VGRAM: Improving Performance of Approximate Queries on String Collections Using Variable-Length...
46
VGRAM: Improving Performance of Approximate Queries on String Collections Using Variable-Length Grams Chen Li Bin Wang and Xiaochun Yang Northeastern University, China
-
Upload
chrystal-ramsey -
Category
Documents
-
view
219 -
download
1
Transcript of VGRAM: Improving Performance of Approximate Queries on String Collections Using Variable-Length...

VGRAM: Improving Performance of Approximate Queries on String
Collections Using Variable-Length Grams
Chen Li Bin Wang and Xiaochun Yang
Northeastern University, China

2
Approximate string selectionsKeanu Reeves
Samuel Jackson
Schwarzenegger
Samuel Jackson
…
Schwarrzenger
Query errors: Limited knowledge about data Typos Limited input device (cell phone) input
Data errors Typos Web data OCR
Applications Spellchecking Query relaxation …
3
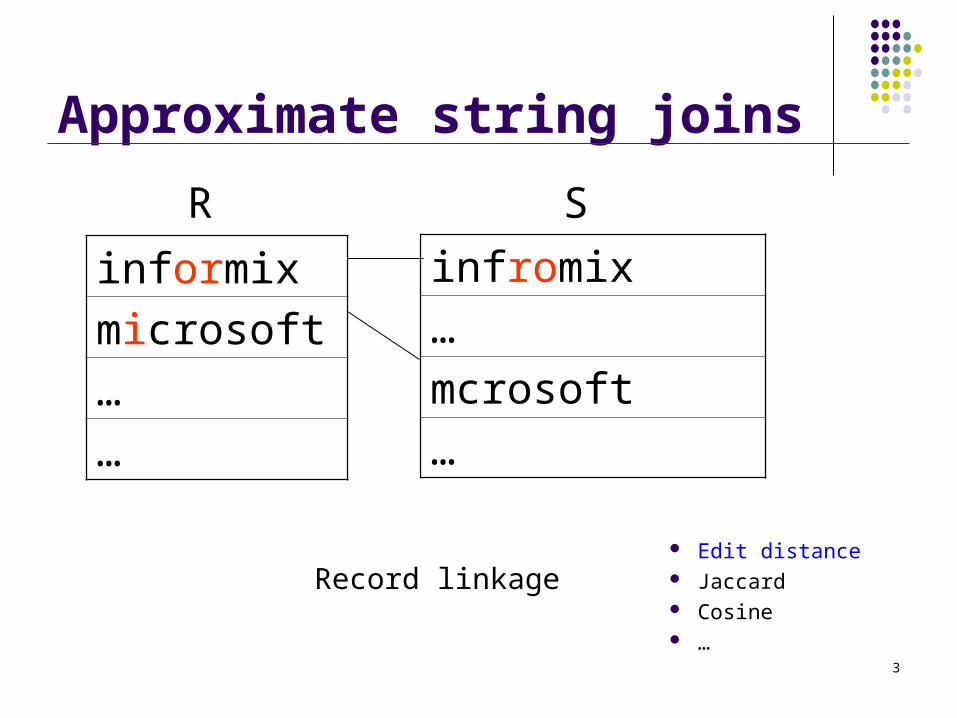
Approximate string joins
R
informix
microsoft
…
…
S
infromix
…
mcrosoft
…
Record linkage Edit distance Jaccard Cosine …

4
Goal Reducing index size (memory) Reducing running time

5
“q-grams” of strings
u n i v e r s a l
2-grams

6
q-gram inverted lists
id strings01234
richstickstichstuckstatic
4
2 30
1 4
2-grams
atchckicristtatituuc
201 30 1 2 4
41 2 433
7
# of common grams >= 3
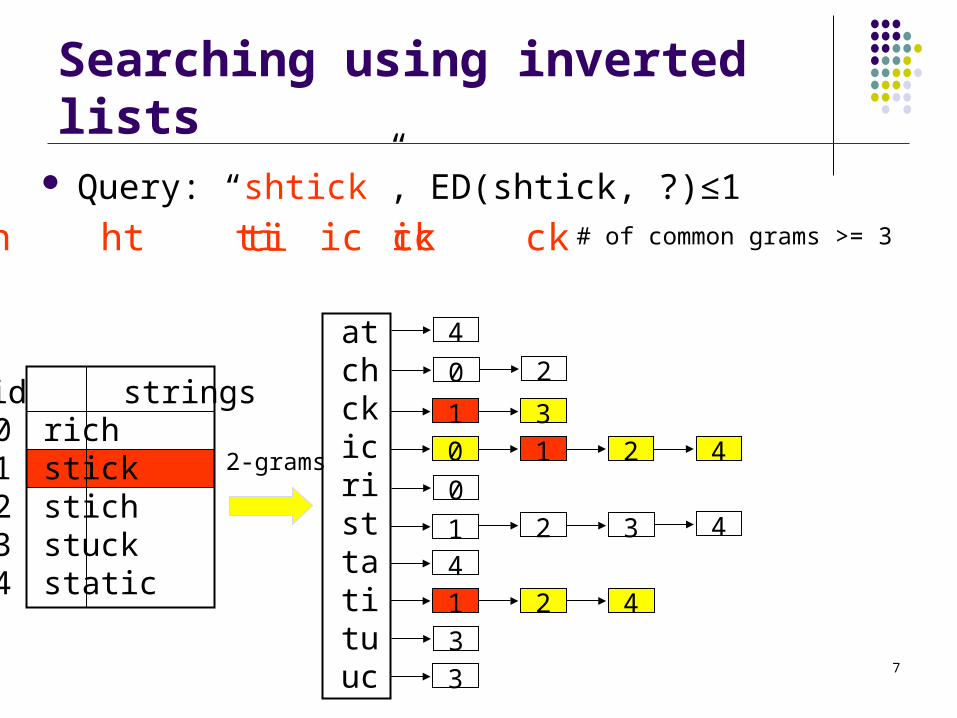
Searching using inverted lists Query: “shtick”, ED(shtick, ?)≤1
id strings01234
richstickstichstuckstatic
2-grams
atchckicristtatituuc
4
2 30
1 4
201 30 1 2 4
41 2 433
ti ic cksh ht ti ic ck

8
# of common grams >= 1
2-grams -> 3-grams? Query: “shtick”, ED(shtick, ?)≤1
id strings01234
richstickstichstuckstatic
3-grams
atiichickricstastistutattictucuck
tic icksht hti tic ick
4
24
1
2010
3413
42
3
id strings01234
richstickstichstuckstatic
id strings01234
richstickstichstuckstatic

