
TRƯỜNG HÈ VỀ HỌC MÁY THỐNG KÊ - Trang...
70
Trường ngẫu nhiên có điều kiện và ứng dụng Phan Xuân Hiếu Phòng thí nghiệm Công nghệ Tri thức, Khoa CNTT, Trường ĐH Công nghệ, ĐHQG Hà Nội Email: [email protected] 1 TRƯỜNG HÈ VỀ HỌC MÁY THỐNG KÊ
Transcript of TRƯỜNG HÈ VỀ HỌC MÁY THỐNG KÊ - Trang...

Trường ngẫu nhiên có điều kiện và ứng dụng
Phan Xuân Hiếu
Phòng thí nghiệm Công nghệ Tri thức,
Khoa CNTT, Trường ĐH Công nghệ, ĐHQG Hà Nội
Email: [email protected]
1
TRƯỜNG HÈ VỀ HỌC MÁY THỐNG KÊ

2
tâm_sự
danh từ động từtính từ
từ loại?
…
detective
danh từ động từtính từ
từ loại?
…

3
tâm_sự
danh từ động từtính từ
từ loại?
…
detective
danh từ động từtính từ
từ loại?
…
… có nhiều tâm_sự trong lòng …tâm_sự
… mình muốn tâm_sự với bạn …tâm_sự
Sherlock Holmes is a great detective .detective
This is a great detective novel .detective

4
This
từ loại?
is
từ loại?
a
từ loại?
great
từ loại?
detective
từ loại?
novel
từ loại?
.
từ loại?
danh từ động từtính từ …
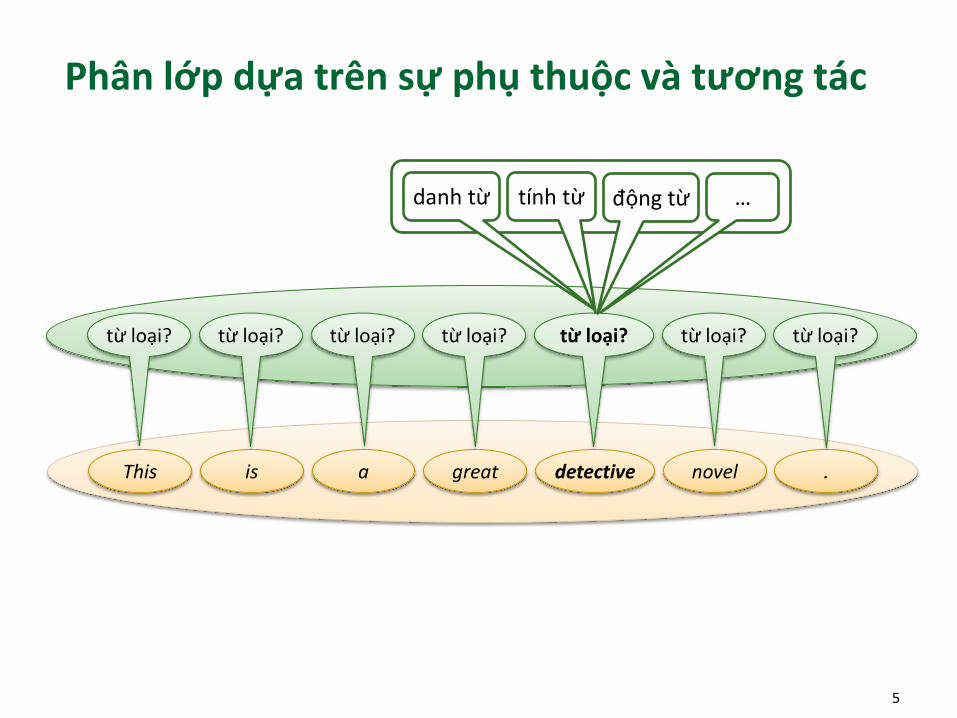
Phân lớp đơn lẻ và độc lập
5
This
từ loại?
is
từ loại?
a
từ loại?
great
từ loại?
detective
từ loại?
novel
từ loại?
.
từ loại?
danh từ động từtính từ …
Phân lớp dựa trên sự phụ thuộc và tương tác

Đoán nhận trên dữ liệu có cấu trúcstructured (output) prediction/learning
6

7
This
từ loại?
is
từ loại?
a
từ loại?
great
từ loại?
detective
từ loại?
novel
từ loại?
.
từ loại?
danh từ động từtính từ …
Chuỗi trạng thái (state sequence)
Chuỗi dữ liệu quan sát (observation sequence)
Tập nhãn (label set)
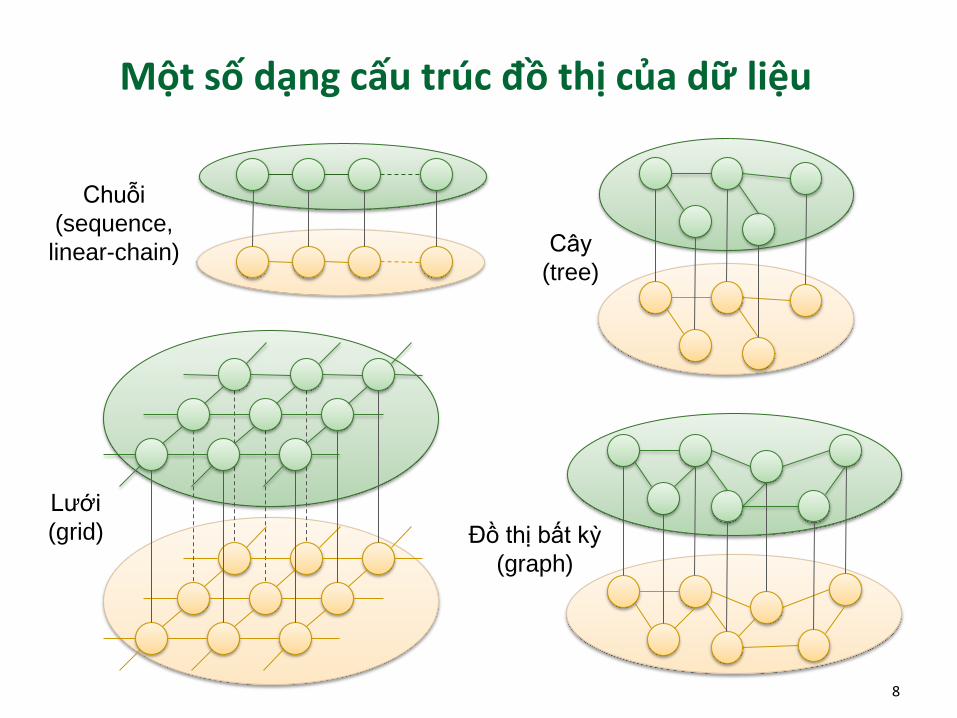
Một số dạng cấu trúc đồ thị của dữ liệu
8
Chuỗi
(sequence,
linear-chain) Cây
(tree)
Lưới
(grid) Đồ thị bất kỳ
(graph)

