
ĐẠI HỌC QUỐC GIA HÀ NỘI TRƯỜNG ĐẠI HỌC CÔNG...
53
ĐẠI HỌC QUỐC GIA HÀ NỘI TRƯỜNG ĐẠI HỌC CÔNG NGHỆ NGUYỄN ĐỨC VIỆT GIẢI BÀI TOÁN LẬP LỊCH THEO TÍN CHỈ SỬ DỤNG GIẢI THUẬT TÌM KIẾM TABU LUẬN VĂN THẠC SĨ CÔNG NGHỆ THÔNG TIN Hà Nội – 2014
Transcript of ĐẠI HỌC QUỐC GIA HÀ NỘI TRƯỜNG ĐẠI HỌC CÔNG...

ĐẠI HỌC QUỐC GIA HÀ NỘI TRƯỜNG ĐẠI HỌC CÔNG NGHỆ
NGUYỄN ĐỨC VIỆT
GIẢI BÀI TOÁN LẬP LỊCH THEO TÍN CHỈ SỬ DỤNG GIẢI THUẬT TÌM KIẾM TABU
LUẬN VĂN THẠC SĨ CÔNG NGHỆ THÔNG TIN
Hà Nội – 2014

ĐẠI HỌC QUỐC GIA HÀ NỘI TRƯỜNG ĐẠI HỌC CÔNG NGHỆ
NGUYỄN ĐỨC VIỆT
GIẢI BÀI TOÁN LẬP LỊCH THEO TÍN CHỈ SỬ DỤNG GIẢI THUẬT TÌM KIẾM TABU
LUẬN VĂN THẠC SĨ CÔNG NGHỆ THÔNG TIN
Hà Nội – 2014
Nghành: Công nghệ thông tin Chuyên nghành: Kỹ thuật phần mềm Mã số: 60480103
NGƯỜI HƯỚNG DẪN KHOA HỌC: TS. LÊ NGUYÊN KHÔI

Lời cảm ơn
Đầu tiên, tôi xin chân thành cảm ơn TS. Lê Nguyên Khôi đã tận tâm hướng dẫn chỉ bảo và giúp đỡ tôi hoàn thành đề tài luận văn này. Một lần nữa, em xin chân thành cảm ơn thầy.
Với lòng biết ơn sâu sắc nhất, tôi xin gửi đến quý thầy cô ở khoa Công nghệ Thông tin, phòng Đào tạo trường Đại học Công nghệ – Đại học Quốc gia Hà Nội đã tạo điều kiện thuận lợi, dồn bao công sức tâm huyết để truyền đạt vốn kiến thức quý báu cho các học viên cao học như tôi trong suốt thời gian học tập tại trường.
Tôi cũng xin gửi lời cám ơn đến gia đình, bạn bè và đồng nghiệp, những người đã luôn bên tôi, động viên và khuyến khích tôi trong quá trình thực hiện đề tài nghiên cứu của mình.
Tuy đã có những cố gắng nhất định, tiếp cận với thực tế để tìm hiểu và áp dụng khoa học vào cuộc sống, nhưng do thời gian và trình độ còn nhiều hạn chế nên luận văn này khó tránh khỏi các thiếu sót. Kính mong nhận được sự đóng góp ý kiến của thầy cô và các bạn.
Sau cùng, tôi xin kính chúc quý thầy cô trong khoa Công nghệ Thông tin cũng như Ban Giám đốc Đại học Công nghệ - Đại học Quốc Gia Hà Nội dồi dào sức khỏe, niềm tin để tiếp tục thực hiện sứ mệnh cao đẹp của mình là truyền đạt kiến thức cho thế hệ mai sau.
Trân trọng.
Hà Nội, ngày 11 tháng 08 năm 2014
Học viên
Nguyễn Đức Việt

4
Lời cam đoan
Tôi xin cam đoan rằng số liệu và kết quả nghiên cứu trong luận văn này là trung thực và không trùng lặp với các đề tài khác của cá nhân tôi, được thực hiện dưới sự hướng dẫn khoa học của Tiến sĩ Lê Nguyên Khôi.
Tôi cũng xin cam đoan rằng mọi sự giúp đỡ cho việc thực hiện luận văn này đã được cảm ơn và các thông tin trích dẫn trong luận văn đã được chỉ rõ nguồn gốc
Học viên
Nguyễn Đức Viêt

MỤC LỤC
Lời cảm ơn ........................................................................................................................... 3
Lời cam đoan ........................................................................................................................ 4
MỤC LỤC ............................................................................................................................ 5
DANH MỤC CÁC KÝ HIỆU VÀ CHỮ VIẾT TẮT .......................................................... 7
DANH MỤC CÁC BẢNG ................................................................................................... 8
DANH MỤC CÁC HÌNH VẼ VÀ ĐỒ THỊ ........................................................................ 9
MỞ ĐẦU ............................................................................................................................ 10
1. Lý do chọn đề tài: ............................................................................................................... 10
2. Mục đích nghiên cứu ........................................................................................................... 10
3. Nhiệm vụ nghiên cứu .......................................................................................................... 11
4. Đối tượng và phạm vi nghiên cứu ....................................................................................... 11
5. Phương pháp nghiên cứu .................................................................................................... 11
Chương 1: TỔNG QUAN VỀ BÀI TOÁN LẬP LỊCH HIỆN NAY VÀ CÁC CÁCH TIẾP CẬN .......................................................................................................................... 12
1.1 Bài toán lập thời khóa biểu cho trường phổ thông (School timetabling) ............................. 13
1.2 Bài toán lập thời khóa biểu cho trường đại học (University timetabling) ........................... 13
1.3 Bài toán lập lịch thi (Examination timetabling) ................................................................... 14
1.4 Bài toán lập lịch theo tín chỉ ................................................................................................ 15
1.5 Ưu điểm của phương thức đào tạo theo tín chỉ .................................................................... 17
1.6 Các cách tiếp cận hiện nay ................................................................................................... 18
Chương 2: TỔNG QUAN VỀ CÁC PHƯƠNG PHÁP TÌM KIẾM .................................. 21
2.1 Xung đột tối thiểu (Min-conflict) ........................................................................................ 21
2.2 Thuật giải mô phỏng luyện kim (Simulated Annealing) ..................................................... 21
2.3 Thuật giải leo đồi (Hill-climbing) ........................................................................................ 22
2.4 Tìm kiếm Tabu (Tabu search) .............................................................................................. 22
2.5 Thuật giải di truyền (Genetic Algorithm) ............................................................................ 23

6
2.6 Kết luận ................................................................................................................................ 23
Chương 3: CƠ SỞ TÌM KIẾM TABU ............................................................................... 24
3.1 Lược Sử Về Tabu Search ..................................................................................................... 24
3.1.1 Giới Thiệu ..................................................................................................................... 24
3.1.2 Tabu Search – Một Dạng Meta-heuristic ...................................................................... 25
3.1.3 Các Giai Đoạn Phát Triển Của Tabu Search ................................................................. 25
3.2 Nguyên Lý Chung Của Tabu Search ................................................................................... 26
3.3 Cách Sử Dụng Bộ Nhớ ........................................................................................................ 27
3.3.1 Một Minh Họa ............................................................................................................... 28
3.4 Chiến Lược Tăng Cường (Intensification) và Chiến Lược Đa Dạng (Diversification) ...... 30
3.5 Lập Trình Với Bộ Nhớ Tương Thích (Adaptive Memory Programming) ........................... 31
3.6 Các Nhân Tố Của Bộ Nhớ Tương Thích ............................................................................. 31
Chương 4: BÀI TOÁN LẬP LỊCH THEO TÍN CHỈ ......................................................... 33
4.1 Các khái niệm ...................................................................................................................... 33
4.2 Mô hình của bài toán ............................................................................................................ 35
4.3 Các ràng buộc cứng .............................................................................................................. 36
4.4 Các ràng buộc mềm ............................................................................................................. 36
4.5 Ví dụ minh họa: ................................................................................................................... 37
4.6 Hướng tiếp cận cho bài toán ................................................................................................ 38
4.6.1 Bước 1: Khởi tạo lời giải ban đầu ngẫu nhiên .............................................................. 39
4.6.2 Bước 2: Cải thiện chất lượng lời giải bằng giải thuật tìm kiếm Tabu ........................... 40
4.7 Định dạng tập tin dữ liệu CSV đầu vào: .............................................................................. 44
4.8 Khảo sát và thống kê kết quả thực nghiệm thực tế .............................................................. 45
4.9 So sánh kết quả thực nghiệm với kết quả của phần mềm Open Course Timetable ............. 47
KẾT LUẬN ........................................................................................................................ 49
TÀI LIỆU THAM KHẢO .................................................................................................. 50
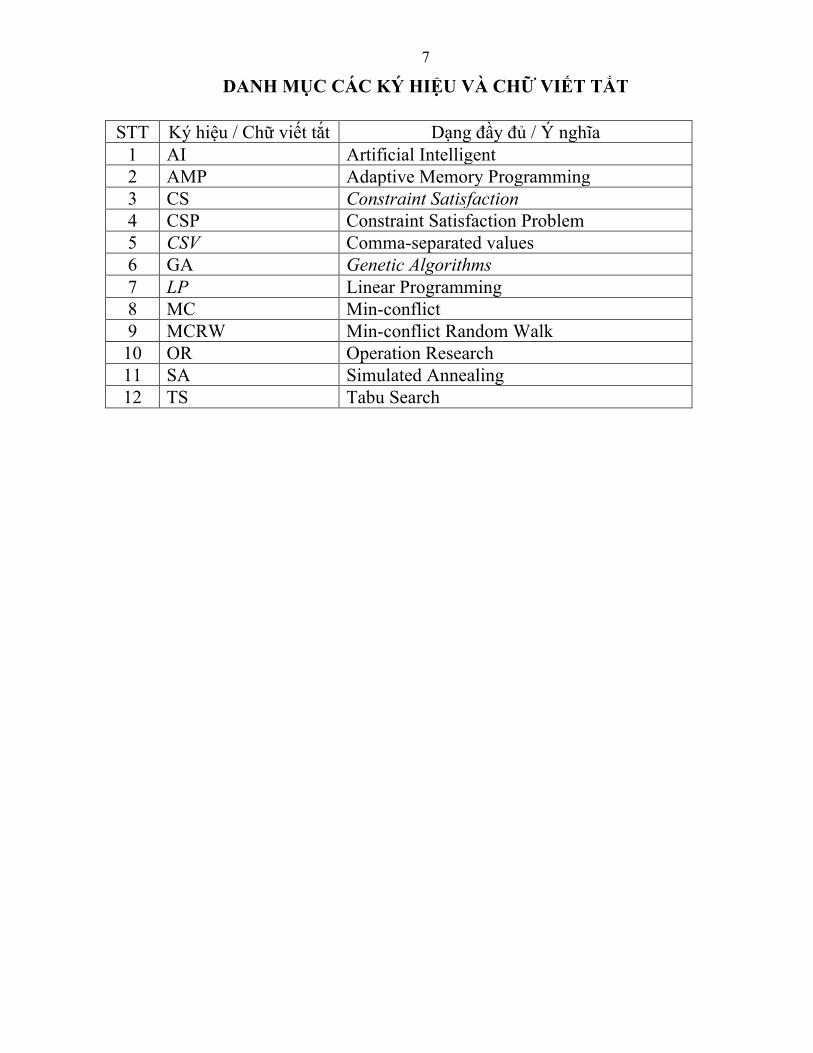
7
DANH MỤC CÁC KÝ HIỆU VÀ CHỮ VIẾT TẮT
STT Ký hiệu / Chữ viết tắt Dạng đầy đủ / Ý nghĩa 1 AI Artificial Intelligent 2 AMP Adaptive Memory Programming 3 CS Constraint Satisfaction 4 CSP Constraint Satisfaction Problem 5 CSV Comma-separated values 6 GA Genetic Algorithms 7 LP Linear Programming 8 MC Min-conflict 9 MCRW Min-conflict Random Walk
10 OR Operation Research 11 SA Simulated Annealing 12 TS Tabu Search

8
DANH MỤC CÁC BẢNG
Bảng 1 - Mô tả cách tính của hàm mục tiêu ........................................................... 38
Bảng 2 – Bảng mô tả ánh xạ tập dữ liệu và mô hình hệ thống ................................ 45
Bảng 3 – Ví dụ ánh xạ từ tập dữ liệu vào mô hình hệ thống ................................... 45
Bảng 4 – Thống kê kết quả thực nghiệm ................................................................. 46
Bảng 5 – So sánh giữa phần mềm vTimeTabler và Open Course TimeTabler ....... 47

9
DANH MỤC CÁC HÌNH VẼ VÀ ĐỒ THỊ
Hình 1 – Biểu diễn khái niệm bài toán sắp thời khóa biểu ...................................... 13
Hình 2 – Bốn chiều Tabu Search ............................................................................. 28
Hình 3 – Bài toán cây tối ưu minh họa .................................................................... 29
Hình 4 – Tăng cường và Đa dạng ............................................................................ 30
Hình 5 – Mối quan hệ giữa Giảng viên, Lớp học và Môn học ................................ 33
Hình 6 – Khởi tạo lời giải ngẫu nhiên ban đầu ........................................................ 39
Hình 7 – Sơ đồ cài đặt giải thuật .............................................................................. 42
Hình 8 – Phép chuyển mới ....................................................................................... 43
Hình 9 – Biểu đồ minh họa quá trình tìm kiếm lời giải ........................................... 46

