
![[발표] 페이스북 페이지 활용하기](https://static.fdocument.pub/doc/165x107/54828b37b4af9f430f8b46a7/-54828b37b4af9f430f8b46a7.jpg)

![[발표] 페이스북 페이지 활용하기(블로터앵콜)](https://static.fdocument.pub/doc/165x107/556687ced8b42a0f168b5103/-556687ced8b42a0f168b5103.jpg)




Languages
Pages
Legal


Part 1 ORACLE │173
SQL 튜닝에 Dictionary View 활용하기 - Part2
㈜엑셈 컨설팅본부/DB컨설팅팀 정 동기
개요
SQL 성능을 개선하기 위해서는 판단할 수 있는 근거를 수집하는 작업이 중요하다. SQL에 사용
된 관련 테이블 정보 및 인덱스 정보들을 수집하여 종합적으로 판단 해야만 좀더 효율적인 성능
개선을 이끌어 낼 수 있기 때문이다. 오라클은 이러한 정보들을 Dictionary View를 통해서 사
용자에게 전달 하고 있다. 그 중 이번 화이트 페이퍼에서는 테이블과 인덱스 관련 정보를 토대로
SQL 성능 개선에 어떻게 활용되는 지를 서술하고 있다.
테이블, 인덱스 통계를 활용 개선 사례
테이블과 인덱스 관련 정보들은 Dictionary View를 통해서 살펴 볼 수 있다. 오라클은
DBA_TABLES, DBA_TAB_COLUMNS, DBA_INDEXES, DBA_IND_COLUMNS,
DBA_IND_EXPRESSIONS의 View들을 통해서 관련 정보들을 검색 활용 할 수 있도록 제공하
고 있다. 그렇다면 테스트를 통해 해당 View들이 어떻게 활용 되는지를 알아 보도록 하자.
인덱스 효율성 판단 사례
SELECT c1 ,
c2 ,
c3 ,
c4 ,
c5 ,
c6
FROM dict_view_t1 t
WHERE c2 = 'B'
AND c3 = '11'
AND c4 = 'RED'

174│2013 기술백서 White Paper
AND c5 = '1981'
AND C1 = 1
-------------------------------------------------------------------------------------
| Id | Operation | Name |Starts| E-Rows | A-Rows | A-Time |
-------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 1 | 00:00:00.02 |
|* 1 | TABLE ACCESS FULL|DICT_VIEW_T1 | 1 | 1 | 1 | 00:00:00.02 |
-------------------------------------------------------------------------------------
해당 SQL의 실행 계획을 살펴 보면 총 추출 건수 가 1건으로 매우 적지만 TABLE FULL SCAN
을 통하여 정보를 추출하고 있으므로 효율적인지를 판단해 볼 필요성이 있다. 그렇다면 TABLE
FULL SCAN이 효율적인 것인지 그렇지 않다면 해당 TABLE에 적합한 인덱스가 존재 하는지,
인덱스가 존재 한다면 어떠한 인덱스가 효율적인 지를 따져봐야 할 것이다. 오라클은 관련
Dictionary View를 통해서 해당 자료들을 제공하고 있다.
우선 테이블 인덱스 존재 여부는 DBA_INDEXES를 통해서 확인 가능하다.
[Script 3 수행 결과]
INDEX_NAME U TABLESPACE DISTINCT CLUSTERING FACTOR BLEVEL LEAF_BLK
--------------------------- - ---------- --------- ------------------ ------ ---------
DICT_VIEW_T1_IDX_01(SH) N USERS 1000000 3377 2 2226
DICT_VIEW_T1_IDX_02(SH) N USERS 10 33770 2 3540
또한 해당 인덱스의 구성 칼럼 정보들은 DBA_IND_COLUMNS를 통해서 살펴볼 수 있다.
