







Languages
Pages
Legal


Serverless Anti-PatternsKeisuke Nishitani (@Keisuke69)
Amazon Web Services Japan K.K.Mar 09, 2017
Photo via VisualHunt.com

ProfileKeisuke NishitaniSpecialist Solutions Architect, ServerlessAmazon Web Service Japan K.K
@Keisuke69 Keisuke69
✤ RESTおじさん✤ 餃⼦の王将エヴァンジェリスト(⾃称)✤ ⾳楽が好きです、フジロッカーです、今年も⾏きます✤ ブログ: http://keisuke69.hatenablog.jp/
Keisuke69 Keisuke69Keisuke69x

What is Serverless?
Serverless = No servers to manage and scale

サーバレスのメリット✤ サーバレスはバックエンドのアウトソース
⎻ サーバサイドやインフラがわからないフロントエンジニアだけでシステムを実現することも可能
⎻ バックエンド側のコードとサーバが減るため開発運⽤コストが最⼩化⎻ ⾃分の書いたコードをすぐ試せる、トライ&エラーが容易⎻ サービスプロバイダによってマネージされ、スケーラビリティやキャパシティ、
セキュリティの⼼配が不要⎻ ⾮常にコスト効率化が⾼く、多くの場合コスト減が⾒込める
✤ 開発者がビジネスにフォーカスできる

You donʼt do that, we do that.

アーキテクチャパターン

AWSにおけるアプリケーションの実⾏パターン✤ Amazon Elastic Compute Cloud (EC2)
✤ Docker + Amazon EC2 Container Service(ECS)
✤ AWS Lambda

AWSのComputeサービス
Amazon EC2 Amazon ECS AWS Lambda
スケールの単位 インスタンス アプリケーション ファンクション
抽象化 ハードウェア OS ランタイム

AWSのComputeサービス
Amazon EC2 Amazon ECS AWS Lambda
スケールの単位 インスタンス アプリケーション ファンクション
抽象化 ハードウェア OS ランタイム

AWSのComputeサービス
Amazon EC2 Amazon ECS AWS Lambda
スケールの単位 インスタンス アプリケーション ファンクション
抽象化 ハードウェア OS ランタイム

AWSのComputeサービス
Amazon EC2 Amazon ECS AWS Lambda
スケールの単位 インスタンス アプリケーション ファンクション
抽象化 ハードウェア OS ランタイム

すべてのデベロッパーをハッピーに
AWS Lambda
⾼いコスト効率インフラ管理不要
使った分だけ100ms単位で課⾦
⾃分のコードを実⾏
標準的な⾔語のコードを実⾏ビジネスロジックにフォーカス
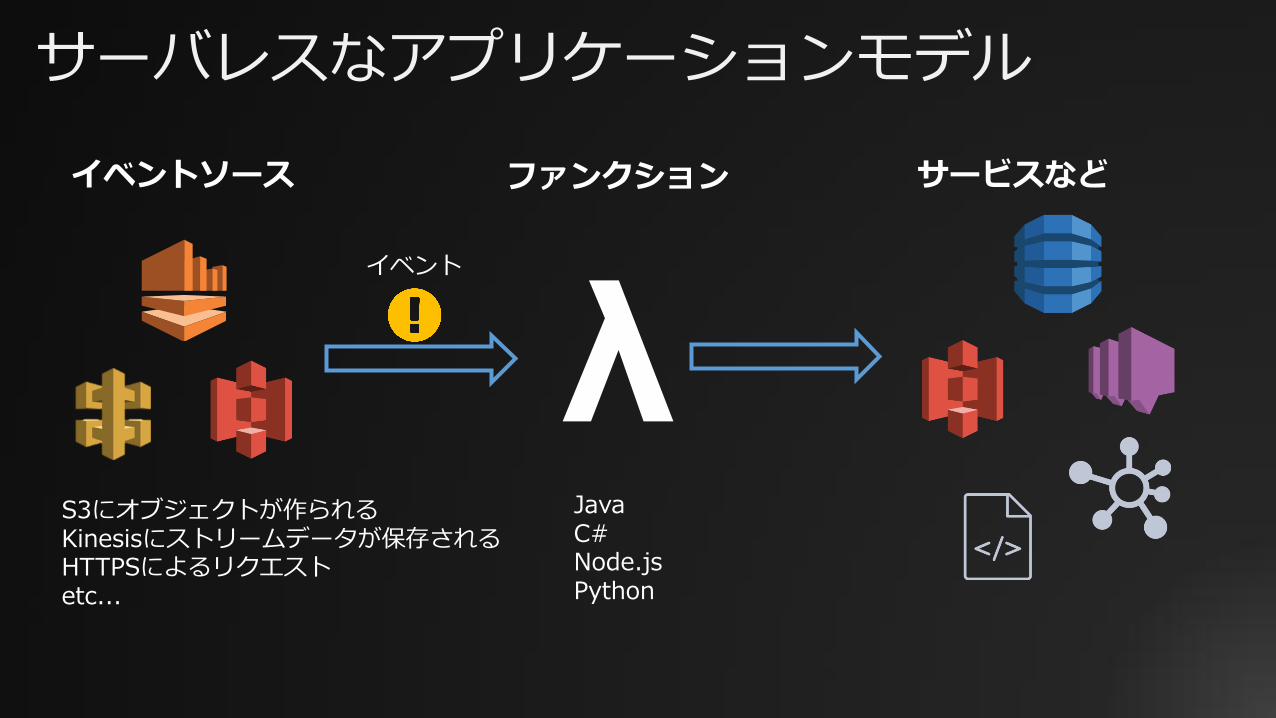
サーバレスなアプリケーションモデルイベントソース ファンクション サービスなど
JavaC#Node.jsPython
λイベント
S3にオブジェクトが作られるKinesisにストリームデータが保存されるHTTPSによるリクエストetc...

