
Introduction to gpu architecture
55
Introduction to GPU Architectures for Graphics Ludan 滷蛋
-
Upload
chihte-lu -
Category
Technology
-
view
328 -
download
5
Transcript of Introduction to gpu architecture

Introduction to GPU Architectures for Graphics
Ludan 滷蛋

Outline● GPU Pipeline● Rendering (CPU vs GPU)

GPU Pipeline⬅ Rendering (CPU vs GPU)
RasterizationRasterizing 較ray tracing, radiosity等適合被實作於硬體(相依性的考量),在GPU中負責將向量圖形sample到pixel space,非常花運算,現在由GPU來做這件事
Ref : http://www.zedalos.org/2014/05/introduction-into-zedalos-computer-graphics-the-rendering-pipeline/
GPU Pipeline⬅ Rendering (CPU vs GPU)
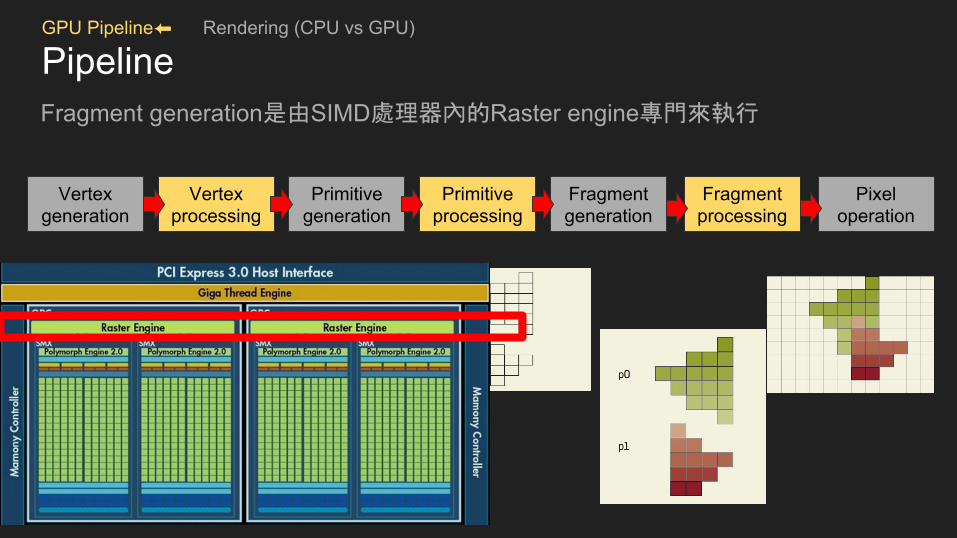
PipelineFragment generation是由SIMD處理器內的Raster engine專門來執行
Ref : https://queue.acm.org/detail.cfm?id=1365498
Vertex generation
Vertex processing
Primitive generation
Primitive processing
Fragment generation
Fragment processing
Pixel operation
GPU Pipeline⬅ Rendering (CPU vs GPU)
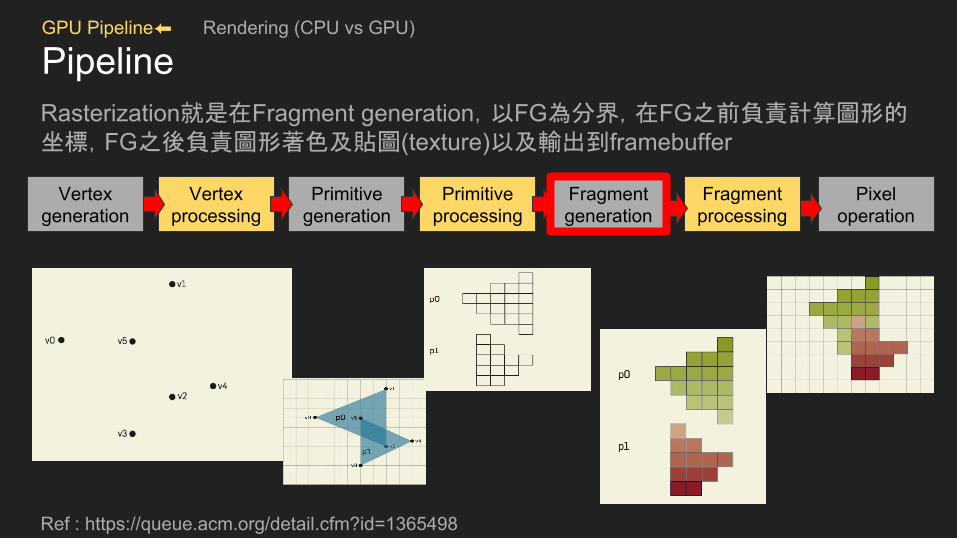
PipelineRasterization就是在Fragment generation,以FG為分界,在FG之前負責計算圖形的坐標,FG之後負責圖形著色及貼圖(texture)以及輸出到framebuffer
Ref : https://queue.acm.org/detail.cfm?id=1365498
Vertex generation
Vertex processing
Primitive generation
Primitive processing
Fragment generation
Fragment processing
Pixel operation
GPU Pipeline⬅ Rendering (CPU vs GPU)
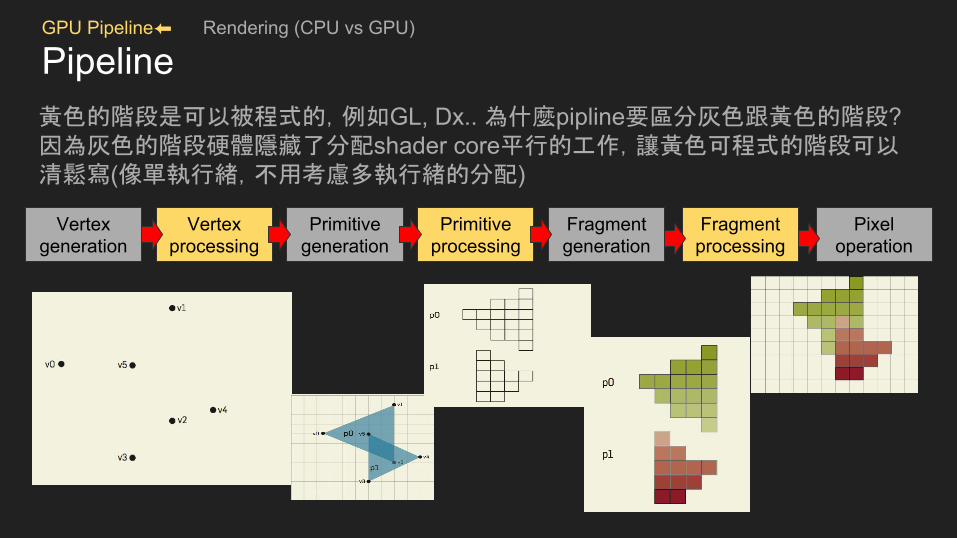
Pipeline黃色的階段是可以被程式的,例如GL, Dx.. 為什麼pipline要區分灰色跟黃色的階段? 因為灰色的階段硬體隱藏了分配shader core平行的工作,讓黃色可程式的階段可以清鬆寫(像單執行緒,不用考慮多執行緒的分配)
Ref : https://queue.acm.org/detail.cfm?id=1365498
Vertex generation
Vertex processing
Primitive generation
Primitive processing
Fragment generation
Fragment processing
Pixel operation
GPU Pipeline⬅ Rendering (CPU vs GPU)
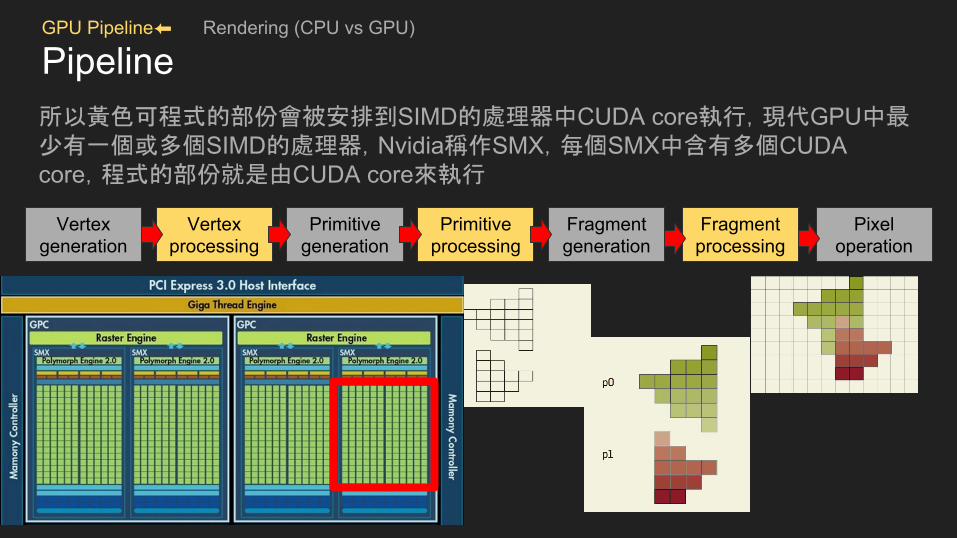
Pipeline所以黃色可程式的部份會被安排到SIMD的處理器中CUDA core執行,現代GPU中最少有一個或多個SIMD的處理器,Nvidia稱作SMX,每個SMX中含有多個CUDA core,程式的部份就是由CUDA core來執行
Ref : https://queue.acm.org/detail.cfm?id=1365498
Vertex generation
Vertex processing
Primitive generation
Primitive processing
Fragment generation
Fragment processing
Pixel operation
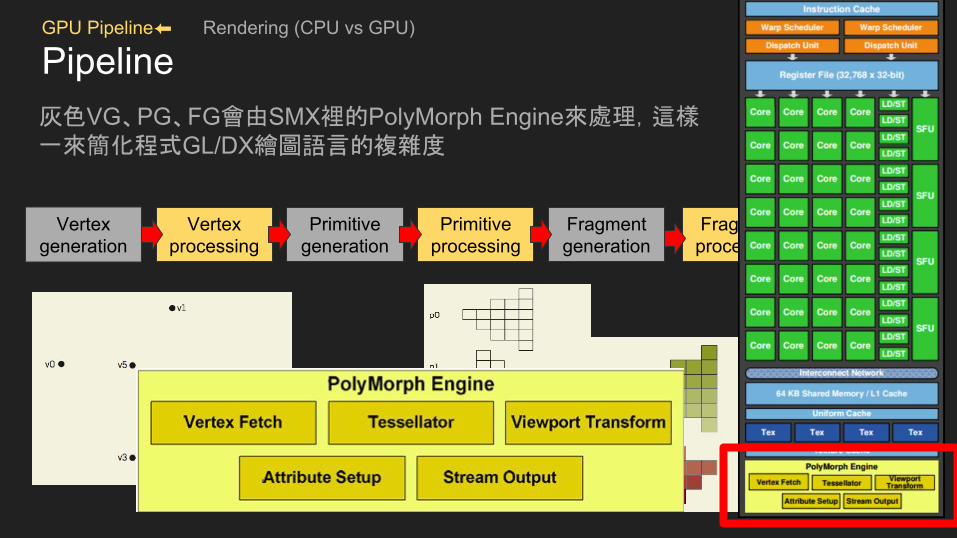
GPU Pipeline⬅ Rendering (CPU vs GPU)
Pipeline灰色VG、PG、FG會由SMX裡的PolyMorph Engine來處理,這樣一來簡化程式GL/DX繪圖語言的複雜度
