
SAS (statistics analysis system) 统计软件简介
150
SAS SAS (statistics analysis system) 计计计计计 统 计计计计计 统 顾顾顾 顾顾顾顾顾顾顾 2010 顾 3 顾
description
SAS (statistics analysis system) 统计软件简介. 顾世梁 扬州大学农学院 2010 年 3 月. 0 SAS 简介. 0.1 概况 SAS 是美国 SAS 软件研究所研制的一套大型集成应用软件系统,它具有完备的数据存取、管理、分析和展现功能。其创业产品 — 统计分析系统部分,以应有尽有、包罗万象和强大精准的数据分析能力,一直为业界推崇,被视为最权威的统计分析标准软件。 经过 30 多年发展, SAS 已被全世界 120 多个国家和地区的科研机构和人员普遍采用,涉及教育、科研、金融等各个领域。. 0.2 发生发展(历史). - PowerPoint PPT Presentation
Transcript of SAS (statistics analysis system) 统计软件简介

SASSAS(statistics analysis system)
统计软件简介统计软件简介
顾世梁扬州大学农学院
2010 年 3 月

0 SAS0 SAS 简介简介0.1 概况SAS 是美国 SAS 软件研究所研制的一套大型集
成应用软件系统,它具有完备的数据存取、管理、分析和展现功能。其创业产品—统计分析系统部分,以应有尽有、包罗万象和强大精准的数据分析能力,一直为业界推崇,被视为最权威的统计分析标准软件。
经过 30 多年发展, SAS 已被全世界 120 多个国家和地区的科研机构和人员普遍采用,涉及教育、科研、金融等各个领域。

SAS (发音 sass )是“统计分析软件”( statistical analysis software )的首字母缩写,由 Jim Goodnight 和北卡罗莱那州立大学的同事(包括 John Sall )于上世纪 70 年代初开始从事农业及生物试验研究数据分析。随着统计软件需求市场增大,于 1976 年成立了 SAS 软件研究所,主要从事统计计算软件开发和销售,逐步发展成为全球一流的商业智能软件和服务提供商。
0.2 发生发展(历史)

1976 : SAS 软件研究院 ( 北卡罗莱那州 ) 成立;推出首个产品 - Base SAS 软件;
1977 : SAS 由创业初期的 7 名员工组成;1978 : SAS 的客户数达到了 600 ;1979 : SAS 公司软件第一次外销; SAS 软件取得技术进步,可以运行
在 IBM 的 VM/CMS 主机环境下; 1980 : SAS 欧洲总部在英国开张;公司迁于美国北卡州卡莉市的 A 座
新址; SAS/GRAPH 软件和 SAS/ETS 计量经济学软件以及 SAS时间序列分析软件的图形展现模块发布;
1981 : SAS 软件销售速度加快; 3000 多个软件安装点上安装 SAS 软件;1982 :欧洲总部搬迁到海德堡;亚太(新西兰办事处、澳大利亚分公
司)成立;与 DEC 公司建立合作关系;1983 : E 座办公楼竣工使用; SAS 软件全球销量增加;1984 :项目管理软件上市; SAS 收购 SYSTEM 2000 数据管理软件;
SAS 软件扩展,从大型机到微型计算机。
公司大事记

1985 :与 HP 合作; SAS/AF 、 SAS/DMI 和( SAS/IML )软件;首个PC DOS SAS System 版本( Base SAS 和 SAS/RTERM 软件)推出; PC 的微型机-大型机链接( SAS/C 编译器)上市;
1986 : SAS 软件研究所收购 Lattice 有限公司;与微软公司建立合作关系; SAS/QC 、 SAS/IML 和 SAS/STAT 软件上市;
1987 : J 座办公楼竣工;与苹果电脑合作; SAS/SHARE 、 DB2 和 SQ
L-DS ;用 C 语言重新编写了 SAS 系统; 6.03 版上市;1988 :员工人数达千名;收购 NeoVisuals 公司;与 Sun Microsystems
合作 ; MultiVendor Architecture(MVA) 、 SAS/ACCESS 、 SAS/ASSIST 、 SAS/CPE 上市;
1989 :面向 Macintosh 的 JMP 软件上市。
公司大事记(续)

1990 :与 Intel 合作;在中国成立分公司;全新的客户机 / 服务器计算功能支持先进的分布式计算模式; MVS 、 CMS 和 OpenV
MS 6.06 版 本 上 市; SAS/CONNECT 软件和 SAS/ACCESS
数据库接口系列上市;
1991 :数据可视化功能集成到 SAS/INSIGHT 软件覆盖范围越来越广的决策支持工具中;
1992 :决策支持功能扩展; SAS 垂直市场软件:制药行业的临床分析系统上市; SAS/CALC 、 SAS/TOOLKIT 、 SAS/PH-Clini
cal 和 SAS/LAB 软件上市;
1993 : R 座大厦竣工; EIS 上市; MVS 、 CMS 、 VMS 、 VSE 、OS/2 和 Windows 6.08 版本上市。
公司大事记(续)

1994 : SAS 全球员工人数达 3,000 人; SAS/SPECTRAVIEW, SAS/SHARE*NET 、JMP 上市;
1995 : Rapid Warehousing Program ; EIS 市场领先; SAS for Macintosh ( 6.1
0 版本)上市。面向 Windows95 、 Windows NT 和 UNIX 的 Orlando ( S
AS System 6.11 版本)上市;
1996 :支持 Web , JMP 软件和 SAS 软件通过 Windows 95 标志认证;
1997 : SAS 的全球员工人数达 5,000 人; S 座办公楼竣工; SAS 收购生命科学统计软件 Stat View ; SAS 总裁 Jim Goodnight 荣获 1997 年 American Aca
demy of Achievements 颁发的荣誉;《 Fortune 》杂志的“美国 100 强公司”评比中排名第 3 ; SAS/Warehouse Administrator 、 SAS/IntrNet 软件投入生产;
1998 : SAS 推出 CRM 、 SAS/ACCESS 、 OLE-DB for OLAP 和 SAS/Enterpris
e Reporter 和 HR Vision 上市;
1999 : SAS 收入超过 10 亿美元; T 座办公楼开放; SAS 支持报刊调查工作;美国食品和药品管理局选择 SAS 技术,作为分析数据的标准。
公司大事记(续)
2000 : SAS 在 Intel Developer Forum 中将电子智能集成到 64位计算中; SAS 将软件移植到 Linux ;
2001 : SAS 庆贺公司成立 25周年;用户评选 SAS 为分析软件冠军;
2002 : SAS 连续第 6 年荣登 Fortune 的“美国 100 强公司”名单; SA
S 成立 Rapid Risk Deployment ; Sun 、 FEA 初期解决方案合作伙伴;
2003 : SAS 收购 Marketmax ; Bank of America Foundation 、 DPI 、SAS in School 向北卡罗莱纳学校捐赠礼物;收购 OpRisk Analy
tics ; IBM 和 SAS 成立战略联盟;推出 SAS9.10 ;
2004 : SAS CEO Jim Goodnight 荣获 StevieTM Award for Best Execut
ive奖; SAS 历史上最重要的发布新的 SAS9 软件对商业智能行业带来革命性的影响;这是一个功能强大的分析软件,能够进行数百万个高质量的、自动化预测。
公司大事记(续)
2005 : SAS CEO Jim Goodnight 在 2004 美国商业大奖中荣获 Stevi
eTM最佳企业管理人奖;新推出的 SAS Enterprise ETL Serv
er 在性能方面无人能及;
2006 : SAS实现年销售收入 19 亿美元;
2007 : Ann Goodnight 进入北卡罗莱那大学董事会;
2008 :销售收入为 22.6 亿美元; SAS 在全球约有 45,000家客户;《财富》全球 500 强企业前 100家企业中有 91家是 SAS 客户;2007 年销售收入的 22% 用于研发投入; SAS 在全球设有 400
多个办事处。
公司大事记(续)

1 )功能强大,统计方法齐、新、优SAS提供了从基本统计数计算到各种试验设计的
方差分析,相关回归分析以及多变量分析的各种统计分析过程,几乎囊括了所有的最新统计分析方法,其分析技术先进,可靠。有些机构和杂志只认 SAS分析的结果。
2 )使用简便,操作灵活SAS 以一个通用的数据步产生数据集,尔后以不
同的过程用以完成各种数据分析。其编程语句简洁,短小,通常只需很小的几个语句即可完成一些复杂的运算,得到满意的结果。
3 )运算速度快,联机帮助功能强大
0.3 SAS 的特点

4) SAS 的模块化结构SAS 系统是一个组合软件系统,它一共由 50 个
左右的功能模块组合而成。SAS 的基本部分是 SAS/BASE 模块,该模块是 S
AS 系统的核心,承担着主要的数据管理任务,并管理 SAS 的用户使用环境,进行用户语言的处理,调用其它 SAS 模块和产品。
在 SAS/BASE 的基础上,用户还可以增加各种模块而增加不同的功能,如 SAS/STAT( 统计分析模块 ) 、SAS/GRAPH( 绘图模块 ) 、 SAS/OR( 运筹学模块 ) 、SAS/IML(交互式矩阵程序设计语言模块 )等。

SAS是第四代计算机语言的代表性软件,用户只需清楚干什么,不必清楚怎么做!使用相对方便,用户可以完成所有统计分析、预测、建模和模拟抽样等工作。
此外, SAS还提供了各类概率分析函数、分位数函数、样本统计函数和随机数生成函数,用户能方便地实现各类特殊统计要求。
0.4 SAS 的操作方式
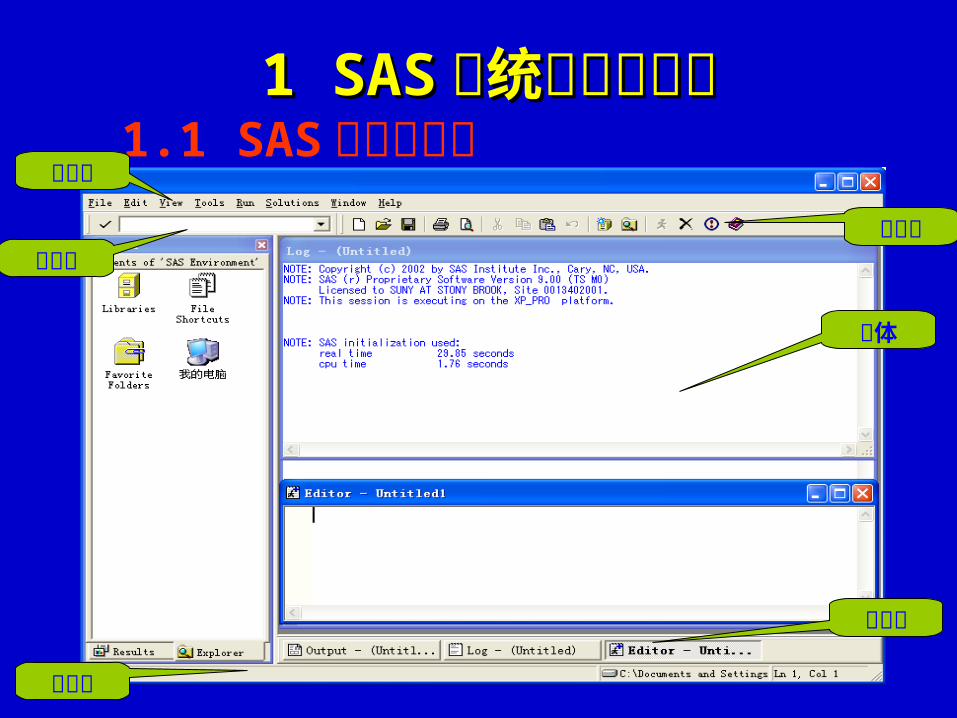
1.1 SAS 的工作界面菜单栏
命令栏
状态栏
工具栏
窗体
窗口栏
1 SAS1 SAS 系统的工作环境系统的工作环境
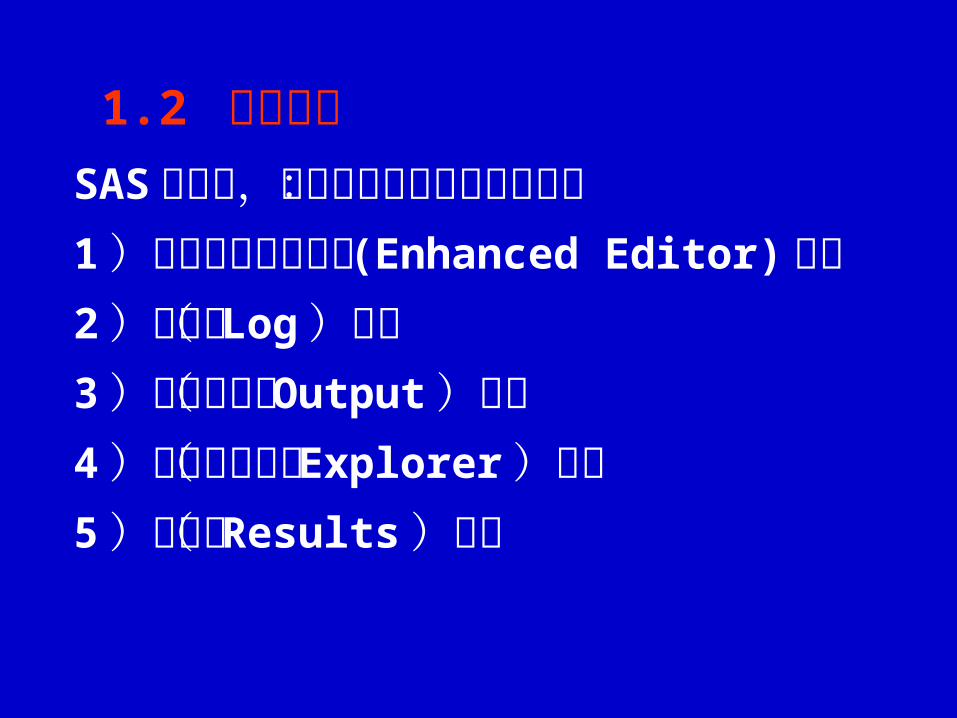
SAS启动时,默认会打开以下五个窗口:1 )增强型程序编辑器 (Enhanced Editor)窗口2 )日志( Log )窗口3 )结果输出( Output )窗口4 )资源管理器( Explorer )窗口5 )结果( Results )窗口
1.2 主要窗口

