
Università degli studi Roma Tre - didattica.sic.uniroma3.it · strumentario opzionale interfaccia...
57
Università degli studi Roma Tre Corso di Laurea Magistrale in Ingegneria delle Infrastrutture viarie e trasporti (D.M.270/04) RELAZIONE DI FINE TIROCINIO ANALISI DI DATI FCD PER LA CALIBRAZIONE DI UN MODELLO DI PARK & RIDE A.A. 2016/2017 Relatrice: Prof.ssa Marialisa Nigro Correlatore: Dott. Carlo Liberto Laureanda: Martina Trojani
Transcript of Università degli studi Roma Tre - didattica.sic.uniroma3.it · strumentario opzionale interfaccia...

Università degli studi Roma Tre
Corso di Laurea Magistrale in
Ingegneria delle Infrastrutture viarie e trasporti
(D.M.270/04)
RELAZIONE DI FINE TIROCINIO
ANALISI DI DATI FCD PER LA CALIBRAZIONE DI UN
MODELLO DI PARK & RIDE
A.A. 2016/2017
Relatrice:
Prof.ssa Marialisa Nigro
Correlatore:
Dott. Carlo Liberto
Laureanda:
Martina Trojani

1
1. ABSTRACT
In questa relazione si vuole descrivere il progetto svolto in collaborazione con il centro
di ricerca ENEA, sito in Via Anguillarese, 301, 00123 Roma. Il tirocinio finalizzato alla tesi
è stato svolto nel “Dipartimento Tecnologie Energetiche”, divisione “Produzione,
Conversione e Uso efficienti dell’energia” ed in particolare nel “Laboratorio Sistemi e
tecnologie per la Mobilità e l’Accumulo”, con una durata di 150 ore.
Il tema della mobilità sostenibile sta divenendo negli ultimi anni uno degli argomenti
di maggiore dibattito nell’ambito delle politiche ambientali locali, nazionali e
internazionali che possiamo identificare con l’insieme di azioni volte a ridurre l’impatto
ambientale derivante dalla mobilità delle persone e delle merci. Il miglioramento del
sistema dei trasporti, in particolare in ambito urbano, rappresenta una delle priorità per
i paesi che vogliono favorire una migliore qualità della vita dei cittadini, in termini di
relazioni sociali e culturali, in ambito locale, nazionale e internazionale e nel creare nuove
opportunità economiche.
Le aree urbane si vanno sempre più qualificando come ambienti dove si lavora, ci si
muove, si fanno affari e dove la vita è regolata dalla funzionalità dei servizi pubblici ma
anche dai nuovi stili di vita dei singoli cittadini legati ad esempio al tempo libero. La
mobilità urbana è diventata una delle più grandi opportunità di sviluppo e nel contempo
fonte di problemi della vita contemporanea, il cui maggiore fattore strutturale è legato ai
cambiamenti della morfologia urbana e alle trasformazioni dell’intero sistema urbano nel
suo complesso. Il traffico urbano è senza dubbio uno dei principali problemi della nostra
epoca e le sue conseguenze si ripercuotono su molteplici aspetti della vita degli individui.
Esiste la possibilità del Park and ride, che consente agli automobilisti diretti verso il
centro città di parcheggiare il proprio mezzo nei parcheggi custoditi, utilizzando così un
bus navetta per raggiungere il centro città. Le tariffe della sosta sono agevolate o in alcuni
casi, come per il caso del comune di Roma, la sosta è gratuita per tutti gli abbonati al
servizio pubblico Atac.
L’obiettivo di questo tirocinio è studiare dei dati FCD forniti dall’Ente di Ricerca ENEA
e carpire, attraverso un modello matematico implementato attraverso tecniche di
Machine Learning, quali fattori incidono maggiormente nella politica di Park & Ride
effettuata nel comune di Roma. In particolare lo sviluppo di questo tirocinio formativo
sarà utile per la stesura della tesi ai fini dell’implementazione del modello di Random
Forest utile a stimare le variabili indipendenti del modello e un’eventuale variazione

2
della quota di Park & Ride generata da un’origine in funzione di modifiche o inserimento
di variabili esterne.
2. INTRODUZIONE
I dati a supporto di questa analisi hanno richiesto una prima fase di elaborazione poiché
appartenenti a diverse metodologie di raccolta. Per quanto riguarda il trasporto privato
sarà utilizzata una banca dati costituita da dati derivanti da veicoli sonda (Floating Car
Data, flotta Octotelematics); a supporto di questi per la calibrazione del modello saranno
utilizzati anche dati del trasporto pubblico, derivanti dagli Open Data, resi disponibili
dalle principali aziende di TP della città di Roma, riferiti solamente agli spostamenti
all’interno del comune.
In relazione ai dati a disposizione saranno ipotizzate delle variabili indipendenti
secondo il quale il modello verrà successivamente calibrato: l’insieme delle variabili
indipendenti, a cui saranno associate le relative quote percentuali di Park & Ride emesse
da ogni zona, andrà a costituire il database su cui si effettuerà la stima del modello. Prima
però, il database dovrà essere depurato di tutti quegli elementi che non saranno
rappresentativi o che possano in qualche modo disturbare la calibrazione del modello ed
infine saranno studiate e applicate tecniche di Machine Learning quali Random Forest.
PROGRAMMI UTILIZZATI
L’esperienza di tirocinio è stata fondamentale per l’acquisizione di competenze tecniche
e informatiche relative all’utilizzo dei software MatLab e Quantum GIS e al linguaggio
di programmazione Python.
2.1.1. MATLAB
MATLAB (abbreviazione di Matrix Laboratory) è un ambiente per il calcolo numerico e
l'analisi statistica scritto in C, che comprende anche l'omonimo linguaggio di
programmazione creato dalla MathWorks. MATLAB consente di manipolare matrici,
visualizzare funzioni e dati, implementare algoritmi, creare interfacce utente, e
interfacciarsi con altri programmi. Nonostante sia specializzato nel calcolo numerico, uno
strumentario opzionale interfaccia MATLAB con il motore di calcolo simbolico di Maple.
MATLAB è usato da milioni di persone nell'industria e nelle università per via dei suoi
numerosi strumenti a supporto dei più disparati campi di studio applicati e funziona su
diversi sistemi operativi, tra cui Windows, Mac OS, GNU/Linux e Unix.

3
MATLAB è spesso utilizzato per costruire i sistemi avanzati di Big Data Analytics di
oggi, dalla manutenzione predittiva e telematica ai sistemi avanzati di assistenza alla
guida e all'analisi dei sensori.
QUANTUM GIS
QGIS è un Sistema di Informazione Geografica Open Source facile da usare, rilasciato
sotto la GNU General Public License. QGIS è un progetto ufficiale della Open Source
Geospatial Foundation (OSGeo). QGIS offre un numero in continua crescita di
funzionalità dal programma principale e dai plugin. È possibile visualizzare, gestire,
modificare, analizzare dati e comporre mappe stampabili. stato utilizzato per analizzare
la localizzazione dei parcheggi di scambio e i flussi relativi.
2.2.1. PYTHON
Python è un linguaggio di programmazione ad alto livello, rilasciato pubblicamente per
la prima volta nel 1991 dal suo creatore Guido van Rossum, programmatore olandese
attualmente operativo in Dropbox. Deriva il suo nome dalla commedia Monty Python's
Flying Circus dei celebri Monty Python, in onda sulla BBC nel corso degli anni 70.
Attualmente, lo sviluppo di Python (grazie e soprattutto all'enorme e dinamica comunità
internazionale di sviluppatori) viene gestito dall'organizzazione no-profit Python
Software Foundation.
Python supporta diversi paradigmi di programmazione, come quello object-oriented
(con supporto all'ereditarietà multipla), quello imperativo e quello funzionale, ed offre
una tipizzazione dinamica forte. È fornito di una libreria built-in estremamente ricca, che
unitamente alla gestione automatica della memoria e a robusti costrutti per la gestione
delle eccezioni fa di Python uno dei linguaggi più ricchi e comodi da usare.
Python è un linguaggio pseudocompilato: un interprete si occupa di analizzare il codice
sorgente (semplici file testuali con estensione .py) e, se sintatticamente corretto, di
eseguirlo. In Python, non esiste una fase di compilazione separata (come avviene in C, o
in Java) che generi un file eseguibile partendo dal sorgente. L'essere pseudointerpretato
rende Python un linguaggio portabile. Una volta scritto un sorgente, esso può essere
interpretato ed eseguito sulla gran parte delle piattaforme attualmente utilizzate, siano
esse di casa Apple (Mac) che PC (Microsoft Windows e GNU/Linux). Semplicemente,
basta la presenza della versione corretta dell'interprete.

4
Queste caratteristiche hanno fatto di Python il protagonista di un enorme diffusione in
tutto il mondo, e anche in Italia, negli ultimi anni. Questo perché garantisce lo sviluppo
rapido di applicazioni di qualsiasi complessità in tutti i contesti: dal desktop al web,
passando dallo sviluppo di videogiochi e dallo scripting di sistema, infatti rappresenta
una delle tecnologie principali del core business di colossi come Google (YouTube è
basato su Python) e ILM.
3. IL MACHINE LEARNING E LE RANDOM FOREST
Il Machine Learning (ML), in italiano apprendimento automatico, è una sotto branca
dell’informatica originariamente nata come approccio per il raggiungimento di
un’intelligenza artificiale. Questo obiettivo è stato successivamente sostituito, in un’ottica
più concreta, con l’affrontare e risolvere problemi di natura pratica.
L’idea alla base del ML è quella di replicare il processo di apprendimento mirato
all’esecuzione di un compito, sia esso specifico o meno, tramite la realizzazione di
algoritmi generici il cui scopo è quello di creare dei modelli per i dati trattati. Grazie a
questi modelli è possibile superare le limitazioni derivanti da programmi o algoritmi
espliciti (statici) e riuscire ad effettuare decisioni e predizioni basate invece sui dati che si
hanno a disposizione. Il ML risulta molto legato ad altre discipline, come ad esempio il
Data Mining con cui condivide diverse metodologie, tuttavia si differenzia da esse in un
aspetto importante: lo scopo dell’apprendimento è quello di ottenere la migliore
generalizzazione di un problema per riuscire ad effettuare delle predizioni quanto più
accurate possibile sui dati che verranno presentati al sistema. L’evoluzione ed il
miglioramento di un sistema di questo tipo quindi non sarà più legata ad ulteriori
sviluppi di un determinato programma, bensì al continuo utilizzo di dati più aggiornati
non appena questi vengono resi disponibili.
Un processo di apprendimento, identificabile come un compito di ML, può essere
classificato secondo tre categorie principali che si differenziano in base al feedback che il
sistema riceve durante il procedimento:
Apprendimento supervisionato: vengono presentati i dati di input e i risultati
desiderati. Lo scopo è di apprendere una regola generale che colleghi i dati in ingresso
con quelli in uscita;

