荃灣浸信會...B02.1031 聖研導讀叢書--顛覆現實的基督論 鮑維均 天道書樓有限公司 註釋、輔讀、新釋一般資料 1 B02.1032 聖研導讀叢書--從路加著作看顛覆現實的基督信仰鮑維均
description

信賴區間與信心水準的解讀
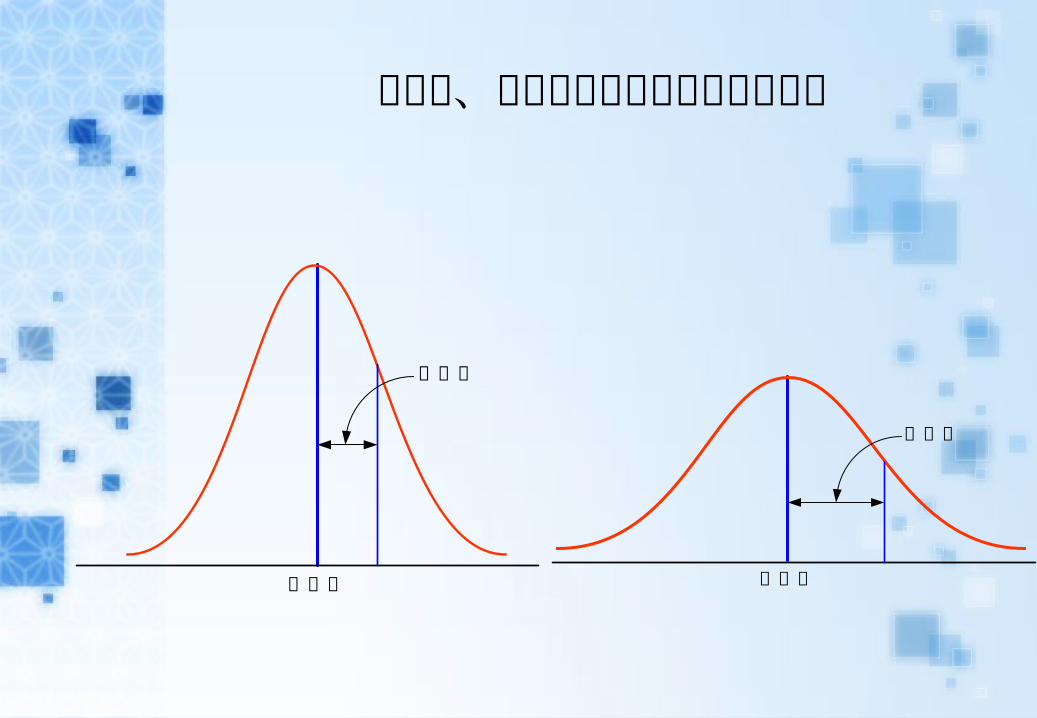
一、常態分布
為何成績單只要有個人成績加上平均數、標準差,就足夠估計學生大約的名次?
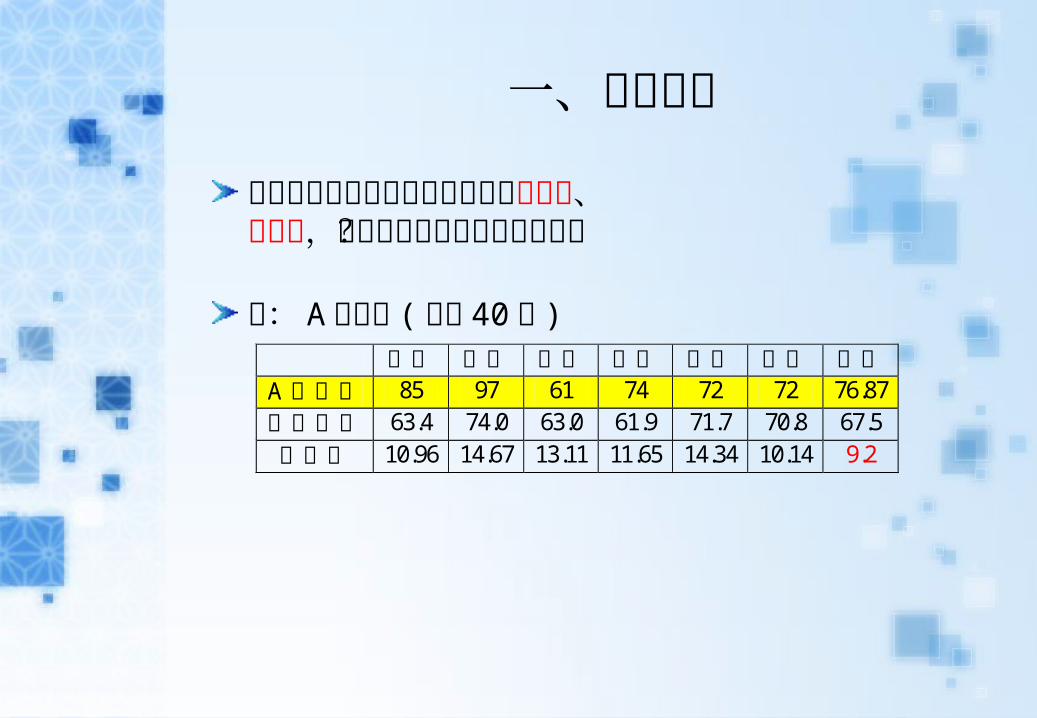
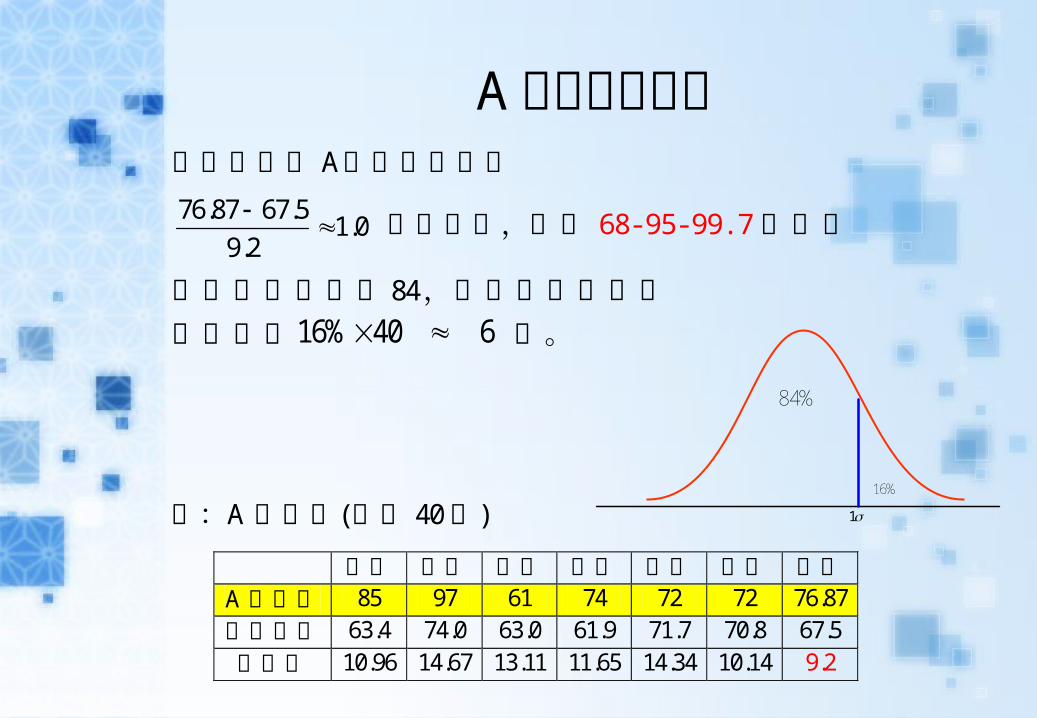
例: A 生成績 ( 全班 40 人 ) 國文 英文 數學 物理 化學 生物 平均
A生成績 85 97 61 74 72 72 76.87
全班平均 63.4 74.0 63.0 61.9 71.7 70.8 67.5
