
SISTEMAS INTELIGENTES - aic.uniovi.esaic.uniovi.es/ssii/SSII-T10-RedesNeuronales.pdf · para que...
25
Centro de Inteligencia Artificial Universidad de Oviedo Sistemas Inteligentes - T10: Redes Neuronales SISTEMAS INTELIGENTES T10: Redes Neuronales www.aic.uniovi.es/ssii
Transcript of SISTEMAS INTELIGENTES - aic.uniovi.esaic.uniovi.es/ssii/SSII-T10-RedesNeuronales.pdf · para que...

Centro de Inteligencia Artificial
Universidad de Oviedo
Sistemas Inteligentes - T10: Redes Neuronales
SISTEMAS INTELIGENTES
T10: Redes Neuronales
www.aic.uniovi.es/ssii

Centro de Inteligencia Artificial
Universidad de Oviedo
Sistemas Inteligentes - T10: Redes Neuronales
Índice • Redes Neuronales Artificiales
° Fundamentos biológicos
• Perceptrón ° Funciones de activación
• Redes de neuronas
• Entrenamiento: ° Perceptrón ° Descenso de gradiente: regla delta ° Backpropagation

Centro de Inteligencia Artificial
Universidad de Oviedo
Sistemas Inteligentes - T10: Redes Neuronales
Redes de Neuronas Artificiales (ANNs) • Están inspiradas en los sistemas neuronales biológicos • Neurona: célula cerebral encargada de recoger, procesar y
transmitir señales eléctricas • No alcanzan su nivel de complejidad (ni de prestaciones L)
° Número de neuronas en el cerebro humano: ~1010
° Tiempo de activación/inhibición: ~10-3 ° Conexiones (sinapsis) por neurona: ~104–105
° Reconocimiento de escenas: 0.1 segundos ° Procesamiento no lineal ° Masivo grado de paralelismo ° Representaciones distribuidas ° Adaptativo
• Tratan de capturar este modelo de funcionamiento, pero: ° Normalmente, menos de 1000 neuronas ° No capturan todo el comportamiento neuronal

Centro de Inteligencia Artificial
Universidad de Oviedo
Sistemas Inteligentes - T10: Redes Neuronales
Neuronas humanas • Soma: contiene el núcleo
celular • Dendritas: entradas • Axon/Sinapsis: conexión entre
neuronas • La información fluye
unidireccionalmente • El soma a través de axon/
sinapsis puede mandar un mensaje de excitación/inhibición (neurotransmisión)
• Éste será captado por las dendritas de otra neurona
• A lo largo del tiempo (aprendizaje), la conexión entre dos neuronas se hará más fuerte o más débil

Centro de Inteligencia Artificial
Universidad de Oviedo
Sistemas Inteligentes - T10: Redes Neuronales
Definición y propiedades “sistema compuesto por múltiples unidades de
proceso que operan en paralelo y cuya funcionalidad depende de la estructura de la
red, de la fuerza de las conexiones, y del procesamiento realizado en cada
nodo” [DARPA, 98] • Propiedades:
° Formadas por conjuntos de neuronas individuales activadas por umbral
° Muchas conexiones con pesos entre las neuronas ° Procesamiento distribuido y paralelo ° El aprendizaje consistente en ajustar los pesos de las
conexiones entre las neuronas