Vertex generation
Vertex processing
Primitive generation
Primitive processing
Fragment generation
Fragment processing
Pixel operation

GPU Pipeline⬅ Rendering (CPU vs GPU)
Vertex generation先來看第一個階段: Vertex generation 這個階段GPU會將欲繪製的點坐標(CPU傳來的),組成input stream分配給shader core
Vertex generation
Vertex processing
Primitive generation
Primitive processing
Fragment generation
Fragment processing
Pixel operation
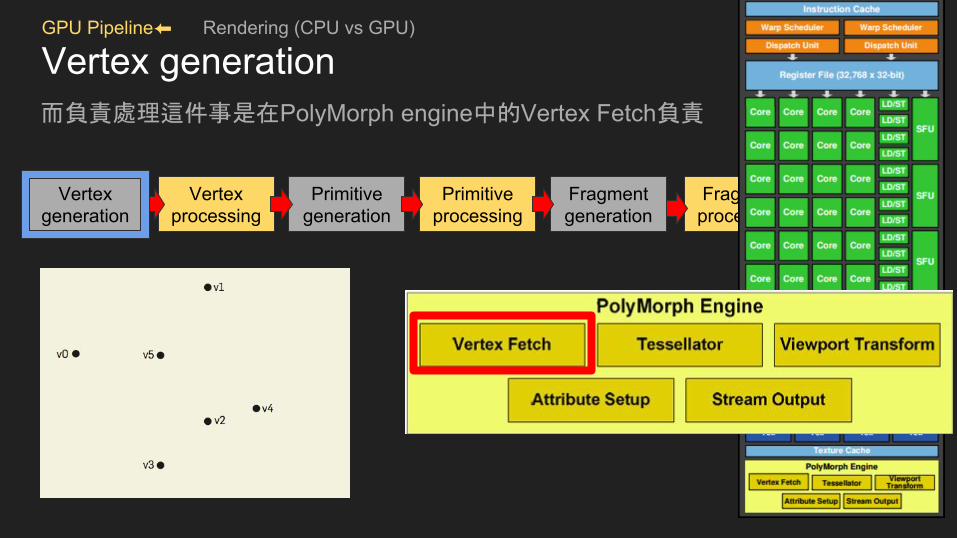
GPU Pipeline⬅ Rendering (CPU vs GPU)
Vertex generation而負責處理這件事是在PolyMorph engine中的Vertex Fetch負責
Vertex generation
Vertex processing
Primitive generation
Primitive processing
Fragment generation
Fragment processing
Pixel operation
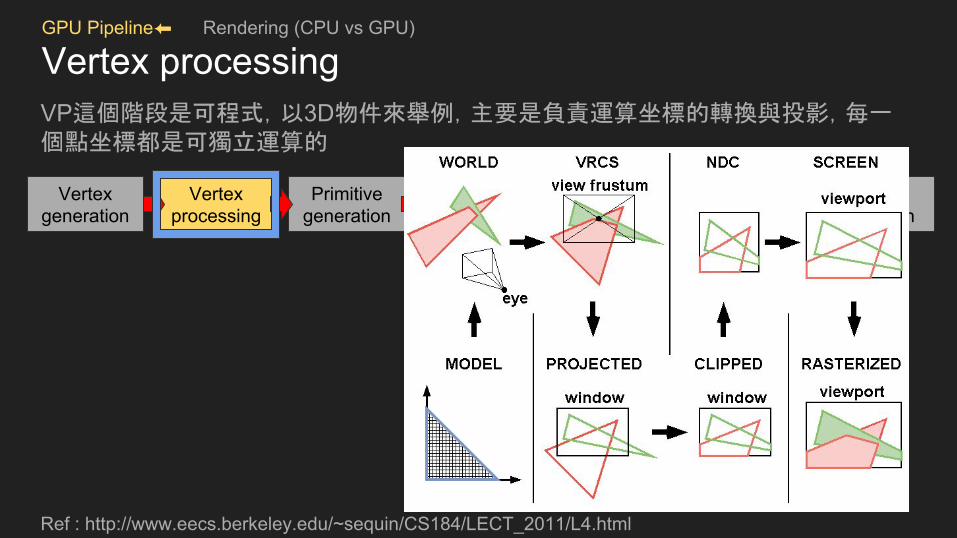
GPU Pipeline⬅ Rendering (CPU vs GPU)
Vertex processingVP這個階段是可程式,以3D物件來舉例,主要是負責運算坐標的轉換與投影,每一個點坐標都是可獨立運算的
Ref : http://www.eecs.berkeley.edu/~sequin/CS184/LECT_2011/L4.html
Vertex generation
Vertex processing
Primitive generation
Primitive processing
Fragment generation
Fragment processing
Pixel operation
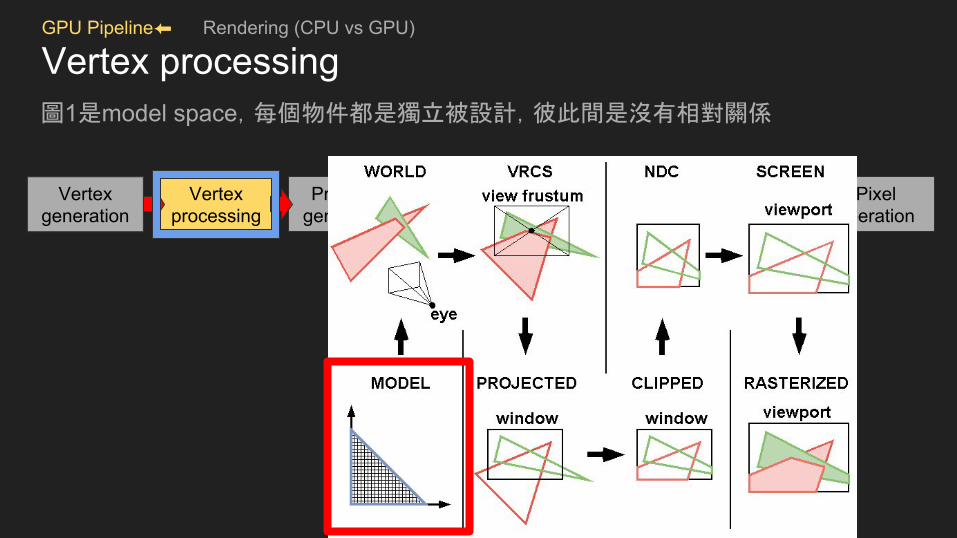
GPU Pipeline⬅ Rendering (CPU vs GPU)
Vertex processing圖1是model space,每個物件都是獨立被設計,彼此間是沒有相對關係
Vertex generation
Vertex processing
Primitive generation
Primitive processing
Fragment generation
Fragment processing
Pixel operation
GPU Pipeline⬅ Rendering (CPU vs GPU)
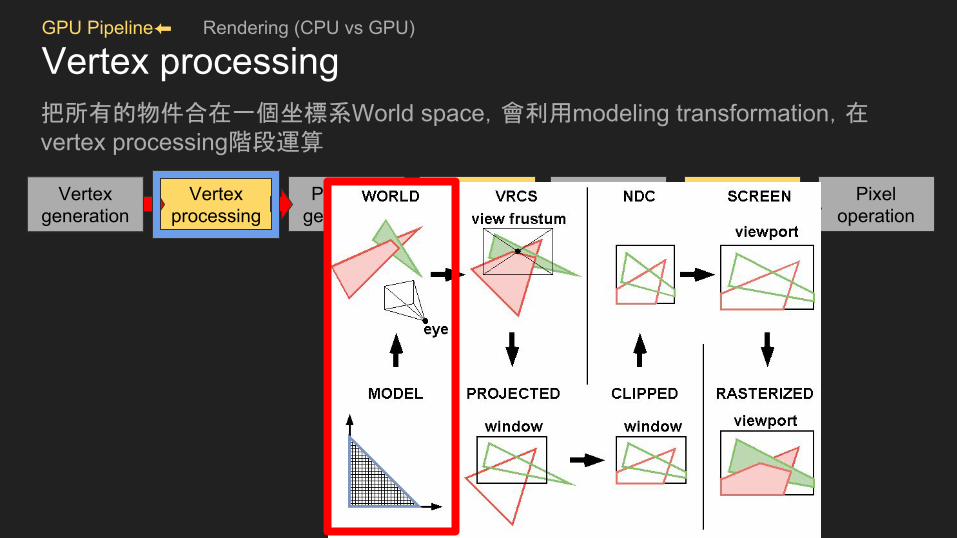
Vertex processing把所有的物件合在一個坐標系World space,會利用modeling transformation,在vertex processing階段運算
Vertex generation
Vertex processing
Primitive generation
Primitive processing
Fragment generation
Fragment processing
Pixel operation
GPU Pipeline⬅ Rendering (CPU vs GPU)
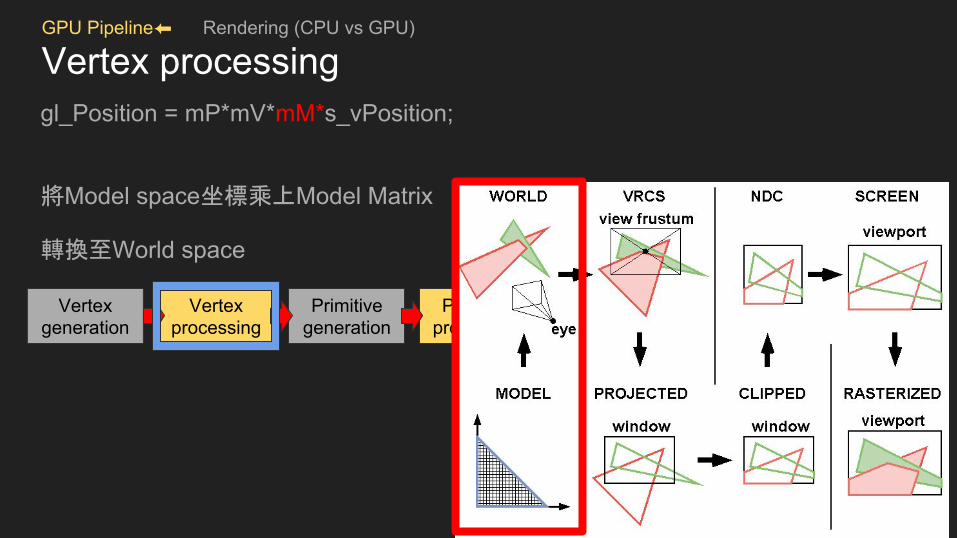
Vertex processinggl_Position = mP*mV*mM*s_vPosition;
將Model space坐標乘上Model Matrix
轉換至World space
Vertex generation
Vertex processing
Primitive generation
Primitive processing
Fragment generation
Fragment processing
Pixel operation
GPU Pipeline⬅ Rendering (CPU vs GPU)
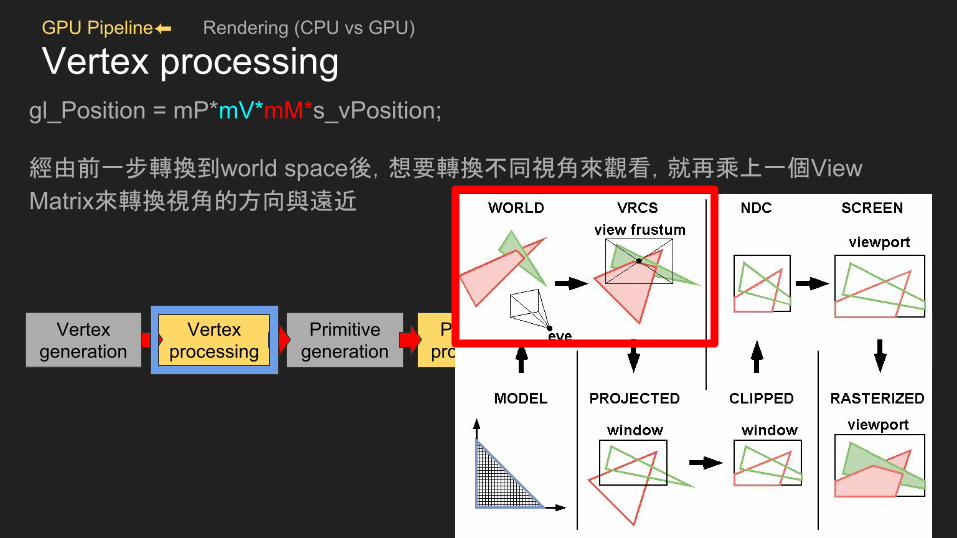
Vertex processinggl_Position = mP*mV*mM*s_vPosition;
經由前一步轉換到world space後,想要轉換不同視角來觀看,就再乘上一個View Matrix來轉換視角的方向與遠近
Vertex generation
Vertex processing
