
The introduction to FRMQN model
48
ディープラーニングの最新動向 強化学習とのコラボ編④ FRMQN 2016/8/18 株式会社ウェブファーマー 大政 孝充
-
Upload
- -
Category
Data & Analytics
-
view
318 -
download
1
Transcript of The introduction to FRMQN model

ディープラーニングの最新動向 強化学習とのコラボ編④ FRMQN
2016/8/18 株式会社ウェブファーマー
大政 孝充

今回取り上げるのはこれ
[1]J. Oh, V. Chockalingam, S. Singh, H. Lee. “Control of Memory, Active Perception, and Action in Minecraft” arXiv:1605.09128, 2016. DQNに記憶装置をとりつけることで、Minecraftでの得点で従来手法を上回った!

通常のDQN部分は・・・
通常のDQN部分の全体像は塚原裕史氏「論文紹介 Playing Atari with Deep Reinforcement Learning」[2] http://www.slideshare.net/htsukahara/paper-intoduction-playing-atari-with-deep-reinforcement-learning や藤田康博氏「Playing Atari with Deep Reinforcement Learning」[3] http://www.slideshare.net/mooopan/ss-30336609 もしくは私の「ディープラーニングの最新動向 強化学習とのコラボ編① DQN」[4] http://www.slideshare.net/ssuser07aa33/introduction-to-deep-q-learning などを参照してください

解説のポイント
①記憶装置ってどんなの? ②contextってどうやって求めるの? ③結果どうなった?

