ID3 und Apriori im Vergleich - wi.hs-wismar.decleve/vorl/projects/dm/ss13/Assoziation/... · ID3...
17
ID3 und Apriori im Vergleich Lassen sich bei der Klassifikation mittels Apriori bessere Ergebnisse als durch ID3 erzielen? Sebastian Boldt, Christian Schulz, Marc Thielbeer KURZFASSUNG Das folgende Dokument umfasst die Beschreibung der Algorithmen ID3 und Apriori und deren Vergleich im Bezug auf die Klassifizierung.
Transcript of ID3 und Apriori im Vergleich - wi.hs-wismar.decleve/vorl/projects/dm/ss13/Assoziation/... · ID3...

ID3 und Apriori im Vergleich
Lassen sich bei der Klassifikation mittels Apriori bessere
Ergebnisse als durch ID3 erzielen?
Sebastian Boldt, Christian Schulz, Marc Thielbeer
KURZFASSUNG
Das folgende Dokument umfasst die Beschreibung der Algorithmen ID3
und Apriori und deren Vergleich im Bezug auf die Klassifizierung.

Table of Contents
1. Klassifikation mittels ID3 ................................................................................... 3
1.1 Realisierung in KNIME ............................................................................................................................ 6
2. Assoziationsanalyse mittels Apriori ................................................................... 8
2.1 Apriori in KNIME ....................................................................................................................................... 9
2.2 Datenvorverarbeitung für Apriori in KNIME .............................................................................. 10
2.3 Beispiel Hautkrebsdatensatz ............................................................................................................. 11
3. Klassifikation mittel Apriori ............................................................................. 12
3.1 Realisierung in KNIME ......................................................................................................................... 12
4. Probleme bei der Umsetzung .......................................................................... 14
5. Auswertung der Ergebnisse ............................................................................. 15
6. Zusammenfassung und Ausblick ...................................................................... 16

1. Klassifikation mittels ID3
Bei der Klassifikation mittels ID3-Aglorithmus wird der berechnete
Entscheidungsbaum zum Klassifizieren der Datensätze genutzt, das heißt die
Daten werden in entsprechende Klassen aufgeteilt.
Der ID3-Algorithmus wird meistens dann verwendet, wenn bei großen
Datenmengen zahlreiche verschiedene Attribute von Bedeutung sind. Und somit
ein Entscheidungsbaum ohne große Berechnungen generiert werden soll.
Mit Hilfe dieses Algorithmus entstehen meist einfache Entscheidungsbäume. Das
der mit ID3 berechnete Entscheidungsbaum der Beste (kompakteste) ist kann
nicht garantiert werden, es könnte auch besseren Bäume geben. Er basiert auf
einer iterativen Struktur. Zu jedem noch nicht benutzten Attribut, der
Trainingsmenge wird der Informationsgehalt berechnet. Das Attribut mit dem
höchsten Informationsgehalt, also der größten Entropie, wird gewählt und
daraus ein neuer Baum-Knoten generiert. Das Verfahren terminiert, wenn alle
Trainingsinstanzen klassifiziert wurden, d.h. wenn jedem Blattknoten eine
Klassifikation zugeordnet ist.
Die Funktion des ID3-Algorithmus wird am besten ein einem kleinen Beispiel
deutlich. Hierzu wurde der Wetterdatensatz gewählt. Dieser Datensatz gibt
Auskunft darüber ob ein Golfspiel stattfindet oder nicht. Es soll also die Klasse
Play klassifiziert werden.
outlook temperature in F humidity windy play
sunny 85 85 FALSE no
sunny 80 90 TRUE no
overcast 83 86 FALSE yes
rainy 70 96 FALSE yes
rainy 68 80 FALSE yes
rainy 65 70 TRUE no
overcast 64 65 TRUE yes
sunny 72 95 FALSE no
sunny 69 70 FALSE yes
rainy 75 80 FALSE yes
sunny 75 70 TRUE yes
overcast 72 90 TRUE yes
overcast 81 75 FALSE yes
rainy 71 91 TRUE no
Um aus dieses Tabelle einen Entscheidungsbaum, der für die Vorhersage der
Zielklasse (Play) verwendet werden kann, erzeugen zu können, müssen die
Daten vorverarbeite werden. Die ist notwendig um den Arbeitsaufwand zu
minimieren. Es müssen die metrischen Datentypen der Spalten temperature und
humidity in Intervalle aufgeilt werden. Diesen Intervallen werden dann mit

