


![[爬过草地的乌龟 小老板创业大策划]](https://static.fdocument.pub/doc/165x107/5596a3b71a28ab1c5b8b45de/-5596a3b71a28ab1c5b8b45de.jpg)






Languages
Pages
Legal


=>
Half hour of code:
Joe @ Taichun.py 2016.01.09

• PyConTW HoC
•
•
• …

•
• HTTP / HTML / CSS / JS python
•
• DEMO
•

Crawler

CRAWLER

Crawler •
• JS
•
• JS
•
• JS
•
• JS
•
• BUG
•
•
HoC

Crawler •
• JS
•
• JS
•
• JS
•
• JS
•
• BUG
•
•

Crawler •
• JS
•
• JS
•
• JS
•
• JS
•
• BUG
•
•

C 299
# # …

=>
@

STEP 1: • 1.1
• whois
•
• Python whois module
• online service
• cmd tools

STEP 1: • 1.2
• robot.txt sitemap.xml
• ….
•
• HTTP GET
• Python robotparser module parse
•

STEP 1: • 1.3
•
•
• Python builtwith module
• Browser

STEP 2: • 2.0
• XD
• HoC
•
• Python requests module
• curl … httpie
• API


STEP 3: •
•
• BeautifulSoup lxml parse
• HoC
• BeautifulSoup parser : html.parser / lxml / lxml-xml / html5lib
•
• parser


STEP 3:
•
• BJ4
• http -b www.google.com | hxnormalize -x | hxselect -c 'title'


STEP 3: •
•
• scrapely “train / learn”
• scrapy =>
• scapy =>
•
•

… train http lib

•
• HTTP
• parse

=>
@

STEP 1:
•
•
• View Source Code vs Element View (chrome)
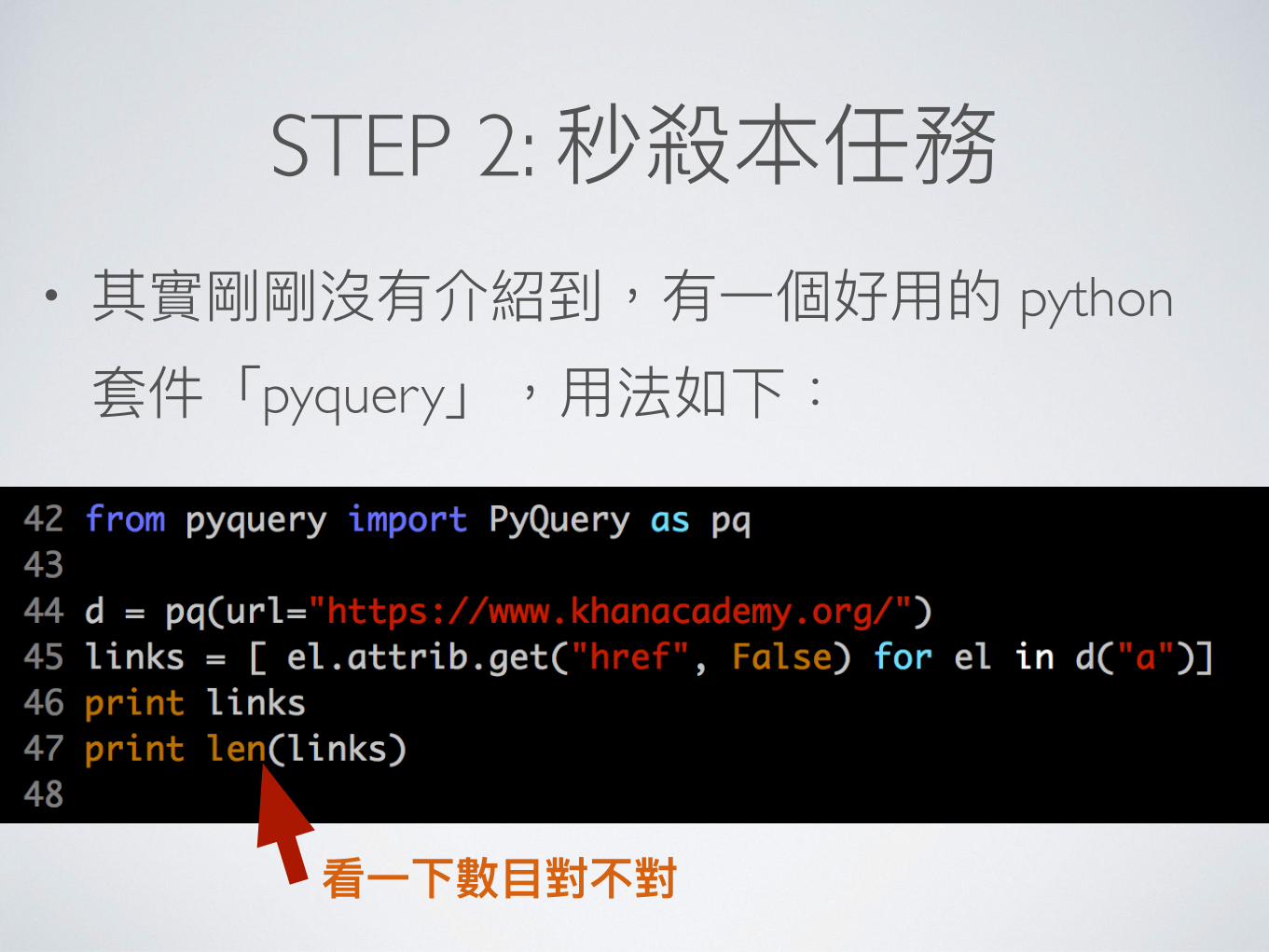
STEP 2: • python
pyquery

– JS render

STEP 2 : •
•
• javascript implement
•
• JS render
• WebView
•
• headless

STEP 2 : • JS render
• WebView
• Python Binding
• PyQt or PySide … ( )
•
• Selenium Python
• headless
• Phantomjs( Casperjs) Slimerjs …

•
•
•
…
• solution

CAPTCHA =>
@

•
• img alt
• OCR
• pytesseract or pytesser
• xx learning + ….
• XD captcha
•

IP =>
@

• proxy
• Python

DER =>
@

• python threading /multiprocessing coroutine module
• browser automation
• cookies handoff

BLOCK @
@IE ONLY
@
SPIDER TRAP@
HEADLESS MODE JS EVENT

• crawler
•
• scrapy

XD
<=

=>
@


1/24 14:00 GLIACLOUD DAVID
X

•
• K-12
• /
• /
• /
•
• GAE (python)
• backbone.js / react.js
• AWS
• SCRUM
Top Related