
Learning Cooperative Visual Dialog with Deep Reinforcement Learning(関東CV勉強会 ICCV 2017...
54
ICCV 2017 読み会 Learning Cooperative Visual Dialog with Deep Reinforcement Learning 牛久 祥孝 losnuevetoros
-
Upload
- -
Category
Technology
-
view
604 -
download
2
Transcript of Learning Cooperative Visual Dialog with Deep Reinforcement Learning(関東CV勉強会 ICCV 2017...

ICCV 2017 読み会
Learning Cooperative Visual Dialogwith Deep Reinforcement Learning
牛久祥孝
losnuevetoros

自己紹介
~2014.3 博士(情報理工学)、東京大学
• 画像説明文の自動生成
• 大規模画像分類
2014.4~2016.3 NTT コミュニケーション科学基礎研究所
2016.4~ 東京大学大学院情報理工学系研究科
知能機械情報学専攻講師 (原田・牛久研究室)
その他 関東CV勉強会幹事・PRMU研究会専門委員

最近のイベント
結婚式を挙げました


どれが12/10の様子の写真でしょう?・質問2回までok
・左側の画像?みたいな聞き方は×



この遊びをエージェントがやる論文を読みます

本日の論文
視覚データに基づく協調的な対話を実現する強化学習手法
目標は画像あてっこゲームをやるエージェントの実現

研究背景~手法の説明
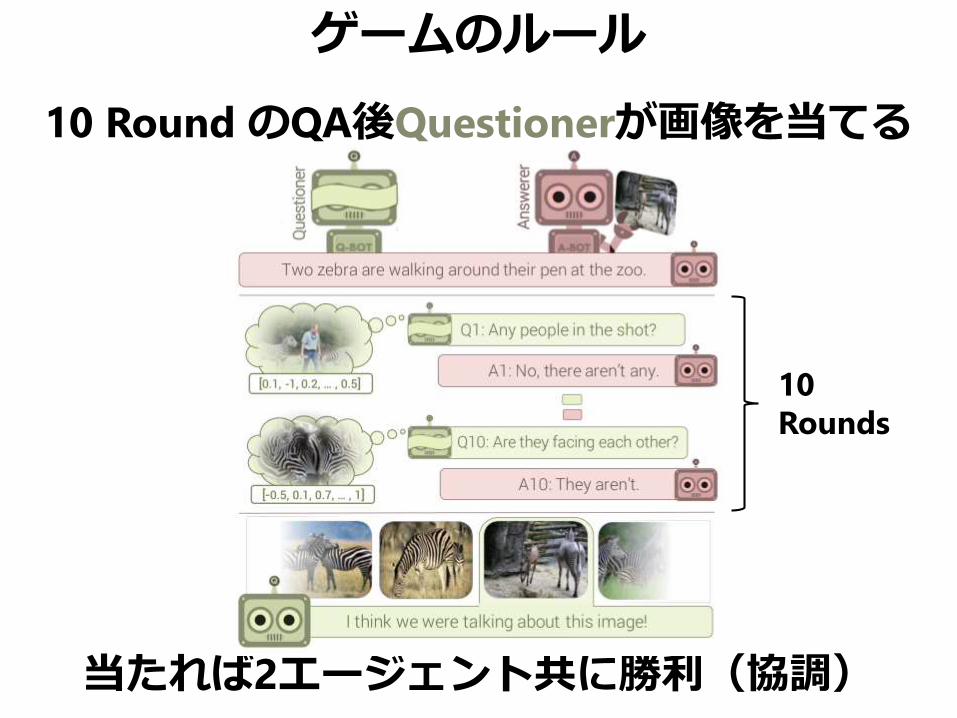
ゲームのルール
10 Round のQA後Questionerが画像を当てる
当たれば2エージェント共に勝利(協調)
10
Rounds
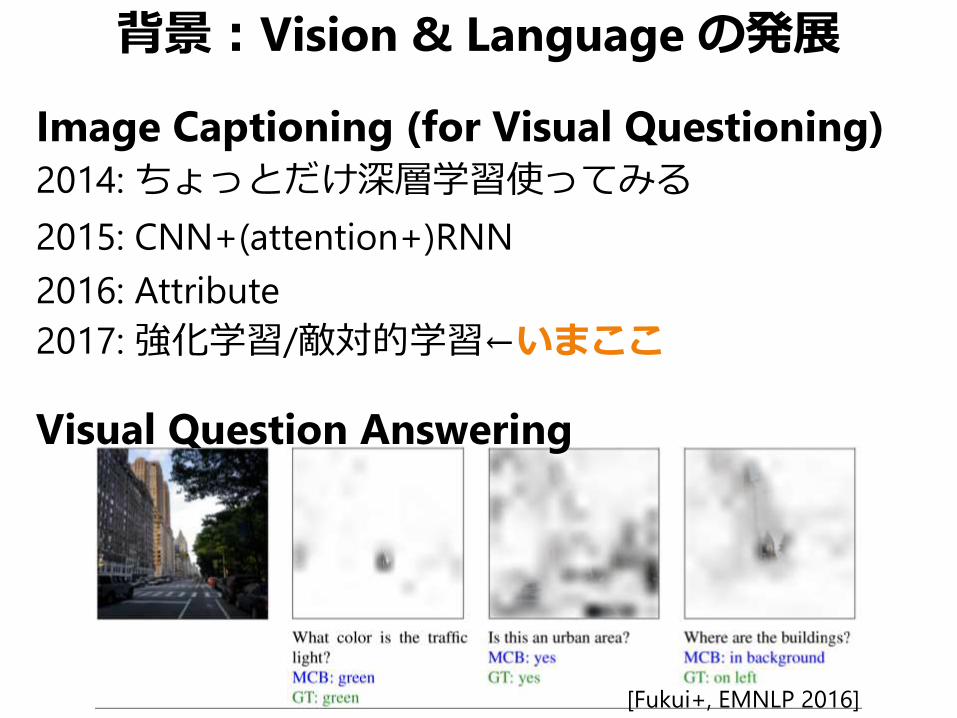
背景:Vision & Language の発展
Image Captioning (for Visual Questioning)
2014: ちょっとだけ深層学習使ってみる
2015: CNN+(attention+)RNN
2016: Attribute
2017: 強化学習/敵対的学習←いまここ
Visual Question Answering
[Fukui+, EMNLP 2016]
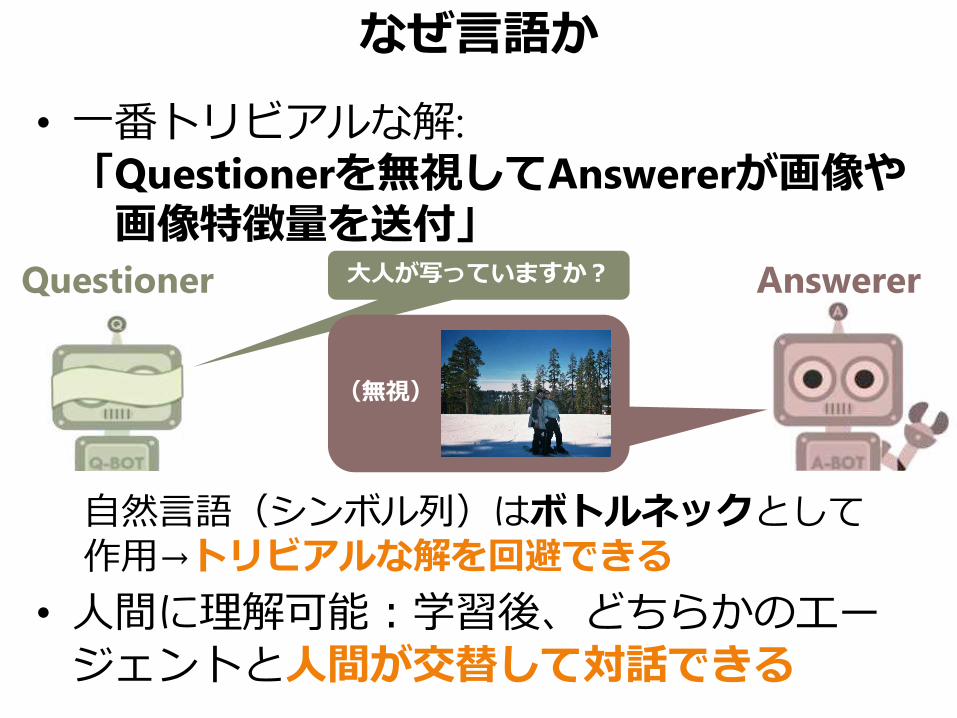
なぜ言語か
• 一番トリビアルな解:
「Questionerを無視してAnswererが画像や画像特徴量を送付」
自然言語(シンボル列)はボトルネックとして作用→トリビアルな解を回避できる
• 人間に理解可能:学習後、どちらかのエージェントと人間が交替して対話できる
Questioner Answerer大人が写っていますか?
(無視)