Primitive generation
Primitive processing
Fragment generation
Fragment processing
Pixel operation
GPU Pipeline⬅ Rendering (CPU vs GPU)
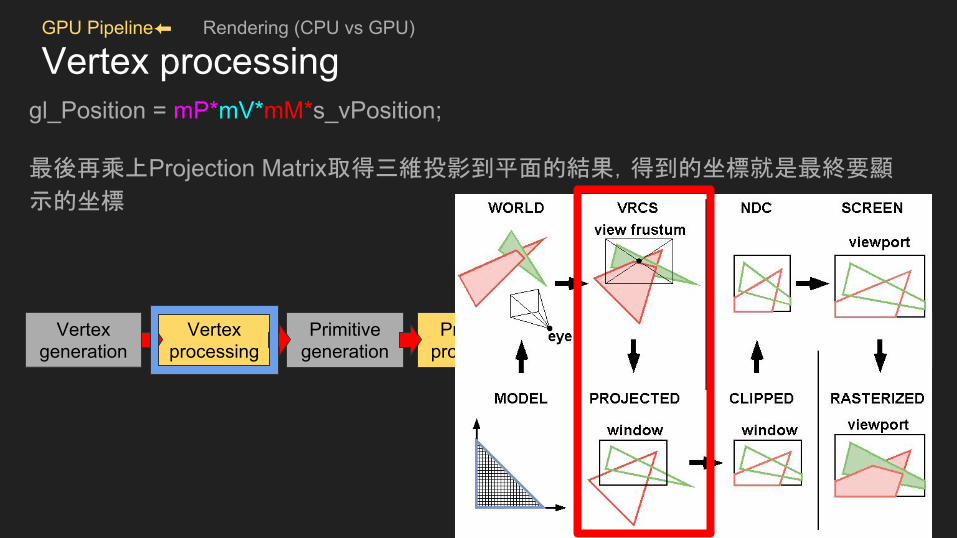
Vertex processinggl_Position = mP*mV*mM*s_vPosition;
最後再乘上Projection Matrix取得三維投影到平面的結果,得到的坐標就是最終要顯
示的坐標
Vertex generation
Vertex processing
Primitive generation
Primitive processing
Fragment generation
Fragment processing
Pixel operation
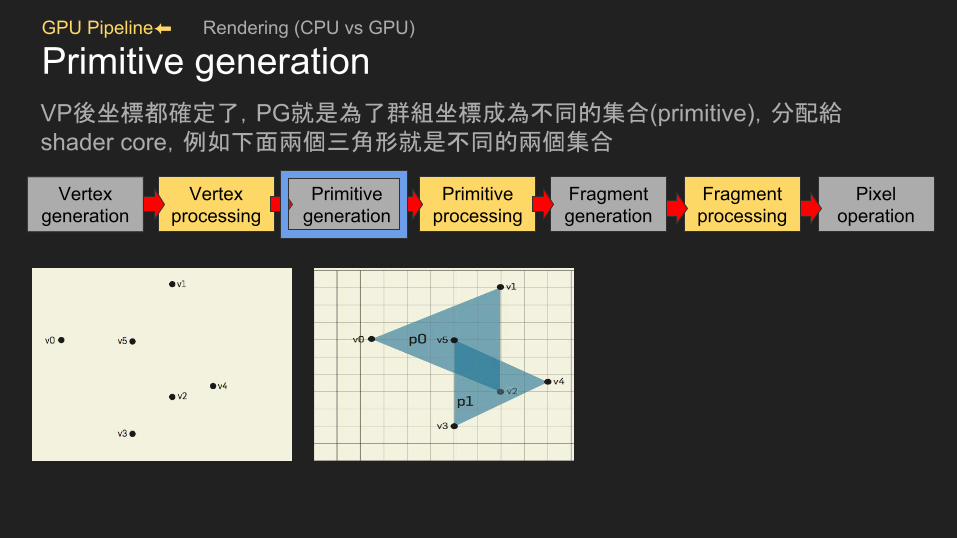
GPU Pipeline⬅ Rendering (CPU vs GPU)
Primitive generationVP後坐標都確定了,PG就是為了群組坐標成為不同的集合(primitive),分配給shader core,例如下面兩個三角形就是不同的兩個集合
Vertex generation
Vertex processing
Primitive generation
Primitive processing
Fragment generation
Fragment processing
Pixel operation
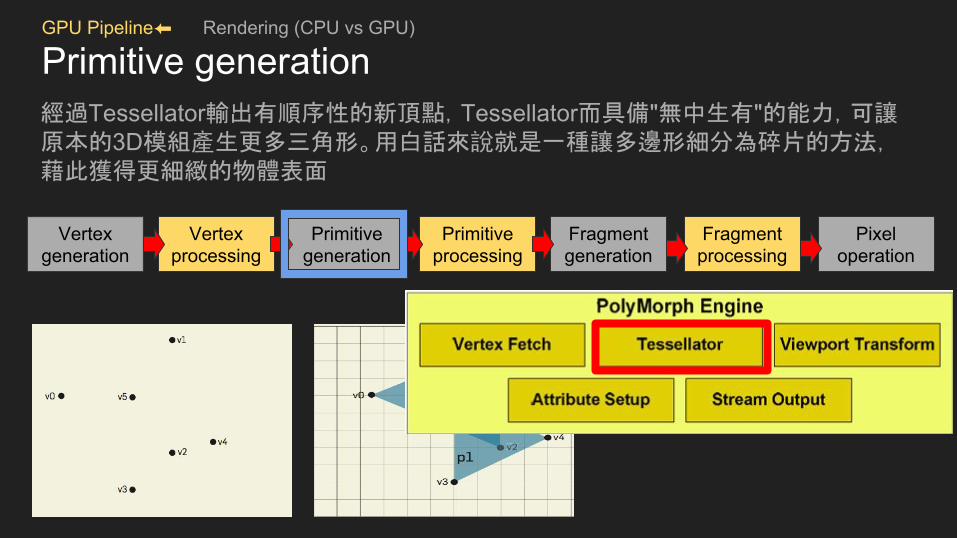
GPU Pipeline⬅ Rendering (CPU vs GPU)
Primitive generation經過Tessellator輸出有順序性的新頂點,Tessellator而具備"無中生有"的能力,可讓原本的3D模組產生更多三角形。用白話來說就是一種讓多邊形細分為碎片的方法,藉此獲得更細緻的物體表面
Vertex generation
Vertex processing
Primitive generation
Primitive processing
Fragment generation
Fragment processing
Pixel operation
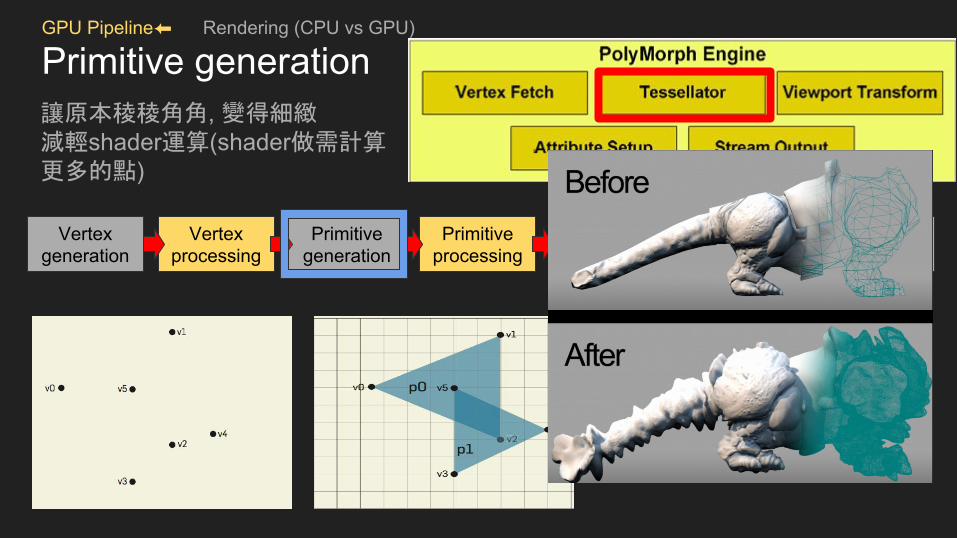
GPU Pipeline⬅ Rendering (CPU vs GPU)
Primitive generation讓原本稜稜角角, 變得細緻減輕shader運算(shader做需計算更多的點)
ref : http://maxpgiganti.com/tutorials/using-tessellation-and-dispacement-maps/
Vertex generation
Vertex processing
Primitive generation
Primitive processing
Fragment generation
Fragment processing
Pixel operation
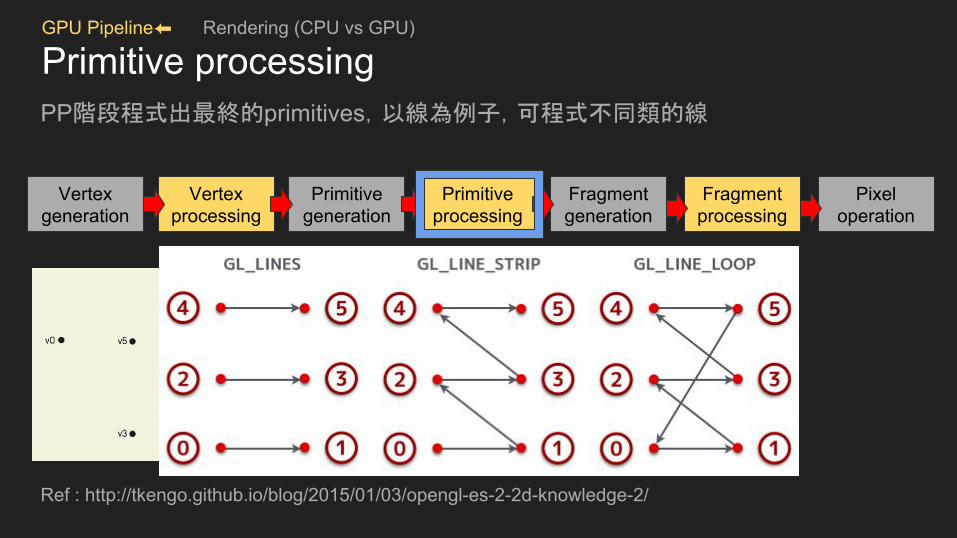
GPU Pipeline⬅ Rendering (CPU vs GPU)
Primitive processingPP階段程式出最終的primitives,以線為例子,可程式不同類的線
Ref : http://tkengo.github.io/blog/2015/01/03/opengl-es-2-2d-knowledge-2/
Vertex generation
Vertex processing
Primitive generation
Primitive processing
Fragment generation
Fragment processing
Pixel operation
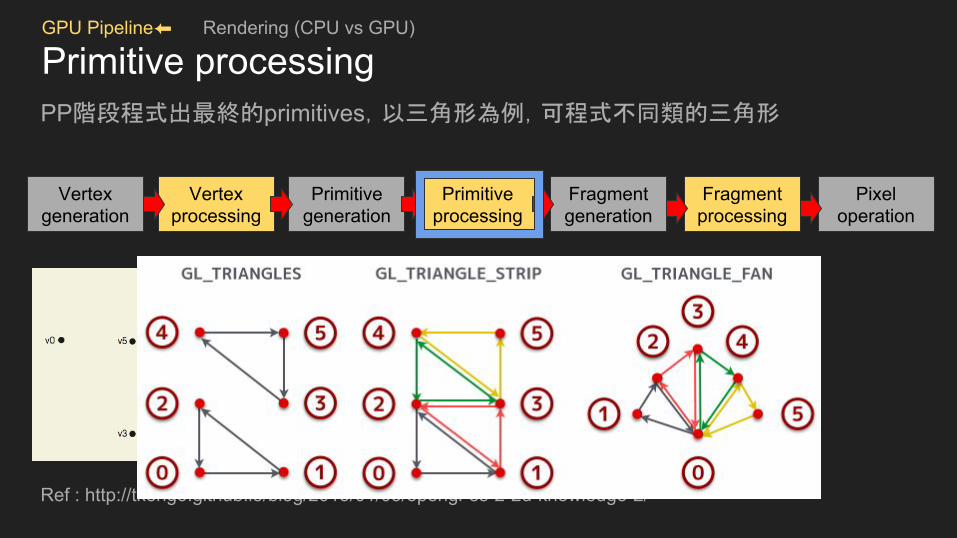
GPU Pipeline⬅ Rendering (CPU vs GPU)
Primitive processingPP階段程式出最終的primitives,以三角形為例,可程式不同類的三角形
Ref : http://tkengo.github.io/blog/2015/01/03/opengl-es-2-2d-knowledge-2/
Vertex generation
Vertex processing
Primitive generation
Primitive processing
Fragment generation
Fragment processing
Pixel operation
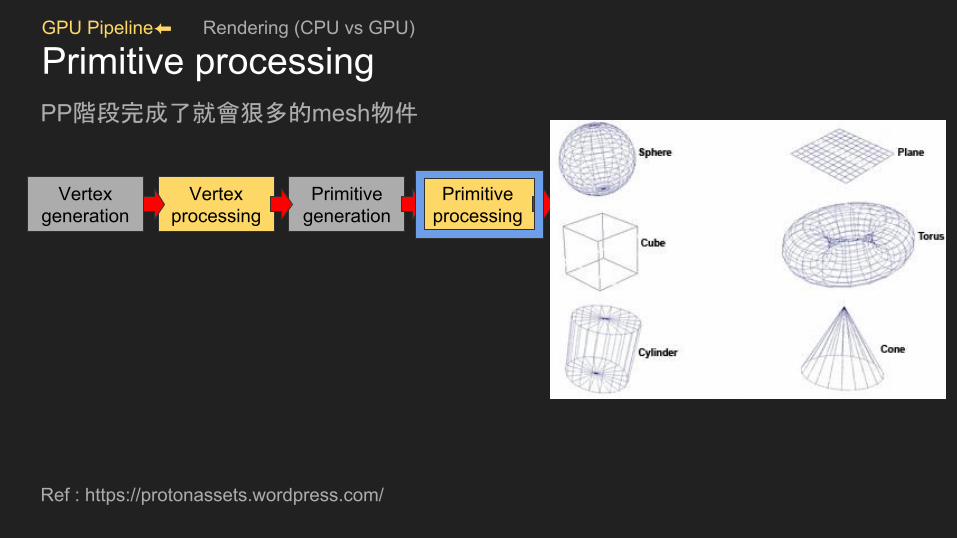