9
Outline
Motivation VGRAM
Main idea Decomposing strings to grams Choosing good grams Effect of edit operations on grams Adopting vgram in existing algorithms
Experiments
10
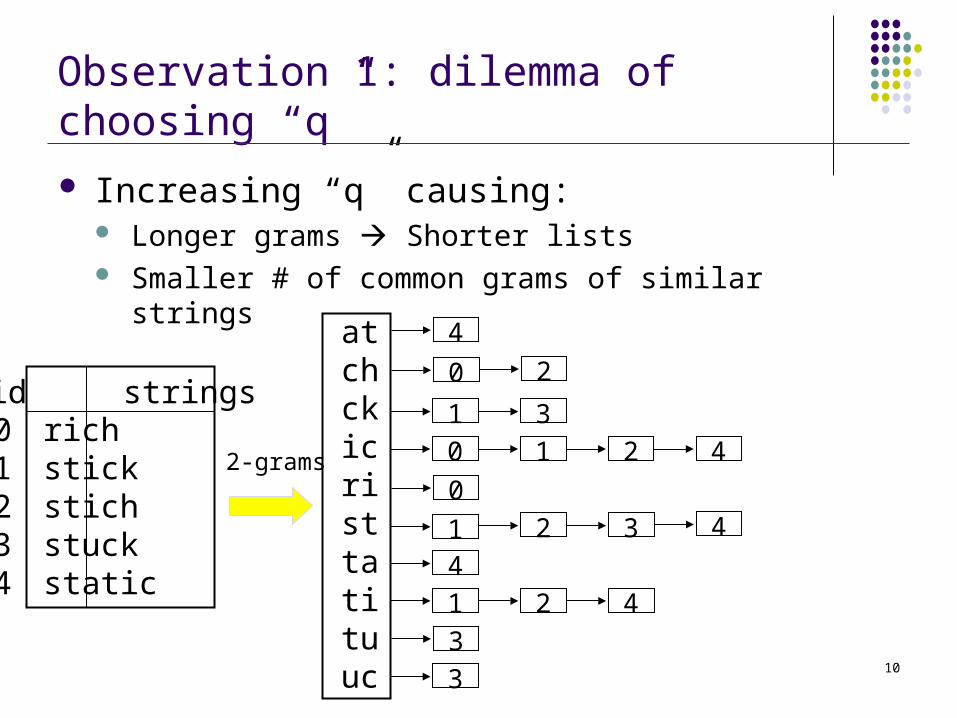
Observation 1: dilemma of choosing “q”
Increasing “q” causing: Longer grams Shorter lists Smaller # of common grams of similar strings
id strings01234
richstickstichstuckstatic
4
2 30
1 4
2-grams
atchckicristtatituuc
201 30 1 2 4
41 2 433
11
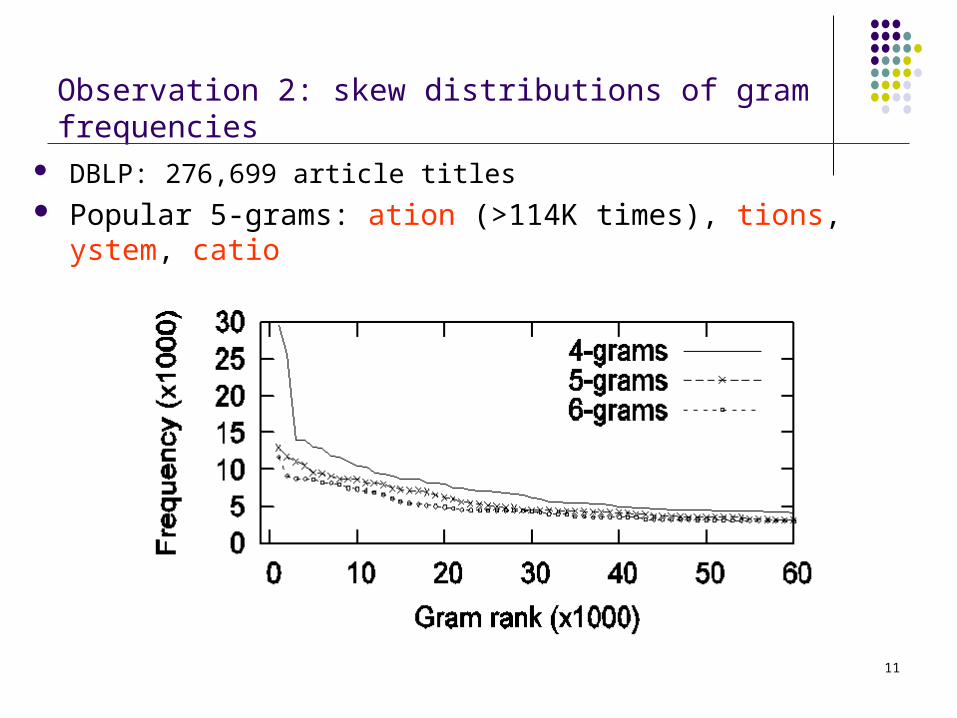
Observation 2: skew distributions of gram frequencies DBLP: 276,699 article titles Popular 5-grams: ation (>114K times), tions, ystem, catio

12
VGRAM: Main idea
Grams with variable lengths (between qmin and qmax) zebra
ze(123) corrasion
co(5213), cor(859), corr(171) Advantages
Reduce index size Reducing running time Adoptable by many algorithms

13
Challenges
Generating variable-length grams? Constructing a high-quality gram dictionary? Relationship between string similarity and their
gram-set similarity? Adopting VGRAM in existing algorithms?