関連研究
• Visual Dialog [Das+, CVPR 2017]
– 今日読む論文の著者らの仕事
– データセット公開(口述)
– 自動対話手法のベースライン
• GuessWhat?! Visual object discovery through
multi-modal dialogue [de Vries+, CVPR 2017]
同様のモチベーションの研究は実はすでにある!…が

関連研究の問題点
いずれも対話生成の教師あり学習
• Answererを例にとると、𝑡番目のQAでは…
– Round 𝑡 − 1迄の質問𝑞1, … , 𝑞𝑡−1と応答𝑎1, … , 𝑎𝑡−1
– Round 𝑡の質問𝑞𝑡
→𝑎𝑡を出力できるように学習
• Answererが推定した 𝑎𝑡が𝑎𝑡とは違っても、対話としては正しい可能性がある
–が、学習時には単純に無視される
– 𝑎𝑡に対応した質問𝑞𝑡+1はデータセットに無い
–学習中にエージェント自身が対話を制御できる機会は与えられない

本研究の方針
• 強化学習の活用
– AlphaGo [Silver+, Nature 2016]からの着想
–画像あてゲームの成功/失敗を報酬として最適化
• Fine-tuneとして採用
–事前学習はこれまで同様教師あり学習
–フルスクラッチでの強化学習だと…
• 画像と言語の関係やコミュニケーションプロトコルの学習が困難
• 学習できたとしても、結果としてエージェントが人間の言葉を喋る可能性は低い
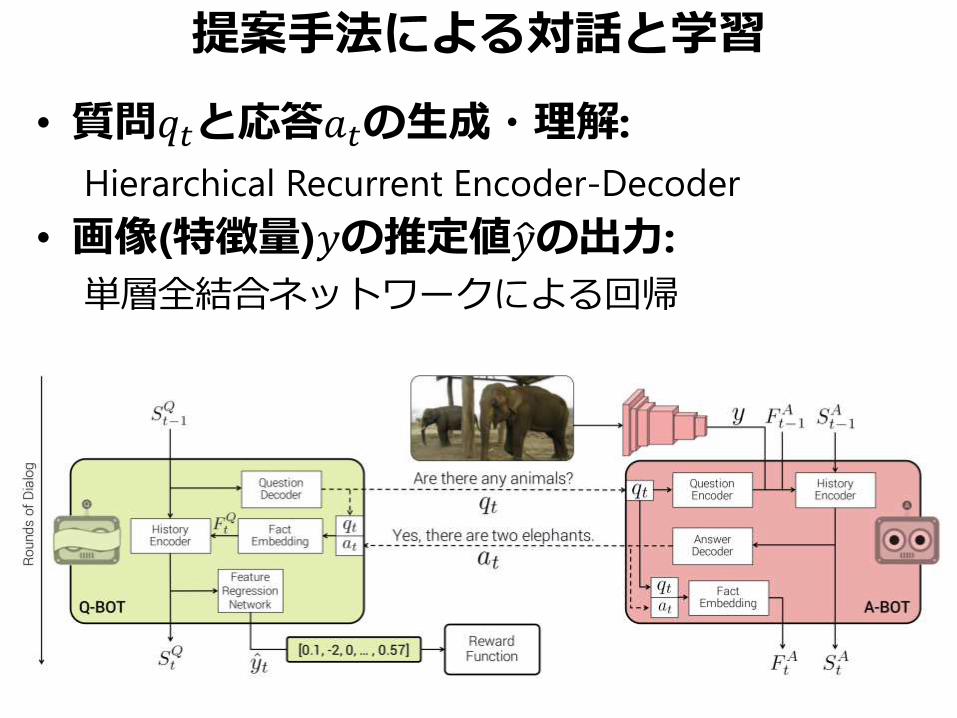
提案手法による対話と学習
