
㈜에버원소프트 · 기능 & 성능 테스트 ... •환경 종합 보고서 시스템 운영 정보 관리 시스템 공통 기준 정보 관리 시스템 오류 및 로그
date post
25-Jul-2016Category
view
289download
36description



목차|IV
시작하며 3
성능이란? 501 장
1.1 동시 사용자 6
1.2 처리량 7
1.3 응답시간 8
1.4 자원 12
1.4.1 적정성 12
1.4.2 효율성 13
1.4.3 안정성 13
1.4.4 가용성 13
1.4.5 확장성 14
성능특성 1502 장
2.1 성능 곡선 15
2.2 성능에 대한 이해 16
성능이론 1903 장
3.1 기초 성능 이론 19
3.2 사용률 이론 22
3.3 비율 분석 23
성능테스트 2504 장
4.1 성능 테스트 유형 25
4.2 성능 테스트 구성 요소 27
성능기초
01부

목차 | V
4.3 성능 테스트 시 주의사항 28
4.3.1 테스트 데이터 28
4.3.2 화면 처리시간 30
4.3.3 네트워크 30
4.3.4 가상 사용자 특성 31
4.3.5 업무 시나리오 32
4.3.6 대상 업무와 성능 개선 33
기본자세 3501 장
성능분석시작하기 3702 장
2.1 애플리케이션 서버 응답시간 분석 38
2.2 클라이언트 응답시간 분석 39
상황별분석단계 4103 장
3.1 화면 응답시간 저하 41
3.2 시스템 내 응답시간 저하 44
3.3 서비스 멈춤 현상 47
3.4 시스템 전반에 걸친 성능 개선 49
3.5 서버 자원 사용량 확인 50
3.6 CPU 과다 사용 분석 51
3.7 메모리 과다 사용 분석 53
3.8 디스크 과다 사용 분석 57
개선방향성 6104 장
성능개선
02부

목차|VI
기본방향 6501 장
HTTP의이해 6702 장
2.1 프로토콜 구조 67
2.2 HTTP 요청 68
2.3 HTTP 응답 72
2.4 데이터 송수신 78
화면응답시간모니터링 8003 장
3.1 인터넷 익스플로러 프로파일링 83
3.2 피들러 86
3.3 HTTP 분석 접근 91
웹기반시스템성능개선 9204 장
4.1 화면 콘텐츠 구성 92
4.1.1 콘텐츠 수 축소 92
4.1.2 크기별 이미지 준비 96
4.1.3 이미지 콘텐츠 파일의 크기 축소 97
4.1.4 CDN 사용 98
4.1.5 텍스트 콘텐츠의 크기 축소 99
4.1.6 압축 적용 100
4.1.7 웹 가속기 106
4.2 캐시 동작 107
4.2.1 브라우저 캐시 107
4.3 병렬/비동기 처리 118
4.3.1 네트워크 연결 증가 118
화면응답시간분석
03부

목차 | VII
4.3.2 AJAX와 DOM을 이용한 비동기 처리 119
4.4 기타 성능 개선 120
4.5 웹 서버 설정 121
4.5.1 최대 병렬 처리 수 121
4.5.2 Keepalive 122
웹서버모니터링 12705 장
5.1 웹 요청 응답시간 모니터링 127
5.2 웹 서버 성능 모니터링 129
HTTPS 13606 장
기본방향 14101 장
수행중인코드 14302 장
2.1 스택에 대한 이해 143
2.2 스택 정보를 이용한 성능 분석 146
2.2.1 스택 대기 분석 147
2.2.2 교착상태 157
2.2.3 스택 성능 분석 161
2.3 스택 수집 164
2.4 프로세스 스택 분석 도구 171
2.4.1 환경설정 173
2.4.2 주요 기능 설명 191
2.4.3 SDPA를 이용한 성능 분석 195
프로세스이해하기
04부

목차|VIII
통신/파일상태 19803 장
3.1 파일 지시자의 이해 198
3.2 연계 통신/파일 상태 정보를 수집하는 방법 201
통신/파일간동작 20704 장
4.1 시스템 콜에 대한 이해 207
4.2 통신/파일 상태와 동작 연계 분석 210
4.3 스택 정보와 통신/파일 간 동작 연계 분석 212
4.4 통신/파일 간 동작 모니터링 방법 213
기타 21905 장
5.1 프로그램 소스코드 보기 219
5.2 바이너리 코어 덤프에서 자바 스택이나 힙 정보를
추출하는 방법 220
5.3 프로세스의 현재 작업 디렉터리를 확인하는 법 222
5.4 프로그램에서 사용하는 공유 라이브러리 확인 222
5.5 프로세스 생성 관계 보기 223
5.6 프로세스의 수행 환경 확인 224
기본방향 22701 장
불필요한작업제거 23002 장
2.1 로깅 230
2.1.1 잘못 사용된 로깅 수준 230
2.1.2 로깅을 위한 불필요한 메시지 생성 231
소스코드최적화
05부

목차 | IX
2.1.3 로깅을 효율적으로 하기 위한 개선 233
2.1.4 트랜잭션 저널 로그 234
2.2 불필요한 로직 236
2.3 반복 로직 237
로직최적화 24103 장
3.1 락 최소화 241
3.1.1 락 범위 최소화 241
3.1.2 락 제거 243
3.2 문자열 처리 개선 247
3.2.1 String.format 메서드 247
3.2.2 String.replaceAll 메서드 248
3.2.3 문자열 합치기 249
3.3 리플렉션 호출 제거 250
3.4 채번 251
3.5 날짜 연산 256
3.6 시간 문자열 처리 263
3.7 순차 검색 제거 266
3.8 파일 입출력 단위 268
3.9 SQL 270
3.10 BigDecimal 275
3.11 비대기 입출력 사용 278
3.12 기타 성능 개선 279
3.13 코드 성능 측정 281
적극적인캐시사용 28404 장

목차|X
효율적인아키텍처구성 28705 장
5.1 병렬 처리 287
5.2 통신전문 291
5.3 고객정보 조회 이력 로깅과 마스킹 293
5.4 대량 조회 프레임워크 구성 294
5.5 내부 연계시스템 295
5.6 수직확장과 수평확장 296
기본방향 30101 장
SQL튜닝을위한지본지식 30302 장
2.1 데이터베이스의 기본 구조 303
2.2 블록 단위 처리 306
2.3 캐시 IO 대 물리 IO 309
성능개선대상식별 31003 장
3.1 SQL 수행 통계 310
3.2 실행 중인 세션 상태 312
3.3 수행 중인 SQL의 수행 상태 확인 314
3.4 락 대기 317
3.5 AWR 보고서 319
3.6 StatsPack 328
SQL튜닝
06부

목차 | XI
SQL실행계획 33604 장
4.1 SQL 실행계획과 수행 결과 336
4.1.1 SQL 실행계획 보기 336
4.1.2 SQL 수행 결과 확인 338
4.2 실행계획의 이해 342
4.2.1 조인 344
4.2.2 SQL 실행계획의 동작 355
4.3 인덱스 360
4.3.1 인덱스 구조 361
4.3.2 인덱스 종류 362
4.3.3 인덱스 사용 원칙 365
4.3.4 인덱스 탐색 방식 366
4.3.5 인덱스 수와 성능 370
4.4 테이블 371
4.4.1 Direct-Path와 Conventional-Path 371
4.4.2 파티션 테이블 372
4.5 테이블 통계 보기 374
SQL성능개선 38005 장
5.1 힌트 사용 380
5.2 SQL 성능 개선 389
5.2.1 인덱스 부재 389
5.2.2 인덱스 항목 순서 390
5.2.3 LIKE에 의한 성능 저하 392
5.3.4 테이블 조인 이상 392
5.3.5 실행 횟수와 조인 393

목차|XII
기본방향 39901 장
중복SQL수행제거 40102 장
2.1 애플리케이션 캐시의 종류 402
2.1.1 블록 캐시 402
2.1.2 요청 캐시 403
2.1.3 사용자 세션 캐시 404
2.1.4 프로세스 캐시 404
2.1.5 프로세스간 공유 캐시 405
2.1.6 캐시 특성 분류 406
2.2 요청 캐시 구현 코드 407
2.3 캐시 적용 411
불필요한SQL수행제거 41403 장
최적수행 41904 장
4.1 Rownum 추가 419
4.2 파티션 키 추가 425
4.3 조회 항목 사용 여부(테이블 조인 제거) 430
쿼리통합 43105 장
5.1 메인/서브 쿼리 431
5.2 병렬 쿼리 통합 432
애플리케이션입장에서의SQL튜닝
07부

목차 | XIII
DB집합처리 43306 장
트랜잭션처리 43507 장
기타 43708 장
8.1 복합적인 기능을 수행하는 쿼리 제거 437
8.2 스칼라 서브 쿼리 사용 시 주의사항 441
8.3 페이징 처리 443
배치성능개선 44709 장
9.1 전체 테이블 탐색 448
9.2 파티션 453
9.3 해시 조인 454
9.4 병렬 처리 457
9.5 쿼리 통합 459
9.5.1 메인리더와 건별 처리 쿼리 통합 459
9.5.2 메인리더와 Insert 통합 462
9.5.3 Select / Insert / Update 통합 463
9.6 자바 배치 모니터링 방안 464
APM활용 47110 장
10.1 스카우터 473

목차|XIV
기본방향 48301 장
CPU 48602 장
2.1 사용량 분석 486
2.2 CPU 확인 488
2.3 동시 다중 스레딩 489
2.4 CPU를 많이 사용하는 스레드 식별하기 491
2.5 프로세스의 누적 CPU 사용량 확인하기 492
2.6 CPU를 많이 사용하는 모듈(코드) 식별하기 494
메모리 50903 장
3.1 가상 메모리 510
3.2 메모리 관련 주요 용어 511
3.3 사용량 분석 513
3.4 메모리 확인 520
디스크 52104 장
4.1 사용량 분석 521
4.2 유닉스/리눅스 디스크 관리 532
4.3 파일시스템의 입출력 방식 537
4.3.1 비동기 입출력 537
4.3.2 직접 입출력 538
4.3.3 동시 입출력 539
4.4 스토리지 543
서버OS모니터링
08부

목차 | XV
4.5 레이드 545
4.5.1 레이드 0 – 스트라이핑 545
4.5.2 레이드 1 – 미러링 546
4.5.3 레이드 0+1 - 스트라이핑과 미러링 546
4.5.4 레이드 4 – 스트라이핑과 전용 패리티 547
4.5.5 레이드 5 – 스트라이핑과 분산 패리티 547
통합모니터링도구 54805 장
5.1 nmon 548
5.2 topas 552
5.3 GlancePlus 553
5.4 top 559
기본방향 56301 장
바이너리메모리관리 56402 장
2.1 메모리 누수 조사 570
2.1.1 윈도우 571
2.1.2 AIX 576
2.1.3 솔라리스 578
2.1.4 HPUX 585
2.1.5 리눅스 589
2.1.6 기타 592
프로세스의메모리구조
09부

