
I. Introducción - aaep.org.ar · En resumen, realizar pronósticos de series de tiempo diarias es...
23
1 Modelo Estructural de Espacio de Estado para la demanda diaria promedio de energía eléctrica en la República Argentina Blaconá, María Teresa 1 , Abril, Juan Carlos 2 I. Introducción El Mercado Eléctrico Mayorista (MEN) en la Argentina está regulado por ley. Según la normativa vigente, el MEN es el ámbito donde se encuentran en tiempo real la oferta y la demanda de energía eléctrica de la República Argentina. Todos los generadores de energía deben ser agentes del MEN, así como el resto de las empresas que interactúan en el mercado, con la única excepción de los consumos pequeños. Estos agentes entregan toda la información que se requiere para la base de datos del sistema a la Compañía Administradora del Mercado Mayorista Eléctrico (Cammesa), que es el ente que construye dicha base de datos y que lo pone a disposición de dichos agentes. Más del 90% de la demanda de energía eléctrica de la República Argentina es abastecida por el MEN, siendo Cammesa la que se encarga de determinar las centrales que entrarán en funcionamiento, además de cumplir algunas funciones de fiscalización. Uno de los principales objetivos de un sistema eléctrico es el de abastecer el mercado de energía eléctrica con el menor número de interrupciones manteniendo la calidad de la energía ofrecida. Por lo tanto es de gran importancia contar con un sistema eficiente de previsión de carga. Por tal motivo en este trabajo se intenta encontrar un modelo parsimonioso para: a) describir el comportamiento de la serie de demanda diaria promedio de energía eléctrica en la República Argentina y b) realizar pronósticos a corto plazo. Para ello, se aborda la modelación mediante el enfoque estructural de los modelos de espacio de estado. La principal dificultad que presenta modelar series de tiempo diarias es el ajuste del componente estacional, debido a que se presentan dos tipos de estacionalidad: i) la semanal y ii) la anual. En el caso i) para modelar es suficiente un modelo estructural básico, donde el componente estacional se modela por términos trigonométricos o con variables "dummy". En cambio cuando se considera ii), el problema es mucho más complejo porque los modelos tradicionales requerirían un número muy grande de parámetros, no cumpliendo el principio de parsimonia. Para solucionar este problema se proponen modelos estructurales de series de tiempo (Harvey y Koopman, 1993; Harvey, Koopman y Riani, 1996), que pueden ser interpretados como regresiones sobre funciones de tiempo en las cuales los parámetros varían, lo que permite tratar patrones estacionales que varían en forma compleja. Cuando se ajusta un modelo conveniente, el componente estacional se puede estimar por algún algoritmo de suavizado. En otras palabras un componente determinístico se puede generalizar en tal forma que se vuelva estocástico. Para el tratamiento de la estacionalidad anual, una técnica recomendada es la de "spline"(Poirier, 1973), por ser muy simple de implementar y porque permite que un 1 IITAE, Facultad de Ciencias Económicas y Estadística, Universidad Nacional de Rosario. 2 INIE, Facultad de Ciencias Económicas, Universidad Nacional de Tucumán.
Transcript of I. Introducción - aaep.org.ar · En resumen, realizar pronósticos de series de tiempo diarias es...

1
Modelo Estructural de Espacio de Estado para la demanda diaria promedio de
energía eléctrica en la República Argentina
Blaconá, María Teresa1, Abril, Juan Carlos2
I. Introducción El Mercado Eléctrico Mayorista (MEN) en la Argentina está regulado por ley. Según la normativa vigente, el MEN es el ámbito donde se encuentran en tiempo real la oferta y la demanda de energía eléctrica de la República Argentina. Todos los generadores de energía deben ser agentes del MEN, así como el resto de las empresas que interactúan en el mercado, con la única excepción de los consumos pequeños. Estos agentes entregan toda la información que se requiere para la base de datos del sistema a la Compañía Administradora del Mercado Mayorista Eléctrico (Cammesa), que es el ente que construye dicha base de datos y que lo pone a disposición de dichos agentes. Más del 90% de la demanda de energía eléctrica de la República Argentina es abastecida por el MEN, siendo Cammesa la que se encarga de determinar las centrales que entrarán en funcionamiento, además de cumplir algunas funciones de fiscalización. Uno de los principales objetivos de un sistema eléctrico es el de abastecer el mercado de energía eléctrica con el menor número de interrupciones manteniendo la calidad de la energía ofrecida. Por lo tanto es de gran importancia contar con un sistema eficiente de previsión de carga. Por tal motivo en este trabajo se intenta encontrar un modelo parsimonioso para: a) describir el comportamiento de la serie de demanda diaria promedio de energía eléctrica en la República Argentina y b) realizar pronósticos a corto plazo. Para ello, se aborda la modelación mediante el enfoque estructural de los modelos de espacio de estado. La principal dificultad que presenta modelar series de tiempo diarias es el ajuste del componente estacional, debido a que se presentan dos tipos de estacionalidad: i) la semanal y ii) la anual. En el caso i) para modelar es suficiente un modelo estructural básico, donde el componente estacional se modela por términos trigonométricos o con variables "dummy". En cambio cuando se considera ii), el problema es mucho más complejo porque los modelos tradicionales requerirían un número muy grande de parámetros, no cumpliendo el principio de parsimonia. Para solucionar este problema se proponen modelos estructurales de series de tiempo (Harvey y Koopman, 1993; Harvey, Koopman y Riani, 1996), que pueden ser interpretados como regresiones sobre funciones de tiempo en las cuales los parámetros varían, lo que permite tratar patrones estacionales que varían en forma compleja. Cuando se ajusta un modelo conveniente, el componente estacional se puede estimar por algún algoritmo de suavizado. En otras palabras un componente determinístico se puede generalizar en tal forma que se vuelva estocástico. Para el tratamiento de la estacionalidad anual, una técnica recomendada es la de "spline"(Poirier, 1973), por ser muy simple de implementar y porque permite que un
1 IITAE, Facultad de Ciencias Económicas y Estadística, Universidad Nacional de Rosario.
2 INIE, Facultad de Ciencias Económicas, Universidad Nacional de Tucumán.

