
MODUL 3 GENERALIZED LINEAR MODELS · PDF file3.2 Generalized Linear Models untuk Respon Biner...
28
MODUL 3 GENERALIZED LINEAR MODELS Dalam Agresti (2007) Bab II Bab 2 dijelaskan metode untuk menganalisis tabel kontingensi. Metode-metode tersebut membantu kita menjelaskan pengaruh variabel penjelas terhadap variabel respon kategori. Bagian lain dari Agresti (2007) ini membahas model-model sebagai dassar analisis. Pada kenyataannya metode-metode pada Bab II juga menghasilkan simpulan dari analisis dari data kategori, tetapi model dapat menangani situasi yang lebih rumit seperti analisis dari beberapa variabel penjelas secara simultan.
-
Upload
truongdiep -
Category
Documents
-
view
234 -
download
0
Transcript of MODUL 3 GENERALIZED LINEAR MODELS · PDF file3.2 Generalized Linear Models untuk Respon Biner...

MODUL 3
GENERALIZED LINEAR MODELS
Dalam Agresti (2007) Bab II Bab 2 dijelaskan metode untuk menganalisis tabel
kontingensi. Metode-metode tersebut membantu kita menjelaskan pengaruh variabel
penjelas terhadap variabel respon kategori. Bagian lain dari Agresti (2007) ini
membahas model-model sebagai dassar analisis. Pada kenyataannya metode-metode
pada Bab II juga menghasilkan simpulan dari analisis dari data kategori, tetapi model
dapat menangani situasi yang lebih rumit seperti analisis dari beberapa variabel
penjelas secara simultan.

Model yang fit memiliki beberapa keuntungan. Struktur persamaan dari model
menjelaskan pola dan interaksi diantara variabel. Besaran nilai parameter menjelaskan
kekuatan atau kepentingan pengaruh suatu variabel. Inferensi parameter variabel
mengevaluasi variabel penjelas mana yang memiliki pengaruh terhadap respon. Model
juga digunakan untuk memprediksi data dan menyempurnakan taksiran rata-rata
respon pada suatu nilai variabel penjelas.
Model-model dalam agresti (2007) menampilkan generalized linear model. Secara
garis besar model-model meliputi regresi biasa dan Analisis Varians (ANOVA)
dengan respon kontinu sebaik model-model dengan respon diskrit. Bab III dalam
Agresti (2007) membahas generalized linear
models untuk data dengan respon kategori dan respon diskrit yang lain.

3.1 Komponen dalam Generalized Linear Models
Seluruh model dalam Generalized Linear Models (GLM) memiliki tiga komponen
yaitu:
1.Komponen Acak: Diidentifikasi oleh variabel respon (Y) dan diasumsikan
memiliki distribusi.
2.Komponen sistematik: Meliputi variabel-variabel penjelas dari model.
3.Fungsi penghubung (link function): yaitu suatu fungsi yang menghubungkan
ekspektasi respon (Y) dengan variabel-variabel penjelas melalui persamaan linier.
g(μ) = β0 + β1X1 + … + βkXk
Fungsi penghubung akan menentukan model yang akan digunakan dalam GLM.
Fungsi penghubung paling sederhana adalah g(μ) = μ disebut sebagai penghubung
identitas (identity link) merupakan model regresi linier dengan respon kontinu. Fungsi
penghubung yang lain akan menghubungkan μ secara nonlinier terhadap prediktor.

