
Kvantitativ metode - Hjemmeeksamen 2 (2014)
50
02.02.2015 MET 405 - Kvantitative metoder Hjemmeeksamen 2 Høsten 2014 Bjørne Fjellheim Øen Ole Christian Kvernberg
-
Upload
ole-christian-kvernberg -
Category
Documents
-
view
158 -
download
7
description
Andre hjemmeeksamen i MET405 Kvantitativ metode ved HBV Hønefoss. Skrevet av Bjørne Fjellheim Øen og Ole Christian Kvernberg
Transcript of Kvantitativ metode - Hjemmeeksamen 2 (2014)

02.02.2015
MET 405 - Kvantitative metoder Hjemmeeksamen 2 Høsten 2014
Bjørne Fjellheim Øen
Ole Christian Kvernberg

Hjemmeeksamen 2 – Høsten 2014 MET 405 Kvantitative metoder 02.02.2015
1
Forord
Denne oppgaven er del 2 av hjemmeeksamen i faget MET 405 Kvantitative metoder høsten
2014. Oppgaven er skrevet av tre mastergradsstudenter ved Høgskolen i Buskerud og
Vestfold. Formålet med denne oppgaven er å få en dypere forståelse av pensumet i
kvantitative metoder som omhandler målutvikling og –validering og
eksperimentdataanalyse. Analysene er utført i analyseprogrammet SPSS på to forskjellige
datasett. Oppgave 1 bruker datasettet som omhandler hotell, og oppgave 2 bruker
datasettet som omhandler bank.
I oppgave 1.2 og 1.3 som omhandler målvalidering lot vi være å ta med analyser for
regresjonsforutsetning 6 og 8 på grunn av plassmangel. Vi forutsetter derfor at
datamaterialet tilfredsstiller kravet til regresjonsforutsetningene 6 og 8.
I oppgave 2 som omhandler eksperimentdataanalyse, synes vi det var relevant med å ta med
hypoteser. Vi ønsker å understreke at rasjonaler har blitt holdt kortfattet, for dette har blitt
allerede jobbet mye med i den første hjemmeeksamenen. Vi anser det som mindre sentralt i
denne oppgaven.

Hjemmeeksamen 2 – Høsten 2014 MET 405 Kvantitative metoder 02.02.2015
2
Innholdsfortegnelse
1.1 Målutvikling .......................................................................................................................... 4
Målutviklingsteori ................................................................................................................... 4
Konseptavklaring .................................................................................................................... 4
Bedriftslønnsomhet ............................................................................................................ 5
Bedriftsøkonomisk lønnsomhet .......................................................................................... 5
Identifisere dimensjoner og latente variabler til hvert begrep .............................................. 6
Markedssituasjon ................................................................................................................ 6
Lojalitet ............................................................................................................................... 6
Produksjon .......................................................................................................................... 7
Logistikk ............................................................................................................................... 7
Utforme mål ........................................................................................................................... 7
Markedssituasjon ................................................................................................................ 7
Lojalitet ............................................................................................................................... 7
Produksjon .......................................................................................................................... 8
Logistikk ............................................................................................................................... 8
Spesifisere forholdet mellom mål og latente variabler .......................................................... 8
1.2 Målvalidering ........................................................................................................................ 9
Steg 1 ...................................................................................................................................... 9
Strategi ................................................................................................................................ 9
Produktkvalitet .................................................................................................................. 10
Tilfredshet ......................................................................................................................... 11
Lojalitet ............................................................................................................................. 11
Steg 2 .................................................................................................................................... 11
Steg 3 .................................................................................................................................... 13
1.3 Modelltest .......................................................................................................................... 14
Simulering ............................................................................................................................. 14
2.1 Modelltest .......................................................................................................................... 15
Oppgave 2.2.............................................................................................................................. 17
Multivariate analysen ........................................................................................................... 18
Oppgave 2.3.............................................................................................................................. 22
Testing the assumption of Homogeneity of regression slopes (Andy Field, 2012) .............. 23
Oppgave 2.4 Kritisk Realisme ................................................................................................... 24

Hjemmeeksamen 2 – Høsten 2014 MET 405 Kvantitative metoder 02.02.2015
3
Kritisk realistisk perspektiv for rammeverk for utvikling og testing av teori ....................... 25
2.5 Utforming av design ........................................................................................................... 27
Validitetstrusler .................................................................................................................... 28
Intern- vs ekstern validitet .................................................................................................... 29
Litteraturliste ............................................................................................................................ 30
Skriftlige kilder til litteraturreferanser ................................................................................. 30
Skriftlige kilder ...................................................................................................................... 30
Andre kilder .......................................................................................................................... 31
Vedlegg ..................................................................................................................................... 32
2.1.1 Forutsetninger for MANOVA ....................................................................................... 32
2.1.2 Utskrift av den multivariate analysen ......................................................................... 34
2.1.3 Forutsetning nr 1 for ANOVA for oppgave 2.1 ............................................................ 35
2.2.1 Forutsetning for ANOVA: Levene’s test og Box’s test ................................................. 36
2.2.2 Post hoc test mellom infokvalitet og sparing .............................................................. 37
2.2.3 Post hoc test for Infokvalitet * Sparing * Lønnsinntekt .............................................. 39
2.3.1 Korrelasjonsmatrise ..................................................................................................... 41
2.3.2 Multivariat med kontrollvariabler mot uavhengig ...................................................... 42
2.3.3 Multivariat analyse med kontrollvariabler .................................................................. 43
Syntaks .................................................................................................................................. 45
1.2: Faktoranalyser............................................................................................................ 45
1.2: Reliabilitetstest .......................................................................................................... 46
1.2: Indekserte variabler ................................................................................................... 47
1.2: Korrelasjonsanalyse ................................................................................................... 47
1.2: Indekserte variable med 100 skala ............................................................................ 47
1.3: Regresjonsanalyse ...................................................................................................... 47
2.2: Multivariat analyse .................................................................................................... 48
2.2: Post-Hoc test: Infokvalitet * Sparing ......................................................................... 48
2.2: Post-Hoc test: Infokvalitet * Sparing * Lønnsinntekt ................................................ 48
2.3: Korrelasjonsmatrise ................................................................................................... 48
2.3: Multivariat med kontrollvariabler mot uavhengig .................................................... 49
2.3: Den multivariate med kontrollvariabler: ................................................................... 49

Hjemmeeksamen 2 – Høsten 2014 MET 405 Kvantitative metoder 02.02.2015
4
1.1 Målutvikling Målutvikling er et viktig verktøy som brukes mye av forskere, spesielt i kvantitative forskningsmetoder hvor datamateriale består av talldata. Det kan beskrives som en prosess hvor et konsept er linket til én eller flere latente variabler, mens disse igjen er relatert til direkte observerbare variabler (Bollen, 1989). Vi bruker målutvikling for å sikre at vi utvikler gode og gjennomtenkte mål for variablene som man skal bruke i en studie. En av de utfordringene man står ovenfor som forsker, er å klare å måle det man faktisk ønsker å måle, og oppnå minst mulig målefeil. Det er også nødvendig at respondentene forstår meningsinnholdet i spørsmålene som stilles i en spørreundersøkelse. Det er derfor viktig at vi får gode mål som faktisk måler det tiltenkte begrepet, og som reflekterer dimensjonene til variablene. En god måleutvikling vil sikre begrepsvaliditet og minske risikoen for målefeil, og etablere sammenhenger mellom latente og observerte variabler, konsept og begrep (Bollen, 1989). Målutvikling vil også være selve grunnlaget for undersøkelsen og kvaliteten på datamaterialet senere (Mitchell & Jolley, 2013). Ved å bruke et målutviklingsverktøy, så får vi latente variabler som representerer det begrepet vi skal måle på en bra måte, vi minimerer sjansen for målefeil og respondentene forstår bedre meningsinnholdet i spørsmålene som stilles.
Målutviklingsteori Det finnes flere modeller som kan brukes til målutvikling. I vår oppgave, kommer vi til å bruke Bollens 4-stegs målutviklingsprosess som mal for å utvikle mål. Vi bruker en slik prosess for å kunne utvikle mål for å kunne "se" begrepene som i seg selv ikke er observerbare. Vi prøver altså i denne prosessen å binde et begrep til dimensjoner, som igjen bindes til latente variabler som til slutt bindes til mål/spørsmål i et spørreskjema. Målprosessen starter med at vi har et konsept som kan være alt fra abstrakte konsept som intelligens, til mer konkrete konsept som kjønn. Bollen mener at for å gi mening til konseptet, så er det viktig med latente variabler som representerer det vi er ute etter å måle. Å måle variabler som ikke er direkte målbare, er det vi er ute etter fordi et begrep kan består av mange aspekter. I vår oppgave er konseptet lønnsomhet, og vi vil ut ifra målutviklingsstegene nedenfor komme fram til gode mål på dette. Hele prosessen inneholder fire steg som vi på de neste sidene vil gå igjennom steg for steg:
Konseptavklaring
Identifisere dimensjoner og latente variabler til hvert begrep
Utforme mål
Spesifisere forholdet mellom mål og latente variabler
Konseptavklaring
Konseptavklaring er det første steget i Bollens 4-stegs målutviklingsprosess, og går ut på å utvikle en teoretisk definisjon til konseptet i studien. En målutviklingsprosess starter med et konsept, og det er derfor nødvendig å avklare konseptet så tidlig som mulig før vi går videre med de andre stegene i prosessen. Et konsept kan defineres på mange forskjellige måter i forhold til kontekst, men generelt sett er det en idé som samler et fenomen under ett enkelt begrep. I konseptavklaringen prøver vi å finne latente variabler for å representere konseptet, altså prøver vi å gi mening til konseptet. Ved å gi mening til, og presisere konseptet til noe

Hjemmeeksamen 2 – Høsten 2014 MET 405 Kvantitative metoder 02.02.2015
5
målbart, så får vi et mer nøyaktig begrep som spesifikt sier hva vi ønsker å undersøke. For å få til å gi mening til begrepet, må vi derfor etablere den teoretiske definisjonen. Den teoretiske definisjonen avgrenser og spesifiserer betydningen av hva som ligger i konseptet (Bollen, 1989:180). Med en god definisjon får vi også skilt ut de mulige dimensjonene som begrepet består av, som er viktig slik at en vet hva man undersøke i en studie. Når en teoretisk definisjon gir en så enkel og presis mening til konseptet som mulig, kan vi gå videre til neste steg i målutviklingsprosessen.
Bedriftslønnsomhet
Bedriftslønnsomhet er et begrep som brukes i mange sammenhenger i bedrifter. Det er et begrep som mange tenker de vet hva er, men som de synes det er vanskelig å definere på noen klar og tydelig måte. Mange sliter med å enes om hva bedriftslønnsomhet egentlig er, og hvilke dimensjoner det består av. Dette er fordi det finnes mange typer bedriftslønnsomhet ut ifra hvilken kontekst man tenker på. Når folk hører begrepet bedriftslønnsomhet, så tenkes det veldig ofte kun på penger, men det kan også være andre aspekt ved bedriftslønnsomhet som for eksempel miljø, effektivitet, nytteverdi eller kunnskap. Siden bedriftslønnsomhet er et begrep som kan tolkes på mange forskjellige måter i forhold til hvilken sammenheng man er i, så er det derfor viktig å tydelig gjøre rede for hvilken type lønnsomhet man er ute etter å studere. Det er nettopp dette det første steget i Bollens målutviklingsprosess går ut på, å avklare og gi mening til konseptet slik at man vet hva man er ute etter å se videre på. I vår oppgave så har vi valgt å fokusere på bedriftsøkonomisk lønnsomhet, og den teoretisk definisjon blir der etter. Siden vi velger å se på økonomisk lønnsomhet, kommer vi til å fokusere på å finne objektive mål. Objektive mål er naturlig innenfor økonomi da det meste er målbart i form av inntekt, kostnader osv. Bedriftsøkonomisk lønnsomhet er lønnsomhet som ser på det økonomiske aspektet til bedrifter. Denne typen lønnsomhet er den mest vanlige, og er allerede definert av flere. Definisjonene varierer litt fra hverandre, og folk er uenige om nøyaktig hva bedriftsøkonomisk lønnsomhet virkelig er. Dette er blant annet fordi det finnes flere typer økonomisk lønnsomhet. Det kan være bedriftsøkonomisk lønnsomhet i sin helhet for hele bedriften totalt sett, eller det kan også være kun for én investering, prosjekt eller lignende. På grunn av at det finnes flere typer økonomisk lønnsomhet, så medfører det at det utvikles definisjoner som hovedsakelig nesten er like, men som har noen forskjeller seg imellom. En annen grunn til at definisjonene varierer fra hverandre, er rett og slett fordi at folk ikke er enige om hva begrepet faktisk betyr. Noen mener at økonomisk lønnsomhet kun er differansen mellom kostander og inntekter, og at det faktisk går an ha negativ lønnsomhet hvor man går i underskudd. Andre mener derimot at lønnsomhet kun er når inntektene overstiger kostnadene slik at man går i overskudd, og at "negativ lønnsomhet" heller betegnes som tap.
Klima- og miljødepartementet har definert bedriftsøkonomisk lønnsomhet på sin nettside, og siden dette er en god og troverdig kilde så velger vi å bruke definisjonen som de har utarbeidet. De definerer bedriftsøkonomisk lønnsomhet som: "En virksomhets evne til å gi avkastning på den investere kapitalen, beregnet til de priser på ferdigprodukter og innsatsfaktorer (for eksempel arbeidskraft) som foretaket står ovenfor i markedet."(Klima- og miljødepartementet, 2000).

