
Kapitel 2: Gauß-Markov-Annahmen · Spieß-Vorlesung: Handbuch Gauß-Markov-Annahmen Seite 3 von 19...
20
Kapitel 2: Gauß-Markov-Annahmen 1. Das klassische lineare Modell .......................................................................................................... 1 1.1. Erweiterung der A2 ................................................................................................................. 2 2. Verletzung der Gauß-Markov-Annahmen ....................................................................................... 3 2.1. Gauß-Markov-A1 verletzt ........................................................................................................ 3 2.2. Gauß-Markov-A2 verletzt ........................................................................................................ 4 2.3. Gauß-Markov-A3 verletzt ........................................................................................................ 5 2.4. Gauß-Markov-A4 verletzt ........................................................................................................ 8 3. Das klassische lineare Modell in Matrixnotation .......................................................................... 10 4. Maßnahmen gegen die Verletzungen ........................................................................................... 11 4.1. Maßnahmen gegen systematische Fehler (GM-A1 & GM-A2) .............................................. 11 4.2. Maßnehmen gegen Heteroskedastizität ............................................................................... 11 4.2.1. Robuste Standardfehler ................................................................................................ 12 4.2.2. Weighted Least Sqares (WLS) ........................................................................................ 13 4.2.3. Feasible Generalized Least Sqaures (FGLS) ................................................................... 13 4.3. Maßnahmen gegen Autokorrelation ..................................................................................... 14 4.3.1. Annahmen bei Messwiederholungsdesigns .................................................................. 15 4.3.2. Gründe für die Annahmen............................................................................................. 18 5. Zusammenfassung ......................................................................................................................... 18
Transcript of Kapitel 2: Gauß-Markov-Annahmen · Spieß-Vorlesung: Handbuch Gauß-Markov-Annahmen Seite 3 von 19...

Kapitel 2: Gauß-Markov-Annahmen
1. Das klassische lineare Modell .......................................................................................................... 1
1.1. Erweiterung der A2 ................................................................................................................. 2
2. Verletzung der Gauß-Markov-Annahmen ....................................................................................... 3
2.1. Gauß-Markov-A1 verletzt ........................................................................................................ 3
2.2. Gauß-Markov-A2 verletzt ........................................................................................................ 4
2.3. Gauß-Markov-A3 verletzt ........................................................................................................ 5
2.4. Gauß-Markov-A4 verletzt ........................................................................................................ 8
3. Das klassische lineare Modell in Matrixnotation .......................................................................... 10
4. Maßnahmen gegen die Verletzungen ........................................................................................... 11
4.1. Maßnahmen gegen systematische Fehler (GM-A1 & GM-A2) .............................................. 11
4.2. Maßnehmen gegen Heteroskedastizität ............................................................................... 11
4.2.1. Robuste Standardfehler ................................................................................................ 12
4.2.2. Weighted Least Sqares (WLS) ........................................................................................ 13
4.2.3. Feasible Generalized Least Sqaures (FGLS) ................................................................... 13
4.3. Maßnahmen gegen Autokorrelation ..................................................................................... 14
4.3.1. Annahmen bei Messwiederholungsdesigns .................................................................. 15
4.3.2. Gründe für die Annahmen ............................................................................................. 18
5. Zusammenfassung ......................................................................................................................... 18

Spieß-Vorlesung: Handbuch Gauß-Markov-Annahmen
Seite 1 von 19
1. Das klassische lineare Modell
A1 bedeutet, dass der Erwartungswert des Fehlers einer jeden Beobachtung Null ist. Im Mittel fällt
dieser Fehler also für die wahre bzw. Populationsregression weg. Das gilt für alle Beobachtung .
A2 bedeutet, dass der Fehler einer Beobachtung unabhängig ist von den Prädiktoren im Modell.
Dies gilt für alle Prädiktoren und für alle Beobachtungen .
A3 bedeutet, dass die Varianz der Störgrößen für alle Beobachtungen gleich ist. Die Fehler sind
homoskedastisch1. Dies gilt für alle Beobachtungen .
A4 bedeutet, dass keine Autokorrelation vorliegt. Die Kovarianz der Fehler beträgt also Null. Sie
teilen sich keine Varianz. Sie sind damit nicht linear voneinander abhängig. Das bedeutet, dass der
Fehler der Beobachtung nichts über den Fehler der Beobachtung aussagen kann. Allerdings gilt
dies nur wenn es sich bei der Beobachtung und eine andere Beobachtung handelt. Dieselbe
Beobachtung korreliert natürlich zu 1 miteinander.
Sind alle diese Angaben erfüllt spricht man auch von „independent and identically distributed errors“
kurz iid, wobei die Unabhängigkeitsannahme immer implizit angenommen wird (Folie 54):
, alle Fehler (sind unabhängig von den Prädiktoren und) haben den Erwartungswert Null: A1
, alle Fehler (sind unabhängig von den Prädiktoren und) sind identisch verteilt: A3
, alle Fehler (sind unabhängig von den Prädiktoren und) sind unabhängig verteilt: A4
1 „Homo“ = „gleich“; „Skedastisch“ = „Streuung“; „Homoskedastisch“ = „Gleiche Streuung“
Das Modell (Folie 146)
Für eine Zufallsstichprobe mit Beobachtungen,
Und Prädiktoren,
Lineare Einfachregression als Spezialfall (Folie 83)
Annahmen nach Gauß-Markov (Folie 92)
A1: für alle
A2: und sind unabhängig für alle
A3: für alle
A4: für alle

Spieß-Vorlesung: Handbuch Gauß-Markov-Annahmen
Seite 2 von 19
Der Fehler ist eine ZV, die nie zu beobachten ist! Wenn der Fehler aber nie zu beobachten ist, wie
kann man dann kontrollieren, ob seine Annahmen erfüllt sind? Der Fehler steckt im Schätzwert des
Kriteriums (das macht das Kriterium übrigens selbst zu einer ZV) und deswegen gelten alle Aussagen
und Annahmen, die wir über den Fehler machen, auch für den Schätzwert des Kriteriums (Folie 54).
So sind Verletzungen der Annahmen (z. B. Heteroskedastizität) manchmal bereits in der Verteilung
der beobachteten Daten (also der ) zu erkennen, die in einem einfachen Ausgabeplot (Folie
116+119) abgebildet werden können (siehe Abschnitte 2.3.+2.4):
1.1. Erweiterung der A2
Es gibt zwei Arten von Prädiktoren. Man unterscheidet zwischen festen (fixen) oder zufälligen
Effekten, die ein Prädiktor haben kann.
Feste Effekte: Ein fester Effekt berücksichtigt alle möglichen Ausprägungen des Prädiktors. Z. B.
beschreibt der Prädiktor „Geschlecht“ einen festen Effekt, da „männlich“ und „weiblich“ alle
möglichen Ausprägungen dieses Prädiktors darstellen. Dabei sei angemerkt, dass die Anzahl an
Ausprägungen eines Prädiktors evtl. vom Untersucher abhängig ist. Beispiel „Wohnungsgröße“ als
Prädiktor mit den Ausprägungen „klein“, „mittelgroß“ und „groß“. Es wären aber auch nur die
Ausprägungen „klein“ und „groß“ möglich gewesen. Die mittelgroßen Wohnungen hätten sich auf
beide Ausprägungskategorien verteilt. Wichtig ist, dass, egal wie viele Ausprägung es gibt, alle
vorkommenden Fälle an Ausprägungen des Prädiktors berücksichtig werden und vor der
Untersuchung festgelegt wurden. Das macht den Effekt des Prädiktors fest.