[Script 4 수행 결과]
INDEX_NAME TYPE U COLUMN LIST
-------------------- ---- -- --------------
DICT_VIEW_T1_IDX_01 NORM N C1
DICT_VIEW_T1_IDX_02 NORM N C2, C3, C4, C5
그리고 인덱스 구성 칼럼의 CARDINALITY나 DISTINCT VALUE등을 살펴 보기 위해서는
DBA_TABLES 와 DBA_TAB_COLUMNS를 통해서 관련 정보를 얻을 수 있다.

Part 1 ORACLE │175
CARDINALITY = ( DBA_TABLES.NUM_ROWS – DBA_TAB_COLUMN.NUM_NULLS ) /
DBA_TAB_COLUMNS.NUM_DISTINCT
[활용 Script 1 결과]
TABLE NAME TABLESPACE NAME NUM_ROWS DEGREE BLOCKS
---------------- --------------- -------- ------ ------
DICT_VIEW_T1(SH) USERS 1000000 1 3439
[활용 Script 2 결과]
COLUMN_NAME DATA_TYPE DATALEN NN DISTINCT DENSITY NUM_NULLS BUCKET SAMPLE_SIZE
------------ -------- ---------- -- --------- ----------- ---------- ------ ----------
C1 NUMBER 22 N 1000000 0.000001000 0 1 1000000
C2 VARCHAR2 1 Y 2 0.500000000 0 1 1000000
C3 NUMBER 22 Y 10 0.100000000 0 1 1000000
C4 VARCHAR2 5 Y 5 0.200000000 0 1 1000000
C5 NUMBER 22 Y 10 0.100000000 0 1 1000000
이렇게 해당 Dictionary View을 통해서 관련 정보들을 제공 받을 수 있다. 우리는 이러한 정보
들을 활용하여 성능 문제를 개선하기 위한 판단 근거로 활용 할 수 있다. 그렇다면 해당 SQL의
관련 정보들을 활용하여 효율성을 판단해 보도록 하자. 먼저 SQL의 WHERE 조건 절을 살펴 보
면 검색 조건으로 C1 ~C5까지 존재 한다. 또한 TABLE DICT_VIEW_T1에는 2개의 인덱스가
존재하는 것을 Dictionary View를 통해서 확인 하였다. 먼저 2개의 인덱스
DICT_VIEW_T1_IDX_01, DICT_VIEW_T1_IDX_02 중 어떠한 인덱스가 효율적인 지를 판단
