







Languages
Pages
Legal


Chapitre 10: Tests et intervalles deconfiance pour proportions
1. Test statistique pour une proportion
2. Intervalle de confiance pour une proportion
3. Test statistique pour deux proportions
1

1. Test statistique pour une proportion
Ex: Taux d’individus ayant une caracteristique A dans une population.
Soit p = P (A) ce taux.
De facon generale dans ce chapitre, on utilisera la notation q = 1− p
(de meme, q = 1− p, etc.)
2

– Hypotheses
H0: p = p0 H1: p 6= p0
– Echantillon
Tirage aleatoire de n individus
– Statistique de test (“distance” entre H0 et les observations)
K = Nombre d’individus avec A dans l’echantillon
3
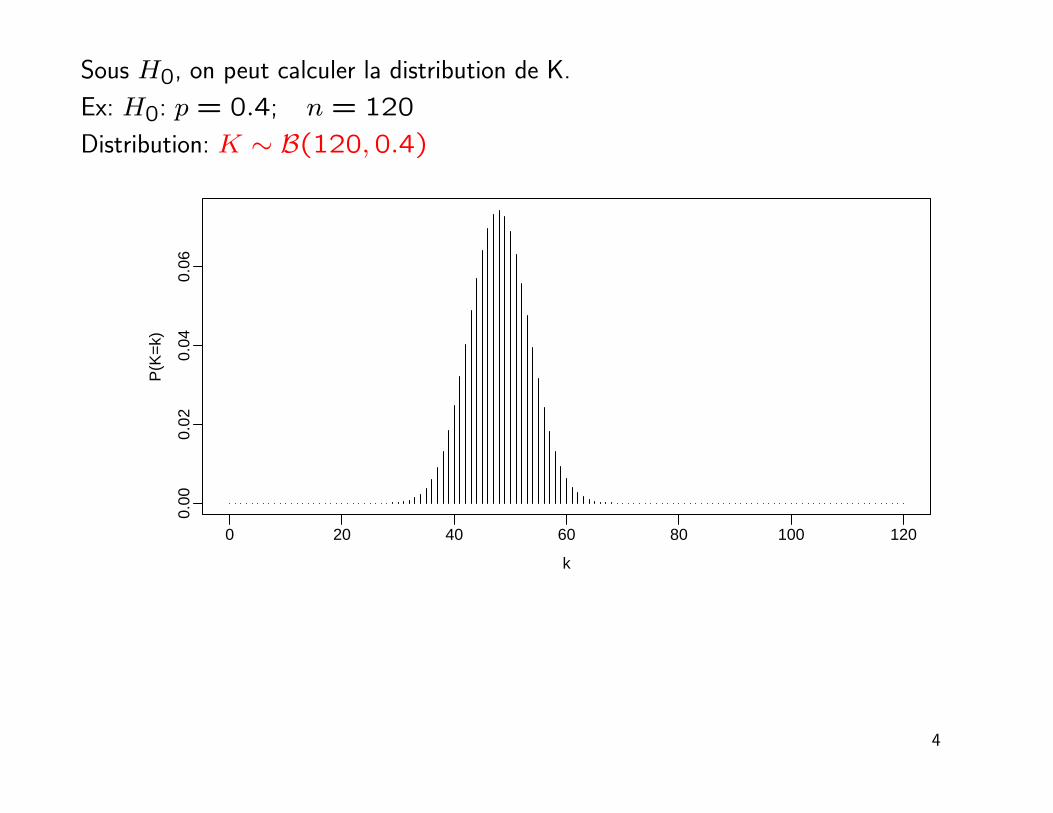
Sous H0, on peut calculer la distribution de K.
Ex: H0: p = 0.4; n = 120
Distribution: K ∼ B(120,0.4)
0 20 40 60 80 100 120
0.00
0.02
0.04
0.06
k
P(K
=k)
On peut par exemple adopter la regle de decision suivante:
Regle de decision: rejeter H0 si k ≤ 37 ou si k ≥ 60
Niveau: p1+ p2 = 0.041
4
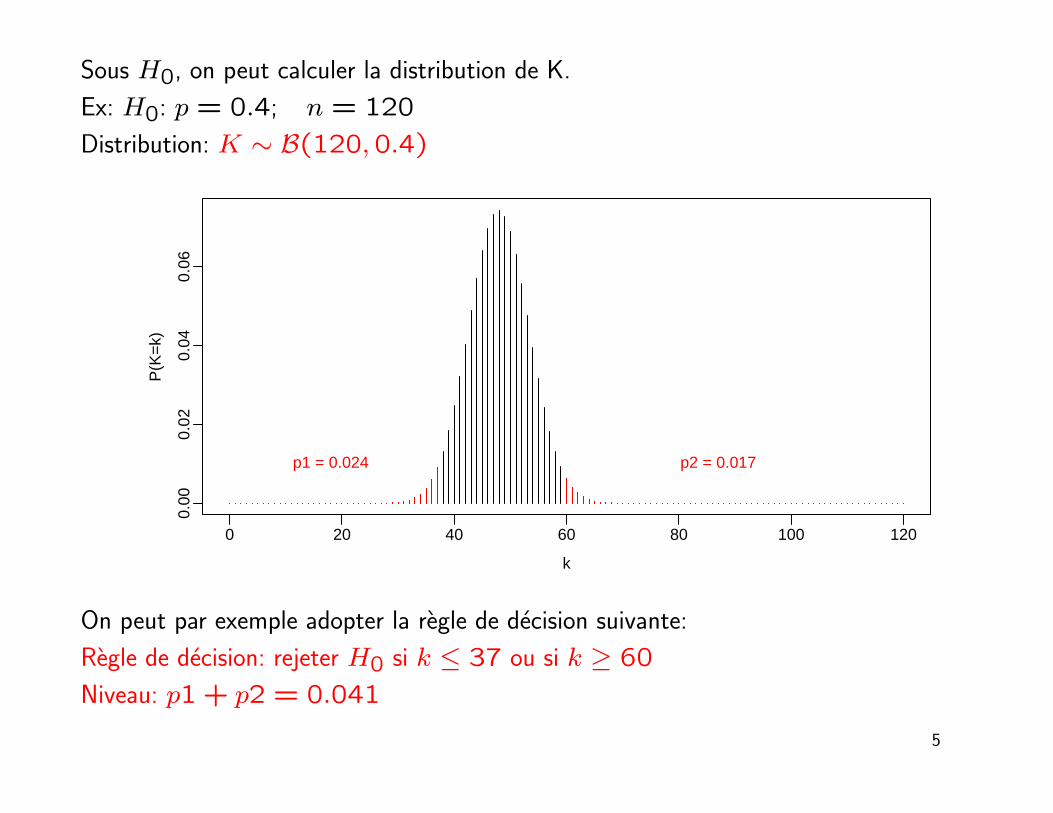
Sous H0, on peut calculer la distribution de K.
Ex: H0: p = 0.4; n = 120
Distribution: K ∼ B(120,0.4)
0 20 40 60 80 100 120
0.00
0.02
0.04
0.06
k
P(K
=k)
p1 = 0.024 p2 = 0.017
On peut par exemple adopter la regle de decision suivante:
Regle de decision: rejeter H0 si k ≤ 37 ou si k ≥ 60
Niveau: p1+ p2 = 0.041
5

