


경종민 [email protected] Embedded Processor 의 설계.
41
-
Upload
cassandra-mckenzie -
Category
Documents
-
view
219 -
download
1
Transcript of 경종민 [email protected] Embedded Processor 의 설계.

Contents• Trends in Embedded Processor Design• Design Example of Embedded Processor• Low-power Design for Embedded Processor• Compiler Issues for Embedded Processor• Embedded OS

Trends in Embedded-Microprocessor Design
• What are the Embedded Processor ?• The Embedded Marketplace• What are the Differences Between Desktop and
Embedded Processors ?• Evaluation Parameter for Embedded Processors• The Future of the Embedded Processors
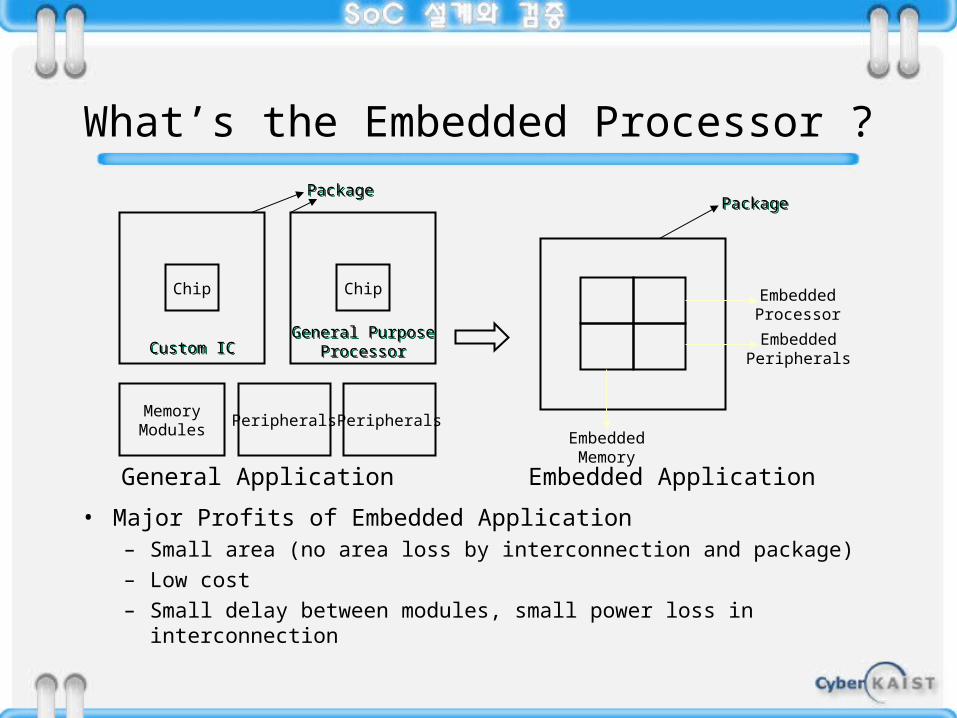
What’s the Embedded Processor ?
• Major Profits of Embedded Application– Small area (no area loss by interconnection and package)
– Low cost
– Small delay between modules, small power loss in interconnection
General Application Embedded Application
Custom ICCustom IC
ChipChip
MemoryModules
Peripherals Peripherals
PackagePackage
General PurposeProcessor
General PurposeProcessor
PackagePackage
EmbeddedProcessor
EmbeddedMemory
EmbeddedPeripherals

The Embedded Marketplace
• Today’s Embedded-processor market– There are more than 100 vendors and two dozen instruction
set architectures
• Architectures for the Embedded Market– Motorola’s 68000 architecture (most successful in 1996)– Intel’s I960, Motorola’s Coldfire, Sun’s Sparc, Intel’s x86– Advanced RISC Machines’ ARM, MIPS Technology’s MIPS
• Selling their architecture to licensees as cores• Manufactured in different versions by various semiconductor co
mpanies
• The Growing Success of Embedded Processor– The demand for video games, handheld computers, digital st
ill cameras, and cellular phones

What are the Differences Between Desktop and Embedded Processors ? (1)
• Traditional ways to partition the microprocessor world
• In the past, it was sufficient to partition the market into four basic, clearly separated, target markets.– Emerging handheld, mobile, and multimedia applications require new classes of
embedded processors.

What are the Differences Between Desktop and Embedded Processors ? (2)
• What issues can differentiate embedded processor from desktop CPU?– Power consumption
– Cost
– Integrated peripherals (display, sound, etc.)
• Other important features for embedded processor– Interrupt response time
– Amount of on-chip RAM or ROM
– Number of I/O ports
• The most important point– Embedded microprocessor must do the job for a particular
application at the lowest possible cost within the timing constraint.

