곡 higher• 압축률 lower -> 부호율 higher -> 평균왜곡 lower
d (평균 왜곡값)d1
RC(d1)
RS(d1)
R (부호율)
dS dC
R1
RC(d) : 복잡한 화면의 율-왜곡 곡선
RS(d) : 단순한 화면의 율-왜곡 곡선
RC(d)
RS(d)
distortion이 dc보다 작아야 하는조건에서 요구되는 정보량의최소치는 R1임
32
질의/응답


