3.1 Generalized Linear Models dalam R
Dalam software R GLM terdapat dalam fungsi glm yang terdapat dalam paket
“stats”. Paket “stat“ sudah disertakan secara default didalam software R sehingga kita
dapat langsung menggunakannya saja. Secara umum metode penaksiran yang
digunakan dalam fungsi glm adalah iteratively reweighted least squares (IWLS) yang
menggunakan metode Fisher scoring untuk optimasinya. Untuk metode lain seperti
kemungkinan maksimum dan metode optimasi Newton-Rhapson untuk optimasinya
tidak diimplementasiakn dalam fungsi ini. Dengan demikian kita harus menggunakan
fungsi lain seperti fungsi optim atau kita dapat membuat fungsi sendiri atau
menggunakan fungsi yang telah dibuat oleh orang lain seperti fungsi berikut ini
(Venables & Ripley, 2002)

logit.reg <- function(x, y, wt = rep(1, length(y)), intercept =
T, start = rep(0, p), ...)
{
if(!exists("optim")) library(MASS)
## Awal bagian yang dapat di ubah
fmin <- function(beta, X, y, w) {
p <- plogis(X %*% beta)-sum(2*w*ifelse(y,log(p), log(1-p)))
}
gmin <- function(beta, X, y, w) {
eta <- X %*% beta; p <- plogis(eta)
t(-2 * (w *dlogis(eta) * ifelse(y, 1/p, -1/(1-p))))%*% X
}
## akhir bagian yang dapat diubah
if(is.null(dim(x))) dim(x) <- c(length(x), 1)
dn <- dimnames(x)[[2]]

if(!length(dn)) dn <- paste("Var", 1:ncol(x), sep="")
p <- ncol(x) + intercept
if(intercept) {x <- cbind(1, x); dn <- c("(Intercept)", dn)}
if(is.factor(y)) y <- (unclass(y) != 1)
fit <- optim(start, fmin, gmin, X = x, y = y, w = wt, ...)
names(fit$par) <- dn
cat("\nCoefficients:\n"); print(fit$par)
cat("\nResidual Deviance:", format(fit$value), "\n")
cat("\nConvergence message:", fit$convergence, "\n")
invisible(fit)
}

Untuk model linier probability ubah bagian yang diberi tanda “bagian yang dapat
diubah” dengan fungsi berikut ini
fmin <- function(beta, X, y, w) {
p <- X %*% beta-sum(2 * w * ifelse(y, log(p), log(1-p)))
}
gmin <- function(beta, X, y, w) {
p <- X %*% beta;
t(-2 * (w * ifelse(y, 1/p, -1/(1-p))))%*% X
}

Untuk model probit ubah bagian yang diberi tanda “bagian yang dapat diubah dengan
fungsi berikut ini
fmin <- function(beta, X, y, w) {
p <- X %*% beta
-sum(2 * w * ifelse(y, log(p), log(1-p)))
}
gmin <- function(beta, X, y, w) {
p <- X %*% beta;
t(-2 * (w * ifelse(y, 1/p, -1/(1-p))))%*% X
}

3.2 Generalized Linear Models untuk Respon Biner
Variabel respon banyak yang hanya memiliki dua kategori misalnya kelulusan
dalam tes (lulus atau tidak), pengobatan penyakit (sembuh atau tidak) dan lain-lain.
Secara umum dapat dikatakan bahwa variabel respon Y hanya memiliki dua hasil yang
mungkin yaitu “sukses” yang dilambangkan dengan angka satu (1) dan “gagal” yang
dilambangkan dengan angka nol (0). Variabel seperti ini disebut sebagai variabel
biner. Distribusi dari Y memiliki peluang sukses P(Y = 1) = π dan peluang gagal P(Y =
0) = (1 − π ) dengan ekspektasi E(Y) = π. Untuk sebuah pengamatan Y akan
mengikuti distribusi Bernoulli. Dengan demikian untuk n pengamatan yang saling
bebas, banyak “sukses” akan memiliki distribusi Binomial dengan parameter π .
Dalam bagian ini kita akan membahas GLM dengan respon biner dengan sebuah
variabel penjelas (X) saja meskipun sebenarnya GLM dapat digunakan untuk variabel
penjelas lebih dari satu. Perubahan nilai π dipengaruhi oleh perubahan X.