목차|XVI
자바메모리관리 59303 장
3.1 JVM 메모리 구조 593
3.2 가비지 컬렉션 594
3.3 오라클/HP JVM의 힙 메모리 구조 595
3.4 오라클/HP JVM의 GC 방식 598
3.4.1 Serial GC(-XX:+UseSerialGC) 598
3.4.2 Incremental GC(-Xincgc) 598
3.4.3 Parallel GC(-XX:+UseParallelGC) 599
3.4.4 Parallel Old GC(-XX:+UseParallelOldGC) 599
3.4.5 Concurrent Mark and Sweep(CMS) GC GC
(-XX:+UseConcMark SweepGC) 600
3.4.6 Garbage First(G1) GC(-XX:+UseG1GC) 602
3.4.7 GC 선정 기준 605
3.5 IBM JVM의 메모리 구조 609
3.5.1 단일 공간 메모리 구조 610
3.5.2 Generation space 메모리 구조 613
3.6 IBM JVM의 GC 방식 614
3.7 자바 힙 메모리 누수 615
3.8 자바 힙 메모리 모니터링 623
3.8.1 jstat 624
3.8.2 모니터링 콘솔 626
3.8.3 GC 로깅 629
3.9 자바 힙 덤프 수집 637
3.9.1 jmap 638
3.9.2 이벤트 설정 639
3.9.3 HPROF 640
3.10 메모리 분석(이클립스 MAT 1.2.1 버전) 644
3.10.1 시작하기 646
3.10.2 화면 구성 647
3.10.3 주요 용어 설명 648
3.10.4 주요 메뉴 655

목차 | XVII
기본방향 66501 장
네트워크기초 66702 장
2.1 OSI 7 계층 668
2.2 TCP/IP와 UDP/IP 670
2.3 스위치 671
2.4 운영체제별 네트워크 설정 확인 672
IP 67403 장
3.1 기본 개념 674
3.1.1 IP 주소 674
3.1.2 IP 주소의 클래스 676
3.1.3 IP 주소의 사이더 677
3.1.4 서브넷 마스크 678
3.1.5 게이트웨이 679
3.1.6 점보 프레임 680
3.2 IPv6 681
3.3 IP 프로토콜 네트워크 체크 명령 681
3.3.1 호스트 IP 설정 확인 681
3.3.2 Ping 명령 683
3.3.3 호스트의 라우팅 테이블 확인 686
3.3.4 Trace route 명령 687
3.3.5 nbtstat 명령 689
네트워크모니터링
10부

목차|XVIII
TCP 69004 장
4.1 기본 개념 690
4.2 TCP 전송 보장 698
4.2.1 전송 보장 알고리즘 698
4.2.2 선별적인 ACK 705
4.3 전송 제어 706
4.3.1 수신 윈도우 707
4.3.2 송신 윈도우 708
4.3.3 슬라이딩 윈도우 711
4.4 네이글 알고리즘 712
4.5 TCP KeepAlive 716
4.6 TCP 프로토콜 네트워크 체크 717
4.6.1 telnet [IP address] [port] 명령 717
4.6.2 netstat –an 명령 719
4.6.3 netstat –s –p [protocol] 명령 720
UDP 72505 장
기타프로토콜 72706 장
6.1 DNS 727
6.2 FTP 730

목차 | XIX
네트워크데이터수집방법 73207 장
7.1 유닉스/리눅스 공통 733
7.2 HP-UX 736
7.3 IBM AIX 737
7.4 오라클 솔라리스 738
7.5 윈도우 739
네트워크패킷분석(와이어샤크1.10.6버전) 741
08 장
8.1 화면 구성 741
8.1.1 패킷 목록 743
8.1.2 패킷 프로토콜 정보 743
8.2 필터링 744
8.3 기초 분석 메뉴 748
8.5 응답시간 분석 751
8.5.1 네트워크 시간 752
8.5.2 서버 시간 754
8.5.3 클라이언트 시간 755
8.6 전문 분석 756
8.7 재전송 분석 757
8.8 와이어샤크를 이용한 성능 분석 760

시스템 성능 개선과 문제해결 분야에서 15년간 활동하면서 쌓인 경험을 정리해 후배와 성능 관련
업무를 시작하는 분들에게 도움이 되고자 이 책을 씁니다.
성능 개선과 관련해서 데이터베이스 SQL 튜닝을 다룬 책은 시중에 많이 있고, 데이터베이스 최적화
전문가 시장도 상당히 큽니다. 하지만 실제 업무 로직이 수행되는 애플리케이션 코드 측면에서 성능
을 분석하고, 데이터베이스에 접근하는 책은 거의 없을 뿐 아니라 시장에서 애플리케이션 최적화 인
력은 찾기도 어려운 실정입니다. 애플리케이션 최적화 전문가는 서버와 데이터베이스부터 업무 로
직까지 복합적인 지식이 필요하기 때문에 진정한 시스템 최적화 전문가라고 할 수 있습니다.
이 책에서는 단순한 성능 개선 프로세스와 원칙에 대한 원론적인 설명은 최소화하고, 기술적인 내용
을 중심으로 업무에 도움될 수 있는 실질적인 성능 분석과 개선 사례 위주로 내용을 담았습니다. 시
스템 성능은 서버, 애플리케이션, 데이터베이스, 네트워크에 관한 개별 지식만으로는 분석하는 데
한계가 있습니다.
성능 개선을 위해서는 각 기술 요소의 특성과 동작 방식을 전체 시스템 관점에서 이해하고 분석할
수 있는 능력이 필요하므로 새로운 신기술보다는 프로그램 동작을 정확히 분석할 수 있는 기초 지식
에 대한 이해도가 높아야 합니다. 그래서 이 책에서는 애플리케이션과 다소 연관성이 떨어져 보이
는 운영체제, 네트워크 같은 부분에 대한 기초 지식을 다룸으로써 독자의 시스템 이해도를 높이려고
노력했습니다. 기술 영역은 기반 기술이라 할 수 있는 HTTP, 자바, 오라클 데이터베이스, 유닉스,
TCP/IP를 중심으로 기술했습니다.
시작하며

3시작하며
성능을 개선할 때는 서비스를 처리하는 각 구성 요소의 처리시간을 세분화해서 성능 분석을 해야
합니다. 그러나 처음 접하거나 구성이 복잡한 시스템을 효과적으로 세분화해서 측정한다는 것은 쉬
운 과정이 아닙니다. 그래서 효율적으로 시스템의 동작 방식과 구성을 이해하고 분석할 수 있게 지
원하는 적절한 모니터링 도구의 선정이 무엇보다 중요합니다.
그러나 인터넷을 검색해 보면 수많은 성능 개선과 문제해결 사례가 있고, 업무에 참조할 수 있는 모
니터링 도구도 많지만 이것들을 체계적으로 정리한 사이트나 책이 없는 것이 현실입니다. 그래서 모
니터링 도구를 단순히 나열하는 것으로도 보일 수 있지만 시스템의 각 부분에 적용 가능한 모니터링
도구를 최대한 많이 다루고, 실제로 사용하는 모습을 담아 독자의 이해를 조금이나마 높이고자 했습
니다.
성능 개선은 대상 시스템이 어떤 기능을 수행하는 데 시간과 자원을 많이 사용하는지 파악하는 것에
서 출발합니다. 이 연장선 상에서 성능을 이해하는 데 각 도구를 어떤 용도로 활용할 수 있는지 생각
하면서 이 책을 읽으면 도움될 것입니다.
마지막으로 집필이라는 새로운 일을 할 수 있게 힘이 되어준 사랑하는 아내 경선과 두 아들 지용, 지
훈, 그리고 책 출판을 처음 제안해 준 동기 김창선에게 고마움을 전합니다.
01성능기초
부

일반인에게 물을 보내는 파이프의 성능이 무엇인지 물어본다면 “시간당 보내는 물의 양”이라고 대
부분 답할 것이다. 그리고 파이프의 성능에 영향을 미치는 요소는 물이 흐르는 속도와 파이프의 직
경이라고 대답할 것이다.
이는 대부분의 사람들이 성능의 의미를 이미 알고 있다는 뜻이다. 파이프의 직경이 동일한 경우
10M/sec 속도로 보내는 파이프가 5M/sec로 보내는 파이프에 비해 시간당 보내는 물의 양이 2배
많으므로 성능 측면에서도 2배라고 말할 수 있다.
시스템 성능도 파이프의 성능과 동일하다. 시스템 성능은 시간당 처리량이며, 영향을 미치는 요소는
응답시간과 동시에 처리할 수 있는 프로세스 수다.
직경
속도 응답시간
파이프시스템
프로세스 수
[그림 1-1] 성능에 영향을 미치는 요소
파이프에 끈적끈적한 기름을 보내는 경우에는 기름의 성질 때문에 흘러가는 속도가 느려져 물을 보
내는 경우에 비해 같은 시간 동안 보낼 수 있는 양이 줄어든다. 이것은 동일한 파이프라고 하더라도
성능이란?
01장

1부 _ 성능 기초6
어떤 내용물을 보내느냐에 따라 성능이 달라진다는 것을 의미한다. 시스템도 마찬가지다. 고객의 업
무 특성과 아키텍처에 따라 응답시간에 차이가 나타나고 성능도 달라진다.
응답시간은 사용자의 특성과 환경에 따라 요구하는 수준이 다르므로 동일한 응답시간에 대해 고객
마다 만족도는 다르게 나타난다. 이는 모든 시스템과 사용자에게 일률적으로 적용할 수 있는 응답시
간의 기준은 없다는 것을 의미한다.
앞에서 설명한 내용을 종합하면 성능을 다음과 같이 정의할 수 있다.
“고객의 특정 업무를 대상으로 운영환경하에서 고객이 수긍할 수 있는 응답시간 내에 처리할 수 있
는 거래량”
이어서 성능을 평가할 때 일반적으로 사용하는 용어를 설명하겠다.
1.1동시사용자
성능 테스트나 운영 시 시스템에 발생하는 부하(Load)의 의미로 많이 사용되는 용어가 바로 동시
사용자(Concurrent User)다. 하지만 동시 사용자에 대한 정의를 개발자와 업무담당자 간에도 다르
게 해석하는 경우가 많다. 일반적으로 “시스템과 접속을 유지하고 있는 사용자 수”로 해석되지만 일
부는 “동시(일정 시점)에 시스템에 트랜잭션을 유발시키는 사용자”로 해석하기도 한다. 고객이 의미
하는 동시 사용자가 동시 부하를 발생시키는 후자의 의미였는데, 접속 사용자로 해석했다면 측정 값
은 신뢰를 완전히 잃어버리고 만다.
성능 분석이나 테스트 시 공식적으로 적용되는 동시 사용자라는 의미는 대상 서버에 접속하고 있는
사용자로 정의한다. 현재 일반화돼 있는 웹 기반 시스템의 경우 비연결 상태로 서버와 접속 및 인증
상태가 유지되는데, 이 경우에도 사용자가 화면을 보고 있거나 입력하고 있다면 동시 사용자에 포함
된다.
동시 사용자는 아래와 같이 다시 두 유형으로 나뉘며, “동시 사용자 수 = 요청 사용자 수 + 비요청
사용자 수”라는 공식이 성립한다.
1. 요청 사용자(Active user): 대상 서버에 부하를 발생시키고 있는 사용자로서 서버에 서비스를 요청한 후 응답을 기
다리고 있는 사용자
2. 비요청 사용자(Inactive user): 대상 서버에 접속해 화면 내용을 읽고 있거나 화면에 값을 입력하는 중이라서 현재
서버에 서비스 요청을 보내고 있지 않는 사용자