해 보도록 하자. 인덱스 DICT_VIEW_T1_IDX_01은 칼럼 C1으로 구성되어 있다. C1의
CARDINALITY를 살펴보면 (1000000 – 0) / 1000000 = 1로 매우 효율적인 것을 확인 할 수
있다. 즉 TABLE DICT_VIEW_T1 의 NUM_ ROWS값이 1000000 이고 인덱스
DICT_VIEW_T1_IDX_01 의 DISTINCT 값이 1000000이므로 인덱스 평균 추출 건수가
(1000000/1000000 = 1) 약 1 건이라는 것을 판단 할 수 있다. 이번에는 인덱스
DICT_VIEW_T1_IDX_02의 효율성을 확인해 보도록 하자. DICT_VIEW_T1_IDX_02의 구성
칼럼은 C2, C3, C4, C5로 구성되어 있다. 인덱스 DICT_VIEW_T1_IDX_02 구성 칼럼에 각각
의 CARDINALITY는 C2 =(10000000 – 0) / 2 = 5000000, C3 =(10000000 – 0) / 10 =
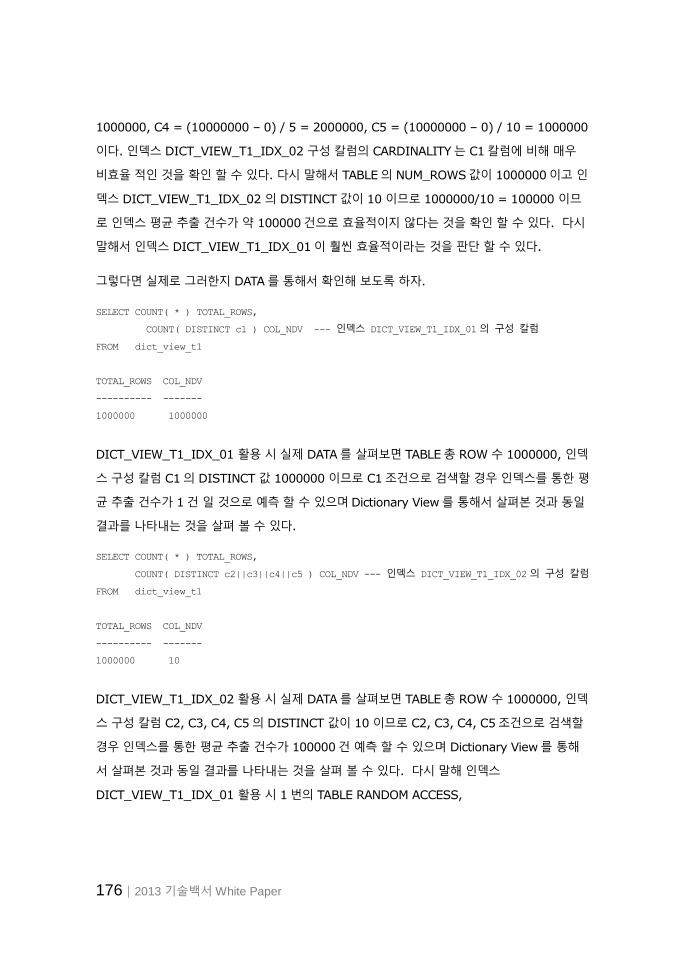
176│2013 기술백서 White Paper
1000000, C4 = (10000000 – 0) / 5 = 2000000, C5 = (10000000 – 0) / 10 = 1000000
이다. 인덱스 DICT_VIEW_T1_IDX_02 구성 칼럼의 CARDINALITY는 C1칼럼에 비해 매우
비효율 적인 것을 확인 할 수 있다. 다시 말해서 TABLE의 NUM_ROWS값이 1000000이고 인
덱스 DICT_VIEW_T1_IDX_02 의 DISTINCT 값이 10 이므로 1000000/10 = 100000 이므
로 인덱스 평균 추출 건수가 약 100000건으로 효율적이지 않다는 것을 확인 할 수 있다. 다시
말해서 인덱스 DICT_VIEW_T1_IDX_01이 훨씬 효율적이라는 것을 판단 할 수 있다.
그렇다면 실제로 그러한지 DATA를 통해서 확인해 보도록 하자.
SELECT COUNT( * ) TOTAL_ROWS,
COUNT( DISTINCT c1 ) COL_NDV --- 인덱스 DICT_VIEW_T1_IDX_01의 구성 칼럼
FROM dict_view_t1
TOTAL_ROWS COL_NDV
---------- -------
1000000 1000000
DICT_VIEW_T1_IDX_01 활용 시 실제 DATA를 살펴보면 TABLE총 ROW 수 1000000, 인덱
스 구성 칼럼 C1의 DISTINCT 값 1000000 이므로 C1조건으로 검색할 경우 인덱스를 통한 평
균 추출 건수가 1건 일 것으로 예측 할 수 있으며Dictionary View를 통해서 살펴본 것과 동일
결과를 나타내는 것을 살펴 볼 수 있다.
