
Identificação de Processos Industriais utilizando...
89
UNIVERSIDADE FEDERAL DE SANTA CATARINA CURSO DE ENGENHARIA DE CONTROLE E AUTOMAÇÃO INDUSTRIAL Identificação de Processos Industriais utilizando tecnologia Foundation Fieldbus Monografia submetida à Universidade Federal de Santa Catarina como requisito para a aprovação da disciplina: DAS 5511 Projeto de Fim de Curso Gustavo Martins Concer Florianópolis, Outubro de 2005
Transcript of Identificação de Processos Industriais utilizando...

UNIVERSIDADE FEDERAL DE SANTA CATARINA
CURSO DE ENGENHARIA DE CONTROLE E AUTOMAÇÃO INDUSTRIAL
Identificação de Processos Industriais
utilizando tecnologia Foundation Fieldbus
Monografia submetida à Universidade Federal de Santa Catarina como requisito
para a aprovação da disciplina:
DAS 5511 Projeto de Fim de Curso
Gustavo Martins Concer
Florianópolis, Outubro de 2005

2
Identificação de Processos Industriais utilizando tecnologia
Foundation Fieldbus
Monografia submetida à Universidade Federal de Santa Catarina
como requisito para a aprovação da disciplina:
DAS 5511: Projeto de Fim de Curso
Gustavo Martins Concer
Florianópolis, Outubro de 2005

Identificação de Processos Industriais utilizando tecnologia Foundation Fieldbus
Gustavo Martins Concer
Esta monografia foi julgada no contexto da disciplina DAS 5511: Projeto de Fim de Curso
e aprovada na sua forma final pelo Curso de Engenharia de Controle e Automação Industrial
Banca Examinadora:
Eng.º Luis Carlos Geron Orientador Empresa
Prof. Msc. Agustinho Plucenio Orientador do Curso
Prof. Augusto Humberto Bruciapaglia Responsável pela disciplina
Prof. Julio Elias Normey Rico, Avaliador
Hugo Rocha Barros Vieira de Oliveira, Debatedor
Marcelo Pires Adur, Debatedor

i
Agradecimentos
Agradeço à Smar Equipamentos Industriais pela oportunidade e condições
favoráveis fornecidas ao longo do projeto.
Também à Agência Nacional do Petróleo – ANP, e da Financiadora de
Estudos e Projetos – FINEP, por meio do Programa de Recursos Humanos da ANP
para o Setor de Petróleo e Gás PRH-34 ANP/MCT.
Não poderiam faltar os meus agradecimentos aos orientadores Prof. Daniel
Pagano e Prof. Agustinho Plucenio da Universidade Federal de Santa Catarina, e ao
Eng. Luís Carlos Geron da Smar. Aos demais colegas do Departamento de
Engenharia de Aplicações e do Setor de Desenvolvimento Eletrônico da Smar pelo
suporte oferecido ao longo das atividades realizadas.
Em especial, gostaria de agradecer à minha família por todo o apoio
desempenhado ao longo destes anos de faculdade que possibilitaram o
desenvolvimento de todo trabalho relatado neste documento.

ii
Resumo
A tecnologia de informação está hoje se popularizando, estando presente no
comércio, nos bancos, nos meios de transporte, em nossas casas e na indústria
principalmente. Uma tendência atual é a pressão pela padronização exigindo que os
fornecedores de tecnologia se adaptem a novas normas e padrões. Os
componentes estão evoluindo rapidamente em termos de memória e capacidade de
processamento, e o hardware tendo seu custo reduzido. No ramo de controle de
processos o uso de redes do tipo Foundation Fieldbus apresenta diversas
vantagens que vão a favor desta corrente de especificações. Foundation Fieldbus
consiste em uma solução completa para sistemas de controle baseados em redes.
Um sistema aberto regido pela Fieldbus Foundation que possui uma linguagem de
blocos funcionais padronizada para implementar as funções de controle do sistema.
Para tornar este sistema mais abrangente, novos blocos funcionais vêm sendo
desenvolvidos como os blocos funcionais para compensação de atraso Transfer
Function e Smith Predictor. Este trabalho visa o melhoramento destes blocos com o
objetivo de tornar o seu uso mais simples. Para isso foi elaborado um algoritmo de
identificação de sistemas de primeira e segunda ordem estáveis, para
implementação na empresa como uma nova funcionalidade do bloco Transfer
Function, que vai auxiliar o usuário na etapa de configuração do mesmo, além de
estimulá-lo no seu uso.

iii
Abstract
The information technology is becoming popular, being present in the
commerce, banks, means of transportation and specialy in the industry. A current
trend is the pressure for standardization demanding that suppliers conform to the
new norms ands standards. Components are quickly improving in terms of memory
and processing capacity and hardware having its cost reduced. To the process
control branch, the use of Foundation Fieldbus nets brigns a lot of advantages that
are in behalf of actual specifications chain. Foundation Fieldbus is a complete
solution for nets based control systems. An open system, conducted by the Fieldbus
Foundation, that has a language of standardized function blocks to implement all
control functions of the system. New function blocks have been developed in order to
make the tecnology more complete, like the ones for delay compensation as the
Transfer Function and Smith Predictor block. This work aims at the improvement of
these blocks and the objective is to make its use simpler. A system identification
algorithm for first and second order stable plants was elaborated to do this. It will be
implementated in the company as a new functionality of the Transfer Function block,
that will assist the user in the stage of block configuration and stimulate its use.

iv
Sumário
Agradecimentos................................................................................................. i
Resumo ............................................................................................................ ii
Abstract ........................................................................................................... iii
Sumário ........................................................................................................... iv
Capítulo 1: Introdução ......................................................................................1
1.1: O Programa de Formação de Recursos Humanos................................5
1.2: A Empresa .............................................................................................5
1.3: A Metodologia de trabalho .....................................................................6
Capítulo 2: Funcionamento de uma rede do tipo Foundation Fieldbus. ...........8
2.1: Arquitetura de uma Rede Foundation Fieldbus .....................................8
2.2: Blocos de Função (Function Blocks)......................................................9
2.3: O Protocolo ..........................................................................................10
2.3.1: Camada Física ..............................................................................12
2.3.2: Camada de Enlace de Dados (DLL Data Link Layer) ...................13
2.3.3: Camada de Aplicação ...................................................................16
2.3.4: Camada de Usuário ......................................................................19
2.4: Configurando uma rede Foundation Fieldbus......................................20
2.5: Os Blocos Funcionais Transfer Function e Smith Predictor.................23
2.5.1: Transfer Function ..........................................................................25
2.5.2: Smith Predictor ..............................................................................25
2.5.3: Estratégia para compensação de atraso.......................................27
2.6: Vantagens da tecnologia .....................................................................28

v
Capítulo 3: Conceitos sobre Identificação de Processos Monovariáveis com
Modelos Lineares......................................................................................................30
3.1: Introdução ............................................................................................30
3.2: Técnicas de Identificação ....................................................................31
3.2.1: Estimador dos Mínimos Quadrados Não Recursivo......................33
3.2.2: Estimador do Mínimos Quadrados Recursivo ...............................35
3.3: Validação do Modelo ...........................................................................40
Capítulo 4: O Algoritmo de Identificação proposto .........................................42
4.1: A Tecnologia OPC ...............................................................................42
4.2: O Algoritmo ..........................................................................................43
4.2.1: Método Não Recursivo x Método Recursivo .................................44
4.2.2: Ensaio de Identificação .................................................................45
4.2.3: Etapa de Pré-Teste .......................................................................46
4.2.4: Etapa de Identificação...................................................................49
4.2.5: Implementação da Validação ........................................................51
4.2.6: Transformada S.............................................................................52
4.3: Proposta de Bloco Funcional ...............................................................52
Capítulo 5: Identificação com blocos já existentes na tecnologia Foundation
Fieldbus.....................................................................................................................54
5.1: O Bloco Flexible Mathematical.............................................................54
5.2: A Estratégia .........................................................................................55
5.2.1: Operações.....................................................................................55
5.2.2: Configuração dos Blocos ..............................................................56
Capítulo 6: Resultados e Discussão...............................................................60
6.1: Resultados de Simulação ....................................................................60
6.1.1: Planta de Primeira Ordem.............................................................61
6.1.2: Planta de Segunda Ordem............................................................66

vi
6.2: Resultados Reais.................................................................................70
6.2.1: Processo de Vazão com inserção de Atraso.................................70
6.2.2: Processo de Temperatura.............................................................74
Capítulo 7: Conclusões e Perspectivas ..........................................................78
Bibliografia:.....................................................................................................80

1
Capítulo 1: Introdução
Em tempos onde a competitividade dita o ritmo de desenvolvimento das
empresas e a complexidade dos processos de produção exige cada vez mais da
instrumentação encontrada nas plantas industriais, muitas tentativas de
modernização em busca de mais eficiência podem ser visualizadas. Pode-se notar
atualmente o surgimento de muitas alternativas tecnológicas com o objetivo de
suprir a demanda por novas funcionalidades ou melhores características de
operação dos sistemas industriais de produção.
Com o setor petrolífero não é diferente. A tecnologia de redes para o controle
de processos é uma alternativa hoje bastante freqüente nestas plantas industriais,
possibilitando integração entre os dispositivos componentes destes sistemas que
podem operar conjuntamente. A comunicação, antes predominantemente analógica,
vai migrando para sistemas digitais permitindo maior quantidade de informação
tratada, as mais variadas funções de controle e supervisão executadas, além da
considerável redução de hardware que a comunicação digital permite.
Figura 1 – Fieldbus é uma tecnologia inovadora em automação
Uma destas redes de controle é a do tipo Foundation Fieldbus [1]. Esta é a
rede encontrada no projeto da Automação de um Sistema de Separação de Petróleo
realizado pela empresa Smar em parceria com a empresa contratante do serviço. A
função principal de um separador por gravidade é disponibilizar as três fases do
petróleo (água, óleo e gás) vindo do poço, da forma mais pura possível. Um dos
desafios enfrentados neste projeto foi a compensação de atraso de transporte

2
necessária ao controle do processo de injeção de desemulsificante existente no
separador. A injeção de desemulsificantes é feita com o intuito de reduzir a emulsão
formada pela mistura entre água e óleo durante o processo de elevação do petróleo
para a plataforma que dificulta o controle de nível no separador. O atraso existe pois
há um “tempo morto” entre a injeção do desemulsificante e a conseqüente medição
de redução do percentual de água no óleo dentro do separador.
Figura 2 - Visão Geral de um Separador trifásico por gravidade
O efeito prejudicial do atraso em um sistema de controle pode ser entendido
a partir do seu conceito. Segundo [11], a técnica de controle consiste em três
passos: Medir a variável a controlar; Comparar o valor medido com o valor desejado
e; Agir no sistema no sentido de diminuir a diferença entre ambos os valores. Um
exemplo é o processo de controle de temperatura de água (Figura 3), onde a
variável controlada a ser medida é a temperatura da água aquecida. O valor desta
temperatura é comparado com a temperatura desejada para a água e uma ação
sobre a válvula de controle de vapor que aquecerá a água é tomada neste sentido.
Figura 3 – Controle de temperatura

3
A presença de um tempo morto entre a atuação (abertura ou fechamento da
válvula de vapor) e a medição do efeito desta ação (aumento ou redução da
temperatura) neste processo, consiste na demora da temperatura “começar a reagir”
a uma variação no sinal de abertura da válvula de vapor. Isto é ruim para o sistema
de controle pois a ação de abrir a válvula de vapor não provocará efeito imediato de
aumento de temperatura fazendo com que o sistema de controle forneça uma
abertura maior do que a necessária à válvula. Após o tempo morto, a temperatura
começará a aumentar e provavelmente aumentará mais do que o desejado e as
ações de controle posteriores tornarão o sistema oscilatório ou até instável.
Uma maneira de lidar com o atraso de transporte é tentar compensá-lo de
forma a poder controlar o processo como se o atraso não estivesse presente. Muitos
processos ligados à área do petróleo, por se tratarem de processos envolvendo
transporte de matéria ou energia, apresentam esta característica. Quando este
atraso é considerável, o controle fica dificultado, exigindo o uso de estruturas
especiais de controle para compensação do atraso. A teoria clássica apresenta a
estrutura do Preditor de Smith como solução para este problema.
Figura 4 - Diagrama de Blocos do Preditor de Smith
Em vista disso, a empresa providenciou o desenvolvimento de novas
funcionalidades ao seu sistema de controle do tipo Foundation Fieldbus através da
criação de novos blocos funcionais dentro da filosofia da tecnologia. Este trabalho
foi realizado por um bolsista egresso do programa de formação de recursos
humanos da ANP durante a realização de seu projeto de fim de curso [8] na
empresa e originou a necessidade do desenvolvimento do trabalho relatado neste
presente documento.

4
Duas novas funcionalidades foram criadas: um bloco para representação de
funções de transferência no domínio freqüencial “s” e outro para implementar
estrutura semelhante à do Preditor de Smith. Assim seria possível disponibilizar esta
alternativa de controle para outros projetos futuros que necessitassem de uma
solução como esta.
No entanto, a estrutura do Preditor de Smith requer para seu funcionamento,
um conhecimento adequado dos parâmetros matemáticos que compõe a função de
transferência, que representa o modelo do processo a ser controlado. Este
reconhecimento se faz através da modelagem matemática destes sistemas, ou
geralmente, através de ensaios de identificação realizados em procedimento de
partida dos mesmos.
O objetivo do presente trabalho é, portanto, o estudo de uma técnica de
identificação de processos industriais monovariáveis que possa ser aplicada para
suporte ao uso dos dois blocos criados e venha a estimar de forma automática os
coeficientes da função de transferência do processo necessária ao Preditor. Será
estudada então a viabilidade de implementar uma técnica como esta na forma de
uma nova funcionalidade à tecnologia.
Um desenvolvimento como este é muito importante pois se sabe que no setor
industrial muitas vezes nem todas as pessoas que operam os processos de
produção têm conhecimento de estruturas avançadas como o Preditor de Smith e
representações de processos como funções de transferência. Assim, tudo que
venha a simplificar o trabalho, desta forma com a automação da tarefa de
identificação é de muita utilidade ao setor.
Para o cumprimento do trabalho, as disciplinas da área de controle de
processos do Curso de Engenharia de Controle e Automação foram de grande
utilidade para elaboração do algoritmo de identificação. Além destas, as disciplinas
de Redes de Computadores e Instrumentação para Controle e Automação foram
bastante úteis para o entendimento da tecnologia utilizada no trabalho. Muito
importante também foram os conceitos adquiridos ao longo das disciplinas de
especialização, cursadas no programa de formação de recursos humanos – PRH
34, que propiciaram um contato inicial direto com a instrumentação utilizada na
pesquisa e muito freqüente em diversos segmentos da indústria.

5
1.1: O Programa de Formação de Recursos Humanos
Este trabalho está inserido no último período dentro da grade curricular do
curso de Engenharia de Controle e Automação da Universidade Federal de Santa
Catarina e também no último período da etapa de especialização dentro do
programa de formação de recursos humanos da ANP. O PRH-34 é um dos muitos
programas acadêmicos financiados pela ANP – FINEP, que se destina a formar
Engenheiros nas áreas de Automação, Controle e Instrumentação do setor de
Petróleo e Gás.
Para a Engenharia de Controle e Automação Industrial, o programa tem a
missão de propiciar ao engenheiro uma formação complementar que forneça
conhecimentos a respeito das indústrias do petróleo e gás, evidenciando as
características diferenciadas dos processos deste tipo de indústria. Pretende-se
também disponibilizar uma formação específica em sistemas de controle,
automação, instrumentação e informática industrial particulares destas indústrias,
fornecendo conhecimentos básicos necessários para a participação em atividades
de Pesquisa e Desenvolvimento nesta área.
O PRH-34, através de seus projetos e parcerias com o setor industrial vem
propiciando a realização de estágios curriculares a seus integrantes como este
realizado na empresa SMAR Equipamentos Industriais.
1.2: A Empresa
A SMAR Equipamentos Industriais foi fundada em 1º de abri de 1974 com
objetivo de prestar serviços de campo para turbinas à vapor da indústria açucareira
brasileira. Seus co-fundadores Sr. Mauro Sponchiado e Sr. José Martinussi
aproveitaram seus sobrenomes para formar o nome da empresa. A sua matriz
encontra-se instalada na cidade de Sertãozinho – SP com filiais espalhadas
estrategicamente pelo Brasil e escritórios em diversos países do mundo.
A empresa continuou prestando serviços de manutenção em turbinas à vapor
até 1978. Foi quando a indústria açucareira começou a utilizar as novas turbinas a
vapor com reguladores de velocidade eletrônicos.

