
Re Gresi on Poli No Mial
17
MODELOS POLINOMIALES DE REGRESIÓN Introducción.- El modelo de regresión lineal Y = Xβ + ε es un modelo general de ajuste de toda relación que sea lineal en los parámetros desconocidos β. Entre las relaciones están incluidos los “modelos polinomiales de regresión”. En general, el modelo polinomial de orden k en una variable es: y = β 0 + β 1 x + β 2 x 2 +… + β k x k + ε Si definimos: X 1 =X, X 2 =X 2 ,..., X k =X k , el modelo polinomial se transforma en un MRLM con k regresores. Así, un modelo polinomial se puede ajustar con las técnicas que ya se estudiaron. Los modelos polinomiales se deben utilizar : Cuando el analista sabe que hay efectos curvilíneos presentes en la función verdadera de respuesta. Cuando se aproximan funciones a relaciones no lineales, desconocidas y posiblemente muy complejas. I.- Modelo Polinomial en una Variable: El siguiente modelo se llama modelo de segundo orden en una variable. y = β 0 + β 1 x + β 2 x 2 + ε Donde β 1 es el parámetro de efecto lineal, β 2 parámetro de efecto cuadrático y β 0 es el promedio de “y” cuando x = 0, si x = 0 está dentro del rango de x, en caso contrario, β 0 no tiene interpretación física. I.1.- Principios básicos. Cuando se ajustan modelos polinomiales de una variable se deben tener en cuenta varias consideraciones importantes: Orden del modelo.- Se debe mantener tan bajo como sea posible el orden del modelo, se deben intentar transformaciones para mantener un modelo de primer orden, si lo anterior falla se debe intentar un polinomio de orden 2. Como regla general, debemos evitar el uso de polinomios de orden superior (k>2), a
-
Upload
denis-pozo -
Category
Documents
-
view
224 -
download
0
description
regresion
Transcript of Re Gresi on Poli No Mial

MODELOS POLINOMIALES DE REGRESIÓN
Introducción.-El modelo de regresión lineal Y = Xβ + ε es un modelo general de ajuste de toda relación que sea lineal en los parámetros desconocidos β. Entre las relaciones están incluidos los “modelos polinomiales de regresión”.En general, el modelo polinomial de orden k en una variable es:
y = β0 + β1x + β2x2 +… + βkxk + ε
Si definimos: X1=X, X2=X2,..., Xk=Xk, el modelo polinomial se transforma en un MRLM con k regresores. Así, un modelo polinomial se puede ajustar con las técnicas que ya se estudiaron.
Los modelos polinomiales se deben utilizar :
Cuando el analista sabe que hay efectos curvilíneos presentes en la función verdadera de respuesta.
Cuando se aproximan funciones a relaciones no lineales, desconocidas y
posiblemente muy complejas.I.- Modelo Polinomial en una Variable: El
siguiente modelo se llama modelo de segundo orden en una variable.y = β0 +
β1x + β2x2 + εDonde β1 es el parámetro de efecto lineal, β2 parámetro de
efecto cuadrático y β0 es el promedio de “y” cuando x = 0, si x = 0 está dentro del rango de x, en caso contrario, β0 no tiene interpretación física.I.1.- Principios básicos.Cuando se ajustan modelos polinomiales de una variable se deben tener en cuenta varias consideraciones importantes:Orden del modelo.- Se debe mantener tan bajo como sea posible el orden del modelo, se deben intentar transformaciones para mantener un modelo de primer orden, si lo anterior falla se debe intentar un polinomio de orden 2. Como regla general, debemos evitar el uso de polinomios de orden superior (k>2), a menos que se pueda justificar por razones ajenas a los datos. Se debe usar el modelo más simple posible que sea consistente con los datos y el conocimiento del ambiente del problema.Estrategia para la construcción del modelo.- Un método es ajustar en forma sucesiva modelos de orden creciente hasta que la prueba “t” para el termino de máximo orden sea no significativo. Un método alterno es ajustar el modelo de orden máximo adecuado, y luego eliminar términos, uno por uno, comenzando con el de orden máximo. Esos dos métodos son selección en avance y eliminación en reversa, respectivamente.