2
efecto no lineal se transforme en una regresión lineal múltiple, facilitando la estimación. Además, es posible trabajar con "splines" periódicas y realizar restricciones que aseguren que los pronósticos del componente estacional sobre un año sumen cero, en esta forma se asegura que no exista confusión entre el componente de tendencia y el de estacionalidad. En algunos casos es conveniente adicionar al modelo una o varias variables explicativas relacionadas con el fenómeno en estudio. En este caso se incluye la serie temperatura diaria promedio, para ayudar a explicar el comportamiento de la demanda diaria promedio de energía. Una vez que se formula el modelo, es relativamente directo el manejo estadístico mediante la forma de espacio de estado. La característica de espacio de estado para modelar un sistema sobre el tiempo es que incorpora dos procesos estocásticos diferentes. En uno, la distribución de los datos en cada punto en el tiempo se especifica condicional a un conjunto de parámetros indexados por el tiempo. Un segundo proceso describe la evolución de los parámetros sobre el tiempo. En resumen, realizar pronósticos de series de tiempo diarias es una tarea dificultosa que se debe desarrollar en forma permanente, es decir a diario. La característica dominante de muchas de series de tiempo diarias es que el patrón estacional cambia persistentemente sobre el tiempo. La modelación por espacio de estado con sus técnicas de estimación recursivas y su correspondiente metodología estadística es un método atractivo para abordar el problema mencionado. Los modelos propuestos en este trabajo para modelar series diarias fueron utilizados anteriormente por Harvey y Koopman (1993), para predecir la serie por hora de demanda de electricidad de la compañía Puget Sound Power and Light (EEUU) y por Gordon, (1996), para modelizar las series diarias de demanda de energía de tres compañías LIGHT, CEMIG y COPEL (Brasil). En ambos trabajos se obtuvieron resultados satisfactorios de ajuste y predicción, lo que alentó a probar una metodología similar para el análisis de la serie de demanda diaria promedio de energía en la República Argentina, suministrada por la Compañía Administradora del Mercado Mayorista Eléctrico (CAMMESA). II. Características de la Serie
La información que se dispone es la demanda diaria promedio de energía medida en Gigawath (Gwh), en la República Argentina en el período 1 de agosto de 1995 a 12 de septiembre de 1999, la cual fue suministrada por Cammesa. También se cuenta con la serie de temperatura media diaria medida en grados centígrados (ºC), en el mismo período, registrada por la misma fuente. La serie de demanda de energía presenta un crecimiento suave a través del período en estudio y un evidente comportamiento estacional (Gráfico II.1). Este comportamiento estacional se caracteriza por presentar dos comportamientos periódicos muy marcados uno anual (Gráfico II.2 ) y otro semanal (Gráfico II.3). El comportamiento estacional anual se puede deber a una combinación de factores, entre los que se pueden destacar: a) climáticos como temperatura, vientos, horas de luz solar, etc, b) económicos, como el ciclo productivo, precio (esta variable no sería realmente importante en series diarias, porque la relación se hace imperceptible) y c) demográficos, los que tampoco serían perceptibles en series diarias.

3
Gráfico II.1: Demanda de Energía Diaria Promedio en Argentina
(01-08-95 - 12-09-99)
100,0
120,0
140,0
160,0
180,0
200,0
220,0
240,0
260,0
1
72
143
214
285
356
427
498
569
640
711
782
853
924
995
1066
1137
1208
1279
1350
1421
1492
días
Energ
ía (Gwh)
Fuente: Cammesa
Con respecto a la estacionalidad semanal, los gráficos muestran un comportamiento bien diferenciado de la demanda de electricidad en los días hábiles (lunes a viernes) con respecto a la de los sábados (donde la demanda disminuye) y a su vez de estos dos respecto a la de los domingos (que es el día de menor demanda de energía). Se destaca también que en los días feriados la demanda disminuye y que dicha disminución puede variar de acuerdo al día de la semana en que se produzca el feriado (Gráficos II.3).

4
Gráfico II.2: Demanda de Energía diaria promedio en Argentina 1-
8-98 - 31-7-99
140,0
160,0
180,0
200,0
220,0
240,0
1
20
39
58
77
96
115
134
153
172
191
210
229
248
267
286
305
324
343
362
días
Energ
ía (Gwh)
Gráfico II.3: Demanda de Energía diaria promedio en
Argentina Agosto 1998
140,0
160,0
180,0
200,0
220,0
240,0
1 3 5 7 9
11
13
15
17
19
21
23
25
27
29
31
días
Energ
ía (Gwh)
Por lo enunciado en los párrafos anteriores se intuye que no es tarea fácil encontrar un modelo parsimonioso (con pocos parámetros) que refleje todos los comportamientos que presenta la serie de demanda promedio diaria de energía.

5
III.- Modelos Estructurales III.1 Introducción Los modelos estructurales pueden ser interpretados como regresiones sobre funciones del tiempo en los cuales los parámetros varían en el tiempo. Esto hace que sean un vehículo natural para tratar comportamiento estacionales complejos. III.2 Modelo básico de espacio de estado
El modelo básico de espacio de estado (MBEE), también se conoce como modelo lineal Gaussiano de espacio de estado, se puede expresar como
),,0(~,tttttt
HNIDZy ⁄⁄∼ ΗΖ
),,0(~,1 ttttttt
QNIDRT ♣♣∼∼ ΗΖϑ
(III.2.1)
donde yt es un vector de orden px1 de observaciones, ∼t es un vector de orden mx1 no observable denominado vector de estado, las matrices Zt(pxm), Tt(mxm) y
Rt(mxg) son conocidas y ♣t es un vector aleatorio de orden gx1. Se introduce la matriz Rt como matriz de selección, está formada de ceros y unos de acuerdo a si
los ♣ son determinísticos o aleatorios. A la primera ecuación de (III.2.1) por lo general se la llama ecuación de medida y a la segunda ecuación de transición. En las secciones siguientes se especificará un modelo estructural adecuado para series de tiempos diarias. III.3 Estimación de los componentes no observables
En la sección anterior se ha propuesto un modelo de espacio de estados, donde en el estado del sistema intervienen componentes no observables, el próximo paso es estimar dichos componentes, para lo cual se deben realizar varias etapas, que brevemente se especifican a continuación: i.- Filtrado, es una operación donde se va actualizando el sistema cada vez que aparece una nueva observación yt. Este filtrado se realiza mediante el conocido filtro de Kalman. ii.- Iniciación del filtro, se debe especificar como se comienza el filtro, es decir que valores iniciales toman los componentes. iii.- Suavizado, considera la estimación de los componentes tomando información de la muestra completa. El suavizado y el filtrado se deben realizar simultáneamente. Se van a obtener dos estimaciones de los componentes una filtrada y otra suavizada, la óptima desde el punto de vista de Fisher es la suavizada porque utiliza toda la información de la muestra.

