Pagina de rosto - Espelho Bibliográfico em
220
INPE-7011-TDI/659 SIMULAÇÃO DE FILAS GI/G/m E VERIFICAÇÃO DE APROXIMAÇÕES DESTAS POR FILAS Ph/Ph/m José Olimpio Ferreira Dissertação de Mestrado em Computação Aplicada, orientada pela Dr. Sólon Venâncio de Carvalho, aprovada em agosto de 1998. INPE São José dos Campos 1999
-
Upload
dinhnguyet -
Category
Documents
-
view
213 -
download
0
Transcript of Pagina de rosto - Espelho Bibliográfico em

INPE-7011-TDI/659
SIMULAÇÃO DE FILAS GI/G/m E VERIFICAÇÃO DE APROXIMAÇÕES DESTAS POR FILAS Ph/Ph/m
José Olimpio Ferreira
Dissertação de Mestrado em Computação Aplicada, orientada pela Dr. Sólon Venâncio de Carvalho, aprovada em agosto de 1998.
INPE São José dos Campos
1999

519.8 FERREIRA, J. O.
Simulação de filas GI/G/m e verificação de apro-ximações destas por filas Ph/Ph/m / J. O. Ferreira. – São José dos Campos: INPE, 1998.
220p. – (INPE-7011-TDI/659). 1. Processos estocásticos. 2. Simulação. 3.Sistemas de
filas. 4.Simulações de filas. 5.Pesquisa operacional. I.Título.



O engajamento na ciência (empregando a palavra na acepção geral alemã
Wissenschaft) não reside na discordância sobre fatos verificados, mas sobre sua
escolha e combinação, e sobre o que se pode inferir a partir dos mesmos.
Eric Hobsbawn (1917-), historiador, em “Sobre Historia”.
E para que executar projetos, já que o projeto é, nele mesmo, um prazer
suficiente?
Charles Baudelaire (1821-1867), poeta francês, em “Pequenos poemas em prosa”.


Dedico carinhosamente esta dissertação
aos meus pais Manoel e Elizena ( )
aos meus filhos Vitor, Vinicius e Natália
a minha esposa Maria das Graças
e a todos aqueles que me incentivaram e apoiaram.


AGRADECIMENTOS
Gostaria de agradecer ao meu orientador Dr. Solon Venâncio de Carvalho por ter me
orientado e ajudado neste trabalho, pela sua imensa paciência e disponibilidade e,
principalmente, pelo respeito e incentivo demonstrados durante este período à minha
“independência intelectual”.
Agradeço à minha esposa Maria das Graças e à minha filha Natália que suportaram
minhas angústias, ansiedades e nervosismo e me apoiaram neste período. E,
especialmente, aos meus filhos Vitor e Vinicius que souberam compreender a minha
ausência durante estes dois anos e meio para a concretização deste trabalho.
Gostaria de agradecer a Universidade Católica de Goiás – UCG - e a CAPES/MEC por
terem proporcionado as condições financeiras para que eu pudesse cursar o Mestrado
em Computação Aplicada no Instituto Nacional de Pesquisas Espaciais – INPE.
Agradeço, também, aos amigos e colegas que me apoiaram e incentivaram a fazer este
curso de Mestrado em Computação Aplicada, e que me aconselharam nos momentos
mais delicados.


RESUMO
A avaliação de desempenho de um sistema de fila GI/G/m é um clássico problema
difícil. Estes sistemas de filas com múltiplos servidores são notoriamente difíceis de
serem analisados analiticamente, sendo que uma solução analítica exata somente é
possível para casos especiais, tais como as filas M/M/m, M/D/m, M/K2 /m, GI/H2/m,
GI/EK/m, GI/Ph/m, Ph/D/m e Ph/Ph/m. Os modelos de simulação por computadores,
apesar de exigirem muitos recursos de hardware (memória de trabalho e de
armazenagem de massa, velocidade de processamento da CPU) e de consumirem muito
tempo na execução das rodadas da simulação, permitem considerações mais próximas
das situações reais. Os modelos de simulação podem ser bastante úteis na checagem de
suposições necessárias num modelo analítico e na checagem dos resultados do modelo
analítico. Este trabalho trata da estimação de medidas de desempenho, em equilíbrio, de
filas GI/G/m através de simulação. Também é tratada a verificação de aproximações de
filas GI/G/m por filas Ph/Ph/m.


GI/G/m QUEUEING SIMULATION AND GI/G/m QUEUE APROXIMATIONS
FOR Ph/Ph/m QUEUES
ABSTRACT
The performance evaluation of a GI/G/m queueing system is a classic hard problem.
These multi-server queues are notoriously difficult to be evaluated analytically and, a
analytic solutions is possible only for special cases, just as the queues M/M/m, M/D/m,
M/K2 /m, GI/H2/m, GI/EK/m, GI/Ph/m, Ph/D/m e Ph/Ph/m. The computer simulation
models, despite of requiring many hardware resources (work memory, storage memory,
processing speed of the CPU) and consuming large amount of computer times in the
execution of the simulation runs, allow the evaluation of more realistic models. The
computer simulation models can be convenient enough to check the validity of
assumptions needed in an analytic model and to check the results of the analytic model.
This study deals with the estimation of steady-state (long-run) measures of performance
for GI/G/m queueing systems through simulation models. It also checks the GI/G/m
queues approximations by Ph/Ph/m queues.


SUMÁRIO
Pág.
CAPÍTULO 1 – INTRODUÇÃO 37
1.1 - Introdução 37
1.2 - Problema 41
1.3 - Objetivo do estudo 44
1.4 - Revisão bibliográfica 45
CAPÍTULO 2 – CONCEITOS BÁSICOS 49
2.1 - Introdução 49
2.2 - Simulação 49
2.2.1- O Processo de simulação 57
2.3 - A Fila GI/G/m 60
2.3.1- Medidas de performance da Fila GI/G/m 64
2.3.1.1- Medidas de performance da fila M/M/m 67
2.3.1.2- Medidas de performance da fila D/D/m 68
2.3.2- Relações de Little 68
2.3.3- Estimativas das medidas de performance da fila GI/G/m a partir de uma
execução da simulação 70

2.3.3.1- Número médio no sistema e número médio na fila 70
2.3.3.2- Tempo médio no sistema e espera média na fila 72
2.3.3.3- As fórmulas de Little e as estimativas qq WWLL ˆ e ˆ,ˆ,ˆ 73
2.4 - Distribuições de probabilidade 73
2.4.1- Distribuição exponencial 74
2.4.2- Distribuição Gamma (Gm) 76
2.4.3- Distribuição de Weibull (W) 78
2.4.4- Distribuição de Erlang de ordem k (Ek) 79
2.4.4.1- Misturas de Erlangs de ordens k E k-1 (Ek-1, k) 81
2.4.5- Distribuição hiperexponencial de ordem k (Hk) 82
2.4.5.1 - Distribuição hiperexponencial de ordem 2 com médias balanceadas
(H2b) 84
2.4.5.2 - Distribuição hiperexponencial de ordem 2 com normalização Gamma
(H2g) 85
2.4.5.3 - Distribuição H2 ajustada pelos três primeiros momentos 86
2.4.6- Distribuições do tipo fase (Ph) 86
2.4.6.1- Distribuição de Cox de ordem 2 com normalização gamma (C2g) 90
2.4.7- Distribuição histograma 92

CAPÍTULO 3 – MODELO DE SIMULAÇÃO 95
3.1 - Introdução 95
3.2 - Modelo comunicativo 96
3.3 - Modelo programado 96
3.4 - Verificação e validação do modelo de simulação 98
3.4.1- Metodologia para aplicação dos testes para a uniformidade e para a
independência 103
3.4.1.1- Teste de Kolmogorov-Smirnov 107
3.4.1.2- Teste de execuções acima e abaixo da média 109
CAPÍTULO 4 – MODELO EXPERIMENTAL 111
4.1 - Introdução 111
4.2 - Projeto de experimento 112
4.2.1- Especificação 115
4.2.2- Configurações – cenários 116
4.2.3- Replicações 117
4.2.4- Experimentação 117
4.3 - Análise dos resultados do experimento 117

4.3.1- Método das Replicações independentes para a estimação dos intervalos
de confiança 119
4.3.2- Intervalos de confiança com uma precisão especificada 122
4.3.3- Procedimento de aplicação do teste-t de Student 123
4.3.4- Aplicação do teste-t de Student na comparação da fila GI/G/m contra a
fila Ph/Ph/m 126
4.3.5- Metodologia para o cálculo da probabilidade de cobertura observada 128
CAPÍTULO 5 – PERÍODO DE INICIALIZAÇÃO E TEMPO DE
EXECUÇÃO 131
5.1- Introdução 131
5.2- Período de inicialização 132
5.3- Tempo de execução 146
5.3.1- Metodologia para determinação do tempo de execução TE 148
5.3.1.1- Análise estatística padrão 151
5.3.1.2- Os casos especiais M/G/1 155
5.3.1.3- Limites de tráfego pesado 160
5.3.1.4- Movimento Browniano Regulado (RBM) 160
5.3.1.5- O limite de tráfego pesado assumido e a aproximação por RBM 163
5.3.1.6- Refinamentos M/M/1 165

5.3.1.7- A qualidade da aproximação normal em 5.21 167
CAPÍTULO 6 – APRESENTAÇÃO DOS RESULTADOS 169
6.1 - Introdução 169
6.2 - Verificação e validação do modelo de simulação 170
6.3 - Análise dos resultados da simulação da fila Gm/Gm/2 179
6.4 - Análise dos resultados da simulação da fila Ph/Ph/2 184
6.5 - Análise dos resultados da aproximação da fila Gm/Gm/2 pela fila
Ph/Ph/2 189
CAPÍTULO 7 – CONCLUSÕES E COMENTÁRIOS 197
REFERÊNCIAS BIBLIOGRÁFICAS 201
APÊNDICE 1 – VARIÁVEIS E CÓDIGOS DO MODELO PROGRAMADO 205


LISTA DE FIGURAS
Pág.
2.1 - Fluxo de controle para a abordagem de avanço do tempo orientada ao
próximo evento de uma simulação a eventos discretos 54
2.2 - Passos num estudo de simulação 59
2.3 - Layout da fila GI/G/m 64
2.4 - Número de clientes na fila, L(t), no tempo t 71
2.5 - Diagrama de transição de estados da distribuição de Erlang de ordem 80
2.6 - Diagrama de estados de uma mistura Ek-1, k de Erlangs de ordens k e k-1 82
2.7 - Diagrama de estados de uma distribuição Hk 83
2.8 - Diagrama de estados da distribuição H2 85
2.9 - Diagrama de estados de uma Ph na forma da configuração de Cox 87
2.10 - A distribuição de Cox com duas fases 90
2.11 - Gráfico da distribuição de freqüências 93
3.1 - DCAs (C = Cliente e S = Servidor) 96
3.2 - Diagrama de rede do modelo programado 97
5.1 - Fases da execução da simulação 132


LISTA DE TABELAS
Pág.
2.1 - Distribuição de freqüências 92
2.2 - Tabela transformada da distribuição de freqüências 94
6.1 – Tamanhos iniciais dos experimentos para a verificação e validação do
modelo de simulação com β = 0,05 eε = 0,02 171
6.2 – Valores verdadeiros e resultados da simulação da fila M/M/1 com
taxa de utilização de 20% 175
6.3 – Valores verdadeiros e resultados da simulação da fila M/M/1 com
taxa de utilização de 80% 176
6.4 – Valores verdadeiros e resultados da simulação da fila M/M/2 com
taxa de utilização de 20% 176
6.5 – Valores verdadeiros e resultados da simulação da fila M/M/2 com
taxa de utilização de 80% 177
6.6 – Valores verdadeiros e resultados da simulação da fila E2 /H2b/5 com
taxa de utilização de 80% 177
6.7 – Valores verdadeiros e resultados da simulação da fila H2b/E2
b/5 com
taxa de utilização de 80% 178
6.8 – Valores verdadeiros e resultados da simulação da fila D/D/1 com taxa
de utilização de 80% 178
6.9 – Valores verdadeiros e resultados da simulação da fila D/D/2 com
taxa de utilização de 80% 178

6.10 – Aplicações das relações de Litlle para os resultados da simulação dos
experimentos para verificação e validação 179
6.11 – Testes do gerador de números aleatórios do software de simulação
“Micro Saint” 179
6.12 – Tamanhos iniciais dos experimentos de simulação de filas Gm/Gm/2
com ρ = 75%, β = 0,05 e ε = 0,02 181
6.13 – Tamanhos necessários (finais) dos experimentos de simulação de filas
Gm/Gm/2 com ρ = 75%, β = 0,05 e ε = 0,02 181
6.14 – Resultados da simulação da fila Gm/Gm/2 com 5,0 E 5,0 22 == ST cc 182
6.15 – Resultados da simulação da fila Gm/Gm/2 com 1 E 5,0 22 == ST cc 182
6.16 – Resultados da simulação da fila Gm/Gm/2 com 2 E 5,0 22 == ST cc 182
6.17 – Resultados da simulação da fila Gm/Gm/2 com 5,0 E 1 22 == ST cc 183
6.18 – Resultados da simulação da fila Gm/Gm/2 com 2 E 1 22 == ST cc 183
6.19 – Resultados da simulação da fila Gm/Gm/2 com 5,0 E 2 22 == ST cc 183
6.20 – Resultados da simulação da fila Gm/Gm/2 com 1 E 2 22 == ST cc 184
6.21 – Resultados da simulação da fila Gm/Gm/2 com 2 E 2 22 == ST cc 184
6.22 – Tamanhos iniciais dos experimentos de simulação de filas C2/C2/2
com ρ = 75%, β = 0,05 e ε = 0,02 186
6.23 – Tamanhos necessários (finais) dos experimentos de simulação de filas
C2/C2/2 com ρ = 75%, β = 0,05 e ε = 0,02 186

6.24 – Resultados da simulação da fila C2/C2/2 com 5,0 E 5,0 22 == ST cc 187
6.25 – Resultados da simulação da fila C2/C2/2 com 1 E 5,0 22 == ST cc 187
6.26 – Resultados da simulação da fila C2/C2/2 com 2 E 5,0 22 == ST cc 187
6.27 – Resultados da simulação da fila C2/C2/2 com 5,0 E 1 22 == ST cc 188
6.28 – Resultados da simulação da fila C2/C2/2 com 2 E 1 22 == ST cc 188
6.29 – Resultados da simulação da fila C2/C2/2 com 5,0 E 2 22 == ST cc 188
6.30 – Resultados da simulação da fila C2/C2/2 com 1 E 2 22 == ST cc 189
6.31 – Resultados da simulação da fila C2/C2/2 com 2 E 2 22 == ST cc 189
6.32 – Tamanhos dos experimentos de simulação utilizados na verificação
da aproximação de filas Gm/Gm/2 por filas C2/C2/2 com ρ = 75%, β
= 0,05 e ε = 0,02 191
6.33 – Resultado da verificação da aproximação da fila Gm/Gm/2 pela fila
C2/C2/2 com 5,0 E 5,0 22 == ST cc 191
6.34 – Resultado da verificação da aproximação da fila Gm/Gm/2 pela fila
C2/C2/2 com 1 E 5,0 22 == ST cc 192
6.35 – Resultado da verificação da aproximação da fila Gm/Gm/2 pela fila
C2/C2/2 com 2 E 5,0 22 == ST cc 192
6.36 – Resultado da verificação da aproximação da fila Gm/Gm/2 pela fila
C2/C2/2 com 5,0 E 1 22 == ST cc 193

6.37 – Resultado da verificação da aproximação da fila Gm/Gm/2 pela fila
C2/C2/2 com 2 E 1 22 == ST cc 193
6.38 – Resultado da verificação da aproximação da fila Gm/Gm/2 pela fila
C2/C2/2 com 5,0 E 2 22 == ST cc 194
6.39 – Resultado da verificação da aproximação da fila Gm/Gm/2 pela fila
C2/C2/2 com 1 E 2 22 == ST cc 194
6.40 – Resultado da verificação da aproximação da fila Gm/Gm/2 pela fila
C2/C2/2 com 2 E 2 22 == ST cc 195

LISTA DE SIMBOLOS
A(t) Distribuição dos tempos entre chegadas
arg argumento
B(t) Distribuição dos tempos de serviço
Biasa vício absoluto
Biasr vício relativo
[ ]θBias Vício do estimador θ devido às condições de inicialização
[ ]θBias^
Estimativa da [ ]θBias
C2 Distribuição de Cox de ordem 2
C2g Distribuição de Cox de ordem 2 com normalização gamma
AA Cc ou Coeficiente de variação dos tempos entre chegadas
22 ou AA Cc Quadrado do coeficiente de variação dos tempos entre chegadas
Cr Distribuição de Cox de ordem r
SS Cc ou Coeficiente de variação dos tempos de serviço
22 ou SS Cc Quadrado do coeficiente de variação dos tempos de serviço
C(t) Função de (auto) covariância
CR(t) Função de (auto) covariância do RBM canônico

CW(t) Função de (auto) covariância do processo {W(n): n = 0, 1, 2, ...}
( )tC yz Função de (auto) covariância do processo escalado ( )tLyzq
( )tCρ Função de (auto) covariância do processo ( )tLqρ
d* Ponto de truncamento da amostra
rd r-ésima diferença entre as estimativas rr ZY ˆ e ˆ da r-ésima replicação
dos processos Y e Z
d Estimativa da do valor esperado do processo Y-Z
Dβ Valor crítico para um teste de Kolmogorov-Smirnov
D Estatística para um teste de Kolmogorov-Smirnov
D Distribuição Determinística
Dn Espera na fila do n-ésimo cliente (excluindo o tempo de serviço)
(n)D Estimativa da média E[D(0)]
DCAs Diagrama de Ciclos de Atividades
E0 Espaço de estados para o sistema vazio e parado
EI Espaço de estados para o sistema após o período de inicialização TI
Er Distribuição de Erlang de ordem r
E[D(0)] Espera média, em equilíbrio, de um cliente arbitrário na fila, supondo
estacionariedade do processo D(t)

E[L] Número médio, em equilíbrio, de clientes presentes no sistema para um
tempo arbitrário
E[L(0)] Número médio, em equilíbrio, de clientes presentes no sistema para um
tempo arbitrário, supondo estacionariedade do processo L(t)
E[Lq] Número médio, em equilíbrio, de clientes esperando na fila para um
tempo arbitrário
E[Lq(0)] Número médio, em equilíbrio, de clientes esperando na fila para um
tempo arbitrário, supondo estacionariedade do processo Lq(t)
( )[ ]0yzqLE
Número médio, em equilíbrio, de clientes esperando na fila para um
tempo arbitrário, supondo a estacionariedade do processo (t)Lq yz
E[S] Tempo médio, em equilíbrio, de serviço
E[T] Tempo médio, em equilíbrio, entre chegadas
E[V(0)] Carga média, em equilíbrio, de trabalho de um processo V(t)
estacionário
E[W] Espera média, em equilíbrio, de um cliente arbitrário no sistema
E[W(0)] Espera média, em equilíbrio, de um cliente arbitrário no sistema,
supondo estacionariedade do processo W(t)
E[Wq] Espera média, em equilíbrio, de um cliente arbitrário na fila
[ ]cGGIqWE
// Tempo médio aproximado de espera na fila GI/G/c
[ ]cMMqWE
// Tempo médio aproximado de espera na fila M/M/c
E[Y] Média em equilíbrio do processo de interesse
G Distribuição Geral do tempo de serviço

GI Distribuição Geral Independente do tempo entre chegadas
Gm Distribuição gamma
H0 Hipótese nula
H1 Hipótese alternativa
H2 Distribuição Hiperexponencial de ordem 2
H2b Distribuição Hiperexponencial de ordem 2 com médias balanceadas
H2g Distribuição Hiperexponencial de ordem 2 com normalização gamma
Hr Distribuição Hiperexponencial de ordem r
Hl Meia largura (metade) do intervalo de confiança
hla Meia largura (metade) do intervalo de confiança segundo o critério do
erro padrão absoluto
hlr Meia largura (metade) do intervalo de confiança segundo o critério do
erro padrão relativo
I Contador ou enumerador
Iid Independentes e identicamente distribuídas
I Número de variáveis de entrada da simulação
J Número de variáveis de saída da simulação
K Número de micro-replicações
L Estimativa do número médio de clientes presentes no sistema, obtida
dos dados de saída da simulação

qL Estimativa do número médio de clientes esperando na fila, obtida dos
dados de saída da simulação
L(t) Número de clientes no sistema no instante t (incluindo aqueles em
serviço)
(t)L Estimativa da média E[L(0)]
Lq(t) Número de clientes na fila no instante t (excluindo aqueles em serviço)
( )tLyzq Escalamento do processo Lq(t) com escalares y e z positivos arbitrários
( )tLqρ O processo Lq(t) com taxa de utilização ρ
( )tLqρˆ Normalização do processo ( )tLqρ
q(t)L Estimativa da média E[Lq(0)]
)q(L ∞ Limite de q(t)L quando t → ∞
LN Distribuição logonormal
M Número de servidores
M Distribuição Markoviana (exponencial ou de Poisson)
Mim minimizar
mk k-ésimo momento
mmax Maior valor de m tal que a estimativa obtida através da heurística de
relaxação do tempo tenha passado no teste de remoção do vício
Mr Média em equilíbrio de uma característica do processo

^mr
Estimativa da média mr através da simulação de n cópias de um
processo
MSE Erro quadrado médio (do inglês “Mean Squared Error”)
^MSE Estimativa do erro quadrado médio do estimador θ
N Número ou quantidade de ...
N Número ou quantidade de ...
NSO Número de servidores ocupados
^NSO Estimativa de NSO obtida a partir dos dados da simulação
N(0, σ2) Distribuição normal com média 0 e variância σ2
Pco Probabilidade de cobertura observada
Q*(t) Limite inferior para o valor verdadeiro (em equilíbrio) do número
esperado de clientes na fila em função do tempo
Q(∞) Número esperado de clientes na fila em função do tempo, em equilíbrio
Q(t) Número esperado de clientes na fila em função do tempo
Rn Quantidade de tempo gasto pelo n-ésimo cliente no sistema (incluindo o
tempo de serviço)
R Número de replicações (ou de macro-replicações) da simulação
R(t; a, b, X) RBM com direção a (> 0) e coeficiente de difusão b (> 0)
( )... Yes Erro padrão do estimador .Y

des ˆ.. Erro padrão do estimador d
S2 Variância da amostra
S Estimativa do tempo médio de serviço, obtida dos dados de saída da
simulação
S Desvio padrão da amostra
t0 Estatística para um teste de normalidade da hipótese para o teste t de
Student
ta (ε , β) Tamanho necessário da simulação para se obter uma precisão estatística
desejada, ε , segundo o critério da largura absoluta do Intervalo de
tr (ε , β) Tamanho necessário da simulação para se obter uma precisão estatística
desejada, ε , segundo o critério da largura relativa do Intervalo de
2β,1−Rt Valor crítico para um teste de normalidade da hipótese para o teste t de
Student
T Estimativa do tempo médio entre chegadas, obtida dos dados de saída
da simulação
TI Período (ou tempo) de inicialização da simulação
TE Período (ou tempo) de execução da simulação
TN Período (ou tempo) necessário de execução da simulação para que a
aproximação normal seja razoável
U Distribuição uniforme
U(0, 1) Distribuição uniforme no intervalo [0, 1]
^Var Estimativa da variância do estimador θ

Var Variância do estimador θ
V(t) Processo do tempo de espera virtual ou carga de trabalho
(t)V Estimativa da média E[V(0)]
W Distribuição de Weibull
W Estimativa da espera média de um cliente arbitrário no sistema, obtida
dos dados de saída da simulação
qW Estimativa da espera média de um cliente arbitrário na fila, obtida dos
dados de saída da simulação
Wa Largura absoluta do intervalo de confiança para um β dado
Wr Largura relativa do intervalo de confiança para um β dado
(n)W Estimativa da média E[W(0)]
( )Ei TY Estimador não viciado da média verdadeira da i-ésima cópia de um
certo processo da simulação
rY Estimador não viciado da média verdadeira de uma característica de um
dado processo da r-ésima replicação da simulação
.Y Estimador não viciado da média verdadeira de uma característica de um
dado processo através de R replicações da simulação
( )dnY , Média de uma amostra de tamanho n com o descarte de d dados iniciais
Z0 Estatística para um teste de normalidade da hipótese para o teste Z
normal
Zβ/2 Valor crítico para um teste de normalidade da hipótese para o teste Z
normal

α Parâmetro de escala
β Nível de significância para um teste de hipóteses
β(TI , TE) vício do estimador ^
mr
ITβ vício do estimador ^
mr para um dado TI, quando TE → ∞
0β vício do estimador ^
mr para TI = 0, quando TE → ∞
ε Precisão relativa especificada
φ Estimador não viciado da média verdadeira de uma característica de um
dado processo a tempo contínuo
φ Média verdadeira de uma característica de um dado processo a tempo
contínuo
λ Taxa média de chegadas de clientes
λ Estimativa da taxa média de chegadas, obtida dos dados de saída da
simulação
µ0 Valor especificado na hipótese nula
µ Taxa média de serviços de clientes ou valor da média verdadeira de
uma característica de um certo processo
ν Parâmetro de locação
θ Estimador não viciado da média verdadeira de uma característica de um
dado processo a tempo discreto
θ Média verdadeira de uma característica de um dado processo a tempo
discreto ou Parâmetro de forma de uma função de densidade

θa Aproximação para média verdadeira θ
ρ Taxa de utilização do sistema
τ Tempo constante ou “tempo de relaxação”
Rτ Estimativa, proposta por Odoni e Roth (1983), do tempo constante ou
“tempo de relaxação”
σ Valor do desvio padrão verdadeiro de uma característica de um dado
processo
σ2 Valor da variância verdadeira de uma característica de um dado
processo
2Dσ Variância assintótica da média amostral (t)D
2Lσ Variância assintótica da média amostral (t)L
2qLσ Variância assintótica da média amostral q(t)L
2Rσ Variância assintótica do RBM canônico
2Vσ Variância assintótica da média amostral (t)V
2Wσ Variância assintótica da média amostral (t)W
( )tyz2σ Variância assintótica do processo escalado ( )tL
yzq
( ).2 Yσ Variância do estimador .Y
( ).2 ˆˆ Yσ Estimador de ( ).2 Yσ
2ρσ Variância assintótica do processo ( )tLqρ

LISTA DE SIGLAS E ABREVIATURAS
FCFS “First-Come, First-Served” (primeiro a chegar, primeiro a ser servido)
FIFO “First-In, First-Out” (primeiro a entrar, primeiro a sair)
LIFO “Last-In, First-Out” (último a entrar, primeiro a sair)
MSEAT Heurística de truncamento pelo critério do erro quadrado médio usando
aproximação (do inglês “Mean Squared Error Approximation
Truncation”)
MSEASVT Heurística de truncamento pelo critério do erro quadrado médio usando
aproximação e variância da amostra (do inglês “Mean Squared Error
Approximation Sample Variance Truncation”)
RBM Movimento browniano refletor (do inglês “Reflecting Brownian Motion”)


37
CAPÍTULO 1
INTRODUÇÃO
1.1- INTRODUÇÃO
No cotidiano contextos de sistemas de filas ocorrem freqüentemente: pacientes num
consultório médico esperando por uma consulta; consumidores num supermercado
esperando em frente aos caixas; aviões esperando para decolar (aterrizar) num
aeroporto; chamadas telefônicas esperando serem roteadas pelo operador de PABX;
chamadas telefônicas para uma central de telefonia; etc.
Um sistema de filas pode também ser olhado num contexto de integração, formando
redes de filas, onde a saída de uma fila pode formar a chegada de outra fila e a saída
desta última pode ser decomposta para formar chegadas de outros sistemas, etc. Estas
redes de filas surgem naturalmente em processos de produção industrial onde partes
concluídas de itens têm que ser submetidas a um número de processos antes que elas
estejam prontas para distribuição a consumidores. Podem surgir, também, de contextos
da comunicação eletrônica e redes de transmissão, onde mensagens para transmissão
são codificadas em sinais eletrônicos e estes sinais têm que ser processados no
transmissor, em pontos no sistema de transmissão, e novamente na recepção onde são
decodificados.
Os problemas de fila tiveram basicamente sua origem no trabalho de Erlang em
telefonia no início do século. E, atualmente, a aplicação de teoria de fila na análise de
performance de sistemas de computação, comunicações, produção industrial, transporte,
manutenção, entre outros, tem estimulado muitas pesquisas aplicadas em aspectos
computacionais de modelos de filas.
Os modelos de filas são motivados por situações em que o processo de chegada a um
serviço, ou o processo de serviço, ou ambos são probabilísticos, resultando
possivelmente numa fila de espera. Desta forma pode-se imaginar várias situações da
vida real onde existe um fluxo de clientes (pessoas, veículos, pedidos, transações, etc.)

38
em busca de um serviço (caixas de banco ou supermercados, pedágios, estações de uma
rede, distribuidora, banco de dados, etc.). Estes sistemas têm uma capacidade máxima
de atendimento e estão sujeitos a demandas, aleatórias ou não, e a tempos de chegadas
de clientes, programados ou não. A caracterização destas duas quantidades, aleatórias
ou não, os tempos de chegadas e os tempos de serviço, e a evolução dos seus efeitos
podem provocar a formação de filas de clientes, ou causar problemas de
congestionamento. É bem conhecido que congestionamentos em sistemas de filas
ocorrem largamente por causa de flutuações aleatórias no processo de chegada e nos
tempos de serviço e que existem muitos resultados mostrando que congestionamentos
crescem com o aumento da variabilidade. A ferramenta primária para estudar os
problemas de congestionamento ou fenômenos de fila é conhecida como teoria de filas.
Neste estudo foram considerados sistemas de filas em isolamento, onde os clientes
requerem um único serviço e abandonam o sistema após ter recebido o serviço. É
importante ressaltar que os resultados fundamentais da análise destes sistemas também
são, geralmente, úteis na análise de sistemas de redes de filas.
Este trabalho trata da fila GI/G/m, ou seja, do sistema de filas que tem as seguintes
características:
1. m servidores em paralelo e uma única fila com disciplina First-In, First-Out
(FIFO) com sala de espera ilimitada alimentando todos os servidores;
2. uma população ilimitada de prováveis clientes;
3. os tempos entre chegadas T1 , T2 .....são variáveis aleatórias iid;
4. os tempos de serviço S1 , S2 .....são variáveis aleatórias iid;
5. Os Ti’s e Si’s são independentes.
Este sistema com as características descritas acima é denominado um sistema de filas
GI/G/m, onde GI (Geral independente) refere-se à distribuição das variáveis aleatórias
Ti’s e G (Geral) refere-se à distribuição das variáveis aleatórias Si’s.

39
Para uma avaliação descritiva de um sistema de fila GI/G/m recorre-se a um modelo de
avaliação de desempenho. Um modelo de avaliação de desempenho é descritivo e
oferece medidas de avaliação de desempenho para o entendimento da operação do
sistema. Num sistema de filas as medidas usuais de avaliação de desempenho são:
intensidade de tráfego ou utilização dos serviços; tempo médio de permanência no
sistema; tempo médio de espera na fila; número médio de clientes no sistema; número
médio de clientes na fila; número médio de clientes recebendo serviço; utilização do
sistema ou carga de trabalho; taxa média de serviço.
A forma com a qual são tratados os modelos de avaliação de desempenho podem ser
classificados basicamente em: (i) métodos exatos; (ii) métodos aproximados; e (iii)
simulação e técnicas relacionadas. E para cada situação deve ser avaliada a propriedade
de se adotar um método exato, ou um método aproximado, ou uma simulação.
A avaliação de desempenho de um sistema de fila GI/G/m é um clássico problema
difícil. Estes sistemas de filas com múltiplos servidores são notoriamente difíceis de
serem analisados analiticamente, sendo que uma análise algorítmica exata somente é
possível para casos especiais (os sistemas de filas M/M/m, M/D/m, M/C2 /m, GI/H2 /m,
GI/EK /m, GI/Ph/m, Ph/D/m e Ph/Ph/m). Deve ser lembrado que existem soluções
obtidas através de métodos aproximados, que podem ser úteis para propósitos práticos.
Os modelos de simulação por computadores, apesar de exigirem muitos recursos de
“hardware” (memória de trabalho e de armazenamento de massa, velocidade de
processamento da CPU) e consumirem muito tempo na execução das rodadas da
simulação, permitem considerações mais próximas das situações reais por exigirem
menos hipóteses simplificadoras. Por esta razão os modelos de simulação podem ser
bastante úteis na verificação de suposições, necessárias num modelo analítico, e na
checagem dos resultados do modelo analítico.
Este trabalho trata da obtenção de medidas de desempenho, em equilíbrio, de filas
GI/G/m através de simulação. Também é tratado a verificação de aproximações de filas
GI/G/m por filas Ph/Ph/m. Os objetivos deste trabalho foram formalizados na Seção 1.3.

40
Até onde se tem conhecimento, nenhum trabalho foi encontrado na literatura que
tratasse formalmente da simulação de filas GI/G/m. Existem trabalhos que abordam
questões relevantes do projeto de experimento da fila GI/G/m. Alguns resultados destes
trabalhos serão utilizados neste estudo, e serão referidos nas seções específicas.
Este trabalho insere-se no contexto da modelagem estocástica de sistemas, área em
pleno desenvolvimento. Um grande número de trabalhos têm sido publicados na área de
filas e de redes de filas, tanto ao nível teórico quanto aplicado.
Este trabalho foi organizado da seguinte forma. Neste capítulo será apresentada uma
formalização do problema e dos objetivos do estudo, bem como uma revisão
bibliográfica sobre simulação da fila GI/G/m e temas correlatos de interesse para este
estudo.
No Capítulo 2, apresentam-se alguns conceitos básicos. Na Seção 2.2 encontra-se um
breve resumo sobre simulação. Na Seção 2.3 caracteriza-se a fila GI/G/m, apresentam-
se as definições das medidas de performance consideradas neste estudo e algumas
suposições sobre estas medidas, e é tratada a obtenção das estimativas destas medidas a
partir dos dados de saída da simulação. Na Seção 2.4 encontram-se resumos de algumas
distribuições de probabilidades.
No Capítulo 3, apresenta-se o modelo de simulação. São apresentados o modelo
comunicativo, o modelo programado e as metodologias para a verificação do modelo
programado e a validação do modelo de simulação.
No Capítulo 4, é apresentado o modelo experimental. Apresentam-se o projeto de
experimento e a metodologia de análise dos resultados do experimento.
No Capítulo 5, apresentam-se as metodologias para a determinação do período de
inicialização (“warm-up”) e para a determinação do tempo de execução.
No Capítulo 6, são apresentados os resultados da verificação do modelo programado, da
validação do modelo de simulação e do experimento.

41
No Capítulo 7, são apresentadas as conclusões do estudo e indicações de possíveis
futuras extensões deste estudo.
1.2- O PROBLEMA
Como já foi citado, a obtenção de medidas de avaliação de desempenho de um sistema
de filas GI/G/m é um clássico problema difícil, e soluções analíticas exatas somente são
possíveis para os casos especiais M/M/m, M/D/m, M/K2 /m, GI/H2 /m, GI/EK /m,
GI/Ph/m, Ph/D/m e Ph/Ph/m.
Em princípio qualquer processo prático (aplicação) de fila pode ser modelado como um
processo de Markov pela incorporação de suficiente informação na descrição dos
estados, mas a dimensionalidade do espaço de estados cresceria rapidamente além de
qualquer limite prático (Tijms, 1986).
Deste modo, é natural buscar aproximações analíticas relativamente simples de sistemas
de filas GI/G/m, que são suficientemente precisas para propósitos de aplicações
práticas. Estas aproximações simples podem servir como ponto de partida para o
desenvolvimento de aproximações para sistemas mais complicados, para os quais
soluções exatas não estão disponíveis. Elas são particularmente úteis para incorporar
modelos de filas GI/G/m em modelos maiores, tais como redes de filas, nos quais as
aproximações podem ser componentes de ferramentas de modelagem rápida.
Uma outra via para obter estimativas para sistemas de filas GI/G/m é através da
simulação por computadores. Tais estimativas podem ser mais confiáveis que aquelas
obtidas através de aproximações analíticas, desde que sejam obtidas através de uma
metodologia apropriada de análise dos dados de saída da simulação. Estas estimativas
são úteis no desenvolvimento de modelos analíticos, tanto aproximados quanto exatos,
pois elas permitem que os resultados destes modelos sejam aferidos (ou verificados)
quanto a exatidão e a precisão. Desta forma as suposições necessárias na construção de
um modelo analítico podem ser validadas através da simulação de tal modelo.

42
Portanto um modelo confiável de simulação da fila GI/G/m torna-se quase que
imprescindível no estudo de sistemas de filas GI/G/m. E a elaboração de um modelo de
simulação formal, que possa servir de base para o estudo destes sistemas de filas, pode
ser considerado no mínimo desejável.
Este estudo é dedicado a esta empreitada, ou seja, procurou-se formalizar um modelo
de simulação da fila GI/G/m, que sirva de base para futuros estudos nesta área de teoria
de filas.
Por outro lado sabe-se que: qualquer distribuição geral pode ser aproximada, para
qualquer grau de exatidão, por uma distribuição do tipo fase (Miranda, 1996), (Tijms,
1986) e (Wolff, 1989); a estrutura markoviana das distribuições do tipo fase permite o
uso de eficientes técnicas numéricas; o conjunto de distribuições do tipo fase é fechado
sob (o domínio de) misturas e convoluções finitas.
Desta forma, em análise de sistemas de filas, freqüentemente é conveniente aproximar a
distribuição do tempo entre chegadas (ou do tempo de serviço) por uma distribuição que
seja constituída de uma soma finita ou de uma mistura finita de componentes
distribuídos exponencialmente. Esta abordagem, geralmente, é referida como o método
de fases (estágios). Mais geralmente pode-se considerar a então denominada
distribuição do tipo fase (Ph), que é interpretada como a distribuição do tempo até a
primeira passagem numa cadeia de Markov a tempo contínuo, veja Neuts (1981).
Entretanto, segundo Tijms (1986 e 1994), para propósitos práticos, geralmente, é
suficiente trabalhar com determinadas distribuições, especiais, do tipo fase, tais como
misturas finitas de distribuições de Erlang com os mesmos parâmetros de escala, por
exemplo a distribuição Ek-1, k , e distribuições Hiperexponenciais, por exemplo a
distribuição H2 .
A distribuição Hiperexponencial, sendo uma mistura de distribuições exponenciais com
médias diferentes, tem sempre um coeficiente de variação maior que ou igual a 1 e tem
densidade decrescente. Esta distribuição é particularmente apropriada para modelos com
tempos entre chegadas (ou de serviço) irregulares.

43
O conjunto de misturas de distribuições de Erlang com os mesmos parâmetros de escala
é muito mais versátil que o conjunto de distribuições Hiperexponenciais e permite
cobrir qualquer valor do coeficiente de variação. Em particular, mistura de distribuições
Ek-1 e E k com os mesmos parâmetros de escala podem ser usadas para representar
tempos entre chegadas (ou de serviço) regulares, possuindo coeficiente de variação
menor que ou igual a 1 (Tijms, 1986).
Outra distribuição do tipo fase particularmente útil, para propósitos práticos, é
distribuição de Cox de ordem 2 (C2). Ela pode cobrir qualquer valor do coeficiente de
variação, pois uma mistura de distribuições Ek-1 e E k com os mesmos parâmetros de
escala é um caso particular da distribuição de Cox (Ck) e a distribuição Hk pode ser
representada por uma Ck.
Desta forma, usando técnicas numéricas especiais para resolver grandes sistemas de
equações de equilíbrio para cadeias de Markov, a abordagem da cadeia de Markov a
tempo contínuo tem provado ser extremamente útil para tratar analiticamente sistemas
de fila com múltiplos servidores e distribuições, do tempo de serviço e do tempo entre
chegadas, do tipo fase (Ph), desde que o número de servidores não seja muito grande
(Tijms, 1986).
Existem aproximações simples de uma fila GI/G/m por uma fila Ph/Ph/m, considerando
apenas os dois primeiros momentos (média e variância), ver Tijms (1986 e 1994) e
Allen (1990). Estas aproximações são baseadas em: (i) misturas de distribuições de
Erlang Ek-1 e Ek designadas por Ek-1,k, com os mesmos parâmetros de escala; (ii)
misturas de duas distribuições exponenciais com médias diferentes e balanceadas (ou
com normalização gamma), denominadas distribuições Hiperexponenciais de ordem 2
com médias balanceadas (ou com normalização gamma), e são designadas por H2b (ou
H2g); (iii) uma distribuição de Cox de ordem 2 (C2). As distribuições de Erlang-k e a
Hiperexponencial de ordem k são casos particulares da distribuição Ph. As distribuições
de Erlang Ek-1 e Ek designadas por Ek-1,k são distribuições do tipo fase Ph, na forma da
configuração de Cox.

44
Bobbio e Telek (1992), Bobbio e Cumai (1992) e Miranda (1996) apresentam métodos e
algoritmos para aproximações de distribuições de probabilidades genéricas por
distribuições do tipo fase. Os métodos utilizados são o da máxima verossimilhança em
Bobbio e Telek (1992) e em Bobbio e Cumai (1992) e o da minimização de uma função
de distância estocástica em Miranda (1996). Estes algoritmos apresentam bons
resultados de performance e exatidão, sendo que em ambos o tempo de execução
aumenta com o número de estados. Foram utilizados um IBM-RISC 6000 e DEC-
VAXstation 2000 em Bobbio e Telek, (1992) e um IBM-PC Pentium 133 Mhz em
Miranda (1996).
1.3 - OBJETIVO DO ESTUDO
O objetivo deste estudo é elaborar um modelo de simulação de filas GI/G/m e Ph/Ph/m
para:
1. Obter estimativas de medidas de performance em equilíbrio das filas GI/G/m e das
filas Ph/Ph/m correspondentes através dos dados (amostrais) de saída da execução
do modelo programado da simulação.
2. Verificar a exatidão e precisão de aproximações de filas GI/G/m por filas
Ph/Ph/m. Mais precisamente de aproximações simples que levem em
consideração apenas os dois primeiros momentos (média e variância), como
aquelas sugeridas em Tijms (1986 e 1994).
Para esta verificação foram consideradas as medidas de avaliação de desempenho de
sistemas de filas GI/G/m e das filas Ph/Ph/m correspondentes, em equilíbrio ou regime,
por um longo período de tempo de execução. Para isso, escolheu-se cenários descritos
por ρ ∈ (0, 1), m ∈ [1, 2], [ ]2 ;5,02 ∈xc e por processos de chegada (GI) e de serviço (G)
caracterizados pela distribuição Gama (Gm), onde ρ é a taxa de utilização do sistema e 2xc é o quadrado do coeficiente de variação da distribuição do processo de chegadas
(GI) ou do processo de serviço (G).

