
Long Short-term Memory
25
Long Short-term Memory 2015-07-31 サイボウズラボ機械学習勉強会 西尾泰和
Transcript of Long Short-term Memory

Long Short-term Memory
2015-07-31
サイボウズラボ機械学習勉強会西尾泰和

不定長の入力
自然言語で書かれた文章とか
お客さんがある操作をして別の操作をして…
という操作ログとか
そういう不定長の入力を扱いたい
2

Grid Long Short-term Memory
面白そうな論文 ”Grid Long Short-term Memory”
[Kalchbrenner+ 2015]
Long Short-term Memory(LSTM)を縦横につなげてやるとWikipediaの文字予測タスクでNN界最強
中国語英語翻訳でもphrase-based reference
systemよりはるかに性能がいい
これを理解するために遡っていく…
3
http://arxiv.org/abs/1507.01526

LONG SHORT-TERM MEMORY
今回解説するのはこれ、LSTM元祖の論文
“LONG SHORT-TERM MEMORY”
[Hochreiter&Schmidhuber 1997]
Recurrent Neural Networkの問題点を指摘し、LSTMを考案した
4
http://deeplearning.cs.cmu.edu/pdfs/Hochreiter97_lstm.pdf

Recurrent Neural Network
「不定長の入力を受け付けたい」
「ならばNNの中にループを作ろう」
直前の自分の活性を入力として受け取ることによって「記憶」のあるNNを実現、時系列入力として与えることで不定長入力を可能にする
5

Backpropagation Through Time
ループのあるNNをどうやって学習するか?
時間軸方向に展開して仮想の多層ネットワークの学習として扱う
[Williams&Zipser 1992]
6

問題
勾配を何度も掛け算→エラー情報が消滅or発散
振動したり、学習にとても時間がかかったりする
エラー情報が消滅発散しないようにしよう!そこで…
7

Constant Error Carrousel(CEC)
1つのニューロンが自分の出力を受け取ることを考える、エラー情報が一定であるためには
・ニューロンの活性化関数が線形・他の入力がないとき活性は一定
が必要。この論文では以下の設定を用いる:
・活性化関数は f(x) = x
・リカレント結合の重みは1.0
8
[Hochreiter&Schmidhuber 1997]

問題: Input Weight Conflict
(著者曰く勾配ベースの手法すべてにある問題)
ある情報を、必要になるまで覚えておきたい
つまり、その情報が来たときにニューロンの活性は変わってほしい
しかし、他の情報が来たときにニューロンの活性は変わってほしくない
変わるか変わらないかが重みの値で表現されている仕組みでは、この衝突が学習の妨げになる
9

問題: Output Weight Conflict
出力に関しても同様に「覚えておいた値を使う」と「必要になるまで使わない」とを出力重みの値で表現するのはConflict
10

解決策
書くのか書かないのか、読むのか読まないのか、「記憶」に対する読み書きオペレーションが重みという一つのスカラー値で決まるのではなく入力に基づいてコントロールされるメカニズムが必要である
そこで…
11
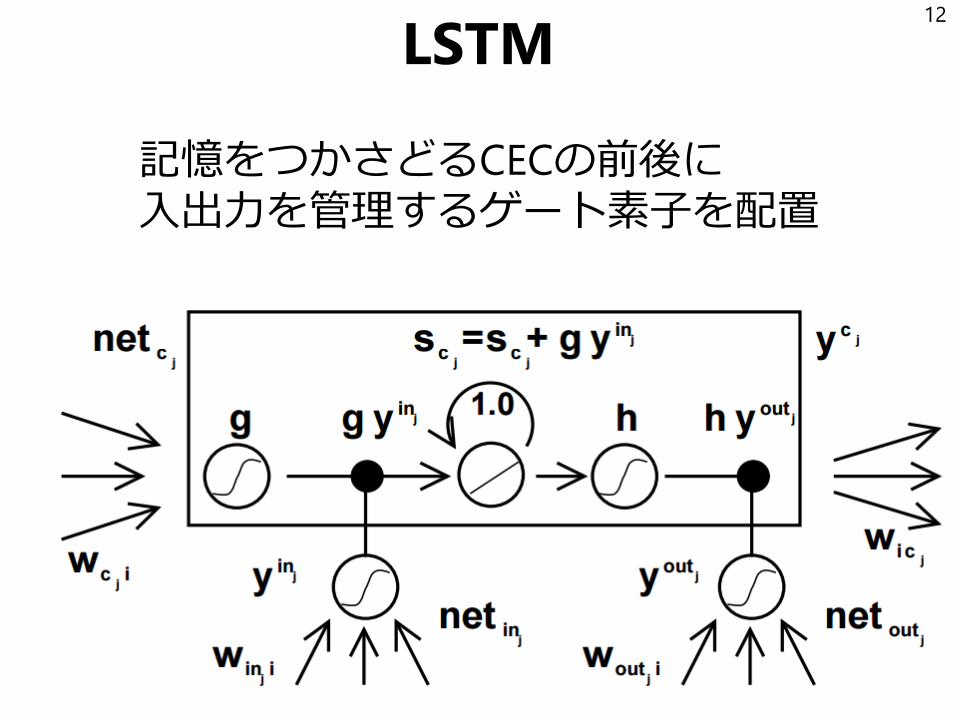
LSTM
記憶をつかさどるCECの前後に入出力を管理するゲート素子を配置
12