10
MỞ ĐẦU
1. Lý do chọn đề tài:
Bài toán lập lịch luôn là một bài toán cổ điển thuộc lớp bài toán NP-khó. Từ lâu đã thu hút được sự quan tâm, nghiên cứu và phát triển của nhiều tổ chức giáo dục, các nhà khoa học bởi tính ứng dụng cao và độ phức tạp của nó. Các bài toán lập lịch thường rất phong phú, đa dạng bởi các ràng buộc và yêu cẩu của từng doanh nghiệp, tổ chức, trường học.
Trong nhiều thập niên qua đã có rất nhiều các phương pháp giải được đưa ra. Tuy nhiên, tính hiệu quả của lời giải cho lớp bài toán vẫn còn nhiều bàn cãi. Bài toán lập lịch có thể được dịnh nghĩa là một bài toán tìm kiếm chuỗi tối ưu để thực hiện một tập các hoạt động chịu tác ñộng của một tập các ràng buộc cần phải được thỏa mãn. Người lập lịch thường cố gắng thử đến mức tối đa sự sử dụng các tài nguyên nhân lực, vật lực, máy móc và tối thiểu thời gian đòi hỏi để hoàn thành toàn bộ quá trình nhằm sắp xếp lịch tối ưu nhất. Vì thế bài toán lập lịch là một vấn đề rất khó để giải quyết.
Những năm gần đây, đã có nhiều hướng phát triển phong phú của các giải thuật nhằm đưa ra lời giải tốt nhất cho bài toán này. Với đề tài “Giải bài toán lập lịch theo tín chỉ sử dụng giải thuật tìm kiếm Tabu”, khóa luận mạnh dạn nghiên cứu một phương pháp mới cho việc giải các bài toán lập lịch cho mô hình các đơn vị, các cơ sở đào tạo có hình thức tổ chức, hoạt động giống với các Trung tâm Đào tạo Chứng chỉ Quốc tế theo Tín chỉ.
2. Mục đích nghiên cứu
Bài toán lập lịch đã từ lâu trở thành một bài toán nổi tiếng và thu hút được sự quan tâm của rất nhiều nhà nghiên cứu, nhiều chuyên gia trong các lĩnh vực liên quan. Sự “nổi tiếng” của bài toán này không chỉ được đo bởi độ phức tạp của vấn đề, mà còn ở tính thực tiễn, khả năng áp dụng rất cao trên thực tế. Do đó mục tiêu của luận văn là: Nghiên cứu kỹ thuật của giải thuật tìm kiếm Tabu cho bài toán lập lịch theo tín chỉ.
Luận văn sẽ xem xét áp dụng kỹ thuật này vào việc xây dựng chương trình lập lịch cho mô hình một trung tâm đào tạo theo tín chỉ.

11
3. Nhiệm vụ nghiên cứu
Nghiên cứu, tìm hiểu giải thuật tìm kiếm Tabu và trên cơ sở đó tiếp cận để giải bài toán lập lịch, sắp xếp thời khóa biểu cho mô hình giảng dạy trong các trung tâm đào tạo theo tín chỉ hiện nay.
4. Đối tượng và phạm vi nghiên cứu
Tìm hiểu bài toán lập lịch và các hướng giải quyết truyền thống
Tìm hiểu về giải thuật tìm kiếm Tabu
Ứng dụng thuật giải tìm kiếm Tabu vào bài toán lập lịch
Xây dựng ứng dụng lập thời khóa biểu cho các trung tâm đào tạo theo tín chỉ
5. Phương pháp nghiên cứu
Dựa trên tài liệu thu thập từ nhiều nguồn (tài liệu, bài báo do giảng viên hướng dẫn cung cấp, sách, báo, tạp chí, internet…) tổng hợp, phân tích và trình bày lại theo sự hiểu biết của bản thân
Mở rộng các cách tiếp cận trước đây trên cơ sở phân tích đặc thù bài toán cần giải quyết để đưa ra những ý kiến, đề xuất cải tiến hợp lý.
Ứng dụng những kết quả dựa trên nghiên cứu trên vào thực tế.

12
TỔNG QUAN VỀ BÀI TOÁN LẬP LỊCH HIỆN NAY VÀ CÁC Chương 1:CÁCH TIẾP CẬN
Bài toán lập lịch luôn là một bài toán khó, mang tính khoa học đồng thời tính thực tiễn cũng rất cao. Không chỉ Việt Nam mà trên toàn cầu từ lâu việc lập lịch đã trở thành một vấn đề có tính thời sự, một bài toán gây được sự chú ý, quan tâm của nhiều người.
Bài toán lập thời khóa biểu là một nhánh của bài toán lập lịch trong đó đưa ra một chuỗi các sự kiện (thông thường là các môn học, bài giảng hoặc các môn thi) và bao gồm các giáo viên và học viên trong một khoảng thời gian định trước và thỏa mãn một tập hợp các ràng buộc của từng loại thời khóa biểu khác nhau.
Mỗi bài toán có các tính chất riêng, khi sắp lịch thi bài toán đặt ra là phải đáp ứng được yêu cầu về thời gian (như không được trùng hay quá sát nhau) giữa các lần thi liên tiếp của cùng một học sinh, sinh viên. Còn khi sắp lịch cho trường phổ thông thì chúng ta cần quan tâm giờ rảnh mà giáo viên đăng ký và các tiết trống giữa giờ học của học sinh đóng vai trò rất quan trọng cho việc đánh giá kết quả của thời khóa biểu. Đối với đại học, bài toán cần giải quyết cũng là việc tránh xung đột giữa các thành phần tham gia trong thời khóa biểu (giáo viên, lớp học, phòng học và thiết bị). Vì thế, mục tiêu cuối cùng của người sắp thời khóa biểu là tạo ra một thời khóa biểu với ít xung đột nhất.
Cũng đã có các khảo sát về bài toán sắp thời khóa biểu. Như việc đưa ra tổng quan các vấn đề về sắp thời khóa biểu thuộc ba dạng ta đã đề cập ở trên của Schaerf, 1995 [1]. Các khảo sát về sắp lịch thi Carter & Laporte, 1996 [2] và sắp lịch cho trường đại học Carter & Laporte, 1998 [3] Bardadym, 1996 [4].

13
Hình 1 – Biểu diễn khái niệm bài toán sắp thời khóa biểu
Khái niệm được thể hiện bằng hình hộp, các quan hệ là các đường nối các hình hộp đó. Các khái niệm và các quan hệ giữa các khái niệm đó trong một bài toán lập lịch được mô tả tổng quát ở hình (a) và được mô tả cụ thể hơn ở hình (b)
1.1 Bài toán lập thời khóa biểu cho trường phổ thông (School timetabling)
Bài toán lập thời khóa biểu cho trường phổ thông hay bài toán phân chia giáo viên, lớp học trong một tuần đối với tất cả các môn học của một trường học. Với ba tập hợp cho trước là tập giáo viên, tập lớp học và tập tiết học và một ma trận ràng buộc số bài giảng một giáo viên được phân công dạy một lớp.
Bài toán yêu cầu phân chia các bài giảng vào các tiết sao cho không giáo viên hay lớp học nào có cùng một bài giảng trong cùng một thời gian và mỗi giáo viên đều có một số lượng nhất định các bài giảng với mỗi lớp học.
1.2 Bài toán lập thời khóa biểu cho trường đại học (University timetabling)
Bài toán lập thời khóa biểu cho trường đại học là bài toán lập lịch cho các bài giảng (lectures) vào từng khóa học với một số lượng phòng học và tiết học cho trước. Điểm khác biệt chính với bài toán lập thời khóa biểu trường phổ thông là đặc trưng của các khóa học ở trường đại học, các sinh viên tham dự khóa học, trong khi các lớp học ở trường phổ thông được tạo bởi tập hợp các học sinh và có thể coi như là một thực thể đơn. Ở các trường đại học, hai khóa học khác nhau có thể có trùng sinh viên tham dự và điều đó có thể tạo ra xung đột và sẽ không thể lập lịch được
Người
Địa điểm Thời gian
Sự kiện
(a)
Buổi học
Phòng học
Giáo viên Lớp học
Môn học
(b)

14
trong cùng một tiết học. Thêm vào đó, các giáo viên ở trường phổ thông luôn dạy nhiều hơn một lớp trong khi ở trường đại học một giảng viên thường chỉ dạy một vài khóa học hay một vài môn học trong một kỳ. Cuối cùng, với bài toán trường đại học kích cỡ các phòng học chiếm một vai trò quan trọng trong khi với bài toán trường phổ thông vấn đề này là không quan trọng bởi vì trong hầu hết các trường phổ thông mỗi lớp có một phòng học riêng.
1.3 Bài toán lập lịch thi (Examination timetabling)
Bài toán lập lịch thi tương tự như bài toán lập thời khóa biểu cho trường đại học nhưng ta cần phân biệt sự khác nhau giữa hai bài toán này. Bài toán lập lịch thi có những đặc điểm khác sau đây:
• Chỉ có một kỳ thi cho mỗi một môn thi.
• Các điều kiện xung đột nói chung là hạn chế. Thực tế, chúng ta có thể chấp nhận một sinh viên có thể bỏ qua một bài giảng do sự chồng chéo các môn học; nhưng không có sinh viên nào được phép bỏ qua một kỳ thi hết môn đã học vì nếu sinh viên không qua được kỳ thi này coi như trượt môn đó.
• Và một số ràng buộc khác như hầu hết một sinh viên sẽ chỉ có một môn thi trong một ngày và không có nhiều quá các môn thi liên tiếp nhau với một sinh viên.
• Thời gian thi của các môn thi có thể khác nhau, ngược lại với bài toán lập thời khóa biểu cho trường đại học thì thời gian học được tính bằng tiết (45 – 50 phút tùy quy định của trường).
• Có thể có nhiều hơn một môn được thi trong một phòng nhưng lại thì không thể có nhiều bài giảng được diễn ra trong một phòng tại một thời điểm.

15
1.4 Bài toán lập lịch theo tín chỉ
Trước hết để xây dựng được mô hình bài toán lập lịch theo tín chỉ ta cần phải tìm hiểu và trả lời được câu hỏi “Tín chỉ là gì?”
Có rất nhiều định nghĩa về tín chỉ, khoảng 60 định nghĩa khác nhau, có định nghĩa coi trọng khía cạnh định tính, có định nghĩa coi trọng khía cạnh định lượng, có định nghĩa nhấn mạnh vào chuẩn đầu ra của sinh viên, có định nghĩa lại nhấn mạnh vào các mục tiêu của chương trình học. Một định nghĩa về tín chỉ được các nhà quản lý và nhà nghiên cứu giáo dục ở Việt Nam biết đến nhiều nhất có lẽ là của học giả người Mỹ gốc Trung Quốc James Quann thuộc ĐH Washington. Cách hiểu của ông về tín chỉ được theo bảo dịch của Bộ Giáo dục và Đào tạo như sau:
“Tín chỉ học tập là một đại lượng đo toàn bộ thời gian bắt buộc của một người học bình thường để học một môn cụ thể, bao gồm: 1. Thời gian lên lớp; 2. Thời gian ở trong phòng thí nghiệm, thực tập hoặc các phần việc khác đã được quy định ở thời khoá biểu; 3. Thời gian dành cho đọc sách, nghiên cứu giải quyết vấn đề, viết hoặc chuẩn bị bài...; đối với môn học lý thuyết một tín chỉ là một gìờ lên lớp (với 2 giờ chuẩn bị bài) trong tuần và kéo dài trong một học kỳ 15 tuần; đối với các môn học ở sudio hay phòng thí nghiệm, ít nhất là 2 giờ trong một tuần (với 1 giờ chuẩn); đối với các môn tự học, ít nhất là 3 giờ trong một tuần. “
Theo cách hiểu của PGS.TS Hoàng Văn Vân khoa sau ĐH – ĐH Quốc gia Hà Nội như sau:
“Tín chỉ là đại lượng dùng để đo khối lượng kiến thức, kỹ năng của một môn học mà người học cần phải tích luỹ trong một khoảng thời gian nhất định thông qua các hình thức: 1. Học tập trên lớp; 2. Học tập trong phòng thí nghiệm, thực tập hoặc làm các phần việc khác (có sự hướng dẫn của giáo viên); 3. Tự học ngoài lớp như đọc sách, nghiên cứu, giải quyết vấn đề hoặc chuẩn bị bài... Tín chỉ còn được hiểu là khối lượng lao động của người học trong một khoảng thời gian nhất định trong những điều kiện học tập tiêu chuẩn.”
Như vậy, có 7 điểm cần phải làm rõ từ định nghĩa về tín chỉ này.
Thứ nhất, hoạt động dạy - học theo tín chỉ được tổ chức theo ba hình thức: lên lớp, thực hành, và tự học. Trong ba hình thức tổ chức dạy - học này, hai hình thức đầu được tổ chức có sự tiếp xúc trực tiếp giữa giáo viên và sinh viên (giáo