標準差 10.96 14.67 13.11 11.65 14.34 10.14 9.2
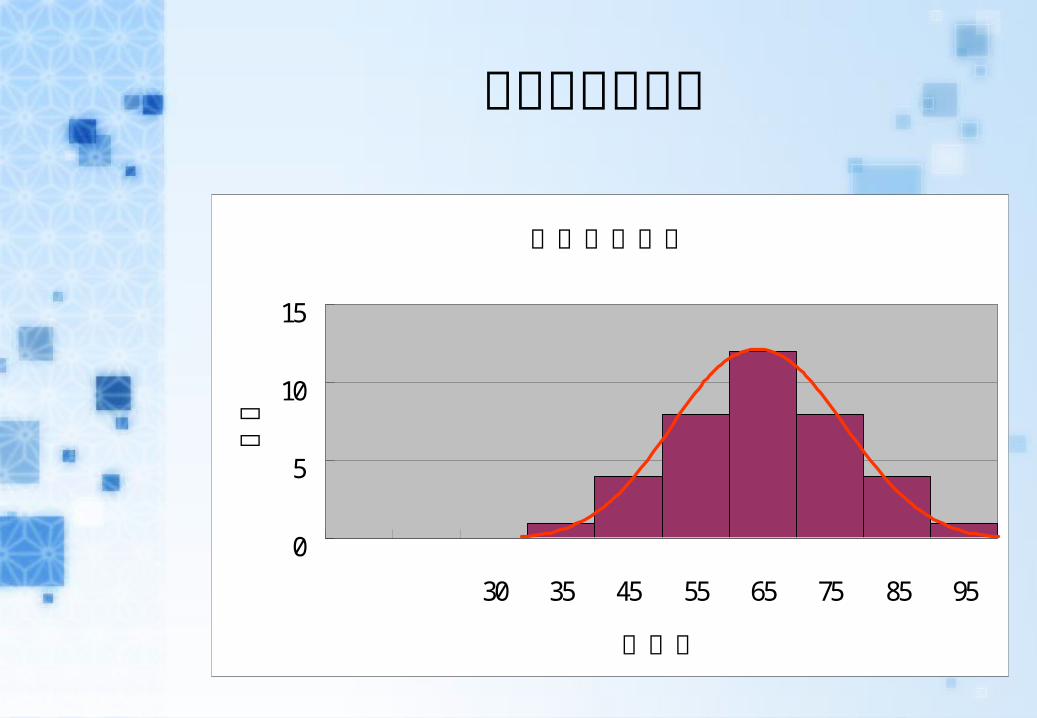
全班成績直方圖
月考平均分數
0
5
10
15
30 35 45 55 65 75 85 95
組中點
人數
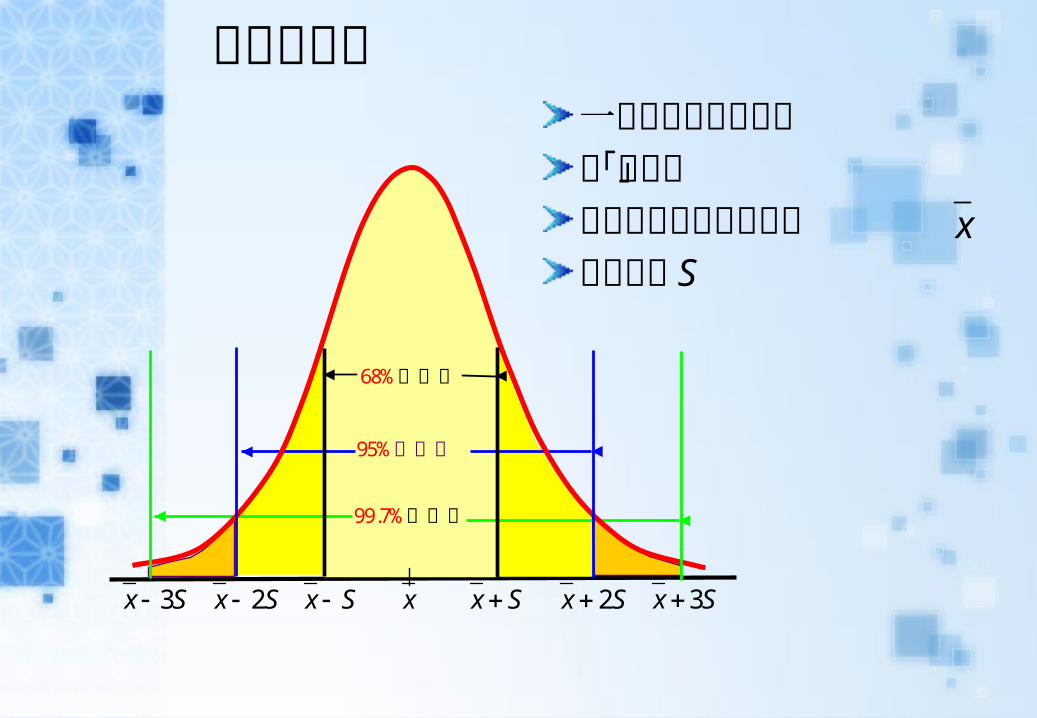
常態曲線圖一種理想的次數分配呈「鐘型」中間最高為算術平均數標準差為 S
x
68%的資料
99.7%的資料
95%的資料
3x S 2x S x 2x Sx S x S 3x S
平均數、標準差決定常態分布曲線函數
標準差
平均數
標準差
平均數
A 生名次的約估
例:A生成績(全班 40人)
國文 英文 數學 物理 化學 生物 平均 A生成績 85 97 61 74 72 72 76.87
全班平均 63.4 74.0 63.0 61.9 71.7 70.8 67.5