Avantage de cette approche: le niveau est connu exactement, pas
d’approximation.
Desavantage: Il faut trouver les bornes“manuellement”pour chaque valeur
de n et de p0.
6
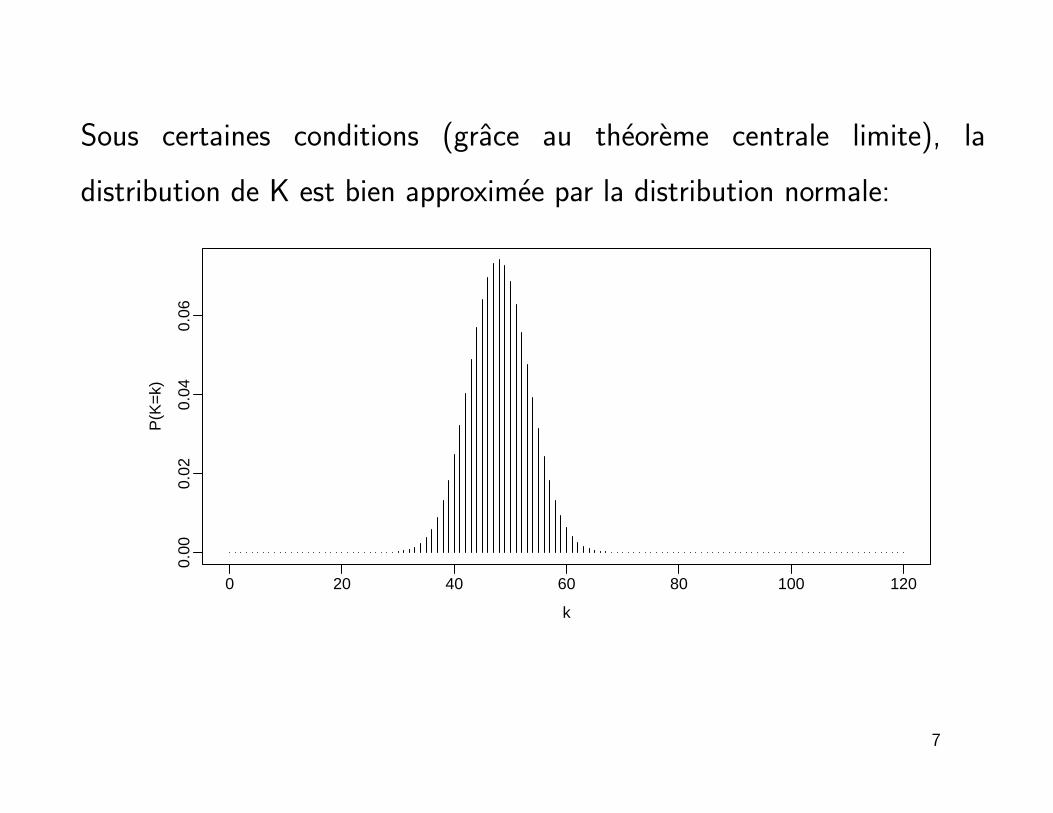
Sous certaines conditions (grace au theoreme centrale limite), la
distribution de K est bien approximee par la distribution normale:
0 20 40 60 80 100 120
0.00
0.02
0.04
0.06
k
P(K
=k)
7
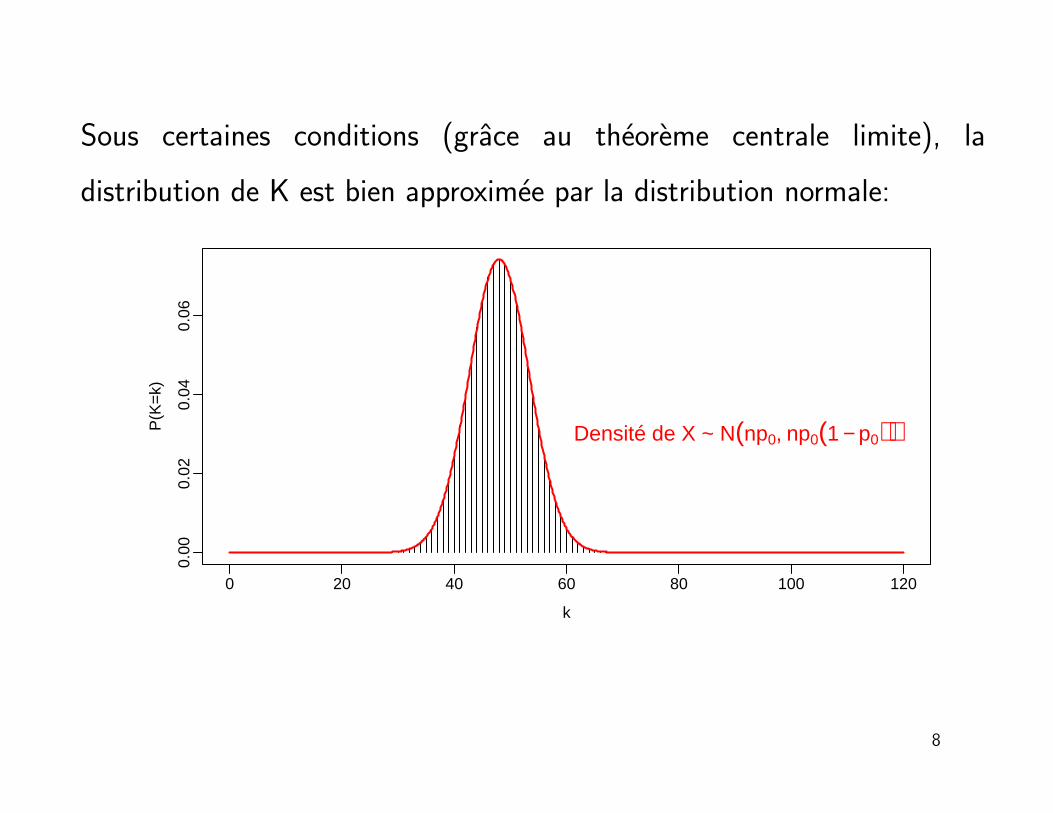
Sous certaines conditions (grace au theoreme centrale limite), la
distribution de K est bien approximee par la distribution normale:
0 20 40 60 80 100 120
0.00
0.02
0.04
0.06
k
P(K
=k)
Densité de X ~ N(np0, np0(1 − p0))
8