Hjemmeeksamen 2 – Høsten 2014 MET 405 Kvantitative metoder 02.02.2015
6
Definisjonen ser altså på lønnsomhet som en evne i form av det å være lønnsom. Lønnsomheten betegnes som en egenskap eller tilstand som bedrifter er i når de får avkastning på investert kapital på for eksempel et prosjekt. Som sagt tidligere, så mener vi at man kun er lønnsom dersom man går i overskudd, altså at man har høyere avkastning enn investert kapital. Definisjonen til klima- og miljødepartementet sier derimot ingenting om avkastningen skal være høyere eller lavere enn den investerte kapitalen for at en bedrift skal betraktes som lønnsom, men vi velger å tro at dette kommer av at folk også har ulike oppfatninger av hva avkastning er. Av noen så viser avkastning kun til vinning/gevinst, altså at man går i overskudd, mens hos andre så viser det kun til utbytte som med andre ord betyr at avkastning kan være lavere enn den investerte kapitalen. Vi velger å se på avkastning som at man går i overskudd, og tolker derfor definisjonen til miljødepartementet som at man må ha positiv avkastning for å betegnes som lønnsom.
Identifisere dimensjoner og latente variabler til hvert begrep
Steg 2 i Bollens målutviklingsprosess går ut på å finne dimensjonene og de latente variablene som kan brukes til å måle begrepet man ønsker å undersøke. Dette gjør vi for å bryte ned komplekse begrep inn i homogene og validerbare begrep (Bollen, 1989). Å finne dimensjoner er viktig for de neste stegene i målutviklingsprosessen, siden de dimensjonene vi kommer frem til her representerer de ulike sidene til det overordnede begrepet. Dimensjonene skal vi finne ved å ta utgangspunkt i den teoretiske definisjonen som ble etablert i konseptavklaring. Hver enkelt dimensjon av begrepet bør representeres av minst én latent variabel for å fange opp all variansen i konseptet. Ut fra dette har vi et grunnlag for å danne mål til begrepet vi arbeider med (Bollen, 1989), som vi skal gjøre i steg 3. I steg 2 skal vi altså finne dimensjoner og latente begrep som representerer bedriftsøkonomisk lønnsomhet. Hvis vi undersøker den teoretiske definisjonen vi kom fram til i konseptavklaringen, så er den hovedsakelig delt i 2. På den ene siden har vi avkastning, mens på den andre siden har vi investert kapital. Dette mener vi er to dimensjoner som dekker lønnsomhets begrepet bra da avkastning tar for seg inntektene man får inn, mens investert kapital tar for seg kostnadene man har brukt. Videre, så kom vi fram til latente variabler ut ifra dimensjonene vi nettopp identifiserte. Latente variabler er variabler som er ikke er direkte observerbare/målbare, men som er viktige for å beskrive lønnsomhet på en riktig måte.
Den første dimensjonen var som nevnt avkastning, og ut ifra denne kom vi fram til følgende latente variabler: Markedssituasjon og lojalitet.
Markedssituasjon mener vi er en viktig variabel da avkastning avhenger mye av hvordan situasjonen er i markedet. Det forteller om forholdet mellom bedriften og konkurrentene, samtidig som det sier noe om blant annet etterspørsel og priser i det nåværende markedet. Alle disse tingene er med å påvirker avkastning i stor grad, og representerer dimensjonen godt.
Lojalitet er også en god variabel på avkastning, da det sier noe om hvor lojal kunden er mot bedriften. Lojale kunder vil gjerne vende tilbake til samme bedrift for å kjøpe varer som igjen fører til økt avkastning. Lojalitet sier noe om forholdet mellom kunder og bedriften, og har stor betydning for utfallet av avkastningen, og er avgjørende for om en bedrift er lønnsom eller ikke.

Hjemmeeksamen 2 – Høsten 2014 MET 405 Kvantitative metoder 02.02.2015
7
Den andre dimensjonen vi kom fram til var investert kapital. Ut ifra denne dimensjonen kom vi fram følgende latente variable: Produksjon og logistikk.
Produksjon er en stor del av kostnadene til en bedrift da det sier noe både om produktivitet og produksjonsprosessen, og representerer dimensjonen godt da begge disse tingene har mye å si for størrelsen på kostnadene i en bedrift.
Logistikk sier noe om planlegging og administrasjon av håndtering av produkter og materialer i en bedrift. Logistikk har stor påvirkning på graden av kostnadene til en bedrift og representerer kostnadsdimensjonen bra mener vi.
Utforme mål
Tredje, og neste siste steg i målutviklingsprosessen er å formulere målformene. "The operational definition describes the procedures to follow to form measures of the latent variable(s) that represent a concept" (Bollen 1989, 181). Vi skal altså lage operasjonelle definisjoner til dimensjonene vi kom fram til i forrige steg. Når vi skal lage spørsmål, må vi passe på slik at vi ikke lager for avanserte spørsmål, som gjør at kunnskapsnivået til målgruppen blir overvurdert, samt at man bør være forsiktig med bruk av fremmedord (Ringdal, 2007). Gjennom operasjonaliseringen, får vi klargjort hva som måler de latente begrepene. Målene som utvikles skal representere begrepet på en slik måte at intensjonen bak variabelen blir bevart, noe som også vil være avgjørende for målenes overflatevaliditet (Mitchell & Jolley, 2013). Overflatevaliditet er viktig i Bollens målutviklingsprosess, og defineres som i hvilken grad et mål reflekterer hva det er tiltenkt å måle. For å sikre god overflatevaliditet så er det som sagt tidligere, viktig at respondentene forstår spørsmålene som formuleres. I tillegg til overflatevaliditet, er det viktig at vi kommer fram til mål som både er pålitelige og valide. For å komme fram til mål på de latente variablene, har vi prøvd å finne ut hvordan tidligere forskning har operasjonalisert begrepene. Vi har også prøvd å se om det finnes allerede etablerte og valide måleskalaer for disse begrepene. Der vi ikke har funnet tidligere forskning som operasjonaliserer begrepene våre, har vi formulert spørsmålene selv slik at vi tror dem måler begrepene på best mulig måte. Alle målene vi enten har laget selv, eller funnet ifra tidligere forskning er målt med en 6-punkts Likert-skala hvor 1 er "Helt uenig", mens 6 er "Helt enig".
Markedssituasjon
I1-Vår bedrift har få konkurrenter innenfor samme industri
I2-Vår bedrift har en høy etterspørselen etter produkter våre
I3-Vår bedrift er alene om å tilby typen produkter som vi lager
Lojalitet
I4-Våre kunder anbefaler i stor grad bedriften til venner og familie
I5-Våre kunder oppfordrer venner til å bruke bedriften
I6-Våre kunder ville sannsynligvis byttet til konkurrerende bedrifter ved lavere priser
Operasjonell definisjon på avkastning blir ut ifra dette: "Avkastning måles av inntekter påvirket av markedssituasjonen og lojaliteten kundene har til bedriften.

Hjemmeeksamen 2 – Høsten 2014 MET 405 Kvantitative metoder 02.02.2015
8
Produksjon
I7-Våre ansatte er effektive i arbeidet som utføres
I8-Vår ansatte bruker mye tid på ikke-produksjonsrelaterte oppgaver
I9-Bedriften har i stor grad moderne utstyr som øker produktiviteten
Logistikk
I10-Administrasjonen bruker mye tid på å optimalisere planlegging og administrasjon av varetransport
I11-Våre ansatte er effektive når det kommer til lagerstyring
I12-Våre ansatte er godt koordinerte i sine arbeidsoppgaver
Operasjonell definisjon på investert kapital blir ut ifra dette: "Investert kapital måles av kostnader påvirket av produksjon og logistikk til bedriften.
Spesifisere forholdet mellom mål og latente variabler Det siste punktet i Bollens målutviklingsprosess, går ut på at man skal spesifisere forholdet mellom målene og de latente variablene ved å lage en målemodell (Bollen, 1989). En målemodell er en modell som spesifiserer forholdet mellom målene og de latente variablene. Bollen skiller mellom to typer målemodeller, den ene er refleksiv og den andre er formativ. En refleksiv målemodell er en modell hvor målene reflekterer det overordnede begrepet slik at det ikke gjør noe om vi fjerner én av dem. I en slik målemodell så er målene effektindikatorer som betyr at de er effekter av den latente variabelen, og de vil være sterkt korrelert med hverandre da de fanger opp samme hovedbegrep (Bollen, 1989). I den formative målemodellen så går pilene omvendt i forhold til på den refleksive. Her går pilene fra målene og til den latente variabelen, og de er med å forme det overordnede begrepet. Målene kalles i denne modellen da for årsaksindikatorer, da de nå ikke er en effekt av den latente variabelen, men de er årsaken til den isteden. Hvert mål er med å forme begrepet, og vi kan ikke fjerne en av dem for da blir ikke meningen i den latente variabelen den samme.
Ut ifra målene vi kom fram til i steg 3, så ser vi at de reflekterer de overordnede latente variablene. Målene for hver latente variabel er effektindikatorer, og er sterkt korrelerte med hverandre da de fanger opp samme hovedbegrep. Det gjør ingenting om vi forkaster én av dem siden de reflekterer og ikke former den overordnede variabelen. Ut ifra dette så har vi derfor en refleksiv målemodell.

Hjemmeeksamen 2 – Høsten 2014 MET 405 Kvantitative metoder 02.02.2015
9
1.2 Målvalidering I oppgave 1.2 skulle vi validere målene til begrepene som stod i oppgaveteksten, ut ifra kravene til konvergens og divergens på både mål- og begrepsnivå. Målvalidering gjør vi for å sjekke om variablene måler det de er ment å måle. De fire mest brukte typene for validitet er innholdsvaliditet, internvaliditet, begrepsvaliditet og konvergent/divergent validitet (Bollen, 1989). I denne oppgaven kommer vi til å fokusere på konvergent og divergent validitet på indikator og begrepsnivå. Konvergent validitet beskriver hvorvidt itemene vi tror representeres begrepet virkelig er mål på denne faktoren (Sørebø, 2012, 32). Divergent validitet beskriver i hvilken grad spørsmålene for et begrep skiller seg fra spørsmål som tilhører andre begrep (Sørebø, 2012, 39). Begrepene som vi skulle teste var som følgende: strategi, produktkvalitet, tilfredshet og lojalitet. Begrepene ble testet hver for seg, og indikatorene ble kjørt gjennom faktoranalyser i SPSS for å se på sammenhenger i datamaterialet. Vanlige bivariate korrelasjonsanalyser er også en måte å sjekke sammenhenger i datamaterialet på, men faktoranalyser foretrekkes da de kan avdekke komplekse sammenhenger, mens bivariate analyser kun måler bivariate sammenhenger (Sandvik, 2014). Faktoranalyser kan med andre ord finne sammenhenger som er umulig å se med det blotte øyet. Analysene ble kjørt ved å trykke på "AnalyseDimension ReductionFactor", og så la vi inn alle indikatorene for begrepet vi testet inn i "variables" boksen. Etter at variablene var lagt inn, så valgte vi "maximum likelihood" som ekstraksjons metode fordi den har vist seg å være den mest riktige og robuste gjennom simuleringsstudier (Sandvik, 2014). Ekstraksjonen ble satt vi til å basere seg på eigenvalue som er forklart varians av en faktor for alle indikatorene. Vi satt også "maximum number of iterations" til 2500 slik at om SPSS sliter med å generere faktorer, så kjører den flere iterasjoner enn det som er standard for å øke sjansen for å klare å genere faktorer. Så gikk vi inn på rotasjon å valgte "direct oblimin (oblik rotasjon)" som ser på fri korrelasjon mellom faktorene. Delta verdien lot vi stå på 0, noe som betyr at det ikke legges inn noen begrensning på korrelasjonen. Vi satt også iterasjoner til 2500 på rotasjon på samme måte som for ekstraksjonsmetoden. Etter at innstillingene var satt, gikk vi i gang med steg 1 som er å teste indikatorene for hvert begrep hver for seg i forhold til konvergens og divergens.
Steg 1
Strategi
Faktoranalysen for strategi indikatorene genererte to faktorer, og når det er mer enn én faktor skal man se på "pattern matrix" istedenfor "factor matrix" (Sørebø, 2012).
I faktoranalysen er det et flertall av høye faktorladninger på faktor 2, så derfor ser vi på dette som den tiltenkte faktoren for begrepet. Det normale kravet for at en indikator skal være konvergent valid, er at faktorladningen er over 0,5 (Sandvik, 2014). Om begrepet har få indikatorer som måler begrepet godt, og indikatorspørsmålet er formulert på en god måte i forhold til det begrepet skal måle, så kan man alternativt godta faktorladninger ned til 0,3 (Sandvik, 2014). Alle indikatorene på faktor 2 bortsett fra indikator 4-5 og 6, har