14
Challenge 1: String Variable-length grams?
Fixed-length 2-grams
Variable-length grams
u n i v e r s a l
niivrsalunivers
[2,4]-gram dictionaryu n i v e r s a l

15
Representing gram dictionary as a trie
niivrsalunivers
16
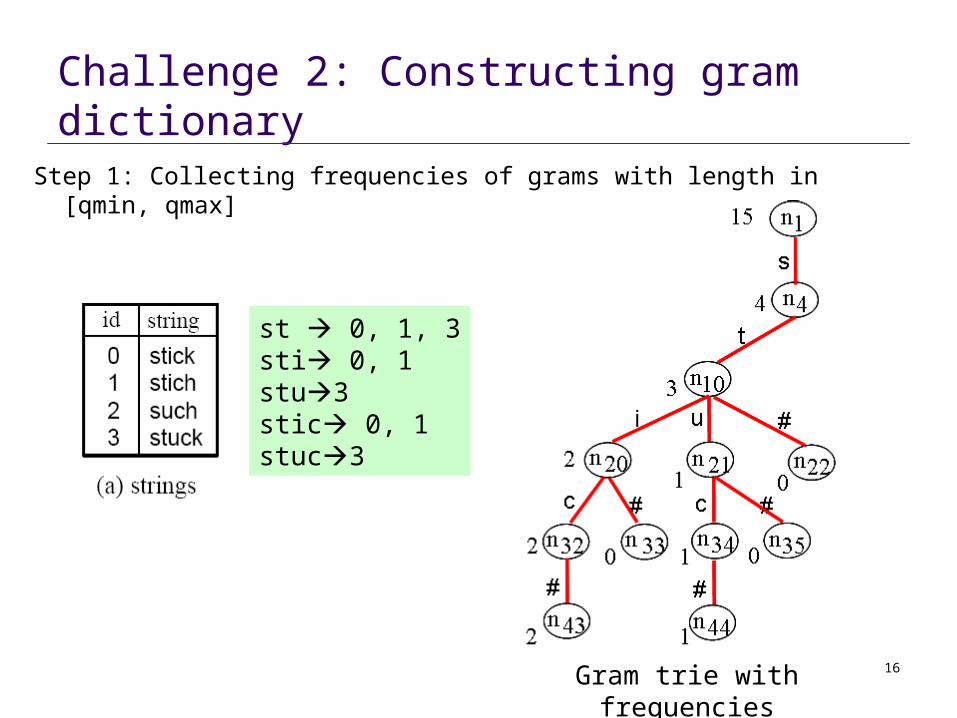
Challenge 2: Constructing gram dictionary
st 0, 1, 3sti 0, 1stu3stic 0, 1stuc3
Step 1: Collecting frequencies of grams with length in [qmin, qmax]
Gram trie with frequencies

17
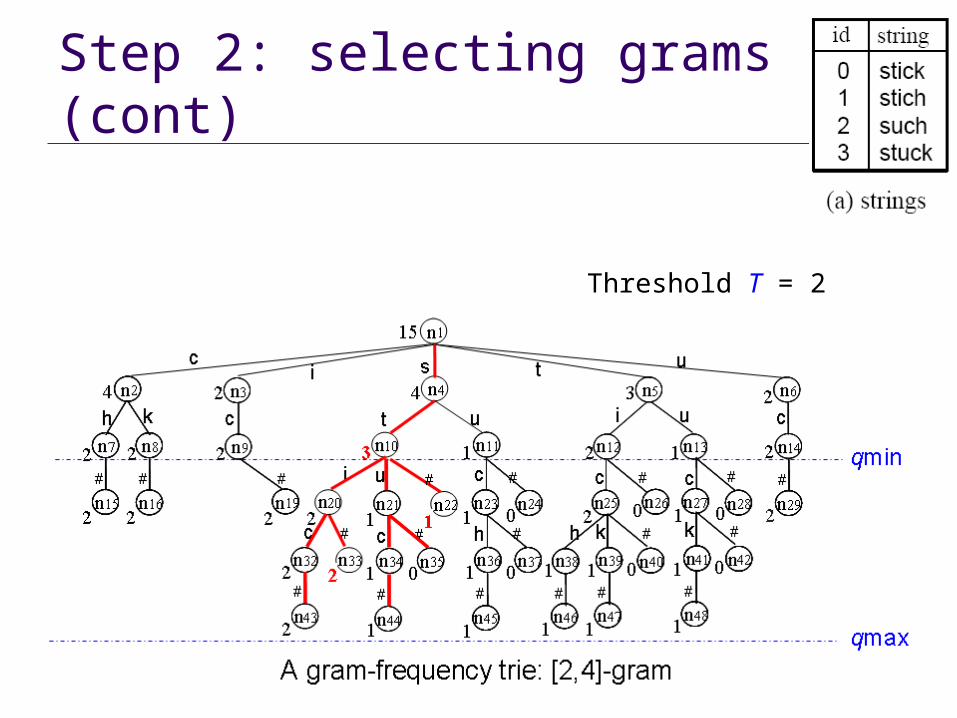
Step 2: selecting grams Pruning trie using a frequency threshold T (e.g., 2)
18
Step 2: selecting grams (cont)
Threshold T = 2
19
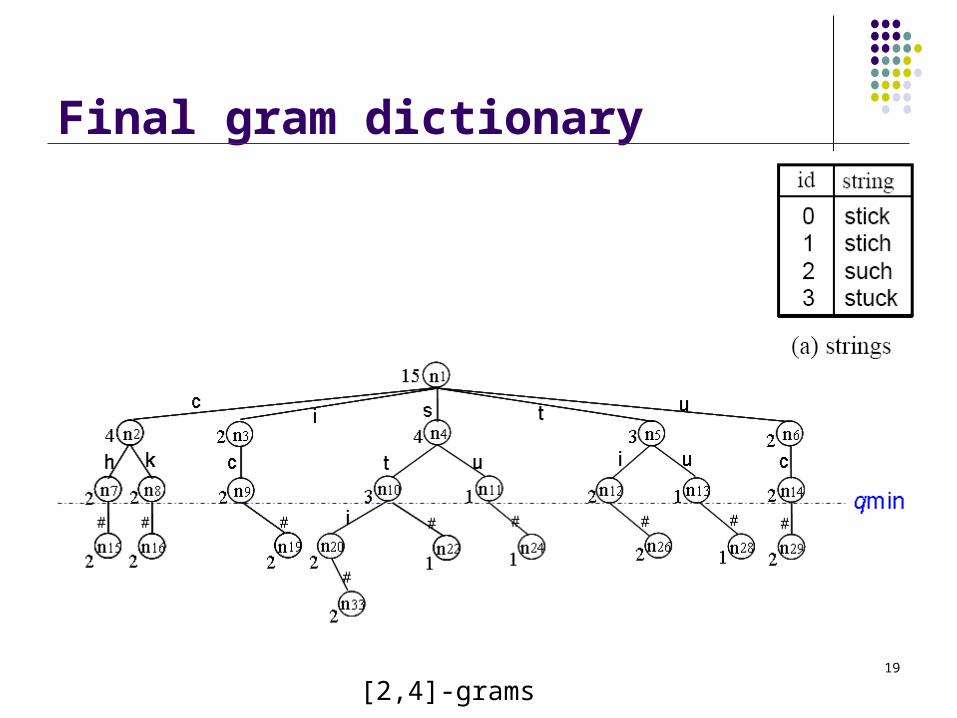
Final gram dictionary
[2,4]-grams