解説のポイント
①記憶装置ってどんなの? ②contextってどうやって求めるの? ③結果どうなった?
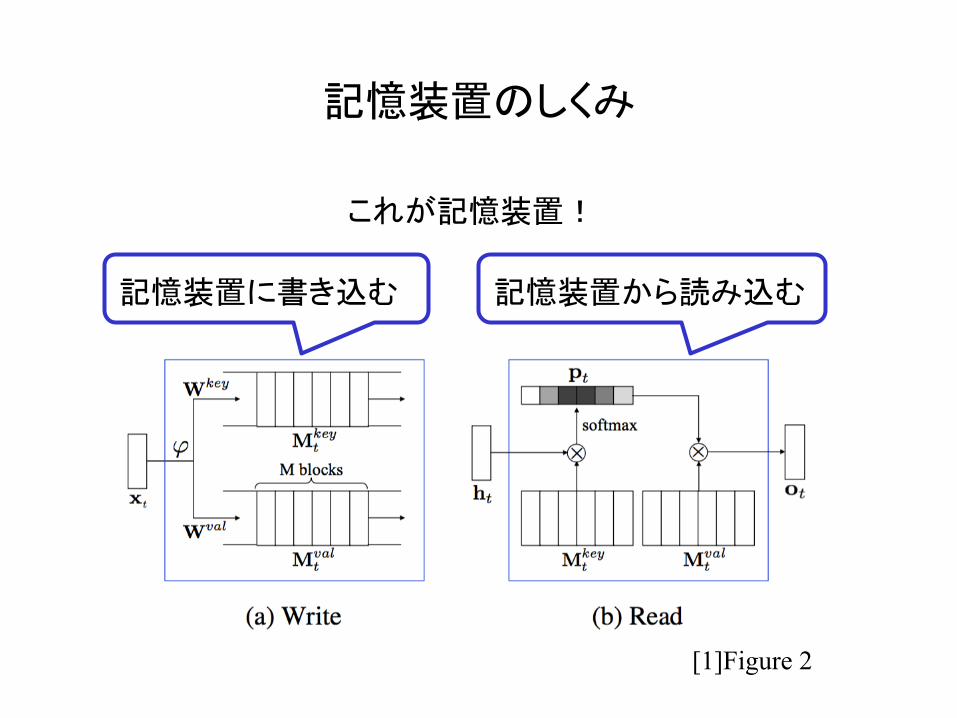
記憶装置のしくみ
記憶装置に書き込む 記憶装置から読み込む
[1]Figure 2
これが記憶装置!
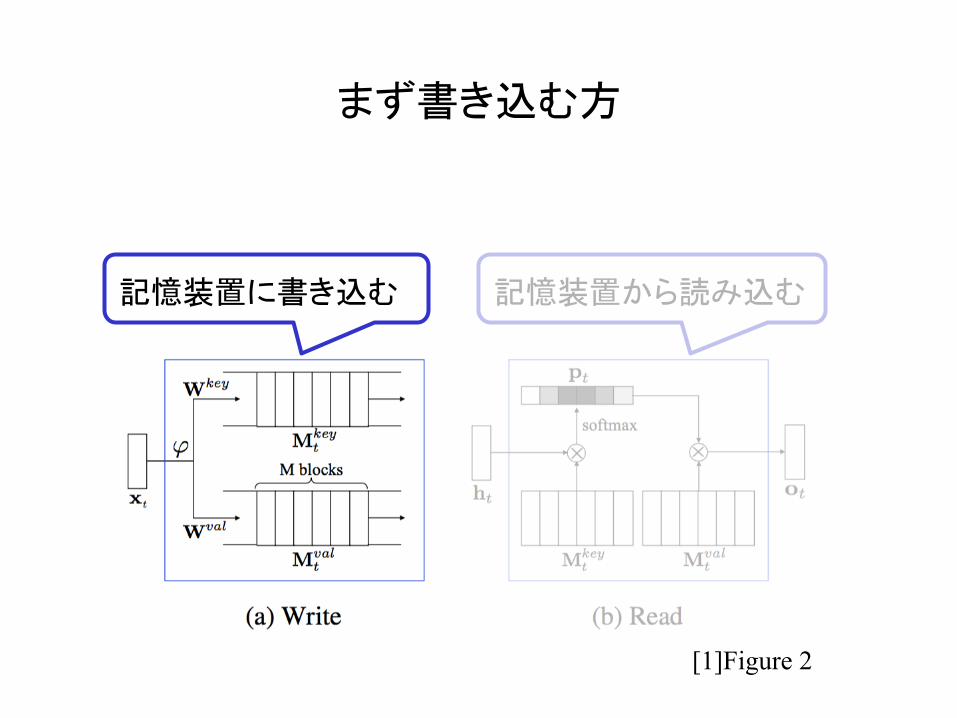
まず書き込む方
記憶装置に書き込む 記憶装置から読み込む
[1]Figure 2
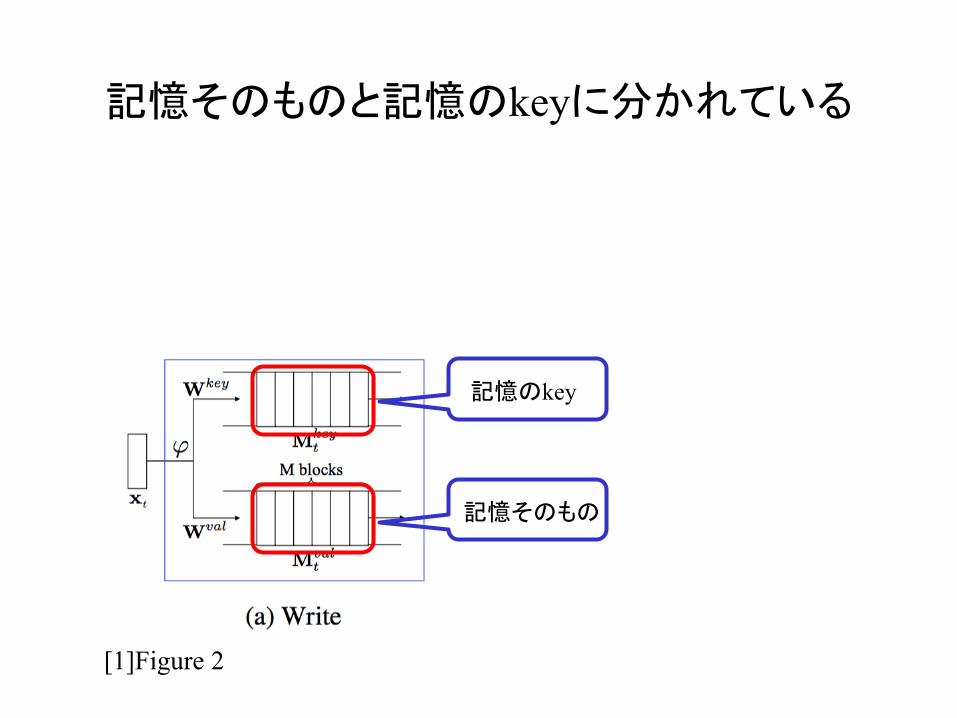
記憶そのものと記憶のkeyに分かれている
[1]Figure 2
記憶そのもの
記憶のkey
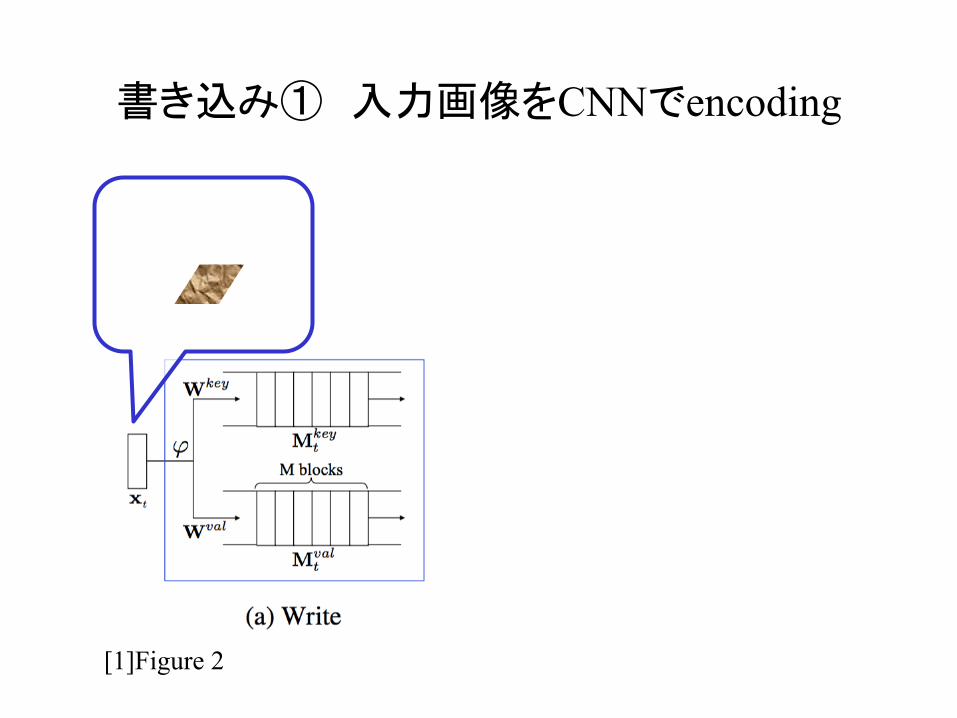
書き込み① 入力画像をCNNでencoding
[1]Figure 2
h c
w入力画像 xt CNNでencoding →
et =ϕ xt( ) e
et
xt ∈ Rc×h×w
et ∈ Re
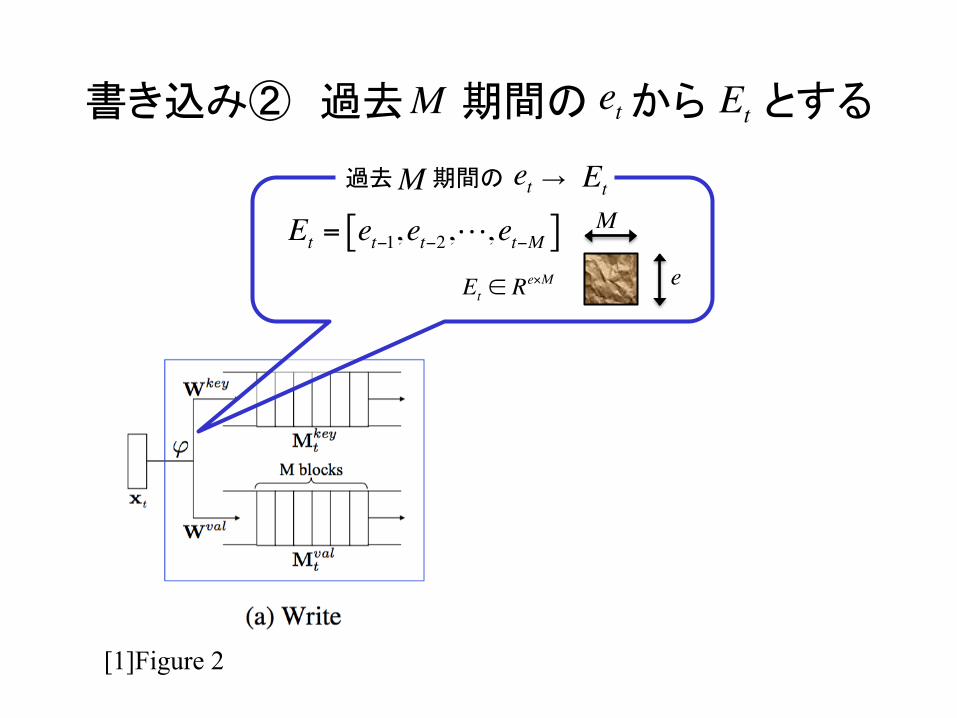
書き込み② 過去 期間の から とする
[1]Figure 2
過去 期間の →
Et = et−1,et−2,!,et−M[ ]e
Et
Et ∈ Re×M
etM Et
etMM
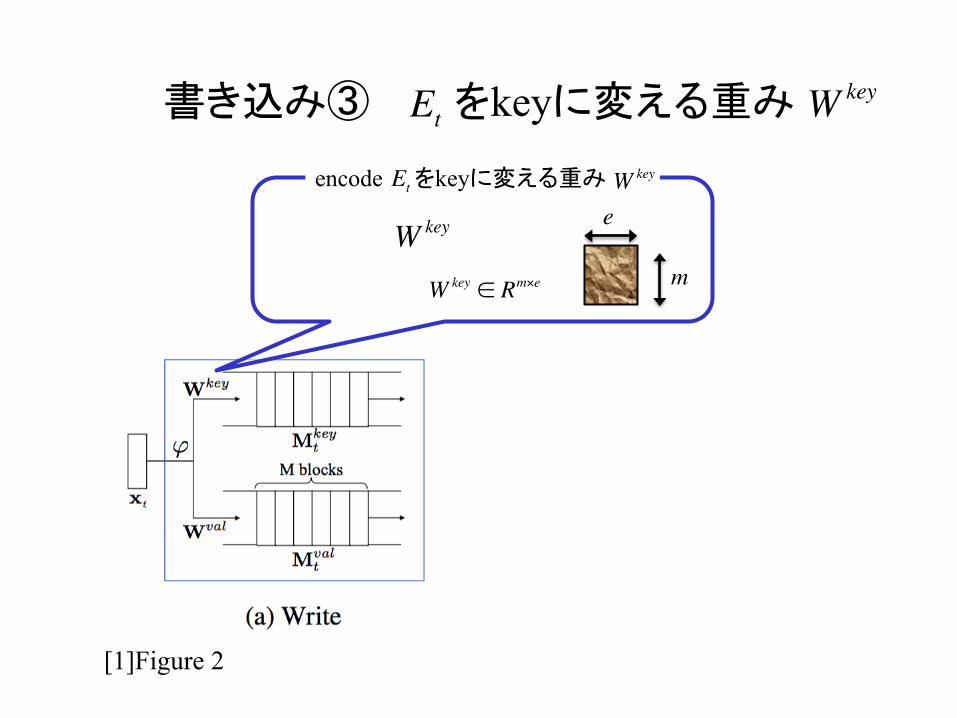
書き込み③ をkeyに変える重み
[1]Figure 2
encode をkeyに変える重み
Wkey eEt
Wkey ∈ Rm×e
Wkey
m
WkeyEt
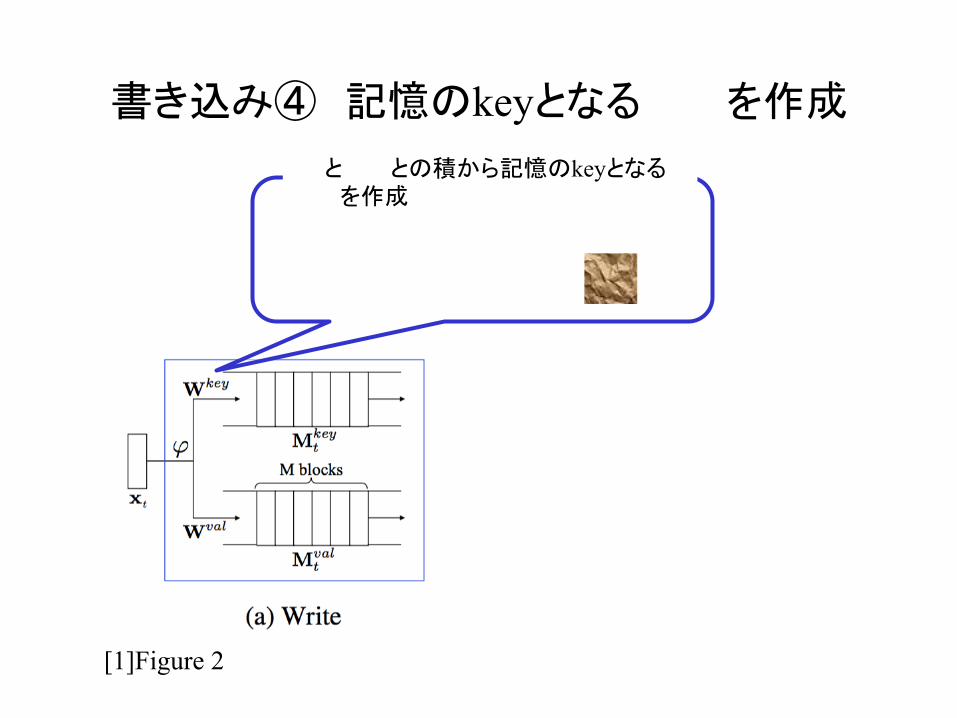
書き込み④ 記憶のkeyとなる を作成
[1]Figure 2
と との積から記憶のkeyとなる を作成
M
Et
Mtkey ∈ Rm×M
Mtkey
mMt
key =WkeyEt
Mtkey
Wkey
