Our long road to….continuous improvement (DevOps Days Boston 2014)
26
Our long road to…. continuous improvement Kevin Amorin
-
Upload
kevin-amorin -
Category
Technology
-
view
103 -
download
2
Transcript of Our long road to….continuous improvement (DevOps Days Boston 2014)

Our long road to…. continuous improvement
Kevin Amorin

BitSight Team
15 yrs in Enterprise & Startups Enterprise Internal IT IT Virtualization Software SaaS low latency, high volume SaaS Big Data, Analytics
team: Issa Ashwash Isaac Boehman Sathya Ragavan Pavel Sadikov
Kevin

starting the journey
it’s a journey not a destination no silver bullet
“always make new mistakes” do not re-invent wheel continuous improvement
find and reduce the bottleneck (Lean)

Greenfield


first 100 days
ask questions and listen hiring (co-ops) Marketing the message
‘devops’
continuous improvement evaluate current condition & improve
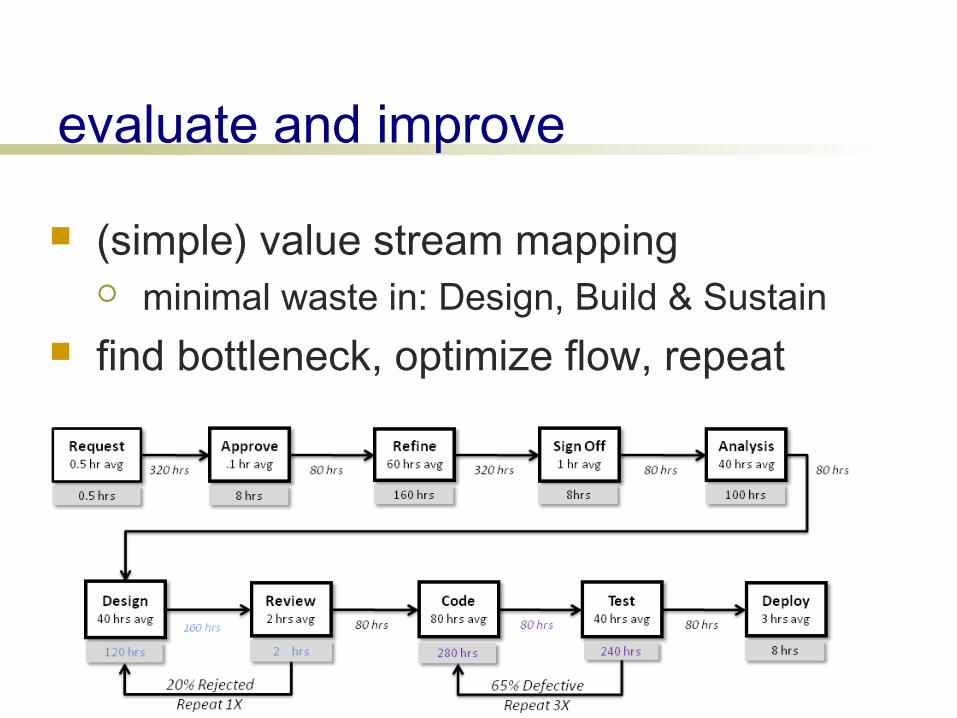
evaluate and improve
(simple) value stream mapping minimal waste in: Design, Build & Sustain
find bottleneck, optimize flow, repeat

bottleneck:symptoms or cause?

improvement:simple yet difficult

infrastructure v1
what does this server do?symptom: lost time on debugging/managing products in data center
cause: organic growth, little planning
improvement: redesign infrastructure & process for naming (host+subnet+app), access (vpn), users, deployment

build v1
build is broken!symptom: lost time on broken build debugging
cause: lack of uniform build environment, committed code with minimal testing and review
improvement: centralized build & CI, branching, pull requests, additional unit tests

deployment v1
that system doesn’t have my fix.symptom: lost time debugging on wrong code
cause: lack of revisioned artifacts
improvement: central artifact repo each package with banch, time, commit

communication v1
what new feature?symptom: lost time with misinformation
cause: siloing of information
improvement: chat, single issue tracking & process, representatives in standup & retrospective

infrastructure v2
that system is missing pip module.symptom: lost time debugging misconfigured application & systems
cause: lack of consistency of systems & applications
improvement: config management, monitoring & alerting

build v2
ran in my local system…symptom: code freeze branch would not run end to end. lost time debugging which change caused issue
cause: lack of regression/functional test
improvement: functional tests & require it to run before merge

deployment v2
db is not correct?symptom: database schema/data did not match code
cause: inconsistent process & manual steps on schema/data updates
improvement: db schema management tool + process

deployment v3new server didn’t come up right?symptom: lost time with misconfigured or failed provisioned nodes in AWS
cause: inconsistent semi-automated provisioning steps did not have the flexibility needed for a growing product line
improvement: knife-bs provisioning & deploymenthttp://github.com/CBitLabs/knife-bs

provisioning research & design
Netflix Asgard: Web interface for application deployments and cloud management in Amazon Web Services (AWS)
Infochimps Ironfan: Chef orchestration layer -- your system diagram come to life
Chef Knife-ec2: plugin gives knife the ability to create, bootstrap, and manage EC2 instances.

knife-bs
cloud provisioning tool build on top of opscode/knife-ec2. Using a description of your infrastructure and stacks (in either YAML or JSON), knife-bs will build correct the stack in the correct environment and bootstrap chef.