6
III.4 Estimación de los hiperparámetros por máxima verosimilitud Los parámetros en los modelos de espacio de estado usualmente se los denomina hiperparámetros, presumiblemente para distinguirlos de los elementos del vector de estado los cuales pueden ser pensados como parámetros aleatorios.
Sea el vector de hiperparámetros ♥, el cual se estima por máxima verosimilitud. Como en series de tiempo por lo general las observaciones no son independientes, para el cálculo de la verosimilitud, se utilizan propiedades de las distribuciones condicionales como
T
t
ttYypYL
1
1),,/(),(
Ζ
ϑΖ ♥♥ (III.4.1)
donde ).,(~)/(1 ttttt
FaZNYypϑ
Por lo tanto si se toma logaritmo se tiene
,2
1log
2
1)2log(
2log
1
1'
1
t
T
t
tt
T
t
tvFvF
TpL ��
Ζ
ϑ
Ζ
ϑϑϑΖ ↓ (III.4.3)
donde tttt
aZyv ϑΖ , es el error de predicción distribuido NID(0, t
F ) . A (III.4.3) se la
llama la descomposición del error de predicción del logaritmo de la verosimilitud y
debe ser maximizada respecto de los elementos del vector ♥♥♥♥ de hiperparámetros desconocidos.
En el caso difuso cuando 0
a y 0P son desconocidos, si se supone que ≥ es el
menor valor de t para el cual )/(tt
Yp ∼ existe. Entonces se toma la verosimilitud
condicional con ≥Y fijo, resultando
.2
1log
2
1)2log(
2
)(log
1
1
'
1
tt
T
t
t
T
t
tvFvF
pTL
ϑ
ΗΖΗΖ
�� ϑϑ
ϑ
ϑΖ
≥≥
↓
≥
(III.4.4)
Las expresiones (III.4.3) y (III.4.4) en la práctica son maximizadas a través de un algoritmo de maximización. El método de optimización usado por STAMP5.0(Software usado en este trabajo), se basa en el método llamado BFGS Quase- Newton (Koopman y otros, 1995). III.5 Diagnóstico del modelo Las pruebas que se realizan para ver si un modelo es adecuado se basan en las
innovaciones estandarizadas estimadas 2/1ˆ/ˆ
ϑ
ttFv , t = d+1, ..., T (Koopman y otros,
1995), calculadas a partir de los residuos suavizados tv̂ . Si el modelo está bien
especificado estos residuos tienen la ventaja de ser aproximadamente no correlacionados. La medida básica de la bondad del ajuste es el PVE, variancia del error de
predicción, es la variancia de los errores y se la denota con 2~
″ .
Otra medida de ajuste es desviación media de los residuos que esta definida por

7
�ΗΖ
ϑ
Ζ
T
dt
tv
dTmd
1
~″
, si el modelo está bien especificado el cociente
2
2~2
mdc
↓
″
Ζ , debería ser aproximadamente uno.
Existen varias estadísticas para probar la bondad del modelo estimado, de las cuales se presentarán las que permiten identificar si el modelo presenta: Heterosedasticidad : Se basa en un test bilateral Fh,h, no paramétrico de heterosedasticidad, se construye la estadística
� �ΗϑΖ
ΗΗ
ΗΖ
Ζ
T
hTt
hd
dt
ttvvhH
1
1
1
22 /)( ,
donde h es el entero más cercano a (T-d)/3. Correlación de los residuos : Existen básicamente dos estadísticas para probar si los residuos están correlacionados. i.- La estadística de Durbin-Watson, que permite probar si los residuos presentan autocorrelación de primer orden y viene dada por
))1(1(2)(2
1
2
rvvDWt
T
dt
tϑ]ϑΖ
ϑ
ΗΖ
� ,
si el modelo está bien especificado DW se distribuye aproximadamente N(2, 4/T). ii.- La estadística Q de Box-Ljung que permite probar si las primeras P autocorrelaciones son iguales a cero y viene dada por
�Ζ
ϑΗΖ
P
j
j jTrTTkPQ1
2 ),/()2(),(
bajo la hipótesis de no correlación de los residuos se distribuye como 2
k′ , donde k =
P-n+1 y n es el número de hiperparámteros. Una medida que resulta útil para comprobar cuán bueno es el ajuste es el coeficiente de determinación . Para los casos que se analicen series estacionales con tendencia como por lo general son las series diarias se utiliza un coeficiente ajustado que viene dado por
SSDSM
dTR
s
2~)(1 ″ϑϑ
Ζ ,
donde SSDSM es la suma de cuadrados que se obtiene restando la media estacional a la primer diferencia de yt. Para comparar modelos con distinto número de parámetros el PEV no es conveniente, se debe definir un coeficiente más apropiado como es el Criterio de Información de Akaike(AIC), el cual penaliza el PVE por el número de parámetros estimados en el modelo. El AIC se define como
AIC = log PEV + 2m/T,

8
donde m es el número de hiperparámetros más el número de componentes no observables. En consecuencia, cuando menor sea el valor de AIC mejor será el ajuste. Además de todas las medidas mencionadas de bondad de ajuste, es importante destacar que: i.- la estimación de los hiperparámetros permite conocer si los componentes se mueven en forma estocástica. El número real no es fácil de interpretar. Sin embargo un valor cero en el hiperparámetro indica que el correspondiente comportamiento es determinístico. ii.- El comportamiento de los componentes suavizados a través de sus gráficos da una guía de si la descomposición que se realizó mediante el modelo ajustado es útil. En términos de predicción la tendencia estimada es la parte de la serie que si se extrapola indica el movimiento futuro a largo plazo (Harvey, 1989), por ello es importante que la misma no contenga ningún comportamiento periódico.
III.6 Predicción
En el modelo Gaussiano MBEE (III.2.1), el filtro de Kalman conduce a T
a , el
estimador de error mínimo cuadrático de T
∼ basado en todas las observaciones de
la muestra. Además se sabe que
TTTTaTa
1/1 ΗΗΖ , (III.6.1)
entonces la predicción una etapa hacia adelante viene dada por
TTTTTaZy
/11/1
~
ΗΗΗΖ . (III.6.2)
Ahora si se considera el problema de predicción varias etapas hacia delante, es decir realizar las predicciones de los valores futuros en los momentos T+2, T+3, ..., T+h, donde h es el horizonte de la predicción, sustituyendo repetidamente en la ecuación de transición, en el momento T+h se tiene
,...3,2,))(()(1
1 )11
ΖΗΗΖΗΗΗΗ
ϑ
Ζ ΗΖ
Η
Ζ
ΗΗ � hRRTT hThTjTjT
h
i
h
ji
iT
h
j
TjThT ♣♣∼∼ . (III.6.3)
Por otro lado, se conoce que el estimador de ECMM de hT Η∼ en el momento T es
la esperanza condicional de hT Η∼ . Aplicando esperanza condicional al momento T a
(III.6.3) se tiene
T
h
j
jTThThT aTaTE )()/(1
/ Ζ
ΗΗΗΖΖ∼ . (III.6.4)
La distribución condicional de hT Η∼ es Gaussiana y su matriz de variancia y
covariancias ThT
P/Η, se puede obtener de (III.6.3) y (III.6.4). En el caso de que sea
invariante en el tiempo la expresión apropiada es