45
Neste estudo foram considerados somente sistemas de filas Gm/Gm/m, pois os
experimentos em simulação consomem muito tempo. Desta forma o desenvolvimento
de experimentos para uma variedade maior de sistemas de filas GI/G/m (por exemplo as
filas W/W/m e Histograma/Histograma/m) estenderia este trabalho por alguns meses.
Esta escolha se deve ao potencial de aplicações destas filas na modelagem de sistemas
reais e à dificuldade atual de se obter soluções analíticas exatas para estes sistemas de
filas.
1.4 – REVISÃO BIBLIOGRÁFICA
A teoria de filas tem sido bastante estudada nos últimos anos. Há uma grande
quantidade de artigos sobre este assunto na literatura e existem vários manuais
dedicados a este assunto ou que lhe dão destaque. Para uma introdução a teoria de filas
pode-se recorrer Allen (1990), a Gross e Harris (1974), a Kleinrock (1975 e 1976), a
Tijms (1986 e 1994) e Wolff (1989).
Sobre a simulação da fila GI/G/m ou sobre tópicos específicos de simulação, que são de
interesse para este estudo, pode se destacar os seguintes trabalhos dentre os encontrados
na literatura: Delaney e Rossetti (1995); Delaney, Rossetti e White (1995); Odoni e
Roth (1983); Kleijnen (1992); Roth (1994); Whitt (1989a, 1989b e 1991).
Odoni e Roth (1983) examinam o comportamento transiente de sistemas de filas M/M/1.
Eles examinam sistemas de filas que são markovianos, ou seja, sistemas que para todos
os tempos têm uma descrição discreta do espaço de estados, como um processo de
Markov de primeira ordem. Sistemas em que os tempos de serviço e os tempos entre
chegadas podem ser representados por distribuições exponenciais, de Erlang,
Hiperexponenciais e do tipo fase. Esta definição exclui muitos sistemas em que somente
a cadeia embutida no processo é de primeira ordem, p. e., muitos sistemas de filas
M/G/1. Neste estudo eles se concentram no número esperado de clientes na fila em
função do tempo t, denotado por Q(t).
Roth (1994) desenvolveu uma heurística de relaxação do tempo para reduzir o vício
devido a inicialização em simulações de Monte Carlo de sistemas de filas markovianas

46
estacionárias, M/M/m. Ela é baseada em características do modelo teórico subjacente e
não requer execuções preliminares da simulação.
Delaney e Rossetti (1995) investigam o uso de aproximações analíticas para auxiliar na
atenuação dos efeitos do período transiente inicial em simulações de filas GI/G/m em
equilíbrio. Eles investigam o uso de aproximações de filas para configurar
estocasticamente (aleatoriamente) as condições iniciais da simulação e desenvolvem um
novo conjunto de heurísticas baseadas nestas aproximações analíticas de filas GI/G/m.
Estas novas heurísticas são baseadas no descobrimento do ponto de truncamento da
amostra (dados de saída) da simulação que minimiza o erro quadrado médio da
característica do sistema de fila GI/G/m que está sendo estimada. As aproximações
analíticas da fila GI/G/m utilizadas por eles são devidas a Whitt (1993). Eles apresentam
a performance das heurísticas para a estratégia de simulação de replicações
independentes com descarte de uma parte inicial dos dados de saída da simulação e
discutem a adaptação destas heurísticas para a estratégia de uma única execução longa
da simulação com análise de médias de grupos.
Delaney, Rossetti e White (1995) apresentam a performance das heurísticas
apresentadas por Delaney e Rossetti (1995) relativas à estratégia de uma única execução
longa da simulação com análise de médias de grupos, para a atenuação dos efeitos do
período transiente inicial em simulações de filas GI/G/m em equilíbrio.
Whitt (1989a) propõe fórmulas heurísticas simples para estimar o tamanho necessário
da execução da simulação para obter a precisão estatística desejada em simulações de
sistemas de fila. Pretende-se através destas fórmulas auxiliar nos estágios de
planejamento inicial antes que dados tenham sido coletados. As fórmulas são aplicáveis
a simulações de filas através de uma única execução longa para obter estimativas de
características em regime, como por exemplo tamanho esperado da fila em equilíbrio.
Estas fórmulas podem ser aplicadas para planejar experimentos de simulação e para
desenvolver e avaliar aproximações de filas. As fórmulas são baseadas em limites de
tráfego pesado (intenso) para filas (o comportamento limite quando a intensidade de
tráfego aproxima-se do limite superior para a estabilidade) e aproximações por difusão,

47
associadas. Estas fórmulas são aplicadas, em particular, a processos estocásticos que
podem ser aproximados por movimento Browniano refletido.
Whitt (1989b) propõe a obtenção de estimativas preliminares do tamanho da execução
da simulação requerido para obter a precisão estatística desejada em experimentos de
simulação estocástica, através da aproximação do modelo estocástico de interesse por
um modelo de Markov mais elementar, que possa ser analisado analiticamente. Em
outras palavras, quando se deseja obter estimativas de quantidades em equilíbrio através
de médias amostrais (dos dados de saída da simulação), o tamanho necessário da
execução, muitas vezes, pode ser obtido calculando a variância assintótica e vício
assintótico da média amostral no modelo de Markov.
Whitt (1991) avalia a eficiência de uma única execução longa versus múltiplas
replicações independentes em simulações a eventos discretos em equilíbrio, assumindo-
se que uma porção inicial dos dados de cada replicação são descartados para permitir
que o processo tenda ao equilíbrio. Ele fornece evidências em favor de uma única
execução longa da simulação, mas, também, mostra que múltiplas replicações
independentes podem ser mais eficientes. A vantagem de uma única execução longa
cresce se a quantidade de dados descartados cresce ou se a função de covariância
decresce mais rapidamente (assumindo que ela é não negativa e decrescente). Desta
forma, assumindo-se que a quantidade de dados descartados dependem da forma que o
processo aproxima-se do equilíbrio, uma única execução longa tende a ser mais
eficiente quando a função de covariância decai rapidamente comparada à taxa que o
processo aproxima-se do equilíbrio. Também, discute-se vias para determinar a porção
inicial a ser descartada.
Kleijnen (1992) faz uma inspeção e investigação dos modelos de validação e
verificação, especialmente dos modelos de simulação em pesquisa operacional. E é
apresentada uma bibliografia com 61 referências.

49
CAPÍTULO 2
CONCEITOS BÁSICOS
2.1 – INTRODUÇÃO
Neste capítulo apresentam-se conceitos básicos que serão utilizados na elaboração do
modelo de simulação da fila GI/G/m, para obtenção de estimativas das medidas de
performance de uma determinada configuração desta fila.
Na Seção 2.2 é apresentada uma definição de simulação, fundamentada em Law e
Kelton (1982), e os passos que devem ser seguidos num estudo de simulação.
Na Seção 2.3 apresentam-se a caracterização e definição da fila GI/G/m, as medidas de
performance de interesse para a avaliação de desempenho da fila GI/G/m, as relações de
Little aplicáveis à fila GI/G/m e a obtenção de estimativas das medidas de performance
da fila GI/G/m a partir dos dados de saída de uma execução da simulação.
Na Seção 2.4 são definidas as distribuições de probabilidade que foram utilizadas na
programação do modelo de simulação. Algumas destas distribuições foram utilizadas
nos experimentos realizados neste estudo e outras poderão ser utilizadas em futuros
experimentos.
2.2 - SIMULAÇÃO
Os conceitos e definições contidos nesta seção foram tomados basicamente de Law e
Kelton (1982) e somente foram referenciados quando provenientes de outras fontes.
Simulação se refere à técnicas, largamente usadas em pesquisa operacional e ciência do
gerenciamento (“management science”), para imitar ou simular, usando computadores,
a operação de várias classes de processos ou serviços do mundo real ou de sistemas
idealizados. A simulação envolve a geração de uma história artificial do sistema e o uso
desta história artificial para fazer inferências a respeito das características do sistema em
estudo (Banks e Carson II, 1984).

50
Os processos ou serviços de interesse são, geralmente, denominados sistemas e, para
estudá-los cientificamente, na maioria das vezes é necessário fazer suposições sobre o
modo de funcionamento destes. Estas suposições, que normalmente tomam a forma de
relações lógicas ou matemáticas, constituem o modelo. O modelo é usado para
experimentar e obter algum entendimento de como o sistema correspondente se
comporta.
Métodos matemáticos tais como álgebra, cálculo, ou teoria das probabilidades, quando
disponíveis, podem ser usados para obter informações exatas sobre as questões de
interesse nestes sistemas. Estas soluções exatas obtidas por métodos matemáticos são
denominadas soluções analíticas. Entretanto existem muitos sistemas que são
complexos demais para admitir que modelos realistas sejam avaliados analiticamente, e
que podem ser estudados por meio de simulação.
Um modelo de simulação é um tipo particular de modelo matemático de um sistema. Na
simulação, um computador é usado para avaliar um modelo numericamente por um
período de tempo de interesse, e dados são coletados para estimar as verdadeiras
características de interesse do modelo.
Em alguns estudos, ambos os modelos, analítico e de simulação, podem ser úteis. Uma
simulação pode ser usada para verificar a validade de suposições necessárias num
modelo analítico. Um modelo analítico pode sugerir alternativas razoáveis para serem
investigadas num estudo de simulação.
Entretanto existem algumas restrições quanto à utilização de simulação. A primeira é
que modelos usados para estudar sistemas de grande escala tendem a ser muito
complexos, e escrever um programa de computador para simulá-los pode ser uma tarefa
realmente difícil. Esta tarefa tem sido facilitada pelo desenvolvimento de várias
linguagens de propósito específico para simulação por computadores, que fornecem
automaticamente muitas das funções necessárias para codificar um modelo de
simulação. A segunda restrição é que a simulação de sistemas complexos requerem uma
grande quantidade de recursos e de tempo de computação, entretanto esta dificuldade
tem sido abrandada pela queda constante do custo dos computadores. E finalmente

51
existe uma restrição proveniente da utilização inadequada de um modelo programado
(de simulação) para fazer inferências sobre o sistema em foco; posturas que
negligenciam a questão fundamental de como um modelo adequadamente codificado
deveria ser usado para fazer inferências sobre o sistema de interesse têm levado a
conclusões errôneas em muitos estudos de simulação. Estas questões de metodologia da
simulação são independentes da linguagem de programação e do “hardware” usado.
Em simulação um sistema é definido como uma coleção de entidades (pessoas,
máquinas, coisas, etc.) que agem e interagem para a realização de alguma finalidade
lógica. O estado de um sistema é uma coleção de variáveis necessárias para descrever
um sistema num tempo específico, relativa aos objetivos de um estudo.
Os sistemas podem ser categorizados em dois tipos: discretos e contínuos. Um sistema
discreto é aquele em que o estado das variáveis muda somente em um número contável
de pontos no tempo, por exemplo, o número de clientes num banco muda somente
quando um cliente chega ou quando um cliente termina de ser servido e saí do banco.
Um sistema é contínuo quando o estado das variáveis muda continuamente com respeito
ao tempo, por exemplo um aeroplano se movendo no ar é um exemplo de sistema
contínuo pois o estado das variáveis quanto a posição ou velocidade mudam
continuamente com respeito ao tempo. Na prática poucos sistemas são completamente
discretos ou contínuos, mas desde que um tipo de mudanças predomina para a maioria
dos sistemas, então seria possível classificar um sistema como sendo ou discreto ou
contínuo.
Neste trabalho assume-se que um modelo é a representação de um sistema desenvolvido
para o propósito de estudar este sistema. O modelo deve ser suficientemente detalhado
ou “válido” para permitir que um analista ou um gerente possa usá-lo para tomar a
mesma decisão que seria tomada se fosse viável experimentar com o próprio sistema.
Ainda que não se devesse definir explicitamente um modelo de simulação, geralmente,
os modelos de simulação podem ser distinguidos entre aqueles que são estáticos ou
dinâmicos, determinísticos ou estocásticos, e discretos ou contínuos. Um modelo de
simulação é estático quando representa o sistema num determinado ponto do tempo. É

52
dinâmico quando ele representa um sistema que evolui através do tempo. É dito ser
estocástico se contém uma ou mais variáveis aleatórias, e em caso contrário é dito ser
determinístico. É discreto quando o estado das variáveis muda somente num número de
pontos contáveis do tempo, e é contínuo quando o estado das variáveis muda
continuamente através do tempo.
Simulação de Monte Carlo é um modelo de simulação que usa números aleatórios,
gerados por variáveis aleatórias U (0, 1) para resolver certos problemas estocásticos ou
determinísticos onde a passagem do tempo não é essencial. Assim, simulações de Monte
Carlo são, geralmente, mais estáticas que dinâmicas. Mas alguns autores definem
simulação de Monte Carlo como sendo qualquer simulação envolvendo o uso de
números aleatórios. Neste estudo foi assumida a primeira postura, defendida por Law e
Kelton (1982).
Um modelo de simulação que seja discreto, dinâmico e estocástico, geralmente é
denominado modelo de simulação a eventos discretos. Desde que modelos
determinísticos são um caso especial de modelos estocásticos, a restrição para
estocásticos não envolve perda de generalidade.
Simulação a eventos discretos trata da modelagem de um sistema que evolui através do
tempo, mas o estado das variáveis muda somente para um número contável de pontos
no tempo. Estes pontos no tempo são aqueles em que um evento ocorre, onde evento é
definido como uma ocorrência instantânea que pode mudar o estado do sistema.
Neste estudo foi adotado o modelo de simulação a eventos discretos, pois o sistema de
fila GI/G/m evolui através do tempo mas o estado de suas variáveis muda somente nos
instantes em que ocorre a chegada de um cliente ou o término do serviço a um cliente
(eventos).
Duas abordagens principais têm sido sugeridas para o mecanismo de avanço do tempo
de simulação, ou melhor, para avançar o relógio de simulação, a saber, avanço do tempo
orientado ao próximo evento e avanço do tempo por incrementos fixos. Neste estudo foi

53
adotada uma abordagem de mecanismo de avanço do tempo orientado ao próximo
evento.
Com a abordagem de avanço do tempo orientado ao próximo evento, o relógio de
simulação é inicializado em zero e os tempos de ocorrências de eventos futuros são
determinados. Então o relógio de simulação é avançado para o tempo do (novo) mais
eminente evento, o estado do sistema é atualizado, e eventos futuros são determinados,
etc. Este processo de avanço do relógio de simulação de um tempo-evento para um
outro é continuado até que eventualmente alguma condição de parada preestabelecida
seja satisfeita.
Em muitos modelos de simulação a eventos discretos, usando a abordagem de avanço
do tempo de simulação orientada ao próximo evento, são encontrados os seguintes
componentes:
• as variáveis de estado do sistema, usadas para descrever o sistema num instante de
tempo particular;
• o relógio de simulação, que fornece o valor corrente do tempo simulado;
• a lista de eventos, contendo os tempos agendados dos próximos eventos, ou seja,
os tempos programados para a ocorrência dos próximos eventos;
• as variáveis ou contadores estatísticos, usadas para armazenar informações
estatísticas sobre a performance do sistema;
• a rotina de inicialização, usada para inicializar o modelo de simulação para o
tempo zero;
• a rotina de sincronização de eventos, que determina o próximo evento da lista de
eventos e então avança o relógio de simulação para o tempo em que aquele evento
irá ocorrer;

54
• a rotina de eventos, que atualiza o estado do sistema quando um determinado tipo
de evento ocorre, sendo uma rotina para cada tipo de evento;
• o gerador de relatório, que calcula as estimativas da(s) medida(s) de desempenho
desejada(s) e imprime um relatório quando a simulação termina;
• o programa principal, que chama a rotina de sincronização para determinar o
próximo evento e então transfere o controle para a correspondente rotina de
evento atualizar o estado do sistema apropriadamente.
A relação lógica entre estes componentes é mostrada na Figura 2.1, adaptada da Figura
1.2 de Law e Kelton (1982).
Rotina de inicialização
Programa principal
Rotina de evento i
Gerador de relatório
Rotina de sincronização
1. Inicializa o relógio de simulação em 0 (zero) 2. Inicializa as variáveis de estado do sistema e os
contadores estatísticos 3. Inicializa a lista de eventos
1. Chama a rotina de sincronização2. Chama a rotina de evento i
1. Determina o tipo do próximo evento i
2. Avança o relógio de simulação
1. Atualiza as variáveis de estado do sistema
2. Atualiza os contadores estatísticos 3. Gera eventos futuros e os adicionam
à lista de eventos
A simulação está completa?
1. Calcule as estimativas de interesse 2. Imprima o relatório
Não
Sim
Fig. 2.1 – Fluxo de controle para o avanço do tempo orientada ao próximo evento.

55
Na programação da maior parte dos modelos de simulação a eventos discretos, são
necessárias funções especificas para:
• gerar números aleatórios, isto é, variáveis aleatórias U (0, 1);
• gerar variáveis aleatórias de uma distribuição especificada;
• avançar o tempo simulado;
• determinar o próximo evento da lista de eventos e passar o controle ao bloco de
código apropriado;
• adicionar ou remover registros de uma lista;
• colecionar dados;
• analisar dados;
• relatar os resultados;
• detectar condições de erro.
A freqüência destas e de outras funções na maioria dos programas de simulação é que
levou ao desenvolvimento de linguagens de simulação de propósito específico. Além
disso, acredita-se que o aperfeiçoamento, padronização e maior disponibilidade destas
linguagens têm sido os principais fatores para o crescimento da popularidade da
simulação.
Existem vantagens e desvantagens relativas a utilização de linguagens de simulação de
propósito específico ou de linguagens de programação de propósito geral na
programação de um modelo de simulação. Dentre as vantagens pode-se citar as
seguintes:
• As linguagens de simulação automaticamente fornecem a maioria das funções
necessárias na programação de um modelo, se não todas, resultando num
decréscimo no tempo de programação, que pode , muitas vezes, ser significante.

56
• As linguagens de simulação fornecem uma estrutura (esqueleto) natural para
modelagem de simulação. Seus blocos de construção são mais familiares para
simulação que aqueles numa linguagem de propósito geral (C, C++, FORTRAN,
etc.).
• Modelos de simulação são geralmente mais fáceis de serem mudados ou
estendidos quando escritos em linguagem de simulação.
• A maioria das linguagens de simulação fornecem alocação dinâmica de
armazenagem durante a execução.
• As linguagens de simulação fornecem melhor detecção de erros porque muitos
tipos potenciais de erros já foram identificados e são checados automaticamente.
E como, em geral, exigem poucas linhas de código, a chance de se cometer um
erro provavelmente seria menor.
Dentre as desvantagens pode-se citar as seguintes:
• Pode ser difícil para o usuário encontrar os erros que estão contidos numa nova
versão de uma linguagem de simulação.
• A maioria dos desenvolvedores de modelos já conhecem uma linguagem de
propósito geral, mas isto, freqüentemente, não é o caso com uma linguagem de
simulação.
• Um programa eficientemente escrito numa linguagem de propósito geral (C, C++,
Pascal, FORTRAN, etc.) pode requerer menos tempo de execução que o programa
correspondente escrito numa linguagem de simulação. Isto acontece porque uma
linguagem de simulação é projetada para modelar uma grande variedade de
sistemas com um conjunto de blocos de construção, enquanto um programa em
linguagem de propósito geral pode ser feito sob medida para uma determinada
aplicação.

57
• Linguagens de propósito geral permitem maior flexibilidade de programação que
certas linguagens de simulação. Por exemplo, cálculos numéricos complicados
não são fáceis em Sistema de Simulação de Propósito Geral (GPSS).
Levando-se em consideração os prós e contras levantados acima optou-se, neste estudo,
por programar o modelo de simulação utilizando uma linguagem de simulação, de
propósito específico. Foi utilizado para a construção do modelo programado o pacote de
software de simulação em redes denominado “Micro Saint”, versão estudantil 1.2-k.
Este software reúne todos os mecanismos e componentes, como os descritos
anteriormente, para a modelagem de um sistema de simulação a eventos discretos, além
de permitir a construção do modelo pelo processo de arrastar e colocar blocos na área de
serviço formando uma rede.
2.2.1 – O PROCESSO DE SIMULAÇÃO
A realização de um estudo de simulação completo (ou minucioso) e seguro (idôneo)
envolve a observância de alguns passos, que são consensuais na literatura sobre
simulação. E uma breve descrição destes passos é apresentada a seguir.
Formulação do problema: Um estudo de simulação deveria iniciar com uma declaração
(enunciado ou especificação) do problema a ser investigado.
Estabelecimento de objetivos: Os objetivos do estudo devem ser especificados. Os
objetivos indicam as questões a serem respondidas pela simulação. Neste ponto deve ser
determinado se a simulação é uma metodologia apropriada para o problema formulado.
Construção do modelo: Esta fase refere-se à elaboração conceitual e comunicativa do
modelo. A formulação conceitual do modelo é transcrita (ou representada) num modelo,
geralmente, denominado comunicativo. Dessa forma o modelo comunicativo é uma
abstração do sistema sob estudo expressa na forma de relações lógicas-matemáticas.
Codificação do modelo: O processo de codificação ou programação do modelo consiste
da transcrição do modelo comunicativo num programa escrito em linguagem de
programação de computadores para a execução do modelo de simulação em

58
computadores, visando a obtenção de resultados. A linguagem de programação a ser
utilizada na codificação pode ser uma de propósito geral ou uma linguagem de
propósito específico para simulação.
Verificação: O modelo programado (ou o programa de computador) deve ser testado
para averiguar se este funciona como o pretendido, se o código não possui “bugs”. Este
passo, geralmente, é referido em programação de computadores como processo de
depuração do código do programa.
Validação: O objetivo da validação é determinar o quanto o modelo conceitual é uma
representação razoável do sistema real (ou idealizado) que está sendo modelado. Deve-
se responder as seguintes questões: Quão precisamente o modelo simulado representa o
sistema real (ou idealizado)? O modelo simulado pode ser utilizado no lugar do sistema
real (ou idealizado) para tomada de decisões relativas ao sistema idealizado?
Projeto experimental: O projeto ou modelo experimental determina a estratégia de
simulação a ser utilizada (uma única execução longa da simulação versus replicações
independentes da simulação), o tamanho do período de inicialização (“warm-up”), o
tamanho da(s) execução(ões) da simulação, e o número de replicações a ser feito em
cada experimento da simulação (se aplicável).
Realização e análise das execuções: A realização de execuções da simulação para se
obter dados de saída, e sua subseqüente análise, são usados para estimar medidas de
performance para o(s) projeto(s) de sistema(s) que está(ão) sendo simulado(s).
Execuções adicionais: Baseado na análise das execuções que foram completadas, o
simulador determina se execuções adicionais são necessárias e que projeto estes
experimentos adicionais deveriam obedecer.
Documentação do programa e relatório dos resultados: A operação do modelo deve ser
documentada e um relatório dos resultados deve ser preparado.

59
A ordem e a inter-relação entre estes passos estão explicitados na Figura 2.2, a seguir,
adaptada da Figura 12.1 de Banks, Carson II e Goldsman (1990).
SimSim
Não
Não
Formulação do problema
Estabelecimento de objetivos
Construção do modelo
Codificação do modelo
Verificado?
Validado?
Projeto experimental
Realização e análise das execuções
Execuções adicionais?
Documentação do programa e relatório
dos resultados
Fig. 2.2 – Passos num estudo de simulação.
Sim
Sim
Não

60
2.3 - A FILA GI/G/m
Um sistema de filas é um sistema consistindo de um ou mais servidores que fornecem
serviço de alguma classe para clientes que chegam ao posto de serviços. Clientes que na
chegada encontram todos os servidores ocupados (geralmente) formam uma ou mais
filas (ou linhas) em frente aos servidores, daí o nome ‘sistema de filas’.
Um sistema de filas é caracterizado pelos seguintes componentes: o processo de
chegadas, o mecanismo de serviço, a disciplina da fila, o tamanho da sala de espera e a
população de clientes. O processo de chegadas descreve como os clientes chegam para o
sistema e especifica a distribuição de probabilidade dos tempos entre chegadas de
clientes. Denota-se por Ti o tempo entre as chegadas do (i - 1)-ésimo e do i-ésimo
clientes. Se as variáveis aleatórias T1 , T2 ..... são assumidas serem iid (independentes e
identicamente distribuídas), então a taxa de chegadas de clientes é )(1 TE=λ , onde
E(T) denota o tempo esperado (médio) entre chegadas.
O mecanismo de serviço especifica o número de servidores, se cada servidor tem sua
própria fila ou se existe uma única fila alimentando todos os servidores, e a distribuição
de probabilidade dos tempos de serviços de clientes. Denota-se por Si o tempo de
serviço do i-ésimo cliente que chegou. Se as variáveis aleatórias S1 , S2 ..... são
assumidas serem iid, então a taxa de serviços de um servidor é )(1 SE=µ , onde E(S)
denota o tempo esperado (médio) de serviço de um cliente.
A disciplina da fila refere-se às regras que um servidor usa para escolher o próximo
cliente da fila, caso exista(m) cliente(s) esperando na fila, quando o servidor completa o
serviço do cliente atual. As disciplinas de fila comumente usadas incluem: FIFO – os
clientes são servidos na ordem de chegada; Last In, First Out (LIFO) – os clientes são
servidos na ordem inversa de chegada; Prioridades - os clientes são servidos na ordem
de sua importância ou com base em seus requerimentos de serviço.
O tamanho da sala de espera se refere à quantidade máxima de clientes que podem estar
presentes no sistema ao mesmo tempo, contando aqueles que estão na fila e aqueles que

61
estão recebendo serviço. E a população de clientes se refere aos prováveis clientes, ao
seu número e origem.
Certos sistemas de filas ocorrem tão freqüentemente na prática que notações padrões
têm sido desenvolvidas para eles. Uma notação popularmente usada é a notação de
Kendall.
A notação de Kendall para sistemas de fila é uma notação abreviada que envolve cinco
elementos, compondo o padrão A/B/m/m+K/M. O símbolo A especifica a distribuição
dos tempos entre chegadas, o símbolo B especifica a distribuição dos tempos de
serviço, o símbolo m especifica o número de servidores, m+K especifica a capacidade
da sala de espera, e M especifica o tamanho da população de clientes.
Uma notação mínima que envolve os três primeiros elementos do padrão A/B/m/m+K/M
geralmente é utilizada. Está implícito nesta notação mínima, A/B/m, as seguintes
suposições: que os tempos entre chegadas, exceto para o caso G, e os tempos de serviço
são seqüências de variáveis aleatórias independentes, e que cada seqüência é
i.i.d.(independente e identicamente distribuída); que a capacidade da sala de espera é
ilimitada; que na existência de mais de um servidor, eles são alimentados por uma fila
única; que a população de clientes é ilimitada.
Os seguintes símbolos são freqüentemente usados para referir-se às famílias de
distribuições específicas:
• Er = Erlang de ordem r (ou de r estágios);
• Ck = Cox de ordem k (ou de k estágios);
• D = Determinística;
• G = Genérica;
• GI = Genérica Independente;
• Gm = Gamma;

62
• Hr = Hiperexponencial de ordem r (ou com r estágios);
• Ph = tipo fase (Phase-type);
• M = Exponencial ou Poisson (Markoviana);
• W = Weibull.
Em particular, considere o sistema de filas que tem as seguintes características:
• m servidores em paralelo e uma única fila FIFO com sala de espera ilimitada
alimentando todos os servidores;
• uma população ilimitada de prováveis clientes;
• os tempos entre chegadas T1 , T2 .....são variáveis aleatórias iid;
• os tempos de serviço S1 , S2 .....são variáveis aleatórias iid;
• Os Ti’s e Si’s são independentes.
Este sistema com as características descritas acima é denominado um sistema de filas
GI/G/m. Onde GI (Geral independente) refere-se à distribuição das variáveis aleatórias
Ti’s e G (Geral) refere-se à distribuição das variáveis aleatórias Si’s.
A quantidade ( )µλρ m= , denominada taxa ou fator de utilização do sistema de filas, é
uma medida de quão intensamente os recursos do sistema de filas são utilizados.
Este estudo trata de um sistema de filas idealizado, o sistema de filas GI/G/m. Este
sistema tem o propósito de possibilitar uma abordagem teórica geral sobre os sistemas
de filas.
Neste estudo não foram considerados sistemas de filas reais, apesar de existirem
sistemas de filas reais que possam, sob alguma(s) hipótese(s) simplificadora(s), serem
representados por um sistema de filas GI/G/m.

63
O leiaute (ver Figura 2.3) e as características funcionais da fila GI/G/m que será tratada
neste estudo são mostrados a seguir.
As características funcionais de uma fila GI/G/m são:
• a fila é única, com sala de espera ilimitada e com disciplina First-Come, First-
Served (FCFS), às vezes referida como FIFO;
• possui m servidores;
• o processo de chegadas é GI
• processo de renovações,
• os tempos entre chegadas formam uma seqüência de variáveis aleatórias iid
com distribuição geral;
• o processo de serviço é G
• os tempos de serviço formam uma seqüência de variáveis aleatórias iid com
distribuição geral;
• cada cliente
• requer somente um único serviço,
• sendo o primeiro da fila, na existência de um ou mais servidores livres
• escolhe aleatoriamente um servidor livre,
• e começa a ser servido imediatamente,
• caso contrário ele espera na fila por um servidor livre,
• deixa a estação logo após o término do serviço;

64
• são considerados apenas dois estados para os servidores, ocupados ou livres, e
não é permitido servidores livres na existência de clientes esperando na fila.
2.3.1 – MEDIDAS DE PERFORMANCE DA FILA GI/G/m
Na avaliação do desempenho ou da performance de um sistema de filas GI/G/m são
levados em consideração características ou medidas de interesse. Estas características
ou medidas de interesse são denominadas medidas de performance (ou de avaliação) do
sistema de filas GI/G/m. Pode-se perceber, através da abundante literatura existente
sobre sistemas de filas uma uniformidade no tratamento destas medidas, tanto com
relação à definições, quanto com relação à importância de cada uma destas medidas.
Neste trabalho o interesse está na estimação das medidas de avaliação de desempenho
em equilíbrio da fila GI/G/m, ou seja, em medidas de performance consideradas para o
sistema em regime.
Segundo Tijms (1994), para a fila GI/G/m, as seguintes suposições são feitas.
Suposição 1. Para a fila GI/G/m, a utilização do servidor, definida por mSE )(λρ = , é
menor que 1.
Posto de Serviços
Fila
Chegada
Servidores1
2
3
m
Saídas
Fig. 2.3 – Leiaute da fila GI/G/m.

65
Na fila GI/G/m a quantidade ρ pode ser interpretada como a fração do tempo, para o
sistema em equilíbrio, que um dado servidor está ocupado. O que explica o nome de
utilização do servidor. Em muitos sistemas com um único servidor é desejável ter uma
utilização do servidor ρ que não seja maior que 0,8, pois de outra forma um pequeno
acréscimo na carga oferecida pode levar a acréscimos consideráveis no tamanho médio
da fila e na espera média na fila por cliente. Contudo, sistemas com muitos servidores
levam em conta valores mais altos de utilização do servidor ρ, pois um pequeno
acréscimo na carga oferecida pode não causar uma grande degradação na performance
do sistema.
Suposição 2. a) A distribuição do tempo entre chegadas A(t) ou a distribuição do tempo
de serviço B(t) tem uma densidade positiva em algum intervalo.
b) A probabilidade que o tempo entre chegadas T seja maior do que o
tempo de serviço S é positiva.
Define-se um ciclo como o tempo decorrido entre duas chegadas consecutivas que
encontram o sistema vazio. Então, sob as suposições 1 e 2, pode ser mostrado que o
valor esperado do tamanho do ciclo é sempre finito.
Sejam as seguintes variáveis aleatórias:
• L(t) = número de clientes no sistema no instante t (incluindo aqueles em serviço).
• Lq(t) = número de clientes na fila no instante t (excluindo aqueles em serviço).
• Dn = espera na fila do n-ésimo cliente (excluindo o tempo de serviço).
• Rn = quantidade de tempo gasto pelo n-ésimo cliente no sistema (incluindo o
tempo de serviço).
Os processos estocásticos a tempo contínuo {L(t), t ≥ 0} e {Lq(t), t ≥ 0} e os processos
estocásticos a tempo discreto {Dn, n ≥ 0} e {Rn, n ≥ 0} são todos regenerativos. As
épocas de regeneração são as épocas em que um cliente encontra o sistema vazio, na

66
chegada. Os ciclos de regeneração têm média finita. Deste modo as seguintes médias
em equilíbrio existem e são constantes com probabilidade 1:
• Número médio de clientes presentes no sistema para um tempo arbitrário:
[ ] ( )∫∞→=
t
tduuL
tLE
0
1lim .
• Número médio de clientes esperando na fila para um tempo arbitrário:
[ ] ( )∫∞→=
t
qtq duuLt
LE
0
1lim .
• Espera média de um cliente arbitrário na fila:
[ ] ∑=
∞→=
n
kknq D
nWE
1
1lim .
• Espera média de um cliente arbitrário no sistema:
[ ] ∑=
∞→=
n
kkn
Rn
WE1
1lim .
É importante notar que a distribuição do número de clientes no sistema é invariante com
relação a ordem de serviço quando a disciplina da fila é independente do tempo de
serviço e “work-conserving”. Aqui independente do tempo de serviço significa que a
regra para selecionar o próximo cliente a ser servido não depende do tempo de serviço
de um cliente, enquanto “work-conserving” significa que o trabalho ou requerimento de
serviço de um cliente não é afetado pela disciplina da fila. Disciplinas de fila que
possuem esta propriedade incluem FIFO, LIFO e serviço em ordem aleatória. A
distribuição do tempo de espera obviamente dependerá da ordem de serviço (Tijms,
1994).
2.3.1.1 – MEDIDAS DE PERFORMANCE DA FILA M/M/m

67
A fila M/M/m tem as seguintes características: m servidores idênticos; uma fila única
com disciplina FIFO e sala de espera ilimitada alimentando todos os servidores;
população de clientes ilimitada; tempos entre chegadas e tempos de serviço distribuídos
exponencialmente. Os tempos entre chegadas e tempos de serviço são variáveis
aleatórias iid, e independentes entre si.
Resultados analíticos exatos para a fila M/M/m já foram estabelecidos e podem ser
encontrados em manuais clássicos sobre teoria de fila, por exemplo: Kleinrock (1976),
Gross e Harris (1974), Allen (1990), Wolff (1989).
As medidas de performance de interesse da fila M/M/m para este estudo podem ser
determinadas exatamente pelas seguintes equações, para ρ < 1:
µρ
m1
=
( ) ( )1
1
00 1
1!
1!
−−
=
−
+
= ∑ ρ
ρρm
mk
mP mm
k
k
( ) ( )( )ρρ
−=≥
1!)( 0
mPm
mxLPm
[ ] ( )ρ
ρρ−
≥+=
1)( mxLPmLE
[ ] [ ]λLEWE =
[ ] [ ]µ1
−= WEWE q
[ ] [ ] ( )ρ
ρλ−
≥==
1)( mxLPWELE qq

68
[ ] [ ]µλρ ==− mLELE q
2.3.1.2 – MEDIDAS DE PERFORMANCE DA FILA D/D/m
A fila D/D/m tem as seguintes características: m servidores idênticos; uma fila única
com disciplina FIFO e sala de espera ilimitada alimentando todos os servidores;
população de clientes ilimitada.
Resultados analíticos exatos para a fila D/D/m já foram estabelecidos e podem ser
encontrados em manuais clássicos sobre teoria de fila, por exemplo: Gross e Harris
(1974), Wolff (1989).
As medidas de performance de interesse da fila D/D/m para este estudo podem ser
determinadas exatamente), para ρ < 1, pelas seguintes equações:
[ ] [ ] [ ] [ ] 0 e ,0 , , 2 ======= qq WEmWELEmLEm ρµ
λµµ
λρµ
λρ .
2.3.2 – RELAÇÕES DE LITTLE
Talvez o resultado mais básico para sistemas de filas seja a fórmula de Little. Esta
fórmula relaciona certas médias, como o número médio de clientes na fila e a espera
média na fila por cliente. Segundo Tijms (1994), a fórmula de Little é valida para quase
todos os sistemas de filas. E segundo Wolff (1989), ela é sempre verdadeira para
propósitos práticos. Uma prova para a fórmula de Little é apresentada por Wolff (1989)
na Seção 5.15.
Em particular, para a fila GI/G/m, tem-se as seguintes relações fundamentais:
[ ] [ ][ ] [ ]
[ ]SEses ocupadoe servidoruilíbrio dédio em eqo número mWELE
WELE qq
λλ
λ
==
=
,
,

69
Levando em consideração a última relação (fórmula de Little), tem-se que, desde que
cada um dos m servidores suportem em média a mesma carga, então a:
[ ] mSEado está ocupo servidorque um dadequilíbrioemtempodofração λ= .
Na fila GI/G/m, em particular, a fração do tempo em equilíbrio que um dado servidor
está ocupado é igual a ρ .
Para motivar estas relações Tijms (1994) argüi da seguinte forma. Assume-se que, para
cada cliente aceito no sistema, incorre-se num custo de acordo com uma regra
específica. Então, aplica-se o seguinte princípio:
ido)ente admitme por cliio em regi(custo médme)ia em regihegada méd(taxa de ctempo nidade de tema por uo pelo sise contraído em regimcusto médi
×=
Uma prova deste princípio para sistemas regenerativos pode ser encontrada na Seção
1.6 de Tijms (1994). Para visualizar a primeira relação de Little estabelecida acima,
assume-se que para cada cliente admitido, o sistema contrai um custo a uma taxa de 1
enquanto o cliente está na fila. Então, o custo médio em regime contraído por cliente
admitido é igual a E[Wq]. Por outro lado, desde que o sistema contraí um custo a uma
taxa de j enquanto j clientes estão esperando na fila, o custo médio em regime contraído
pelo sistema por unidade de tempo é igual a E[Lq]. A primeira relação de Little, então, é
obtida observando que a taxa de chegada média em regime de clientes admitidos é λ. A
segunda relação de Little é obtida assumindo-se que, para cada cliente admitido, o
sistema contraí um custo a uma taxa de 1 enquanto o cliente está no sistema. Para
visualizar a terceira relação acima, assume-se que cada cliente aceito paga uma taxa de
1 por unidade de tempo, enquanto em serviço. Então a recompensa conseguida por um
cliente é igual ao tempo de serviço do cliente. Por outro lado, o sistema consegue uma
recompensa a uma taxa de j por unidade de tempo quando j servidores estão ocupados.
Conseqüentemente a recompensa média conseguida pelo sistema por unidade de tempo
é igual ao número médio de servidores ocupados. E desta forma a relação é obtida.

70
2.3.3 – ESTIMATIVAS DAS MEDIDAS DE PERFORMANCE DA FILA GI/G/m
A PARTIR DE UMA EXECUÇÃO DA SIMULAÇÃO
Existem dois tipos de estimadores a considerar com relação as medidas de performance
de uma fila GI/G/m. O primeiro tipo se refere a estimativas que são obtidas a partir dos
dados de saída da simulação através da média aritmética ordinária e o segundo tipo se
refere a estimativas obtidas através da média aritmética ponderada pelo tempo
(freqüentemente, referida como média integrada no tempo).
2.3.3.1 – NÚMERO MÉDIO NO SISTEMA E NÚMERO MÉDIO NA FILA
Seja o número de clientes no sistema no instante t (incluindo aqueles em serviço)
denotado por L(t). Considere a simulação de um sistema de fila sobre um período de
tempo T, onde Ti denota o tempo total em que o sistema contém exatamente i clientes
durante [0, T]. Dessa forma tem-se que ∑∈
=Ei
i TT , onde E = {0, 1, 2, ..., k}e,
eventualmente, pode-se ter E = {0, 1, 2, 3, ...}.
O número médio de clientes no sistema pode ser, então, estimado por:
∑∑∑
∈∈
∈ =
==Ei
iEi
iEii
iTTT
Ti
T
iTL 1ˆ .
Para ilustrar e motivar esta definição, considere a simulação de um tal sistema de fila
durante um período de tempo T, como o mostrado na Figura 2.4.
Pela Figura 2.4, ( ) 158,119134211130ˆ ≅×+×+×+×=L . Note que TTi é a
proporção do tempo que o sistema de fila contém exatamente i clientes. O estimador L é
um exemplo de uma média aritmética ponderada pelo tempo.

