סיכום סטטיסטיקה סמסטר א.pdf
22
)תשע"ה( שיטות סטטיסטיות במחקר פסיכולוגי חזרה על נושאים רלוונטיים משנה שעברה................................ ................................ ....... 2 א. מונחי יסוד בסיסיים................................ ................................ ................................ .... 2 א. 1 . אוכלוסיה, סטטיסטי וזה................................ ................................ ..................... 2 א. 2 . בדיקת השערות................................ ................................ ............................... 2 א. 3 . טעויות היסק................................ ................................ ................................ .... 2 דוגמה לשלבי בדיקת השערות בהתפלגותZ ................................ ................................ .. 2 ב. השוואה בין ממוצעים כשהשונויות אינן ידועות................................ ................................ . 3 ב. 1 מבחןT לבדיקת השערות למדגם בודד................................ ................................ ... 3 דוגמה למבחןT למדגם בודד................................ ................................ ..................... 4 ב. 2 . מבחניT למדגמים בלתי תלויים................................ ................................ ........... 5 דוגמה למבחןT למדגמים בלתי תלויים................................ ................................ ......... 5 ב. 3 . מבחניT למדגמים מזווגים................................ ................................ .................. 6 דוגמה למבחןT למדגמים מזווגים................................ ................................ ............... 7 התפלגותF וניתוח שונות חד- גורמי................................ ................................ ................ 8 א. התפלגותF ................................ ................................ ................................ .............. 8 דוגמה למבחןF : ................................ ................................ ................................ ...... 8 ב. ניתוח שונות חד- גורמי................................ ................................ ................................ 9 ממוצע ריבועים: ................................ ................................ ................................ .......... 10 דוגמה לניתוח שונות חד- גורמי................................ ................................ ................. 11 השוואות מתוכננות והשוואות פוסט- הוק................................ ................................ ........ 12 א. השוואות מתוכננות– קונטרסטים................................ ................................ ............... 12 דוגמה למבחן השוואות מתוכננות................................ ................................ .............. 13 ב. השוואות פוסט הוק................................ ................................ ................................ .. 14 דוגמה למבחן טוקי................................ ................................ ................................ . 15 ניתוח שונות דו- גורמי................................ ................................ ................................ . 16 דוגמה לניתוח שונות דו- גורמי................................ ................................ ................... 17 רגרסיה ומתאם, ניבוי, רגרסיה מרוב ה................................ ................................ ........... 19 א. רגרסיה בציוני תקן................................ ................................ ................................ ... 19 ב. רגרסי ה בציוני גלם................................ ................................ ................................ ... 20 דוגמה לחישוב משוואת ניבוי בציוני גלם................................ ................................ ..... 20 ג. השונויות השונות................................ ................................ ................................ ..... 21 ג. 1 . השונות המוסברת................................ ................................ ........................... 21 ד. רגרסיה אל הממוצע................................ ................................ ................................ . 22
-
Upload
reggev-eyal -
Category
Documents
-
view
124 -
download
1
Transcript of סיכום סטטיסטיקה סמסטר א.pdf

שיטות סטטיסטיות במחקר פסיכולוגי )תשע"ה(
2 ....................................................................... שעברה משנה רלוונטיים נושאים על חזרה
2 .................................................................................................... בסיסיים יסוד מונחי. א
2 ..................................................................................... וזה סטטיסטי, אוכלוסיה. 1.א
2 ............................................................................................... השערות בדיקת. 2.א
2 .................................................................................................... היסק טעויות. 3.א
Z .................................................................. 2 בהתפלגות השערות בדיקת לשלבי דוגמה
3 ................................................................. ידועות אינן כשהשונויות ממוצעים בין השוואה. ב
3 ................................................................... בודד למדגם השערות לבדיקת T מבחן 1.ב
4 ..................................................................................... בודד למדגם T למבחן דוגמה
5 ........................................................................... תלויים בלתי למדגמים T מבחני. 2.ב
5 .........................................................................תלויים בלתי למדגמים T למבחן דוגמה
6 .................................................................................. מזווגים למדגמים T מבחני. 3.ב
7 ............................................................................... מזווגים למדגמים T למבחן דוגמה
8 ................................................................................ גורמי-חד שונות וניתוח F התפלגות
F .............................................................................................................. 8 התפלגות. א
F: ...................................................................................................... 8 למבחן דוגמה
9 ................................................................................................ גורמי-חד שונות ניתוח. ב
10 .......................................................................................................... :ריבועים ממוצע
11 ................................................................................. גורמי-חד שונות לניתוח דוגמה
12 ........................................................................ הוק-פוסט והשוואות מתוכננות השוואות
12 ............................................................................... קונטרסטים – מתוכננות השוואות. א
13 .............................................................................. מתוכננות השוואות למבחן דוגמה
14 .................................................................................................. הוק פוסט השוואות. ב
15 ................................................................................................. טוקי למבחן דוגמה
16 ................................................................................................. גורמי-דו שונות ניתוח
17 ................................................................................... גורמי-דו שונות לניתוח דוגמה
19 ........................................................................... המרוב רגרסיה, ניבוי, ומתאם רגרסיה
19 ................................................................................................... תקן בציוני רגרסיה. א
20 ................................................................................................... גלם בציוני הרגרסי. ב
20 ..................................................................... גלם בציוני ניבוי משוואת לחישוב דוגמה
21 ..................................................................................................... השונות השונויות. ג
21 ........................................................................................... המוסברת השונות. 1.ג
22 ................................................................................................. הממוצע אל רגרסיה. ד

חזרה על נושאים רלוונטיים משנה שעברה
בסיסיים מונחי יסודא.
. אוכלוסיה, סטטיסטי וזה1א.
. יש של משתנה מקרי באוכלוסיהערכים שונים האוכלוסיה מתפלגת כך שיש הסתברות כלשהי לקבל
הם הפרמטרים מדדים שונים שניתן לאפיין באמצעותם את ההתפלגות הזו, והם מכונים פרמטרים.
מה שהסטטיסטיקאי מעוניין בו.
מאחר שאין לנו גישה לאוכלוסיה, אנחנו משתמשים במדגם. מדד שמאפיין את המדגם הוא סטטיסטי,
ל האוכלוסיה. ובאמצעותו אנחנו מסיקים מסקנות ע
של אינסוף )נניח, הממוצעים( התפלגות הדגימה היא התפלגות תיאורטית של כל הסטטיסטים
מדגמים אפשריים בגודל מסוים.
בעוד שתוחלת התפלגות הדגימה של הממוצע זהה לתוחלת המשתנה באוכלוסיה, השונות של
התפלגות כזו קטנה משונות האוכלוסיה בפקטור של גודל המדגם:
הנוסחה להמרה לציוני תקן:
:דגימה של הממוצעיםה ציון התקן של ממוצע המדגם בהתפלגות
התפלגות הדגימה היא באופן פרקטי נורמלית. n>30אם
. בדיקת השערות2א.
אינטליגנטיים נניח שערכנו ניסוי לחקר השאלה האם ילדים שהוריהם מתנדבים לניסויים הם ילדים
. הפרוצדורה 100, בעוד הממוצע הכללי הוא 109מהממוצע. יצא לנו שהממוצע של ילדים כאמור הוא
( היא מקרית, או שאכן אפשר לקבוע 109של בדיקת השערות עוזרת לנו להבין האם התוצאה שלנו )
על בסיסה שילדים כאמור הם אינטליגנטיים מהממוצע.
גיקה של הוכחה על דרך השלילה. אנחנו מניחים שזו תוצאה מקרית, אנחנו עורכים את הבדיקה בלו
כלומר שהשערת האפס נכונה ואין אפקט, ואז בודקים אם הגענו למסקנה סבירה או לא.
. טעויות היסק3א.
טעות מסוג ראשון = אזעקת שווא. השכיחות לטעות כזו מושפעת אך ורק מהאלפא שקבענו.
ות לטעות כזו מושפעת מהאלפא שנקבעה ומהמרחק בין השערת טעות מסוג שני = החטאה. השכיח
האפס לבין השערת המחקר )ככל שההשערות קרובות, יש חפיפה בין העקומות וביתא גדולה יותר(.
המרחק בין השערת האפס לבין השערת המחקר מכונה "גודל האפקט". ברור שככל שאנחנו
הסיכוי שלנו לטעות מסוג שני.מחפשים גודל אפקט גדול יותר, אנחנו מקטינים את
החפיפה בין ההתפלגות של השערת האפס לבין ההתפלגות של השערת המחקר מושפעת גם מגודל
האפקט שבחרנו, אבל גם משונות התפלגות הדגימה. שונות התפלגות הדגימה מושפעת משונות
האוכלוסיה ומגודל המדגם.
1-β המחקר. זו עוצמת המבחן. זו ההסתברות לגלות את השערת
Zדוגמה לשלבי בדיקת השערות בהתפלגות
xxExE )()(
x
xxZx
n
xZ
x
H
x/
0
n
xx
22