系统默认提供的程序编辑窗口,编辑 SAS应用程序。以不同的颜色显示 SAS程序中不同的部分,便于进行语法检查。如用深蓝色表示数据步 /程序步开始;蓝色表示关键字;棕色表示字符串;浅黄色表示数据块;红色表示可能的错误。增强型程序编辑器窗口中的内容在保存时被存
为 SAS程序格式,实际上就是扩展名为“ .sas” 的纯文本文件。
1) 增强型程序编辑 (Enhanced Editor)窗口
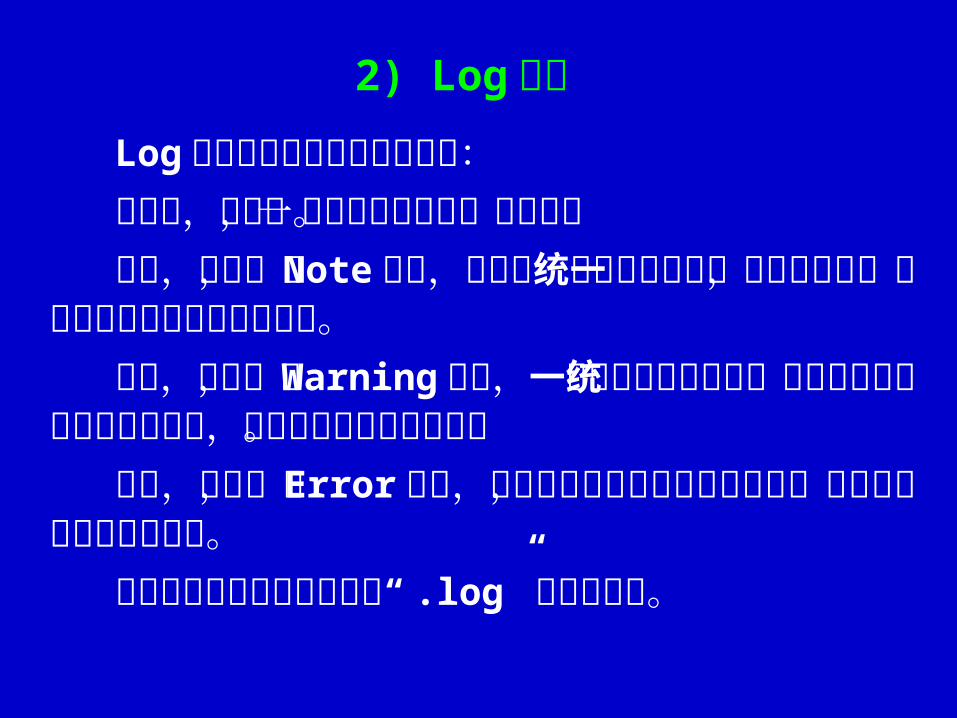
Log窗口显示程序运行有关信息:程序行,黑色,记录执行过的每一条语句。提示,蓝色,以 Note 开始,提供系统或程序运行
的一些常规信息,大多数时候我们可以视而不见。警告,绿色,以 Warning 开始,一般在程序中含
有系统可以自动更正的小错误时出现,此时会提供错误序列号。错误,红色,以 Error 开始,当出现该信息说明
程序有错误,执行结构必然是不正确的。窗口内容可保存为扩展名为“ .log” 的文本文件。
2) Log窗口

该窗口显示 SAS程序输出结果。
结果输出窗口中的内容是分页显示的,页上方显示标题,日期和时间。
当结果输出非常长时,为了能够方便地查阅某一部分结果,可以利用结果( Results )窗口中的目录树进行快速定位。
结果输出窗口中的内容可以保存为扩展名为 .ls
t 的纯文本文件。
3) 结果输出( Output )窗口
结果窗口帮助用户浏览和管理所提交 SAS程序的输出结果。
在该窗口中将 SAS 系统的所有输出结果依次按照目录树的结构加以排列,每一个过程步的结果被表示为一个节点,展开该节点就可进一步看到表示不同输出内容的子节点,使用鼠标右键单击每个节点,就可对输出结果的各部分进行察看、存储、打印、删除等操作。
4) 结果( Results )窗口

资源管理器窗口的作用类似于 Windows操作系统的资源管理器,用于浏览和管理 SAS 系统中的各种文件。
6) 其它子窗口除了增强型编辑器外, SAS还提供了普通的
程序编辑( program editor )窗口;当使用 SAS 作图时,相应的统计图会在专门
的 Graph窗口中输出;SAS 的数据集显示窗口 Viewtable等。
5) 资源管理器( Explorer )窗口

SAS 系统主菜单是动态变化的,随当前激活窗口不同而有不同的组织结构,提供不同的主菜单命令。其中的主要命令及功能:File(文件 ) -支持 SAS文件的调入、保存及打印。Edit( 编辑 ) -支持基本编辑操作(例如:清空、复
制、剪切等)。View(浏览 ) -支持 SAS 系统用户在多窗口之间切换。Tools( 工具 ) -提供对各种输出结构进行编辑的工具,
如:表格、图形、报告等,并支持进行系统环境和状态的设置。
Run( 运行 ) -用于执行或调用程序。Solutions(解决方案 ) -支持用户进行统计分析。
1.3 菜单和工具栏
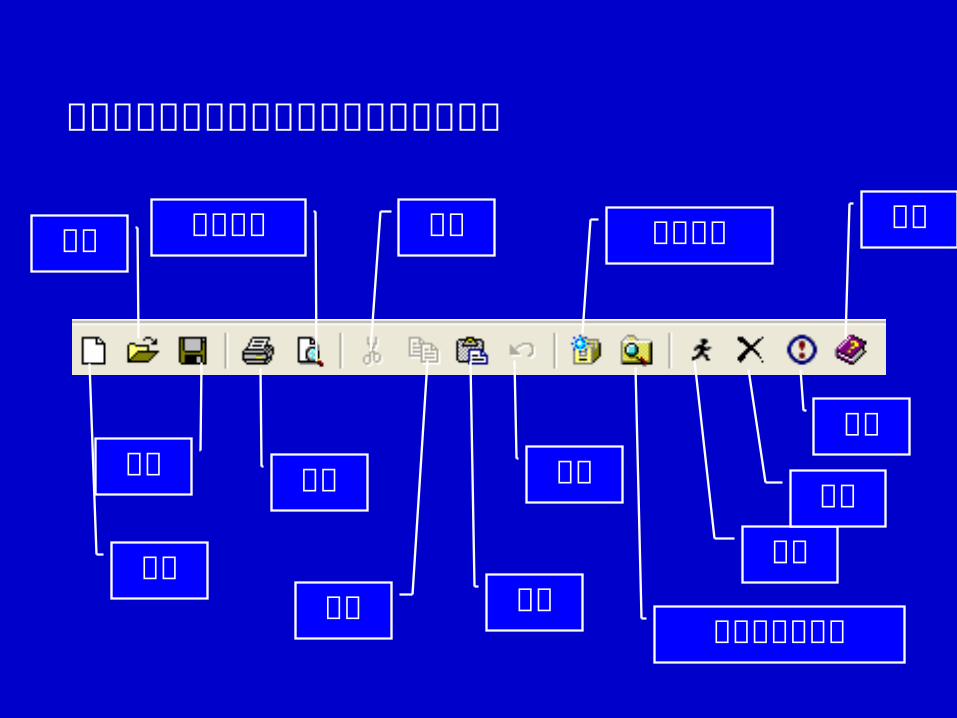
工具栏图标提供了常见任务的快捷操作方式
新建
打开
保存 打印
打印预览 剪切
复制 粘贴
撤销
建立新库
资源浏览器窗口
执行清除
暂停
帮助
在命令栏可输入一些命令,可方便地实现某些功能。如 clear, undo, recall 等。
在命令栏内还可输入 help ,获得即时帮助。如 help anova ,即可获得有关 anova
procedure 的帮助信息,对软件的正确操作很有帮助。
1.3 命令栏

2 SAS2 SAS 程序语句基本结构简介程序语句基本结构简介2.1 数据步与过程步SAS 软件就是将数据交给 SAS 过程 (proc) 计算
分析并显示结果的软件。很多统计分析难度较大,常令非统计专业人士头疼。用 SAS 软件,你不必清楚怎么做,但需清楚做什么!只需将数据按一定格式准备,交由过程步即可实现相应的统计分析。
在 SAS 中主要有两种程序步:数据步 (Data Step) 创建用于统计分析的数据集。过程步 (Proc Step)将数据集完成相应统计分析。

SAS程序由若干条语句组成,多数语句由特定的关键字开始,语句中可包含变数名,运算符等,它们之间以空格分隔。最终以分号“ ;”结束。
PROC 过程名 <DATA=数据集名 > < 选项 >;
<VAR 变数 ;> , <WHERE 条件表达式 ;> ,<BY 变数 ;> , <class 变数; >等。
RUN;
注:尖括号内的选项可以省略,过程将按最通常的情况来处理,即:处理最新建立的 SAS 数据集及其中所有的变数。
2.2 SAS 语句基本结构
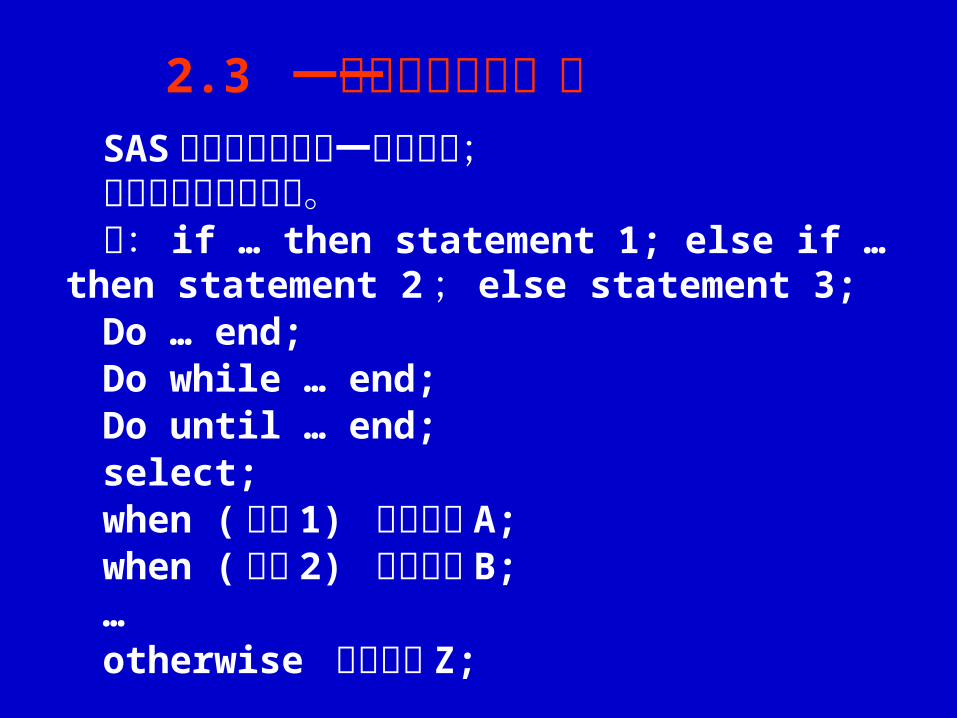
SAS 多句语句可在同一行内出现;有些语句需多行完成。如: if … then statement 1; else if … then stateme
nt 2 ; else statement 3;Do … end; Do while … end;Do until … end;select;when (条件 1) 执行语句 A;when (条件 2) 执行语句 B;…otherwise 执行语句 Z;
2.3 一行多句与多行一句

为使长程序清晰易读,在相应程序段间可以使用空行分隔,也可以使用注释加以说明。其基本格式为:注释语句:使用星号“ *” 开始,可占多行,以
分号“ ;”结束。注释段落:用字符组“ /*” 和“ */”包括起来的
任何字符内容,可占多行。注释语句显示为绿色。
2.4 注释

3 SAS3 SAS 的数据的数据 (data)(data) 步步通俗的讲, SAS 软件就是将数据交给 SAS 过
程( proc )计算分析并显示结果的软件。很多统计分析难度较大,常令非统计专业人士头疼。有了 S
AS 软件,你不必清楚怎么做,但应清楚做什么!只需将数据按 SAS 过程步的格式准备好,交由其完成相应的统计分析。但统计分析大多比较复杂,不同的过程有不同的数据格式要求,数据准备亦有一定的难度。对于复杂的数据准备,拟在稍后再作交代,本节只讨论相对简单的数据准备。

SAS程序运行的数据需存放在逻辑库中的某个数据库中, data 语句 ( 步 ) 生成的数据以数据名的方式驻存在数据库中。
数据库可以分为永久库和临时库两种。临时库只有 1 个,名为 work ,它在每次
启动 SAS 系统后自动生成,关闭 SAS 时,库中的所有内容自动删除。永久库通过 Libname 语句由用户自行定
义,永久库的数据文件将被保留,可以重复使用。
3.1 永久库和临时库

DATA 语句的功能:1 )标志数据步开始;2 )命名将要创建的 SAS 数据集;DATA 语句一般格式: data 数据集名;如: data new;
此时在临时库 work 中生成了一个名为 new 的数据集。若原来就有该数据集,则把其中的内容清除。
3.2 data 语句

若 libname mylib ‘e:\work’;
Data mylib.mydata;
则系统逻辑库中建立 mylib 数据库,其中有 mydata 数据集 (e:\work\mydata.ssd) ,其中的数据可重复使用。以后若调用该数据集(先需用 libname 指明路径,并)需使用两级名称来指定,第一级库名,第二级数据集名,中间用“ .”隔开。如: data=mylib.mydata 。

Input 语句的功能是确定变数的读入模式,即数据域中的数据对应了哪些变数。基本格式为: input 变数名 <变数类型起止列数 > ;例如:Input x y z ; *确定 x 、 y 、 z 三个变数;Input x1-x10; *确定 x1-x10 十个变数;Input x$ y @@ ; *$指明变量 x为字符变数,
@@表明数据是连续读入的;
3.3 Input 语句

data temp; * 数据集为 work.temp ;input x y @@; *输入变数 x,y, @@意指连续输入 ;
cards; * 直接输入数据,数据块开始;34 56 78 90 35 67
89 10 23 65 77 45 * 数据块;; * 数据块结束;
数据步实例 1(连续性数据读入 )

Data class;Input name $1-10 sex $ age height weight;Cards;Zhang Shan F 18 176 75Li Si M 19 163 55Wang Wu F 17 169 70Zhao Liu M 18 173 72;Proc print;Run; [eg5] , [eg52]
数据步实例 2( 多种变数类型读入 )

Cards 语句或 datalines 语句的功能相同,只是前者适用于任何版本,而后者只在 8.0 以后的版本中才适用。它们均可用于标志数据块的开始,随后紧跟需要读入的数据。格式为:
Cards ;数据块;需要注意的是数据块必须单独占一行或多行,最
后表示数据块结束的分号也必须另起一行书写。
3.4 Cards/datalines 语句

Data aaa;
Infile ‘e:\work\eg6.txt’;
Input x1-x4 @@;
即可将 e:\work\eg6.txt 中的数据 x1-x4读入到aaa 数据集中 [eg6] 。几点注意: 1 )该命令只能读入 txt文本或 d
bf文件; 2 )文本文件必须是纯文本格式(不带逗号、不带制表符或 TAB符); 3 )也不宜有表头等格式。
3.5 数据文件的读入
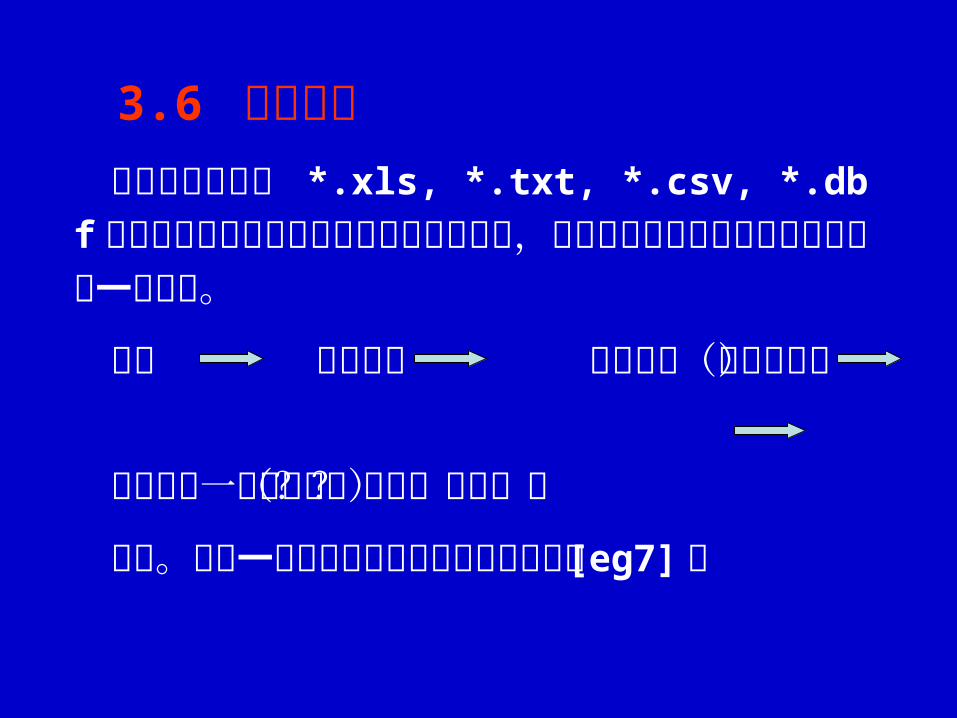
外部数据文件如 *.xls, *.txt, *.csv, *.dbf等可以通过数据导入的方式导入至数据集,此后即可与其他方式创建的数据集一样使用。
文件 导入数据 文件类型(有些选项)
导入至哪一个数据集(临时?永久?)
应用。这是一种更为常用的建立数据步的方式[eg7] 。
3.6 导入数据