Bài toán gắn nhãn và phân đoạn trên dữ liệu chuỗi
Ký hiệu là tập q nhãn (lớp) được định nghĩa trước.
Cho là một chuỗi dữ liệu đầu vào (input data sequence) bao gồm T thành phần dữ liệu (data observations)
Vấn đề gắn nhãn hoặc phân đoạn là đoán nhận (predict) dãy nhãn đầu phù hợp nhất (the most likely output label sequence) cho
9

Bài toán gắn nhãn và phân đoạn trên dữ liệu chuỗi
Ký hiệu là tập q nhãn (lớp) được định nghĩa trước.
Cho là một chuỗi dữ liệu đầu vào (input data sequence) bao gồm T thành phần dữ liệu (data observations)
Vấn đề gắn nhãn hoặc phân đoạn là đoán nhận (predict) dãy nhãn đầu phù hợp nhất (the most likely output label sequence) cho
10
Rolls_NNP Royce_NNP Motor_NNP Cars_NNPS Inc._NNP said_VBD it_PRP
expects_VBZ its_PRP$ U.S._NNP sales_NNS to_TO remain_VB steady_JJ ...
Ví dụ về gắn nhãn (labeling): gắn nhãn từ loại

Bài toán gắn nhãn và phân đoạn trên dữ liệu chuỗi
Ký hiệu là tập q nhãn (lớp) được định nghĩa trước.
Cho là một chuỗi dữ liệu đầu vào (input data sequence) bao gồm T thành phần dữ liệu (data observations)
Vấn đề gắn nhãn hoặc phân đoạn là đoán nhận (predict) dãy nhãn đầu phù hợp nhất (the most likely output label sequence) cho
11
Rolls_NNP Royce_NNP Motor_NNP Cars_NNPS Inc._NNP said_VBD it_PRP
expects_VBZ its_PRP$ U.S._NNP sales_NNS to_TO remain_VB steady_JJ ...
Ví dụ về gắn nhãn (labeling): gắn nhãn từ loại
[Rolls Royce Motor Cars Inc. NP] [said VP] [it NP] [expects VP]
[its U.S. sales NP] [to remain VP] [steady ADJP] ...
Ví dụ về phân đoạn (segmentation): phân đoạn cụm từ

Trường ngẫu nhiên có điều kiện mô hình hóa, định nghĩa và khái niệm
12

Lịch sử Conditional Random Fields (CRFs)
John Lafferty, Andrew McCallum, and Fernando Pereira. Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data, ICML 2001.
13
Test-of-Time Award of ICML 2011.
Được trích dẫn: hơn 1600 lần trên ACM và hơn 8000 lần trênGoogle Scholar (08/2015)

Linear-chain CRFs
Tập nhãn:
Chuỗi dữ liệu quan sát (data observation sequence):
Chuỗi trạng thái/nhãn (state/label sequence):
Mô hình CRFs:
Đoán nhận (prediction) chuỗi nhãn phù hợp nhất:
14

Markov Random Fields (MRFs)
Ký hiệu đồ thị với tập đỉnh và tập cạnh
Mỗi đỉnh nhận giá trị từ một tập hữu hạn cho trước.
Phân bố cần quan tâm:
15
Chuỗi (sequence, linear-chain)Đồ thị tổng quát (graph)

Markov Random Fields (cont’d)
Gọi là tập tất cả các đồ thị con đầy đủ cực đại (maximal cliques) trong
Theo định lý cơ bản về trường ngẫu nhiên (random fields) bởi Hammersley và Clifford (1971), có thể được phân rã như sau:
Trong đó: là hàm địa phương (local/potential function) và
là hàm chuẩn hóa (normalization function)
Chuỗi (sequence, linear-chain)Đồ thị tổng quát (general graph)
16
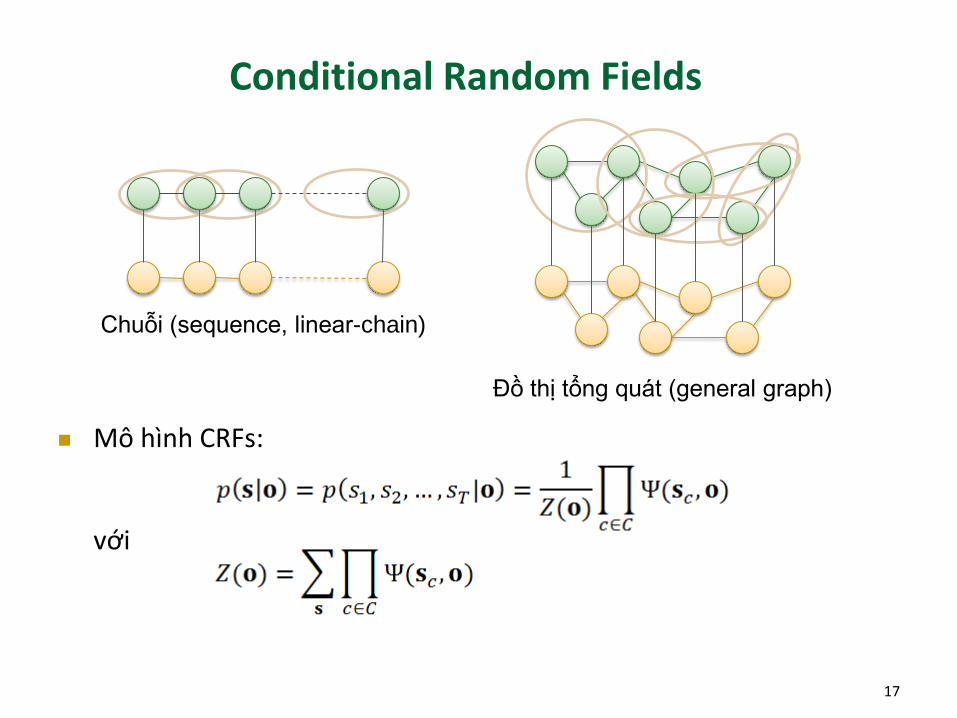
Conditional Random Fields
Mô hình CRFs:
với
17
Chuỗi (sequence, linear-chain)
Đồ thị tổng quát (general graph)

Conditional Random Fields (cont’d)
Lafferty et al. 2001 định nghĩa hàm tiêm năng:
Khi đó, mô hình CRFs có thể được viết lại:
Trong đó:
là tập thuộc tính (feature)
là tập trọng số tương ứng với các thuộc tính
18

Linear-chain Conditional Random Fields
Các đồ thị con đầy đủ cực đại (maximal cliques) chính là tập các cặp đỉnh/trạng thái liền kề.
Có thể viết lại mô hình:
19
Chuỗi (sequence, linear-chain)

Các dạng thuộc tính trong CRFs
Hai dạng thuộc tính:
Thuộc tính cạnh (e – edge feature): phụ thuộc Markov giữa các vị trí liền kề
Thuộc tính quan sát (o – observation feature): đặc điểm quan sát được từ chuỗi dữ liệu đầu vào
20
ll’
o1 o2 o3 oT
s1 s2 s3 sT...
f e
f o
label l needs to
be predicted
xi(o, t)...
the current position
t = 3

