







Languages
Pages
Legal


8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 1/120

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 2/120
2

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 3/120
Contents
1 Complexitatea algoritmilor 71.1 Aspecte generale . . . . . . . . . . . . . . . . . . . . . . . . . . 71.2 Evaluarea complexitatii . . . . . . . . . . . . . . . . . . . . . . . 8
1.3 Clase de complexitate . . . . . . . . . . . . . . . . . . . . . . . . 14
2 Problema cautarii 212.1 Cautarea secventiala . . . . . . . . . . . . . . . . . . . . . . . . 21
2.2 Cautarea binara . . . . . . . . . . . . . . . . . . . . . . . . . . . 222.2.1 Arbori binari de cautare . . . . . . . . . . . . . . . . . . 24
2.3 Pattern Matching . . . . . . . . . . . . . . . . . . . . . . . . . . 252.3.1 Algoritmul de cautare naiva . . . . . . . . . . . . . . . . 26
2.3.2 Algoritmul Rabin-Karp . . . . . . . . . . . . . . . . . . . 26
3 Problema sortarii 293.1 Sortare prin metoda interschimbarilor . . . . . . . . . . . . . . . 30
3.1.1 Buble Sort . . . . . . . . . . . . . . . . . . . . . . . . . . 30
3.2 Sortare prin metoda insertiei . . . . . . . . . . . . . . . . . . . . 303.2.1 Sortare prin insertie directa . . . . . . . . . . . . . . . . 303.2.2 Shell Sort - sortare prin metoda secventelor amestecate . 31
3.3 Sortare prin metoda distribuirii . . . . . . . . . . . . . . . . . . 333.3.1 Radix Sort - sortare prin metoda distribuirii in pachete . 33
3.4 Sortare prin metoda selectiei . . . . . . . . . . . . . . . . . . . . 343.4.1 Heap Sort . . . . . . . . . . . . . . . . . . . . . . . . . . 34
3

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 4/120
4 CONTENTS
3.5 Sortare prin metoda inteclasarii . . . . . . . . . . . . . . . . . . 423.5.1 Merge Sort . . . . . . . . . . . . . . . . . . . . . . . . . 42
3.6 Sortare prin metoda pivotarii . . . . . . . . . . . . . . . . . . . 42
3.6.1 Quick Sort . . . . . . . . . . . . . . . . . . . . . . . . . . 42
4 Metoda Divide-and-Conquer 454.1 Descrierea metodei . . . . . . . . . . . . . . . . . . . . . . . . . 454.2 Modelul Algoritmic . . . . . . . . . . . . . . . . . . . . . . . . . 46
4.2.1 Modelul Algoritmic pentru cazul general . . . . . . . . . 46
4.3 Eficienta metodei . . . . . . . . . . . . . . . . . . . . . . . . . . 464.4 Studii de caz . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
4.4.1 Sortarea prin interclasare . . . . . . . . . . . . . . . . . . 48
4.4.2 Sortarea rapida (C.A.R. Hoare) . . . . . . . . . . . . . . 50
5 Metoda Greedy 555.1 Descrierea metodei . . . . . . . . . . . . . . . . . . . . . . . . . 55
5.2 Modelul matematic . . . . . . . . . . . . . . . . . . . . . . . . . 565.3 Eficienta metodei . . . . . . . . . . . . . . . . . . . . . . . . . . 575.4 Studii de caz . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
5.4.1 Interclasare optimala . . . . . . . . . . . . . . . . . . . . 575.4.2 Compresiile de date. Arbori Huffman . . . . . . . . . . . 625.4.3 Drum minim ıntr-un graf (sursa–destinatie) . . . . . . . 65
5.4.4 Problema rucsacului (Knapsack) . . . . . . . . . . . . . . 67
6 Programarea dinamica 716.1 Descrierea metodei . . . . . . . . . . . . . . . . . . . . . . . . . 716.2 Modelul matematic . . . . . . . . . . . . . . . . . . . . . . . . . 746.3 Eficienta metodei . . . . . . . . . . . . . . . . . . . . . . . . . . 76
6.4 Comparatie ıntre metoda programarii dinamice si metoda greedy 77
6.5 Studii de caz . . . . . . . . . . . . . . . . . . . . . . . . . . . . 786.5.1 Problema rucsacului (0/1) . . . . . . . . . . . . . . . . . 78
6.5.2 Inmultire optima de matrici . . . . . . . . . . . . . . . . 816.5.3 Arbori binari de cautare optimali . . . . . . . . . . . . . 84

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 5/120
CONTENTS 5
7 Metoda Backtracking 917.1 Descrierea metodei . . . . . . . . . . . . . . . . . . . . . . . . . 917.2 Modelul Algoritmic . . . . . . . . . . . . . . . . . . . . . . . . . 967.3 Studii de caz . . . . . . . . . . . . . . . . . . . . . . . . . . . . 98
7.3.1 Problema celor 8 dame . . . . . . . . . . . . . . . . . . . 987.3.2 Submultimi de suma data . . . . . . . . . . . . . . . . . 100
8 Metoda branch&bound 1038.1 Descrierea metodei . . . . . . . . . . . . . . . . . . . . . . . . . 103
8.2 Branch and bound cu strategie cost minim . . . . . . . . . . . . 1048.2.1 Aspecte generale . . . . . . . . . . . . . . . . . . . . . . 1048.2.2 Modelul Algoritmic pentru Branch&bound cu strategie
cost minim . . . . . . . . . . . . . . . . . . . . . . . . . 1078.3 Branch&Bound cu strategie cost minim si marginire . . . . . . . 108
8.3.1 Aspecte generale . . . . . . . . . . . . . . . . . . . . . . 1088.3.2 Modelul Algoritmic pentru Branch&Bound cu strategie
cost minim si marginire . . . . . . . . . . . . . . . . . . . 1098.4 Studii de caz . . . . . . . . . . . . . . . . . . . . . . . . . . . . 110
8.4.1 Problema 15-puzzle . . . . . . . . . . . . . . . . . . . . . 110
8.4.2 Problema 0/1 a rucsacului . . . . . . . . . . . . . . . . . 113

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 6/120
6 CONTENTS

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 7/120
Capitolul 1
Complexitatea algoritmilor
1.1 Aspecte generale
Teoria complexitatii are ca obiect de studiu clasificarea problemelor, bazata petimpul de executie si spatiul de lucru utilizat de algoritmi pentru solutionarealor. Cand se analizeaza algoritmi paraleli, se poate lua ın considerare sinumarul de procesoare.
Desi teoria complexitatii a fost dezvoltata pentru probleme de decizie,aceasta nu este o restrictie severa deoarece multe alte probleme pot fi formu-late ın termeni de probleme de decizie. De exemplu, o problema de optimizarepoate fi rezolvata prin punerea ıntrebarii existentei unei solutii cu cel mult saucel putin o valoare specificata.
La evaluarea (estimarea) algoritmilor se pune ın evidenta necesarul de timpsi de spatiu de memorare. Atunci cand se studiaza complexitatea spatiu se auın vedere resursele de memorie temporara (suplimentara) utilizate de algoritm.Memoria rezervata reprezentarii instantei problemei nu intereseaza ın analizacomplexitatii spatiu.
Studierea complexitatii presupune:1. analiza configuratiei de date cea mai defavorabila (cazurile degenerate);
2. analiza configuratiei de date cea mai favorabila;
7

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 8/120
8 CAPITOLUL 1. COMPLEXITATEA ALGORITMILOR
3. comportarea medie.
Comportarea medie presupune probabilitatea de aparitie a diferitelorconfiguratii de date la intrare.
Comportarea algoritmului ın cazul onfiguratiei de date cea mai defavora-bila este cel mai studiat aspect si este folosit, de obicei, pentru comparareaalgoritmilor.
1.2 Evaluarea complexitatii
Complexitatea unui algoritm se exprima de regula prin notatia O.
Definitie:
Fie f : N → N ti g : N → N dou˘ a functii. Spunem c˘ a f ∈ O(g) si not amf = O(g) dac˘ a si numai dac˘ a exist˘ a o constant˘ a c ∈ R+ si un num˘ ar n0 ∈ N
astfel ıncat pentru ∀n > n0, f (n) < c · g(n).
Observatie: n reprezinta, de obicei, dimensiunea datelor de intrare iar f (n)timpul de lucru al algoritmului exprimat ın “pasi”.
Lema:Daca f este o functie polinomiala de grad k, de forma: f (n) =
ak · nk + ak−1 · nk−1 + · · · + a1 · n + a0, atunci f = O(nk).
Efectuınd majorari ın membrul drept, obtinem rezultatul de mai sus:
f (n) ≤ |ak|· nk+|ak−1|· nk−1 +· · ·+|a1|· n+|a0| < nk ·(|ak|+|ak−1|+|a0|) < nk ·c
pentru ∀n > 1 ⇒ f (n) < c · nk, cu n0 = 1.
Concluzie: f = O(nk), si ordinul O exprima viteza de variatie a functiei,functie de argument.
Exemplul 1: Cautarea secventiala.
Fie A, de ordin n, un tablou unidimensional. Se cere sa se determine dacaelementul b se afla printre elementele tabloului.

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 9/120
1.2. EVALUAREA COMPLEXIT ATII 9
SECV SEARCH(A,n,b)
i←1;
WHILE ( A[i]<>b and i<n ) DO i←i+1 END WHILE
IF (A[i]=b) THEN
RETURN(i); // b a fost gasit pe pozitia i ın tabloul A
ELSE
RETURN(0); // b nu a fost gasit ın tabloul A
END IF
ENDComplexitatea timp:
Cazul cel mai defavorabil : situatia ın care elementul b nu apartine multimiisecventializate implementata de tabloul A.
Daca notam cu T (n) timpul de executie ın pasi al acestui algoritm, atunciT (n) = 1+ 2n − 1+ 1 = 2n +1 = numarul de atribuiri si comparatii. O expre-sie logica este asimilata ın cele ce urmeaza cu o comparatie (ex. A[I]<>b and
i<=n ) . Putem spune ca T (n) = O(n) deoarece T (n) este o functie polinomialade gradul I. Conteaza deci doar gradul polinomului, nu polinomul ın ansam-
blu si nici coeficientul termenului de grad maxim , iar la numararea pasilorconcentrarea se focalizeaza asupra numarului buclelor, nu asupra pasilor dininteriorul buclei. O secventa de pasi de dimensiune constanta nu este relevantadeoarece aceasta poate diferi de la algoritm la algoritm funct ie de gradul dedetaliere ( ex. aux←a; a←b; b←aux versus inteschimbare(a,b);).
Comportarea medie: Se poate considera ca probabilitatea ca elementul b sase afle ın tabloul A pe pozitia i sau ın afara acestuia este aceasi 1
n+1pentru
fiecare i = 1, . . . , n sau i > n. In aceste conditii T (n) = 1n+1
(3 + 5 + . . . +
2n − 1 + 2n + 1 + 2n + 1) = 1n+1
{2[1 + 2 + . . . + n + (n + 1)] + n − 1} =2(n+1)(n+2)
2(n+1)+ n−1
n+1< n + 3 = O(n)
Observatie: Cazul ın care elementul b se afla pe pozitia n ın tabloul Ase rezova ın timp egal cu cazul ın care elementul b nu se afla ın tabloul A.Aceasta deorece ultimul test analizeaza situatia ın care elementul b este ın unadin aceste doua situatii.

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 10/120
10 CAPITOLUL 1. COMPLEXITATEA ALGORITMILOR
Complexitatea spatiu:
Memoria auxiliara utilizata de algoritmul SECV SEARCH este cea nece-sara reprezentarii valorilor lui i deci un numar fix de locatii. Rezulta ca dimen-siunea spatiului de memorie suplimentara este o constanta deci un polinom degrad zero. Astfel complexitatea spatiu este O(1).
In continuare va fi analizata doar complexitatea timp pe cazul cel maidefavorabil. Complexitate timp mediu si complexitatea spatiu vor fi calculatedoar pentru algoritmi relevanti ın acest sens.
Exemplul 2: Calcularea maximului unui sir.
MAX SIR (A,n) max ← A[1];
F O R i = 2 t o n D O
IF A[i]) > max THEN
max ← A[i];
END IF
END FOR
RETURN (max)
ENDCazul cel mai defavorabil : situatia ın care vectorul este ordonat crescator
(pentru ca de fiecare data se face si comparatie si atribuire).In acest caz numarul de atribuiri si comparatii = T (n) = 1 + 2(n − 1).
Exemplul 3: Sortarea prin inserare (Insertion Sort)
Algoritmul INSERTION SORT considera ca ın pasul k, elementele A[1 ÷k − 1] sunt sortate, iar elementul k va fi inserat, astfel ıncat, dupa aceastainserare, primele elemente A[1 ÷ k] sa fie sortate.
Inserarea elementului k ın secventa A[1 ÷ k − 1] presupune:- memorarea elementului ıntr-o variabila temporara;
- deplasarea tuturor elementelor din vectorul A[1 ÷ k − 1] care sunt maimari decat A[k], cu o pozitie la dreapta (aceasta presupune o parcurgere de ladreapta la stanga);
- plasarea lui A[k] ın locul ultimului element deplasat.

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 11/120
1.2. EVALUAREA COMPLEXIT ATII 11
INSERTION SORT (A,n)FOR k = 2 to n DO
temp ← A[k];
i ← k-1;
WHILE (i >=1 and A[i] > temp) DO
A[i+1] ← A[i]; i ← i-1;
END WHILE
A[i+1] ← temp;
END FOR
ENDCazul cel mai defavorabil : situatia ın care deplasarea (la dreapta cu o
pozitie ın vederea inserarii) se face pana la ınceputul vectorului, adica siruleste ordonat descrescator.
Estimarea timpului de lucru:
T (n) = 3 · (n − 1) + 3 · (1 + 2 + 3 + · · · + n − 1) = 3(n − 1) + 3n(n − 1)/2
Rezulta complexitatea: T (n) = O(n2) – functie polinomiala de gradul II.
Exemplul 4: Inmultirea a doua matrici.
PROD MAT (A,B,C,n)FOR i = 1 to n DO
FOR j = 1 to n DO
C[i,j] ← 0;
F O R k = 1 gets n DO
C[i,j] ← C[i,j] + A[i,k] * B[k,j];
END FOR
END FOR
END FOR
ENDRezulta complexitatea O(n3).
Exemplul 5: Cautarea binara (Binary Search).
Fie A, de ordin n, un vector ordonat crescator. Se cere sa se determine dacao valoare b se afla printre elementele vectorului. Limita inferioara se numeste

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 12/120
12 CAPITOLUL 1. COMPLEXITATEA ALGORITMILOR
low , limita superioara se numeste high , iar mijlocul virtual al vectorului, mid (de la middle).
BINARY SEARCH (A,n,b)low ← 1; high ← n;
WHILE (low =< high) DO
mid ← (low + high)/2; // partea ıntreaga
IF (A[mid]=b) THEN RETURN (mid);
ELSE
IF A[mid]>b THEN
high← mid-1; // restrang cautarea la partea stanga
ELSE
low ← mid+1; // restrang cautarea la dreapta
END IF
END IF
END WHILE
RETURN(0)
ENDCalculul complexitatii algoritmului consta ın determinarea numarului de
ori pentru care se executa bucla while.
Se observa ca, la fiecare trecere, dimensiunea zonei cautate se ınjumatateste.Ca si la cautarea secventiala, cazul cel mai defavorabil este situatia ın care vec-torul A nu contine valoarea cautata.
Pentru simplitate, se considera n = 2k unde k este numarul de ınjumatatiri.Rezulta k = log2 n si printr-o majorare, T (n) ≤ log2 n + 1.
Deci complexitatea timp a acestui algoritm este O(log2 n). Baza logarit-mului se poate ignora deoarece: loga x = loga b logb x si loga b este o constanta,deci ramane O(log n), adica o functie logaritmica.
Proprietat i ale ordinului de complexitate O:
1) Fie f, g : N → N. Dac˘ a f = O(g) atunci k × f = O(g) si f =O(k × g), ∀k ∈ R
Aceasta propriatate este utila ın ma jorarile care apar necesare atunci candse estimeaza dimensiunea resursei timp sau spatiu utilizata de un algoritm ın

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 13/120
1.2. EVALUAREA COMPLEXIT ATII 13
perspectiva ıncadrarii acestuia ıntr-o clasa uzuala de complexitate.
2) Fie f , g , h : N → N si f = O(g), g = O(h). Rezulta f = O(h)Proprietatea 2) poate fi folosita la schimbarea ıncadrarii unui algoritm ıntr-
o clasa de complexitate.
3) Fie f 1, f 2, g1, g2 : N → N. si f 1 = O(g1), f 2 = O(g2) Rezulta f 1 + f 2 =O(g1 + g2) si f 1 × f 2 = O(g1 × g2)
Proprietatea 3) permite ca, atunci cand doua secvente (de complexitatidiferite) sunt succesive, complexitatea secventei rezultata prin concatenarea
celor doua secvente consecutive sa sa fie obtina prin adunarea complexitatiloracestora.
Daca secventa este formata din bucle incluse una ın alta, complexitateaansamblului se obtine prin ınmultirea complexitatilor buclelor.
Teorema:Fie doua constante c > 0, a > 1. Daca f : N → N este o functie
monotona strict crescatoare, atunci (f (n))c = O(af (n)).
Demonstratia se bazeaza pe limita limx→∞
x p
ax.
Notatia O este utilizata pentru clasificarea algoritmilor. Cele mai cunoscuteclase sunt:
{A | T A = O(1)} = clasa algoritmilor constanti;{A | T A = O(log n)} = clasa algoritmilor logaritmici;{A | T A = O(logkn)} = clasa algoritmilor polilogaritmici;{A | T A = O(n)} = clasa algoritmilor liniari;{A | T A = O(n2)} = clasa algoritmilor patratici;{A | T A = O(nk+1)} = clasa algoritmilor polinomiali;{A | T A = O(2n)} = clasa algoritmilor exponentiali.
T A = timpul de executie a algoritmului A.
Cu notatiile de mai sus, doi algoritmi, care rezolva aceeasi problema,pot fi comparate numai daca au timpii de executie ın clase de functii (core-spunzatoare notatiilor O) diferite. De exemplu, un algoritm A cu T A(n) =