• 質問𝑞𝑡と応答𝑎𝑡の生成・理解:
Hierarchical Recurrent Encoder-Decoder
• 画像(特徴量)𝑦の推定値 𝑦の出力:
単層全結合ネットワークによる回帰
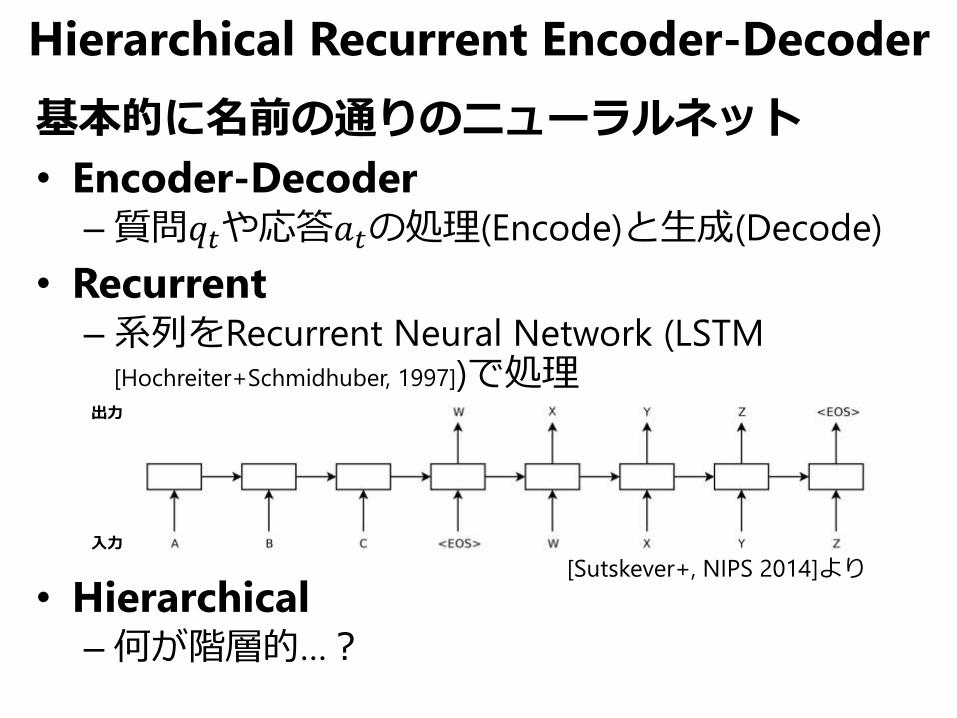
Hierarchical Recurrent Encoder-Decoder
基本的に名前の通りのニューラルネット
• Encoder-Decoder–質問𝑞𝑡や応答𝑎𝑡の処理(Encode)と生成(Decode)
• Recurrent–系列をRecurrent Neural Network (LSTM
[Hochreiter+Schmidhuber, 1997])で処理
• Hierarchical–何が階層的…?
入力
出力
[Sutskever+, NIPS 2014]より
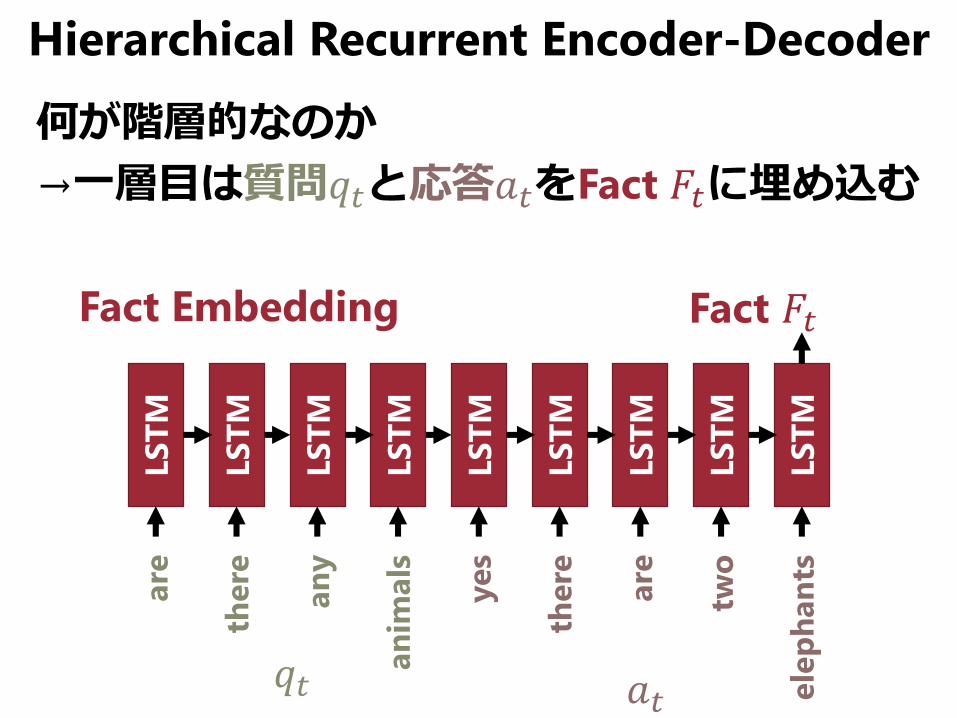
Hierarchical Recurrent Encoder-Decoder
何が階層的なのか
→一層目は質問𝑞𝑡と応答𝑎𝑡をFact 𝐹𝑡に埋め込む
Fact Embedding
are
𝑞𝑡
LS
TM
LS
TM
LS
TM
LS
TM
LS
TM
LS
TM
LS
TM
LS
TM
LS
TM
there
an
y
an
imals
are
there
yes
ele
ph
an
ts
two
𝑎𝑡
Fact 𝐹𝑡
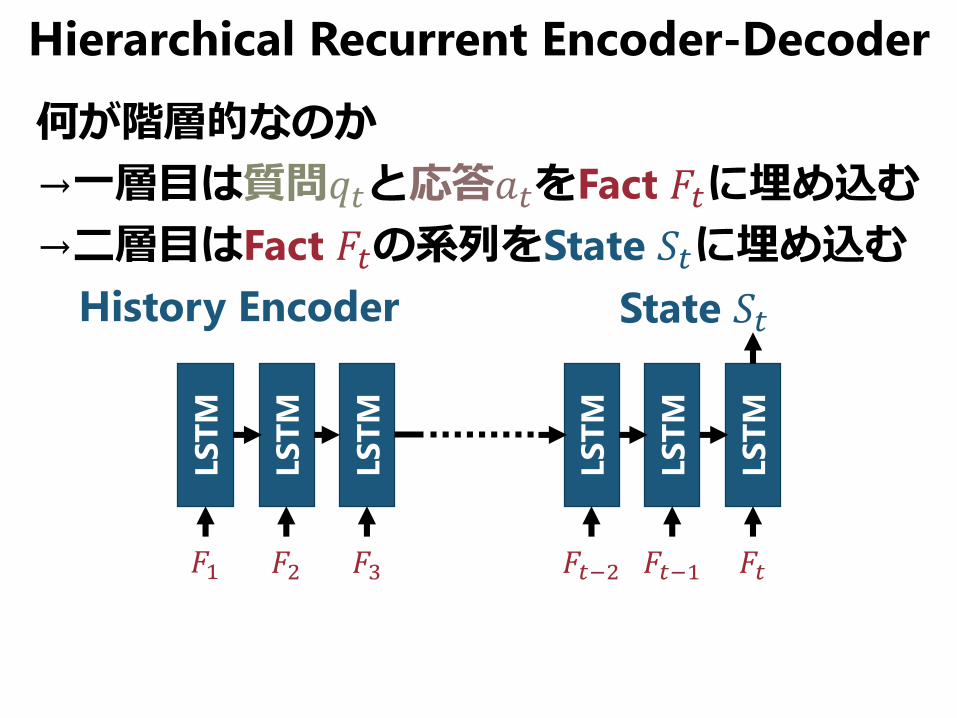
Hierarchical Recurrent Encoder-Decoder