Edge feature và observation feature
Thuộc tính cạnh (edge feature):
Ví dụ:
Thuộc tính quan sát (observation feature):
Ví dụ:
21

Trích chọn thuộc tính cho CRFs như thế nào?
Thống kê đơn lẻ (singleton statistics)
Kết hợp của các thống kê đơn lẻ (conjuction of singleton statistics)
Overlapping features
Bất cứ dạng thuộc tính nào cần thiết cho việc đoán nhận
22
…
s1 s2 s3 sT…
o1 o2 o3 oT

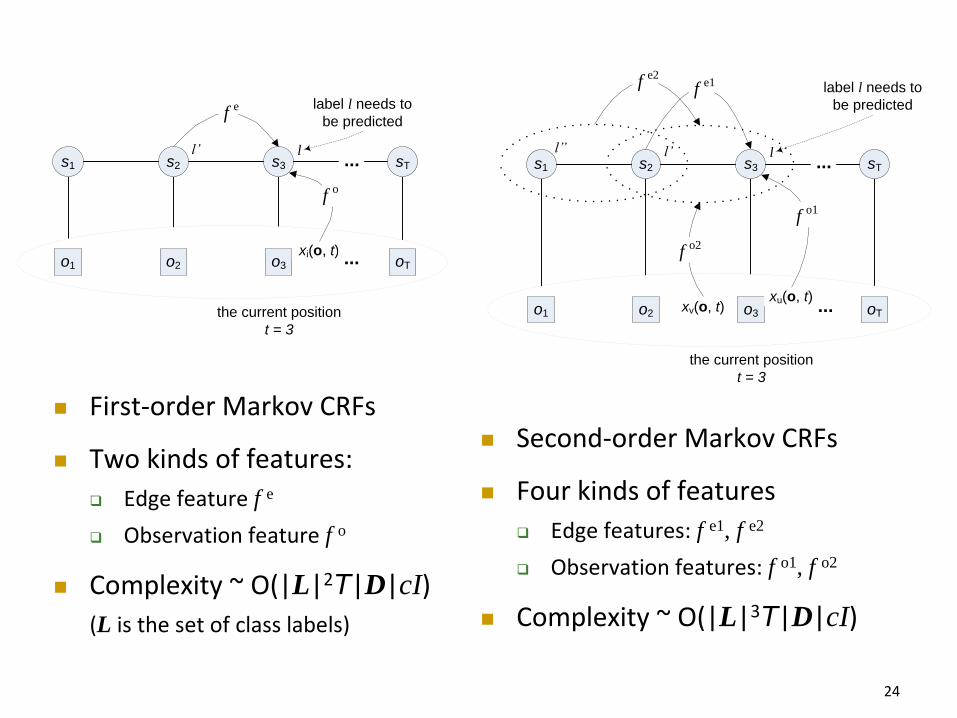
CRFs phụ thuộc Markov cấp I và cấp IIFirst- and second-order Markov CRFs
23
24
First-order Markov CRFs
Two kinds of features:
Edge feature f e
Observation feature f o
Complexity ~ O(|L|2T|D|cI)
(L is the set of class labels)
Second-order Markov CRFs
Four kinds of features
Edge features: f e1, f e2
Observation features: f o1, f o2
Complexity ~ O(|L|3T|D|cI)
ll’
o1 o2 o3 oT
s1 s2 s3 sT...
f e
f o
label l needs to
be predicted
xi(o, t)...
the current position
t = 3
ll’l”
o1 o2 o3 oT
s1 s2 s3 sT...
f e2
f e1
f o2
f o1
label l needs to
be predicted
xv(o, t)xu(o, t)
...
the current position
t = 3

Ước lượng tham số hay huấn luyện mô hìnhmodel training or parameter estimation
25
Mô hình hóa và ước lượng tham số cho các mô hình học máy thống kê
26

Mô hình hóa và ước lượng tham số cho CRFs
27
Phương pháp ước lượnghay huấn luyện mô hình

Các phương pháp ước lượng tham số cho CRFs
Maximum Likelihood
Iterative scaling (GIS, IIS)
Gradient descent
Conjugate gradient
Newton’s method (limited quasi-Newton method – L-BFGS)
Stochastic Gradient Methods
Parallelism
28
Efficient Training of Conditional Random Fields (by Hana M. Wallach)

Ước lượng theo maximum likelihood với L-BFGS
Hàm likelihood của mô hình CRFs là hàm lồi (convex).
Thuật toán tối ưu: limited memory quasi-Newton method (L-BFGS):
D. Liu and J. Nocedal. On the limited memory BFGS method for large scale optimization, Mathematical Programming, 1989.
Là phương pháp tối ưu cấp 2 (second-order ), cần ước lượng ma trận Hessian.
L-BFGS có thể ước lượng xấp xỉ ma trận Hessian thông qua giá trị hàm mục tiêu và véc tơ đạo hàm cấp 1.
Trong nội dung bài giảng: xem L-BFGS như một thủ tục hộp đen (black-box procedure)
29

Thủ tục huấn luyện mô hình với L-BFGS
30

Hàm log-likelihood
31
Euclidean norm regularization: giảm overfitting và tránh cân
bằng các thuộc tính

Đạo hàm riêng cấp một hàm log-likelihood
32

Ước lượng hàm log-likelihood và đạo hàm cấp một
Để tính:
Hàm log-likelihood và
Véc tơ gradient
Cần tính:
33
...
...
...
Summing over all possible label paths
Dynamic programming
O(|L|2T): first-order
O(|L|3T): second-order
(L is the set of labels)

Parallelism – Huấn luyện CRFs song song
34

Suy diễn hay đoán nhận với mô hình CRFsinference or prediction in linear-chain CRFs
35

Đoán nhận chuỗi nhãn phù hợp với mô hình CRFs
Bộ tham số tối ưu và mô hình tương ứng:
Sử dụng mô hình này để đoán nhận (predict) chuỗi nhãn phù hợp nhất (most likely label sequence) cho mỗi chuỗi dữ liệu đầu vào (input data observation sequence) như sau:
36