Describe: Infrastructure & Application
environmentregion
vpc subnet
stack profile profile
profile naming, type, volumes, raid, sg, raid,
spot_price, eip, ami… run_list

knife-bs examples
knife bs server create ame1.prod \ portal -count 10 -ebs 10 -eip -ami-id=xxxx
knife bs stack create ame1.stag \ hadoop flavor=c3.xlarge -spot-price=1.00
knife bs server delete ame1.stag tt

infrastructure v3
can I grab a cluster?symptom: who is using what, what state is it in?
cause: lack of visibility of ownership & state of application
improvement: infrastructure web UI which overlays org meta-data
http://github.com/CBitLabs/atlas
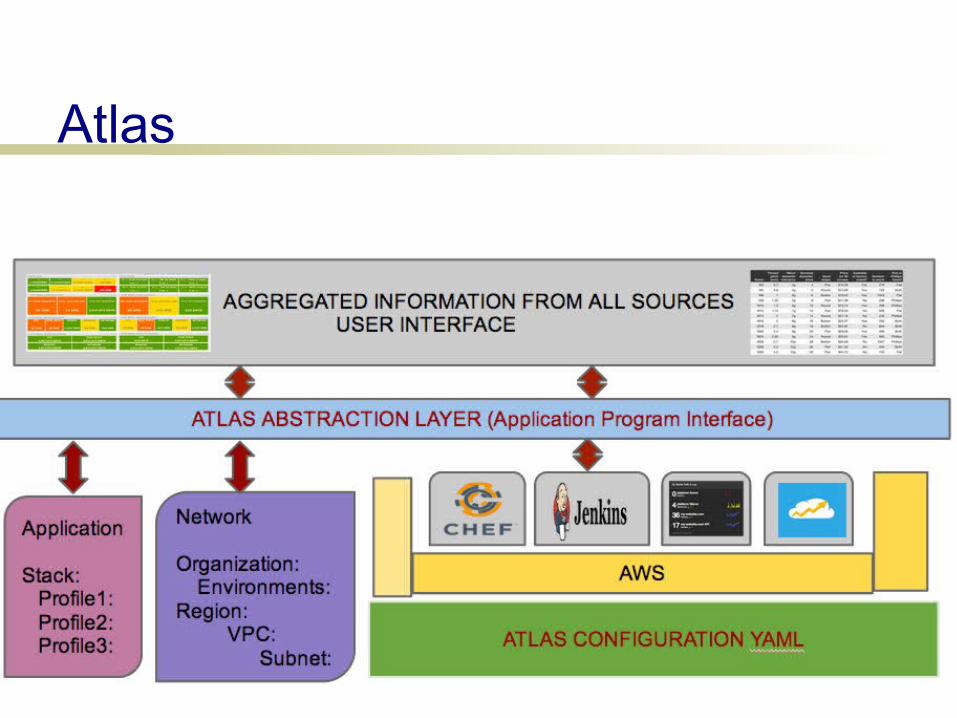
Atlas
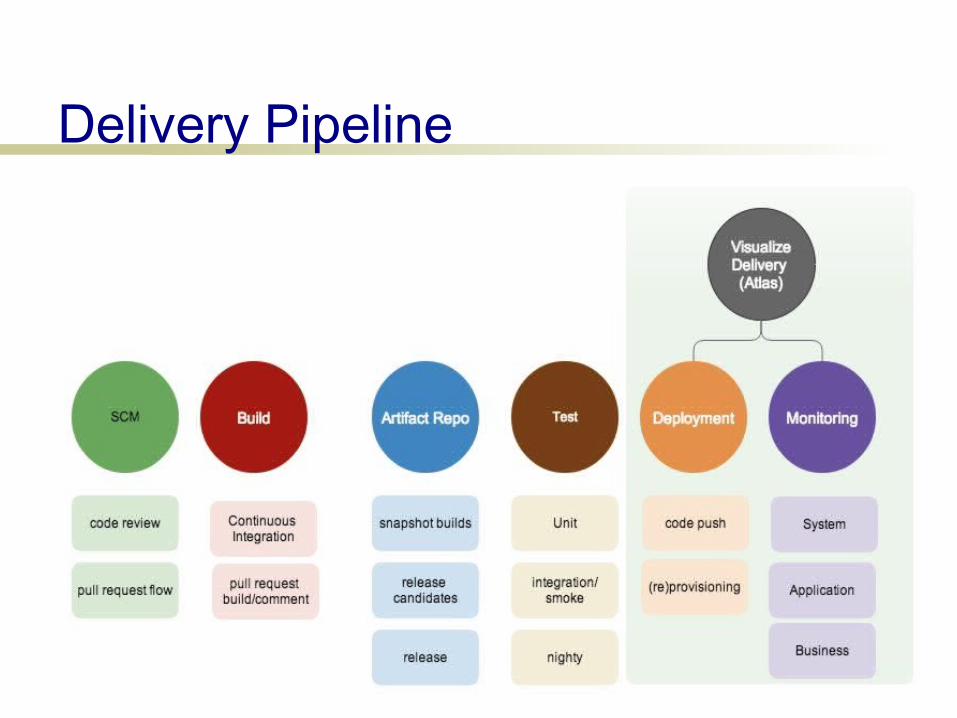
Delivery Pipeline

Lessons Learned
‘devops’ messaging analyze current state use symptom to find cause find solution that fits KISS then scale