
Information et Codage
81
Information et Codage Chaps. 1–5 Olivier RIOUL TELECOM ParisTech [email protected] Chaps. 6–7 Benoît GELLER ENSTA ParisTech [email protected]
Transcript of Information et Codage

Information et Codage
Chaps. 1–5Olivier RIOUL
TELECOM [email protected]
Chaps. 6–7Benoît GELLER
ENSTA [email protected]

2

Avant-propos
Ce cours vise tout d’abord à établir solidement les bases de codage de sourcesur les outils de la théorie de l’information, de manière à ce que les connais-sances acquises puissent être étendues rapidement aux problématiques plusrécentes. Puis, on aborde une caractérisation des outils essentiels de la compres-sion de source : quantification scalaire et vectorielle, codage à longueur variable,codage par transformée, allocation de débit.
De nombreux exercices sont proposés en appendice de ce document, regrou-pés par chapitre.
Bonne lecture !
Mots clés
Théorie de l’information, Théorèmes de Shannon, Codage entropique à lon-gueur variable, Quantification scalaire et vectorielle, Algorithme de Lloyd-Max,Gain de codage par transformée, Transformée de Karhunen-Loève, Allocationoptimale de débits binaires, Compression d’images.
3

4

Bibliographie
[1] Olivier Rioul, Théorie de l’information et du codage, Hermes Sciences-Lavoisier, 2007.
[2] Robert Mc Eliece, The Theory of Information and Coding, Addison Wesley,1977.
[3] Thomas Cover, Joy Thomas, Elements of Information Theory, J. Wiley & sons,1991.
[4] Nicolas Moreau, Techniques de Compression des Signaux, Masson CNET-ENST, 1994.
[5] Allan Gersho, Robert Gray, Vector Quantization and Signal Compression,Kluwer Academic, 1992.
5

6 BIBLIOGRAPHIE

Chapitre 1
Outils de la théorie de l’information
1.1 Description d’un système de codage de source.
On considère une source d’information qu’on suppose constituée d’unesuite d’échantillons ou de symboles x. La source peut être codée symbole parsymbole (codage scalaire) ou par bloc de n symboles x = (x1, . . . , xn) (codagevectoriel en dimension n). Le cas scalaire correspond à n = 1.
Le codeur de source associe à chaque entrée x une étiquette ou index i misesous forme binaire ; les index peuvent prendre un nombre fini M de valeurspossibles, chaque index est donc représenté en moyenne sur log2 M bits etreprésente la source x sous forme codée.
Cet index est ensuite transmis (pour des applications de transmission numé-rique) ou stocké (pour des applications de stockage numérique).
Le décodeur de source récupère chaque index i au niveau du destinataire etfournit un bloc y de n symboles correspondant, dans le domaine source. Ce yreprésente la source reconstruite pour le destinataire.
Il y a deux paramètres fondamentaux dans un système de codage de source :
1. Le taux de codage (coding rate) R est le nombre moyen de bits codés parsymbole de source :
R = log2 M
n
Ce taux s’exprime donc en bits par symbole ; il est lié au débit binaireen bits/sec (voir exercice). La compression de source est d’autant plusimportante que R est petit.
2. Le critère de distorsion D sert à mesurer (de manière objective) la qua-lité ou la fiabilité de la reconstruction. Typiquement (pour des échan-tillons d’un signal, par exemple) on choisit un critère d’erreur quadratique
7

8 CHAPITRE 1. OUTILS DE LA THÉORIE DE L’INFORMATION
moyenne (mean square error m.s.e.) par symbole de source :
D = 1
nE (‖X −Y ‖2)
où E désigne l’espérance de sorte à disposer d’un critère moyen sur l’en-semble de tous les blocs de source. Le système est de qualité d’autant plusgrande que D est petit.
Le but du concepteur d’un système de codage de source est de réaliser laplus grande compression (R petit) tout en garantissant une bonne fiabilité (Dpetit). Il y a donc un compromis à trouver entre R et D . Le compromis optimalthéorique va être fourni par la théorie de l’information de Shannon.
1.2 Rappels sur les variables aléatoires.
Le destinataire ne connait pas à l’avance l’information-source émise ; pourlui, les symboles de source x apparaissent aléatoires. On modélise donc unesource par un modèle probabiliste : un échantillon ou bloc X de source est unevariable aléatoire (v.a.) qui suit une distribution de probabilité p(x).
Dans le cas d’un source discrète (ou numérique), chaque symbole x peutprendre un nombre fini de valeurs et p(x) est la probabilité que X = x.
Dans le cas d’une source continue, chaque échantillon x appartient à uncontinuum de valeurs (réelles ou complexes), et p(x) est une densité de proba-bilité.
Dans tous les cas on adopte une notation unifiée ; p(x) est telle que p(x)>
0 et∑∫
xp(x) = 1. Le calcul d’une probabilité quelconque se fait à l’aide de la
formule :
P r ob{X ∈ A} =∑∫x∈A
p(x).
1.3 Traitement et probabilités conditionnelles.
En théorie de l’information chaque traitement (codage, décodage, canal detransmission, etc.) est aussi modélisé de façon probabiliste ; ce modèle permetde décrire aussi bien des traitements déterministes qu’aléatoires.
Un traitement T d’entrée X et de sortie Y est décrit par les probabilités detransition p(y |x). Ici p(y |x) est une probabilité conditionnelle de y sachant x,définie par :
p(y |x) = p(x, y)
p(x).

1.4. SUITE DE TRAITEMENTS ET CHAÎNE DE MARKOV. 9
C’est une distribution de probabilité en y pour toute valeur fixée de x.La sortie du traitement Y est donnée en fonction de l’entrée X par la formule :
p(y) =∑∫x
p(x)p(y |x).
On rappelle que les v.a. X et Y sont dits indépendantes si p(y |x) = p(y), c’està dire si p(x, y) = p(x)p(y). Le traitement X → Y est alors «opaque».
1.4 Suite de traitements et chaîne de Markov.
Dans un système de codage apparaît une suite de traitements point à point.Si on considère par exemple une suite de deux traitements : X → Y → Z , lestrois v.a. X ,Y , Z vérifient nécessairement une condition de chaîne de Markovqui exprime que Z ne dépend des autres v.a. que par l’intermédiaire de Y (dontil est issu par traitement). Ceci s’écrit :
p(z|x, y) = p(z|y).
On généralise immédiatement cette condition de chaîne de Markov au cas deplusieurs (> 2) traitements.
1.5 Divergence D(p, q).
On se donne une v.a. X de distribution de probabilité p(x), et une autre dis-tribution de probabilité q(x) définie pour les mêmes valeurs de x. La divergencede Kullback-Leibler ou entropie relative de q(x) par rapport à p(x) est donnéepar la formule :
D(p, q) =∑∫x
p(x) log2p(x)
q(x)= E log2
p(X )
q(X )
Cette divergence s’exprime en unités binaires (bits) à cause du choix de la base2 du logarithme.
Le résultat fondamental suivant est à la base de la plupart des résultatsimportants en théorie de l’information :
D(p, q)> 0
avec égalité (D(p, q) = 0) si et seulement si p(x) = q(x) p.p.On peut écrire ce résultat sous la forme suivante (inégalité de Gibbs) :∑∫
xp(x) log2
1
p(x)6
∑∫x
p(x) log21
q(x)
avec égalité si et seulement si p(x) = q(x) p.p.

10 CHAPITRE 1. OUTILS DE LA THÉORIE DE L’INFORMATION
1.6 Information mutuelle I (X ,Y ).
L’information mutuelle I (X ,Y ) peut se définir comme une mesure de dépen-dance entre X et Y , c’est à dire comme la divergence de la loi q(x, y) = p(x)p(y)(que suivraient X ,Y si elles étaient indépendantes) par rapport à p(x, y) :
I (X ,Y ) =∑∫x,y
p(x, y) log2p(x, y)
p(x)p(y)
D’après le résultat fondamental des divergences, I (X ,Y )> 0 et I (X ,Y ) = 0 si etseulement si X et Y sont indépendantes.
On peut réécrire I (X ,Y ) sous la forme :
I (X ,Y ) = E log2p(Y |X )
p(Y )
qui est la divergence moyenne entre les distributions de probabilité de Y sachantx et ne sachant pas x. Ainsi I (X ,Y ) (en bits) s’interprète comme la quantitéd’information moyenne qu’apporte une réalisation de X sur la connaissance deY . Cette information est «mutuelle» car I (X ,Y ) = I (Y , X ).
1.7 Information mutuelle et entropie.
En développant l’expression de I (X ,Y ) on obtient la formule :
I (X ,Y ) = H(Y )−H(Y |X )
où
H(Y ) =∑∫y
p(y) log21
p(y)
est appelée entropie de la v.a. Y , et où :
H(Y |X ) = E y H(Y |X = x) =∑∫x
p(x)∑∫
yp(y |x) log2
1
p(y |x)
est appelée entropie conditionnelle de Y sachant X . Cette dernière entropieest une moyenne non seulement sur y , mais aussi sur le «conditionnement» x.
Dans le cas d’une v.a. discrète Y (pouvant prendre un nombre fini M devaleurs), l’entropie
H(Y ) =∑y
p(y) log21
p(y)
est une quantité > 0, qui s’annule si et seulement si Y est «déterministe» Y = y0
p.p. L’entropie maximale log2 M est atteinte lorsque Y est une v.a. uniforme

1.7. INFORMATION MUTUELLE ET ENTROPIE. 11
(symboles y équiprobables). On peut ainsi interpréter H(Y ) comme une me-sure d’aléa de Y , ou comme une mesure d’incertitude moyenne sur Y (avantréalisation Y = y).
L’entropie conditionnelle H(Y |X ) mesure donc l’incertitude moyenne sur Yqui reste sachant X . La différence des deux incertitudes H (Y )−H (Y |X ) = I (X ,Y )est bien l’information moyenne qu’apporte X sur Y .
Dans le cas d’une v.a. continue Y , l’entropie
H(Y ) =∫
yp(y) log2
1
p(y)d y
n’est plus nécessairement > 0 ; on ne peut plus l’interpréter comme une me-sure d’incertitude. Dans ce cas H (Y ) est qualifiée d’entropie différentielle (voirchapitre 2).

12 CHAPITRE 1. OUTILS DE LA THÉORIE DE L’INFORMATION

Chapitre 2
Théorie de l’information appliquéeau codage
2.1 Théorème du traitement de données.
Le théorème du traitement de données dit que «tout traitement fait perdrede l’information» (en tout cas ne peut pas en faire gagner). Formellement, onconsidère une succession de traitements :
· · ·→ X →···→I →···→J →···→ Y →On a alors :
I (X ,Y )6 I (I ,J )
Autrement dit l’information mutuelle entre deux v.a. «proches» dans une chaînede traitements est plus grande que ou égale à celle entre v.a. plus éloignées.
2.2 Fonction taux-distorsion (codage avec pertes).Théorème de Shannon.
Si on applique le théorème du traitement de données au système de codagede source présenté à la leçon 1, on obtient :
I (X ,Y )6 I (I ,I ) = H(I )
puisqu’on a supposé I =J (transmission ou stockage sans erreur).Pour obtenir la plus forte inégalité possible on maximise H(I ) (maximum
= log2 M) et on minimise I (X ,Y ). On obtient, en se ramenant à des bits parsymbole source :
min1
nI (X ,Y )6
log2 M
n= R
13

14 CHAPITRE 2. THÉORIE DE L’INFORMATION APPLIQUÉE AU CODAGE
Le minimum d’information mutuelle s’effectue sur n et sur le choix de p(y |x),puisque p(x) est fixé pour une source donnée ; il s’effectue aussi sous la contraintede fiabilité donnée par un certain niveau de distorsion D. On obtient donc ladéfinition suivante :
R(D) = infn
minp(y |x)
{1
nI (X ,Y ) | 1
nE (‖X −Y ‖2)6D}
qu’on appelle fonction taux-distorsion R(D) de Shannon.Ainsi le théorème du traitement de données implique l’inégalité
R >R(D)
qui indique que R(D) est une borne inférieure sur le taux de codage : il est impos-sible de comprimer les données en deçà de R(D) pour un niveau de distorsionD donné.
Le théorème de Shannon (1959) pour le codage de source avec pertes montreque R(D) est la meilleure borne possible, dans le sens où on peut toujours trou-ver un système de codage (fusse-t-il très complexe, pour n assez grand) quipermette de s’approcher d’aussi près qu’on veut de la borne R(D).
2.3 Entropie d’une source (codage sans pertes).
Un système de codage de source est dit sans pertes si Y = X , c’est à dire sion peut reconstruire parfaitement la source au destinataire (avec D = 0).
Dans ce cas, la borne de Shannon R(D = 0) est égale à l’entropie de la sourcedéfinie par :
H = infn
1
nH(X )
Cette entropie est naturellement une borne inférieure sur le taux de codage :R >H . On ne peut pas comprimer des données (sans pertes) en deçà de l’en-tropie.
Le théorème de Shannon (1948) pour le codage de source sans pertes (casparticulier D = 0) dit qu’on peut s’approcher de l’entropie H d’aussi près qu’onveut (voir chapitre 3).
2.4 Cas d’une source sans mémoire.
Une source est dite sans mémoire si les symboles ou échantillons de sourcesont indépendants et identiquement distribués (iid), c’est à dire :
p(x) = p(x1)p(x2) · · ·p(xn).

