
Pocítaˇ cová simulace a analýzaˇ vybraných frontových...
85
Univerzita Jana Evangelisty Purkynˇ e v Ústí nad Labem Pˇ rírodovˇ edecká fakulta Po ˇ cítaˇ cová simulace a analýza vybraných frontových systém ˚ u BAKALÁ ˇ RSKÁ PRÁCE Vypracovala: Markéta Temkoviˇ cová Vedoucí práce: RNDr. Jiˇ rí Škvor, Ph.D. Studijní program: Aplikovaná informatika Studijní obor: Informaˇ cní systémy Ú STÍ NAD L ABEM 2014
Transcript of Pocítaˇ cová simulace a analýzaˇ vybraných frontových...

Univerzita Jana Evangelisty Purkyne
v Ústí nad Labem
Prírodovedecká fakulta
Pocítacová simulace a analýzavybraných frontových systému
BAKALÁRSKÁ PRÁCE
Vypracovala: Markéta Temkovicová
Vedoucí práce: RNDr. Jirí Škvor, Ph.D.
Studijní program: Aplikovaná informatika
Studijní obor: Informacní systémy
ÚSTÍ NAD LABEM 2014


zde vložte zadání!!!


Prohlášení
Prohlašuji, že jsem tuto bakalárskou práci vypracovala samostatne a použila jen pramenu,
které cituji a uvádím v priloženém seznamu literatury.
Byla jsem seznámena s tím, že se na moji práci vztahují práva a povinnosti vyplývající ze
zákona c. 121/2000 Sb., ve znení zákona c. 81/2005 Sb., autorský zákon, zejména se sku-
tecností, že Univerzita Jana Evangelisty Purkyne v Ústí nad Labem má právo na uzavrení
licencní smlouvy o užití této práce jako školního díla podle § 60 odst. 1 autorského zákona,
a s tím, že pokud dojde k užití této práce mnou nebo bude poskytnuta licence o užití ji-
nému subjektu, je Univerzita Jana Evangelisty Purkyne v Ústí nad Labem oprávnena ode
mne požadovat primerený príspevek na úhradu nákladu, které na vytvorení díla vynaložila,
a to podle okolností až do jejich skutecné výše.
V Teplicích dne 30. dubna 2014 Podpis: . . . . . . . . . . . . . . . . . .


Podekování
Na tomto míste bych ráda podekovala vedoucímu práce RNDr. Jirímu Škvorovi, Ph.D.
za neocenitelné rady, vecné pripomínky, nápady, trpelivost a pomoc pri tvorbe této
bakalárské práce. Dále bych také chtela podekovat svým kamarádum za jejich rady pri
rešení nekterých problému, které se vyskytly behem zpracovávání této práce.


AbstraktTématem predložené práce jsou vybrané kapitoly z teorie front, která nachází uplatnení
pri rešení rady manažerských i technických úloh. Díky technickému pokroku se pocíta-
cové simulace frontových systému stávají stále vyhledávanejším nástrojem pro tyto typy
úloh. V úvodní cásti práce je prezentována rešerše systému hromadné obsluhy a existují-
cího programového vybavení. V praktické cásti práce jsou predstaveny vybrané modely, je-
jich programová implementace a statistická analýza simulacních dat. Porovnání techto dat
s teoretickým predpokladem poukázalo na správnou funkcnost aplikací priložených na CD.
Za hlavní praktický prínos práce lze pokládat prípadovou studii provedenou pro pobocku
Ceské pošty v Ústí nad Labem. Na základe analýzy poskytnutých dat bylo provedeno zhod-
nocení celého systému vcetne jeho nedostatku.
Klícová slova: Markovovy retezce, stochastické modelování, systémy hromadné obsluhy,
Kendallova klasifikace
AbstractThe thesis is focused on selected chapters from queuing theory, which can be applied for
solving various managerial or technical problems. Due to the technological progress, com-
puter simulations of queueing systems are constantly becoming sought-after tool for these
tasks. The research of queueing systems and existing software is presented in the introduc-
tory part of the thesis. The practical part introduces selected models, their software imple-
mentations and the statistical analysis of simulation data. The comparison between these
data and theoretical assumptions pointed to the correct functionality of applications on the
enclosed CD. As the main contribution of the thesis can be considered the case study per-
formed for the branch of Czech Post in Ústí nad Labem. Based on the analysis of the data
provided, an evaluation of the entire system was executed, including its imperfections.
Key words: Markov chains, stochastic modelling, queueing systems, Kendall classification


Obsah
Úvod 13
1. Teoretická cást 151.1. Stochastické modely . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
1.2. Markovovy retezce . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
1.3. Poissonuv proces . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
1.4. Poissonovo a exponenciální rozdelení pravdepodobnosti . . . . . . . . . . . . . 18
1.5. Statistická analýza . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
1.5.1. Popisná statistika . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
1.5.2. Matematická statistika . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
1.6. Systémy hromadné obsluhy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
1.6.1. Charakteristika SHO . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
1.6.2. Kendallova klasifikace SHO . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
1.7. Jednotlivé modely SHO . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
1.7.1. Exponenciální model jednoduché obsluhy M/M/1 . . . . . . . . . . . . . . 24
1.7.2. Exponenciální model vícenásobné obsluhy M/M/c . . . . . . . . . . . . . 25
1.7.3. Model M/D/1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
1.7.4. Model D/M/1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
1.7.5. Model jednoduché obsluhy s omezenou kapacitou M/M/1/K . . . . . . . 27
1.7.6. Uzavrený exponenciální model jednoduché obsluhy M/M/1/./N . . . . . . 28
1.7.7. Exponenciální model vícenás. obsluhy s omezenou kapacitou M/M/c/K . 29
1.8. Optimalizace SHO . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
1.9. Generování náhodných císel a simulace metodou Monte Carlo . . . . . . . . . . 31
1.10.Simulacní software . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
1.10.1. Simul8 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
1.10.2. Witness . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
1.10.3. Arena . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
1.10.4. Free software . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
2. Simulace vybraných modelu systému hromadné obsluhy 412.1. Simulace modelu M/M/1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
2.2. Simulace modelu M/D/1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
2.3. Simulace modelu D/M/1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
2.4. Simulace modelu M/M/c . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
11

Obsah
2.5. Simulace modelu M/M/1/K . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
2.6. Simulace modelu M/M/c/K . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
2.7. Simulace modelu M/M/1/./N . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
3. Prípadová studie 553.1. Analýza príchodu zákazníku . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
3.1.1. Test dobré shody na Poissonovo rozložení . . . . . . . . . . . . . . . . . . 57
3.1.2. Test dobré shody na exponenciální rozdelení . . . . . . . . . . . . . . . . 61
3.1.3. Další hypotézy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
3.2. Analýza využití služeb . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
3.3. Analýza obsluhy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
3.3.1. Test rozdelení doby obsluhy . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
3.3.2. Cekání ve fronte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
3.4. Analýza prepážek . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
3.5. Výsledky analýzy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
4. Záver 77
Seznam obrázku 81
Seznam tabulek 84
A. Obsah priloženého CD 85
12

Úvod
Tématem této bakalárské práce je analýza a modelování systému hromadné obsluhy. Se sys-
témy hromadné obsluhy se setkáváme v každodenním živote neustále. Cekáme v bankách,
na úradech nebo na svetelných križovatkách. Každý z nás si nekdy položil otázku, proc v tom
supermarketu mají tolik pokladen, ale obsluhuje jen cást z nich. Pro zákazníka by bylo preci
výhodnejší, kdyby obsluhovalo více pokladen, nejlépe všechny. To však nemusí platit pro
provozovatele, který má na situaci zcela jiný pohled. Pro nej je nejduležitejší, aby mel co
nejvetší zisky, tedy co nejvetší pocet obsloužených zákazníku, ale zároven se snaží dostat
provozní náklady na minimum. Proto je nutné systémy hromadné obsluhy navrhnout tak,
aby vyhovoval obema stranám. U jednoduchých modelu mužeme využívat i analytické re-
šení. To spocívá v tom, že na základe známých vstupních parametru modelu odhadneme
pomocí teorie pravdepodobnosti jeho charakteristiky, které nás zajímají (napr. prumernou
cekací dobu ve fronte). Pri analýze chování složitejších systému se neobejdeme bez simu-
lace. V simulacních modelech mužeme zkoumat, jak se systém bude v case vyvíjet, a lze
tak navrhnout optimální rešení bez potreby testovat chod systému v reálném experimentu.
Teoreticky se touto problematikou zabývá teorie front.
Jako cíle práce si klademe následující body:
• provést rešerši modelu systému hromadné obsluhy
• vybrané modely naprogramovat
• testovat funkcnost techto programu
– analýzou vybraných charakteristik daných modelu ve smyslu porovnání simu-
lacních dat s analytickým rešením
– v rámci testování demonstrovat chování daných modelu prostrednictvím rešení
modelových úloh
• realizovat prípadovou studii pro reálný systém
– provést statistickou analýzu dat
– zhodnotit chování daného systému
V úvodní cásti práce jsou predstaveny základní poznatky o stochastických modelech, ne-
kterých speciálních náhodných procesech a jsou v ní popsány obecné vlastnosti systému
13

Úvod
hromadné obsluhy. Dále jsou popsány jednotlivé modely se svými charakteristikami, je na-
stínena problematika optimalizace techto systému a je provedena rešerše existujícího pro-
gramového vybavení. V praktické cásti je práce zamerena na simulaci jednotlivých modelu
a jejich analýzu. V poslední cásti práce je provedena analýza casového pokrytí prepážek
a služeb spolu s hodnocením vyvolávacího systému na pobocce Ceské pošty, s.p., jakožto
složitého systému hromadné obsluhy.
14

1. Teoretická cást
1.1. Stochastické modely
Stochastické modely jsou založeny na teorii pravdepodobnosti - rozsáhlé matematické dis-
ciplíne, jejíž hlavním cílem je studium zákonu popisujících náhodu. Základním pojmem,
s kterým pracuje teorie pravdepodobnosti, je pravdepodobnostní prostor. Dalším duležitým
pojmem je náhodná velicina (též nazývaná náhodná promenná ci stochastická velicina).
Se zkoumáním množiny techto náhodných velicin souvisí pojem náhodný proces. Obecne
lze náhodný proces definovat jako množinu náhodných velicin, závislých na urcitém poctu
parametru. [1]
Pravdepodobnostní prostor (Ω, A, P ) predstavuje trojici pojmu [1]:
• Ω – neprázdná množina, tzv. prostor elementárních jevu
• A – systém vytvorený z podmnožin prostoru elementárních jevu Ω, tzv. systém ná-
hodných jevu
• P – normovaná míra definovaná na A, tzv. pravdepodobnostní míra (pravdepodob-
nost)
Náhodná velicina X je velicina [1], která muže obecne nabývat více hodnot x, a to
každou s nejakou pravdepodobností. Jakou hodnotu z x náhodná velicina X bude mít, je
ovlivneno náhodnými vlivy.
Stochastický proces X = X (t ), t ∈ T je soubor náhodných velicin na pravdepodob-
nostním prostoru (Ω, A, P ). Tedy pro každé t z indexové množiny T je X (t ) náhodná veli-
cina. Obvykle t oznacuje cas. Každá realizace náhodného procesu X se nazývá trajektorie.
X (t ) popisuje stav procesu v case t . Stochastickým procesem mužeme obecne rozumet po-
sloupnost náhodných promenných. [2]
Definicní obor T definovaného stochastické procesu budeme chápat jako množinu caso-
vých okamžiku (casových indexu). Na základe charakteru této množiny lze rozdelit stochas-
tické procesy na dva typy. Jestliže je množina T konecnou nebo spocetnou množinou, mlu-
15

1. Teoretická cást
víme o tzv. stochastickém procesu s diskrétním casem. V prípade, kdy definicní obor T je
nespocetnou množinou, se jedná o stochastické procesy se spojitým casem. Stochastické
procesy mužeme rozdelit dle charakteru stavového prostoru, neboli oboru hodnot stochas-
tického procesu, na dva typy. Stavove diskrétním stochastickým procesem se rozumí proces,
jehož obor hodnot je spocetná (diskrétní) množina, v opacném prípade se jedná o stavove
spojitý stochastický proces. [3]
1.2. Markovovy retezce
Markovovy retezce jsou speciálním prípadem stochastických procesu. Markovovým retez-
cem (nebo též markovský retezec) nazveme takový stochastický proces, kde výskyt stavu v ur-
citém casovém okamžiku t ∈ T je závislý pouze na predchozím casovém okamžiku (t−1) ∈ T
a zároven je množina T diskrétní. Jestliže je množina T spojitá, hovorí se o Markovove pro-
cesu se spojitým casem. Tyto dva procesy jsou užitecným nástrojem pro zkoumání stochas-
tických systému, tedy i pro systémy hromadné obsluhy.
Definice: [4] Uvažujme o stochastickém procesu Xn ,n = 0,1,2, . . . se spocetnou nebo
konecnou množinou hodnot.1 Jestliže Xn = i , pak se proces nachází ve stavu i v case n.
Predpokládáme, že pokud je proces ve stavu i , tak se s urcitou pravdepodobností Pi j do-
stane do stavu j :
P Xn+1 = j |Xn = i , Xn−1 = in−1, . . . , X1 = i1, X0 = i0 = Pi j (1.1)
pro všechny stavy i0, i1, . . . , in−1, i , j a pro všechna n ≥ 0. Takovýto stochastický proces na-
zveme Markovovým retezcem. Hodnota Pi j vyjadruje pravdepodobnost toho, že se proces ze
stavu i dostane do stavu j . Vzhledem k tomu, že pravdepodobnosti jsou nezáporné a proces
musí provést prechod do nejakého stavu tak platí:
Pi j ≥ 0, i , j ≥ 0;∞∑
j=0Pi j = 1, i = 0,1, . . .
Poznámky: [1]
• okamžik (n − 1), ve kterém nastal stav Xn−1 = i a v nemž se stochastický proces ted’
nachází, predstavuje soucasnost
• okamžiky (n −2), . . . ,1, ve kterých nastaly stavy Xn−2 = k, . . . , X1 a jimiž proces prošel,
predstavují minulost
• okamžik 0 je okamžikem startu pro proces, a to z pocátecního stavu X0 = m, patrí do
minulosti1Pokud není uvedeno jinak, rozumíme tím množinu nezáporných celých císel.
16

1. Teoretická cást
• okamžik n predstavuje budoucnost pro proces, a to bezprostredne následnou bu-
doucnost, ve která nastane stav Xn = j práve podle uvedené podmínené pravdepo-
dobnosti
• Markovovuv retezec je diskrétní náhodná posloupnost, u které výskyt stavu v bezpro-
stredne následné budoucnosti dané podmínenou pravdepodobností závisí na stavu,
ve kterém se tento stochastický proces nalézá v soucasnosti
• podmínená pravdepodobnost výskytu stavu j v okamžiku n závisí jen na stavu, který
se vyskytuje v okamžiku (n-1), neboli nezávisí na tom, ve kterých stavech proces byl
v krocích predcházejících – mužeme tedy ríct, že Markovovuv retezec udává budouc-
nost jen na základe soucasnosti a nezná minulost
• podmínená pravdepodobnost splnuje Markovovu podmínku (vlastnost), když platí:
Je-li Markovovuv retezec ve stavu n, tak jeho budoucí vývoj stavu je urcen pouze jeho
okamžitým stavem n a nezáleží na tom, jak se do tohoto stavu dostal. [3]
1.3. Poissonuv proces
Poissonuv proces je speciální stochastický proces, pri nemž jsou zmeny možné pouze pre-
chodem do nejblíže vyššího stavu. Za urcitých predpokladu vyjadruje napríklad pravdepo-
dobnost jistého poctu událostí, které se odehrají behem fixního casového intervalu, známe-
li intenzitu výskytu techto událostí a je-li tento pocet nezávislý na délce casového intervalu.
V praxi vyvstává také pri zkoumání takzvaných poissonovských procesu a modeluje množ-
ství prirozených jevu, které za urcitých predpokladu nastávají vícekrát behem jistého caso-
vého intervalu, nebo prostorového výseku. Muže se jednat napríklad o pocet klientu, kterí
prijdou do banky za den nebo pocet prístupu k webovému serveru za hodinu. [5]
Definice: Uvažujme událost, která se vyskytuje v krátkém case (t ; t +∆t ) (napr. pocet prí-
stupu k danému serveru za nejaký casový okamžik). V casovém intervalu (t ; t +∆t ) nastane
práve jedna událost s pravdepodobností λ∆t +o(∆t ) a více než jedna s pravdepodobností
o(∆t ) nezávisle na t a na poctu událostí nastalých v intervalu (0; t ). Necht’ náhodná veli-
cina X t je pocet výskytu urcitých událostí (napr. pocet prístupu) v casovém intervalu (0; t ),
pak X t t≥0 je spocetný Markovovuv proces s množinou stavu S = 0,1,2, . . . a s pocátec-
ním rozdelením p0(0) = 1 a pi (0) = 0 pro stav i 6= 0. Poissonuv proces predstavuje napríklad
príchody zákazníku do nejakého systému obsluhy, tok poruch zarízení atd. [3]
Pro Poissonuv proces jsou charakteristické následující znaky:
1. Nezávislost – pocet jevu pripadající na urcitý casový interval nezávisí na poctu jevu
v libovolném jiném casovém intervalu.
17

