







Languages
Pages
Legal


Solving Logical Puzzles with Natural Language
ProcessingPycon-India 2015
byAshutosh Trivedi
Founder, bracketPywww.bracketpy.com
Pycon-India-2015

The NLP Story
I know Natural Language I know Processing
Pycon-India-2015Pycon-India-2015

To understand natural language programatically
But how ?
Part of SpeechVocabulary
n-gramWord style
Noun detection
The NLP Story..
Pycon-India-2015

The NLP Story..Hey, I am a sentence.. can you
process me ?
current wordprevious word
next wordcurrent word n-gram
POS tagsurrounding POS tag sequence
word shape (all Caps?)surrounding word shape
presence of word in left/right windowInfo
rmat
ion
Pycon-India-2015

What to Do With the Information?Lets learn a model…
F1 —) current wordF2 —) previous wordF3—) next wordF4—) current word n-gramF5—) POS tagF6—) surrounding POS tag sequenceF7—) word shape (all Caps?)F8—) surrounding word shapeF9—) presence of word in left/right window
Features -
Pycon-India-2015
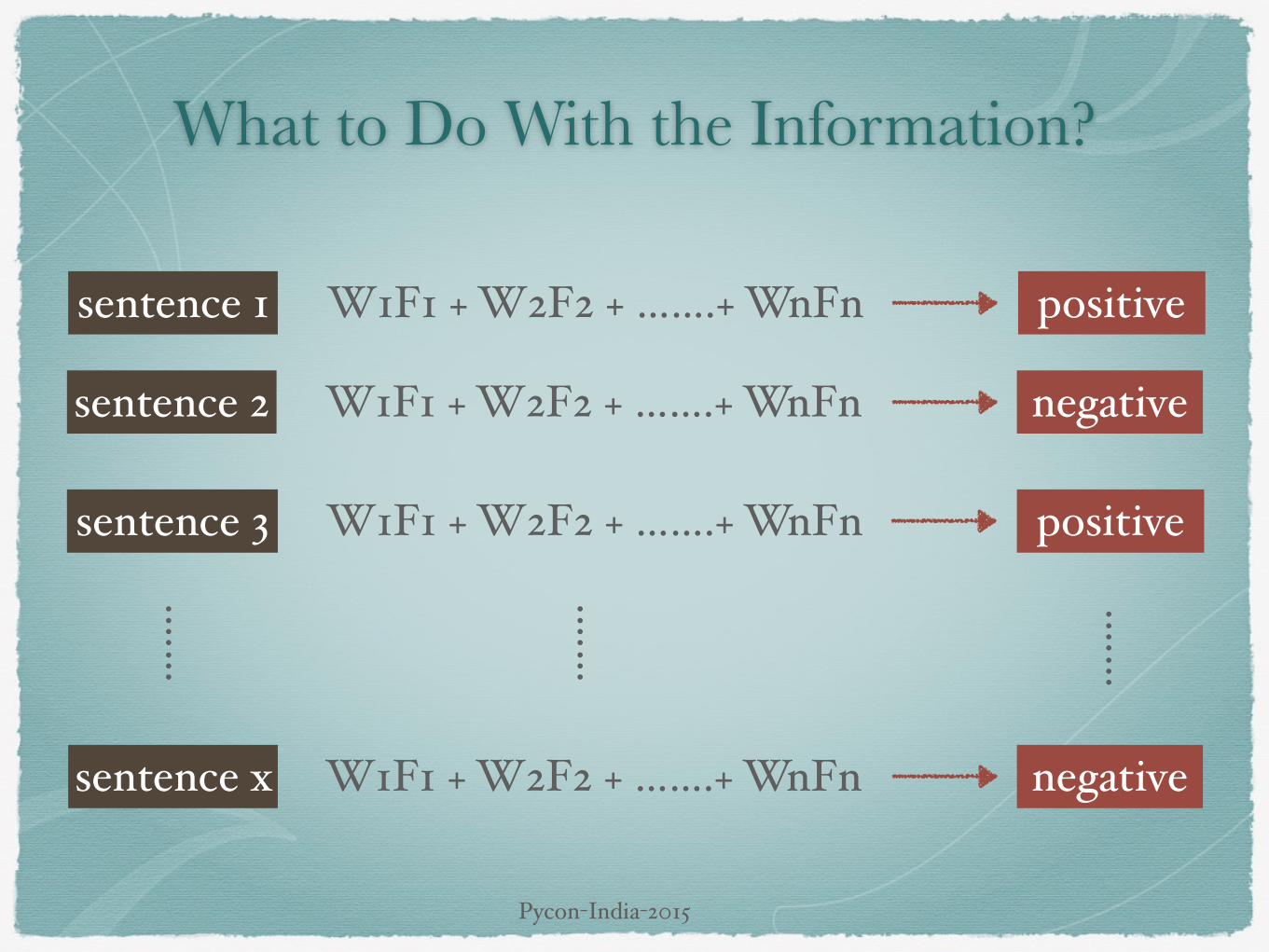
What to Do With the Information?
W1F1 + W2F2 + …….+ WnFnsentence 1 positive
W1F1 + W2F2 + …….+ WnFnsentence 2 negative
W1F1 + W2F2 + …….+ WnFnsentence 3 positive
W1F1 + W2F2 + …….+ WnFnsentence x negative
……
.
……
.
……
.
Pycon-India-2015