Hjemmeeksamen 2 – Høsten 2014 MET 405 Kvantitative metoder 02.02.2015
10
faktorladninger på over 0,5 som betyr at de er konvergent valide. Dette underbygges også når vi regner ut "SigmaT" som måler den sanne variansen til indikatoren. SigmaT er også et mål for konvergent validitet, og kravet for å bli godkjent er at den sanne variansen er over 0,25 (25%) (Sandvik, 2014). Indikatorene som bestod konvergentkravet har også sann varians på over 25%, som er med å bekrefter at indikatorene er konvergent valide. Siden faktoranalysen generer 2 faktorer, så kan vi også se på den divergente validiteten. Kravet for divergent validitet er at differansen mellom faktorene er over 0,2, og samtidig at SigmaR som er restvariansen er over 5%. Alle indikatorene har differanse over 0,2, men indikator 4-6 har en restvarians som er under 5% og er derfor ikke divergent valid. Indikator 4-6 måler i tillegg høyt på en annen faktor enn den tiltenkte, som kan bety at denne indikatoren egentlig måler noe annet. Vi vurderte derfor å dele opp strategibegrepet, men siden det er kun én indikator som er over 0,5 på faktor 1 så droppet vi dette da et begrep minst bør måles av to, helst tre indikatorer (Sørebø, 2012). For at vi skal beholde indikatorene for videre analyser, er det et krav til at indikatorene må være både konvergente og divergente. Ut ifra resultatene i faktoranalysen, velger vi derfor å forkaste indikator 4-6 på grunn av mangel på både divergent og konvergent validitet. Vi forkaster også indikator 4-5, da denne ikke var konvergent. Vi sitter da igjen med indikatorene 4-1,2,3,4,7 som både er konvergent- og divergent valide. Disse beholdes derfor for videre analyser.
Produktkvalitet
Vi tenker at faktor 1 er den tiltenkte faktoren her fordi flere av indikatorene måler like oppunder kravet til konvergent validitet. Vi mener også at indikatorene som har høyest faktorladning på faktor 2 ikke måler produktkvalitet noe bra ut ifra spørsmålene som er stilt. I forhold til konvergent validitet, så er indikator 5-3 godt over kravet, og har i tillegg en sann varians på hele 66%. Indikator 5-1,4,5 er alle like under kravet på 0,5, men siden vi her kun har én indikator som måler begrepet veldig bra så velger vi å godkjenne disse i forhold til det alternativet kravet på 0,3. Vi mener også at indikatorene måler produktkvalitet bra ut ifra spørsmålene som er stilt. Disse har en sann varians like i underkant av 25%, noe som gjenspeiler den litt lave faktorladningen. Indikator 5-2,6,7 har faktorladninger som er langt under kravet for konvergent validitet, som igjen underbygges av en sann varians som er langt under 25%. I forhold til divergent validitet, så har indikatorene 5-1,3,4,5 en differanse til den "gale" faktoren på over 0,2 og oppfyller dermed kravet. Dette bekreftes også med at restvariansen for disse indikatorene er langt over 5%. Blant indikatorene som ikke oppfylte kravet til konvergent validitet, så oppfyller 5-6,7 kravet for divergent validitet siden differansen er over 0,2 og restvariansen er over 5%, mens 5-2 har en differanse som er under 0,2 og oppfyller derfor ikke kravet. Hvis vi oppsummerer resultatene fra faktoranalysen, så beholder vi 5-1,3,4,5, mens vi forkaster indikatorene 5-2,6 og 7.

Hjemmeeksamen 2 – Høsten 2014 MET 405 Kvantitative metoder 02.02.2015
11
Tilfredshet
Faktoranalysen for tilfredshet genererte kun én faktor, og vi ser derfor kun på konvergent validitet her. Alle indikatorene oppfyller kravet både for konvergent validitet og sann varians. På bakgrunn av dette beholder vi alle tre indikatorene for begrepet tilfredshet.
Lojalitet
Indikatorene 5-11,12,13,14,15 oppfyller kravet på konvergent validitet og sann varians. Noe som er viktig å ta hensyn til i denne faktoranalysen er at indikator 5-16 er et negativt formet spørsmål, mens alle de andre spørsmålene er positivt formet. Det vil si at hvis noen svarer høyt på de positive indikatorene så måler det høy lojalitet, mens hvis noen svarer høyt på den negative indikatoren, så måler det lav lojalitet. De måler altså det motsatte av hverandre, og vi må derfor reversere den negativt formede indikatorer slik at alle indikatorene måler det samme. Indikatoren ble reversert i SPSS med "Transform Recode into same variables". Som vi ser av tabellen, så oppfyller ikke indikator 5-16 kravet for verken konvergent validitet, eller sann varians. Ut ifra resultatene i faktoranalysen, forkaster vi indikator 5-16, og beholder indikatorene 5-11,12,13,14 og 15.
Steg 2
I steg 2 så skal vi teste de indikatorene som vi beholdt i steg 1 inn i en ny felles faktoranalyse, for så å vurdere alle begrepene samlet for både konvergent og divergent validitet som helhet.
Vi kjørte først en faktoranalyse hvor vi hadde stilt inn ekstraksjonen i SPSS på "eigenvalue" slik at den prøver å finne antall forskjellige faktorer på egen hånd. Da fikk vi først en

Hjemmeeksamen 2 – Høsten 2014 MET 405 Kvantitative metoder 02.02.2015
12
faktoranalyse med kun 3 faktorer, noe som tyder på at det kanskje er overlapp mellom noen begreper siden vi egentlig regnet med å få 4 faktorer. Siden vi har 4 begreper, så kjørte vi en ny faktoranalyse hvor vi stilte inn ekstraksjonen i SPSS på "fixed factor 4", som tvinger SPSS til å se etter antall faktorer som man setter. Da fikk vi faktoranalysen som er vist ovenfor med fire forskjellige faktorer. Indikatorladningene er ikke sortert på størrelse fordi vi syntes det gjorde analysen uoversiktlig. Spørsmålene står samlet begrep for begrep for å lettere se hvilken faktor hvert begrep hører til-
Øverst i analysen har vi de 5 indikatorene på strategi som vi beholdt fra steg 1. Indikator 4- 1,2,3,7 har alle en faktorladning som er over kravet for konvergent validitet, og en sann varians som er på langt over 25%. Derimot så lader indikator 4-4 både under 0,5, og har en sann varians på under 25%. Siden vi har 4 andre gode konvergente indikatorer på strategibegrepet, så velger vi derfor ikke å godkjenne indikator 4-4 i forhold til konvergent validitet. Alle strategiindikatorene er derimot divergente med differanser til andre faktorer på over 0,2 og restvarians på over 5%.
Går vi videre ned i analysen, kommer vi til produktkvalitetsbegrepet. Her ser vi at 5-1,2 lader over 0,5 og har en sann varians på over 25%. Indikator 5-4,5 er begge under 0,5 kravet og har sann varians under 25%, men siden vi her kun har én indikator som lader høyt på produktkvalitet og spørsmålet gir god mening, så velger vi å godkjenne indikatorene på et 0,3 nivå. Alle produktkvalitetsindikatorene oppfyller kravet til divergens i forhold til differansen mellom faktorene og restvariansen tilfredsstiller kravene, men indikator 5-4 kan allikevel ikke betegnes som divergent valid fordi den lader over 0,3 på mer enn én faktor. Det betyr at den måler et annet begrep omtrent like godt som det tiltenkte begrepet. Et vanlig cutoff-kriterium er at variabler som lader over 0,30 på flere enn én komponent, utelukkes fra videre analyser (Eikmo & Clausen, 2007).
Ett hakk lenger ned i tabellen, ser vi indikatorer på begrepet tilfredshet. Disse er tiltenkt å måle på faktor 4 siden alle de andre begrepene fordeler seg på de andre faktorene. I forhold til konvergent validitet, så oppfyller ingen av tilfredshetsindikatorene kravet på 0,5 og den sanne variansen er under 25%. Indikator 5-8,10 er divergente i forhold til differansen mellom faktorene og restvarians over 5%, mens 5-9 har for lav differanse mellom faktor 4 og 2. Selv om 5-8,10 oppfyller de to nevnte kravene til divergent validitet, kan vi ikke godkjenne disse indikatorene som divergente fordi de måler over 0,3 på flere enn én faktor. De måler relativt høyt på lojalitetsbegrepet, og det fikk oss til å vurdere om vi skulle inkludere 5-8,10 sammen med de andre lojalitetsindikatorene. Siden spørsmålene til indikatorene 5-8,10 gir dårlig mening i forhold til lojalitetsbegrepet så droppet vi å slå de sammen.
Til slutt nederst i tabellen på faktor 1, har vi lojalitetsindikatorene. I forhold til konvergent validitet, så oppfyller 5-11,12,13 kravet på 0,5 og en sann varians på over 25%. 5-14,15 derimot, tilfredsstiller ikke kravene og kan ikke regnes som konvergent valide. Siden vi her har tre gode indikatorer på lojalitet, så godtar vi ikke faktorladninger under 0,5 på lojalitetsbegrepet. Alle indikatorene er divergent valide med differanser på over 0,2 og restvarians på over 5%, bortsett ifra 5-14 som har for liten differanse mellom faktor 1 og 3.
Om vi da oppsummerer steg 2, så forkaster vi indikator 4-4 for strategi, 5-4 for produktkvalitet, 5-8,9,10 for tilfredshet, og 5-14,15 for lojalitet. Dette betyr at vi forkaster alle 3 indikatorene på tilfredshetsbegrepet siden det vises ut ifra en felles faktoranalyse at begrepet verken er konvergent eller divergent valid. Vi beholder da indikatorene (4-1,2,3,7), (5-1,3,5) og (5-11,12,13) for de tre begrepene vi står igjen med.

Hjemmeeksamen 2 – Høsten 2014 MET 405 Kvantitative metoder 02.02.2015
13
Steg 3 I steg 3 skal vi ta for oss validitetsvurderinger.
Etter at vi hadde forkastet indikatorer i steg 2, så kjørte vi en ny felles faktoranalyse hvor vi kun tok med de godkjente indikatorene. Denne gangen lot vi SPSS finne faktorene selv med eigenvalue på ekstraksjonsinnstillingene, og den fant nå 3 faktorer som stemmer overens med at vi har forkastet tilfredshetsbegrepet. Tidligere har vi testet både konvergent og divergent validitet på indikatornivå, men nå skal vi se på konvergent validitet og reliabilitet på begrepsnivå. Dette gjør vi ved å se på AVE (Average Variance Extracted) og cronbachs alpha verdier. AVE regnes ut ved å ta gjennomsnitt av den sanne variansen på alle indikatorene for ett begrep, mens cronbachs alpha finner vi ved å kjøre en reliabilitetsanalyse i SPSS. Hvis vi starter helt til venstre med lojalitetsbegrepet på faktor 1, så ser vi at AVE for dette begrepet er på 62,3 % som er godt over kravet på 50%. Under AVE, ser vi at cronbachs alpha verdien er på 0,851, som er godt over kravet på 0,7. Videre ser vi at AVE for strategibegrepet er på 46%, som er like under kravet, mens cronbachs alpha verdien er på 0,728 som er akkurat over det anbefalte kravet. Helt til høyre på faktor 3 finner vi produktkvalitetsbegrepet, som har en AVE på 37,1% og en cronbachs alpha verdi på 0.592. Begge verdiene er dermed under kravene som er satt for disse to testene. Ut ifra resultatene fra denne faktoranalysen så betyr dette at lojalitetsbegrepet er det eneste begrepet som både er konvergent valid og reliabelt. Strategibegrepet oppfyller kun cronbachs alpha kravet, men ikke AVE kravet, og kan derfor ikke regnes som et konvergent valid begrep. Cronbachs alpha brukes mindre og mindre på grunn av svakheter som at det "belønner" feilvarians, og at verdien blir høy ved mange indikatorer, og derfor kan vi ikke stole på denne verdien alene. Cronbachs alpha erstattes/komplementeres derfor med AVE (Sandvik, 2014). Produktkvalitetsbegrepet oppfyller ingen av kravene, og kan derfor verken regnes som et reliabelt eller konvergent valid begrep.
Videre i steg 3 skulle vi også sjekke divergent validitet på begrepsnivå. Vi lagde indekserte for hvert begrep med de godkjente indikatorene. Deretter sjekket vi de ved å kjøre en bivariat korrelasjonsanalyse for å se om begrepene er unike og forskjellige fra hverandre.
For at begrepene skal være divergent valide, så må korrelasjonen mellom dem være under 0,6, alternativt 0,8 for små antall. I denne undersøkelsen har vi et antall på nesten 300, så derfor gjelder kravet på 0,6 her. Det er
viktig at vi ikke har så like begrep at de flyter inn i hverandre. Som vi ser i tabellen så er alle korrelasjonene mellom begrepene godt under 0,6, og de var samtidig også signifikante som betyr at resultatet ikke skyldes tilfeldigheter. På bakgrunn av så lave korrelasjonsverdier, så oppfyller alle begrepene kravet for divergent validitet, og et eventuelt multikollinaritetsproblem kan også utelukkes.