SELECT COUNT( * ) TOTAL_ROWS,
COUNT( DISTINCT c2||c3||c4||c5 ) COL_NDV --- 인덱스 DICT_VIEW_T1_IDX_02의 구성 칼럼
FROM dict_view_t1
TOTAL_ROWS COL_NDV
---------- -------
1000000 10
DICT_VIEW_T1_IDX_02 활용 시 실제 DATA를 살펴보면 TABLE총 ROW 수 1000000, 인덱
스 구성 칼럼 C2, C3, C4, C5의 DISTINCT 값이 10 이므로 C2, C3, C4, C5조건으로 검색할
경우 인덱스를 통한 평균 추출 건수가 100000건 예측 할 수 있으며 Dictionary View를 통해
서 살펴본 것과 동일 결과를 나타내는 것을 살펴 볼 수 있다. 다시 말해 인덱스
DICT_VIEW_T1_IDX_01 활용 시 1번의 TABLE RANDOM ACCESS,

Part 1 ORACLE │177
DICT_VIEW_T1_IDX_02 활용 시 최대 100000 번의 TABLE RANDOM ACCESS가 발생 할
수 있으므로 DICT_VIEW_T1_IDX_01가 훨씬 효율적이라고 판단 할 수 있다.
마지막으로 해당 인덱스를 활용하여 실제 실행계획을 살펴 보도록 하자.
SELECT c1 ,
c2 ,
c3 ,
c4 ,
c5 ,
c6
FROM dict_view_t1 t
WHERE c2 = 'B'
AND c3 = '11'
AND c4 = 'RED'
AND c5 = '1981'
AND c1 = 1
----------------------------------------------------------------------------------------
| Id | Operation | Name | A-Rows | A-Time | Buffers |
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 |00:00:00.01 | 4 |
|* 1 | TABLE ACCESS BY INDEX ROWID| DICT_VIEW_T1 | 1 |00:00:00.01 | 4 |
|* 2 | INDEX RANGE SCAN |DICT_VIEW_T1_IDX_01 | 1 |00:00:00.01 | 3 |
----------------------------------------------------------------------------------------
인덱스 DICT_VIEW_T1_IDX_01를 활용한 SQL의 실행 계획이다. 인덱스를 통해 1건을 추출
후 1번의 TABLE RANDOM ACCESS가 발생 하였으며 총 4 BLOCKS를 READ하였다. 인덱스
구성 칼럼 C1이 UNIQUE하므로 인덱스 BLOCK READS량 또한 매우 적은 것을 알 수 있다.
SELECT c1 ,
c2 ,
c3 ,
c4 ,
c5 ,
c6
FROM dict_view_t1 t
WHERE c2 = 'B'
AND c3 = '11'
AND c4 = 'RED'
AND c5 = '1981'
AND c1 = 1

178│2013 기술백서 White Paper
----------------------------------------------------------------------------------------
| Id | Operation | Name | A-Rows | A-Time | Buffers |
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 |00:00:00.09 | 3715 |
|* 1 | TABLE ACCESS BY INDEX ROWID| DICT_VIEW_T1 | 1 |00:00:00.09 | 3715 |
|* 2 | INDEX RANGE SCAN | DICT_VIEW_T1_IDX_02 | 100K |00:00:00.89 | 338|
----------------------------------------------------------------------------------------
CLUSTERING FACTOR가 33770 이므로 약 30 ROW당 1 TABLE RANDOM ACCESS이므로 BLOCK
READS량 감소
인덱스 DICT_VIEW_T1_IDX_02를 활용한 SQL의 실행 계획이다. 인덱스를 통해 100000건
을 추출 후 약 3715-338 = 3377번의 TABLE RANDOM ACCESS가 발생 하였으며 총 3715
BLOCK READS가 발생하였으며 인덱스 BLOCK READS량 또한 DICT_VIEW_T1_IDX_01에
비해서 비효율 적인 것을 알 수 있다.
총 3가지의 SQL 실행 계획을 정리해 보면, 첫 번째 TABLE FULL SCAN 하였을 경우 총 3348
BLOCK, 두 번째 인덱스 DICT_VIEW_T1_IDX_01를 활용 하였을 경우 인덱스 3 BLOCK
READS 그리고 1번의 TABLE RANDOM ACCESS, 세 번째 DICT_VIEW_T1_IDX_02를 활용
하였을 경우 인덱스 338 BLOCK READS와 약 3377번의 TABLE RANDOM ACCESS가 발생
하고 있다. 즉 Dictionary View를 통해 살펴 본 결과와 동일하게 인덱스
DICT_VIEW_T1_IDX_01를 활용 했을 때 가장 효율적이라는 것을 실제 실행계획을 통해서 확
인 할 수 있다.