5
Apprendimento non supervisionato: vengono presentati i dati di input ma nessun
risultato desiderato. Lo scopo è quello di scoprire schemi o modelli nascosti nei dati
presentati;
Apprendimento con rinforzo: vengono raccolti i dati di input tramite l’interazione
con un ambiente dinamico; ad ogni azione in questo ambiente corrisponde una
ricompensa (anche negativa) e l’obiettivo è quello di svolgere un determinato compito
massimizzando il valore della ricompensa.
VALIDAZIONE EFFICACE DEI MODELLI DI MACHINE LEARNING
La validazione dei modelli è stata un’area di estremo interesse per molte istituzioni
finanziarie che si affidano ai modelli statistici per l’underwriting, il pricing, il reserving e il
Capital Management. Tradizionalmente, per creare modelli che permettessero di fare
previsioni sono state utilizzate tecniche relativamente trasparenti e consolidate
all’interno del mondo statistico quali la regressione lineare (LM), i modelli lineari
generalizzati (GLMs) e altri metodi statistici. Tuttavia, i recenti sviluppi tecnologici e dei
software open source hanno aumentato la potenza computazionale, favorendo la fruibilità
di algoritmi di elaborazione dati più efficaci, generando un aumento della richiesta di
soluzioni predittive più avanzate e sofisticate. A tale richiesta, il mercato ha risposto con
gli algoritmi di Machine Learning.
Limitate sino a qualche anno fa al solo mondo accademico, queste tecniche di modelling
predittivo sono in grado di effettuare previsioni più accurate rispetto ai metodi di
modelling più tradizionali. Tuttavia, l’aumento del potere predittivo porta con sé maggiori
rischi legati appunto alla modellazione. I processi che consentono a queste nuove
tecniche di ottenere buoni risultati fanno sì che i processi stessi siano complessi e meno
trasparenti di quelli tradizionali. Se vi è scarsa trasparenza nel processo di modelling è
facile per un utente non esperto usare impropriamente le tecniche di Machine Learning e
generare risultati di tipo “black box”, a causa di una inadeguata comprensione delle
relazioni sottostanti e rendendo ancora più cruciale la validazione del modello.
Le tecniche di Machine Learning appartengono ad una famiglia di algoritmi che
racchiudono insieme la statistica applicata e le scienze informatiche. A differenza dei
metodi tradizionali di regressione, le Machine Learning sono tecniche non parametriche,
ovvero non vincolate da una forma funzionale e libere da qualsiasi tipo di assunzione a
priori di distribuzione statistica. Nelle tecniche parametriche, di cui la regressione lineare
è un esempio, un aumento di una variabile indipendente (ad esempio la variabile che
spiega un risultato quale la variazione dei prezzi delle abitazioni) deve determinare
esclusivamente un aumento o una diminuzione della variabile dipendente (ad esempio,

6
il risultato che si sta stimando, come il numero delle persone con mutuo che sono in
difficoltà o che falliscono). Nelle tecniche di Machine Learning, l’effetto di una variabile
indipendente su quella dipendente può differire in base ai livelli e alle interazioni con
altre variabili. La capacità di catturare queste interazioni attraverso diversi valori delle
variabili consente a queste tecniche di andare oltre i tradizionali modelli parametrici.
OVERFITTING (ECCESSIVO ADATTAMENTO)
Le tecniche di Machine Learning e gli algoritmi di classificazione sono più sensibili al
fenomeno dell’overfitting rispetto ai più tradizionali modelli di previsione. L’overfitting si
verifica quando un modello basa le sue previsioni su correlazioni spurie all’interno di un
campione di dati anziché su relazioni autentiche esistenti all’interno della popolazione
nel suo complesso. Mentre i modelli lineari ed i GLMs possono generare livelli contenuti
di overfitting, gli algoritmi di Machine Learning sono ancora più sensibili a questo tipo di
criticità, principalmente a causa della mancanza di vincoli parametrici. In assenza di una
forma funzionale, questi algoritmi possono utilizzare ogni relazione, lineare e non, tra le
variabili nei dati del campione di training, per eseguire raggruppamenti e/o fare
previsioni. Il maggior rischio è che ogni singolo campione, su cui viene costruito il
modello, abbia le proprie peculiarità che non riflettano puntualmente la vera
popolazione, riducendo il potere di replicabilità del fenomeno osservato nella totalità dei
dati. Gli alberi di Classificazione e di Regressione sono particolarmente sensibili a questa
tipologia di criticità, in quanto possono suddividere i dati fino a raggiungere la
classificazione perfetta o quasi perfetta, generando così alcune partizioni fuorvianti.
Se un modello caratterizzato da overfitting viene applicato a nuovi dati appartenenti alla
stessa popolazione, può, potenzialmente, produrre previsioni poco accurate. Vista
l’importanza che molte aziende attribuiscono nei processi decisionali alle analisi
predittive, questa mancata accuratezza può avere effetti molto distorsivi.
RIDUZIONE DELLA TRASPARENZA
Le tecniche di Machine Learning riducono, inoltre, la trasparenza del processo
interpretativo del modello previsionale. Con le tecniche di regressione più tradizionali, è
più intuitivo vedere come interagiscono le variabili all’interno del modello; infatti per
valutare la significatività e la direzione di un effetto, è sufficiente esaminare un singolo
coefficiente. Se quest’ultimo è positivo, ciò implica una relazione positiva tra la variabile
indipendente di interesse e la variabile dipendente, e viceversa. La maggior parte delle
tecniche di apprendimento automatico non produce tuttavia risultati così facilmente
interpretabili. Alcuni algoritmi, come gli alberi di Classificazione e Regressione semplici,
presentano grafici abbastanza comprensibili, ma altri, quali il Gradient Boosting, le Random

7
Forest e le Reti Neurali, funzionano come delle specie di “scatole nere” diminuendo la
trasparenza e l’interpretabilità della metodologia sottostante. Sebbene un utente possa
inserire i dati e le specificità del modello e pur essendo possibile esaminare i vari steps
intermedi generati dall’algoritmo per capire come è in grado di generare le previsioni,
spesso è necessario ed opportuno possedere una conoscenza molto approfondita e
consolidata di queste tecniche per poter valutare con trasparenza e giudizio critico
l’intero processo.
Nelle tecniche di regressione tradizionali, uno sguardo alla direzione e alla
significatività del singolo coefficiente, agli standard error ed all’adattamento complessivo
dei modelli ai dati, consente agli utenti di avere un’idea, per quanto approssimativa, del
corretto potere predittivo dei modelli utilizzati. Se la maggioranza dei coefficienti delle
variabili risultano non significativi, la bontà di adattamento del modello è inaccurata, o
se le variabili non hanno il potere esplicativo previsto, l’utente sa che il modello potrebbe
contenere un errore o un settaggio non ottimale. Il modello potrebbe essere stato adattato
su dati non adeguati, scarsamente specificati o utilizzati in un contesto non corretto. Con
le tecniche di Machine Learning, tuttavia, la mancanza di trasparenza nelle previsioni
rende più difficoltosa l’individuazione di questi tipi di criticità.
ANALISI DEI RISULTATI
Con analisi dei risultati si intende la comparazione dei risultati stimati rispetto ai dati
osservati. Per queste tecniche avanzate di previsione, l’analisi dei risultati rappresenta,
pur nella sua semplicità, un approccio molto utile per comprendere e valutare le
interazioni e le potenziali criticità del modello implementato. Un modo per comprendere
il potere predittivo del modello è quello di rappresentare in un diagramma i valori della
variabile indipendente in funzione sia del risultato osservato che di quello stimato,
insieme al numero di osservazioni. Ciò consente all’utente di osservare la relazione
univariata all’interno del modello e valutare il livello di overfitting prodotto. Per valutare
le possibili interazioni, possono essere creati anche diagrammi incrociati valutando i
risultati in due dimensioni anziché in una. Oltre le due dimensioni diventa difficile
valutare i risultati, ma osservando le interazioni univoche si acquisisce una prima
comprensione del comportamento del modello rispetto alle singole variabili indipendenti
utilizzate.
I dati campionari vengono solitamente suddivisi in proporzione 80-20, in cui l’80%
viene utilizzato per adattare o “addestrare” il modello (training data set) e il restante 20%
(validation data set) viene impiegato per valutarne la capacità predittiva.

8
LE RANDOM FOREST
Le random forest sono uno strumento di classificazione introdotto per la prima volta
nel 2001 da Leo Breiman, nate da lavori precedenti dello stesso autore volti a migliorare
le prestazioni ottenibili da singoli alberi di decisione, introducendo alcune componenti
aleatorie nella costruzione degli stessi e un meccanismo di voto per la determinazione del
risultato della classificazione.
Le Random Forest sono un metodo di apprendimento di insieme per la classificazione
o la regressione che operano costruendo una moltitudine di alberi decisionali durante il
periodo di addestramento e forniscono il risultato che è la modalità delle classi (nel caso
della classificazione) o la previsione media (nel caso della regressione) dei singoli alberi.
LE RANDOM FOREST: ESEMPIO ESPLICATIVO
Consideriamo un insieme di punti su un piano cartesiano a cui ad ogni punto è associato
un vettore di attributi, in questo caso una coppia (x1, x2) che rappresenta la posizione sul
piano. Ogni punto può appartenere ad una di 4 classi distinte, Verde, Rosso, Giallo o Blu.
Attraverso un albero decisionale è possibile classificare il dataset in maniera tale da
riuscire a prevedere il colore di nuovi punti in funzione della loro posizione (x1, x2).
Figura 1 - Analisi spaziale esempio applicativo
Il punto di partenza dell’albero decisionale (in questo caso Classification Tree) è la
radice, ovvero l’insieme che comprende tutto il campione da analizzare in cui ogni classe
ha probabilità 𝑝𝑡(𝑐|𝑣) = 𝑁𝑐/𝑁𝑡𝑜𝑡 (la probabilità che il t-esimo albero scelga la classe c per
l’elemento v è uguale al numero di elementi appartenenti alla classi c fratto il numero di
elementi totali). Ad ogni nodo a partire dalla radice l’algoritmo suddivide il campione in
2 sottoinsiemi 𝑆𝑖𝐿 𝑒 𝑆𝑖
𝐷 (tali che 𝑆𝑖 = 𝑆𝑖𝐿 ⋃ 𝑆𝑖
𝐷 ) in funzione di un attributo: ad esempio,
posto un valore soglia di x1*, nel primo sottoinsieme ricadranno i punti con il valore di
x1 < x1* e nel secondo quelli con x1 ≥ x1*. La scissione di ogni insieme avviene in modo