Memory Cell Block
1個のメモリセルは「ニューロン1個分」の1次元の情報しか記憶できない
→複数のメモリセルでゲートの重みを共有する一時に複数の次元を記憶できるようになる
13

Abuse Problem
学習序盤は、メモリセルを使わなくても誤差が減少する
なのでメモリセルを記憶以外のこと(定数オフセットなど)に使ってしまう問題が起きる
一度そういう変な学習をすると、解放されるまでに時間がかかる
14

Abuse Problem
複数のメモリーセルが同じ内容を記憶してしまう問題も起きる
(Q:出力に影響はないのでは? A:せっかくのメモリセルが有効活用されないのが問題)
15

解決策
(1)ネットワークの学習が止まった時にちょっとずつメモリーセルを足す
(2)出力ゲートをマイナスのオフセットで初期化出力ゲートが「出力OK」のシグナルを出せるようになるまで学習ステップが余計に必要になることで序盤にメモリセルが使われることを防ぐ
16

Internal state drift
メモリセルへの入力が正ばかり(または負)だと、メモリセルの値が一方的に大きくなり勾配が消滅する(活性化関数がシグモイドとかだと問題ないんだけど今回線形なんで)
序盤の間、入力ゲートの出力が0に近づくようにバイアスする
(学習がしばらく進むと他のニューロンがドリフトを吸収するので、それまでの間耐え忍ぶ)
17

Forget Gate
[Gers+ 1999] “Learning to Forget: Continual
Prediction with”
従来のLSTMは手動で記憶をリセットしていたがそれを自動でリセットできるようにしたよ、という論文
http://citeseerx.ist.psu.edu/viewdoc/download?do
i=10.1.1.55.5709&rep=rep1&type=pdf
18
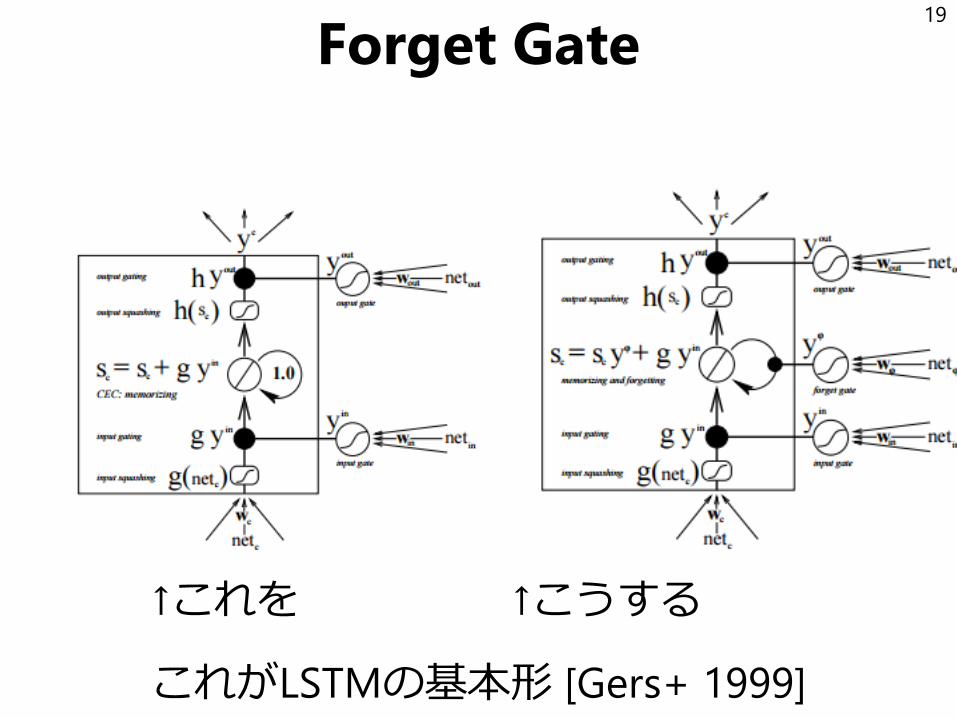
Forget Gate
↑これを ↑こうする
これがLSTMの基本形 [Gers+ 1999]
19