nominalen Datentypen bezeichnet. Die Anzahl der Intervalle sollte sinnvoll und
möglichst klein sein.
Die Spalte temperatur wurde wie folgt aufgeteilt: cool � -∞°F bis 70°F; mild � 71°F bis 80°F; hot � 81°F bis ∞°F. Die Aufteilung der Spalte humidity erfolgte nach normal � -∞% bis 70% und high 71% bis ∞. Zu Beginn wird der Informationsgehalt des Datensatzes ermittelt. Hierzu werden
die Wahrscheinlichkeiten der unterschiedlichen Werte des Zielattributs benötigt.
����� = � ���� � = �
Anschließend wird der Informationsgehalt der Tabelle bzw. des Datensatzes
berechnet.
���������� = ������� = − 514 ∗ ���� � 5
14 −914 ∗ ���� � 9
14 = 0,940
Da für die Entscheidung, welches Attribut den nächsten Knoten bildet, der
Gewinn an Informationen des jeweiligen Attributes benötigt wird, muss für
jeden Wert jedes Attributes der Informationsgehalt ermittelt werden. Es wird
nur die Wahrscheinlichkeitsverteilung innerhalb der Play-Spalte betrachtet, da
dieses das Zielattribut ist. Im nachfolgenden werden die Informationsgehalte
und der jeweilige Gewinn berechnet.
outlook play
yes no
sunny 2 3
overcast 4 0
rainy 3 2
$�%&''�� = −25 ∗ ���� �25 −
35 ∗ ���� �35 = 0,971
$��+�,-�%.� = − 44 ∗ ���� �44 = 0
$�,�/'�� = −35 ∗ ���� �35 −
35 ∗ ���� �25 = 0,971
0��&.���1� = − 514 ∗ ���� � 5
14 ∗ 2 = 0,694
3�45����&.���1� = 0,940 − 0,694 = 0,246
temperatur play
yes no
cool 3 1
mild 4 3
hot 2 1

$�-���� = − 34 ∗ ���� �34 −
14 ∗ ���� �14 = 0,811
$�7/�8� = −47 ∗ ���� �47 −
37 ∗ ���� �37 = 0,985
$�ℎ�.� = − 23 ∗ ���� �23 −
13 ∗ ���� �13 = 0,981
0�.�7��,�.&,� = 414 ∗ 0,811 + 714 ∗ 0,985 + 3
14 ∗ 0,918 = 0,921
3�45���.�7��,�.&,� = 0,940 − 0,918 = 0,022
humidity play
yes no
normal 3 1
high 6 4
$�'�,7��� = − 34 ∗ ���� �34 −
14 ∗ ���� �14 = 0,811
$�ℎ/�ℎ� = − 610 ∗ ���� � 6
10 −310 ∗ ���� � 3
10 = 0,963
0�.�7��,�.&,� = 414 ∗ 0,811 + 1014 ∗ 0,963 = 0,919
3�45���.�7��,�.&,� = 0,940 − 0,919 = 0,021
windy play
yes no
FALSE 6 2
TRUE 3 3
$�;<=>?� = −68 ∗ ���� �68 −
28 ∗ ���� �28 = 0,811
$��@A?� = − 36 ∗ ���� �36 −
36 ∗ ���� �36 = 0,918
0�.�7��,�.&,� = 814 ∗ 0,811 + 614 ∗ 0,918 = 0,892
3�45���.�7��,�.&,� = 0,940 − 0,892 = 0,048