테이블, 인덱스 Dictionary View 상세 설명 및 활용 스크립트
위의 개선 사례로 보았듯이 Dictionary View에는 SQL성능을 개선하기 위한 판단 자료로 유용
한 View들이 존재 한다. DBA_TABLES, DBA_TAB_COLUMNS, DBA_INDEXES,
DBA_IND_COLUMNS, DBA_IND_EXPRESSIONS 등을 활용하여 성능 개선에 유용하게
사용될 수 있다.
Note. 문서에서 기술될 Dictionary View의 버전은 11g R2버전이다.

Part 1 ORACLE │179
TABLE, INDEX 관련 DBA_* VIEW
SQL성능 이슈에 도움이 되는 TABLE, INDEX관련 Dictionary View 인 DBA_TABLES,
DBA_TAB_COLUMNS, DBA_INDEXES, DBA_IND_COLUMNS, DBA_IND_EXPRESSIONS
에 관하여 자세히 알아보도록 하자.
DB A_TABLES
DBA_TABLES는 데이터베이스에 있는 모든 TABLE에 관한 정보들을 설명한 VIEW다. 이
View의 중요 컬러 정보는[표 1]와 같다.
Column Name Data Type Descrption
OWNER VARCHAR2(30) TABLE 의 OWNER
TABLE_NAME VARCHAR2(30) TABLE의 이름
TABLESPACE_NAME VARCHAR2(30) TABLE 이 속해 있는 TABLESAPCE 명
PCT_FREE NUMBER 블록의 최소 여유 공간 (백분율)
PCT_USED NUMBER 블록에 대해 유지하려는 사용 공간의 최소 치(백
분율)
NEXT_EXTENT NUMBER 다음 extent 의 Size
MIN_EXTENTS NUMBER 세그먼트에 허용 된 extents의 최소 수
NUM_ROWS* NUMBER TABLE ROW 수
BLOCKS* NUMBER TABLE에 사용 된 DATA BLOCK수
DEGREE NUMBER TABLE을 병렬 처리 시 사용되는 Process 수
PARTITIONED VARCHAR2 파티션 TABLE 인지를 나타낸다.
LAST_ANALYZED DATE 마지막 통계정보가 생성된 날짜
AVG_SPACE NUMBER DATA BLOCK의 평균 Free Space
AVG_ROW_LEN NUMBER TABLE ROW 의 평균 길이(In Bytes)
EMPTY_BLOCKS NUMBER TABLE에 비어있는 BLOCK 수
[표 1] DBA_TABLES 중요 칼럼
Script 1>
SELECT table_name||'(' ||owner||')' || CHR( 10 ) ||tablespace_name
||decode( partitioned , 'YES' , '* Partitioned ' , '' )
||decode( TEMPORARY , 'Y' , '* Temporary ' , '' ) AS "TAB_INFO" ,
TRUNC( num_rows ) num_rows ,

180│2013 기술백서 White Paper
avg_row_len ,
blocks || CHR( 10 ) || empty_blocks AS "BLK_INFO" ,
TRIM( degree ) degree ,
avg_space ,
chain_cnt ,
pct_free || '/' || pct_used || '/' || pct_increase pct ,
ini_trans || '/' ||max_trans tran ,
decode( SIGN( FLOOR( initial_extent/1024/1024 ) ) , 1 ,
ROUND( initial_extent/1024/1024 )
||'m' , ROUND( initial_extent/1024 ) ||'k' ) || '/'
|| decode( SIGN( FLOOR( next_extent/1024/1024 ) ) , 1 ,
ROUND( next_extent/1024/1024 )
||'m' , ROUND( next_extent/1024 ) ||'k' ) || CHR( 10 ) || min_extents ||'/'
|| decode( max_extents , 2147483645 , 'Unlimit' , max_extents ) inext ,
FREELISTS || '/' || freelist_groups free ,
TO_CHAR( last_analyzed , 'yyyy-mm-dd:hh24:mi:ss' ) last_analFROM dba_tables
WHERE table_name = UPPER( TRIM( :table_name ) )
AND owner = UPPER( TRIM( :schname ) )
[Scrpit 1] DBA_TABLES 활용
DBA_TAB_COLUMNS
DBA_TAB_COLUMNS는 데이터베이스에 있는 Clusters, Tables, Views의 모든 칼럼 정보들
을 담고 있다. 이 View의 중요 칼럼 정보는 [표 2]와 같다.