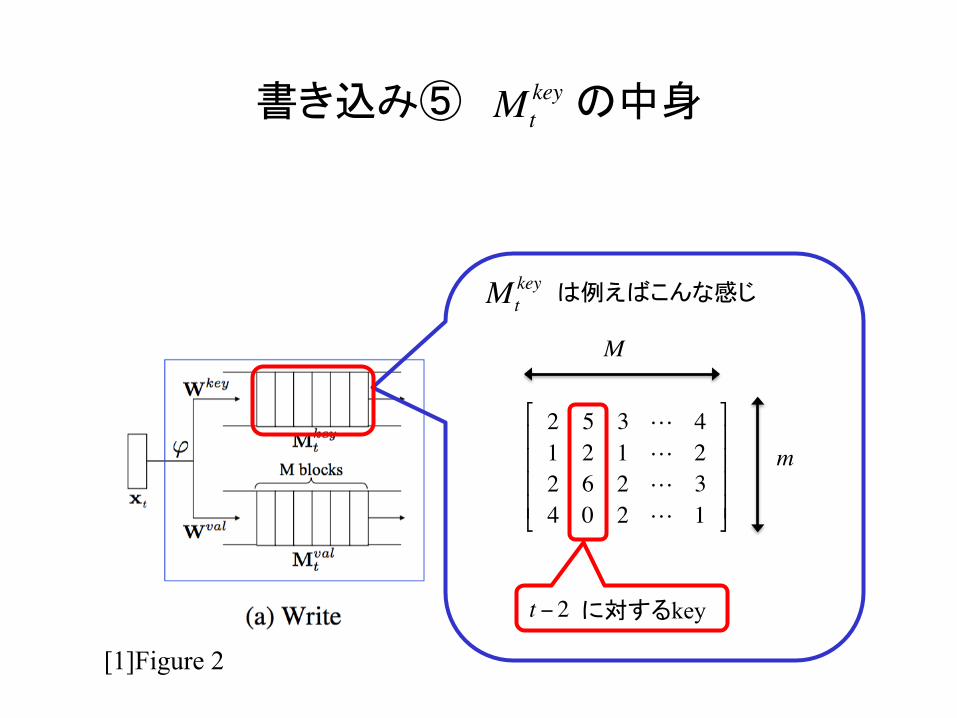
書き込み⑤ の中身
[1]Figure 2
M
2 5 3 ! 41 2 1 ! 22 6 2 ! 34 0 2 ! 1
⎡
⎣
⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥
m
Mtkey
に対するkey t − 2
は例えばこんな感じ Mtkey
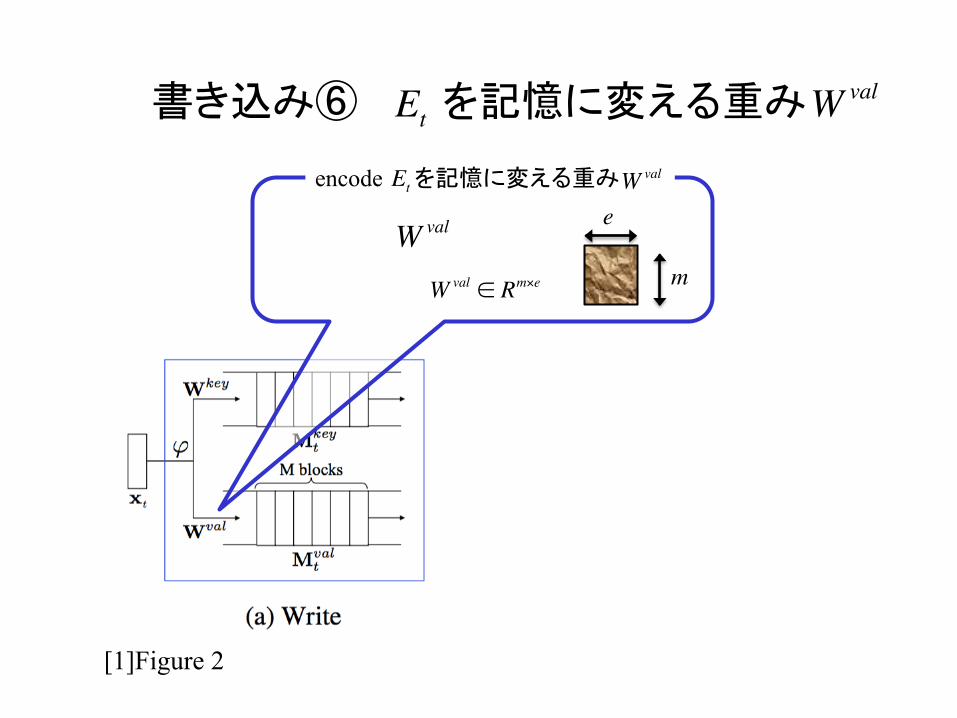
書き込み⑥ を記憶に変える重み
[1]Figure 2
encode を記憶に変える重み
Wval eEt
Wval ∈ Rm×e
Wval
m
WvalEt
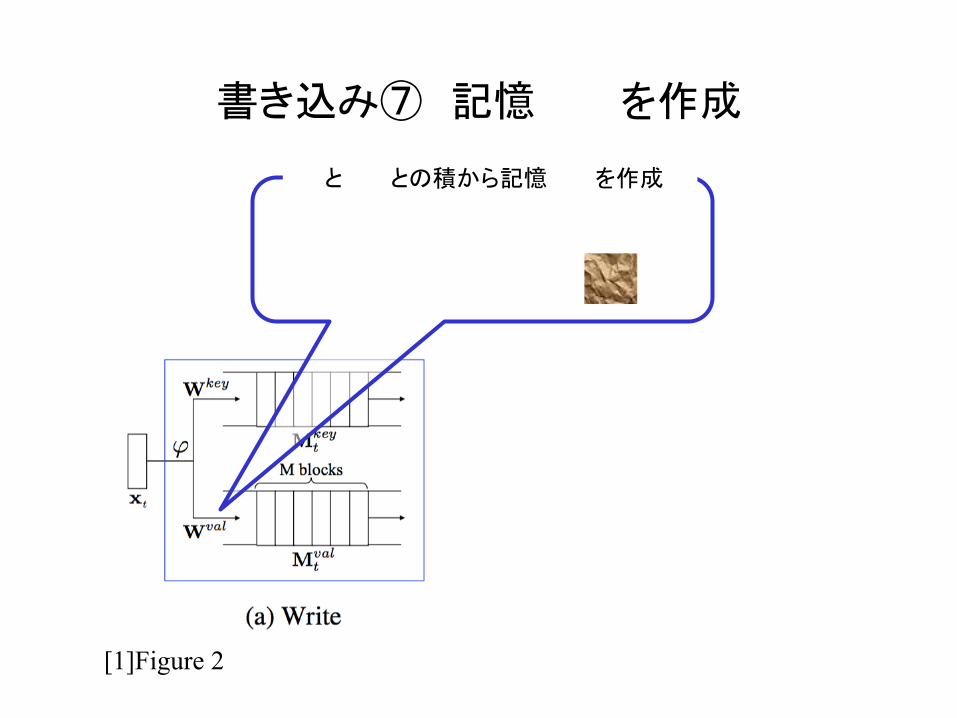
書き込み⑦ 記憶 を作成
[1]Figure 2
と との積から記憶 を作成
M
Et
Mtval ∈ Rm×M
Mtval
mMt
val =WvalEt
Mtval
Wval
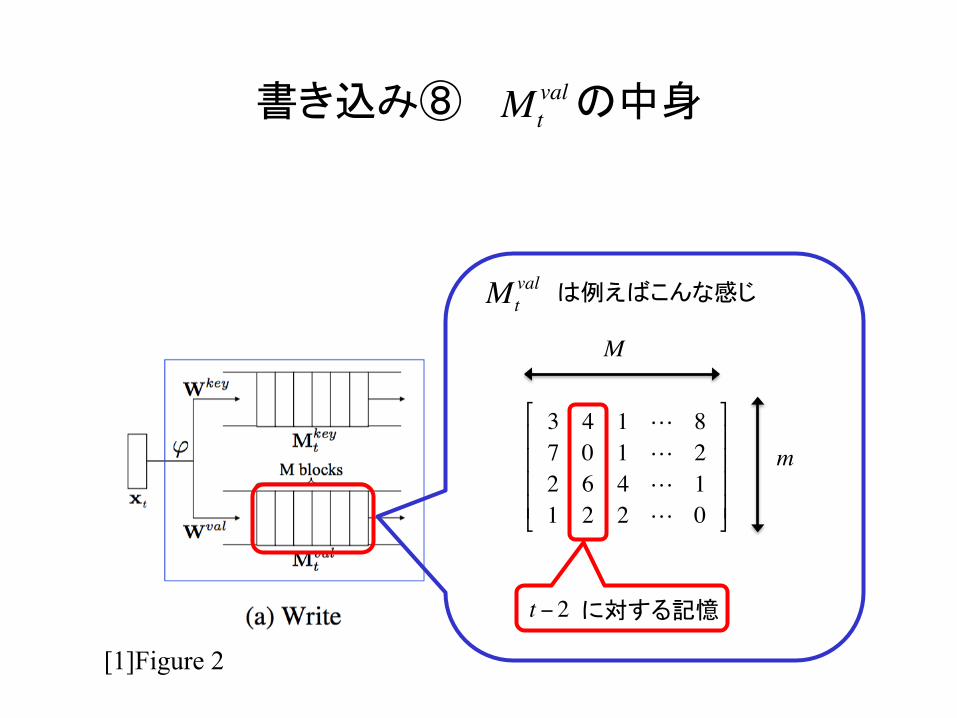
書き込み⑧ の中身
[1]Figure 2
M
3 4 1 ! 87 0 1 ! 22 6 4 ! 11 2 2 ! 0
⎡
⎣
⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥
m
Mtval
に対する記憶 t − 2
は例えばこんな感じ Mtval
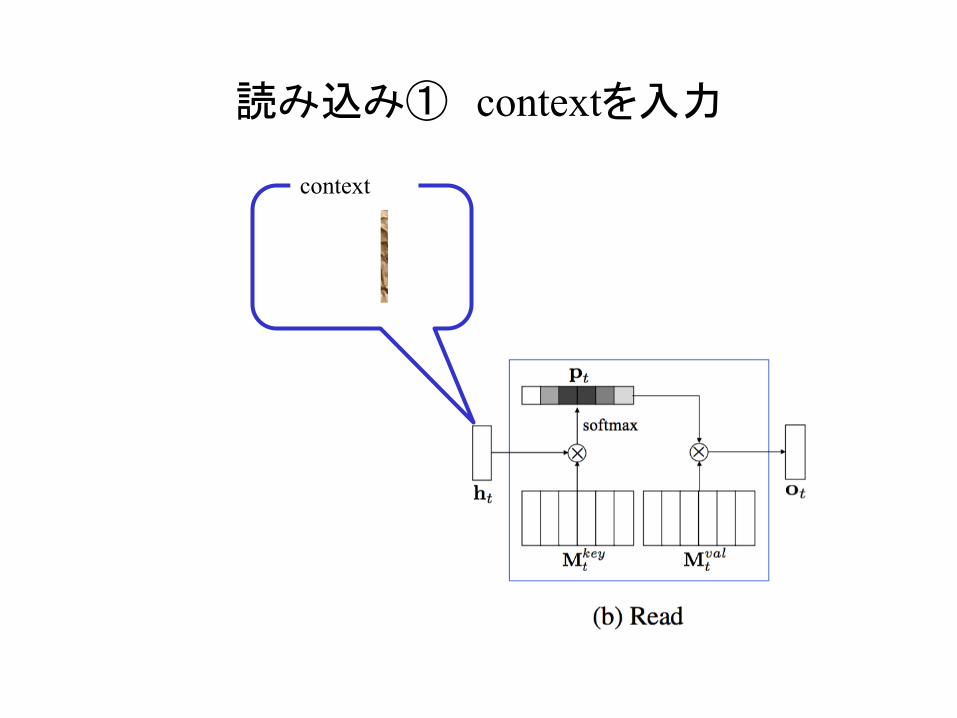
読み込み① contextを入力
context
m
ht
ht ∈ Rm
3271!4
⎡
⎣
⎢⎢⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥⎥
m
に関する部分 t − 2
[1]Figure 2
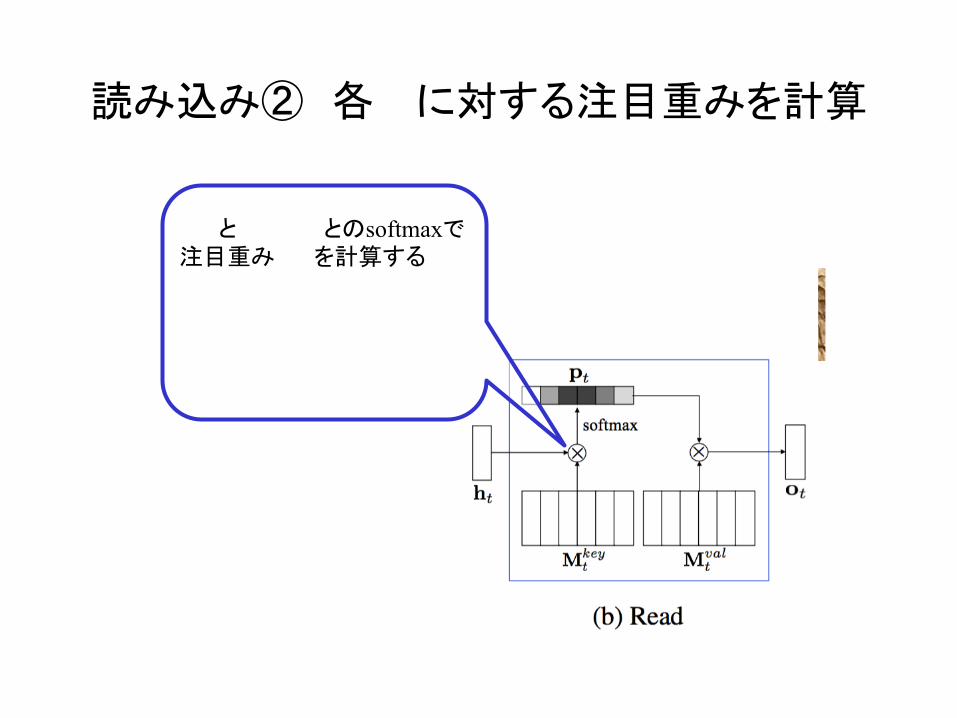