6
Não habituada a trabalhar com eletrônica, buscou assessoramento. O Sr.
Edmundo Gorini e seus colegas Paulo Lorenzato e Carlos Liboni aceitaram o convite
de tornarem-se sócios da Smar. Logo em seguida, Sr. Caldeira, também um
engenheiro, integrou-se a empresa. Este foi o início de uma nova era para a
empresa. Nessa época, a empresa era composta por 13 pessoas, sendo 10 sócios
e 3 funcionários.
A prestação de serviço em turbinas à vapor proporcionou o capital para os
trabalhos iniciais de Pesquisa e Desenvolvimento. A empresa cresceu rapidamente,
impulsionada por uma iniciativa bem sucedida do governo federal, o Pró-álcool, que
visava substituir a gasolina por álcool como combustível de veículos automotores.
Em 1981, com o decréscimo dos investimentos na indústria sucro-alcooleira,
a empresa decidiu partir para o projeto de uma linha de instrumentos para controle
de processos. Essa decisão foi bem sucedida e a empresa continuou crescendo.
Em 1986, com seu contínuo crescimento no mercado nacional, a empresa
buscou se expandir no mercado internacional. Após testar os novos produtos no
mercado brasileiro, a SMAR incrementou seus esforços de venda, inicialmente nos
Estados Unidos, a partir de 1989, e depois na Europa, a partir de 1990.
Em 1988 a SMAR tornou-se o maior fabricante de instrumentos para controle
de processos no Brasil. Atualmente, mais de um terço da produção da empresa são
vendidos no mercado internacional. Como o mercado mundial para produtos como
os que a SMAR produz movimenta mais de 5 bilhões de dólares por ano, a empresa
tem enormes possibilidades para continuar a crescer ao longo dos próximos anos.
1.3: A Metodologia de trabalho
Nos próximos capítulos serão apresentados de início uma introdução à
tecnologia de Redes do tipo Foundation Fieldbus assim como os conceitos básicos
para entendimento deste documento. A seguir serão passados os conceitos de
identificação de processos assim como as duas técnicas de identificação estudadas
ao longo do trabalho. É reservado um capítulo para o algoritmo de identificação
proposto neste trabalho assim como os testes executados com o mesmo. Por fim
são apresentados uma solução em identificação feita com os recursos já existentes
na tecnologia e os resultados que comprovam a viabilidade de implementação de

7
mais uma nova funcionalidade à tecnologia. Ao final de tudo as conclusões e
perspectivas futuras são discutidas.

8
Capítulo 2: Funcionamento de uma rede do tipo Foundation
Fieldbus.
A tecnologia Foundation Fieldbus [1] consiste em um protocolo de
comunicação serial digital bidirecional. O fato de ser bidirecional significa que os
equipamentos conectados a rede desempenham papel de emissor e receptor de
dados embora não simultaneamente. A utilização de dispositivos de campo
(transmissores, posicionadores, etc) com processadores embarcados também
permite que os mesmos desempenhem funções de controle tornando possível
implementar controle distribuído. Foundation Fieldbus é essencialmente uma rede
local (LAN) para os dispositivos de campo.
Embora se trate de um protocolo complexo, o conhecimento completo de
como a tecnologia funciona internamente não é fundamental para o seu uso, pois os
fabricantes tipicamente o implementam de tal forma a aparecer transparente aos
usuários. Entretanto, o desenvolvimento de projetos que utilizem esta tecnologia
exige treinamento por parte dos projetistas.
2.1: Arquitetura de uma Rede Foundation Fieldbus
Uma rede fieldbus admite dois níveis físicos em sua arquitetura. O nível H1 e
o nível HSE. O primeiro opera com velocidade de 31,25 Kbit/s e efetua a conexão
entre os equipamentos encontrados no chão de fábrica (atuadores, sensores e
dispositivos de entrada e saída I/O). O nível superior ao H1, conhecido como HSE
(High Speed Ethernet), opera a uma taxa de 100 Mbits/s, e é quem liga o nível H1
às estações de operação, aos controladores mais rápidos como CLP’s além de
permitir a conexão entre diferentes níveis H1. Há um dispositivo responsável pela
ligação entre os dois níveis H1 e HSE que é conhecido como Linking Device e
desempenha o papel de ponte entre os mesmos. A topologia de uma rede fieldbus
pode ser vista na Figura 5. No sistema desenvolvido pela SMAR, quem desempenha
o papel da ponte é um instrumento denominado DFI que também exerce a função
de LAS. O papel do LAS dentro da rede fieldbus é descrito na seção 2.3 deste
mesmo capítulo.

9
Figura 5 - Topologia de uma rede fieldbus
Figura 6 - Detalhe da conexão dos dispositivos ao barramento do canal H1 da rede fieldbus
2.2: Blocos de Função (Function Blocks)
A base fundamental para implementar a distribuição das funções de controle
ao longo dos equipamentos em campo é uma entidade chamada bloco, que
representa uma função ou algoritmo como, por exemplo, um controlador PID, um
integrador, entrada ou saída analógica, entrada ou saída discreta, etc. Por essa
razão a tecnologia é normalmente chamada de tecnologia orientada a blocos ou
Block Oriented Technology.
Todo bloco é composto por um conjunto de parâmetros e um algoritmo
associado. Os parâmetros são classificados como:
- parâmetros de Entrada, que fornecem dados para o algoritmo;

10
- parâmetros de Saída, que representam o resultado do processamento, ou
- parâmetros Contidos para todas as outras funções que não sejam troca
de dados entre blocos.
Nesta tecnologia, toda e qualquer aplicação de usuário é baseada em blocos
funcionais, cuja interface e comportamento são definidos na norma que regulamenta
o padrão Foundation Fieldbus e definem uma linguagem universal para descrição de
aplicações de controle de processos e automação.
A Fieldbus Foundation definiu um conjunto básico de parâmetros usados por
qualquer bloco, chamados parâmetros universais. Foram definidas também classes
de blocos, por exemplo, blocos de entrada, de saída, de controle e de cálculo, sendo
que cada uma destas classes tem um grupo de parâmetros padrão.
Assim, atualmente existe uma série de blocos dentro da biblioteca padrão da
tecnologia tornando possível que fabricantes adicionem funcionalidades aos blocos
já existentes ou mesmo desenvolvam novos blocos. Estas opções estão previstas
em norma. A SMAR, como líder mundial em FIELDBUS trabalha com um contínuo
desenvolvimento de blocos funcionais para dar a tecnologia uma abrangência cada
vez maior no ramo de controle de processos.
Na seção seguinte serão passados mais detalhes a respeito dos blocos
funcionais assim como detalhes do protocolo do sistema.
2.3: O Protocolo
O protocolo utilizado em redes fieldbus é baseado no modelo de referência
OSI definido na norma ISO 7498. O modelo OSI é composto de um conjunto de 7
camadas, cada uma desempenhando uma série de funções, que pode ser visto na
Figura 7. As mensagens transmitidas vão passando por estas camadas sendo que
cada uma fica responsável por uma parcela da informação contida nas mesmas.
Assim, por exemplo, as camadas dos dispositivos que estão emitindo a informação
adicionam “pedaços” à mensagem original que serão captados pelas camadas
correspondentes dos dispositivos receptores.

11
Figura 7 - Modelo OSI aplicado em tecnologias fieldbus
A maioria dos protocolos de redes industriais como Profibus, Hart, assim
como Foundation Fieldbus não implementam todas estas 7 camadas. Protocolos no
nível do campo, como o FOUNDATION H1, usualmente só implementam as
camadas 1, 2 e 7. No caso específico do FOUNDATION H1 há ainda uma camada
de usuário não presente no modelo de referência OSI. Já os protocolos de níveis
superiores como o FOUNDATION HSE implementam além destas, as camadas 3 e
4.
Comparado com o modelo de referência OSI, as 4 camadas do nível H1 são
assim mapeadas:
- a camada física é a camada 1 do modelo OSI;
- a camada de enlace de dados é a camada OSI 2;
- a camada de aplicação é a camada OSI 7 ;
- a camada de aplicação de usuário não é definida no modelo OSI.
O nível HSE se diferencia do anterior adotando o padrão Ethernet para
implementar as camadas 1 e 2 do modelo OSI, o protocolo de internet (IP)
empregado na camada 3 e ainda o User Datagram Protocol (UDP), para a camada
4.
Para que seja possível a comunicação entre diferentes tipos de instrumentos
dentro de uma rede é necessário que todas as camadas citadas sejam
implementadas da mesma maneira fazendo com que estes instrumentos sejam
compatíveis entre si. No entanto, a característica marcante de interoperabilidade da
tecnologia fieldbus se faz graças ao nível de detalhamento especificados nas suas

12
camadas de aplicação e de usuário. Neste protocolo não se especifica somente
como os dados são transmitidos, mas sim toda a semântica, isto é, todo o
significado destas informações.
A seguir serão detalhadas as quatro camadas presentes no nível H1 da rede
fieldbus. O funcionamento das camadas do nível HSE, por se tratarem de padrões
bastante comuns, não será descrito neste documento.
2.3.1: Camada Física
A camada física define o formato no qual os dados serão fisicamente
transmitidos ao longo do meio de comunicação. Esta camada não executa nenhum
tipo de interpretação dos dados, apenas recebe as mensagens da camada de
enlace de dados e as converte em sinais físicos a ser transmitidos pelo barramento
fieldbus, também efetuando o caminho contrário passando as mensagens à camada
seguinte.
Estas conversões incluem ações como adição e remoção de preâmbulos, de
delimitadores iniciais e finais das mensagens transmitidas. O preâmbulo é
transmitido no começo da mensagem e utilizado com o objetivo de “acordar” os
demais dispositivos da rede fazendo com que os mesmos possam sincronizar seus
relógios internos com o sinal a ser recebido. O delimitador de início denota o fim do
preâmbulo e o começo da mensagem propriamente dita indo para ou vinda da
camada de enlace de dados que termina com o delimitador final.
Figura 8 - Formato dos dados da camada física
2.3.1.1: Codificação dos sinais
Os sinais fieldbus utilizam a codificação Manchester bifásica do tipo L. São
sinais síncronos seriais, pois misturam informação de temporização (clock) com

13
dados em um mesmo sinal como mostra a Figura 9. As mensagens podem ser
transmitidas de forma contínua sendo que os bits de dados “0” e “1” são codificados
como transições de subida e descida respectivamente. Nas transmissões, os bits
são convertidos nas correspondentes transições, enquanto que nas recepções se
faz o procedimento reverso.
Figura 9 - Codificação Manchester Bifásica do tipo L
Os sinais na codificação Manchester são transmitidos pela modulação de
corrente com amplitude aproximada de 10 mA. Como a rede possui um módulo de
impedância de 50 ohms entre os dispositivos e a alimentação, é criada uma tensão
de 1 volt pico a pico modulada sobre a componente DC da tensão de alimentação.
2.3.2: Camada de Enlace de Dados (DLL Data Link Layer)
Esta camada, imediatamente superior à camada física, desempenha 3
funções em destaque. Primeiro, é ela quem controla quando e por quanto tempo um
dispositivo ganha o acesso a rede de forma a evitar conflitos entre os diversos
dispositivos que desejam transmitir dados simultaneamente. Ainda efetua o
endereçamento para garantir que a mensagem chegue ao seu correto destino. Por
fim, a camada é também responsável pela detecção de erros possíveis nas
transmissões de dados.

14
2.3.2.1: LAS (Agendador de Link Ativo)
No padrão Foundation Fieldbus, qualquer dispositivo pode iniciar
comunicação desde que o mesmo possua este direito. Este controle a respeito da
distribuição de quem possui o direito ao longo do tempo é efetuado pelo LAS
(Agendador do Link Ativo). O LAS é geralmente desempenhado pela ponte do
sistema conforme citado no item da arquitetura da rede, embora seja possível
configurar alguns dispositivos de campo como transmissores ou atuadores para
desempenhar o papel de LAS caso ocorra uma falha nestas pontes permitindo a
continuação da comunicação e garantindo confiabilidade e redundância ao sistema.
Figura 10 - DFI-302: A solução SMAR para as pontes das redes Fieldbus
2.3.2.2: Comunicação gerenciada e não gerenciada
Existem dois tipos de comunicação tratados na camada de enlace de dados:
A comunicação gerenciada (tráfego foreground) e a comunicação não gerenciada
(tráfego background).
Os dados comunicados com baixa freqüência são transmitidos de forma
acíclica utilizando a comunicação não gerenciada. Nesta comunicação os
dispositivos recebem permissão do LAS através de um mecanismo de fichas (pass
token). Uma vez que o dispositivo tem a posse desta ficha ele pode enviar suas
mensagens até que ele termine ou se esgote o tempo máximo de posse da ficha.
Exemplos da comunicação acíclica são leitura ou escrita de dados por parte de uma
estação de operação da rede.
A forma de comunicação gerenciada tem maior prioridade dentro da rede. Os
dados que necessitam de comunicação periódica são transmitidos desta forma.
Incluem-se, por exemplo, as informações das variáveis pertencentes aos laços de
controle dos sistemas que necessitam de comunicação constante. Neste caso, o
LAS possui uma espécie de agenda onde são especificados quando os dados dos

15
dispositivos devem ser transmitidos. Para isso o LAS transmite uma mensagem de
requisição CD (Compel Data) para o dispositivo fazendo com que o mesmo publique
esta informação na rede.
Torna-se necessário neste momento definir alguns itens importantes
presentes na tecnologia Foundation Fieldbus como os conceitos de macrocycle e
live-list.
2.3.2.3: O macrocycle
O macrocycle é o período em que toda a parte cíclica se repete na rede.
Dentro deste período estão inclusos o tempo escalonado para as informações
cíclicas (tráfego foreground) e também os tempos destinados a atividades acíclicas
como de manutenção, supervisão, configuração, etc (tráfego background). Pode-se
entender como um tempo no qual todos os dispositivos têm suas variáveis
atualizadas na rede. No âmbito dos sistemas de controle pode-se caracterizar o
macrocycle como o período de amostragem do sistema sendo que não é possível
ter dentro de um mesmo macrocycle valores diferentes para uma mesma variável de
controle.
Figura 11 - Ilustração do macrocycle da rede
2.3.2.4: Live-List
O conceito de live-list se refere à lista dos dispositivos presentes na rede
Foundation Fieldbus. O LAS mantém esta lista atualizada através do envio de

16
mensagens periódicas à endereços não utilizados com o objetivo de identificar
novos equipamentos na rede.
Figura 12 - Live-List da rede
2.3.2.5: O controle de Erros
A detecção de erros efetuada nesta camada se dá pela transmissão de um
Frame Check Sequence (FCS) na mensagem gerada pelo emissor. No dispositivo
receptor, o FCS que chega é comparado com um FCS calculado internamente para
fins de checagem.
2.3.3: Camada de Aplicação
A camada de aplicação é a camada responsável pela interoperabilidade
oferecida pelas tecnologias fieldbus. É nesta camada que os tipos de dados e
objetos são definidos. Para formar objetos de dados mais complexos, são
combinados alguns dos 13 tipos simples de dados definidos.
A camada de aplicação das redes do tipo Foundation consiste de duas
subcamadas: a Fieldbus Access Sublayer (FAS) e a Fieldbus Message Specification
(FMS). O Fieldbus Access Sublayer (FAS) utiliza as características da camada de
enlace de dados (DLL) para fornecer serviços ao Fieldbus Message Specification
(FMS) na forma de “Virtual Communication Relationships” (VCR), ou seja relações
virtuais de comunicação. Existem 3 tipos básicos de VCRs:

17
O modelo publisher/subscriber VCR é utilizado para publicações cíclicas de
saídas de blocos funcionais que são subscritas em entradas de outros blocos. Este
tipo de comunicação é buferizada de forma que quando um bloco funcional gera
novo valor de saída, este valor sobrescreve o anterior.
O segundo tipo de comunicação é o report distribution VCR, utilizado para
transmissões acíclicas como alarmes, notificações de eventos para a estação de
operação. Nesta comunicação os eventos são enviados em ordem determinada por
prioridade e data de ocorrência e não sobrescrevem eventos anteriores.
A última forma é o modelo client/server VCR para transmissões acíclicas
como leitura e escrita de parâmetros nos dispositivos e download de configuração
da estação de operação. Este modelo também não sobrescreve requisições
anteriores.
2.3.3.1: Foundation Object Dictionary (OD)
O protocolo Foundation é orientado a objetos, isto é, a informação dentro dos
equipamentos da rede é acessada desta forma. Na subcamada FMS, os parâmetros
dos blocos funcionais, para configuração dos dispositivos e construção de
estratégias, são representados por objetos e listados em um dicionário. Assim cada
objeto é identificado por um index, ou seja, todos os blocos funcionais e seus
parâmetros possuem um index. Como alguns parâmetros são ainda subdivididos em
elementos para guardar mais de uma informação, todos estes elementos possuem
um subindex.
O dicionário de objetos mapeia os dados reais contidos na memória de cada
equipamento fieldbus e os tipos de dados dos parâmetros dentro dos blocos de
função. No entanto, os usuários não têm acesso direto aos endereços de memória
dos equipamentos, assim como aos VFDs ou indexes, interagindo apenas com os
tags e nomes dos parâmetros dos blocos. Os Tags são nomes dados aos blocos
funcionais, pelos usuários, dentro da sua aplicação com o objetivo de identificá-los
na rede. Assim como os blocos, cada parâmetro tem seu nome que é uma
composição do tag do instrumento, no qual está inserido, mais o tag do bloco e o
nome do parâmetro em questão.

