
事務用品 · メモ(伝言メモ) コクヨ セミナーレポート オキナ CamiAPP〈キャミアップ〉 コクヨ 集計用紙 コクヨ 測量野帳 コクヨ ショットノート
Upload
-Category
view
501download
6
SimilarWeb APIを使ってみた
2015-02-28 下野寿之
この文書はメモであり、5日間程度集中して分かったことを忘
れないようにするために、まとめたものです。人に説明することが多いので、この文書が公開されるときは、参照用に使ってもらえればと思う意図で、公開されています。

SimilarWeb
•大きく3通りくらい使い方はある。(1) トップページで調べたいサイト名を入力する
(2) APIで、サイトのいろいろな情報を得る(有料) ←
(3) SimilarWeb PROを使う(有料)
•本文書では、特に記載の無い限り、(2)の場合の話とする。
(1) http://www.similarweb.com/
(2) http://developer.similarweb.com/
(3) http://www.similarweb.com/pro

developer.similarweb.com本文書では、ブラウザで左記のページから始めるとやりやすい。
(価格情報、APIテストページなどがすぐ分かりやすいため)
価格は、3通り。月ごと
• Basic (2.5万API,249ドル)
• Advanced (8万,499ドル)
• Professional (25万,999ドル)

初めに(1/4)• クレジットカードなどでAPIを使う権利を購入した場合、有効期限は、月末まで。購入してから1ヶ月ではない。
• APIは少なくとも21個用意されている。• similarweb.com でサイト名を入力して現れる情報は全て取れる。
• それらは、Traffic, Content, Sourcesなどに分類できる。
• 使いこなすのに、やや時間がかかる。
• (このメモ作成者は3日間、サポートと連絡を何度も取り合って、やや使いこなせるようになった。)
• 聞けば教えてくれる、APIもあったりする。
• BASICを購入すると、2万5000個APIを発行できる• ただし、「似たサイト」「同時に訪れやすいサイト」などは
1回のAPI発行で、3回分消費される。
• 「トラフィック」は1回のAPIで、1年間約365日の毎日の訪問者数を返してくれる。(APIごとに大きな情報を取得できることが可能な場合もある。)
• 2012年8月以降のデータが取れるようだ。

初めに(2/4)•サイトがどの分野(カテゴリ)のものであるか、どの国のものであるか、判定してくれる。• カテゴリは、210個強ある。
similarweb.com/categoryを参照。自然言語関連技術で分類しているらしいが、英語以外はあてにならない。
• 国は50個前後ある。Similarweb.com/coutryを参照。(台湾はあるが、韓国や中国は含まれて無い。)
カテゴリの例▼
国の例▼

初めに(3/4)• おそらく世界中の数百人の1人のブラウザから閲覧URL情報が送信されている。• データからの分析結果が偏る可能性はあるので、どう偏りうるか、検討することが大事。
• 推定値は誤差があるので、信頼区間をどう構成するかも鍵。
▼いろんなサイトの訪問者数の返り値の月ごとの変化の様子