Amazon S3 Amazon DynamoDB
Amazon Kinesis
AWS CloudFormation
AWS CloudTrail
Amazon CloudWatch
Amazon SNSAmazonSES
AmazonAPI Gateway
Amazon Cognito
AWSIoT
AmazonAlexa
Cron events
DATASTORES ENDPOINTS
REPOSITORIES EVENT/MESSAGESERVICES
AWS Lambdaと連携するイベントソース
Amazon Config
Amazon Aurora

AWS Lambdaのユースケース
Data Processing Control SystemsBackends

AWS Lambdaを利⽤する場合のユースケース
データの変更、システム状態の遷移もしくはユーザによるアクションといったものに対応したコードの実⾏
レスポンスのカスタマイズとAWS内の状態やデータ変更に対するワークフローのレスポンス
Web、モバイル、IoTや外部APIへのリクエストを扱うバックエンドロジックの実⾏
Data Processing
Backends
Control Systems
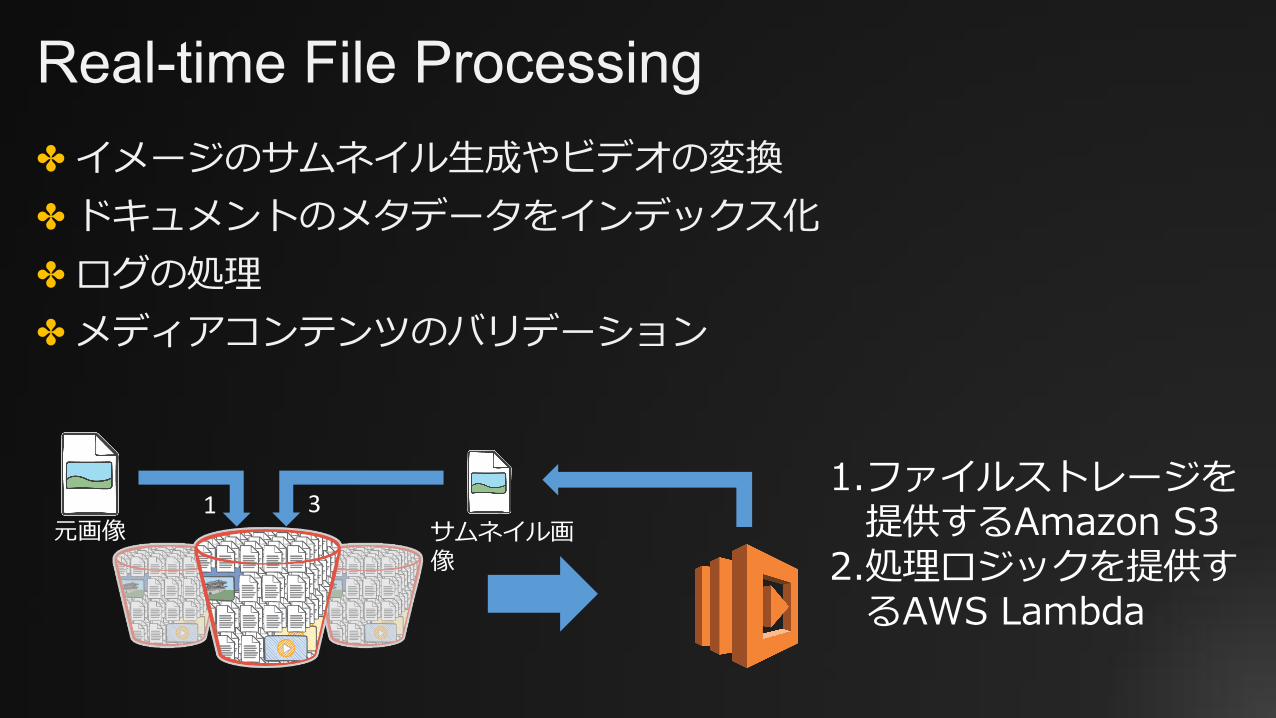