16
viên giảng bài, hướng dẫn, sinh viên nghe giảng, thực tập dưới sự hướng dẫn của giáo viên...), hình thức thứ ba không có sự tiếp xúc giữa giáo viên và sinh viên (giáo viên giao nội dung để sinh viên tự học, tự nghiên cứu, tự thực hành). Ba hình thức tổ chức dạy - học này tương ứng với ba kiểu giờ tín chỉ: giờ tín chỉ lên lớp, giờ tín chỉ thực hành và giờ tín chỉ tự học. Theo đó, một giờ tín chỉ lên lớp bao gồm 1 tiết (50 phút) giáo viên giảng bài và 2 tiết sinh viên tự học, tự nghiên cứu ở nhà; một giờ tín chỉ thực hành bao gồm 2 tiết giáo viên hướng dẫn, điều khiển và giúp đỡ sinh viên thực hành, thực tập; và một giờ tín chỉ tự học bao gồm 3 tiết sinh viên tự học, tự nghiên cứu, tự thực hành theo những nội dung giáo viên giao và những gì sinh viên thấy cần phải nghiên cứu hoặc thực hành thêm (những hoạt động học tập này có thể được thực hiện ở nhà hoặc ở trong phòng thí nghiệm, trong studio...).
Thứ hai, trong ba hình thức tổ chức dạy - học, cụ thể là trong ba kiểu giờ tín chỉ, lượng kiến thức sinh viên thu được có thể khác nhau nhưng để thuận tiện cho việc tính toán (giờ chuẩn cho giáo viên, kinh phí cho từng môn học, nhân lực để phục vụ cho dạy - học...), ba kiểu giờ tín chỉ này được coi là có giá trị ngang nhau.
Thứ ba, có hai thuật ngữ dễ gây nhầm lẫn: đó là, một giờ tín chỉ (a credit hour) và một tín chỉ (a credit). Trong các tài liệu nghiên cứu của các nhà nghiên cứu Âu - Mỹ, hai thuật ngữ này thường được sử dụng thay cho nhau, chỉ chung một giá trị. Trong cách hiểu của chúng tôi, tín chỉ và giờ tín chỉ là hai khái niệm có nội dung khác. Theo đó, một tín chỉ gồm 15 giờ tín chỉ, thực hiện trong một học kỳ, kéo dài 15 tuần, mỗi tuần 01 giờ tín chỉ.
Thứ tư, có thể có những môn học chỉ gồm một kiểu giờ tín chỉ, nhưng có thể có những môn học gồm nhiều hơn một kiểu giờ tín chỉ. Trong mọi trường hợp, công thức tính cho mỗi môn học là không đổi: 1+ 0 + 2 cho môn học thuần lý thuyết, 0+ 2 + 1 cho môn học thuần thực hành, thực nghiệm, và 0+ 0 + 3 cho môn học thuần tự học.
Thứ năm, người học trong phương thức đào tạo theo tín chỉ được cấp bằng theo hình thức tích lũy đủ tín chỉ, và đánh giá theo thang điểm A, B, C, D, F trong đó F là mức chưa đạt yêu cầu phải học và thi lại tín chỉ đó.
Thứ sáu, định nghĩa tín chỉ trên mới đo năng lực học tập của người học thông qua thời lượng và số lượng tín chỉ được tích luỹ, nó chưa đo được mục tiêu hay chất lượng đầu ra của quá trình học tập. Tuy nhiên người học được cấp bằng

17
không chỉ phụ thuộc vào số tín chỉ mà họ tích lũy đủ mà còn phụ thuộc vào điểm trung bình chung quy định cho từng thời kỳ, từng kiểu văn bằng (cử nhân, thạc sĩ, tiến sĩ). Những quy định này phần lớn là do từng trường ĐH quyết định.
Cuối cùng, thứ bảy, khác với phương thức đào tạo truyền thống, phương thức đào tạo theo tín chỉ xem tự học như là một thành phần hợp pháp trong cơ cấu giờ học của sinh viên: ngoài việc nghe giảng và thực hành trên lớp, sinh viên được giao những nội dung để tự học, tự thực hành, tự nghiên cứu; những nội dung này được đưa vào thời khoá biểu để phục vụ cho công tác quản lý và phải đưa vào nội dung các bài kiểm tra thường xuyên và bài thi hết môn học.
1.5 Ưu điểm của phương thức đào tạo theo tín chỉ
Thứ nhất, việc tự học, tự nghiên cứu của sinh viên được coi trọng được tính vào nội dung và thời lượng của chương trình. Đây là phương thức đưa giáo dục ĐH về với đúng nghĩa của nó, người học tự học, tự nghiên cứu, giảm sự nhồi nhét kiến thức của người dạy, và do đó phát huy được tính chủ động, sáng tạo của người học.
Thứ hai, chương trình được thiết kế theo phương thức đào tạo tín chỉ bao gồm một hệ thống những môn học thuộc khối kiến thức chung, những môn học thuộc khối kiến thức chuyên ngành, những môn học thuộc khối kiến thức cận chuyên ngành. Mỗi khối lượng kiến thức đều có số lượng môn học lớn hơn số lượng các môn học hay số lượng tín chỉ được yêu cầu. Sinh viên có thể tham khảo giáo viên hoặc cố vấn để chọn những môn học phù hợp với mình, để hoàn thành một văn bằng và để phục vụ cho nghề nghiệp tương lai của mình.
Thứ ba, sinh viên được cấp bằng khi đã tích luỹ đầy đủ số lượng tín chỉ do trường ĐH quy định; do vậy họ có thể hoàn thành những điện kiện để được cấp bằng tuỳ theo khả năng và nguồn lực của mình.
Thứ tư, phản ánh được những mối quan tâm và những yêu cầu của người học như là những người sử dụng kiến thức và nhu cầu của các nhà sử dụng lao động trong các tổ chức quản lý kinh doanh và tổ chức quản lý hành chính nhà nước.

18
Thứ năm, phương thức đào tạo này sẽ tạo được sự liên thông giữa các cơ sở đào tạo ĐH trong nước và nước ngoài.
Bên cạnh những ưu điểm cho giáo viên và sinh viên còn có các lợi ích cho các nhà quản lý giáo dục. Vì nó vừa là thước đo khả năng học tập của người học, vừa là thước đo hiệu quả của giáo viên; là cơ sở để các trường ĐH tính toán ngân sách chi tiêu, nguồn nhân lực; và là cơ sở để báo các số liệu của trường cho các cơ quan cấp trên và các đơn vị liên quan. Một khi thước đo giờ tín chỉ được phát triển và kiện toàn, việc sử dụng nó như là một phương tiện giám sát bên ngoài, để báo cáo và quản lý hành chính hữu hiệu hơn.
Chính vì thế mà đào tạo theo tín chỉ có sức hấp dẫn với các nước trên thế giới trong đó có Việt Nam. Ngày nay, trong xu thế hội nhập vừa tạo ra thời cơ đồng thời vừa là thách thức đối với nước ta trên lĩnh vực Giáo dục - Đào tạo. Việt Nam đang trên đà phát triển vì vậy cần có tư duy mới để bứt phá đưa đất nước phát triển điều đó phụ thuộc rất nhiều vào giáo dục nước nhà, tạo ra con người chủ động, tích cực, sáng tạo. Muốn vậy, cần có hệ thống giáo dục hợp lý, để nâng cao chất lượng Giáo dục - Đào tạo cho hệ thống trung học chuyên nghiệp (THCN), CĐ, ĐH cần chuyển đổi từ phương thức đào tạo theo niên chế sang đào tạo theo hệ thống tín chỉ. Phương thức đào tạo này có ý nghĩa to lớn trong việc hội nhập và tiến dần đến phương thức đào tạo tiên tiến, tạo nhiều cơ hội cho người học - chủ nhân tương lai của đất nước.
1.6 Các cách tiếp cận hiện nay
Bài toán thời khóa biểu nói riêng và các bài toán tối ưu tổ hợp nói chung rất khó giải. Sự khó khăn của chúng được thể hiện ở độ phức tạp tính toán và với những bài toán thuộc lớp NP-khó như vậy thời gian để giải thường tăng theo hàm mũ của kích thước bài toán.
Như chúng ta đã biết, trong thuật toán “vét cạn” (brute force) (tìm kiếm theo bề rộng hoặc theo độ sâu), thì về mặt nguyên tắc các phương pháp tìm được nghiệm của bài toán nếu bài toán đó có nghiệm. Song trên thực tế những bài toán NP-khó không thể áp dụng được phương pháp này vì ta phải phát triển một không

19
gian tìm kiếm rất lớn trước khi tìm được lời giải, nhưng do những hạn chế về thời gian tính toán và dung lượng bộ nhớ không cho phép chúng ta làm được điều đó.
Bài toán sắp lịch cho trường đại học có mục tiêu chính là việc sắp các phân công giảng dạy hàng tuần. Bài toán này bao gồm việc sắp các phân công giảng dạy vào các tiết theo một cách nào đó mà giảng viên (hay lớp học) có liên quan không được phép tham gia một lúc hai phân công, và các ràng buộc khác cần phải được thỏa mãn. Bài toán này thuộc loại NP-khó và thường được giải quyết bằng các phương pháp Heuristic.
Thông thường, người giáo vụ cần phải mất vài ngày để sắp được một thời khóa biểu bằng tay. Mà lời giải còn có thể chứa những kết quả không tốt lắm, ví dụ như việc giáo viên bị trống tiết giữa trong một buổi giảng. Ngoài ra trong quá trình sắp người giáo vụ phải tương tác rất nhiều với giảng viên để thỏa thuận giờ giảng khi xảy ra việc tranh chấp tài nguyên.
Bởi lý do ở trên, nhu cầu đặt ra là cần một chương trình sắp thời khóa biểu tự động. Trong hơn bốn mươi năm qua, bắt đầu từ thập niên 60, với Gotlieb (1963) [5] và những người khác, nhiều bài báo có liên quan đến việc sắp thời khóa biểu tự động đã xuất hiện ở các hội nghị và tạp chí khoa học, và các ứng dụng đã bắt đầu được phát triển cho ra các kết quả khá tốt.
Các kỹ thuật sơ khai của Schmidt-Strohlein, 1979 [6]; Junginger, 1986 [7] được dựa trên việc giả lập quá trình sắp lịch của con người trong việc giải bài toán. Các kỹ thuật này được gọi là heuristics trực tiếp (direct heuristic) được dựa trên việc mở rộng liên tục (successive augmentation). Nghĩa là, họ sẽ sắp một phần thời khóa biểu, lần lượt từng phân công, cho đến khi tất cả các phân công đã được sắp hoặc không sắp được thêm phân công nào nữa do vi phạm các ràng buộc.
Sau này, các nhà nghiên cứu đã bắt đầu áp dụng các kỹ thuật tổng quát hơn trên bài toán này. Do đó ta thấy các thuật toán dựa trên lập trình tuyến tính (integer programming) của Tripathy trong các năm 1984, 1992 [8, 9], luồng mạng (network flow) của Ostermann-de Werra, 1983 [10], và còn những loại khác nữa. Ngoài ra bài toán này cũng được giải quyết bằng cách đưa nó về bài toán nổi tiếng: tô màu đồ thị (graph coloring) của Neufeld-Tartar, 1974 [11].
Gần đây nhất, những tiếp cận dựa trên những hướng nghiên cứu mới bao gồm tôi luyện thép (simulated annealing) (Abramson, 1991 [12]), Tabu search

20
(Costa, 1994 [13]), thuật giải di truyền (genetic algorithms) (Colorni, Dorigo, và Maniezzo, 1992 [14]), thỏa mãn ràng buộc (constraint satisfaction) (Yoshikawa, Kaneko, Nomura và Watanabe, 1994 [15]) và một kết hợp của các phương pháp khác (Cooper và Kingston, 1993 [16]) nhằm tìm ra lời giải “tốt nhất có thể” cho lớp các bài toán NP-khó nói chung và có thể áp dụng riêng cho nhánh bài toán lập lịch được đề cập trong luận văn này. Trong chương 2 chúng ta sẽ cùng nhau tìm hiểu chi tiết hơn một vài thuật toán phổ biến hiện nay.