Wie aus den Berechnungen hervorgeht hat das Attribut outlook den höchsten
Gewinn an Information. Darum wird outlook als Wurzelknoten des Baumes
gewählt. Von diesem Knoten gehen Zweige entsprechend der verschiedenen
Werte des Attributs ab.
Die Knoten zu denen die Zweige führen sind noch nicht bekannt. Sie werden
nach dem selben Prinzip wie der Wurzelknoten ermittelt. Allerdings muss nun
nicht mehr die komplette Datenbank bzw. der komplette Datensatz betrachtet
werden. Es müssen lediglich alle Fälle zum zu berechnenden Knotenpunkt
führen betrachtet werden. Das heißt für Konten 1 müssen nur alle Fälle in den
outlook = sunny ist betrachtet werden. Dieses Prinzip wird solange fortgesetzt
bis alle Attribute auf Knoten abgebildet sind.
1.1 Realisierung in KNIME
Das Erzeugen von Entscheidungsbäumen kann mithilfe von KNIME relativ
einfach umgesetzt werden, da alle benötigten Bausteine vorhanden sind. Die
Daten werden über den File Reader eingelesen. Wenn in diesen Daten nicht nur
overcast
outlook
1?
2?
3?
overcast
outlook
humidity windy
yes yes no yes no

ausschließlich nominale Werte vorhanden sind, müssen diese mithife des
Numeric-Binners in Intervalle aufgeteilt und durch einen nominalen Wert
dargestellt werden. Wie schon erwähnt sollte eine möglichst logische und
geringe Intervallaufteilung erfolgen um die Komplexität des Baumes zu
minimieren.
Sind die Daten in das richtige Format umgewandelt muss, falls keine
Trainingsdaten vorhanden sind, eine Partitionierung in Test und Trainingsdaten
erfolgen. In den Experimenten wurden stets 30% der Testdaten zum Training
genutzt. Anschließend wird über das ID3-Modul der Entscheidungsbaum aus den
Trainingsdaten generiert. Für die Klassifizierung bzw. für das Vorhersagen der
Klasseneinteilung der Testdaten wird der Weka-Predictor mit dem generierten
Entscheidungsbaum und den Testdaten gefüttert. Die Anzahl der korrekt
zugeordneten Datensätze wird mithilfe des Scorer-Moduls ausgegeben.
Um neben dem Apriori und dem ID3 noch einen weiteren Vergleichswert
zuhaben, wurde parallel zum ID3 noch der „normale“ Decision Tree von KNIME
zur Auswertung hinzugezogen. Der „Decision Tree Learner“ bekommt die
gleichen Daten wie das „ID3“-Modul, intern wird der Baum aber dann mit Hilfe
des C4.5-Algorithmus berechnet. Auf diesen wird aber nicht genauer
eingegangen. Der „Decision Tree Predictor“ bekommt für die Vorhersage der
Klassen ebenfalls die gleichen Testdaten, aber auch den mit dem zugehörigen
Learner erzeugten Baum.

2. Assoziationsanalyse mittels Apriori
Bei dem Apriori-Algorithmus handelt es sich um ein iteratives Verfahren zur
Erzeugung von Assoziationsregeln. Der Algorithmus benötigt eine Datenbasis
mit Transaktion (Tupeln) aus binären Items.
Weiterhin werden als Eingabeparameter ein minimaler Supportwert sowie eine
minimale Konfidenz benötigt. Die Funktionsweise lässt sich in 2 Abschnitte
untergliedern.
1. Join und Pruning Phase: Zunächst einmal wird für jedes Item einzeln betrachtet ob es den Support erfüllt.
Ein Support von 0,1 sagt z.B. aus, dass das Item mit einer Wahrscheinlichkeit von
10% in einer Transaktion binär eins gesetzt ist. Die Items, die den Support nicht
erfüllen werden, werden im Folgenden ignoriert.
Im nächsten Schritt werden Itemsets aus allen möglichen Zweierkombinationen
der restlichen Items gebildet. Es folgt wiederum die Prüfung des Supports der
Itemsets und ein Herausnehmen derer, die den Support nicht erfüllen.
Ab einer Itemsetsgröße von drei wird das Pruning betrachtet, hierbei wird für
jedes Itemset geprüft, ob alle Teilmengen den Support erfüllen. Tut dies eine
Teilmenge nicht, wird auch das gesamte Itemset den Support nicht mehr erfüllen
und fällt so heraus. Dieser Abschnitt endet, sobald eine Maximalgröße an
Itemsets gefunden wurde, die den Support erfüllt.
2. Bilden der Regeln
Anhand der gefundenen Itemsets werden nun Assoziationsregeln gebildet. In
diesem Schritt wird zusätzlich zum Support auch die minimale Konfidenz
betrachtet. Ein Itemset aus drei Items kann theoretisch zu drei
Assoziationsregeln führen. Somit muss für jede Kombination geprüft werden, ob
die minimale Konfidenz zutrifft. Die Konfidenz ergibt sich aus dem Support der
zur Regel führenden Transaktionen geteilt durch den Support des Zielattributes.
Führen A und B zu C ist die Konfidenz dieser Regeln das Verhältnis der
Häufigkeit des Itemsets {A, B, C} zu der Häufigkeit vom Itemset {C}.

