
最新のインテル®Parallel Studio XEを用い た 迅速 …Sandy Bridge ) インテル®...
68
最新のインテル® Parallel Studio XE を用い た 迅速なベクトル化と並列化手法 インテル株式会社 技術本部ソフトウェア技術統括部 シニア・スタッフ・エンジニア 池井 満
Transcript of 最新のインテル®Parallel Studio XEを用い た 迅速 …Sandy Bridge ) インテル®...

最新のインテル® Parallel Studio XE を用いた迅速なベクトル化と並列化手法インテル株式会社
技術本部ソフトウェア技術統括部
シニア・スタッフ・エンジニア
池井 満

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
議題
• プロセッサーの動向とコード・モダナイゼーション
• インテル® アドバンスト・ベクトル・エクステンション 512 (インテル®
AVX-512) 命令と演算性能
• ベクトル化を支援するインテル® Advisor– ループの性能を可視化するルーフライン表示
• 姫野ベンチマークを用いたインテル® Xeon Phi™ プロセッサー上でのケー
ス
スタディー– 並列化とベクトル化の検討
– インテル® VTune™ Amplifier によるメモリー使用表示
– メモリー階層 (高速メモリー) の影響
– NUMA 構成 (クラスター) の影響
• まとめ2

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
Hi-K メタルゲート
ストレインド・シリコン
3D トランジスター
65nm 45nm 32nm 22nm 14nm 10nm 7nm90nm
高機能で複雑な新しい製品を、電力、価格、大きさを制御しながら提供する
予測に沿った半導体の微細化
ムーアの法則に沿って製造を続ける
3

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
インテル® Xeon®
プロセッサー
64-bit
インテル® Xeon®
プロセッサー
5100シリーズ
インテル® Xeon®
プロセッサー
5600シリーズ
インテル® Xeon®
プロセッサー
E5-2600 (Sandy
Bridge✝)
インテル® Xeon®
プロセッサー
E5-2600 v2(Ivy Bridge✝)
インテル® Xeon®
プロセッサー
E5-2600 v3(Haswell✝)
インテル® Xeon®
Platinum 81xx
プロセッサー(Skylake✝)
インテル® Xeon Phi™コプロセッサー
Knights Landing✝
コア数 1 2 6 8 12 18 28 61 72
スレッド数 2 2 12 16 24 36 56 244 288
SIMD 幅 128 128 128 256 256 256 512 512 512
インテル®SSE2
インテル®SSSE3
インテル®SSE4.2
インテル®AVX
インテル®AVX
インテル®AVX2FMA
インテル®AVX-512
IMCIインテル®AVX-512
より多いコア数. より幅広いベクトル. コプロセッサー性能を活かすにはすべての並列性を利用することが必要
Images do not reflect actual die sizes
3+ Tflops
✝開発コード名
4

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
インテル® Xeon®
プロセッサー
64-bit
インテル® Xeon®
プロセッサー
5100シリーズ
インテル® Xeon®
プロセッサー
5600シリーズ
インテル® Xeon®
プロセッサー
E5-2600 (Sandy
Bridge✝)
インテル® Xeon®
プロセッサー
E5-2600 v2(Ivy Bridge✝)
インテル® Xeon®
プロセッサー
E5-2600 v3(Haswell✝)
インテル® Xeon®
Platinum 81xx
プロセッサー(Skylake✝)
インテル® Xeon Phi™コプロセッサー
Knights Landing✝
コア数 1 2 6 8 12 18 28 61 72
スレッド数 2 2 12 16 24 36 56 244 288
SIMD 幅 128 128 128 256 256 256 512 512 512
インテル®SSE2
インテル®SSSE3
インテル®SSE4.2
インテル®AVX
インテル®AVX
インテル®AVX2FMA
インテル®AVX-512
IMCIインテル®AVX-512
より多いコア数. より幅広いベクトル. コプロセッサー性能を活かすにはすべての並列性を利用することが必要
Images do not reflect actual die sizes
3+ Tflops
✝開発コード名
単精度数 16 個の FMA 演算を 2 個同時に計算できる
64 SP 演算
5
× 28 コア = 1792

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
プログラミング方法の再検討
コード・モダナイゼーション• 数コアのプロセッサーから始まって一貫したモデル、言語、ツールや手法で
メニーコアに対応することで、持続的な価値を生み出すことができる
• アプリケーションは利用できるすべての並列性を活用する
- 命令レベル: コアの特性を知り、考慮
- データレベル: SIMD 命令を用いるようにベクトル化
- スレッドレベル: OpenMP* などの標準ツールで並列化
- クラスターレベル: MPI などの標準ツールで並列化
• 専門家がプロセッサーに最適化した標準ライブラリーや言語を利用する
• ヘテロジニティーまで考慮した最適化を検討する
6

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
Cluster EditionProfessional EditionComposer Edition
インテル® Parallel Studio XE高速なコードを素早く開発
コードを強力に支援 - isus.jp/intel-parallel-studio-xe/
スケールクラスターツール
インテル® Trace Analyzer & Collector
MPI チューニングと解析
インテル® MPI ライブラリーメッセージ・パッシング・
インターフェイス・ライブラリー
インテル® Cluster Checkerクラスター診断エキスパート・システム
1 Composer Edition でのみ利用可能2インテル® スレッディング・ビルディング・ブロック3インテル® マス・カーネル・ライブラリー4インテル® インテグレーテッド・パフォーマンス・プリミティブ5インテル® データ・アナリティクス・アクセラレーション・ライブラリー
インテル® VTune™ Amplifier
パフォーマンス・プロファイラー
解析解析ツール
インテル® Advisorベクトル化の最適化と
スレッドのプロトライプ生成
インテル® Inspectorメモリー/スレッドのデバッ
ガー
オペレーティング・システム: Windows*、Linux*、macOS*1
インテル® アーキテクチャー・ベースのプラットフォーム
ビルドコンパイラーとライブラリー
インテル® C/C++ コンパイラー
最適化コンパイラー
インテル® Distribution for Python*ハイパフォーマンスなスクリプト
インテル® MKL3
高速なマス・カーネル・ライブラリー
インテル® IPP4
画像、信号、データ処理
インテル® TBB2
C++ スレッド・ライブラリー
インテル® DAAL5
データ解析、マシンラーニング・ライブラリー
インテル® Fortran コンパイラー
最適化コンパイラー
7

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
Cluster EditionProfessional EditionComposer Edition
インテル® Parallel Studio XE高速なコードを素早く開発
コードを強力に支援 - isus.jp/intel-parallel-studio-xe/
スケールクラスターツール
インテル® Trace Analyzer & Collector
MPI チューニングと解析
インテル® MPI ライブラリーメッセージ・パッシング・
インターフェイス・ライブラリー
インテル® Cluster Checkerクラスター診断エキスパート・システム
1 Composer Edition でのみ利用可能2インテル® スレッディング・ビルディング・ブロック3インテル® マス・カーネル・ライブラリー4インテル® インテグレーテッド・パフォーマンス・プリミティブ5インテル® データ・アナリティクス・アクセラレーション・ライブラリー
インテル® VTune™ Amplifier
パフォーマンス・プロファイラー
解析解析ツール
インテル® Advisorベクトル化の最適化と
スレッドのプロトライプ生成
インテル® Inspectorメモリー/スレッドのデバッ
ガー
オペレーティング・システム: Windows*、Linux*、macOS*1
インテル® アーキテクチャー・ベースのプラットフォーム
ビルドコンパイラーとライブラリー
インテル® C/C++ コンパイラー
最適化コンパイラー
インテル® Distribution for Python*ハイパフォーマンスなスクリプト
インテル® MKL3
高速なマス・カーネル・ライブラリー
インテル® IPP4
画像、信号、データ処理
インテル® TBB2
C++ スレッド・ライブラリー
インテル® DAAL5
データ解析、マシンラーニング・ライブラリー
インテル® Fortran コンパイラー
最適化コンパイラー
SIMD 命令を活用するための強力なツール
インテル® Advisor
8

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
新機能: ルーフライン、高速な解析、ほか…インテル® Advisor – ベクトル化の最適化
ルーフライン解析により効率良く最適化
影響の大きい最適化されていないループを見つける
キャッシュまたはベクトル化の最適化が必要か?
演算負荷の高いアルゴリズムのほうが良いか?
高速なデータ収集
モジュールでフィルター – 必要なもののみ計算
詳細な解析を追跡 – すべてのサイトが実行されたら停止する
より多くのデータと推奨事項により的確な判断が可能
インテル® MKL フレンドリー – コードが最適化されているか? 最適なバージョンが使用されているか?
トリップカウントと関数呼び出しカウント
上位 5 つの推奨事項をサマリーに表示
動的な命令ミックス – エキスパート機能により各命令の正確なカウントを表示
簡単に MPI を起動
コマンドライン・ダイアログで MPI をサポート
9