21
TỔNG QUAN VỀ CÁC PHƯƠNG PHÁP TÌM KIẾM Chương 2:
Tìm kiếm cục bộ dựa vào một ý tưởng tổng quát và đơn giản. Gọi P là một bài toán tối ưu tổ hợp cần giải, và s là lời giải hiện hành giả sử là một lời giải khả thi của P, và có hàm chi phí f(s). Miền lân cận N(s) được định nghĩa cho s, là tập những lời giải láng giềng khả thi s’ của s sao cho từ s ta có thể đạt tới s’ nhờ vào một bước chuyển m. Bước chuyển có tác dụng biến đổi s thành ra một lời giải láng giềng. Thao tác biến đổi này được lặp cho đến khi hội tụ về một lời giải tốt. Lời giải này là lời giải cận tối ưu, mà trong một số bài toán thực tế, không sai biệt gì nhiều với lời giải tối ưu.
2.1 Xung đột tối thiểu (Min-conflict)
Thuật giải xung đột tối thiểu (Min-conflict) [17], viết tắt là MC đã được dùng khá phổ biến để giải hệ ràng buộc quá mức. Thuật giải MC chọn ngẫu nhiên một biến nào đó dính líu đến một ràng buộc bị vi phạm và rồi chọn một trị từ miền trị của biến này sao cho tối thiểu hoá số lượng những vị phạm ràng buộc có thể xảy ra. Vì thuật giải MC thuần túy có thể không thoát ra được điểm tối ưu cục bộ, Thuật giải thường kết hợp với một chiến lược bước ra ngẫu nhiên (random walk). Với một biến nào đó được chọn, chiến lược bước ra ngẫu nhiên lấy ngẫu nhiên một trị từ miền trị của biến này với xác xuất p, và áp dụng theo Thuật giải MC với xác xuất 1- p. Giá trị của thông số p có ảnh hưởng lên hiệu quả của Thuật giải. Thuật giải này được gọi là MCRW (Min-conflict Random Walk)
2.2 Thuật giải mô phỏng luyện kim (Simulated Annealing)
Mô phỏng luyện kim (Simulated Annealing) [18] viết tắt SA, là một kỹ thuật tìm kiếm ngẫu nhiên (stochastic search) tỏ ra rất hữu hiệu cho những bài toán tối ưu hóa qui mô lớn. Trong kỹ thuật này, nhiệt độ là biến được khởi tạo ở một giá trị cao và dần dần giảm dần xuống trong quá trình tìm kiếm. Trong quá trình tìm kiếm SA thay lời giải hiện thời bằng cách chọn ngẫu nhiên lời giải láng giềng với

22
một xác suất phụ thuộc vào sự chênh lệch giữa giá trị hàm mục tiêu và tham số điều khiển là biến nhiêt độ toàn cục. Tại những giá trị nhiệt độ cao, các bước chuyển được chấp nhận một cách ngẫu nhiên bất luận chúng là bước chuyển có cải thiện hàm chi phí của lời giải hay không. Khi nhiệt độ được giảm xuống, xác xuất xuất hiện lời giải có cải thiện sẽ tăng lên và xác xuất xuất hiện lời giải không cải thiện sẽ giảm xuống. Có một số cách thức giảm nhiệt độ dần xuống được dùng trong một Thuật giải SA, được gọi là lịch biểu làm nguội (cooling schedule).
2.3 Thuật giải leo đồi (Hill-climbing)
Thuật giải leo đồi (Hill-climbing) [19] chính là nền tảng cơ sở của các kỹ thuật tìm kiếm cục bộ. Mặc dù đây là Thuật giải đơn giản nhưng lại nó lại rất mạnh và hiệu quả trong việc giải quyết các bài toán phải thỏa mãn các ràng buộc lớn (CSP – Constraint Satisfaction Problem). Thuật ngữ “leo đồi” (hill-climbing) xuất phát từ cơ chế “tu chỉnh lập”: ở mỗi bước của việc tìm kiếm, chúng ta sẽ chọn một bước chuyển mà nó cải thiện giá trị hàm mục tiêu để thực hiện. Trong thuật giải leo đồi, chỉ những bước chuyển cải thiện được hàm chi phí hoặc không làm cho hàm chi phí thay đổi mới được chọn vì vậy việc tìm kiếm sẽ liên tục bước lên vị trí cao hơn cho đến khi nó gặp điều kiện dừng.
2.4 Tìm kiếm Tabu (Tabu search)
Tìm kiếm Tabu được đề xuất bởi Glover năm 1986 ([20]). Đây là một phương pháp dò tìm trong không gian lời giải bằng cách di chuyển từ một lời giải s tại lượt lặp t về một lời giải tốt nhất s’ trong tập con N* của miền lân cận N(s). Vì s’ không nhất thiết cải thiện chi phí của s, một cơ chế được đặt ra để ngăn chặn quá trình khỏi lặp vòng trên một chuỗi các lời giải. Một cách để tránh sự lặp vòng là cấm quá trình tìm kiếm quay về những lời giải đã gặp rồi, nhưng làm như vậy đòi hỏi phải lưu trữ khá nhiều thông tin. Thay vì làm thế, chỉ một vài thuộc tính của những lời giải đã gặp sẽ được lưu trong danh sách tabu (tabu list) và bất kỳ lời giải nào sở hữu những thuộc tính này sẽ không được xét đến trong θ lần lặp, ví dụ như ta có thể lưu trong danh sách tabu này chi phí của lời giải đã gặp được tính toán

23
thông qua hàm phạt. Cơ chế này thường được gọi là bộ nhớ ngắn hạn và θ được gọi là kỳ hạn tabu. Tìm kiếm tabu được phát triển thành nhiều dạng cải tiến như giải thuật tìm kiếm Tabu thích ứng (Reactive Tabu Search) và tìm kiếm tabu với hai danh sách tabu: bộ nhớ ngắn hạn (short term memory) và bộ nhớ dài hạn (long term memory).
2.5 Thuật giải di truyền (Genetic Algorithm)
Thuật giải di truyền (GA) (Goldberg, 1989 [21]) đã tỏ ra khá thành công trong một số những áp dụng. GA mượn ý tưởng trong quá trình tiến hóa của sinh vật.
Ý tưởng chính của Thuật giải là duy trì một quần thể các lời giải ứng viên. Các lời giải ứng viên này sẽ được cho cơ hội riêng lẻ để sản sinh ra con cái tùy thuộc vào độ thích nghi (fitness) của chúng. Độ thích nghi được đo bằng một hàm mục tiêu. Thuật giải GA đã được áp dụng vào việc giải hệ ràng buộc ([22]).
Việc dùng Thuật giải GA vào các bài toán tối ưu hóa có ràng buộc làm phát sinh nhiều vấn đề mà các nhà nghiên cứu phải quan tâm giải quyết. Một trong những vấn đề quan trọng là làm thế nào để đưa các ràng buộc vào các hàm thích nghi (fitness function) để điều khiển quá trình tìm kiếm một cách đóng đắn.
2.6 Kết luận
Sự thành công của bất kỳ Thuật giải tìm kiếm cục bộ nào nêu trên cũng tùy thuộc vào các đặc điểm thi công, tức là tùy thuộc vào các tham số kỹ thuật đặc thù mà người sử dụng phải xác định khi áp dụng Thuật giải tìm kiếm cục bộ đó vào bài toán cụ thể. Quá trình thực nghiệm để xác định các thông số kỹ thuật của một Thuật giải tìm kiếm cục bộ nào đó khi áp dụng vào một bài toán cụ thể được gọi là quá trình điều chỉnh thông số (parameter tuning).
Trong những năm gần đây việc kết hợp các loại giải thuật tìm kiếm cục bộ và một số giải thuật khác là một trong số các cách tiếp cận mới nhất. Trong chương 3 chúng ta sẽ tìm hiểu chi tiết giải thuật tìm kiếm Tabu

24
CƠ SỞ TÌM KIẾM TABU Chương 3:
3.1 Lược Sử Về Tabu Search
3.1.1 Giới Thiệu Sự phức tạp trong các vấn đề tối ưu được gặp trong thực tế như các vấn đề
trong ngành viễn thông, hậu cần, kế hoạch tài chính, vận chuyển và việc sản xuất đã thúc đẩy mạnh việc phát triển các kỹ thuật tối ưu mạnh mẽ. Những kỹ thuật này thường là kết quả của các ý tưởng phát sinh từ các lĩnh vực nghiên cứu khác nhau, với hy vọng có thể phát triển được các phương pháp hiệu quả và có thể xử lý được những phức tạp trong các vấn đề về tối ưu.
Dạng cơ bản nhất của TS được đề nghị từ ý tưởng của Fred Glover [24]. Phương pháp này được dựa trên các quy trình được thiết kế để vượt qua các giới hạn của tính khả thi hoặc tối ưu cục bộ.
Tabu search là một loại “meta-heuristic” dẫn dường cho một quy trình tìm kiếm “heuristic cục bộ” để mở rộng không gian lời giải ra bên ngoài vùng tối ưu cục bộ. Quy trình cục bộ này là việc tìm kiếm sử dụng một thao tác gọi là “phép chuyển” (move) để tạo ra các lời giải xung quanh lời giải ban đầu. Và một trong các thành phần chính của TS chính là “bộ nhớ thích nghi” (adaptive memory), giúp tạo ra các hướng tìm kiếm linh hoạt hơn.
Cùng với phương pháp “tôi luyện thép” và “thuật giải di truyền”, tabu search được đánh giá là “rất có triển vọng” cho các ứng dụng thực tế trong báo cáo của hội đồng Committee on the Next Decade of Operations Research (CONDOR 1988) [23]. Sự phát triển nhanh và mạnh của tabu search trong 20 năm qua đã chứng minh được đánh giá đó là chính xác. Cách tiếp cận “thuần” (pure) và “lai” (hybrid) đã lập kỷ lục mới trong việc tìm kiếm các lời giải tốt hơn cho những vấn đề về kế hoạch sản xuất, phân chia tài nguyên, thiết kế mạng trong viễn thông và nhiều lĩnh vực khác nữa.

25
3.1.2 Tabu Search – Một Dạng Meta-heuristic Nền tảng của tabu search phản ánh chủ đề về các heuristic tốt được thúc đẩy
bởi nhiều thuật toán tốt có liên quan. Hơn nữa, các heuristic và thuật toán tương tự nhau có thể kế thừa những lợi ích từ các nguyên lý tổng hợp từ các phạm vi trí tuệ nhân tạo (artificial intelligent – AI) và vận trù học (operation research – OR). Thiết kế hiệu quả của các phương pháp này có thể góp phần để phát triển những phiên bản nguyên lý mới và sâu sắc hơn trong các lĩnh vực của AI và OR có liên quan về các kỹ thuật cải thiện việc giải quyết vấn đề.
Ngày nay nhiều nhà nghiên cứu trong lĩnh vực AI và OR đã quên rằng hai ngành này đã phát triển cùng nhau và chia sẻ nhiều kiến thức cho nhau. Cả hai ngành đều bắt đầu từ những kết quả của việc phát triển các phương thức giải quyết vấn đề. Những bài báo đầu tiên về heuristic chấp nhận các tiếp cận có ý thức về cầu nối giữa AI và OR (ví dụ Simon và Newell, 1958 [30]; Fisher và Thompson, 1963 [31]; Crowston, 1963 [32]). Tuy nhiên không lâu sau hai lĩnh vực này bắt đầu chia rẽ, với OR thì tập trung về các kết quả, trong khi AI thì chú trọng về tượng trưng và các phân tích định lượng.
Trong thời gian việc phân chia giữa hai ngành vẫn chưa rõ ràng, vẫn có vài cố gắng để giới thiệu những tiếp cận không truyền thống trong lĩnh vực tối ưu. Cùng lúc đó cũng có những cố gắng để giới thiệu xác suất và các khái niệm thiết kế tích hợp vào trong các quy trình heuristic. Không may, những phát triển này lại bị nhận chìm trong nhiều năm. Nhưng chúng cung cấp nền tảng cho các ý tưởng nổi lên lại vào giữa cuối thập niên 80 và trở thành nguồn gốc của các chiến lược mà bây giờ là trái tim của tabu search.
3.1.3 Các Giai Đoạn Phát Triển Của Tabu Search Bốn giai đoạn phát triển chính của tabu search gồm: (1) các chiến lược kết
hợp các luật quyết định dựa trên tái cấu trúc logic và tìm kiếm với các chiều sâu biến đổi (non-monotonic search), (2) Khả năng khôi phục và xung đột hệ thống, (3) bộ nhớ linh hoạt dựa trên tính vừa xảy ra và tính thường xuyên và (4) các quy trình được chọn để kết hợp các lời giải, áp dụng cho quần thể được duy trì có hệ thống.
Giai đoạn phát triển đầu tiên đến từ việc nghiên cứu các luật quyết định cho vấn đề phân công việc. Fisher và Thompson (1963) [31] giới thiệu sự đổi mới của

26
việc thay đổi lần lượt giữa các luật ở mỗi quyết định chọn nút bằng chiến lược xác suất. Cách tiếp cận này thúc đẩy việc xem xét của một chiến lược ngược lại (Glover, 1963) [33], tìm kiếm để khai thác một tập hợp các luật quyết định bằng việc xây dựng một cách để kết hợp chúng để tạo ra luật mới.
Ý tưởng của giai đoạn phát triển thứ hai đã đánh dấu cho sự phát triển những chiến lược có liên quan đến tabu search về sau. Những ý tưởng này được đưa vào trong phương thức giải quyết vấn đề lập trình tuyến tính bằng việc tham khảo hồi phục đa diện (polyhedral relaxation) (Glover, 1966, 1969) [35, 36, 37, 38]. Theo thuật ngữ được công bố bởi Papadimitriou và Steiglitz (1982) [39], cách tiếp cận tạo một thực thể của cái mới xảy ra được gọi là phương thức “chiều sâu biến dổi”.
Giai đoạn phát triển thứ ba cũng liên quan đến cách tiếp cận chính xác của vấn đề lập trình tuyến tính. Trong trường hợp này quy trình bên dưới được tìm ra trên phép mở rộng của phương pháp đơn hình trong lập trình tuyến tính (linear programming – LP).
Giai đoạn cuối cùng bao gồm việc giới thiệu các phương pháp ràng buộc thay thế cho lập trình tuyến tính (Glover 1965) [34]. Các phương thức này dựa trên chiến lược kết hợp các ràng buộc để tạo ra những ràng buộc mới, với mục tiêu của việc mang lại thông tin không chứa riêng biệt trong các ràng buộc cha.
3.2 Nguyên Lý Chung Của Tabu Search
Tabu được viết lại từ chữ “taboo”, taboo mang ý nghĩa chỉ sự cấm kỵ trong tiếng Anh. Tabu search tất nhiên là không có liên quan đến ý nghĩa như vậy, nhưng TS lợi dụng những giới hạn để dẫn đường cho quy trình tìm kiếm để vượt qua các vùng khó tìm kiếm. Những giới hạn này hoạt động dưới các hình thức khác nhau, cả bằng việc loại trừ trực tiếp các lựa chọn “bị cấm”, cũng như bằng cách chuyển thành các đánh giá và khả năng lựa chọn. Các giới hạn được lợi dụng hoặc được tạo bởi việc tham khảo các cấu trúc bộ nhớ được thiết kế nhằm mục đích cụ thể.
Tabu search dựa trên giả thuyết vấn đề đã được giải, kết hợp chặt chẽ “bộ nhớ thích nghi” (adaptive memory) và “thăm dò phản ứng” (responsive exploration). Giống như việc leo núi, người leo núi phải nhớ có chọn lọc các thành