18
2.3.3.2: Foundation Virtual Field Device (VFD)
VFD é uma subdivisão lógica da informação contida nos dispositivos
Foundation Fieldbus, isto é dispositivos virtuais menores dentro do equipamento
físico. Cada equipamento Foundation consiste de pelo menos 2 VFDs, o primeiro
contém o gerenciamento do sistema (SM, System Managment) e da rede (NM,
Network Managment). O segundo é utilizado para acesso aos blocos funcionais da
aplicação (FBAP, Funcion Block Aplication Process). Na Figura 13, pode-se
observar a presença dos dois principais VFDs de um dispositivo fieldbus.
Figura 13 - 2 principais VFDs de um dispositivo fieldbus
2.3.3.3: Serviços de Comunicação
É a subcamada FMS quem provê a série de serviços como leitura, escrita, e
acesso a objetos. Existem ao todo 7 grupos de serviços destinados a diferentes
tipos de objetos. Entre eles estão serviços como gerenciamento de VFDs,
gerenciamento do dicionário de objetos, acesso (leitura/escrita) a objeto de blocos

19
funcionais, download / upload de dados em áreas específicas da memória dos
dispositivos, estabelecimento de conexões, invocação de programas dentro dos
dispositivos, etc.
2.3.4: Camada de Usuário
A camada de usuário, também conhecida como camada de aplicação de
usuário (User Application Layer), é onde a verdadeira funcionalidade do sistema
acontece. É nesta camada que os transmissores medem, posicionadores atuam, e
usuários interagem com a rede. É este o nível onde os formatos de dados e sua
semântica são definidos permitindo que os dispositivos fieldbus possam entender os
dados e atuar de acordo com o desejado pela aplicação. As redes do tipo
Foundation têm uma camada de aplicação de usuário orientada a objetos que se
baseia nos blocos funcionais previamente citados neste documento. Estes blocos
são distribuídos entre os instrumentos na rede. Dentro de cada instrumento, os
blocos ficam contidos em uma Function Block Application Process (FBAP) alocada
em uma VFD.
2.3.4.1: Foundation Block Objects
Uma FBAP é dividida em duas partes: um processo de aplicação do
dispositivo (DAP) e um processo de aplicação de controle (CAP). A DAP contém os
blocos responsáveis pela configuração dos dispositivos e a CAP, os blocos
funcionais que irão implementar a estratégia de controle da aplicação. Os blocos
Foundation Fieldbus se classificam em três tipos:
Resource Block: É padronizado e há apenas um em cada VFD. Ele descreve as
características gerais do equipamento tais como fabricante, tipo, versão, dentre
outras.
Transducer Block (Bloco Transdutor): São eles que conectam os blocos
funcionais ao mundo externo, cuidando de detalhes relativos ao hardware de cada
equipamento como calibração do sensor, tipo do sensor, diagnóstico, faixa de
operação, etc.
Function Blocks (Blocos Funcionais): Representam as funções ou algoritmos a
ser executados pelo sistema, como por exemplo, medir, atuar, calcular.

20
As aplicações de controle são construídas com o uso destes tipos de blocos
funcionais. Isto inclui tanto a configuração dos blocos resource e transducer como a
configuração e manipulação das entradas e saídas dos blocos funcionais
propriamente ditos para a criação das estratégias de controle.
2.3.4.2: Foundation Link Objects
Os blocos funcionais propriamente ditos podem ser conectados entre si de
forma a trocar informações e formar as estratégias. Estas conexões recebem a
denominação de links e são efetuadas entre as entradas e saídas dos blocos.
Além dos Blocks e Link Objects, existem outros tipos de objetos como Trend
Objects para armazenar histórico de variáveis e Alarm Objects para reportar alarmes
e eventos às estações de operação.
2.3.4.3: Foundation Device Description (DD)
A descrição de um equipamento Foundation Fieldbus é feita através de dois
arquivos conhecidos como Device Description (DD) e Capability File (CF). O DD
descreve todos dados do equipamento enquanto que o CF contém as informações a
respeito da comunicação do mesmo. Ambos os arquivos são escritos e fornecidos
pelos fabricantes.
2.4: Configurando uma rede Foundation Fieldbus
A configuração de uma rede objetivando a criação do sistema de controle de
um processo é feita com o uso de um programa configurador. Este programa é
geralmente baseado em PC e é instalado na estação de operação do sistema,
mostrada anteriormente na Figura 5, onde se observa a topologia da rede. O
programa se comunica com os equipamentos do nível H1 da rede através de uma
interface Foundation Fieldbus (PCI) ou de um Linking Device. No caso do Linking
Device esta comunicação é via Ethernet e o instrumento que faz esta ponte é o
componente DFI302, Ponte Universal Fieldbus presente no sistema System 302 da
empresa SMAR.

21
O programa configurador presente no SYSTEM 302 da SMAR é o SYSCON
cujo ambiente pode ser visualizado nas próximas figuras. No programa configurador,
o usuário deve configurar a rede assim como a estratégia de controle e os
dispositivos presentes na rede. Esta ferramenta permite a criação de estratégias em
modo off-line, ou seja, as informações são armazenadas em uma base de dados
não nos instrumentos. A idéia é que, em um momento inicial, - estágio de
desenvolvimento de uma solução de controle para um processo - a configuração
seja off-line para que, depois de pronta, seja carregada em um procedimento
conhecido como Download, onde as informações serão armazenadas nos
instrumentos. A partir daí, a ferramenta também permite fazer alterações em modo
on-line. Por razões de segurança, somente algumas alterações podem ser
realizadas em modo on-line como mudanças de parâmetros. Alterações mais
consideráveis só podem ser realizadas off-line e depois carregadas novamente.
Na etapa de configuração off-line, estão inclusos os aspectos físicos e lógicos
da aplicação. Primeiro o programa configurador cria a rede fieldbus. A partir daí, a
configuração se divide em duas partes: configuração da Área 1 e da Fieldbus
Networks.
Figura 14 - Áreas Física e Lógica de uma rede Foundation Fieldbus
A área Fieldbus Networks é onde se configura a rede fisicamente. Nesta
parte são selecionados os instrumentos que farão parte da aplicação. Assim cada
instrumento recebe um nome (tag). Este tag é depois associado a um número de
identificação do dispositivo (ID) para que o instrumento possa ser identificado na
aplicação através do seu tag. Na Figura 15 mostra-se também a possibilidade de
escolha de instrumentos de diversos fabricantes pertencentes a Fieldbus
Foundation.

22
Figura 15 - Inserção de novo instrumento na rede
Depois de adicionados todos os dispositivos, o usuário deve adicionar todos
os blocos funcionais a cada instrumento de acordo com a necessidade da aplicação.
Nesta etapa deve ser respeitado o fato de que todos os instrumentos devem possuir
os blocos fundamentais como: resource, transducer e display (responsável pela
formatação da informação mostrada no display do instrumento). É neste momento
que o usuário escolhe também os tags dos blocos.
Por fim todos os blocos devem ser configurados o que inclui setar uma série
de parâmetros contidos nos mesmos para que as funções desejadas sejam
executadas corretamente. Na Figura 13 mostrada anteriormente pode se observar
os blocos instanciados nos dispositivos da rede.
Na Área 1 é realizada a criação da estratégia de controle propriamente dita,
ou seja a modelagem lógica do sistema. Nela os blocos funcionais do terceiro tipo
(conforme seção 2.3.4), que contém entradas e saídas e podem ser conectadas,
são “arrastados” da área física para a lógica. Este arraste é um procedimento
bastante simples onde o programa configurador oferece uma maneira bastante
agradável de programação. Assim, as conexões são feitas e as estratégias
implementadas. Um exemplo de controle PID tradicional pode ser visto na Figura 16.

23
Figura 16 - Estratégia com blocos funcionais conectados
Vale ressaltar que as conexões podem ser feitas entre blocos contidos no
mesmo dispositivo ou mesmo entre blocos de diferentes equipamentos. Por
exemplo, em um controle PID tradicional de nível, um bloco PID e um bloco Analog
Input são instanciados em um transmissor de nível e um bloco Analog Output em
uma válvula para atuação.
Depois de finalizada a etapa de configuração off-line o download da mesma é
efetuado. No download, toda a configuração é passada aos equipamentos de
campo de acordo com a rede criada. No modo on-line é possível monitorar o
andamento do processo com os valores dos parâmetros disponíveis em tempo real.
Entre as alterações permitidas neste modo, está a mudança nos valores de alguns
parâmetros como setpoints, e parâmetros de controladores. O que não se permite,
no entanto, é fazer nenhuma alteração nas conexões entre os blocos, ou seja, na
estratégia.
2.5: Os Blocos Funcionais Transfer Function e Smith Predictor
Os blocos criados para implementar o preditor de Smith, de onde surgiu a
necessidade de uma identificação automática de processos se encaixam no grupo
dos blocos funcionais (Function Blocks) que fazem parte da estratégia de controle
do sistema. Como exemplos destes blocos temos:

24
• Analog Input: Utilizado para representação de entradas analógicas
provenientes de transmissores de pressão, temperatura, densidade, etc.
• Discrete Input: Representa um sinal de entrada discreto vindo por exemplo de
um cartão de entradas discretas.
• Analog Output: Utilizado para sinais analógicos de saída dos atuadores
Fieldbus como posicionadores de válvula, conversores de sinal digital em
corrente (4-20mA), etc.
• Discrete Output: Sinais de saída discretos utilizados, por exemplo para
interligar a lógica de controle analógico fieldbus com instrumentos de
operação discreta como bombas, válvulas solenóide, etc.
• PID: Bloco funcional que executa a funcionalidade do controlador clássico
PID para controle de processos.
• Arithmetic: Permite executar uma série de operações aritméticas,
previamente programadas, entre os sinais de uma estratégia de controle.
Figura 17 - Esquemático do Bloco Funcional PID com suas entradas, processamento e saídas
Estes são apenas alguns dos blocos funcionais, parte da tecnologia. Entre os
muitos blocos, os dois blocos Transfer Function e Smith Predictor [8] serão
explicados mais em detalhe para melhor entendimento do corrente projeto.

25
2.5.1: Transfer Function
O bloco Transfer Function tem como finalidade representar modelos
matemáticos de sistemas de até segunda ordem, através de parâmetros internos
nomeados de A, B, C, D, E e F como os coeficientes de uma função de
transferência do tipo:
2
2
As Bs CDs Es F
+ ++ +
Possui uma entrada para conexão da variável de atuação do processo
representado (variável manipulada) e uma saída gerando o sinal de saída do
processo. O bloco foi construído de modo que o usuário da aplicação edite uma
função de até segunda ordem contínua, que é transformada para o domínio
discreto. A entrada do bloco é então aplicada à equação a diferenças, resultante
desta transformação e, de acordo com a amostragem do sistema (macrocycle da
rede fieldbus), produz o sinal de saída. Isto no entanto fica transparente ao usuário
que pode trabalhar no domínio contínuo “s”.
Figura 18 - Esquemático do Bloco Transfer Function
2.5.2: Smith Predictor
O bloco Smith Predictor é quem realmente implementa as operações do
preditor de Smith. Ele necessita do bloco Transfer Function para representar o

26
modelo do processo controlado de acordo com a própria estrutura do Preditor de
Smith.
Possui três entradas. Uma é a entrada do processo real (IN_1) com atraso de
transporte vinda por exemplo de um bloco Analog Input. A segunda (IN_2) é a
entrada do modelo do processo sem atraso que originalmente deve ser conectada a
saída de um bloco Transfer Function. Já a terceira é o próprio atraso do processo
(DELAY_TIME) que pode ser configurado pelo usuário, pois é um parâmetro interno
do bloco, ou receber um valor proveniente de outro bloco através de um link, para
sistemas que tenham um atraso variável por exemplo.
Como saída, o bloco tem apenas uma que depende do modo em que o bloco
está operando. O bloco pode funcionar como BYPASS e neste caso a saída tem o
valor da sua entrada do processo real. Também pode funcionar como um atrasador
de sinal (DELAY) e neste caso, a saída é o sinal da entrada do modelo do processo
atrasado de acordo com o parâmetro DELAY_TIME. No caso da operação como
preditor (SMITH PREDICTOR), a saída é o sinal de realimentação do preditor a ser
conectado a entrada de processo de um bloco PID. Abaixo o funcionamento do
bloco é melhor entendido através de seu esquemático.
Figura 19 - Esquemático do bloco Smith Predictor
Uma implementação que utilize o Preditor de Smith para controle de plantas
com atraso de transporte pode ser visualizada através de uma estratégia com
blocos funcionais mostrada na próxima seção.

