






Languages
Pages
Legal


Ad Networks analytics using Hadoop and Splout SQL
Iván de Prado Alonso – CEO of Datasalt www.datasalt.es @ivanprado @datasalt

Big Data consulting & training

Agenda
1. Analy,cs for Ad Networks 2. Our solu,on
1. Hadoop + Splout SQL 2. Splout SQL in detail 3. Pre-‐aggregaFons v.s. Sampling
3. Conclusions

Analy,cs for Ad Networks

Ad Networks
" Principal agents › AdverFser › Publisher
• Web pages • Mobile apps
" Ad Network › Network of agents that mediate between
adverFsers and publishers › DSPs, SSPs, DMPs, ADTs, ITDs, etc

For the sake of simplicity...
" Let’s consider a monolithic Ad Network › Single agent between adverFsers and publishers
" But the exposed solu,on is also useful for DSPs, SSPs, DMPs, etc.

Need for analy,cs
" For adver,sers › Monitoring campaigns › Improve ROI
" For publishers › Improve ad placement
" But there can be › Tens of thousands of adverFsers › Hundred of thousands of publishers

Analy,cs
" Coun,ng impressions, clicks and CPC › For a given range of dates › Filtered by
• Campaign • LocaFon • Language • Browser/device • Ad type • ... or any combinaFon of the above!

Two-‐fold usage
" Opera,onal › For invoicing, accounFng, etc. › Limited set of parameter variaFons
• Fixed date ranges and common aggregaFons
› Exact results expected
" Exploratory › Unlimited variaFons of parameters
• Ad-‐hoc filtering › Approximated results are enough

Challenges
" Billions of events and hundreds of gigabytes per day › Need for a distributed system
" Query flexibility › Need to cope with operaFonal and exploratory
queries
" Web latencies › Queries must return in milliseconds

Exploding
" Data needed to serve analy,cs panels is Big Data › Thousands of adverFser panels › Even more for publisher panels
" But individually each agent panel can be served with one machine › At least for the 98% of adverFsers/publishers › Horizontal parFFoning is a good strategy

Our solu,on
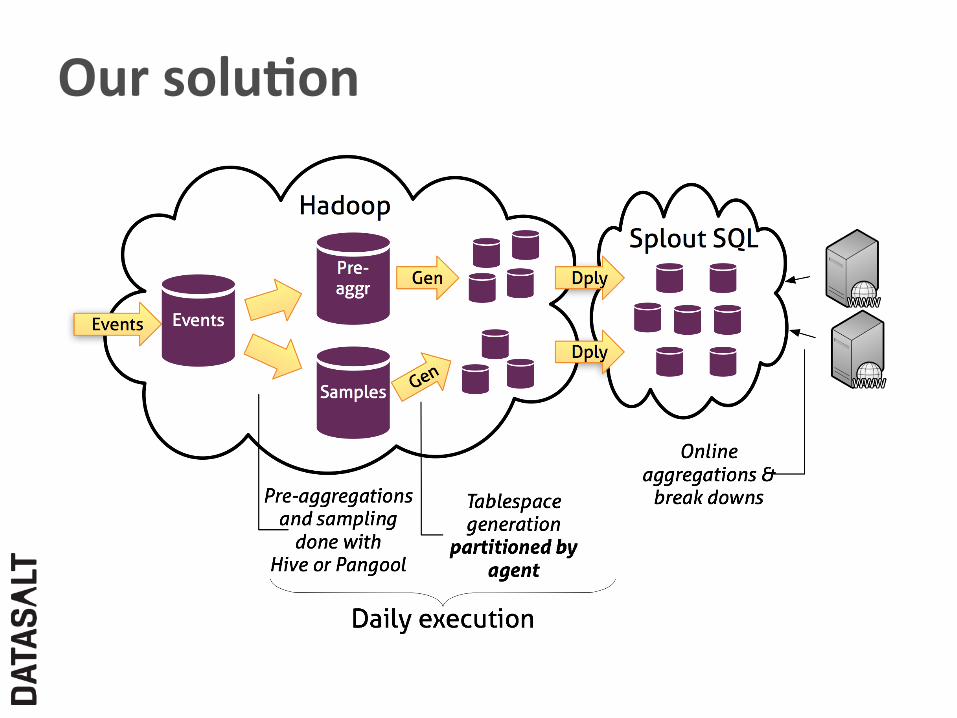
Our solu,on

Hadoop
" Scalable › Storage of raw data › CompuFng capabiliFes
" Good for › CreaFng pre-‐computed aggregaFons (views) › GeneraFng samples of data
" Bad for › Serving data › On-‐line aggregaFons