1. Teoretická cást
2. Intenzity pravdepodobnosti prechodu (nezávisí na case)
µi j =λ pro j = i +1
µi j = 0 pro j 6= i , i +1
µi j =−λ pro j = i
(1.2)
3. Pri dostatecne malém ∆ a konstantní hodnote λ se pravdepodobnosti prechodu ze
stavu n do stavu n +1 v intervalu (t ; t +∆t ) rovnají
pn,n+1(t ; t +∆t ) =λ∆t +o(∆t ) (1.3)
Pro pravdepodobnost setrvání ve stejném stavu v casovém intervalu (t ; t +∆t ) platí
pn,n(t ; t +∆t ) = 1−λ∆t +o(∆t ) (1.4)
Pravdepodobnost ostatních prechodu je v porovnání s predešlými zanedbatelná a je
∞∑j=i+2
pi j (t +∆t ) = o(∆t ) (1.5)
1.4. Poissonovo a exponenciální rozdelenípravdepodobnosti
Rekneme, že diskrétní náhodná velicina X má Poissonovo rozdelení [6] s parametrem λ> 0,
nabývá-li hodnot k = 0,1,2, . . . , každou z nich s pravdepodobností
fk = P (X = k) = e−λ λk
k !k = 0,1,2, . . . (1.6)
Distribucní funkce je
F (x) = ∑k<x
fk (1.7)
Strední hodnota náhodné veliciny s Poissonovým rozdelením je
E(x) =λ (1.8)
a rozptyl D2(X ) je
D2(X ) =λ (1.9)
Hustota spojité náhodné veliciny X s exponenciálním rozdelením s parametrem λ > 0, je
dána predpisem:
f (x) = 0 prox ≤ 0
λ ·e−λ(x) prox > 0(1.10)
18

1. Teoretická cást
Distribucní funkce F je dána vztahem
F (x) = 0 prox ≤ 0
1−e−λ(x) prox ≥ 0(1.11)
Strední hodnota je:
E(X ) = 1
λ(1.12)
rozptyl je pak roven
D2(X ) = 1
λ2(1.13)
Tato dve rozdelení se v systémech hromadné obsluhy vyskytují nejcasteji. Pro další podrob-
nosti a jiná rozdelení je možno nahlédnout napríklad do kapitoly 3 v [6].
1.5. Statistická analýza
1.5.1. Popisná statistika
Popisná statistika se zabývá popisem stavu nebo vývojem hromadných jevu. Nejprve se vy-
mezí soubor prvku, na nichž se bude uvažovaný jev zkoumat. Následne se všechny prvky
vyšetrí z hlediska studovaného jevu. Výsledky šetrení, vyjádreny predevším císelným popi-
sem, tvorí obraz studovaného hromadného jevu vzhledem k vyšetrovanému souboru. Pro
zpracování velkého množství dat je vhodné využívat nástroje popisné statistiky. Predevším
se jedná o grafy cetností, histogramy, tabulky a císelné charakteristiky, napríklad prumer
a rozptyl.
Cetnosti delíme na absolutní a relativní. Absolutní cetnosti udávají pocet výskytu daného
prvku a jejich soucet je roven poctu dat. Relativní cetnosti odkazují na relativní zastoupení
prvku vzhledem k celkovému množství dat (tj. jedná se o cetnosti prvku delených poctem
dat), suma techto cetností je rovna jedné.
Histogram je sloupcový graf, kde se na vodorovné ose x vyskytují tzv. trídy (intervaly), do
kterých trídíme data a na svislé ose y zachycuje cetnosti výskytu prvku. Takovýto graf zná-
zornuje rozložení dané veliciny.
1.5.2. Matematická statistika
Máme-li statisticky zpracovat velký soubor existujících, resp. možných výsledku nejakého
náhodného pokusu (pro nejž prijmeme nejaký pravdepodobnostní model), zjistíme pomery
19

1. Teoretická cást
jen v relativne malé cásti souboru výsledku, tzv. výberovém souboru, a získanou informaci
zobecníme na puvodní velký soubor.[7] Jednou z duležitých statistik je výberový prumer:
X = 1
n·
n∑i=1
xi
Testování statistických hypotéz
Pro srovnání získaných dat s predpoklady slouží mimo jiné statistické hypotézy a jejich tes-
tování. Postup je následující:
1. stanovení nulové a alternativní hypotézy,
2. provedení náhodného výberu,
3. zvolení hladiny významnosti α, která udává pravdepodobnost, že nesprávne zamít-
neme nulovou hypotézu (tzv. chyba prvního druhu),
4. volba testovacího kritéria,
5. výpocet hodnoty testovacího kritéria,
6. urcení kritické hodnoty testovacího kritéria,
7. rozhodnutí – zamítnutí ci nezamítnutí nulové hypotézy
Pro další statistické metody je možno nahlédnout do odborné literatury, napríklad do [6]
nebo [7].
1.6. Systémy hromadné obsluhy
Systémem hromadné obsluhy (SHO) mužeme obecne chápat takový systém, ve kterém exis-
tují jistá zarízení (kanály), na kterých dochází k obsluze vstupního proudu požadavku (zá-
kazníku) vstupujících do systému v náhodných okamžicích (tzv. stochastický vstupní proud).
Možnosti obsluhy mohou být omezeny, napr. poctem kanálu, dochází tak k hromadení po-
žadavku. Následne se bud’ tvorí fronty požadavku nebo požadavek odejde ze systému bez
obsloužení (rezignuje na obsluhu).[1]
Místo pojmu teorie hromadné obsluhy se lze setkat s pojmem teorie front. Protože existují
i systémy hromadné obsluhy, které frontu neobsahují, je první termín obecnejší. Teorie hro-
madné obsluhy si klade za cíl analýzu a následnou optimalizaci SHO s ohledem na jeho
efektivní fungování, tzn. aby se pred obslužnými linkami nevytvárely príliš velké fronty ce-
kajících požadavku a na druhé strane nedocházelo k neefektivním prostojum pri práci ob-
služných linek. [8] Se systémy hromadné obsluhy se setkáváme denne v bežném živote. Ty-
pickými príklady jsou zákazníci v supermarketech cekající u pokladen, svetelná signalizace
20

1. Teoretická cást
na križovatce, ci komunikace pocítacu po síti – poslání paketu a cekání paketu na volný ko-
munikacní kanál.
Obrázek 1.1.: Schéma základních pojmu systému hromadné obsluhy (vlastní zpracování)
1.6.1. Charakteristika SHO
Základní pojmy
Základními prvky, které charakterizují SHO jsou (viz také obr. 1.1): [1]
• Vstupní proud požadavku – intenzita vstupu požadavku spolecne s intenzitou jejich
obsluhy urcují základní charakteristiky SHO. Nejjednodušší modely predpokládají, že
vstupní proud charakterizovaný poctem požadavku vstupujících do systému za jistý
casový interval vyhovuje Poissonove procesu. Exponenciální systém je takový systém,
u kterého platí tvrzení: Mají-li pocty požadavku, které vstupují do SHO behem doby t
Poissonovo rozdelení, pak mají doby mezi dvema po sobe následujícími vstupujícími
požadavky (chápané jako náhodné veliciny) exponenciální rozdelení. Vstupní proud
muže být popsán i jinými procesy, u nichž doby mezi príchody dvou následných po-
žadavku mají jiná rozdelení. Zdroje požadavku urcují, zda se jedná o systém otevrený
ci uzavrený. Jestliže máme neomezený zdroj požadavku, jedná se o systém otevrený.
Uzavrený systém má zdroje s konecným resp. omezeným poctem požadavku. V praxi
považujeme za otevrený systém i takový prípad, kdy jsou zdroje v principu omezené,
avšak nelze presne urcit, kolik požadavku z takového zdroje bude požadovat obsluhu.
• Fronta - množina cekajících požadavku na obsluhu.
• Doba obsluhy - neboli intenzita obsluhy. Nejjednodušší modely opet predpokládají
dobu obsluhy za náhodnou velicinu s exponenciální rozdelením. Existují i modely
SHO s dobou obsluhy rídící se jinými rozdeleními.
21

1. Teoretická cást
• Disciplína cekání ve fronte – typ chování požadavku po nejaké dobe cekání ve fronte.
Nejjednodušším typem je trpelivé cekání na obsluhu, tedy cekání s nekonecnou mí-
rou trpelivosti. Jestliže nejsou z jakéhokoli duvodu obslouženy všechny požadavky,
pak v SHO vznikají ztráty. Duvodem muže být netrpelivost požadavku na obsluhu
nebo omezený pocet míst v SHO, a to bud’ celkový v systému nebo ve fronte. Spe-
ciálním prípadem jsou systémy bez cekání. Pokud je obsluha plne obsazena, tak po-
žadavek do systému ani nevstoupí.
• Režim fronty – urcuje typ razení požadavku do fronty.
– FIFO – First In, First Out – nejcastejší výskyt, založena na principu "kdo drív pri-
jde, ten bude dríve obsloužen."
– LIFO – Last In, First Out – první bude obsloužen požadavek, který prišel do sys-
tému jako poslední.
– SIRO – Selection In Random Order – dochází k náhodnému výberu požadavku
na obsluhu.
– PRIO – Priority – obsluha rízená prioritou požadavku. Priorita muže být abso-
lutní nebo relativní. Absolutní priorita znamená, že požadavek je obsloužen oka-
mžite, bez ohledu na eventuální probíhající obsluhu jiného požadavku, zatímco
relativní muže mít obecne i nekolik stupnu, umožnuje nastoupit obsluhu jakmile
se uvolní nejaké místo v obsluze. Pokud známe prioritu požadavku pred vstupem
do SHO, pak jde o tzv. apriorní prioritu. Jestliže je priorita stanovena behem ce-
kání na obsluhu, mluvíme o aposteriorní priorite.
Režimy SIRO a PRIO jsou systémy s neusporádanou frontou.
• Režim obsluhy – popisuje usporádání a pocet obslužných míst. V nejjednodušším prí-
pade je jen jedno usporádání. Podle poctu obslužných míst se rozlišují SHO na tzv. jed-
nokanálové (s jednoduchou) a vícekanálové (s vícenásobnou obsluhou), popr. adap-
tabilní, u kterých je pocet aktivních obslužných míst urcován behem fungování SHO,
napr. délkou fronty. Podle usporádání se rozlišují paralelne nebo sériove usporádané
obsluhy. U paralelních systému se predpokládá, že každé místo je stejné jako jiné
v témže systému, tzn. každé místo je schopné plne poskytnout požadovanou obsluhu,
zatímco sériové usporádání vzniká u tzv. vícefázové obsluhy, kdy požadavek muže ci
dokonce musí projít jednotlivými fázemi obsluhy v nejakém poradí.
1.6.2. Kendallova klasifikace SHO
V roce 1951 vytvoril D. G. Kendall klasifikaci pro jednotný systematický popis systému hro-
madné obsluhy a jejich roztrídení. Klasifikace má ve zkratce zakódované základní informace
o systému hromadné obsluhy. Obvykle se uvádejí tri typy standardního oznacování SHO -
22

1. Teoretická cást
Obrázek 1.2.: SHO s paralelním usporádáním obslužných linek a netrpelivostí zákazníku,
zdroj [9]
trí-, peti- a šestisymbolové. Trí- a petisymbolové jsou jen zvláštními prípady šestisymbolo-
vého znacení.
A/B/C/D/E/F
• A – charakterizuje vstupní tok, oznacuje rozdelení intervalu mezi príchody požadavku,
• B – charakterizuje pravdepodobnostní rozdelení dob trvání obsluhy
Symboly A a B mohou nabývat ruzných znakových hodnot:
– D – deterministický proud vstupních požadavku, tj. príchody jsou konstantní,
– M – exponenciální rozdelení mající Markovovu vlastnost,
– Ek – Erlangovo k-fázové rozdelení,
– G – obecné rozdelení, doba mezi príchody je dána svou distribucní funkcí,
• C – pocet paralelne usporádaných obslužných míst,
• D – kapacita, tj. celkový pocet míst v systému (není-li receno jinak, predpokládáme ∞,
tedy neomezenou kapacitu),
• E – pocetnost zdroje požadavku, není-li dána, predpokládá se, že je ∞ a jde o tzv.
otevrený systém, v opacném prípade, je-li dána konecným císlem, pak jde o uzavrený
(cyklický) systém,
• F – režim fronty
Nejjednodušším oznacením je trísymbolové A/B/C a nejjednodušším stochastickým mode-
lem je M/M/1 (viz. kapitola 1.7.1). Jestliže nejsou uvedeny další symboly, predpokládá se, že
D a E jsou ∞ a F charakterizuje FIFO, tj. prirozené poradí. [1]
23

1. Teoretická cást
1.7. Jednotlivé modely SHO
V této kapitole jsou prevzaté a upravené vztahy podle [1, 12, 13]. Pro popis jednoduchých
modelu systému hromadné obsluhy nám postací následující základní charakteristiky:
1. λ (intenzita vstupního procesu, tj. prumerný pocet vstupujících požadavku za jed-
notku casu), resp. 1λ (prumerná délka casového intervalu mezi vstupy požadavku)
2. µ (intenzita obsluhy, tj. prumerný pocet požadavku, které mohou být obslouženy
za jednotku casu), resp. 1µ
(prumerný cas strávený požadavkem v obsluze)
Níže uvedená tabulka zavádí znacení dalších základních charakteristik a vztahu mezi nimi
za obvykle splnených podmínek.
prumerný
cas strávený požadavkem pocet požadavku
v obsluze To = 1µ No =λTo
ve fronte T f N f =λT f
v systému Ts = To +T f Ns =λTs = No +N f
Tabulka 1.1.: Vztahy mezi nekterými charakteristikami systému hromadné obsluhy.
Pravdepodobnost, že v systému není žádný požadavek oznacme p0 (resp. pravdepodob-
nosti pn vyjadrují, že v systému je práve n požadavku). Jestliže limitní (cas t → ∞) neboli
stacionární pravdepodobnost p0 existuje a je konecná, pak ríkáme, že je splnena podmínka
stabilizace systému a systém se tak nezahlcuje cekajícími požadavky.
V odborné literature zabývající se pravdepodobnostními modely nebo teorií front je možno
najít ruzné vztahy (napr. pro prumerný pocet požadavku v systému) a jejich analytické od-
vození.
1.7.1. Exponenciální model jednoduché obsluhy M/M/1
Systém M/M/1 je základní a také nejduležitejší model systému hromadné obsluhy, který se
casto využívá ve srovnání s modely ostatními. Jedná se zároven o nejjednodušší a nejobec-
nejší model SHO, kde rozdelení dob mezi príchody a dob obsluhy mají charakter exponen-
ciálního rozdelení. Jedná se o otevrený systém, tzn. zdroj požadavku je neomezený. Velikost
fronty není nijak omezena a zároven všechny požadavky trpelive cekají ve fronte na obsluhu,
i když nedostacuje kapacita systému. Požadavky do systému vstupují v prirozeném poradí,
tzn. systém pracuje v režimu FIFO.
Podmínka stabilizace systému má tvar λ<µ. Oznacíme-li podíl λµ
jako intenzitu provozu ρ,
24

1. Teoretická cást
Obrázek 1.3.: Exponenciální model M/M/1
lze podmínku stabilizace systému vyjádrit ve tvaru
ρ < 1 (1.14)
Potom platí
p0 = 1−ρ (1.15)
a
T f =λ
µ(µ−λ)(1.16)
K výpoctum nekterých dalších užitecných velicin lze snadno použít vztahy v tabulce 1.1.
1.7.2. Exponenciální model vícenásobné obsluhy M/M/c
Jedná se o model s paralelne usporádanými kanály. U takového modelu predpokládáme[8]:
• v systému se nachází c stejných obslužných kanálu
• intervaly mezi príchody požadavku lze popsat exponenciálním rozdelením s parame-
trem λ
• doba obsluhy na každém kanálu je náhodná velicina s exponenciálním rozdelením
s parametrem µ
• systém má neomezenou kapacitu, neomezený zdroj požadavku a funguje v režimu
FIFO
• požadavky mají nekonecnou trpelivost, tzn. cekají ve fronte až do momentu obslou-
žení
Celková intenzita provozu celého systému je rovna výrazu λcµ . Tato charakteristika predsta-
vuje zároven prumerné využití všech obslužných kanálu v systému. Aby fronta neomezene
nenarustala nad všechny meze, je potreba splnit podmínku stabilizace systému, podobne
jako u jednoduchého exponenciálního modelu. V tomto prípade musí platit: cµ>λ, tedy:
λ
cµ= ρ
c< 1 (1.17)
25