2.5. CAS D’UNE SOURCE GAUSSIENNE. 15
Dans la conception d’un système de codage de source on peut souvent se rame-ner à ce cas simple (voir leçon 5).
Pour une source sans mémoire, l’expression de R(D) se simplifie car elledevient indépendante de la valeur de n :
R(D) = minp(y |x)
{I (X ,Y ) | E ((X −Y )2)6D}
En codage sans pertes il vient H = H(X ), l’entropie de la v.a. X .
2.5 Cas d’une source gaussienne.
En codage avec pertes d’une source gaussienne sans mémoire de distributionde probabilité :
p(x) = 1p2πσ2
e− (x−µ)2
2σ2
on peut calculer explicitement R(D). On trouve :
R(D) ={
12 log2
σ2
D D 6σ2,
0 D >σ2.
où σ2
D est le rapport signal à bruit.Ceci correspond à une borne optimale de Shannon qu’on peut exprimer
sous la forme d’une fonction distorsion/taux :
D(R) =σ22−2R .
On obtient une courbe théorique de performances optimales où le rapportsignal à bruit (en dB) croît linéairement en R, avec une pente de 6 dB/bit.

16 CHAPITRE 2. THÉORIE DE L’INFORMATION APPLIQUÉE AU CODAGE

Chapitre 3
Codage entropique à longueurvariable
3.1 Description d’un système de codage à longueurvariable.
On se donne une source discrète (données, fichier, . . . ) dont chaque symbolex prend une parmi M valeurs possibles {x1, x2, . . . , xM }.
Une distribution de probabilité p(x) caractérise les statistiques de cettesource, on la suppose connue (ou estimée) sous la forme {p1, p2, . . . , pM }, où pi
est la probabilité d’occurrence du symbole xi .
Le codeur code chaque symbole de source xi par un mot de code ci . Le codeest l’ensemble des mots de codes {c1, . . . ,cM }.
Un code à longueur variable (VLC : Variable-Length Code) est tel que lesdifférents mots de code n’ont pas nécessairement la même longueur, en bits. Onnote li la longueur en bits du mot de code ci . La distribution des longueurs ducode est donc {l1, l2, . . . , lM }.
Le décodeur reconstruit les symboles de source à partir de la séquencebinaire des mots de codes. Le taux de codage (coding rate) R est le nombremoyen de bits codés par symbole de source, c’est à dire
R =M∑
i=1pi li .
Un code est donc d’autant plus efficace en compression que R est petit.
17

18 CHAPITRE 3. CODAGE ENTROPIQUE À LONGUEUR VARIABLE
3.2 Codes uniquement décodables et instantanés. Condi-tion du préfixe.
Le but du codage de source sans pertes est de comprimer ces données defaçon telle que l’on puisse reconstruire parfaitement (sans pertes, sans erreur)la source au destinaire.
Pour cela, il faut que le décodage ait lieu sans ambiguïté, c’est à dire qu’uneséquence codée donnée doit être interprétable de façon unique comme unesuccession (concaténation) de mots de codes déterminés. Un code permettantun tel décodage (sans ambiguïté) est qualifié d’uniquement décodable (u.d.).
Certains codes u.d. nécessitent une implantation complexe du décodeur, quidoit lire la séquence codée binaire suffisamment loin à l’avance pour décoderun symbole de source.
D’autres codes u.d., par contre, sont très simples à décoder ; on les appellecodes instantanés, car le décodeur n’a besoin de lire que les li premiers bitsd’une séquence codée pour pouvoir l’interpréter «instantanément» et de ma-nière unique comme étant le mot de code ci , représentant le symbole xi .
Une code instantané est caractérisé par la condition du préfixe : Aucun motde code n’est le préfixe d’un autre mot de code (c’est à dire aucun ci ne débuteun c j , j 6= i ).
3.3 Inégalité de Kraft-McMillan.
Pour trouver le meilleur code pour une source donnée, il faut minimiser letaux R sous la contrainte que le code soit u.d.
Afin de réaliser cette optimisation, on caractérise d’abord le fait qu’un codesoit u.d. sur la distribution des longueurs :
1. Tout code u.d. vérifie l’inégalité de Kraft-McMillan :
M∑i=1
2−li 6 1
2. Réciproquement, si l’inégalité de Kraft-McMillan est vérifiée, alors il existeun code u.d., et même instantané, qui admette {l1, l2, . . . , lM } comme dis-tribution de longueurs.
Il en résulte qu’on peut limiter la recherche du meilleur code à l’ensembledes codes instantanés. Il y a un algorithme simple qui fournit un code instan-tané {c1, . . . ,cM } à partir d’une distribution de longueurs {l1, l2, . . . , lM } vérifiantl’inégalité de Kraft-McMillan.

3.4. OPTIMISATION. CODES DE FANO-SHANNON ET DE HUFFMAN. 19
3.4 Optimisation. Codes de Fano-Shannon et de Huff-man.
D’après le paragraphe précédant, pour trouver le meilleur code pour unesource donnée, il faut minimiser le taux R sous la contrainte de l’inégalité deKraft-McMillan :
min{R =∑i
pi li |∑
i2−li 6 1}
Si on applique brutalement la méthode du Lagrangien on trouve que R estminimisé lorsque li = log2
1pi
, auquel cas le taux minimal est l’entropie de lasource :
H = H(U ) =M∑
i=1pi log2
1
pi
Cependant ce résultat ne donne pas, en général, des longueurs li entières !Une façon d’obtenir des longueurs entières est de prendre 1
li = dlog21
pie
On obtient la famille des codes de Fano-Shannon, qui vérifient bien l’inégalitéde Kraft-McMillan, et pour lesquels on trouve
H 6R 6 H +1.
Cependant ces codes ne sont pas toujours optimaux.La résolution complète du problème de recherche du meilleur code est don-
née par algorithme itératif sur M appelé algorithme de Huffman. On obtientalors un code de Huffman dont le taux R est minimal pour une source donnée(par les pi ).
3.5 Théorème de Shannon.
D’après ci-dessus le taux de codage du meilleur code vérifie l’inégalité H 6R 6 H +1. Comme le montre l’exemple d’une source binaire (M = 2) d’entropiefaible, on ne peut pas en général améliorer l’inégalité R 6 H +1 en codant lasource symbole par symbole.
En pratique on utilise alors des techniques de codage par plage (RLC : Run-Length Coding) pour améliorer les performances.
1. dxe désigne le plus petit entier > x.

20 CHAPITRE 3. CODAGE ENTROPIQUE À LONGUEUR VARIABLE
Une autre possibilité est de coder la source par blocs de n symboles. Onobtient alors pour R en bits/symbole l’encadrement :
H 6R 6 H + 1
n,
où H est l’entropie d’ordre n de la source. En faisant n → ∞, on obtient lethéorème de Shannon pour le codage de source sans pertes, qui affirme qu’onpeut s’approcher de l’entropie de la source d’aussi près qu’on veut.
3.6 Autres systèmes de codage sans pertes.
D’autres systèmes de codage de source sans pertes ont été proposés pourprendre en compte les dépendances temporelles (d’un symbole à l’autre) de lasource (source avec mémoire) ; Ces sytèmes de codage permettent de coder unesource quelconque sans connaitre a priori ses statistiques (codage «universel»),mais sont plus complexes à mettre en oeuvre. Les plus connus sont les systèmesde codage de Lempel-Ziv et de Codage arithmétique.

Chapitre 4
Quantification scalaire
4.1 Description d’un système de quantification sca-laire.
On se donne une source continue X modélisée par des échantillons aléa-toires de densité de probabilité p(x). Le quantificateur Q code chaque échan-tillon x par une étiquette binaire ou index i pouvant prendre M valeurs. Ledéquantificateur «Q−1» reconstruit les échantillons y à partir des index binaires.
Le taux de quantification R est toujours le nombre moyen de bits codés paréchantillon, c’est à dire
R = log2 M .
On considérera ici (comme dans la plupart des applications) une distorsionquadratique ou erreur quadratique moyenne (e.q.m.) :
D = E {(X −Y )2} =∫
p(x)(x − y)2 d x
Afin d’optimiser le système de quantification, on cherche à minimiser D pourun taux R donné.
Concevoir un quantificateur revient à partionner l’ensemble des valeurspossibles de X en M cellules ou régions de quantification notées R1,R2, . . . ,RM ,de sorte que x est quantifié sur l’index i si et seulement si x ∈ Ri .
Concevoir un déquantificateur revient à se donner M représentants notésy1, y2, . . . , yM , un par cellule, se sorte que i est déquantifié sur y = yi . L’ensemblede ces représentants s’appelle le dictionnaire (codebook).
Optimiser le système revient donc à choisir des cellules Ri et des représen-
21

22 CHAPITRE 4. QUANTIFICATION SCALAIRE
tants yi optimaux tels que la distorsion D soit minimale :
D =M∑
i=1
∫Ri
p(x)(x − yi )2 d x.
Insistons sur le fait qu’ici la quantification est scalaire, c’est à dire qu’onquantifie échantillon par échantillon. On ne peut donc pas exploiter la mémoirede la source.
4.2 Conditions du plus proche voisin et du centroïde
En pratique il est trop difficile de minimiser D directement. On procèdedonc par optimisation séparée : en fonction des cellules d’une part, et desreprésentants d’autre part.
4.2.1 Condition du plus proche voisin
Ici on cherche à optimiser D sur le choix des cellules R1,R2, . . . ,RM pour undictionnaire y1, y2, . . . , yM donné. Autrement dit, on optimise le quantificateurpour un déquantificateur donné.
Pour cela, il suffit de remarquer que l’erreur quadratique (x−y)2 est minimalelorsque y est le représentant le plus proche de x. Cette condition, appelée condi-tion du plus proche voisin, revient à choisir les cellules optimales suivantes(appelées cellules de Voronoï) :
Ri = {x tel que |x − yi |6 |x − y j | pour tout j }
Autrement dit, les Ri sont des intervalles du type (xi−1, xi ) dont les frontières xi
sont les milieux entre deux représentants successifs :
xi = yi + yi+1
2.
4.2.2 Condition du centroïde
Ici on cherche à optimiser D sur le choix du dictionnaire y1, y2, . . . , yM pourdes cellules R1,R2, . . . ,RM données. Autrement dit, on optimise le déquantifica-teur pour un quantificateur donné.
Pour cela, il suffit de minimiser la contribution de yi à la distorsion totale Dpour tout i :
min∫
Ri
p(x)(x − yi )2 d x

4.3. ALGORITHME DE LLOYD-MAX 23
En annulant la dérivée de cette fonction quadratique on trouve la condition ducentroïde :
yi =∫
Rixp(x)d x∫
Rip(x)d x
qui exprime que yi est le «centroïde» (barycentre) de Ri selon la distribution deprobabilité de la source.
4.3 Algorithme de Lloyd-Max
L’algorithme de Lloyd-Max (1960) consiste à itérer les deux conditions précé-dentes qui ne sont que des conditions nécessaires d’optimalité, afin d’obtenirune solution vérifiant simultanément les deux conditions.
On initialise l’algorithme par un choix arbitraire des centroïdes (par exemple).On applique ensuite la condition du plus proche voisin qui détermine les cellules,puis on recalcule les centroïdes par la condition du centroïde, et on recommencejusqu’à convergence.
1. Cette convergence arrive-t-elle toujours ? Oui, car la distortion globaleD ne peut que diminuer à chaque étape de l’algorithme ; elle convergedonc vers une valeur limite. En pratique, à la convergence, la solution restestationnaire et vérifie donc simultanément les deux conditions du plusproche voisin et du centroïde.
2. Obtient toujours un minimum global ? Non, car on peut trouver des contre-exemples avec minima locaux (cf. exercice). Cependant, on peut montrerque si la fonction
log p(x)
est concave, alors la solution obtenue après convergence est effectivementl’optimum global. C’est le cas, par exemple, pour une source gaussienneou uniforme.
4.4 Performances en haute résolution
Le système de quantification est dit en «haute résolution» si les cellules dequantification sont assez petites pour qu’on puisse les considérer infinitésimalespour le calcul des performances. Cela suppose un taux de codage R élevé.
Sous cette condition, la distorsion quadratique s’écrit :
D ≈∑i
∫ yi+qi /2
yi−qi /2pi (x − yi )2 d x = 1
12
∑i
pi q3i