Zufällige (stochastische) Effekte: Ein Prädiktor kann aber auch ohne vorher festgelegte Einteilung in
Kategorien als stetige Variable in das Modell mit einbezogen werden. Z. B. kann „Größe“ als stetige
Variable in das Modell eingehen, ohne dass die Ausprägungen vorher in „klein“, „mittelgroß“ und
„groß“ eingestuft wurden. Welche Ausprägungen nun in dem kontinuierlich ausgeprägten Prädiktor
in die Untersuchung mit einfließen sind zufällig. Das macht den Prädiktor in diesem Fall zu einer ZV
und deswegen heißt sein Effekt auch zufällig.
Da wir bei den zufälligen Effekten nicht alle Ausprägungen des Prädiktors berücksichtigen müssen,
bedingen wir einfach unsere Unabhängigkeitsannahme auf die beobachten Ausprägungen des
Prädiktors und nicht auf alle möglichen Ausprägungen (Folie 93). Eine kleine Übersicht, was damit
gemeint ist:
1. Stärkste Annahme: und ist unabhängig von allen Prädiktoren
„Der Störterm hat einen Erwartungswert von Null und ist von den Prädiktoren unabhängig.“
2. Schwächste Annahme: und für alle Prädiktoren
„Der Störterm hat einen Erwartungswert von Null, ist aber nicht mehr unbedingt unabhängig,
von den Prädiktoren, sondern lediglich nicht linear abhängig (keine Korrelation).“
3. Die schwächere Annahme: unabhängig von allen Prädiktoren
„Der Störterm hat – bei jeder beobachteten Ausprägung der Prädiktoren – einen
Erwartungswert von Null.“

Spieß-Vorlesung: Handbuch Gauß-Markov-Annahmen
Seite 3 von 19
Die dritte Unabhängigkeitsannahme liegt zwischen der ersten und zweiten Annahme. Sie wird auch
in der Regel für zufällige Effekte (also stetige Prädiktoren) angenommen. Diese Implikation kann auch
auf die anderen Annahmen „übertragen“ werden:
für alle
, für alle
Nun heißt es immer: „Unter der Annahme, dass die Fehler von den beobachteten Ausprägungen der
Prädiktoren unabhängig sind (Implikation der A2.3), ist der Erwartungswert der Fehler Null (A1), die
Fehler sind homoskedastisch (A3) und es liegt keine Autokorrelation vor (A4).“
2. Verletzung der Gauß-Markov-Annahmen
Die Parameter des linearen Modells werden z. B. mit der Methode der kleinsten Quadrate geschätzt
(KQ). Jetzt stellt sich die Frage, wie sehr kann man den Werten der KQ trauen, bzw. was ist, wenn
bestimmte Annahmen verletzt sind (Folie 106)? Wenn die Gauß-Markov-Annahmen verletzt sind
befinden wir uns automatisch nicht mehr im „klassischen“ linearen Modell, sondern im
„allgemeinen“ linearen Modell (Folie 141+148).
2.1. Gauß-Markov-A1 verletzt
Ist der Erwartungswert der Fehler nicht Null, hätten wir einen Bias in unserem Modell. Das hätte zur
Folge, dass unser Intercept durch die KQ verzerrt geschätzt würde. wird also nicht
erwartungstreu geschätzt:
Allerdings hätte das weniger dramatische Folgen für unsere restlichen Parameter, also keine
Auswirkung auf unsere Prädiktoren! Warum? Unser Modell für eine lineare Einfachregression sieht
wie folgt aus:
Wenn nun der Erwartungswert der Fehler nicht 0 ist, der Fehler also nicht wegfällt, würde in
unserem Modell eine zweite Konstante stehen. Diese zweite Konstante würde sich mit unserer
ersten Konstanten additiv zusammensetzen. Beispiel: „Sind die Punkte in einer Klausur (linear)
auf die Intelligenz zurückzuführen?“
Unsere KQ hat für und für ergeben. Angenommen, wir ermitteln unsere Punkte
grundsätzlich nur bei hohen, sommerlichen Temperaturen. Dies hätte zur Folge, dass die (wahren)
Punkte immer unterschätzt werden, wir haben also einen Bias. Dieser Bias könnte bei 3 Punkten
liegen: . Unser Modell sieht nun wie folgt aus:
Spieß-Vorlesung: Handbuch Gauß-Markov-Annahmen
Seite 4 von 19
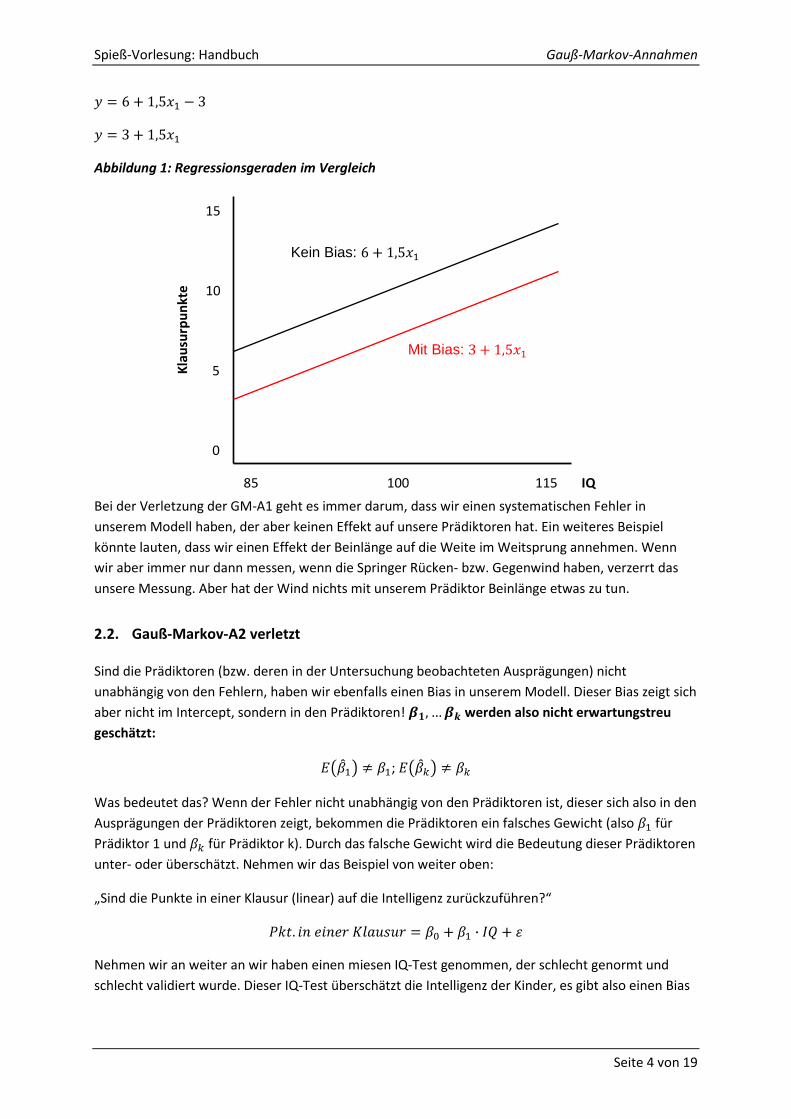
Abbildung 1: Regressionsgeraden im Vergleich
Bei der Verletzung der GM-A1 geht es immer darum, dass wir einen systematischen Fehler in
unserem Modell haben, der aber keinen Effekt auf unsere Prädiktoren hat. Ein weiteres Beispiel
könnte lauten, dass wir einen Effekt der Beinlänge auf die Weite im Weitsprung annehmen. Wenn
wir aber immer nur dann messen, wenn die Springer Rücken- bzw. Gegenwind haben, verzerrt das
unsere Messung. Aber hat der Wind nichts mit unserem Prädiktor Beinlänge etwas zu tun.