Tìm chuỗi nhãn phù hợp với thuật toán Viterbi
Thuật toán quy hoạch động, sử dụng rộng rãi với mô hình HMMs
Lưu lại xác suất của chuỗi nhãn phù hợp nhất từ đầu cho đến vị trí nào đó trong chuỗi và kết thúc với trạng thái (hàm ý )
Ký hiệu xác suất đó là ( ) và là xác suất xuất phát của chuỗi.
Chúng ta có công thức đệ quy như sau:
Việc tính toán đệ quy kết thúc khi và xác suất lớn nhất (chưa chuẩn hóa) là
37
Backtracking dựa trên các thông tin đãlưu để tìm chuỗi nhãn phù hợp nhất
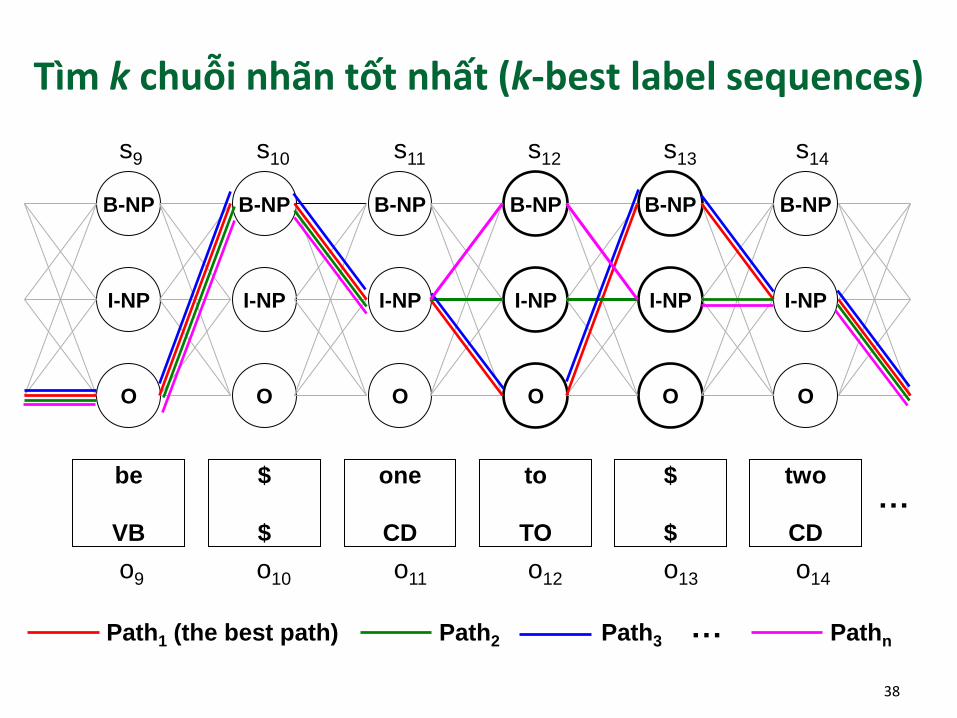
Tìm k chuỗi nhãn tốt nhất (k-best label sequences)
38
B-NP
I-NP
O
be
VB
B-NP
I-NP
O
$
$
B-NP
I-NP
O
one
CD
B-NP
I-NP
O
to
TO
B-NP
I-NP
O
$
$
B-NP
I-NP
O
two
CD
…
o9 o10 o11 o12 o13 o14
s9 s10 s11 s12 s13 s14
Path1 (the best path) Path2 Path3 Pathn…

Các ưu và nhược điểm của mô hình CRFsadvantages and limitations of CRFs
39
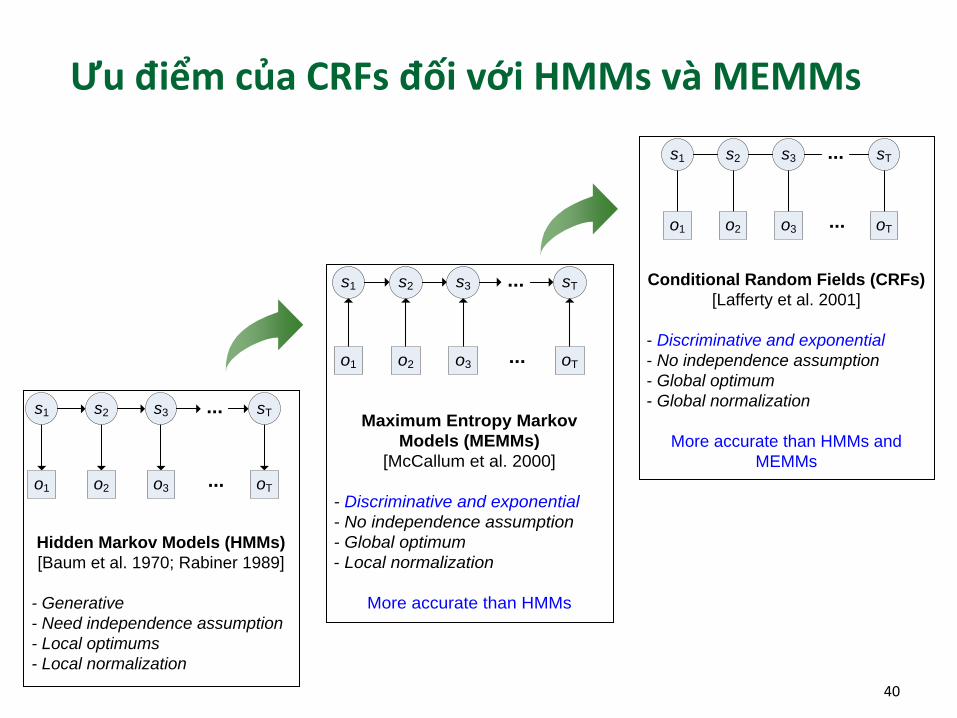
Ưu điểm của CRFs đối với HMMs và MEMMs
40
o1 o2 o3 oT
s1 s2 s3 sT...
...
Hidden Markov Models (HMMs)
[Baum et al. 1970; Rabiner 1989]
- Generative
- Need independence assumption
- Local optimums
- Local normalization
o1 o2 o3 oT
s1 s2 s3 sT...
...
Maximum Entropy Markov
Models (MEMMs)
[McCallum et al. 2000]
- Discriminative and exponential
- No independence assumption
- Global optimum
- Local normalization
More accurate than HMMs
o1 o2 o3 oT
s1 s2 s3 sT...
...
Conditional Random Fields (CRFs)
[Lafferty et al. 2001]
- Discriminative and exponential
- No independence assumption
- Global optimum
- Global normalization
More accurate than HMMs and
MEMMs
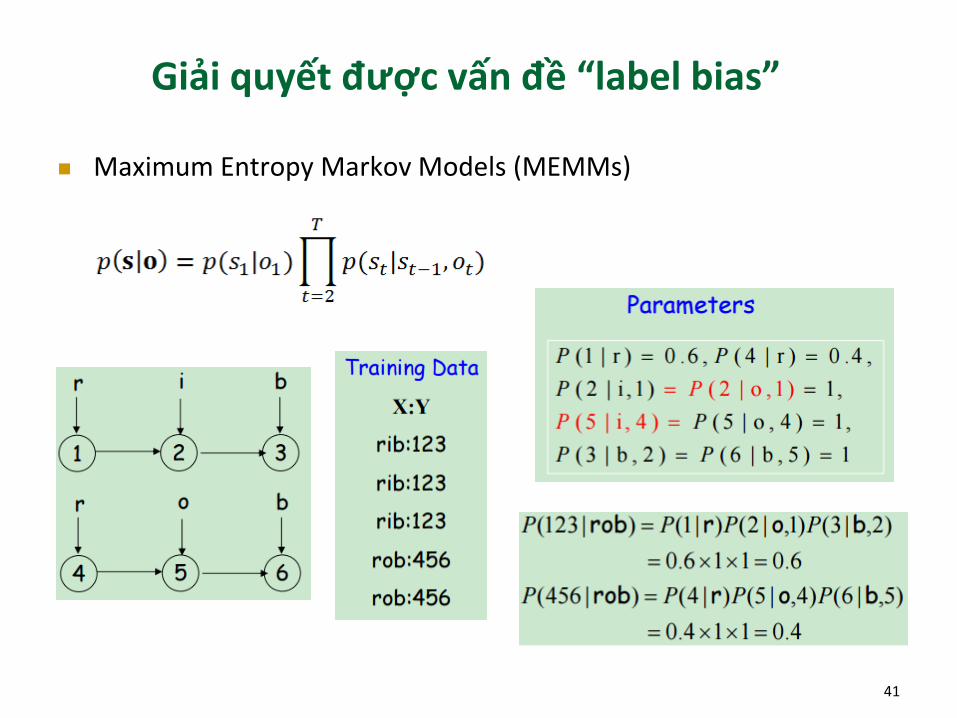
Giải quyết được vấn đề “label bias”
Maximum Entropy Markov Models (MEMMs)
41