Is that it ?
Data features
Through other processes
Machine Learning
learn weights(optimise weights)
Is it scalable ?
Pycon-India-2015

So what is wrong ?
We are talking about AI
Pycon-India-2015

How do we represent a word?
Index in vocab..
30th word [0,0,…….1,0,0,0,…0]30
45th word [0,0,…….0,0,0,…0,1,…0]45
How would a processor know that ‘good’ at index 30 is synonym for ‘nice’ at index 45
Pycon-India-2015

Wordnets..
Problems
Manual labour
Scalability
New words
Nouns
Pycon-India-2015

Wordnets..
Ipython Demo
Pycon-India-2015

So how do we remember words.. ?
Our human hooks —
associated wordpersoncontext
tastesmelltimevisual
feelings
Pycon-India-2015

how to represent words programmatically ?
You, as an individual is average of 5 people you spend time with everyday.
You shall know a word by the company it keeps-J.R.Firth 1957
Pycon-India-2015

How to make neighbours represent the word ?
One of the most successful ideas of statistical NLP
Co-occurrence matrix
Capture both syntactical and semantical information
Pycon-India-2015
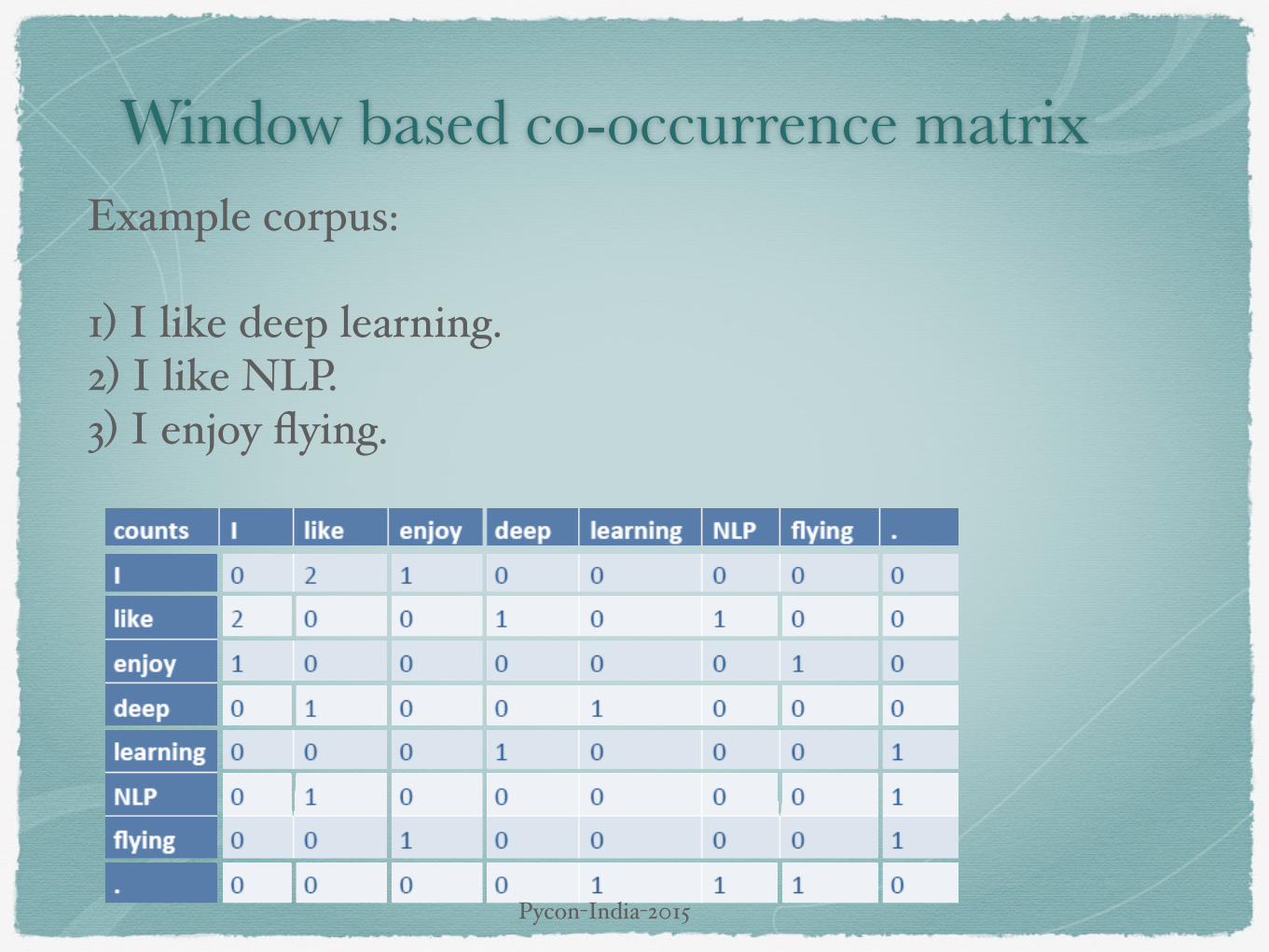
Window based co-occurrence matrixExample corpus:
1) I like deep learning.2) I like NLP. 3) I enjoy flying.
Pycon-India-2015