4 SAS4 SAS 过程步之描述性统计过程步之描述性统计4.1 SAS 过程步基础PROC 过程名 <data= 数据集名 > <其他选项 >;
<Var 变数序列 ;> , <Where 条件表达式 ...;>
<By 变数序列 ;>
Run;
注:尖括号内的选项可以省略,过程将按最通常的情况来处理,即:处理最新建立的 SAS 数据集及其中所有的变数。

Data= 数据集 该选项用于指明所需处理的数据集名,无此选项时将处理最后打开的数据集。
Var 语句指明分析一个或几个特定的变数。
如在数据集中有 x 、 y 、 z三个变数,若只想对个别变数统计处理,则 print 过程如下:
Proc print ; *对变数列出显示;var x ; *仅对 x变数进行处理;Var x, y; *仅对 x , y变数进行处理;Run ;
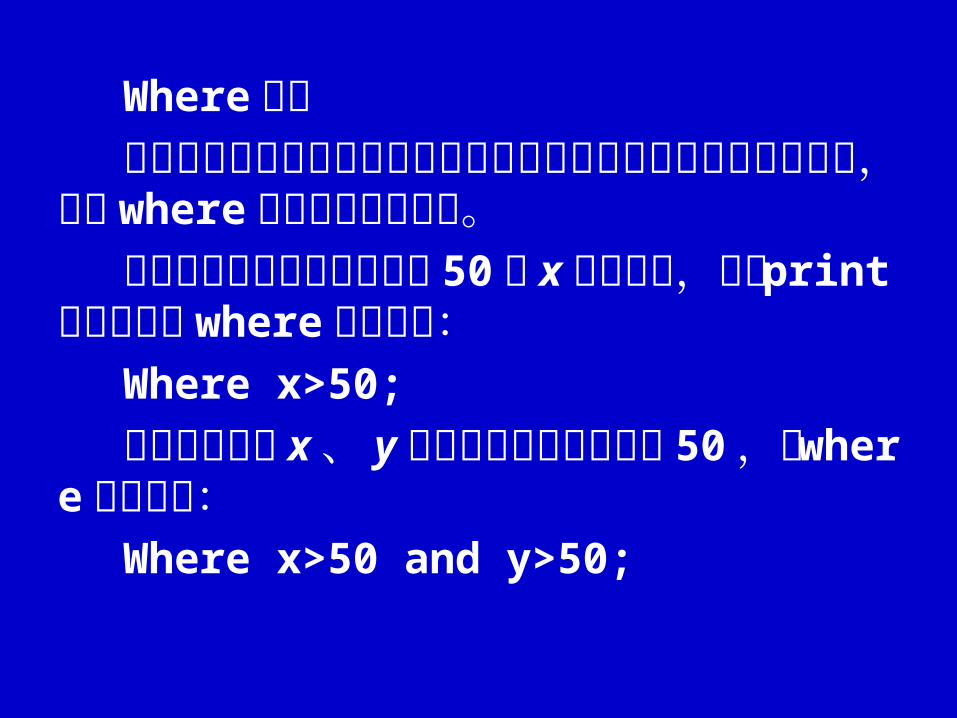
Where 语句如果你想处理的不是整个数据集而只是其
中符合某种条件的子集,那么 where 语句将会非常有用。如上例中我们只想显示大于 50 的 x变数
的值,则在 print 过程中加入 where 语句如下:Where x>50;
如果条件变为 x 、 y两个变数的值都要大于 50 ,则 where 语句改为:
Where x>50 and y>50;
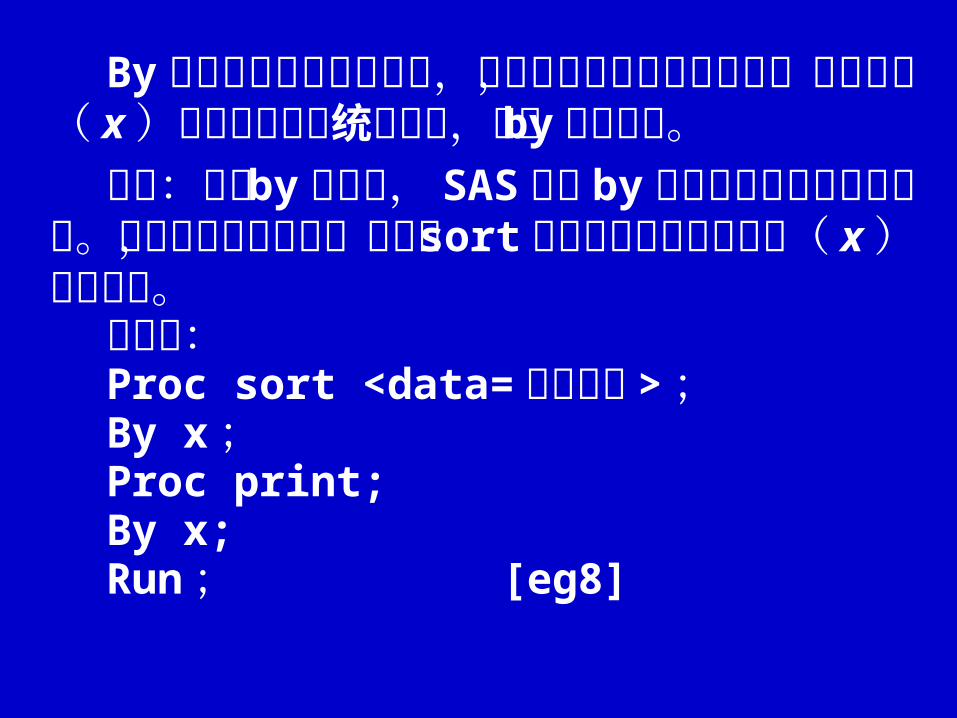
By 语句用于指定分组变数,如果你需要分组处理数据,例如要按( x )类别分组输出统计结果,采用 by 语句即可。注意:在用 by 语句时, SAS要求 by指定的
变数已经按序排列。若原数据未经排序,应使用 sort 过程对相应的分组变数( x )进行排序。格式为:Proc sort <data= 数据集名 > ; By x ;Proc print;By x;Run ; [eg8]

从科研或生产中获得的数据常需计算一些基本的统计数,以反映数据的分布和( /或)变异特性,这可由 SAS 的一个或几个描述性统计分析过程实现。
这些过程主要有: means, summary, univariate 。
4.2 描述性统计过程
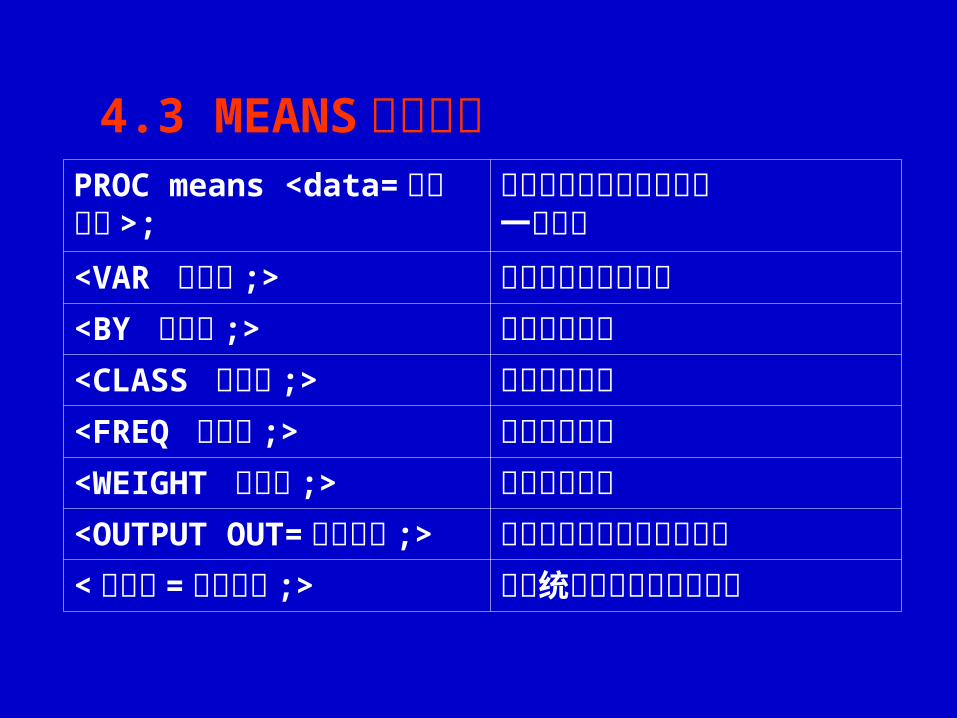
4.3 MEANS 过程格式PROC means <data=数据集名 >;
指定要分析的数据集名及一些选项
<VAR 变量表 ;> 指明需要分析的变量<BY 变量表 ;> 指明分组变量<CLASS 变量表 ;> 指明分类变量<FREQ 变量表 ;> 指明频数变量<WEIGHT 变量表 ;> 指明加权变量<OUTPUT OUT=数据集名 ;
>指定统计量的输出数据集名
<关键字 =新变量名 ;> 指定统计量对应的新变量名

MEANS 语句的选项设定结果输出的统计数,如 STD, MEAN,
VAR等(可选项有 CSS, CV, KURTOSIS, MAX, MEAN, MEDIAN, MIN, N, P1, P99, PROBT, Q1, Q3, QRANGE, RANGE, SKEWNESS, STDDEV, STDERR, SUM, SUMWGT, T, VAR 等共 38 项)。未指定时,输出的统计数只有 N, MEAN,
STD, MAX 和 MIN 。NOPRINT ,将不输出分析结果。MAXDEC= n ,设定结果输出时的小数
位数,缺省为 [eg9] 。
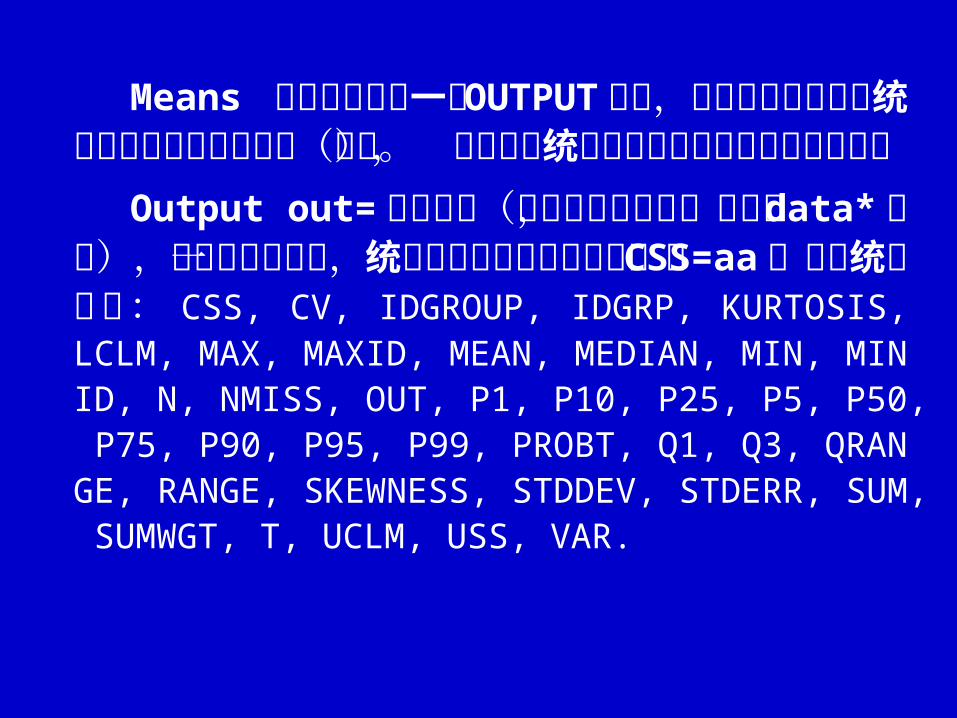
Means 过程可以再加一个 OUTPUT 语句,它的作用是将下列统计数以新的变数名输出(利用),以防新的统计数的计算将此前的结果冲掉。
Output out= 数据集名(若无指定数据集,自动以 data* 命名),其后可将下列之一统计数给以新的变数命名,如 CSS=aa 。这些统计数有: CSS, CV, IDGROUP, IDGRP, KURTOSIS, LCLM, MAX, MAXID, MEAN, MEDIAN, MIN, MINID, N, NMISS, OUT, P1, P10, P25, P5, P50, P75, P90, P95, P99, PROBT, Q1, Q3, QRANGE, RANGE, SKEWNESS, STDDEV, STDERR, SUM, SUMWGT, T, UCLM, USS, VAR.

