









Languages
Pages
Legal


Institut Mines-Télécom
Bases de données orientées colonne
Cassandra, Hbase,Bigtable, …

Institut Mines-Télécom
BD NoSQL orientée colonnes
§ Les données sont stockées par colonne, il est facile d’ajouter des colonnes
§ Ressemble logiquement aux bases de données relationnelles (tables) mais le nombre de colonnes :
• est dynamique • peut varier d’un enregistrement à un autre
§ Utile pour les tâches d’analyses sur des colonnes et dans les
traitements massifs (via des opérations de MapReduce)
§ Utile pour les données éparses
§ Exemples : • Hbase (version open source de Big Table de Google) • Cassandra

Institut Mines-Télécom
Modèle de données
§ Colonne • couple clé/valeur • représente un champ de
données • une colonne contenant d’autres
colonnes est une super colonne
§ Famille de colonnes • regroupe plusieurs colonnes ou
super-colonnes • les colonnes sont regroupées
en lignes • chaque ligne est identifiée par
un identifiant unique
§ Chaque famille de colonnes peut être partitionnée séparément
clé : objet
clé : objet
clé : objet
ligne
ligne
ligne
objet 1
colonne 1
objet 23
colonne 2
objet 31
colonne 3
objet 2
colonne 2
objet 4
colonne 4
objet 3
colonne 3
Clé Famille de colonnes 1

Institut Mines-Télécom
Principales caractéristiques
§ Consistance • plusieurs niveaux de consistance possibles avec Cassandra
§ Transactions • pas de transactions au sens traditionnel du terme, écriture atomique au niveau ligne § Requêtes • basiques avec Classandra-cli (get, set, del, create) • indexation secondaire possible • requêtes SQL-Like avec CQL (Cassandra Query Language)
§ Scalabilité • haute disponibilité • mode distribué sans maître • disponibilité gérée par la formule du quorum : (R+W)>N (W : nombre de nœuds où l’écriture doit se
faire correctement, R : nombre de nœuds qui doivent répondre avec succès à une lecture, N: facteur de réplication

Institut Mines-Télécom
Forces et Faiblesses
§ Forces • modèle de données plus riche • scalabilité horizontale et utilisation de MapReduce • résultats des requêtes en temps réel
§ Faiblesses • difficile à utiliser pour les données interconnectés
(distance, trajectoire) • maintenance lors de l’ajout/suppression de colonnes • ne pas utiliser pour les requêtes non temps réel et
inconnues

Institut Mines-Télécom
Cas d’usage
§ A utiliser pour • la journalisation d’évènements • les compteurs (analytique sur le web) • applications avec beaucoup d’écritures et peu de lectures,
priorité à la disponibilité • analyse en temps réel (cerner l’audience)
§ A ne pas utiliser pour • applications avec des besoins de transactions ACID • Agrégation par requêtes (sera effectuée par l’application
client)

Institut Mines-Télécom
BigTable
§ Base de données propriétaire gérée en interne chez Google
§ Accessible au public uniquement via • Google App Engine
§ Ecrite en C++ § Cohérence forte (strong consistency)
• L'ensemble des clients voient la même valeur d'une donnée après les mises à jour
§ Stockage de données • Basé sur le système de fichiers distribués GFS (Google File
Systems)
http://labs.google.com/papers/bigtable.html

Institut Mines-Télécom
Client
Client
Misc. servers
Client
Rep
licas
Masters
GFS Master
GFS Master
C0 C1
C C5
Chunkserver 1
C0
C
C5
Chunkserver N
C1
C C5
Chunkserver 2
… • Master manages metadata • Data transfers happen directly between clients/chunkservers • Files broken into chunks (typically 64 MB) • Chunks triplicated across three machines for safety
Google File System (GFS)

Institut Mines-Télécom
BigTable-Modèle de données
§ Map multi-dimensionnel § Row key
• Clé unique d'une entité (string de 64KB)
§ Column family • Représente un groupe d'attributs (colonnes) reliés
§ Column • Comporte différentes versions de la donnée (ordonnées par
timestamp décroissant)
§ L'accès à une donnée se fait par: • (Row key à column family à column à timestamp)

Institut Mines-Télécom
11
BigTable-Modèle de données
(row, column, timestamp) → cell contents
“www.cnn.com”
“contents:”
Rows
Columns
Timestamps
t3 t11
t17 “<html>…”