En la mayor parte de los casos se debería restringir la atención a polinomios de primer y segundo orden.
Extrapolación.- La extrapolación con modelos polinomiales puede ser peligroso. En general los modelos polinomiales pueden dirigirse hacia direcciones imprevistas e inadecuadas, tanto en la interpolación como la extrapolación.Mal acondicionamiento I.- A medida que aumenta el orden del polinomio, X´X se vuelve mal acondicionada, es decir, que los cálculos de inversión de la matriz serán inexactos y se puede introducir error en los estimados de β. El “mal acondicionamiento no esencial” causado por la elección arbitraria del origen se puede eliminar, centrado primero las regresoras, es decir,

corregir x por su promedio ( ), pero a pesar de esto todavía se pueden obtener grandes correlaciones muestrales entre ciertos coeficientes de regresión. Mal acondicionamiento II.- si los valores de x se limitan a un rango estrecho, puede haber mal acondicionamiento o multicolinealidad apreciables en las columnas de
la matriz X. Por ejemplo, si x varía entre 1 y 2, entonces x2 varía entre 1 y 4, lo
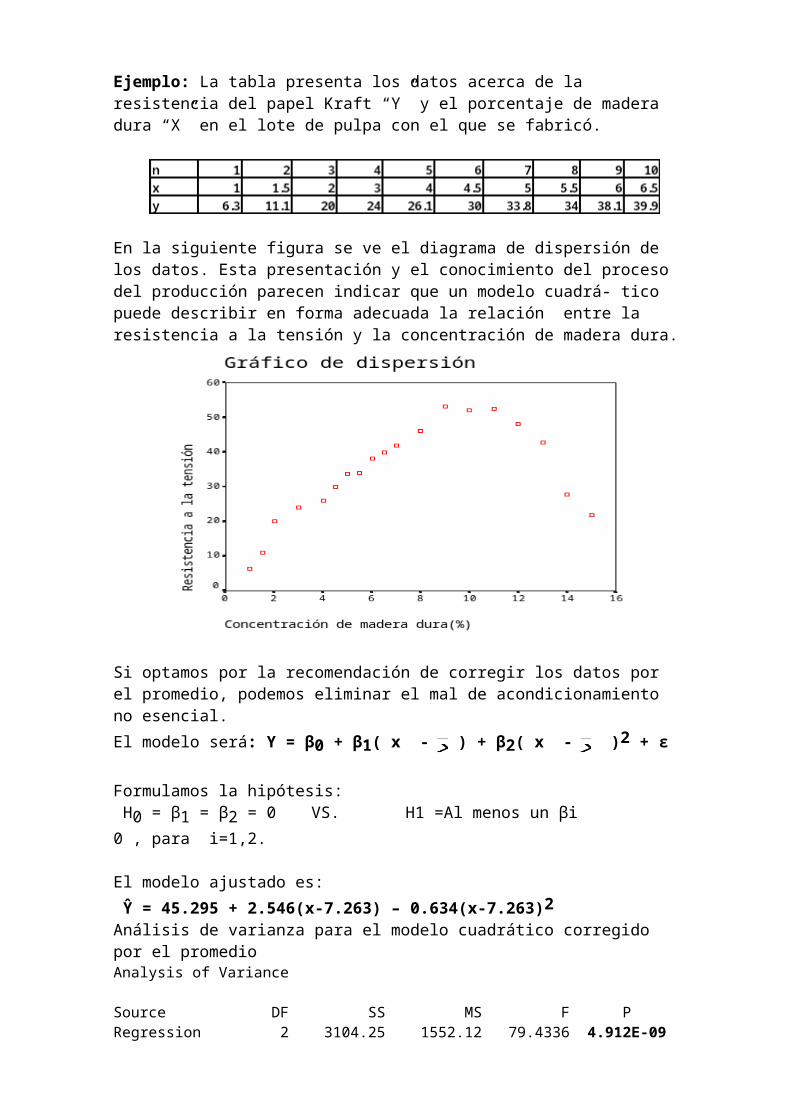
cual podría crear una fuerte multicolinealidad entre x y x2 .Ejemplo: La tabla presenta los datos acerca de la resistencia del papel Kraft “Y” y el porcentaje de madera dura “X” en el lote de pulpa con el que se fabricó.En la siguiente figura se ve el diagrama de dispersión de los datos. Esta presentación y el conocimiento del proceso del producción parecen indicar que un modelo cuadrá- tico puede describir en forma adecuada la relación entre la resistencia a la tensión y la concentración de madera dura.