GPU Pipeline⬅ Rendering (CPU vs GPU)
Primitive processingPP階段完成了就會狠多的mesh物件
Ref : https://protonassets.wordpress.com/
Vertex generation
Vertex processing
Primitive generation
Primitive processing
Fragment generation
Fragment processing
Pixel operation
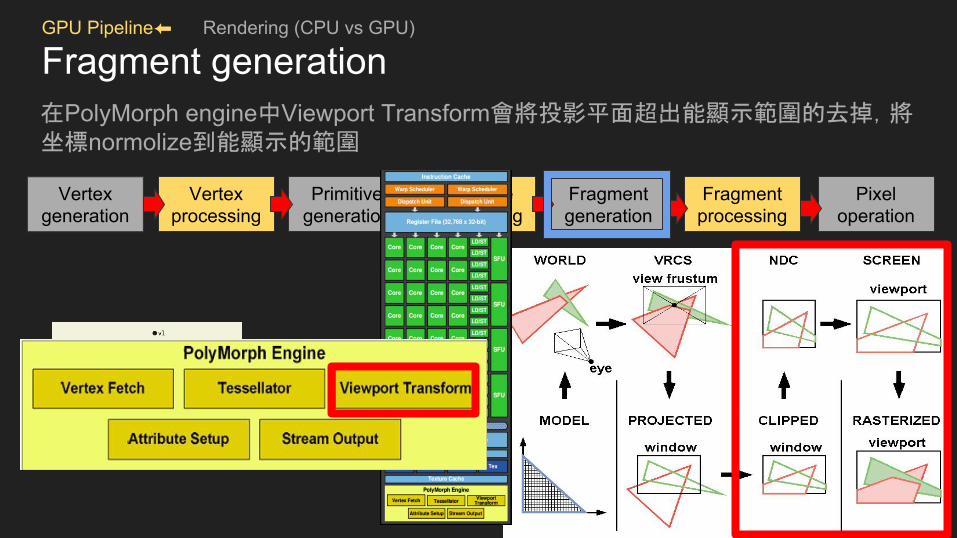
GPU Pipeline⬅ Rendering (CPU vs GPU)
Fragment generation在PolyMorph engine中Viewport Transform會將投影平面超出能顯示範圍的去掉,將坐標normolize到能顯示的範圍
Vertex generation
Vertex processing
Primitive generation
Primitive processing
Fragment generation
Fragment processing
Pixel operation
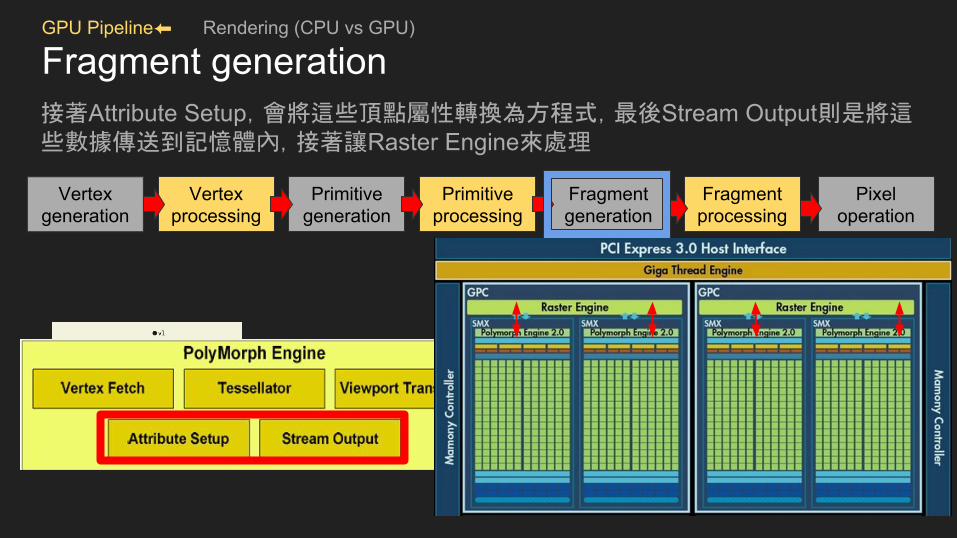
GPU Pipeline⬅ Rendering (CPU vs GPU)
Fragment generation接著Attribute Setup,會將這些頂點屬性轉換為方程式,最後Stream Output則是將這些數據傳送到記憶體內,接著讓Raster Engine來處理
Vertex generation
Vertex processing
Primitive generation
Primitive processing
Fragment generation
Fragment processing
Pixel operation
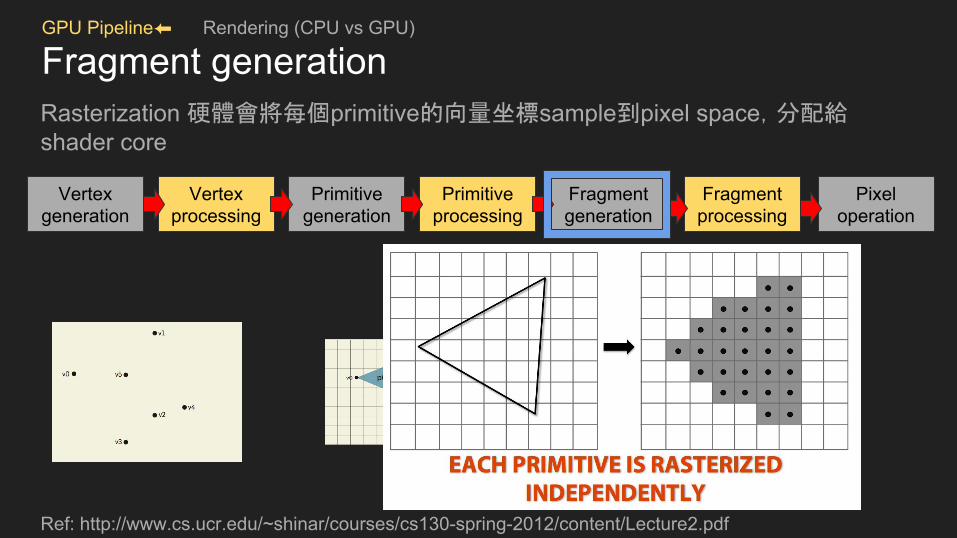
GPU Pipeline⬅ Rendering (CPU vs GPU)
Fragment generationRasterization 硬體會將每個primitive的向量坐標sample到pixel space,分配給shader core
Ref: http://www.cs.ucr.edu/~shinar/courses/cs130-spring-2012/content/Lecture2.pdf
Vertex generation
Vertex processing
Primitive generation
Primitive processing
Fragment generation
Fragment processing
Pixel operation
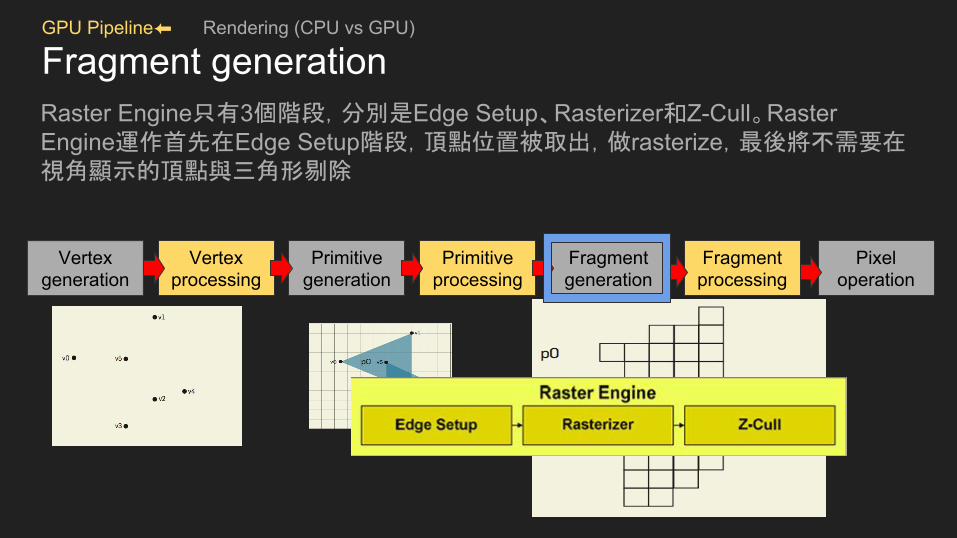
GPU Pipeline⬅ Rendering (CPU vs GPU)
Fragment generationRaster Engine只有3個階段,分別是Edge Setup、Rasterizer和Z-Cull。Raster Engine運作首先在Edge Setup階段,頂點位置被取出,做rasterize,最後將不需要在視角顯示的頂點與三角形剔除
Vertex generation
Vertex processing
Primitive generation
Primitive processing
Fragment generation
Fragment processing
Pixel operation
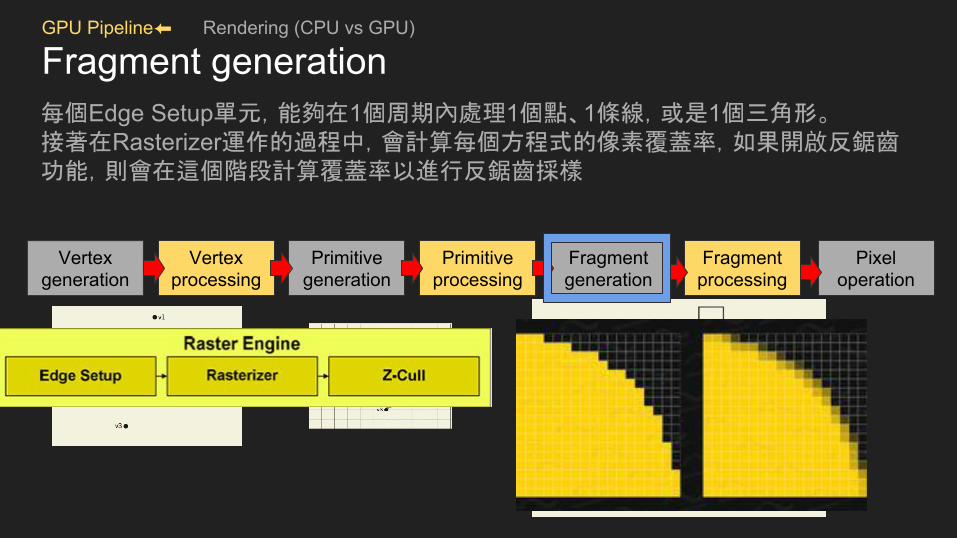
GPU Pipeline⬅ Rendering (CPU vs GPU)
Fragment generation每個Edge Setup單元,能夠在1個周期內處理1個點、1條線,或是1個三角形。接著在Rasterizer運作的過程中,會計算每個方程式的像素覆蓋率,如果開啟反鋸齒功能,則會在這個階段計算覆蓋率以進行反鋸齒採樣
Vertex generation
Vertex processing
Primitive generation
Primitive processing
Fragment generation
Fragment processing
Pixel operation
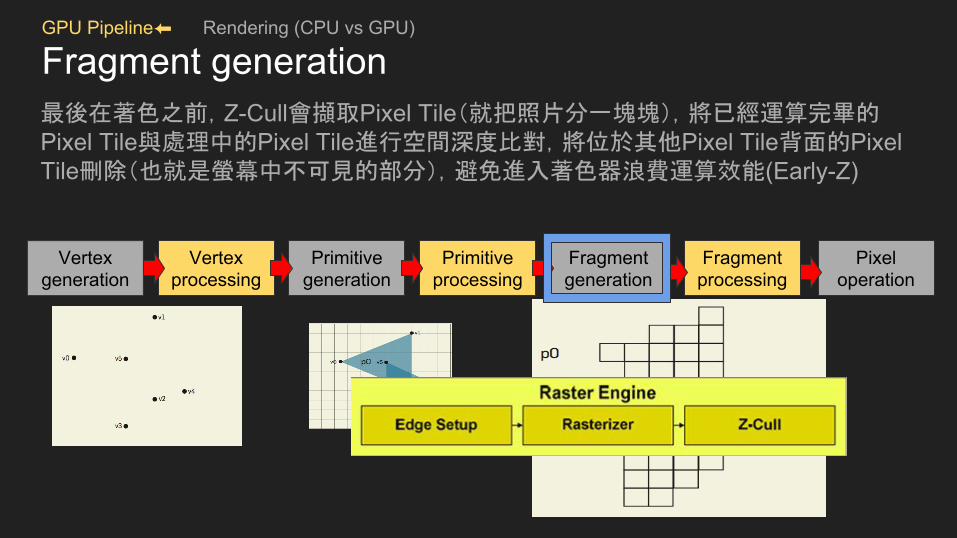
GPU Pipeline⬅ Rendering (CPU vs GPU)
Fragment generation最後在著色之前,Z-Cull會擷取Pixel Tile(就把照片分一塊塊),將已經運算完畢的Pixel Tile與處理中的Pixel Tile進行空間深度比對,將位於其他Pixel Tile背面的Pixel Tile刪除(也就是螢幕中不可見的部分),避免進入著色器浪費運算效能(Early-Z)