Nhược điểm
Tính phụ thuộc Markov trong dữ liệu (bản chất dữ liệu)
Thời gian tính toán (huấn luyện) tăng khi số nhãn nhiều.
Mô hình có thể lớn (tốn bộ nhớ)
42

CRFs với các bài toán ứng dụng thực tếCRFs and its real-world applications
43

CRFs for Image Processing and Computer Vision
K. Murphy et al. Using The Forest to See The Trees: A Graphical Model Relating Features, Objects, and Scenes, NIPS 2003.
S. Kumar and M. Hebert. Discriminative Fields for Modeling Spatial Dependencies in Natural Images, NIPS 2003.
X. He et al. Multiscale Conditional Random Fields for Image Labeling, CVPR 2004.
C. Smimchisescu et al. Conditional Models for Contextual Human Motion Recognition, ICCV 2005.
A. Quattoni et al. Conditional Random Fields for Object Recognition, NIPS 2005.
A. Torralba et al. Contextual Models for Object Detection using Boosted Random Fields, NIPS 2005.
Y. Wang and Q. Ji. A Dynamic Conditional Random Field Model for Object Segmentation in Image Sequences, CVPR 2005.
44

CRFs for Bioinformatics & Computational Biology
K. Sato and Y. Sakakibara. RNA secondary structural alignment with conditional random fields, Bioinformatics 2005.
Y. Liu et al. Protein fold recognition using segmentation conditional random fields, Journal of Computational Biology 2006.
M. Li et al. Protein-protein interaction site prediction based on conditional random fields, Bioinformatics 2007.
F. Zhao et al. A probabilistic graphical model for ab initio folding, Research in Computational Molecular Biology, 2009.
X. Geng et al. Protein backbone dihedral angle prediction based on probabilistic models, iCBBE 2010.
T. Gehrmann et al. Conditional random fields for protein function prediction, PRIB 2013.
45

CRFs for NLP and Information Extraction
Word segmentation
Part-of-speech tagging
Phrase chunking (shallow parsing)
Named entity recognition (NER)
Both general text and biomedical text
Information extraction from text/web
Text: table, author-affiliation (research papers), for form filling, …
Web: product description, transforming semi-structured into structured data
46

Một số bài toán ứng dụng CRFs
Gắn nhãn (labeling):
Gắn nhãn từ loại (part-of-speech tagging) cho tiếng Anh
Phân đoạn (segmentation):
Xác định cụm danh từ (noun phrase chunking) cho tiếng Anh
Xác định cụm từ (phrase chunking/shallow parsing) cho tiếng Anh
Tách từ (word segmentation) cho tiếng Việt
47

Flexible Conditional Random Fields
48

Part-of-Speech Tagging on WSJ Corpus
WSJ Corpus:
Training set: sections 00-18
Development test set: sections 19-21
Final test set: sections 22-24
First and second-order Markov CRFs49
Rolls_NNP Royce_NNP Motor_NNP Cars_NNPS Inc._NNP said_VBD it_PRP
expects_VBZ its_PRP$ U.S._NNP sales_NNS to_TO remain_VB steady_JJ ...

Feature Templates for Part-of-Speech Tagging
50

Part-of-Speech Tagging Comparison on WSJ
51
Methods Devel.
Acc.%
Final
Acc.%
Toutanova et al. 2003 (Dependency Network,
4-order Markov dependencies, 2-forward, 2-backward)
97.15 97.24
Ours (second-order Markov CRFs) 97.05 97.16
Collins 2002 (Discriminative HMMs) 97.07 97.11
Ours (first-order Markov CRFs) 96.92 96.92

Phrase Chunking on Wall Street Journal Corpus
52
Rolls_NNP Royce_NNP Motor_NNP Cars_NNPS Inc._NNP said_VBD it_PRP
expects_VBZ its_PRP$ U.S._NNP sales_NNS to_TO remain_VB steady_JJ ...
[Rolls Royce Motor Cars Inc. NP] [said VP] [it NP] [expects VP]
[its U.S. sales NP] [to remain VP] [steady ADJP] ...
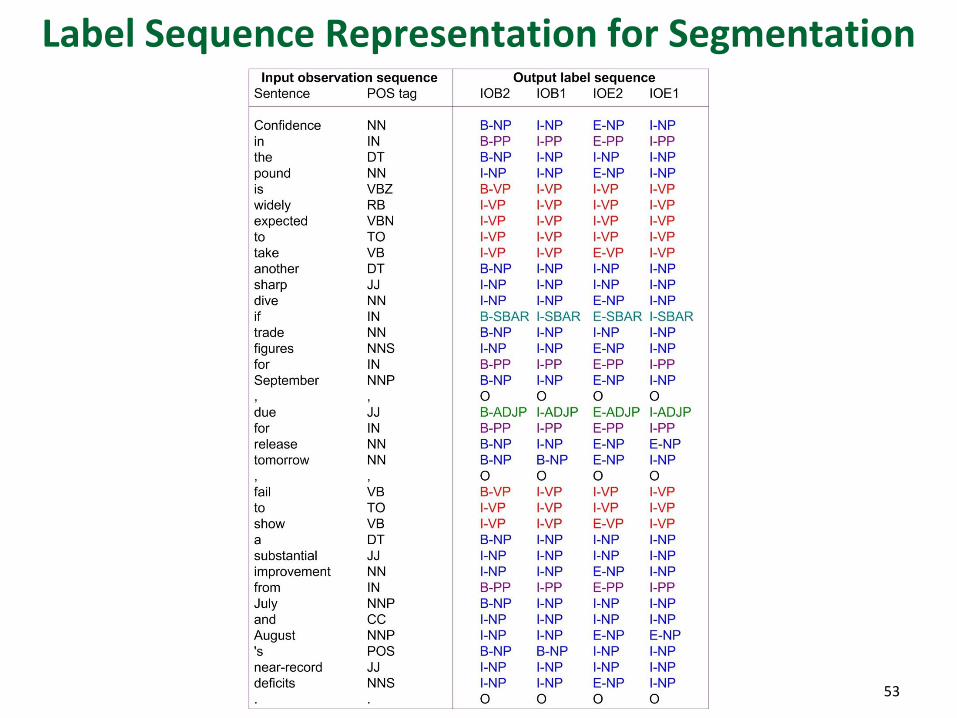
Label Sequence Representation for Segmentation
53