9
�ϑ
Ζ
ΗΖΗΖ
1
0
/,...2,1,'''
h
j
jjh
T
h
ThT hTRQRTTPTP . (III.6.5)
El estimador ECM de hTy Η se puede obtener directamente de
ThTa
/Η, tomando
esperanza condicional a la ecuación de medida en el momento T+h, resultando
,...2,1,~)/(//
ΖΖΖΗΗΗΗ
haZyTyEThThTThThT
. (III.6.6)
La matriz de ECM es
ECM ,...2,1,)~( '
//ΖΗΖ
ΗΗΗΗΗhHZPZy
hThTThThTThT. (III.6.7)
Se debe recordar que las matrices de ECM, ThT
P/Η no tienen en cuenta el error
que surge de estimar los parámetros desconocidos del sistema de matrices Tt y otros parámetros.
III.6.1 Bondad de las predicciones
Para probar si un modelo es adecuado no sólo se debe tener en cuenta la bondad del ajuste, sino que también es muy importante probar su bondad para predecir, ya que es bien conocido que no todos los modelos que ajustan bien también funcionan bien para predecir. Se pueden realizar test predictivos post-muestrales, usando todas o algunas observaciones. También es posible realizar test dentro de la muestra. Cuando se especifican en el modelo variables explicativas y/o intervenciones, los residuos que se usan en los test predictivos dentro de la muestra son los residuos recursivos generalizados wt para t = d*+1, ..., T donde d* = d+k, siendo k el número de variables explicativas en el modelo (excluyendo las variables que no aparecen después del momento T-L). Estos residuos se obtienen a partir de los residuos estandarizados, pero ahora se obtienen de un Filtro de Kalman aumentado con d+k columnas para At+1/t, acompañado por un conjunto de regresiones recursivas para los cálculos de la inversión de St. La banda del error de los residuos se basa en dos veces la raíz de la suma cuadrado de error. En base a estos residuos se calcula el CUSUM como
CUSUM(t) = Tdtww
t
dj
j
w
,...,1*,)(ˆ
1 2
1*
ΗΖϑ�ΗΖ
″
. (III.6.1.1)
Un test formal para chequear el CUSUM se basa en probar si este cruza las lineas de las dos bandas dadas por
CUSUM(t) = �(0.85 T +1.7t/ T ), (III.6.1.2)
estas bandas se basan en un nivel de significación del 10%. Se construye el test de Chow dentro de la muestra como
Chow = ,/*
1*
2
1
2
��ϑ
ΗΖΗϑΖ
ϑΗhT
dt
t
T
hTt
tww
h
dhT (III.6.1.3)

10
el cual se distribuye aproximadamente como Fh,T-h-d*. Cuando se debe llevar a cabo un test predictivo post-muestral, las estimaciones de los coeficientes de las variables explicativas y/o de intervención se mantienen las mismas que los del estado del final de la muestra. Los correspondientes residuos estandarizados se los llama vt para t = T+1, ...,L . Un test estadístico post-muestral característico es el test t de la forma
,
1
2/1
�Ζ
Η
ϑ
Ζ
L
j
jTvLcusumt (III.6.1.4)
el cual se distribuye aproximadamente como una tT-L-d*. Otras dos medidas muy usadas para probar el desempeño predictivo de los modelos son: a) para el período muestral el MAPE (“Mean absolute percentual error”) y b) para el período post muestral el PSMAPE (“Post sample mean absolute percentual error”), los cuales se definen de la siguiente manera:
,1001
n
e
MAPE
n
t
t�Ζ
Ζ (III.6.1.5)
,1001
H
e
PSMAPE
H
h
ht�Ζ
Η
Ζ (III.6.1.6)
donde realvalor
adelantepasounpredichovalorrealvaloret
ϑ
Ζ , n es el número de
predicciones realizadas dentro de la muestra y
realvalor
adelantepasoshpredichovalorrealvalore
ht
ϑ
ΖΗ
, H es el número de
predicciones efectuadas fuera de la muestra. III.7 Modelo estructural básico Sea la serie de tiempo y1, ..., yT. El modelo estructural básico (BSM) se formula en términos de los componentes tendencia, estacionalidad e irregular. El modelo se puede escribir
),0(~, 2
⁄″⁄⁄ƒ← Ny
tttttΗΗΖ ,t=1,...,T, (III.7.1)
donde ←t, ƒt y ⁄t representan a la tendencia, estacionalidad e irregular respectivamente. En algunas aplicaciones los componentes se presentan en forma multiplicativa, en estos casos aplicando logaritmo el modelo se reduce al (III.7.1). La idea central de los modelos estructurales se basa en el hecho que, en muchas aplicaciones, la tendencia y los efectos estacionales conforman los aspectos más destacables de las series de tiempo. Es por ello, que la construcción del modelo está orientada a la estimación y análisis de estos componentes.
La especificación de los componentes ←t, ƒt y ⁄t se basa en el conocimiento que se tenga acerca del proceso que se esta analizando y en técnicas estadísticas básicas.

11
La estacionalidad generalmente se representa por funciones trigonométricas estocásticas en las frecuencias estacionales s/2 (s período estacional), o también es posible hacerlo mediante variables “dummy”. El punto clave es que aunque el componente estacional sea no estacionario, tiene la propiedad que el valor esperado de la suma sobre los s períodos previos es cero. Esto asegura que el efecto estacional no se confunde con la tendencia y también significa que los pronósticos del componente estacional deberán sumar cero sobre cualquier período anual.
En cambio, en los modelos clásicos, generalmente, ←t se define como un polinomio
en el tiempo, ƒt se especifica a través de variables “dummy” o funciones
trigonométricas, y ⁄t como un proceso del tipo ARMA (Box&Jenkis,1971). Es decir,
tanto la tendencia como los efectos estacionales se suponen determinísticos. En muchos casos estos supuestos no se cumplen, en cuyo caso resultan de gran utilidad los modelos estructurales. III.8 Especificación del modelo para serie diaria de energía
Como se mencionó anteriormente el componente primordial en el ajuste de series diarias es el estacional, debido a que se presentan dos tipos de estacionalidad: i) la semanal y ii) la anual. En la siguiente sección se tratara el punto i), dejando el punto de ii) para ser desarrollado más adelante mediante la técnica de “spline”, para luego ser incorporado al modelo estructural. También es importante tener en cuenta la influencia en la serie de los días feriados. Además al modelo se le pueden incluir variables explicativas que ayuden a interpretar la serie en estudio. III.8.1 Estacionalidad semanal En las series de tiempo diarias por lo general se presenta un comportamiento periódico semanal (s=7) el cual puede ser tratado primordialmente de dos maneras: a) con variables “dummy” o b) términos trigonométricos. En este trabajo se lo trata como a).
Sea el vector de parámetros ƒj, j=1,...,7. En el caso de considerar estacionalidad determinística se debe realizar la restricción que la suma de los efectos estacionales en el período debe ser cero, es decir
�Ζ
Ζ
7
1
0
j
jƒ (III.8.1.1)
o equivalentemente 0
6
1
Ζ�Ζ
ϑ
j
jtƒ , por lo tanto
�Ζ
ϑΖϑΖ
6
1
,....8,7,j
jtttƒƒ (III.8.1.2)
Por otro lado existen muchas situaciones donde la estacionalidad varía en el tiempo, por lo que se la considera estocástica. Una forma sencilla de tratarlo es agregar un término de error a (III.8.1.2)
).,0(~,,...,1, 2
6
1
wtt
j
jttNIDwTtw ″ƒƒ ΖΗϑΖ �
Ζ
ϑ (III.8.1.3)