Centro de Inteligencia Artificial
Universidad de Oviedo
Sistemas Inteligentes - T10: Redes Neuronales
Tipos de problemas adecuados • Entradas formadas por vectores de valores
discretos o reales
• Pueden ser problemas de clasificación o regresión
• Puede producir vectores de valores
• Los usuarios finales no quieren obtener explicaciones: no producen conocimiento inteligible (caja negra)
• Los datos de entrenamiento pueden contener errores
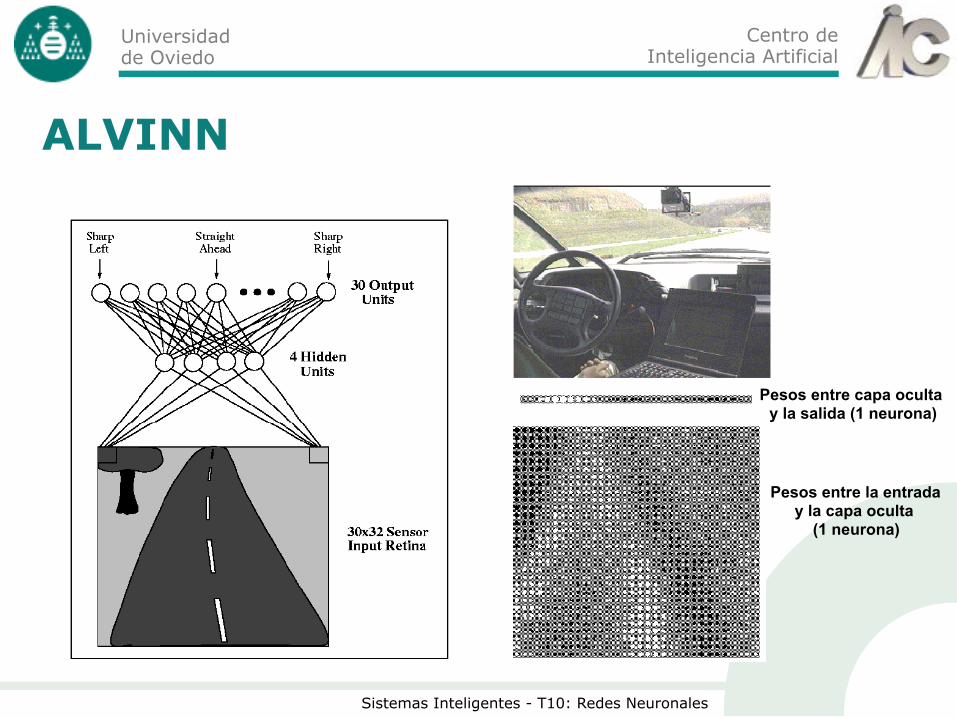
Centro de Inteligencia Artificial
Universidad de Oviedo
Sistemas Inteligentes - T10: Redes Neuronales
ALVINN
Pesos entre capa oculta y la salida (1 neurona)
Pesos entre la entrada y la capa oculta
(1 neurona)

Centro de Inteligencia Artificial
Universidad de Oviedo
Sistemas Inteligentes - T10: Redes Neuronales
Perceptrón
{ } | 1+ℜ∈= nwwH
x1
x2
xn
Σ
w1
w2
wn
x0 = 1
w0 ∑=
n
iii xw
0
⎩⎨⎧
−
>⋅=⋅=
caso otroen 10 si1
)sgn()(xw
xwxh
Representa UNA neurona
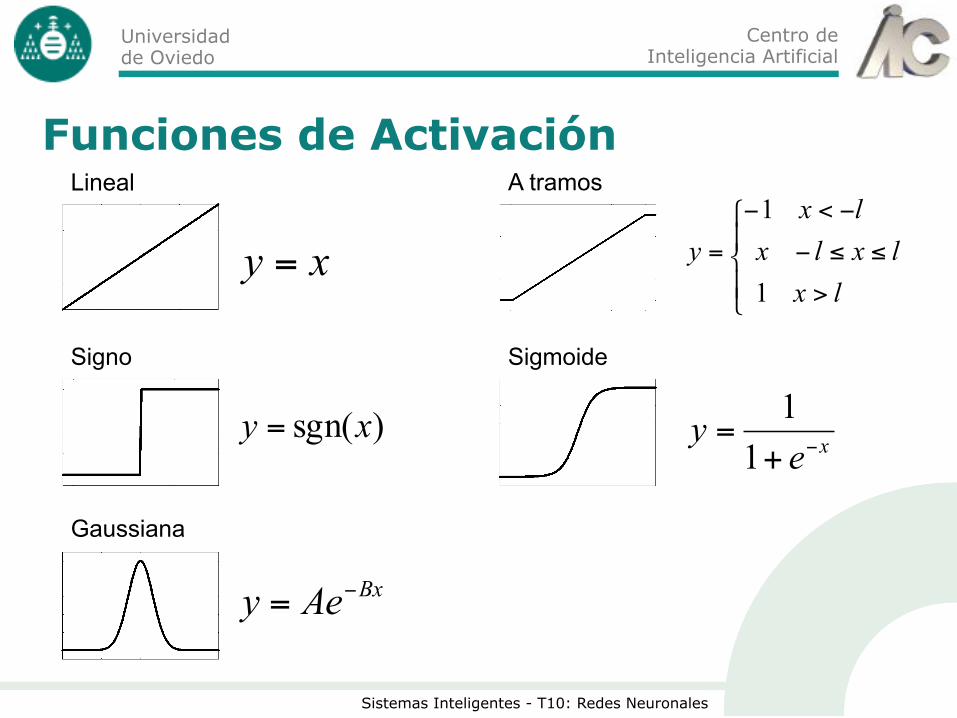
Centro de Inteligencia Artificial
Universidad de Oviedo
Sistemas Inteligentes - T10: Redes Neuronales
Funciones de Activación
xy =
)sgn(xy =
⎪⎩
⎪⎨
⎧
>
≤≤−
−<−
=
1
1
lxlxlx
lxy
Lineal A tramos
Signo Sigmoide
Gaussiana
xey
−+=11
BxAey −=

