
ミクロ経済学の展開とエージェンシー理論Discussion Paper Series No.183 ミクロ経済学の展開とエージェンシー理論 -情報の経済学とガバナンス-
Upload
garrett-stewartCategory
view
17download
1description

事例研究 ( ミクロ経済政策 問題分析 ・ III)
- 規制産業と料金 価格制度 ・ -
( 第 10 回 - 手法 (6) 意志決定モデル )
2013 年 7 月 5 日
戒能一成

0. 本講の目的
( 手法面) - 企業 家計の行動を分析する際に有益な、意志 ・
決定モデルの典型的な手法を理解する ・ モデルの選択基準 ( 離散 or 連続 反復・ , 1 財 or 2 財以上 ,
相手方との相互作用の有無 ) ・ 典型的な意志決定モデル ( 行動原理型 , Tobit, 線形型 , CD 型など)
(内容面) - 意志決定モデルの基礎的考え方を理解する
2

1. 意志決定モデルの選択
1-1. 意志決定の種類 (1) 離散 or 連続 反復・
- 企業 家計が何らかの意志決定をする行動を ・モデルで記述する際、最初に考えるべき問題は 当該意志決定が「離散」型か「連続 反復・ 」型か、という点である
○ 離散型 - 大学や就職先の選択 - 高額耐久消費財の購入 ( 住宅 , 自動
車 ・・・ ) ○ 連続 反復型・ - 日用財の選択 ( 「和洋中」選択 , 消費量選
択 ) - 経路 行先選択 ・ ( 頻繁に行く買物先 , 行楽地 ) 3
1. 意志決定モデルの選択
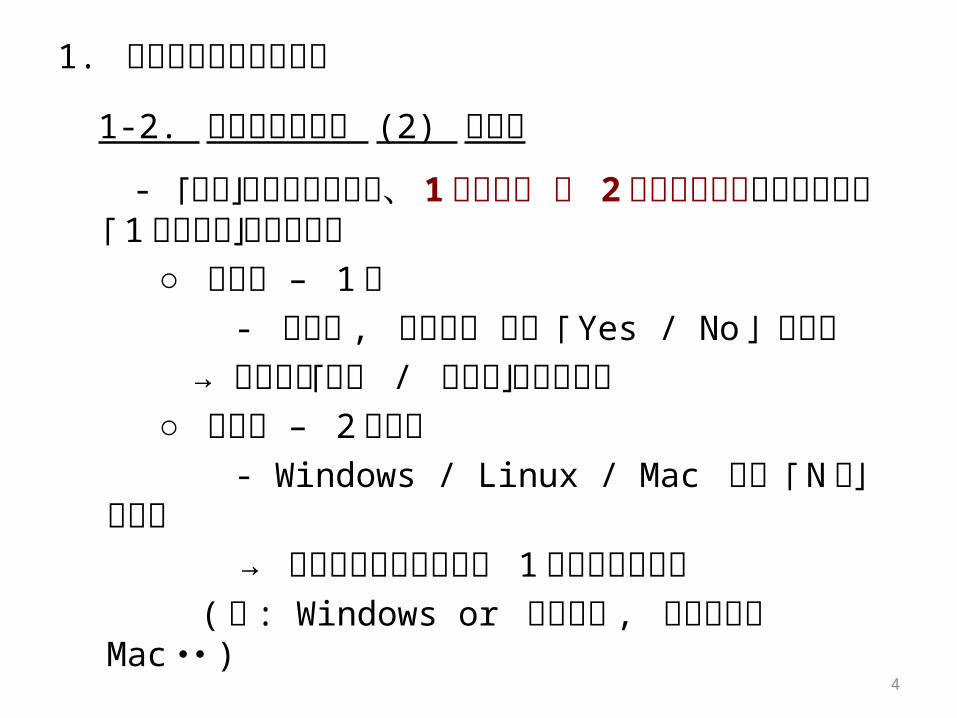
1-2. 意志決定の種類 (2) 離散型
- 「離散」型の意志決定は、 1 財の選択 と 2 財以上の選択が存在するが「 1 財の選択」で表現可能
○ 離散型 – 1 財 - 自動車 , 住宅購入 など 「 Yes / No 」 で決定 → 当該財の「消費 / 非消費」が検討対象 ○ 離散型 – 2 財以上 - Windows / Linux / Mac など 「 N 択 」 で決
定 → 階層化することにより 1 財型で表現可能 ( 例 : Windows or それ以外 , それ以外中 Ma
c ・・ )
4