א. השערות:
H0: 𝜇𝑥≤70
H1: 𝜇𝑥>70
ב. הנחות:
.דגימה מקרית ובלתי תלויה
) 152,𝜇X~N( כלומר(X 15מתפלג נורמלית באוכלוסיה וסה"ת.)
ג. סטטיסטי המבחן והתפלגותו:
)152
10X~N(70,
N = 10
ד. רמת מובהקות וכלל הכרעה:
α=0.05
0.05, one sided)=1.645Z( זהZ .קריטי
15
√10= 77.803X=70+1.645* על סמך הנוסחה(
𝑋−��
𝑆𝐷 Z=)
קריטי(. Zקריטי )דרך חלופית ל X, אז נדחה את השערת האפס. זה x >77.803אם
ה. ערך נצפה וביצוע המבחן:
הקריטי אפשר לדחות את השערת האפס, כי זה גדול X-. לפי ה80נניח שהממוצע במדגם יצא
.77.803מ
של התוצאה שלנו: Z-היינו מגיעים לאותה תוצאה גם מחישוב ה
=2.10880−70
15
√10
=Z
Z הנצפה גדול מ-Z .קריטי, ולכן אפשר לדחות את השערת האפס גם כך
ו. מסקנה
השערת האפס נדחית
ידועותהשוואה בין ממוצעים כשהשונויות אינן ב.
לבדיקת השערות למדגם בודד Tמבחן 1ב.
(, ולכן איננו יכולים לתקנן לציוני תקן σ2ברוב המקרים, איננו יודעים את שונות המשתנה באוכלוסיה )
את הממוצע שקיבלנו במדגם )הנוסחה להמרה לציוני תקן כוללת את ערך השונות וצריך לדעת אותו(.
השונות. קצה החוט שיש לנו כדי לאמוד את השונות הוא כדי להתגבר על זה, אנחנו אומדים את
𝑆𝑥השונות שקיבלנו במדגם )(. אבל השונות היא אומד מוטה כלפי מטה )התוחלת של שונות המדגם 2
קטנה מתוחלת השונות באוכלוסיה(, בפקטור המושפע מגודל המדגם. לכן ניצור אומד בלתי מוטה
(. N-1)/N-דגם בלשונות האוכלוסיה, ע"י הכפלת שונות המ

שנדגמים מהאוכלוסיה(: Nהאומד לשונות של התפלגות הדגימה )של אינסוף ממוצעים בגודל
טעות התקן )סטיית התקן של התפלגות הדגימה(:
מאחר ששונות האוכלוסיה אינה ידועה ואנחנו אומדים אותה, אנחנו משתמשים בסטטיסטי אחר, והוא
T זה בדיוק כמו .Z טעות תקןרק שבמכנה במקום סטיית תקן יש :
ידועה ונאמדת ע"י , כי הוא תלוי בשונות האוכלוסיה שאינה Zהוא פחות קבוע מהערך של Tהערך של
.Zגבוהה יותר מהשונות של Tהשונות המקרית שיצאה לנו במדגם. כלומר, השונות של
למדגם בודד Tדוגמה למבחן
חוקר מסוים רוצה להראות שטיפול פסיכואנליטי משפר את מצב הרוח. תוחלת מצב הרוח באוכלוסיה
.5עם ס"ת 12הם הוא מטופלים ומגלה שממוצע מצב הרוח של 30. החוקר דוגם 10היא
א. השערות:
H1 :𝜇<10 הטיפול משפיע( 10תוחלת מצב הרוח של מי שטופל גבוהה מ(
H0 :𝜇≤10 הטיפול לא משפיע( 10תוחלת הציונים לא גבוהה מ(
ב. סטטיסטי המבחן והתפלגותו:
N=30
:סטטיסטי~t(n-1) ��−𝜇𝑆𝐷
√𝑛−1
ג. רמת מובהקות וכלל הכרעה:
��−10
5
√29
α=0.05
T(29)=1.699
t≥1.699אזור הדחייה:
t<1.699אזור הקבלה:
ד. ערך נצפה וביצוע המבחן:
)1(~1//ˆ
00
n
x
H
x
Ht
nS
x
nS
x
22
1ˆ
xx Sn
nS
1)1(
ˆˆ
2222
n
S
nn
nS
n
SS xxx
x
1
ˆˆ
n
S
n
SS xx
x

12 − 10
5
√29
T=2.154
נדחית. 0H ה. מסקנה:
למדגמים בלתי תלויים T. מבחני 2ב.
במקרה הזה אנחנו רוצים לדעת האם שני פרמטרים מאוכלוסיות שונות שונים זה מזה. מה שחשוב
להבין כאן הוא שבכל מדידה אנחנו מקבלים שני ממוצעים, ומחשבים את ההפרש ביניהם. בעצם זו
ת הדגימה של הפרשי הממוצעים:התפלגות הדגימה של הפרשי הממוצעים. זו שונות התפלגו
זהו הסטטיסטי המבוקש:
זהו האומד המשוקלל לשונות
ואם נציב אותו בסטטיסטי, נגיע לכך שזהו הסטטיסטי:
למדגמים בלתי תלויים Tדוגמה למבחן
גברים שממוצע 5חוקר רוצה לבדוק את השערתו כי רמת החרדה של גברים גבוהה יותר. יש
(.9, 11, 8, 5, 7) 8שממוצע חרדתן הוא נשים 5(. יש 12, 11, 10, 9, 8)התצפיות 10חרדתם הוא
.4, ושל הגברים 2נתחיל בחישוב שוניות המדגמים. שונות מדגם הגברים יוצאת
:השערות .1
H0 :𝜇𝑥 − 𝜇𝑦 ≤ 0
H1 :𝜇𝑥 − 𝜇𝑦 > 0
:הנחות .2
תלות בין הקבוצות, וגם אי תלות בדגימה בתוכן.-אי
y
y
x
xyxyx
nn
22222
y
y
x
x
yx
yx
nn
yxz
22
)()(
2
22
yx
yyxx
nn
SnSn
)2(22
~
)11
)(2
(
)()(
yx nn
yxyx
yyxx
yxt
nnnn
SnSn
yx