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
インテル® Xeon® プロセッサーとインテル® Xeon Phi™ プロセッサー向け命令セット・アーキテクチャー (ISA)
KNL✝
インテル® Xeon Phi™プロセッサー
SSE*
AVX
AVX2
SKL✝
インテル® Xeon®スケーラブル・プロセッサー
SSE*
AVX
AVX2
SNB✝
SSE*
AVX
HSW✝
SSE*
AVX
AVX2
NHM✝
SSE*
AVX512F AVX512F
AVX512CD AVX512CD
AVX512ER
AVX512PF
Pftchwt1
AVX512DQ
AVX512BW
AVX512VL大きいコア低レイテンシーに注力/マルチスレッド・シングルスレッドエンタープライズ、HPC 向け SIMD サポートベスト・パフォーマンスで一般的なワークロードのパフォーマンスを最適化
小さいコアスループットに注力/多くのスレッド (メニーコア)HPC 向け SIMD サポートパフォーマンス/ワットにおいて業界のリーダーシップ
SKL: インテル® Xeon® スケーラブル・プロセッサー (開発コード名Skylake)KNL: インテル® Xeon Phi ™ プロセッサー (開発コード名 Knights Landing)HSW: 開発コード名 HaswellSNB: 開発コード名 Sandy BridgeNHM: 開発コード名 Nehalem
✝開発コード名
10

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
論理レジスターファイルの拡張
EAX RAX
RBX
RCX
RDX
RBP
RSI
RDI
RSP
R8
R9
R10
R11
R12
R13
R14
R15
EBX
ECX
EDX
EBP
ESI
EDI
ESP
MM0/ST0
MM1/ST1
MM2/ST2
MM3/ST3
MM4/ST4
MM5/ST5
MM6/ST6
MM7/ST7
EFLAGS
RIP
XMM0 ZMM0
XMM1 ZMM1
XMM2 ZMM2
XMM3 ZMM3
XMM4 ZMM4
XMM5 ZMM5
XMM6 ZMM6
XMM7 ZMM7
XMM8 ZMM8
XMM9 ZMM9
XMM10 ZMM10
XMM11 ZMM11
XMM12 ZMM12
XMM13 ZMM13
XMM14 ZMM14
XMM15 ZMM15
K0
K1
K2
K3
K4
K5
K6
K7
インテル® SSE (128)/インテル® AVX (256)/インテル® AVX (512) レジスター
MASK レジスター(64)
汎用レジスター (32/64) インテル® MMX® テクノロジーおよび
浮動小数点レジスター (64)
プログラムカウンター (32/64)
インテル® SSE: インテル® ストリーミング SIMD 拡張命令インテル® AVX : インテル® アドバンスト・ベクトル・エクステンション
11
ZMM16
ZMM17
ZMM18
ZMM19
ZMM20
ZMM21
ZMM22
ZMM23
ZMM24
ZMM25
ZMM26
ZMM27
ZMM28
ZMM9
ZMM30
ZMM31

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
単一のベクトルレーンを使用しない!ベクトル化およびスレッド化されていないソフトウェアは、パフォーマンスを得られません
12

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
SIMD (Single Instruction Multiple Data) 命令
for(i = 0; i <= MAX; i++)c[i] = a[i] + b[i];
+
a[i]
b[i]
c[i]
+
a[i]
b[i]
c[i]
+
a[i] a[i+1] a[i+2] a[i+3] a[i+4] a[i+5] a[i+6] a[i+7]
b[i] b[i+1] b[i+2] b[i+3] b[i+4] b[i+5] b[i+6] b[i+7]
c[i] c[i+1] c[i+2] c[i+3] c[i+4] c[i+5] c[i+6] c[i+7]
+
a[i] a[i+1] a[i+2] a[i+3] a[i+4] a[i+5] a[i+6] a[i+7]
b[i] b[i+1] b[i+2] b[i+3] b[i+4] b[i+5] b[i+6] b[i+7]
c[i] c[i+1] c[i+2] c[i+3] c[i+4] c[i+5] c[i+6] c[i+7]
for(i = 0; i <= MAX; i+8)
c[i:8] = a[i:8] + b[i:8];
13

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
一般的なループのベクトル化の問題
ループの反復 (イテレーション) 間に依存性があってはならない
– 一部の依存ループはベクトル化が可能
ループ内の変数は明確でなければならない
多くの関数呼び出しはベクトル化できない
条件分岐はベクトル化を妨げる
– 比較的単純な IF 文はマスクによりベクトル化可能
ループはカウント可能でなければならない
ネストするループの外部ループはベクトル化できない
混在データ型はベクトル化できない
14

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
インテル® Advisorスレッド化とベクトル化によるアプリケーションのパフォーマンスを向上
コンパイラーは常にコードをベクトル化するとは限りません
インテル® Advisor を使用してループ伝搬依存をチェック
ベクトル化を強制しても問題ないか? C++: pragma simd、Fortran: SIMD ディレクティブ
ベクトル化が常に効率的とは限りません
ストライド 1 はストライド 2 よりもキャッシュに効率的インテル® Advisor で解析
データ配置の再構成を検討SIMD Data Layout Templates が有効
構造体配列はデータを直観的に構成するには優れていますが、配列構造体ほど効率的ではありません。SIMD Data Layout Templates (SDLT) を使用して、ベクトル化に効率良いデータにマッピングします
15

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
問題: インテル® AVX2 向けの再コンパイルでは、
わずかなゲイン
どこをベクトル化するか?
新しいアーキテクチャー向けに組込み関数を使用すべきか?
コンパイラー・レポートの内容が分からない?
高速なコードを迅速に開発: インテル® Advisorベクトル化の最適化
データ主導型のベクトル化: 最も効率良いベクトル化の候補は?
ベクトル化を妨げているものは? その原因?
ループはベクトル化に適しているか?
データの再構成でパフォーマンスを改善可能か?
単純に pragma simd を使用しても安全か?
「インテル® Advisor のベクトル化アドバイザーは、開発者が本来行うべき作業に集中することを可能にします。最適化に費やすことができる時間が限られている場合、非常に有効です。」
ハイエンド・コンピューティング・アイルランド・センターシニア・ソフトウェア・アーキテクトGilles Civario
16

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
姫野ベンチマークでの試行
姫野ベンチマークは、理化学研究所情報基盤センターのセンター⻑である姫野龍太郎氏が非圧縮流体解析コードの性能評価のために考えたもので、ポアソン方程式解法をヤコビの反復法で解く場合に主要なループの処理速度を計るものです
• 非圧縮流体解析のポアソン方程式をヤコビの反復法で解く場合に使用する主要なループの処理速度を測定 (19 点ステンシルコード)
• 単精度の MFLOPS を性能として比較する• C または Fortran77/90のソースコードで供給• クラスターシステム用に MPI を、またマルチプロセッサー用に
OpenMP* のものを準備
17

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
ステンシルの例 (6 点)
i
j
k
A_new(I,J,K)= F( A(I-1,J,K),
A(I+1,J,K),A(I,J-1,K), A(I,J+1,K),
A(I,J,K+1), A(I,J,K-1) )
全格子点について
18