標準差 10.96 14.67 13.11 11.65 14.34 10.14 9.2
由資料可知 A生距離平均數
76.87 67.51.0
9.2
個標準差,利用 68-95-99.7法則知
他的百分等級是 84,亦即他在班上的
排名是第16% 40 6 名。
84%
16%
1
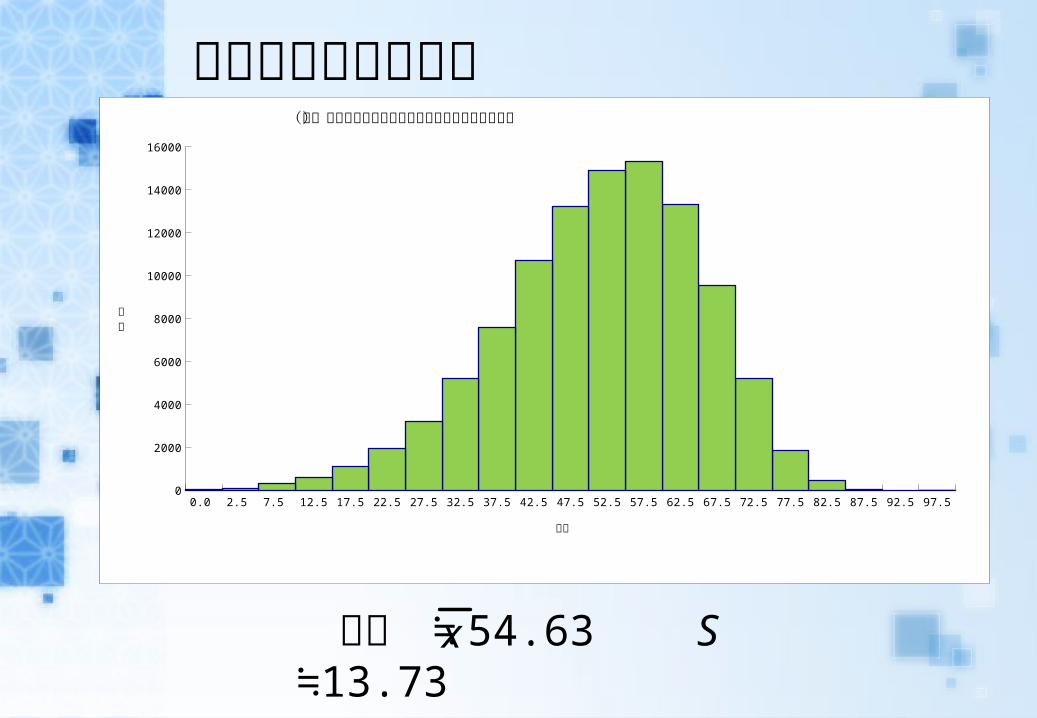
大學聯考的統計資料
已知 ≒ 54.63 S 13.73≒
0.0 2.5 7.5 12.5 17.5 22.5 27.5 32.5 37.5 42.5 47.5 52.5 57.5 62.5 67.5 72.5 77.5 82.5 87.5 92.5 97.5 0
2000
4000
6000
8000
10000
12000
14000
16000
(九)九十五學年指定科目考試國文科成績人數分布圖
分數
人數
x

某生國文成績為 24.7 分
這個分數距離平均值 2 個標準差:
利用常態分配表推知他的百分等級是 2.5% , 但由大考中心資料得知他實際的百分等級是 4%
上述兩個例子是用常態分配去近似班級考試分配及大學指考分配,但只是近似,顯然不可能
完全正確推算名次
24.7 54.632
13.73ix x
S

二、信賴區間92 年 7 月 19 日,某報就『成年人對公立大學學費是否太貴』的議題進行調查,於 20 日報導:『成功訪問了 871 位成年人。在百分之九十五的信心水準下,有 46% 民眾認為學費太貴,抽樣誤差在正負3.3% 之內』,而該調查是以台灣地區住宅電話為母體作尾數兩位隨機抽樣。
這代表信賴區間為 (0.46-0.033,0.46+0.033)
我們每次做抽樣調查時都可以做出一個區間估計,例如上例的區間為 (0.427,0.499) ,而所謂百分之九十五的信心水準,即指每次做出的區間會涵蓋實際比例的機率為 95% 。
但是,這些區間與 95% 如何求出?