9
tale da massimizzare la probabilità 𝑝𝑡(𝑐|𝑣) per classificare correttamente l’elemento e con
il numero minimo di iterazioni.
La Random Forest si ottiene combinando più alberi decisionali paralleli e mediando la
probabilità ottenuta da ogni albero.
Al crescere del numero di alberi 𝑝(𝑐|𝑣) → 𝑝(𝑐|𝑣)∗ mentre al crescere della profondità
degli alberi cresce la possibilità di andare in overfitting (eccessivo adattamento al
campione).
Per evidenziare meglio la differenza tra Decision Tree e Random Forest è stata effettuata
una comparazione dei 2 metodi a livello numerico. È stato creato un insieme di dati
costituito da 500 coppie (x, y) il cui andamento può essere approssimato con una funzione
y = log(x), ad eccezione di alcuni valori che possiamo considerare come “rumore”, ed è
stato sottoposto ad entrambe le tecniche.
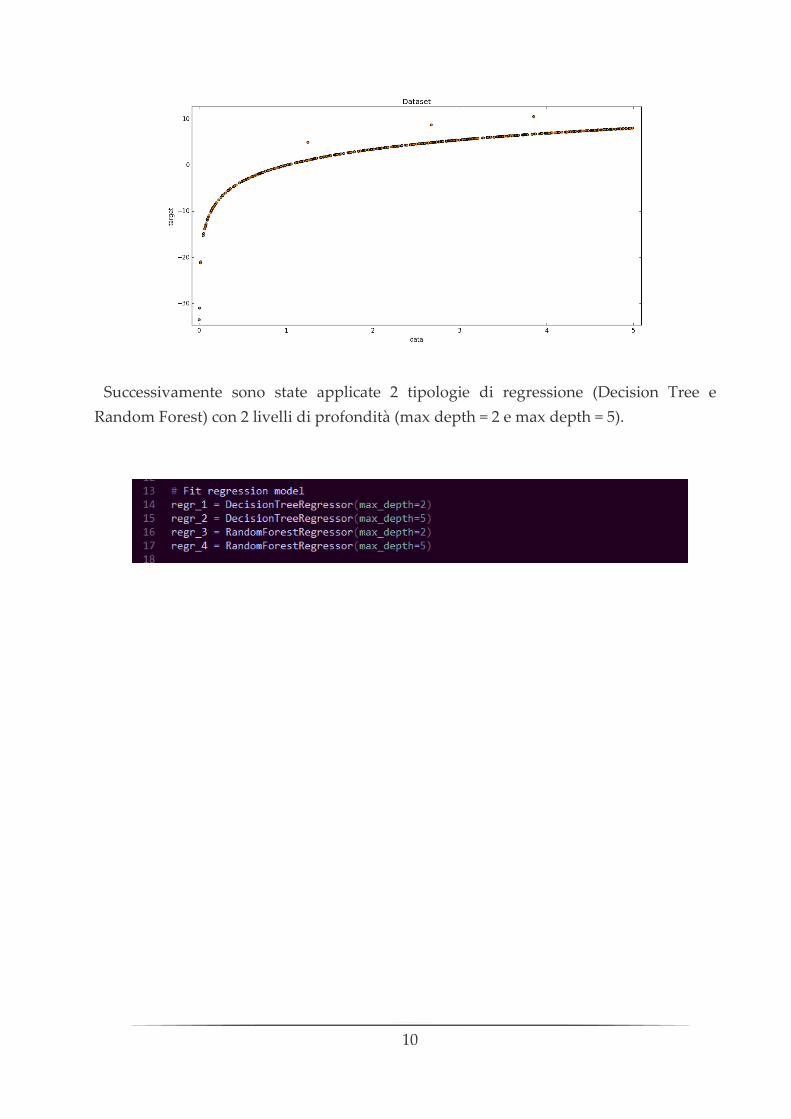
10
Successivamente sono state applicate 2 tipologie di regressione (Decision Tree e
Random Forest) con 2 livelli di profondità (max depth = 2 e max depth = 5).

11
I risultati ottenuti sono stati i seguenti:

12
4. I FLOATING CAR DATA
I Floating Car Data sono dati derivanti da veicoli sonda, cioè vengono raccolti dalle On
Board Unit (OBU) installate, per lo più a scopi assicurativi, su veicoli stradali. Questi
costituiscono, quindi, dei "sensori mobili" nel flusso veicolare che non richiedono alcun
tipo di installazione aggiuntiva lungo la sede stradale.
Il veicolo sonda manda i dati di traffico più recenti continuamente o con periodicità ad
un sistema centrale di raccolta dati, che colleziona tutte le provenienze dai vari veicoli
della flotta FCD e mette i dati a disposizione degli analisti di traffico. I dati rilevati dalle
OBU (tipicamente la posizione e la relativa velocità istantanea, ad intervalli regolari
sufficientemente ravvicinati) presentano numerosi pregi, ai fini di un utilizzo per
osservazioni ed analisi sulla mobilità:
a differenza dei dispositivi fissi di monitoraggio, la tecnica FCD consente di
ottenere informazioni più affidabili sui viaggi in termini di lunghezza dei percorsi e
tempi di percorrenza, e di valutare i flussi origine-destinazione;
è più economicamente sostenibile rispetto alle altre tecniche di monitoraggio: i dati
sono acquisiti per altre finalità e, quindi, a costo marginale nullo;
i dati sono acquisiti in maniera regolare e protratta nel tempo, così da consentire
analisi di tendenza;
questa tecnica fornisce il vantaggio di copertura dell’intera rete stradale: i dati sono
diffusi sul territorio nazionale (ed extranazionale), anche se con intensità variabile.
I dati acquistati dalla compagnia OCTO Telematics rappresentano una raccolta di dati
sugli spostamenti compiuti dai veicoli quali: posizione, velocità, tempo, distanza
percorsa. Il set di dati disponibili riguarda la città metropolitana di Roma e la sua
provincia per il mese di maggio 2013. Il campione OCTO Telematics, all’epoca del
rilevamento, era accreditato per circa il 7% dell’intero parco circolante nell’area romana,
che è stato oggetto del nostro studio.
5. L’ELABORAZIONE DEI DATI
I parcheggi di scambio sono delle aree in cui è possibile effettuare un cambio di modalità
di trasporto, generalmente privato-pubblico. A Roma i parcheggi di scambio sono situati
presso le stazioni della metropolitana A, B, B1 e C, presso le fermate delle ferrovie
metropolitane (Ferrovie Laziali, Roma-Viterbo, Roma-Lido) e nei principali nodi di
interscambio con le linee di superficie.
Nelle analisi descritte successivamente non saranno considerati i parcheggi aperti dopo
il mese di maggio 2013.

13
Dagli Open Data reperibili On-line dal sito ufficiale di Roma Servizi Mobilità sono stati
riconosciuti 56 parcheggi di scambio con relative caratteristiche, quali Nome, Indirizzo,
Posti auto disponibili, Tipologia, Interscambio con TPL, Orario, Costo.
Analizzando la localizzazione di questi parcheggi in relazione alla zonizzazione ISTAT,
formata da 13'656 zone di Roma + 122 comuni esterni, è stato possibile rilevare delle
informazioni aggiuntive relative ai parcheggi:
53 parcheggi risultano interni al comune di Roma, mentre 3 risultano nel comune
di Monte Compatri;
Figura 2 - Parcheggi dell'area oggetto di studio
Alcuni parcheggi rappresentano gli ingressi della stessa area di parcheggio
(Anagnina, Rebibbia, Pantano)
Figura 3 - Parcheggio di Anagnina

14
In totale quindi abbiamo 51 aree di parcheggio, in cui ogni area comprende uno o più
parcheggi.
Il database con i dati FCD utilizzati, risalente al mese di maggio 2013, contiene i dati
relativi a spostamenti, distanze e tempi nei soli giorni feriali martedì, mercoledì e giovedì
e i veicoli entrati/usciti dalle aree di parcheggio, ad intervalli temporali di 1h, dalle 00:00
alle 23:59.
Gli spostamenti forniti rappresentano i movimenti effettuati dagli utenti rilevati dal
momento in cui il veicolo viene acceso al momento in cui viene spento, non considerando
però eventuali brevi soste intermedie. Sono stati quindi uniti tutti gli spostamenti la cui
destinazione di uno coincideva con l’origine dell’altro e il cui intervallo temporale tra
arrivo e partenza non superasse i 15 minuti. Considerando poi la zonizzazione ISTAT è
stato possibile ricreare le seguenti matrici:
• Matrice Origine – Destinazione: 13’656 zone di Roma + 122 comuni esterni
(spostamenti, distanze, tempi con relativi dev. Standard e valori min e max);
• Matrice Origine – Parcheggio: 13’656 zone di Roma + 122 comuni esterni x 51 park
(spostamenti, distanze, tempi con relativi dev. Standard e valori min e max);
• Occupazione parcheggi: veicoli entrati/usciti dalle aree di parcheggio per ogni area
di parcheggio e per ogni intervallo t.
In seguito alla creazione delle matrici di occupazione dei parcheggi è stata necessaria
un’analisi di quest’ultimi: in particolare bilanciando le entrate e le uscite ci si aspetta un
riempimento crescente fino al punto massimo e in seguito uno svuotamento del
parcheggio, come accade per esempio nel parcheggio di Anagnina:
Figura 4 - Trend del riempimento del parcheggio di Anagnina
15
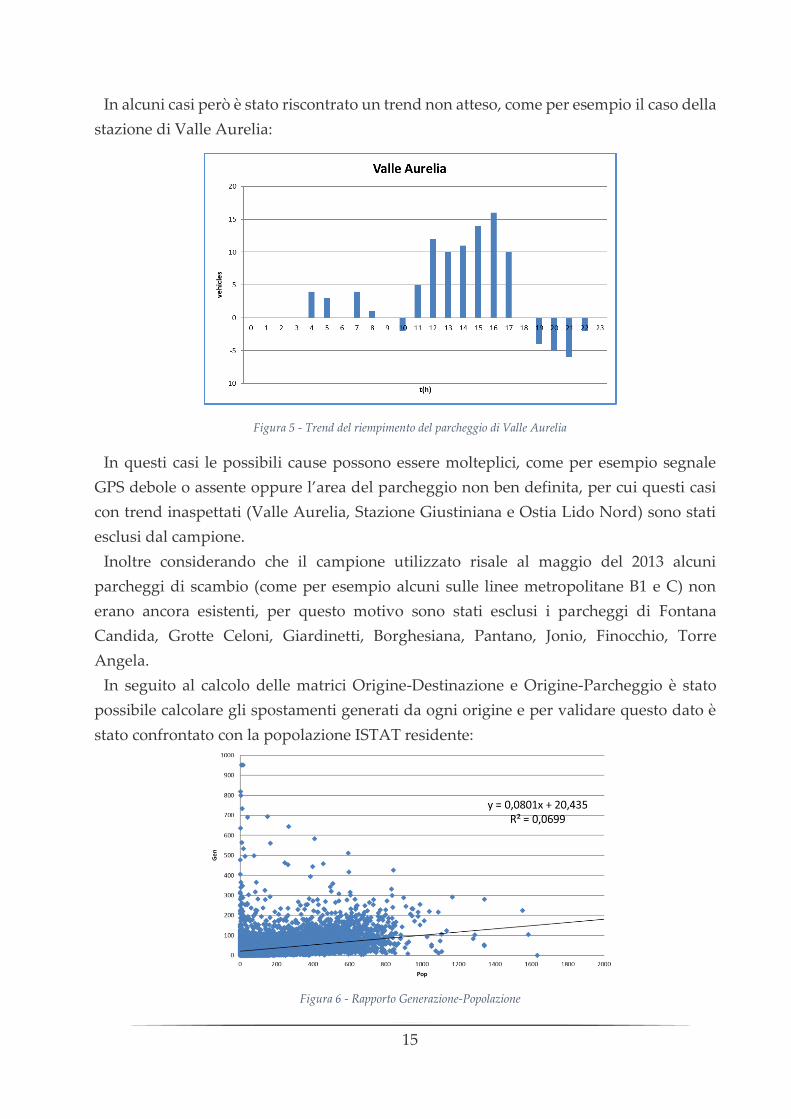
In alcuni casi però è stato riscontrato un trend non atteso, come per esempio il caso della
stazione di Valle Aurelia:
Figura 5 - Trend del riempimento del parcheggio di Valle Aurelia
In questi casi le possibili cause possono essere molteplici, come per esempio segnale
GPS debole o assente oppure l’area del parcheggio non ben definita, per cui questi casi
con trend inaspettati (Valle Aurelia, Stazione Giustiniana e Ostia Lido Nord) sono stati
esclusi dal campione.
Inoltre considerando che il campione utilizzato risale al maggio del 2013 alcuni
parcheggi di scambio (come per esempio alcuni sulle linee metropolitane B1 e C) non
erano ancora esistenti, per questo motivo sono stati esclusi i parcheggi di Fontana
Candida, Grotte Celoni, Giardinetti, Borghesiana, Pantano, Jonio, Finocchio, Torre
Angela.
In seguito al calcolo delle matrici Origine-Destinazione e Origine-Parcheggio è stato
possibile calcolare gli spostamenti generati da ogni origine e per validare questo dato è
stato confrontato con la popolazione ISTAT residente:
Figura 6 - Rapporto Generazione-Popolazione