27
phần của quãng đường đã qua (sử dụng adaptive memory) và lập ra các lựa chọn chiến lược trên đường (sử dụng responsive exploration). Bộ nhớ thích nghi này cho phép việc tìm kiếm trong không gian lời giải một cách tiết kiệm và hiệu quả.
Việc nhấn mạnh vào đặc điểm “thăm dò phản ứng” (responsive exploration) của tabu search được lý giải rằng, dù một lựa chọn chiến lược kém thì vẫn cung cấp nhiều thông tin hơn một lựa chọn ngẫu nhiên tốt. (Trong hệ thống sử dụng bộ nhớ, một lựa chọn kém nhưng dựa trên chiến lược có thể cung cấp nhiều thông tin hơn về cách mà chiến lược đã thay đổi thuận lợi như thế nào.)
Thăm dò phản ứng tích hợp các nguyên lý cơ bản của tìm kiếm thông minh (nghĩa là khai thác những đặc điểm lời giải tốt trong khi vẫn tìm kiếm những vùng có tiềm năng khác). Tabu search được phối hợp với việc tìm kiếm những con đường mới và hiệu quả hơn trong việc kết hợp những điểm mạnh của những kỹ thuật có liên quan đến cả “bộ nhớ thích nghi” (adaptive memory) và “thăm dò phản ứng” (responsive exploration).
3.3 Cách Sử Dụng Bộ Nhớ
Các kiến trúc bộ nhớ trong tabu search hoạt động bằng việc tham khảo bốn chiều chính sau: tính chất “mới xảy ra” (recency), tính chất “thường xuyên” (frequency), “chất lượng” (quality) và “ảnh hưởng” (influence). Bộ nhớ recency-based và frequency-based hỗ trợ lẫn nhau. Chiều chất lượng thể hiện khả năng phân biệt chất lượng của các lời giải được tìm thấy trong quá trình tìm kiếm. Trong ngữ cảnh này, bộ nhớ có thể sử dụng để nhận dạng các thành phần hoặc các con đường dẫn tới lời giải tốt. Tính chất lượng hướng tới việc tạo ra các “thành-phần-khích-lệ” (inducement) để cung cấp các hướng dẫn đến lời giải tốt, và các “thành-phần-vi phạm” (penalty) để ngăn chặn các hướng dẫn đến lời giải kém. Khái niệm chất lượng được sử dụng trong tabu search rộng hơn so với cái được sử dụng trong phương pháp tối ưu chuẩn. Chiều thứ tư là “tính ảnh hưởng” (influence) xem việc ảnh hưởng của các lựa chọn được tạo trong quá trình tìm kiếm không những trên chất lượng mà còn trên cấu trúc. (Có thể xem tính chất chất lượng là một dạng đặc biệt của tính chất ảnh hưởng).

28
Hình 2 – Bốn chiều Tabu Search
Bộ nhớ sử dụng trong tabu search là “bộ nhớ hiện” (explicit memory) và “bộ nhớ thuộc tính” (attributive memory). Bộ nhớ hiện ghi nhận toàn bộ lời giải, thường là chứa các lời giải tốt trong quá trình tìm kiếm. Những lời giải tốt đã ghi nhận sẽ được dùng dể mở rộng tìm kiếm cục bộ. Nhưng ứng dụng của loại bộ nhớ này giới hạn ở chỗ, vì cần phải thiết kế cấu trúc dữ liệu để không tốn quá nhiều bộ nhớ.
Thay vào đó, TS sử dụng bộ nhớ thuộc tính. Loại bộ nhớ này lưu lại thông tin về các thuộc tính của lời giải khi có thay đổi từ lời giải này sang lời giải khác. Ví dụ, trong đồ thị hay mạng, các thuộc tính có thể bao gồm các nút hoặc các cung được thêm hoặc bớt đi bởi phép chuyển.
3.3.1 Một Minh Họa Đây là một minh họa cho thấy các thuộc tính có thể được sử dụng như thế
nào trong cấu trúc bộ nhớ recency-based. Xem một vấn đề tìm cây tối ưu trên đồ thị với các nút được đánh số từ 1 đến 7. Và 3 đồ thị sau thể hiện cho đồ thị ở bước
2,1, ++ kkk trong quá trình tạo ra các trạng thái để tìm lời giải. Với quy định là khi
Cấu trúc bộ nhớ
Chất lượng
(Quality)
Mới xảy ra (Recent)
Thường xuyên (Frequency)
Ảnh hưởng (Influence)

29
một phép chuyển được thực hiện sẽ bao gồm một cạnh được lấy ra và một cạnh được thêm vào để giữ nguyên cây.
Hình 3 – Bài toán cây tối ưu minh họa
Phép chuyển áp dụng ở bước k để tạo ra một cây ở bước 1+k bao gồm việc gỡ cạnh (1,3) và thêm vào cạnh (4,6). Được thể hiện ở hình 2, là cạnh được đánh dấu và cạnh đứt nét. Ở bước thứ k , cạnh (1,3) và cạnh ảo (4,6) trong cây được xem là hai thuộc tính lời giải (solution attribute) khác nhau, và được gọi là (1,3) trong và (4,6) ngoài. Các thuộc tính này được xem là tabu-active, được dùng để định nghĩa ra trạng thái tabu (tabu status) của các phép chuyển ở các bước tiếp theo.
Ví dụ trong bộ nhớ recency-based ta có thể cho cạnh (1,3) trong là tabu-active trong 3 bước, để giữ cho cạnh (1,3) không bị thêm lại vào cây hiện tại trong những bước này. Do đó cạnh (1,3) chỉ có thể thêm vào cây ở bước gần nhất là bước
4+k . Tương tự, nếu cho cạnh (4,6) ngoài tabu-active trong 1 bước để giữ cho cạnh (4,6) khỏi bị gỡ ra trong 1 bước. Những điều kiện này giúp cho việc thực hiện các phép chuyển tránh lặp lại những lần chuyển ở những bước trước.
Số bước mà một cạnh trong trạng thái tabu-active được gọi là “tabu tenure”. Nếu giá trị tabu tenure quá lớn sẽ làm cho chất lượng của lời giải không được cải thiện. Nhưng nếu tabu tenure quá nhỏ sẽ làm cho hàm mục tiêu lặp lại theo chu kỳ.

30
Trong ví dụ trên, khi bộ nhớ hiện mở rộng các lời giải hàng xóm trong khi tìm kiếm cục bộ (bằng cách nhớ các lời giải tốt), thì bộ nhớ thuộc tính làm giảm các lời giải đó (bằng cách giữ hoặc cấm các phép chuyển có chọn lọc).
Ngoài ra còn có một loại bộ nhớ đặc biệt được tạo ra bằng cách thực hiện hàm băm. Loại này được xem như là một loại “bộ nhớ bán hiện” (semi-explicit memory) có thể được dùng để thay cho bộ nhớ thuộc tính.
3.4 Chiến Lược Tăng Cường (Intensification) và Chiến Lược Đa Dạng (Diversification)
Hai thành phần rất quan trọng của tabu search là chiến lược tăng cường và chiến lược đa dạng. Chiến lược tăng cường dựa trên việc thay đổi các luật lựa chọn để tăng việc kết hợp các phép chuyển và các đặc tính của lời giải tốt trong quá trình tìm kiếm. Vì các lời giải tốt được ghi nhận lại để đánh giá các hàng xóm kề chúng, nên bộ nhớ hiện có liên hệ đến các cài đặt cho chiến lược tăng cường này.
Hình 4 – Tăng cường và Đa dạng
Khác biệt chính giữa chiến lược tăng cường và đa dạng là trong chiến lược tăng cường, việc tìm kiếm chú trọng đến việc đánh giá hàng xóm của các lời giải tốt. Ngược lại, chiến lược đa dạng, thúc đẩy quá trình tìm kiếm khảo sát các vùng chưa được đến thăm và tạo ra các lời giải khác nhau bằng nhiều cách khác nhau từ những lời giải đã có từ trước.
Ở đây từ “hàng xóm” (neighborhood) mang ý nghĩa rộng hơn là trong ngữ cảnh thường dùng của từ “tìm kiếm hàng xóm”. Có nghĩa là, ngoài xem các lời giải gần với các lời giải tốt bằng những phương thức chuyển bình thường thì chiến lược tăng cường còn tạo ra các “hàng xóm” bằng cách ghép các thành phần của các lời

31
giải tốt hoặc bằng cách sử dụng các ước lượng đề nghị các thành phần tốt cho lời giải hiện tại.
3.5 Lập Trình Với Bộ Nhớ Tương Thích (Adaptive Memory Programming)
Trong thực tế tabu search có hai phiên bản: một đơn giản và một phức tạp.
Phương pháp đơn giản kết hợp chặt chẽ các phần giới hạn của thiết kế TS và đôi khi sử dụng trong các phân tích sơ bộ để kiểm tra hiệu suất của các thành phần của một tập con giới hạn và thường chỉ sử dụng bộ nhớ ngắn hạn.
Phương pháp phức tạp sử dụng “bộ nhớ dài hạn” (longer term memory) cùng với các chiến lược tăng cường, đa dạng liên quan. Cách tiếp cận này chú trọng vào việc khai thác tập hợp của các thành phần trong bộ nhớ, và đôi khi được gọi là lập trình với “bộ nhớ tương thích” (Adaptive Memory Programming – AMP).
3.6 Các Nhân Tố Của Bộ Nhớ Tương Thích
Bộ nhớ tương thích (adaptive memory) dựa trên thuộc tính và phụ thuộc vào bốn nhân tố: vừa xảy ra, thường xuyên, chất lượng và ảnh hưởng.
Bốn nhân tố này che đi các khả năng đầy bất ngờ, mà sẽ lộ rõ ra khi chúng được kết hợp và phân biệt cho các lớp thuộc tính qua các loại khác nhau và các thời điểm khác nhau. Các câu hỏi dưới đây sẽ cho thấy rõ hơn về các nhân tố này, đồng thời chúng có liên quan nhiều đến việc thiết kế các phương thức tìm kiếm.
1. Loại thuộc tính lời giải nào có thể được khai thác hiệu quả nhất bằng bộ nhớ tương thích? (Tác động ra sao của các chiến lược khai thác bộ nhớ trong việc chọn lựa hàng xóm để hướng dẫn việc tìm kiếm?)
2. Loại phương pháp nào hữu ích cho việc tạo ra các thuộc tính mới, ví dụ như việc kết hợp các thuộc tính? (Các phương pháp đó có liên quan ra sao cho các phương pháp “xây dựng từ vựng” (vocabulary building method) trong tabu search?)

32
3. Các thước đo có liên quan đến tính chất ảnh hưởng, ví dụ như việc phản ánh thay đổi của thuộc tính bằng việc chuyển một lời giải này sang lời giải khác? (Làm thế nào các thước đó này hỗ trợ cho các tính chất độc lập của các đường đi trước có liên quan tới việc tìm kiếm đường đi hiện tại?)
4. Các ngưỡng nào nên xây dựng để xác định các cấp của tính vừa xảy ra, tính thường xuyên, chất lượng và ảnh hưởng? (Những cấp độ này đóng vai trò như thế nào trong việc xác định giới hạn tabu và “tiêu chuẩn tham vọng” (aspiration criteria)? Các ngưỡng này được sử dụng ra sao để tạo ra vi phạm và thưởng cho các phép chuyển được chọn hoặc để thay đổi pha của việc tìm kiếm?)
5. Làm thế nào để thiết kế ngẫu nhiên nhằm lấy thông tin thuận lợi được cung cấp bởi các thước đánh giá và ngưỡng? (Phương thức và phạm vi tìm kiếm nào nên được chi phối bởi biến xác suất và cái nào nên được định ra trước?)
6. Bộ nhớ có thể được áp dụng như thế nào để kết hợp cách sử dụng “các hàng xóm ghép” (compound neiborhood) một cách hiệu quả nhất? (Dạng bộ nhớ nào hữu dụng nhất để đưa ra loạt các chiến lược, như một cơ sở để ghép các “phép chuyển” (move) được chọn thành các khả năng tốt hơn?)
7. Những tiếp cận thu gom và mẫu phân loại gì là thích hợp nhất để thuận lợi cho quá trình tìm kiếm? (Các tiếp cận này được kết hợp như thế nào để cải thiện chiến lược tăng cường và đa dạng trong tabu search?)
8. Những bộ nhớ tương thích nào tốt nhất cho từng loại vấn đề cụ thể? (Dạng chung nào hiệu quả nhất cho các vấn đề mà cấu trúc của nó không được xác định trước?)