Hjemmeeksamen 2 – Høsten 2014 MET 405 Kvantitative metoder 02.02.2015
14
1.3 Modelltest Etter at målene for begrepene var nøye vurdert og analysert i oppgave 1.2, så skulle vi kjøre
en multippel regresjonsanalyse i oppgave 1.3 for å teste modellen. Før vi kjørte
regresjonsanalysen så gjorde vi de indekserte variablene fra forrige oppgave om til variabler
med 100-skalaer. Dette gjorde vi fordi det er mer naturlig med skalaer på 100, og det letter
forståelsen av simuleringsanalysen som vi skal gå igjennom lenger ned. På grunn av lite plass
så måtte vi la være å ta med analysene for regresjonsforutsetning 6 og 8. Vi forutsetter
derfor at datamaterialet både oppfyller kravet til homoskedastisitet, og at skjevheten og
spissheten er ok. Regresjonsanalysen ble deretter kjørt med lojalitet som avhengig variabel,
og strategi og produktkvalitet som uavhengige.
Som vi ser av den første tabellen som er oppsummeringer for hele modellen, så fikk vi en
forklaringskraft (R Square) på 0,186. Det betyr at strategi og produktkvalitet forklarer 18,6%
av observert endring på lojalitet. Dette regnes som en svak forklaringskraft siden R2 er under
0,2 (Jacobsen 2000: 333). Videre ser vi av ANOVA tabellen i midten som tar for seg hele
forskningsmodellen som en helhet, at signifikansen er på 0,000. Det betyr at modellen er
signifikant på et 1% nivå som betyr at det ikke er noe sannsynlighet for at funnene er
tilfeldige (Sørebø 2012: 47). Til slutt har vi koeffisient tabellen til høyre. Her kan vi se
forklaringskraften som hver enkelt av de uavhengige variablene har til modellen (Sørebø
2012: 48). Strategi har en beta verdi (B) på 0,176, som betyr at den korrelerer positivt, altså
at en endring i strategi/tilpasning, vil føre til en økning av lojalitet. Ser vi på "sig. Kolonnen",
ser vi at signifikansen er på 0,003, som er signifikant på et 1% nivå og betyr at vi kan stole på
at funnet er gyldig. For produktkvalitet så har vi en beta verdi på 0,317 og et signifikansnivå
på 0,000. Det betyr at en økning av produktkvalitet fører til en økning av lojalitet, og at vi kan
stole på at funnet ikke er tilfeldig.
Simulering Ut ifra regresjonsanalysen lagde vi en
simuleringsanalyse i Excel for å estimere
en lojalitetsscore i forhold til
styringsparameterne som var de uavhengige variablene strategi og produktkvalitet. Det var
her 100-skalaer kom til nytte, da det er mye lettere å jobbe med tall fra 0-100, enn 1-6. Det
gir en mer naturlig skala som er lettere å bruke. Som vi ser i den første simuleringen så vil lav
strategi/tilpasning og produktkvalitet, føre til en nokså lav lojalitetsscore til hotellet.
Derimot, om strategi/tilpasningen og produktkvaliteten er høy, vil det gi en mye høyere
lojalitetsscore. Det betyr at jo bedre strategi, mer tilpasset hotellet er for kundenes behov,
og jo høyere produktkvaliteten er, jo mer lojale er kundene mot hotellet. Siden
produktkvalitet var den variabelen med høyest beta verdi, så betyr det at det er den som
påvirker lojaliteten mest av disse to variablene.

Hjemmeeksamen 2 – Høsten 2014 MET 405 Kvantitative metoder 02.02.2015
15
2.1 Modelltest
H1: Infokvalitet påvirker kundenes 2 produktpreferanser.
H1 a: Infokvalitet påvirker preferansen mot sparing i enkeltaksjer
H2 b: Infokvalitet påvirker preferansen mot sparing i hedgefond.
Rasjonale H1: Hvordan en kunde blir presentert informasjon om et sparingsprodukt, og ikke
minst hva som blir gitt av informasjon, vil antakelig ha en effekt på kundens
sparingspreferanse, enten det er negativt eller positivt. Det kan være at flyeren som kommer
hjem i posten kun viser det positive med et sparingsprodukt, mens en kundesamtale vil gi
mer svar til kunden på om det er et produkt som faktisk passer kunden. Det at enkeltaksjer
og hedgefond er veldig forskjellige typer sparing gjør at de antakeligvis ikke passer for alle,
og gjør at det er naturlig og putte disse produktene i hver sin hypotese.
Vi tester H1 ved å kjøre en MANOVA analyse. Forutsetningene for en MANOVA analyse er
gjennomgått i vedlegg 2.1.1 (Her gjennomgås også variablene brukt i oppgave 2.2, siden den
er en utvidelse av oppgave 2.1). Selv om noen forutsetninger brytes så kjører vi analysene
allikevel og har i bakhodet at funnene videre ikke er helt til å stole på, nettopp på grunn av
dette.
Det er lav fordeling mellom høy og lav
infokvalitet. De fleste respondentene har fått
høy infokvalitet. Dette svekker internvaliditeten
(Ibenfeldt 2014). Dette vil ha påvirkningen på
resultater vi får i vår multivariate analyse.
Konsekvensene av dette er beskrevet nærmere
i vedlegg for 2.1.1, hvor vi har gått igjennom forutsetningene for en MANOVA analyse.
Ut i fra gjennomsnittene ser vi følgende:
- Høy infokvalitet gir økt preferanse mot enkeltaksjer som sparingsprodukt.
- Høy infokvalitet gir minsket preferanse mot hedgefond som sparingsprodukt.

Hjemmeeksamen 2 – Høsten 2014 MET 405 Kvantitative metoder 02.02.2015
16
Under er det et plott med gjennomsnittsverdien for hver avhengige variabel. Verdiene som
vises her, er de samme som mean value fra Descriptive Statistics tabellen på forrige side.
Vi ser at det er informasjonskvalitet som påvirker ulikt mellom de to sparingsproduktene.
Det kan være at hedgefond kan se flott og fint ut på papiret, siden de fleste hedgefond har
som mål å oppnå positiv avkastning uansett markedsutvikling. Ser man nærmere på
hedgefond, så viser det seg at det er sparingsalternativ som ikke passer for den
gjennomsnittlige nordmann, men heller for de mer avanserte sparerne. Dette hovedsakelig
på grunn av at et hedgefond gjerne krever en ganske høy minsteinvestering. Samtidig tror vi
at de som sparer i hedgefond, eller generelt sparer mye, vil i mindre grad påvirkes av
informasjon gitt fra banken.
Enkeltaksjer tror vi passer bedre for flere, og jo mer informasjon den gjennomsnittlige
nordmann får om egenskaper til enkeltaksjer, jo mer øker preferansen mot enkeltaksjer som
et sparingsalternativ. Investeringer i aksjer tenkes kanskje på som skummelt eller risikofylt
for de som ikke sparer så mye, men at høy infokvalitet kan virke avskrekkende for denne
gruppen mennesker.
Vi har sett på tendensene til hvordan infokvaliteten påvirker, men i vår multivariate analyse
får vi ikke støtte for H1 (Utskrift av den multivariate analysen ligger i vedlegg 2.1.2). Pillai’s
Trace test viser at infokvalitet ikke har noen signifikant effekt på de 2 produktpreferansene
hvor F < 3.4 og p > 0.05. Vi sjekker den univariate analysen også, og ser at signifikansverdien
er over 0.05 for både hedgefond og enkeltaksjer. Modellen har en meget lav forklaringskraft
med 0,5% for enkeltaksjer og 2% for hedgefond. Vi forkaster H1.

Hjemmeeksamen 2 – Høsten 2014 MET 405 Kvantitative metoder 02.02.2015
17
Oppgave 2.2
Uavhengig: Infokvalitet
Moderatorer: Lønnsinntekt og Sparing
Avhengig: Produktpreferanse (herunder enkeltaksjer
og hedgefond)
Ut ifra vår tolkning av oppgaveteksten, får vi følgende
hypoteser:
H2: Grad av lønnsinntekt har effekt på relasjonen mellom infokvalitet og kundens 2
produktpreferanser
- H2a: Grad av lønnsinntekt har effekt på relasjonen mellom infokvalitet og
preferansen mot sparing i enkeltaksjer
- H2b: Grad av sparing har effekt på relasjonen mellom infokvalitet og preferansen
mot sparing i hedgefond.
H3: Grad av sparing har effekt på relasjonen mellom infokvalitet og kundens 2
produktpreferanser
- H3a: Grad av sparing har effekt på relasjonen mellom infokvalitet og preferansen mot
sparing i enkeltaksjer
- H3b: Grad av sparing har effekt på relasjonen mellom infokvalitet og preferansen
mot sparing i hedgefond.
H4: Kombinasjonen av grad av sparing og lønnsinntekt har sammen en effekt på relasjonen
mellom infokvalitet og kundens 2 produktpreferanser
Vi tester disse hypotesene med en multivariat analyse. Før vi går på testingen av
hypotesene, ser vi på om forutsetningene for analysene blir oppfylt. Forutsetningene ligger i
vedlegg 2.1.1. En av forutsetningene er Levene’s og Box’s test, utfallet av disse testene ligger
i vedlegg 2.2.3.
Infokvalitet, Lønnsinntekt og Sparing deles alle inn i 2 kategorier; høy eller lav. Alle de
uavhengige variablene kalles dikotome variabler for spørsmålene gir kun to svaralternativer
(Mitchell & Jolley, 2010). Det blir et 2x2x2 forskningsdesign. Slik vi tolker oppgaveteksten er
hvert fall hypotese 2 og 3 klar. Vi tar med hypotese 4 siden det blir et 2x2x2 design, hvor
man må se om det finnes en treveis interaksjon.
For å se om det er en signifikant interaksjonseffekt mellom de uavhengige variablene utfører
vi en MANOVA analyse. Interaksjon er hvordan virkningen av en faktor (uavhengig variabel)
avhenger av nivået på den andre faktoren (Ibenfeldt 2014). I et 2x2x2 design er det åtte
forskjellige kombinasjoner av verdier. Disse åtte forskjellige kombinasjonene vil komme til
syne i post-hoc testen (vedlegg 2.2.3), som har med alle tre uavhengige variabler. Vi velger
derfor å ikke lage noen generell matrise som viser alle mulige kombinasjoner av disse. Med
to avhengige variabler vil det bli to 2x2x2 matriser.

