
Probabilistische Graphische Modelle - techfak.uni-bielefeld.deswachsmu/GM06/folien-09.pdf · 4.3.1...
51
Probabilistische Graphische Modelle Sven Wachsmuth Universit¨ at Bielefeld, Technische Fakult¨ at, AG Angewandte Informatik WS 2006/2007 Probabilistische Graphische Modelle 1
Transcript of Probabilistische Graphische Modelle - techfak.uni-bielefeld.deswachsmu/GM06/folien-09.pdf · 4.3.1...

Probabilistische Graphische Modelle
Sven Wachsmuth
Universitat Bielefeld, Technische Fakultat, AG Angewandte Informatik
WS 2006/2007
Probabilistische Graphische Modelle 1

Ubersicht uber die Vorlesung
Probabilistische Graphische Modelle 2

4.3 Approximative Inferenz
Approximative Inferenz:
Grundidee: Komplexitat des Inferenzverfahrens von derKomplexitat des Graphen entkoppeln.
I Stochastische Simulation
I Mean field Algorithmus
I Loopy Belief Propagation
I Variationsansatz
Probabilistische Graphische Modelle 3

4.3.1 Approximative Inferenz – stochastische Simulation
Stochastische Simulation
Grundidee: Berechnung von (bedingten) Wk. durch Auszahlenvon generierten Beispielen.
Sampling (Generierung von Beispielen / Abtastung) einerVerteilung P(x1, . . . , xN):
I Problemzerlegung durch Conditioning:
P(x1|x2, . . . , xN)︸ ︷︷ ︸ P(x2, . . . , xN)︸ ︷︷ ︸Berechnung Sampling
Probabilistische Graphische Modelle 4

4.3.1 Approximative Inferenz – stochastische Simulation
Sampling-Schritt
Gegeben ein bereitsgeneriertes Beispiel x2, . . . , xN :
I Partitioniere Intervall [0, 1] entsprechend der VerteilungP(X1|x2, . . . , xn)
I Ziehe gleichverteilte Zufallszahl im Intervall [0, 1].
I Wahle X1 = x1 nach dem ausgewahlten Intervall
⇒ Bayes-Netze implizieren bereits eine naturlicheVariablenreihenfolge(entlang der Eltern-Kind Relation)
Probabilistische Graphische Modelle 5

4.3.1 Approximative Inferenz – stochastische Simulation
Problem:
I Sample-Reihenfolge: X1, . . . ,X6
I Inferenzaufgabe P(X1, x6)
Beim bisherigen Sample-Ansatz mussen alle generierten Beispieleverworfen werden, die nicht X6 = x6 enthalten.
Losung:
I X6 = x6 von Anfang an festklemmen
I Generierung von Beispielen durch eine Markov-Kette
Probabilistische Graphische Modelle 6

4.3.1 Approximative Inferenz – stochastische Simulation
Generierung einer Markov-Kette
1 Initialisierung:
. Weise alle beobachteten Werte zu
. Belege nicht-beobachtete Werte mit Zufallszahlen
2 Propagierung:
Berechne fur alle Variablen Xi , i ← 1 . . .N
. Berechne P(Xi |xJ ) = P(Xi |xBi )wobei J = {1 . . .N} − {i} und Bi Markov-Blanket von Xi .
. Generiere neuen Wert Xi = x i entsprechend der VerteilungP(Xi |xBi )
. Falls Xi Abfragevariable, erhohe Count fur x i
. Wiederhole Schritt (2) bis max. Iterationen erreicht sind.
Probabilistische Graphische Modelle 7

4.3.1 Approximative Inferenz – stochastische Simulation
I Der Algorithmus generiert eine Markov-Kette uberBelegzustande
I Propagierung in der Markov-Kette benotigt eineBurn-In-Phase (ca. 5%).
Feller Theorem:
Falls die Wahrscheinlichkeit von einem beliebigen Zustand i ineinen beliebigen Zustand j in einer endlichen Anzahl von Schrittenuberzugehen positiv ist, nahert sich die Wk. fur einen Belegzustandeinem Grenzwert (Stationaritatsbed.)
P(j) =∑
i
P(i) P(j |i)
Probabilistische Graphische Modelle 8