71장. 성능이란?
1.2처리량
처리량(throughput)은 서버가 일정 시간 내에 처리한 트랜잭션(transaction)의 양이다. 그런데 서
버가 인식하는 트랜잭션과 사용자가 인식하는 트랜잭션은 다르다. 예를 들어, 어떤 웹 기반 고객정
보 조회 화면이 12개의 이미지, CSS(Cascading Style Sheets), JS(JavaScript)와 메인 JSP(Java
Server Pages), 그리고 5개의 AJAX(Asynchronous JavaScript and XML) 호출로 이뤄져 있고,
JSP와 AJAX 호출 중 3개에 DB 호출이 있고 100개의 쿼리가 수행된다고 가정해 보자. 아래와 같이
각 서버 입장에서 트랜잭션을 보면 서버의 역할과 화면을 구성하는 방식에 따라 트랜잭션 수가 달라
진다.
[표 1-1] 서버별 트랜잭션 수
서버 구분 트랜잭션 수 트랜잭션 구성
웹 18 이미지/CSS/JS 12개 + JSP 1개 + AJAX 5개
애플리케이션 6 JSP 1개 + AJAX 5개
DB 100 JSP/AJAX 3개에서 100개 쿼리 수행(DB 트랜잭션 처리 3개)
하지만 해당 서비스를 요청하는 고객 입장에서는 고객 조회라는 1개의 트랜잭션을 보냈을 뿐이으로
서버 입장에서의 트랜잭션과는 다르다.
성능에서 중요한 것은 DB가 데이터를 몇 건 처리하고, 웹 서버가 이미지나 CSS 콘텐츠를 몇 건 처
리했는가가 아니라 고객의 업무를 얼마나 빨리 처리할 수 있는가다. 따라서 처리량의 평가 단위로서
TPS(Transaction Per Second)의 “T”는 고객의 업무 처리 건수가 되는 것이 고객과의 의사소통
을 위해서나 업무 시스템을 평가하는 데 적합하다.
그러나 시스템을 설계하고 분석하는 엔지니어 입장에서는 서버가 인식하는 트랜잭션 또한 시스템을
이해하고 개선 방향을 수립하는 데 중요한 의미를 지닌다. TPS 이외의 처리량 평가 단위로 PPS와
HPS가 있다.
1. PPS(Page Per Second)
웹 성능을 분석할 때는 화면 단위(Page)를 트랜잭션 평가 단위로 사용하기도 한다.
“사용자 등록 화면 → (ID 입력) → ID 중복 확인 화면 → 주소 검색 초기 화면 → 주소 검색 결과 화면 → (기타 정보
입력) → 사용자 등록 성공 화면” 단계로 사용자 등록 흐름이 구성돼 있다면 PPS 관점에서의 처리량은 화면이 전환
되는 기준으로 5가 된다.
그러나 업무를 기준으로 한 TPS 관점에서의 처리량은 사용자 등록이라는 하나의 업무이므로 1이 된다.

1부 _ 성능 기초8
2. HPS(Hit Per Second)
웹 서버에서 이미지, 스크립트 파일, 스타일 파일, JSP, ASP 등 모든 컴포넌트는 별개의 요청으로 구성되며, 각각이
1개의 Hit가 된다. 따라서 HPS를 측정 단위로 삼는다면 TPS나 PPS에 비해 세분화된 것으로 볼 수 있다.
그동안의 경험을 비춰볼 때 대부분의 시스템은 최대 500TPS 이내인 것이 일반적이다. 은행의 뱅킹
시스템이나 통신사의 고객정보시스템과 과금시스템 같은 시스템 정도가 돼야 1,000TPS가 넘는다.
1.3응답시간
응답시간은 요청(Request)한 후부터 응답(Response)을 받을 때까지 소요된 시간으로, 측정하는
위치에 따라 여러 유형으로 나뉜다.
1. 클라이언트 응답시간
사용자가 요청한 후부터 화면에 응답이 나타날 때까지 경과된 시간을 의미한다. 따라서 클라이언트 내부 처리시간
도 포함된다.
그리고 화면이 보이기 시작할 때를 기준으로 할지, 화면이 완성됐을 때를 기준으로 할지에 따라 응답시간이 달라진
다. 성능 개선에서는 사용자가 느끼는 감성 측면의 응답시간도 중요한 요소로서 진행상태 표시 등 화면을 구성하는
방식과 응답이 보이기 시작하는 시점 같은 것도 개선의 대상이 된다.
클라이언트 응답시간을 세분화하면 클라이언트 내부 처리시간과 네트워크 응답시간으로 나눌 수 있으며, 내부 처리
시간은 다시 화면 렌더링 시간과 클라이언트 로직 처리시간으로 나뉜다.
2. 네트워크 응답시간
사용자 요청이 클라이언트(PC) 네트워크에서 전송된 후부터 응답이 클라이언트 네트워크에 도착하는 데까지 경
과된 시간을 의미한다. 대표적인 성능 테스트 도구인 HP사의 로드러너(LoadRunner)1는 웹 테스트를 수행할 때
HTTP/HTTPS 프로토콜을 기반으로, TP Monitor 테스트 시에는 TP API Call 기반으로 응답시간 측정이 이뤄지므
로 클라이언트 로직 처리와 화면 렌더링 시간은 제외돼 있다. 따라서 HTTP나 TP Monitor 테스트 시에 측정된 로드
런너 응답시간은 네트워크 응답시간이다.
네트워크 시간을 세분화하면 DNS 룩업 시간과 서비스 업로드/다운로드에 소요된 네트워크 시간, 그리고 서버 응답
시간으로 구분된다.
3. 서버 응답시간
서버가 사용자 요청을 받은 후부터 처리 결과를 내보내는 데까지 경과된 응답시간이다. 웹 액세스로그나 애플리케
이션 서버 로그 혹은 APM(Application Performance Management) 기반으로 측정하는 경우가 여기에 해당한다.
서버 응답시간을 세분화하면 웹 서버, 애플리케이션 서버, 데이터베이스 서버 내의 각 처리시간과 대내외 타 시스템
연계 응답시간으로 나뉜다.
1 http://www8.hp.com/kr/ko/software-solutions/loadrunner-load-testing/

91장. 성능이란?
4. 연계 응답시간
서버 처리 중 대외 기관이나 내부 타 시스템과 연계해서 처리할 경우 대내외 연계 서버에 요청을 보내 응답을 받기
까지 경과된 시간이다.
대외 기관과 연계된 서비스의 경우 전체 응답시간에서 대외기관의 응답시간을 구분해서 관리하는 것은 성능 분석
및 개선 시 접근 방향을 설정하기 위한 중요한 기초 데이터가 된다.
대내외 연계 응답시간은 연계 서버(FEP, ESB) 내 처리시간과 연계 서버를 기준으로 한 타 시스템과의 네트워크 응
답시간과 서버 응답시간으로 구분할 수 있다.
네트워크 응답시간
클라이언트 응답시간
서버 응답시간
연계 응답시간
클라이언트 처리시간
렌더링 화면 로직
DNS
웹
업로드
애플리케이션 데이터베이스 연계 서버 타 시스템
다운로드 서버 처리시간
네트워크 처리시간
[그림 1-2] 응답시간 구분
당연히 측정하는 위치가 서버에 가까워질수록 응답시간은 줄어들어 실 사용자가 체감하는 응답시간
과 차이가 발생한다. 따라서 정확한 성능 분석을 위해서는 실 사용자가 위치한 곳에서 클라이언트
응답시간을 측정하는 것이 가장 정확하다.
단순평가를 위한 측정이라면 응답시간만 측정해도 무방하지만 성능 개선을 목적으로 한다면 전체
응답시간 이외에 내부 각 구성 요소에 대해 세분화된 처리시간을 수집하고 분석해야 성능 개선을 어
느 부분에 집중할지 대상을 설정할 수 있다. 따라서 성능 개선 작업을 예정하고 있다면 처리시간을
세분화해서 측정할 수 있는 방안을 수립하는 것이 선행돼야 한다.
성능 개선에서는 “아는 만큼 보인다”라는 진리가 “보이는 만큼 개선할 수 있다”로 연결된다. 클라이
언트, 웹 서버, 애플리케이션 서버, 데이터베이스 서버, 연계 서버 등 많은 서버에 대해 모두 측정할
수 있는 방안을 마련해야 할까? 그렇지는 않다.
사용자가 응답시간이 느리다고 하면 클라이언트 응답시간을 기준으로 분석을 시작할 것이다. 클라
이언트 응답시간 분석을 통해 오래 걸리는 부분이 클라이언트 내부인지, 네트워크인지, 화면 콘텐츠
나 서비스 요청 구성 때문인지, 서버 내부인지 구분할 수 있다.
1부 _ 성능 기초10
서버의 성능이 나쁘다면 애플리케이션 서버를 중심으로 성능을 분석한다. 애플리케이션 서버는 가
장 중요한 핵심 업무 로직이 존재하고, 애플리케이션 서버를 기준으로 웹 서버를 포함한 앞단 처리
시간, 데이터베이스 처리시간, 애플리케이션 내부 처리시간, 연계 서버 처리시간 등을 구분해서 측
정할 수 있어 서버 한 곳에서 측정하지만 가장 세분화된 처리시간을 얻을 수 있는 곳이다. 그래서 성
능을 분석할 때 애플리케이션 서버에서 모니터링하는 제니퍼 같은 APM이 핵심적인 역할을 하는 것
이다.
그러나 성능 개선 전문가라면 모든 시스템에 APM과 같은 모니터링 도구가 설치돼 있는 것은 아니
므로 애플리케이션 서버나 연계 서버에 대해 세부 응답시간을 분석할 수 있는 능력을 갖춰야 한다.
필요에 따라서는 APM에서 보여주는 측정 데이터 이상으로 더욱 세분화해서 분석해야 하는 경우도
많다.
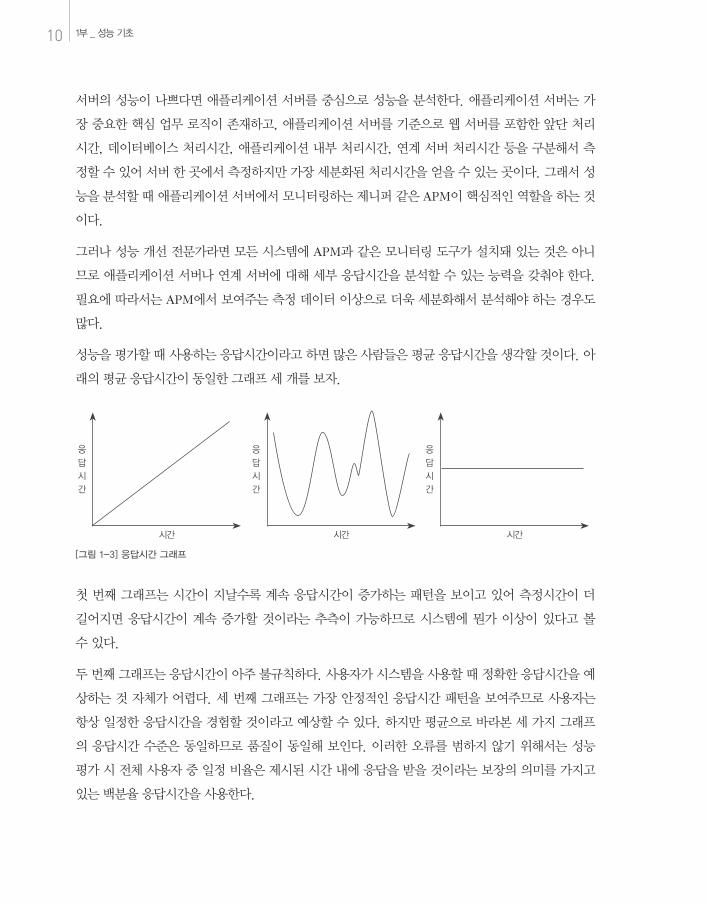
성능을 평가할 때 사용하는 응답시간이라고 하면 많은 사람들은 평균 응답시간을 생각할 것이다. 아
래의 평균 응답시간이 동일한 그래프 세 개를 보자.
응
답
시
간
응
답
시
간
응
답
시
간
시간 시간 시간
[그림 1-3] 응답시간 그래프
첫 번째 그래프는 시간이 지날수록 계속 응답시간이 증가하는 패턴을 보이고 있어 측정시간이 더
길어지면 응답시간이 계속 증가할 것이라는 추측이 가능하므로 시스템에 뭔가 이상이 있다고 볼
수 있다.
두 번째 그래프는 응답시간이 아주 불규칙하다. 사용자가 시스템을 사용할 때 정확한 응답시간을 예
상하는 것 자체가 어렵다. 세 번째 그래프는 가장 안정적인 응답시간 패턴을 보여주므로 사용자는
항상 일정한 응답시간을 경험할 것이라고 예상할 수 있다. 하지만 평균으로 바라본 세 가지 그래프
의 응답시간 수준은 동일하므로 품질이 동일해 보인다. 이러한 오류를 범하지 않기 위해서는 성능
평가 시 전체 사용자 중 일정 비율은 제시된 시간 내에 응답을 받을 것이라는 보장의 의미를 가지고
있는 백분율 응답시간을 사용한다.

