
SX-ACEにおける流体コードの 高速化事例紹介SX-ACE における流体コードの...
13
SX-ACEにおける流体コードの 高速化事例紹介 2015年12月 一般財団法人 高度情報科学技術研究機構 神戸センター 産業利用推進室 浅見 暁
Transcript of SX-ACEにおける流体コードの 高速化事例紹介SX-ACE における流体コードの...

SX-ACEにおける流体コードの 高速化事例紹介
2015年12月 一般財団法人 高度情報科学技術研究機構
神戸センター 産業利用推進室 浅見 暁

高速化施策とその効果 MPI通信(派生データタイプ)の修正 メモリアクセスの削減(アウターアンロール) メモリアクセスの削減(ループ融合) (修正前と比較して)約2倍の高速化
1

計算条件 流体コード(Fortran) 有限差分法 格子点数 180x180x240(約780万点) 反復回数 50 フラットMPI 対象マシン SX-ACE 27MPIプロセス(分割3x3x3)
2

性能情報(ftrace) 849sec, 2700MFLOPS(全体) para_send_recv 時間コスト 50%、MPI通信部分 bicgstab 時間コスト 33%、4500MFLOPS(ピーク性能比 7%) subA 時間コスト 4.8%、初期化ルーチン (メインループの外側) FREQUENCY EXCLUSIVE AVER.TIME MOPS MFLOPS V.OP AVER. VECTOR I-CACHE O-CACHE BANK CONFLICT ADB HIT PROC.NAME
TIME[sec]( % ) [msec] RATIO V.LEN TIME MISS MISS CPU PORT NETWORK ELEM.% 210983 497.768( 49.8) 2.359 936.8 0.3 69.43 106.1 248.331 11.173 39.973 1.576 49.883 0.00 para_send_recv 50 333.472( 33.4) 6669.437 10961.8 4468.8 97.99 65.6 252.982 1.191 3.367 0.094 84.930 30.43 bicgstab 1 48.373( 4.8) 48373.480 20563.6 6327.1 98.64 254.2 39.019 0.000 0.672 0.042 0.102 99.32 subA 50 37.977( 3.8) 759.532 4458.5 558.0 98.69 191.4 31.762 0.020 0.183 0.593 5.968 18.86 subB 2500 19.313( 1.9) 7.725 27139.5 14092.2 99.81 61.7 19.310 0.001 0.001 0.000 6.296 75.26 subC ELAPSED COMM.TIME COMM.TIME IDLE TIME IDLE TIME AVER.LEN COUNT TOTAL LEN PROC.NAME TIME[sec] [sec] / ELAPSED [sec] / ELAPSED [byte] [byte] 497.983 440.644 0.885 253.739 0.510 721.1 67961738 45.6G para_send_recv 333.641 94.022 0.282 16.405 0.049 16.0 619940 9.5M bicgstab 48.386 0.000 0.000 0.000 0.000 0.0 0 0.0 subA 37.988 32.740 0.862 17.038 0.449 82.1M 800 64.1G subB 19.325 0.000 0.000 0.000 0.000 0.0 0 0.0 subC
3