2.1 Apriori in KNIME
KNIME bietet mit der
WEKA Erweiterung ein
Apriori Modul. Dieses
Modul erwartet als
Eingang einen
Datensatz mit binären Daten.
Die Erzeugung dieser binären
Daten wird im Abschnitt zur
Datenenvorverarbeitung genauer
beleuchtet.
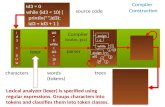
Auf dem Bild erkennt man zur
Rechten erkennt die
Einstellungsmöglichkeiten des
Moduls.
Der lowerBoundMinSupport steht
für den minimum Support dem
man übergibt.
metricType ist standardweise auf Confidence gestellt,
weswegen man in dem Feld minMetric die minimale Konfidenz angibt.
Außerdem von Bedeutung ist das Feld numRules. Hierbei wird angegeben
wieviele gefundene Assoziationsregeln das Apriori Modul ausgeben soll.
Dabei tritt eine Besonderheit auf, denn das
Modul besitzt keinen Ausgang. Es kann
lediglich ein Textfeld mit den gefundenen
Itemsets und den daraus erzeugten Regeln
angezeigt werden, wie im Rechten Bild zu
sehen. Demnach ergeben sich auch bestimmte
Anforderungen für die Weiterverarbeitung wie
im Kapitel (3.1) aufgezeigt wird.

2.2 Datenvorverarbeitung für Apriori in KNIME
Bei der Datenvorverarbeitung für Apriori sind folgende Module von Bedeutung:
Der Numeric-Binner wird verwendet um Attribute mit
numerischen Daten in Intervalle zu untergliedern.
Da Apriori nur mit binären Werten umgehen kann, müssen alle
Attribute mit mehr als zwei Intervallen in mehrere Spalten mit
binärem Wert unterteilt werden. Also werden aus Spalte X mit
möglichen Wert {a,b,c} Spalten A,B,C mit jeweils dem Wert 1 oder 0.
Dieses Modul ist dazu da alle nummerischen Werte in Strings
umzuwandeln. Das Apriori Modul erwartet als Eingabe nur
Attribute dieses Typs.
Das Partitionierungsmodul dient zur Aufteilung der Datenmenge in
Trainings- und Testdaten. Es bietet hierbei auch die Möglichkeit
einzustellen, dass das Zielattribut im Verhältnis von Trainings- und
Testdaten gleichmäßig aufgeteilt wird und die Einstellung eines
Seed-Wertes, um für einen Vergleich eine identische Verteilung zu
erreichen.
Der Column-Filter ermöglicht das Herausnehmen von Spalten aus
einem Datensatz. Im Apriori Ablauf wird er benötigt, um z.B. die
Spalte eines Zielattributes zu löschen, das Zuvor mit dem
„One2Many“ Modul in mehrere Spalten aufgeteilt wurde.

2.3 Beispiel Hautkrebsdatensatz
Eine besondere Herausforderung
stellt der Hautkrebsdatensatz dar.
Dieser besitzt eine Reihe an
Attributen mit nummerischen
Werten, die in der
Datenvorverarbeitung in binäre
umgewandelt werden müssen.
Besonders auffällig ist hierbei
aber das Zielattribut state. Dieses
kann drei unterschiedliche Werte
annehmen und somit wird es im
One2Many -Modul in drei Spalten
aufgeteilt. Von diesen drei Spalten
gelangt jeweils eine in ein
separates Apriori Modul.
Die Begründung für die Dreiteilung liegt in der Auswertung der Apriori
Ergebnisse, denn Apriori würde ohne die Filterung der anderen Spalten viele
Regeln finden, in denen die beiden anderen Zielattribute selbstverständlich den
invertierten Wert des betrachteten aufweisen.
Diese Regeln weisen außerdem eine Konfidenz mit dem Wert 1 auf und stehen
dann den eigentlichen Regeln in der Ausgabe des Apriori Moduls im Weg, wenn
diese manuell herausgefiltert werden müssen.