12
En este caso, en lugar de realizarse la restricción de que la suma sea cero, se requiere que la esperanza sea cero, lo que hace que las variables “dummy” sean flexibles para cambiar en el tiempo. III.8.2 Días feriados En las series de tiempo diarias por lo general existe un efecto de día feriado que afecta la serie de tiempo en estudio. Su tratamiento se puede abordar, construyendo variables “dummy” para tal fin. Como los feriados se pueden considerar como un componente periódico anual, los efectos correspondientes a los mismos deben sumar cero cada año. Es decir las
variables “dummy” se pueden representar por °ij , i=1, ..., q , donde i representa, el día o un conjunto de días de la semana que se presenta el feriado, j=1, ..., m, donde j representa el año.
Se define nij como el número de veces que °i se presenta en el año j, para que el efecto feriado no influya el nivel se debe cumplir que
�Ζ
Ζ
q
i
ijijn
1
0° , (III.8.2.1)
en consecuencia
ij
q
i
ij
qj
qj n
n
°° �ϑ
Ζ
ϑΖ
1
1
1. (III.8.2.2)
Dado las características de los feriados en Argentina y su influencia en el consumo de energía, se definen las siguientes variables, que miden los efectos de los feriados:
° 1: efecto del feriado cuando ocurre en lunes,
° 2: efecto del feriado cuando ocurre de martes a viernes,
° 3: efecto del feriado cuando ocurre en sábado,
° 4: efecto del feriado jueves santo,
° 5: no feriado.
�Ζ
Ζ
5
1
0
i
ijijn ° ,
en consecuencia
ij
i
ij
j
j n
n
°° �Ζ
ϑΖ
4
15
5
1.

13
III.8.3 Variables explicativas En el marco de los modelos estructurales se pueden incorporar fácilmente variables explicativas y efectos de intervención. Por ejemplo si se suponen k regresores x1t,..., xkt en la ecuación del modelo se incorporarían directamente,
agregando al modelo de espacio de estado el término �Ζ
k
j
jtj x
1
≤ . Se procede en
forma similar si se deben añadir variables de intervención por presencia de “outliers” o cambios de nivel. En el caso de demanda de energía, existe relación cuadrática con la temperatura, ya que el consumo de energía aumenta en los días de muy bajas temperatura y en forma más pronunciada en días de muy alta temperatura. Con respecto a las variables que puedan medir el ciclo productivo, no se registran en forma diaria, por lo que no se puede estudiar dicha relación en forma explícita. En cuanto a la variable precio los cambios se hacen imperceptibles para la demanda diaria de energía. IV. Técnica de “Spline” La idea original de “spline se debe a Schoenberg, (1946) y resulta una técnica útil
cuando se quiere representar un comportamiento no lineal de datos.
En series temporales diarias, el comportamiento periódico anual no lineal, requiere un número muy grande de parámetros para representarlo. Pero los cambios estructurales que van ocurriendo lentamente se pueden representar mediante regresión en etapas usando “spline” cúbico (Poirier, 1973). Las ventajas primordiales de esta técnica son: i)preserva la continuidad de la función estimada mediante funciones a tramos y ii) no presenta muchos inconvenientes para implementarla computacionalmente.
IV.1 “Spline” y modelos de regression
Se supone un modelo de regresión no lineal
yt = f(xt) + ⁄t , t=1,…,T (IV.1.1)
⁄t ~ IID(0, ″2)
En lugar de ajustar f(.) por una única curva, se aproxima por un “spline” cúbico g(x) (polinomio a lo sumo de grado 3, con tal que preserve la continuidad de la derivada segunda). Se definen k funciones cúbicas basadas en {x0,..., xk} (conocida como red, los
puntos individuales x son llamados “knots”) y las correspondientes ordenadas f(xj)=ƒj,
j=0,...k en los puntos observados. En el caso de “spline” periódica ƒ0=ƒk y d1(x0)=dk(xk) y d1
2(x0) = dk2(xk).

14
Dados los “knots” y los valores asociados de las ordenadas, se puede mostrar que
cualquier punto sobre la funciín “spline” es una combinación lineal de los ƒj, de la forma
g(x) = w’ ƒ’, (IV.1.2) wj: vector kx1 que depende de la posición de los “knots” y la distancia entre ellos hj=xj-xj-1 y los valores de xj. Su deducción algebraica es relativamente sencilla, mediante propiedades de las derivadas y las restricciones impuestas.
Los ƒj son estimados por mínimos cuadrados ordinarios.
��ϑ
Ζƒ
t
tt
t
1
tt)yw())'ww((ˆ . (IV.1.3)
En consecuencia una estimación de efectos no lineales se transforma en un problema de regresión lineal a través de “spline cúbicos. IV. 2 Aplicación de la Técnica de “spline” a series de tiempo diarias
Para series de tiempo con observaciones diarias, sea ÷t, el componente correspondiente a la estacionalidad anual
Parametrizar el componente estacional ÷t por un “spline” cúbico periódico significa que se tiene i) xj = j , j = 1, 2, ..., s, para el caso de series diarias s = 365, y k<s, en este caso por las características de la serie k=6, o sea x0=1 y xk=365;
ii) ÷t = ÷j cuando el j-ésimo efecto estacional está presente;
iii) ÷t = w’j ÷÷÷÷ , wj : vector de pesos que depende de los “knots” y el indice j y
÷÷÷÷’ = (÷1,..., ÷ 6) el vector de parámetros a ser estimado.
Para evitar multicolinealidad con el nivel ←t se tiene la siguiente restricción
� �Ζ Ζ
Ζ÷Ζ÷Ζ÷
6
1j
6
1j
jj 0'w'w , (IV.2.1)
esta restricción equivale a
�Ζ
÷ϑΖ÷
5
1j
ikij *)w/*w(* (IV.2.2)
donde wi* es el i-ésimo elemento de
�Ζ
Ζ
6
1j
jw*w (IV.2.3)
el componente estacional se expresa en función de (k-1) parámetros. Luego se tiene
÷j = zj ÷*, (IV.2.4) donde :
÷* = (÷1,..., ÷k-1) zj : vector (k-1)x1 con su i-ésimo elemento dado por zji = wji – (wjk w*i/w*k) (IV.2.5)
donde wji es el I-ésimo elemento de wj. En el caso de la demanda de energía, se eligen los xi , i=1, ..., 6,: x0 = 1 , x1 = 71 , x2 = 137 , x3 = 237 , x4 = 325 , x5 = 365.

