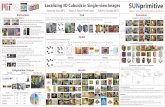
Localizing 3D Cuboids in Single-view...
1
S (I,p)= i∈V w H i ·HOG(I,p i )+ ij ∈E w D ij ·Displacement 2D (p i ,p j )+ ij ∈E w E ij ·Edge(I,p i ,p j )+w S ·Shape 3D (p) min β,ξ ≥0 1 2 β · β + C n ξ n ∀n ∈ pos β · Φ(I n ,p n ) ≥ 1 - ξ n ∀n ∈ neg, ∀p ∈ P β · Φ(I n ,p) ≤-1+ ξ n S (I,p)= i∈V w H i · HOG(I,p i )+ ij ∈T w D ij · Displacement 2D (p i ,p j ) stove (5/13) refrigerator (5/8) night table occluded (5/12) kitchen island (5/6) cabinets (5/22) brick (5/5) stand (7/11) CPU (7/8) table (8/26) desk (8/22) box (9/18) chest of drawers (10/10) bed (15/22) cabinet (28/87) others 97 categories (168/883) night table (15/29) building (16/49) screen (5/16) Localizing 3D Cuboids in Single-view Images Jianxiong Xiao (MIT) Bryan C. Russell (Intel Labs) Antonio Torralba (MIT) SUN primitive Evaluation SUNprimitive Dataset Dataset + Code: http://SUNprimitive.csail.mit.edu Input Image Output Detection Result 3D Cuboid Detector detect Synthesized New Views −100 −90 −80 −70 −60 −50 −40 −30 −20 −10 image distance transformed edge pixels on line dot-product 0.03 0.13 0.55 2.34 10 0 20 40 60 80 100 120 Height (log axes) 1° 9° 18° 26° 37° 43° 10 0 10 1 10 −2 10 −1 10 0 10 1 10 2 Width (log axes) Height (log axes) 0 15 30 45 −45 0 45 90 Azimuth Elevation 0 30 60 90 0 15 30 45 Zenith Elevation 3D rotation angles Cuboids Cylinders 3D aspect ratios 3D rotation angles 3D aspect ratios Annotation tool The annotator sets anchor points. X x image (2D) unit cuboid (3D) x = P*L*X Cuboid Scoring function for corner locations in image: HOG features for corners 2D displacement Results Given a depth map, we still cannot manipulate an object. Because there is no high level representation of the 3D world. Obtaining a good depth map = = Inventing a digital camera. Machine perception of three-dimensional solids. Roberts, 1963. 1963 1982 Stereo correspondence. Dev 1974; Marr and Poggio 1976; Marr, 1982. Dense stereo matching. Boykov, Veksler and Zabih, 2001. 2001 5. 3D reconstruction is not just low-level 4. Geon and RBC: recognition by geometric primitive components Motivations Recognition by components: a theory of human interpretation. Biederman,1987. Quantitative evaluation: corner localization 0 0.2 0.4 0.6 0.8 1 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 recall reprojection accuracy (criteria=0.150) Root Filter [0.25] 2D Tree Approximation [0.30] Full Model−Edge [0.37] Full Model−Shape [0.37] Full Model [0.38] 0 0.2 0.4 0.6 0.8 1 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 recall reprojection accuracy (criteria=0.150) Root Filter [0.47] 2D Tree Approximation [0.75] Full Model−Edge [0.78] Full Model−Shape [0.80] Full Model [0.80] 0 0.2 0.4 0.6 0.8 1 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 recall reprojection accuracy (criteria=0.150) Root Filter [0.50] 2D Tree Approximation [0.63] Full Model−Edge [0.60] Full Model [0.66] 0 0.2 0.4 0.6 0.8 1 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 recall reprojection accuracy (criteria=0.150) Root Filter [0.42] 2D Tree Approximation [0.48] Full Model−Edge [0.48] Full Model−Shape [0.51] Full Model [0.51] Cuboid (scene) Cuboid (non-scene) Cylinder Pyramid • Corner location is correct if it lies within threshold. • Threshold is set to a fraction of the ground truth bounding box. Comparison with 2D parts model Ours Ground truth 2D tree-based parts model Synthesized