Column Name Data Type Descrption
OWNER VARCHAR2(30) TABLE, VIEW, CLUSTER 의 OWNER
TABLE_NAME VARCHAR2(30) TABLE, VIEW, CLUSTER 의 이름
COLUMN_NAME VARCHAR2(30) COLUMN의 이름
DATA_TYPE VARCHAR2(106) COLUMN의 DATA TYPE
DATA_LENGTH NUMBER COLUMN의 길이(In bytes)
NULLABLE VARCHAR2(1) NULL 사용가능 여부
NUM_DISTINCT NUMBER COLUMN의 DISTINCT 값(DATA VALUE 의 종류
수)
DENSITY NUMBER COLUMN의 DENSITY 값
NUM_NULLS NUMBER COLUMN에 포함 된 NULL 의 수
SAMPLE_SIZE NUMBER 통계정보 수집 시 사용되는 SAMPLE SIZE
LAST_ANALYZED DATE 마지막 통계정보가 생성된 날짜

Part 1 ORACLE │181
HISTOGRAM VARCHAR2 히스토그램의 TYPE(NONE, FREQUENCY, HEIFHT
BALANCED)
[표 2] DBA_TAB_COLUMNS 중요 칼럼
Script 2 >
SELECT column_name ,
data_type ,
data_length ,
decode( data_precision || '/' || data_scale , '/' ,
NULL , data_precision || '/' || data_scale ) dpds ,
nullable nn ,
num_distinct ,
density ,
num_nulls ,
num_buckets ,
sample_size ,
TO_CHAR( last_analyzed , 'yyyy-mm-dd' ) last_anal
FROM dba_tab_columns
WHERE owner = UPPER( TRIM( :schname ) )
AND table_name = UPPER( TRIM( :table_name ) )
[Scrpit 2] DBA_TAB_COLUMNS 활용
DBA_INDEXES
DBA_INDEXES는 데이터베이스에 존재하는 모든 인덱스 정보를 담고 있다. 이 View의 중요
칼럼 정보는 [표 3]와 같다.