Feature Templates for Phrase Chunking
54
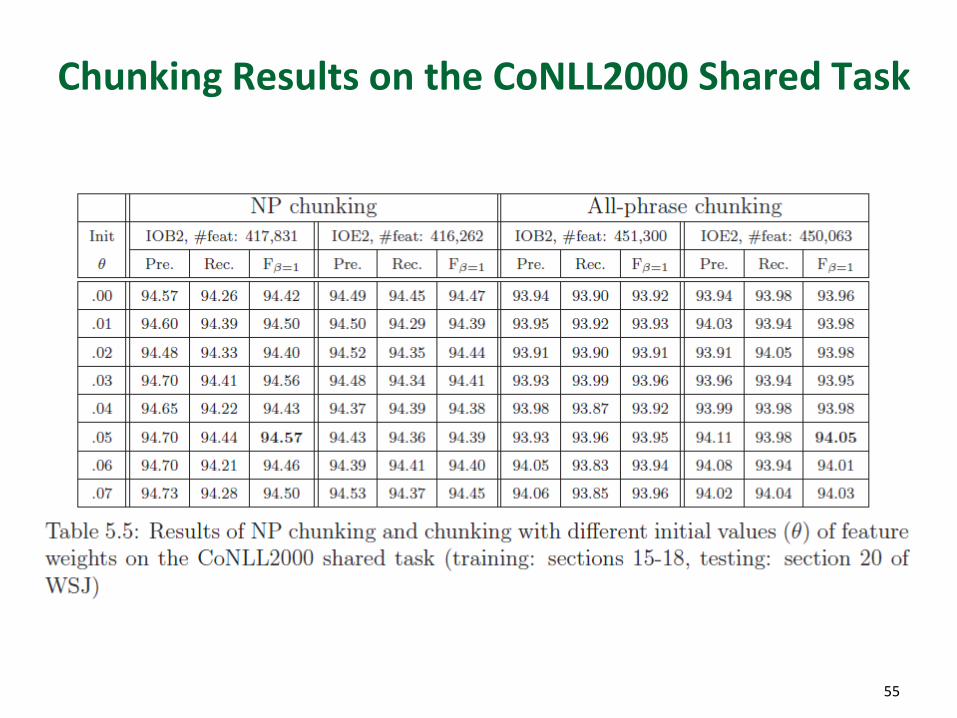
Chunking Results on the CoNLL2000 Shared Task
55
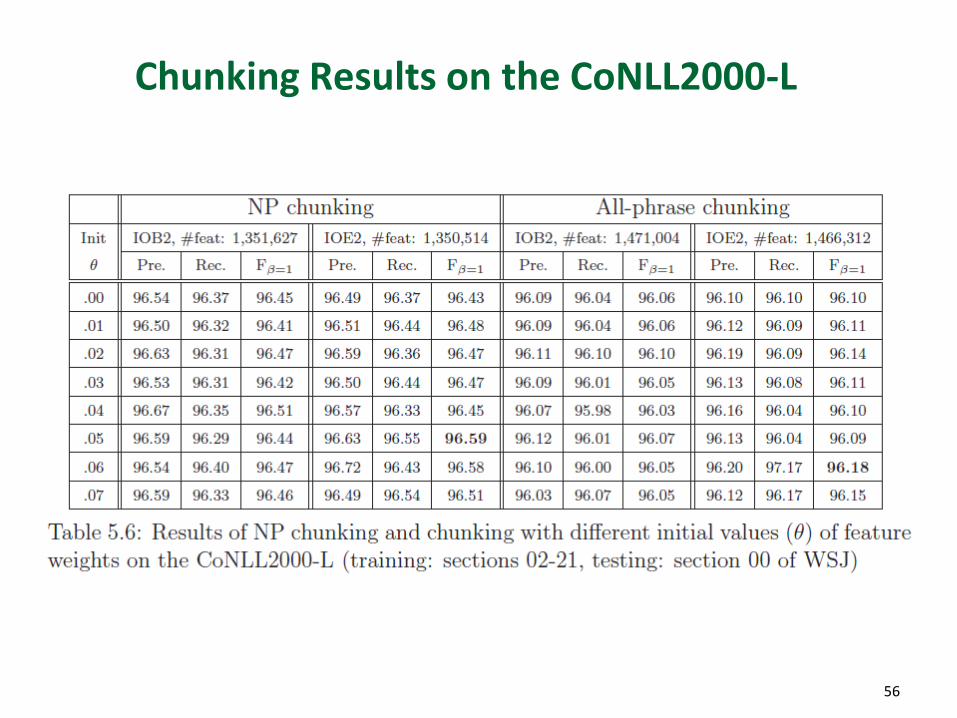
Chunking Results on the CoNLL2000-L
56
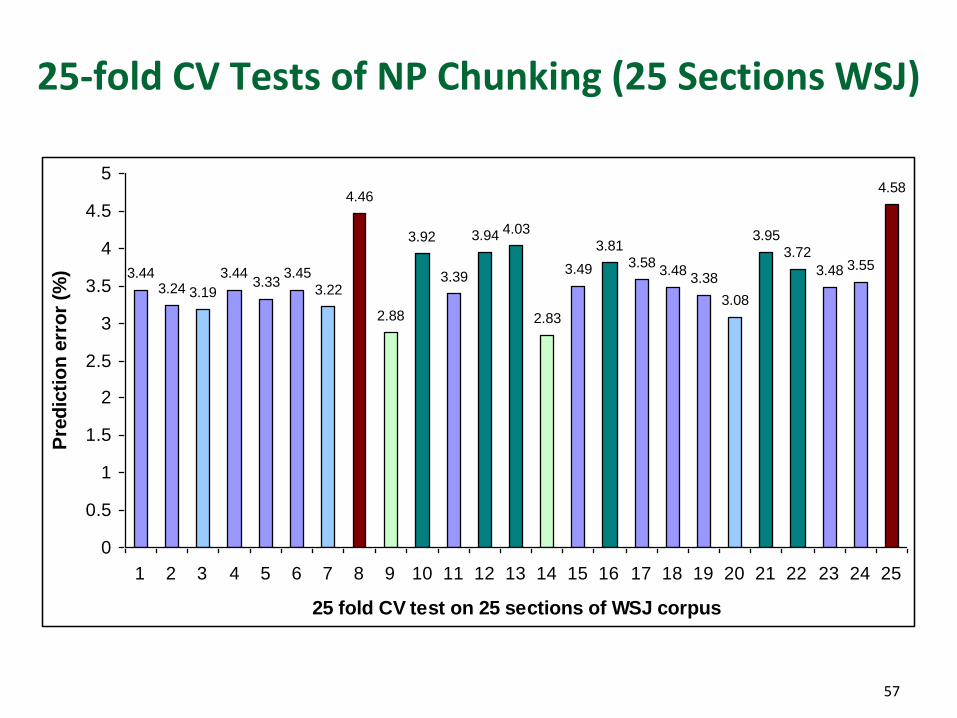
25-fold CV Tests of NP Chunking (25 Sections WSJ)
57
3.443.24 3.19
3.443.33
3.45
3.22
4.46
2.88
3.92
3.39
3.94 4.03
2.83
3.49
3.81
3.583.48
3.38
3.08
3.95
3.72
3.48 3.55
4.58
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
5
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
25 fold CV test on 25 sections of WSJ corpus
Pre
dic
tio
n e
rro
r (%
)
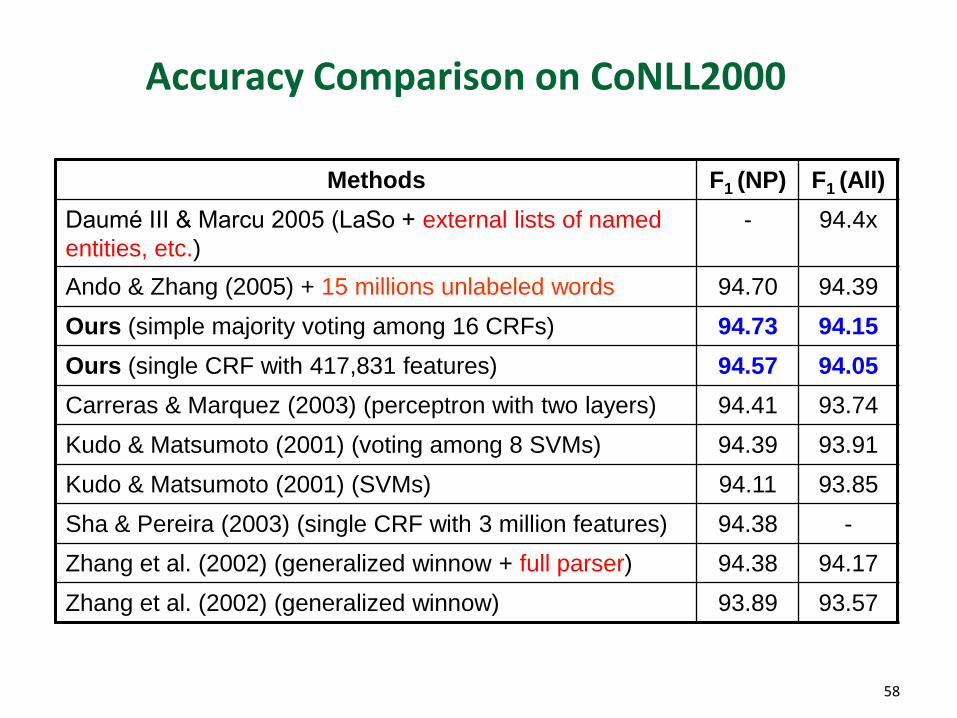
Accuracy Comparison on CoNLL2000
58
Methods F1 (NP) F1 (All)
Daumé III & Marcu 2005 (LaSo + external lists of named