Real-time File Processing✤ イメージのサムネイル⽣成やビデオの変換✤ ドキュメントのメタデータをインデックス化✤ ログの処理✤ メディアコンテンツのバリデーション
元画像 サムネイル画像
1 31.ファイルストレージを
提供するAmazon S32.処理ロジックを提供す
るAWS Lambda
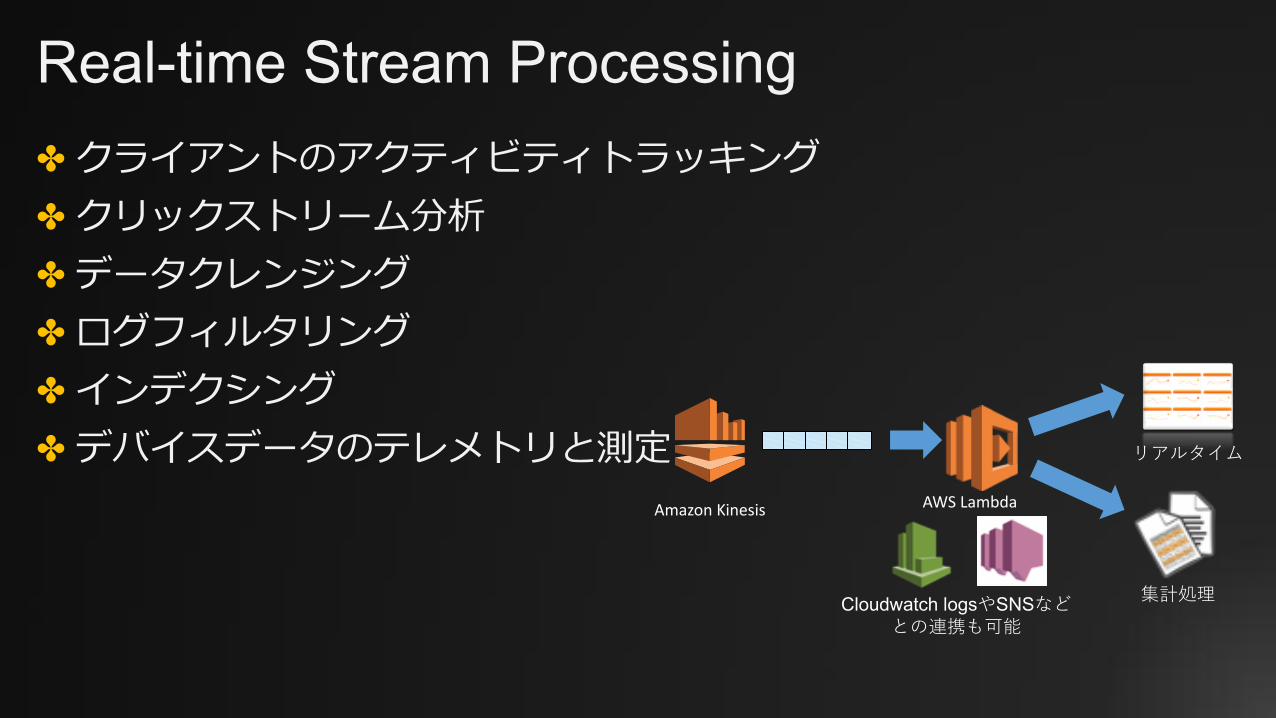
Real-time Stream Processing✤ クライアントのアクティビティトラッキング✤ クリックストリーム分析✤ データクレンジング✤ ログフィルタリング✤ インデクシング✤ デバイスデータのテレメトリと測定
AWSLambdaAmazonKinesis
集計処理
リアルタイム
Cloudwatch logsやSNSなどとの連携も可能
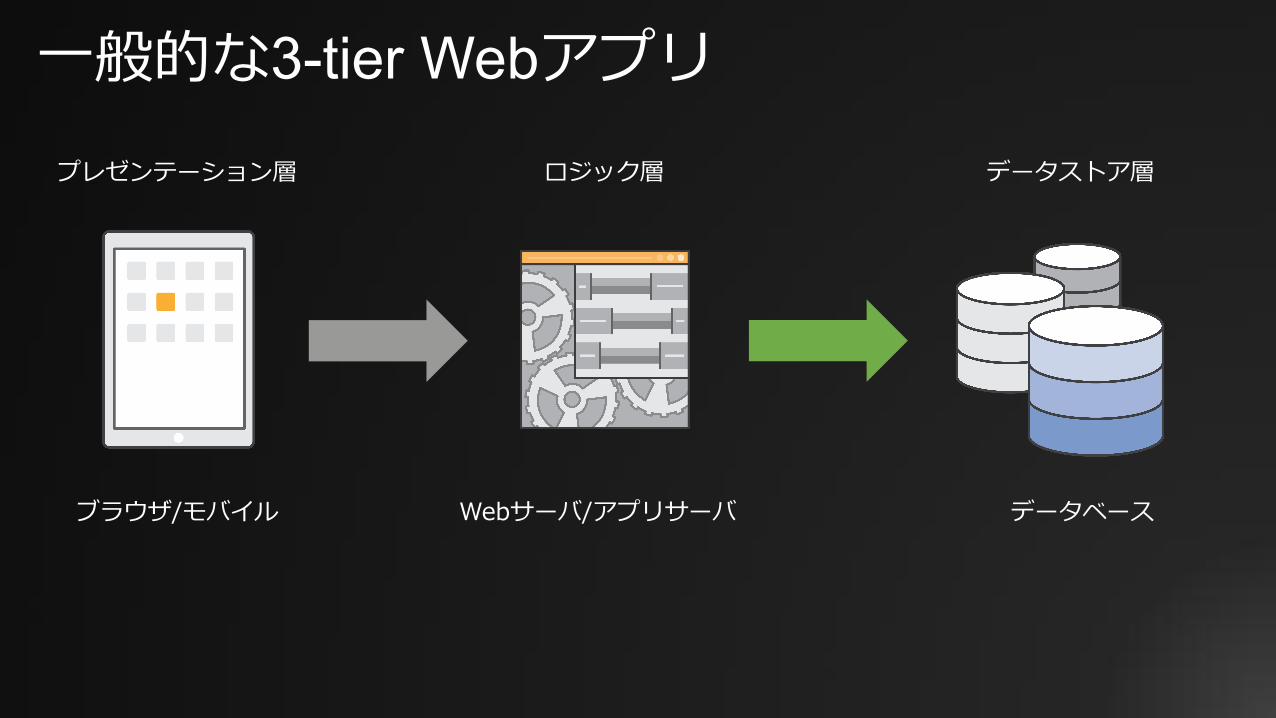
⼀般的な3-tier Webアプリプレゼンテーション層 ロジック層 データストア層
Webサーバ/アプリサーバブラウザ/モバイル データベース
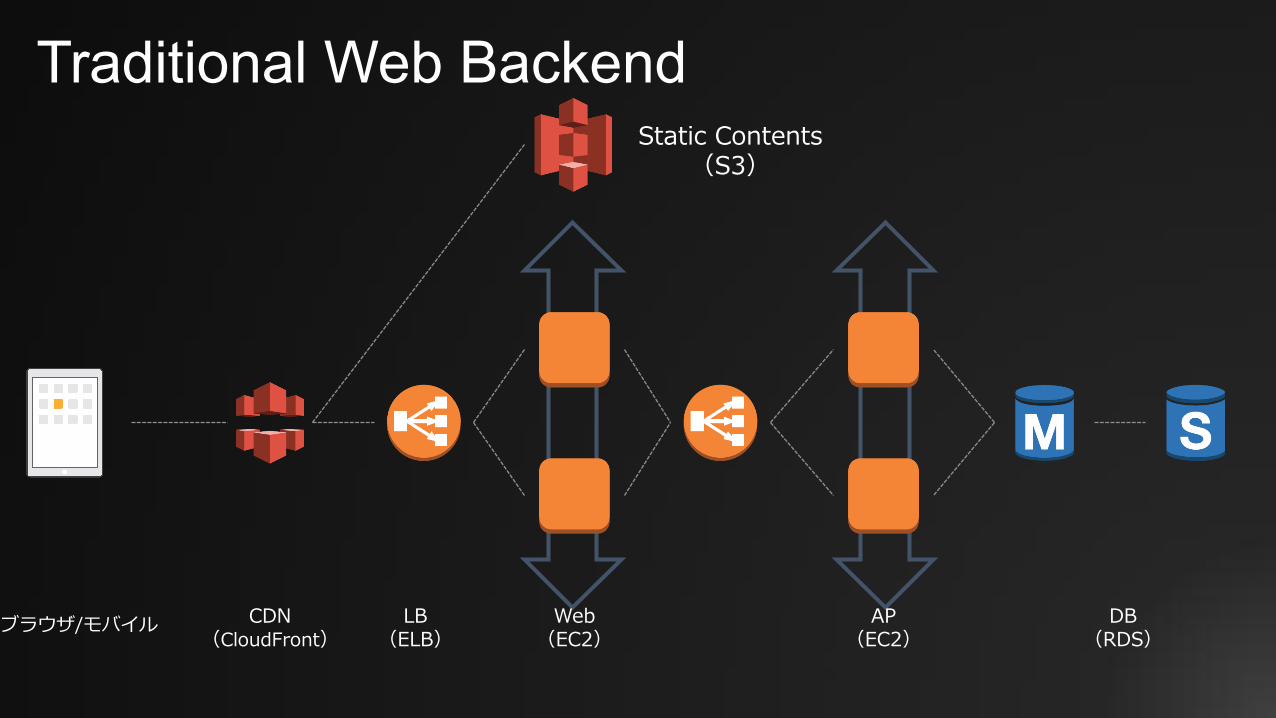
Traditional Web Backend
AP(EC2)
DB(RDS)
LB(ELB)
Web(EC2)
Static Contents(S3)
ブラウザ/モバイル CDN(CloudFront)