16
Come è possibile notare dal valore del coefficiente di correlazione R2 = 0,0699 non c’è
una buona correlazione tra le variabili il che potrebbe portare ad errori significativi
nell’analisi, per cui è stato deciso di effettuare un’aggregazione delle zone passando da
13'656 zone a 155 zone:
Figura 7 - Nuova zonizzazione proposta
Confrontando quindi i valori di Popolazione e Generazione delle Origini in seguito
all’aggregazione si può notare un netto miglioramento del valore di R2:
Nelle zone interne:
Figura 8 - Rapporto Generazione-Popolazione zone interne con la nuova zonizzazione

17
Nelle zone esterne:
Figura 9 - Rapporto Generazione-Popolazione delle zone esterne con la nuova zonizzazione
Quindi, riassumendo, i dati a disposizione relativi al trasporto privato sono:
• 𝐺𝑜𝐹𝐶𝐷 spostamenti generati da O (277 origini x 24 ore);
• 𝐺𝑜𝐹𝐶𝐷/𝑃𝐴𝑅𝐾
spostamenti generati da O che fanno Park&Ride (277 origini x 24 ore);
• Rapporto tra 𝐺𝑜𝐹𝐶𝐷/𝑃𝐴𝑅𝐾
e 𝐺𝑜𝐹𝐶𝐷 (277 origini x 24 ore);
• 𝐴𝑑𝐹𝐶𝐷 spostamenti attratti da D (277 destinazioni x 24 ore);
• 𝐴𝑝𝐹𝐶𝐷 spostamenti attratti da P (40 parcheggi x 24 ore);
• Matrici flussi, tempi e distanze O/D (277 o x 277 d x 24 ore);
• Matrici flussi, tempi e distanze O/P (277 o x 40 park x 24 ore);
• Matrice riempimenti parcheggi (40 park x 24 ore).
I dati relativi al trasporto pubblico derivano dalla simulazione descritta in precedenza
e sono costituiti da:
• matrice dei TEMPI (matrice 333x333, 56 parcheggi + 155 zone comune di
Roma + 122 zone comuni esterni x 56 parcheggi + 155 zone comune di Roma + 122
zone comuni esterni)

18
• matrice dei MEZZI (matrice 333x333, 56 parcheggi + 155 zone comune di
Roma + 122 zone comuni esterni x 56 parcheggi + 155 zone comune di Roma + 122
zone comuni esterni)
Da queste sono state estratte delle sottomatrici dei dati utili al nostro studio, ovvero:
• matrice dei tempi area di parcheggio-destinazione (matrice 40x277, 40 aree
park x 155 + 122 destinazioni);
• matrice dei mezzi area di parcheggio-destinazione (matrice 40x277, 40 aree
park x 155 + 122 destinazioni)
6. LE VARIABILI INDIPENDENTI
La fase modellistica del problema segue un procedimento ad albero mirato a
comprendere al meglio le scelte possibili che possono essere effettuate dall’utente: si parte
dalla radice, l’origine dello spostamento, in cui la prima suddivisione riguarda la scelta
tra la modalità Auto, ovvero raggiungere la destinazione con la propria autovettura,
oppure con la modalità Park&Ride, ovvero raggiungere il parcheggio di scambio con la
propria autovettura per poi effettuare il cambio modale mezzo privato/mezzo pubblico.
Se si considera una scelta di percorso effettuata totalmente sul privato il ramo è interrotto,
mentre se la scelta ricade sulla modalità Park&Ride allora la scelta successiva sarà il
parcheggio di scambio utilizzato per effettuare il cambio modale.

19
Nella fase iniziale del modello, ovvero nella scelta della modalità, ci si aspetta che la
quota parte degli utenti che effettueranno il cambio modale sia strettamente dipendente
dall’offerta di trasporto pubblico, oltre che dal numero totale di utenti. Sono state quindi
ipotizzate delle variabili di input che dovranno essere in grado, successivamente alla
calibrazione del modello, di fornire una stima della quota di Park&Ride per ogni origine
e per ogni intervallo temporale.
I DATI DI RIFERIMENTO
Prima di descrivere il procedimento per il calcolo delle variabili di input utilizzate per
la calibrazione del modello è opportuno descrivere i dati di riferimento alla base del
calcolo per capire meglio su cosa è fondata l’analisi.
I dati di riferimento sono relativi alle singole origini e, dove possibile, sono suddivisi
per intervallo orario (nel caso di tempi e flussi) e sono i seguenti:
- Area: un vettore di 277 elementi, uno per ogni origine, che rappresenta l’estensione
geografica in Km2 delle aree di origine dei flussi;
- Densità: un vettore analogo al precedente in cui è calcolato il rapporto tra la
popolazione patentata e presumibilmente occupata (età compresa tra i 19 e i 70 anni)
e l’area;
- Matrice dei flussi O/D: una matrice tridimensionale formata da 277 zone di
origine, 277 zone di destinazione e 20 intervalli temporali (04:00 – 24:00) in cui ogni
elemento è il flusso medio rilevato dall’origine O alla destinazione D nell’intervallo
temporale T;
- Gen_O_FCD: sommando il flusso di tutte le destinazioni per ogni origine e per
ogni intervallo temporale si ottiene la Generazione delle origini;
- Matrice dei flussi O/P: una matrice tridimensionale formata da 277 zone di
origine, 40 aree di parcheggio e 20 intervalli temporali (04:00 – 24:00) in cui ogni
elemento è il flusso medio rilevato dall’origine O al parcheggio P nell’intervallo
temporale T;
- Gen_O_FCD_PARK: sommando il flusso di tutte le aree di parcheggio per ogni
origine e per ogni intervallo temporale si ottiene la Generazione di Park&Ride delle
origini;
- Matrice binaria O/P: una matrice di 277 x 40 elementi in cui ogni elemento può
valere 1 se è stato rilevato almeno un veicolo che parte dall’origine O diretto al
parcheggio P in qualsiasi intervallo temporale, ovvero se il parcheggio è nell’insieme
di scelta dei parcheggi dell’origine O, 0 altrimenti;

20
- Matrici dei tempi: analoghe alle matrici dei flussi sono suddivise in matrici dei
tempi O/P e O/D;
- Parcheggi di O: sommando le righe della matrice binaria O/P è possibile ricavare
un vettore 277 x 1 in cui in ogni elemento è presente il numero di parcheggi del bacino
dell’origine O;
- Matrice dei tempi su Trasporto Pubblico: una matrice 40 x 277 x 20 di tempi da
ogni parcheggio verso tutte le destinazioni in ogni intervallo temporale. I tempi qui
riportati sono comprensivi di tempi di attesa e tratti a piedi ed è stato posto un limite
superiore pari a 4 ore;
- Matrice dei mezzi su Trasporto Pubblico: una matrice 40 x 277 x 20 di trasbordi
effettuati per raggiungere la destinazione D dal parcheggio P nell’intervallo
temporale. È stato posto un limite superiore pari a 5 trasbordi;
- Riempimenti dei parcheggi: rapporto tra veicoli rilevati all’interno dei parcheggi
e capacità per ogni parcheggio e per ogni intervallo temporale (40 x 20).
IL CALCOLO DELLE VARIABILI
Le variabili indipendenti calcolate a partire dai dati di riferimento sopra descritti sono
suddivise in variabili funzione sia delle origini che dell’intervallo temporale, variabili
funzione delle sole origini e variabili funzione dei soli intervalli temporali. In ogni caso,
essendo questo un modello basato sulla generazione delle origini le variabili verranno
calcolate per ogni origine (277) e per ogni intervallo temporale (20) per un totale di 5540
elementi per ogni variabile.
LA VARIABILE X1 – IMPEDENZA SUL TRASPORTO PRIVATO
La prima variabile di input calcolata è l’impedenza sul trasporto privato, un tempo
medio di accesso ai parcheggi appartenenti all’origine pesato per gli effettivi flussi O/P
ed è calcolato come segue:
L’ipotesi alla base è che all’aumentare dei tempi di accesso tramite mezzo privato ai
parcheggi del bacino dell’origine, la propensione a utilizzare un parcheggio di scambio
diminuisca; oltretutto pesare i tempi origine – parcheggio per i flussi origine – parcheggio
implica che i tempi O/P in cui sono stati rilevati flussi O/P maggiori incidano in maniera

21
più consistente sul risultato finale. Questa variabile, essendo funzione dei tempi e dei
flussi sarà calcolata per ogni origine e per ogni intervallo temporale.
Tuttavia i dati FCD non garantiscono l’intera copertura del territorio in esame in tutti
gli intervalli orari, per cui a volte il valore del denominatore della formula sopra descritta
è pari a 0. Una più accurata analisi è necessaria al fine di individuare la causa di questo
valore pari a 0: non è stato monitorato nessun flusso di Park and Ride in uscita a causa
della non completa copertura dei Floating Car Data oppure in quell’origine e in
quell’intervallo orario ogni utente ritiene che la combinazione privato-pubblico non sia
la scelta più conveniente.
Nei casi in cui il dato 𝐺𝑜 𝐹𝐶𝐷|𝑃𝐴𝑅𝐾
è pari a 0, ai fini di un’analisi matematica oltre che
trasportistica, è stato assegnato il valore standard di 1010 minuti, un valore
esageratamente alto, ma che indica l’impedenza infinita che presenta la zona in
quell’intervallo orario: successivamente, una volta calcolate tutte le variabili, verrà
effettuata un’analisi dei dati per capire come gestire queste eccezioni.
LA VARIABILE X2 – IMPEDENZA SUL TRASPORTO PUBBLICO (1)
La seconda variabile riportata rappresenta l’impedenza del trasporto pubblico come un
tempo medio di viaggio dai parcheggi dell’Origine a tutte le destinazioni pesato per i
flussi che accedono ai parcheggi di O ed è calcolato come segue:
L’ipotesi è che in caso di un buon collegamento del parcheggio con la rete di trasporto
pubblico l’utenza sarà portata a scegliere quel parcheggio piuttosto che un altro. Indice
di un buon collegamento è il tempo medio da un parcheggio a tutte le destinazioni, se
poi come prima questo viene pesato per i flussi che accedono al parcheggio si può avere
una stima più accurata.
La matrice dei tempi sul trasporto pubblico risulta incompleta, la parte mancante (NaN)
è quella relativa al collegamento tra i parcheggi e le 155 zone esterne di Roma, motivo
per il quale è stato deciso di assegnare un valore limite pari a 4 ore.