:סטטיסטי המבחן והתפלגותו .3
(X − Y ) − (μ𝑥− μ
𝑦)
√(𝑆𝑥
2 ∗ 𝑁𝑥)+(𝑆𝑦2 ∗ 𝑁𝑦)
𝑛𝑥 + 𝑛𝑦 − 2 ∗ (1𝑛𝑥
+1𝑛𝑦)
~𝑡𝑑𝑓(𝑛𝑥+𝑛𝑦−2)
:רמת מובהקות וערכים קריטיים .4
וההשערה היא חד זנבית. 0.05רמת המובהקות היא
Df(8)=1.86 .אם נקבל ערך שגדול מערך זה, נדחה את השערת האפס
:ביצוע המבחן וערך נצפה .5
(10− 8) − (0)
√(2 ∗ 5) + (4 ∗ 5)5 + 5 − 2
∗ (15+15)
= 𝟏. 𝟔𝟑
:מסקנה .6
איננו דוחים את השערת האפס. לא ניתן לומר שרמת החרדה של גברים גבוהה יותר, ברמת
0.05מובהקות של
למדגמים מזווגים T. מבחני 3ב.
נעשה בו שימוש כאשר המדגמים מתייחסים לאוכלוסיות שיש ביניהן קשר )לדוגמה, מחקרי תאומים(.
זה משפיע על השונות, כי כעת השונות היא לא רק סכום השונות של כל מדגם, אלא יש שונות
אמוד את השונות המשותפת, הוא משותפת שעלינו להחסירה. הפתרון לכך שאיננו יכולים ל
של ממוצע בודד. T( מכל זוג מדידות. על אותו הפרש אפשר לבצע מבחני dלהשתמש בציון ההפרש )
כמו קודם, אין לנו בעיה לאמוד את השונות מתוך שונות ההפרש של המדגם:
יקת השערות על הפרשיםזה הסטטיסטי לבד
*מה בין מדגמים מזווגים לבין בלתי תלויים?
ראשית, יש שוני במידת הקושי לדחות את השערת האפס במדגמים מזווגים בהשוואה למדגמים
בין המדגמים אם התלות בלתי תלויים, בגלל ההבדל בשונות )שנובע משונות משותפת במזווגים(.
במדגמים מזווגים בהשוואה לבלתי תלויים )כי יהיה קל יותר לדחות את השערת האפס היא חיובית,
אנחנו מחסירים מסכום השונויות את השונות המשותפת, שהיא ערך חיובי במקרה כזה(. אם התלות
שלילית, יהיה קשה יותר לדחות את השערת האפס במדגמים מזווגים )תלות חיובית = כשהם
תלות שלילית = ככל שאחד גדל, השני קטן(.משתנים לאותו כיוון.
נותנת ערך קטן יותר. לכן, כשאנחנו משתמשים במזווגים אנחנו T-גדל, טבלת ה N-שנית, ככל ש
Tמקטינים בחצי את מספר התצפיות )כי התצפיות הן ההפרשים, ולא הנבדקים( וכך מקבלים ערכי
גבוהים יותר, שמקשים על דחיית השערת האפס.
ם להשתמש במדגמים בלתי תלויים או במדגמים מזווגים, תלויה בנסיבות המחקר. ניתן ההחלטה א
הקריטי גדול יותר )כי יש פחות דרגות חופש( ולכן כביכול קשה יותר T-לטעון שבמדגמים מזווגים ה
למדגמים בלתי תלויים. עם זאת, מה Tלדחות את השערת האפס, ועל כן עדיף להשתמש במבחן
1ˆ
22
n
SS d
d
)1(22
~)1/(/ˆ
n
d
d
d
d tnS
d
nS
d

הקריטי הגדול יותר במבחן מדגמים מזווגים, הוא שאם אנחנו יודעים שהמתאם בין T-שמחפה על ה
שתי האוכלוסיות הנבחנות הוא חיובי, נקבל שונות קטנה יותר בהשוואה לזו שנקבל במדגמים בלתי
הגדול. Tתלויים. השונות הקטנה הזו יכולה לחפות על ה
למדגמים מזווגים Tדוגמה למבחן
8נשים שממוצע חרדתן הוא 5(. יש 12, 11, 10, 9, 8)התצפיות 10חרדתם הוא גברים שממוצע 5
.4, ושל הגברים 2(. שונות מדגם הגברים יוצאת 9, 11, 8, 5, 7)
אנחנו יכולים ליצור מזה מדגם בודד של תצפיות, כאשר כל תצפית היא ההפרש בין הגבר לאשה.
ה, נתייחס רק לנתוני ההפרשים.. מרגע ז1, 4, 2, 0, 3נקבל חמש תצפיות שערכן
:השערות .1
H0 :𝜇𝑑 ≤ 0
H1 :𝜇𝑑 > 0
:הנחות .2
התפלגות נורמלית של אוכלוסיית ההפרשים.
תלות בין זוג לזוג(.-דגימה מקרית ובלתי תלויה של המדגם הראשון )כלומר אי
:סטטיסטי המבחן והתפלגותו .3
D − μ𝑑
Sd
√n − 1
~𝑡𝑓𝑑(𝑛𝑑−1)
:רמת מובהקות וערכים קריטיים .4
. הערך FD=4וההשערה היא חד זנבית. לפי הטבלה, כאשר 0.05רמת המובהקות היא
. אם נקבל ערך שגדול מערך זה, נדחה את השערת האפס.2.13הקריטי לפי הטבלה הוא
:ביצוע המבחן וערך נצפה .52 − μ
𝑑
Sd
√5 − 1
= 𝟐. 𝟖𝟑
:מסקנה .6
החרדה של , ניתן לומר שרמת 0.05אנו דוחים את השערת האפס. ברמת מובהקות של
גברים גבוהה יותר.

גורמי-וניתוח שונות חד Fהתפלגות
Fא. התפלגות
פעמים רבות אנחנו מניחים שוויון שונויות בין מדגמים, אלא שעלינו לבדוק את הנחה זו סטטיסטית.
תה. כשיש לנו שני אנחנו בודקים את ההשערה הזו באותה לוגיקה של בדיקת השערות שראינו עד ע
. מקובל לשים Fאומדנים בלתי תלויים לאותה שונות, היחס ביניהם מתפלג בהתפלגות סדורה שהיא
אם כן הוא היחס בין האומדנים, כשכל אומדן מחושב כרגיל: Fבמונה את האומד הגדול יותר.
היא לא סימטרית, היא יכולה לקבל רק ערכים חיוביים, והיא משפחת התפלגויות שמה Fהתפלגות
שמבחין ביניהן הוא שני ערכים של דרגות חופש.
שמה שמבחין ביניהן הוא הסדר של ערכי דרגות החופש )כלומר, Fזהו הקשר בין שתי התפלגויות
אם דרגות החופש של המונה יהיו אלה שבמכנה ולהפך(:
כלומר, אם במקרה חילקנו כך שהאומד הנמוך היה במונה )בטעות(, נוכל להמיר את התוצאה
הנכון. Fלחלק לתוצאה שקיבלנו( ולדעת מה ה 1עות נוסחת ההיפוך הזו )באמצ
שליליים שיאזנו את החיוביים הקיצוניים )שהרי אין F, כי אין ציוני 1-גבוהה מעט מ Fהתוחלת של
פש של המכנה, חלקי דרגות החופש של המכנה היא דרגות החו Fשונויות שליליות(. התוחלת של
:2פחות
הוא מעט יותר F-זה אומר שתחת השערת האפס, כלומר השערת שוויון שונויות, אנחנו מניחים ש
.1-גדול מ
:Fדוגמה למבחן
נניח שאנו בוחנים האם אנשים בעלי ציון גבוה במדד רצייה חברתית מתאפיינים בשונות נמוכה יותר
H0: 𝜎1מאשר אנשים בעלי ציון נמוך. כלומר, = 𝜎2 תמיד ב(F .)נתעסק בהשערות דו זנביות
נניח שיצאו לנו במדגם התוצאות הבאות:
𝑆12=18
𝑁1 = 37
𝑆22 = 6
𝑁2 = 25
האומדנים לשונויות:נחשב את שני
),(2
2
2
1
21~
ˆ
ˆ
dfdfFS
S
),,2
(
),,2
1(
21
12
1
vv
vv FF
2)(
2
2
v
vFE
2
1
2
11
ˆ Sn
nS
2
2
2
21
ˆ Sn
nS