Evaluation Parameterfor Embedded Processors
• Essential criteria to compare embedded processors– Low power consumption– High code density– Less overhead of peripheral integration and number/cost of
chipsets– Equipped with multimedia acceleration and acceleration of
special application software– Lower price/performance ratio

Power Consumption
• Embedded domain application cannot use a heat sink or a fan.• Most embedded microprocessors have three modes
– Fully operational;• Clock signal is propagated to the entire processor
– Stand-by;• Processor is not actually executing instructions, but all its stored
information is still available
– Power down;• System has to be restarted
• Reducing power consumption– Reduced voltage level– Stopping transistor activity when a particular block is not in use– Integration of off-chip power-consuming peripherals– Announced target of all vendors in the 32-bit embedded arena is
1,000 MIPS/watt.

Code Density
• Most RISC processors use fixed-length instructions– MIPS, Sparc, PowerPC– Fixed 32-bit instruction length negatively affected code densi
ty of programs for 32-bit RISC processors
• To overcome fixed-length problem– SuperH(Hitachi), M-Core(Motorola)
• Only 16 bits (rather than 32) for each instruction
– Thumb extension(ARM)• recode 32-bit ARM instruction to 16-bit opcodes• on-chip logic decompresses Thumb code to ARM instruction in
real time
• Quality of C compilers

Peripherals and Higher Integration
• More peripherals– increase chip complexity– increase cost
• reduce yield• need more pins
– need more testing
• Integrated peripherals must simplify system design and shorten the development cycle of complete systems
• Embedded DRAM– dissipates less power, because of the extremely small load
capacitance of the bus

Multimedia Acceleration
• Typical instructions for multimedia support– multiply-accumulate operation for fast FIR filtering– enhanced addressing modes– graphics acceleration– Discrete Cosine Transform for JPEG and MPEG image compression
• Embedded microprocessors execute functions that a separate DSP processor performed in the past– in case of cellular phone, application needs
• a lot of control to handle the protocol stack and interface the external world
• equalization• voice encoding/decoding and compression
– which was traditionally handled with a low-performance microcontroller and a DSP processor

Classification of the New 32-bit Embedded Processors
• Classification of the New 32-bit Embedded Processors

The Future of the embedded processors
• Embedded processor of the future will– offer plenty of MIPS– run DSP program like a dedicated DSP processor– integrate all its peripherals– cost only a few cents
• No dominating architecture like the x86– because the embedded world is driven by a variety of applications
• Trend to use standard operating systems and platforms– to reduce the development cost– increase reusability– shorten design cycle time
• Each market segment will have its dominant architecture and perhaps vendor
Design Flow
module A(sum, a, b); sum = a + b;endmodule
ArchitectureRefinement
RTL description&
Verification
Synthesis &Gate-levelVerification
Place & Route
A B
C D
module A(sum, a, b); fa1 U1(.S(sum), .A(a), .B(b));endmodule
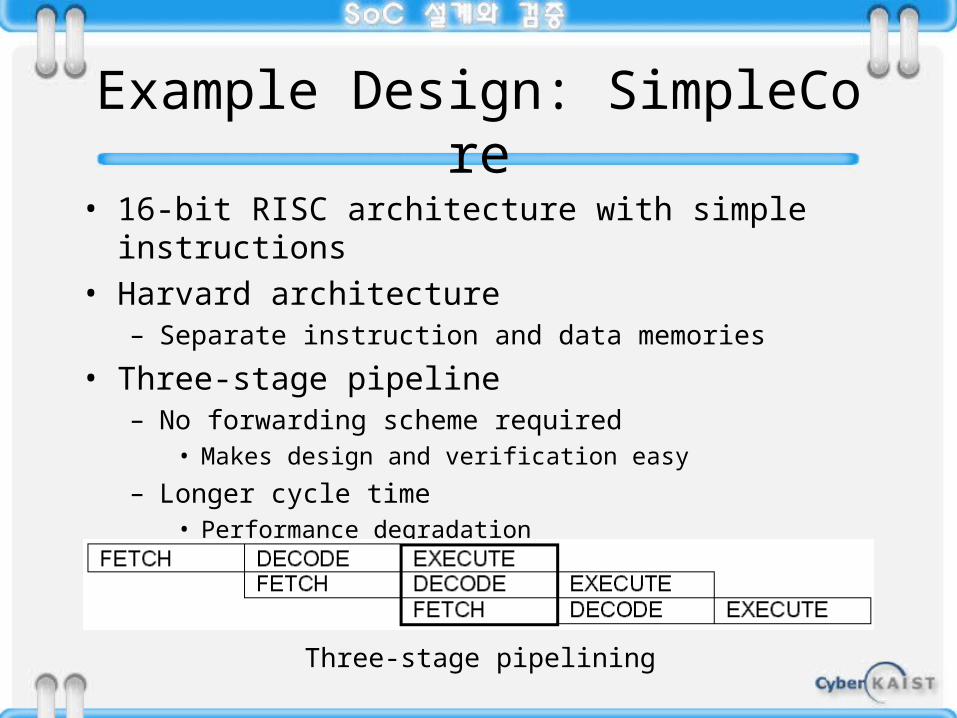
Example Design: SimpleCore
• 16-bit RISC architecture with simple instructions• Harvard architecture
– Separate instruction and data memories
• Three-stage pipeline– No forwarding scheme required
• Makes design and verification easy
– Longer cycle time• Performance degradation
Three-stage pipelining