15
� h1 = 70 , h2 = 66 , h3 = 100, h4 = 88, h5 = 40.
Para calcular las series zit, i = 1, ..., 4 , t = 1, ..., 1461, se utiliza el procedimiento IML de SAS. Una vez calculadas las zit, éstas actuarán como variables explicativas en el modelo de espacio de estados. Para el año 1996 bisiesto, se toma dos veces el z del 28 de febrero. V. Modelo de espacio de estados para la serie demanda de energía diaria El modelo seleccionado resulta
t
t
i
ititt
i
itttt
OOOOO
ARzxxy
⁄×××××
′÷≤≤°ƒ←
ΗΗΗΗΗ
ΗΗΗΗΗΗΗΗΖ ��ΖΖ
55443322111
1
4
1
2
1211
4
1
)1( t = 1, ..., 1461
ttt♣←← ΗΖ
ϑ1, (nivel aleatorio),
t
j
jtt wΗϑΖ �Ζ
ϑ
6
1
ƒƒ , (estacionalidad semanal aleatoria),
ij
4
1i
°�Ζ
, (efecto días feriados fijo),
x1j : (variable explicativa temperatura fija),
ij
4
1i
ijz�Ζ
÷ , ( “spline” de estacionalidad anual fija),
,cos
cos
**
)1(1
)1(1
1*
1
1
��
���
�Η
��
�
�
��
�
���
���
�
ϑΖ�
�
���
�
ϑ
ϑ
t
t
t
t
cc
cc
t
t
sen
sen
♠
♠
′
′
↔↔
↔↔±
′
′(ciclo aleatorio),
AR(1)= ,10
01**
)1(2
)1(2
2*
2
2
��
���
�Η�
�
���
���
���
�Ζ�
�
���
�
ϑ
ϑ
t
t
t
t
t
t
♠
♠
′
′±
′
′(ciclo aleatorio AR(1)),
O1=��� ϑϑΖ
casootroen
tsi
0
951281,
O2 =��� ϑϑΖ
casootroen
tsi
0
969281,
O3 =��� ϑϑΖ
casootroen
tsi
0
9612241,
O4 =��� ϑϑΖ
casootroen
tsi
0
978151,
O5 =��� ϑϑΖ
casootroen
tsi
0
9812311, (V.1)
Oi: i=1-5, “outliers”,
),0(~),,0(~),,0(~ 222
wtttNIDwNIDNID ″″♣″⁄
♣⁄, ),0(~ 2*
♠″♠♠ NIDy
tt,
todos los efectos aleatorios mutuamente independientes.