ソースコード修正 MPI通信の修正(tune1) コンパイラ指示行の挿入(tune2) ループ融合(tune3)
4

MPI通信の修正(tune1) 派生データタイプ†の変更 MPI関数の呼び出し回数の削減 通信データサイズの拡大
5
†派生データタイプ アドレスが飛び飛びのデータ(不連続データ)を、まとめて通信できるように新たに設定したデータタイプ。
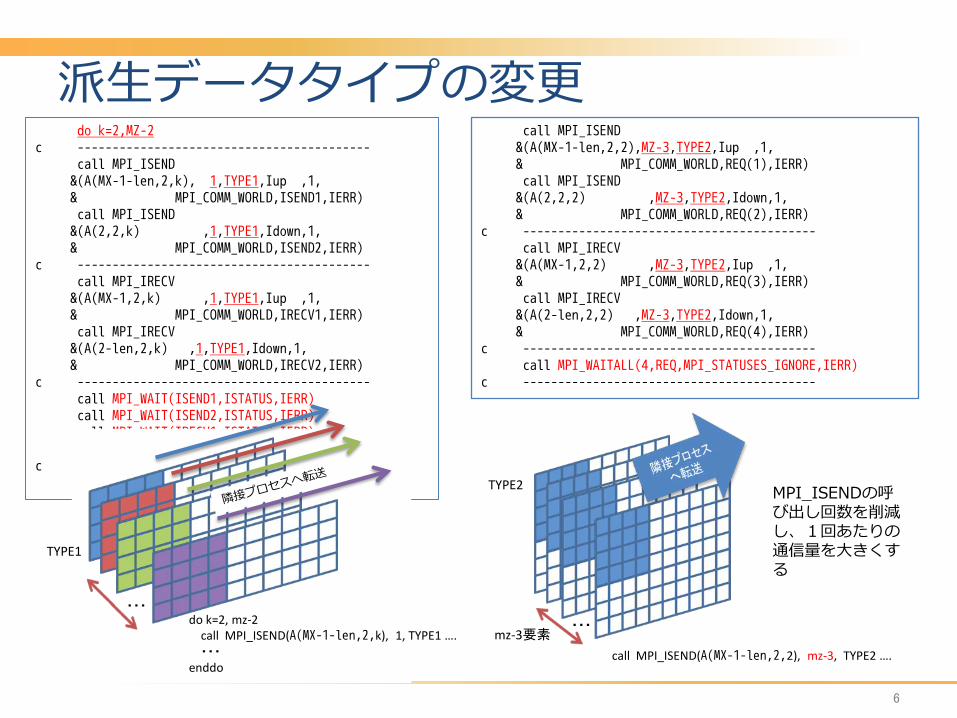
派生データタイプの変更 do k=2,MZ-2 c ------------------------------------------ call MPI_ISEND &(A(MX-1-len,2,k), 1,TYPE1,Iup ,1, & MPI_COMM_WORLD,ISEND1,IERR) call MPI_ISEND &(A(2,2,k) ,1,TYPE1,Idown,1, & MPI_COMM_WORLD,ISEND2,IERR) c ------------------------------------------ call MPI_IRECV &(A(MX-1,2,k) ,1,TYPE1,Iup ,1, & MPI_COMM_WORLD,IRECV1,IERR) call MPI_IRECV &(A(2-len,2,k) ,1,TYPE1,Idown,1, & MPI_COMM_WORLD,IRECV2,IERR) c ------------------------------------------ call MPI_WAIT(ISEND1,ISTATUS,IERR) call MPI_WAIT(ISEND2,ISTATUS,IERR) call MPI_WAIT(IRECV1,ISTATUS,IERR) call MPI_WAIT(IRECV2,ISTATUS,IERR) c ------------------------------------------ enddo
call MPI_ISEND &(A(MX-1-len,2,2),MZ-3,TYPE2,Iup ,1, & MPI_COMM_WORLD,REQ(1),IERR) call MPI_ISEND &(A(2,2,2) ,MZ-3,TYPE2,Idown,1, & MPI_COMM_WORLD,REQ(2),IERR) c ------------------------------------------ call MPI_IRECV &(A(MX-1,2,2) ,MZ-3,TYPE2,Iup ,1, & MPI_COMM_WORLD,REQ(3),IERR) call MPI_IRECV &(A(2-len,2,2) ,MZ-3,TYPE2,Idown,1, & MPI_COMM_WORLD,REQ(4),IERR) c ------------------------------------------ call MPI_WAITALL(4,REQ,MPI_STATUSES_IGNORE,IERR) c ------------------------------------------
6
do k=2, mz-2 call MPI_ISEND(A(MX-1-len,2,k), 1, TYPE1 …. ・・・ enddo
・・・
TYPE1
mz-3要素 call MPI_ISEND(A(MX-1-len,2,2), mz-3, TYPE2 ….
MPI_ISENDの呼び出し回数を削減し、1回あたりの通信量を大きくする
TYPE2
・・・
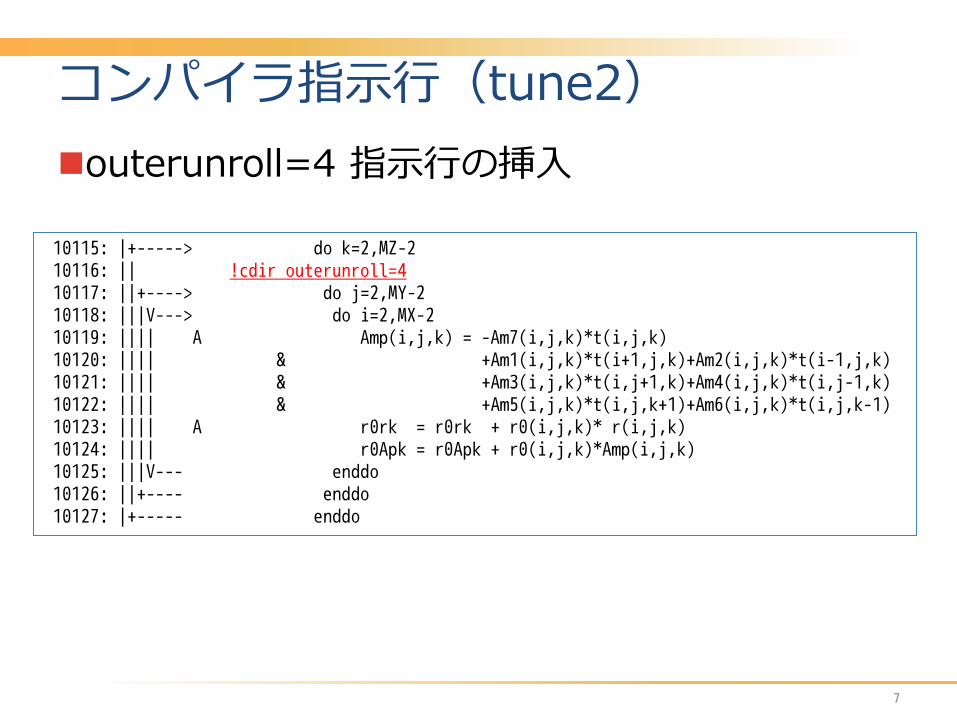
コンパイラ指示行(tune2) outerunroll=4 指示行の挿入
10115: |+-----> do k=2,MZ-2 10116: || !cdir outerunroll=4 10117: ||+----> do j=2,MY-2 10118: |||V---> do i=2,MX-2 10119: |||| A Amp(i,j,k) = -Am7(i,j,k)*t(i,j,k) 10120: |||| & +Am1(i,j,k)*t(i+1,j,k)+Am2(i,j,k)*t(i-1,j,k) 10121: |||| & +Am3(i,j,k)*t(i,j+1,k)+Am4(i,j,k)*t(i,j-1,k) 10122: |||| & +Am5(i,j,k)*t(i,j,k+1)+Am6(i,j,k)*t(i,j,k-1) 10123: |||| A r0rk = r0rk + r0(i,j,k)* r(i,j,k) 10124: |||| r0Apk = r0Apk + r0(i,j,k)*Amp(i,j,k) 10125: |||V--- enddo 10126: ||+---- enddo 10127: |+----- enddo
7