実装
[Hochreiter&Schmidhuber 1997]のp.23から
ALGORITHM DETAILS
Tomonari MASADA先生による数式と実装*
実装はCで966行
Chainerでの実装** 228行
RNNLIBっていうC++実装もあるらしい。単に使うだけならこれがよい??
20
* http://diversity-mining.jp/wp/?p=407
** https://github.com/pfnet/chainer/blob/master/chainer/functions/lstm.py

数式読解
LSTMによる隠れ層がN層重なっている構造
21

数式読解
Wは重み、下の添え字xιなどが「入力xから入力ゲートιへの重み」をあらわしており、上の添え字nが「n層目の重み」をあらわしている
𝑊ℎ− ιのハイフンはマイナスではなく「前の隠れ層h-から入力ゲートιへの重み」という意味
22

数式読解
𝜄𝑡𝑛はn層目の時刻tの入力ゲートの出力で、Dn次元のベクトル
ι、φ、ωは重みが違うだけでほぼ同じ式。入力、下の隠れ層の出力、自分の1時刻前の出力、CEC
の出力、が使われている。
23

数式読解
ωと小文字のwは別物。CECの出力ηを使う際に、同じ層の他のLSTMのηは使わないので重み行列が対角行列になり、その対角成分だけ取ってベクトルになってるのでWが小文字になっている。
要素積してるのもベクトル形で書いたから。対角行列なら普通の行列積になる。
24
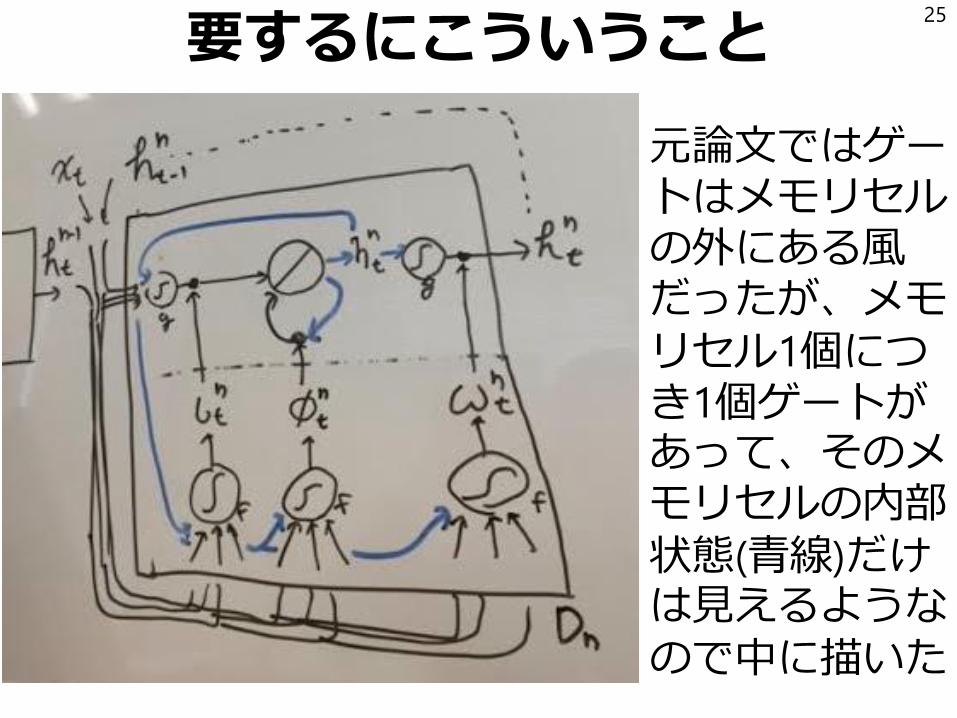
要するにこういうこと
元論文ではゲートはメモリセルの外にある風だったが、メモリセル1個につき1個ゲートがあって、そのメモリセルの内部状態(青線)だけは見えるようなので中に描いた
25


