A la place de K, on prend comme statistique de test:
Z =K/n− p0√p0(1− p0)/n
.
Sous H0, et sous les conditions d’application (v. p. suivante), Z a approximativement
une distribution N (0,1).
→ Regle de decision:
Rejeter H0 si |z| > z1−α/2
ou z est la valeur observee de Z et z1−α/2 est le quantile 1− α/2 de la distribution
N (0,1).
Remarque: pour faire le test unilateral de H0: p = p0 contre H1: p > p0, on utilisera
la regle de decision
Rejeter H0 si z > z1−α .
9

Conditions d’application: il faut que n soit suffisamment grand pour que
l’approximation normale soit bonne. Or, plus p est extreme (proche de 0
ou de 1), plus n doit etre grand. Concretement, si n et p sont tels que
np > 5 et n(1− p) > 5,
alors
K/n− p√p(1− p)/n
a approximativement une distribution N (0,1).
Nous avons deja rencontre ces conditions dans le chapitre 8.
10

2. Intervalle de confiance pour une proportion
Rappel: un intervalle de confiance contient toutes les valeurs du parametre
d’interet qui ne seraient pas rejetees par un test.
Ici, ce sont les valeurs de p telles que
|z| =|k/n− p|√p(1− p)/n
≤ z1−α/2, (1)
ou k est la valeur observee de K dans l’echantillon.
11

La relation (1) est satisfaite pour des valeurs de p situees entre
pi =1
1+ c
(p+ c/2−
√c2/4+ cp(1− p)
)
et
ps =1
1+ c
(p+ c/2+
√c2/4+ cp(1− p)
),
ou
c = z21−α/2/n et p = k/n.
Cet intervalle s’appelle l’intervalle de Wilson, que l’on notera ICWI . On
a donc
ICWI = [pi, ps].
12

Au chapitre precedent, nous avons vu une methode generale pour construire des
intervalles de confiance pour un parametre θ, appelee la methode de Wald. Elle se base
sur la valeur observee θ de l’estimateur du parametre et definit l’intervalle avec niveau
de couverture 1− α comme
[θ − z1−α2 sd(θ) , θ+ z1−α2sd(θ)],
ou sd(θ) est une estimation de l’ecart-type de θ.
Dans le cas ou le parametre est une proportion p, on a:• Estimateur de p: p = K
n , la proportion observee dans l’echantillon.Que vaut sd(p)? → On sait que K, le nombre de personnes avec la caracteristique
d’interet (“succes”) dans l’echantillon, suit une distribution binomiale B(n, p). Son ecart
type est donc sd(K) =√npq. On en deduit (propriete de l’ecart-type) que sd(p) =√
pq/n, que l’on estime par
sd(p) =√pq/n.
On obtient donc que l’intervale de confiance de Wald pour une proportion, note ICWA
est donne par
ICWA =[p− z1−α2
√pq/n , p+ z1−α2
√pq/n
].
13