Si optamos por la recomendación de corregir los datos por el promedio, podemos eliminar el mal de acondicionamiento no esencial.El modelo será: Y = β0 + β1( x - ) + β2( x - )2 + ε
Formulamos la hipótesis: H0 = β1 = β2 = 0 VS. H1 =Al menos un βi 0 , para i=1,2.
El modelo ajustado es: Ŷ = 45.295 + 2.546(x-7.263) – 0.634(x-7.263)2 Análisis de varianza para el modelo cuadrático corregido por el promedioAnalysis of VarianceSource DF SS MS F PRegression 2 3104.25 1552.12 79.4336 4.912E-09Error 16 312.64 19.54 Total 18 3416.89 Observamos que el p-value = 4.912E-09 <0.01=alfa. Por tanto rechazamos la H0 y llegamos a la conclusión que el término lineal o el cuadrático o ambos contribuyen al modelo en forma significativa.
Además dado que R2= 0.9085, esto nos indica que el 90.85% de la variabilidad en la resistencia de tensión es explicada por la variabilidad del porcentaje de la concentración de madera dura.Ahora supóngase que se desea investigar la contribución del término cuadrático
al modelo:H0 : β2 = 0 vs H1 : β2 distinto de 0.Realizando cálculos para obtener la estadística F0.F0 = (SSR (β2 / β0 β1) /1)/ CMerror= 105.47Como F0 = 105.47 >
8.53 = Ftabla , rechazamos la H0, concluimos que el término cuadrático contribuye al modelo en forma significativa.

POLINOMIOS ORTOGONALESEn el ajuste de modelos polimoniales en una variable, aun cuando se elimine el mal acondicionamiento no esencial mediante el
centrado, pueden haber haber todavía altos niveles de multicolinealidad. Algunas de esas dificultades se pueden eliminar usando Polinomios Ortogonales para ajustar el
modelo, supóngase que el modelo es:En general, las columnas de la matriz no serán ortogonales, además, si se aumenta el orden del polinomio agregándole un termino
se debe calcular y cambiarán los estimados de los parámetros de
órdenes inferiores Ahora, supóngase que se ajusta el modeloEn donde
es un polinomio ortogonal de u-esimo orden, definido de tal modo que:Entonces nuestro modelo se transforma en siendo la matriz :Como esta matriz tiene
columnas ortogonales, la matriz es:Modelos Polinomiales de RegresiónLos estimadores de por mínimos cuadrados se calculan a partir de
como sigue:Como es un polinomio de grado cero, se puede igualar y en consecuencia La suma de cuadrados de los residuales es: La suma de cuadrados de la regresión para cualquier parámetro del modelo, no depende de los demás parámetros de
este. Esta suma de cuadrados de regresión es:Si se desea evaluar el significado del término de orden máximo, se debe probar:Esto equivale a probar: Para esto
usaremos:Como el estadístico . Además, nótese que si cambia el orden del modelo a , sólo se deben calcular los nuevos coeficientes.Los coeficientes no
cambian, por la propiedad de la ortogonalidad de los polinomios. Así se facilita el cómputo del ajuste secuencial del modelo.Los polinomios ortogonales se forma con facilidad para el caso en que los niveles de tiene igual espaciamiento. Los cinco primeros polinomios ortogonales son:En las que es el espacio de niveles de y las
son constantes que se eligen de tal modo que los polinomios tengan valores enteros. En la tabla A.5 del apéndice del Libro Regresión Lineal de Montgomery[2004]
se presentan algunos valores numéricos de estos polinomios ortogonales. Se pueden encontrar tablas más extensas en DeLury[1960] y en Pearson y
Hartley[1966].Ejemplo:Un analista de investigación de operaciones ha desarrollado un modelo de cómputo para simulación de un sistema de inventarios con un solo artículo.