4.3.1 Approximative Inferenz – stochastische Simulation
Sequential Importance Sampling (SIS)
I Implementiert einen Bayesian Filter durchMonte-Carlo-Simulation
I Wird angewendet falls P(xt |z{1..t}) nicht normalverteilt ist(sonst (Extended) Kalman Filter)
I Technik ist auch bekannt als CONDENSATION (conditionaldensity propagation), particle filtering, survival of the fittest,etc.
Probabilistische Graphische Modelle 9
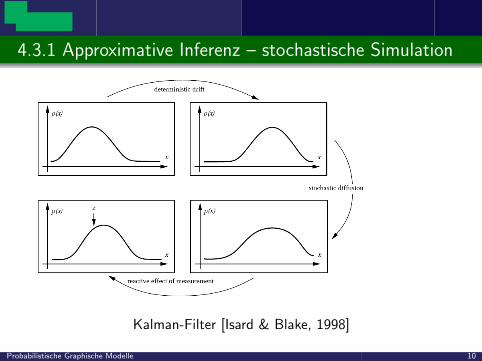
4.3.1 Approximative Inferenz – stochastische Simulation
Kalman-Filter [Isard & Blake, 1998]
Probabilistische Graphische Modelle 10
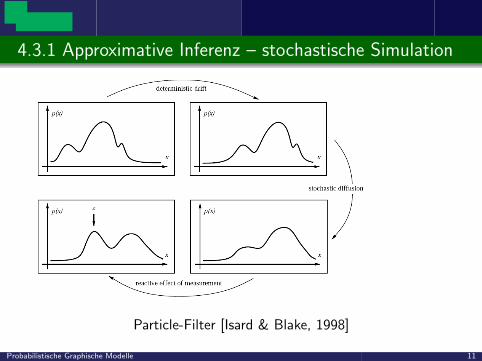
4.3.1 Approximative Inferenz – stochastische Simulation
Particle-Filter [Isard & Blake, 1998]
Probabilistische Graphische Modelle 11

4.3.1 Approximative Inferenz – stochastische Simulation
Importance Sampling
Grundidee: Reprasentation der Posterior-Dichte durch eine Mengevon Samples mit assoziierten Gewichten {x i
{0..t},wit}
Nsi=1.
P(x{0..t}|z{0..t}) ≈Ns∑i=1
w itδ(x{0..t} − x i
{0..t});∑
i
w it = 1.
I Schatzungen der Zielgroßen werden auf der Basis der Samplesund Gewichte bestimmt.
I Aufgrund der assoziierten Gewichte werden insgesamt wenigerSamples als bei Monte Carlo benotigt.
Probabilistische Graphische Modelle 12

4.3.1 Approximative Inferenz – stochastische Simulation
Importance Sampling (Fortsetzung)
Die Wahl der Gewichte basiert auf dem Prinzip des importancesamplings,
w it ∝
P(x i{0..t}|z{1..t})
q(x i{0..t}|z{1..t})
, wobei
I P(x) bis auf einen Proportionalitatsfaktor auswertbar ist,jedoch keine Samples generiert werden konnen.
I x i ∼ q(x), i = 1..Ns (importance density) ein Vorschlag fur dieDichte ist, aus der einfach Samples generiert werden konnen.
Probabilistische Graphische Modelle 13
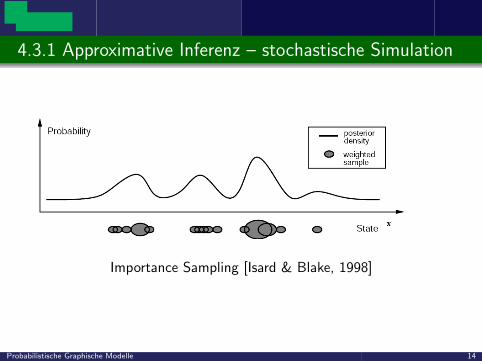
4.3.1 Approximative Inferenz – stochastische Simulation
Importance Sampling [Isard & Blake, 1998]
Probabilistische Graphische Modelle 14