24 CHAPITRE 4. QUANTIFICATION SCALAIRE
où qi est la longueur («pas» de quantification) de la cellule Ri et où pi est la valeur≈ constante de p(x) dans Ri . En réapproximant le résultat par une intégrale ilvient :
D = E(q(X )2
12
)où q(x) est la pas de quantification variable (= qi pour x ∈ Ri ).
Noter que si la quantification est uniforme (pas constant qi = q) on obtientla formule (classique) :
D = q2
12
On introduisant la fonctionλ(x) = 1M q(x) qui représente la densité des cellules
de quantification (cf. exercice), et en notant que M = 2R , on obtient la formulede Bennett :
D = 1
12
[∫p(x)
λ(x)2d x
]2−2R
où λ(x)> 0 et∫λ(x)d x = 1.
La formule de Bennett donne les performances d’une quantification scalairenon uniforme quelconque, caractérisée par sa densité λ(x). En optimisant cettedensité par rapport à la source on obtient (cf. exercice) :
D = 1
12
(∫p(x)1/3 d x
)3
2−2R .
On montre en exercice que, pour une source gaussienne de variance σ2, on a :
D = πp
3
2σ22−2R .
à comparer avec la limite de Shannon D =σ22−2R . La caractéristique de rapportsignal à bruit (en décibels), fonction du taux de quantification en bits, laisse
apparaître une différence de 10log10πp
32 = 4.35 dB en dessous de la limite de
Shannon. On est encore loin de l’optimal !
4.5 Performances en présence d’un codeur entropique
Une façon d’améliorer le système est de faire suivre la quantification parun codage entropique (sans pertes, cf. leçon précédente). La distorsion D =1
12 E q(X )2 est alors inchangée mais le taux a diminué ; on peut l’évaluer comme

4.5. PERFORMANCES EN PRÉSENCE D’UN CODEUR ENTROPIQUE 25
l’entropie de l’index de distribution de probabilité p(i ) = pi qi avec les notationsprécédentes. On obtient
R =∑i
pi qi log21
pi qi
que l’on peut réapproximer comme une intégrale ; il vient :
R = H(X )+E log21
q(X )
où H (X ) est l’entropie différentielle de la source. En utilisant l’inégalité de Jensen(concavité du logarithme, cf. exercice du chapitre 1) sur q(X ), on obtient unedistorsion minimale :
D = 1
1222H(X )2−2R
qui est atteinte dans le cas d’égalité de l’inégalité de Jensen, c’est à dire quandq(x) est constant = q .
Autrement dit, lorsqu’elle est suivi d’un codage entropique, la quantificationscalaire optimale est uniforme.
Dans le cas d’une source gaussienne il vient
D = 2πe
12σ22−2R .
On est plus qu’à 10log102πe12 = 1.53 dB en dessous de la limite de Shannon. Le
codage entropique a apporté un gain important, en tout cas en haute résolution,c’est à dire pour un fort rapport signal à bruit.

26 CHAPITRE 4. QUANTIFICATION SCALAIRE

Chapitre 5
Codage par transformée
5.1 Description d’un système de codage par trans-formée.
On se donne une source continue X modélisée par des échantillons aléa-toires de densité de probabilité p(x) et de variance σ2
X . On ne suppose pas ici lasource sans mémoire.
Le codage par transformée consiste à envoyer un vecteur
X = (X1, . . . , Xn)
de n échantillons de cette source dans une transformée (inversible) T. On ob-tient ainsi un vecteur U = T(X ) dans le domaine transformé.
Chaque échantillon Ui en sortie de la transformée est ensuite quantifié parun quantificateur Qi sur Mi niveaux de quantification. Pour chacune de cessources, on a ainsi un taux de quantification de Ri = log2 Mi bits par échantillon.
Le déquantificateur «Q−1» reconstruit les échantillons Vi ; la transforméeinverse T−1 est finalement appliqué au vecteur V pour fournir la source recons-truite Y = T−1(V ).
Le taux de quantification global R est toujours le nombre moyen de bitscodés par échantillon de source X , c’est à dire
R = 1
n
∑i
Ri
Insistons sur le fait qu’ici la quantification est scalaire, mais porte sur des coef-ficients transformés d’un vecteur de source. Bien que l’on quantifie les coeffi-cients transformés échantillon par échantillon, on peut quand même exploiterla mémoire de la source.
27

28 CHAPITRE 5. CODAGE PAR TRANSFORMÉE
On considérera ici (comme dans la plupart des applications) une distorsionquadratique pour les quantificateurs Qi :
Di = E {(Ui −Vi )2}.
Pour chacune des sources Ui à quantifier, on supposera qu’il existe une formuledu type "formule de Bennett" établie dans la leçon précédente, qui donne ladistorsion Di due à la quantification Qi :
Di = ciσ2Ui 2−2Ri
Dans cette expression, la constante ci dépend du type de source Ui et du type dequantificateur Qi . Il n’y a pas de raison que les constantes soient toutes égales,sauf par exemple dans le cas d’une quantification scalaire optimale d’une source
gaussienne où on a vu que ci = πp
32 .
5.2 Codage par transformée orthogonale.
Pour simplifier l’exposé on choisit une transformée orthogonale, c’est à direune transformée linéaire T, représentée à l’aide d’une matrice carrée T de taillen ×n, qui préserve la norme quadratique :
‖T ·X ‖ = ‖X ‖pour des vecteurs colonne X . Autrement dit, la transformée T est telle que
T T t = T t T = I .
et la transformée inverse est T −1 = T t .Pour une transformée orthogonale, on peut aisément obtenir la distortion
globale du système :
D = 1
nE {‖X −Y ‖2}
= 1
nE {‖T tU −T t V ‖2}
= 1
nE {‖U −V ‖2}
= 1
n
∑i
Di .
Noter que, avec un calcul analogue, la conservation de la norme peut se voir surles variances :
σ2X = 1
n
∑iσ2
Ui.

5.3. POURQUOI UNE TRANSFORMÉE ? 29
5.3 Pourquoi une transformée ?
On va effectuer une comparaison d’un codeur classique (quantification sanstransformée) et d’un codeur par transformée, avec les mêmes quantificateurs,de sorte les différentes distorsions Di obtenues après transformée sont égalesentre elles, et donc à la distorsion totale :
Di = D.
De même, la distortion D0 introduite par le quantificateur scalaire habituel (sanstransformée) sur la source X est D0 = D = Di . Ainsi la distortion globale n’a paschangé malgré l’introduction de la transformée. Le codage étant un compromisentre taux R et distortion D , il faut donc regarder ce qui se passe sur R.
Dans le système de codage par transformée, on a R = 1n
∑i Ri où Di =
ciσ2Ui 2−2Ri , d’où en supposant les ci = c constants :
R = 1
2log2
c n√∏
i σ2Ui
D
Pour le système classique sans transformée, on a pour le quantificateur lamême formule de Bennett qui relie distorsion globale D0 = D et taux R0 :D0 = cσ2
X 2−2R0 , c’est à dire :
R0 = 1
2log2
cσ2X
D
Sachant que σ2X = 1
n
∑i σ
2Ui
, on obtient un gain sur les taux de
1
2log2 GTC bits
où
GT C =1n
∑i σ
2Ui
n√∏
i σ2Ui
est le gain de codage par transformée (Transform Coding Gain). Ce gain decodage est toujours > 1 (voir exercice) : Une transformée orthogonale apportetoujours un gain !
5.4 Répartition optimale des taux après transformée
Dans un système de codage par transformée, quelle est la répartition op-timale des taux Ri qui, pour un taux global R = 1
n
∑i Ri donné, minimise la
distorsion globale D = 1n
∑i Di ?

30 CHAPITRE 5. CODAGE PAR TRANSFORMÉE
C’est un problème de minimisation sous contrainte qui se résout par laméthode du multiplicateur de Lagrange : en tenant compte de la formule deBennett, le Lagrangien est :
L = 1n
∑i
cσ2Ui 2−2Ri −λ
∑i
Ri .
En dérivant le lagrangien par rapport aux variables Ri on obtient
Di = Constante
ce qui correspond précisément à la situation du paragraphe précédent. On adonc une distorsion minimale :
Dmin = c n
√∏iσ2
Ui2−2R
et le gain de codage par transformée GTC défini ci-dessus donne le gain endistorsion dû à la transformée :
D0
Dmin=GTC .
pour un taux de codage R donné.Rappelons que pour obtenir l’expression de GT C , on a utilisé des formules
de Bennett valables en haute résolution. Le gain GTC n’est donc valable qu’enfort débit.
De plus, les constantes ci dans les formules de Bennett sont supposées touteségales. Ceci correspondrait à une situation où la source est gaussienne et oùtous les quantificateurs utilisés sont optimisés.
5.5 Transformée optimale
Sous les mêmes hypothèses qu’énoncées ci-dessus, on peut trouver la trans-formée orthogonale qui maximise le gain de codage GTC (voir exercice). Cettetransformée est la transformée de Karhunen-Loève et est obtenue comme unematrice dont les colonnes sont les vecteurs propres de la matrice d’autocova-riance de la source.
En pratique, on utilise des approximations de la transformée de Karhunen-Loève qui sont indépendantes de la source et qui se comportent de la mêmemanière pour des signaux très corrélés. C’est le cas de la transformée en cosinusdiscrète (DCT : Discrete Cosine Transform) utilisée en compression d’images.

B. GELLER Générali tés sur les codes correcteurs
1
6. GENERALITES SUR LES CODES CORRECTEURS
6.1 PRINCIPE DE L’ENCODAGE (AU NIVEAU D'UN EMETTEUR)
Source Canal Destinataire
Information perturbations
Pour être retrouvée par le destinataire, une information perturbée doit être répétée
d'une manière ou d'une autre à l’émission.
Récepteur
Lecteur
0
1
Emetteur TV
Musique d'un CD
B. GELLER Générali tés sur les codes correcteurs
2
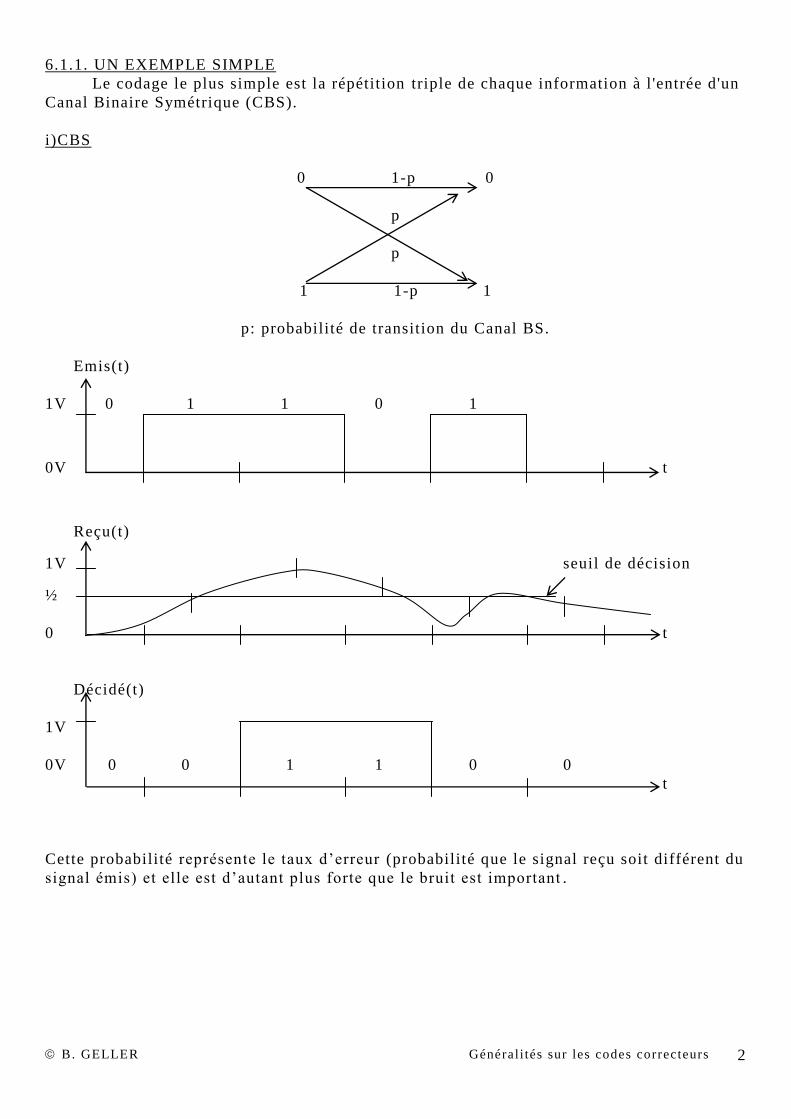
6.1.1. UN EXEMPLE SIMPLE
Le codage le plus simple est la répétition triple de chaque information à l 'entrée d'un
Canal Binaire Symétrique (CBS).
i)CBS
0 1-p
0
p
p
1 1-p 1
p: probabilité de transition du Canal BS.
Emis(t)
1V 0 1 1 0 1
0V t
Reçu(t)
1V seuil de décision
½
0 t
Décidé(t)
1V
0V 0 0 1 1 0 0
t
Cette probabilité représente le taux d’erreur (probabilité que le signal reçu soit différent du
signal émis) et elle est d’autant plus forte que le bruit est important .