何が階層的なのか
→一層目は質問𝑞𝑡と応答𝑎𝑡をFact 𝐹𝑡に埋め込む
→二層目はFact 𝐹𝑡の系列をState 𝑆𝑡に埋め込む
History Encoder
𝐹1
LS
TM
LS
TM
LS
TM
LS
TM
LS
TM
LS
TM
𝐹𝑡−2 𝐹𝑡𝐹𝑡−1
State 𝑆𝑡
𝐹2 𝐹3
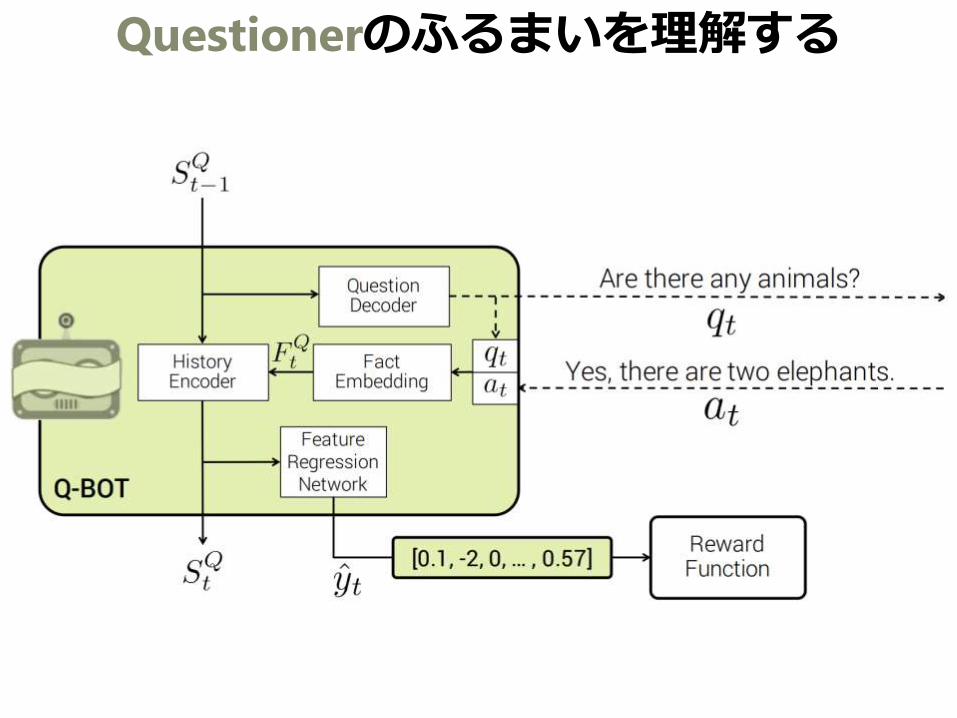
Questionerのふるまいを理解する
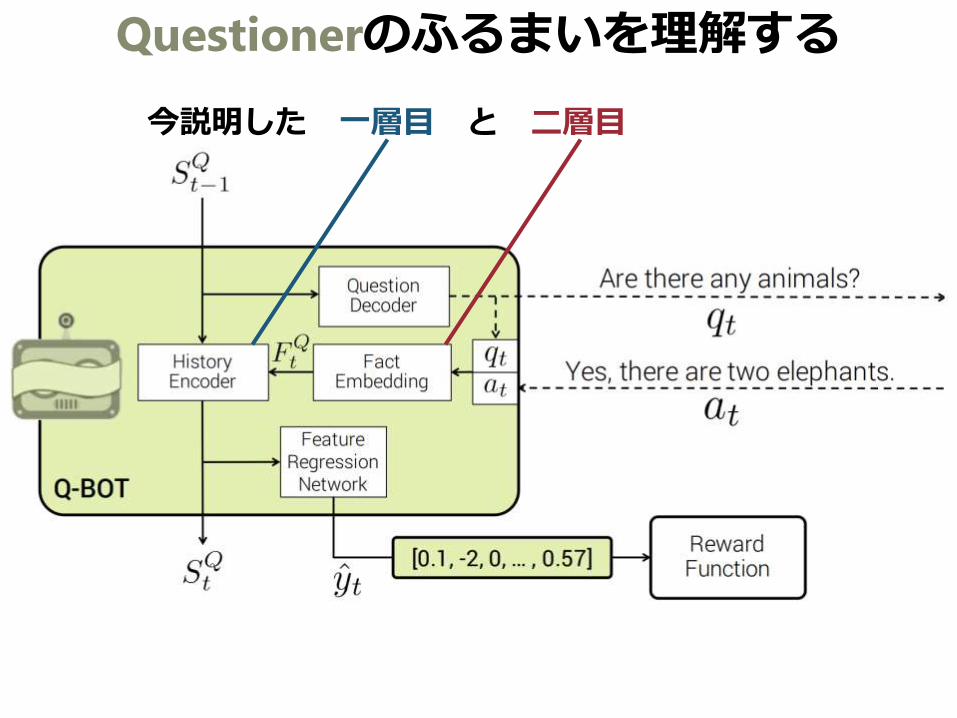
Questionerのふるまいを理解する
今説明した 一層目 と 二層目
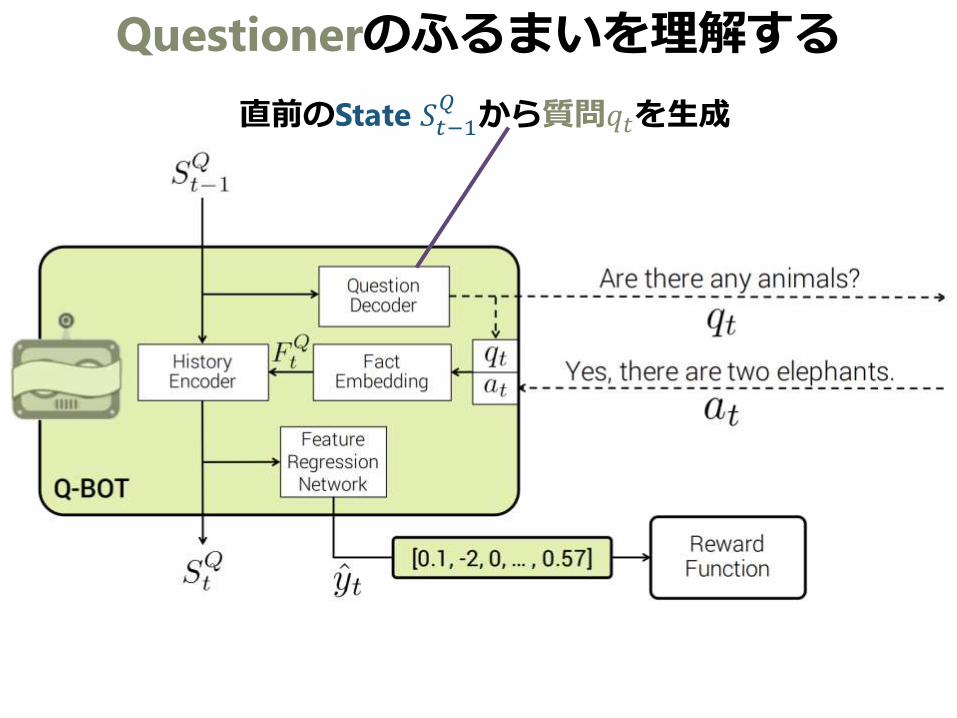
Questionerのふるまいを理解する
直前のState 𝑆𝑡−1𝑄から質問𝑞𝑡を生成
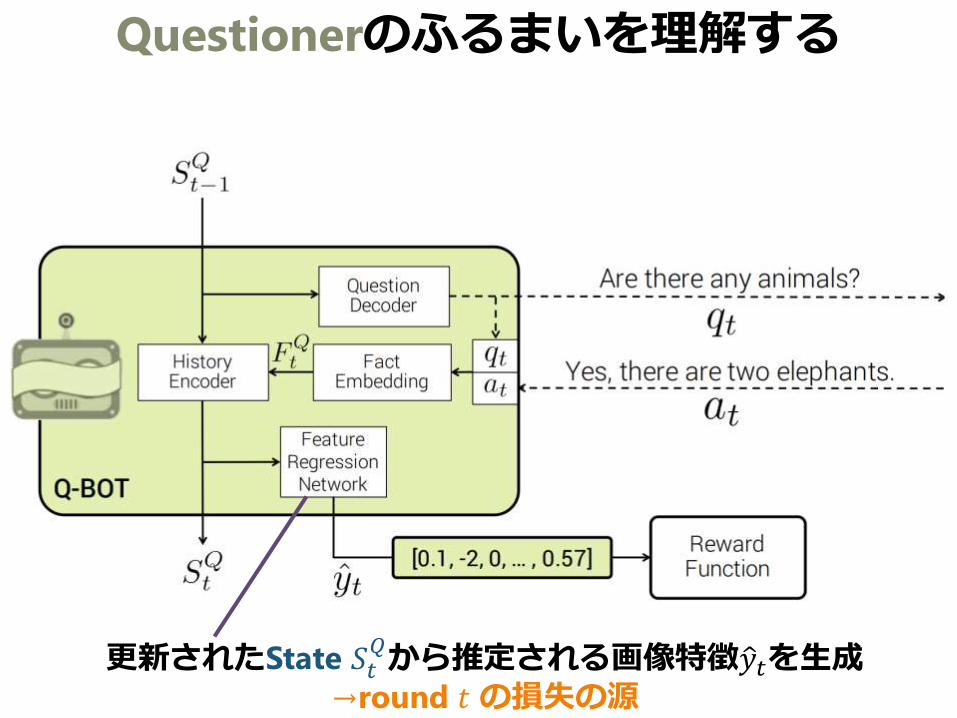
Questionerのふるまいを理解する
更新されたState 𝑆𝑡𝑄から推定される画像特徴 𝑦𝑡を生成
→round 𝑡の損失の源
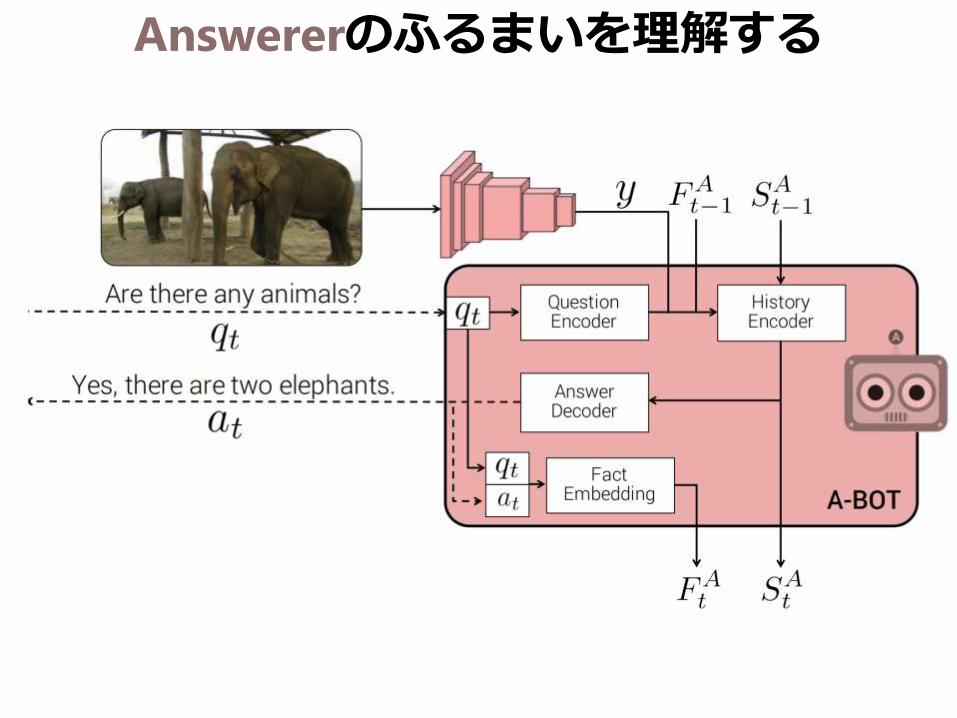
Answererのふるまいを理解する
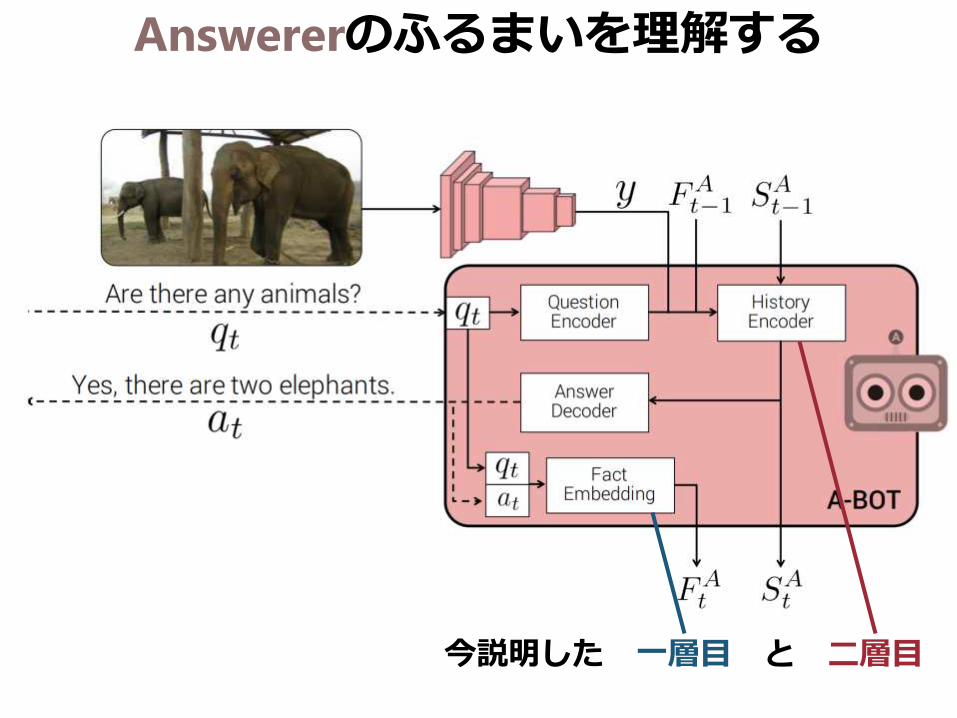
Answererのふるまいを理解する
今説明した 一層目 と 二層目
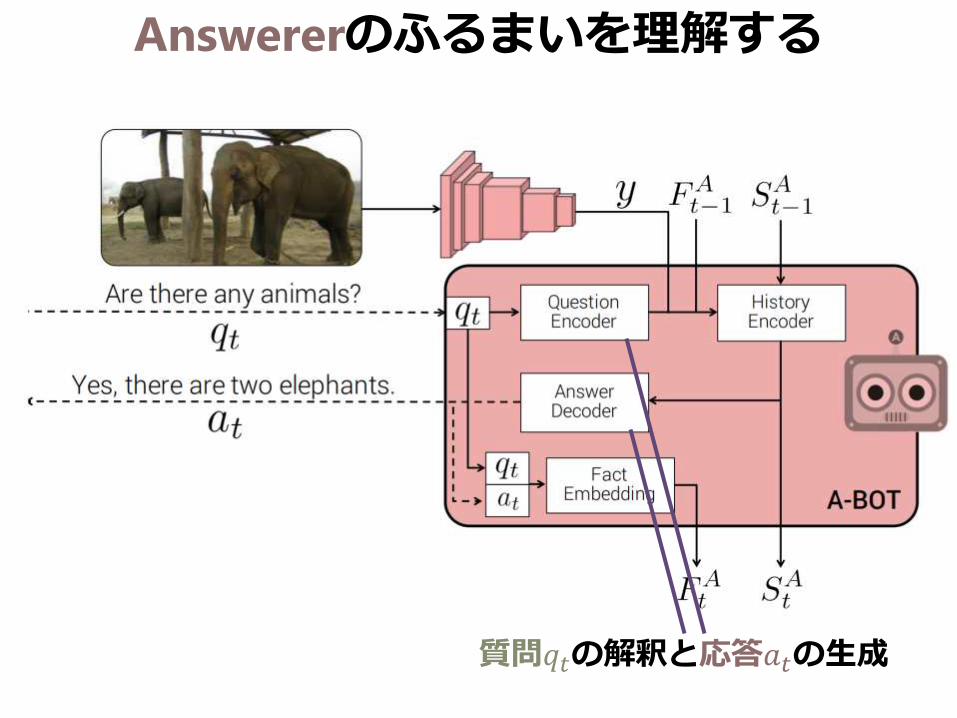
Answererのふるまいを理解する
質問𝑞𝑡の解釈と応答𝑎𝑡の生成