読み込み② 各 に対する注目重みを計算
と とのsoftmaxで 注目重み を計算する
m
ht
pt,i ∈ R
t
Mtkey i[ ]pt,i
pt,i =exp ht
ΤMtkey i[ ]⎡⎣ ⎤⎦
exp htΤMt
key j[ ]⎡⎣ ⎤⎦j=1
M∑
[1]Figure 2
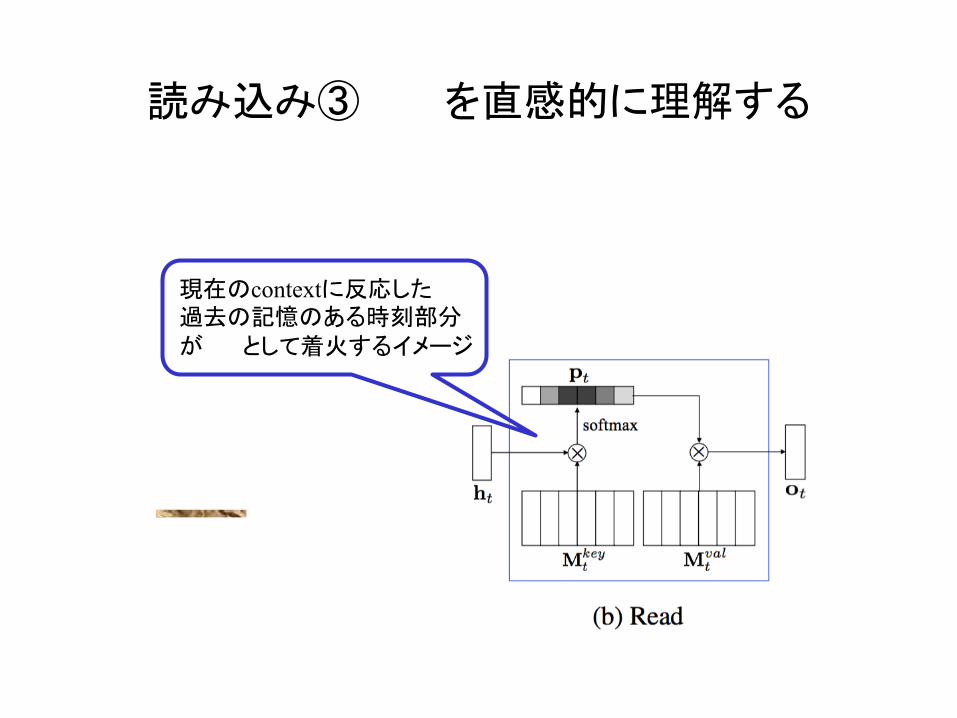
読み込み③ を直感的に理解する
現在のcontextに反応した 過去の記憶のある時刻部分が として着火するイメージ
htΤ
pt,i
mm⊗
[1]Figure 2
Mtkey i[ ]
t = 2
pt,i
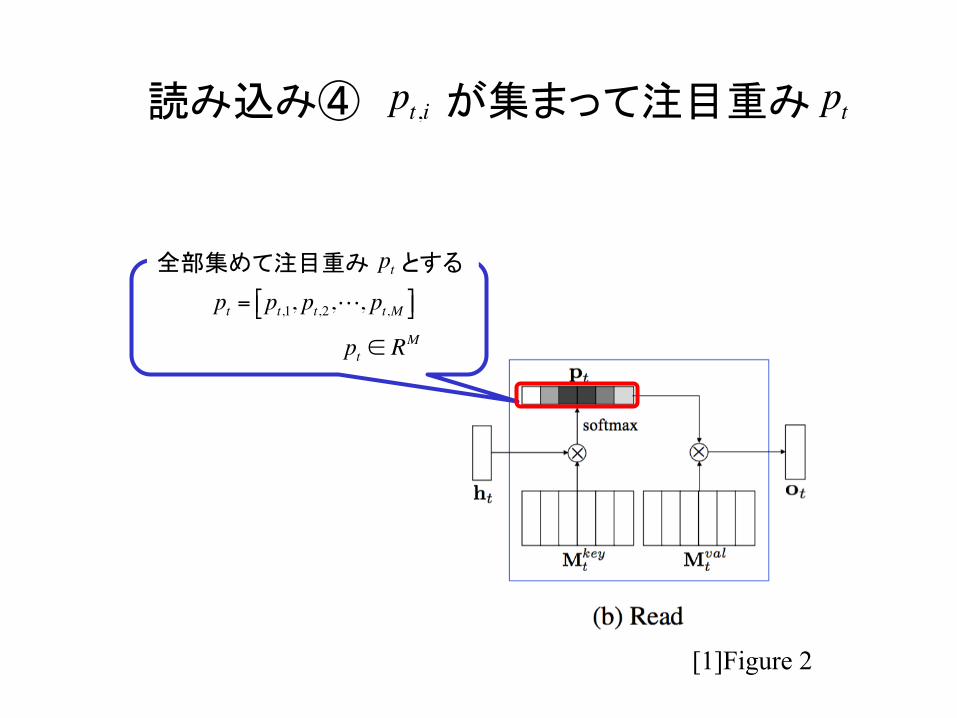
読み込み④ が集まって注目重み pt
[1]Figure 2
pt = pt,1, pt,2,!, pt,M⎡⎣ ⎤⎦
pt,i
全部集めて注目重み とする pt
pt ∈ RM
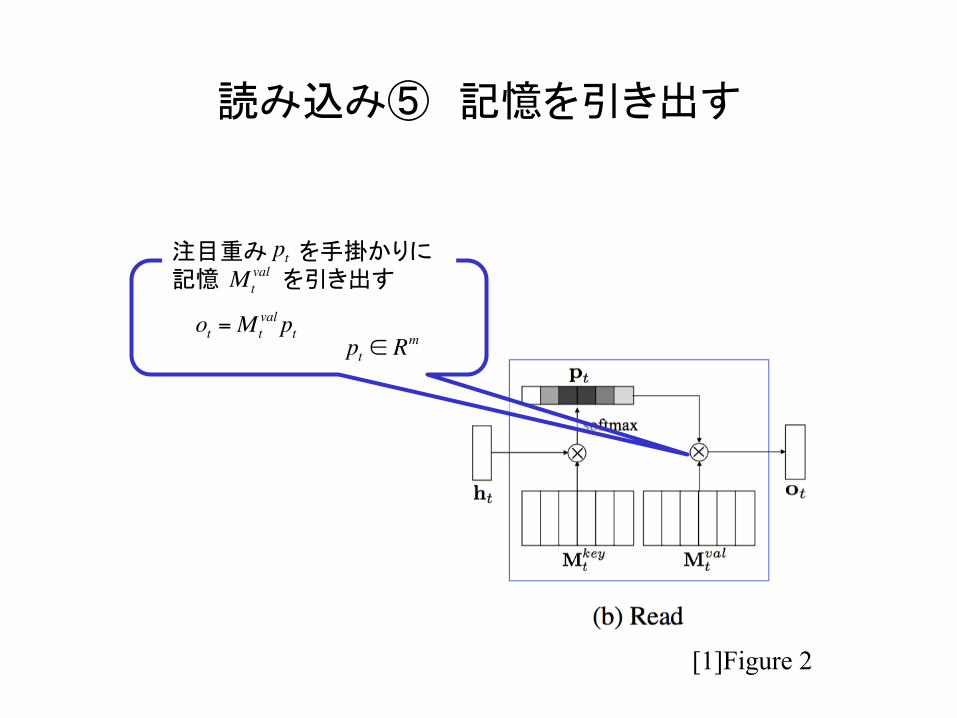
読み込み⑤ 記憶を引き出す
[1]Figure 2
ot =Mtval pt
注目重み を手掛かりに 記憶 を引き出す
pt
pt ∈ Rm
Mtval
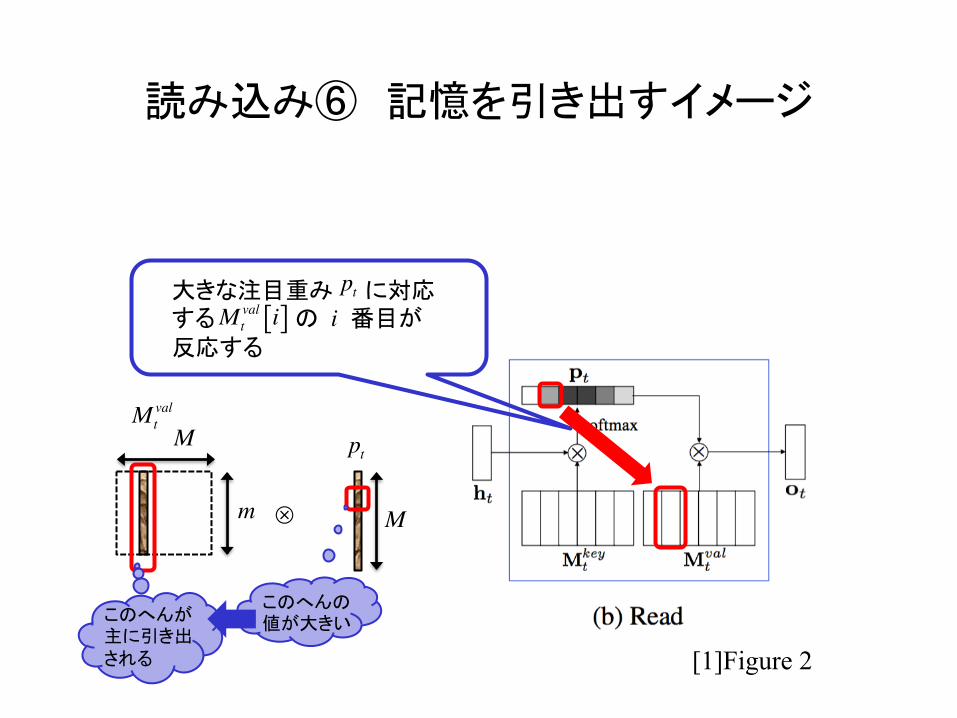
読み込み⑥ 記憶を引き出すイメージ
[1]Figure 2
大きな注目重み に対応する の 番目が 反応する
ptMt
val i[ ]
pt
m ⊗
Mtval
M
i
M
このへんの 値が大きい このへんが
主に引き出される
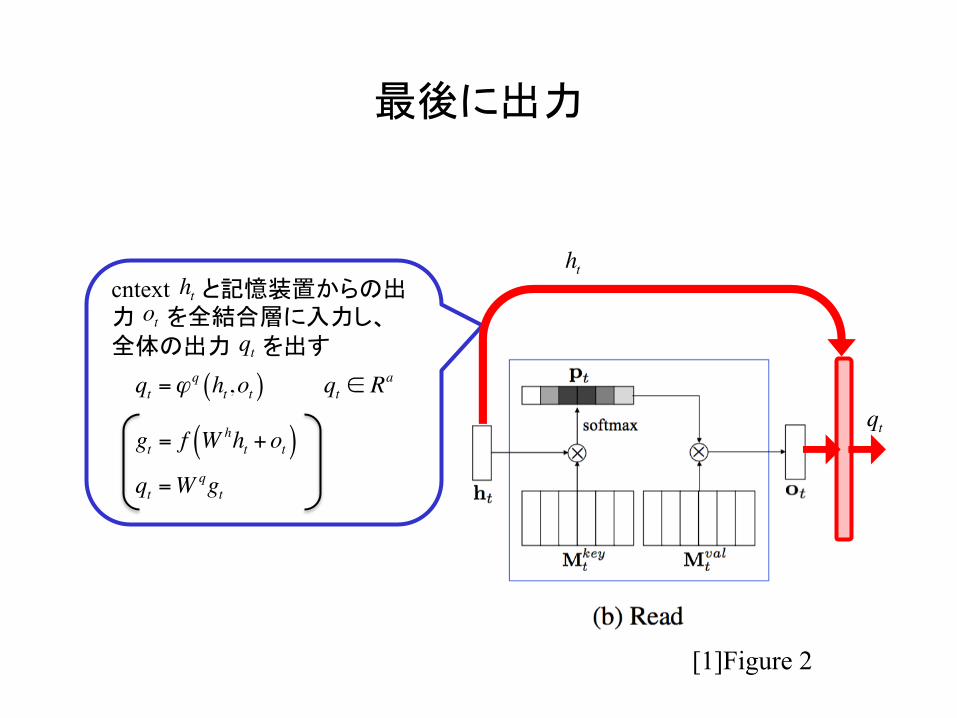
最後に出力
[1]Figure 2
qt =ϕq ht,ot( )
cntext と記憶装置からの出力 を全結合層に入力し、全体の出力 を出す
ht
qtot
ht
qtqt ∈ Ra
gt = f Whht +ot( )
qt =Wqgt