4.3.1 Approximative Inferenz – stochastische Simulation
Sequential Importance Sampling
Annahme: Problem kann uber einen rekursiven Filter gelostwerden (Faktorisierung der Importance Density).
q(x{0..t}|z{0..t}) = q(xt |x{0..t−1}, z{0..t})q(x{0..t−1}|z{0..t−1})
Jetzt kann x i{0..t} ∼ q(x i
{0..t}|zi{0..t}) durch Erweiterung eines
existierenden Samples x i{0..t−1} ∼ q(x i
{0..t−1}|zi{0..t−1}) mit einem
neuen Zustand x it ∼ q(xt |x i
{0..t−1}, zi{0..t}) erzeugt werden.
Probabilistische Graphische Modelle 15

4.3.1 Approximative Inferenz – stochastische Simulation
Sequential Importance Sampling (Fortsetzung)
Aus der Gleichung
P(x i{0..t}|z
i{0..t}) ∝ P(zt |xt) P(xt |xt−1) P(x i
{0..t−1}|zi{0..t−1})
folgt direkt fur das modifizierte Gewicht:
w it ∝ w i
t−1
P(zt |xt) P(xt |xt−1)
q(x it |x i
t−1, zt)
Probabilistische Graphische Modelle 16

4.3.1 Approximative Inferenz – stochastische Simulation
Sequential Importance Sampling (Algorithmus)
[{x it ,w
it}Ns
i=1] = SIS [{x it−1,w
it−1}
Nsi=1, zk ]
Fur alle samples i ← 1..Ns
. Ziehe x it ∼ q(xk |x i
t−1, zk)
. Berechne neues Gewicht
w it ∝ w i
t−1
P(zt |xt) P(xt |xt−1)
q(x it |x i
t−1, zt)
I Problem: die Gewichte degenerieren schnell zu einer Losungmit nur einem Partikel mit signifikantem Gewicht.
Probabilistische Graphische Modelle 17

4.3.1 Approximative Inferenz – stochastische Simulation
Reduktion des Degenerationseffekts durch Resampling
I Generiere einen neue Menge von Samples {x it∗}Ns
i=1 von derapproximativen diskreten Reprasentation von P(xt |z{1..t})
P(xt |z{1..t}) ≈Ns∑i=1
w itδ(xt − x i
t)
so dass P(x it∗
= x jt ) = w j
t .
I Setze die Gewichte w it auf
w it =
1
Ns, da IID-Annahme fur Samples gilt.
Probabilistische Graphische Modelle 18

4.3.1 Approximative Inferenz – stochastische Simulation
Resampling Algorithm
[{x jt
∗,w j
t , ij}Ns
j=1] = RESAMPLE [{x it ,w
it}
Nsi=1]
. Initialisiere CDF: c1 = 0
. Fur alle i ← 2..Ns
. Konstruiere CDF: ci = ci−1 + w it
. Starte am Anfang der CDF: i = 1
. Ziehe einen Startpunkt: u1 ∼ [0,N−1s ]
. Fur alle j ← 1..Ns
. Gehe weiter entlang der CDF: uj = u1 + N−1s (j − 1)
. Solange uj > ci , i = i + 1
. Zuweisung: x jt
∗= x i
t , w jt = N−1
s , i j = i
I Problem: eventuell viele Samples mit identischem Wert(sample impoverishment)
Probabilistische Graphische Modelle 19

4.3.1 Approximative Inferenz – stochastische Simulation
Particle Filtering Algorithmus
[{x it ,w
it}Ns
i=1] = PF [{x it−1,w
it−1}
Nsi=1, zk ]
. Fur alle i ← 1..Ns
. Ziehe x it ∼ q(xt |x i
t−1, zk)
. Berechne neues Gewicht w it = w i
t−1P(zt |xt) P(xt |xt−1)
q(x it |x i
t−1,zt)
. Normalisiere {w it}
Nsi=1
. Berechne Neff = 1PNsi=1(w
it )
2(Maß fur degenerierte Verteilung)
. Falls Neff < NT
. Resample: [{x it ,w
it ,−}
Ns
i=1] = RESAMPLE [{x it ,w
it}
Ns
i=1]
Probabilistische Graphische Modelle 20