33
BÀI TOÁN LẬP LỊCH THEO TÍN CHỈ Chương 4:
4.1 Các khái niệm
• Tuần (Week): chu kỳ lặp lại của thời khóa biểu, có thể gồm nhiều tuần.
• Ngày (Day): các ngày dạy trong một tuần.
• Tiết học (Period): tiết dạy trong ngày.
• Môn học (Subject): môn học được giảng dạy trong trường. • Giáo viên (Teacher): giáo viên tham gia vào thời khóa biểu.
• Lớp học (Class): lớp học tham gia vào thời khóa biểu.
• Buổi học (Lesson): buổi học của một lớp do một giáo viên được phân công dạy môn nào đó.
• Phòng học (Room): phòng học để sắp lịch cho các buổi học.
• Tài nguyên (Resource): các tài nguyên cung cấp cho thời khóa biểu. Bao gồm: như micro, máy chiếu… Lớp học và môn học là khác nhau: một giảng viên có thể dạy một môn, ví
dụ như môn Cơ sở dữ liệu là ánh xạ 1-1, còn giảng viên này dạy 3 lớp hiện đang học môn Cơ sở dữ liệu là ánh xạ 1-m. Vậy trong mô hình ta đã biết trước giảng viên này dạy môn gì, dạy lớp nào thì bài toán sẽ trở nên đơn giản hơn.
Hình 5 – Mối quan hệ giữa Giảng viên, Lớp học và Môn học
Subject:
Java language

34
Chi tiết hơn ta có thể dễ dàng nhận thấy rằng việc xếp thời khóa biểu là việc sắp các buổi học có các thông tin gồm:
• Class: lớp nào • Subject: học môn gì • Teacher: ai dạy • Room: học ở đâu • Week-Day-Period: học khi nào
Nhưng khi sắp lịch thì người giáo vụ, Trưởng/Phó phòng Đào tạo thường sẽ biết trước, có sẵn thông tin về nghiệp vụ của họ rằng “tuần tiếp theo / tháng tiếp theo / học kỳ tiếp theo thì lớp X sẽ học môn Y và do giáo viên Z giảng dạy.
Biết trước, không cần xếp lịch Phải xếp lịch Class Room Subject Week-Day-Period Teacher
Trong thực tế thì kết quả của việc sắp lịch sẽ giúp cho họ và giảng viên giảng dạy biết lớp mình sẽ phụ trách, giúp cho sinh viên các lớp biết mình sẽ học môn gì, ở đâu, thầy cô nào dạy và mục đích chính là để phục vụ các đối tượng này.
ð Rút ra kết luận là việc sắp lịch học cho các lớp và sắp lịch dạy cho giảng viên là tương đương nhau qua phép ánh xạ trên.
Vậy ta có thể xây dựng mô hình theo 2 cách hoàn toàn tương đương và chỉ còn lại 3 chiều là:
• Lớp học, phòng học, tiết học
• Giảng viên, phòng học, tiết học. Sau khi tìm hiểu sơ bộ về một số vấn đề trên chúng ta sẽ cùng nhau xây
dựng mô hình bài toán cho trường hợp thứ nhất (lớp học, phòng học, tiết học):

35
4.2 Mô hình của bài toán
T – là tập các giảng viên (gồm giảng viên cơ hữu và giảng viên part time)
L – là tập các buổi học cần xếp lịch
𝐿!(𝑡 ∈ 𝑇) – là tập các buổi học mà giảng viên T dạy
P – là tổng số tiết học có thể sắp lịch trong tuần: P ≤ 5 ca x 6 ngày = 30 ca
R – là tập các phòng học
Rl (l ∈ L) – là số phòng học còn trống có thể sắp lịch được cho buổi học l.
𝑅!(𝑝 ∈ 𝑃) – là số phòng học còn trống có thể sắp lịch được trong tiết học p.
Ta có biến quyết định
𝑋!!! =𝜕 > 0 − 𝑝ℎò𝑛𝑔 𝑟 𝑐ó 𝑏𝑢ổ𝑖 ℎọ𝑐 𝑙 𝑣à𝑜 𝑡ℎờ𝑖 𝑔𝑖𝑎𝑛 𝑝0 − 𝑝ℎò𝑛𝑔 𝑟 𝑘ℎô𝑛𝑔 𝑐ó 𝑏𝑢ổ𝑖 ℎọ𝑐 𝑙 𝑣à𝑜 𝑡ℎờ𝑖 𝑔𝑖𝑎𝑛 𝑝
(r ∈ R, l ∈ L, p ∈ P)
Trong đó giá trị 𝜕 của biến quyết định Xrlk được tính qua các ràng buộc, ta có 2 loại ràng buộc chính để mô tả buổi học l do giảng viên t dạy vào giờ p tại phòng học r nếu không thỏa mãn mỗi:
• Ràng buộc cứng: nếu vi phạm 1 tiêu chí + 100 điểm
• Ràng buộc mềm: nếu vi phạm 1 tiêu chí + 1 → 10 điểm [41]
Việc lựa chọn trọng số cho mỗi ràng buộc dựa theo nhu cầu thực tế khi ta xây dựng hệ thống. Nếu ràng buộc quan trọng, cần ưu tiên cao và có ảnh hưởng lớn tới quá trình lập thời khóa biểu thì ta nên đặt trọng số cao. Còn nếu ràng buộc không quá quan trọng ta có thể thiết lập trọng số nhỏ hơn cho phù hợp.
Từ đó ta xây dựng hàm mục tiêu sau đây và nhiệm vụ chính là xây dựng giải thuật để hàm mục tiêu này đạt MIN:
𝑋!!!!!!

36
Qua đây có thể thấy rằng với các trọng số có các giá trị khác thì nhau ngoài việc giúp ta phân loại mức ưu tiên cho các ràng buộc, việc này còn giúp ta đưa ra chiến lược tốt hơn để tìm MIN cho hàm mục tiêu bằng cách ưu tiên giải quyết các ràng buộc có trọng số cao để hàm mục tiêu tiệm cận MIN nhanh hơn.
Cụ thể hơn giải thuật sẽ ưu tiên giải quyết các ràng buộc cứng trước do có trọng số cao sau đó sẽ sắp xếp thêm để tối ưu kết quả sắp lịch.
4.3 Các ràng buộc cứng
• 𝑋!!! = 1(𝑙 ∈ 𝐿)!! – ràng buộc mô tả mỗi buổi học l chỉ học vào 1 tiết học p trong tuần tại 1 phòng học r cụ thể - Class conflict
• 𝑋!!! = 0(𝑟 ∉ 𝑅!, 𝑙 ∈ 𝐿! , 𝑝 ∈ 𝑃) – mô tả việc giáo vụ sẽ không lên lịch cho lớp l vào tiết học p nếu hiện phòng học r đang có lớp học – Period conflict.
• 𝑋!!! = 0 (𝑟 ∉ 𝑅! , 𝑙 ∈ 𝐿! , 𝑝 ∈ 𝑃) – mô tả sẽ không sắp lịch được cho buổi học l vào tiết học p nếu hiện phòng học r không đủ điều kiện cơ sở vật chất – Room conflict.
• 𝑋!!! = 0 𝑟 ∈ 𝑅! 𝑟 ∈ 𝑅! , 𝑙 ∉ 𝐿! , 𝑝 ∈ 𝑃) – mô tả không thể lên lịch cho buổi học l vào tiết học p tại phòng học r do giảng viên t hiện đang bận – Teacher conflict
4.4 Các ràng buộc mềm
• S – là tập các môn học • 𝑆!(𝑡 ∈ 𝑇) – là tập các môn mà giảng viên t có thể dạy • Rl (l ∈ L) – số phòng học còn trống có thể sắp lịch được cho buổi học l. • 𝑅!(𝑝 ∈ 𝑃) – số phòng học còn trống có thể sắp lịch trong tiết học p. • 𝐿!(𝑡 ∈ 𝑇) – số lớp tối đa mà giảng viên t có thể dạy được (Lt ≤ 30) • 0 ≤ 𝑋!!! ≤ 𝐿!!! (𝑡 ∈ 𝑇) – ràng buộc giáo viên có thể không dạy lớp
nào và số lớp dạy không quá Lt (có thể dạy quá do thiếu giảng viên) • 𝑋!!! ≤ 𝑅! (𝑝 ∈!! 𝑃) – ràng buộc để kiểm tra với một tiết học p thì có
các phòng học nào còn trống

37
• 𝑋!!! ≤ 𝑅! (𝑙 ∈ 𝐿!! ) – ràng buộc để kiểm tra với một môn học l thì có các phòng học nào còn trống
• 𝑋!!!! ≤1 − 𝑃𝑇𝑈4 − 𝑁𝐼𝐼𝑇
3 − 𝑐á𝑐 𝑘ℎó𝑎 𝑛𝑔ắ𝑛 ℎạ𝑛 (𝑡 ∈ 𝑇, 𝑘 ∈ 𝐾) – mô tả một giảng viên
t dạy một buổi học l không quá số buổi qui định/tuần (có thể tăng hoặc giảm)
4.5 Ví dụ minh họa:
Xét ví dụ sau đây: giảng viên Nguyễn Tiến Cường là giảng viên dạy bộ môn mạng máy tính, hiện giảng viên này dạy lớp N0902 và yêu cầu dạy tại phòng lab cho lớp mạng có thiết bị thực hành (ràng buộc cứng) vào thứ 2 thứ 4 hàng tuần (ràng buộc mềm).
Nếu ta xếp được lịch cho giảng viên Cường dạy đúng như yêu cầu thì:
Y = 0 + 0 + 0 = 0
Nếu ta chỉ xếp được lịch dạy cho giảng viên Cường dạy ở phòng lab nhưng vào thứ 2 và thứ 5 thì:
Y = 0 + 0 + 3 = 3
Nếu ta chỉ xếp được lịch dạy cho giảng viên Cường dạy ở phòng lab nhưng vào thứ 3 và thứ 4 thì:
Y = 0 + 5 + 0 = 5
Nếu ta chỉ xếp được lịch dạy cho giảng viên Cường dạy ở phòng lab vào thứ 3 và thứ 4 thì:
Y = 0 + 5 + 3 = 8
Còn trong các trường hợp khác khi không thỏa mãn ràng buộc cứng đều không được chấp nhận (Y ≥ 100).
Ta có thể dễ dàng thống kê các trường hợp trong ví dụ trên theo bảng dưới đây:

38
Ràng buộc cứng (phòng lab)
Ràng buộc mềm (thứ 2)
Ràng buộc mềm (thứ 4)
Hàm mục tiêu Y
Kết quả
0 0 0 0 Tốt nhất 0 0 3 3
Chấp nhận được
0 5 0 5 0 5 3 8
100 0 0 100
Loại 100 0 3 103 100 5 0 105 100 5 3 108
Bảng 1 - Mô tả cách tính của hàm mục tiêu
Lý do ta đưa việc tính toán giá trị Y vào cho biến X ở đây là để tiện cho việc áp dụng thuật toán tabu search tìm ra giải pháp tối ưu nhất là giải pháp mà trong đó mọi Xrlp đạt giá trị MIN có thể (thỏa mãn nhiều ràng buộc nhất).
Thuật toán tìm kiếm Tabu sẽ xuất phát từ 1 đáp án bất kỳ, đáp án này có thể tạo nên bằng cách đơn giản là cứ xếp tuần tự để tìm được một lời giải mà không cần quan tâm đến chất lượng lời giải, sau đó sẽ tìm kiếm lời giải tốt hơn dựa trên lời giải ban đầu. Cách khác tốt hơn là đưa ra 1 đáp án sắp xếp mà thỏa mãn các ràng buộc chặt trước, sau đó ta sẽ cải tiến đáp án cho tốt hơn bằng cách thay đổi việc sắp lịch cho các giảng viên để thỏa mãn được càng nhiều ràng buộc lỏng càng tốt, nếu sau khi thay đổi mà Xrlp mới có giá trị nhỏ hơn Xrlp cũ thì đương nhiên ta có giải pháp tốt hơn.
4.6 Hướng tiếp cận cho bài toán
Thuật toán gồm 2 bước chính:
Bước 1: Khởi tạo lời giải ban đầu ngẫu nhiên
Bước 2: Cải thiện chất lượng lời giải bằng giải thuật tìm kiếm Tabu
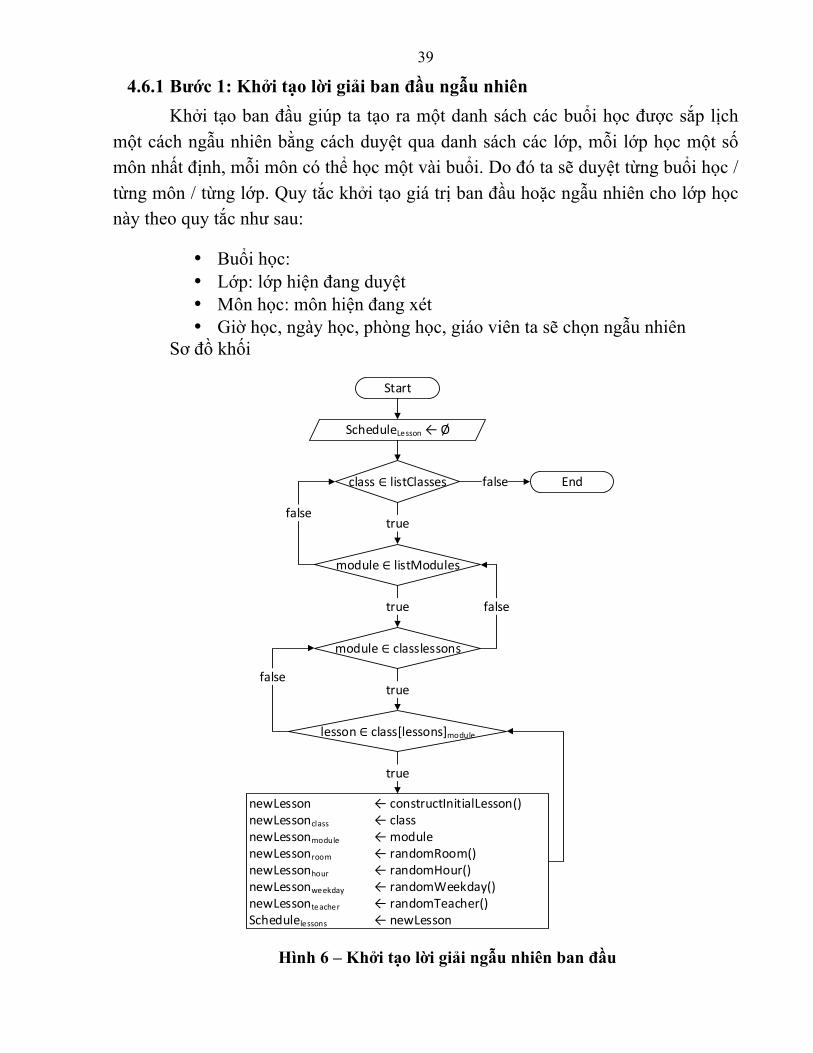
39
4.6.1 Bước 1: Khởi tạo lời giải ban đầu ngẫu nhiên Khởi tạo ban đầu giúp ta tạo ra một danh sách các buổi học được sắp lịch
một cách ngẫu nhiên bằng cách duyệt qua danh sách các lớp, mỗi lớp học một số môn nhất định, mỗi môn có thể học một vài buổi. Do đó ta sẽ duyệt từng buổi học / từng môn / từng lớp. Quy tắc khởi tạo giá trị ban đầu hoặc ngẫu nhiên cho lớp học này theo quy tắc như sau:
• Buổi học: • Lớp: lớp hiện đang duyệt • Môn học: môn hiện đang xét • Giờ học, ngày học, phòng học, giáo viên ta sẽ chọn ngẫu nhiên
Sơ đồ khối
Start
ScheduleLesson ← Ø
class ∈ listClasses
module ∈ listModules
module ∈ classlessons
lesson ∈ class[lessons]module
true
true
true
newLesson ← constructInitialLesson()newLessonclass ← classnewLessonmodule ← modulenewLessonroom ← randomRoom()newLessonhour ← randomHour()newLessonweekday ← randomWeekday()newLessonteacher ← randomTeacher()Schedulelessons ← newLesson
true
false
false
false
false End
Hình 6 – Khởi tạo lời giải ngẫu nhiên ban đầu