20
Outline
Motivation VGRAM
Main idea Decomposing strings to grams Choosing good grams Effect of edit operations on grams Adopting vgram in existing algorithms
Experiments

21
Challenge 3: Edit operation’s effect on grams
k operations could affect k * q grams
u n i v e r s a lFixed length: q

22
Deletion affects variable-length grams
i-qmax+1 i+qmax- 1Deletion
Not affected Not affectedAffected
i
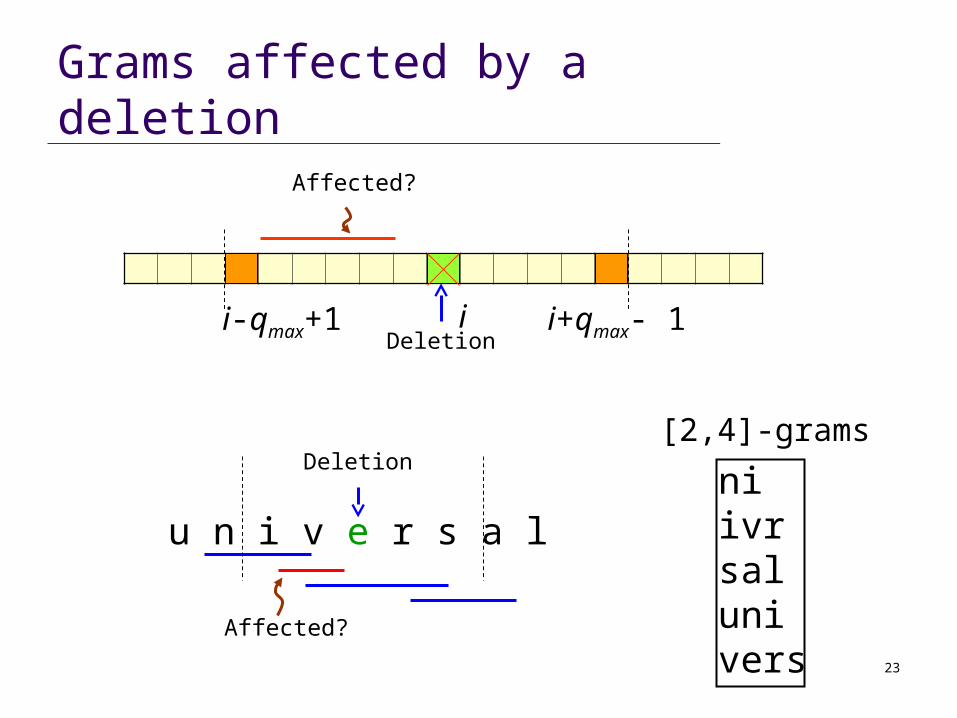
23
Grams affected by a deletion
niivrsalunivers
[2,4]-grams
u n i v e r s a l
i-qmax+1 i+qmax- 1Deletioni
Affected?
Deletion
Affected?

24
Grams affected by a deletion (cont)
i-qmax+1 i+qmax- 1Deletioni
Affected?
Trie of grams Trie of reversed grams

25
# of grams affected by each operation
_ u _ n _ i _ v _ e _ r _ s _ a _ l _0 1 1 1 1 2 1 2 2 2 1 1 1 2 1 1 1 1 0
Deletion/substitution Insertion

26
Max # of grams affected by k operations
Vector of s = <2,4,6,8,9>
With 2 edit operations, at most 4 grams can be affected
Called NAG vector (# of affected grams) Precomputed and stored
27
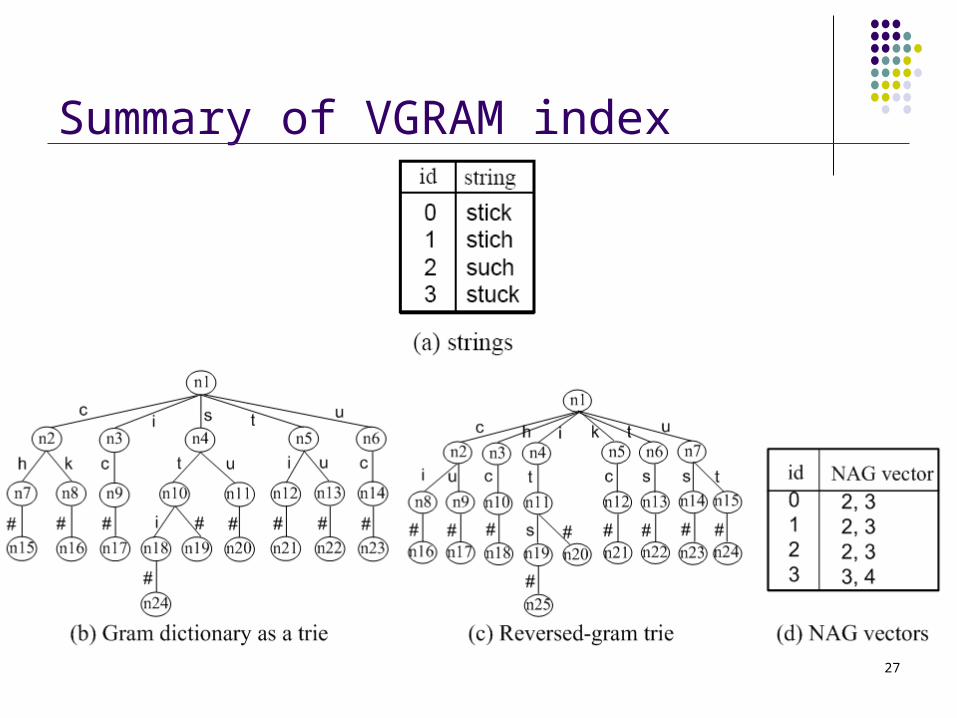
Summary of VGRAM index

28
Challenge 4: adopting VGRAM
Easily adoptable by many algorithms
Basic interfaces: String s grams String s1, s2 such that ed(s1,s2) <= k min
# of their common grams