4.3.1 Approximative Inferenz – stochastische Simulation
SIR Particle Filter (Sampling Importance Resampling)
[{x it ,w
it}Ns
i=1] = SIR[{x it−1,w
it−1}
Nsi=1, zk ]
. Fur alle i ← 1..Ns
. Ziehe x it ∼ P(xt |x i
t−1)(generiere Rauschen v i
t−1 ∼ Pv (vt−1), berechnex it = ft(x
it−1, v
it−1) uber Dynamikgleichung).
. Berechne neues Gewicht w it = P(zt |x i
t )
. Normalisiere {w it}Ns
i=1
. Resample: [{x it ,w
it ,−}
Nsi=1] = RESAMPLE [{x i
t ,wit}
Nsi=1]
I Resampling wird in jeder Iteration durchgefuhrt
I Entspricht CONDENSATION-Algorithmus
Probabilistische Graphische Modelle 21
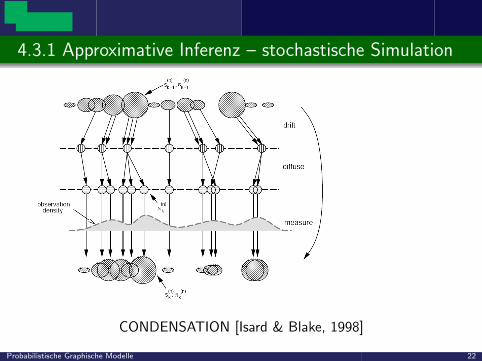
4.3.1 Approximative Inferenz – stochastische Simulation
CONDENSATION [Isard & Blake, 1998]
Probabilistische Graphische Modelle 22

4.3.1 Approximative Inferenz – stochastische Simulation
Zusammenfassung
I Stochastische Simulation wird haufig bei MRFs eingesetzt
I Sequential Importance Sampling (SIS) wendet stochastischeSimulation auf State-Space-Modelle an (Zustand nichtGaußverteilt).
I SIS-Techniken (Particle Filter) werden haufig eingesetzt inTracking und SLAM-Problemen.
Probabilistische Graphische Modelle 23
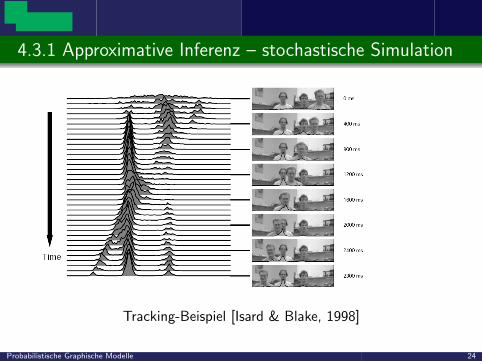
4.3.1 Approximative Inferenz – stochastische Simulation
Tracking-Beispiel [Isard & Blake, 1998]
Probabilistische Graphische Modelle 24

4.3.2 Approximative Inferenz – mean field Algorithmus
Bisher: approximative Inferenz durch zufalliges generierenvon Beispielen.→ Problematisch bei dichten Graphen undhoher-dimensionaler ZV’en, da ein sehr großer Raumabgetastet werden muss.
Alternative: deterministische Verfahren zur approximativenInferenz.
Probabilistische Graphische Modelle 25

4.3.2 Approximative Inferenz – mean field Algorithmus
Wdh: Generierung einer Markov-Kette
1 Initialisierung:
. Weise alle beobachteten Werte zu
. Belege nicht-beobachtete Werte mit Zufallszahlen
2 Propagierung:
Berechne fur alle Variablen Xi , i ← 1 . . .N
. Berechne P(Xi |xJ ) = P(Xi |xBi )wobei J = {1 . . .N} − {i} und Bi Markov-Blanket von Xi .
. Generiere neuen Wert Xi = x i entsprechend der VerteilungP(Xi |xBi )
. Falls Xi Abfragevariable, erhohe Count fur x i
. Wiederhole Schritt (2) bis max. Iterationen erreicht sind.
→ einfache Idee: ersetze Zufallsupdate durch Mittelwert
Probabilistische Graphische Modelle 26