entities, etc.)
- 94.4x
Ando & Zhang (2005) + 15 millions unlabeled words 94.70 94.39
Ours (simple majority voting among 16 CRFs) 94.73 94.15
Ours (single CRF with 417,831 features) 94.57 94.05
Carreras & Marquez (2003) (perceptron with two layers) 94.41 93.74
Kudo & Matsumoto (2001) (voting among 8 SVMs) 94.39 93.91
Kudo & Matsumoto (2001) (SVMs) 94.11 93.85
Sha & Pereira (2003) (single CRF with 3 million features) 94.38 -
Zhang et al. (2002) (generalized winnow + full parser) 94.38 94.17
Zhang et al. (2002) (generalized winnow) 93.89 93.57
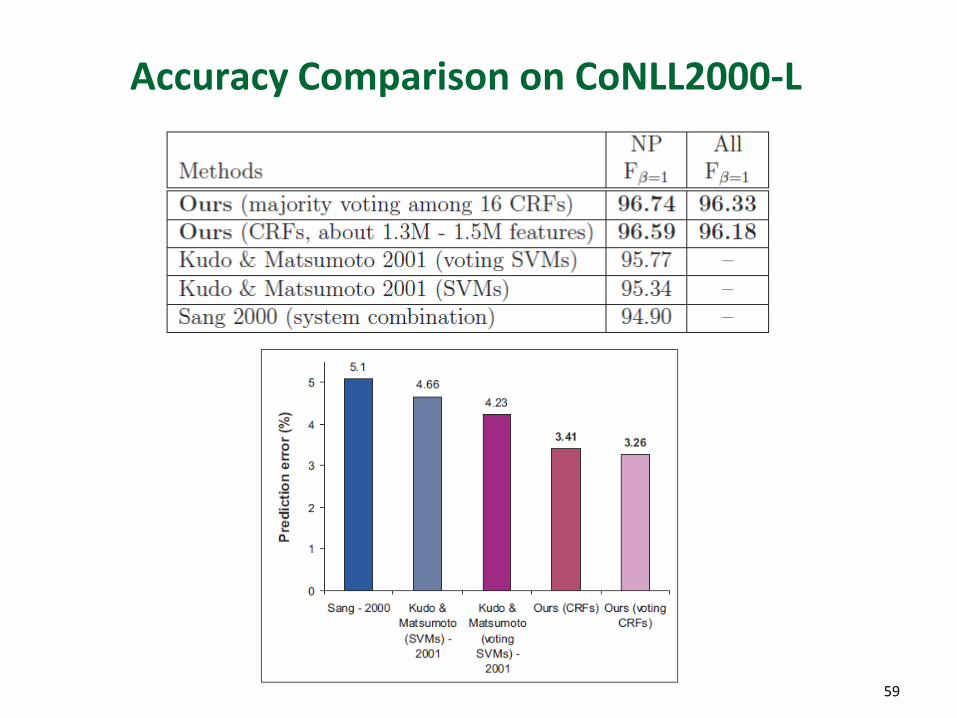
Accuracy Comparison on CoNLL2000-L
59
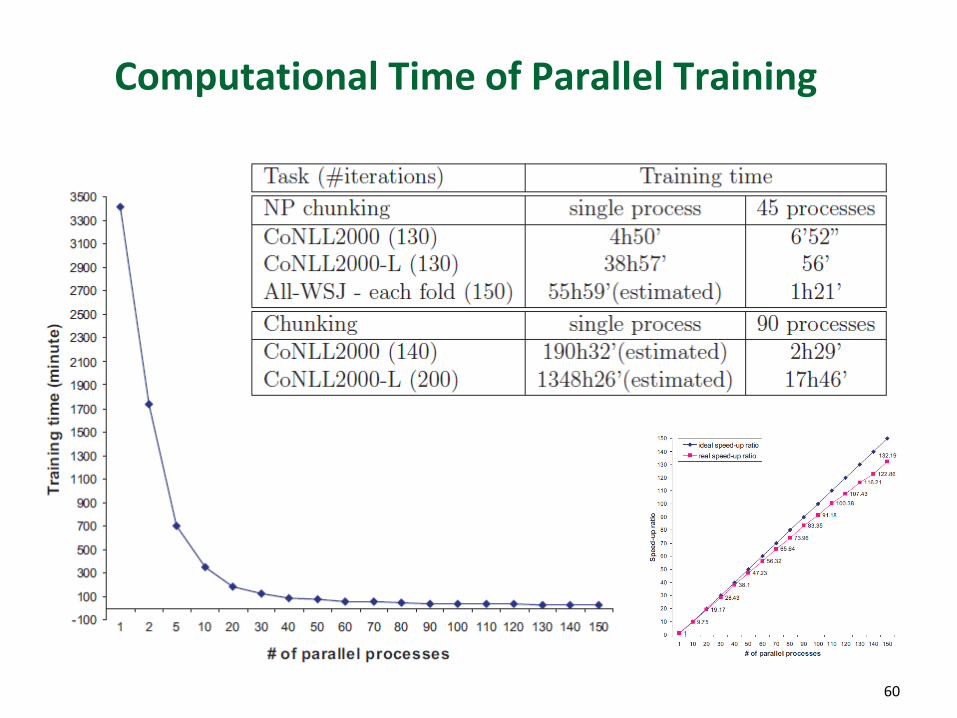
Computational Time of Parallel Training
60