解説のポイント
①記憶装置ってどんなの? ②contextってどうやって求めるの? ③結果どうなった?

contextを求める3つの仕組み
context を求める仕組みを3種類考えた 1)MQN 2)RMQN 3)FRMQN
ht

contextを求める3つの仕組み
まずこれから 1)MQN 2)RMQN 3)FRMQN
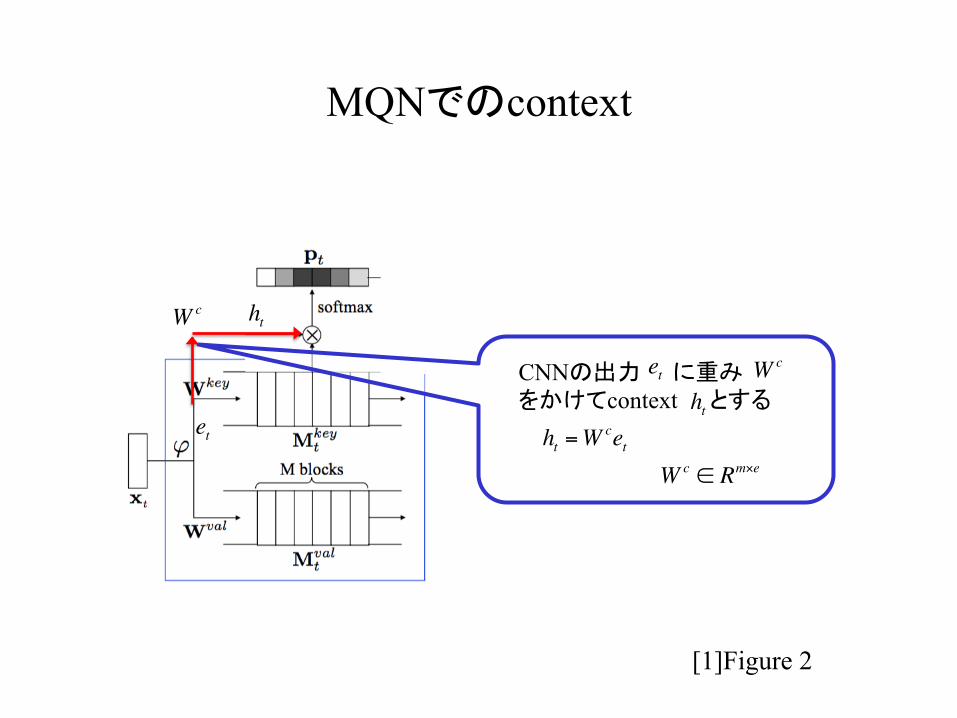
MQNでのcontext
[1]Figure 2
htCNNの出力 に重み をかけてcontext とする ht =W
cet
Wcet
etht
htWc
Wc ∈ Rm×e

contextを求める3つの仕組み
次はこれ 1)MQN 2)RMQN 3)FRMQN
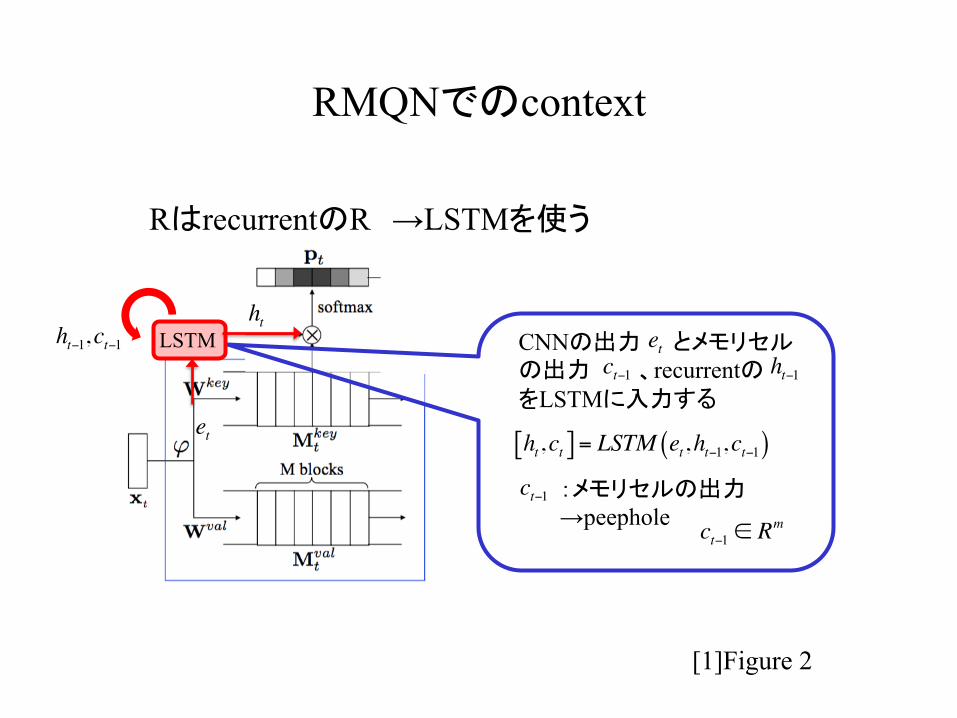
RMQNでのcontext
[1]Figure 2
ht
CNNの出力 とメモリセルの出力 、recurrentの をLSTMに入力する
ht,ct[ ] = LSTM et,ht−1,ct−1( )
et
et
ht−1
ht
RはrecurrentのR →LSTMを使う
LSTM ht−1,ct−1
ct−1 :メモリセルの出力→peephole
ct−1
ct−1 ∈ Rm