Traditional Web Backend✤ メリット
⎻ 実績が多く枯れた構成⎻ カスタマイズ性が⾼い⎻ 知⾒を持っている⼈が多い
✤ デメリット⎻ サーバのスペック、台数などスケールを意識して設計する必要がある⎻ サーバの運⽤は利⽤者が負う必要がある⎻ アイドル時にもコストが発⽣する

Serverless Web Backend
ブラウザ/モバイル API Gateway AWS Lambda DynamoDB etc
S3CloudFront
AWSによるマネージ(フルマネージド)

Serverless Web Backend✤ メリット
⎻ クライアント側の実装は従来とあまり変わらずノウハウを活かせる⎻ サーバの運⽤、スケールはAWSに⼀任できる⎻ サービスの組み合わせだけで、セキュアなAPIアクセス制御などが実装できる⎻ コスト効率が⾼い
✤ デメリット⎻ カスタマイズ性が低い⎻ 設計および運⽤ノウハウが枯れていない
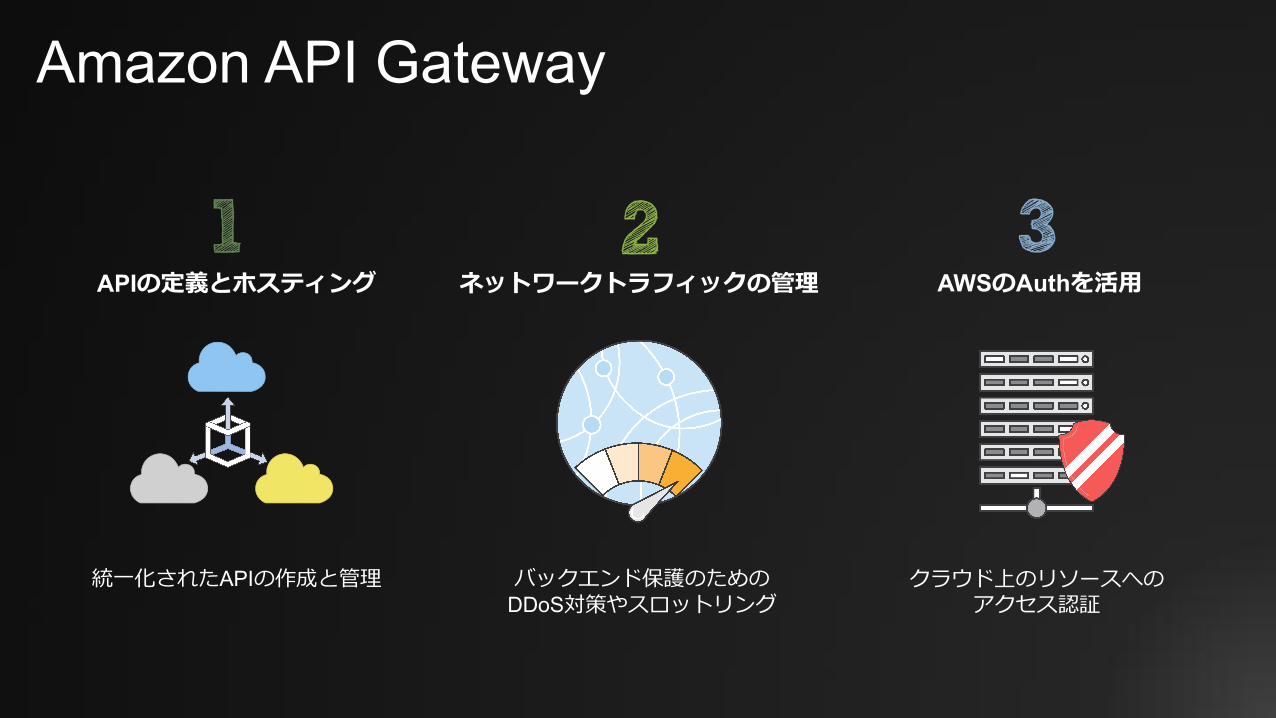
Amazon API Gateway
統⼀化されたAPIの作成と管理
APIの定義とホスティング
クラウド上のリソースへのアクセス認証
AWSのAuthを活⽤
バックエンド保護のためのDDoS対策やスロットリング
ネットワークトラフィックの管理