2.2. Gauß-Markov-A2 verletzt
Sind die Prädiktoren (bzw. deren in der Untersuchung beobachteten Ausprägungen) nicht
unabhängig von den Fehlern, haben wir ebenfalls einen Bias in unserem Modell. Dieser Bias zeigt sich
aber nicht im Intercept, sondern in den Prädiktoren! werden also nicht erwartungstreu
geschätzt:
;
Was bedeutet das? Wenn der Fehler nicht unabhängig von den Prädiktoren ist, dieser sich also in den
Ausprägungen der Prädiktoren zeigt, bekommen die Prädiktoren ein falsches Gewicht (also für
Prädiktor 1 und für Prädiktor k). Durch das falsche Gewicht wird die Bedeutung dieser Prädiktoren
unter- oder überschätzt. Nehmen wir das Beispiel von weiter oben:
„Sind die Punkte in einer Klausur (linear) auf die Intelligenz zurückzuführen?“
Nehmen wir an weiter an wir haben einen miesen IQ-Test genommen, der schlecht genormt und
schlecht validiert wurde. Dieser IQ-Test überschätzt die Intelligenz der Kinder, es gibt also einen Bias
15
10
5
0
Kla
usu
rpu
nkt
e
85 115 100
Mit Bias:
Kein Bias:
IQ
Spieß-Vorlesung: Handbuch Gauß-Markov-Annahmen
Seite 5 von 19
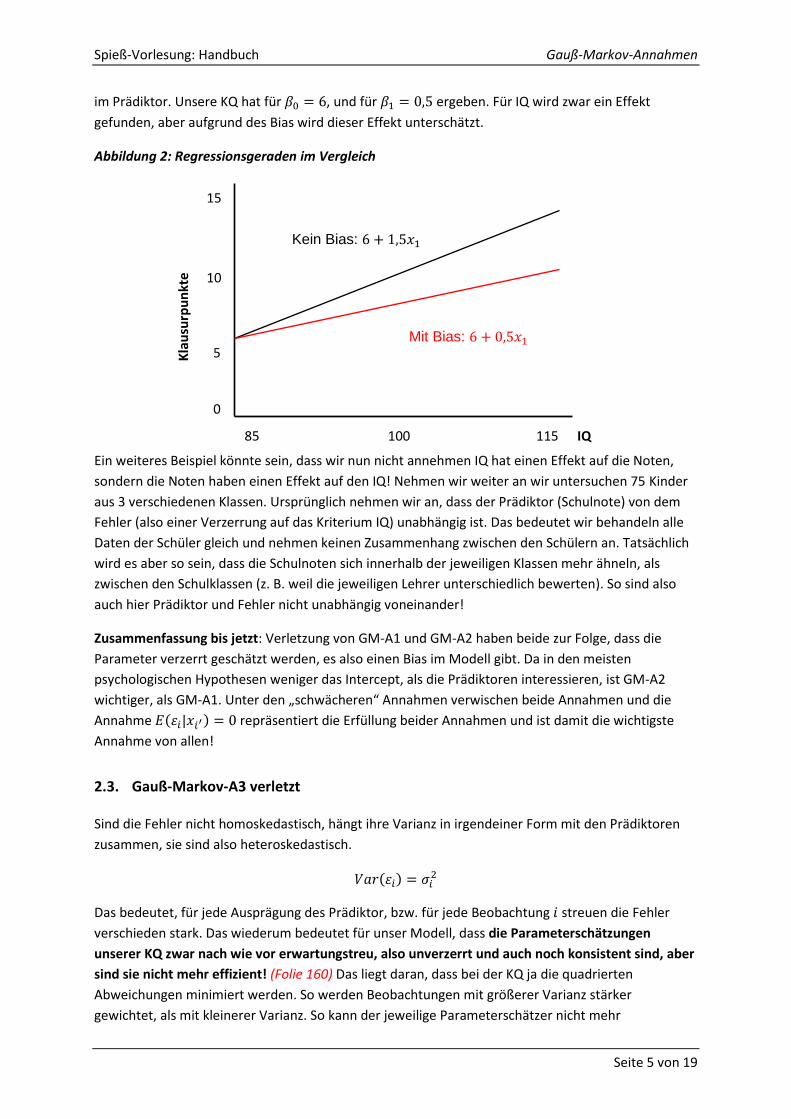
im Prädiktor. Unsere KQ hat für , und für ergeben. Für IQ wird zwar ein Effekt
gefunden, aber aufgrund des Bias wird dieser Effekt unterschätzt.
Abbildung 2: Regressionsgeraden im Vergleich
Ein weiteres Beispiel könnte sein, dass wir nun nicht annehmen IQ hat einen Effekt auf die Noten,
sondern die Noten haben einen Effekt auf den IQ! Nehmen wir weiter an wir untersuchen 75 Kinder
aus 3 verschiedenen Klassen. Ursprünglich nehmen wir an, dass der Prädiktor (Schulnote) von dem
Fehler (also einer Verzerrung auf das Kriterium IQ) unabhängig ist. Das bedeutet wir behandeln alle
Daten der Schüler gleich und nehmen keinen Zusammenhang zwischen den Schülern an. Tatsächlich
wird es aber so sein, dass die Schulnoten sich innerhalb der jeweiligen Klassen mehr ähneln, als
zwischen den Schulklassen (z. B. weil die jeweiligen Lehrer unterschiedlich bewerten). So sind also
auch hier Prädiktor und Fehler nicht unabhängig voneinander!
Zusammenfassung bis jetzt: Verletzung von GM-A1 und GM-A2 haben beide zur Folge, dass die
Parameter verzerrt geschätzt werden, es also einen Bias im Modell gibt. Da in den meisten
psychologischen Hypothesen weniger das Intercept, als die Prädiktoren interessieren, ist GM-A2
wichtiger, als GM-A1. Unter den „schwächeren“ Annahmen verwischen beide Annahmen und die
Annahme repräsentiert die Erfüllung beider Annahmen und ist damit die wichtigste
Annahme von allen!
2.3. Gauß-Markov-A3 verletzt
Sind die Fehler nicht homoskedastisch, hängt ihre Varianz in irgendeiner Form mit den Prädiktoren
zusammen, sie sind also heteroskedastisch.
Das bedeutet, für jede Ausprägung des Prädiktor, bzw. für jede Beobachtung streuen die Fehler
verschieden stark. Das wiederum bedeutet für unser Modell, dass die Parameterschätzungen
unserer KQ zwar nach wie vor erwartungstreu, also unverzerrt und auch noch konsistent sind, aber
sind sie nicht mehr effizient! (Folie 160) Das liegt daran, dass bei der KQ ja die quadrierten
Abweichungen minimiert werden. So werden Beobachtungen mit größerer Varianz stärker
gewichtet, als mit kleinerer Varianz. So kann der jeweilige Parameterschätzer nicht mehr
15
10
5
0
Kla
usu
rpu
nkt
e
85 115 100
Mit Bias:
Kein Bias:
IQ
Spieß-Vorlesung: Handbuch Gauß-Markov-Annahmen
Seite 6 von 19
automatisch die kleinste Varianz besitzen2. Ein noch größeres Problem als der Verlust der Effizienz ist,
dass die Standardfehler (SE) der Parameterschätzer verzerrt geschätzt werden. Das wiederum liegt
daran, dass aus den Residuen die SE für die Parameter geschätzt werden. Wenn aber für jede
Ausprägung des Prädiktors verschiedene Residuen vorliegen, wie sollen da vernünftige SE für die
Parameter geschätzt werden?! Wenn aber die SE der Parameter verzerrt sind, können wir die
Parameter nicht mehr auf Signifikanz überprüfen, denn die SE der Parameterschätzer gehen in
Konfidenzintervalle und Punktschätzer (z. B. t-Tests) mit ein. Wenn wir keine Aussage über die
Signifikanz treffen können, wissen wir aber nicht, ob unser Prädiktor wirklich wichtig ist, bzw. einen
„echten“ Effekt auf unser Kriterium hat!
