
Sébastien Coutu: Copy this Meetup Devops - microservices - infrastructure immutable
42
Micro-services sous Docker et Kubernetes Présentation: Sébastien Coutu
-
Upload
msdevmtl -
Category
Technology
-
view
296 -
download
0
Transcript of Sébastien Coutu: Copy this Meetup Devops - microservices - infrastructure immutable

Micro-services sous Docker et
KubernetesPrésentation:
Sébastien Coutu

Qui suis-je?● Tech lead DevOps chez Mnubo, startup IoT
● 5 ans dans le monde Big Data
● 19 ans d’expérience en opérations.
● Amateur d’escalade et d’ébénisterie.

Qu’est-ce que mnubo offre?● Une plateforme SaaS pour l’analytique de données d’objets connectés
● “Data”, “Analytics”, “Intelligence” as a service
● Marchés visés:
○ Produits consommateurs
○ Produits commerciaux
○ Agriculture
○ Industriel léger

● Des applications quasi-monolithiques
● Des performances très variables
● Des déploiements à tous les quelques mois: les nouvelles fonctionnalités
se faisaient attendre trop longtemps.
● Des déploiements qui prennent entre 6 à 12 heures à exécuter.
L’architecture des services de mnubo il y a 2 ans.

● Identifier où le temps est perdu.
● Identifier les changements architecturaux requis pour changer la
situation.
● Identifier les technologies pouvant aider à changer la situation.
● Mettre en place les bons éléments humains pour pousser le changement.
Comment donner un coup de barre?

Pourquoi une infrastructure basée sur des micro-services?● Afin d’éviter des blocs monolithiques d’applications
● Afin d’être capable de “scaler” indépendamment les différents
composants.
● Afin d’améliorer la vitesse de mise en production des fonctionnalités.
● Afin d’améliorer la vélocité générale du développement.

Premier composant de la solution: Docker
Cas d’utilisation typiques:
● Environnements avec micro-services● Intégration continue● Déploiement continu: déploiements automatisés
“Une plateforme ouverte pour applications distribuées pour développeurs et administrateurs de systèmes.”
- Source http://www.docker.com

Pourquoi des conteneurs?● Packaging
○ Toutes les dépendances sont “bundlées” à l’intérieur du conteneur○ Aucun conflit de versions possible○ Diminue les “moving parts” lors de mises à jour.
● Simplification des serveurs○ Seul requis au niveau des opérations est de fournir un kernel et
une version de docker compatible.○ Les conteneurs sont isolés entre eux.
○ Il est possible de restreindre les ressources allouées aux conteneurs.

Pourquoi des conteneurs?● Simplification de l’automatisation
○ Conventions requises entre les opérations et le développement.
○ La même “image” est utilisée sur le laptop du développeur, en intégration, en QA et sur le serveur de production.
● Réutilisation des couches identiques.○ Chaque conteneur est bâti en utilisant des couches qui sont
réutilisables entre les images.○ Espace disque utilisé est minimisé sur les serveurs.○ Rapidité de téléchargement des couches différentes seulement.

Prochain composant de la solution: Kafka
Cas d’utilisation typiques:
● Messaging● Agrégation de logs et de métriques● Tracking d’activité web● Stream processing● Event sourcing
“Kafka est une plateforme de streaming distribuée”- Source:http://kafka.apache.org

Prochain composant de la solution: Persistance des données

Les technologies de base sont identifiées, ensuite?● Migration d’un modèle semi-monolithique vers un modèle de
micro-services
● La multiplication des micro-services
● L’architecture d’un pipeline qui “scale”
● Révision complète des outils de build
● Révision complète des outils de déploiement

Rendre les micro-services immuables● S’assurer que les configurations ne changent pas.
○ Définir des environnements au besoin
○ Maximiser l’utilisation de paramètres par défaut
○ Ne PAS utiliser de nom d’hôte dans les fichiers de configuration, toujours des alias.
● Éviter les différences entre les environnements.○ Certaines ne peuvent être évitées: Paramètres RAM, nombre de réplicas, etc.
● Utiliser les mêmes conteneurs du laptop du développeur/Jenkins jusqu’à
la production.

Déployer et orchestrer les micro-services● Nous désirons déployer les micro-services là où il y a des ressources
disponibles.
● Nous désirons maximiser l’utilisation des machines abritant les
micro-services.
● Nous désirons accéder dynamiquement et répartir la charge entre les
conteneurs d’une même application.