AWSのサーバレスオファリング
AWS LambdaAmazon API Gateway
Amazon DynamoDB
Amazon Kinesis Amazon Mobile Analytics
Amazon SNS
Amazon Cognito
AWS IoT
Amazon S3 Amazon Elastic Transcoder
AWS CloudWatch
AWS CloudTrail
Amazon SESAmazon Machine Learning
Amazon Route53Amazon SQS

アンチパターン

アンチパターン①LambdaでRDBMS使いがち問題

LambdaでRDBMS使いがち問題✤ Lambda + RDBMSがアンチパターンな理由
⎻ コネクション数の問題⎻ Lambdaはステートレスなプラットフォームであるため、コネクションプールの実装は難しい⎻ Lambdaがスケールする、つまりファンクションのコンテナが⼤量に⽣成された場合に、各コン
テナからDBへコネクションが張られることになり、耐えられないケースがある⎻ VPCコールドスタートの問題
⎻ VPCのコールドスタートが発⽣する場合、通常のコールドスタートに⽐べて10秒程度の時間を必要とする
✤ ベストプラクティス⎻ DynamoDBを使う⎻ 何らかの理由でRDBMSとの連携が必要な場合はDynamoDB StreamsとLambdaを利⽤
して⾮同期にする

アンチパターン②メモリやたら少ない問題

メモリやたら少ない問題✤ メモリ設定
⎻ 設定値としてはメモリとなっているが実際はコンピューティングリソース全体の設定
⎻ メモリサイズと⽐例してCPU能⼒も割り当てられる⎻ メモリ設定はパフォーマンス設定と同義⎻ コストを気にしがちだが、メモリを増やすことで処理時間がガクンと減り、結
果的にコストはそれほど変わらずとも性能があがることもある
✤ ベストプラクティス⎻ 最⼩から少しずつ調整し、変更しても性能が変わらない値が最適値

アンチパターン③同期実⾏にこだわりすぎ問題

同期実⾏にこだわりすぎ問題✤ 同期でInvokeすると同時実⾏数の制限に引っかかってつまりがち
⎻ 同時実⾏数の計算は「1 秒あたりのイベント数 * 関数の実⾏時間」⎻ ⾮同期呼び出しの場合、許可された同時実⾏数内で順次処理をし、バーストも許容さ
れている⎻ 同期呼び出しの場合、許可された同時実⾏数を超えた時点でエラーが返されてしまう⎻ 同時実⾏数は制限緩和可能だが、実際にスロットルされていない状態でいきなり申請
しても基本的に通らない
✤ ベストプラクティス⎻ できるだけ⾮同期でInvokeするのがオススメ
⎻ その処理、本当にレスポンス必要ですか?⎻ 特にAPI Gatewayとの組み合わせの場合、PUT系の処理をGatewayのバックエンドと
してLambdaで直接処理するのではなく、サービスプロキシとして構成してSQS、Kinesisに流すなどする

アンチパターン④サーバレスに夢⾒がち問題

サーバレスに夢⾒がち問題✤ サーバレスであれば全く運⽤が必要ない、インフラ費⽤が10分の1に
なる⎻ サーバの管理は不要だが運⽤は必要⎻ コスト効率が⾼いため、サーバを並べて同様のことを実装するよりは安くなる
可能性が⾼いが、リクエスト数が多い場合などはそれなりの費⽤になる⎻ インフラ費⽤だけでなく、トータルコストで考える必要がある⎻ 複雑なことをやろうとすると、設計・開発コストがあがる可能性も⼤きい
✤ シンプルに使うべきものはシンプルに使いましょう

アンチパターン⑤サーバレスで難しいことしがち問題

サーバレスで難しいことしがち問題✤ サーバレスはシンプルに使ったほうが効果は⾼い
⎻ 基本は「Aが発⽣したら処理をしてBにアウトプット」⎻ シンプルに使うべきものを複雑な箇所に適⽤しようとすると難易度は上がる
⎻ 分散環境の考慮、失敗時のリトライなど

サーバレスで難しいことしがち問題✤ サーバレスはシンプルに使ったほうが効果は⾼い
⎻ 基本は「Aが発⽣したら処理をしてBにアウトプット」⎻ シンプルに使うべきものを複雑な箇所に適⽤しようとすると難易度は上がる
⎻ 分散環境の考慮、失敗時のリトライなど
✤ サーバレス以外と同じこと⎻ 標準的なプログラミング⾔語とプロトコル⎻ 標準的なデプロイとテストのプラクティス

サーバレスで難しいことしがち問題✤ サーバレスはシンプルに使ったほうが効果は⾼い
⎻ 基本は「Aが発⽣したら処理をしてBにアウトプット」⎻ シンプルに使うべきものを複雑な箇所に適⽤しようとすると難易度は上がる
⎻ 分散環境の考慮、失敗時のリトライなど
✤ サーバレス以外と同じこと⎻ 標準的なプログラミング⾔語とプロトコル⎻ 標準的なデプロイとテストのプラクティス
✤ サーバレス特有のこと⎻ イベント/リクエストドリブン⎻ モジュラー⎻ ステートレス⎻ 12 factor/Microservices/Reactive..