111장. 성능이란?
백분율 응답시간은 측정시간 동안 발생한 모든 트랜잭션을 응답시간이 빠른 것부터 일렬로 줄을 세
워 트랜잭션 전체 수 대비 해당 %(th)에 위치한 응답시간을 의미한다.
응답시간
트랜잭션
100%90%80%70%50%
Max
Min
[그림 1-4] 백분율 응답시간 그래프
측정시간 동안 200개의 트랜잭션이 발생했고, 가장 응답시간이 빠른 것부터 줄을 세워 180등을 기
록한 트랜잭션의 응답시간을 봤더니 3.5초였다고 한다면 해당 업무의 90% 응답시간은 3.5초가 되
는 것이다.
90th 응답시간 3.5초 = 200 * 0.9(90%)등을 기록한 트랜잭션의 응답시간
170등을 기록한 트랜잭션의 응답시간이 3초라면 85% 응답시간이 되는 것이다.
85th 응답시간 3.0초 = 200 * 0.85(85%)등을 기록한 트랜잭션의 응답시간
90th 응답시간이 3.5초라면 해당 업무를 사용하는 전체 사용자의 90%는 3.5초 이내의 응답시간을
경험하리라고 보장하는 의미를 가지고 있어 성능 평가에 효과적이다. 그런데 혹시 이런 생각을 하는
독자도 있을 것이다.
“그럼 100% 응답시간을 사용하면 전체 거래에 대한 응답시간이 보장되어 좋겠네”
시스템을 개발해서 운영해 보신 분이라면 운영 환경에서도 예상치 못한 응답시간을 보이는 경우가
종종 있다. 사용자가 입력한 데이터의 특성, 시스템 내부 자원의 순간적인 부족 등의 이유로 항상 1
초 이내에 처리되던 업무가 5초에서 10초 이상 걸리는 경우도 발생한다.

1부 _ 성능 기초12
이러한 예외적인 상황이 발생했을 때 응답시간을 성능 평가에서 제외하는 목적으로도 백분율 응
답시간을 사용한다. 따라서 통상적인 업무 시스템에서는 100% 응답시간을 사용하는 경우가 없고
90% 응답시간을 사용하는 것이 일반적이다. 다만 핵심 기간계 시스템에서는 95% 응답시간을 사용
하는 경우도 있다.
평균 응답시간을 성능 평가 기준으로 정했다면 평균 응답시간 외에 표준편차와 최솟값, 최댓값도 함
께 표기해야 성능을 판단할 수 있다. 평균 응답시간이 동일하더라도 표준편차가 작은 것이 안정적인
응답시간을 제공한다는 것을 의미하고, 최솟값과 최댓값의 차이가 너무 크다면 측정 시 시스템에 이
상이 있거나 예상치 못한 대량의 데이터 처리가 있었다는 것을 의미한다. 성능에서 평균 응답시간이
의미를 가지려면 일반적으로 표준편차가 평균 응답시간의 1/3 이하여야 한다.
1.4자원
성능에서 자원(Resource)은 다양한 시스템 구성 요소를 지칭하는 포괄적인 용어다. 서버의 CPU,
메모리, 디스크, 네트워크 자원부터 WAS(Web Application Server)의 스레드 풀, DB 연결 풀, 힙
메모리, 그리고 DB의 최대 프로세스 수, 오픈 가능한 커서 수, 공유 캐시 메모리 크기 등 물리적인
자원부터 시스템 소프트웨어의 설정값에 이르기까지 다양한 자원이 있다.
그럼 성능 측면에서 자원은 어떻게 정의할 수 있을까? 성능 측면에서 자원은 한정된 값을 가진 시스
템 구성 요소 중 애플리케이션이 동작할 때 사용하며, 부족한 경우나 사용량 변화에 따라 성능에 영
향을 미치는 요소를 의미한다. 자원은 목표 성능을 달성할 수 있게 하는 중요 기반요소로서, 성능 평
가나 분석 시 자원 사용량도 모니터링해서 다음과 같은 관점에서 평가한다.
1.4.1적정성
적정성(Suitability)은 핵심 항목으로, 자원 사용량에 대한 목표 달성과 부족 여부를 확인하는 것이
다. 자원이 부족한 경우 경합과 대기가 발생해 성능이 저하되므로 늘려줘야 하지만 다른 자원에 악
영향을 주어 개선 효과를 보지 못할 수도 있고, 다른 자원 부족의 여파로 영향을 받은 부수적인 부족
문제일 수도 있으므로 세심한 판단과 대응이 필요하다.
예를 들어, WAS 스레드 풀(Thread pool)에 있는 모든 스레드들이 작업 중이라서 새로 요청하는
서비스가 큐잉되고 있다고 하자. 이때 스레드 풀 설정이 부족하다고 판단해 일방적으로 늘려서는 안
된다. 당시 CPU나 자바 힙 메모리와 같은 인프라 자원의 상태와 애플리케이션 상의 락이나 DB 내

131장. 성능이란?
저성능 쿼리 존재 여부 등과 같은 애플리케이션 상태를 종합적으로 판단해 스레드 풀 자원의 설정을
늘려줄지 또는 다른 방안을 모색할지 결정해야 한다.
이미 CPU 사용량이 90% 이상이라면 스레드 풀을 늘려봤자 무슨 소용이 있겠는가? 이때는 오히려
스레드 풀을 줄여서 CPU가 70% 내외의 안정적인 범위에 있게 함으로써 성능을 개선할 수도 있다.
각 자원의 부족 여부를 판단할 때는 다른 자원과의 상관관계와 인과관계를 잘 파악해서 평가해야
한다.
1.4.2효율성
어떤 두 시스템이 동일한 업무를 수행하지만 아키텍처 구조는 다르다고 하자. 이 두 시스템을 평가
하는 기준은 TPS와 응답시간이 핵심이겠지만 업무를 처리하면서 사용한 자원 사용량 또한 중요 평
가 기준이 된다. 동일한 TPS를 기준으로 할 때 CPU나 메모리를 적게 사용하는 시스템이 효율적으
로 작업을 수행한 것이다. 시스템 구축과 운영 시 효율성(Efficiency)은 직접적인 비용에 영향을 미
치는 요소로서 BMT(Benchmark Test) 같은 성능 비교 평가에서는 중요 평가지표가 된다.
그리고 성능 개선이라는 작업 자체가 시스템의 효율성을 높이려는 활동이다. 응답시간을 줄인다는
것은 DB 사용을 줄이고, 애플리케이션 코드의 수행시간을 줄여 시스템 자원을 더 적게 사용하도록
개선함으로써 효율성을 높이는 것이다.
1.4.3안정성
안정성(Stability)은 시스템 운영시간이 지남에 따라 성능이 저하되거나 장애가 발생하는 등의 문제
가 발생하지 않아야 한다는 것이다. 메모리나 DB 연결에 누수가 있다면 애플리케이션을 재기동하
지 않는 이상 언젠가는 해당 자원의 부족으로 장애가 발생할 것이고, 데이터가 증가함에 따라 응답
시간이 서서히 증가한다면 언젠가는 성능 저하로 사용에 불편을 느끼게 될 것이다.
시스템에 일정한 부하가 발생했을 때 시간이 지나더라도 응답시간이나 자원 사용량이 일정하게 유
지되는지 확인하는 것이 시스템 자원에 대한 안정성 평가다.
1.4.4가용성
가용성(Availability)은 일정 기간(년) 동안 시스템이 정상적으로 서비스된 시간 비율을 의미한다.
카드 승인시스템, 인터넷 쇼핑몰, 홈쇼핑 송출시스템 같은 시스템은 해당 사업에서 매출을 창출하는