Contoh: Dengkuran dan Penyakit Jantung
Contoh berikut diambil dari Agresti (2007) bagian 3.2.2. Data yang digunakan
didasarkan pada survei epidemiologi dari 2484 orang responden (subjek) yang diduga
mendengkur pada saat tidur dan mempunyai resiko terkena serangan jantung. Subjek
dikelompokkan berdasarkan tingkat dengkurannya yang di jelaskan oleh pasangan
mereka. Data disajikan dalam tabel berikut ini
Table 3.1. Hubungan Penyakit Jantung dengan Kebiasaan Mendengkur
DengkuranPenyakit Jantung
Proporsi YaYa Tidak
Tidak Pernah 24 1355 0,017
Kadang-kadang 35 603 0,06
Sering 21 192 0,10
Selalu 30 224 0,12Sumber: P. G. Norton and E. V. Dunn, Br. Med. J., 291: 630–632, 1985, published
by BMJ Publishing Group.

Analisis untuk data tersebut dilakukan untuk nilai skor yang diberikan bagi kategori
prediktornya yang digunakan dalam Agresti (2007) yaitu (0, 2, 4, 5). Berikut analisis
untuk data tersebut didalam R. Pertama-tama kita input datanya kedalam R dengan
cara sebagai berikut
> dengkur <-matrix(c(24,1355,35,603,21,192,30,224),
ncol=2, byrow=TRUE)
> dimnames(dengkur) <-
list(dengkur=c("tidak","kadang","sering","selalu"),sakit.
jantung=c("ya","tidak"))

> dengkur
sakit.jantung
dengkur ya tidak
tidak 24 1355
kadang 35 603
sering 21 192
selalu 30 224
> nilai <- c(0,2,4,5)
Analisis data tersebut menggunakan regresi logistik dengan cara sebagai berikut

> dengkuran <- glm(dengkur~nilai, family=binomial() )
> summary(dengkuran)
Call:
glm(formula = dengkur ~ nilai, family = binomial())
Deviance Residuals:
tidak kadang sering selalu
-0.8346 1.2521 0.2758 -0.6845
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -3.86625 0.16621 -23.261 < 2e-16 ***
nilai 0.39734 0.05001 7.945 1.94e-15 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for binomial family taken to be 1)

Null deviance: 65.9045 on 3 degrees of freedom
Residual deviance: 2.8089 on 2 degrees of freedom
AIC: 27.061
Number of Fisher Scoring iterations: 4
> coef(dengkuran)
(Intercept) nilai
-3.8662481 0.3973366
> predict(dengkuran, type="response")
tidak kadang sering selalu
0.02050742 0.04429511 0.09305411 0.13243885

Dalam fungsi “glm” secara default digunakan fungsi penghubuang logit. Apabila
fungsi penghubung yang digunakan adalah probit maka kita dapat menggunakan cara
berikut ini:
> dengkuran.probit <- glm(dengkur~nilai,
family=binomial(link="probit") )
> summary(dengkuran.probit)
Call:
glm(formula = dengkur ~ nilai, family = binomial(link =
"probit"))
Deviance Residuals:
tidak kadang sering selalu
-0.6188 1.0388 0.1684 -0.6175

Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -2.06055 0.07017 -29.367 < 2e-16 ***
nilai 0.18777 0.02348 7.997 1.28e-15 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 65.9045 on 3 degrees of freedom
Residual deviance: 1.8716 on 2 degrees of freedom
AIC: 26.124
Number of Fisher Scoring iterations: 4