L’intervalle de Wald plus simple mais moins precis que l’intervalle de
Wilson, qui fait moins d’approximations. Concretemement, on ne l’utilisera
que lorsque
• 0.3 ≤ p ≤ 0.7 et
• n ≥ 50.
Pour l’intervalle de Wald, il peut arriver que la formule de la page
precedente donne une valeur inferieure a 0 pour la borne inferieure ou
une valeur superieure a 1 pour la borne superieure. Il faut alors corriger
l’intervalle en mettant respectivement 0 ou 1 a la place de la borne qui
sort de l’intervalle [0,1]. L’intervalle de Wilson n’a pas ce probleme, ses
bornes etant automatiquement comprises entre 0 et 1.
14

3. Test statistique pour deux proportions
Ex: Taux p1 et p2 d’individus ayant une caracteristique A dans deux
populations differentes.
On se demande si les proportions d’individus ayant la caracteristique
d’interet sont les memes dans les deux populations ou si elles sont
differentes.
15

– Hypotheses
H0: p1 = p2 H1: p1 6= p2
– Echantillon
Tirage aleatoire de n1 individus dans la premiere
population et n2 dans la deuxieme
– Statistique de test (“distance” entre H0 et les observations)
Sous H0 et si n1 et n2 sont suffisamment grands, la variable
Z =K1/n1 −K2/n2√pq/n1 + pq/n2
a approximativement une distribution N (0,1).
Ici K1 est le nb d’individus avec A dans le premier echantillon et
analoguement pour K2, et p = p1 = p2.
16

Pour effectuer le test, on calcule la valeur observee de Z sur nos echantillons:
z =p1 − p2√
pq(1/n1 +1/n2)
ou
p1 = k1/n1, p2 = k2/n2
et
p = (k1 + k2)/(n1 + n2)
Regle de decision:
Rejeter H0 si |z| > z1−α/2 .
Remarque: pour faire le test unilateral de H0: p1 = p2 contre H1: p1 > p2, on
utilisera la regle de decision
Rejeter H0 si z > z1−α .
17

Les donnees peuvent etre presentees de la facon suivante:
Caractere A
Echantillon Present Absent Total1 n11 n12 n1.2 n21 n22 n2.
Total n.1 n.2 n
On peut demontrer que
z2 =n(n11n22 − n12n21)2
n1.n2.n.1n.2
Regle de decision equivalente (pour un test bilateral):
Rejeter H0 si z2 > χ21,1−α, ou χ21,1−α est le quantile 1− α de la distribution χ2 a
un degre de liberte, notee χ21.
(En effet, on rappelle que, par definition de la distribution χ2, si Z ∼ N (0,1), alors Z2 ∼ χ21.)
Remarque:
L’utilisation de z2 a la place de z n’est pas possible pour un test unilateral, car z2 ne
distingue pas entre les cas p1 > p2 et p1 < p2.
18
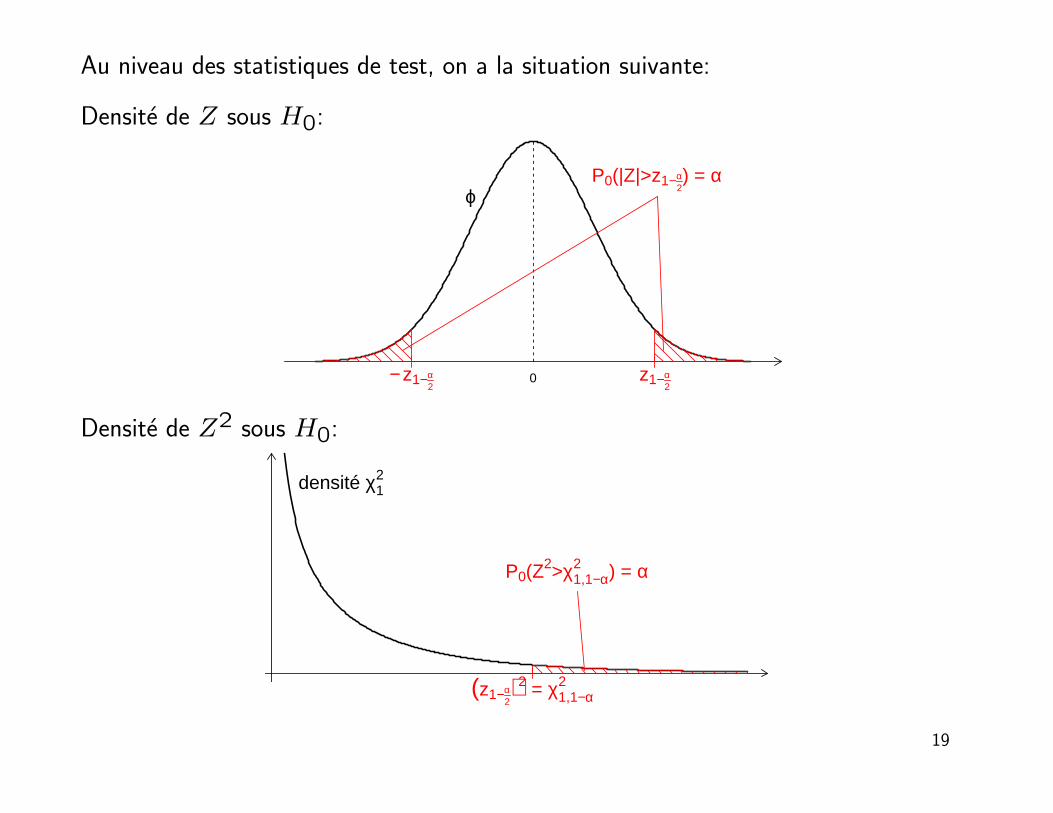
Au niveau des statistiques de test, on a la situation suivante:
Densite de Z sous H0:
0
ϕ
− z1−α2
z1−α2
P0(|Z|>z1−α2) = α
Densite de Z2 sous H0:
(z1−α2)2 = χ1,1−α
2
P0(Z2>χ1,1−α2 ) = α
densité χ12
19