S12=
n
n − 1∗ S1
2 = 18.5
S22=
n
n − 1∗ S2
2 = 6.25
S12
S22 =
18.5
6.25= הקריטי. F-ערך ה= 3.5
F(24,26) = 1.8
, ולכן אנחנו דוחים את השערת האפס.3.5קטן מהערך הקריטי 1.8
גורמי-ב. ניתוח שונות חד
ניתוח שונויות משמש אותנו למקרה בו המחקר כולל יותר משתי קבוצות ניסוי. השאלה האופיינית
היא לגבי השפעה של כמה רמות של משתנה בלתי תלוי, המשתנה התלוי.
השאלה העומדת למבחן בבדיקה הזו היא האם קיים הבדל מובהק בין הממוצעים שהתקבלו בניסוי,
אותה אוכלוסיה ואין לייחס את ההבדלים ביניהם לתנאים השונים של או שסביר שהממוצעים נדגמו מ
תלוי.-המשתנה הבלתי
יש שני מודלים לניתוח שונות:
החוקר קובע מראש את הרמות השונות של המתנה הבלתי - Fixed effect –האפקט הקבוע .1
פלקציה תלוי שמעניינות אותו, ומשווה בין הממוצעים של הקבוצות. אם החוקר ירצה לבצע ר
על הניסוי הזה, הוא יחזור בדיוק על אותן ארבע רמות וידגום נבדקים חדשים. לכן המודל
קבוע. המסקנות שהחוקר יכול להסיק נוגעות אך ורק לרמות הספציפיות של המשתנה
תלוי שאותן הוא בחר. הוא לא יכול להסיק מסקנה כללית על המשתנה הבלתי תלוי.-הבלתי
יש לחוקר השערה כללית על אפשרות השפעת – Random effect –אפקט רנדומאלי .2
משתנה בלתי תלוי מסוים על המשתנה התלוי. ההשערה שלו לא נוגעת לרמות ספציפיות
של המשתנה הבלתי תלוי. החוקר יבחר רנדומאלית את הרמות השונות של המשתנה
נות למשתנה. הבלתי תלוי. אם הוא ירצה לחזור על הניסוי בשנית, הוא יבחר רמות שו
מסקנתו תהיה הרבה יותר כללית, ולא תתייחס לתנאי ניסוי ספציפי, אלא להשפעתו הכללית
של המשתנה הבלתי תלוי )במצב זה לא נטפל השנה(.
. במודל הקבוע, אנחנו מגדירים שסך כל האפקט הוא Iושל הנבדק הוא Jהאינדקס של הקבוצה הוא
אפס, כי דגמנו את כל האוכלוסיות הרלוונטיות, והתוחלת שלהן היא ממוצע התוחלות.
במודל הרנדומאלי לא דגמנו את כל האוכלוסיות, ולכן לא נכון שסך כל האפקט הוא אפס. גם דרגות
כלוסיות ידוע. החופש משתנות, כי לא ניתן להביא בחשבון שמספר האו
הסטייה של ציון כלשהו מהממוצע הכללי היא הסטייה של הציון מממוצע הקבוצה שלו, בתוספת
.יה של הקבוצה מהממוצע הכללייהסט
סטיית הציון מממוצע הקבוצה שלו משקפת את כל מה שלא קשור לטיפול ולא נוצר בזכות האפקט,
בוצה מהממוצע הכללי משקפת את האפקט הטיפולי. ואילו סטיית ממוצע הק
01
k
j
j
)()( ,, xxxxxx jjjiji

בניתוח שונויות, למרות שהוא ניתוח שונויות, אנחנו משערים השערה על התוחלות. אנחנו בוחנים את
-השונות הטעותית שהיא בין –ההשערה על התוחלות, באמצעות פירוק של השונות לשני רכיבים
אישית, והשונות הטיפולית שנובעת מהאפקט.
( SSBתוח שונות משתמשים בשני אומדים לשונות האוכלוסיה: אומד לשונות בין קבוצות הטיפול )בני
(. שני האומדנים הללו בלתי תלויים. SSWואומד לשונות בתוך קבוצות הטיפול )
אם השערת האפס נכונה, למעשה לקחנו את כל התצפיות ממדגם אחד. ואז יש לנו שני סוגי אומדנים
ות )שונות האוכלוסיה, שהיא אחת, משום שבמצב כזה אין הבדל בין השונות בין שונים לאותה שונ
הקבוצות לבין השונות בתוך הקבוצות(. במקרה כזה, נצפה שהאומדנים יהיו דומים אחד לשני. אנחנו
מספקת לנו את Fיגדל. ההתפלגות F-. אם הם שונים, יחס הFגם יודעים שאז היחס ביניהם מתפלג
תברות שיחס מסוים בין שני האומדנים הללו נלקח מאותה אוכלוסיה. המידע מה ההס
כלומר, סכום ריבועי הסטיות מורכב מהסטיות בתוך הקבוצות )הסטיות של הנבדקים מהקבוצה
שלהם( ומהסטיות בין הקבוצות )הסטיות של הקבוצות מהממוצע הכללי(:
ממוצע ריבועים:
ים הם ריבועי הסטיות, כפי שהסברנו. אותם אנחנו מחלקים בדרגות החופש, ומה שאנחנו SS-ה
(. Mean squaresמקבלים הוא ממוצע ריבועי הסטיות )
אם השערת האפס נכונה, ואין לטיפול אפקט, נצפה כי כל השונות במערך תהיה השונות הטעותית
)שהרי השונות הטיפולית אפסית(: 22 e נדגיש כי בכל מקרה, ללא קשר לנכונות השערת .
. כלומר, בין אם השערת האפס נכונה ובין אם היא היא השונות הטעותית MSWהאפס, התוחלת של
שגויה, הסטיות של הנבדקים בתוך אותה קבוצה נובעות רק מהשונות הטעותית:
גויה. לגבי השונות הטיפולית, צריך להבחין בין מצב עובדתי שהשערת האפס נכונה לבין מצב שהיא ש
אם השערת האפס נכונה, אז הסטיות של הקבוצות מהממוצע הכללי מורכבות רק מהשונות
הטעותית, ואז התוחלת של סטיות הקבוצות מהממוצע הכללי שווה לתוחלת סטיות הנבדקים ממוצעי
היא: MSBהקבוצות. במצב כזה התוחלת של
1
k
SSB
df
SSBMSB
B
kN
SSW
df
SSWMSW
W
2)( eMSWE
22)( eMSBE

MSWלא שווה לתוחלת של MSBלעומת זאת, אם יש אפקט והשערת האפס שגויה, אז התוחלת של
ולשונות הטעותית אלא גדולה ממנה. זאת, משום שאם יש אפקט טיפולי, אז הסטיות של הקבוצות
מהממוצע הכללי כוללות גם את השונות הטעותית וגם את השונות הטיפולית. במצב כזה, התוחלת
:היא MSBשל
, אנחנו שואלים מה ההסתברות לפער כזה תחת MSW-גדול מאוד ביחס ל MSBכשאנחנו מקבלים
נמוך, נטען שכנראה אלה אומדנים לאותה שונות. Fהנחת נכונותה של השערת האפס. אם
גורמי-דוגמה לניתוח שונות חד
רוצה לבדוק את השפעת סוגי מוזיקה על מצב הרוח נניח שחוקר
מספר נבדק (1לאונרד כהן ) (2ויטני יוסטון ) (3בוב מארלי )
8 3 7 1
9 10 5 2
12 14 6 3
13 8 4 4
10 5 3 5
8 14 6
9 7
��1=5 𝑛1 = 5 K =3
��2=9 𝑛2 = 7 N=18
��3=10 𝑛3 = 6 X=8.22
השערות:
HO: 𝜇1 = 𝜇2 = 𝜇3 = 𝜇
H1: Ho
הנחות:
דגימה מקרית ובלתי תלויה בין הקבוצות
Xi,j )מתפלג נורמלי )התפלגות האוכלוסיה
השוניות בתוך כל קבוצה שוות זו לזו
:0Hסטטיסטי המבחן והתפלגותו תחת
𝑀𝑆𝐵
𝑀𝑆𝑊~𝑓((𝑘−1),(𝑛−𝑘))
F :קריטי
F(2,15) = 3.68
ביצוע המבחן:
SST - :הסכום הכללי של ריבועי הסטיות של כל תצפית מהממוצע הכללי
(7 − 8.22) 2+ …. + (3 − 8.22)2 … = (8-8.22) = 211.11
2
1
2
2
1)(
k
j
jj
ek
nMSBE

SSW – סכום ריבועי הסטיות בתוך הקבוצות. עבור כל אחת מהתצפיות מחסירים את הממוצע של
הקבוצה ומעלים בריבוע:
(7 − 5)2… + (3 − 9)2+ …. (8 − 10)2 = 136
SSB – ריבועי הסטיות בין הקבוצות:סכום
5(5 − 8.22)2 + 7(9 − 8.22)2 + 6(10 − 8.22)2 = 75.11
מחסירים מהממוצע של הקבוצה את הממוצע הכללי של כל המערך ומעלים בריבוע, ומכפילים
במספר הנבדקים שיש בכל קבוצה.
MSW - :אומד בלתי מוטהMSW = 𝑆𝑆𝑊
𝑁−𝐾=
136
15= 9.067
MSB - :ממוצע ריבועים בין הקבוצותMSB = 𝑆𝑆𝐵
𝐾−1=
75.11
2= 37.55
F = 37.55
9.067= 4.14
מסקנה:
.H0, ניתן לדחות את השערת 0.05ברמת מובהקות של
הוק -השוואות מתוכננות והשוואות פוסט
קונטרסטים –א. השוואות מתוכננות
, רק T, במצב בו היו לחוקר השערות אפריוריות, ממש כמו במבחני Fהטכניקה הזו באה במקום מבחן
ונעשית לאחר שכבר התקבלו תוצאות Fעל יותר משתי קבוצות. זו לא טכניקה שמשלימה את מבחן
ניתוח השונות.
אנחנו יוצרים משתנה חדש שהוא קומבינציה לינארית של כל האוכלוסיות. התוחלת של המשתנה
החדש תהיה סכום התוחלות של האוכלוסיות, והשונות של המשתנה החדש תהיה סכום השונויות של
הלינארית: האוכלוסיות, כשכל אחת מהן מוכפלת במשקל שלה בקומבינציה
כל השוואה מתוכננת ניתן לייצג באמצעות קומבינציה כזו, שהיא הקונטרסט.
הסטטיסטי של הקונטרסט הוא אומד בלתי מוטה אליו:
זוהי שונות התפלגות הדגימה של האומד הבלתי מוטה לקונטרסט:
)(.....)()()()( 332211 nn xECxECxECxECyE
222
3
2
3
2
2
2
2
2
1
2
1
2 ..... nny CCCC
k
j
jjkk CCCCC1
332211 .....
k
j
jjkk xCxCxCxCxC1
332211 .....ˆ
k
j j
j
n
C
1
2
22
ˆ