初めに(4/4)
•取得した数値に大きな誤差が無いかは、本当は検討が必要。• Google Analytics と数値は比較可能とのこと。
• アクセス数を公表しているサイトがあれば比較すべき。
• AlexaやWolframAlphaとの数値の乖離を見るべき。
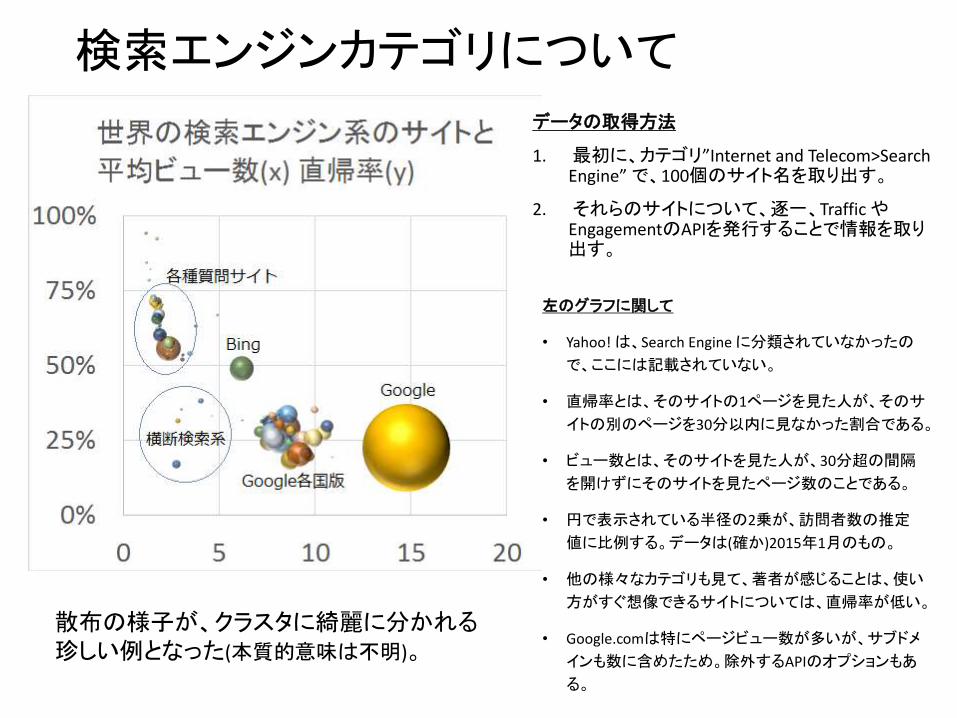
検索エンジンカテゴリについて
データの取得方法
1. 最初に、カテゴリ”Internet and Telecom>Search Engine” で、100個のサイト名を取り出す。
2. それらのサイトについて、逐一、Traffic やEngagementのAPIを発行することで情報を取り出す。
左のグラフに関して
• Yahoo! は、Search Engine に分類されていなかったの
で、ここには記載されていない。
• 直帰率とは、そのサイトの1ページを見た人が、そのサ
イトの別のページを30分以内に見なかった割合である。
• ビュー数とは、そのサイトを見た人が、30分超の間隔
を開けずにそのサイトを見たページ数のことである。
• 円で表示されている半径の2乗が、訪問者数の推定
値に比例する。データは(確か)2015年1月のもの。
• 他の様々なカテゴリも見て、著者が感じることは、使い
方がすぐ想像できるサイトについては、直帰率が低い。
• Google.comは特にページビュー数が多いが、サブドメ
インも数に含めたため。除外するAPIのオプションもあ
る。
散布の様子が、クラスタに綺麗に分かれる珍しい例となった(本質的意味は不明)。
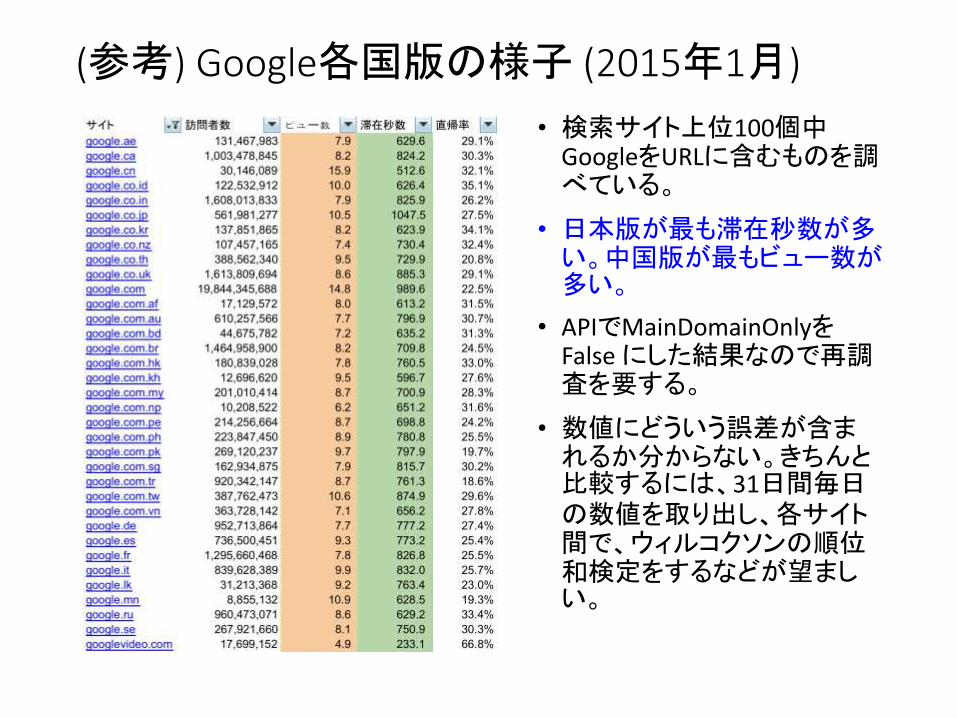
(参考) Google各国版の様子 (2015年1月)
• 検索サイト上位100個中GoogleをURLに含むものを調べている。
• 日本版が最も滞在秒数が多い。中国版が最もビュー数が多い。
• APIでMainDomainOnlyをFalse にした結果なので再調査を要する。
• 数値にどういう誤差が含まれるか分からない。きちんと比較するには、31日間毎日の数値を取り出し、各サイト間で、ウィルコクソンの順位和検定をするなどが望ましい。