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
姫野ベンチマーク (http://accc.riken.jp/supercom/himenobmt/download/mpi-vpp)
279 #pragma omp parallel shared(a,p,b,c,bnd,wrk1,wrk2,nn,imax,jmax,kmax,omega,gosa) private(i,j,k,s0,ss,gosa1,n)280 {281 for(n=0 ; n<nn ; n++){282 #pragma omp barrier283 #pragma omp master284 {285 gosa = 0.0;286 }287 gosa1= 0.0;288 #pragma omp for nowait289 for(i=1 ; i<imax; i++)290 for(j=1 ; j<jmax ; j++)291 for(k=1 ; k<kmax ; k++){292 s0= MR(a,0,i,j,k)*MR(p,0,i+1,j, k)293 + MR(a,1,i,j,k)*MR(p,0,i, j+1,k)294 + MR(a,2,i,j,k)*MR(p,0,i, j, k+1)295 + MR(b,0,i,j,k)296 *( MR(p,0,i+1,j+1,k) - MR(p,0,i+1,j-1,k)298 - MR(p,0,i-1,j+1,k) + MR(p,0,i-1,j-1,k) )299 + MR(b,1,i,j,k)300 *( MR(p,0,i,j+1,k+1) - MR(p,0,i,j-1,k+1)
19
© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
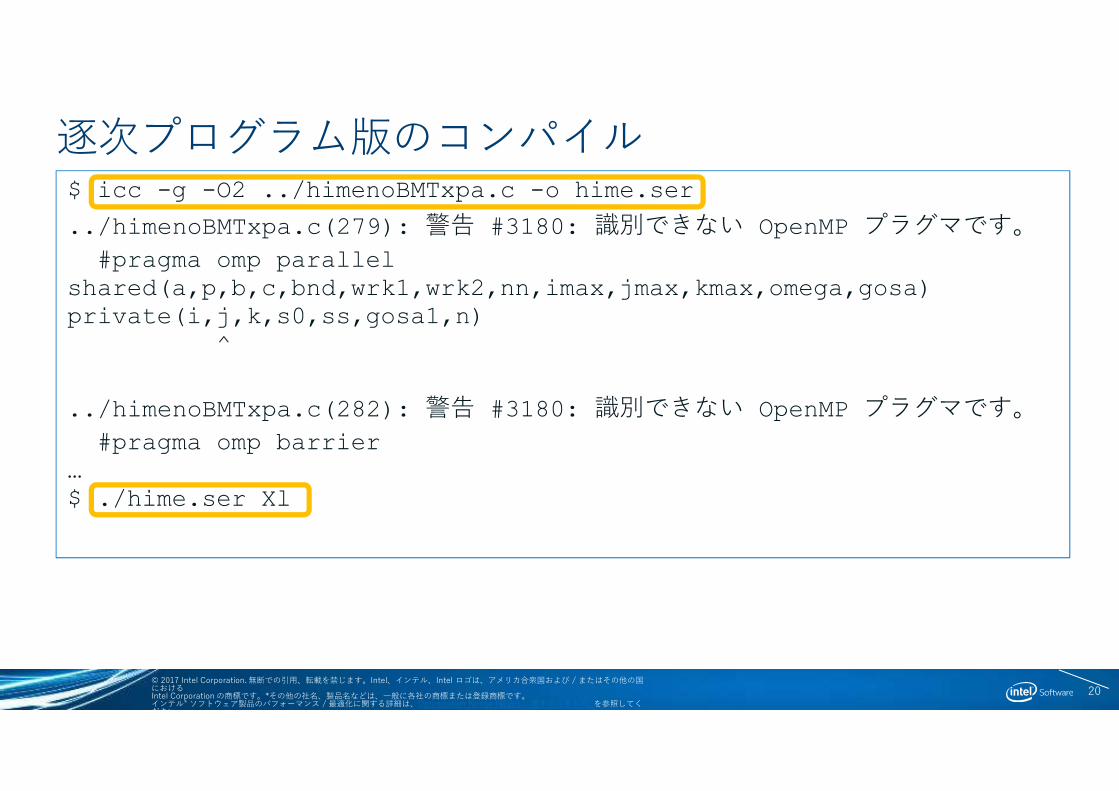
逐次プログラム版のコンパイル$ icc -g -O2 ../himenoBMTxpa.c -o hime.ser
../himenoBMTxpa.c(279): 警告 #3180: 識別できない OpenMP プラグマです。
#pragma omp parallel shared(a,p,b,c,bnd,wrk1,wrk2,nn,imax,jmax,kmax,omega,gosa) private(i,j,k,s0,ss,gosa1,n)
^
../himenoBMTxpa.c(282): 警告 #3180: 識別できない OpenMP プラグマです。
#pragma omp barrier…$ ./hime.ser Xl
20

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
逐次プログラム版の実行$ ./hime.ser XlGrid-size = Xl
mimax = 512 mjmax = 512 mkmax = 1024imax = 511 jmax = 511 kmax =1023Start rehearsal measurement process.Measure the performance in 3 times.
MFLOPS: 601.735307 time(s): 45.059454 6.103516e-05
…
cpu : 44.971282 sec.Loop executed for 3 timesGosa : 6.103516e-05 MFLOPS measured : 602.915087Score based on Pentium III 600MHz using Fortran 77: 7.278067
21

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
OpenMP* 版のコンパイルと実行$ icc -g -O3 -qopenmp -qopt-streaming-stores always ./himenoBMTxpa.c -o hime.par$ ./hime.par Xlmimax = 512 mjmax = 512 mkmax = 1024imax = 511 jmax = 511 kmax =1023Start rehearsal measurement process.Measure the performance in 3 times.
MFLOPS: 6028.912509 time(s): 4.497306 4.365373e-04
…
cpu : 58.707601 sec.Loop executed for 40 timesGosa : 4.255282e-04 MFLOPS measured : 6157.945238Score based on Pentium III 600MHz using Fortran 77: 74.335408
22