Column Name Data Type Descrption
OWNER VARCHAR2(30) INDEX의 OWNER
INDEX_NAME VARCHAR2(30 INDEX의 NAME
INDEX_TYPE VARCHAR2(27) INDEX의 TYPE (NORMAL, BITMAP, FUNCTION-
BASED NORMAL 등)
TABLE_OWNER VARCHAR2(30) INDEX를 소유하고 있는 TABLE의 OWNER
TABLE_NAME VARCHAR2(30) INDEX를 소유하고 있는 TABLE의 이름
TABLE_TYPE CHAR(5) INDEX OBJECT 의 TYPE (NEXT OBJECT, INDEX,
TABLE등)
UNIQUENESS VARCHAR2(9) INDEX가 UNIQUE OR NONUNIQUE 인지 식별
TABLESPACE_NAME VARCHAR2(30) INDEX가 포함된 TABLE SPACE 이름

182│2013 기술백서 White Paper
BLEVEL* NUMBER B-TREE 레벨 값
LEAF_BLOCKS* NUMBER INDEX의 LEAF BLOCK 의 수
DISTINCT_KEYS* NUMBER INDEX의 DISTINCT 값
PARTITIONED VARCHAR2(3) INDEX의 파티션 유무
CLUSTERING_FACTOR NUMBER DATA가 INDEX ORDER 순으로 모여있는 정도를
나타냄
NUM_ROW NUMBER INDEX의 총 ROW 수
LAST_ANALYZED DATE 마지막 통계정보가 생성된 날짜
[표 3] DBA_INDEXES 중요 칼럼
Script 3 >
SELECT index_name||'(' ||owner||')' index_name ,
SUBSTR( uniqueness , 1 , 1 ) u ,
tablespace_name||decode( partitioned , 'YES' , '*Partitioned ' , '' )
||decode( TEMPORARY , 'Y' , '*Temporary ' , '' ) TABLESPACE ,
TO_CHAR( TRUNC( num_rows ) ) ||chr( 10 ) ||to_char( distinct_keys ) AS
"NUM_ROWS_DISTINCT" ,
clustering_factor ,
leaf_blocks || CHR( 10 ) || blevel AS "BLK_INFO" ,
avg_leaf_blocks_per_key || '/' ||avg_data_blocks_per_key alb_adb ,
ini_trans || '/' ||max_trans tran ,
decode( SIGN( FLOOR( initial_extent/1024/1024 ) ) , 1 ,
ROUND( initial_extent/1024/1024 )
||'m' , ROUND( initial_extent/1024 ) ||'k' ) || '/' ||
decode( SIGN( FLOOR( next_extent/1024/1024 ) ) ,
1 , ROUND( next_extent/1024/1024 ) ||'m' , ROUND( next_extent/1024 ) ||'k' ) ||
CHR( 10 )
|| min_extents ||'/' || decode( max_extents , 2147483645 , 'unlimit' ,
max_extents ) inext ,
FREELISTS || '/' || freelist_groups free ,
TO_CHAR( last_analyzed , 'yyyy-mm-dd' ) last_anal
FROM dba_indexes
WHERE table_name = UPPER( TRIM( :table_name ) )
AND table_owner = UPPER( TRIM( :schname ) )
[Scrpit 3] DBA_INDEXES 활용

Part 1 ORACLE │183
DBA_IND_COLUMNS
DBA_IND_COLUMNS는 데이터베이스에 있는 Clusters, Tables, Views의 모든 인덱스 칼럼
정보들을 담고 있다. 이 View의 중요 칼럼 정보는 [표 4]와 같다
Column Name Data Type Descrption
OWNER VARCHAR2(30) INDEX의 OWNER
INDEX_NAME VARCHAR2(30 INDEX의 NAME
INDEX_TYPE VARCHAR2(27) INDEX의 TYPE (NORMAL, BITMAP, FUNCTION-
BASED NORMAL 등)
TABLE_OWNER VARCHAR2(30) INDEX OBJECT 의 소유자(OWNER)
COLUMN_POSITION NUMBER INDEX 구성 COLUMN의 순서
DESCEND VARCHAR2 SORT 상태를 나타냄
[표 4] DBA_IND_COLUMNS 중요 칼럼
Script 4 >
SELECT index_name ,
SUBSTR( index_type , 1 , 4 ) TYPE ,
SUBSTR( uniqueness , 1 , 1 ) u ,
(
SELECT MAX( decode( column_position , 1 , column_name ) ) ||
decode( MAX( decode( column_position , 2 , column_name ) ) , NULL ,
NULL , ', ' ) ||
MAX( decode( column_position , 2 , column_name ) ) ||
decode( MAX( decode( column_position , 3 , column_name ) ) , NULL ,
NULL , ', ' ) ||
MAX( decode( column_position , 3 , column_name ) ) ||