Exemple: On veut tester si la proportion de nouveaux nes dont le poids a
la naissance est inferieur a 2500g est differente dans les deux populations
suivantes:
– Age de la mere ≤ 20 ans
– Age de la mere > 20 ans
On preleve deux echantillons de taille 100 et on obtient la situation
suivante:
Poids a la naissanceAge Proportion de faibles
maternel ≤ 2500g > 2500g Total poids a la naissance
≤ 20 20 80 100 0.20 (= p1)
> 20 10 90 100 0.10 (= p2)
Total 30 170 200 0.15 (= p)
20
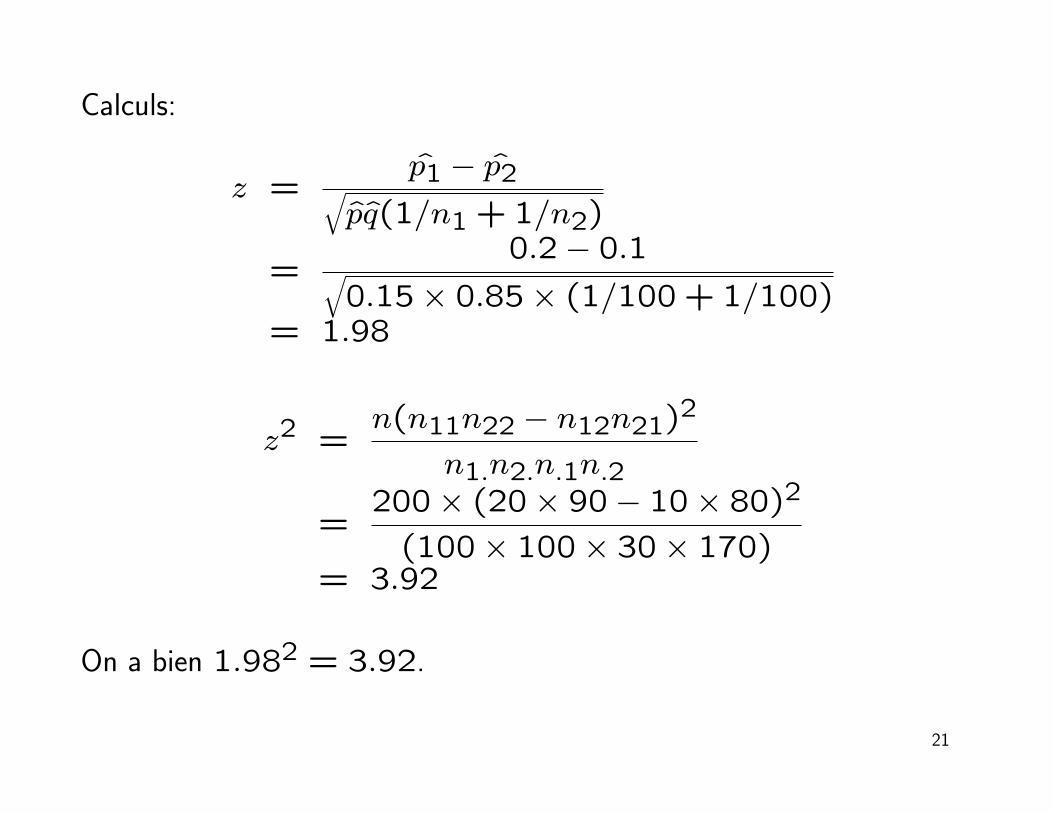
Calculs:
z =p1 − p2√
pq(1/n1 +1/n2)
=0.2− 0.1√
0.15× 0.85× (1/100+ 1/100)= 1.98
z2 =n(n11n22 − n12n21)2
n1.n2.n.1n.2
=200× (20× 90− 10× 80)2
(100× 100× 30× 170)= 3.92
On a bien 1.982 = 3.92.
21