1. 意志決定モデルの選択
1-3. 意志決定の種類 (3) 連続 反復型・
- 「連続 反復・ 」型の意志決定は、通常は 1 財の消費量を決定するか、 2 財以上の消費量 選択比 ・ を決定する問題に分類される
○ 連続 反復型 ・ – 1 財 - ガソリン , 電力など「必需品」の消費量 → 1 財の量に関する部分均衡を考えれば可 ○ 連続 反復型 ・ – 2 財以上 - 食費支出のうち「和食」の頻度 比率・ - 工業生産の投入要素選択 ( 資本 労・
働・・・ ) → 2 財以上での最適選択を考える必要あり
5

1. 意志決定モデルの選択
1-4. 意志決定種類とモデル選択 [ 重要 ]
- 意志決定の種類に応じたモデル選択
○ 離散型 → 「行動原理型」モデル → 「 Tobit 型」モデル (Logit, Probit, Heckit
・・ ) ○ 連続 反復型 ・ – 1 財 → ( 対数 ) 線形型モデル ○ 連続 反復型 ・ – 2 財以上 → 「行動原理型」 , 「ゲーム理論形」モデル → Cobb-Douglas 型モデル , CES 型モデ
ル 6

2. 離散型 : 行動原理型モデル
2-1. 行動原理型モデルとは
- 企業 家計が何らかの意志決定をする際に、当・該企業 家計が・ どのような主観的行動原理に従っているかを仮定し観察結果を分析するモデル
- この形態のモデルでは通常「相手」との相互作用は仮定しない (← cf. ゲーム理論「支配戦略」型 )
- モデル化に用いる行動原理には、下記の典型的な 6 分類があるが、期待値型と Mini-Max が多い
・ Laplace 型 , 期待値型 ・Mini-max 型 , Maxi-max 型 , Hurwicz 型 ・Mini-max-regret 型
7

2. 離散型 : 行動原理型モデル
2-2. Laplace 型 ( 「無情報型」 )
- 意志決定に際し、状態の発生確率に関する情報が得られないことが判明している場合に、全ての状態が同一確率で発生すると仮定したモデル
( 例 : 家計による行楽選択 : 効用は既知(要調査 )) 状 態 : 晴天 雨天 効 用 / 発生確率 : ( 不明 ; 50%と仮定 ) 日光紅葉鑑賞 + 90 + 10 (E= 50) ○○○ーランド + 60 + 40 (E= 50) → 晴天 :雨天の確率は 50:50 と推定した上で、 現実の行楽客の行動を分析 (ex イベントの影響 )
8

2. 離散型 : 行動原理型モデル
2-3. 期待値型
- 意志決定に際し、状態の発生確率に関する情報がある程度得られ、期待値の大小に従って意志決定が行われていると仮定したモデル、最も普遍的
( 例 : 家計による行楽選択 ) 状 態 : 晴天 雨天 効 用 / 発生確率 : 80% 20% 期
待値 日光紅葉鑑賞 + 90 + 10 (E=
74) ○○○ーランド + 60 + 40 (E=
56) → 日光 :ランドの基礎客足は 74 : 56 ( 期待値の 比 ) と推定し他の影響を分析 9

2. 離散型 : 行動原理型モデル
2-4. Mini-max 型 ( 最悪状態重視型 )
- 意志決定に際し、当該主体が最悪の状態に陥った際の効用が最も高い (= Mini-max) よう保守的に意志決定を行っていると仮定したモデル
( 例 : 家計による行楽選択 ) 状 態 : 晴天 雨天 効 用 / 発生確率 : 80% 20% 期待
値 日光紅葉鑑賞 + 90 + 10 (E= 74) ○○○ーランド + 60 + 40 (E= 56) → 日光 :ランドの基礎客足は 10 : 40 (雨天の効用 比)と推定し他の影響を分析
10

2. 離散型 : 行動原理型モデル
2-5. 他の類型(詳細略 )
- Maxi-Max 型 ( 最善状態重視型 , Mini-Max の逆 )
考え得る最善の状態での効用が最も高い (= Maxi-max) よう射幸的に意志決定を行うと仮定
- Hurvitz 型 当該主体の楽観度 α を仮定 ( 測定 ) し、最善状態
の効用 * α + 最悪状態の効用 * (1-α) が最も高いよう中庸的に意志決定を行っていると仮定
- Mini-Max-Regret 型 ( 後悔最小型 , Savage 型 ) 最善の状態からの差 (=後悔度 ) が最小化される
ように意志決定を行っていると仮定11