日本の新聞系サイト6個のトラフィック
世間の動きとの関連
• 2014.09.27の御嶽山の噴火の日に朝日新聞のサイトは訪問者数が多かった。
• 2014.12.14の衆議院選挙の日は、朝日・読売が大きく伸びた。
• それ以外であまり大きな動きが検出できないことこそ、本当は考察に値しそうだ。
API使用上の注意点
• 1サイトにつき、1回のAPIの消費で上記のグラフは描ける。
(1年間分の情報が1APIで取得できるため。)
• したがって、上記のグラフは6個のAPIの消費で済む。
• しかし、実際には、それまでに試行錯誤で、数十から数
百のAPIの消費が、練習のために必要であろう。

平均滞在秒数 (Avg. Visit Duration)
• 2014年の1年間の週ごとの様子をプロットした。
• 一般的な意味の解釈しやすい例が得られた。
(サイトごとの違いや時間変化も分かりやすかった。)
ただし、日ごとにすると、意味が分かりにくくなった。
時系列のグラフは描き方に工夫が必要。
(一般に凸凹の多いグラフは、視覚的に意味が分かりにくい。)
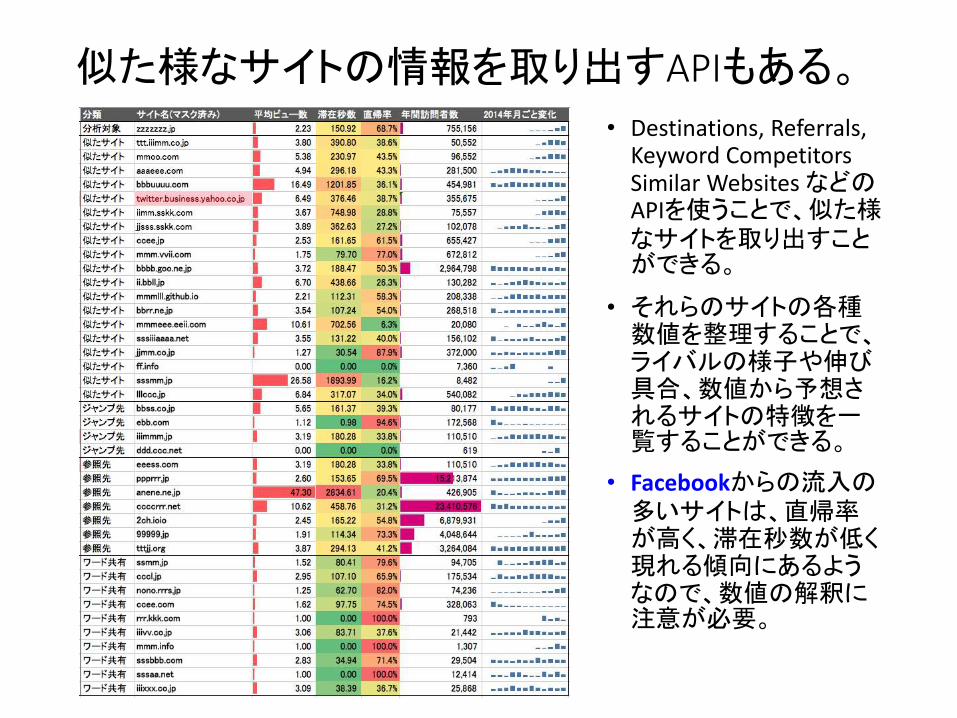
似た様なサイトの情報を取り出すAPIもある。
• Destinations, Referrals, Keyword Competitors Similar Websites などのAPIを使うことで、似た様なサイトを取り出すことができる。
• それらのサイトの各種数値を整理することで、ライバルの様子や伸び具合、数値から予想されるサイトの特徴を一覧することができる。
• Facebookからの流入の多いサイトは、直帰率が高く、滞在秒数が低く現れる傾向にあるようなので、数値の解釈に注意が必要。