信賴區間的實驗
老師為全班每個同學各準備一籤筒,事先不讓學生知道籤筒裡放了幾支籤,內含若干有獎籤,然後做實驗:讓每個同學在籤筒內抽取一支籤,記錄是否為有獎籤後放回,連續抽取 20 次。 ( 類似於民調中成功訪問了 20 人 )
如果抽出 7 支有獎籤,則推估有獎籤的比例為
,你有多少信心支持自己的推估正確?7
ˆ20
p
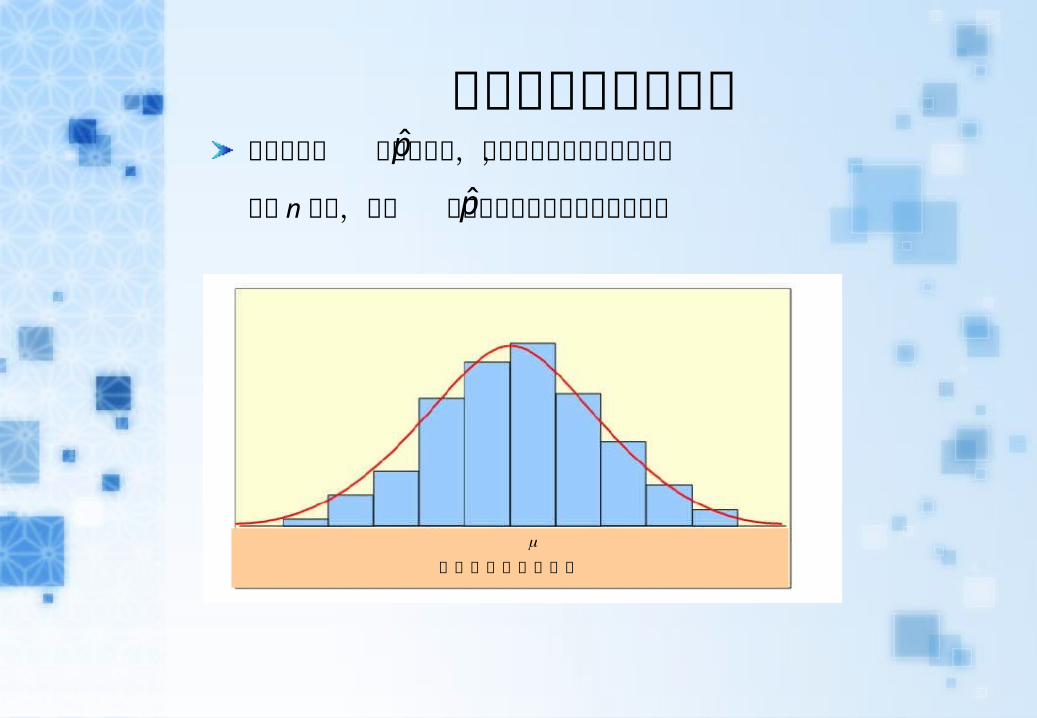
樣本比例的抽樣分布每個同學的 雖然在變動,但中央極限定理告訴我們,
只要 n 夠大,這些 可以被常態分布描繪的相當接近
樣本比例的抽樣分布
p̂
p̂
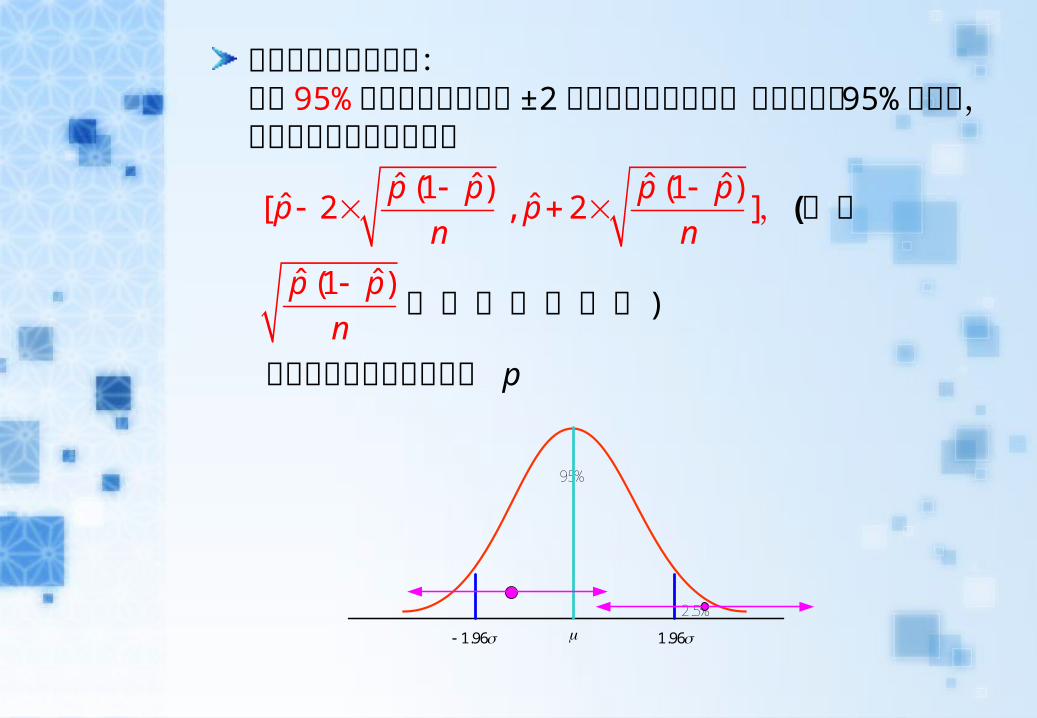
前面提到常態分配中:約有 95% 的資料會在期望值 ±2 個標準差的範圍中,所以大約有 95% 的機會,我們每個人所求出的區間
會包含真正的有獎籤比例 p
ˆ ˆ ˆ ˆ(1 ) (1 )ˆ ˆ[ 2 , 2 ]
p p p pp p
n n
,(其中
ˆ ˆ(1 )p p
n
為近似的標準差)
95%
2.5%
1.96 1.96

信賴區間的計算
將每位同學的中獎比例代入下列公式:
設中獎比例 ˆ 0.3p ,代入區間半徑公式:
ˆ ˆ(1 ) 0.3 (1 0.3)2 2 0.20
20
p p
n
則信賴區間為[0.3 0.2 , 0.3 0.2] [0.1 , 0.5]
區間半徑公式ˆ ˆ(1 )
2p p
n
指的是 2個標準差
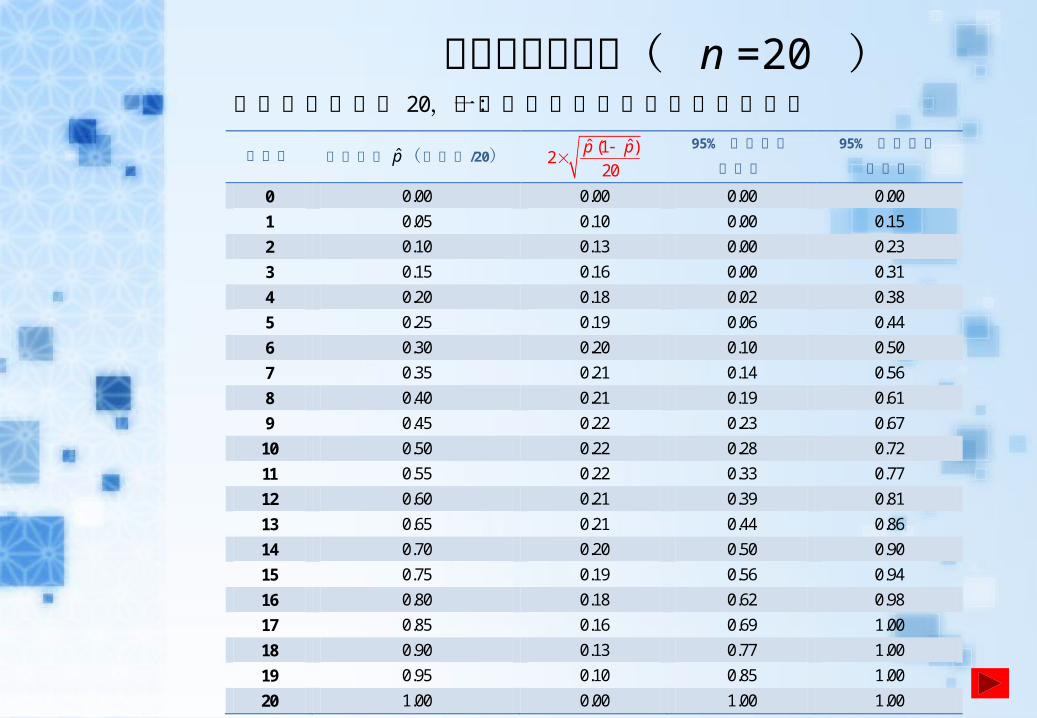
區間公式對照表( n =20 )實驗的取樣數為 20,記錄內容必為下列表格其中一列:
中籤數 中獎比例 p̂(中籤數 /20) ˆ ˆ(1 )