Centro de Inteligencia Artificial
Universidad de Oviedo
Sistemas Inteligentes - T10: Redes Neuronales
Definición de Red de Neuronas • Conjunto de neuronas artificiales conectadas
entre sí mediante una serie de arcos llamados conexiones
• Estas conexiones tienen números reales asociados, llamados pesos de la conexión
• Las neuronas generalmente se distribuyen en capas de distintos niveles, con conexiones que unen las neuronas de las distintas capas (pueden ser también de la misma capa)

Centro de Inteligencia Artificial
Universidad de Oviedo
Sistemas Inteligentes - T10: Redes Neuronales
Ejemplo de Red de Neuronas
1.1
2.7
3.0
-1.3
2.7
4.2
-0.8
7.1
2.1
-1.2
1.1
0.2
0.3
CAPAS OCULTAS CAPA DE ENTRADA
EN
TR
AD
A
SAL
IDA
CAPA DE SALIDA CLASE
LOS VALORES SE PROPAGAN POR LA RED
A
B
C
Se escoge la clase que produce un valor mayor
Valor calculado usando Los valores de entrada

Centro de Inteligencia Artificial
Universidad de Oviedo
Sistemas Inteligentes - T10: Redes Neuronales
Aprendizaje en una red de neuronas • Aprendizaje: la red modifica los pesos de las conexiones
para que las salidas de la red se vayan adaptando de manera paulatina al funcionamiento que se considera correcto
• La modificación de los pesos depende del paradigma de aprendizaje que estemos usando:
° Aprendizaje supervisado: para cada ejemplo presentado a la red existe una respuesta deseada. La respuesta de la red se compara con su salida esperada, y en base a esa comparación se ajustan los pesos de la red
° Aprendizaje no supervisado: no se especifica a la red cuál es la respuesta correcta. La red descubre las relaciones presentes en los ejemplos

Centro de Inteligencia Artificial
Universidad de Oviedo
Sistemas Inteligentes - T10: Redes Neuronales
La red más simple • Una neurona artificial • Aprendizaje de conceptos: ejemplos puntos en el
espacio Un, con su clase asociada • Separador lineal: dado un conjunto de ejemplos
determina el hiperplano capaz de discriminar los ejemplos en dos clases
• Es interesante estudiarlo porque nos permite diseñar redes con más neuronas
nnxwxwxwwxh ++++= ...)( 22110

Centro de Inteligencia Artificial
Universidad de Oviedo
Sistemas Inteligentes - T10: Redes Neuronales
Separador Lineal
• Problema: el conjunto puede no ser linealmente separable (Ejemplo XOR)
• Solución: emplear redes multicapa
+
+
+
+ -
-
-
- +
+ -
- w

Centro de Inteligencia Artificial
Universidad de Oviedo
Sistemas Inteligentes - T10: Redes Neuronales
Aprendizaje Perceptrón Algoritmo Aprendizaje Perceptron(w,X): w es Inicialización aleatoria del vector de pesos <w0, . . . ,wn> Mientras (no se cumpla la condición de parada) hacer Para cada ejemplo de entrada <(x1,...,xn), f(x1,...,xn)> Se calcula la salida de la red: h(x1,...,xn)= x1w1+ … + xnwn + w0
Si ( h(x1,...,xn) != f(x1,...,xn) ) entonces Se actualizan los pesos <w0, . . . ,wn> Fin si Fin Para Fin Mientras Retornar w Fin Algoritmo
• Para actualizar los pesos se siguen conceptos expuestos por Hebbian (si dos neuronas están activas, su conexión se refuerza)