Problem with simple co-occurrence matrix
Increase size with vocabulary
very high dimensional— Requires a lot of storage
subsequent classification model has sparsity issues
Pycon-India-2015

Reduce the dimension
store information in few dimension - 25 to 1000
dense vectors
less space
Pycon-India-2015

Singular Value Decomposition (SVD)
Pycon-India-2015

SVD
Ipython Demo
Pycon-India-2015

Problem with SVD
Computational cost scales quadratically for N x M matrix
Bad for million of words or document
Hard to incorporate new words
Pycon-India-2015

Word2VecDirectly learn low dimensional vectors
Instead of capturing co-occurrence counts directly, Predictsurrounding words of every word
“Glove: Global Vectors for WordRepresentation” by Pennington et al. (2014)
Faster and can easily incorporate a new sentence/ documentor add a word to the vocabulary
Pycon-India-2015

Word2Vec
The Skip-gram Model
objective of the Skip-gram model is to find word representations by the surrounding words in a sentence or a document.
W1, W2, W3, . . . , Wt — sentence/document
Maximise the log probability of any context word given the current centre word.
Pycon-India-2015

Word2Vec
The Skip-gram Model
For a window of ‘T=3’
w1,w2,w3,Wc,w4,w5,w6
Maximise the probability of (w1,w2,w3, w4,w5,w6) for givenword Wc
Pycon-India-2015

Word2Vec
Unsupervised method
We are just optimising the probability of words with respectto its neighbours
creating a low dimensional space (probabilistic)
Pycon-India-2015

Lower DimensionsDimension of Similarity
Dimension of sentiment ?
Dimension of POS ?
Dimension of all word having 5 vowels
It can be anything ….
word embeddings
Pycon-India-2015