サーバレスで難しいことしがち問題✤ サーバレスはシンプルに使ったほうが効果は⾼い
⎻ 基本は「Aが発⽣したら処理をしてBにアウトプット」⎻ シンプルに使うべきものを複雑な箇所に適⽤しようとすると難易度は上がる
⎻ 分散環境の考慮、失敗時のリトライなど
✤ サーバレス以外と同じこと⎻ 標準的なプログラミング⾔語とプロトコル⎻ 標準的なデプロイとテストのプラクティス
✤ サーバレス特有のこと⎻ イベント/リクエストドリブン⎻ モジュラー⎻ ステートレス⎻ 12 factor/Microservices/Reactive..
✤ つまり⎻ モノリスは分解する必要がある⎻ ファンクションのコミュニケーションをどうするか考え、サービス境界をクリアにする必要がある⎻ 障害発⽣を前提とした設計の必要性、結果整合性の理解が必要

サーバレスで難しいことしがち問題✤ サーバレスはシンプルに使ったほうが効果は⾼い
⎻ 基本は「Aが発⽣したら処理をしてBにアウトプット」⎻ シンプルに使うべきものを複雑な箇所に適⽤しようとすると難易度は上がる
⎻ 分散環境の考慮、失敗時のリトライなど
✤ サーバレス以外と同じこと⎻ 標準的なプログラミング⾔語とプロトコル⎻ 標準的なデプロイとテストのプラクティス
✤ サーバレス特有のこと⎻ イベント/リクエストドリブン⎻ モジュラー⎻ ステートレス⎻ 12 factor/Microservices/Reactive..
✤ つまり⎻ モノリスは分解する必要がある⎻ ファンクションのコミュニケーションをどうするか考え、サービス境界をクリアにする必要がある⎻ 障害発⽣を前提とした設計の必要性、結果整合性の理解が必要
✤ したがって⎻ シンプルに使うべきものはシンプルに使いましょう⎻ フルサーバレスにこだわらず、コンテナなども使って適材適所で

アンチパターン⑥何となくVPC使いがち問題

何となくVPC使いがち問題✤ VPCは必須でない。必要でない限り使⽤しない
⎻ 使うのはVPC内のリソースにどうしてもアクセスする必要があるときだけ⎻ VPCアクセスを有効にしているとコールドスタート時に10秒から30秒程度余計
に必要になる
✤ ベストプラクティス⎻ 同期実⾏が必要な箇所やコールドスタートを許容できない箇所ではなるだけ使
わない⎻ VPC内のリソースとの通信が必要なのであれば⾮同期にする
⎻ RDBMSのデータ同期が必要なのであればDynamoDB StreamsとLambdaを使って⾮同期に

アンチパターン⑦Limit Increase通らない問題
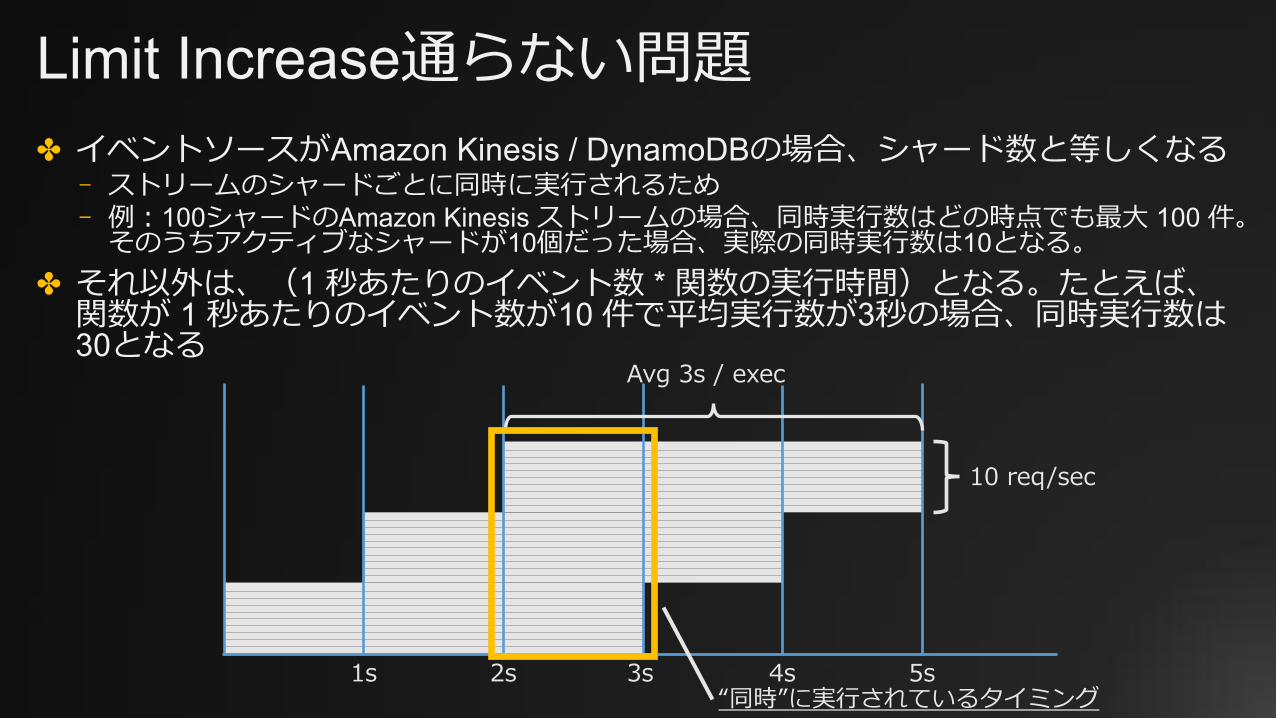
Limit Increase通らない問題✤ イベントソースがAmazon Kinesis / DynamoDBの場合、シャード数と等しくなる
⎻ ストリームのシャードごとに同時に実⾏されるため⎻ 例:100シャードのAmazon Kinesis ストリームの場合、同時実⾏数はどの時点でも最⼤ 100 件。
そのうちアクティブなシャードが10個だった場合、実際の同時実⾏数は10となる。✤ それ以外は、(1 秒あたりのイベント数 * 関数の実⾏時間)となる。たとえば、
関数が 1 秒あたりのイベント数が10 件で平均実⾏数が3秒の場合、同時実⾏数は30となる
1s 2s 3s 4s 5s
10 req/sec
Avg 3s / exec
“同時”に実⾏されているタイミング