Vertex generation
Vertex processing
Primitive generation
Primitive processing
Fragment generation
Fragment processing
Pixel operation
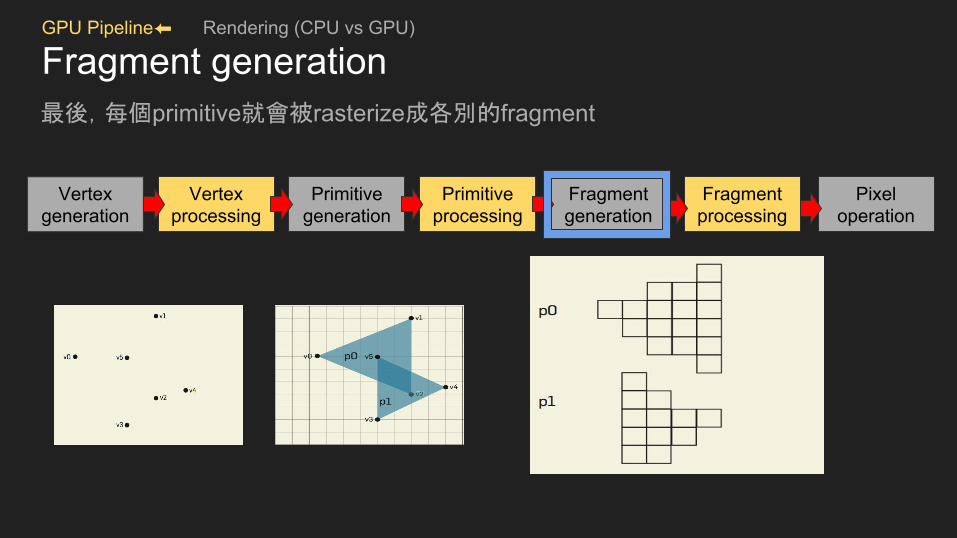
GPU Pipeline⬅ Rendering (CPU vs GPU)
Fragment generation最後,每個primitive就會被rasterize成各別的fragment
Vertex generation
Vertex processing
Primitive generation
Primitive processing
Fragment generation
Fragment processing
Pixel operation
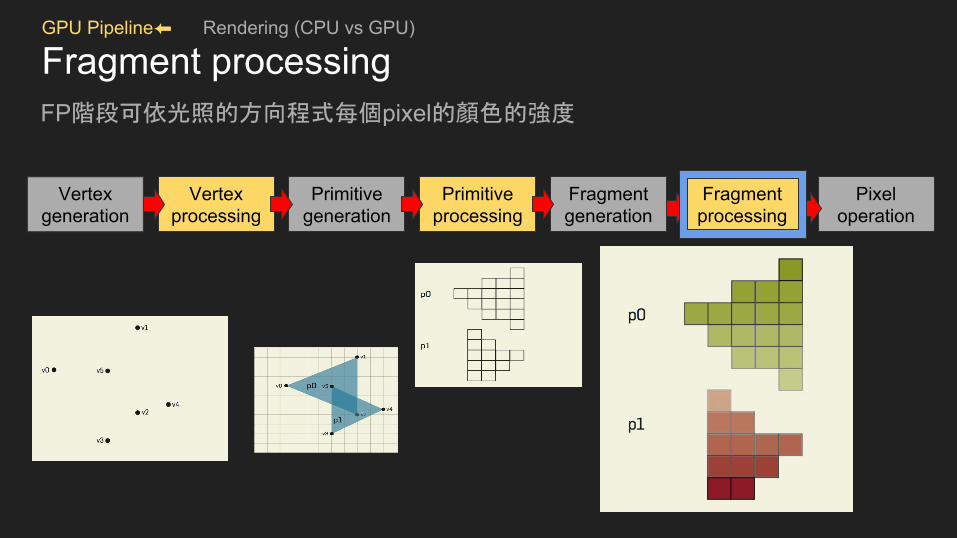
GPU Pipeline⬅ Rendering (CPU vs GPU)
Fragment processingFP階段可依光照的方向程式每個pixel的顏色的強度
Vertex generation
Vertex processing
Primitive generation
Primitive processing
Fragment generation
Fragment processing
Pixel operation

GPU Pipeline⬅ Rendering (CPU vs GPU)
Fragment processing舉例光線角度會影響到pixel的顏色強弱,可程式光對顏色的不同表現
vec3 N = normalize(fN);vec3 L = normalize(fL);
float diffuse_intensity = max(dot(N, L), 0.0);
if (diffuse_intensity == 0) { fColor = vec4(0.05, 0.05, 0.05, 1.0);} else { fColor = vec4(diffuse_intensity, diffuse_intensity, diffuse_intensity, 0.5);}
Ref : http://marcinignac.com/blog/pragmatic-pbr-setup-and-gamma/
Vertex generation
Vertex processing
Primitive generation
Primitive processing
Fragment generation
Fragment processing
Pixel operation
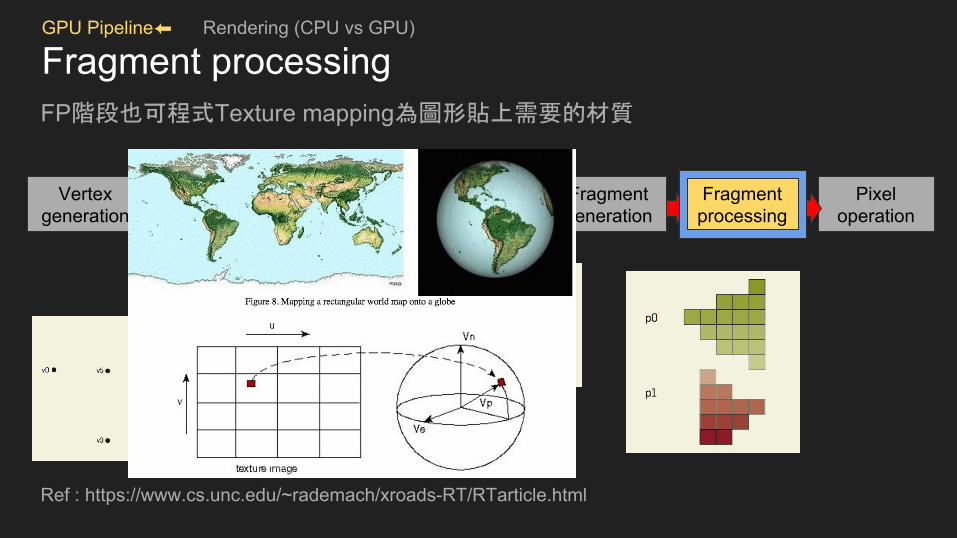
GPU Pipeline⬅ Rendering (CPU vs GPU)
Fragment processingFP階段也可程式Texture mapping為圖形貼上需要的材質
Ref : https://www.cs.unc.edu/~rademach/xroads-RT/RTarticle.html
Vertex generation
Vertex processing
Primitive generation
Primitive processing
Fragment generation
Fragment processing
Pixel operation
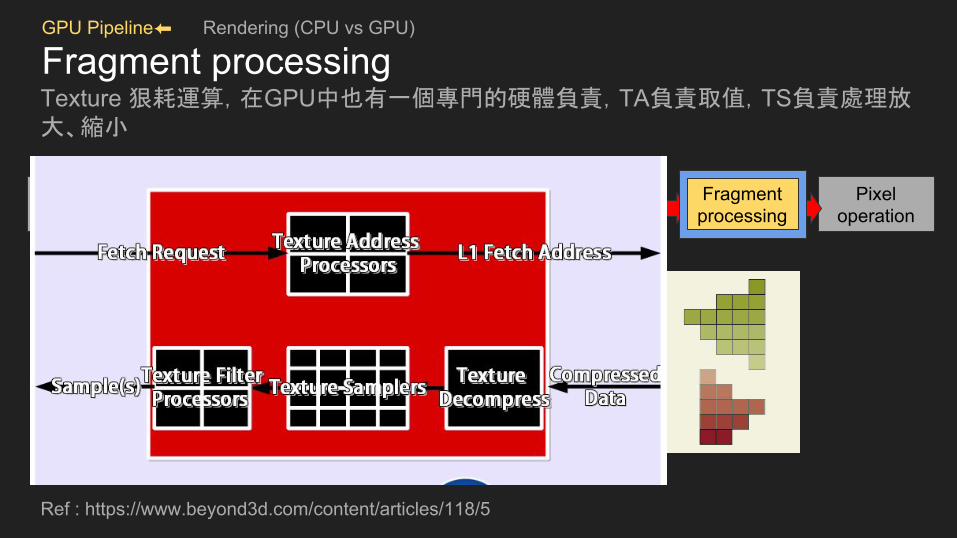
GPU Pipeline⬅ Rendering (CPU vs GPU)
Fragment processingTexture 狠耗運算,在GPU中也有一個專門的硬體負責,TA負責取值,TS負責處理放大、縮小
Ref : https://www.beyond3d.com/content/articles/118/5
Vertex generation
Vertex processing
Primitive generation
Primitive processing
Fragment generation
Fragment processing
Pixel operation

GPU Pipeline⬅ Rendering (CPU vs GPU)
Pixel operation最後的階段就是要把畫好的圖貼進 frame buffer 了. 比方說要畫個眼睛在臉上, 眼睛總不能大過臉, 因此要在可以畫眼睛的範圍以外塗上框框, 這個框就是模板 (stencil). 當然後景不蓋前景, 需要更新的區域才更新等基本限制, 在真正畫出去之前, 要先做這類的測試. 例如 scissor test, alpha test, depth and stencil test 等等.