22
LA VARIABILE X2 BIS – IMPEDENZA SUL TRASPORTO PUBBLICO (1)
La terza variabile descritta è perfettamente analoga alla precedente con la sola
differenza nelle matrici del trasporto pubblico: in questa variabile compaiono il numero
dei trasbordi al posto del tempo impiegato per raggiungere la destinazione partendo dal
parcheggio.
LA VARIABILE X3 – IMPEDENZA SUL TRASPORTO PUBBLICO (2)
Analisi ben più differente va fatta per l’ultima tipologia di impedenza calcolata: si tratta
infatti di un tempo medio di percorrenza dai parcheggi dell’origine O a tutte le
destinazioni pesato per i flussi O/D ed è calcolato come segue:
L’ipotesi è che in caso di un buon collegamento del parcheggio con la rete di trasporto
pubblico l’utenza sarà portata a scegliere quel parcheggio piuttosto che un altro. Indice
di un buon collegamento è il tempo medio da un parcheggio a tutte le destinazioni, anche
se questa volta per avere una stima più accurata vengono pesati per il flusso O/D.
I dati FCD non garantiscono l’intera copertura del territorio in esame in tutti gli
intervalli orari, per cui a volte il valore del denominatore della formula sopra descritta è
pari a 0. A differenza delle precedenti impedenze quando il valore del denominatore
della formula assume il valore 0 questo può indicare solamente una scopertura del
rilevamento dei dati FCD, poiché è inimmaginabile che in un intervallo orario un’origine
non generi neanche un veicolo in uscita.
Nei casi in cui il dato 𝐺𝑜 𝐹𝐶𝐷 è pari a 0, ai fini di un’analisi matematica oltre che
trasportistica, è stato assegnato il valore standard di 1010 minuti, un valore
esageratamente alto, ma che indica un’impedenza infinita che presenta la zona in
quell’intervallo orario: successivamente, una volta calcolate tutte le variabili, verrà
effettuata un’analisi dei dati per capire come gestire queste eccezioni.

23
LA VARIABILE X3 BIS – IMPEDENZA SUL TRASPORTO PUBBLICO (2)
Perfettamente analoga alla precedente il procedimento è il medesimo, sostituendo alla
matrice iniziale dei tempi parcheggio-destinazione la matrice dei trasbordi parcheggio-
destinazione.
LA VARIABILE X4 – BENEFICIO TEMPORALE
Con la seguente variabile si vuole stimare il beneficio in termini di tempo che l’utente
avrà in seguito all’adozione della modalità di Park&Ride al posto della modalità
interamente su mezzo privato. In particolare sarà la differenza tra i tempi origine
destinazione (O/D) e la media sui parcheggi dei tempi origine parcheggio (O/P) con i
tempi parcheggio destinazione (P/D). La formula è riportata di seguito:
Chiaramente da questa variabile ci si aspetta che ogni valore calcolato sia negativo, dati
i tempi aggiuntivi di attesa e trasbordo dovuti all’utilizzo dei mezzi pubblici, ma tuttavia
un aumento del valore di questa variabile, collegato al miglioramento delle altre,
potrebbe comunque portare un aumento della quota di Park&Ride.
LA VARIABILE X5 – RIEMPIMENTO DEI PARCHEGGI
La 7’ variabile rappresenta il riempimento medio dei parcheggi appartenenti alle
origini. Questa variabile è frutto dell’analisi descritta nel Capitolo 6 ed è calcolata come
segue:
Questa variabile ha una doppia valenza: per bassi valori di riempimento nei periodi
antecedenti al periodo di punta l’utenza sarà invogliata alla modalità di Park&Ride,
mentre alti valori di riempimento nei periodi successivi al periodo di punta indicano un
forte utilizzo dei parcheggi e quindi della modalità di Park&Ride.
Il numeratore della formula si può facilmente calcolare effettuando una moltiplicazione
matriciale tra la Matrice Binaria O/P (277x40) e la matrice dei riempimenti dei parcheggi

24
(40x20). Il denominatore della formula è semplicemente il numero di parcheggi
appartenenti all’origine e si può facilmente ottenere sommando le righe della matrice
binaria origine parcheggio.
Dato che alcune origini non hanno parcheggi nel proprio bacino si dovrà imporre la
condizione di esistenza del denominatore e si andrà ad imporre il valore della variabile
pari a 0 (come se i parcheggi del bacino non fossero accessibili e quindi vuoti); se
viceversa esistessero parcheggi appartenenti al bacino allora sarà possibile calcolare il
rapporto sopra descritto.
Con questa variabile si chiude l’insieme delle variabili che sono funzione sia delle
origini che degli intervalli temporali.
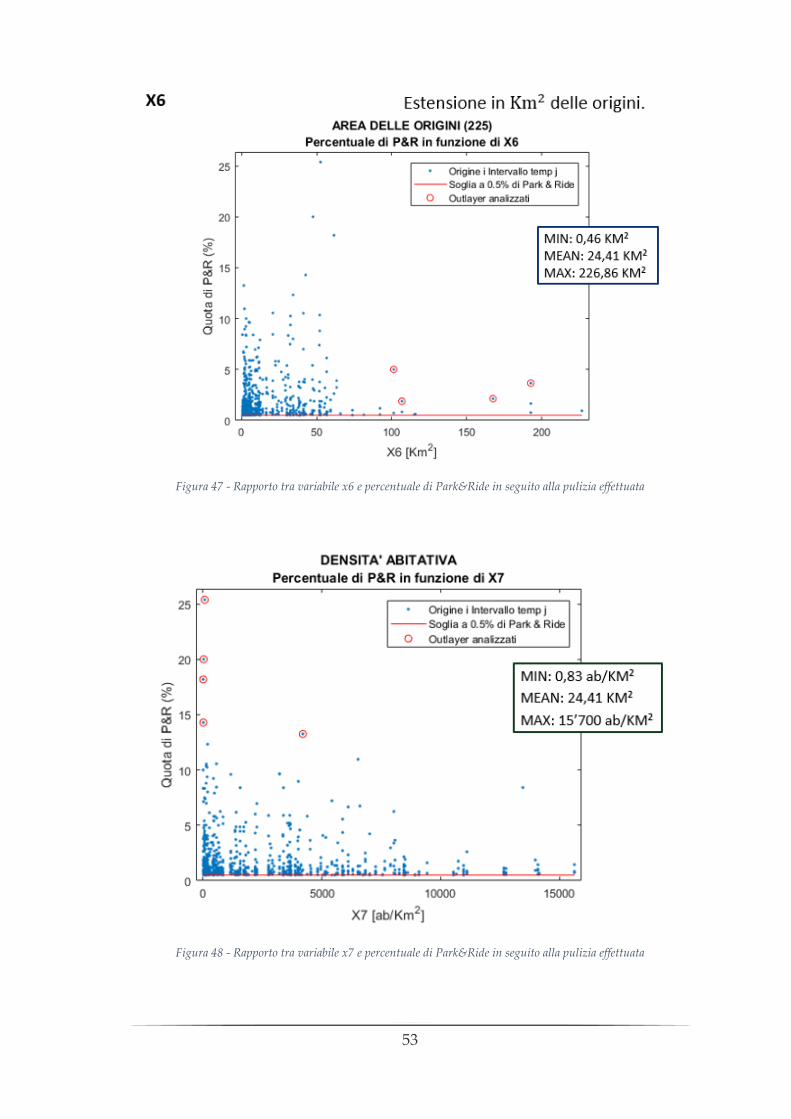
LA VARIABILE X6 – AREA DELLE ORIGINI
La variabile X6 è la prima dell’insieme delle variabili che sono funzione solamente delle
origini e non degli intervalli temporali: queste variabili saranno infatti calcolate per ogni
origini e successivamente saranno ripetute per ogni intervallo temporale solamente ai fini
della quadratura della matrice finale delle variabili.
La variabile X6 è la variabile rappresentativa dell’estensione geografica delle origini ed
è possibile osservarla graficamente:
Figura 10 - Aree delle origini

25
Dal momento in cui l’area delle origini a disposizione è espressa in m2, per evitare di
lavorare con numeri eccessivamente grandi inutilmente è stata trasformata in km2
dividendo per 1'000'000.
LA VARIABILE X7 – DENSITÀ ABITATIVA
La variabile X7 rappresenta la densità abitativa delle origini in esame. Al numeratore
del rapporto Popolazione/Area sono compresi solo gli utenti con età compresa tra i 19 e i
70 anni, poiché sono i potenziali utenti utilizzatori della modalità Park&Ride (patentati e
occupati).
Il risultato è visibile graficamente nella seguente figura:
Figura 11 - Densità abitativa suddivisa per classi

26
LA VARIABILE X8 – DENTRO/FUORI GRA
La variabile X8 è una variabile binaria che vale 1 se l’origine è compresa all’interno del
Grande Raccordo Anulare, 0 altrimenti. L’ipotesi alla base è che gli utenti che risiedono
nelle aree periferiche (fuori il raccordo), data la maggior congestione che dovranno subire
per recarsi verso la propria destinazione, si presuppone che siano i più predisposti
all’utilizzo della modalità di Park&Ride.
Si rappresenta di seguito la distinzione delle aree:
Figura 12 - Suddivisione delle aree
Ai fini del calcolo per la matrice delle variabili è stato utilizzato insieme a Matlab il
software Q-Gis per determinare le origini interne al Grande Raccordo Anulare e quelle
esterne. Il vettore calcolato è stato ripetuto per tutti gli intervalli temporali e impostato
come un vettore di dimensioni 5540x1.
LA VARIABILE X9 – NUMERO DI STAZIONI
Così come per la precedente, anche la variabile X9 è stata calcolata attraverso l’utilizzo
di Q-Gis. In questa variabile è rappresentato il numero di stazioni di ferrovie e
metropolitana presenti nell’origine. Ci si aspetta che maggiore sia il numero di stazioni
presenti nell’origine, più gli utenti residenti abbiano una maggiore propensione ad
effettuare il percorso origine - destinazione interamente con la modalità trasporto
pubblico.