2. 離散型 : 行動原理型モデル
2-6. 行動原理型モデルの選択
- 6 分類形態のどのモデルを当てはめるかという「モデル選択」問題については、実績値を用いた検討 検証が望ましいが、実際には弾力的に応用され・ている
( 演繹的検討 ) - 高齢者世帯 → Mini-max 型 ( 最悪状態重視 )
- 土日休日 → Maxi-max 型 ( 最善状態重視 )
( 帰納的検討 ) - 関連統計解析 , アンケート調査 - シミュレーション , 比較分析 12

3. 離散型 : Tobit 型モデル
3-1. Tobit 型モデル (1) 二択モデル (Probit, Logit)
- 離散型の選択が、ある観察可能な変数 zi で決定 される確率に従うと考えられる場合、二択モデル (Binary Outcome Model) が適用可
( 離散値 Di の選択 )
1 0
Pr(Di=1,zi’β) =∫-∞(zi-z0)’β/σ (2πσ2)-1/2 * exp(-1/2*s2/σ2)ds
( Probit ; 正規確率密度関数 φ((zi-z0)’β/σ) の積分 )
Pr(Di=1, zi’β) = 1 / (1 + exp(-zi’β)) [ 頻出 ] ( Logit; 対数確率関数 Λ(zi’β))
13
Di = Di = Pr(Di=1, zi’β) +εi

3. 離散型 : Tobit 型モデル
3-2. Tobit 型モデル (2) 二択モデルの考え方
14
選択確率関数 Pr (Di=1, zi’β) = 確率密度関数の積分値 (-∞ で 0, +∞ で 1)
説明変数(zi-z0)’β/σ
0z0 (zi の平均 )
確率密度関数Pr (正規確率密度 関数の場合 )
-∞ (z i – zo)’β/σ
二択変数 Di
1
0
説明変数 zi
Z i
選択結果 Di (1 or 0)
措置群 (Di =1)
対照群 (Di =0)
「現 実」「脳 内」
( 例 : Di - 家計 i 高級外車購入の有無 zi - 家計 i の所得 )

3. 離散型 : Tobit 型モデル
3-3. Tobit 型モデル (3) ダミー変数モデル
- 離散値 Di の選択に応じ、 Di = 1 の場合のみ 結果指標 yi が zi により決定される場合、ダ
ミー 変数モデル (Dummy Dependent Model) が適用
可
( 第 1段階 : 離散値 Di の選択 : ( 例 ) 高級外車購入 ) 1 if Di* > 0 ; 0 if Di* ≦ 0 ;
( 第 2段階 : 結果指標 yi の決定 : ( 例 ) 外車購入額 ) yi* if Di* > 0 ; yi* = zi2’β2 +ε2i
0 if Di* ≦ 0 ; ( ← 観察不能 ) 15
Di =
yi =
Di* = zi1’β1 +ε1i
( 通常 誤差 ε1i は正規分布と 仮定し Probit 型で β1 を推定 )

3. 離散型 : Tobit 型モデル
3-4. ダミー変数モデル (4) 推計の考え方
16
ダミー変数Di, Di*( 観察不可 )
1
0
説明変数 zi (観察可 )
結果指標 yi( 観察可 )
説明変数 zi (観察可 )
Zc (Di* = 0) Zc ( ? )
選択ダミー Di (1 or 0)
選択ダミ-関数 Di* = zi’β1 + ε1i
措置群 (Di =1)
対照群 (Di =0)
結果指標の誤差 ε2i(ε1i との関 係を仮定 )
0
選択ダミー変数の誤差 ε1i = Di* - zi’β1
(正規分布を仮定 ) 措置群 (Di =1)
対照群 (Di =0) → yi = 0
「現 実」「脳 内」
yi
( 例 : yi - 家計 i の外車購入額 Di – 外車購入ダミー ( 観察不可 ) zi - 家計 i の所得 )
結果指標 yi* = zi’β2 + ε2i
( or 0 )