ref: https://open.gl/depthstencils
Vertex generation
Vertex processing
Primitive generation
Primitive processing
Fragment generation
Fragment processing
Pixel operation

GPU Pipeline⬅ Rendering (CPU vs GPU)
Pixel operation每個pixel的位置要貼在framebuffer哪裡確定完,會處理某個pixel是由多個fragment合成的像是半透明作alpha blending,千辛萬之後才能進到framebuffer
Vertex generation
Vertex processing
Primitive generation
Primitive processing
Fragment generation
Fragment processing
Pixel operation
GPU Pipeline⬅ Rendering (CPU vs GPU)
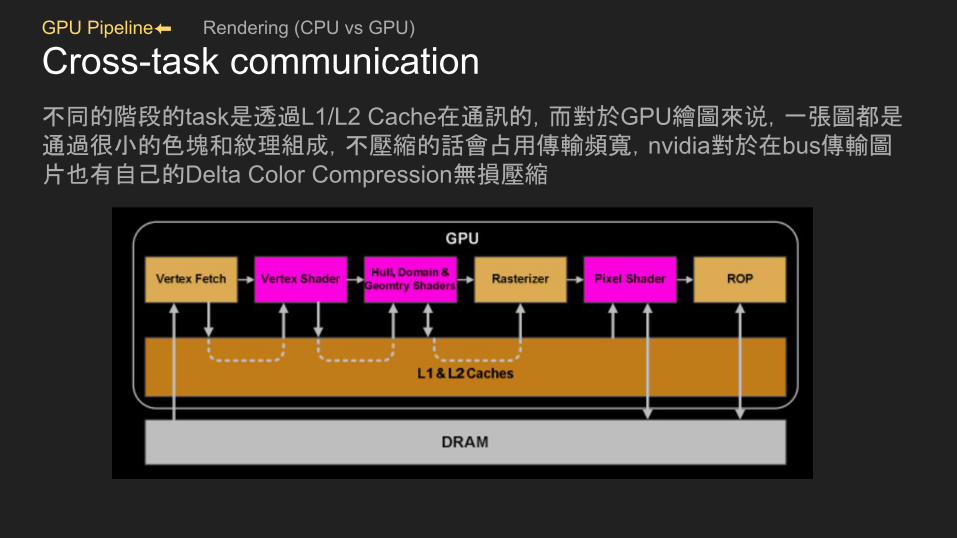
Cross-task communication不同的階段的task是透過L1/L2 Cache在通訊的,而對於GPU繪圖來说,一張圖都是通過很小的色塊和紋理組成,不壓縮的話會占用傳輸頻寬,nvidia對於在bus傳輸圖片也有自己的Delta Color Compression無損壓縮
GPU Pipeline Rendering (CPU vs GPU)⬅
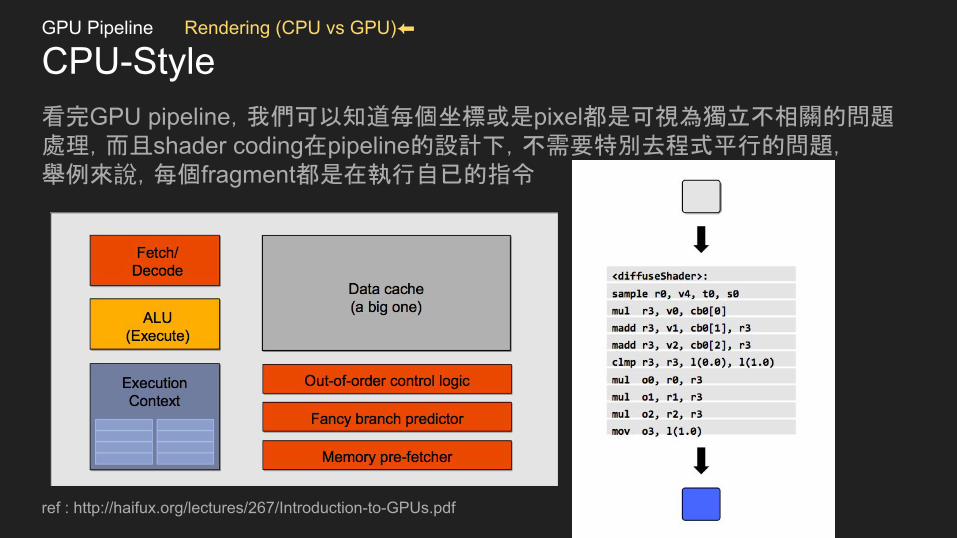
CPU-Style看完GPU pipeline,我們可以知道每個坐標或是pixel都是可視為獨立不相關的問題處理,而且shader coding在pipeline的設計下,不需要特別去程式平行的問題,舉例來說,每個fragment都是在執行自已的指令
ref : http://haifux.org/lectures/267/Introduction-to-GPUs.pdf
GPU Pipeline Rendering (CPU vs GPU)⬅
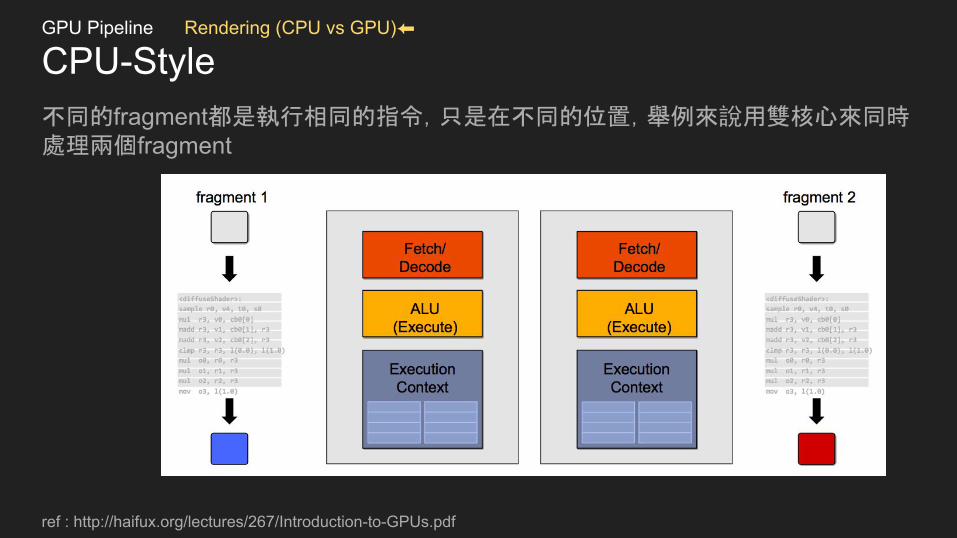
CPU-Style不同的fragment都是執行相同的指令,只是在不同的位置,舉例來說用雙核心來同時處理兩個fragment
ref : http://haifux.org/lectures/267/Introduction-to-GPUs.pdf
GPU Pipeline Rendering (CPU vs GPU)⬅
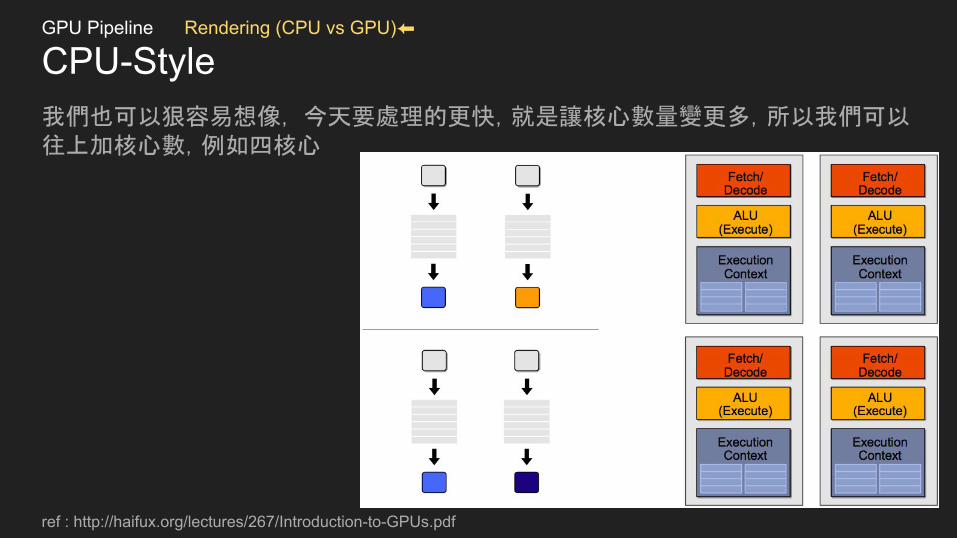
CPU-Style我們也可以狠容易想像, 今天要處理的更快,就是讓核心數量變更多,所以我們可以往上加核心數,例如四核心
ref : http://haifux.org/lectures/267/Introduction-to-GPUs.pdf