4.3.2 Approximative Inferenz – mean field Algorithmus
Bsp. Ising-Modell
I Markov Random Field mitG = (X , E), mit X = (X1, . . . ,XN),V = {1, . . . ,N}
I Binare Zufallsvariablen x ∈ {0.1}N .
I Paare von benachbarten Knoten sind uber ein Gewicht θst
gekoppelt.
I Jeder Knoten hat ein Observationsgewicht θs .
P(x ; θ) ∝ exp{∑s∈V
θsxs +∑
(s,t)∈E
θstxsxt}
Probabilistische Graphische Modelle 27

4.3.2 Approximative Inferenz – mean field Algorithmus
Gibbs-Update:
x(p+1)s =
{1 falls u ≤ {1 + exp[−(θs +
∑t∈N (s) θstx
(p)t )]}−1
0 sonst.
Mean field Algorithmus:
µs ← {1 + exp[−(θs +∑
t∈N (s)
θstµt)]}−1
Diese Art von Algorithmen kann als Message-Passing Algorithmusauf der Graph-Struktur interpretiert werden.(hier wird Nachricht µs geschickt)
Probabilistische Graphische Modelle 28

4.3.3 Approximative Inferenz – Loopy Belief Propagation
Loopy Belief Propagation
Anwendung von Pearl’s Belief Propagation Algorithmus furPolytrees bzw. von dem SUM-PRODUCT-Algorithmus aufGraphen mit Zyklen.
I Wie soll der Algorithmus gestartet werden?
I Wird der Algorithmus konvergieren?
I Wird der Algorithmus gegen das korrekte Ergebniskonvergieren?
Probabilistische Graphische Modelle 29

4.3.3 Approximative Inferenz – Loopy Belief Propagation
SUM-PRODUCT Algorithmus
I Nachrichten von einem Variablenknoten i zu einemFaktorknoten s (ν-SENDMESSAGE(i , s))
νis(xi ) =∏
t∈N (i)−s
µti (xi )
I Nachrichten von einem Faktorknoten s zu einemVariablenknoten i (µ-SENDMESSAGE(s, i))
µsi (xi ) =∑
xN (s)−{i}
(fs(xN (s))∏
j∈N (s)−{i}
νjs(xj))
I Die Gleichungen werden genau dann aufgerufen, wenn dieNachrichten von allen anderen Nachbarknoten vorliegen.
Probabilistische Graphische Modelle 30

4.3.3 Approximative Inferenz – Loopy Belief Propagation
Initialisierung:
I Alle Nachrichten werden auf den Vektor 1 gesetzt.
I Damit sind alle Knoten zum Aussenden von Nachrichtenaktiviert.
Propagierungsschedule:
I Spezifikation welche Nachrichten in einem Zeitschrittversendet werden.
I flooding schedule: Nachrichten werden fur alle Kanten desGraphen in jede Richtung verschickt.
I serial schedule: Es wird immer nur eine Nachricht proZeitschritt verschickt.
Probabilistische Graphische Modelle 31