SUMMARY 过程的使用和 MEANS 过程类似,差别在于:
SUMMARY 过程通常不输出计算结果,一般在PROC SUMMARY 语句选项中设定 print ,以给出分析结果。
在默认情况下,即不使用 VAR 语句指定分析变数时, SUMMARY 过程仅进行对观测值的计数工作,其他各种统计数的计算都将被忽略。
4.4 SUMMARY 过程

univariate 过程除可计算基本统计数之外,主要用于计算分位数( Quartile ,中位数为一特例,即 50%分位数)、绘制分布图、次数表及正态分布测验等。
Univariate 过程的重点在于描述变量的分布。
4.5 UNIVARIATE 过程
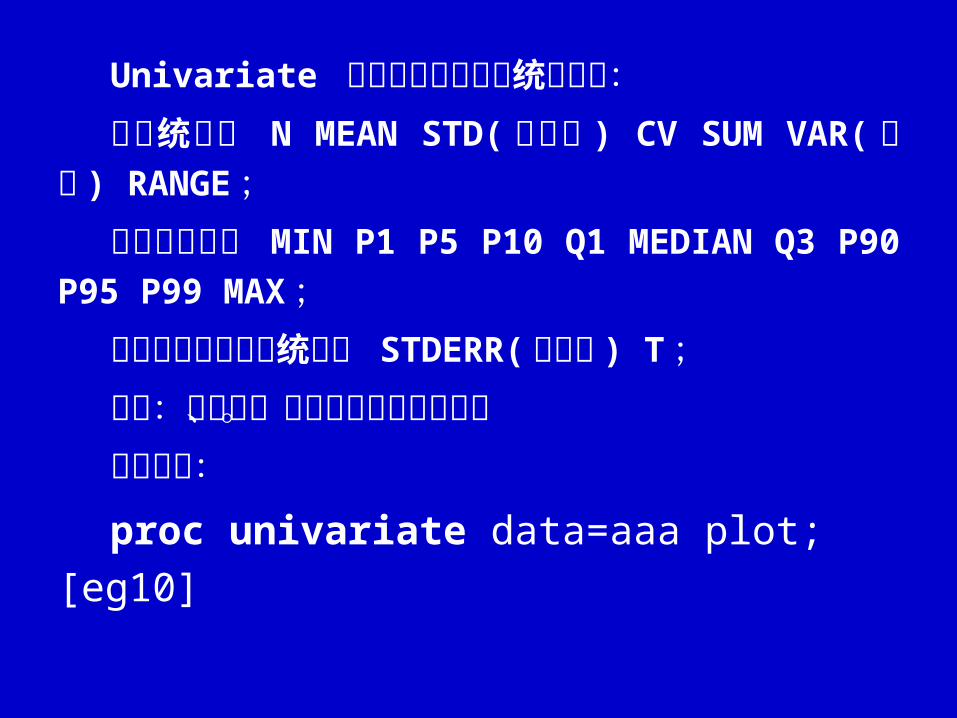
Univariate 过程提供的描述性统计数有:基本统计量 N MEAN STD( 标准差 ) CV SUM V
AR(方差 ) RANGE ;百分位数描述 MIN P1 P5 P10 Q1 MEDIAN Q3
P90 P95 P99 MAX ;与假设检验有关的统计量 STDERR( 标准误 ) T ;图形:茎叶图、盒形图及正态概率图。语句行例:
proc univariate data=aaa plot; [eg10]

4.6 SAS/INSIGHT 进行描述统计分析
建立所需分析的数据集
选择菜单【 Solutions】【 Analysis】【 I
nteractive Data Analysis】打开 SAS/INSI
GHT窗口
打开要分析的数据集
【 Analyze】【 Distribution】

4.7 窗口的管理SAS窗口由 DMS (display management s
ysytem) 管理,一般将其分成输出、结果、日志和程序编辑窗等。在运行程序后,输出、日志等窗口的内容将在其中累积,有时影响相关信息的查看,有必要将其清除。方法一是在命令栏内输入 clear 命令;方法二是采用 dm 语句:Dm ‘output; clear; log; clear;’;

5 5 统计推断统计推断统计推断是统计分析的重要内容,用于
显著性测验的 SAS 过程主要有 MEANS 和 TTEST 。
上述两过程均可对总体平均数是否为零或两个平均数是否相等做出测验。
在成对比较时,一般先计算对比差值 d ,然后利用 MEANS 过程进行分析。
组群比较则直接利用 TTEST 过程完成。

5.1 means 过程MEANS 过程格式:PROC MEANS N MEAN STD STDERR
T PRT;
RUN;
结果输出包括测验平均数与 0差异显著性的 t 值和概率 p 。
由 t 值及其概率 p 即可做出统计推断。

5.2 应用举例 1 -单个平均数的测验
测定某稻田的地表光强 4 次,得结果为 3.4, 2.8, 3.
5, 4.1 (千勒克斯),试测验该结果与根据 Beer-Lam
bert定律推出的理论值 μ0=3.0是否有显著差异?data new;input y @@;y=y-3;cards;3.4 2.8 3.5 4.1;proc means n mean stderr t prt;run; [eg11]
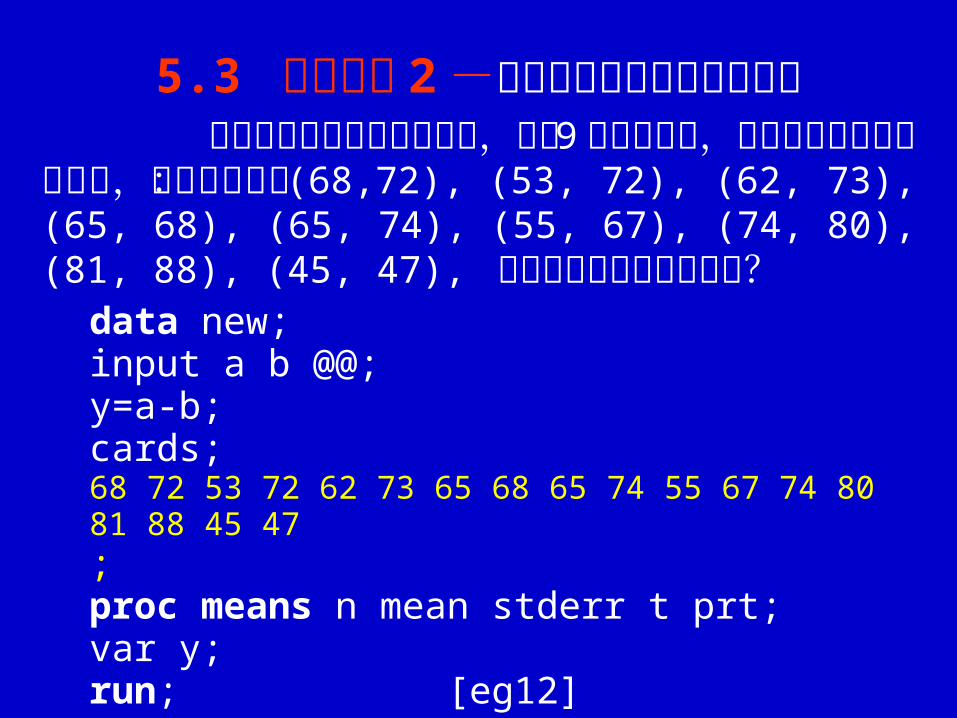
5.3 应用举例 2 -两个样本平均数的成对比较
为检验工人技术培训的效果,抽选 9 名生产工人,记录培训前后的效率分数,得如下数据: (68,72), (53, 72), (62, 73), (65, 68), (65, 74), (55, 67), (74, 80), (81, 88), (45, 47), 试测验培训效果是否显著? data new;
input a b @@;y=a-b;cards;68 72 53 72 62 73 65 68 65 74 55 67 74 80 81 88 45 47 ;proc means n mean stderr t prt;var y;run; [eg12]

5.4 TTEST 过程PROC TTEST < 选项 >; <*如 data=new
>;
CLASS 变量 ; *指明分类变量,这里分类变量只能有两个水平,该语句是必需的;
VAR 变量 ; *设定分析变量;
RUN;
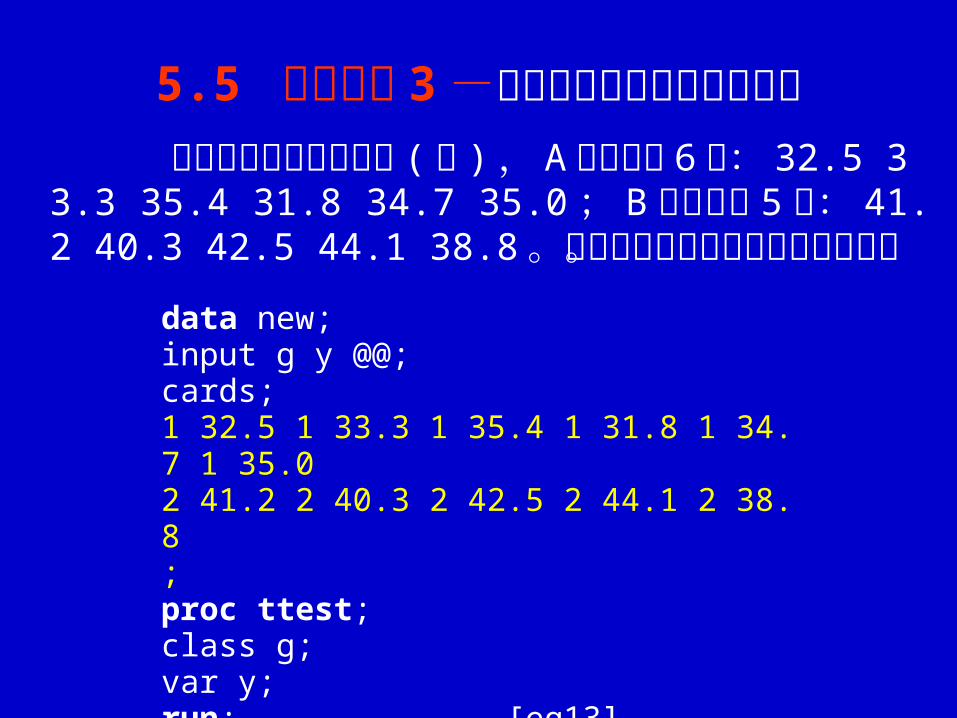
5.5 应用举例 3 -两个样本平均数的组群比较
测定两小麦品种千粒重 ( 克 ) , A 品种取样 6 次:32.5 33.3 35.4 31.8 34.7 35.0 ; B 品种取样 5 次: 41.2 40.3 42.5 44.1 38.8 。测验两品种千粒重差异的显著性。 data new;
input g y @@;cards;1 32.5 1 33.3 1 35.4 1 31.8 1 34.7 1 35.0 2 41.2 2 40.3 2 42.5 2 44.1 2 38.8;proc ttest;class g;var y;run; [eg13]

NEANS 过程可用于推断单个样本是否抽自平均数为 0 的总体。对于成对比较,可先计算比对差值,然后应用
MEANS 过程测验差值平均数与 0 有无显著差异。TTEST 过程用于两个独立样本的平均数差异显
著性测验。该过程同时对两样本方差是否同质做出测验,
并给出总体方差相等和不等两种情况下的平均数测验结果供选择。
5.6 推断过程的比较和选择

6 6 方差分析方差分析两个平均数的假设测验,一般可以采用 t 测验
的方法完成。
对于多个平均数的假设测验,由于测验程序繁杂、误差估计不精确,尤其是犯第一类错误的概率增加等原因,一般不再利用 t 测验两两进行,而采用新的统计方法-方差分析( analysis of variance ,简计为 ANOVA )。

方差分析的基本思想是将所有观察值的总变异分解成不同变异来源的平方和和自由度,进而获得不同变异来源的方差估计,以 F测验鉴定多个样本平均数之间的差异显著性。
当处理效应为固定模型时,对各个平均数进行多重比较。
当处理效应为随机模型时,估计方差分量。
方差分析是应用最广泛的统计方法,在科学研究和生产实践中有着极其重要的用途。
6.1 概述

在 SAS 中用于方差分析的主要过程有ANOVA (方差分析)和 GLM (广义线性模型)。
对于平衡资料(数据均衡,没有发生缺失),一般应用 ANOVA 过程。
对于非平衡资料,应采用 GLM 过程。
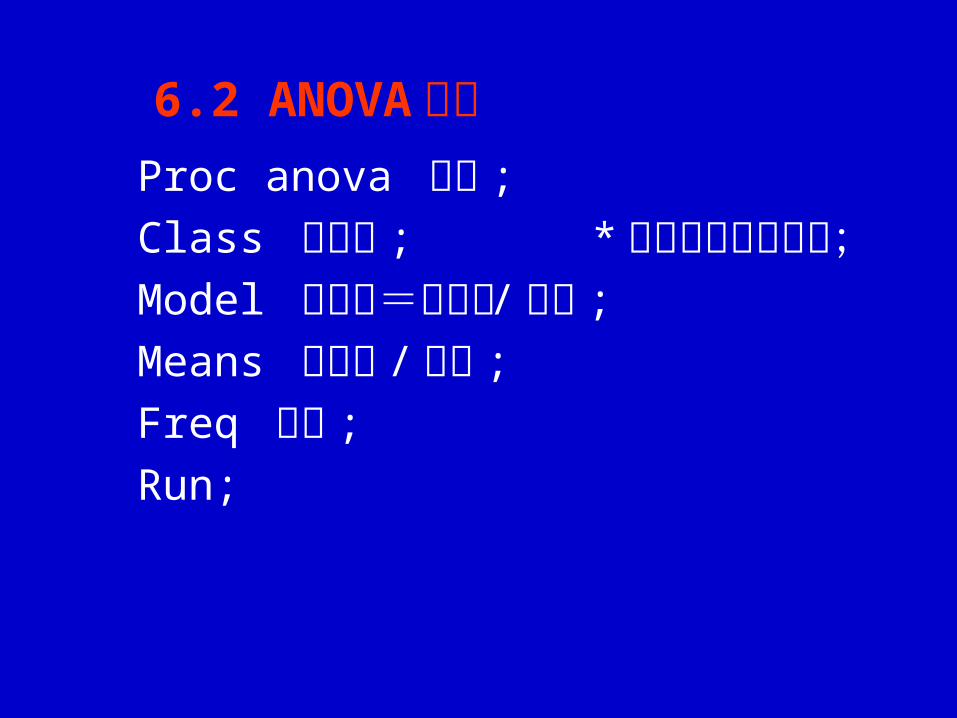
Proc anova 选项 ;
Class 变数表 ; * 用于指明分类变数;Model 依变数=效应表 / 选项 ;
Means 效应表 / 选项 ;
Freq 变数 ;
Run;
6.2 ANOVA 过程

Means ,计算效应平均数,用于设定多重比较方法和确定比较的显著水平( α )等。
多重比较方法选择有 T 或 LSD (配对 t 测验或 Fisher氏最小显著差数法), DUNCAN ( Duncan氏新复极差测验法), TUCKY( Tukey氏固定极差测验法)和 DUNNETT( Dunnett氏新复极差测验法)等。显著水平的确定采用 ALPHA=设定,例
如 ALPHA= 0.01 ,将显著水平设定为 0.01 ,缺省时为 0.05 。

Model 线性数学模型上述语句在于定义线性数学模型。同一试
验资料,分析结果依模型不同而异。因而应依据试验设计,给出正确的线性数学模型。
model y=a; 单因素方差分析。Model y=a b; 两因素主效模型。Model y=a b a*b; 两因素带互作模型。Model y=a b(a) ;嵌套( nested )模型,
用于系统分组资料。