Institut Mines-Télécom
BigTable- Architecture
§ La tablet est l'unité de distribution de données • Intervalle de ligne triées par ordre lexicographique des clés
[start key-end key]
§ Tablet server • Gère un ensemble de tablets (généralement quelques centaines)
§ Chubby server • Maintient des connexions avec les Tablet Servers à l'aide de
fichiers de verrouillage • Attribution dynamique des Tablets aux Tablet Servers • Responsable de la répartition de charge et de la tolérance aux
fautes

Institut Mines-Télécom
BigTable - Architecture

Institut Mines-Télécom
Ecriture/lecture de données
§ Opérations d'écriture sont stockées dans une table en mémoire memtable
§ Quand la taille de la memtable atteint un seuil prédéfini • La memtable est figée et ensuite convertie en SSTable par le
GFS • Une nouvelle memtable est créée
§ Opérations de lecture sont effectuées sur une combinaison de memtables et SSTables

Institut Mines-Télécom
BigTable-Utilisateurs
§ Google analytics § Google finance § Orkut (réseau social tenu par Google) § Personalized search § Writely (éditeur de texte on-line racheté par
Google) § Google earth

Institut Mines-Télécom
Hbase
§ Basé sur BigTable
• HDFS (GFS), ZooKeeper (Chubby) • Master Node (Master Server), Region Servers (Tablet
Servers) • HStore (tablet), memcache (memtable), HFile (SSTable)
§ Écrit en Java § Utilise HDFS § Licence Apache 2.0 § Sponsorisé par :
• Yahoo!, Microsoft, HP, Facebook, Covalent, IONA, AirPlus International, BlueNog, Intuit, Joost, Matt Mullenweg, Two Sigma Investiments.
http://hadoop.apache.org/hbase/

Institut Mines-Télécom
Hbase : exemple d’usage
§ create 'cars', ’features’
§ put 'cars', 'row1', 'features:make', 'bmw’ § put 'cars', 'row1', 'features:model', '5 series’ § put 'cars', 'row1', 'features:year', '2012’
§ put 'cars', 'row2', 'features:make', 'mercedes’ § put 'cars', 'row2', 'features:model', 'e class’ § put 'cars', 'row2', 'features:year', '2012'
table key Column family
column value
http://akbarahmed.com/2012/08/13/

Institut Mines-Télécom
HBase
§ Hbase propose: • Modèle de données similaire à celui de BigTable • Des classes natives pour la connexion avec MapReduce • Accès REST (JSON, XML, etc.) • Hive/Pig pour les analyses • Java API • Web Usage Interface
─ Tâches administratives, monitoring, ajout/suppression de noeuds, etc.
• Interface Thrift avec support pour plus de 10 langages ─ Python, PHP, Perl, Ruby, C++, Erlang, etc.

Institut Mines-Télécom
Hbase
§ Clone de BigTable ─ conçu pour être distribué ─ se base sur Hadoop et HDFS pour distribuer son stockage
Les tables sont shardées automatiquement et séparées en régions : ─ gérées par le serveur de région (RegionServer) ─ la table est tout d’abord contenue dans une seule région ─ lorsque la taille d’une région dépasse un seuil défini, Hbase la découpe en 2 régions
Eléments de Hbase : ─ RegionServer : gère les régions permettant de distribuer les tables ─ ZooKeeper : service centralisé de maintenance de la configuration (maintenir l’état des
nœuds, promouvoir un nouveau maître, etc.) ─ HMaster : le moteur de la base de données. Gère plusieurs RegionServers et centralise la
gestion d’un cluster Hbase.
§ Ecritures : ─ dans un buffer mémoire (memstore) ─ lorsqu’il atteint une taille définie, il est écrit sur HDFS dans un Hfile, un ensemble trié de
clés-valeurs
Les régions assurent la distribution, et HDFS la réplication

Institut Mines-Télécom
Hbase- architecture maître/esclave
§ Master • Responsable de l'allocation des régions aux RegionServers
§ RegionServer • Responsable d'un ensemble de régions • Chaque région est un ensemble de rangées ordonnées
§ Hbase client • Interroge le master pour savoir sur quel RegionServer se
retrouve la région recherchée • Ensuite communique directement avec la RegionServer pour
obtenir les données

Institut Mines-Télécom
Hbase-Architecture

Institut Mines-Télécom
Hbase - modèle de données
§ Une table est composée des éléments suivants : • la clé est le point d’entrée. Elles sont triées en ordre lexicographique • Une famille de colonnes permet de regrouper un certain nombre de colonnes. Toutes
les colonnes de la famille sont stockées dans un Hfile • Une colonne contient une donnée versionnée (accompagnée d’un timestamp) • Le timestamp sert à gérer la cohérence finale et les versions au niveau de la logique
cliente
HFile
HFile
Clé
Colonne Colonne
Famille Table
Colonne Colonne
Famille

Institut Mines-Télécom
ZooKeeper
§ basé sur Chubby Server de Google) est utilisé pour gérer différents serveurs (afin de résoudre le problème de Single Point of Failure).