כאשר השונות ידועה, ניתן לומר כי האומד הבלתי מוטה לקונטרסט מתפלג כך:
הוא האומד הבלתי MSW-וכאשר השונות אינה ידועה, אנחנו יודעים שהיא השונות הטעותית וש
מוטה לה. ולכן הסטטיסטי מתפלג כך:
קסטים השונים. אחרת, טעות מסוג ראשון משתנה תלות סטטיסטית בין הקונטר-יש להקפיד על אי
תלות מתקיימת כאשר סכום מכפלות המשקולות בין -ולא נוכל להעריך אותה. אי 0.05והיא כבר לא
הקונטרסטים שווה לאפס:
הבלתי קבוצות הוא , כאשר מתוכן מספר ההשוואות Kמספר ההשוואות שייתכנו בין כל
.K-1שייתכנו הוא תלויות
תשומת לב לכך שמספר ההשוואות הבלתי תלויות שייתכנו הוא זהה למספר דרגות החופש של
MSB.
לבין קונטרסטים. הסיבה היא Tגם כשיש השוואה רק בין שתי קבוצות, יש הבדל בין מבחן
האומד לשונות טוב יותר כי הוא מבוסס על כל הקבוצות, אבל זה לא מחייב. יתכן שבקונטרסטים
t-שאני משתמשת בקונטקסטים של ארבע קבוצות ואחת רחוקה משמעותית מהאחרות, ואז דווקא ב
אני אקבל אומד אמין יותר כביכול. זה עניין הסתברותי.
, כי אנחנו Tותר מאשר במבחן הבדל נוסף הוא שדרגות החופש במבחן קונטרסטים גבוהות י
מתייחסים לכלל התצפיות.
משקלל F-מובהק בניתוח שונויות בהכרח. ה Fהעובדה שיצא קונטרסט מובהק אינה אומרת שיהיה
את ההבדלים בין כל הקבוצות, שיכולים "לדלל" את האפקט שנמצא בקונטרסט כך שהוא לא ייצא
מובהק.
דוגמה למבחן השוואות מתוכננות
וצה לבדוק את השפעת מי ההשקיה על צמיחת הפרחים. הוא רוצה לבדוק האם מי ברז מעודדים גנן ר
פחות גדילה בהשוואה לשאר סוגי המים.
J 5קבוצה 4קבוצה 3קבוצה 2קבוצה 1קבוצה
מי ברז )ביקורת(
)מים (4)תמי )נביעות( )מי עדן( מורתחים(
10 12 11 15 9 N
50 65 68 80 59 X
N = 57 ;K = 5 ;MSW = 28
א. השערות:
Ψ = 4 ∗ 𝜇1 − (𝜇2 + 𝜇3 + 𝜇4 + 𝜇5) = 𝜇1 −(𝜇2 + 𝜇3 + 𝜇4 + 𝜇5)
4
H𝑜: 𝛹 ≥ 0
),(~ˆ
1
2
2
k
j j
j
n
CN
KNk
j j
j
t
n
CMSW
~
ˆ
1
2
0.....)2()1()2(
2
)1(
2
)2(
1
)1(
1
1
)2()1(
kk
k
j
jj CCCCCCCC
2
)1( kk

H1: 𝛹 < 0
ב. הנחות
אי תלות בין הקבוצות
שוויון שונויות
התפלגות אוכלוסיה נורמלית
דגימה מקרית ובלתי תלויה של תצפיות
ג. סטטיסטי המבחן והתפלגותו:
𝑡(𝑁−𝐾)~Ψ − Ψ
√𝑀𝑆𝑊 ∗ ∑ (𝐶𝑗
2
𝑛𝑗)𝑘
𝑗=1
ד. רמת מובהקות וערכים קריטיים:
α=0.05
N-K = 57-5=52
T(52)=-1.675
ה. ביצוע המבחן:
:t-שלבי ביניים אותם נציב ב
(:59 ,80 ,68 ,65 ,50נחליף את התוחלות בממוצעי הקבוצות )שהם Ψ)שלב ביניים א':( למציאת
Ψ = 4 ∗ X1 − (X2 + X3 + X4 + X5) = −72
.Cj/Nj)שלב ביניים ב':( נחשב את
∑(𝐶𝑗
2
𝑛𝑗)
𝑘
𝑗=1
=42
10+−12
12+−12
11+−12
15+−12
9= 1.95
שנתון בשאלה(: MSW)תוך שאנו נעזרים בערך t-כעת נציב ב
𝑡 =−72
√28 ∗ 1.95= −9.74
ה. מסקנה:
, השערת האפס נדחית.0.05ברמת מובהקות של
ב. השוואות פוסט הוק
מובהק, החוקר Fבמקרים רבים החוקר לא מגיע למחקר עם השערות ספציפיות. רק אחרי קבלת
יחפש השערות ספציפיות. טכניקת השוואות פוסט הוק לא מחליפה ניתוח שונות, אלא משלימה אותו.