27
Si riporta graficamente il numero delle stazioni presenti nelle origini:
Figura 13 - Numero di stazioni metro/ferrovia presenti all'interno dell'origine
Con questa variabile si conclude l’insieme di variabili funzione delle origini, ma non degli
intervalli temporali.
LA VARIABILE X10 – INTERVALLO ORARIO
L’ultima variabile è binaria ed è funzione solamente dell’intervallo temporale e non
delle origini. Rappresenta infatti la distinzione tra periodo di punta (6:00 – 11:00) e
periodo di morbida (4:00 – 6:00 e 11:00 – 24:00).
Ci si aspetta infatti che gli utenti abituali della modalità Park&Ride siano quelli che la
utilizzano per recarsi al posto di lavoro, per cui considerando sia i lavoratori full-time che
i lavoratori part-time del pomeriggio, la fascia di punta è stata ipotizzata tra le ore 6:00 e
le ore 11:00.

28
7. COSTRUZIONE DEL DATASET
Come detto in precedenza l’obiettivo di questa analisi è stimare la quota percentuale di
utenti che utilizzano la modalità Park and Ride in funzione delle variabili indipendenti
precedentemente descritte. Saranno calcolati vari esempi, ogni esempio rappresenta
un’origine in un intervallo temporale a cui sono associati 12 valori di variabili (x1, x2,
ecc.) e un valore della quota di P&R (y).
Il primo Dataset, denominato Dataset_0, contiene tutti i valori calcolati per ogni origine
(277) e per ogni intervallo temporale (20), per un totale di 5540 esempi a cui sono associate
12 variabili di input.
Figura 14 - Costruzione del Dataset 0
Tutti i Dataset successivi sono frutto di differenti pulizie effettuate su quest’ultimo.
La prima pulizia effettuata sul Dataset_0, che andrà a costituire il Dataset_1, è stata
effettuata sui flussi di Park&Ride: in particolare sono state rimosse tutte le origini che non
presentavano flusso generato di Park&Ride nell’arco dell’intera giornata.
A tal proposito è stata fatta quindi un’analisi geografica di queste zone attraverso il
software Q-Gis al fine di cercare il motivo dell’esclusione.

29
Le 52 origini evidenziate in rosa sono quelle oggetto di analisi. Si può notare come esse
siano prevalentemente nell’area periferica della provincia oggetto di studio e quindi le
ipotesi che giustificherebbero una mancanza di flusso, oltre alla bassa copertura del
campione, sono sostanzialmente 2: gli utenti effettuano il cambio modale in parcheggi
non appartenenti al comune di Roma e quindi non sono stati rilevati, oppure gli utenti
non trovano conveniente effettuare il cambio modale, poiché questo avverrebbe in
prossimità della destinazione finale dell’utente.
In entrambi i casi risulta comunque opportuno escludere le origini selezionate dal
Dataset_0. Di seguito sono elencate le origini escluse dall’analisi oggetto di studio:
Figura 16 - Le origini rimosse dal Dataset
Figura 15 - Analisi geografica delle origini in funzione della generazione di Park & Ride

30
Rimuovere queste origini comporta rimuovere tutti gli intervalli temporali relativi a
queste zone, ovvero 52 x 20 = 1040 esempi rimossi. Il Dataset_1 sarà quindi composto
dalle rimanenti 225 origini x 20 intervalli temporali, ovvero 4500 esempi x 12 variabili di
input.
Dall’analisi del Dataset_1 e dalla modalità di calcolo delle variabili indipendenti emerge
che, essendo ancora presenti origini che in alcuni intervalli temporali non presentano
flusso in uscita di alcun tipo (Generazione nulla), è impossibile calcolare il valore delle
variabili x3 e x3 bis, le cui formule sono ricordate di seguito:
Figura 17 - Formule per il calcolo delle variabili x3 e x3 bis
I casi in cui un’origine in un intervallo temporale non presentava flusso monitorato in
uscita (12 esempi) sono stati rimossi e il campione residuo formerà il Dataset_2 che sarà
quindi composto da 4488 esempi x 12 variabili di input.
Analizzando i valori nel Dataset_2 relativi alle variabili calcolate si può notare che sono
ancora presenti valori non calcolabili, questo perché alcune origini non hanno generato
flusso di Park&Ride in alcuni intervalli temporali. Tali esempi potrebbero influenzare in
maniera negativa la calibrazione del modello, per cui sono stati rimossi. Rimuovendo
questi esempi (3246) si andrà a costituire il Dataset_3 composto da 2294 esempi x 12
variabili di input.
7.1.1. ANALISI DEI DATI
Su un campione finale di 2294 elementi è stata effettuata l’analisi dei dati e delle
distribuzioni di ogni variabile calcolata per capire l’incidenza sulla quota percentuale di
flusso di Park&Ride. Di seguito è riportata l’analisi della distribuzione e il confronto tra
valore della variabile e quota percentuale di Park&Ride associata per verificare la
corrispondenza tra risultato atteso e risultato reale.

31
La variabile X1
Il campione totale è costituito dalla prima variabile indipendente ed è costituito da 2294
elementi di cui è stato calcolato valore minimo, valore massimo, media e deviazione
standard che sono così riportati:
Valore massimo = 114,55 minuti
Valore minimo = 1,2167 minuti
Media = 22,11 minuti
Deviazione standard = 14,19 minuti
In relazione a questi dati il campione è stato suddiviso in un numero di classi k che
dovrà essere abbastanza piccolo da fornire un’adeguata sintesi, ma abbastanza grande da
mantenere un livello accettabile di dettaglio dell’informazione, in questo caso 13.
Sono stati calcolati prima il numero di elementi che ricadevano all’interno di ogni classe
e successivamente la frequenza relativa di ogni classe ed il risultato è il seguente:
Figura 18 - Frequenze relative della variabile x1

32
L’aspetto positivo di questa distribuzione è che sia la media che la moda sono
concentrate intorno ai 20 minuti, questo sta ad indicare una buona accessibilità dei
parcheggi dalle zone di origine, evidenziato anche dalla bassa probabilità di trovare
tempi origine-parcheggio maggiori di 40 minuti (inferiore al 5%).
Essendo questa variabile un tempo medio pesato di accesso ai parcheggi appartenenti
all’origine ci si aspetta che per valori bassi gli utenti saranno invogliati ad effettuare il
cambio modale e che quindi il rapporto tra flussi generati di Park&Ride e flussi totali
generati aumenti. Viceversa, un tempo medio di accesso elevato indica una scarsa
accessibilità dei parcheggi e quindi una bassa quota percentuale di Park&Ride.
L’andamento atteso è quindi monotono decrescente. È possibile verificare questa ipotesi
riportando in un grafico l’andamento della quota di P&R in funzione della variabile X1.
Figura 19 - Relazione tra variabile x1 e quota percentuale di Park&Ride
Purtroppo la scarsa copertura del campione non ci permette di ottenere un andamento
ben definito, infatti è presente un elevato numero di elementi con una quota di
Park&Ride inferiore all’1%, ma questo non indica assolutamente che il dato sia effettivo.
La variabile X2
La variabile in esame è dipendente, come è possibile notare dalla formula di calcolo
presente nel grafico, dai tempi sul trasporto pubblico. Gli Open Data disponibili sono

33
riferiti solamente alle aree interne al Comune di Roma, per cui data la mancanza di dati
sul trasporto pubblico per le aree esterne al comune (40 aree di parcheggio x 122 zone) è
stato ipotizzato un tempo pari a 4h per ogni collegamento parcheggio – destinazione in
ogni intervallo temporale, comprensivi di tempi di attesa e trasbordi. Dato l’elevato
numero di dati mancanti (97’600 dati mancanti su 221’600 ≈ 44%) il valore della variabile
è una forte stima per eccesso, ma utilizzando questa ipotesi si renderà la variabile
calcolabile per le origini esterne e quindi sarà possibile verificare la sua incidenza ai fini
della stima del modello.
Come per la variabile precedente sono stati calcolati i valori: minimo, massimo, media
e deviazione standard e sono riportati di seguito:
Valore massimo = 240 minuti
Valore minimo = 235 minuti
Media = 238 minuti
Deviazione standard = 1,05
Essendo rimasto invariato il numero di elementi analizzati, anche il numero delle classi
è rimasto invariato e il grafico delle frequenze relative è il seguente:
Figura 20 - Frequenze relative della variabile x2

34
È possibile notare attraverso la deviazione standard di 1,05 su un campione di 2294
elementi come essi siano tutti concentrati intorno al valore medio: questo fa capire il peso
che deriva dai dati mancanti e che falsa l’analisi in questione.
La variabile analizzata rappresenta la facilità di raggiungere tutte le destinazioni, in
termini di tempo, a partire da un’Origine, quindi ci si aspetta che per tempi sul TP bassi
ci sarà un’alta quota di P&R e viceversa. Tuttavia i dati a disposizione non riescono ad
interpretare l’andamento monotono decrescente atteso.
Figura 21 - Relazione tra variabile x2 e quota percentuale di Park&Ride
Il dato così come si presenta difficilmente potrà essere utilizzato ai fini della calibrazione
del modello, ma si analizzerà la scelta successivamente con l’ausilio della Random Forest.