Decision:
z > 1.96 = z0.975 et donc on rejette H0.
De facon equivalente:
z2 > 3.84 = χ21,0.95 et donc on rejette H0.
On vient de tester l’hypothese d’independance entre les variables“poids a
la naissance inferieur a 2500g” et “age de la mere inferieur a 20 ans”. En
effet, demander si la proprotion de bebes dont le poids a la naissance est
inferieur a 2500g differe entre les populations des meres de moins et de
plus de 20 ans revient a demander s’il y a une dependance entre ces deux
variables. Si les proportions different cela implique que le fait de connaıtre
l’age de la mere donne une information sur le poids du bebe, ce qui est le
propre d’une dependance entre deux variables.22

De facon generale, on pourra donc tester l’independance entre deux variablesdichotomiques (i.e. qui n’ont que deux modalites) de la facon ci-dessus. Souvent,ces variables indiquent la presence ou l’absence d’un caractere (ex.: age ≤ 20 ans),et on parle alors de test sur l’independance de deux caracteres. Donc, pour testerl’independance entre deux caracteres A et B, on pose
H0 : A et B independants H1 : A et B pas independants
et on construit le tableau suivant:
B present B absent TotalA present n11 n12 n1.A absent n21 n22 n2.
Total n.1 n.2 n
On calcule ensuite la valeur observee de la statistique de test Z2:
z2 =n(n11n22 − n12n21)2
n1.n2.n.1n.2.
On rejette alors H0 si z2 > χ21,1−α, ou χ21,1−α est le quantile 1−α de la distributionχ2 a un degre de liberte.
23

Pour information:
Souvent, lorsqu’on s’interesse a la dependance entre deux caracteres, il y a un caractere,
appele facteur antededant ou facteur de risque qui cause potentiellement l’autre (par
exemple une maladie). Par exemple, le facteur antecedent fumer cause potentiellement
le caractere cancer du poumon. Il y a alors trois types d’etudes qui se distinguent par
leur mode d’echantillonnage:• Etude prospective: On preleve des echantillons de tailles fixees dans les populations
avec et sans le facteur de risque, et on observe ensuite quels individus developpent la
maladie.
• Etude retrospective: On preleve des echantillons de tailles fixees dans les
populations avec et sans la maladie et on regarde quels individus ont le facteur de
risque.
• Etude transversale: On preleve un seul echantillon dans la population globale et
on determine quels individus ont (ou developpent) la maladie et quels individus ont le
facteur de risque.Suivant la situation, on choisira le type d’etude le plus approprie (ou le plus realisable).
Par exemple, dans le cas d’une maladie rare, une etude retrospective est generalement
plus puissante, car avec les deux autres types on obtiendrait tres peu d’individus avec la
maladie.
Dans les trois cas, on pourra utiliser la methode ci-dessus pour tester l’independance.
24
Top Related