Beispiel: Nehmen wir an wir wollen untersuchen, ob die sich die Investition in Werbung auf den
Verkauf von Musikplatten auswirkt:
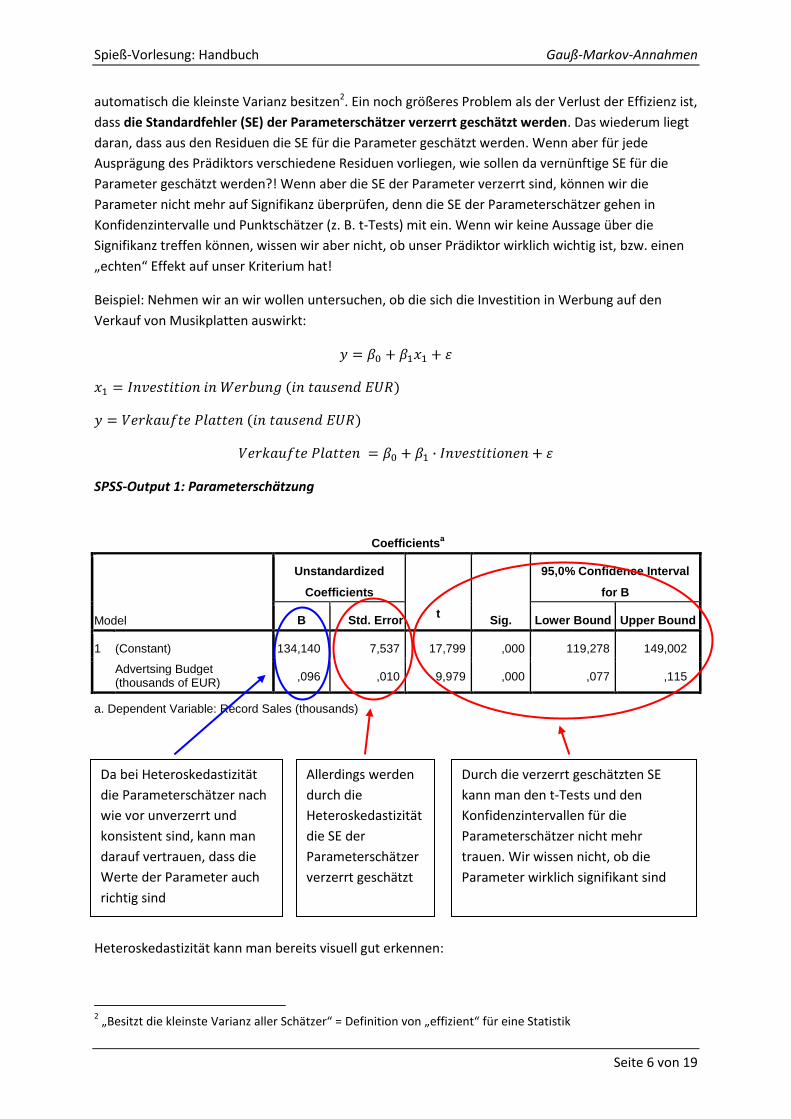
SPSS-Output 1: Parameterschätzung
Heteroskedastizität kann man bereits visuell gut erkennen:
2 „Besitzt die kleinste Varianz aller Schätzer“ = Definition von „effizient“ für eine Statistik
Coefficientsa
Model
Unstandardized
Coefficients
t Sig.
95,0% Confidence Interval
for B
B Std. Error Lower Bound Upper Bound
1 (Constant) 134,140 7,537 17,799 ,000 119,278 149,002
Advertsing Budget (thousands of EUR)
,096 ,010 9,979 ,000 ,077 ,115
a. Dependent Variable: Record Sales (thousands)
Da bei Heteroskedastizität
die Parameterschätzer nach
wie vor unverzerrt und
konsistent sind, kann man
darauf vertrauen, dass die
Werte der Parameter auch
richtig sind
Allerdings werden
durch die
Heteroskedastizität
die SE der
Parameterschätzer
verzerrt geschätzt
Durch die verzerrt geschätzten SE
kann man den t-Tests und den
Konfidenzintervallen für die
Parameterschätzer nicht mehr
trauen. Wir wissen nicht, ob die
Parameter wirklich signifikant sind
Spieß-Vorlesung: Handbuch Gauß-Markov-Annahmen
Seite 7 von 19
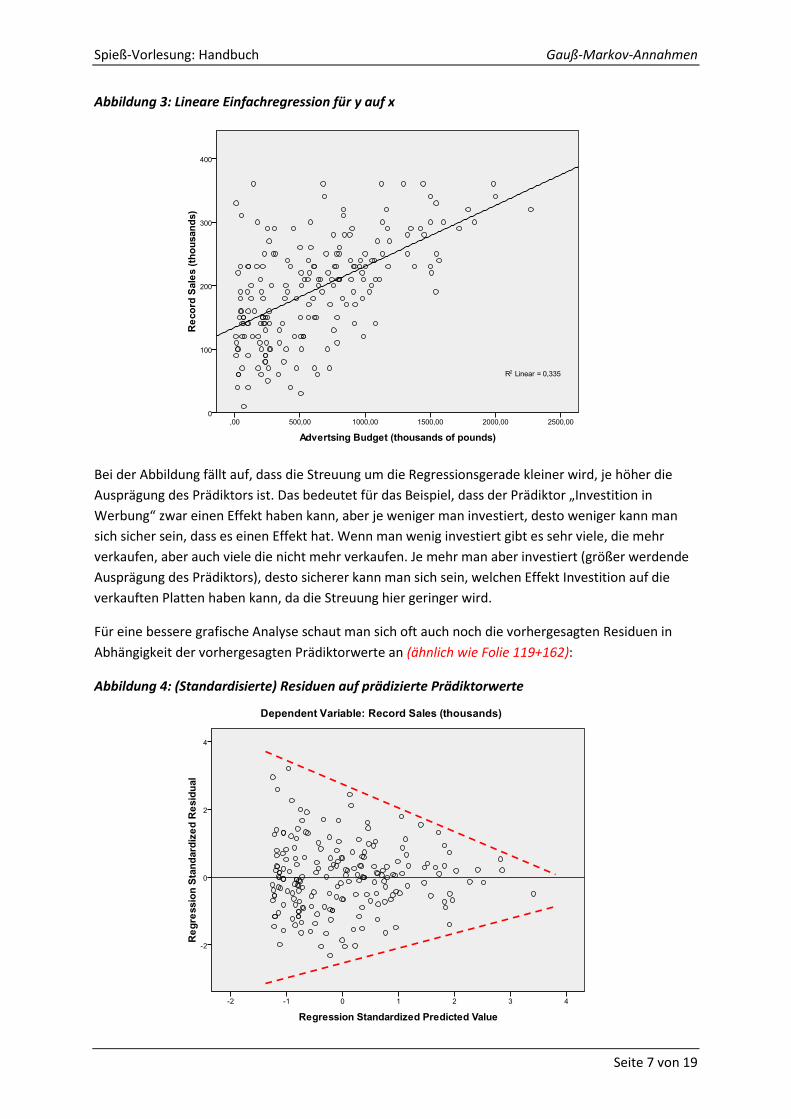
Abbildung 3: Lineare Einfachregression für y auf x
Bei der Abbildung fällt auf, dass die Streuung um die Regressionsgerade kleiner wird, je höher die
Ausprägung des Prädiktors ist. Das bedeutet für das Beispiel, dass der Prädiktor „Investition in
Werbung“ zwar einen Effekt haben kann, aber je weniger man investiert, desto weniger kann man
sich sicher sein, dass es einen Effekt hat. Wenn man wenig investiert gibt es sehr viele, die mehr
verkaufen, aber auch viele die nicht mehr verkaufen. Je mehr man aber investiert (größer werdende
Ausprägung des Prädiktors), desto sicherer kann man sich sein, welchen Effekt Investition auf die
verkauften Platten haben kann, da die Streuung hier geringer wird.