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 14/120
14 CAPITOLUL 1. COMPLEXITATEA ALGORITMILOR
O(n) este mai eficient decat un algoritm A cu T A(n) = O(n2). Daca cei doialgoritmi au timpii de executie ın aceeasi clasa, atunci compararea lor devinemai dificila pentru ca trebuie determinate si constantele cu care se ınmultescreprezentantii clasei.
1.3 Clase de complexitate
Din punctul de vedere al calculului secvential, sunt relevante trei clase: P,
NP, Pspace.Clasa P : contine problemele solvabile ın timp polinomial, ceea ce ınseamnaca pentru aceste probleme exista algoritmi deterministi secventiali cu timpulde executie marginit de un polinom de variabila “dimensiunea problemei”.Problemele din P sunt numite, ın mod curent, bine solut ionabile sau usoare.
NP : este clasa problemelor pentru care exista un algoritm sevential nede-terminist cu timp de executie polinomial (echivalent : nu exista un algoritmsecvential determinist cu timp de executie polinomial).
Pspace : contine problemele care sunt solvabile utilizand un spatiu poli-nomial, adica spatiul de lucru este marginit de un polinom de variabila “di-mensiunea problemei”.
Evident, P ⊆ NP ⊆ Pspace. Se presupune ca ambele incluziuni suntproprii (stricte).
O alta clasa inclusa ın Pspace este Polylogspace. Aici sunt incluse prob-lemele rezolvabile ın spatiu polilogaritmic (spatiul de lucru este marginit deun polinom de variabila “log(dimensiunea problemei)”). Multe probleme dinP apartin lui Polylogspace, dar ın general, se crede ca P ⊂ Polylogspace.Se stie totusi ca Polylogspace = Pspace.
Remarcabile ın Pspace si NP sunt problemele complete. ProblemelePspace-complete sunt generalizari ale tuturor celorlalte probleme din Pspaceın termeni de transformari care necesita timp polinomial. Mai precis: o
problema este Pspace-completa sub transformari de timp polinomial dacaapartine lui Pspace si oricare alta problema din Pspace este reductibila la eaprin transformari care necesita timp polinomial. Urmeaza ca daca o problemaPspace-completa ar apartine lui P, atunci Pspace = P. Deoarece se crede

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 15/120
1.3. CLASE DE COMPLEXITATE 15
ca aceasta egalitate nu este adevarata, este improbabil sa existe un algoritmde timp polinomial pentru o problema Pspace-completa. Problemele NP sedefinesc ın mod asemanator, rezultand aceleasi concluzii.
Clasa P are si ea problemele ei complete. Problemele P-complete suntgeneralizari ale tuturor celorlalte probleme din clasa P, ın termenii trans-formarilor care necesita spatiu de lucru logaritmic. Formal, o problema este P-completa sub transformari spatiale logaritmice daca apartine clasei P si oricealta problema din P este reductibila la ea prin transformari ce utilizeaza spatiulogaritmic. Daca o problema P-completa ar apartine clasei Polylogspace,
atunci ar fi adevarata incluziunea P ⊆ Polylogspace. Cum aceasta incluzi-une se presupune a fi falsa, nu este de asteptat sa existe un algoritm pentru oproblema P-completa care sa utilizeze spatiu de lucru polilogaritmic.

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 16/120
16 CAPITOLUL 1. COMPLEXITATEA ALGORITMILOR

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 17/120
Metode de proiectare
Construirea unui algoritm care rezolva o problema presupune ca etapa inter-mediara elaborarea modelului matematic corespunzator problemei. Ratiuniledefinirii modelului matematic sunt urmatoarele:
• de multe ori problemele sunt descrise informal (verbal); ın acest fel, uneleaspecte ale problemei pot fi omise sau formulate ambiguu; construct iamodelului matematic evidentiaza si elimina aceste lipsuri;
• instrumentele matematice de investigare, ın perspectiva identificarii sidefinirii solutiei, sunt mult mai puternice;
• definirea solutiei ın termenii modelului matematic usureaza foarte multactivitatea de construire a algoritmului.
O metoda de proiectare a algoritmilor se bazeaza pe un anumit tip demodel matematic. Definirea unui model matematic cuprinde urmatoarele treiaspecte:
1. conceptual : presupune identificarea si conceptualizarea componentelordin domeniul problemei;
2. analitic: implica descoperirea tuturor relatiilor ıntre conceptele care con-
duc la identificarea si descrierea solutiei;3. computat ional : se refera la evaluarea calitativa a algoritmului ce con-
struieste solutia.
17

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 18/120
18 CAPITOLUL 1. COMPLEXITATEA ALGORITMILOR

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 19/120
Metode specifice de proiectare aalgoritmilor
19

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 20/120
20 CAPITOLUL 1. COMPLEXITATEA ALGORITMILOR

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 21/120
Capitolul 2
Problema cautarii
Problema apartenentei unui obiect la o multime de obiecte nu ın mod necesardistincte sau a incluziunii unei secvente ın alta secventa apare frecvent casubproblemaın rezolvarea unei probleme prin metode algoritmice. Din acestmotiv algoritmii de cautare constituie o clasaspeciala, masiv studiatasi foarteimportanta.
2.1 Cautarea secventiala
Cautarea secventialaporneste de la premiza camultimea de procesat este secven-tializata ıntr-un mod oarecare . Algoritmul de cautare secventiala consta ınparcurgerea secventei element cu element pana cand fie este gasit obiectulcautat fie secventa se termina. O secventa poate fi implementata prin tablouriunidimensionale (vectori) sau liste liniare simplu ınlantuite. Corespunzatorcelor doua tipuri de structuri de date rezulta doi algoritmi: Algoritmul 1 re-
spectiv Algoritmul 2.Algoritmul 1
Fie A, de ordin n, un tablou unimesional. Se cere sa se determine dacaelementul b se afla printre elementele tabloului.
21

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 22/120
22 CAPITOLUL 2. PROBLEMA C AUT ARII
SECV SEARCH(A,n,b)i←1;
WHILE ( A[i]<>b and i<n ) DO i←i+1 END WHILE
IF (A[i]=b) THEN
RETURN(i); // b a fost gasit pe pozitia i ın tabloul A
ELSE
RETURN(0); // b nu a fost gasit ın tabloul A
END IF
END
Algoritmul 2Fie L o lista liniara simplu ınlantuita. Se cere sa se determine daca obiectul
b se afla printre elementele listei.SSECV SEARCH L(L,b)// cauta ın lista L obiectul b// data(p) = informatia de continut a atomului adresat de p
// leg(p)=adresa atomului ce urmeaza ın lista
p←L; // atomului adresat de p
WHILE (data(p)<>b and p<>null ) DO p ←leg(p) END WHILE
IF (p=null) THEN RETURN(0);// b nu a fost gasit ın lista L
ELSE RETURN(p); // b a fost gasit ın lista L,
// ca informatie de continut a atomului aflat
// pe pozitia adresata de pointerul p
END IF
ENDComplexitatea timp pentru cazul ce mai nefavorabil este O(n) pentru ambii
algoritmi.
2.2 Cautarea binara
Cautarea binara foloseste ca ipoteza faptul ca multimea de procesat este secven-tializata dupa o cheie de sortare calculata ın functie de compozitia obiectelorsecventei sau inclusa ın structura obiectelor ca o componenta a acestora. Decisecventa tinta este sortata. Algoritmul de cautate binara consta ın eliminarea

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 23/120
2.2. C AUTAREA BINAR ˘ A 23
succesiva a unei jumatati din subsecventa aflata ın curs de procesare panacand fie elementul cautat este gasit fie subsecventa ramasa nu mai paote fi di-vizata. Aceasta eliminare a unei portiuni din subsecventa ın curs de procesareeste permisa de ipoteza ordonarii care faciliteaza posibilitatea deciziei asupraimposibilitatii aflarii elementului cautat ın una din jumatatile subsecventei.De exemplu daca cheia elementului din mijlocul subsecventei curente este 10si cheia cautata este 12 iar ordonarea este crescatoare atunci sigur elemen-tul cautat (10) nu va fi gasit ın prima jumatate. Implementare prin listea secevntei nu aduce un spor de eficienta algoritmului datorita caracterului
prin excelenta secvential al unei liste care face imposibila accesarea directaa elementului aflat la mijlocul listei. De aceea algoritmul de cautare binarafoloseste implementarea secventei sortate sub forma de tablouri unidimesionale(vectori).
Fie A, de ordin n, un vector ordonat crescator. Se cere sa se determine dacao valoare b se afla printre elementele vectorului. Limita inferioara se numestelow, limita superioara se numeste high, iar mijlocul virtual al vectorului, mid(de la middle).
BINARY SEARCH (A,n,b)low ← 1; high ← n;
WHILE (low =< high) DO mid ← (low + high)/2; // partea ıntreaga
IF (A[mid]=b) THEN RETURN (mid);
ELSE
IF A[mid]>b THEN
high← mid-1; // restrang cautarea la partea stanga
ELSE
low ← mid+1; // restrang cautarea la dreapta
END IF
END IF
END WHILERETURN(0)
Complexitatatea: Timpul de executie a acestui algoritm este din clasaO(log2 n) (vezi capitolul 1). Baza logaritmului se poate ignora deoarece: loga x =

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 24/120
24 CAPITOLUL 2. PROBLEMA C AUT ARII
loga b logb x si loga b este o constanta, deci ramane O(log n), adica o functie log-aritmica.
2.2.1 Arbori binari de cautare
Multimea de obiecte ın care se face cautarea poate fi organizata ca arbore binarde cautare. Aceasta permite construirea de algoritmi de cautare eficienti. Ar-borii binari de cautare sınt acei arbori ale caror noduri sınt organizate ın functiede valorile unor chei care sınt calculate functie de valorile nodurillor. Pentrufiecare nod, cheia sa este mai mare decıt valorile cheilor tuturor nodurilor dinsubarborele stıng si este mai mica decıt toate cheile de noduri din subarboreledrept. Nodurile arborelui au chei distincte. In figura urmatoare este dat unarbore binar de cautare.
Traversarea ın inordine pe un arbore binar de cautare produce o secventasortata crescator dupa valorile cheilor.
Operatia de creare a unui arbore binar de cautare este O(n2) timp pentrucazul cel mai defavorabil cınd arborele se construieste sub forma unei listeınlantuite. Pentru acest caz operatiile de insertie, stergere si de cautare aunui atom se fac ın O(n). Pentru cazul mediu crearea se face ın O(n * logn) iar insertia, stergerea, cautarea se face ın O(log n). O clasa speciala de
arbori binari de cautare anume arborii binari echilibrati pentru care insertia,stergerea si cautarea se face ın O(log n) pentru cazul cel mai defavorabil.
Se considera functia de cautare ıntr-un arbore binar de cautare.

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 25/120
2.3. PATTERN MATCHING 25
SEARCH(r,x)
p ← r;
WHILE p!=null DO
IF x<data(p) THEN
p ← lchild(p);
ELSE
IF x>data(p) THEN
p ← rchild(p);
ELSERETURN(p);
END IF
END IF
END WHILE
RETURN(p) //return null
END
Complexitatatea
Pentru un arbore echilibrat functia lucreaza ın O(logn) timp, ceea ce ınseamna
ca arborele binar echillibrat este arborele binar optim atunci cınd se cauta unelement aleatoriu ales.
2.3 Pattern Matching
Problema incluziunii unei secvente de obiecte ın alta secventa de acelasi ( deexemplu a unui sir de caractere ca subsir al altuia de acelasi tip) este cunoscutasub numele de pattern matching. Algoritmii de pattern matching au aplicatiiın procesarea de imagini, recunoasterea de caractere. Vom prezenta ın cadrul
acestei lucrari doi dintre acestia: algoritmul de cautare naiva si algoritmulRabin-Karp. Primul este important pentru ıntelegerea conceptului de patternmatching iar al doilea poate fi extins la pattern-uri bidimesionale deci poate fiutilizat in domeniile anterior mentionate.

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 26/120
26 CAPITOLUL 2. PROBLEMA C AUT ARII
2.3.1 Algoritmul de cautare naiva
Este un algoritm foarte simplu dar si foarte ineficient: pentru fiecare pozitieposibila ın sir se testeaza daca pattern-ul se potriveste cu subsirul care ıncepecu acea pozitie.
PM Naiv(s,n,p,m)//cauta ın sirul s de dimnsiune n pattern-ul p de dimesiune m
i← 0;
WHILE (i<n-m and not gasit) DO
i←i+1; // pozitia ın sirj←i;// pozitia in subsir
k←1;// psozitia ın pattern
WHILE (s[j]=p[k] and not gasit) DO
IF k=m // a fost gasita o aparitie a pattern-ului
gasit ← true;
ELSE
j=j+1;// ınainteza ın subsir
k←k+1;// ınainteaza ın pattern
END IF
END WHILE
IF (not gasit)
THEN RETURN(0);// pattern-ul p nu apare ın sirul s
ELSE RETURN(i);// pattern-ul p apare ın s pe pozitia i
END IF
END
Evident complexitatea timp a algoritmului pentru cazul cel mai nefavorabilO(nm)
2.3.2 Algoritmul Rabin-Karp
Algoritmul Rabin-Karp utilizeaza tehnica tabelelor de dispersie (hashing). Unsimbol este o subsecventa de m obiecte a secventei s de dimesiune n . Sapresupumen ca simbolurile sunt memorate ıntr-o tabela de dispersie suficient demare astfel incat sa nu existe coliziune. A testa daca pattern-ul p coincide cu un

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 27/120
2.3. PATTERN MATCHING 27
subsir de lungime m din sirul s este echivalent cu a testa daca valoarea functieide dispersie h este aceeasi pentru ambele simboluri. Pentru ca o asemeneaabordare sa fie justificata, timpul necesar evaluarii functiei h pentru un simboldin tabela de dispersie trebuie sa fie mult mai mic decat cel necesar comparariia doua siruri de lungime m. Aceasta se rezolva ın felul urmator|:
Se codifica fiecare sir de lungime m ca un numar ıntreg ın baza d, unde deste numarul maxim de obiecte din sirul s. Astfel subsirului s[i..i+m-1] ıi core-spunde numarul x=index(s[i])dm-1 + index(s[i+1])dm-2 + . . . + index(s[i+m-1]) unde index este o functie care asociaza unui obiect din s numarul sau de
ordine ıntr-o secventializare a multimii obiectelor care compun s.Functia de dispersie H va fi definita prin h(x)=x mod q , unde q este un
numar prim suficient de mare. O deplasare la dreapta ın sirul s va corespundeınlocuirii lui x cu (x- index(s[i])dm-1)d + index(s[i+m])
PM-RK(s,n,p,m)// cauta ın sirul s de dimnsiune n pattern-ul p de dimesiune m
dm1← 1;
FOR i=1 TO m-1 DO
dm1=dm1*d mod q
END FOR
// dm1 = (puterea m-1 a lui d modulo) qhp← 0;
FOR i=1 TO m DO
hp=hpd +index(p[i])
END FOR
// hp = valoare functiei de dispersie pentru
// simbolul p
hsm← 0;
FOR i=1 TO m DO
hsm=hsmd +index(s[i]);
END FOR// hsm = valoare functiei de dispersie
// pentru simbolul s[1..m]
i←1;

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 28/120
28 CAPITOLUL 2. PROBLEMA C AUT ARII
WHILE (hp= hsm and i< n-m) DO
hsm ← (hsm + qd - index(s[i]) dm-1 ) mod q;
hsm ← (hsmd + index(s[i+m])) mod q;
// hsm = valoare functiei de dispersie
// pentru simbolul s[i+1..i+m]
i←i+1;// deplasare la dreapta ın sirul s
END WHILE
IF (hp=hsm)
THEN return i;// pattern-ul p apare ın s pe pozitia i
ELSE return 0;// pattern-ul p nu apare ın sirul s }END IF
END
Complexitatea timp a algoritmului Rabin-Karp pentru cazul cel mai nefa-vorabil O(nm) dar ın practica algoritmul executa apoximativ n+m pasi.