1. Teoretická cást
Obrázek 1.4.: Prechodový graf systému M/M/c, prevzato z [12, str.419]
Potom platí
p0 =(
c−1∑i=0
ρi
i !+ ρc
c !
1
1− ρc
)−1
(1.18)
a
T f =p0
λ
(ρc
)c+1
c !
cc(1− ρ
c
)2 (1.19)
1.7.3. Model M/D/1
Jedná se o jednoduchý model, kde intervaly mezi príchody požadavku pocházejí z expo-
nenciální rozdelení a doba obsluhy je dána deterministicky, tedy je pro všechny požadavky
stejná.
Podmínka stabilizace systému má tvar
ρ = λ
µ< 1 (1.20)
Potom platí
p0 = 1−ρ (1.21)
a
T f =λ
2µ(µ−λ)(1.22)
1.7.4. Model D/M/1
V tomto modelu jsou intervaly mezi príchody požadavku do systému konstantní, tj. mají
deterministický charakter. Podmínka stabilizace systému má tvar
ρ = λ
µ< 1 (1.23)
Potom platí
p0 = 1−ρ (1.24)
26

1. Teoretická cást
a
T f =x
µ(1−x)(1.25)
kde x je koren rovnice
x = exp
(x −1
ρ
)(1.26)
hledaný na intervalu(0,1+ρ lnρ
), kde ρ ∈ (0,1).
1.7.5. Model jednoduché obsluhy s omezenou kapacitou M/M/1/K
V tomto prípade se jedná o exponenciální model s jedním kanálem obsluhy a omezenou
kapacitou požadavku v systému. Jejich maximální pocet je roven císlu K , z toho jeden po-
žadavek je obsluhován a ve fronte je maximálne (K −1) požadavku. V prípade, že se do plne
obsazeného systému snaží dostat další požadavek, je odmítnut a dochází ke ztrátám. Sys-
tém je stabilní pro libovolné kladné λ a µ, což platí pro jakýkoli systém s omezenou kapaci-
tou systému, protože se nemuže zahltit cekajícími požadavky. Opet oznacíme ρ = λµ . Potom
platí, že
p0 =
1−ρ1−ρK+1 pro ρ 6= 1
1K+1 pro ρ = 1
(1.27)
a
pn = p0ρn
Dále platí, že
N f =
ρ2(1−ρK )−(1−ρ)KρK+1
(1−ρ)(1−ρK+1)pro ρ 6= 1
K (K−1)2(K+1) pro ρ = 1
(1.28)
Nezapomínejme, že v tomto modelu s omezenou kapacitou se nám vyskytují dve intenzity
príchodu, ponevadž požadavku, který se snaží vstoupit do systému v dobe, kdy je naplnena
jeho kapacita K, není dovoleno vstoupit. λ znací intenzitu, s jakou se požadavky do systému
snaží vstoupit, λ∗ pak oznacuje intenzitu, s jakou požadavky do systému skutecne vstupují.
Platí, že
λ∗ =λ(1−pK )
Ve vztazích v tabulce 1.1 je treba dosazovat intenzitu skutecných príchodu do systému,
tedy λ∗.
Jednoduchý exponenciální model M/M/1/1
Jedná se o speciální prípad systému M/M/1/K, kde k = 1. V takovém systému neexistuje
fronta a vyskytuje se v nem maximálne jeden požadavek, a to v obslužném kanále. Pro popis
SHO slouží také tzv. graf prechodu mezi stavy systému. Za stav systému považujeme pocet
27

1. Teoretická cást
požadavku nacházejících se v daném okamžiku v systému. Príchod nového požadavku zvýší
pocet požadavku o jeden a realizuje prechod systému do vyššího stavu. Naopak ukoncení
obsluhy snižuje pocet požadavku v systému a predstavuje prechod do nižšího stavu SHO.
Jinak SHO zustává v aktuálním stavu. Graf prechodu v tomto systému obsahuje pouze dva
stavy - prázdný systém (stav 0) nebo obsazený obslužný kanál (stav 1).[11]
Obrázek 1.5.: Graf prechodu systému M/M/1/1, zdroj: [11, str. 57]
Graf prechodu je charakterizován maticí prechodu P (t , t + (∆t )).
P (t , t + (∆t )) =1−λ∆t λ∆t
µ∆t 1−µ∆t
S využitím této matice lze odvodit napríklad rozložení pravdepodobností stavu SHO pro
libovolný cas, matici intenzity prechodu nebo pravdepodobnost odmítnutí. Více napríklad
v [11, str. 57].
1.7.6. Uzavrený exponenciální model jednoduché obsluhyM/M/1/./N
V tomto modelu charakterizuje N maximální pocet požadavku ve zdroji vstupních poža-
davku. Po ukoncení obsluhy požadavky systém opouštejí a stávají se znovu prvky množiny
potenciálních požadavku ve zdroji, jde tedy o uzavrený (cyklický) SHO. Intenzita obsluhy
v tomto prípade ovlivnuje intenzitu vstupu požadavku. V rámci uzavreného systému není
velikost fronty omezena a všechny požadavky v ní trpelive cekají na obsluhu, i když nedo-
stacuje kapacita obslužné linky.
V tomto modelu se tedy celkove nachází N požadavku, z nichž každý je bud’ v systému
(ceká na obsluhu, nebo je obsluhován), nebo mimo nej (ve zdroji vstupních požadavku).
λ je v tomto prípade parametr exponenciálního rozdelení, ze kterého pochází casové inter-
valy, po kterou je každý z požadavku mimo systém. Opet tedy platí, že toto λ není tím ve
vztazích v tabulce 1.1. Namísto nej je tak treba dosazovat λ∗, které má požadovaný význam
28

1. Teoretická cást
prumerného poctu vstupujících požadavku za jednotku casu a pro které platí
λ∗ =µ(1−p0)
kde
p0 =(
N∑i=0
ρi N !
(N − i )!
)−1
(1.29)
pricemž jsme opet oznacili ρ = λµ
. Potom platí
N f = N − (1−p0
)(1+ 1
ρ
)(1.30)
1.7.7. Exponenciální model vícenásobné obsluhy s omezenoukapacitou M/M/c/K
Jedná se o systém hromadné obsluhy, ve kterém je kapacita SHO omezena poctem poža-
davku. V systému se jich vyskytuje maximálne K , pricemž muže být soucasne obsluhováno
nejvýše c požadavku a zbývajících maximálne (K − c) ceká ve fronte na obsluhu. Jedná se
tedy o systém se ztrátami. Každá obslužná linka má stejnou intenzitu obsluhy µ, požadavky,
které vstoupily do fronty, trpelive cekají na obsluhu, do které postupují v prirozeném poradí
(FIFO). Pro tento model platí stejne jako pro jeho výše uvedený speciální prípad, kdy c = 1,
že systém je stabilní pro libovolné kladné λ a µ. Stejne pak také ze stejných duvodu platí, že
ve vztazích v tabulce 1.1 je treba dosazovat λ∗ =λ(1−pK ) namísto λ.
Tentokrát oznacíme ρ prumernou intenzitu provozu λµc . Potom platí
p0 =(
c−1∑i=0
(cρ
)i
i !+
K∑i=c
(cρ
)i
c !c i−c
)−1
(1.31)
a
pK = p0ccρK
c !(1.32)
Dále platí
N f = p0ccρc+1
c !(1−ρ)2
[1−ρK−c+1 − (1−ρ)(K − c +1)ρK−c] (1.33)
Modelu hromadné obsluhy existuje celá rada. Z ostatních mužeme jmenovat napríklad sys-
tém M/Er /1/∞. Jedná se o systém s jedním obslužným kanálem, kde príchody jsou rízeny
Poissonovým procesem s parametrem λ a doba obsluhy je náhodná velicina s Erlangovo
rozdelením s parametry k a µ. V naší práci jsme popsali pouze takové modely, které mají
analytické rešení a zároven je budeme v další kapitole simulovat.
29

1. Teoretická cást
1.8. Optimalizace SHO
Modely SHO mají za úkol, krome popisu chování celého systému, sloužit jako nástroj pro
rozhodování a optimalizaci celého systému podle urcených kritérií. Abychom systém mohli
optimalizovat, je nutné mít možnost ovlivnit nekteré jeho prvky a soucasne s tím i základní
charakteristiky efektivnosti. Vedle toho ješte predpokládáme, že mužeme explicitne formu-
lovat kvantitativní kriteriální funkci, která vyjadruje jistý zamýšlený cíl. Budeme-li uvažovat
o jednoduchém exponenciálním modelu, zjistíme, že zmenšováním intenzity obsluhy bude
narustat fronta, prumerný cas ve fronte se prodlouží a muže docházet ke ztrátám u poža-
davku s netrpelivostí. Jestliže intenzitu obsluhy príliš zvýšíme, bude docházet k prostojum
linky. Vznikají zde náklady na provoz, ale bezprostredne jim neodpovídají žádné tržby.
Z pohledu zákazníka muže být cílem optimalizace zkrácení cekací doby, avšak z pohledu
provozovatele systému je duležité mít co nejmenší ztráty na zákaznících, prípadne opti-
malizovat vytížení a pocet obslužných linek. V rozhodovacích úlohách je tedy nutné najít
kompromis, který bude vyhovovat obema stranám. Kriteriální funkce muže být orientována
nákladove, ziskove nebo tak, že kritérium bude predstavovat kritickou hodnotu nekteré ze
základních charakteristik efektivnosti systému obsluhy, kterou nelze prekrocit (napr. ome-
zení prumerné cekací doby, prumerné využití ci prostoje obslužných kanálu). Jestliže cílem
optimalizace je dosažení minima ocekávaných celkových nákladu na provoz SHO, pak kri-
teriální funkce zpravidla zahrnuje následující druhy ztrát [13]:
1. Náklady prostoje obslužné linky v hodnotovém vyjádrení vztažené na jednotku casu.
2. Náklady cekání na obsluhu, popr. náklady setrvání požadavku v systému, vztažené na
jeden požadavek za jednotku casu.
3. Náklady na obsluhu jednoho požadavku za casovou jednotku.
4. Náklady vyvolané ztrátou jednoho požadavku v SHO se ztrátami.
V prípade stabilizovaného exponenciálního systému M/M/c mužeme vyjádrit kriteriální
funkci takto:
N (S) = cn N f + cz S, (1.34)
kde
• cn – hodnotove vyjádrené náklady cekání jednoho požadavku na obsluhu za zvolenou
casovou jednotku,
• cz – ztráty v penežních jednotkách vznikající v dusledku nevyužití jednoho zarízení
obsluhy za jednotku casu,
• N f – prumerná délka fronty,
• S - prumerný pocet nevyužitých zarízení obsluhy.
30

1. Teoretická cást
Ze vztahu 1.34 plyne, že hodnota kriteriální funkce závisí pri konstantních cn a cz na poctu
zarízení obsluhy S, popr. na provozních podmínkách systému. Pri optimalizaci uvedeného
systému je zpravidla cílem urcit takový pocet obslužných kanálu, abychom minimalizovali
celkove ocekávané náklady. Více napríklad v [1, kapitola 7.12] nebo [13, kapitola 9.10].
1.9. Generování náhodných císel a simulace metodouMonte Carlo
Základní charakteristiky reálných systému hromadné obsluhy zpravidla nelze analyticky
odvodit. Toto rešení je dostupné jen pro nejjednodušší modely. Vytvorení simulacního mo-
delu je tak jediným zpusobem, jakým mužeme tyto charakteristiky daného systému získat,
resp. odhadnout.
Simulace se charakterizuje jako experimentování s modelem reálného systému, tedy na-
podobování jeho chování v case. V operacním výzkumu se casto význam termínu "simu-
lace" zužuje na simulaci chování stochastických (nekdy však i deterministických) systému
(modelu) metodou Monte Carlo (MC). Tato simulace probíhá tak, že reálný systém nahra-
díme jeho simulacním modelem se stejnými pravdepodobnostními charakteristikami, a cho-
vání reálného systému mnohonásobne simulujeme na zkonstruovaném modelu. K pres-
nému odhadu dané pravdepodobnostní charakteristiky potrebujeme obvykle velmi mnoho
pokusu. Cím více pokusu provedeme, tím presnejší odhad získáme. [6]
Generování náhodných císel
Základem pro naší simulaci je generování náhodných císel2, resp. pri simulaci metodou
MC slouží vygenerované hodnoty náhodných císel ke generování hodnot náhodných ve-
licin s daným rozdelením. Metod pro transformaci náhodných císel na hodnoty náhodných
velicin s daným rozdelením existuje nekolik, napr. vylucovací(zamítací) metoda, metoda in-
verzní transformace, tabulková metoda.
Metoda inverzní transformace
V našem prípade potrebujeme generovat dobu mezi príchody jednotlivých požadavku a dobu
trvání obsluhy. V obou prípadech se bude jednat o náhodné veliciny s exponenciálním roz-
delením s príslušným parametrem. Pro generování hodnot této veliciny použijeme metodu
inverzní funkce (transformace).
2mechanismy pro generování náhodných císel jsou popsány napr. v kapitole 5.4 v [6]
31

1. Teoretická cást
K aplikaci této metody musíme znát distribucní funkci F náhodné veliciny X . Pritom dis-
tribucní funkce F musí být rostoucí na intervalu ⟨a,b⟩, a musí zobrazovat interval ⟨a,b⟩ na
interval ⟨0,1⟩ [6].
Postup je následující: vygenerujeme náhodné císlo y z rovnomerného rozdelení na intervalu
⟨0,1⟩ a císlo y považujeme za hodnotu distribucní funkce v dosud neznámém bode x: F (x) =y . Z tohoto vztahu vypocteme hodnotu x:
x = F−1(y) (1.35)
kde F−1 oznacuje inverzní funkci k funkci F . Pokud máme náhodnou velicinu X s exponen-
ciálním rozdelením, pak její distribucní funkce je dána vztahem:
F (x) = 1−e−λx (1.36)
Vztah pro generování náhodných hodnot s exponenciálním rozdelením pak mužeme odvo-
dit následovne:
y = F (x) = 1−e−λx
e−λx = 1− y
−λx = ln(1− y)
x =− 1
λln(1− y) =− ln y
λ(1.37)
Zachycení casu v simulacích
Pri simulacních experimentech je nutné rozhodnout, jak vyjádríme dynamické vlastnosti
modelu, tj. jakou strategii zvolíme pro zachycení casu. Existují dve možnosti – metoda pev-
ného casového kroku a metoda promenného casového kroku. V prvním prípade se vždy
po uplynutí pevného casového intervalu zjišt’uje, k jakým zmenám došlo. V metode pro-
menného casového kroku hranice casových kroku predstavují práve ty okamžiky, kdy dojde
ke zmene v systému, napr. prijde nový požadavek do systému nebo se ukoncí obsluha po-
žadavku a požadavek systém opustí. [9]
1.10. Simulacní software
Simulacní software pro dynamickou diskrétní simulaci procesu je v dnešní dobe schopen
predpovedet chování systému dle predem stanovených podmínek. Software zahrnuje návrh
2Jestliže y je náhodné císlo z rovnomerného rozdelení, pak i (1-y) je náhodné císlo z rovnomerného rozdelení
a vztah 1.37 lze takto upravit.
32

1. Teoretická cást
a modelování s nejruznejšími aspekty výroby, vcetne plánování, výberu vybavení, strategie
rízení, manipulaci s materiálem atd. V závislosti na zvolených cílech muže být simulacní
model složitý a datove nárocný. Na druhé strane, simulacní software je pouze analytický ná-
stroj, optimalizovat nebo racionalizovat široký rozsah výrobních systému vyžaduje odborný
zásah. Výstupní parametry, jako napríklad celková produkce, prostoje a využití prístroje, ná-
sledne využívají odborníci pro hodnocení chování systému a urcují oblasti pro možná zdo-
konalení. Základem simulování je generování náhodných císel. [14]
K výhodám patrí jednoduché grafické rozhraní a intuitivní ovládání programu. K prezentaci
výsledku modelování slouží rada grafických výstupu, at’ už jednotlivé grafy, tabulky nebo
celý model. Nejvetším záporem je vysoká porizovací cena. Ta se pohybuje v rádech desetiti-
sícu, nekdy i statisícu. K nejpoužívanejšímu softwaru patrí Simul8, Witness a Arena.
1.10.1. Simul8
Simul8 je jedním z nejrozšírenejších softwarových produktu pro dynamickou diskrétní si-
mulaci podnikových procesu. Lze ho použít napríklad pro modelování výrobních systému,
logistických systému ci systému obsluhy zákazníku nebo poskytování služeb, zvlášte pak
pro modely obsluhy klientu na bankovních prepážkách, volajících klientu v call-centrech
nebo zákazníku u pokladen v supermarketu. Generátor v Simul8 obsahuje 30 000 sekvencí
náhodných císel. Od roku 2006 podporuje software nahrazení vestaveného generátoru ge-
nerátorem vlastním, vytvoreným v dynamické knihovne.
1.10.2. Witness
Witness je simulacní balícek pro simulaci diskrétních událostí spolecnosti Lanner Group
Ltd. Modelovací prostredí je objektove orientované a je založené na teorii front. Ke gene-
rování náhodných císel využívá šesti sekvencí, které se dají uživatelem zmenit. Witness vy-
užívá vygenerované císlo mezi 0 a 1 jako vzorek ze statistického rozložení pro casování a
clenení cinnosti apod.
1.10.3. Arena
Arena využívá implementaci simulacního prostredí SIMAN, které je zamereno predevším na
modelování výrobních procesu. Nejvetší predností tohoto softwaru je jednoduchý grafický
vzhled modelu. Model se vytvárí pomocí umístení jednotlivých ikon na kreslící plochu a po-
mocí propojení ikon nebo bloku uživatel definuje vztahy mezi nimi. Pro generování náhod-
ných císel lze použít prednastavenou sekvenci císel, nebo si uživatel muže vybrat z dalších
10 sekvencí. Všechny distribuce programu generují císla pomocí rovnomerného rozložení
33