35
La variabile X2 bis
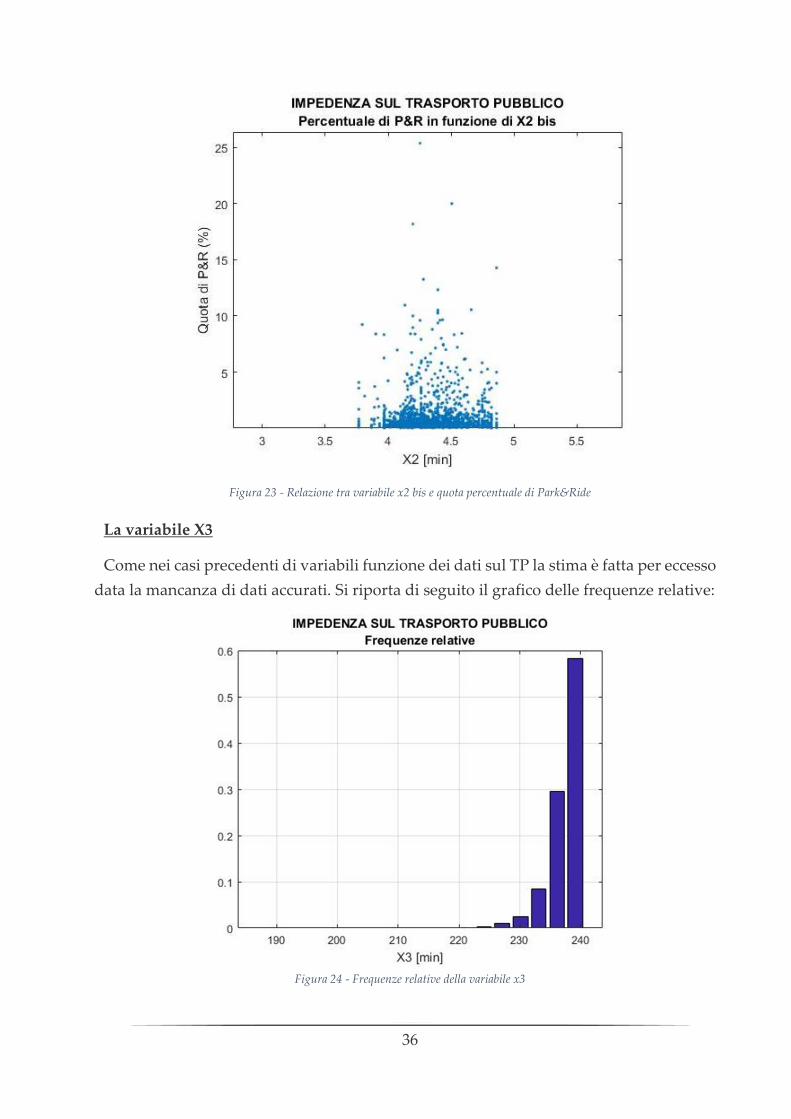
Ragionamento perfettamente analogo è stato fatto per la variabile x2 bis, che si
differenzia dalla precedente solamente per l’utilizzo dei trasbordi effettuati dal
parcheggio alla destinazione al posto dei tempi parcheggio-destinazione. Anche in
questo caso il dato relativo alle zone esterne è mancante, per cui è stato attribuito un
valore massimo di 5 trasbordi effettuabili ed è stata fatta l’analisi delle frequenze relative
e successivamente del rapporto con la quota di Park&Ride.
Valore massimo = 4,86 trasbordi
Valore minimo = 3,77 trasbordi
Media = 4,32 trasbordi
Deviazione standard = 0,22
Figura 22 - Frequenze relative della variabile x2 bis
Analoga alla variabile precedente questa rappresenta la facilità di raggiungere, in
termini di trasbordi effettuati, tutte le destinazioni a partire da un’Origine, quindi ci si
aspetta anche qui che per pochi trasbordi effettuati ci sarà un’alta quota di P&R e
viceversa.
Tuttavia i dati a disposizione non riescono ad interpretare l’andamento monotono
decrescente atteso.
36
Figura 23 - Relazione tra variabile x2 bis e quota percentuale di Park&Ride
La variabile X3
Come nei casi precedenti di variabili funzione dei dati sul TP la stima è fatta per eccesso
data la mancanza di dati accurati. Si riporta di seguito il grafico delle frequenze relative:
Figura 24 - Frequenze relative della variabile x3

37
La variabile analizzata rappresenta la facilità di raggiungere tutte le destinazioni, in
termini di tempo, a partire da un’Origine, quindi ci si aspetta anche qui che per tempi sul
TP bassi ci sarà un’alta quota di P&R e viceversa.
Tuttavia i dati a disposizione non riescono ad interpretare l’andamento monotono
decrescente atteso.
Figura 25 - Relazione tra variabile x3 e quota percentuale di Park&Ride
La variabile X3 bis
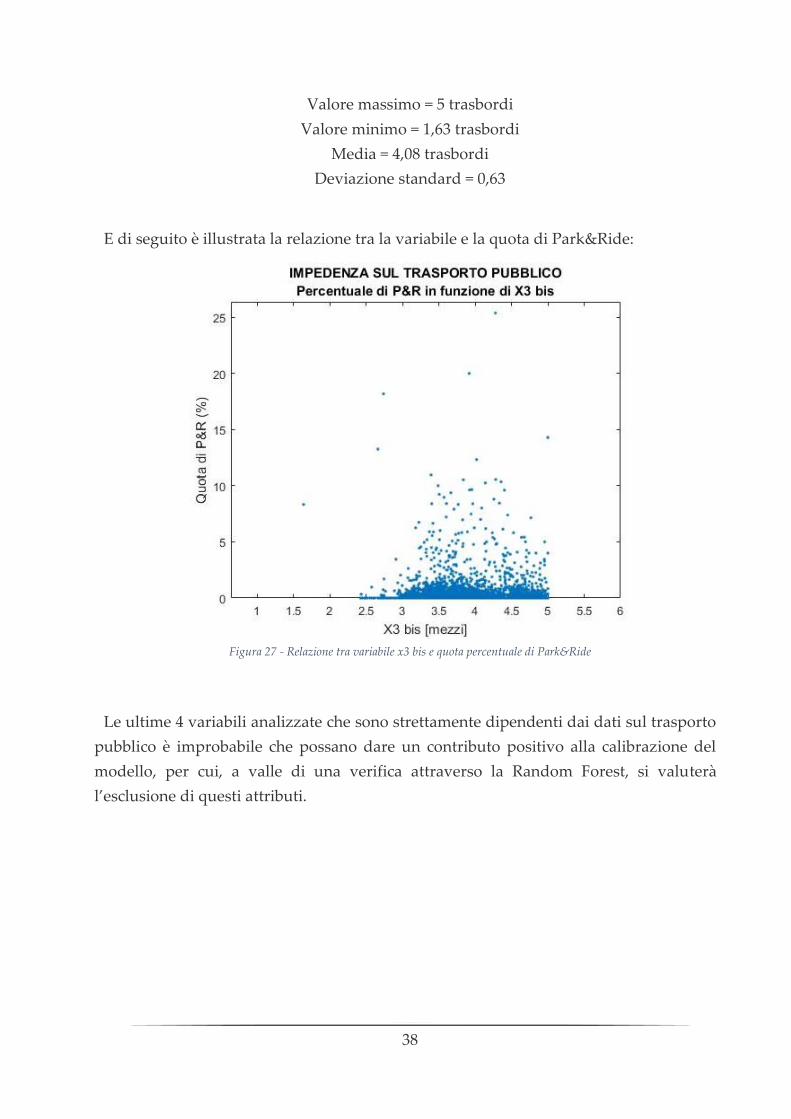
Perfettamente analoga alla precedente si riporta l’analisi della variabile x3 bis:
Figura 26 - Frequenze relative variabile x3 bis
38
Valore massimo = 5 trasbordi
Valore minimo = 1,63 trasbordi
Media = 4,08 trasbordi
Deviazione standard = 0,63
E di seguito è illustrata la relazione tra la variabile e la quota di Park&Ride:
Figura 27 - Relazione tra variabile x3 bis e quota percentuale di Park&Ride
Le ultime 4 variabili analizzate che sono strettamente dipendenti dai dati sul trasporto
pubblico è improbabile che possano dare un contributo positivo alla calibrazione del
modello, per cui, a valle di una verifica attraverso la Random Forest, si valuterà
l’esclusione di questi attributi.

39
La variabile X4
La variabile x4 rappresenta il beneficio temporale determinato come differenza media
di tempo impiegato attraverso la modalità interamente su privato e la modalità
Park&Ride. Anche questa variabile è in funzione dei tempi sul trasporto pubblico, ma la
presenza dei tempi origine destinazione su privato, derivanti dai dati FCD potrebbero
apportare delle variazioni utili al modello.
Valore massimo = -209 minuti
Valore minimo = -328 minuti
Media = -232 minuti
Deviazione standard = 7,77
Figura 28 - Frequenze relative della variabile x4

40
Da questa variabile non ci aspettiamo dei valori positivi, poiché i viaggi su trasporto
privato sono diretti e seguono, a grandi linee, i percorsi di costo minimo, mentre i viaggi
sul trasporto pubblico compiono delle tratte più lunghe per coprire un bacino di utenza
più ampio e sono comprensivi di tempi di attesa e di trasbordi. Tuttavia è plausibile che
ad un aumento del valore della variabile, ossia all’avvicinarsi allo 0, ci si aspetti un
incremento della quota di Park&Ride. È possibile verificare questa ipotesi attraverso la
relazione tra la variabile e la quota di Park&Ride, di seguito in figura:
Figura 29 - Relazione tra variabile x4 e quota percentuale di Park&Ride
Trascurando la fascia sotto l’1% di Park&Ride, è possibile notare l’andamento crescente
atteso.

41
La variabile X5
La variabile x5 rappresenta il riempimento medio dei parcheggi appartenenti alle
origini nei 20 intervalli temporali e la distribuzione di frequenze sono di seguito riportate:
Figura 30 - Frequenze relative della variabile x5
La distribuzione delle frequenze non è facilmente intuibile come nei precedenti casi, ma
solo per il fatto che sono compresi i valori di tutti gli intervalli orari e quindi una stessa
origine può cadere in più classi a seconda dell’intervallo considerato.
Figura 31 - Relazione tra variabile x5 e la quota percentuale di Park&Ride

42
La variabile X6
La variabile x6 rappresenta l’estensione territoriale in km2 delle origini ed è variabile
come mostrato in figura:
Figura 32 - Variabilità dell'estensione delle origini
Già dalla figura è evidente come ci sia una concentrazione di origini con un’area molto
moderata, valutazione confermata dall’analisi delle frequenze relative:
Figura 33 - Frequenze relative variabile x7

43
Da questa variabile ci si aspetta che visto che più ci si allontana dal centro della città e
più l’estensione delle zone aumenta e visto che la modalità Park&Ride è più appetibile
per gli utenti che provengono dalle aree periferiche della città, allora all’aumentare delle
aree dovrebbe corrispondere un aumento della quota di Park&Ride. Questa ipotesi è
verificabile attraverso il confronto tra variabile e quota di Park&Ride.
Dall’immagine è possibile notare una conferma dell’ipotesi, ad eccezione di alcuni
“Outlayer” in cui a elevati valori di area corrispondono bassi valori di Park&Ride: questi
valori anomali andranno verificati con più attenzione in un’analisi puntuale
successivamente.
Figura 34 - Relazione tra variabile x6 e quota percentuale di Park&Ride
La variabile X7
La variabile x7 è rappresentativa della densità. Come detto in precedenza l’ipotesi alla
base della modalità P&R è che gli utenti siano patentati e occupati, quindi la popolazione
considerata per il calcolo della densità è solamente quella compresa tra i 19 e i 70 anni. Il
valore della variabile è così distribuito:

44
Figura 35 - Distribuzione della densità abitativa sulla provincia
Si riporta di seguito il grafico delle frequenze relative e successivamente la relazione
con la quota di Park&Ride.
Figura 36 - Frequenze relative della variabile x7

45
Figura 37 - Relazione tra variabile x7 e quota percentuale di Park&Ride
Ci si aspetterebbe che le quote maggiori di Park&Ride corrispondano ad alti valori di
densità, poiché la popolazione è maggiore, in realtà sono presenti alcuni punti con
Park&Ride elevato e densità molto bassa: questi “Outlayer” verranno studiati
singolarmente in una più accurata analisi successivamente.
La variabile X9
La variabile x9 ricordiamo rappresenta il numero di stazioni presenti all’interno di ogni
origine e sono così distribuite:
Figura 38 - Numero di stazioni nelle origini