Dimension of similarity
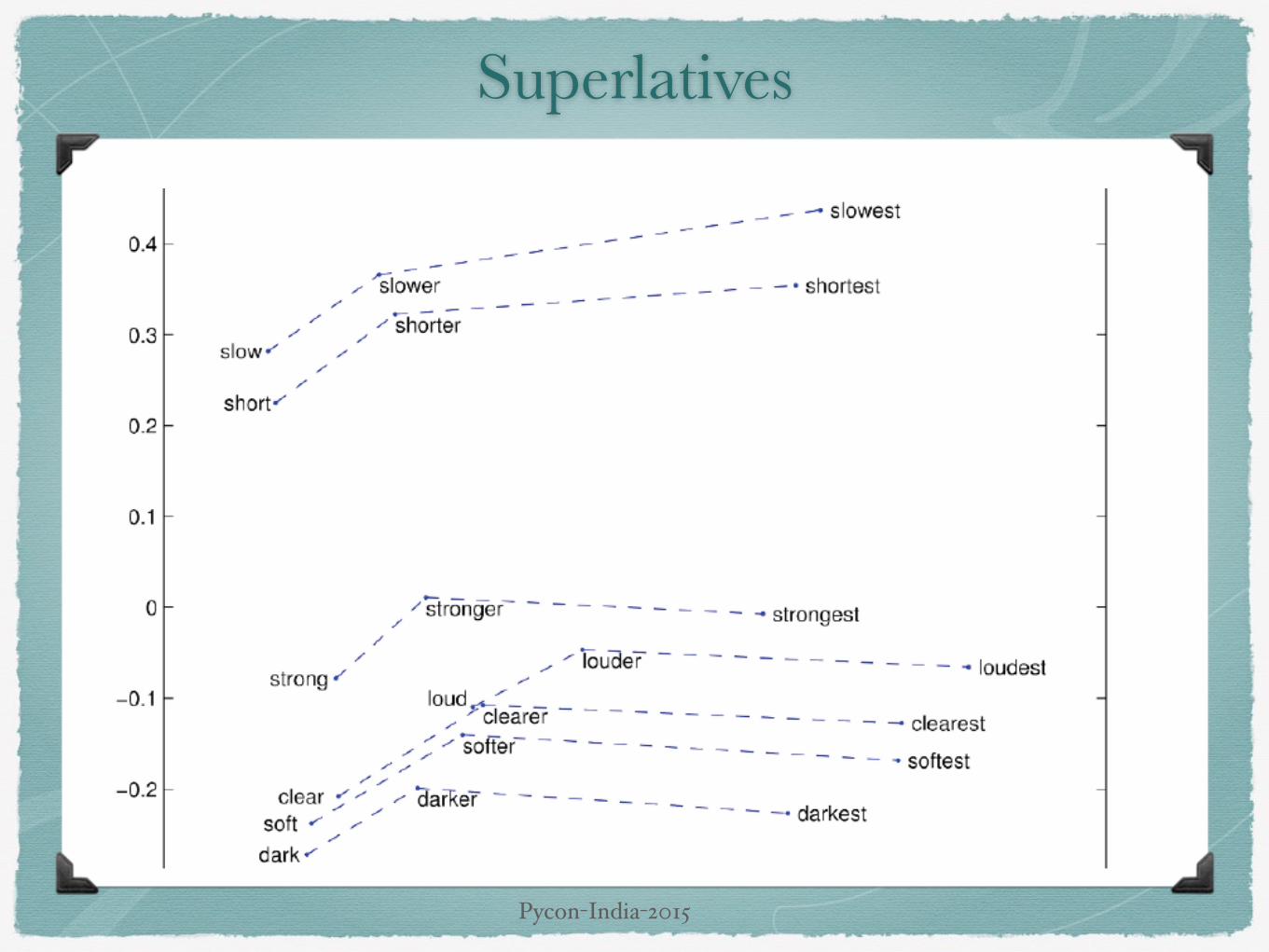
Analogies testing dimensions of similarity can be solved quitewell just by doing vector subtraction in the embedding spaceSyntactically.
X𝑎𝑝𝑝𝑙𝑒 − X𝑎𝑝𝑝𝑙𝑒𝑠 ≈ X𝑐𝑎𝑟 − X𝑐𝑎𝑟𝑠 ≈ X𝑓𝑎𝑚𝑖𝑙𝑦 − X𝑓𝑎𝑚𝑖𝑙𝑖𝑒𝑠
Syntactical - Singular, Plural
Pycon-India-2015