Institut Mines-Télécom
Hbase-Utilisateurs
§ http://www.yahoo.com/ § http://www.adobe.com/ § http://www.stumbleupon.com/ § http://www.bedrock.com/ § http://www.filmweb.pl/ § http://www.flurry.com/ § http://www.drawntoscaleconsulting.com/ § http://www.kalooga.com/ § http://www.mahalo.com/ § http://www.meetup.com/ § http://ning.com/ § http://www.openplaces.org/ § http://www.powerset.com/ § http://www.readpath.com/ § http://www.runa.com/ § http://www.socialmedia.com/ § http://www.streamy.com/ § http://www.stumbleupon.com/ § http://www.subrecord.org/ § etc.

Institut Mines-Télécom
Cassandra
§ Initiateur • Facebook en 2007 (solution pour le problème « inbox search »)
§ Licence Apache 2.0 § Ecrit en Java § Modèle de données
• Basé sur BigTable (modèle de données) et Dynamo (partitionnement et cohérence)
§ Interface Thrift • Ruby, Perl, Python, Scala et Java, … • CQL (Cassandra Query Langage) : ressemble au SQL au niveau
des commandes.
http://cassandra.apache.org

Institut Mines-Télécom
Cassandra
§ Décentralisation • Pas d'architecture maître/esclave • Chaque nœud dans le cluster est identique
§ Tolérance aux fautes • Les données sont répliquées sur N (facteur de réplication)
nœuds • 'Always writable': accepte l'écriture de données même en cas de
défaillance § Extensibilité
• Ajout de nouveaux nœuds à l'aide d'un protocole 'gossip' • Le débit de lecture/écriture augmente de manière linéaire avec
l'augmentation du nombre de machines § Cohérence « tunable »
• Les écritures et les lectures offrent un niveau de cohérence configurable
Haute performance, peut être utilisée pour le temps-réel

Institut Mines-Télécom
Fonctionnalités
• Conçu pour traiter un grand nombre de données sur plusieurs serveurs
• Facile à déployer
• Imite les bases de données relationnelles
29
Cassandra
Distribuée
décentralisée
Elasticité
Hautement
scalabale Tolérante
aux pannes
Conhérence
« tunable »
Orientée colonne
Open source

Institut Mines-Télécom
Caractéristiques
30

Institut Mines-Télécom
Adapté pour des données éparses
31

Institut Mines-Télécom
Performance § Sa conception lui permet de surpasser les BDs
concurrentes § Très bons débits en lecture/écriture: s’améliore
linéairement avec l’ajout de nouveaux nœuds § “In terms of scalability, there is a clear winner throughout our experiments. Cassandra
achieves the highest throughput for the maximum number of nodes…” - University of Toronto
32

Institut Mines-Télécom
Architecture de cassandra
Cassandra 33

Institut Mines-Télécom
Aperçu
• Cassandra a été conçue en considérant que des défaillances systèmes peuvent se produire
• Système P2P, distribué • Tous les nœuds jouent le même rôle • Les données sont partitionnées sur les nœuds • Les données sont répliquées (selon la demande de l’utilisateur) • Google Big Table – Modèle de données
• Basé colonne • MemTables • SSTables
• Amazon Dynamo – Architecture décentralisée • Hachage cohérent • Partitionnement • Réplication
34

Institut Mines-Télécom
Cassandra- Utilisateurs (2011 vs. 2012)
2012

Institut Mines-Télécom
Scalabilité horizontale et haute disponibilité
36 Cassandra
1
2
3
4
5
6
1
7
10 4
2
3
5
6 8
9
11
12
PerformanceDébit=N
PerformanceDébit=Nx2

Institut Mines-Télécom
Opérations d’écriture
37

Institut Mines-Télécom
Opérations d’écriture
• Commit log • 1er endroit où l’écriture est enregistrée • Mécanisme de récupération en cas de crash
• MemTable • Structure de donnée en mémoire • Données sont enregistrées dans Memtable une fois enregistrée
dans commitlog • Si memTable atteint un seuil, les données sont ajoutées à
SSTable • Lectures se font en priorité à partir de MemTable
• SSTable • Stocké sur disque • Immuable une fois écriture faite • Compacté périodiquement pour raison de performance
§
38