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
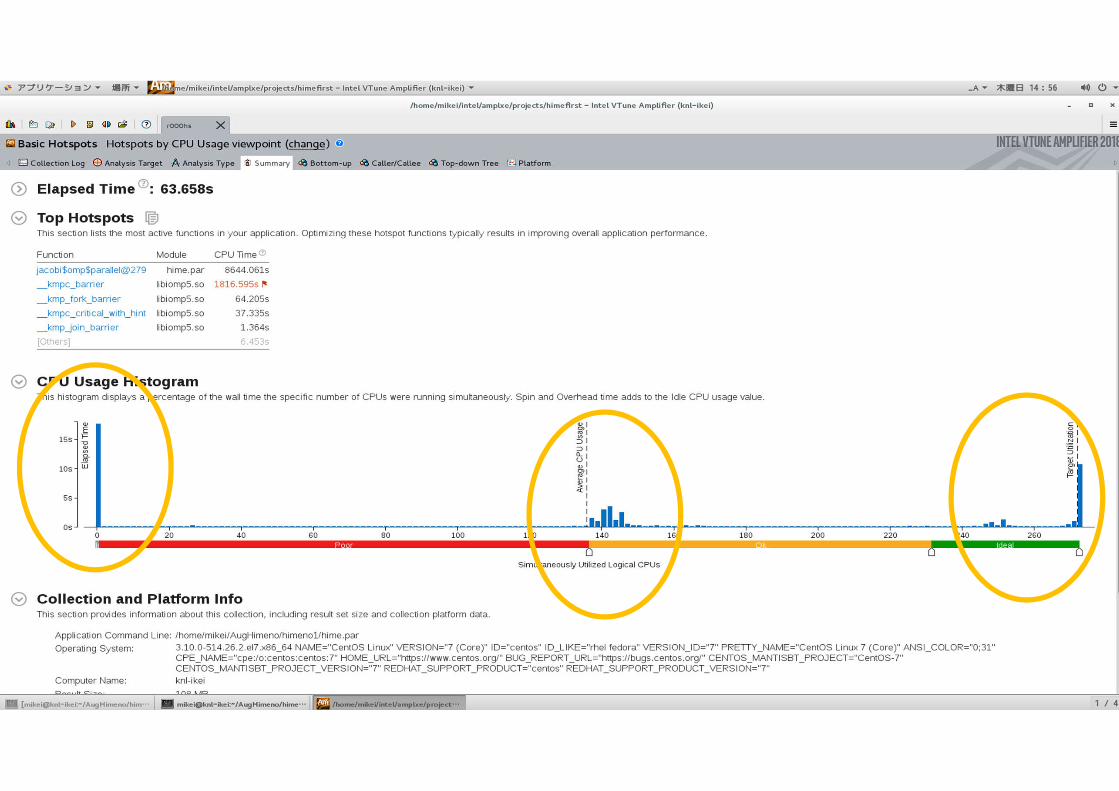
性能解析ツールの実行(インテル® VTune™ Amplifier とインテル® Advisor)
$ amplxe-gui
もしくは
$ amplxe-cl -collect hotspots -app-working-dir himeno/openmp -- himeno/openmp/hime.par Xl
$ advixe-gui
もしくは
$ advixe-cl -collect survey -no-support-multi-isa-binaries
-interval=10 -data-limit=100 -resume-after=0 -project-dir micperf/himeno -- micperf/himeno/openmp/hime.par Xl
23
© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
PLATINUM 81xxPLATINUM 81xxPLATINUM 81xxPLATINUM 81xx
© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
25
PLATINUM 81xx
© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
26
PLATINUM 81xx
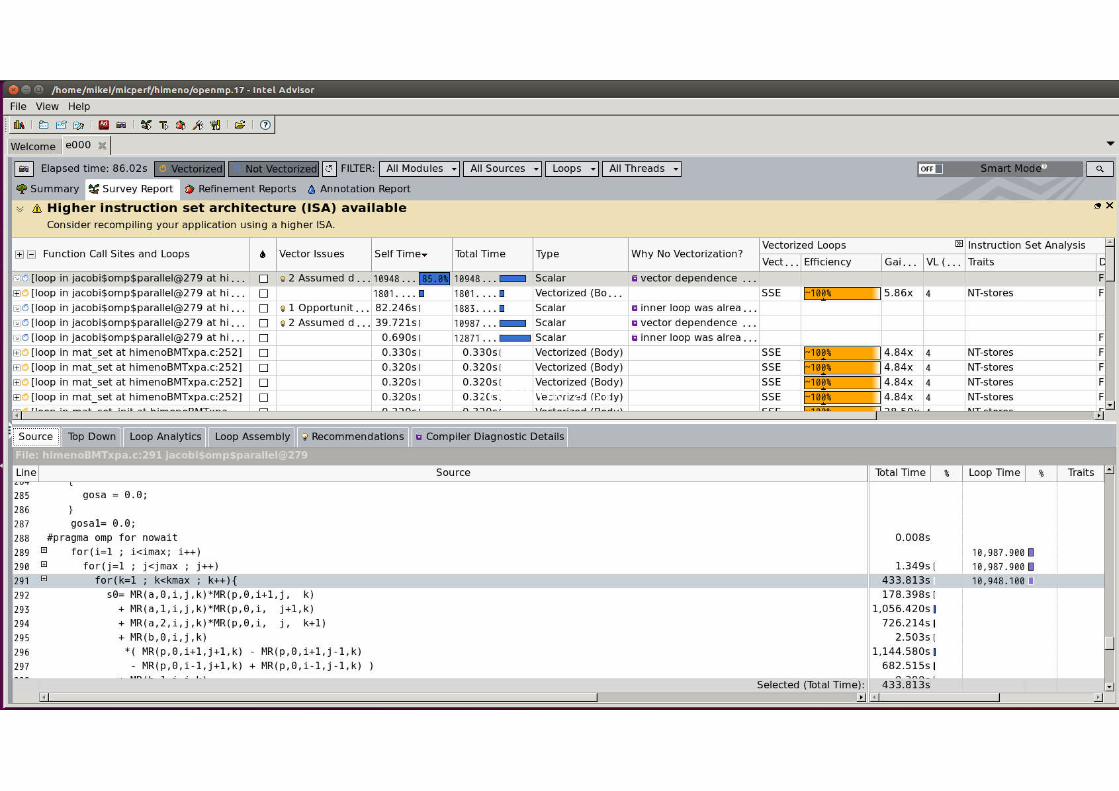
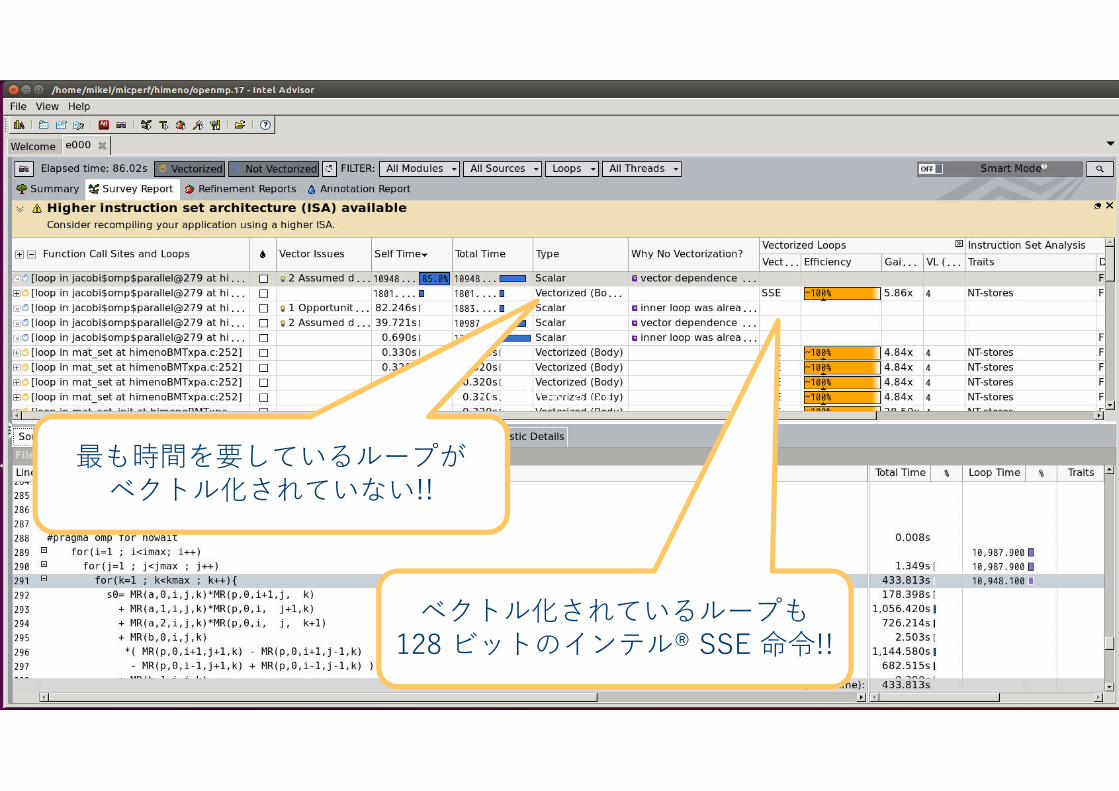
最も時間を要しているループがベクトル化されていない!!
ベクトル化されているループも128 ビットのインテル® SSE 命令!!

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
ベクトル化のために pragma を追加279 #pragma omp parallel shared(a,p,b,c,bnd,wrk1,wrk2,nn,imax,jmax,kmax,omega,gosa) private(i,j,k,s0,ss,gosa1,n)280 {281 for(n=0 ; n<nn ; n++){282 #pragma omp barrier283 #pragma omp master284 {285 gosa = 0.0;286 }287 gosa1= 0.0;288 #pragma omp for nowait289 for(i=1 ; i<imax; i++)290 for(j=1 ; j<jmax ; j++)291 #pragma omp simd reduction(+:gosa1) 292 for(k=1 ; k<kmax ; k++){293 s0= MR(a,0,i,j,k)*MR(p,0,i+1,j, k)294 + MR(a,1,i,j,k)*MR(p,0,i, j+1,k)295 + MR(a,2,i,j,k)*MR(p,0,i, j, k+1)296 + MR(b,0,i,j,k)297 *( MR(p,0,i+1,j+1,k) - MR(p,0,i+1,j-1,k)
27

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
インテル® AVX-512 版のコンパイルと実行$ icc -g -O2 -qopenmp -xMIC-AVX512 -qopt-streaming-stores alwayshimeno2.c -o hime2.avx
$ ./hime2.avx Xl
…
Wait for a while
cpu : 53.044081 sec.Loop executed for 138 timesGosa : 4.136810e-04 MFLOPS measured : 23513.231616Score based on Pentium III 600MHz using Fortran 77: 283.839107
28

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
インテル® Xeon® プロセッサーとインテル® Xeon Phi™ プロセッサー向け命令セット・アーキテクチャー (ISA)
KNL✝
インテル® Xeon Phi™プロセッサー
SSE*
AVX
AVX2
SKL✝
インテル® Xeon®スケーラブル・プロセッサー
SSE*
AVX
AVX2
SNB✝
SSE*
AVX
HSW✝
SSE*
AVX
AVX2
NHM✝
SSE*
AVX512F AVX512F
AVX512CD AVX512CD
AVX512ER
AVX512PF
Pftchwt1
AVX512DQ
AVX512BW
AVX512VL大きいコア低レイテンシーに注力/マルチスレッド・シングルスレッドエンタープライズ、HPC 向け SIMD サポートベスト・パフォーマンスで一般的なワークロードのパフォーマンスを最適化
小さいコアスループットに注力/多くのスレッド (メニーコア)HPC 向け SIMD サポートパフォーマンス/ワットにおいて業界のリーダーシップ
SKL: インテル® Xeon® スケーラブル・プロセッサー (開発コード名Skylake)KNL: インテル® Xeon Phi ™ プロセッサー (開発コード名 Knights Landing)HSW: 開発コード名 HaswellSNB: 開発コード名 Sandy BridgeNHM: 開発コード名 Nehalem
✝開発コード名
29