1. Teoretická cást
v rozsahu 0 až 1. Studentská verze Areny je dostupná na webových stránkách vydavatele
http://www.arenasimulation.com/.
V tomto softwaru si ukážeme príklad jednoduché fronty s jedním rozhodovacím procesem.
Obrázek 1.6.: Prostredí simulacního programu Arena
Model bude generovat príchody zákazníku jako náhodnou velicinu s exponenciálním rozde-
lením a prumerem 0,5 zákazníka za minutu. Následne se zákazník rozhodne, zda-li pujde do
fronty, nebo ze systému odejde bez obsloužení. Jako podmínku stanovíme napríklad délku
fronty o velikosti 4, tzn. pokud ve fronte bude menší pocet lidí jak 5, zákazník si stoupne do
fronty. Pokud ve fronte bude 5 a více lidí, zákazník odejde neobsloužen. Toto budeme simu-
lovat po dobu 8 hodin. Statistickou analýzu modelu nám software vytvorí sám do formátu
pdf.
Obrázek 1.7.: Vývojový diagram modelu
34

1. Teoretická cást
Obrázek 1.8.: Nastavení generování príchodu zákazníku
Obrázek 1.9.: Nastavení rozhodovacího procesu
35

1. Teoretická cást
Obrázek 1.10.: Nastavení obsluhy
Obrázek 1.11.: Výsledky simulace
36

1. Teoretická cást
Obrázek 1.12.: Analýza simulace - obsluha
Obrázek 1.13.: Analýza simulace - fronta
37
1. Teoretická cást
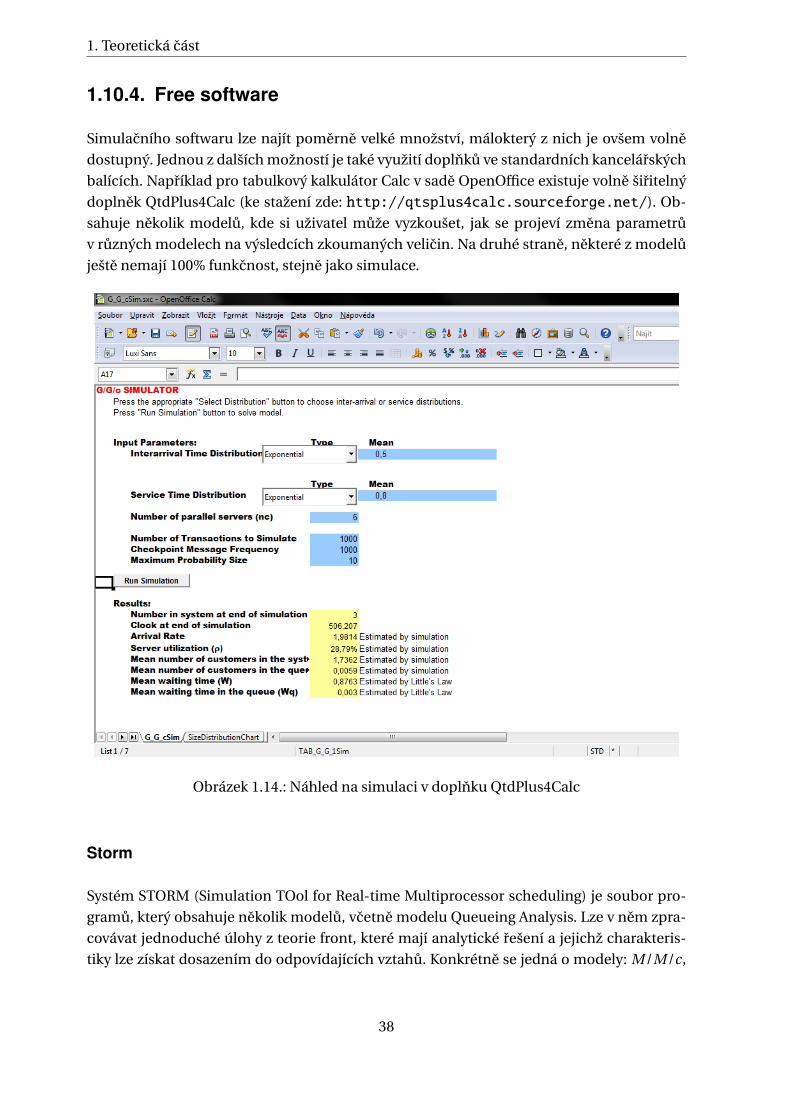
1.10.4. Free software
Simulacního softwaru lze najít pomerne velké množství, málokterý z nich je ovšem volne
dostupný. Jednou z dalších možností je také využití doplnku ve standardních kancelárských
balících. Napríklad pro tabulkový kalkulátor Calc v sade OpenOffice existuje volne širitelný
doplnek QtdPlus4Calc (ke stažení zde: http://qtsplus4calc.sourceforge.net/). Ob-
sahuje nekolik modelu, kde si uživatel muže vyzkoušet, jak se projeví zmena parametru
v ruzných modelech na výsledcích zkoumaných velicin. Na druhé strane, nekteré z modelu
ješte nemají 100% funkcnost, stejne jako simulace.
Obrázek 1.14.: Náhled na simulaci v doplnku QtdPlus4Calc
Storm
Systém STORM (Simulation TOol for Real-time Multiprocessor scheduling) je soubor pro-
gramu, který obsahuje nekolik modelu, vcetne modelu Queueing Analysis. Lze v nem zpra-
covávat jednoduché úlohy z teorie front, které mají analytické rešení a jejichž charakteris-
tiky lze získat dosazením do odpovídajících vztahu. Konkrétne se jedná o modely: M/M/c,
38

1. Teoretická cást
M/M/c/K , M/M/c/K /K , M/D/c a M/G/c. STORM umožnuje i optimalizace systému hro-
madné obsluhy. [13] Ovládá se pomocí jazyka Java, samotná simulace se provádí pomocí
souboru XML. Její výsledky jsou zpracovány do diagramu, tabulek a dalších souboru pro
následnou analýzu. STORM je volne širitelný software pod licencí Creative Commons, je
dostupný na webových stránkách http://storm.rts-software.org/.
39


2. Simulace vybraných modelusystému hromadné obsluhy
Všechny simulacní modely, které budou predstaveny na následujících stránkách práce, jsou
napsány v jazyce C#. Každý model má v sobe obsažené výpocty duležitých charakteristik
systému, které se pocítají jak ze samotné simulace, tak analyticky dle zavedených vzorcu
v teoretické cásti. Výsledkem simulace je práve srovnání takto získaných hodnot. V simula-
cích nejsou zavedeny podmínky stabilizace jednotlivých modelu. Ukoncovací podmínkou
pro každý model je urcený cas, po jehož uplynutí požadavky nejsou vpušteny do systému.
V tabulkách s výsledky je používáno znacení zavedené v teoretické cásti.
2.1. Simulace modelu M/M/1
Jak bylo zmíneno v teoretické cásti práce, model M/M/1 znací jeden kanál obsluhy, který
pracuje v režimu FIFO a fronta požadavku je neomezená. Intenzitu príchodu predstavuje
Poissonuv proces s parametrem λ, v tomto prípade doby mezi jednotlivými príchody mají
exponenciální rozdelení s parametrem 1λ a doba obsluhy je také náhodná velicina s expo-
nenciálním rozdelením s parametrem µ.
V systému jsou pouze dve hlavní události - príchod nového požadavku do systému a odchod
požadavku, který dokoncil obsluhu.
Listing 2.1: Ukázkový kód pro model M/M/1
Random rnd = new Random(DateTime.Now.Millisecond); / / g e n e r a t o r
nahodnych c i s e l
double tgen; / / gene ro v any c a s
double lambda=1.0; / / i n t e n z i t a p r i c h o d u
double lambda_rec=1/lambda; / / p r e v r a c e n a hodnota i n t e n z i t y p r i c h o d u
= s t r e d n i doba mezi p r i c h o d y
double mu=1.25; / / i n t e n z i t a o b s l u h y
double mu_rec=1/mu; / / p r e v r a c e n a hodnota i n t e n z i t y o b s l u h y = s t r e d n i
doba o b s l u h y
double tp=0; / / c a s p r i c h o d u d a l s i h o z a k a z n i k a ( uvazujeme , ze do
systemu v s t u p u j e 1 . z a k a z n i k v ~ c a s e 0 )
double to; / / c a s odchodu p o s l e d n i h o obsluhovaneho z a k a z n i k a
41

2. Simulace vybraných modelu systému hromadné obsluhy
int i=1; / / p o c e t o b s l o u z e n y c h z a k a z n i k u
double tp_sum=0, to_sum=0, tf_sum=0, te_sum=0; / / pro v y p o c e t
prumerne doby mezi p r i c h o d y , doby obsluhy , doby c e k a n i ve f r o n t e
a doby , po k t e r o u j e system prazdny
/ / generujeme c a s odchodu 1 . z a k a z n i k a
tgen=-Math.Log(rnd.NextDouble())*mu_rec; to_sum+=tgen;
to=tgen;
while(true)/ / generujeme c a s p r i c h o d u d a l s i h o z a k a z n i k a
tgen=-Math.Log(rnd.NextDouble())*lambda_rec; tp_sum+=tgen;
tp+=tgen;
if(tp>1000000) break;i++;
if(tp<to) / / do systemu v c h a z i d a l s i z a k a z n i k , k t e r y s e r a d i
do f r o n t y ( p r e p a z k a j e obsazena ) a ceka ( generujeme c a s
j e h o odchodu )
tf_sum+=to-tp; / / v y p o c e t doby c e k a n i ve f r o n t e
tgen=-Math.Log(rnd.NextDouble())*mu_rec; to_sum+=tgen;
to+=tgen;
else / / do systemu v c h a z i d a l s i z a k a z n i k , k t e r y j d e o k a m z i t e
k~volne prepazce (generujeme cas jeho odchodu)
te_sum+=tp-to; / / v y p o c e t doby , po k t e r o u j e system prazdny
tgen=-Math.Log(rnd.NextDouble())*mu_rec; to_sum+=tgen;
to=tp+tgen;
Model jsme otestovali se vstupními parametry λ = 1,0 a µ = 1,25 s konecnými casy 1 000,
10 000, 100 000, 1 000 000. Výsledky jsou v tabulce 2.1. Se zvyšující se hodnotou konecného
casu je videt, že se výsledky v souladu s predpokladem približují analytickému rešení. Další
výsledky s jinými testovanými vstupními parametry jsou v tabulce 2.2.
Klasickým príkladem tohoto modelu muže být napríklad fronta u lékare. Pacienti jsou ob-
sluhováni jeden po druhém a trpelive cekají, až prijdou na radu.
42

2. Simulace vybraných modelu systému hromadné obsluhy
Testovaný cas Obslouženo λ−1 To T f p0
1 000 1 031 0,9709 0,8141 3,8666 0,1646
10 000 10 064 0,9937 0,8067 3,3043 0,1882
100 000 100 285 0,9972 0,8027 3,2298 0,1951
1 000 000 997 793 1,0022 0,7997 3,1695 0,2021
10 000 000 10 003 431 0,9997 0,7999 3,2030 0,1997
Analyticky: — 1,0 0,8 3,2 0,2
Tabulka 2.1.: Porovnání analytického a simulacního rešení modelu M/M/1
Cas simulace λ= 1,5 λ= 1,1 λ= 1
1 000 000 µ= 3 µ= 1,5 µ= 1,1
Výsledky: simulace analyt. simulace analyt. simulace analyt.
Obslouženo: 1 498 623 ——- 1 101 566 ——- 998 729 ——-
λ−1: 0,66728 0,66667 0,90780 0,90909 1,00127 1,00000
To : 0,33325 0,33333 0,66732 0,66667 0,90926 0,90909
T f : 0,33238 0,33333 1,85575 1,83333 8,97006 9,09091
p0: 0,50059 0,50000 0,26490 0,26667 0,09191 0,09091
Tabulka 2.2.: Testování modelu M/M/1
2.2. Simulace modelu M/D/1
Tento model se liší od predchozího jen v tom, že negenerujeme dobu obsluhy pro jednotlivé
požadavky, ale priradíme jim konstantu. Všechny požadavky budou obsluhovány stejnou
dobu. Volíme µ = 1.75, doba obsluhy každého požadavku je µ−1.
Test. cas Obslouženo λ−1 T f T p0
1 000 1 512 0,6620 1,7938 2,3653 0,1372
10 000 14 797 0,6758 1,4115 1,9830 0,1544
100 000 150 261 0,6655 1,8429 2,4143 0,1414
1 000 000 1 499 800 0,6667 1,6830 2,2544 0,1430
10 000 000 14 993 647 0,6667 1,7003 2,2717 0,1432
Analyticky: — 0,6667 1,7143 2,2857 0,1429
Tabulka 2.3.: Porovnání analytického a simulacního rešení modelu M/D/1
43

2. Simulace vybraných modelu systému hromadné obsluhy
Cas simulace λ= 3 λ= 2,8 λ= 2,85
1 000 000 µ= 10 µ= 5 µ= 3
Výsledky: simulace analyt. simulace analyt. simulace analyt.
Obslouženo: 2 997 622 — 2 800 850 — 2 847 274 —
λ−1: 0,33360 0,33333 0,35703 0,35714 0,35121 0,35088
T f : 0,02131 0,02143 0,12736 0,12727 3,15909 3,16667
T : 0,12131 0,12143 0,32736 0,32727 3,49242 3,50000
p0: 0,70024 0,70000 0,43983 0,44000 0,05091 0,05000
Tabulka 2.4.: Testování modelu M/D/1
Tento model si lze predstavit jako ústní zkoušení studentu. Zkoušející zde hraje roli obslužné
linky a je zpravidla jen jeden. Doba obsluhy, tedy samotné zkoušení studenta, je konstantní.
2.3. Simulace modelu D/M/1
Tento model je stejný jako model M/M/1, jen místo generování casu príchodu zákazníku
zvolíme konstantní rozdíl mezi jednotlivými príchody (λ = 1). Navíc ješte potrebujeme vy-
hledat koren rovnice 1.26. V našem prípade jsme zvolili vyhledání korene pomocí metody
pulení intervalu (viz. [15]).
Listing 2.2: Ukázka kódu metody bisekce
static double KorenBisekci(double lambda, double mu)
double rho = lambda / mu;double a = -0.000001, b = 1 + rho * Math.Log(rho);double stred = (a + b) / 2;
while (!(stred.Equals(a) || stred.Equals(b)))
if (f(a, rho) * f(stred, rho) < 0) b = stred;else a = stred;
stred = (a + b) / 2;
return stred;
44

2. Simulace vybraných modelu systému hromadné obsluhy
Test. cas Obslouženo To T f T p0
1 000 1 500 0,5606 0,9816 1,5422 0,1596
10 000 15 000 0,5618 1,2748 1,8366 0,1574
100 000 150 000 0,5721 1,5180 2,0900 0,1420
1 000 000 1 500 000 0,5716 1,5298 2,1015 0,1425
10 000 000 15 000 000 0,5713 1,5354 2,1067 0,1431
Analyticky: —– 0,5714 1,5339 2,1054 0,1429
Tabulka 2.5.: Porovnání analytického a simulacního rešení modelu D/M/1
Cas simulace λ= 3 λ= 0,5 λ= 10
1 000 000 µ= 8 µ= 0,8 µ= 12
Výsledky: simulace analyt. simulace analyt. simulace analyt.
Obslouženo: 3 000 000 ——- 500 000 ——- 10 000 000 ——-
To : 0,12500 0,12500 1,24918 1,25000 0,08332 0,08333
T f : 0,01198 0,01203 0,69705 0,69701 0,18214 0,18231
T : 0,13698 0,13703 1,94624 1,94710 0,26547 0,26565
p0: 0,62499 0,62500 0,37541 0,37500 0,16678 0,16667
Tabulka 2.6.: Testování modelu D/M/1
2.4. Simulace modelu M/M/c
Simulace probíhá obdobne jako v prípade jednoduché obsluhy modelu M/M/1. Jediným roz-
dílem je pocet obslužných míst. Pro tento prípad si potrebujeme uchovávat informace o od-
chodu jednotlivých zákazníku nacházejících se v sytému, podle kterých pak rozhodujeme,
ke kterému kanálu pristoupí další požadavek. V našem prípade požadavek vstoupí do ka-
nálu, který je nejdéle volný (hledáme minimum v dobách odchodu).
Uvažujme exponenciální systém hromadné obsluhy se dvema obslužnými linkami, neome-
zeným zdrojem požadavku, jež trpelive vyckávají ve fronte, která funguje v režimu FIFO.
Tabulka 2.7 pak znázornuje prubeh simulace se vstupními parametry λ = 1,5 a µ = 1.2 a
casový úsek 20 minut.
V tabulce 2.8 je videt znacné odchýlení simulacních a analytických výsledku. To je zpuso-
beno krátkým testovaným casem (20 minut). Proto model otestujeme v ruzných casových
úsecích, stejne jako modely ostatní.
45