71
A área total sob a função L(t) pode ser decomposta em retângulos de peso i e tamanho
Ti, o que permite obter a seguinte relação: ∫∑ =∈
T
Eii dttLiT
0 )( . E, consequentemente,
tem-se que:
∫∑ ==∈
T
Eii dttL
TiT
TL
0 )(11ˆ .
Estas equações são válidas para qualquer sistema de fila, indiferentemente do número
de servidores, da disciplina da fila, ou qualquer outra circunstância especial.
Muitos sistemas de filas exibem um tipo de estabilidade (equilíbrio ou regime) em
termos de suas medidas de performance. E este é o caso da fila GI/G/m, sob
consideração neste estudo, com 1<ρ . Para tais sistemas, quando T torna-se
suficientemente grande, o número médio de clientes observado no sistema, L , se
aproxima de um valor limite, E[L], que é chamado de número médio, em equilíbrio ou
em regime, de clientes no sistema. Isto é, com probabilidade 1,
∞→→= ∫ TLEdttLT
LT
quando ][)(1ˆ
0 .
2 4
3
2
1
0 18 16 14121086
L(t)
t
T1T1 T1 T1
T2 T2
T3
Fig. 2.4 – Número de clientes na fila, L(t), no tempo t.
T0
T0

72
Se o tamanho da execução da simulação é suficientemente longo e o vício devido às
condições iniciais do sistema for minimizado através de um procedimento específico,
diz-se que a estimativa obtida através do estimador L é não viciada. Desta forma o
estimador L é dito ser consistente (coerente) para E[L].
Seja Lq(t) o número de clientes na fila no instante t (excluindo aqueles em serviço), e Tiq
o tempo total em que existem exatamente i clientes na fila durante [0, T]. Dessa forma
tem-se que ∑∈
=Ei
qi TT , onde { }kE ,,3,2,1,0 K= e, eventualmente, pode-se ter
{ }K,3,2,1,0=E .
Então, de forma análoga, o número médio, em regime ou equilíbrio, de clientes no
sistema pode ser estimado por:
∞→→== ∫∑∈
TLEdttLT
iTT
L q
T
qEi
qiq quando ][)(11ˆ
0 .
2.3.3.2 – TEMPO MÉDIO NO SISTEMA E ESPERA MÉDIA NA FILA
Seja a quantidade de tempo Rn gasta pelo n-ésimo cliente no sistema (incluindo o tempo
de serviço). Considere a simulação de um sistema de fila sobre um período de tempo T.
Dessa forma R1, R2, ..., RN representam a quantidade de tempo gasto por cada cliente no
sistema durante [0, T], onde N é o número de chegadas durante [0, T]. Então o tempo
médio gasto por cliente no sistema, chamado de tempo médio no sistema, é dado pela
média amostral ordinária (simples) a seguir:
∑=
=N
iiR
NW
1
1ˆ .
Para sistemas estáveis (em equilíbrio ou regime), quando N → ∞, [ ]WEW →ˆ com
probabilidade 1, onde E[W] é a média em equilíbrio do tempo no sistema, ou seja, o
tempo esperado que um cliente gaste no sistema, para um sistema em equilíbrio.

73
Se o sistema em consideração é uma fila de espera (excluindo os clientes em serviço)
então o tempo médio gasto na fila por cliente, chamado de tempo médio de espera, é
dado pela média amostral ordinária (simples) a seguir:
∑=
=N
iiq D
NW
1
1ˆ .
Onde Dn é a espera na fila do n-ésimo cliente (excluindo o tempo de serviço) durante
[ ]T,0 .
E de forma análoga tem-se que, para sistemas estáveis (em equilíbrio ou regime),
quando N → ∞, [ ]qq WEW →ˆ com probabilidade 1, onde E[Wq] é a média em equilíbrio
do tempo na fila, ou seja, o tempo esperado que um cliente gaste na fila, para um
sistema em equilíbrio.
Os estimadores qWW ˆ e ˆ são influenciados pelas condições iniciais I do sistema e pelo
tamanho da execução T, analogamente aos estimadores qLL ˆ e ˆ .
2.3.3.3 – AS FÓRMULAS DE LITTLE E AS ESTIMATIVAS qq WWLL ˆ e ˆ,ˆ,ˆ
Pode ser derivado da Figura 2.4, veja em Banks e Carson II (1984), que: WL ˆˆˆ λ= . E,
quando T → ∞ e N → ∞, tem-se que WL ˆˆˆ λ= → ][][ WELE λ= , onde λ é a taxa média
de chegadas observada (média amostral dos dados de saída da simulação) e λ é a taxa
média de chegadas para o sistema em equilíbrio (geralmente um parâmetro fornecido).
E de forma análoga tem-se que: qq WL ˆˆˆ λ= . E, quando T → ∞ e N → ∞, tem-se que
qq WL ˆˆˆ λ= → ][][ qq WELE λ= .
2.4 - DISTRIBUIÇÕES DE PROBABILIDADE
Nesta seção são abordadas as seguintes distribuições de probabilidade:

74
• distribuição exponencial;
• distribuição gamma;
• distribuição de Weibull;
• distribuição de Erlang de ordem k e misturas de Erlangs de ordens k e k-1;
• distribuição Hiperexponencial de ordem 2 com médias balanceadas;
• distribuições do tipo fase, especialmente a distribuição de Cox de ordem 2 com
normalização gamma;
• distribuição histograma.
São apresentadas definições resumidas e algumas aplicações destas distribuições, bem
como o ajuste ou estimação dos parâmetros destas distribuições para que possam ser
utilizadas pelo modelo, programado, de simulação.
2.4.1 - DISTRIBUIÇÃO EXPONENCIAL
Existem muitas situações onde o número de ocorrências de um evento num tempo
especificado segue uma distribuição de Poisson, ou seja, se x é o número de ocorrências
no tempo t, a probabilidade de x ocorrências é dado por: ( ) ( ) tx
extxP αα −=!
, onde α é a
taxa de ocorrências por unidade de tempo e t é o número de unidades de tempo.
Pode facilmente ser visto que a probabilidade de nenhuma ocorrência até um instante t,
x = 0, é ( ) teP α−=0 . E desta expressão pode-se escrever a função de distribuição
cumulativa, a probabilidade da primeira ocorrência num tempo menor ou igual a t,
( ) tetF α−−=1 . Diferenciando F(t) obtém-se a função de densidade: ( ) tetf αα −= . A
função de densidade f(t) é geralmente referida como a distribuição exponencial.

75
Como foi indicado, se a probabilidade de x ocorrências no tempo t segue a distribuição
de Poisson, então a distribuição de probabilidade do tempo até a primeira ocorrência (ou
o tempo entre ocorrências) segue a distribuição exponencial.
Desta forma a distribuição exponencial tem função densidade de probabilidade xexf αα −=)( , função de distribuição cumulativa ( ) xexF α−−=1 , esperança α1][ =XE
e variância 21][ α=XV . A esperança E[X] é, freqüentemente, referida como o tempo
médio até uma falha ou o tempo médio entre ocorrências de eventos, dependendo da
aplicação.
A distribuição exponencial tem uma forma simples e é definida no intervalo (0, ∞), seu
coeficiente de variação é sempre igual a 1 e seu parâmetro de escala α pode ser
ajustado, sem ambigüidade, apenas com o primeiro momento. Ela possui taxa de falhas
condicional (“hazard rate”) constante e igual a α, sendo que a taxa de falhas condicional
é definida por ( )( )xF
xfxh−
=1
)( .
O mais simples dos modelos de tempo de vida corresponde ao caso onde a taxa de
falhas condicional é constante, ou seja, ao caso em que a distribuição do tempo de vida
é exponencial. Este modelo é usado para equipamentos que não sofrem desgaste devido
ao uso sobre o seu tempo de vida operante. Em outras palavras, a probabilidade de falha
num período de tempo fixado, dado que o equipamento está em operação, é constante e
independente da idade do equipamento.
A distribuição exponencial tem sido usada em muitas aplicações por causa de sua
simplicidade e da facilidade de determinar percentis, estimadores, testes de hipóteses e
intervalos de confiança. Alguns exemplos de aplicação são: o tempo de espera para a
chegada do próximo cliente ou o tempo entre chegadas em sistemas de filas, o tempo até
uma falha num sistema complexo de componentes não redundantes, e o tempo para
completar uma tarefa.

76
Esta distribuição está disponível no pacote de software Micro Saint para fornecer ou
gerar tempos de atividades exponencialmente distribuídos.
2.4.2 - DISTRIBUIÇÃO GAMMA (Gm)
A distribuição gamma pode ser interpretada como a distribuição da soma de variáveis
aleatórias exponenciais independentes e identicamente distribuídas. Esta distribuição
tem sido usada para representar a distribuição do tempo de espera da k-ésima chegada
em um posto de serviço, o tempo de falha de um sistema composto de unidades
redundantes, onde uma unidade redundante é ligada quando uma unidade em operação
falha e o tempo até a falha de algum mecanismo ou organismo, onde a falha é causada
por uma acumulação de danos (a falha ocorre após um número fixo de ocorrências de
danos) e estes danos ocorrem independentemente para uma taxa fixa. Em todas estas
instâncias assume-se que, para uma primeira aproximação, a distribuição subjacente seja
exponencial.
A distribuição gamma tem muitas aplicações em controle de estoques, teoria de filas, e
estatística teórica. Dois casos especiais desta são as distribuições de Erlang-k e do Qui-
quadrado. A taxa de falhas condicional para a distribuição gamma é limitada, e isto
pode ser usado como critério para se escolher entre ela e a distribuição de Weibull (taxa
de falhas condicional ilimitada).
A distribuição gamma tem função densidade de probabilidade dada por:
( ) 0 , )(
)( 1 >Γ
= −− xexxf xαθθαθθ
αθ ,
onde:
( ) ∫∞ −−=Γ
0
1 dxet xθθ ,
para todo θ > 0.

77
O parâmetro θ é chamado parâmetro de forma e α é chamado parâmetro de escala. O
parâmetro θ determina a forma da distribuição, quando 1=θ o modelo exponencial é
obtido com uma taxa de falhas condicional constante. Quando 1>θ a função densidade
é zero na origem, cresce para até um máximo global (mono-modal) e decresce para zero
quando x → ∞; sua taxa de falhas condicional cresce até um limite superior. Quando
1<θ a função de densidade tem uma assintótica no ponto t = 0.
Quando o parâmetro k=θ (inteiro) a distribuição gamma é freqüentemente referida (ou
classificada) como a distribuição de Erlang de ordem k.
Integrando por partes a função densidade de probabilidade da distribuição gamma pode-
se mostrar que: ( ) ( ) ( )1 1 −Γ−=Γ θθθ . E se θ é um inteiro, então usando Γ(1)=1, pode
ser visto que: ( ) ( )! 1−=Γ θθ .
Para θ = x +1, com x real, pode-se utilizar a série assintótica de Stirling para estimar os
valores da função gamma:
( )
+−++=+Γ − ...
51840139
2881
1211 21 32 xxx
exxx xxπ .
Mas em Flannery et alli (1990) é apresentada uma aproximação devida a Lanczos,
derivada da aproximação de Stirling, com uma série de correções, dada por:
( ) ( ) ( )
++
+⋅⋅⋅++
++
+++=+Γ ++−+ επγ γ
Nxc
xc
xc
cexx Nxx
21 2 1 21
021 2
121
para x > 0. Para esta aproximação com γ = 5, N = 6 e um certo conjunto de coeficientes
c’s, o erro é menor que 10102 −×<ε . O conjunto de coeficientes é o que segue:
;16775053203294,86 ;71461800917294,76 ;900150000000001,1
2
1
0
−===
ccc

78
.5E9535395239384,0 ;2E8661791208650973.0
;501552317395724,1 ;30910140982408,24
6
5
4
3
−−=−=
−==
cccc
A distribuição gamma tem esperança α1][ =XE e variância θα 21][ =XV .
Esta distribuição está disponível no pacote de software Micro Saint para fornecer ou
gerar tempos de atividades.
Os seus parâmetros são ajustados pelo pacote de software Micro Saint, bastando
fornecer a média (esperança) e o desvio padrão.
Para maiores informações sobre a distribuição gamma veja Banks e Carson II (1984),
Gottfried (1984) e Spiegel (1992).
2.4.3 - DISTRIBUIÇÃO DE WEIBULL (W)
A distribuição de Weibull tem uma propriedade muito interessante: ela pode representar
qualquer uma dos três possíveis tipos de taxas de falhas condicionais, isto é, taxas de
falhas crescentes, decrescentes e constantes.
A distribuição de Weibull tem sido usada para modelar o tempo até a falha em diversos
sistemas, pois uma escolha apropriada de seus parâmetros pode representar
características de tempo de vida de uma grande diversidade de equipamentos. Ela
também pode ser usada como um modelo de distribuição para um grande número de
variáveis aleatórias cujas funções de densidade são limitadas à esquerda.
A distribuição de Weibull tem função densidade de probabilidade dada por:
να
να
ναθ θθ
≥
−
−
−
=−
xxxtf ,exp)(1
.
O parâmetro θ > 0 é chamado parâmetro de forma, α > 0 é chamado parâmetro de
escala e ν é chamado parâmetro de locação, -∞ < ν < +∞.

79
Quando ν = 0 a função densidade de probabilidade Weibull torna-se:
0 ,exp)(1
≥
−
=
−
xxxxfθθ
αααθ .
O parâmetro θ determina a forma da distribuição; quando θ > 1 a taxa de falhas
condicional cresce com o tempo, é ilimitada, quando θ < 1 ela decresce para zero, e
quando θ = 1 a distribuição de Weibull reduz-se à distribuição exponencial com taxa de
falhas condicional constante.
A esperança e a variância da distribuição de Weibull são dadas por:
+Γ−
+Γ=
+Γ+=
22 1112][ e 11][
θθα
θαν XVXE .
E a função Γ(⋅) está definida na distribuição gamma.
2.4.4 - DISTRIBUIÇÃO DE ERLANG DE ORDEM k (Ek)
A distribuição de Erlang de ordem k é um caso especial da distribuição gamma. A
distribuição gamma com parâmetro θ = k (inteiro) é freqüentemente referida (ou
classificada) como a distribuição de Erlang de ordem k.
A distribuição de Erlang pode surgir no seguinte contexto: Considere uma série de k
estações, conforme o diagrama da Figura 2.5, onde um cliente precisa passar sem
interrupção para completar o serviço requerido. Cada estação processa uma parte do
serviço, que pode ser pensado com estágio ou fase do serviço. Um cliente adicional
(novo) não pode entrar na primeira estação (ou iniciar o seu serviço) até que o cliente
em processo (sendo servido) tenha passado por todas as fases ou estágios do serviço,
onde o tempo de serviço de cada estação (ou de cada fase ou estágio) tem uma
distribuição exponencial com parâmetro kα.

80
Esta noção de decompor a distribuição do tempo de serviço (ou do tempo entre
chegadas, ou de outro processo qualquer) numa coleção estruturada de distribuições
exponenciais, geralmente, é referida como o “método dos estágios”.
O princípio em que o método dos estágios está baseado é a propriedade da falta de
memória da distribuição exponencial. Esta falta de memória é traduzida (ou revelada)
pelo fato de que a distribuição do tempo remanescente (futuro ou vida restante) para
uma variável aleatória exponencialmente distribuída é independente do tempo já
decorrido (passado ou idade adquirida) dessa variável aleatória.
A distribuição de Erlang tem função densidade de probabilidade dada por:
( ) ( ) 0 ,! 1
)()( ,! 1
)()( 11 >
−
=−
= −−−− xexk
xfouexk
kxf xkk
kxkk
αα αα .
O parâmetro k > 0 (inteiro) é chamado parâmetro de ordem, e α > 0 é chamado
parâmetro de escala.
A esperança e a variância da distribuição de Erlang são dadas por:
2
1][ e 1][αα k
XVXE == .
Uma variável aleatória com esta densidade é com probabilidade p = 1 distribuída como
a soma de k densidades exponenciais independentes com média comum k/α, conforme
representado na Figura 2.5, a seguir.
1 1 1 1 1 2 3 k
α/k α/k α/k α/k
Fig. 2.5 – Diagrama de transição de estados da distribuição de Erlang de ordem k.

81
Pode ser notado que para um valor médio E[X], fixado, a variância de X, V[X], decresce
quando k cresce e, no limite, tende a zero. Em outras palavras, para um dado parâmetro
α, se o número de fases cresce, a variância decresce, a média permanece constante e o
tamanho médio da fase decresce. Desta forma, como a família de distribuições de
Erlang-k varia sobre uma ampla faixa, ela é extremamente útil para aproximar qualquer
variável aleatória não negativa cuja variância não exceda o quadrado de sua média.
Assim, se uma determinada variável aleatória pode ser bem aproximada por uma
variável aleatória distribuída por uma Erlang-k, então modelos matemáticos bem
conhecidos podem ser aplicados, simplificando cálculos.
Para selecionar uma variável aleatória X de Erlang-k para aproximar uma determinada
variável aleatória Y, procede-se da seguinte forma para determinar os parâmetros α e k
da variável aleatória X de Erlang-k:
Passo 1. Determine ou forneça a média E[Y].
Passo 2. Determine ][1 YE=α .
Passo 3. Determine k como o maior inteiro menor que ou igual a ][][ 2 YVYE .
2.4.4.1 – MISTURAS DE ERLANGS DE ORDEM k E k-1 (Ek-1,k)
Uma distribuição Erlang-k (Ek) pode ser representada como a soma de k variáveis
aleatórias independentes e exponencialmente distribuídas com a mesma média.
Uma distribuição Ek-1,k é definida como uma mistura de distribuições de Erlang Ek-1 e
Ek com os mesmos parâmetros de escala.
A função densidade de probabilidade de uma distribuição Ek-1,k , tem a seguinte forma:
( ) ( ) .10 e 0 ,! 1
)1(! 2
)(12
1 ≤≤≥−
−+−
= −−
−−
− ptektpe
ktptf t
kkt
kk αα αα

82
Uma variável aleatória com esta densidade é com probabilidade p (respectivamente 1-p)
distribuída como a soma de k-1 (respectivamente k) densidades exponenciais
independentes com média comum 1/α, conforme o diagrama da Figura 2.6.
Os parâmetros p e α podem ser ajustados pelos dois primeiros momentos de uma
variável aleatória positiva X, como:
( ){ }[ ]1
11 que desde ,][
e 11
1 22122222 −
≤≤−
=−+−+
=k
ckXE
pkckckkcc
p XXXXX
α .
Somente coeficientes de variação ao quadrado entre 0 e 1, 10 2 << Xc , podem ser
obtidos por misturas do tipo Ek-1,k. A distribuição Ek-1,k é sempre unimodal e para
( )21 3 2 ≤≥ Xck tem a mesma forma da distribuição gamma, ou seja, a densidade
primeiro cresce a partir de 0 (zero) até um máximo e depois decresce para 0 (zero).
Nota-se também que esta densidade tem taxa de falhas condicional crescente.
Para maiores detalhes sobre o ajuste de distribuições Ek-1,k veja (Tijms, 1986 e 1994).
2.4.5 – DISTRIBUIÇÃO HIPEREXPONENCIAL DE ORDEM k (Hk)
Para a distribuição de Erlang-k foi visto na Seção 2.4.4 que a sua média pode ser
selecionada por uma escolha apropriada de α, e que pode-se selecionar uma faixa de
coeficientes de variação simplesmente pelo ajuste de k. Contudo esta faixa de variação
está restrita a coeficientes de variação que são menores que ou iguais ao coeficiente de
variação da distribuição exponencial.
1-p
p
1 2 k-11 1
α α α
k 1
α
Fig. 2.6 – Diagrama de estados de uma mistura Ek-1, k de Erlangs de ordens k e k-1.

83
Uma combinação de estágios que resulta em coeficientes de variação maiores que a
exponencial (maiores do que 1) pode ser obtida através de uma disposição em paralelo
de estágios exponenciais, com médias diferentes. Uma distribuição com esta
combinação de estágios exponenciais, com médias diferentes em paralelo, é
denominada Hiperexponencial. O diagrama de estados para a distribuição
Hiperexponencial de ordem k (Hk) é dado na Figura 2.7.
A distribuição Hiperexponencial de ordem k tem função densidade e transformada de
Laplace da função de distribuição dadas, respectivamente, por:
( ) ( ) ∑∑==
−
+=≥=
k
i i
ii
k
i
tii s
psFteptf i
1
*
1 e ,0 ,
αα
α α , onde ∑=
=k
iip
11.
Para esta distribuição tem-se que:
[ ] [ ] [ ] [ ] [ ]( )22
12
2
1 e 2 , XEXEXV
pXE
pXE
k
i i
ik
i i
i −=== ∑∑== αα
.
α2
α1
αi
αk
i
1
k
2
p1
p2
pi
pk
Fig. 2.7 – Diagrama de estados de uma distribuição Hk.

84
Pode ser mostrado facilmente, veja Kleinrock (1975), que o coeficiente de variação,
[ ] [ ]XEXVcX = , agora é maior do que 1 e, portanto, representa uma variação maior
do que aquela da distribuição exponencial. Desta forma, como a família de distribuições
Hiperexponenciais-k variam sobre uma ampla faixa, ela é extremamente útil para
aproximar qualquer variável aleatória não negativa cuja variância exceda o quadrado de
sua média.
Pode-se ilustrar a distribuição Hk da seguinte forma. Imagine que a estrutura da Figura
2.7 seja um posto de serviço, onde um cliente entrando em serviço recebe o serviço do
estágio i (i = 1, 2, ..., k) com probabilidade pi (o somatório de todos os pi’s é igual a 1) e,
então, após receber o serviço do estágio i deixa o posto de serviço. Um novo cliente só é
admitido (entra em serviço) após a partida do cliente que se encontra em processo de
serviço, ou seja, durante a fase de serviço de um cliente outro cliente não pode entrar em
serviço.
2.4.5.1 – DISTRIBUIÇÃO HIPEREXPONENCIAL DE ORDEM 2 COM MÉDIAS
BALANCEADAS (H2b)
Uma distribuição Hiperexponencial de ordem 2 (H2) é uma mistura de duas
exponenciais com médias diferentes α1 e α2.
A função densidade de probabilidade de uma distribuição H2, tem a seguinte forma:
.1 e 1,0 , 0 ,)( 2121221121 =+≤≤≥+= −− pppptepeptf tt αα αα
Uma variável aleatória com esta densidade é com probabilidade p1 (respectivamente p2)
distribuída como uma densidade exponencial com média 1/α1 (respectivamente 1/α2),
conforme o diagrama da Figura 2.8.
Os parâmetros da distribuição Hiperexponencial de ordem 2 (H2) não são unicamente
ajustados pelos primeiros dois momentos. Entretanto H2 é unimodal com um máximo
para t = 0.

85
Diz-se que uma distribuição H2 tem médias balanceadas se a normalização 2
2
1
1
ααpp
= é
considerada.
Os parâmetros da densidade de H2 com médias balanceadas ajustados pelos dois
primeiros momentos são dados por:
][2
e ][
2 ,1 ,
11
121 2
21
1122
2
1 XEp
XEp
ppcc
pX
X ==−=
+−
+= αα
Para maiores detalhes sobre o ajuste de distribuições H2, ver Tijms (1986 e 1994) e
Allen (1990).
2.4.5.2 – DISTRIBUIÇÃO H2 COM NORMALIZAÇÃO GAMMA (H2g)
Uma variável aleatória X com média E[X] e 12 >Xc pode ser ajustada pelos dois
primeiros momentos de uma distribuição H2 com normalização gamma (H2g). Este
ajuste produz uma variável aleatória H2 com a mesma média, E[X], e o mesmo
coeficiente de variação ao quadrado, 12 >Xc , que a variável aleatória X, e além disso
tem o terceiro momento igual ao da variável aleatória gamma com estes mesmos
parâmetros E[X] e 12 >Xc .
Os parâmetros da densidade de H2 com normalização gamma ajustados pelos dois
primeiros momentos, são dadas por:
1
α1
2
α2
p2
p1
Fig. 2.8 – Diagrama de estados da distribuição H2.

86
( ) 1 ,
1][ ,
][4 ,
1)21(
1][
212
12
211122
2
1 ppXE
pXEc
cXE X
X −=−
−=−=
+−
+=αα
ααααα .
Para maiores detalhes sobre o ajuste de distribuições H2, ver Tijms (1986 e 1994) e
Allen (1990).
2.4.5.3 – DISTRIBUIÇÃO H2 AJUSTADA PELOS TRÊS PRIMEIROS
MOMENTOS
Num contexto um pouco mais geral, pode-se obter uma outra normalização que
acredita-se, seja mais natural. O ajuste em três momentos por uma densidade H2 nem
sempre é possível, mas é único se ele existir.
Uma densidade H2 somente pode ser ajustada para os três primeiros momentos m1, m2 e
m3 de uma variável aleatória positiva X com 12 >Xc quando o requerimento 222
331 mmm ≥ for satisfeito. E, então, os parâmetros do ajuste de três momentos são
dados por:
( ) ( )12
21
12112
21121 1 ,
1 ,4
21 pp
mpaaa −=
−−
=−±==αα
αααα ,
onde: ( ) ( )31221212 )23()3(6 mmmmmma −−= e ( ) ( )12211 21 mamma += .
O requerimento 222
331 mmm ≥ é sustentado para uma variável aleatória X, com 12 >Xc ,
distribuída tanto por uma densidade gamma quanto por uma densidade lognormal.
Para maiores detalhes sobre o ajuste de distribuições H2, ver Tijms (1986 e 1994) e
Allen (1990).
2.4.6 – DISTRIBUIÇÕES DO TIPO FASE (Ph)
Esta noção de decompor a distribuição do tempo de serviço (ou do tempo entre
chegadas, ou de outro processo qualquer) numa coleção estruturada de distribuições
exponenciais, geralmente, é referida como “método dos estágios ou de fases”. Em

87
outras palavras, uma distribuição que seja constituída de uma combinação de estágios
exponencialmente distribuídos, em série e (ou) em paralelo, ou seja, uma distribuição
constituída de uma soma finita ou de uma mistura finita de componentes distribuídos
exponencialmente.
Toda distribuição que seja constituída de uma combinação de estágios
exponencialmente distribuídos, em série e (ou) em paralelo, pode ser colocada na forma
do diagrama da Figura 2.9, denominada configuração (ou distribuição) de Cox
(Kleinrock, 1975) e (Allen, 1990).
Para ilustrar o diagrama da Figura 2.9, imagine um centro de serviços que seja
representado como uma rede de estágios (ou nós, ou fases). Somente um cliente é
admitido por vez no centro de serviço, só podendo admitir outro quando o cliente em
processo completar o seu serviço e deixar o centro de serviços. Neste sistema existem k
estágios de serviço e somente um destes pode ser ocupado para um determinado tempo.
Clientes entram da esquerda e partem da direita. Antes da admissão (do ingresso) no i-
ésimo estágio uma escolha deve ser feita de forma que o cliente inicia a fase de serviço
do i-ésimo estágio com probabilidade pi , ou o cliente parte imediatamente do centro de
serviços com probabilidade qi . Claramente é requerido que pi + qi = 1, para i = 1, 2, ...,
k. Após completar o k-ésimo estágio, o cliente parte do (deixa o) centro de serviços com
probabilidade 1.
A probabilidade que um cliente alcance o estágio i é dada por Ai = p0 p1 ... pi-1
),,3,2,1( ki K= e a probabilidade que um cliente visite os estágios 1, 2, ..., i e deixe o
Fig. 2.9 – Diagrama de estados de uma Ph na forma da configuração de Cox.
α1 p1
α2 α3 αk p2 p3 pk-1
q1 q2 q3q0
p0
1qk-1

88
centro de serviços é dada por Aiqi. Conseqüentemente, o tempo W que um cliente gasta
no centro de serviços é, com probabilidade Aiqi, a soma de i, independentes, variáveis
aleatórias exponencialmente distribuídas. Então, o valor esperado de W é dado por:
[ ] ∑∑∑∑====
=
=
k
j j
k
iii
k
jj
k
iii qAXEqAWE
1111
1α
(Allen, 1990).
Similarmente, tem-se que:
[ ] [ ]∑=
=k
iiii YEqAWE
1
22 ,
onde Yi = X1 + X2 + … + Xi , e:
[ ]
.22222222
2
1321312122
221
222
21
2
iiii
mlmlii XXXXXEYE
ααααααααααααα −
≠
++++++++++=
=
++++= ∑
LLL
L
Segundo Allen (1990), não é difícil mostrar que a transformada de Laplace-Stieltjes de
uma distribuição de Cox é dada por:
( ) ∏∑==
−∗
++=
i
j j
jk
iii s
qpppqsF11
1100 αα
K .
É importante notar que para a modelagem de sistemas de filas, o interesse no sistema
mostrado na Figura 2.9 é somente para os casos onde p0 = 1 e q0 = 0.
Pode-se considerar transições mais gerais entre os estágios que as mostradas na Figura
2.9. Por exemplo, ao invés de escolher somente entre imediata partida e imediata
entrada no próximo estágio, podem ser consideradas retroalimentação (“feedback”) e/ou
transição adiante (“feedforward”) para outros estágios. Entretanto, já foi mostrado que
este conceito de “feedback” e “feedforward” não introduz mais generalidade sobre o
sistema mostrado na Figura 2.9 (Kleinrock, 1975).

89
Este método de representação de estágios é a forma mais geral de construir uma variável
aleatória de estágios (ou fases) exponenciais independentes. Deste modo, uma Erlang-k,
uma Hiperexponencial, ou qualquer outra variável aleatória não negativa que possui
transformada de Laplace-Stieltjes racional é uma distribuição de Cox (Allen, 1990).
Mais geralmente pode-se considerar a então denominada distribuição do tipo fase (Ph),
que é interpretada como a distribuição do tempo até a primeira passagem numa cadeia
de Markov a tempo contínuo, ver Neuts (1981). Esta classe de distribuições do tipo fase,
apresentada em Neuts (1981), representa o tempo até a absorção numa cadeia de
Markov com n +1 estados, sendo n transitórios e um absorvente.
A combinação de estágios é representada nos modelos de Markov pela introdução de
estados fictícios, tornando possível a utilização do ferramental analítico disponível para
os processo de Markov (Carvalho, 1991). Estas distribuições de probabilidade do tipo
fase são definidas a partir das cadeias de Markov, podendo ser discretas ou contínuas,
dependendo se as cadeias de Markov são a tempo discreto ou a tempo contínuo.
As distribuições do tipo fase podem ser cíclicas ou acíclicas. Sendo que o maior
interesse tem sido nas acíclicas. E estas são uma subclasse das distribuições do tipo fase
que são geradas a partir de uma cadeia de Markov a tempo contínuo (ou a tempo
discreto) acíclica. Uma distribuição é considerada acíclica se corresponde a uma
combinação em série/paralelo de estados fictícios, onde cada estado é atingido somente
uma vez antes da absorção em uma cadeia de Markov.
As distribuições do tipo fase acíclicas fornecem representações mínimas únicas,
denominadas formas canônicas, com taxas de transição reais e não decrescentes. Uma
das formas canônicas básicas pode ser considerada como uma restrição do modelo (ou
configuração) de Cox, onde as taxas de transição são obrigatoriamente reais (Miranda,
1996).
As distribuições de Erlang-k (de ordem k), misturas de Erlangs-k (por exemplo E k-1, k )
e Hiperexponencial são casos especiais da distribuição do tipo fase. Sendo que as

90
distribuições Ek e E k-1, k se encontram na forma da configuração de Cox e a Hk pode ser
representada por uma distribuição de Cox.
2.4.6.1 – DISTRIBUIÇÃO DE COX DE ORDEM 2 COM NORMALIZAÇÃO
GAMMA (C2g)
Uma variável aleatória X é dita ser distribuída segundo uma Cox-2 (C2) se X pode ser
representada como:
−+
=, 1 adeprobabilid com
, adeprobabilid com
1
21
pXpXX
X
onde X1 e X2 são variáveis aleatórias exponencialmente distribuídas, respectivamente,
com médias 21 1 e 1 αα . Em outras palavras, imagine um posto de serviço onde só é
admitido um cliente de cada vez e um novo cliente só é admitido quando o cliente em
processo deixar o posto de serviço. Um cliente admitido no posto de serviços recebe a
primeira fase X1 de serviço e, imediatamente, após esta fase ou ele recebe uma segunda
fase X2 de serviço com probabilidade p e deixa o posto de serviço, ou ele deixa o posto
de serviço, sem receber a segunda fase X2 de serviço, com probabilidade 1-p, ver Figura
2.10.
Pode ser assumido, sem perda de generalidade, que α1 ≥ α2. Pois, uma distribuição C2
com parâmetros (p, α1, α2) e α1 < α2 tem a mesma função densidade que a distribuição
C2 com parâmetros (p*, α1*, α2
*) onde α1* = α2, α2
* = α1 e ( )21* )1(1 ααpp −−= .
A função densidade de uma variável aleatória X distribuída por uma C2 é dada por:
exp(α1) exp(α2)
p1-p
Fig. 2.10 – A distribuição de Cox com duas fases.

91
( ) ( )( )
=−+
≠−+=
−−
−−
, se 1
, se 1
21211
2121
11
21
αααα
αααααα
αα
xx
xx
xeqeq
eqeqxf
onde ( ) 2121211 se 1 e se 1 ααααααα =−=≠−−= pqpq .
Assim, pode ser verificado por simples inspeção que a classe de densidades H2 e de
densidades Ek-1, k estão contidas na classe de densidades C2.
A densidade C2 tem sempre uma forma unimodal para 212 ≥Xc . Para valores 12 ≥Xc a
densidade é da forma )exp()exp( 222111 xqxq αααα −+− , tal que q1 e q2 são não
negativos. E como a distribuição C2 tem três parâmetros (p, α1, α2), um número infinito
de densidades C2 pode, em princípio, ser usado para um ajuste de dois momentos de
uma variável aleatória Y com 212 >Yc (a única escolha possível quando 2
12 =Yc é a
densidade E2).
Uma escolha, geralmente, útil para um ajuste de dois momentos de uma variável
aleatória Y, com média E[Y] e coeficiente de variação ao quadrado 2Yc , é a densidade C2
com parâmetros dados por:
+
−+=
11
][2
2212
1Y
Y
cc
YEα , 12 ][
4 αα −=YE
, ( )1][11
2 −= YEp ααα
.
Esta densidade C2, em particular, tem a notável propriedade de que seu terceiro
momento é o mesmo que o da densidade gamma com média E[Y] e coeficiente de
variação ao quadrado 2Yc . Em outras palavras, este ajuste produz uma variável aleatória
C2 com a mesma média, E[Y], e o mesmo coeficiente de variação ao quadrado, 2Yc , que
a variável aleatória X, e com o mesmo terceiro momento que a variável aleatória gamma
com estes mesmos parâmetros E[Y] e 2Yc .
A única densidade C2 com esta propriedade, geralmente, é referida como a densidade C2
com normalização gamma.

92
Neste estudo, para a aproximação de uma fila Gm/Gm/2 por uma Ph/Ph/2, foi utilizada
a densidade C2 (com normalização gamma) para ajustar a função de densidade gamma
como uma densidade Ph.
2.4.7 - DISTRIBUIÇÃO HISTOGRAMA
Às vezes não é possível encontrar um bom modelo, expresso por uma distribuição
conhecida, para prover a entrada de dados. Pode-se, neste caso, usar os dados empíricos
agrupados numa distribuição de freqüências, na forma da Tabela 2.1.
TABELA 2.1 – DISTRIBUIÇÃO DE FREQÜÊNCIAS
Intervalos fi fri fci
L ≤ x < X1 f1 fr1 fc1
X1 ≤ x < X2 f2 fr2 fc2
X2 ≤ x < X3 f3 fr3 fc3
.... ... ... ...
Xi ≤ x < Xi+1 fi fri fci
.... ... ... ...
Xn-1 ≤ x ≤ U fn frn fcn
Totais Σfi 1 -
Onde: fi é a freqüência absoluta do intervalo i; fri é a freqüência relativa do intervalo i; e
fci é a freqüência acumulada até o intervalo i.

93
Recomenda-se que os intervalos sejam pequenos, tanto quanto possível. Na prática o
número de intervalos deve ser entre 20 e 50 intervalos.
A distribuição de probabilidades subjacente, F(x), é desconhecida. Mas pode-se utilizar
(x)F para estimar F(x), e toma-se F(x) ≅ (x)F .
Usa-se as informações da distribuição de freqüências para definir (x)F e têm-se que:
><
=Ux para 1
Lx para 0)(F x
Pela técnica da transformação inversa, temos que os valores de X são dados por:
)(RF)(RFX i1
i1 −− ≅= ,
onde: 1R0 ≤≤ i é um número aleatório gerado, ver Figura 2.11.
1
Ri
0 L Xi X Xi+1 U
X
fc
(x)F
Fig. 2.11 – Gráfico da distribuição de freqüências.

94
Para fins computacionais transforma-se a Tabela 2.1, de distribuição de freqüências,
onde:
1ii
1iii fcfc
XXa
−
−
−−
= ,
ver a Tabela 2.2. De forma que os valores de X podem ser obtidos por:
( )iii rRaxX −+= .
Desta forma o algoritmo para a geração de valores aleatórios segundo a distribuição de
freqüências (empírica) é:
Passo 1: Gerar R (número aleatório 0 ≤ R ≤ 1);
Passo 2: Encontrar o intervalo i a que R pertença (ri ≤ R ≤ ri+1);
Passo 3: Calcular ( )iii rRaxX −+= .
TABELA 2.2 – TABELA TRANSFORMADA DA DISTRIBUIÇÃO DE
FREQÜÊNCIAS
i (intervalos) ri (entrada) xi (saída) ai(inclinação)
1 0 L a1
2 fc1 X1 a2
... ... ... ...
i fci-1 Xi-1 ai
... ... ... ...
n 1 U -

95
CAPÍTULO 3
MODELO DE SIMULAÇÃO
3.1 - INTRODUÇÃO
Neste estudo um modelo é entendido como um conjunto de hipóteses sobre a estrutura
ou o comportamento de um sistema (geralmente físico) pelo qual se procuram explicar
ou prever, dentro de uma teoria científica, as propriedades do sistema. Em outras
palavras, os processos ou serviços de interesse são, geralmente, denominados sistemas
e, para estudá-los cientificamente, na maioria das vezes, é necessário fazer suposições
sobre o modo de funcionamento destes. Estas suposições, que normalmente tomam a
forma de relações lógicas ou matemáticas, constituem um modelo. Este modelo é usado
para experimentar e obter algum entendimento de como o sistema correspondente se
comporta.
Em primeiro lugar procede-se à formulação conceitual do modelo. Nesta fase deve-se
estudar o sistema, procurando entender sua estrutura, funcionamento e restrições. A
formulação conceitual do modelo é, então, transcrita ou representada por um modelo,
geralmente, denominado comunicativo. Dessa forma o modelo comunicativo é uma
abstração do sistema sob estudo expressa na forma de relações lógicas ou matemáticas.
Neste capítulo apresenta-se um modelo conceitual de simulação da fila GI/G/m na
forma de relações lógicas. Assim o modelo comunicativo é apresentado através de um
diagrama de Ciclos de Atividades (DCAs).
Também é apresentado neste capítulo o modelo programado, ou seja, a transcrição (ou
codificação) do modelo comunicativo num programa (código) escrito em linguagem de
programação de computadores para a execução do modelo de simulação em
computadores, visando a obtenção de resultados. Na codificação do modelo foi utilizado
uma linguagem de propósito específico para simulação denominada Micro Saint.

96
3.2 - MODELO COMUNICATIVO
A lógica do sistema de filas GI/G/m foi modelada através de um diagrama de ciclo de
atividades (DCAs), e pode ser vista na Figura 3.1.
No DCAs, apresentado na Figura 3.1, as atividades são representadas por retângulos e
identificadas pelos verbos inscritos dentro destes. As filas são representadas por círculos
e as entidades que compõem as filas são identificadas pelas letras inscritas dentro destes
(C = Cliente e S = Servidor). As duas elipses sobrepostas e com a inscrição “Mundo
Exterior” representam a população de clientes (o mundo exterior ao Posto de Serviço),
de onde chegam os clientes e para onde eles retornam após terem sido atendidos.
Para uma descrição mais detalhada dos DCAs pode-se recorrer a Poole e
Szymankiewicz (1977).
3.3 - MODELO PROGRAMADO
Na programação do modelo comunicativo apresentado na seção anterior foi utilizado o
pacote de software Micro Saint 1.2-k para Windows com visualizador do processo,
versão estudantil, que é um pacote comercial de software de simulação em rede, que
permite a construção de modelos para simular processos da vida real. A Figura 3.2
mostra o diagrama de rede do modelo programado no Micro Saint.
CHEGAR
SAIR
SERVIR
C C
C
S
Mundo Exterior
Mundo Exterior
Fig. 3.1 - DCAs (C = Cliente e S = Servidor).

97
No diagrama da Figura 3.2, podem ser vistos 4 tipos de figuras geométricas e linhas
unindo-as. As figuras maiores em forma de elipse representam atividades, o triângulo
acima da atividade 1 indica o ponto de início (partida) das atividades ou trabalho, os
trapézios são nós de decisão de roteamento de entidades (clientes, servidores, etc.) e as
linhas são as rotas (caminhos) entre as atividades.
Fig. 3.2 – Diagrama de rede do modelo programado.
Neste modelo a atividade 1, denominada “Gerador”, é o ponto de partida da simulação e
simplesmente gera uma entidade que é roteada para as atividades 2 e 3,
simultaneamente, provocando a primeira execução destas atividades. A atividade 1 é
executada somente uma vez em cada execução da simulação.
A atividade 2, denominada “Chegar”, é responsável por gerar as chegadas de clientes,
com tempo entre chegadas determinísticos ou distribuídos por uma distribuição de
probabilidades especificada.
A atividade 3, denominada Gerar-Servidor, simplesmente gera o número de servidores
especificado pelo simulador. Foi considerado a geração de no máximo 100 servidores,
ou seja, foi considerado sistemas com no máximo 100 servidores.
A atividade 4, denominada Posto-Serviço, é uma atividade inserida no modelo para
possibilitar o controle da fila de clientes esperando por um servidor livre. Por exemplo,
a liberação de um cliente da fila está vinculada à existência de servidores livres.