contextを求める3つの仕組み
最後はこれ 1)MQN 2)RMQN 3)FRMQN
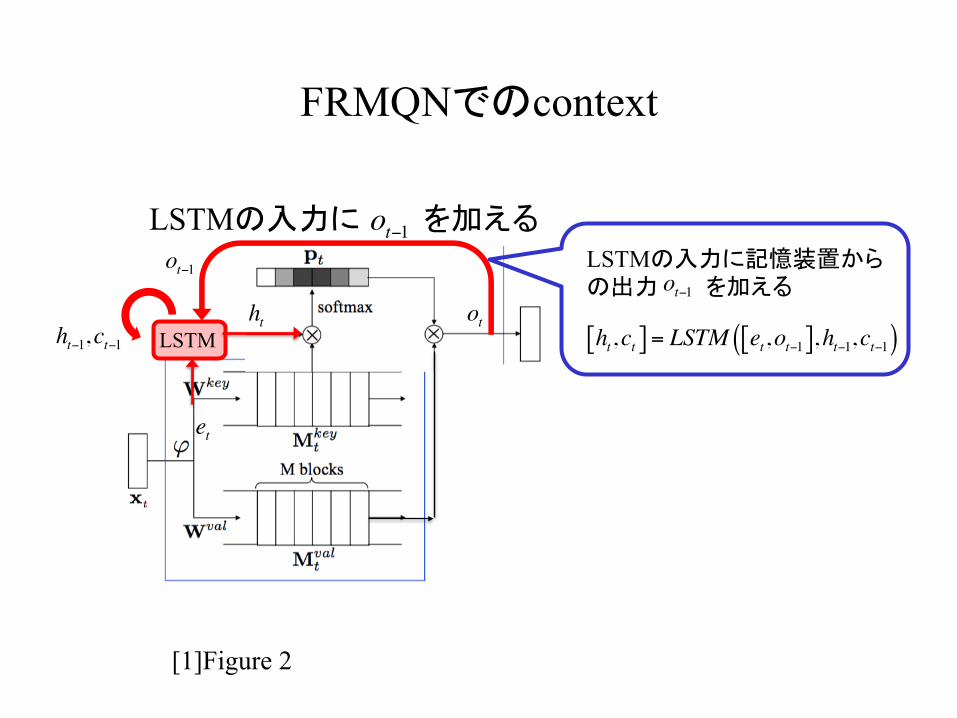
FRMQNでのcontext
LSTMの入力に記憶装置からの出力 を加える
ht,ct[ ] = LSTM et,ot−1[ ],ht−1,ct−1( )
et
ot−1ht
LSTMの入力に を加える
LSTM ht−1,ct−1
ot−1
ot
ot−1
[1]Figure 2
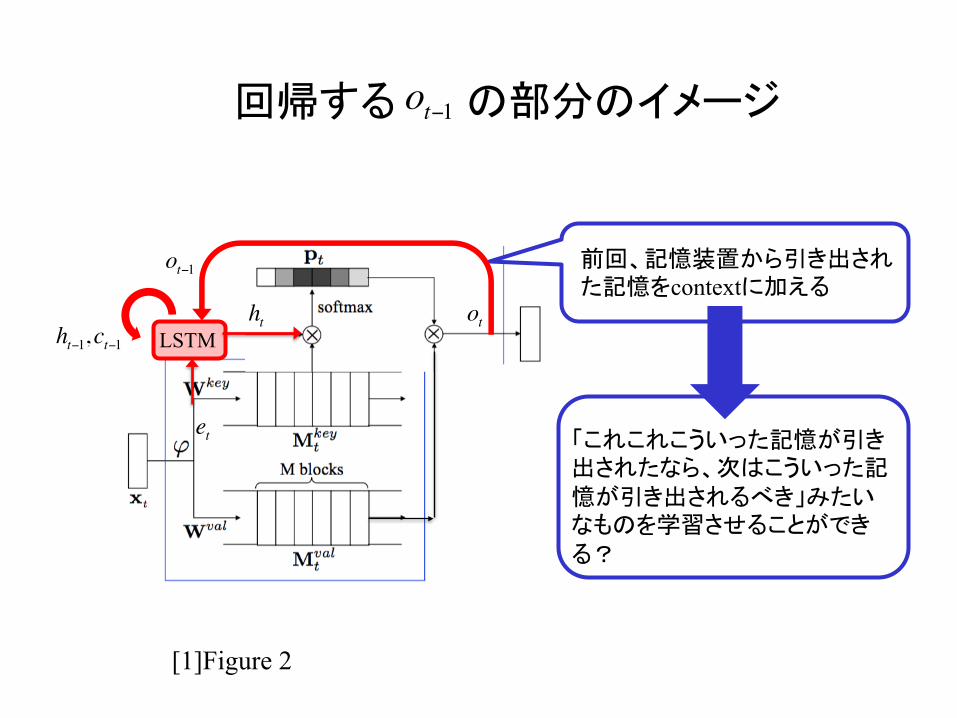
回帰する の部分のイメージ
[1]Figure 2
前回、記憶装置から引き出された記憶をcontextに加える
et
htLSTM ht−1,ct−1
ot
ot−1
ot−1
「これこれこういった記憶が引き出されたなら、次はこういった記憶が引き出されるべき」みたいなものを学習させることができる?
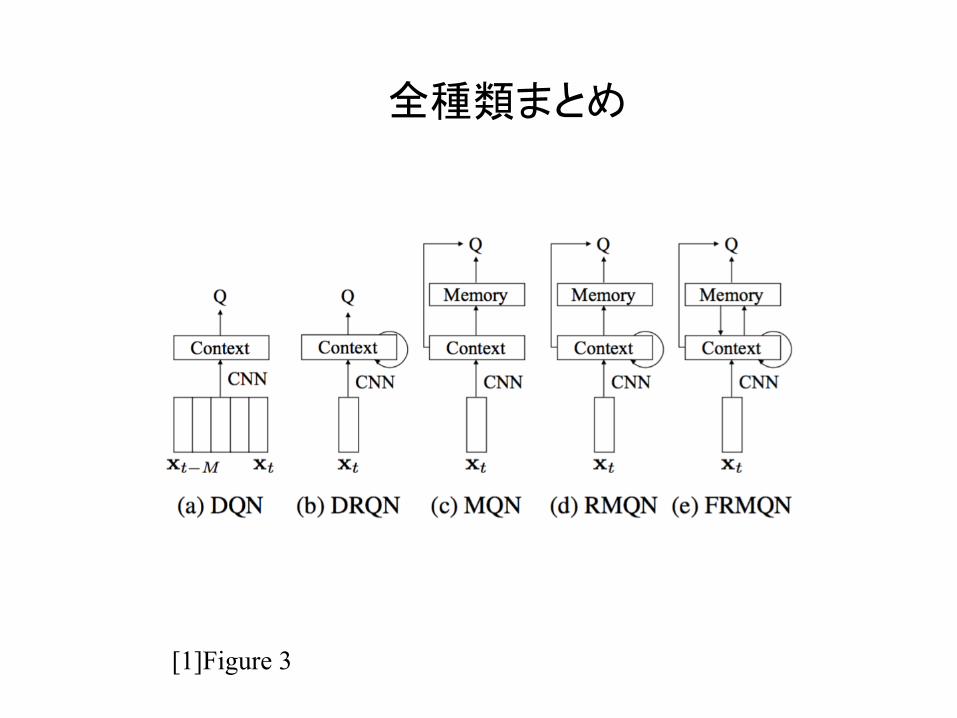
全種類まとめ
[1]Figure 3

解説のポイント
①記憶装置ってどんなの? ②contextってどうやって求めるの? ③結果どうなった?