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 29/120
Capitolul 3
Problema sortarii
Sortarea este o operatie foarte des ıntalnita ın rezolvarea unei probleme prinmetode algoritmice. Din acest motiv, algoritmii de sortare constituie o clasaextrem de importanta care merita o atentie speciala, iar o analiza a celor mai
cunoscuti algoritmi de sortare este utila si necesara. Exista o vasta literaturaavand ca subiect probleme de sortare. Aceasta se explica prin importantaproblemei, operatiile de sortare fiind aproape omniprezente ın compozitia al-goritmilor.
29

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 30/120
30 CAPITOLUL 3. PROBLEMA SORT ARII
3.1 Sortare prin metoda interschimbarilor
3.1.1 Buble Sort
Bubble sort (a,n)
flag ←1;
k ← n;
WHILE flag = 0 AND k>=1 DO
k ← k-1;
flag ← 0;
FOR i=1,...,k DO
IF A[i]>A[i+1] THEN
INTERCHANGE (A[i], A[i+1]);
flag ← 1;
END IF
END WHILE
END{Bubble sort}
Complexitatea
Evident O(n2
).
3.2 Sortare prin metoda insertiei
3.2.1 Sortare prin insertie directa
Algoritmul Insertion Sort considera ca ın pasul k, elementele A[1 ÷ k − 1] suntsortate, iar elementul de pe pozitia k va fi inserat astfel ıncat, dupa aceastainserare, primele elemente A[1 ÷ k] sa fie sortate.
Pentru a realiza inserarea elementului k ın secventa A[1 ÷ k − 1], aceastapresupune:
• memorarea elementului ıntr-o variabila temporara;

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 31/120
3.2. SORTARE PRIN METODA INSERTIEI 31
• deplasarea tuturor elementelor din vectorul A[1 ÷ k − 1] care sunt maimari decat A[k] cu o pozitie la dreapta (aceasta presupune o parcurgerede la dreapta la stanga);
• plasarea lui A[k] ın locul ultimului element deplasat.
Secv Insertion sort(A,n)
FOR k = 2,...,n DO
temp ← A[k];
i ← k-1;WHILE i>=1 AND A[i]>temp DO
A[i+1] ← A[i];
i ←i-1;
END WHILE
A[i+1] ← temp;
END FOR
END{Insertion Sort}ComplexitateaCazul cel mai defavorabil : situatia ın care deplasarea (la dreapta cu o
pozitie ın vederea inserarii) se face pana la ınceputul vectorului, adica siruleste ordonat descrescator.
Exprimarea timpului de lucru:
T (n) = 3(n − 1) + (1 + 2 + 3 + · · · + n − 1) = 3(n − 1) + 3n(n − 1)/2.
Rezulta complexitatea: O(n2) – functie polinomiala de gradul II.
3.2.2 Shell Sort - sortare prin metoda secventelor ameste-cate
Sortarea se face asupra unor subsecvente care devin din ce ın ce mai maripana la dimensiunea n. Fiecare subsecventa i este determinata de un hi numitincrement. Incrementii satisfac conditia: ht > ht−1 > · · · > h2 > h1.
Fie hi = h. Avem urmatoarele subsecvente:

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 32/120

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 33/120
3.3. SORTARE PRIN METODA DISTRIBUIRII 33
ComplexitateaDaca secventa de incremente ht−1, . . . , h0 satisface conditia
hs+1 mod hs = 0 pentru 0 ≤ s < t − 1
atunci complexitatea timp pentru cazul cel mai nefavorabil este O(n2).
Complexitatea timp ın cazul cel mai nefavorabil a algoritmului ShellSort
este O(n3
2 ) cand hs = 2s − 1, 0 ≤ s ≤ t − 1 = [log2 n].
3.3 Sortare prin metoda distribuirii
3.3.1 Radix Sort - sortare prin metoda distribuirii inpachete
Se presupune ca cheile de sortare sunt numere ıntregi reprezentate ın bazab <= 10. Fiecare element din secventa de sortat are k cifre c1c2...ck.
Radix sort (A,n,k)
// secventa se afla ıntr-o coada globala gq iar
// q[j], j=0,...,b-1, sunt cozi;
FOR i = 0,...b-1 DO
q[i] ← Φ;
END FOR
FOR i = k,k-1,...,1 DO
WHILE NOT isempty(gq) DO
x ← del(gq); c[i] ← cifra i din x; add(q[c[i]],x);
END WHILE
FOR j = 0,...b-1 DO
WHILE NOT isempty(q[j]) DO
add(gq,del(q[j])); // adauga coada q[i] la coada
//globalaEND WHILE
END FOR
END FOR

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 34/120
34 CAPITOLUL 3. PROBLEMA SORT ARII
FOR i = 1,...,n DO
A[i] ← del(gq);
END FOR
END{Radix sort}Complexitatea: O(nk).
3.4 Sortare prin metoda selectiei
3.4.1 Heap Sort
Definitie: Se numeste arbore heap un arbore binar T = (V, E ) cu urmatoareleproprietati:(1) ∃ functia key : V → R care asociaza fiecarui nod o cheie;
(2) ∀ un nod v ∈ V cu degree(v) > 0 (nu este nod terminal), atunci:
key(v) > key(left child(v)), daca ∃ left child(v);
key(v) > key(right child(v)), daca ∃ right child(v).
(Pentru fiecare nod din arbore, cheia nodului este mai mare decat cheile
descendentilor.)Observat ie: De obicei, functia cheie reprezinta selectia unui subcamp din
campul de date memorate ın nod.
Generare HeapGenerare Heap prin inserari repetateHeap gen 1 (A,V,n)
// A[1..n] -- secventa de sortat
// V -- vectorul ce contine reprezentarea heap-ului
// N -- numarul de noduri din heap
// se considera pentru ınceput un heap cu un singur element,
// dupa care toate celelalte elemente vor fi inserate// ın acest heap
N ← 1
V[1] ← A[1];

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 35/120
3.4. SORTARE PRIN METODA SELECTIEI 35
FOR i=2,...,n DO
insert(V,N,A[i]);
END FOR
END{heap gen}
insert (V,N,a)
// V -- vectorul ce contine reprezentarea implicita a
// heap-ului
// N -- numarul de noduri din heap
// ambele sunt plasate prin referinta
// (functia insert le poate modifica);
// a -- atomul de inserat;
// 1) ın reprezentarea implicita: V[n+1] ← a; N ← N+1
// astfel ıncat ın continuare se reorganizeaza
// structura arborelui sa-si pastreze structura de heap
// 2) se utilizeaza interschimbarile; comparatii:
// se iau 2 indici: child ← N si
// parent ← [N/2]
// se compara V[child] cu V[parent]
// interschimbare daca V[child] nu este mai mic decat
// V[parent]
// 3) ınaintare ın sus:
// child ← parent
// parent ← [child/2]
// 4) se reia pasul 2) pana cand nu se mai face
// interschimbarea
N ← N+1;V[N] ← a;
child ← N;
parent ← [N/2];

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 36/120

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 37/120
3.4. SORTARE PRIN METODA SELECTIEI 37
un nod la ultimul nivel. Pentru nivelul 2 sunt doua noduri. La inserarea lorse va face cel mult o retrogradare (comparat ie).
nivelul 2 : 2 noduri, 1 comparatienivelul 3 : 4 noduri, 2 comparatiinivelul 4 : 8 noduri, 3 comparatii————————————————–nivelul i : 2i−1 noduri, i − 1 comparatiiConsiderand un arbore complet (nivel complet) ⇒ n = 2k − 1 ⇒ numarul
total de comparatii pentru toate nodurile este T (n) de la nivelul 2 la nivelul
k. Vom calcula:
T (n) =ni=2
(i − 1) · 2i−1.
Sa aratam:
T (n) =k−1i=1
i · 2i
cu tehnica T (n) = 2 · T (n) − T (n). Asadar:
T (n) = 2 ·k−1i=1
i · 2i −k−1i=1
i · 2i =k−1i=1
i · 2i+1 −k−1i=1
i · 2i =
1 · 22 + 2 · 23 + 3 · 24 + · · · + (k − 2) · 2k−1 + (k − 1) · 2k − 1 · 21 − 2 · 22 − 3 · 23−
· · · − (k − 1) · 2k−1 = −2 + (k − 1) · 2k −k−1i=2
2i = (k − 1) · 2k − 2 + 20 + 21−
−k−1i=0
2i = (k − 1) · 2k + 1 − (2k − 1) = (k − 2) · 2k + 2
Rezulta: T (n) = (k − 2) · 2k + 2 = (k − 2) · (2k − 1) + k − 2 + 2 =n · (k − 2) + k, iar k = log2(n + 1), din n = 2k − 1. Rezulta: T (n) =n · (log2(n + 1) − 2)
termen dominant
+log2(n + 1).

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 38/120
38 CAPITOLUL 3. PROBLEMA SORT ARII
Facandu-se majorari, rezulta complexitatea O(n log n) pentru heap gen 1.
Generare heap prin retrogradari repetateConstruim heap-ul de jos ın sus (de la dreapta la stanga). Cele mai multe
noduri sunt la baza, doar nodurile din varf parcurg drumul cel mai lung.
ms2.picPresupunem ca elementele V [i + 1, n] ındeplinesc conditia de structura a
heap-ului:
∀ j > i avem: V [ j] > V [2 ∗ j], daca 2 ∗ j ≤ nV [ j] > V [2 ∗ j + 1], daca 2 ∗ j + 1 ≤ n
Algoritmul consta ın adaugarea elementului V [i] la structura heap-ului. Elva fi retrogradat la baza heap-ului (prelucrare prin retrogradare).
Heap gen 2(A,V,n)
// A[1..n] - secventa de sortat
// V - vectorul ce contine reprezentarea heap-ului
FOR i=1,...,n DO
V[i] ← A[i];
END FOR
FOR i=n/2,...,1
retrogradare(V,n,i);
END FOR
END{Heap gen 2}
retrogradare(V,n,i)
parent ← i;
child ← 2*i; //fiu stanga al lui i
WHILE child<=n DOIF child+1<=n AND key(V[child+1])>key(V[child]) THEN
child ← child+1;
END IF

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 39/120
3.4. SORTARE PRIN METODA SELECTIEI 39
IF key(V[parent])<key(V[child]) THEN
interchange(V[parent],V[child]);
parent ← child;
child ← 2*parent;
ELSE
break
END IF
END WHILE
END{retrogradare}Complexitatea
Fie un arbore complet cu n = 2k −1. Cazul cel mai defavorabil este situatiaın care la fiecare retrogradare se parcurg toate nivelele:
nivel k : nu se fac operatiinivel k − 1 : 2k−2 noduri o operatie de comparatienivel k − 2 : 2k−3 noduri 2 operatii———————————————–
nivel i : 2i−1 k − i operatii———————————————–nivel 2 : 21 k − 2 operatiinivel 1 : 20 k − 1 operatii
Se aduna si rezulta:
T (n) =
k−1i=1
(k − i) · 2i−1
.
Tehnica de calcul este aceeasi: T (n) = 2 · T (n) − T (n).

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 40/120
40 CAPITOLUL 3. PROBLEMA SORT ARII
T (n) =k−2i=1
(k − i) · 2i −k−2i=1
(k − i) · 2i−1 = (k − 1) · 21 + (k − 2) · 22+
+(k − 3) · 23 + · · · + 3 · 2k−3 + 2 · 2k−2 − (k − 1) · 20 − (k − 2) · 21−
−(k − 3) · 22 − · · · − 2 · 2k−3 = 2 · 2k−2 − (k − 1) +k−3i=1
21 = 2k−1 − (k − 1) − 20+
+k−3
i=0
21 = 2k−1 + 2k−2 − 2 − (k − 1) = 2k−2 · (2 + 1) − k − 1 = 3 · 2k−2 − k − 1.
Rezulta:
T (n) = 3 · 2k−2 − k − 1 < 3 · (2k − 1) − k − 1,
T (n) < 3 · n termen dominant
− log2(n + 1) − 1.
Rezulta complexitatea O(n) pentru heap gen 2.
Algoritmul Heap Sort
heap sort(A,n)heap gen(A,V,n);
N ← n;
FOR i=n,n-1,...,2 DO
N ← i;
A[i] ← remove(V,N);
END FOR
END{heap sort}Aceasta procedura sorteaza un vector A cu N elemente: transforma vec-
torul A ıntr-un heap si sorteaza prin extrageri succesive din acel heap.
c
partea sortataa vectoruluiiheap
max min

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 41/120
3.4. SORTARE PRIN METODA SELECTIEI 41
remove(V,N)
// V - vectorul ce contine reprezentarea implicita a heap-ului;
// N - numarul de noduri din heap;
// ambele sunt plasate prin referinta
// functia remove le poate modifica;
// se scoate elementul cel mai mare care este radacina
// heap-ului;
// se initializeaza cei 2 indici;
// se reorganizeaza structura arborilor: se ia ultimul nod de
// pe nivelul incomplet si se aduce ın nodul// radacina si aceasta valoare va fi retrogradata
// pana cand structura heap-ului este realizata;
// parent = max(parent,left child,right child);
// Exista trei cazuri:
// 1. conditia este ındeplinita deodata;
// 2. max este ın stanga ⇒ retrogradarea se face ın stanga;
// 3. max este ın dreapta ⇒ retrogradarea se face ın dreapta.
a ← V[1];
V[1] ← V[N];
N ← N-1;parent ← 1;
child ← 2;
WHILE child<=N DO
IF child+1<=N AND key(V[child+1])>key(V[child]) THEN
child ← child+1;
END IF
IF key(V[parent])<key(V[child]) THEN
interchange(V[parent],V[child]);
parent ← child;
child ← 2*parent;ELSE
break;
END IF

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 42/120

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 43/120
Metode generale de proiectare aalgoritmilor
Aspecte generale
O metoda generala de proiectare a algoritmilor se bazeaza pe un anumit tipde model matematic si pune la dispozitie procedee prin care se poate construisi implementa un model particular corespunzator unei probleme.
Cele mai cunoscute metode generale de proiectare a algoritmilor sunt urma-toarele: divide-and-conquer, greedy, programarea dinamica, backtracking,branch-and-bound.
43

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 44/120
44 CAPITOLUL 3. PROBLEMA SORT ARII

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 45/120

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 46/120
46 CAPITOLUL 4. METODA DIVIDE-AND-CONQUER
4.2 Modelul Algoritmic
4.2.1 Modelul Algoritmic pentru cazul general
Metoda poate fi descrisa astfel:D and C(P(n))
IF n<=n0 THEN
rezolva subproblema P(n) prin metode elementare;
ELSE
// divizarea problemeiımparte problema P(n) ın subproblemele
P1(n1),...,Pa(na);
// rezolvarea subproblemelor
rezolva recursiv subproblemele P1(n1),...,Pa(na),
obtinandu-se solutiile S1,...,Sa;
// asamblarea solutiilor
combina solutiile S1,...,Sa pentru a obtine solutia S
a problemei P(n);
END IF
END{D and C}Deoarece metoda are un caracter recursiv, aplicarea ei trebuie precedata de
o generaizare de tipul problem˘ a → subproblem˘ a prin care dimensiunea proble-mei devine o variabila libera.
4.3 Eficienta metodei
Vom presupune ın continuare ca dimensiunea problemei P i este ni si satisfaceni ≤ n/b, b > 1. De asemenea, vom presupune ca divizarea problemei ınsubprobleme si asamblarea solutiilor necesita timpul O(nk). Complexitatea
timp T (n) a algoritmului D and C este data de urmatoarea relatie de recurenta:
T (n) =
O(1), daca n ≤ n0,a · T
nb
+ O(nk), daca n > n0.

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 47/120
4.3. EFICIENTA METODEI 47
Teorema 1. Dac˘ a n > n0, atunci:
T (n) =
O(nlogb a), daca a > bk,O(nk logb n), daca a = bk,O(nk), daca a < bk.
Demonstrat ie:Fara a restrange generalitatea se poate presupune n = bm·n0. De asemenea,
se mai poate presupune ca T (n) = c·nk0, daca n ≤ n0 si T (n) = a·T (n/b)+c·nk,
daca n > n0. Pentru n > n0 rezulta:
T (n) = aT n
b
+ cnk
= aT (bm−1n0) + cnk
= a
aT (bm−2n0) + c
n
b
k+ cnk
= a2T (bm−2n0) + c
an
b
k+ nk
= . . .
= amT (n0) + c am−1 n
bm−1k
+ · · · + an
b k
+ nk= amcnk
0 + c
am−1bknk0 + · · · + a(bm−1)knk
0 + (bm)knk0
= cnk
0am
1 +bk
a+ · · · +
bk
a
m= cam
mi=0
bk
a
j
unde cnk0 a fost renotat prin c.
Se disting cazurile:
1. a > bk
. Seria
mi=0
bk
a j este convergenta si deci sirul sumelor partiale este
convergent. De aici rezulta T (n) = O(am) = O(alogb n) = O(nlogb a).
2. a = bk. Rezulta am = bm = cnk si de aici T (n) = O(nkm) = O(nk logb n).

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 48/120
48 CAPITOLUL 4. METODA DIVIDE-AND-CONQUER
3. a < bk. Avem T (n) = O(am(bk/a)m) = O(bkm) = O(nk). QED.
Daca pentru fiecare nivel r al recursiei, subproblemele P i(r), i = 1,...,q(r),ale acestui nivel satisfac conditia ca d(P i(r)) ≤ (1/b) · d(P T (P i(r))), unded(P i) reprezinta dimensiunea subproblemei P i, P T problema tata, iar b este oconstanta pozitiva supraunitara, atunci adancimea recursiei este logaritmica.
Relativ la arborele de calcul, divide-and-conquer realizeaza parcurgereaacestuia ın stil top-down si apoi bottom-up. Aceasta se datoreaza recursiei.
4.4 Studii de caz
4.4.1 Sortarea prin interclasare
Pentru a sorta o secventa de n elemente ale unui vector A, se ımparte vectorulın 2 segmente de lungime n/2 care sunt sortate separat recursiv, dupa careurmeaza interclasarea.
Pseudocod . Procedura merge sort primeste ca argumente A – vectorul desortat si doi indici care delimiteaza o portiune din acest vector. Apelul initialva fi merge sort(A,1,n).
merge sort(A,low,high)
IF low>=high THEN
RETURN
ELSE
mid ← (low+high)/2; //partea ıntreaga
merge sort(A,low,mid); //sortare separata
merge sort(A,mid+1,high); //sortare separata merge(A,low,mid,high); //interclasare
END IF
END{ merge sort}

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 49/120
4.4. STUDII DE CAZ 49
Procedura merge interclaseaza secventele sortate A[low ÷ mid] si A[mid +1 ÷ high]. Pentru aceasta este nevoie de un vector auxiliar B, de aceeasidimensiune cu A.
merge(A,low,mid,high)
i ← low ← mid+1; k ← low;
WHILE i<=mid AND j<=high DO
I
IF A[i] < A[j]THEN
B[k] ← A[i]; i ← i + 1;ELSE
B[k] ← A[j]; j ← j + 1;END IF
k ← k + 1;END WHILE
WHILE i<=mid DO
IIB[k] ← A[i]; i ← i + 1;k ← k + 1;
END WHILE
WHILE j<=high DO
IIIB[k] ← A[j]; j ← j + 1
k ← k + 1;END WHILE
FOR k=low,...,high DO
A[k] ← B[k];
END FOR
END{ merge}.
Corectitudinea
Lema 1. Procedura merge sort sorteaz˘ a cresc˘ ator elementele vectorului A.
Demonstrat ie. Este suficient sa demonstram corectitudinea procedurii merge.Presupunem prin reducere la absurd ca ın urma executiei procedurii merge ex-
ista un indice k pentru care B[k] > B[k + 1]. Aceasta ar putea rezulta dinurmatoarele situatii:
1. B[k] a fost initializat ın bucla I, iar B[k + 1] ın bucla II.
2. B[k] a fost initializat ın bucla I, iar B[k + 1] ın bucla III.