16
Este modelo indica que existe un nivel aleatorio, la estacionalidad semanal aleatoria se representa por variables “dummy”, la estacionalida anual se representa por funciones “spline”, la variable explicativa temperatura aparece en forma lineal y cuadrática, se tiene en cuenta el efecto día feriado, están presentes dos ciclos uno de ellos autorregresivo y se representan cinco “outliers”.
La estimación del modelo se presentan en la Tabla V.1. Todos los coeficientes
resultan significativos, excepto el correspondiente al segundo “spline”, no se lo
elimina porque de hacerlo el modelo no resulta satisfactorio.
Tabla V.1: Estimación de los componentes del modelo al final del vector de estado
Coeficiente Estimación Valor t Prob.asociada
←t 225.21 66.606 0.0000
′1t -2.2796
′1t
* -0.1400
ƒ1t -11.247 -19.987 0.0000
ƒ2t 9.8745 17.703 0.0000
ƒ3t 9.1415 16.406 0.0000
ƒ4t 9.1976 16.549 0.0000
ƒ5t 9.3016 16.727 0.0000
ƒ6t 5.8841 10.52 0.0000
AR(1) -1.9964
°1 -32.403 -46.594 0.0000
°2 -35.040 -48.994 0.0000
°3 -12.451 -7.3214 0.0000
°4 -5.9580 -3.9769 0.0001
≤1 -2.9310 -17.591 0.0000
≤2 0.0960 22.318 0.0000
÷1 -6.6402 -3.96 0.0001
÷2 -2.8927 -1.3919 0.1642
÷3 -6.3385 -3.7472 0.0002
÷4 9.7487 6.2248 0.0000
Out. 8-12-95 -25.389 -8.5888 0.0000
Out.28-9-96 12.165 4.1352 0.0000
Out.24-12-96 -12.852 -4.3021 0.0000
Out.15-8-97 8.0946 2.7514 0.0060
Out.31-12-98 -12.677 -4.2728 0.0000
Las medidas de bondad de ajuste se muestran en la Tabla V.2, todas ellas son apropiadas. Tabla V.2: Medidas de bondad de ajuste del modelo
H ″~ C DW Q(37,30) Rs AIC
1.071 3.885 1.16 1.944 42.24 0.8271 2.7539 Las estimaciones de los coeficientes estacionales semanales al final del período, resultan altamente significativos (p=0.0000), se presentan en la Tabla V.3.
17
Tabla V.3: Estimación de los coeficientes estacionales semanales al fin del período
lunes martes Miércoles Jueves viernes Sábado Domingo
ƒ̂ 5.884 9.302 9.198 9.142 9.874 -11.25 -32.15
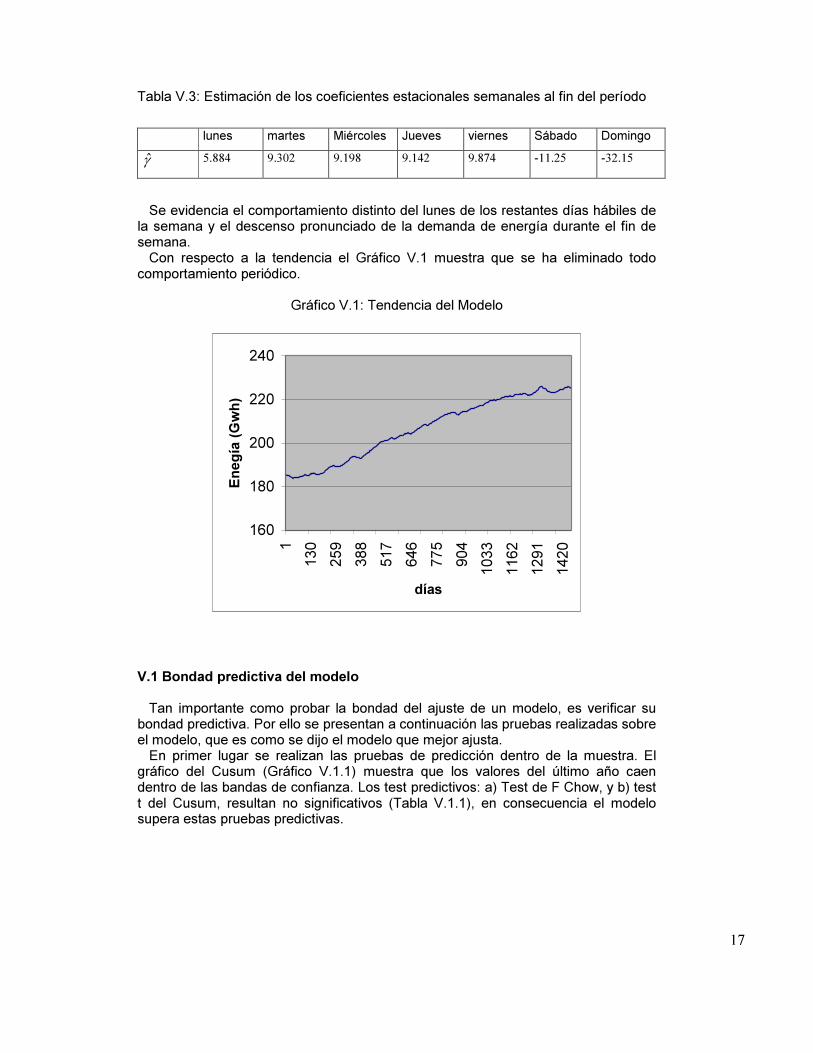
Se evidencia el comportamiento distinto del lunes de los restantes días hábiles de la semana y el descenso pronunciado de la demanda de energía durante el fin de semana. Con respecto a la tendencia el Gráfico V.1 muestra que se ha eliminado todo comportamiento periódico.
Gráfico V.1: Tendencia del Modelo
160
180
200
220
240
1
130
259
388
517
646
775
904
1033
1162
1291
1420
días
Enegía (Gwh)
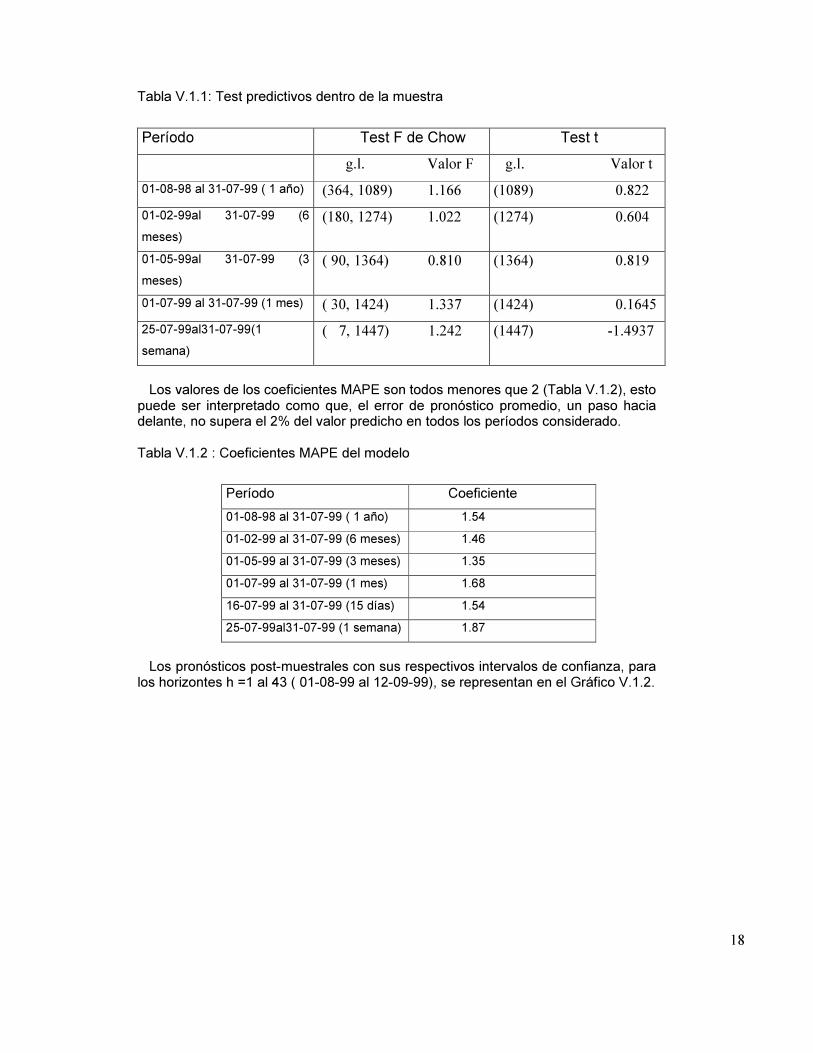
V.1 Bondad predictiva del modelo Tan importante como probar la bondad del ajuste de un modelo, es verificar su bondad predictiva. Por ello se presentan a continuación las pruebas realizadas sobre el modelo, que es como se dijo el modelo que mejor ajusta. En primer lugar se realizan las pruebas de predicción dentro de la muestra. El gráfico del Cusum (Gráfico V.1.1) muestra que los valores del último año caen dentro de las bandas de confianza. Los test predictivos: a) Test de F Chow, y b) test t del Cusum, resultan no significativos (Tabla V.1.1), en consecuencia el modelo supera estas pruebas predictivas.
18
Tabla V.1.1: Test predictivos dentro de la muestra
Período Test F de Chow Test t
g.l. Valor F g.l. Valor t
01-08-98 al 31-07-99 ( 1 año) (364, 1089) 1.166 (1089) 0.822
01-02-99al 31-07-99 (6
meses)
(180, 1274) 1.022 (1274) 0.604
01-05-99al 31-07-99 (3
meses)
( 90, 1364) 0.810 (1364) 0.819
01-07-99 al 31-07-99 (1 mes) ( 30, 1424) 1.337 (1424) 0.1645
25-07-99al31-07-99(1
semana)
( 7, 1447) 1.242 (1447) -1.4937
Los valores de los coeficientes MAPE son todos menores que 2 (Tabla V.1.2), esto puede ser interpretado como que, el error de pronóstico promedio, un paso hacia delante, no supera el 2% del valor predicho en todos los períodos considerado. Tabla V.1.2 : Coeficientes MAPE del modelo
Período Coeficiente
01-08-98 al 31-07-99 ( 1 año) 1.54
01-02-99 al 31-07-99 (6 meses) 1.46
01-05-99 al 31-07-99 (3 meses) 1.35
01-07-99 al 31-07-99 (1 mes) 1.68
16-07-99 al 31-07-99 (15 días) 1.54
25-07-99al31-07-99 (1 semana) 1.87
Los pronósticos post-muestrales con sus respectivos intervalos de confianza, para los horizontes h =1 al 43 ( 01-08-99 al 12-09-99), se representan en el Gráfico V.1.2.