decode( MAX( decode( column_position , 4 , column_name ) ) , NULL ,
NULL , ', ' ) ||
MAX( decode( column_position , 4 , column_name ) ) ||
decode( MAX( decode( column_position , 5 , column_name ) ) , NULL ,
NULL , ', ' ) ||
MAX( decode( column_position , 5 , column_name ) ) ||
decode( MAX( decode( column_position , 6 , column_name ) ) , NULL ,
NULL , ', ' ) ||
MAX( decode( column_position , 6 , column_name ) ) ||
decode( MAX( decode( column_position , 7 , column_name ) ) , NULL ,
NULL , ', ' ) ||
MAX( decode( column_position , 7 , column_name ) ) ||
decode( MAX( decode( column_position , 8 , column_name ) ) , NULL ,

184│2013 기술백서 White Paper
NULL , ', ' ) ||
MAX( decode( column_position , 8 , column_name ) ) ||
decode( MAX( decode( column_position , 9 , column_name ) ) , NULL ,
NULL , ', ' ) ||
MAX( decode( column_position , 9 , column_name ) ) ||
decode( MAX( decode( column_position , 10 , column_name ) ) , NULL ,
NULL , ', ' ) ||
MAX( decode( column_position , 10 , column_name ) ) ||
decode( MAX( decode( column_position , 11 , column_name ) ) , NULL ,
NULL , ', ' ) ||
MAX( decode( column_position , 11 , column_name ) ) ||
decode( MAX( decode( column_position , 12 , column_name ) ) , NULL ,
NULL , ', ' ) ||
MAX( decode( column_position , 12 , column_name ) ) ||
decode( MAX( decode( column_position , 13 , column_name ) ) , NULL ,
NULL , ', ' ) ||
MAX( decode( column_position , 13 , column_name ) ) ||
decode( MAX( decode( column_position , 14 , column_name ) ) , NULL ,
NULL , ', ' ) ||
MAX( decode( column_position , 14 , column_name ) ) ||
decode( MAX( decode( column_position , 15 , column_name ) ) , NULL ,
NULL , ', ' ) ||
MAX( decode( column_position , 15 , column_name ) )
FROM all_ind_columns col
WHERE col.index_name = a.index_name
AND col.table_owner = a.table_owner
AND col.table_name = a.table_name
) AS column_list
FROM dba_indexes a
WHERE a.table_name = UPPER( TRIM( :table_name ) )
AND a.table_owner= UPPER( TRIM( :schname ) )
ORDER BY index_name
[Scrpit 4] DBA_IND_COLUMNS 활용
DBA_IND_EXPRESSIONS
DBA_IND_EXPRESSIONS는 데이터베이스의 Clusters, Tables, Views있는 모든
FUNCTION-BASE 인덱스 관련 정보를 담고 있다. 이 View의 중요 칼럼 정보는 [표 5]와 같다

Part 1 ORACLE │185
Column Name Data Type Descrption
INDEX_OWNER VARCHAR2(30) INDEX의 OWNER
INDEX_NAME VARCHAR2(30 INDEX의 NAME
TABLE_OWNER VARCHAR2(30) INDEX를 소유하고 있는 TABLE의 OWNER
TABLE_NAME VARCHAR2(30) INDEX OBJECT 의 NAME
COLUMN_EXPRESSION LONG FUNCTION-BASED INDEX COLUMN의 표현 식
을 나타낸다.
COLUMN_POSITION NUMBER INDEX 구성 COLUMN 순서
[표 5] DBA_IND_EXPRESSIONS 중요 칼럼
결론
이번 기술 백서에서는DBA_TABLES, DBA_TAB_COLUMNS, DBA_INDEXES,
DBA_IND_COLUMNS의 간단한 활용 사례와 각각의 구성 칼럼들에 대하여 알아 보았다. 이처
럼 오라클은 성능 이슈에 활용 할 수 있는 다양한 Dicationary View들을 제공해 오고 있다. 각
각의 View들이 갖고 있는 정보들을 숙지하고 활용 한다면 SQL 성능 개선의 판단 자료로 활용
할 수 있을 것이다.