Hjemmeeksamen 2 – Høsten 2014 MET 405 Kvantitative metoder 02.02.2015
18
Multivariate analysen
Ut ifra tabellen over, ser vi at det ikke er
noen signifikans på noen av variablene.
Sparing * Infokvalitet er ganske nære
signifikant med en verdi på 0,053. Pillai’s
test er ganske god med like grupper
(Ibenfeldt 2014), men det er ikke like
grupper i dette tilfellet. Vi tar dette med oss
videre når vi nå skal se på den univariate
analysen.
Hjemmeeksamen 2 – Høsten 2014 MET 405 Kvantitative metoder 02.02.2015
19
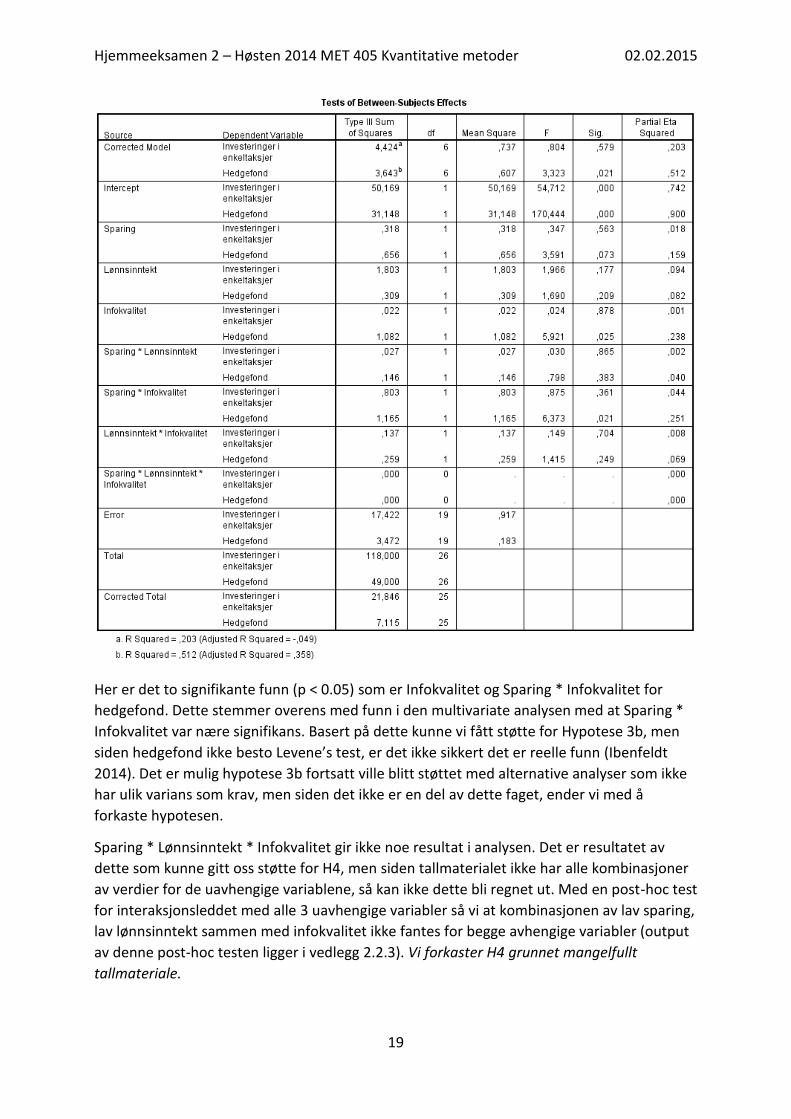
Her er det to signifikante funn (p < 0.05) som er Infokvalitet og Sparing * Infokvalitet for
hedgefond. Dette stemmer overens med funn i den multivariate analysen med at Sparing *
Infokvalitet var nære signifikans. Basert på dette kunne vi fått støtte for Hypotese 3b, men
siden hedgefond ikke besto Levene’s test, er det ikke sikkert det er reelle funn (Ibenfeldt
2014). Det er mulig hypotese 3b fortsatt ville blitt støttet med alternative analyser som ikke
har ulik varians som krav, men siden det ikke er en del av dette faget, ender vi med å
forkaste hypotesen.
Sparing * Lønnsinntekt * Infokvalitet gir ikke noe resultat i analysen. Det er resultatet av
dette som kunne gitt oss støtte for H4, men siden tallmaterialet ikke har alle kombinasjoner
av verdier for de uavhengige variablene, så kan ikke dette bli regnet ut. Med en post-hoc test
for interaksjonsleddet med alle 3 uavhengige variabler så vi at kombinasjonen av lav sparing,
lav lønnsinntekt sammen med infokvalitet ikke fantes for begge avhengige variabler (output
av denne post-hoc testen ligger i vedlegg 2.2.3). Vi forkaster H4 grunnet mangelfullt
tallmateriale.

Hjemmeeksamen 2 – Høsten 2014 MET 405 Kvantitative metoder 02.02.2015
20
Vi kjører en post-hoc test (output av denne i vedlegg 2.2.2), for å se på retningen av
hypotese 3b selv om vi endte med å forkaste hypotesen. Hadde vi hatt en retning på
hypotesen, ville vi brukt kontraster i SPSS (Ibenfeldt 2014). Vi tar utgangspunkt i rasjonalen
fra oppgave 2.1. Her nevner vi blant annet at hedgefond antakeligvis er mest preferert av de
avanserte sparerne. Med dette mener vi at de som har en lav grad av sparing, vil ha en
lavere preferanse mot hedgefond med bedre infokvalitet.
Ingen av hypotesene får støtte. Vi går uansett videre med å presentere hvordan samspillet
mellom infokvalitet og sparing/lønnsinntekt med plots fra den multivariate analysen. Hvert
plott er en post-hoc analyse hvor snittverdiene for de forskjellige kombinasjonene av
variablene. Det er kun utført post-hoc analyse for infokvalitet * sparing siden denne
interaksjonseffekten var signifikant i analysen. Dette kunne vi gjort for infokvalitet *
lønnskvalitet også, men vi nøyer oss med å vise snittverdiene grafisk.
Her ser vi plottene infokvalitet * sparing og infokvalitet * lønnsinntekt mot enkeltaksjer.
Lav infokvalitet gir store sprik mellom de som sparer mye, og lite på preferanse mot
enkeltaksjer. Med høy infokvalitet utjevnes forskjellene og krysser hverandre. Samme
tendensen ser vi med infokvalitet mot lønnsinntekt, men her krysser ikke linja.

Hjemmeeksamen 2 – Høsten 2014 MET 405 Kvantitative metoder 02.02.2015
21
Her ser vi plottene infokvalitet * sparing og infokvalitet * lønnsinntekt mot hedgefond.
Grad av infokvalitet har stor innflytelse på de som sparer lite, mens de som sparer mye har
grad av infokvalitet veldig lite og si da linja for høy grad av sparing nesten er horisontal.
Tendensen her passer godt med det vi drøftet tidligere hvor vi har nevnt at hedgefond
antakelig passer best for avanserte sparere.
Høyere grad av infokvalitet fører til noe økt preferanse mot hedgefond for de med lav
lønnsinntekt. For de med høy lønnsinntekt har høy infokvalitet senket preferansen mot
hedgefond drastisk.
Vi legger merke til at det er generelt de samme tendensene for hedgefond og enkeltaksjer.
Også her ser vi at det er veldig stort sprik mellom gruppene når det er lav grad av infokvalitet
kontra høy grad av infokvalitet.
Siden ingen av linjene er parallelle, så indikerer dette at det er interaksjonseffekter.
At de som sparer lite har høy preferanse til hedgefond ved lav informasjonskvalitet, tror vi
rett og slett er av uvitenhet da vi ser på hedgefond som et godt alternativ for de som
allerede har spart en del penger i f.eks. enkeltaksjer. I vedlegg 2.2.1 vises det at infokvalitet *
sparing for hedgefond er signifikant, og kan dermed konkludere med at de som sparer lite,
blir sterkt påvirket av grad av infokvalitet. Vi har sett på tendensene av samspillet av de
uavhengige mot de avhengige gjennom plots, men siden det kun er ett signifikant funn (som
heller ikke besto Levene’s test), kan vi ikke stole på at analysene er helt korrekte.
Hjemmeeksamen 2 – Høsten 2014 MET 405 Kvantitative metoder 02.02.2015
22
Oppgave 2.3
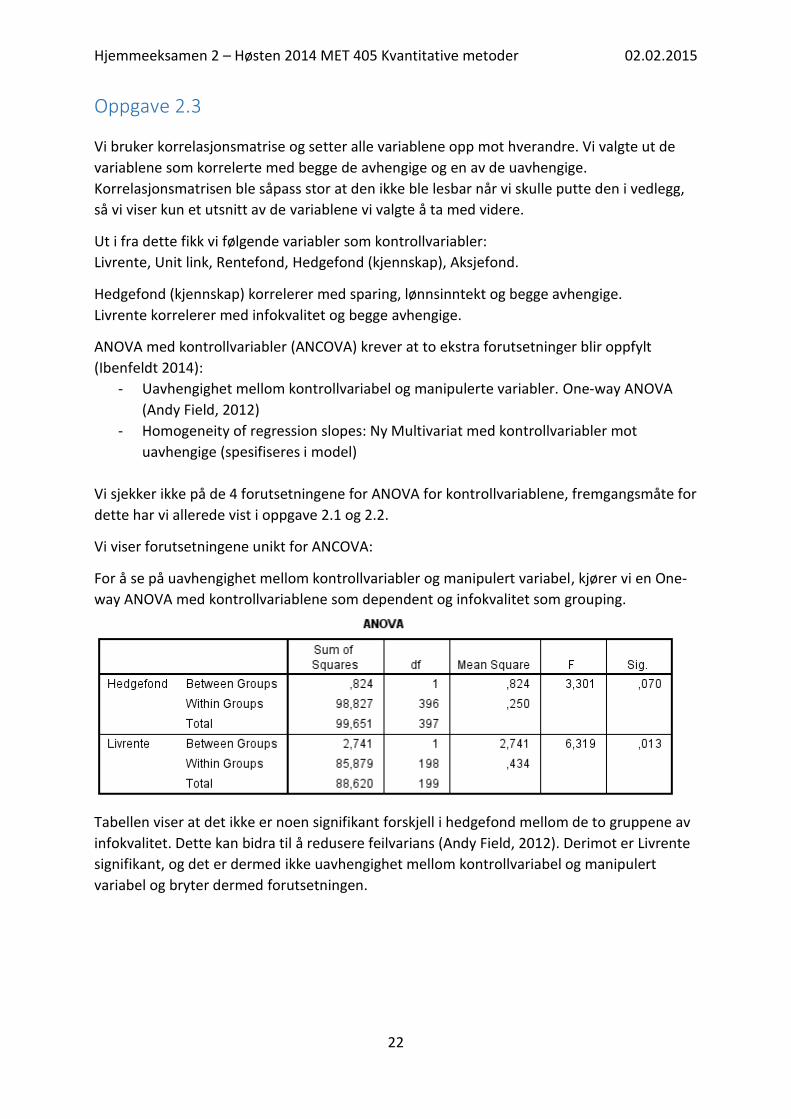
Vi bruker korrelasjonsmatrise og setter alle variablene opp mot hverandre. Vi valgte ut de
variablene som korrelerte med begge de avhengige og en av de uavhengige.
Korrelasjonsmatrisen ble såpass stor at den ikke ble lesbar når vi skulle putte den i vedlegg,
så vi viser kun et utsnitt av de variablene vi valgte å ta med videre.
Ut i fra dette fikk vi følgende variabler som kontrollvariabler:
Livrente, Unit link, Rentefond, Hedgefond (kjennskap), Aksjefond.
Hedgefond (kjennskap) korrelerer med sparing, lønnsinntekt og begge avhengige.
Livrente korrelerer med infokvalitet og begge avhengige.
ANOVA med kontrollvariabler (ANCOVA) krever at to ekstra forutsetninger blir oppfylt
(Ibenfeldt 2014):
- Uavhengighet mellom kontrollvariabel og manipulerte variabler. One-way ANOVA
(Andy Field, 2012)
- Homogeneity of regression slopes: Ny Multivariat med kontrollvariabler mot
uavhengige (spesifiseres i model)
Vi sjekker ikke på de 4 forutsetningene for ANOVA for kontrollvariablene, fremgangsmåte for
dette har vi allerede vist i oppgave 2.1 og 2.2.
Vi viser forutsetningene unikt for ANCOVA:
For å se på uavhengighet mellom kontrollvariabler og manipulert variabel, kjører vi en One-
way ANOVA med kontrollvariablene som dependent og infokvalitet som grouping.
Tabellen viser at det ikke er noen signifikant forskjell i hedgefond mellom de to gruppene av
infokvalitet. Dette kan bidra til å redusere feilvarians (Andy Field, 2012). Derimot er Livrente
signifikant, og det er dermed ikke uavhengighet mellom kontrollvariabel og manipulert
variabel og bryter dermed forutsetningen.

Hjemmeeksamen 2 – Høsten 2014 MET 405 Kvantitative metoder 02.02.2015
23
Testing the assumption of Homogeneity of regression slopes (Andy Field, 2012) MANOVA med model hvor Infokvalitet*Kontrollvariabel legges sammen som interaction skal
ikke korrelere, men det vil det jo selvfølgelig gjøre for livrente, fordi den ble valgt ut for å
kontrollere relasjonen mellom infokvalitet og de avhengige.
Her velges kontrollvariabler kun på bakgrunn av de som korrelerer med hver sin avhengige.
Utskriften fra SPSS med kontrollvariabler ligger i vedlegg 2.3.2.
For enkeltaksjer er begge kontrollvariablene ikke signifikant, derfor bestås forutsetningen for
homogeneity of regression slopes. Men for hedgefond er begge kontrollvariablene
signifikant. Dette bryter med forutsetning for homogeneity of regression slopes og resultater
fra MANCOVA med disse to som kontrollvariabler kan ikke stoles på (Andy Field, 2012).
Nok en gang brytes forutsetninger, men vi fortsetter med den multivariate analysen med
kontrollvariabler allikevel. Resultatet av dette ligger i vedlegg 2.3.3.
Med kontrollvariabler har modellen høyere forklaringskraft for hedgefond med 58,3% i
motsetning til 51,2 %.
Med kontrollvariabler har modellen en lavere forklaringskraft for enkeltaksjer med 14,2% i
motsetning til 20,3 %.
Ingen main effects eller toveis interaksjonseffekter er signifikante med kontrollvariabler.
Sammenlignet med resultatene fra oppgave 2.2 har signifikansverdiene endret seg.
Ettersom signifikansen i våre stimuli endrer seg, betyr det at variansen ikke blir beskrevet
godt nok i modellen vår uten kontrollvariablene. Vi konkluderer med at kontrollvariablene
hedgefond (kjennskap) og livrente forklarer noe av effekten på hedgefond, mens de ikke gjør
det for enkeltaksjer.