> coef(dengkuran.probit)
(Intercept) nilai
-2.0605516 0.1877705
> predict(dengkuran.probit, type="response")
tidak kadang sering selalu
0.01967292 0.04599325 0.09518763 0.13099515
Dalam fungsi “glm” tidak disertakan model linear probability sehingga kita harus
menggunakan fungsi “logit.reg” dengan menggunakan model linear probability
sehingga akan berbentuk sebagai berikut

lpm.reg <- function(x, y, wt = rep(1, length(y)), intercept =
T, start = rep(0, p), ...)
{
if(!exists("optim")) library(MASS)
fmin <- function(beta, X, y, w) {
p <- X %*% beta
-sum(2 * w * ifelse(y, log(p), log(1-p)))
}
gmin <- function(beta, X, y, w) {
p <- X %*% beta;
t(-2 * (w * ifelse(y, 1/p, -1/(1-p))))%*% X
}
if(is.null(dim(x))) dim(x) <- c(length(x), 1)
dn <- dimnames(x)[[2]]
if(!length(dn)) dn <- paste("Var", 1:ncol(x), sep="")

p <- ncol(x) + intercept
if(intercept) {x <- cbind(1, x); dn <- c("(Intercept)", dn)}
if(is.factor(y)) y <- (unclass(y) != 1)
fit <- optim(start, fmin, gmin, X = x, y = y, w = wt, ...)
names(fit$par) <- dn
cat("\nCoefficients:\n"); print(fit$par)
cat("\nResidual Deviance:", format(fit$value), "\n")
cat("\nConvergence message:", fit$convergence, "\n")
invisible(fit)
}
Fungsi “lpm.reg” dapat digunakan pada data dengan format yang berbeda dengan data
dengkur diatas sehingga kita ubah data tersebut dengan cara sebagai berikut
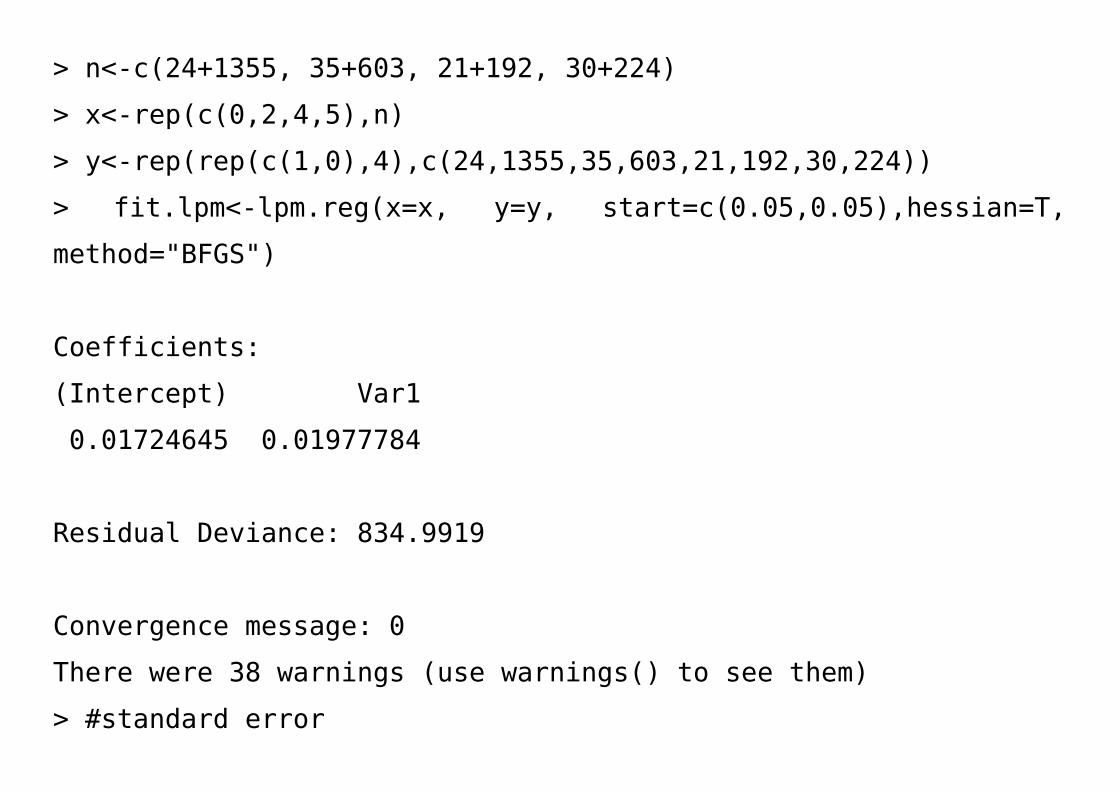
> n<-c(24+1355, 35+603, 21+192, 30+224)
> x<-rep(c(0,2,4,5),n)
> y<-rep(rep(c(1,0),4),c(24,1355,35,603,21,192,30,224))
> fit.lpm<-lpm.reg(x=x, y=y, start=c(0.05,0.05),hessian=T,
method="BFGS")
Coefficients:
(Intercept) Var1
0.01724645 0.01977784
Residual Deviance: 834.9919
Convergence message: 0
There were 38 warnings (use warnings() to see them)
> #standard error