29
Lower bound on # of common grams
If ed(s1,s2) <= k, then their # of common grams >=:
(|s1|- q + 1) – k * q
u n i v e r s a l
Fixed length (q)
Variable lengths: # of grams of s1 – NAG(s1,k)
30
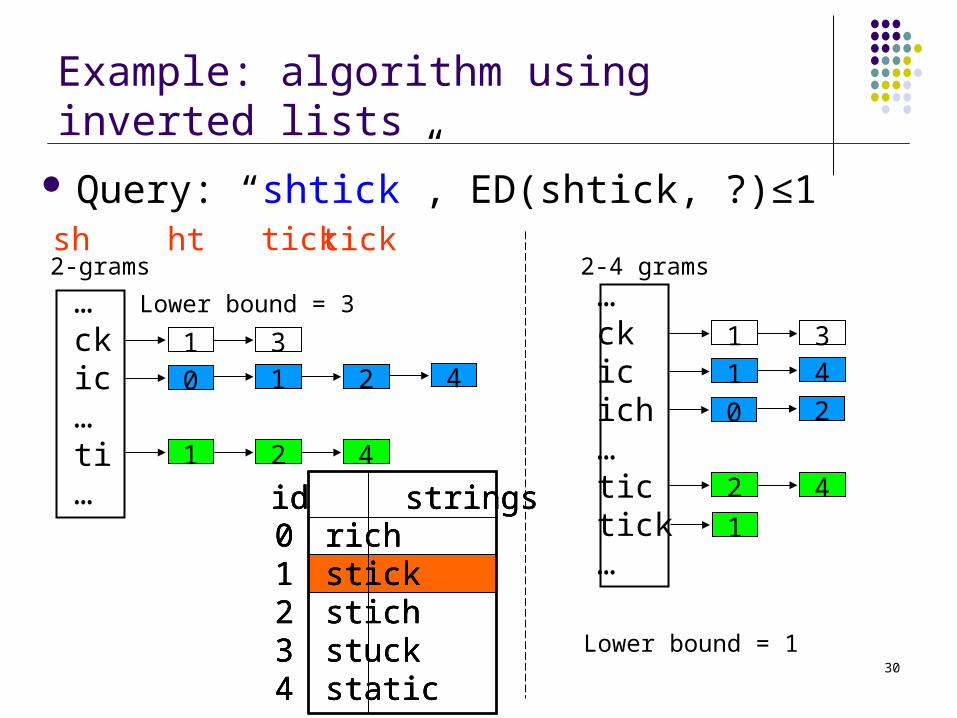
Example: algorithm using inverted lists
Query: “shtick”, ED(shtick, ?)≤1
1 2 4
1 210 4
3
…ckic…ti…
Lower bound = 3
Lower bound = 1
sh ht tick
2 4
1
4
0
11
2
3
…ckicich…tictick…
2-4 grams2-gramstick
id strings01234
richstickstichstuckstatic
id strings01234
richstickstichstuckstatic
id strings01234
richstickstichstuckstatic

31
PartEnum + VGRAM
PartEnum, fixed q-grams:
ed(s1,s2) <= k
hamming(grams(s1),grams(s2)) <= k * q
VGRAM:
ed(s1,s2) <= k
hamming(VG (s1),VG(s2)) <= NAG(s1,k) + NAG(s2,k)

32
PartEnum + VGRAM (naïve)
Bm(R) = max(NAG(r,k))
R
Bm(S) = max(NAG(s,k))
S
• Both are using the same gram dictionary.• Use Bm(R) + Bm(S) as the new hamming bound.
33
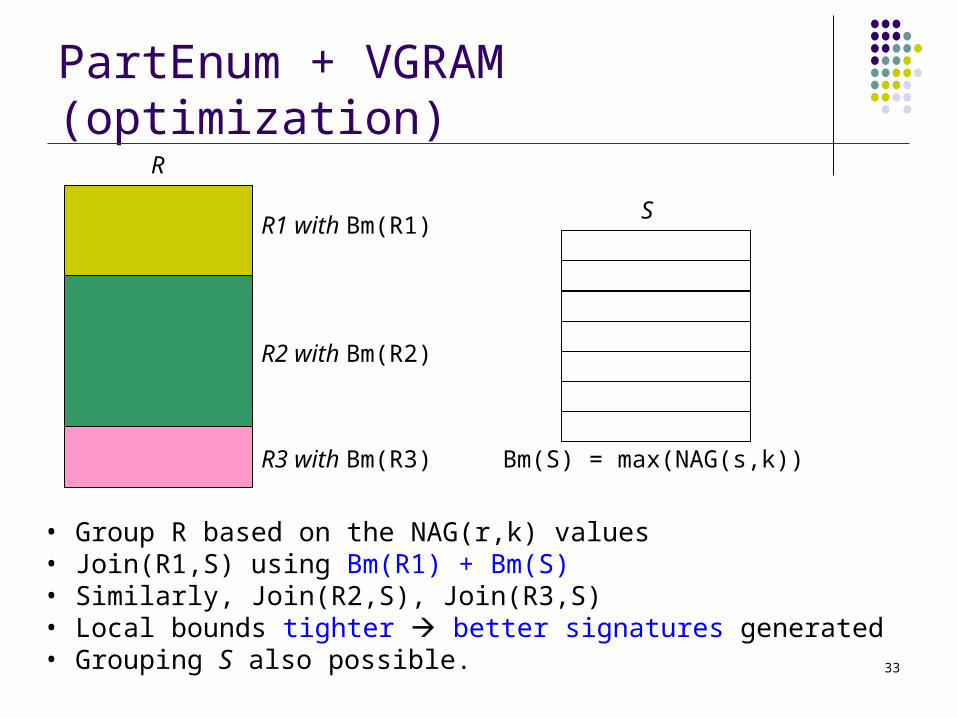
PartEnum + VGRAM (optimization)R
Bm(S) = max(NAG(s,k))
S
• Group R based on the NAG(r,k) values• Join(R1,S) using Bm(R1) + Bm(S)• Similarly, Join(R2,S), Join(R3,S)• Local bounds tighter better signatures generated• Grouping S also possible.
R1 with Bm(R1)
R2 with Bm(R2)
R3 with Bm(R3)