Example Design: SimpleCore
• 2001 년 7 월 부터 현재까지 IDEC Newsletter 에 연재되고 있는 강좌 ‘마이크로프로세서설계 무작정 따라하기’를 위해 설계
• 설계자 : 배영돈 (KAIST 박사과정 )• Source code available: http://www.donny.co.kr/simple
core • 2,000 downloads made so far• Status:
– Part I: RTL description– Part II: Development environment (Compiler, Assembler, etc)– Part III: Synthesis and place & route ( 연재 중 )

Register file
• 15 general purpose registers
• A program counter• A status register
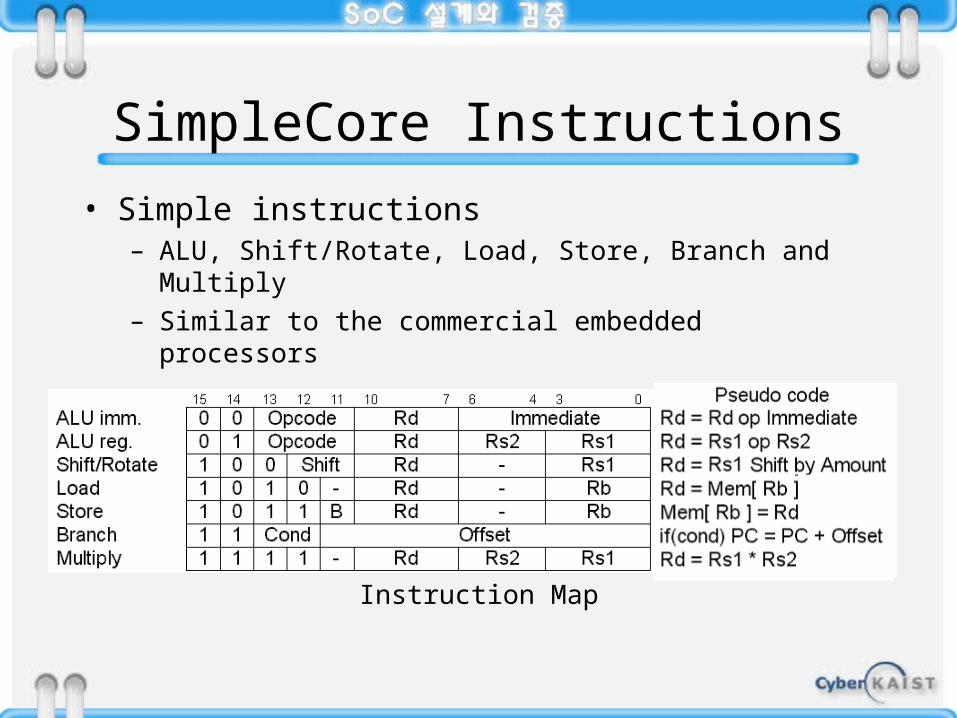
SimpleCore Instructions
• Simple instructions– ALU, Shift/Rotate, Load, Store, Branch and Multiply– Similar to the commercial embedded processors
Instruction Map

SimpleCore Instructions
• ALU instructions
Exit condition of a simulation

SimpleCore Instructions
• Shift Instructions
• Branch Instruction

Datapath• SimpleCore’s datapath consists of
– pc: program counter, incr: address incrementor– regFile: register file, sr: status register– alu: ALU, shifter: barrel shifter, mul: multiplier– dIn: data input register, dOut: data output register

Design of Datapath• Datapath has regular structures
– Data processing is often timing critical and requires large area; hence optimization is very important
– Usually designed using datapath compiler or by full custom design manner
Die photo of ARM7TDMI processorThe datapath occupies about 40% of total area
DATAPATHDATAPATH
CONTROL LOGICCONTROL LOGIC
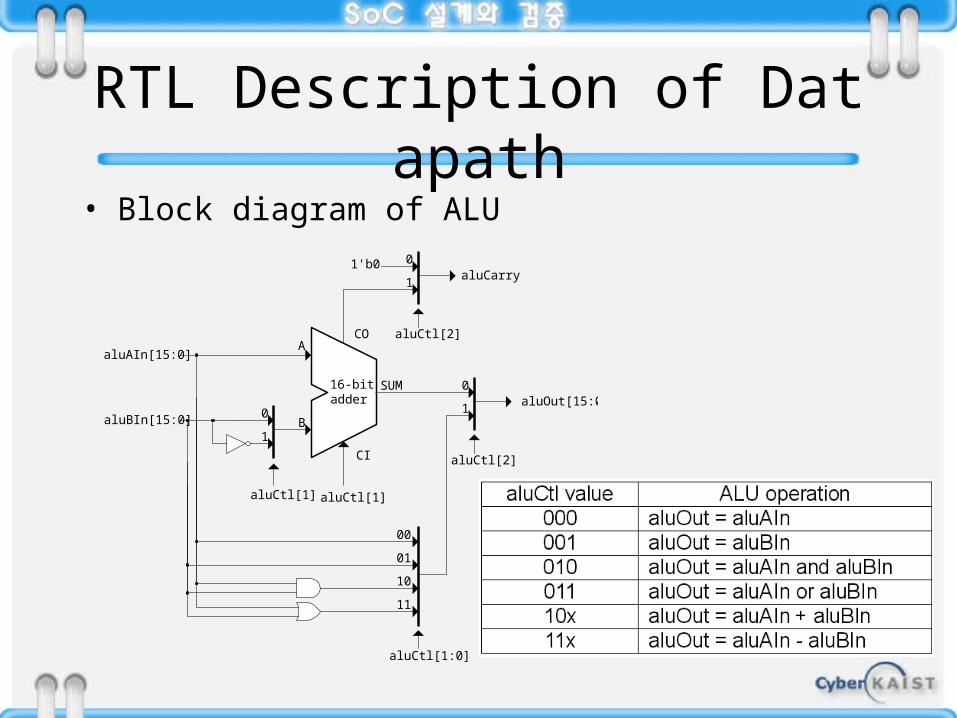
RTL Description of Datapath• Block diagram of ALU
aluCtl[2]
0
1
16-bitadder
aluAIn[15:0]
aluBIn[15:0]
aluCtl[1]
1'b0
CO
CI
SUM
A
B
aluCtl[1:0]
00
01
10
11
aluCtl[2]
0
1
aluCarry
aluOut[15:0]0
1
aluCtl[1]