4.3.3 Approximative Inferenz – Loopy Belief Propagation
Serial schedule
Eine Nachricht ist anhangig an Kante e von Knoten v , falls derKnoten nach dem letzten Aussenden eine Nachricht uber eineandere Kante als e bekommen hat.
I Der Empfang einer einer Nachricht in Knoten v uber Kante eerzeugt anhangige Nachrichten an allen anderen Kanten vonv .
I Es werden uber eine First-In-First-Out Queue alle anhangigenNachrichten abgearbeitet.
I Der Algorithmus wird fur zyklische Graphen nicht anhalten!
I Abbruchkriterium ist meistens eine maximale Anzahl vonIterationen.
Probabilistische Graphische Modelle 32
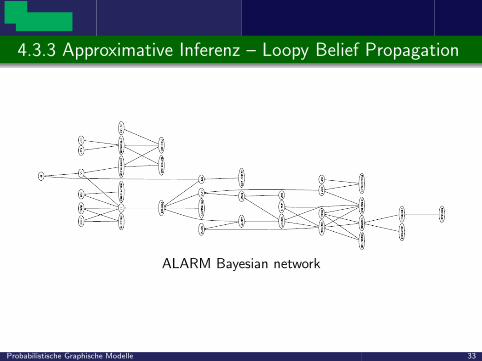
4.3.3 Approximative Inferenz – Loopy Belief Propagation
ALARM Bayesian network
Probabilistische Graphische Modelle 33

4.3.3 Approximative Inferenz – Loopy Belief Propagation
(a) Loopy-Belief-Propagation(200 Iterationen)
(b) Stochastisches Sampling(200 Iterationen)
(c) Stochastisches Sampling(1000 Iterationen)
Probabilistische Graphische Modelle 34
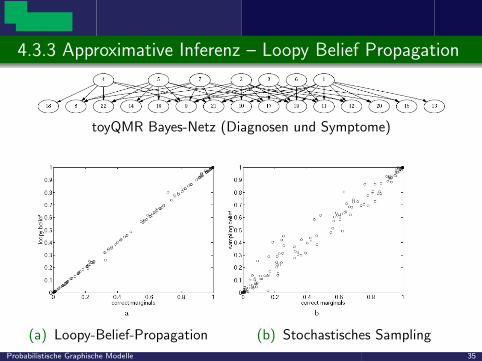
4.3.3 Approximative Inferenz – Loopy Belief Propagation
toyQMR Bayes-Netz (Diagnosen und Symptome)
(a) Loopy-Belief-Propagation (b) Stochastisches Sampling
Probabilistische Graphische Modelle 35
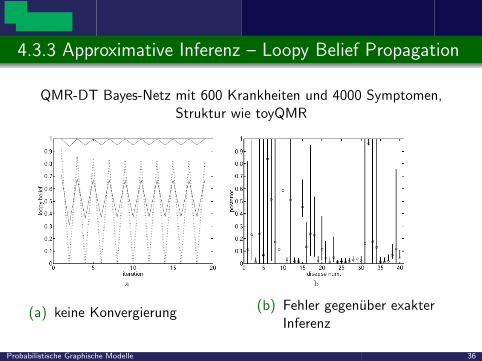
4.3.3 Approximative Inferenz – Loopy Belief Propagation
QMR-DT Bayes-Netz mit 600 Krankheiten und 4000 Symptomen,Struktur wie toyQMR
(a) keine Konvergierung (b) Fehler gegenuber exakterInferenz
Probabilistische Graphische Modelle 36

4.3.3 Approximative Inferenz – Loopy Belief Propagation
Zusammenfassung von Loopy Belief Propagation
I Algorithmus ist als Approximation interessant, daBerechnungen lokal sind.
I Falls Loopy-Belief-Propagation konvergiert, ist die Losung einesehr gute Naherung (z.B. Turbo-Codes)
I Falls der Algorithmus nicht konvergiert, ist die Losung nichtbrauchbar.
I Es ist bisher unbekannt, wovon genau die Konvergenzabhangt.
Probabilistische Graphische Modelle 37

4.3.4 Approximative Inferenz – Variational Inference
Variational Inference
Gegeben sei ein PGM P(x) = 1ZP
∏i Ψi (xDi
), bei dem dasInferenzproblem nicht exakt losbar ist.
Idee: Approximiere die gewunschte Zielverteilung uber einLernverfahren auf einem vereinfachten PGMQ(x) = 1
ZQ
∏j Φj(xCj
), bei dem exakteInferenzverfahren anwendbar sind.
Minimiere die KL-Distanz zwischen P und Q:
minΦD(Q||P) = minΦ
∑x
QΦ(x) logQΦ(x)
P(x)
Probabilistische Graphische Modelle 38