> sqrt(diag(solve(fit.lpm$hessian)))
[1] 0.002426329 0.001976457
> #nilai peluang fit
> unique(cbind(1, x)%*%fit.lpm$par)
[,1]
[1,] 0.01724645
[2,] 0.05680213
[3,] 0.09635782
[4,] 0.11613566
Catatan: fungsi “logit.reg” dapat digunakan juga untuk probit (misalnya diberi nama
probit.reg) dengan sedikit modifikasi dengan cara sebagai berikut

probit.reg <- function(x, y, wt = rep(1, length(y)), intercept
= T, start = rep(0, p), ...)
{
fmin <- function(beta, X, y, w) {
p <- pnorm(X %*% beta)
-sum(2 * w * ifelse(y, log(p), log(1-p)))
}
gmin <- function(beta, X, y, w) {
eta <- X %*% beta; p <- pnorm(eta)
t(-2 * (w *dnorm(eta) * ifelse(y, 1/p, -1/(1-p))))%*% X
}
if(is.null(dim(x))) dim(x) <- c(length(x), 1)
dn <- dimnames(x)[[2]]
if(!length(dn)) dn <- paste("Var", 1:ncol(x), sep="")
p <- ncol(x) + intercept

if(intercept) {x <- cbind(1, x); dn <- c("(Intercept)", dn)}
if(is.factor(y)) y <- (unclass(y) != 1)
fit <- optim(start, fmin, gmin, X = x, y = y, w = wt, ...)
names(fit$par) <- dn
cat("\nCoefficients:\n"); print(fit$par)
cat("\nResidual Deviance:", format(fit$value), "\n")
cat("\nConvergence message:", fit$convergence, "\n")
invisible(fit)
}
Dengan fungsi ini kita dapat menghitung nilai peluang prediksi untuk fungsi
penghubung probit dan dengan fungsi logit.reg kita dapat menghitung peluang