Phrase Chunker for English
61

Tách từ cho tiếng Việt
Evaluation data: VLSP Corpus ++
Feature tempates: very rich, a lot of regular expressions for time, email, url, currency, number, name, etc.
Parameters:
First-order Markov CRFs
Training sentences: 46160
Test sentences: 11533
#Context predicates: 567149
#Features: 659933 (after pruning)
Feature rare threshold: 1
Context predicate rare threshold: 2
#Training iterations: 200
Sigma square: 10.0
Number of approximated Hessian matrixes: 7
62
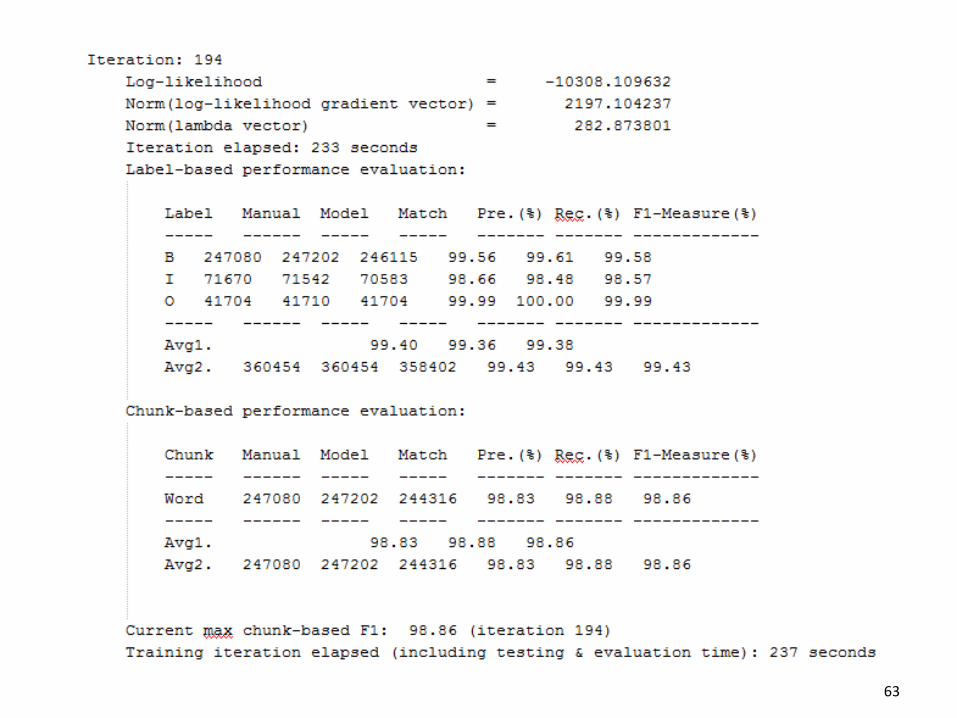
63

Một số cài đặt của mô hình CRFsimplementation of CRFs
64
65
https://en.wikipedia.org/wiki/Conditional_random_field
By Xuan-Hieu Phan, Le-Minh Nguyen, and Cam-Tu Nguyen (2004): + first C/C++ implementation+ second-order Markov+ parallelism (MPI)

Những kinh nghiệm xây dựng ứng dụng với CRFsbuilding applications with CRFs: experience and lessons learnt
66

Trước khi quyết định dùng CRFs:
Xem xét bản chất của dữ liệu (nature of data)
Sequential dependencies phổ biến mức nào? mạnh mức nào?
Long-range dependencies?
Huấn luyện mô hình CRFs:
Chọn window size phù hợp
Nhiều thuộc tính chưa chắc tốt: overfitting, tăng thời gian tính toán, mô hình bị phình to
Trích chọn mẫu thuộc tính (feature templates) tỉ mỉ và kỹ lưỡng, cần nhiều thuốc tính có tính phân biệt cao (highly discriminative)
Phân tích lỗi, điều chỉnh thuộc tính, điều chỉnh dữ liệu huấn luyện
Nên có development test set
Hiệu quả và chi phí khi sử dụng CRFs:
Mang lại kết quả vượt trội so với các mô hình phân lớp đơn lẻ
Triển khai dưới dạng web services hay mobile services?
67

Kết luận bài giảngSummary
68

Những nội dung chính đã học
Đoán nhận trên dữ liệu có cấu trúc
Mô hình hóa CRFs
Markov random fields
Conditional random fields: linear-chain and general CRFs
Feature types of CRFs
CRFs phụ thuộc cấp I và cấp II (first- and second-order Markov CRFs)
Ước lượng tham số cho mô hình CRFs
Maximum likelihood estimation với phương pháp tối ưu L-BFGS
Huấn luyện CRFs song song
Suy diễn/đoán nhận với CRFs
Các ưu/nhược điểm của CRFs
CRFs với các bài toán ứng dụng thực tế
Những kinh nghiệm khi xây dựng ứng dụng với CRFs69

Thank you.
70
Q&A time


