" Scalable › Serving of full SQL queries (unlike NoSQLs)
" Good for › Ad-‐hoc aggregaFons over pre-‐computed views › Serving low-‐latency web pages with concurrency

A well-‐balanced solu,on
" Hadoop › Provides a scalable repository for impressions › Performs off-‐line pre-‐aggregaFons and sampling
" Splout SQL › Serves queries › Performs on-‐line aggregaFons in sub-‐second
latencies • Each parFFon contains only data for a few agents, which ensures performance

Splout SQL (in detail)
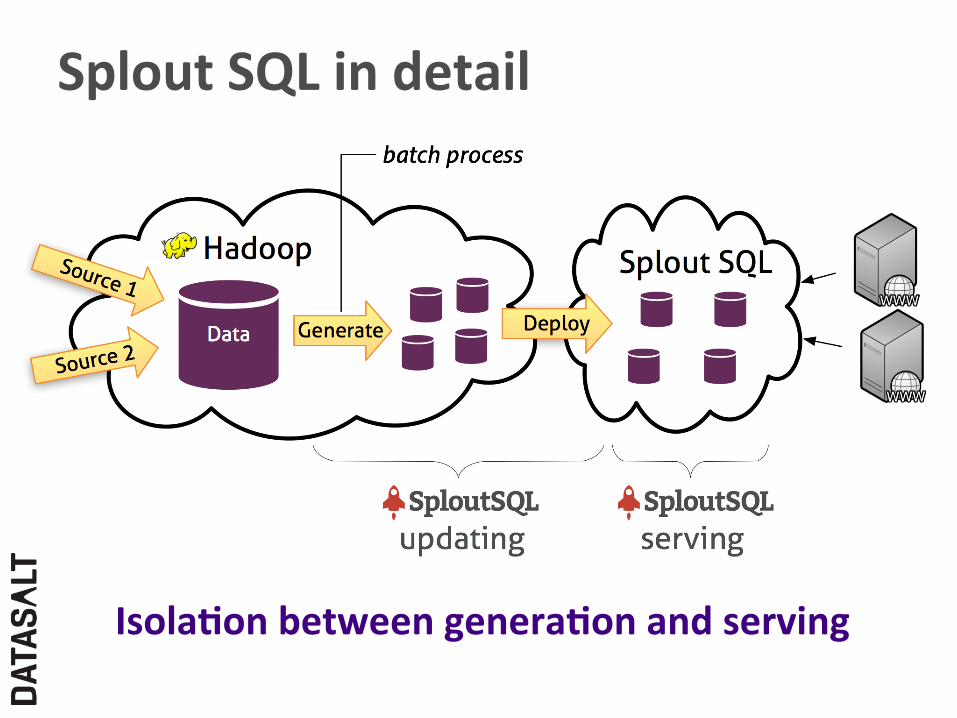
Splout SQL in detail
Isola,on between genera,on and serving
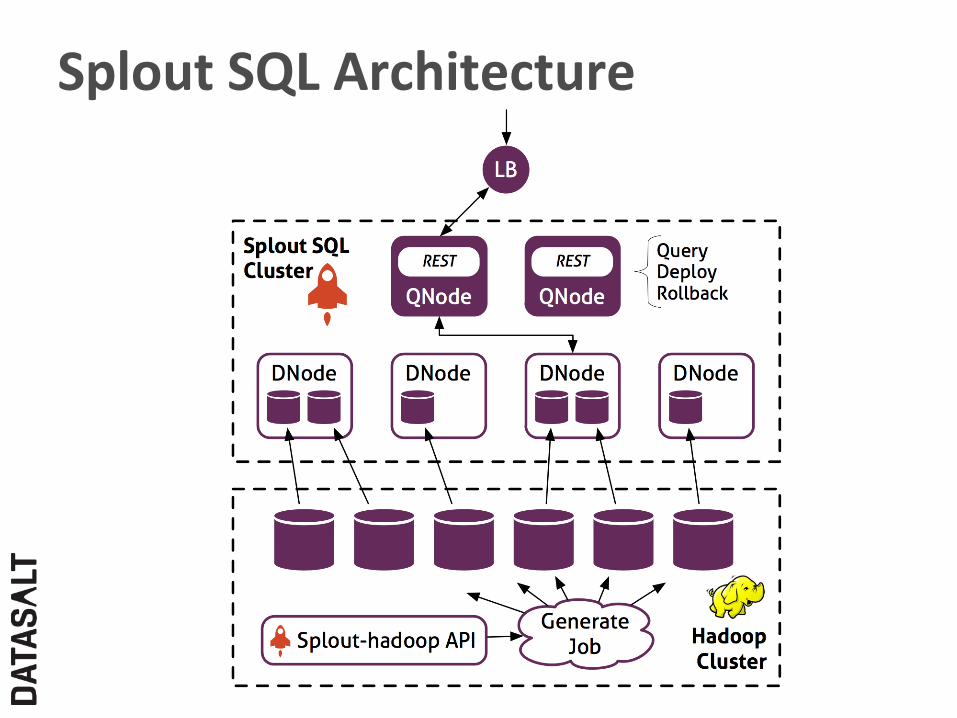
Splout SQL Architecture
IMPRESSIONS
PID AID Amount
S100 U20 102
S101 U20 60
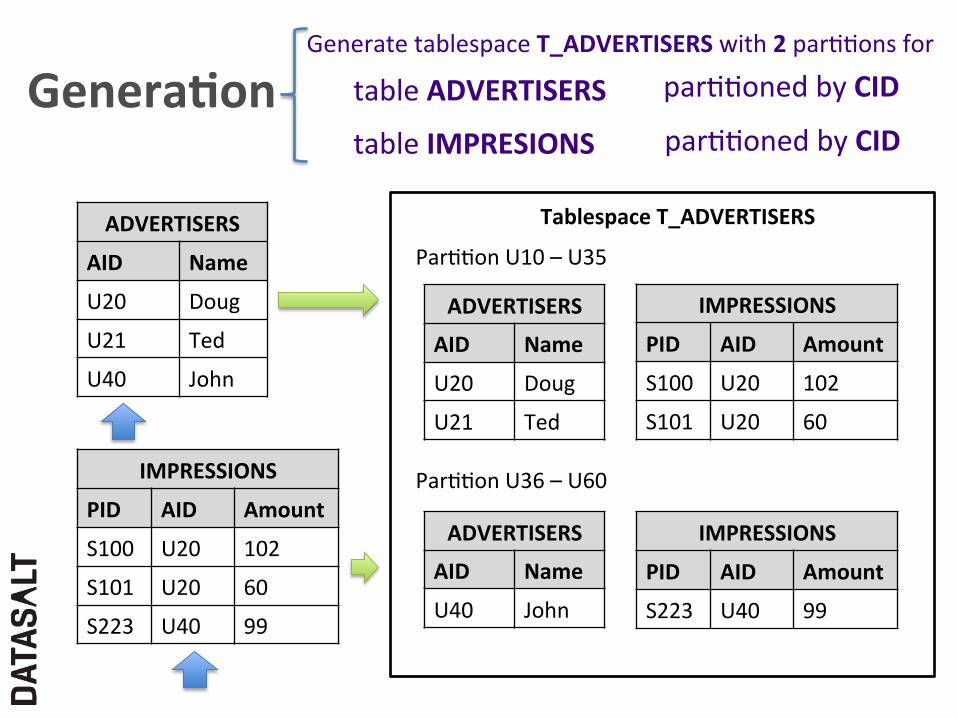
Tablespace T_ADVERTISERS ADVERTISERS
AID Name
U20 Doug
U21 Ted
U40 John
IMPRESSIONS
PID AID Amount
S100 U20 102
S101 U20 60
S223 U40 99
table ADVERTISERS
table IMPRESIONS
Generate tablespace T_ADVERTISERS with 2 parFFons for
parFFoned by CID
parFFoned by CID
ParFFon U10 – U35
ParFFon U36 – U60
ADVERTISERS
AID Name
U40 John
IMPRESSIONS
PID AID Amount
S223 U40 99
Genera,on
ADVERTISERS
AID Name
U20 Doug
U21 Ted