3. 離散型 : Tobit モデル
3-5. ダミー変数モデル (5) モデルの種類
- Two Part モデル 第 1段階を Probit 型で推計し、第 2段階で正の観察値のみ回帰推計 (= 第 1段階 第・ 2段階の確率や誤差の関係を仮定しないが、第 1段階で
の 選択の有無 (= 第 2段階が不存在か “ 0” が存在か ) を識別する必要有 )
- Tobit モデル ( 狭義の Tobit モデル , Type 2) 第 1段階 第・ 2段階の誤差が二元正規分布に従うと仮定し、第 1段階の Probit 型推計の結果 ( 回帰係数 β1) を用い、第 2段階を推計
- Heckman 2段モデル (Heckit) [ 頻出 ] 第 1段階 第・ 2段階の誤差が線形関係と仮定し、第 1段階の Probit 型推計 の結果 ( 回帰係数 β1) を用い、第 2段階で正の観察値のみを推計
E( yi | Di > 0 ) = zi2’β2 + σ12*λ(zi1’β1) ← 最尤値 (ML)推計
σ12: 誤差間の線形回帰係数
λ(zi’β1): 逆ミルズ比 正規分布確率密度関数φと確率の比 = φ ( -zi’β1/σ) / ( 1 - ∫-∞-zi’β1/σ φ( s) ds )
17

3. 離散型 : Tobit 型モデル
3-6. ダミー変数モデル (6) 仮定と検定
- ダミー変数モデルの多くは、少なくとも第 1段階の
選択過程の誤差が正規分布に従うと仮定 → 誤差の正規性検定 (- linktest など ) が必須
18
→ 実はポアソン分布

4. 連続 反復型・
4-1. 線形モデル (1 財 )
- 意志決定の対象として 1 財の消費量など連続 反復・的な選択のみを考えればよい場合、影響因子を説明変数として用いた線形モデルが適用可
- 通常は対数線形型を用いる場合が多い ( → 変数を定常化しやすく、かつ係数 βi が弾力 性を示すため解釈が容易 ) - 時系列データである場合、同時決定となる場合な
どに要注意 ln(Y(t)) = β0 + Σi ( βi * ln(Xi(t)) ) + εi(t) Y(t); 消費量 Xi(t); 価格 , 所得 , 天候 , 年齢
・・・
19

4. 連続 反復型・
4-2. ゲーム理論型モデル (1)
- 企業 家計が何らかの意志決定をする際に、・当該企業 家計が・ 「相手」との相互作用を考慮に入れつつ、どのような行動原理に従っているかを仮定し観察結果を分析するモデル
- 通常は「期待値型」の行動原理を仮定 - モデルとしては 2 分類(支配戦略型
Dominant Strategy, 混合戦略型 Mixed Strategy) があるが、連続 反復型の意志決定・は通常は「混合戦略型 Mixed Strategy 」のモデルを用いる
20

4. 連続 反復型・
4-3. ゲーム理論型モデル (2)
- 混合戦略型モデルとは、企業 家計が・ 「相手」の反応を前提にある比率で挙動を組合せて対応することが最適な場合が存在し、当該比率に従うと仮定し観察結果を分析するモデル
( 例 : 家計による行楽選択 +) 日光 100%
/ 婆 日光 ランド 爺 日光 2, 1 0, 0 爺 ランド 0, 0 1, 2 ランド 100%
→ 日光 1/3, ランド 1/3, 決裂 1/3 婆21
(2, 1)
(1, 2)
(1 , 1)

4. 連続 反復型・
4-4. Cobb-Dougl as(CD) 型モデル ; 2 財以上
- 企業 家計が ・ Cobb-Douglas 型の生産 効用関・数
を持つと仮定し、最大化問題の解に従い各財を 投入 消費していると仮定するモデル・ ( 家計消費 ) max Πi ( Xiαi ) (Σi αi = 1 ) s.t. Σi ( pi * Xi ) = I ⇒ Xi = αi * I * pi-1
- CD 型モデルは、簡単で計測容易な利点があるが、価格弾力性 -1, 所得弾力性 1, 交差弾力性 0 など先験的に強い前提条件を置くことに注意
( → cf. CES 型 )22

4. 連続 反復型・
4-5. CES 型モデル ; 2 財以上
- CD 型モデル同様の枠組で、財間の代替性を考慮して CES 型生産 効用関数・ を用いたモデル
max ( Σi ( αi * Xi ( σ-1)/σ )) σ/(σ-1)
s.t. Σi ( pi * Xi ) = I σ: 代替弾力性 , 0 ≦σ ⇒ Xi =αiσ* pi(1-σ) *(Σi (αiσ* pi(1-σ)) ) -1 * I *
pi-1
- CD 型の問題点である「弾力性の前提条件」を、簡素性を殆ど犠牲にせず解決できるため多用される
- 対数をとって解くとほぼ「線形」型となる点に留意 23