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 50/120
50 CAPITOLUL 4. METODA DIVIDE-AND-CONQUER
Cazul 1. Aceasta ınseamna ca, imediat dupa initializarea elementului B[k],situatia indicilor i si j este urmatoarea: i ≤ mid si j > high. Deci A[i] ≥A[high], B[k] = A[high] si B[k + 1] = A[i]. Din B[k] > B[k + 1] rezulta caA[high] > A[i] ≥ A[high]. Absurd.
Cazul 2. Aceasta ınseamna ca imediat dupa initializarea elementului B[k]situatia indicilor i si j este urmatoarea: j ≤ high si i > mid. Deci A[mid] <A[ j], B[k] = A[mid] si B[k + 1] = A[ j]. Din B[k] > B[k + 1] rezulta caA[mid] > A[ j] > A[mid]. Absurd.
Complexitatea
Lema 2. Timpul de execut ie al algoritmului merge sort este:
T (n) =
0, n = 12T (n/2) + n, n > 1
Demonstrat ie: Consideram n = 2k. Evident, procedura merge este decomplexitate O(n).
T (n) = 2 · T (n/2) + n = 2[2 · T (n/4) + n/2] + n = · · · = 22 · T (n/22) + 2n =
= 22(2 · T (n/23) + n/22) + 2n = 23 · T (n/23) + 3n = · · · = 2k · T (n/2k) + k · n ⇒
⇒ T (n) = k · n = n · log2 n, pentru ca n = 2k si, deci, k = log2 n.Asadar, complexitatea algoritmului este O(n · log n).
4.4.2 Sortarea rapida (C.A.R. Hoare)
Pentru a sorta o secventa de n elemente ale unui vector A se partitioneazavectorul ın 2 segmente, dupa schema urmatoare, utilizand un element cu statutspecial numit pivot .
elemente≤pivot
l →
A[k] =pivotelemente>pivot
← h
Urmeaza apoi sortarea recursiva a secventelor separate de pivot .

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 51/120
4.4. STUDII DE CAZ 51
Quick sort(A,low,high)
IF high>low THEN
k ← Partition(A,low,high); //procedura de partitionare
Quick sort(A,low,k-1);
Quick sort(A,k+1,high);
END IF
END{Quick sort}Pseudocodul pentru functia Partition:Partition(A,low,high)
l ← low; h ← high;x ← A[l];
WHILE l<h DO
I WHILE A[l]<=x AND l<=high DO
i ← i+1;
END WHILE
II WHILE A[h]>x AND h>=low DO
h ← h-1;
END WHILE
IF l<h THEN
interchange(A[l],A[h]);END IF
END WHILE
interchange(A[h],A[low]);
RETURN(h);
END{Partition}Procedura Partition considera pivotul ca fiind: A[low]. Indicele l par-
curge vectorul de la stanga la dreapta, iar indicele h parcurge vectorul de ladreapta la stanga. Ei se apropie pana se ıntalnesc (l = h). Deci, l lasa ın urmanumai elemente A[i] ≤ pivot, iar h lasa ın urma numai elemente A[i] > pivot.
Ciclul I WHILE ınseamna ca ınainteaza l cat timp A[l] ≤ pivot. Acest cicluse opreste pe conditia A[l] > pivot, fixandu-se aici.
Ciclul II WHILE ınseamna ca ınainteaza h cat timp A[h] > pivot. Acestciclu se opreste pe conditia A[h] ≤ pivot, fixandu-se aici.

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 52/120
52 CAPITOLUL 4. METODA DIVIDE-AND-CONQUER
Cele doua pozitii se schimba, astfel ıncat sa se permita ınaintarea indicilormai departe.
c
hlow
Corectitudinea
Lema 3. Procedura Quick sort sorteaz˘ a cresc˘ ator elementele vectorului A.
Demonstrat ie. Inductie dupa n.
Pasul 1. Pentru un tablou unidimensional A de dimensiune 2, evident,algoritmul functioneaza corect.
Pasul 2. Presupunem ca procedura Quick sort functioneaza pentru tablouriunidimensionale A de dimensiuni ≤ n si demonstram ca functioneaza corect sipentru A de dimensiune n + 1.
Procedura Partition separa vectorul A ın doua segmente S 1 cu elemente≤ pivot si S 2 cu elemente > pivot.
Procedura Quick sort aplicata asupra vectorilor S 1 si S 2 functioneaza con-form ipotezei de inductie.
Rezulta ın final A = S 1 ∪ { pivot}. Datorita proprietatilor pivotului si ale
vectorilor S 1 si S 2, vectorul rezultat A este sortat crescator.Complexitatea
Lema 4. Timpul de execut ie al algoritmului Quick sort este: T (n) = n(n−1)/2.
Demonstrat ie. Cercetam cazul cel mai defavorabil. Fie cazul ın care vec-torul este ordonat descrescator. Pivotul gasit, la primul pas, este elementulmaxim din vector si rezulta ca trebuie plasat ın ultima pozit ie. Pivotul va fimaximul dintre elementele secventei, deci, va fi plasat ın ultima pozitie dinsecventa.
Problema se ımparte ın 2 subprobleme: P (n) → P (n − 1), P (0).
Numarul de comparatii pentru functia Partition este (n − 1). Vectorul separcurge ın doua directii, dar o singura data.
Rezulta ca timpul de functionare al algoritmului Quick sort este: T (n) =(n − 1) + T (n − 1).

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 53/120
4.4. STUDII DE CAZ 53
Rezolvand aceasta ecuatie, avem:
T (n) = n − 1 + T (n − 1) = n − 1 + n − 2 + T (n − 2) = · · ·
= n − 1 + n − 2 + n − 3 + · · · + 1 + T (1),
unde T (1) este 0 (nu se partitioneaza). Rezulta:
T (n) =n−1i=1
i =n(n − 1)
2.
Aceasta suma este de complexitate O(n2). Rezulta ca este un algoritmineficient.
Spat iul ocupat de algoritmul Quick sort
klow high
Avem ın acest algoritm doua apeluri recursive.
Cazul cel mai defavorabil:
low high
k
Consideram consumul de memorie ın stiva: M (n) = c + M (n − 1) ⇒
M (n) = O(n) ⇒ un ordin de complexitate mare.Pivotul ımparte secventa de sortat ın doua subsecvente. Daca subsecventa
mica este rezolvata recursiv, iar subsecventa mare este rezolvata iterativ, atunciconsumul de memorie se reduce:

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 54/120
54 CAPITOLUL 4. METODA DIVIDE-AND-CONQUER
Quick sort(A,low,high)
WHILE low < high DO
k ← Partition(A,low,high);
IF k-low > high-k THEN
Quick sort(A,k+1,high);
high ← k-1;
ELSE
Quick sort(A,low,k-1);
low ← k+1;
END IFEND WHILE
END{Quick sort}Necesarul de memorie pentru acesta este M (n) ≤ c + M (n/2), ınsemnand
ca oricare ar fi secventa mai mica, ea este mai mica decat jumatatea secventeidin care a fost obtinuta. Rezulta M (n) = O(log n), adica am redus ordinul decomplexitate.

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 55/120
Capitolul 5
Metoda Greedy
5.1 Descrierea metodei
Metoda Greedy este o metoda de proiectare a algoritmilor care consta ın con-struirea solutiei globale optimale printr-un sir de solutii cu caracter de optimlocal atunci cand este posibila exprimarea “optimului global” ca o combinatie
de “optime locale”.Schema de proiectare. Problema se prezinta sub forma unei multimi S cu
n componente. O parte din submultimile lui S reprezinta solutii care sat-isfac un anume criteriu si se numesc solut ii admisibile. In spatiul solutiiloradmisibile prezinta interes o solutie care maximizeaza/minimizeaza o functieobiectiv. Solutiile admisibile au proprietatea ca, odata cu o solutie admisi-bila, toate submultimile sale sunt de asemenea admisibile. Metoda Greedysugereaza un algoritm de constructie a solutiei optimale pas cu pas, pornindde la multimea vida. La fiecare pas se selecteaza un element nou care va fi“ınghitit” ın solutie (greedy ) ın baza unei proceduri de selectie. De exemplu, la
problemele de optimizare procedura de selectie alege acel element care face sacreasca cel mai mult valoarea functiei obiectiv. Desigur, nu ın toate problemeleaceasta strategie conduce la solutia optima, metoda Greedy nefiind o metodauniversala.
55

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 56/120

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 57/120
5.3. EFICIENTA METODEI 57
In practica construirii de algoritmi greedy, este recomandabil sa fie lasatalibera definitia optimului local. Exista totusi restrictia ca definitia acestuia sanu depinda de alegerile ulterioare sau de solutiile subproblemelor. In schimb,poate depinde de selectiile facute la acel moment. In acest fel, se obtine o flexi-bilitate mai mare ın proiectarea de algoritmi greedy, dar de fiecare data trebuiedemonstrat ca selectia conform optimului local conduce la o baza pentru carese obtine optimul global pentru functia obiectiv.
Din pacate, numai conditiile de optim local si admisibilitate nu asiguraexistenta unui cirteriu de selectie locala care sa conduca la determinarea unei
baze optime. Aceasta ınseamna ca pentru anumite probleme algoritmii greedynu construiesc o solutie optima, ci numai o baza pentru care functia obiectivpoate avea valori apropiate de cea optima. Acesta este cazul unor problemeNP-complete.
5.3 Eficienta metodei
Se presupune ca pasul de alegere greedy selectioneaza elemente x ın O(k p)timp, unde k = #S 1, iar testarea conditiei B ∪ {x} ∈ C necesita O(lq) timp,l = #B, k + l ≤ n. De asemenea, se presupune ca operatiile B ∪ {x} si S \ {x}necesita O(l) timp. Rezulta:
T (n) = O(n p+lq)+· · ·+O(l p+nq) = O(l p+· · ·+n p+lq+· · ·+nq) = O(nmax( p+1,q+1)).
5.4 Studii de caz
5.4.1 Interclasare optimala
Definirea problemei. Avem secventele X 1, X 2,...,X n, fiecare sortata. Sase gaseasca o strategie de interclasare doua cate doua astfel ıncat numarul deoperatii sa fie minim.
Exemplu. Fie urmatoarele secvente X 1, X 2, X 3, unde

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 58/120
58 CAPITOLUL 5. METODA GREEDY
X 1 are 30 elemente,X 2 are 20 elemente,X 3 are 10 elemente.
Se aplica cateva variante de organizare a interclasarii.
1. Y=merge(X1,X2) 50 operatii Y-50 elemente
Z=merge(Y,X3) 60 operatii
-----------
110 operatii
2. Y=merge(X2,X3) 30 operatii Y-30 elemente
Z=merge(Y,X1) 60 operatii
-----------
90 operatii
Solut ia . Problema se rezolva aplicand o tehnica Greedy la fiecare pas candse interclaseaza cele mai mici 2 secvente. Problema se poate reprezenta ca unarbore binar.
Exemplu
x4 x3105
15
y1
20
35
y2
x1
30 30
60 y3
x2x5
95 y4
X 3, X 4 → Y 1 – 15 elementeX 1, Y 1 → Y 2 – 35 elemente

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 59/120
5.4. STUDII DE CAZ 59
X 2, X 5 → Y 3 – 60 elementeY 3, Y 2 → Y 4 – 95 elemente
205 elementeNodul x4 este la distanta 3 de nodul y4, deci valoarea din x4 se va aduna
de 3 ori.Daca notam cu di distanta de la radacina la nodul frunza xi si cu qi valoarea
nodului, atuncidi = level(qi) − 1ni=1 qidi = nr. total operatii
5 ∗ 3 + 10 ∗ 3 + 20 ∗ 2 + 30 ∗ 2 + 30 ∗ 2 = 15 + 30 + 40 + 60 + 60 = 205
S =ni=1
qidi se numeste lungimea drumurilor externe ponderate ale arbore-
lui.O interclasare optimal˘ a corespunde construirii unui arbore binar optimal
relativ la S .
Algoritm pentru construirea unui arbore binar optimal
tree(C,n)
// C - o colectie de arbori;// initial, contine arbori de forma (val,0,0) - noduri terminale
// se foloseste:
// get node() - crearea unui nod
// least(C) - sterge din C arborele cu valoarea din
// radacina minima
// insert(L,t) - insereaza ın C un arbore
FOR i=1,...,n-1 DO
t ← get node();
lchild(t) ← least(); rchild(t) ← least();
data(t) ← data(lchild(t))+data(rchild(t)); insert(C,t);END FOR
RETURN(least(C));
END{tree}

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 60/120
60 CAPITOLUL 5. METODA GREEDY
Teorema 1. Fie algoritmul tree si L cont inand init ial n arbori cu cate un singur nod de valori (q1, q2,...,qn). Atunci tree genereaz˘ a un arbore binar cu
S =ni=1
diqi minim˘ a ( di – distant a de la r˘ ad˘ acin˘ a la nodul qi).
Demonstrat ie se face prin inductie dupa n.
1. n = 1 evident, arbore minimal.
2. P (n − 1): Pentru orice secventa initiala de valori, nod(q1, q2,...,qm), 1 ≤m ≤ n − 1, tree genereaza un arbore T ma optimal. Presupunem P (n − 1)adevarata.
P (n): Pentru orice secventa initiala de valori, nod(q1, q2,...,qn), tree genereaza
un arore T n
a optimal. Demonstram P (n) adevarata.
Lema 1. Fie qi si q j cele mai mici dou˘ a valori ale secvent ei (nodurile carevor fi returnate ın prima iterat ¸ie a buclei for de funct ia least. Fie T un arbore optimal (nu neap˘ arat cel construit de tree. Fie P nodul interior cel mai ındep artat de r˘ ad˘ acin˘ a si presupunem c˘ a descendent ii lui P au valorileqk, ql diferite de qi, q j: (qi, qk) si/sau (q j, ql) se pot interschimba ın arborele T ,obt inandu-se un arbore T care r˘ amane optimal.
Demonstrat ie. Fie di – distanta de la nodul de valoare qi la radacina; d j– distanta de la nodul de valoare q j la radacina; dk – distanta de la nodul devaloare qk la radacina; dl – distanta de la nodul de valoare ql la radacina.

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 61/120
5.4. STUDII DE CAZ 61
qk ql
q j
qi
S (T ) =n
r=1r=i,k
qrdr + qidi + qkdk
Dupa interschimbarea valorilor qi, qk se obtine:
S (T ) =n
r=1r=i,k
qrdr + qkdi + qidk.
Avem D = S (T ) − S (T ) = qi(dk − di) − qk(dk − di) = (dk − di)(qi − qk) =−(dk − di)(qk − qi).
Dardk ≥ di pentru ca P -ul mai ındepartat
qk ≥ qi pentru ca qi, q j minime
⇒
⇒ S (T
) − S (T ) ≤ 0 ⇒ S (T
) ≤ S (T )T minimal ⇒ S (T ) = S (T )
Analog, se procedeaza pentru perechea (q j, ql). Se obtine T pentru careS (T ) = S (T ).

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 62/120
62 CAPITOLUL 5. METODA GREEDY
Revenim la demonstratia P (n) adevarata.Din lema anterioara rezulta ca T este optimal pentru secventa de valori
nod(q1, q2,...,qn) si contine nodul P care are ın descendenti valorile qi, q j celemai mici.
Inlocuim subarborele P cu un nod care are valoarea qi + q j. Noul arboreT fiind un subarbore al arborelui T este optimal pentru secventa de valorinod(q1...qi−1qi + q jqi+1...q j−1q j+1...qn), deci S (T ) = q1d1 + · · · + qi−1di−1 +(qi + q j)di+ j + qi+1di+1 + · · · + q j−1d j−1 + q j+1d j+1 + · · · + qndn minima.
S (T )−S (T ) = (qidi+q jd j)−(qi+q j)di+ j = qi(di−di+ j)+q j(d j−di+ j) = qi+q j.
Rezulta S (T ) = S (T ) + qi + q j.Nodul P este construit de tree ın prima iteratie, dupa care ın iteratia
urmatoare se intra ın secventa de valori nod(q1...qi−1qi + q jqi+1...q j−1q j+1...qn).Conform ipotezei inductive, algoritmul construieste un arbore optimal T n−1
a
pentru secventa de valori nod(q1...qi−1qi+q jqi+1...q j−1q j+1...qn) minima. RezultaS (T n−1
a ) = S (T ). Din modul de constructie a lui T n−1a si T na avem S (T na ) −
S (T n−1a ) = (qidi + q jd j) − (qi + q j)di+ j = qi(di − di+ j) + q j(d j − di+ j) = qi + q j.
Rezulta ın final S (T na ) = S (T n−1a ) + qi + qr = S (T ) + qi + q j = S (T ), deci T na
este optimal.Complexitatea . Bucla for se executa de n ori.Functiile least() si insert():C – lista ınlantuita: least() – O(n)
insert() – O(1) tree O(n2)C – Lista ınlantuita ordonata: least() – O(1)
insert() – O(n)C – heap: least() – O(log n) tree O(n log n)
insert() – O(log n)Observat ie. Metoda functioneaza si pentru arbori k-ari (fiecare nod cu k
descendenti).
5.4.2 Compresiile de date. Arbori Huffman
Definirea problemei . Fie D = (D1, D2,...,Dn) un grup de date, fiecare de

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 63/120
5.4. STUDII DE CAZ 63
lungime l si M un mesaj compus din aceste date. Exemplu: Di octeti dedate si M un fisier). Se cunoaste ca Di apare ın M de qi ori, i = 1, n. Sa seconstruiasca un sistem de coduri binare pentru elementele lui D, astfel ıncatM sa fie de lungime minima.
Solut ia . Se codifica fiecare data Di, i = 1, n cu un numar variabil de bitipe baza unui arbore binar cu arcele etichetate astfel: 0 – pentru arcele deforma (p,left(p)), 1 – pentru arcele de forma (p,right(p)). Arborele aren noduri terminale, cate unul asociat fiecarei date Di. Codul asociat datei Di
va fi secventa de biti (0,1) care apar ca etichete pe drumul de la radacina laDi.
Exemplu .
D = (D1, D2,...,Dn) = (rosur
, alba
, verdev
, cremc
, bleub
, galbeng
, negrun
, marom
)
coduri(D)=(000,001, ..., 111).
r a v c b g n m
10101010
0 1 0 1
10
Insa, de asemenea, poate fi si coduri(00,01,100,101,1100,1101,11110,11111)
Observat ie. Pentru a codifica n obiecte sunt necesare log2n biti.