API -‐ Genera,on Command line Loading CSV files
Java API
HCatalog
$ hadoop jar splout-*-hadoop.jar generate …
Hive Pig
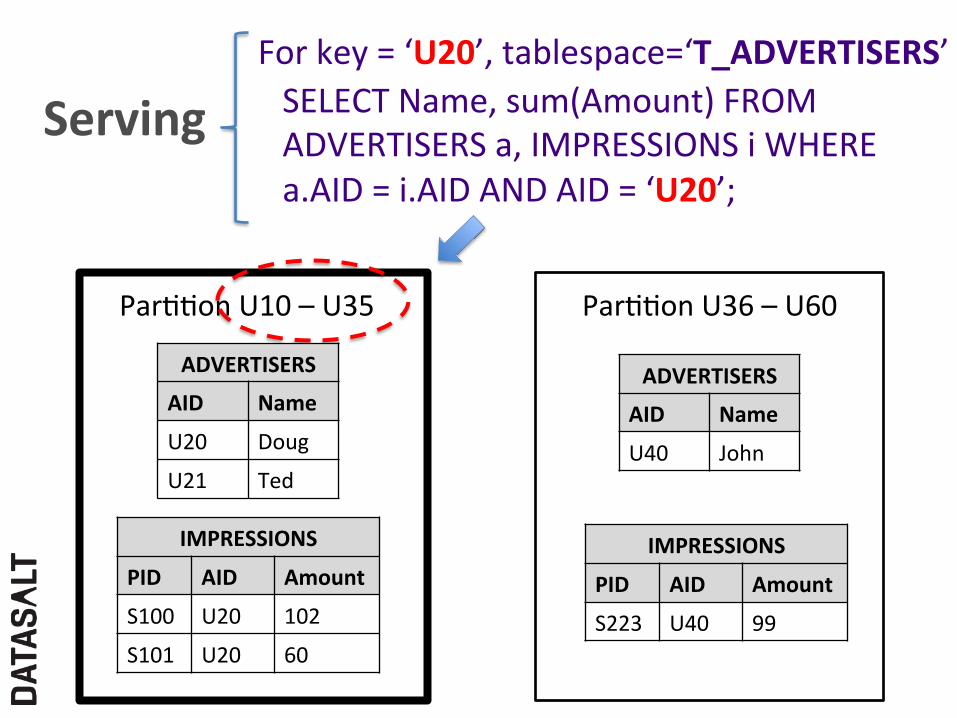
SELECT Name, sum(Amount) FROM ADVERTISERS a, IMPRESSIONS i WHERE a.AID = i.AID AND AID = ‘U20’;
For key = ‘U20’, tablespace=‘T_ADVERTISERS’
ParFFon U10 – U35
Serving
ParFFon U36 – U60
ADVERTISERS
AID Name
U20 Doug
U21 Ted
IMPRESSIONS
PID AID Amount
S100 U20 102
S101 U20 60
ADVERTISERS
AID Name
U40 John
IMPRESSIONS
PID AID Amount
S223 U40 99
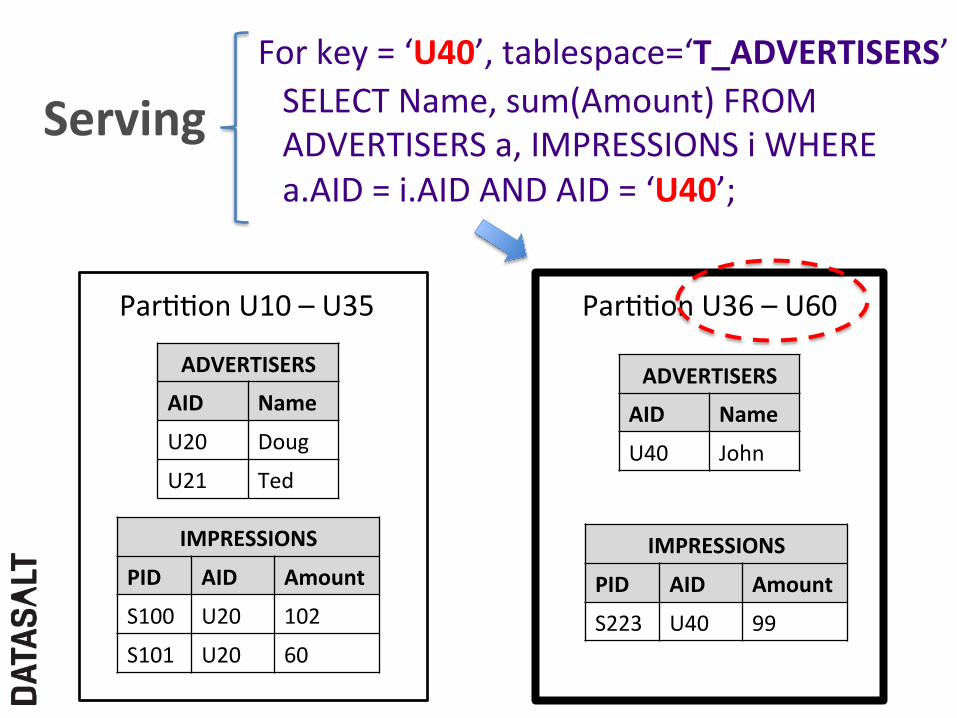
SELECT Name, sum(Amount) FROM ADVERTISERS a, IMPRESSIONS i WHERE a.AID = i.AID AND AID = ‘U40’;
For key = ‘U40’, tablespace=‘T_ADVERTISERS’
Serving
ParFFon U36 – U60 ParFFon U10 – U35
ADVERTISERS
AID Name
U20 Doug
U21 Ted
IMPRESSIONS
PID AID Amount
S100 U20 102
S101 U20 60
ADVERTISERS
AID Name
U40 John
IMPRESSIONS
PID AID Amount
S223 U40 99