Round 𝑡 − 1における推定のズレ
Round 𝑡における推定のズレ
損失の計算
• Roundごとに損失𝑟𝑡が発生
→パラメータ𝜃𝑄、𝜃𝐴、𝜃𝑓を更新– 𝜃𝑄:QuestionerのHierarchical Recurrent Encoder-Decoder
– 𝜃𝐴:AnswererのHierarchical Recurrent Encoder-Decoder
– 𝜃𝑓:単層全結合ネットワークによる回帰のパラメータ
• 雰囲気としては、round 𝑡 のQAを踏まえてより正解画像に近づければOK!

勾配の計算
• 𝜃𝑄、𝜃𝐴の勾配は直接計算できない
– REINFORCE [Williams, 1992]で計算
– REINFORCEは画像キャプション生成でも利用され始めている
Cf. CVPR 2017読み会で読んだ論文
– 𝜃𝑓の勾配は通常の偏微分
Round 𝑡 − 1における推定のズレ
Round 𝑡における推定のズレ

実験結果~まとめ
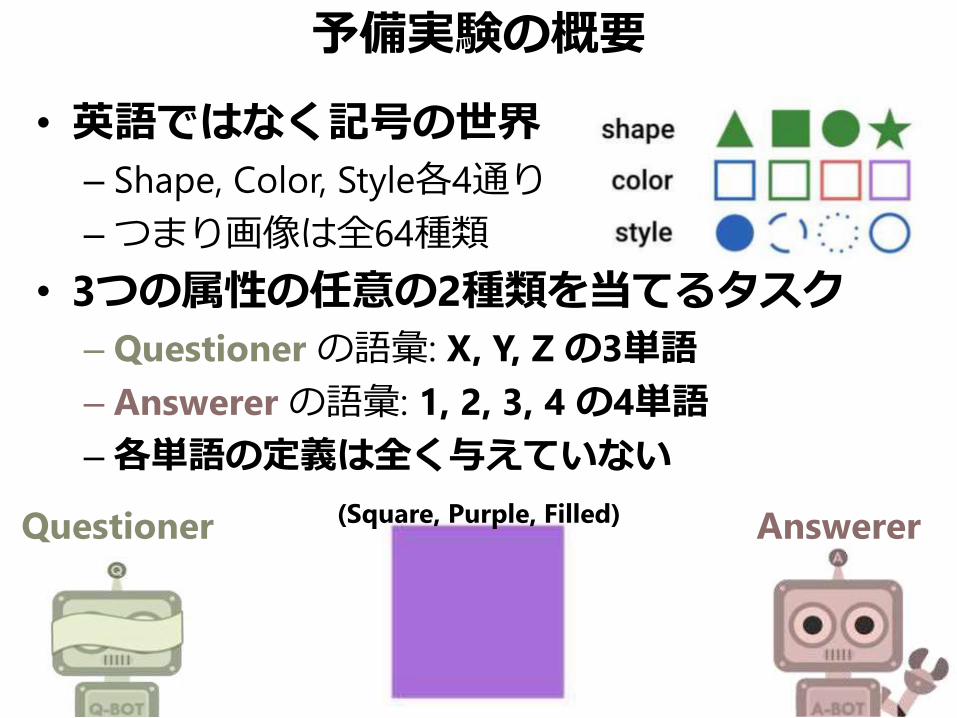
予備実験の概要
• 英語ではなく記号の世界
– Shape, Color, Style各4通り
–つまり画像は全64種類
• 3つの属性の任意の2種類を当てるタスク
– Questioner の語彙: X, Y, Z の3単語
– Answerer の語彙: 1, 2, 3, 4 の4単語
–各単語の定義は全く与えていない
Questioner Answerer(Square, Purple, Filled)
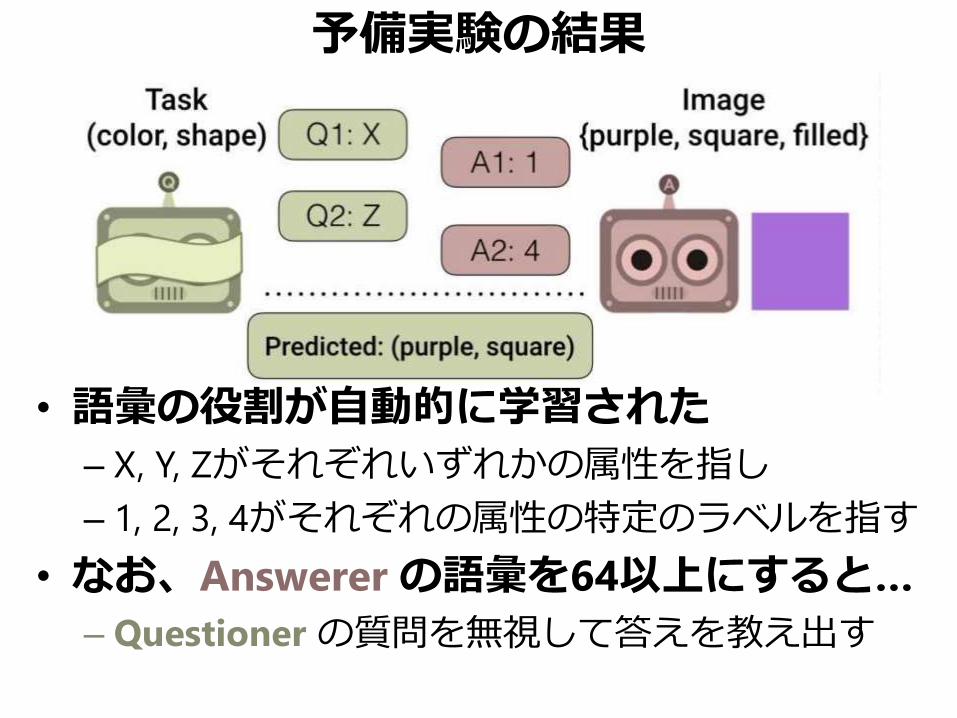
予備実験の結果
• 語彙の役割が自動的に学習された
– X, Y, Zがそれぞれいずれかの属性を指し
– 1, 2, 3, 4がそれぞれの属性の特定のラベルを指す
• なお、Answerer の語彙を64以上にすると…
– Questioner の質問を無視して答えを教え出す
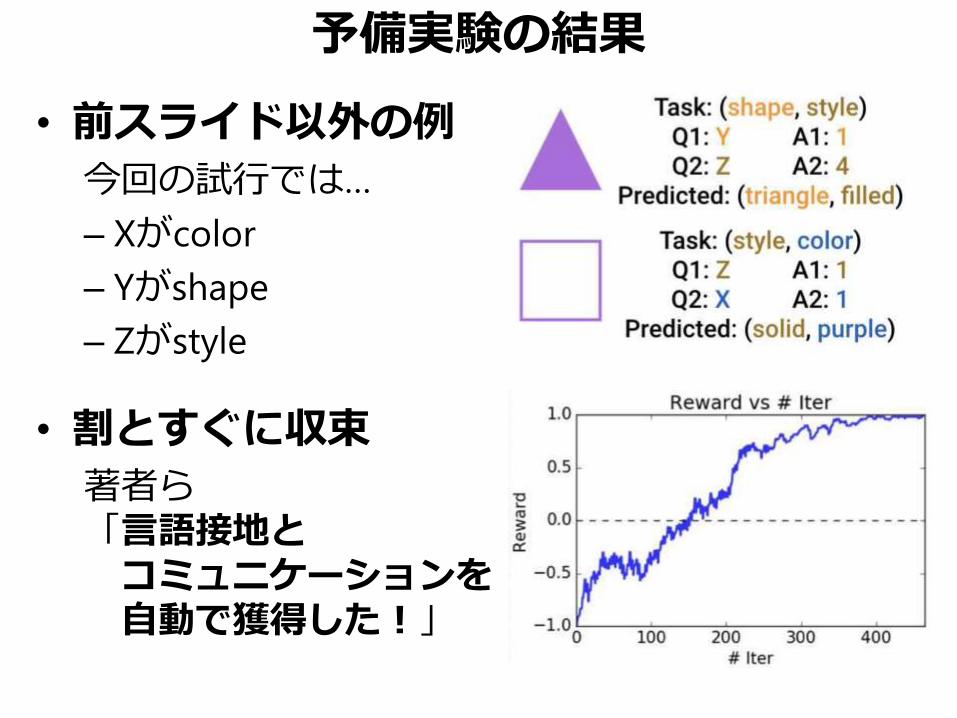
予備実験の結果
• 前スライド以外の例
今回の試行では…
– Xがcolor
– Yがshape
– Zがstyle
• 割とすぐに収束
著者ら「言語接地とコミュニケーションを自動で獲得した!」

本実験:VisDial データセット [Das+, CVPR 2017]
• MS COCOが基本
– 12万枚の画像
– 5キャプション/画像
• 1対話/画像を収集
– Amazon Mechanical Turk
– QA形式で10ラウンド
• 本論文はv0.5を利用
–画像約7万枚の対話
– 2017年12月現在はv0.9(画像約12万枚の対話)

学習方法
1. Supervised Pretraining
– 15エポック
– 通常の教師あり学習
2. Curriculum Learning
– 10エポック
– Kエポック目は…
• 10-Kラウンドまで教師あり学習
• その後のKラウンドが強化学習
– エポックが進むと自由度が増す
→ Curriculum Learning [Bengio+, ICML 2009]
(どこかに良い資料があればなあ…)

比較手法
• SL-pretrained
–教師あり学習
• Frozen-Q
• Frozen-A
• Frozen-f
– 𝜃𝑄、𝜃𝐴、𝜃𝑓のどれかをSL-pretrainのまま固定
–そのほかの2つのパラメータ群を強化学習
• RL-full-Qaf
– 𝜃𝑄、𝜃𝐴、𝜃𝑓すべてのパラメータ群を強化学習

定性的な対話結果例①
Questioner Answerer
A couple of people
in the snow on skis.

人間同士だと…
Questioner Answerer
A couple of people
in the snow on skis.
What are their genders?
Are they both adults?
Do they wear goggles?
Do they have hats on?
Are there any other people?
What color is man’s hat?
Is it snowing now?
What is woman wearing?
Are they smiling?
Do you see trees?
1 man 1 woman
Yes
Looks like sunglasses
Man does
No
Black
No
Blue jacket and black pants
Yes
Yes

SL-Pretrained(教師あり事前学習のみ)
Questioner Answerer
A couple of people
in the snow on skis.
2
I can’t tell
I can’t tell, they are far away
I can’t tell
Yes
Yes
Yes
Yes
Yes
Yes
How many people?
Male or female?
What are they wearing?
What color are skis?
Are they wearing goggles?
Are they wearing goggles?
Are they wearing goggles?
Are they wearing goggles?
Are they wearing hats?
Are they wearing goggles?