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
インテル® Xeon® スケーラブル・プロセッサー対応コンパイラー・オプション一覧
オプション 説明
-xCORE-AVX512 xCORE-AVX2 からのスムーズな移行(エンタープライズ向け)
-xCORE-AVX512 –qopt-zmm-usage=high 512 ビット命令のメリットが大きいアプリケーション(HPC 向け)
-xCOMMON-AVX512 512ビット 命令のメリットが大きくインテル® Xeon Phi™プロセッサー (KNL✝) とバイナリー互換が必要なアプリケーション
-xCORE-AVX2 クライアント・アプリケーション、インテル® Xeon® プロセッサー E5 v4 ファミリー (Broadwell✝) と互換性またはインテル® Xeon Phi™ プロセッサー (KNL✝) と互換性が必要な場合
[OpenMP* 4.5] #pragma omp simd simdlen() simdlen を追加し SIMD チャンクごと必要な反復数を指定
#pragma omp declare simd simdlen(16)
インテル® C/C++ コンパイラー 18.0 コンパイラー・オプション
✝開発コード名
30

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
31
© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
32
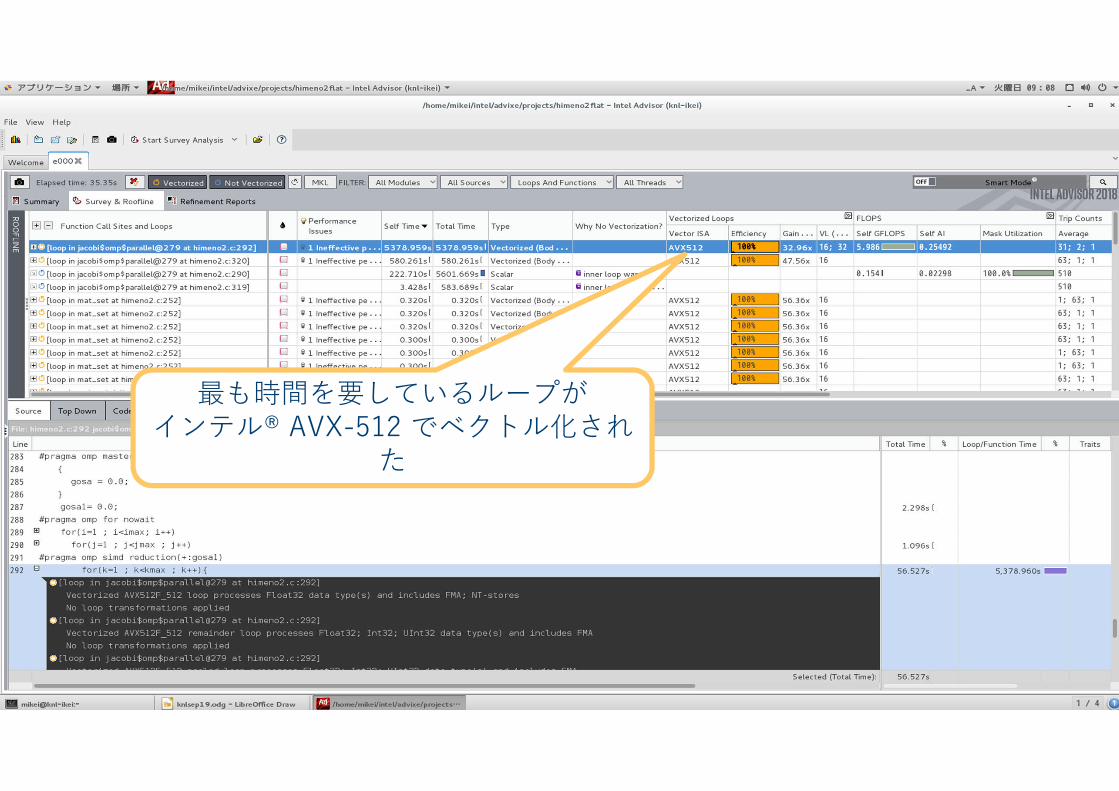
最も時間を要しているループがインテル® AVX-512 でベクトル化され
た

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
Knights Landing✝本当のブレークスルーに向けての統合的な取り組み
…
…
..
.
..
.
内蔵インテル® Omni-Path ファブリック
60 以上のコア
プロセッサー・パッケージ
. . . . . .
. . .
. . . .
..
..
..
..
計算
インテル® Xeon® プロセッサーとバイナリー互換
3+ TFLOPS1, 3X ST2 (単一スレッド) KNC✝ の性能比
2D メッシュ
Out-of-Order コア
パッケージ内メモリー 5x 以上 STREAM vs. DDR43
最大 16GB (>450GB/S)
システムメモリー最大 384GB DDR4 (6 ch > 90GB/S, 2400 T/S)
インテル® Omni-Pathファブリック(オプション)
最初の統合化したインテル® プロセッサー
I/O 最大 36 PCIe* 3.0 レーン
✝開発コード名
33
© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
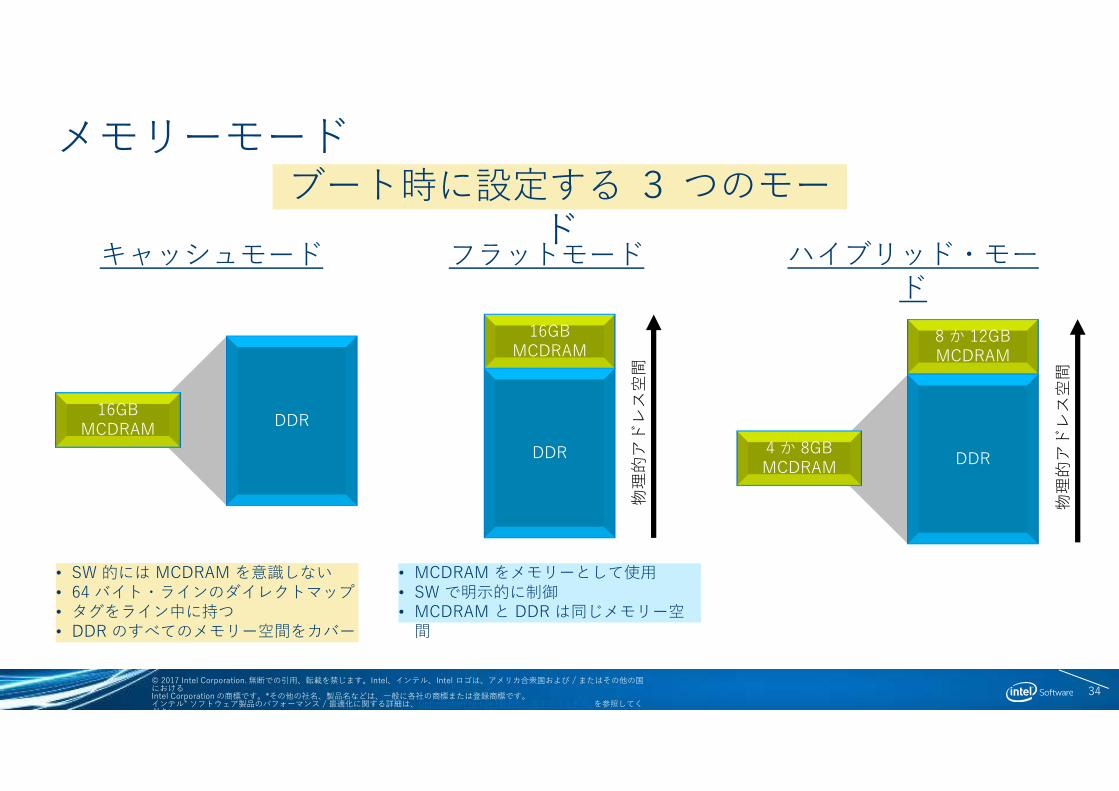
メモリーモード
キャッシュモード
ブート時に設定する 3 つのモード
16GBMCDRAM
DDR
フラットモード
16GBMCDRAM
DDR
ハイブリッド・モード
4 か 8GBMCDRAM
DDR
8 か 12GBMCDRAM
• SW 的には MCDRAM を意識しない• 64 バイト・ラインのダイレクトマップ• タグをライン中に持つ• DDR のすべてのメモリー空間をカバー
• MCDRAM をメモリーとして使用• SW で明示的に制御• MCDRAM と DDR は同じメモリー空
間物
理的
アド
レス
空間
物理
的ア
ドレ
ス空
間
34

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
Knights Landing✝ ブロック図
MCDRAM
DRAM
MCDRAM
MCDRAM
MCDRAM
DRAM
共用キャッシュ1MB
コア+
2 VPU
タイルの構成
CH
A コア+
2 VPU
✝開発コード名
35