2. Simulace vybraných modelu systému hromadné obsluhy
cas doba 1. kanál 1. kanál 2. kanál 2.kanál doba, doba
vstupu obsluhy obsluhy obsluhy obsluhy obsluhy po kterou cekání
požadavku zacátek konec zacátek konec v systému na
není žádný obsluhu
požadavek
08:00:00 00:49 08:00:00 08:00:49
08:00:04 01:42 08:00:04 08:01:46
08:00:52 00:16 08:00:52 08:01:08
08:02:00 00:11 08:02:00 08:02:11 00:14
08:03:01 00:05 08:03:01 08:03:06 00:50
08:03:17 01:23 08:03:17 08:04:40 00:11
08:03:46 00:05 08:03:46 08:03:51
08:05:00 00:19 08:05:00 08:05:19 00:20
08:05:21 00:28 08:05:21 08:05:49 00:02
08:05:32 00:41 08:05:32 08:06:13
08:07:02 01:51 08:07:02 08:08:53 00:49
08:08:49 00:07 08:08:49 08:08:56
08:09:59 00:19 08:09:59 08:10:18 01:03
08:10:28 00:49 08:10:28 08:11:17 00:10
08:10:58 01:04 08:10:58 08:12:02
08:11:27 01:38 08:11:27 08:13:05
08:11:38 00:04 08:12:02 08:12:06 00:24
08:12:03 01:38 08:12:06 08:13:44 00:03
08:12:11 00:22 08:13:05 08:13:27 00:54
08:12:16 01:26 08:13:27 08:14:53 01:11
08:13:12 02:14 08:13:44 08:15:58 00:32
08:14:52 01:12 08:14:53 08:16:05 00:01
08:15:24 01:15 08:15:58 08:17:13 00:34
08:15:46 00:45 08:16:05 08:16:50 00:19
08:17:37 00:40 08:17:37 08:18:17 00:24
08:18:22 00:08 08:18:22 08:18:30 00:05
08:19:14 00:18 08:19:14 08:19:32 00:44
Tabulka 2.7.: Ukázka simulace modelu M/M/c systému hromadné obsluhy
46

2. Simulace vybraných modelu systému hromadné obsluhy
Srovnání výsledku: simulacní analytické
Prumerná doba mezi príchody: 0,76234568 0,66666667
Prumerná doba obsluhy: 0,80802469 0,83333333
Prumerná doba cekání v systému: 0,14691358 0,53418803
Pravdepodobnost, že systém je prázdný: 0,24914676 0,23076923
Tabulka 2.8.: Výsledky simulace modelu M/M/c pro krátký casový úsek
Test. cas Obslouženo λ−1 To T f T p0
1 000 1 531 0,6535 0,8178 0,4752 1,2930 0,2330
10 000 15 116 0,6616 0,8417 0,5588 1,4005 0,2230
100 000 149 966 0,6668 0,8340 0,5279 1,3619 0,2305
1 000 000 1 500 130 0,6666 0,8321 0,5295 1,3616 0,2314
10 000 000 14 999 173 0,6667 0,8332 0,5346 1,3678 0,2308
Analyticky: — 0,6667 0,8333 0,5342 1,3675 0,2308
Tabulka 2.9.: Porovnání analytického a simulacního rešení modelu M/M/c
Cas simulace λ= 3.05 λ= 0,8
1 000 000 µ= 1.2 µ= 1
Pocet prepážek: 3 5 10 3 5 10
Obslouženo: 3 051 129 3 052 113 3 052 390 798 396 799 187 800 128
λ−1: 0,32775 0,32764 0,32762 1,25251 1,25128 1,24980
To : 0,83362 0,83282 0,83324 0,99973 0,99979 1,00238
T f : 1,32991 0,04645 0,00004 0,02316 0,00032 0,00000
T : 2,16353 0,87929 0,83328 1,02289 1,00011 1,00238
p0: 0,04042 0,07671 0,07894 0,44794 0,44978 0,44863
Tabulka 2.10.: Simulacní výsledky pro model M/M/c s ruznými pocty prepážek
Položme si nyní otázku: Máme dva systémy hromadné obsluhy. První z nich je jednokaná-
lový systém M/M/1, v nemž má kanál obsluhy intenzitu 3µ, druhý systém je systém M/M/3,
kde jednotlivé kanály mají intenzitu obsluhy µ. Který z nich je výhodnejší pro zákazníka?
V tabulce 2.11 na následující strane vidíme, že pokud zvýšíme pocet prepážek a rozdelíme
intenzitu obsluhy mezi ne, tak to ješte neznamená, že se nám zrychlí celý proces požadavku
v systému. Sice se nám sníží cas strávený ve fronte, na druhou stranu intenzita obsluhy muže
47

2. Simulace vybraných modelu systému hromadné obsluhy
Cas simulace λ= 0,8 λ= 3 λ= 1,5
1 000 000 µ= 3 µ= 1 µ= 3,6 µ= 1,2 µ= 2,1 µ= 0,7
Pocet prepážek: 1 3 1 3 1 3
Obslouženo: 800 515 800 587 2 999 571 3 002 020 1 500 733 1 500 021
λ−1: 1,24919 1,24908 0,33338 0,33311 0,66634 0,66666
To : 0,33310 1,00126 0,27780 0,83291 0,47603 1,42750
T f : 0,12115 0,02410 1,38012 1,18357 1,19962 0,85389
T : 0,45425 1,02536 1,65796 2,01648 1,67566 2,28129
p0: 0,73336 0,44685 0,16672 0,04495 0,28560 0,08967
Tabulka 2.11.: Srovnání modelu M/M/1 a M/M/3
být tak pomalá, že celkový cas strávený v systému bude nakonec vetší, než v prípade s jed-
nou prepážkou.
S tímto modelem se mužeme setkat napríklad v bankách nebo v supermarketech.
2.5. Simulace modelu M/M/1/K
U tohoto modelu máme omezenou kapacitu požadavku v systému. Všechny požadavky,
které se snaží do systému vstoupit pri naplnení kapacity K , jsou odmítnuty a do systému vu-
bec nevstoupí. I v tomto prípade si potrebujeme uchovávat údaje o odchodech požadavku
v systému. V momente, kdy se vygeneruje príchod požadavku, odstraníme ze seznamu ty,
které už v systému nejsou a následne mužeme rozhodnout, zda požadavek bude vpušten do
systému ci nikoliv na základe naplnení kapacity systému.
Listing 2.3: Rozdíl kódu pro model M/M/1/K oproti modelu M/M/1
int K~= 5; / / k a p a c i t a systemu
LinkedList <double> Lto = new LinkedList <double >(); / / seznam casu
odchodu
/ / generujeme c a s odchodu 1 . z a k a z n i k a
tgen = -Math.Log(rnd.NextDouble()) * mu_rec; to_sum += tgen;
to = tgen;
Lto.AddLast(to);
while (true)
/ / generujeme c a s p r i c h o d u d a l s i h o z a k a z n i k a
48

2. Simulace vybraných modelu systému hromadné obsluhy
....
/ / vyradime ze seznamu z a k a z n i k u t y , k t e r i v ~danem c a s e j i z v ~
systemu n e j s o u p r i t o m n i
for (int j = 0; j < Lto.Count; j++)
if (Lto.First.Value < tp) Lto.RemoveFirst();else break;
if (Lto.Count < K) / / k a p a c i t a systemu n e ni naplnena
i++;
if (tp < to) / / do systemu v c h a z i d a l s i z a k a z n i k , k t e r y s e r a d i do
f r o n t y ( p r e p a z k a j e obsazena ) a ceka ( generujeme c a s
j e h o odchodu )
....
Lto.AddLast(to);
else / / do systemu v c h a z i d a l s i z a k a z n i k , k t e r y j d e o k a m z i t e k~
v o l n e p r e p a z c e ( generujeme c a s j e h o odchodu )
....
Lto.AddLast(to);
Testujeme se vstupními parametry: λ= 1,5, µ= 1,75 a kapacita systému K = 5.
Test. cas Obslouženo λ∗ To T f T p0
1 000 1 322 0,7566 0,5801 0,9847 1,5648 0,2349
10 000 13 504 0,7406 0,5706 0,9516 1,5222 0,2296
100 000 133 342 0,7499 0,5734 0,9812 1,5546 0,2354
1 000 000 1 336 658 0,7481 0,5710 0,9652 1,5362 0,2368
10 000 000 13 357 286 0,7487 0,5714 0,9678 1,5398 0,2367
Analyticky: — 0,7487 0,5714 0,9685 1,5399 0,2367
Tabulka 2.12.: Porovnání analytického a simulacního rešení modelu M/M/1/K
Typickým príkladem tohoto systému, jak je uvedeno napríklad i v [13], je situace, kdy v to-
várne máme nekolik stroju a na starosti je má práve jeden údržbár. Délka intervalu bezpo-
ruchového provozu jednotlivých stroju odpovídá intenzite vstupu požadavku do systému,
49

2. Simulace vybraných modelu systému hromadné obsluhy
Cas simulace λ= 1,5 λ= 3 λ= 1,2
1 000 000 µ= 2 µ= 5 µ= 1,3
Kapacita K : 5 10 2 20 8 15
Obslouženo: 1 391 518 1 477 876 2 447 844 2 999 519 1 106 264 1 161 603
λ∗: 0,71864 0,67665 0,40852 0,33338 0,90395 0,86094
To : 0,49905 0,50034 0,20013 0,20003 0,76875 0,76923
T f : 0,71936 1,20194 0,07503 0,29941 2,36976 4,26210
T : 1,21841 1,70228 0,27516 0,49944 3,13851 5,03133
p0: 0,30557 0,26056 0,51011 0,40000 0,14955 0,10652
Tabulka 2.13.: Testování modelu M/M/1/K
doba oprav každého stroje je pak dobou obsluhy.
2.6. Simulace modelu M/M/c/K
V tomto modelu, stejne jako v predchozím máme omezený pocet požadavku v systému.
Speciálním prípadem tohoto modelu je model, kdy c = K . V systému se tedy nachází takový
pocet požadavku, který je roven poctu obslužných linek. V takovém systému požadavky ne-
musí cekat na obsluhu, jedná se tedy o systém s nulovým casem stráveným ve fronte.
Listing 2.4: Rozdíl kódu pro model M/M/c/K oproti modelu M/M/1/K
LinkedList <double> Lto = new LinkedList <double >(); / / seznam casu
odchodu
LinkedListNode <double> Ln;
while (true)
if (Lto.Count < K)/ / n e j p r v e vyradime ze seznamu z a k a z n i k u t y , k t e r i v ~danem c a s e
j i z v ~ systemu n e j s o u p r i t o m n i
/ / k a p a c i t a systemu n e n i naplnena
i++;
i_to_min = IndexMin(to, c, out to_min); / / hledame prepazku ,
k t e r a j e v o l n a r e s p . bude j a k o p r v n i v o l n a
if (tp < to_min)
50

2. Simulace vybraných modelu systému hromadné obsluhy
/ / do systemu v c h a z i d a l s i z a k a z n i k , k t e r y s e r a d i do f r o n t y (
vsechny p r e p a z k y j s o u obsazene ) a ceka
else / / do systemu v c h a z i d a l s i z a k a z n i k , k t e r y j d e o k a m z i t e k~
v o l n e p r e p a z c e ( generujeme c a s j e h o odchodu )
/ / z a r a z u j e m e v y g e n e r o v a n y casu odchodu p r i c h o z i h o z a k a z n i k a na
s e r a z e n y seznam casu odchodu
if (Lto.Count == 0 || Lto.First.Value >= to[i_to_min])Lto.AddFirst(to[i_to_min]);
else
Ln = Lto.Last;
for (int j = 0; j < Lto.Count; j++)
if (Ln.Value < to[i_to_min])
Lto.AddAfter(Ln, to[i_to_min]);
break;
Ln = Ln.Previous;
Vstupní parametry pro první test zvolíme: λ= 1,5,µ= 0,75,c = 3,K = 10.
Test. cas Obslouženo λ∗ To T f T p0
1 000 1 437 0,6959 1,3977 0,4303 1,8281 0,0996
10 000 14 788 0,6763 1,3314 0,4826 1,8140 0,1170
100 000 148 469 0,6735 1,3386 0,4963 1,8350 0,1134
1 000 000 1 485 831 0,6730 1,3321 0,4859 1,8180 0,1139
10 000 000 14 873 881 0,6723 1,3338 0,4912 1,8250 0,1128
Analyticky: — 0,6726 1,3333 0,4897 1,8231 0,1131
Tabulka 2.14.: Porovnání analytického a simulacního rešení modelu M/M/c/K
Príkladem tohoto systému muže být benzinová cerpací stanice, kde je pocet obslužných
míst dán poctem pump a maximální pocet míst v systému je omezen prostorem, do kterého
se vejde práve K aut.
51

2. Simulace vybraných modelu systému hromadné obsluhy
Cas simulace λ= 1,5 λ= 10
1 000 000 µ= 2 µ= 5
Pocet prepážek c: 2 9 15
Kapacita K : 7 10 15
Obslouženo: 1 497 403 1 498 234 10 000 839
λ∗: 0,66782 0,66745 0,09999
To : 0,49933 0,50057 0,19993
T f : 0,07918 0,00102 0,00000
T : 0,57850 0,50057 0,19993
p0: 0,45570 0,47230 0,13548
Tabulka 2.15.: Testování modelu M/M/c/K
2.7. Simulace modelu M/M/1/./N
V tomto prípade máme jednoduchý exponenciální systém a k dispozici je omezený pocet
požadavku, které cyklicky do systému vstupují (ne však nutne ve stejném poradí), jsou ob-
slouženi a vystupují ze systému. Po každém obsloužení požadavku je vygenerován jeho nový
príchod do systému a tato hodnota uložena. Minimum z techto hodnot pak udává, který po-
žadavek prijde k obsluze jako další.
Vstupními parametry modelu jsou: λ= 1.5, µ= 13, pocet požadavku N = 15.
Test. cas Obslouženo λ∗ To T f T p0
1 000 12 704 0,0787 0,0776 0,4355 0,5131 0,0151
10 000 128 370 0,0779 0,0767 0,4264 0,5031 0,0154
100 000 1 278 654 0,0785 0,0771 0,4282 0,5051 0,0155
1 000 000 12 796 378 0,0782 0,0769 0,4288 0,5057 0,0155
10 000 000 127 985 907 0,0781 0,0769 0,4284 0,5054 0,0156
Analyticky: — 0,0781 0,0769 0,4286 0,5055 0,0156
Tabulka 2.16.: Porovnání analytického a simulacního rešení modelu M/M/1/./N
52

2. Simulace vybraných modelu systému hromadné obsluhy
Listing 2.5: Ukázka kódu pro model M/M/1/./N
...
int j; / / i n d e x a k t u a l n i h o z a k a z n i k a
int N = 15; / / p o c e t z a k a z n i k u
/ / generujeme c a s y p r i c h o d u z a k a z n i k u
for (j = 0; j < N; j++)tp[j] = -Math.Log(rnd.NextDouble()) * lambda_rec;
j = IndexMin(tp, N, out t); tp_sum = -t;
while (true)
/ / z j i s t u j e m e c a s p r i c h o d u d a l s i h o z a k a z n i k a
j = IndexMin(tp, N, out t);if (t < to) / / do systemu v c h a z i d a l s i z a k a z n i k , k t e r y s e r a d i do f r o n t y (
p r e p a z k a j e obsazena ) a ceka
....
else / / do systemu v c h a z i d a l s i z a k a z n i k , k t e r y j d e o k a m z i t e k~
v o l n e p r e p a z c e
.....
j = IndexMin(tp, N, out t);
static int IndexMin(double[] pole, int N, out double min) / / v r a c i
i n d e x prvku s ~ n e j m e n s i hodnotou v ~ p o l i
int IMin = 0;min = pole[IMin];
for (int i = 1; i < N; i++)
if (pole[i] < min)
IMin = i;
min = pole[IMin];
return IMin;
53