19
Gráfico V.1.2: Cusum último año
Gráfico V.1.3: Predicciones post-
muestrales e intervalos de
confianza
150
170
190
210
230
250
1 4 7
10
13
16
19
22
25
28
31
34
37
40
43
horizonte
Energ
ía
Predicción LI LS V.Real
Los valores de los coeficientes PSMAPE se mantienen inferiores a 2.5 (Tabla V.1.3), esto indica que los errores de pronósticos, en el período post-muestral, hasta 43 pasos hacia delante, en promedio, no superan el 2.5% del valor predicho. Los
20
valores reales caen en su mayoría dentro de los intervalos de confianza, sólo para los horizontes 22, 23 y 24 superan el limite superior. Tabla V.1.3: Coeficientes PSMAPE
Período Coeficiente
01-08-98 al 31-07-99 ( 1 año) 1.54
01-02-99 al 31-07-99 (6 meses) 1.46
01-05-99 al 31-07-99 (3 meses) 1.35
01-07-99 al 31-07-99 (1 mes) 1.68
16-07-99 al 31-07-99 (15 días) 1.54
25-07-99al31-07-99 (1 semana) 1.87
Todos los resultados encontrados muestran que el modelo presentado puede ser considerado como ampliamente satisfactorio para realizar predicciones. Se debe realizar la salvedad que los pronósticos se realizan conociendo los valores futuros de la variable explicativa temperatura. Esto por lo general no se cumple, porque al momento de realizar la predicción es muy probable que no se disponga de dichos valores. V.2. Modelo de pronóstico alternativo cuando se desconocen las temperaturas futuras Se sabe que pronosticar los valores futuros de temperatura puede ser más dificultoso que pronosticar la misma serie. Para resolver este inconveniente se proponen dos soluciones. i.- Realizar pronósticos para los distintos escenarios de acuerdo a valores posibles de temperaturas, ya que por lo general el rango de temperaturas posibles, para un período corto de tiempo, es bastante estrecho. ii.- Plantear un modelo un poco distinto, pensando que la demanda de energía sólo se ve afectada por temperaturas extremas (altas o bajas). Por lo tanto se pueden construir variables “dummy” que reflejen el comportamiento en tales casos. Como los pronósticos requeridos para series diarias por lo general son a corto plazo, es más fácil determinar si en los días subsiguientes las temperaturas serán extremas. Se prueba un modelo construyendo tres variables “dummy” según sean las temperaturas, una para las superiores a 28 grados, otra para las inferiores a 8 grados y la tercera para las intermedias. Se las incorpora al modelo en lugar del polinomio de segundo grado para la variable temperatura. Sólo resulta significativa la que refleja temperaturas superiores a 28 grados. Si bien las estadísticas de bondad de ajuste resultan inferiores a las del modelo anterior, la tendencia no presenta periodicidades. La bondad predictiva dentro de la muestra es buena, el CUSUM del último año cae dentro del intervalo de confianza, el coeficiente MAPE del último mes resulta 1.63 y el test de Chow resulta no significativo. Por lo que se podría utilizar como método alternativo cuando se desconocen los valores exactos de las temperaturas.

21
VI. Consideraciones Finales
Este trabajo muestra la utilidad de los modelos de espacio de estados para el ajuste y pronóstico de series diarias, como así también la conveniencia de usar la técnica de “spline” cúbico periódico para el tratamiento de la estacionalidad anual. El modelo estructural propuesto para la serie de demanda de energía promedio diaria en la República Argentina: tendencia, efecto estacional semanal, efecto estacional anual, efecto de días feriados, dos ciclos, uno de ellos autorregresivo, y a la temperatura como variable explicativa, se encuentran resultados altamente satisfactorios tanto a nivel de ajuste como de pronósticos e interpretabilidad de sus componentes, entre los que se pueden destacar: i) el ajuste explica más del ochenta por ciento de la variabilidad de la serie; ii) la técnica de “spline cúbico periódico” permite encontrar el comportamiento del componente tendencia libre de cualquier componente periódico; iii) los errores de pronóstico dentro de la muestra (un paso adelante) para distintos valores de n, no superan en promedio, el dos por ciento del valor verdadero; iv) los errores de pronósticos post-muestrales para un horizonte de pronóstico de hasta 43 períodos hacia delante, no supera en promedio el 2.5 por ciento del valor real; v) el modelo permite interpretar en forma sencilla el efecto estacional semanal que muestra el comportamiento distinto de los días lunes respecto de los otros días hábiles y de éstos respecto de los sábados y domingos; vi) el efecto de los días feriados varía de acuerdo al día de la semana en que éste se produzca; vii) la relación existente con la temperatura muestra el efecto no lineal de la misma, acrecentándose la demanda de energía, tanto cuando las temperaturas son bajas y más aún cuando son extremadamente altas, debido probablemente en que en Argentina no se presentan en los años en estudio, temperaturas en promedio muy bajas. También se recomiendan métodos alternativos cuando se desconocen los valores futuros de la temperatura: i) el de escenarios para distintos valores futuros o ii) un modelo con variables “dummy” para temperaturas extremas como variables explicativas, este último modelo presenta muy buenas medidas de ajuste y bondades predictivas. Existen en la literatura, otros modelos para ajustar y pronosticar series diarias o de mayor frecuencia, entre ellos se destacan los modelos ARIMA, los modelos de regresión y los modelos de redes neuronales. Podría ser de interés en el futuro comparar el comportamiento de todos ellos. Otra línea de investigación sería encontrar modelos para otras frecuencia, como por ejemplo las horarias y/o las mensuales y comparar comportamientos y desempeño de los modelos. También se podría intentar modelos para distintas regiones, ya que las mismas posiblemente tengan comportamientos distintos.
VII.- Referencias
Box G.E.P. and Jenkins G.M. (1970). “Times Series Analysis Forecasting and Control”, San Francisco: Holden Day. Gordon F. (1996). “Previsao de Carga Diária Através de Modelos Estruturais Usando Spline”. Tesis Doctoral, Pontifícia Universidade Católica de Rio de Janeiro, Rio de Janeiro.

22
Harvey A.C. (1989). “Forecasting Structural Time Series and the Kalman Filter”. Cambridge, U.K. Cambridge, University Press. Harvey A.C. and Koopman S.J. (1993). “Forecasting Hourly Electricity Demand Using Time Varying Splines”. Journal of the American Statistical Association, Vol.
88, Nº 424, pags. 1228-1236. Harvey A.C. , Koopman S.J. and Riani M. (1996). “The Modeling and Seasonal Adjustment of Weekly Observations”. Journal of Business and Economic Statistics,
15, pags. 354-368. Koopman S.J., Harvey A., Doornik J.A. and Shepard N. (1995). STAMP 5.0. Manual. Poirier D.J. (1973). “Piecewise Regression Using Cubic Spline”. Journal of the American Statistical Association, Vol. 68, pags. 515-524. Poirier D.J. (1973). “Piecewise Regression Using Cubic Spline”. Journal of the American Statistical Association, Vol. 68, pags. 515-524. Shoenberg, I.J., (1946). “On the Problem of Smoothing or Graduation. A First Class of Analytic Approximation Formulae”, Quartely Journal of Applied Mathematics, April, pags. 45-49.
Referencia Softwers SAS, Versión 6.12, Modulo IML, SAS Institute INC, USA. STAMP 5.0, London School of Economics, UK.

23








![Presentacion pronósticos[1]](https://static.fdocument.pub/doc/165x107/556cee54d8b42ac3528b5448/presentacion-pronosticos1.jpg)