コンパイラ指示行(tune2 続き) Jのループで(4段)アンロールされる 同一配列添字のベクトルロード命令が削減される その結果、メモリアクセスが減り、実行時間の短縮につながる
. do j = j1 + 1, my - 3, 4 . !cdir nodep . !cdir on_adb(r,r0,t,amp,am1,am7,am2,am3,am4,am5,am6) . do i = 1, mx-3 . amp(1+i,j+1,k) = am1(1+i,j+1,k)*t(2+i,j+1,k) - am7(1+i,j+1,k . 1 )*t(1+i,j+1,k) + am2(1+i,j+1,k)*t(i,j+1,k) + am3(1+i,j+1 . 2 ,k)*t(1+i,j+2,k) + am4(1+i,j+1,k)*t(1+i,j,k) + am5(1+i,j . 3 +1,k)*t(1+i,j+1,k+1) + am6(1+i,j+1,k)*t(1+i,j+1,k-1) . amp(1+i,j+2,k) = am1(1+i,j+2,k)*t(2+i,j+2,k) - am7(1+i,j+2,k . 1 )*t(1+i,j+2,k) + am2(1+i,j+2,k)*t(i,j+2,k) + am3(1+i,j+2 . 2 ,k)*t(1+i,j+3,k) + am4(1+i,j+2,k)*t(1+i,j+1,k) + am5(1+i . 3 ,j+2,k)*t(1+i,j+2,k+1) + am6(1+i,j+2,k)*t(1+i,j+2,k-1) . amp(1+i,j+3,k) = am1(1+i,j+3,k)*t(2+i,j+3,k) - am7(1+i,j+3,k . 1 )*t(1+i,j+3,k) + am2(1+i,j+3,k)*t(i,j+3,k) + am3(1+i,j+3 . 2 ,k)*t(1+i,j+4,k) + am4(1+i,j+3,k)*t(1+i,j+2,k) + am5(1+i . 3 ,j+3,k)*t(1+i,j+3,k+1) + am6(1+i,j+3,k)*t(1+i,j+3,k-1) . amp(1+i,j+4,k) = am1(1+i,j+4,k)*t(2+i,j+4,k) - am7(1+i,j+4,k . 1 )*t(1+i,j+4,k) + am2(1+i,j+4,k)*t(i,j+4,k) + am3(1+i,j+4 ・・・
8
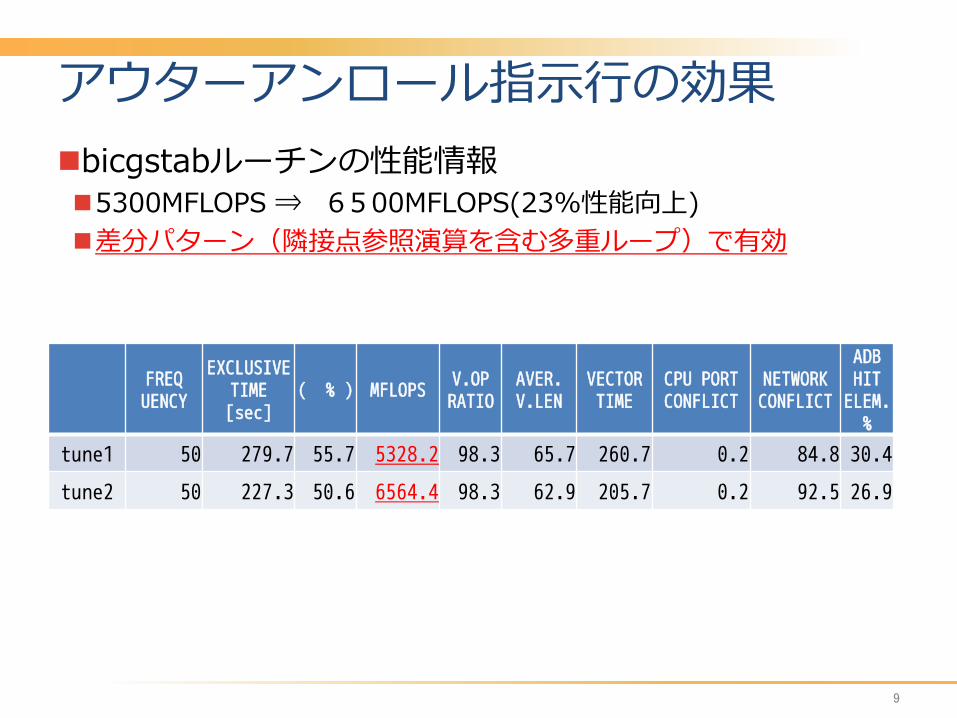
アウターアンロール指示行の効果 bicgstabルーチンの性能情報 5300MFLOPS ⇒ 6500MFLOPS(23%性能向上) 差分パターン(隣接点参照演算を含む多重ループ)で有効
FREQ UENCY
EXCLUSIVE TIME [sec]
( % ) MFLOPS V.OP RATIO
AVER. V.LEN
VECTOR TIME
CPU PORT CONFLICT
NETWORK CONFLICT
ADB HIT ELEM.%
tune1 50 279.7 55.7 5328.2 98.3 65.7 260.7 0.2 84.8 30.4
tune2 50 227.3 50.6 6564.4 98.3 62.9 205.7 0.2 92.5 26.9
9