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 64/120
64 CAPITOLUL 5. METODA GREEDY
0 1
1010
r a0 1 0 1
1010cv
b g n m
Decodarea . 1) Codurile sunt de aceeasi lungime. Este suficienta o tabelade indirectare. 2) Codurile sunt de lungime variabila. Se foloseste arborele decodare. Aceasta se bazeaza pe faptul ca se obtine un sistem de coduri care sunt“prefix distinctibile”, adica ∀i, j, cod(Di) nu este prefix al secventei cod(D j).
Exemplu . M = 01a
1111m
00r
00r
01a
01a
01a
101c
1110n
1100b
00r
100v
1101g
1101g
.
Lungime mesaj: M = a m r r a a a c n b r v g g, ın prima codare:l(M ) = 14 ∗ 3 = 42 biti; ın a doua codare: l(M ) = 40 biti.
Observat ie. Problema determinarii unei codari care sa minimizeze lungimealui M se reduce la determinarea unui arbore binar cu lungimea drumurilorexterne ponderate minime.
Fie M = Di1Di2...Dik, compus din datele (D1, D2,...,Dn) cu frecventelede aparitii Q = (q1, q2,...,qn), qi = numarul de aparitii ın M ale datelor Di,atunci:
l(M ) =n
i=1
qi ∗ lungime(cod(Di)) =n
i=1
qi ∗ dist(Di),
dist(Di) – distanta de la radacina la Di.Pentru exemplul anterior:M = a m r r a a a c n b r v g g,

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 65/120
5.4. STUDII DE CAZ 65
D = (b,m,v,n,c,g,r,a),Q = (1,1,1,1,1,2,3,4).Rezulta M de forma:
M = 01a
1111m
00r
00r
01a
01a
01a
101c
1110n
1100b
00r
100v
1101g
1101g
−39 biti
cu desenul din figura urmatoare:
1 1 1 1
1 2
34
14
2 6
4
22
0 1
1010
a 0 1 0 1 r
gc1010
bm v n
Observat ii :– metoda este eficienta atunci cand frecventa aparitiilor este cunoscuta
exact, si nu estimata;– ambele procese codor, decodor trebuie sa cunoasca arborele;– pastrarea codificarii lui M ımpreuna cu arborele de decodificare ridica
probleme de ineficienta ocuparii spatiului;– pentru texte se foloseste un arbore cu qi estimate statistic;– exemplu pentru un CD-ROM cu carti ınmagazinate, se poate pastra un
album cu 38 frunze (alfabetul latin plus semnele de punctuatie).
5.4.3 Drum minim ıntr-un graf (sursa–destinatie)
Definirea problemei . Se da G = (V, E ) un graf, e : E → R+ functia de

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 66/120
66 CAPITOLUL 5. METODA GREEDY
etichetare. Se cere un drum (s = v1v2...vk = d), unde dist(s, d) =k−1i=1
e(vi, vi+1)
minimal.
Observat ie. Exista un algoritm care da toate aceste drumuri (cu ınmultirede matrice, de cost O(n3)).
Algoritmul Greedy pentru determinarea drumurilor minime de la noduli la toate celelalte noduri:
short path(G,C,s,n)
//G=(V,E), V={1,2,...,n}
//C -- matrice de cost, C[i,j]= e(i, j), (i, j) ∈ E
+∞, altfel//folosim vectorii dist[1..n] si pred[1..n]
//S -- multimea nodurilor atinse
S← {s}FOR i=1,...,n DO
dist[i] ← C[s,i];
pred[i] ← s;
END FOR
FOR k=2,...,n-1 DO
fie u astfel ıncat dist[u]= minx∈V \S
{dist[w]};
S ← S∪{u};
FOR all v∈ V \ S DO
IF dist[v]>dist[u]+C[u,v] THEN
dist ← dist[u]+C[u,v];
pred[v] ← u;
END IF
END FOR
END FOR
RETURN(dist,pred);END{short path}
Teorema 2. Algoritmul obt ine drumurile minime de la s la orice nod v ∈ V .
Complexitatea : O(n2).

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 67/120

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 68/120
68 CAPITOLUL 5. METODA GREEDY
FOR i=1,...,n DO
X(i) ← 0; i ← 1;
END FOR
C ← M; //C - capacitatea ramasa
WHILE C>W(i) AND i<=n DO
C ← C-W(i);
X(i) ← 1;
i ← i+1;
END WHILE
IF i<=n THEN
X(i) ← C/W(i);
END IF
RETURN(X);
END{greedy knapsack}Teorema 3. Solut ia generat˘ a de greedy knapsack este optimal˘ a.Demonstrat ie. Fie X = (x1, x2,...,xn) solutia generata de algoritm. Din
modul de constructie rezultani=1
wixi = M . Daca X = (1, 1, ..., 1), rezulta X
optimala.
Daca X = (1, 1,...1), fie j indicele pentru care xi = 1, 1 ≤ i < j; 0 ≤
x j < 1; xi = 0, j < i ≤ n. Rezulta ji=1
wixi = M . Presupunem ca X
nu este optimala. Fie Y = (y1, y2,...,yn) o solutie admisibila, astfel ıncati
piyi >i
pixi. Putem presupune cani=1
wiyi = M .
(***) Fie k cel mai mic indice pentru care kk = yk. Demonstram yk < xk.Exista urmatoarele posibilitati:1) k < j, atunci xk = 1; dar yk = xk, deci yk < 1; rezulta yk < xk;2) k = j
ni=1
wiyi = M =
j−1i=1
wiyi + w jy j +n
i= j+1
wiyi =
j−1i=1
wixi + w jy j +n
i= j+1
wiyi =

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 69/120
5.4. STUDII DE CAZ 69
= M − w jx j + w jy j +n
i= j+1
wiyi = M + w j(y j − x j) +n
i= j+1
wiyi.
Daca y j > x j , atunci M =ni=1
wiyi = M + w j(y j − x j) +n
i= j+1
wiyi > M .
Imposibil. Deci y j < x j , adica yk < xk.3) k > j
n
i=1
wiyi =k−1
i=1
wiyi +n
i=k
wiyi =k−1
i=1
wixi +n
i=k
wiyi =
=
ji=1
wixi +k−1i= j+1
wixi +n
i=k
wiyi = M + 0 +n
i=k
wiyi > M.
Imposibil.Crestem acum yk pana la xk si descrestem yk+1, yk+2,...,yn atat cat este
necesar astfel ıncatni=1
wiyi = M (capacitatea totala ramane M ). Se obtine o
solutie Z = (z1, z2,...,zn) cu zi = xi, i = 1,...,k sin
i=k+1
wi(yi − zi) = wk(zk −
yk). Suma ponderilor descresterilor yk+1, yk+2,...,yn este egala cu pondereacresterii lui yk.
Pentru Z avem:ni=1
pizi =ni=1
piyi+(zk−yk) pk+n
i=k+1
(zi−yi) pi =ni=1
piyi+(zk−yk)wk pk/wk−
−n
i=k+1
(yi − zi)wi pi/wi ≥ni=1
piyi +
(zk − yk)wk −
ni=k+1
(yi − zi)wi
pk/wk =
=
ni=1
piyi >
ni=1
pixi.
In relatia anterioara au fost utilizate inegalitatile pi/wi ≥ pi+1/wi+1, i =1,...,n − 1.

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 70/120

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 71/120
Capitolul 6
Programarea dinamica
6.1 Descrierea metodei
Se aplica atunci cand solutia unei probleme poate fi privita ca rezultat al uneisecvente de decizii.
Exemple:
a) problema rucsacului – decizia 1: xi1 ponderea obiectului i1;– decizia 2: xi2 ponderea obiectului i2 ...
b) interclasarea optimala – decizia 1: prima pereche;– decizia 2: a doua pereche ...
c) drumuri minime de la i la celelalte noduri– decizia 1: ın S se adauga i;– decizia 2: ın S se adauga nodul de distanta minima ...
Nu toate problemele permit ca la fiecare pas s a se determine decizia care
conduce la solutia optimala. Exemplu: drum minim de la i la jinitial: P = {i}decizia 1: care din vecinii lui i vor fi pe drumul minim?O solutie este a se ıncerca toate variantele posibile de decizie.
71

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 72/120
72 CAPITOLUL 6. PROGRAMAREA DINAMIC A
Programarea dinamic˘ a reduce num˘ arul de ıncerc˘ ari eliminand o serie desecvent e care nu pot fi optimale si aceasta apeland la principiul optimalit˘ at ii:
“O secventa optimala de decizii are proprietatea ca pornind de la o stareinitiala si considerand prima decizie d1, secventa de decizii ramase d2,...,Dn
trebuie sa fie optimala relativ la starea rezultata din prima decizie”.Problemele care ındeplinesc acest principiu sunt susceptibile de a fi rezol-
vate prin programare dinamica.ExempleDrum minim de la i la j, doua noduri ıntr-un graf . Drumul minim de la i la
j este de forma (i, i1, i2,...,im, j). Presupunem ca s-a luat decizia ca i1 esteprimul nod dupa i ın solutia optimala. Secventa (i1, i2,...,im, j) trebuie safie drum minim de la i1 la j, altfel, daca (i1, r1, r2, ...r1, j) este drumul minimde la i1 la j, atunci (i, i1, r1, r2,...,r1, j) este drumul minim de la i la j si nu(i, i1, i2,...,im, j).
Problema rucsacului [0,1]. Problema rucsacului 0/1 se enunta ın mod identiccu problema generala a rucsacului, cu observatia ca obiectele sunt indivizibile,adica apare restrictia suplimentara asupra ponderilor xi care trebuie sa fie 0sau 1. Formularea problemei:
• se cunosc obiectele i1, i2,...,in;
• obiectele au greutatile w1, w2,...,wn;
• obiectele au valorile (profiturile) p1, p2,...,pn;
• se considera o capacitate M ;
• o alegere de obiecte este un vector X = (x1, x2,...,xn), unde xi = 1semnifica faptul ca obiectul i a fost ales, iar xi = 0 semnifica faptul carespectivul obiect nu a fost ales;
• problema consta ın determinarea acelei alegeri care nu depaseste capac-
itatea, dar care maximizeaza profitul, adica:ni=1
xi pi − maxim, iarni=1
xiwi ≤ M.

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 73/120
6.1. DESCRIEREA METODEI 73
Problema se noteaza cu: knap(l,n,M). Presupunem ca exista o secventaX = (x1, x2,...,xn) reprezentand o alegere optimala.
Exista urmatoarele doua variante:1) xi = 0 si atunci secventa (x2, x3,...,xn) este optimala pentru problema
knap(2,n,M);2) xi = 1 si atunci secventa (x2, x3,...,xn) este optimala pentru problema
knap(2,n,M-w1).Se observa ca si ın acest caz principiul optimalitatii se respecta.
Fie s0 starea init ¸ial˘ a a problemei. Presupunem c˘ a sunt necesare n de-cizii d1, d2,...,dn. Prima decizie poate lua una din valorile mult ¸imii D ={r1, r2,...,rk}. Dac˘ a decizia d1 ia valoarea ri, fie si starea problemei dup˘ a aceast˘ a decizie si fie Ri secvent a optimal˘ a corespunz˘ atoare subproblemei core-spunz˘ atoare st˘ arii si. Dac˘ a este ındeplinit principiul optimalit˘ at ii, secvent a optim˘ a global˘ a va fi cea mai bun˘ a din secvent ele: r1R1, r2R2,...,rkRk.
ExempleDrum minim. Se cauta ıntr-un graf drumul minim de la nodul i la nodul j.
Fie E i = {i1, i2,...,is} multimea succesorilor nodului i si fie drumurile minimecorespunzatoare de la fiecare din acesti succesori la j, anume Rk = drumulminim de la ik la j (k = 1,...,s). Atunci drumul minim de la nodul i la nodul j a fi cel mai mic dintre drumurile (i Rk), k = 1,...,s.
Problema rucsacului 0/1. Fie problema knap(1,n,M) si fie π0(M ) valoareaprofitului maxim pentru aceasta problema. In general, pentru o problemaknap(j+1,n,Y) valoarea profitului maxim se noteaza cu π j(Y ). Deoarece x1
ia valori din multimea de decizii D1 = {0, 1}, avem:
π0(M ) = max{π1(M ), π1(M − w1) + p1}. (∗)
Dac˘ a pentru o problem˘ a dat˘ a este valabil principiul optimalit˘ at ii ın starea init ial˘ a, atunci se poate aplica acest principiu si la urm˘ atoarele st˘ ari interme-
diare.ExempleDrum minim. Daca (i, i1, i2,...,im, j) este drumul minim de la nodul i la
nodul j si ik este un nod intermediar, atunci secventa (i, i1, i2,...,ik) este drum

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 74/120
74 CAPITOLUL 6. PROGRAMAREA DINAMIC A
minim de la nodul i la nodul ik, iar secventa (ik, ik+1,...,j) este drum minimde la nodul ik la nodul j.
Problema rucsacului 0/1. Fie (x1, x2,...,xn) o secventa alegereoptimalapentru problema knap(1,n,M). Atunci pentru orice valoare j ( j = 1, n):
(x1, x2,...,x j) este solutie optimala pentru problema knap
1, j,
ji=1
wixi
, iar
(x j+1, x j+2,...,xn) este solutie optimala pentru problema knap
j + 1, n , M −
ji=1
wixi
.
Relatia (*) se generalizeaza la
π j(Y ) = max{π j+1(Y ), π j+1(Y − w j+1) + p j+1}. (∗∗)
Relatia (**) este o recurenta care se poate calcula stiind ca πn(Y ) = 0 pentruorice Y numar real.
Exemplele anterioare evident iaz˘ a recurent e de tip “forward” (ın fat a). Sepot defini aceste recurent e si ın mod “backward”.
ExempleDrum minim. Daca (i, i1, i2,...,im, j) este drumul minim de la nodul i la
nodul j, fie E j = {k; (k, j) = arc din graf }, |E | = p multimea predecesorilor
nodului j. Pentru fiecare predecesor k, fie Rk drumul minim de la nodul i lanodul k. Evident, drumul minim general va fi cel mai scurt drum din drumurilede forma (Rk j) pentru k = 1,...,p.
Problema rucsacului 0/1. Daca se noteaza cu f i(x) valoarea optima a prob-lemei knap(1,i,x), se obtin recurentele:
f i(x) = max{f i−1(x), f i−1(x − wi) + pi}, i = 1, 2,...,n.
Recurentele sunt rezolvabile stiind ca f 0(x) = 0, ∀x ≥ 0, f 0(x) = −∞, ∀x < 0.
6.2 Modelul matematicProblemele ale caror solutii se pot obtine prin programare dinamica sunt prob-leme de optim. Un prototip de astfel de problema este urmatorul:

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 75/120
6.2. MODELUL MATEMATIC 75
S˘ a se determine:optimR(x1,...,xm), (1)
ın condit iile ın care acestea satisfac restrict ii de forma
g(x1,...,xm)?0, (2)
unde ? ∈ {<, ≤, =, ≥, >}.Prin optim se ıntelege, de obicei, min sau max , iar ecuatia (1) se mai
numeste si funct ie obiectiv . Un alt prototip este furnizat de digrafurile ponder-
ate, unde R(x1,...,xm) exprima suma ponderilor arcelor x1,...,xm, iar restrictiileimpun ca x1,...,xm sa fie drum sau circuit cu anumite proprietati.
Metoda programarii dinamice propune determinarea valorii optime prin lu-area unui sir de decizii d1,...,dn, numit si politic˘ a , unde decizia di transformastarea (problemei) si−1 ın starea si, aplicand principiul de optim :
Secvent a optim˘ a de decizii (politic˘ a optimal˘ a) care corespunde st˘ arii s0 areproprietatea ca dup˘ a luarea primei decizii, care transform˘ a starea s0 ın starea s1, secvent a de decizii (politica) r˘ amas˘ a este optim˘ a pentru starea s1.
De cele mai multe ori, prin stare a problemei se ıntelege o subproblema.Unei stari i se asociaza o valoare z si se defineste f (z) astfel ıncat, daca starea
s corespunde problemei initiale, atunci:
f (z) = optimR(x1,...,xm). (3)
Principiul de optim conduce la obtinerea unei ecuatii functionale de forma:
f (z) = optimy
[H (z, y, f (T (z, y)))], (4)
unde z este valoarea asociata starii s, T (z, y) calculeaza valoarea asociatastarii s rezultata ın urma deciziei y, iar H exprima algoritmul de calcul alvalorii f (z) data de decizia y care transforma starea s ın starea s. Dintre
toate deciziile cae se pot lua ın starea s (producand s), se alege una care davaloarea optima ın conditiile ın care politica aplicata ın starea s este si eaoptima.
Exemplu

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 76/120
76 CAPITOLUL 6. PROGRAMAREA DINAMIC A
Problema rucsacului.
πi(Y i) = max{πi+1(Y i), πi+1(Y i − wi+1) + pi+1},
unde πi(Y i) = valoarea de optim pentru knap(i+1,n,Yi), Y i = M −i
k=1
wkxk.
Notatiile din (4) conduc la urmatoarele:
z = i, s = si, f (i) = optim − knap(i + 1, n , Y i) = πi(Y i). Rezulta: f (i) =f (i + 1) + pi+1xi+1;
y ∈ {0, 1}, T [i, y] = i + 1, s = si+1, H (i,y,f (T (i, y))) = f (i + 1) + pi+1y;H (i, 0, f (T (i, 0))) = H (i, 0, f (i + 1)) = f (i + 1) = πi+1(Y i+1) = πi+1(Y i);
H (i, 1, f (T (i, 1))) = H (i, 1, f (i + 1)) = f (i + 1) + pi = πi+1(Y i+1) + pi+1 =πi+1(Y i − wi+1) + pi+1.
Rezulta: f (i) = max{πi+1(Y i), πi+1(Y i − wi+1) + pi+1}.
Principiul de optim implica proprietatea de substructura optima a solutiei,care afirma ca solut ia optim˘ a a problemei include solut iile optime ale sub-problemelor sale. Aceasta proprietate este utilizata la gasirea solutiilor core-spunzatoare starilor optime. In general, programele care implementeaza mod-elul dat de programarea dinamica au doua parti:
1) determinarea valorilor optime date de sirul de decizii optime, prin re-zolvarea ecuatiilor (4);
2) construirea solutiilor (valorilor xi care dau optimul) corespunzatoarestarilor optime pe baza valorilor calculate ın prima parte, utilizand propri-etatea de substructura optima.
6.3 Eficienta metodei
In general, nu se recomanda scrierea unui program recursiv care sa calculeze
valorile optime. In cazul programelor recursive, daca ın procesul de descom-punere problema → subproblema, o anumita subproblema apare de mai multeori, ea va fi rezolvata ori de cate ori apare. Asa se procedeaza ın cazul aplicariimetodei Divide-and-Conquer. Este mult mai convenabil ca valorile optime

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 77/120
6.4. COMPARATIE INTRE METODA PROGRAM ARII DINAMICE SI METODA GREEDY 77
corespunzatoare subproblemelor sa fie memorate ıntr-un tablou si apoi com-binate pe baza ecuatiilor (4) pentru a obtine valoarea optima a unei sub-probleme. In acest fel, orice subproblema este solutionata o singura data, iarcalcularea valorilor optime se face de la subproblemele mai mici la cele maimari (“bottom-up”). Prin memorarea valorilor optime ıntr-un tablou se reducesi timpul de calcul pentru optimul unei subprobleme, datorita accesului la unelement dintr-un tablou ın O(1) timp.
Complexitatea algoritmilor care implementeaza metoda programarii di-namice depinde direct de tipul de recursivitate implicat de recurentele rezultate
prin aplicarea principiului optimalitatii. In cazul recursiei liniare, valorile op-time pot fi calculate ın timp liniar. In cazul recursiei ın cascada, rezulta 2n
subprobleme. De obicei, ın aceste situatii se studiaza posibilitatea redefiniriistarilor astfel ıncat sa rezulte o recursie liniara.
6.4 Comparatie ıntre metoda programarii di-namice si metoda greedy
1. Metoda greedy utilizeaza proprietatea alegerii locale: solutia globala optima
este construita prin selectii optime locale.Metoda programarii dinamice utilizeaza proprietatea de substructura op-
tima: solutia optima a unei probleme include ın structura sa solutiile optimeale subproblemelor.
2. Alegerea locala ın cazul metodei greedy nu depinde de alegerile ulte-rioare, deci metoda greedy nu are caracter recursiv.
Proprietatea de substructura optima utilizata ın programarea dinamicaare un caracter recursiv: pentru a construi solutia optima a problemei estenecesara cunoasterea solutiilor subproblemelor. Deci, rezolvarea problemeiimplica rezolvarea subproblemelor.
3. Parcurgerea arborelui subproblemelor ın cazul metodei greedy se face ınmaniera top-down.
Parcurgerea arborelui subproblemelor ın cazul metodei programarii dinam-ice este facuta ın stil bottom-up.