模型定义中可用 | 和 @n 简化表达方法
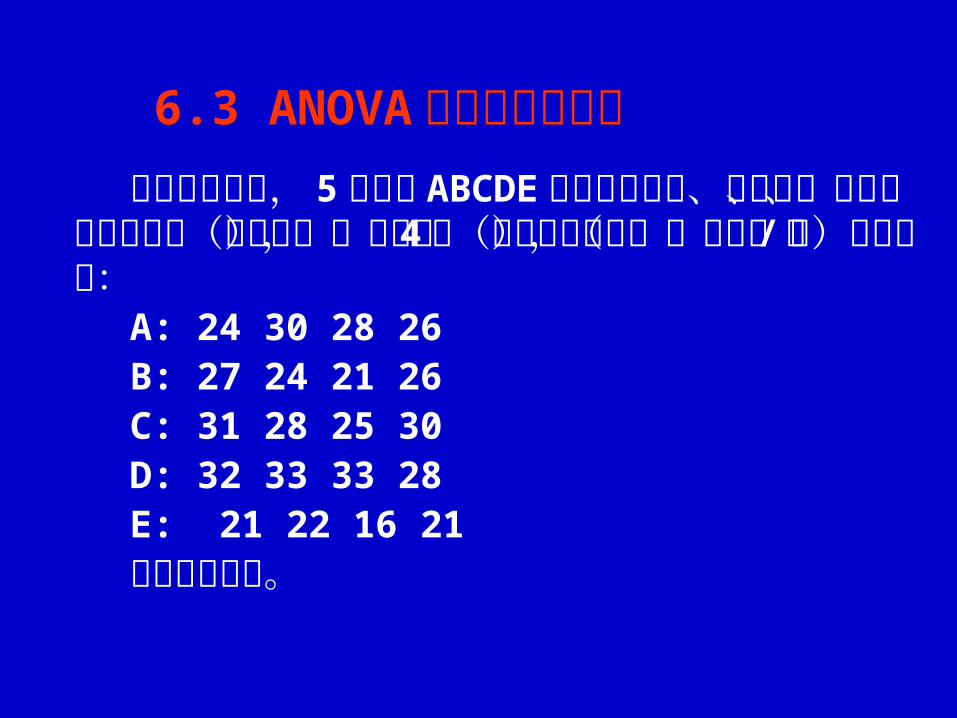
水稻施肥试验, 5 个处理 ABCDE 分别代表氨水、废氨水、碳铵、尿素和对照(不施肥),每处理 4盆(完全随机试验),产量(克 /盆)结果如下:
A: 24 30 28 26B: 27 24 21 26C: 31 28 25 30D: 32 33 33 28E: 21 22 16 21请作方差分析。
6.3 ANOVA 模型的应用实例
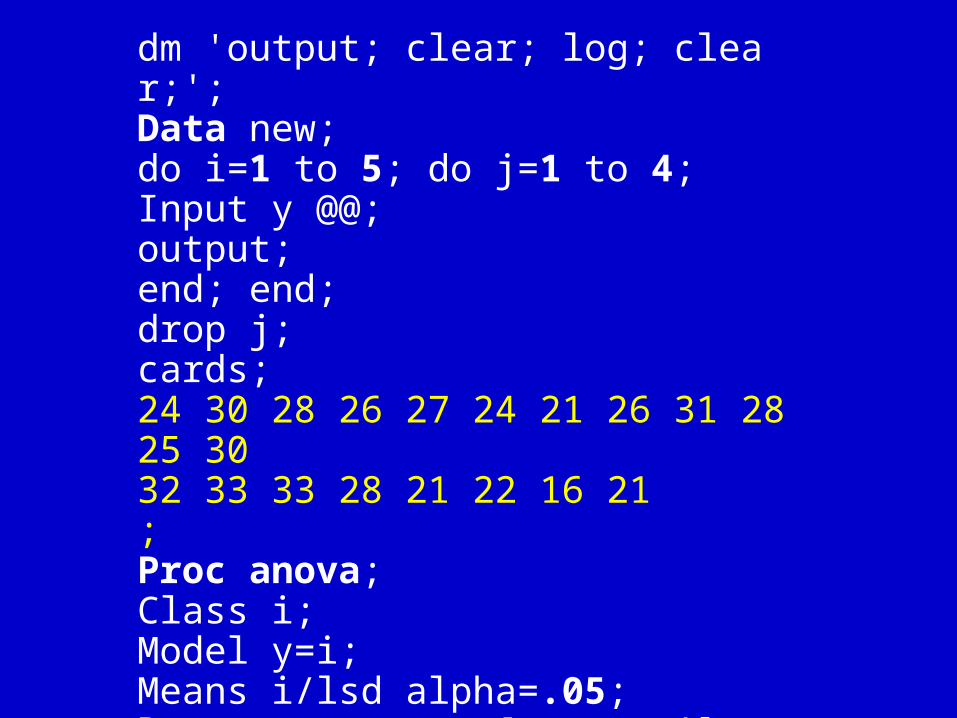
dm 'output; clear; log; clear;';Data new;do i=1 to 5; do j=1 to 4;Input y @@;output;end; end;drop j;cards;24 30 28 26 27 24 21 26 31 28 25 3032 33 33 28 21 22 16 21;Proc anova;Class i;Model y=i;Means i/lsd alpha=.05;Run; [eganova1]

GLM 过程应用范围较广,除了用于方差分析外,还可用于回归分析、协方差分析等。
当用于方差分析时,主要处理非平衡资料,可进行多个变量的对比检验。
与 ANOVA 过程相比, GLM 过程运行时一般占用较多的计算机内存和时间。
6.4 GLM 过程

GLM 过程格式Proc glm 选项 ;
Class 变数表 ;
Model 依变数=效应表 / 选项 ;
Means 效应表 / 选项 ;
Random 效应表 / 选项 ;
Run;

语句说明Proc glm 语句设定分析数据集和输出数据集等。Class 语句指定分类变数,此语句必须设定,并且应
出现在 model 语句之前。Model 语句用于定义数学模型和结果输出项。

语句说明:Means 语句计算平均数,并可选用多种方法进行多重
比较。Random 语句指定模型中的随机效应。在 SAS 中,数据行中的小数点“ .”代表
缺失数据。

某职业病防治院对 31 名石棉矿工中的石棉肺患者、可疑患者和非患者进行了肺活量( L )测定的数据,测验三组矿工的肺活量有无差别。
石棉肺患者: 1.8 1.4 1.5 2.1 1.9 1.7 1.8 1.9 1.8 1.8 2.0
可疑患者: 2.3 2.1 2.1 2.1 2.6 2.5 2.3 2.4 2.4
非患者: 2.9 3.2 2.7 2.8 2.7 3.0 3.4 3.0 3.4 3.3 3.5
6.5 GLM 过程应用实例

data new;do i=1 to 3; do j=1 to 11;Input y @@;output;end; end; drop j;cards;1.8 1.4 1.5 2.1 1.9 1.7 1.8 1.9 1.8 1.8 2.02.3 2.1 2.1 2.1 2.6 2.5 2.3 2.4 2.4 . .2.9 3.2 2.7 2.8 2.7 3.0 3.4 3.0 3.4 3.3 3.5;proc print;proc glm;class i;model y=i;means i/lsd alpha=.05;run; [eganova12]

设有 A 和 B两个因素, A因素有 a 个水平, B因素有 b 个水平,每一处理有单个观察值,全试验共有 a*b 个观察值,如下表:
6.6 两向分组资料的方差分析
A因素B因素
Ti.B1 B2 … Bb
A1 Y11 Y12 … Y1b T1.
A2 Y21 Y22 … Y2b T2.
… … … … … …
Aa Ya1 Ya2 … Yab Ta.
T.j T.1 T.2 … T.b T

两向分组资料方差分析表
2 2. / /iT b T ab
2 2. / /jT a T ab
2 2 /Y T ab
变异来源 df SS MS F
A因素 a-1 MSA MSA/MSe
B因素 b-1 MSB MSB/MSe
误差 (a-1)(b-1) SST-SSA-SSB MSe
总变异 ab-1
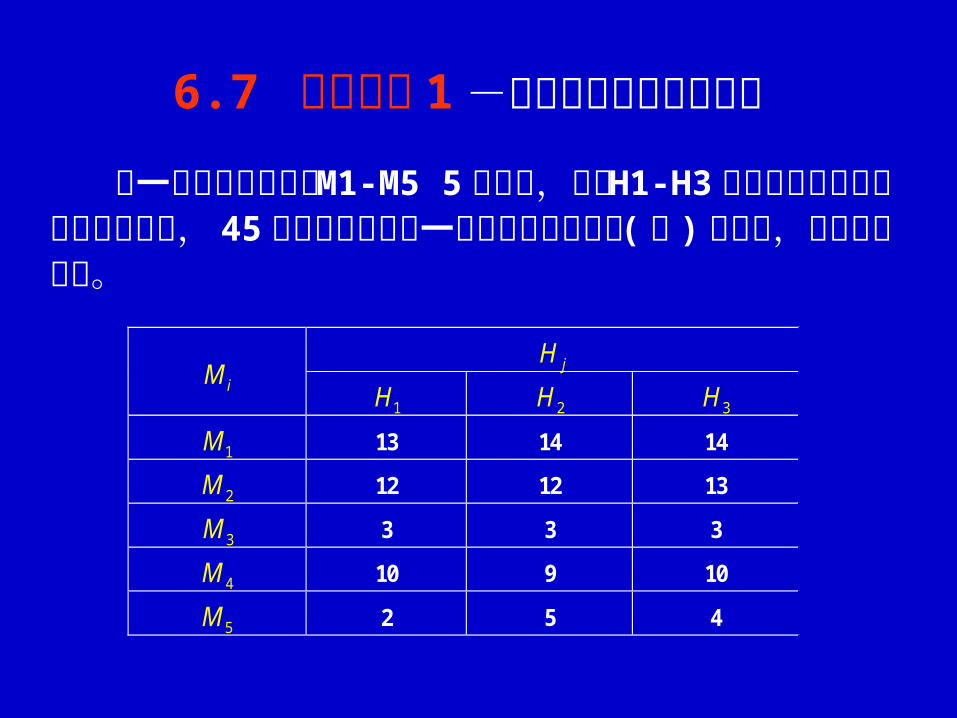
jH iM
1H 2H 3H
1M 13 14 14
2M 12 12 13
3M 3 3 3
4M 10 9 10
5M 2 5 4
将一种生长激素配成 M1-M5 5种浓度,并用 H1-H3三种时间浸渍某大豆品种的种子, 45天后得各处理每一植株的平均干物重 (克 ) 于下表,试作方差分析。
6.7 应用举例 1 -两向分组资料方差分析

Data new;Do a=1 to 5; Do b=1 to 3;Input y @@;Output;End; End;Cards;13 14 14 12 12 13 3 3 3 10 9 10 2 5 4;proc print;Proc anova;Class a b;Model y=a b;Means a b/duncan;Run; [eganova2]

二因素有重复资料的方差分析 A因素有 a 个水平,B因素有 b 个水平,共有 ab 个处理组合,每一组合有 n 个观察值,则该资料有 abn 个观察值。
二因素有重复资料方差分析表

ANOVA 的例子data new;do a=1 to 3; do b=1 to 3; do i=1 to 3;input y @@;output;end; end; end;cards;21.4 21.2 20.1 19.6 18.8 16.4 17.6 16.6 17.512.0 14.2 12.1 13.0 13.7 12.0 13.3 14.0 13.912.8 13.8 13.7 14.2 13.6 13.3 12.0 14.6 14.0;proc anova;class a b;model y=a | b;means a b/duncan;run; [eganova22]