prediksi untuk fungsi penghubuang logit. Untuk data yang sudah diubah menjadi x
dan y cara yang digunakan adalah sebagai berikut
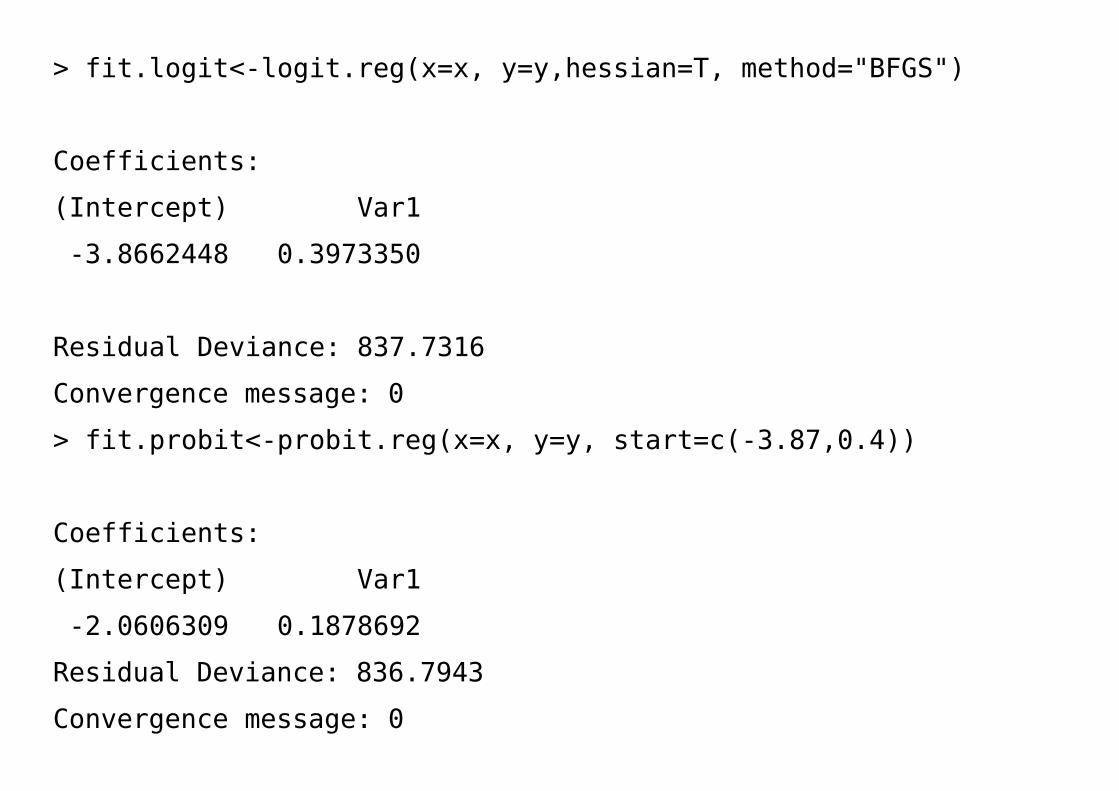
> fit.logit<-logit.reg(x=x, y=y,hessian=T, method="BFGS")
Coefficients:
(Intercept) Var1
-3.8662448 0.3973350
Residual Deviance: 837.7316
Convergence message: 0
> fit.probit<-probit.reg(x=x, y=y, start=c(-3.87,0.4))
Coefficients:
(Intercept) Var1
-2.0606309 0.1878692
Residual Deviance: 836.7943
Convergence message: 0

Menggabungkan nilai peluang prediksi dari fungsi penghubung linear probability,
logit dan probit dengan cara sebagai berikut
> p.lpm<-(cbind(1, x)%*%fit.lpm$par)
> eta.logit<-(cbind(1, x)%*%fit.logit$par)
> p.logit=exp(eta.logit)/(1+exp(eta.logit))
> eta.probit<-(cbind(1, x)%*%fit.probit$par)
> p.probit<-pnorm(eta.probit)
> res<-cbind(lpm=unique(p.lpm),logit=unique(p.logit),
probit=unique(p.probit))
> dimnames(res)<-list(unique(x),c("lpm","logit","probit"))

> res
lpm logit probit
0 0.01724645 0.02050748 0.01966914
2 0.05680213 0.04429512 0.04600466
4 0.09635782 0.09305386 0.09524107
5 0.11613566 0.13243832 0.13108329
Apabila kita akan menggambarkan plot dari ketiga peluang prediksi untuk fungsi
penghubung linear probability, probit dan logit dapat dilakukan dengan cara sebagai
berikut