RTL Description of Datapath• RTL description of ALU
always @ (aluAIn or aluBIn or aluCtl)begin casex(aluCtl) 3'b000: // MOVA {aluCarry, aluOut} = {1'b0, aluAIn}; 3'b001: // MOVB {aluCarry, aluOut} = {1'b0, aluBIn}; 3'b010: // AND {aluCarry, aluOut} = {1'b0, aluAIn & aluBIn}; 3'b011: // OR {aluCarry, aluOut} = {1'b0, aluAIn | aluBIn}; 3'b10?: // ADD {aluCarry, aluOut} = aluAIn + aluBIn; 3'b11?: // SUB {aluCarry, aluOut} = aluAIn - aluBIn; endcaseend

RTL Description of Datapath• Block diagram of barrel shifter
– Logic level implementation example– It can shift by any number of bits in a cycle
shiftAmt[0]: 1
shiftAmt[1]: 0
shiftAmt[2]: 1
shiftAmt[3]: 0
shiftIn [15:0]
shiftOut [15:0]
Concept of barrel shifter (case of logical shift left by 5)

RTL Description of Datapath• RTL description of barrel shifter
input [15:0] shiftIn; // shifter inputinput [ 3:0] shiftAmt; // shift amountinput [ 2:0] shiftCtl; // control input {left/right, arith/logic, rotate}output [15:0] shiftOut; // shifter output reg [15:0] shiftOut; always @ (shiftIn or shiftAmt or shiftCtl)begin casex(shiftCtl) 3'b0?? : // LSL (logical shift left) shiftOut = shiftIn << shiftAmt; 3'b100 : // LSR (logical shift right) shiftOut = shiftIn >> shiftAmt; 3'b101 : // ASR (arithmetic shift right) shiftOut = ({16{shiftIn[15]}}<<(16-shiftAmt)) | (shiftIn >> shiftAmt); 3'b11? : // ROR (rotate right) shiftOut = (shiftIn >> shiftAmt) | (shiftIn << (16-shiftAmt)); endcaseend

RTL Description of Datapath• Design of the multiplier
– Multiplier occupies large area and is slower than other units– Many tools can synthesize multipliers but more sophisticated
approaches are required for high performance• e.g., using module generator, employing Modified Booth
algorithm, etc.
• RTL description of multiplier
input [15:0] mulAIn; // multiplier input Ainput [15:0] mulBIn; // multiplier input Boutput [15:0] mulOut; // multiplier output
assign mulOut = mulAIn * mulBIn;
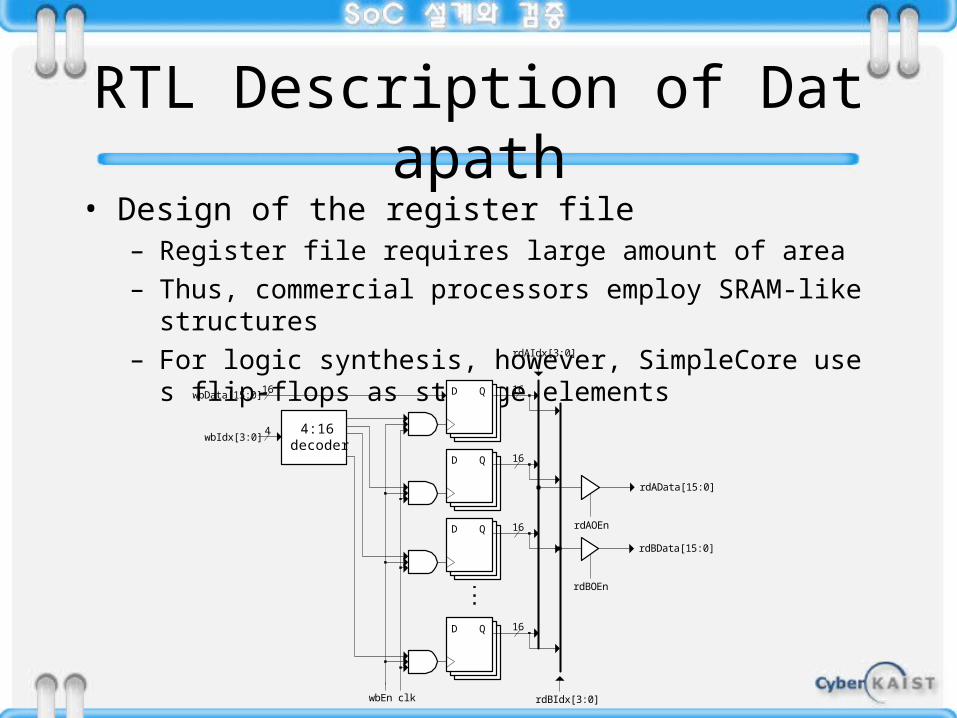
RTL Description of Datapath• Design of the register file
– Register file requires large amount of area– Thus, commercial processors employ SRAM-like structures– For logic synthesis, however, SimpleCore uses flip-flops as
storage elementsD 16Q
D 16Q
D 16Q
D 16Q
rdBData[15:0]
rdBOEn
rdBIdx[3:0]
rdAData[15:0]
rdAOEn
4:16decoder
clk
4
16
wbEn
wbData[15:0]
wbIdx[3:0]
rdAIdx[3:0]