1부 _ 성능 기초14
핵심 기반 시스템으로서, 장애는 사업 기회의 손실로 이어지므로 100%에 가까운 가용성을 유지하
고자 각 회사들은 이중화 구성이나 DR 구축 등에 투자하며 노력한다.
그런데 문제는 이중화만 돼 있다고 가용성이 향상되는 것은 아니라는 점이다. 서버 구성이 이중화된
경우 대부분 모든 서버를 동작 상태로 운영하므로 자원에 여유가 있어 안정적인 서비스가 가능했을
것이다. 문제는 일부 장비의 장애로 가용자원이 줄었을 때도 정상적인 서비스가 이뤄져야 한다는 것
이다. 정상적인 서비스라면 시스템에 일부 장애가 발생하더라도 사용자가 큰 불편 없이 업무 처리가
가능한 수준으로 성능이 확보돼야 한다. 그래서 가용성 테스트를 할 때 서비스 중단시간과 서비스
안정성 외에 응답시간, TPS, 자원 사용량 변화와 같은 성능지표도 함께 측정해서 평가한다.
1.4.5확장성
확장성(Scalability)은 향후 시스템 사용량 증가에 따라 시스템 증설이 필요할 때 각 자원이 얼마나
용이하게 증설될 수 있는가를 평가하는 것이다. 이것은 현 시스템 성능에 대한 평가는 아니지만 운
영 시 향후 처리량과 성능 변화에 따라 유연한 대응이 가능하도록 구성해야 한다는 측면에서 이뤄지
는 평가다.
확장성은 크게 수직 확장(Scale up)과 수평 확장(Scale out)으로 나눠서 평가한다. 수직 확장은 현
재 사용 중인 서버 내의 주요 자원을 증설해 한 서버에서 처리할 수 있는 용량을 확장하는 것이고,
수평 확장은 동일한 기능을 수행하는 서버의 대수를 늘려서 처리 용량을 확장하는 것이다. 따라서
서버 수직 확장의 경우 CPU와 메모리 증설이 가능한 빈 슬롯이 현재 사용량 대비 얼마나 남아 있느
냐가 관건이다. 수평 확장은 서버의 하드웨어적인 한계에 영향을 받는 것이 아니라 서버 내에서 동
작하는 소프트웨어가 수평 확장을 지원하느냐가 관건이다. 서버 한 대는 증설 한계가 존재하고, 초
기에 도입할 때 필요 이상으로 큰 서버를 도입하는 경우는 드물기 때문에 수직 확장은 수평 확장에
비해 확장성이 떨어지는 것으로 평가한다. 통상 DB 서버는 수평 확장에 한계가 있어 수직 확장을
주로 고려하지만 웹 서버나 WAS 서버는 수평 확장에 대한 유연성을 갖추고 있다.

5.1힌트사용
SQL의 실행계획은 옵티마이저가 판단해서 최적 경로를 설정하게 하는 것이 바람직하다. 관리자는
옵티마이저가 제대로 된 판단을 할 수 있게 테이블 액세스 경로 유형에 맞는 인덱스와 테이블 통계
를 적절하게 만들어 주면 된다.
그런데 복잡한 조인 관계와 옵티마이저의 기능적 한계로 인해 불합리한 실행계획이 만들어지기도
한다. 이런 경우에는 SQL 문에 힌트를 제공해 실행계획을 바로잡아야 한다. 그런데 말 그대로 옵티
마이저에게 힌트를 주는 것으로 옵티마이저가 100% 힌트를 따르는 것은 아니다. 그래서 SQL을 일
부 변형해야 하는 경우도 있다.
SQL 힌트는 SELECT 바로 뒤에 /*+hints */ 내에 기술된다. 그리고 힌트 내에 테이블명을 기입할
때는 테이블명과 테이블명의 축약된 가명(Alias)도 사용 가능하다.
SELECT /*+ INDEX(A TEST001IX) USE_HASH(A B) */ A.*
FROM TEST001 A, TEST002 B
WHERE A.KEY1 = B.KEY1
AND A.KEY2 = B.KEY2
AND B.DIVISION NOT IN (SELECT /*+ HASH_AJ */ CODE
FROM COM001 WHERE DIV = '001' AND CODE != '0000')
INSERT /*+ APPEND */ INTO TEST001 VALUES(:1, :2, :3, :4, :5, :6)
[그림 6-61] SQL 힌트 표기 예
SQL성능개선
05장
힌트 기술 부분

3815장. SQL 성능 개선
옵티마이저 정책 변경
FIRST_ROWS를 사용하면 첫 번째 레코드를 조회하는 데 가장 빠른 내포 조인을 사용하는 빈도가
높아지는 반면 ALL_ROWS를 사용하면 병합 조인이나 해시 조인으로 실행계획이 수립될 가능성이
높아진다. 이 힌트는 데이터베이스 설정에 지정된 기본 옵티마이저 정책을 쿼리 단위에서 변경할 때
사용한다.
[표 6-26] 옵티마이저 정책 변경 힌트
힌트 설명
ALL_ROWS SQL의 전체 결과를 처리하는 데 최적화된 실행계획을 수립하도록 유도한다. 즉, 처리량 기준으로
최적화되어 전체 자원 사용량이 절약되게 한다.
FIRST_ROWS
FIRST_ROWS(n)
SQL의 조회 결과 중 첫 번째 레코드가 조회되는 시간이 짧은 실행계획을 수립한다. n은 건수를
의미하며, 해당 수만큼 조회하는 데 최적화되도록 유도한다.
테이블 조인 순서 유도
조인 순서는 성능에 큰 영향을 미치는 항목 중 하나로 다수의 테이블을 조인하는 경우 조인 순서에
혼선이 있어 잘못된 조인이 존재하는 경우 이를 바로잡기 위해 사용하는 것이 일반적이다. 그리고
내포 조인이나 해시 조인은 조인 후보 데이터가 작은 쪽이 선행 테이블로 지정되는 것이 성능에 유
리하며 이 순서가 잘못된 경우에도 사용한다.
[표 6-27] 테이블 조인 순서 유도 힌트
힌트 설명
ORDERED FROM 절에 기술된 테이블 순서대로 조인이 이뤄지도록 유도한다.
“SELECT /*+ ORDERED */ * FROM TAB1, TAB2, TAB3 WHERE …”으로 기술돼 있으면 TAB1
을 선행 테이블로 TAB1과 TAB2과 조인되고, 그 결과가 TAB3과 조인된다.
LEADING(table…) FROM 절에 기술된 순서에 상관없이 힌트에 지정된 테이블 순서대로 조인이 이뤄지도록 유도한
다.
“SELECT /*+ LEADING(C B) */ * FROM TAB1 A, TAB2 B, TAB3 C WHERE …”이면 TAB3을
선행 테이블로 TAB2와 조인되고 그 결과 TAB1과 조인되게 한다. ORDERED가 LEADING보다 우
선순위가 높다.

6부 _ SQL 튜닝382
테이블 조인 방식 유도
조회 대상 데이터와 각 조인 방식의 특성을 잘 이해하고 있어야 적합한 테이블 조인 방식을 선정할
수 있다.
[표 6-28] 테이블 조인 방식을 유도하는 힌트
힌트 설명
USE_NL(table…) 지정된 테이블들은 내포 조인이 되도록 유도한다.
USE_NL_WITH_INDEX
(table index)
내포 조인을 하면서 지정된 인덱스를 사용하게 한다.
“SELECT /*+ USE_NL_WITH_INDEX(B TAB02IX) */ * FROM TAB1 A, TAB2 B
WHERE…”인 경우 TAB1과 TAB2는 내포 조인이 되고 TAB2 테이블 액세스 시 TAB02IX
인덱스를 사용한다.
USE_MERGE(table…) 지정된 테이블들은 병합 조인을 사용하도록 유도한다.
USE_HASH(table…) 지정된 테이블들은 해시 조인을 사용하도록 유도한다.
NO_USE_NL(table…)
NO_HASH(table…)
NO_MERGE(table…)
옵티마이저가 해당 조인은 사용하지 말고 다른 조인 방식을 검토하도록 유도한다.
테이블 액세스 방식 유도
테이블 액세스 방식을 유도하는 힌트는 조인 순서와 조인 방식을 지정하는 힌트와 함께 가장 흔히
사용하는 힌트에 속한다.
[표 6-29] 테이블 액세스 방식을 유도하는 힌트
힌트 설명
FULL(table…) 지정된 테이블들은 인덱스를 사용하지 않고 테이블을 전체 탐색(Full scan)하도록 유도한
다. 배치에서는 대량 건을 조회할 때 인덱스를 사용하면 오히려 오래 걸리는 경우가 있어
일부러 전체 탐색을 유도하기도 한다.
INDEX(table index) 지정된 테이블을 액세스할 때는 지정된 인덱스를 사용하도록 유도한다.
INDEX_ASC(table index)
INDEX_DESC(table index)
지정된 인덱스를 경유해 테이블을 액세스할 때 인덱스 리프 블록을 읽는 순서를 오름차
순(Ascending)으로 할지 내림차순(Descending)으로 할지 유도한다.
INDEX_FFS(table index) 지정된 인덱스 사용 시 고속 전체 탐색(FAST FULL SCAN)하도록 유도한다. INDEX_FFS
는 테이블에 FULL 힌트를 준 것과 같은 효과를 인덱스에 주는 것이다. 테이블에 FULL
힌트를 주면 전체 범위 탐색을 수행하면서 Multi-block read가 이뤄지듯이 인덱스에서도
Multi-block read가 이뤄져 인덱스 전체 리프 블록을 빠르게 읽어들인다.

3835장. SQL 성능 개선
힌트 설명
INDEX_SS(table index) 조회 조건에 인덱스의 선행 항목이 없지만 인덱스를 사용하고 스킵 탐색(Skip scan)하도
록 유도한다. 스킵 탐색은 인덱스 선행 항목 값의 종류가 매우 한정적일 때 사용한다. 선
행 항목의 선택도가 아주 좋은데 스킵 탐색을 사용하면 인덱스 테이블을 순차적으로 모
두 읽는 것과 마찬가지가 되어 성능이 크게 저하된다.
INDEX_COMBINE
(table index1 index2 …)
보통 한 테이블을 액세스할 때는 인덱스를 한 개만 사용한다. 그런데 여러 개의 인덱스를
사용할 수 있는 조회 조건이 들어왔을 때 2개 이상의 인덱스로 비트맵 인덱스를 만들고
결합해서 테이블을 액세스하도록 유도하는 것이다.
INDEX_JOIN(table index) 2개 이상의 인덱스만으로 조인하도록 유도한다. 인덱스만으로 조인하므로 쿼리에서 사
용하는 모든 항목이 인덱스 내에 존재해야 한다. 인덱스 조인은 범위 탐색한 두 개 이상
의 결과를 ROWID로 해시 조인한다.
INDEX_RS(table index) 인덱스 탐색 시 범위 탐색(Range Scan)하도록 유도한다.
NO_INDEX(table index)
NO_INDEX_SS(table index)
NO_INDEX_FFS(table index)
지정된 인덱스를 해당 액세스 방식으로 사용하는 것을 제외하고 실행계획을 세우도록 유
도한다.
인덱스 힌트는 /*+ INDEX(table index) */ 형식으로 인덱스명이 힌트에 지정됐다. 그래서 인덱스
항목은 동일하더라도 인덱스명이 달라져 버리면 지정된 힌트가 무의미해진다. 그래서 오라클 10g
부터는 /*+ INDEX(table table(column, column)) */ 형식으로 인덱스명을 지정하지 않고 인덱
스에 포함된 항목을 지정할 수 있는 기능이 제공되기 시작했다. 그래서 TEST002 테이블에 KEY1,
KEY2 항목을 멤버로 하는 인덱스를 사용하고자 할 때 /*+ INDEX(TEST002 TEST002(KEY1,
KEY2)) */로 힌트를 줄 수 있다.
<힌트 추가 전>
SELECT *
FROM TEST002 A
WHERE KEY1 = '000010'
AND DIVISION = '0001'