Dimension of similarity
Semantical
Similarly for verb and adjective morphological formsSemantically (Semeval 2012 task 2)
X𝑠h𝑖𝑟𝑡 − X𝑐𝑙𝑜𝑡𝑖𝑛𝑔 ≈ X𝑐h𝑎𝑖𝑟 − X𝑓𝑢𝑟𝑛𝑖𝑡𝑢𝑟𝑒X𝑘𝑖𝑛𝑔 − X𝑚𝑎𝑛 ≈ X𝑞𝑢𝑒𝑒𝑛 − X𝑤𝑜𝑚𝑎n
Pycon-India-2015
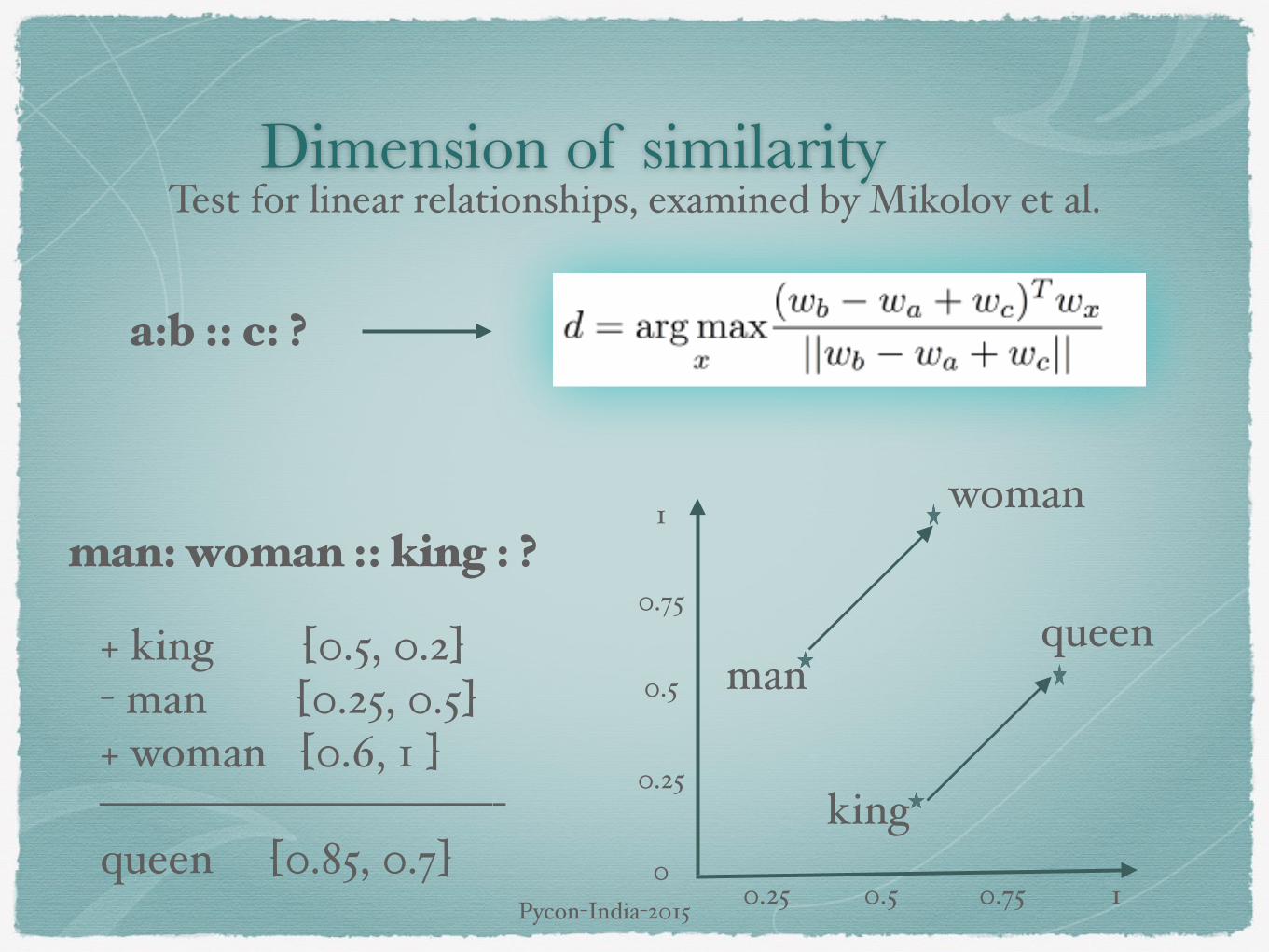
Dimension of similarityTest for linear relationships, examined by Mikolov et al.
a:b :: c: ?
man: woman :: king : ?
man
king
woman
queen
1
0.75
0.5
0.25
00.25 0.5 0.75 1
+ king [0.5, 0.2]- man [0.25, 0.5]+ woman [0.6, 1 ]—————————-queen [0.85, 0.7]
Pycon-India-2015