98
A atividade 5, denominada Serv. ociosos, é uma atividade artificial no modelo para
possibilitar um melhor controle do estado dos servidores. Por exemplo, a mudança de
estado de um servidor está vinculada à existência de clientes para serem atendidos.
A atividade 6, denominada Servir, gera os tempos de serviço para cada servidor, que
podem ser determinísticos ou distribuídos por uma distribuição de probabilidades
especificada.
A atividade 7, denominada Sair, é utilizada para calcular o tempo entre a saída de dois
clientes consecutivos.
Para uma compreensão mais detalhada do modelo programado vide o anexo 1.
3.4 - VERIFICAÇÃO E VALIDAÇÃO DO MODELO DE SIMULAÇÃO
Verificação consiste em determinar se um programa de simulação em computadores
funciona como o pretendido (Law e Kelton, 1982). A verificação é um processo de
depuração da implementação computacional do modelo conceitual (código). O
propósito da verificação do modelo programado é determinar a precisão e a exatidão da
implementação computacional (código) do modelo conceitual (Banks e Carson II, 1984)
e (Carson II, 1989). Em outras palavras, pretende-se com a verificação implementar um
código que não tenha erros de programação e que seja mais eficiente.
Através da validação pretende-se determinar o quanto o modelo conceitual de simulação
(como oposto ao programa de computador) é uma representação precisa do sistema em
estudo. O objetivo da validação é determinar o quanto o modelo conceitual é uma
representação razoável do sistema real que está sendo modelado (Law e Kelton, 1982).
Devem ser respondidas as seguintes questões: Quão precisamente o modelo simulado
representa o sistema real? O modelo simulado pode ser utilizado no lugar do sistema
real para tomada de decisões? (Banks e Carson II, 1984) e (Carson II, 1989).
Infelizmente não existem soluções perfeitas para o problema de verificação e validação
em simulação. A totalidade do processo tem elementos de arte tão bem como de ciência
(Kleijnen, 1995).

99
Na prática, verificação e validação são questões importantes. Um programa de
computador com “bugs” pode gerar saídas que são completamente sem sentido, ou pior,
pode gerar saídas ligeiramente sem sentido que passam despercebidas. Um modelo não
validado pode levar (conduzir) a decisões erradas ou viciadas. Na prática, verificação e
validação são freqüentemente misturadas ou confundidas, pois muitas das técnicas
utilizadas para o processo de verificação são também utilizadas no processo de
validação (Kleijnen, 1995).
Existem muitas técnicas disponíveis, que podem ser classificadas como subjetivas ou
como estatísticas. As técnicas subjetivas freqüentemente recorrem à autoridade de
especialistas da área de estudo ou de técnicos e dirigentes envolvidos com o sistema real
para julgamento da validade do modelo conceitual. Este estudo recorrerá sempre que
possível, principalmente, à técnicas estatísticas para a avaliação do modelo no processo
de verificação e validação. Pois estas técnicas produzem dados sobre a qualidade do
modelo de simulação que são objetivos, quantitativos e reprodutíveis (Kleijnen, 1995).
A precisão e exatidão do modelo programado necessárias à verificação foi feita através
da comparação entre as estimativas das medidas de performance oriundas do modelo
simulado e os valores destas medidas obtidas por modelos analíticos correspondentes,
para umas poucas configurações de filas dentre as que possuem soluções analíticas
exatas. Segundo Kleijnen (1995) pode-se recorrer a livros texto em teoria de fila para
encontrar fórmulas para medidas de performance de interesse, em equilíbrio (regime),
entretanto estas fórmulas, geralmente, assumem tempos de serviço e intervalos entre
chegadas Markovianas, com m servidores: modelos M/M/m. Também pode-se incluir
configurações de filas com soluções analíticas exatas, nem sempre simples, disponíveis
tais como: D/D/m, M/Ph/m, Ph/M/m, Er/Ek/m e Ph/Ph/m. Deve-se lembrar que quando
o modelo tem somente entradas determinísticas (D/D/m) o uso de matemática
estatística não é necessária para verificar a correção do modelo de simulação. E em
última hipótese sempre é possível recorrer à verificação da taxa de utilização efetiva do
sistema ou à verificação do número de servidores efetivamente ocupados, estimados dos
dados de saída da simulação, para verificar a precisão e exatidão do modelo
programado.

100
Quanto à validação do modelo, deve-se ressaltar que o sistema em foco neste estudo é
um sistema idealizado, e não um sistema real. E por este motivo, foi usada a
terminologia sistema idealizado no lugar de sistema real, obtendo a seguinte definição:
o objetivo da validação é determinar o quanto o modelo conceitual é uma representação
razoável do sistema idealizado que está sendo modelado. Deve-se responder as
seguintes questões: Quão precisamente o modelo simulado representa o sistema
idealizado? O modelo simulado pode ser utilizado no lugar do sistema idealizado para
tomada de decisões?
Um modelo de simulação deveria ser, sempre, desenvolvido para um propósito
(objetivo) específico. Na verdade, um modelo validado para um propósito específico
poderia não ser válido para outro propósito.
Um modelo de simulação deveria ser validado com relação a um conjunto específico de
critérios, a saber, os critérios que serão realmente usados para a tomada de decisões.
Law e Kelton (1982), Banks e Carson II (1984), Carson II (1989) e Kleijnen (1995)
recomendam uma abordagem de três passos para a validação de um modelo de
simulação, a saber:
a) Desenvolver um modelo com alta aparência de validade (“face validity”);
b) Validar empiricamente as suposições do modelo de simulação;
c) Validar os resultados do modelo.
O objetivo no primeiro passo de validação é desenvolver um modelo com alta aparência
de validade (“face validity”), ou seja, um modelo que, na superfície, pareça razoável às
pessoas que possuem conhecimento do sistema em estudo e/ou dos usuários finais do
modelo. Neste primeiro passo de validação o desenvolvedor (ou a equipe de
desenvolvedores) precisa fazer uso da informação existente sobre o sistema (teoria
existente, conhecimento geral, observações do sistema, etc.).

101
O objetivo do segundo passo de validação é testar quantitativamente as suposições
(hipóteses) feitas durante os estágios iniciais de desenvolvimento do modelo de
simulação.
O objetivo do terceiro passo da validação é determinar a representatividade dos
resultados da simulação. Talvez o mais definitivo teste de validade de um modelo de
simulação seja estabelecer que os dados resultantes do modelo de simulação
assemelham-se estritamente aos dados que seriam esperados do sistema real (ou
idealizado). E embora não se possa estar seguros que o modelo do sistema proposto seja
“válido”, pode se ter mais confiança do que se a comparação não tivesse sido feita.
No presente estudo as suposições referem-se aos dados de entrada e de saída do modelo
de simulação de filas GI/G/m, ou seja, as suposições referem-se ao gerador de números
aleatórios, às estimativas das medidas de performance e às relações estabelecidas pelas
fórmulas de Little.
Pode-se avaliar o gerador de números aleatórios através de um teste de aderência, pode-
se averiguar se as estimativas das medidas de performance, em equilíbrio, oriundas do
modelo simulado estão de acordo com as relações estabelecidas pelas fórmulas de
Little, averiguar se a exatidão e a precisão destas estão de acordo com o especificado,
através de verificação do vício, da construção de intervalos de confiança, da aplicação
de testes estatísticos padrões.
Números aleatórios, por definição, são variáveis estatísticas contínuas, uniformemente
distribuídas entre zero e um, e estatisticamente independentes. Entretanto, na prática, os
geradores de números aleatórios são determinísticos e produzem números que são
pseudo-aleatórios, no sentido de serem prognosticáveis, ou seja, quando se especifica
uma semente, que gera o primeiro número, toda a seqüência de números está
determinada, podendo ser obtida novamente pelo simples fornecimento da mesma
semente. Entretanto estes números parecem ser tirados de uma distribuição uniforme, no
intervalo [0, 1], no sentido em que eles passam numa série de testes estatísticos para a
uniformidade e independência. Neste sentido o gerador de números aleatórios precisa
ser submetido a testes para a avaliação da uniformidade e da independência dos

102
números gerados. O gerador de números aleatórios pode ser validado quanto à
uniformidade por um teste de aderência, tal como o teste do Qui-quadrado, o de
Kolmogorov-Smirnov e o de Anderson-Darling, e quanto a independência por um teste
de corridas ou execuções (runs tests).
Neste estudo as estimativas das medidas de performance oriundas do modelo simulado
foram comparadas com aquelas provenientes de modelos analíticos correspondentes,
para alguns modelos de filas dentre aqueles que possuem soluções analíticas já
estabelecidas. Aqui pode se recorrer a testes estatísticos padrões como teste t de
Student, a estimação de intervalos de confiança, e a comparações entre o nível de
confiança especificado de 100(1-β) e a probabilidade de cobertura observada nos dados
de saída da simulação.
A metodologia para a estimação dos intervalos de confiança, para a aplicação do teste t
de Student e para a estimação da probabilidade de cobertura observada estão detalhadas
nas seções 4.3.1, 4.3.3 e 4.3.5, respectivamente. E as metodologias para a aplicação dos
testes para a uniformidade e para a independência foram detalhadas, em tópico
específico, nesta seção.
Neste estudo o sistema, que está sendo modelado, é idealizado e, por este motivo,
somente é possível obter dados bastante limitados a respeito do sistema, a saber: os
parâmetros das distribuições de entrada, que são fornecidos; os valores esperados das
medidas de performance de pouquíssimas configurações das filas GI/G/m (M/M/m,
D/D/m, ...) e Ph/Ph/m, obtidos através de modelos analíticos correspondentes. Neste
sentido foram utilizadas as seguintes configurações para proceder ao processo de
verificação e validação do modelo de simulação:
Configuração 1 - a fila D/D/1 com ρ = 0,8 (E(T) = 1,25; E(S) = 1);
Configuração 2 - a fila D/D/2 com ρ = 0,8 (E(T) = 0,625; E(S) = 1);
Configuração 3 - a fila M/M/1 com ρ = 0,2 (E(T) = 5; E(S) = 1);
Configuração 4 - a fila M/M/1 com ρ = 0,8 (E(T) = 1,25; E(S) = 1);

103
Configuração 5 - a fila M/M/2 com ρ = 0,2 (E(T) = 2,5; E(S) = 1).
Configuração 6 - a fila M/M/2 com ρ = 0,8 (E(T) = 0,625; E(S) = 1).
Configuração 7 - a fila H2b/ E2 /5 com ρ = 0,8; (E(T) = 0,25; 22 =Tc ; E(S) = 1;
5,02 =Sc ).
Configuração 8 - a fila E2 /H2b/5 com ρ = 0,8; (E(T) = 0,25; 5,02 =Tc ; E(S) = 1;
22 =Sc ).
O período de inicialização T0 e o tempo de execução TE foram determinados conforme
metodologia descrita no Capítulo 5 (período de inicialização e tempo de execução).
Os valores exatos das características das configurações das filas M/M/m e D/D/m foram
determinados pelas fórmulas apresentadas nas seções 2.3.1.1 e 2.3.1.2.
Na verificação da relações entre as medidas de performance foram utilizadas as
fórmulas de Little, apresentadas na Seção 2.3.2.
3.4.1 - METODOLOGIA PARA APLICAÇÃO DOS TESTES PARA A
UNIFORMIDADE E PARA A INDEPENDÊNCIA
Segundo Law e Kelton (1982) todos os métodos de geração de números aleatórios da
distribuição uniforme no intervalo [0, 1] – esta distribuição é denotada por U (0, 1)-
usados em simulação através de computadores são na realidade completamente
determinísticos. Deste modo, pode ser pensado somente que os números aleatórios
gerados pareçam como se eles fossem variáveis aleatórias U (0, 1) iid.
As linguagens de simulação, de propósito específico, têm um gerador de números
aleatórios embutido e, geralmente, as linguagens de propósito geral também
disponibilizam procedimentos para gerar números aleatórios na sua biblioteca de
funções, de exemplos ou de classes. A menos que um determinado gerador seja um dos
“bons” já identificados e testados em alguma lugar na literatura, ele deve ser submetido
a testes empíricos. Portanto, se uma das bem conhecidas linguagens de simulação ou um

104
dos “bons” geradores de números aleatórios foram utilizados, provavelmente seja
desnecessário a submissão a tais testes.
Para determinar se um gerador de números aleatórios fornece números que possuem as
propriedades desejadas, certos testes devem ser realizados. Estes testes, empíricos,
podem ser divididos em duas categorias, de acordo com as propriedades de interesse,
testes para a uniformidade e testes para a independência. Na primeira categoria se
encontram os testes de freqüência, que usam o teste do Qui-quadrado ou o teste de
Kolmogorov-Smirnov para comparar a distribuição do conjunto de números gerados a
uma distribuição uniforme (Banks e Carson II, 1984). A segunda categoria usa um dos
quatro testes seguintes, para testar a independência dos números gerados:
• Teste de corridas ou execuções (runs test), que testa as corridas ascendentes e
descendentes ou as execuções acima e abaixo da média, comparando os valores
correntes (atuais, efetivos) aos valores esperados;
• Teste de auto-correlação (autocorrelation test), que testa a correlação entre
números e compara a correlação da amostra à correlação esperada, que é igual a
zero;
• Teste de abertura (gap test), que conta o número de dígitos que aparecem entre as
repetições de um determinado dígito e, então usa o teste de Kolmogorov-Smirnov
para comparar com o número esperado de aberturas (gaps);
• Tteste de pôquer (poker test), que lida com números agrupados juntamente com
uma mão de pôquer e, então as mãos obtidas são comparadas à que é esperada
usando o teste do Qui-quadrado.
Tanto o teste de Kolmogorov-Smirnov quanto o teste do Qui-quadrado são aceitáveis
para testar a uniformidade de uma amostra de dados, desde que o tamanho da amostra
seja grande. Entretanto, o teste de Kolmogorov-Smirnov é o mais potente dos dois e é
recomendado. Além disso, o teste de Kolmogorov-Smirnov pode ser aplicado para
tamanhos pequenos de amostras, enquanto o teste do Qui-quadrado é válido somente

105
para grandes amostras, diga-se N ≥ 50 (Banks e Carson II, 1984). Neste sentido, foi
adotado neste trabalho o teste Kolmogorov-Smirnov para testar a uniformidade do
gerador de números aleatórios do pacote de software de simulação Micro Saint. Neste
sentido usa-se o gerador para gerar alguns números aleatórios, U (0, 1), que, então,
serão examinados estatisticamente, através do teste Kolmogorov-Smirnov, para se
determinar quão próximos eles se assemelham a variáveis aleatórias U (0, 1) iid. O teste
de Kolmogorov-Smirnov foi especificado na Seção 3.4.11.
Law e Kelton (1982) sugerem a aplicação dos testes de rodadas ou execuções (runs test)
como uma mais direta averiguação da suposição de independência. E como estes
examinam unicamente a independência, provavelmente seria uma boa idéia aplicá-los
antes de se realizar o teste de uniformidade, no caso o teste de Kolmogorov-Smirnov.
Eles afirmam, também, que os testes de execuções ou rodadas são potentes, no sentido
em que muitos geradores têm passado em testes de uniformidade (Qui-quadrado, Serial,
etc.) e falhados em testes de execuções ou rodadas (runs test).
Existem vários tipos de testes de execuções (runs test), tais como contando execuções
ascendentes ou descendentes na mesma seqüência, ou simplesmente contando o número
de execuções sem considerar o seu tamanho. Entretanto neste estudo foi considerado
somente o teste de execuções acima e abaixo da média conforme definição apresentada
em Banks e Carson II (1984). O teste de execuções acima e abaixo da média foi
especificado na Seção 3.4.1.2.
Segundo Law e Kelton (1982) uma desvantagem potencial dos testes empíricos é que
eles são somente locais; somente aquele segmento do ciclo que foi de fato utilizado para
gerar números aleatórios U (0, 1) para o teste é examinado, por isso não se pode dizer
qualquer coisa sobre como o gerador pode funcionar em outros segmentos do ciclo. Por
outro lado, esta natureza local dos testes empíricos pode ser vantajosa, desde que ela
possa permitir a análise dos números aleatórios correntes, que serão usados, logo mais,
na simulação. Desta forma, pelo menos em tese, a totalidade do fluxo de números
aleatórios pode ser testado empiricamente, espera-se, sem custo excessivo. E um teste
empírico mais global poderia ser realizado, replicando um teste, na sua totalidade,

106
varias vezes e comparando estatisticamente o teste estatístico contra a distribuição sob
(sob o domínio de) a hipótese nula.
Na execução de um teste para a uniformidade as hipóteses são como as que seguem:
( )( )1 ,0~:
1 ,0~:
1
0
URHURH
i
i
/
Para este teste a hipótese nula, H0, indica que os números são distribuídos
uniformemente no intervalo [0, 1].
Na execução de um teste para a independência as hipóteses são como as que seguem:
sdependente são s' os :tesindependen são s' os :
1
0
i
i
RHRH
Para este teste a hipótese nula, H0, indica que os números são independentes.
Segundo Meyer (1978) fundamentalmente um teste estatístico põe a prova duas
hipóteses: a hipótese da nulidade ou hipótese básica (H0) contra a hipótese alternativa
(H1). Se a hipótese H0 não é rejeitada então não há razão para se rejeitar o valor
estimado. E se a hipótese H0 é rejeitada então o valor estimado é rejeitado.
Entretanto deve ser lembrado que, um teste estatístico não conduzirá sempre à decisão
correta. Existem, fundamentalmente, dois tipos de erros que podem ser cometidos:
• Erro Tipo 1: Rejeitar H0 quando H0 for verdadeira.
• Erro Tipo 2: Aceitar H0 quando H0 for falsa.
O erro do tipo 1 à vezes é referido como o risco de construção do modelo, e o erro do
tipo 2 como o risco de uso do modelo. Na prática tenta-se manter pequena a
probabilidade de cometer esses erros, pois eles não podem ser completamente evitados.
É necessário estabelecer um nível de significância β para cada teste. Valores usuais para
β são 0,01 e 0,05, onde β é a probabilidade de se rejeitar a hipótese nula dado que esta é

107
verdadeira, ou ( )o verdadeir|rejeitar β 00 HHP= . Desta forma, a rejeição da hipótese
nula, H0, é uma conclusão forte, dado que o risco de rejeitar H0 dado que H0 seja
verdadeiro é pequeno.
Desta forma se 100 conjuntos de números forem submetidos a teste, com β = 0,05,
pode-se esperar que 5 destes testes possam ser rejeitados exclusivamente por
probabilidade (risco). Ou seja, se o número de rejeições em 100 testes é próximo a
100β, então não há razão obrigando (impelindo, forçando) a descartar o gerador.
3.4.1.1 - TESTE DE KOLMOGOROV-SMIRNOV
O teste de uniformidade é um teste básico que sempre deveria ser realizado para validar
um novo gerador. Estes testes medem o grau de concordância entre a distribuição de
uma amostra de números aleatórios gerados e a distribuição uniforme, teórica, U (0, 1),
ou seja, de que não existe diferenças significantes entre a distribuição da amostra e a
distribuição teórica.
Dentre os testes disponíveis, neste trabalho foi adotado o teste de Kolmogorov-Smirnov
para testar a uniformidade do gerador de números aleatórios do pacote de software de
simulação Micro Saint. A definição dada a seguir para o teste de Kolmogorov-Smirnov
foi retirada de (Banks e Carson II, 1984).
O teste de Kolmogorov-Smirnov compara a função de distribuição contínua, ( )xF , da
distribuição uniforme com a função de distribuição empírica, ( )xS N , da amostra de N
observações. Por definição ( ) 1x0 ≤≤= xxF .
Seja a amostra do gerador de números aleatórios denotada por NRRR ,,, 21 K . Então a
função de distribuição empírica, ( )xS N , é definida por:
( )N
xRRRxS N
N≤
= são que ,...,, de número 21 .

108
À medida que N aumenta, ( )xS N deveria tornar-se uma melhor aproximação para ( )xF ,
considerando que a hipótese nula seja verdadeira. A função de distribuição de uma
distribuição empírica, no caso a função de distribuição ( )xS N , é uma função escada
(degrau) com saltos para cada valor observado.
O teste de Kolmogorov-Smirnov é baseado no maior desvio absoluto entre ( )xF e
( )xS N sobre a faixa de variação da variável aleatória. Ou seja, ele é baseado na
estatística ( ) ( )xSxF N−= maxD .
A distribuição de amostragem de D é conhecida e é tabulada como uma função de N. E
para este estudo foi utilizada a Tabela A.7 dada em Banks e Carson II, (1984).
Para submeter a estatística D a um teste contra a função de distribuição uniforme, o
procedimento de teste segue os seguintes passos:
Passo1. Ordene os dados em ordem crescente. Seja ( )iR a i-ésima (menor)
observação, tal que ( ) ( ) ( )NRRR ≤≤≤ L21 .
Passo2. Compute ( )
−=
≤≤
+iNi
RNi
1maxD e ( )
−
−=≤≤
−
NiR iNi
1maxD1
.
Passo3. Compute ( )−+= D,DmaxD .
Passo4. Determine o valor crítico, βD , da Tabela A.7 dada em Banks e Carson II
(1984) para o nível de significância β especificado e o tamanho N da
amostra dado.
Passo5. Se βDD > , então rejeite a hipótese nula de que os dados são uma amostra da
distribuição uniforme U (0, 1). Se βDD ≤ , conclui-se que não tem sido
detectada diferença entre a verdadeira distribuição de { }NRRR ,,, 21 K e a
distribuição uniforme U (0, 1).

109
3.4.1.2 - TESTE DE EXECUÇÕES ACIMA E ABAIXO DA MÉDIA
Os testes de execuções (runs) examinam a disposição (arranjo, combinação) de números
numa seqüência para testar a hipótese de independência. Uma execução (run) é definida
como uma sucessão de eventos similares precedidos e seguidos por um evento diferente.
O tamanho de uma execução (run) é o número de eventos que ocorrem na execução.
Existem duas possíveis preocupações (ou interesse) num teste de execução para uma
seqüência de números. O número de execuções é a primeira preocupação e o tamanho
das execuções é uma segunda preocupação. Os tipos de execuções contadas no primeiro
caso podem ser execuções acima e abaixo da média. Uma execução acima da média é
uma seqüência de números em que cada um destes é seguido por número acima de um
valor médio, determinado para a seqüência de números em análise. Uma execução
abaixo da média é uma seqüência de números em que cada um destes é seguido por
número abaixo do valor médio. Este valor médio, no caso de números, com seis dígitos
decimais após a vírgula, gerados de uma distribuição uniforme no intervalo [0, 1], é
determinado da seguinte forma: ( ) 4999995,02999999,0000000,0 =+=m . Para um
procedimento feita à mão, pode se usar um sinal “+” para denotar uma observação
acima da média, e um sinal “-“ para denotar uma observação abaixo da média. Desta
forma pode se determinar as seqüências existentes acima e abaixo da média, o tamanho
e o número destas seqüências.
Sejam 1n e 2n o número de observações individuais acima e abaixo da média,
respectivamente, e seja b o número total de execuções. Note que o número máximo de
execuções é 21 nnN += , e o número mínimo de execuções é um (1).
Dados 1n e 2n , a média e a variância de b são determinadas por:
( )( )122
212
221212
21
−−
=
+=
NNNnnnn
Nnn
b
b
σ
µ .

110
Para 1n ou 2n maior que 20, b é aproximadamente normalmente distribuído. E o teste
estatístico pode ser formulado como segue:
( )( )
21
22121
21
0
122
212
Z
−
−
+−=
NNNnnnn
Nnn
b .
Rejeita-se a hipótese de independência quando | Z0 | > Zβ/2. Consequentemente a
hipótese de independência não é rejeitada quando 2β02β ZZZ ≤≤− , onde β é o nível
de significância e 2βZ é o valor crítico de uma distribuição normal padrão, que pode ser
obtido de uma tabela normal padrão.

111
CAPÍTULO 4
MODELO EXPERIMENTAL
4.1 - INTRODUÇÃO
A estratégia proposta para o modelo experimental tem como objetivo possibilitar a
coleta das informações desejadas sobre o modelo, em regime, para que se possa fazer
inferências sobre o nível de confiança destes resultados.
Neste ponto deve se abordar duas questões consideradas como cruciais na simulação a
eventos discretos de um sistema em regime, a saber: vício devido a inicialização e
autocorrelações.
O vício devido a inicialização é a diferença entre o valor esperado de uma determinada
característica e o valor de sua estimativa, aqui entendido ser a média amostral dos dados
de saída da simulação. Esta diferença ocorre porque não se pode iniciar o processo em
regime, existindo, portanto, um período transiente, com estados transitórios, a ser
considerado, até que o sistema entre em regime, com estados recorrentes.
O vício devido a inicialização pode ser reduzido descartando uma porção inicial da
execução, ou configurando o estado inicial do sistema para que ele seja representativo
do sistema em regime, ou fazendo com que o tamanho da execução seja suficientemente
grande para que o processo simulado seja independente dos estados iniciais, transitórios.
Autocorrelações são correlações entre sucessivos valores do processo. Autocorrelações
ocorrem porque os novos estados do processo tipicamente dependem dos anteriores. A
função de autocorrelação, com relação a sistemas de filas GI/G/m, é tipicamente
positiva e decrescente (ou pelo menos aproximadamente), refletindo o fato de que novos
estados do processo são similares aos estados anteriores, com a similaridade
decrescendo (numa via aleatória) com a evolução do processo (Whitt, 1991).
Os efeitos de autocorrelações podem ser reduzidos usando replicações independentes,
mas ao custo de ter que descartar uma porção inicial de cada replicação. Desta forma

112
surge a seguinte questão: é melhor fazer uma execução longa ou muitas replicações
independentes com descarte?
Segundo Whitt (1991) esta questão tem sido estudada por vários pesquisadores, mas,
evidentemente, não existe consenso sobre qual é a estratégia de simulação apropriada.
Isto é inevitável pois não existe uma resposta simples.
Outra questão importante e delicada na simulação a eventos discretos de um sistema em
regime é a quantidade de observações requeridas para que se possa obter uma boa
estimativa; uma estimativa que seja menos viciada e menos variável, que satisfaça a
padrões de exatidão e precisão pré-determinados.
É muito vantajoso ter com antecedência pelo menos uma previsão, ainda que grosseira,
do tamanho requerido da execução, em cada caso, para se obter as desejadas exatidão
(menos biased) e precisão (menos variável) estatística. Esta previsão do tamanho da
execução para cada experimento é desejável e vantajosa, pois eliminaria a necessidade
de execuções preliminares para estimar grosseiramente este tamanho, e reduziria a
utilização de procedimentos estatísticos padrões durante a execução do experimento.
Isto reduziria custos, tempo e recursos.
Neste sentido, ainda nos estágios iniciais de planejamento, antes que qualquer dado
tenha sido coletado, pode-se lançar mão de fórmulas simples, ver Seção 5.3, já
existentes na literatura, para estimar o tamanho requerido da execução da simulação
(Whitt, 1991). Estes tamanhos das execuções da simulação estimados podem então
serem usados para projetar o experimento; para determinar que casos considerar, que
exatidão e precisão estatística almejar, que recursos experimentais são necessários, e
para que casos o experimento deve ser conduzido (Whitt, 1991).
4.2 - PROJETO DE EXPERIMENTO
Whitt (1991) compara as estratégias de se fazer uma execução longa ou muitas
replicações independentes com descarte. Este estudo não tem o objetivo de identificar a
melhor estratégia de simulação, considerando o balanço de todos os critérios relevantes,

113
mas o de fornecer percepção adicional no trade-off entre o vício devido a inicialização e
autocorrelações entre valores sucessivos.
Usando o critério de estimação da eficiência, que é definido como sendo o inverso do
produto do erro quadrado médio pelo tamanho (tempo ou número de clientes) total da
execução da simulação, Whitt (1991) fornece suporte para a conclusão que usualmente
é mais eficiente fazer uma longa execução do que fazer independentes replicações, mas
conclui que isto normalmente não tem importância preponderante. Pois se o tamanho
total da execução da simulação é longo o suficiente para se obter aproximações
razoavelmente boas, então várias replicações são geralmente tão eficientes quanto uma
execução mais longa. Ele exclui da análise somente um número muito grande de
replicações independentes de execuções muito pequenas.
A análise feita por Whitt (1991) indica que fazer poucas replicações independentes é
mais eficiente quando as autocorrelações decrescem rapidamente em relação à taxa que
o processo caminha para entrar em regime. Mas, geralmente, não é possível determinar
precisamente como as autocorrelações decrescem ou como o processo caminha para
entrar em regime. Ainda assim esta conclusão parece fornecer diretrizes práticas para
escolher estratégias de simulação, pois muitas vezes se tem alguma idéia sobre o que
deveria acontecer com estas taxas.
Desta forma conclui-se que a chave para responder a questão da replicação versus uma
longa execução é o comportamento transiente do processo estocástico em estudo. A
questão é se o estimador com sua condição inicial especificada, através do descarte de
uma porção inicial da execução ou da configuração do estado inicial do processo por
estados representativos deste em regime - de forma que o processo seja
aproximadamente estacionário -, caminha ou não para entrar em regime mais rápido do
que a função de covariância decai.
A análise de Whitt (1991) parece justificar a prática comum, para simulações de
sistemas de filas em regime, de se fazer uma longa execução, descartando uma porção
inicial dos dados de saída da simulação.

114
Mas as execuções de simulações de sistemas de filas em regime muitas vezes
necessitam ser surpreendentemente longas, porque estas de fato necessitam serem
longas, ou porque não se tem suficiente informação sobre o processo. E neste caso,
segundo Whitt (1991) a eficiência tende a ser praticamente a mesma tanto para uma
longa execução quanto para um pequeno número de replicações (aproximadamente 10)
ligeiramente menores.
O maior problema relativo ao truncamento da saída de dados, descarte de uma porção
inicial dos dados de saída, é a determinação do ponto de truncamento. Se a saída de
dados é truncada muito cedo, então os dados remanescentes ainda podem conter vícios
significantes devido a inicialização. Se a saída é truncada muito tarde então observações
(dados) “boas” são perdidas (Banks, Carson II e Goldsman; 1990). Contudo é preferível
perder “bons" dados e permanecer do lado seguro.
O descarte de uma porção inicial dos dados de saída deve ser maior do que o necessário
para se estar do lado seguro, mas o resto da execução deve ser longo o suficiente tal que
a porção descartada seja praticamente desprezível, certamente menor que 5% (Whitt,
1991). Assume-se que o tamanho da porção inicial a ser descartada de cada execução
seja suficientemente grande, tal que o processo estocástico em questão possa ser
considerado estritamente estacionário ou pelo menos aproximadamente.
Uma vez que seja adotada a estratégia de se fazer uma única execução longa da
simulação usa-se, tipicamente, para estimar intervalos de confiança, médias sobre
grupos não sobrepostos, dividindo-se os dados de saída da simulação em
aproximadamente 20 grupos não sobrepostos, agindo como se eles fossem
independentes e normalmente distribuídos. Contudo, quando se deseja ter intervalos de
confiança mais precisos Whitt (1991) recomenda fazer cerca de 10 replicações
independentes com execuções de tamanho ligeiramente menores, que os de uma longa
execução, fazendo com que estas execuções ligeiramente menores sejam
suficientemente longas tal que a eficiência seja quase a mesma de uma longa execução.
Isto assegura independência mas não a distribuição normal, podendo ainda existir
problemas de cobertura, ou seja, a probabilidade de cobertura observada dos dados de

115
saída da simulação é significativamente diferente daquela especificada em projeto, que
na maioria das vezes é de 95%. A probabilidade de cobertura é a probabilidade de que
um intervalo de confiança de 100(1-β )% contenha o valor verdadeiro da característica
do sistema que está sendo estimada.
Segundo Banks e Carson II (1984) se o vício da estimativa foi reduzido a um nível
desprezível, o método de replicações independentes pode ser usado para estimar a
variabilidade da estimativa e construir intervalos de confiança. Mas se o vício da
estimativa ainda permanece significativa e um grande número de replicações são
utilizadas para reduzir a variabilidade da estimativa, o intervalo de confiança resultante
pode ser viciado. Isto acontece porque o vício não é afetado pelo número de replicações,
mas somente pelo descarte de mais dados ou pelo aumento do tamanho da execução de
cada replicação. Assim, se o vício ainda é significativo, incrementar o número de
replicações pode produzir menores intervalos de confiança em torno de uma estimativa
viciada, e não em torno do valor real da variável sob estimação.
Este trabalho objetiva a obtenção de estimativas confiáveis para as medidas de
desempenho de filas GI/G/m. Neste sentido será adotado neste experimento de
simulação a estratégia de replicações independentes com descarte de uma porção inicial
de cada replicação, e com tamanhos de execuções das replicações suficientemente
longos para atenuar o vício.
A metodologia para a determinação do tamanho da porção inicial a ser descartada, bem
como do tamanho de cada execução para se obter a exatidão e a precisão estatística
desejada, serão tratadas em tópicos específicos.
4.2.1 - ESPECIFICAÇÃO
Este trabalho objetiva a obtenção de estimativas confiáveis para as medidas de
desempenho de filas GI/G/m, ou seja, a obtenção de estimativas com uma precisão
relativa de pelo menos 2% (ε = 0,02) para um nível de confiança de 95%. Também,
deseja-se verificar a exatidão (vício) e a precisão (variabilidade) da aproximação de filas
Gm/Gm/2 por filas C2g/C2
g/2,em outras palavras, verificar a exatidão e a precisão de

116
medidas de avaliação de desempenho de algumas configurações de filas GI/G/m com as
respectivas medidas obtidas pela aproximação das filas Gm/Gm/2 por filas C2g/C2
g/2.
Estas medidas de desempenho serão estimadas através de simulação.
Deseja-se verificar o nível de confiança das medidas de avaliação de desempenho,
obtidas através da simulação dos sistemas de filas previstos, em regime. E para esta
finalidade será considerado um nível de confiança de 95%, com uma precisão
especificada de pelo menos 2% da medida de desempenho sob análise.
O experimento de simulação para cada configuração dos sistemas de filas previstos
consistirá de 10 replicações com fluxos de números aleatórios (sementes) diferentes
para cada replicação.
Nos experimentos onde se conhece os valores verdadeiros das medidas de performance
que estão sendo estimadas, pode ser utilizado um segundo critério de verificação da
exatidão da estimativa (remoção do vício) como em Roth (1994), através da avaliação
da probabilidade de cobertura observada, ou seja, a probabilidade de que a média
verdadeira esteja contida no intervalo de confiança de 95% sobre a media observada. E
neste caso cada replicação será dividida em 10 micro-replicações.
Dado a natureza finita dos experimentos, a probabilidade de cobertura observada, com
uma adequada remoção do vício, não seria necessariamente igual ao valor de projeto, de
95%. Mas espera-se que ela não difira muito deste valor de projeto (Roth, 1994).
4.2.2 – CONFIGURAÇÕES - CENÁRIOS
Serão consideradas 8 configurações - cenários de filas Gm/Gm/2, através da
especificação de ρ = 0,75 e cx2 ∈0,5; 1; 2, onde, mSE )(λρ = é a taxa de utilização
do servidor, e cx2 é o coeficiente de variação ao quadrado dos processo de chegada ou
de serviço.
O tempo médio de serviço será considerado sempre igual a 1, ou seja, E(S) = 1, o que
implica em mλρ = .

117
A unidade de medida do tempo de simulação será o minuto, a menos que seja
explicitada outra unidade.
4.2.3 - REPLICAÇÕES
Para cada configuração-cenário serão considerados 10 replicações, descritas pelos
parâmetros seguintes:
a) TI = período de inicialização (1ª fase);
b) TE = período de execução para a coleta de dados (2ª fase);
c) Seqüências de números aleatórios gerados por sementes geradoras diferentes.
4.2.4 - EXPERIMENTAÇÃO
A experimentação consistirá da execução do modelo programado para cada replicação,
de cada cenário, de cada configuração, levando-se em consideração o período de
inicialização e o tamanho de cada execução para se obter as medidas de desempenho
para o sistema em regime com uma precisão especificada.
Devido ao fato de que o sistema proposto neste estudo é executado para a obtenção de
medidas para o sistema em regime, assume-se que os efeitos de inicialização sejam
removidos através do truncamento de dados.
O processo de experimentação produz os resultados para satisfazer cada um dos
cenários de teste, através da execução de 10 replicações para cada configuração-cenário.
4.3 - ANÁLISE DOS RESULTADOS DO EXPERIMENTO
A análise dos resultados do experimento consiste da análise dos dados gerados na
experimentação. Seu propósito é predizer (prognosticar) a performance de um sistema,
ou comparar a performance de dois ou mais projetos alternativos de um sistema (Banks
e Carson II, 1984).

118
Os resultados referentes à performance de um sistema em estudo obtidos de uma
execução da simulação são estimativas das medidas de performance deste sistema. Estas
estimativas não podem ser tomadas, simplesmente, como respostas “verdadeiras” para o
sistema, pois elas são variáveis aleatórias e podem apresentar grande variância; numa
execução da simulação, em particular, elas podem diferir muito das respostas
verdadeiras (Law e Kelton, 1982).
A necessidade de análise estatística dos resultados está assentada na observação de que
os dados resultantes de uma execução da simulação exibem variabilidade aleatória
quando geradores de números aleatórios são usados para produzirem os valores das
variáveis de entrada; dois diferentes fluxos de números aleatórios produzirão dois
conjuntos de resultados que (provavelmente) diferirão (Banks e Carson II, 1984).
A análise dos resultados da experimentação consistirá da:
1. Verificação da precisão relativa especificada de 2% (∈ ≤ 0,02) para um nível de
confiança, com grau de confiança da ordem de 95% ou superior, das medidas de
desempenho, em equilíbrio, das diferentes configurações – cenários - replicações
do sistema de filas GI/G/m previstos no projeto de experimento.
2. Análise dos resultados da aplicação de testes estatísticos padrões, como o teste t
de Student, quando os valores verdadeiros das medidas em observação são
conhecidos.
3. Averiguação da probabilidade de cobertura verificada nos dados de saída da
simulação, quando os valores verdadeiros das medidas em observação são
conhecidos.
A análise dos resultados da experimentação consistirá, também, da comparação das
estimativas oriundas das observações provenientes da execução de R replicações da
simulação de uma dada configuração de uma determinada fila GI/G/m contra a
correspondente configuração da fila Ph/Ph/m. Esta comparação pode ser efetivada
através da aplicação de testes estatísticos padrões, como o teste t de Student. Como o

119
interesse está na verificação da exatidão e precisão da aproximação de uma determinada
fila GI/G/m por uma fila Ph/Ph/m correspondente, assume-se que as estimativas obtidas
através da simulação da fila GI/G/m sirvam de base para a comparação, levando-se em
conta, é claro, o nível de confiança e o resultado do teste de hipóteses verificado para
estas estimativas, tanto quanto para aquelas obtidas através da simulação da fila
Ph/Ph/m.
A metodologia para a estimação dos intervalos de confiança, do teste t de Student e da
probabilidade de cobertura observada será detalhada a seguir.
4.3.1 - MÉTODO DAS REPLICAÇÕES INDEPENDENTES PARA A
ESTIMAÇÃO DOS INTERVALOS DE CONFIANÇA
Sejam os processos estocásticos subjacentes em observação, que podem ser discretos ou
contínuos no tempo, denotados, respectivamente, por { }nnX n K,3,2,1; = e
( ){ }TttZ ≤≤0; . E sejam considerados para estes processos os seguintes parâmetros,
dados, respectivamente, por:
)(1lim)( e 1lim)(
0 1
∫∑ ∞→=
∞→====
T
T
N
nnN
dttZT
ZEXN
XE φθ .
Suponha que R replicações independentes sejam feitas, cada uma com um fluxo de
números aleatórios diferente (determinado por uma semente de números aleatórios
diferente). Suponha que já se tenha descartado uma porção inicial suficientemente longa
de cada replicação, de forma que a média da amostra de cada processo subjacente, em
observação, não sejam viciadas. As observações resultantes em cada replicação são
estimativas de θ = E(X) ou de φ = E(Z) que são colhidas no final da execução de cada
replicação, após um período de inicialização (truncamento da amostra) e de execução
suficientemente longos, determinados conforme metodologia descrita anteriormente.
Desta forma estas estimativas, para uma determinada replicação, podem ser obtidas
pelos seguintes estimadores não viciados:

120
)(1)(ˆ e 1)(ˆ
0 1
∫∑ =====
TN
nn dttZ
TZEX
NXE φθ .
Estas estimativas podem ser referenciadas, sem perda de generalidade, como sendo a
variável aleatória rY , r = 1, ..., R, denotando a r-ésima estimativa da média (média
amostral) de um determinado processo estocástico subjacente, de interesse, referente a
r-ésima replicação.
Define-se .Y e S2 como estimadores para a média µ e a variância σ2 do processo
subjacente, onde ( )rrYrV
∞→≡ lim2σ , da seguinte forma:
( ) ( )
−
−=−
−== ∑∑∑
===
2.
1
2
1
2
.2
1.
ˆˆ 1
1ˆˆ 1
1 e ˆ 1ˆ YRYR
YYR
SYR
YR
rr
R
rr
R
rr .
Desde que a variância de .Y é dada por ( )R
Y2
.2 ˆ σσ = , um estimador não viciado de
( ).2 Yσ com R-1 graus de liberdade é dado por ( )
RSY
2
.2 ˆˆ =σ , e o erro padrão de .Y é
denotado por ( ) ( )R
SYYes == ..ˆˆˆ.. σ .
Portanto, manipulações estatísticas padrões produzem, para R grande, o seguinte
estimador aproximado para o intervalo de confiança, com grau de confiança dado por
100(1 - β)%, de µ , é: R
SY β/2. Zˆ ± ,
onde Zβ/2 é o valor crítico da correspondente distribuição normal e é obtido das tábuas
normais padrões.
Para R pequeno é preciso substituir Zβ/2 por tR-1,β/2, o correspondente valor crítico da
distribuição de Student. Neste caso o estimador para o intervalo de confiança será dado
por, R
StY R 2β,1. −± . Para fazer esta substituição é requerida a suposição de que a

121
distribuição subjacente de Yr seja normal. Entretanto esta substituição também é valida
para os casos em que os efeitos de inicialização (vício) podem ser praticamente
removidos (o vício tende a zero).
Note que as médias replicadas .Y são independentes por construção, e que os Yr são
independentes entre replicações mas não necessariamente dentro das replicações. Além
do que a normalidade de médias replicadas independentes não é garantida, e
consequentemente o intervalo de confiança é valido se e somente se os efeitos de
inicialização sejam praticamente reduzidos a zero.
Segundo Law e Kelton (1982) o procedimento apresentado acima é válido para a
construção de intervalos de confiança para uma única medida de performance,
entretanto para a maioria das simulações várias medidas de performance são de
interesse. E este é o caso com o presente estudo, onde 5 medidas de avaliação de
desempenho foram consideradas.
Seja Ij um intervalo de confiança de ( )%β1100 j− para a medida de performance
( )kjj ,,2,1 K=µ . Então a probabilidade de que todos k intervalos de confiança
simultaneamente contenham suas, respectivas, medidas verdadeiras satisfaz
{ } ∑=
−≥=∈k
jjj kjIP
1jβ1,...,2,1 todopara µ
se os Ij’s são ou não independentes.
Este resultado é conhecido como desigualdade de Bonferroni e tem sérias implicações
para um estudo de simulação. Por exemplo, suponha que se deseje construir intervalos
de confiança de 90% para 10 medidas de performance diferentes, com 1,0β j = para
cada j. Então a probabilidade de que cada um dos 10 intervalos de confiança contenha
sua verdadeira medida somente pode ser reivindicada que seja maior ou igual a zero.
Este problema é conhecido na literatura estatística como o problema das múltiplas
comparações.