6부 _ SQL 튜닝384
<힌트 추가 후>
SELECT /*+ INDEX_COMBINE(A TEST002PK TEST002IX2) */ *
FROM TEST002 A
WHERE KEY1 = '000010'
AND DIVISION = '0001'
[그림 6-62] INDEX_COMBINE 힌트의 사용 예
서브 쿼리 조인 방식 유도
[표 6-30] 서브 쿼리 조인 방식을 유도하는 힌트
힌트 설명
HASH_SJ
MERGE_SJ
세미 조인 시 해시 세미 조인이나 병합 세미 조인이 되도록 유도한다.
HASH_AJ
MERG_AJ
안티 조인 시 해시 안티 조인이나 병합 안티 조인이 되도록 유도한다.
UNNEST 서브 쿼리가 메인 쿼리와 같은 레벨에서 조인이 이뤄지도록 유도한다. 즉, 서브 쿼리가 메인 쿼리의
FROM 절로 들어가는 것을 생각하면 된다.
NO_UNNEST 서브 쿼리가 UNNEST되지 않도록 유도하는 것이 NO_UNNEST다.
PUSH_SUBQ 이 힌트는 서브 쿼리를 먼저 수행하도록 유도하는 힌트로 알고 있는 사람들이 많은데, 사실은 서브 쿼
리가 관련된 테이블과 함께 수행되도록 유도한다. PUSH_SUBQ는 NO_UNNEST 힌트와 함께 사용해
야 한다.
서브 쿼리가 상대적으로 가볍고 관련 테이블의 수를 크게 줄일 수 있다면 서브 쿼리를 관련 테이블
과 함께 초기에 실행해 다른 테이블과 조인되는 건수를 줄여 성능 향상에 도움을 줄 수 있다. 그런데
SQL 변형이 발생하지 않은 서브 쿼리는 실행계획을 수립할 때 마지막 단계에 실행된다.
PUSH_SUBQ 힌트를 주면 관련 테이블과 함께 서브 쿼리가 실행될 수 있게 한다. 아래 예와 같이
FROM 절에 TABLE1, TABLE2, TABLE3, TABLE4 테이블이 있고 TABLE2와 관련 있는 서브 쿼
TEST002PK 인덱스 선행 칼럼
TEST002IX2 인덱스 칼럼

3855장. SQL 성능 개선
리 SUBQUERY1과 TABLE3과 관련된 서브 쿼리 SUBQUERY2가 있을 때 실행계획이 TABLE1 →
TABLE2 → TABLE3 → TABLE4 → SUBQUERY1 → SUBQUERY2 순으로 조인되어 서버 쿼리
가 관련 테이블과 멀리 분리됨으로써 성능에 불리한 경우가 있다. 이때 PUSH_SUBQ 힌트를 주면
TABLE1 → TABLE2 → SUBQUERY1 → TABLE3 → SUBQUERY2 → TABLE4와 같이 관련 테
이블 다음에 서브 쿼리가 수행되도록 유도한다.
아래와 같이 메인 테이블에 관련 서브 쿼리가 있는 경우
SELECT …
FROM TABLE1
TABLE2
TABLE3
TABLE4
WHERE …
SUBQUERY1
SUBQUERY2
조인 순서 잘못 풀린 경우 PUSH_SUBQ 힌트 사용 후
TABLE1 TABLE1
TABLE2 TABLE2
TABLE3 SUBQUERY1
TABLE4 TABLE3
SUBQEURY1 SUBQUERY2
SUBQEURY2 TABLE4
관련 서브 쿼리
[그림 6-63] PUSH_SUBQ 동작의 예
오라클은 필요하다고 판단되면 SQL을 변형해 좀 더 효율적으로 수행하려 한다. 오라클의 SQL 변형
은 크게 세 가지 형태로 이뤄진다.
[표 6-31] 오라클의 SQL 변형
SQL 변형 종류 설명
Inline View
Merge
FROM 절에 있는 뷰나 인라인 쿼리를 분해해 메인 쿼리와 동등하게 통합하는 것이다. 뷰와 인라인 쿼리
내에 있던 테이블은 메인 쿼리의 FROM 절에 위치하고 조회 조건은 WHERE 조건으로 통합된다. 단, 뷰
나 인라인 쿼리에 GROUP BY가 사용된 경우에는 Inline View Merge가 되지 않는다.
SELECT …
FROM TABLE1 A
(SELECT …
FROM TABLE2 B
WHERE B.COL2 = 'A')
WHERE A.COL1 = B.COL1
AND A.COL3 = '1234'
SELECT …
FROM TABLE1 A
, TABLE2 B
WHERE B.COL2 = 'A'
AND A.COL1 = B.COL1
AND A.COL3 = '1234'

6부 _ SQL 튜닝386
Push
Predicates
FROM 절에 있는 뷰나 인라인 쿼리는 내부 조회 조건으로 먼저 실행되어 데이터를 조회한 후 다른 테이
블과 조인이 이뤄진다.
그러나 Push Predicate가 이뤄지면 메인 쿼리의 WHERE 절에 있는 뷰나 인라인뷰와 관련된 조회 조건
이 뷰와 인라인 쿼리 내부로 들어간다. 즉, 메인 쿼리에 있는 다른 선행 테이블의 조회가 이뤄진 후 해당
레코드들이 뷰와 인라인 쿼리의 조회 조건으로 들어가 조회가 이뤄진다. 그래서 선행 테이블의 조인 대
상 후보 건수만큼 뷰와 인라인 쿼리가 반복 수행된다.
SELECT …
FROM TABLE1 A
(SELECT …
FROM TABLE2 B
WHERE B.COL2= 'A')
WHERE A.COL1 = B.COL1
AND A.COL3 = '1234'
SELECT …
FROM TABLE1 A
(SELECT …
FROM TABLE2 B
WHERE B.COL2= 'A'
AND A.COL1 = B.COL1)
WHERE A.COL3 = '1234'
참고) 위 그림은 개념을 설명하는 SQL로 실제와 다름
Sub Query
Unnest
WHERE 절에 있는 서브 쿼리를 메인 쿼리의 FROM 절로 옮겨서 제공자 역할을 하게 한다.
IN 아래에 있는 서버 쿼리가 Unnest되어 메인 쿼리의 FROM 절로 들어가게 되면 DISTINCT가 추가되고
ORDERED 힌트가 붙으며 WHERE 조건은 조인 조건이 된다. 그래서 UNNEST(SORT (UNIQUE)) 같은
플랜으로 동작한다.
SELECT …
FROM TABLE1 A
WHERE A.COL3 = '1234
AND A.COL1 IN
(SELECT B.COL1
FROM TABLE B
WHERE B.COL2 ='A')
SELECT …
FROM (SELECT DISTINCT B.COL1
FROM TABLE B
WHERE B.COL2 ='A') B
, TABLE1 A
WHERE A.COL3 = '1234
AND A.COL1 = B.COL1
SQL 튜닝을 하다 보면 SQL 변형을 방지해야 주어진 힌트가 제대로 먹히는 경우도 있고, UNNEST
가 발생하면 SQL 실행계획을 수립할 때 수초씩 소요되는 성능 저하가 발생하기도 하는데 UNNEST
를 막음으로써 해소하는 경우도 있었다. 그리고 필요에 따라서는 쿼리 변형을 유도해 성능을 개선하
는 경우도 있어 위 개념을 알고 상황에 따라 적용해 보기 바란다.
서브 쿼리를 정확히 이해하려면 확인자와 제공자의 개념을 이해하고 있어야 한다. 서브 쿼리가 확인
자 역할을 할 때는 메인 쿼리가 먼저 실행되어 조회된 레코드를 서브 쿼리에서 확인한다. 서브 쿼리
가 제공자 역할을 할 때는 메인 쿼리보다 서브 쿼리가 먼저 수행되어 조회된 결과가 메인 쿼리 조회
의 입력 값으로 사용되는 경우다. 메인 쿼리의 조회 결과가 많은 경우에는 서브 쿼리가 제공자가 될
수 있게 하는 것이 유리하다.

3875장. SQL 성능 개선
제공자
확인자
메인 쿼리
서브 쿼리
[그림 6-64] 서브 쿼리의 확인자와 제공자 역할
<힌트 추가 전>
SELECT *
FROM TEST002 A
WHERE A.KEY1 < '000010'
AND A.DIVISION IN (SELECT CODE FROM COM001 WHERE DIV = '001')
<힌트 추가 후>
SELECT *
FROM TEST002 A
WHERE A.KEY1 < '000010'
AND A.DIVISION IN (SELECT /*+ NO_UNNEST */ CODE FROM COM001 WHERE DIV = '001')
[그림 6-65] NO_UNNEST 힌트의 예
뷰와 인라인 뷰 동작 유도
뷰와 인라인 뷰가 해체되어 메인 쿼리와 통합되는 것을 유도하거나 방지할 수 있는 힌트들이 있다.
[표 6-32] 뷰와 인라인 뷰 동작 유도 힌트
힌트 설명
MERGE(view) 뷰를 해제해 메인 쿼리의 FROM 절과 WHERE 절로 합치는 뷰 병합을 유도한다. 주로 복잡한
뷰나 인라인 뷰일 때 가끔 적용해 보면 상당한 효과를 보는 경우가 가끔 있다.
NO_MERGE(view) 뷰 병합이 일어나지 않도록 유도하는 힌트다.
서브 쿼리에 있는 COM001은 내포 조인의 후행 테이블이
되어 확인자 역할을 수행함
서브 쿼리에 있는 COM001을 탐색해 조회된 결괏값으로
TEST002 테이블에 액세스하므로 제공자 역할을 수행함

6부 _ SQL 튜닝388
힌트 설명
PUSH_PRED(view) 뷰나 인라인 뷰의 외부에 있는 조인 조건을 내부에 넣도록 유도하는 힌트다. 뷰가 먼저 수행된
후 그 결과에 조인되는 것이 아니라 조인 조건이 들어와 있으므로 내포 조인으로 풀리면 선행
테이블의 조회 결과만큼 뷰나 인라인 뷰가 동작하는 것과 같다. 선행 테이블의 조인 후보가 소
량이고, 뷰와 조인되는 조건이 뷰 내에 들어왔을 때 탐색 범위가 획기적으로 줄어드는 경우에
효과적인 방식이다.
NO_PUSH_PRED(view) PUSH_PRED로 동작하는 것을 막는 힌트다.
병렬처리 유도
[표 6-33] 병렬 처리 유도 힌트
힌트 설명
PARALLEL(table, degree) 지정된 테이블에 액세스할 때 지정된 병렬도(degree)로 읽어들이도록 유도한다. 병렬도는
테이블을 액세스할 때 몇 개의 병렬 작업으로 동시 처리할 것인지 지정하는 숫자다.
NO_PARALLEL(table) 병렬도가 1 이상으로 지정된 테이블을 조회할 때 자동으로 병렬처리되는 것을 방지하기
위해 사용하는 힌트다. 테이블이나 인덱스에 별도로 병렬도를 지정하지 않으면 기본값은 1
로서 병렬처리를 하지 않는다.
대용량 테이블을 참조할 때 하나의 서버 프로세스로 처음부터 끝까지 순차적으로 읽어낸다면 성능
이 저하될 수밖에 없다. 이 경우 병렬처리 힌트를 사용하면 지정된 병렬도 값만큼의 병렬 프로세스
들이 균등하게 테이블 블록을 나누어 동시에 수행함으로써 빠르게 데이터를 읽어들인다.
그러나 병렬 처리를 무한정 수행할 수 있는 것은 아니다. 서버 용량에 따라 설정할 수 있는 병렬 프
로세스 수에 제약이 있어 이를 초과하면 더는 병렬 처리가 불가능해져서 대기하는 현상이 발생한다.
SELECT /*+ PARALLEL(A, 4) */ * FROM TEST002 A
[그림 6-66] 병렬 처리 힌트의 예