Prochain composant de la solution: Déploiement et orchestration des conteneurs

Assembler les micro-services sous une même adresse● En premier lieu: routage HTTP fait par un serveur Apache
○ Beaucoup de coupures de sessions lors de changement d’API.
○ Health-checking non adéquat
● En second lieu: routage HTTP fait par HAproxy○ Scale beaucoup mieux mais aucune modification programmatique facile.
● Maintenant: Séparation de la couche d’encryption SSL et du routage HTTP

Prochain composant de la solution: Routage d’API HTTP

Prochain composant de la solution: Visibilité sur l’infrastructure

● Une plateforme basée sur plus de 20 micro-services.
● Des performances prévisibles.
● De multiples déploiements chaque jour sont possibles.
● Les “downtime” ne sont plus requis pour la majorité des déploiements.
● Plus de 80% du pipeline est automatisé.
L’architecture des services de mnubo aujourd’hui

● Jenkins
● Docker Registry
● SBT
● Gitlab
● Artifactory
Outils d’infrastructure

Crédits image

Deuxième Partie: Google Kubernetes
Crédits image

Qu’est-ce que Kubernetes (K8s)?● Un système d’orchestration de conteneurs Docker.
● Il permet de placer dynamiquement les conteneurs là où les ressources
sont disponibles.
● Il comporte un système d’auto-découverte pour router les requêtes là où
les conteneurs sont démarrés.

Où trouver Kubernetes?● La documentation et le lien vers les sources sont disponibles sur
http://kubernetes.io/
● Kubernetes est disponible en ligne chez Google avec le Google Container
Engine (GKE)
● Le projet fourni également des instructions pour l’installation locale ou
sur plusieurs fournisseurs “cloud”.

Principaux éléments de Kubernetes● Master
● Worker node
● Compte de services
● Namespace
● Pod

Principaux éléments de Kubernetes (suite)● Volume
● Label
● Service
● Replication Controller
● Secret

Architecture de K8s sous Docker (local)● Déploiement simple
“tout-en-un” sur la même machine.
● Permet de se familiariser avec les différents composants.
● Fonctionnalité complète présente.
* Image tirée de la documentation de Kubernetes
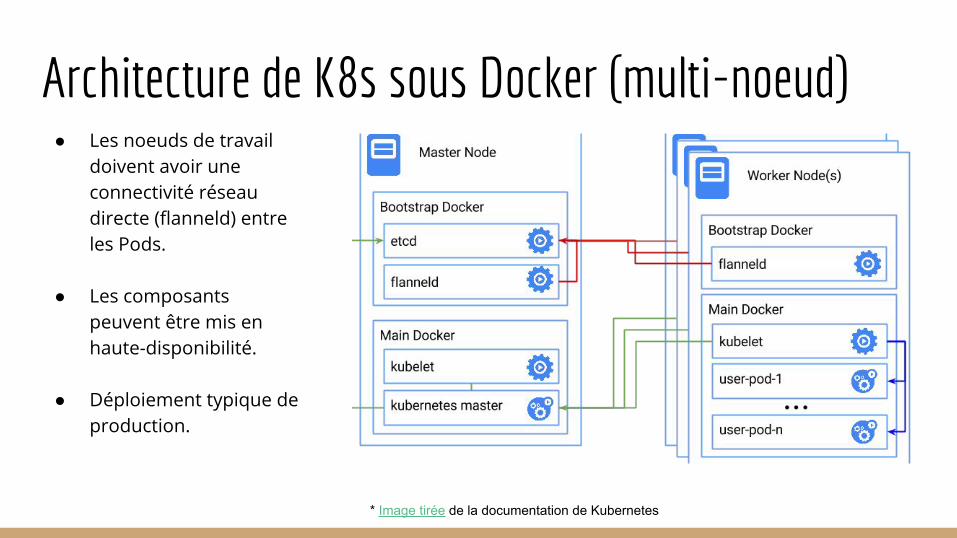
Architecture de K8s sous Docker (multi-noeud)● Les noeuds de travail
doivent avoir une connectivité réseau directe (flanneld) entre les Pods.
● Les composants peuvent être mis en haute-disponibilité.
● Déploiement typique de production.
* Image tirée de la documentation de Kubernetes

Comment configurer et interagir avec Kubernetes● En utilisant l’API HTTP(s)● À l’aide de l’utilitaire kubectl, utilitaire CLI se connectant à l’API HTTP.● En utilisant un des modules Python:
○ kubernetes-py*○ python-kubernetes-wrapper○ pykube○ python-k8sclient
● En utilisant des outils d’automatisation:○ Salt○ Puppet○ Ansible
* Avertissement: Je suis l’auteur de cette librairie mise en ligne par mnubo.