F A E D C G B 区组 1
20 24 22 18 21 20 20 A D C F B E G
区组 2 26 16 19 21 19 20 19 F B G E C A D
区组 3 21 21 21 23 20 23 19
有一大麦品比试验, 7 个品种( A 、 B 、 C 、D 、 E 、 F 、 G ,其中 G 为对照),随机区组设计, 3 次重复,得小区产量( y )于下表,试进行方差分析。
6.7 应用举例 2— 单因素随机区组试验
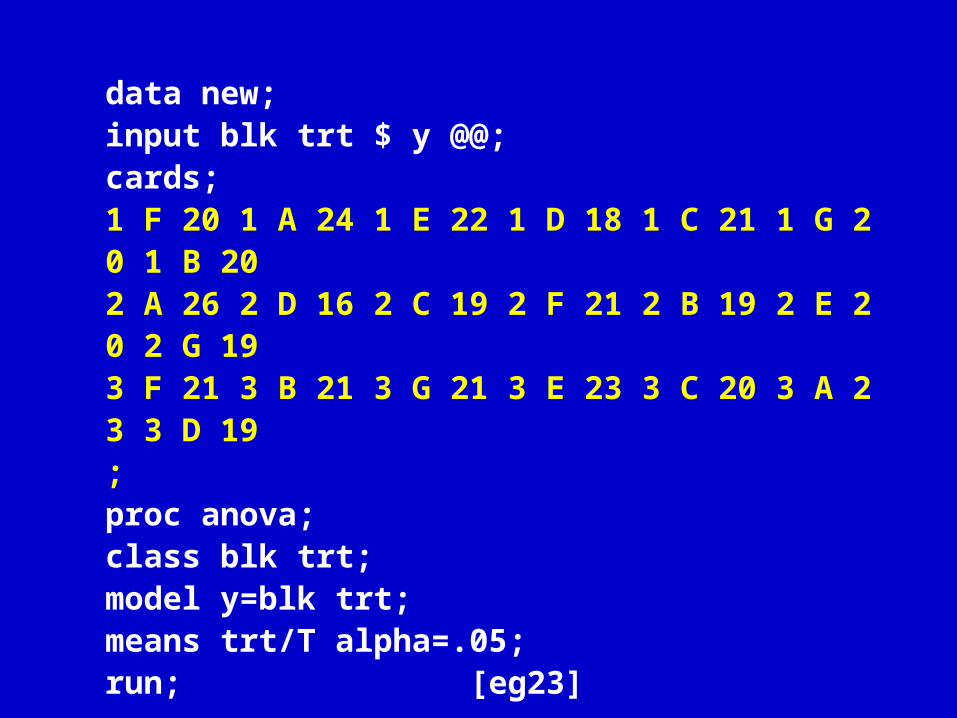
data new;input blk trt $ y @@;cards;1 F 20 1 A 24 1 E 22 1 D 18 1 C 21 1 G 20 1 B 202 A 26 2 D 16 2 C 19 2 F 21 2 B 19 2 E 20 2 G 193 F 21 3 B 21 3 G 21 3 E 23 3 C 20 3 A 23 3 D 19;proc anova;class blk trt;model y=blk trt;means trt/T alpha=.05;run; [eg23]
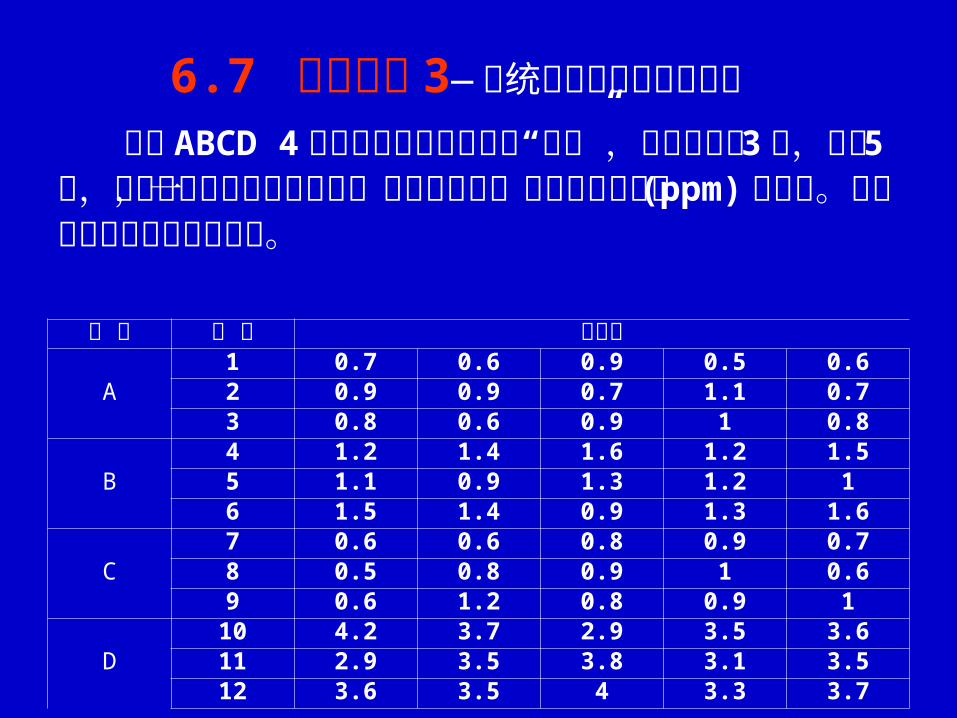
研究 ABCD 4种水生蔬菜对砷污染的“抗性”,每种蔬菜种 3盆,每盆 5株,生长期间施用有机砷农药,收获时对每一植株测定砷含量 (ppm)见下表。试对该组数据进行方差分析。
品 种 盆 号 砷含量
A1 0.7 0.6 0.9 0.5 0.62 0.9 0.9 0.7 1.1 0.73 0.8 0.6 0.9 1 0.8
B4 1.2 1.4 1.6 1.2 1.55 1.1 0.9 1.3 1.2 16 1.5 1.4 0.9 1.3 1.6
C7 0.6 0.6 0.8 0.9 0.78 0.5 0.8 0.9 1 0.69 0.6 1.2 0.8 0.9 1
D10 4.2 3.7 2.9 3.5 3.611 2.9 3.5 3.8 3.1 3.512 3.6 3.5 4 3.3 3.7
6.7 应用举例 3— 系统分组资料的方差分析
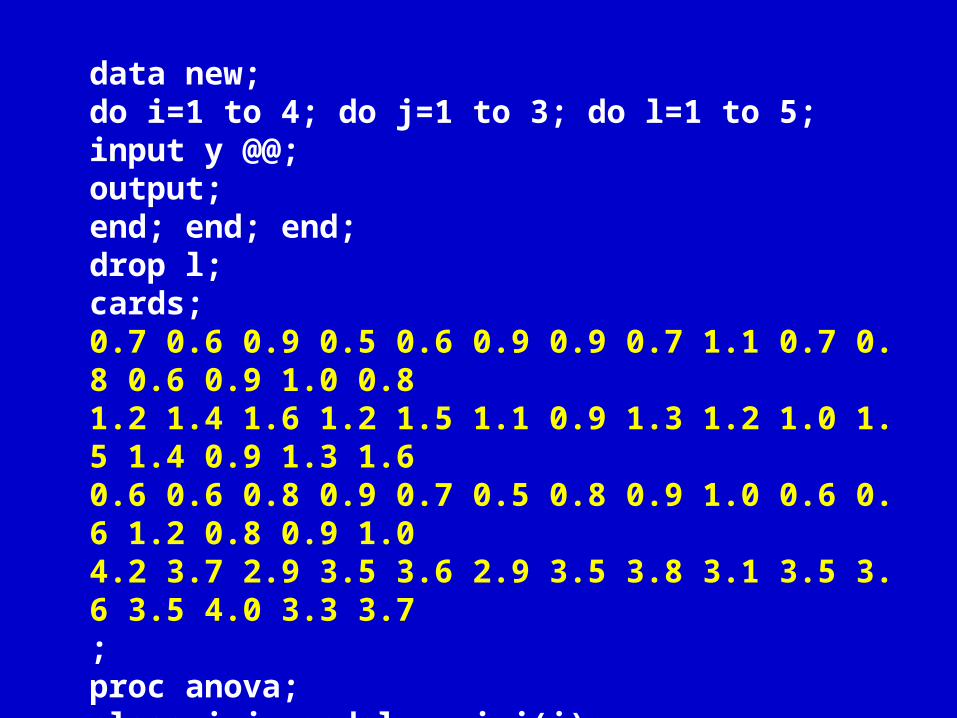
data new;do i=1 to 4; do j=1 to 3; do l=1 to 5;input y @@;output;end; end; end;drop l;cards;0.7 0.6 0.9 0.5 0.6 0.9 0.9 0.7 1.1 0.7 0.8 0.6 0.9 1.0 0.81.2 1.4 1.6 1.2 1.5 1.1 0.9 1.3 1.2 1.0 1.5 1.4 0.9 1.3 1.60.6 0.6 0.8 0.9 0.7 0.5 0.8 0.9 1.0 0.6 0.6 1.2 0.8 0.9 1.04.2 3.7 2.9 3.5 3.6 2.9 3.5 3.8 3.1 3.5 3.6 3.5 4.0 3.3 3.7;proc anova;class i j; model y= i j(i);means i/duncan alpha=.05;run; [eg15]
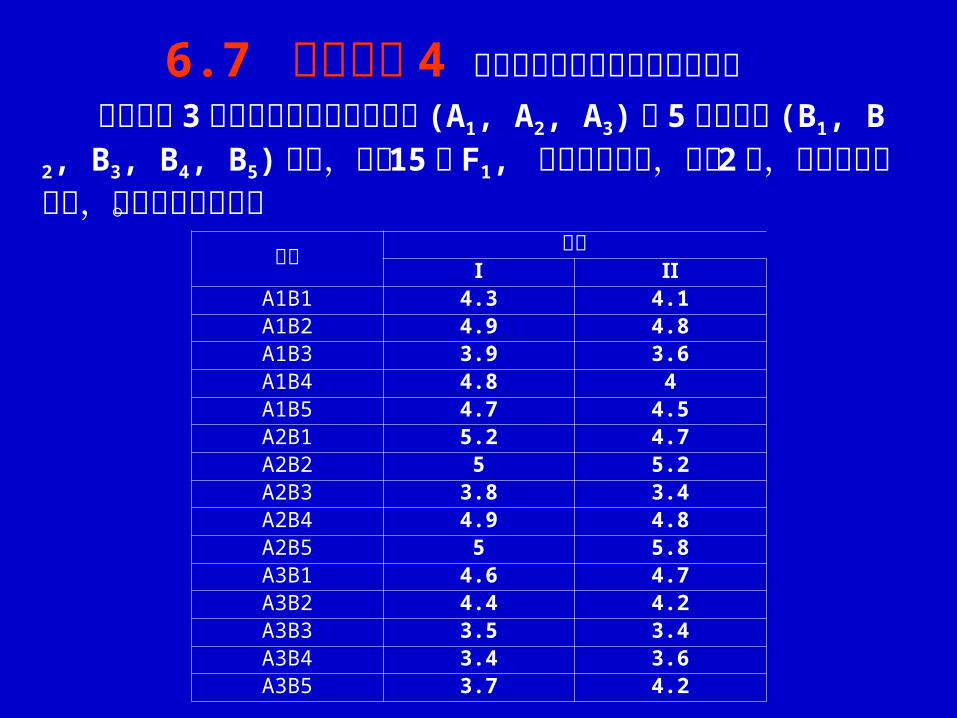
将水稻的 3个不同细胞质源的不育系 (A1, A2, A3) 和 5 个恢复系 (B1, B2, B3, B4, B5) 杂交,配成 15 个 F1, 随机区组设计,重复 2 次,产量结果见下表,试进行方差分析。
处理 区组Ⅰ Ⅱ
A1B1 4.3 4.1A1B2 4.9 4.8A1B3 3.9 3.6A1B4 4.8 4A1B5 4.7 4.5A2B1 5.2 4.7A2B2 5 5.2A2B3 3.8 3.4A2B4 4.9 4.8A2B5 5 5.8A3B1 4.6 4.7A3B2 4.4 4.2A3B3 3.5 3.4A3B4 3.4 3.6A3B5 3.7 4.2
6.7 应用举例 4 二因素随机区组试验的方差分析

data new;do a=1 to 3; do b=1 to 5; do blk=1 to 2;input y @@;output;end; end; end;cards;4.3 4.1 4.9 4.8 3.9 3.6 4.8 4 4.7 4.5 5.2 4.7 5 5.2 3.8 3.4 4.9 4.8 5 5.84.6 4.7 4.4 4.2 3.5 3.4 3.4 3.6 3.7 4.2;proc print;proc anova;class a b blk;model y=blk a b a*b;means a b/duncan;run;

在 SAS 的统计分析系统中提供了各种SAS函数( SAS Functions ),用以计算和赋值,熟练掌握这些函数的功能和使用方法,将为数据的整理、交换、编程及统计学分析、作图等带来很大的方便。

算术函数ABS ( argument )-绝对值函数MAX ( argument , argument ,…)-最大值函数MIN ( argument , argument ,… )-最小值函数MOD ( argument-1 , argument-2 )-取模函数SQRT ( argument )-平方根函数概率和密度函数CDF ('dist',quantile,<,parm-1, . . . ,parm-k>) PDF ('dist',quantile,parm-1, . . . ,parm-k) PROBCHI(x,df<,nc>) PROBF(x,ndf,ddf<,nc>) PROBBNML(p,n,m) PROBBNML(p,n,m)

样本统计数函数CSS(argument-1<,argument-n>) -离差平方和CV(argument,argument, . . .) -变异系数N(argument,argument, . . .) -样本容量RANGE(argument,argument, . . .) -极差STD(argument,argument, . . .) -标准差SUM(argument,argument, ...) -和VAR(argument,argument, . . .) -方差STDERR(argument,argument, . . .) -标准误

数学和三角函数EXP(argument) -指数LOG(argument) -以 e 为底的自然对数值LOG2(argument) -以 2 为底的对数值LOG10(argument) -以 10 为底的对数值ARCOS (argument) -反余弦函数ARSIN (argument) -反正弦函数ATAN (argument) -反正切函数COS (argument) -余弦函数SIN(argument) -正弦函数TAN(argument) -正切函数

7 7 统计图统计图统计图是统计描述的重要工具,它可以直观的
反映变数间的关系。
SAS 的许多程序步,如 Univariate 过程等,也有相应的绘图功能,本章不再涉及。
SAS 中专门用于作图的过程有很多,本章简单介绍两个―― GCHART 过程和 GPLOT 过程。
GCHART 用于绘制各种常用的统计图;
GPLOT则用于绘制散点图或曲线图。

早期 DOS 版 本 的 SAS 只提供低分辨率图 形(即用键盘字符模拟输出的图形)。而在 WINDOWS 时代,美观漂亮也成为了软件
最重要的性能指标之一,因此 SAS 公司推出了高分辨率图形。
比起 EXCEL等软件来,它的高分辨率图形仍然不那么令人满意,但至少已经有所进步。高分辨率图形在专门的 GRAPH窗口中输出,
而低分辨率图形在 OUTPUT窗口中一同输出。

GCHART 过程可以绘制水平、竖直条图 (HBAR , VBAR) 、区域图 (BLOCK) 、饼图 (PIE) 和星状图 (STAR)等。
我们可以用这些图来了解单个变量的分布或者多个变量之间的关系。
7.1 GCHART 过程

7.2 GCHART 过程-语句格式 PROC GCHART 选项 1; 主语句:调用 GCHART语句进行绘图
HBAR 变量表/选项 2; 水平条形图
VBAR 变量表/选项 2; 垂直条形图
BLOCK 变量表/选项 3; 区域图
PIE 变量表/选项 4; 饼图
STAR 变量表/选项 5; 星形图
AXISn 选项 6; 定义坐标轴
BY 变量表; 选择要进行作图的变量
LEGENDn 选项 7; 插图的注解
PATTERNn 选项 8 图案模型
TITLEn 选项 9’ 标题名称’ ; 标题内容
FOOTNOTEn 选项 10’ 脚注’ ; 脚注内容
NOTE 选项 11’ 注解’ ; 内容说明

GCHART 中至少选一个 HBAR 语句 (或 VBAR 、BLOCK 、 PIE 、 STAR) ,其余的语句则是任选的。HBAR 和 VBAR绘图语句中的选项DISCRETE :画出不连续、不累积的条形图。TYPE= 作图类型关键字。主要有 :
FREQ :频次; CFREQ :累积频次; PERCENT :百分比; CPERCENT :累积百分比; SUM: 只能与SUMVAR 选项同时使用,要求图中的每一条代表:变量在横轴表示的取值范围内时, SUMVAR 指定变量的总和; MEAN: 只能与 SUMVAR 选项同时使用,要求图中的每一条代表:变量在横轴表示的取值范围内时, SUMVAR指定变量的均数。 默认为默认为 FREQFREQ

HBAR 和 VBAR绘图语句中的选项SUMVAR=变量:通常用于求均值、和。默认
为计算和数。MIDPOINTS=值:指定中点值,一般用系统
约定值。LEVELS= n :将区间变量的数据分为 n 组。GROUP= x :给变量 x 的每个值画一组条形。

7.3 GCHART 过程应用实例
DATA exam; 建立数据集 exam
INFILE 'e:\work\eg31.txt';
读入外部文件 :e:\work\eg31.txt
INPUT x @@; 连续输入变量 x
PROC GCHART; 调用绘图程序步 gchart
VBAR x / levels=10;将 x 全距分为 10 组 ,绘出直方
图RUN; 运行以上程序

GPLOT 过程可用于产生一对变量的散点图或曲线图。
图中的横、纵坐标分别代表两个变量。
7.4 GPLOT 过程

data new2;do x=0 to 10 by .01;output;y=sin(x);end;proc print;proc gplot;plot y*x;run;
7.5 GPLOT 过程-语句格式
PROC GPLOT/选项; GPLOT程序的主语句
PLOT 纵坐标变量*横坐标变
量/选项 1;
绘图语句。可画各对变量的散点图、连线(即折线、拟合、
回归、特定线条)组成的曲线图
PLOT2 纵坐标变量*横坐标
变量/选项 1;
与 PLOT配对。两语句的横坐标应相同,以便把两条曲线合
为一图,左右显示两个不同的纵坐标
BY 变量 对 BY后面的变量的每个值画一幅图
SYMBOLn 选项 2; 指定画图的连线,默认为+号
PATTERNn 选项 2; 指定图案的花纹
TITELn 选项 2; 标题内容,n为第 n行
FOOTNOTEn 选项 2; 脚注内容,n为第 n行
NOTE 选项 2; 内容注解

绘图语句 PLOT 中的选项OVERLAY 同一语句做的图重叠在同
一个坐标系中显示。 HAXIS= 数值 定义横坐标的刻度。 VAXIS= 数值 定义纵坐标的刻度。 CAXIS=颜色 定义坐标轴的颜色。CTEXT=颜色 定义坐标轴文本的颜色。

SYMBOL 语句选项 :
VALUE=符号 可用的符号及相应名称有:+ PLUS STAR ■ SQUARE DIAMOND ▲ TRI★ ◆
ANGLE
I=连线方式I=NEEDLE :点与点之间不连,但每点向横轴画垂线。I=SPLINE :用特定线条平滑曲线中的连线。I=JOIN 用线段连接两点。I=SMnn :随机的平滑曲线。 0<nn<99 。 nn 越大越平
滑。I=R?:回归拟合。?为 L代表线性回归;?为 Q代
表二次回归;?为 C代表三次回归。