27
2.5.3: Estratégia para compensação de atraso
Para entender como um processo com tempo morto é controlado com o uso
de blocos funcionais criados, inicia-se com o controle de temperatura do capítulo 1,
com a inserção dos instrumentos fieldbus em uma rede do tipo Foundation (Figura
20a). A visualização da estrutura de controle clássica do Preditor de Smith é
mostrada na Figura 20b que corresponde em diagrama de blocos funcionais à
estratégia da Figura 20d. Dentro desta estratégia, o bloco nomeado DFI_SPB que é
do tipo Smith Predictor, tem seu esquemático ampliado na Figura 20c.
Figura 20 – a. Visão do processo real com instrumentação Foundation Fieldbus – b. Diagrama de
Blocos do Preditor de Smith – c. Esquemático do bloco SMITH PREDICTOR – d. Estratégia de
controle com blocos funcionais
Neste exemplo de controle de temperatura, o sinal de número 1 corresponde
ao sinal de temperatura medido pelo transmissor de temperatura TT302 e
disponibilizado pelo bloco Analog Input (TT_AI), instanciado neste transmissor. O
sinal de número 2 é o sinal de saída do modelo do processo, gerado pelo bloco
Transfer Function (DFI_TF), enquanto o sinal 3 é o sinal 2 atrasado no tempo. Este
sinal de número 3 é interno ao bloco Smith Preditctor (DFI_SPB) que, junto com o
bloco Transfer Function e o bloco de controle PID (DFI_PID) são instanciados
dentro da unidade DFI302. O sinal de número 4 é a saída do bloco Smith Predictor

28
que é a própria realimentação do controle PID. O sinal de número 5 é a ação de
controle do sistema que é enviada à válvula para atuação através do bloco Analog
Output (FY_AO) instanciado no posicionador fieldbus FY302 da válvula. Todos estes
três instrumentos utilizados neste exemplo pertencem à linha de equipamentos
Foundation Fieldbus da SMAR.
A identificação automática, objetivo do presente projeto, é o auxílio na
configuração dos parâmetros do modelo do processo, representado pelo bloco
Transfer Function (DFI_TF) dentro desta estratégia (Figura 20d).
O uso conjunto dos blocos Transfer Function e Smith Predictor, para
composição de uma estratégia como a mostrada nesta seção, permite o controle de
plantas industriais de primeira ou segunda ordem estáveis. Para o controle de
plantas integradoras [8], faz-se necessário algumas alterações no diagrama de
blocos do Preditor e conseqüentemente, a utilização de outros blocos funcionais,
como por exemplo o bloco Aritmético, e uma estratégia com blocos funcionais
ampliada para implementação destas alterações.
2.6: Vantagens da tecnologia
Para finalizar este capítulo alguns conceitos importantes, presentes na
tecnologia de redes Foundation Fieldbus, para os sistemas de controle da
atualidade. Entre os principais, temos:
Redução de Hardware: As funções de controle dos sistemas são desempenhadas
pelos blocos funcionais dentro de cada dispositivo. Isto reduz o número de
componentes como: entradas e saídas, elementos de controle como cartões,
gabinetes, etc.
Qualidade e Quantidade de Informação: Estas redes possuem formato que
permite que os equipamentos possam ser conectados a um barramento
compartilhado onde a informação é transmitida de forma digital. Isto reduz os custos
de cabeamento das aplicações tradicionais, onde se faz necessário um cabo para
cada variável transmitida e permite maior quantidade de dados a serem
transmitidos. Além disso, as características da comunicação digital possibilitam uma
maior qualidade das informações contidas na rede.

29
Interoperabilidade: Como Foundation Fieldbus é um protocolo aberto, todos os
fabricantes certificados pela Fieldbus Foundation podem fornecer equipamentos que
serão capazes de se comunicar com qualquer outro dentro de uma rede desta
tecnologia.
Controle distribuído: Devido à eletrônica embarcada nos equipamentos, as tarefas
podem ser divididas tornando os sistemas mais simples e eficientes.
Diagnóstico: A inteligência de cada instrumento Foundation Fieldbus permite
aumentar a disponibilidade e a segurança operacional reduzindo os custos de
manutenção da rede.
Redundância: A rede proporciona imunidade a falhas que possam ocorrer com
alguns de seus equipamentos ou a sua estrutura. Isto é possível pois as redes
podem ser instaladas de modo a operar com redundância de equipamentos,
cabeamento, etc.

30
Capítulo 3: Conceitos sobre Identificação de Processos
Monovariáveis com Modelos Lineares
3.1: Introdução
O conceito de sistema [5] pode ser definido de diferentes formas. Em controle
de processos, denota-se como um objeto ou uma coleção de objetos que realiza um
certo objetivo e cujas propriedades pretende-se estudar. Alguns exemplos são:
sistema de fabricação de papel ou cerâmica, sistema solar, circuito elétrico,
servomecanismo de posição, manipulador robótico, reator, coluna de destilação,
entre muitos outros como o próprio sistema de aquecimento de temperatura do
capítulo 1.
Figura 21 - Componentes de um Sistema Monovariável
Os problemas associados à estrutura acima presentes no ramo de controle
de processos podem ser entendidos como:
• Análise: é conhecida a entrada u(.), o sistema g(.) e deve-se obter a saída y(.).
• Projeto: é conhecido o sistema g(.), a saída que se deseja y(.) e deve-se obter a
entrada u(.) que proporcione tal saída.
• Identificação: conhece a entrada u(.) e a saída y(.) e quer-se obter o sistema g(.)
que estabeleça a relação correta entre entrada e saída. Deste modo a aplicação
da entrada u(.) ao sistema obtido g(.) deve produzir uma saída estimada y^(.)
que deve-se aproximar ao máximo da saída real y(.).
A identificação é portanto uma das atividades necessárias para o controle de
processos industriais e antecede o Projeto e Análise dos mesmos. Os

31
procedimentos envolvidos na elaboração de modelos matemáticos para
representação dos processos podem ser classificados de duas formas:
• Análise físico-matemática: baseia-se nas leis da física que caracterizam um
processo em particular, como as leis de conservação de massa, de energia e
de momento, por exemplo.
• Análise experimental: baseia-se em medidas ou observações acerca do
processo.
Estes procedimentos permitem a obtenção de modelos que representem a
dinâmica do processo, também conhecido como planta. Para fins de controle de
processos, não se pretende encontrar um modelo exato, mas um modelo adequado
para uma determinada aplicação. Este é o caso da estrutura do Preditor de Smith,
que necessita de um modelo matemático linear da planta com atraso que se deseja
controlar, para poder realizar a compensação do atraso em sua estrutura.
A representação de sistemas lineares pode ser realizada de diferentes
maneiras como: funções de transferência contínua ou discretas, resposta impulsiva,
equações de estados, etc. A estrutura do Preditor requer o formato das funções de
transferência para identificar o processo em questão.
3.2: Técnicas de Identificação
A identificação de processos constitui-se assim em uma atividade complexa,
tratada muitas vezes como um problema de otimização onde se busca estimar, com
a melhor precisão possível, modelos matemáticos representativos. A seleção destes
modelos e os ajustes de seus parâmetros são influenciados por muitos fatores
como: conhecimento a priori do sistema, propriedades do modelo, presença de
ruídos, critérios a serem minimizados na identificação, etc. Qualquer das técnicas
existentes pode facilmente falhar na estimação do modelo caso estes e alguns
outros fatores não sejam respeitados ao longo do ensaio de identificação. A noção
de um bom modelo também é subjetiva o que faz com que a “tentativa e erro” seja
uma regra bastante empregada atualmente na engenharia.

32
A meta de um algoritmo de identificação é a minimização de um critério de
desempenho e se todas as condições e restrições forem atendidas, um modelo
obtido pode ser aceito. Isto caracteriza um problema de otimização.
A área de identificação tem tido considerável interesse nos últimos anos para
fins como de previsão, supervisão, diagnóstico e controle. Observa-se a sua
aplicação em diversos campos da engenharia, tais como processos químicos,
sistemas elétricos, biomédicos entre outros.
Fundamentalmente, a identificação de sistemas consiste na determinação do
modelo matemático que represente os aspectos essenciais de um sistema,
caracterizado pela manipulação dos sinais de entrada e saída e que estão
relacionados através de uma função de transferência contínua ou discreta (Ljung,
1999). Para isso, diferentes procedimentos existem para geração destes sinais de
entrada, coleta e armazenamento dos sinais de saída e estimação do modelo.
Como exemplos temos:
- Identificação pelo teste de resposta ao degrau: aplica-se uma variação do tipo
degrau na entrada do processo armazenando-se de alguma forma os dados da
saída conseqüente. Esta curva de reação obtida é submetida então à técnicas
gráficas ou numéricas para estimação do modelo do processo. Como o sinal degrau
é um sinal com pobre composição freqüencial, este método serve para processos de
ordens inferiores (primeira e segunda ordem).
- Identificação pelo teste reposta em freqüência: aplica-se uma entrada do tipo
senoidal e analisam-se as curvas de magnitude e fase, identificando a freqüência de
corte e a função de transferência estimada.
- Identificação off-line: excita-se o processo com sinais de teste apropriados e
armazenam-se as medidas de entrada e saída do ensaio de identificação para
estimação posterior dos parâmetros do modelo. Neste caso necessita-se de coleta
de dados e memória para armazenamento de dados, pois o cálculo dos parâmetros
é feito após o ensaio.
- Identificação on-line: diferencia-se do tipo anterior pelo fato de ser um
procedimento iterativo em que o cálculo dos parâmetros é feito simultaneamente ao
ensaio de identificação. Não há a necessidade de coleta de dados como no tipo
anterior e métodos recursivos são empregados para atualização dos parâmetros da

33
função de transferência, a cada período de amostragem da identificação. A
identificação segue até a convergência dos parâmetros estimados.
Todas estas técnicas consideram modelos lineares para representação de
sistemas. O uso de sistemas lineares para representação de processos industriais é
largamente utilizado. Isto pelo fato destes modelos poderem aproximar bem
sistemas industriais em torno de determinados pontos de operação. Além disso as
propriedades dos modelos lineares facilitam o estudo do comportamento dos
processos a ser identificados.
Dois métodos que se encaixam nos dois últimos tipos citados acima foram
estudados ao longo do projeto e serão explicados mais em detalhe na seqüência
deste capítulo. Estes métodos se baseiam no estimador dos mínimos quadrados
(Ljung, 1999), que é a base para muitas outras técnicas de identificação.
3.2.1: Estimador dos Mínimos Quadrados Não Recursivo
O método dos Mínimos Quadrados é um método de identificação largamente
utilizado. Ele possui duas variantes de formulação [6]: off-line e on-line. Estas duas
variações são respectivamente os casos não recursivo e recursivo.
Uma forma de entender a formulação dos métodos MQR é iniciar pela
representação de modelos por funções de transferência discretas. A função de
transferência discreta entre a entrada U e a saída Y para um sistema de primeira
ordem é:
( )( )
Y z bU z z a
=+
que corresponde a equação de diferenças:
( 1) . ( ) . ( )y k a y k b u k+ = − +
Para o caso de um processo com atraso de transporte equivalente ao termo
“d”, têm-se:
( )( )
dY z bz
U z z a−=
+

34
Multiplicando-se o numerador e o denominador da equação anterior por 1z− ,
têm-se:
1
1
( ).
( ) 1
dY z bzU z az
− −
−=+
A partir desta expressão obtém-se a equação à diferenças:
( ) ( 1) ( 1 )y k ay k bu k d= − − + − −
Nota-se que os operadores z e z-1 significam respectivamente avanço e
atraso de um tempo de amostragem.
Considerando que seja aplicada uma entrada u(k) variante no tempo desde o
tempo zero (k = 1) até o tempo T (k = N), pode-se agrupar os dados das leituras em
um vetor de saídas Y e uma matriz com os valores passados de saída e entrada X.
Têm-se então um sistema matricial:
Y X Eθ= +
Onde Y é o vetor de saídas com dimensão Nx1 onde N é igual ao número de
amostras coletadas. A matriz X contém as saídas e entradas passadas e tem
dimensão Nx2. O vetor θ tem os coeficientes desejados para a identificação. Estes
coeficientes são os termos da função de transferência, no domínio discreto, do
processo que se deseja identificar.
(2)(3)...( )
Y
YY
Y N
� �� �� �=� �� �� �
(1) (1)(2) (2)
( 1) ( 1)
Y U
Y U
X
Y N U N
−� �� �−� �� �=� �− − −� �� �� �
� a
bθ � �
= � �� �
No caso de um sistema de segunda ordem a matriz Y continua tendo
dimensão Nx1 e a matriz X passa a ter dimensão Nx4 e o vetor θ sendo 4x1.
1 2 1 2( ) ( 1) ( 2) ( 1) ( 2)y k a y k a y k b u k b u k= − − − − + − + −
(3)(4)...( )
YY
Y
Y N
� �� �� �=� �� �� �
(2) (1) (2) (1)(3) (2) (3) (2)
... ... ... ...( 1) ( 2) ( 1) ( 2)
Y Y U UY Y U U
X
Y N Y N U N U N
− −� �� �− −� �=� �� �− − − − − −� �
1212
aabb
θ
� �� �� �=� �� �� �

35
O que se deseja calcular é o vetor θ sendo que se tem Y e X. Se formula
então um problema de otimização que procura determinar θ de forma a minimizar o
somatório do quadrado do erro e(k) para k = 2:N
Como E Y Xθ= −
Para minimizar o erro calculamos a derivada primeira de J e igualamos a zero
obtendo:
Como XTX é quadrada pode-se calcular sua inversa e obter a matriz desejada
θ.
Esta operação é realizada uma vez ao final da coleta dos dados e da
montagem das matrizes X e Y. A precisão da resposta encontrada pode ser
verificada na matriz TX X . Esta matriz deve primeiramente ser não singular e
portanto inversível. Além disso deve possuir um número de condição adequado. O
número de condição de uma matriz identidade é 1 enquanto que o número de
condição de uma matriz singular tende ao infinito. Portanto uma matriz com alto
número de condição é uma matriz mal condicionada e isto pode gerar soluções com
grandes erros.
3.2.2: Estimador do Mínimos Quadrados Recursivo
Em um método de identificação recursivo, os parâmetros do modelo desejado
são calculados recursivamente no tempo. Isto significa que não são armazenadas
uma série de amostras como no método não recursivo. Quando houver uma

36
estimativa �θ (k-1) baseada em dados no instante k-1, então, �θ (k) será calculada a
partir de �θ (k-1). Para detalhamento do método, recorre-se à mesma equação do
método não recursivo:
1( )T TX X X Yθ −=
Neste método será adotada uma nova notação para a matriz X, porém a
forma de montá-la é a mesma do método não recursivo. Ela será substituída pela
matriz φ . A matriz φ no instante k é representada por ( )kφ e contém todas as
amostras coletadas até este instante. Isto significa que no instante k, a equação
anterior se torna:
� 1( ) [ ( ) ( )] ( ) ( )T Tk k k k Y kθ φ φ φ−=
A cada novo instante a matriz ( )kφ é aumentada em uma linha com as novas
amostras coletadas. Como esta matriz ( )kφ contém todas as amostras coletadas
até o instante k, introduz-se a notação do vetor ( )T kϕ que corresponde à última
linha da matriz ( )kφ , isto é, apenas as últimas amostras coletadas. Isto pode ser
melhor entendido através do equacionamento seguinte:
1 1
1 1
1 1
(1) (1)( 1)(2) (2)
( 1) ... ( )( )... ...
( 1) ( )
T Txn xn
T Txn xn
T
T Txn xn
kk k
k
k k
ϕ ϕφϕ ϕ
φ φϕ
ϕ ϕ
� � � �� � � � −� �� � � �− = = = � �� � � � � �� � � �
−� � � �� � � �
O mesmo ocorre com o vetor ( )Y k . A cada instante é adicionada uma nova
linha a este vetor-coluna. Neste caso a notação do escalar ( )y k é utilizada para
representar o último termo de ( )Y k .
1 1 1 1
1 1 1 1
1 1 1 1
(1) (1)(2) (2) ( 1)
( 1) ... ( )... ... ( )( 1) ( )
x x
x x
x x
y y
y y Y kY k Y k
y ky k y k
� � � �� � � � −� �� � � �− = = = � �� � � � � �� � � �−� � � �
No instante k, têm-se então os vetores �( 1) , ( 1) , ( )k k Y kθ φ− − , coleta-se as
novas amostras atuais, atualizando ( 1)kφ − para ( )kφ , e calcula-se o novo vetor de
parâmetros estimados �( )kθ .