> dengkur.plot<-unique(x)
> plot(x,p.logit,type="n",xlim=c(0,5),
ylim=c(-.005,.20),xlab="Tingkat Dengkuran", ylab="Peluang
Prediksi", bty="L")
> lines(dengkur.plot,unique(p.lpm),type="l",lty=1)
> lines(dengkur.plot,unique(p.logit),type="b",pch=16)
> lines(dengkur.plot,unique(p.probit),type="b",pch=17)
> legend(x=.05,y=.18,legend=c("Logistic","Probit","Linear"),
lty=c(1,1,1), pch=c(16,17,-1), cex=.85, text.width=1, adj=-.5)
maka akan muncul grafik seperti gambar dibawah ini
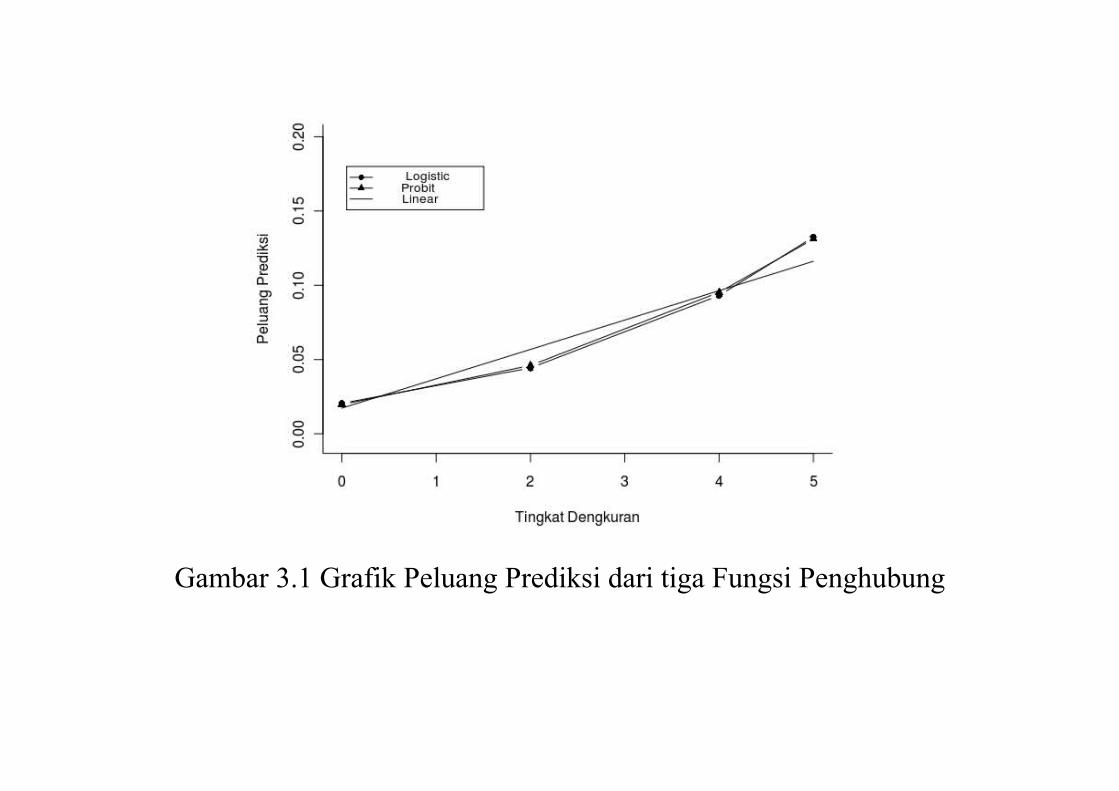
Gambar 3.1 Grafik Peluang Prediksi dari tiga Fungsi Penghubung







![Generalized Linear Model Generalized Linear Model [[GLMGLM]] · Generalized linear models No. of obs = 100 Optimization : ML: Newton-Raphson Residual df = 98 Scale param = 1 Deviance](https://static.fdocument.pub/doc/165x107/5f64725087b77a66e73cf63c/generalized-linear-model-generalized-linear-model-glmglm-generalized-linear.jpg)