122
Entretanto se a quantidade k de medidas de performance é pequena, e se deseje um nível
de confiança total associado com k intervalos de pelo menos ( )%β1100 − , pode-se
escolher os βj’s de forma que ββ1
j =∑=
k
j (os βj’s não precisam ser iguais). Law e Kelton
(1982) recomendam que k não seja maior do que 10.
Como a quantidade k de medidas de performance sob avaliação neste estudo é igual a 5,
este procedimento pode ser empregado. Desta forma os βj’s neste estudo serão iguais a
0,01, com β = 0,05.
Para mais detalhes ver Gross e Harris (1974), Law e Kelton (1982), Banks e Carson II
(1984) e Banks, Carson II e Goldsman (1990).
4.3.2 - INTERVALOS DE CONFIANÇA COM UMA PRECISÃO
ESPECIFICADA
Em uma simulação de longa duração ou não terminante, que visa a obtenção de medidas
de desempenho para um sistema em regime, a determinação de intervalos de confiança
com uma precisão especificada pode ser obtida através do incremento do número de
replicações ( R ) ou do incremento do tamanho da execução (TE).
A média µ de um processo subjacente em observação pode ser estimado por .Y com
uma precisão ε > 0, com probabilidade 1 - β. Assim pode-se tomar R ou TE
suficientemente grande, ou uma combinação de ambos, tal que P(| .Y - µ| < ε) ≥ 1 - β.
Considerando que o tamanho da execução (TE) e o período de inicialização (TI) sejam
suficientes para atenuar o vício devido a inicialização e obter dados representativos do
sistema em regime, a precisão especificada poderá ser, portanto, tratada através do
incremento do número R de replicações.
A metodologia consiste de:
• Faz-se inicialmente R0 replicações, recomenda-se pelo menos 4 ou 5.

123
• Obtém-se uma estimativa inicial, S02 , da variância σ2.
• Determina-se R ≥ R0 , tal que εR
Sthl R ≤= −
01,2β , onde hl é a metade do intervalo
de confiança.
• Isola-se R na inequação anterior, visto que R é o menor inteiro que satisfaz R ≥
R0, obtendo-se: 2
01,2β
≥ −
εSt
R R .
• Desde que tβ/2,R-1 ≥ Zβ/2, uma estimativa inicial para R pode ser dada por: 2
02β
≥
εSZ
Rinicial .
• Executa-se as R - R0 replicações adicionais e determina-se o intervalo de
confiança com base nas R replicações.
• Verifica se hl ≤ ε. Se afirmativo encerra-se o procedimento, caso contrário o
procedimento pode ser repetido.
Para mais detalhes sobre a garantia da precisão especificada para as medidas de
desempenho vide Gross e Harris (1974), Banks e Carson II (1984) e Banks, Carson II e
Goldsman (1990).
4.3.3 - PROCEDIMENTO DE APLICAÇÃO DO TESTE-T DE STUDENT
Neste trabalho será empregado o teste t de Student para confirmar ou rejeitar o valor
estimado através dos dados amostrais provenientes da simulação, de uma determinada
medida de interesse. Para tanto admite-se, neste estudo, que o valor de um parâmetro de
interesse seja a estimativa .Y obtida dos dados amostrais da simulação e utiliza-se a
informação da amostra para confirmar ou rejeitar essa estimativa.

124
Nesta parte do estudo as hipótese serão especificadas da seguinte forma, H0 : µ 0 = .Y
contra H1: µ 0 ≠ .Y , o que caracteriza um teste de duas caudas, ou bicaudal, ou de dois
lados.
Segundo Banks e Carson II (1984) o teste t estatístico é conduzido através dos passos
estabelecidos a seguir. Estes passos já se encontram adaptados para o procedimento
adotado neste estudo e são:
Passo 1. Escolhe-se o nível de significância β e o tamanho da amostra R. Neste
estudo 05,0β e 10 ==R , onde R é o número de replicações.
Passo 2. Compute a média .Y e o desvio padrão S sobre as R replicações, conforme
o definido acima.
Passo 3. Tome os valores críticos de 1,2β −Rt de uma tábua padrão de percentis da
distribuição de Student.
Passo 4. Compute a estatística RS
Yt 0.
0
ˆ µ−= , onde µ 0 é o valor especificado na
hipótese nula.
Passo 5. Compare os valores críticos de 1,2β −Rt com as estatísticas t0. Para o teste
de duas caudas rejeite H0 se 1,2β0 −> Rtt , caso contrário H0 não será
rejeitado.
É importante notar que, quando se está testando hipóteses, a rejeição da hipótese nula
H0 é uma grande conclusão, porque ( ) βa verdadeiré |rejeitar 00 =HHP e o nível de
significância é escolhido pequeno, como o especificado acima, β = 0,05 .
Segundo Kleijnen (1995) quando se está procedendo à interpretação dos resultados do
teste t estatístico devem ser levados em consideração três pontos, a saber:

125
1. Quanto maior é o tamanho da amostra, menor é o valor crítico 1,2β −Rt . Por isso,
todas outras coisas sendo iguais, um modelo de simulação tem alta chance de ser
rejeitado quando o tamanho da amostra é muito grande.
2. Um número R muito grande de replicações da simulação dá estimativas .Y
precisas e conseqüentemente valores significantes para a estatística t0. Isto
acontece porque o denominador de t0, RS , tende a zero por causa de R, e no
numerador de t0, .Y tem valor esperado diferente de µ 0, de maneira que a
estatística t0 tende para o infinito. Portanto um modelo incorretamente
especificado sempre levaria a rejeição se o tamanho da amostra R fosse infinito.
3. A estatística t0 pode ser significante e todavia sem importância. Se a amostra é
muito grande, então a estatística t0 é quase sempre significante para 0. µ≠Y ,
entretanto as médias real e estimada (simulada) podem ser praticamente a mesma,
de forma que a simulação seja suficientemente válida, para propósitos práticos.
As suposições justificando um teste t de hipóteses, em particular o teste t de Student, é
que as observações sejam normalmente e independentemente distribuídas. Neste estudo
é razoável assumir que as observações rY sejam aproximadamente normalmente
distribuída, pois os efeitos de inicialização (vício) são praticamente removidos (o vício
tende a zero). As observações rY são por projeto estatisticamente independentes, isto é,
pela escolha de sementes de números aleatórios diferentes para cada replicação de um
experimento (Banks e Carson II, 1984). Mas se as observações colhidas da simulação
não são aproximadamente normalmente distribuídas, então o teste t de Student ainda
pode ser aplicado porque este teste não é muito sensível à normalidade, especialmente
se o tamanho da execução é grande (Kleijnen, 1995).
O procedimento apresentado acima para aplicação do teste t de Student é apropriado
para uma única medida de performance, contudo, para a maioria das simulações, várias

126
medidas de performance são de interesse. E este é o caso com o presente estudo, onde 5
medidas são de interesse.
Considere que o programa de computador transforme I entradas em J saídas, com
0 e 0 ≥≥ JI . Essa transformação precisa ser correta para todas os tipos de respostas.
Conseqüentemente, a probabilidade de se rejeitar a hipótese nula provavelmente cresce
quando J cresce, mesmo se o programa for correto. Esta propriedade segue da definição
de erro to tipo 1 (ou β erro) de um teste estatístico. Felizmente existe uma solução
simples, baseada na desigualdade de Bonferroni (Kleijnen, 1995).
Tradicionalmente o valor 1−mt é comparado num teste de duas caudas com o valor
crítico 2β;1−mt . Mas com base na desigualdade de Bonferroni, substitui-se β por J/β .
Isto implica que maiores discrepâncias entre as verdadeiras medidas e as estimativas
oriundas da simulação são aceitáveis. Este procedimento baseado na desigualdade de
Bonferroni mantém a probabilidade total de erro do tipo 1 no experimento abaixo do
valor β (Kleijnen, 1995).
Law e Kelton (1982) recomendam que este procedimento seja aplicado somente para
um número de medidas de interesse menores ou iguais a 10. Como a quantidade de
medidas de performance sob avaliação neste estudo é igual a 5, então este procedimento
pode ser empregado. Desta forma os βj’s neste estudo serão iguais a 0,01, com α = 0,05.
4.3.4 - APLICAÇÃO DO TESTE-T DE STUDENT NA COMPARAÇÃO DA
FILA GI/G/m COM A FILA Ph/Ph/m
Seja a variável aleatória rY , r = 1, ..., R, denotando a r-ésima estimativa da média
(média amostral) de um determinado processo estocástico subjacente, de interesse,
referente a r-ésima replicação de uma determinada fila GI/G/m.
Seja a variável aleatória rZ , r = 1, ..., R, denotando a r-ésima estimativa da média
(média amostral) de um determinado processo estocástico subjacente, de interesse,
referente a r-ésima replicação de uma determinada fila Ph/Ph/m.

127
Define-se a variável aleatória rrr ZYd ˆˆˆ −= , r = 1, ..., R, denotando a r-ésima diferença
entre as estimativas rY e rZ .
As observações ^
rd são por projeto estatisticamente independentes, isto é, pela escolha
de sementes de números aleatórios diferentes para cada replicação de um experimento
(Banks e Carson II, 1984). Portanto, é razoável assumir que as observações ^
rd sejam
aproximadamente normalmente distribuídas, pois o vício devido a inicialização foi
praticamente removido.
Define-se .d e S2 como estimadores para a média µ e a variância σ2 do processo
subjacente da seguinte forma:
( )
−
−=
−
−== ∑∑∑
===.
1
2
1
2
.2
1.
ˆˆ 1
1ˆˆ 1
1 e ˆ 1ˆ dRdR
ddR
SdR
dR
rr
R
rr
R
rr .
Desde que a variância de .d é dada por R
d2
.2 ˆ σσ =
, uma estimador não viciado de
.2 dσ com R-1 graus de liberdade é dado por
RSd
2
.2 ˆˆ =
σ . E o erro padrão de .Y é
denotado por R
Sddes =
=
..ˆˆˆ.. σ .
Nesta parte do estudo as hipótese serão especificadas da seguinte forma, 0.0ˆ: µ=dH
contra 0.0ˆ: µ≠dH , onde 00 =µ , o que caracteriza um teste de duas caudas, ou
bicaudal, ou de dois lados.
O teste t estatístico será conduzido através dos passos estabelecidos a seguir:
Passo 1. Escolhe-se o nível de significância β e o tamanho da amostra R. Sendo que
neste estudo R = 10 e β = 0,05, onde R é o número de replicações.

128
Passo 2. Compute a média .d e o desvio padrão S sobre as R replicações, conforme
o definido acima.
Passo 3. Tome os valores críticos de 1,2β −Rt de uma tábua padrão de percentis da
distribuição de Student.
Passo 4. Compute a estatística Rs
dt 0.
0
ˆ µ−= , onde µ 0 é o valor especificado na
hipótese nula.
Passo 5. Compare os valores críticos de 1,2β −Rt com os da estatística t0. Para o teste
de duas caudas rejeite H0 se 1,2β0 −> Rtt , caso contrário não rejeite H0.
4.3.5 - METODOLOGIA PARA O CÁLCULO DA PROBABILIDADE DE
COBERTURA OBSERVADA
Esta metodologia exige o conhecimento do valor verdadeiro da medida que está sendo
estimada. E ela é apropriada num contexto de macro e micro-replicações ou de
replicações divididas em grupos não sobrepostos, onde cada grupo pode ser encarado
como uma microreplicação.
Seja a variável aleatória krY ,ˆ , r = 1, ..., R, k = 1,..., K, denotando a k-ésima estimativa
da média (média amostral) de um determinado processo estocástico subjacente, de
interesse, referente a k-ésima micro-replicação da r-ésima macro-replicação.
Define-se ,.rY e 2rS , r = 1, ..., R, como a r-ésima estimativa da média (média amostral)
e da variância de um determinado processo estocástico subjacente, de interesse,
referente a r-ésima macro-replicação:
( ) ( )
−
−=−
−== ∑∑∑
===
K
krkr
K
krkrr
K
kkrr YRY
RYY
RSY
RY
1
2,.
2
,1
2
,.,2
1,,.
ˆˆ1
1ˆˆ1
1 e ˆ1ˆ

129
Desde que a variância de ,.rY é dada por ( )R
Yr
2
,.2 ˆ σσ = , uma estimador não viciado de
( ),.2
rYσ com R-1 graus de liberdade é dado por ( )R
SY r
r
2
,.2 ˆˆ =σ . E o erro padrão de ,.rY é
denotado por ( ) ( )R
SYYes r
rr == ,.,.ˆˆˆ.. σ .
A probabilidade de cobertura observada, Pco, é a probabilidade que a média verdadeira
esteja contida no intervalo de confiança de 95% sobre a média observada (estimada). E
desde que os experimentos são projetados para fornecer 95% de cobertura, então se os
intervalos de confiança para a probabilidade de cobertura raramente contém 0,95, então,
uma hipótese de adequada remoção do vício é suspeita (Roth, 1994).
Para estimar a probabilidade de cobertura observada, Pco, será examinado a cobertura,
do intervalo de confiança em cada um dos R conjuntos de replicações de um
experimento. A probabilidade de cobertura é igual a fração de conjuntos de replicações
para os quais o intervalo de confiança de 95% sobre a média observada para o conjunto,
rY , contenha a média verdadeira Y (Roth, 1994).
Para avaliar isto define-se uma variável indicadora Ir, para identificar se a média
verdadeira está coberta, com sucesso, no conjunto r. Especificamente, tem-se que:
( )
≤−
=contrário caso 0
ˆ se 1 ,. rrr
hlYYI .
A meia largura do intervalo de confiança, hlr , é estimada por: R
Sthl r
Rr 2β,1−= , onde
2β,1−Rt é o valor crítico do teste estatístico t de Student de duas caudas com 95% de
confiança e K-1 graus de liberdade num conjunto de K micro-replicações.
Desta maneira a probabilidade de cobertura, Pco, pode ser expressa como:

130
∑=
=R
rrco RIP
1 .
Dada a natureza finita dos experimentos, mesmo com adequada remoção do vício, a Pco
não será necessariamente igual ao valor de projeto de 0,95. Apesar disso espera-se que
os intervalos de confiança para Pco consistentemente cobrirão uma grande quantidade da
região na vizinhança de 0,95.

131
CAPÍTULO 5
PERÍODO DE INICIALIZAÇÃO E TEMPO DE EXECUÇÃO
5.1 - INTRODUÇÃO
Um sistema de simulação é considerado estar em regime se seu comportamento corrente
é independente das condições iniciais, de inicialização ou partida, e se a probabilidade
de estar em um destes estados é determinada por uma função de probabilidade fixada.
Estas condições iniciais do modelo de simulação são caracterizadas pelos valores
iniciais de todas as variáveis de estado do sistema.
A escolha dos estados iniciais ou de partida de um modelo de simulação não-terminante,
em equilíbrio (ou regime), pode ter efeitos bastante nocivos na tentativa de estimação da
performance deste modelo. Este problema é conhecido como vício de inicialização e
pode levar a erros ou tendenciosidade (Banks e Carson II, 1984).
O efeito das condições iniciais, para propósito de análise estatística, é que os dados de
saída, observados, de um modelo de simulação podem não ser identicamente
distribuídos e as observações iniciais podem não ser representativas do comportamento
do sistema em regime.
A detecção de vícios provocados pelas condições de inicialização do sistema e da
propagação destes vícios à medida que uma execução da simulação está em curso, bem
como o tratamento destes efeitos de inicialização são problemas não totalmente
resolvidos em simulação de sistemas. Entretanto, existem diversos métodos para a
redução dos efeitos de inicialização, causados pelo uso de condições iniciais artificiais e
irreais numa simulação em regime.
O vício devido à inicialização pode ser reduzido descartando uma porção inicial da
execução, ou configurando o estado inicial do sistema para que ele seja representativo
do sistema em regime, ou fazendo com que o tamanho da execução seja suficientemente
grande para que o processo simulado seja independente dos estados iniciais, transitórios.

132
Neste estudo será implementado um procedimento, para reduzir os vícios devido à
inicialização, que conjuga o descarte de uma porção inicial de cada execução e a
realização de execuções longas.
Cada execução da simulação será dividida em duas fases, a fase de inicialização e a fase
da coleta de dados, veja Figura 5.1 a seguir . A fase de inicialização vai do tempo 0,
com o espaço de estados E0 caracterizado pelo sistema vazio e os servidores ociosos, até
o tempo TI. E a fase de coleta de dados vai do tempo TI , com o espaço de estados EI do
sistema em TI , ao tempo de parada TI + TE . Note que o espaço de estados EI é uma
variável aleatória e é o espaço de estados das condições iniciais do “sistema em
regime”.
5.2 - PERÍODO DE INICIALIZAÇÃO
Como se deseja fazer R replicações independentes de tamanho TE e descartar um
intervalo de tamanho TI de cada replicação para reduzir o vício devido à inicialização,
o tamanho total da execução da simulação é R(TI + TE).
Considerando ( ){ } RittYi ≤≤≥ 1 ,0: , R cópias independentes de um processo
estocástico ( ){ }0: ≥ttY , que se deseje simular, então a média mr, em regime, pode ser
estimada pela média de grandes amostras:
( ) ( )∑=
−=≡n
iEiE TYRTRrmrm
1
1,ˆˆ ,
E0
0 TI
EI
TI + TE
Fase de inicialização de tamanho TI .
Fase de coleta de dados de tamanho TE .
Fig. 5.1 – Fases da execução da simulação.

133
onde ( )Ei TY é a média da amostra do processo i no intervalo [TI , TI + TE], dada por:
( ) ( )∫+−= EI
I
TT
T iEEi duuYTTY 1 . (5.1)
Segundo Whitt (1991) a quantidade TI a ser descartada de cada replicação é
determinada, tipicamente, pelas considerações de vício. E considerando que foi
descartada uma porção inicial de tamanho TI e que foi feita uma simulação de tamanho
TE para cada processo ( ){ }0: ≥ttYi , 1 ≤ i ≤ R, então o vício é dado por:
( ) ( )[ ]∫+− −= EI
I
TT
TEEI dumruYETTT
1 ,β , (5.2)
onde ( )[ ] ( )∑=
=n
ii uYuYE
1 para todo u ∈ [TI , TI + TE].
Se TE é muito grande, então o vício tende a ser desprezível, sendo dominado por 01β−
ET ,
onde:
( )EIETT TTTE
I,lim ββ
∞→= , (5.3)
é geralmente finito. Contudo para TE muito pequeno, o vício é aproximadamente
( )[ ] mrTYE I − . Assim, para TE pequeno espera-se que o vício relativo
( ) ( )[ ] mrmrTYEmrTT IEI −≈,β seja convenientemente pequena. Logo, o vício como
definido acima é decrescente tanto em TI quanto em TE .
Dado que ( )[ ] mrTYE E − normalmente decresce primeiro rapidamente e depois mais
lentamente quando TE cresce, então, considerável redução do vício é obtido fazendo TI
positivo. Mas deve ser considerado que a redução do vício decresce quando TI cresce, i.
é, o vício decresce primeiro rapidamente e depois mais lentamente quando TI cresce.
A porção inicial a ser descartada TI pode ser escolhida de maneira que
( )[ ] mrmrTYE E − seja convenientemente pequeno, para todo IE TT ≥ . Desta forma

134
pode-se supor que processo ( ){ }tY seja aproximadamente estacionário para IE TT ≥ ,
onde TI é escolhido segundo o critério:
( )[ ]
≤−≥=
≥εmrmruYEtT
tuI sup:0inf , (5.4)
e ε seja um pequeno número, por exemplo 0,01 (Whitt,1991).
Embora este critério de escolha para TI seja razoável para a redução do vício, ele é
questionável como um critério para que o processo ( ){ }tY verdadeiramente alcance o
equilíbrio (regime).
Contudo procedimentos para implementar o critério em (5.4) envolveriam execuções
preliminares da simulação, e deveria sofrer um processo de investigação ou
experimentação, o que está fora do escopo deste trabalho. E como o interesse aqui está
em soluções mais simples e menos dispendiosas em termos de tempo e recursos, esta
solução, portanto, não parece razoável.
Outra via para implementar o critério em (5.4) seria recorrer a aproximações
exponenciais para modelar o decrescimento de ( )[ ] mrmruYE − . Whitt (1991) propõe
a seguinte aproximação:
( )[ ]0u , ≥=
− − temr
mruYE αγ , (5.5)
com parâmetros dados por: 1=γ e:
βα mr≈ , (5.6)
onde 0ββ ≈ .
De (5.2), (5.5) e (5.6) tem-se que o vício aproximado resultante é dado por:

135
( )( )( ) ( )( )
E
TTT
E
TTT
EI Tee
TeemrTT
EIIEII +−−+−− −≈
−=
βα
β , .
Whitt (1991), então, sugere que γ e α em (5.5) ou mr e β em (5.6) podem ser
determinados por procedimentos estatísticos de estimação. E, portanto, assumindo (5.5)
e possivelmente (5.6), recorre-se ao critério em (5.4) para determinar um valor
apropriado para TI . Mas Whitt (1991) lança esta idéia para ser explorada em futuras
investigações. A experimentação com esta idéia foge do escopo deste trabalho.
Segundo Banks e Carson II (1984) as metodologias para se determinar o período de
inicialização não são eficientes e precisas e a mais largamente usada é uma baseada na
visualização gráfica dos vícios provocados pelas condições de inicialização do sistema e
da propagação destes vícios à medida que uma execução da simulação está em curso. E
na maioria das vezes o que se consegue é reduzir estes vícios para um nível aceitável,
quer dizer, fazer com que estes vícios tendam a zero.
Neste procedimento o tamanho do período de inicialização, TI, será, portanto,
determinado através da detecção visual dos efeitos de inicialização, levando-se em
consideração dados preliminares colhidos em R replicações; recomenda-se pelo menos 5
replicações, com sementes geradoras diferentes. Os dados de saída de cada replicação
são divididos em grupos de dados; recomenda-se pelo menos 10 grupos, com o mesmo
intervalo de tempo para cada agrupamento. Organizam-se gráficos com as médias
acumuladas destes dados sem o descarte de nenhum grupo e considerando o descarte de
1, 2, 3, ..., d grupos e observa-se o comportamento dos dados visualizando estes
gráficos. Escolhe-se, então, aquele gráfico que apresente um padrão de comportamento
mais “suave”. Para maiores detalhes sobre a metodologia de aplicação deste
procedimento ver Banks e Carson II (1984).
Odoni e Roth (1983) examinam o comportamento transiente de sistemas de filas
M/M/1. Eles examinam sistemas de filas que são markovianos, ou seja, sistemas que
para todos os tempos têm uma descrição discreta do espaço de estados, como um
processo de Markov de primeira ordem; sistemas em que os tempos de serviço e os

136
tempos entre chegadas podem ser representados por distribuições exponenciais, de
Erlang, Hiperexponenciais e do tipo fase. Esta definição exclui muitos sistemas em que
somente a cadeia embutida no processo é de primeira ordem, por exemplo, muitos
sistemas de filas M/G/1. Neste estudo eles se concentram no número esperado de
clientes na fila em função do tempo t, denotado por Q(t).
Odoni e Roth (1983) afirmam que talvez a mais importante observação sobre o
comportamento transiente de filas seja: “para muitos sistemas de filas, a taxa com que
uma fila converge para o equilíbrio (regime), independentemente dos estados iniciais do
sistema, eventualmente torna-se (para valores grandes de tempo t) dominada por um
termo exponencial da forma exp(-t/τ), onde τ é uma característica do sistema de filas”.
Esta característica do sistema de filas, τ, é denominada tempo constante ou “tempo de
relaxação”.
Odoni e Roth (1983) testam várias expressões fechadas para a determinação do tempo
constante (tempo de relaxação) τ, com base nas seguintes observações intuitivas:
i. “...como o coeficiente de variação é uma medida da variabilidade relativa de uma
variável aleatória, espera-se que τ varie diretamente com potências de CA e CS, os
coeficientes de variação para os tempos entre chegadas e de serviço,
respectivamente....”
ii. “...quando o sistema aproxima-se da saturação (ρ →1), espera-se que o sistema
requeira uma grande quantidade de tempo para alcançar o equilíbrio e assim
espera-se que τ varie diretamente com alguma potência de 1/(1-ρ).
Usando resultados numéricos e uma abordagem de ensaio-e-erro, [Odoni e Roth, 1983]
encontram uma expressão para τ, nomeada τR, que se ajusta bem com seus resultados
numéricos:
( ) ( ) ( )( ) ( ) ( )
−+=−
++=
222222218,218,21 ρµρµρτ SASAR CCCC . (5.7)

137
Segundo Odoni e Roth (1983), suas experiências com muitas soluções numéricas para
sistemas de filas M/M/1 indicam que:
a) Para pequenos valores de t, o comportamento de Q(t) é fortemente influenciado
pelo estado inicial do sistema de fila. Para sistemas com condições iniciais
determinísticas, pode ser, em geral, prognosticado que seu comportamento segue
um pequeno número de padrões.
b) Após um período inicial de tempo e independente das condições iniciais, a forma
com que Q(t) aproxima-se de Q(∞) pode ser bem aproximada por uma
exponencial negativa. O tempo de relaxação constante τ associado com esta
função exponencial é uma característica de cada sistema de fila e é independente
das condições iniciais. A equação para τR definida em (5.7) parece fornecer uma
boa aproximação para os valores observados de τ.
c) Assim, sobre a suposição de que o sistema está efetivamente em equilíbrio quando
a variável sob observação está a 1% de seu valor de equilíbrio, o número esperado
de “clientes” na fila no tempo t pode ser limitado abaixo por
( )[ ] 0 t,exp1)()( >−−∞=∗ τtQtQ . E define-se o ponto t*, de 99% de
decaimento, satisfazendo a )(01,0)()( ∗∗ =−∞ tQtQQ .
Uma vez que )()( tQtQ <∗ para todo ∗< tt , uma conseqüência bastante útil do
resultado acima é que )(tQ∗ pode ser usado para limitar, acima, a quantidade de tempo
para que )(tQ esteja com uma distância especificada de )(∞Q .
Desta forma a equação (5.7) pode ser usada para determinar um limite superior para a
quantidade de tempo requerida para que Q(t) esteja, para a maior parte dos propósitos
práticos, muito próximo de Q(∞). Por exemplo, para um sistema com condições iniciais
configuradas deterministicamente como parado e vazio, o tempo requerido para que
Q(t) seja cerca de 2% próximo de Q(∞) pode ser limitado acima por t= 4τR .

138
Roth (1994) desenvolve uma heurística de relaxação do tempo para reduzir o vício
devido a inicialização em simulações de Monte Carlo de sistemas de filas markovianas
estacionárias, M/M/m. Ela é baseada em características do modelo teórico subjacente e
não requer execuções preliminares da simulação. O resultado de Odoni e Roth (1983)
foi estendido para a determinação do tempo constante dominante ou tempo de
relaxação, τ, quando 99% do comportamento transiente inicial foi dissipado.
Para um sistema de fila M/M/m que parte para o equilíbrio, a estimativa do tempo de
relaxação Rτ é dado por:
( )[ ] 1214,1−
−= ρµτ sR , (5.8)
para todo maxmm ≤ , onde mmax é o maior valor de m tal que a estimativa obtida através
da heurística de relaxação do tempo tenha passado no teste de remoção do vício, um
teste de hipóteses clássico (o teste estatístico t de Student ou o teste estatístico z para a
normalidade).
A heurística proposta por Roth (1994) é semelhante àquela proposta por Odoni e Roth
(1983). A heurística de relaxação do tempo para sistemas de filas M/M/m com não mais
que mmax servidores, é: descarte dados representativos dos primeiros Rτ4 de tempos do
modelo, onde Rτ é definido pela equação (5.8). A performance desta heurística é
comparada com a de outras heurísticas alternativas com respeito a efetividade da
remoção do vício devido à inicialização. São utilizados dois procedimentos: primeiro
verifica-se que as heurísticas passaram no teste de remoção do vício, um teste de
hipóteses clássico; como uma segunda medida de vício é avaliada a probabilidade de
cobertura observada, a probabilidade que a média verdadeira esteja contida no intervalo
de confiança de 95% sobre a média observada. E mostram que a heurística de relaxação
do tempo é um instrumento apropriado para remover o vício, devido à inicialização, do
número de clientes em um sistema de fila M/M/m em regime.
Delaney e Rossetti (1995) investigam o uso de aproximações analíticas de sistemas de
filas para auxiliar na atenuação dos efeitos do período transiente inicial em simulações

139
de sistemas de filas GI/G/m em equilíbrio. Eles utilizam aproximações analíticas de filas
para configurar estocasticamente as condições iniciais da simulação e desenvolvem um
novo conjunto de heurísticas de truncamento baseado nestas aproximações analíticas de
filas GI/G/m. Novas heurísticas de truncamento são estabelecidas para encontrar o ponto
de truncamento numa realização da simulação que minimiza o erro quadrado médio da
estimativa. Eles apresentam a performance da heurística para replicação-descarte, e a
adaptação para uma longa execução com médias de grupo é discutida. Segundo eles o
resultado da metodologia proposta é um estimador, menos viciado e menos variável do
tempo médio de espera na fila.
Delaney, Rossetti e White Jr. (1995) apresentam heurísticas semelhantes para a análise
de médias de grupos (batch) de uma única execução longa da simulação. Conjugam
duas abordagens usadas para reduzir os efeitos do vício devido a inicialização que são: a
primeira abordagem é a configuração dos estados iniciais da simulação
estocasticamente; e a segunda é o truncamento de uma porção inicial da amostra, com o
restante dos dados sendo usados para fornecer uma estimativa da medida de
performance desejada.
Configurar estocasticamente os estados iniciais da simulação envolve amostragem da
distribuição em equilíbrio para se obter o estado inicial. E o problema com está técnica é
que na maioria das vezes não se conhece a distribuição em equilíbrio. Eles propõem
usar as aproximações desenvolvidas por Whitt (1993) para as distribuições em
equilíbrio do número de clientes no sistema, contando aqueles que estão em serviço ou
não, para estocasticamente configurar os estados iniciais (condições iniciais) do sistema
que se pretende simular.
O desafio básico na abordagem que trunca uma porção inicial dos dados da amostra é
determinar um ponto de truncamento que controla os efeitos do vício devido a
inicialização sem aumentar a variância do estimador. Eles utilizam nas heurísticas
propostas o erro quadrado médio como critério de exame desta penalidade de
truncamento. O erro quadrado médio é definido por:

140
( ) [ ] [ ]θθθθ ˆVarˆBiasˆMSE 22+=
−= E ,
onde θ é um estimador de θ. O erro quadrado médio considera ambos, o vício e a
variância do estimador.
Seja uma estimativa do erro quadrado médio do estimador dada a seguir:
[ ] [ ] [ ]θθθ ˆVarˆBiasˆMSE2 ∧∧∧
+= (5.9)
Assumindo que o valor verdadeiro seja conhecido e que os Yi são independentes, o vício
e a variância do estimador da amostra truncada podem ser estimados por:
[ ] ( ) θθ −=∧
dnY ,ˆBias (5.10)
e
[ ]( )
( )∑+=
∧
−−
=n
diiY
dn 1
22
1ˆVar θθ , (5.11)
onde n e d representam o tamanho total da amostra e a quantidade de dados iniciais a
serem descartados e ( )dnY
dnYn
di i
−=
∑ += 1, é a média da amostra.
Desta forma eles propõem duas heurísticas de truncamento: a primeira é a heurística de
truncamento segundo o critério do erro quadrado médio usando aproximações, referida
como MSEAT (mean squared error approximation truncation); e a segunda é a
heurística de truncamento segundo o critério do erro quadrado médio usando
aproximações e a variância amostral, referida como MSEASVT (mean squared error
approximation and sample variance truncation).
Seja θa uma aproximação analítica para θ. A primeira heurística é baseada na
substituição de θ por θa nas equações (5.10) e (5.11) para se obter uma estimativa

141
aproximada do MSE da equação (5.9) e então encontrar o valor de d que minimiza a
estimativa resultante para o erro quadrado médio.
E desta forma obtêm-se as seguintes equações:
( ) [ ] [ ]θθ ˆVarˆBias,MSE2
a
∧∧∧
+=dn ,
[ ] ( ) adnY θθ −=∧
,ˆBias , (5.12)
[ ]( )
( )∑+=
∧
−−
=n
diaiY
dn 1
22
1ˆVar θθ ,
onde o ponto de truncamento *d é determinado por: ( )dnd a ,MSEmin argnd0
*∧
≤≤= .
Observando que a primeira heurística é muito dependente da aproximação obtida de um
modelo analítico correspondente, eles, então, mantêm a equação para o vício e usam
uma equação diferente para a variância, obtendo desta forma a segunda heurística
referida como MSEASVT, que julgam ser mais apropriada. A heurística MSEASVT é
dada por:
[ ] [ ]θθ ˆVarˆBias min arg2
nd0
*∧∧
≤≤+=d ,
onde:
[ ] ( ) adnY θθ −=∧
,ˆBias e [ ] ( )( )( )( )1
,ˆVar 1
2
−−−
−=
∑ +=∧
dndndnYYn
di iθ .
Para replicação-descarte eles encontram, através de uma de suas heurísticas, um valor
ótimo d para cada replicação e a correspondente média da amostra truncada. Sendo que
a estimativa final é a média obtida, através das replicações, sobre todas as médias das
amostras truncadas.

142
Estes algoritmos heurísticos requerem que os dados de cada replicação sejam salvos e
então analisados no final da replicação. E para convenientemente longas execuções da
simulação isto pode gerar uma quantidade significativa de dados, que pode chegar
facilmente na casa de 100 Mbytes.
Eles usam fluxos de números aleatórios comuns para comparar a performance das
heurísticas para o sistema com estados iniciais configurados estocasticamente e para o
sistema com condições iniciais caracterizadas pelo sistema parado e vazio.
As aproximações para o tempo médio de espera na fila GI/G/m são tomadas de Whitt
(1993) e são baseadas numa abordagem de aproximação do sistema que modifica o
resultado da fila M/M/m. A relação funcional básica tem a seguinte forma:
[ ] ( ) [ ]sMMsGGI qSAq WEsccWE
////,,, 22ρΦ= , onde ρ é intensidade de tráfego, 22 e SA cc são os
quadrados dos coeficientes de variação das distribuições entre-chegadas e de serviços,
respectivamente, m é o número de servidores, e a função ( )mcc SA ,,, 22ρΦ pode ser
pensada como um fator de correção. Mas apesar da função ( )mcc SA ,,, 22ρΦ ter forma
complexa, ela ainda é fácil de se computar.
Para testar as heurísticas, eles configuram uma série de modelos de filas não-padrões
com intensidade de tráfego ρ ≥ 0. Modelos de filas M/M/m não são usados, pois as
aproximações de Whitt (1993) são exatas para estes modelos.
Cada experimento é constituído de 25 micro-replicações para todos os modelos e de 30
micro-replicações para o modelo de fila E2/E4/4 com ρ = 0,9, e 10 micro-replicações
para os demais. O tamanho de cada micro-replicação em Delaney e Rossetti (1995) são
de 10.000 chegadas de clientes para o modelo de fila E2/E4/4 com ρ = 0,9, de 21.000
chegadas de clientes para a fila E2/E4/4 com ρ = 0,98 e de 30.000 chegadas de clientes
para a fila U/LN/3, sendo que o tamanho total da execução foi de 5.250.000 clientes
para a fila E2/E4/4 com ρ = 0,98 e de 7.500.000 para os demais modelos de filas.
Delaney e Rossetti (1995) apresentam a partir de seus resultados as seguintes
conclusões:

143
1. Usar aproximações de filas obtidas de modelos analíticos correspondentes para
configurar estocasticamente os estados iniciais da simulação reduz o vício devido
a inicialização de uma estimativa da medida de performance do parâmetro quando
se tem recursos computacionais limitados;
2. Configurar estocasticamente os estados iniciais reduz o tamanho do período
transiente, embora uma execução de tamanho finito não possa alcançar o final de
um período transiente;
3. Adicionalmente usam as aproximações para fazer um truncamento posterior
(atrasado) dos dados de saída da simulação para o ponto onde ocorre MSE
estimado mínimo reduz o vício da estimativa;
4. A heurística (regra de truncamento) proposta alcançou o objetivo estabelecido de
se obter uma melhor, menos viciada e menos variável, estimativa do tempo médio
de espera na fila. Entretanto ela não satisfaz o objetivo pressuposto de 95% de
cobertura através dos experimentos, todavia eles atribuem isto diretamente a
precisão exata que a heurística dá;
5. Ainda resta a questão do que é melhor, uma melhor cobertura com a possibilidade
de significante vício e variância ou menos cobertura com pouca ou nenhum vício
e variância reduzida.
Tem-se também que, se TE é muito grande, o vício tende a ser desprezível, sendo
dominado por 01β−
ET , com 0β (geralmente finito) dado por (5.3). Contudo para TE
muito pequeno, o vício é aproximadamente ( )[ ] mrTYE I − (Whitt, 1991). E segundo
Roth (1994) o tamanho da replicação precisa ser suficientemente pequeno tal que o
período transiente responda por uma porção significante de cada replicação, senão os
dados viciados representativos do comportamento transiente podem ser dominados por
dados não-viciados representativos do comportamento em equilíbrio. Desta forma as
heurísticas propostas por Delaney e Rossetti (1995) não são apropriadas para o tamanho
das replicações previstas nos experimentos propostos neste trabalho, pois os tamanhos

144
das execuções das replicações são grandes demais para que os dados viciados não sejam
dominados pelos dados não-viciados.
Estas heurísticas propostas por Delaney e Rossetti (1995), apesar da simplicidade,
acabam por requerer uma grande quantidade de recursos computacionais para tamanhos
de execuções das micro-replicações suficientemente grandes para aproximações com
melhores probabilidades de coberturas observadas. As replicações previstas nos
experimentos deste trabalho são significativamente maiores que aquelas previstas por
Delaney e Rossetti (1995), e os arquivos de saídas de dados poderiam chegar a mais de
100 Mbytes. E estes arquivos gerados pelo modelo construído no Micro Saint, que é
uma ferramenta de simulação de propósitos gerais, precisariam ser editados num editor
de textos antes de serem submetidos a análise através de um programa escrito numa
linguagem de propósito geral tais como C++ ou Pascal. Desta forma, estas heurísticas
não foram usadas neste trabalho.
Segundo Whitt (1989a) se o processo sendo simulado não é estacionário, então se tem
vício caracterizado pela diferença entre a média do estimador e a média verdadeira.
Neste caso pode-se usar a aproximação RBM (Movimento Browniano Refletido ou
Regulado) em (5.34) para considerar o vício para o RBM canônico observado sobre
[ ]0,0 t , quando o RBM canônico inicia na origem. Pode-se estimar o vício, quando se
está estimando a média em regime (equilíbrio) ( )[ ]211,1; =−∞RE pela média amostral
( )∫ −= − 0
0
0
10 0,1,1;
t
t dssRtR de um sistema que inicialmente estava vazio e parado, usando
a aproximação Hiperexponencial dada por:
( ) ( )[ ] 0 t,138,036,00,1,1;21 764,023,5 ≥+≈−− −− tt eetRE . (5.13)
Tem-se que:

145
( ) ( ) ( )[ ] ( )( )
( )[ ] ( )( )0
0
10
0
10
41210,1,1;
210,1,1;21 0
0
tdssREt
dstREtREt
t
=−−≈
≈−−=−
∫
∫∞−
−
(5.14)
para t0 grande.
Segundo Whitt (1989a) o vício assintótico para RBM, em muitas circunstâncias, é
assintoticamente inversamente proporcional ao tamanho t0 da execução. E desde que a
largura do intervalo de confiança é proporcional a 210−t , ver (5.22) e (5.24), o vício para
o RBM é assintoticamente desprezível quando comparado com a largura do intervalo de
confiança.
A aproximação do vício em (5.39) e (5.40) sugere, que quando se inicia com uma fila
vazia, pode-se querer seguir uma prática comum de descartar uma porção inicial dos
dados. O escalamento do tempo na aproximação RBM em (5.52) indica que o tamanho
da porção inicial a ser descartada no processo de fila deveria crescer com ρ; em
particular este também deveria ser da ordem de ( )22 1 ρ−ab . Para o RBM canônico
pode-se estimar o vício resultante quando se deleta uma porção inicial em [0, t],
mudando a integral em (5.40) do intervalo [0, t0] para o intervalo [t1, t1+t0] (Whitt,
1989a).
E como, segundo Whitt (1989a), ( )[ ]0,1,1;−tRE para t = 4 está cerca de 1% de sua
média em equilíbrio (regime), uma regra grosseira para determinar o tamanho t do
intervalo de tempo inicial [0, t] a ser descartado, numa simulação de fila com uma
precisão estatística relativa da ordem de 5-10%, é descartar o segmento inicial
correspondente a:
( )22 14 ρ−ab (5.15)
tempos de serviços esperados.