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
メモリー階層の確認$ numactl -Havailable: 2 nodes (0-1)node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 …224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271node 0 size: 98200 MBnode 0 free: 92941 MBnode 1 cpus:node 1 size: 16384 MBnode 1 free: 15897 MBnode distances:node 0 1
0: 10 31 1: 31 10
36

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
メモリー階層の確認$ numactl -Havailable: 2 nodes (0-1)node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 …224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271node 0 size: 98200 MBnode 0 free: 92941 MBnode 1 cpus:node 1 size: 16384 MBnode 1 free: 15897 MBnode distances:node 0 1
0: 10 31 1: 31 10
DDR メモリーがノード 0
16GB の MCDRAM はノード 1
37

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
インテル® AVX-512 版のコンパイルと実行$ icc -g -O2 -qopenmp -xMIC-AVX512 -qopt-streaming-stores alwayshimeno2.c -o hime2.avx
$ ./hime2.avx Xl
…
Wait for a while
cpu : 53.044081 sec.Loop executed for 138 timesGosa : 4.136810e-04 MFLOPS measured : 23513.231616Score based on Pentium III 600MHz using Fortran 77: 283.839107
38

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
39
PLATINUM 81xxPLATINUM 81xxPLATINUM 81xxPLATINUM 81xx
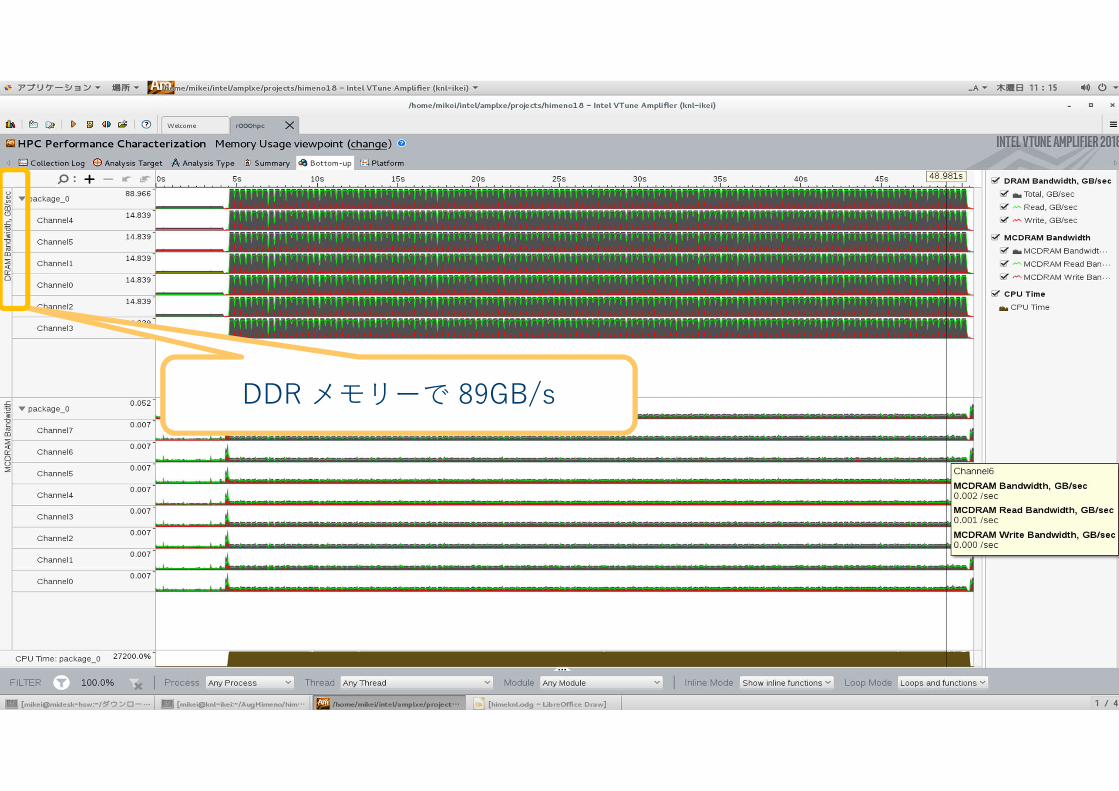
© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
40
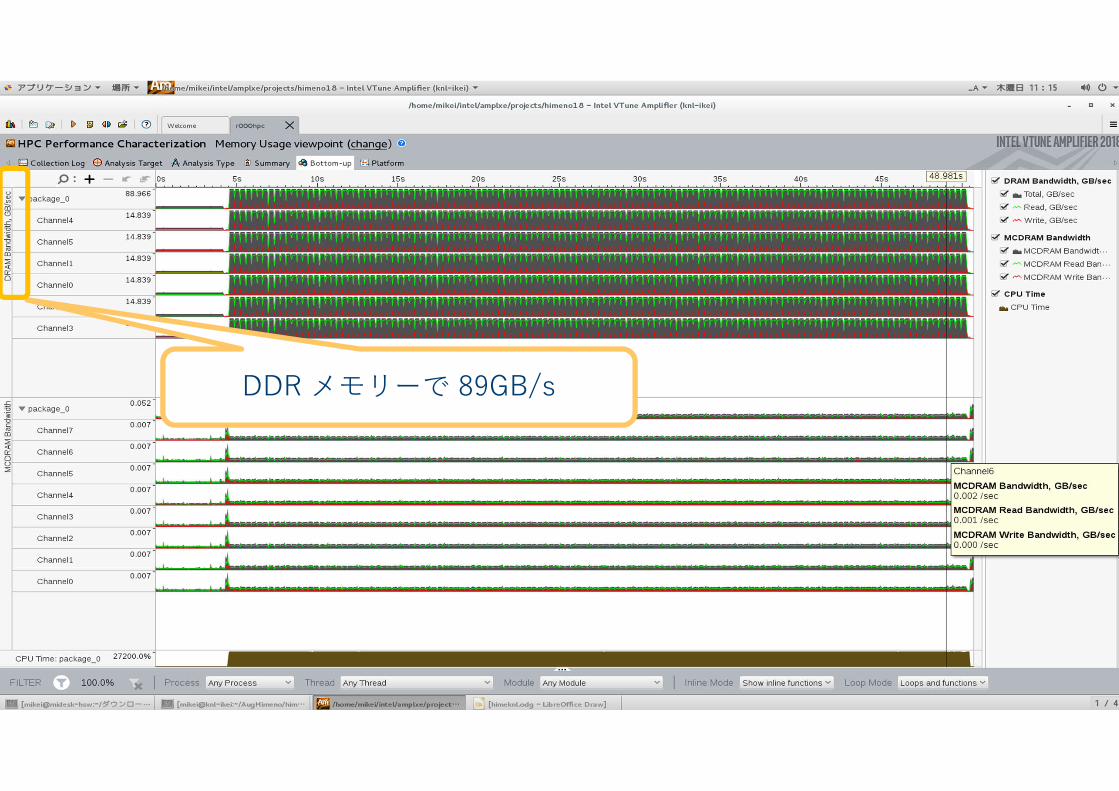
PLATINUM 81xxPLATINUM 81xxPLATINUM 81xxPLATINUM 81xxDDR メモリーで 89GB/s

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
41
PLATINUM 81xxPLATINUM 81xxPLATINUM 81xxPLATINUM 81xx
コア周波数の変動

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
ルーフライン・モデルとは? どれくらい高速化できるか理解しているか?
バークレーの研究者により提唱された
パフォーマンスは、計算式/実装およびコード生成/ハードウェアにより制限されます
2 つのハードウェア要件
ピーク FLOPS
ピーク帯域幅
アプリケーションのパフォーマンスは、ハードウェアの仕様により制限されます
GFLOPS= ��� ��������� ����
�������� �� ∗ ��
算術密度 (Flop/バイト)
42

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
理論値は仕様によって算出可能例) 2 ソケットのインテル® Xeon® プロセッサー E5-2697 v2ピーク FLOP = 2 x 2.7 x 12 x 8 x 2 = 1036.8 GFLOPS
より現実的な値は Linpack を実行して求めることができます=~ 930 GFLOPS (2 ソケットのインテル® Xeon® プロセッサー E5-2697 v2)
プラットフォームのピーク FLOPS1 秒あたりの浮動小数点演算数
ソケット数
コア周波数
コア数
SIMD レジスター中の単精度要素の数
1 つのポートを加算に、もう 1 つを乗算に
GFLOPS= ��� ��������� ����
�������� �� ∗ ��
43