10 名 20岁男青年身高 (cm)与臂长 (cm) 如下,请绘出散点图 。
身 高 170 173 160 155 173 168 178 183 180 165
臂长 45 42 44 41 47 50 47 46 49 43
7.6 GPLOT 过程实例
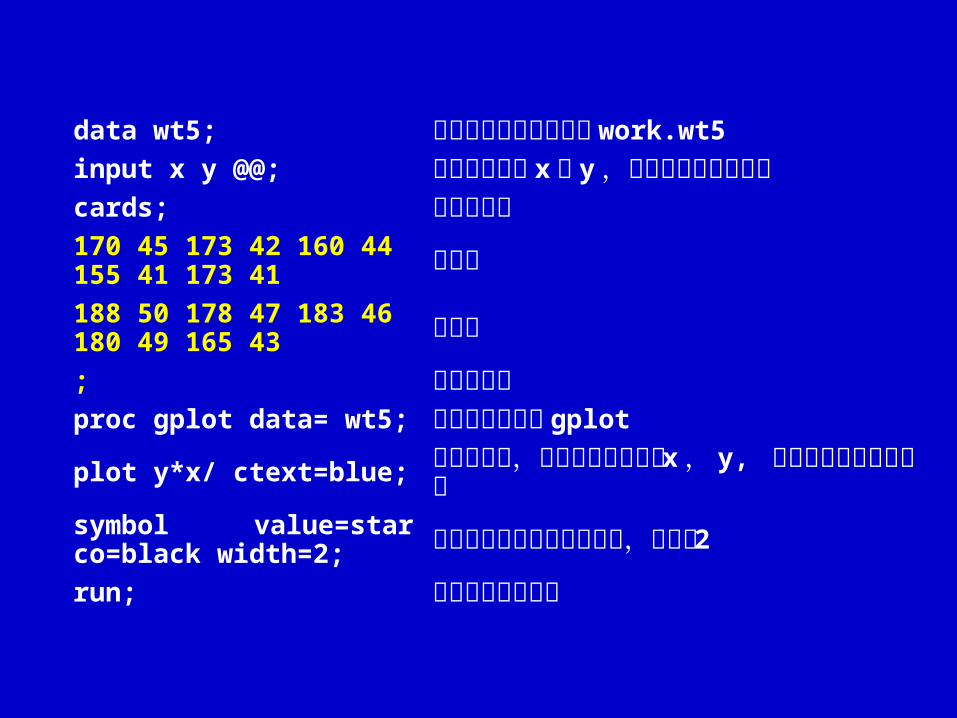
data wt5; 指定要建立的数据集为 work.wt5
input x y @@; 输入的变量为 x 和 y ,采用连续输入的格式
cards; 数据块开始170 45 173 42 160 44 155 41 173 41 数据块
188 50 178 47 183 46180 49 165 43 数据块
; 数据块结束proc gplot data= wt5; 调用绘图程序步 gplot
plot y*x/ ctext=blue; 绘出散点图,用于绘图的变量为 x , y, 坐标轴文本颜色为蓝色
symbol value=star co=black width=2; 定义散点标记为粉红色星号,大小为 2
run; 开始运行以上程序

7.7 SAS/INSIGHT 统计图制作Windows 版本的 SAS提供了方便的菜单窗
口操作,可以方便用户进行简单统计分析、计算变量的分布情况。
对于统计图的绘制也可以通过菜单操作进行分析。

利用 SAS/INSIGHT 进行统计图制作
SAS/INSIGHT 分析步骤首先建立需要分析的数据集【 Solutions】【 Analysis】【 Interactiv
e Data Analysis】点击【 Open】打开要分析的数据集。对统计图进行修改右键菜单中选择【 Ticks】命令

8 8 协方差分析协方差分析8.1 基本概念协方差分析解决的问题为多组(多个处
理) x, y双变数资料,其自变数(协同变数)x往往对目标变数 y 有一定的线性回归效应。要真正反映目标变数 y 的处理效应,应先
将不易控制的自变数 x对目标变数 y 的影响剔除,再进行方差分析,这种分析即是协方差分析。

类似于方差分析中总变异自由度和平方和的分解,协方差分析将总协方作同样分解,即将总的乘积和与自由度分解为不同变异来源的乘积和与自由度,利用回归分析的原理分析目标变数 y 与自变数 x之间的关系,从而将方差分析和相关、回归分析结合起来。协方差分析的 SAS 过程为广义线性模
型( GLM )。

例:为研究 A 、 B 、 C三种肥料对于苹果树的增产效果,选了 24株同龄的苹果树,记下各树基础生产力 ( 上年度的产量, X) ,将每种肥料随机施于 8株苹果树上,记下当年产量 (Y ,公斤 ) 。得结果于下表。试作协方差分析。
肥料 变数 观察值
AX: 47 58 53 46 49 56 54 44
Y: 54 66 63 51 56 66 61 50
BX: 52 53 64 58 59 61 63 66
Y: 54 53 67 62 62 63 64 69
CX: 44 48 46 50 59 57 58 53
Y: 52 58 54 61 70 64 68 66

分析方法先对 x 、 y 进行方差分析,检验其差异显著性,
然后对处理内(误差)项做回归分析,测验去除处理影响的 x 与 y是否存在显著的线性回归关系。若无,表明 x对 y无影响,对 y 作方差分析即
能说明 3种肥料对苹果树产量的效应差异显著性。若 x 和 y之间存在线性回归关系,说明基础生
产力对来年产量有影响,不能用原有的 y值进行方差分析,必须消去 x 的不同对 y带来的影响,即通过求 y依 x 的线性回归方程,将各处理的 yi都矫正到 x 在同一水平时的值。最后对矫正平均数作方差分析,比较 3种肥料
对苹果树产量的影响有无显著差异。

8.2 GLM 过程过程格式PROC GLM 选项;CLASS 变量表;MODEL 依变量 = 效应 / 选项;MEANS 效应 / 选项;LSMEANS 效应 / 选项;RUN ;
语句说明PROC GLM 语句选项为可设定分析数据集等。CLASS 语句指明分类变量,协方差分析时必须设立,
且必须出现在 MODEL 语句之前。MODEL 语句定义协方差分析的线性数学模型。例如: MODEL y=a t ;选项 SOLUTION给出参数的估计值。MEANS 语句用于计算依变量的平均数。选项用于多
重比较。LSMEANS 语句计算效应的最小二乘估计的平均数
( LSM )。选项 E=效应,设定测验误差项,缺省为试验分析误差。STDERR给出 LSM 的标准误。 TDIFF , PDIFF要求
显示测验 H0 : LSM ( i ) =LSM ( j )的 t值和概率值。结果输出包括依变量的方差分析表、参数估计值和最
小二乘估计的平均数等。
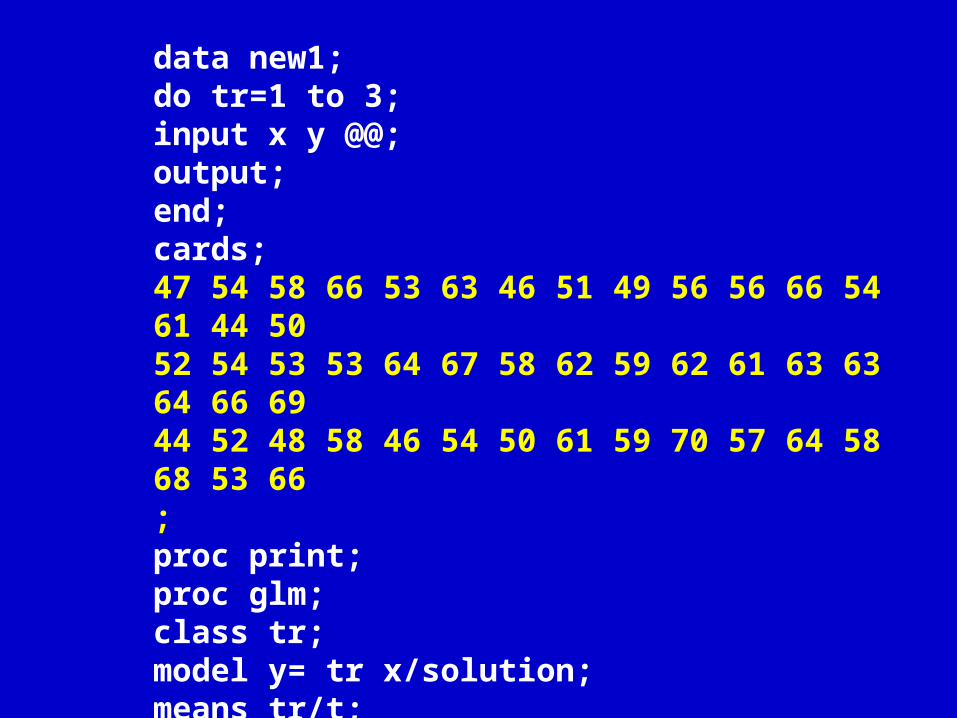
data new1;do tr=1 to 3;input x y @@;output;end;cards;47 54 58 66 53 63 46 51 49 56 56 66 54 61 44 5052 54 53 53 64 67 58 62 59 62 61 63 63 64 66 6944 52 48 58 46 54 50 61 59 70 57 64 58 68 53 66;proc print;proc glm;class tr;model y= tr x/solution;means tr/t;lsmeans tr /stderr pdiff tdiff;run;


9 9 相关和回归分析相关和回归分析9.1 概述在科学研究和生产实践中,经常需要进行
两类变量之间关系的分析。例如种植密度和作物产量、气象因子和害
虫的发生量、生长天数和动物体重等,这些变数之间的关系分析即相关和回归分析。相关和回归分析是生物学研究中最为常用
的统计分析方法之一。

9.2 相关和回归分析基本概念回归分析( Regression Analysis )是研究一个
依变数与一个或多个自变数之间数量关系的统计方法。在建立(线性)回归模型的条件下,以离回归平方和最小 (最小二乘法 )为目标求解模型统计数,获得优化回归方程和离回归标准误。从而能依据自变数 x 的数据对目标变数 y 进行预测或插值。
相关分析( Correlation Analysis )是用来考察两个变量间( x 与 y )的相互变化的关联关系, x与 y 的地位是平等的,两变量间没有因果关系。

回归分析依自变数个数的多少分为一元回归和多元回归;依依变数和自变数之间关系的性质分为线性回归和非线性回归。
相关分析计算反映各个变数之间相关密切程度和性质的统计数。
线性相关和回归分析的 SAS 过程主要有相关分析( CORR )、回归分析( REG )和广义线性模型( GLM )。
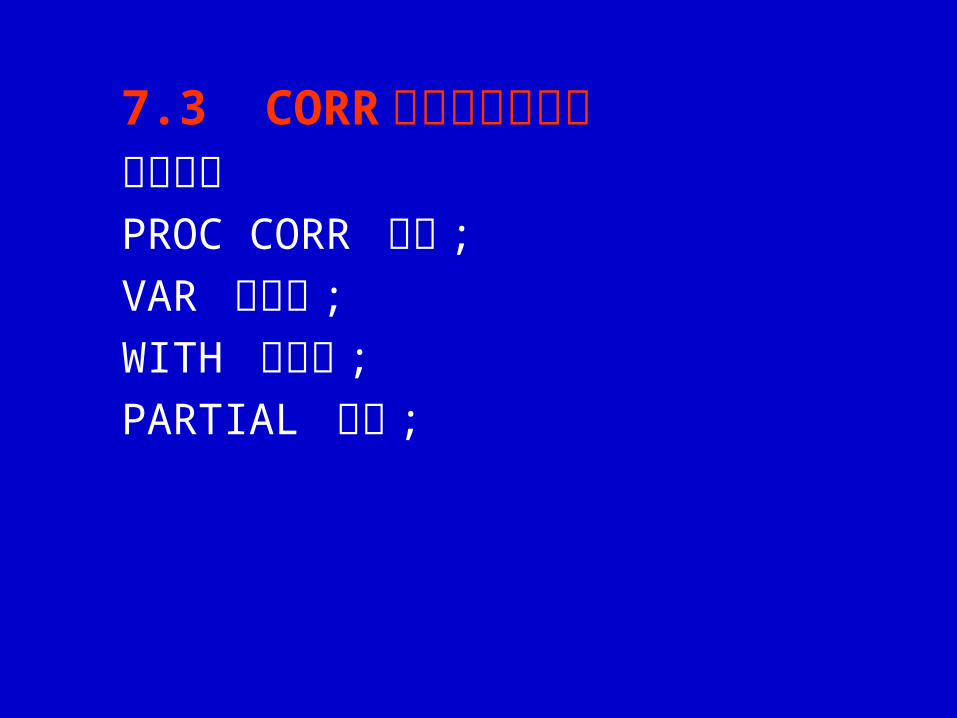
7.3 CORR 过程的实现方法过程格式PROC CORR 选项 ;
VAR 变量表 ;
WITH 变量表 ;
PARTIAL 变量 ;

语句说明除了 PROC 语句为必需,其他语句都是可选的,
如果省略所有的可选语句,则对所有变量作相关分析。 默认情况下, CORR 过程所进行的相关分析将
给出分析变量的描述性统计结果、 Pearson相关系数以及每个分析变量所对应的概率值。
PROC CORR 语句选项设定相关系数,例如 Pearson , Spearman
等,缺省为 Pearson相关系数。VAR 语句 指明分析的变量。

语句说明with 语句设定放在左边的变数此时 var 语句的变数间和 with 语句的变数间的
相关系数不给出,只输出两组变数间的相关系数。With 语句缺省时,将计算 var 语句的变数之间
的两两相关系数。PARTIAL 语句指明偏相关变数。设定 partial变数时进行偏相关分析。相关分析结果输出包括简单统计数和相关系数及
显著性。

9.4 Corr 过程-一个实例 许多害虫的发生都和气象条件有一定的关系。 1964~19
73年 10年间测定 7月下旬的温雨系数 (雨量 mm/平均温度℃ ) 和大豆第二代造桥虫发生量 (每百株大豆上的虫数 )
的关系如下表,试求相关系数。
温雨系数 虫口密度 温雨系数 虫口密度
1.58 180 2.41 175
9.98 28 11.01 40
9.42 25 1.85 160
1.25 117 6.04 120
0.3 165 5.92 80

data new2;input x y @@;cards;1.58 180 2.41 175 9.98 28 11.01 40 9.42 25 1.85 160 1.25 117 6.04 120 0.3 165 5.92 80;proc corr;var x y;run;

REG 过程是一个通用的回归过程。它采用最小二乘法拟合线性回归模型。它还提供多种选择最优线性回归方程的方法,是一个应用最广泛的回归过程。
过程格式Proc reg 选项 ;Model 依变量=自变量 / 选项 ;Weight 变量 ;Print 选项 ;Plot y轴变量 *x轴变量 ;
9.5 REG 过程

语句选项Proc reg语句Data =输入数据集Outsscp =输出数据集,存储平方-乘积和矩阵
Outest =输出数据集,存储参数估计值等。Simple 给出简单统计数Corr 给出简单相关系数

语句选项Model语句 设定线性数学模型等,Selection =模型选择方法包括 none( 全模型 ) 、 stepwise( 逐步回归 ) 、
forward(逐个选入 ) 、 backward(逐个剔除 )等。Weight语句指定加权系数变量Plot语句制作散点图

data new2;input x y @@;cards;1.58 180 2.41 175 9.98 28 11.01 40 9.42 25 1.85 160 1.25 117 6.04 120 0.3 165 5.92 80;proc reg;model y=x;run;