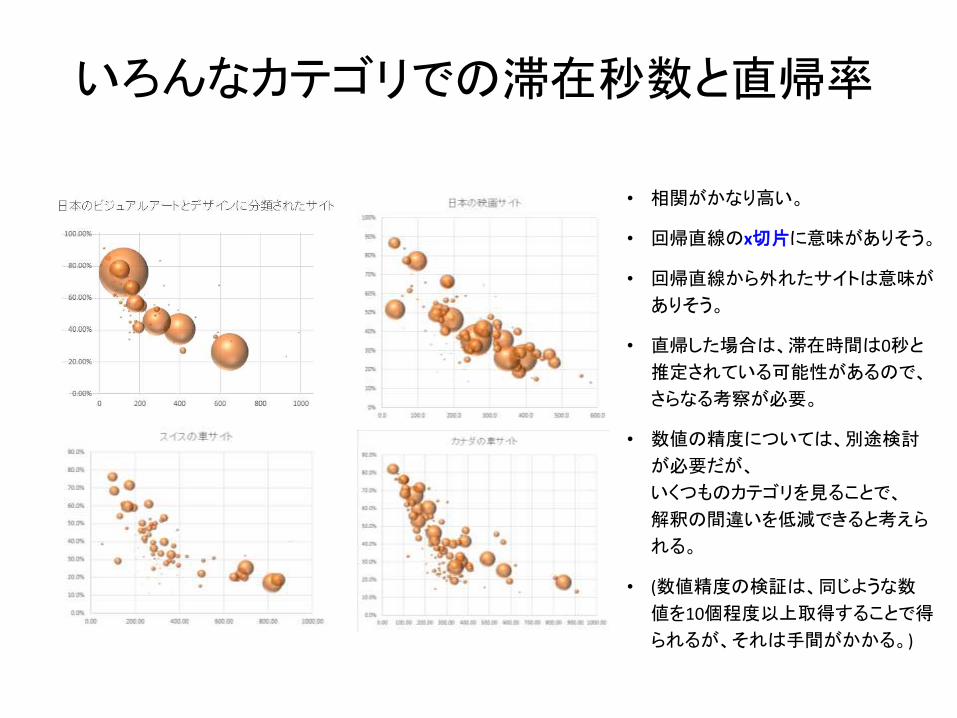
いろんなカテゴリでの滞在秒数と直帰率
• 相関がかなり高い。
• 回帰直線のx切片に意味がありそう。
• 回帰直線から外れたサイトは意味が
ありそう。
• 直帰した場合は、滞在時間は0秒と
推定されている可能性があるので、
さらなる考察が必要。
• 数値の精度については、別途検討
が必要だが、
いくつものカテゴリを見ることで、
解釈の間違いを低減できると考えら
れる。
• (数値精度の検証は、同じような数
値を10個程度以上取得することで得
られるが、それは手間がかかる。)

検索されたキーワードについて(Organic Search KeywordsのAPI)
• サイト名から、どういうキーワードで検索されているか、知ることができる。1個のAPIで10個ずつ取得できる。

検索ワードを取り出せるだけ取り出すことも可能。
上記は、kamel.ioの場合。20回超のAPI発行で200個以上のワードを取り出せた。(数百人に1人が使った検索語であることに注意は必要な場合がある。)

今回の分析で気が付いたこと•多数のバブルチャートを描いて初めて気付くことが多かった。• ヒストグラムより、意味が分かりやすかった。
(どれが少数のインパクトのあるサイトか分かるため)
• 強い相関を発見することで、SimilarWeb社の情報収集の仕組みが分かるきっかけがつかめることが多い。
•バブルチャートに各バブルにラベルを貼りたかった。• R言語なら可能。
• SSRI社のエクセル統計なら容易である。ただし数万円。


