5. 事例 : 経路選択 “駅馬車問題”
5-1. 問題設定
- 某国の国道では、ゲリラが出没するため貨物輸送に高額の保険金が掛けられているとする
- 国道毎の距離と保険料率は下記のとおり
- 当該国の運送会社は各トラック運転手に対し如何なる経路選択を指示すべきか?
24
100km #2 都市 20km 0.04 #4 都市 40km
0.01 0.02
20km 25km
#1 出発都市 0.03 0.01#6 目的都市
60km 最危険
経路 #3-5 15km
0.02 #3 都市 10km 0.07 #5 都市 0.01

5. 事例 : 経路選択 “駅馬車問題”
5-2. 前提条件設定
- トラックの速度は一律で、燃料と運転手の労賃合計 ( 輸送費 ) は積荷に関係なく一律 $ 5.0/km とする
- トラックは同じ都市を 2 回通らずに #1 出発都市から #6 目的都市に向かうものとする
- 積荷は総額別に以下の 3種類とし、保険料率は現実のゲリラによる損失を概ね反映しているとする
a: 石 炭 $ 1,250- b: ウイスキー $ 12,500- c: 金塊 $125,000-
25

5. 事例 : 経路選択 “駅馬車問題”
5-3. 選択可能な経路の選定
累計保険料率 距離
Ⅰ #1→ #2→#3→#5→ #6 0.12 145km Ⅱ #1→ #2→#3→#5→ #4→ #6 0.14 195
× Ⅲ #1→ #2→ #4→ #6 0.07 160 Ⅳ #1→ #2→ #4→ #5→ #6 0.07 160 Ⅴ #1→ #3→ #2→ #4→ #6 0.11 140 Ⅵ #1→ #3→ #2→ #4→ #5→ #6 0.11 140 Ⅶ #1→#3→#5→ #6 0.10 85 Ⅷ #1→#3→#5→ #4→ #6 0.12 135
26

5. 事例 : 経路選択 “駅馬車問題”
5-4. 各経路の総費用 ( 輸送費 ($5.0/km)+保険料 )
保険料率 距離・ 総費用 a 石炭 b 酒 c 金塊
Ⅰ 12356 0.12 145 875 2225 15725Ⅱ × Ⅲ 1246 0.07 160 888 1675 9550Ⅳ 12456 0.07 160 888 1675 9550
Ⅴ 13246 0.11 140 838 2075 14450Ⅵ 132456 0.11 140 838 2075 14450Ⅶ 1356 0.10 85 550 1675 12925Ⅷ 13546 0.12 135 825 2175 15675
27

5. 事例 : 経路選択 “駅馬車問題”
5-5. 感度分析 (輸送費 ( 労賃上昇$10.0/km)+ 保険料 )
保険料率 距離・ 総費用 a 石炭 b 酒 c 金塊 Ⅰ 12356 0.12 145 1600 2950 16450Ⅱ × Ⅲ 1246 0.07 160 1688 2475 10350Ⅳ 12456 0.07 160 1688 2475 10350
Ⅴ 13246 0.11 140 1538 2775 15150Ⅵ 132456 0.11 140 1538 2775 15150Ⅶ 1356 0.10 85 975 2100 13350Ⅷ 13546 0.12 135 1500 2850 16350
28

5. 事例 : 経路選択 “駅馬車問題”
5-6. 経路選択モデルの選択 展開・ (1)
( 離散型 ) - 年数回の低頻度での輸送や国営運送公社 1社の選択の場合など、当該経路選択が「離散型」であると見なせる場合
行動原理型モデル・ : 期待値型 → 5-4. の費用が最小となる経路を常に選
択 ・ Tobit 型モデル : Logit 型 → 5-4. の費用を変数とした確率分布
で選択 29

5. 事例 : 経路選択 “駅馬車問題”
5-7. 経路選択モデルの選択 展開・ (2)
( 連続 反復型・ ) - 年間数百回の高頻度での輸送や運送公社が多
数存在する場合など、当該経路選択が「連続 反復・型」であると見なせる場合
・ CD 型モデル , CES 型モデル → 5-4. の費用を変数とし、「利得」が最大化す るよう 2 経路を選択 ゲーム理論型モデル・ → ゲリラ側の対応を与件として 2 経路を
選択30


