Hjemmeeksamen 2 – Høsten 2014 MET 405 Kvantitative metoder 02.02.2015
24
Oppgave 2.4 Kritisk Realisme
Kritisk realisme er en relativt ny posisjon innen vitenskapsfilosofien (Davidsen 2004). Slik denne posisjonen har blitt utviklet, framstår den som et metodologisk alternativ som inntar en mellomstilling mellom positivismen og den tidlige Popper på den ene side, og mer sosialkonstruktivistiske posisjoner innen den post-moderne tradisjonen på den annen side (Davidsen, 2004).
Vi skal først se nærmere på positivisme og sosial konstruktivisme, for å gi en bedre oversikt på hvilke forskjeller og likheter kritisk realisme har med andre nære vitenskapsfilosofier.
Positivisme ser på det aktuelle (noe som er observerbart) og det empiriske. Positivisme forholder seg til det som kan sanses. Som følge av dette har det blant annet ført til at spørsmål om prinsipper for teorietablering og teoriutvikling har kommet noe i bakgrunnen (Davidsen, 2004). Etter hvert som begrensningene ved empiriske tester gradvis er blitt erkjent, har den vitenskapsfilosofiske, og dermed også den økonomisk-metodologiske, tenkningen utviklet seg i flere retninger (Davidsen, 2004). Det har blant annet blitt søkt i retning av det som gjerne kalles sosiale kriterier for teorievaluering og teorivalg. Sosialkonstruktivismen forholder seg til den sosiale realitet og virkeligheten er basert på hva hvert enkelt menneske tenker. Vi som IT-studenter synes denne innfallsvinkelen virker litt fjernt fra vårt studieobjekt. Mest fordi vi synes det kan være vanskelig å begrunne ut i fra sosiale kriterier, selv om det helt klart kan bidra til å forklare hva som faktisk foregår innenfor vårt domene. I tillegg er det under enhver omstendighet klart at slike sosiale tilnærminger til økonomisk-metodologiske problemstillinger foreløpig er lite utviklede (Davidsen, 2004). I forhold til positivisme, tar kritisk realisme med seg det reelle og teori i tillegg til det observerbare. Spørsmålet «hvorfor?» stilles til det observerbare og til funn fra empiri. Teorier forklarer funn i det empiriske, og tilfører på den måten noe ekstra til positivismen ved å prøve og forklare det observerbare med noe uobserverbart. Kritisk realisme understreker at mye av virkeligheten er uobserverbar. Sagt på en annen måte sies det at virkeligheten er stratifiserbar (Sørebø 2014). I begrepet kritisk, legger vi i at muligheten til å observere virkeligheten er begrenset, fordi mye av virkeligheten er uobserverbar. Sannheten sies å være et ideal. Med realisme tenker vi på at vi har en menneskeuavhengig virkelighet, i motsetning til sosial konstruktivisme, hvor virkeligheten avhenger av mennesket (Sørebø 2014).
Kritiske realisme sier at noe er stratifisert:
- Mekanismer / Strukturer / Sammenhenger
o Kausale krefter
o Tendenser
- Erfaringer
- Begivenheter
Punktene over er faktorer som er med på å gi en felles (menneskeuavhengig) forståelse av
virkeligheten i et kritisk realistisk perspektiv.

Hjemmeeksamen 2 – Høsten 2014 MET 405 Kvantitative metoder 02.02.2015
25
Positivisme Kritisk realisme Sosial konstruktivisme
Sannhet Sansedata Den beste teori/forklaring
Den sosial realitet
Virkelighet Det aktuelle Det reelle Det vi tenker
Tilnærming Kvantitativ Kvantitativ/Kvalitativ Kvalitativ
Kjernen i kritisk realistisk filosofi er bundet sammen av ontologi og epistemologi (Miller & Tsang). Ontologi i denne sammenhengen er læren om hva som er virkelighet, mens epistemologi er læren om å produsere kunnskap (Sørebø, 2014).
Med et realistisk syn på virkeligheten (menneskeuavhengig, det reelle) og med et sosialt syn på epistemologien (menneskeavhengig, vil aldri ha fasit), vil i sum oppmuntre til å prøve og falsifisere eksisterende teorier for å komme lenger i forskningen. Falsifiseringer vil aldri være «fasiten» og kan alltid bli revidert. (Miller & Tsang, 2010). I et kritisk realistisk perspektiv vil man kun forholde seg til den beste teorien eller forklaringen på det gitte tidspunktet, med den erkjennelsen at teorien eller forklaringen kan på et senere tidspunkt bli erstattet.
Ved bruk av den kritiske realismens ontologiske teorier som grunnlag for teoriutvikling eller analysering av eksisterende teorier, må man inkludere en større helhet i teorien. Dette kan minne om funksjonen til en rasjonale, som har som mål og forklare en hypotese gjennom logisk tankegang og vise til relaterte mekanismer/sammenhenger/erfaringer/begivenheter.
Kritisk realistisk perspektiv for rammeverk for utvikling og testing av teori
Miller & Tsang (2010) har utviklet et rammeverk til kritisk realisme for å utvikle og teste teorier. Rammeverket består av følgende fire steg:
1) Identifisere de hypotetiske
mekanismene
2) Test for tilstedeværelsen av
mekanismene i en empirisk setting
3) Isolerte tester av de kausale
forholdene
4) Test det teoretiske systemet

Hjemmeeksamen 2 – Høsten 2014 MET 405 Kvantitative metoder 02.02.2015
26
Vi bruker rammeverket for å vurdere oppgave 2.1-2.3 i et kritisk realistisk perspektiv.
1) Vi utviklet hypoteser for oppgave 2.1 og 2.2. Vi utviklet ikke rasjonale for hypotesene
i oppgave 2.2, og dette er en klar svakhet sett i et kritisk realistisk perspektiv, da det
er sentralt å forklare hvilke mekanismer som ligger bak hver hypotese. For de
hypotesene vi utviklet rasjonale for (oppgave 2.1) prøvde vi å tenke logisk, ved å
sette oss inn i forskjellige praktiske situasjoner for å forklare hypotesen. Siden det er
utallige latente variabler som påvirker utfallet hypotesene, er rasjonalen svært
begrenset i forhold til å identifisere og forklare alle de hypotetiske mekanismene.
2) Dette steget går på å se om det er lagt til rette for å teste hypotesene rent empirisk.
Gjennomgående i oppgave 2.1 – 2.3 har vi sett nærmere på tallmateriale med
statistiske analyser for å se om det oppfyller forutsetninger for testing av hypoteser.
Her ser man gjerne på om begrepene brukt i teorien inneholder alle
forklaringsmekanismene. Hvert begrep måles kun av ett spørsmål. Fra et kritisk
realistisk perspektiv hadde det vært mer optimalt å inkludere flere årsaksmekanismer
i et begrep, og gjerne brukt mer presise mål enn for eksempel høy/lav som ble brukt i
noen begreper i vårt tilfelle. Siden noen forutsetninger har blitt brutt og kan fra et
kritisk realistisk perspektiv konkludere med at det ikke er lagt til rette for å teste alle
hypotesene empirisk. Hvilke hypoteser som har oppfylt krav og ikke, står nærmere
beskrevet i selve oppgave 2.1 – 2.3.
3) I både oppgave 2.1 og 2.2 kjørte vi multivariate analyser og tok konklusjoner basert
på resultatet av disse. I de multivariate analysene tok vi med alle variabler. Ideelt sett
skulle vi kjørt analyser som tok for seg en og en hypotese for å isolere mest mulig,
men det gjorde vi ikke. På bakgrunn av dette og at dataene er samlet inn via en
spørreundersøkelse gjort av en bank, så har vi ikke testet de kausale relasjonene
isolert nok.
4) Som nevnt i steg 3 kjørte vi multivariate analyser hvor vi tok med alle variabler. På
denne måten får vi testen hele modellen på en gang. I tillegg ble modellen testet
med kontrollvariabler i oppgave 2.3. På denne måten får vi testet hele modellen og
sett på hvordan eventuelle andre mekanismer påvirker modellen vår.

Hjemmeeksamen 2 – Høsten 2014 MET 405 Kvantitative metoder 02.02.2015
27
2.5 Utforming av design
Halvparten av denne oppgaven består av design og gjennomføring av eksperimentet, mens siste halvpart består av drøfting av validitetstrusler.
Med et 2x2 design må vi finne to variabler. Minst én av variablene skal være manipulerbare (stimuli), mens den andre kan også være en egenskapsvariabel (ikke manipulerbar).
Dette eksperimentet tar for seg hvordan status påvirker preferansen mot hedgefond. Vi ønsker å se om økt sosial status vil være med på å øke preferansen mot investering i hedgefond. Noen av de mer unike egenskapene ved hedgefond er at det er begrensninger i antall investorer i et fond, det er gjerne ganske høy minsteinvestering og det er ikke lov til å reklamere for et hedgefond. Disse egenskapene taler for eksklusivitet og «rikdom», noe som kan gi følelse av økt sosial status. I en laboratorium setting kan noen investeringsalternativer presenteres på to måter. Den ene presentasjonen legger vekt på hedgefonds egenskaper som relateres til sosial status (høy). Den andre presentasjonen er lik, bortsett fra at hedgefond presenteres uten særlig fokus på status, og er mer på lik linje med de andre investeringsalternativene (lav).
Vi ønsker også å se på om tid brukt på investeringer har sammenheng med preferanse til hedgefond. Siden hedgefond kan være ganske komplekst og mye og sette seg inn i, tror vi at de som bruker mer tid på pengeforvaltningen har økt preferanse mot hedgefond. Dette er en egenskapsvariabel, altså noe som ikke kan manipuleres, så det gjelder å plukke ut deltakere med jevn fordeling av liten vs mye tid brukt på pengeforvaltning (Ibenfeldt 2014). De som kvalifiserer til å bruke mye tid på investeringer setter vi en grense på flere timer hvert år. Vi ser på dette som mye, da en gjennomsnittlig nordmann antakelig ikke bruker noe som helst tid på å vurdere sparingsalternativer, for penger til overs går gjerne til å nedbetale gjeld.
Det finnes to grunnleggende forskningsdesign knyttet til eksperimentell forskningsstrategi (Ibenfeldt 2014):
- Between subjects design: Vi henter gjennomsnittsverdier fra de ulike gruppene som har blitt testet på forskjellige deltakere. (Manipulasjonseffekt)
- Within-subjects design: Verdiene fra gruppene er hentet fra det samme utvalget (Effekt av endring)
Ved utføring av eksperimentet på denne måten er det essensielt at hver unike deltaker får stimuli kun én gang, for ellers så vil de antakeligvis forstå hva eksperimentet er ute etter å finne ut, og kan derfor påvirke svar. På bakgrunn av dette velger vi «between-subject» design. Forøvrig vil deltakere som skjønner hva eksperimentet prøver å finne ut, skape outliers i datasettet og må derfor fjernes fra analysene i ettertid (Ibenfeldt 2014). I hver gruppe skal vår egenskapsvariabel tidsbruk være jevnt fordelt mellom mye og lite tid brukt.
Det vil bli to grupper, ene gruppen med høy status, andre med lav. Hvem som blir valgt til hvilken gruppe skal være helt tilfeldig. Deltakerne blir bedt om å fylle ut et spørreskjema to ganger; før og etter stimuli. De med lav status presentasjon vil være vår kontrollgruppe, mens de med høy status presentasjon vil være den eksperimentelle gruppen.