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
理論値は仕様によって算出可能例) 2 ソケットのインテル® Xeon® プロセッサー E5-2697 v2ピーク BW = 2 x 1.866 x 8 x 4 = 119GB/秒
より現実的な値は Stream を実行して求めることができます=~ 100 Gflop/秒 (2 ソケットのインテル® Xeon® プロセッサー E5-2697 v2)
プラットフォームのピーク帯域幅1 秒あたりの転送バイト数
ソケット数 メモリー周波数チャネルあたりのバイト数 メモリーチャネル数
GLOPS = ��� ��������� ����
�������� �� ∗ ��
44

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
ルーフラインを描く限界を定義
AI [Flop/バイト] 8.7
2 ソケットのインテル® Xeon® プロセッサー E5-2697 v2ピーク Flops = 1036 GFLOPSピーク BW = 119GB/秒
GFLOPS = ��� ��������� ����
�������� �� ∗ ��
45
GFLOPS
1036

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
ルーフラインを描く限界を定義
GFLOPS
1036
2 ソケットのインテル® Xeon® プロセッサー E5-2697 v2ピーク Flops = 1036 GFLOPSピーク BW = 119GB/秒
GFLOPS = ��� ��������� ����
�������� �� ∗ ��
1
119
46
AI [Flop/バイト] 8.7
© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
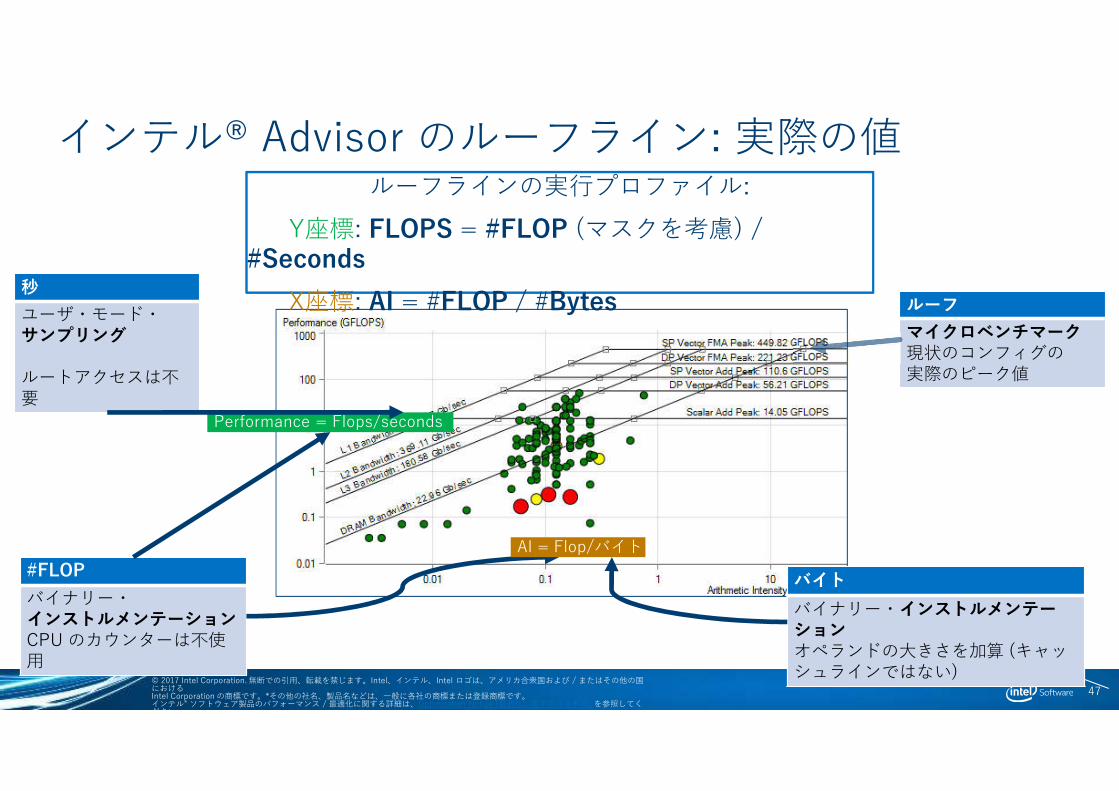
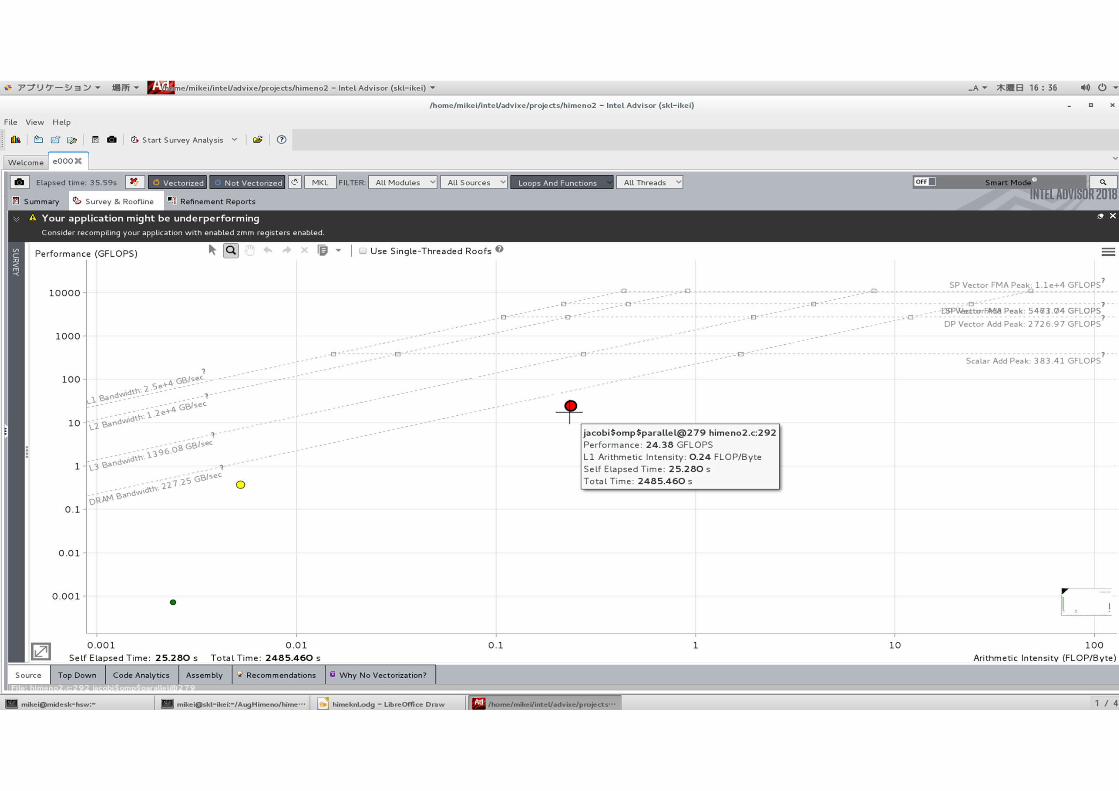
インテル® Advisor のルーフライン: 実際の値
#FLOP
バイナリー・インストルメンテーションCPU のカウンターは不使用
秒
ユーザ・モード・サンプリング
ルートアクセスは不要
バイト
バイナリー・インストルメンテーションオペランドの大きさを加算 (キャッシュラインではない)
ルーフ
マイクロベンチマーク現状のコンフィグの実際のピーク値
AI = Flop/バイト
Performance = Flops/seconds
ルーフラインの実行プロファイル:
Y座標: FLOPS = #FLOP (マスクを考慮) / #Seconds
X座標: AI = #FLOP / #Bytes
47

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
48

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
メモリー階層の確認$ numactl -Havailable: 2 nodes (0-1)node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 …224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271node 0 size: 98200 MBnode 0 free: 92941 MBnode 1 cpus:node 1 size: 16384 MBnode 1 free: 15897 MBnode distances:node 0 1
0: 10 31 1: 31 10
DDR メモリーがノード 0
16GBの MCDRAM はノード 1
49
© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
50
PLATINUM 81xxPLATINUM 81xxPLATINUM 81xxPLATINUM 81xxDDR メモリーで 89GB/s

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
高速メモリーでの実行$ numactl -m 1 ./hime2.avx Xl…mimax = 512 mjmax = 512 mkmax = 1024imax = 511 jmax = 511 kmax =1023Start rehearsal measurement process.Measure the performance in 3 times.
…cpu : 37.734588 sec.Loop executed for 354 timesGosa : 3.960919e-04 MFLOPS measured : 84787.887420Score based on Pentium III 600MHz using Fortran 77: 1023.513851
51