new views from detections Cylinder and Pyramid Cuboid, non-scenes Cuboid, scenes Cylinder Pyramid Shape # images 371 414 156 407 # annotations 443 826 303 407 Detect on Image Synthesize New Views Model Task = Inference Training Corner Localization + + + ≈ 1. Standalone boxy object detector Given a single-view input image, our goal is to detect the 2D corner locations of the cuboids depicted in the image. With the output part locations we can subsequently recover information about the camera and 3D shape via camera resectioning. Supervised corner-location training with Structural SVM. Step 1: Approximation by a tree (dynamic programming + distance transform). Step 2: Local search (hill climbing or ICM). Thinking inside the box: Using appearance models and context based on room geometry. Hedau, Hoiem and Forsyth, 2010. View-based model? 3D view-invariant model? Mental rotation? 3. View-invariant 3D detector 2. Cuboidness: not category Dalal and Triggs, 2005. Acknowledgements J.X. is supported by Google U.S./Canada Ph.D. Fellowship in Computer Vision. B.C.R. was funded by the Intel Science and Technology Center for Pervasive Computing (ISTC-PC). This work is funded by ONR MURI N000141010933 and NSF Career Award No. 0747120 to A.T. References [1] Articulated pose estimation using flexible mixtures of parts. Yang and Ramanan. In CVPR, 2011. [2] Recognizing scene viewpoint using panoramic place representation. Xiao, Ehinger, Oliva and Torralba. In CVPR, 2012. [3] Reconstructing the world’s museums. Xiao and Furukawa. In ECCV, 2012. [4] Basic level scene understanding: From labels to structure and beyond. Xiao, Russell, Hays, Ehinger, Oliva, and Torralba. In SIGGRAPH Asia, 2012.
Transcript of Localizing 3D Cuboids in Single-view...
![Page 1: Localizing 3D Cuboids in Single-view Images3dvision.princeton.edu/projects/2012/SUNprimitive/poster.pdf · 2013-04-23 · [2] Recognizing scene viewpoint using panoramic place representation.](https://reader035.fdocument.pub/reader035/viewer/2022081402/5f10e2117e708231d44b454d/html5/thumbnails/1.jpg)
S(I, p) =∑i∈V
wHi ·HOG(I, pi)+
∑ij∈E
wDij ·Displacement2D(pi, pj)+
∑ij∈E
wEij ·Edge(I, pi, pj)+wS ·Shape3D(p)
1
minβ,ξ≥0
1
2β · β + C
∑n
ξn
∀n ∈ pos β · Φ (In, pn) ≥ 1− ξn
∀n ∈ neg, ∀p ∈ P β · Φ (In, p) ≤ −1 + ξn
1
S(I, p) =∑i∈V
wHi · HOG(I, pi) +
∑ij∈T
wDij · Displacement2D(pi, pj)
1
stove (5/13) refrigerator (5/8)night table occluded (5/12)
kitchen island (5/6)cabinets (5/22)
brick (5/5)stand (7/11)
CPU (7/8)table (8/26)desk (8/22)box (9/18)chest of drawers (10/10)
bed (15/22)
cabinet (28/87)
others97 categories
(168/883)
night table (15/29)
building (16/49)
screen (5/16)
Localizing 3D Cuboids in Single-view ImagesJianxiong Xiao (MIT) Bryan C. Russell (Intel Labs) Antonio Torralba (MIT)
SUNprimitiveEvaluation
SUNprimitive Dataset
Dataset + Code: http://SUNprimitive.csail.mit.edu
Input Image Output Detection Result3D Cuboid Detector
detect
Synthesized New Views
−100
−90
−80
−70
−60
−50
−40
−30
−20
−10
image distance transformed edge pixels on line
dot-product
0.03 0.13 0.55 2.34 100
20
40
60
80
100
120
Height (log axes)
1° 9° 18° 26° 37° 43°
100
10110−2
10−1
100
101
102
Width (log axes)
Hei
ght (
log
axes
)
0 15 30 45−45
0
45
90
Azimuth
Elev
atio
n
0 30 60 900
15
30
45
Zenith
Elev
atio
n
3D rotation anglesCuboids Cylinders
3D aspect ratios 3D rotation angles 3D aspect ratiosAnnotation tool
The annotator sets anchor points.