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 78/120
78 CAPITOLUL 6. PROGRAMAREA DINAMIC A
6.5 Studii de caz
6.5.1 Problema rucsacului (0/1)
Relatiile de recurenta “backward” rezultate din aplicarea principiului de optimsunt urmatoarele:
f i(x) = max{f i−1(x), f i−1(x − wi) + pi}, i = 1, 2,...,n, (∗)
unde f i(x) este valoarea optima a problemei knap(1,i,x).Recurentele sunt rezolvabile stiind ca f 0(x) = 0, ∀x ≥ 0, f 0(x) = −∞, ∀x <
0.
Exemplu : n = 3, (w1, w2, w3) = (2, 3, 4), ( p1, p2, p3) = (1, 2, 5), M = 6
f 0(x) = 0 g1(x) = f 0(x − w1) + p1 = f 0(x − 2) + 1
T
E
T
E
f 1(x) = max{f 0(x), f 0(x − 2 ) + 1} g2(x) = f 1(x − w2) + p2 = f 1(x − 3 ) + 2
E
T T
E
f 2(x) = max{f 1(x), f 1(x − 3 ) + 2} g3(x) = f 2(x − w3) + p3 = f 2(x − 4 ) + 5
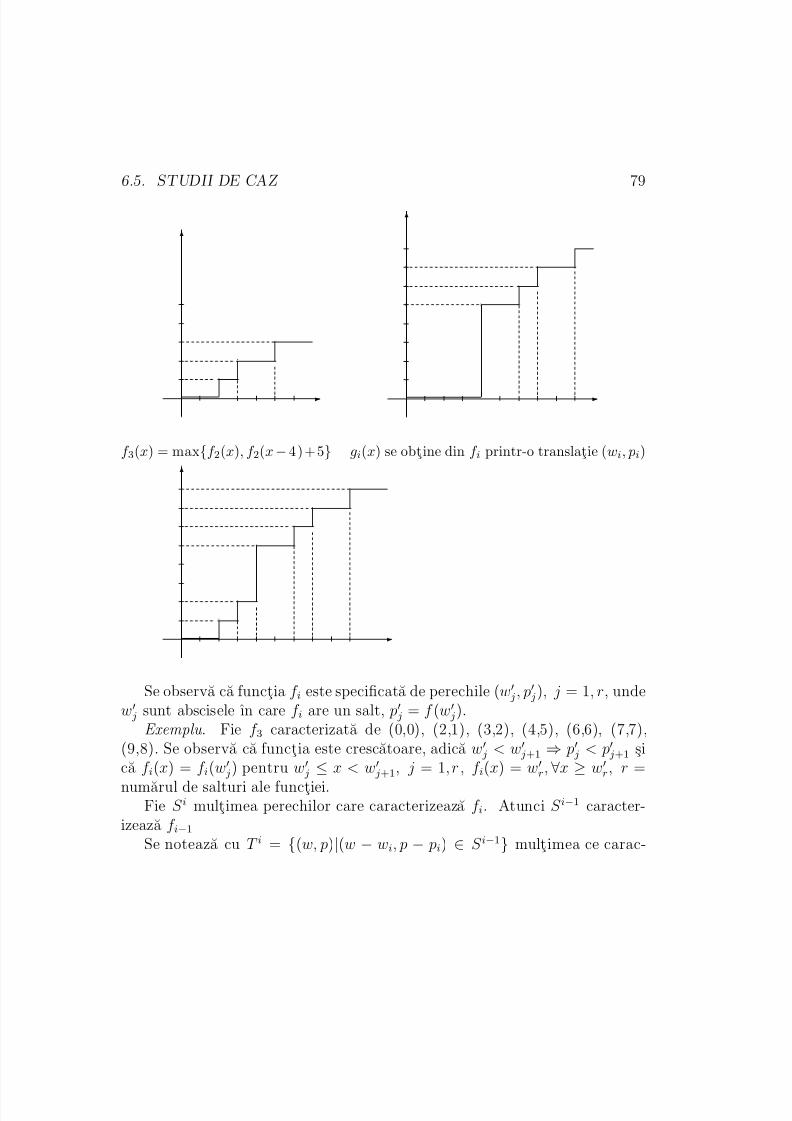
8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 79/120
6.5. STUDII DE CAZ 79
T
E
T
E
f 3(x) = max{f 2(x), f 2(x− 4)+5} gi(x) se obtine din f i printr-o translatie (wi, pi)
T
E
Se observa ca functia f i este specificata de perechile (w j, p j), j = 1, r, unde
w j sunt abscisele ın care f i are un salt, p j = f (w
j).Exemplu . Fie f 3 caracterizata de (0,0), (2,1), (3,2), (4,5), (6,6), (7,7),
(9,8). Se observa ca functia este crescatoare, adica w j < w
j+1 ⇒ p j < p j+1 sica f i(x) = f i(w
j) pentru w j ≤ x < w
j+1, j = 1, r , f i(x) = wr, ∀x ≥ w
r, r =
numarul de salturi ale functiei.Fie S i multimea perechilor care caracterizeaza f i. Atunci S i−1 caracter-
izeaza f i−1
Se noteaza cu T i = {(w, p)|(w − wi, p − pi) ∈ S i−1} multimea ce carac-

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 80/120
80 CAPITOLUL 6. PROGRAMAREA DINAMIC A
terizeaza gi(x) = f i−1(x − wi) + pi. T i se obtine din S i−1 adunand la fiecarepereche (wi, pi). S i se obtine combinand T i cu S i−1 astfel ıncat sa se obtinamaxim din cele doua functii f i−1 si gi. Combinarea celor doua multimi T i siS i−1 se face dupa urmatorul principiu (principiul dominantei):
Fie (w j , p j) ∈ T i si (w
k, pk) ∈ S i−1 sau (w j, p j) ∈ S i−1 si (wk, pk) ∈ T i.
Dac˘ a p j < pk si w j > w
k, atunci (w j, p j) se elimin˘ a.
Pentru exemplul anterior:
S 0 = {(0, 0)} T 1 = {(2, 1)}S 1 = {(0, 0), (2, 1)} T 2 = {(3, 2), (5, 3)}S 2 = {(0, 0), (2, 1), (3, 2), (5, 3)} T 3 = {(4, 5), (6, 6), (7, 7), (9, 8)}S 3 = {(0, 0), (2, 1), (3, 2), (5, 3), (4, 5), (6, 6), (7, 7), (9, 8)}
Observat ii . 1) In calculul multimilor S i, se pot elimina toate perechile(w, p) cu w > M , deoarece nu se calculeaza f i(x) cu x > M .
2) In conditiile eliminarilor de la obs.1), valoarea de optim a solutiei estedata de ultima pereche din S n, (w, p), anume p este valoarea de optim.
3) Metoda prezentata nu ofera ınca o solutie completa. Cum se deducesolutia (x1, x2,...,xn)? Fie (w, p) ultima pereche din S n. Daca (w, p) ∈ S n−1,atunci xn = 0, altfel xn = 1. Daca (w, p) ∈ S n−1, atunci (w − wn, p − pn) ∈S n−1. Se considera (w, p) = (w − wn, p − pn), daca (w, p) ∈ S n−1; altfel(w, p) = (w, p). Se testeaza (w, p) ∈ S n−2 etc.
Pentru exemplul anterior:
M = 6, S 3 = {(0, 0), (2, 1), (3, 2), (4, 5), (6, 6)}
(w, p) = (6, 6), (6, 6) ∈ S 2, deci x3 = 1
(6 − w3, 6 − p3) = (2, 1)
(2, 1) ∈ S 2, (2, 1) ∈ S 1 ⇒ x2 = 0
(2, 1) ∈ S 1, (2, 1) ∈ S 0 ⇒ x1 = 1

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 81/120
6.5. STUDII DE CAZ 81
dinamic knapsack(w,p,n,M)
S0 ← {(0, 0)};
FOR i=1,...,n DO
Ti ← {(w,p)|(w-wi,p-pi)∈Si−1 si w<=M};
Si ← combine(Ti,Si−1);
END FOR
fie (w,p) ultima pereche din Sn;
FOR i=n,n-1,...,1 DO
IF (w,p)∈Si−1 THEN
xi ← 0;
ELSE
xi ← 1; w←w-wi; p←p-pi;
END IF
END FOR
END{dinamic knapstack}Complexitate
Algoritmul construieste element cu element multimile S 0, S 1,...,S n. Incazul cel mai defavorabil, cand nu se elimina nimic, |S 0| = 1, |S 1| = 2,..., |S i| =
2 ∗ |S
i−1
| = 2
i
,... Un calcul simplu produce urmatorul rezultat:n−1i=0
|S i| =n−1i=0
2i = 2n − 1.
Rezulta o complexitate de timp si de spatiu exponentiala O(2n). Metoda, deci,este extrem de ineficienta.
6.5.2 Inmultire optima de matrici
Presupunem ca avem produsul de matrice A1 ×A2 ×A3 × · · · ×An, unde, pentrui = 1,...,n, Ai are dimensiuni di si di+1. Pentru ınmultirea acestor matrice,numarul total de operatii este d1 ∗ d2 ∗ · · · ∗ dn. Asociativitatea permite ostrategie de solutie care sa minimizeze numarul total de ınmultimi.

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 82/120
82 CAPITOLUL 6. PROGRAMAREA DINAMIC A
Exemplu . Fie produsul de matricede dimensiuni
A1(100,1)
× A2(1,100)
× A3(100,1)
× A4(1,100)
. Con-
sideram urmatoarele variante de asociere a ınmultirilor:
1) (A1 × A2) × (A3 × A4) ⇒ nr.oper.=10.000+10.000+1.000.000=1.020.000
2) (A1 × (A2 × A3)) × A4 ⇒ nr.oper.=100+100+10.000=10.200.
Rezolvarea problemei prin programare dinamica:
Fie Aij = Ai × Ai+1 × · · · × A j, 1 ≤ i ≤ j ≤ n si cost[i, j] – costul ınmultirii.
Observam: cost[i, i] = 0, ∀1 ≤ i ≤ n; cost[i, i + 1] = di ∗ di+1 ∗ di+2 pentru
1 ≤ i ≤ n − 1.Principiul optimalitatii se poate formula astfel:
pentru un pas general al ınmultirii
(Ai × Ai+1 × · · · × Ak) × (Ak+1 × Ak+2 × · · · × A j)
di, di+1 di+1, di+2 dk, dk+1 dk+1, dk+2 dk+2, dk+3 d j , d j+1
cost[i, j] = min{cost[i, k] + costi≤k<j
[k + 1, j] + di ∗ dk+1 ∗ d j+1}. (∗)
Putem calcula acest cost[i, j] ın ordinea: j − i = 1 j − i = 2... j − i = n − 1 pana la cost[1, n]
Construim matricea cost[i, j]. Observam ca matricea este triunghiulara.

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 83/120

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 84/120
84 CAPITOLUL 6. PROGRAMAREA DINAMIC A
cost[1,4]=min{cost[1,1]+cost[2,4]+d1d2d5, cost[1,2]+cost[3,4]+d1d3d5,cost[1,3]+cost[4,4]+d1d4d5}=min{0+200+10000, 10000+10000+1000000, 200+0 + 10000} = 10200.
ComplexitateSe poate usor observa ca algoritmul lucreaza ın O(n3), ıntrucat sunt doua
bucle for plus numarul de comparatii pentru selectia minimului.
n−1
k=1
n−k
i=1 ( j − i − 1) =
n−1
k=1
n−k
i=1 (i + k − i − 1) =
n−1
k=1(n − k)(k − 1) =
n−1
k=1 nk−
−n−1k=1
n−n−1k=1
k2 +n−1k=1
k = nn(n − 1)
2−n2n+n−
n(n − 1)(2n − 1)
6+
n(n − 1)
2=
= O(n3).
6.5.3 Arbori binari de cautare optimali
Arborii binari de cautare sunt acei arbori ale caror noduri sunt organizate ınfunctie de valorile unor chei care sunt calculate functie de valorile nodurilor.Pentru fiecare nod, cheia sa este mai mare decat valorile cheilor tuturor nodurilordin subarborele stang si este mai mica decat toate cheile de noduri din sub-arborele drept. Nodurile arborelui au chei distincte. In figura urmatoare estedat un arbore binar de cautare.
d d
d d
d d
1582
7
4
12
20

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 85/120

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 86/120
86 CAPITOLUL 6. PROGRAMAREA DINAMIC A
Problema arborelui de cautare optimal
Fie A = (a1, a2,...,an) secventa sortata crescator cu valori din care se con-struieste un arbore de cautare. Se considera ca operatia de cautare se executacu anumite frecvente. Anume:
P = ( pi; pi− probabilitatea de a fi cautat elementul ai, i = 1, n)Q = (qi; qi− probabilitatea de a fi cautat un element x cu proprietatea
ai < x < ai+1, i = 0, n), unde a0 = −∞, an+1 = +∞In aceste conditii se noteaza:ni=1
pi – probabilitatea de succes;ni=0
qi – probabilitatea de insucces
iarni=1
pi +ni=0
qi = 1.
Pentru P si Q date, arborele binar de cautare optimal este cel pentrucare operatia de cautare ofera timp mediu minim. Pentru a pune ın evidentatimpul mediu se considera arborele binar de cautare completat cu o serie de
pseudonoduri corespunzatoare intervalelor de insucces, pseudonoduri care seasociaza pointerilor nuli. In exemplul de mai jos, se prezinta un arbore sicompletatul sau.
E2 E3
E1E0 E4
d d
d d
d d
4 4
4 4 a2
a4
a3
a1a2
a1 a4
a3
d d
Nodul E i corespunde tuturor cautarilor fara succes pentru valori cuprinseın intervalul (ai, ai+1). Timpul unei operatii de cautare pentru un element x

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 87/120
6.5. STUDII DE CAZ 87
este dat de adancimea nodului de valoare x sau de adancimea pseudonoduluicorespunzator intervalului care-l contine pe x.
Costul unui arbore reprezinta timpul mediu al unei cautari pentru o valoarex, adica:
cost(T ) =ni=1
pi ∗ level(ai) +ni=0
qi ∗ (level(E i) − 1).
Prin level(a) se noteaza nivelul nodului a si reprezinta numarul de comparatii
efectuate de functia de cautare pe drumul de la radacina pana la nodul a. Pon-derand acest numar cu probabilitatea de a fi cautat nodul a si efectuand sumapentru toate nodurile se obt ine timpul mediu de cautare cu succes a unuinod. In mod similar, se calculeaza timpul mediu de cautare pentru insuc-ces, cu observatia ca din level(E i) se scade valoarea 1, deoarece decizia deapartenenta la un interval nu se face la nivelul pseudonodului, ci la nivelulparintelui sau.
Data fiind secventa de valori A, se pot construi o mmultime de arbori binaride cautare cu cheile nodurilor din A. Un arbore binar de cautare optimal estearborele de cost minim.
Din punct de vedere al programarii dinamice, construirea unui arboreconsta ıntr-un sir de decizii privind nodul care se alege ca radacina ın fiecarepas.
Fie (a1, a2,...,ak,...,an) secventa de noduri sortata crescator si presupunemca ın primul pas se alege ca radacina nodul ak. Conform principiului opti-malitatii vom avea:
• subarborele stang L este construit cu secventa (a1, a2,...,ak−1) si clasele(E 0, E 1,...,E k−1)
cost(L) =
k−1i=1
pi ∗ level(ai) +
k−1i=0
qi ∗ (level(E i) − 1);
• subarborele drept R este construit cu secventa (ak+1, ak+2,...,an) si clasele

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 88/120
88 CAPITOLUL 6. PROGRAMAREA DINAMIC A
(E k, E k+1,...,E n)
cost(R) =k−1
i=k+1
pi ∗ level(ai) +n
i=k
qi ∗ (level(E i) − 1).
Valoarea level() se calculeaza relativ la subarborii L, R, respectiv. Costulasociat arborelui devine:
cost(T ) = pk + cost(L) + cost(R) +k−1i=1
pi +k−1i=0
qi +n
i=k+1
pi +n
i=k
qi. (∗)
Sumelek−1i=1
pi +k−1i=0
qi +n
i=k+1
pi +n
i=k
qi reprezinta valorile suplimentare care
apar datorita faptului ca arborele ıntreg T introduce un nivel suplimentar (celal radacinii) fata de subarborii L, R. In continuare, relatia (*) se rescrie ca:
cost(T ) = pk + cost(L)+cost(R) + q0 +
k−1i=1
( pi + qi) + qk +
ni=k+1
( pi + qi). (∗∗)
Notand wi,j = qi + j
k=i+1
( pk + qk), se obtine:
cost(T ) = pk + cost(L) + cost(R) + w0,k−1 + wk,n. (∗ ∗ ∗)
Atunci cand acest cost este minimal, el devine egal cu cost(L)+cost(R)+w0,n.Principiul optimalitatii este respectat deoarece subarborii L si R trebuie
sa fie optimi.
Se noteaza cu ci,j costul unui arbore optimal T i,j care are nodurile dinsecventa (ai+1, ai+2,...,a j) si pseudonodurile din (E i, E i+1,...,E j).
Pentru situatia discutata anterior, ın conditiile ın care arborele cu nodulradacina ak este optimal, notatiile devin: c0,k−1 = cost(L), ck,n = cost(R).