API -‐ Service Rest API
JSON response
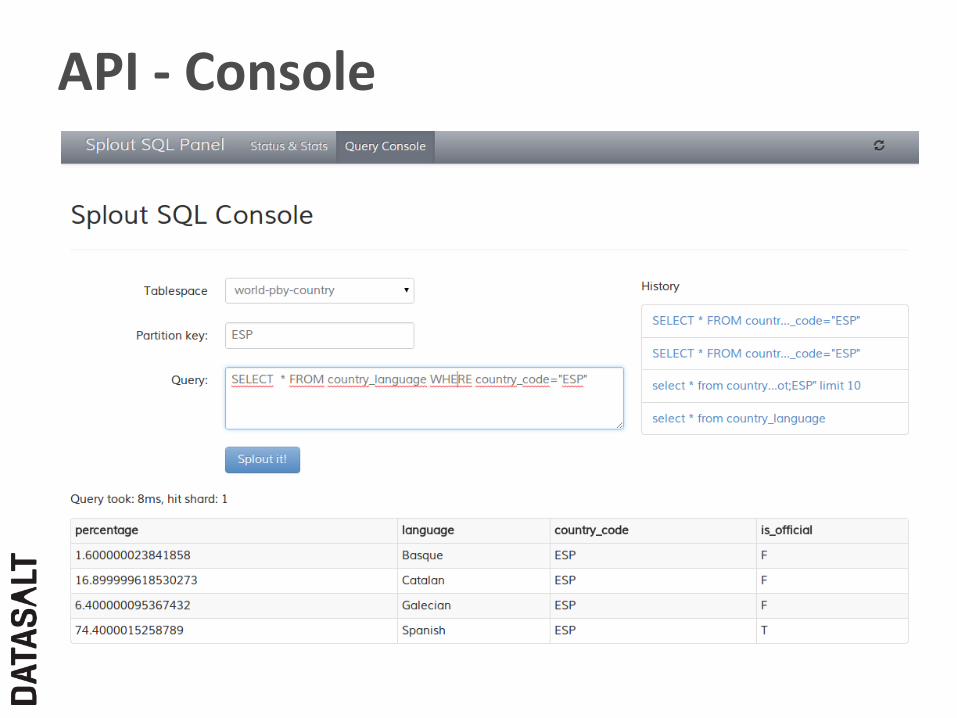
API -‐ Console