3895장. SQL 성능 개선
기타
[표 6-34] 기타 힌트
힌트 설명
QB_NAME(name) 쿼리 블록에 대해 이름을 지정해 쿼리 블록 외부의 힌트에서 쿼리 블록과 관련된 힌트를 줄 수
있게 한다. 이 힌트 자체가 특정 동작을 유도하는 것은 아니다.
CACHE(table)
NOCACHE(table)
CACHE는 읽은 데이터 블록을 데이터 캐시 LRU 상에 가장 최근에 사용된 위치인 맨 앞에 위치
시키고, NO_CACHE는 가장 끝에 위치시켜 캐시에서 금방 사라지게 하는 힌트다.
APPEND INSERT에 사용해 SGA의 데이터 캐시를 경유하지 않는 Direct-path 방식으로 빠른 입력이 되도
록 유도한다. 단 테이블 블록 중간에 사용할 수 있는 블록이 존재해도 가장 끝에 있는 HWM(High
Water Mark) 다음에 저장한다. 이때는 테이블 락 상태에서 수행하므로 일반 온라인에서는 사용
하지 않는다.
DRIVING_SITE(table) DB 링크를 사용해 원격 테이블과 조인할 때 쿼리가 수행될 사이트를 테이블 기준으로 지정한다.
USE_CONCAT OR에 있는 조건들이 각기 개별 테이블 액세스로 분리되어 개별 액세스가 이뤄진 후 결과를 합치
도록 유도한다.
NO_EXPAND USE_CONCAT의 반대로 개별 처리 후 합치지 못하도록 유도한다.
5.2SQL성능개선
5.2.1인덱스부재
인덱스 부재는 흔히 나타나는 성능 저하 원인이다. 운영 중인 시스템에 인덱스가 없어 성능이 저하
되는 경우가 있을까 싶겠지만 생각보다 많다. 적절한 인덱스가 있는지 여부를 확인할 때는 아래 세
가지 항목을 확인한다.
• 테이블 전체 탐색: 실행계획상에 TABLE ACCESS FULL이 있는지 확인한다.
• 넓은 범위 탐색: 읽은 레코드 건수에 비해 읽은 논리 블록 수(Buffers) 수가 크다.
• 넓은 범위 탐색: INDEX RANGE SCAN을 수행하고 있으나 TABLE ACCESS BY INDEX ROWID와 A-Rows 건수
에 큰 차이가 있다.

6부 _ SQL 튜닝390
<SQL>
SELECT * FROM TEST002 WHERE NAME = 'Name-3-7'
<인덱스 부재>
------------------------------------------------------------------------------------------
| Id | Operation |Name |Starts |E-Rows|A-Rows | A-Time |Buffers |Reads |
------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 1 |00:00:00.95 | 7349 | 7345 |
|* 1 | TABLE ACCESS FULL| TEST002 | 1 | 1 | 1 |00:00:00.95 | 7349 | 7345 |
------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("NAME"='Name-3-7')
<인덱스 존재>
------------------------------------------------------------------------------------------
| Id | Operation |Name |Starts|E-Rows|A-Rows| A-Time |Buffers|Reads|
------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 1 |00:00:00.01 | 5 | 2 |
| 1 | TABLE ACCESS BY INDEX ROWID| TEST002 | 1 | 1 | 1 |00:00:00.01 | 5 | 2 |
|* 2 | INDEX RANGE SCAN | TEST002IX | 1 | 1 | 1 |00:00:00.01 | 4 | 2 |
------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("NAME"='Name-3-7')
[그림 6-67] 인덱스 유무에 따른 읽은 블록 수의 차이
5.2.2인덱스항목순서
아래 예는 선행 항목이 일치 조건인 경우와 비교 조건인 경우의 읽는 블록 수의 차이를 보여준다.
선택도의 높고 낮음에 상관없이 항상 일치 조건으로 들어오는 항목이 인덱스의 선행 항목이 돼야
한다.
테이블 전체 탐색
인덱스 사용 여부에 따라 실제 조회된
A-Rows 건수가 1건인데 7,349블록과
5블록으로 큰 차이가 있음조회 조건이 테이블 필터로 사용됨
인덱스 범위 탐색
조회 조건이 인덱스 액세스로 사용되어
바로 리프 블록을 찾아갔음을 알 수 있음

3915장. SQL 성능 개선
<SQL>
SELECT * FROM TEST001 WHERE KEY1 <= '010000' AND KEY2 = 1
<인덱스>
TEST001PK (KEY1, KEY2) TEST001IX3 (KEY2, KEY1)
선택도: KEY1 = 1/100,096 = 0.00000999 KEY2 = 1/25 = 0.04 (선택도는 KEY1이 좋음)
<범위 조건 항목이 선행인 인덱스 사용>
----------------------------------------------------------------------------------------
| Id | Operation |Name |Starts|E-Rows|A-Rows| A-Time |Buffers|
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 610 |00:00:00.01 | 616 |
| 1 | TABLE ACCESS BY INDEX ROWID|TEST001 | 1 | 580 | 610 |00:00:00.01 | 616 |
|* 2 | INDEX RANGE SCAN |TEST001PK | 1 | 580 | 610 |00:00:00.01 | 518 |
----------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("KEY2"=1 AND "KEY1"<='010000')
filter("KEY2"=1)
<일치 조건 항목이 선행인 인덱스 사용>
-----------------------------------------------------------------------------------------
| Id | Operation |Name |Starts|E-Rows|A-Rows| A-Time |Buffers|
-----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 610 |00:00:00.01 | 109 |
| 1 | TABLE ACCESS BY INDEX ROWID|TEST001 | 1 | 580 | 610 |00:00:00.01 | 109 |
|* 2 | INDEX RANGE SCAN |TEST001IX3 | 1 | 580 | 610 |00:00:00.01 | 11 |
-----------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("KEY2"=1 AND "KEY1"<='010000')
[그림 6-68] 인덱스의 선행 항목이 WHERE 절에 사용된 조건에 따른 차이
인덱스를 구성할 때 기억해야 하는 조건은 모두가 일치 조건으로 들어온다면 다양한 값으로 구성
된 선택도 수치가 낮은 항목이 선행돼야 한다는 것이다. SELECT에서 MIN/MAX 값을 구할 때는
WHERE 조건에 있는 인덱스 구성 항목들이 MIN/MAX 대상이 되는 항목보다 선행 항목이 돼야 인
덱스를 최소 탐색할 수 있다.
동일한 두 항목으로 순서만 다른 인덱스를
만들어 인덱스 탐색의 A-Rows 건수는 610
으로 동일하나 읽은 블록 수는 518과 11로 큰
차이가 있음
선행 항목이 범위 조건으로 KEY2가 인덱스 필터로 동작함
인덱스 액세스로만 대상 건을 정확히 조회함

6부 _ SQL 튜닝392
위와 같은 조건을 생각하고 인덱스를 바라보면 기존에 만들어진 인덱스들도 항목 순서를 바꾸면 개
선될 수 있는 것들이 보인다.
5.2.3LIKE에의한성능저하
LIKE 검색은 게시판의 내용, 주소, 성명 등을 검색할 때 흔히 사용한다. 그리고 LIKE도 인덱스를 사
용할 수 있게 되면서 사용하는 데 빠른 부담이 많이 감소했다. 그런데 LIKE가 인덱스를 사용하기 위
해서는 검색하는 문자열 앞에 %가 붙으면 안 된다. 꼭 검색 문자열 뒤에 %가 붙어야 한다.
다음은 회원명부 테이블에 들어있는 회원을 검색하는 간단한 조회문이다. 바인드 변수인 str 뒤에
‘%’ 조건을 붙여 성명 인덱스를 사용할 수 있게 했다. 그리고 인덱스 사용 효과를 높이기 위해 검색
문자열은 최소한 2자 이상은 포함되게 하면 검색 효과를 높일 수 있다.
SELECT 성명, 전화번호, 주소 FROM 회원명부 WHERE 성명 LIKE :str || '%'
도로명 주소 검색 같은 경우에는 시도와 시군구까지 선택하게 해서 검색 대상을 줄인 후 LIKE 검색
을 해야 성능을 보장할 수 있다. 그럼 인덱스는 시도, 시군구, 도로명의 세 항목이 순서대로 구성
된다.
SELECT 우편번호, 시도, 시군구, 도로명, 건물명 FROM 도로명주소
WHERE 시도 = :city AND 시군구 = :gungu AND 도로명주소 LIKE :road || '%'
LIKE 검색은 선택도를 정확히 계산하기 힘들고 입력 값에 따라 선택도가 천차만별이므로 예상 카디
널리티가 높게 설정된다. 그래서 입력된 검색 문자열이 길어 선택도가 우수하더라도 LIKE가 포함된
인덱스를 사용하지 않고 WHERE 조건에 있는 선택도가 나쁜 다른 항목이 포함된 인덱스를 사용하
는 경우가 종종 있다. 이런 경우에는 힌트를 지정해 인덱스를 유도해야 한다.
5.3.4테이블조인이상
테이블 간에 조인 순서와 방식이 잘못 풀리는 경우는 여러 원인에 의해 발생할 수 있다. 첫 번째는
테이블과 인덱스에 대한 통계가 갱신되지 않아 실제 데이터의 양과 분포 상태를 통계가 제대로 반영
하고 있지 못한 경우다. 그래서 실행계획이 이상하게 만들어지는 경우에는 통계의 갱신 시점과 실제
데이터 분포를 제대로 반영하고 있는지 확인하는 것이 우선이다. 그래서 통계가 없거나 제대로 반영
하고 있지 않다면 통계를 갱신한 후 다시 실행계획을 확인한다.
:str – ‘권문’