146
A regra sugerida por Whitt (1989a) para determinar a porção inicial dos dados de saída
da execução da simulação que serão descartados parece razoável para os propósitos
desse trabalho, pois ela exige menos recursos computacionais, é simples de se
implementar, não descarta dados em excesso, evitando desperdício, e está de acordo
com os resultados obtidos para regras desenvolvidas para modelos de filas M/M/m.
Desta forma, o tempo TI de inicialização da simulação, durante o qual a simulação
executará sem que sejam coletados dados de saída da simulação, será determinado por
(5.15) e multiplicado por um fator igual 10 para garantir uma adequada remoção do
vício. Portanto tem-se que:
( )22 140 ρ−= abTI . (5.16)
5.3 - TEMPO DE EXECUÇÃO
A coleta de dados somente será considerada após o período de inicialização, por um
período de tempo TE (tempo de execução); será feito um truncamento na saída de dados.
Este truncamento removerá ou minimizará (praticamente reduzirá a zero) o impacto dos
efeitos da inicialização no sistema.
Whitt (1989a) desenvolve fórmulas heurísticas simples para estimar o tamanho
necessário da execução da simulação para se obter a precisão estatística desejada em
simulações de sistemas de filas em equilíbrio (regime). E Whitt (1989b) desenvolve
estimativas, através de análise matemática preliminar, do tamanho necessário da
simulação para se obter a precisão estatística desejada em experimentos de simulação
estocástica de sistemas em equilíbrio. Nestes trabalhos são consideradas replicações
simples das execuções das simulações estocásticas dos sistemas de interesse, ou seja,
uma execução longa da simulação para estimar características do sistema em equilíbrio.
Estas fórmulas podem ser aplicadas para auxiliar na elaboração de projetos de
experimentos de simulação estocástica, nos estágios iniciais de planejamento antes que
quaisquer dados tenham sido coletados.

147
Este estudo, entretanto, prevê experimentos baseados em replicações independentes, ao
invés de uma longa execução da simulação, como já foi argumentado anteriormente,
com base principalmente nos dois argumentos apresentados a seguir.
Primeiro as execuções de simulações de sistemas de filas em regime muitas vezes
necessitam ser surpreendentemente longas, porque estas de fato necessitam serem
longas, ou porque não temos suficiente informação sobre o processo. E neste caso a
eficiência tende a ser praticamente a mesma tanto para uma longa execução quanto para
um pequeno número de replicações (aproximadamente 10) ligeiramente menores.
E, como segundo argumento, quando se deseja ter intervalos de confiança mais
confiáveis, Whitt (1991) recomenda fazer cerca de 10 replicações independentes com
execuções de tamanho ligeiramente menores, que os de uma longa execução, fazendo
com que estas execuções ligeiramente menores sejam suficientemente longas tal que a
eficiência seja quase a mesma de uma longa execução. Isto assegura independência mas
não a distribuição normal, podendo ainda existir problemas de cobertura.
O tamanho destas R replicações ligeiramente menores pode ser obtido dividindo-se o
tamanho estimado para uma execução longa por R, como foi sugerido nos exemplos
apresentados por Whitt (1991). E como estes valores são aproximações obtidas
analiticamente, através de análise matemática preliminar, antes que quaisquer dados de
saída da simulação tenham sido obtidos, eles podem ser corrigidos durante a condução
do experimento. Neste sentido serão considerados no experimento mais 2 valores para
os tamanhos de execução destas 10 replicações, consistindo do valor inicial acrescido de
25% e 50%, respectivamente.
Nos experimentos onde se conhece os valores verdadeiros das medidas de performance
que estão sendo estimadas, pode ser utilizado um segundo critério de verificação da
exatidão da estimativa (remoção do vício), através da avaliação da probabilidade de
cobertura observada, a probabilidade de que a média verdadeira esteja contida no
intervalo de confiança de 95% sobre a media observada (Roth, 1994). E neste caso cada

148
replicação será dividida em 10 micro-replicações independentes, cada uma com período
de inicialização TI e período de execução de tamanho 10ET .
5.3.1 – METODOLOGIA PARA A DETERMINAÇÃO DO TEMPO DE
EXECUÇÃO TE
A análise feita por Whitt (1989a) é baseada em teoria estatística geral, mas é
inteiramente voltada para modelos de filas. Ele explora a estrutura de modelos de filas
com o objetivo de estimar a quantidade de dados requeridos para se obter intervalos de
confiança especificados. Este trabalho foi motivado por experimentos de simulação
conduzidos para desenvolver e avaliar aproximações de características em regime, em
equilíbrio, de modelos de filas complexos, em particular por esforços recentes em
projetar experimentos para estudar filas em redes de comunicação de pacotes – estas
filas têm múltiplas classes de clientes com diferentes características de serviço e
processos de chegadas explosivos.
Já em Whitt (1989b) a análise também é baseada em teoria estatística padrão e abrange
outros modelos estocásticos além dos modelos de filas.
Estes dois trabalhos de Whitt (1989a e 1989b) estão voltados para o tamanho da
simulação necessário para se obter a precisão estatística desejada (especificada). E têm
como pano de fundo a simulação de modelos estocásticos, em equilíbrio (regime), para
obtenção de medidas de interesse.
Supõe-se que o modelo estocástico que se deseja simular seja relativamente complicado,
de forma que não seja fácil calcular analiticamente as medidas de interesse. O objetivo é
obter estimativas do tamanho da execução da simulação e das medidas de interesse, e
projetar o experimento inicial fazendo alguma análise matemática preliminar, que não
seja mais complicada do que resolver o próprio modelo estocástico em questão.
Desta forma Whitt (1989a e 1989b) sugere aproximar o modelo estocástico de interesse
por um modelo estocástico mais elementar, que possa ser analisado analiticamente.
Calculam-se para este modelo aproximado: a quantidade de interesse, em equilíbrio, a

149
variância e o vício assintóticas. E, então, com estas quantidades estima-se o tamanho
necessário da execução da simulação para se obter a precisão estatística desejada no
modelo original.
São necessários, portando, dois procedimentos: primeiro, é necessário encontrar uma
aproximação conveniente para o modelo estocástico em questão; e, segundo, é preciso
calcular as quantidades assintóticas de interesse para o modelo aproximado.
As fórmulas propostas por Whitt (1989a) são baseadas em limites de tráfego pesado
para filas e aproximações por difusão associadas. Em particular, as fórmulas se aplicam
a processos estocásticos que podem ser aproximados por movimento Browniano
refletido. Os limites de tráfego pesado descrevem como o processo de fila comporta-se
quando a intensidade de tráfego ρ aproxima-se de seu valor crítico para a estabilidade,
neste caso 1. Em particular, os limites de tráfego pesado permitem relacionar como o
tempo t ou o número de clientes n cresceria - o tamanho da execução da simulação -
quando ρ → 1.
Whitt (1989a) considera em seu trabalho modelos de filas bastante gerais, indo além do
modelo GI/G/m. Na verdade ele especifica um conjunto de modelos considerando que o
processo de interesse, com normalização padrão, converge em distribuição para
Movimento Browniano Refletor (RBM) quando ρ → 1. Mas sua análise não se aplica a
processos de filas que não são bem aproximados por RBM, tais como filas com um
número infinito de servidores e pequenas redes de filas fechadas.
A análise feita por Whitt (1989a) indica que o impacto da intensidade de tráfego na
precisão estatística de estimativas é aproximadamente o mesmo que o do modelo M/M/1
para uma grande classe de modelos. Além do que, para modelos de filas mais
complexos que o M/M/1, a precisão estatística de estimativas para um dado tamanho de
execução da simulação não é afetado somente pela intensidade de tráfego, mas também
pela variabilidade dos processos básicos de chegada e de serviço.
Segundo Whitt (1989a) a experiência indica que, para uma precisão estatística
especificada, a quantidade de dados requeridos cresce quando a intensidade de tráfego

150
cresce e quando a variabilidade dos tempos de serviço e dos tempos entre chegadas
(apropriadamente quantificados) cresce. E a análise feita por ele indica que, para se
obter um erro padrão relativo (a razão entre o erro padrão da medida de interesse na
simulação e a estimativa simulada de sua media) uniforme, previamente especificado,
sobre todos ρ, o tamanho da amostra deveria ser aproximadamente proporcional a
( )211 ρ− chegadas. E para o erro padrão absoluto, o tamanho seria aproximadamente
proporcional a ( )411 ρ− chegadas.
A análise em Whitt (1989a) indica que, para se obter um erro padrão (absoluto ou
relativo) previamente especificado, o tamanho da execução da simulação deveria ser
aproximadamente proporcional a variabilidade dos processos básicos de chegada e de
serviço, enquanto medida por um apropriado parâmetro de variabilidade assintótica, que
emerge dos limites de tráfego pesado. Desde que os tempos de serviço e os tempos entre
chegadas são iid, o parâmetro de variabilidade assintótica para o critério do erro padrão
relativo é justamente a soma dos quadrados dos coeficientes de variação (variância
dividida pelo quadrado da média) das distribuições dos tempos de serviço e dos tempos
entre chegadas, e estão disponíveis antes do início da simulação. Esta mesma análise
também indica que, se o critério é o erro padrão absoluto, o tamanho da execução da
simulação deveria ser aproximadamente proporcional ao cubo deste mesmo parâmetro
de variabilidade assintótica.
Segundo Whitt (1989a) comparações com resultados de simulação indicam que estas
fórmulas para o efeito de variabilidade são bastante precisas para intensidades de
tráfego pesado, por exemplo para ρ ≥ 0,8, mas menos precisas para intensidades de
tráfego leves (de qualquer forma quando este é menos crítico). Mas ele propõe o uso de
limites de tráfego pesado não como fórmulas finais, mas como guia para auxiliar na
determinação dos tamanhos das execuções de simulações. E neste sentido, para
intensidades de tráfego leves, as fórmulas prognosticam corretamente o comportamento
qualitativo e fornecem aproximações rápidas e grosseiras (que estão muito abaixo da
precisão especificada).

151
5.3.1.1 - ANÁLISE ESTATÍSTICA PADRÃO
Seja ( ){ }0: ≥ttLq o processo estocástico que representa o número de clientes na fila
para o tempo t. Pode-se, também, pensar em Lq como o processo que representa o
número de clientes no sistema para o tempo t, ou como outro processo de interesse.
E assume-se ( ){ }0: ≥ttLq como um processo estritamente estacionário com
( )[ ] ∞<2tLE q .
O objetivo é estimar a média ( )[ ]0qLE pela média ponderada no tempo:
( ) ( )∫ ≥= − t
qq tdssLttL
0
1 0 , . (5.17)
A análise estatística padrão, segundo Whitt (1989a), assumindo uma grande quantidade
de dados, é baseada na suposição (hipótese) do teorema do limite central para ( )tLq
quando t → ∞. Seja ( )2,σmN uma variável aleatória normalmente distribuída com
média m e variância σ 2, então o limite desejado é:
( )[ ] ( ) , quando ,00 221 ∞→⇒
− tNLELt qq σ (5.18)
onde:
( )[ ] ( ) ( )∫∫∞
−∞→∞→∞<=
−==
0
2 21limlim dttCdssCts
LVartt
ttqtσ , (5.19)
o símbolo ⇒ significa convergência em distribuição e C(t) é a função de (auto)
covariância definida por:
( ) ( ) ( )[ ] ( )[ ]( )2 00 qqq LEtLLEtC −= . (5.20)

152
Whitt (1989a) assume que o limite em (5.18) é válido, como geralmente é feito, e chama
σ 2 em (5.19) de variância assintótica da média amostral ( )tLq . E baseado no limite
(5.18) define a seguinte aproximação:
( ) ( )[ ]( )tLENtL qq2, 0 σ≈ , (5.21)
para um dado t (grande) de interesse, onde σ 2 é dado por (5.19).
É importante observar que (5.21) envolve três aproximações: que a distribuição é
normalmente distribuída, que a média é E[Lq(0)] (sem vício, que é conseqüência da
estacionariedade assumida até aqui), e que a variância é σ 2/t para σ 2 dado em (5.19).
Para as aproximações, grosseiras, pretendidas para o propósito de planejamento geral
parece razoável assumir (5.21), desde que o tamanho t da execução da simulação seja
suficientemente grande para que (5.21) seja uma aproximação razoável. No contexto de
simulação de sistemas de filas, a experiência indica que o crescimento de t precisa ser
proporcional ao de ρ para que (5.21) seja uma boa aproximação, ou seja, este
requerimento é de mesma ordem que aquele exigido em t para que a precisão estatística
baseada em (5.21) seja adequada. E uma resposta a essa suposição também emerge da
aproximação por RBM (Whitt, 1989a).
Baseado em (5.21), um intervalo, com ( ) %100β1 − , de confiança para E[Q(0)] é dado
por:
( ) ( ) ( ) ( )[ ]2122β
2122β , tztLtztL qq σσ +− (5.22)
onde:
( )( ) β11,0 2β2β −=+≤≤− zNzP . (5.23)
Segundo Whitt (1989a) a largura do intervalo de confiança em (5.22) fornece uma
medida natural da precisão estatística, existindo dois critérios naturais a considerar:
largura absoluta e largura relativa. Note que estes dois critérios correspondem ao erro

153
padrão absoluto e ao erro padrão relativo, já mencionados acima. E para qualquer β
dado, a largura absoluta e a largura relativa são:
( ) ( )( )[ ]0
2β e
2β 21
2β21
2β
qra LEt
zW
tz
Wσσ
== . (5.24)
Para um nível de precisão β e uma largura absoluta ε especificados, o tamanho da
simulação requerido, dado (5.21), é:
( ) 2
22β
24β,
ε
σε
zta = . (5.25)
Para um nível de precisão β e uma largura relativa ε especificados, o tamanho da
simulação requerido, dado (5.21), é:
( )( )[ ]( )22
22β
2
0
4β,
qr LE
zt
ε
σε = . (5.26)
Das equações (5.25) e (5.26) se tira uma importante e bem conhecida conclusão: que
ambos ( ) ( )β, e β, εε ra tt são inversamente proporcional a ε 2 e diretamente
proporcional a σ 2 e 22βz .
Pode-se estimar as quantidades desconhecidas σ 2 e E[Lq(0)], recorrendo-se à teoria
estatística padrão, através de amostras colhidas de execuções preliminares da simulação.
Mas ao invés disso Whitt (1989a) recorre a informações adicionais sobre o modelo para
obter estimativas preliminares grosseiras para σ 2 e E[Lq(0)], sem a necessidade de
execuções preliminares para a coleta de dados. Ele assume que o modelo subjacente é
um modelo de fila que se comporta aproximadamente como a fila GI/G/1 (e
particularmente como a fila M/G/1) e que o processo estocástico de interesse se
comporta como o processo tamanho da fila de espera para o modelo GI/G/1 (e,
particularmente, se comporta como o processo tamanho da fila de espera para o modelo
M/G/1), que se comporta aproximadamente como o RBM, desde que a intensidade de

154
tráfego ρ não seja muito baixa. Ele trata deste problema estatístico obtendo grosseiras
estimativas de σ 2 e E[Lq(0)] em termos de parâmetros básicos do sistema de filas, tais
como a intensidade de tráfego ρ .
Apesar de se partir da suposição de que o processo Lq(t) em observação é estritamente
estacionário, sabe-se que na prática, contudo, normalmente não se pode iniciar em
equilíbrio, e em vez disso tem-se somente um processo assintoticamente estacionário.
Apesar disso, o limite (5.18) normalmente é válido e a aproximação (5.21) normalmente
é apropriada quando t é suficientemente grande, desde que seja substituída E[Lq(0)] em
(5.18) e (5.21) pela média em equilíbrio ( )∞qL , o limite de ( )tLq em (5.17) quando
∞→t é assumido existir com probabilidade 1. Além disso, o vício devido às condições
iniciais normalmente é desprezível quando t é suficientemente grande, de forma que a
variância assintótica em (5.19) coincide com o correspondente erro quadrado médio.
Portanto, ele propõe as aproximações (5.21) – (5.26) para uma larga classe de
simulações em equilíbrio com condições iniciais não-estacionárias.
Até o momento têm sido focalizados apenas processos estocásticos a tempo contínuo,
mas pode-se ter processos a tempo discreto, tais como o processo do tempo de espera do
n-ésimo cliente, que novamente assume-se que seja estacionário com ( )[ ] ∞<nWE 2 .
Então estima-se a média E[W(0)] pela média amostral ( ) ( )∑−
=
−=1
0
1n
kkWnnW e aplica-se o
limite assumido:
( ) ( )[ ]( ) ( )221 ,00 WNWEnWn σ⇒− , (5.27)
onde:
( )( ) ( )( ) ( )∑∞
=∞→
+==1
2 20limknW kCWVarnWnVarσ (5.28)

155
e C(k) é a função de (auto) covariância, definida por
( ) ( ) ( ) ( )[ ] ( )[ ]( ) 0 ,00 2 ≥−=≡ kWEkWWEkCkC W , dos quais obtêm-se equações
análogas às de (5.21) – (5.26).
Neste ponto é importante observar que, para uma vasta classe de sistemas de filas, as
versões do teorema do limite central para processos do tamanho da fila a tempos
contínuos, como em (5.18), e processos associados do tempo de espera a tempos
discretos, como em (5.27), são intimamente relacionadas através de uma extensão da
Lei de Little L=λW. E daí pode-se tirar uma importante conclusão da equação L=λW,
que é: com estimadores apropriados, aproximadamente a mesma quantidade de dados
são necessários para a estimação de medidas dos dois processos.
5.3.1.2 - OS CASOS ESPECIAIS M/G/1
Whitt (1989a) inicia a análise de sistemas de filas considerando alguns casos especiais.
Ele considera os casos especiais da fila M/G/1 para ter alguns resultados concretos para
comparar com as aproximações e fornecer uma base para criar aproximações refinadas.
No que concerne ao tamanho da fila, Whitt (1989a) supõe uma fila M/G/1 estacionária
com taxa de serviço µ = 1 e taxa de chegadas λ = ρ < 1. Seja mk o k-ésimo momento do
tempo de serviço e seja o quadrado do coeficiente de variação do tempo de serviço
( ) 1221
212
2 −=−= mmmmcS . Então o tamanho esperado da fila em regime é dado por:
( )[ ] ( ) ( )ρρ −+= 1210 22Sq cLE . (5.29)
E pode-se expressar a variância assintótica 2qLσ definida em (5.19) em termos dos
primeiros quatro momentos da distribuição dos tempos de serviço, ou seja, pode-se
expressar ( ) 21qLσρ− exatamente como:

156
( )
( )
−+
+
++
+
−+
+
+
−+
=−
ρρρρ
ρρρ
ρρσρ
11
123
31
11
325
11
21
2
2
42
2
3
222
2
33324
2
S
SSL
cm
mmm
cmmc
q
(5.30)
Desde que 122 += Scm , é fácil ver que cada termo em (5.30) é não-decrescente em ρ,
m2, m3, e m4. E tem-se que para os casos especiais M/D/1 e M/M/1,
1k e 11 +=+ kk mm , respectivamente, tal que:
( )( ) ( )
1// para 1
41
44124
2
4
3222 MM
qL ρρ
ρρρρρσ
−≈
−
+−+= (5.31)
e
( )( ) ( )
1// para 12112
31211444
322 DM
qL ρρ
ρρρρρσ
−≈
−+−+
= (5.32)
com as aproximações em (5.31) e (5.32) sendo razoavelmente boas se ρ não é muito
pequeno, por exemplo ρ ≥ 0,3, e 2qLσ cresce muito rapidamente quando ρ → 1.
O limite de alto tráfego para a fila M/G/1 é obtido, segundo Whitt (1989a),
considerando somente o primeiro termo em (5.30), i. é, para ρ grande:
( ) ( )4322 121 ρσ −+≈ SL cq
. E ( ) ( )4324 121 ρρ −+Sc é, de fato, um limite inferior para
2qLσ .
Motivado por este limite de alto tráfego, Whitt (1989a) obtém uma aproximação para o
caso 10 2 ≤≤ Sc , tomando uma combinação convexa de fatores adicionais em (5.31) e
(5.32). Ele, particularmente, reescreve o último termo para M/M/1 em (5.31) como
( ) ( )4322 121 ρρ −+Sc , onde 12 =Sc , e reescreve o último termo para M/D/1 em (5.32)

157
como ( ) ( )432 121 ρρ −+Sc , onde 02 =Sc . Então a aproximação para o sistema de fila
M/G/1,geral, com parâmetro 10 2 ≤≤ Sc , é:
( ) ( )( ) ( )[ ]( )( )4
322222
12111
1//11//ρ
ρρσ
−
+−−=−+≈ SS
SSLcc
DMcMMcq
. (5.33)
Comparações com valores extremos em (5.30) mostram que a aproximação em (5.33) é
geralmente (para distribuições típicas tais como Erlang ou exponencial alterada) muito
boa para as intensidades de tráfego de principal interesse, por exemplo, ρ ≥ 0.
Entretanto, desde que é teoricamente possível existirem terceiro ou quarto momentos
ilimitados com um segundo momento qualquer, o valor exato de 2qLσ em (5.30) pode de
fato ser infinito, de forma que (5.33) seria uma aproximação muito ruim. Isto mostra
que, mesmo para o caso relativamente simples da fila M/G/1, não existe limite nos
possíveis erros devido ao uso de (5.33) ou das aproximações RBM de alto tráfego. É
importante compreender que as aproximações RBM têm esta limitação. Contudo, casos
patológicos raros não deveriam impedir a obtenção de aproximações práticas (Whitt,
1989a).
Para complementar (5.33), Whitt (1989a) considera o caso 12 ≥Sc da fila M/G/1. Ele usa
as aproximações ( ) ( )2225132
414
22313 1124 e 13 +≈≈+≈ SSSS ccmmmmmccmm em
(5.30), quando 12 ≥Sc , para obter a seguinte aproximação para a fila M/G/1:
( ) ( ) ( )( )
−+
++++
−+
++
−+
=−ρ
ρρρρ
ρρρ
ρσρ1
11311
112
51
12
12
22222
2324
2 SSS
SSSL
ccccccq
. (5.34)
Note que, para 2Sc grandes, cada termo em (5.34) é aproximadamente proporcional a
( )32 1+Sc desde que ρ não seja muito pequeno. E de forma geral a aproximação (5.34) é
consistente com ( ) 32 para 122 ≤≤+≈ xcK xSLq
σ (Whitt, 1989a).

158
Se ao invés disso for usado os limites gerais ( ) ( )324
221
223 1 e 1 +≥+=≥ SS cmcmmm
em (5.30), então a equação análoga à de (5.34) que seria obtida, seria um limite para
(5.30) (Whitt, 1989a).
Desta forma Whitt (1989a) propõe a seguinte aproximação global, simples e grosseira,
para o sistema de fila M/G/1 geral:
( ) ( )43222 121 ρρσ −+≈ SL c
q. (5.35)
De (5.31) vê-se que (5.35) é boa para M/M/1, mas de (5.32) vê-se que (5.35) é ruim para
M/D/1, é muito pequena devido a um fator de ρ. Contudo a simplicidade faz de (5.35)
uma útil substituta prática para (5.30), (5.33) e (5.34).
O tamanho estimado da execução da simulação para o sistema de fila M/G/1, para os
critérios da largura absoluta e da largura relativa, pode ser determinado
aproximadamente combinando (5.25) com (5.35) e (5.26) e (5.29) com (5.35). Dessa
forma tem-se:
( ) ( )( )
( ) ( )( ) 222
22β
2
24
22β
322
1
18β, e
1
12β,
ερρε
ερ
ρε
−
+≈
−
+≈
zct
zct S
rS
a . (5.36)
Note que as duas estimativas aproximadas da execução da simulação têm evidentemente
comportamentos diferentes em tráfego pesado e em tráfego leve (Whitt, 1989a):
( ) ( )( )
( ) ( )( )
1 quando 1
18β, e
1
12β,
22
22β
2
24
22β
32
→−
+≈
−
+≈ ρ
ερε
ερε
zct
zct S
rS
a , (5.37)
( ) ( ) ( ) ( )0 quando
18β, e
12β, 22
22β
2
2
22β
322
→+
≈+
≈ ρερ
εε
ρε
zct
zct S
rS
a . (5.38)
É importante notar que o tamanho requerido da execução para o critério da largura
relativa, tr, não é crescente para todos os ρs (tr → ∞ quando ρ → 0). Mas ta é
proporcional a ( )411 ρ− , enquanto tr é proporcional a ( )211 ρ− quando ρ → 1. Nota-

159
se, também, que ta e tr são proporcionais aos parâmetros de variabilidade
( ) ( )1 e 1 232 ++ SS cc , respectivamente, em (5.37) e (5.38). E de (5.31) vê-se que estes
limites se mantêm para os valores M/M/1 exatos.
Outros processos do modelo de fila M/M/1 são considerados a seguir.
Seja o processo do número de clientes no sistema, incluindo os clientes em serviço,
{L(t): t ≥ 0}, então, segundo Whitt (1989a), ( )[ ] ( )ρρ −= 10LE e a variância assintótica
de ( ) ( )∫−=t
dssLttL0
1 é:
( ) ( )42 112 ρρρσ −+=L . (5.39)
Alternativamente, se o processo considerado é o da carga de trabalho (ou tempo de
espera virtual) {V(t): t ≥ 0}, então, segundo Whitt (1989a), ( )[ ] ( )ρρ −= 10VE e a
variância assintótica de ( ) ( )∫−=t
dssVttV0
1 é dada por:
( ) ( )42 132 ρρρσ −−=V (5.40)
Se o processo considerado é o tempo de espera na fila (antes de iniciar o serviço) a
tempo discreto {D(n): n ≥ 0}, então, segundo Whitt (1989a), ( )[ ] ( )ρρ −= 10DE e a
variância assintótica de ( ) ( )∑ −
=−=
1
01 n
kkDnnD é:
( ) ( ) ( )44322 141452 ρρρρρρρσ −≈−+−+=D (5.41)
Note que os parâmetros de variabilidade assintótica (5.31), (5.39), (5.40) e (5.41) para
os quatros processos são, segundo Whitt (1989a), assintoticamente da forma
( )42 14~ ρσ − quando ρ → 1; ou seja, em cada caso ( ) 41 24 →− σρ quando ρ → 1.
O comportamento de tráfego pesado para o modelo M/G/1 é o mesmo para todos os
quatro processos.

160
5.3.1.3 - LIMITES DE TRÁFEGO PESADO
As aproximações em Whitt (1989a) para modelos de filas gerais têm origem em limites
de tráfego pesado, mas ele não apresenta nenhum teorema novo; ele aplica teoremas já
existentes. Pois, para modelos de filas mais gerais, por exemplo para a fila GI/G/m, não
se pode fazer uma análise correspondente àquelas feitas para modelos de filas M/G/1.
Desta forma Whitt (1989a) faz da existência de limites de tráfego pesado sua suposição
básica.
Estas aproximações se aplicam a modelos que são estáveis para ρ < 1 e instáveis para
1≥ρ , com a congestão rigorosamente crescendo quando ρ → 1. Desta forma estas
aproximações se aplicam a sistemas gerais de filas, GI/G/m, com múltiplos servidores,
com sala de espera ilimitada e com um número de servidores não muito grande. Mas
não se aplicam a sistemas correspondentes com salas de espera limitadas, onde
chegadas são perdidas quando o sistema está cheio, ou a sistemas com infinitos
servidores. Segundo Whitt (1989a) uma extensa literatura existente para tráfego pesado
fornece muitos exemplos de sistemas para os quais estas aproximações se aplicam.
5.3.1.4 - MOVIMENTO BROWNIANO REGULADO (RBM)
Em Whitt (1989a) um papel de destaque é dado ao movimento unidimensional
Browniano regulado (ajustado) ou refletido, que é um movimento Browniano na linha
real positiva com direção negativa constante, com coeficiente de difusão positivo
constante e uma barreira de reflexão impenetrável na origem. RBM é um processo de
Markov com realizações contínuas, isto é, um processo de difusão. RBM é importante
porque é um processo limite comum. E todos os processos de filas que convergem para
RBM sob uma normalização especificada quando ρ → 1 estão no domínio das fórmulas
de aproximação propostas por Whitt (1989a).
Segundo Whitt (1989a), R(t; a, b, X) representa um RBM com direção a < 0 e
coeficiente de difusão b > 0, partindo para o estado aleatório ( )( )00 ≥= XRX . Pode-se
reescalar RBM de forma que é suficiente considerar o caso com direção a = -1 e
coeficiente de difusão b = 1, que é chamado de RBM canônico. A redução para RBM

161
canônico é importante porque todas as descrições de RBM podem ser feitas por um
único e simples processo, não sendo necessário realizar cálculos separados para valores
de parâmetros diferentes.
Whitt (1989a) propõe a seguinte re-escala do processo RBM, pois esta permite fazer
todos processos limite idênticos:
( ){ } ( ){ }( ){ } ( ){ }
,1 e 1 , ,,0:,1,1;0:,,;
,0:,1,1;0:,,;
22
11
dcbcdaabdbactcXtRtXbatdcR
tcXtdRctXbatRd
d
=−===
≥−=≥
≥−=≥ −−
(5.42)
onde d= significa igualdade em distribuição.
Por exemplo, supõe-se que Xn(t) converge em distribuição para R(t; a, b, X) quando
∞→t . Por uma elementar aplicação de (5.42) e do teorema do mapeamento contínuo
tem-se que: cXn(td) converge em distribuição para R(t; -1, 1, cX), para c e d definidos
por (5.42) (Whitt, 1989a).
Segundo Whitt (1989a), a distribuição estacionária de R(t; a, b, X) é exponencial com
média ab 2 , e se a posição inicial X é distribuída segundo esta exponencial, então
RBM torna-se um processo estacionário. E é fácil ver que o re-escalamento (5.42)
preserva a estacionariedade. Para o RBM canônico, a distribuição estacionária é
exponencial com média 21 .
Uma expressão satisfatória, segundo Whitt (1989a), para a função de covariância do
processo RBM é uma simples representação espectral (mistura de exponenciais), dada a
seguir:
( ) ( ) ( )∫ −= −1
0
2 12 dxxxetC xtR π
. (5.43)

162
E a função de covariância do processo RBM canônico pode ser expressa diretamente
(sem integração) como:
( ) ( ) ( )[ ] ( ) ( )212112121 121212 tttttttCR φ++Φ−−−= −− , (5.44)
onde φ (t) é a função densidade e Φ (t) é a função de distribuição cumulativa da
distribuição N(0,1). E destas expressões ele deduz a variância assintótica do processo
RBM canônico, que é dada a seguir:
( ) ( )2121,1;Va lim
0
0
12 ==
−= ∫∫
∞−
∞→dttCdssRtrt R
t
tRσ . (5.45)
Pois para as aplicações baseadas em (5.21) não é necessária a função de covariância
completa, mas somente a variância assintótica dada por (5.45).
Para Whitt (1989a) um aspecto essencial da análise de tráfego pesado é o escalamento
do espaço e do tempo. E antes de considerar os limites de tráfego pesado, ele considera
como o escalamento afeta a função de covariância C(t) em (5.20) e a variância
assintótica σ 2 em (5.19).
Para o processo estacionário geral Lq(t), que poderia ser um RBM, seja ( )tLyzq um
processo escalado associado, definido por ( ) ( ) ,0 , ≥= tztyLtL qqyzonde y e z são
escalares positivos arbitrários. Sejam ( ) 2yz e σtC yz , respectivamente, a função de
covariância e variância assintótica de ( )tLyzq . Segundo Whitt (1989a) tem-se que:
( )[ ] ( )[ ] ( ) ( ) zyztCytCtLEytLE yzqq yz
222yz
2 e , σσ === (5.46)
(para 2yzσ faz-se a mudança de variável u = zt na integração). Em particular note que a
razão chave em tr(ε,β) para o critério da largura relativa em (5.26) é:

163
( )[ ] ( )[ ] zLELE qqyz yz
22
22 00
=
σσ , (5.47)
que é independente de y. A conclusão a ser tirada de (5.47) é que para tr(ε,β) o
escalamento do tempo z tem um papel essencial. E na estrutura de fila o limite de
tráfego pesado determina de que maneira esse escalamento do tempo poderia ser.
5.3.1.5 - O LIMITE DE TRÁFEGO PESADO ASSUMIDO E A APROXIMAÇÃO
POR RBM
Para um modelo de fila geral, Whitt (1989a) considera uma família de processos de filas
estacionários, isto é, o ρ-ésimo sistema tem intensidade de tráfego ρ. Particularmente,
ele considera a família de processos tamanho da fila de espera { }0: ≥tLqρ, mas poderia
ser a família de processos carga de trabalho ou alguma outra. Tal família de processos
pode ser obtida de um dado modelo por um simples escalamento do tempo no processo
de chegada, por exemplo, ( ) ( )tAtA λλ = tem taxa de chegada λ se A(t) tem taxa de
chegada 1. E a suposição chave é que versões apropriadamente normalizadas de ( )tLqρ
convergem para uma versão estacionária de RBM quando ρ → 1. Ele apresenta uma
aproximação básica e um refinamento desta aproximação.
Ele usa escalamento do espaço (1 - ρ) e o escalamento do tempo ( )211 ρ− , que são
consistentes com maioria dos teoremas de limite de tráfego pesado existentes, para obter
o processo normalizado definido por:
( ) ( ) ( )( ) 0 ,11ˆ 2 ≥−−= − ttLtL qq ρρρρ
. (5.48)
Sejam ( ) ( )tCtC ρρˆ e as funções de covariância de ( ) ( )tLtL qq ρρ
ˆ e , respectivamente,
e sejam 22 ˆ e ρρ σσ as variâncias assintóticas correspondentes. De (5.46) e (5.48), vê-se
que:

164
( ) ( ) ( )( ) ( ) 24222 1ˆ e 11ˆρρρρ σρσρρ −=−−= −tCtC . (5.49)
Note que o termo (1 - ρ)4, que aparece na relação da variância assintótica em (5.49),
mostra o efeito de primeira ordem de ρ.
Whitt (1989a) assume, então, que ( )tLqρˆ em (5.48) converge em distribuição para um
RBM estacionário. Ele admite coeficientes de difusão e direção gerais (a, b) no limite; o
processo limite, necessariamente estacionário, é denotado por R(t; a, b). E para tratar a
covariância exige-se (é necessário) a convergência conjunta para dois pontos de tempo
quaisquer. Em particular é assumido que:
( ) ( )[ ] ( ) ( )[ ] ,;,,;ˆ,ˆ2121 batRbatRtLtL qq ⇒
ρρ (5.50)
em R2 quando ρ → 1 para todo t2 > t1 > 0.
E adicionalmente é assumido que:
( )[ ] ( )[ ]
( ) ( )[ ] ( ) ( )[ ]
( ) ( ) ( )[ ]∫∫∞∞
→→
→
→
==
=
==
001
2
1
21211
11
,,;,ba,0;RCov2ˆ2limˆlim
,,;,;ˆˆlim
,2,;ˆlim
dtbatRdttC
batRbatREtLtLE
abbatREtLE
q
ρρρρ
ρ
ρ
σ
ρρ
ρ
(5.51)
para todo t2 > t1 > 0.
Segundo Whitt (1989a) a literatura de tráfego pesado contém uma abundância de
resultados suportando (5.50). E para propósitos práticos, segundo Whitt (1989a), é
suficiente provar (5.50) ou, de forma análoga, a convergência da distribuição
unidimensional, pois atualmente pode ser muito difícil provar (5.51).
Então Whitt (1989a) usa (5.42) para reescalar ( )tLqρˆ em (5.48) e obter o RBM canônico
como um limite. O processo ( ) ( ) 0, t,ˆ 2 ≥abtLba qρ converge para o RBM canônico.
As aproximações resultantes são:

165
( ){ } ( )( ) ( )( ){ }( )[ ] ( )[ ] ( )[ ] ( )( ) ( )[ ] ( )
( )[ ] ( )( )[ ] ( ) .120
e 121
,121,1;1ˆ11
,0:1,1;110;
2222
44324432
22
ρσ
ρσρσ
ρρρ
ρρ
ρ
ρρ
ρ
ρ
ρ
−≈
−=−≈
−=−−≈−=
≥−−−≈≥
abLE
abab
abtREabtLEtLE
tbtaRabttL
q
R
q
(5.52)
Obtêm-se os tamanhos estimados da execução da simulação necessários
( ) ( )βεβε , e , ra tt substituindo (5.52) em (5.25) e (5.26), respectivamente. Da mesma
forma como Whitt (1989a) procedeu na análise estatística padrão, na qual a suposição
crítica foi a aproximação normal (5.21) preferivelmente que o limite de sustentação
(5.18), aqui a suposição crítica é a aproximação por difusão (5.52) preferivelmente que
os limites de sustentação (5.50) e (5.51).
5.3.1.6 - REFINAMENTOS M/M/1
A aproximação RBM de tráfego pesado é (5.52), mas baseado nos resultados M/G/1
para o tamanho esperado da fila, especialmente (5.35), é natural, segundo Whitt
(1989a), modificar (5.52) multiplicando ( )[ ] 22 por e ρσ ρρtLE q . Deste modo ele
propõe as seguintes aproximações refinadas:
( )[ ] ( ) ( ) ( )[ ]( ) ( ).
12
0 e
12 ,
120 2222
2
44
232
2
ρρ
σ
ρρσ
ρρ
ρ
ρ
ρρ
−≈
−≈
−≈
ab
LEab
abLE
qq (5.53)
Whitt (1989a) obtém (5.53) formalmente aplicando o limite de tráfego pesado duas
vezes, uma vez para o sistema de interesse e uma vez para o modelo; ele primeiro
aproxima a fila geral por RBM e então aproxima o RBM por M/M/1 usando (5.31).
A aproximação final para o tamanho necessário (requerido) estimado da execução da
simulação com os critérios da largura absoluta e da largura relativa são obtidos
substituindo (5.53) em (5.25) e (5.26), respectivamente. Esta é dada a seguir:

166
( )( )
( )( )
.1
8, e
1
2, 2222
22
424
22
23
ρερβε
ρε
ρβε ββ
−=
−=
a
bzt
a
zbt ra (5.54)
A primeira tarefa a ser executada na aplicação de (5.54) é identificar os dois parâmetros
a e b, e de forma particular, neste estudo, identificá-los para o modelo de fila GI/G/m
padrão.
Para a fila GI/G/m com tempo médio de serviço igual 1, a condição (5.50) é mantida,
segundo Whitt (1989a), para o processo tamanho da fila (contando os clientes em
serviço ou não) com os parâmetros ( ). e 22SA ccmbma +=−= . A qualidade da
aproximação RBM tipicamente melhora quando ρ cresce, ρ → 0. E para um dado ρ a
qualidade da aproximação tipicamente decresce quando m cresce. Desta forma, ele
obtém a partir de (5.53) as seguintes aproximações para o estacionário tamanho da fila
GI/G/m, não contando os clientes em serviço:
( )[ ] ( )( )
( )( ) ( )[ ]( )
( )( )
.1
20
e 12
,12
0 22
22
2
2
4
32222
222
ρρ
σ
ρρ
σρ
ρ
ρ
ρ
ρρ
−
+≈
−
+≈
−+
≈m
ccLEm
ccccLE SA
q
SASAq (5.55)
Note que (5.55) harmoniza-se com (5.35) para o caso especial M/G/1. E o tamanho final
necessário (requerido) estimado da execução da simulação da fila GI/G/m, com os
critérios da largura absoluta e da largura relativa, são obtidos substituindo (5.55) em
(5.25) e (5.26), respectivamente, ou substituindo ( ). e 22SA ccmbma +=−= em (5.54).
Esta aproximação final para a fila GI/G/m é dada a seguir:
( ) ( )( )
( ) ( )( )
.1
8, e
1
2, 222
22
22
42
22
2322
ρερβε
ρε
ρβε ββ
−
+=
−
+=
m
zcct
m
zcct SA
rSA
a (5.56)
Desta forma o período (ou tempo) total de execução TE da simulação será determinado
através de tr (ε, β) dado em (5.56). Tem-se, portanto que:

167
( )( )
.1
8222
22
22
ρερβ
−
+=
m
zccT SA
E (5.57)
5.3.1.7 - A QUALIDADE DA APROXIMAÇÃO NORMAL EM 5.21
Como já foi assinalado anteriormente, toda análise feita por Whitt (1989a) depende da
aproximação Normal em (5.21), que por sua vez depende do tamanho t da execução da
simulação. O tamanho t da execução da simulação não precisa ser somente
suficientemente grande de forma que a precisão estatística estimada baseada em (5.21)
seja adequada, mas precisa ser, também, suficientemente grande tal que (5.21) seja ela
mesma uma razoável aproximação. E esta idéia grosseira sobre o tamanho t da execução
da simulação, necessário para que (5.21) seja uma aproximação razoável, também segue
da aproximação RBM em (5.52).
Para se ter uma idéia aproximada sobre o tamanho da execução necessário para que
(5.21) seja válida, Whitt (1989a) faz a aproximação (5.52) e indaga se (5.21) é
aproximadamente válido para um dado intervalo de tamanho, quando o processo em
questão é o RBM canônico.
O escalamento de tempo em (5.52) implica que ( ) bta 22 1 ρ− precisa ser
suficientemente grande para que (5.21) seja uma boa aproximação para o processo do
sistema de filas, pois este é o tamanho da execução da simulação para o RBM canônico
aproximado. Isto significa que o tamanho t da execução da simulação para o processo
do sistema de filas como uma função de ρ precisa ser da ordem de ( )22 1 ρ−ab , para
que (5.21) seja uma aproximação razoável.
Para qualquer ρ fixado, (5.21) envolve um erro de aproximação para qualquer t finito e
é assintoticamente correta quando t → ∞. Contudo se for considerado t como uma
função de ρ e o duplo limite ( ) 1 e →∞→ ρρt , (5.21) não é, necessariamente,
assintoticamente correta. E dada a aproximação RBM em (5.52), vê-se do escalamento

168
de tempo que (5.21) é assintoticamente correto neste duplo limite se e somente se
( ) ( ) 1 quando 1 2 →∞→− ρρρ t .
A conseqüência prática desta análise é que o tamanho da execução da simulação não
deveria ser somente de ordem ( ) 221 ab ρ− , mas deveria ser ( ) 221 abTN ρ− para TN
convenientemente grande (Whitt, 1989a). Em particular, pode-se assumir que o
tamanho t da execução da simulação é escolhido para satisfazer ( ) 221 abTt N ρ−= ,
para algum TN fixado independente de a, b e ρ, e então considerar o problema de
estimação para o RBM canônico em [0, TN]. E se, particularmente, for usado ( )β,εrt em
(5.54) tem-se que o tamanho da execução da simulação para o RBM canônico é dado
por:
( ) 22
22β8
,β,ερ
ρεz
TT NN =≡ . (5.58)
O ρ 2 no denominador de (5.54) e (5.58) é resultado do refinamento (5.53), e para o
RBM pode-se fixar ρ = 1, pois o ρ 2 no denominador significa possíveis dificuldades se
a fila é de tráfego muito leve (Whitt, 1989a). Ele afirma que TN em (5.58) normalmente
é suficientemente grande.