RL-full-QAf(提案手法)
Questioner Answerer
A couple of people
in the snow on skis.
Are people male or female or both?
What are they wearing?
Is it snowing?
Can you see any trees?
Can you see any buildings in background?
Can you see any trees?
Can you see any buildings in background?
Can you see any trees?
Can you see any buildings in background?
Does it look like they are in park?
I think 1 is male, can’t see other 1 ...
They are all wearing snow pants and jackets
It does not appear to be snowing at moment
Yes, there are lot of trees in background
No, I can not
Yes, there are lot of trees in background
No, I do not see any buildings
Yes, there are lot of trees in background
No , I do not see any buildings
It does not appear to be

定性的な対話結果例②
Questioner Answerer
A man riding a skateboard
down the side of a ramp.

人間同士だと…
Questioner Answerer
A man riding a skateboard
down the side of a ramp.
How old is man?
Is he wearing helmet?
Is he wearing any protective gear?
What color is his hair?
What color is his shirt?
Is he wearing shorts?
What color are his shorts?
Are there other people visible?
What color are his shoes?
Is this at skate park?
In his teens
No
No
Dirty blonde or dark brown
Black with red letters
Yes
Denim
No
I can’t see them
Yes

SL-Pretrained(教師あり事前学習のみ)
Questioner Answerer
A man riding a skateboard
down the side of a ramp.
How old is man?
What is he wearing?
What color is his shirt?
what color are his pants?
what color is his shirt?
What color are his shoes?
What color are his shoes?
What color are his shoes?
What color are his shoes?
What color are his shoes?
I can’t see his face, I don’t know
shorts and t shirt
white
black
blue
Black
Black
Black
Black
Black

RL-full-QAf(提案手法)
Questioner Answerer
A man riding a skateboard
down the side of a ramp.
What color is skateboard?
Is he wearing helmet?
Is he wearing knee pads?
Is it day or night?
Is it sunny?
Can you see any other people?
Is it day or night?
Is it sunny?
What color is skateboard?
Is he wearing helmet?
It is hard to tell but I think it’s black
Yes
No, no knee pads
It is daytime
It is bright out, but I see no shadows, so I can not
There are 2 other people in background
It is daytime
Yes, it is sunny
It is hard to tell but I think it’s black
Yes, he is wearing helmet

定性的な対話生成結果から
SL-Pretrainedは…
• 無限ループにはまりがち
–提案手法にもある
–が、その数はずっと少ない
• 無難な表現を頻出させがち
– QuestionもAnswerも
–キャプション生成「あるある」
–テキスト対話[Li+, EMNLP 2016]でも発生
–提案手法はより詳細で多様な表現
What color is his shirt? white
What color are his pants? black
what color is his shirt? blueWhat color are his shoes? Black
What color are his shoes? Black
What color are his shoes? Black
What color are his shoes? Black
What color are his shoes? Black
Questioner Answerer