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
高速メモリーでの実行$ numactl -m 1 ./hime2.avx Xl…mimax = 512 mjmax = 512 mkmax = 1024imax = 511 jmax = 511 kmax =1023Start rehearsal measurement process.Measure the performance in 3 times.
…cpu : 37.734588 sec.Loop executed for 354 timesGosa : 3.960919e-04 MFLOPS measured : 84787.887420Score based on Pentium III 600MHz using Fortran 77: 1023.513851
52

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
53

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
54
MCDRAM メモリーで 327GB/s

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
Skylake1上での実行$ icc -g -O2 -qopenmp -xCORE-AVX512 -qopt-streaming-stores always -qopt-streaming-cache-evict=0 himeno2.c -o himeno2 …
$ ./himeno2 Xlmimax = 512 mjmax = 512 mkmax = 1024imax = 511 jmax = 511 kmax =1023Start rehearsal measurement process.Measure the performance in 3 times.
…
cpu : 26.680347 sec.Loop executed for 185 timesGosa : 4.090138e-04MFLOPS measured : 62668.661618Score based on Pentium III 600MHz using Fortran 77: 756.502434
1開発コード名インテル® Xeon® Platinum 8170 CPU @ 2.10GHz 26 コア
55
© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
56

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
57

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
58

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
Sub NUMA クラスター
MCDRAM
MCDRAM
MCDRAM
MCDRAM
3. SNC-4: 4 ソケットのマシン (コア数は 4 分の 1) として見える
$ numactl -H
available: 8 nodes (0-7)
node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 64 65....
node 0 size: 24452 MB
node 0 free: 22976 MB
node 1 cpus: 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 80 ...
node 1 size: 24576 MB
node 1 free: 23698 MB
node 2 cpus: 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 96 ...
node 2 size: 24576 MB
node 2 free: 23843 MB
node 3 cpus: 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 112 ...
…
node 4 cpus:
node 4 size: 4096 MB
node 4 free: 3982 MB
node 5 cpus:
…
node 7 cpus:
node 7 size: 4096 MB
node 7 free: 3982 MB
59

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
MPI 版の姫野プログラムをハイブリッドに370 integer,intent(in) :: nn371 real(4),intent(inout) :: gosa372 integer :: i,j,k,loop,ierr373 real(4) :: s0,ss,wgosa374 ! 375 do loop=1,nn376 gosa=0.0377 wgosa=0.0378 !$OMP PARALLEL DO SHARED (kmax,jmax,imax,nn,a,p,b,c,bnd,wrk1,wrk2) &379 !$OMP PRIVATE (k,i,j,s0,ss) REDUCTION (+:wgosa)380 do k=2,kmax-1381 do j=2,jmax-1382 do i=2,imax-1383 s0=a(I,J,K,1)*p(I+1,J,K) &384 +a(I,J,K,2)*p(I,J+1,K) &385 +a(I,J,K,3)*p(I,J,K+1) &386 +b(I,J,K,1)*(p(I+1,J+1,K)-p(I+1,J-1,K) &387 -p(I-1,J+1,K)+p(I-1,J-1,K)) &388 +b(I,J,K,2)*(p(I,J+1,K+1)-p(I,J-1,K+1) &389 -p(I,J+1,K-1)+p(I,J-1,K-1)) &
60

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
ハイブリッド版のコンパイルと実行$ mpiifort -g -O3 -xMIC_AVX512 -qopenmp -qopt-streaming-storesalways himeno4.f90 -o himeno4.avx$ export OMP_NUM_THREADS=2
$ numactl -m 4,5,6,7 mpiexec.hydra -n 64 ./himeno4.avx…
The loop will be excuted in 1008 times.This will take about one minute.Wait for a while.Loop executed for 1008 timesGosa : 3.6641795E-04MFLOPS: 155347.575570096 time(s): 58.6443572044373Score based on Pentium III 600MHz : 1875.273
61

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
62
MCDRAM メモリーで 386GB/s

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
高速メモリーをプログラムから使用する方法 (F90)module pres
implicit nonereal(4),dimension(:,:,:),allocatable :: p
!DEC$ ATTRIBUTES FASTMEM :: pend module pres!module mtrx
implicit nonereal(4),dimension(:,:,:,:),allocatable :: a,b,c
!DEC$ ATTRIBUTES FASTMEM :: a,b,cend module mtrx!
63

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
高速メモリーをプログラムから使用する方法 (C)…#include <hbwmalloc.h>…Mat->m= NULL;Mat->m= (float*)hbw_malloc(mnums * mrows * mcols * mdeps * sizeof(float));
return(Mat->m != NULL) ? 1:0;}
voidclearMat(Matrix* Mat){
if(Mat->m)hbw_free(Mat->m);
Mat->m= NULL;Mat->mnums= 0;
64

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
コード・モダナイゼーションのまとめ
項目 利用するツールなど 考察
1. スレッド化 OpenMP* OpenMP* を使用してコア数 × 4 のスレッドを活用
2. ベクトル化 SIMD pragma インテル® AVX-512 により 512b の VPU を活用
3. ブロック化 (MPI による分割)
4. キャッシュ クラスターモード フラットかキャッシュか? AllToAll、Quadrant、SNC4?
5. ファブリック MPI インテル® Omni−Path アーキテクチャーなどの高速ファブリックを利用
6. データレイアウト
メモリー階層 Numactl や FASTMEM、HBMMALLOC を利用
65

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
結論
• プロセッサーのコア数と SIMD 幅が広がり、並列化 = コード・モダナイゼーションは必須
• インテル® AVX-512 命令でベクトル化の重要性が大きく
– インテル® Advisor により、重要なループを効果的にベクトル化
• キャッシュやパッケージメモリーなどのメモリーの階層構造の演算性能への影響も大きく
– インテル® VTune™ Amplifier でメモリー性能を可視化
– インテル® Advisor のルーフライン表示によりループ性能を可視化
• より高性能で複雑になる IA アーキテクチャー上でもインテル® Parallel Studio XE で迅速なプログラムの最適化を実現
66

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。
本資料の情報は、現状のまま提供され、本資料は、明示されているか否かにかかわらず、また禁反言によるとよらずにかかわらず、いかなる知的財産権のライセンスも許諾するものではありません。製品に付属の売買契約書『Intel's Terms and Conditions of Sale』に規定されている場合を除き、インテルはいかなる責任を負うものではなく、またインテル製品の販売や使用に関する明示または黙示の保証 (特定目的への適合性、商品性に関する保証、第三者の特許権、著作権、その他、知的財産権の侵害への保証を含む) をするものではありません。
性能に関するテストに使用されるソフトウェアとワークロードは、性能がインテル® マイクロプロセッサー用に最適化されていることがあります。SYSmark* や MobileMark* などの性能テストは、特定のコンピューター・システム、コンポーネント、ソフトウェア、操作、機能に基づいて行ったものです。結果はこれらの要因によって異なります。製品の購入を検討される場合は、他の製品と組み合わせた場合の本製品の性能など、ほかの情報や性能テストも参考にして、パフォーマンスを総合的に評価することをお勧めします。
© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴ、Intel Inside、Intel Inside ロゴ、Intel Core、Xeon、Intel Xeon Phi、VTune は、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。
法務上の注意書きと最適化に関する注意事項
最適化に関する注意事項
インテル® コンパイラーでは、インテル® マイクロプロセッサーに限定されない最適化に関して、他社製マイクロプロセッサー用に同等の最適化を行えないことがあります。これには、インテル® ストリーミング SIMD 拡張命令 2、インテル® ストリーミング SIMD 拡張命令 3、インテル® ストリーミング SIMD 拡張命令 3 補足命令などの最適化が該当します。インテルは、他社製マイクロプロセッサーに関して、いかなる最適化の利用、機能、または効果も保証いたしません。本製品のマイクロプロセッサー依存の最適化は、インテル® マイクロプロセッサーでの使用を前提としています。インテル® マイクロアーキテクチャーに限定されない最適化のなかにも、インテル® マイクロプロセッサー用のものがあります。この注意事項で言及した命令セットの詳細については、該当する製品のユーザー・リファレンス・ガイドを参照してください。
注意事項の改訂 #20110804
67

© 2017 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国におけるIntel Corporation の商標です。*その他の社名、製品名などは、一般に各社の商標または登録商標です。インテル® ソフトウェア製品のパフォーマンス / 最適化に関する詳細は、Optimization Notice (最適化に関する注意事項) を参照してください。


