Limit Increase通らない問題✤ 標準では100、実績がない状態でいきなり数千とか数万を申請しても
通らない⎻ 実際にThrottleされているかどうかの確認を⎻ Throttleされているかなどはメトリクスで確認可能
✤ Limit Increaseしても性能上のボトルネックは解消しないこともある⎻ ストリーム系の場合、シャード数を増やしたりバッチサイズを調整したり⎻ そもそもファンクションの実⾏に時間がかかっている場合、レイテンシは改善
しない

アンチパターン⑧コールドスタート気にしすぎ問題

コールドスタート気にしすぎ問題✤ 安定的にトラフィックが発⽣している場合、コールドスタートの発⽣
頻度は多くない⎻ コールドスタートによる遅延が⼀切許容できないのであればそもそもLambda
をやめることも検討を⎻ コールドスタートの時間は⾔語の特性と⼤きく関連する
✤ コールドスタートは⼀年前とくらべて半分くらいの時間になっている⎻ そもそも、基本的にこの領域はお客様でできることは少ない
✤ それでも気になるなら、コールドスタートを頑張って速くするしかない

コールドスタートを速くする

コールドスタートを速くする✤ Lambdaファンクションに対してPingする
⎻ 定期的にInvokeを⾏うことでコンテナが破棄されることを回避する⎻ 5分間隔程度がオススメ⎻ API Gatewayを利⽤している場合は該当のAPIへリクエスト⎻ それ以外は必要な数だけ⾮同期でInvokeする
✤ コンピューティングリソースを増やす⎻ メモリ設定⎻ コンピューティングリソースの割当を増やすことで初期化処理⾃体も速くなる
✤ ランタイムを変える⎻ JVMの起動は遅い⎻ ただし、⼀度温まるとコンパイル⾔語のほうが速い傾向

コールドスタートを速くする✤ VPCを使わない
⎻ そもそもLambdaと関係なくENIの⽣成とアタッチ処理は遅い⎻ コールドスタートを速くしたいならデータストアはDynamoDBが鉄則⎻ DBの問題でどうしてもVPCを利⽤したい場合はDynamoDB Streamsを利⽤した⾮同期反映を
検討する
✤ パッケージサイズを⼩さくする⎻ サイズが⼤きくなるとコールドスタート時のコードのロードおよびZipの展開に時間がかかる⎻ 不要なコードは減らす⎻ 依存関係を減らす
⎻ 不要なモジュールは含めない⎻ 特にJavaは肥⼤しがち
⎻ JavaだとProGuardなどのコード最適化ツールを使って減らすという⼿もある⎻ 他の⾔語でも同様のものはある

コールドスタートを速くする✤ Javaの場合だけ
⎻ POJOではなくバイトストリームを使う⎻ 内部で利⽤するJSONシリアライゼーションライブラリは多少時間がかかるので、バイトス
トリームにしてより軽量なJSONライブラリを使ったり最適化することも可能⎻ https://github.com/FasterXML/jackson-jr⎻ http://docs.aws.amazon.com/lambda/latest/dg/java-handler-io-type-stream.html
⎻ 匿名クラスをリプレースするようなJava8の機能を利⽤しない(lambda、メソッド参照、コンストラクタ参照など)

コールドスタートを速くする✤ 初期化処理をハンドラ外に書くとコールドスタートが遅くなるので遅
延ロードを⾏う
import boto3
client = None
def my_handler(event, context): global clientif not client:
client = boto3.client("s3")
# process

アンチパターン⑨IP固定したがり問題

IP固定したがり問題✤ API GatewayやLambdaから別システムや外部APIにアクセスする際のソー
スIPアドレスを固定したい
✤ 実は⽇本固有の事情だったりする⎻ IPを固定すること⾃体はセキュリティでもなんでもない⎻ 署名や証明書などで担保すべき⎻ IPアドレスを固定するということはスケーラビリティを捨てることにもつながる
✤ LambdaではVPCを利⽤してNATインスタンスを使うという⽅法もなくはないが…⎻ VPCのコールドスタート問題⎻ ⾃前のNATインスタンスの場合、その可⽤性、信頼性、スケーラビリティを考慮する
必要がある

アンチパターン⑩監視しなくていいと思ってる問題

監視しなくていいと思ってる問題✤ Serverless != Monitorless
✤ 処理の異常を検知して対応するのはユーザの仕事⎻ 適切にログ出⼒を⾏い、適切にモニタする
✤ ベストプラクティス⎻ CloudWatchのメトリクスを利⽤(Errors, Throttles)⎻ CloudWatch Logsへのログ出⼒とアラーム設定

アンチパターン⑫信⽤しすぎ問題

信⽤しすぎ問題✤ Lambdaと⾔えど通常の他のサービスと同様に障害発⽣を前提として
実装をする⎻ リトライ⎻ Dead Letter Queueの活⽤(⾮同期の場合)
✤ 冪等性はお客様のコードで確保する必要がある⎻ AWS Lambdaで保証しているのは最低1回実⾏することであり1回しか実⾏しな
いことではない⎻ 同⼀イベントで同⼀Lambdaファンクションが2回起動されることがまれに発⽣
する⎻ DynamoDBを利⽤するなどして冪等性を担保する実装を⾏うこと