3種類の実験とその結果
① I 字型迷路 ②パターンマッチング ③ランダムな迷路

3種類の実験とその結果
① I 字型迷路 ②パターンマッチング ③ランダムな迷路
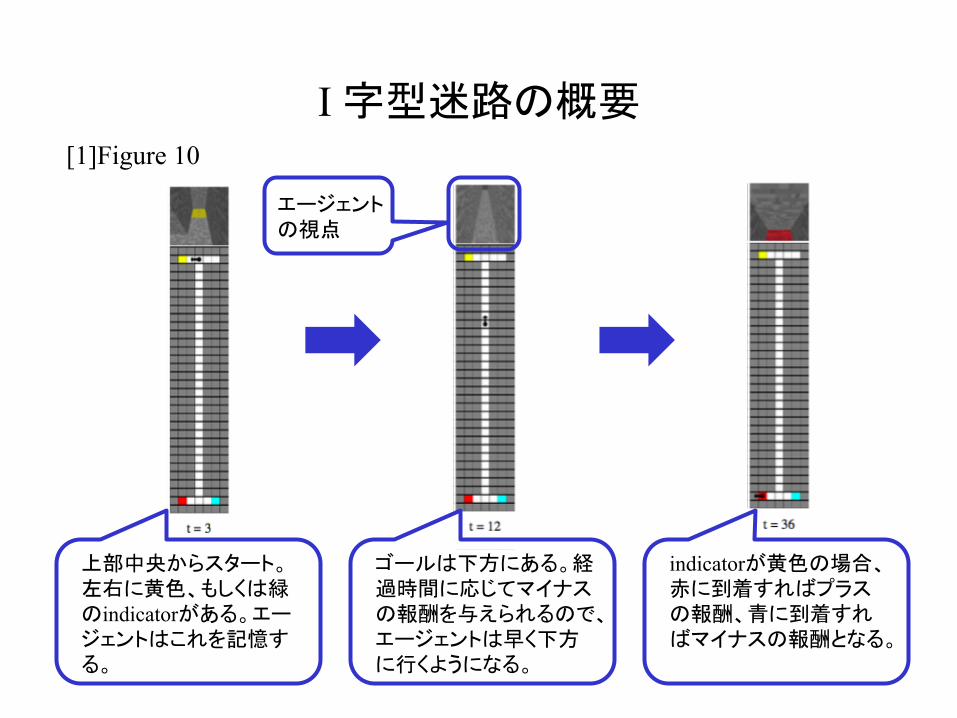
I 字型迷路の概要
上部中央からスタート。左右に黄色、もしくは緑のindicatorがある。エージェントはこれを記憶する。
ゴールは下方にある。経過時間に応じてマイナスの報酬を与えられるので、エージェントは早く下方に行くようになる。
indicatorが黄色の場合、赤に到着すればプラスの報酬、青に到着すればマイナスの報酬となる。
エージェントの視点
[1]Figure 10
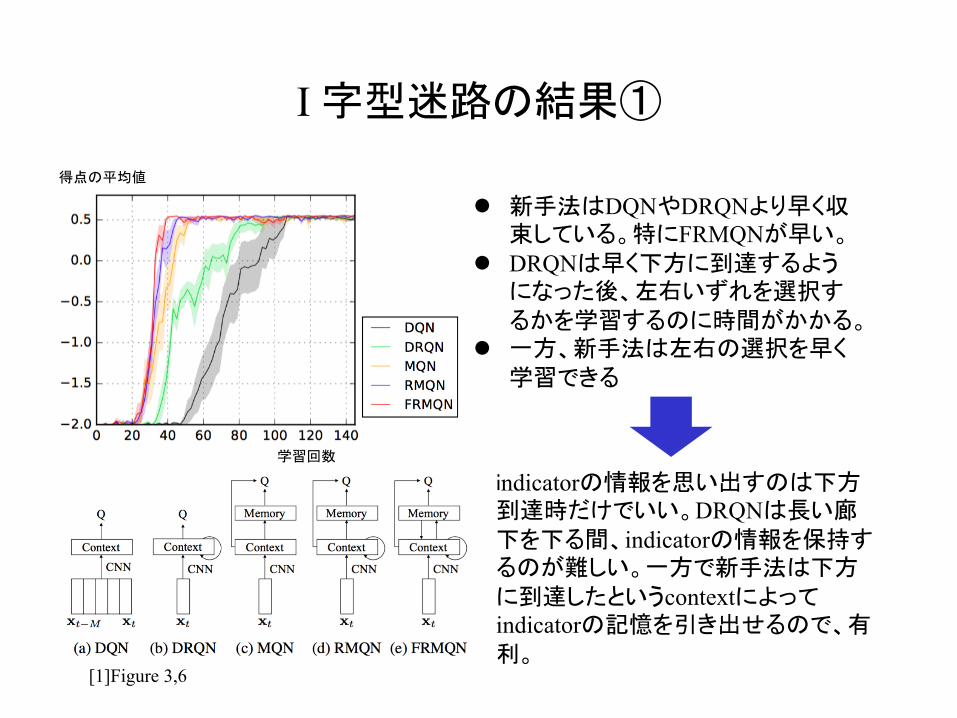
I 字型迷路の結果①
l 新手法はDQNやDRQNより早く収束している。特にFRMQNが早い。
l DRQNは早く下方に到達するようになった後、左右いずれを選択するかを学習するのに時間がかかる。
l 一方、新手法は左右の選択を早く学習できる
[1]Figure 3,6
indicatorの情報を思い出すのは下方到達時だけでいい。DRQNは長い廊下を下る間、indicatorの情報を保持するのが難しい。一方で新手法は下方に到達したというcontextによってindicatorの記憶を引き出せるので、有利。
得点の平均値
学習回数
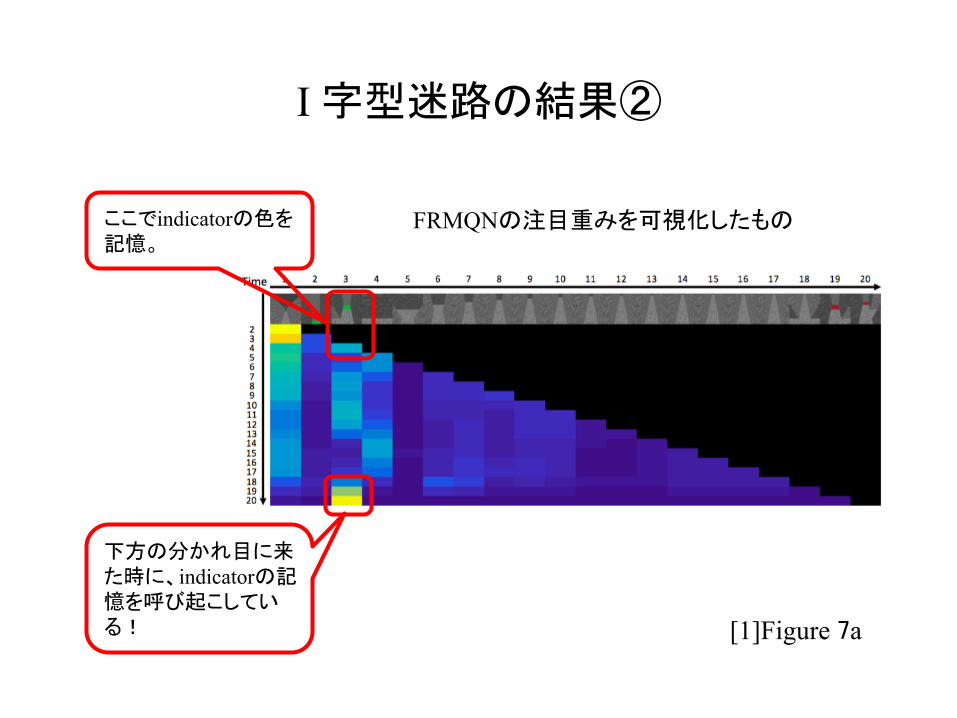
I 字型迷路の結果②
[1]Figure 7a
下方の分かれ目に来た時に、indicatorの記憶を呼び起こしている!
ここでindicatorの色を記憶。
FRMQNの注目重みを可視化したもの

3種類の実験とその結果
① I 字型迷路 ②パターンマッチング ③ランダムな迷路
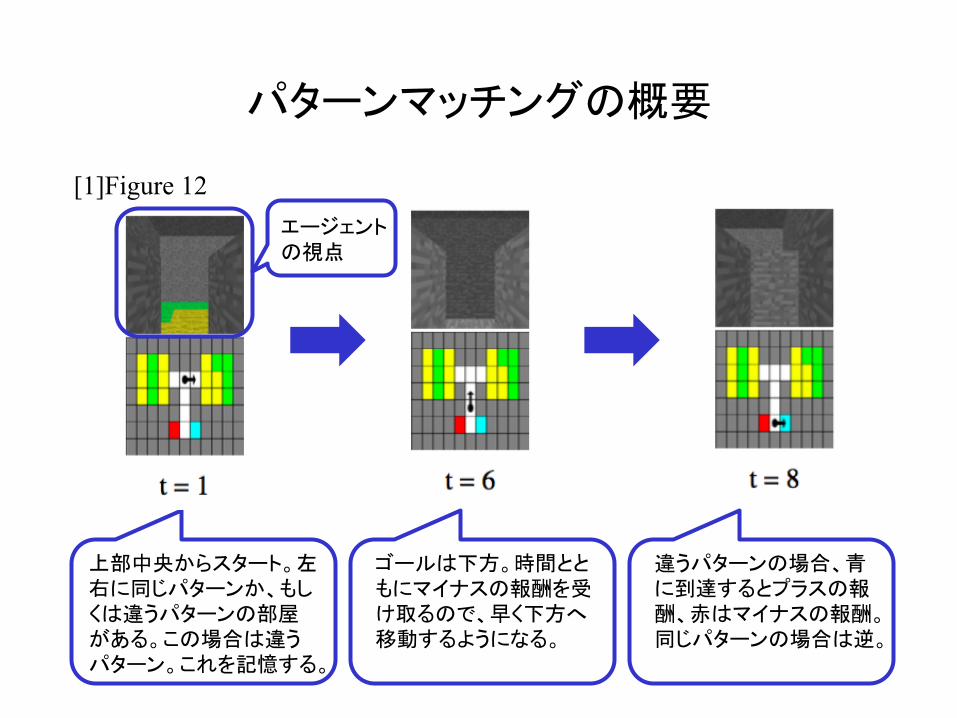
パターンマッチングの概要
上部中央からスタート。左右に同じパターンか、もしくは違うパターンの部屋がある。この場合は違うパターン。これを記憶する。
[1]Figure 12 エージェントの視点
ゴールは下方。時間とともにマイナスの報酬を受け取るので、早く下方へ移動するようになる。
違うパターンの場合、青に到達するとプラスの報酬、赤はマイナスの報酬。同じパターンの場合は逆。
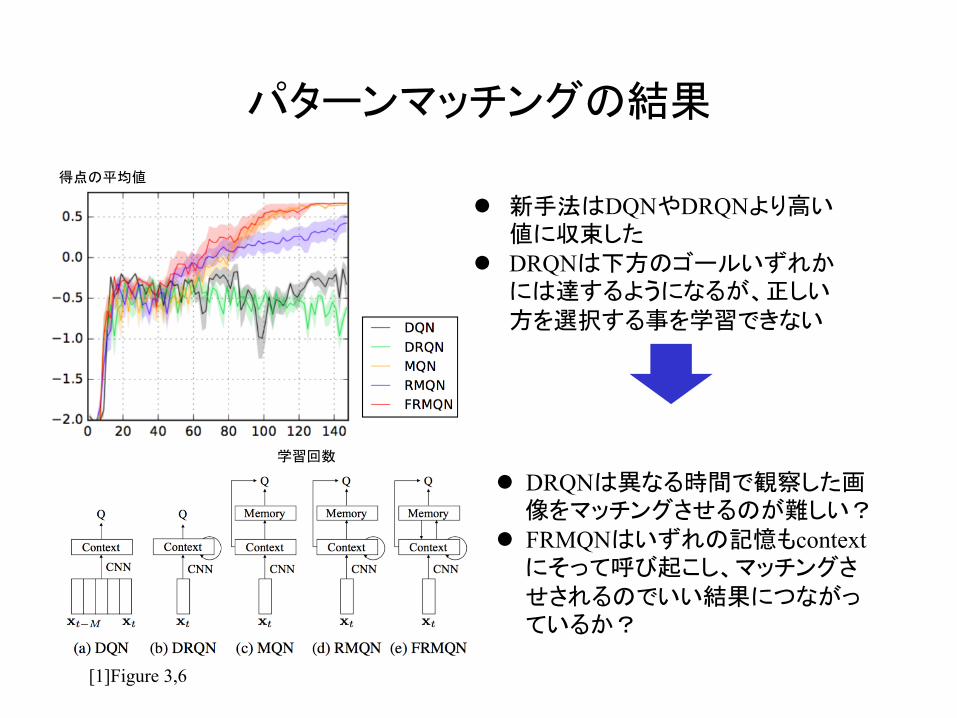
パターンマッチングの結果
l 新手法はDQNやDRQNより高い値に収束した
l DRQNは下方のゴールいずれかには達するようになるが、正しい方を選択する事を学習できない
[1]Figure 3,6
l DRQNは異なる時間で観察した画像をマッチングさせるのが難しい?
l FRMQNはいずれの記憶もcontextにそって呼び起こし、マッチングさせされるのでいい結果につながっているか?
得点の平均値
学習回数