Design of Control Logic• Design of the decode unit
– Instructions are compressed expression of execution information
• Increases code density
• Reduce the size of program memory
– Decode unit extracts all the information required for execution
00add opcode Rd Immediate 1010load Rd Rb 11branch cond offset
decodeoutput
opcode Immediate Rd Rbcond
zero extend
sign extend
Instruction Decoding
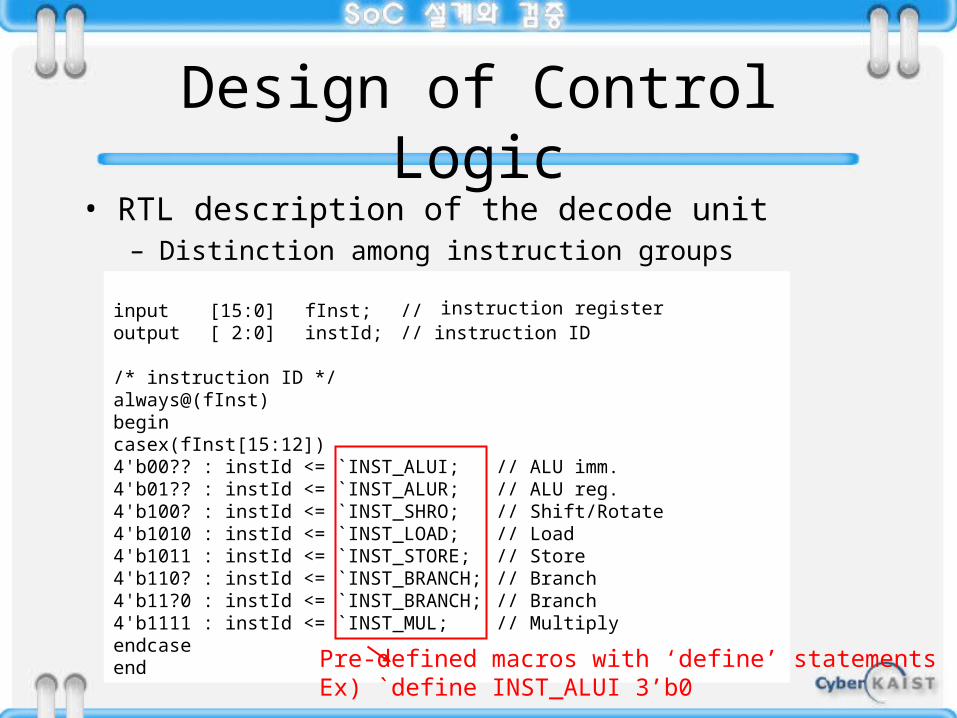
Design of Control Logic• RTL description of the decode unit
– Distinction among instruction groups
input [15:0] fInst; // fetch dataoutput [ 2:0] instId; // instruction ID /* instruction ID */always@(fInst)begincasex(fInst[15:12])4'b00?? : instId <= `INST_ALUI; // ALU imm.4'b01?? : instId <= `INST_ALUR; // ALU reg.4'b100? : instId <= `INST_SHRO; // Shift/Rotate4'b1010 : instId <= `INST_LOAD; // Load4'b1011 : instId <= `INST_STORE; // Store4'b110? : instId <= `INST_BRANCH; // Branch4'b11?0 : instId <= `INST_BRANCH; // Branch4'b1111 : instId <= `INST_MUL; // Multiplyendcaseend Pre-defined macros with ‘define’ statements
Ex) `define INST_ALUI 3’b0
instruction register