220
p p
95% 信賴區間
左端點
95% 信賴區間
右端點
0 0.00 0.00 0.00 0.00
1 0.05 0.10 0.00 0.15
2 0.10 0.13 0.00 0.23
3 0.15 0.16 0.00 0.31
4 0.20 0.18 0.02 0.38
5 0.25 0.19 0.06 0.44
6 0.30 0.20 0.10 0.50
7 0.35 0.21 0.14 0.56
8 0.40 0.21 0.19 0.61
9 0.45 0.22 0.23 0.67
10 0.50 0.22 0.28 0.72
11 0.55 0.22 0.33 0.77
12 0.60 0.21 0.39 0.81
13 0.65 0.21 0.44 0.86
14 0.70 0.20 0.50 0.90
15 0.75 0.19 0.56 0.94
16 0.80 0.18 0.62 0.98
17 0.85 0.16 0.69 1.00
18 0.90 0.13 0.77 1.00
19 0.95 0.10 0.85 1.00
20 1.00 0.00 1.00 1.00
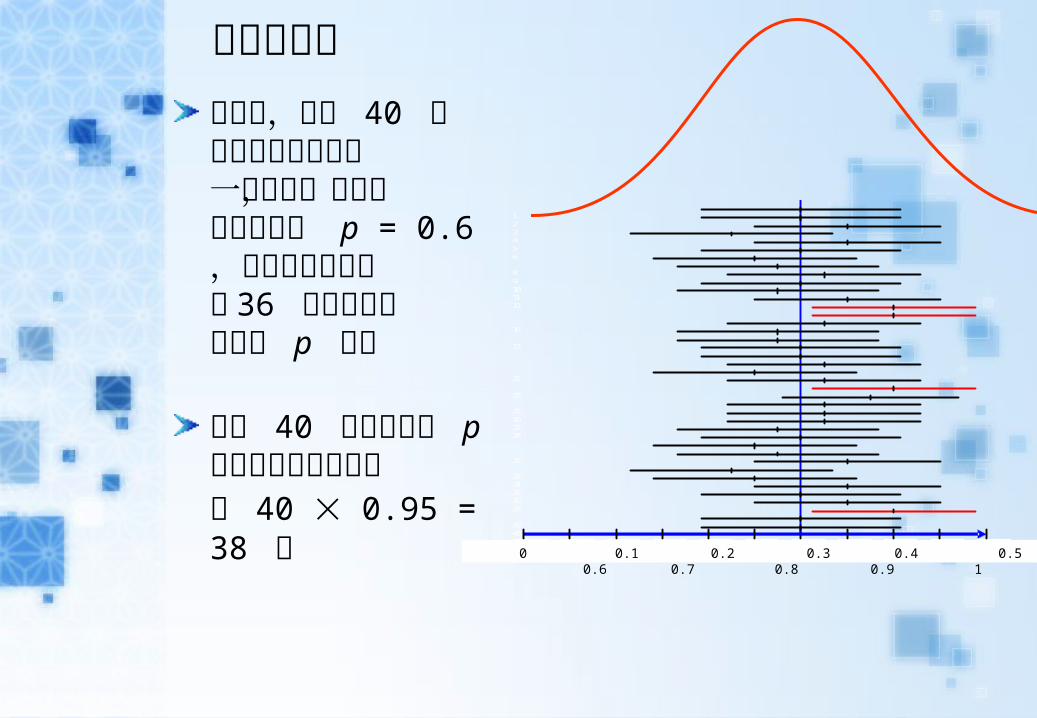
信賴區間圖右圖中,全班 40 個學生每個人都得到一個區間,如果老師事先知道 p = 0.6,那麼從圖中可知有 36 個區間包含真實的 p 值。
全班 40 個學生包含 p 值區間個數的期望值為 40 0.95 = 38 個
1 2 3 4 5 6
8 9 10 11 12
15
17
21
23
25 26 27 28
31
33 34 35 36 37
39 40