Institut Mines-Télécom
partitionnement et réplication dans cassandra
• Partitionnement à travers les nœuds du cluster
• Chaque nœud est responsable d’une partie de la base de données
• les données sont insérées par l’utilisateur dans une famille de colonnes
• elles sont ensuite placées sur un nœud selon la clé de la colonne
• l’utilisateur choisit le facteur de
réplication lors de la création du keyspace
• les données insérées par l’i-utilisateur dans une famille de colonnes sont répliquées dans les nœuds du cluster selon le facteur de réplication 1
2
3 4
5 donnée
copie de la donnée
keyspace twitter
twitter_id nom followers
facteur de réplication = 2

Institut Mines-Télécom
stratégies de réplication dans cassandra
• stratégie simple • le premier réplica est placé sur un
nœud déterminée par le partitionneur • Les réplicas suivants sont placés sur
les nœuds suivants dans l’anneau sans considérer la topologie (racks et data centers)
• A utiliser pour un unique data center • stratégie sur la topologie du réseau
• plusieurs data centers : on spécifie le nombre de réplicas sur chaque data center
• les réplicas sur un même data center sont placés en parcourant l’anneau jusqu’à trouver un nœud dans un autre rack
• la réplication asymétrique est possible (3 réplicas sur un DC pour les requêtes temps-réel, et 1 sur un autre Dc pour l’analytique)
1
2
3 4
5 donnée
copie de la donnée
1
2
3 4
5
copie de la donnée
1
2
3 4
5
donnée
copie de la donnée
Rack 1
Rack 2

Institut Mines-Télécom
Cohérence dans cassandra
• Architecture « Read and Write Everywhere »
• L’utilisateur peut se connecter à n’importe quel nœud, dans n’importe quel data center, et lire/écrire les données qu’il veut
• Cassandra est la base de données NoSQL la plus rapide en écriture
• Extension de la notion de consistance éventuelle à une cohérence ajustable
• Le choix de la consistance est faite par requête : clause USING
CONSISTENCY (le niveau ONE est celui par défaut)

Institut Mines-Télécom
Niveaux de cohérence (Consistency)
§ Pour une écriture • Le niveau ONE
─ Assure que l'écriture a été effectuée dans au moins un nœud • Le niveau ALL
─ Assure que l'écriture a été effectuée vers tous les N nœuds (avec N=ReplicationFactor)
• Le niveau QUORUM ─ Assure que l'écriture a été effectuée sur les M nœuds (avec M=ReplicationFactor/
2+1) § Pour une lecture
• Le niveau ONE ─ Envoie l'enregistrement retourné par le premier nœud qui a répondu
• Le niveau ALL ─ Requête tous les nœuds et retourne l'enregistrement avec le timestamp le plus
récent ─ Si un nœud ne répond pas, l'opération échoue
• Le niveau QUORUM ─ Requête tous les nœuds et retourne l'enregistrement avec le timestamp le plus
récent retourné par la majorité des noeuds
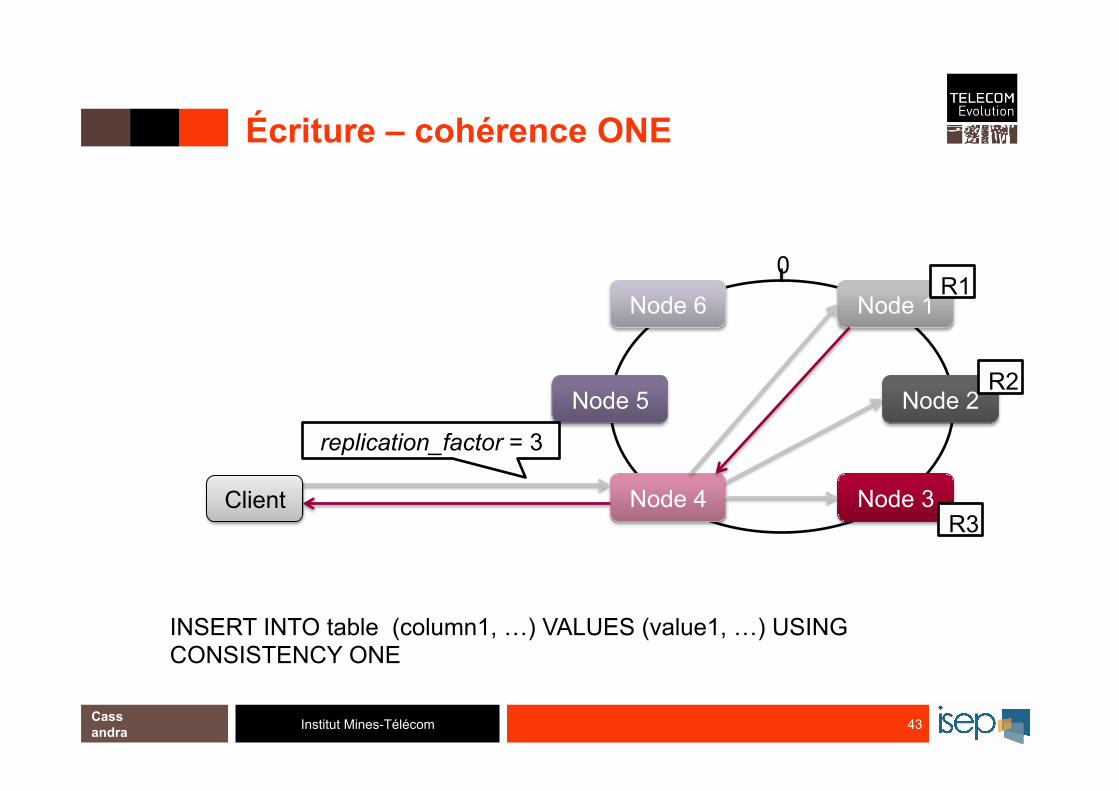
Institut Mines-Télécom
Écriture – cohérence ONE
43 Cassandra
INSERT INTO table (column1, …) VALUES (value1, …) USING CONSISTENCY ONE
0
Node 1
Node 2
Node 3 Node 4
Node 5
Node 6
replication_factor = 3
R1
R2
R3 Client