37
( ) ( 1) ( )T Tk k kφ φ ϕ� �= −� �
( 1)( ) ( ) ( 1) ( )
( )T T
T
kk k k k
kφ
φ φ φ ϕϕ
−� �� �= − � �� �
� �
( ) ( ) ( 1) ( 1) ( ) ( )T T Tk k k k k kφ φ φ φ ϕ ϕ= − − +
No entanto, deve-se encontrar uma maneira de atualizar a matriz �( )kθ sem
ter que calcular a inversa de ( ) ( )Tk kφ φ a cada iteração do método. Para isso se
introduz a notação:
1( 1) [ ( 1) ( 1)]TP k k kφ φ −− = − −
( 1) ( 1) ( 1)TB k k Y kφ− = − −
Assim, a matriz �( )kθ fica:
�( ) ( ) ( )k P k B kθ =
�( 1) ( 1) ( 1)k P k B kθ − = − −
1 1( ) ( 1) ( ) ( )TP k P k k kϕ ϕ− −= − +
( ) ( 1) ( ) ( )B k B k k y kϕ= − +
Deseja-se obter B(k) a partir de B(k-1) e P(k) a partir de P(k-1). Para isso é
utilizado o seguinte Lema de Inversão de matrizes:
1 1 1 1 1 1 1
1
( ) ( )
( 1) , 1 , ( ) , ( )T
A BCD A A B C DA B DA
A P k C B k D kϕ ϕ
− − − − − − −
−
+ = − += − = = =
então,
1 1 1 1
1
( ) [ ( )] [ ( 1) ( ) ( )]
( 1) ( 1) ( )[1 ( ) ( 1) ( )] ( ) ( 1)
( ) ( ) ( 1)( ) ( 1)
1 ( ) ( 1) ( )
onde 1 ( ) ( 1) ( ) é um escalar.
T
T T
T
T
T
P k P k P k k k
P k P k k k P k k k P k
k k P kP k P k I
k P k k
k P k k
ϕ ϕϕ ϕ ϕ ϕ
ϕ ϕϕ ϕ
ϕ ϕ
− − − −
−
= = − + == − − − + − −
� �−� = − −� �+ −� �
+ −
De acordo com a equação do erro de previsão ε(k):

38
� �
�
�
( ) ( ) ( ) ( 1) ( ) ( ) ( 1) ( )
( ) ( 1) ( ) ( ) ( 1) ( )[ ( ) ( 1) ( )]
( ) ( 1) ( ) ( ) ( 1) ( ) ( )
T T
T
T
k y k k k y k k k k
B k B k k y k B k k k k k
B k B k k k k k k
ε ϕ θ ϕ θ ε
ϕ ϕ ϕ θ ε
ϕ ϕ θ ϕ ε
= − − � = − +
= − + = − + − +
= − + − +
Da equação anterior: � �1( ) ( ) ( ) ( 1) ( 1) ( 1)k P k B k B k P k kθ θ−= � − = − −
� � �
� �
1
1
( ) ( )[ ( 1) ( 1) ( ) ( ) ( 1) ( ) ( )]
( ) ( )[ ( 1) ( ) ( )] ( 1) ( ) ( ) ( )
T
T
k P k P k k k k k k k
k P k P k k k k P k k k
θ θ ϕ ϕ θ ϕ ε
θ ϕ ϕ θ ϕ ε
−
−
= − − + − +
= − + − +
Mas como 1 1( 1) ( ) ( ) ( )TP k k k P kϕ ϕ− −− + = , chega-se a:
� �( ) ( 1) ( ) ( ) ( )k k P k k kθ θ ϕ ε= − +
O termo ( ) ( )P k kϕ é um vetor coluna e é denominado ganho do estimador
K(k), ou seja,
( 1) ( )( ) ( ) ( )
1 ( ) ( 1) ( )T
P k kK k P k k
k P k kϕϕ
ϕ ϕ−= =
+ −
O vetor de parâmetros estimados é calculado por:
� �( ) ( 1) ( ) ( )k k K k kθ θ ε= − +
A equação que calcula P(k) fornece a atualização de P(k-1) para P(k) sem
inversão de matriz. Pode-se utilizar a definição da matriz K(k) para reescrever a
equação de atualização de P(k).
( 1) ( ) ( ) ( 1)( ) ( 1) ( ) ( 1) ( ) ( ) ( 1)
1 ( ) ( 1) ( )
TT
T
P k k k P kP k P k P k P k K k k P k
k P k kϕ ϕ ϕ
ϕ ϕ− −= − − � = − − −
+ −
Chega-se assim as equações fundamentais que compõem o método
recursivo, onde ε(k) é o erro de predição que é a diferença entre a saída medida e a
saída do modelo predito baseada nos parâmetros do instante k-1, o vetor K(k) é o
ganho do estimador e a matriz P é denominada matriz de covariância. Note que
estas equações não exigem o armazenamento de todas as amostras do ensaio
como no método não recursivo. Isto pois as equações do método mostradas a
seguir só utilizam os dados do instante atual k da iteração e do instante anterior k-1.

39
�
� �
1 1
1
1
2 2
4 4
( ) ( ) ( ) ( 1)
( 1) ( )( )
1 ( ) ( 1) ( )
( ) ( 1) ( ) ( ): 1ª ordem
( ) ( 1) ( ) ( ) ( 1) : 2ª ordem
Tx
nx T
nx
xT
x
k y k k k
P k kK k
k P k k
k k K k k
PP k P k K k k P k
P
ε ϕ θϕ
ϕ ϕ
θ θ ε
ϕ
= − −−=
+ −
= − +
= − − −
O erro de previsão torna-se zero quando �θ θ→ . A medida da qualidade do
estimador pode ser inferida a partir da magnitude dos elementos da diagonal
principal da matriz P, denominada como matriz de covariância do estimador. Assim,
por exemplo, se o termo (1,1) da matriz P é pequeno, significa que a estimativa do
primeiro parâmetro da identificação é adequada. Por outro lado se o termo (n,n) da
matriz P é grande, significa que o termo “n” do vetor θ, não é uma boa estimativa
para o modelo do processo em questão.
Para inicialização do algoritmo, deve-se atribuir valores iniciais para �θ (0) e
P(0). Como em geral não se tem conhecimento a respeito dos parâmetros do
modelo do processo a ser identificado, �θ (0) é inicializado como um vetor contendo
valores pequenos e P como uma matriz identidade multiplicada por um fator grande
(por exemplo 104). Caso alguma condição inicial a respeito dos parâmetros é
disponível, esta informação deve ser utilizada para �θ (0) enquanto a matriz P será
uma matriz identidade multiplicada por um fator não tão grande (por exemplo 10). A
partir do momento que o algoritmo processa suas iterações, os elementos de P
decrescem em magnitude, de modo que o ganho, torna-se aproximadamente nulo
fazendo com que �( 1) ( )k kθ θ+ ≈ .
No entanto, a medida que o vetor ganho tende a zero, o estimador perde a
capacidade de adaptação à processos variantes no tempo. Esta capacidade pode
ser mantida dando-se uma importância maior às novas medidas da identificação
pela regulagem de um fator de esquecimento conhecido como λ. O fator de
esquecimento portanto evita que os elementos de P e por conseqüência de K,
tendam a zero, mantendo o estimador em alerta para rastrear dinâmicas variantes
no tempo. Na prática utiliza-se um valor de λ entre 0.9 e 1 para uma ponderação
maior às medidas atuais, sendo que quando λ = 1 há a mesma ponderação entre as
medidas mais antigas e atuais.

40
O uso do fator de esquecimento é uma das formas de tratar com processos
variantes no tempo. Outro método existente é o método Covariance Resetting, onde
a matriz P é resetada periodicamente, isto é, assume seu valor inicial em alguns
períodos de tempo. No entanto a importância de um método como este é maior para
casos de sistema de controle adaptativo. No caso deste trabalho, se propõe um
ensaio de identificação com tempo de duração relativamente curto, o que não torna
muito necessária a atualização periódica da matriz de covariância, assim como o
uso do fator de esquecimento.
Os passos do método recursivo com a inclusão do fator de esquecimento λ
podem ser assim descritos:
• Atualização do vetor de medidas φ com as leituras no instante k ( ) [ ( 1) ( 1 )] 1ª ordem
( ) [ ( 1) ( 2) ( 1 ) ( 2 )] 2ª ordem
T
T
k y k u k d
k y k y k u k d u k d
ϕϕ
= − − − − →= − − − − − − − − →
• Cálculo do erro de previsão
�( ) ( ) ( ) ( 1)Tk y k k kε ϕ θ= − − • Cálculo do ganho do estimador
( 1) ( )( )
( ) ( 1) ( )T
P k kK k
k P k kϕ
λ ϕ ϕ−=
+ −
• Cálculo do vetor de parâmetros estimados
� �( ) ( 1) ( ) ( )k k K k kθ θ ε= − + • Atualização da matriz de covariância
[ ( 1) ( ) ( ) ( 1)]( )
TP k K k k P kP k
ϕλ
− − −=
3.3: Validação do Modelo
Uma vez concluída a identificação e tendo o processo parametrizado, deve-
se qualificar o modelo estimado a partir de algum critério. Um critério muito utilizado
é a comparação gráfica das respostas real frente à resposta do modelo estimado
obtidas em ensaios idênticos. Esta no entanto é uma forma de validação de difícil
implementação em um ambiente computacional e portanto prefere-se o uso de
outros índices de desempenho.

41
O índice de desempenho adotado ao longo do trabalho para validação das
identificações realizadas foi o Coeficiente de Correlação Múltipla – R2 [5].
� 2
2 1
2
1
[ ( ) ( )]1
[ ( ) ]
N
kN
k
y k y kR
y k y
=
=
−= −
−
�
�
Na equação acima, y(k) é a saída real do processo no instante “k”, �y (k), a
saída estimada, obtida pela aplicação dos parâmetros obtidos na identificação, e y ,
a média das N amostras de y ao longo da identificação. Um valor de R2 entre 0.9 e 1
pode ser considerado suficiente para muitas aplicações práticas em identificação.

42
Capítulo 4: O Algoritmo de Identificação proposto
O papel do aluno ao longo do projeto relatado neste documento foi o estudo
de uma técnica de identificação passível de implementação como uma nova
funcionalidade à tecnologia. A idéia principal foi elaborar um algoritmo para criação
de um novo bloco funcional a ser disponibilizado na biblioteca de blocos funcionais
da tecnologia Foundation Fieldbus. Com esta finalidade e para demonstração da
viabilidade da implementação do algoritmo proposto, ambos os métodos estudados
e descritos no capítulo anterior foram implementados para testes.
Estas implementações foram realizadas com o uso do Software MATLAB e
de um controle ActiveX que permite a comunicação entre o MATLAB e as variáveis
de uma aplicação Foundation Fieldbus através da tecnologia OPC.
4.1: A Tecnologia OPC
A tecnologia OPC (OLE for Process Control) é um padrão introduzido pela
OPC Foundation para permitir a conexão entre dispositivos, base de dados e
aplicações cliente para controle de processos. OPC constitui-se atualmente em um
padrão industrial cliente-servidor amplamente aceito para troca de parâmetros entre
aplicações e possibilitar que variáveis dos dispositivos estejam disponíveis em um
modo padrão onde múltiplos clientes podem simultaneamente acessá-las, não
importando se o servidor está localizado em uma mesma estação de trabalho ou
remotamente. O pacote System 302 da SMAR contém um servidor OPC para tratar
das variáveis configuradas no SYSCON (SmarDFIOLEServer).

43
Figura 22 – Tecnologia OPC
O controle ActiveX utilizado nos testes permite que sejam desenvolvidos
Scripts no MATLAB que funcionem como aplicações cliente acessando um servidor
OPC para leitura e escrita de dados na rede. A configuração do script no MATLAB
segue critérios presentes na estrutura de acesso de dados de um cliente OPC
padrão. De acordo com estes critérios, um cliente possui uma série de grupos OPC
e cada um destes, uma série de itens que correspondem aos dados acessados
junto ao servidor.
Figura 23 - Componentes de Cliente OPC
4.2: O Algoritmo
O que se descreve a seguir é o algoritmo proposto para identificação de
plantas de primeira ou segunda ordem estáveis, com o que se deve respeitar para o

44
seu funcionamento, baseado na implementação feita em PC com o uso do
MATLAB. Detalhes de código desenvolvido para uso com o MATLAB, assim como
detalhes do algoritmo que dizem respeito à implementação do bloco funcional, não
estão disponibilizados neste documento por motivos de sigilo industrial.
4.2.1: Método Não Recursivo x Método Recursivo
No método de identificação não recursivo, excita-se um processo com a
aplicação de uma determinada entrada, coleta-se os dados e no final do ensaio
realizado, todos estes dados são processados para a estimação dos parâmetros do
modelo do processo. Já no método recursivo, os parâmetros do modelo são
atualizados a cada iteração ao longo do ensaio realizado, de forma a minimizar o
erro entre a saída do modelo parcial obtido e a saída real do processo.
O algoritmo não recursivo tem como desvantagens a complexidade dos seus
cálculos. Estes são realizados apenas uma única vez ao final do ensaio, porém
levam em consideração todas as amostras coletadas. Ele precisa de operações
como inversa, multiplicação e transposta de matrizes que possuem certa
complexidade quando as matrizes têm dimensões muito grandes, o que ocorre
quando o número de amostras coletadas é grande. Além disso é necessário
armazenamento de todos estes dados do ensaio de identificação.
O método recursivo, por sua vez, requer menos tipos de operações. São
necessárias apenas operações como transposta e multiplicação de matrizes. No
entanto, neste método, a cada iteração é realizada uma série de cálculos para obter
um modelo que será utilizado na próxima iteração até que o método convirja. Deve-
se obedecer, portanto, ao fato de que todos os cálculos de cada iteração possam
ser feitos dentro de um tempo hábil. Isto porque a coleta de dados deve ser feita
respeitando determinado período de amostragem que deve ser o mais constante
possível.
O que se pensou a princípio foi a opção pelo método não recursivo por se
tratar de um método mais simples e onde se necessitaria de menos parâmetros de
interação com o usuário, pois o que se pretende com o bloco funcional a ser
desenvolvido é o maior grau de autonomia e simplicidade possível. No entanto, a
complexidade do cálculo final deste método não recursivo e a quantidade de

45
memória necessária ao armazenamento de todas as amostras do ensaio
dificultariam a implementação do algoritmo dentro de um bloco funcional. Deve-se
observar que o poder de processamento de um device Foundation Fieldbus é
consideravelmente menor do que o de um PC.
Assim é preferível a implementação do algoritmo recursivo, que não
necessitará de um cálculo final de natureza extremamente complexa, mas sim de
pequenos cálculos realizados com uma maior freqüência (a cada iteração do
método). A sua própria natureza recursiva facilita a implementação em
microcomputadores. Os testes realizados ao longo do trabalho mostraram que
ambos os métodos recursivo e não recursivo, apresentam resultados semelhantes
para ensaios de identificação equivalentes. Portanto o algoritmo passado pelo aluno
ao setor de Desenvolvimento Eletrônico da empresa foi baseado no método
recursivo.
Os resultados da implementação dos algoritmos recursivo e não recursivo, no
MATLAB, são mostrados no capítulo 6.
4.2.2: Ensaio de Identificação
Todo o processo de identificação é realizado através de um ensaio feito com
o processo como dito anteriormente. Para que este ensaio e a própria identificação
comece, deve-se certificar que o processo esteja em regime permanente em um
ponto de operação, isto é com os valores de saída e de entrada ambos “constantes”.
Isto quer dizer por exemplo, que em um processo de controle de temperatura como
mostrado neste documento, a temperatura encontra-se em um “patamar constante”
durante um intervalo de tempo em que a válvula de controle da entrada de vapor
encontra-se em posição inalterada. Por esta razão, o algoritmo se limita a
identificação de plantas de primeira ou segunda ordem estáveis. A identificação de
plantas integradoras é uma limitação do algoritmo proposto.
Outro ponto fundamental é que para que a identificação possa ser executada,
o usuário deve ter a malha que deseja identificar em malha aberta. Isto se faz
necessário, pois, durante a identificação, tentar-se-á escrever na variável
manipulada do processo de acordo com a excitação gerada no algoritmo. No
exemplo do controle de temperatura, o fechamento da malha impede que seja

46
aplicada certa excitação ao sinal de abertura de válvula, que é determinado pelo
controlador PID.
Como visualizado na figura 20, o Preditor de Smith é geralmente
implementado em uma estrutura que tem como um de seus integrantes, o bloco
PID, responsável pelo sinal de controle enviado ao atuador da malha. A identificação
proposta no algoritmo é em Malha Aberta, e por isso passa-se o modo deste bloco
para manual para poder escrever na sua saída (parâmetro OUT) o sinal de
excitação da identificação.
A partir do momento que o sistema encontra-se em regime permanente e o
modo do PID da malha foi passado para modo manual, o algoritmo de identificação
pode começar a excitar o sistema. Os valores das variáveis de saída (variável de
processo – PV) e de entrada (variável manipulada – MV) neste instante serão
denominados como pontos de referência (PV_ref e MV_ref). A identificação será
procedida então, em torno desta referência que é o ponto de operação do processo.
4.2.3: Etapa de Pré-Teste
Assume-se neste algoritmo que o usuário não possui conhecimento acerca
da dinâmica do processo. Sendo assim, uma primeira etapa a ser realizada é um
degrau para levantamento aproximado desta dinâmica. Esta etapa foi denominada
pré-teste e é necessária, pois a qualidade da identificação se relaciona diretamente
à excitação e a amostragem da coleta de dados que devem ser adequados à
dinâmica do processo que está se identificando. Além disso, para realizar a
identificação de um processo com atraso de transporte, é necessária a quantificação
deste tempo morto, que é utilizado para determinar os demais coeficientes da
função de transferência do modelo do processo.
Nesta etapa, o algoritmo determina o atraso, o tempo de amostragem da
identificação e o sinal de excitação do processo necessário à identificação. Para isto
é aplicado um degrau na entrada do processo de amplitude definida pelo usuário.
Segundo Brosilow e Joseph (2002), citados em [5], têm-se uma adequada excitação
quando a razão sinal ruído do processo é superior a 6.
Esta primeira etapa do algoritmo é ilustrada na figura a seguir:

47
Figura 24 – Etapa de Pré-Teste
Ao final desta primeira etapa o algoritmo define então a excitação e a
amostragem da próxima etapa, que é a identificação propriamente dita.
Sabe-se da teoria de controle [5], que o tempo necessário para que após
aplicação de um degrau na entrada, a saída atinja 98% do seu valor final (tempo de
estabilização), corresponde a 4 constantes de tempo de um processo de primeira
ordem. O algoritmo, durante o pré-teste, calcula o tempo que o processo leva desde
a aplicação do degrau até o tempo em que a saída atinja outro valor de regime
permanente e infere uma constante de tempo aproximada τ.
A partir do valor de τ determina-se o tempo de chaveamento do sinal de
excitação utilizado na identificação. Este sinal é composto por uma série de degraus
de amplitude definida pelo usuário e com tempo de chaveamento igual ao tempo da
constante de tempo aproximada do processo.
Segundo Rivera e Flores (2000) e Brosilow e Joseph citados em [5], para
sistemas monovariáveis a largura da banda de freqüências do sinal de excitação é
definida como:
1 s
s
αω ω ωβ τ τ
= ≤ ≤ =
onde sβ é o fator representando o tempo de estabilização do processo e sα é
o fator representando a velocidade da resposta em malha fechada como um múltiplo
do tempo de resposta em malha aberta. Como a identificação do algoritmo proposto
é em malha aberta têm-se que sα = 1 e o fator sβ (para T98%) = 4.