2. Simulace vybraných modelu systému hromadné obsluhy
Cas simulace λ= 1,5 λ= 5 λ= 1,3
1 000 000 µ= 13 µ= 13 µ= 1,5
Pocet požadavku N : 5 15 5 15 5 15
Obslouženo: 635 904 1 279 529 1 200 470 1 299 983 149 301 150 249
λ∗: 0,15723 0,07815 0,08330 0,07692 0,66980 0,66557
To : 0,07695 0,07693 0,07684 0,07692 0,66610 0,66560
T f : 0,04203 0,42796 0,13950 0,87674 1,91135 8,55114
T : 0,11897 0,50489 0,21634 0,95367 2,57745 9,21674
p0: 0,51069 0,01565 0,07760 0,00010 0,00525 0,00000
Tabulka 2.17.: Testování modelu M/M/1/./N
Príkladem tohoto modelu muže být opet továrna s nekolika stroji, u nichž dochází k poru-
chám, které spravuje nekolik opraváru.
Všechny výše uvedené modely, resp. jejich zdrojové kódy, jsou priloženy na CD ve složce
Simulace.
54

3. Prípadová studie
Pro konkrétní analýzu systému hromadné obsluhy byla vybrána pobocka Ceské pošty, s.p.,
která se nachází v Ústí nad Labem, a její vyvolávací systém. Tento systém lze charakterizovat
jako otevrený, nebot’ pocet požadavku je nekonecný a velikost fronty není kapacitne ome-
zena. Jelikož zákazníci do systému vstupují v náhodných casových intervalech, mužeme kla-
sifikovat vstupní tok jako stochastickou velicinu.
Ceská pošta, s.p. pro naší práci poskytla údaje z vyvolávacího systému jedné pobocky za rocní
období od dubna 2013 do brezna roku 2014. V datech nejsou zaznamenány údaje ze dnu 17.
- 21. ríjna 2013, nebot’ došlo k poruše systému. Tato pobocka má standardní provozní dobu
ve všední dny 8 - 18 hod., v soboty 8 - 12 hod. Data ze systému jsou exportována do formátu
CSV. Puvodní data, ze kterých byla vyjmuta jména pracovníku, se nachází v príloze ve složce
Data VS. 1
Vyvolávací systém poskytuje podniku údaje o casech príchodu jednotlivých požadavku, dobu
trvání obsluhy a dobu cekání ve fronte. V tomto prípade lze disciplínu cekání ve fronte cha-
rakterizovat jako cekání s mírou netrpelivosti. Ta je však u každého zákazníka jiná, jedná
se tedy o náhodnou velicinu. Klient, který opustí systém dríve, než je obsloužen, zustává
v systému zaregistrován jako cekající požadavek. Po jeho vyvolání, kdy se klient k prepážce
opakovane nedostaví, je oznacen za obslouženého zákazníka s minimální dobou obsluhy.
Muže tak docházet ke zkreslení údaju o poctu obsloužených klientu a jejich dobe obsluhy.
Informace o tom, jak se z fronty vybírá klient, který prijde na radu v momente, kdy se uvolní
prepážka, jsme nezískali, resp. nebylo možné nám je poskytnout jakožto tretí strane. Víme
jen obecné informace, napríklad to, že systém umožnuje pracovat s relativní prioritou po-
žadavku, která se obcas využívá pro duchodovou službu, v závislosti na výplatních dnech
duchodu.
1V rámci dohody s Ceskou poštou o využití dat v bakalárské práci, nesmí být zverejnena jména zamestnancu,
ani informace o tom, ze které pobocky data pochází.
55

3. Prípadová studie
V každém souboru najdeme data zpracovaná pro jeden mesíc, a to vždy s následujícími
údaji:
• Datum
• Cas - konkrétní cas ve formátu hh:mm:ss
• Událost - urcuje, co se deje v systému, prípadne se systémem. Narazíme tu na položky:
– Inicializace jednotky
– Aktivace systému
– Diagnostika - Automatické smazání fronty
– Prihlášení obsluhujícího
– Zarazení do fronty, tisk.2, odhad cekání [s] - systém dokáže predpovídat dobu
cekání klienta v závislosti na soucasném vytížení prepážek
– Vyvolání klienta
– Opakované vyvolání klienta
– Ukoncení obsluhy
– Vyvolání klienta mimo poradí
– Odhlášení obsluhujícího
– Deaktivace systému
• Klient - oznacení klienta poradovým císlem, pod kterým vystupuje v celém systému
• Cinnost - oznacení pro službu, kterou klient požaduje (služby jsou oznaceny T01 -
T09)
• Prepážka - poradová císla pro prepážky P01 - P11
• Doba cekání klienta
• Doba obsluhy klienta
Pro zpracování dat od Ceské pošty,s.p. byla vytvorena jednoduchá aplikace v jazyce C#, která
zpracovává údaje do grafu a vygeneruje potrebná data do souboru CSV. Následná statistická
analýza byla provádena v tabulkovém kalkulátoru.
56

3. Prípadová studie
3.1. Analýza príchodu zákazníku
Testy dobré shody
Test χ2 dobré shody užíváme v prípade, kdy chceme na základe jednoho náhodného výberu
o rozsahu n rozhodnout o tom, jestli zamítnout nebo naopak nezamítnout hypotézu, zda
náhodný výber pochází ze zcela konkrétního rozdelení.
3.1.1. Test dobré shody na Poissonovo rozložení
V našem prvním prípade budeme zkoumat, zda príchody zákazníku do systému mají Pois-
sonovo rozdelení.
Zvolíme hypotézy:
• nulová hypotéza H0 - namerená data se rídí predpokládaným Poissonovo rozdelením,
• alternativní hypotéza - H1 data se Poissonovo rozdelením nerídí.
Za náhodný výber budeme považovat pocet príchodu zákazníku ze dne 30. zárí 2013 a to
v desetiminutových intervalech za celý den, tedy od casu 7:58 do 17:58. Poslední klient dora-
zil na poštu v case 17:51:07. Pocet klientu v jednotlivých intervalech si necháme vygenerovat
naší aplikací do souboru ve formátu csv.
Zvolení hladiny významnosti. Standardne se volí α z intervalu (0.01, 0.10). V našem prípade
otestujeme více variant, zvolíme "tradicní" hladiny:
α0 = 0,10 α1 = 0,05 α2 = 0,025 α3 = 0,01
Testovací kritérium je ve tvaru:
χ2 =k∑
i=0
(mi −n ·pi )2
n ·pi, [6] (3.1)
kde n znací rozsah výberu,
mi empirické cetnosti,
pi jsou teoretické pravdepodobnosti.
Nejprve je nutné spocítat empirické cetnosti. Maximum klientu, kterí prišli v 10 minutovém
intervalu, je 30, stací nám tedy zkoumat cetnosti 0 - 30. Pro výpocet hodnoty testovacího kri-
téria potrebujeme nejdríve získat parametr teoretického rozdelení pravdepodobnosti. Pois-
sonovo rozdelení má jen jeden parametr - λ. Odhad tohoto parametru získáme metodou
57

3. Prípadová studie
maximální verohodnosti. V tomto prípade odhadneme strední hodnotu jako výberový pru-
mer:
E(X ) = X = 1
n·
k∑i=0
xi (3.2)
v našem prípade:
E(X ) = 0 ·0+1 ·1+2 ·0+3 ·0+4 ·0+ ...+28 ·0+29 ·0+30 ·1
60= 15,76666667
Získali jsme odhad parametru λ, protože pro Poissonovo rozdelení pravdepodobnosti platí
E(X ) =λ.
λ= 15,76666667 klientu / 10 minut.
Nyní potrebujeme získat teoretické pravdepodobnosti. Ty získáme ze vzorce 1.6
pi = P (X = i ) = λ2
i !·e−λ pro i = 0,1,2, ..,45 a λ= 15,76666667
Následne vypocítáme teoretické cetnosti n ·pi .
58

3. Prípadová studie
Trída Pocet klientu i Cetnost mi pi n ·pi
1 0 0 1,4211E-07 8,5266E-06
2 1 1 2,2406E-06 0,00013444
3 2 0 1,76634E-05 0,0010598
4 3 0 9,28308E-05 0,00556985
5 4 0 0,000365908 0,02195448
6 5 0 0,00115383 0,0692298
7 6 0 0,003032009 0,18192054
8 7 1 0,006829239 0,40975436
9 8 0 0,013459293 0,80755755
10 9 4 0,023578687 1,4147212
11 10 3 0,037175729 2,23054375
12 11 5 0,053285212 3,19711271
13 12 4 0,070010848 4,20065087
14 13 4 0,084910592 5,09463554
15 14 3 0,0956255 5,73753002
16 15 7 0,100513026 6,03078156
17 16 5 0,099047211 5,94283266
18 17 2 0,091861433 5,51168598
19 18 4 0,080463811 4,82782864
20 19 3 0,066770846 4,00625079
21 20 2 0,052637684 3,15826104
22 21 2 0,039520039 2,37120233
23 22 2 0,028322695 1,69936167
24 23 2 0,019415412 1,16492474
25 24 3 0,012754847 0,76529084
26 25 0 0,008044057 0,48264342
27 26 1 0,004877999 0,29267992
28 27 1 0,00284851 0,17091062
29 28 0 0,001603983 0,09623896
30 29 0 0,00087205 0,05232302
31 30 1 0,000458311 0,02749865
suma n 60
Tabulka 3.1.: První cást tabulkové metody
59

3. Prípadová studie
Tento test vyžaduje, aby všechny teoretické cetnosti n ·pi byly vetší než 5. Pokud toto není
dodrženo, je nutno sloucit trídy tak, aby podmínka byla dodržena. V našem prípade tedy
sloucíme trídy 1 - 11, 12 + 13, 19 + 20 a 21 - 31. Nové empirické cetnosti, teoretické pravde-
podobnosti a teoretické cetnosti získáme jako sumy techto puvodních parametru z tabulky
3.1. Vznikne nám nová tabulka:
trída i mi pi n ·pi mi −n ·pi (mi −n ·pi )2 (mi−n·pi )2
n·pi
1-11 0-10 9 0,0857075 5,14245430 3,85754569 14,8806588 2,89368809
12-13 11-12 9 0,1232960 7,39776357 1,60223642 2,56716154 0,34701859
14 13 4 0,0849105 5,09463554 -1,0946355 1,19822696 0,23519385
15 14 3 0,0956255 5,73753002 -2,7375300 7,49407063 1,30614926
16 15 7 0,1005130 6,03078155 0,96921844 0,93938438 0,15576495
17 16 5 0,0990472 5,94283266 -0,9428326 0,88893342 0,14958076
18 17 2 0,0918614 5,51168597 -3,5116859 12,3319384 2,23741678
19-20 18-19 7 0,1472346 8,83407943 -1,8340794 3,36847359 0,38078074
21-31 20-30 14 0,1713555 10,2813352 3,71866478 13,8284678 1,34500699
Tabulka 3.2.: Tabulková metoda pro testování hypotéz
Nyní mužeme vypocítat hodnotu testovacího kritéria podle vzorce 3.1.
χ2 = 9,05059997
Podle hladin významnosti urcíme kritické hodnoty testovacího kritéria. Ty jsou závislé na po-
ctu stupnu volnosti. V našem prípade je pocet stupnu volnosti v = r −k −1 = 7. Parametr r
predstavuje pocet tríd (ten nám po sloucení tríd klesl na 9), k znací pocet odhadovaných
(neznámých) parametru (v tomto prípade byl jeden - λ). Kritické hodnoty mužeme najít ve
statistických tabulkách nebo v Excelu pomocí funkce CHIINV(hladina významnosti; pocet
stupnu volnosti).
hladina významnosti α kritická hodnota χ2kr i t
0,01 18,47530691
0,025 16,01276427
0,05 14,06714045
0,1 12,01703662
Tabulka 3.3.: Kritické hodnoty testovacího kritéria Poissonova rozdelení
Zjistili jsme, že χ2 < χ2kr i t pro jakékoli námi zvolené α. Záverem je, že nezamítáme nulové
hypotézy o tom, že pocty príchodu klientu do systému se rídí Poissonovým rozdelením.
60

3. Prípadová studie
3.1.2. Test dobré shody na exponenciální rozdelení
Jak bylo zmíneno v teoretické cásti, casto se vyskytují tzv. exponenciální systémy hromadné
obsluhy, jejichž pocty požadavku, které vstupují do systému behem doby t , mají Poissonovo
rozdelení a doby mezi následujícími vstupujícími požadavky mají rozdelení exponenciální.
Otestujeme, zda doby mezi príchody klientu analyzovaného systému mají exponenciální
rozložení.
Postup je analogický s postupem testování Poissonova rozdelení.
H0: data se rídí exponenciálním rozdelením,
H1: data se exponenciálním rozdelením nerídí.
Za náhodný výber budeme považovat casové úseky mezi jednotlivými príchody zákazníku
ze dne 30. zárí 2013.
Hladiny významnosti zvolíme stejné, jako v predchozím prípade:
α0 = 0,10 α1 = 0,05 α2 = 0,025 α3 = 0,01
Pro tento test je nutné rozdelit výber do k-tríd s krajními body ai , v posledním intervalu pak
položíme ak =∞. Rozdelení na trídy vypadá:
< 0, a1),< a1, a2),< a2, a3), ...,< ak−2, ak−1),< ak−1,∞).
Cetnosti techto tríd oznacíme mi a∑k
i=1 mi = n. Stred trídy (tzv. trídní znak) oznacme zi .
Distribucní funkce exp. rozdelení je dána vztahem F (x) = 1−e− xλ . Potom mužeme pi vyjádrit
takto:
pi = F (ai )−F (ai−1) = 1−e− aiλ −1+e− ai−1
λ = e− ai−1λ −e− ai
λ pro i = 1,2, ...,k (3.3)
Testovací kritérium je ve tvaru:
χ2 =k∑
i=1
(mi −n ·pi )2
n ·pi. (3.4)
Exponenciální rozdelení má jeden parametr - λ, pro který platí: E(X ) = 1λ
, tedy λ = 1E(X ) .
I v tomto prípade potrebujeme nejprve získat jeho odhad. Opet použijeme metodu maxi-
mální verohodnosti a odhadneme strední hodnotu jako výberový prumer.
E(X ) = 1
λ= X =
k∑i=1
1
n·mi · zi (3.5)
V našem prípade získáme hodnoty: X = 42,883068, což znamená, že prumerne prijde jeden
zákazník za 43 sekund. Z této hodnoty odhadneme parametr rozdelení, cili λ = 0,023319.
Následne mužeme vypocítat teoretické pravdepodobnosti pi a teoretické cetnosti n ·pi .
61

3. Prípadová studie
Trída Hranice intervalu mi zi pi n ·pi
1 0 50 718 25 0,688377 650,5163
2 50 100 145 75 0,214514 202,7158
3 100 150 62 125 0,066848 63,1709
4 150 200 14 175 0,020831 19,6855
5 200 250 5 225 0,006491 6,134454
6 250 300 0 275 0,002023 1,911637
7 300 350 0 325 0,00063 0,59571
8 350 ∞ 1 374,5 0,000285 0,269673
Tabulka 3.4.: Test exponenciálního rozdelení
I v tomto prípade potrebujeme, aby platilo n ·pi ≥ 5. Sloucíme trídy 5 - 8 do jedné. Nyní mu-
žeme vypocítat hodnoty testovací kritéria pro príslušné trídy. Jejich soucet nám dá hodnotu
testovacího kritéria tohoto výberu.
Trída Hranice intervalu mi zi pi n ·pi Test. kritérium
1 0 50 718 25 0,688377 650,5163 7,000665992
2 50 100 145 75 0,214514 202,7158 16,43243695
3 100 150 62 125 0,066848 63,1709 0,021703059
4 150 200 14 175 0,020831 19,6855 1,642067613
5-8 200 ∞ 6 225 0,00943 8,911473 0,951209444
n = 945 1 945 χ2 = 26,048083
Tabulka 3.5.: Upravená tabulka pro test exponenciálního rozdelení
Hodnota testovacího kritéria: χ2 = 26,04808305. Následne zjistíme kritické hodnoty testova-
cího kritéria pro ruzné hladiny významnosti a porovnáme. V tomto prípade hledáme hod-
noty pro tri stupne volnosti.
hladina významnosti α kritická hodnota χ2kr i t
0,01 11,34487
0,025 9,348404
0,05 7,814728
0,1 6,251389
Tabulka 3.6.: Kritické hodnoty testovacího kritéria exponenciálního rozdelení
62