GPU Pipeline Rendering (CPU vs GPU)⬅
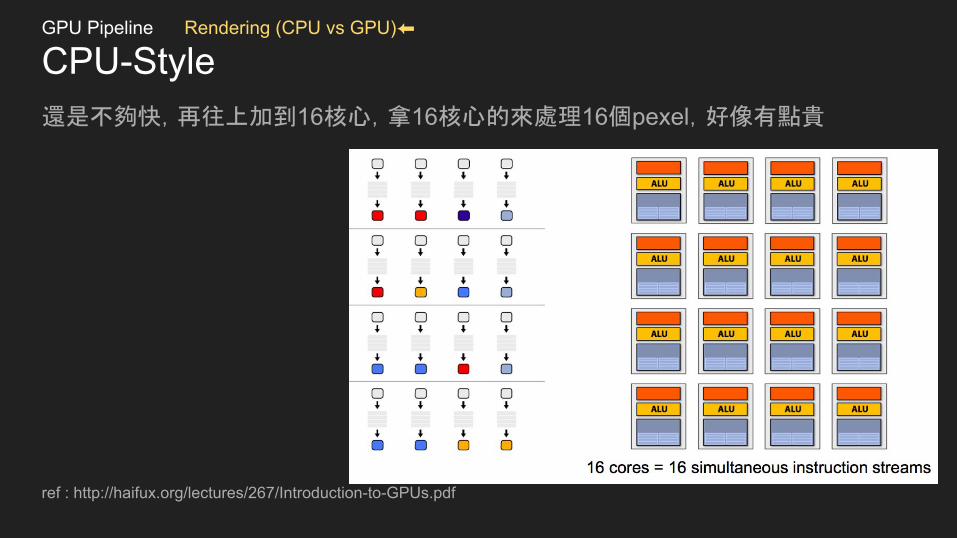
CPU-Style還是不夠快,再往上加到16核心,拿16核心的來處理16個pexel,好像有點貴
ref : http://haifux.org/lectures/267/Introduction-to-GPUs.pdf

GPU Pipeline Rendering (CPU vs GPU)⬅
CPU-Style當我們狠聰明的狂加核心數的同時,我們發現每個fragment都是被同樣的指令所處理,那是不是可以share咧
ref : http://haifux.org/lectures/267/Introduction-to-GPUs.pdf
GPU Pipeline Rendering (CPU vs GPU)⬅
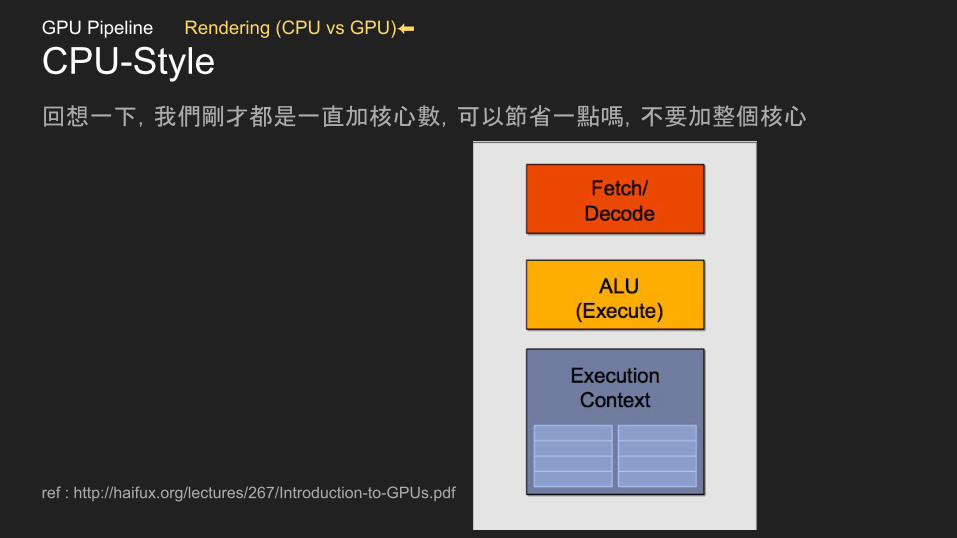
CPU-Style回想一下,我們剛才都是一直加核心數,可以節省一點嗎,不要加整個核心
ref : http://haifux.org/lectures/267/Introduction-to-GPUs.pdf
GPU Pipeline Rendering (CPU vs GPU)⬅
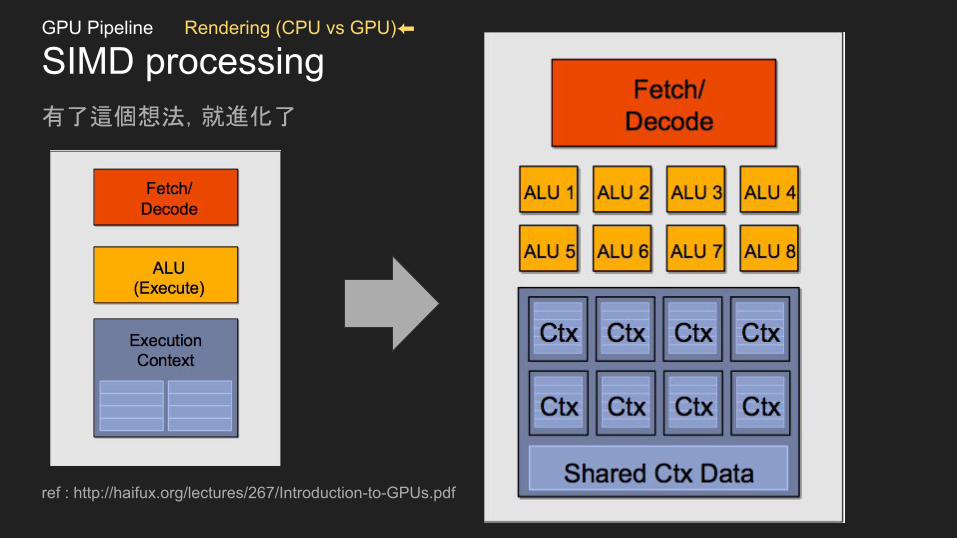
SIMD processing有了這個想法,就進化了
ref : http://haifux.org/lectures/267/Introduction-to-GPUs.pdf
GPU Pipeline Rendering (CPU vs GPU)⬅
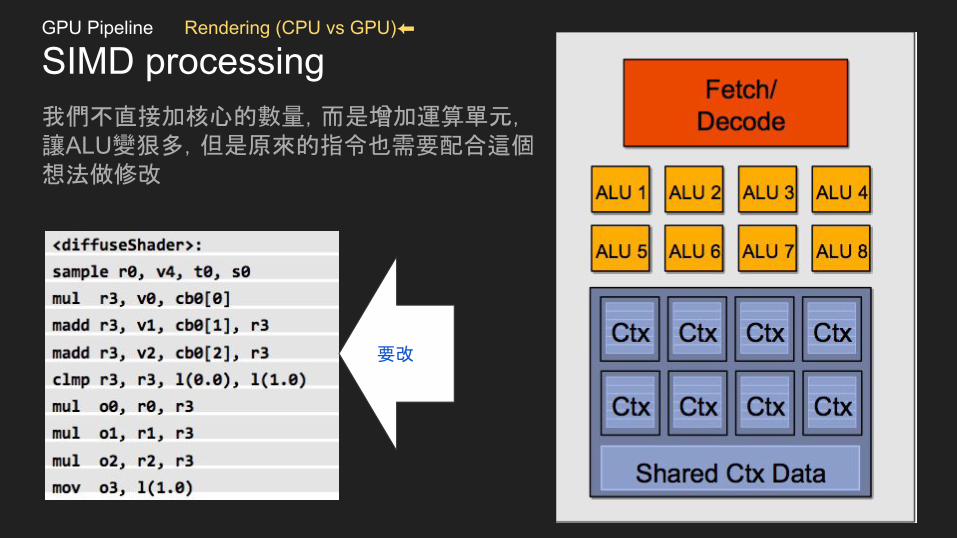
SIMD processing我們不直接加核心的數量,而是增加運算單元,讓ALU變狠多,但是原來的指令也需要配合這個想法做修改
要改

GPU Pipeline Rendering (CPU vs GPU)⬅
SIMD processing我們重新編譯出新的shader,將原來的問題,當成向量來處理
ref : http://haifux.org/lectures/267/Introduction-to-GPUs.pdf

GPU Pipeline Rendering (CPU vs GPU)⬅
SIMD processing於是一個指令就可以處理不同的分向量,在同一個核心中,這就是single instruction multiple data
GPU Pipeline Rendering (CPU vs GPU)⬅
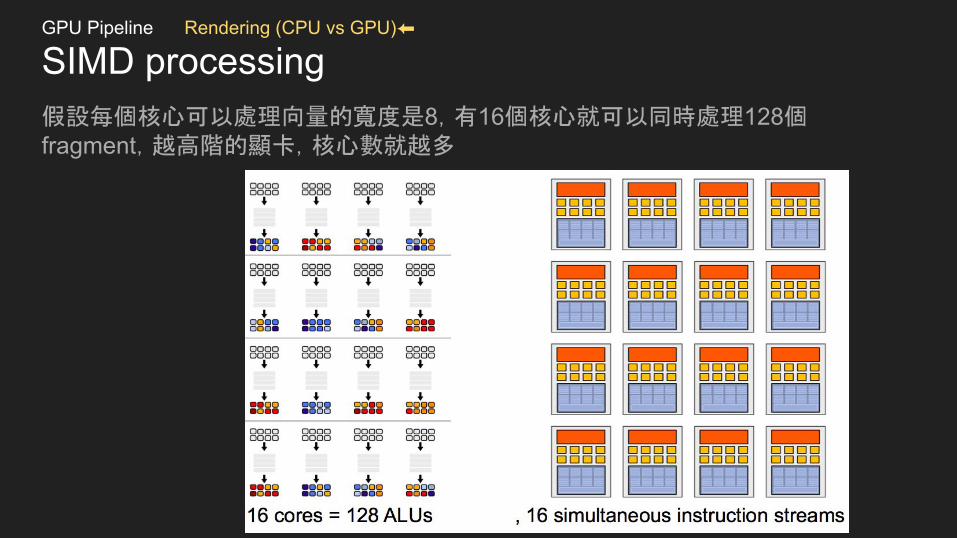
SIMD processing假設每個核心可以處理向量的寬度是8,有16個核心就可以同時處理128個fragment,越高階的顯卡,核心數就越多
GPU Pipeline Rendering (CPU vs GPU)⬅
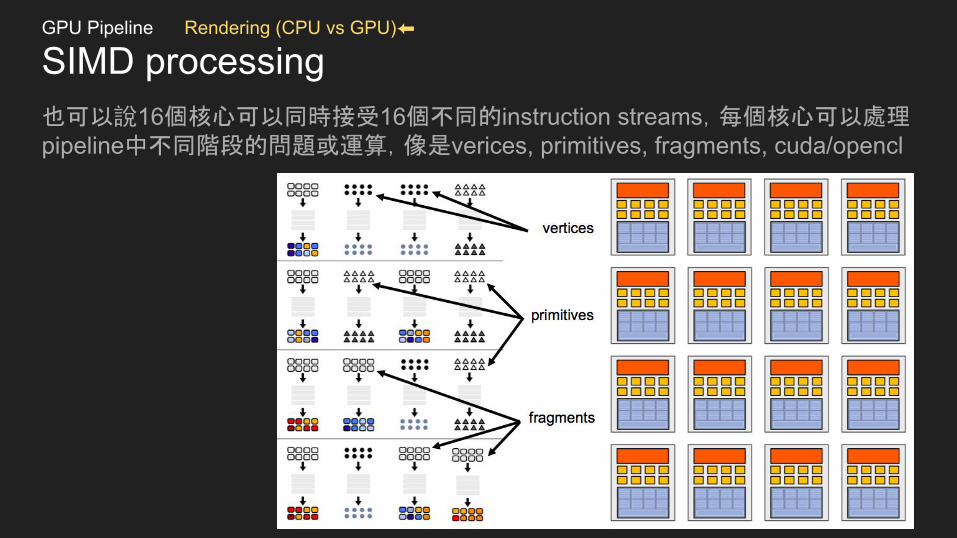