ループ融合(tune3) 同一添字配列tのベクトルロード命令を削減 メモリアクセスを減らすことが可能
10227: |+-----> do k=1,MZ 10228: ||+----> do j=1,MY 10229: |||V---> do i=1,MX 10230: |||| A x(i,j,k) = x(i,j,k) + alpha*p(i,j,k) + omega*t(i,j,k) 10231: |||| c enddo 10232: |||| c enddo 10233: |||| c enddo 10234: |||| 10237: |||| c do k=1,MZ 10238: |||| c do j=1,MY 10239: |||| c do i=1,MX 10240: |||| A r(i,j,k) = t(i,j,k) - omega*Am(i,j,k) 10241: |||| A r0rk1 = r0rk1 + r0(i,j,k)*r(i,j,k) 10242: |||V--- enddo 10243: ||+---- enddo 10244: |+----- enddo
10
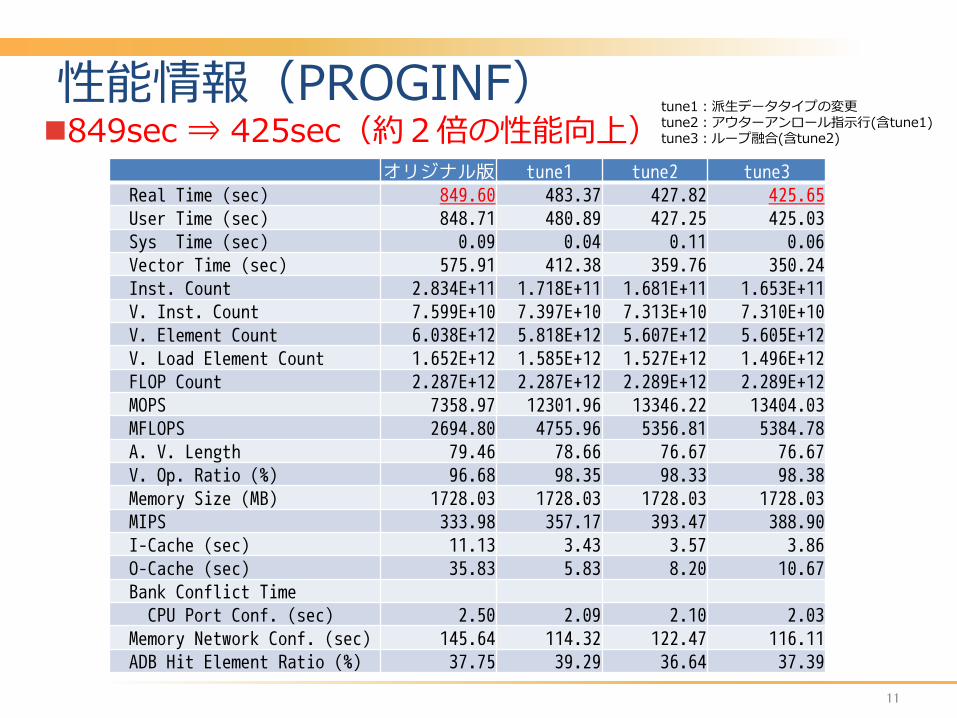
性能情報(PROGINF) 849sec ⇒ 425sec(約2倍の性能向上)
tune1:派生データタイプの変更 tune2:アウターアンロール指示行(含tune1) tune3:ループ融合(含tune2)
オリジナル版 tune1 tune2 tune3 Real Time (sec) 849.60 483.37 427.82 425.65 User Time (sec) 848.71 480.89 427.25 425.03 Sys Time (sec) 0.09 0.04 0.11 0.06 Vector Time (sec) 575.91 412.38 359.76 350.24 Inst. Count 2.834E+11 1.718E+11 1.681E+11 1.653E+11 V. Inst. Count 7.599E+10 7.397E+10 7.313E+10 7.310E+10 V. Element Count 6.038E+12 5.818E+12 5.607E+12 5.605E+12 V. Load Element Count 1.652E+12 1.585E+12 1.527E+12 1.496E+12 FLOP Count 2.287E+12 2.287E+12 2.289E+12 2.289E+12 MOPS 7358.97 12301.96 13346.22 13404.03 MFLOPS 2694.80 4755.96 5356.81 5384.78 A. V. Length 79.46 78.66 76.67 76.67 V. Op. Ratio (%) 96.68 98.35 98.33 98.38 Memory Size (MB) 1728.03 1728.03 1728.03 1728.03 MIPS 333.98 357.17 393.47 388.90 I-Cache (sec) 11.13 3.43 3.57 3.86 O-Cache (sec) 35.83 5.83 8.20 10.67 Bank Conflict Time CPU Port Conf. (sec) 2.50 2.09 2.10 2.03 Memory Network Conf. (sec) 145.64 114.32 122.47 116.11 ADB Hit Element Ratio (%) 37.75 39.29 36.64 37.39
11

高速化のポイント MPI通信回数の削減 派生データタイプの変更 有限差分法の隣接参照パターン アウターアンロール指示行が有効 コンパイラリスト(編集リスト)のループ処理の確認 ループ融合
編集リストの出力方法 sxf90の場合 –R5(または-R2)オプション
12


