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
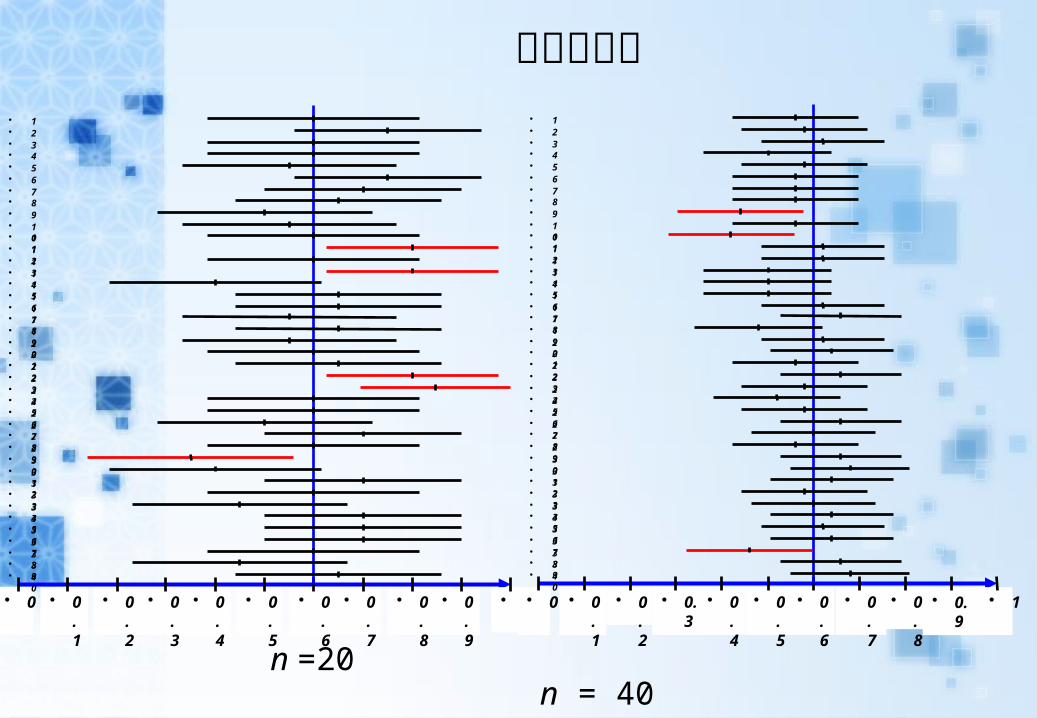
區間比較圖
n =20 n = 40
• 0
• 0.1
• 0.2
• 0.3
• 0.4
• 0.5
• 0.6
• 0.7
• 0.8
• 0.9
• 1
• 1
• 2
• 3
• 4
• 5
• 6
• 7
• 8
• 9
• 10
• 1
1
• 1
2
• 1
3
• 1
4
• 1
5
• 1
6
• 1
7
• 1
8
• 1
9
• 2
0
• 2
1
• 2
2
• 2
3
• 2
4
• 2
5
• 2
6
• 2
7
• 2
8
• 2
9
• 3
0
• 3
1
• 3
2
• 3
3
• 3
4
• 3
5
• 3
6
• 3
7
• 3
8
• 3
9
• 4
0
• 0
• 0.1
• 0.2
• 0.3
• 0.4
• 0.5
• 0.6
• 0.7
• 0.8
• 0.9
• 1
• 1
• 2
• 3
• 4
• 5
• 6
• 7
• 8
• 9
• 10
• 1
1
• 1
2
• 1
3
• 1
4
• 1
5
• 1
6
• 1
7
• 1
8
• 1
9
• 2
0
• 2
1
• 2
2
• 2
3
• 2
4
• 2
5
• 2
6
• 2
7
• 2
8
• 2
9
• 3
0
• 3
1
• 3
2
• 3
3
• 3
4
• 3
5
• 3
6
• 3
7
• 3
8
• 3
9
• 4
0

n = 20 與 n = 40 的區間估計的差異
因區間半徑等於 ,
所以較大的 n 值具有較小的區間半徑,也意味著有較佳區間估計的效果。
ˆ ˆ(1 )2