B. GELLER Générali tés sur les codes correcteurs
3
ii)Codeur par répétition triple
Source 0 1 0 Codeur 0 0 0 1 1 1 0 0 0 Canal 0 0 1 1 1 1 0 0 0 Décodeur Destinataire
Le codeur répète trois fois chaque information source :
0 000
1 111
iii) Stratégies de décodage
6.1.2 DEFINITIONS
i)Rôle du codage canal :
Améliorer la fiabilité au prix du traitement d'une redondance qui n'apporte aucune
information réelle.
ii)Rôle du codeur :
Introduire une redondance suivant une certaine loi univoque £ .
Dans le cas du codage bloc, on transforme un bloc de k informations source en n symboles
à transmettre au canal (n>k).
Remarque :
Les symboles sont à choisir dans un alphab et Asou rce .
Exemple :
Asou rce = ℤ/2ℤ ;{0,1}où toutes les opérations + et x se font modulo 2 :
+ 0 1 x 0 1
0 0 1 0 0 0
1 1 0 1 0 1

B. GELLER Générali tés sur les codes correcteurs
4
Exemples :
•Codage par répétition k=1, n=3
£ ℤ/2ℤ(ℤ/2ℤ)3
b (b,b,b)
• Codage de parité : transforme k bits en n=k+1 bits où le dernier bit est somme des
précédent bits d’information (modulo 2). En particulier pour k=7, n=8 et on a :
(ℤ/2ℤ)7 (ℤ/2ℤ)
8
£ (b1 ,b2 ,b3 ,b4 ,b5 ,b6 ,b7) (b1 ,b2 ,b3 ,b4 ,b5 ,b6 ,b7 ,b8)
avec b8= 7
i
1
bi
2 bit de parité.
iii)Trois définitions pour un code en bloc
iii1) Codage sous forme systématique
(Asou rce
)k (A
sou rce)
n a
1=c
1
£ avec a2=c
2
(a1 , . . . , ak) (c1 , . . .ck , . .cn) :
ak=ck
iii2) Redondance = n
kn ; Rendement = 1
n
k - Redondance
i ii3) Im (£) est un sous-ensemble de (A sou rce)n à [Card (A sou rce)]
k éléments parmi les
[Card (A sou rce)] n
n-uplets possibles.
iii4)Exemple :
(ℤ/2ℤ)2 (ℤ/2ℤ)
3
£
(b1 ,b2) (b2 ,b1 ,b1)
avec £
(0 0) (0 0 0)
(0 1) (1 0 0)
(1 0) (0 1 1) 4 mots possibles parmi 8 dans (ℤ/2ℤ)3
(1 1) (1 1 1)

B. GELLER Générali tés sur les codes correcteurs
5
6.2 STRATEGIE DE DECODAGE
6.2.1 RÔLE DU DECODEUR (AU NIVEAU DU RECEPTEUR)
1°) Il vérifie que la loi de codage £ est remplie. Si cette loi n'est pas vérifiée, une
erreur est détectée pour le n -uplet reçu.
Exemple: £ bit de parité
Mot reçu r =(10101) parité non respectée erreur de transmission
2°) a) Soit le décodeur cherche à corriger lui -même les erreurs en choisissant le mot
codé le plus vraisemblablement émis (i.e. celui qui ressemble le plus au mot reçu)
FEC = Forward Error Correction
b) Soit il demande la reémission de ce qui est détecté comme faux
ARQ = Automatic Repeat reQuest.
6.2.2 FEC/ARQ ?
* FEC est choisi lorsqu’on a une application du type "canal unidirectionnel"
(Exemple: CD, fusée...)
FEC/ARQ + -
* Rapide * Décodeur complexe(cher)
* Trafic plus fluide * La probabilité de commettre une erreur
est généralement plus élevée
*ARQ
- ARQ avec attente d'acquittement : l 'émetteur attend systé matiquement l 'accusé de
réception (positif ACK ou négatif NAK) de chaque mot qu'il émet avant d'émettre le
suivant. Ceci entraîne une perte de temps.
- ARQ continu : le récepteur acquitte quand il le peut les séries de mots émis. Une
gestion de buffers à l 'émission et en réception doit être prise en compte. (Cette gestion est
particulièrement lourde pour un protocole ARQ continu "sélectif").
Les réseaux informatiques fonctionnent généralement en ARQ.

B. GELLER Générali tés sur les codes correcteurs
6
6.2.3 LIMITATION DU DECODEUR
Il n'y a pas de décodeur parfait : on n'est jamais sûr de ne pas commettre d'erreur. On peut
néanmoins atteindre une certaine fiabilité, mesurée par un taux moyen d’erreur défini par le
cahier des charges, en choisissant des mots codés de longueur suffisamment élevée.
Exemple:
Répétition triple
Si le récepteur reçoit (0 0 0 1 1 1) il va décider que l’information source était 0 1
probabilité (erreur
/bit) = p3 = 10
-6
Si on veut être plus fiable, il faut augmenter la redondance et la longueur du mot codé ;
par exemple si on répète huit fois :
1 (1111 1111) 0 (00000000) probabilité (erreur
/bit) = p8 = 10
-1 6
£ £
Les performances ne peuvent s’améliorer qu’au prix d’un temps de traitement et d’une
complexité plus élevés ; ceci constitue un premier compromis.
6.3 CARACTERISATION DE LA REDONDANCE NECESSAIRE
6.3.1 UNE QUALIFICATION POSSIBLE DE LA REDONDANCE NECESSAIRE :
DISTANCE DE HAMMING
Définitions:
1/ Un décodeur est dit complet au sens d’un Maxim um de Vraisemblance (MV) si, étant
donnée une distance définie pour les n -uplets, pour tout mot reçu r, le décodeur choisit le
mot de code cmin tel que d(r, cmin) = min {d(r, c)}, c étant un mot quelconque du code.
2/ Soient x = (x1 . . . . .xn)
y = (y1 . . . . .yn)
d(x,y) = card Ax y avec Ax y = { i / x i yi } ( nombre de symboles différents)
Il s’agit bien d’une distance au sens mathématique .
(cf justification en petites classes)

B. GELLER Générali tés sur les codes correcteurs
7
Exemple: A sou rce=Alphabet, C ={(ALPHA) ; (TANGO)}. Que vaut d ?
Théorème Fondamental :
Soit C l 'ensemble des mots d'un code. Soit d min la plus petite distance entre deux mots
quelconques du code.
- Ce code peut détecter dmin - 1 transitions du canal.
- Ce code peut corriger e =Int
2
1dmin transitions.
Exemples:
1/ C={(000);(111)} ; d’après le théorème ci dessus, C détecte 2 erreurs et corrige 1 erreur.
Par exemple, dans la configuration : 0 000 110 ,
codeur canal
C permet de détecter au plus deux transitions, mai s ne permet pas de les corriger.
2/ A = {0,1,2,3,4} C = {(00) ; (12) ; (23) ; (34) ; (41)}. Quelles sont les capacités de
détection et de correction de ce code ?
0 1 2 3 4
0
1
2
3
4
En général, les décodeurs sont incomplets au sens du maximum de vraisemblance ; en
d’autres termes, ils sont capables de trouver cmin tel que d(r,cmin) = min {d(r,c)}, si et
seulement si r est dans une sphère suffisamment proche d’un mot de code : d(r,c i)<B, où
souvent B=e.
Définition:
Codes équivalents :
Ce sont des codes qui ont même distribution de distances entre mots.
Des codes équivalents ont même di stance minimale et capacité de détection/correction.

B. GELLER Générali tés sur les codes correcteurs
8
Exemple:
(0000) (0000)
(0011) (1010)
C 0= (1100) C ´0= (0101)
(1111) (1111)
Propriété:
Soit un CBS, de probabilité de transition arbitrairement faible (p<<1). Soit un codeur à
l 'entrée du canal, de capacité de correction e et d e longueur n fixés. On suppose que le
décodeur en sortie se limite à corriger toutes les combinaisons de e ou moins transitions.
La probabilité pour qu'un mot non codé de n symboles soit erroné, est proportionnelle à p.
La probabilité pour qu'un mot codé de n symboles soit erroné, est proportionnelle à
pe+1
<<p, ce qui est donc meilleur pour p suffisamment faible.
Une redondance quantifiée , comme nous allons le voir, par le théorème de Shannon et
construite de manière à obtenir une certaine distance minimal e entre mots codés permet
donc de garantir une plus faible probabilité d’erreur pour un rapport Signal à Bruit
suffisant (p<<1).
Démonstration :
- Mot non codé
proba (n bits justes) = (1-p)n
proba (au moins 1 erreur parmi n)=1-(1-p)nnp (si p <<1)
- Mot codé
p (se trompe) =
n
1ekC
n
k p
k (1-p)
n -k (p<<1)
pe+1
CQFD.
Limitation sur la distance minimale :
- Le calcul de dmin d'un code est très lourd en général.
- Certains codes qui ont des mots éloignés entre eux, sauf une exception où deux mots du
code sont très proches, peuvent avoir de faibles probabilités d'erreurs en moyenne bien
que dmin reste faible. Ceci est en particulier vrai pour les canaux à faibles RSB
(Rapports Signal à Brui t) i .e. pour p non négligeable devant 1 .

B. GELLER Générali tés sur les codes correcteurs
9
6.3.2 UNE QUANTIFICATION DE LA REDONDANCE NECESSAIRE :
LE THEOREME DE SHANNON DU CODAGE
Définition : On appelle capacité d’un canal d’entrée X et de sortie Y, l’information
mutuelle maximum entre l’entrée et la sortie du canal :
( )
max I(X,Y)p x
C où I(X,Y)=H(X) –H(X|Y) et p(x) est la d.d.p. de X.
Dans le cas d’un canal, l’information mutuelle entre l’entrée et la sor tie représente donc la
quantité d’information de la source à l’entrée , diminuée par l’incertitude due au canal.
En particulier, lorsque le canal est parfait X=Y et donc H(X|Y) = H(X|X) = 0 car il n’y a
aucune incertitude sur X lorsqu’on connaît X. Au co ntraire, si le canal est tellement
mauvais que sa sortie Y ne dépend pas de son entrée X, l’observation de la sortie n’ap porte
aucune connaissance : H(X|Y) = H(X) et C = H(X)-H(X) = 0. Entre ces deux cas extrêmes,
l’information mutuelle est d’autant meilleure que le canal distord peu et a donc une
capacité à véhiculer de l’information.
La capacité n’ est qu’un cas particulier d’information mutuelle du canal considéré , où l’on
répartit au mieux les informations de la source placée à l’entrée du canal (« max par
rapport à p(x) »), afin que l’information soit la plus importante possible. Souvent, pour des
canaux dont les transitions sont symétriques par rapport aux symboles d’entrée (comme le
CBS), on trouve que la capacité est l’information mutuelle obtenue d ans le cas
d’équirépartition des symboles à l ’entrée ( i .e. p(x i)=1/Card(ASou rce) ).
Exemple de référence : Le Canal Binaire Symétrique
0 1-p
0
p
X Y
p
1 1-p 1
I(X,Y) = H(X) – H(X|Y) = H(Y) – H(Y|X). Montrons que H(Y|X) est indépendant de p(x) si
bien que maximiser I(X,Y) pour trouver la capacité du CBS reviendra à maximiser H(Y).
B. GELLER Générali tés sur les codes correcteurs
10
2
x y
H(Y|X) = p(x)H(Y|X=x) où H(Y|X=x) = - p(Y|X=x)log (p(Y|X=x))
Lorsque X=0, H(Y|X=0) = - p(Y=0|X=0) log2(p(Y=0|X=0)) - p(Y=1|X=0) log2(p(Y=1|X=0))
= -(1-p) log2(1-p) - p log2(p) = H(p),
où H(p) désigne l’expression analytique de l’entropie binaire associée à la probabilité p.
De même lorsque X=1, H(Y|X=1) = -p log2(p) - (1-p) log2(1-p) = H(p).
Donc x x x
H(Y|X) = p(x)H(Y|X=x) = p(x)H(p) = H(p) p(x) = H(p) est bien indépendant de p(x) et
ne dépend que de la probabilité de transition du canal p.
Par conséquent maximiser par rapport à p(x), l’information mutuelle :
I(X,Y) = H(Y) –H(Y|X)= H(Y) – H(p) revient à maximiser H(Y).
L’entropie de Y est maximum et vaut 1 lorsque Y=0 et Y=1 sont équiprobables :
P(Y=0) = p(X=0) (1-p) + p(X=1) p = 0.5
P(Y=1) = p(X=1) p + p(X=0) (1-p) = 0.5
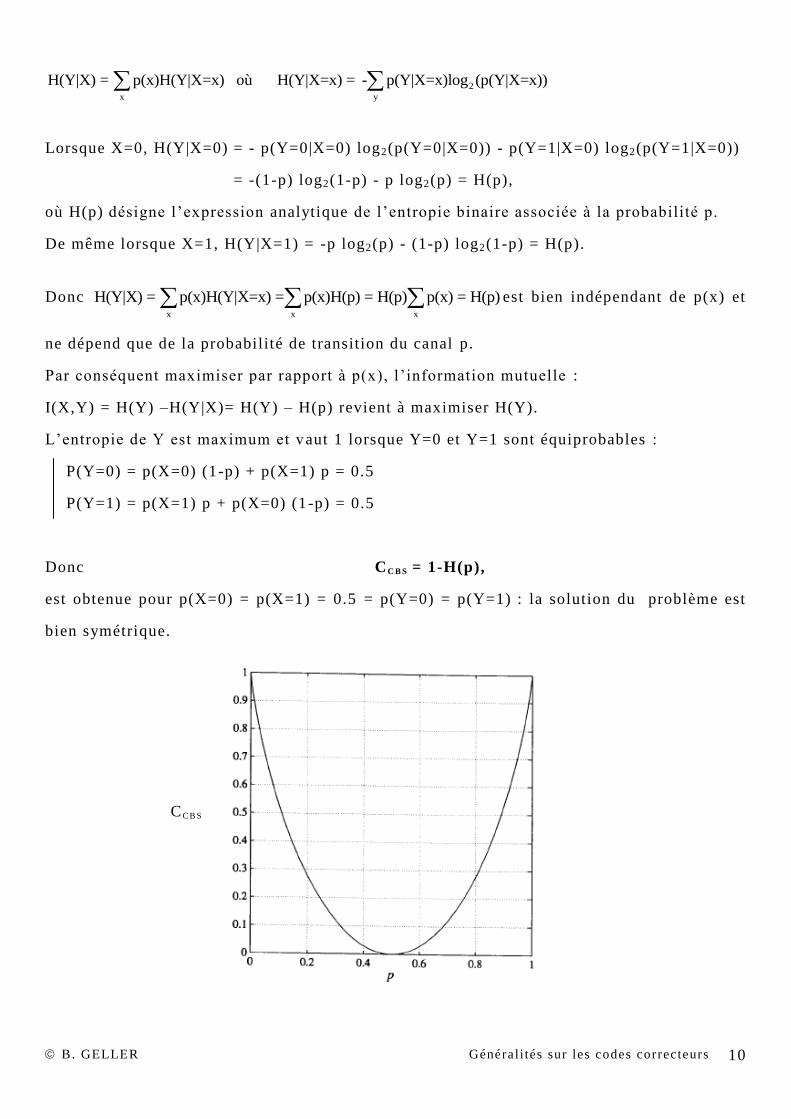
Donc CC B S = 1-H(p),
est obtenue pour p(X=0) = p(X=1) = 0.5 = p(Y=0) = p(Y=1) : la solution du problème est
bien symétrique.
CC B S