Ha probado ese modelo para investigar el efecto de diversas cantidades de pedidos sobre el costo promedio anual del inventario. Los datos obtenidos se verán en la
siguiente tabla.
Cantidad de Pedido Costo Anual Promedio
50 335
75 326
100 316
125 313
150 311
175 314
200 318
225 328
250 337
275 345
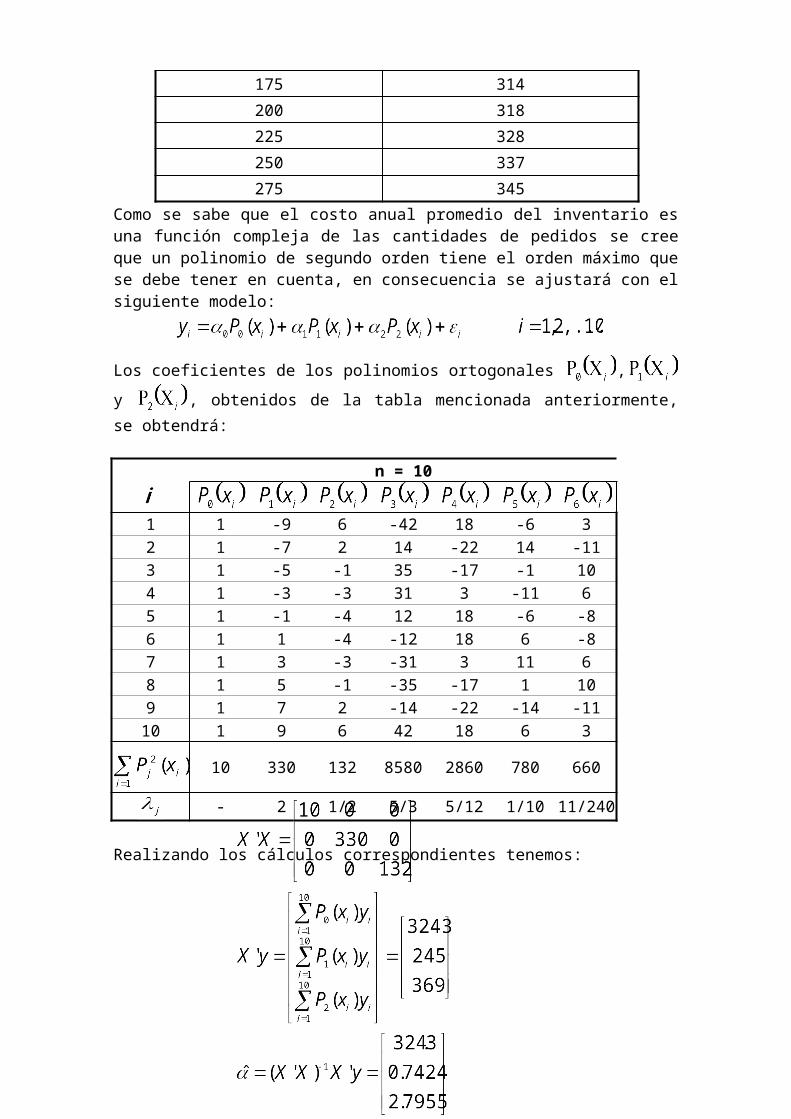
Como se sabe que el costo anual promedio del inventario es una función compleja de las cantidades de pedidos se cree que un polinomio de segundo orden tiene el orden

máximo que se debe tener en cuenta, en consecuencia se ajustará con el siguiente modelo:Los coeficientes de los polinomios ortogonales , y , obtenidos de la tabla mencionada anteriormente, se obtendrá:
n = 10
1 1 -9 6 -42 18 -6 3
2 1 -7 2 14 -22 14 -11