p p
n

信賴區間的解讀全班依照這樣的區間公式求出的 40 個區間, 由模擬的實驗結果,可以發現並非一定有 95% 的區間會涵蓋實際值 p 。
每個學生一旦做出區間,就只可能有兩種情形:包含真實 p 值,或不包含真實 p 值。因此一旦做出區間後,並不能說「真實 p 值在此區間的機率為 95% 」

回顧抽樣調查的例子
92 年 7 月 19 日,某報就『成年人對公立大學學費是否太貴』的議題進行調查,於 20 日報導:『成功訪問了 871 位成年人。在百分之九十五的信心水準下,有 46% 民眾認為學費太貴,抽樣誤差在正負3.3% 之內』,而該調查是以台灣地區住宅電話為母體作尾數兩位隨機抽樣。
這是否代表「認為公立大學學費太貴的民眾比例在(0.427,0.493) 這個區間範圍內」?
所謂百分之九十五的信心水準下,你可以說明出其涵義嗎?

例題 1A工廠生產的 A飲料經隨機抽樣,得平均容量為330.04cc ,在 95% 的信心水準下,抽樣誤差為 1.54cc;而 B工廠生產的 B飲料經隨機抽樣,得平均容量為329.56cc ,在 95% 的信心水準下,抽樣誤差為 1.24cc ,今隨機抽出一罐 A飲料測量後告訴大家,再隨機抽出一罐B飲料,試問下列何者正確?(1)B飲料的容量必在 [328.32,330.80](2)A飲料的容量有 95% 的機率在 [328.50,331.58] 中(3)A飲料的容量大於 B飲料的容量(4)假若兩種飲料罐子皆標示容量 330cc ,則這兩 種飲料都不能說其標示不實
Ans:(4)說明 :A 的信賴區間 [328.50,331.58] , B 的信賴區間 [328.32,330.80]
真正的容量是一個固定的數,非隨機的點,不可以用機率來解釋