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 89/120
6.5. STUDII DE CAZ 89
Principiul optimalitatii se scrie astfel:
c0,n = min1≤k≤n
{c0,k−1 + ck,n + pk + w0,k−1 + wk,n}. (∗ ∗ ∗∗)
Generalizand,
ci,j = mini+1≤k≤ j
{ci,k−1 + ck,j + pk + wi,k−1 + wk,j} = mini+1≤k≤ j
{ci,k−1 + ck,j + wi,j}.
Costul optimal c0,n se poate calcula efectiv folosind ultima relatie de recurenta
pentru i − j = 1, apoi j − i = 2,...,j − i = n. Valorile initiale suntci,i = 0, wi,i = qi, 0 ≤ i ≤ n. In plus, se foloseste relatia wi,j = p j + q j + wi,j−1.Algoritmul de calcul al arborelui optimal:
opt-bst(P,Q,n)
//(a1,a2,...,an) secventa de noduri (valori)
//P,Q secventele de succes si insucces
//se calculeaza:
// C=(ci,j) (costurile), W=(wi,j) si
// R (matricea de indici ai radacinilor
// ri,j - indicele nodului radacina al subarborelui optimal
// format din secventa (ai+1,ai+2,...,a j)
FOR i=1,...,n-1 DO
ci,i ← 0; ri,i ← 0; wi,i ← qi;
ci,i+1 ← qi+pi+1+qi+1; ri,i+1 ← i+1; wi,i+1 ← qi+pi+1+qi+1;
END FOR
wn,n ←qn; rn,n ← 0; cn,n ← 0;
FOR m=2,...,n DO
FOR i=0,...,n-m DO
j ← i+m;
wi,j ←wi,j−1+p j+q j;
fie k indicele care realizeaza valoarea minima pentru
{ci,h−1+ch,j; h∈ I=[i+1,j]}; //(xxx)ci,j ←wi,j+ci,k−1+ck,j;
ri,j ←k;
END FOR

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 90/120
90 CAPITOLUL 6. PROGRAMAREA DINAMIC A
END FOR
END{opt-bst}Complexitatea : Evident O(n3). Exista o observatie a lui Knuth prin care,
daca ın linia marcata (xxx) nu se considera intervalul de indici I = [i + 1, j],ci intervalul I = [ri,j+1, ri+1,j], se obtine complexitatea timp = O(n2).

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 91/120
Capitolul 7
Metoda Backtracking
7.1 Descrierea metodei
Metoda este prin execelenta secventiala.
Metoda backtracking se aplica ın probleme de cautare. Metoda este adec-vata problemelor ın care solutia se poate exprima ca un n-uplu (x1, x2,...,xn), xi ∈S i – finita, i = 1, n. Solutia trebuie sa satisfaca sau sa minimizeze/maximizeze
o functie criteriu P (x1, x2,...,xn). Uneori, se solicita toate solutiile. Daca|S 1| = m1, |S 2| = m2, ..., |S n| = mn, atunci numarul total de n-uple estem = m1m2...mn. Metoda nu asigura ca nu se vor ıncerca toate cele mposibilitati, dar practic reduce mult numarul de n-uple care se ıncearca prinfolosirea functiei criteriu. Ideea este de a folosi o forma partiala a functieicriteriu P i(x1, x2,...,xi) care elimina familii ıntregi de n-uple. Daca, de exem-plu, solutia partiala (x1, x2,...,xi) nu are nici o sansa de a conduce la o solutiecompleta, toate cele mi+1mi+2...mn n-uple cu (x1, x2,...,xi) pe primele i pozitiise abandoneaza.
Spatiul solutiilor. Restrictii
S 1 ×S 2 × · · · ×S n se numeste spatiul solutilor problemei, iar restrictiile de forma(x1, x2,...,xn) ∈ S 1 × S 2 × · · · × S n se numesc restrictii explicite; restrictiile
91

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 92/120
92 CAPITOLUL 7. METODA BACKTRACKING
(x1, x2,...,xn) satisfacand P se numesc restrictii implicite.Exemplul 1. Problema celor 8 dame pe tabla de sah. Data fiind S =
{1, 2, 3, ..., 8} = multimea celor 8 dame si o tabla de sah (8 linii si 8 coloane),sa se plaseze cele 8 dame astfel ıncat sa nu existe doua dame pe aceeasi linie,coloana sau diagonala.
O solutie poate fi exprimata printr-un 8-uplu X = (x1, x2,...,x8), unde xi
= coloana pe care se plaseaza dama I (linia pe care se plaseaza dama I estei).
Deoarece S i = S, i = 1, ..., 8, rezulta ca spatiul de solutii S × S × S × · · · × S de 8 ori
are 88 8-uple.Restrictia explicita: 1 ≤ xi ≤ 8, i = 1, ..., 8.Restrictii implicite: o singura dama pe o coloana – xi = x j , ∀i = j,i,j =
1, ..., 8; o singura dama pe o diagonala – |i − j| = |xi − x j |, ∀i = j,i,j = 1, ..., 8.Exemplul 2 . Submultimi de suma data. Date fiind S = {w1, w2,...,wn}, wi ≥
0, 1 ≤ i ≤ n si M – o valoare, M > 0, sa se determine toate submultimileS ⊆ S, S = {x1, x2,...,xk} cu proprietatea x1 + x2 + · · · + xk = M .
Cazul n = 4 S = {11, 13, 24, 7}, M = 31; solutii: X 1 = (11, 13, 7), X 2 =(24, 7) sau exprimate prin indicii i ai elementelor wi ∈ S, X 1 = (1, 2, 4), X 2 =
(3, 4).Pentru cazul exorimarii solutiilor prin indicii i ai elementelor wi ∈ S
restrictiile sunt urmatoarele:– restrictii explicite, 1 ≤ xi ≤ n, i = 1,...,n;– restrictii implicite, xi = x j si
xi∈X
wxi = M ; xi < xi+1 pentru a evita
generarea aceleiasi multimi (ex., {1, 2, 4} = {2, 4, 1}.
O alta abordare: X = (x1, x2,...,xn), xi = 0 sau 1;ni=1
xiwi = M .
Spatiul solutiilor este de dimensiune 2n.
Organizarea sub forma de arbore a spatiului solutiilor
Metoda backtracking rezolva o problema prin cautarea sistematica a solutiei ınspatiul solutiilor. Conceptual, aceasta cautare foloseste o organizare a spatiului

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 93/120
7.1. DESCRIEREA METODEI 93
solutiilor sub forma unui arbore.
Exemplul 1. Problema celor n dame. Folosim n = 4.
f f f f
¢ ¢
¢ ¢
3 3 3 3 3 3 3 3
3 3 3 3 3 3 3 3
f f
f f ¢ ¢
¢ ¢ v v
v v
1 x1=4
x1=3x1=2
x1=1
2x2=4
x2=3
x2=2
3 8 13
424x3=3
4 6 9 11243x4=4
5 7 10 12
In acest arbore arcele de la nivel i la i + 1 sunt etichetate cu valori xi.
Spatiul solutiilor = secventele de etichete de la radacina la nodurile frunza.
Nodurile sunt etichetate ın sensul parcurgerii depth-first .
Exemplul 2 . Submultimi de suma data: (11,13,24,7), M = 31.

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 94/120
94 CAPITOLUL 7. METODA BACKTRACKING
5 5
5 5
i i i i ¥
¥ ¥ ¥ d
d d d
¥ ¥ ¥ ¥ i
i i i
1x1=1
2 34
5432x2=2 3 4 3 4 4
11109876
x3=3 4 4 4
15141312x4=4
16
Traversare breadth-first .Notiuni:– starea problemei = fiecare nod ıntr-un arbore defineste o stare a proble-
mei;– spatiul starilor = toate drumurile de la radacina la noduri;– stari solutie = acele stari (noduri) pentru care exista drum de la radacina
la nod etichetat cu un n-uplu;– stari raspuns = stari care satisfac conditiile implicite P ;– arborele spatiului starilor = spatiul starilor problemei organizat sub forma
de arbore.Arborii construiti astfel sunt arbori statici si nu depind de instanta proble-
mei. Exista arbori dinamici care depind de problema. Un exemplu ar fi cazulın care functie de valoarea lui x1 se decide daca la primul nivel este x1 sau x2
s.a.m.d.
Backtracking si Branch-and-Bound
Exista doua strategii de generare a nodurilor corespunzatoare starilor proble-mei: depth-first si breadth-first .
Nodurile se clasifica ın:

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 95/120
7.1. DESCRIEREA METODEI 95
nod viu – nod generat pentru care nu s-au generat descendenti;
E-noduri – noduri ın expandare – noduri vii pentru care procesul de generarea descendentilor este ın curs;
nod mort – nod generat care nu are descendent (si nici nu va avea) sau pentrucare toti descendentii s-au generat.
In strategia depth-first , pentru E-nodul curent se identifica un descendentC care devine noul E-nod si procesul se aplica recursiv.
In strategia breadth-first , pentru E-nodul curent se genereaza toti descendentiisi se trec ın lista de noduri vii sau moarte.
In ambele strategii, ın orice moment, se aplica functia criteriu (restrictiileimplicite), numita si functia de marginire care seteaza un nod ca nod mortfara a-i mai genera descendentii.
Prima tehnica este numita backtracking.A doua tehnica este numita Branch-and-Bound.
Exemplu pentru tehnica backtracking . Problema celor 4 dame:
1 1* 2
12
* *
12
3
12
3*
1 1* * 2
12
34
Ordinea de generare este:

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 96/120
96 CAPITOLUL 7. METODA BACKTRACKING
l l
l l
5 5
5 5 5
¥ ¥ ¥ ¥ i
i i i
d d
d d
¥ ¥ ¥ ¥ i
i i i
1x1=1 x1=2
182x2=2 3 4 x2=1 3 4
2924181383
x3=2B 4 2 3 B B x3=1
301614119B B
x4=3
15 31
x4=3
B
7.2 Modelul Algoritmic
Fie (x1, x2,...,xi) un drum de la radacina la un nod ıntr-un arbore spatiu destari.
Fie T (x1, x2,...,xi) multimea tuturor valorilor posibile pentru xi+1 astfelıncat (x1, x2,...,xi, xi+1) este de asemenea un drum de la r adacina la un nod.
Fie Bi+1(x1, x2,...,xi+1) functia (predicatul) de marginire derivata din P – functia criteriu. Bi+1(x1, x2,...,xi+1) = false, daca xi+1 este nod mort, deblocaj si = true, daca xi+1 se extinde.

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 97/120
7.2. MODELUL ALGORITMIC 97
Backtrack-iterativ(n)
//Solutiile sunt generate ın x[1..n]
//T (x1,...,xk−1) = {xk|(x1, x2,...,xk−1, xk) - drum de la radacina la nod}//Bk(x1,...,xk) - functie (predicat) de marginire;
k ← 1;
WHILE k>0 DO
IF ∃y ∈ T (x1, x2,...,xk−1) neıncercat
si Bk(x1, x2,...,xk−1, xk = y) =true THEN
IF (x1, x2,...,xk) =solutie (nod raspuns) THEN
print (x1, x2,...,xk);END IF
k ← k+1;
ELSE
k ← k+1;
END IF
END WHILE
END{Backtrack-iterativ}
backtrack-recursiv(k)
//Solutiile sunt generate ın x[1..n]
//T (x1,...,xk−1) = {xk|(x1, x2,...,xk−1, xk) - drum de la radacina la nod}//Bk(x1,...,xk) - functie (predicat) de marginire
FOR ∀xk a.i. xk = y ∈ T (x1,...,xk−1) si Bk(x1,...,xk−1, xk) = true DO
IF (x1,...,xk−1, xk) = solutie (nod de raspuns) THEN
print (x1,...,xk−1, xk);
END IF
backtrack-recursiv(k+1);
END FOR
END{backtrack-recursiv}Observat ii . 1) Eficient a algoritmului depinde de
– timpul pentru generarea urmatorului xk;– numarul de elemente din T (x1,...,xk−1);– functia de marginire B;– numarul total de noduri.

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 98/120
98 CAPITOLUL 7. METODA BACKTRACKING
2) Pentru multe probleme, multimile S i se pot lucra ın orice ordine, iarelementele din T (x1,...,xk−1) la fel. Folosind aceasta observatie, se pot stabilianumite euristici – strategii de organizare a elementelor lui S i cu scopul de areduce nivelul de backtracking.
3) Ordinul de complexitate este O(2n) sau O(n!). Metoda ınsa rezolva, deobicei, mult mai rapid problemele, dar fara a se sti exact cat de repede. Uneorise poate ıncerca o estimare a timpului backtracking si aceasta pornind de la oestimare a numarului de noduri.
Estimarea numarului de noduri se poate face prin urmatoarea procedura
generala:estimate()
nr ← 1; r ← 1; k ← 1; t ← true;
WHILE t DO
T k ← {xk|xk ∈ T (x1,...,xk−1) si Bk(x1,...,xk) = true;
IF |T k| = 0 THEN
break;
END IF
r ← r∗|T k|; nr ← nr+r; xk ← random-choose(T k); k ← k+1;
END WHILE
return(nr)END{estimate}
7.3 Studii de caz
7.3.1 Problema celor 8 dame
Daca se considera 2 elemente pe aceeasi diagonala (i, j), (k, l), i − j = k −l, j − l = i − k sau i + j = k + l, j − l = k − i, adica se poate folosi conditia| j − l| = |k − i|.
Construim functia place(k) care returneaza true daca dama cu numarulde ordine k poate fi plasata pe coloana data de x[k].
Operatiile care se fac sunt:– se testeaza daca x[k] = x[i], i = 1, 2,...,k − 1;

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 99/120
7.3. STUDII DE CAZ 99
– se testeaza daca nu exista alta dama ın aceeasi diagonala.
Functia place are complexitatea timp O(k − 1).
place(k)
i ← 1;
WHILE i<k
IF x[i]=x[k] sau abs(x[l]-x[k]=abs(i-k) THEN
return false
END IF
i ← i+1;END WHILE return true
END{place}
n-queen(n)
//x[1..n] - vectorul de solutii
x[1] ← 0; k ← 1;
WHILE k>0 DO
x[k] ← x[k]+1;
WHILE x[k]<=n si place(k)=false DO
x[k] ← x[k]+1;END WHILE
IF x[k]<=n THEN //place(k)=true - o pozitie gasita
IF k=n THEN //solutia este completa?
print(x);
ELSE
k ← k+1; x[k] ← 0;
END IF
ELSE
k ← k-1; //x[k]>n ⇒ backtrackEND IF
END WHILE
END{n-queen}

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 100/120
100 CAPITOLUL 7. METODA BACKTRACKING
7.3.2 Submultimi de suma data
Fie n numere pozitive,S = {w1, w2,...,wn}, wi > 0, wi = w j, ∀i = j si M > 0.Sa se determine toate submultimile S ⊆ S cu
w∈S
w = M .
Folosim notatia solutiei sub forma X = {x1, x2,...,xn}, xi = 0 sau 1:
ni=1
xiwi = M.
Arborele spatiului starilor va fi de forma:
1x1=1 0
32x2=1 0 1 0
7654
Consideram w1, w2,...,wn ın ordine crescatoare (fara a fi o restrictie gen-
erala).Functia de marginire
Bk(x1, x2,...,xk) =
true dacak
i=1
xiwi +n
i=k+1
wi ≥ M sik
i=1
xiwi + wk+1 ≤ M,
wi − cresc.false, altfel
SumSubset(s,k,r)
//(x1, x2,...,xn) - vectorul solutie; presupunem x1,...,xk−1 calculati
//s ←
k−1i=1 xiwi, r ←
ni=k wi
//presupunem w1 ≤ M sini=1
wi ≥ M [deci initial (k = 1)Bk−1 =true]
xk ← 1;

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 101/120
7.3. STUDII DE CAZ 101
IF s + wk = M THEN
print(x j, j = 1..k) //nu se mai ıncearca valori pentru xk+1 > 0...ELSE
IF s + wk + wk+1 ≤ M THEN //Bk =true xxx
//nu se mai verificak
i=1
xiwi +n
i=k+1
wi ≥ M deoarece s + r > M
si xk = 1SumSubset(s + wk, k + 1, r − wk) //apel recursiv
END IF
IF s + r − wk ≥ M si s + wk+1 ≤ M THEN //Bk = true//genereaza arborele din dreapta cu (xk = 0)xk ← 0;
SumSubset(s, k + 1, r − wk);
END IF
END IF
return
END{SumSubset}Observat ie. Functia intra ın executie avand asigurate conditiile Bk−1 =true:
s + wk ≤ M si s + r ≥ M .
Initial, wi ≤ M si 0+ni=1
wi ≥ M corespunzand apelului SumSubset0, 1,ni=1
wi.
Aceste conditii sunt asigurate la apelul recursiv.Nu se verifica explicit k > n deoarece initial s = 0 < M si s + r ≥ M .
Rezulta r = 0 deci k nu poate depasi n. De asemenea, ın linia xxx, deoareces + wk < M , rezulta r = wk, deci k + 1 ≤ n.