40
Việc sinh ra lời giải ban đầu ngẫu nhiên này có thể vi phạm nhiều ràng buộc, thậm chí không thỏa mãn một số ràng buộc cứng – hard constraints - nhưng lưu ý rằng đây chỉ là lời giải ban đầu mà từ đó ta sẽ dùng giải thuật tìm kiếm Tabu để tìm ra phương án sắp xếp tối ưu thỏa mãn tất cả các ràng buộc cứng và cố gắng giảm tối đa số lượng vi phạm các ràng buộc mềm – soft constraints
4.6.2 Bước 2: Cải thiện chất lượng lời giải bằng giải thuật tìm kiếm Tabu Xuất phát từ cơ sở của giải thuật tìm kiếm Tabu, luận văn sẽ đi vào triển
khai cài đặt thực tế cho mô hình được đề cập bên trên để từ đó xây dựng ra một phần mềm nhằm giải quyết nhu cầu thực tế hiện nay tại cơ quan tác giả đang làm việc.
Mã giả giải thuật tìm kiếm Tabu – Pseudocode [40]
s ← s0 sBest ← s tabuList ← null
while (not stoppingCondition()) candidateList ← null
for (sCandidate in sNeighborhood) if (not containsTabuElements(sCandidate,
tabuList))
candidateList ← candidateList + sCandidate end
end sCandidate ← LocateBestCandidate(candidateList) if(fitness(sCandidate) > fitness(sBest))
tabuList ← featureDifferences(sCandidate, sBest) sBest ← sCandidate
while(size(tabuList) > maxTabuListSize) ExpireFeatures(tabuList)
end
end end return(sBest)

41
4.6.2.1 Tính hàm mục tiêu đánh giá chất lượng của lời giải Với mỗi biến quyết định Xrlp như đã đề cập trong mô hình bài toán
𝑋!"#!!!
Hàm mục tiêu đánh giá chất lượng của lời giải dựa trên hai yếu tố:
o Vi phạm mỗi ràng buộc cứng: + 100 điểm o Vi phạm mỗi ràng buộc mềm: + 1 → 10 điểm
Dưới đây là một số hàm xây dựng phục vụ việc cài đặt giải thuật tìm kiếm Tabu trong việc đưa ra lời giải cho bài toán sắp xếp thời khóa biểu:
• evaluate(): tính toán tổng số điểm phạt cho mỗi ràng buộc o có một cờ generateCandidates dùng để sinh ra một buổi học mới –
proposedCandidates – cho các ràng buộc cứng khi thiết lập smartSearch = true và số bước lặp của smartSearch < số bước lặp dừng trong giải thuật để ưu tiên tìm kiếm các lời giải mới không vi phạm các ràng buộc cứng giúp ta nhanh chóng hạ số điểm phạt của hàm mục tiêu.
• stopCriteriaReach(): đánh giá tiêu chí dừng của giải thuật o hàm mục tiêu bằng 0 – đạt giá trị MIN o sau 1000 bước lặp o sau 100 bước lặp mà chất lượng lời giải không được cải thiện
• generateNextCandidate(): hàm sinh phép chuyển có o input : buổi học – lesson – hiện đang xét o output: một phép chuyển ngẫu nhiên có thể thay đổi ngày / giờ /
phòng học / giáo viên cho buổi học hiện tại • getNeighborhood() – trả về một danh sách các phép chuyển lân cận • calculateTotalEvaluation() – tính tổng số điểm phạt cho một lời giải
Dưới đây là sơ đồ mô tả luồng xử lí khi ta cài đặt giải thuật tìm kiếm Tabu cho mô hình bài toán sắp thời khóa biểu đã được đề cập từ đầu đến nay trong luận văn

42
initialize
!stopCriteriaReach()
getSurrounding()
True
For Change in listChange
Evaluate()
bestTotalPoint =
currentTotalPoint
currentTotalPoint <
bestTotalPoint
True
True
generateNextChange()
TaboList ← currentChange
End
Start
False
False
False
Hình 7 – Sơ đồ cài đặt giải thuật

43
4.6.2.2 Phép chuyển Như đã đề cập, bên trên yếu tố cốt lõi để giải thuật tìm được lời giải mới tốt
hơn các lời giải trước đó dựa trên kỹ thuật cài đặt phép chuyển nhằm sinh ra một lời giải mới, hiện nay có nhiều tác giã đã đưa ra các phép chuyển khác nhau nhằm mục tiêu giải quyết bài toán lập lịch. Trong thời gian học tập, nghiên cứu tại trường Đại học Công nghệ và công tác tại cơ quan, tác đã đề xuất một cách sinh phép chuyển đơn giản để sinh ra các lời giải mới. Phép chuyển này có thể chưa phải là tốt nhất, tối ưu nhất nhưng cũng đã cho ra kết quả tốt phù hợp với mô hình bài toán đề ra. Sau đây là sơ đồ khối phép chuyển sinh ra một lời giải mới
Start
lesson
choice is Weekday
choice is Hour
choice is Room
choice is Teacher
true
true
true
true
false
false
false
false
End
candidate ← Ø candidateTotalPoint ← scheduleTotalPoint
choice ← randomChoice()
candidateUnitBefore ← lessonWeekday candidateUnitAfter ← randomWeekday()
return candidate
candidateUnitBefore ← lessonHour candidateUnitAfter ← randomHour()
candidateUnitBefore ← lessonRoom candidateUnitAfter ← randomRoom()
candidateUnitBefore ← lessonTeachercandidateUnitAfter ← randomTeacher()
Hình 8 – Phép chuyển mới

44
4.6.2.3 Hàm mong đợi (Aspiration Function) Xét một phép chuyển m:
• Gọi S là lời giải hiện tại
• S’ là lời giải mới tạo thành sau khi thực hiện phép chuyển m lên S’
• S* là lời giải tốt nhất hiện tại
• f(S) là hàm mục tiêu
• phép chuyển m được gọi là thỏa hàm mong đợi chỉ khi f(S) < f(S*)
4.6.2.4 Điều kiện dừng của thuật toán
Thuật toán dừng khi một trong các điều kiện sau đây được thỏa mãn – hàm stopCriteriaReach:
• Sau 1000 bước lặp.
• Hàm mục tiêu của lời giải tốt nhất hiện tại đạt MIN = 0 (đã thỏa hết tất cả các ràng buộc cứng và mềm).
• Sau một số bước lặp nhất định (ví dụ 100 bước lặp) liên tiếp mà chất lượng lời giải tốt nhất hiện tại không đổi
4.7 Định dạng tập tin dữ liệu CSV đầu vào:
Mô hình hệ thống phần mềm được xây dựng nhằm giúp ta dễ dàng đọc các file dữ liệu đầu vào theo định dạng CSV một cách dễ dàng. Do đó hệ thống đã xây dựng sẵn các class dưới đây để có thể mô hình hóa nghiệp vụ sắp xếp thời khóa biểu, từ đó dễ dàng cài đặt giải thuật tìm kiếm Tabu cho hệ thống.

45
Model CSV Model name [0] Name [1] ID [2] OtherModel [3] [OtherModel Constraint] [4] … … Chữ in nghiêng – italic là tùy chọn
Bảng 2 – Bảng mô tả ánh xạ tập dữ liệu và mô hình hệ thống
Ví dụ: với dữ liệu đầu vào từ file CSV là: “hour”;“9h45-11h45”;“8”
Model CSV Model name: hour [0]: hour Name: 9h45-11h45 [1]: 9h45-11h45 ID: 8 [2]: 8
Bảng 3 – Ví dụ ánh xạ từ tập dữ liệu vào mô hình hệ thống
4.8 Khảo sát và thống kê kết quả thực nghiệm thực tế
Dựa trên phần mềm được xây dựng tạm đặt tên là vTimeTabler, luận văn đã một vài kết quả lời giải được sinh ra trên tập dữ liệu thực tế của Trung tâm Đào tạo Chứng chỉ Quốc tế NIIT-Thăng Long. Tập dữ liệu này được sử dụng để xếp thời khóa biểu hàng ngày cho tập thể giảng viên, học viên các lớp hiện đang theo học tại trung tâm. Chi tiết số liệu thống kê của tập dữ liệu như sau:
• 7 phòng học • 25 lớp học • 17 giáo viên • 28 môn học • 109 buổi học