Centro de Inteligencia Artificial
Universidad de Oviedo
Sistemas Inteligentes - T10: Redes Neuronales
Perceptrón: regla de entrenamiento wi = wi + Δwi
Δwi = η [f(x) – h(x)] xi donde:
° f(x) es el valor de la función objetivo en el ejemplo x ° h(x) es la salida del preceptrón ° η es una pequeña constante que controla el ritmo de
aprendizaje (decrece con el tiempo)
• Función de activación: con umbral • Los pesos se actualizan para cada ejemplo • El algoritmo converge si:
° los ejemplos de entrada son linealmente separables ° η is suficientemente pequeña

Centro de Inteligencia Artificial
Universidad de Oviedo
Sistemas Inteligentes - T10: Redes Neuronales
Descenso de gradiente (I) • Converge sólo asintóticamente al mínimo aún cuando el problema no es
linealmente separable • Es la base del algoritmo Backpropagation • Descenso de gradiente: consideremos una neurona lineal sin umbral
(salida continua)
h(x)=w0 + w1 x1 + … + wn xn
• Entrenamiento: minimizar el error cuadrático
E[w0,…,wn] = ½ Σx∈X (f(x) –h(x))2
• ¿Cómo minimizarlo? ° Nos movemos en la dirección que más reduce el error ° Dirección negativa del vector gradiente
• Diferencias: ° Perceptrón función de activación con umbral, Gradiente no ° Perceptrón actualización por ejemplo, Gradiente todos los datos ° Perceptrón: minimiza w ° Gradiente: minimiza error

Centro de Inteligencia Artificial
Universidad de Oviedo
Sistemas Inteligentes - T10: Redes Neuronales
[ ]
[ ]
( ) ( )( )
( ) ( )( )∑
∑
∈
∈
⎥⎦
⎤⎢⎣
⎡−
∂
∂=
∂
∂
⎥⎦
⎤⎢⎣
⎡−
∂
∂=
∂
∂
∂
∂−=Δ
⎥⎦
⎤⎢⎣
⎡
∂
∂
∂
∂
∂
∂≡∇
∇−=Δ
Dx
2
ii
Xx
2
ii
ii
n10
xhxfw2
1wE
xhxf21
wwE
wEw
wE,,
wE,
wEwE
wEw
η
η
…
( ) ( )( ) ( ) ( )( ) ( ) ( )( ) ( )( )
( ) ( )( )( )[ ]∑
∑∑
∈
∈∈
−−=∂
∂
⎥⎦
⎤⎢⎣
⎡⋅−
∂
∂−=⎥
⎦
⎤⎢⎣
⎡−
∂
∂−=
∂
∂
Xxi
i
Xx iXx ii
xxhxfwE
xwxfw
xhxfxhxfw
xhxf221
wE
Descenso de gradiente (II) (w1,w2)
(w1+Δw1,w2 +Δw2)

Centro de Inteligencia Artificial
Universidad de Oviedo
Sistemas Inteligentes - T10: Redes Neuronales
Descenso de gradiente (III) Algoritmo Aprendizaje Gradiente(w,X): w es Inicialización aleatoria del vector de pesos <w0, . . . ,wn> Mientras (no se cumpla la condición de parada) hacer Δwi ← 0 para todo i Para cada ejemplo de entrada <(x1,...,xn), f(x1,...,xn)> Se calcula la salida de la red: h(x1,...,xn)= x1w1+ … + xnwn + w0
Para cada peso wi hacer Δwi ← Δwi + η ( f(x1,...,xn) - h(x1,...,xn) ) xi
Fin Para Fin Para wi ← wi + Δ wi Fin Mientras Retornar w Fin Algoritmo