Für eine bessere grafische Analyse schaut man sich oft auch noch die vorhergesagten Residuen in
Abhängigkeit der vorhergesagten Prädiktorwerte an (ähnlich wie Folie 119+162):
Abbildung 4: (Standardisierte) Residuen auf prädizierte Prädiktorwerte

Spieß-Vorlesung: Handbuch Gauß-Markov-Annahmen
Seite 8 von 19
Mit zunehmender vorhergesagter Größe des Prädiktors, werden die (standardisierten) Residuen
kleiner.
Ein weiteres Beispiel für heteroskedastische Daten könnten z. B. Urlaubsausgaben in Abhängigkeit
vom Einkommen sein. Die Varianz bei reicheren Haushalten ist sicherlich größer, als bei ärmeren
Haushalten, da diese nicht unbedingt viel ausgeben müssen, aber können, während ärmere
Haushalte grundsätzlich nur wenig ausgeben können. Es geht bei der Heteroskedastizität immer
darum, dass mit der Ausprägung des Prädiktors sich die Streuung systematisch mit verändert!
2.4. Gauß-Markov-A4 verletzt
Ist die Kovarianz der Fehler nicht Null bedeutet dies, dass sie in irgendeiner Form linear
zusammenhängen. Die Fehler korrelieren also mit sich selbst – sie autokorrelieren.
Das bedeutet entweder, dass auf einen negativen (bzw. positiven) Störterm tendenziell wieder ein
negativer (bzw. positiver) Störterm folgt (positive Autokorrelation) oder dass jeweils ein Störterm mit
gegenteiligem Vorzeichen auf seinen Vorgänger folgt (negative Autorkorrelation). Das hat dieselben
Probleme, aus denselben Gründen wie bei der Heteroskedastizität zur Folge:
1. KQ-Schätzer sind nach wie vor erwartungstreu und konsistent,
2. aber sie sind nicht mehr effizient
3. und die SE der Schätzer sind verzerrt, was bedeutet, dass wir den Hypothesentests (z. B.
t-Tests und Konfidenzintervalle) nicht mehr trauen können
Es gibt zwei klassische Gründe dafür, wie Autokorrelation entstehen kann. Entweder das Modell ist
fehlspezifiziert oder wir haben eine wichtige Variable vergessen.
1. Modellfehlspezifikation: Die lineare Einfachregression nimmt immer nur einen linear
verlaufenden An- oder Abstieg im Kriterium im Zusammenhang mit der Veränderung des
Prädiktors an. Was aber, wenn es keinen geradlinigen Zusammenhang, sondern einen
parabelförmigen oder exponentialen Zusammenhang gibt? Ein Beispiel könnte der
Zusammenhang zwischen Alkohol auf die Reaktionszeit sein. Wir nehmen ursprünglich einen
einfachen linearen Zusammenhang an, aber in Wirklichkeit steigt die Reaktionszeit exponential
zum Alkoholkonsum an. Autokorrelation kann also einen Hinweis darauf sein, dass ich einen
falschen Zusammenhang zwischen Prädiktoren und Kriterium annehme.
2. Vergessene Variable: Wenn die Fehler systematisch miteinander zusammenhängen kann das
auch bedeuten, dass eine wichtige Variable im Modell vergessen wurde. Z. B. nehmen wir an es
gibt einen positiven Zusammenhang zwischen Fleiß in der Schule und guten Noten. Eine weitere
wichtige Variable könnte aber noch sein, das neben Fleiß auch hohe Konzentration während
einer Klausur einen Effekt auf gute Noten haben kann.
Ein immer wieder genannten Beispiel für eine Autokorrelation sind wiederholte Messungen. Es liegt
praktisch auf der Hand, dass die Messung von Karina zum Zeitpunkt mit der Messung von Karina
zum Zeitpunkt miteinander korrelieren wird. Allerdings gilt nach wie vor, dass Karinas Messung
nicht unbedingt etwas mit Toms Messung zu tun haben muss.
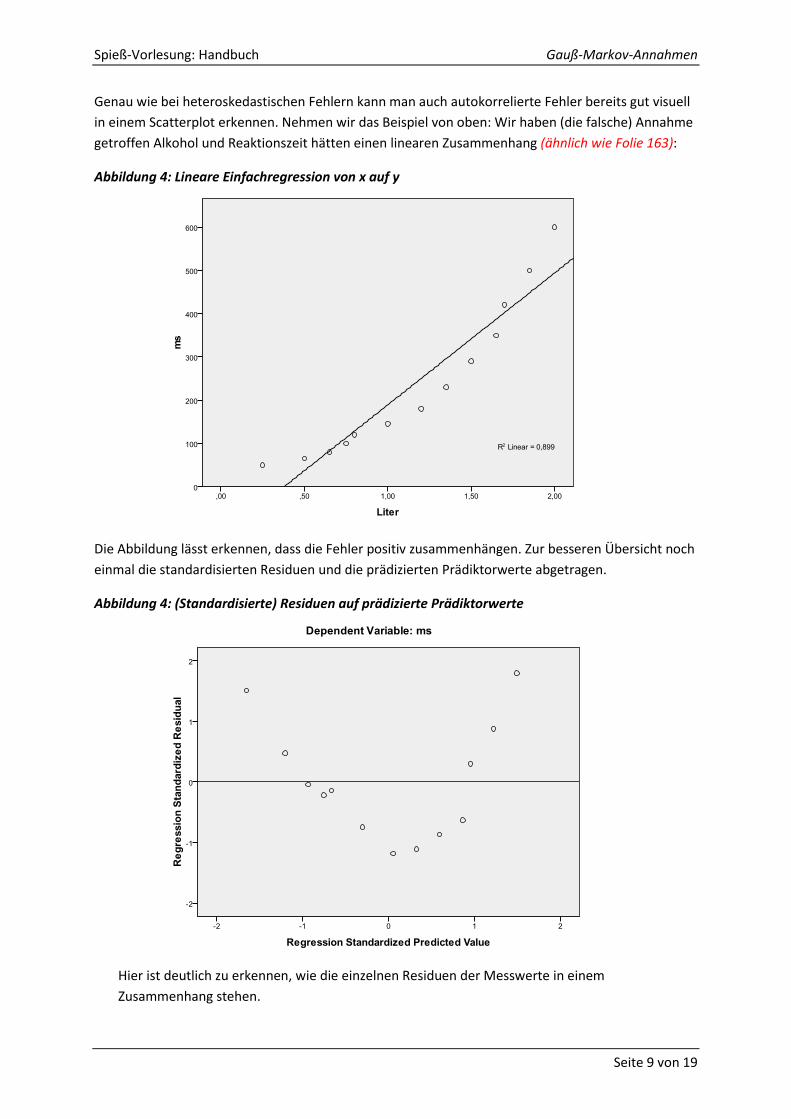
Spieß-Vorlesung: Handbuch Gauß-Markov-Annahmen
Seite 9 von 19
Genau wie bei heteroskedastischen Fehlern kann man auch autokorrelierte Fehler bereits gut visuell
in einem Scatterplot erkennen. Nehmen wir das Beispiel von oben: Wir haben (die falsche) Annahme
getroffen Alkohol und Reaktionszeit hätten einen linearen Zusammenhang (ähnlich wie Folie 163):
Abbildung 4: Lineare Einfachregression von x auf y
Die Abbildung lässt erkennen, dass die Fehler positiv zusammenhängen. Zur besseren Übersicht noch
einmal die standardisierten Residuen und die prädizierten Prädiktorwerte abgetragen.
Abbildung 4: (Standardisierte) Residuen auf prädizierte Prädiktorwerte
Hier ist deutlich zu erkennen, wie die einzelnen Residuen der Messwerte in einem
Zusammenhang stehen.