3. Klassifikation mittel Apriori
Bei der Klassifikation mittels Apriori werden die über die Assoziationsanalyse
aufgestellten Regeln dafür genutzt die Daten in bestimmte Klassen zu
unterteilen. Da der Apriori-Algorithmus nur mit booleschen Werten arbeiten
kann müssen bei der Daten-Vorverarbeitung besonderen Schritte beachtet
werden. Zum einen müssen die Daten der Datensätze die keine booleschen
Werte enthalten sinnvoll aufgeteilt werden.
Dazu das folgende Beispiel:
Nehmen wir an in einer Tabelle befinden sich Datensätze von Personen. Für die Klasse Person wurde das Attribut Alter als numerischer Wert definiert. Apriori kann allerdings nur boolesche Werte verarbeiten. Die Spalte muss dem zu folge in mehrere logische Kategorien unterteilt werden von denen jede in eine Spalte umgewandelt wird. Beispielsweise könnte man die Spalte Alter in 3 Intervalle unterteilen: Alter < 18 (A), Alter =>18 & < 50(B), Alter >= 50(C). Die Menge aller Werte für dieses Attribut wurde somit auf 3 diskrete Intervalle, A,B, C herunter gebrochen. 3 Intervalle d.h. 3 unterschiedliche Werte die eine Variable annehmen kann. Um die Spalte nun für Apriori nutzbar zu machen muss die Spalte auf 3 Spalten aufgeteilt werden.
ID Alter
1 10
2 17
3 40
4 23
5 60
6 101
Nachdem die Daten entsprechend vorverarbeitet worden sind können sie mittels
Apriori-Assoziationsanalyse erzeugt werden. (siehe Kapitel :
Assoziationsanalyse mittels Apriori). Die für das Zielattribut relevanten Regeln
können anschließend aus dem Datensatz der gewonnenen Regeln extrahiert und
für die Klassifikation genutzt werden.
3.1 Realisierung in KNIME
Für die Erzeugung der relevanten Assoziationsregeln wird wie in Kapitel 2
beschrieben, das Apriori Modul genutzt. Zu beachten war hier zum einen das
beseitigen der irrelevanten Spalten. Beispielsweise könnte eine Einteilung in 3
unterschiedliche Klassen vorgenommen werden. Für jede dieser Klassen wird
eine Spalte benötigt. Nehmen wir an, es sollen Assoziationsregeln für die Klassen
X, Y, und Z erzeugt werden. So spielen beispielsweise die Klassen X und Y bei der
Klassifizierung nach Z keine Rolle. Sie können also aus dem Datensatz entfernt
werden. Nachdem die Regeln für jede Klasse erzeugt worden sind, können sie auf
die zu untersuchenden Daten angewendet werden. In KNIME wird für das
Klassifizieren mittels bestimmter Regeln die RULE-Einige zur Verfügung gestellt.
ID Alter
1 A
2 A
3 B
4 B
5 C
6 C
ID A B C
1 1 0 0
2 1 0 0
3 0 1 0
4 0 1 0
5 0 0 1
6 0 0 1

Hier können die Regeln manuell eingetragen werden um sie anschließend über
den Scorer auszugeben. Ein einfacher Aufbau könnte folgendermaßen aussehen.
Problem bei dieser Konfiguration ist, dass sie für eine größere Anzahl von
Klassen nicht angewendet werden kann. Die Rule-Engine kann lediglich eine
neue Spalte an die bestehende Tabelle anhängen. Es lassen sich also nicht alle
regeln für die unterschiedlichen Klassen in einer Rule-Engine sammeln. Weshalb
Für die Klassifizierung mehrerer Klassen mehrere Rule-Engines genutzt