34
Outline
Motivation VGRAM
Main idea Decomposing strings to grams Choosing good grams Effect of edit operations on grams Adopting vgram in existing algorithms
Experiments
35
Data sets Data set 1: Texas Real Estate
Commission. 151K person names, average length = 33.
Data set 2: English dictionary from the Aspell spellchecker for Cygwin. 149,165 words, average length = 8.
Data set 3: DBLP Bibliography. 277K titles, average length = 62.
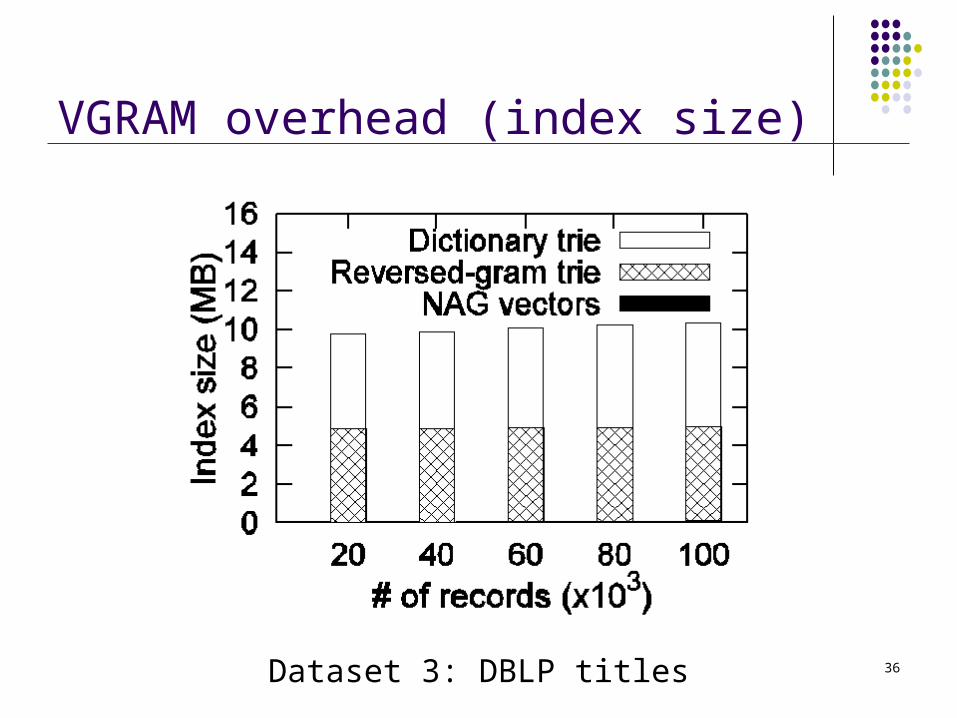
36
VGRAM overhead (index size)
Dataset 3: DBLP titles
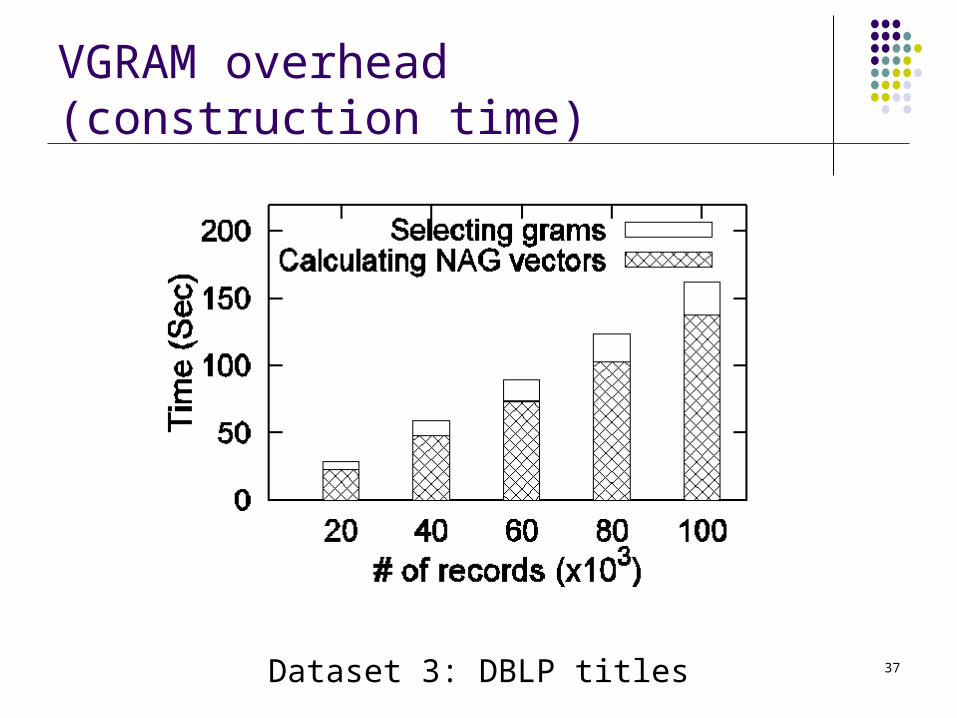