48
1 14
ω ω ωτ τ
= ≤ ≤ =
4Tτ τ≤ ≤
No algoritmo proposto foi adotado um valor para o período T do sinal de
excitação equivalente a duas constantes de tempo, logo o tempo de chaveamento
entre o valor positivo do sinal e o valor negativo é igual a uma constante de tempo
segundo a aproximação calculada no pré-teste com a adição ou não do atraso do
sistema. Com isso o formato da excitação do sistema é o de uma “onda quadrada”
com amplitude definida pelo usuário e duração determinada pelo parâmetro
calculado nesta etapa. Esta excitação será aplicada na entrada do processo para
realização do ensaio de identificação. No exemplo do capítulo 1, envolvendo
controle de temperatura, uma excitação que provoque uma variação de 10% na
abertura da válvula de entrada de vapor e após o tempo de chaveamento, uma
variação negativa de 10%, repetindo-se este ciclo ao longo do ensaio.
Para o cálculo do período de amostragem da identificação, como se prefere a
opção pelo método recursivo, não há a necessidade de coletar dados e portanto,
pode-se trabalhar com uma amostragem da identificação igual ao macrocycle da
rede. No entanto, para processos muito lentos, uma amostragem muita pequena
pode gerar erros à identificação. O que se faz na prática é ter uma amostragem no
máximo igual a 1/10 e no mínimo igual 1/100 da constante de tempo. A
implementação do método recursivo no MATLAB utilizou o número de 50 amostras
a cada período de tempo equivalente a constante de tempo do processo.
O formato de onda quadrada com tempo de chaveamento simples adotado
neste trabalho possui uma pobre composição em freqüência. No entanto a
implementação realizada no Matlab para o método recursivo obteve resultados
satisfatórios mesmo com este tipo de excitação, que são mostrados no capítulo 6.
Estes testes foram feitos sobre plantas de ordem reduzida (primeira e segunda
ordem), objetivo deste trabalho. Em trabalhos futuros pode-se estudar a
necessidade do uso de sinais de excitação do tipo PRBS para excitar o sistema
identificado em uma faixa de freqüências mais ampla. Deste modo o formato da
onda teria uma amplitude definida e tempo de chaveamento variável para ser
possível a excitação do sistema em variados graus de intensidade que dependem

49
das suas características, as denominadas freqüências naturais ou modos do
sistema.
4.2.4: Etapa de Identificação
Nos itens a seguir são mostrados alguns aspectos da identificação, etapa
posterior ao pré-teste implementada no MATLAB para os casos da identificação não
recursiva e recursiva.
4.2.4.1: Coleta de Dados (Caso da Identificação Não Recursiva)
Concluída a etapa de reconhecimento ou pré-teste do sistema e de posse do
atraso do processo assim como da forma de onda a ser gerada, pode-se começar a
coleta de dados e armazenamento dos mesmos, para posterior inferência dos
demais parâmetros da função de transferência do sistema, de acordo com o método
de identificação não recursiva.
A forma de armazenamento dos dados é feita de acordo como mostrado no
item 3.2.1. Caso o sistema tenha atraso, deve-se transladar as entradas para que as
mesmas fiquem em sincronia com as saídas, como se o processo não tivesse
atraso. Por exemplo:
Primeira Ordem:
(2 )(3 )
...( )
Y nd
Y ndY
Y N
+� �� �+� �=� �� �� �
(1 ) (1)(2 ) (2)
( 1) ( 1 )
Y nd U
Y nd U
X
Y N U N nd
− +� �� �− +� �� �=� �− − − −� �� �� �
� a
bθ � �
= � �� �
Segunda Ordem:

50
(3 )(4 )
...( )
Y nd
Y ndY
Y N
+� �� �+� �=� �� �� �
(2 ) (1 ) (2) (1)(3 ) (2 ) (3) (2)
... ... ... ...( 1) ( 2) ( 1 ) ( 2 )
Y nd Y nd U U
Y nd Y nd U UX
Y N Y N U N nd U N nd
− + − +� �� �− + − +� �=� �� �− − − − − − − −� �
1212
a
a
b
b
θ
� �� �� �=� �� �� �
Ao final da coleta de dados, quando todos os degraus já foram efetuados, é
efetuada a operação para determinação da matriz φ.
1( . ) . .T TX X X Yθ −=
4.2.4.2: Iterações (caso da Identificação Recusiva)
Após a etapa de pré-teste no caso da identificação recursiva, com o atraso e
tempo de amostragem definidos, as iterações são realizadas. Cada iteração deve
ser executada dentro do tempo de amostragem da coleta que pode ser superior ao
macrocycle da rede dependendo de como este tempo foi definido.
Inicializa-se a matriz de covariância P2x2 (primeira ordem) ou P4x4 (segunda
ordem) como uma matriz identidade multiplicada por um fator.
P =10000
0
0
10000
�
� �
P =
10000
0
0
0
0
10000
0
0
0
0
10000
0
0
0
0
10000
�
� �
Define-se o vetor �inicial como um vetor nulo de dimensão que também varia
de acordo com a ordem do sistema.
θ = 0
0
�
� �
θ =
0
0
0
0
�
� �

51
Outro termo definido é o fator de esquecimento λ do método. Nas
implementações realizadas o valor utilizado para este parâmetro foi o de 0.99.
A partir daí, ao longo do ensaio realizado de acordo com a excitação aplicada
ao sistema, são feitas as leituras das variáveis de entrada e saída e realizadas as
operações mostradas anteriormente no item de apresentação do método.
( ( 1) _ ( 1 ) _ ) 1ª ordem
( ( 1) _ ( 2) _ ( 1 ) _ ( 2 ) _ ) 2ª ordem
T
T
y k pv ref u k d mv ref
y k pv ref y k pv ref u k d mv ref u k d mv ref
ϕϕ
= − − + − − − →= − − + − − + − − − − − − →
.Terro Y ϕ θ= −
.. .T
Pk
Pϕ
λ ϕ ϕ=
+
.k erroθ θ= +
. .TP k PP
ϕλ
−=
No método recursivo, o ensaio termina quando os parâmetros obtidos para a
função de transferência convergirem. A indicação disto é feita conforme a amplitude
dos termos da diagonal da matriz de covariância P e do erro.
4.2.5: Implementação da Validação
A validação do modelo obtido após a execução de qualquer um dos métodos
explicitados anteriormente foi feita conforme explicado no capítulo anterior segundo
o coeficiente de correlação múltipla.
� 2
2 1
2
1
[ ( ) ( )]1
[ ( ) ]
N
kN
k
y k y kR
y k y
=
=
−= −
−
�
�
Os procedimentos de validação são geralmente realizados com base em
outro ensaio realizado sobre o processo. Neste novo ensaio uma entrada é aplicada
ao processo, coletando-se a saída real e calculando a saída estimada com base no
modelo obtido.

52
O cálculo do valor da saída do modelo �y depende da ordem do modelo
escolhido para a identificação e utiliza os parâmetros da função de transferência
obtida ao final da identificação. As equações para o cálculo de �y nos casos de
primeira e segunda ordem, são as seguintes:
� � �
� � � � �
1 2
1 2 3 4
( ) ( 1) ( 1 ) Primeira Ordem
( ) ( 1) ( 2) ( 1 ) ( 2 ) Segunda Ordem
y k y k u k d
y k y k y k u k d u k d
θ θ
θ θ θ θ
= − − + − − �
= − − − − + − − + − − �
Estes parâmetros 1θ , 2θ , ... 4θ , são os parâmetros da função de transferência
discreta do sistema. Como os mesmos foram calculados com base em um período
de amostragem utilizado na identificação, eles só podem ser utilizados na validação
se o período de amostragem da validação for o mesmo período de amostragem da
identificação.
4.2.6: Transformada S
De posse de um modelo válido para representação do processo, é preciso
transformar a função de transferência discreta obtida para sua correspondente
formulação contínua (domínio S) que possa ser utilizada para configurar o bloco
funcional Transfer Function. Adota-se a seguinte relação para obtenção da função
de transferência contínua do sistema, aproximação tipo backward [5]:
1z Ts= +
onde T é o período de amostragem da identificação
4.3: Proposta de Bloco Funcional
Com base no algoritmo citado na seção anterior, foi definida a implementação
do mesmo, como uma nova funcionalidade do bloco já existente Transfer Function,
e não como a criação de um novo bloco funcional exclusivo para este fim.
Esta idéia permite que a identificação automática possa ser realizada em uma
estratégia de controle, isto é, para que não seja necessário criar uma estratégia no
SYSCON exclusiva para a autoconfiguração do bloco Transfer Function
(identificação automática). A inclusão desta nova funcionalidade tem por objetivo
torná-lo mais amigável para o usuário, facilitando e estimulando o uso de sua

53
funcionalidade. O objetivo é fazer com que o processo de determinação da função
de transferência e do tempo morto (atraso de transporte) possa ser feito a partir de
um único comando do usuário. E é por isso que o algoritmo foi dividido em três
etapas (Pré-teste, Identificação e Validação), uma vez que se pretende o maior grau
de autonomia.
A estratégia de controle com o novo bloco Transfer Function fica um pouco
diferente daquela mostrada na Figura 20. Há a inclusão de dois links extra, um para
passagem do atraso de transporte do processo identificado pelo bloco Tranfer
Function para o bloco Smith Predictor. O outro link é para fornecer ao bloco Transfer
Function o valor da variável de saída do processo – variável medida, necessária a
identificação. Estes dois links são marcados em vermelho na Figura 25.
Figura 25 – Estratégia de Controle com novo bloco TF
A identificação automática exigiu a ampliação da lista de parâmetros do bloco. Além
dos parâmetros que existem atualmente, foi necessária a inclusão de mais alguns
ao seu conteúdo. A implementação do bloco funcional será iniciada em tempo
posterior a escrita deste documento e portanto, a lista final de parâmetros poderá
sofrer alterações futuras. Maiores detalhes a respeito da nova configuração do bloco
Transfer Function não devem ser mostrados neste documento por questões de sigilo
industrial.

54
Capítulo 5: Identificação com blocos já existentes na
tecnologia Foundation Fieldbus
O objetivo principal deste capítulo é a criação de um ambiente para teste do
algoritmo proposto, o mais próximo possível do funcionamento de um bloco
funcional a ser desenvolvido. Isto pelo fato do bloco funcional, do qual o algoritmo
deste trabalho propõe a implementação, não ter seu desenvolvimento concluído a
tempo para permitir sua utilização. Entretanto, implementa-se o algoritmo do método
recursivo de uma forma alternativa, utilizando as funcionalidades atuais da
tecnologia.
5.1: O Bloco Flexible Mathematical
Foi utilizado um bloco funcional do tipo flexível. Os blocos funcionais flexíveis
são envelopes onde o usuário pode livremente determinar o seu algoritmo. O bloco,
denominado Flexible Mathematical, permite a configuração por parte do usuário de
até 10 expressões matemáticas envolvendo suas entradas, variáveis auxiliares
internas e saídas. Possui ao todo 10 entradas analógicas, 4 entradas discretas, 2
saídas analógicas e 2 saídas discretas, além de 20 variáveis auxiliares analógicas e
10 variáveis auxiliares discretas.
Figura 26 – Blocos Funcionais Flexíveis
Este bloco ainda não se encontra liberado para uso comercial e deve estar
sendo disponibilizado nas novas versões do pacote System302 da SMAR.

55
Cada uma das 10 expressões matemáticas tem um limite de 100 caracteres,
limitando a possibilidade de inserção de expressões muito longas.
5.2: A Estratégia
A estratégia criada utilizou ao todo 3 blocos flexíveis, 1 bloco aritmético, 2
blocos constantes, 3 blocos Smith Predictor e um bloco Transfer Function. Para
implementar a estratégia, foi preciso transformar todas as operações matriciais do
algoritmo (sintetizadas em 3.2.2) em operações aritméticas simples envolvendo
apenas números. Por isso a limitação no número de 10 operações do bloco
impossibilitou a implementação de uma identificação de segunda ordem. Foi
implementada então uma identificação de primeira ordem onde o ensaio, o
preenchimento dos valores referência de saída e entrada, são feitos de forma
manual, pelo usuário. Esta implementação não tem o objetivo de ser empregada em
aplicações industriais, mas sim a comprovação do funcionamento do método
quando implementado sob as especificações de um dispositivo fieldbus. Além disso
o período de amostragem da identificação não é calculado e é igual ao macrocycle
da rede. Isto porque o bloco Flexible Mathematical não possui parâmetro que
possibilite determinar seu período de atualização.
5.2.1: Operações
As operações matriciais do método de identificação recursivo de primeira
ordem são decompostas em operações aritméticas simples de acordo com o
equacionamento seguinte:
1 1
2 2
( 1) _
( 1 ) _
y k pv ref
u k d mv ref
φ φφ
φ φ= − − +� �
= �� � = − − −� �
1 1 2 2
.( ) _ . .
Terro Y
erro y k pv ref
θ φθ φ θ φ
= −= − − −
1 1 3 21 2 2
1 1 2 2 1 2 3
3 1 2 22 2 2
1 1 2 2 1 2 3
. .2. ..
. .. .2. .
T
P PK
P P PPK
P PPK
P P P
φ φλ φ φ φ φφ
φ φλ φ φλ φ φ φ φ
+=+ + +
= �++ =
+ + +

56
1 1 1
2 2 2
..
.K erro
K erroK erro
θ θθ θ
θ θ= +
= + �= +
1 1 1 1 2 31
1 3 2 2 1 3 2 22
3 2
3 1 1 3 2 23
.( )
.( )
.( )
P K P PP
P P P K P PP
P PP K P P
P
φ φλφ φλ
φ φλ
− +=
� � − +� =� �
� �− +=
Estas operações facilitam a implementação uma vez que elas excluem a
necessidade de métodos de multiplicação e soma de matrizes necessários ao
cálculo matricial.
5.2.2: Configuração dos Blocos
A planta a ser identificada é representada por um bloco Transfer Function
mais um bloco Preditor de Smith configurado como atraso.
Figura 27 - Simulação do processo em blocos funcionais
O primeiro bloco Flexible Mathematical é configurado com duas expressões
de soma e subtração de modo a gerar em suas saídas os valores das leituras
subtraídos de seus pontos de referência a ser utilizados no cálculo da matriz φ.
Figura 28 – Configuração de um Bloco Flexível da estratégia
A montagem da matriz é feita de acordo com a seção 4.2. É necessário o
armazenamento da amostra da variável de saída do instante anterior e da variável

57
de entrada de alguns instantes anteriores, número equivalente ao atraso do
processo. Esta coleta é feita com o uso de dois blocos Smith Predictor configurados
como atraso de sinal. Assim é possível disponibilizar a saída do processo de um
macrocycle anterior e a entrada do mesmo de (d+1) macrocycles anteriores de
acordo com o atraso d do sistema.
Figura 29 – Obtenção dos elementos da Matriz φ
A identificação propriamente dita é feita com outro bloco flexível. Neste bloco
são feitas as quatro operações fundamentais do método recursivo, de acordo com
as equações do item 5.2.1. Ele recebe os parâmetros da matriz φ (φ1 e φ2) e o valor
atual da variável y (-y(i)+pv_ref)).
Figura 30 - Bloco flexível implementador das operações método recursivo
O cálculo do atraso, a validação do modelo e a transformação do modelo
discreto obtido para o modelo contínuo, que pode ser inserido no bloco Transfer
Function, é realizada em outro bloco flexível. O usuário deve aplicar um degrau ao
sistema, aguardar até que o atraso seja calculado para utilizar este valor na
identificação, que é feita com outro ensaio. Após o final da identificação, o usuário
deve executar outro ensaio para validação e cálculo on-line do valor de R2 conforme
seção 4.2.5.