Design of Control Logic• RTL description of the decode unit (cont’d)
– Execution information extraction• Opcode, register indices, immediate values, condition flags, etc.
/* field extraction */assign opcode = fInst[13:11];assign shift = fInst[12:11];assign rs1Idx = fInst[ 3: 0];assign rs2Idx = {1'b0, fInst[ 6: 4]};assign rdIdx = fInst[10: 7];assign imm = (instId == `INST_BRANCH) ?{{4{fInst[11]}}, fInst[11:0]} : // sign extension{9'b0, fInst[6:0]}; // zero extensionassign immFlag = (instId == `INST_ALUI);assign cmpFlag = (fInst[15:11] == 5'b00101);assign branchFlag = (instId == `INST_BRANCH);assign exitFlag = (fInst[15:11] == 5'b00111); // end of simulationassign srWbEn = (fInst[15:11] == 5'b00110) || (fInst[15:11] == 5'b00101); // MSR or CMPassign srOEn = (fInst[15:11] == 5'b00111); // MRS

Design of Control Logic• Design of the execute unit
– Most of the operation in execute stage are performed in the datapath
– Execute unit generates control signals for the functional units in the datapath
– Design of the execute unit is assigning of values of each control signal for the corresponding instruction
Control signals for the functional unit
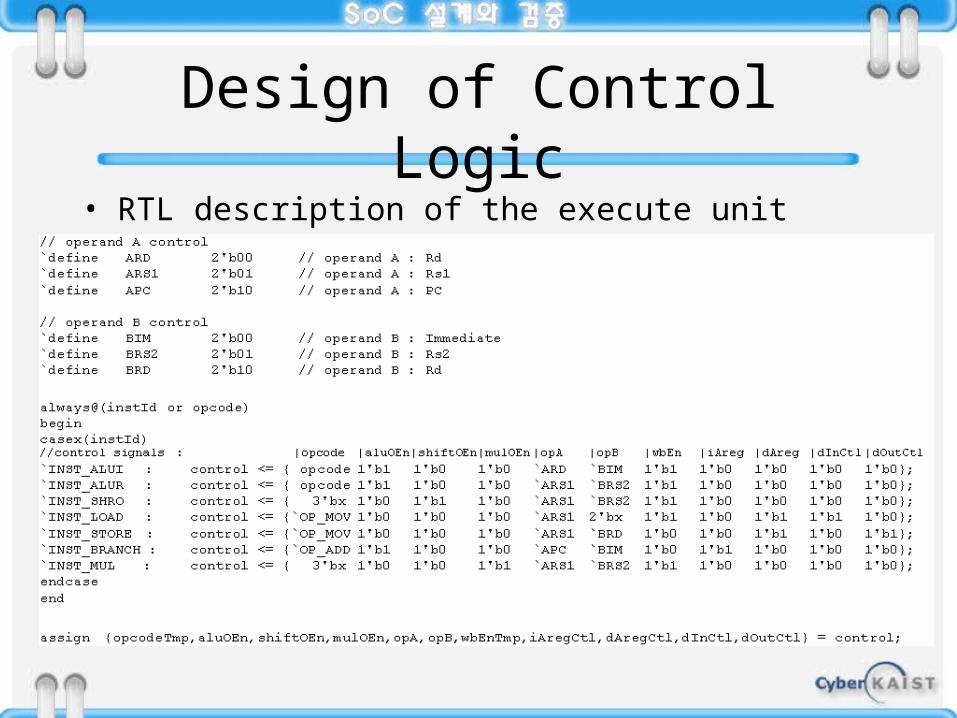
Design of Control Logic• RTL description of the execute unit
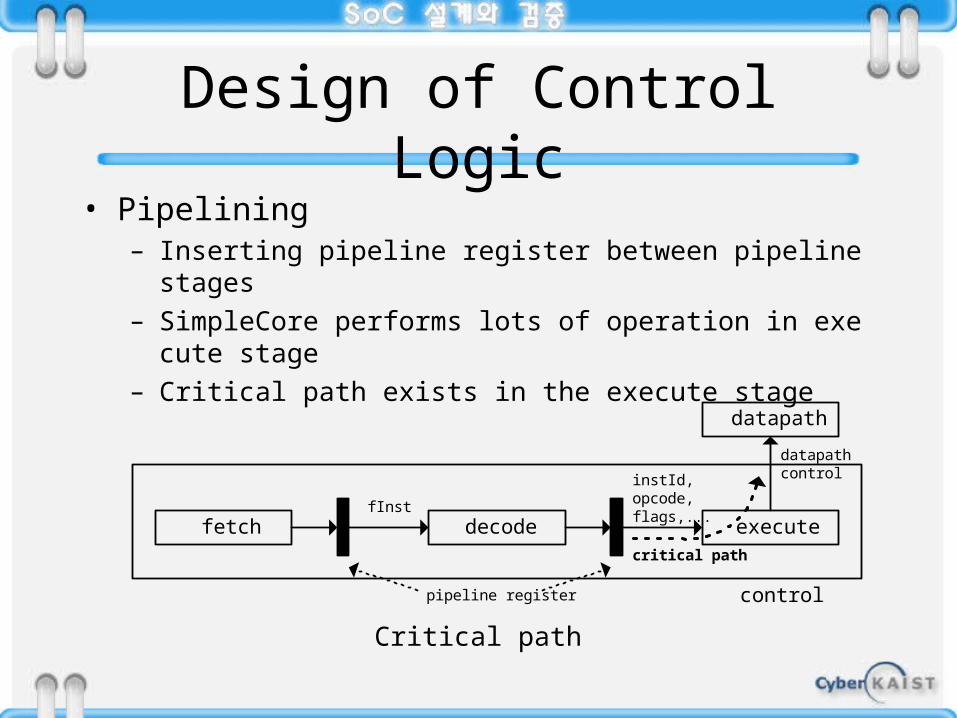
Design of Control Logic• Pipelining
– Inserting pipeline register between pipeline stages– SimpleCore performs lots of operation in execute stage– Critical path exists in the execute stage
fetch decode executefInst
instId,opcode,flags,...
datapath control
datapath
critical path
controlpipeline register
Critical path
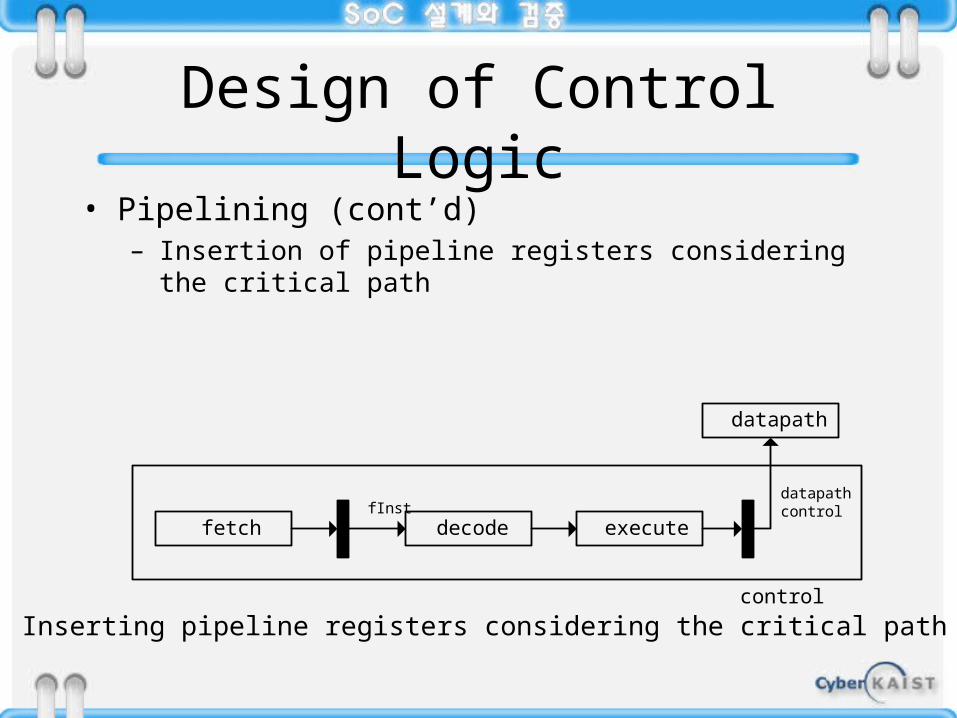
Design of Control Logic• Pipelining (cont’d)
– Insertion of pipeline registers considering the critical path
fetch decode executefInst
datapath control
datapath
control
Inserting pipeline registers considering the critical path