X x
image (2D) unit cuboid (3D)
x = P*L*X
Cuboid
Scoring function for corner locations in image:
HOG features for corners 2D displacement
Results
Given a depth map, we still cannot manipulate an object.Because there is no high level representation of the 3D world.Obtaining a good depth map = = Inventing a digital camera.
Machine perception of three-dimensional solids. Roberts, 1963.1963
1982 Stereo correspondence.Dev 1974; Marr and Poggio 1976; Marr, 1982.Dense stereo matching.Boykov, Veksler and Zabih, 2001.
2001
5. 3D reconstruction is not just low-level
4. Geon and RBC: recognition by geometric primitive components
Motivations
Recognition by components: a theory of human interpretation. Biederman,1987.
Quantitative evaluation: corner localization
0 0.2 0.4 0.6 0.8 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
recall
repr
ojec
tion
accu
racy
(crit
eria
=0.1
50)
Root Filter [0.25]2D Tree Approximation [0.30]Full Model−Edge [0.37]Full Model−Shape [0.37]Full Model [0.38]
0 0.2 0.4 0.6 0.8 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
recall
repr
ojec
tion
accu
racy
(crit
eria
=0.1
50)
Root Filter [0.47]2D Tree Approximation [0.75]Full Model−Edge [0.78]Full Model−Shape [0.80]Full Model [0.80]
0 0.2 0.4 0.6 0.8 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
recall
repr
ojec
tion
accu
racy
(crit
eria
=0.1
50)
Root Filter [0.50]2D Tree Approximation [0.63]Full Model−Edge [0.60]Full Model [0.66]
0 0.2 0.4 0.6 0.8 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
recall
repr
ojec
tion
accu
racy
(crit
eria
=0.1
50)
Root Filter [0.42]2D Tree Approximation [0.48]Full Model−Edge [0.48]Full Model−Shape [0.51]Full Model [0.51]
Cuboid (scene) Cuboid (non-scene) CylinderPyramid
• Corner location is correct if it lies within threshold.• Threshold is set to a fraction of the ground truth bounding box.
Comparison with 2D parts model
Ours
Groundtruth
2D tree-basedparts model
Synthesized new views from detections
Cylinder and Pyramid
Cuboid, non-scenes
Cuboid, scenes
Cylinder
Pyramid
Shape # images
371
414
156
407
# annotations
443
826
303
407
Det
ect o
n Im
age
Synt
hesi
ze N
ew V
iew
s
Model
Task
=
Inference Training
Corner Localization
+ + +
≈
1. Standalone boxy object detector Given a single-view input image, our goal is to detect the 2D corner locations of the cuboids depicted in the image. With the output part locations we can subsequently recover information about the camera and 3D shape via camera resectioning.
Supervised corner-location training with Structural SVM.Step 1: Approximation by a tree (dynamic programming + distance transform).
Step 2: Local search (hill climbing or ICM).
Thinking inside the box: Using appearance models and context based on room geometry. Hedau, Hoiem and Forsyth, 2010.
View-based model?3D view-invariant model?Mental rotation?
3. View-invariant 3D detector2. Cuboidness: not category
Dalal and Triggs, 2005.
AcknowledgementsJ.X. is supported by Google U.S./Canada Ph.D. Fellowship in Computer Vision. B.C.R. was funded by the Intel Science and Technology Center for Pervasive Computing (ISTC-PC). This work is funded by ONR MURI N000141010933 and NSF Career Award No. 0747120 to A.T.
References[1] Articulated pose estimation using �exible mixtures of parts. Yang and Ramanan. In CVPR, 2011.[2] Recognizing scene viewpoint using panoramic place representation. Xiao, Ehinger, Oliva and Torralba. In CVPR, 2012.[3] Reconstructing the world’s museums. Xiao and Furukawa. In ECCV, 2012.[4] Basic level scene understanding: From labels to structure and beyond. Xiao, Russell, Hays, Ehinger, Oliva, and Torralba. In SIGGRAPH Asia, 2012.