SIMD processing也可以說16個核心可以同時接受16個不同的instruction streams,每個核心可以處理pipeline中不同階段的問題或運算,像是verices, primitives, fragments, cuda/opencl
GPU Pipeline Rendering (CPU vs GPU)⬅
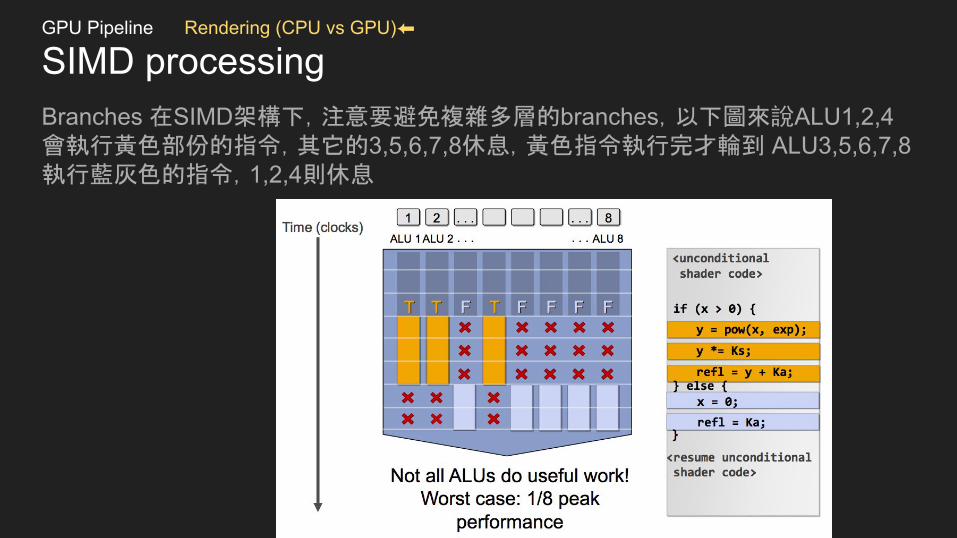
SIMD processingBranches 在SIMD架構下,注意要避免複雜多層的branches,以下圖來說ALU1,2,4會執行黃色部份的指令,其它的3,5,6,7,8休息,黃色指令執行完才輪到 ALU3,5,6,7,8執行藍灰色的指令,1,2,4則休息
GPU Pipeline Rendering (CPU vs GPU)⬅
SIMD processing所以要避免錯綜複雜的if esle,屁如說你的branch有八種分支的可能,那最壞的情形就是每種都做一次,這樣就8個ALU每次都只有一個會動,其它都睡著了。
GPU Pipeline Rendering (CPU vs GPU)⬅
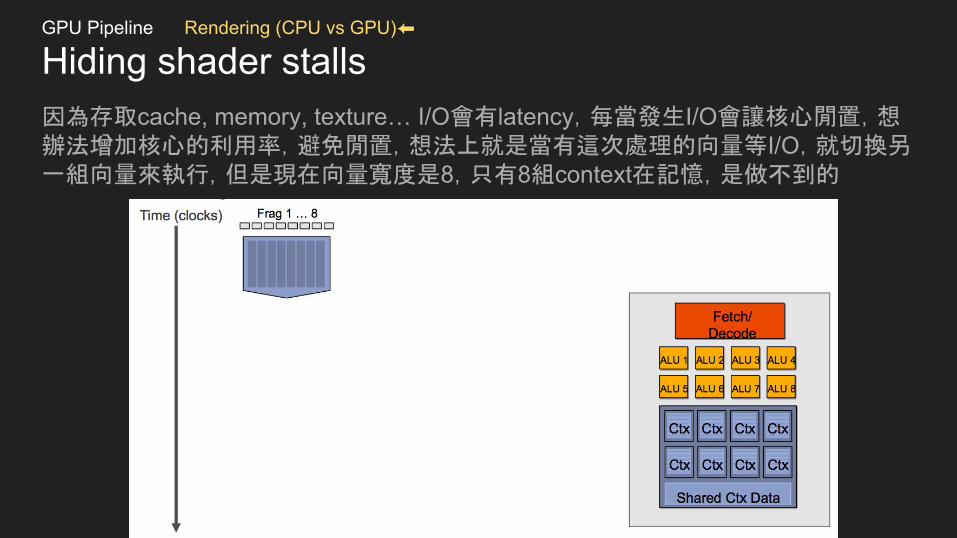
Hiding shader stalls因為存取cache, memory, texture… I/O會有latency,每當發生I/O會讓核心閒置,想辦法增加核心的利用率,避免閒置,想法上就是當有這次處理的向量等I/O,就切換另一組向量來執行,但是現在向量寬度是8,只有8組context在記憶,是做不到的
GPU Pipeline Rendering (CPU vs GPU)⬅
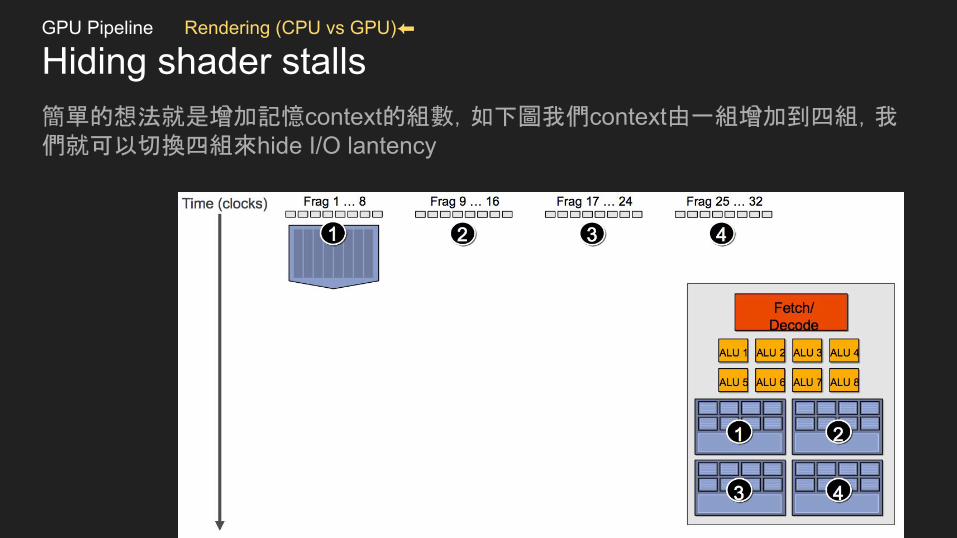
Hiding shader stalls簡單的想法就是增加記憶context的組數,如下圖我們context由一組增加到四組,我們就可以切換四組來hide I/O lantency
GPU Pipeline Rendering (CPU vs GPU)⬅
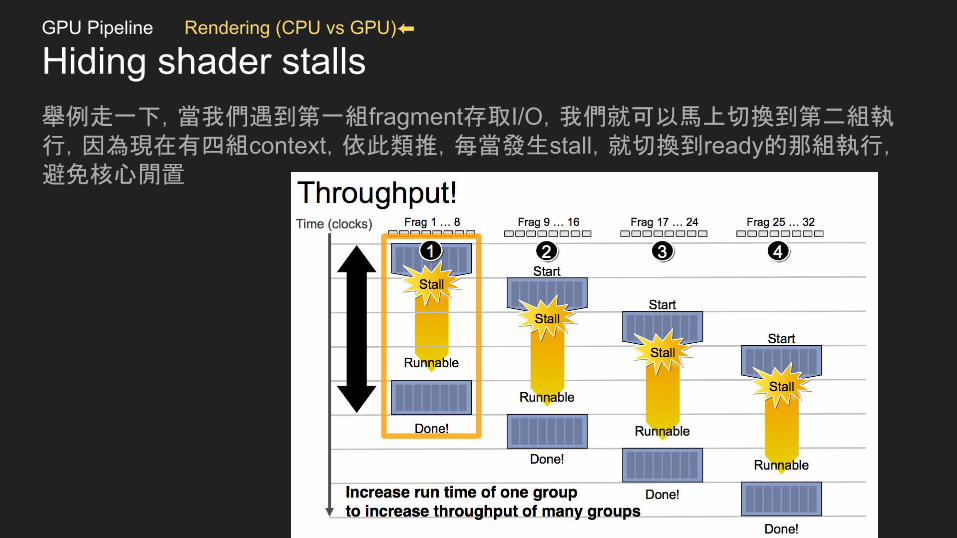
Hiding shader stalls舉例走一下,當我們遇到第一組fragment存取I/O,我們就可以馬上切換到第二組執行,因為現在有四組context,依此類推,每當發生stall,就切換到ready的那組執行,避免核心閒置
GPU Pipeline Rendering (CPU vs GPU)⬅
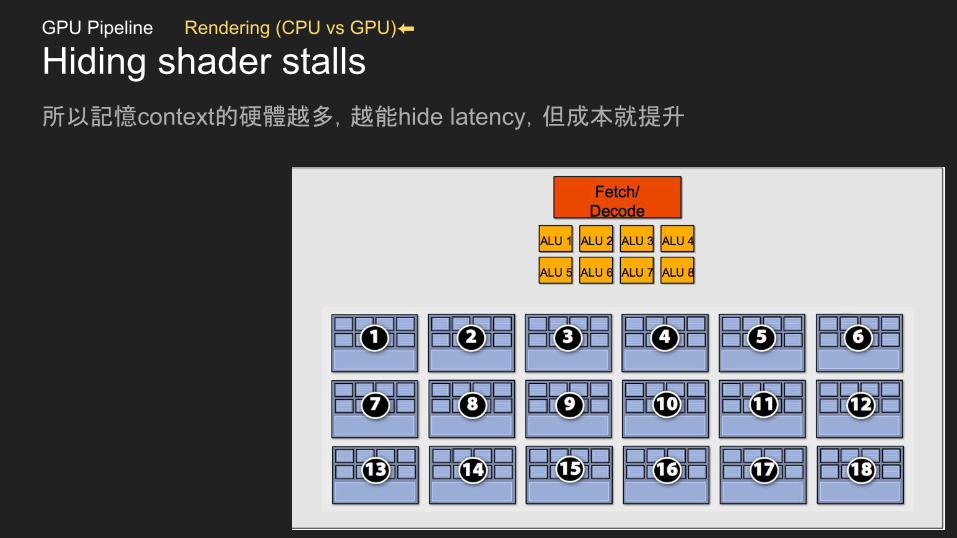
Hiding shader stalls所以記憶context的硬體越多,越能hide latency,但成本就提升

GPU Pipeline Rendering (CPU vs GPU)⬅
Hiding shader stallsHide lantency在GPU來說是狠重要的,所以可以想像如果今天你的所要運算的資料量不是狠大,在GPU上來說沒有足夠的運算量來切換來hide lantency,這樣用GPU是不會得到好處地,講到這裡就講完了,希望有幫助溜。


