46
STT Lời giải tốt nhất (điểm)
Tại vòng lặp số Hết thời gian (giây)
1 1397 348 77,85s 2 1414 491 87,08 3 1395 447 99,36 4 1368 430 82,62 5 1380 448 129,77 6 1434 500 82,79 7 1392 437 95,35 8 1349 500 92,41 9 1359 412 84,02
10 1337 384 83,67 Bảng 4 – Thống kê kết quả thực nghiệm
Kết quả kiểm nghiệm thực tế cho thấy trong phạm vi 500 vòng lặp đã cho ra kết quả tốt đáp ứng được nhu cầu sử dụng thực tế tại cơ quan tác giả đang công tác.
Hình 9 – Biểu đồ minh họa quá trình tìm kiếm lời giải
47
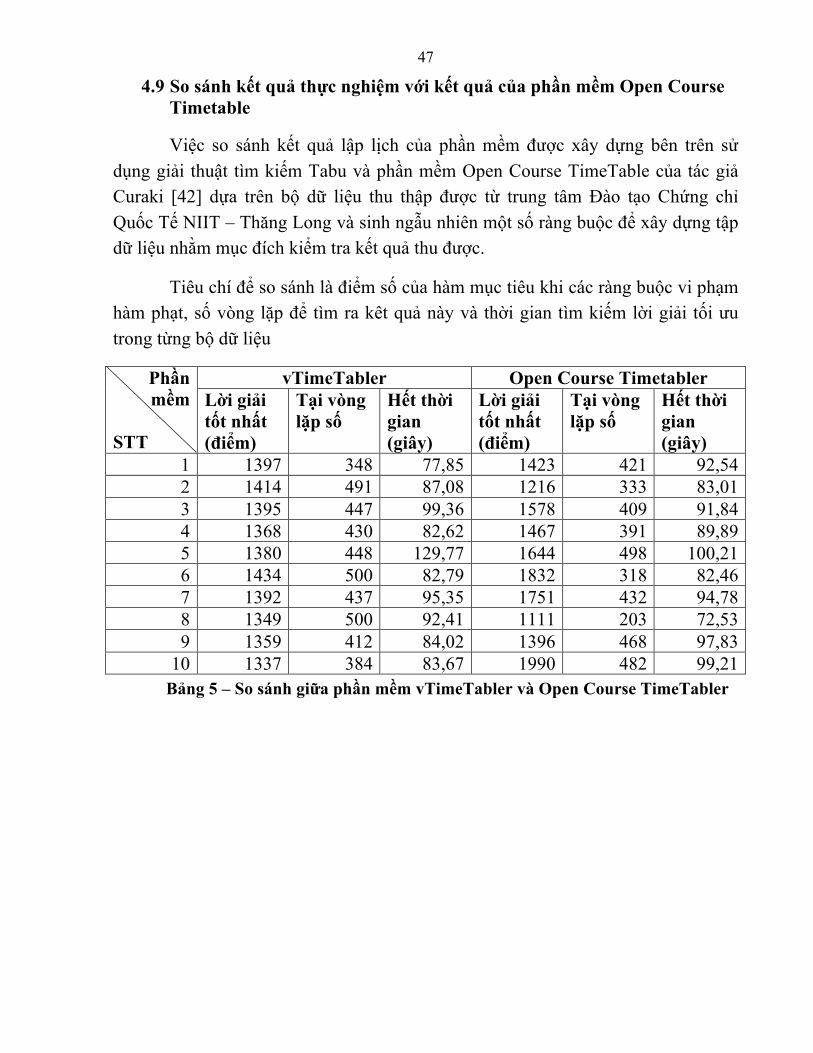
4.9 So sánh kết quả thực nghiệm với kết quả của phần mềm Open Course Timetable
Việc so sánh kết quả lập lịch của phần mềm được xây dựng bên trên sử dụng giải thuật tìm kiếm Tabu và phần mềm Open Course TimeTable của tác giả Curaki [42] dựa trên bộ dữ liệu thu thập được từ trung tâm Đào tạo Chứng chỉ Quốc Tế NIIT – Thăng Long và sinh ngẫu nhiên một số ràng buộc để xây dựng tập dữ liệu nhằm mục đích kiểm tra kết quả thu được.
Tiêu chí để so sánh là điểm số của hàm mục tiêu khi các ràng buộc vi phạm hàm phạt, số vòng lặp để tìm ra kêt quả này và thời gian tìm kiếm lời giải tối ưu trong từng bộ dữ liệu
Phần mềm
STT
vTimeTabler Open Course Timetabler Lời giải tốt nhất (điểm)
Tại vòng lặp số
Hết thời gian (giây)
Lời giải tốt nhất (điểm)
Tại vòng lặp số
Hết thời gian (giây)
1 1397 348 77,85 1423 421 92,54 2 1414 491 87,08 1216 333 83,01 3 1395 447 99,36 1578 409 91,84 4 1368 430 82,62 1467 391 89,89 5 1380 448 129,77 1644 498 100,21 6 1434 500 82,79 1832 318 82,46 7 1392 437 95,35 1751 432 94,78 8 1349 500 92,41 1111 203 72,53 9 1359 412 84,02 1396 468 97,83
10 1337 384 83,67 1990 482 99,21 Bảng 5 – So sánh giữa phần mềm vTimeTabler và Open Course TimeTabler

48
Như vậy sau khi thực hiện việc so sánh có một số nhận xét sau:
1. Phần lớn kết quả thực nghiệm của phần mềm vTimeTabler cho kết quả tốt hơn phần mềm Open Course Timetabler của tác giả Curaki.
2. Trong một số trường hợp kết quả của phần mềm Open Course Timetabler cho kết quả tốt hơn.
3. Thời gian thực hiện tìm kiếm lời giải tối ưu giữa 2 phần mềm có sự chênh lệch đáng kể
Rút ra kết luận rằng kết quả này có được là do phần mềm vTimeTabler được xây dựng nhằm mục tiêu tối ưu và phù hợp với mô hình thực tế tại trung tâm Đào tạo Chứng chỉ Quốc tế NIIT – Thăng Long mà tác giả hiện đang công tác.

49
KẾT LUẬN
Một trong những yếu tố quan trọng trong việc nghiên cứu và thực hiện luận văn này là luận văn đã xuất phát từ nhu cầu thực tế của cơ quan tổ chức hiện tác giả đang làm việc, kết quả của luận văn này đã được phòng Đào tạo trực thuộc Trung tâm Đào tạo Chứng chỉ Quốc tế NIIT – Thăng Long sử dụng trong việc sắp lịch học cho các lớp, bố trí công tác cho cán bộ, giảng viên của trung tâm từ đó giúp cho Trưởng/Phó phòng Đào tạo và cán bộ Quản lý phụ trách đào tạo trong công việc hàng ngày, giúp học viên các lớp, các giảng viên giảng dạy nắm bắt rõ lịch học tập công tác của mình.
Tổng quan lại luận văn đã đạt được những kết quả sau:
1. Xây dựng được một mô hình toán học cho việc lập lịch tại các Trung tâm Đào tạo Chứng chỉ Quốc tế
2. Cài đặt giải thuật tìm kiếm Tabu để giải quyết mô hình trên
3. Phát triển một phần mềm ứng dụng hỗ trợ người dùng trong thực tế
Do thời gian có hạn nên việc nghiên cứu luận văn tạm dừng ở đây và cũng mong muốn trong tương lai luận văn sẽ có thể được phát triển thêm theo hướng:
1. Cải tiến giải thuật tìm kiếm Tabu để có được kết quả tốt hơn như:
a. Tối ưu hóa phép chuyển để sinh ra các lời giải mới hiệu quả hơn
b. Kết hợp giữa giải thuật tìm kiếm tabu và một sô giải thuật khác để có kết quả tối ưu hơn (hiện nay là xu hướng được nhiều nghiên cứu đang hướng tới).
2. Cải tiến sự tiện dụng của hệ thống phần mềm đơn giản thân thiện hơn với người dung
3. Thay đổi chỉnh sửa trong mô hình được đề xuất trong luận văn để có thể áp dụng rộng rãi hơn cho các trường học, cơ quan tổ chức khác

50
TÀI LIỆU THAM KHẢO
[1] Schaerf, A survey of automated timetabling, Technical Report CSR9567, CWI, Amsterdam, The Netherlands, 1995
[2] Carter, M.W., And G. Laporte, Recent developments in practical examination timetabling, in: E.K. Burke and P. Ross (eds.), Practice and Theory of Automated Timetabling, First International Conference, Selected papers, Lecture Notes in Computer Science 1153, Springer, 1996, 3–21.
[3] Carter, M.W., And G. Laporte, Recent developments in practical course timetabling, in: E.K. Burke and M.W. Carter (eds.), Practice and Theory of Automated Timetabling II, Second International Conference, PATAT ’97, Selected papers, Lecture Notes in Computer Science 1408, Springer, 1998, 3–19.
[4] Bardadym, V.A. , Computer-aided school and university timetabling: The new wave?, in: E.K. Burke and P. Ross (eds.), Practice and Theory of Automated Timetabling, First International Conference, Selected papers, Lecture Notes in Computer Science 1153, Springer, 1996, 22–45.
[5] Gotlieb, C. C. The construction of class-teacher timetables. In Popplewell, C. M. (Ed.), IFIP congress 62, (73-77). North-Holland, 1963.
[6] Schmidt, G., & Strohlein, T. Timetable construction – an annotated bibliography. The Computer Journal, 23(4), (307-316), 1979.
[7] Junginger, W. Timetabling in Germany – a survey. Interfaces, (16, 66-74), 1986.
[8] Tripathy, A. School timetabling - A case in large binary integer linear programming. Management Science, 30 (12), (1473-1489) 1984.
[9] Tripathy, A. Computerised decision aid for timetabling - A case analysis. Discrete Applied Mathematics, 35(3), (313-323), 1992.
[10] Ostermann, R. & de Werra, D. Some experiments with a timetabling system. OR Spektrum, 3, (199-204), 1983
[11] Neufeld, G. A., & Tartar, J. Graph coloring conditions for the existence of solutions to the timetable problem. Communications of the ACM, 17(8), (450-453), 1974.

51
[12] Abramson, D. Constructing school timetables using simulated annealing: sequential and parallel algorithms. Management Science, 37(1) (98-113), 1991.
[13] Costa, D. A tabu search algorithm for computing an operational timetable. European Journal of Operational Research, 76, (98-110), 1994.
[14] Colorni, A., Dorigo, M., & Maniezzo, V. A genetic algorithm to solve the timetable problem. Tech. rep. (90-160) revised, Politecnico di Milano, Italy, 1992.
[15] Yoshikawa, M., Kaneko, K., Nomura, Y., & Watanabe, M. A constraint-based approach to high-school timetabling problems: a case study. In Proc. of the 12th Nat. Conf. on Artificial Intelligence (AAAI-94), (1111-1116), 1994.
[16] Cooper, T. B., & Kingston, J. H. The solution of real instances of the timetabling problem. The Computer Journal, 36(7), 645-653, 1993.
[17] Steven Minton, Mark D. Johnston, Andrew B. Philips, and Philip Laird. Minimizing conflicts: a heuristic repair method for constraint satisfaction and scheduling problems. Artificial Intelligence, 58:161–205, 1992.
[18] S. Kirkpatrick, C. D. Gelatt, and M. P. Vecchi. Optimisation by simulated annealing. Science, Number 4598, 13 May 1983, 220, 4598:671–680, 1983
[19] Zbigniew Michalewicz and David B. Fogel. How to Solve It: Modern Heuristics. Spinger, 2000.
[20] Fred Glover - Manuel Laguna, TabuSearch, Kluwer Academic Publishers, United States of America, 1998.
[21] Goldberg, David (1989). Genetic Algorithms in Search, Optimization and Machine Learning. Reading, MA: Addison-Wesley Professional. ISBN 978-0201157673.
[22] Arabinda Tripathy, School Timetabling—A Case In Large Binary Integer Linear Programming, Management Science, Vol. 30. No. 12. December 1984
[23] Rhydian Marc Rhys Lewis, Metaheuristics for University Course Timetabling, August, 2006.

52
[24] Simon, H. A. and A. Newell. Heuristic Prolem Solving: The Next Advance in Operations Research, Operation Research, Vol. 6, No.1, 1958 .
[25] Fisher, H. and G. L. Thompson. Probabilistic Learning Combinations Of Local Job Shop Scheduling Rules, Industrial Scheduling, J. F. Muth and G. L. Thompson (eds.), Prentice-Hall (225-251), 1963.
[26] Crownston, W. B., F. Glover, G. L. Thomspon and J.D. Trawick Probabilistic and Parametric Learning Combinations of Local Job Shop Scheduling Rules, ONR Research Memorandum No. 117, GSIA, Carnegie-Mellon University, Pittsburgh, PA, 1963.
[27] Glover, F. Parametric Combinations of Local Job Shop Rules, Chapter IV, ONR Research Memorandum No. 117, GSIA, Carnegie-Mellon University, Pittsburgh, PA, 1963.
[28] Glover, F. A Multiphase-dual Algorithm for the Zero-one Integer Programming Problem, Operations Research, Vol. 13 (879-919), 1965.
[29] Glover, F. An Algorithm for Solving the Linear Integer Programming Prolem over a Finite Additive Group, with Extensions to Solving Generaland Certain Non-linear Integer Programs, CRC (66-29), University of California at Barkeley, 1966.
[30] Glover, F. A Pseudo Primal-Dual Integer Programming Algorithm, Journal of Research of the National Bureau of Standards – B, Marthematics and Physical, Vol 71B, No. 4 (187-195), 1967
[31] Glover, F. “Surrogate Constraints, Operations Research, Vol. 16 (741-749), 1968.
[32] Glover, F. Integer Programming Over a Finite Additive Group, SIAM Joural on Control, Vol. 7 (213-231), 1969.
[33] Papadimitriou, C.H and K. Steiglitz. Combinatorial Optimization: Algorithms and Coplexity, Prentice Hall, New York, 1982.
[34] Glover, F. A Multiphase-Dual Algorithm for the Zero-One Integer Programming Problem, Operations Research, Vol. 13, No. 6, (November-December 1965), 879-919
[35] Glover, F. Surrogate Constraints, Operations Research, Vol. 16, No. 4, (July-August 1968), 741-749.

53
[36] Glover, F. A Note on Linear Programming and Integer Feasibility, Operations Research, Vol. 16, No. 6, (November-December 1968), 1212-1216.
[37] Glover, F. Management Decision and Integer Programming, Accounting Review, Vol. XLIV, No. 2, (April 1969), 300-303. 14. "Integer Programming Over a Finite Additive Group," SIAM Journal of Control, Vol. 7, No. 2, (May 1969), 213-231.
[38] Glover, F. Integer Programming Over a Finite Additive Group, SIAM Journal of Control, Vol. 7, No. 2, (May 1969), 213-231.
[39] Papadimitriou with Ken Steiglitz. Combinatorial optimization: algorithms and complexity (second edition by Dover, 1998), Prentice-Hall, 1982
[40] Jason Brownlee. Clever Algorithms: Nature-Inspired Programming Recipes, http://www.cleveralgorithms.com/nature-inspired/stochastic/tabu_search.html
[41] A. Nareyek. An empirical analysis of weight-adaptation strategies for neighborhoods of heuristics, In Fourth Metaheuristic International Conference MIC’2001, pages 211–215, Porto, Portugal, July 16-20 2001.
[42] Curaki. Open Course Time Tabler version 0.8.1, http://sourceforge.net/projects/openctt, March 31st 2008.


