4. Probleme bei der Umsetzung
Im folgenden Abschnitt sollen die Probleme die bei der Umsetzung der
Aufgabenstellung aufgetreten sind kurz zusammengefasst werden.
In einigen Datensätze sind numerische Werte vorhanden. Diese müssen mithilfe
des Numeric-Binnes in Intervalle eingeteilt werden. Damit das Apriori-Modul mit
diesen Werten arbeiten kann, müssen die entsprechenden Intervalle auf
mehrere Spalten mit booleschen Attributwerten aufgeteilt werden.
Besitzt der Datensatz ein Zielattribut mit drei Klassen steigt somit der Aufwand
für die Umsetzung, weil der Workflow nach der Partitionierung der Daten
dreigeteilt werden muss.
Das schwerwiegendste Problem ergibt sich ebenfalls durch die KNIME Apriori
Umsetzung, da das Modul keinen Ausgang besitzt. Die Regeln, die das Apriori
Modul ausgibt müssen per Hand in die Rule-Engine eingetragen werden, welche
wiederrum eine aufwendige Benutzeroberfläche aufweist.
Mit ansteigender Anzahl an Klassen ergibt sich zum einen die Problematik, dass
die gefundenen Regeln des Apriori Moduls sinnvoll zu filtern sind und zum
Anderen, dass diese anschließend per Hand in die Rule-Engine eingetragen
werden müssen. Der zeitliche Aufwand der damit verbunden ist, ist im Rahmen
der Umsetzung ab einem bestimmten Grenzwert nicht mehr zu tragen.
Im Ergebnis war der Vergleich von Apriori und ID3 willkürlichen Faktoren
unterworfen, der Auswahl der Regeln für die Rule-Engine und der Begrenzung
der Anzahl der gefundenen Regeln durch den Wert numRules im Apriori Modul.

5. Auswertung der Ergebnisse
Bei den Ausarbeitungen wurde der Fokus auf vier unterschiedliche Datensätze
gelegt. Sie unterscheiden sich sowohl in der Anzahl der Datentupel als auch in
der Anzahl der Attribute. Im nachfolgenden Bild ist ein Vergleich der
unterschiedlichen Verfahren unter Verwendung von verschieden Datensätzen
dargestellt. Der Graph stellt dabei die Anzahl der korrekt klassifizierten
Datensätze dar.
Datensatz Anzahl Einträge Anzahl Attribute Anzahl Zustände Zielattributs
Wetter 14 4 2
Bronchitis 1246 4 2
Hautkrebs 206 7 3
DMC 2007 50000 22 3
Ergebnis dieser Arbeit ist, dass sich für die untersuchten Datensätze, die
Klassifikation mittels Apriori annähernd gleich verhält wie ID3. Probleme wie
insbesondere das Fehlen von Ein und Ausgängen an den KNIME-Modulen
hinderten das Team aufgrund des zusätzliches Aufwands daran den Ansatz für
größere Datensätze durchzuführen. Abhängig von der Anzahl der Klassen wurde
eine bessere Klassifizierung mittels Apriori war genommen. Allerdings kann
aufgrund der geringen Anzahl der untersuchten Datensätze nur eine Vermutung
aufgestellt werden. In Zukunft müsste diese These durch die Untersuchung
unterschiedlichster Datensätze genauer betrachtet und eventuell gefestigt
werden.

6. Zusammenfassung und Ausblick
Ergebnis dieser Arbeit ist, dass sich für die untersuchten Datensätze, die
Klassifikation mittels Apriori annähernd gleich verhält wie ID3. Probleme wie
insbesondere das Fehlen von Ein und Ausgängen an den KNIME-Modulen
hinderten das Team aufgrund des zusätzliches Aufwands daran den Ansatz für
größere Datensätze durchzuführen. Abhängig von der Anzahl der Klassen wurde
eine bessere Klassifizierung mittels Apriori war genommen. Allerdings kann
aufgrund der geringen Anzahl der untersuchten Datensätze nur eine Vermutung
aufgestellt werden. In Zukunft müsste diese These durch die Untersuchung
unterschiedlichster Datensätze genauer betrachtet und eventuell gefestigt
werden.