3. Prípadová studie
Zjistili jsme, že χ2 > χ2kr i t pro jakékoli námi zvolené α. Mužeme ríci, že nulové hypotézy
pro jednotlivé hladiny významnosti o tom, že doba mezi jednotlivými príchody klientu se
rídí exponenciálním rozdelením, zamítáme. Analyzovaný systém není exponenciální. Že je
náš výsledek správný, si mužeme potvrdit grafem cetností príchodu klientu v jednotlivých
casových pásmech behem celého roku.
Obrázek 3.1.: Návštevnost v jednotlivých casových pásmech behem roku
3.1.3. Další hypotézy
Za zdroj hypotézy mužeme považovat predchozí zkušenost. Jedna z nejjednodušších hy-
potéz muže napríklad znít: V prosinci na poštu dorazí nejvíce klientu. Naše úvaha vychází
z toho, že v tomto období zákazníci využívají prepravních spolecností, a tedy i Ceské pošty,
pro zasílání vánocních dárku.
Z grafu 3.2 na následující stránce je zrejmé, že naše hypotéza byla špatná. Nejvíce klientu
dorazilo v kvetnu. Duvodem muže být vyplácení vrácených daní pres poštovní složenky ci
placení nedoplatku / vrácení preplatku z bytových družstev. Dále také vidíme, že v období
letních mesícu, kdy lidé nejcasteji odjíždí na dovolenou, se pocet klientu výrazne nemení.
Další hypotézou, kterou otestujeme je následující predpoklad: V období mezi 11. a 20. dnem
v mesíci prijde na poštu nejvíce klientu z celého mesíce. Naše tvrzení mužeme oprít o zna-
losti z poštovního provozu. V tomto období dochází predevším k vyplácení duchodu, rodi-
covských príspevku a placení SIPO.
Naše hypotéza platí pro vetšinu mesícu v roce, jak dokazuje graf 3.3 na další strane. Vý-
jimky tvorí mesíce kveten 2013, ríjen 2013 a leden 2014. Naopak v únoru 2014 prišlo v tomto
období 50% klientu tohoto mesíce. Vztáhneme-li tuto hypotézu na celý rok, pak jsme se ne-
mýlili a hypotézu mužeme potvrdit (viz tabulka 3.7).
63

3. Prípadová studie
Obrázek 3.2.: Cetnost príchodu klientu behem roku
Obrázek 3.3.: Cetnost príchodu klientu v prubehu mesíce
Období Pocet klientu
1. - 10. 59 450
11. - 20. 79 117
21. - 31. 65 726
Tabulka 3.7.: Pocet klientu v jednotlivých obdobích za celý rok
64

3. Prípadová studie
3.2. Analýza využití služeb
Naše zkoumaná pobocka poskytuje všechny základní poštovní služby a nekteré speciální.
Zákazník si pri príchodu na pobocku vybere z nabídky, kterou službu požaduje. Systém jej
pak zaradí podle zvolené služby k odpovídající prepážce.
Oznacení služby Poskytovaná služba
T01 Listovní služby - výdej, jednotlivé podání max. do 5 položek
T02 Listovní služby - hromadné podání
T03 Balíková služba - príjem a výdej balíku a cenných psaní,
príjem a výdej EMS (Express Mail Service)
T04 Penežní služby, SIPO
Poštovní sporitelna (vklady a výplaty)
T05 Duchodová služba
T06 Poštovní sporitelna (vklady a výplaty) - specializovaná prepážka
T07 CZECHPOINT, DINO 3
T08 Ostatní služby
T09 Služba pro osoby se sníženou schopností pohybu a orientace
Tabulka 3.8.: Prehled poskytovaných služeb
Každá služba je v systému rozdelena ješte na konkrétní služby, napríklad u podání balíko-
vých zásilek pošta eviduje, zda klient využil službu Balík do ruky, Balík na poštu, Obycejný
balík atd. Data s temito informacemi nám bohužel nebyla poskytnuta.
V grafu 3.4 na následující strane vidíme, že nejvíce využívaná je listovní služba pro podání
jednotlivých zásilek a výdej uložených zásilek, hojne využívaná je i balíková služba spo-
lecne s penežními službami, kam spadá napríklad vyplácení poštovních poukázek. Naopak
nejméne využívanou službou, krome služby pro osoby se sníženou schopností pohybu a
orientace, je služba kontaktního místa verejné správy.
3CZECHPOINT - jedná se o tzv. kontaktní místo verejné správy. Klienti zde mohou získat napr. výpis z Ka-
tastru nemovitostí, Obchodního rejstríku, Rejstríku trestu, Živnostenského rejstríku, ci z bodového hod-
nocení ridice, DINO - Dluhové inkaso obyvatelstva - Služba je urcena pro veritele jako nástroj pro rešení
vzniklých penežních pohledávek prostrednictvím mimosoudního oslovení dlužníka a inkasa pohledávky.
Prevzato z http://www.ceskaposta.cz/sluzby/platebni-a-financni-sluzby-cr/dino
65

3. Prípadová studie
Obrázek 3.4.: Využití služeb behem roku
U služeb si otestujeme napríklad hypotézu: V posledním týdnu v mesíci bude využití du-
chodové služby (T05) požadovat maximálne 5% klientu ze všech, kterí službu za daný mesíc
využijí.
Obrázek 3.5.: Využití duchodové služby behem jednotlivých dní za ctvrtletí
Naši hypotézu o tom, že službu v posledním týdnu využívá maximálne 5% všech klientu
zamítáme (viz tabulka 3.9).
66

3. Prípadová studie
Datum Pocet klientu %
1. - 6. 3313 16,82
7. - 12. 5364 27,22
13. - 18. 5002 25,4
19. - 24. 4973 25,24
25. - 31. 1048 5,32
celkem 19700 100
Tabulka 3.9.: Využití duchodové služby
3.3. Analýza obsluhy
Mezi nejvýznamnejší vlastnosti, které popisují systém, se radí prumerná doba cekání po-
žadavku ve fronte a prumerná doba obsluhy. Ceská pošta, s.p. se snaží dostat prumernou
dobu obsluhy na každé pobocce, stejne jako dobu cekání, pod 5 minut pro co nejvetší pocet
klientu (ocekávají se císla kolem 75 - 85 % zákazníku). Oba parametry se liší pro jednotlivé
služby. Napríklad pro službu specializované prepážky Poštovní sporitelny se ocekává nej-
vyšší doba cekání ve fronte. Je to dáno tím, že tuto službu zpracovává pouze jedna prepážka
a klienti musí vyckat, než je prepážka uvolnená. Naopak u služby T07 (Czechpoint, DINO) se
dá ocekávat nejdelší prumerná doba obsluhy. Žádá-li klient výpis z jakéhokoli rejstríku, pra-
covník pošty musí zkontrolovat totožnost dotycného v databázi neplatných dokladu, vyplnit
s klientem žádost o výpis a poslat ji na príslušné pracovište. Poté je bud’ zaslán elektronický
výpis nebo informace o tom, že žádost nemohla být vyrízena elektronicky.
Obrázek 3.6.: Prumerná doba obsluhy v minutách podle jednotlivých služeb
67

3. Prípadová studie
3.3.1. Test rozdelení doby obsluhy
U doby obsluhy se standardne predpokládá, že bude mít exponenciální rozdelení. Otestu-
jeme ho pomocí testování hypotéz, stejne jako doby mezi príchody zákazníku.
Jako náhodný výber použijeme data z 15. ledna 2014, kdy na poštu dorazilo celkem 721 kli-
entu v dobe mezi 8. - 18. hodinou. Za nulovou hypotézu zvolíme predpoklad: Doba obsluhy
se rídí exponenciálním rozdelením. Naše hypotéza vychází i z následujícího grafu.
Obrázek 3.7.: Doba obsluhy a cekání 15. ledna 2014
Doby obsluhy jednotlivých zákazníku prevedeme na sekundy, poté výberový prumer E(X ) =178,4119. Z toho vyplývá, že parametr exponenciálního rozdelení λ = 0,005605. A dopoc-
teme vše ostatní viz. následující tabulka 3.10.
Trída Hranice intervalu mi zi pi n ·pi Test. kritérium
1 0 130 379 65 0,51744 373,0745 0,094113
2 130 260 200 195 0,249696 180,0307 2,215029
3 260 390 80 325 0,120493 86,87554 0,544147
4 390 520 29 455 0,058145 41,92263 3,983393
5 520 650 14 585 0,028058 20,23017 1,918668
6 650 780 6 715 0,01354 9,762261 1,449931
7 780 ∞ 113 845 0,012627 9,104184 1,667077
n = 721 1 721 χ2 = 11,87236
Tabulka 3.10.: Hodnoty pro test exponenciálního rozdelení doby obsluhy
Nyní nalezneme kritické hodnoty testovacího kritéria pro stupen volnosti 5 a rozhodneme
o zamítnutí / nezamítnutí nulové hypotézy.
68

3. Prípadová studie
hladina významnosti α kritická hodnota χ2kr i t
0,01 15,08627
0,025 12,8325
Zjistili jsme, žeχ2 <χ2kr i t pro námi zvolenéα. Mužeme ríci, že nulové hypotézy nezamítáme
a doba obsluhy se rídí exponenciálním rozdelením. Tuto informaci mužeme následne využít
i pro simulaci.
3.3.2. Cekání ve fronte
Doba cekání ve fronte je nejduležitejším ukazatelem spokojenosti zákazníka. Doba cekání
vyjadruje cas od zarazení klienta do vyvolávacího systému (tj. okamžik, kdy zákazník stiskne
tlacítko pro požadovanou službu) až po jeho vyvolání k prepážce.
Obrázek 3.8.: Prumerná doba cekání v minutách podle jednotlivých služeb
Jako další si zvolíme hypotézu o dobe cekání ve fronte.
Podle grafu 3.9 si položme hypotézu HO : V dopoledních hodinách klient stráví ve fronte více
casu než odpoledne. Postupovat budeme následovne. Zjistíme, zda-li rozložení doby cekání
ve fronte je stejné (v našem prípade predpokládáme exponenciální) pro oba casové intervaly
a následne porovnáme jejich strední hodnoty.
Z tabulky 3.12 vidíme, že náš odhad testovacího kritéria vyhovuje kritickému oboru, nebot’
χ2 < χ2kr i t pro námi zvolené hladiny významnosti. Doba cekání v dopoledních hodinách se
rídí exponenciálním rozložení s prumerem E(Xdop ) = 181,4658.
Dle tabulky 3.14 mužeme tvrdit, že i odpolední doby cekání ve fronte se rídí exponenciálním
rozdelením. Prumer E(Xod p ) = 145,1554.
69

3. Prípadová studie
Obrázek 3.9.: Doba cekání 15. ledna 2014 v intervalu 130s
Trída Hranice intervalu mi zi pi n ·pi Test. kritérium
1 0 130 199 65 0,511487 186,6927 0,811338
2 130 260 92 195 0,249868 91,20184 0,006985
3 260 390 34 325 0,122064 44,55331 0,499755
4 390 520 23 455 0,05963 21,76488 0,070091
5 520 650 4 585 0,02913 10,63243 4,137264
6 650 ∞ 13 715 0,027822 10,15488 0,797126
n = 365 1 365 χ2 = 8,322558
Tabulka 3.11.: Test exponenciálního rozložení pro dopolední dobu cekání
hladina významnosti α kritická hodnota χ2kr i t
0,01 13,2767
0,025 11,14329
0,05 9,487729
Tabulka 3.12.: Kritické hodnoty kritéria pro dopoledne
Jelikož platí E(Xdop ) > E(Xod p ), tak nulovou hypotézu o cekání ve fronte nezamítáme.
70

3. Prípadová studie
Trída Hranice intervalu mi zi pi n ·pi Test. kritérium
1 0 130 236 65 0,591634 228,3708 0,254872
2 130 260 98 195 0,241603 93,25883 0,241035
3 260 390 32 325 0,098663 38,08373 0,971852
4 390 520 12 455 0,04029 15,5521 0,811299
5 520 ∞ 8 585 0,02781 10,73459 0,696623
n = 386 1 386 χ2 = 2,975681
Tabulka 3.13.: Test exponenciálního rozložení pro odpolední dobu cekání
hladina významnosti α kritická hodnota χ2kr i t
0,01 11,34487
0,025 9,348404
0,05 7,814728
Tabulka 3.14.: Kritické hodnoty kritéria pro odpoledne
3.4. Analýza prepážek
Jedním z duležitých ukazatelu celého systému je vytíženost kanálu, se kterou souvisí pro-
stoje a efektivita práce. V našich získaných datech z vyvolávacího systému se nacházejí in-
formace o prihlášení a odhlášení obsluhujících na jednotlivé prepážky. Z toho mužeme zjis-
tit vytíženost jednotlivých prepážek. V tomto systému prepážky P01 - P10 mohou obsluho-
vat všechny dostupné služby na pobocce s výjimkou služby T06, pro kterou je vyhrazena
specializovaná prepážka P11 pro služby Poštovní sporitelny. Zpravidla to tak nebývá. Každá
prepážka má urceny napr. tri až ctyri služby, které bude behem dne obsluhovat.
Z tabulky 3.15 vidíme, že specializovaná prepážka P11 je znacne nevytížená. Obecne se do-
porucuje, aby vytíženost systému byla na hranici 80 %. Je-li vyšší, muže a také dochází k pro-
dloužení casu doby cekání požadavku ve fronte. Naopak císla kolem 60 - 70% znací krátké
doby cekání. Mezi neaktivní cas u prepážky se v našem prípade zapocítává i doba, kdy obslu-
hující plní své povinnosti vnitrní služby (napríklad prijímá zásilky k uložení od dorucovatelu
a ty následne trídí a rovná do skladu, vypravuje nove podané zásilky na kurzy). Ze systému
se totiž neodhlašuje. Údaje o tom, kolik casu zamestnanec stráví temito službami nemáme
k dispozici, muže tedy docházet ke zkreslení údaju.
71

3. Prípadová studie
Obrázek 3.10.: Ukázkový graf vytíženosti prepážky P03 a P11 behem roku
Prepážka Pocet aktivních hodin Pocet neaktivních hodin Využití [%]
P01 1086,735 332,5992 76,56653
P02 1152,358 326,7628 77,90831
P03 818,3806 131,3067 86,17369
P04 873,9994 224,8331 79,53891
P05 1291,919 275,5244 82,42205
P06 950,3192 487,2603 66,10551
P07 549,6428 268,3614 67,19315
P08 558,8389 192,1331 74,41201
P09 683,5844 223,1869 75,38664
P10 824,0906 328,9214 71,47286
P11 557,5633 1890,383 22,77678
Tabulka 3.15.: Vytíženost jednotlivých prepážek v období 04/2013 - 03/2014
3.5. Výsledky analýzy
Ve zkoumaném období na poštu prišlo celkem 204 297 klientu, kterí byli obslouženi ve 296
dnech, což je prumerne 690 klientu za den. Mesícní prumerná návštevnost cinila 17 025
klientu obsloužených ve 25 dnech (presneji 24,6667 dne). Byla zjištena prumerná doba ob-
sluhy klienta 2 minuty a 41 sekund, prumerná doba cekání ve fronte 6 minut a 9 sekund a
prumerná doba, kterou zákazník strávil v systému (cas od jeho príchodu, resp. zarazení do
fronty do ukoncení jeho obsluhy). Její hodnota je 8 minut a 48 vterin.
Ve sledovaném období bylo z celkového poctu 204 297 klientu obslouženo, nebo zacalo být
72

3. Prípadová studie
obsluhováno, do 5 minut po príchodu na pobocku 114 691 klientu, což je 56,14% ze všech
klientu. Do 10 minut to bylo celkem 160 752 klientu, tedy 78,69% ze všech. Tato císla se radí
mezi nejhorší v regionu Severní Cechy, pod které spadá 22 pobocek s vyvolávacím systé-
mem. Prumerne bývá do 5 minut vyvoláno k obsluze 75% klientu, do 10 minut je to pak
90%. U doby obsluhy naopak pobocka patrí v regionu k lepšímu prumeru. Do 5 minut od
vyvolání klienta bylo obslouženo 179 929 klientu, což je 87,5%, do 10 minut pak celkove 200
081 klient (97,3%). Další intervaly jsou rozepsány v tabulce 3.16. Prumerne je otevreno 6
obsluhujících kanálu, které musí pokrýt všechny služby.
Casový interval Pocet klientu % Pocet klientu %
(doba cekání) (doba obsluhy)
0 - 5 minut 114 691 56,14 179 929 87,5
5 - 10 minut 46 061 22,55 20 152 9,8
10 - 15 minut 23 737 11,62 3 715 1,8
15 - 20 minut 11 594 5,67 1 060 0,5
20 - 25 minut 4 731 2,32 393 0,2
25 - 30 minut 2 093 1,02 178 0,1
30 minut a více 1 386 0,68 192 0,1
Tabulka 3.16.: Prehled doby cekání ve fronte a doby obsluhy za celý rok
Obrázek 3.11.: Porovnání prumerných dob cekání, obsluhy a doby strávené v systému be-
hem dne
73

3. Prípadová studie
Obrázek 3.12.: Pocet aktivních prepážek behem casových intervalu
Obrázek 3.13.: Porovnání prumerných dob cekání, obsluhy podle jednotlivých služeb
Služba Doba cekání Doba obsluhy Doba strávená v systému
T01 06m 07s 02m 30s 08m 37s
T02 05m 55s 02m 55s 08m 49s
T03 06m 29s 03m 08s 09m 37s
T04 06m 04s 02m 00s 08m 04s
T05 06m 40s 02m 48s 09m 28s
T06 05m 59s 04m 04s 10m 03s
T07 05m 28s 05m 47s 11m 14s
T08 05m 22s 02m 42s 08m 04s
T09 02m 13s 02m 37s 04m 50s
Tabulka 3.17.: Prumerné doby cekání, obsluhy a doby strávené v systému dle služeb
74