定性的な画像あて結果例
• 第1,3,6Roundのやり取り
• 赤枠:Questionerが1枚目にランクした画像
• 他の画像:正解画像との距離が赤枠の画像のそれと同じような画像
正解画像+キャプション
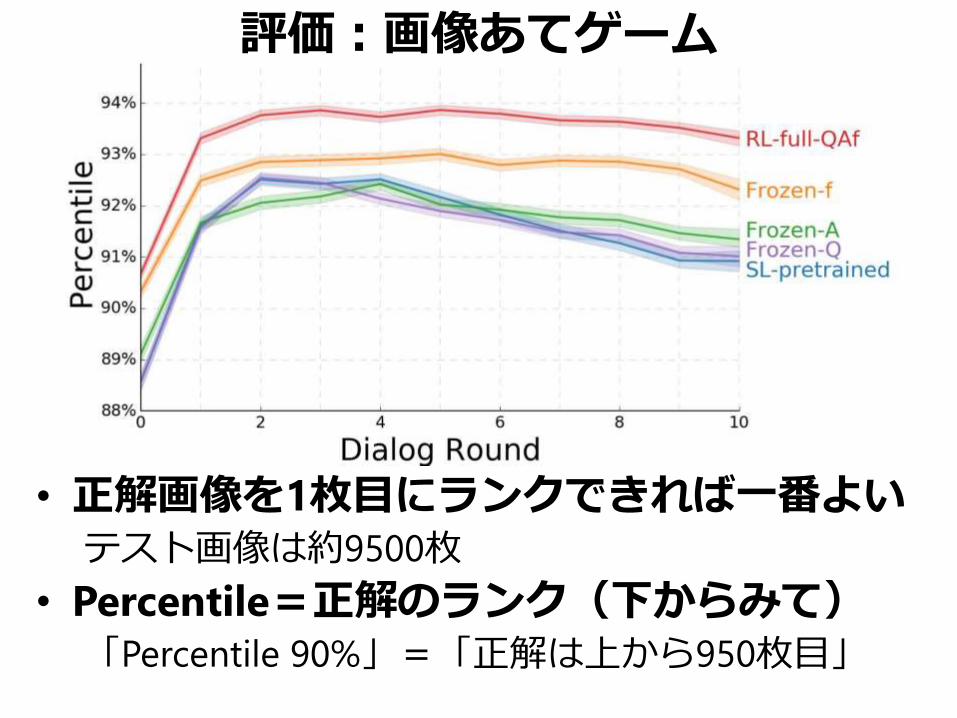
評価:画像あてゲーム
• 正解画像を1枚目にランクできれば一番よいテスト画像は約9500枚
• Percentile=正解のランク(下からみて)「Percentile 90%」=「正解は上から950枚目」
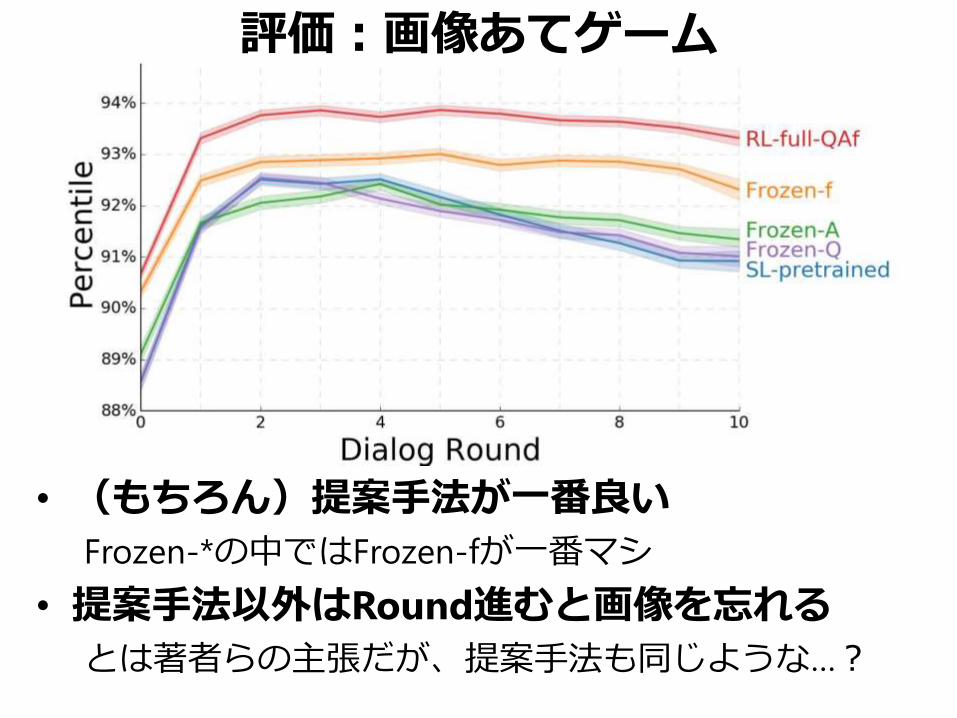
評価:画像あてゲーム
• (もちろん)提案手法が一番良い
Frozen-*の中ではFrozen-fが一番マシ
• 提案手法以外はRound進むと画像を忘れる
とは著者らの主張だが、提案手法も同じような…?
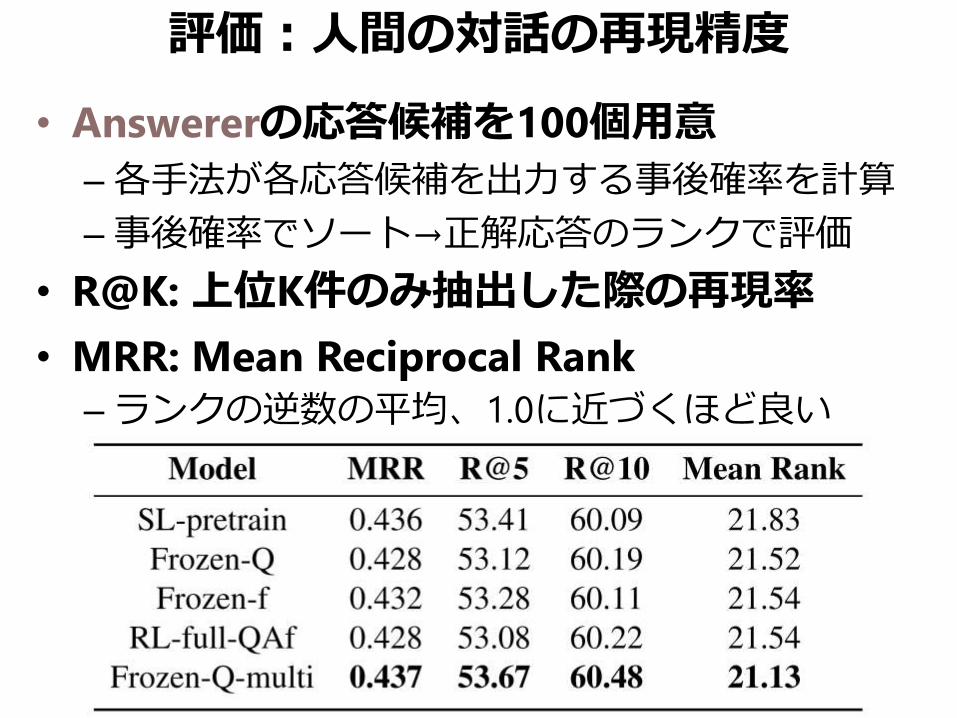
評価:人間の対話の再現精度
• Answererの応答候補を100個用意
–各手法が各応答候補を出力する事後確率を計算
–事後確率でソート→正解応答のランクで評価
• R@K: 上位K件のみ抽出した際の再現率
• MRR: Mean Reciprocal Rank
–ランクの逆数の平均、1.0に近づくほど良い
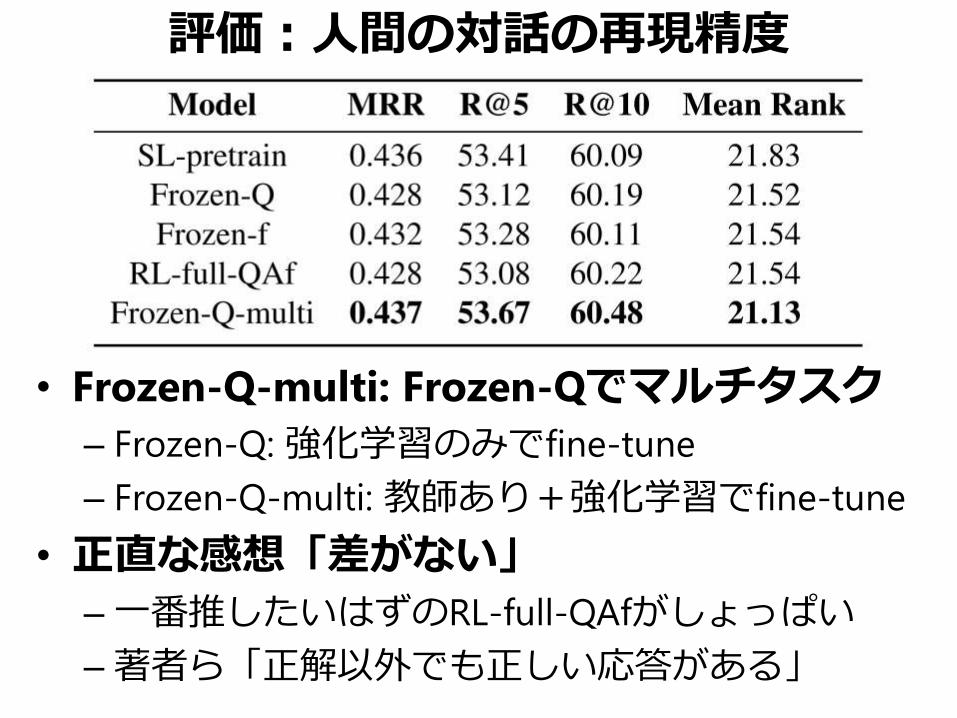
評価:人間の対話の再現精度
• Frozen-Q-multi: Frozen-Qでマルチタスク
– Frozen-Q: 強化学習のみでfine-tune
– Frozen-Q-multi: 教師あり+強化学習でfine-tune
• 正直な感想「差がない」
–一番推したいはずのRL-full-QAfがしょっぱい
–著者ら「正解以外でも正しい応答がある」

まとめ
• Image Guessing ゲームをする2エージェントの強化学習
–視覚に基づく対話の機械学習に取り組んだ
–教師あり学習→強化学習の効果を示した
• 研究のプランニングがうまい
同一グループの研究が矢継ぎ早に出ている
– VisDialデータセットとベースライン[Das+, CVPR 2017]
– QuestionerとAnswererの強化学習[Das+, ICCV 2017]
–人間とAIの協調作業[Chattopadhyay+, HCOMP 2017]
• 視覚に基づいた対話研究は増える兆し
• 精度としてはまだまだ改善の余地あり

最後に
寒すぎて味噌ラーメンが食べたい?


ぜひご参加ご検討ください!特に若手プログラムへ
https://sites.google.com/view/miru2018sapporo/
来年の夏ですが