3 1 -5 -1 35 -17 -1 10
4 1 -3 -3 31 3 -11 6
5 1 -1 -4 12 18 -6 -8
6 1 1 -4 -12 18 6 -8
7 1 3 -3 -31 3 11 6
8 1 5 -1 -35 -17 1 10
9 1 7 2 -14 -22 -14 -11
10 1 9 6 42 18 6 3
10 330 132 8580 2860 780 660
- 2 1/2 5/3 5/12 1/10 11/240
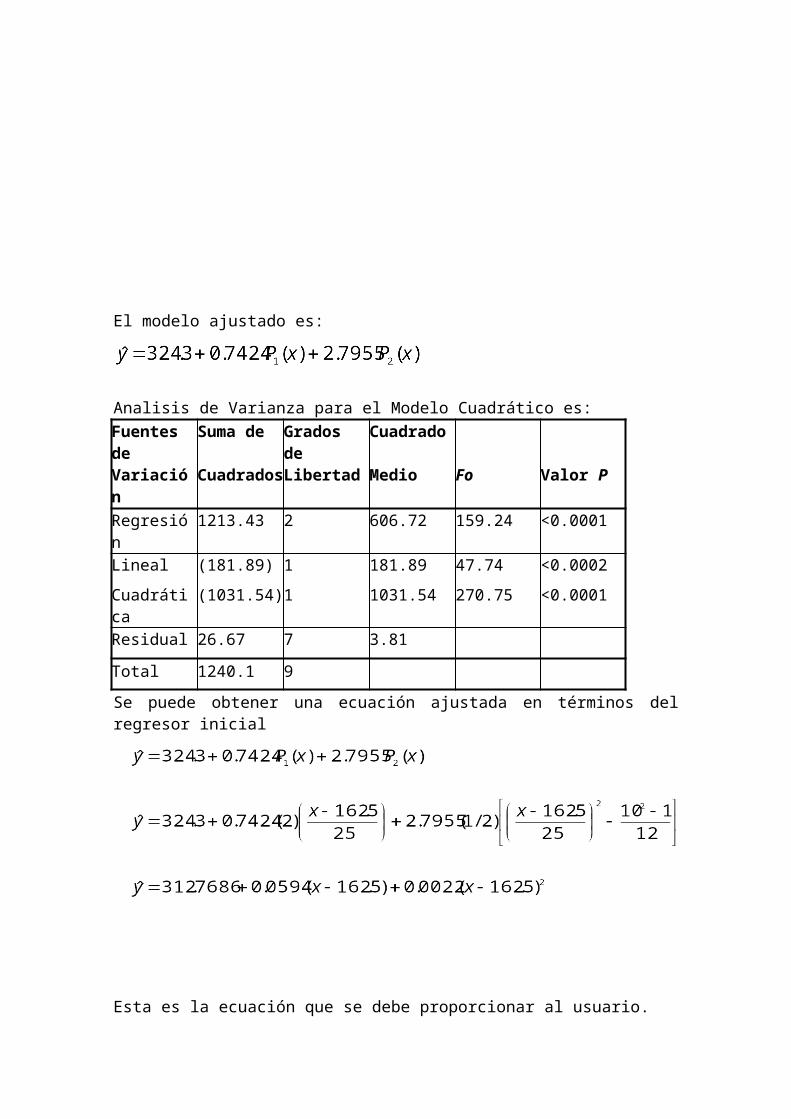
Realizando los cálculos correspondientes tenemos:El modelo ajustado es:Analisis de Varianza para el Modelo Cuadrático es:Fuentes de Suma de Grados de Cuadrado
Variación Cuadrados Libertad Medio Fo Valor P
Regresión 1213.43 2 606.72 159.24 <0.0001
Lineal (181.89) 1 181.89 47.74 <0.0002
Cuadrática (1031.54) 1 1031.54 270.75 <0.0001
Residual 26.67 7 3.81
Total 1240.1 9
Se puede obtener una ecuación ajustada en términos del regresor inicialEsta es la ecuación que se debe proporcionar al usuario.