Spieß-Vorlesung: Handbuch Gauß-Markov-Annahmen
Seite 10 von 19
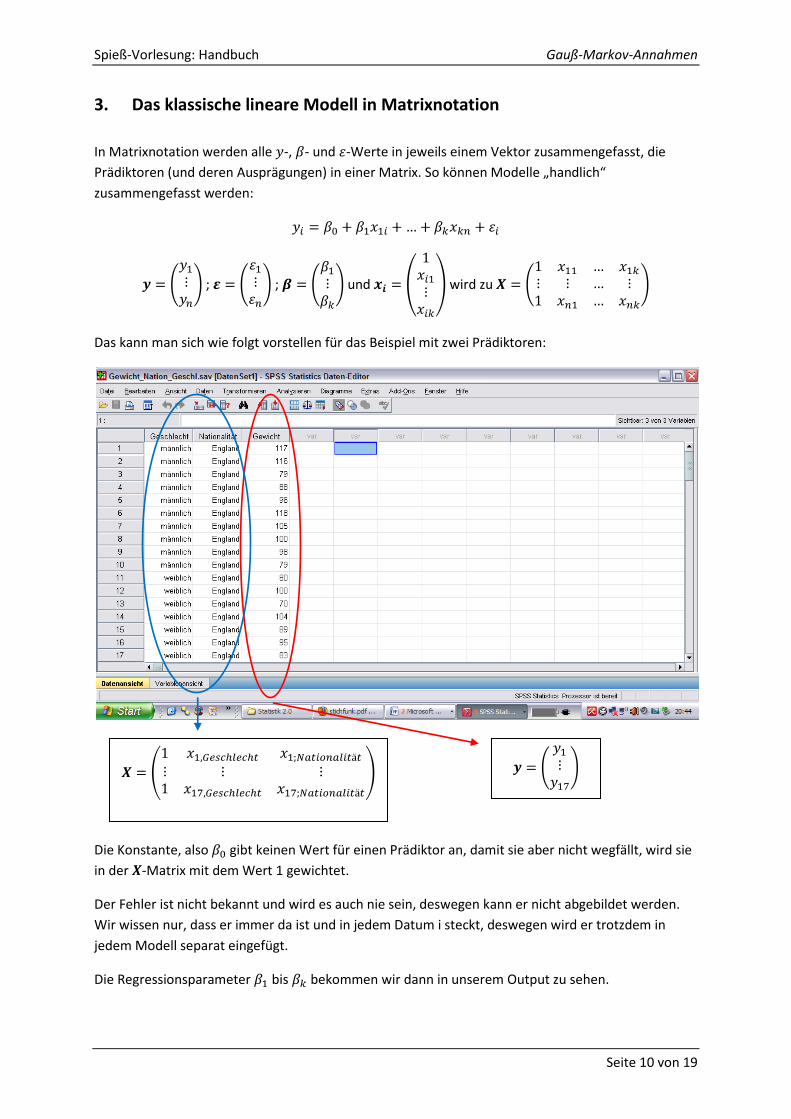
3. Das klassische lineare Modell in Matrixnotation
In Matrixnotation werden alle -, - und -Werte in jeweils einem Vektor zusammengefasst, die
Prädiktoren (und deren Ausprägungen) in einer Matrix. So können Modelle „handlich“
zusammengefasst werden:
; ; und wird zu
Das kann man sich wie folgt vorstellen für das Beispiel mit zwei Prädiktoren:
Die Konstante, also gibt keinen Wert für einen Prädiktor an, damit sie aber nicht wegfällt, wird sie
in der -Matrix mit dem Wert 1 gewichtet.
Der Fehler ist nicht bekannt und wird es auch nie sein, deswegen kann er nicht abgebildet werden.
Wir wissen nur, dass er immer da ist und in jedem Datum i steckt, deswegen wird er trotzdem in
jedem Modell separat eingefügt.
Die Regressionsparameter bis bekommen wir dann in unserem Output zu sehen.

Spieß-Vorlesung: Handbuch Gauß-Markov-Annahmen
Seite 11 von 19
4. Maßnahmen gegen die Verletzungen
4.1. Maßnahmen gegen systematische Fehler (GM-A1 & GM-A2)
Das Problem mit dem Fehler ist, dass er per Definition nicht beobachtet werden kann. Das zeigt sich
vor allem als Problem bei der GM-A1 und GM-A2. Wir können nie wirklich sicher sein, ob nicht ein
außenstehender systematischer Fehler in unserer Untersuchung vorherrscht oder unsere Prädiktoren
mit dem Fehler zusammenhängen. Es gibt keine Koeffizienten und keine deskriptive Analyse, die
einen Verstoß gegen diese Annahme aufzeigen würden. Vielmehr muss man präventiv einfach eine
gute theoretische Grundlage habe und dementsprechend seine Prädiktoren auswählen und sorgfältig
die Untersuchung durchführen.
4.2. Maßnehmen gegen Heteroskedastizität
Wie sieht nun die Heteroskedastizität in Matrixschreibweise aus und was kann man gegen sie tun?
Nehmen wir an es liegt Homoskedastizität vor. In Matrixnotation bedeutet das (Folie151):
= Einheitsmatrix:
Rechenregel bei Matrizenrechnung:
Wird eine Matrix mit der Einheitsmatrix mal genommen, entsteht wieder die Original-Matrix. Ich
rechne sozusagen „mal eins“ und so haben wir überall dieselbe Varianz!
Die Varianz des KQ-Schätzers ermittelt sich wie folgt (Folie 154):
Jetzt stellt sich die Frage, wie aussieht. Liegt Homoskedastizität vor wird daraus
Das Modell (Folie 147+148)
Annahmen nach Gauß-Markov (Folie 153)
A1:
A2: und sind unabhängig
A3:
A4:

Spieß-Vorlesung: Handbuch Gauß-Markov-Annahmen
Seite 12 von 19
das verkürzt sich zu
In dieser Form ist der KQ-Schätzer für die Varianzen erwartungstreu.
Liegt keine Homoskedastizität vor, wird die Varianz nicht mit der Einheitsmatrix mal genommen,
sondern mit einer Matrix (Folie 148).
So haben wir natürlich nicht mehr überall dieselbe Varianz!
Das hat zur Folge, dass sich die Varianz etwas anders bildet:
Das bedeutet, dass die Varianzen nicht mehr erwartungstreu sind! Es stellt sich die Frage was wir
über die Heteroskedastizität wissen und wie dementsprechend diese ominöse -Matix aussieht, die
die Heteroskedastizität beschreibt.
4.2.1. Robuste Standardfehler
Wissen wir nur sehr wenig über die Ursache der Heteroskedastizität, empfiehlt es sich trotzdem
auch weiterhin die Parameter mit der KQ zu schätzen (da die KQ ja erwartungstreu und konsistent
sind), aber anstatt die SE der Parameter durch die KQ zu berechnen, werden diese durch robuste SE
ersetzt. Die robusten SE wurden erstmals von Hal White eingeführt, weswegen man sie auch White-
Schätzer nennt. Unteranderem wird der White-Schätzer auch „Sandwich-Schätzer“ (Folie 160)
genannt, warum zeigt sich wie folgt (Folie 154):
Diese -Matrix liegt zwischen den -Matrizen wie ein Stück Käse zwischen zwei Brotscheiben, daher
der Name „Sandwich-Schätzer“.
Was wir nun wissen wollen sind die -Elemente dieser Matrix, also ihre Diagonale. White hat
gezeigt, dass wir für die Diagonale die quadrierten Residuen (also die Varianzen der Residuen)
nehmen können: .

Spieß-Vorlesung: Handbuch Gauß-Markov-Annahmen
Seite 13 von 19
Vorteil dieser Methode ist, dass wir nichts über die -Matrix (bzw. Über die Heteroskedastizität)
wissen müssen, da wir einfach die Residuen nehmen können! Der Nachteil ist, dass wir nur
asymptotisch korrekte Schätzungen bekommen, d.h. dieses Verfahren funktioniert nur bei einer
großen Stichprobe. Außerdem sind die Varianzen relativ hoch.