Proc glm 选项 ;设定分析所用的数据集和数据显示方式。
Model 依变量=自变量 / 选项 ; 定义模型和需要输出的统计数。回归分析模型一般有以下形式 Model y=x; 一元线性回归模型;
Model y=x1 x2 x3; 三元线性回归模型;Model y=x1 x2 x1*x2 x1*x1 x2*x2; 二
元多项式回归模型;Run;
9.6 GLM 过程
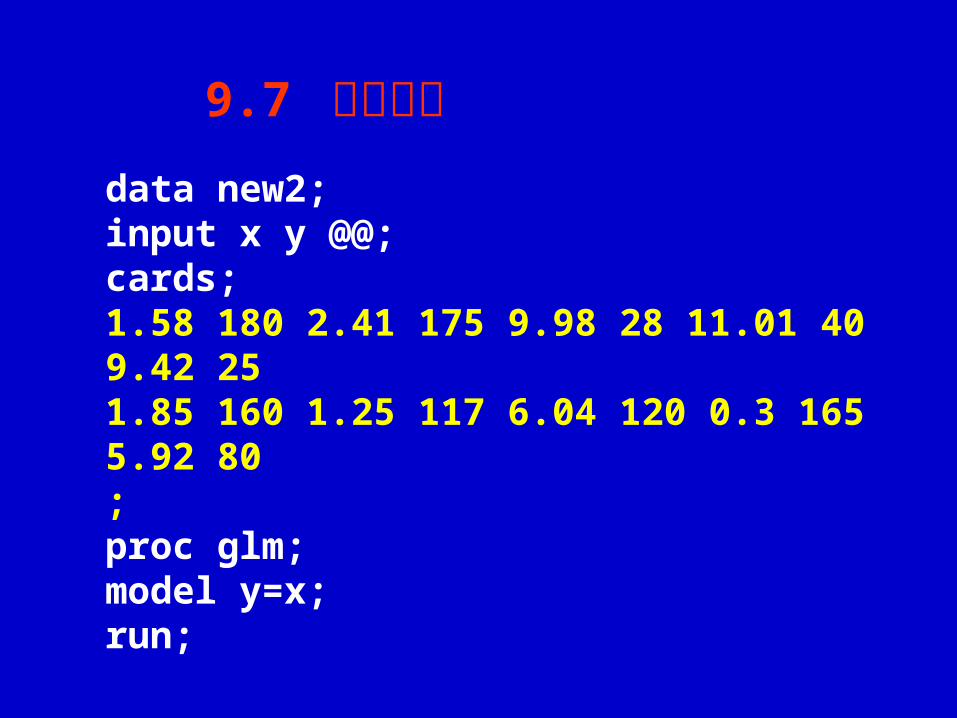
data new2;input x y @@;cards;1.58 180 2.41 175 9.98 28 11.01 40 9.42 25 1.85 160 1.25 117 6.04 120 0.3 165 5.92 80;proc glm;model y=x;run;
9.7 应用举例

REG 过程不仅可以完成只有一个自变量的简单直线回归,还可以作含有多个自变量的多元线性回归。
作多元线性回归时 REG 过程的语法格式与简单直线回归的语法几乎完全相同,只要把要分析的多个自变量名放在 MODEL 语句中应变量后即可。
因为多元线性回归时一般要作自变量的筛选,涉及到 MODEL 语句的选项。
9.8 多元线性回归

语法选项SELECTION=method ,规定变量筛选的方法,
method 可以是以下几种选项 FORWARD(或 F) ,前进法,按照 SLE规定的
P值从无到有依次选一个变量进入模型; BACKWARD (或 B ),后退法,按照 SLS规
定的 P值从含有全部变量的模型开始,依次剔除一个变量;
STEPWISE (或 S ),逐步法,按照 SLE 的标准依次选入变量,同时对模型中现有的变量按 SLS的标准剔除不显著的变量;
NONE ,即不选择任何选项,不作任何变量筛选,此时使用的是含有全部自变量的全回归模型。

语法选项SELECTION=method ,规定变量筛选的方法,
method 可以是以下几种选项 SLE= 概率值,入选标准,规定变量入选模型的
显著性水平,前进法的默认是 0.5 ,逐步法是 0.15
SLS= 概率值,剔除标准,指定变量保留在模型的显著水平,后退法默认为 0.10 ,逐步法是 0.15
标准化偏回归系数 STB 可用来比较各个自变量作用的大小。

应用实例 1data new2;input x1 x2 y @@;cards;16.6 146.5 81.3 15.9 163.5 77.2 18.8 140.0 78.019.9 122.4 82.6 23.5 140.0 66.2 14.4 174.3 77.916.4 145.9 80.4 17.3 147.5 77.7 18.4 139.1 79.719.3 126.8 80.6 19.9 125.2 83.3;proc reg corr;model y=x1 x2;run;

应用实例 2data new2;do i=1 to 15;input x1-x4 y @@;output;end; drop i;cards;10 23 3.6 113 15.7 9 20 3.6 106 14.510 22 3.7 111 17.5 13 21 3.7 109 22.510 22 3.6 110 15.5 10 23 3.5 103 16.9 8 23 3.3 100 8.6 10 24 3.4 114 1710 20 3.4 104 13.7 10 21 3.4 110 13.410 23 3.9 104 20.3 8 21 3.5 109 10.2 6 23 3.2 114 7.4 8 21 3.7 113 11.6 9 22 3.6 105 12.3;
proc reg;model y=x1-x4 /selection=forward; run;

10 10 非线性回归分析非线性回归分析
在农学和生物学研究中,大多数变数之间的关系不是简单的线性关系,而是各种各样的非线性关系,非线性回归分析比较复杂,主要有三个方面的内容:一是选择合适的模型;二是非线性方程的参数估计;三是非线性方程和参数的假设测验。以上三个方面的问题均有很大难度。 SAS 的 nlin 过程主要在于参数估计。

对于有些非线性问题如多项式回归问题,可通过适当的变量转换,转化为线性回归方程利用 REG 过程求解。
在 SAS 系统中,更为一般的方法是利用非线性回归过程( NLIN )直接进行非线性最小二乘拟合。
10.1 非线性回归分析

10.2 NLIN 过程格式Proc nlin 选项 ;
Model 依变量=模型表达式 ;
Parms 参数=初值 ;
Der.参数=偏导表达式 ;
Run;

语句说明
PROC NLIN 语句选项 Data=分析数据集;Method=循环迭代方法;包括 Gauss(高斯-
牛顿法 ) , Marquardt(麦夸特法 ) , Newton(牛顿法 ) , Gradient(梯度法 ) 和 DUD (试位法)等。
MODEL 语句 定义非线性回归模型,直接给出非线性回归方程的表达式,例如 Logistic方程可以写作: y=k/(1+a*exp ( -b*x ) ) ;

语句说明PARMS 语句设定参数初始值。初始值的设定有时会对计算结果产生较大
影响。当迭代不能收敛时,可以尝试使用不同的
初始值重新计算。DER 语句给出非线性回归方程对参数的一阶或二阶
偏导。

应用实例
测定江苏某地越冬代棉红铃虫的化蛹进度( y, % )和天数( x ,以 5月 31日为 0 ),得结果于程序数据行,试拟合 Logistic 生长曲线。data new2;input x y @@;cards;5 3.5 10 6.4 15 14.6 20 31.4 25 45.6 30 60.435 75.2 40 90.2 45 95.4 50 97.5;proc nlin method=dud;parms k=100 a=1 b=.1;model y=k/(1+a*exp(-b*x));run;

data new2;input x y @@;cards;2 .3 4 .86 6 1.73 8 2.2 10 2.47 12 2.67 14 2.8;proc nlin method=dud;parms k=3 a=.5 b=.5 m=2;model y=k/(1+a*exp(-b*x))**m;output predicted=yhat;proc gplot;plot y*x; symbol1 value=dot color=black; plot2 yhat*x;symbol2 i=spline color=red width=3; run;
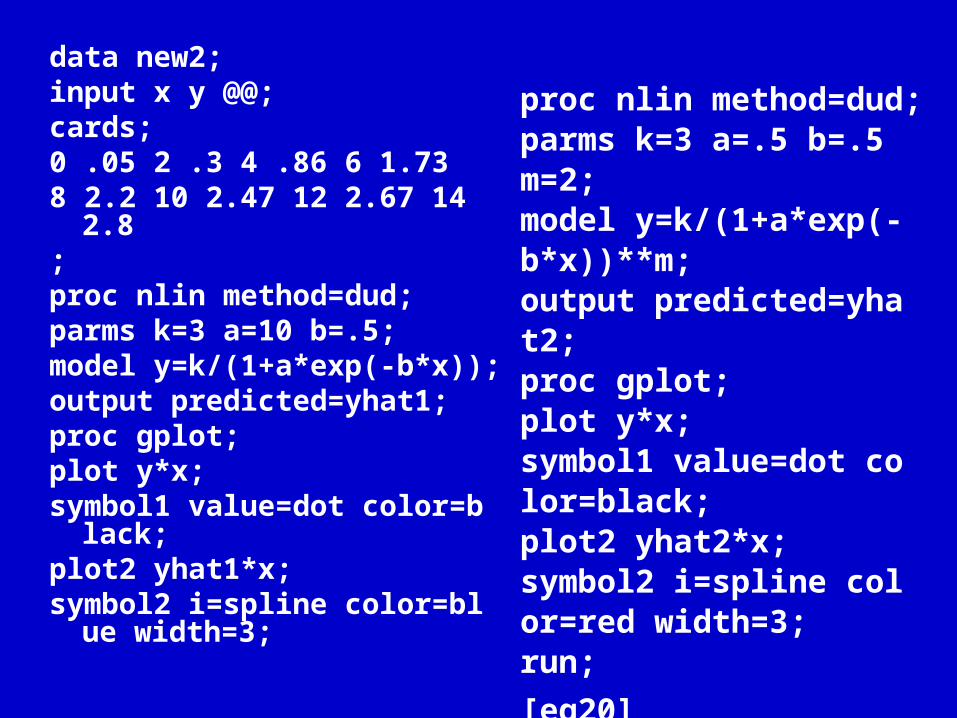
data new2;input x y @@;cards;0 .05 2 .3 4 .86 6 1.73 8 2.2 10 2.47 12 2.67 14 2.8;proc nlin method=dud;parms k=3 a=10 b=.5;model y=k/(1+a*exp(-b*x));output predicted=yhat1;proc gplot;plot y*x; symbol1 value=dot color=bl
ack; plot2 yhat1*x;symbol2 i=spline color=blue
width=3;
proc nlin method=dud;parms k=3 a=.5 b=.5 m=2;model y=k/(1+a*exp(-b*x))**m;output predicted=yhat2;proc gplot;plot y*x; symbol1 value=dot color=black; plot2 yhat2*x;symbol2 i=spline color=red width=3; run;
[eg20]

11 11 聚类分析聚类分析聚类分析( Cluster Analysis )是将 n 个个
体根据其相似、相异程度分成 g 个组别的统计分析方法。一般事前对个体的类别不甚清楚,甚至总共可能有几类也并不完全确定的情形。
聚类一般依样本间的距离或相似系数进行。
聚类方法有很多,常用的有系统聚类法 (hie
rarchical cluster) 和动态聚类法( non-hierarch
ical cluster )两大类。

系统聚类 按照某种规则定义类间距离,先将 n 个个体视为 n类,将距离最小的两类合并成一个新类,重新计算类间距离。如此反复进行,直到所有个体合并成为一类。最后结果用聚类分支图表示。
动态聚类 首先将 n 个个体初分成 g类,计算每一类的“中心点”。然后将每一个体按最近中心点重新分类。如此反复迭代,直到中心点不再改变为止。

SAS 软件主要有以下 4 个聚类过程:CLUSTER
FASTCLUS
VARCLUS
TREE

11.1 CLUSTER 过程过程格式PROC CLUSTER 选项;VAR 变量表;COPY 变量表;RUN ;

语法格式PROC CLUSTER 选项DATA= 数据数据集OUTTREE=输出数据集,供 TREE 过程调用METHOD= 算法主要算法包括: WARD (离差平方和法), AV
ERAGE (类平均法), CENTROID (重心法),COMPLETE (最长距离法), SINGLE (最短距离法), MEDIAN (中间距离法), DENSITY(密度法), FLEXIBLE (可变距离法), TWOSTAGE (两段连锁密度法)。

语法格式VAR 语句此语句列出在聚类分析中所使用的数值
型变量。缺省时使用全部变量。COPY 语句指明从输入数据集中拷贝一些变量到输
出数据集中。

本过程利用 CLUSTER 过程和 VARCLUSTER过程生成的数据集绘制树状结构图。
过程格式PROC TREE 选项;RUN ;语句说明PROC TREE 选项DATA=输入数据集OUT=输出数据集Horizontal 规定树的高度为水平方向,根在左
侧,如缺省,则高度轴为垂直方向,根在上部。
11.2 TREE 过程

data new;infile 'e:\work\eg25.txt';input x y @@;proc print;proc cluster outree=tree method=average;proc tree data=tree horizontal;run;[eg25]

FASTCLUS 过程叫动态聚类过程,也叫快速聚类。它是在一个变量或几个变量的欧式距离
基础上对数据进行分类,这些类之间互不相交。此过程主要用于大数据集的聚类,其观
测数应在 100-100000之间。
11.3 FASTCLUS 过程

过程格式PROC FASTCLUS 选项;VAR 变量;BY 变量;RUN ;

语句说明PROC FASTCLUS 语句DATA=输入数据集OUT=输出数据集MAXCLUSTERS|MAXC=n :指定结果中最
多可形成的类别数与 PRINT 过程配合使用可以显示分类结果。
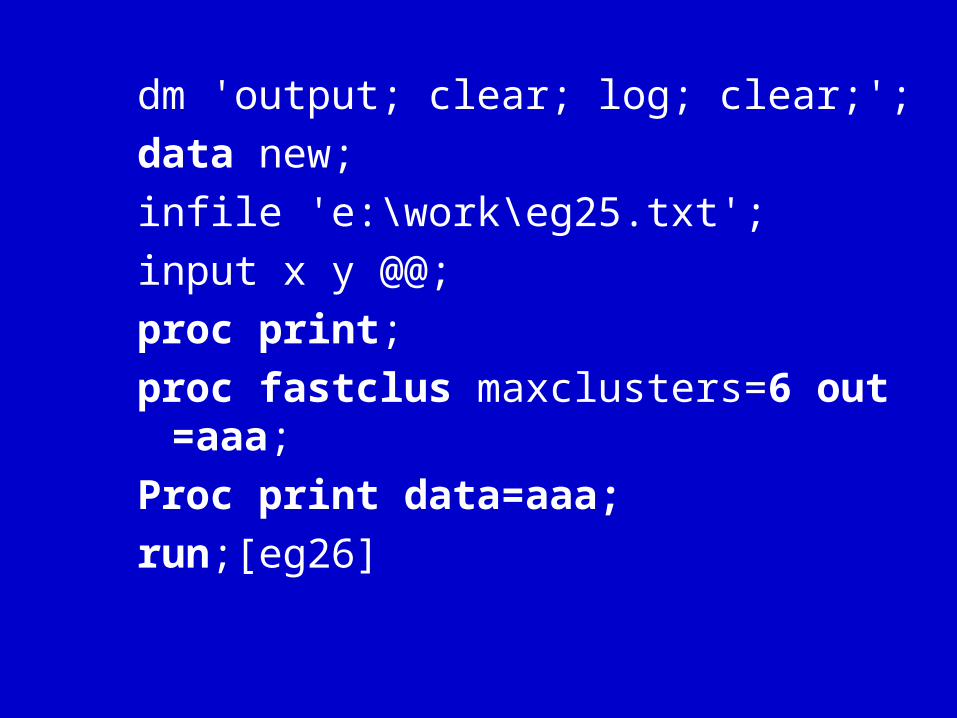
dm 'output; clear; log; clear;';
data new;
infile 'e:\work\eg25.txt';
input x y @@;
proc print;
proc fastclus maxclusters=6 out=aaa;
Proc print data=aaa;
run;[eg26]


