Hjemmeeksamen 2 – Høsten 2014 MET 405 Kvantitative metoder 02.02.2015
28
Eksperimentell gruppe R X O1
Kontrollgruppe R O2
Fordelen med at det gis en presentasjon for flere sparealternativer for begge grupper, er at kunnskapsnivået vil utjevnes slik at de som eventuelt ikke kjenner så godt til de ulike sparingsalternativene, vil bli i bedre stand til å svare på spørsmål som omhandler nettopp dette i spørreskjemaet. Det er på den måten enklere å gjøre seg opp en mening. Baktanken med at ikke kun hedgefond presenteres,er for at deltakerne ikke skal vite hva eksperimentet prøver å finne ut av.
I dette eksperimentet vil det være mulig å gjennomføre en pretest-posttest, fordi deltakerne har mulighet til å svare på spørsmål som omhandler preferanse mot forskjellige sparealternativ både før og etter stimuli.
Fordelen med inkludering av pretest, er at den kontrollerer for randomisering og gir større statistisk kontroll. Fordeler med between-subjects som forskningsdesign er (Ibenfeldt 2014):
- Hver enkelt verdi er uavhengig av andres verdier - Påvirkes ikke av følgende:
o Praksis eller erfaring underveis i studiet o Tretthet eller kjedsomhet gjennom ulike manipuleringer o Interaksjonsmuligheter ved å sammenlikne to uavhengige variabler opp mot
den samme avhengige variabelen
Ulemper er: - Stort antall med deltakere. Eksperimentet vårt burde ha minst 30 deltakere per
gruppe - Individuelle forskjeller. Kan skape forstyrrende variabler i studien.
Validitetstrusler For å se hvor mye effekt vår stimuli har, er det viktig at all annen variasjon holdes under
kontroll. Dette kan oppnås ved å isolere mest mulig. Isolasjon er et uoppnåelig ideal i praksis,
fordi det er umulig å holde alt helt likt utenom stimulus (Mitchell & Jolley, 2013).
Vi ønsker å sikre intern validitet. Campbell og Stanley (1963) lister åtte trusler mot intern
validitet: selection, selection by maturation interaction, mortality, instrumentation,
regression, maturation, history og testing (Mitchell & Jolley, 2013). Vi går gjennom disse ved
å forklare hva de betyr og samtidig gi en løsning for å gjøre truslene minst mulig.
Selection og selection-maturation interaction: I eksperimentet er det to forskjellige grupper med deltakere, hver deltaker er ulik og dermed er det to ulike grupper før stimulus. Det er

Hjemmeeksamen 2 – Høsten 2014 MET 405 Kvantitative metoder 02.02.2015
29
mest optimalt å ha to helt like grupper, men dette er vanskelig å få til i praksis. Som oftest er dette den største trusselen mot internvaliditeten for «two-group» design, men siden dette eksperimentet er en pretest-posttest vil eksperimentet ikke være sårbar overfor dette (Mitchell & Jolley, 2013). Truslene elimineres.
Det er tre grunner til at deltakere vil endres uavhengig av stimulus:
- Mortality: Flere som hopper av i en gruppe enn en annen pga stimulus. I vårt tilfelle gjelder det å holde studien over en kort periode, slik at færrest mulig hopper av.
- History: Faktorer på utsiden som påvirker deltakeren til å forandre seg. Det at ting skjer rundt deltakere hele tiden kan ikke unngås, men trusselen kan minimeres ved at studien går over en kort periode
- (Re)Testing: Ved at deltakerene tar pretesten vil de forandre seg, slik at resultatet endres i posttesten. Siden det blir spurt om preferanse mot noe, så er ikke denne trusselen like stor for hverken erfaring eller øvelse fra tidligere vil påvirke et preferansespørsmål i samme grad som et kunnskapsspørsmål. Det at man får samme spørsmål, vil kanskje få deltakeren til å tenke mer gjennom spørsmålet, det vil gi et mer presist svar på preferanse mot hedgefond slik vi ser det.
Tre grunner til at deltakerens score på spørreskjemaet endrer seg, selv om deltakerne ikke har det:
- Regression: Deltakere med ekstreme resultater på pretesten, dras sannsynligvis mot gjennomsnittet/medianen i posttesten. Ikke velg deltakere basert på ekstreme resultater, og bruk et pålitelig mål for å redusere trusselen.
- Maturation: Faktorer på innsiden av deltakere, gjør at de endres. F.eks. hjerneutvikling/modning. Dette er ikke til å unngå, men trusselen kan minimeres ved at studien går over en kort periode.
- Instrumentation: Får forskjellige resultater fordi måleinstrumentet brukt i pretesten er forskjellig fra den som er brukt i posttesten. I dette eksperimentet gjelder det å bruke samme skalaer for hvert spørsmål i pretest som i posttest.
Intern- vs ekstern validitet Internvaliditet er litt i konflikt med eksternvaliditet: Et tiltak for å øke eksternvaliditeten kan
være med på å svekke internvaliditeten og omvendt. Vi bruker eksperimentet vårt som
eksempel: Vi øker internvaliditeten ved å utføre eksperimentet i kontrollerte omgivelser, og
det kan dermed argumenteres for at det ikke lar seg generalisere og overføres til det
virkelige liv (Mitchell & Jolley, 2013).
Til slutt samles spørreskjemaene med data om hvem som har fått hvilken type stimuli,og om
de bruker mye eller lite tid på vurdering av sparingsalternativer. Dataene blir lagt inn i et
program som SPSS eller lignende, slik at det kan utføres analyser som gir svar på om det er
signifikante hovedeffekter eller interaksjonseffekter i eksperimentet.

Hjemmeeksamen 2 – Høsten 2014 MET 405 Kvantitative metoder 02.02.2015
30
Litteraturliste Skriftlige kilder til litteraturreferanser Bollen, W. D. (1989): Structural equations with latent variables, New York, Wiley.
Sørebø, A. (2012): En innføring i kvantitativ dataanalyse med SPSS – 17.0, Høyskolen i Buskerud og Vestfold.
Eikmo, T. A. & Clausen, T. H (2007): Kvantitativ analyse med SPSS, Tapir akademisk forslag, Trondheim
Mitchell, M. & Jolley, J. M. (2013): Research design explained, Belmont, Wadsworth.
RINGDAL, K. (2007). Enhet og Mangfold, Bergen.
Klima- og miljødepartementet. (2000): Et kvotesystem for klimagasser, Definisjon og forklaring av en del faguttrykk.
Sandvik, K. (2014): Powerpoint fra forelesning, Regresjon_del_1 11/09/2014, Høyskolen i Buskerud og Vestfold.
Sandvik, K. (2014): Powerpoint fra forelesning, Regresjon_del_2 28/10/2014, Høyskolen i Buskerud og Vestfold.
Ibenfeldt, C. (2014): Powerpoint fra forelesning, Eksperimentelle design HBV 03/11/2014,
Høyskolen i Buskerud og Vestfold
Ibenfeldt, C. (2014): Powerpoint fra forelesning, Eksperimentelle design HBV 2 04/11/2014,
Høyskolen i Buskerud og Vestfold
Jacobsen, D.I. (2000): ”Hvordan gjennomføre undersøkelser?”, Høyskoleforlaget.
Davidsen (2004) Kritisk Realisme og Økonomisk-Vitenskapelig Arbeid, Norsk Økonomisk
Tidsskrift, 118, 62-76.
Miller & Tsang (2010): Testing Management Theories: Critical Realist Philosophy and
Research Methods, Strategic Management Journal, 32: 139–158.
Skriftlige kilder
Stabel, S & Stabell, K (2013). Motivasjonelt klima og oppfattet kompetanse: Hvilke sammenhenger er det mellom motivasjonelt klima, oppfattet kompetanse, motivasjon, effektivitet og velvære blant ansatte?, Masteravhandling, Høyskolen i Buskerud og Vestfold.
Bråthen, A & Ulsaker, A (2014). Merker i krise: Effektene av ansvar og kjennskap på forbrukernes holdning, Masteravhandling, Høyskolen i Buskerud og Vestfold.
Haslestad, L & Nybakken, C (2013). Hvordan påvirker formelle kompetansehevende tiltak arbeidstakers subjektive velvære, arbeidsmotivasjon og ytelse på arbeidsplassen, og i hvilken grad fungerer behovet for kompetanse som en mediator på dette forholdet?, Masteravhandling, Høyskolen i Buskerud og Vestfold.

Hjemmeeksamen 2 – Høsten 2014 MET 405 Kvantitative metoder 02.02.2015
31
Skarsten, T & Ellefsen, S (2012). Lønnstilfredshet, rettferdighet og arbeidsmotivasjon i et selvbestemmelsesperspektiv: En kvantitativ studie i seks norske banker, Masteravhandling, Høyskolen i Buskerud og Vestfold.
Tveit, T (2014). Motivasjon i frivillig arbeid: En kvantitativ studie av speiderledere i Norges speiderforbund, Masteravhandling, Høyskolen i Buskerud og Vestfold.
Steinsbu, L (2013). Ledelsens innvirkning på motivasjon og arbeidsmiljø: En kvantitativ studie i Tronrud Gruppen AS, Masteravhandling, Høyskolen i Buskerud og Vestfold.
Kjellevold, B & Bjercke, E. (2012). Motivasjon og brukeraksept: Hvilken av de mest brukte indre motivasjonsvariablene fra IS-litteraturen predikerer best i en IS-aksept sammenheng? Masteravhandling, Høyskolen i Buskerud og Vestfold
Anonymt (2013. MET 410 Kvantitativ metoder, Hjemmeeksamen, Høyskolen i Buskerud og Vestfold.
Sandvik, K. (2014): Powerpoint fra forelesning, Målutvikling og –validering 29/10/2014, Høyskolen i Buskerud og Vestfold.
Andre kilder Aaberge, A (2003). Hva er lønnsomt? Internettartikkel,
Nærings- og fiskeridepartementet (2006). Strukturvirkemidler i fiskeflåten. Internettartikkel, http://www.regjeringen.no/nb/dep/nfd/dok/nou-er/2006/nou-2006-16/8/7.html?id=392213
Wikipedia (endret 2013). Lønnsomhet. Internettartikkel, http://no.wikipedia.org/wiki/L%C3%B8nnsomhet
Andy Field (2012). Discovering statistics: ANCOVA/MANCOVA
http://www.statisticshell.com/docs/ancova.pdf
Sørebø, Øystein (2014). Forelesning i kritisk realisme ved HBV.

Hjemmeeksamen 2 – Høsten 2014 MET 405 Kvantitative metoder 02.02.2015
32
Vedlegg
2.1.1 Forutsetninger for MANOVA
Forutsetninger for ANOVA (Ibenfeldt 2014):
1. Varians i hver gruppe bør være relativ lik
2. Observasjonene skal være uavhengige
3. Avhengig variabel bør minimum være på intervall-nivå
4. Data skal være normaldistribuerte innad i gruppene
1. Denne forutsetningen ser vi på i selve ANOVA analysen, gjennom Leneve’s test og Box’s
test.
2. Vi går ut i fra at hver rad i datasettet representerer en unik deltaker og at hver deltaker
har kun blitt utsatt for simulusvariabelen en gang. Dvs. at det ikke er noen deltaker som
både har fått flyer i posten og personlig kundesamtale.
3. Avhengige variablene er ordinale variabler som er representert med en numerisk verdi fra
1-3, der 1 er lite aktuell, 2 er kan være aktuell, 3 er svært aktuell. Verdien hvert tall
representerer vil vi si er definert slik at avstanden på verdiene mellom 2 og 1, og 2 og 3 er lik.
De avhengige variablene oppfyller derfor kravet.
4. Dette ser vi når vi kjører frequencies på variablene: Standard avvik > 1, Skewness/Kurtosis
mellom +/- 2.
Datamaterialets N, min og max verdier, gjennomsnitt, standard avvik, skewness (skjevhet) og
kurtosis (spisshet). Min og Max er indikatorer på overflatebehandling av data og et krav til
standard avvik er >1. Det er en nødvendighet at hver indikator i datasettet oppfyller krav til
skewness og kurtosis, om ikke så er tilfelle bør målet i sin helhet fjernes fra videre analyse.
Når en indikator er normalfordelt vil både skewness og kurtosis være lik null, og dette gir en
karakteristisk kurve over fordelingen av datamaterialet (Bagozzi, 1994). I et datasett med
mange indikatorer, vil vi kunne se avvik fra normalen. Det vil være vesentlig å finne verdier

Hjemmeeksamen 2 – Høsten 2014 MET 405 Kvantitative metoder 02.02.2015
33
for standard avvik, skewness og kurtosis som ikke utgjør en trussel for videre analyser. I
denne avhandlingen er kravet for normalfordeling, ved skewness og kurtosis, satt mellom
+/-2. (Ibenfeldt, 2014)
Vi ser at ingen variabler oppfyller kravet til standard avvik større enn 1. Kravet om skewness
og kurtosis blir oppfylt for alle variabler utenom infokvalitet. Infokvalitet har en veldig
høyreskjev fordeling. Med et gjennomsnitt på 0,8945 vil det si at 89,5% av de som har svart,
har fått høy informasjonskvalitet. Mange som har svart på undersøkelsen har fått høy
informasjonskvalitet, her hadde det vært mulig for banken og heller gitt flere lav
informasjonskvalitet slik at gruppene hadde jevnet seg ut.
Siden variablene ikke er normalfordelt, skal de ikke tas med i analysen. En eventuell løsning
for å få de med er å gjennomføre bootstrapping, en metode for å gjøre dataene
normalfordelte (Ibenfeldt 2014). Vi har forstått det slik at dette ikke er pensum i dette faget,
og vi går derfor videre i analysen uten å gjøre noe med dette. Vi beholder variablene slik de
er og gjennomfører ikke bootstrapping.
I tillegg til at det søkes å oppnå normalfordelt datamateriale på indikatornivå, er det i
MANOVA også et krav om at de uavhengige variablene har multivariate normaliteter innen
grupperingene. Dette lar seg ikke teste i SPSS (Field, 2005: 593), men man benytter ofte en
bivariat korrelasjonsmatrise for å se at begrepene ikke bærer preg av multikollinearitet.
Analysen vil kunne fortelle om begrepene har multikollineære tendenser om korrelasjonen
er over 0,8 (Berry, 1993). Høy grad av korrelasjon mellom avhengige variabler kan tyde på
multikolinearitet, og bør vurderes fjernet eller slåes sammen der det er empirisk forsvarlig
(Ibenfeldt, 2014).
Kjører en bivariat korrelasjonsanalyse og ser at det ikke er korrelasjon over 0,8 og at
korrelasjonen ikke er signifikant. De avhengige variablene har ingen multikollineære
tendenser og vi kan derfor beholde de som hver sin variabel.
Vi kjører en multivariat analyse for å teste modellen vår i helhet. Denne viser også en av
forutsetningene for ANOVA gjennom Levene’s og Box test. Resultatet av disse testene ligger
i vedlegg 2.1.3 for oppgave 2.1 og i vedlegg 2.2.1 for oppgave 2.2.