46
In relazione al numero di stazioni presenti all’interno di una generica origine ci si
aspetta che all’aumentare del numero di stazioni (metropolitana e/o ferrovia) aumenta la
probabilità di avere una stazione vicino il luogo di origine dello spostamento, quindi
aumenta la probabilità che l’utente effettui il viaggio interamente su mezzi pubblici e
quindi che la quota di Park&Ride sia ridotta.
Di seguito sono riportate le frequenze relative e la relazione tra variabile e quota di
Park&Ride.
Figura 39 - frequenze relative della variabile x9
Figura 40 - Relazione tra variabile e quota di Park&Ride

47
Possiamo notare nell’ultima immagine la conferma dell’ipotesi fatta precedentemente.
Effettuata la pulizia (Generazioni delle origini mancanti) e l’analisi dei dati si è
proceduto con l’analisi della correlazione tra le variabili: è stato caricato il Dataset_3 (2294
esempi x 12 variabili di input) sul software Excel ed è stata calcolata la matrice di
correlazione tra le variabili che è di seguito riportata:
Figura 41 - Matrice di correlazione tra le variabili
Successivamente al calcolo della matrice di correlazione sono state evidenziati i valori
più elevati: in rosso troviamo le variabili fortemente correlate (una correlazione maggiore
di 0.7 o minore di -0.7) e in giallo le variabili abbastanza correlate (correlazione compresa
tra 0.5 e 0.7 oppure tra -0.7 e -0.5). Questa analisi è stata effettuata al fine di stimare più
modelli e vedere quali variabili incidono in maniera più significativa sul risultato finale.
Nell’analisi di correlazione non sono presenti le variabili x8 e x10, rispettivamente
Dentro/Fuori GRA e Intervallo orario, poiché variabili dummy (binarie).
Quindi in relazione al risultato emerso da questa prima analisi risulta evidente che
l’utilizzo della variabile x2 bis (impedenza sul trasporto pubblico calcolata con i trasbordi
effettuati) è inutile e quindi è stata rimossa.
Il risultato finale, denominato Dataset_4 sarà composto da 2294 esempi x 11 variabili di
input.

48
7.1.2. VERIFICA DEI DATASET
Per effettuare la verifica del Dataset quest’ultimo è stato suddiviso in 2 parti: la prima
che servirà all’addestramento del modello (TRAIN = 70%) e la seconda che servirà per la
validazione (TEST = 30%), in modo tale che nessuna origine rimanga esclusa dalla fase di
addestramento, secondo questa metodologia:
a) Si stabilisce inizialmente una percentuale di esempi da attribuire al test (%);
b) Per ogni Origine si calcola il numero di esempi ancora presenti riferiti a
quell’origine (L);
c) Si calcola quanti elementi di quell’origine andranno a comporre la fase di test (%*L),
approssimando per eccesso;
d) Si suddivide l’origine in tante classi quanti sono gli esempi da accantonare (%*L) e
si estrae in maniera random un elemento da ogni classe;
e) Completata la procedura si sarà accantonato l’intero campione per il test che però,
date le approssimazioni, non è detto che sarà esattamente pari alla % stabilita del
totale, per cui bisognerà controllare il rapporto:
#𝑡𝑒𝑠𝑡
#𝑡𝑒𝑠𝑡 + #𝑡𝑟𝑎𝑖𝑛
f) E se necessario modificare la percentuale iniziale di suddivisione (%).
L’algoritmo crea inizialmente un vettore (ii) che va da 1 fino al numero di elementi, in
questo caso 2294. Per tante volte quante sono gli elementi da destinare al test estrae un
numero da 1 al massimo valore di ii che sarà rimosso da ii e sarà inserito in un nuovo
vettore chiamato ind. Alla fine della procedura si avranno 2 vettori, in cui nessun
elemento compare in entrambi, che rappresentano gli indici rispettivamente di train e
test.
Una volta definiti i campioni di train e test bisogna sottoporli alla Random Forest che
inizialmente è stata così definita:
model = RandomForestRegressor(n_estimator=2000,
max_depth=None)
Dove n_estimators è il numero di alberi, impostato a 2000, con cui si vuole addestrare il
modello e max_depth è la profondità massima di ogni albero, impostata a “nessuna
profondità massima”.

49
Al fine di valutare la bontà del modello sono stati stabiliti anche degli indicatori di
errore statistico che andiamo a descrivere:
𝑀𝑆𝐸 =1
𝑚∑ 𝑓𝑡
2𝑚𝑡=1 𝑅𝑀𝑆𝐸 = √
1
𝑚∑ 𝑓𝑡
2𝑚𝑡=1
2
𝑀𝐴𝐸 =1
𝑚∑ |𝑓𝑡|𝑚
𝑡=1 𝑀𝐴𝑃𝐸 =1
𝑚∑
|𝑓𝑡|
𝑦𝑡𝑒𝑠𝑡∗ 100𝑚
𝑡=1
𝑐𝑜𝑛 𝑓𝑡 = 𝑦𝑡𝑒𝑠𝑡 − 𝑦𝑚𝑜𝑑𝑒𝑙𝑙𝑜
Scelti gli indicatori con cui verificare la bontà del modello è possibile effettuare le pulizie
del campione. Come detto in precedenza l’addestramento del modello sarà fatto su una
parte del campione estratta in maniera random e la Random Forest verrà addestrata con
2000 alberi e nessuna profondità massima.
Nella seguente immagine sono riportati:
1) Feature importance, un indicatore che rappresenta l’importanza che l’attributo ha
nella suddivisione del campione per calibrare del modello. Il valore espresso è in
percentuale, infatti la somma dei fattori dà come risultato 1;
2) Una tabella con una breve descrizione del campione di TRAIN (valore minimo,
medio e massimo) e una descrizione dei risultati delle previsioni del campione di TRAIN
(sempre in termini di valore minimo, medio e massimo);
3) I 4 indicatori di errore descritti in precedenza più ulteriori 3 indicatori: il MEDIAN
A E (la mediana degli scarti tra valore reale e valore da modello), R2 train (la correlazione
tra variabile reale facente parte del campione di train e variabile calcolata da modello,
indica quanto è riuscito ad apprendere il modello) e R2 test (la correlazione tra variabile
reale facente parte del campione di test e variabile calcolata da modello, indica quanto è
riuscito a prevedere il modello).

50
Figura 42 - Indicatori risultanti del modello calcolati attraverso Random Forest
I risultati non sono ottimali: nonostante in media il modello effettui un errore di un
punto percentuale (RMSE e MSE) il valore dell’errore percentuale è elevato (132%) e
inoltre la correlazione del campione di test è scarsa (R2=0.39).
Nelle analisi effettuate in precedenza, in particolare nelle relazioni tra valore delle
variabili e relativa percentuale di Park&Ride, è emerso che una notevole quota del
campione presentava una bassa quota di Park&Ride nonostante una elevata variazione
del valore della variabile: ciò indica la bassa copertura del campione rispetto alla
popolazione e non essendo rappresentativo è considerato “rumore” e pertanto è
opportuno escluderlo dalle analisi in quanto disturba l’apprendimento del modello.
Analizzando i grafici esposti precedentemente un buon compromesso tra eliminare il
più possibile i dati non rappresentativi e mantenere un buon numero di elementi su cui
addestrare il modello è porre una soglia a 0,5% sulla quota percentuale di Park&Ride
eliminando tutti i casi con una quota inferiore a quella dettata dalla soglia.
Inoltre le variabili relative ai dati sul trasporto pubblico rimanenti (x2, x3, x3 bis) non
presentano alcun andamento riscontrabile, per cui, almeno per il momento, sono state
escluse dall’analisi.
Così facendo da 2294 casi x 11 variabili del Dataset_4 si passa a 846 casi x 8 variabili che
andranno a costituire il Dataset_5. Di seguito si espone una breve analisi di quest’ultimo
dataset.

51
Saranno evidenziati in rosso i casi che non potranno essere esclusi dalla soglia apportata
al campione, ma che meritano una più accurata analisi in quanto valori inaspettati e per
questo soggetti a indagini puntuali.
Figura 43 - Rapporto tra variabile x1 e percentuale di Park&Ride in seguito alla pulizia effettuata
Figura 44 - Rapporto tra variabile x4 e percentuale di Park&Ride in seguito alla pulizia effettuata

52
Figura 45 - Rapporto tra variabile x5 e percentuale di Park&Ride in seguito alla pulizia effettuata
Figura 46 - Rapporto tra variabile x5 e percentuale di Park&Ride in seguito alla pulizia effettuata (nella fascia oraria 04:00 -
06:00)
53
Figura 47 - Rapporto tra variabile x6 e percentuale di Park&Ride in seguito alla pulizia effettuata
Figura 48 - Rapporto tra variabile x7 e percentuale di Park&Ride in seguito alla pulizia effettuata

54
Figura 49 - Rapporto tra variabile x9 e percentuale di Park&Ride in seguito alla pulizia effettuata
Effettuata la pulizia del campione si è proceduto con una prima prova di addestramento
della Random Forest e di seguito è riportato il risultato:
Figura 50 - Risultati Random Forest Dataset_5
Considerati questi casi come anomali si è ritenuto opportuno escluderli dal campione
di analisi. A tal proposito si è deciso di porre un filtro nel Dataset_5 in base alle
caratteristiche da escludere, che si riporta di seguito:
Impedenza > 30 minuti & Park&ride > 14%;
Beneficio temporale < -230 minuti & Park&ride > 14%;
Area > 90 km2 & Park&ride > 1.85%;
Densità < 3000 ab/km2 & Park&ride > 13%;
Intervallo orario > 13 & Park&ride > 2.5%;
Eliminati i casi intercettati dal filtro si è creato il Dataset_6 costituito da 832 casi x 8
variabili di input. Successivamente per verificare un eventuale miglioramento del

55
modello è stata riaddestrata la Random Forest sulla base di quest’ultimo Dataset e il
risultato è il seguente:
Figura 51 - Risultati Random Forest Dataset_6
Come è possibile notare i risultati sono migliorati una volta eliminati i casi anomali, sia
in termini di errori che in termini di correlazione tra valore reale e valore da modello.
8. CONCLUSIONI
L’attività di tirocinio svolta nel centro di ricerca ENEA è risultata fondamentale ai fini
dello studio degli strumenti che verranno utilizzati in fase di tesi.
In particolare lo studio approfondito del linguaggio di programmazione Python e
successivamente delle Random Forest ha permesso di apprendere delle basi
fondamentali per la creazione del Database delle variabili indipendenti su cui si andrà ad
effettuare la calibrazione e la validazione del modello di Random Forest.
Il database costruito sarà l’oggetto di input nella seconda parte dello studio in cui verrà
non solo calibrato il modello, ma anche validato attraverso analisi di stabilità dello stesso,
stabilità alla variazione dei parametri del modello e sensitività al variare delle variabili.

56
9. SITOGRAFIA
www.python.it/about/
https://it.wikipedia.org/wiki/MATLAB
https://www.qgis.org/it/site/about/index.html
www.github.com
10. BIBLIOGRAFIA
Biscaglia Nicola, “Validazione efficace dei modelli di Machine Learning”, 2017
Hastie, Tibshirani, Friedman, “The Elements of Statistical Learning: Data Mining, Inference,
and Prediction”, 2013


