その他、今となっては不要なこと

今となっては不要なこと✤ Descriptionにパラメータを保管する
⎻ 環境変数を利⽤すること
✤ ファンクションのネストや連鎖的な呼び出し⎻ Step Functionsを使う

最後にもうひとつ

ローカルでテストをしたい

Lambdaのランタイムをエミュレートする✤ Lambdaでは各ランタイムごとで使われているAMIを公開している
⎻ Amazon Linuxを利⽤⎻ 使っているランタイムのバージョンも公開している⎻ 内部的には標準的なコンテナ技術を使っている
✤ ファンクションといってもただのプログラムなのでローカル環境でも容易に実⾏できる⎻ ハンドラを呼び出すテストドライバを書くだけ⎻ Contextとイベントをエミュレーションする必要があるが、単に必要な値を⼊
れたオブジェクトを⽤意するだけいい⎻ イベントのサンプルは公開されている

テストドライバ例
import jsonimport lambda_function
f = open(“event.json”)event = json.load(f)f.close()
context = "”
lambda_function.lambda_handler(event,context)

テストドライバ例
import jsonimport lambda_function
f = open(“event.json”)event = json.load(f)f.close()
context = "”
lambda_function.lambda_handler(event,context)
イベントを静的ファイルとして⽤意しておき、ロード
<= 必要に応じて設定する(今回は空)
<= ファンクションの実⾏
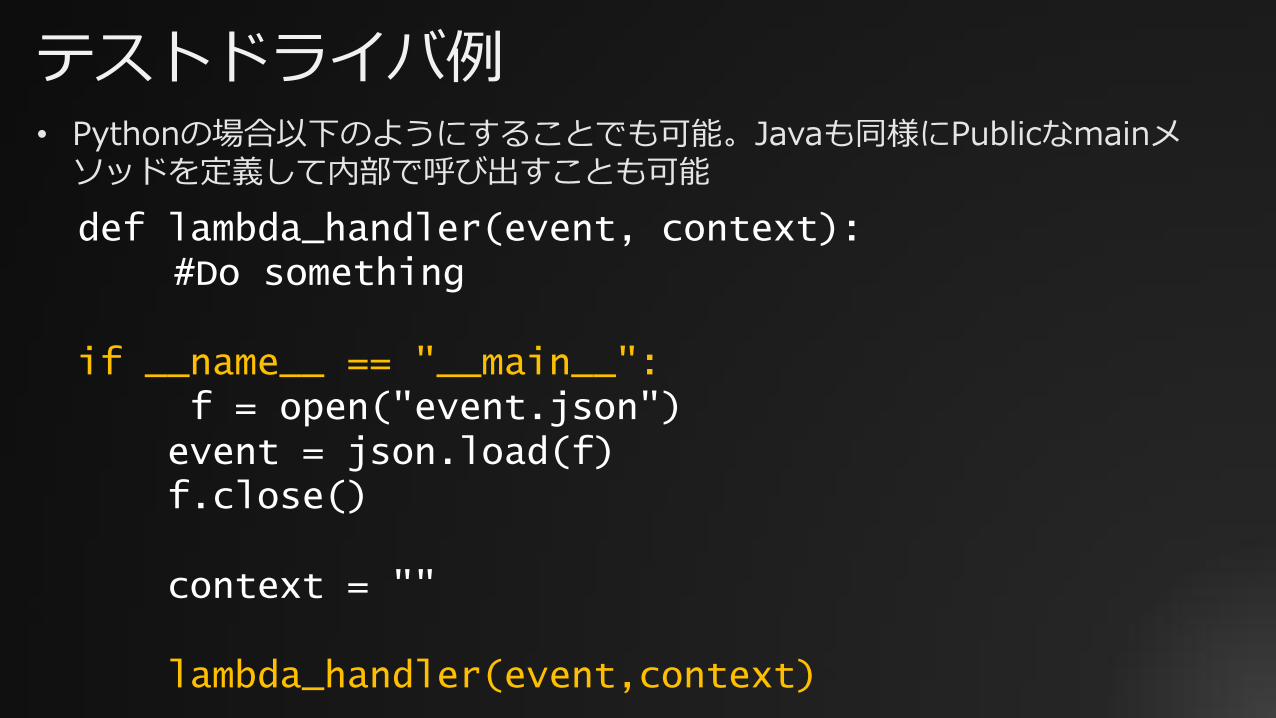
テストドライバ例
def lambda_handler(event, context):#Do something
if __name__ == "__main__":f = open("event.json")event = json.load(f)f.close()
context = ""
lambda_handler(event,context)
• Pythonの場合以下のようにすることでも可能。Javaも同様にPublicなmainメソッドを定義して内部で呼び出すことも可能

もしくは✤ Serverlessのようなローカルテスト機能をもったサードパーティ製フ
レームワークを利⽤する
✤ 各ランタイム⽤のOSSなテストツールを利⽤する
lambda-local on npm
python-lambda-local on pip
aws-lambda-local-runner on maven

もしくは✤ Serverlessのようなローカルテスト機能をもったサードパーティ製フ
レームワークを利⽤する
✤ 各ランタイム⽤のOSSなテストツールを利⽤する
lambda-local on npm
python-lambda-local on pip
aws-lambda-local-runner on maven
個⼈的なオススメは⾃分でテスト⽤のドライバを書くか、ローカルテストツールを利⽤

まとめ✤ アンチパターンはなるべく避ける
✤ ただし、絶対悪ではない。いろんな事情で仕⽅ない場合もある⎻ 外部APIがIP固定を要求しているとか
✤ できるだけ避けることを考えつつ、適当なところで⼿を打つのがいい

Top Related