B. GELLER Générali tés sur les codes correcteurs
11
Théorème de Shannon : Pour une longueur de code n suffisamment longue, une
transmission avec une probabilité d’erreur arbitrairement faible est possible si le rendement
du code est inférieur à la capacité du canal.
Démonstration pour le CBS :
La probabilité de transition du canal vaut :p=d/n où d est le nombre de transitions parmi n
symboles émis (où n tend vers l’ infini).
En d’autres termes, lorsque n tend vers l’infini, le mot reçu se trouve sur une sphère à une
distance de Hamming d=np du mot de code émis, ce qui donne n
d
n!C =
d!(n-d)! possibilités.
Une condition suffisante pour qu’il n’y ait pas d’erreurs est que l’ensemble des sphères
soit disjointes entre elles et que le volume de leur empilement soit inférieur au volume de
l’espace possible : n k n n-k
d
n!2 >2 C 2 >
d!(n-d)!
En prenant le log à base 2 de l’inégalité précédente et en utilisant l’approximation pour
les grands nombres log2(N!)= Nlog2(N)-N issue de la formule de Sterling (cf annexe), on
obtient donc :
n-k > (n.log2(n)-n)-((n-d).log2(n-d)-(n-d))-(d.log2(d)-d)
= n.log2(n)-(n-d).log2(n-d)-d.log2(d)
En remplaçant d=np, et en divisant de part et d’autre par n, on obtient alors :
1-k/n > log2(n)-(1-p)log2(n-np)-plog2(np)
soit finalement,
k/n <1- log2(n)+(1-p)log2(n-np)+plog2(np)
=1+(1-p)log2(1-p)+plog2p=1- H(p)=CC B S CQFD.

B. GELLER Générali tés sur les codes correcteurs
12
Exemple d’application :
Source Codeur Canal Destinataire
{0,1} (k,n) 0 0
p(0)=p(1)=½ p
1 1
On a : k T sou rce = n Tcan a l où k : nombre de symboles à l 'entrée du codeur
n : longueur des blocs en sortie du codeur
et le théorème de Shannon s’écrit :
k
n > C
où C: capacité canal
Si p=10-2
, C=0,919. Dans ce cas, si par exemple, k=1000 alo rs il faut que n 1089. Il
faudra rajouter 89 symboles (au moins) aux 1000 informations binaires suivant une certaine
loi de codage si l’on veut transmettre avec probabilité d’erreur fixée arbitrairement faible.
En d’autres termes, le codeur introduit dan s la liaison pour la rendre plus fiable, peut être
vu comme une source secondaire directement branchée au canal, dont l’information
moyenne délivrée par symbole émis est k/n (la redondance n’apporte aucune information).
Le théorème du codage de Shannon revient alors à dire que l’entropie de la source branchée
à l’entrée du canal doit être inférieure à la capacité du canal.
Deux Remarques:
1/ Supposons que le cahier des charges définit comme arbitrairement petite, une probabilité
d'erreur p(erreur)=10-5
. Si p=10-2
, un décodage par vote majoritaire de la répétition
n=(2m + 1) fois de chaque bit, donne après décodage une probabilité d'erreur :
2m+1
m+1p(erreur)=C p
m+1 (1-p)
m < 10
-5 pour m=2 et n=5.
Dans ce cas, l’entropie H=1/5 bit par symbole canal : H<< 0,919 ; la redondance du codage
par répétition pour obtenir une probabilité d’erreur arbitrairement petite est trop élevée.
2/ Le théorème de Shannon sur le codage (« Deuxième théorème de Shannon ») permet de
donner une quantification de la redondance nécessaire, valable pour une longueur n
arbitrairement large . Malheureusement, ce théorème n’est pas constructif et ne permet pas
de construire en pratique des codes correcteurs.

B. GELLER Générali tés sur les codes correcteurs
13
Capacité et théorème de Shannon ne sont pas des notions limitées aux canaux discrets mais
s’étendent à tous les canaux , en particulier, ceux à entrée et sortie continues.
Exemple : Le canal à bruit additif blanc Gaussien (BABG, AWGN)
Un canal AWGN signifie qu’entre la sortie Y e t l’entrée du canal X , on a la relation :
Y = X + B,
où le bruit B 2(0, )N , et où les échantillons de bruit b sont indépendants (bruit blanc) ; la
puissance de sortie est donc égale à la somme de celle fixée de l’entrée et de celle du b ruit.
L’information mutuelle s’écrit :
I(X,Y) = H(X) – H(X|Y) = H(Y) – H(Y|X).
Comme pour le CBS, montrons que H(Y|X) est indépendant de p(x) si bien que maximiser
I(X,Y) pour trouver la capacité du canal AWGN reviendra à maximiser H(Y). Pour obtenir
H(Y|X), on peut détailler les calculs (cf annexe) ou on peut tirer parti de certaines
propriétés de H ; l’entrée informative du canal X et le bruit B sont indépendants donc :
H(Y|X) = H(X|X) + H(B|X) = H(B|X) = H(B) = 2
2
1log 2πeσ
2 (car B 2(0, )N ).
H(Y|X) est bien indépendant de p(x) et donc maximiser par rapport à p(x), l’information
mutuelle I(X,Y) = H(Y) –H(Y|X)= H(Y) – H(p) revient à maximiser H(Y). (Notons au
passage que H(Y|X) vaut exactement l’expression de l’entropie diff érentielle du bruit
Gaussien B : l’incertitude vaut exactement celle rajoutée par le bruit indépendant de la
source). Or l’entropie différentielle Y est maximum lorsque Y est une variable aléatoire
Gaussienne. Comme Y=X+B, ceci a lieu lorsque X est également une variable Gaussienne
2(m , )X XN car Y suit alors la distribution 2 2(m , )X XN comme somme de deux variables
Gaussiennes indépendantes .
Par conséquent H(Y) = 2 2
2
1log 2πe( +σ )
2X et :
C = H(Y)-H(Y|X) = 2
2 2
1log 1+
2
X
(en bits par symbole réel émis).
On trouve souvent une expression alternative à cette expression pour les signaux réels à
bande passante limitée. En notant S= 2
X la puissance du signal émis, B= 2 la puissance du
bruit AWGN et en supposant que le canal avec une bande passante de W H ertz permet de
transmettre 2W symboles par seconde, la capacité en bit/s s’exprime par la relation :

B. GELLER Générali tés sur les codes correcteurs
14
C = 2W log 1+S
B
Cette relation es t très souvent utilisée en télécoms pour connaître le débit que l’on peut
espérer transmettre.
Par exemple, pour un canal téléphonique de bande passante 4 kHz et de rapport signal sur
bruit 40 dB,
C = 4000 log2( 10001) = 53 kbit/s.
Pour augmenter le débi t il faut soit augmenter la bande passante, soit beaucoup augmenter
la puissance du signal émis (…ce qui rend la ressource spectrale d’autant plus chère). C’est ce
qui est fait dans l’ADSL où on a étendu la transmission à 256 canaux parallèles de 4 kHz.
Notons enfin que le plus souvent une expression analytique simple de la capacité d’un
canal est difficile à obtenir et qu’il faut alors recourir à des méthodes numériques.
SYNTHESE :
Du fait de la distorsion du canal, il faut rajouter de la redondance aux messages émis pour
les fiabiliser. Le codage résultant doit alors avoir un rendement inférieur à la capacité du
canal. On a donné l’exemple de deux codes simples :
- Code de parité
(n,k=n-1,dmin=2)
Excellent rendement R= n
1n
00000000 d=2
00000011
capacité de détection 1, de correction 0...
- Code de répétition (n, k=1,d min=n=nombre de répétition)
Rendement très mauvais, mais très bonne capacité de correction.
Entre ces caractéristiques extrêmes, il existe des familles de code permettant de faire un
meilleur compromis redondance / capacité de correction et d’approcher la capacité d’un
canal. Ce sont les codes linéaires qui seront étudiés dans le(s) chapitre(s) suivant(s).

B. GELLER Générali tés sur les codes correcteurs
15
ANNEXES :
A1 - Formule de Sterling Première démonstration :
La distribution de Poisson, entièrement caractérisé e par un paramètre (qui est égal à sa
moyenne et à sa variance) s’écrit :
P(N)= N
expN!
Pour N suffisamment large, cette distribution tend vers la Gaussienne de même moyenne et
variance (cf. figure pour =15).
On peut alors écrire N 2λ 1 (N-λ)
exp-λ exp-N! 2λ2πλ
pour N proche de la moyenne . En
particulier pour N= , on obtient : NN 1
exp-NN! 2πN
, soit la formule de Sterling : N! N exp-N 2πNN .
Finalement, toujours pour N large, en prenant le logarithme de la formule de Sterling, on
obtient :
log2(N!)= Nlog2(N)-N+0.5log2(2N) Nlog2(N)-N.
(On pourrait même dans l’expression précédente négliger le terme en -N devant Nlog2(N)
sans aucune incidence sur la démonstration du deuxième théorème de Shannon .)
Deuxième démonstration :
La croissance de la fonction ln() entraine l’encadrement suivant des intégrales sur un
intervalle de longueur 1 :
1
1)ln()ln()ln(
k
k
k
kdttkdtt ;
donc en sommant sur tous les intervalles de 1 à N :
1
21)ln()!ln()ln(
NN
dttNdtt ;
en intégrant on obtient :
Nln(N)-N+1< ln(N!)< (N+1)ln(N+1)-(N+1)-(2ln2-2),
soit en faisant tendre N vers l’infini : ln(N!) Nlog2(N)-N

B. GELLER Générali tés sur les codes correcteurs
16
A2 - Calcul de H(Y|X) pour le canal AWGN
H(Y|X)= dxdyxpxypxypdxdyyxpxyp )()()(log),()(log 22
dxdyxp )(2σ
xyexp
σ2π
1
2σ
xyexp
σ2π
1log
2
2
2
2
2
=
dxdyxpe
)(2σ
xyexp
σ2π
1
2σ
)(logxy
σ2π
1log
2
2
2
2
2
2
(car log2(t)=ln(t)/ln(2)=ln(t)log2(e))
=
dxdyxpe
dxdyxp )(2σ
xyexp
σ2π2σ
)(logxy)(
2σ
xyexp
σ2π
1
σ2π
1log
2
2
2
2
2
2
2
2
Le premier terme de cette somme s’écrit :
dxdyxp )(
2σ
xyexp
σ2π
1
σ2π
1log
2
2
2
=
dydxxp
2
2
22σ
xyexp
σ2π
1)(
σ2π
1log
=
dxxp )(
σ2π
1log 2
2
)σ2(log 2
2 e,
tandis que le second terme se simplifie avec b = y-x :
dxdyxp
e)(
2σ
xyexp
σ2π2σ
)(logxy2
2
2
2
2
=
dxxpdbe
)(2σ
bexp
σ2π2σ
)(logb2
2
2
2
2
=
dbe
2
2
2
2
2
2σ
bexp
σ2π2σ
)(logb=
2
)(log 2 e
car par définition même de la variance, 2 2σ = b p(b) db .
Donc H(Y|X)= 2
)σ2(log 2
2 +
2
)(log 2 e=
2
)σ2(log 2
2 e .
H(Y|X) est donc bien indépendant de p(x).