3935장. SQL 성능 개선
두 번째로는 인덱스 이상으로 생기는 경우다. 인덱스는 옵티마이저가 실행계획을 세울 때 참조하는
핵심 정보다. 그래서 조회하는 데이터의 양에 비해 부적절하게 전체 탐색하거나 해시 또는 병합 조
인을 수행하는 경우에는 인덱스가 있는지 확인하는 것이 우선이다.
세 번째는 SQL 문이 복잡해서 두 테이블 간에 연결고리가 누락되어 카테시안 곱으로 조인되면서 성
능 저하를 유발하는 것이다. WHERE 절에 조회 조건을 작성할 때 이미 알고 있는 값임에도 바인드
변수로 입력 처리 하지 않고 다른 테이블과의 조인을 통해 가져오게 해서 조인이 이상하게 풀리는
경우도 있다. 이 경우는 SQL 작성 오류로 간혹 발생한다.
네 번째는 통계와 인덱스, SQL 문장에는 이상이 없으나 옵티마이저가 실행계획을 잘못 세우는 경우
다. 이때는 SQL을 일부 변형하거나 SQL 힌트를 추가해 옵티마이저가 제대로 된 실행계획을 세우도
록 유도하는 작업이 필요하다.
조인을 설명하면서 내포 조인과 해시 조인에서는 조인 대상 건수가 작은 테이블이 선행 테이블이 되
는 것이 중요하다고 했다. 내포 조인의 경우 선행 테이블의 건수만큼 후행 테이블의 액세스가 발생
하기 때문이고, 해시 테이블은 소량의 데이터로 해시 맵을 구성하는 것이 효율적이기 때문이다.
그리고 서브 쿼리가 확인자로 사용되는 경우 메인 쿼리에서 확인 대상이 되는 건수가 많으면 성능에
불리해진다. 이 경우에는 확인자에서 제공자로 관계를 바꿀 수 있는지 타진해보고, 안 되면 FROM
절로 올려서 조인 관계로 풀어나가는 것을 시도해 볼 수 있다.
스칼라 쿼리의 경우에는 조회되는 레코드 건수만큼 수행되기 때문에 조회되는 데이터가 소량인 경
우 사용한다. 그리고 테이블 탐색 또한 인덱스를 통해 최소한의 블록을 읽을 수 있어야 한다. 건수가
많거나 테이블의 탐색 범위가 넒은 경우에는 메인 쿼리의 FROM 절에 인라인 쿼리로 들어가 조인
관계로 풀리는 경우가 오히려 성능이 우수하다.
5.3.5실행횟수와조인
SQL의 실행 통계를 참조하며 성능 개선을 진행할 때 결국 수행시간을 줄여야 하므로 가장 먼저 참
조하는 값은 각 동작별 수행시간인 A-Time일 것이다. 어느 동작에서 오래 걸렸는지 확인해 튜
닝 부위를 식별하는 것이다. 그리고 다음으로 확인하는 것이 각 단계에서 선별된 레코드 건수인
A-Rows와 읽은 논리 블록 수인 Buffers다. 해당 수치가 크다면 결국 시간이 오래 걸리고 최종 결
과에 비해 많은 데이터를 액세스하고 있을 수 있다. 수행시간이 높은 부분을 보면 읽은 블록 수가 많
은 부분과 일치하는 경우가 대부분이다. 마지막으로 확인하는 것이 각 동작의 실행 횟수를 의미하는
Starts다. 각 동작의 실행 횟수를 줄여야 읽은 블록 수와 수행시간을 줄일 수 있다.

6부 _ SQL 튜닝394
성능 개선을 하기 위해서는 SQL의 동작을 정확히 이해하는 것이 선행돼야 한다. 그래서 실행계획의
이해 부분에서 자세히 설명했으나 그 중요성을 강조하기 위해 여기서 다시 한 번 설명한다.
<SQL>
SELECT A.VALUE1,
(SELECT MAX(B.NAME) FROM TEST002 B WHERE A.KEY1 = B.KEY1 AND B.KEY3 = 1 ) AS NAME
FROM TEST001 A
WHERE A.KEY1 BETWEEN '000001' AND '001000'
AND A.KEY2 IN (SELECT TO_NUMBER(CODE) FROM COM001 WHERE DIV = '000')
<인덱스>
TEST001(KEY1, KEY2) TEST002PK(KEY1, KEY2, KEY3)
<실행 결과>
------------------------------------------------------------------------------------------
| Id | Operation | Name |Starts|E-Rows|A-Rows| A-Time |Buffers|
------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 201 |00:00:00.21| 195 |
| 1 | SORT AGGREGATE | | 201 | 1 | 201 |00:00:00.01| 448 |
| 2 | TABLE ACCESS BY INDEX ROWID| TEST002 | 201 | 1 | 61 |00:00:00.01| 448 |
* 3 | INDEX RANGE SCAN | TEST002PK | 201 | 1 | 61 |00:00:00.01| 414 |
| 4 | NESTED LOOPS | | 1 | | 201 |00:00:00.21| 195 |
| 5 | NESTED LOOPS | | 1 | 462 | 201 |00:00:00.21| 164 |
| 6 | SORT UNIQUE | | 1 | 8 | 3 |00:00:00.01| 2 |
* 7 | INDEX RANGE SCAN | COM001PK | 1 | 8 | 3 |00:00:00.01| 2 |
* 8 | INDEX RANGE SCAN | TEST001PK | 3 | 58 | 201 |00:00:00.21 162 |
| 9 | TABLE ACCESS BY INDEX ROWID| TEST001 | 201 | 58 | 201 |00:00:00.01| 31 |
------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("B"."KEY1"=:B1 AND "B"."KEY3"=1)
filter("B"."KEY3"=1)
7 - access("DIV"='000')
8 - access("SYS_ALIAS_1"."KEY1">='000001' AND "SYS_ALIAS_1"."KEY2"=TO_NUMBER("CODE")
AND "SYS_ALIAS_1"."KEY1"<='001000')
filter("SYS_ALIAS_1"."KEY2"=TO_NUMBER("CODE"))
[그림 6-69] 실행계획에서의 조인과 실행 횟수 이해
스칼라 서브 쿼리
서브 쿼리의 UNNEST
성능을 좌우한 동작
동작별 인덱스 필터 설명

3955장. SQL 성능 개선
위 예에서 수행시간이 가장 긴 부분은 TEST01PK를 INDEX RANGE SCAN하는 데 걸린 0.21초다.
서브 쿼리로 있던 COM001 테이블은 조회된 CODE 항목을 SORT UNIQUE로 유일 항목으로 만
들어 드라이빙(Driving) 테이블이 되면서 서브 쿼리에서 빠져나와 메인 FROM 절로 들어감으로써
UNNEST가 이뤄졌다. 드라이빙 테이블이란 SQL 문 전체에서 가장 먼저 액세스되는 선행 테이블을
말한다.
SELECT STATEMENT 밑에 조인과 관계 없이 바로 조회가 이뤄진 TEST002는 스칼라 쿼리가 조회
된 것이다. 그리고 ID 항목의 숫자 번호 앞에 *가 붙어 있는 것은 액세스나 필터가 이뤄지는 부분으
로, Predicate Information에서 상세하게 설명하고 있다. TABLE ACCESS BY INDEX ROWID
는 액세스지만 테이블 액세스는 ROWID로 읽어내는 한 가지뿐이므로 Predicate Information에서
는 생략됐다.
ID 8에서 TEST008PK 인덱스를 탐색할 때 인덱스 액세스로 KEY1, KEY2 항목이 모두 사용됐
는데 KEY2는 인덱스 필터로도 사용됐다. 그 이유는 KEY1 조회 조건이 BETWEEN 범위 조건
으로 들어오면서 KEY2가 “KEY1=‘000001’ AND KEY2=TO_NUMBER(CODE)”에 해당하
는 첫 번째 인덱스 레코드가 있는 리프 블록을 찾아가는 인덱스 액세스로 사용됐지만 그 이후에는
“KEY1=‘001000’ AND KEY2=TO_NUMBER(CODE)”까지 읽어가면서 다양하게 나타나는 KEY2
값들에서 TO_NUMBER(CODE)와 일치하는 레코드를 필터에서 걸러내기 때문이다.
이제는 테이블 조인 관계에서 Starts, A-Rows, A-Time, Buffers 값에 대해 알아보자.
| Id | Operation | Name | Starts | A-Rows | Buffers |
-----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 201 195
| 1 | SORT AGGREGATE | | 201 201 448
| 2 | TABLE ACCESS BY INDEX ROWID| TEST002 | 201 61 448
|* 3 | INDEX RANGE SCAN | TEST002PK | 201 61 414
| 4 | NESTED LOOPS | | 1 201 195
| 5 | NESTED LOOPS | | 1 201 164
| 6 | SORT UNIQUE | | 1 3 2
|* 7 | INDEX RANGE SCAN | COM001PK | 1 3 2
|* 8 | INDEX RANGE SCAN | TEST001PK | 3 201 162
| 9 | TABLE ACCESS BY INDEX ROWID| TEST001 | 201 201 31
[그림 6-70] 조인 관계에서의 Starts, A-Rows, A-Time, Buffers 이해

6부 _ SQL 튜닝396
드라이빙 테이블인 COM001은 COM001PK 인덱스를 RANGE SCAN해서 레코드 3건을 찾아
CODE 항목에 대해 SORT UNIQUE를 수행해 유일한 값들을 추출했으나 역시 3건이었다. 이때
Starts가 1이므로 탐색은 1번 이뤄졌고, Buffers는 2로 인덱스 블록 2개를 읽었다.
COM001 테이블에서 탐색된 레코드 3건으로 TEST001과 내포 조인(NESTED LOOPS)이 이뤄졌
다. 내포 조인은 선행 테이블의 각 레코드에 대해 후행 테이블 탐색이 이뤄지므로 TEST001PK 인덱
스를 3번 탐색해 Starts가 3이다. 3번의 탐색으로 총 201개의 레코드를 찾았고, 이를 위해 162개의
인덱스 블록을 읽었다. TEST001PK 탐색에서 나온 201건의 ROWID로 TEST001에 내포 조인으로
201번 탐색해 201건의 레코드를 조회했다.
이 201건이 메인 SELECT에 조회된 레코드 건수다. 그리고 SELECT에 스칼라 서브 쿼리가 있어
201건 각각에 대해 실행됐다. 스칼라 서브 쿼리는 MAX 값을 구하는 SELECT로 조회 결과 역시
201건이 조회됐다. 이에 위해 읽은 블록은 448 블록이다.
스칼라 서브 쿼리 수행을 자세히 보면 TEST002PK 탐색이 201번 이뤄졌는데, 추출된 대상 레코드
는 61건이다. 그리고 RANGE SCAN이었으므로 한번 탐색에 중복 레코드가 나올 수도 있는 조건이
다. 따라서 스칼라 서브 쿼리 수행에서 최대 61건만이 MAX에서 값이 있었고 나머지는 NULL 값이
조회됐다는 것을 알 수 있다. 위와 같은 흐름을 이해했다면 SQL 성능 개선을 시도할 수 있는 기본적
인 지식은 갖춘 것이니 자신감을 가지고 시도해 보기 바란다.






![3 . 시스템 구성 [ 데이타방송 시스템 ]](https://static.fdocument.pub/doc/165x107/56815759550346895dc502a6/3-56815759550346895dc502a6.jpg)