4.3.4 Approximative Inferenz – Variational Inference
Anstatt das globale Minimum zu finden, suchen wir eine Iterationfur Q, die den Abstand verringert und einen Fixpunkt bezuglichD(Q||P) hat:
∆ΦD(Q||P) = 0, wobei Φ = {Φj}j .Ansatz:
D(Q||P) =∑x
Q(x) logQ(x)
P(x)= −[H(Q) + EQ [log P(x)]]
Probabilistische Graphische Modelle 39

4.3.4 Approximative Inferenz – Variational Inference
Fuhrt nach umformen von H(Q) und EQ [log P(x)] zu(gesucht ist die Update-Formel fur Φj(xCj
))
H(Q) = H(Q(Cj)) + H(Q(X |Cj))
= −∑Cj
Q(cj) log Q(cj)−∑Cj
Q(cj)∑
X−Cj
Q(x |cj) log Q(x |cj)
= −∑Cj
Q(cj) log Q(cj)−∑Cj
Q(cj)∑k
∑Ck−Cj
Q(ck |cj) log Q(ck |cj)
EQ [ log P(x)] =∑
i
∑Cj
Q(cj)∑
X−Cj
Q(x |cj) log Ψi (di )− log(ZP)
=∑Cj
Q(cj)∑
i
∑Di−Cj
Q(di |cj) log Ψi (di )− log(ZP)
Probabilistische Graphische Modelle 40

4.3.4 Approximative Inferenz – Variational Inference
Und beim Einsetzen in D(Q||P) ergibt sich die folgendenGleichung mit Update-Term γj(cj):
D(Q||P) =∑Cj
Q(cj) logQ(cj)
Γj(cj)+ log(ZP), Γj(cj) = exp(γj(cj)).
γj(cj) = −∑
k
∑Ck−Cj
Q(ck |cj) log Q(ck |cj)︸ ︷︷ ︸+
∑i
∑Di−Cj
Q(di |cj) log Ψi (di )︸ ︷︷ ︸Term aus H(Q),Ck ∩ Cj 6= ∅ Term aus EQ [logP(x)]
Probabilistische Graphische Modelle 41

4.3.4 Approximative Inferenz – Variational Inference
Variational Inference Procedure (VIP)
Eingabe: Menge von Potentialen Ψi (di ), die die Ziel-VerteilungP(x) = 1
ZP
∏i Ψi (di ) definieren und eine Menge von Clustern
Cj , j = 1 . . . J mit initialen nicht-negativen Potentialen Φj(cj).
Ausgabe: Ein revidierte Menge von Potentialen Φj(cj), die eineVerteilung Q(x) = 1
ZQ
∏j Φj(cj) definiert, so dass Q ein Fixpunkt
der KL-Distanz D(Q||P) ist.
Graph wird charakterisiert durch Indikatorfunktionen
gkj = 0, falls Ck ∩ Cj = ∅fij = 0, falls Di ∩ Cj = ∅
Probabilistische Graphische Modelle 42

4.3.4 Approximative Inferenz – Variational Inference
Variational Inference Procedure (VIP)
Iteriere uber alle Cluster Cj bis zur Konvergenz
. Fur jede Instanz cj des Clusters Cj ,
γj(cj)←−∑
{k:gkj=1}
∑Ck−Cj
Q(ck |cj) log Q(ck |cj)
+∑
{i :fij=1}
∑Di−Cj
Q(di |cj) log Ψi (di )
Φj(cj)← exp(γj(cj))
Zur Berechnung von Q(ck |cj) und Q(di |cj) wird der sum-productAlgorithmus auf Q(X ) =
∏i Φi (Ci ) verwendet.
Probabilistische Graphische Modelle 43

4.3.4 Approximative Inferenz – Variational Inference
I Der Mean-Field Algorithmus ist ein spezieller Fall des VIP,wobei jeder Cluster Cj nur eine einzelne Variable enthalt.
γj(cj)←∑
{i :fij=1}
∑Di−Cj
Q(di |cj) log Ψi (di ).
I Der Loopy-Belief-Propagation Algorithmus ist ebenfalls eineVariante des VIP.
Probabilistische Graphische Modelle 44