Centro de Inteligencia Artificial
Universidad de Oviedo
Sistemas Inteligentes - T10: Redes Neuronales
Descenso de gradiente (IV) • Es un paradigma muy importante de aprendizaje
• Su estrategia de búsqueda en espacios de hipótesis infinitos puede ser aplicada cuando:
° el espacio de hipótesis contiene hipótesis que pueden parametrizarse de una forma continua (e.g. pesos de una función lineal)
° podemos derivar el error respecto a los parámetros de la hipótesis
• Dificultades: ° converger al mínimo puede ser lento ° si hay mínimos locales no se garantiza alcanzar el
mínimo global

Centro de Inteligencia Artificial
Universidad de Oviedo
Sistemas Inteligentes - T10: Redes Neuronales
Algunas consideraciones • Importancia de la constate η que controla el
ritmo de aprendizaje ° Dado que sólo existe un mínimo global, el algoritmo
converge aunque no sea LS, siempre que η sea suficientemente pequeña
° Si es demasiado grande, el algoritmo puede saltarse el mínimo
° Se suele ir reduciendo su valor para evitarlos
• Problemas: ° Si η es pequeña el algoritmo es más lento ° Si hay varios mínimos locales, el algoritmo puede
quedarse atrapado en ellos y no alcanzar el mínimo global
• ¿Cuándo se debe parar el aprendizaje?

Centro de Inteligencia Artificial
Universidad de Oviedo
Sistemas Inteligentes - T10: Redes Neuronales
Descenso de gradiente incremental • Es una aproximación estocástica • Incremental: actualiza el peso tras cada ejemplo
Δwi = η ( f(x1,...,xn) - h(x1,...,xn) ) xi
• Puede aproximar el método del gradiente si la constate η es suficientemente pequeña
• Es mucho más rápido • Aunque existan varios mínimos locales, el
método incremental puede evitarlos ya que usa los grandientes de cada ejemplo (varios)
• La fórmula anterior se denomina también Regla Delta/LMS (Widrow-Hoff)

Centro de Inteligencia Artificial
Universidad de Oviedo
Sistemas Inteligentes - T10: Redes Neuronales
Redes Multicapa (MLP) • Definición: una red multicapa está formada por
una capa de entrada, una o más capas intermedias, y una capa de salida
• Sólo las capas ocultas y la de salida contienen perceptrones
• Permiten representar funciones no lineales • Dificultad para diseñarlas • Se requiere mucho tiempo de entrenamiento • Usan funciones de activación no lineales:
sigmoide

Centro de Inteligencia Artificial
Universidad de Oviedo
Sistemas Inteligentes - T10: Redes Neuronales
Backpropagation Algoritmo BackPropagation es Inicialización aleatoria de todos los pesos de la red (valores pequeños) Mientras (no se cumpla la condición de parada) hacer Para cada ejemplo de entrada <(x1,...,xn), f(x1,...,xn)> Se calcula la salida de cada neurona s de salida hs(x1,...,xn)
Propagar los errores a través de la red Para cada neurona s de la capa de salida se calcula su error hacer δs=hs(1-hs)(fs-hs) Para cada neurona o de la capa oculta hacer
δo=ho(1-ho)Σswso δs Para todos los pesos de la red wji ← wji + Δwji donde Δwji = wji + η δoxji Fin Mientras Retornar pesos Fin Algoritmo

Centro de Inteligencia Artificial
Universidad de Oviedo
Sistemas Inteligentes - T10: Redes Neuronales
Características • Usa el gradiente sobre toda la red de pesos • Fácil de generalizar para otros grafos dirigidos • Encuentra un mínimo local, no necesariamente global • A pesar de ello, es efectivo en la práctica • No hay desarrollos teóricos para garantizar la convergencia • Se han desarrollado heuríticos para mejorar el proceso
° Añadir momentum en el cálculo de los pesos Δwi,j(n)= η δj xi,j + α Δwi,j (n-1)
° Usar el gradiente estocástico o incremental ° Entrenar la misma red con diferentes pesos iniciales, se selecciona
la que produzca un error menor en un conjunto de validación ° Se podría combina la salidad de todas las redes
• Entrenamiento muy lento







![Ppt ssii per_jun2012-wil[1]](https://static.fdocument.pub/doc/165x107/5564fcd3d8b42a021d8b5331/ppt-ssii-perjun2012-wil1.jpg)