REGRESIÓN NO PARAMÉTRICAEs un procedimiento muy relacionado con la regresión polinomial por segmentos. Este procedimiento consiste básicamente en
desarrollar una base de modelo libre para predecir la respuesta sobre el rango de los datos. La idea fundamental de la regresión no paramétrica es la naturaleza del valor predicho. Considerando los mínimos cuadrados ordinarios se tiene que: Por lo que se
tiene que Entonces se tiene que el valor predicho para la i-ésima respuesta es una combinación lineal de los datos originales.Regresión De KernelLlamado el método
alisador de Kernel, el cual esta basado en un promedio ponderado de los datos. Si es el estimado del alisador de núcleo para i-ésima respuesta, se tiene que el alisador de
Kernel es Donde wij es el factor de ponderación y tales que . Como resultado se tiene que Donde S= [wij] es la matriz de alisamiento. Generalmente los factores de
ponderación se escogen de tal forma que wij ≈ 0 para todas las yi fuera de la proximidad del lugar de interés especifico. Los alisadores de Kernel usan un ancho de banda b para definir la proximidad de interés. Cuando b es grande da como resultado que un mayor
número de datos se usaran para predecir la respuesta en el lugar especifico. Este método se llama alisador de Kernel dado que usa una función d Kernel K para especificar los
pesos. Las propiedades de las funciones de Kernel son las siguientes:
1.
2.
Estas propiedades también son las de una función de densidad simétrica de probabilidades.Los pesos específicos del alisador de Kernel se calculan con
Regresión Ponderada Localmente (Loess)Es otro método de regresión no paramétrica al que se le llama loess. Este tipo de regresión también utiliza los datos próximos al lugar específico. La proximidad se define como el tramo, que es la fracción de los puntos totales que se usan para formar las proximidades. Este procedimiento usa los puntos en la proximidad para generar un estimado por mínimos por mínimos cuadrados ponderados, d la respuesta especifica. Los pesos o factores de ponderación para la parte de mínimos cuadrados ponderados de la estimación se basan en la distancia de los puntos que se usaron en la estimación, al lugar especifico de interés.
El proceso de loess de estimación se resume como sigue:
En donde S es la matriz de alisamiento creada por la regresión localmente ponderada.El concepto de suma de residuales al cuadrado lleva en forma directa a la regresión no paramétrica. En particular

En forma asintótica este procedimiento de alisamiento es insesgado, por consiguiente el valor asintótico esperado de SSRes es
Es importante observar que S es una matriz cuadrada n x n. Entonces la traza[S’]=traza[S], y así
Se puede e interpretar a [2traza(S) –traza(S´S)] como los grados de libertad asociados con el modelo total. En algunos programas de computo [2traza(S) –traza(S´S)] es llamada la cantidad equivalente de parámetros, y representa una medida de la complejidad del procedimiento de estimación. Un estimado de σ2 es:
Por ultimo, se puede definir una versión de R2 como sigue:
Que tiene la misma interpretación que el R2 conocido de mínimos cuadrados ordinarios.
Este tipo de modelos son usados en casos en los que ningún modelo paramétrico simple proporciona un ajuste adecuado a los datos, o cuando no existe una teoría que guié al analista, o en situaciones donde no se puede aplicar transformaciones sencillas adecuadas, en este tipo de casos la regresión no paramétrica proporciona un ajuste adecuado a los datos.
MODELOS POLINOMIALES CON DOS O MÁS VARIABLES
El ajuste de un modelos polinomial con dos o mas variables regresoras es una extensión del modelo polinomial con una variable.El caso de un modelo con dos variables es el más usado y es expresado como sigue
Donde existe dos parámetros de efecto lineal, β1 y β2, dos parámetros de efecto cuadrático, β12 y β22, y un parámetro de interacción, β12.A la función de regresión
Se le llama superficie de respuesta. Este tipo de superficie de respuesta se puede representar en forma grafica trazando los ejes x1 y x2 en el plano, y visualizando al eje E(y) como perpendicular a ese plano.