58
Figura 31 - Bloco Flexível utilizado para o restante das operações do método
A estratégia completa utilizada nos testes de simulação mostrados no
capítulo seguinte é mostrada na Figura 32.
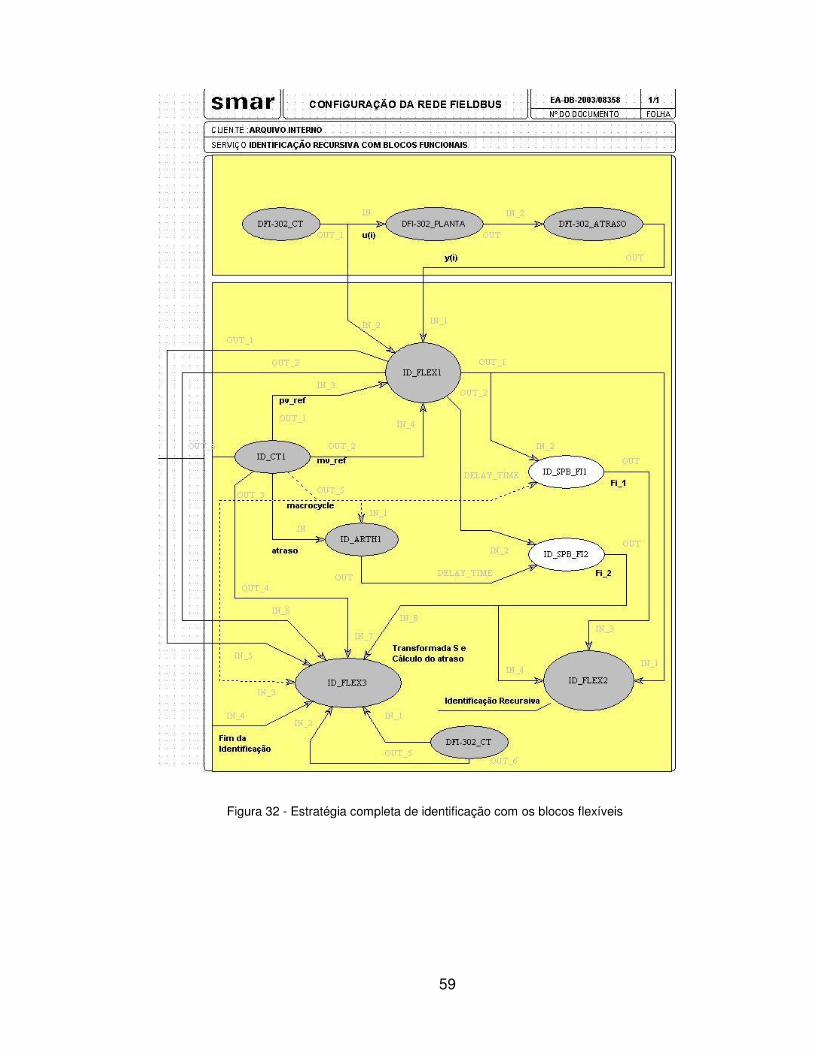
59
Figura 32 - Estratégia completa de identificação com os blocos flexíveis

60
Capítulo 6: Resultados e Discussão
Neste capítulo são apresentados e discutidos os resultados obtidos ao longo
do trabalho. Primeiramente mostram-se os resultados provenientes de ensaios de
simulação em uma rede fieldbus com os dois algoritmos implementados no
MATLAB e também com a implementação de primeira ordem utilizando o bloco
Flexible Mathematical. Por fim, os resultados desta última implementação com o
bloco Flexible Mathematical sobre processos reais com instrumentação Foundation
Fieldbus, para comprovação de que o método recursivo pode ser implementado com
o poder de processamento de um device fieldbus.
Em todos os ensaios de identificação realizados, o que se deseja é chegar à
modelos válidos, representados por funções de transferência, cujos parâmetros
estejam adequados aos processos em questão.
6.1: Resultados de Simulação
Os resultados mostrados nesta seção foram obtidos com o uso de uma
estratégia de controle geralmente utilizada para implementação do Preditor de
Smith. Nesta estratégia há dois blocos Transfer Function fazendo o papel de planta
e modelo do sistema (DFI-302_PLANTA e DFI-302_MODELO respectivamente). Há
um bloco Smith Predictor (DFI-302_ATRASO) funcionando como atraso de sinal
linkado na saída da planta, responsável pela inserção do atraso do sistema. O outro
bloco Smith Predictor (DFI-302_SPB) desempenha o papel do preditor de Smith. Há
ainda um bloco PID para controle do processo. Nestas simulações não há blocos de
medição de sinal nem de atuação. Como se trata de um processo simulado na rede,
ambos os sinais de entrada do Preditor de Smith vêm de funções de transferência
enquanto que a atuação, saída do bloco PID é linkada na entrada dos blocos
Transfer Function da Planta Real e do Modelo do Processo.

61
Figura 33 - Estratégia do Preditor de Smith com blocos funcionais
6.1.1: Planta de Primeira Ordem
Estipulou-se uma planta de primeira ordem com atraso para a realização
desta identificação.
502( )
100 1sG s e
s−=
+
A aplicação do algoritmo recursivo implementado no MATLAB gerou os
seguintes resultados:

62
a b
c
Figura 34 - Ensaio de Identificação com algoritmo recursivo: a. Pré-Teste, b - Identificação, c -
Validação
O atraso obtido durante o Pré-teste foi equivalente a 52 segundos e o modelo
obtido teve ganho igual 1.969 e constante de tempo igual 97.94. O tempo de
chaveamento obtido para o sinal de entrada foi igual a 174 segundos mas o
resultado convergiu antes deste tempo. O tempo de amostragem durante o Pré-
teste era igual a 2 segundos e passou a 3 na identificação. O valor de R2 ficou em
0.9998 o que comprova a validade do modelo.
A inserção de um ruído na leitura dos dados feito no MATLAB, igual a randn/5
provocou os seguintes resultados:
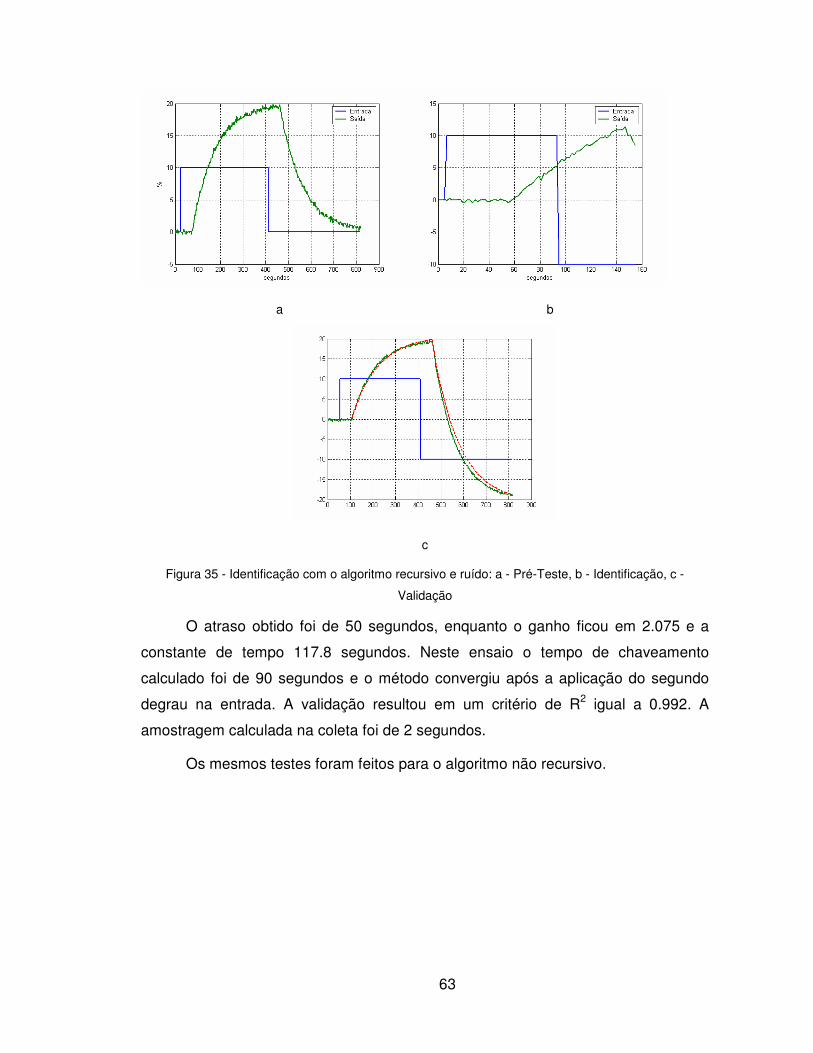
63
a b
c
Figura 35 - Identificação com o algoritmo recursivo e ruído: a - Pré-Teste, b - Identificação, c -
Validação
O atraso obtido foi de 50 segundos, enquanto o ganho ficou em 2.075 e a
constante de tempo 117.8 segundos. Neste ensaio o tempo de chaveamento
calculado foi de 90 segundos e o método convergiu após a aplicação do segundo
degrau na entrada. A validação resultou em um critério de R2 igual a 0.992. A
amostragem calculada na coleta foi de 2 segundos.
Os mesmos testes foram feitos para o algoritmo não recursivo.

64
a b
c
Figura 36 - Identificação com o algoritmo não recursivo: a - Pré-Teste, b - Identificação, c - Validação
Na identificação não recursiva implementada, o número de degraus utilizados
para a identificação é setado pelo usuário, neste caso igual a 4 degraus. Os
parâmetros obtidos foram: atraso igual a 54 segundos, ganho igual a 1.92 e
constante de tempo de 96.64 segundos. A amostragem da coleta ficou em 2
segundos, o tempo de chaveamento igual a 175 segundos e o número de amostras
coletadas foi de 354. O valor de R2 foi de 0.9989.
Da mesma forma que no caso anterior, a inserção de um ruído produziu
resultados com qualidade inferior, mas mesmo assim válidos.
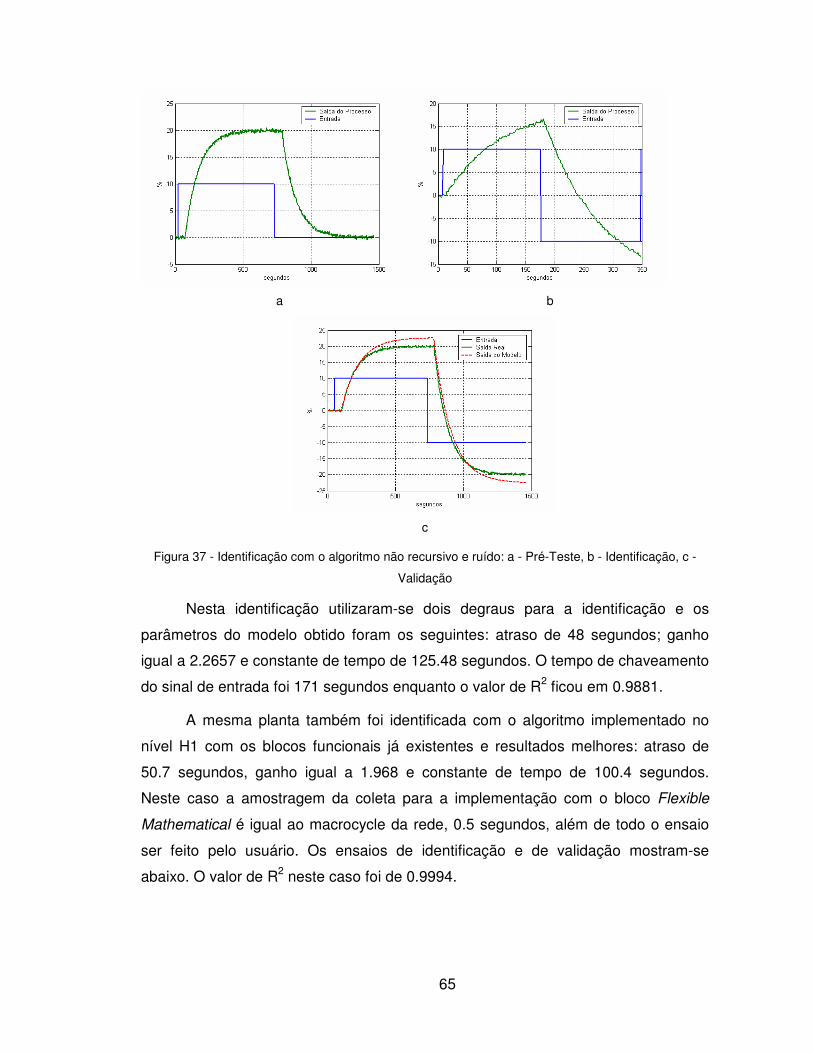
65
a b
c
Figura 37 - Identificação com o algoritmo não recursivo e ruído: a - Pré-Teste, b - Identificação, c -
Validação
Nesta identificação utilizaram-se dois degraus para a identificação e os
parâmetros do modelo obtido foram os seguintes: atraso de 48 segundos; ganho
igual a 2.2657 e constante de tempo de 125.48 segundos. O tempo de chaveamento
do sinal de entrada foi 171 segundos enquanto o valor de R2 ficou em 0.9881.
A mesma planta também foi identificada com o algoritmo implementado no
nível H1 com os blocos funcionais já existentes e resultados melhores: atraso de
50.7 segundos, ganho igual a 1.968 e constante de tempo de 100.4 segundos.
Neste caso a amostragem da coleta para a implementação com o bloco Flexible
Mathematical é igual ao macrocycle da rede, 0.5 segundos, além de todo o ensaio
ser feito pelo usuário. Os ensaios de identificação e de validação mostram-se
abaixo. O valor de R2 neste caso foi de 0.9994.