![[DL輪読会]Continuous Deep Q-Learning with Model-based Acceleration](https://static.fdocument.pub/doc/165x107/58b87a5a1a28ab44078b48bf/dlcontinuous-deep-q-learning-with-model-based-acceleration.jpg)

![Stare de urgenta pentru consumul populaÈ iei Raport ICCV...> ] } µ o } u µ ] ] o ]](https://static.fdocument.pub/doc/165x107/610ed1ee324cfa52856f6162/stare-de-urgenta-pentru-consumul-popula-iei-raport-o-u-.jpg)



![[DL輪読会]Learning to simplify fully convolutional networks for rough sketch](https://static.fdocument.pub/doc/165x107/587148651a28ab55588b5eeb/dllearning-to-simplify-fully-convolutional-networks-for-rough-sketch.jpg)
![[RL輪読会]Distral: Robust Multitask Reinforcement Learning](https://static.fdocument.pub/doc/165x107/5a64798b7f8b9a5d568b4705/rldistral-robust-multitask-reinforcement-learning.jpg)



![[Dl輪読会]AdaNet: Adaptive Structural Learning of Artificial Neural Networks](https://static.fdocument.pub/doc/165x107/5a6478dd7f8b9a2c568b468b/dladanet-adaptive-structural-learning-of-artificial-neural-networks.jpg)
![[DL輪読会]Learning What and Where to Draw (NIPS’16)](https://static.fdocument.pub/doc/165x107/58b87a731a28ab44078b4917/dllearning-what-and-where-to-draw-nips16.jpg)
![[DL輪読会]Learning to Skim Text](https://static.fdocument.pub/doc/165x107/5a6479287f8b9a57568b4659/dllearning-to-skim-text.jpg)