37
VGRAM overhead (construction time)
Dataset 3: DBLP titles
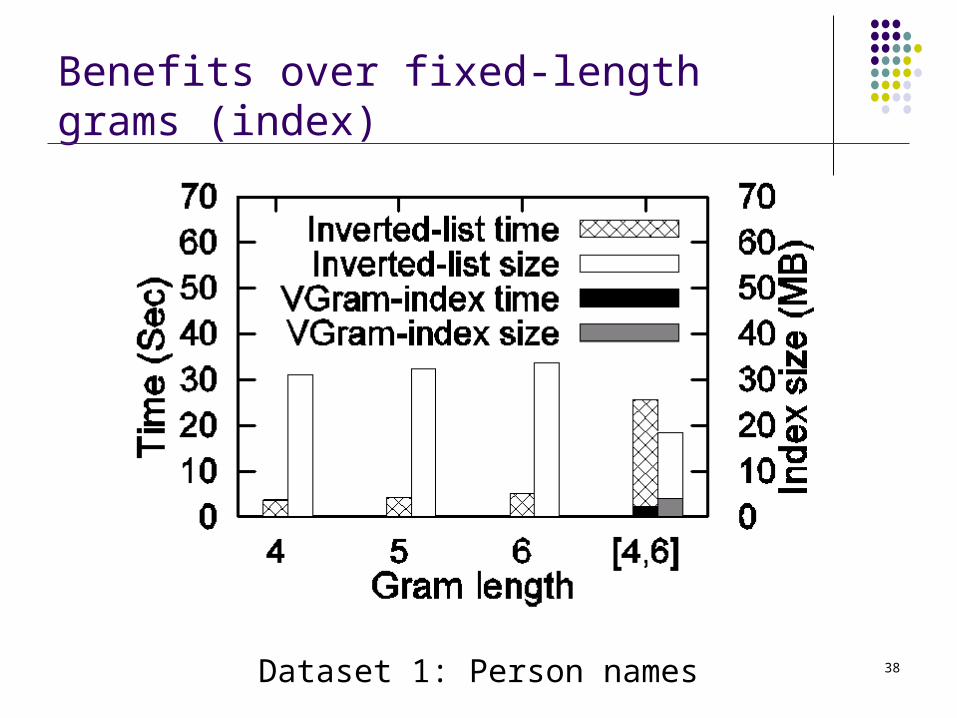
38
Benefits over fixed-length grams (index)
Dataset 1: Person names
39
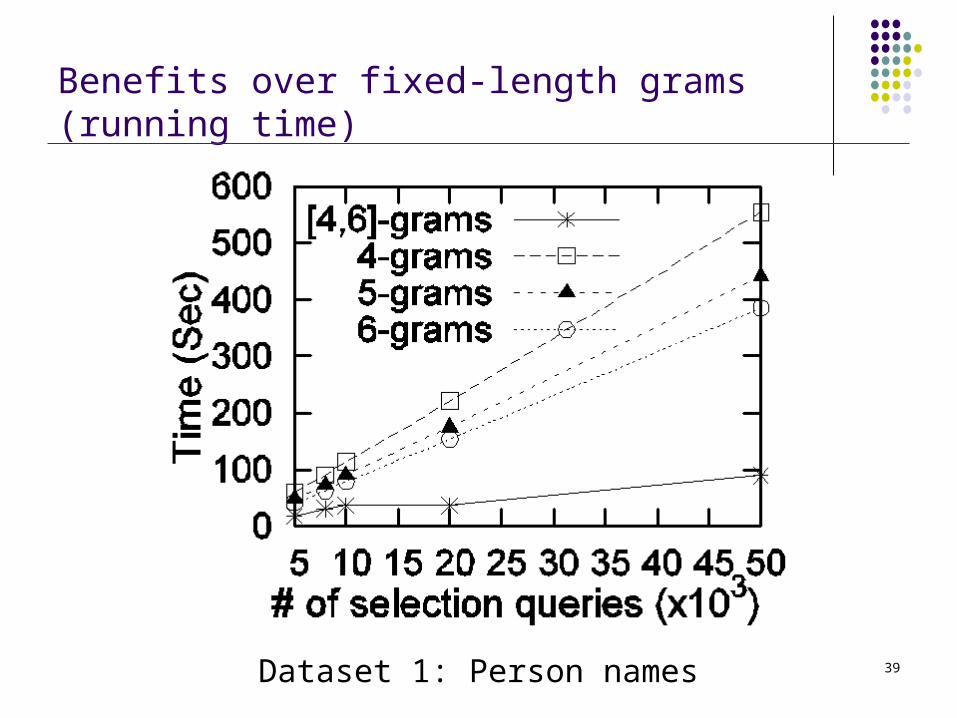
Benefits over fixed-length grams (running time)
Dataset 1: Person names
40
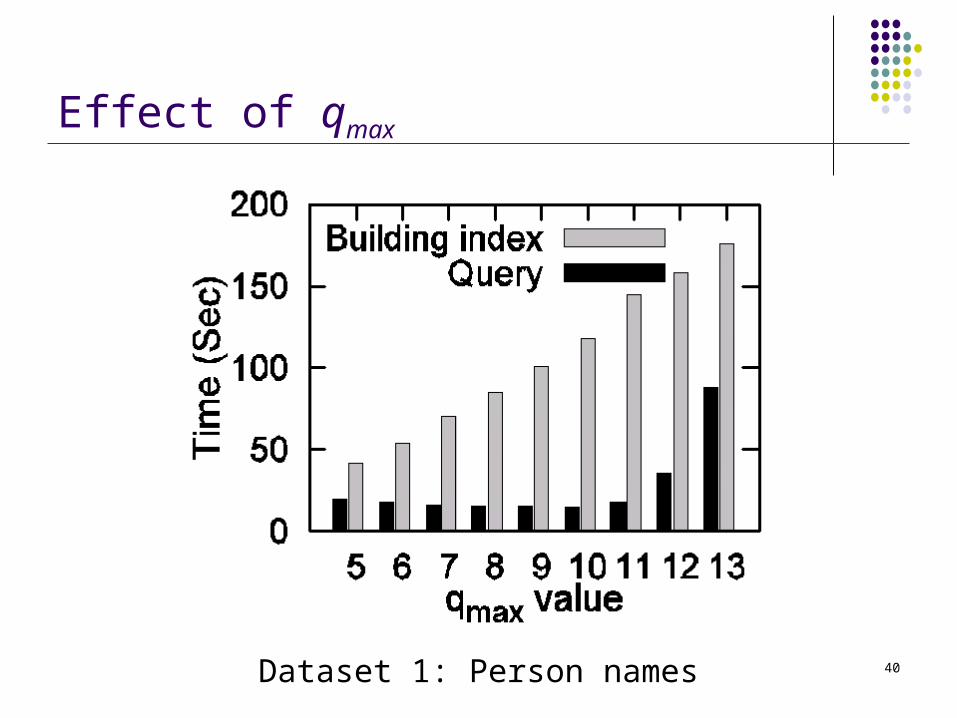
Effect of qmax
Dataset 1: Person names
41
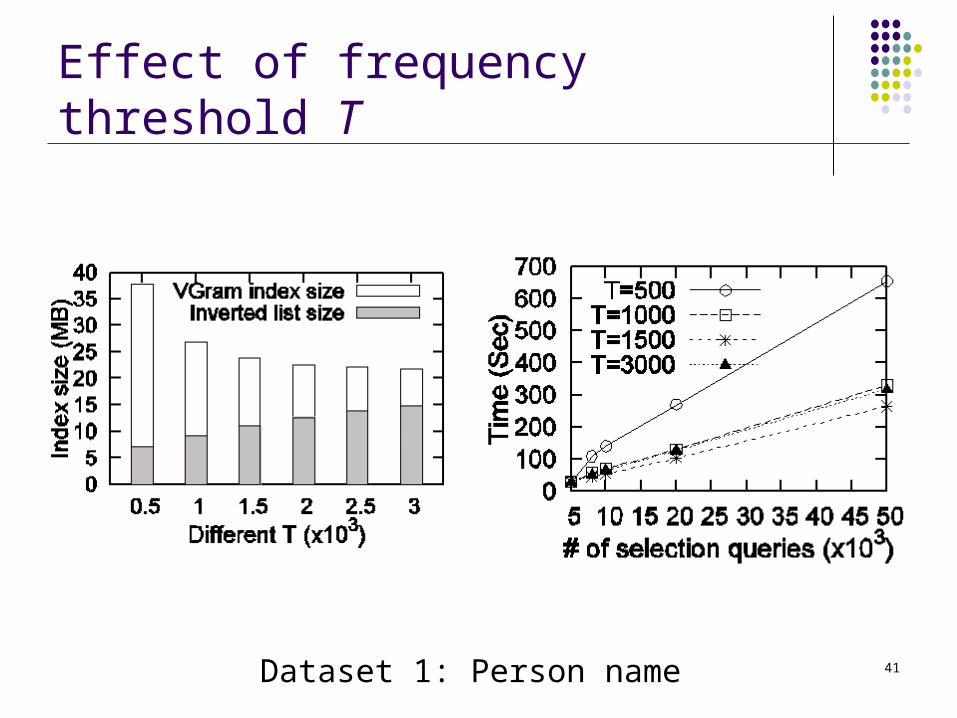
Effect of frequency threshold T
Dataset 1: Person name
42
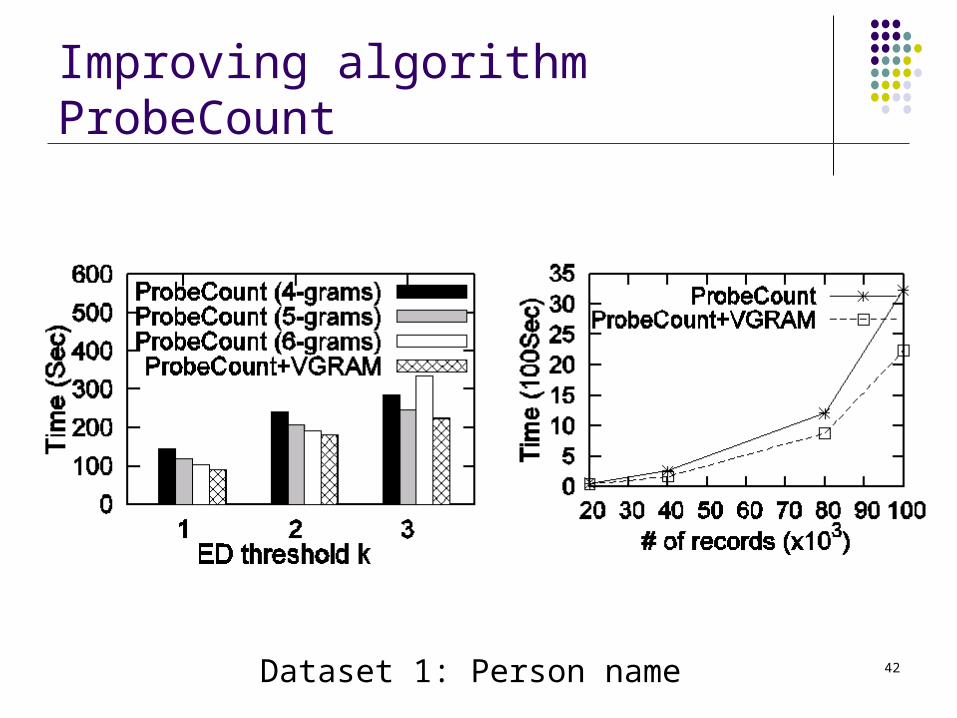
Improving algorithm ProbeCount
Dataset 1: Person name