B. GELLER Générali tés sur les codes correcteurs
17
A3 - Entropie différentielle des v.a. continues par rapport à la Gaussienne
L’entropie différentielle de la Gaussienne se calcule directement à partir de sa défi nition :
H(XG)=
dx
2σ
μxexp
σ2π
1g(x)logg(x)dxg(x)log
2
X
2
X
X
22
g(x)dxμx
2σ
)(logg(x)dx
σ2π
1log
2
X2
X
2
X
2
e(car log2(t)=ln(t)/ln(2)=ln(t)log2(e))
=
X
2σ2π
1log +
2
X
2
2σ
)(log e 2
Xσ = 2
)σ2(log 2
X2 e
Si on considère à présent une v.a . X prenant ses valeurs x avec une densité de probabilité
p(x) de moyenne Xμ et de variance 2
Xσ identique à la Gaussienne précédente , le calcul de
2- p(x) log g(x)dx mène directement , en remplaçant g(x) par son expression analytique, au
même résultat :
).(e2πlog
2
1dx
2σ
μxexp
σ2π
1p(x)logg(x)dxp(x)log 2
X22
X
2
X
X
22
.
Or si l’on définit :
)()( XHXf
dx
xg
xpxpdxxgxpdxxpxpdxxgxp
)(
)(log)()(log)()(log)()(log)( 2222 ,
de l’inégalité de Jensen :
2 2 2 2log log log log 1 0
p x g xp x dx p x dx g x dx
g x p x
.
Par conséquent :
2f X =H X + p x log g x dx 0 .
et )(H)2(log2
1)(log)()(H 2
22 GX XedxxgxpX .
Par conséquent, à puissance 2
Xσ fixée, l’entropie différentielle de la Gaussienne est
supérieure aux autres distributions , l’égalité ne se produisant que pour X=X G.

B. GELLER Les codes blocs l inéaires 1
7. LES CODES BLOCS LINEAIRES
Nous allons voir que les codes blocs linéaires sont simplement des codes blocs de taille
fixe n (kn) dont la loi de codage £ est constituée d'équations linéaires.
La redondance linéaire résultante es t comprise entre celle du codage par répétition et celle
du codage par parité et elle est choisie afin d’approcher au mieux la capacité du canal.
7.1 CODAGE
Soit A un alphabet qui est un corps ; par exemple, souvent, A= ℤ/2ℤ.
Soit r un n-uplet r= (r1, . . . ,r
n) A
n; on peut aussi écrire : r =
n
1i
ii er avec ei=(0..0100..0) où
la coordonnée qui vaut 1 est en ii ème
position ; on retrouve que An est un espace vectoriel
de dimension n.
Définition:
Un code linéaire C est un sous-espace vectoriel (s.e.v) de An engendré par k vecteurs
indépendants (générateurs) g1…gk .
c C {ai}Ak / c =
k
1iii ga
C = Vect (g1 , . . . ,gk)
7.1.1 RAPPELS SUR DES PROPRIETES ELEMENTAIRES DES ESPACES VECTORIELS
i) 0 C : 0=
k
1ii
g0 Vect (gi)
ii) Si (c1 , c2) C 2
, , A2, alors c1+ c2 C
(en effet c1=
k
1i
c i 1g1 , c2 =
k
1i
c i 2g i c1+ c
2=
k
1i
(c i 1+ c i 2)g i Vect (g i) )
i) Si Card A=q, C est un sous-ensemble à qk éléments de A
n, qui lui en compte q
n.
En effet, soit c un mot quelconque du code : c=
k
1i
ai gi ou les coordonnées a i peuvent
prendre q valeurs possibles. Etant donné qu'il y a k coordonnées distinctes, il y a bien qk
choix possibles pour les mots du corps.

B. GELLER Les codes blocs l inéaires 2
k
i=1
7.1.2 MATRICE GENERATRICE
Définition :
Une matrice k x n dont les lignes sont formées par une famille de vecteurs générateurs
gi du code, est nommée matrice génératrice du code.
Notation :
g j = (g j 1 . . .g j n)
g1 1 . . . g1 n g1
G = g2 1 . . . g2 n = g2
… … …
gk 1 gk n gk
Remarque :
Une matrice génératrice, tout comme une base d'un sous espace vectoriel n'est
généralement pas unique.
Propriétés :
Tout mot du code s'écrit sous la forme
c = a G
1 xn 1 xk k xn
Démonstration:
Soit c= a i g i C
c = (
k
i 1
a i g i 1 ,
k
i 1
a i g i 2 , . . .
k
i 1
a i g i n)
= a G où a = (a1 . . .ak) CQFD.

B. GELLER Les codes blocs l inéaires 3
Conséquence :
Un codeur peut être vu comme un automate effectuant une multiplication matricielle
(a1 . . .ak) (c1 . . .cn)
c=a G
k symboles n symboles
Exercice :
Quelle est la capacité de correction d'un code à coefficients binaires dont une matrice
génératrice est :
100101
G = 011101
110110
k= 3

B. GELLER Les codes blocs l inéaires 4
7.2 POIDS D'UN CODE LINEAIRE
Définition:
Etant donné un n-uplet r, le poids de r est le nombre de coordonnées non nulles.
w {(111000)}=3
Propriétés :
Pour un code linéaire dmin=min{w(c), c C / (0) } =wmin . Ceci permet de calculer
beaucoup plus rapidement la distance minimale d'un code. (cf. exemple précédent).
Démonstration:
Soient c1 , c2 deux mots distincts de C .
d(c1 ,c2) = Nombre de coordonnées distinctes entre c1 et c2
= w (c1 - c2) : toute distance est un poids d’un mot du code (c1-c2 C car le code
est linéaire)
Réciproquement, w(c)=d(c,0) : tout poids est une distance.
L'ensemble des poids d'un code est donc confondu avec l 'ensemble des distances entre mots
du code. Ces deux ensembles d'entier s admettent le même plus petit élément: w min = dmin .
On peut aussi remarquer que pour tout élément c du code, la distribution des distances
entre c et les autres mots du code D(c),est la même indépendamment de c :
D(c)={d(c,c i), c i C }={w(c-c i),c i C }= { w (c j),c j C } CQFD.
7.3 DETECTION D'ERREUR PAR MATRICE DE CONTROLE
7.3.1 TROIS RAPPELS
i) Produit scalaire : x . y = (x1 . . .xn).(y1 . . .yn)
= x1y1 + x2y2 + .. + xnyn
(souvent + et x modulo 2)
ii) Orthogonalité: xy x.y = 0
iii) L'ensemble C constitué par l 'ensemble des vecteurs orthogonaux à un s.e.v. de
dimension k est un s.e.v. de dimension n-k.

B. GELLER Les codes blocs l inéaires 5
7.3.2 MATRICE DE CONTROLE
Définition :
Soit C un code linéaire, C est un s.e.v. de dimension n-k.
C'est donc un code engendré par n -k vecteurs notés h1 . . .hn -k .
Une matrice génératrice de C formée par n-k lignes hi est appelée matrice de contrôle de
C :
h1
H = n-k
hn -k
n
Propriété utile 1 :
c C ssi c tH = 0
1n nn-k 1 n-k
ou, en transposant le tout :
H tc = 0 n-k
0
1
Démonstration:
Soit c C : ctH = c (th1 . . . thn -k) = ([cth1] , [c th2] , . . ,[c thn -k] )
= (c.h1 ,c.h2 , . .) = 0 car [cthi] =
n
j 1
c j h i j = c.hi = 0 (car hi est dans C )
Réciproquement :c tH = 0
i {1,.. . ,n-k } c . hi = 0 ou les hi sont générateurs de C :
c est donc orthogonal à tout vecteur de l’orthogonal de C .
c (C ) = C CQFD
Pratique :
Lorsqu’on reçoit un n -uplet r, on fabrique au niveau du récepteur, le syndrome
s = r tH
1n-k 1n nn-k
Si ce syndrome est non nul, on a détecté une erreur de transmission.

B. GELLER Les codes blocs l inéaires 6
r = (r1 . . .rn) s 0n -k erreur détectée
r tH = 0
n -k mot reçu est un mot codé (pas forcément émis)
Un détecteur d'erreur peut -être vu comme un automate câblé qui effectue au niveau du
récepteur une multiplication matricielle.
Propriété utile 2:
Il existe un mot du code de poids w ssi il existe une combinaison linéaire de w
colonnes de H qui soit elle-même nulle.
Démonstration :
Soit c = ( c1 . .cn) un n-uplet
c a pour poids w Card {ci 0} = w.
Or c C
H tc =t0n - k
h1 1 . . . .h1 n c1
h2 1 . . . h2 n = 0
. . . . . . …
hn -k1 hn -k n cn
c1h1 1 +c2h1 2+... +cnh1 n = 0 h1 1 h1 2 h1 n 0
c1h2 1 +c2h2 2+... +cnh2 n = 0 c1 + c2 +...+ cn =
c1hn -k1+ … +cnhn -k n = 0 hn -k1 hn -k 2 hn -k n 0
Donc c du code a pour poids w ssi il y a w coordonnés ci qui sont non nulles et qu’il existe
une combinaison linéaire de w colonnes de H qui est elle même nulle. CQFD.
Conséquence :
Si H est une matrice telle que toute combinaison linéaire de w -1 ou moins colonnes est non
nulle et qu'une combinaison l inéaire de w colonnes est nulle alors :
dmin = w

B. GELLER Les codes blocs l inéaires 7
Le problème de calcul de la distance de Hamming ( et donc de la capacité de correction) est
par conséquent simplifié dans le cas d’un code linéaire par rapport à un code quelconque.
Exemple :
Code Hamming d'ordre D: c'est un code dont une matrice de contrôle est formée par
tous les D-uplets non nuls distincts.
Par exemple, pour D = 3
0001111
H = 0110011 n-k = D
1010101
n = 2D
-1
col3 = col1+col2 wmin = 3
Un code de Hamming corrige 1 erreur
n-k = D k=n-D = 2D
-1-D
Rendement = 112
D12
n
kD
D
D
Le calcul d'une matrice de contrôle revient à la recherche d'une base orthogonale à un
s.e.v.. Ce problème est fastidieux mais il est résolu sans problème par ordinateur. En fait,
ce calcul est inutile et le paragraphe suivant va permettre d'obtenir directement H à partir
de G.
7.4 CODE LINEAIRE SOUS FORME SYSTEMATIQUE
7.4.1 RAPPELS
i) Deux codes sont équivalents s’ils ont même d istribution de distances entre eux.
Exemple:
C 0={ (0000), (0011), (1100), (1111) } C 1={ (0000), (1010), (0101), (1111) }
Une permutation de coordonnées permet d'obtenir des codes équivalents.
Exemple:
Colonnes 4 et 1 de l 'exemple précédent.