Pre-‐aggrega,ons v.s.
Sampling

Opera,onal usage
" Invoicing, accoun,ng, monitoring, etc. › Exact results › Constrained space of aggregaFons
" Pre-‐computed aggregates done in Hadoop › For example:
• per day • per day per locaFon
" Extended aggrega,ons done on-‐line › Using Splout SQL › For example, aggregate per week based on daily
stats

Why not to pre-‐compute everything?
" Create one table per each dimension combina,on › For two dimensions (day, locaFon):
• day • locaFon • locaFon, day
" For n dimensions › 2n – 1 combinaFons › It explodes!

Exploratory usage
" Ad-‐hoc filters to learn from data › Approximated results are enough
" Intensive use of sampling › It can provide good accuracy with fast response
" Confidence interval › p=proporFon › n=sample size › z=normal distribuFon
p± z! /2p ! (1" p)
n

Samples
" Created on Hadoop › Different sample sets
• For last X days • For last year
" Splout SQL for serving them • On-‐line analyFcs over samples • 1 Million records per second* (44 bytes per row) • Faster with data in memory
ü Warming data prior use ü 2.7 Million records per second*
* Measured in a laptop

Pre-‐aggrega,ons pros & cons
" Advantages › Exact results › Good for exploring the long-‐tail
" Limita,ons › Only for a constrained amount of aggregaFon
combinaFons › Not good for exploratory analysis

Sampling pros & cons
" Advantages › Fast filtering for any set of dimensions › Good accuracy for Top N queries
" Limita,ons › Bad for narrow dimension filters › Bad for exploring the long-‐tail › Approximated results

Conclusions

Conclusions
" Analy,cs in Ad Networks is a complex ques,on › Due to the amount of data › Due to the amount of agents
" It can be solved using Hadoop + Splout SQL › By the use of parFFoning › Using pre-‐aggregaFons
• For operaFve usages › Using sampling
• For exploratory profiles

Questions?
Iván de Prado Alonso – CEO of Datasalt www.datasalt.es @ivanprado @datasalt
Top Related