Design of Control Logic• Hazard
– Data Hazard• Not exists in SimpleCore as data are read and written in the same pipeli
ne stage (no forwarding)
– Control Hazard (Branch)• Newly fetched instructions are executed rather than prefetched instructi
ons (cf., delayed branch)
Branch instruction
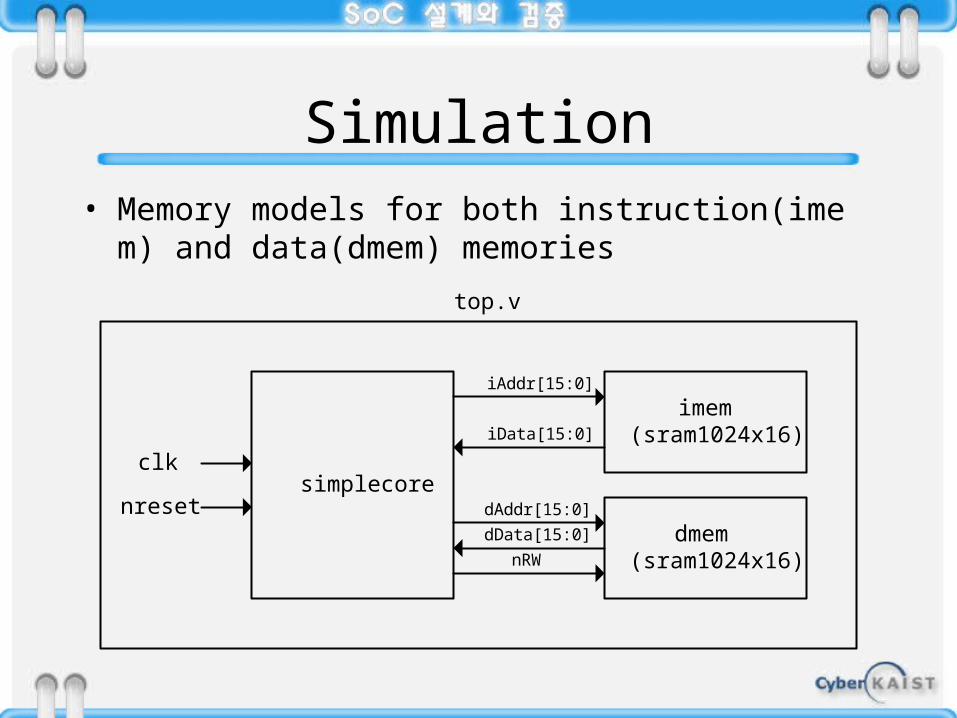
Simulation• Memory models for both instruction(imem) and data
(dmem) memories
simplecore
top.v
clk
iAddr[15:0]
imem(sram1024x16)iData[15:0]
dAddr[15:0]
dData[15:0] dmem(sram1024x16)nRW
nreset
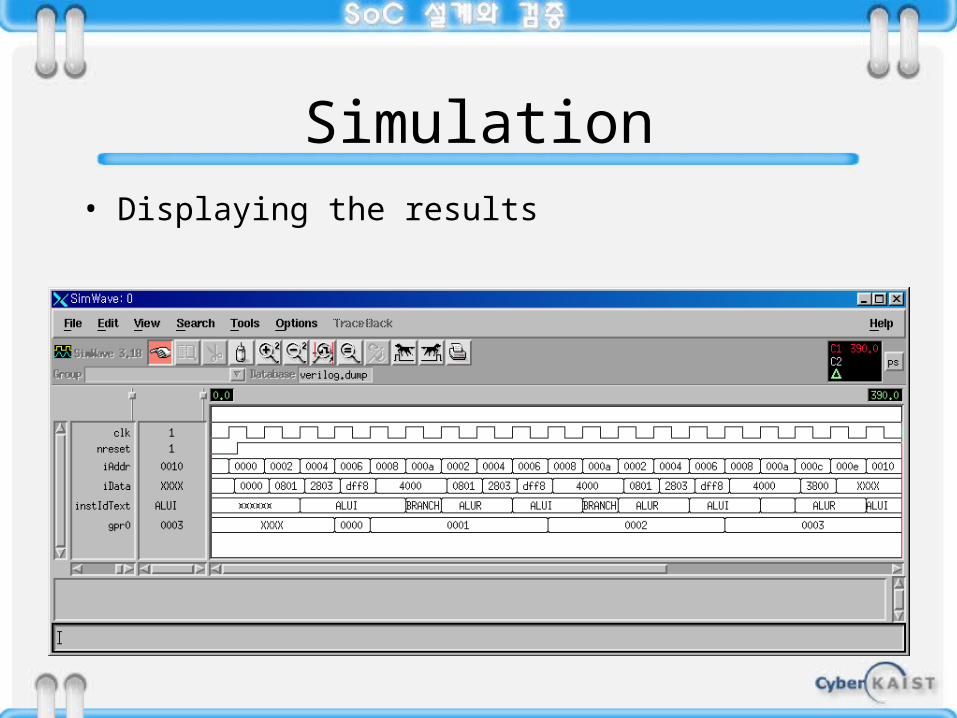
Simulation• Displaying the results