169
CAPÍTULO 6
APRESENTAÇÃO DOS RESULTADOS
6.1 - INTRODUÇÃO
Neste capítulo apresentam-se os resultados e a análise: da verificação e validação do
modelo de simulação da fila GI/G/m; dos experimentos com o modelo de simulação da
fila GI/G/m; e das aproximações de filas Gm/Gm/2 por filas C2g/C2
g/2.
Na Seção 6.2, os resultados da verificação e validação do modelo de simulação são,
então, analisados na perspectiva de se determinar o quanto o modelo programado
(código) é uma implementação precisa e exata do modelo conceitual, e o quanto o
modelo conceitual é uma representação razoável do sistema de fila GI/G/m.
Na Seção 6.3 e 6.4, os resultados do experimento com o modelo de simulação das filas
Gm/Gm/2 e C2g/C2
g/2, respectivamente, são analisados na perspectiva de se fazer
inferências sobre o nível de confiança destes resultados. Esta análise consiste na
verificação da precisão relativa especificada de 2% (ε ≤ 0,02), para um nível de
confiança da ordem de 95%, das medidas de desempenho, em equilíbrio, das diferentes
configurações – cenários - replicações do sistema de filas GI/G/m previstos no projeto
de experimento. Para as filas em que os valores verdadeiros das características em
observação são conhecidos, também são analisados os resultados da aplicação de testes
estatísticos padrões, como o teste t de Student, e são averiguadas as probabilidades de
cobertura verificada nos dados de saída da simulação.
Na Seção 6.5, os resultados do experimento relativo às aproximações de filas Gm/Gm/2
por filas C2g/C2
g/2 são analisados. Em outras palavras, são analisadas as comparações
das estimativas oriundas das observações provenientes da execução de R replicações da
simulação de uma dada configuração da fila Gm/Gm/2 contra a correspondente
configuração da fila C2g/C2
g/2. Ou seja, são analisados os resultados dos testes
estatísticos, dos testes t de Student, utilizados para se obter inferências sobre estas
comparações. Nestas comparações foi levado em conta, é claro, a precisão estatística

170
verificada na análise das observações oriundas da simulação das filas comparadas, para
um nível de confiança de 95%.
6.2 - VERIFICAÇÃO E VALIDAÇÃO DO MODELO DE SIMULAÇÃO
Os valores de projeto para os experimentos da verificação e validação do modelo de
simulação são o período (ou tempo) de inicialização TI, o período de execução TE e o
período TN de execução necessário para que a aproximação normal utilizada para a
obtenção destes tempos seja ela mesma uma aproximação razoável. As equações
utilizadas para determinar estes valores são as seguintes:
a) A equação em (5.16) para o período de inicialização TI ;
b) A equação em (5.57) para o período de execução TE ;
c) A equação em (5.58) para o período de execução TN , com ρ = 1.
Estes valores foram projetados tendo em vista a obtenção de estimativas das medidas de
desempenho, em equilíbrio, das 8 configurações de filas GI/G/m previstas no projeto de
experimento para a verificação e validação do modelo de simulação com uma precisão
relativa especificada de 2% (ε ≤ 0,02) e um nível de confiança da ordem de 95%. A
Tabela 6.1 contém os valores iniciais de projeto dos tamanhos necessários das
execuções da simulação destas 8 configurações de filas GI/G/m, ao nível de micro-
replicação, macro-replicação e tamanho total da simulação. O tamanho total da
simulação foi dividido em 10 macro-replicações de tamanhos 10ET e cada uma destas
macro-replicações foi dividida em 10 micro-replicações independentes de tamanhos
1010ET
, onde cada uma destas micro-replicações independentes tem semente geradora,
própria, de números aleatórios e período de inicialização TI. O tamanho total da
simulação foi acrescido de 25% e de 50% e colhem-se dados para o tempo original TE,
para o tempo 1,25TE e para o tempo 1,5TE .
Como o modelo programado de simulação transforma 0≥I entradas em 5=J saídas é
importante salientar que o nível de significância β = 0,05 especificado para a análise

171
estatística foi repassado por 01,0505,0β J == , para cada saída { }5,4,3,2,1J ∈ , com base
na desigualdade de Bonferroni, ver seções 4.3.1 e 4.3.3. Isto implica que maiores
discrepâncias entre os valores esperados das medidas de performance e as estimativas
oriundas da simulação são aceitáveis e, conseqüentemente, mantém a probabilidade
total de erro do tipo 1 no experimento abaixo do valor β = 0,05.
Para 4 destes experimentos foi obtida, com os valores originalmente previstos, uma
precisão relativa menor ou igual a 2% ( 02,0≤ε ). Mas para os experimentos referentes
às filas E2 /H2b/5 e H2
b/E2 /5 a precisão relativa hlr para o processo Lq foi de 0,021372 e
0,020570, respectivamente e, para o processo Wq foi de 0,021261 e 0,020337,
respectivamente. Para estas filas foram necessários tamanhos totais de execução da
simulação 25% maiores que os originalmente previstos, para a obtenção da precisão
relativa de 2%. Estes tempos que originalmente eram de 1.500.600 segundos foram
revistos para 1.875.700 segundos. Os outros dois experimentos se referem às filas
D/D/1 e D/D/2, para as quais os resultados obtidos foram exatamente iguais aos valores
verdadeiros das características destas filas de interesse para este estudo.
TABELA 6.1 – TAMANHOS INICIAIS DOS EXPERIMENTOS PARA A
VERIFICAÇÃO E VALIDAÇÃO DO MODELO DE SIMULAÇÃO COM β = 0,05 E
ε = 0,02
TE Filas ρ TI TN
Total Macro Micro
20% 125 76.829 6.002.300 600.230 60.023 M/M/1
80% 2.000 76.829 6.002.300 600.230 60.023
20% 63 76.829 3.001.100 300.110 30.011 M/M/2
80% 1.000 76.829 3.001.100 300.110 30.011
E2 /H2b/5 80% 500 76.829 1.500.600 150.060 15.006
H2b/E2 /5 80% 500 76.829 1.500.600 150.060 15.006
D/D/1 80% 200 76.829 600.226 - -
D/D/2 80% 100 76.829 300.113 - -

172
A probabilidade de cobertura observada (Pco) foi da ordem de 100% para 5 destes
experimentos, com exceção daquele relativo à fila M/M/2 com taxa de utilização de
20%, para o qual a probabilidade de cobertura para a estimativa do número de
servidores ocupados (^
NSO ) foi de 90%. O tamanho da execução deste experimento foi
revisto, tomando-se um período total de simulação 25% maior que o originalmente
previsto, ou seja, o tempo que originalmente era de 3.001.100 segundos foi revisto para
3.751.400 segundos. E com este novo período total de execução da simulação obteve-se
100% de cobertura. A probabilidade de cobertura observada (Pco) não se aplica para aos
experimentos relativos às filas D/D/1 e D/D/2.
A obtenção de valores da ordem de 100% para as Pco, verificadas nos dados de saída da
simulação, se justifica devido:
• A uma adequada remoção do vício nestes experimentos, pois o Biasr é
praticamente desprezível, sendo que a ocorrência de maior magnitude se deu para
o processo Lq (número de clientes na fila) da fila M/M/2 com ρ = 80% e foi da
ordem de 0,007339, ou seja, de 0,7339%.
• Ao repasse do nível de significância β = 0,05 especificado para a análise
estatística por 01,0505,0β J == , para cada saída { }5,4,3,2,1J ∈ , com base na
desigualdade de Bonferroni, pois isto implica que maiores discrepâncias entre os
valores esperados das medidas de performance e as estimativas oriundas da
simulação são aceitáveis.
Os resultados dos 8 experimentos de simulação previstos para a verificação e validação
do modelo de simulação da fila GI/G/m em equilíbrio estão resumidos nas Tabelas 6.2 a
6.9. E para todas as estimativas das medidas de performance previstas no experimento,
pode-se notar observando o resultados resumidos nas Tabelas 6.2 a 6.7, que:
• As meias larguras relativas do intervalo de confiança foram inferiores a 0,02,
conforme a especificação de projeto para uma precisão relativa de 2% (ε ≤ 0,02);

173
• As probabilidades de cobertura observada, Pco , foram todas da ordem de 100% e
portanto superiores àquelas de 95% previstas no projeto de experimento;
• O teste de hipóteses para um nível de confiança de 95% não rejeitou a hipótese de
nulidade, H0, para todas estas estimativas e, dessa forma, não foram detectadas
evidências de que estas estimativas difiram dos valores verdadeiros destas
características;
• A Biasr em todos estes experimentos é praticamente desprezível, sendo que a
ocorrência de maior magnitude se deu para o processo Lq (número de clientes na
fila) da fila M/M/2 com ρ = 80% e foi da ordem de 0,007339, ou seja, de
0,7339%.
E observando as Tabelas 6.8 e 6.9 pode ser verificado que os experimentos relativos às
filas D/D/1 e D/D/2 com ρ = 80% produziram estimativas, das medidas de performance
destas filas, exatamente iguais aos valores verdadeiros destas características, obtidas de
um modelo analítico exato.
Considerando que o modelo programado da simulação produz estimativas
suficientemente precisas (a meia largura, hlr, do intervalo de confiança é menor ou igual
a 2%) e exatas (a Biasr é praticamente desprezível), que a probabilidade de cobertura
observada, Pco , é de 100% contra o valor projetado de 95% e, que estas estimativas
passaram pelo teste de hipóteses (não há evidências de que elas difiram do valor
verdadeiro destas características, em equilíbrio), pode-se concluir que o modelo
programado (código) para a simulação em equilíbrio de filas GI/G/m é uma
implementação suficientemente precisa e exata do modelo conceitual do sistema de filas
GI/G/m. Em outras palavras, para os valores de projeto da simulação em equilíbrio de
filas GI/G/m, o modelo programado (código) de simulação funciona como o pretendido.
As distribuições dos tempo entre chegadas e dos tempos de serviço da fila GI/G/m são
por hipótese variáveis aleatórias iid, portanto o gerador de números aleatórios usado
pelo modelo de simulação deve produzir números que estatisticamente assemelham-se à
variáveis aleatórias U (0, 1) iid. Pode ser notado na Tabela 6.11 que o gerador de

174
números aleatórios do pacote de software “Micro Saint” passou nos testes para a
uniformidade e independência, já que pelos resultados dos testes para a uniformidade e
para a independência do gerador, pode-se concluir que não existem evidências de que os
números gerados não sejam uniformemente distribuídos e independentes entre si.
Uma das suposições mais básicas para um sistema de filas GI/G/m são as relações ou
fórmulas de Little. Pode ser notado analisando a Tabela 6.10 que as estimativas destas
médias em equilíbrio, para T1ˆ =λ , satisfazem as relações WL ˆˆˆ λ= , qq WL ˆˆˆ λ= e
SNSO ˆˆ^λ= , dado que a maior diferença observada entre os resultados destas relações de
Little e o valor da estimativa obtida dos dados da simulação é da ordem de 0,0226%
para qq WL ˆˆˆ λ− referente à fila M/M/2 com ρ = 80%.
As medidas de performance de interesse para este estudo são consideradas para um
sistema em equilíbrio. Desta maneira o modelo de simulação de filas GI/G/m proposto
neste estudo tem como suposição a simulação de sistemas não terminantes ou em
equilíbrio. E pode ser notado nas Tabelas 6.2 a 6.9 que as estimativas das características
de interesse, obtidas dos dados de saída da simulação, estão dentro das especificações
de precisão e exatidão pretendidas para os experimentos propostos, o que já foi
analisado em parágrafos anteriores. Em outras palavras, os valores de projeto para o
período de inicialização TI, o período de execução TE (aqueles inicialmente previstos, ou
aumentados em 25% ou 50%), e o período TN necessário para que a aproximação
normal seja ela mesma uma boa aproximação foram suficientes para a obtenção de
estimativas para as medidas de performance de filas GI/G/m em equilíbrio. Quando o
período de execução TE inicialmente previsto não foi suficiente para produzir
estimativas conforme o especificado, os valores do período de execução TE aumentados
em 25% ou 50%, previstos no projeto de experimento, foram suficientes para produzir
as estimativas dentro das especificações desejadas.
Desta forma, considerando que as principais suposições do modelo conceitual de
simulação para o sistema de filas GI/G/m em equilíbrio foram satisfeitas, e que os dados
resultantes do modelo de simulação assemelham-se aos dados que seriam esperados do

175
sistema de filas GI/G/m, pode-se concluir que o modelo conceitual é uma representação
razoável do sistema de filas GI/G/m em equilíbrio. Estas suposições já comentadas
anteriormente são as seguintes: simulação de sistemas de filas GI/G/m em equilíbrio; os
processo de chegadas e de serviços são variáveis aleatórias iid; as relações de Little se
aplicam para a fila GI/G/m em equilíbrio.
TABELA 6.2 – VALORES VERDADEIROS E RESULTADOS DA SIMULAÇÃO
DA FILA M/M/1 COM TAXA DE UTILIZAÇÃO DE 20%
Medidas L(t) Lq(t) Rn Dn NSO A(t) B(t)
E[Y] 0,25 0,05 1,25 0,25 0,2 5 1
.Y 0,249881 0,049767 1,247766 0,248491 0,200114 4,994069 0,999276
)ˆ.(. .Yes 0,000371 0,000177 0,001306 0,000802 0,000254 0,006742 0,000873
Biasr 0,000477 0,004669 0,001787 0,006038 0,000569 0,001186 0,000724
hlr 0,004827 0,011571 0,003401 0,010490 0,004118 0,004387 0,002840
Pco 1,0 1,0 1,0 1,0 1,0 - -
tR-1, b/2 3,249843 3,249843 3,249843 3,249843 3,249843 - -
|t0| 0,321190 1,317491 1,710708 1,881913 0,448658 - -
H0 aceita aceita aceita aceita aceita - -

176
TABELA 6.3 – VALORES VERDADEIROS E RESULTADOS DA SIMULAÇÃO
DA FILA M/M/1 COM TAXA DE UTILIZAÇÃO DE 80%
Medidas L(t) Lq(t) Rn Dn NSO A(t) B(t)
E[Y] 4 3,2 5 4 0,8 1,25 1
.Y 3,981471 3,181077 4,975465 3,975150 0,800396 1,249822 1,000322
)ˆ.(. .Yes 0,015756 0,015444 0,018066 0,017984 0,000378 0,000540 0,000387
Biasr 0,004632 0,005914 0,004907 0,006212 0,000496 0,000142 0,000322
hlr 0,012861 0,015778 0,011800 0,014703 0,001534 0,001404 0,001256
Pco 1,0 1,0 1,0 1,0 1,0 - -
tR-1, b/2 3,249843 3,249843 3,249843 3,249843 3,249843 - -
|t0| 1,175979 1,225298 1,358030 1,381781 1,049395 - -
H0 aceita aceita aceita aceita aceita - -
TABELA 6.4 – VALORES VERDADEIROS E RESULTADOS DA SIMULAÇÃO
DA FILA M/M/2 COM TAXA DE UTILIZAÇÃO DE 20%
Medidas L(t) Lq(t) Rn Dn NSO A(t) B(t)
E[Y] 0,416667 0,016667 1,041667 0,041667 0,4 2,5 1
.Y 0,416837 0,016653 1,040848 0,041578 0,400184 2,497216 0,999270
)ˆ.(. .Yes 0,000626 0,000087 0,000953 0,000206 0,000593 0,003065 0,000914
Biasr 0,000410 0,000797 0,000786 0,002135 0,000459 0,001114 0,000730
hlr 0,004883 0,017064 0,002976 0,016139 0,004818 0,003989 0,002972
Pco 1,0 1,0 1,0 1,0 1,0 - -
tR-1, b/2 3,249843 3,249843 3,249843 3,249843 3,249843 - -
|t0| 0,272645 0,151947 0,859203 0,430872 0,309745 - -
H0 aceita aceita aceita aceita aceita - -

177
TABELA 6.5 – VALORES VERDADEIROS E RESULTADOS DA SIMULAÇÃO
DA FILA M/M/2 COM TAXA DE UTILIZAÇÃO DE 80%
Medidas L(t) Lq(t) Rn Dn NSO A(t) B(t)
E[Y] 4,444444 2,844444 2,777778 1,777778 1,6 0,625 1
.Y 4,422141 2,823569 2,765073 1,765465 1,598575 0,625329 0,999609
)ˆ.(. .Yes 0,015998 0,015235 0,009411 0,009128 0,000995 0,000257 0,000524
Biasr 0,005018 0,007339 0,004574 0,006926 0,000891 0,000526 0,000391
hlr 0,011757 0,017535 0,011060 0,016802 0,002024 0,001335 0,001702
Pco 1,0 1,0 1,0 1,0 1,0 - -
tR-1, b/2 3,249843 3,249843 3,249843 3,249843 3,249843 - -
|t0| 1,394149 1,370234 1,350058 1,348888 1,431397 - -
H0 aceita aceita aceita aceita aceita - -
TABELA 6.6 – VALORES VERDADEIROS E RESULTADOS DA SIMULAÇÃO
DA FILA E2 /H2b/5 COM TAXA DE UTILIZAÇÃO DE 80%
Medidas L(t) Lq(t) Rn Dn NSO A(t) B(t)
E[Y] 6,394 2,394 1,5985 0,5985 4,0 0,25 1
.Y 6,383158 2,382659 1,595573 0,595574 4,000487 0,249971 1,000000
)ˆ.(. .Yes 0,013164 0,012199 0,003345 0,003066 0,001413 0,000040 0,000372
Biasr 0,001696 0,004737 0,001831 0,004889 0,000122 0,000117 0,000000
hlr 0,006702 0,016639 0,006812 0,016728 0,001148 0,000521 0,001208
Pco 1,0 1,0 1,0 1,0 1,0 - -
tR-1, b/2 3,249843 3,249843 3,249843 3,249843 3,249843 - -
|t0| 0,823640 0,929634 0,875054 0,954370 0,344472 - -
H0 aceita aceita aceita aceita aceita - -

178
TABELA 6.7 – VALORES VERDADEIROS E RESULTADOS DA SIMULAÇÃO
DA FILA H2b/E2
b/5 COM TAXA DE UTILIZAÇÃO DE 80%
Medidas L(t) Lq(t) Rn Dn NSO A(t) B(t)
E[Y] 7,039 3,039 1,75975 0,75975 4,0 0,25 1
.Y 7,060542 3,058376 1,763933 0,764013 4,002153 0,249850 0,999918
)ˆ.(. .Yes 0,018620 0,018020 0,004606 0,004488 0,001476 0,000094 0,000185
Biasr 0,003060 0,006376 0,002377 0,005611 0,000538 0,000598 0,000082
hlr 0,008570 0,019148 0,008485 0,019091 0,001198 0,001219 0,000602
Pco 1,0 1,0 1,0 1,0 1,0 - -
tR-1, b/2 3,249843 3,249843 3,249843 3,249843 3,249843 - -
|t0| 1,156925 1,075276 0,908222 0,949896 1,458964 - -
H0 aceita aceita aceita aceita aceita - -
TABELA 6.8 – VALORES VERDADEIROS E RESULTADOS DA SIMULAÇÃO
DA FILA D/D/1 COM TAXA DE UTILIZAÇÃO DE 80%
Medidas L(t) Lq(t) Rn Dn NSO A(t) B(t)
E[Y] 0,8 0 1 0 0,8 1,25 1
.Y 0,8 0 1 0 0,8 1,25 1
TABELA 6.9 – VALORES VERDADEIROS E RESULTADOS DA SIMULAÇÃO
DA FILA D/D/2 COM TAXA DE UTILIZAÇÃO DE 80%
Medidas L(t) Lq(t) Rn Dn NSO A(t) B(t)
E[Y] 1,6 0 1 0 1,6 0,625 1
.Y 1,6 0 1 0 1,6 0,625 1

179
TABELA 6.10 - APLICAÇÕES DAS RELAÇÕES DE LITLLE PARA OS
RESULTADOS DA SIMULAÇÃO DOS EXPERIMENTOS PARA VERIFICAÇÃO E
VALIDAÇÃO
Filas ρ T1ˆ =λ Wλ WL ˆˆˆ λ− qWλ qq WL ˆˆˆ λ− Sλ SNSO ˆˆ^λ−
% % % 20% 0,200238 0,249850 0,0125 0,049757 0,0190 0,200093 0,0106
M/M/1 80% 0,800114 3,980939 0,0134 3,180573 0,0158 0,800371 0,0032
20% 0,400446 0,416803 0,0082 0,016650 0,0226 0,400154 0,0075 M/M/2
80% 1,599159 4,421791 0,0079 2,823260 0,0109 1,598534 0,0026
E2 /H2b/5 80% 4,000469 6,383041 0,0018 2,382576 0,0035 4,000470 0,0004
H2b/E2/5 80% 4,002395 7,059956 0,0083 3,057883 0,0161 4,002065 0,0022
TABELA 6.11 - TESTES DO GERADOR DE NÚMEROS ALEATÓRIOS DO
SOFTWARE DE SIMULAÇÃO “MICRO SAINT”
Designação Teste de uniformidade
(Kolmogorov-Smirnov)
Teste de independência
(execuções acima e abaixo da média)
Amostra 3.191 observações 100 observações
Estatística D = 0,012182 Z0 = -1,102023
Valor crítico Dβ = 0,024 Zβ/2 = 1,959961
Teste Rejeitar H0 se D > Dβ Rejeitar H0 se | Z0 | > Zβ/2
Conclusão Não rejeição de H0 Não rejeição de H0
6.3 - ANÁLISE DOS RESULTADOS DA SIMULAÇÃO DA FILA Gm/Gm/2
Os valores de projeto para os experimentos de simulação da fila Gm/Gm/2 são o
período (ou tempo) de inicialização TI, o período (ou tempo) de execução TE e o período
(ou tempo) TN de execução necessário para que a aproximação normal utilizada para a
obtenção destes tempos seja ela mesma uma aproximação razoável. Estes valores foram
projetados tendo em vista a obtenção de estimativas das medidas de desempenho, em
equilíbrio, das 8 configurações de filas Gm/Gm/2 previstas no projeto de experimento

180
do modelo de simulação com uma precisão relativa especificada de 2% (ε ≤ 0,02) e um
nível de confiança da ordem de 95%. A Tabela 6.12 contém os valores iniciais de
projeto dos tamanhos necessários das execuções da simulação destas 8 configurações
de filas Gm/Gm/2, ao nível de replicações e tamanho total da simulação. O tamanho
total da simulação foi dividido em 10 replicações. O tempo de execução da simulação
foi acrescido de 25% e de 50% e colheram-se dados para o tempo original TE, para o
tempo 1,25TE e para o tempo 1,5TE .
Para 4 destes experimentos foi obtida uma precisão relativa menor ou igual a 2%
( 02,0≤ε ) para um nível de confiança da ordem de 95%, com os valores originalmente
previstos. Mas para os outros 4 experimentos foram necessários tamanhos totais de
execução da simulação maiores que os originalmente previstos, para a obtenção da
precisão relativa de 2%. Para a fila Gm/Gm/2 com 5,0 e 5,0 22 == ST cc e a fila
Gm/Gm/2 com 1 e 5,0 22 == ST cc foram necessários tempos totais de execução da
simulação 50% maiores que os valores inicialmente previstos, veja os valores na Tabela
6.13. E para a fila Gm/Gm/2 com 2 e 5,0 22 == ST cc e a fila Gm/Gm/2 com
2 e 2 22 == ST cc foram necessários tempos totais de execução da simulação 25%
maiores que os valores inicialmente previstos, veja os valores na Tabela 6.13.
Os resultados dos 8 experimentos de simulação da fila Gm/Gm/2 em equilíbrio estão
resumidos nas Tabelas 6.14 a 6.21. Os valores do período (ou tempo) de inicialização
TI, o período (ou tempo) de execução TE e o período (ou tempo) TN de execução
necessário para que a aproximação normal utilizada para a obtenção destes tempos seja
ela mesma uma aproximação razoável, utilizados na simulação destas filas para a
obtenção destes resultados, estão resumidos na Tabela 6.13.
Para todas as estimativas das medidas de performance previstas no experimento, pode-
se notar, observando o resultados resumidos nas Tabelas 6.2 a 6.7, que as meias larguras
relativas do intervalo de confiança foram inferiores a 0,02, conforme a especificação de
projeto para uma precisão relativa de 2% (ε ≤ 0,02) e um nível de confiança da ordem
de 95%.

181
TABELA 6.12 – TAMANHOS INICIAIS DOS EXPERIMENTOS DE SIMULAÇÃO
DE FILAS Gm/Gm/2 COM ρ = 75%, β = 0,05 E ε = 0,02
TE 2Tc 2
Sc TI TN Total Replicações
0,5 0,5 320 76.829 1.092.680 109.268
0,5 1 480 76.829 1.639.020 163.902
0,5 2 800 76.829 2.731.700 273.170
1 0,5 480 76.829 1.639.020 163.902
1 2 960 76.829 3.277.040 327.704
2 0,5 800 76.829 2.731.700 273.170
2 1 960 76.829 3.278.040 327.804
2 2 1280 76.829 4.370.710 437.071
TABELA 6.13 – TAMANHOS NECESSÁRIOS (FINAIS) DOS EXPERIMENTOS DE
SIMULAÇÃO DE FILAS Gm/Gm/2 COM ρ = 75%, β = 0,05 E ε = 0,02
TE 2Tc 2
Sc TI TN Total Replicações
0,5 0,5 320 76.829 1.639.020 163.902
0,5 1 480 76.829 2.458.530 245.853
0,5 2 800 76.829 3.414.620 341.462
1 0,5 480 76.829 1.639.020 163.902
1 2 960 76.829 3.277.040 327.704
2 0,5 800 76.829 2.731.700 273.170
2 1 960 76.829 3.278.040 327.804
2 2 1280 76.829 5.463.390 546.339

182
TABELA 6.14 –RESULTADOS DA SIMULAÇÃO DA FILA Gm/Gm/2 COM
5,0 E 5,0 22 == ST cc
Medidas L(t) Lq(t) Rn Dn NSO
.Y 2,351655 0,852865 1,568903 0,568987 1,498786
)ˆ.(. .Yes 0,004758 0,004100 0,002669 0,002553 0,000806
hlr 0,006575 0,015622 0,005528 0,014580 0,001748
TABELA 6.15 –RESULTADOS DA SIMULAÇÃO DA FILA Gm/Gm/2 COM
1 E 5,0 22 == ST cc
Medidas L(t) Lq(t) Rn Dn NSO
.Y 2,801454 1,302509 1,868317 0,868666 1,498975
)ˆ.(. .Yes 0,008797 0,007987 0,005483 0,005136 0,000981
hlr 0,010205 0,019929 0,009538 0,019216 0,002127
TABELA 6.16 –RESULTADOS DA SIMULAÇÃO DA FILA Gm/Gm/2 COM
2 E 5,0 22 == ST cc
Medidas L(t) Lq(t) Rn Dn NSO
.Y 3,730143 2,229307 2,484220 1,484907 1,501229
)ˆ.(. .Yes 0,012126 0,011013 0,007690 0,007104 0,001194
hlr 0,010564 0,016055 0,010060 0,015548 0,002584

183
TABELA 6.17 –RESULTADOS DA SIMULAÇÃO DA FILA Gm/Gm/2 COM
5,0 E 1 22 == ST cc
Medidas L(t) Lq(t) Rn Dn NSO
.Y 2,972005 1,470757 1,979391 0,979544 1,501253
)ˆ.(. .Yes 0,007822 0,007357 0,005222 0,004914 0,000911
hlr 0,008554 0,016257 0,008574 0,016304 0,001971
TABELA 6.18 –RESULTADOS DA SIMULAÇÃO DA FILA Gm/Gm/2 COM
2 E 1 22 == ST cc
Medidas L(t) Lq(t) Rn Dn NSO
.Y 4,354340 2,854450 2,900414 1,901683 1,500339
)ˆ.(. .Yes 0,017654 0,016858 0,011160 0,010861 0,001279
hlr 0,013176 0,019194 0,012505 0,018561 0,002771
TABELA 6.19 –RESULTADOS DA SIMULAÇÃO DA FILA Gm/Gm/2 COM
5,0 E 2 22 == ST cc
Medidas L(t) Lq(t) Rn Dn NSO
.Y 4,243076 2,742385 2,826166 1,826612 1,500694
)ˆ.(. .Yes 0,014592 0,014457 0,010224 0,009952 0,000612
hlr 0,011176 0,017133 0,011756 0,017706 0,001325

184
TABELA 6.20 –RESULTADOS DA SIMULAÇÃO DA FILA Gm/Gm/2 COM
1 E 2 22 == ST cc
Medidas L(t) Lq(t) Rn Dn NSO
.Y 4,722919 3,221298 3,141654 2,142902 1,501822
)ˆ.(. .Yes 0,014447 0,013452 0,007931 0,007800 0,001280
hlr 0,009941 0,013571 0,008204 0,011829 0,002770
TABELA 6.21 –RESULTADOS DA SIMULAÇÃO DA FILA Gm/Gm/2 COM
2 E 2 22 == ST cc
Medidas L(t) Lq(t) Rn Dn NSO
.Y 5,684333 4,185544 3,786023 2,789088 1,500329
)ˆ.(. .Yes 0,020837 0,020271 0,013374 0,013150 0,000987
hlr 0,011913 0,015740 0,011480 0,015323 0,002138
6.4 - ANÁLISE DOS RESULTADOS DA SIMULAÇÃO DA FILA C2g/C2
g/2
Os valores de projeto para os experimentos de simulação da fila C2g/C2
g/2 são o período
(ou tempo) de inicialização TI, o período (ou tempo) de execução TE e o período (ou
tempo) TN de execução necessário para que a aproximação normal utilizada para a
obtenção destes tempos seja ela mesma uma aproximação razoável. Estes valores foram
projetados tendo em vista a obtenção de estimativas das medidas de desempenho, em
equilíbrio, das 8 configurações de filas C2g/C2
g/2 previstas no projeto de experimento
do modelo de simulação com uma precisão relativa especificada de 2% (ε ≤ 0,02) e um
nível de confiança da ordem de 95%. A Tabela 6.22 contém os valores iniciais de
projeto dos tamanhos necessários das execuções da simulação destas 8 configurações
de filas C2g/C2
g/2, ao nível de replicações e tamanho total da simulação. O tamanho total
da simulação foi dividido em 10 replicações. O tempo de execução da simulação foi

185
acrescido de 25% e de 50% e colheu-se dados para o tempo original TE, para o tempo
1,25TE e para o tempo 1,5TE .
Para 6 destes experimentos foi obtida uma precisão relativa menor ou igual a 2%
( 02,0≤ε ) para um nível de confiança da ordem de 95%, com os valores originalmente
previstos. Mas para os outros 2 experimentos foram necessários tamanhos totais de
execução da simulação maiores que os originalmente previstos, para a obtenção da
precisão relativa de 2%. Para a fila C2g/C2
g/2 com 5,0 e 5,0 22 == ST cc foi necessário um
tempo total de execução da simulação 25% maior que o valor inicialmente previsto, ver
Tabela 6.23. E para a fila C2g/C2
g/2 com 5,0 e 1 22 == ST cc foi necessário um tempo total
de execução da simulação 50% maior que o valor inicialmente previsto, ver Tabela
6.23.
Os resultados dos 8 experimentos de simulação da fila C2g/C2
g/2 em equilíbrio estão
resumidos nas Tabelas 6.24 a 6.31. Os valores do período (ou tempo) de inicialização
TI, o período (ou tempo) de execução TE e o período (ou tempo) TN de execução
necessário para que a aproximação normal utilizada para a obtenção destes tempos seja
ela mesma uma aproximação razoável, utilizados na simulação destas filas para a
obtenção destes resultados, estão resumidos na Tabela 6.23.
Para todas as estimativas das medidas de performance previstas no experimento, pode-
se notar, observando o resultados resumidos nas Tabelas 6.2 a 6.7, que as meias larguras
relativas do intervalo de confiança foram inferiores a 0,02, conforme a especificação de
projeto para uma precisão relativa de 2% (ε ≤ 0,02) e um nível de confiança da ordem
de 95%.

186
TABELA 6.22 – TAMANHOS INICIAIS DOS EXPERIMENTOS DE SIMULAÇÃO
DE FILAS C2g/C2
g/2 COM ρ = 75%, β = 0,05 E ε = 0,02
TE 2Tc 2
Sc TI TN Total Replicações
0,5 0,5 320 76.829 1.092.680 109.268
0,5 1 480 76.829 1.639.020 163.902
0,5 2 800 76.829 2.731.700 273.170
1 0,5 480 76.829 1.639.020 163.902
1 2 960 76.829 3.277.040 327.704
2 0,5 800 76.829 2.731.700 273.170
2 1 960 76.829 3.278.040 327.804
2 2 1280 76.829 4.370.710 437.071
TABELA 6.23 – TAMANHOS NECESSÁRIOS (FINAIS) DOS EXPERIMENTOS DE
SIMULAÇÃO DE FILAS C2g/C2
g/2 COM ρ = 75%, β = 0,05 E ε = 0,02
TE 2Tc 2
Sc TI TN Total Replicações
0,5 0,5 320 76.829 1.365.850 136.585
0,5 1 480 76.829 1.639.020 163.902
0,5 2 800 76.829 2.731.700 273.170
1 0,5 480 76.829 2.458.530 245.853
1 2 960 76.829 3.277.040 327.704
2 0,5 800 76.829 2.731.700 273.170
2 1 960 76.829 3.278.040 327.804
2 2 1280 76.829 4.370.710 437.071

187
TABELA 6.24 –RESULTADOS DA SIMULAÇÃO DA FILA C2g/C2
g/2 COM
5,0 E 5,0 22 == ST cc
Medidas L(t) Lq(t) Rn Dn NSO
.Y 2,359004 0,857706 1,572130 0,571602 1,501309
)ˆ.(. .Yes 0,004836 0,004163 0,002923 0,002683 0,001083
hlr 0,006662 0,015772 0,006043 0,015256 0,002345
TABELA 6.25 –RESULTADOS DA SIMULAÇÃO DA FILA C2g/C2
g/2 COM
1 E 5,0 22 == ST cc
Medidas L(t) Lq(t) Rn Dn NSO
.Y 2,822637 1,320385 1,881387 0,880088 1,502259
)ˆ.(. .Yes 0,008474 0,007221 0,005291 0,004649 0,001459
hlr 0,009756 0,017773 0,009140 0,017166 0,003157
TABELA 6.26 –RESULTADOS DA SIMULAÇÃO DA FILA C2g/C2
g/2 COM
2 E 5,0 22 == ST cc
Medidas L(t) Lq(t) Rn Dn NSO
.Y 3,702472 2,203952 2,469099 1,469823 1,498635
)ˆ.(. .Yes 0,012625 0,011848 0,008139 0,007756 0,001282
hlr 0,011081 0,017470 0,010712 0,017149 0,002780

188
TABELA 6.27 –RESULTADOS DA SIMULAÇÃO DA FILA C2g/C2
g/2 COM
5,0 E 1 22 == ST cc
Medidas L(t) Lq(t) Rn Dn NSO
.Y 2,947676 1,449253 1,966438 0,966811 1,498431
)ˆ.(. .Yes 0,009677 0,008492 0,005753 0,005316 0,001273
hlr 0,010668 0,019044 0,009508 0,017869 0,002760
TABELA 6.28 –RESULTADOS DA SIMULAÇÃO DA FILA C2g/C2
g/2 COM
2 E 1 22 == ST cc
Medidas L(t) Lq(t) Rn Dn NSO
.Y 4,348587 2,849395 2,898197 1,899213 1,499520
)ˆ.(. .Yes 0,012925 0,012579 0,008882 0,008560 0,000811
hlr 0,009659 0,014347 0,009960 0,014647 0,001757
TABELA 6.29 –RESULTADOS DA SIMULAÇÃO DA FILA C2g/C2
g/2 COM
5,0 E 2 22 == ST cc
Medidas L(t) Lq(t) Rn Dn NSO
.Y 4,220540 2,721087 2,813793 1,814148 1,499437
)ˆ.(. .Yes 0,014700 0,014178 0,009026 0,008963 0,000805
hlr 0,011319 0,016933 0,010425 0,016057 0,001744

189
TABELA 6.30 –RESULTADOS DA SIMULAÇÃO DA FILA C2g/C2
g/2 COM
1 E 2 22 == ST cc
Medidas L(t) Lq(t) Rn Dn NSO
.Y 4,713201 3,211954 3,140044 2,139997 1,501417
)ˆ.(. .Yes 0,008336 0,007895 0,005472 0,005181 0,000733
hlr 0,005748 0,007988 0,005663 0,007867 0,001588
TABELA 6.31 –RESULTADOS DA SIMULAÇÃO DA FILA C2g/C2
g/2 COM
2 E 2 22 == ST cc
Medidas L(t) Lq(t) Rn Dn NSO
.Y 5,646583 4,147632 3,761805 2,763830 1,499903
)ˆ.(. .Yes 0,011788 0,011686 0,007752 0,007775 0,000906
hlr 0,006784 0,009156 0,006697 0,009142 0,001963
6.5 – ANÁLISE DOS RESULTADOS DA APROXIMAÇÃO DA FILA Gm/Gm/2
PELA FILA C2g/C2
g/2
Os valores do tempo total de execução, TE , considerados para a verificação da
aproximação das filas Gm/Gm/2 por filas C2g/C2
g/2, previstas neste trabalho, foram
determinados levando-se em consideração os valores do tempo total de execução, TE ,
para os quais obtiveram-se uma precisão relativa menor ou igual a 2% (ε ≤ 0,02) para
um nível de confiança da ordem de 95%, tanto para a fila Gm/Gm/2 quanto para a fila
C2g/C2
g/2 correspondente. Estes valores estão resumidos na Tabela 6.32.
Para a verificação destas aproximações foram consideradas as estimativas produzidas
pelas 10 replicações da simulação de uma dada fila Gm/Gm/2 contra outras produzidas
pelas 10 replicações da fila C2g/C2
g/2 correspondente. Foram determinadas as
diferenças, par-a-par, para as 10 replicações, de cada uma das 5 medidas de

190
performance consideradas neste estudo. Depois calculou-se a diferença média e o erro
padrão para cada uma das 5 medidas de performance. E, finalmente, estas estimativas da
diferença esperada entre os processos subjacentes, correspondentes, das filas Gm/Gm/2
e C2g/C2
g/2 foram submetidas a um teste de hipóteses para verificar a hipótese, H0 , de
que não existe diferença entre as amostras representativas das distribuições destes
processos, ou seja, de que estas amostras foram obtidas da mesma distribuição. Os
resultados destes testes estão resumidos nas Tabelas 6.33 a 6.40.
Observando os resultados, resumidos nas Tabelas 6.33 a 6.40, nota-se que houve falha
em rejeitar a hipótese de nulidade, H0 , para todas as comparações efetuadas entre os
processos subjacentes, correspondentes, das filas Gm/Gm/2 e C2g/C2
g/2. Desta forma,
pode-se concluir que não há evidências da existência de diferenças entre as amostras
representativas das distribuições destes processos, ou seja, não há evidências de que
estas amostras não foram obtidas da mesma distribuição.
Pode se notar que a maior diferença média relativa ocorreu para o processo Lq(t)
relativo às filas Gm/Gm/2 e C2g/C2
g/2 com 5,0 E 1 22 == ST cc e foi da ordem de
0,020351, ver a Tabela 6.36. E como estes experimentos abrangeram uma faixa de
coeficientes de variação de 0,5 a 2, pode-se concluir que a distribuição de Cox de ordem
2 com normalização gamma são aproximações muito boas para as distribuições dos
tempos entre chegadas e de serviço de filas Gm/Gm/2.