3. Prípadová studie
Také jsme zkoumali, zda-li systém funguje v režimu FIFO alespon v rámci jednotlivých slu-
žeb. Bylo zjišteno, že z celkových 204 297 klientu, kterí prišli za zkoumané období na poštu,
celkem 21 175 klientu (10,365 %) v systému predbehlo. Tedy byli vyvoláni k odbavení dríve,
než klient, který dorazil do systému pred nimi a požadoval tutéž službu. Režimem FIFO se
tedy vyvolávací systém nerídí.
V takto obsáhlém systému hromadné obsluhy je možné vymyslet nepreberné množství hy-
potéz. V naší analýze jsme otestovali jen nekteré. Námetem k dalšímu zkoumání mohou být
napríklad tyto hypotézy:
• V sudé datum chodí více klientu než v liché (v sudé dny mezi 2. - 24. se jedná o výplatní
termíny duchodu). Ovšem tato hypotéza muže být ztížena mimorádnými situacemi,
napríklad vyjde-li termín na sobotu, duchodci si mohou prijít již v pátek pred termí-
nem, naopak vyjde-li na nedeli, musí pockat do pondelí. K podobným zmenám do-
chází i pri státních svátcích.
• V prosinci je prumerná doba strávená ve fronte vetší než v ostatních mesících.
• V pracovních dnech v odpoledních hodinách chodí na poštu více lidí než dopoledne.
• Intenzita obsluhy je vyšší v zátežových obdobích (tzn. období svátku)
• Jestliže v pátek prijde výrazne méne klientu, než je denní prumer, naroste jejich pocet
v sobotu, resp. v pondelí?
75


4. Záver
V predložené bakalárské práci jsme ctenáre seznámili s problematikou systému hromadné
obsluhy nejen prostrednictvím teoretického popisu v rešeršní cásti, ale také pomocí rešení
modelových úloh v rámci testování vytvorených aplikací v praktické cásti. Zároven jsme
v praktické cásti predstavili systém hromadné obsluhy, o nemž predpokládáme, že do ne-
jaké jeho varianty (pobocky) vetšina ctenáru za svuj život vstoupila. Poskytnutá data o tomto
systému v práci zevrubne zkoumáme.
Jedním z prínosu naší práce je práve jednoduchý popis vybraných modelu hromadné ob-
sluhy spolu s jejich programovou implementací, která zámerne neprekracuje obsah úvod-
ních kurzu výuky programování. Zdrojové kódy, jež jsou doprovázeny komentári, mohou
poskytnout úvod do této problematiky i méne zdatným programátorum, napr. z rad stu-
dentu.
Druhý prínos práce je samotná prípadová studie. Poukázala na chování složitého reálného
(vyvolávacího) systému, používaného na pobockách Ceské pošty, s.p. Oproti jednoduchým
modelum, jimiž jsme se zabývali v kapitole o simulaci, má radu svých specifik. Prvním z nich
je množství poskytovaných služeb, tedy už samotné požadavky vstupující do systému se od
sebe navzájem liší. Kanály obsluhy také nemužeme považovat za homogenní, nebot’ každá
prepážka obsluhuje jiné služby. Navíc jsme zjistili, že pro každou službu existuje rozdílná
intenzita obsluhy, címž se model znacne komplikuje. V momente, kdy do analýzy zahrneme
ješte ruznou výkonnost pracovníku, naroste nám opet pocet neznámých parametru mo-
delu. Analýza také vyvrátila, že by systém fungoval v režimu FIFO. Systém funguje v atypic-
kém režimu fronty, jež se nám nepodarilo rozluštit. V systému, jak jsme zjistili z poskytnu-
tých údaju, je možno vyvolávat klienty napríklad podle priority služeb, podle priority pre-
pážek nebo zcela mimo poradí. Bohužel nevíme, cím presne je to zpusobeno, nebot’ nám
nebylo umožneno nahlédnout ani do manuálu k ovládání, ani do nastavení samotného soft-
waru vyvolávacího systému. Pobocka pomerne dobre reaguje na ranní špicku príchodu kli-
entu. Nejvíce lidí dochází v rozmezí od 8 do 11 hodin a od 15 do 17 hodin. V ranním provozu
dosahuje pocet otevrených prepážek prumerne poctu sedmi, v odpolední špicce naopak
jen šesti, jako je to v prumeru celého dne. V odpoledních hodinách tedy dochází ke zvýšení
prumerné cekací doby klientu. Toto považujeme za nedostatek, který by mela pošta urcite
zlepšit. Všeobecne receno, prumerná cekací doba na této pobocce je vysoká. Zákazník má
témer 20 % pravdepodobnost, že ve fronte bude cekat déle než 10 minut. V systému se nám
také nelíbí zminované predbíhání klientu v rámci služeb.
77

4. Záver
Nad rámec formulovaných cílu práce jsme se pokoušeli navrhnout model, který by odpo-
vídal našim požadavkum, tj. model, v nemž bychom dosáhli snížení doby cekání klientu
pri zachování stejného poctu prepážek v provozu a dodržení režimu FIFO alespon v rámci
služeb. Model není bohužel úplný, nicméne jeho ukázka se nachází na priloženém CD. Pro
kompletní zhodnocení a návrh rešení nového vyvolávacího systému nemáme dostatek žá-
doucích informací. Pro optimalizaci nákladu by bylo potreba získat nákladové charakte-
ristiky na provoz systému, které nám nebyly poskytnuty. Také nemáme k dispozici data
o presné pracovní dobe obsluhujících. V systému totiž dochází k situacím, kdy nevíme, zda
se obsluhující zapomnel ze systému odhlásit pri konci své pracovní doby, nebo je stále v pra-
covním nasazení na pobocce, ale neobsluhuje další zákazníky a plní si své povinnosti vnitrní
služby. Z dat také není zrejmé, kolik klientu rezignuje behem doby cekání na obsluhu a ze
systému odcházejí neobslouženi. V systému zcela chybí informace o tom, kolik zákazníku
rezignuje na obsluhu ješte pred tím, než stihne do systému vstoupit. Pokud bychom chteli
maximalizovat spokojenost zákazníku (podle teze, že nejlepší marketing je spokojený zá-
kazník), bylo by treba provést studii zákaznického chování a marketingový výzkum spoko-
jenosti zákazníku, protože spokojený zákazník nemusí být vždy ten, který stráví v systému
nejkratší dobu. Maximalistickým cílem do budoucna by bylo navrhnout jednak vyvolávací
systém a jednak systém casového pokrytí prepážek a služeb s využitím simulacního modelu
ku prospechu jak podniku, tak zákazníku.
78

Seznam použité literatury
[1] LUKÁŠ, Ladislav, Pravdepodobnostní modely v managementu: Markovovy retezce a sys-
témy hromadné obsluhy. Vydání 1., Praha: Academia, 2009, 135 s. ISBN 978-80-200-
1704-8.
[2] KOLÁR, Martin, Ucební text ze Stochastické analýzy [online]. Ucební materiál, Masa-
rykova Univerzita Brno. [cit. 2014-01-28]. Dostupné také z: http://www.math.muni.
cz/~mkolar/skripta002.pdf
[3] VETCHÝ, Josef, Teorie hromadné obsluhy a její aplikace na model križovatky. Olomouc:
Diplomová práce, Univerzita Palackého v Olomouci, Prírodovedecká fakulta, Katedra
matematické analýzy a aplikací matematiky, 2010. [cit. 2014-03-01]. Dostupné také z:
http://theses.cz/id/jjbh7h/122406-679142669.pdf
[4] ROSS, Sheldon M., Introduction to probability models. 9th ed. Boston: Academic Press,
c2007, xviii, 782 p. ISBN 01-237-3635-8.
[5] ŠVUB, Miroslav, Poissonovo rozložení pravdepodobnosti. Brno: Bakalárská práce, Masa-
rykova univerzita, Prírodovedecká fakulta, 2007. [cit. 2014-03-03]. Dostupné z: http:
//is.muni.cz/th/60478/prif_b/poissonovo_rozlozeni_svub.pdf
[6] KLVANA, Jaroslav, Modelování 20: operacní výzkum 2. Vyd. 3. Vydavatelství CVUT.
2005c1993, 246 s. ISBN 80-010-3263-9.
[7] CIHLÁR, Jirí, Statistika, Pedagogická fakulta Ústí nad Labem, 1982.
[8] JABLONSKÝ, Josef, Operacní výzkum: kvantitativní modely pro ekonomické rozhodování
2. vyd. Praha: Professional Publishing, 2002, 323 s. ISBN 80-864-1942-8.
[9] ŠEDA, Miloš, Modely hromadné obsluhy [online]. Clánek, Vysoké ucení technické
v Brne, Fakulta strojního inženýrství. [cit. 2014-02-20]. Dostupné z: http://web2.
vslg.cz/fotogalerie/acta_logistica/2011/2_cislo/3_seda.pdf
[10] ZIMOLA, Bedrich, Operacní výzkum. 2. vyd. Zlín: VUT v Brne, 2000, 168 s. ISBN 80-214-
1664-5.
[11] RÁLEK, Petr, NOVÁK, Josef, CHUDOBA, Josef, Metody užívané v logistice [online]. Ucební
materiál, Technická univerzita v Liberci, Fakulta mechatroniky, informatiky a meziobo-
rových studií. [cit. 2014-03-08]. Dostupné z: http://www.nti.tul.cz/cz/images/
79

Seznam použité literatury
0/0a/Mul_skripta_101101.pdf.
[12] STEWART, William J., Probability, Markov chains, queues, and simulation: the mathema-
tical basis of performance modeling, Princeton: Princeton University Press, 2009, xviii,
758 s. ISBN 978-0-691-14062-9.
[13] KORENÁR, Václav, Stochastické procesy. 2. preprac. vyd. Praha: Vysoká škola ekono-
mická v Praze, 2010, 228 s. ISBN 978-80-245-1646-2.
[14] SEMANCO, Pavel, MARTON, David, Simulation Tools Evaluation using Theoretical Ma-
nufacturing Model [online]. Acta Polytechnica Hungarica - Journal of Applied Sciences,
2013. [cit. 2014-02-18]. Dostupné z: http://www.uni-obuda.hu/journal/Semanco_
Marton_40.pdf
[15] QUARTERONI, Alfio, SACCO, Riccardo a SALERI, Fausto. Numerical mathematics. New
York: Springer, c2000, xx, 654 p. ISBN 03-879-8959-5.
80

Seznam obrázku
1.1. Schéma základních pojmu systému hromadné obsluhy (vlastní zpracování) . . 21
1.2. SHO s paralelním usporádáním obslužných linek a netrpelivostí zákazníku . . 23
1.3. Exponenciální model M/M/1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
1.4. Prechodový graf systému M/M/c . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
1.5. Graf prechodu systému M/M/1/1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
1.6. Prostredí simulacního programu Arena . . . . . . . . . . . . . . . . . . . . . . . . 34
1.7. Vývojový diagram modelu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
1.8. Nastavení generování príchodu zákazníku . . . . . . . . . . . . . . . . . . . . . . 35
1.9. Nastavení rozhodovacího procesu . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
1.10.Nastavení obsluhy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
1.11.Výsledky simulace . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
1.12.Analýza simulace - obsluha . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
1.13.Analýza simulace - fronta . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
1.14.Náhled na simulaci v doplnku QtdPlus4Calc . . . . . . . . . . . . . . . . . . . . . 38
3.1. Návštevnost v jednotlivých casových pásmech behem roku . . . . . . . . . . . . 63
3.2. Cetnost príchodu klientu behem roku . . . . . . . . . . . . . . . . . . . . . . . . . 64
3.3. Cetnost príchodu klientu v prubehu mesíce . . . . . . . . . . . . . . . . . . . . . 64
3.4. Využití služeb behem roku . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
3.5. Využití duchodové služby behem jednotlivých dní za ctvrtletí . . . . . . . . . . . 66
3.6. Prumerná doba obsluhy v minutách podle jednotlivých služeb . . . . . . . . . . 67
3.7. Doba obsluhy a cekání 15. ledna 2014 . . . . . . . . . . . . . . . . . . . . . . . . . 68
3.8. Prumerná doba cekání v minutách podle jednotlivých služeb . . . . . . . . . . . 69
3.9. Doba cekání 15. ledna 2014 v intervalu 130s . . . . . . . . . . . . . . . . . . . . . 70
3.10.Ukázkový graf vytíženosti prepážky P03 a P11 behem roku . . . . . . . . . . . . . 72
3.11.Porovnání prumerných dob cekání, obsluhy a doby strávené v systému behem
dne . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
3.12.Pocet aktivních prepážek behem casových intervalu . . . . . . . . . . . . . . . . 74
3.13.Porovnání prumerných dob cekání, obsluhy podle jednotlivých služeb . . . . . 74
81


Seznam tabulek
1.1. Vztahy mezi nekterými charakteristikami systému hromadné obsluhy. . . . . . 24
2.1. Porovnání analytického a simulacního rešení modelu M/M/1 . . . . . . . . . . 43
2.2. Testování modelu M/M/1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
2.3. Porovnání analytického a simulacního rešení modelu M/D/1 . . . . . . . . . . . 43
2.4. Testování modelu M/D/1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
2.5. Porovnání analytického a simulacního rešení modelu D/M/1 . . . . . . . . . . . 45
2.6. Testování modelu D/M/1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
2.7. Ukázka simulace modelu M/M/c systému hromadné obsluhy . . . . . . . . . . 46
2.8. Výsledky simulace modelu M/M/c pro krátký casový úsek . . . . . . . . . . . . 47
2.9. Porovnání analytického a simulacního rešení modelu M/M/c . . . . . . . . . . 47
2.10.Simulacní výsledky pro model M/M/c s ruznými pocty prepážek . . . . . . . . 47
2.11.Srovnání modelu M/M/1 a M/M/3 . . . . . . . . . . . . . . . . . . . . . . . . . . 48
2.12.Porovnání analytického a simulacního rešení modelu M/M/1/K . . . . . . . . . 49
2.13.Testování modelu M/M/1/K . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
2.14.Porovnání analytického a simulacního rešení modelu M/M/c/K . . . . . . . . . 51
2.15.Testování modelu M/M/c/K . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
2.16.Porovnání analytického a simulacního rešení modelu M/M/1/./N . . . . . . . 52
2.17.Testování modelu M/M/1/./N . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
3.1. První cást tabulkové metody . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
3.2. Tabulková metoda pro testování hypotéz . . . . . . . . . . . . . . . . . . . . . . . 60
3.3. Kritické hodnoty testovacího kritéria Poissonova rozdelení . . . . . . . . . . . . 60
3.4. Test exponenciálního rozdelení . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
3.5. Upravená tabulka pro test exponenciálního rozdelení . . . . . . . . . . . . . . . 62
3.6. Kritické hodnoty testovacího kritéria exponenciálního rozdelení . . . . . . . . . 62
3.7. Pocet klientu v jednotlivých obdobích za celý rok . . . . . . . . . . . . . . . . . . 64
3.8. Prehled poskytovaných služeb . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
3.9. Využití duchodové služby . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
3.10.Hodnoty pro test exponenciálního rozdelení doby obsluhy . . . . . . . . . . . . 68
3.11.Test exponenciálního rozložení pro dopolední dobu cekání . . . . . . . . . . . . 70
3.12.Kritické hodnoty kritéria pro dopoledne . . . . . . . . . . . . . . . . . . . . . . . 70
3.13.Test exponenciálního rozložení pro odpolední dobu cekání . . . . . . . . . . . . 71
3.14.Kritické hodnoty kritéria pro odpoledne . . . . . . . . . . . . . . . . . . . . . . . 71
83

Seznam tabulek
3.15.Vytíženost jednotlivých prepážek v období 04/2013 - 03/2014 . . . . . . . . . . . 72
3.16.Prehled doby cekání ve fronte a doby obsluhy za celý rok . . . . . . . . . . . . . 73
3.17.Prumerné doby cekání, obsluhy a doby strávené v systému dle služeb . . . . . . 74
84

A. Obsah priloženého CD
soubor/adresár obsah
bakalarska_prace.pdf originální text bakalárské práce
Data_VS/ složka s daty vyvolávacího systému CP, s.p.
Analyza_VS/ složka s projektem vytvoreným pro analýzu
dat
Simulace/ složka s vytvorenými simulacními modely
Simulace/MMc/ složka se simulací modelu M/M/c
Simulace/MMc/MMc.cs zdrojový kód k modelu M/M/c
Simulace/MMc/Tex/Main.cs zdrojový kód k modelu M/M/c, který ná-
sledne vygeneruje prubeh simulace do sou-
boru txt
Simulace/DM1.cs zdrojový kód k modelu D/M/1
Simulace/MD1.cs zdrojový kód k modelu M/D/1
Simulace/MM1.cs zdrojový kód k modelu M/M/1
Simulace/MM1.N.cs zdrojový kód k modelu M/M/1/./N
Simulace/MM1K.cs zdrojový kód k modelu M/M/1/K
Simulace/MMcK.cs zdrojový kód k modelu M/M/c/K
Navrh_modelu/ složka s projektem navrhovaného modelu
85


