66
Figura 38 - Identificação e Validação com o uso de blocos Flexíveis
6.1.2: Planta de Segunda Ordem
Da mesma maneira que o caso de primeira ordem, estipulou-se uma planta
de segunda ordem com atraso para os mesmos testes de identificação.
1002
1.5( )
80 10 1sG s e
s s−=
+ +
A aplicação do método recursivo sobre esta planta resultou no seguinte
modelo:
1022
2
1.52( )
71.61 42.52 10.9976
sG s es s
R
−=+ +
=
a b
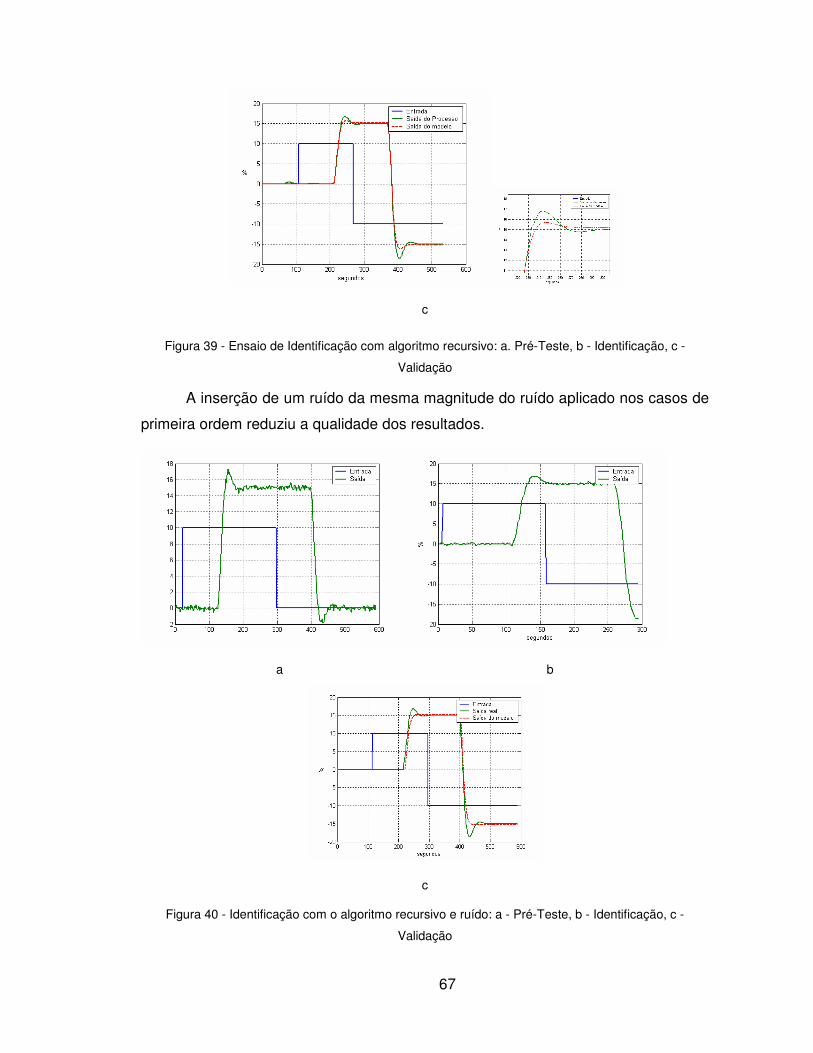
67
c
Figura 39 - Ensaio de Identificação com algoritmo recursivo: a. Pré-Teste, b - Identificação, c -
Validação
A inserção de um ruído da mesma magnitude do ruído aplicado nos casos de
primeira ordem reduziu a qualidade dos resultados.
a b
c
Figura 40 - Identificação com o algoritmo recursivo e ruído: a - Pré-Teste, b - Identificação, c -
Validação

68
1062
2
1.528( )
50.23 31.89 10.9889
sG s es
R
−=+ +
=
O algoritmo não recursivo não produziu resultados melhores que os
resultados acima. A seguir mostram-se dois ensaios com e sem a inserção de ruído
nesta seqüência.
a b
c
Figura 41 - Identificação com o algoritmo não recursivo: a - Pré-Teste, b - Identificação, c - Validação
1022
2
1.5881( )
52.41 34.0016 10.9889
sG s es
R
−=+ +
=

69
a b
c
Figura 42 - Identificação com o algoritmo não recursivo e ruído: a - Pré-Teste, b - Identificação, c -
Validação
1042
2
1.6019( )
41.7973 28.4639 10.9775
sG s es
R
−=+ +
=
Todos estes ensaios e muitos outros realizados ao longo do trabalho
mostram que ambos os métodos, não recursivo e recursivo apresentam resultados
de qualidade semelhante quando obtidos sobre os mesmos ensaios. Além disso
nota-se que a inserção de ruído reduz a qualidade da identificação mas mesmo
assim obtendo modelos válidos segundo o critério de correlação múltipla adotado.
No método não recursivo, o usuário não tem nenhuma resposta on-line do método
sobre a qualidade da sua identificação. É deixado a cargo do usuário o número de
degraus a serem aplicados ao processo e só ao final de todos estes, o mesmo tem
o modelo. Mesmo assim é só após o ensaio de validação que se tem a certeza do
modelo ser adequado ou não. Prefere-se optar pelo método recursivo onde o
método processa suas iterações até que os resultados atinjam uma convergência e

70
todo este processo pode ser acompanhado on-line pelo usuário. Um ponto
observado nos testes de identificação com plantas de segunda ordem simuladas, foi
a obtenção de modelos válidos, porém de qualidade inferior aos resultados de
primeira ordem. Para melhora da qualidade destes resultados, o uso de sinais PRBS
pode ser considerado como uma melhoria futura ao algoritmo.
6.2: Resultados Reais
6.2.1: Processo de Vazão com inserção de Atraso
A alternativa de identificação com blocos já existentes atualmente na
tecnologia, apresentada no capítulo 5, foi aplicada para determinação do modelo de
um processo real. O processo adotado pertence à Planta Didática de número 3 da
SMAR, com instrumentação Foundation Fieldbus e tem como entrada, a variável
abertura de válvula enviada pelo posicionador FY302, e saída, a vazão de entrada
do tanque de aquecimento medida pelo transmissor de pressão diferencial LD302,
como mostra a figura 43.
Figura 43 – Ilustração do processo de Identificação de um sistema de controle de Vazão
Este é um processo originalmente rápido e sem atraso. Para os testes de
identificação, um atraso artificial foi inserido com o uso do bloco Preditor de Smith
configurado como atrasador de sinal assim como feito nas estratégias de simulação
anteriores. Devido aos ruídos na leitura de vazão, um filtro foi utilizado para
amenizar a taxa de variação aleatória das medidas, o que também fez com que o
processo se tornasse mais lento. Isto foi feito com a configuração do parâmetro
PV_FTIME do bloco ANALOG INPUT do transmissor de vazão, que corresponde à

71
constante de tempo de um filtro de primeira ordem para o sinal medido pelo
transmissor.
Assim foi possível testar a solução desenvolvida para 3 situações diferentes.
A primeira situação testada foi sem a inserção de atraso e sem filtro, o que resultou
nos seguintes ensaios de identificação e validação:
Figura 44 – Ensaio de Identificação e Validação
O modelo de primeira ordem obtido teve ganho igual a 14.59 e constante de
tempo equivalente a 0.78 segundos. Já o critério de correlação múltipla da validação
resultou no valor de 0.9617, indicando um modelo aceitável para o processo. A
convergência dos parâmetros estimados ao longo do ensaio de identificação pode
ser visualizada nas figuras seguintes.
Figura 45 – Convergência dos Parâmetros Estimados
Pode-se notar que toda vez que é aplicado uma variação na entrada do
processo, há uma perturbação na identificação fazendo com que os parâmetros
estimados tenham que voltar a convergir para valor adequado. Isto explica o porquê

72
da importância de uma excitação adequada, que não venha a perturbar o processo
continuadas vezes antes do mesmo reagir às excitações anteriores, pois isto poderá
acarretar na não convergência do método a um modelo adequado.
A inclusão de um filtro propositadamente mal ajustado, com constante de
tempo equivalente a 20 segundos, possibilitou aplicar a solução na identificação de
um processo mais lento, com constante de tempo muito maior que o macrocycle da
rede, que para todos estes testes, foi igual a 190 ms.
a b
c
d

73
Figura 46 – Ensaio de Identificação (a) e de Validação (b) e Convergência dos parâmetros estimados:
ganho (c) e constante de tempo (d)
O modelo obtido neste caso teve ganho equivalente a 14.41 e constante de
tempo de 29.7 segundos com um valor de R2 igual a 0.9860 também indicando um
modelo válido.
A inserção de um atraso igual a 50 segundos, atraso este gerado pela
passagem do sinal de vazão pelo bloco Preditor de Smith, fez com que a
identificação fosse aplicada a uma planta de primeira ordem com atraso. Os ensaios
de identificação e validação assim como a convergência dos parâmetros é mostrada
nas figuras seguintes.
Figura 47 – Ensaio de Identificação e Validação

74
Figura 48 – Convergência dos Parâmetros Estimados
A presença do atraso faz com que os parâmetros estimados comecem a
convergir apenas após o atraso e a saída começar a responder frente à variação
produzida na entrada do sistema. Neste caso, foi obtido um modelo com ganho igual
a 15.21 e constante de tempo de 24.13 segundos e um R2 de validação de 0.9990.
6.2.2: Processo de Temperatura
Um processo originalmente com atraso também foi testado. É um processo
também presente na Planta Didática de número 3 da SMAR. Como se pode ver na
Figura 50, o sistema é constituído por dois tanques. Um é o tanque de aquecimento,
onde entra água fria que é aquecida por resistências elétricas de imersão,
comandadas pela corrente emitida por um conversor de corrente fieldbus – FI302. A
água aquecida neste tanque é então misturada com água fria em outro tanque, o
tanque de mistura. A temperatura do tanque de mistura é medida por um termopar
que envia o sinal ao transmissor de temperatura TT302.
Figura 49 – Ilustração do processo de Identificação de um sistema de controle de Temperatura

75
A variável de entrada deste processo é o sinal de corrente enviada pelo
conversor de corrente fieldbus, enquanto a variável de saída é a temperatura da
mistura de água no tanque de mistura. O tempo morto entre a saída e a entrada
neste caso é devido ao transporte de energia – temperatura – no aquecimento da
água fria que entra no tanque de aquecimento e ao transporte de matéria, pois esta
água aquecida é levada de um tanque ao outro pela tubulação entre os dois
tanques.
A estratégia de controle adotada é semelhante à mostrada no capítulo 5
utilizada em um dos ensaios de simulação da seção 6.1. A única diferença é que
neste caso real, não há a necessidade de simular uma planta através de uma
função de transferência. No entanto há um bloco para disponibilizar a temperatura –
bloco ANALOG INPUT, TIT-32_AI1 – e outro para atuação sobre a corrente do
conversor – bloco ANALOG OUTPUT, TY-31_AO1. A única diferença entre esta e a
estratégia do outro caso real, item 6.2, é o fato destes dois blocos para medição e
atuação estarem instanciados em outros dispositivos, transmissor de pressão
diferencial (LD302) e posicionador fieldbus de válvula (FY302,) respectivamente.
Figura 50 – Estratégia para Identificação do processo

76
O ensaio de identificação deste processo é mostrado na Figura 51.
Figura 51 – Ensaio de Identificação do processo – Corrente e Temperatura
Figura 52 – Convergência dos parâmetros do modelo
Figura 53 – Ensaio de Validação
O ensaio de identificação resultou em um modelo com atraso igual a 76
segundos, ganho igual 0.19 e constante de tempo de 157 segundos. O coeficiente
de correlação múltipla R2 do ensaio de validação foi igual a 0.92, significando um
modelo adequado para o processo. Estes testes foram importantes para comprovar

77
a possibilidade de implementação de um algoritmo como este no nível H1 de uma
rede fieldbus.

78
Capítulo 7: Conclusões e Perspectivas
A identificação de processos industriais, tarefa necessária à implementação
de sistemas de controle, é uma atividade geralmente realizada através de ensaios
nas plantas industriais em procedimentos de partida e de forma manual com o total
acompanhamento de profissionais capacitados. A automação desta atividade acaba
se tornando uma tarefa complexa pois, para que os resultados obtidos da
identificação tenham qualidade adequada, muitos requisitos de operação devem ser
garantidos. E esta garantia deve ser atingida de forma automática. Fatores como
ruídos nos sinais medidos, processos onde é difícil impor um ponto de operação
quando em malha aberta, processos não lineares, taxa de amostragem da
identificação não adequada e existência de tempo morto, são apenas alguns
exemplos do que pode fazer com que um ensaio de identificação falhe.
O que se propôs neste trabalho foi a elaboração de um algoritmo que
pudesse efetuar a identificação de processos de primeira e segunda ordem estáveis,
baseado em um método largamente utilizado, a formulação recursiva do método dos
mínimos quadrados criado por Ljung. Neste algoritmo procurou-se aliar os anseios
do setor industrial, que deseja o mínimo de perturbação a um processo de produção
– com a aplicação de poucos distúrbios nas variáveis envolvidas através de ondas
quadradas com o mínimo de pulsos possíveis – e da forma mais automática –
menor necessidade de conhecimento do operador. Mas também foi necessário
atender às exigências acadêmicas dos profissionais de controle que precisam
analisar a dinâmica do sistema identificado para garantir que o modelo encontrado é
adequado.
O algoritmo elaborado pelo aluno será implementado como uma nova
funcionalidade à tecnologia dos blocos funcionais Foundation Fieldbus da empresa
e permitirá que em trabalhos futuros, o novo bloco Transfer Function possa ser
testado e melhorado caso haja necessidade. O novo bloco Transfer Function poderá
então ser aplicado no projeto de automação do separador, que originou o seu
desenvolvimento.

79
A alternativa de identificação elaborada pelo aluno no capítulo 5 com o uso
de blocos funcionais flexíveis permite concluir que funcionalidades mais complexas
podem ser implementadas com o uso de blocos funcionais de uma rede Foundation
Fieldbus. E é por isso que as perspectivas apontam para o desenvolvimento de
novos blocos funcionais para o tratamento de problemas mais avançados em um
nível onde, são os instrumentos da rede fieldbus que executam as funções de
controle. O próprio bloco flexível utilizado em parte do trabalho segue esta
tendência, uma vez que o mesmo permite que uma série de operações
configuráveis possa ser implementada. Atividades como as descritas neste trabalho
contribuem portanto, para aumentar a abrangência da tecnologia e torná-la mais
robusta para ser aplicada a plantas cada vez maiores e mais complexas.

80
Bibliografia:
[ 1 ] Berge, J., "Fieldbuses for Process Control: Engineering, Operation and
Maintenance ", ISA, 2002.
[ 2 ] Thomas, J. E., "Fundamentos da Engenharia do Petróleo", Editora Interciência,
2001.
[ 3 ] Smar Equipamentos Industriais, "Manual de Blocos Funcionais", Sertãozinho,
2004.
[ 4 ] Smar Equipamentos Industriais, "Como Implementar projetos com Foundation
Fieldbus", Documento Interno Smar, 2001.
[ 5 ] Coelho, A. A. R. e Coelho, L. S., "Identificação de Sistemas Dinâmicos
Lineares", Editora da UFSC, 2004.
[ 6 ] Plucênio, A. e Pagano, D. J., "Uma Introdução a Identificação Paramétrica",
Universidade Federal de Santa Catarina, Documento Interno, 2005.
[ 7 ] Normey-Rico, J. N., "Apostila do Curso de Sistemas Realimentados", Disciplina
do Curso de graduação em Engenharia de Controle e Automação,
Universidade Federal de Santa Catarina, Documento Interno, 2004.
[ 8 ] Weiss, L. A., "Desenvolvimento de Blocos Funcionais para Compensação de
Atraso de Transporte utilizando a tecnologia Foundation Fieldbus",
Monografia submetida à Universidade Federal de Santa Catarina, 2004.
[ 9 ] Santos, S. C., "Identificação Multivariável aplicada a Processos Químicos:
Estudo de Caso", Dissertação de Mestrado submetida à Universidade
Federal de São Carlos, 2000.
[ 10 ] Aguirre, L. A., "Introdução a Identificação de Sistemas, Técnicas Lineares e
Não Lineares aplicadas a sistemas reais", Editora UFMG, 2000.
[ 11 ] Bruciapaglia, A. H., "Apostila do Curso de Processos em Engenharia",
Disciplina do Curso de graduação em Engenharia de Controle e Automação,
Universidade Federal de Santa Catarina, 2000.