Ejemplo:Se tiene un experimento donde se desea estudiar el efecto de de dos variables: la temperatura de reacción T y la concentración C, sobre el porcentaje de conversión y en un proceso químico. Los ingenieros de proceso habían usado un método para mejorar este proceso basado en experimentos diseñados. El primer experimento fue uno de cribado, donde intervinieron algunos factores que aislaban a la temperatura y la concentración con carácter de las dos variables más importantes. Como los experimentadores creían que este proceso estaba trabajando cerca del óptimo, optaron por ajustar un modelo cuadrático que relacionara el rendimiento con la temperatura y la concentración, ajuste dicho modelo a los siguientes datos:
A BObservación Orden
de la corrida
Temperatura(ºC)T
Conc.(%)C
x1 x2 y
123456789101112
412115671381092
200250200250
189.65260.35
225225225225225225
151525252020
12.9327.07
20202020
-11-11
-1.4141.414
000000
-1-11100
-1.4141.414
0000
437869734876657476798381
La parte A muestra los niveles que se usaron de T y C en las unidades naturales de medida, y la parte B muestra los niveles en función de las variables codificadas x1 y x2.
El modelo ajustado de segundo orden es
Usando las variables codificadas. La matriz X y el vector y son:
Donde la segunda y tercera columna representan a las variables x1 y x2, y la cuarta y quinta columna representan a las variables x1
2 y x22, y la ultima columna representan a la
variable x1x2.La matriz X´X y el vector X´y son:
Y a partir de se obtiene
Entonces el modelo ajustado del porcentaje de conversión es
El análisis de varianza para este modelo se muestra a continuación:
Analysis of Variance
Source DF SS MS F PRegression 5 1733.57 346.71 58.86 0.000Residual Error 6 35.34 5.89 Lack of Fit 3 8.59 2.86 0.32 0.812 Pure Error 3 26.75 8.92Total 11 1768.92
Dado que hay replicas en los datos, se puede agrupar la suma de cuadrados de residuales en componentes de error puro y falta de ajuste, para este caso la falta de ajuste es para el modelo cuadrático. Dado que el valor P=0.812 para esta prueba es grande se puede decir que el modelo cuadrático es adecuado para estos datos. La prueba F para la significancía de la regresión es F0=58.86, y como su valor P es muy pequeño, se rechaza

la hipótesis de que los coeficientes son todos iguales a cero. A continuación se muestra la suma de cuadrados debido a todas las variables en el modelo:
Source DF Seq SSx1 1 772.20x2 1 142.20x1_2 1 410.82x2_2 1 168.10x1_x2 1 240.25
Con estas sumas de cuadrados se puede probar la contribución de los términos lineales y cuadráticos al modelo. Para los terminos lineales seria:
Cuyo valor P=5.2 x 10-5.Y para los terminos cuadráticos seria:
Cuyo valor P=0.0002. por tanto los terminos lineales y cuadráticos contribuyen al modelo en forma significativa. A continuación también se muestran los valores para las pruebas t da cada variable individual, las cuales muestran que no hay terminos no significativos en el modelo.
Predictor Coef SE Coef T PConstant 79.750 1.214 65.72 0.000x1 9.8255 0.8582 11.45 0.000x2 4.2164 0.8582 4.91 0.003x1_2 -8.8750 0.9594 -9.25 0.000x2_2 -5.1250 0.9594 -5.34 0.002x1_x2 -7.750 1.214 -6.39 0.001
A continuación también se muestran los valores de R2 y R2 ajustada, asi como el valor del PRESS y el R2
predicción.
S = 2.42706 R-Sq = 98.0% R-Sq(adj) = 96.3%
PRESS = 108.667 R-Sq(pred) = 93.86%
Los cuales son satisfactorios para el modelo, dado que indican que el modelo explica probablemente un 94% más o menos de la variabilidad de los datos.
EjercicioEl grado de carbonatación de una bebida gaseosa se afecta por la temperatura del producto y por la presión de funcionamiento de la llenadora. Se obtuvieron 12 observaciones, y los datos resultantes se presentan a continuación.
Carbonatación,y Temperatura,x1 Presión,x22.602.4017.32
31.031.031.5
21.021.024.0

15.6016.125.366.1910.172.622.986.927.06
31.531.530.531.530.531.030.531.030.5
24.024.022.022.023.021.521.522.522.5
a. Ajustar un polinomio de segundo orden.b. Probar la significancia de la regresión.c. Probar la falta de ajuste y llegar a conclusiones.d. ¿Contribuye al modelo el término de interacción, en forma significativa?e. ¿Contribuye al modelo los términos de segundo orden, en forma significativa?


