Hjemmeeksamen 2 – Høsten 2014 MET 405 Kvantitative metoder 02.02.2015
34
2.1.2 Utskrift av den multivariate analysen

Hjemmeeksamen 2 – Høsten 2014 MET 405 Kvantitative metoder 02.02.2015
35
2.1.3 Forutsetning nr 1 for ANOVA for oppgave 2.1
Vi merker oss at Levene’s test ikke er signifikant for både enkeltaksjer og hedgefond.
Box’s test er heller ikke signifikant. Modellen vår består dermed forutsetning nr 1 for
ANOVA.

Hjemmeeksamen 2 – Høsten 2014 MET 405 Kvantitative metoder 02.02.2015
36
2.2.1 Forutsetning for ANOVA: Levene’s test og Box’s test Equal variances assumed vs. Not assumed: Levene’s test. Sjekker for om gruppene møter
forutsetning om lik varians. Om denne testen BLIR sig – så er det forskjellig varians mellom
gruppene, og vi har dermed brutt en av forutsetningene for å gjennomføre t Test.
Forskjellig varians mellom gruppene hvis Levene’s test er signifikant.
Hvis forskjellig varians: Se på equal variances not assumed.
Hvis lik varians: Se på equal variances assumed (Ibenfeldt, 2014)
Levene’s test for investeringer i enkeltaksjer er ikke signifikant og kan tas med videre.
Hedgefond er signifikant og bryter dermed forutsetning 4 for ANOVA.
Box’s test tar med kovarians i resultatet og komplementeres derfor med Levene’s test og
skal heller ikke være signifikant (Ibenfeldt 2014). Modellen består Box’s test.

Hjemmeeksamen 2 – Høsten 2014 MET 405 Kvantitative metoder 02.02.2015
37
2.2.2 Post hoc test mellom infokvalitet og sparing

Hjemmeeksamen 2 – Høsten 2014 MET 405 Kvantitative metoder 02.02.2015
38

Hjemmeeksamen 2 – Høsten 2014 MET 405 Kvantitative metoder 02.02.2015
39
2.2.3 Post hoc test for Infokvalitet * Sparing * Lønnsinntekt

Hjemmeeksamen 2 – Høsten 2014 MET 405 Kvantitative metoder 02.02.2015
40

Hjemmeeksamen 2 – Høsten 2014 MET 405 Kvantitative metoder 02.02.2015
41
2.3.1 Korrelasjonsmatrise

Hjemmeeksamen 2 – Høsten 2014 MET 405 Kvantitative metoder 02.02.2015
42
2.3.2 Multivariat med kontrollvariabler mot uavhengig

Hjemmeeksamen 2 – Høsten 2014 MET 405 Kvantitative metoder 02.02.2015
43
2.3.3 Multivariat analyse med kontrollvariabler

Hjemmeeksamen 2 – Høsten 2014 MET 405 Kvantitative metoder 02.02.2015
44

Hjemmeeksamen 2 – Høsten 2014 MET 405 Kvantitative metoder 02.02.2015
45
Syntaks
1.2: Faktoranalyser
FACTOR
/VARIABLES a4.1 a4.2 a4.3 a4.4 a4.5 a4.6 a4.7
/MISSING LISTWISE
/ANALYSIS a4.1 a4.2 a4.3 a4.4 a4.5 a4.6 a4.7
/PRINT INITIAL EXTRACTION ROTATION
/CRITERIA MINEIGEN(1) ITERATE(2500)
/EXTRACTION ML
/CRITERIA ITERATE(2500) DELTA(0)
/ROTATION OBLIMIN.
FACTOR
/VARIABLES a5.1 a5.2 a5.3 a5.4 a5.5 a5.6 a5.7
/MISSING LISTWISE
/ANALYSIS a5.1 a5.2 a5.3 a5.4 a5.5 a5.6 a5.7
/PRINT INITIAL EXTRACTION ROTATION
/CRITERIA MINEIGEN(1) ITERATE(2500)
/EXTRACTION ML
/CRITERIA ITERATE(2500) DELTA(0)
/ROTATION OBLIMIN.
FACTOR
/VARIABLES a5.8 a5.9 a5.10
/MISSING LISTWISE
/ANALYSIS a5.8 a5.9 a5.10
/PRINT INITIAL EXTRACTION ROTATION
/CRITERIA MINEIGEN(1) ITERATE(2500)
/EXTRACTION ML
/CRITERIA ITERATE(2500) DELTA(0)
/ROTATION OBLIMIN.
FACTOR
/VARIABLES a5.11 a5.12 a5.13 a5.14 a5.15 a5.16
/MISSING LISTWISE
/ANALYSIS a5.11 a5.12 a5.13 a5.14 a5.15 a5.16
/PRINT INITIAL EXTRACTION ROTATION
/CRITERIA MINEIGEN(1) ITERATE(2500)
/EXTRACTION ML
/CRITERIA ITERATE(2500) DELTA(0)
/ROTATION OBLIMIN.

Hjemmeeksamen 2 – Høsten 2014 MET 405 Kvantitative metoder 02.02.2015
46
FACTOR
/VARIABLES a4.1 a4.2 a4.3 a4.4 a4.7 a5.1 a5.3 a5.4 a5.5 a5.8 a5.9 a5.10 a5.11 a5.12
a5.13 a5.14 a5.15
/MISSING LISTWISE
/ANALYSIS a4.1 a4.2 a4.3 a4.4 a4.7 a5.1 a5.3 a5.4 a5.5 a5.8 a5.9 a5.10 a5.11 a5.12
a5.13 a5.14 a5.15
/PRINT INITIAL EXTRACTION ROTATION
/CRITERIA FACTORS(4) ITERATE(2500)
/EXTRACTION ML
/CRITERIA ITERATE(2500) DELTA(0)
/ROTATION OBLIMIN.
FACTOR
/VARIABLES a4.1 a4.2 a4.3 a4.7 a5.1 a5.3 a5.5 a5.11 a5.12 a5.13
/MISSING LISTWISE
/ANALYSIS a4.1 a4.2 a4.3 a4.7 a5.1 a5.3 a5.5 a5.11 a5.12 a5.13
/PRINT INITIAL EXTRACTION ROTATION
/CRITERIA MINEIGEN(1) ITERATE(2500)
/EXTRACTION ML
/CRITERIA ITERATE(2500) DELTA(0)
/ROTATION OBLIMIN.
1.2: Reliabilitetstest
RELIABILITY
/VARIABLES=a5.11 a5.12 a5.13
/SCALE('ALL VARIABLES') ALL
/MODEL=ALPHA
/STATISTICS=SCALE.
RELIABILITY
/VARIABLES=a4.1 a4.2 a4.3 a4.7
/SCALE('ALL VARIABLES') ALL
/MODEL=ALPHA
/STATISTICS=SCALE.
RELIABILITY
/VARIABLES=a5.1 a5.3 a5.5
/SCALE('ALL VARIABLES') ALL
/MODEL=ALPHA
/STATISTICS=SCALE.

Hjemmeeksamen 2 – Høsten 2014 MET 405 Kvantitative metoder 02.02.2015
47
1.2: Indekserte variabler
COMPUTE Strategi=MEAN(a4.1,a4.2,a4.3,a4.7).
EXECUTE.
COMPUTE Produktkvalitet=MEAN(a5.1,a5.3,a5.5).
EXECUTE.
COMPUTE Lojalitet=MEAN(a5.11, a5.12, a5.13).
EXECUTE.
1.2: Korrelasjonsanalyse
CORRELATIONS
/VARIABLES=Strategi Produktkvalitet Lojalitet
/PRINT=TWOTAIL NOSIG
/MISSING=PAIRWISE.
1.2: Indekserte variable med 100 skala
COMPUTE Strategi100=MEAN((Strategi-1)*(100/(6-1))).
EXECUTE.
COMPUTE Produktkvalitet100=MEAN((Produktkvalitet-1)*(100/(6-1))).
EXECUTE.
COMPUTE Lojalitet100=MEAN((Lojalitet-1)*(100/(6-1))).
EXECUTE.
1.3: Regresjonsanalyse
REGRESSION
/MISSING LISTWISE
/STATISTICS COEFF OUTS R ANOVA
/CRITERIA=PIN(.05) POUT(.10)
/NOORIGIN
/DEPENDENT Lojalitet100
/METHOD=ENTER Strategi100 Produktkvalitet100.

Hjemmeeksamen 2 – Høsten 2014 MET 405 Kvantitative metoder 02.02.2015
48
2.2: Multivariat analyse
DATASET ACTIVATE DataSet1.
GLM s3_3 s3_11 BY Infokvalitet Sparing Lønnsinntekt
/CONTRAST(Sparing)=Difference
/METHOD=SSTYPE(3)
/INTERCEPT=INCLUDE
/PLOT=PROFILE(Infokvalitet*Sparing Infokvalitet*Lønnsinntekt)
/PRINT=DESCRIPTIVE ETASQ HOMOGENEITY
/CRITERIA=ALPHA(.05)
/DESIGN= Infokvalitet Sparing Lønnsinntekt Infokvalitet*Sparing Infokvalitet*Lønnsinntekt
Sparing*Lønnsinntekt Infokvalitet*Sparing*Lønnsinntekt.
2.2: Post-Hoc test: Infokvalitet * Sparing
GLM s3_3 s3_11 BY Infokvalitet Sparing Lønnsinntekt
/METHOD=SSTYPE(3)
/INTERCEPT=INCLUDE
/PLOT=PROFILE(Infokvalitet*Sparing Infokvalitet*Lønnsinntekt)
/PRINT=DESCRIPTIVE ETASQ HOMOGENEITY
/CRITERIA=ALPHA(.05)
/EMMEANS=TABLES(Sparing*Infokvalitet) COMPARE(Infokvalitet) ADJ(BONFERRONI)
/DESIGN= Infokvalitet Sparing Lønnsinntekt Infokvalitet*Sparing Infokvalitet*Lønnsinntekt
Sparing*Lønnsinntekt Infokvalitet*Sparing*Lønnsinntekt.
2.2: Post-Hoc test: Infokvalitet * Sparing * Lønnsinntekt
GLM s3_3 s3_11 BY Infokvalitet Sparing Lønnsinntekt
/METHOD=SSTYPE(3)
/INTERCEPT=INCLUDE
/PLOT=PROFILE(Infokvalitet*Sparing*Lønnsinntekt)
/PRINT=DESCRIPTIVE ETASQ HOMOGENEITY
/CRITERIA=ALPHA(.05)
/EMMEANS=TABLES(Infokvalitet*Sparing*Lønnsinntekt) COMPARE(Infokvalitet)
ADJ(BONFERRONI)
/DESIGN= Infokvalitet Sparing Lønnsinntekt Infokvalitet*Sparing Infokvalitet*Lønnsinntekt
Sparing*Lønnsinntekt Infokvalitet*Sparing*Lønnsinntekt.
2.3: Korrelasjonsmatrise
CORRELATIONS
/VARIABLES=s2_1 s2_2 s2_3 s2_4 s2_5 s2_6 s2_7 s2_8 s2_9 s2_10 s2_11 s3_1 s3_2 s3_3
s3_4 s3_5 s3_6 s3_7 s3_8 s3_9 s3_10 s3_11 s10 s11 Sparing Lønnsinntekt Alder Infokvalitet
/PRINT=TWOTAIL NOSIG
/MISSING=PAIRWISE.

Hjemmeeksamen 2 – Høsten 2014 MET 405 Kvantitative metoder 02.02.2015
49
2.3: Multivariat med kontrollvariabler mot uavhengig
GLM s3_3 s3_11 BY Infokvalitet Sparing Lønnsinntekt WITH s2_11 s3_7
/METHOD=SSTYPE(3)
/INTERCEPT=INCLUDE
/CRITERIA=ALPHA(.05)
/DESIGN=s3_7 s2_11 Infokvalitet*s2_11 Infokvalitet*s3_7.
2.3: Den multivariate med kontrollvariabler:
GLM s3_3 s3_11 BY Sparing Lønnsinntekt Infokvalitet WITH s2_11 s3_7
/METHOD=SSTYPE(3)
/INTERCEPT=INCLUDE
/PLOT=PROFILE(Infokvalitet*Sparing Infokvalitet*Lønnsinntekt)
/CRITERIA=ALPHA(.05)
/DESIGN=s2_11 s3_7 Sparing Lønnsinntekt Infokvalitet Sparing*Lønnsinntekt
Sparing*Infokvalitet
Lønnsinntekt*Infokvalitet Sparing*Lønnsinntekt*Infokvalitet.


