43
Improving algorithm ProbeCluster
Dataset 1: Person name
44
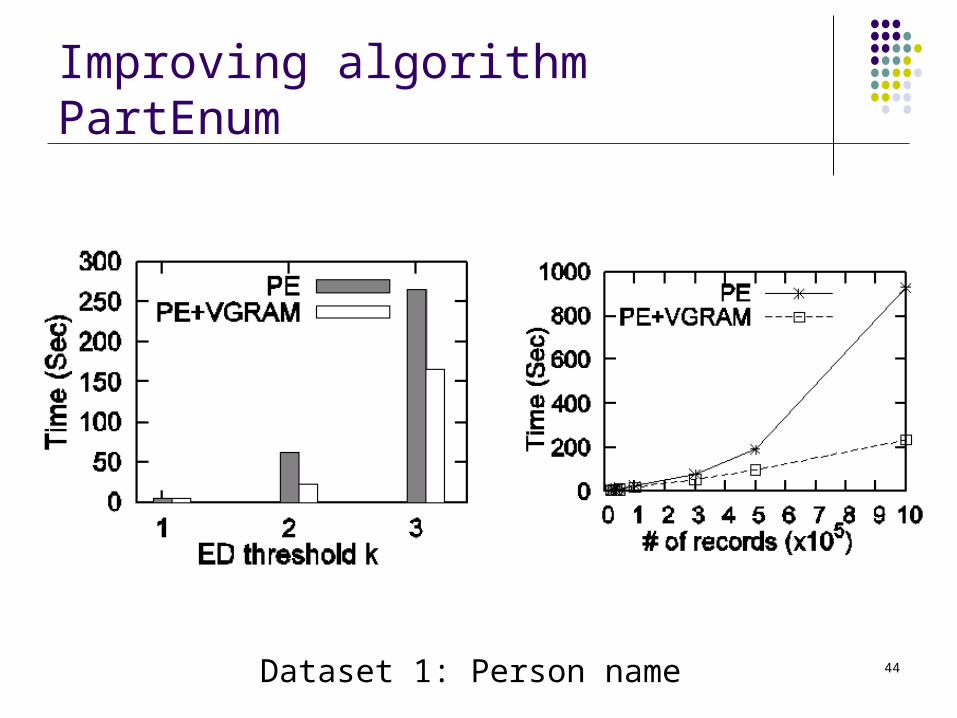
Improving algorithm PartEnum
Dataset 1: Person name

45
Discussions Dynamic maintenance Edit distance variants
Approximate substring queries Block moves
Using VGRAM in DBMS

46
Conclusions VGRAM: using grams of
variable-length high-quality
Adoptable in existing algorithms Reduce index size Reduce running time