Verification• Compare the status(e.g., register file) and data on the
IOs between C-model(ISS) and RTL using PLI (program language interface)
simplecore(RTL)
top.v
clk
iAddr[15:0]
imem(sram1024x16)iData[15:0]
dAddr[15:0]
dData[15:0] dmem(sram1024x16)nRW
nreset
simplecore(C-model)
consistency check




![[ 제 차 ] 경종민 kyung@ee.kaist.ac.kr 1 Overview of SoC Design process.](https://static.fdocument.pub/doc/165x107/56649e055503460f94af16bc/-kyungeekaistackr-1-overview-of-soc-design-process.jpg)

![KYUNG HEE UNIVERSITYkyunghee.edu/upload/05_2020khu_foreigner_mojip.pdf · KYUNG HEE UNIVERSITY. 4 , 5o. 4ð,¿ 20204ð-ª.9 2u2 ,Å/Ê4q0 2 5 / 2é2 ,[ 2020)º ¥ % Ù Î ]' % e*v](https://static.fdocument.pub/doc/165x107/5f99377af6fa9863782e439b/kyung-hee-kyung-hee-university-4-5o-4-20204-9-2u2-4q0-2-5-.jpg)






![[ 제 차 ] 경종민 kyung@ee.kaist.ac.kr 1 Platform-based design.](https://static.fdocument.pub/doc/165x107/56649f3a5503460f94c5806f/-kyungeekaistackr-1-platform-based-design.jpg)