Définition d’un objet● La définition d’un objet permet à Kubernetes de comprendre ce que
l’usager désire accomplir. ● Elle peut être écrite en YAML ou en JSON. (YAML est préférable)
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
Création d’un Pod● Créer un fichier avec la définition du Pod, ensuite:
● Vérifier que le Pod a bel et bien été créé:
$ kubectl create -f docs/user-guide/walkthrough/pod-nginx.yaml
$ kubectl get pod
● Pour effacer le Pod
$ kubectl delete pod nginx
● En supposant que l’IP du Pod est accessible tester l’accès au Pod
$ curl http://$(kubectl get pod nginx -o go-template={{.status.podIP}})

Persistance des données - Volumes● Les volumes permettent de persister les données de Pod au travers de
redémarrage de conteneurs et même selon le volume, au travers de redémarrage sur différents noeuds.
● Ils sont définis au niveau du Pod:
apiVersion: v1
kind: Pod
metadata:
name: redis
spec:
…volumes: - name: redis-persistent-storage emptyDir: {}

Persistance des données - Volumes (Suite)● Ils sont par la suite associés à un ou plusieurs conteneurs pour être
utilisés.apiVersion: v1kind: Podmetadata: name: redisspec: containers: - name: redis image: redis ports: - containerPort: 6389 volumeMounts: - name: redis-persistent-storage mountPath: /data/redisvolumes: - name: redis-persistent-storage emptyDir: {}

Grouper des Pod - Labels● Pour sélectionner des Pod une fois créés, nous utilisons des “labels”:
● Les “labels” seront par la suite utilisés pour cibler des Pod:
apiVersion: v1kind: Podmetadata: name: nginx labels: app: nginxspec: containers: - name: nginx image: nginx ports: - containerPort: 80
$ kubectl get pods -l app=nginx

Accéder des Pod via un Service● Un service permettra
d’exposer un port réseau d’un ou plusieurs Pod à d’autres.
● Ils sont utilisés comme système de découverte automatisé.
● Ils utilisent des “labels” comme sélecteurs pour cibler un ou des Pod.
apiVersion: v1kind: Servicemetadata: name: nginx-servicespec: ports: - port: 8000 # the port that this service should serve on # the container on each pod to connect to, can be a name # (e.g. 'www') or a number (e.g. 80) targetPort: 80 protocol: TCP # just like the selector in the replication controller, # but this time it identifies the set of pods # to load balance traffic to. selector: app: nginx

Cycle de vie d’un Service● Créer un fichier avec la définition du service, ensuite:
● Vérifier que le service a bel et bien été créé:
$ kubectl create -f docs/user-guide/walkthrough/service.yaml
$ kubectl get service
● Pour effacer le service
$ kubectl delete service nginx-service

Répliquer des Pod - Replication Controller● Un replication controller
permet de créer de multiples Pod identiques.
● Ils permettent de recréer un Pod sur un noeud différent si un noeud disparaît.
● Ils utilisent les labels pour retracer les Pod qu’ils ont créé.
apiVersion: v1kind: ReplicationControllermetadata: name: nginx-controllerspec: replicas: 2 selector: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx ports: - containerPort: 80

Cycle de vie d’un Replication Controller● Créer un fichier avec la définition du replication controller● Utiliser l’utilitaire kubectl pour créer le replication controller:
● Vérifier que le replication controller a bel et bien été créé:
$ kubectl create -f docs/user-guide/walkthrough/replication-controller.yaml
$ kubectl get rc
● Pour effacer le replication controller
$ kubectl delete rc nginx-controller
● Vérifier que la quantité de réplicas est valide:
$ kubectl get pod -l app=nginx

Liens utiles● Kubernetes-dashboard: Une interface web permettant de visualiser les
différents éléments de Kubernetes.● Cluster DNS: Service permettant d’utiliser des noms de domaine pour
trouver un élément Kubernetes à la place d’une adresse IP.● kubectl pour usagers Docker● Accéder aux logs applicatifs● Surveillance du cluster● Exécuter des commandes dans un Pod● Exemples de logiciels dans Kubernetes

Crédits image

Démonstration: minikube
Crédits image

Micro-services sous Docker et
KubernetesPrésentation:
Sébastien Coutu


