Institut Mines-Télécom
Écriture – cohérence Quorum
44 Cassandra
INSERT INTO table (column1, …) VALUES (value1, …) USING CONSISTENCY QUORUM
0
Node 1
Node 2
Node 3 Node 4
Node 5
Node 6
replication_factor = 3
R1
R2
R3 Client

Institut Mines-Télécom
Généralités
• Conçu comme un système de gestion de base de données distribuée • l'utiliser si beaucoup de données réparties sur plusieurs
serveurs • Les performances d'écriture est toujours
excellente, mais les performances de lecture dépend des modèles de données • concevoir le schéma approprié en fonction de la requête
45

Institut Mines-Télécom
Avantages et inconvénients
• Adapté pour des séries temporelles
• Haute performance • Décentralisation • Evolutivité linéaire • Support de réplication • Pas de SPOF • Possibilité de MapReduce
46
• Pas d'intégrité référentielle • Interrogation des données
pour la récupération limitée • Le tri des données fait
partie de la conception • pas GROUP BY • Modèle de données en
fonction de chaque requête

Institut Mines-Télécom
Modèle de données
Cassandra 47

Institut Mines-Télécom
Modèle clé-colonne(s)
• Un enregistrement est une collection de colonnes labellisés (avec un nom)
• Famille de colonnes = Table (Par analogie avec RDBMS)
• Un enregistrement doit contenir au moins une colonne
48

Institut Mines-Télécom
Exemple
49

Institut Mines-Télécom
Keyspace
§ Ensemble de familles de colonnes (~Base de données)
50

Institut Mines-Télécom
Méthodologie – E/R model
§ Diagramme ER (Chen): entités, associations, cardinalités, etc.
51

Institut Mines-Télécom
Modèle de données pour cassandra
52

Institut Mines-Télécom
Cassandra query language - CQL
Cassandra 53

Institut Mines-Télécom
Keyspace
• Création CREATEKEYSPACEdemo
WITHreplicaCon={‘class’:’SimpleStrategy’,replicaCon_factor’:3};
• Utilisation USE demo;
• Suppression DROP KEYSPACE demo;
54

Institut Mines-Télécom
Creation d’une table (famille de colonnes)
CREATETABLEusers(emailvarchar,biovarchar,birthday;mestamp,ac;veboolean, PRIMARYKEY(email));
55
CREATE TABLE tweets( email varchar PRIMARY KEY, time_posted timestamp, tweet varchar);

Institut Mines-Télécom
Insertion
INSERTINTOusers(email,bio,birthday,ac;ve)VALUES(‘[email protected]’,‘Associateprofessor’, 516513600000,true);
Importeràpar;rd’unfichierCSV COPY table1 (column1, column2, column3, column4) FROM ’data.csv'; Avec entête COPY table1 (column1, column2, column3, column4) FROM ’data.csv’ WITH HEADER=true; 56