4.3 Approximative Inferenz
Zusammenfassende Bemerkungen
Die vorgestellten Verfahren zur approximativen Inferenz beruhenalle auf Verfahren zum Lernen der gesuchten bedingtenWk.verteilung durch
I Auszahlen simulierter Daten (stochastische Simulation)
I Anwendung des Variationsprinzip auf einem ’Distanzmaß’zwischen der zu lernenden Wk.verteilung und derZielverteilung.
Probabilistische Graphische Modelle 45

5. Lernen von PGMs
Lernen von PGMs: Problem-Varianten
I Vollstandige Beobachtung vs. partielle Beobachtung
I Diskrete ZV’en vs. kontinuierliche ZV’en
I Gerichtete vs. ungerichtete Graphen
I Lernen der Parameter vs. Lernen der Struktur
Probabilistische Graphische Modelle 46

5.1 Lernen von PGMs: vollst., diskret, gerichtet
Gerichtete PGMs und vollst. Beobachtung
Sei G = (X , E) ein gerichteter Graph auf den ZVX = {X1, . . . ,XN}.
Das Wahrscheinlichkeitsmodell ergibt sich zu
P(x |θ) =N∏
i=1
P(xi |xπi , θi )
wobei θi die Parameter der bed. Wk.
θ die Parameter des Gesamtmodells
Sei V = {1, . . . ,N} die Indexmenge der Knoten in dem PGM undxV eine vollstandige Beobachtung.
Probabilistische Graphische Modelle 47

5.1 Lernen von PGMs: vollst., diskret, gerichtet
Gerichtete PGMs und vollst. Beobachtung
Problemstellung: Was ist die Parametrisierung eines PGMs, daseine beobachtete Folge von Knotenbelegungen
D = (xV,1, xV,2, . . . , xV,M)
mit maximaler Wk. erklart (Maximum Likelihood Schatzer)
Ansatz:
P(D|θ) =∏i
P(xV,i |θ) =∏j
∏i
P(x i ,j |xπi ,j , θi )
Typischer Weise betrachtet als Logarithmus (log likelihood)
l(θ;D) =∑
j
∑i
log P(x i ,j |xπi ,j , θi )
Probabilistische Graphische Modelle 48

5.1 Lernen von PGMs: vollst., diskret, gerichtet
Gerichtete diskrete PGMs und vollst. Beobachtung
Counts: Sei m(xV) ≡∑
j δ(xV , xV,j)die Anzahl, mit der die Variablen XV im Datensatz Dmit der Belegung xV vorkommen.
Wk.-Matrizen: Sei φi ≡ {xi} ∪ πi (Familie von Xi )Parameter P(xi |xπi , θi ) ≡ θi (xφi
)mit Nebenbed.
∑xi
θi (xφi) =
∑xi
θi (xi , xπi ) = 1
Gesamtmodell: P(xV |θ) =∏
i θi (xφi)
Probabilistische Graphische Modelle 49

5.1 Lernen von PGMs: vollst., diskret, gerichtet
Da sich die Nebenbedingungen nur auf die einzelnen Faktoren θi
beziehen, kann das Problem der opt. Parameterschatzung getrenntfur jeden einzelnen Faktor untersucht werden.
log P(D|θ) = log(∏j
P(xV,j |θ))
=∑
j
log(∏xV
P(xV |θ)δ(xV ,xV,j ))
=∑xV
m(xV) log(∏i
θi (xΦi))
=∑
i
∑xΦi
m(xΦi) log θi (xΦi
)
︸ ︷︷ ︸Term local fur Φi definiert
Probabilistische Graphische Modelle 50

5.1 Lernen von PGMs: vollst., diskret, gerichtet
... mit dem Lagrange-Ansatz (Nebenbed.∑
xiθi (xΦi
) = 1)ergibt sich:
θi ,ML(xΦi) =
m(xΦi)
m(xπi )=
m(xi , xπi )
m(xπi )
Probabilistische Graphische Modelle 51


