עקרונית, לא יכול להיות שנקבל הבדל בפוסט הוק, בלי שמצאנו הבדל בניתוח שונות )יש לזה חריגים
ממש יוצאי דופן, לא נתייחס אליהם(.
אם קודם היו השערות אפריוריות שאמורות להיות בלתי תלויות, שבהתאם אליהן מתקבלים הבדלים;
אז כאן קודם יורים את החץ ואז מסמנים את המטרה.
הבעיה היא שיש חשש שניצור ניפוח אלפא, כלומר הגדלה של הטעות מסוג ראשון כך שהסיכוי לה
. זה או קורה במצב של תלות בין הקבוצות, או במקרה בו החוקר מנסח את 0.05וה מיהיה גב
ההשערות לאחר צפייה בנתונים.
כדי להתגבר על המצב בו תיתכן אלפא שהיא גדולה יותר, אנחנו מחמירים את קריטריון הדחייה.
י קבוצות , שמסמן את ההפרש המינימלי בין ממוצעי שתHSDאנחנו משתמשים בחישוב ערך של
על אף ההחמרה, H0הדרוש כדי שיהיה ניתן לקבוע הבדל ביניהן. אם אנחנו מצליחים לדחות את
מקרי. -אנחנו יכולים לומר שההבדל הוא מספיק מחמיר כדי להיות לא
המחיר של המבחן הזה הוא שהוא מגדיל את הסיכוי לטעות מסוג שני. יכול להיות שיש אפקט, אבל
אנחנו לא מצליחים למצוא אותו. זהו המחיר שאנו נאלצים לשלם כשאנחנו שבגלל המבחן המחמיר
מנסחים השערה לאחר שצפינו בנתונים.
ההשערות שייתכנו, כדי לא לשלם את המחיר כלאת מראשניתן לתהות מדוע לא עדיף לחוקר לשער
ער המון של השערה לאחר צפייה בנתונים, ולא להקטין את עוצמת המבחן. התשובה היא שאם נש
, 0.05-של המחקר כולו( תהיה הרבה יותר גדולה מ α-המצטברת שלהן )כלומר ה α-השערות, ה
שזה מחיר עוד יותר גרוע לשלם. הפתרון התיאורטי לזה הוא שאכן נשער מראש את כל ההשערות,
, אלא 0.05אבל האלפא שנקבע להן לא תהיה 0.05
מספר ההשערות. כך האלפא המצטברת שלהן תישאר
ולא תגדל )אנחנו לא הולכים להשתמש בזה(. 0.05
ההשוואות האפשריות. זו אלפא גלובלית עבור כל כלמתייחסת ל TUKEYחשוב לציין שאלפא במבחני
ההשוואות הזוגיות האפשריות בתוך המערך, ולא לגבי השוואה ספציפית. ככל שמספר ההשוואות
. זה לא קשור H0יתה קטן הסיכוי לדחות את גדל, וכך אלפא קטנה וא HSDהאפשריות הולך וגדל,
למספר ההשוואות שהחוקר מעוניין לבצע.
, טבלה המסמנת ערך קריטי מסוים. ככל שמספר zו t, שהיא כמו טבלת qאנחנו משתמשים בטבלת
עולה, וקשה יותר HSDהקבוצות עולה, הערך הקריטי הולך ועולה. אם הערך הקריטי הולך ועולה,
כמובן קשור למספר ההשוואות( לבין לדחות את השערת האפס. זהו הקשר בין מספר הקבוצות )ש
ולבין קושי הדחייה. qערך
הוא: HSDכשהקבוצות שוות בגודלן,
.q הוא סטטיסטי שנלקח מהתפלגות שלא נגזרת מהתפלגות דגימה של ממוצעים, אלא מהשוואות
של כמה ממוצעים.
זוג בנפרד, לפי זה:-שווים, אי אפשר להשוות סימולטנית אלא צריך להשוות זוג ים לאN-כשה
דוגמה למבחן טוקי
j
KNKn
MSWqHSD ),(
)11
(2 21
),(nn
MSWqHSD KNK
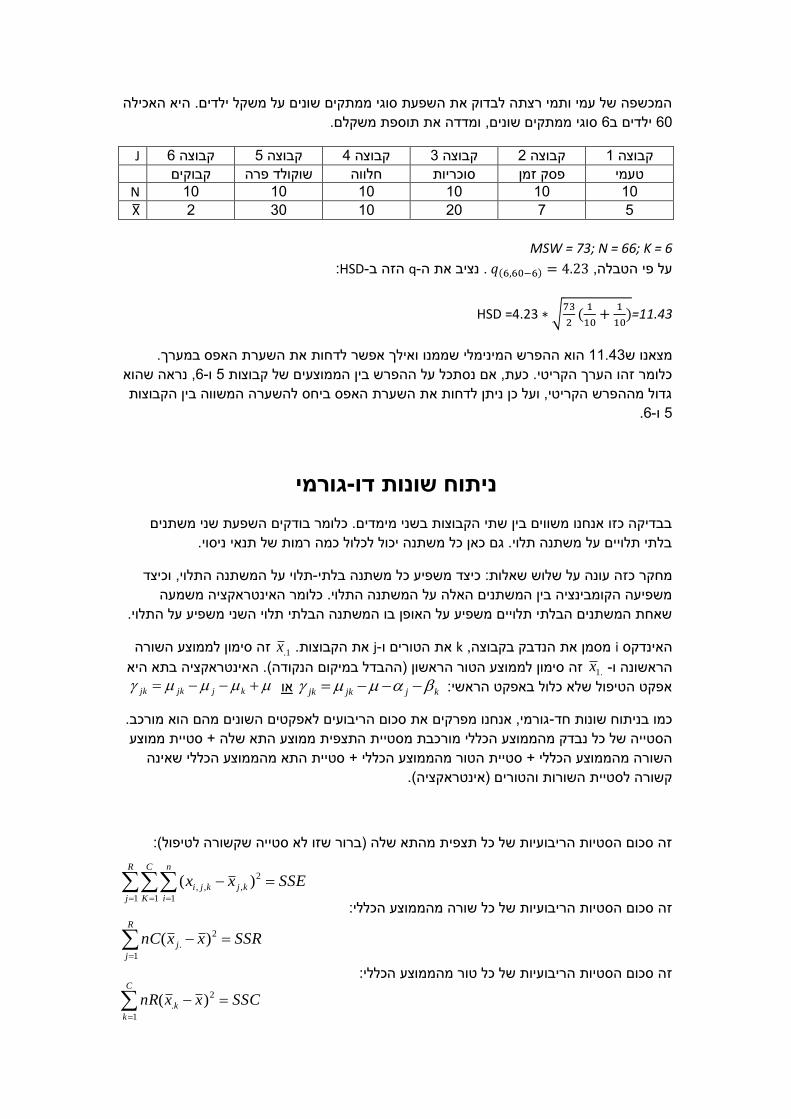
המכשפה של עמי ותמי רצתה לבדוק את השפעת סוגי ממתקים שונים על משקל ילדים. היא האכילה
סוגי ממתקים שונים, ומדדה את תוספת משקלם. 6ילדים ב 60
J 6קבוצה 5קבוצה 4 קבוצה 3קבוצה 2קבוצה 1קבוצה
קבוקים שוקולד פרה חלווה סוכריות פסק זמן טעמי
10 10 10 10 10 10 N
5 7 20 10 30 2 X
MSW = 73; N = 66; K = 6
𝑞(6,60−6) על פי הטבלה, = :HSD-הזה ב q-. נציב את ה4.23
HSD =4.23 ∗ √73
2(1
10+
1
10)=11.43
ואילך אפשר לדחות את השערת האפס במערך. הוא ההפרש המינימלי שממנו 11.43מצאנו ש
, נראה שהוא 6-ו 5כלומר זהו הערך הקריטי. כעת, אם נסתכל על ההפרש בין הממוצעים של קבוצות
גדול מההפרש הקריטי, ועל כן ניתן לדחות את השערת האפס ביחס להשערה המשווה בין הקבוצות
.6-ו 5
גורמי-ניתוח שונות דו
בבדיקה כזו אנחנו משווים בין שתי הקבוצות בשני מימדים. כלומר בודקים השפעת שני משתנים
בלתי תלויים על משתנה תלוי. גם כאן כל משתנה יכול לכלול כמה רמות של תנאי ניסוי.
תלוי על המשתנה התלוי, וכיצד -משפיע כל משתנה בלתימחקר כזה עונה על שלוש שאלות: כיצד
משפיעה הקומבינציה בין המשתנים האלה על המשתנה התלוי. כלומר האינטראקציה משמעה
שאחת המשתנים הבלתי תלויים משפיע על האופן בו המשתנה הבלתי תלוי השני משפיע על התלוי.
את הקבוצות. זה סימון לממוצע השורה j-את הטורים ו kמסמן את הנדבק בקבוצה, iהאינדקס
ינטראקציה בתא היא זה סימון לממוצע הטור הראשון )ההבדל במיקום הנקודה(. הא -הראשונה ו
אואפקט הטיפול שלא כלול באפקט הראשי:
גורמי, אנחנו מפרקים את סכום הריבועים לאפקטים השונים מהם הוא מורכב. -כמו בניתוח שונות חד
מוצע סטיית מ +שלה ת התצפית ממוצע התאיסטיהסטייה של כל נבדק מהממוצע הכללי מורכבת מ
סטיית התא מהממוצע הכללי שאינה + סטיית הטור מהממוצע הכללי + השורה מהממוצע הכללי
. )אינטראקציה( קשורה לסטיית השורות והטורים
זה סכום הסטיות הריבועיות של כל תצפית מהתא שלה )ברור שזו לא סטייה שקשורה לטיפול(:
זה סכום הסטיות הריבועיות של כל שורה מהממוצע הכללי:
זה סכום הסטיות הריבועיות של כל טור מהממוצע הכללי:
1.x
.1x
kjjkjk kjjkjk
SSExxR
j
C
K
n
i
kjkji 1 1 1
2
,,, )(
SSRxxnCR
j
j 1
2
. )(
SSCxxnRC
k
k 1
2
. )(