Institut Mines-Télécom
Interrogation
SELECT*FROMusers;SELECTcount(*)fromusers;SELECT*FROMusersLIMIT10;SELECTemailFROMusersWHEREac;ve=true;
57

Institut Mines-Télécom
Place à la pratique Exercices adaptés de la formation Datastax
Cassandra 58

Institut Mines-Télécom
Création de la keyspace
CREATE KEYSPACE demoVideo WITH REPLICATION = {
'class': 'SimpleStrategy', 'replication_factor' : 1
}; USE demoVideo; Remarque: SOURCE './myscript.cql';
60

Institut Mines-Télécom
Exemple introductif-creation de la table
CREATE TABLE videos ( id int, name text, runtime int, year int, PRIMARY KEY (id) );
61

Institut Mines-Télécom
insertion
- Insérer ces données dans une table videos - Soit directement avec la clause INSERT ou en
utilisant un fichier CSV et la clause COPY
62

Institut Mines-Télécom
requêtage
- Combien de lignes ont été insérées - Afficher tous les enregistrements - Afficher les informations concernant la vidéo
« insurgent » - Afficher les vidéos dont l’année est supérieure à
2014
- Qu’obtenez vous? Pourquoi?
63

Institut Mines-Télécom
Stockage physique
64

Institut Mines-Télécom
Stockage partitionné
65

Institut Mines-Télécom
une solution aux requêtes précédentes?
§ Créer la table suivante:
CREATE TABLE videos_by_name_year ( name text, runtime int, year int, PRIMARY KEY ((name, year)) );

Institut Mines-Télécom
Requêtes
§ Trouver le film « Insurgent » réalisé en 2015 § Trouver les informations du film « Interstellar » § Quels sont les films réalisés en 2014
67 Cassandra

Institut Mines-Télécom
Cassandra-UPSERTS
INSERT INTO videos_by_name_year (name , year , runtime) VALUES ('Insurgent',2015, 127) ; SELECT count(*) from videos_by_name_year
§ Que se passe-t-il?
68 Cassandra
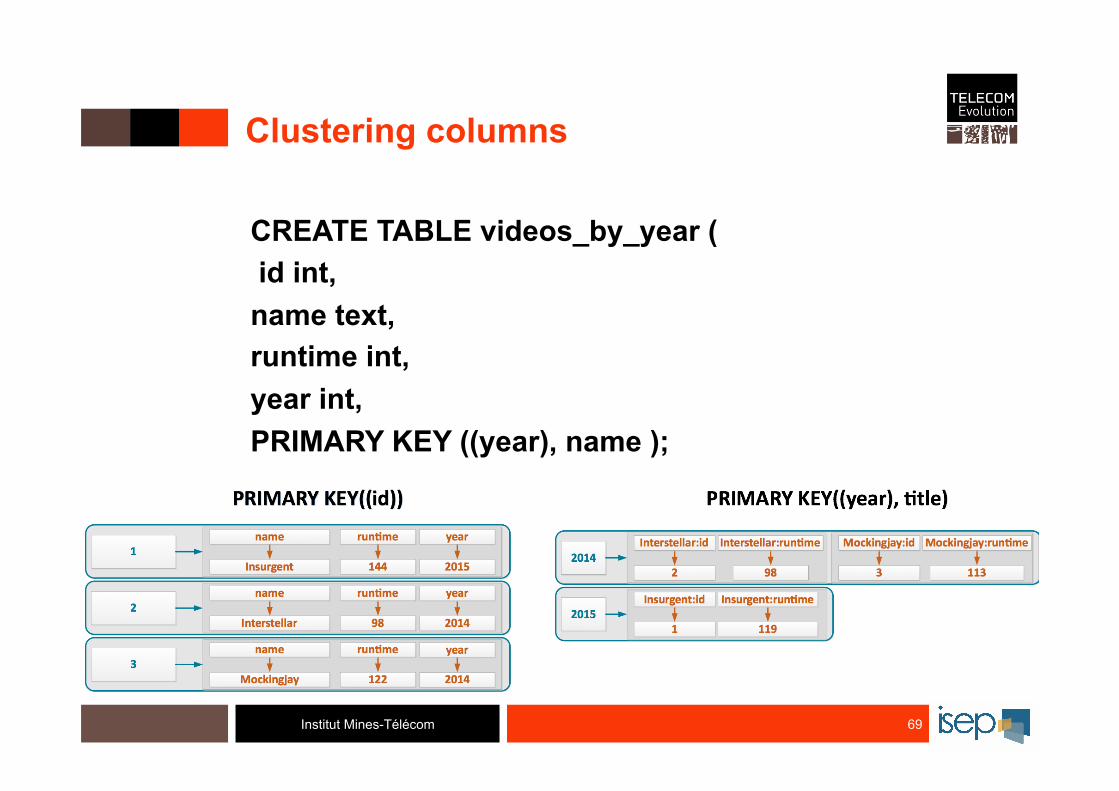
Institut Mines-Télécom
Clustering columns
CREATE TABLE videos_by_year ( id int, name text, runtime int, year int, PRIMARY KEY ((year), name );
69