Word2Vec
Ipython Demo
Pycon-India-2015
Pycon-India-2015
Pycon India , Ashutosh Trivedi
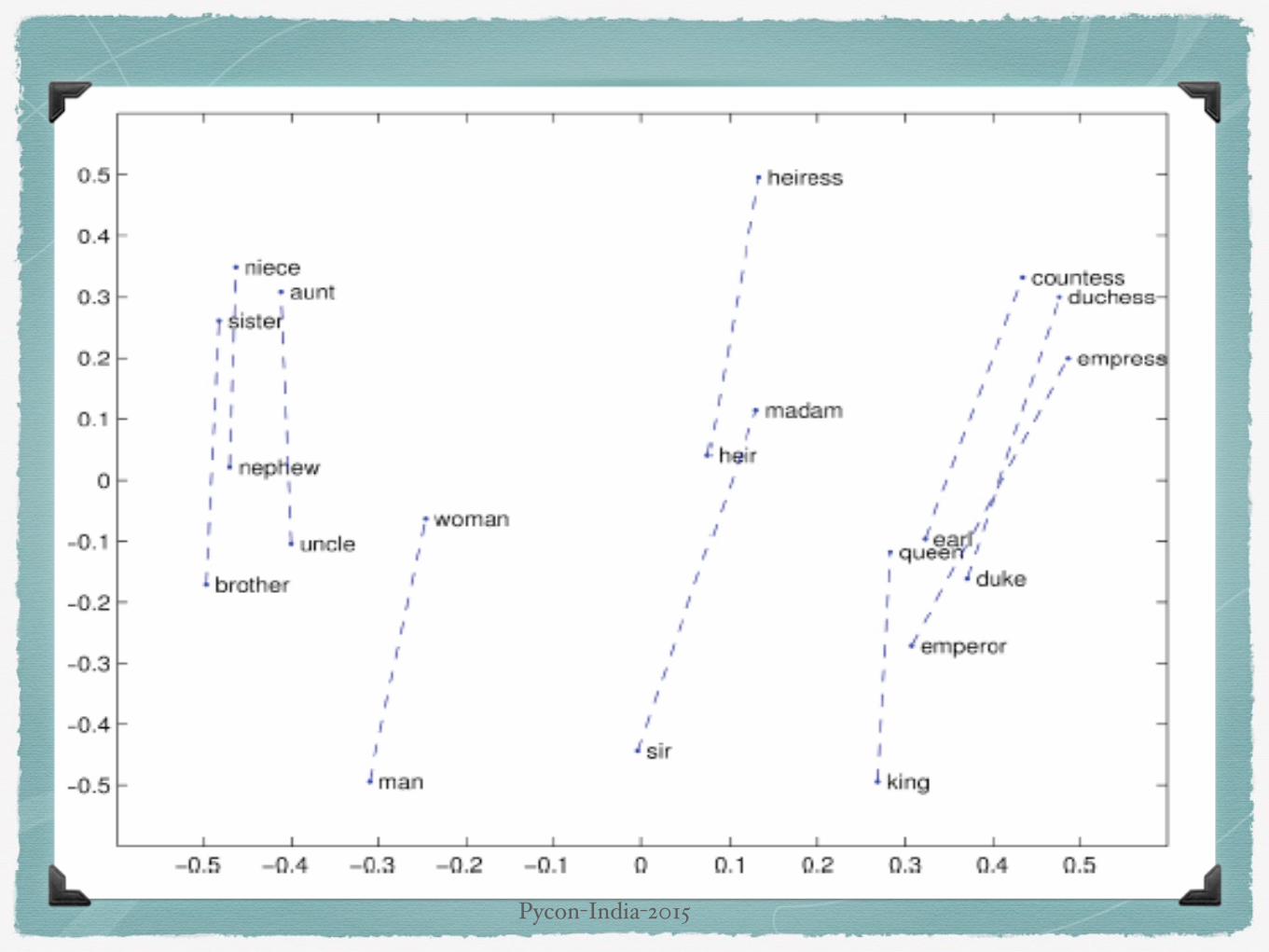
Superlatives
Pycon-India-2015
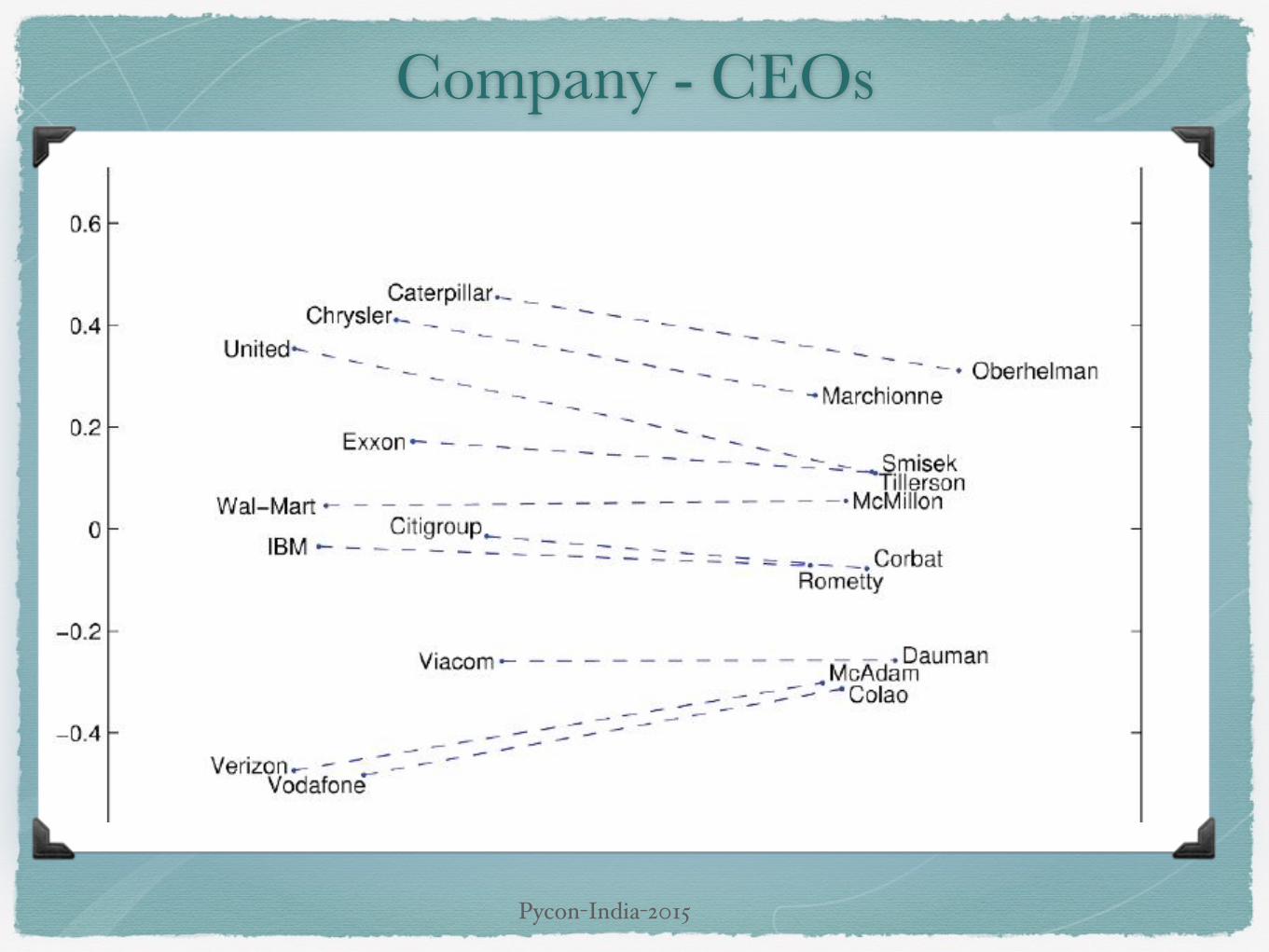
Company - CEOs
Pycon-India-2015

Reference
Deep Learning for Natural Language Processing CS224d Stanfor.edu (http://cs224d.stanford.edu/)
Mikolov, G. C. T., K. Chen, and J. Dean. "word2vec (2013).“
Pennington, Jeffrey, Richard Socher, and Christopher D. Manning. "Glove: Global vectors for word representation." Proceedings of the Empiricial Methods in Natural Language Processing (EMNLP 2014) 12 (2014): 1532-1543.
gensim : Topic Modeling for Humans (https://radimrehurek.com/gensim/)
Pycon-India-2015