זה סכום הסטיות של כל תא מהממוצע הכללי, שלא קשור לאפקטי הטורים והשורות:
(, אנחנו צריכים לחלק כל אחד מריבועי mean squaresכדי לקבל אומדנים בלתי מוטים לשונות )
הסטיות האלה לדרגות החופש שלנו.
ים מביאות בחשבון את סכום האפקטים ואת השונות הטעותית:MS-התוחלות של כל אחד מה
הם שני אומדנים בלתי מוטים לאותה שונות, בגלל שהם לקוחים MSE-ו MSRתחת השערת האפס,
F-מאותה אוכלוסיה )כי אין אפקט וכל השונות היא השונות הטעותית(. לכן, ניתן לחשב את ערך ה
ליחס בין שניהם:
:MSE-ו MSCכנ"ל לגבי
כלומר, אנחנו יכולים בקלות לבחון את השערת האפס לגבי אפקטי הטורים והשורות.
לגבי אפקט האינטראקציה, זה ממוצע ריבועי הסטיות שלו:
ונות תלוי נוסף לאוכלוסיה שמורכב רק מהש-גם כאן, תחת השערת האפס מדובר באומדן בלתי
בינו לבין השונות הטעותית: F-הטעותית, ולכן אפשר לחשב את יחס ה
גורמי-דוגמה לניתוח שונות דו
יסודי תיכון אונ'
6 11 10 9 (10)
7 4 1 (4)
5 4 3 (4)
גברים
10 12 13 17 (14)
7 6 5 (6)
12 10 8 (10)
נשים
SSIntxxxxnR
j
C
k
kjkj 1 1
2
.., )(
)1(
nCR
SSEMSE
1
R
SSRMSR
`1
C
SSCMSC
2)( eMSEE
1)(
1
2
2
R
C
MSRE
R
j
j
e
1)( 1
2
2
C
R
MSCE
C
k
k
e
0( )
( 1),( )~RH
R N RC
MSRF
MSE
0( )
( 1),( )~CH
C N RC
MSCF
MSE
)1)(1(
int
CR
SSMSInt
0( )
(( 1) ( 1),( )~IntH
C R N RC
MSIntF
MSE

8 12 5 7
השערות:
𝐻0(𝑅): 𝜇1 = 𝜇2 = 𝜇
𝐻1(𝑅): Ho
𝐻0(𝐶): 𝜇1 = 𝜇2 = 𝜇3 = 𝜇
𝐻1(𝐶): Ho
𝐻0(𝑖𝑛𝑡) אינטראקציה: אין אפקט
𝐻1(𝑖𝑛𝑡) אינטראקציה: יש אפקט
הנחות:
דגימה מקרית ובלתי תלויה של התצפיות
התפלגות האוכלוסיה נורמלית
השוניות הומוגניות בין התאים
אין תלות בין התאים
:0Hסטטיסטי המבחן והתפלגותו תחת
𝑀𝑆𝑅
𝑀𝑆𝐸~𝑓((𝑅−1),(𝑛−𝑅𝐶))
𝑀𝑆𝐶
𝑀𝑆𝐸~𝑓((𝐶−1),(𝑁−𝑅𝐶))
𝑀𝑆𝑖𝑛𝑡
𝑀𝑆𝐸~𝑓((𝑅−1)(𝐶−1),(𝑁−𝑅𝐶))
F :קריטי
F(1,12) = 4.75הראשון .1
F(2,12) = 3.89השני .2
F(2,12) = 3.89השלישי .3
ביצוע המבחן:
SSR : ]=72(10 − 8)2+[(6 − 8)2SSR = 3*3*
MSR: =72
2−1= 72MSR
SSC: אחסיר מכל אחד מממוצעי הטורים את ממוצע המערך, ואכפיל במספר השורות כפול מספר
SSC = 3*2*[(7 התצפיות בכל תא. − 8)2+(5 − 8)2 + (12 − 8)2]=156
MSC: 𝑀𝑆𝐶 =156
3−1= 78
SSint: ]=12(14 − 10 − 12 + 8)2+…+ (4 − 6 − 7 + 8)2SSint=3*[
SintMS: 12
(3−1)(2−1)= 6MSint =

SSE: .זו בעצם החסרה של כל תצפית ותצפית ממוצע התא שלה והעלאתה בריבוע
(3 − 4)2 +…(17 − 13)2=46
MSE: 𝑆𝑆𝐸
𝑁−𝑅∗𝐶=
46
18−2∗3= 3.83MSE =
18.78ראשון יוצא ה .1
20.35השני יוצא .2
-1.57השלישי יוצא .3
מסקנה:
לגבי גורם השורות. H0, ניתן לדחות את השערת 0.05ברמת מובהקות של .1
לגבי גורם הטורים. H0, ניתן לדחות את השערת 0.05ברמת מובהקות של .2
לגבי אפקט האינטראקציה. H0, לא ניתן לדחות את השערת 0.05ברמת מובהקות של .3
כלומר, לא ניתן לומר כי האפקט של המגדר על כמות המסתכלים בראי תלוי בגיל הנבדק
היא סימטרית(. האינטראקציה)אפשר לנסח את המסקנה הזו גם הפוך, כי
רגרסיה ומתאם, ניבוי, רגרסיה מרובה
ככל שיש קשר לינארי חזק יותר בין שני משתנים, דיאגרמת הפיזור שלהם תתכנס לקו ישר. לקשר
לינארי יש מדד של כיוון )חיובי או שלילי( ומדד של עוצמה. מקדם המתאם של פירסון הוא המדד
ציוני התקן של התצפיות:לבחינת קשר לינארי. מדובר בעצם בממוצע מכפלות
. Y-מתואמת עם ההשתנות ב X-( עולה ככל שההשתנות בcovההשתנות המשותפת של משתנים )
ההשתנות המשותפת גדלה כאשר הסטיות מהממוצע של שני המשתנים גדולות, ובאותו כיוון:
( אנחנו שואלים מהי הנוסחה הלינארית שמבטאת בצורה המיטבית את 1-/ 1כאשר אין מתאם מלא )
Y-הקשר בין המשתנים. הנוסחה המיטבית היא זו שתמזער את סך ריבועי הסטיות מהקו. ערך ה
. המנובא הוא ואנחנו רוצים למזער את ריבועי הסטיות
.b=rוכאשר a=oתמזער את ריבועי הסטיות מהקו, כאשר המשוואה הלינארית
א. רגרסיה בציוני תקן
במקדם המתאם Xהוא להכפיל את ציון התקן של -, הניבוי הטוב ביותר ל אם נתון לנו
:r-, כלומר בY-ו Xהלינארי בין
, והשונות שלהם תהיה . חשוב לשים לב שאפילו 0הממוצע של אותם ציונים מנובאים יהיה
שלציוני תקן יש תכונות אופייניות, זה לא התכונות של שהם ציוני התקן המנובאים ולא הם עצמם.
n
ZZr ii yx
xy
n
yyxxyx ii ))((),cov(
yxSS
yx ),cov(
iy~iy
iy ~
ixyi
ixyi
ZyrxZ
ZxryZ
~
~
abxy ii ~
iZxiZy
2
xyr
yZ~