Institut Mines-Télécom
Clustering column avec ordre
§ Par défaut ordre ascendant § SI on veut spécifier un ordre descendant:
CREATE TABLE videos_by_year ( id int, name text, runtime int, year int, PRIMARY KEY ((year), name) ) WITH CLUSTERING ORDER BY (name DESC);
70 Cassandra

Institut Mines-Télécom
Requêtage sur les clustering Columns
SELECT * FROM videos_by_year WHERE year = 2014 AND name = 'Mockingjay'; § Ou (opérations de comparaison) SELECT * FROM videos_by_year WHERE year = 2014 AND name >= 'Interstellar';
71

Institut Mines-Télécom
Alter table
§ Ajout d’une colonne ALTER TABLE table1 ADD another_column text;
§ Suppression d’une colonne ALTER TABLE table1 DROP another_column;
§ La colonne PRIMARY KEY ne peut être modifiée
§ Suppression de toutes les données TRUNCATE table1;
72

Institut Mines-Télécom
Colonne multi-valuée
§ Une colonne peut contenir plusieurs valeurs (contrairement à RDBMS)
• SET<TEXT> collection de valeurs typées et ordonnées (selon la valeur)
• LIST<TEXT> ordonnée par position • MAP<TEXT,INT> collection de clé-valeur ordonnée par
clé
73

Institut Mines-Télécom
UDT (User defined type)
CREATE TYPE address ( street text, city text, zip_code int, phones set<text> ); CREATE TYPE full_name ( first_name text, last_name text );
74

Institut Mines-Télécom
Modifier la table videos
- Ajouter une colonne tags (pouvant contenir plusieurs valeurs de tags)
- Ajouter quelques tags aux vidéos de votre fichier csv
- Insérer les tags dans la table videos - Méthode TRUNCATE puis réinsertion - Méthode UPSERT
75

Institut Mines-Télécom
UDT
§ Créer un UDT video_encoding suivant l’exemple suivant {encoding: '1080p', height: 1080, width: 1920, bit_rates: {'3000 Kbps', '4500 Kbps', '6000 Kbps'}
§ Créer un fichier videos_encoding.csv contenant video_id et les informations d’encodage
§ Exemple: § 1,"{encoding: '1080p', height: 1080, width: 1920, bit_rates: {'3000 Kbps', '4500
Kbps', '6000 Kbps'}}"
Field Name Data Type
encoding text
height int
width int
bit_rates set<text>

Institut Mines-Télécom
Alter table et ajout des infos
- Ajouter une nouvelle colonne encoding à la table videos
- Insérer les nouvelles informations à partir du fichier videos_encoding.csv créé précédemment
- Afficher le contenu de videos
77

Institut Mines-Télécom
counter
§ Créer une nouvelle table avec un compteur permettant de mettre à jour le nombre de vidéos pour chaque tag et année
CREATE TABLE videos_count_by_tag ( tag TEXT, added_year INT, video_count counter, PRIMARY KEY (tag, added_year) );
78 Cassandra

Institut Mines-Télécom
Counter (suite)
§ Pour mettre à jour le compteur: (lancez quelques updates sur la table)
UPDATE videos_count_by_tag SET video_count = video_count + 1 WHERE tag=‘MyTag’ AND added_year=2015; § Afficher le résultat
§ Essayer un update du compteur avec un tag et une année qui n’existe pas dans votre table. Qu’obtenez vous?
79 Cassandra

Institut Mines-Télécom
Dénormalisation
Cassandra 80

Institut Mines-Télécom
Rappels - exemple
81

Institut Mines-Télécom
Commentaires pour chaque vidéo
§ SELECT comment § FROM videos JOIN comments ON videos.id =
comments.video_id
82