4.2.2. Weighted Least Sqares (WLS)
Hat man eine relativ gute Vorstellung über die Art und Ursache der Heteroskedastizität empfiehlt
es sich den WLS-Schätzer (auch Aitken-Schätzer genannt) zu nehmen.
Bei der KQ-Schätzung werden alle Beobachtungen gleich gewichtet. Bei Homoskedastizität ist das
auch so wünschenswert, da ja auch überall bei jeder Beobachtung die gleiche Varianz herrscht. Bei
Heteroskedastizität bedeutet das aber, dass die Beobachtungen mit den größten Störtermen auch
den größten Einfluss bekommen. Ziel der WLS ist es, den einzelnen Beobachtungen ein Gewicht
beizumessen, sodass dieses Ungleichgewicht wieder ausgeglichen wird. Die Daten werden also derart
transformiert, dass die Fehler wieder homoskedastisch sind (Folie 165-167).
Damit die größeren Abweichungen keinen größeren Einfluss auf die KQ haben, als die kleineren
Abweichungen, wird i. d. R. die Wurzel für jeden Datenpunkt gezogen3:
In Matrixschreibweise teile ich, indem ich mit dem Kehrwert mal nehme und ziehe die Wurzel, indem
ich die Potenz halbiere, daraus folgt:
Vereinfacht lässt sich für das transformiertes Modell schreiben:
Für das transformierte Modell sind die Fehler wieder homoskedastisch und damit sind die Varianzen
der Parameter auch wieder erwartungstreu.
4.2.3. Feasible Generalized Least Sqaures (FGLS)
Die WLS-Schätzer sind ein Spezialfall der FGLS. Bei der FGLS werden die einzelnen Gewichte geschätzt
und dann entsprechend auf das Modell angewendet, deswegen nennt man die FGLS auch
„zweistufige Schätzung“ (Folie 170-172). Wir brauchen Informationen über die Varianzen der Fehler
3 Im Prinzip ist aber auch jede andere Transformation der Daten zulässig: Hauptsache die Störterme sind wieder
homoskedastisch

Spieß-Vorlesung: Handbuch Gauß-Markov-Annahmen
Seite 14 von 19
(also ) um darauf auf die schließen zu können. Da wir die Fehler nicht direkt beobachten
können, führen wir erst die „normale“ KQ-Schätzung durch, um so auf die schließen zu können.
Dann können wir mithilfe der die schätzen und kommen so auf unsere -Matrix.
1. Die Gewichte ermitteln
1.1 Wir führen eine normale KQ-Schätzung für auf durch. Wir schätzen also den
Faktor der Prädiktoren , der den Effekt auf unser Kriterium beschreiben soll.
Wir schätzen also und bekommen . Die Abweichungen unseres Modells stellen
unsere geschätzten Fehler dar. Zum Quadrat ergeben diese die geschätzten
Varianzen unserer Residuen, also .
1.2 Wir führen eine KQ-Schätzung für auf durch. sind alle Prädiktoren, die die
Varianzen unserer Fehler beeinflussen. In der Regel ist das unser Modell-Prädiktor-
Vektor . Da aber theoretisch noch andere Prädiktoren einen Einfluss auf die
Varianzen der Fehler haben könnten, nennen wir diesen Vektor halt . Wir schätzen
also nun den Faktor der Prädiktoren, der den Effekt auf unsere geschätzten
Varianzen beschreiben soll. Wir schätzen also und bekommen . Dieses Alpha hat
NICHTS mit der Konstante aus der Regressionsgerade zu tun! ist die Gewichtung,
der den Effekt der Prädiktoren auf die geschätzten Fehlervarianzen schätzt.
1.3 Da wir nun haben, können wir schätzen und erhalten:
Dieser Schätzer für kann negative Werte beinhalten! Deswegen können wir anstatt
einer Regression mit KQ-Schätzer unter 1.2 auch eine logistische Regression durchführen,
sodass keine negativen Zahlen mehr beinhalten kann. Wir erhalten dann:
2. Gewichtete Regression (siehe WLS)
2.1 Wir führen die gewichtete KQ-Schätzung durch da die nun bekannt sind, bzw.
geschätzt wurden.
4.3. Maßnahmen gegen Autokorrelation
Haben wir den Fall, dass die Fehler nicht heteroskedastisch verteilt sind, sondern auch miteinander
korrelieren, sieht die Varianz der Fehler wie folgt aus:
Um unsere Matrix nun schätzen zu können, müssen wir also auch schätzen. Hier gehen wir
ähnlich vor wie im Fall für nur heteroskedastische Fehler, indem wir zweistufig schätzen. So erhalten
wir erst und können dann in unsere Matrix einsetzen und erhalten so .

Spieß-Vorlesung: Handbuch Gauß-Markov-Annahmen
Seite 15 von 19
Da Messwiederholungsdesigns am ehesten mit Autokorrelation zu kämpfen haben, gibt es hier ein
spezielleres Vorgehen. Messwiederholungsdesigns erlauben uns mehr Annahmen über die Art der
Autokorrelation zu machen, was einem „eleganteren“ Weg entspricht, als die
Korrelationskoeffizienten zu schätzen, da ja eine Schätzung immer mit Fehler behaften sind.
Es scheint plausibel, dass man annehmen kann, dass die Einheiten (also die Personen ) voneinander
unabhängig sind. Damit vereinfacht sich unsere zu schätzende -Matrix zu:
Das „einzige“ Problem hierbei ist jetzt nur noch, dass die -Elemente auch Matrizen sind, die
geschätzt werden müssen. Jede Matrix stellt den Zusammenhang einer jeden Person dar. Ist
also die Korrelationsmatrix für jede Person . Allerdings nehmen wir an, dass jede Korrelationsmatrix
gleich aussieht! Es gilt also für alle Personen .
Inhaltlich macht das folgendermaßen Sinn: Der Grund warum das Ergebnis der Person zum
Messzeitpunkt mit dem Ergebnis zum Messzeitpunkt (also ein anderer Messzeitpunkt) korreliert,
ist derselbe, warum das Ergebnis der Person (also einer anderen Person) zum Messzeitpunkt mit
dem Ergebnis zum Messzeitpunkt korreliert!
Wir beobachten maximal Einheiten (=Personen), ist eine Einheit, die beobachtet wird.
Des Weiteren haben wir maximal Messzeitpunkte, ist ein Messzeitpunkt:
Wenn die gesamte Anzahl an Personen zu einem Messzeitpunkt sind, folgt daraus, dass es
Daten gibt. Jede -Matrix ist x groß, d. h. die Korrelationsmatrix für jede Person ist
quadratisch und die Gesamtmenge an Beobachtungen gibt die Größe der Korrelationsmatrix an.
4.3.1. Annahmen bei Messwiederholungsdesigns
Die Annahmen in Messwiederholungsdesigns sind ähnlich denen der ursprünglichen Gauß-Markov-
Annahmen (Folie 173-177).
Der Fehler der Person , setzt sich zusammen aus einem „Personenfaktor“ und dem allgemeinen
Messfehler :

Spieß-Vorlesung: Handbuch Gauß-Markov-Annahmen
Seite 16 von 19
Ein „Personenfaktor“ kann z. B. Ermüdung über die einzelnen Messzeitpunkte sein oder
Übungseffekte. Irgendetwas was das Ergebnis der zweiten Beobachtung (systematisch) beeinflusst,
weil schon eine erste Beobachtung durchgeführt wurde.
Der Messfehler tritt für die Person über alle Messzeitpunkte auf:
Wir nehmen weiterhin an, dass der Erwartungswert für den Personenfaktor für alle Personen Null ist.