)כמו של ציוני התקן עצמם( רק כאשר יש מתאם מלא, 1השונות של ציוני התקן המנובאים אכן תהיה
.r = 1 / -1כלומר
. ממוצע ציוני הטעות )כלומר ההפרשים בין ציון התקן המקורי לבין המנובא( הוא
. שונות ציוני הטעות )ההפרשים בין ציון התקן המקורי לבין המנובא( היא
מתקבל ש:
ב. רגרסיה בציוני גלם
רים אלא על ניבוי. המתאם כשאנחנו מדברים על רגרסיה, בניגוד למתאם, אנחנו מדברים לא על קש
. נדגיש שהניבוי הוא לא בהכרח על תצפיות שאין בידינו, Xעבור משתנה Yעצמו אינו יכול לנבא ציון
אלא גם על תצפיות שיש לנו. אם אין קשר בין המשתנים, הניבוי הכי טוב שנוכל לתת הוא הממוצע
. Yשל ערכי
𝒃משוואת הניבוי היא: , כאשר = 𝑟𝑥.𝑦 ∗𝑆𝑦
𝑆𝑥𝒂 -ו = �� − 𝑏��
דוגמה לחישוב משוואת ניבוי בציוני גלם
נתון מחקר שבודק את מספר העמודים שסטודנט סיכם בשנה לבין ציונו הסופי בקורס.
Yציון Xעמודים נבדק
1 8 100
2 10 90
3 6 80
4 2 70
5 4 70
x=6 y=82
𝑆𝑥2=8 𝑆𝑦
2=136
ההשתנות המשותפת היא:
(8−6)(100−82)+(10−6)(90−82)+(6−6)(80−82)+(2−6)(70−82)+(4−6)(70−82)
5=
140
5= 28=
והמתאם הוא:
=28
√8∗√136 =0.85
השיפוע של משוואת הניבוי הוא:
)~
(2
ii yZZyS 21 r
xyr
n
yyxxyx ii ))((),cov(
yxSS
yx ),cov(
abxy ii ~
0~
ii yZZy
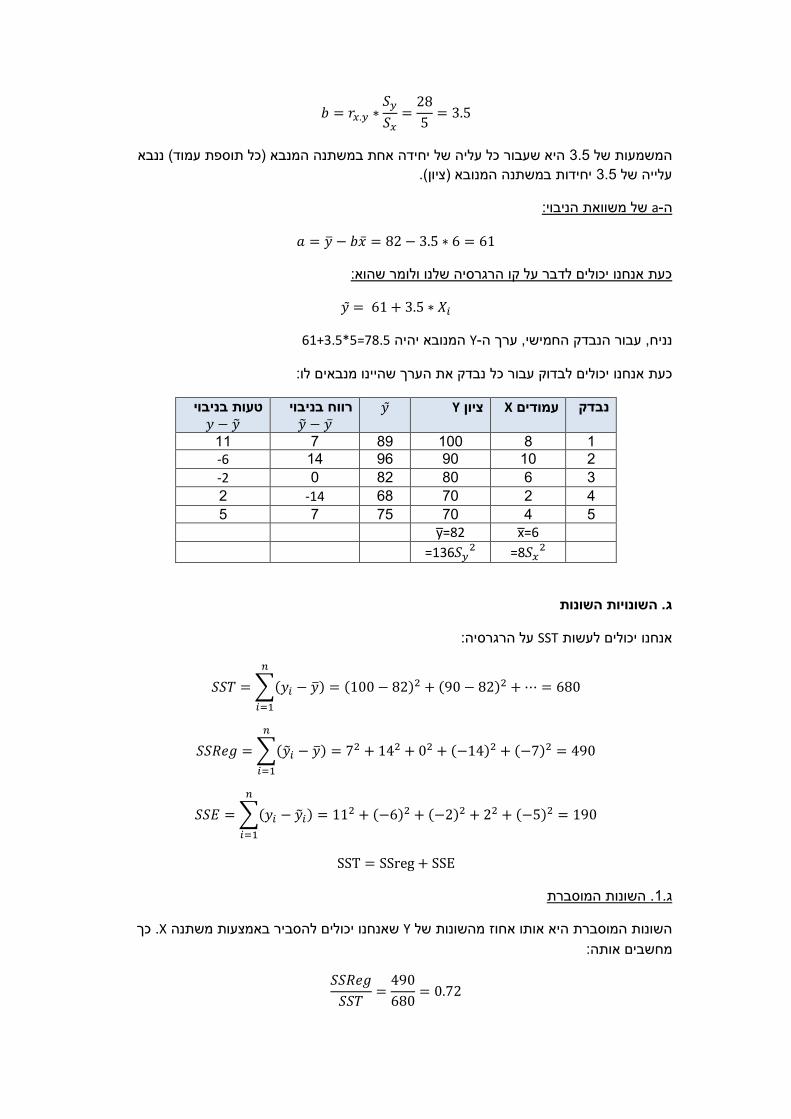
𝑏 = 𝑟𝑥.𝑦 ∗𝑆𝑦
𝑆𝑥=28
5= 3.5
עמוד( ננבא היא שעבור כל עליה של יחידה אחת במשתנה המנבא )כל תוספת 3.5המשמעות של
יחידות במשתנה המנובא )ציון(. 3.5עלייה של
של משוואת הניבוי: a-ה
𝑎 = �� − 𝑏�� = 82 − 3.5 ∗ 6 = 61
כעת אנחנו יכולים לדבר על קו הרגרסיה שלנו ולומר שהוא:
𝑦 = 61 + 3.5 ∗ 𝑋𝑖
78.5=5*61+3.5המנובא יהיה Y-נניח, עבור הנבדק החמישי, ערך ה
ל נבדק את הערך שהיינו מנבאים לו:כעת אנחנו יכולים לבדוק עבור כ
רווח בניבוי Y 𝑦ציון Xעמודים נבדק
�� − �� טעות בניבוי
𝑦 − ��
1 8 100 89 7 11
2 10 90 96 14 -6 3 6 80 82 0 -2
4 2 70 68 -14 2
5 4 70 75 7 5
x=6 y=82 𝑆𝑥
2=8 𝑆𝑦2=136
ג. השונויות השונות
על הרגרסיה: SSTאנחנו יכולים לעשות
𝑆𝑆𝑇 =∑(𝑦𝑖 − ��) = (100 − 82)2 + (90 − 82)2 +⋯ = 680
𝑛
𝑖=1
𝑆𝑆𝑅𝑒𝑔 =∑(��𝑖 − ��) = 72 + 142 + 02 + (−14)2 + (−7)2 = 490
𝑛
𝑖=1
𝑆𝑆𝐸 =∑(𝑦𝑖 − ��𝑖) = 112 + (−6)2 + (−2)2 + 22 + (−5)2 = 190
𝑛
𝑖=1
SST = SSreg + SSE
. השונות המוסברת1ג.
. כך Xשאנחנו יכולים להסביר באמצעות משתנה Yהשונות המוסברת היא אותו אחוז מהשונות של
מחשבים אותה:
𝑆𝑆𝑅𝑒𝑔
𝑆𝑆𝑇=490
680= 0.72

𝑅2 = 0.852 = 0.72
כשנתונים ציוני הגלם, אז המתאם בריבוע מבטא את פרופורציית שונות הניבויים מתוך השונות
האמיתית. כלומר כמה מהשונות מוסברת ע"י המשתנה המסביר. קשר מושלם משמעו שכל השונות
.Xמוסברת ע"י המשתנה Yשל המשתנה
ע ד. רגרסיה אל הממוצ
(, ממוצע ציוני התקן המנובאים של אחד המשתנים יהיה r≠1כל עוד המתאם בין המשתנים אינו מלא )
(. RTMקטן ממוצע ציוני התקן המקוריים של המשתנה השני. תופעה זו מכונה רגרסיה אל הממוצע )
הרגרסיה אל הממוצע תהיה חזקה יותר ככל שהמתאם חלש.
זה נובע מכך שבהינתן שני משתנים שביניהם מתאם חלקי, בהכרח לציוני תקן גבוהים במשתנה אחד
Yהמנובא יהיה קרוב יותר לממוצע של Yיהיו ציוני תקן נמוכים יותר במשתנה השני, בממוצע. כלומר,
Y-וגם ב X-זה בגלל שלא סביר שהטעות גם ב. Xמסוים מהממוצע של Xבהשוואה לקיצוניות של
תהיה גבוהה מאוד.
גרסיה אל הממוצע, שעלולה לגרום לאשליה של השפעת משתנה ל רחשוב להיות ערים לתופעה ש
בלתי תלוי, למרות שהתופעה הזו היא תולדה מתמטית של קשר חלקי בין שני משתנים.
במבחן מאודנצפה לכך שמי שקיבל ציון קיצוני מבצעים מבחן פעמייםלדוגמה, בכל בדיקה בה
אשון יקבל ציון פחות קיצוני במבחן השני )בממוצע(.הר
פשוט את הממוצע של Y-, כלומר ננבא ל0ציון תקן Y)אין קשר לינארי כלל(, ננבא ל r=0כאשר
ציונים הקרובים Y-נמוך יותר, ננבא ל r-. זו משמעות הרגרסיה אל הממוצע, כלומר ככל שYהמשתנה
יותר אל הממוצע שלו.
ה. רגרסיה מרובה
באמצעות יותר ממשתנה אחד. במקרה כזו: yלעתים נרצה לנבא את
Y1 = 𝑎 + 𝑏1𝑥1 + 𝑏2𝑥2 +⋯
Yמתוך Xו. ניבוי של
שווה בשני המקרים. רק הסימנים של נוסחת הקו משתנים R-, הYמתוך Xאם אני רוצה לנבא את
כשאנחנו מתייחסים לציוני תקן, אבל בציוני גלם זה מסתבך.
Xנוסחת הקו תהיה = b ∗ Y + a
𝒃כאשר =𝑆𝑥
𝑆𝑦∗ 𝑟 ו- 𝐚 = X − by
זהה אבל יש הבדל שמתקבל מההבדל בשונות. R-קווי הניבוי הם שונים, כי אמנם ה
2
~2
2
y
y
S
Sr