Institut Mines-Télécom
Commentaires pour chaque login utilisateur
83

Institut Mines-Télécom
Dénormalisation dans cassandra
84

Institut Mines-Télécom
Tables
§ Créer les tables et insérer des enregistrements § Ecrire les requêtes permettant de trouver les
commentaires pour un film particulier/ d’un utilisateur particulier
§ On veut classer les vidéos commentés par un utilisateur du plus récent au plus ancien. Que doit-on faire?
85

Institut Mines-Télécom
MCD: Modèle conceptuel de données
Cassandra 86

Institut Mines-Télécom
Clés des associations
87

Institut Mines-Télécom
One-to-one
§ Trouver la clé de cette relation
88

Institut Mines-Télécom
One-To-many
89

Institut Mines-Télécom
ManY-tO-many
90
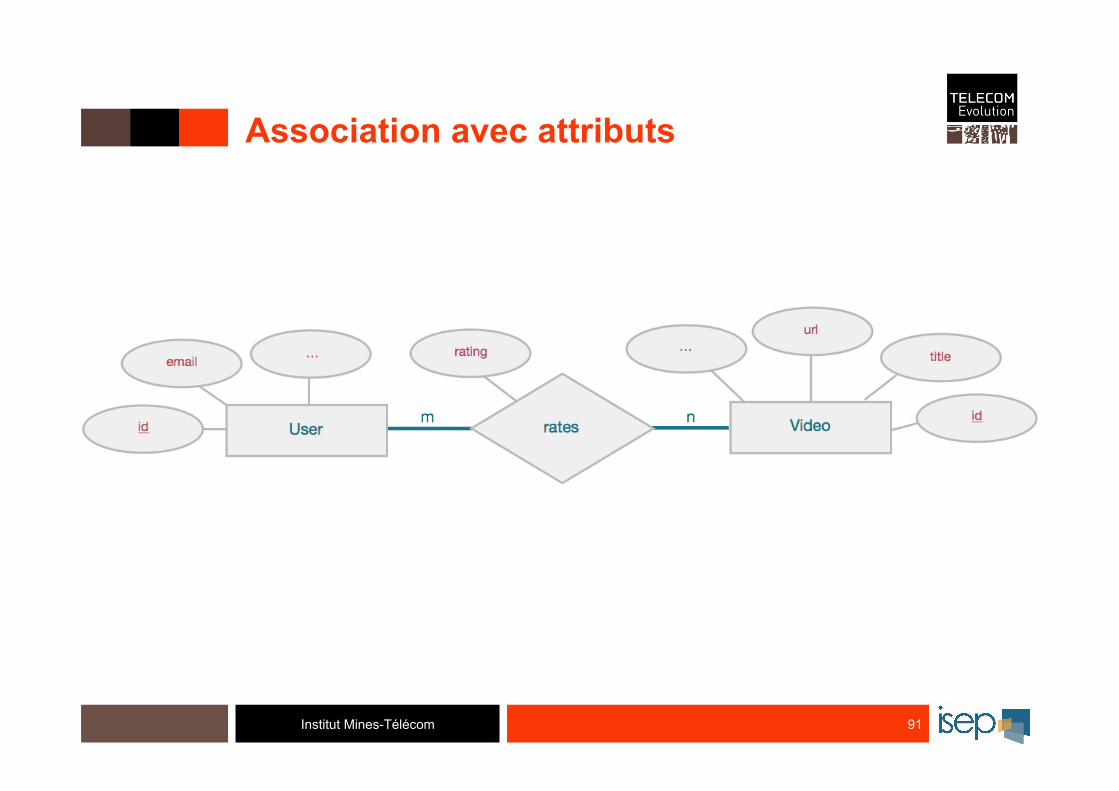
Institut Mines-Télécom
Association avec attributs
91

Institut Mines-Télécom
Vers le modèle Logique de données
92

Institut Mines-Télécom
Modèle Logique: Diagramme de Chebotko
§ Diagramme des tables et des requêtes (patterns d’accès)
93

Institut Mines-Télécom
Diagramme de Chebotko: Notation

Institut Mines-Télécom
Plus d’informations
§ Dev: http://www.datastax.com/dev § Docs:http://docs.datastax.com/en/index.html § Planet Cassandra: http://planetcassandra.org/ § blogs: http://tobert.github.io/ § http://patrickmcfadin.com/ § http://rustyrazorblade.com/ § https://ahappyknockoutmouse.wordpress.com/author/ anukeus/ § http://thelastpickle.com/blog/ § Livre : http://www.amazon.com/Cassandra-High-
Availability-Robbie-Strickland/dp/1783989122 § DataStax Academy: https://academy.datastax.com/ § Formation: http://www.datastax.com/what-weoffer/ products-services/training
95
Top Related