Genau so nehmen wir an, dass der Messfehler für jede Person zum Messzeitpunkt Null ist (vgl.
GM-A1):
Wir können weiterhin annehmen, dass die Varianzen für den Personenfaktor und für die Messfehler
homoskedastisch sind, aber jeweils eigene Varianzen besitzen (vgl. GM-A3):
Außerdem darf der Personenfaktor nichts mit dem Messfehler zu tun haben, sie sind also unabhängig
voneinander, das gilt für alle Personen (vgl. GM-A2):
und sind unabhängig voneinander für alle
Aus den Annahmen für den Personenfaktor und dem Messfehler können wir Folgendes ableiten:
Der Erwartungswert für die Fehler für jede Person zum Messzeitpunkt setzt sich zusammen aus
dem Erwartungswert des Personenfaktors für die Person und dem Erwartungswert des Messfehlers
für die Person zum Messzeitpunkt . Da die Erwartungswerte für Personenfaktor und Messfehler
beide Null sind folgt daraus, dass auch der Erwartungswert für den Fehler der Person zum
Messzeitpunkt Null sein muss!
Die Varianz für die Fehler für jede Person für die Beobachtung setzt sich zusammen aus der
Varianz des Personenfaktors für die Person und der Varianz des Messfehlers für die Person zum
Messzeitpunkt :
bedeutet also
Die Varianz für die Fehler für jede Person zum Messzeitpunkt setzt sich zusammen aus der Varianz
des Personenfaktors für die Person und der Varianz des Messfehlers für die Person zum
Messzeitpunkt .

Spieß-Vorlesung: Handbuch Gauß-Markov-Annahmen
Seite 17 von 19
Dann gilt für die Kovarianz:
und dementsprechend für die Korrelation:
Da die Beobachtungen von den unterschiedlichen Personen unabhängig sind, korrelieren die Fehler
der Person zum Messzeitpunkt zu Null mit dem Fehler einer anderen Person zu einem anderen
Messzeitpunkt.
Person korreliert natürlich perfekt mit sich selbst, wenn es auch um dieselbe Messung geht.
Das Ergebnis der einen Beobachtung korreliert zu mit dem Ergebnis einer anderen Beobachtung,
wenn es um dieselbe Person geht. Das ist interessant, denn hier steckt die Autokorrelation drin!
Haben wir die Korrelationen der Personen über die verschiedenen Messzeitpunkte erfasst, können
wir eine Korrelationsmatrix modellieren.
Die Korrelationsmatrix für die Person (bzw. ) ist folgendermaßen zu lesen:
Beschreibt die Höhe der Korrelation des Ergebnisses vom ersten Messzeitpunkt mit dem
Ergebnis vom zweiten Messzeitpunkt.
Beschreibt die Höhe der Korrelation des Ergebnisses vom dritten Messzeitpunkt mit dem
Ergebnis vom zweiten Messzeitpunkt.
Beschreibt die Höhe der Korrelation des Ergebnisses vom zweiten Messzeitpunkt mit dem
Ergebnis vom dritten Messzeitpunkt.
Beschreibt die Höhe der Korrelation des Ergebnisses vom vierten Messzeitpunkt mit dem
Ergebnis vom vierten Messzeitpunkt – muss also 1 sein!
usw.
(Folienfrage: „Bei Homoskedastizität sind alle Korrelationen identisch, warum?“
Homoskedastizität würde bedeutet: ; unter „Restriktion“ (siehe 4.3.2.)
gilt auch:

Spieß-Vorlesung: Handbuch Gauß-Markov-Annahmen
Seite 18 von 19
Die Varianzen, bzw. die Standardabweichungen wären ja überall gleich, also bekomme ich überall
auch dieselbe Korrelation heraus!)
Habe ich meine Korrelationsmatrix , die die Zusammenhänge zwischen den Messzeitpunkten
beschreibt, kann ich meine Gewichtungsmatrix für jede Person modellieren, also . Zur
Erinnerung: Es gilt , also brauche ich nur eine Gewichtungsmatrix modellieren um mein
zu bekommen! Mit meiner -Matrix kann ich meine -Matrix modellieren:
Mit meiner W-Matrix kann ich wiederum die Varianzen meiner Fehler schätzen:
4.3.2. Gründe für die Annahmen
Wo liegt die Vereinfachung durch diese Annahmen? Hätte ich die oben genannten Annahmen nicht
getroffen, so würde meine -Matrix bei Autokorrelation ziemlich frei sein. Ich hätte mehrere
Parameter zu schätzen gehabt (siehe Autokorrelationsmatrix oben)! Aber unter den oben gemachten
Angaben muss ich nur meine für nur eine Person schätzen. Dafür brauche ich nur alle
Standardabweichungen für alle Beobachtung , also (für alle Beobachtungen) und die Varianz
für den Personenfaktor, also . Insgesamt also nur +1 Parameter um letztendlich auf meine -
Matrix zu kommen. Ich kann sogar noch mehr „restringieren“ bzw. mehr Annahmen für unser Modell
vorwegnehmen:
Die Standardabweichung zu jedem Messzeitpunkt ist gleich. Macht inhaltlich auch Sinn: Der Grund
warum mein Ergebnis zum Messzeitpunkt schwankt ist ja derselbe, warum er zum Messzeitpunkt
schwankt. Diese Annahme habe ich schon vorher festgelegt. Also kann ich auch davon ausgehen,
dass das Ergebnis im selben Ausmaße schwankt.
Unter diesen Bedingungen muss ich sogar tatsächlich nur noch zwei Parameter schätzen: und .
Zur Erinnerung: Wir wollen so wenig wie möglich schätzen und dafür so viel wie möglich Annahmen
machen!
5. Zusammenfassung
- Um sicher gehen zu können, dass wir den Werten, die wir für unsere Parameter bekommen
auch trauen können, müssen machen wir (a priori) Annahmen über unsere Daten und damit
über die Störterme: Gauß-Markov-Annahmen 1 bis 4
- Sind die Annahmen 1 und 2 verletzt kann man dem ganzen Modell nicht mehr trauen
o Maßnahmen: Gute, theoretisch fundierte Auswahl der Prädiktoren und sorgfältige
Datensammlung
- Ist die Annahme 3 verletzt (Heteroskedastizität liegt vor), stimmen die Werte der
Parameterschätzung zwar noch (sie sind erwartungstreu), aber wir können sie nicht mehr
zufallskritisch absichern (deren SE sind nicht mehr erwartungstreu)

Spieß-Vorlesung: Handbuch Gauß-Markov-Annahmen
Seite 19 von 19
o Identifikation des Problems: Evtl. schon durch visuelle Analyse der deskriptiven
Statistik erkennbar (z. B. Scatterplot), oder aber entsprechende Tests durchführen
(wurden hier nicht besprochen)
o Maßnahmen: Je nachdem wie viel wir über die Heteroskedastizität wissen entweder
robusten Schätzer (White-Schätzer), WLS (Aitken-Schätzer) oder zweistufige
Schätzung (FGLS-Schätzer) nehmen
- Ist die Annahme 4 verletzt (Autokorrelation liegt vor), stimmen die Werte der
Parameterschätzung zwar noch (sie sind erwartungstreu), aber wir können sie nicht mehr
zufallskritisch absichern (deren SE sind nicht mehr erwartungstreu)
o Identifikation des Problems: Evtl. schon durch visuelle Analyse der deskriptiven
Statistik erkennbar (z. B. Scatterplot), oder aber entsprechende Tests durchführen
(wurden hier nicht besprochen)
o Maßnahmen: Wenn es sich um ein Messwiederholungsdesign handelt kann man
Annahmen über bestimmte Gegebenheiten machen (ähnlich wie GM-Annahmen nur
für den Fall das Autokorrelation vorliegt) und dann den WLS-Schätzer nehmen


