3種類の実験とその結果
① I 字型迷路 ②パターンマッチング ③ランダムな迷路
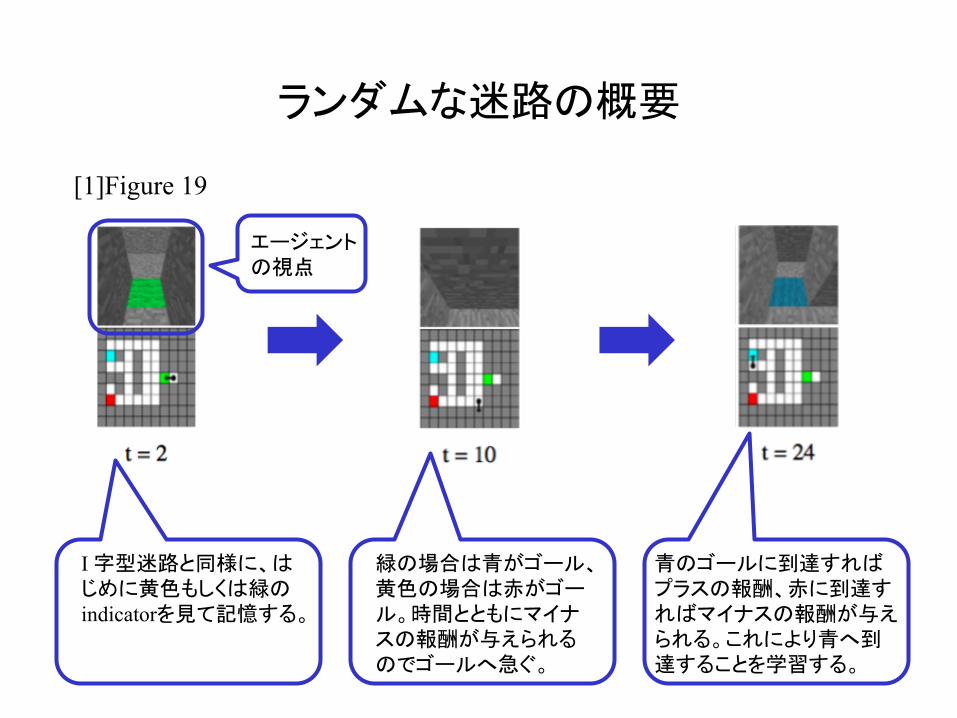
ランダムな迷路の概要
[1]Figure 19
エージェントの視点
I 字型迷路と同様に、はじめに黄色もしくは緑のindicatorを見て記憶する。
緑の場合は青がゴール、黄色の場合は赤がゴール。時間とともにマイナスの報酬が与えられるのでゴールへ急ぐ。
青のゴールに到達すればプラスの報酬、赤に到達すればマイナスの報酬が与えられる。これにより青へ到達することを学習する。
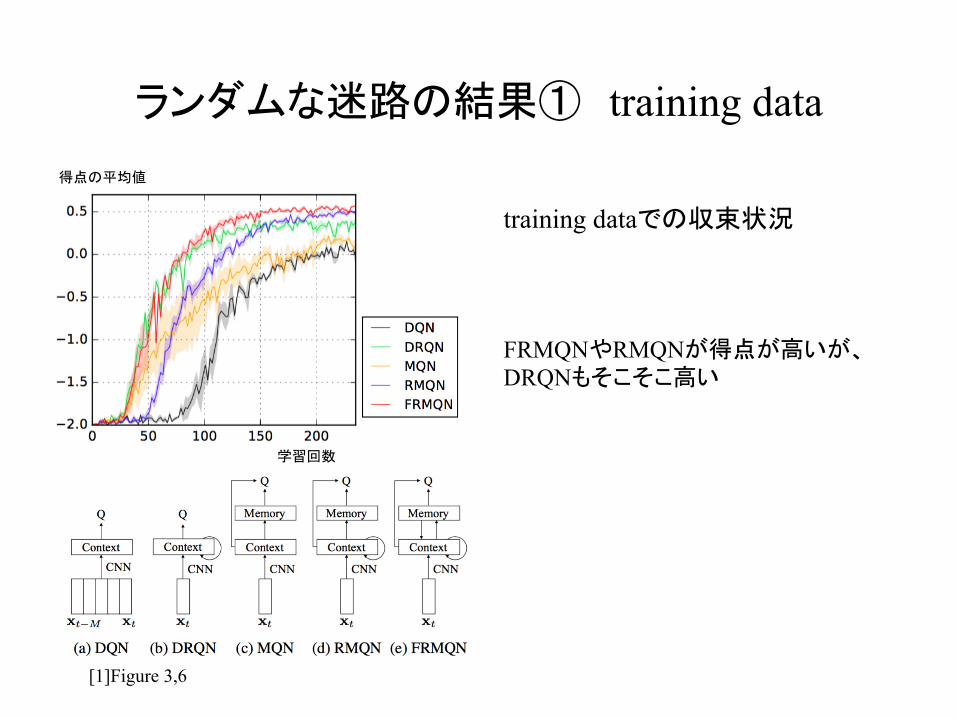
ランダムな迷路の結果① training data
training dataでの収束状況
[1]Figure 3,6
得点の平均値
学習回数
FRMQNやRMQNが得点が高いが、DRQNもそこそこ高い
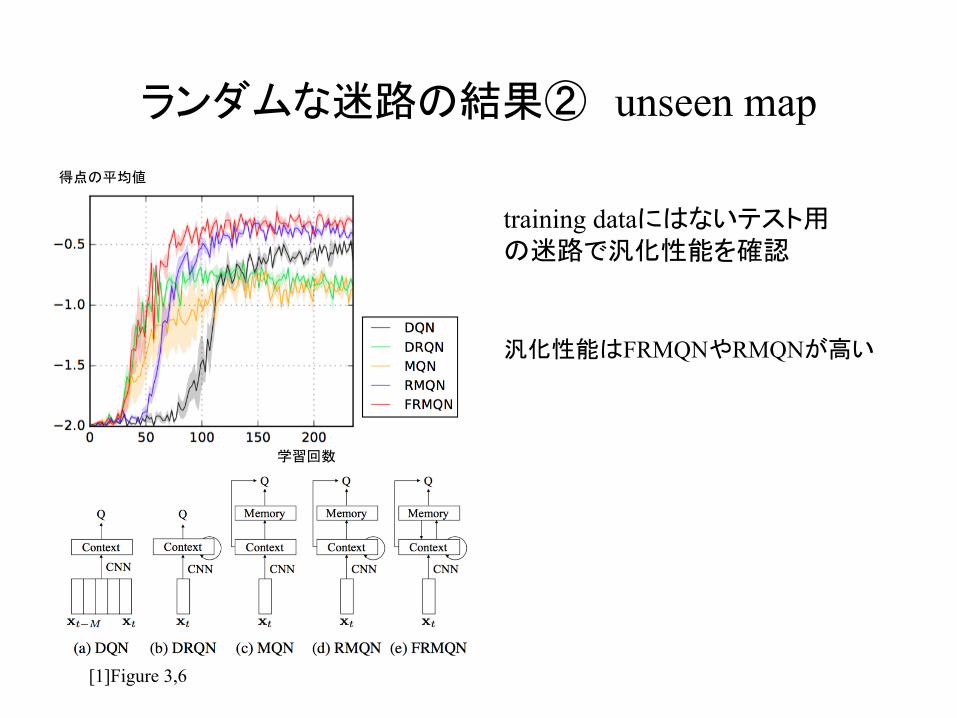
ランダムな迷路の結果② unseen map
training dataにはないテスト用の迷路で汎化性能を確認
[1]Figure 3,6
得点の平均値
学習回数
汎化性能はFRMQNやRMQNが高い

結 論
このようなMincraftの迷路では、新手法は高い得点をあげる 特にFRMQNがいい!

終わり


