B. GELLER Les codes blocs l inéaires 8
Par conséquent, deux matrices génératrices dont les colonnes sont permutées les unes des
autres donnent naissance à deux codes équivalents ( ayant même distribution de poids et
donc de distance minimale).
ii) Codage sous forme systématique
Ak A
n c1=a1
£ avec :
(a1 , . . . ,ak) (c1 , . . . ,cn) ck=ak
Propriété :
Pour un codage sous forme systématique :
G = Id k Pk ,n -k k
k n-k
Démonstration:
En effet c = ( a1 . .ak ,c1 , . .cn -k) = (a1 . . .ak) ( Idk | Pk n -k ) CQFD.
Propriété :
Tout code est équivalent à un code mis sous forme systématique.
Démonstration:
On transforme G en utilisant la méthode du pivot de Gauss. CQFD.
Exemples
i)
1001
G = 0101 du bit de parité
0011
(a1 ,a2 ,a3)(a1 ,a2 ,a3 ,a4 ,=a1+a2+a3 2 )
ii) Trouver une matrice sous forme systématique, équivalente à la matrice suivante :
100101
G = 011101
110110

B. GELLER Les codes blocs l inéaires 9
Conséquence :
Il suffit donc d'étudier les codes mis sous forme systématique.
Exemple :
Trouver un code linéaire qui puisse corriger une erreur avec le moins de redondance
possible pour encoder ( +, , ,- ), où on suppose que les 4 opérations sont équiprobables.
Source Codage source
+ - + 00 k=2
01 Codeur
10
- 11

B. GELLER Les codes blocs l inéaires 10
7.4.2 DEUX CONSEQUENCES DU CODAGE SOUS FORME SYSTEMATIQUE
i) Si on connaît la matrice génératrice d'un codage sous forme systématique
G = ( Idk | P k ,n -k), on connaît automatiquement une matrice d e contrôle :
H = ( tPk ,n -k | -Idn -k )
= ( tPk ,n -k | Idn -k ) dans le cas où l’alphabet est binaire (+= -).
Démonstration :
c = aG = a( Idk | Pk ,n -k) = (a,p)où p contient les n-k symboles de contrôle: p=a Pk ,n -k .
Pk ,n -k
Or 0 = p + p = a Pk ,n -k + p = (a,p) Idn -k = c tH. CQFD.
On peut aussi vérifier cette propriété en effectuant les produits scalaires entre tout
vecteur ligne de G et tout vecteur ligne de H et voir que ces vecteurs sont orthogonaux.
CQFD.
Exemple:
G = B = 100 101 H = 101 100
010 011 011 010
001 110 110 001
Id3 P3 ,3
Un vecteur reçu r = (100000) est-il entaché d'erreur?
101
011
110
s = rtH = (100000) 100 = (101)0 . L’erreur est détectée.
010
001

B. GELLER Les codes blocs l inéaires 11
i i) Il est strictement équivalent de caractériser un code par sa matrice génératrice ou par sa
matrice de contrôle : elles décrivent les mêmes n -k équations linéaires ( à n variables )
définissant l’hyperplan de dimension k, qu’est un code correcteur bloc.
Démonstration :
1 0 p1 1 … p1 j … p1 n -k
G = … p i j … k
0 1 pk1 … pk j … pkn -k
k n-k
p1 1 . . . pk1 -1
: : 0
H = p1 j pk j 0
: :
p1 n -k . . .pkn -k -1
Le codage s'écrit : c = ( a1 . . . ak ) G
= ( a1 . . . ak c1 . . . cn -k )
avec c j = i
k
1
a i p i j j = 1 .. . n-k (C)
Le décodage s'écrit ctH = 0n -k
p1 1 . . . p1 j . . . p1 n -k
. . . p i j . . .
pk1 . . . pk j . . . pkn -k
(a1 . . .ak c1 . . .cn -k) -1 0 0 = 0n -k
0 -1 0 0
. . . . . .
0 0 -1
a ip i j-c j=0 où j=1 …n-k (D)
On retrouve donc dans (D) les mêmes (n -k) équations (C)du codage. CQFD.
Nous avons décrit comment des erreurs pouvaient être détectées. Nous allons maintenant
voir comment un décodeur peut les corriger.

B. GELLER Les codes blocs l inéaires 12
7.5 CORRECTION DES ERREURS
7.5.1 TABLEAU DE DECHIFFREMENT
Avant de corriger d'éventuelles erreurs, il faut déjà les avoir dét ectées et le récepteur
comme précédemment doit calculer le syndrome s = rtH, où r est le n-uplet reçu et H est la
matrice de contrôle du code C(n,k) (On choisit pour simplifier l 'alphabet A = ℤ/2ℤ mais le
procédé de correction qui va être décrit s 'étend directement à to ut alphabet de cardinal q en
remplaçant le nombre 2 par q)
Un n-uplet binaire reçu r peut prendre 2n valeurs distinctes. On range les 2
n mots possibles
dans un tableau dit de déchiffrement, que nous allons apprendre à construire afin
d’effectuer ensuite la correction des mots reçus.
Chaque ligne du tableau va être constituée par les vecteurs ayant même syndrome.
Soit l1 un n-uplet quelconque ; montrons qu’il existe 2k vecteurs ayant même syndrome que
l1 de la forme u i=(l1+c i) où c i est un mot quelconque du code ( éventuellement nul) :
u i tH =(c i+l1)
tH = c i
tH+l1
tH=l1
tH=s1 , pour l i 2
k
On peut donc remplir la première ligne du tableau :
l1 l1+c1 l1+c2 . . . . l1+c2k
- 1 | s1
Soit l2 un n-uplet qui n'est pas un des 2k n-uplets précédents (2n-2
k possibilités). De même
les 2k mots de la forme l2+c i ont même syndrome que l2 et constituent la deuxième ligne du
tableau de déchiffrement :
l1 l1+c1 l1+c2 . . . l1+c2k
- 1 s1
l2 l2+c1 l2+c2 . . . l2+c2k
- 1 s2
Ainsi de proche en proche, on peut construire un tableau à 2n/2
k=2
n -k lignes où le n-uplet
sur la i ième ligne et j ième colonne vaut l i+c j .Les 2n vecteurs de ce tableau sont tous les
n-uplets distincts (en effet s’il existait deux entiers i < j tels que c i+l i=c j+l j alors l j-l i=c j-c i
; mais le code étant linéaire c j-c i est un mot du code noté ck :l j-l i=ck ou l j=l i+ck : ceci

B. GELLER Les codes blocs l inéaires 13
signifierait que l 'on a pris un leader qui est déjà sur une ligne précédente ce qui est
contraire à la construction du tableau).
Les éléments li s 'appellent les leaders. On choisit souvent comme leaders les éléments de
poids le plus faible possible et pour un code linéaire de capacité de correction
e=Int.[(dmin-1)/2], tout n-uplet de poids inférieur ou égal à e peut être pris comme leader.
Exemple :
A = ℤ/2ℤ k=2 n=5
11100
H = 10010 G = 10110
01001 01101 Card C = 2k=4 mots : 0000000
0101101
1010110
1111011
Leaders Syndromes C (00000) (10110) (01101) (11011) (0,0,0) (10000) (00110) (11101) (01011) (1,1,0) (01000) (11110) (00101) (10011) (1,0,1) (00100) (10010) (01001) (11111) (1,0,0) (00010) (10100) (01111) (11001) (0,1,0) (00001) (10111) (01100) (11010) (0,0,1) (11000) (01110) (10101) (00011) (0,1,1) (10001) (00111) (11100) (01010) (1,1,1)

B. GELLER Les codes blocs l inéaires 14
7.5.2 IMPLANTATION MATERIELLE DE LA CORRECTION
i)Matériel nécessaire :
- Un automate câblé pour effectuer la multiplication matricielle du syndrome ( r 1 . . .rn )tH.
- Une mémoire de taille 2n -k
mots. Chaque mot est composé de deux parties : un syndrome
( taille (n-k)), un leader de classe correspondant (taille n).(Pour l’implantation, le
syndrôme peut être l’adresse où est mis en mémoire le leader correspondant.)
i i)Procédure de décodage :
1) Pour le dernier n-uplet reçu, calculer le syndrome r tH.
2) Identifier le syndrome dans le tableau de déchiffrement (physiquement dans la mémoire)
et sélectionner le leader de classe correspondant l.
3) Décider que cémis = r-l.
A la lumière des exemples précédents, on voit que les leaders du tableau de déchiffrement
l j peuvent s 'identifier avec les erreurs que l 'on veut corriger selon la capacité de correction
du code (code 1-correcteur dans notre exemple ) : r-l j =(c i+erreur)-l j = c i erreur = l j
La complexité du décodage par syndrome ramène la complexité exponentielle à un ordre de
grandeur 2n -k
par rapport à
2k du décodeur du maximum de vraisemblance. Ceci n’est
intéressant que si n-k<k soit R=k/n>1/2.
iii) Limitations d'un tel décodage:
C'est la réalisation matérielle.
En effet, on a vu que des codes pour assurer une certaine fiabilité devaient avoir une taille
suffisamment grande. Par exemple pour un code à symbole dans ℤ/2ℤ (n=100,k=70) sont
des valeurs raisonnables.
-Calculer le syndrome revient à calculer n -k équations linéaires à n cordonnées soit30x100
additions et multiplications si k=70 et n=100.
-Taille mémoire : 21 0 0 -7 0
=23 0
mots101 0 : gigantesque.

B. GELLER Les codes blocs l inéaires 15
SYNTHESE :
Nous avons appris à générer la redondance par une matrice génératrice G, détecter les
erreurs reçues par une matrice de redondance H décrivant les mêmes n -k équations
linéaires, et enfin corriger les erreurs par tableau de déchiffremen t. Mis à part le cas des
codes de petites tailles (simples), la réalisation pratique de tels décodeurs est trop
complexe.
C'est la raison pour laquelle les élèves - ingénieurs suivant le cours IN202 de Réseaux
étudieront, une classe spéciale de codes linéaires, dont la structure algébrique est beaucoup
plus subtile, mais dont la réalisation du décodeur est rendue simple.

B. GELLER Les codes blocs l inéaires 16

64

Annexe A
Exercices pour le chapitre 1 :Outils de la théorie de l’information
A.1 Débit d’un modem téléphonique.
Sur le réseau NUMERIS le signal de parole est échantilloné à 8 kHz (largeurde bande maximale < 4 kHz par le théorème d’échantillonnage de Nyquist).Chaque échantillon du signal de parole est ensuite quantifié sur 256 niveauxd’amplitude. Calculer le taux de codage R et le débit binaire correspondant enkb/s.
A.2 Variable gaussienne.
Calculer la moyenne et la variance de la v.a. X de distribution de probabilité :
p(x) = 1p2πσ2
e− (x−µ)2
2σ2
où µ et σ2 > 0 sont des paramètres. Commenter.
A.3 Formule de Bayes. Traitement réciproque
Montrer la formule de Bayes :
p(x|y) = p(y |x)p(x)∑∫x
p(y |x)p(x).
Commenter cette formule en considérant le «traitement réciproque» d’entrée Yet de sortie X .
65

A.4 Chaînes de Markov.
1. En s’aidant de la formule p(x, y) = p(x)p(y |x), montrer la même formuleconditionnée par z :
p(x, y |z) = p(x|z)p(y |x, z)
2. En déduire que X → Y → Z forme une chaîne de Markov si et seulementsi X et Z sont indépendants sachant y , i.e. :
p(x, z|y) = p(x|y)p(z|y)
3. Montrer que si X → Y → Z est une chaîne de Markov, alors la chaîne«réciproque» Z → Y → X l’est aussi.
A.5 Positivité de la divergence.
1. Montrer que la fonction logarithme est strictement concave.
2. En déduire l’inégalité de Jensen :
E log2 f (X )6 log2 E f (X )
avec égalité si et seulement si la fonction f est constante p.p.
3. En considérant −D(p, q) démontrer le résultat fondamental du coursconcernant la positivité de la divergence.
4. (Facultatif) Retrouver ce résultat avec l’inégalité loge x 6 x −1.
A.6 Propriétés de l’entropie.
On considère l’entropie H(X ) d’une v.a. discrète X (pouvant prendre unnombre fini M de valeurs).
1. Montrer que H (X ) est une «auto-information» H (X ) = I (X , X ). Interpréterce résultat.
2. Montrer que H(X )> 0 et déterminer le cas d’égalité.
3. En s’aidant du résultat fondamental sur les divergences (inégalité deGibbs), montrer que H(X )6 log2 M et déterminer le cas d’égalité.
66

A.7 La connaissance réduit l’incertitude.
Montrer et interpréter (dans le cas de v.a. discrète) l’inégalité suivante :
H(Y |X )6 H(Y ).
La connaissance réduit-elle toujours l’incertitude ?
A.8 Entropie différentielle et entropie absolue.
(Facultatif).On considère une v.a. continue X que l’on quantifie uniformément avec un
pas de quantification q pour obtenir une v.a. discrète [X ].En approximant l’intégrale H(X ) = ∫
x p(x) log21
p(x) par une somme de Rie-mann, établir que
H(X ) ≈ H([X ])− log2(1/q)
Interpréter ce résultat lorsque q → 0 et expliquer le terme «entropie différen-tielle».
67

68

Annexe B
Exercices pour le chapitre 2 :Application de la théorie del’information au codage
B.1 Démontration du théorème du traitement de don-nées.
1. A l’aide des deux formules p(x, y) = p(x)p(y |x) et p(x, y |z) = p(x|z)p(y |x, z)(voir exo leçon 1), démontrer la formule :
I ((X ,Y ); Z ) = I (X , Z )+ I (Y , Z |X )
2. On considère dorénavant une chaîne de Markov X → Y → Z . DévelopperI ((X ,Y ); Z ) de deux manières différentes et en déduire le théorème dutraitement de données dans un cas particulier : I (Y , Z )> I (X , Z ).
3. Sachant que Z → Y → X est également une chaîne de Markov (voir exoleçon 1), montrer que I (X ,Y )> I (X , Z ).
4. En déduire l’énoncé général du théorème du traitement de données.
B.2 Fonction taux-distorsion : Cas extrêmes.
On considère la fonction taux-distorsion R(D) pour une source sans mé-moire.
1. Cas D = 0 (codage sans pertes). Etablir la borne de Shannon R(D = 0) dansce cas. Commenter
2. Cas R = 0 (pas de transmission). Etablir D à la borne de Shannon R(D) = 0dans ce cas. Comenter.
69