191
TABELA 6.32 – TAMANHOS DOS EXPERIMENTOS DE SIMULAÇÃO
UTILIZADOS NA VERIFICAÇÃO DA APROXIMAÇÃO DE FILAS Gm/Gm/2 POR
FILAS C2g/C2
g/2 COM ρ = 75%, β = 0,05 E ε = 0,02
TE 2Tc 2
Sc TI TN Total Replicações
0,5 0,5 320 76.829 1.639.020 163.902
0,5 1 480 76.829 2.458.530 245.853
0,5 2 800 76.829 3.414.620 341.462
1 0,5 480 76.829 2.458.530 245.853
1 2 960 76.829 3.277.040 327.704
2 0,5 800 76.829 2.731.700 273.170
2 1 960 76.829 3.278.040 327.804
2 2 1280 76.829 5.463.390 546.339
TABELA 6.33 – RESULTADO DA VERIFICAÇÃO DA APROXIMAÇÃO DA FILA
Gm/Gm/2 PELA FILA C2g/C2
g/2 COM 5,0 E 5,0 22 == ST cc
Medidas L(t) Lq(t) Rn Dn NSO
d -0,008168 -0,005670 -0,003659 -0,003126 -0,002511
2//ˆˆ
GmGmYd -0,003487 -0,006743 -0,002346 -0,005585 -0,001671
)ˆ.(. .des 0,006011 0,005399 0,003336 0,003361 0,000960
tR-1, b/2 3,249843 3,249843 3,249843 3,249843 3,249843
|t0| 1,358770 1,050131 1,096770 0,930023 2,615806
H0 aceita aceita aceita aceita aceita
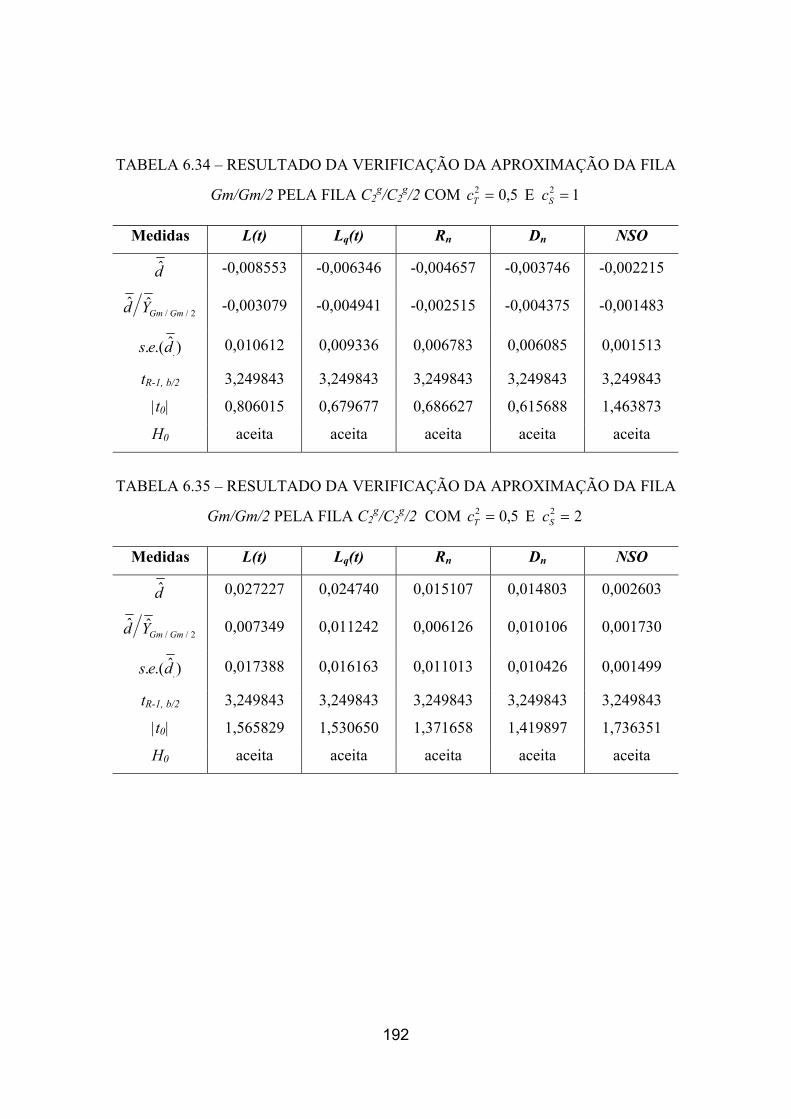
192
TABELA 6.34 – RESULTADO DA VERIFICAÇÃO DA APROXIMAÇÃO DA FILA
Gm/Gm/2 PELA FILA C2g/C2
g/2 COM 1 E 5,0 22 == ST cc
Medidas L(t) Lq(t) Rn Dn NSO
d -0,008553 -0,006346 -0,004657 -0,003746 -0,002215
2//ˆˆ
GmGmYd -0,003079 -0,004941 -0,002515 -0,004375 -0,001483
)ˆ.(. .des 0,010612 0,009336 0,006783 0,006085 0,001513
tR-1, b/2 3,249843 3,249843 3,249843 3,249843 3,249843
|t0| 0,806015 0,679677 0,686627 0,615688 1,463873
H0 aceita aceita aceita aceita aceita
TABELA 6.35 – RESULTADO DA VERIFICAÇÃO DA APROXIMAÇÃO DA FILA
Gm/Gm/2 PELA FILA C2g/C2
g/2 COM 2 E 5,0 22 == ST cc
Medidas L(t) Lq(t) Rn Dn NSO
d 0,027227 0,024740 0,015107 0,014803 0,002603
2//ˆˆ
GmGmYd 0,007349 0,011242 0,006126 0,010106 0,001730
)ˆ.(. .des 0,017388 0,016163 0,011013 0,010426 0,001499
tR-1, b/2 3,249843 3,249843 3,249843 3,249843 3,249843
|t0| 1,565829 1,530650 1,371658 1,419897 1,736351
H0 aceita aceita aceita aceita aceita

193
TABELA 6.36 – RESULTADO DA VERIFICAÇÃO DA APROXIMAÇÃO DA FILA
Gm/Gm/2 PELA FILA C2g/C2
g/2 COM 5,0 E 1 22 == ST cc
Medidas L(t) Lq(t) Rn Dn NSO
d 0,032412 0,028976 0,018341 0,017714 0,003431
2//ˆˆ
GmGmYd 0,011096 0,020351 0,009426 0,018676 0,002292
)ˆ.(. .des 0,010472 0,009442 0,006361 0,006007 0,001397
tR-1, b/2 3,249843 3,249843 3,249843 3,249843 3,249843
|t0| 3,095178 3,068930 2,883188 2,949024 2,455381
H0 aceita aceita aceita aceita aceita
TABELA 6.37 – RESULTADO DA VERIFICAÇÃO DA APROXIMAÇÃO DA FILA
Gm/Gm/2 PELA FILA C2g/C2
g/2 COM 2 E 1 22 == ST cc
Medidas L(t) Lq(t) Rn Dn NSO
d 0,005753 0,005056 0,002217 0,002470 0,000819
2//ˆˆ
GmGmYd 0,001350 0,001827 0,000780 0,001338 0,000548
)ˆ.(. .des 0,020125 0,019502 0,013529 0,013100 0,001356
tR-1, b/2 3,249843 3,249843 3,249843 3,249843 3,249843
|t0| 0,285868 0,259255 0,163866 0,188559 0,604099
H0 aceita aceita aceita aceita aceita

194
TABELA 6.38 – RESULTADO DA VERIFICAÇÃO DA APROXIMAÇÃO DA FILA
Gm/Gm/2 PELA FILA C2g/C2
g/2COM 5,0 E 2 22 == ST cc
Medidas L(t) Lq(t) Rn Dn NSO
d 0,022536 0,021298 0,012374 0,012464 0,001257
2//ˆˆ
GmGmYd 0,005375 0,007898 0,004424 0,006928 0,000840
)ˆ.(. .des 0,023829 0,023435 0,015708 0,015519 0,000977
tR-1, b/2 3,249843 3,249843 3,249843 3,249843 3,249843
|t0| 0,945721 0,908787 0,787700 0,803112 1,286343
H0 aceita aceita aceita aceita aceita
TABELA 6.39 – RESULTADO DA VERIFICAÇÃO DA APROXIMAÇÃO DA FILA
Gm/Gm/2 PELA FILA C2g/C2
g/2 COM 1 E 2 22 == ST cc
Medidas L(t) Lq(t) Rn Dn NSO
d 0,009718 0,009344 0,001610 0,002905 0,000405
2//ˆˆ
GmGmYd 0,002077 0,002942 0,000517 0,001374 0,000270
)ˆ.(. .des 0,011535 0,010387 0,006038 0,005786 0,001275
tR-1, b/2 3,249843 3,249843 3,249843 3,249843 3,249843
|t0| 0,842544 0,899557 0,266707 0,502049 0,317547
H0 aceita aceita aceita aceita aceita

195
TABELA 6.40 – RESULTADO DA VERIFICAÇÃO DA APROXIMAÇÃO DA FILA
Gm/Gm/2 PELA FILA C2g/C2
g/2 COM 2 E 2 22 == ST cc
Medidas L(t) Lq(t) Rn Dn NSO
d 0,034268 0,033888 0,021713 0,022085 0,000477
2//ˆˆ
GmGmYd 0,006098 0,008220 0,005801 0,008040 0,000318
)ˆ.(. .des 0,017661 0,017475 0,012261 0,012045 0,000922
tR-1, b/2 3,249843 3,249843 3,249843 3,249843 3,249843
|t0| 1,940306 1,939216 1,770836 1,833466 0,517614
H0 aceita aceita aceita aceita aceita

197
CAPÍTULO 7
CONCLUSÕES E COMENTÁRIOS
Este trabalho trata da obtenção de medidas de desempenho de filas GI/G/m através de
simulação. Também é tratado a verificação de aproximações de filas GI/G/m por filas
Ph/Ph/m.
Os modelos de simulação por computadores, apesar de exigirem muitos recursos de
“hardware” (memória de trabalho e de armazenamento de massa, velocidade de
processamento da CPU) e consumirem muito tempo na execução das rodadas da
simulação, permitem considerações mais próximas das situações reais. E por esta razão
eles podem ser bastante úteis na checagem de suposições, necessárias, num modelo
analítico, e na checagem dos resultados do modelo analítico.
As estimativas obtidas através de simulação podem ser mais confiáveis (exatas e
precisas) que aquelas obtidas através de aproximações analíticas, desde que sejam
obtidas através de uma metodologia apropriada de análise dos dados de saída da
simulação.
A metodologia de análise dos dados de saída da simulação já está formalizada e pode
ser encontrada em manuais dedicados à simulação, por exemplo: Banks e Carson II
(1984) e Law e Kelton (1982).
Desta forma, a atenção se volta para a verificação e validação do modelo de simulação e
para a obtenção dos dados de saída da simulação que satisfaçam os requisitos
especificados. Em outras palavras, o problema se resume à especificação do projeto de
experimento que possa produzir dados de saídas da simulação que satisfaçam os
requisitos especificados e à verificação e validação do modelo de simulação.
A especificação do projeto de experimento da simulação se refere à estratégia de
simulação e aos valores do período de inicialização TI e do período de execução da
simulação TE. A estratégia de simulação adotada neste estudo foi a de replicações
independentes com o descarte de uma porção inicial dos dados de cada replicação.

198
Foram considerados 3 tamanhos de execução da simulação, a saber, os períodos TE ,
1,25TE e 1,5TE . Os valores do período de inicialização TI e do período de execução da
simulação TE foram determinados através das seguintes equações:
a) A equação em (5.16) para o período de inicialização TI ;
b) A equação em (5.57) para o período de execução TE ;
c) A equação em (5.58) para o período de execução TN , com ρ = 1.
É importante salientar que as equações para a determinação dos períodos de execução
TE e de inicialização TI levam em consideração a taxa de utilização do sistema, ρ , e os
quadrados dos coeficientes de variação dos processos de chegada e de serviço da fila
GI/G/m. O tamanho da execução TE e da inicialização TI são aproximadamente
proporcionais a ( )211 ρ− chegadas e a 22ST cc + . Observa-se, também, que o tamanho
da execução TE é proporcional a 21 ε , onde ε é a precisão estatística especificada.
A estratégia de simulação por replicações independentes, com os períodos de execução
TE , 1,25TE e 1,5TE e período de inicialização TI, se mostrou adequada para a obtenção
das estimativas das medidas de performance das filas GI/G/m previstas nos
experimentos deste estudo, com a precisão especificada de 2% (ε = 0,02) para um nível
de confiança de 95%. Foram consideradas as filas D/D/m, M/M/m, E2/H2b/5 e H2
b/E2/5
simuladas para os experimentos de verificação e validação do modelo de simulação e,
para as filas Gm/Gm/m e C2g/C2
g/m simuladas para a verificação das aproximações de
filas GI/G/m por filas Ph/Ph/m.
Para todos os experimentos de verificação e validação do modelo simulado, o período
de inicialização TI foi suficiente para uma adequada remoção do vício relativo; o vício
foi sempre menor que 1% (ou 0,01) para a filas M/M/m, E2/H2b/5 e H2
b/E2/5 e, igual a
zero para as filas D/D/m.
Para cinco dos oito experimentos de verificação e validação do modelo simulado, o
tempo de execução TE foi suficiente, necessitando apenas para três experimentos um

199
tempo de execução de 1,25TE ou 1,5TE . Para as filas D/D/m, as estimativas das medidas
de performance obtidas foram exatamente aquelas obtidas através de modelos
analíticos. E, para a filas M/M/m, E2/H2b/5 e H2
b/E2/5 com um e dois servidores e taxas
de utilização do sistema de 20% e 80% (tráfego leve e tráfego pesado), foram obtidos
resultados com uma precisão relativa menor ou igual 2% (ε = 0,02). Para as filas
M/M/m, E2/H2b/5 e H2
b/E2/5, a probabilidade de cobertura observada – a probabilidade
de que o intervalo de confiança contenha o valor verdadeiro da medida de performance
em consideração – foi de 100% para todas as medidas de performance consideradas.
Para os oito experimentos com as filas Gm/Gm/2 e os oito experimentos com as filas
C2g/C2
g/2, todas com quadrados dos coeficientes de variação dos processos de chegadas
e de serviços pertencentes ao intervalo [0,5; 2], foram obtidos resultados com uma
precisão relativa menor ou igual 2% (ε = 0,02). Para a metade dos experimentos com as
filas Gm/Gm/2 e para 6 dos experimentos com as filas C2g/C2
g/2, o tempo de execução
TE foi suficiente, para os outros experimentos foram necessários tempos de execução da
ordem de 1,25TE ou 1,5TE .
Desta forma, a Equação (5.16) para a determinação do período de inicialização se
mostrou adequada para a remoção do vício. E a Equação (5.57) quando multiplicada por
um fator de no máximo 1,5 se mostrou suficiente para a obtenção de estimativas dentro
de uma precisão estatística relativa especificada das configurações de filas GI/G/2
previstas nos experimentos. Mas parece razoável que fossem executados experimentos
com outras configurações de filas GI/G/m, com processos de chegadas e ou de serviços
distribuídos segundo a distribuição de Weibull, por exemplo: W/W/m, Gm/W/m,
W/Gm/m.
Observando a equação (5.57), nota-se que o período de execução TE é crescente para
15,0 <≤ ρ e decrescente para 5,00 ≤≤ ρ . Consequentemente o período de execução TE
é o mesmo para ρ = 0,1 e ρ = 0,9. Questiona-se, então, se a equação em (5.57) é
adequada para a determinação do período de execução TE para 5,00 ≤≤ ρ , pois estes
períodos de execução TE parecem longos demais para esta faixa de variação de ρ. Não

200
seria suficiente um período de execução TE da ordem daquele para ρ = 0,5 ou menor do
que este período para a faixa de taxas de utilização do sistema 5,00 ≤≤ ρ .
Os experimentos para verificação de aproximações de filas GI/G/m por filas Ph/Ph/m
indicam que filas Gm/Gm/m são muito bem aproximadas por filas C2g/C2
g/m, mas será
que, também, seriam bem aproximadas por filas C2b/C2
b/m, ou por outras configurações
de filas Ph/Ph/m, com distribuições dos tempos entre chegadas e de serviço dadas por
Ek-1, k , H2b ou H2
g? E as filas W/W/m, Gm/W/m e W/Gm/m seriam bem aproximadas por
filas C2g/C2
g/m,ou por filas C2b/C2
b/m, ou por outras configurações simples de filas
Ph/Ph/m?
Desta forma deixa-se como sugestão para outras investigações as seguintes questões:
• Será que o tamanho da execução de simulações de 1,5TE é adequado para
configurações de filas GI/G/m, com processos de chegadas e ou de serviços
distribuídos segundo a distribuição de Weibull, por exemplo: W/W/m, Gm/W/m,
W/Gm/m?
• Dever-se-ia investigar alguma mudança na equação (5.57) que produzisse tempos
de execuções adequados para a faixa de taxas de utilização do sistema
5,00 ≤≤ ρ ? Pois aqueles produzidos pela equação (5.57) parecem
excessivamente longos.
• Dever-se-ia investigar se filas Gm/Gm/m seriam bem aproximadas por filas
C2b/C2
b/m, ou por outras configurações de filas Ph/Ph/m, com distribuições dos
tempos entre chegadas e de serviço dadas por Ek-1, k , H2b ou H2
g?
• Dever-se-ia investigar se filas W/W/m, Gm/W/m e W/Gm/m seriam bem
aproximadas por filas C2g/C2
g/m, ou por filas C2b/C2
b/m, ou por outras
configurações simples de filas Ph/Ph/m?

201
REFERÊNCIAS BIBLIOGRÁFICAS
Allen, A. O. Probability, statistics, and queueing theory with coputer science
applications. San Diego: Academic Press Ic., 1990. 740 p.
Banks, J.; Carson II, J. S. Discrete-event system simulation. Englewood Cliffs:
Prentice-Hall, 1984. 514 p.
Banks, J.; Carson II, J. S.; Goldsman, D. Computer simulation. In: Wadsworth Jr., H.
M. ed. Handbook of statistical methods for engineers and scientists. New
York: McGraw-Hill, 1990, Cap.12, p. 12.1-12.36.
Bobbio, A.; Cumani, A. ML estimation of parameters of a PH distribution in triangular
canonical form. In: Balbo, G.; Serazzi, G. ed. Computer performance
evaluation. Amsterdam: Elsevier Science Publishers B.V., 1992, p. 33-45.
Bobbio, A.; Telek, M. Parameter estimation of phase type distributions. Torino:
Instituto Eletrotecnico Nazionale Galileo Ferraris, 1992. 51 p. (R.T. 423/1992).
Carson II, J. S. Verification and validation: a consultant’s perspective. In: Winter
Simulation Conference, Washington, 1989. Proceedings. New York: Heidelberg,
P.; MacNair, E. A.; Musselman, K. J. ed., 1989, p. 552-558.
Carvalho, S.V. Modèles stochastiques appliqués a l’optimisation de la performance
et de la sûrete de fonctionnement des systèmes de production. Toulouse. Tese
(Doutorado em Automática e Engenharia de Produção) - Université Paul Sabatier,
1991.
Delaney, C. P. T. P. J.; Rossetti, M. D. Control of initialization bias in queueing
simulations using queueing approximations. In: Winter Simulation Conference,
Arlington, 1995. Proceedings. New York: Alexpoulos, C.; Kang, K.; Lilegdon,
W.R.; Goldsman, D. ed., 1995, p. 322-329.
Delaney, C. P. T. P. J.; Rossetti, M. D.; White Jr., K. P. Generalizing the half-width
minimization heuristic for mitigating initialization bias. In: IEEE International

202
Conference on Systems, Man and Cybernetics: Intelligent Systems for the 21st
Century, Vancouver, 1995. Proccedings. Piscataway: IEE, 1995, v. 1, p. 212-216.
Flannery, B.P.; Press, W.H.; Teukolsky, S.A. ; Vetterling, W.T. Special Functions. In:
Numerical recipies in C – the art of scientific computing. New York:
Cambridge University Press, 1990, Cap. 6, p. 213-216.
Gottfried, B. S. Elements of stochastic process simulation. Englewood Cliffs:
Prentice-Hall, 1984. 300 p.
Gross, D; Harris, C. M. Fundamentals of queueing theory. New York: John Wiley &
Sons, 1974. 556 p.
Kleijnen, J. P. C. Verification and validation of simulation models. European Journal
of Operational Research, v .82, n. 1, p. 145-162, 1995.
Kleinrock, L. Queueing systems: theory. New York: Jonh Wiley & Sons, 1975, v. 1,
417 p.
Kleinrock, L. Queueing systems: computer applications. New York: Jonh Wiley &
Sons, 1976, v. 2. 549 p.
Law, A. M.; Kelton, W. D. Simulation modeling and analysis. New York: McGraw-
Hill, 1982. 400 p.
Meyer, Paul L. Probabilidade: aplicações à estatística. Rio de Janeiro: Livros
Técnicos e Científicos, 1978. 391 p.
Miranda, M. N. Aproximação de distribuições de probabilidades não exponenciais
por distribuições do tipo fase. Dissertação (mestrado em Computação Aplicada)
- Instituto Nacional de Pesquisas Espaciais, 1996.
Neuts, M. F. Matrix-geometric solutions in stochastic models. Baltimore: The Johns
Hopkins University Press, 1981. 332 p.

203
Odoni, A. R.; Roth, E. An empirical investigation of the transient behavior of stationary
queueing systems. Operations Research, v. 31, n. 3, p. 432-455, 1983.
Poole, T.G.; Szymankiewicz, J. Using simulation to solve problems. London:
MacGraw Hill, 1977.
Roth, E. The relaxation time heuristic for the initial transient problem in M/M/k
queueing systems. European Journal of Operational Research, v. 72, p. 376-
386, 1994.
Spiegel, M. R. Manual de fórmulas, métodos e tabelas de matemática. 2. ed. Rio
de Janeiro: Mc Graw Hill, 1992. 419 p.
Tijms, H. C. Stochastic modeling and analysis: A Computational Approach.
Chichester: John Wiley & Sons, 1986. 418 p.
Tijms, H. C. Stochastic models: An Algorithmic Approach. Chichester: John Wiley &
Sons, 1994. 375 p.
Whitt, W. Planning queueing simulations. Management Science, v. 35, n. 11, p. 1341-
1366, 1989a.
Whitt, W. Simulation run length planning. In: Winter Simulation Conference,
Washington, 1989. Proceedings. New York: Heidelberg, P.; MacNair, E. A.;
Musselman, K. J. ed., 1989b, p. 106-112.
Whitt, W. The efficiency of one long run versus independent replications in steady-
state simulation. Management Science, v. 37, n. 6, p. 645-666, 1991.
Whitt, W. A pproximations for the GI/G/m Queue. Production and Operations
Management, v. 2, n. 2 , p. 114-161, 1993.
Wolff, R. W. Stochastic modeling and the theory of queues. Englewood Cliffs:
Prentice Hall, 1989. 555 p.

204

205
APÊNDICE 1 – VARIÁVEIS E CÓDIGOS DO MODELO PROGRAMADO
VARIÁVEIS E VETORES
• Variáveis de sistema
• clock - variável real de controle do tempo decorrido (em unidades de tempo de
simulação) desde o início da execução do modelo
• duration - variável real de controle do tempo gasto (em unidades de tempo de
simulação) por cada entidade na atividade ou fila em que ela se encontra no
momento
• run - variável inteira que controla o número da execução corrente.
• tag - variável inteira de controle da identificação de cada entidade, quando se tem
múltiplas entidades em processamento na rede de atividades
• Variáveis inteiras
• i - contador de propósito geral
• j - contador de propósito geral
• s - variável inteira que armazena o número de servidores no sistema
• Variáveis reais
• aux – variável auxiliar de propósito geral
• cc2 – variável real que armazena o quadrado do coeficiente de variação da
distribuição de chegadas
• cs2 - variável real que armazena o quadrado do coeficiente de variação da
distribuição de serviços

206
• L2 - contador do número de clientes que deixaram o sistema
• L4 - contador do número de chegadas de clientes no sistema
• L5 - contador do número de saídas de clientes da fila 4 (fila de clientes esperando
para serem servidos)
• mc - variável real que armazena a média da distribuição de chegadas
• ms - variável real que armazena a média da distribuição de serviços
• a[ ] - vetor de reais usado como variável auxiliar
• a[0] - usado como variável auxiliar na geração de tempos de serviço
• a[1] - usado como variável auxiliar para armazenar a época da observação anterior
• a[2] - usado como variável auxiliar para armazenar o somatório dos produtos
relativos ao número de clientes presentes no sistema , L[0], pelo intervalo de
tempo entre observações, T[4]
• a[3] - usado como variável auxiliar para armazenar o somatório dos intervalos de
tempo entre observações, T[4]
• a[4] - usado como variável auxiliar para armazenar o somatório dos produtos
relativos ao número de clientes esperando na fila, L[1], pelo intervalo de tempo
entre observações, T[4]
• a[5] - usado como variável auxiliar para armazenar o somatório dos intervalos de
tempo entre chegadas, T[0]
• a[6] - usado como variável auxiliar para armazenar o somatório dos tempos de
serviço, T[tag], 100 < tag ≤ 16960
• a[7] - usado como variável auxiliar para armazenar o somatório dos tempos de
espera de clientes na fila, a[tag]

207
• a[8] - usado como variável auxiliar para armazenar o somatório dos tempos de
permanência de clientes no sistema, E[tag]
• a[9] - usado como variável auxiliar para armazenar a época da saída anterior
• a[10] - usado como variável auxiliar para armazenar a época da saída atual
• a[11] - usado como variável auxiliar para armazenar o somatório dos tempos entre
saídas, T[3]
• a[12] - usado como variável auxiliar para armazenar a época da alteração anterior
• a[13] - usado como variável auxiliar para armazenar o somatório dos produtos
relativos ao número de servidores ocupados, c[4], pelo intervalo de tempo entre
duas alterações consecutivas do número de servidores ociosos, T[5]
• a[14] - usado como variável auxiliar para armazenar o somatório dos tempos entre
alterações, T[5]
• a[15] – duração do serviço do n-ésimo cliente
• a[16] – duração da espera na fila do n-ésimo cliente
• c[ ] - vetor de inteiros usado como variável auxiliar - contador
• c[0] - contador do número de servidores livres
• c[1] - contador auxiliar na liberação da atividade Serv. Ociosos - conta o número
de servidores livres
• c[2] - variável de estado auxiliar na liberação da atividade Serv. Ociosos (0 =
liberar e 1 = não liberar)
• c[3] - variável de estado auxiliar na liberação da atividade Posto de Serviço (1 =
liberar e 0 = não liberar)

208
• c[4] - contador do número de servidores ocupados
• d[i] - vetor de reais usado para armazenar a declividade do intervalo i de uma
distribuição de freqüências
• k[ ] - vetor de inteiros usado para armazenar o número de fases ou o número de
intervalos de uma distribuição
• p[ ] - vetor de reais usado para armazenar as probabilidades de transição para
uma distribuição ou o limite inferior do intervalo i relativo ao eixo dos
intervalos de uma distribuição de freqüências
• t[ ] - vetor de reais usado para armazenar as taxas de transição para uma
distribuição ou o limite inferior das freqüências relativas acumuladas no
intervalo i
• ta[ ] - vetor de reais usado para armazenar os tempos de atividades gerados
para a atividade chegar e a atividade servir
• E[ ] - vetor de reais usado para armazenar as medidas de desempenho do
sistema (médias)
• E[0] - usado para armazenar o número médio de clientes no sistema
• E[1] - usado para armazenar o número médio de clientes esperando na fila
• E[2] - usado para armazenar o tempo médio entre duas chegadas de clientes no
sistema
• E[3] - usado para armazenar o tempo médio de serviço
• E[4] - usado para armazenar o tempo médio de espera de clientes na fila
• E[5] - usado para armazenar o tempo médio de permanência de clientes no
sistema

209
• E[6] - usado para armazenar o tempo médio entre saídas de clientes do sistema
• E[7] - usado para armazenar o número médio de servidores ocupados
• L[ ] - vetor de inteiros usado como variável/contador de clientes
• L[0] - contador do número de clientes presentes no sistema
• L[1] - contador do número de clientes esperando na fila
• L[3] - contador do número de clientes servidos (número de serviços)
• T[ ] - vetor de reais usado para registro de tempos
• T[0] - usado para armazenar o tempo entre duas chegadas consecutivas de clientes
• T[2] - usado para armazenar o tempo de permanência de um cliente arbitrário no
sistema
• T[3] - usado para armazenar o tempo entre duas saídas consecutivas de clientes
• T[4] - usado para armazenar o tempo entre duas observações consecutivas de
clientes
• T[5] - usado para armazenar o tempo entre duas alterações consecutivas do
número de servidores ociosos
CÓDIGOS PARA O CÁLCULO DAS MEDIDAS DE DESEMPENHO DO
SISTEMA
• Cálculo de E[0]
• ending effects da atividade Chegar.
T[4]:=clock-a[1]; a[1]:=clock; a[2]:=a[2]+L[0]*T[4]; a[3]:=a[3]+T[4];
E[0]:=a[2]/a[3]; L[0]:=L[0]+1;

210
• beginning effects da atividade Sair.
if ((tag<=0)|(tag>100)) then T[4]:=clock-a[1], a[1]:=clock,
a[2]:=a[2]+L[0]*T[4], a[3]:=a[3]+T[4], E[0]:=a[2]/a[3], L[0]:=L[0]-1;
• Cálculo de E[1]
• ending effects da atividade Chegar.
a[4]:=a[4]+L[1]*T[4]; E[1]:=a[4]/a[3];
• ending effect da atividade Chegar
L[1]:=L[1]+1;
• beginning effect da atividade Posto-serviço
L[1]:=L[1]-1;
• beginning effects da atividade Sair
if ((tag<=0)|(tag>100)) then a[4]:=a[4]+L[1]*T[4], E[1]:=a[4]/a[3];
• Cálculo de E[2]
• launch effect da atividade Chegar
T[0]:=duration;
• ending effect da atividade Chegar
a[5]:=a[5]+T[0]; L4:=L4+1; E[2]:=a[5]/L4;
• Cálculo de E[3]
• launch effect da atividade Servir

211
if ((tag<=0)|(tag>100)) then a[15]:=duration, L2:=L2+1, a[6]:=a[6]+duration,
E[3]:=a[6]/L2;
• Cálculo de E[4]
• departing effect queue 4
a[16]:=duration;
• beginning effect atividade Posto-Serviço
a[7]:=a[7]+a[16]; L5:=L5+1; E[4]:=a[7]/L5;
• Cálculo de E[5]
• Departing effect da fila 4
a[16]:=duration;
• launch effect da atividade Servir
if ((tag<=0)|(tag>100)) then L2:=L2+1, a[8]:=a[8]+durantion+a[16],
E[5]:=a[8]/L2;
• Cálculo de E[6].
• ending effect da atividade Sair
if L2<>0 then a[9]:=a[10], a[10]:=clock, T[3]:=a[10]-a[9], a[11]:=a[11]+T[3],
E[6]:=a[11]/L2;
• Cálculo de E[7].
• entering effect queue 5
if clock>0 then c[4]:=s-c[0], T[5]:=clock-a[12], a[12]:=clock,
a[13]:=a[13]+c[4]*T[5], a[14]:=a[14]+T[5], E[7]:=a[13]/a[14];

212
• departing effect queue 5
c[4]:=s-c[0]; T[5]:=clock-a[12]; a[12]:=clock; a[13]:=a[13]+c[4]*T[5];
a[14]:=a[14]+T[5]; E[7]:=a[13]/a[14];
• Códigos de controle.
• controle de parada de uma execução
• ending effect da atividade servir.
if tag== ???? then halt();
• controle da ordenação (rotulação ou numeração) dos clientes
• ending effect da atividade servir.
if tag==0 then tag:=101 else tag:=tag+1;
• controle da ordenação (rotulação ou numeração) dos servidores
• ending effect da atividade Gerar-servidor.
tag:=tag+1;
• nó de decisão após a atividade Gerar-servidor.
tag < s;
• controle da liberação de clientes da fila
• release condition da atividade Posto-serviço.
c[3]==1 & L[1]>0;
• entering effect queue 4
L[1]:=L[1]+1;

213
• beginning effect da atividade Posto-serviço.
c[3]:=0; L[1]:=L[1]-1;
• departing effect queue 5
c[3]:=1;
• controle da liberação de servidores ociosos
• release condition da atividade Serv. Ociosos.
L[1]>0 & c[1]>0 & c[2]==0;
• entering effect queue 5
c[1]:=c[1]+1;
• beginning effect da atividade Serv. Ociosos.
c[1]:=c[1]-1; c[2]:=1;
• ending effect da atividade Serv. Ociosos
c[2]:=0;
• controle de roteamento das entidades (clientes ou servidores)
• nó de decisão 1
• condição de roteamento para a atividade 2: 1;
• condição de roteamento para a atividade 3: 1;
• nó de decisão 2
• condição de roteamento para a atividade 4: 1;

214
• condição de roteamento para a atividade 2: 1;
• nó de decisão 3
• condição de roteamento para a atividade 5: 1;
• condição de roteamento para a atividade 3: tag<s;
• nó de decisão 6
• condição de roteamento para a atividade 5: (tag>0)&(tag<=100);
• condição de roteamento para a atividade 7: (tag<0)|(tag>100);
FUNÇÕES E DISTRIBUIÇÕES
• Funções e distribuições embutidas no Micro Saint
• gamma - retorna um número aleatório de uma distribuição gamma e seus
parâmetros de definição são a média e o desvio padrão.
• exponencial - retorna um número aleatório de uma distribuição exponencial e seu
parâmetro de definição é a média.
• weibull - retorna um número aleatório de uma distribuição de weibull e seus
parâmetros de definição são o de escala (scale) e o de forma (shape), os quais são
obtidos a partir da média e do coeficiente de variação.
• Funções desenvolvidas para o modelo
• cox - retorna um número aleatório de uma distribuição de cox e seus parâmetros
de definição são a média e o coeficiente de variação.
• erlang - retorna um número aleatório de uma distribuição de erlang e seus
parâmetros de definição são a média e o coeficiente de variação.

215
• hiperexponencial – retorna um número aleatório de uma distribuição
Hiperexponencial e seus parâmetros de definição são a média e o coeficiente de
variação.
• mistura de Elangs de ordem k e k-1 - retorna um número aleatório de uma
distribuição mistura de Elangs de ordem k e k-1 e seus parâmetros de definição
são a média e o coeficiente de variação.
• histograma - retorna um número aleatório de uma distribuição de valores
empíricos.
• Código para a distribuição COX
• auxcox_c {fornece as probabilidades p[] e as taxas t[] para uma distribuição dos
tempos entre chegadas cox}
if cc2==0.5 then t[8]:=mc/2; if cc2>0.5 then t[9]:=(2/mc)*(1+((cc2-
1/2)/(cc2+1))^(1/2)), t[10]:=(4/mc)-t[9], p[6]:=(t[10]/t[9])*(t[9]*mc-1);
• auxcox_s {fornece as probabilidades p[] e as taxas t[] para uma distribuição dos
tempos de serviços cox}
if cs2==0.5 then t[11]:=ms/2; if cs2>0.5 then t[12]:=(2/ms)*(1+((cs2-
1/2)/(cs2+1))^(1/2)), t[13]:=(4/ms)-t[12], p[7]:=(t[13]/t[12])*(t[12]*ms-1);
• coxian_s {gerar tempos de serviço conforme a distribuição cox}
ta[1]:=0; if cs2==0.5 then ta[1]:=expon(t[11])+expon(t[11]); if cs2>0.5 then
acx2;
• coxian_c {gerar tempos de chegadas conforme a distribuição cox}
ta[0]:=0; if cc2==0.5 then ta[0]:=expon(t[8])+expon(t[8]); if cc2>0.5 then acx1;
• acx1 {auxiliar de coxian_c}

216
if random()<=p[6] then ta[0]:=expon(1/t[9])+expon(1/t[10]) else
ta[0]:=expon(1/t[9]);
• acx2 {auxiliar de coxian_s}
if random()<=p[7] then ta[1]:=expon(1/t[12])+expon(1/t[13]) else
ta[1]:=expon(1/t[12]);
• Código para a distribuição ERLANG
• auxerlang_c {fornece parâmetros para a distribuição dos tempos de chegadas
Erlang}
k[2]:=truncate(1/cc2); t[6]:=mc/k[2];
• auxerlang_s {fornece parâmetros para a distribuição dos tempos de serviços
Erlang}
k[3]:=truncate(1/cs2); t[7]:=ms/k[3];
• erlangian_c {gera tempos de chegada conforme a distribuição erlang}
i:=1; ta[0]:=0; while i<=k[2] do ta[0]:=ta[0]+expon(t[6]), i:=i+1;
• erlangian_s {gera tempos de serviço conforme a distribuição erlang}
i:=1; ta[1]:=0; while i<=k[3] do ta[1]:=ta[1]+expon(t[7]), i:=i+1;
• Código para a distribuição HIPEREXPONENCIAL
• auxhiperex_c {fornece parâmetros para a distribuição dos tempos de chegadas
Hiperexponencial}
if cc2>1 then p[1]:=(1/2)*(1+((cc2-1)/(cc2+1))^(1/2)), p[2]:=1-p[1],
t[1]:=1/(2*p[1]/mc), t[2]:=1/(2*p[2]/mc);

217
• auxhiperex_s {fornece parâmetros para a distribuição dos tempos de serviços
Hiperexponencial}
if cs2>1 then p[4]:=(1/2)*(1+((cs2-1)/(cs2+1))^(1/2)), p[5]:=1-p[4],
t[4]:=1/(2*p[4]/ms), t[5]:=1/(2*p[5]/ms);
• hiperexp_c {gera tempos de chegadas conforme a distribuição
Hiperexponencial}
if random()<=p[1] then ta[0]:= expon(t[1]) else ta[0]:=expon(t[2]); ta[0];
• hiperexp_s {gera tempos de serviços conforme a distribuição Hiperexponencial}
if random()<=p[4] then ta[1]:= expon(t[4]) else ta[1]:=expon(t[5]); ta[1];
• Código para a distribuição MISTURA DE ERLANGS DE ORDEM k e k-1
• auxmistura_c {fornece parâmetros para a distribuição dos tempos de chegadas
misturas de Erlangs de ordem k e k-1}
if cc2<1 then aux:=1/cc2, k[0]:=1+truncate(aux), p[0]:=(1/(1+cc2))*(k[0]*cc2-
(k[0]*(1+cc2)-k[0]^2*cc2)^(1/2)), t[0]:=1/((k[0]-p[0])/mc);
• auxmistura_s {fornece parâmetros para a distribuição dos tempos de serviços
mistura de Erlangs de ordem k e k-1}
if cs2<1 then k[1]:=1+truncate(1/cs2), p[3]:=(1/(1+cs2))*(k[1]*cs2-
(k[1]*(1+cs2)-k[1]^2*cs2)^(1/2)), t[3]:=1/((k[1]-p[3])/ms);
• mistura_c {gera tempos de chegadas conforme a distribuição mistura de
Erlangs de ordem k e k-1}
i:=1; while i<k[0]-1 do ta[0]:=ta[0]+expon(t[0]), i:=i+1; if random()<=p[0]
then ta[0]:=ta[0]+expon(t[0]) else ta[0]:=ta[0]+expon(t[0]),
ta[0]:=ta[0]+expon(t[0]); ta[0];

218
• mistura_s {gera tempos de serviços conforme a distribuição mistura de Erlangs
de ordem k e k-1}
i:=1; while i<k[1]-1 do ta[1]:=ta[1]+expon(t[3]), i:=i+1; if random()<=p[3] then
ta[1]:=ta[1]+expon(t[3]) else ta[1]:=ta[1]+expon(t[3]),
ta[1]:=ta[1]+expon(t[3]); ta[1];
• Código para a distribuição HISTOGRAMA
• histograma_c {gera tempos de chegada distribuídos conforme um Histograma}
mc:=randon(); i:=14; j:=14; while j<=k[4] do if p[i]<=mc then j:=k[4]+14
else i:=i+1, j:=j+1; ta[0]:=t[i]+d[i]*(mc-p[i]);
• histograma_s {gera tempos de serviço distribuídos conforme um Histograma}
ms:=randon(); i:=64; j:=64; while j-64<=k[5] do if p[i]<=ms then
j:=k[5]+64 else i:=i+1, j:=j+1; ta[1]:=t[i]+d[i]*(ms-p[i]);
• Funções desenvolvidas para outros software
• Determinação dos parâmetros da distribuição Weibull
O código para a determinação dos parâmetros da distribuição Weibull foi
desenvolvido no LINGO (versão educacional), que é um pacote comercial de
programação não-linear.
• Código para a Determinação dos parâmetros da distribuição Weibull
model:
!determina os parâmetros a (scale) e b (shape) de uma distribuição Weibull;
!dados a média (m) e o coeficiente de variação (c);
!Para c^2<1 tem-se que b>1, para c^2>1 tem-se b<1, e para c=1 tem-se b=1;

219
a=m/gama1;
a=(m^2*(c^2+1)/gama2)^(1/2);
gama1=(1/b+5.5)^(1/b+0.5)*(1/@EXP(1/b+5.5))*(2*3.14159265358979323846
2643)^0.5*(1+(76.18009172947146/(1/b+1))-
(86.50532032941677/(1/b+2))+(24.01409824083091/(1/b+3))-
(1.231739572450155/(1/b+4))+(0.001208650973866179/(1/b+5))-
(0.000005395239384953/(1/b+6))+0.00000000019999999999);
gama2=(2/b+5.5)^(2/b+0.5)*(1/@EXP(2/b+5.5))*(2*3.14159265358979323846
2643)^0.5*(1+(76.18009172947146/(2/b+1))-
(86.50532032941677/(2/b+2))+(24.01409824083091/(2/b+3))-
(1.231739572450155/(2/b+4))+(0.001208650973866179/(2/b+5))-
(0.000005395239384953/(2/b+6))+0.00000000019999999999);
a>0;
b>0;
c=0.5;
m=5;
end
• Funções auxiliares.
• cox_c {auxiliar da geração de tempos chegada coxian}
coxian_c; ta[0];
• cox_s {auxiliar da geração de tempos serviço coxian}
if (tag>0)&(tag<=100) then coxian_s, ta[1], a[0]:=ta[1] else a[0]; a[0];
• erlang_c {auxiliar da geração de tempos chegada erlang}

220
erlangian_c; ta[0];
• erlang_s {auxiliar da geração de tempos serviço erlang}
if (tag>0)&(tag<=100) then erlangian_s, ta[1], a[0]:=ta[1] else a[0]; a[0];
• E_k_1_k_c {auxiliar da geração de tempos chegadas de uma mistura de Erlangs
de ordem k e k-1}
mistura_c; ta[0];
• E_k_1_k_s {auxiliar da geração de tempos serviços de uma mistura de Erlangs de
ordem k e k-1}
if (tag>0)&(tag<=100) then mistura_s, ta[1], a[0]:=ta[1] else a[0]; a[0];
• hiperexpon_c {auxiliar da geração de tempos chegadas de uma Hiperexponencial
de ordem k}
hiperexp_c; ta[0];
• hiperexpon_s {auxiliar da geração de tempos serviços de uma Hiperexponencial
de ordem k }
if (tag>0)&(tag<=100) then hiperexp_s, ta[1], a[0]:=ta[1] else a[0]; a[0];
• histogra_c { auxiliar da geração de tempos chegada histograma}
histograma_c; ta[0];
• histogra_s { auxiliar da geração de tempos serviço histograma}
if (tag>0)&(tag<=100) then histograma_s, a[0]:=ta[1] else a[0]; a[0];