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 102/120
102 CAPITOLUL 7. METODA BACKTRACKING

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 103/120
Capitolul 8
Metoda branch&bound
8.1 Descrierea metodei
Metoda este ca si backtracking prin execelenta secventiala.
Se aplica la probleme de forma urmatoare:
Se dau multimile S 1, S 2,...,S n.
Sa se determine x = (x1, x2,...,xn) ∈ S 1 × S 2 × · · · × S n (spatiu de solutii)
care satisface P (x1, x2,...,xn)
−maxim−minim−conditii booleene
Spatiul solutiilor se organizeaza sub forma unui arbore. Atunci cand ar-borele se genereaza prin tehnica parcurgerii ın adancime – backtrack .
Cand generarea nodurilor se face prin traversare ın latime (sau traversareaD) – branch and bound . Conform acestei tehnici, pentru nodul viu x care este
E-nodul curent, se genereaza toate nodurile (descendenti) si se depun ın listade noduri vii, dupa care se trece la urmatorul E-nod care se alege din listanodurilor vii. Daca aceasta lista e o coada, avem de-a face cu o traversare ınlatime; daca lista se organizeaza ca stiva, avem de-a face cu o traversare D .
103

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 104/120
104 CAPITOLUL 8. METODA BRANCH&BOUND
Exemplu .
DFS: 1,2,4,3,11,5,6,8,9,7,10;
BFS: 1,2,5,7,4,3,6,8,9,10,11;
D: 1,7,10,5,9,8,6,2,3,11,4.
r r r r r r r
¨ ¨ ¨ ¨ ¨ ¨ ¨
1x1=1
23
752
x2=1 2 12
31
1098634
11
T (x1, x2,...,xi) = numarul de valori posibile pentru xi+1 (restrictia ex-plicita);
Bi+1(x1, x2,...,xi) = predicatul de marginire derivat din T (restrictia im-
plicita).Aceste concepte nu se mai pot folosi ın traversarile FS, D. Branch and
bound numeste, de fapt, toate tehnicile care au ın comun faptul ca ın E-nodulcurent se genereaza toate nodurile descendentilor, dupa care se alege urmatorulE-nod, dupa o strategie oarecare.
8.2 Branch and bound cu strategie cost minim
8.2.1 Aspecte generale
Deoarece arborele spatiului de solutii este foarte mare sau chiar infinit, aceastastrategie trebuie sa contina elementele care sa limiteze cautarea.

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 105/120
8.2. BRANCH AND BOUND CU STRATEGIE COST MINIM 105
Exemplu . Problema celor 4 dame.
x1 2
x2 2
x3 2
x4 2
Arborele FIFO Branch and bound:
r r r r r r ¨ ¨ ¨ ¨ ¨ ¨
$ $ $ $ $ $ $ $ $ $ $ $ $ $ $
d d
d d
d d
d d
i i i i ¥
¥ ¥ ¥ i
i i i ¥
¥ ¥ ¥ i
i i i ¥
¥ ¥ ¥ i
i i i ¥
¥ ¥ ¥ i
i i i ¥
¥ ¥ ¥ i
i i i
¥ ¥ ¥ ¥
Se observa ca backtracking lucreaza mai eficient ca spatiu. In cazul branch-and-bound (BB) se pastreaza o coada de situatii destul de mari. Se sug-ereaza determinarea unei functii care sa dirijeze cautarea (o strategie diferitade FIFO).
Printr-un calcul suplimentar sa presupunem ca se poate calcula pentrufiecare nod x o functie cost c(x).
Exemplu : c(x) = lungimea drumului minim de la x la un nod raspuns dinsubarborele de radacina x.
Folosind functia c(x), se poate genera arboree ıntr-un mod dirijat.

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 106/120
106 CAPITOLUL 8. METODA BRANCH&BOUND
¥ ¥ ¥ ¥ i
i i i
¢ ¢
¢ f f
f d d
d d
1
2 3 4 5
9 10 11
22 23
30
Aceasta functie c (ideala) este greu de determinat. Se lucreaza cu o estimarea acestei functii, c∗, si, de obicei, c∗(x) = f (h(x)) + g∗(x), unde: h(x) = costuldrumului de la radacina la x (de exemplu, lungimea drumului); f – o functieoarecare; g∗(x) = costul estimat al atingerii unui nod raspuns pornind din x.
In plus, se asigura ca c∗(x) ≤ c(x), ∀x – un nod. Aceasta se face prin subes-timarea atingerii unui nod raspuns pornind din x. Astfel, g∗(x) va constituicomponenta optimista a costului c∗(x).
Strategia BFS se obtine pentru f (h(x)) = level(x) si g∗ = 0.
Strategia D se obtine pentru f (h(x)) = 0 si g∗ o functie care asigura g∗(y) =min
z∈lista noduri vii{c∗(z)} − 1.
Aceasta metoda de cautare (dupa c∗(x) = f (h(x)) + g∗(x)) se numestecautare LC (min cost ) si este un prim criteriu care intervine ın metoda BB.Pentru problema damelor este dificil de pus ın evidenta o estimare eficienta.

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 107/120
8.2. BRANCH AND BOUND CU STRATEGIE COST MINIM 107
8.2.2 Modelul Algoritmic pentru Branch&bound cu strate-gie cost minim
BB LC(T,c*) // LC = least cost
//cauta ın arborele T al spatiului solutiilor un nod raspuns de cost
minim
//e = E-nodul curent
//add(x) - depunde x ın lista de noduri vii
//min() - returneaza nodul x cu c*(x) minim din lista de noduri vii
IF exista solutii THENe←T; //primul E-nod
WHILE nu a fost gasita o solutie DO
IF e = nod r aspuns THEN //c*(e)=c(e)
a fost gasita o solutie;
afiseaza drumul de la T la e;
return
ELSE
FOR fiecare x = descendentt al lui e DO
add(x); //insereaza x ın lista de noduri vii
parent(x)←e; //ınlantuire pentru refacerea drumuluiEND FOR
END IF //x = nod raspuns
e← min();
END WHILE
END IF //exista solutii
END{BB LC(T,c*)}Teorema 1. e este un nod r˘ aspuns de cost minim .
Demonstrat ie. Din definitia costului estimat optimist c∗ rezulta urmatoarele:
• pentru un nod raspuns r : c∗(r) = c(r);
• un nod x satisface c∗(x) ≤ c∗(s), ∀s fiu al lui x; rezulta prin tranzitivitateca c∗(x) ≤ c∗(d), ∀d descendent al lui x.

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 108/120
108 CAPITOLUL 8. METODA BRANCH&BOUND
Nodul e este primul nod raspuns extras din lista de noduri vii, deci celelaltenoduri raspuns (daca exista) sunt ın lista de noduri vii sau sunt descendentiai unor noduri din lista de noduri vii.
Rezulta:
• c(e) = c∗(e) ≤ c∗(x), ∀x nod din lista de noduri vii (e = min())
• c∗(x) ≤ c∗(r) = c(r), ∀r nod raspuns descendent al lui x = nod aflat ın
lista de noduri vii.
In consecinta, c(e) ≤ c(r), ∀r nod raspuns.
8.3 Branch&Bound cu strategie cost minim simarginire
8.3.1 Aspecte generale
Unele probleme (ex: problemele de optimizare) permit si definirea unei functii(criteriu) de marginire: c∗(x) ≤ c(x) ≤ u(x); c(x) este necunoscuta.
Marginea superioara u are proprietatea ca u(s) ≤ u(x), ∀s fiu al lui x.Aceasta rezulta din structura lui u(x) = f (h(x)) + k∗(x), unde f si h ausemnificatiile de la c∗, iar k∗(x) exprima o estimare supraevaluata (pesimista)a costului de la x la un nod raspuns (o solutie). Din u(s) ≤ u(x), ∀s fiu al luix, rezulta prin tranzitivitate ca u(d) ≤ u(x), ∀d descendent al lui x.
Se pune problema determinarii unui nod raspuns r (r ∈ R = multimea
nodurilor raspuns) pentru care u(r) = min{u(x)|x ∈ R}.Observat ie. Pentru un nod raspuns, c∗(x) = c(x) = u(x). Deci, problema
determinarii lui r este echivalenta cu problema determinarii unui nod raspunsde cost minim.

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 109/120

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 110/120
110 CAPITOLUL 8. METODA BRANCH&BOUND
conduce ınsa la generarea unor noduri care pot avea u(x) ≥ u deoarecec∗(x) < u nu asigura u(x) < u.
2. Atunci cand un nod raspuns este generat, acesta va avea costul c∗(x) =c(x) = u(x) inferior lui u, deci costul sau va defini noua valoare a lui u.
3. Nodurile x care schimba valoarea lui u, si nu sunt noduri raspuns, nupot fi ultimele care realizeaza aceasta modificare. Demonstratie: c∗(x) ≤u(x) < u(x)+ε = u, deci x este un posibil viitor E-nod (urmeaza, deci, si
alte iteratii); c
∗
(y) ≤ u(y) ≤ u(x) < u(x) + ε = u, ∀y descendent al lui x,deci toti descendentii lui u vor fi generati deoarece u ramane neschimbatpana la terminarea executiei algoritmului; deoarece u(x) = ∞, rezulta caprintre descendentii lui x exista z = nod raspuns; rezulta ca va fi generatun nod raspuns fara ca acesta sa schimbe valoarea lui u, deoarece x esteultimul care a facut aceasta (qed).
Din 1-3. rezulta ca ultimul nod raspuns retinut (r) va fi si ultimul caremicsoreaza u, iar alte noduri care pot micsora u nu mai exista. Rezulta ca rsatisface u(r) = u = min{u(x)|x ∈ R}.
8.4 Studii de caz
8.4.1 Problema 15-puzzle
1 3 4 5
6 2E c
' T7
8 9 10 1211 13 14 15
→
1 2 3 45 6 7 89 10 11 12
13 14 15
Spatiul solutiilor contine 16! combinatii (∞ daca nu se verifica ciclitatile).
In plus, intereseaza modul de obtinere a solutiilor, adica drumul de la radacinala solutia finala. Pentru o pozitie data, se poate decide daca pozitia are solutie(poate conduce la pozitia finala) ori nu.
Se defineste o ordine a locatiilor ın patrat, anume:

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 111/120
8.4. STUDII DE CAZ 111
1 2 3 45 6 7 89 10 11 12
13 14 15 16
In fapt, o configuratie este o aplicatie injectiva:
poz :{1, 2, 3, ..., 15,16↑
piatra libera
} → {1, 2, 3, ..., 16}
poz(x) = i – piatra notata cu x se afla pe pozitia i; ın exemplul anterior,poz(3) = 2, poz(16) = 7 etc.
Pentru fiecare configuratie si pentru orice piatra de valoare i se defineste
least(i) = |{ j|1 ≤ j ≤ 16, j < i, poz( j) > poz(i)}|.
In exemplul anterior: least(6) = 1, least(7) = 0, least(16) = 9.Teorema. Pentru o configurat ie dat˘ a exist˘ a un sir de transform˘ ari pan˘ a la
configurat ia scop ddac˘ a
S =1
i=1
6(least(i)) + p = nr.par,
unde p se calculeaz˘ a astfel: fie i, j ∈ {1, 2, 3, 4} – linia si coloana unde esteplasat spat iul liber (piatra nr.16),
p =
0, dac˘ a i + j – par (pozit ia alb˘ a)1, dac˘ a i + j – impar (pozit ia hasurat a)

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 112/120
112 CAPITOLUL 8. METODA BRANCH&BOUND
Demonstrat ie. Pentru configuratia scop I : S (I ) = 0 + 0 – par. Fie oconfiguratie T pentru care S (T ) = nr.par si T obtinut din T prin una dinmutarile permise.
Cazul 1:
E E
T T
pT = ( pT +1)mod2, leastT (16) = leastT (16)–1 ⇒ leastT (i) = leastT (i), ∀i =16. Rezulta S (T ) – nr.par.
Cazul 2 :
E
T T
'
Identic.
Cazul 3 :
y z
x
y z
xk
k
T T
c
d d
d d
E
pT = ( pT + 1)mod2 (*)
leastT (16) = leastT (16)–4 (**) (3 casute de la (i, j) la (i + 1, j)).
Fie x,y,z placutele pentru pozitia initiala a lui k si cea finala. Avem
situatiile:a) k < x, k schimba locul cu 16 – se scade 1 din least(x);
b) k > x se aduna 1 la least(k).
Oricum, ın suma totala se scade sau se aduna 1.

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 113/120
8.4. STUDII DE CAZ 113
Observat ia de mai sus este valabila pentru x,y,z, deci la S se aduna sause scade un numar impar (1 sau 3). Combinand cu (*) si (**), se observa caS (T ) ramane par.
Cazul 4:
T
Simetric.
Spunem ca o configuratie T este valida ddaca exista un sir de transformaride la T la configuratia scop I . Deoarece prin transformarile →↑↓← nu seschimba paritatea valorii S si S (I ) – para ⇒ T valida ddaca S (T ) para.
Pentru acest exemplu, vom considera:
c∗(x) = f (x) + g∗(x)
f (x) = level(x),
iar g∗(x) = numarul de placute care nu sunt la locul lor. In plus, se asigura cac∗(x) ≤ c(x), ∀x – un nod.
8.4.2 Problema 0/1 a rucsacului
Definirea problemei . Datele problemei sunt:obiectele: i1, i2,...,in;greutatile: w1, w2,...,wn;profiturile: p1, p2,...,pn;capacitatea: M .Se cere o alegere X = (x1, x2,...,xn), xi ∈ {0, 1} astfel ıncat
i
xiwi ≤ M (∗)

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 114/120
114 CAPITOLUL 8. METODA BRANCH&BOUND
si i
xi pi − maxim. (∗∗)
O solutie admisibila satisface (*).
O solutie optima este admisibila si satisface (**).
Observat ie. Daca i wi ≤ M , solutia optimala este xi = 1, i = 1,...,n.
Deci problema are sens pentru i
wi > M .
Spatiul solutiilor se poate organiza sub forma unui arbore binar:
e e e ¡
¡ ¡
e e e ¡
¡ ¡
1x1=0 1
32x2=0 1 0 1
xi =
0, obiectul i se ignora1, obiectul i se introduce ın rucsac
Nodurile raspuns sunt cele care reprezinta solutii admisibile:ni=1
xiwi ≤ M .
Pentru orice nod raspuns, c(x) = −ni=1
xi pi.
Pentru orice nod terminal care nu este nod raspuns, c(x) = +∞.
Pentru orice alt nod y se defineste c(y) = min{c(lchild(y)), c(rchild(y))}.
Construim doua functii: c∗(x) si u(x) astfel ıncat c∗(x) ≤ u(x).
Fie un nod de pe nivel k; valorile x1, x2,...,xk−1 sunt deja calculate.

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 115/120

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 116/120
116 CAPITOLUL 8. METODA BRANCH&BOUND
Algoritmul BB LC pentru problema 0/1 a rucsacului
Crearea si ad˘ augarea unui nod ın lista de noduri vii
newnode(nod,par,lev,t,cap,prof,cost)
//creeaza un nod nou i si ıl adauga la lista de noduri vii
getnode(nod);
patent(nod)←par; level(nod)←lev; tag(nod)←t;
rw(nod)←cap; cp(nod)←prof; c*(nod)←cost;
add(nod)
END{newnode}Procedura BB LC UB pentru problema 0/1 a rucsacului
KnapSack LC UB(p,w,M,n,s)
//obiectele sunt ordonate astfel ıncat p(i)/w(i)>=p(i+1)/w(i+1)
bound(p,w,M,0,n,l,c*x,ux); //calculeaza valorile initiale
// pentru c*x si ux
IF c*x=ux THEN return(‘‘toate obiectele pot fi ıncarcate’’)
ELSE
u←ux+ε; getnode(e); parent(e)←0; level←1; rw(e)←M;
cp(e)←0; c*(e)=c*x; //creeaza primul E-nod=eWHILE (c*x<u) wedge (mai exista noduri vii) DO
i←level(e); cap←rw(e); prof←cp(e);
//vezi daca fiul din stanga poate deveni viu
IF cap>=w(i) THEN //c*x=c*(e), deci c*(x)<u
newnode(x,e,i+1,1,cap-w(i),prof+p(i),c*(e));
IF i=n THEN
u←-[prof+p(i)];
r←x; //nod raspuns c*(x)=c(x)=-[prof+p(i)]
ELSE u← min(u,ux+ε);END IF
END IF //vezi daca fiul din dreapta poate deveni viu
bound(p,w,cap,prof,n,i+1,c*x,ux);

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 117/120
8.4. STUDII DE CAZ 117
IF c*x<u THEN //fiul din dreapta devine viu
newnode(x,e,i+1,0,cap,prof,c*x);
IF i=n THEN
u←-prof; r←x; //nod raspuns: c*(x)=c*x=x(x)=-prof
ELSE u← min(u,ux+ε);
END IF
END IF
e← min(); //e=nul ⇔ nu mai exista noduri vii
END WHILE
return(r)END IF
END{KnapSack LC UB}

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 118/120
118 CAPITOLUL 8. METODA BRANCH&BOUND

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 119/120
Bibilografie
1. E. Horowitz, S. Sahni - Fundamentals of Computer Algoritms, ComputerScience Press, 1985
2. T. Cormen, C. Leiserson, R. Rivest- Introduction to Algorithms, Massa-chusetts Institute of Technology, 1990
3. T. Cormen, C. Leiserson, R. Rivest - Introducere n algoritmi, ComputerLibris Agora, 2000
4. D.E. Knuth - Tratat de programarea calculatoarelor, volumul 1: Algo-ritmi fundamentali. , Editura tehnica,Bucuresti, 1974
5. D.E. Knuth - Tratat de programarea calculatoarelor, volumul 3: Sortaresi cautare, Editura tehnica,Bucuresti, 1976
6. S. Sahni - Data Structures and Algorithms in C++, WCB McGraw-Hill,1998
7. K.Mehlhorn - Data Structures and Efficient Algorithms, Springer Verlag,1984
8. Mark Allen Weiss - Data Structures and Algorithm Analysis in C, The
Benjamin/Cummings Publishing Company, Inc., 1992
9. D.Lucanu - Bazele proiectarii programelor si algoritmilor,Editura Uni-versitatii ”Al. I. Cuza”, Iasi, 1996
119

8/14/2019 Pa 209 Pa1 Craus
http://slidepdf.com/reader/full/pa-209-pa1-craus 120/120
120 CAPITOLUL 8. METODA BRANCH&BOUND
10. C.Croitou - Tehnici de baza n optimizarea combinatorie, Editura Uni-versitatii ”Al. I. Cuza”, Iasi, 1992
Top Related