B.3 Entropie d’une source gaussienne.
1. Calculer l’entropie différentielle H(X ) lorsque X est une v.a. gaussienne.Commenter.
2. Montrer que l’entropie d’une v.a. X de variance σ2 est maximale lorsqueX est gaussienne.
B.4 Fonction taux-distorsion : Cas gaussien.
On considère une source gaussienne sans mémoire de moyenne nulle et devariance σ2.
1. Montrer que R(D) = H(X )−max H(X |Y ).
2. Trouver le maximum de l’entropie conditionnelle sachant que H(X |Y ) =H (X −Y |Y )6 H (X −Y ). Justifier que ce maximum peut être effectivementatteint.
3. En déduire l’expression cherchée de R(D).
70

Annexe C
Exercices pour le chapitre 3 :Codage entropique à longueurvariable
C.1 Condition du préfixe.
1. Justifier qu’un code vérifiant la condition du préfixe est décodable demanière instantanée.
2. Réciproquement, montrer qu’un code instantané vérifie la condition dupréfixe.
3. En utilisant les résultats du cours sur l’inégalité de Kraft-McMillan, mon-trer que tout code u.d. peut être remplacé par un code instantané (à pré-fixe) de même distribution de longueurs et donc de même taux. Commen-ter.
C.2 Démonstration de l’inégalité de Kraft-McMillan.
1. Montrer que pour un code u.d., toute séquence de l bits peut se dé-composer d’au plus une façon comme concaténation de mots de codesci1 ci2 · · ·cik où li1 + li2 +·· ·+ lik = l .
2. En déduire que le nombre total Nl (k) de concaténations possibles de kmots de codes donnant une séquence codée de longueur totale l bitsvérifie l’inégalité : Nl (k)6 2l .
3. Montrer par ailleurs que
(M∑
i=1x li )k =∑
lNl (k)x l
71

4. Conclure en faisant x = 1/2 et k →∞.
C.3 Construction d’un code instantané.
On se donne une distribution de longueurs l1 6 l2 6 . . . 6 lM vérifiant l’in-égalité de Kraft-McMillan. A chaque mot de code ci (à trouver) on associe lenombre c̄i = 0,ci ∈ [0,1[ dont les décimales de l’écriture en base 2 est formée desbits de ci . On note Ii l’intervalle Ii = [c̄i ; c̄i +2−li [.
Par exemple, ci = 010 donne c̄i = 0,010 = 14 . et Ii = [0,010;0,011[= [ 1
4 ; 38 [ est
l’ensemble des nombres de [0;1[ dont les décimales en base 2 commencent parci .
1. Montrer que ci détermine Ii , et réciproquement.
2. Montrer que le code est instantané si et seulement si les Ii sont des inter-valles disjoints.
3. Interpréter l’inégalité de Kraft-McMillan sur les Ii est en déduire un algo-rithme de construction du code.
4. Préciser cet algorithme sur des exemples pour l1 6 l2 6 . . .6 lM , en com-mençant par c̄1 = 0.0. . .0, et en posant c̄i+1 = extrémité droite de Ii àchaque étape.
5. Que se passe-t-il si les li ne vérifient pas l’inégalité de Kraft-McMillan ?Donner un exemple.
C.4 Algorithme de Huffman. Préliminaires
On considère un code VLC optimal pour une source de distribution deprobabilité p1 > p2 > · · ·> pM .
1. Montrer que nécessairement l1 6 l2 6 · · ·6 lM (raisonner par l’absurde ensupposant pi > p j et li > l j ). Commenter.
2. Montrer que nécessairement l’inégalité de Kraft McMillan est une égalité(raisonner par l’absurde en supposant
∑i 2−li < 1, et montrer qu’alors on
peut remplacer lM par lM −1).
3. Déduire du raisonnement de la question précédente que lM−1 = lM , etqu’on peut toujours se ramener au cas où les deux mots de codes cM−1 etcM ne diffèrent que par le dernier bit.
72

C.5 Algorithme de Huffman.
On considère une source M-aire de distribution de probabilité p1 > p2 >· · ·> pM . La réduction de Huffman consiste à considérer la source (M −1)-aire,dite «réduite», de distribution de probabilité p1, p2, · · · , pM−2, p ′
M−1 = pM−1+pM
(on «combine» les deux symboles les moins probables).On note {c1, . . . ,cM−1,cM } le code optimal cherché (à l’ordre M). D’après ci-
dessus, cM−1 et cM ne diffèrent que par le dernier bit ; on peut écrire cM−1 =[c ′M−10] et cM = [c ′M−11]
1. En comparant les taux de codage de la source initiale et de la source réduiteaprès réduction de Huffman, montrer que le code
{c1, . . . ,cM−2,c ′M−1}
est optimal pour la source réduite.
2. Donner un moyen de contruire le code optimal {c1, . . . ,cM−1,cM } à partirde {c1, . . . ,cM−2,c ′M−1}.
3. Par réductions de Huffman successives jusqu’au cas M = 2 (où le code {0,1}est optimal), obtenir un algorithme de construction du code {c1, . . . ,cM−1,cM }.
N.B. : Il faut réordonner à chaque étape les probabilités après chaqueréduction de Huffman.
73

74

Annexe D
Exercices pour le chapitre 4 :Quantification scalaire.
D.1 Caractéristique Débit-Distorsion en haute réso-lution
On effectue une quantification scalaire uniforme haute résolution d’unesource quelconque de variance σ2 et de densité de probabilité à support bornédans [−A, A].
1. Calculer la distorsion en fonction du taux de quantification. On écrira lerésultat en fonction du facteur γ= A
σ.
2. Expliquer le terme «6 dB par bit» pour qualifier la caractéristique dé-bit/distorsion.
D.2 Minima locaux de l’algorithme de Lloyd-Max.
On considère un signal aléatoire X de densité de probabilité :
p(x) =
1 pour 16 x 6 1.5
2 pour −1.256 x 6−1
0 sinon.
Il est quantifié scalairement sur 3 niveaux. On considère les deux solutionssuivantes caractérisées par la position des centroïdes :
{−1− 3
16,−1− 1
16,1.25} et {−1− 1
8,1+ 1
8,1+ 3
8}
75

1. Donner, pour chacune de ces solutions, les cellules de quantificationoptimales.
2. Vérifier que ces deux situations vérifient les conditions de convergence(point stationnaire) de l’algorithme de Lloyd-Max.
3. Calculer la contribution à la distorsion quadratique d’une cellule du type[−q, q] correspondant à une amplitude A de la densité de probabilité.
4. En déduire les valeurs des distorsions totales dans les deux cas considérés.Quelle est la solution la meilleure ?
5. Qu’en déduire sur l’algorithme de Lloyd-Max ? La fonction log p(x) est-elleconcave ?
D.3 Densité des cellules de quantification
Justifier que λ(x) = 1M q(x) représente la «densité» des cellules en évaluant
l’intégrale∫
I λ(x)d x prise sur un intervalle I .
D.4 Optimisation de la formule de Bennett
1. Dans la formule de Bennett, quelle est la densité des cellules λ(x) = 1M q(x)
qui minimise la distorsion ? Indication : Ecrire le lagrangien correspon-dant.
2. Calculer la distorsion minimale correspondante.
3. Appliquer ces résultats à la source gaussienne.
D.5 Réalisation de la quantification scalaire non uni-forme par non-linéarités.
On réalise une quantification scalaire non uniforme d’une source U de lamanière suivante : On transforme d’abord la source X = f (U ) à l’aide d’une fonc-tion non lineaire f . On applique ensuite une quantification scalaire uniforme àX qui fournit Y , et on applique enfin la non-linéarité inverse V = f −1(Y ).
1. Faire un dessin.
2. Sous les hypothèses de haute résolution, déterminer la densité des cellulesλ(u) = 1
M q(u) en fonction de la non-linéarité f .
3. En déduire la non-linéarité optimale qui rend la distorsion quadratiqueminimale, en fonction de la densité de probabilité de la source p(u). Indi-cation : Utiliser l’exercice précédent.
76

D.6 Quantification vectorielle
En quantification vectorielle en dimension n, on attribue à chaque vecteur desource X = (X1, X2, . . . , Xn) une étiquette binaire correspondant à un centroïdeY en dimension n.
1. Reprendre, dans le cas vectoriel, les conditions du plus proche voisin etdu centroïde vues en cours.
2. En déduire l’algorithme de Lloyd-Max dans ce cas.
3. Montrer que l’algorithme de Lloyd-Max peut converger vers un minimumlocal, même si log p(x) est concave. On considérera pour cela une sourceuniforme X dans l’intervalle [−1,1] quantifiée en dimension 2 sur 1 bitpar échantillon (c’est à dire 4 centroïdes en 2 dimensions) et les deuxsituations suivantes :
centroïdes y = (±1
2,±1
2)
et
centroïdes y = (±1
4,0) et (±3
4,0).
77

78

Annexe E
Exercices pour le chapitre 5 :Codage par transformée
E.1 Gain de Codage
1. Donner l’inégalité de concavité du logarithme.
2. En déduire que le gain de codage par transformée est toujours > 1. Quelest le cas d’égalité ?
3. Donner un exemple de source pour laquelle le gain de codage est tou-jours = 1.
E.2 Inégalité de Hadamard
Soit X un vecteur aléatoire, de composantes Xi de variance σ2i . On définit la
matrice d’autocovariance :R = E (X ·X t ).
1. Donner les coefficients ri , j de la matrice R.
2. Quelle est la forme particulière de R pour des composantes Xi décorré-lées ?
3. Les composantes réduites sont X ′i = Xi
σi. Donner la matrice d’autocova-
riance R ′ des X ′i en fonction de R.
4. En déduire detR en fonction de detR ′ et des σ2i .
5. Montrer que detR ′ 6 1 (raisonner sur les valeurs propres de R ′).
6. En déduire l’inégalité de Hadamard :
detR 6∏
iσ2
i
79

7. Quel est le cas d’égalité ?
E.3 Transformée de Karhunen-Loève
1. En considérant le gain de codage, montrer que la transformée optimaleest celle qui minimise le produit des variances en sortie de la transformée.
2. A l’aide de l’inégalité de Hadamard, montrer que la transformée optimaleest celle qui décorrèle la sortie.
3. Comment obtenir la transformée optimale à partir de RX X
= E(X X t ) ?
Cette transformée s’appelle la transformée de Karhunen-Loève.
4. Expliciter le gain de codage optimal.
5. Pour quel type de source le codage par transformée s’avère-t-il inutile ?Est-il pour autant nuisible ?
E.4 Codage par transformée pour n = 2
bits codés
U2
U1
-
-
C2
C1
-
-
Q2
Q1
-
-
Tsource X
-
On considère un schéma de codage de source par transformée orthogonaledont la partie «codage» est représentée dans la figure. Chaque bloc de sourceX = ( X1
X2
)est transformée en deux échantillons
(U1U2
)=U avant d’être quantifié etcodé. On a donc :
U = T ·X
où T est la matrice de la transformée orthogonale (TTt = I).Les quantificateurs sont scalaires uniformes et les codeurs entropiques sont
des codeurs de Huffmann. Pour chaque branche i (i = 1,2), la distorsion quadra-tique moyenne dûe au quantificateur Qi est notée Di et le taux binaire moyenaprès codage de Huffmann Ci est noté Ri .
On modélise les signaux en sortie de transformée par des sources lapla-ciennes de variances σ2
1 et σ22. On admet la relation :
Di = cσ2i 2−2Ri pour i = 1,2
80

où c est une constante.
1. Justifier, d’après le cours, que les distorsion quadratique moyenne globaleD et taux global R sont donnés par :
D = D1 +D2
2et R = R1 +R2
2
2. Justifier (sans calcul), d’après le cours, qu’après optimisation des taux R1
et R2 la distorsion minimisée est donné par la formule :
D∗ = cσ1σ22−2R
La matrice d’autocorrélation du signal d’entrée X est donnée par :
R = E(X X t ) =σ2X ·
(1 ρ
ρ 1
)où ρ est un coefficient de corrélation (−1 < ρ < 1).
3. Calculer la matrice d’autocorrélation de U en fonction de R et T.
4. En déduire la matrice d’autocorrélation de U lorsque
T =β ·(1 11 −1
)(On déterminera d’abord la valeur de β pour que T soit orthogonale).
5. Justifier que la transformée optimale est celle donnée à la question précé-dente. Sous quel nom est-elle connue ?
6. Donner l’expression de la distorsion D∗ pour cette transformée en fonc-tion de c, σ2
x , ρ et R.
7. Qu’observe-t-on si ρ augmente ? Commenter.
81


















